
自动抓取网页数据
自动抓取网页数据(优采云采集器(www.ucaiyun.com)绿色安装版是一款功优秀的数据采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-10 02:01
优采云采集器()绿色安装版是极品资料采集器,优采云采集器完美支持采集对于网页在所有编码格式中,优采云采集器也可以直接将采集的数据封装到库中,优采云采集器在使用过程中非常稳定。
软件功能
1、通用。
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,也可以通过数据库导入的方式将数据灵活保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或连续地执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
11、有条件的保存——可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别 - 使用此功能识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布-已经采集的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、预留编程接口——定义多个编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
特殊功能
1、支持所有网站编码:完美支持所有编码格式的采集网页,程序可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站@模块 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。 查看全部
自动抓取网页数据(优采云采集器(www.ucaiyun.com)绿色安装版是一款功优秀的数据采集器)
优采云采集器()绿色安装版是极品资料采集器,优采云采集器完美支持采集对于网页在所有编码格式中,优采云采集器也可以直接将采集的数据封装到库中,优采云采集器在使用过程中非常稳定。
软件功能
1、通用。
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,也可以通过数据库导入的方式将数据灵活保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或连续地执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
11、有条件的保存——可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别 - 使用此功能识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布-已经采集的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、预留编程接口——定义多个编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
特殊功能
1、支持所有网站编码:完美支持所有编码格式的采集网页,程序可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站@模块 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。
自动抓取网页数据( Python编程技术使用迭代器自动链式处理数据的实例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-10 01:18
Python编程技术使用迭代器自动链式处理数据的实例(组图))
requests.gPython 使用 requests.get 获取网页内容为空
我们先来看一个例子:
import requests
result=requests.get("http://data.10jqka.com.cn/financial/yjyg/")
result
输出结果:
表示请求处理成功,一般返回此状态码;200表示没问题
继续运行,发现返回了一个空值。请求网页爬取时,输出文本信息中会出现sorry、inaccessible等字样。这就是禁止爬取,需要借助反爬取机制来解决这个问题。headers是解决请求反爬的方法之一,相当于我们进入这个网页,假装自己在爬数据的时候服务器本身。对于反爬虫网页,可以设置一些headers信息来模拟浏览器访问网站。
一、如何设置标题
以两种常见的浏览器为例:
1、QQ浏览器
接口 F12
单击网络并键入 CTRL+R
单击第一个底部是我需要将他设置为标题以解决问题
2、微软边缘
二、微软自己的浏览器
F12也可以打开开发者工具
单击网络,CTRL+R
修改之前的代码:
import requests
ur="http://data.10jqka.com.cn/financial/yjyg/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400 '}
result = requests.get(ur, headers=headers)
result.text
成功解决无法爬取的问题
关于requests.gPython使用requests.get获取网页内容为空''文章到此介绍,更多相关requests.gPython使用requests.get获取网页内容为空' '请搜索以前的文章,希望以后支持编程宝库!
下一节:Python遍历迭代器自动链式处理数据实例Python编程技术
使用迭代器链式处理数据,在Process类的__iter__方法中执行挂载的预处理方法。可以嵌套和包裹多层处理方法,类似于 KoaJs 的洋葱模型。在for循环期间,自动执行预处理方法,并返回处理完数据分析... 查看全部
自动抓取网页数据(
Python编程技术使用迭代器自动链式处理数据的实例(组图))
requests.gPython 使用 requests.get 获取网页内容为空
我们先来看一个例子:
import requests
result=requests.get("http://data.10jqka.com.cn/financial/yjyg/";)
result
输出结果:

表示请求处理成功,一般返回此状态码;200表示没问题

继续运行,发现返回了一个空值。请求网页爬取时,输出文本信息中会出现sorry、inaccessible等字样。这就是禁止爬取,需要借助反爬取机制来解决这个问题。headers是解决请求反爬的方法之一,相当于我们进入这个网页,假装自己在爬数据的时候服务器本身。对于反爬虫网页,可以设置一些headers信息来模拟浏览器访问网站。
一、如何设置标题
以两种常见的浏览器为例:
1、QQ浏览器
接口 F12

单击网络并键入 CTRL+R

单击第一个底部是我需要将他设置为标题以解决问题
2、微软边缘
二、微软自己的浏览器
F12也可以打开开发者工具

单击网络,CTRL+R

修改之前的代码:
import requests
ur="http://data.10jqka.com.cn/financial/yjyg/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400 '}
result = requests.get(ur, headers=headers)
result.text
成功解决无法爬取的问题
关于requests.gPython使用requests.get获取网页内容为空''文章到此介绍,更多相关requests.gPython使用requests.get获取网页内容为空' '请搜索以前的文章,希望以后支持编程宝库!
下一节:Python遍历迭代器自动链式处理数据实例Python编程技术
使用迭代器链式处理数据,在Process类的__iter__方法中执行挂载的预处理方法。可以嵌套和包裹多层处理方法,类似于 KoaJs 的洋葱模型。在for循环期间,自动执行预处理方法,并返回处理完数据分析...
自动抓取网页数据(拼接字符串的性能闲话不多.8.1.2 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2022-01-09 11:04
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
自动抓取网页数据(拼接字符串的性能闲话不多.8.1.2
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
自动抓取网页数据( 官方谷歌蜘蛛最新名称为Googlebot十分“勤奋抓爬”的蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-09 11:02
官方谷歌蜘蛛最新名称为Googlebot十分“勤奋抓爬”的蜘蛛)
各个搜索引擎蜘蛛的介绍,搜索引擎蜘蛛抓取网站和抓取数据的规则
1、百度蜘蛛:BaiduSpider
常见的Baiduspider和Baiduspider-image(抓图)
百度还有其他几个蜘蛛:Baiduspider-video(抓取视频)、Baiduspider-news(抓取新闻)、Baiduspider-mobile(抓取wap),没有一个是常见的
百度爬虫UA:
PC:Mozilla/5.0(兼容;Baiduspider-render/2.0;+)
移动设备:Mozilla/5.0(iPhone;CPU iPhone OS 9_1,如 Mac OS X)AppleWebKit/601.1.46(KHTML,如 Gecko)版本/9.0手机/13B143 Safari/601.1(兼容;Baiduspider-render/2.0;+)
图片:“百度蜘蛛图片+(+)”
2、谷歌蜘蛛:谷歌机器人
有人说谷歌蜘蛛就是GoogleBot。Google 官方蜘蛛的最新名称是 Googlebot,Googlebot-Mobile 也被发现了。名字应该是爬取wap内容。
Google Spider Crawler UA:“Mozilla/5.0(兼容;Googlebot/2.1;+)”
3、360Spider:360Spider
它是一只非常“勤奋”的蜘蛛
360蜘蛛爬虫UA:
Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.1;三叉戟/5.0);
4、搜狗蜘蛛:搜狗新闻蜘蛛
搜狗还有其他几种蜘蛛:搜狗网络蜘蛛、搜狗inst蜘蛛、搜狗蜘蛛2、搜狗博客、搜狗猎户蜘蛛、冬镜只在日志中找到了常见的搜狗新闻蜘蛛。(参考百度的robots文件,搜狗蜘蛛的名字可以用搜狗来概括,但不知道有没有用。)
搜狗爬虫UA:
“搜狗网络蜘蛛/4.0(+#07)”
5、必应蜘蛛:bingbot
必应蜘蛛爬行者 UA:
“Mozilla/5.0(兼容;bingbot/2.0;+)”
6、SOSO 蜘蛛:Sosospider
腾讯死了,交给搜狗
soso蜘蛛爬虫UA:“Sosospider+(+)”
7、雅虎蜘蛛:雅虎!Slurp 中国(雅虎中国)或雅虎!啜饮(雅虎英语)
雅虎蜘蛛爬虫 UA:
雅虎!中国:“Mozilla/5.0(兼容;Yahoo! Slurp 中国;)”
雅虎!英语:“Mozilla/5.0(兼容;Yahoo! Slurp;)”
8、MSN 蜘蛛:msnbot,msnbot-media
重庆seo似乎只看到msnbot-media疯狂爬行...
MSN 蜘蛛爬虫 UA:*msnbot/1.0 (+”)
还有其他蜘蛛:YisouSpider,Alexa蜘蛛:ia_archiver,一搜蜘蛛:EasouSpider,即时蜘蛛:JikeSpider,还有YandexBot、AhrefsBot和ezooms.bot等蜘蛛。据说这些外国蜘蛛不好
搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,并建立索引库,让用户可以在搜索引擎中搜索到你的网站网页、图片、视频等内容。
一般用法是“蜘蛛+URL”,下面的URL(网址)就是搜索引擎的踪迹。如果你想查看搜索引擎是否抓取了你的网站,可以查看服务器日志中是否有这个URL。,还可以查看时间、频率等。
1、百度蜘蛛:可以根据服务器的负载能力调整访问密度,大大降低了服务器的服务压力。根据以往的经验,百度蜘蛛通常会过度重复爬取同一页面,导致其他页面无法爬取,无法收录。这种情况可以通过机器人协议进行调整。
2、Google Spider:Google Spider 是一个比较活跃的网站 扫描工具,它每 28 天左右发出“蜘蛛”来检索更新或修改的网页。与百度蜘蛛最大的不同在于,谷歌蜘蛛比百度蜘蛛的爬取深度更大。
3、雅虎中国蜘蛛:如果某个网站在Google网站下没有很好的收录,在Yahoo下也不会有很好的收录和爬行。雅虎蜘蛛数量庞大,但平均效率不是很高,相应的搜索结果质量也不高。
4、微软必应蜘蛛:必应与雅虎有着深厚的合作关系,所以基本的操作模式与雅虎蜘蛛类似。
搜索引擎蜘蛛的爬取规则提供以下四点供参考:
1、搜索引擎蜘蛛需要能够看到链接文本
这是搜索引擎蜘蛛在爬行时可以检索到的文本。如果文本或链接是通过 JavaScript 调用的,则蜘蛛无法检索它。主要内容在页面文字内容中的位置越高,越有利。例如,产品名称在页面上的位置越高,产品关键词在页面上的排名越有利。
2、搜索引擎蜘蛛可以抓取没有被nofollow处理的链接
此项列出了搜索引擎蜘蛛可以检索到的链接,蜘蛛可以通过这些链接访问网站 其他页面。@> 更有可能。
3、搜索引擎蜘蛛可以找到图片的链接并阅读这些图片的含义
该页面主要展示搜索引擎蜘蛛和国际W3C标准化监视器检索到的图片。搜索引擎可以根据图片at=""判断图片的类型、性质和主题。有很大帮助,可以有效提高产品展示页面的搜索引擎排名。根据W3C标准,页面上的所有图片都必须添加alt=""图片注释,网站Logo使用网站的名称和简短的描述,产品图片使用产品名称,以及页框图像留空。
4、搜索引擎蜘蛛擅长识别 HTML 代码
模拟搜索引擎蜘蛛爬取页面时,得到的“简化代码->指过滤css和JavaScript后的代码”,可见减少空行、行等冗余代码空间非常重要休息,空格等。
5、搜狗蜘蛛:搜狗蜘蛛的爬行速度比较快,爬行的次数比速度略少。最大的特点是不爬取robot.text文件。
6、搜搜蜘蛛:搜搜早期使用了谷歌的搜索技术。谷歌有收录,搜搜肯定有收录。2011年,搜搜宣布采用自己的独立搜索技术,但搜搜蜘蛛和谷歌蜘蛛的特点还是有相似之处。
8、有道蜘蛛:和其他搜索引擎蜘蛛一样,任何权重网站的链接一般都可以是收录。爬取的原理也是通过链接之间的爬取。 查看全部
自动抓取网页数据(
官方谷歌蜘蛛最新名称为Googlebot十分“勤奋抓爬”的蜘蛛)
各个搜索引擎蜘蛛的介绍,搜索引擎蜘蛛抓取网站和抓取数据的规则
1、百度蜘蛛:BaiduSpider
常见的Baiduspider和Baiduspider-image(抓图)
百度还有其他几个蜘蛛:Baiduspider-video(抓取视频)、Baiduspider-news(抓取新闻)、Baiduspider-mobile(抓取wap),没有一个是常见的
百度爬虫UA:
PC:Mozilla/5.0(兼容;Baiduspider-render/2.0;+)
移动设备:Mozilla/5.0(iPhone;CPU iPhone OS 9_1,如 Mac OS X)AppleWebKit/601.1.46(KHTML,如 Gecko)版本/9.0手机/13B143 Safari/601.1(兼容;Baiduspider-render/2.0;+)
图片:“百度蜘蛛图片+(+)”
2、谷歌蜘蛛:谷歌机器人
有人说谷歌蜘蛛就是GoogleBot。Google 官方蜘蛛的最新名称是 Googlebot,Googlebot-Mobile 也被发现了。名字应该是爬取wap内容。
Google Spider Crawler UA:“Mozilla/5.0(兼容;Googlebot/2.1;+)”
3、360Spider:360Spider
它是一只非常“勤奋”的蜘蛛
360蜘蛛爬虫UA:
Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.1;三叉戟/5.0);
4、搜狗蜘蛛:搜狗新闻蜘蛛
搜狗还有其他几种蜘蛛:搜狗网络蜘蛛、搜狗inst蜘蛛、搜狗蜘蛛2、搜狗博客、搜狗猎户蜘蛛、冬镜只在日志中找到了常见的搜狗新闻蜘蛛。(参考百度的robots文件,搜狗蜘蛛的名字可以用搜狗来概括,但不知道有没有用。)
搜狗爬虫UA:
“搜狗网络蜘蛛/4.0(+#07)”
5、必应蜘蛛:bingbot
必应蜘蛛爬行者 UA:
“Mozilla/5.0(兼容;bingbot/2.0;+)”
6、SOSO 蜘蛛:Sosospider
腾讯死了,交给搜狗
soso蜘蛛爬虫UA:“Sosospider+(+)”
7、雅虎蜘蛛:雅虎!Slurp 中国(雅虎中国)或雅虎!啜饮(雅虎英语)
雅虎蜘蛛爬虫 UA:
雅虎!中国:“Mozilla/5.0(兼容;Yahoo! Slurp 中国;)”
雅虎!英语:“Mozilla/5.0(兼容;Yahoo! Slurp;)”
8、MSN 蜘蛛:msnbot,msnbot-media
重庆seo似乎只看到msnbot-media疯狂爬行...
MSN 蜘蛛爬虫 UA:*msnbot/1.0 (+”)
还有其他蜘蛛:YisouSpider,Alexa蜘蛛:ia_archiver,一搜蜘蛛:EasouSpider,即时蜘蛛:JikeSpider,还有YandexBot、AhrefsBot和ezooms.bot等蜘蛛。据说这些外国蜘蛛不好

搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,并建立索引库,让用户可以在搜索引擎中搜索到你的网站网页、图片、视频等内容。
一般用法是“蜘蛛+URL”,下面的URL(网址)就是搜索引擎的踪迹。如果你想查看搜索引擎是否抓取了你的网站,可以查看服务器日志中是否有这个URL。,还可以查看时间、频率等。
1、百度蜘蛛:可以根据服务器的负载能力调整访问密度,大大降低了服务器的服务压力。根据以往的经验,百度蜘蛛通常会过度重复爬取同一页面,导致其他页面无法爬取,无法收录。这种情况可以通过机器人协议进行调整。
2、Google Spider:Google Spider 是一个比较活跃的网站 扫描工具,它每 28 天左右发出“蜘蛛”来检索更新或修改的网页。与百度蜘蛛最大的不同在于,谷歌蜘蛛比百度蜘蛛的爬取深度更大。
3、雅虎中国蜘蛛:如果某个网站在Google网站下没有很好的收录,在Yahoo下也不会有很好的收录和爬行。雅虎蜘蛛数量庞大,但平均效率不是很高,相应的搜索结果质量也不高。
4、微软必应蜘蛛:必应与雅虎有着深厚的合作关系,所以基本的操作模式与雅虎蜘蛛类似。

搜索引擎蜘蛛的爬取规则提供以下四点供参考:
1、搜索引擎蜘蛛需要能够看到链接文本
这是搜索引擎蜘蛛在爬行时可以检索到的文本。如果文本或链接是通过 JavaScript 调用的,则蜘蛛无法检索它。主要内容在页面文字内容中的位置越高,越有利。例如,产品名称在页面上的位置越高,产品关键词在页面上的排名越有利。
2、搜索引擎蜘蛛可以抓取没有被nofollow处理的链接
此项列出了搜索引擎蜘蛛可以检索到的链接,蜘蛛可以通过这些链接访问网站 其他页面。@> 更有可能。
3、搜索引擎蜘蛛可以找到图片的链接并阅读这些图片的含义
该页面主要展示搜索引擎蜘蛛和国际W3C标准化监视器检索到的图片。搜索引擎可以根据图片at=""判断图片的类型、性质和主题。有很大帮助,可以有效提高产品展示页面的搜索引擎排名。根据W3C标准,页面上的所有图片都必须添加alt=""图片注释,网站Logo使用网站的名称和简短的描述,产品图片使用产品名称,以及页框图像留空。
4、搜索引擎蜘蛛擅长识别 HTML 代码
模拟搜索引擎蜘蛛爬取页面时,得到的“简化代码->指过滤css和JavaScript后的代码”,可见减少空行、行等冗余代码空间非常重要休息,空格等。
5、搜狗蜘蛛:搜狗蜘蛛的爬行速度比较快,爬行的次数比速度略少。最大的特点是不爬取robot.text文件。
6、搜搜蜘蛛:搜搜早期使用了谷歌的搜索技术。谷歌有收录,搜搜肯定有收录。2011年,搜搜宣布采用自己的独立搜索技术,但搜搜蜘蛛和谷歌蜘蛛的特点还是有相似之处。
8、有道蜘蛛:和其他搜索引擎蜘蛛一样,任何权重网站的链接一般都可以是收录。爬取的原理也是通过链接之间的爬取。
自动抓取网页数据(历史消息界面将屏幕向上滑动每次都可以加载10条历史)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-09 11:01
安装证书并设置好手机IP代理后,点一个微信公众号文章(这里用这个公众号)
从图中可以看出,阅读、重看、点赞的url是./mp/getappmsgext(提示:如果没有这个链接,可以刷新右上角的文章角),然后再看一下request请求需要什么
你只需要一个 文章 url、user-agent、cookie 和 body,四个基本数据。别看下面正文中的 20 或 30 个数据,它们实际上很吓人。只需要其中的7个,分别是__biz、mid、idx、sn这四个参数是获取公众号文章内容的基石,可以在文章 url处获取。其他三个参数的数据分别固定is_only_read = 1、is_temp_url = 0、appmsg_type = 9。getappmsgext请求中的appmsg_token是时间敏感参数。
分析完链接就可以写代码了
# articles.py
import html
import requests
import utils
from urllib.parse import urlsplit
class Articles(object):
"""文章信息"""
def __init__(self, appmsg_token, cookie):
# 具有时效性
self.appmsg_token = appmsg_token
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
}
def read_like_nums(self, article_url):
"""获取数据"""
appmsgstat = self.get_appmsgext(article_url)["appmsgstat"]
return appmsgstat["read_num"], appmsgstat["old_like_num"], appmsgstat["like_num"]
def get_params(self, article_url):
"""
获取到文章url上的请求参数
:param article_url: 文章 url
:return:
"""
# url转义处理
article_url = html.unescape(article_url)
"""获取文章链接的参数"""
url_params = utils.str_to_dict(urlsplit(article_url).query, "&", "=")
return url_params
def get_appmsgext(self, article_url):
"""
请求阅读数
:param article_url: 文章 url
:return:
"""
url_params = self.get_params(article_url)
appmsgext_url = "https://mp. weixin.qq.com/mp/getappmsgext?appmsg_token={}&x5=0".format(self.appmsg_token)
self.data.update(url_params)
appmsgext_json = requests.post(
appmsgext_url, headers=self.headers, data=self.data).json()
if "appmsgstat" not in appmsgext_json.keys():
raise Exception(appmsgext_json)
return appmsgext_json
if __name__ == '__main__':
info = Articles('1068_XQoMoGGBYG8Tf8k23jfdBr2H_LNekAAlDDUe2aG13TN2fer8xOSMyrLV6s-yWESt8qg5I2fJr1r9n5Y5', 'rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWl3Xy1saXVWYllIVjAzdlM1VkNDNHgxeWpHOG9pckdkREMwTFEwYmNWMl9FZWtRU3pRRnhDS0pyV1BaZUVMWXN1ZWN0WnZ6aHFXdVBnbVhTY21BYnBSUXNCQUFBMLLAjfgFOA1AAQ==')
a, b,c = info.read_like_nums('http://mp. weixin.qq.com/s?__biz=MzU1NDk2MzQyNg==&mid=2247486254&idx=1&sn=c3a47f4bf72b1ca85c99190597e0c190&chksm=fbdad3a3ccad5ab55f6ef1f4d5b8f97887b4a344c67f9186d5802a209693de582aac6429a91c&scene=27#wechat_redirect')
print(a, b, c)
样本结果
# 阅读数 点赞数 再看数
1561 23 18
动态获取cookies和appmsg_token
appmsg_token 是一个时间敏感的参数,需要像 cookie 一样改变。当这两个参数过期时,需要从抓包工具(MitmProxy)到代码中ctrl+C和ctrl+V,非常麻烦。
MitmProxy 可以使用命令行界面 mitmdumvp 运行 Python 代码来监控抓取的链接。如果 /mp/getappmsgext 被捕获,它将被保存在本地文件中并退出捕获
mitmdump 命令
# -s 运行的python脚本, -w 将截取的内容保持到文件
mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
监控脚本
# coding: utf-8
# write_cookie.py
import urllib
import sys
from mitmproxy import http
# command: mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
class WriterCookie:
"""
mitmproxy的监听脚本,写入cookie和url到文件
"""
def __init__(self, outfile: str) -> None:
self.f = open(outfile, "w")
def response(self, flow: http.HTTPFlow) -> None:
"""
完整的response响应
:param flow: flow实例,
"""
# 获取url
url = urllib.parse.unquote(flow.request.url)
# 将url和cookie写入文件
if "mp. weixin.qq.com/mp/getappmsgext" in url:
self.f.write(url + '\n')
self.f.write(str(flow.request.cookies))
self.f.close()
# 退出
exit()
# 第四个命令中的参数
addons = [WriterCookie(sys.argv[4])]
监控脚本写好后,编写启动命令和解析url和cookie文件的模块
# read_cookie.py
import re
import os
class ReadCookie(object):
"""
启动write_cookie.py 和 解析cookie文件,
"""
def __init__(self, outfile):
self.outfile = outfile
def parse_cookie(self):
"""
解析cookie
:return: appmsg_token, biz, cookie_str·
"""
f = open(self.outfile)
lines = f.readlines()
appmsg_token_string = re.findall("appmsg_token.+?&", lines[0])
biz_string = re.findall('__biz.+?&', lines[0])
appmsg_token = appmsg_token_string[0].split("=")[1][:-1]
biz = biz_string[0].split("__biz=")[1][:-1]
cookie_str = '; '.join(lines[1][15:-2].split('], [')).replace('\'','').replace(', ', '=')
return appmsg_token, biz, cookie_str
def write_cookie(self):
"""
启动 write_cookie。py
:return:
"""
#当前文件路径
path = os.path.split(os.path.realpath(__file__))[0]
# mitmdump -s 执行脚本 -w 保存到文件 本命令
command = "mitmdump -s {}/write_cookie.py -w {} mp.weixin.qq.com/mp/getappmsgext".format(
path, self.outfile)
os.system(command)
if __name__ == '__main__':
rc = ReadCookie('cookie.txt')
rc.write_cookie()
appmsg_token, biz, cookie_str = rc.parse_cookie()
print("appmsg_token:" + appmsg_token , "\nbiz:" + biz, "\ncookie:"+cookie_str)
样本结果
解析cookie.txt文件内容后
appmsg_token:1068_av3JWyDn2XCS2fwFj3ICCnwArRb2kU4Y5Y5m9Z9NkWoCOszl3a-YHFfBkAguUlYQJi2dWo83AQT4FsNK
biz:MzU1NDk2MzQyNg==
cookie:rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWktTHpUSEJnTTdhU0hVZTEtZXpZZEY4a3lNY29zc0VZeEFvLS01YmJRRnQ5eFRmR2dOY29nUWdKSTRVWG13WE1obGs1blhQcVh0V18tRnBSRnVlc1VhOHNCQUFBMPeIjfgFOA1AAQ==
ReadCookie模块可以自动获取appmsg_token和cookies,作为参数传递给Articles模块,这样就可以解放双手,永远不用复制粘贴appmsg_token和cookies,只需要在appmsg_token过期时刷新公众号文章就是这样它,省心省时间
批量提取
在公众号历史消息界面向上滑动屏幕,每次可加载10条历史消息。盲目猜测,这个翻页就是批量抓取的请求链接。使用MitmProxy的WEBUI界面在Response面板中找到,找到一个是/mp /profile_ext?action=getmsg&__biz=MzU1NDk2MzQyNg==&f=json&offset=10&count=10...有多个文章 headers 在它的response返回值中,然后看这个链接的offset =10&count=10 参数,一看就是页面偏移量和每页显示的条数,仅此而已
链接中比较重要的参数有:__biz、offset、pass_ticket、appmsg_token,这些数据可以在cookie和appmsg_token中获取。
# utils.py
# 工具模块,将字符串变成字典
def str_to_dict(s, join_symbol="\n", split_symbol=":"):
s_list = s.split(join_symbol)
data = dict()
for item in s_list:
item = item.strip()
if item:
k, v = item.split(split_symbol, 1)
data[k] = v.strip()
return data
# coding:utf-8
# wxCrawler.py
import os
import requests
import json
import urllib3
import utils
class WxCrawler(object):
"""翻页内容抓取"""
urllib3.disable_warnings()
def __init__(self, appmsg_token, biz, cookie, begin_page_index = 0, end_page_index = 100):
# 起始页数
self.begin_page_index = begin_page_index
# 结束页数
self.end_page_index = end_page_index
# 抓了多少条了
self.num = 1
self.appmsg_token = appmsg_token
self.biz = biz
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.cookie = cookie
def article_list(self, context):
articles = json.loads(context).get('general_msg_list')
return json.loads(articles)
def run(self):
# 翻页地址
page_url = "https://mp. weixin.qq.com/mp/profile_ext?action=getmsg&__biz={}&f=json&offset={}&count=10&is_ok=1&scene=&uin=777&key=777&pass_ticket={}&wxtoken=&appmsg_token=" + self.appmsg_token + "&x5=0f=json"
# 将 cookie 字典化
wx_dict = utils.str_to_dict(self.cookie, join_symbol='; ', split_symbol='=')
# 请求地址
response = requests.get(page_url.format(self.biz, self.begin_page_index * 10, wx_dict['pass_ticket']), headers=self.headers, verify=False)
# 将文章列表字典化
articles = self.article_list(response.text)
for a in articles['list']:
# 公众号中主条
if 'app_msg_ext_info' in a.keys() and '' != a.get('app_msg_ext_info').get('content_url', ''):
print(str(self.num) + "条", a.get('app_msg_ext_info').get('title'), a.get('app_msg_ext_info').get('content_url'))
# 公众号中副条
if 'app_msg_ext_info' in a.keys():
for m in a.get('app_msg_ext_info').get('multi_app_msg_item_list', []):
print(str(self.num) + "条", m.get('title'), a.get('content_url'))
self.num = self.num + 1
self.is_exit_or_continue()
# 递归调用
self.run()
def is_exit_or_continue(self):
self.begin_page_index = self.begin_page_index + 1
if self.begin_page_index > self.end_page_index:
os.exit()
最后使用自动cookie启动程序并刷新公众号文章
# coding:utf-8
# main.py
from read_cookie import ReadCookie
from wxCrawler import WxCrawler
"""程序启动类"""ss
if __name__ == '__main__':
cookie = ReadCookie('E:/python/cookie.txt')
cookie.write_cookie()
appmsg_token, biz, cookie_str = cookie.parse_cookie()
wx = WxCrawler(appmsg_token, biz, cookie_str)
wx.run()
样本结果
总结
这篇文章虽然可能有点头条党,但并没有完全自动抓取数据,需要人为刷新公众号文章。希望大家不要介意。如需刷微信文章,建议参考本公众号【第129天:爬取微信公众号文章内容】。 查看全部
自动抓取网页数据(历史消息界面将屏幕向上滑动每次都可以加载10条历史)
安装证书并设置好手机IP代理后,点一个微信公众号文章(这里用这个公众号)

从图中可以看出,阅读、重看、点赞的url是./mp/getappmsgext(提示:如果没有这个链接,可以刷新右上角的文章角),然后再看一下request请求需要什么


你只需要一个 文章 url、user-agent、cookie 和 body,四个基本数据。别看下面正文中的 20 或 30 个数据,它们实际上很吓人。只需要其中的7个,分别是__biz、mid、idx、sn这四个参数是获取公众号文章内容的基石,可以在文章 url处获取。其他三个参数的数据分别固定is_only_read = 1、is_temp_url = 0、appmsg_type = 9。getappmsgext请求中的appmsg_token是时间敏感参数。
分析完链接就可以写代码了
# articles.py
import html
import requests
import utils
from urllib.parse import urlsplit
class Articles(object):
"""文章信息"""
def __init__(self, appmsg_token, cookie):
# 具有时效性
self.appmsg_token = appmsg_token
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
}
def read_like_nums(self, article_url):
"""获取数据"""
appmsgstat = self.get_appmsgext(article_url)["appmsgstat"]
return appmsgstat["read_num"], appmsgstat["old_like_num"], appmsgstat["like_num"]
def get_params(self, article_url):
"""
获取到文章url上的请求参数
:param article_url: 文章 url
:return:
"""
# url转义处理
article_url = html.unescape(article_url)
"""获取文章链接的参数"""
url_params = utils.str_to_dict(urlsplit(article_url).query, "&", "=")
return url_params
def get_appmsgext(self, article_url):
"""
请求阅读数
:param article_url: 文章 url
:return:
"""
url_params = self.get_params(article_url)
appmsgext_url = "https://mp. weixin.qq.com/mp/getappmsgext?appmsg_token={}&x5=0".format(self.appmsg_token)
self.data.update(url_params)
appmsgext_json = requests.post(
appmsgext_url, headers=self.headers, data=self.data).json()
if "appmsgstat" not in appmsgext_json.keys():
raise Exception(appmsgext_json)
return appmsgext_json
if __name__ == '__main__':
info = Articles('1068_XQoMoGGBYG8Tf8k23jfdBr2H_LNekAAlDDUe2aG13TN2fer8xOSMyrLV6s-yWESt8qg5I2fJr1r9n5Y5', 'rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWl3Xy1saXVWYllIVjAzdlM1VkNDNHgxeWpHOG9pckdkREMwTFEwYmNWMl9FZWtRU3pRRnhDS0pyV1BaZUVMWXN1ZWN0WnZ6aHFXdVBnbVhTY21BYnBSUXNCQUFBMLLAjfgFOA1AAQ==')
a, b,c = info.read_like_nums('http://mp. weixin.qq.com/s?__biz=MzU1NDk2MzQyNg==&mid=2247486254&idx=1&sn=c3a47f4bf72b1ca85c99190597e0c190&chksm=fbdad3a3ccad5ab55f6ef1f4d5b8f97887b4a344c67f9186d5802a209693de582aac6429a91c&scene=27#wechat_redirect')
print(a, b, c)
样本结果
# 阅读数 点赞数 再看数
1561 23 18
动态获取cookies和appmsg_token
appmsg_token 是一个时间敏感的参数,需要像 cookie 一样改变。当这两个参数过期时,需要从抓包工具(MitmProxy)到代码中ctrl+C和ctrl+V,非常麻烦。
MitmProxy 可以使用命令行界面 mitmdumvp 运行 Python 代码来监控抓取的链接。如果 /mp/getappmsgext 被捕获,它将被保存在本地文件中并退出捕获
mitmdump 命令
# -s 运行的python脚本, -w 将截取的内容保持到文件
mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
监控脚本
# coding: utf-8
# write_cookie.py
import urllib
import sys
from mitmproxy import http
# command: mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
class WriterCookie:
"""
mitmproxy的监听脚本,写入cookie和url到文件
"""
def __init__(self, outfile: str) -> None:
self.f = open(outfile, "w")
def response(self, flow: http.HTTPFlow) -> None:
"""
完整的response响应
:param flow: flow实例,
"""
# 获取url
url = urllib.parse.unquote(flow.request.url)
# 将url和cookie写入文件
if "mp. weixin.qq.com/mp/getappmsgext" in url:
self.f.write(url + '\n')
self.f.write(str(flow.request.cookies))
self.f.close()
# 退出
exit()
# 第四个命令中的参数
addons = [WriterCookie(sys.argv[4])]
监控脚本写好后,编写启动命令和解析url和cookie文件的模块
# read_cookie.py
import re
import os
class ReadCookie(object):
"""
启动write_cookie.py 和 解析cookie文件,
"""
def __init__(self, outfile):
self.outfile = outfile
def parse_cookie(self):
"""
解析cookie
:return: appmsg_token, biz, cookie_str·
"""
f = open(self.outfile)
lines = f.readlines()
appmsg_token_string = re.findall("appmsg_token.+?&", lines[0])
biz_string = re.findall('__biz.+?&', lines[0])
appmsg_token = appmsg_token_string[0].split("=")[1][:-1]
biz = biz_string[0].split("__biz=")[1][:-1]
cookie_str = '; '.join(lines[1][15:-2].split('], [')).replace('\'','').replace(', ', '=')
return appmsg_token, biz, cookie_str
def write_cookie(self):
"""
启动 write_cookie。py
:return:
"""
#当前文件路径
path = os.path.split(os.path.realpath(__file__))[0]
# mitmdump -s 执行脚本 -w 保存到文件 本命令
command = "mitmdump -s {}/write_cookie.py -w {} mp.weixin.qq.com/mp/getappmsgext".format(
path, self.outfile)
os.system(command)
if __name__ == '__main__':
rc = ReadCookie('cookie.txt')
rc.write_cookie()
appmsg_token, biz, cookie_str = rc.parse_cookie()
print("appmsg_token:" + appmsg_token , "\nbiz:" + biz, "\ncookie:"+cookie_str)
样本结果

解析cookie.txt文件内容后
appmsg_token:1068_av3JWyDn2XCS2fwFj3ICCnwArRb2kU4Y5Y5m9Z9NkWoCOszl3a-YHFfBkAguUlYQJi2dWo83AQT4FsNK
biz:MzU1NDk2MzQyNg==
cookie:rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWktTHpUSEJnTTdhU0hVZTEtZXpZZEY4a3lNY29zc0VZeEFvLS01YmJRRnQ5eFRmR2dOY29nUWdKSTRVWG13WE1obGs1blhQcVh0V18tRnBSRnVlc1VhOHNCQUFBMPeIjfgFOA1AAQ==
ReadCookie模块可以自动获取appmsg_token和cookies,作为参数传递给Articles模块,这样就可以解放双手,永远不用复制粘贴appmsg_token和cookies,只需要在appmsg_token过期时刷新公众号文章就是这样它,省心省时间
批量提取
在公众号历史消息界面向上滑动屏幕,每次可加载10条历史消息。盲目猜测,这个翻页就是批量抓取的请求链接。使用MitmProxy的WEBUI界面在Response面板中找到,找到一个是/mp /profile_ext?action=getmsg&__biz=MzU1NDk2MzQyNg==&f=json&offset=10&count=10...有多个文章 headers 在它的response返回值中,然后看这个链接的offset =10&count=10 参数,一看就是页面偏移量和每页显示的条数,仅此而已

链接中比较重要的参数有:__biz、offset、pass_ticket、appmsg_token,这些数据可以在cookie和appmsg_token中获取。
# utils.py
# 工具模块,将字符串变成字典
def str_to_dict(s, join_symbol="\n", split_symbol=":"):
s_list = s.split(join_symbol)
data = dict()
for item in s_list:
item = item.strip()
if item:
k, v = item.split(split_symbol, 1)
data[k] = v.strip()
return data
# coding:utf-8
# wxCrawler.py
import os
import requests
import json
import urllib3
import utils
class WxCrawler(object):
"""翻页内容抓取"""
urllib3.disable_warnings()
def __init__(self, appmsg_token, biz, cookie, begin_page_index = 0, end_page_index = 100):
# 起始页数
self.begin_page_index = begin_page_index
# 结束页数
self.end_page_index = end_page_index
# 抓了多少条了
self.num = 1
self.appmsg_token = appmsg_token
self.biz = biz
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.cookie = cookie
def article_list(self, context):
articles = json.loads(context).get('general_msg_list')
return json.loads(articles)
def run(self):
# 翻页地址
page_url = "https://mp. weixin.qq.com/mp/profile_ext?action=getmsg&__biz={}&f=json&offset={}&count=10&is_ok=1&scene=&uin=777&key=777&pass_ticket={}&wxtoken=&appmsg_token=" + self.appmsg_token + "&x5=0f=json"
# 将 cookie 字典化
wx_dict = utils.str_to_dict(self.cookie, join_symbol='; ', split_symbol='=')
# 请求地址
response = requests.get(page_url.format(self.biz, self.begin_page_index * 10, wx_dict['pass_ticket']), headers=self.headers, verify=False)
# 将文章列表字典化
articles = self.article_list(response.text)
for a in articles['list']:
# 公众号中主条
if 'app_msg_ext_info' in a.keys() and '' != a.get('app_msg_ext_info').get('content_url', ''):
print(str(self.num) + "条", a.get('app_msg_ext_info').get('title'), a.get('app_msg_ext_info').get('content_url'))
# 公众号中副条
if 'app_msg_ext_info' in a.keys():
for m in a.get('app_msg_ext_info').get('multi_app_msg_item_list', []):
print(str(self.num) + "条", m.get('title'), a.get('content_url'))
self.num = self.num + 1
self.is_exit_or_continue()
# 递归调用
self.run()
def is_exit_or_continue(self):
self.begin_page_index = self.begin_page_index + 1
if self.begin_page_index > self.end_page_index:
os.exit()
最后使用自动cookie启动程序并刷新公众号文章
# coding:utf-8
# main.py
from read_cookie import ReadCookie
from wxCrawler import WxCrawler
"""程序启动类"""ss
if __name__ == '__main__':
cookie = ReadCookie('E:/python/cookie.txt')
cookie.write_cookie()
appmsg_token, biz, cookie_str = cookie.parse_cookie()
wx = WxCrawler(appmsg_token, biz, cookie_str)
wx.run()
样本结果

总结
这篇文章虽然可能有点头条党,但并没有完全自动抓取数据,需要人为刷新公众号文章。希望大家不要介意。如需刷微信文章,建议参考本公众号【第129天:爬取微信公众号文章内容】。
自动抓取网页数据(基于大数据开发一个网络爬虫设计的技术理论发展和应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-09 11:00
齐宝德
武汉大学信息工程学院,湖北武汉 430212
摘要:本文开发了一种基于大数据的网络爬虫设计,利用Python相关模块实现从网站一本书中自动下载感兴趣的图书信息的功能。包括单页图书信息下载、图书信息提取、多页图书信息下载等。
关键词:网络爬虫、信息提取、内容分析
基金资助:资助项目(新一代信息技术创新项目,课题编号2018A02016)
0 前言
网络爬虫是从互联网打开数据采集的重要手段。本文开发了一个简单的爬虫设计,利用Python的相关模块实现从某本书网站中自动下载感兴趣的书籍信息的功能。实现的主要功能有单页图书信息下载、图书信息提取、多页图书信息下载等。基于人工智能技术的新一代采集模式,操作极其简单,只需输入采集的URL,智能识别网页中的内容和分页按钮,无需配置采集规则即可完成采集的数据。
自 2004 年以来,Google 已在其应用程序中成功使用 AJAX 技术,例如 Google Discussion Groups、Google Maps、Gmail 等。同时因为该技术支持 Mozilla/Geck。,并先后被网站专业采用。GWT、Atlas、Doj等各种异步交互网络框架。也应运而生。但随之而来的是一个新问题:由于AJAX框架网站是建立在异步JavascriPt基础上的网络应用技术,传统网络搜索引擎中的网络爬虫(WebCrawler)无法解决异步交互网络网址(URL) 提取。一方面,大量基于AJAx的网站不断涌现,另一方面,这些网站网址却被搜索引擎忽略,这意味着越来越多的有意义的数据不会被搜索引擎检索到。. 这个问题也引起了国内外学者的广泛关注:异步交互网络地址解析方法的研究对于互联网领域技术理论的发展和应用具有重要意义。
1 任务描述和数据来源
前段时间在图书馆借了很多书,借多了很容易忘记每本书的到期日。一直担心会违约,影响以后借阅,但又懒得老是登录学校图书馆借阅系统。查,所以我打算写一个爬虫来抓取我的借阅信息,把每本书的到期日爬下来,写成一个txt文件,这样每次忘记的时候可以打开txt文件查,而且每我借的时候。如果信息发生了变化,只要再次运行程序,原来的txt文件就会被新的文件覆盖,里面的内容也会被更新。详细介绍智能模式的基本操作流程。
1.1 涉及的技术:
Python版本是?2.7,同时使用了urllib2、cookielib和re三个模块。urllib2 用于创建请求,抓取网页信息,返回类似文件类型的响应对象;
cookielib用于存储cookie对象,实现模拟登录功能;re 模块提供了对正则表达式的支持,用于匹配抓取的页面信息,得到你想要的信息。
创建一个智能模式任务,输入正确的 URL,采集 任务就完成了一半。从当当搜索页面,根据关键词进行搜索,使用Python编写爬虫(如图1))自动爬取书名、出版商、价格、作者、书籍介绍搜索结果中的信息。当当网搜索页面:.
图1 Web爬虫自动爬取流程
2、单页书资料下载
2.1 网页下载
采集支持单个URL和多个URL采集,支持从本地TXT文件导入URL,支持批量生成参数URL。Python中的requests库可以自动帮助我们构造一个请求对象,用于向服务器请求资源,并返回一个响应对象,用于服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。在下面的代码中,我们首先导入 requests 库,定义当当搜索页面的 URL,并将 search关键词 设置为“机器学习”。然后使用 ?requests.get? 获取网页内容的方法。最后,打印并显示网页的前 1000 个字符。
导入请求库 test_url = '' + '机器学习',设置网页的url地址 content_page = requests.get(test_url).text ,执行页面请求,返回页面内容 print(content_page[:1000]) ,把页面的前1000个字符都打印出来并显示出来。
2.2本书内容分析
接下来开始解析页面,分析源码。使用Chrome浏览器直接打开URL Machine Learning?。然后选择任何书籍信息,右键单击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,点击第一个标签,发现下面还有几个。
标签,分类为“名称”、“详细信息”、“价格”等。这些标签存储了产品的标题、详细信息、价格等信息。
以提取书名信息为例,进行具体说明。单击 ?p? ?li? 下的类属性为 name 的标记 标签,我们发现书名信息存储在?a?的title属性中。名称属性值为“itemlist-title”的标签。可以使用xpath直接将上述定位信息描述为?//li/p/a[@name="itemlist-title"]/@title?。然后使用 ?lxml? 模块提取页面中的标题信息。请参阅 ?用于 xpath。
导入etree模块 page = etree.HTML(content_page) #将页面字符串解析成树形结构 book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') # 使用xpath提取书名信息。book_name[:10] #打印提取的前10个书名。同理,我们可以提取图书的出版信息(作者、出版商、出版时间等)、当前价格、星级、评论数等。这些信息对应的xpath路径如下表所示。
接下来,我们编写一个函数?extract_books_from_content,输入一个页面内容,自动提取页面中收录的所有书籍信息。
2.3 图书数据存储
在上一节中,我们成功地从网页中提取了图书信息,并将其转换为 DataFrame 格式。您可以选择将此图书信息保存为 CSV 文件、Excel 文件或数据库。这里我们使用 ?to_csv? DataFrame 提供的保存为 CSV 文件的方法。
books_df.to_csv("./input/books_test.csv",index=None)
3、多页图书资料下载
查看搜索页面底部,输入一个关键词,一般会返回多页结果,点击任意页面按钮,观察浏览器地址栏变化。我们发现可以通过在浏览器 URL 中添加 page_index 属性来添加不同的页面。例如,如果我们搜索“机器学习”关键词,要访问第 10 页的结果,请使用以下 URL:machine learning&page_index=10
假设我们要下载一共10页的内容,我们可以通过下面的代码来完成。
import timekey_word = "machine learning" #设置搜索关键词max_page = 10 #下载书的页数_total = []for page in range(1,max_page+1): 查看全部
自动抓取网页数据(基于大数据开发一个网络爬虫设计的技术理论发展和应用)
齐宝德
武汉大学信息工程学院,湖北武汉 430212
摘要:本文开发了一种基于大数据的网络爬虫设计,利用Python相关模块实现从网站一本书中自动下载感兴趣的图书信息的功能。包括单页图书信息下载、图书信息提取、多页图书信息下载等。
关键词:网络爬虫、信息提取、内容分析
基金资助:资助项目(新一代信息技术创新项目,课题编号2018A02016)
0 前言
网络爬虫是从互联网打开数据采集的重要手段。本文开发了一个简单的爬虫设计,利用Python的相关模块实现从某本书网站中自动下载感兴趣的书籍信息的功能。实现的主要功能有单页图书信息下载、图书信息提取、多页图书信息下载等。基于人工智能技术的新一代采集模式,操作极其简单,只需输入采集的URL,智能识别网页中的内容和分页按钮,无需配置采集规则即可完成采集的数据。
自 2004 年以来,Google 已在其应用程序中成功使用 AJAX 技术,例如 Google Discussion Groups、Google Maps、Gmail 等。同时因为该技术支持 Mozilla/Geck。,并先后被网站专业采用。GWT、Atlas、Doj等各种异步交互网络框架。也应运而生。但随之而来的是一个新问题:由于AJAX框架网站是建立在异步JavascriPt基础上的网络应用技术,传统网络搜索引擎中的网络爬虫(WebCrawler)无法解决异步交互网络网址(URL) 提取。一方面,大量基于AJAx的网站不断涌现,另一方面,这些网站网址却被搜索引擎忽略,这意味着越来越多的有意义的数据不会被搜索引擎检索到。. 这个问题也引起了国内外学者的广泛关注:异步交互网络地址解析方法的研究对于互联网领域技术理论的发展和应用具有重要意义。
1 任务描述和数据来源
前段时间在图书馆借了很多书,借多了很容易忘记每本书的到期日。一直担心会违约,影响以后借阅,但又懒得老是登录学校图书馆借阅系统。查,所以我打算写一个爬虫来抓取我的借阅信息,把每本书的到期日爬下来,写成一个txt文件,这样每次忘记的时候可以打开txt文件查,而且每我借的时候。如果信息发生了变化,只要再次运行程序,原来的txt文件就会被新的文件覆盖,里面的内容也会被更新。详细介绍智能模式的基本操作流程。
1.1 涉及的技术:
Python版本是?2.7,同时使用了urllib2、cookielib和re三个模块。urllib2 用于创建请求,抓取网页信息,返回类似文件类型的响应对象;
cookielib用于存储cookie对象,实现模拟登录功能;re 模块提供了对正则表达式的支持,用于匹配抓取的页面信息,得到你想要的信息。
创建一个智能模式任务,输入正确的 URL,采集 任务就完成了一半。从当当搜索页面,根据关键词进行搜索,使用Python编写爬虫(如图1))自动爬取书名、出版商、价格、作者、书籍介绍搜索结果中的信息。当当网搜索页面:.
.png)
图1 Web爬虫自动爬取流程
2、单页书资料下载
2.1 网页下载
采集支持单个URL和多个URL采集,支持从本地TXT文件导入URL,支持批量生成参数URL。Python中的requests库可以自动帮助我们构造一个请求对象,用于向服务器请求资源,并返回一个响应对象,用于服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。在下面的代码中,我们首先导入 requests 库,定义当当搜索页面的 URL,并将 search关键词 设置为“机器学习”。然后使用 ?requests.get? 获取网页内容的方法。最后,打印并显示网页的前 1000 个字符。
导入请求库 test_url = '' + '机器学习',设置网页的url地址 content_page = requests.get(test_url).text ,执行页面请求,返回页面内容 print(content_page[:1000]) ,把页面的前1000个字符都打印出来并显示出来。
2.2本书内容分析
接下来开始解析页面,分析源码。使用Chrome浏览器直接打开URL Machine Learning?。然后选择任何书籍信息,右键单击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,点击第一个标签,发现下面还有几个。
标签,分类为“名称”、“详细信息”、“价格”等。这些标签存储了产品的标题、详细信息、价格等信息。
以提取书名信息为例,进行具体说明。单击 ?p? ?li? 下的类属性为 name 的标记 标签,我们发现书名信息存储在?a?的title属性中。名称属性值为“itemlist-title”的标签。可以使用xpath直接将上述定位信息描述为?//li/p/a[@name="itemlist-title"]/@title?。然后使用 ?lxml? 模块提取页面中的标题信息。请参阅 ?用于 xpath。
导入etree模块 page = etree.HTML(content_page) #将页面字符串解析成树形结构 book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') # 使用xpath提取书名信息。book_name[:10] #打印提取的前10个书名。同理,我们可以提取图书的出版信息(作者、出版商、出版时间等)、当前价格、星级、评论数等。这些信息对应的xpath路径如下表所示。
.png)
接下来,我们编写一个函数?extract_books_from_content,输入一个页面内容,自动提取页面中收录的所有书籍信息。
2.3 图书数据存储
在上一节中,我们成功地从网页中提取了图书信息,并将其转换为 DataFrame 格式。您可以选择将此图书信息保存为 CSV 文件、Excel 文件或数据库。这里我们使用 ?to_csv? DataFrame 提供的保存为 CSV 文件的方法。
books_df.to_csv("./input/books_test.csv",index=None)
3、多页图书资料下载
查看搜索页面底部,输入一个关键词,一般会返回多页结果,点击任意页面按钮,观察浏览器地址栏变化。我们发现可以通过在浏览器 URL 中添加 page_index 属性来添加不同的页面。例如,如果我们搜索“机器学习”关键词,要访问第 10 页的结果,请使用以下 URL:machine learning&page_index=10
假设我们要下载一共10页的内容,我们可以通过下面的代码来完成。
import timekey_word = "machine learning" #设置搜索关键词max_page = 10 #下载书的页数_total = []for page in range(1,max_page+1):
自动抓取网页数据( 这是简易数据分析系列的第4篇文章(图)实操)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-08 08:03
这是简易数据分析系列的第4篇文章(图)实操)
这是简易数据分析系列文章 的第四部分。
原文首发于博客园:简单数据分析04。
今天我们开始数据抓取的第一课,完成我们的第一个爬虫。因为只是开始,所以我会很详细的讲解操作,可能会有点啰嗦。我希望你不要不喜欢它:)
有些人之前可能学过一些爬虫知识,但是总觉得这是个复杂的东西,比如HTTP、HTML、IP池,这里就不考虑这些东西了。一是少量的数据根本不需要考虑,二是这些乱七八糟的东西根本不提爬虫的本质。
爬行动物的本质是什么?其实就是找规律。
而且,爬行动物找规律的难点,多半是小学三年级数学题的水平。
举个例子来说明,下图历史文章的截图,我们可以清楚的看到每条推文都可以分为标题、图片和作者三部分,我们只需要找到这个规律,您可以批量捕获此类数据。
好了,理论讲完了,我们开始实操吧。
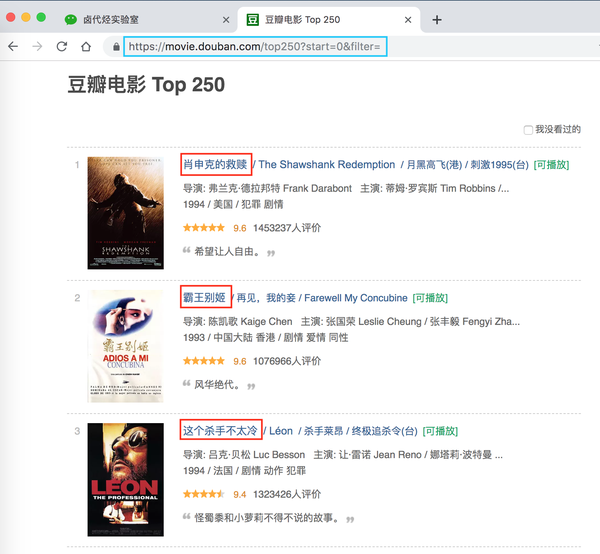
只要练习爬取,第一个爬取的网站通常是豆瓣电影TOP 250,URL链接是/top250?start=0&filter=。第一次爬取的内容尽量简单,所以只爬取首页的电影片名。
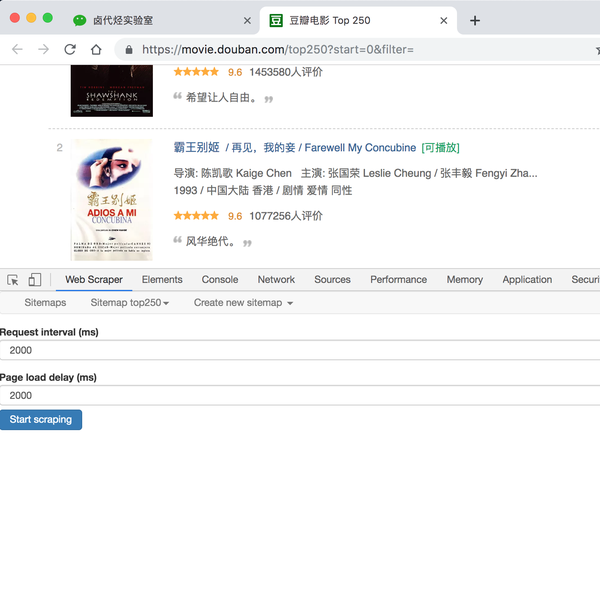
浏览器按F12打开控制台,把控制台放在网页底部(详情见上篇文章),然后找到Web Scraper Tab,点击,就到了Web Scraper 控制页面。
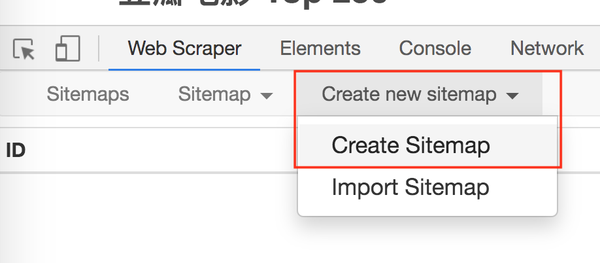
进入Web Scraper的控制页面后,我们按照Create new sitemap -> Create Sitemap的操作路径新建一个爬虫。站点地图的含义并不重要,您只需将其视为爬虫的别名。
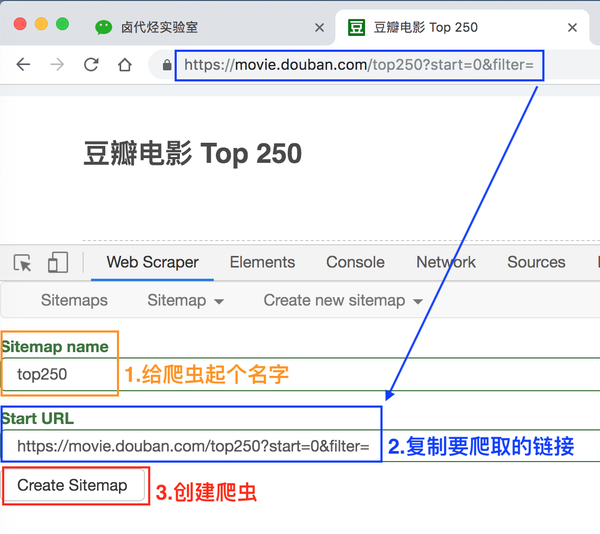
我们在接下来出现的输入框中依次输入爬虫名称和要爬取的链接。
爬虫名称可能有字符类型限制,我们只看规则规避,最后点击 Create Sitemap 按钮创建我们的第一个爬虫。
这时候会跳转到一个新的操作面板,别的不用管,我们直接点击蓝底白字的添加新选择器按钮,顾名思义,创建一个选择器来选择我们的元素想抢。
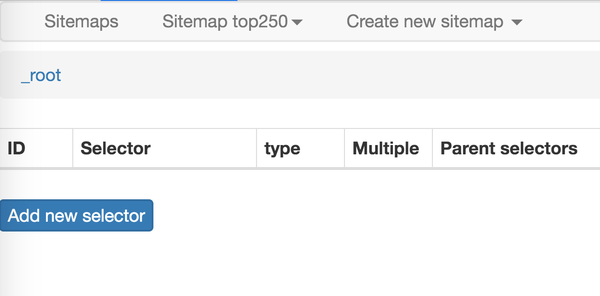
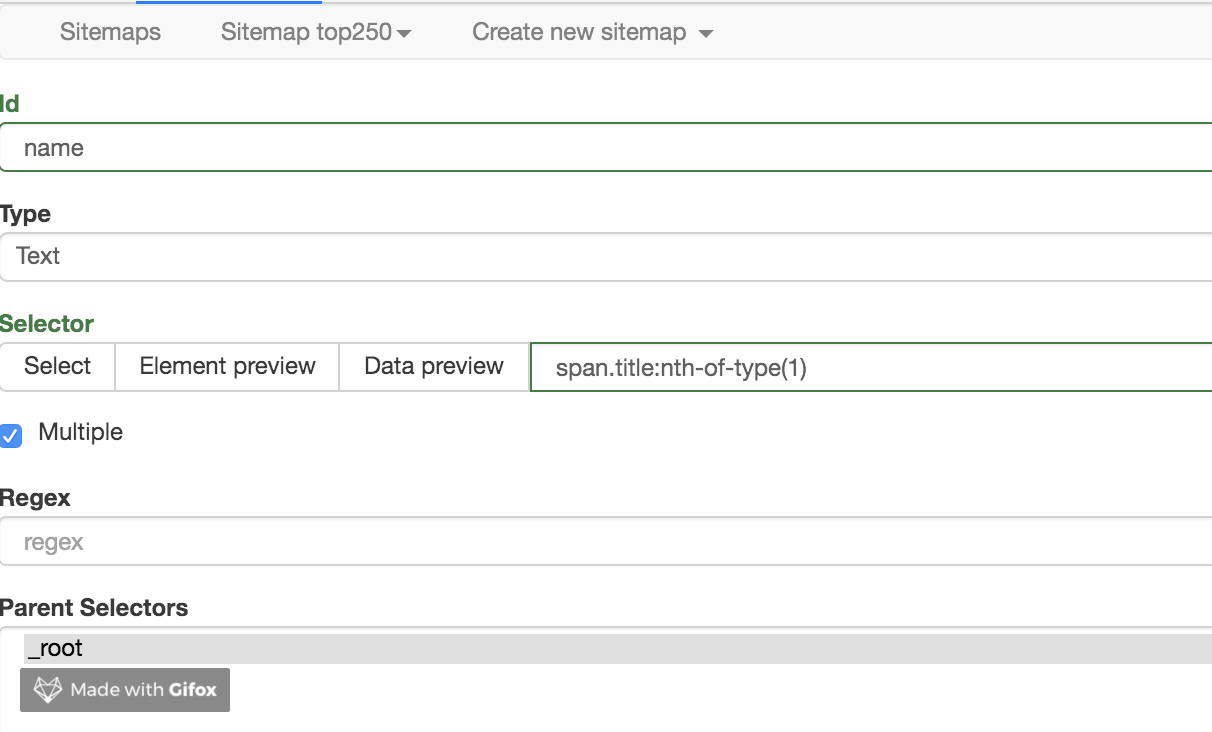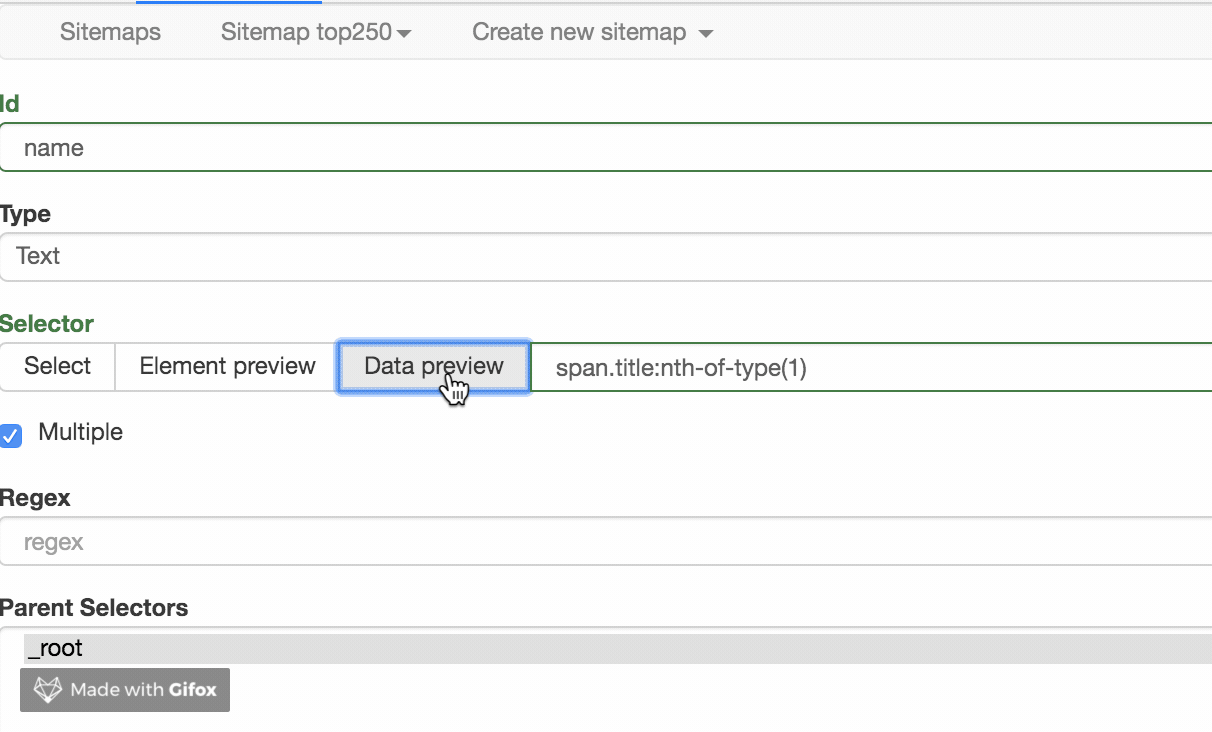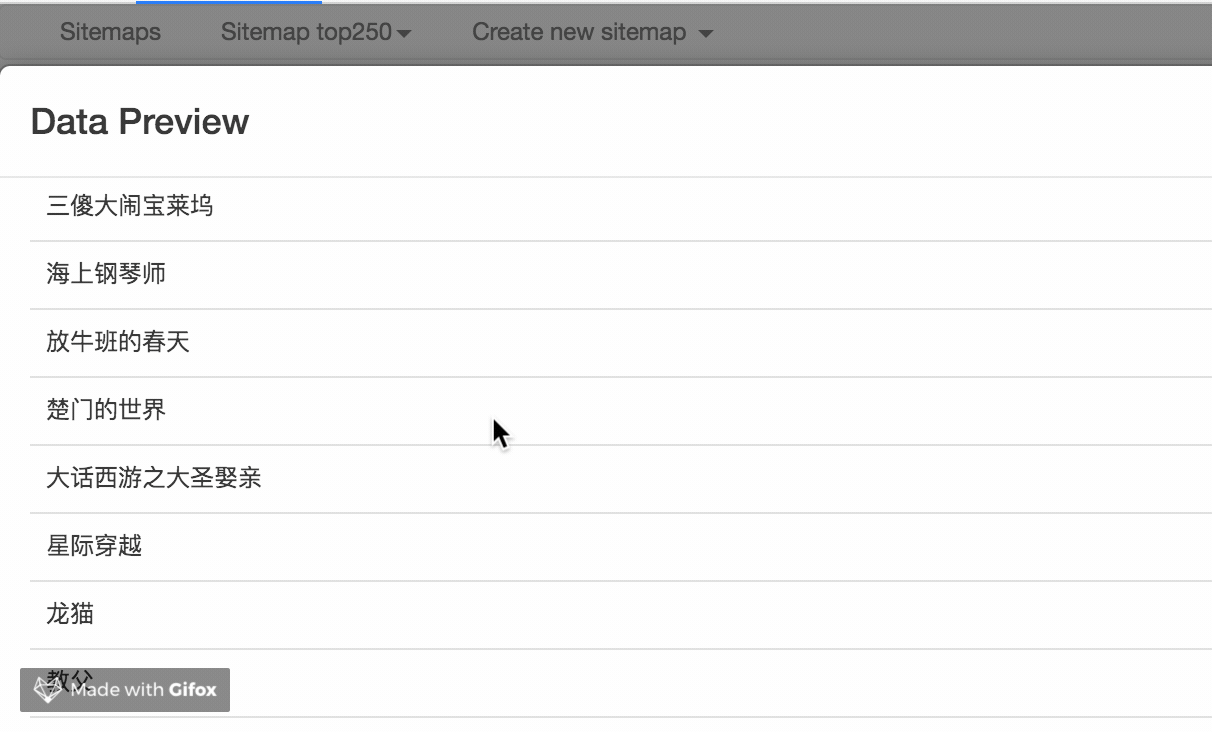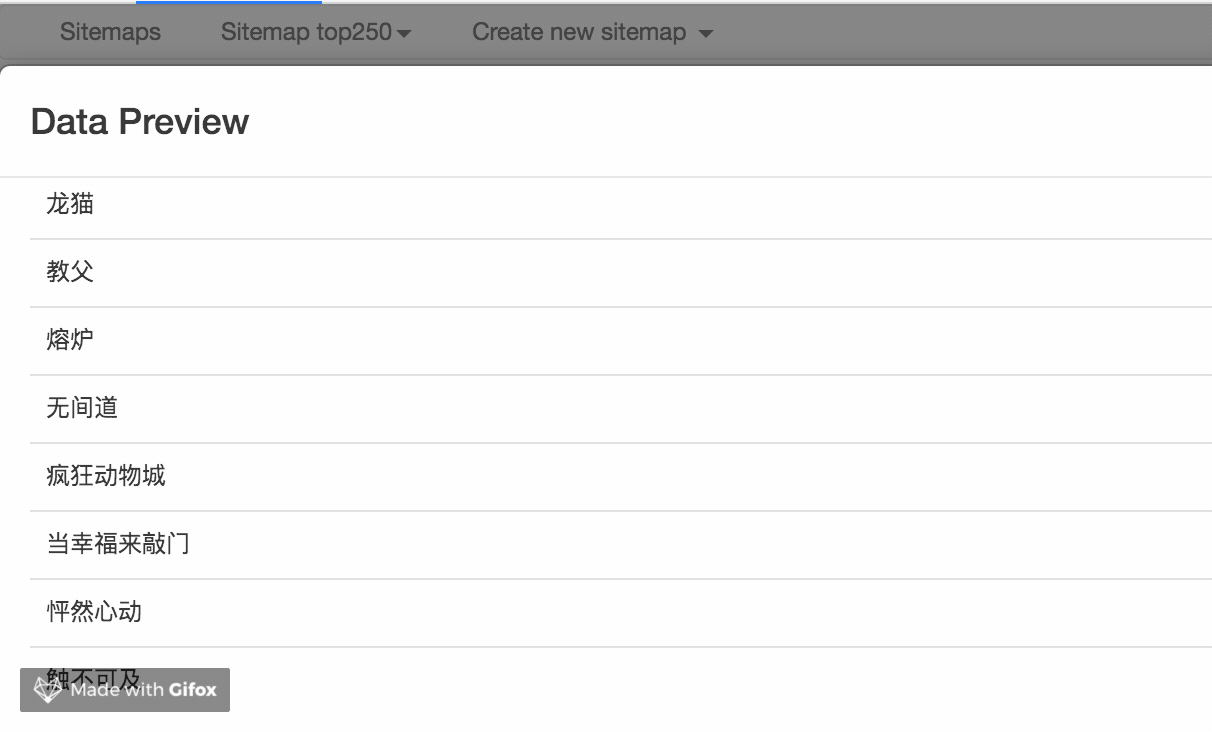
是时候开始正式的数据采集会话了!我们先来看看这个面板有什么:
1.首先有一个Id,这个是给我们要爬取的内容标记一个id,因为我们要爬取电影的名字,为了简单起个名字就行了;
2.电影的名字显然是一段文字,所以Type类型必须是Text。在这个爬虫工具中,默认的Type类型是Text,这个爬取工作不需要改变;
3.我们勾选了多选按钮Multiple,因为我们要抓取的是批量数据,不勾选就只能抓取一个;
4.最后,我们点击黄圈中的选择,开始在网页上查看电影名称;
当您将鼠标移动到网页上时,您会发现网页上出现绿色方块。这些方块是网页的组成元素。当我们点击鼠标时,绿色方块会变成红色,表示该元素被选中。:
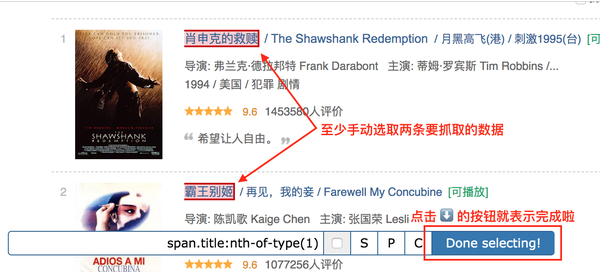
至此,我们就可以进行爬取工作了。
我们先选择《肖申克的救赎》的标题,再选择《霸王别姬》的标题(注:要达到多选的效果,必须手动选择两个以上的内容)
选择这两个片名后,向下滚动页面,你会发现所有电影片名都被选中:
拉网页再次查看,发现所有电影片名都被选中了,我们可以点击完成选择!按钮,表示选择完成;
点击按钮后,你会发现下图红框中会出现一些字符。一般如果出现这个,就说明选择成功了:
我们点击数据预览按钮来预览我们的抓取效果:
如果没有问题,关闭数据预览弹窗,转到面板底部,有一个蓝色的保存选择器按钮,点击后,我们会回到上一个面板。
这时候你会发现多了一行数据,其实就是我们刚才记录的操作的内容。
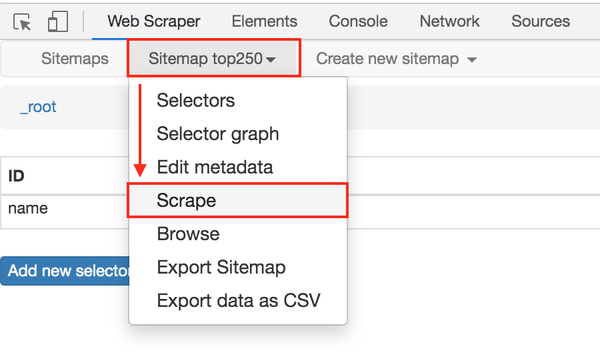
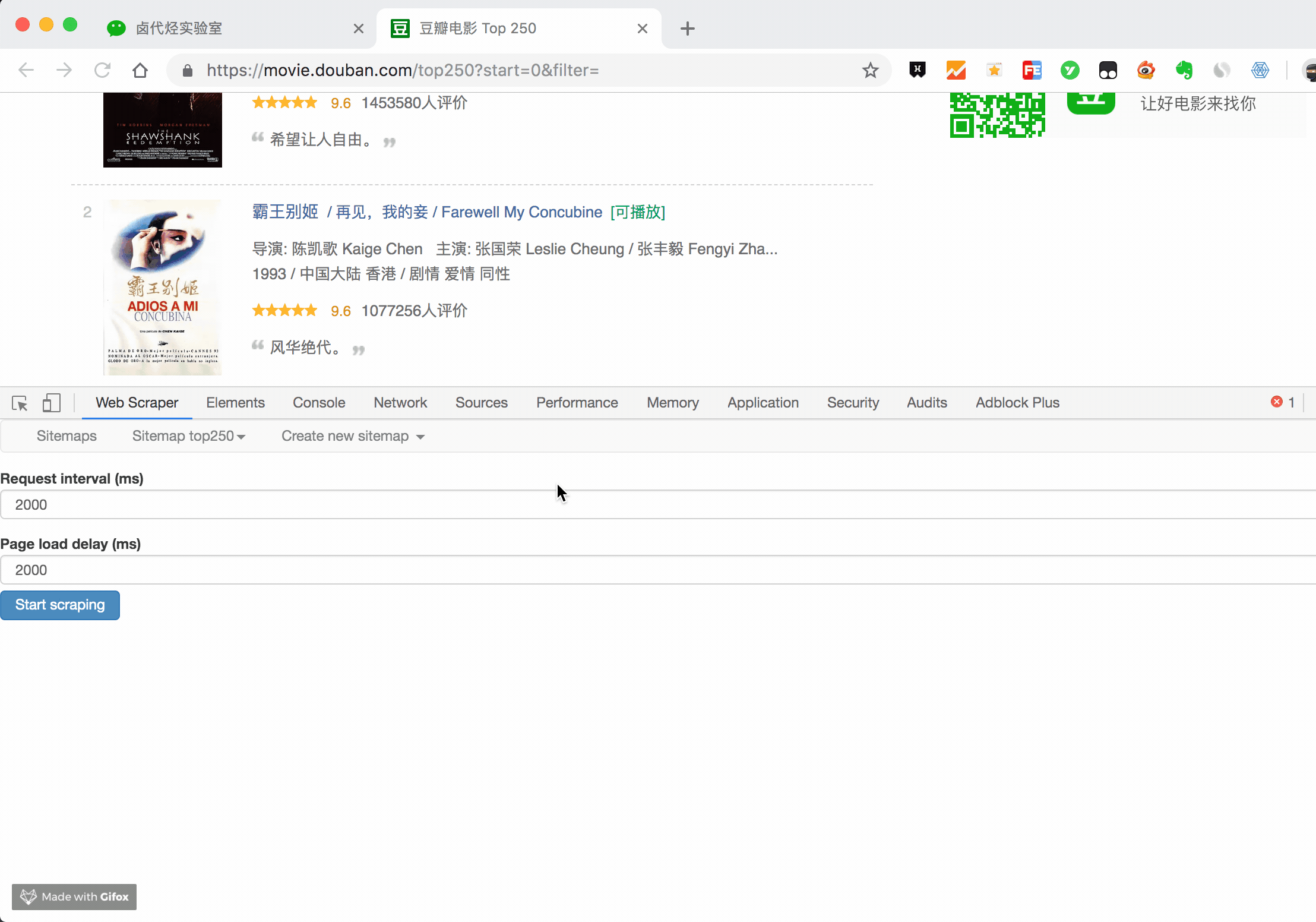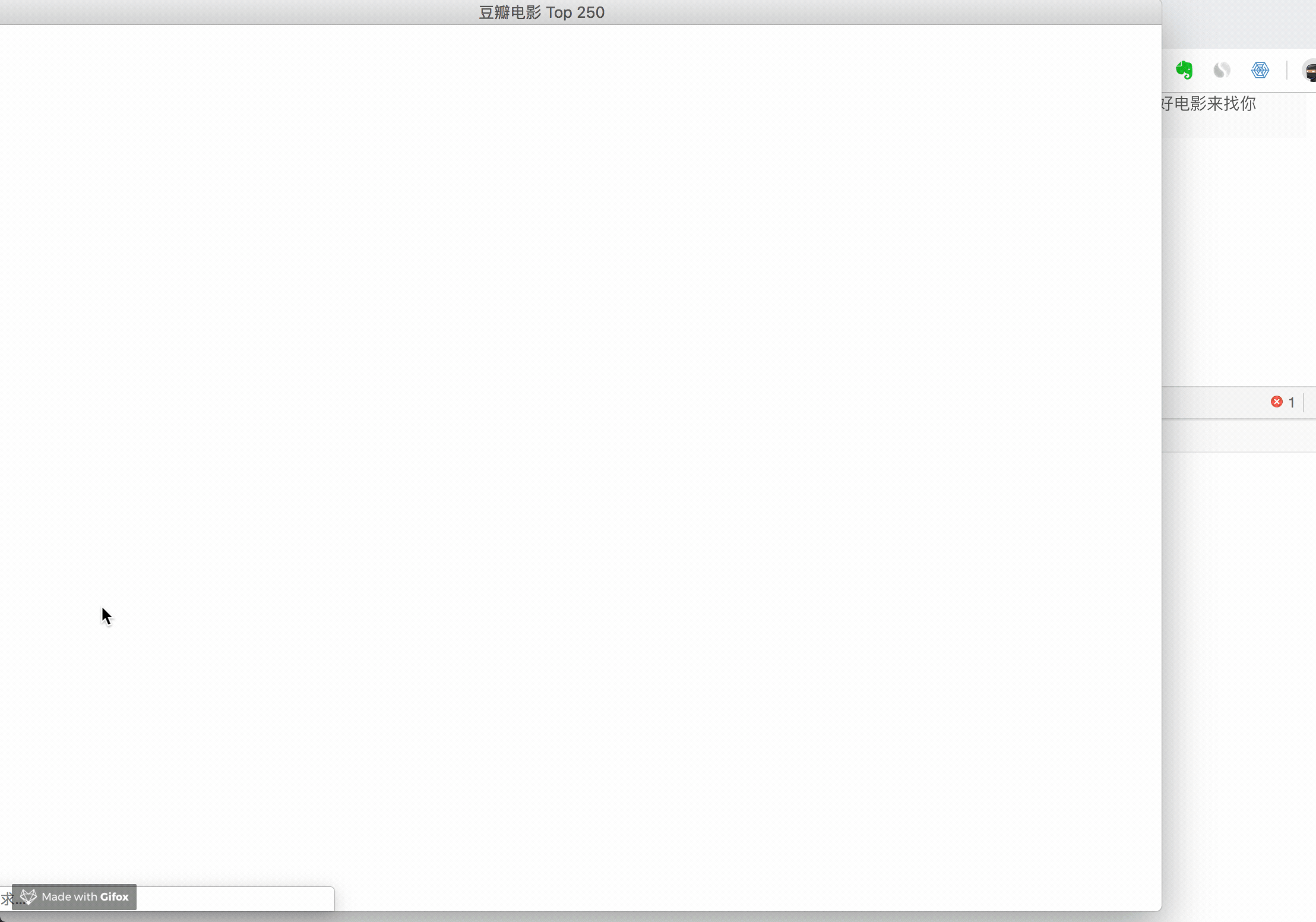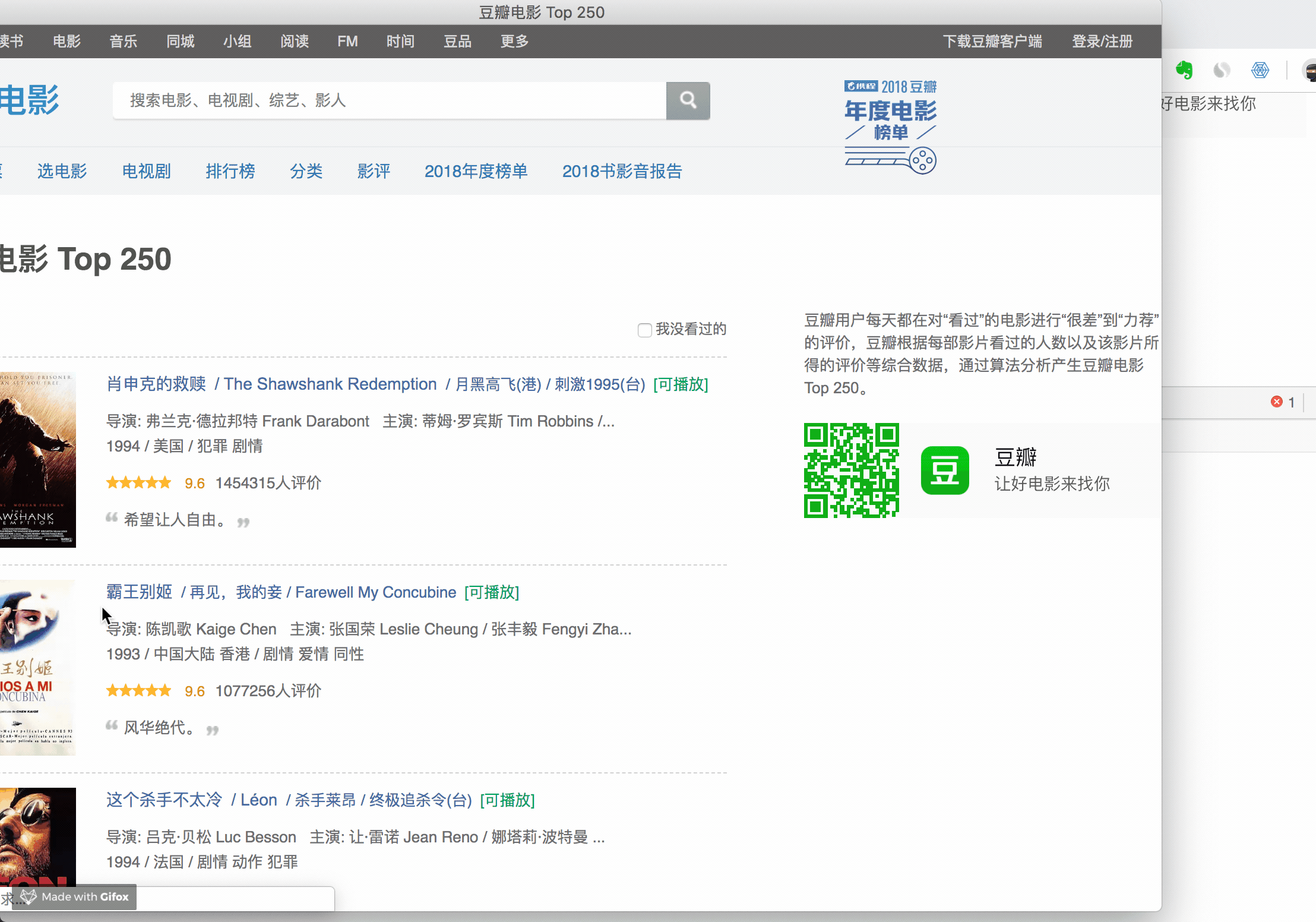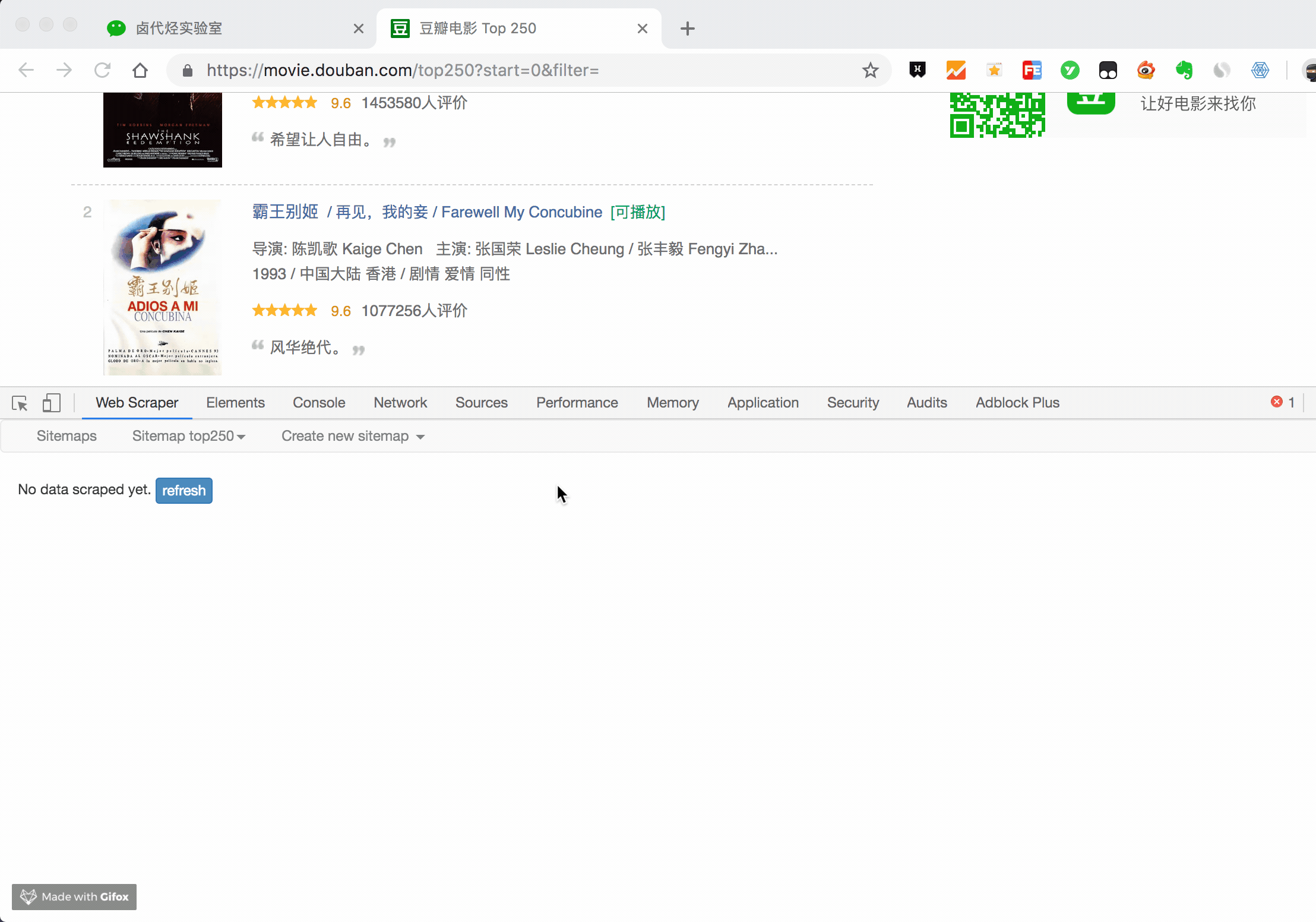
在顶部的标签栏中,有一个Sitemap top250 标签,就是我们刚刚创建的爬虫。点击它,然后点击下拉菜单中的 Scrape 按钮,开始我们的数据抓取。
这时候会跳转到另一个面板,有两个输入框,不管是什么,一共输入2000就行了。
点击开始抓取蓝色按钮后,会弹出一个新的网页,Web Scraper插件会在这里抓取数据:
一般情况下,弹出网页的自动关闭意味着数据采集结束。我们点击面板上的刷新蓝色按钮,就可以看到我们抓到的数据了!
在这个预览面板中,第一列是网络爬虫自动添加的数字,没有意义;第二列是爬取的链接,第三列是我们爬取的数据。
这个数据会保存在我们的浏览器中,我们也可以在Sitemap top250下点击Export data as CSV,这样我们就可以导出.csv格式的数据了,这个格式可以用Excel打开,我们可以用Excel做一些数据格式化手术。
今天我们爬取了豆瓣电影TOP250的首页数据(也就是排名前25的电影),下一篇我们会讲如何抓取所有电影名。 查看全部
自动抓取网页数据(
这是简易数据分析系列的第4篇文章(图)实操)

这是简易数据分析系列文章 的第四部分。
原文首发于博客园:简单数据分析04。
今天我们开始数据抓取的第一课,完成我们的第一个爬虫。因为只是开始,所以我会很详细的讲解操作,可能会有点啰嗦。我希望你不要不喜欢它:)
有些人之前可能学过一些爬虫知识,但是总觉得这是个复杂的东西,比如HTTP、HTML、IP池,这里就不考虑这些东西了。一是少量的数据根本不需要考虑,二是这些乱七八糟的东西根本不提爬虫的本质。
爬行动物的本质是什么?其实就是找规律。
而且,爬行动物找规律的难点,多半是小学三年级数学题的水平。
举个例子来说明,下图历史文章的截图,我们可以清楚的看到每条推文都可以分为标题、图片和作者三部分,我们只需要找到这个规律,您可以批量捕获此类数据。
好了,理论讲完了,我们开始实操吧。
只要练习爬取,第一个爬取的网站通常是豆瓣电影TOP 250,URL链接是/top250?start=0&filter=。第一次爬取的内容尽量简单,所以只爬取首页的电影片名。
浏览器按F12打开控制台,把控制台放在网页底部(详情见上篇文章),然后找到Web Scraper Tab,点击,就到了Web Scraper 控制页面。

进入Web Scraper的控制页面后,我们按照Create new sitemap -> Create Sitemap的操作路径新建一个爬虫。站点地图的含义并不重要,您只需将其视为爬虫的别名。
我们在接下来出现的输入框中依次输入爬虫名称和要爬取的链接。
爬虫名称可能有字符类型限制,我们只看规则规避,最后点击 Create Sitemap 按钮创建我们的第一个爬虫。
这时候会跳转到一个新的操作面板,别的不用管,我们直接点击蓝底白字的添加新选择器按钮,顾名思义,创建一个选择器来选择我们的元素想抢。
是时候开始正式的数据采集会话了!我们先来看看这个面板有什么:
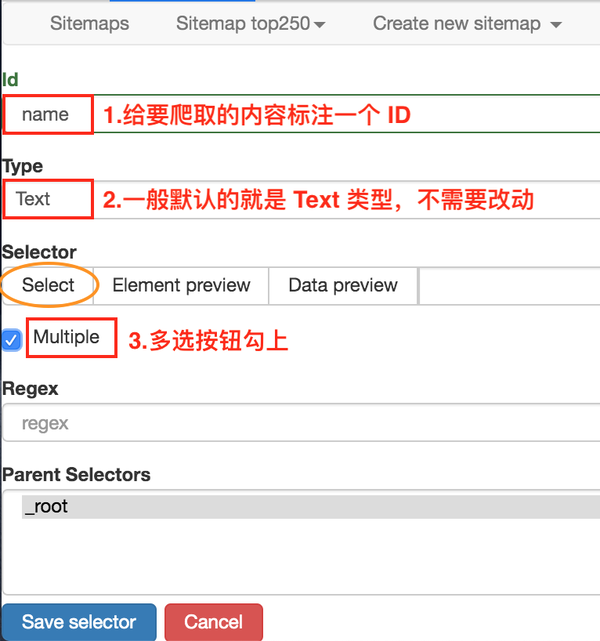
1.首先有一个Id,这个是给我们要爬取的内容标记一个id,因为我们要爬取电影的名字,为了简单起个名字就行了;
2.电影的名字显然是一段文字,所以Type类型必须是Text。在这个爬虫工具中,默认的Type类型是Text,这个爬取工作不需要改变;
3.我们勾选了多选按钮Multiple,因为我们要抓取的是批量数据,不勾选就只能抓取一个;
4.最后,我们点击黄圈中的选择,开始在网页上查看电影名称;
当您将鼠标移动到网页上时,您会发现网页上出现绿色方块。这些方块是网页的组成元素。当我们点击鼠标时,绿色方块会变成红色,表示该元素被选中。:
至此,我们就可以进行爬取工作了。
我们先选择《肖申克的救赎》的标题,再选择《霸王别姬》的标题(注:要达到多选的效果,必须手动选择两个以上的内容)
选择这两个片名后,向下滚动页面,你会发现所有电影片名都被选中:

拉网页再次查看,发现所有电影片名都被选中了,我们可以点击完成选择!按钮,表示选择完成;
点击按钮后,你会发现下图红框中会出现一些字符。一般如果出现这个,就说明选择成功了:

我们点击数据预览按钮来预览我们的抓取效果:
如果没有问题,关闭数据预览弹窗,转到面板底部,有一个蓝色的保存选择器按钮,点击后,我们会回到上一个面板。
这时候你会发现多了一行数据,其实就是我们刚才记录的操作的内容。
在顶部的标签栏中,有一个Sitemap top250 标签,就是我们刚刚创建的爬虫。点击它,然后点击下拉菜单中的 Scrape 按钮,开始我们的数据抓取。
这时候会跳转到另一个面板,有两个输入框,不管是什么,一共输入2000就行了。
点击开始抓取蓝色按钮后,会弹出一个新的网页,Web Scraper插件会在这里抓取数据:
一般情况下,弹出网页的自动关闭意味着数据采集结束。我们点击面板上的刷新蓝色按钮,就可以看到我们抓到的数据了!
在这个预览面板中,第一列是网络爬虫自动添加的数字,没有意义;第二列是爬取的链接,第三列是我们爬取的数据。
这个数据会保存在我们的浏览器中,我们也可以在Sitemap top250下点击Export data as CSV,这样我们就可以导出.csv格式的数据了,这个格式可以用Excel打开,我们可以用Excel做一些数据格式化手术。
今天我们爬取了豆瓣电影TOP250的首页数据(也就是排名前25的电影),下一篇我们会讲如何抓取所有电影名。
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-07 11:04
)
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。
任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browserbrowser = Browser('chrome') #打开谷歌浏览器browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;) #访问链接
打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。# find_by_xpath(XPath地址) 返回值是储存在列表中的# 这里是只有一个元素的列表,所以要选择列表第一个元素的值r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页# 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browserbrowser = Browser('chrome')browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;)r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.valuer1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.valuer1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.valuebrowser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit() 查看全部
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录
)
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。

任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browserbrowser = Browser('chrome') #打开谷歌浏览器browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;) #访问链接

打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。# find_by_xpath(XPath地址) 返回值是储存在列表中的# 这里是只有一个元素的列表,所以要选择列表第一个元素的值r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页# 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browserbrowser = Browser('chrome')browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;)r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.valuer1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.valuer1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.valuebrowser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit()
自动抓取网页数据(超长正整数(超出long表数范围)的相加算法(Java实现))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-05 15:13
超长正整数(超出长表号范围)的加法算法(Java实现)
输入:一个表示超长正整数的字符串 a 表示一个超长正整数的字符串 b 输出:字符串 a 和 b 表示的正整数相加后的字符串 c 代码: import java.util.Scanner; /***@作者 wzy*@Date April 8, 2018*@Version JDK 1.8*@Description */public class run {public...
嵌入式Linux是我的line-u-boot-2009.08移植详解2440(二)_b02330224的专栏-程序员宝贝
我的嵌入式Linux线,主要讲述和总结学习嵌入式Linux的每一步。一是总结经验,二是为想入门嵌入式Linux的人提供方便。如果有任何错误,请纠正我。共享资源,欢迎转载:一、移植环境宿主:VMWare--Fedora 9开发板:Mini2440--64MB Nand,Kernel:2.6.30.4编译器
HTML基础文件,CSS基础_weixin_30649859的博客-程序员分享
HTML一、HTML 基础文件[meta tag] 1、charset 属性:单独使用。设置文档字符集编码格式。>>>编写:<meta charset="utf8"> >>>常用中文编码格式:GB-2312:国标码、简体中文GBK:扩展国际码、...
剑指Offer 16. 数值整数幂---二分法,python,c++
c++:class 解决方案 {public: double myPow(double x, int n) {if(x==0||x==1){ return x;} // 考虑溢出情况 long b=(long) n; //如果指数小于0,则指数为正,底为倒数 if(b<0){ x=1/x; b=-b...
scrapy 设置和一些默认值_byseaz 的博客程序员寻求
Scrapy 组件中描述的功能可以使用 Scrapy 设置进行修改。如果您有多个 Scrapy 项目,也可以在 Scrapy 项目当前处于活动状态时选择这些设置。要指定设置,您必须在放弃 网站 时告知您使用的 Scrapy 设置。为此,应使用关键内容环境变量 SCRAPY_SETTINGS_MODULE,其值应在 Python 路径语法中。填充设置 下表显示了一些可以用来填充设置的机制: SN 机制和描述 1. Co...
Dijkstra算法解决最短路径问题
标题:Dijkstra 算法解决最短路径问题日期:2020-01-07 16:18:25tags:数据结构单源最短路径问题:计算源点到彼此顶点的最短路径长度全局最短路径问题:任意两个图中节点之间的最短路径 上述两个问题都可以归结为最短路径问题(实际上,全局最短路径可以通过为每个节点找到单源最短路径来解决)Dijkstra算法用于解决单源最短路径,但它无法找到具有负边权的最短路径...... 查看全部
自动抓取网页数据(超长正整数(超出long表数范围)的相加算法(Java实现))
超长正整数(超出长表号范围)的加法算法(Java实现)
输入:一个表示超长正整数的字符串 a 表示一个超长正整数的字符串 b 输出:字符串 a 和 b 表示的正整数相加后的字符串 c 代码: import java.util.Scanner; /***@作者 wzy*@Date April 8, 2018*@Version JDK 1.8*@Description */public class run {public...
嵌入式Linux是我的line-u-boot-2009.08移植详解2440(二)_b02330224的专栏-程序员宝贝
我的嵌入式Linux线,主要讲述和总结学习嵌入式Linux的每一步。一是总结经验,二是为想入门嵌入式Linux的人提供方便。如果有任何错误,请纠正我。共享资源,欢迎转载:一、移植环境宿主:VMWare--Fedora 9开发板:Mini2440--64MB Nand,Kernel:2.6.30.4编译器
HTML基础文件,CSS基础_weixin_30649859的博客-程序员分享
HTML一、HTML 基础文件[meta tag] 1、charset 属性:单独使用。设置文档字符集编码格式。>>>编写:<meta charset="utf8"> >>>常用中文编码格式:GB-2312:国标码、简体中文GBK:扩展国际码、...
剑指Offer 16. 数值整数幂---二分法,python,c++
c++:class 解决方案 {public: double myPow(double x, int n) {if(x==0||x==1){ return x;} // 考虑溢出情况 long b=(long) n; //如果指数小于0,则指数为正,底为倒数 if(b<0){ x=1/x; b=-b...
scrapy 设置和一些默认值_byseaz 的博客程序员寻求
Scrapy 组件中描述的功能可以使用 Scrapy 设置进行修改。如果您有多个 Scrapy 项目,也可以在 Scrapy 项目当前处于活动状态时选择这些设置。要指定设置,您必须在放弃 网站 时告知您使用的 Scrapy 设置。为此,应使用关键内容环境变量 SCRAPY_SETTINGS_MODULE,其值应在 Python 路径语法中。填充设置 下表显示了一些可以用来填充设置的机制: SN 机制和描述 1. Co...
Dijkstra算法解决最短路径问题
标题:Dijkstra 算法解决最短路径问题日期:2020-01-07 16:18:25tags:数据结构单源最短路径问题:计算源点到彼此顶点的最短路径长度全局最短路径问题:任意两个图中节点之间的最短路径 上述两个问题都可以归结为最短路径问题(实际上,全局最短路径可以通过为每个节点找到单源最短路径来解决)Dijkstra算法用于解决单源最短路径,但它无法找到具有负边权的最短路径......
自动抓取网页数据(可自动分析网页中表单已经填写的内容,功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-05 15:12
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。
/pic.php?url=http://8.pic.pc6.com/thumb/up/ ... 0.jpg
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
自动抓取网页数据(可自动分析网页中表单已经填写的内容,功能介绍)
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。
/pic.php?url=http://8.pic.pc6.com/thumb/up/ ... 0.jpg
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
自动抓取网页数据(servlet自动获取前端页面及代码1)提交数据介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-29 03:07
servlet自动获取前端页面的jsp提交数据
下面是我在学习过程中由于前端页面提交参数太多,后台servlet封装实体类太麻烦而写的一个工具类。应用jsp/servlet数据提交后,基于MVC+MyBatis的数据持久化过程。这里只介绍将数据封装对象从页面提交到servlet(控制器)的过程。MVC+MyBatis 对数据库的访问这里就不介绍了。
1.前端页面和代码
1)前端表单页面构建(用来测试简单构建的页面有点丑~)
2)前端jsp页面代码
这里使用ajax异步get,去除缓存提交表单。请按传统方式自测。我已经测试过了,我不会在这里展示它。
注:Ajax提交表单部分使用了jQuery的serialize()序列化函数,初学者可以参考jQuery帮助文档。如果不明白,可以使用数据部分中的“字符串”或json对象,以常规方式提交数据。
1
3
4
5
6
7 Insert title here
8
9
10 $(function(){
11 $("#submitBtn").click(function(){
12 $.ajax({
13 url:"${pageContext.request.contextPath }/testPage",
14 data:$("#formId").serialize(), //jQuery中的函数,序列化表单数据
15 type:"get",
16 cache:false,
17 success:function(jsonObj){
18 alert(jsonObj.msg);
19 $("#formId")[0].reset();//重置表单
20 }
21 })
22 });
23 })
24
25
26
27
28
29 ID:
30 姓名:
31 性别:
32 年龄:
33 价格:
34
35
36
37
2.实体类
5个属性并提供set/get方法
1 package com.domain;
2
3 public class Person {
4 String username;
5 String sex;
6 int age;
7 Double price;
8 Long id;
9 public String getUsername() {
10 return username;
11 }
12 public void setUsername(String username) {
13 this.username = username;
14 }
15 public String getSex() {
16 return sex;
17 }
18 public void setSex(String sex) {
19 this.sex = sex;
20 }
21 public int getAge() {
22 return age;
23 }
24 public void setAge(int age) {
25 this.age = age;
26 }
27 public Double getPrice() {
28 return price;
29 }
30 public void setPrice(Double price) {
31 this.price = price;
32 }
33 public Long getId() {
34 return id;
35 }
36 public void setId(Long id) {
37 this.id = id;
38 }
39 }
3.后台Servlet代码
1)封装实体类对象
这里只有前端提交数据并输出到控制台,证明数据已经获取到并封装在对象中。
其中,p = (Person) EncapsulationUtil.getJavaBean(Person.class, request); 我用的是打包工具,懒得自己写的,后面提供源码。稍后将给出详细说明。
注意:当前端提交的数据和我们需要保存到数据库的数据不完整时,可以在servlet中获取到包对象后手动设置。比如数据的主键id一般是后台生成UUID设置的,需要手动设置。
<p> 1 package com.controller;
2
3 import java.io.IOException;
4 import java.util.HashMap;
5 import java.util.Map;
6
7 import javax.servlet.ServletException;
8 import javax.servlet.http.HttpServlet;
9 import javax.servlet.http.HttpServletRequest;
10 import javax.servlet.http.HttpServletResponse;
11
12 import com.domain.Person;
13 import com.fasterxml.jackson.databind.ObjectMapper;
14 import com.utils.EncapsulationUtil;
15
16 public class testPage extends HttpServlet {
17
18 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
19 //定义数据封装体的对象
20 Person p;
21 //定义用于返回json的数据存放集合
22 Map map = new HashMap();
23
24 try {
25 //获取前端页面表单提交的数据
26 p = (Person) EncapsulationUtil.getJavaBean(Person.class, request);
27 //打印封装体中的数据结果
28 System.out.println("ID---->"+p.getId()+""+p.getUsername()+""+p.getAge()+" 查看全部
自动抓取网页数据(servlet自动获取前端页面及代码1)提交数据介绍)
servlet自动获取前端页面的jsp提交数据
下面是我在学习过程中由于前端页面提交参数太多,后台servlet封装实体类太麻烦而写的一个工具类。应用jsp/servlet数据提交后,基于MVC+MyBatis的数据持久化过程。这里只介绍将数据封装对象从页面提交到servlet(控制器)的过程。MVC+MyBatis 对数据库的访问这里就不介绍了。
1.前端页面和代码
1)前端表单页面构建(用来测试简单构建的页面有点丑~)
2)前端jsp页面代码
这里使用ajax异步get,去除缓存提交表单。请按传统方式自测。我已经测试过了,我不会在这里展示它。
注:Ajax提交表单部分使用了jQuery的serialize()序列化函数,初学者可以参考jQuery帮助文档。如果不明白,可以使用数据部分中的“字符串”或json对象,以常规方式提交数据。
1
3
4
5
6
7 Insert title here
8
9
10 $(function(){
11 $("#submitBtn").click(function(){
12 $.ajax({
13 url:"${pageContext.request.contextPath }/testPage",
14 data:$("#formId").serialize(), //jQuery中的函数,序列化表单数据
15 type:"get",
16 cache:false,
17 success:function(jsonObj){
18 alert(jsonObj.msg);
19 $("#formId")[0].reset();//重置表单
20 }
21 })
22 });
23 })
24
25
26
27
28
29 ID:
30 姓名:
31 性别:
32 年龄:
33 价格:
34
35
36
37
2.实体类
5个属性并提供set/get方法
1 package com.domain;
2
3 public class Person {
4 String username;
5 String sex;
6 int age;
7 Double price;
8 Long id;
9 public String getUsername() {
10 return username;
11 }
12 public void setUsername(String username) {
13 this.username = username;
14 }
15 public String getSex() {
16 return sex;
17 }
18 public void setSex(String sex) {
19 this.sex = sex;
20 }
21 public int getAge() {
22 return age;
23 }
24 public void setAge(int age) {
25 this.age = age;
26 }
27 public Double getPrice() {
28 return price;
29 }
30 public void setPrice(Double price) {
31 this.price = price;
32 }
33 public Long getId() {
34 return id;
35 }
36 public void setId(Long id) {
37 this.id = id;
38 }
39 }
3.后台Servlet代码
1)封装实体类对象
这里只有前端提交数据并输出到控制台,证明数据已经获取到并封装在对象中。
其中,p = (Person) EncapsulationUtil.getJavaBean(Person.class, request); 我用的是打包工具,懒得自己写的,后面提供源码。稍后将给出详细说明。
注意:当前端提交的数据和我们需要保存到数据库的数据不完整时,可以在servlet中获取到包对象后手动设置。比如数据的主键id一般是后台生成UUID设置的,需要手动设置。


<p> 1 package com.controller;
2
3 import java.io.IOException;
4 import java.util.HashMap;
5 import java.util.Map;
6
7 import javax.servlet.ServletException;
8 import javax.servlet.http.HttpServlet;
9 import javax.servlet.http.HttpServletRequest;
10 import javax.servlet.http.HttpServletResponse;
11
12 import com.domain.Person;
13 import com.fasterxml.jackson.databind.ObjectMapper;
14 import com.utils.EncapsulationUtil;
15
16 public class testPage extends HttpServlet {
17
18 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
19 //定义数据封装体的对象
20 Person p;
21 //定义用于返回json的数据存放集合
22 Map map = new HashMap();
23
24 try {
25 //获取前端页面表单提交的数据
26 p = (Person) EncapsulationUtil.getJavaBean(Person.class, request);
27 //打印封装体中的数据结果
28 System.out.println("ID---->"+p.getId()+""+p.getUsername()+""+p.getAge()+"
自动抓取网页数据(自动抓取网页数据,公有云管理协议都有机会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-26 04:00
自动抓取网页数据,就像蚂蚁森林一样,这是国家提倡的。这是整合行业的效果。2018年应该是经济下行,制造业寒冬。但信息安全领域可以看到,国家再推进,肯定能带动一部分自动化方面的需求。像云盘协议与带宽通道费用,已经这么高了,国家肯定会减少带宽使用。所以如果做信息安全行业,或许会有很多空间,但是前提是,业务能够从单一领域走向多元化,目前更多的是向企业云管理协议,专业云上管理协议,分离云和企业it解决方案迈进。从业务上看,企业应用安全,个人网站安全,公有云管理协议都有机会。
这个题目很久之前有的,现在感觉又被挖了出来,信息安全现在发展的非常好,机会大大的有。互联网金融、电信诈骗、盗号这些只要做不少年,肯定不会有问题,普通投资者别听信暴利,不然就做错了。
信息安全,人工智能,区块链,边缘计算,大数据,等等。都非常有前景。
一直把信息安全放在第一位,可能会从事这个,但是可能不是很有优势。毕竟,单靠安全行业的个人安全,和组织安全太弱。选择什么样的行业,看你个人的能力,不要因为安全行业暴利和人为因素的危害而停止了前进。
最近几年,安全行业确实发展很快,所有传统厂商都转入到企业安全领域,企业安全成为主流;从投资角度来看,以前中国互联网相对高速,其实企业安全并不很在重视,尤其是电子商务方面,很难出现这方面的第一名,但是这几年,国内企业安全方面从游戏、金融、社交、出行、p2p、直播...逐渐展现出来安全领域的格局,只要是互联网企业有安全方面的需求,安全员安全研发方面的压力会变得很大,如果互联网公司本身有安全要求,也确实需要最好同时配备有安全研发人员,看好这个方向,目前的起点高了,后期发展空间不错,毕竟国内基本企业安全都是个人安全厂商在做。 查看全部
自动抓取网页数据(自动抓取网页数据,公有云管理协议都有机会)
自动抓取网页数据,就像蚂蚁森林一样,这是国家提倡的。这是整合行业的效果。2018年应该是经济下行,制造业寒冬。但信息安全领域可以看到,国家再推进,肯定能带动一部分自动化方面的需求。像云盘协议与带宽通道费用,已经这么高了,国家肯定会减少带宽使用。所以如果做信息安全行业,或许会有很多空间,但是前提是,业务能够从单一领域走向多元化,目前更多的是向企业云管理协议,专业云上管理协议,分离云和企业it解决方案迈进。从业务上看,企业应用安全,个人网站安全,公有云管理协议都有机会。
这个题目很久之前有的,现在感觉又被挖了出来,信息安全现在发展的非常好,机会大大的有。互联网金融、电信诈骗、盗号这些只要做不少年,肯定不会有问题,普通投资者别听信暴利,不然就做错了。
信息安全,人工智能,区块链,边缘计算,大数据,等等。都非常有前景。
一直把信息安全放在第一位,可能会从事这个,但是可能不是很有优势。毕竟,单靠安全行业的个人安全,和组织安全太弱。选择什么样的行业,看你个人的能力,不要因为安全行业暴利和人为因素的危害而停止了前进。
最近几年,安全行业确实发展很快,所有传统厂商都转入到企业安全领域,企业安全成为主流;从投资角度来看,以前中国互联网相对高速,其实企业安全并不很在重视,尤其是电子商务方面,很难出现这方面的第一名,但是这几年,国内企业安全方面从游戏、金融、社交、出行、p2p、直播...逐渐展现出来安全领域的格局,只要是互联网企业有安全方面的需求,安全员安全研发方面的压力会变得很大,如果互联网公司本身有安全要求,也确实需要最好同时配备有安全研发人员,看好这个方向,目前的起点高了,后期发展空间不错,毕竟国内基本企业安全都是个人安全厂商在做。
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-21 20:16
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。
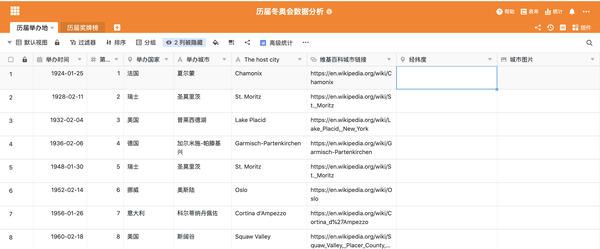
SeaTable表格字段自动获取城市经纬度到表格的“纬度和经度”字段
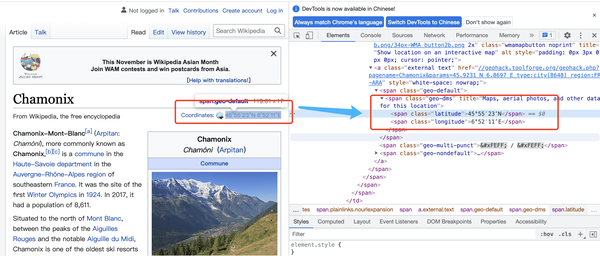
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:
只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
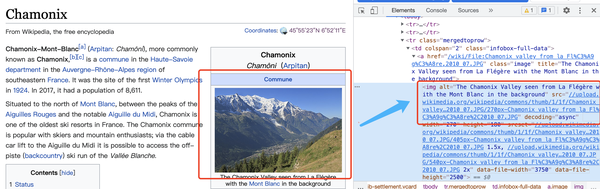
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:
img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。
使用SeaTable的地图插件自动生成城市地图
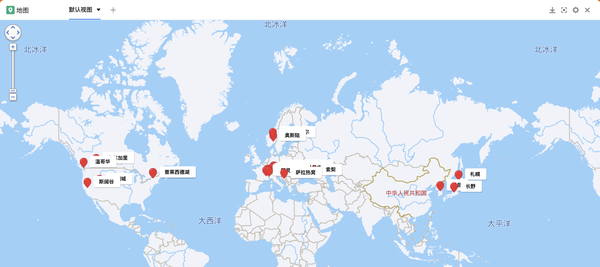
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。
使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。
此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。
总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。 查看全部
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。
SeaTable表格字段自动获取城市经纬度到表格的“纬度和经度”字段
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:
只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:
img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。

使用SeaTable的地图插件自动生成城市地图
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。
使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。
此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。
总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-21 20:15
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。
自动获取城市的经纬度到表格的“经纬度”字段中
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:
只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:
img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。
使用SeaTable的地图插件自动生成城市地图
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。
使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。
此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。
总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。 查看全部
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。

自动获取城市的经纬度到表格的“经纬度”字段中
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:

只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:

img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。

使用SeaTable的地图插件自动生成城市地图
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。

使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。

此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。

总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。
自动抓取网页数据(使用VC的socket编程,网上能找到一大堆http的get和post方法程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-20 09:15
最近突然有了一个想法,通过程序在客户端自动完成一些比较复杂的功能,比如自动注册论坛发帖,使用一些网站搜索功能自动搜索组织感兴趣的数据, 站内自动发送短信甚至自动发送邮件;说白了就是一些所谓的“饮水机”、“爆款机”、“垃圾机”。当然,我的出发点是学习和提高。
由于之前没接触过这方面的东西,所以决定先实现一小部分功能,打下基础。这个小项目的功能是使用该程序在论坛中自动发表评论。可以在人输入文字后由程序提交,也可以由程序自动获取网友发表的评论并作为关键词google,得到结果后回复论坛。,后面的功能本来是想智能聊天的,但是为了实现简单的处理,效果并不好,下面讨论这个功能的实现。
程序中要做的工作是用用户名和密码登录,2、获取某个栏目的页面,然后依次搜索每个主题,并保存标题、超链接和其他信息,3、通过比较最后一个回复者的名字来确定回复的主题,输入主题,通过计算和使用主键的方法找到最后一个回复,4、截取部分内容, URL-encode后提交到google搜索页面,5、同样通过主键方法和简单计算索引到第一个搜索结果,6、对结果进行URL-encode后提交给论坛相应主题完成回复。
使用VC socket编程,在网上可以找到很多http get和post方法的程序。通过这些方法,程序可以自动获取和提交数据。以下是该项目的一些困难。要提交中文,必须对其进行编码。不同的网站可能使用不同的编码,主要是GBK和UTF-8。论坛是前者,谷歌是后者。浏览器有这些编码功能,那么我程序的本质就是将一种编码数据的数据交换到另一种编码数据,然后返回到原来的编码数据。编码方式也可以在网上搜索。提交数据时,http头需要给出提交的内容,所以程序应该根据提交数据的长度自动合成一个声明长度的提交字符串。此外,通过获取的网页数据搜索感兴趣的话题和其他信息也很关键。可以通过分析html源代码找到合适的算法。 查看全部
自动抓取网页数据(使用VC的socket编程,网上能找到一大堆http的get和post方法程序)
最近突然有了一个想法,通过程序在客户端自动完成一些比较复杂的功能,比如自动注册论坛发帖,使用一些网站搜索功能自动搜索组织感兴趣的数据, 站内自动发送短信甚至自动发送邮件;说白了就是一些所谓的“饮水机”、“爆款机”、“垃圾机”。当然,我的出发点是学习和提高。
由于之前没接触过这方面的东西,所以决定先实现一小部分功能,打下基础。这个小项目的功能是使用该程序在论坛中自动发表评论。可以在人输入文字后由程序提交,也可以由程序自动获取网友发表的评论并作为关键词google,得到结果后回复论坛。,后面的功能本来是想智能聊天的,但是为了实现简单的处理,效果并不好,下面讨论这个功能的实现。
程序中要做的工作是用用户名和密码登录,2、获取某个栏目的页面,然后依次搜索每个主题,并保存标题、超链接和其他信息,3、通过比较最后一个回复者的名字来确定回复的主题,输入主题,通过计算和使用主键的方法找到最后一个回复,4、截取部分内容, URL-encode后提交到google搜索页面,5、同样通过主键方法和简单计算索引到第一个搜索结果,6、对结果进行URL-encode后提交给论坛相应主题完成回复。
使用VC socket编程,在网上可以找到很多http get和post方法的程序。通过这些方法,程序可以自动获取和提交数据。以下是该项目的一些困难。要提交中文,必须对其进行编码。不同的网站可能使用不同的编码,主要是GBK和UTF-8。论坛是前者,谷歌是后者。浏览器有这些编码功能,那么我程序的本质就是将一种编码数据的数据交换到另一种编码数据,然后返回到原来的编码数据。编码方式也可以在网上搜索。提交数据时,http头需要给出提交的内容,所以程序应该根据提交数据的长度自动合成一个声明长度的提交字符串。此外,通过获取的网页数据搜索感兴趣的话题和其他信息也很关键。可以通过分析html源代码找到合适的算法。
自动抓取网页数据(如何使用Python和pandas库从web页面获取表数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-16 10:17
如今,人们可以随时随地连接到互联网。Internet 可能是最大的公共数据库。学习如何从 Internet 获取数据很重要。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但这里的功能要强大 100 倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器就会向目标网站的服务器发送请求。
2. 服务器接收到请求,并发送回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不使用浏览器,而是使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同样,下面的代码会在浏览器上画一个表格,你可以尝试将它复制粘贴到记事本中,然后将其保存为“table example.html”文件,你应该可以在浏览器中打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语存储在...标签中。pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 Pandas 从不收录任何表格(...标记)的网页中“提取数据”,您将无法获得任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的例子大多是一些数据点很少的小表,我们用稍微大一点的数据来处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误,根据错误提示处理。我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图2
第一个数据框df[0]好像和这个没有关系,而是页面爬取的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界财富500强的排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得数据框列表而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。 查看全部
自动抓取网页数据(如何使用Python和pandas库从web页面获取表数据?)
如今,人们可以随时随地连接到互联网。Internet 可能是最大的公共数据库。学习如何从 Internet 获取数据很重要。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但这里的功能要强大 100 倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器就会向目标网站的服务器发送请求。
2. 服务器接收到请求,并发送回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不使用浏览器,而是使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同样,下面的代码会在浏览器上画一个表格,你可以尝试将它复制粘贴到记事本中,然后将其保存为“table example.html”文件,你应该可以在浏览器中打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语存储在...标签中。pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 Pandas 从不收录任何表格(...标记)的网页中“提取数据”,您将无法获得任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的例子大多是一些数据点很少的小表,我们用稍微大一点的数据来处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误,根据错误提示处理。我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图2
第一个数据框df[0]好像和这个没有关系,而是页面爬取的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界财富500强的排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得数据框列表而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。
自动抓取网页数据(网络爬虫获取到网上的海量信息怎么破?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-15 20:07
搜索引擎如果要获取互联网上的大量信息,就需要发布一个程序(按照一定的规则自动抓取万维网上信息的程序或脚本)来抓取互联网上的信息。这个程序叫做 Internet。爬虫。在百度、360、搜搜等搜索引擎中,网络爬虫也被称为搜索引擎蜘蛛,如百度蜘蛛、360Spider、Sosospider等;而在谷歌搜索引擎中,网络爬虫被称为谷歌机器人(googlebot)。下面我们将详细分析网络爬虫的工作原理和爬取网站的过程。
网络爬虫的工作是不断从互联网上检索信息,然后将索引数据存储在搜索引擎的服务器上。这个过程称为网络爬行。
网络爬虫工作的一般流程
由于搜索引擎并未公布其网络爬虫的工作原理,所以只能粗略估计网络爬虫的大致流程。
第一步,从精心挑选的种子网址中选取一部分,将这些网址放入待抓取的网址队列中;
第二步,服务器发送Request请求,获取对应的内容(Response),如果HTTP状态码为200,则发送网络爬虫对url页面进行爬取;如果是其他状态码(例如:404、50 0),网络爬虫会停止爬取url页面并记录状态。
第三步,网络爬虫查看网站的robots.txt文件,如果robots协议允许,就会抓取url的页面内容并发回服务器。如果robots协议不允许,网页数据将不会被抓取。, 直接返回,在数据库中标记。
第四步,下载该URL对应的网页,存储到下载的网页库中,并将这些URL放入爬取的URL队列中。
第五步,对爬取的URL队列中的页面进行分析,如果发现新的URL,则将新的URL放入待爬取的URL队列中,从而进入下一个循环。
网络爬虫只负责发现信息、爬取信息、去除网页重复、划分网页质量等级。这些任务是网络爬虫抓取数据后算法程序的工作。网络爬虫不参与。
有的朋友可能认为,网络爬虫只要进入网站,就会往下爬,然后爬取网站的所有页面内容。事实上,情况并非如此。网络爬虫不是贪吃蛇,它只是抓取当前网页信息并返回。对服务器后台数据进行分析后,如果发现新的网址,则将其添加到未抓取的网址列表中,搜索引擎会将其发送出去。新的网络爬虫用新的 URL 抓取网页。
事实上,网络爬虫更像是寻找食物的蚂蚁。网站 就像一大块食物。当一只小蚂蚁发现食物时,它会回去通知其他朋友,然后一批又一批的小蚂蚁就会离开。将食物带回并存放在仓库中。一只小蚂蚁找到一大块食物拼命把它带回去是不现实的。所以,领导自己觉得网络爬虫更像是蚂蚁,而不是蜘蛛。将其与蚂蚁进行比较会更合适。 查看全部
自动抓取网页数据(网络爬虫获取到网上的海量信息怎么破?(图))
搜索引擎如果要获取互联网上的大量信息,就需要发布一个程序(按照一定的规则自动抓取万维网上信息的程序或脚本)来抓取互联网上的信息。这个程序叫做 Internet。爬虫。在百度、360、搜搜等搜索引擎中,网络爬虫也被称为搜索引擎蜘蛛,如百度蜘蛛、360Spider、Sosospider等;而在谷歌搜索引擎中,网络爬虫被称为谷歌机器人(googlebot)。下面我们将详细分析网络爬虫的工作原理和爬取网站的过程。

网络爬虫的工作是不断从互联网上检索信息,然后将索引数据存储在搜索引擎的服务器上。这个过程称为网络爬行。
网络爬虫工作的一般流程
由于搜索引擎并未公布其网络爬虫的工作原理,所以只能粗略估计网络爬虫的大致流程。

第一步,从精心挑选的种子网址中选取一部分,将这些网址放入待抓取的网址队列中;
第二步,服务器发送Request请求,获取对应的内容(Response),如果HTTP状态码为200,则发送网络爬虫对url页面进行爬取;如果是其他状态码(例如:404、50 0),网络爬虫会停止爬取url页面并记录状态。
第三步,网络爬虫查看网站的robots.txt文件,如果robots协议允许,就会抓取url的页面内容并发回服务器。如果robots协议不允许,网页数据将不会被抓取。, 直接返回,在数据库中标记。
第四步,下载该URL对应的网页,存储到下载的网页库中,并将这些URL放入爬取的URL队列中。

第五步,对爬取的URL队列中的页面进行分析,如果发现新的URL,则将新的URL放入待爬取的URL队列中,从而进入下一个循环。
网络爬虫只负责发现信息、爬取信息、去除网页重复、划分网页质量等级。这些任务是网络爬虫抓取数据后算法程序的工作。网络爬虫不参与。
有的朋友可能认为,网络爬虫只要进入网站,就会往下爬,然后爬取网站的所有页面内容。事实上,情况并非如此。网络爬虫不是贪吃蛇,它只是抓取当前网页信息并返回。对服务器后台数据进行分析后,如果发现新的网址,则将其添加到未抓取的网址列表中,搜索引擎会将其发送出去。新的网络爬虫用新的 URL 抓取网页。
事实上,网络爬虫更像是寻找食物的蚂蚁。网站 就像一大块食物。当一只小蚂蚁发现食物时,它会回去通知其他朋友,然后一批又一批的小蚂蚁就会离开。将食物带回并存放在仓库中。一只小蚂蚁找到一大块食物拼命把它带回去是不现实的。所以,领导自己觉得网络爬虫更像是蚂蚁,而不是蜘蛛。将其与蚂蚁进行比较会更合适。
自动抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-14 15:03
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。在浏览的同时,网络爬虫还可以用于金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时候,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网上的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
查看全部
自动抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能

网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。在浏览的同时,网络爬虫还可以用于金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时候,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网上的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,回车安装。(注意网络连接)如下图

安装完成,如图

自动抓取网页数据(自动抓取网页数据的应用你肯定见过吧,那就对了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-14 12:07
自动抓取网页数据的应用你肯定见过吧,那就对了,自动抓取网页数据我用过很多了,最近打算开发一个简单的,即通过http请求自动抓取一些网页数据,可以实现中国联通100m宽带到你那里提速到20m宽带的一个功能。具体可以参考一下:一键抓取运营商网页数据,
你问问题的时候没有描述清楚啊,应该是要一个自动记录下对方登录到自己的浏览器哪些网页,然后自动抓取对方的浏览器的页面,转到对方的邮箱或者手机app,根据对方的浏览器提示回复自己的浏览器网址。
做一个信息采集器,然后比如网站那种,存个脚本,存个网址啥的,先抓取个差不多再处理需要的,就没那么麻烦了,然后就有自动记录网页截图自动转发账号网址了,就可以卖钱,还是很赚钱的吧。
楼上说的挺对的,我也回复一下,多网站都不是很好抓,我说一下自己,初步用了一些比较赚钱的赚钱方法,一天赚五十左右。起先是做web中的外挂,发现它很赚钱,然后在付费版本里免费下,赚了一点一直没做,后来喜欢上一个女孩子,想追她,但是那个女孩子脾气很暴躁,每次都对她发火,然后就去玩各种色情网站,她不和我说话我就打她了,偶尔有种喜欢她的感觉。
后来嫌弃累就不玩了,其他赚钱的不敢说,赚点生活费肯定是够了,包括但不限于如下赚钱方法:p2p,其实利润还是很不错的,而且风险低,在前不久十一放假的时候,碰上某行业的培训会,感觉一下子找到一份高薪工作,利润很好,还是当时感觉很赚钱,工作很积极。套现,就是银行给你的额度使你可以花钱买很多价值不是很高的东西,不同的人有不同的回报率,有几千块钱的也有几百万,还是比较赚钱的,还有现金贷,一直感觉很赚钱,还有分期付款,利润也不小,还有黑卡,他给你的不是一点小钱,他会给你很多现金,但是,一旦黑你的比较多,就有可能冻结你的账户,还有就是上面提到的培训会,很有用。 查看全部
自动抓取网页数据(自动抓取网页数据的应用你肯定见过吧,那就对了)
自动抓取网页数据的应用你肯定见过吧,那就对了,自动抓取网页数据我用过很多了,最近打算开发一个简单的,即通过http请求自动抓取一些网页数据,可以实现中国联通100m宽带到你那里提速到20m宽带的一个功能。具体可以参考一下:一键抓取运营商网页数据,
你问问题的时候没有描述清楚啊,应该是要一个自动记录下对方登录到自己的浏览器哪些网页,然后自动抓取对方的浏览器的页面,转到对方的邮箱或者手机app,根据对方的浏览器提示回复自己的浏览器网址。
做一个信息采集器,然后比如网站那种,存个脚本,存个网址啥的,先抓取个差不多再处理需要的,就没那么麻烦了,然后就有自动记录网页截图自动转发账号网址了,就可以卖钱,还是很赚钱的吧。
楼上说的挺对的,我也回复一下,多网站都不是很好抓,我说一下自己,初步用了一些比较赚钱的赚钱方法,一天赚五十左右。起先是做web中的外挂,发现它很赚钱,然后在付费版本里免费下,赚了一点一直没做,后来喜欢上一个女孩子,想追她,但是那个女孩子脾气很暴躁,每次都对她发火,然后就去玩各种色情网站,她不和我说话我就打她了,偶尔有种喜欢她的感觉。
后来嫌弃累就不玩了,其他赚钱的不敢说,赚点生活费肯定是够了,包括但不限于如下赚钱方法:p2p,其实利润还是很不错的,而且风险低,在前不久十一放假的时候,碰上某行业的培训会,感觉一下子找到一份高薪工作,利润很好,还是当时感觉很赚钱,工作很积极。套现,就是银行给你的额度使你可以花钱买很多价值不是很高的东西,不同的人有不同的回报率,有几千块钱的也有几百万,还是比较赚钱的,还有现金贷,一直感觉很赚钱,还有分期付款,利润也不小,还有黑卡,他给你的不是一点小钱,他会给你很多现金,但是,一旦黑你的比较多,就有可能冻结你的账户,还有就是上面提到的培训会,很有用。
自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-13 10:26
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。
WebHarvy 函数介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以抓取数据并将其导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 更新日志
修复页面启动时连接可能被关闭的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。

WebHarvy 函数介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以抓取数据并将其导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 更新日志
修复页面启动时连接可能被关闭的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
自动抓取网页数据(优采云采集器(www.ucaiyun.com)绿色安装版是一款功优秀的数据采集器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-10 02:01
优采云采集器()绿色安装版是极品资料采集器,优采云采集器完美支持采集对于网页在所有编码格式中,优采云采集器也可以直接将采集的数据封装到库中,优采云采集器在使用过程中非常稳定。
软件功能
1、通用。
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,也可以通过数据库导入的方式将数据灵活保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或连续地执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
11、有条件的保存——可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别 - 使用此功能识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布-已经采集的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、预留编程接口——定义多个编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
特殊功能
1、支持所有网站编码:完美支持所有编码格式的采集网页,程序可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站@模块 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。 查看全部
自动抓取网页数据(优采云采集器(www.ucaiyun.com)绿色安装版是一款功优秀的数据采集器)
优采云采集器()绿色安装版是极品资料采集器,优采云采集器完美支持采集对于网页在所有编码格式中,优采云采集器也可以直接将采集的数据封装到库中,优采云采集器在使用过程中非常稳定。
软件功能
1、通用。
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,也可以通过数据库导入的方式将数据灵活保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或连续地执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
11、有条件的保存——可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复内容——软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别 - 使用此功能识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布-已经采集的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、预留编程接口——定义多个编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
特殊功能
1、支持所有网站编码:完美支持所有编码格式的采集网页,程序可以自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站@模块 > 程序之间的完美集成。
3、全自动:无人值守工作,程序配置好后,程序会根据您的设置自动运行,无需人工干预。
自动抓取网页数据( Python编程技术使用迭代器自动链式处理数据的实例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-10 01:18
Python编程技术使用迭代器自动链式处理数据的实例(组图))
requests.gPython 使用 requests.get 获取网页内容为空
我们先来看一个例子:
import requests
result=requests.get("http://data.10jqka.com.cn/financial/yjyg/")
result
输出结果:
表示请求处理成功,一般返回此状态码;200表示没问题
继续运行,发现返回了一个空值。请求网页爬取时,输出文本信息中会出现sorry、inaccessible等字样。这就是禁止爬取,需要借助反爬取机制来解决这个问题。headers是解决请求反爬的方法之一,相当于我们进入这个网页,假装自己在爬数据的时候服务器本身。对于反爬虫网页,可以设置一些headers信息来模拟浏览器访问网站。
一、如何设置标题
以两种常见的浏览器为例:
1、QQ浏览器
接口 F12
单击网络并键入 CTRL+R
单击第一个底部是我需要将他设置为标题以解决问题
2、微软边缘
二、微软自己的浏览器
F12也可以打开开发者工具
单击网络,CTRL+R
修改之前的代码:
import requests
ur="http://data.10jqka.com.cn/financial/yjyg/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400 '}
result = requests.get(ur, headers=headers)
result.text
成功解决无法爬取的问题
关于requests.gPython使用requests.get获取网页内容为空''文章到此介绍,更多相关requests.gPython使用requests.get获取网页内容为空' '请搜索以前的文章,希望以后支持编程宝库!
下一节:Python遍历迭代器自动链式处理数据实例Python编程技术
使用迭代器链式处理数据,在Process类的__iter__方法中执行挂载的预处理方法。可以嵌套和包裹多层处理方法,类似于 KoaJs 的洋葱模型。在for循环期间,自动执行预处理方法,并返回处理完数据分析... 查看全部
自动抓取网页数据(
Python编程技术使用迭代器自动链式处理数据的实例(组图))
requests.gPython 使用 requests.get 获取网页内容为空
我们先来看一个例子:
import requests
result=requests.get("http://data.10jqka.com.cn/financial/yjyg/";)
result
输出结果:
表示请求处理成功,一般返回此状态码;200表示没问题
继续运行,发现返回了一个空值。请求网页爬取时,输出文本信息中会出现sorry、inaccessible等字样。这就是禁止爬取,需要借助反爬取机制来解决这个问题。headers是解决请求反爬的方法之一,相当于我们进入这个网页,假装自己在爬数据的时候服务器本身。对于反爬虫网页,可以设置一些headers信息来模拟浏览器访问网站。
一、如何设置标题
以两种常见的浏览器为例:
1、QQ浏览器
接口 F12
单击网络并键入 CTRL+R
单击第一个底部是我需要将他设置为标题以解决问题
2、微软边缘
二、微软自己的浏览器
F12也可以打开开发者工具
单击网络,CTRL+R
修改之前的代码:
import requests
ur="http://data.10jqka.com.cn/financial/yjyg/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400 '}
result = requests.get(ur, headers=headers)
result.text
成功解决无法爬取的问题
关于requests.gPython使用requests.get获取网页内容为空''文章到此介绍,更多相关requests.gPython使用requests.get获取网页内容为空' '请搜索以前的文章,希望以后支持编程宝库!
下一节:Python遍历迭代器自动链式处理数据实例Python编程技术
使用迭代器链式处理数据,在Process类的__iter__方法中执行挂载的预处理方法。可以嵌套和包裹多层处理方法,类似于 KoaJs 的洋葱模型。在for循环期间,自动执行预处理方法,并返回处理完数据分析...
自动抓取网页数据(拼接字符串的性能闲话不多.8.1.2 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2022-01-09 11:04
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
自动抓取网页数据(拼接字符串的性能闲话不多.8.1.2
)
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
自动抓取网页数据( 官方谷歌蜘蛛最新名称为Googlebot十分“勤奋抓爬”的蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-09 11:02
官方谷歌蜘蛛最新名称为Googlebot十分“勤奋抓爬”的蜘蛛)
各个搜索引擎蜘蛛的介绍,搜索引擎蜘蛛抓取网站和抓取数据的规则
1、百度蜘蛛:BaiduSpider
常见的Baiduspider和Baiduspider-image(抓图)
百度还有其他几个蜘蛛:Baiduspider-video(抓取视频)、Baiduspider-news(抓取新闻)、Baiduspider-mobile(抓取wap),没有一个是常见的
百度爬虫UA:
PC:Mozilla/5.0(兼容;Baiduspider-render/2.0;+)
移动设备:Mozilla/5.0(iPhone;CPU iPhone OS 9_1,如 Mac OS X)AppleWebKit/601.1.46(KHTML,如 Gecko)版本/9.0手机/13B143 Safari/601.1(兼容;Baiduspider-render/2.0;+)
图片:“百度蜘蛛图片+(+)”
2、谷歌蜘蛛:谷歌机器人
有人说谷歌蜘蛛就是GoogleBot。Google 官方蜘蛛的最新名称是 Googlebot,Googlebot-Mobile 也被发现了。名字应该是爬取wap内容。
Google Spider Crawler UA:“Mozilla/5.0(兼容;Googlebot/2.1;+)”
3、360Spider:360Spider
它是一只非常“勤奋”的蜘蛛
360蜘蛛爬虫UA:
Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.1;三叉戟/5.0);
4、搜狗蜘蛛:搜狗新闻蜘蛛
搜狗还有其他几种蜘蛛:搜狗网络蜘蛛、搜狗inst蜘蛛、搜狗蜘蛛2、搜狗博客、搜狗猎户蜘蛛、冬镜只在日志中找到了常见的搜狗新闻蜘蛛。(参考百度的robots文件,搜狗蜘蛛的名字可以用搜狗来概括,但不知道有没有用。)
搜狗爬虫UA:
“搜狗网络蜘蛛/4.0(+#07)”
5、必应蜘蛛:bingbot
必应蜘蛛爬行者 UA:
“Mozilla/5.0(兼容;bingbot/2.0;+)”
6、SOSO 蜘蛛:Sosospider
腾讯死了,交给搜狗
soso蜘蛛爬虫UA:“Sosospider+(+)”
7、雅虎蜘蛛:雅虎!Slurp 中国(雅虎中国)或雅虎!啜饮(雅虎英语)
雅虎蜘蛛爬虫 UA:
雅虎!中国:“Mozilla/5.0(兼容;Yahoo! Slurp 中国;)”
雅虎!英语:“Mozilla/5.0(兼容;Yahoo! Slurp;)”
8、MSN 蜘蛛:msnbot,msnbot-media
重庆seo似乎只看到msnbot-media疯狂爬行...
MSN 蜘蛛爬虫 UA:*msnbot/1.0 (+”)
还有其他蜘蛛:YisouSpider,Alexa蜘蛛:ia_archiver,一搜蜘蛛:EasouSpider,即时蜘蛛:JikeSpider,还有YandexBot、AhrefsBot和ezooms.bot等蜘蛛。据说这些外国蜘蛛不好
搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,并建立索引库,让用户可以在搜索引擎中搜索到你的网站网页、图片、视频等内容。
一般用法是“蜘蛛+URL”,下面的URL(网址)就是搜索引擎的踪迹。如果你想查看搜索引擎是否抓取了你的网站,可以查看服务器日志中是否有这个URL。,还可以查看时间、频率等。
1、百度蜘蛛:可以根据服务器的负载能力调整访问密度,大大降低了服务器的服务压力。根据以往的经验,百度蜘蛛通常会过度重复爬取同一页面,导致其他页面无法爬取,无法收录。这种情况可以通过机器人协议进行调整。
2、Google Spider:Google Spider 是一个比较活跃的网站 扫描工具,它每 28 天左右发出“蜘蛛”来检索更新或修改的网页。与百度蜘蛛最大的不同在于,谷歌蜘蛛比百度蜘蛛的爬取深度更大。
3、雅虎中国蜘蛛:如果某个网站在Google网站下没有很好的收录,在Yahoo下也不会有很好的收录和爬行。雅虎蜘蛛数量庞大,但平均效率不是很高,相应的搜索结果质量也不高。
4、微软必应蜘蛛:必应与雅虎有着深厚的合作关系,所以基本的操作模式与雅虎蜘蛛类似。
搜索引擎蜘蛛的爬取规则提供以下四点供参考:
1、搜索引擎蜘蛛需要能够看到链接文本
这是搜索引擎蜘蛛在爬行时可以检索到的文本。如果文本或链接是通过 JavaScript 调用的,则蜘蛛无法检索它。主要内容在页面文字内容中的位置越高,越有利。例如,产品名称在页面上的位置越高,产品关键词在页面上的排名越有利。
2、搜索引擎蜘蛛可以抓取没有被nofollow处理的链接
此项列出了搜索引擎蜘蛛可以检索到的链接,蜘蛛可以通过这些链接访问网站 其他页面。@> 更有可能。
3、搜索引擎蜘蛛可以找到图片的链接并阅读这些图片的含义
该页面主要展示搜索引擎蜘蛛和国际W3C标准化监视器检索到的图片。搜索引擎可以根据图片at=""判断图片的类型、性质和主题。有很大帮助,可以有效提高产品展示页面的搜索引擎排名。根据W3C标准,页面上的所有图片都必须添加alt=""图片注释,网站Logo使用网站的名称和简短的描述,产品图片使用产品名称,以及页框图像留空。
4、搜索引擎蜘蛛擅长识别 HTML 代码
模拟搜索引擎蜘蛛爬取页面时,得到的“简化代码->指过滤css和JavaScript后的代码”,可见减少空行、行等冗余代码空间非常重要休息,空格等。
5、搜狗蜘蛛:搜狗蜘蛛的爬行速度比较快,爬行的次数比速度略少。最大的特点是不爬取robot.text文件。
6、搜搜蜘蛛:搜搜早期使用了谷歌的搜索技术。谷歌有收录,搜搜肯定有收录。2011年,搜搜宣布采用自己的独立搜索技术,但搜搜蜘蛛和谷歌蜘蛛的特点还是有相似之处。
8、有道蜘蛛:和其他搜索引擎蜘蛛一样,任何权重网站的链接一般都可以是收录。爬取的原理也是通过链接之间的爬取。 查看全部
自动抓取网页数据(
官方谷歌蜘蛛最新名称为Googlebot十分“勤奋抓爬”的蜘蛛)
各个搜索引擎蜘蛛的介绍,搜索引擎蜘蛛抓取网站和抓取数据的规则
1、百度蜘蛛:BaiduSpider
常见的Baiduspider和Baiduspider-image(抓图)
百度还有其他几个蜘蛛:Baiduspider-video(抓取视频)、Baiduspider-news(抓取新闻)、Baiduspider-mobile(抓取wap),没有一个是常见的
百度爬虫UA:
PC:Mozilla/5.0(兼容;Baiduspider-render/2.0;+)
移动设备:Mozilla/5.0(iPhone;CPU iPhone OS 9_1,如 Mac OS X)AppleWebKit/601.1.46(KHTML,如 Gecko)版本/9.0手机/13B143 Safari/601.1(兼容;Baiduspider-render/2.0;+)
图片:“百度蜘蛛图片+(+)”
2、谷歌蜘蛛:谷歌机器人
有人说谷歌蜘蛛就是GoogleBot。Google 官方蜘蛛的最新名称是 Googlebot,Googlebot-Mobile 也被发现了。名字应该是爬取wap内容。
Google Spider Crawler UA:“Mozilla/5.0(兼容;Googlebot/2.1;+)”
3、360Spider:360Spider
它是一只非常“勤奋”的蜘蛛
360蜘蛛爬虫UA:
Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.1;三叉戟/5.0);
4、搜狗蜘蛛:搜狗新闻蜘蛛
搜狗还有其他几种蜘蛛:搜狗网络蜘蛛、搜狗inst蜘蛛、搜狗蜘蛛2、搜狗博客、搜狗猎户蜘蛛、冬镜只在日志中找到了常见的搜狗新闻蜘蛛。(参考百度的robots文件,搜狗蜘蛛的名字可以用搜狗来概括,但不知道有没有用。)
搜狗爬虫UA:
“搜狗网络蜘蛛/4.0(+#07)”
5、必应蜘蛛:bingbot
必应蜘蛛爬行者 UA:
“Mozilla/5.0(兼容;bingbot/2.0;+)”
6、SOSO 蜘蛛:Sosospider
腾讯死了,交给搜狗
soso蜘蛛爬虫UA:“Sosospider+(+)”
7、雅虎蜘蛛:雅虎!Slurp 中国(雅虎中国)或雅虎!啜饮(雅虎英语)
雅虎蜘蛛爬虫 UA:
雅虎!中国:“Mozilla/5.0(兼容;Yahoo! Slurp 中国;)”
雅虎!英语:“Mozilla/5.0(兼容;Yahoo! Slurp;)”
8、MSN 蜘蛛:msnbot,msnbot-media
重庆seo似乎只看到msnbot-media疯狂爬行...
MSN 蜘蛛爬虫 UA:*msnbot/1.0 (+”)
还有其他蜘蛛:YisouSpider,Alexa蜘蛛:ia_archiver,一搜蜘蛛:EasouSpider,即时蜘蛛:JikeSpider,还有YandexBot、AhrefsBot和ezooms.bot等蜘蛛。据说这些外国蜘蛛不好
搜索引擎蜘蛛是搜索引擎的自动程序。它的功能是访问互联网上的网页、图片、视频等内容,并建立索引库,让用户可以在搜索引擎中搜索到你的网站网页、图片、视频等内容。
一般用法是“蜘蛛+URL”,下面的URL(网址)就是搜索引擎的踪迹。如果你想查看搜索引擎是否抓取了你的网站,可以查看服务器日志中是否有这个URL。,还可以查看时间、频率等。
1、百度蜘蛛:可以根据服务器的负载能力调整访问密度,大大降低了服务器的服务压力。根据以往的经验,百度蜘蛛通常会过度重复爬取同一页面,导致其他页面无法爬取,无法收录。这种情况可以通过机器人协议进行调整。
2、Google Spider:Google Spider 是一个比较活跃的网站 扫描工具,它每 28 天左右发出“蜘蛛”来检索更新或修改的网页。与百度蜘蛛最大的不同在于,谷歌蜘蛛比百度蜘蛛的爬取深度更大。
3、雅虎中国蜘蛛:如果某个网站在Google网站下没有很好的收录,在Yahoo下也不会有很好的收录和爬行。雅虎蜘蛛数量庞大,但平均效率不是很高,相应的搜索结果质量也不高。
4、微软必应蜘蛛:必应与雅虎有着深厚的合作关系,所以基本的操作模式与雅虎蜘蛛类似。
搜索引擎蜘蛛的爬取规则提供以下四点供参考:
1、搜索引擎蜘蛛需要能够看到链接文本
这是搜索引擎蜘蛛在爬行时可以检索到的文本。如果文本或链接是通过 JavaScript 调用的,则蜘蛛无法检索它。主要内容在页面文字内容中的位置越高,越有利。例如,产品名称在页面上的位置越高,产品关键词在页面上的排名越有利。
2、搜索引擎蜘蛛可以抓取没有被nofollow处理的链接
此项列出了搜索引擎蜘蛛可以检索到的链接,蜘蛛可以通过这些链接访问网站 其他页面。@> 更有可能。
3、搜索引擎蜘蛛可以找到图片的链接并阅读这些图片的含义
该页面主要展示搜索引擎蜘蛛和国际W3C标准化监视器检索到的图片。搜索引擎可以根据图片at=""判断图片的类型、性质和主题。有很大帮助,可以有效提高产品展示页面的搜索引擎排名。根据W3C标准,页面上的所有图片都必须添加alt=""图片注释,网站Logo使用网站的名称和简短的描述,产品图片使用产品名称,以及页框图像留空。
4、搜索引擎蜘蛛擅长识别 HTML 代码
模拟搜索引擎蜘蛛爬取页面时,得到的“简化代码->指过滤css和JavaScript后的代码”,可见减少空行、行等冗余代码空间非常重要休息,空格等。
5、搜狗蜘蛛:搜狗蜘蛛的爬行速度比较快,爬行的次数比速度略少。最大的特点是不爬取robot.text文件。
6、搜搜蜘蛛:搜搜早期使用了谷歌的搜索技术。谷歌有收录,搜搜肯定有收录。2011年,搜搜宣布采用自己的独立搜索技术,但搜搜蜘蛛和谷歌蜘蛛的特点还是有相似之处。
8、有道蜘蛛:和其他搜索引擎蜘蛛一样,任何权重网站的链接一般都可以是收录。爬取的原理也是通过链接之间的爬取。
自动抓取网页数据(历史消息界面将屏幕向上滑动每次都可以加载10条历史)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-09 11:01
安装证书并设置好手机IP代理后,点一个微信公众号文章(这里用这个公众号)
从图中可以看出,阅读、重看、点赞的url是./mp/getappmsgext(提示:如果没有这个链接,可以刷新右上角的文章角),然后再看一下request请求需要什么
你只需要一个 文章 url、user-agent、cookie 和 body,四个基本数据。别看下面正文中的 20 或 30 个数据,它们实际上很吓人。只需要其中的7个,分别是__biz、mid、idx、sn这四个参数是获取公众号文章内容的基石,可以在文章 url处获取。其他三个参数的数据分别固定is_only_read = 1、is_temp_url = 0、appmsg_type = 9。getappmsgext请求中的appmsg_token是时间敏感参数。
分析完链接就可以写代码了
# articles.py
import html
import requests
import utils
from urllib.parse import urlsplit
class Articles(object):
"""文章信息"""
def __init__(self, appmsg_token, cookie):
# 具有时效性
self.appmsg_token = appmsg_token
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
}
def read_like_nums(self, article_url):
"""获取数据"""
appmsgstat = self.get_appmsgext(article_url)["appmsgstat"]
return appmsgstat["read_num"], appmsgstat["old_like_num"], appmsgstat["like_num"]
def get_params(self, article_url):
"""
获取到文章url上的请求参数
:param article_url: 文章 url
:return:
"""
# url转义处理
article_url = html.unescape(article_url)
"""获取文章链接的参数"""
url_params = utils.str_to_dict(urlsplit(article_url).query, "&", "=")
return url_params
def get_appmsgext(self, article_url):
"""
请求阅读数
:param article_url: 文章 url
:return:
"""
url_params = self.get_params(article_url)
appmsgext_url = "https://mp. weixin.qq.com/mp/getappmsgext?appmsg_token={}&x5=0".format(self.appmsg_token)
self.data.update(url_params)
appmsgext_json = requests.post(
appmsgext_url, headers=self.headers, data=self.data).json()
if "appmsgstat" not in appmsgext_json.keys():
raise Exception(appmsgext_json)
return appmsgext_json
if __name__ == '__main__':
info = Articles('1068_XQoMoGGBYG8Tf8k23jfdBr2H_LNekAAlDDUe2aG13TN2fer8xOSMyrLV6s-yWESt8qg5I2fJr1r9n5Y5', 'rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWl3Xy1saXVWYllIVjAzdlM1VkNDNHgxeWpHOG9pckdkREMwTFEwYmNWMl9FZWtRU3pRRnhDS0pyV1BaZUVMWXN1ZWN0WnZ6aHFXdVBnbVhTY21BYnBSUXNCQUFBMLLAjfgFOA1AAQ==')
a, b,c = info.read_like_nums('http://mp. weixin.qq.com/s?__biz=MzU1NDk2MzQyNg==&mid=2247486254&idx=1&sn=c3a47f4bf72b1ca85c99190597e0c190&chksm=fbdad3a3ccad5ab55f6ef1f4d5b8f97887b4a344c67f9186d5802a209693de582aac6429a91c&scene=27#wechat_redirect')
print(a, b, c)
样本结果
# 阅读数 点赞数 再看数
1561 23 18
动态获取cookies和appmsg_token
appmsg_token 是一个时间敏感的参数,需要像 cookie 一样改变。当这两个参数过期时,需要从抓包工具(MitmProxy)到代码中ctrl+C和ctrl+V,非常麻烦。
MitmProxy 可以使用命令行界面 mitmdumvp 运行 Python 代码来监控抓取的链接。如果 /mp/getappmsgext 被捕获,它将被保存在本地文件中并退出捕获
mitmdump 命令
# -s 运行的python脚本, -w 将截取的内容保持到文件
mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
监控脚本
# coding: utf-8
# write_cookie.py
import urllib
import sys
from mitmproxy import http
# command: mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
class WriterCookie:
"""
mitmproxy的监听脚本,写入cookie和url到文件
"""
def __init__(self, outfile: str) -> None:
self.f = open(outfile, "w")
def response(self, flow: http.HTTPFlow) -> None:
"""
完整的response响应
:param flow: flow实例,
"""
# 获取url
url = urllib.parse.unquote(flow.request.url)
# 将url和cookie写入文件
if "mp. weixin.qq.com/mp/getappmsgext" in url:
self.f.write(url + '\n')
self.f.write(str(flow.request.cookies))
self.f.close()
# 退出
exit()
# 第四个命令中的参数
addons = [WriterCookie(sys.argv[4])]
监控脚本写好后,编写启动命令和解析url和cookie文件的模块
# read_cookie.py
import re
import os
class ReadCookie(object):
"""
启动write_cookie.py 和 解析cookie文件,
"""
def __init__(self, outfile):
self.outfile = outfile
def parse_cookie(self):
"""
解析cookie
:return: appmsg_token, biz, cookie_str·
"""
f = open(self.outfile)
lines = f.readlines()
appmsg_token_string = re.findall("appmsg_token.+?&", lines[0])
biz_string = re.findall('__biz.+?&', lines[0])
appmsg_token = appmsg_token_string[0].split("=")[1][:-1]
biz = biz_string[0].split("__biz=")[1][:-1]
cookie_str = '; '.join(lines[1][15:-2].split('], [')).replace('\'','').replace(', ', '=')
return appmsg_token, biz, cookie_str
def write_cookie(self):
"""
启动 write_cookie。py
:return:
"""
#当前文件路径
path = os.path.split(os.path.realpath(__file__))[0]
# mitmdump -s 执行脚本 -w 保存到文件 本命令
command = "mitmdump -s {}/write_cookie.py -w {} mp.weixin.qq.com/mp/getappmsgext".format(
path, self.outfile)
os.system(command)
if __name__ == '__main__':
rc = ReadCookie('cookie.txt')
rc.write_cookie()
appmsg_token, biz, cookie_str = rc.parse_cookie()
print("appmsg_token:" + appmsg_token , "\nbiz:" + biz, "\ncookie:"+cookie_str)
样本结果
解析cookie.txt文件内容后
appmsg_token:1068_av3JWyDn2XCS2fwFj3ICCnwArRb2kU4Y5Y5m9Z9NkWoCOszl3a-YHFfBkAguUlYQJi2dWo83AQT4FsNK
biz:MzU1NDk2MzQyNg==
cookie:rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWktTHpUSEJnTTdhU0hVZTEtZXpZZEY4a3lNY29zc0VZeEFvLS01YmJRRnQ5eFRmR2dOY29nUWdKSTRVWG13WE1obGs1blhQcVh0V18tRnBSRnVlc1VhOHNCQUFBMPeIjfgFOA1AAQ==
ReadCookie模块可以自动获取appmsg_token和cookies,作为参数传递给Articles模块,这样就可以解放双手,永远不用复制粘贴appmsg_token和cookies,只需要在appmsg_token过期时刷新公众号文章就是这样它,省心省时间
批量提取
在公众号历史消息界面向上滑动屏幕,每次可加载10条历史消息。盲目猜测,这个翻页就是批量抓取的请求链接。使用MitmProxy的WEBUI界面在Response面板中找到,找到一个是/mp /profile_ext?action=getmsg&__biz=MzU1NDk2MzQyNg==&f=json&offset=10&count=10...有多个文章 headers 在它的response返回值中,然后看这个链接的offset =10&count=10 参数,一看就是页面偏移量和每页显示的条数,仅此而已
链接中比较重要的参数有:__biz、offset、pass_ticket、appmsg_token,这些数据可以在cookie和appmsg_token中获取。
# utils.py
# 工具模块,将字符串变成字典
def str_to_dict(s, join_symbol="\n", split_symbol=":"):
s_list = s.split(join_symbol)
data = dict()
for item in s_list:
item = item.strip()
if item:
k, v = item.split(split_symbol, 1)
data[k] = v.strip()
return data
# coding:utf-8
# wxCrawler.py
import os
import requests
import json
import urllib3
import utils
class WxCrawler(object):
"""翻页内容抓取"""
urllib3.disable_warnings()
def __init__(self, appmsg_token, biz, cookie, begin_page_index = 0, end_page_index = 100):
# 起始页数
self.begin_page_index = begin_page_index
# 结束页数
self.end_page_index = end_page_index
# 抓了多少条了
self.num = 1
self.appmsg_token = appmsg_token
self.biz = biz
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.cookie = cookie
def article_list(self, context):
articles = json.loads(context).get('general_msg_list')
return json.loads(articles)
def run(self):
# 翻页地址
page_url = "https://mp. weixin.qq.com/mp/profile_ext?action=getmsg&__biz={}&f=json&offset={}&count=10&is_ok=1&scene=&uin=777&key=777&pass_ticket={}&wxtoken=&appmsg_token=" + self.appmsg_token + "&x5=0f=json"
# 将 cookie 字典化
wx_dict = utils.str_to_dict(self.cookie, join_symbol='; ', split_symbol='=')
# 请求地址
response = requests.get(page_url.format(self.biz, self.begin_page_index * 10, wx_dict['pass_ticket']), headers=self.headers, verify=False)
# 将文章列表字典化
articles = self.article_list(response.text)
for a in articles['list']:
# 公众号中主条
if 'app_msg_ext_info' in a.keys() and '' != a.get('app_msg_ext_info').get('content_url', ''):
print(str(self.num) + "条", a.get('app_msg_ext_info').get('title'), a.get('app_msg_ext_info').get('content_url'))
# 公众号中副条
if 'app_msg_ext_info' in a.keys():
for m in a.get('app_msg_ext_info').get('multi_app_msg_item_list', []):
print(str(self.num) + "条", m.get('title'), a.get('content_url'))
self.num = self.num + 1
self.is_exit_or_continue()
# 递归调用
self.run()
def is_exit_or_continue(self):
self.begin_page_index = self.begin_page_index + 1
if self.begin_page_index > self.end_page_index:
os.exit()
最后使用自动cookie启动程序并刷新公众号文章
# coding:utf-8
# main.py
from read_cookie import ReadCookie
from wxCrawler import WxCrawler
"""程序启动类"""ss
if __name__ == '__main__':
cookie = ReadCookie('E:/python/cookie.txt')
cookie.write_cookie()
appmsg_token, biz, cookie_str = cookie.parse_cookie()
wx = WxCrawler(appmsg_token, biz, cookie_str)
wx.run()
样本结果
总结
这篇文章虽然可能有点头条党,但并没有完全自动抓取数据,需要人为刷新公众号文章。希望大家不要介意。如需刷微信文章,建议参考本公众号【第129天:爬取微信公众号文章内容】。 查看全部
自动抓取网页数据(历史消息界面将屏幕向上滑动每次都可以加载10条历史)
安装证书并设置好手机IP代理后,点一个微信公众号文章(这里用这个公众号)
从图中可以看出,阅读、重看、点赞的url是./mp/getappmsgext(提示:如果没有这个链接,可以刷新右上角的文章角),然后再看一下request请求需要什么
你只需要一个 文章 url、user-agent、cookie 和 body,四个基本数据。别看下面正文中的 20 或 30 个数据,它们实际上很吓人。只需要其中的7个,分别是__biz、mid、idx、sn这四个参数是获取公众号文章内容的基石,可以在文章 url处获取。其他三个参数的数据分别固定is_only_read = 1、is_temp_url = 0、appmsg_type = 9。getappmsgext请求中的appmsg_token是时间敏感参数。
分析完链接就可以写代码了
# articles.py
import html
import requests
import utils
from urllib.parse import urlsplit
class Articles(object):
"""文章信息"""
def __init__(self, appmsg_token, cookie):
# 具有时效性
self.appmsg_token = appmsg_token
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
}
def read_like_nums(self, article_url):
"""获取数据"""
appmsgstat = self.get_appmsgext(article_url)["appmsgstat"]
return appmsgstat["read_num"], appmsgstat["old_like_num"], appmsgstat["like_num"]
def get_params(self, article_url):
"""
获取到文章url上的请求参数
:param article_url: 文章 url
:return:
"""
# url转义处理
article_url = html.unescape(article_url)
"""获取文章链接的参数"""
url_params = utils.str_to_dict(urlsplit(article_url).query, "&", "=")
return url_params
def get_appmsgext(self, article_url):
"""
请求阅读数
:param article_url: 文章 url
:return:
"""
url_params = self.get_params(article_url)
appmsgext_url = "https://mp. weixin.qq.com/mp/getappmsgext?appmsg_token={}&x5=0".format(self.appmsg_token)
self.data.update(url_params)
appmsgext_json = requests.post(
appmsgext_url, headers=self.headers, data=self.data).json()
if "appmsgstat" not in appmsgext_json.keys():
raise Exception(appmsgext_json)
return appmsgext_json
if __name__ == '__main__':
info = Articles('1068_XQoMoGGBYG8Tf8k23jfdBr2H_LNekAAlDDUe2aG13TN2fer8xOSMyrLV6s-yWESt8qg5I2fJr1r9n5Y5', 'rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWl3Xy1saXVWYllIVjAzdlM1VkNDNHgxeWpHOG9pckdkREMwTFEwYmNWMl9FZWtRU3pRRnhDS0pyV1BaZUVMWXN1ZWN0WnZ6aHFXdVBnbVhTY21BYnBSUXNCQUFBMLLAjfgFOA1AAQ==')
a, b,c = info.read_like_nums('http://mp. weixin.qq.com/s?__biz=MzU1NDk2MzQyNg==&mid=2247486254&idx=1&sn=c3a47f4bf72b1ca85c99190597e0c190&chksm=fbdad3a3ccad5ab55f6ef1f4d5b8f97887b4a344c67f9186d5802a209693de582aac6429a91c&scene=27#wechat_redirect')
print(a, b, c)
样本结果
# 阅读数 点赞数 再看数
1561 23 18
动态获取cookies和appmsg_token
appmsg_token 是一个时间敏感的参数,需要像 cookie 一样改变。当这两个参数过期时,需要从抓包工具(MitmProxy)到代码中ctrl+C和ctrl+V,非常麻烦。
MitmProxy 可以使用命令行界面 mitmdumvp 运行 Python 代码来监控抓取的链接。如果 /mp/getappmsgext 被捕获,它将被保存在本地文件中并退出捕获
mitmdump 命令
# -s 运行的python脚本, -w 将截取的内容保持到文件
mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
监控脚本
# coding: utf-8
# write_cookie.py
import urllib
import sys
from mitmproxy import http
# command: mitmdump -s write_cookie.py -w outfile mp.weixin.qq.com/mp/getappmsgext
class WriterCookie:
"""
mitmproxy的监听脚本,写入cookie和url到文件
"""
def __init__(self, outfile: str) -> None:
self.f = open(outfile, "w")
def response(self, flow: http.HTTPFlow) -> None:
"""
完整的response响应
:param flow: flow实例,
"""
# 获取url
url = urllib.parse.unquote(flow.request.url)
# 将url和cookie写入文件
if "mp. weixin.qq.com/mp/getappmsgext" in url:
self.f.write(url + '\n')
self.f.write(str(flow.request.cookies))
self.f.close()
# 退出
exit()
# 第四个命令中的参数
addons = [WriterCookie(sys.argv[4])]
监控脚本写好后,编写启动命令和解析url和cookie文件的模块
# read_cookie.py
import re
import os
class ReadCookie(object):
"""
启动write_cookie.py 和 解析cookie文件,
"""
def __init__(self, outfile):
self.outfile = outfile
def parse_cookie(self):
"""
解析cookie
:return: appmsg_token, biz, cookie_str·
"""
f = open(self.outfile)
lines = f.readlines()
appmsg_token_string = re.findall("appmsg_token.+?&", lines[0])
biz_string = re.findall('__biz.+?&', lines[0])
appmsg_token = appmsg_token_string[0].split("=")[1][:-1]
biz = biz_string[0].split("__biz=")[1][:-1]
cookie_str = '; '.join(lines[1][15:-2].split('], [')).replace('\'','').replace(', ', '=')
return appmsg_token, biz, cookie_str
def write_cookie(self):
"""
启动 write_cookie。py
:return:
"""
#当前文件路径
path = os.path.split(os.path.realpath(__file__))[0]
# mitmdump -s 执行脚本 -w 保存到文件 本命令
command = "mitmdump -s {}/write_cookie.py -w {} mp.weixin.qq.com/mp/getappmsgext".format(
path, self.outfile)
os.system(command)
if __name__ == '__main__':
rc = ReadCookie('cookie.txt')
rc.write_cookie()
appmsg_token, biz, cookie_str = rc.parse_cookie()
print("appmsg_token:" + appmsg_token , "\nbiz:" + biz, "\ncookie:"+cookie_str)
样本结果
解析cookie.txt文件内容后
appmsg_token:1068_av3JWyDn2XCS2fwFj3ICCnwArRb2kU4Y5Y5m9Z9NkWoCOszl3a-YHFfBkAguUlYQJi2dWo83AQT4FsNK
biz:MzU1NDk2MzQyNg==
cookie:rewardsn=; wxtokenkey=777; wxuin=1681274216; devicetype=android-29; version=27001037; lang=zh_CN; pass_ticket=H9Osk2CMhrlH34mQ3w2PLv/RAVoiDxweAdyGh/Woa1qwGy2jGATJ6hhg7syTQ9nk; wap_sid2=COjq2KEGEnBPTHRVOHlYV2U4dnRqaWZqRXBqaWktTHpUSEJnTTdhU0hVZTEtZXpZZEY4a3lNY29zc0VZeEFvLS01YmJRRnQ5eFRmR2dOY29nUWdKSTRVWG13WE1obGs1blhQcVh0V18tRnBSRnVlc1VhOHNCQUFBMPeIjfgFOA1AAQ==
ReadCookie模块可以自动获取appmsg_token和cookies,作为参数传递给Articles模块,这样就可以解放双手,永远不用复制粘贴appmsg_token和cookies,只需要在appmsg_token过期时刷新公众号文章就是这样它,省心省时间
批量提取
在公众号历史消息界面向上滑动屏幕,每次可加载10条历史消息。盲目猜测,这个翻页就是批量抓取的请求链接。使用MitmProxy的WEBUI界面在Response面板中找到,找到一个是/mp /profile_ext?action=getmsg&__biz=MzU1NDk2MzQyNg==&f=json&offset=10&count=10...有多个文章 headers 在它的response返回值中,然后看这个链接的offset =10&count=10 参数,一看就是页面偏移量和每页显示的条数,仅此而已
链接中比较重要的参数有:__biz、offset、pass_ticket、appmsg_token,这些数据可以在cookie和appmsg_token中获取。
# utils.py
# 工具模块,将字符串变成字典
def str_to_dict(s, join_symbol="\n", split_symbol=":"):
s_list = s.split(join_symbol)
data = dict()
for item in s_list:
item = item.strip()
if item:
k, v = item.split(split_symbol, 1)
data[k] = v.strip()
return data
# coding:utf-8
# wxCrawler.py
import os
import requests
import json
import urllib3
import utils
class WxCrawler(object):
"""翻页内容抓取"""
urllib3.disable_warnings()
def __init__(self, appmsg_token, biz, cookie, begin_page_index = 0, end_page_index = 100):
# 起始页数
self.begin_page_index = begin_page_index
# 结束页数
self.end_page_index = end_page_index
# 抓了多少条了
self.num = 1
self.appmsg_token = appmsg_token
self.biz = biz
self.headers = {
"User-Agent": "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0Chrome/57.0.2987.132 MQQBrowser/6.2 Mobile",
"Cookie": cookie
}
self.cookie = cookie
def article_list(self, context):
articles = json.loads(context).get('general_msg_list')
return json.loads(articles)
def run(self):
# 翻页地址
page_url = "https://mp. weixin.qq.com/mp/profile_ext?action=getmsg&__biz={}&f=json&offset={}&count=10&is_ok=1&scene=&uin=777&key=777&pass_ticket={}&wxtoken=&appmsg_token=" + self.appmsg_token + "&x5=0f=json"
# 将 cookie 字典化
wx_dict = utils.str_to_dict(self.cookie, join_symbol='; ', split_symbol='=')
# 请求地址
response = requests.get(page_url.format(self.biz, self.begin_page_index * 10, wx_dict['pass_ticket']), headers=self.headers, verify=False)
# 将文章列表字典化
articles = self.article_list(response.text)
for a in articles['list']:
# 公众号中主条
if 'app_msg_ext_info' in a.keys() and '' != a.get('app_msg_ext_info').get('content_url', ''):
print(str(self.num) + "条", a.get('app_msg_ext_info').get('title'), a.get('app_msg_ext_info').get('content_url'))
# 公众号中副条
if 'app_msg_ext_info' in a.keys():
for m in a.get('app_msg_ext_info').get('multi_app_msg_item_list', []):
print(str(self.num) + "条", m.get('title'), a.get('content_url'))
self.num = self.num + 1
self.is_exit_or_continue()
# 递归调用
self.run()
def is_exit_or_continue(self):
self.begin_page_index = self.begin_page_index + 1
if self.begin_page_index > self.end_page_index:
os.exit()
最后使用自动cookie启动程序并刷新公众号文章
# coding:utf-8
# main.py
from read_cookie import ReadCookie
from wxCrawler import WxCrawler
"""程序启动类"""ss
if __name__ == '__main__':
cookie = ReadCookie('E:/python/cookie.txt')
cookie.write_cookie()
appmsg_token, biz, cookie_str = cookie.parse_cookie()
wx = WxCrawler(appmsg_token, biz, cookie_str)
wx.run()
样本结果
总结
这篇文章虽然可能有点头条党,但并没有完全自动抓取数据,需要人为刷新公众号文章。希望大家不要介意。如需刷微信文章,建议参考本公众号【第129天:爬取微信公众号文章内容】。
自动抓取网页数据(基于大数据开发一个网络爬虫设计的技术理论发展和应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-09 11:00
齐宝德
武汉大学信息工程学院,湖北武汉 430212
摘要:本文开发了一种基于大数据的网络爬虫设计,利用Python相关模块实现从网站一本书中自动下载感兴趣的图书信息的功能。包括单页图书信息下载、图书信息提取、多页图书信息下载等。
关键词:网络爬虫、信息提取、内容分析
基金资助:资助项目(新一代信息技术创新项目,课题编号2018A02016)
0 前言
网络爬虫是从互联网打开数据采集的重要手段。本文开发了一个简单的爬虫设计,利用Python的相关模块实现从某本书网站中自动下载感兴趣的书籍信息的功能。实现的主要功能有单页图书信息下载、图书信息提取、多页图书信息下载等。基于人工智能技术的新一代采集模式,操作极其简单,只需输入采集的URL,智能识别网页中的内容和分页按钮,无需配置采集规则即可完成采集的数据。
自 2004 年以来,Google 已在其应用程序中成功使用 AJAX 技术,例如 Google Discussion Groups、Google Maps、Gmail 等。同时因为该技术支持 Mozilla/Geck。,并先后被网站专业采用。GWT、Atlas、Doj等各种异步交互网络框架。也应运而生。但随之而来的是一个新问题:由于AJAX框架网站是建立在异步JavascriPt基础上的网络应用技术,传统网络搜索引擎中的网络爬虫(WebCrawler)无法解决异步交互网络网址(URL) 提取。一方面,大量基于AJAx的网站不断涌现,另一方面,这些网站网址却被搜索引擎忽略,这意味着越来越多的有意义的数据不会被搜索引擎检索到。. 这个问题也引起了国内外学者的广泛关注:异步交互网络地址解析方法的研究对于互联网领域技术理论的发展和应用具有重要意义。
1 任务描述和数据来源
前段时间在图书馆借了很多书,借多了很容易忘记每本书的到期日。一直担心会违约,影响以后借阅,但又懒得老是登录学校图书馆借阅系统。查,所以我打算写一个爬虫来抓取我的借阅信息,把每本书的到期日爬下来,写成一个txt文件,这样每次忘记的时候可以打开txt文件查,而且每我借的时候。如果信息发生了变化,只要再次运行程序,原来的txt文件就会被新的文件覆盖,里面的内容也会被更新。详细介绍智能模式的基本操作流程。
1.1 涉及的技术:
Python版本是?2.7,同时使用了urllib2、cookielib和re三个模块。urllib2 用于创建请求,抓取网页信息,返回类似文件类型的响应对象;
cookielib用于存储cookie对象,实现模拟登录功能;re 模块提供了对正则表达式的支持,用于匹配抓取的页面信息,得到你想要的信息。
创建一个智能模式任务,输入正确的 URL,采集 任务就完成了一半。从当当搜索页面,根据关键词进行搜索,使用Python编写爬虫(如图1))自动爬取书名、出版商、价格、作者、书籍介绍搜索结果中的信息。当当网搜索页面:.
图1 Web爬虫自动爬取流程
2、单页书资料下载
2.1 网页下载
采集支持单个URL和多个URL采集,支持从本地TXT文件导入URL,支持批量生成参数URL。Python中的requests库可以自动帮助我们构造一个请求对象,用于向服务器请求资源,并返回一个响应对象,用于服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。在下面的代码中,我们首先导入 requests 库,定义当当搜索页面的 URL,并将 search关键词 设置为“机器学习”。然后使用 ?requests.get? 获取网页内容的方法。最后,打印并显示网页的前 1000 个字符。
导入请求库 test_url = '' + '机器学习',设置网页的url地址 content_page = requests.get(test_url).text ,执行页面请求,返回页面内容 print(content_page[:1000]) ,把页面的前1000个字符都打印出来并显示出来。
2.2本书内容分析
接下来开始解析页面,分析源码。使用Chrome浏览器直接打开URL Machine Learning?。然后选择任何书籍信息,右键单击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,点击第一个标签,发现下面还有几个。
标签,分类为“名称”、“详细信息”、“价格”等。这些标签存储了产品的标题、详细信息、价格等信息。
以提取书名信息为例,进行具体说明。单击 ?p? ?li? 下的类属性为 name 的标记 标签,我们发现书名信息存储在?a?的title属性中。名称属性值为“itemlist-title”的标签。可以使用xpath直接将上述定位信息描述为?//li/p/a[@name="itemlist-title"]/@title?。然后使用 ?lxml? 模块提取页面中的标题信息。请参阅 ?用于 xpath。
导入etree模块 page = etree.HTML(content_page) #将页面字符串解析成树形结构 book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') # 使用xpath提取书名信息。book_name[:10] #打印提取的前10个书名。同理,我们可以提取图书的出版信息(作者、出版商、出版时间等)、当前价格、星级、评论数等。这些信息对应的xpath路径如下表所示。
接下来,我们编写一个函数?extract_books_from_content,输入一个页面内容,自动提取页面中收录的所有书籍信息。
2.3 图书数据存储
在上一节中,我们成功地从网页中提取了图书信息,并将其转换为 DataFrame 格式。您可以选择将此图书信息保存为 CSV 文件、Excel 文件或数据库。这里我们使用 ?to_csv? DataFrame 提供的保存为 CSV 文件的方法。
books_df.to_csv("./input/books_test.csv",index=None)
3、多页图书资料下载
查看搜索页面底部,输入一个关键词,一般会返回多页结果,点击任意页面按钮,观察浏览器地址栏变化。我们发现可以通过在浏览器 URL 中添加 page_index 属性来添加不同的页面。例如,如果我们搜索“机器学习”关键词,要访问第 10 页的结果,请使用以下 URL:machine learning&page_index=10
假设我们要下载一共10页的内容,我们可以通过下面的代码来完成。
import timekey_word = "machine learning" #设置搜索关键词max_page = 10 #下载书的页数_total = []for page in range(1,max_page+1): 查看全部
自动抓取网页数据(基于大数据开发一个网络爬虫设计的技术理论发展和应用)
齐宝德
武汉大学信息工程学院,湖北武汉 430212
摘要:本文开发了一种基于大数据的网络爬虫设计,利用Python相关模块实现从网站一本书中自动下载感兴趣的图书信息的功能。包括单页图书信息下载、图书信息提取、多页图书信息下载等。
关键词:网络爬虫、信息提取、内容分析
基金资助:资助项目(新一代信息技术创新项目,课题编号2018A02016)
0 前言
网络爬虫是从互联网打开数据采集的重要手段。本文开发了一个简单的爬虫设计,利用Python的相关模块实现从某本书网站中自动下载感兴趣的书籍信息的功能。实现的主要功能有单页图书信息下载、图书信息提取、多页图书信息下载等。基于人工智能技术的新一代采集模式,操作极其简单,只需输入采集的URL,智能识别网页中的内容和分页按钮,无需配置采集规则即可完成采集的数据。
自 2004 年以来,Google 已在其应用程序中成功使用 AJAX 技术,例如 Google Discussion Groups、Google Maps、Gmail 等。同时因为该技术支持 Mozilla/Geck。,并先后被网站专业采用。GWT、Atlas、Doj等各种异步交互网络框架。也应运而生。但随之而来的是一个新问题:由于AJAX框架网站是建立在异步JavascriPt基础上的网络应用技术,传统网络搜索引擎中的网络爬虫(WebCrawler)无法解决异步交互网络网址(URL) 提取。一方面,大量基于AJAx的网站不断涌现,另一方面,这些网站网址却被搜索引擎忽略,这意味着越来越多的有意义的数据不会被搜索引擎检索到。. 这个问题也引起了国内外学者的广泛关注:异步交互网络地址解析方法的研究对于互联网领域技术理论的发展和应用具有重要意义。
1 任务描述和数据来源
前段时间在图书馆借了很多书,借多了很容易忘记每本书的到期日。一直担心会违约,影响以后借阅,但又懒得老是登录学校图书馆借阅系统。查,所以我打算写一个爬虫来抓取我的借阅信息,把每本书的到期日爬下来,写成一个txt文件,这样每次忘记的时候可以打开txt文件查,而且每我借的时候。如果信息发生了变化,只要再次运行程序,原来的txt文件就会被新的文件覆盖,里面的内容也会被更新。详细介绍智能模式的基本操作流程。
1.1 涉及的技术:
Python版本是?2.7,同时使用了urllib2、cookielib和re三个模块。urllib2 用于创建请求,抓取网页信息,返回类似文件类型的响应对象;
cookielib用于存储cookie对象,实现模拟登录功能;re 模块提供了对正则表达式的支持,用于匹配抓取的页面信息,得到你想要的信息。
创建一个智能模式任务,输入正确的 URL,采集 任务就完成了一半。从当当搜索页面,根据关键词进行搜索,使用Python编写爬虫(如图1))自动爬取书名、出版商、价格、作者、书籍介绍搜索结果中的信息。当当网搜索页面:.
图1 Web爬虫自动爬取流程
2、单页书资料下载
2.1 网页下载
采集支持单个URL和多个URL采集,支持从本地TXT文件导入URL,支持批量生成参数URL。Python中的requests库可以自动帮助我们构造一个请求对象,用于向服务器请求资源,并返回一个响应对象,用于服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。在下面的代码中,我们首先导入 requests 库,定义当当搜索页面的 URL,并将 search关键词 设置为“机器学习”。然后使用 ?requests.get? 获取网页内容的方法。最后,打印并显示网页的前 1000 个字符。
导入请求库 test_url = '' + '机器学习',设置网页的url地址 content_page = requests.get(test_url).text ,执行页面请求,返回页面内容 print(content_page[:1000]) ,把页面的前1000个字符都打印出来并显示出来。
2.2本书内容分析
接下来开始解析页面,分析源码。使用Chrome浏览器直接打开URL Machine Learning?。然后选择任何书籍信息,右键单击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,点击第一个标签,发现下面还有几个。
标签,分类为“名称”、“详细信息”、“价格”等。这些标签存储了产品的标题、详细信息、价格等信息。
以提取书名信息为例,进行具体说明。单击 ?p? ?li? 下的类属性为 name 的标记 标签,我们发现书名信息存储在?a?的title属性中。名称属性值为“itemlist-title”的标签。可以使用xpath直接将上述定位信息描述为?//li/p/a[@name="itemlist-title"]/@title?。然后使用 ?lxml? 模块提取页面中的标题信息。请参阅 ?用于 xpath。
导入etree模块 page = etree.HTML(content_page) #将页面字符串解析成树形结构 book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') # 使用xpath提取书名信息。book_name[:10] #打印提取的前10个书名。同理,我们可以提取图书的出版信息(作者、出版商、出版时间等)、当前价格、星级、评论数等。这些信息对应的xpath路径如下表所示。
接下来,我们编写一个函数?extract_books_from_content,输入一个页面内容,自动提取页面中收录的所有书籍信息。
2.3 图书数据存储
在上一节中,我们成功地从网页中提取了图书信息,并将其转换为 DataFrame 格式。您可以选择将此图书信息保存为 CSV 文件、Excel 文件或数据库。这里我们使用 ?to_csv? DataFrame 提供的保存为 CSV 文件的方法。
books_df.to_csv("./input/books_test.csv",index=None)
3、多页图书资料下载
查看搜索页面底部,输入一个关键词,一般会返回多页结果,点击任意页面按钮,观察浏览器地址栏变化。我们发现可以通过在浏览器 URL 中添加 page_index 属性来添加不同的页面。例如,如果我们搜索“机器学习”关键词,要访问第 10 页的结果,请使用以下 URL:machine learning&page_index=10
假设我们要下载一共10页的内容,我们可以通过下面的代码来完成。
import timekey_word = "machine learning" #设置搜索关键词max_page = 10 #下载书的页数_total = []for page in range(1,max_page+1):
自动抓取网页数据( 这是简易数据分析系列的第4篇文章(图)实操)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-08 08:03
这是简易数据分析系列的第4篇文章(图)实操)
这是简易数据分析系列文章 的第四部分。
原文首发于博客园:简单数据分析04。
今天我们开始数据抓取的第一课,完成我们的第一个爬虫。因为只是开始,所以我会很详细的讲解操作,可能会有点啰嗦。我希望你不要不喜欢它:)
有些人之前可能学过一些爬虫知识,但是总觉得这是个复杂的东西,比如HTTP、HTML、IP池,这里就不考虑这些东西了。一是少量的数据根本不需要考虑,二是这些乱七八糟的东西根本不提爬虫的本质。
爬行动物的本质是什么?其实就是找规律。
而且,爬行动物找规律的难点,多半是小学三年级数学题的水平。
举个例子来说明,下图历史文章的截图,我们可以清楚的看到每条推文都可以分为标题、图片和作者三部分,我们只需要找到这个规律,您可以批量捕获此类数据。
好了,理论讲完了,我们开始实操吧。
只要练习爬取,第一个爬取的网站通常是豆瓣电影TOP 250,URL链接是/top250?start=0&filter=。第一次爬取的内容尽量简单,所以只爬取首页的电影片名。
浏览器按F12打开控制台,把控制台放在网页底部(详情见上篇文章),然后找到Web Scraper Tab,点击,就到了Web Scraper 控制页面。
进入Web Scraper的控制页面后,我们按照Create new sitemap -> Create Sitemap的操作路径新建一个爬虫。站点地图的含义并不重要,您只需将其视为爬虫的别名。
我们在接下来出现的输入框中依次输入爬虫名称和要爬取的链接。
爬虫名称可能有字符类型限制,我们只看规则规避,最后点击 Create Sitemap 按钮创建我们的第一个爬虫。
这时候会跳转到一个新的操作面板,别的不用管,我们直接点击蓝底白字的添加新选择器按钮,顾名思义,创建一个选择器来选择我们的元素想抢。
是时候开始正式的数据采集会话了!我们先来看看这个面板有什么:
1.首先有一个Id,这个是给我们要爬取的内容标记一个id,因为我们要爬取电影的名字,为了简单起个名字就行了;
2.电影的名字显然是一段文字,所以Type类型必须是Text。在这个爬虫工具中,默认的Type类型是Text,这个爬取工作不需要改变;
3.我们勾选了多选按钮Multiple,因为我们要抓取的是批量数据,不勾选就只能抓取一个;
4.最后,我们点击黄圈中的选择,开始在网页上查看电影名称;
当您将鼠标移动到网页上时,您会发现网页上出现绿色方块。这些方块是网页的组成元素。当我们点击鼠标时,绿色方块会变成红色,表示该元素被选中。:
至此,我们就可以进行爬取工作了。
我们先选择《肖申克的救赎》的标题,再选择《霸王别姬》的标题(注:要达到多选的效果,必须手动选择两个以上的内容)
选择这两个片名后,向下滚动页面,你会发现所有电影片名都被选中:
拉网页再次查看,发现所有电影片名都被选中了,我们可以点击完成选择!按钮,表示选择完成;
点击按钮后,你会发现下图红框中会出现一些字符。一般如果出现这个,就说明选择成功了:
我们点击数据预览按钮来预览我们的抓取效果:
如果没有问题,关闭数据预览弹窗,转到面板底部,有一个蓝色的保存选择器按钮,点击后,我们会回到上一个面板。
这时候你会发现多了一行数据,其实就是我们刚才记录的操作的内容。
在顶部的标签栏中,有一个Sitemap top250 标签,就是我们刚刚创建的爬虫。点击它,然后点击下拉菜单中的 Scrape 按钮,开始我们的数据抓取。
这时候会跳转到另一个面板,有两个输入框,不管是什么,一共输入2000就行了。
点击开始抓取蓝色按钮后,会弹出一个新的网页,Web Scraper插件会在这里抓取数据:
一般情况下,弹出网页的自动关闭意味着数据采集结束。我们点击面板上的刷新蓝色按钮,就可以看到我们抓到的数据了!
在这个预览面板中,第一列是网络爬虫自动添加的数字,没有意义;第二列是爬取的链接,第三列是我们爬取的数据。
这个数据会保存在我们的浏览器中,我们也可以在Sitemap top250下点击Export data as CSV,这样我们就可以导出.csv格式的数据了,这个格式可以用Excel打开,我们可以用Excel做一些数据格式化手术。
今天我们爬取了豆瓣电影TOP250的首页数据(也就是排名前25的电影),下一篇我们会讲如何抓取所有电影名。 查看全部
自动抓取网页数据(
这是简易数据分析系列的第4篇文章(图)实操)
这是简易数据分析系列文章 的第四部分。
原文首发于博客园:简单数据分析04。
今天我们开始数据抓取的第一课,完成我们的第一个爬虫。因为只是开始,所以我会很详细的讲解操作,可能会有点啰嗦。我希望你不要不喜欢它:)
有些人之前可能学过一些爬虫知识,但是总觉得这是个复杂的东西,比如HTTP、HTML、IP池,这里就不考虑这些东西了。一是少量的数据根本不需要考虑,二是这些乱七八糟的东西根本不提爬虫的本质。
爬行动物的本质是什么?其实就是找规律。
而且,爬行动物找规律的难点,多半是小学三年级数学题的水平。
举个例子来说明,下图历史文章的截图,我们可以清楚的看到每条推文都可以分为标题、图片和作者三部分,我们只需要找到这个规律,您可以批量捕获此类数据。
好了,理论讲完了,我们开始实操吧。
只要练习爬取,第一个爬取的网站通常是豆瓣电影TOP 250,URL链接是/top250?start=0&filter=。第一次爬取的内容尽量简单,所以只爬取首页的电影片名。
浏览器按F12打开控制台,把控制台放在网页底部(详情见上篇文章),然后找到Web Scraper Tab,点击,就到了Web Scraper 控制页面。
进入Web Scraper的控制页面后,我们按照Create new sitemap -> Create Sitemap的操作路径新建一个爬虫。站点地图的含义并不重要,您只需将其视为爬虫的别名。
我们在接下来出现的输入框中依次输入爬虫名称和要爬取的链接。
爬虫名称可能有字符类型限制,我们只看规则规避,最后点击 Create Sitemap 按钮创建我们的第一个爬虫。
这时候会跳转到一个新的操作面板,别的不用管,我们直接点击蓝底白字的添加新选择器按钮,顾名思义,创建一个选择器来选择我们的元素想抢。
是时候开始正式的数据采集会话了!我们先来看看这个面板有什么:
1.首先有一个Id,这个是给我们要爬取的内容标记一个id,因为我们要爬取电影的名字,为了简单起个名字就行了;
2.电影的名字显然是一段文字,所以Type类型必须是Text。在这个爬虫工具中,默认的Type类型是Text,这个爬取工作不需要改变;
3.我们勾选了多选按钮Multiple,因为我们要抓取的是批量数据,不勾选就只能抓取一个;
4.最后,我们点击黄圈中的选择,开始在网页上查看电影名称;
当您将鼠标移动到网页上时,您会发现网页上出现绿色方块。这些方块是网页的组成元素。当我们点击鼠标时,绿色方块会变成红色,表示该元素被选中。:
至此,我们就可以进行爬取工作了。
我们先选择《肖申克的救赎》的标题,再选择《霸王别姬》的标题(注:要达到多选的效果,必须手动选择两个以上的内容)
选择这两个片名后,向下滚动页面,你会发现所有电影片名都被选中:
拉网页再次查看,发现所有电影片名都被选中了,我们可以点击完成选择!按钮,表示选择完成;
点击按钮后,你会发现下图红框中会出现一些字符。一般如果出现这个,就说明选择成功了:
我们点击数据预览按钮来预览我们的抓取效果:
如果没有问题,关闭数据预览弹窗,转到面板底部,有一个蓝色的保存选择器按钮,点击后,我们会回到上一个面板。
这时候你会发现多了一行数据,其实就是我们刚才记录的操作的内容。
在顶部的标签栏中,有一个Sitemap top250 标签,就是我们刚刚创建的爬虫。点击它,然后点击下拉菜单中的 Scrape 按钮,开始我们的数据抓取。
这时候会跳转到另一个面板,有两个输入框,不管是什么,一共输入2000就行了。
点击开始抓取蓝色按钮后,会弹出一个新的网页,Web Scraper插件会在这里抓取数据:
一般情况下,弹出网页的自动关闭意味着数据采集结束。我们点击面板上的刷新蓝色按钮,就可以看到我们抓到的数据了!
在这个预览面板中,第一列是网络爬虫自动添加的数字,没有意义;第二列是爬取的链接,第三列是我们爬取的数据。
这个数据会保存在我们的浏览器中,我们也可以在Sitemap top250下点击Export data as CSV,这样我们就可以导出.csv格式的数据了,这个格式可以用Excel打开,我们可以用Excel做一些数据格式化手术。
今天我们爬取了豆瓣电影TOP250的首页数据(也就是排名前25的电影),下一篇我们会讲如何抓取所有电影名。
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-07 11:04
)
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。
任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browserbrowser = Browser('chrome') #打开谷歌浏览器browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;) #访问链接
打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。# find_by_xpath(XPath地址) 返回值是储存在列表中的# 这里是只有一个元素的列表,所以要选择列表第一个元素的值r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页# 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browserbrowser = Browser('chrome')browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;)r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.valuer1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.valuer1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.valuebrowser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit() 查看全部
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录
)
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。
任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browserbrowser = Browser('chrome') #打开谷歌浏览器browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;) #访问链接
打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。# find_by_xpath(XPath地址) 返回值是储存在列表中的# 这里是只有一个元素的列表,所以要选择列表第一个元素的值r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页# 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browserbrowser = Browser('chrome')browser.visit('http://femhzs.mofcom.gov.cn/fe ... %2339;)r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.valuer1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.valuer1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.valuebrowser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 打印数据,并退出浏览器print(r1c1,r1c2,r1c3)browser.quit()
自动抓取网页数据(超长正整数(超出long表数范围)的相加算法(Java实现))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-05 15:13
超长正整数(超出长表号范围)的加法算法(Java实现)
输入:一个表示超长正整数的字符串 a 表示一个超长正整数的字符串 b 输出:字符串 a 和 b 表示的正整数相加后的字符串 c 代码: import java.util.Scanner; /***@作者 wzy*@Date April 8, 2018*@Version JDK 1.8*@Description */public class run {public...
嵌入式Linux是我的line-u-boot-2009.08移植详解2440(二)_b02330224的专栏-程序员宝贝
我的嵌入式Linux线,主要讲述和总结学习嵌入式Linux的每一步。一是总结经验,二是为想入门嵌入式Linux的人提供方便。如果有任何错误,请纠正我。共享资源,欢迎转载:一、移植环境宿主:VMWare--Fedora 9开发板:Mini2440--64MB Nand,Kernel:2.6.30.4编译器
HTML基础文件,CSS基础_weixin_30649859的博客-程序员分享
HTML一、HTML 基础文件[meta tag] 1、charset 属性:单独使用。设置文档字符集编码格式。>>>编写:<meta charset="utf8"> >>>常用中文编码格式:GB-2312:国标码、简体中文GBK:扩展国际码、...
剑指Offer 16. 数值整数幂---二分法,python,c++
c++:class 解决方案 {public: double myPow(double x, int n) {if(x==0||x==1){ return x;} // 考虑溢出情况 long b=(long) n; //如果指数小于0,则指数为正,底为倒数 if(b<0){ x=1/x; b=-b...
scrapy 设置和一些默认值_byseaz 的博客程序员寻求
Scrapy 组件中描述的功能可以使用 Scrapy 设置进行修改。如果您有多个 Scrapy 项目,也可以在 Scrapy 项目当前处于活动状态时选择这些设置。要指定设置,您必须在放弃 网站 时告知您使用的 Scrapy 设置。为此,应使用关键内容环境变量 SCRAPY_SETTINGS_MODULE,其值应在 Python 路径语法中。填充设置 下表显示了一些可以用来填充设置的机制: SN 机制和描述 1. Co...
Dijkstra算法解决最短路径问题
标题:Dijkstra 算法解决最短路径问题日期:2020-01-07 16:18:25tags:数据结构单源最短路径问题:计算源点到彼此顶点的最短路径长度全局最短路径问题:任意两个图中节点之间的最短路径 上述两个问题都可以归结为最短路径问题(实际上,全局最短路径可以通过为每个节点找到单源最短路径来解决)Dijkstra算法用于解决单源最短路径,但它无法找到具有负边权的最短路径...... 查看全部
自动抓取网页数据(超长正整数(超出long表数范围)的相加算法(Java实现))
超长正整数(超出长表号范围)的加法算法(Java实现)
输入:一个表示超长正整数的字符串 a 表示一个超长正整数的字符串 b 输出:字符串 a 和 b 表示的正整数相加后的字符串 c 代码: import java.util.Scanner; /***@作者 wzy*@Date April 8, 2018*@Version JDK 1.8*@Description */public class run {public...
嵌入式Linux是我的line-u-boot-2009.08移植详解2440(二)_b02330224的专栏-程序员宝贝
我的嵌入式Linux线,主要讲述和总结学习嵌入式Linux的每一步。一是总结经验,二是为想入门嵌入式Linux的人提供方便。如果有任何错误,请纠正我。共享资源,欢迎转载:一、移植环境宿主:VMWare--Fedora 9开发板:Mini2440--64MB Nand,Kernel:2.6.30.4编译器
HTML基础文件,CSS基础_weixin_30649859的博客-程序员分享
HTML一、HTML 基础文件[meta tag] 1、charset 属性:单独使用。设置文档字符集编码格式。>>>编写:<meta charset="utf8"> >>>常用中文编码格式:GB-2312:国标码、简体中文GBK:扩展国际码、...
剑指Offer 16. 数值整数幂---二分法,python,c++
c++:class 解决方案 {public: double myPow(double x, int n) {if(x==0||x==1){ return x;} // 考虑溢出情况 long b=(long) n; //如果指数小于0,则指数为正,底为倒数 if(b<0){ x=1/x; b=-b...
scrapy 设置和一些默认值_byseaz 的博客程序员寻求
Scrapy 组件中描述的功能可以使用 Scrapy 设置进行修改。如果您有多个 Scrapy 项目,也可以在 Scrapy 项目当前处于活动状态时选择这些设置。要指定设置,您必须在放弃 网站 时告知您使用的 Scrapy 设置。为此,应使用关键内容环境变量 SCRAPY_SETTINGS_MODULE,其值应在 Python 路径语法中。填充设置 下表显示了一些可以用来填充设置的机制: SN 机制和描述 1. Co...
Dijkstra算法解决最短路径问题
标题:Dijkstra 算法解决最短路径问题日期:2020-01-07 16:18:25tags:数据结构单源最短路径问题:计算源点到彼此顶点的最短路径长度全局最短路径问题:任意两个图中节点之间的最短路径 上述两个问题都可以归结为最短路径问题(实际上,全局最短路径可以通过为每个节点找到单源最短路径来解决)Dijkstra算法用于解决单源最短路径,但它无法找到具有负边权的最短路径......
自动抓取网页数据(可自动分析网页中表单已经填写的内容,功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-05 15:12
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。
/pic.php?url=http://8.pic.pc6.com/thumb/up/ ... 0.jpg
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
自动抓取网页数据(可自动分析网页中表单已经填写的内容,功能介绍)
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。
/pic.php?url=http://8.pic.pc6.com/thumb/up/ ... 0.jpg
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
自动抓取网页数据(servlet自动获取前端页面及代码1)提交数据介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-29 03:07
servlet自动获取前端页面的jsp提交数据
下面是我在学习过程中由于前端页面提交参数太多,后台servlet封装实体类太麻烦而写的一个工具类。应用jsp/servlet数据提交后,基于MVC+MyBatis的数据持久化过程。这里只介绍将数据封装对象从页面提交到servlet(控制器)的过程。MVC+MyBatis 对数据库的访问这里就不介绍了。
1.前端页面和代码
1)前端表单页面构建(用来测试简单构建的页面有点丑~)
2)前端jsp页面代码
这里使用ajax异步get,去除缓存提交表单。请按传统方式自测。我已经测试过了,我不会在这里展示它。
注:Ajax提交表单部分使用了jQuery的serialize()序列化函数,初学者可以参考jQuery帮助文档。如果不明白,可以使用数据部分中的“字符串”或json对象,以常规方式提交数据。
1
3
4
5
6
7 Insert title here
8
9
10 $(function(){
11 $("#submitBtn").click(function(){
12 $.ajax({
13 url:"${pageContext.request.contextPath }/testPage",
14 data:$("#formId").serialize(), //jQuery中的函数,序列化表单数据
15 type:"get",
16 cache:false,
17 success:function(jsonObj){
18 alert(jsonObj.msg);
19 $("#formId")[0].reset();//重置表单
20 }
21 })
22 });
23 })
24
25
26
27
28
29 ID:
30 姓名:
31 性别:
32 年龄:
33 价格:
34
35
36
37
2.实体类
5个属性并提供set/get方法
1 package com.domain;
2
3 public class Person {
4 String username;
5 String sex;
6 int age;
7 Double price;
8 Long id;
9 public String getUsername() {
10 return username;
11 }
12 public void setUsername(String username) {
13 this.username = username;
14 }
15 public String getSex() {
16 return sex;
17 }
18 public void setSex(String sex) {
19 this.sex = sex;
20 }
21 public int getAge() {
22 return age;
23 }
24 public void setAge(int age) {
25 this.age = age;
26 }
27 public Double getPrice() {
28 return price;
29 }
30 public void setPrice(Double price) {
31 this.price = price;
32 }
33 public Long getId() {
34 return id;
35 }
36 public void setId(Long id) {
37 this.id = id;
38 }
39 }
3.后台Servlet代码
1)封装实体类对象
这里只有前端提交数据并输出到控制台,证明数据已经获取到并封装在对象中。
其中,p = (Person) EncapsulationUtil.getJavaBean(Person.class, request); 我用的是打包工具,懒得自己写的,后面提供源码。稍后将给出详细说明。
注意:当前端提交的数据和我们需要保存到数据库的数据不完整时,可以在servlet中获取到包对象后手动设置。比如数据的主键id一般是后台生成UUID设置的,需要手动设置。
<p> 1 package com.controller;
2
3 import java.io.IOException;
4 import java.util.HashMap;
5 import java.util.Map;
6
7 import javax.servlet.ServletException;
8 import javax.servlet.http.HttpServlet;
9 import javax.servlet.http.HttpServletRequest;
10 import javax.servlet.http.HttpServletResponse;
11
12 import com.domain.Person;
13 import com.fasterxml.jackson.databind.ObjectMapper;
14 import com.utils.EncapsulationUtil;
15
16 public class testPage extends HttpServlet {
17
18 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
19 //定义数据封装体的对象
20 Person p;
21 //定义用于返回json的数据存放集合
22 Map map = new HashMap();
23
24 try {
25 //获取前端页面表单提交的数据
26 p = (Person) EncapsulationUtil.getJavaBean(Person.class, request);
27 //打印封装体中的数据结果
28 System.out.println("ID---->"+p.getId()+""+p.getUsername()+""+p.getAge()+" 查看全部
自动抓取网页数据(servlet自动获取前端页面及代码1)提交数据介绍)
servlet自动获取前端页面的jsp提交数据
下面是我在学习过程中由于前端页面提交参数太多,后台servlet封装实体类太麻烦而写的一个工具类。应用jsp/servlet数据提交后,基于MVC+MyBatis的数据持久化过程。这里只介绍将数据封装对象从页面提交到servlet(控制器)的过程。MVC+MyBatis 对数据库的访问这里就不介绍了。
1.前端页面和代码
1)前端表单页面构建(用来测试简单构建的页面有点丑~)
2)前端jsp页面代码
这里使用ajax异步get,去除缓存提交表单。请按传统方式自测。我已经测试过了,我不会在这里展示它。
注:Ajax提交表单部分使用了jQuery的serialize()序列化函数,初学者可以参考jQuery帮助文档。如果不明白,可以使用数据部分中的“字符串”或json对象,以常规方式提交数据。
1
3
4
5
6
7 Insert title here
8
9
10 $(function(){
11 $("#submitBtn").click(function(){
12 $.ajax({
13 url:"${pageContext.request.contextPath }/testPage",
14 data:$("#formId").serialize(), //jQuery中的函数,序列化表单数据
15 type:"get",
16 cache:false,
17 success:function(jsonObj){
18 alert(jsonObj.msg);
19 $("#formId")[0].reset();//重置表单
20 }
21 })
22 });
23 })
24
25
26
27
28
29 ID:
30 姓名:
31 性别:
32 年龄:
33 价格:
34
35
36
37
2.实体类
5个属性并提供set/get方法
1 package com.domain;
2
3 public class Person {
4 String username;
5 String sex;
6 int age;
7 Double price;
8 Long id;
9 public String getUsername() {
10 return username;
11 }
12 public void setUsername(String username) {
13 this.username = username;
14 }
15 public String getSex() {
16 return sex;
17 }
18 public void setSex(String sex) {
19 this.sex = sex;
20 }
21 public int getAge() {
22 return age;
23 }
24 public void setAge(int age) {
25 this.age = age;
26 }
27 public Double getPrice() {
28 return price;
29 }
30 public void setPrice(Double price) {
31 this.price = price;
32 }
33 public Long getId() {
34 return id;
35 }
36 public void setId(Long id) {
37 this.id = id;
38 }
39 }
3.后台Servlet代码
1)封装实体类对象
这里只有前端提交数据并输出到控制台,证明数据已经获取到并封装在对象中。
其中,p = (Person) EncapsulationUtil.getJavaBean(Person.class, request); 我用的是打包工具,懒得自己写的,后面提供源码。稍后将给出详细说明。
注意:当前端提交的数据和我们需要保存到数据库的数据不完整时,可以在servlet中获取到包对象后手动设置。比如数据的主键id一般是后台生成UUID设置的,需要手动设置。
<p> 1 package com.controller;
2
3 import java.io.IOException;
4 import java.util.HashMap;
5 import java.util.Map;
6
7 import javax.servlet.ServletException;
8 import javax.servlet.http.HttpServlet;
9 import javax.servlet.http.HttpServletRequest;
10 import javax.servlet.http.HttpServletResponse;
11
12 import com.domain.Person;
13 import com.fasterxml.jackson.databind.ObjectMapper;
14 import com.utils.EncapsulationUtil;
15
16 public class testPage extends HttpServlet {
17
18 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
19 //定义数据封装体的对象
20 Person p;
21 //定义用于返回json的数据存放集合
22 Map map = new HashMap();
23
24 try {
25 //获取前端页面表单提交的数据
26 p = (Person) EncapsulationUtil.getJavaBean(Person.class, request);
27 //打印封装体中的数据结果
28 System.out.println("ID---->"+p.getId()+""+p.getUsername()+""+p.getAge()+"
自动抓取网页数据(自动抓取网页数据,公有云管理协议都有机会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-26 04:00
自动抓取网页数据,就像蚂蚁森林一样,这是国家提倡的。这是整合行业的效果。2018年应该是经济下行,制造业寒冬。但信息安全领域可以看到,国家再推进,肯定能带动一部分自动化方面的需求。像云盘协议与带宽通道费用,已经这么高了,国家肯定会减少带宽使用。所以如果做信息安全行业,或许会有很多空间,但是前提是,业务能够从单一领域走向多元化,目前更多的是向企业云管理协议,专业云上管理协议,分离云和企业it解决方案迈进。从业务上看,企业应用安全,个人网站安全,公有云管理协议都有机会。
这个题目很久之前有的,现在感觉又被挖了出来,信息安全现在发展的非常好,机会大大的有。互联网金融、电信诈骗、盗号这些只要做不少年,肯定不会有问题,普通投资者别听信暴利,不然就做错了。
信息安全,人工智能,区块链,边缘计算,大数据,等等。都非常有前景。
一直把信息安全放在第一位,可能会从事这个,但是可能不是很有优势。毕竟,单靠安全行业的个人安全,和组织安全太弱。选择什么样的行业,看你个人的能力,不要因为安全行业暴利和人为因素的危害而停止了前进。
最近几年,安全行业确实发展很快,所有传统厂商都转入到企业安全领域,企业安全成为主流;从投资角度来看,以前中国互联网相对高速,其实企业安全并不很在重视,尤其是电子商务方面,很难出现这方面的第一名,但是这几年,国内企业安全方面从游戏、金融、社交、出行、p2p、直播...逐渐展现出来安全领域的格局,只要是互联网企业有安全方面的需求,安全员安全研发方面的压力会变得很大,如果互联网公司本身有安全要求,也确实需要最好同时配备有安全研发人员,看好这个方向,目前的起点高了,后期发展空间不错,毕竟国内基本企业安全都是个人安全厂商在做。 查看全部
自动抓取网页数据(自动抓取网页数据,公有云管理协议都有机会)
自动抓取网页数据,就像蚂蚁森林一样,这是国家提倡的。这是整合行业的效果。2018年应该是经济下行,制造业寒冬。但信息安全领域可以看到,国家再推进,肯定能带动一部分自动化方面的需求。像云盘协议与带宽通道费用,已经这么高了,国家肯定会减少带宽使用。所以如果做信息安全行业,或许会有很多空间,但是前提是,业务能够从单一领域走向多元化,目前更多的是向企业云管理协议,专业云上管理协议,分离云和企业it解决方案迈进。从业务上看,企业应用安全,个人网站安全,公有云管理协议都有机会。
这个题目很久之前有的,现在感觉又被挖了出来,信息安全现在发展的非常好,机会大大的有。互联网金融、电信诈骗、盗号这些只要做不少年,肯定不会有问题,普通投资者别听信暴利,不然就做错了。
信息安全,人工智能,区块链,边缘计算,大数据,等等。都非常有前景。
一直把信息安全放在第一位,可能会从事这个,但是可能不是很有优势。毕竟,单靠安全行业的个人安全,和组织安全太弱。选择什么样的行业,看你个人的能力,不要因为安全行业暴利和人为因素的危害而停止了前进。
最近几年,安全行业确实发展很快,所有传统厂商都转入到企业安全领域,企业安全成为主流;从投资角度来看,以前中国互联网相对高速,其实企业安全并不很在重视,尤其是电子商务方面,很难出现这方面的第一名,但是这几年,国内企业安全方面从游戏、金融、社交、出行、p2p、直播...逐渐展现出来安全领域的格局,只要是互联网企业有安全方面的需求,安全员安全研发方面的压力会变得很大,如果互联网公司本身有安全要求,也确实需要最好同时配备有安全研发人员,看好这个方向,目前的起点高了,后期发展空间不错,毕竟国内基本企业安全都是个人安全厂商在做。
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-21 20:16
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。
SeaTable表格字段自动获取城市经纬度到表格的“纬度和经度”字段
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:
只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:
img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。
使用SeaTable的地图插件自动生成城市地图
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。
使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。
此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。
总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。 查看全部
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。
SeaTable表格字段自动获取城市经纬度到表格的“纬度和经度”字段
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:
只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:
img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。
使用SeaTable的地图插件自动生成城市地图
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。
使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。
此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。
总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-21 20:15
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。
自动获取城市的经纬度到表格的“经纬度”字段中
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:
只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:
img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。
使用SeaTable的地图插件自动生成城市地图
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。
使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。
此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。
总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。 查看全部
自动抓取网页数据(如何用Python从维基百科中抓取冬奥会的城市数据可视化?)
使用Python从维基百科、百度百科等中抓取公共数据网站并存入表格。这不是一项艰巨的任务。但是在很多应用场景中,我们不再局限于将捕获的数据存储在表格中,还需要更加直观的进行可视化。比如在这个案例中,使用Python从维基百科中抓取过去举办过冬奥会的城市,然后创建地图、图片库,甚至灵活的共享和协作。为此,如果在抓取数据后使用 Python 来可视化和共享网页,则会更加复杂且效率低下。对于许多非专业人士来说,它会限制性能。而且如果结合SeaTable来实现,会非常方便,任何人都可以上手。
本文将分享如何使用Python从维基百科中抓取城市数据,然后自动填充到SeaTable表中,并使用SeaTable表可视化插件自动生成地图、图库等。下图是一个基本的举办冬季奥运会的城市表。
任务目标:通过各个城市的维基链接找到该城市对应的地理位置(经纬度),并填写“经纬度”字段。同时,从维基百科下载一张城市的宣传图片,上传到“城市图片”栏。
自动获取城市的经纬度到表格的“经纬度”字段中
要从网页中获取信息,需要一些简单的python 爬取技术。这个任务是使用 Python 模块 requests 和 beatifulsoup 实现的。requests模块可以模拟在线请求,返回html的DOM树,beatifulsoup通过解析DOM树获取标签中想要的信息。以维基百科中某个城市的经纬度为例,DOM树的结构如下:
只要在网页中可以看到信息,就可以通过DOM树的源码查询其位置,通过简单的分析就可以提取出想要的内容。具体分析方法可以参考beautifulsoup文档。
下面给出通过url解析其经纬度信息的代码:
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/Chamonix" # 维基百科的城市链接
# 请求该链接, 获取其内容, 网页内容是一段 DOM 树
resp = requests.get(url)
# 把获取的内容装进 beatifulsoup解析器,以待解析
soup = BeautifulSoup(resp.content)
# 纬度, 找到 DOM 属性 class 为 longitude 的结构, 获取其标签值
lon = soup.find_all(attrs={"class": "longitude"})[0].string
# 经度, 找到 DOM 属性 class 为 latitude的结构, 获取其标签值
lat = soup.find_all(attrs={"class": "latitude"})[0].string
上面找到的经纬度格式是标准的地理格式,写成45° 55′ 23.16″ N, 6° 52′ 10.92″ E,保存在SeaTable table 需要转换成十进制格式才能写入。这里需要写一个转换逻辑进行转换。
自动获取城市图片到表格的“城市图片”字段
在这个任务中,除了要知道经纬度信息外,还需要下载一张图片,传到表中。同样,图片的经纬度也是一样的。原创信息也可以在DOM树中找到:
img标签的src值就是我们需要的下载链接。结合SeaTable API的文件操作,可以方便的下载图片,然后上传到表中。以下是该任务的完整代码:
import requests
from bs4 import BeautifulSoup
import re
from seatable_api import Base, context
import os
import time
'''
该脚本演示了通过从维基百科举行冬奥会的城市数据中摘取相关内容,解析,并把其填入 seatable 表格中的案例
数据包括地理位置的经纬度, 以及代表图片
'''
SERVER_URL = context.server_url or 'https://cloud.seatable.cn/'
API_TOKEN = context.api_token or 'cacc42497886e4d0aa8ac0531bdcccb1c93bd0f5'
TABLE_NAME = "历届举办地"
URL_COL_NAME = "维基百科城市链接"
CITY_COL_NAME = "举办城市"
POSITION_COL_NAME = "经纬度"
IMAGE_COL_NAME = "城市图片"
def get_time_stamp():
return str(int(time.time()*10000000))
class Wiki(object):
def __init__(self, authed_base):
self.base = authed_base
self.soup = None
def _convert(self, tude):
# 把经纬度格式转换成十进制的格式,方便填入表格。
multiplier = 1 if tude[-1] in ['N', 'E'] else -1
return multiplier * sum(float(x) / 60 ** n for n, x in enumerate(tude[:-1]))
def _format_position(self, corninate):
format_str_list = re.split("°|′|″", corninate)
if len(format_str_list) == 3:
format_str_list.insert(2, "00")
return format_str_list
def _get_soup(self, url):
# 初始化DOM解析器
resp = requests.get(url)
soup = BeautifulSoup(resp.content)
self.soup = soup
return soup
def get_tu_position(self, url):
soup = self.soup or self._get_soup(url)
# 解析网页的DOM,取出经纬度的数值, 返回十进制
lon = soup.find_all(attrs={"class": "longitude"})[0].string
lat = soup.find_all(attrs={"class": "latitude"})[0].string
converted_lon = self._convert(self._format_position(lon))
converted_lat = self._convert(self._format_position(lat))
return {
"lng": converted_lon,
"lat": converted_lat
}
def get_file_download_url(self, url):
# 解析一个DOM,取出其中一个图片的下载链接
soup = self.soup or self._get_soup(url)
src_image_tag = soup.find_all(attrs={"class": "infobox ib-settlement vcard"})[0].find_all('img')
src = src_image_tag[0].attrs.get('src')
return "https:%s" % src
def handle(self, table_name):
base = self.base
for row in base.list_rows(table_name):
try:
url = row.get(URL_COL_NAME)
if not url:
continue
row_id = row.get("_id")
position = self.get_tu_position(url)
image_file_downlaod_url = self.get_file_download_url(url)
extension = image_file_downlaod_url.split(".")[-1]
image_name = "/tmp/wik-image-%s-%s.%s" % (row_id, get_time_stamp(), extension)
resp_img = requests.get(image_file_downlaod_url)
with open(image_name, 'wb') as f:
f.write(resp_img.content)
info_dict = base.upload_local_file(
image_name,
name=None,
relative_path=None,
file_type='image',
replace=True
)
row_data = {
POSITION_COL_NAME: position,
IMAGE_COL_NAME: [info_dict.get('url'), ]
}
base.update_row(table_name, row_id, row_data)
os.remove(image_name)
self.soup = None
except Exception as e:
print("error", row.get(CITY_COL_NAME), e)
def run():
base = Base(API_TOKEN, SERVER_URL)
base.auth()
wo = Wiki(base)
wo.handle(TABLE_NAME)
if __name__ == '__main__':
run()
下面是一张通过运行脚本自动写入数据的表的结果。可以看出,相对于在线搜索和手动填写每行数据,脚本的自动化操作可以节省大量时间,并且准确高效。
使用SeaTable的地图插件自动生成城市地图
有了之前获取到的城市经纬度信息,我们可以在SeaTable表的“插件”栏中添加一个地图插件,然后简单的点击即可根据“经纬度”在地图上自动标记城市“ 场地。并且还可以标记不同的标签颜色,设置直接和浮动显示字段等。相比单调地查看表格中的每个城市,通过地图进行可视化显然更加生动直观。
使用 SeaTable 的图库插件可视化城市图片
图库插件也可以放在表格工具栏上,方便随时打开查看。在图库插件的设置中,还可以根据表格中的“城市图片”字段,以图库的形式显示图片,还可以设置标题名称等显示字段. 这比浏览表格中的缩略图更美观、更方便,大大提高了浏览体验。并点击图片放大。点击标题也可以直接进入查看和编辑表格中的行内容。
此外,表单还支持灵活的共享和协作权限管控,可以满足详细多样的共享场景。例如,如果您想直接分享地图和图库供他人查看,也可以直接在表单插件的外部应用中添加“地图”和“图库”。更多使用可以自己体验,这里就不介绍了。
总结
SeaTable作为一种新型的协作表和信息管理工具,不仅功能丰富,而且使用方便。当我们通常使用Python来实现一些程序时,可以灵活组合SeaTable表的功能,从而节省编程、开发、维护等时间和人力成本,快速轻松地实现更多有趣的事情和更完整的应用。它还允许使用工具发挥更大的价值。
自动抓取网页数据(使用VC的socket编程,网上能找到一大堆http的get和post方法程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-20 09:15
最近突然有了一个想法,通过程序在客户端自动完成一些比较复杂的功能,比如自动注册论坛发帖,使用一些网站搜索功能自动搜索组织感兴趣的数据, 站内自动发送短信甚至自动发送邮件;说白了就是一些所谓的“饮水机”、“爆款机”、“垃圾机”。当然,我的出发点是学习和提高。
由于之前没接触过这方面的东西,所以决定先实现一小部分功能,打下基础。这个小项目的功能是使用该程序在论坛中自动发表评论。可以在人输入文字后由程序提交,也可以由程序自动获取网友发表的评论并作为关键词google,得到结果后回复论坛。,后面的功能本来是想智能聊天的,但是为了实现简单的处理,效果并不好,下面讨论这个功能的实现。
程序中要做的工作是用用户名和密码登录,2、获取某个栏目的页面,然后依次搜索每个主题,并保存标题、超链接和其他信息,3、通过比较最后一个回复者的名字来确定回复的主题,输入主题,通过计算和使用主键的方法找到最后一个回复,4、截取部分内容, URL-encode后提交到google搜索页面,5、同样通过主键方法和简单计算索引到第一个搜索结果,6、对结果进行URL-encode后提交给论坛相应主题完成回复。
使用VC socket编程,在网上可以找到很多http get和post方法的程序。通过这些方法,程序可以自动获取和提交数据。以下是该项目的一些困难。要提交中文,必须对其进行编码。不同的网站可能使用不同的编码,主要是GBK和UTF-8。论坛是前者,谷歌是后者。浏览器有这些编码功能,那么我程序的本质就是将一种编码数据的数据交换到另一种编码数据,然后返回到原来的编码数据。编码方式也可以在网上搜索。提交数据时,http头需要给出提交的内容,所以程序应该根据提交数据的长度自动合成一个声明长度的提交字符串。此外,通过获取的网页数据搜索感兴趣的话题和其他信息也很关键。可以通过分析html源代码找到合适的算法。 查看全部
自动抓取网页数据(使用VC的socket编程,网上能找到一大堆http的get和post方法程序)
最近突然有了一个想法,通过程序在客户端自动完成一些比较复杂的功能,比如自动注册论坛发帖,使用一些网站搜索功能自动搜索组织感兴趣的数据, 站内自动发送短信甚至自动发送邮件;说白了就是一些所谓的“饮水机”、“爆款机”、“垃圾机”。当然,我的出发点是学习和提高。
由于之前没接触过这方面的东西,所以决定先实现一小部分功能,打下基础。这个小项目的功能是使用该程序在论坛中自动发表评论。可以在人输入文字后由程序提交,也可以由程序自动获取网友发表的评论并作为关键词google,得到结果后回复论坛。,后面的功能本来是想智能聊天的,但是为了实现简单的处理,效果并不好,下面讨论这个功能的实现。
程序中要做的工作是用用户名和密码登录,2、获取某个栏目的页面,然后依次搜索每个主题,并保存标题、超链接和其他信息,3、通过比较最后一个回复者的名字来确定回复的主题,输入主题,通过计算和使用主键的方法找到最后一个回复,4、截取部分内容, URL-encode后提交到google搜索页面,5、同样通过主键方法和简单计算索引到第一个搜索结果,6、对结果进行URL-encode后提交给论坛相应主题完成回复。
使用VC socket编程,在网上可以找到很多http get和post方法的程序。通过这些方法,程序可以自动获取和提交数据。以下是该项目的一些困难。要提交中文,必须对其进行编码。不同的网站可能使用不同的编码,主要是GBK和UTF-8。论坛是前者,谷歌是后者。浏览器有这些编码功能,那么我程序的本质就是将一种编码数据的数据交换到另一种编码数据,然后返回到原来的编码数据。编码方式也可以在网上搜索。提交数据时,http头需要给出提交的内容,所以程序应该根据提交数据的长度自动合成一个声明长度的提交字符串。此外,通过获取的网页数据搜索感兴趣的话题和其他信息也很关键。可以通过分析html源代码找到合适的算法。
自动抓取网页数据(如何使用Python和pandas库从web页面获取表数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-16 10:17
如今,人们可以随时随地连接到互联网。Internet 可能是最大的公共数据库。学习如何从 Internet 获取数据很重要。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但这里的功能要强大 100 倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器就会向目标网站的服务器发送请求。
2. 服务器接收到请求,并发送回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不使用浏览器,而是使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同样,下面的代码会在浏览器上画一个表格,你可以尝试将它复制粘贴到记事本中,然后将其保存为“table example.html”文件,你应该可以在浏览器中打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语存储在...标签中。pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 Pandas 从不收录任何表格(...标记)的网页中“提取数据”,您将无法获得任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的例子大多是一些数据点很少的小表,我们用稍微大一点的数据来处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误,根据错误提示处理。我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图2
第一个数据框df[0]好像和这个没有关系,而是页面爬取的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界财富500强的排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得数据框列表而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。 查看全部
自动抓取网页数据(如何使用Python和pandas库从web页面获取表数据?)
如今,人们可以随时随地连接到互联网。Internet 可能是最大的公共数据库。学习如何从 Internet 获取数据很重要。因此,有必要了解如何使用Python和pandas库从网页中获取表格数据。另外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但这里的功能要强大 100 倍。
从网站获取数据(网络爬虫)
HTML 是每个 网站 背后的语言。当我们访问一个网站时,发生的事情是这样的:
1.在浏览器地址栏中输入地址(URL),浏览器就会向目标网站的服务器发送请求。
2. 服务器接收到请求,并发送回构成网页的 HTML 代码。
3.浏览器接收HTML代码,动态运行,创建一个网页供我们查看。
网页抓取基本上是指我们可以不使用浏览器,而是使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据。
这里不会涉及太多HTML,只介绍一些关键点,让我们对网站和网页抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”被特定的关键字包围。比如下面的HTML代码就是网页的标题,将鼠标悬停在网页中的标签上,浏览器会看到相同的标题。请注意,大多数 HTML 元素需要一个开始标记(例如,)和相应的结束标记(例如,)。
Python pandas获取网页中的表格数据(网络爬虫)
同样,下面的代码会在浏览器上画一个表格,你可以尝试将它复制粘贴到记事本中,然后将其保存为“table example.html”文件,你应该可以在浏览器中打开它。简要说明如下:
用户姓名
国家
城市
性别
年龄
Forrest Gump
USA
New York
M>
50
Mary Jane
CANADA
Toronto
F
30
使用pandas进行网络爬虫的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里之所以只介绍HTML表格,是因为大多数时候,我们尝试从网站中获取数据时,都是表格形式的。pandas 是从 网站 获取表格格式数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语存储在...标签中。pandas 将能够使用我们刚刚介绍的 HTML 标签提取表格、标题和数据行。
如果您尝试使用 Pandas 从不收录任何表格(...标记)的网页中“提取数据”,您将无法获得任何数据。对于那些没有存储在表中的数据,我们需要其他方法来抓取网站。
网页抓取示例
我们之前的例子大多是一些数据点很少的小表,我们用稍微大一点的数据来处理。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误,根据错误提示处理。我电脑没有安装lxml,安装后正常)
上面的df其实是一个列表,很有意思……列表里好像有3个项目。让我们看看pandas为我们采集了哪些数据...
图2
第一个数据框df[0]好像和这个没有关系,而是页面爬取的第一个表。查看网页,可以知道这张表是在中国举办的财富全球论坛。
图 3
第二个数据框 df[1] 是本页的另一个表格。请注意,在它的末尾,这意味着有 [500 行 x 6 列]。这张表是世界财富500强的排名表。
图 4
第三个数据框 df[2] 是页面上的第三个表,最后是 [110 行 x 5 列]。本表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得数据框列表而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。
自动抓取网页数据(网络爬虫获取到网上的海量信息怎么破?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-15 20:07
搜索引擎如果要获取互联网上的大量信息,就需要发布一个程序(按照一定的规则自动抓取万维网上信息的程序或脚本)来抓取互联网上的信息。这个程序叫做 Internet。爬虫。在百度、360、搜搜等搜索引擎中,网络爬虫也被称为搜索引擎蜘蛛,如百度蜘蛛、360Spider、Sosospider等;而在谷歌搜索引擎中,网络爬虫被称为谷歌机器人(googlebot)。下面我们将详细分析网络爬虫的工作原理和爬取网站的过程。
网络爬虫的工作是不断从互联网上检索信息,然后将索引数据存储在搜索引擎的服务器上。这个过程称为网络爬行。
网络爬虫工作的一般流程
由于搜索引擎并未公布其网络爬虫的工作原理,所以只能粗略估计网络爬虫的大致流程。
第一步,从精心挑选的种子网址中选取一部分,将这些网址放入待抓取的网址队列中;
第二步,服务器发送Request请求,获取对应的内容(Response),如果HTTP状态码为200,则发送网络爬虫对url页面进行爬取;如果是其他状态码(例如:404、50 0),网络爬虫会停止爬取url页面并记录状态。
第三步,网络爬虫查看网站的robots.txt文件,如果robots协议允许,就会抓取url的页面内容并发回服务器。如果robots协议不允许,网页数据将不会被抓取。, 直接返回,在数据库中标记。
第四步,下载该URL对应的网页,存储到下载的网页库中,并将这些URL放入爬取的URL队列中。
第五步,对爬取的URL队列中的页面进行分析,如果发现新的URL,则将新的URL放入待爬取的URL队列中,从而进入下一个循环。
网络爬虫只负责发现信息、爬取信息、去除网页重复、划分网页质量等级。这些任务是网络爬虫抓取数据后算法程序的工作。网络爬虫不参与。
有的朋友可能认为,网络爬虫只要进入网站,就会往下爬,然后爬取网站的所有页面内容。事实上,情况并非如此。网络爬虫不是贪吃蛇,它只是抓取当前网页信息并返回。对服务器后台数据进行分析后,如果发现新的网址,则将其添加到未抓取的网址列表中,搜索引擎会将其发送出去。新的网络爬虫用新的 URL 抓取网页。
事实上,网络爬虫更像是寻找食物的蚂蚁。网站 就像一大块食物。当一只小蚂蚁发现食物时,它会回去通知其他朋友,然后一批又一批的小蚂蚁就会离开。将食物带回并存放在仓库中。一只小蚂蚁找到一大块食物拼命把它带回去是不现实的。所以,领导自己觉得网络爬虫更像是蚂蚁,而不是蜘蛛。将其与蚂蚁进行比较会更合适。 查看全部
自动抓取网页数据(网络爬虫获取到网上的海量信息怎么破?(图))
搜索引擎如果要获取互联网上的大量信息,就需要发布一个程序(按照一定的规则自动抓取万维网上信息的程序或脚本)来抓取互联网上的信息。这个程序叫做 Internet。爬虫。在百度、360、搜搜等搜索引擎中,网络爬虫也被称为搜索引擎蜘蛛,如百度蜘蛛、360Spider、Sosospider等;而在谷歌搜索引擎中,网络爬虫被称为谷歌机器人(googlebot)。下面我们将详细分析网络爬虫的工作原理和爬取网站的过程。
网络爬虫的工作是不断从互联网上检索信息,然后将索引数据存储在搜索引擎的服务器上。这个过程称为网络爬行。
网络爬虫工作的一般流程
由于搜索引擎并未公布其网络爬虫的工作原理,所以只能粗略估计网络爬虫的大致流程。
第一步,从精心挑选的种子网址中选取一部分,将这些网址放入待抓取的网址队列中;
第二步,服务器发送Request请求,获取对应的内容(Response),如果HTTP状态码为200,则发送网络爬虫对url页面进行爬取;如果是其他状态码(例如:404、50 0),网络爬虫会停止爬取url页面并记录状态。
第三步,网络爬虫查看网站的robots.txt文件,如果robots协议允许,就会抓取url的页面内容并发回服务器。如果robots协议不允许,网页数据将不会被抓取。, 直接返回,在数据库中标记。
第四步,下载该URL对应的网页,存储到下载的网页库中,并将这些URL放入爬取的URL队列中。
第五步,对爬取的URL队列中的页面进行分析,如果发现新的URL,则将新的URL放入待爬取的URL队列中,从而进入下一个循环。
网络爬虫只负责发现信息、爬取信息、去除网页重复、划分网页质量等级。这些任务是网络爬虫抓取数据后算法程序的工作。网络爬虫不参与。
有的朋友可能认为,网络爬虫只要进入网站,就会往下爬,然后爬取网站的所有页面内容。事实上,情况并非如此。网络爬虫不是贪吃蛇,它只是抓取当前网页信息并返回。对服务器后台数据进行分析后,如果发现新的网址,则将其添加到未抓取的网址列表中,搜索引擎会将其发送出去。新的网络爬虫用新的 URL 抓取网页。
事实上,网络爬虫更像是寻找食物的蚂蚁。网站 就像一大块食物。当一只小蚂蚁发现食物时,它会回去通知其他朋友,然后一批又一批的小蚂蚁就会离开。将食物带回并存放在仓库中。一只小蚂蚁找到一大块食物拼命把它带回去是不现实的。所以,领导自己觉得网络爬虫更像是蚂蚁,而不是蜘蛛。将其与蚂蚁进行比较会更合适。
自动抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-14 15:03
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。在浏览的同时,网络爬虫还可以用于金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时候,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网上的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
查看全部
自动抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,然后重点关注。在浏览的同时,网络爬虫还可以用于金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以用网络爬虫把这多条新闻网站中的新闻信息爬下来,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时,我们可以使用爬虫设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时候,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网上的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
自动抓取网页数据(自动抓取网页数据的应用你肯定见过吧,那就对了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-14 12:07
自动抓取网页数据的应用你肯定见过吧,那就对了,自动抓取网页数据我用过很多了,最近打算开发一个简单的,即通过http请求自动抓取一些网页数据,可以实现中国联通100m宽带到你那里提速到20m宽带的一个功能。具体可以参考一下:一键抓取运营商网页数据,
你问问题的时候没有描述清楚啊,应该是要一个自动记录下对方登录到自己的浏览器哪些网页,然后自动抓取对方的浏览器的页面,转到对方的邮箱或者手机app,根据对方的浏览器提示回复自己的浏览器网址。
做一个信息采集器,然后比如网站那种,存个脚本,存个网址啥的,先抓取个差不多再处理需要的,就没那么麻烦了,然后就有自动记录网页截图自动转发账号网址了,就可以卖钱,还是很赚钱的吧。
楼上说的挺对的,我也回复一下,多网站都不是很好抓,我说一下自己,初步用了一些比较赚钱的赚钱方法,一天赚五十左右。起先是做web中的外挂,发现它很赚钱,然后在付费版本里免费下,赚了一点一直没做,后来喜欢上一个女孩子,想追她,但是那个女孩子脾气很暴躁,每次都对她发火,然后就去玩各种色情网站,她不和我说话我就打她了,偶尔有种喜欢她的感觉。
后来嫌弃累就不玩了,其他赚钱的不敢说,赚点生活费肯定是够了,包括但不限于如下赚钱方法:p2p,其实利润还是很不错的,而且风险低,在前不久十一放假的时候,碰上某行业的培训会,感觉一下子找到一份高薪工作,利润很好,还是当时感觉很赚钱,工作很积极。套现,就是银行给你的额度使你可以花钱买很多价值不是很高的东西,不同的人有不同的回报率,有几千块钱的也有几百万,还是比较赚钱的,还有现金贷,一直感觉很赚钱,还有分期付款,利润也不小,还有黑卡,他给你的不是一点小钱,他会给你很多现金,但是,一旦黑你的比较多,就有可能冻结你的账户,还有就是上面提到的培训会,很有用。 查看全部
自动抓取网页数据(自动抓取网页数据的应用你肯定见过吧,那就对了)
自动抓取网页数据的应用你肯定见过吧,那就对了,自动抓取网页数据我用过很多了,最近打算开发一个简单的,即通过http请求自动抓取一些网页数据,可以实现中国联通100m宽带到你那里提速到20m宽带的一个功能。具体可以参考一下:一键抓取运营商网页数据,
你问问题的时候没有描述清楚啊,应该是要一个自动记录下对方登录到自己的浏览器哪些网页,然后自动抓取对方的浏览器的页面,转到对方的邮箱或者手机app,根据对方的浏览器提示回复自己的浏览器网址。
做一个信息采集器,然后比如网站那种,存个脚本,存个网址啥的,先抓取个差不多再处理需要的,就没那么麻烦了,然后就有自动记录网页截图自动转发账号网址了,就可以卖钱,还是很赚钱的吧。
楼上说的挺对的,我也回复一下,多网站都不是很好抓,我说一下自己,初步用了一些比较赚钱的赚钱方法,一天赚五十左右。起先是做web中的外挂,发现它很赚钱,然后在付费版本里免费下,赚了一点一直没做,后来喜欢上一个女孩子,想追她,但是那个女孩子脾气很暴躁,每次都对她发火,然后就去玩各种色情网站,她不和我说话我就打她了,偶尔有种喜欢她的感觉。
后来嫌弃累就不玩了,其他赚钱的不敢说,赚点生活费肯定是够了,包括但不限于如下赚钱方法:p2p,其实利润还是很不错的,而且风险低,在前不久十一放假的时候,碰上某行业的培训会,感觉一下子找到一份高薪工作,利润很好,还是当时感觉很赚钱,工作很积极。套现,就是银行给你的额度使你可以花钱买很多价值不是很高的东西,不同的人有不同的回报率,有几千块钱的也有几百万,还是比较赚钱的,还有现金贷,一直感觉很赚钱,还有分期付款,利润也不小,还有黑卡,他给你的不是一点小钱,他会给你很多现金,但是,一旦黑你的比较多,就有可能冻结你的账户,还有就是上面提到的培训会,很有用。
自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-13 10:26
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。
WebHarvy 函数介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以抓取数据并将其导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 更新日志
修复页面启动时连接可能被关闭的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。
WebHarvy 函数介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以抓取数据并将其导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 更新日志
修复页面启动时连接可能被关闭的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源

