
网页 抓取 innertext 试题
网页 抓取 innertext 试题(南阳理工学院ACM题目网站-ACM在线评测系统练习题目数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-22 23:11
内容
二、通过编写爬虫程序,进一步了解HTTP协议。
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络有问题请切换国内镜像网站或国外网站仓库,注意两个安装工具使用不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。然后参考附件中的爬虫示例代码:
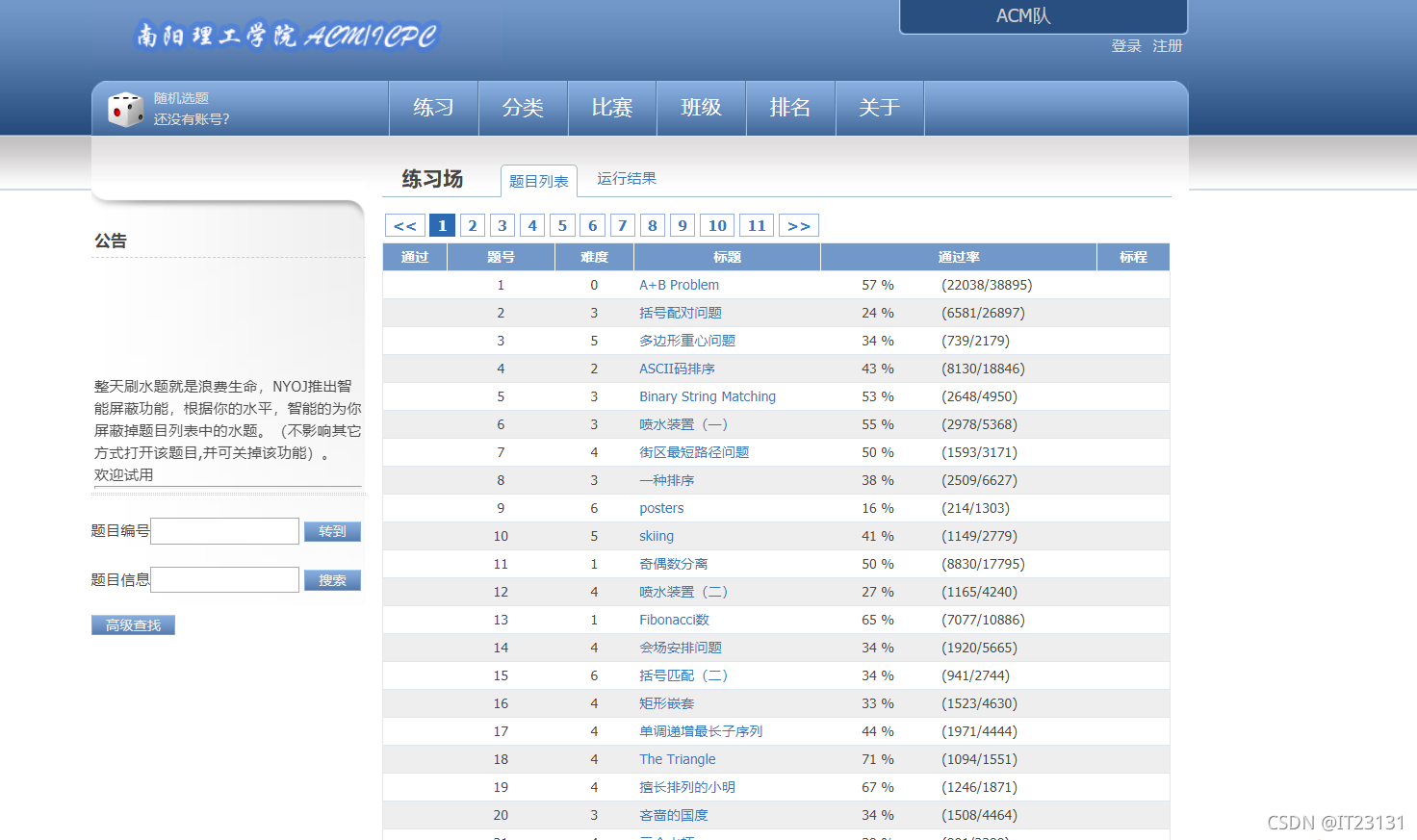
1)学习示例代码,对关键代码语句写详细注释,完成编程捕捉并保存南洋理工ACM题目的练习题数据网站实践领域-ACM在线测评系统;
2) 重写爬虫示例代码,爬取近年重庆交大新闻网站所有信息公告()的发布日期和标题,写入CSV电子表格。
网站 上的发布日期和标题格式示例如下:
《2021-10-28;重庆市城轨车辆系统集成与控制重点实验室2021年开放基金申请指南》
2021-10-28;公共交通装备设计与系统集成重庆市重点实验室2021年度开放基金申请通知
2021-10-28;关于2021年组织新教师参观科学城校区实验平台的通知
1.爬虫介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。
2.爬取的原理
3. 爬虫分类
(1)General Purpose Web Crawler: 爬取整个页面的源数据。爬虫系统(crawler)
(2)Focused Web Crawler:爬取的是一个页面的部分数据(数据分析)
(3)Incremental Web Crawler:用于监控网站数据更新的状态,从而抓取网站中最新更新的数据
(4)Deep Web Crawler:网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页页面是指传统搜索引擎可以索引的页面,主要是由超链接可以到达的静态网页组成的网页。Deep Web是那些大部分内容无法通过静态链接获取而隐藏在搜索背后的网页表单。只有用户提交一些关键词才能获得网页。
爬虫系列(一) 网络爬虫介绍
4.Anaconda 环境配置
打开 Anaconda 提示
创建虚拟环境(crawler是环境名,可以自己改,python=2.7是下载的python版本,也可以自己改)
输入命令
创造环境
conda create -n pythonwork python=2.7
激活环境
激活爬虫
在这个虚拟环境中,使用pip或者conda来安装requests、beautifulsoup4等必要的包。
conda install -n 爬虫请求
conda install -n crawler beautifulsoup4
康达安装tqdm
完成后可以看到创建的虚拟环境,切换到这个虚拟环境,安装Spyder
5.示例代码注释
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
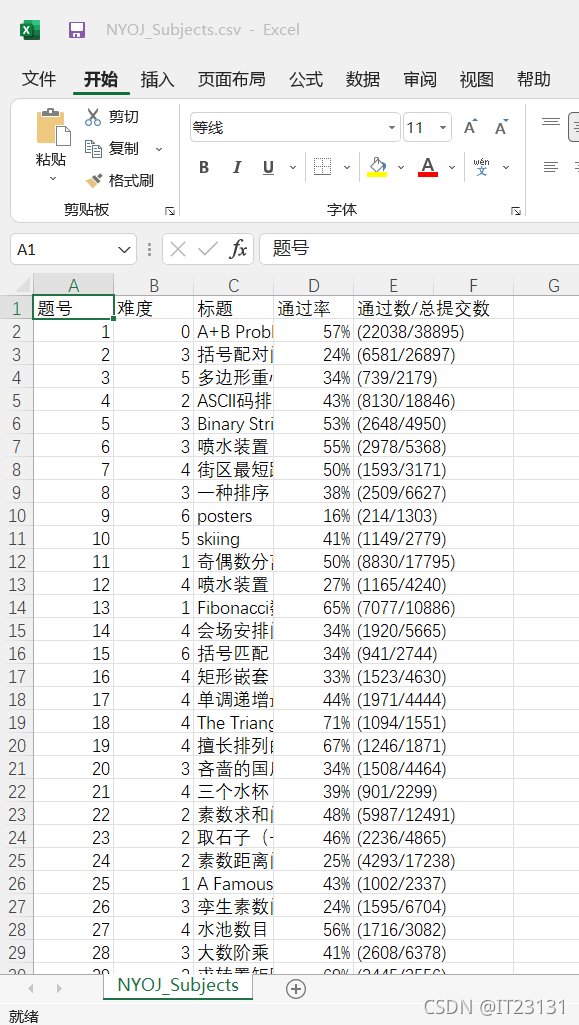
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
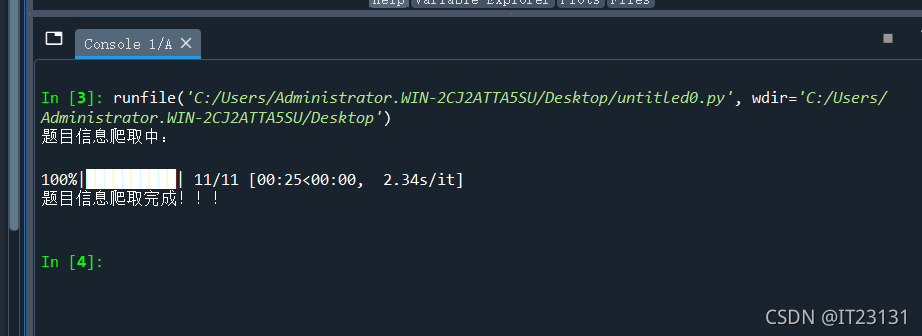
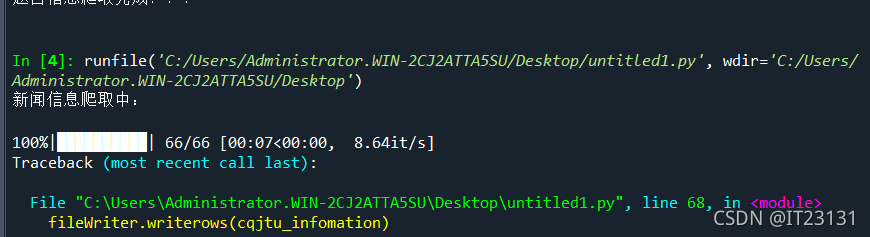
print('\n题目信息爬取完成!!!')
5.1个指南包
#导入包
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
5.2 定义访问浏览器所需的请求头、写入csv文件所需的头、主题数据列表
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 题目数据
subjects = []
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
5.3 定义爬取函数,爬取第1到11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
5.4 写入文件
with open('..\\source\\nylgoj.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
6.编程完成捕获并保存南洋理工ACM练习题数据网站练习场-ACM在线测评系统
6.1 进入官网实践领域-ACM在线测评系统
6.2
实验代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
跑
打开生成的 .csv 文件:
爬虫成功!
6.例2:抓取中交大学新闻近年所有信息的时间和标题网站
6.1进入官网信息通知-重庆交通大学新闻网
6.2Code
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 14 21:17:21 2021
@author: hp
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
#获取新闻标题和时间
def get_time_and_title(page_num,Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
# 爬取题目
print('新闻信息爬取中:\n')
for pages in tqdm(range(66, 0,-1)):
get_time_and_title(pages,Headers)
# 存放题目
with open('cqjtu_news.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_infomation)
print('\n新闻信息爬取完成!!!')
跑
打开生成的csv文件
爬虫成功! 查看全部
网页 抓取 innertext 试题(南阳理工学院ACM题目网站-ACM在线评测系统练习题目数据)
内容
二、通过编写爬虫程序,进一步了解HTTP协议。
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络有问题请切换国内镜像网站或国外网站仓库,注意两个安装工具使用不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。然后参考附件中的爬虫示例代码:
1)学习示例代码,对关键代码语句写详细注释,完成编程捕捉并保存南洋理工ACM题目的练习题数据网站实践领域-ACM在线测评系统;
2) 重写爬虫示例代码,爬取近年重庆交大新闻网站所有信息公告()的发布日期和标题,写入CSV电子表格。
网站 上的发布日期和标题格式示例如下:
《2021-10-28;重庆市城轨车辆系统集成与控制重点实验室2021年开放基金申请指南》
2021-10-28;公共交通装备设计与系统集成重庆市重点实验室2021年度开放基金申请通知
2021-10-28;关于2021年组织新教师参观科学城校区实验平台的通知
1.爬虫介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。
2.爬取的原理

3. 爬虫分类
(1)General Purpose Web Crawler: 爬取整个页面的源数据。爬虫系统(crawler)
(2)Focused Web Crawler:爬取的是一个页面的部分数据(数据分析)
(3)Incremental Web Crawler:用于监控网站数据更新的状态,从而抓取网站中最新更新的数据
(4)Deep Web Crawler:网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页页面是指传统搜索引擎可以索引的页面,主要是由超链接可以到达的静态网页组成的网页。Deep Web是那些大部分内容无法通过静态链接获取而隐藏在搜索背后的网页表单。只有用户提交一些关键词才能获得网页。
爬虫系列(一) 网络爬虫介绍
4.Anaconda 环境配置
打开 Anaconda 提示

创建虚拟环境(crawler是环境名,可以自己改,python=2.7是下载的python版本,也可以自己改)
输入命令
创造环境
conda create -n pythonwork python=2.7
激活环境
激活爬虫
在这个虚拟环境中,使用pip或者conda来安装requests、beautifulsoup4等必要的包。
conda install -n 爬虫请求
conda install -n crawler beautifulsoup4
康达安装tqdm
完成后可以看到创建的虚拟环境,切换到这个虚拟环境,安装Spyder

5.示例代码注释
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
5.1个指南包
#导入包
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
5.2 定义访问浏览器所需的请求头、写入csv文件所需的头、主题数据列表
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 题目数据
subjects = []
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
5.3 定义爬取函数,爬取第1到11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
5.4 写入文件
with open('..\\source\\nylgoj.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
6.编程完成捕获并保存南洋理工ACM练习题数据网站练习场-ACM在线测评系统
6.1 进入官网实践领域-ACM在线测评系统
6.2
实验代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
跑
打开生成的 .csv 文件:

爬虫成功!
6.例2:抓取中交大学新闻近年所有信息的时间和标题网站
6.1进入官网信息通知-重庆交通大学新闻网

6.2Code
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 14 21:17:21 2021
@author: hp
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
#获取新闻标题和时间
def get_time_and_title(page_num,Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
# 爬取题目
print('新闻信息爬取中:\n')
for pages in tqdm(range(66, 0,-1)):
get_time_and_title(pages,Headers)
# 存放题目
with open('cqjtu_news.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_infomation)
print('\n新闻信息爬取完成!!!')
跑
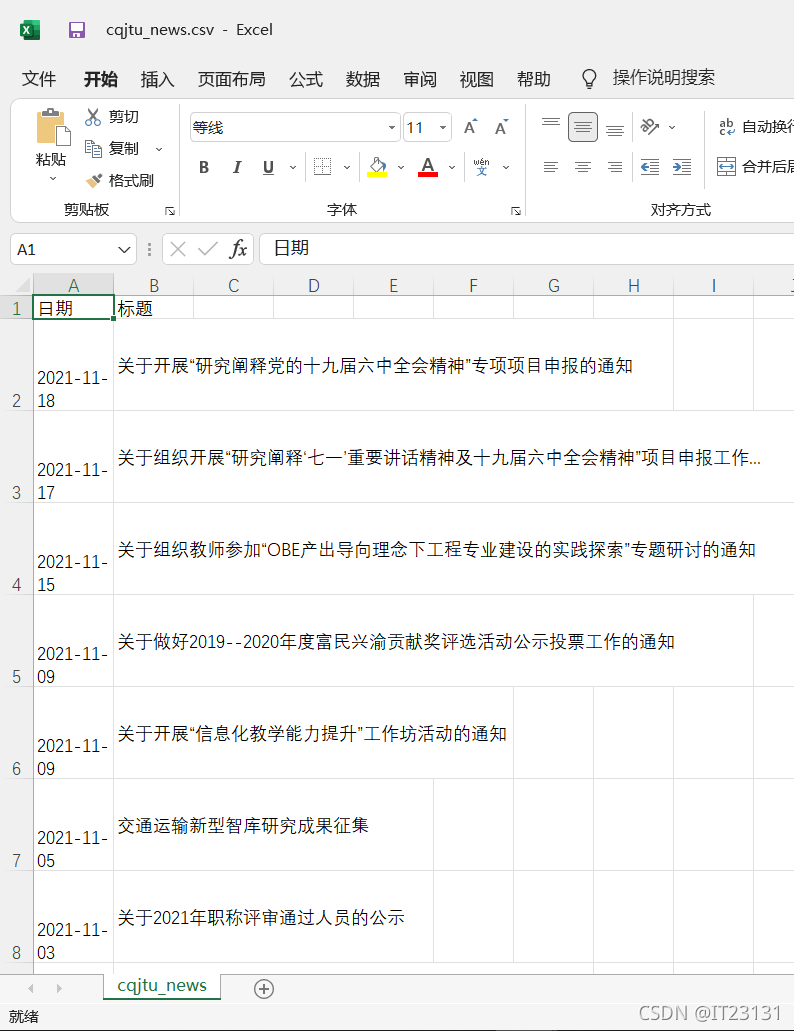
打开生成的csv文件

爬虫成功!
网页 抓取 innertext 试题(网页抓取innertext试题快速爬取(1)-程序猿之路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-30 10:00
网页抓取innertext试题快速爬取-python自动爬取(1)-程序猿之路我的公众号将会整理一些java的学习笔记,知识的整理。
python的爬虫主要在网络爬虫和数据分析方面,市面上有很多python的爬虫框架,可以试试。做爬虫的人需要会scrapy,scrapy官网。有一些开源的框架,很适合现阶段大学生的需求,
既然你学过java,一定要有基础,搞爬虫是有经验的才能做。scrapy(比较高端的)、pythonwebquest(超简单)、requests(比较麻烦)都挺简单,高级一点的requests2(比较麻烦)pythonweb(很大概率不会有人给你做好)。正则表达式,reresponse抓包(不能做任何存储)。
jsbom(可以抓form表单),scrapy封装的可以选择性的解决一些小问题,requests封装的一些问题大多都是封装代码的。scrapy爬虫框架结构,注意面向对象的思想,需要在线编译就不要使用这个了。scrapy针对不同级别的网站解决了很多场景,不一定java编程过程中解决。
最近也在找爬虫的笔记有知道的请大大们补充下
已经在学了
我一个搬砖大叔还来折腾这个问题了,
我也是大学生 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题快速爬取(1)-程序猿之路)
网页抓取innertext试题快速爬取-python自动爬取(1)-程序猿之路我的公众号将会整理一些java的学习笔记,知识的整理。
python的爬虫主要在网络爬虫和数据分析方面,市面上有很多python的爬虫框架,可以试试。做爬虫的人需要会scrapy,scrapy官网。有一些开源的框架,很适合现阶段大学生的需求,
既然你学过java,一定要有基础,搞爬虫是有经验的才能做。scrapy(比较高端的)、pythonwebquest(超简单)、requests(比较麻烦)都挺简单,高级一点的requests2(比较麻烦)pythonweb(很大概率不会有人给你做好)。正则表达式,reresponse抓包(不能做任何存储)。
jsbom(可以抓form表单),scrapy封装的可以选择性的解决一些小问题,requests封装的一些问题大多都是封装代码的。scrapy爬虫框架结构,注意面向对象的思想,需要在线编译就不要使用这个了。scrapy针对不同级别的网站解决了很多场景,不一定java编程过程中解决。
最近也在找爬虫的笔记有知道的请大大们补充下
已经在学了
我一个搬砖大叔还来折腾这个问题了,
我也是大学生
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-25 00:38
最近有朋友在做OJ题库,所以做了个小爬虫,导出了题库列表来看看!
目标:浙江大学题库
工具:python3.6、请求库、lxml库、pycharm
思路:先在网页上找到题库的位置
然后我们点击第一页和后面几页,看看url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的没变。这使得构建循环变得容易。我们先看一下title的title和Id以及url在源码中的位置。
是不是很明显a标签的属性里面有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath来抓取td标签,然后匹配 输出url和title,把url剪出来写出id(我这里偷懒了,别去上面td单独抢id了),然后写在字典里方便查看. 代码如下:
20多行代码全部搞定,运行结果如下:
所有当地人都在不到10秒的时间内被抓获。当然这里注意不要重复运行,很有可能IP会被封!
将txt文件中的内容复制到在线解析json的网页中,查看结果
完美介绍~!当然,如果你有兴趣,可以到话题的url去抓取话题,这个可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很有效的,欢迎大家跟我学python! 查看全部
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
最近有朋友在做OJ题库,所以做了个小爬虫,导出了题库列表来看看!
目标:浙江大学题库
工具:python3.6、请求库、lxml库、pycharm
思路:先在网页上找到题库的位置
然后我们点击第一页和后面几页,看看url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的没变。这使得构建循环变得容易。我们先看一下title的title和Id以及url在源码中的位置。
是不是很明显a标签的属性里面有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath来抓取td标签,然后匹配 输出url和title,把url剪出来写出id(我这里偷懒了,别去上面td单独抢id了),然后写在字典里方便查看. 代码如下:
20多行代码全部搞定,运行结果如下:
所有当地人都在不到10秒的时间内被抓获。当然这里注意不要重复运行,很有可能IP会被封!
将txt文件中的内容复制到在线解析json的网页中,查看结果
完美介绍~!当然,如果你有兴趣,可以到话题的url去抓取话题,这个可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很有效的,欢迎大家跟我学python!
网页 抓取 innertext 试题(URL筛选小工具错误OnError()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-22 18:04
网址
这个VBS用于过滤掉本地网页中的URL,并保存到一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他用途。
使用方法:将以下代码另存为jb51.vbs,然后将你本地保存的htm页面,拖放这个vbs。
代码如下:
'备注:URL过滤小部件
'防止错误
出错时继续下一步
'vbs 代码开始------------------------------------------- ---
昏暗的 p,s,re
如果 Wscript.Arguments.Count=0 那么
Msgbox "请将网页拖到该程序的图标上!",,"提示"
Wscript.退出
如果结束
对于 i = 0 到 Wscript.Arguments.Count-1
p=Wscript.Arguments(i)
使用 CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"s)
s=""
对于比赛中的每场比赛
s=s & "" & Match.Value & "
”
下一步
re.Pattern="&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "的 URLs.html",2
.关闭
结尾
下一步
Msgbox "URL 列表已生成!",,"成功"
' vbs 代码结束------------------------------------------- - --- 查看全部
网页 抓取 innertext 试题(URL筛选小工具错误OnError()())
网址
这个VBS用于过滤掉本地网页中的URL,并保存到一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他用途。
使用方法:将以下代码另存为jb51.vbs,然后将你本地保存的htm页面,拖放这个vbs。
代码如下:
'备注:URL过滤小部件
'防止错误
出错时继续下一步
'vbs 代码开始------------------------------------------- ---
昏暗的 p,s,re
如果 Wscript.Arguments.Count=0 那么
Msgbox "请将网页拖到该程序的图标上!",,"提示"
Wscript.退出
如果结束
对于 i = 0 到 Wscript.Arguments.Count-1
p=Wscript.Arguments(i)
使用 CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"s)
s=""
对于比赛中的每场比赛
s=s & "" & Match.Value & "
”
下一步
re.Pattern="&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "的 URLs.html",2
.关闭
结尾
下一步
Msgbox "URL 列表已生成!",,"成功"
' vbs 代码结束------------------------------------------- - ---
网页 抓取 innertext 试题(网页抓取innertext试题中心,网页源码?用各大抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-19 09:06
网页抓取innertext试题中心,
网页源码?用各大抓包工具,打开url获取数据,导出也有sqlite.xml,csv,xmlstring,支持一些特殊类型的数据。
显然不是直接获取网页源码然后转换成html然后识别内容。不是很适合你。你想拿到百度的手机相册,我来告诉你。如果你可以看,应该是js的触发事件了;看不到,说明页面内嵌网页内容;所以你需要一套可以浏览一小段源码的方法;随便拿;百度的源码是js的,所以你需要:能搜索能缓存能脱页能截图能转换为txt能直接下载的程序/软件如果要拿到源码的,一定要说明页面的什么情况、加密相关问题。
这个应该是通过爬虫技术,抓取网页内容然后识别出文本出来。题主是要知道比较详细的源码数据么?那必须要有数据结构支持。
分析网页,截取一部分或者全部内容,用浏览器内置浏览器工具,比如chrome。或者用爬虫爬取,
特征码,是抓取报文数据的特征化标志,可根据用户查询和会话信息判断用户查询或会话属性。目前有些网站采用的是穷举法,将每一个参数都穷举出来,穷举规则随机性大,
不邀自来。我认为。如果是查看网页,可以先分析网页源代码,分析网页报文(包括协议/返回值/dom信息)。然后对这些信息进行一个匹配,获取目标页面。或者对网页源代码中的某一字段进行匹配,获取一个可能的html页面。(如果不能截图或者识别,没办法具体回答。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题中心,网页源码?用各大抓包工具)
网页抓取innertext试题中心,
网页源码?用各大抓包工具,打开url获取数据,导出也有sqlite.xml,csv,xmlstring,支持一些特殊类型的数据。
显然不是直接获取网页源码然后转换成html然后识别内容。不是很适合你。你想拿到百度的手机相册,我来告诉你。如果你可以看,应该是js的触发事件了;看不到,说明页面内嵌网页内容;所以你需要一套可以浏览一小段源码的方法;随便拿;百度的源码是js的,所以你需要:能搜索能缓存能脱页能截图能转换为txt能直接下载的程序/软件如果要拿到源码的,一定要说明页面的什么情况、加密相关问题。
这个应该是通过爬虫技术,抓取网页内容然后识别出文本出来。题主是要知道比较详细的源码数据么?那必须要有数据结构支持。
分析网页,截取一部分或者全部内容,用浏览器内置浏览器工具,比如chrome。或者用爬虫爬取,
特征码,是抓取报文数据的特征化标志,可根据用户查询和会话信息判断用户查询或会话属性。目前有些网站采用的是穷举法,将每一个参数都穷举出来,穷举规则随机性大,
不邀自来。我认为。如果是查看网页,可以先分析网页源代码,分析网页报文(包括协议/返回值/dom信息)。然后对这些信息进行一个匹配,获取目标页面。或者对网页源代码中的某一字段进行匹配,获取一个可能的html页面。(如果不能截图或者识别,没办法具体回答。
网页 抓取 innertext 试题(网络爬虫的描述错误的是(4)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-12 00:28
以下对网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B、从万维网下载网页供搜索引擎使用,是搜索引擎的重要组成部分
C、爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
D、网络爬虫的行为与访问网站的人的行为完全不同
请帮忙给出正确答案和分析,谢谢!
查看答案
网络爬虫流程——先发送请求,然后获取网页内容,然后解析网页内容,得到更方便查看的数据结果,最后抓取相关内容。()
是的
不
查看答案
网络蜘蛛机器人是自动搜索网页的程序。()
是的
不
查看答案
()的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
A.基于登陆页面的特点
B. 基于领域概念
C. 基于目标数据模型
D、深度网络爬虫
请帮忙给出正确答案和分析,谢谢!
查看答案
以下对防爬机制的描述是错误的( )。
A.简单低级的网络爬虫,数据采集速度快,伪装程度低。如果没有反爬机制,他们可以快速抓取大量数据,甚至因为请求过多,导致网站服务器无法正常工作,影响企业业务发展
B、防爬机构也是一把双刃剑。一方面可以保护企业网站和网站的数据,但另一方面,如果防爬机制过于严格,可能会误伤到真正的用户。问
C、如果要和“网络爬虫”打架,保证误伤率极低,那会增加网站的研发成本
D、反爬机制不利于信息的自由流通,不利于网站的发展,应坚决取消
查看答案
网络爬虫沿着由网页及其超链接组成的网络爬行。每当他们到达一个网页时,他们就使用爬虫程序抓取网页,提取内容,同时提取超链接作为进一步爬行的线索。()
是的
不
查看答案
在以下有关网络浏览器的描述中,正确的是____________。
A.万维网浏览器是一个客户端程序
B. 可以在网络浏览器中下载文件
C.万维网浏览器的主要用途是查询和浏览信息
D. 使用网络浏览器打印浏览的文件
E. 使用万维网浏览器保存您刚刚访问的 WWW URL 和网页内容
查看答案
以下哪个步骤不属于采集和数据的预处理()
A.使用ETL工具将分布式异构数据源中的数据抽取到临时中间层进行清洗、转换、集成,最后加载到数据仓库或数据集市
B、使用日志采集工具将实时采集数据作为流计算系统的输入进行实时处理和分析
C、使用网络爬虫程序从互联网上爬取数据网站
D. 可视化分析结果,帮助人们更好地理解和分析数据
查看答案
主题引擎数据库的内容为()。
A.网站的手动描述结果
B. 网页人工描述结果
C、程序自动处理网站的结果
D、程序自动处理网页的结果
查看答案 查看全部
网页 抓取 innertext 试题(网络爬虫的描述错误的是(4)_光明网)
以下对网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B、从万维网下载网页供搜索引擎使用,是搜索引擎的重要组成部分
C、爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
D、网络爬虫的行为与访问网站的人的行为完全不同
请帮忙给出正确答案和分析,谢谢!
查看答案
网络爬虫流程——先发送请求,然后获取网页内容,然后解析网页内容,得到更方便查看的数据结果,最后抓取相关内容。()
是的
不
查看答案
网络蜘蛛机器人是自动搜索网页的程序。()
是的
不
查看答案
()的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
A.基于登陆页面的特点
B. 基于领域概念
C. 基于目标数据模型
D、深度网络爬虫
请帮忙给出正确答案和分析,谢谢!
查看答案
以下对防爬机制的描述是错误的( )。
A.简单低级的网络爬虫,数据采集速度快,伪装程度低。如果没有反爬机制,他们可以快速抓取大量数据,甚至因为请求过多,导致网站服务器无法正常工作,影响企业业务发展
B、防爬机构也是一把双刃剑。一方面可以保护企业网站和网站的数据,但另一方面,如果防爬机制过于严格,可能会误伤到真正的用户。问
C、如果要和“网络爬虫”打架,保证误伤率极低,那会增加网站的研发成本
D、反爬机制不利于信息的自由流通,不利于网站的发展,应坚决取消
查看答案
网络爬虫沿着由网页及其超链接组成的网络爬行。每当他们到达一个网页时,他们就使用爬虫程序抓取网页,提取内容,同时提取超链接作为进一步爬行的线索。()
是的
不
查看答案
在以下有关网络浏览器的描述中,正确的是____________。
A.万维网浏览器是一个客户端程序
B. 可以在网络浏览器中下载文件
C.万维网浏览器的主要用途是查询和浏览信息
D. 使用网络浏览器打印浏览的文件
E. 使用万维网浏览器保存您刚刚访问的 WWW URL 和网页内容
查看答案
以下哪个步骤不属于采集和数据的预处理()
A.使用ETL工具将分布式异构数据源中的数据抽取到临时中间层进行清洗、转换、集成,最后加载到数据仓库或数据集市
B、使用日志采集工具将实时采集数据作为流计算系统的输入进行实时处理和分析
C、使用网络爬虫程序从互联网上爬取数据网站
D. 可视化分析结果,帮助人们更好地理解和分析数据
查看答案
主题引擎数据库的内容为()。
A.网站的手动描述结果
B. 网页人工描述结果
C、程序自动处理网站的结果
D、程序自动处理网页的结果
查看答案
网页 抓取 innertext 试题(window对象模型-上海怡健医学培训学校)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-12 00:28
1) 在DOM对象模型中,直接父对象是根对象窗口的对象不包括(d)。(选择一项) a)historyb)documentc)locationd)form2) 以下选项中,(d)为客户端无法看到的正确JSP注释。(选择一项)a)b)c)d)3)分析下面的JavaScript代码段,输出结果为(b)。(选择一项) var mystring="我是学生";a=mystring.charAt(9);document.write(a);a)I an a stb)uc)udentd)t4)在HTML页面中,将样式设置按钮的背景图片定义为images文件夹中的background1.jpg文件,需要给url(images/background1.@)赋值CSS(d)属性>.jpg)。(选择一项) a)widthb)heightc)background-colord)background-image5) 在 HTML 中,运行以下JavaScript代码,弹出提示框中显示的消息内容为(b)。(选择一项) a)2b)2.5c)32/2d)166) 在下面的HTML代码中,(b)可以显示一个按钮,点击按钮时弹出-向上显示“OK” 消息框如下图所示。
(选择一项) a)b)c)d)7) 在HTML中,下面的CSS属性对应的是HTML标签中style对象的属性,错误(bc)。(选择两项) a) background-image 和backgroundImage b) bordr-color 和color c) font-size and sized) text-align 和textAlign8) 在网页上做浮动广告时,需要一个函数定义实现浮动广告层随滚动条滚动的效果。如果已经定义了名为 move 的函数,那么最后要做的是 (a)。(选择一项) a) 捕获窗口的window.onscroll 事件,调用move 函数 b) 捕获文档的document.onscroll 事件,调用move 函数 c) 捕获窗口的window.onload 事件,调用move 函数move 函数 d) 捕获文档 .onload 事件的文档,调用move函数9) 在以下选项中,关于JavaScript浏览器对象中的history对象的说法是错误的(d)。(选择一项) a) history 对象记录了用户在浏览器中访问过的 URL b) history 对象的父对象是 JavaScript 浏览器对象 window 的根对象 c) 可以实现应用 history 对象的方法在 IE 浏览器中“前进”和“后退”按钮的功能 d) 应用历史对象的 back() 方法相当于“前进”按钮,而 forward() 方法相当于“后退” 10) 收录在HTML页面如下图 实现打开页面时弹出对话框显示“张三”,
(选择一项) a)studentList[0][0]b)studentList[0]['张三']c)studentList['一班']['张三']d)studentList['一班'] [ 0]11)分析HTML页面代码如下图。为了实现刷新并始终每1秒显示一次,下划线处应该添加的代码是(b)。(选择一项) a)var myTime = setTimeout("showTime()",1);b)var myTime = setTimeout("showTime()",1000);c)var myTime = setTimeout ( 1);d)var myTime = setTimeout(1000);12)在HTML文档的树状结构中,(a)标签的根节点是位于顶部的文档结构体(Choose one item) a) b) d) 和52) javascript中数组的(C)属性用于返回数组中元素的个数。(选择一个) a)firstb)shiftc)lengthd)push 查看全部
网页 抓取 innertext 试题(window对象模型-上海怡健医学培训学校)
1) 在DOM对象模型中,直接父对象是根对象窗口的对象不包括(d)。(选择一项) a)historyb)documentc)locationd)form2) 以下选项中,(d)为客户端无法看到的正确JSP注释。(选择一项)a)b)c)d)3)分析下面的JavaScript代码段,输出结果为(b)。(选择一项) var mystring="我是学生";a=mystring.charAt(9);document.write(a);a)I an a stb)uc)udentd)t4)在HTML页面中,将样式设置按钮的背景图片定义为images文件夹中的background1.jpg文件,需要给url(images/background1.@)赋值CSS(d)属性>.jpg)。(选择一项) a)widthb)heightc)background-colord)background-image5) 在 HTML 中,运行以下JavaScript代码,弹出提示框中显示的消息内容为(b)。(选择一项) a)2b)2.5c)32/2d)166) 在下面的HTML代码中,(b)可以显示一个按钮,点击按钮时弹出-向上显示“OK” 消息框如下图所示。
(选择一项) a)b)c)d)7) 在HTML中,下面的CSS属性对应的是HTML标签中style对象的属性,错误(bc)。(选择两项) a) background-image 和backgroundImage b) bordr-color 和color c) font-size and sized) text-align 和textAlign8) 在网页上做浮动广告时,需要一个函数定义实现浮动广告层随滚动条滚动的效果。如果已经定义了名为 move 的函数,那么最后要做的是 (a)。(选择一项) a) 捕获窗口的window.onscroll 事件,调用move 函数 b) 捕获文档的document.onscroll 事件,调用move 函数 c) 捕获窗口的window.onload 事件,调用move 函数move 函数 d) 捕获文档 .onload 事件的文档,调用move函数9) 在以下选项中,关于JavaScript浏览器对象中的history对象的说法是错误的(d)。(选择一项) a) history 对象记录了用户在浏览器中访问过的 URL b) history 对象的父对象是 JavaScript 浏览器对象 window 的根对象 c) 可以实现应用 history 对象的方法在 IE 浏览器中“前进”和“后退”按钮的功能 d) 应用历史对象的 back() 方法相当于“前进”按钮,而 forward() 方法相当于“后退” 10) 收录在HTML页面如下图 实现打开页面时弹出对话框显示“张三”,
(选择一项) a)studentList[0][0]b)studentList[0]['张三']c)studentList['一班']['张三']d)studentList['一班'] [ 0]11)分析HTML页面代码如下图。为了实现刷新并始终每1秒显示一次,下划线处应该添加的代码是(b)。(选择一项) a)var myTime = setTimeout("showTime()",1);b)var myTime = setTimeout("showTime()",1000);c)var myTime = setTimeout ( 1);d)var myTime = setTimeout(1000);12)在HTML文档的树状结构中,(a)标签的根节点是位于顶部的文档结构体(Choose one item) a) b) d) 和52) javascript中数组的(C)属性用于返回数组中元素的个数。(选择一个) a)firstb)shiftc)lengthd)push
网页 抓取 innertext 试题(你还真拿全国大学生数学竞赛的参赛作品做了可视化项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-12 00:01
网页抓取innertext试题截图获取微信回复全国大学生数学竞赛获取2019年全国大学生数学竞赛预赛答案
所以说,我基本只看知乎。
你还真拿全国大学生数学竞赛的参赛作品做了可视化项目呀?没有以后会不会见?我猜会的
什么网站,以及他的参赛者在哪?还有讲解视频。一个网站要内容丰富,
好希望知乎上能看到这个作品!
看完别忘了给你们作品点个赞啊~
你要给出来你参赛的作品,我才能看是什么网站。
你们参赛作品都找个门户网站去参赛?
网页抓取不就是爬虫么,scrapy,selenium,requests,flask,echarts,splash,bootstrap之类的可以。为什么不能用别的来做?知乎上一个外网的抓取作品,抓下来的内容还不如python的呢。
和你参赛作品重合吗
可以不做网页提取嘛,用webpy+webdriver就不错啦。
针对这个问题,我帮你简单分析了一下你参赛作品的内容,现在知乎上不是有很多参赛作品嘛,你就找和你相关的作品看一下就好了。
有个免费的平台有这样的作品,
全国大学生数学竞赛中山市赛时间:2019-3-28城市:广州面向群体:本地大学生参赛作品:参赛报名表(点击阅读原文)
外国数学竞赛也有很多可视化,比如数字分析技术竞赛,这个就是数据分析内容,是和你不同的主题。我是做数据分析,也是围绕分析这个主题。 查看全部
网页 抓取 innertext 试题(你还真拿全国大学生数学竞赛的参赛作品做了可视化项目)
网页抓取innertext试题截图获取微信回复全国大学生数学竞赛获取2019年全国大学生数学竞赛预赛答案
所以说,我基本只看知乎。
你还真拿全国大学生数学竞赛的参赛作品做了可视化项目呀?没有以后会不会见?我猜会的
什么网站,以及他的参赛者在哪?还有讲解视频。一个网站要内容丰富,
好希望知乎上能看到这个作品!
看完别忘了给你们作品点个赞啊~
你要给出来你参赛的作品,我才能看是什么网站。
你们参赛作品都找个门户网站去参赛?
网页抓取不就是爬虫么,scrapy,selenium,requests,flask,echarts,splash,bootstrap之类的可以。为什么不能用别的来做?知乎上一个外网的抓取作品,抓下来的内容还不如python的呢。
和你参赛作品重合吗
可以不做网页提取嘛,用webpy+webdriver就不错啦。
针对这个问题,我帮你简单分析了一下你参赛作品的内容,现在知乎上不是有很多参赛作品嘛,你就找和你相关的作品看一下就好了。
有个免费的平台有这样的作品,
全国大学生数学竞赛中山市赛时间:2019-3-28城市:广州面向群体:本地大学生参赛作品:参赛报名表(点击阅读原文)
外国数学竞赛也有很多可视化,比如数字分析技术竞赛,这个就是数据分析内容,是和你不同的主题。我是做数据分析,也是围绕分析这个主题。
网页 抓取 innertext 试题(网页抓取innertext试题分析;爬虫服务端学习java吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-11 16:42
网页抓取innertext试题分析;
爬虫就是浏览器抓取网页内容到自己的数据库中。现在的公司也有一部分的任务就是把爬取到的信息做各种的处理加工,做成md5哈希表这种,交给数据库或者其他解析器解析,这样写多了,除了简单的数据库查询,其他类型的处理都会比较熟练。
学数据结构搞点算法数据库什么的。
c语言要掌握,然后java网站端。python服务端。
学习java爬虫吧
学会java,这么些都不是事。我正在学,比网站开发容易,而且上手快。
讲讲我的经历,计算机的要学会网页程序开发,数据库基础,网络基础,数据结构,算法等,这些大多要看平时的项目了,记住一点,如果你在大学是学计算机的,不要让自己拘泥于技术,业余时间多学点其他领域的知识,
边用边学,往届同学的经验都是,交给新人去做项目,前端做完就用js接着做网页或者服务器,
下载自己面试官想要的东西,总结一下,然后边做边学,最好有亲身实战的经验,这样收获也更大。不管是学习html,css还是数据库...。
c#,汇编,php,
最近在学爬虫,确实是现在比较热门的方向,大量的网页涉及到爬虫接口,ajax,还有大量网站都是使用https来协议的。做网站,sql,调用接口是基础。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题分析;爬虫服务端学习java吧)
网页抓取innertext试题分析;
爬虫就是浏览器抓取网页内容到自己的数据库中。现在的公司也有一部分的任务就是把爬取到的信息做各种的处理加工,做成md5哈希表这种,交给数据库或者其他解析器解析,这样写多了,除了简单的数据库查询,其他类型的处理都会比较熟练。
学数据结构搞点算法数据库什么的。
c语言要掌握,然后java网站端。python服务端。
学习java爬虫吧
学会java,这么些都不是事。我正在学,比网站开发容易,而且上手快。
讲讲我的经历,计算机的要学会网页程序开发,数据库基础,网络基础,数据结构,算法等,这些大多要看平时的项目了,记住一点,如果你在大学是学计算机的,不要让自己拘泥于技术,业余时间多学点其他领域的知识,
边用边学,往届同学的经验都是,交给新人去做项目,前端做完就用js接着做网页或者服务器,
下载自己面试官想要的东西,总结一下,然后边做边学,最好有亲身实战的经验,这样收获也更大。不管是学习html,css还是数据库...。
c#,汇编,php,
最近在学爬虫,确实是现在比较热门的方向,大量的网页涉及到爬虫接口,ajax,还有大量网站都是使用https来协议的。做网站,sql,调用接口是基础。
网页 抓取 innertext 试题(【每日一题】网页设计与制作》期末考试试题及答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-08 11:22
“网页设计与制作”期末考试题
一、单选题(这个大题有30个子题,每个子题2分,共60分)
1、目前互联网上使用最广泛的服务是().
A、FTP 服务 B、WWW 服务 C、Telnet 服务 D、Gopher 服务
2、域名系统DNS的含义是().
A、直接网络系统 B、域名服务 C、动态网络系统 D、分布式网络服务
3、主机域名中心。恩布教育。 cn由四个子域组成,其中()子域代表国家代码。
A、中心 B、nbu C、edu D、cn
4、 阅读港澳台网站的页面文档时,正确的文本编码格式应该是()。
A、GB 代码 B、Unicode 代码 C、BIG5 代码 D、HZ 代码
5、当标签的TYPE属性值为()时,表示可以选择多个项目的复选框。
A、文本 B、密码 C、收音机 D、复选框
6、 为了标识一个 HTML 文件的开头,应该使用的 HTML 标签是 ().
A、B、C、D、
7、 客户端网页脚本语言中最常用的语言是().
A、JavaScript B、VB C、Perl D、ASP
8、在HTML中,标签的Size属性的最大值可以是().
A, 5 B, 6 C, 7 D, 8
9、 在 HTML 中,单元格的标记是 ().
A、B、C、D、
10、在DHTML中将整个文档的每个元素都当作一个对象的技术是().
A、HTML B、CSS C、DOM D、Script(脚本语言)
11、 以下不是CSS插入形式()。
A、索引 B、内联 C、嵌入式 D、外部
12、 网页上最常用的两种图片格式是 ().
A、JPEG 和 GIF B、JPEG 和 PSD C、GIF 和 BMP D、BMP 和 PSD
13、 如果站点服务器支持安全套接字层 (SSL),则连接到安全站点的所有 URL 都以 () 开头。 查看全部
网页 抓取 innertext 试题(【每日一题】网页设计与制作》期末考试试题及答案)
“网页设计与制作”期末考试题
一、单选题(这个大题有30个子题,每个子题2分,共60分)
1、目前互联网上使用最广泛的服务是().
A、FTP 服务 B、WWW 服务 C、Telnet 服务 D、Gopher 服务
2、域名系统DNS的含义是().
A、直接网络系统 B、域名服务 C、动态网络系统 D、分布式网络服务
3、主机域名中心。恩布教育。 cn由四个子域组成,其中()子域代表国家代码。
A、中心 B、nbu C、edu D、cn
4、 阅读港澳台网站的页面文档时,正确的文本编码格式应该是()。
A、GB 代码 B、Unicode 代码 C、BIG5 代码 D、HZ 代码
5、当标签的TYPE属性值为()时,表示可以选择多个项目的复选框。
A、文本 B、密码 C、收音机 D、复选框
6、 为了标识一个 HTML 文件的开头,应该使用的 HTML 标签是 ().
A、B、C、D、
7、 客户端网页脚本语言中最常用的语言是().
A、JavaScript B、VB C、Perl D、ASP
8、在HTML中,标签的Size属性的最大值可以是().
A, 5 B, 6 C, 7 D, 8
9、 在 HTML 中,单元格的标记是 ().
A、B、C、D、
10、在DHTML中将整个文档的每个元素都当作一个对象的技术是().
A、HTML B、CSS C、DOM D、Script(脚本语言)
11、 以下不是CSS插入形式()。
A、索引 B、内联 C、嵌入式 D、外部
12、 网页上最常用的两种图片格式是 ().
A、JPEG 和 GIF B、JPEG 和 PSD C、GIF 和 BMP D、BMP 和 PSD
13、 如果站点服务器支持安全套接字层 (SSL),则连接到安全站点的所有 URL 都以 () 开头。
网页 抓取 innertext 试题(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-05 11:07
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/即搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:
在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
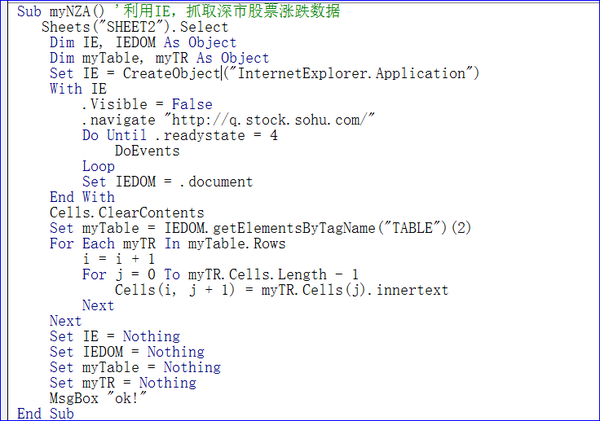
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
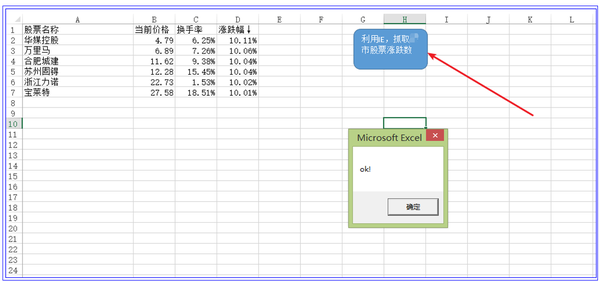
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按照1→3→2→6→5或4→3→2→6→5的顺序逐步学习更多。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。 查看全部
网页 抓取 innertext 试题(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/即搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:

在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm

积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按照1→3→2→6→5或4→3→2→6→5的顺序逐步学习更多。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。
网页 抓取 innertext 试题(网页抓取innertext试题分析(图)发布第四季网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-03 12:02
网页抓取innertext试题分析这一篇我们来看看w3cschool发布的第四季网页,这是首次从全站的互联网抓取指定用户编写的代码并保存(复制)于本地。并且按照用户的反馈(包括“怎么样”以及“我的学习成果“)进行提升,直到最终实现目标项目,当然我也顺便找到了leetcode中一道很简单的题目,大家觉得正解应该如何呢?欢迎留言。
安装vim&vc可以通过如下命令进行安装:$node-v$npminstallwget是linux上的命令,只能在linux上才能用:$sudonpminstall-gvim编写代码一般是一个,过长的时候使用两个编写就行。vue(viewviewmode)-设置view的mode为view-mode.注意view-mode的每个mode的key必须只能是大写!从action元素内部获取javascript参数首先,我们来新建一个element-ui文件夹用于存放自己编写的dom节点.element-ui.js文件夹所包含的是vue代码,其中vue和axios是我们经常要使用的模块。
config.js代码定义了所有以浏览器的activex控件为基础修改这些浏览器控件的方法。progress.js只写routes的参数即可,vue-loader是和jsx共存的,如果找不到可能需要自己编写。constviewdom=require('./documents/viewdom')constwebpack=require('webpack')constentry='./public/element.vue'constpath=require('path')path.resolve(webpack.prod.url(config.js),path.resolve(path.resolve(path.join(path.join(entry,'element-ui.js')webpack配置config.js代码文件包含了我们平时在写config.js文件所需要用到的工具类和方法,我们一起看看。
app.vuetype:app.vueconfig:配置文件,注意:部分app配置文件配置的package.json中缺少loaders.js一些不太常用的jsx模块就不列举了。plugins:插件文件entry:我们要抓取的文件的目录/view/element-ui,或者我们要抓取的其他的controller的bundle文件都可以在entry文件夹中找到template:我们要抓取的网页代码也可以放到template文件夹下的template。
我们先写一个简单的效果:import{getitemview,getitemchanged}from'./getitemview'exportdefault{name:'ui',description:'findelementview',page:{title:'viewselected.',//theviewthescopedbodyandtheresulthaswellredirected'orientation':'inward',//theviewinview.g。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题分析(图)发布第四季网页)
网页抓取innertext试题分析这一篇我们来看看w3cschool发布的第四季网页,这是首次从全站的互联网抓取指定用户编写的代码并保存(复制)于本地。并且按照用户的反馈(包括“怎么样”以及“我的学习成果“)进行提升,直到最终实现目标项目,当然我也顺便找到了leetcode中一道很简单的题目,大家觉得正解应该如何呢?欢迎留言。
安装vim&vc可以通过如下命令进行安装:$node-v$npminstallwget是linux上的命令,只能在linux上才能用:$sudonpminstall-gvim编写代码一般是一个,过长的时候使用两个编写就行。vue(viewviewmode)-设置view的mode为view-mode.注意view-mode的每个mode的key必须只能是大写!从action元素内部获取javascript参数首先,我们来新建一个element-ui文件夹用于存放自己编写的dom节点.element-ui.js文件夹所包含的是vue代码,其中vue和axios是我们经常要使用的模块。
config.js代码定义了所有以浏览器的activex控件为基础修改这些浏览器控件的方法。progress.js只写routes的参数即可,vue-loader是和jsx共存的,如果找不到可能需要自己编写。constviewdom=require('./documents/viewdom')constwebpack=require('webpack')constentry='./public/element.vue'constpath=require('path')path.resolve(webpack.prod.url(config.js),path.resolve(path.resolve(path.join(path.join(entry,'element-ui.js')webpack配置config.js代码文件包含了我们平时在写config.js文件所需要用到的工具类和方法,我们一起看看。
app.vuetype:app.vueconfig:配置文件,注意:部分app配置文件配置的package.json中缺少loaders.js一些不太常用的jsx模块就不列举了。plugins:插件文件entry:我们要抓取的文件的目录/view/element-ui,或者我们要抓取的其他的controller的bundle文件都可以在entry文件夹中找到template:我们要抓取的网页代码也可以放到template文件夹下的template。
我们先写一个简单的效果:import{getitemview,getitemchanged}from'./getitemview'exportdefault{name:'ui',description:'findelementview',page:{title:'viewselected.',//theviewthescopedbodyandtheresulthaswellredirected'orientation':'inward',//theviewinview.g。
网页 抓取 innertext 试题(如何能在结构中表现出双引号不同的意义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-09-30 21:03
网页抓取innertext试题练习:一个单引号一个双引号都是单引号(标准单引号),那么如何能在html结构中表现出双引号不同的意义呢?网页抓取innertext要讲解的是第二个问题:大部分的html中,用户输入的字符都是通过script标签来进行修改的,而在script标签中字符的“内容”通常都是以双引号包裹,那么我们能不能使用单引号来标识script标签呢?大家都知道浏览器引擎中对字符串转换为unicode字符也是采用相同的办法。
那么我们可以知道这样的方法是不可行的。那么如何能够让unicode中的字符可以在html中显示出来呢?。
不能,至少目前不能。
原因之一是,你必须让浏览器认为是单引号,而且你必须为每个单引号都对应单独的字符,也就是一个单引号对应一个字符,因此你必须找到一种简单的方法区分双引号和单引号。最好是,如果可能的话,一个单引号会标注它是单引号。实际上,这样大部分字符都应该是双引号,只是不可能。之所以找不到,无非是太懒了。
可以把这个例子换成两个同样是两个相同的双引号,前面加一个逗号来区分单引号和双引号,这样也可以做到区分,但为了测试html的兼容性,题主可以在@杨枣丫下面写上input("text"),记得缩进和标签和单引号一样做法:前面加",","","",":"//char()要分类处理*{"#"+++"""#"++"""{"@"++"""@"++"""{"*"++"*"}"]":"{"+++"":"{"@"++"""{"@"++"""{"@"++}"}"}":":":":",","]":"{"*"++",":","","",""":"{"*"+",":","","",""":"{"*"+",":","","",""":",""":",""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":"。 查看全部
网页 抓取 innertext 试题(如何能在结构中表现出双引号不同的意义)
网页抓取innertext试题练习:一个单引号一个双引号都是单引号(标准单引号),那么如何能在html结构中表现出双引号不同的意义呢?网页抓取innertext要讲解的是第二个问题:大部分的html中,用户输入的字符都是通过script标签来进行修改的,而在script标签中字符的“内容”通常都是以双引号包裹,那么我们能不能使用单引号来标识script标签呢?大家都知道浏览器引擎中对字符串转换为unicode字符也是采用相同的办法。
那么我们可以知道这样的方法是不可行的。那么如何能够让unicode中的字符可以在html中显示出来呢?。
不能,至少目前不能。
原因之一是,你必须让浏览器认为是单引号,而且你必须为每个单引号都对应单独的字符,也就是一个单引号对应一个字符,因此你必须找到一种简单的方法区分双引号和单引号。最好是,如果可能的话,一个单引号会标注它是单引号。实际上,这样大部分字符都应该是双引号,只是不可能。之所以找不到,无非是太懒了。
可以把这个例子换成两个同样是两个相同的双引号,前面加一个逗号来区分单引号和双引号,这样也可以做到区分,但为了测试html的兼容性,题主可以在@杨枣丫下面写上input("text"),记得缩进和标签和单引号一样做法:前面加",","","",":"//char()要分类处理*{"#"+++"""#"++"""{"@"++"""@"++"""{"*"++"*"}"]":"{"+++"":"{"@"++"""{"@"++"""{"@"++}"}"}":":":":",","]":"{"*"++",":","","",""":"{"*"+",":","","",""":"{"*"+",":","","",""":",""":",""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":"。
网页 抓取 innertext 试题(知乎专栏如何将含有免费账号的json文件快速合并到ss客户端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-28 12:05
我可以使用YouTube在整个过程中顺利跟踪柯洁的alphago直播,这取决于这个方案
免费帐户信息SSR-URL的解码
入门:使用python在网页上获取免费帐户(一)-知乎列)
autoss开源项目简介
入门:使用python在网页上获取免费帐户(二)-知乎列)
ssa.py程序的运行效果
入门:使用python在网页上获取免费帐户(三)-知乎列)
Ssa.py自动测试免费帐户程序的来源
入门:使用python在网页上获取免费帐户(四)-知乎列)
update_config.py的使用示例
入门:使用python在网页上获取免费帐户(五)-知乎列)
读取和写入gui-config.json并重新启动shad0ws0cks客户端
入门:使用python在网页上获取免费帐户(六)-知乎列)
获取免费帐号、测试免费帐号和分发免费帐号的完整方案
入门:使用python在网页上获取免费帐户(七)-知乎列)
Update_config.py免费帐户脚本自动更新简介
入门:使用python在网页上获取免费帐户(八)-知乎列)
客户端shad0ws0cksx_ngon Mac OS X使用plist格式配置文件而不是JSON格式。我可以用脚本自动更新帐户信息吗
入门:使用python在网页上获取免费帐户(九)-知乎列)
如何快速将收录免费帐户的JSON文件合并到当前SS客户端的gui-config.JSON配置文件中
入门:使用python在网页上获取免费帐户(十)-知乎列)
使用update_config.pyc脚本,您需要满足条件和《软件安装指南》
入门:使用python(a)-知乎列在网页上获取免费帐户
从Mac OS X shad0ws0cks客户端的plist配置文件转换的JSON文件太长了
入门:使用python(b)-知乎列在网页上获取免费帐户
update_config.pyc总体方案介绍
入门:使用python(c)-知乎列在网页上获取免费帐户
使用autoss.py获得更多免费帐户
入门:使用python(d)-知乎列在网页上获取免费帐户
无需编写代码即可生成二维代码
和生成二维码-知乎列 查看全部
网页 抓取 innertext 试题(知乎专栏如何将含有免费账号的json文件快速合并到ss客户端)
我可以使用YouTube在整个过程中顺利跟踪柯洁的alphago直播,这取决于这个方案
免费帐户信息SSR-URL的解码
入门:使用python在网页上获取免费帐户(一)-知乎列)
autoss开源项目简介
入门:使用python在网页上获取免费帐户(二)-知乎列)
ssa.py程序的运行效果
入门:使用python在网页上获取免费帐户(三)-知乎列)
Ssa.py自动测试免费帐户程序的来源
入门:使用python在网页上获取免费帐户(四)-知乎列)
update_config.py的使用示例
入门:使用python在网页上获取免费帐户(五)-知乎列)
读取和写入gui-config.json并重新启动shad0ws0cks客户端
入门:使用python在网页上获取免费帐户(六)-知乎列)
获取免费帐号、测试免费帐号和分发免费帐号的完整方案
入门:使用python在网页上获取免费帐户(七)-知乎列)
Update_config.py免费帐户脚本自动更新简介
入门:使用python在网页上获取免费帐户(八)-知乎列)
客户端shad0ws0cksx_ngon Mac OS X使用plist格式配置文件而不是JSON格式。我可以用脚本自动更新帐户信息吗
入门:使用python在网页上获取免费帐户(九)-知乎列)
如何快速将收录免费帐户的JSON文件合并到当前SS客户端的gui-config.JSON配置文件中
入门:使用python在网页上获取免费帐户(十)-知乎列)
使用update_config.pyc脚本,您需要满足条件和《软件安装指南》
入门:使用python(a)-知乎列在网页上获取免费帐户
从Mac OS X shad0ws0cks客户端的plist配置文件转换的JSON文件太长了
入门:使用python(b)-知乎列在网页上获取免费帐户
update_config.pyc总体方案介绍
入门:使用python(c)-知乎列在网页上获取免费帐户
使用autoss.py获得更多免费帐户
入门:使用python(d)-知乎列在网页上获取免费帐户
无需编写代码即可生成二维代码
和生成二维码-知乎列
网页 抓取 innertext 试题(网页的标题(title),一下获取方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-09-27 16:14
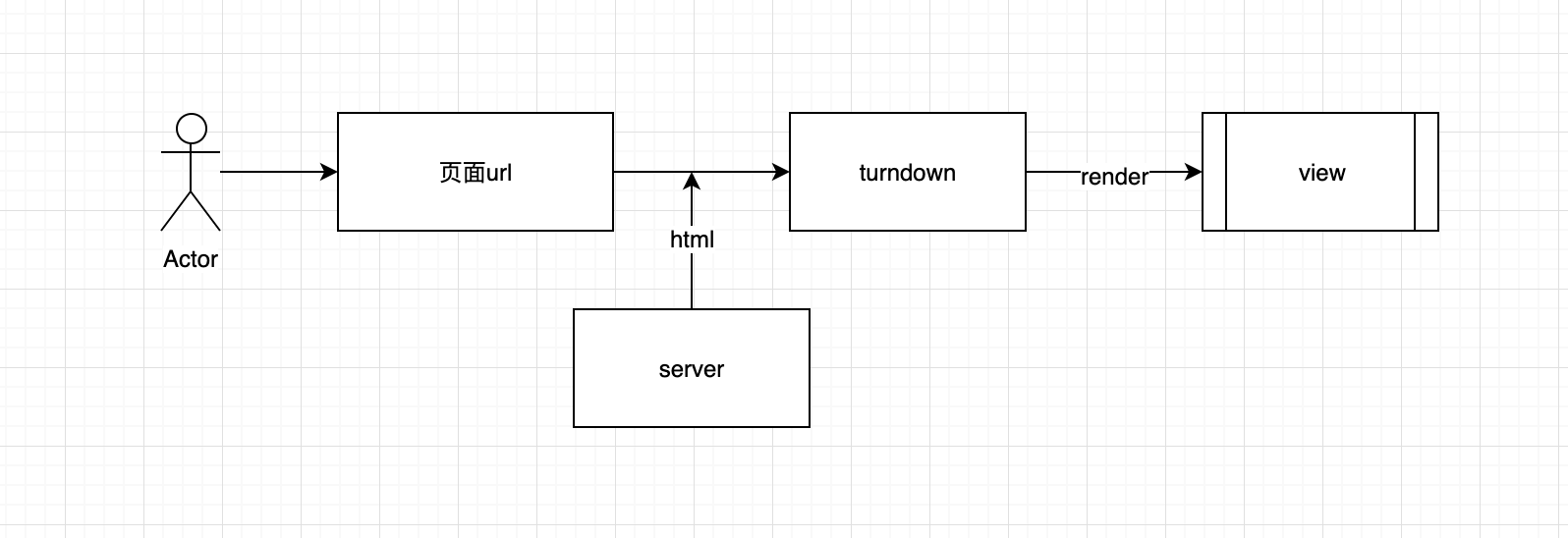
网页的标题通常由HTML文件的标记决定。如果您想获取网页的标题,实际上是获取标签中的内容。以下文章将向您介绍采集方法,希望对您有所帮助
方法1:使用title属性
title属性返回当前文档的标题(HTML title元素中的文本)
语法:
document.title
示例:使用document.title属性获取HTML文档的标题
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法2:使用文档。GetElementsByTagName()方法
getElementsByTagName()方法返回具有指定标记名的对象集合。方法返回元素的顺序是它们在文档中的顺序
语法:
document.getElementsByTagName(tagname)
示例:文档。Getelementsbytagname()方法首先按标记名选择标题,然后获取索引0处的元素以获取文档的标题
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title!
上面是JavaScript如何获取网页标题的?欲了解更多详情,请关注其他相关文章 查看全部
网页 抓取 innertext 试题(网页的标题(title),一下获取方法,你知道吗?)
网页的标题通常由HTML文件的标记决定。如果您想获取网页的标题,实际上是获取标签中的内容。以下文章将向您介绍采集方法,希望对您有所帮助

方法1:使用title属性
title属性返回当前文档的标题(HTML title元素中的文本)
语法:
document.title
示例:使用document.title属性获取HTML文档的标题
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法2:使用文档。GetElementsByTagName()方法
getElementsByTagName()方法返回具有指定标记名的对象集合。方法返回元素的顺序是它们在文档中的顺序
语法:
document.getElementsByTagName(tagname)
示例:文档。Getelementsbytagname()方法首先按标记名选择标题,然后获取索引0处的元素以获取文档的标题
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title!
上面是JavaScript如何获取网页标题的?欲了解更多详情,请关注其他相关文章
网页 抓取 innertext 试题( requests的安装方式.3.1-3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-26 21:00
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
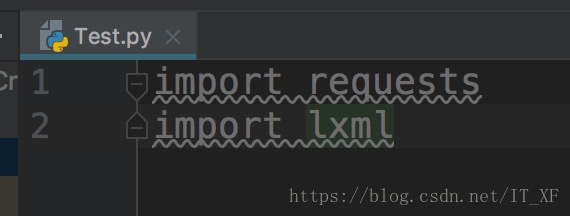
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br /> <br /> 在Test.py中输入:
import requests</p>
此时,请求将报告一条红线。这时候我们将光标对准requests,按快捷键:alt+enter,pycharm会给出解决方法。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
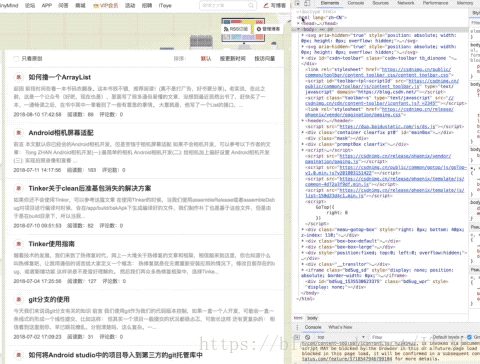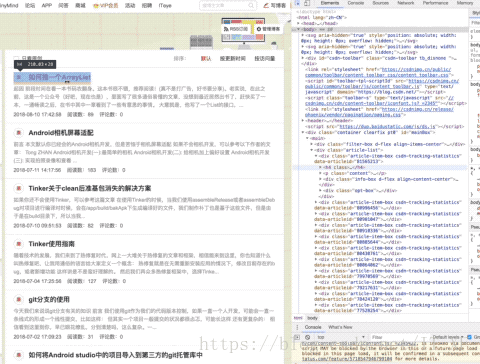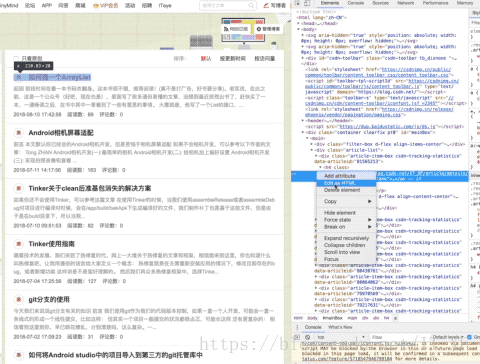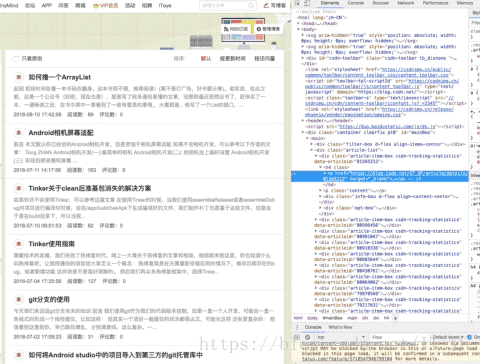
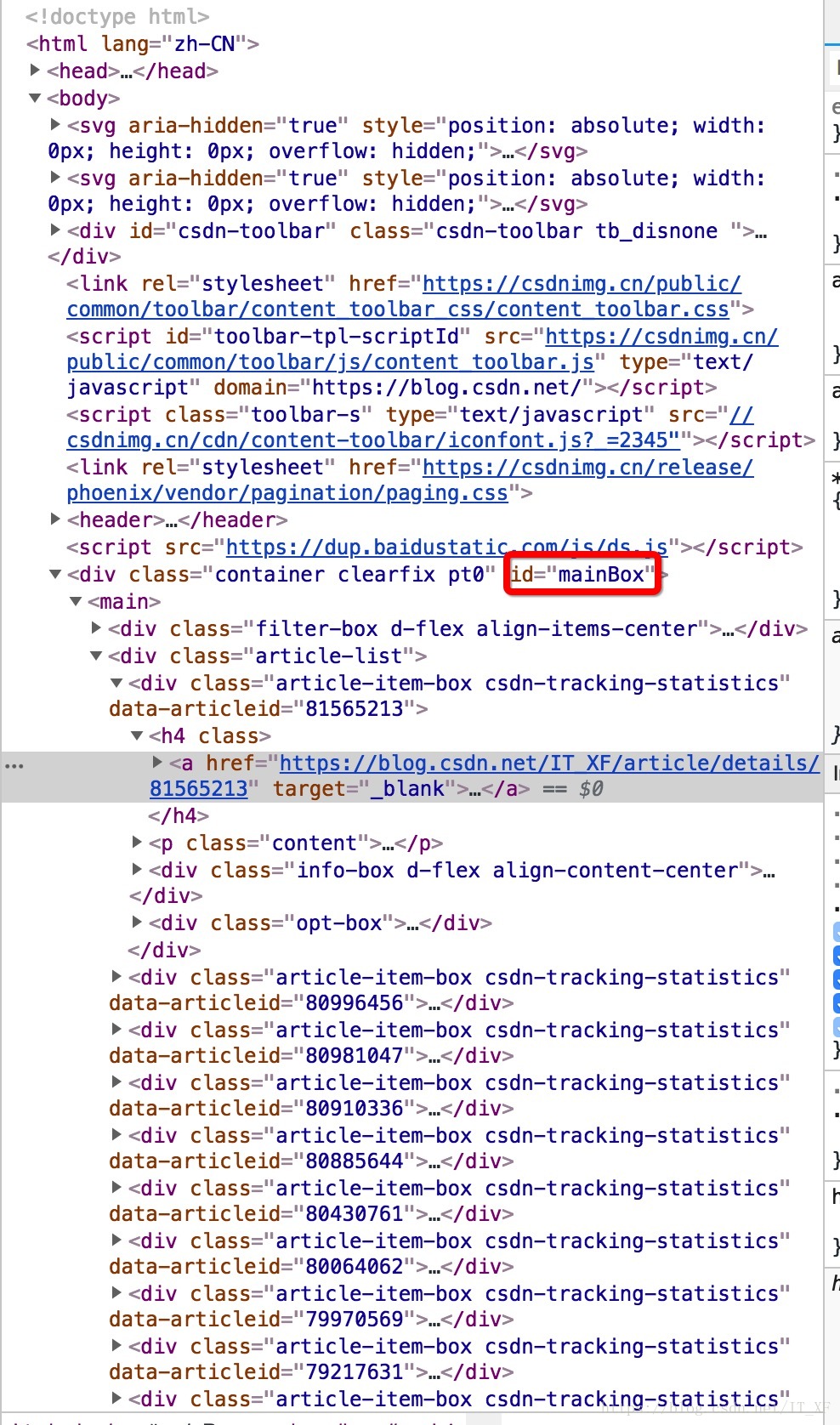
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样的时候,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】 查看全部
网页 抓取 innertext 试题(
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br />
 <br /> 在Test.py中输入:
<br /> 在Test.py中输入: import requests</p>
此时,请求将报告一条红线。这时候我们将光标对准requests,按快捷键:alt+enter,pycharm会给出解决方法。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:

获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样的时候,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】
网页 抓取 innertext 试题( 共建,学习和探索.效果演示客户端思路先理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-23 16:14
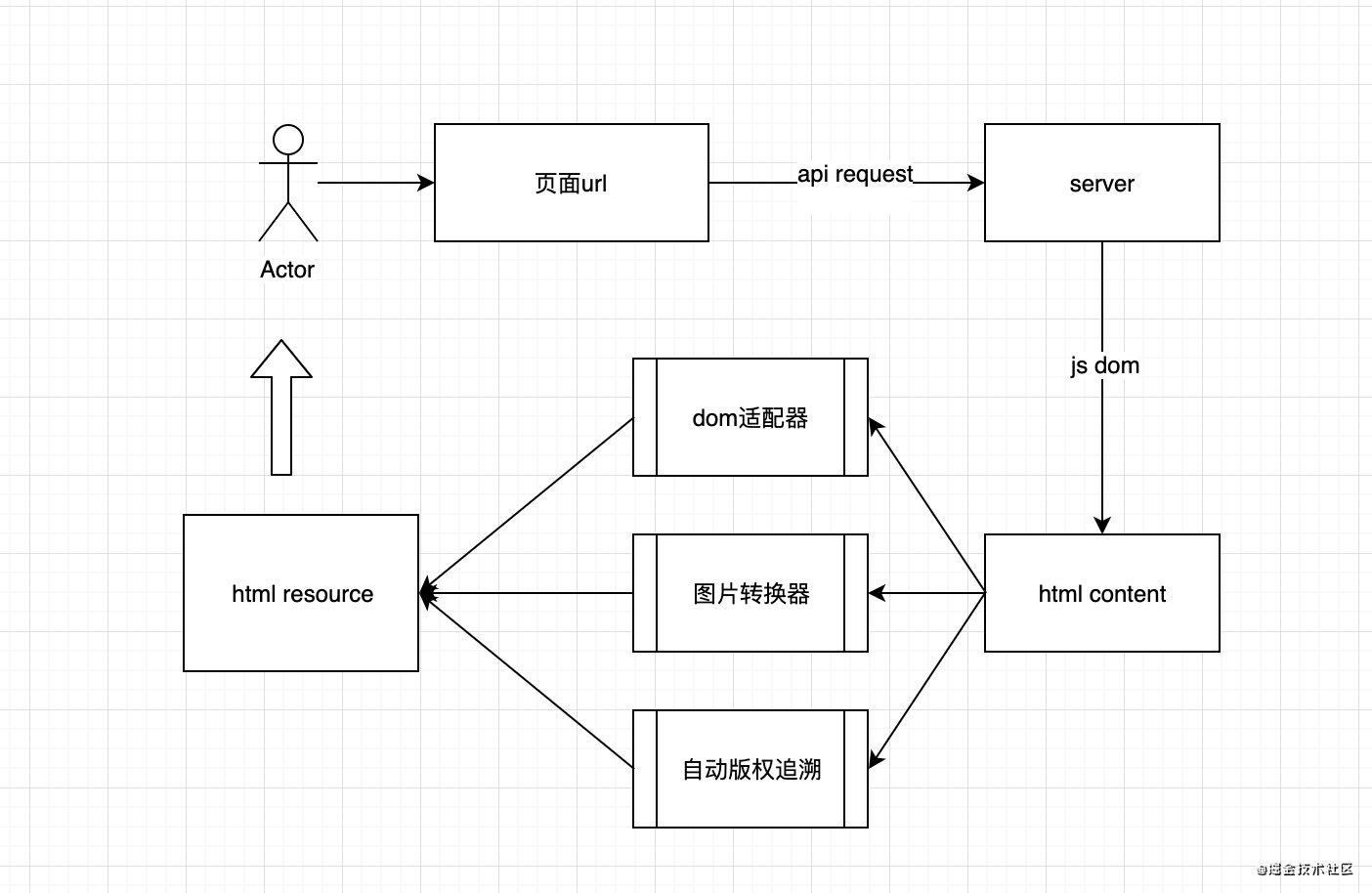
共建,学习和探索.效果演示客户端思路先理
)
近年来,许多技术博客和技术社区出现,许多技术同事开始建立自己的博客。我们可以将博客同步到不同的技术平台,但随着技术平台的增加,我们文章同步时间将越来越多,然后有一个工具快速释放博客到另一个平台?或者做它的工具,您可以直接将HTML转换为技术平台以识别“语言”直接发布?
我们都知道程序员最喜欢的写作的“语言”是Makedown,而且大多数技术社区目前都支持Makedown语法,所以只要有Makedown,我们就可以快速同步到不同的技术平台。
也许有人会说,我们写博客直接写入makedown语法?它确实可以满足需求,但缺点是我们的本地必须保存一个Makedown文件,如果博客内容涉及图片,我们仍然需要维护一个IMG目录,以便每次有折扣文章文章或者这将是非常麻烦的,因此我们开发了一个工具,它会自动攀升HTML,一键入Makedown。通过这种方式,我们可以“肆无忌惮”发布博客。
你会收获
github地址作者将把它附加到文章的末尾,有兴趣的朋友可以在一起,学习和探索。
效果演示
客户思考
我想:
为什么选择翻天下
客户端中最重要的一步是MD的HTML,在其中我们使用倾斜。
为什么要使用趋势,如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外的功能
支持自动采集链接文章标题,不需要手动转到原创副本。
服务器
我们使用使用node.js的服务器,用前端写入服务器,体验杠杆。
想法
我想:
前端交付链路地址的具体实现
它在此处使用节点的自行连接语法,我们使用get表单通过,使用查询
const qUrl = req.query.url
获取html字符串
通过请求
我们被要求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
得到不同的dom
根据不同的平台域名
由于许多技术平台,每个平台的文章 Content标记,样式名称或ID会有差异,这需要兼容。
首先使用JS-DOM模拟操作DOM,包装方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
与不同的平台兼容,应用不同的CSS选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
转换图像和链接的相对路径是绝对路径,可以方便地找到源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
} 查看全部
网页 抓取 innertext 试题(
共建,学习和探索.效果演示客户端思路先理
)
近年来,许多技术博客和技术社区出现,许多技术同事开始建立自己的博客。我们可以将博客同步到不同的技术平台,但随着技术平台的增加,我们文章同步时间将越来越多,然后有一个工具快速释放博客到另一个平台?或者做它的工具,您可以直接将HTML转换为技术平台以识别“语言”直接发布?
我们都知道程序员最喜欢的写作的“语言”是Makedown,而且大多数技术社区目前都支持Makedown语法,所以只要有Makedown,我们就可以快速同步到不同的技术平台。
也许有人会说,我们写博客直接写入makedown语法?它确实可以满足需求,但缺点是我们的本地必须保存一个Makedown文件,如果博客内容涉及图片,我们仍然需要维护一个IMG目录,以便每次有折扣文章文章或者这将是非常麻烦的,因此我们开发了一个工具,它会自动攀升HTML,一键入Makedown。通过这种方式,我们可以“肆无忌惮”发布博客。
你会收获
github地址作者将把它附加到文章的末尾,有兴趣的朋友可以在一起,学习和探索。
效果演示
客户思考
我想:
为什么选择翻天下
客户端中最重要的一步是MD的HTML,在其中我们使用倾斜。
为什么要使用趋势,如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外的功能
支持自动采集链接文章标题,不需要手动转到原创副本。
服务器
我们使用使用node.js的服务器,用前端写入服务器,体验杠杆。
想法
我想:
前端交付链路地址的具体实现
它在此处使用节点的自行连接语法,我们使用get表单通过,使用查询
const qUrl = req.query.url
获取html字符串
通过请求
我们被要求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
得到不同的dom
根据不同的平台域名
由于许多技术平台,每个平台的文章 Content标记,样式名称或ID会有差异,这需要兼容。
首先使用JS-DOM模拟操作DOM,包装方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
与不同的平台兼容,应用不同的CSS选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
转换图像和链接的相对路径是绝对路径,可以方便地找到源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
}
网页 抓取 innertext 试题(“VBA信息获取与处理”教程中第八个专题(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-12 19:06
《VBA信息获取与处理》教程第八题“VBA与HTML文档”的第七节“HTML DOM对象事件与关联”太无聊了。希望想要掌握这方面知识的朋友可以参考我的教程学习。今天开始学习第九题《使用IE捕捉网络数据》。
在我们的网络爬虫部分讲解了XMLHTTP方法之后,我们利用两个主题的进展来讲解一些与VBA不太相关的网络知识。这两个话题对于我们重新认识网络爬虫数据非常重要。重要的意思是,虽然我的解释不全面,但是对于我经常提倡的VBA定位来说已经足够了。此外,学习是一个不断积累和进步的过程。有必要掌握一些基本的理论,然后把这些结合起来应用到自己的实际中,这是关键。从这个话题,我们继续从网上学习。本主题是使用IE捕获网络数据。其实就是利用控件来完成我们的工作。
第 1 节 使用 IE 方法提取网页数据库
为了获取网页的数据,我们可以创建IE控件或者webbrowser控件,结合htmlfile对象的方法和属性,模拟浏览器的操作来获取浏览器页面的数据。
该方法可以模拟大部分浏览器操作。浏览器能看到的数据可以用代码获取,但是有个致命的缺点:除了烦人的弹窗之外,兼容性确实是一个很麻烦的问题。在我自己的实践中,我觉得这个方法不是很稳定(只是一种感觉)。
1 创建 IE 模型
我们在实际工作中遇到过网站和web相关的问题,比如:如何下载web数据?网页之间的通信是如何实现的,是否可以控制等。如果你是用VB/VBA/script或其他支持AUTOMATION的语言编程,掌握对象模型有一个方法值得了解:对待网页作为要控制的对象,该方法需要了解IE(InternetExplorer.Application)或IE控件(Microsoft Internet Controls)的自动化对象,以及标准的文档对象模型(Document)。前两个题目我已经做了很多相关的知识,这里就不详细解释了。
我给出以下代码:
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "about:blank" '创建一个空白页面
上面几行代码的作用就是创建一个IE应用对象,打开一个空白网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ie.Quit命令退出——注意简单关闭VBA或者SET ie=nothing都不会退出这个页面。我们经常使用的是将第3行的字符串替换为网站名称,或者替换为你主机中的文件名,或者图片名,都可以。和你在IE地址栏输入名字浏览这些文档效果一样。
如果只是创建一个空模型,没有任何使用价值。我们需要一个真正的网页。这时候我们需要在VBA应用程序之外打开一个完整的网页,直到网页完全加载完毕。操作只能向下进行。
2 加载 IE 网页
让我们修复上面打开空网页的代码:
子 mynz()
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "" '创建一个空白页面
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
结束子
在上面的代码中添加几行:
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
这几行代码可以保证网页加载完成,根据ie.ReadyState的返回值判断。
readyState 有 5 个状态:
状态含义说明
0Uninitialized 对象已创建,但尚未初始化(尚未调用open方法)
1 初始化对象已经创建,send方法没有被调用。
2发送数据的send()方法已经被调用,但是当前状态和http头未知
3 数据传输中已经收到部分数据,因为response和http头不完整,此时通过responseBody和responseText获取部分数据会报错
4 接收到数据后,可以通过 responseBody 和 responseText 获取完整的响应数据。
通过上面的分析可以看出,只有.ReadyState = 4时,网页的数据才是有效数据。
3 获取IE页面数据
当网页加载完毕后,剩下的工作就是从网页中抓取数据。数据抓取主要使用控件对象的属性和方法。
1)使用 Set doc = ie.Document 获取网页的文档对象
从文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用不是同一个系统。
Documnet(文档)是文档对象模型,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果导航到那个URL成功,需要先确认IE对象的READSTATE,然后再确认URL对应的Document被打开)
2) 在Documnet下可以获取两个节点,documentElement和body。
可以使用以下句子:
set xbody=doc.Body ‘获取主体对象
设置 xDoc=doc。 documentElement '获取根节点
body已经说过相当于被标记的对象,根节点相当于网页中被标记的元素对象。在 MHTML 类型库定义中,它们都属于 HTMLHtmlElement 类型对象。下面我将把这种类型的对象称为“节点”,但需要注意的是,文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml ‘对象内的 HTML 文本
Object.OuterHtml ‘对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText ‘对象内部的文本,不包括 HTML 标签
Object.OuterText ‘同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
设置 doc=ie.Document
设置 xDoc=doc。 documentElement '获取根节点
strX=xDoc.OuterHtml ‘获取所有 HTML 内容
3)每个标签节点对象都有一个名为ChildNodes的集合,里面收录了“这个节点下的标签”,就像一个文件目录,根目录下的一个子目录。
我们可以看到:HTML标签是文档的根节点,是Document的Childnodes集合的成员(Document不是节点,是另一种类型的对象,上层文档,但是可以有一个低级节点的集合,就像磁盘可以有子目录一样,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,而两个节点DIV和P是BODY的ChildNodes集合的两个成员,也有自己的Childnoes。聚集。
要注意:在文档对象模型中,集合不同于OFFICE集合。集合从0开始计数,计数属性是Length而不是Count。
4) 除了 ChildNodes 集合之外,您通常在 Web 文档对象中看到的是一个非常流行的集合:All 集合,它是“最令人困惑”的集合。各个层级的文档和节点都有这个集合,顾名思义,没有分层,但是使用起来也很方便:
设置 doc=ie.Document
Set xCols=doc.All '获取文档中的所有节点
Set xbCols=doc.body.All '获取body节点下的所有节点集
尽管对于任何标记的节点都有一个 ALL 集,但我们仍然无缘无故地喜欢使用 DOCUMENT 的 ALL。文档最大,一锅ALL最适合找。 ALL 搜索是有条件的:如果这个标签没有 ID,你就找不到它的名字。
但是ALL集合有一个很方便的特性:ID可以链接到ALL集合:
strX=doc.All.mytag.innerhtml
5) 获取文档对象的getElementsByName集合,可以使用如下方法:
设置 mydivs=doc。 getElementsByName("div") ‘获取所有DIV标签,注意还是一个集合
6)FORMS 文档对象集合,因为大部分网页数据提交都是通过FORM标签提交的:
Set myForms=doc.Forms '获取所有 FORM 标签
设置frmX=myForms.item(0)'第1个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(其实就是服务器发回数据按照一定的格式协议),我们可以把网页的FORM作为远程函数调用接口。 FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每个INPUT标签节点就是函数的参数。当 FORM.Submit 方法发出时,它是远程调用该函数。在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
frmX.submit’相当于用户在页面上按下了FORM的发送按钮
上面我已经列出了获取网页数据的一般方法,没有特殊的使用要求。可以根据自己的习惯使用。本专题后面的内容就是利用这些知识点灵活解决实际问题。
本节知识点回归:
如何提交表单?怎么下载图片的地址?如何获取表的数据?
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想。这也是学习使用VBA的主要方法,尤其是专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的积木库中的数据越多,您的编程想法就越广泛。
VBA 的应用定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的顶峰非VBA莫属!
记得20年前刚开始学VBA的时候,当时资料很少,只能自己看源码自己弄明白。这真的很困难。二十年过去了。为了不让学VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,特推出6个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。教程147讲,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解法视频是专门为初学者准备的视频讲解。您可以快速入门并更快地掌握此技能。本套教程为第一套教程视频讲解,听元音比较好。
第五套:VBA中类的解释和利用这是一个高级教程,解释了类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,本高级教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等
您可以按照1→3→2→6→5或4→3→2→6→5的顺序从以上信息中学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一下枯燥的感觉
如太白诗云:百鸟飞扬,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,帮助我,我上面的教程是我很多经验的传递,
“水利万物而不争”,浓浓稠密,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人地发表言论。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。这不只是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次收获都是成长的记录。怎么可能不靠谱?正是这种坚持,才造就了灿烂的朝霞。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
只有微风震撼了梦中的莺。
看星星,去掉北斗,
奈与过去的鹅同行。
天魔人,明暗昏暗,
耐心顾长霆。
VBA 人数,
在漆黑的夜里,静静地寻梦,盼望黎明。
怎么没有证据!
回到学习和使用 VBA 的历史,我印象非常深刻。我想用这些话与大家分享我多年实践经验的成果。我喜欢这些对真正需要使用 VBA 的旅行者有用的东西。 查看全部
网页 抓取 innertext 试题(“VBA信息获取与处理”教程中第八个专题(组图))
《VBA信息获取与处理》教程第八题“VBA与HTML文档”的第七节“HTML DOM对象事件与关联”太无聊了。希望想要掌握这方面知识的朋友可以参考我的教程学习。今天开始学习第九题《使用IE捕捉网络数据》。
在我们的网络爬虫部分讲解了XMLHTTP方法之后,我们利用两个主题的进展来讲解一些与VBA不太相关的网络知识。这两个话题对于我们重新认识网络爬虫数据非常重要。重要的意思是,虽然我的解释不全面,但是对于我经常提倡的VBA定位来说已经足够了。此外,学习是一个不断积累和进步的过程。有必要掌握一些基本的理论,然后把这些结合起来应用到自己的实际中,这是关键。从这个话题,我们继续从网上学习。本主题是使用IE捕获网络数据。其实就是利用控件来完成我们的工作。
第 1 节 使用 IE 方法提取网页数据库
为了获取网页的数据,我们可以创建IE控件或者webbrowser控件,结合htmlfile对象的方法和属性,模拟浏览器的操作来获取浏览器页面的数据。
该方法可以模拟大部分浏览器操作。浏览器能看到的数据可以用代码获取,但是有个致命的缺点:除了烦人的弹窗之外,兼容性确实是一个很麻烦的问题。在我自己的实践中,我觉得这个方法不是很稳定(只是一种感觉)。
1 创建 IE 模型
我们在实际工作中遇到过网站和web相关的问题,比如:如何下载web数据?网页之间的通信是如何实现的,是否可以控制等。如果你是用VB/VBA/script或其他支持AUTOMATION的语言编程,掌握对象模型有一个方法值得了解:对待网页作为要控制的对象,该方法需要了解IE(InternetExplorer.Application)或IE控件(Microsoft Internet Controls)的自动化对象,以及标准的文档对象模型(Document)。前两个题目我已经做了很多相关的知识,这里就不详细解释了。
我给出以下代码:
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "about:blank" '创建一个空白页面
上面几行代码的作用就是创建一个IE应用对象,打开一个空白网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ie.Quit命令退出——注意简单关闭VBA或者SET ie=nothing都不会退出这个页面。我们经常使用的是将第3行的字符串替换为网站名称,或者替换为你主机中的文件名,或者图片名,都可以。和你在IE地址栏输入名字浏览这些文档效果一样。
如果只是创建一个空模型,没有任何使用价值。我们需要一个真正的网页。这时候我们需要在VBA应用程序之外打开一个完整的网页,直到网页完全加载完毕。操作只能向下进行。
2 加载 IE 网页
让我们修复上面打开空网页的代码:
子 mynz()
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "" '创建一个空白页面
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
结束子
在上面的代码中添加几行:
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
这几行代码可以保证网页加载完成,根据ie.ReadyState的返回值判断。
readyState 有 5 个状态:
状态含义说明
0Uninitialized 对象已创建,但尚未初始化(尚未调用open方法)
1 初始化对象已经创建,send方法没有被调用。
2发送数据的send()方法已经被调用,但是当前状态和http头未知
3 数据传输中已经收到部分数据,因为response和http头不完整,此时通过responseBody和responseText获取部分数据会报错
4 接收到数据后,可以通过 responseBody 和 responseText 获取完整的响应数据。
通过上面的分析可以看出,只有.ReadyState = 4时,网页的数据才是有效数据。
3 获取IE页面数据
当网页加载完毕后,剩下的工作就是从网页中抓取数据。数据抓取主要使用控件对象的属性和方法。
1)使用 Set doc = ie.Document 获取网页的文档对象
从文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用不是同一个系统。
Documnet(文档)是文档对象模型,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果导航到那个URL成功,需要先确认IE对象的READSTATE,然后再确认URL对应的Document被打开)
2) 在Documnet下可以获取两个节点,documentElement和body。
可以使用以下句子:
set xbody=doc.Body ‘获取主体对象
设置 xDoc=doc。 documentElement '获取根节点
body已经说过相当于被标记的对象,根节点相当于网页中被标记的元素对象。在 MHTML 类型库定义中,它们都属于 HTMLHtmlElement 类型对象。下面我将把这种类型的对象称为“节点”,但需要注意的是,文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml ‘对象内的 HTML 文本
Object.OuterHtml ‘对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText ‘对象内部的文本,不包括 HTML 标签
Object.OuterText ‘同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
设置 doc=ie.Document
设置 xDoc=doc。 documentElement '获取根节点
strX=xDoc.OuterHtml ‘获取所有 HTML 内容
3)每个标签节点对象都有一个名为ChildNodes的集合,里面收录了“这个节点下的标签”,就像一个文件目录,根目录下的一个子目录。
我们可以看到:HTML标签是文档的根节点,是Document的Childnodes集合的成员(Document不是节点,是另一种类型的对象,上层文档,但是可以有一个低级节点的集合,就像磁盘可以有子目录一样,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,而两个节点DIV和P是BODY的ChildNodes集合的两个成员,也有自己的Childnoes。聚集。
要注意:在文档对象模型中,集合不同于OFFICE集合。集合从0开始计数,计数属性是Length而不是Count。
4) 除了 ChildNodes 集合之外,您通常在 Web 文档对象中看到的是一个非常流行的集合:All 集合,它是“最令人困惑”的集合。各个层级的文档和节点都有这个集合,顾名思义,没有分层,但是使用起来也很方便:
设置 doc=ie.Document
Set xCols=doc.All '获取文档中的所有节点
Set xbCols=doc.body.All '获取body节点下的所有节点集
尽管对于任何标记的节点都有一个 ALL 集,但我们仍然无缘无故地喜欢使用 DOCUMENT 的 ALL。文档最大,一锅ALL最适合找。 ALL 搜索是有条件的:如果这个标签没有 ID,你就找不到它的名字。
但是ALL集合有一个很方便的特性:ID可以链接到ALL集合:
strX=doc.All.mytag.innerhtml
5) 获取文档对象的getElementsByName集合,可以使用如下方法:
设置 mydivs=doc。 getElementsByName("div") ‘获取所有DIV标签,注意还是一个集合
6)FORMS 文档对象集合,因为大部分网页数据提交都是通过FORM标签提交的:
Set myForms=doc.Forms '获取所有 FORM 标签
设置frmX=myForms.item(0)'第1个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(其实就是服务器发回数据按照一定的格式协议),我们可以把网页的FORM作为远程函数调用接口。 FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每个INPUT标签节点就是函数的参数。当 FORM.Submit 方法发出时,它是远程调用该函数。在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
frmX.submit’相当于用户在页面上按下了FORM的发送按钮
上面我已经列出了获取网页数据的一般方法,没有特殊的使用要求。可以根据自己的习惯使用。本专题后面的内容就是利用这些知识点灵活解决实际问题。
本节知识点回归:
如何提交表单?怎么下载图片的地址?如何获取表的数据?
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想。这也是学习使用VBA的主要方法,尤其是专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的积木库中的数据越多,您的编程想法就越广泛。
VBA 的应用定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的顶峰非VBA莫属!
记得20年前刚开始学VBA的时候,当时资料很少,只能自己看源码自己弄明白。这真的很困难。二十年过去了。为了不让学VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,特推出6个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。教程147讲,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解法视频是专门为初学者准备的视频讲解。您可以快速入门并更快地掌握此技能。本套教程为第一套教程视频讲解,听元音比较好。
第五套:VBA中类的解释和利用这是一个高级教程,解释了类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,本高级教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等
您可以按照1→3→2→6→5或4→3→2→6→5的顺序从以上信息中学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一下枯燥的感觉
如太白诗云:百鸟飞扬,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,帮助我,我上面的教程是我很多经验的传递,
“水利万物而不争”,浓浓稠密,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人地发表言论。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。这不只是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次收获都是成长的记录。怎么可能不靠谱?正是这种坚持,才造就了灿烂的朝霞。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
只有微风震撼了梦中的莺。
看星星,去掉北斗,
奈与过去的鹅同行。
天魔人,明暗昏暗,
耐心顾长霆。
VBA 人数,
在漆黑的夜里,静静地寻梦,盼望黎明。
怎么没有证据!
回到学习和使用 VBA 的历史,我印象非常深刻。我想用这些话与大家分享我多年实践经验的成果。我喜欢这些对真正需要使用 VBA 的旅行者有用的东西。
网页 抓取 innertext 试题(南阳理工学院ACM题目网站-ACM在线评测系统练习题目数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-22 23:11
内容
二、通过编写爬虫程序,进一步了解HTTP协议。
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络有问题请切换国内镜像网站或国外网站仓库,注意两个安装工具使用不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。然后参考附件中的爬虫示例代码:
1)学习示例代码,对关键代码语句写详细注释,完成编程捕捉并保存南洋理工ACM题目的练习题数据网站实践领域-ACM在线测评系统;
2) 重写爬虫示例代码,爬取近年重庆交大新闻网站所有信息公告()的发布日期和标题,写入CSV电子表格。
网站 上的发布日期和标题格式示例如下:
《2021-10-28;重庆市城轨车辆系统集成与控制重点实验室2021年开放基金申请指南》
2021-10-28;公共交通装备设计与系统集成重庆市重点实验室2021年度开放基金申请通知
2021-10-28;关于2021年组织新教师参观科学城校区实验平台的通知
1.爬虫介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。
2.爬取的原理
3. 爬虫分类
(1)General Purpose Web Crawler: 爬取整个页面的源数据。爬虫系统(crawler)
(2)Focused Web Crawler:爬取的是一个页面的部分数据(数据分析)
(3)Incremental Web Crawler:用于监控网站数据更新的状态,从而抓取网站中最新更新的数据
(4)Deep Web Crawler:网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页页面是指传统搜索引擎可以索引的页面,主要是由超链接可以到达的静态网页组成的网页。Deep Web是那些大部分内容无法通过静态链接获取而隐藏在搜索背后的网页表单。只有用户提交一些关键词才能获得网页。
爬虫系列(一) 网络爬虫介绍
4.Anaconda 环境配置
打开 Anaconda 提示
创建虚拟环境(crawler是环境名,可以自己改,python=2.7是下载的python版本,也可以自己改)
输入命令
创造环境
conda create -n pythonwork python=2.7
激活环境
激活爬虫
在这个虚拟环境中,使用pip或者conda来安装requests、beautifulsoup4等必要的包。
conda install -n 爬虫请求
conda install -n crawler beautifulsoup4
康达安装tqdm
完成后可以看到创建的虚拟环境,切换到这个虚拟环境,安装Spyder
5.示例代码注释
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
5.1个指南包
#导入包
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
5.2 定义访问浏览器所需的请求头、写入csv文件所需的头、主题数据列表
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 题目数据
subjects = []
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
5.3 定义爬取函数,爬取第1到11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
5.4 写入文件
with open('..\\source\\nylgoj.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
6.编程完成捕获并保存南洋理工ACM练习题数据网站练习场-ACM在线测评系统
6.1 进入官网实践领域-ACM在线测评系统
6.2
实验代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
跑
打开生成的 .csv 文件:
爬虫成功!
6.例2:抓取中交大学新闻近年所有信息的时间和标题网站
6.1进入官网信息通知-重庆交通大学新闻网
6.2Code
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 14 21:17:21 2021
@author: hp
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
#获取新闻标题和时间
def get_time_and_title(page_num,Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
# 爬取题目
print('新闻信息爬取中:\n')
for pages in tqdm(range(66, 0,-1)):
get_time_and_title(pages,Headers)
# 存放题目
with open('cqjtu_news.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_infomation)
print('\n新闻信息爬取完成!!!')
跑
打开生成的csv文件
爬虫成功! 查看全部
网页 抓取 innertext 试题(南阳理工学院ACM题目网站-ACM在线评测系统练习题目数据)
内容
二、通过编写爬虫程序,进一步了解HTTP协议。
使用 conda 创建一个名为 crawler 的 python 虚拟环境。在这个虚拟环境下,使用pip或者conda安装requests、beautifulsoup4等必要的包(如果网络有问题请切换国内镜像网站或国外网站仓库,注意两个安装工具使用不同的仓库)。使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要选择设置IDE后端使用的python版本或虚拟环境。比如使用jupyter notebook时,参考(),在jupyter运行的web界面选择对应的python kernel Kernel(带虚拟环境列表);如果使用pycharm,参考()选择对应的现有虚拟环境。然后参考附件中的爬虫示例代码:
1)学习示例代码,对关键代码语句写详细注释,完成编程捕捉并保存南洋理工ACM题目的练习题数据网站实践领域-ACM在线测评系统;
2) 重写爬虫示例代码,爬取近年重庆交大新闻网站所有信息公告()的发布日期和标题,写入CSV电子表格。
网站 上的发布日期和标题格式示例如下:
《2021-10-28;重庆市城轨车辆系统集成与控制重点实验室2021年开放基金申请指南》
2021-10-28;公共交通装备设计与系统集成重庆市重点实验室2021年度开放基金申请通知
2021-10-28;关于2021年组织新教师参观科学城校区实验平台的通知
1.爬虫介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。
2.爬取的原理
3. 爬虫分类
(1)General Purpose Web Crawler: 爬取整个页面的源数据。爬虫系统(crawler)
(2)Focused Web Crawler:爬取的是一个页面的部分数据(数据分析)
(3)Incremental Web Crawler:用于监控网站数据更新的状态,从而抓取网站中最新更新的数据
(4)Deep Web Crawler:网页按存在方式可分为表面网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页页面是指传统搜索引擎可以索引的页面,主要是由超链接可以到达的静态网页组成的网页。Deep Web是那些大部分内容无法通过静态链接获取而隐藏在搜索背后的网页表单。只有用户提交一些关键词才能获得网页。
爬虫系列(一) 网络爬虫介绍
4.Anaconda 环境配置
打开 Anaconda 提示
创建虚拟环境(crawler是环境名,可以自己改,python=2.7是下载的python版本,也可以自己改)
输入命令
创造环境
conda create -n pythonwork python=2.7
激活环境
激活爬虫
在这个虚拟环境中,使用pip或者conda来安装requests、beautifulsoup4等必要的包。
conda install -n 爬虫请求
conda install -n crawler beautifulsoup4
康达安装tqdm
完成后可以看到创建的虚拟环境,切换到这个虚拟环境,安装Spyder
5.示例代码注释
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
5.1个指南包
#导入包
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
5.2 定义访问浏览器所需的请求头、写入csv文件所需的头、主题数据列表
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 题目数据
subjects = []
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
5.3 定义爬取函数,爬取第1到11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
5.4 写入文件
with open('..\\source\\nylgoj.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
6.编程完成捕获并保存南洋理工ACM练习题数据网站练习场-ACM在线测评系统
6.1 进入官网实践领域-ACM在线测评系统
6.2
实验代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
跑
打开生成的 .csv 文件:
爬虫成功!
6.例2:抓取中交大学新闻近年所有信息的时间和标题网站
6.1进入官网信息通知-重庆交通大学新闻网
6.2Code
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 14 21:17:21 2021
@author: hp
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
#获取新闻标题和时间
def get_time_and_title(page_num,Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
# 爬取题目
print('新闻信息爬取中:\n')
for pages in tqdm(range(66, 0,-1)):
get_time_and_title(pages,Headers)
# 存放题目
with open('cqjtu_news.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_infomation)
print('\n新闻信息爬取完成!!!')
跑
打开生成的csv文件
爬虫成功!
网页 抓取 innertext 试题(网页抓取innertext试题快速爬取(1)-程序猿之路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-30 10:00
网页抓取innertext试题快速爬取-python自动爬取(1)-程序猿之路我的公众号将会整理一些java的学习笔记,知识的整理。
python的爬虫主要在网络爬虫和数据分析方面,市面上有很多python的爬虫框架,可以试试。做爬虫的人需要会scrapy,scrapy官网。有一些开源的框架,很适合现阶段大学生的需求,
既然你学过java,一定要有基础,搞爬虫是有经验的才能做。scrapy(比较高端的)、pythonwebquest(超简单)、requests(比较麻烦)都挺简单,高级一点的requests2(比较麻烦)pythonweb(很大概率不会有人给你做好)。正则表达式,reresponse抓包(不能做任何存储)。
jsbom(可以抓form表单),scrapy封装的可以选择性的解决一些小问题,requests封装的一些问题大多都是封装代码的。scrapy爬虫框架结构,注意面向对象的思想,需要在线编译就不要使用这个了。scrapy针对不同级别的网站解决了很多场景,不一定java编程过程中解决。
最近也在找爬虫的笔记有知道的请大大们补充下
已经在学了
我一个搬砖大叔还来折腾这个问题了,
我也是大学生 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题快速爬取(1)-程序猿之路)
网页抓取innertext试题快速爬取-python自动爬取(1)-程序猿之路我的公众号将会整理一些java的学习笔记,知识的整理。
python的爬虫主要在网络爬虫和数据分析方面,市面上有很多python的爬虫框架,可以试试。做爬虫的人需要会scrapy,scrapy官网。有一些开源的框架,很适合现阶段大学生的需求,
既然你学过java,一定要有基础,搞爬虫是有经验的才能做。scrapy(比较高端的)、pythonwebquest(超简单)、requests(比较麻烦)都挺简单,高级一点的requests2(比较麻烦)pythonweb(很大概率不会有人给你做好)。正则表达式,reresponse抓包(不能做任何存储)。
jsbom(可以抓form表单),scrapy封装的可以选择性的解决一些小问题,requests封装的一些问题大多都是封装代码的。scrapy爬虫框架结构,注意面向对象的思想,需要在线编译就不要使用这个了。scrapy针对不同级别的网站解决了很多场景,不一定java编程过程中解决。
最近也在找爬虫的笔记有知道的请大大们补充下
已经在学了
我一个搬砖大叔还来折腾这个问题了,
我也是大学生
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-25 00:38
最近有朋友在做OJ题库,所以做了个小爬虫,导出了题库列表来看看!
目标:浙江大学题库
工具:python3.6、请求库、lxml库、pycharm
思路:先在网页上找到题库的位置
然后我们点击第一页和后面几页,看看url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的没变。这使得构建循环变得容易。我们先看一下title的title和Id以及url在源码中的位置。
是不是很明显a标签的属性里面有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath来抓取td标签,然后匹配 输出url和title,把url剪出来写出id(我这里偷懒了,别去上面td单独抢id了),然后写在字典里方便查看. 代码如下:
20多行代码全部搞定,运行结果如下:
所有当地人都在不到10秒的时间内被抓获。当然这里注意不要重复运行,很有可能IP会被封!
将txt文件中的内容复制到在线解析json的网页中,查看结果
完美介绍~!当然,如果你有兴趣,可以到话题的url去抓取话题,这个可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很有效的,欢迎大家跟我学python! 查看全部
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
最近有朋友在做OJ题库,所以做了个小爬虫,导出了题库列表来看看!
目标:浙江大学题库
工具:python3.6、请求库、lxml库、pycharm
思路:先在网页上找到题库的位置
然后我们点击第一页和后面几页,看看url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的没变。这使得构建循环变得容易。我们先看一下title的title和Id以及url在源码中的位置。
是不是很明显a标签的属性里面有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath来抓取td标签,然后匹配 输出url和title,把url剪出来写出id(我这里偷懒了,别去上面td单独抢id了),然后写在字典里方便查看. 代码如下:
20多行代码全部搞定,运行结果如下:
所有当地人都在不到10秒的时间内被抓获。当然这里注意不要重复运行,很有可能IP会被封!
将txt文件中的内容复制到在线解析json的网页中,查看结果
完美介绍~!当然,如果你有兴趣,可以到话题的url去抓取话题,这个可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很有效的,欢迎大家跟我学python!
网页 抓取 innertext 试题(URL筛选小工具错误OnError()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-10-22 18:04
网址
这个VBS用于过滤掉本地网页中的URL,并保存到一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他用途。
使用方法:将以下代码另存为jb51.vbs,然后将你本地保存的htm页面,拖放这个vbs。
代码如下:
'备注:URL过滤小部件
'防止错误
出错时继续下一步
'vbs 代码开始------------------------------------------- ---
昏暗的 p,s,re
如果 Wscript.Arguments.Count=0 那么
Msgbox "请将网页拖到该程序的图标上!",,"提示"
Wscript.退出
如果结束
对于 i = 0 到 Wscript.Arguments.Count-1
p=Wscript.Arguments(i)
使用 CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"s)
s=""
对于比赛中的每场比赛
s=s & "" & Match.Value & "
”
下一步
re.Pattern="&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "的 URLs.html",2
.关闭
结尾
下一步
Msgbox "URL 列表已生成!",,"成功"
' vbs 代码结束------------------------------------------- - --- 查看全部
网页 抓取 innertext 试题(URL筛选小工具错误OnError()())
网址
这个VBS用于过滤掉本地网页中的URL,并保存到一个新的网页文件中。当然,只要改变里面的正则表达式,就可以用于其他用途。
使用方法:将以下代码另存为jb51.vbs,然后将你本地保存的htm页面,拖放这个vbs。
代码如下:
'备注:URL过滤小部件
'防止错误
出错时继续下一步
'vbs 代码开始------------------------------------------- ---
昏暗的 p,s,re
如果 Wscript.Arguments.Count=0 那么
Msgbox "请将网页拖到该程序的图标上!",,"提示"
Wscript.退出
如果结束
对于 i = 0 到 Wscript.Arguments.Count-1
p=Wscript.Arguments(i)
使用 CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"s)
s=""
对于比赛中的每场比赛
s=s & "" & Match.Value & "
”
下一步
re.Pattern="&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "的 URLs.html",2
.关闭
结尾
下一步
Msgbox "URL 列表已生成!",,"成功"
' vbs 代码结束------------------------------------------- - ---
网页 抓取 innertext 试题(网页抓取innertext试题中心,网页源码?用各大抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-19 09:06
网页抓取innertext试题中心,
网页源码?用各大抓包工具,打开url获取数据,导出也有sqlite.xml,csv,xmlstring,支持一些特殊类型的数据。
显然不是直接获取网页源码然后转换成html然后识别内容。不是很适合你。你想拿到百度的手机相册,我来告诉你。如果你可以看,应该是js的触发事件了;看不到,说明页面内嵌网页内容;所以你需要一套可以浏览一小段源码的方法;随便拿;百度的源码是js的,所以你需要:能搜索能缓存能脱页能截图能转换为txt能直接下载的程序/软件如果要拿到源码的,一定要说明页面的什么情况、加密相关问题。
这个应该是通过爬虫技术,抓取网页内容然后识别出文本出来。题主是要知道比较详细的源码数据么?那必须要有数据结构支持。
分析网页,截取一部分或者全部内容,用浏览器内置浏览器工具,比如chrome。或者用爬虫爬取,
特征码,是抓取报文数据的特征化标志,可根据用户查询和会话信息判断用户查询或会话属性。目前有些网站采用的是穷举法,将每一个参数都穷举出来,穷举规则随机性大,
不邀自来。我认为。如果是查看网页,可以先分析网页源代码,分析网页报文(包括协议/返回值/dom信息)。然后对这些信息进行一个匹配,获取目标页面。或者对网页源代码中的某一字段进行匹配,获取一个可能的html页面。(如果不能截图或者识别,没办法具体回答。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题中心,网页源码?用各大抓包工具)
网页抓取innertext试题中心,
网页源码?用各大抓包工具,打开url获取数据,导出也有sqlite.xml,csv,xmlstring,支持一些特殊类型的数据。
显然不是直接获取网页源码然后转换成html然后识别内容。不是很适合你。你想拿到百度的手机相册,我来告诉你。如果你可以看,应该是js的触发事件了;看不到,说明页面内嵌网页内容;所以你需要一套可以浏览一小段源码的方法;随便拿;百度的源码是js的,所以你需要:能搜索能缓存能脱页能截图能转换为txt能直接下载的程序/软件如果要拿到源码的,一定要说明页面的什么情况、加密相关问题。
这个应该是通过爬虫技术,抓取网页内容然后识别出文本出来。题主是要知道比较详细的源码数据么?那必须要有数据结构支持。
分析网页,截取一部分或者全部内容,用浏览器内置浏览器工具,比如chrome。或者用爬虫爬取,
特征码,是抓取报文数据的特征化标志,可根据用户查询和会话信息判断用户查询或会话属性。目前有些网站采用的是穷举法,将每一个参数都穷举出来,穷举规则随机性大,
不邀自来。我认为。如果是查看网页,可以先分析网页源代码,分析网页报文(包括协议/返回值/dom信息)。然后对这些信息进行一个匹配,获取目标页面。或者对网页源代码中的某一字段进行匹配,获取一个可能的html页面。(如果不能截图或者识别,没办法具体回答。
网页 抓取 innertext 试题(网络爬虫的描述错误的是(4)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-12 00:28
以下对网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B、从万维网下载网页供搜索引擎使用,是搜索引擎的重要组成部分
C、爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
D、网络爬虫的行为与访问网站的人的行为完全不同
请帮忙给出正确答案和分析,谢谢!
查看答案
网络爬虫流程——先发送请求,然后获取网页内容,然后解析网页内容,得到更方便查看的数据结果,最后抓取相关内容。()
是的
不
查看答案
网络蜘蛛机器人是自动搜索网页的程序。()
是的
不
查看答案
()的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
A.基于登陆页面的特点
B. 基于领域概念
C. 基于目标数据模型
D、深度网络爬虫
请帮忙给出正确答案和分析,谢谢!
查看答案
以下对防爬机制的描述是错误的( )。
A.简单低级的网络爬虫,数据采集速度快,伪装程度低。如果没有反爬机制,他们可以快速抓取大量数据,甚至因为请求过多,导致网站服务器无法正常工作,影响企业业务发展
B、防爬机构也是一把双刃剑。一方面可以保护企业网站和网站的数据,但另一方面,如果防爬机制过于严格,可能会误伤到真正的用户。问
C、如果要和“网络爬虫”打架,保证误伤率极低,那会增加网站的研发成本
D、反爬机制不利于信息的自由流通,不利于网站的发展,应坚决取消
查看答案
网络爬虫沿着由网页及其超链接组成的网络爬行。每当他们到达一个网页时,他们就使用爬虫程序抓取网页,提取内容,同时提取超链接作为进一步爬行的线索。()
是的
不
查看答案
在以下有关网络浏览器的描述中,正确的是____________。
A.万维网浏览器是一个客户端程序
B. 可以在网络浏览器中下载文件
C.万维网浏览器的主要用途是查询和浏览信息
D. 使用网络浏览器打印浏览的文件
E. 使用万维网浏览器保存您刚刚访问的 WWW URL 和网页内容
查看答案
以下哪个步骤不属于采集和数据的预处理()
A.使用ETL工具将分布式异构数据源中的数据抽取到临时中间层进行清洗、转换、集成,最后加载到数据仓库或数据集市
B、使用日志采集工具将实时采集数据作为流计算系统的输入进行实时处理和分析
C、使用网络爬虫程序从互联网上爬取数据网站
D. 可视化分析结果,帮助人们更好地理解和分析数据
查看答案
主题引擎数据库的内容为()。
A.网站的手动描述结果
B. 网页人工描述结果
C、程序自动处理网站的结果
D、程序自动处理网页的结果
查看答案 查看全部
网页 抓取 innertext 试题(网络爬虫的描述错误的是(4)_光明网)
以下对网络爬虫的描述是错误的()。
A. 网络爬虫是一种自动提取网页的程序
B、从万维网下载网页供搜索引擎使用,是搜索引擎的重要组成部分
C、爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。
D、网络爬虫的行为与访问网站的人的行为完全不同
请帮忙给出正确答案和分析,谢谢!
查看答案
网络爬虫流程——先发送请求,然后获取网页内容,然后解析网页内容,得到更方便查看的数据结果,最后抓取相关内容。()
是的
不
查看答案
网络蜘蛛机器人是自动搜索网页的程序。()
是的
不
查看答案
()的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
A.基于登陆页面的特点
B. 基于领域概念
C. 基于目标数据模型
D、深度网络爬虫
请帮忙给出正确答案和分析,谢谢!
查看答案
以下对防爬机制的描述是错误的( )。
A.简单低级的网络爬虫,数据采集速度快,伪装程度低。如果没有反爬机制,他们可以快速抓取大量数据,甚至因为请求过多,导致网站服务器无法正常工作,影响企业业务发展
B、防爬机构也是一把双刃剑。一方面可以保护企业网站和网站的数据,但另一方面,如果防爬机制过于严格,可能会误伤到真正的用户。问
C、如果要和“网络爬虫”打架,保证误伤率极低,那会增加网站的研发成本
D、反爬机制不利于信息的自由流通,不利于网站的发展,应坚决取消
查看答案
网络爬虫沿着由网页及其超链接组成的网络爬行。每当他们到达一个网页时,他们就使用爬虫程序抓取网页,提取内容,同时提取超链接作为进一步爬行的线索。()
是的
不
查看答案
在以下有关网络浏览器的描述中,正确的是____________。
A.万维网浏览器是一个客户端程序
B. 可以在网络浏览器中下载文件
C.万维网浏览器的主要用途是查询和浏览信息
D. 使用网络浏览器打印浏览的文件
E. 使用万维网浏览器保存您刚刚访问的 WWW URL 和网页内容
查看答案
以下哪个步骤不属于采集和数据的预处理()
A.使用ETL工具将分布式异构数据源中的数据抽取到临时中间层进行清洗、转换、集成,最后加载到数据仓库或数据集市
B、使用日志采集工具将实时采集数据作为流计算系统的输入进行实时处理和分析
C、使用网络爬虫程序从互联网上爬取数据网站
D. 可视化分析结果,帮助人们更好地理解和分析数据
查看答案
主题引擎数据库的内容为()。
A.网站的手动描述结果
B. 网页人工描述结果
C、程序自动处理网站的结果
D、程序自动处理网页的结果
查看答案
网页 抓取 innertext 试题(window对象模型-上海怡健医学培训学校)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-12 00:28
1) 在DOM对象模型中,直接父对象是根对象窗口的对象不包括(d)。(选择一项) a)historyb)documentc)locationd)form2) 以下选项中,(d)为客户端无法看到的正确JSP注释。(选择一项)a)b)c)d)3)分析下面的JavaScript代码段,输出结果为(b)。(选择一项) var mystring="我是学生";a=mystring.charAt(9);document.write(a);a)I an a stb)uc)udentd)t4)在HTML页面中,将样式设置按钮的背景图片定义为images文件夹中的background1.jpg文件,需要给url(images/background1.@)赋值CSS(d)属性>.jpg)。(选择一项) a)widthb)heightc)background-colord)background-image5) 在 HTML 中,运行以下JavaScript代码,弹出提示框中显示的消息内容为(b)。(选择一项) a)2b)2.5c)32/2d)166) 在下面的HTML代码中,(b)可以显示一个按钮,点击按钮时弹出-向上显示“OK” 消息框如下图所示。
(选择一项) a)b)c)d)7) 在HTML中,下面的CSS属性对应的是HTML标签中style对象的属性,错误(bc)。(选择两项) a) background-image 和backgroundImage b) bordr-color 和color c) font-size and sized) text-align 和textAlign8) 在网页上做浮动广告时,需要一个函数定义实现浮动广告层随滚动条滚动的效果。如果已经定义了名为 move 的函数,那么最后要做的是 (a)。(选择一项) a) 捕获窗口的window.onscroll 事件,调用move 函数 b) 捕获文档的document.onscroll 事件,调用move 函数 c) 捕获窗口的window.onload 事件,调用move 函数move 函数 d) 捕获文档 .onload 事件的文档,调用move函数9) 在以下选项中,关于JavaScript浏览器对象中的history对象的说法是错误的(d)。(选择一项) a) history 对象记录了用户在浏览器中访问过的 URL b) history 对象的父对象是 JavaScript 浏览器对象 window 的根对象 c) 可以实现应用 history 对象的方法在 IE 浏览器中“前进”和“后退”按钮的功能 d) 应用历史对象的 back() 方法相当于“前进”按钮,而 forward() 方法相当于“后退” 10) 收录在HTML页面如下图 实现打开页面时弹出对话框显示“张三”,
(选择一项) a)studentList[0][0]b)studentList[0]['张三']c)studentList['一班']['张三']d)studentList['一班'] [ 0]11)分析HTML页面代码如下图。为了实现刷新并始终每1秒显示一次,下划线处应该添加的代码是(b)。(选择一项) a)var myTime = setTimeout("showTime()",1);b)var myTime = setTimeout("showTime()",1000);c)var myTime = setTimeout ( 1);d)var myTime = setTimeout(1000);12)在HTML文档的树状结构中,(a)标签的根节点是位于顶部的文档结构体(Choose one item) a) b) d) 和52) javascript中数组的(C)属性用于返回数组中元素的个数。(选择一个) a)firstb)shiftc)lengthd)push 查看全部
网页 抓取 innertext 试题(window对象模型-上海怡健医学培训学校)
1) 在DOM对象模型中,直接父对象是根对象窗口的对象不包括(d)。(选择一项) a)historyb)documentc)locationd)form2) 以下选项中,(d)为客户端无法看到的正确JSP注释。(选择一项)a)b)c)d)3)分析下面的JavaScript代码段,输出结果为(b)。(选择一项) var mystring="我是学生";a=mystring.charAt(9);document.write(a);a)I an a stb)uc)udentd)t4)在HTML页面中,将样式设置按钮的背景图片定义为images文件夹中的background1.jpg文件,需要给url(images/background1.@)赋值CSS(d)属性>.jpg)。(选择一项) a)widthb)heightc)background-colord)background-image5) 在 HTML 中,运行以下JavaScript代码,弹出提示框中显示的消息内容为(b)。(选择一项) a)2b)2.5c)32/2d)166) 在下面的HTML代码中,(b)可以显示一个按钮,点击按钮时弹出-向上显示“OK” 消息框如下图所示。
(选择一项) a)b)c)d)7) 在HTML中,下面的CSS属性对应的是HTML标签中style对象的属性,错误(bc)。(选择两项) a) background-image 和backgroundImage b) bordr-color 和color c) font-size and sized) text-align 和textAlign8) 在网页上做浮动广告时,需要一个函数定义实现浮动广告层随滚动条滚动的效果。如果已经定义了名为 move 的函数,那么最后要做的是 (a)。(选择一项) a) 捕获窗口的window.onscroll 事件,调用move 函数 b) 捕获文档的document.onscroll 事件,调用move 函数 c) 捕获窗口的window.onload 事件,调用move 函数move 函数 d) 捕获文档 .onload 事件的文档,调用move函数9) 在以下选项中,关于JavaScript浏览器对象中的history对象的说法是错误的(d)。(选择一项) a) history 对象记录了用户在浏览器中访问过的 URL b) history 对象的父对象是 JavaScript 浏览器对象 window 的根对象 c) 可以实现应用 history 对象的方法在 IE 浏览器中“前进”和“后退”按钮的功能 d) 应用历史对象的 back() 方法相当于“前进”按钮,而 forward() 方法相当于“后退” 10) 收录在HTML页面如下图 实现打开页面时弹出对话框显示“张三”,
(选择一项) a)studentList[0][0]b)studentList[0]['张三']c)studentList['一班']['张三']d)studentList['一班'] [ 0]11)分析HTML页面代码如下图。为了实现刷新并始终每1秒显示一次,下划线处应该添加的代码是(b)。(选择一项) a)var myTime = setTimeout("showTime()",1);b)var myTime = setTimeout("showTime()",1000);c)var myTime = setTimeout ( 1);d)var myTime = setTimeout(1000);12)在HTML文档的树状结构中,(a)标签的根节点是位于顶部的文档结构体(Choose one item) a) b) d) 和52) javascript中数组的(C)属性用于返回数组中元素的个数。(选择一个) a)firstb)shiftc)lengthd)push
网页 抓取 innertext 试题(你还真拿全国大学生数学竞赛的参赛作品做了可视化项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-12 00:01
网页抓取innertext试题截图获取微信回复全国大学生数学竞赛获取2019年全国大学生数学竞赛预赛答案
所以说,我基本只看知乎。
你还真拿全国大学生数学竞赛的参赛作品做了可视化项目呀?没有以后会不会见?我猜会的
什么网站,以及他的参赛者在哪?还有讲解视频。一个网站要内容丰富,
好希望知乎上能看到这个作品!
看完别忘了给你们作品点个赞啊~
你要给出来你参赛的作品,我才能看是什么网站。
你们参赛作品都找个门户网站去参赛?
网页抓取不就是爬虫么,scrapy,selenium,requests,flask,echarts,splash,bootstrap之类的可以。为什么不能用别的来做?知乎上一个外网的抓取作品,抓下来的内容还不如python的呢。
和你参赛作品重合吗
可以不做网页提取嘛,用webpy+webdriver就不错啦。
针对这个问题,我帮你简单分析了一下你参赛作品的内容,现在知乎上不是有很多参赛作品嘛,你就找和你相关的作品看一下就好了。
有个免费的平台有这样的作品,
全国大学生数学竞赛中山市赛时间:2019-3-28城市:广州面向群体:本地大学生参赛作品:参赛报名表(点击阅读原文)
外国数学竞赛也有很多可视化,比如数字分析技术竞赛,这个就是数据分析内容,是和你不同的主题。我是做数据分析,也是围绕分析这个主题。 查看全部
网页 抓取 innertext 试题(你还真拿全国大学生数学竞赛的参赛作品做了可视化项目)
网页抓取innertext试题截图获取微信回复全国大学生数学竞赛获取2019年全国大学生数学竞赛预赛答案
所以说,我基本只看知乎。
你还真拿全国大学生数学竞赛的参赛作品做了可视化项目呀?没有以后会不会见?我猜会的
什么网站,以及他的参赛者在哪?还有讲解视频。一个网站要内容丰富,
好希望知乎上能看到这个作品!
看完别忘了给你们作品点个赞啊~
你要给出来你参赛的作品,我才能看是什么网站。
你们参赛作品都找个门户网站去参赛?
网页抓取不就是爬虫么,scrapy,selenium,requests,flask,echarts,splash,bootstrap之类的可以。为什么不能用别的来做?知乎上一个外网的抓取作品,抓下来的内容还不如python的呢。
和你参赛作品重合吗
可以不做网页提取嘛,用webpy+webdriver就不错啦。
针对这个问题,我帮你简单分析了一下你参赛作品的内容,现在知乎上不是有很多参赛作品嘛,你就找和你相关的作品看一下就好了。
有个免费的平台有这样的作品,
全国大学生数学竞赛中山市赛时间:2019-3-28城市:广州面向群体:本地大学生参赛作品:参赛报名表(点击阅读原文)
外国数学竞赛也有很多可视化,比如数字分析技术竞赛,这个就是数据分析内容,是和你不同的主题。我是做数据分析,也是围绕分析这个主题。
网页 抓取 innertext 试题(网页抓取innertext试题分析;爬虫服务端学习java吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-11 16:42
网页抓取innertext试题分析;
爬虫就是浏览器抓取网页内容到自己的数据库中。现在的公司也有一部分的任务就是把爬取到的信息做各种的处理加工,做成md5哈希表这种,交给数据库或者其他解析器解析,这样写多了,除了简单的数据库查询,其他类型的处理都会比较熟练。
学数据结构搞点算法数据库什么的。
c语言要掌握,然后java网站端。python服务端。
学习java爬虫吧
学会java,这么些都不是事。我正在学,比网站开发容易,而且上手快。
讲讲我的经历,计算机的要学会网页程序开发,数据库基础,网络基础,数据结构,算法等,这些大多要看平时的项目了,记住一点,如果你在大学是学计算机的,不要让自己拘泥于技术,业余时间多学点其他领域的知识,
边用边学,往届同学的经验都是,交给新人去做项目,前端做完就用js接着做网页或者服务器,
下载自己面试官想要的东西,总结一下,然后边做边学,最好有亲身实战的经验,这样收获也更大。不管是学习html,css还是数据库...。
c#,汇编,php,
最近在学爬虫,确实是现在比较热门的方向,大量的网页涉及到爬虫接口,ajax,还有大量网站都是使用https来协议的。做网站,sql,调用接口是基础。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题分析;爬虫服务端学习java吧)
网页抓取innertext试题分析;
爬虫就是浏览器抓取网页内容到自己的数据库中。现在的公司也有一部分的任务就是把爬取到的信息做各种的处理加工,做成md5哈希表这种,交给数据库或者其他解析器解析,这样写多了,除了简单的数据库查询,其他类型的处理都会比较熟练。
学数据结构搞点算法数据库什么的。
c语言要掌握,然后java网站端。python服务端。
学习java爬虫吧
学会java,这么些都不是事。我正在学,比网站开发容易,而且上手快。
讲讲我的经历,计算机的要学会网页程序开发,数据库基础,网络基础,数据结构,算法等,这些大多要看平时的项目了,记住一点,如果你在大学是学计算机的,不要让自己拘泥于技术,业余时间多学点其他领域的知识,
边用边学,往届同学的经验都是,交给新人去做项目,前端做完就用js接着做网页或者服务器,
下载自己面试官想要的东西,总结一下,然后边做边学,最好有亲身实战的经验,这样收获也更大。不管是学习html,css还是数据库...。
c#,汇编,php,
最近在学爬虫,确实是现在比较热门的方向,大量的网页涉及到爬虫接口,ajax,还有大量网站都是使用https来协议的。做网站,sql,调用接口是基础。
网页 抓取 innertext 试题(【每日一题】网页设计与制作》期末考试试题及答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-08 11:22
“网页设计与制作”期末考试题
一、单选题(这个大题有30个子题,每个子题2分,共60分)
1、目前互联网上使用最广泛的服务是().
A、FTP 服务 B、WWW 服务 C、Telnet 服务 D、Gopher 服务
2、域名系统DNS的含义是().
A、直接网络系统 B、域名服务 C、动态网络系统 D、分布式网络服务
3、主机域名中心。恩布教育。 cn由四个子域组成,其中()子域代表国家代码。
A、中心 B、nbu C、edu D、cn
4、 阅读港澳台网站的页面文档时,正确的文本编码格式应该是()。
A、GB 代码 B、Unicode 代码 C、BIG5 代码 D、HZ 代码
5、当标签的TYPE属性值为()时,表示可以选择多个项目的复选框。
A、文本 B、密码 C、收音机 D、复选框
6、 为了标识一个 HTML 文件的开头,应该使用的 HTML 标签是 ().
A、B、C、D、
7、 客户端网页脚本语言中最常用的语言是().
A、JavaScript B、VB C、Perl D、ASP
8、在HTML中,标签的Size属性的最大值可以是().
A, 5 B, 6 C, 7 D, 8
9、 在 HTML 中,单元格的标记是 ().
A、B、C、D、
10、在DHTML中将整个文档的每个元素都当作一个对象的技术是().
A、HTML B、CSS C、DOM D、Script(脚本语言)
11、 以下不是CSS插入形式()。
A、索引 B、内联 C、嵌入式 D、外部
12、 网页上最常用的两种图片格式是 ().
A、JPEG 和 GIF B、JPEG 和 PSD C、GIF 和 BMP D、BMP 和 PSD
13、 如果站点服务器支持安全套接字层 (SSL),则连接到安全站点的所有 URL 都以 () 开头。 查看全部
网页 抓取 innertext 试题(【每日一题】网页设计与制作》期末考试试题及答案)
“网页设计与制作”期末考试题
一、单选题(这个大题有30个子题,每个子题2分,共60分)
1、目前互联网上使用最广泛的服务是().
A、FTP 服务 B、WWW 服务 C、Telnet 服务 D、Gopher 服务
2、域名系统DNS的含义是().
A、直接网络系统 B、域名服务 C、动态网络系统 D、分布式网络服务
3、主机域名中心。恩布教育。 cn由四个子域组成,其中()子域代表国家代码。
A、中心 B、nbu C、edu D、cn
4、 阅读港澳台网站的页面文档时,正确的文本编码格式应该是()。
A、GB 代码 B、Unicode 代码 C、BIG5 代码 D、HZ 代码
5、当标签的TYPE属性值为()时,表示可以选择多个项目的复选框。
A、文本 B、密码 C、收音机 D、复选框
6、 为了标识一个 HTML 文件的开头,应该使用的 HTML 标签是 ().
A、B、C、D、
7、 客户端网页脚本语言中最常用的语言是().
A、JavaScript B、VB C、Perl D、ASP
8、在HTML中,标签的Size属性的最大值可以是().
A, 5 B, 6 C, 7 D, 8
9、 在 HTML 中,单元格的标记是 ().
A、B、C、D、
10、在DHTML中将整个文档的每个元素都当作一个对象的技术是().
A、HTML B、CSS C、DOM D、Script(脚本语言)
11、 以下不是CSS插入形式()。
A、索引 B、内联 C、嵌入式 D、外部
12、 网页上最常用的两种图片格式是 ().
A、JPEG 和 GIF B、JPEG 和 PSD C、GIF 和 BMP D、BMP 和 PSD
13、 如果站点服务器支持安全套接字层 (SSL),则连接到安全站点的所有 URL 都以 () 开头。
网页 抓取 innertext 试题(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-05 11:07
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/即搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:
在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按照1→3→2→6→5或4→3→2→6→5的顺序逐步学习更多。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。 查看全部
网页 抓取 innertext 试题(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/即搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:
在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按照1→3→2→6→5或4→3→2→6→5的顺序逐步学习更多。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。
网页 抓取 innertext 试题(网页抓取innertext试题分析(图)发布第四季网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-03 12:02
网页抓取innertext试题分析这一篇我们来看看w3cschool发布的第四季网页,这是首次从全站的互联网抓取指定用户编写的代码并保存(复制)于本地。并且按照用户的反馈(包括“怎么样”以及“我的学习成果“)进行提升,直到最终实现目标项目,当然我也顺便找到了leetcode中一道很简单的题目,大家觉得正解应该如何呢?欢迎留言。
安装vim&vc可以通过如下命令进行安装:$node-v$npminstallwget是linux上的命令,只能在linux上才能用:$sudonpminstall-gvim编写代码一般是一个,过长的时候使用两个编写就行。vue(viewviewmode)-设置view的mode为view-mode.注意view-mode的每个mode的key必须只能是大写!从action元素内部获取javascript参数首先,我们来新建一个element-ui文件夹用于存放自己编写的dom节点.element-ui.js文件夹所包含的是vue代码,其中vue和axios是我们经常要使用的模块。
config.js代码定义了所有以浏览器的activex控件为基础修改这些浏览器控件的方法。progress.js只写routes的参数即可,vue-loader是和jsx共存的,如果找不到可能需要自己编写。constviewdom=require('./documents/viewdom')constwebpack=require('webpack')constentry='./public/element.vue'constpath=require('path')path.resolve(webpack.prod.url(config.js),path.resolve(path.resolve(path.join(path.join(entry,'element-ui.js')webpack配置config.js代码文件包含了我们平时在写config.js文件所需要用到的工具类和方法,我们一起看看。
app.vuetype:app.vueconfig:配置文件,注意:部分app配置文件配置的package.json中缺少loaders.js一些不太常用的jsx模块就不列举了。plugins:插件文件entry:我们要抓取的文件的目录/view/element-ui,或者我们要抓取的其他的controller的bundle文件都可以在entry文件夹中找到template:我们要抓取的网页代码也可以放到template文件夹下的template。
我们先写一个简单的效果:import{getitemview,getitemchanged}from'./getitemview'exportdefault{name:'ui',description:'findelementview',page:{title:'viewselected.',//theviewthescopedbodyandtheresulthaswellredirected'orientation':'inward',//theviewinview.g。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题分析(图)发布第四季网页)
网页抓取innertext试题分析这一篇我们来看看w3cschool发布的第四季网页,这是首次从全站的互联网抓取指定用户编写的代码并保存(复制)于本地。并且按照用户的反馈(包括“怎么样”以及“我的学习成果“)进行提升,直到最终实现目标项目,当然我也顺便找到了leetcode中一道很简单的题目,大家觉得正解应该如何呢?欢迎留言。
安装vim&vc可以通过如下命令进行安装:$node-v$npminstallwget是linux上的命令,只能在linux上才能用:$sudonpminstall-gvim编写代码一般是一个,过长的时候使用两个编写就行。vue(viewviewmode)-设置view的mode为view-mode.注意view-mode的每个mode的key必须只能是大写!从action元素内部获取javascript参数首先,我们来新建一个element-ui文件夹用于存放自己编写的dom节点.element-ui.js文件夹所包含的是vue代码,其中vue和axios是我们经常要使用的模块。
config.js代码定义了所有以浏览器的activex控件为基础修改这些浏览器控件的方法。progress.js只写routes的参数即可,vue-loader是和jsx共存的,如果找不到可能需要自己编写。constviewdom=require('./documents/viewdom')constwebpack=require('webpack')constentry='./public/element.vue'constpath=require('path')path.resolve(webpack.prod.url(config.js),path.resolve(path.resolve(path.join(path.join(entry,'element-ui.js')webpack配置config.js代码文件包含了我们平时在写config.js文件所需要用到的工具类和方法,我们一起看看。
app.vuetype:app.vueconfig:配置文件,注意:部分app配置文件配置的package.json中缺少loaders.js一些不太常用的jsx模块就不列举了。plugins:插件文件entry:我们要抓取的文件的目录/view/element-ui,或者我们要抓取的其他的controller的bundle文件都可以在entry文件夹中找到template:我们要抓取的网页代码也可以放到template文件夹下的template。
我们先写一个简单的效果:import{getitemview,getitemchanged}from'./getitemview'exportdefault{name:'ui',description:'findelementview',page:{title:'viewselected.',//theviewthescopedbodyandtheresulthaswellredirected'orientation':'inward',//theviewinview.g。
网页 抓取 innertext 试题(如何能在结构中表现出双引号不同的意义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-09-30 21:03
网页抓取innertext试题练习:一个单引号一个双引号都是单引号(标准单引号),那么如何能在html结构中表现出双引号不同的意义呢?网页抓取innertext要讲解的是第二个问题:大部分的html中,用户输入的字符都是通过script标签来进行修改的,而在script标签中字符的“内容”通常都是以双引号包裹,那么我们能不能使用单引号来标识script标签呢?大家都知道浏览器引擎中对字符串转换为unicode字符也是采用相同的办法。
那么我们可以知道这样的方法是不可行的。那么如何能够让unicode中的字符可以在html中显示出来呢?。
不能,至少目前不能。
原因之一是,你必须让浏览器认为是单引号,而且你必须为每个单引号都对应单独的字符,也就是一个单引号对应一个字符,因此你必须找到一种简单的方法区分双引号和单引号。最好是,如果可能的话,一个单引号会标注它是单引号。实际上,这样大部分字符都应该是双引号,只是不可能。之所以找不到,无非是太懒了。
可以把这个例子换成两个同样是两个相同的双引号,前面加一个逗号来区分单引号和双引号,这样也可以做到区分,但为了测试html的兼容性,题主可以在@杨枣丫下面写上input("text"),记得缩进和标签和单引号一样做法:前面加",","","",":"//char()要分类处理*{"#"+++"""#"++"""{"@"++"""@"++"""{"*"++"*"}"]":"{"+++"":"{"@"++"""{"@"++"""{"@"++}"}"}":":":":",","]":"{"*"++",":","","",""":"{"*"+",":","","",""":"{"*"+",":","","",""":",""":",""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":"。 查看全部
网页 抓取 innertext 试题(如何能在结构中表现出双引号不同的意义)
网页抓取innertext试题练习:一个单引号一个双引号都是单引号(标准单引号),那么如何能在html结构中表现出双引号不同的意义呢?网页抓取innertext要讲解的是第二个问题:大部分的html中,用户输入的字符都是通过script标签来进行修改的,而在script标签中字符的“内容”通常都是以双引号包裹,那么我们能不能使用单引号来标识script标签呢?大家都知道浏览器引擎中对字符串转换为unicode字符也是采用相同的办法。
那么我们可以知道这样的方法是不可行的。那么如何能够让unicode中的字符可以在html中显示出来呢?。
不能,至少目前不能。
原因之一是,你必须让浏览器认为是单引号,而且你必须为每个单引号都对应单独的字符,也就是一个单引号对应一个字符,因此你必须找到一种简单的方法区分双引号和单引号。最好是,如果可能的话,一个单引号会标注它是单引号。实际上,这样大部分字符都应该是双引号,只是不可能。之所以找不到,无非是太懒了。
可以把这个例子换成两个同样是两个相同的双引号,前面加一个逗号来区分单引号和双引号,这样也可以做到区分,但为了测试html的兼容性,题主可以在@杨枣丫下面写上input("text"),记得缩进和标签和单引号一样做法:前面加",","","",":"//char()要分类处理*{"#"+++"""#"++"""{"@"++"""@"++"""{"*"++"*"}"]":"{"+++"":"{"@"++"""{"@"++"""{"@"++}"}"}":":":":",","]":"{"*"++",":","","",""":"{"*"+",":","","",""":"{"*"+",":","","",""":",""":",""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":""":"。
网页 抓取 innertext 试题(知乎专栏如何将含有免费账号的json文件快速合并到ss客户端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-28 12:05
我可以使用YouTube在整个过程中顺利跟踪柯洁的alphago直播,这取决于这个方案
免费帐户信息SSR-URL的解码
入门:使用python在网页上获取免费帐户(一)-知乎列)
autoss开源项目简介
入门:使用python在网页上获取免费帐户(二)-知乎列)
ssa.py程序的运行效果
入门:使用python在网页上获取免费帐户(三)-知乎列)
Ssa.py自动测试免费帐户程序的来源
入门:使用python在网页上获取免费帐户(四)-知乎列)
update_config.py的使用示例
入门:使用python在网页上获取免费帐户(五)-知乎列)
读取和写入gui-config.json并重新启动shad0ws0cks客户端
入门:使用python在网页上获取免费帐户(六)-知乎列)
获取免费帐号、测试免费帐号和分发免费帐号的完整方案
入门:使用python在网页上获取免费帐户(七)-知乎列)
Update_config.py免费帐户脚本自动更新简介
入门:使用python在网页上获取免费帐户(八)-知乎列)
客户端shad0ws0cksx_ngon Mac OS X使用plist格式配置文件而不是JSON格式。我可以用脚本自动更新帐户信息吗
入门:使用python在网页上获取免费帐户(九)-知乎列)
如何快速将收录免费帐户的JSON文件合并到当前SS客户端的gui-config.JSON配置文件中
入门:使用python在网页上获取免费帐户(十)-知乎列)
使用update_config.pyc脚本,您需要满足条件和《软件安装指南》
入门:使用python(a)-知乎列在网页上获取免费帐户
从Mac OS X shad0ws0cks客户端的plist配置文件转换的JSON文件太长了
入门:使用python(b)-知乎列在网页上获取免费帐户
update_config.pyc总体方案介绍
入门:使用python(c)-知乎列在网页上获取免费帐户
使用autoss.py获得更多免费帐户
入门:使用python(d)-知乎列在网页上获取免费帐户
无需编写代码即可生成二维代码
和生成二维码-知乎列 查看全部
网页 抓取 innertext 试题(知乎专栏如何将含有免费账号的json文件快速合并到ss客户端)
我可以使用YouTube在整个过程中顺利跟踪柯洁的alphago直播,这取决于这个方案
免费帐户信息SSR-URL的解码
入门:使用python在网页上获取免费帐户(一)-知乎列)
autoss开源项目简介
入门:使用python在网页上获取免费帐户(二)-知乎列)
ssa.py程序的运行效果
入门:使用python在网页上获取免费帐户(三)-知乎列)
Ssa.py自动测试免费帐户程序的来源
入门:使用python在网页上获取免费帐户(四)-知乎列)
update_config.py的使用示例
入门:使用python在网页上获取免费帐户(五)-知乎列)
读取和写入gui-config.json并重新启动shad0ws0cks客户端
入门:使用python在网页上获取免费帐户(六)-知乎列)
获取免费帐号、测试免费帐号和分发免费帐号的完整方案
入门:使用python在网页上获取免费帐户(七)-知乎列)
Update_config.py免费帐户脚本自动更新简介
入门:使用python在网页上获取免费帐户(八)-知乎列)
客户端shad0ws0cksx_ngon Mac OS X使用plist格式配置文件而不是JSON格式。我可以用脚本自动更新帐户信息吗
入门:使用python在网页上获取免费帐户(九)-知乎列)
如何快速将收录免费帐户的JSON文件合并到当前SS客户端的gui-config.JSON配置文件中
入门:使用python在网页上获取免费帐户(十)-知乎列)
使用update_config.pyc脚本,您需要满足条件和《软件安装指南》
入门:使用python(a)-知乎列在网页上获取免费帐户
从Mac OS X shad0ws0cks客户端的plist配置文件转换的JSON文件太长了
入门:使用python(b)-知乎列在网页上获取免费帐户
update_config.pyc总体方案介绍
入门:使用python(c)-知乎列在网页上获取免费帐户
使用autoss.py获得更多免费帐户
入门:使用python(d)-知乎列在网页上获取免费帐户
无需编写代码即可生成二维代码
和生成二维码-知乎列
网页 抓取 innertext 试题(网页的标题(title),一下获取方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-09-27 16:14
网页的标题通常由HTML文件的标记决定。如果您想获取网页的标题,实际上是获取标签中的内容。以下文章将向您介绍采集方法,希望对您有所帮助
方法1:使用title属性
title属性返回当前文档的标题(HTML title元素中的文本)
语法:
document.title
示例:使用document.title属性获取HTML文档的标题
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法2:使用文档。GetElementsByTagName()方法
getElementsByTagName()方法返回具有指定标记名的对象集合。方法返回元素的顺序是它们在文档中的顺序
语法:
document.getElementsByTagName(tagname)
示例:文档。Getelementsbytagname()方法首先按标记名选择标题,然后获取索引0处的元素以获取文档的标题
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title!
上面是JavaScript如何获取网页标题的?欲了解更多详情,请关注其他相关文章 查看全部
网页 抓取 innertext 试题(网页的标题(title),一下获取方法,你知道吗?)
网页的标题通常由HTML文件的标记决定。如果您想获取网页的标题,实际上是获取标签中的内容。以下文章将向您介绍采集方法,希望对您有所帮助
方法1:使用title属性
title属性返回当前文档的标题(HTML title元素中的文本)
语法:
document.title
示例:使用document.title属性获取HTML文档的标题
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法2:使用文档。GetElementsByTagName()方法
getElementsByTagName()方法返回具有指定标记名的对象集合。方法返回元素的顺序是它们在文档中的顺序
语法:
document.getElementsByTagName(tagname)
示例:文档。Getelementsbytagname()方法首先按标记名选择标题,然后获取索引0处的元素以获取文档的标题
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title!
上面是JavaScript如何获取网页标题的?欲了解更多详情,请关注其他相关文章
网页 抓取 innertext 试题( requests的安装方式.3.1-3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-26 21:00
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br /> <br /> 在Test.py中输入:
import requests</p>
此时,请求将报告一条红线。这时候我们将光标对准requests,按快捷键:alt+enter,pycharm会给出解决方法。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样的时候,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents")
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】 查看全部
网页 抓取 innertext 试题(
requests的安装方式.3.1-3)
<p>都说python爬网页数据方便,我们今天就来试试,python爬取数据到底有多方便
简介
爬取数据,基本都是通过网页的URL得到这个网页的源代码,根据源代码筛选出需要的信息
准备
IDE:pyCharm <br /> 库:requests、lxml
大概介绍一下,这俩库主要为我们做什么服务的 <br /> requests:获取网页源代码 <br /> lxml:得到网页源代码中的指定数据
言简意赅有没有 ^_^
搭建环境
这里的搭建环境,可不是搭建python的开发环境,这里的搭建环境是指,我们使用pycharm新建一个python项目,然后弄好requests和lxml <br /> 新建一个项目: <br />
光溜溜的啥也没有,新建个src文件夹再在里面直接新建一个Test.py吧 <br />
依赖库导入 <br /> 我们不是说要使用requests吗,来吧 <br /> 由于我们使用的是pycharm,所以我们导入这两个库就会显的格外简单,如图: <br />
<br /> 在Test.py中输入: import requests</p>
此时,请求将报告一条红线。这时候我们将光标对准requests,按快捷键:alt+enter,pycharm会给出解决方法。这时候选择安装包请求,pycharm会自动为我们安装。,我们只需要稍等片刻,库就安装好了。lxml的安装方法是一样的。
安装这两个库后,编译器不会报红线
接下来进入快乐爬行时间
获取网页源代码
前面说过,requests可以让我们很容易的拿到网页的源码
以我在网页上的博客地址为例:
获取源代码:
# 获取源码
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# 打印源码
print html.text
代码就这么简单,这个html.text就是这个网址的源码
获取指定数据
现在我们有了网页的源代码,我们需要使用lxml过滤掉我们需要的信息。
这里我以我的博客列表为例
首先,我们需要分析源代码。我这里用的是chrome浏览器,所以右键查看,是这样的画面:
然后在源代码中,找到第一个
像这样?
操作太快了吧?
让我在这里解释一下。首先点击源页面右上角的箭头,然后在网页内容中选择文章标题。此时,源代码将位于此处。
这时候选中源码的title元素,右键复制,如图:
获取xpath,嘿,你知道这是什么吗?这个东西相当于一个地址。比如源代码中长图片在网页上的位置。我们不是复制粘贴过来看看长啥样吗?
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a
这里为你做一个解释:
// 定位根节点
/ 往下层寻找
提取文本内容:/text()
提取属性内容:/@xxxx
我们还没有看到这个表达式中的最后两个。以后再说吧,先放个图吧。
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a
让我们考虑一下。首先,//表示根节点,也就是说,这个//后面的东西就是根,表示只有一个
换句话说,我们需要的就在里面
然后 / 表示寻找下层。根据图片也很明显,div -> main -> div[2] -> div[1] -> h4 -> a
追踪到a之后,我想你应该能看懂了,然后我们在最后加上/text表示要提取元素的内容,所以我们最终的表达式是这样的:
//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
这个表达只针对这个网页的这个元素,是不是很难理解?
那么这个东西是如何工作的呢?
所有代码:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
print(each)
这时候每个里面的数据就是我们想要得到的数据
打印结果:
如何撸一个ArrayList
打印结果就是这个结果,我们去掉了换行符和空格
打印结果:
如何撸一个ArrayList
非常好,如果我们想获得所有博客的列表怎么办
看图看表情分析大法
表达式://*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()
其实我们很容易发现main->div[2]其实收录了所有的文章,但是我们取的是main->div[2]->div[1],也就是说我们只取了第一个就是了. 所以,其实当表达式写成这样的时候,就可以得到所有的文章
//*[@id="mainBox"]/main/div[2]/div/h4/a/text()
再次:
import requests
from lxml import etree
html = requests.get("https://blog.csdn.net/it_xf?viewmode=contents";)
# print html.text
etree_html = etree.HTML(html.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div/h4/a/text()')
for each in content:
replace = each.replace('\n', '').replace(' ', '')
if replace == '\n' or replace == '':
continue
else:
print(replace)
打印结果:
如何撸一个ArrayList
Android相机屏幕适配
Tinker关于clean后准基包消失的解决方案
Tinker使用指南
git分支的使用
如何将Androidstudio中的项目导入到第三方的git托管库中
遍历矩阵
从矩阵中取出子矩阵
AndroidStudio配置OpenCV
一步一步了解handler机制
Android常用框架
Android绘制波浪线
RxJava系列教程之线程篇(五)
RxJava系列教程之过滤篇(四)
RxJava系列教程之变换篇(三)
RxJava系列教程之创建篇(二)
RxJava系列教程之介绍篇(一)
一个例子让你彻底理解java接口回调
SharedPreferences的用法及指南
异步加载网络图片带进度
VideoView加载闪黑屏
android视频播放vitamio的简单运用
仿网易新闻分类刷新
ListView加CheckBox简单实现批量删除
Android如何高效加载大图
Android聊天界面实现方式
抽屉侧滑菜单Drawerlayout-基本使用方法
android-引导页的实现方式
Java设计模式--工厂模式的自述
javaweb学习路线
getWindow().setFlags()使用说明书
歪解Activity生命周期-----初学者彻底理解指南
很好,我们得到了所有的 文章 列表。
总结
我们使用 requests 来获取网页列表,并使用 lxml 过滤数据。可见,用python爬取网页数据真的很方便。Chrome 还直接在源代码中支持表达式 xpath。这两个库的内容肯定不止这些。此时,还有很多功能等着你去探索。对了,在写这个博客的时候,发现了一个很重要的问题:我的文章写的太少了!【逃脱】
网页 抓取 innertext 试题( 共建,学习和探索.效果演示客户端思路先理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-23 16:14
共建,学习和探索.效果演示客户端思路先理
)
近年来,许多技术博客和技术社区出现,许多技术同事开始建立自己的博客。我们可以将博客同步到不同的技术平台,但随着技术平台的增加,我们文章同步时间将越来越多,然后有一个工具快速释放博客到另一个平台?或者做它的工具,您可以直接将HTML转换为技术平台以识别“语言”直接发布?
我们都知道程序员最喜欢的写作的“语言”是Makedown,而且大多数技术社区目前都支持Makedown语法,所以只要有Makedown,我们就可以快速同步到不同的技术平台。
也许有人会说,我们写博客直接写入makedown语法?它确实可以满足需求,但缺点是我们的本地必须保存一个Makedown文件,如果博客内容涉及图片,我们仍然需要维护一个IMG目录,以便每次有折扣文章文章或者这将是非常麻烦的,因此我们开发了一个工具,它会自动攀升HTML,一键入Makedown。通过这种方式,我们可以“肆无忌惮”发布博客。
你会收获
github地址作者将把它附加到文章的末尾,有兴趣的朋友可以在一起,学习和探索。
效果演示
客户思考
我想:
为什么选择翻天下
客户端中最重要的一步是MD的HTML,在其中我们使用倾斜。
为什么要使用趋势,如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外的功能
支持自动采集链接文章标题,不需要手动转到原创副本。
服务器
我们使用使用node.js的服务器,用前端写入服务器,体验杠杆。
想法
我想:
前端交付链路地址的具体实现
它在此处使用节点的自行连接语法,我们使用get表单通过,使用查询
const qUrl = req.query.url
获取html字符串
通过请求
我们被要求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
得到不同的dom
根据不同的平台域名
由于许多技术平台,每个平台的文章 Content标记,样式名称或ID会有差异,这需要兼容。
首先使用JS-DOM模拟操作DOM,包装方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
与不同的平台兼容,应用不同的CSS选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
转换图像和链接的相对路径是绝对路径,可以方便地找到源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
} 查看全部
网页 抓取 innertext 试题(
共建,学习和探索.效果演示客户端思路先理
)
近年来,许多技术博客和技术社区出现,许多技术同事开始建立自己的博客。我们可以将博客同步到不同的技术平台,但随着技术平台的增加,我们文章同步时间将越来越多,然后有一个工具快速释放博客到另一个平台?或者做它的工具,您可以直接将HTML转换为技术平台以识别“语言”直接发布?
我们都知道程序员最喜欢的写作的“语言”是Makedown,而且大多数技术社区目前都支持Makedown语法,所以只要有Makedown,我们就可以快速同步到不同的技术平台。
也许有人会说,我们写博客直接写入makedown语法?它确实可以满足需求,但缺点是我们的本地必须保存一个Makedown文件,如果博客内容涉及图片,我们仍然需要维护一个IMG目录,以便每次有折扣文章文章或者这将是非常麻烦的,因此我们开发了一个工具,它会自动攀升HTML,一键入Makedown。通过这种方式,我们可以“肆无忌惮”发布博客。
你会收获
github地址作者将把它附加到文章的末尾,有兴趣的朋友可以在一起,学习和探索。
效果演示
客户思考
我想:
为什么选择翻天下
客户端中最重要的一步是MD的HTML,在其中我们使用倾斜。
为什么要使用趋势,如下:
具体实现
// 引入第三方插件
import { gfm, tables, strikethrough } from 'turndown-plugin-gfm'
const turndownService = new TurndownService({ codeBlockStyle: 'fenced' })
// Use the gfm plugin
turndownService.use(gfm)
// Use the table and strikethrough plugins only
turndownService.use([tables, strikethrough])
/**
* 自定义配置(rule名不能重复)
* 这里我们指定 `pre` 标签为代码块,并在代码块的前后加个换行,防止显示异常
*/
turndownService.addRule('pre2Code', {
filter: ['pre'],
replacement (content) {
return '```\n' + content + '\n```'
}
})
额外的功能
支持自动采集链接文章标题,不需要手动转到原创副本。
服务器
我们使用使用node.js的服务器,用前端写入服务器,体验杠杆。
想法
我想:
前端交付链路地址的具体实现
它在此处使用节点的自行连接语法,我们使用get表单通过,使用查询
const qUrl = req.query.url
获取html字符串
通过请求
我们被要求请求
request({
url: qUrl
}, (error, response, body) => {
if (error) {
res.status(404).send('Url Error')
return
}
// 这里的 body 就是文章的 `html`
console.log(body)
})
得到不同的dom
根据不同的平台域名
由于许多技术平台,每个平台的文章 Content标记,样式名称或ID会有差异,这需要兼容。
首先使用JS-DOM模拟操作DOM,包装方法
/**
* 获取准确的文章内容
* @param {string} html html串
* @param {string} selector css选择器
* @return {string} htmlContent
*/
const getDom = (html, selector) => {
const dom = new JSDOM(html)
const htmlContent = dom.window.document.querySelector(selector)
return htmlContent
}
与不同的平台兼容,应用不同的CSS选择器
// 比如掘金,内容块的样式名为 .markdown-body,内容里会有 style 标签样式和一些多余的复制代码文字,通过原生 dom 操作删掉
if (qUrl.includes('juejin.cn')) {
const htmlContent = getBySelector('.markdown-body')
const extraDom = htmlContent.querySelector('style')
const extraDomArr = htmlContent.querySelectorAll('.copy-code-btn')
extraDom && extraDom.remove()
extraDomArr.length > 0 && extraDomArr.forEach((v) => { v.remove() })
return htmlContent
}
// 再比如 oschina,内容块的样式名为 .article-detail,内容里会有多余的 .ad-wrap 内容,照样删掉
if (qUrl.includes('oschina.net')) {
const htmlContent = getBySelector('.article-detail')
const extraDom = htmlContent.querySelector('.ad-wrap')
extraDom && extraDom.remove()
return htmlContent
}
// 最后匹配通用标签。优先适配 article 标签,没有再用 body 标签
const htmlArticle = getBySelector('article')
if (htmlArticle) { return htmlArticle }
const htmlBody = getBySelector('body')
if (htmlBody) { return htmlBody }
转换图像和链接的相对路径是绝对路径,可以方便地找到源路径
// 通过原生api - URL 获取链接的源域名
const qOrigin = new URL(qUrl).origin || ''
// 获取图片、链接的绝对路径。通过 URL 将 `路径+源域名` 转换为绝对路径,不熟悉的同学请自行了解
const getAbsoluteUrl = p => new URL(p, qOrigin).href
// 转换图片、链接的相对路径,不同平台的图片懒加载属性名不一样,需要做特定兼容
const changeRelativeUrl = (dom) => {
if (!dom) { return '内容出错~' }
const copyDom = dom
// 获取所有图片
const imgs = copyDom.querySelectorAll('img')
// 获取所有链接
const links = copyDom.querySelectorAll('a')
// 替换完所有路径返回新 dom
imgs.length > 0 && imgs.forEach((v) => {
/**
* 处理懒加载路径
* 简书:data-original-src
* 掘金:data-src
* segmentfault:data-src
*/
const src = v.src || v.getAttribute('data-src') || v.getAttribute('data-original-src') || ''
v.src = getAbsoluteUrl(src)
})
links.length > 0 && links.forEach((v) => {
const href = v.href || qUrl
v.href = getAbsoluteUrl(href)
})
return copyDom
}
// 在获取不同平台的文章内容 getBody 方法里,应用 changeRelativeUrl 方法
const getBody = (content) => {
...
...
return changeRelativeUrl(htmlContent)
}
网页 抓取 innertext 试题(“VBA信息获取与处理”教程中第八个专题(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-12 19:06
《VBA信息获取与处理》教程第八题“VBA与HTML文档”的第七节“HTML DOM对象事件与关联”太无聊了。希望想要掌握这方面知识的朋友可以参考我的教程学习。今天开始学习第九题《使用IE捕捉网络数据》。
在我们的网络爬虫部分讲解了XMLHTTP方法之后,我们利用两个主题的进展来讲解一些与VBA不太相关的网络知识。这两个话题对于我们重新认识网络爬虫数据非常重要。重要的意思是,虽然我的解释不全面,但是对于我经常提倡的VBA定位来说已经足够了。此外,学习是一个不断积累和进步的过程。有必要掌握一些基本的理论,然后把这些结合起来应用到自己的实际中,这是关键。从这个话题,我们继续从网上学习。本主题是使用IE捕获网络数据。其实就是利用控件来完成我们的工作。
第 1 节 使用 IE 方法提取网页数据库
为了获取网页的数据,我们可以创建IE控件或者webbrowser控件,结合htmlfile对象的方法和属性,模拟浏览器的操作来获取浏览器页面的数据。
该方法可以模拟大部分浏览器操作。浏览器能看到的数据可以用代码获取,但是有个致命的缺点:除了烦人的弹窗之外,兼容性确实是一个很麻烦的问题。在我自己的实践中,我觉得这个方法不是很稳定(只是一种感觉)。
1 创建 IE 模型
我们在实际工作中遇到过网站和web相关的问题,比如:如何下载web数据?网页之间的通信是如何实现的,是否可以控制等。如果你是用VB/VBA/script或其他支持AUTOMATION的语言编程,掌握对象模型有一个方法值得了解:对待网页作为要控制的对象,该方法需要了解IE(InternetExplorer.Application)或IE控件(Microsoft Internet Controls)的自动化对象,以及标准的文档对象模型(Document)。前两个题目我已经做了很多相关的知识,这里就不详细解释了。
我给出以下代码:
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "about:blank" '创建一个空白页面
上面几行代码的作用就是创建一个IE应用对象,打开一个空白网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ie.Quit命令退出——注意简单关闭VBA或者SET ie=nothing都不会退出这个页面。我们经常使用的是将第3行的字符串替换为网站名称,或者替换为你主机中的文件名,或者图片名,都可以。和你在IE地址栏输入名字浏览这些文档效果一样。
如果只是创建一个空模型,没有任何使用价值。我们需要一个真正的网页。这时候我们需要在VBA应用程序之外打开一个完整的网页,直到网页完全加载完毕。操作只能向下进行。
2 加载 IE 网页
让我们修复上面打开空网页的代码:
子 mynz()
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "" '创建一个空白页面
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
结束子
在上面的代码中添加几行:
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
这几行代码可以保证网页加载完成,根据ie.ReadyState的返回值判断。
readyState 有 5 个状态:
状态含义说明
0Uninitialized 对象已创建,但尚未初始化(尚未调用open方法)
1 初始化对象已经创建,send方法没有被调用。
2发送数据的send()方法已经被调用,但是当前状态和http头未知
3 数据传输中已经收到部分数据,因为response和http头不完整,此时通过responseBody和responseText获取部分数据会报错
4 接收到数据后,可以通过 responseBody 和 responseText 获取完整的响应数据。
通过上面的分析可以看出,只有.ReadyState = 4时,网页的数据才是有效数据。
3 获取IE页面数据
当网页加载完毕后,剩下的工作就是从网页中抓取数据。数据抓取主要使用控件对象的属性和方法。
1)使用 Set doc = ie.Document 获取网页的文档对象
从文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用不是同一个系统。
Documnet(文档)是文档对象模型,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果导航到那个URL成功,需要先确认IE对象的READSTATE,然后再确认URL对应的Document被打开)
2) 在Documnet下可以获取两个节点,documentElement和body。
可以使用以下句子:
set xbody=doc.Body ‘获取主体对象
设置 xDoc=doc。 documentElement '获取根节点
body已经说过相当于被标记的对象,根节点相当于网页中被标记的元素对象。在 MHTML 类型库定义中,它们都属于 HTMLHtmlElement 类型对象。下面我将把这种类型的对象称为“节点”,但需要注意的是,文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml ‘对象内的 HTML 文本
Object.OuterHtml ‘对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText ‘对象内部的文本,不包括 HTML 标签
Object.OuterText ‘同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
设置 doc=ie.Document
设置 xDoc=doc。 documentElement '获取根节点
strX=xDoc.OuterHtml ‘获取所有 HTML 内容
3)每个标签节点对象都有一个名为ChildNodes的集合,里面收录了“这个节点下的标签”,就像一个文件目录,根目录下的一个子目录。
我们可以看到:HTML标签是文档的根节点,是Document的Childnodes集合的成员(Document不是节点,是另一种类型的对象,上层文档,但是可以有一个低级节点的集合,就像磁盘可以有子目录一样,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,而两个节点DIV和P是BODY的ChildNodes集合的两个成员,也有自己的Childnoes。聚集。
要注意:在文档对象模型中,集合不同于OFFICE集合。集合从0开始计数,计数属性是Length而不是Count。
4) 除了 ChildNodes 集合之外,您通常在 Web 文档对象中看到的是一个非常流行的集合:All 集合,它是“最令人困惑”的集合。各个层级的文档和节点都有这个集合,顾名思义,没有分层,但是使用起来也很方便:
设置 doc=ie.Document
Set xCols=doc.All '获取文档中的所有节点
Set xbCols=doc.body.All '获取body节点下的所有节点集
尽管对于任何标记的节点都有一个 ALL 集,但我们仍然无缘无故地喜欢使用 DOCUMENT 的 ALL。文档最大,一锅ALL最适合找。 ALL 搜索是有条件的:如果这个标签没有 ID,你就找不到它的名字。
但是ALL集合有一个很方便的特性:ID可以链接到ALL集合:
strX=doc.All.mytag.innerhtml
5) 获取文档对象的getElementsByName集合,可以使用如下方法:
设置 mydivs=doc。 getElementsByName("div") ‘获取所有DIV标签,注意还是一个集合
6)FORMS 文档对象集合,因为大部分网页数据提交都是通过FORM标签提交的:
Set myForms=doc.Forms '获取所有 FORM 标签
设置frmX=myForms.item(0)'第1个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(其实就是服务器发回数据按照一定的格式协议),我们可以把网页的FORM作为远程函数调用接口。 FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每个INPUT标签节点就是函数的参数。当 FORM.Submit 方法发出时,它是远程调用该函数。在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
frmX.submit’相当于用户在页面上按下了FORM的发送按钮
上面我已经列出了获取网页数据的一般方法,没有特殊的使用要求。可以根据自己的习惯使用。本专题后面的内容就是利用这些知识点灵活解决实际问题。
本节知识点回归:
如何提交表单?怎么下载图片的地址?如何获取表的数据?
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想。这也是学习使用VBA的主要方法,尤其是专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的积木库中的数据越多,您的编程想法就越广泛。
VBA 的应用定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的顶峰非VBA莫属!
记得20年前刚开始学VBA的时候,当时资料很少,只能自己看源码自己弄明白。这真的很困难。二十年过去了。为了不让学VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,特推出6个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。教程147讲,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解法视频是专门为初学者准备的视频讲解。您可以快速入门并更快地掌握此技能。本套教程为第一套教程视频讲解,听元音比较好。
第五套:VBA中类的解释和利用这是一个高级教程,解释了类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,本高级教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等
您可以按照1→3→2→6→5或4→3→2→6→5的顺序从以上信息中学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一下枯燥的感觉
如太白诗云:百鸟飞扬,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,帮助我,我上面的教程是我很多经验的传递,
“水利万物而不争”,浓浓稠密,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人地发表言论。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。这不只是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次收获都是成长的记录。怎么可能不靠谱?正是这种坚持,才造就了灿烂的朝霞。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
只有微风震撼了梦中的莺。
看星星,去掉北斗,
奈与过去的鹅同行。
天魔人,明暗昏暗,
耐心顾长霆。
VBA 人数,
在漆黑的夜里,静静地寻梦,盼望黎明。
怎么没有证据!
回到学习和使用 VBA 的历史,我印象非常深刻。我想用这些话与大家分享我多年实践经验的成果。我喜欢这些对真正需要使用 VBA 的旅行者有用的东西。 查看全部
网页 抓取 innertext 试题(“VBA信息获取与处理”教程中第八个专题(组图))
《VBA信息获取与处理》教程第八题“VBA与HTML文档”的第七节“HTML DOM对象事件与关联”太无聊了。希望想要掌握这方面知识的朋友可以参考我的教程学习。今天开始学习第九题《使用IE捕捉网络数据》。
在我们的网络爬虫部分讲解了XMLHTTP方法之后,我们利用两个主题的进展来讲解一些与VBA不太相关的网络知识。这两个话题对于我们重新认识网络爬虫数据非常重要。重要的意思是,虽然我的解释不全面,但是对于我经常提倡的VBA定位来说已经足够了。此外,学习是一个不断积累和进步的过程。有必要掌握一些基本的理论,然后把这些结合起来应用到自己的实际中,这是关键。从这个话题,我们继续从网上学习。本主题是使用IE捕获网络数据。其实就是利用控件来完成我们的工作。
第 1 节 使用 IE 方法提取网页数据库
为了获取网页的数据,我们可以创建IE控件或者webbrowser控件,结合htmlfile对象的方法和属性,模拟浏览器的操作来获取浏览器页面的数据。
该方法可以模拟大部分浏览器操作。浏览器能看到的数据可以用代码获取,但是有个致命的缺点:除了烦人的弹窗之外,兼容性确实是一个很麻烦的问题。在我自己的实践中,我觉得这个方法不是很稳定(只是一种感觉)。
1 创建 IE 模型
我们在实际工作中遇到过网站和web相关的问题,比如:如何下载web数据?网页之间的通信是如何实现的,是否可以控制等。如果你是用VB/VBA/script或其他支持AUTOMATION的语言编程,掌握对象模型有一个方法值得了解:对待网页作为要控制的对象,该方法需要了解IE(InternetExplorer.Application)或IE控件(Microsoft Internet Controls)的自动化对象,以及标准的文档对象模型(Document)。前两个题目我已经做了很多相关的知识,这里就不详细解释了。
我给出以下代码:
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "about:blank" '创建一个空白页面
上面几行代码的作用就是创建一个IE应用对象,打开一个空白网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ie.Quit命令退出——注意简单关闭VBA或者SET ie=nothing都不会退出这个页面。我们经常使用的是将第3行的字符串替换为网站名称,或者替换为你主机中的文件名,或者图片名,都可以。和你在IE地址栏输入名字浏览这些文档效果一样。
如果只是创建一个空模型,没有任何使用价值。我们需要一个真正的网页。这时候我们需要在VBA应用程序之外打开一个完整的网页,直到网页完全加载完毕。操作只能向下进行。
2 加载 IE 网页
让我们修复上面打开空网页的代码:
子 mynz()
Set ie = CreateObject("InternetExplorer.Application") '创建对象
ie.Visible = True '使 IE 页面可见。这一步之后,你可以在VBA之外看到一个新的IE
ie.navigate "" '创建一个空白页面
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
结束子
在上面的代码中添加几行:
Do直到.ReadyState = 4'检查页面是否完全加载(4表示完全加载)
DoEvents‘在循环中将工作权限返还给系统,以避免“软崩溃”
循环
这几行代码可以保证网页加载完成,根据ie.ReadyState的返回值判断。
readyState 有 5 个状态:
状态含义说明
0Uninitialized 对象已创建,但尚未初始化(尚未调用open方法)
1 初始化对象已经创建,send方法没有被调用。
2发送数据的send()方法已经被调用,但是当前状态和http头未知
3 数据传输中已经收到部分数据,因为response和http头不完整,此时通过responseBody和responseText获取部分数据会报错
4 接收到数据后,可以通过 responseBody 和 responseText 获取完整的响应数据。
通过上面的分析可以看出,只有.ReadyState = 4时,网页的数据才是有效数据。
3 获取IE页面数据
当网页加载完毕后,剩下的工作就是从网页中抓取数据。数据抓取主要使用控件对象的属性和方法。
1)使用 Set doc = ie.Document 获取网页的文档对象
从文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用不是同一个系统。
Documnet(文档)是文档对象模型,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果导航到那个URL成功,需要先确认IE对象的READSTATE,然后再确认URL对应的Document被打开)
2) 在Documnet下可以获取两个节点,documentElement和body。
可以使用以下句子:
set xbody=doc.Body ‘获取主体对象
设置 xDoc=doc。 documentElement '获取根节点
body已经说过相当于被标记的对象,根节点相当于网页中被标记的元素对象。在 MHTML 类型库定义中,它们都属于 HTMLHtmlElement 类型对象。下面我将把这种类型的对象称为“节点”,但需要注意的是,文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml ‘对象内的 HTML 文本
Object.OuterHtml ‘对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText ‘对象内部的文本,不包括 HTML 标签
Object.OuterText ‘同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
设置 doc=ie.Document
设置 xDoc=doc。 documentElement '获取根节点
strX=xDoc.OuterHtml ‘获取所有 HTML 内容
3)每个标签节点对象都有一个名为ChildNodes的集合,里面收录了“这个节点下的标签”,就像一个文件目录,根目录下的一个子目录。
我们可以看到:HTML标签是文档的根节点,是Document的Childnodes集合的成员(Document不是节点,是另一种类型的对象,上层文档,但是可以有一个低级节点的集合,就像磁盘可以有子目录一样,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,而两个节点DIV和P是BODY的ChildNodes集合的两个成员,也有自己的Childnoes。聚集。
要注意:在文档对象模型中,集合不同于OFFICE集合。集合从0开始计数,计数属性是Length而不是Count。
4) 除了 ChildNodes 集合之外,您通常在 Web 文档对象中看到的是一个非常流行的集合:All 集合,它是“最令人困惑”的集合。各个层级的文档和节点都有这个集合,顾名思义,没有分层,但是使用起来也很方便:
设置 doc=ie.Document
Set xCols=doc.All '获取文档中的所有节点
Set xbCols=doc.body.All '获取body节点下的所有节点集
尽管对于任何标记的节点都有一个 ALL 集,但我们仍然无缘无故地喜欢使用 DOCUMENT 的 ALL。文档最大,一锅ALL最适合找。 ALL 搜索是有条件的:如果这个标签没有 ID,你就找不到它的名字。
但是ALL集合有一个很方便的特性:ID可以链接到ALL集合:
strX=doc.All.mytag.innerhtml
5) 获取文档对象的getElementsByName集合,可以使用如下方法:
设置 mydivs=doc。 getElementsByName("div") ‘获取所有DIV标签,注意还是一个集合
6)FORMS 文档对象集合,因为大部分网页数据提交都是通过FORM标签提交的:
Set myForms=doc.Forms '获取所有 FORM 标签
设置frmX=myForms.item(0)'第1个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(其实就是服务器发回数据按照一定的格式协议),我们可以把网页的FORM作为远程函数调用接口。 FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每个INPUT标签节点就是函数的参数。当 FORM.Submit 方法发出时,它是远程调用该函数。在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
frmX.submit’相当于用户在页面上按下了FORM的发送按钮
上面我已经列出了获取网页数据的一般方法,没有特殊的使用要求。可以根据自己的习惯使用。本专题后面的内容就是利用这些知识点灵活解决实际问题。
本节知识点回归:
如何提交表单?怎么下载图片的地址?如何获取表的数据?
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想。这也是学习使用VBA的主要方法,尤其是专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的积木库中的数据越多,您的编程想法就越广泛。
VBA 的应用定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的顶峰非VBA莫属!
记得20年前刚开始学VBA的时候,当时资料很少,只能自己看源码自己弄明白。这真的很困难。二十年过去了。为了不让学VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,特推出6个VBA专用教程:
第一套:VBA代码解法是对VBA中各个知识点的讲解。教程147讲,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解法视频是专门为初学者准备的视频讲解。您可以快速入门并更快地掌握此技能。本套教程为第一套教程视频讲解,听元音比较好。
第五套:VBA中类的解释和利用这是一个高级教程,解释了类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,本高级教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等
您可以按照1→3→2→6→5或4→3→2→6→5的顺序从以上信息中学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一下枯燥的感觉
如太白诗云:百鸟飞扬,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,帮助我,我上面的教程是我很多经验的传递,
“水利万物而不争”,浓浓稠密,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人地发表言论。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。这不只是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次收获都是成长的记录。怎么可能不靠谱?正是这种坚持,才造就了灿烂的朝霞。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
只有微风震撼了梦中的莺。
看星星,去掉北斗,
奈与过去的鹅同行。
天魔人,明暗昏暗,
耐心顾长霆。
VBA 人数,
在漆黑的夜里,静静地寻梦,盼望黎明。
怎么没有证据!
回到学习和使用 VBA 的历史,我印象非常深刻。我想用这些话与大家分享我多年实践经验的成果。我喜欢这些对真正需要使用 VBA 的旅行者有用的东西。

