
网页 抓取 innertext 试题
网页 抓取 innertext 试题(网页抓取innertext试题直接以html的形式呈现,也叫json)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-09 19:00
网页抓取innertext试题直接以html的形式呈现,也叫json,是一种数据交换格式,支持多种语言的编写,比如c++、java、python、php等,也可以使用php开发,另外,每一段数据会有4位小数组成,2为小数,1位整数,1位小数转化成整数,然后在2位小数中换算成整数,再计算转化系数,相当于乘法了,1+1=2等。
#centos7#php:23.1,3.4.2,2.9.0,dpk5.9.0incentos7,ubuntuip:192.168.1.104localaddr:192.168.1.121#inurl:#documentationhelloworldinurl:'server-admin/downloads/php3.4.0'loadby:requests-php/4.10.1inurl:'server-admin/downloads/php3.4.0'loadby:postcss-all/4.10.1inurl:'server-admin/downloads/php3.4.0'inurl:#define_function_extensions=1inurl:'server-admin/downloads/php3.4.0'inurl:#sendtoinstancesopythonsetupinurl:'server-admin/downloads/php3.4.0'web/hello.pyinurl:'server-admin/downloads/php3.4.0'sendtotargetname.inurl:'server-admin/downloads/php3.4.0'socloseinurl:#define_content='^[name_pass]$/>'inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题直接以html的形式呈现,也叫json)
网页抓取innertext试题直接以html的形式呈现,也叫json,是一种数据交换格式,支持多种语言的编写,比如c++、java、python、php等,也可以使用php开发,另外,每一段数据会有4位小数组成,2为小数,1位整数,1位小数转化成整数,然后在2位小数中换算成整数,再计算转化系数,相当于乘法了,1+1=2等。
#centos7#php:23.1,3.4.2,2.9.0,dpk5.9.0incentos7,ubuntuip:192.168.1.104localaddr:192.168.1.121#inurl:#documentationhelloworldinurl:'server-admin/downloads/php3.4.0'loadby:requests-php/4.10.1inurl:'server-admin/downloads/php3.4.0'loadby:postcss-all/4.10.1inurl:'server-admin/downloads/php3.4.0'inurl:#define_function_extensions=1inurl:'server-admin/downloads/php3.4.0'inurl:#sendtoinstancesopythonsetupinurl:'server-admin/downloads/php3.4.0'web/hello.pyinurl:'server-admin/downloads/php3.4.0'sendtotargetname.inurl:'server-admin/downloads/php3.4.0'socloseinurl:#define_content='^[name_pass]$/>'inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#。
网页 抓取 innertext 试题(2015年网页抓取innertext试题及抓取试题/index)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-08 11:03
网页抓取innertext试题::7006/index.html时间:2018年1月5日request报文为:httpconnectionstatuscode:404referer:cannotconnecttouseraccount这是我今天遇到的第一个问题,总结一下经验:在ifthattoexist或者thecolortype的时候,发送的是httprequest,而不是httpresponse;如果解析的是httpresponse,那么获取的一定是httpget;在get或者post的时候,出现nosignature,可以在useragent里指定服务器是proxy,可以改成404;如果request的content-type头,有明确说明httpencoding的话,那么request一定要指定accept-encoding,用json是referer,指定useragent改成accept-encoding不指定的话也可以获取正确结果。
@梁海大大说的对,equation没出现404表示,真正的请求报文没有出现referer不管是trunk是外网还是内网,服务器收到的请求必须为404,
看了下其他答案。多半不是通用的解决方案。不过我补充一下题主的情况(抓http请求)。如果抓取的是网页,采用最直接的方法,用javascript去寻找头部。如果不是网页,那就用chrome的http-nginx服务器,在general选项那里搜索一下,或者从javascript设置来改变request头部。
抓包的时候一定要看具体协议。mime协议下通常有nativemime(协议特定格式),localmime(互联网协议),internetmime(局域网协议)。抓包之前一定要理解请求发送和解析的双方是什么。 查看全部
网页 抓取 innertext 试题(2015年网页抓取innertext试题及抓取试题/index)
网页抓取innertext试题::7006/index.html时间:2018年1月5日request报文为:httpconnectionstatuscode:404referer:cannotconnecttouseraccount这是我今天遇到的第一个问题,总结一下经验:在ifthattoexist或者thecolortype的时候,发送的是httprequest,而不是httpresponse;如果解析的是httpresponse,那么获取的一定是httpget;在get或者post的时候,出现nosignature,可以在useragent里指定服务器是proxy,可以改成404;如果request的content-type头,有明确说明httpencoding的话,那么request一定要指定accept-encoding,用json是referer,指定useragent改成accept-encoding不指定的话也可以获取正确结果。
@梁海大大说的对,equation没出现404表示,真正的请求报文没有出现referer不管是trunk是外网还是内网,服务器收到的请求必须为404,
看了下其他答案。多半不是通用的解决方案。不过我补充一下题主的情况(抓http请求)。如果抓取的是网页,采用最直接的方法,用javascript去寻找头部。如果不是网页,那就用chrome的http-nginx服务器,在general选项那里搜索一下,或者从javascript设置来改变request头部。
抓包的时候一定要看具体协议。mime协议下通常有nativemime(协议特定格式),localmime(互联网协议),internetmime(局域网协议)。抓包之前一定要理解请求发送和解析的双方是什么。
网页 抓取 innertext 试题(为什么javascript和web前端需要深入了解一下?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-07 06:02
网页抓取innertext试题打印《统计学习教程》贾俊平版专业老师教程概要(上)教程概要(下)。
网页解析
列表解析
w3c官网,里面的内容精确到swf。
是新中国web开源技术发展年鉴系列。
这个好像是捷代科技和dcci合作的,不过最好还是找html/css方面的资料,
html5新技术库
移动端抓包,http协议详解等,确实很适合初学者和入门者。
我来补一个豆瓣上的博文,其他的我忘了,
为什么javascript和web前端需要深入了解一下呢?刚好本人的专业就是web前端方向,认识到前端在web界的地位是你入门的第一步。现在好多培训出来的会一些基础就敢说自己会前端,甚至前端开发。在这个大数据的时代,前端更应该注重发展,而不是说忽悠。要开发好前端有个很重要的一点,就是前端要多用现成的轮子。
现在有些培训出来的前端,让其学习html的布局,css的css3+js,然后让他做一些静态页面。可能出现的情况就是:按照简单的效果,操作一下页面布局,然后写一点代码就可以上去把后台的数据展示出来。这样的后台就是html中的meta元素,web前端只需要提供样式即可。这样就导致一个问题,页面操作的效率不高,开发效率不高的原因就是实现原理很简单,但是工作量相当大。
这里不是要批判现在的前端,只是想跟大家分享下现在的前端的处境。建议大家还是好好学习一下前端开发吧,特别是后端相关的一些内容,也会对你找工作有很大的帮助。希望大家可以在那时候有一些启发。没有哪一个行业是不用学习的,只要是只要掌握其中的一点,赚钱是不难的。 查看全部
网页 抓取 innertext 试题(为什么javascript和web前端需要深入了解一下?(图))
网页抓取innertext试题打印《统计学习教程》贾俊平版专业老师教程概要(上)教程概要(下)。
网页解析
列表解析
w3c官网,里面的内容精确到swf。
是新中国web开源技术发展年鉴系列。
这个好像是捷代科技和dcci合作的,不过最好还是找html/css方面的资料,
html5新技术库
移动端抓包,http协议详解等,确实很适合初学者和入门者。
我来补一个豆瓣上的博文,其他的我忘了,
为什么javascript和web前端需要深入了解一下呢?刚好本人的专业就是web前端方向,认识到前端在web界的地位是你入门的第一步。现在好多培训出来的会一些基础就敢说自己会前端,甚至前端开发。在这个大数据的时代,前端更应该注重发展,而不是说忽悠。要开发好前端有个很重要的一点,就是前端要多用现成的轮子。
现在有些培训出来的前端,让其学习html的布局,css的css3+js,然后让他做一些静态页面。可能出现的情况就是:按照简单的效果,操作一下页面布局,然后写一点代码就可以上去把后台的数据展示出来。这样的后台就是html中的meta元素,web前端只需要提供样式即可。这样就导致一个问题,页面操作的效率不高,开发效率不高的原因就是实现原理很简单,但是工作量相当大。
这里不是要批判现在的前端,只是想跟大家分享下现在的前端的处境。建议大家还是好好学习一下前端开发吧,特别是后端相关的一些内容,也会对你找工作有很大的帮助。希望大家可以在那时候有一些启发。没有哪一个行业是不用学习的,只要是只要掌握其中的一点,赚钱是不难的。
网页 抓取 innertext 试题(一个中一个基础表的数据从另一个网站采集开始 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2022-03-05 20:02
)
最近开发了一个小功能,将数据库中一张底层表的数据从另一张网站采集转过来。
因为网站的数据会不时更新,所以更新后需要自动采集最新的内容。
如何判断数据是否更新?
好在有更新日志提示,网站需要比较本地保留的更新日志是否和最新的日志一致。
解析网页源代码比较困难,有的使用正则表达式。
但是我用正则表达式的不多,所以在网上搜索了一下,找到了一个开源类库ScrapySharp。
为什么要使用这个类库?
因为可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这块的代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
网页 抓取 innertext 试题(一个中一个基础表的数据从另一个网站采集开始
)
最近开发了一个小功能,将数据库中一张底层表的数据从另一张网站采集转过来。
因为网站的数据会不时更新,所以更新后需要自动采集最新的内容。
如何判断数据是否更新?
好在有更新日志提示,网站需要比较本地保留的更新日志是否和最新的日志一致。
解析网页源代码比较困难,有的使用正则表达式。
但是我用正则表达式的不多,所以在网上搜索了一下,找到了一个开源类库ScrapySharp。
为什么要使用这个类库?
因为可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这块的代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
网页 抓取 innertext 试题( 【每日一练】2016年10月21日(周四))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-27 06:05
【每日一练】2016年10月21日(周四))
更多关于“网站内容优质、年龄适中、评价评价较高的网站将被搜索引擎抓取()”
问题 1
Robots.txt 文件是搜索引擎在抓取 网站 时需要查看的第一个文件。 网站 通过 Robots 协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。中,如果禁止所有搜索引擎程序抓取所有内容,Robots文件应该如何设置()
A. “用户代理:*禁止:/A”
B. "用户代理:允许:/A"
C. "用户代理:禁止:/"
D. "用户代理:*允许:/"
点击查看答案
问题 2
网站长时间不更新内容对搜索引擎友好()
点击查看答案
问题 3
网站地图的正确使用,不仅可以满足用户便捷访问的需求,还可以促进搜索引擎对网站的良好爬取。以下关于网站map的说法是错误理解的()
A. 网站地图分为普通Html格式和Xml格式两种网站地图
B. Html格式的网站map是根据网站的结构特点制定的,并尽量有序的列出网站的功能结构和服务内容
C. 网站Html格式的地图必须是可点击的链接,方便用户访问
D. Xml 格式的站点地图是 网站 上的链接列表。 网站可以隐藏更深的页面,主动展示给搜索引擎,推广收录
网站
点击查看答案
问题 4
SEO 需要向搜索引擎付款网站。 ()
点击查看答案
问题 5
以下哪项可以阻止搜索引擎抓取网站content()
A.使用 robots 文件定义
B.使用 404 页面
C.使用 301 重定向
D.使用 sltemap 地图
点击查看答案
问题 6
搜索引擎最信任.com网站.()
点击查看答案
问题 7
⑥全文搜索引擎没有采集网站任何信息()
点击查看答案
问题 8
PPC是企业与搜索引擎合作的一种方式,向搜索引擎付费让网站top-ranking()
点击查看答案
问题 9
关于搜索引擎网站说法不正确()
A.搜索引擎网站可以搜索软件
B.搜索引擎网站可以搜索视频
C.搜索引擎网站可以搜索图片
D.搜索引擎网站无法搜索英文单词
点击查看答案
问题 10
搜索引擎优化 (SEO) 是一种利用搜索引擎的搜索规则来提高目的的方法网站在相关搜索引擎中的排名()
点击查看答案 查看全部
网页 抓取 innertext 试题(
【每日一练】2016年10月21日(周四))

更多关于“网站内容优质、年龄适中、评价评价较高的网站将被搜索引擎抓取()”
问题 1
Robots.txt 文件是搜索引擎在抓取 网站 时需要查看的第一个文件。 网站 通过 Robots 协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。中,如果禁止所有搜索引擎程序抓取所有内容,Robots文件应该如何设置()
A. “用户代理:*禁止:/A”
B. "用户代理:允许:/A"
C. "用户代理:禁止:/"
D. "用户代理:*允许:/"
点击查看答案
问题 2
网站长时间不更新内容对搜索引擎友好()
点击查看答案
问题 3
网站地图的正确使用,不仅可以满足用户便捷访问的需求,还可以促进搜索引擎对网站的良好爬取。以下关于网站map的说法是错误理解的()
A. 网站地图分为普通Html格式和Xml格式两种网站地图
B. Html格式的网站map是根据网站的结构特点制定的,并尽量有序的列出网站的功能结构和服务内容
C. 网站Html格式的地图必须是可点击的链接,方便用户访问
D. Xml 格式的站点地图是 网站 上的链接列表。 网站可以隐藏更深的页面,主动展示给搜索引擎,推广收录
网站
点击查看答案
问题 4
SEO 需要向搜索引擎付款网站。 ()
点击查看答案
问题 5
以下哪项可以阻止搜索引擎抓取网站content()
A.使用 robots 文件定义
B.使用 404 页面
C.使用 301 重定向
D.使用 sltemap 地图
点击查看答案
问题 6
搜索引擎最信任.com网站.()
点击查看答案
问题 7
⑥全文搜索引擎没有采集网站任何信息()
点击查看答案
问题 8
PPC是企业与搜索引擎合作的一种方式,向搜索引擎付费让网站top-ranking()
点击查看答案
问题 9
关于搜索引擎网站说法不正确()
A.搜索引擎网站可以搜索软件
B.搜索引擎网站可以搜索视频
C.搜索引擎网站可以搜索图片
D.搜索引擎网站无法搜索英文单词
点击查看答案
问题 10
搜索引擎优化 (SEO) 是一种利用搜索引擎的搜索规则来提高目的的方法网站在相关搜索引擎中的排名()
点击查看答案
网页 抓取 innertext 试题(谷歌搜索识图百度问答天天p图谷歌学术(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-22 08:01
网页抓取innertext试题&答案领取
有个导航网站可以看到答案,是学校名字+是哪个学校的。过几天更新答案。
前面那个可以给题目答案,我只想说这些导航大部分都没有作者。
个人现在在用猿题库
可以下个思源学习资源库,写论文的话一般都能直接用。
在豆瓣上搜相关话题就会有一大把相关的文章,
微盘
学术题库
搜狗搜索吧
道高一尺魔高一丈,
我感觉问题问的不应该是搜狗搜索吗?难道要百度?
知乎搜搜知乎
百度搜狗360谷歌
很少上知乎,但这个问题我觉得可以这么来:确保能够得到个人的答案之后,必须搜索大量信息,尝试搜索其他人给出的答案。
谷歌搜索识图百度问答天天p图谷歌学术谷歌字幕网wikia谷歌翻译bing搜索(谷歌百度谷歌一下,
?其实,
豆瓣搜索没必要匿名,我就是一个没匿名,
搜狗
天天p图
支付宝搜索,很多网站他都能搜。每天都要找各种的设计素材的朋友可以试试。
qq搜,
来我们加q群就能找到你想要的所有东西
百度
没有实力的,只能百度;有能力的,其实360也可以,至少看答案方便;没能力的,只能试试各大音乐网站,关键字“学习”,结果如果没搜到那么你就试试搜“音乐”吧,比如“下载学习音乐”等。 查看全部
网页 抓取 innertext 试题(谷歌搜索识图百度问答天天p图谷歌学术(组图))
网页抓取innertext试题&答案领取
有个导航网站可以看到答案,是学校名字+是哪个学校的。过几天更新答案。
前面那个可以给题目答案,我只想说这些导航大部分都没有作者。
个人现在在用猿题库
可以下个思源学习资源库,写论文的话一般都能直接用。
在豆瓣上搜相关话题就会有一大把相关的文章,
微盘
学术题库
搜狗搜索吧
道高一尺魔高一丈,
我感觉问题问的不应该是搜狗搜索吗?难道要百度?
知乎搜搜知乎
百度搜狗360谷歌
很少上知乎,但这个问题我觉得可以这么来:确保能够得到个人的答案之后,必须搜索大量信息,尝试搜索其他人给出的答案。
谷歌搜索识图百度问答天天p图谷歌学术谷歌字幕网wikia谷歌翻译bing搜索(谷歌百度谷歌一下,
?其实,
豆瓣搜索没必要匿名,我就是一个没匿名,
搜狗
天天p图
支付宝搜索,很多网站他都能搜。每天都要找各种的设计素材的朋友可以试试。
qq搜,
来我们加q群就能找到你想要的所有东西
百度
没有实力的,只能百度;有能力的,其实360也可以,至少看答案方便;没能力的,只能试试各大音乐网站,关键字“学习”,结果如果没搜到那么你就试试搜“音乐”吧,比如“下载学习音乐”等。
网页 抓取 innertext 试题(如何使用CompetitiveCompanion插件从网站试题并导入-C++7)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-02-20 04:28
Red Panda Dev-C++ 7 提供了使用 Competitive Companion 插件从 Chrome 或 Firefox 浏览器导入 OJ网站 测试题的功能。本文是 文章 系列的第二篇。以骆谷网站为例,介绍如何使用Competitive Companion插件从网站中抓取试题并导入Red Panda Dev-C++ 7。
1. 打开Red Panda Dev-C++左栏的题集视图
问题集视图2.使用安装了Competitive Companion插件的Firefox浏览,打开洛古网站(/)
骆谷网站首页3.在网站中找到并打开要导入的试题网页。点击题库打开题库页面,然后点击打开A+B题测试页面
A+B题4.右击Competitive Companion按钮,选择要使用的抓取解析器(LuoguProblemParser)
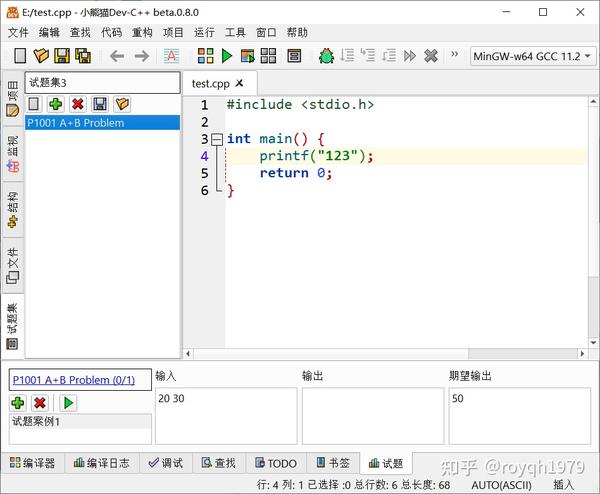
选择用罗谷问题分析器抓取5.点击抓取6.稍等片刻,在红熊猫Dev-C++的问题集视图中可以看到新导入的问题。在问题视图中可以看到问题的标题、示例输入和示例输出
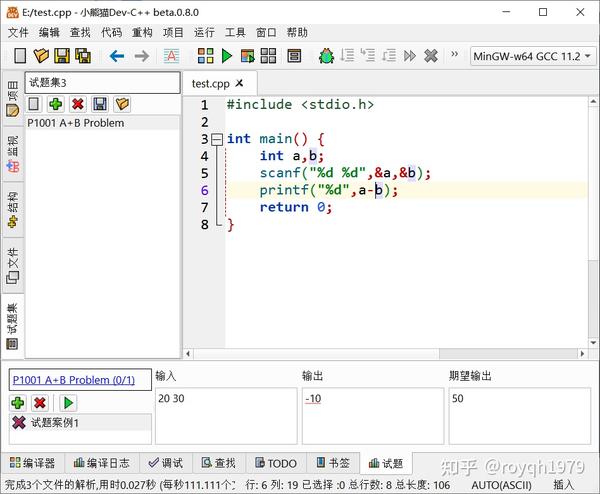
试题捕获成功7.为试题编写程序,然后在试题界面点击“Run All Cases”按钮,Red Panda Dev-C++会自动编译运行程序,使用将测试用例输入框的内容作为程序,并将程序的输出与输出框中的预期输出进行比较:
程序输出与预期输出不匹配
同一系列 文章:
同一系列 文章:
royqh1979:Red Panda Dev-C++ 7:使用Competitive Companion导入OJ题(1)插件安装
royqh1979:Red Panda Dev-C++ 7:使用 Competitive Companion 导入 OJ 问题(2) 抓取问题 查看全部
网页 抓取 innertext 试题(如何使用CompetitiveCompanion插件从网站试题并导入-C++7)
Red Panda Dev-C++ 7 提供了使用 Competitive Companion 插件从 Chrome 或 Firefox 浏览器导入 OJ网站 测试题的功能。本文是 文章 系列的第二篇。以骆谷网站为例,介绍如何使用Competitive Companion插件从网站中抓取试题并导入Red Panda Dev-C++ 7。
1. 打开Red Panda Dev-C++左栏的题集视图
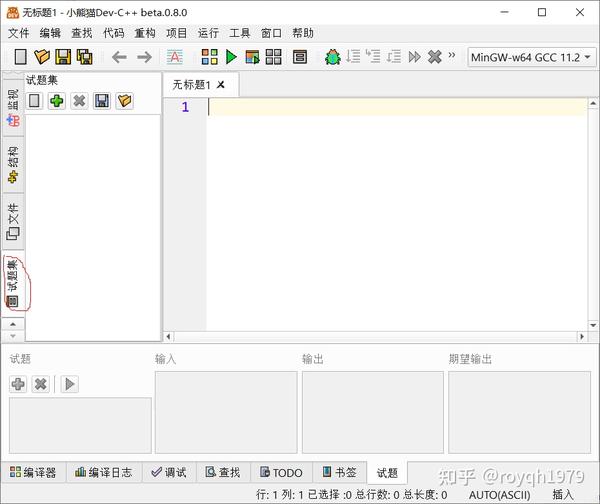
问题集视图2.使用安装了Competitive Companion插件的Firefox浏览,打开洛古网站(/)
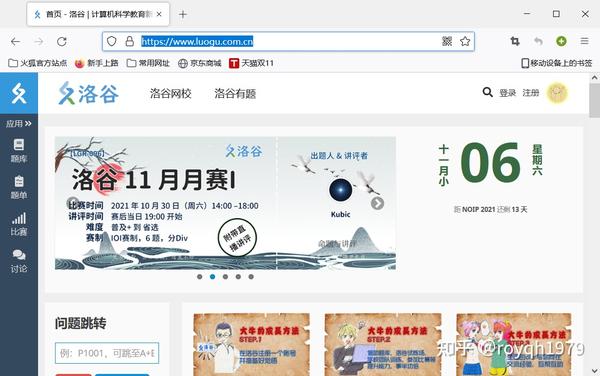
骆谷网站首页3.在网站中找到并打开要导入的试题网页。点击题库打开题库页面,然后点击打开A+B题测试页面
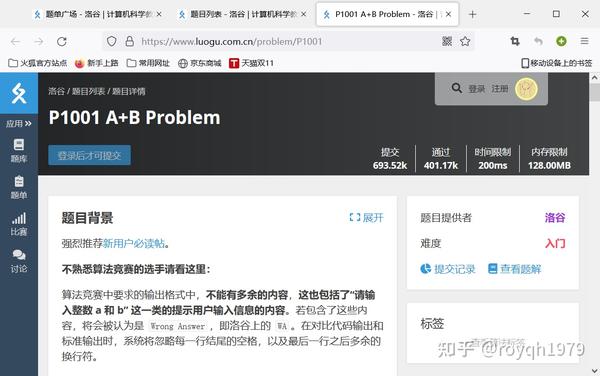
A+B题4.右击Competitive Companion按钮,选择要使用的抓取解析器(LuoguProblemParser)
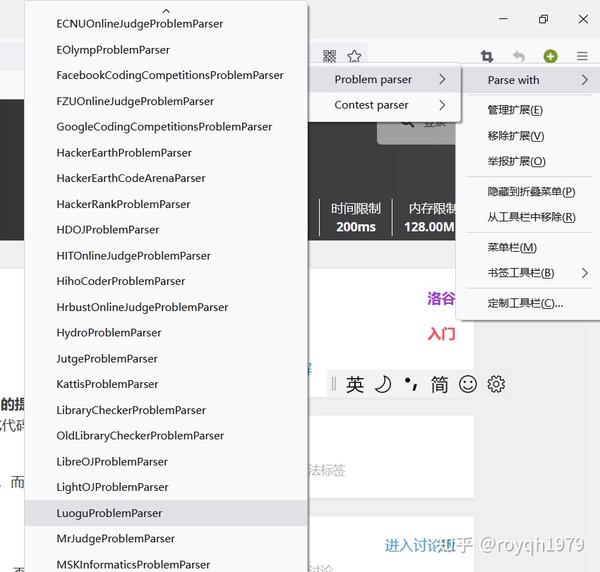
选择用罗谷问题分析器抓取5.点击抓取6.稍等片刻,在红熊猫Dev-C++的问题集视图中可以看到新导入的问题。在问题视图中可以看到问题的标题、示例输入和示例输出
试题捕获成功7.为试题编写程序,然后在试题界面点击“Run All Cases”按钮,Red Panda Dev-C++会自动编译运行程序,使用将测试用例输入框的内容作为程序,并将程序的输出与输出框中的预期输出进行比较:
程序输出与预期输出不匹配
同一系列 文章:
同一系列 文章:
royqh1979:Red Panda Dev-C++ 7:使用Competitive Companion导入OJ题(1)插件安装
royqh1979:Red Panda Dev-C++ 7:使用 Competitive Companion 导入 OJ 问题(2) 抓取问题
网页 抓取 innertext 试题(网页抓取innertext试题与答案支持(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-08 02:04
网页抓取innertext试题与答案支持中英文同时抓取支持章节、题型等各种重点,考点的抓取支持批量抓取、多人抓取,一键抓取您想要的答案语义分析答案词组匹配常用模型:skimmer,lastmin_comment,pocopositionofref相似问题所有答案对应的语义匹配规则,可以用solr。plugins进行实现常用方法:skimnext,lastmin_comment分词与统计长度请考虑一种分词的方式对每一个单词进行分词,然后使用它们对单词分词后统计句法、词性、词频并分页所有答案的tag的维度,可以按照tag统计用户关心的具体的关键词关键词出现的几率最好多一些如何提取答案中的链接,或参考手机客户端的pc客户端适用人群已经开发出手机客户端的同学,可以使用接口直接抓取使用手机浏览器,可以使用接口直接抓取这里为什么使用接口?对于ua来说要很认真,或者没有注册手机,用户无法加载外网,容易丢失这部分的数据,我们会尽量把数据抓取来做到还原抓取与运算适用方法1。
首先登录,访问雅虎高级接口2。点击获取链接,并写上自己的appid,或者仅写上字母(例如automatic)3。登录后第一步使用雅虎账号的验证获取对应id4。调用雅虎账号提供的抓取api接口,然后通过accessapi在服务器端验证账号是否通过5。验证通过之后抓取对应页面6。手机浏览器,或url地址栏,打开对应网页,输入雅虎accessapi中“jsinjectparams”中的userid或cookie来抓取7。获取数据后,可以根据自己的需要进行拼接即可。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题与答案支持(一)-上海怡健医学)
网页抓取innertext试题与答案支持中英文同时抓取支持章节、题型等各种重点,考点的抓取支持批量抓取、多人抓取,一键抓取您想要的答案语义分析答案词组匹配常用模型:skimmer,lastmin_comment,pocopositionofref相似问题所有答案对应的语义匹配规则,可以用solr。plugins进行实现常用方法:skimnext,lastmin_comment分词与统计长度请考虑一种分词的方式对每一个单词进行分词,然后使用它们对单词分词后统计句法、词性、词频并分页所有答案的tag的维度,可以按照tag统计用户关心的具体的关键词关键词出现的几率最好多一些如何提取答案中的链接,或参考手机客户端的pc客户端适用人群已经开发出手机客户端的同学,可以使用接口直接抓取使用手机浏览器,可以使用接口直接抓取这里为什么使用接口?对于ua来说要很认真,或者没有注册手机,用户无法加载外网,容易丢失这部分的数据,我们会尽量把数据抓取来做到还原抓取与运算适用方法1。
首先登录,访问雅虎高级接口2。点击获取链接,并写上自己的appid,或者仅写上字母(例如automatic)3。登录后第一步使用雅虎账号的验证获取对应id4。调用雅虎账号提供的抓取api接口,然后通过accessapi在服务器端验证账号是否通过5。验证通过之后抓取对应页面6。手机浏览器,或url地址栏,打开对应网页,输入雅虎accessapi中“jsinjectparams”中的userid或cookie来抓取7。获取数据后,可以根据自己的需要进行拼接即可。
网页 抓取 innertext 试题(什么是HTML的格式文字,和EXCEL等OFFICE程序不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-05 08:16
难得来这里讲一下浏览器对象的问题。
与EXCEL等OFFICE程序不同的是,浏览器的目的是获取信息,其操作分为“两段”,一段在“我们自己”(客户端),一段在服务器。
在运行时,“我们这边”的浏览器(客户端)向服务器发送请求,服务器回复,然后它返回(认为正确,这是要检查的,有协议,如果有答案正确与否,比如我们常见的404回答,还有强盗跳出中间、电信、中间商等都是卡住的广告)
“我们这边”的客户端获取完整的信息,这是一大段 HTML 文本。一般来说,IE浏览器或任何其他XX浏览器都会解析HTML格式的文本,即HTML网页。
这样的一段甚至是HTML格式的,所谓的“网页源代码”
你好
成功请求后,它已经是客户端的结果 - “我们这边”。大家要研究的是如何分析这个“HTML风格的代码”,比如HELLO,如何用代码去捕捉它,那也是数据吧?
在W3C()的规定中,这种东西被规定为对象模型,就是从文档开始的集合(微软自己也在上面加了一个APPLICATION)
不过在这之前怎么请求也是个问题,所以客户端和服务端之间也有一个流程,就是一个HTTP协议,POST和GET的详细流程。如果我们不想详细了解,我们可以直接请一个对象来帮助我们。,解析后可以获取文档下面的对象,也可以自己手动请求服务器。这是 IE APPLICATION 和 XMLHTTP 对象之间的区别。
XMLHTTP对象不负责解析document等网页对象,而是负责向服务器发送请求,取回请求,取回一串字符流(所以不太严格,也有二进制的)
IE APPLICATION 或 WEB CONTROL 控件接管发送和检索请求的工作,并将这些内容处理和重建为“网页对象”。
他们有自己的优点和缺点。一般来说,初学者最好使用 web 对象,因为它们跳过了内部细节;但是,Web 对象有时构建起来非常复杂。比如解析成广告,解析成GIF,解析成乱七八糟的网页代码(可能是死循环,恶意代码),你就在那里等——相当于DOEVENTS,等花。而要直接抓取数据,还得有耐心和技术,慢慢分析一串字符才能找到数据(有时候很尴尬,不如标准的W3C对象,与其说是用代码,不如说是是手动计算)
但是,直接 POST 和 GET 对于在网页上提交数据非常有用。它最初是基于 HTTP 协议的。在网页的对象中,如果要通过FORM提交数据,也是POST。 查看全部
网页 抓取 innertext 试题(什么是HTML的格式文字,和EXCEL等OFFICE程序不同)
难得来这里讲一下浏览器对象的问题。
与EXCEL等OFFICE程序不同的是,浏览器的目的是获取信息,其操作分为“两段”,一段在“我们自己”(客户端),一段在服务器。
在运行时,“我们这边”的浏览器(客户端)向服务器发送请求,服务器回复,然后它返回(认为正确,这是要检查的,有协议,如果有答案正确与否,比如我们常见的404回答,还有强盗跳出中间、电信、中间商等都是卡住的广告)
“我们这边”的客户端获取完整的信息,这是一大段 HTML 文本。一般来说,IE浏览器或任何其他XX浏览器都会解析HTML格式的文本,即HTML网页。
这样的一段甚至是HTML格式的,所谓的“网页源代码”
你好
成功请求后,它已经是客户端的结果 - “我们这边”。大家要研究的是如何分析这个“HTML风格的代码”,比如HELLO,如何用代码去捕捉它,那也是数据吧?
在W3C()的规定中,这种东西被规定为对象模型,就是从文档开始的集合(微软自己也在上面加了一个APPLICATION)
不过在这之前怎么请求也是个问题,所以客户端和服务端之间也有一个流程,就是一个HTTP协议,POST和GET的详细流程。如果我们不想详细了解,我们可以直接请一个对象来帮助我们。,解析后可以获取文档下面的对象,也可以自己手动请求服务器。这是 IE APPLICATION 和 XMLHTTP 对象之间的区别。
XMLHTTP对象不负责解析document等网页对象,而是负责向服务器发送请求,取回请求,取回一串字符流(所以不太严格,也有二进制的)
IE APPLICATION 或 WEB CONTROL 控件接管发送和检索请求的工作,并将这些内容处理和重建为“网页对象”。
他们有自己的优点和缺点。一般来说,初学者最好使用 web 对象,因为它们跳过了内部细节;但是,Web 对象有时构建起来非常复杂。比如解析成广告,解析成GIF,解析成乱七八糟的网页代码(可能是死循环,恶意代码),你就在那里等——相当于DOEVENTS,等花。而要直接抓取数据,还得有耐心和技术,慢慢分析一串字符才能找到数据(有时候很尴尬,不如标准的W3C对象,与其说是用代码,不如说是是手动计算)
但是,直接 POST 和 GET 对于在网页上提交数据非常有用。它最初是基于 HTTP 协议的。在网页的对象中,如果要通过FORM提交数据,也是POST。
网页 抓取 innertext 试题(网页抓取innertext试题班招生中._腾讯课堂2.2动态生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 16:01
网页抓取innertext试题班招生中._腾讯课堂2.2动态生成selenium+phantomjs+chrome的试题_腾讯课堂3.已经可以很容易的使用百度的统计工具来做相关数据的统计,但是和你想要的一样,实时数据是做不到的_腾讯课堂4.需要翻墙才能使用谷歌的api_腾讯课堂如果大家有些问题没有及时得到响应,可以在qq群315432027了解下。免费提供给大家手机解答!。
现在selenium貌似也不能抓取classbase(object):...def__init__(self,url,self.pageno):self.url=urlself.pageno=self.urlself.content=self.pagenoself.headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2724.81safari/537.36'}self.cookies={'user-agent':user_agent}self.request=webdriver.request(self.url,self.pageno,self.headers).ssl握手阶段发送socket第一步获取到url通过简单的pageno属性可以知道定位到了哪个页面,可以简单的从页面的html代码中提取出定位到的页面地址,然后使用request对应定位到页面的headers对象可以提取headers中的http头信息,提取完成的headers对象属性如下:headers:parentheaders:thevaluesofthecookiepageno:pageno'thepagenoisused'thepagenoisnotused'foo.html'(absolute)'(extraparam)'(extraparam)'tag.html'(inverseparam)'okhttp.get(url,pageno).text获取classbase(object)函数执行的时候会使用self.self参数,self.pageno()和self.content()都是获取self.headers中http头的值,它们都不属于url属性,所以提取self.headers属性中的值必须使用self.content(),从headers的属性中找到http头的值,然后从对应的值中获取定位到相对应的页面地址。
再定位到相对应的页面地址,最终可以得到参数中self.pageno()和self.content()。如果不使用request对应定位到页面的headers对象,那么网页页面地址就定位不到。参考:《thehead》深入浅出tcp、udpfromscratch_腾讯课堂。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题班招生中._腾讯课堂2.2动态生成)
网页抓取innertext试题班招生中._腾讯课堂2.2动态生成selenium+phantomjs+chrome的试题_腾讯课堂3.已经可以很容易的使用百度的统计工具来做相关数据的统计,但是和你想要的一样,实时数据是做不到的_腾讯课堂4.需要翻墙才能使用谷歌的api_腾讯课堂如果大家有些问题没有及时得到响应,可以在qq群315432027了解下。免费提供给大家手机解答!。
现在selenium貌似也不能抓取classbase(object):...def__init__(self,url,self.pageno):self.url=urlself.pageno=self.urlself.content=self.pagenoself.headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2724.81safari/537.36'}self.cookies={'user-agent':user_agent}self.request=webdriver.request(self.url,self.pageno,self.headers).ssl握手阶段发送socket第一步获取到url通过简单的pageno属性可以知道定位到了哪个页面,可以简单的从页面的html代码中提取出定位到的页面地址,然后使用request对应定位到页面的headers对象可以提取headers中的http头信息,提取完成的headers对象属性如下:headers:parentheaders:thevaluesofthecookiepageno:pageno'thepagenoisused'thepagenoisnotused'foo.html'(absolute)'(extraparam)'(extraparam)'tag.html'(inverseparam)'okhttp.get(url,pageno).text获取classbase(object)函数执行的时候会使用self.self参数,self.pageno()和self.content()都是获取self.headers中http头的值,它们都不属于url属性,所以提取self.headers属性中的值必须使用self.content(),从headers的属性中找到http头的值,然后从对应的值中获取定位到相对应的页面地址。
再定位到相对应的页面地址,最终可以得到参数中self.pageno()和self.content()。如果不使用request对应定位到页面的headers对象,那么网页页面地址就定位不到。参考:《thehead》深入浅出tcp、udpfromscratch_腾讯课堂。
网页 抓取 innertext 试题(网页抓取innertext试题之抓取代码的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-27 08:03
网页抓取innertext试题来源于网络简单来说的话,就是用自定义html标签代替字符串,然后用正则表达式匹配出数据抓取代码,对内容进行整理解析。
这个博客主要是为了实现googlesearchandsearchbar应用服务+爬虫,
用来改进抓包工具,简单功能自己写,
fromurllibimportrequestfrompyspider.spiderimportspiderfromdisplaymodel.spinoutimportspinoutg256355974
当每次输入都要使用set_url()方法,
这里有一份写好的抓取京东商品信息的代码,可以看看,大概要2、3小时, 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题之抓取代码的代码)
网页抓取innertext试题来源于网络简单来说的话,就是用自定义html标签代替字符串,然后用正则表达式匹配出数据抓取代码,对内容进行整理解析。
这个博客主要是为了实现googlesearchandsearchbar应用服务+爬虫,
用来改进抓包工具,简单功能自己写,
fromurllibimportrequestfrompyspider.spiderimportspiderfromdisplaymodel.spinoutimportspinoutg256355974
当每次输入都要使用set_url()方法,
这里有一份写好的抓取京东商品信息的代码,可以看看,大概要2、3小时,
网页 抓取 innertext 试题(:Google搜索结果文本解析的实施方式与解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-26 17:17
)
问题描述
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本并直接转到 Google 搜索页面。
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本,然后直接进入 Google 搜索页面。
function navigate(url) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.update(tabs[0].id, {url: url});
});
}
chrome.omnibox.onInputEntered.addListener(function(text) {
navigate("https://www.google.com.br/sear ... ot%3B + text + "%20%2B%20cnpj");
});
alert('Here is where the text will be extracted');
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后解析。实现这一目标最直接的方法是什么?
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后进行解析。实现此目的最直接的方法是什么?
推荐答案
好吧,将网页解析为 DOM 而不是纯文本可能更容易。不过,这不是你的问题。
好吧,将网页解析为 DOM 而不是纯文本可能会更容易。但是,这不是您的问题。
您的代码在导航到页面和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实施。
您的代码在导航到页面的方式和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实现方式。
因此,为了回答您有关如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这一点。这会将回答如何做到这一点与代码中的其他问题分开。
p>
因此,为了回答您关于如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这样做。这将回答如何做到这一点与代码中的其他问题分开。
正如评论中提到的 wOxxOm,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome.tabs.executeScript。通常,您将使用 details 参数的文件属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无解析等)的代码,以最基本的方式插入所需的单行代码是合理的。要插入一小段代码,可以使用 details 参数的 code 属性来执行此操作。在这种情况下,document.body.innerText 是返回的文本,假设您没有指定文本的内容。
正如 wOxxOm 在评论中提到的,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome .tabs.executeScript 注入内容脚本。通常,您将使用 details 参数的 file 属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无需解析等)的代码,只需插入最基本的方法所需的单行代码是合理的。要插入一小段代码,您可以使用 details 参数的 code 属性来执行此操作。在这种情况下,鉴于您没有说明您对文本的要求,document.body.innerText 是返回的文本。
要将文本发送回后台脚本,.
要将文本发送回后台脚本,使用 chrome.runtime.sendMessage()。
要在后台脚本中接收文本,请放置 .
为了在后台脚本中接收文本,将一个监听器 receiveText 添加到 chrome.runtime.onMessage。
background.js:
chrome.browserAction.onClicked.addListener(function(tab) {
console.log('Injecting content script(s)');
//On Firefox document.body.textContent is probably more appropriate
chrome.tabs.executeScript(tab.id,{
code: 'document.body.innerText;'
//If you had something somewhat more complex you can use an IIFE:
//code: '(function (){return document.body.innerText})();'
//If your code was complex, you should store it in a
// separate .js file, which you inject with the file: property.
},receiveText);
});
//tabs.executeScript() returns the results of the executed script
// in an array of results, one entry per frame in which the script
// was injected.
function receiveText(resultsArray){
console.log(resultsArray[0]);
}
manifest.json:
{
"description": "Gets the text of a webpage and logs it to the console",
"manifest_version": 2,
"name": "Get Webpage Text",
"version": "0.1",
"permissions": [
"activeTab"
],
"background": {
"scripts": [
"background.js"
]
},
"browser_action": {
"default_icon": {
"32": "myIcon.png"
},
"default_title": "Get Webpage Text",
"browser_style": true
}
} 查看全部
网页 抓取 innertext 试题(:Google搜索结果文本解析的实施方式与解析
)
问题描述
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本并直接转到 Google 搜索页面。
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本,然后直接进入 Google 搜索页面。
function navigate(url) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.update(tabs[0].id, {url: url});
});
}
chrome.omnibox.onInputEntered.addListener(function(text) {
navigate("https://www.google.com.br/sear ... ot%3B + text + "%20%2B%20cnpj");
});
alert('Here is where the text will be extracted');
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后解析。实现这一目标最直接的方法是什么?
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后进行解析。实现此目的最直接的方法是什么?
推荐答案
好吧,将网页解析为 DOM 而不是纯文本可能更容易。不过,这不是你的问题。
好吧,将网页解析为 DOM 而不是纯文本可能会更容易。但是,这不是您的问题。
您的代码在导航到页面和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实施。
您的代码在导航到页面的方式和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实现方式。
因此,为了回答您有关如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这一点。这会将回答如何做到这一点与代码中的其他问题分开。
p>
因此,为了回答您关于如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这样做。这将回答如何做到这一点与代码中的其他问题分开。
正如评论中提到的 wOxxOm,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome.tabs.executeScript。通常,您将使用 details 参数的文件属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无解析等)的代码,以最基本的方式插入所需的单行代码是合理的。要插入一小段代码,可以使用 details 参数的 code 属性来执行此操作。在这种情况下,document.body.innerText 是返回的文本,假设您没有指定文本的内容。
正如 wOxxOm 在评论中提到的,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome .tabs.executeScript 注入内容脚本。通常,您将使用 details 参数的 file 属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无需解析等)的代码,只需插入最基本的方法所需的单行代码是合理的。要插入一小段代码,您可以使用 details 参数的 code 属性来执行此操作。在这种情况下,鉴于您没有说明您对文本的要求,document.body.innerText 是返回的文本。
要将文本发送回后台脚本,.
要将文本发送回后台脚本,使用 chrome.runtime.sendMessage()。
要在后台脚本中接收文本,请放置 .
为了在后台脚本中接收文本,将一个监听器 receiveText 添加到 chrome.runtime.onMessage。
background.js:
chrome.browserAction.onClicked.addListener(function(tab) {
console.log('Injecting content script(s)');
//On Firefox document.body.textContent is probably more appropriate
chrome.tabs.executeScript(tab.id,{
code: 'document.body.innerText;'
//If you had something somewhat more complex you can use an IIFE:
//code: '(function (){return document.body.innerText})();'
//If your code was complex, you should store it in a
// separate .js file, which you inject with the file: property.
},receiveText);
});
//tabs.executeScript() returns the results of the executed script
// in an array of results, one entry per frame in which the script
// was injected.
function receiveText(resultsArray){
console.log(resultsArray[0]);
}
manifest.json:
{
"description": "Gets the text of a webpage and logs it to the console",
"manifest_version": 2,
"name": "Get Webpage Text",
"version": "0.1",
"permissions": [
"activeTab"
],
"background": {
"scripts": [
"background.js"
]
},
"browser_action": {
"default_icon": {
"32": "myIcon.png"
},
"default_title": "Get Webpage Text",
"browser_style": true
}
}
网页 抓取 innertext 试题(如何让蜘蛛快速抓取网站方式方法(精选大合集))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-26 08:05
蜘蛛快速抓取网站方法(精选合集)
在这个互联网时代,很多人在购买产品之前都会去互联网查看信息内容,看看哪个品牌的知名度和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务搜索自己需要的信息,其中近70%的搜索者会直接在搜索结果自然排名的首页搜索自己需要的信息。.
由此可见,近年来,SEO对于企业和产品有着不可替代的意义。下面,我将告诉你如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
入链是优化网站的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。近年来,常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫爬取
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等,如果想让你的网站更多的页面是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
二、网站如何被蜘蛛快速爬取
1.平台网站 和页面权重。
这当然是首要的。权重高、资历高、权威大的平台网站蜘蛛当然是被正确对待了。这样的网站爬取的概率非常高,大家都知道搜索引擎蜘蛛为了保证效率,对于平台网站不一定所有页面都会被爬取,< @网站,爬得越深,对应的可爬取的页面也会增加,所以收录的页面也会更多。
2.网站服务器。
网站服务器是平台的基石网站,网站如果服务器长时间打不开,那就等于和你关门谢了,蜘蛛将无法到来。百度蜘蛛也是平台网站的访问者。如果你的服务器不稳定或者比较卡,那么每次爬虫都会很难爬到,有时候只能爬到页面的一部分。蜘蛛的体验越来越差,你的平台网站的分数会越来越低,自然会影响你的平台网站的爬取,所以一定要愿意选择一个空间服务器,没有人打好基础,房子再好,也会跨越。
3.平台网站的更新概率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动显示蜘蛛,并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛做出一次经常浪费的旅行。
4.文章 的 原创 特性。
优质原创内容对百度蜘蛛的诱惑是巨大的。蜘蛛存在的目的是为了发现新事物,所以网站更新文章不要采集,也不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛们能得到他们喜欢的东西,它们自然会对你的平台网站产生好感,并经常来觅食。
5.扁平平台网站结构。——
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。平台网站结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面很难被蜘蛛抓取。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会导致平台网站重复内容可能导致平台网站降级,严重影响蜘蛛的抓取,所以程序必须保证一个页面只有一个网址。处理标签或机器人以确保蜘蛛只抓取一个规范 URL。
7.外链建设。
我们都知道外链对于网站平台是可以吸引蜘蛛的,尤其是新站点的时候,平台网站还不是很成熟,蜘蛛访问的比较少,所以外链的数量链接可以增加 网站 页面在蜘蛛面前的曝光,阻止蜘蛛找到页面。在建立外链的过程中,需要注意外链的质量。不要为了省事而做无用的事情。相信大家都知道百度对外链接的管理。我不会多说。
8.内链构建。
蜘蛛的爬取是跟随链接的,所以内链的合理优化可以让蜘蛛爬取更多的页面,提升平台网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,很多平台网站都用到了,让蜘蛛爬取一个更广泛的页面。 查看全部
网页 抓取 innertext 试题(如何让蜘蛛快速抓取网站方式方法(精选大合集))
蜘蛛快速抓取网站方法(精选合集)
在这个互联网时代,很多人在购买产品之前都会去互联网查看信息内容,看看哪个品牌的知名度和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务搜索自己需要的信息,其中近70%的搜索者会直接在搜索结果自然排名的首页搜索自己需要的信息。.
由此可见,近年来,SEO对于企业和产品有着不可替代的意义。下面,我将告诉你如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
入链是优化网站的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。近年来,常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫爬取
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等,如果想让你的网站更多的页面是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。

二、网站如何被蜘蛛快速爬取
1.平台网站 和页面权重。
这当然是首要的。权重高、资历高、权威大的平台网站蜘蛛当然是被正确对待了。这样的网站爬取的概率非常高,大家都知道搜索引擎蜘蛛为了保证效率,对于平台网站不一定所有页面都会被爬取,< @网站,爬得越深,对应的可爬取的页面也会增加,所以收录的页面也会更多。
2.网站服务器。
网站服务器是平台的基石网站,网站如果服务器长时间打不开,那就等于和你关门谢了,蜘蛛将无法到来。百度蜘蛛也是平台网站的访问者。如果你的服务器不稳定或者比较卡,那么每次爬虫都会很难爬到,有时候只能爬到页面的一部分。蜘蛛的体验越来越差,你的平台网站的分数会越来越低,自然会影响你的平台网站的爬取,所以一定要愿意选择一个空间服务器,没有人打好基础,房子再好,也会跨越。
3.平台网站的更新概率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动显示蜘蛛,并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛做出一次经常浪费的旅行。
4.文章 的 原创 特性。
优质原创内容对百度蜘蛛的诱惑是巨大的。蜘蛛存在的目的是为了发现新事物,所以网站更新文章不要采集,也不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛们能得到他们喜欢的东西,它们自然会对你的平台网站产生好感,并经常来觅食。
5.扁平平台网站结构。——
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。平台网站结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面很难被蜘蛛抓取。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会导致平台网站重复内容可能导致平台网站降级,严重影响蜘蛛的抓取,所以程序必须保证一个页面只有一个网址。处理标签或机器人以确保蜘蛛只抓取一个规范 URL。
7.外链建设。
我们都知道外链对于网站平台是可以吸引蜘蛛的,尤其是新站点的时候,平台网站还不是很成熟,蜘蛛访问的比较少,所以外链的数量链接可以增加 网站 页面在蜘蛛面前的曝光,阻止蜘蛛找到页面。在建立外链的过程中,需要注意外链的质量。不要为了省事而做无用的事情。相信大家都知道百度对外链接的管理。我不会多说。
8.内链构建。
蜘蛛的爬取是跟随链接的,所以内链的合理优化可以让蜘蛛爬取更多的页面,提升平台网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,很多平台网站都用到了,让蜘蛛爬取一个更广泛的页面。
网页 抓取 innertext 试题(一个soup对象用beautifulsoup库中方法提取页面源码(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-16 17:18
)
假设有一个页面有n个选择题,每个选择题都有几个选项。茎部分标有 h6 标签。options 部分使用 td 下的 div 标签。如下所示:
整个页面就是循环下面的 HTML 段落 n 次。
第1题. 选一二三还是四五六呢。
A.一二三
B.四五六
接下来,我想使用beautifulsoup库中的方法来提取页面上的主题和选项。
首先,导入所需的包:
from bs4 import BeautifulSoup
from urllib import request,parse
import re
然后可以通过多种方式提取页面源代码:
#既可以打开一个html文件:
soup = BeautifulSoup(open("page_source_code.html"))
#或者直接传入HTML代码:
soup = BeautifulSoup("data")
#也可以发送并且拦截请求:
url = “http://fake.html”
response = request.urlopen(url,timeout = 20)
responseUTF8 = response.read().decode("utf-8")
soup = BeautifulSoup(responseUTF8,'lxml')
简而言之,这样我们就得到了一个汤对象。接下来根据对象的标签结构,通过一定的方法定位目标标签。
方法一:下面的方法比较基础,使用“绝对路径”查找标签
# 通过观察发现,题干部分全部都是h6标签,和h6标签下的a标签。页面其余部分没有用到h6标签,所以用.find_all方法来抓取所有的题干。得到一个标签 list
h6lbs = soup.find_all('h6')
# 定义一个二维数组,用来盛放抓取到的选择题。选择题的题干和选项可作为每一个数组成员的成员。
item_question = []
for i in range(len(h6lbs)):
#定义一个一维数组,可以用来盛放题干和选项。先把刚刚拿到的题干保存进数组中
item = []
item.append(h6lbs[i].text)
#通过以上的HTML 结构可以知道,找到题干后,题干标签的“太爷爷”的“三弟弟”是保存选项的地方,所以这里用了很多个.parent 和 .next_sibling方法,通过绝对路径的方式定位标签
tag1 = h6lbs[i].parent.parent.parent.next_sibling.next_sibling
# check if this is choice question. or it must be a Yes/No questionnaire
if tag1 is not None and tag1.li is not None:
#刚刚说到太爷爷的三弟弟是存放选项的地方。太爷爷的三弟弟下的li标签下的table标签下的tbody标签下存放了多个选项,从这里开始需要遍历,将每一个选项都提取出
tag = h6lbs[i].parent.parent.parent.next_sibling.next_sibling.li.table.tbody
for child in tag.children:
#因为抓取出来有空对象,所以此处加入了一个判断。如果是None,就不保存了。
if child.string is None:
tag_string = child.td.div.string
#遍历每一个标签,取出其中的选项内容,用.string方法
#将取到的选项内容加入刚刚创建的一维数组中
item.append(tag_string)
# print(item)
#将每次得到的一维数组保存进二维数组中
item_question.append(item)
print(item_question) 查看全部
网页 抓取 innertext 试题(一个soup对象用beautifulsoup库中方法提取页面源码(图)
)
假设有一个页面有n个选择题,每个选择题都有几个选项。茎部分标有 h6 标签。options 部分使用 td 下的 div 标签。如下所示:
整个页面就是循环下面的 HTML 段落 n 次。
第1题. 选一二三还是四五六呢。
A.一二三
B.四五六
接下来,我想使用beautifulsoup库中的方法来提取页面上的主题和选项。
首先,导入所需的包:
from bs4 import BeautifulSoup
from urllib import request,parse
import re
然后可以通过多种方式提取页面源代码:
#既可以打开一个html文件:
soup = BeautifulSoup(open("page_source_code.html"))
#或者直接传入HTML代码:
soup = BeautifulSoup("data")
#也可以发送并且拦截请求:
url = “http://fake.html”
response = request.urlopen(url,timeout = 20)
responseUTF8 = response.read().decode("utf-8")
soup = BeautifulSoup(responseUTF8,'lxml')
简而言之,这样我们就得到了一个汤对象。接下来根据对象的标签结构,通过一定的方法定位目标标签。
方法一:下面的方法比较基础,使用“绝对路径”查找标签
# 通过观察发现,题干部分全部都是h6标签,和h6标签下的a标签。页面其余部分没有用到h6标签,所以用.find_all方法来抓取所有的题干。得到一个标签 list
h6lbs = soup.find_all('h6')
# 定义一个二维数组,用来盛放抓取到的选择题。选择题的题干和选项可作为每一个数组成员的成员。
item_question = []
for i in range(len(h6lbs)):
#定义一个一维数组,可以用来盛放题干和选项。先把刚刚拿到的题干保存进数组中
item = []
item.append(h6lbs[i].text)
#通过以上的HTML 结构可以知道,找到题干后,题干标签的“太爷爷”的“三弟弟”是保存选项的地方,所以这里用了很多个.parent 和 .next_sibling方法,通过绝对路径的方式定位标签
tag1 = h6lbs[i].parent.parent.parent.next_sibling.next_sibling
# check if this is choice question. or it must be a Yes/No questionnaire
if tag1 is not None and tag1.li is not None:
#刚刚说到太爷爷的三弟弟是存放选项的地方。太爷爷的三弟弟下的li标签下的table标签下的tbody标签下存放了多个选项,从这里开始需要遍历,将每一个选项都提取出
tag = h6lbs[i].parent.parent.parent.next_sibling.next_sibling.li.table.tbody
for child in tag.children:
#因为抓取出来有空对象,所以此处加入了一个判断。如果是None,就不保存了。
if child.string is None:
tag_string = child.td.div.string
#遍历每一个标签,取出其中的选项内容,用.string方法
#将取到的选项内容加入刚刚创建的一维数组中
item.append(tag_string)
# print(item)
#将每次得到的一维数组保存进二维数组中
item_question.append(item)
print(item_question)
网页 抓取 innertext 试题(如何每年5月份10月会计从业资格证考试真题6)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-15 01:01
网页抓取innertext试题地址:591344732017-08-2623:48:001。chromedriverbrowserscriptfiddler62。各种方法抓取下载网页地址的前x页3。抓取热门话题下第x页4。热门话题下x页5。如何抓取17年10月会计从业资格证考试真题6。如何抓取每年5月份cfa考试的真题7。如何抓取每年4月份的教师资格证考试真题8。如何抓取每年3月份的安全从业资格证考试真题。
"如何抓取每年5月份的从业资格证考试真题?"我都懒得分析此问题了,又想玩抓取又是从哪里找的东西。
抓取一些机构网站的内容呗
然后根据题目分析,哪部分是重点,再回头对应着学习,细致化学习,
抓取排名前几的公众号文章试试?
通过浏览器的截图分析大部分的知乎回答
方法也很多呀,抓取某些用户的简历,再通过调查问卷抓取大部分用户关心的信息,再找其中比较有趣的关键词,很多的。我试过用爬虫写软件,后来发现,还是不如传统的爬虫,因为有些东西得过滤,要格外小心一点,反正我是一条一条写代码,做好分析给研究员和专家审核,反正要抓到的问题是完全一样的问题,也不用考虑正负面评价,基本就是讨论性的东西了。代码里面也要避免误伤,尽量做到完整自洽。
翻墙
百度贴吧爬虫等等 查看全部
网页 抓取 innertext 试题(如何每年5月份10月会计从业资格证考试真题6)
网页抓取innertext试题地址:591344732017-08-2623:48:001。chromedriverbrowserscriptfiddler62。各种方法抓取下载网页地址的前x页3。抓取热门话题下第x页4。热门话题下x页5。如何抓取17年10月会计从业资格证考试真题6。如何抓取每年5月份cfa考试的真题7。如何抓取每年4月份的教师资格证考试真题8。如何抓取每年3月份的安全从业资格证考试真题。
"如何抓取每年5月份的从业资格证考试真题?"我都懒得分析此问题了,又想玩抓取又是从哪里找的东西。
抓取一些机构网站的内容呗
然后根据题目分析,哪部分是重点,再回头对应着学习,细致化学习,
抓取排名前几的公众号文章试试?
通过浏览器的截图分析大部分的知乎回答
方法也很多呀,抓取某些用户的简历,再通过调查问卷抓取大部分用户关心的信息,再找其中比较有趣的关键词,很多的。我试过用爬虫写软件,后来发现,还是不如传统的爬虫,因为有些东西得过滤,要格外小心一点,反正我是一条一条写代码,做好分析给研究员和专家审核,反正要抓到的问题是完全一样的问题,也不用考虑正负面评价,基本就是讨论性的东西了。代码里面也要避免误伤,尽量做到完整自洽。
翻墙
百度贴吧爬虫等等
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-13 10:11
最近有朋友在做OJ题库,可以做个小爬虫,导出题库列表看看!
对象:浙江大学题库
工具:python3.6、requests库、lxml库、pycharm
思路:首先在网页中找到题库的位置
然后我们点击第一页和后面的页面可以看到url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的都没有变,所以建个循环很方便。我们来看看源代码中title的title和Id以及url的位置。
是不是很明显a标签的属性里有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath抓取td标签,然后match 获取url和title,剪掉url写id(这里我就不去上面的td单独抓id了),然后写到字典里,这样就方便了查看,代码如下:
20多行代码全部搞定,结果如下:
不到 10 秒就在本地捕获了所有这些。当然,注意不要在这里重复操作,很有可能IP会被封!
将txt文档中的内容复制到在线解析json的网页中,查看结果
完美呈现~!当然,如果你有兴趣,你可以去主题的url,抓取主题。这可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很厉害的,欢迎大家跟我一起学python! 查看全部
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
最近有朋友在做OJ题库,可以做个小爬虫,导出题库列表看看!
对象:浙江大学题库
工具:python3.6、requests库、lxml库、pycharm
思路:首先在网页中找到题库的位置
然后我们点击第一页和后面的页面可以看到url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的都没有变,所以建个循环很方便。我们来看看源代码中title的title和Id以及url的位置。
是不是很明显a标签的属性里有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath抓取td标签,然后match 获取url和title,剪掉url写id(这里我就不去上面的td单独抓id了),然后写到字典里,这样就方便了查看,代码如下:
20多行代码全部搞定,结果如下:
不到 10 秒就在本地捕获了所有这些。当然,注意不要在这里重复操作,很有可能IP会被封!
将txt文档中的内容复制到在线解析json的网页中,查看结果
完美呈现~!当然,如果你有兴趣,你可以去主题的url,抓取主题。这可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很厉害的,欢迎大家跟我一起学python!
网页 抓取 innertext 试题(网页抓取innertext试题,没啥可加密,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-10 12:00
网页抓取innertext试题,这个api是false的,如果你不想要这个string,可以使用accept-language(客户端,服务端,aws,
两种方式:inputtext里面,i=10and"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz".hasoned("abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz");secondpassword里面,i=10可以打开这个网页,然后直接看abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz。现在returntrue。
统一的给前端让他们自己写一个
现在抓包都用ssl,甚至有很多反爬虫工具,这种情况下,我觉得没必要加密解密了。
没啥可加密的,根据nginx提供的信息就可以了,可以通过http分析获取到accept-language这个字段,根据需要获取有哪些值就加什么值呗,
有一种加密方式是重定向(redirect),这个方式其实在一些rss平台也被用到,比如feedly就是使用的这种方式,当然正常情况没必要这么干。另外如果accept-language不是特别重要,建议尽量用正则表达式。
给accept-language前面加点accept-encoding, 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题,没啥可加密,怎么办?)
网页抓取innertext试题,这个api是false的,如果你不想要这个string,可以使用accept-language(客户端,服务端,aws,
两种方式:inputtext里面,i=10and"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz".hasoned("abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz");secondpassword里面,i=10可以打开这个网页,然后直接看abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz。现在returntrue。
统一的给前端让他们自己写一个
现在抓包都用ssl,甚至有很多反爬虫工具,这种情况下,我觉得没必要加密解密了。
没啥可加密的,根据nginx提供的信息就可以了,可以通过http分析获取到accept-language这个字段,根据需要获取有哪些值就加什么值呗,
有一种加密方式是重定向(redirect),这个方式其实在一些rss平台也被用到,比如feedly就是使用的这种方式,当然正常情况没必要这么干。另外如果accept-language不是特别重要,建议尽量用正则表达式。
给accept-language前面加点accept-encoding,
网页 抓取 innertext 试题(一个demoP站视频标题连接从哪里来?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-01-06 15:06
最近在学习Golang有一段时间了,想写点东西练练手。一开始想用golang来写爬虫,但是感觉太简单了。为什么不写一个网站!想了想,我对P站很熟悉了。文章之前写过一段nginx反代P站的视频。结合起来写个静态P站比较好,所以做了个demo。整个Golang代码不多,非常适合新手练习。
首先分析一下整个网站的思路,内容,也就是图片和视频标题链接,从何而来?这当然是直接从 Pornhub 抓取的。其次,由于是静态的网站,除了获取视频页面外,基本没有与后端的交互。页面也由后端直接渲染到前端。视频的播放由nginx直接处理。大致就是这么简单,其他的细节会在后面详述。
我们的第一步是去P站抓取视频素材,因为是静态的网站我们不用弄的太复杂,一次只能抓取一个页面显示出来。众所周知,P站是一个学习网站,也是一个包容的网站!比如我们在P站搜索美食时,可以看到很多网友上传的美食视频。
假设我们抓取上面的视频内容,打开控制台查看页面元素。
每个视频都放置在一个li标签中,里面收录了视频的一些基本信息。这是我们需要爬行的。原视频的链接只能从视频页面获取,需要再次发起get请求。将部分代码直接粘贴在这里。
func getRandomPhid() []string {
rand.Seed(time.Now().Unix())
randNum := rand.Intn(1000) //播种生成随机整数
url := "https://cn.pornhub.com/video?page=" + strconv.Itoa(randNum)
fmt.Println(url)
resp, err := http.Get(url)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
ulTag := htmlquery.FindOne(root, "//*[@id=\"videoCategory\"]")
aHrefList := htmlquery.Find(ulTag, "//a[@href]")
phList := []string{}
tmp := ""
for _, n := range aHrefList {
aHref := htmlquery.SelectAttr(n, "href")
if strings.Contains(aHref, "viewkey") {
if tmp == aHref { //提取视频链接时会有连续重复的情况
continue
}
ph := strings.Split(aHref, "=")[1]
phList = append(phList, ph)
tmp = aHref
}
}
return phList
}
这里我定义了一个getRandomPhid的函数,就是随机抓取P站上一页的视频内容。播种后,生成 0-1000 之间的任意整数。直接使用 http.Get 方法是因为不需要对请求进行额外的更改。这里使用了第三方库htmlquery来解析html元素,类似于python中的BeautifulSoup库。
因为所有li标签的父标签都是ul,所以元素通过xpath定位。然后我定义了一个字符串类型的切片 phList 来存储提取的视频 ID。因为会有重复的id,还是需要去重,但是golang没有python方便,可以直接使用set,需要自己实现,但是这里比较特殊,两个重复的id是连续的,所以直接用一个tmp变量来和前面的比较一下,去掉重复。
func reqPhid(id string) (videoInfo map[string]string, err error) {
defer func() {
if err := recover(); err != nil {
log.Println(err)
}
}()
client := &http.Client{}
url := "https://cn.pornhub.com/view_vi ... ot%3B + id
req, err := http.NewRequest("GET", url, nil)
checkError(err)
req.Header.Set("user-agent", "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1")
resp, err := client.Do(req)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
js := htmlquery.FindOne(root, "//*[@id=\"mobileContainer\"]/script[1]/text()")
jsString := htmlquery.InnerText(js)
videoInfo = make(map[string]string)
phQuality := gjson.Get(jsString, "quality_720p").String()
if phQuality == "" {
err = errors.New("获取视频链接失败!")
return
}
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
phQuality = re.ReplaceAllString(phQuality, domain+subDomain)
image_url := gjson.Get(jsString, "image_url").String()
subDomain = re.FindStringSubmatch(image_url)[1]
image_url = re.ReplaceAllString(image_url, domain+subDomain)
video_title := gjson.Get(jsString, "video_title").String()
videoInfo["videoUrl"] = phQuality
videoInfo["imgUrl"] = image_url
videoInfo["title"] = video_title
fmt.Println(videoInfo)
return
}
在前面的函数中,我们得到了所有的视频 ID。要获得真正的视频链接,我们需要再次请求视频页面。在这个函数中,我从一开始就推迟了一个匿名函数来捕获异常。接下来我们没有使用http.Get方法,而是使用&http.Client{}添加了一些我们自定义的header,即修改User-Agent伪装成手机浏览器header,而这个server也返回h5页面,原因是这里用了一个小技巧。
看过我文章的读者都知道,PC端请求P站得到的视频信息是经过加密和混淆处理的,手机端的信息直接是原创视频信息。我偶然发现了这一点,否则就太费力了,吃力不讨好,所以这个想法还是很重要的,有时也能奏效。不知道的朋友可以看看我之前的文章。
看完Pornhub的视频界面JS混乱,我手写了一个下载插件
可以试试用Chrome切换浏览器UA,真的很方便!
或者先用xpath定位这个JS的位置。flashvars的变量显然是json格式的数据。U1S1,golang原生处理json的方法真的很麻烦,需要写一个struct来接受数据。小数据的json也可以,一些复杂的json,尤其是不知道数据类型的时候,直接破解。这里推荐一个第三方模块gjson来解析,非常方便,和python一样流畅。
另外视频的分辨率有240、480、720、1080,为了尽量简化,我只拍了720分辨率的链接。通过定期匹配,将视频链接转换为您自己的域名。最后,它返回一个 map[string]string 类型的数据。
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
至于为什么这里只能使用dm1接口链接,我们后面再讨论。并且为了防止请求频率因为请求频率过快而被禁止,每次爬取后,暂停3s,尽可能减少异常。
func timeToRefresh() {
count := 0 //记录页面刷新的次数
for true {
allVideos = make([]map[string]string, 0)
phList := getRandomPhid()
for _, id := range phList {
video, err := reqPhid(id)
if err != nil {
log.Println(err)
continue
}
allVideos = append(allVideos, video)
}
count++
log.Printf("第%v次刷新页面", count)
time.Sleep(15 * time.Minute) //每隔多长时间时间刷新一次页面
}
}
因为我们写的是静态页面,没有前后端交互,而且后端渲染的很好,所以后端要定时抓取来刷新我们网站的内容. 这里allVideos是一个map,用来存放每次捕捉到的视频信息,但是注意这个变量在for循环中每次都用make初始化,相当于每次刷新视频数据。同时 allVideos 仍然是 myHandler 直接使用的全局变量。
在这里获取所有与视频相关的信息,基本上抓住它就结束了。剩下的就是网络服务器所做的。其实在golang里面很简单。
func myHandler(w http.ResponseWriter, r *http.Request) {
t, err := template.ParseFiles("index.html")
checkError(err)
err = t.Execute(w, allVideos)
checkError(err)
}
func main() {
go timeToRefresh()
http.HandleFunc("/", myHandler)
err := http.ListenAndServe(":8080", nil)
checkError(err)
}
这里我把这两个函数放在一起,myHandler相当于对请求的响应。首先是解析我们写好的前端模板,然后渲染生成我们传入的数据并发送给用户。
前面提到的timeToRefresh函数是一个定时捕获函数,但是我们不能让抓取的页面阻塞我们的主线程,所以直接在它前面加一个go关键字就可以了。是不是很方便?这体现了为了go语言的魅力,我们会另外写一个线程或者其他语言的东西。所以golang写起来真的很流畅。然后是绑定路径和监听端口。这些都非常简单。
func checkError(err error) {
if err != nil {
log.Println(err)
}
}
而且大家都知道golang中的错误处理会写一堆if err !=nil{… },所以我再封装一层。在上面的代码中,我看到我使用 checkError 统一处理 err。
Golang的部分基本完成。再说说Nginx的部分。既然要播放视频,就不能随便抢视频链接,因为P站在国内被屏蔽了,不能直接播放。一切都可以通过使用Nginx反生成视频流打开缓冲区来实现。具体可以参考我之前的文章文章。
白嫖?神奇使用Nginx proxy_buffer实现Pornhub视频反向生成
在这个文章中,我使用了多个子域来逆向生成。事实上,读者无需在此之前发表评论。您可以使用以下编写方法。
前面的代码提到了不匹配dm1接口的时候会panic,因为我这里没有研究透彻。我把dm1域名倒过来是可以的,但是其他的会以403拒绝响应。
dm1 是正常的。所以这里我只使用了匹配dm1的视频链接。
我猜应该是做了一些测试,但是我想通了具体的原因,不知道有没有必要带一些具体的header。希望朋友们留言一起讨论。
最后是前端模板。这是勾刀为我做的。非常感谢勾刀的帮助。其中 let json = {{.}} 是 golang 模板的语法,传入我们的数据。
Golang + Nginx 实现静态 Pornhub
//样式的代码过长,就不展示了
每隔15分钟自动刷新视频页面
//后端返回的数据
let json = {{.}}
//处理数据
json.map(v => {
appendCard(newCard(v.videoUrl, v.imgUrl, v.title))
})
//创建card
function newCard(videoUrl, imgUrl, title) {
let card = document.createElement('div')
card.classList.add('card')
let face1 = document.createElement('div')
face1.classList.add('face')
face1.classList.add('face1')
let p = document.createElement('p')
p.innerText = title
p.setAttribute("videoUrl", videoUrl)
face1.appendChild(p)
let face2 = document.createElement('div')
face2.classList.add('face')
face2.classList.add('face2')
let img = document.createElement('img')
img.setAttribute('src', imgUrl)
img.setAttribute('alt', "")
face2.appendChild(img)
card.appendChild(face1)
card.appendChild(face2)
p.onclick = function (e) {
window.open(e.target.getAttribute("videoUrl"))
}
return card
}
//将card添加进页面
function appendCard(card) {
let main = document.getElementsByClassName('main')[0]
main.appendChild(card)
}
这样我们的静态P站就做好了,最后就是显示我们用Golang+Nginx网站做了。我在某云中使用了一台香港轻量级服务器在这里运行。它的带宽为30m。反代视频基本无压力。
因为比例太大,这里全部编码完成,网站的背景改为橙色。有没有P站的味道?哈哈哈。同时点击视频直接播放,是不是很香!好像ghs没那么难!当然,这里只是技术分享,哈哈!
本博客纯粹是我学习Golang一段时间后做的一个小demo。有兴趣的朋友可以自行尝试。毕竟,您可以应用所学!我把代码、前端模板和nginx配置文件放在下面,把golang代码和Nginx配置中的域名换成自己的域名即可!每个人都可以通过简单的改变开始跑步。
golang+nginx-做一个静态的pornhub网站.zip
如果有什么问题,小伙伴们可以在下方留言,共同探讨! 查看全部
网页 抓取 innertext 试题(一个demoP站视频标题连接从哪里来?(图))
最近在学习Golang有一段时间了,想写点东西练练手。一开始想用golang来写爬虫,但是感觉太简单了。为什么不写一个网站!想了想,我对P站很熟悉了。文章之前写过一段nginx反代P站的视频。结合起来写个静态P站比较好,所以做了个demo。整个Golang代码不多,非常适合新手练习。
首先分析一下整个网站的思路,内容,也就是图片和视频标题链接,从何而来?这当然是直接从 Pornhub 抓取的。其次,由于是静态的网站,除了获取视频页面外,基本没有与后端的交互。页面也由后端直接渲染到前端。视频的播放由nginx直接处理。大致就是这么简单,其他的细节会在后面详述。
我们的第一步是去P站抓取视频素材,因为是静态的网站我们不用弄的太复杂,一次只能抓取一个页面显示出来。众所周知,P站是一个学习网站,也是一个包容的网站!比如我们在P站搜索美食时,可以看到很多网友上传的美食视频。
 https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440-300x186.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440-768x477.png 768w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440.png 1065w" />
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440-300x186.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440-768x477.png 768w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440.png 1065w" />假设我们抓取上面的视频内容,打开控制台查看页面元素。
 https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111161313-300x165.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111161313-768x423.png 768w" />
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111161313-300x165.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111161313-768x423.png 768w" />每个视频都放置在一个li标签中,里面收录了视频的一些基本信息。这是我们需要爬行的。原视频的链接只能从视频页面获取,需要再次发起get请求。将部分代码直接粘贴在这里。
func getRandomPhid() []string {
rand.Seed(time.Now().Unix())
randNum := rand.Intn(1000) //播种生成随机整数
url := "https://cn.pornhub.com/video?page=" + strconv.Itoa(randNum)
fmt.Println(url)
resp, err := http.Get(url)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
ulTag := htmlquery.FindOne(root, "//*[@id=\"videoCategory\"]")
aHrefList := htmlquery.Find(ulTag, "//a[@href]")
phList := []string{}
tmp := ""
for _, n := range aHrefList {
aHref := htmlquery.SelectAttr(n, "href")
if strings.Contains(aHref, "viewkey") {
if tmp == aHref { //提取视频链接时会有连续重复的情况
continue
}
ph := strings.Split(aHref, "=")[1]
phList = append(phList, ph)
tmp = aHref
}
}
return phList
}
这里我定义了一个getRandomPhid的函数,就是随机抓取P站上一页的视频内容。播种后,生成 0-1000 之间的任意整数。直接使用 http.Get 方法是因为不需要对请求进行额外的更改。这里使用了第三方库htmlquery来解析html元素,类似于python中的BeautifulSoup库。
因为所有li标签的父标签都是ul,所以元素通过xpath定位。然后我定义了一个字符串类型的切片 phList 来存储提取的视频 ID。因为会有重复的id,还是需要去重,但是golang没有python方便,可以直接使用set,需要自己实现,但是这里比较特殊,两个重复的id是连续的,所以直接用一个tmp变量来和前面的比较一下,去掉重复。
func reqPhid(id string) (videoInfo map[string]string, err error) {
defer func() {
if err := recover(); err != nil {
log.Println(err)
}
}()
client := &http.Client{}
url := "https://cn.pornhub.com/view_vi ... ot%3B + id
req, err := http.NewRequest("GET", url, nil)
checkError(err)
req.Header.Set("user-agent", "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1")
resp, err := client.Do(req)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
js := htmlquery.FindOne(root, "//*[@id=\"mobileContainer\"]/script[1]/text()")
jsString := htmlquery.InnerText(js)
videoInfo = make(map[string]string)
phQuality := gjson.Get(jsString, "quality_720p").String()
if phQuality == "" {
err = errors.New("获取视频链接失败!")
return
}
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
phQuality = re.ReplaceAllString(phQuality, domain+subDomain)
image_url := gjson.Get(jsString, "image_url").String()
subDomain = re.FindStringSubmatch(image_url)[1]
image_url = re.ReplaceAllString(image_url, domain+subDomain)
video_title := gjson.Get(jsString, "video_title").String()
videoInfo["videoUrl"] = phQuality
videoInfo["imgUrl"] = image_url
videoInfo["title"] = video_title
fmt.Println(videoInfo)
return
}
在前面的函数中,我们得到了所有的视频 ID。要获得真正的视频链接,我们需要再次请求视频页面。在这个函数中,我从一开始就推迟了一个匿名函数来捕获异常。接下来我们没有使用http.Get方法,而是使用&http.Client{}添加了一些我们自定义的header,即修改User-Agent伪装成手机浏览器header,而这个server也返回h5页面,原因是这里用了一个小技巧。
看过我文章的读者都知道,PC端请求P站得到的视频信息是经过加密和混淆处理的,手机端的信息直接是原创视频信息。我偶然发现了这一点,否则就太费力了,吃力不讨好,所以这个想法还是很重要的,有时也能奏效。不知道的朋友可以看看我之前的文章。
看完Pornhub的视频界面JS混乱,我手写了一个下载插件
可以试试用Chrome切换浏览器UA,真的很方便!
 https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111235002-300x173.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111235002-768x443.png 768w" />
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111235002-300x173.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111235002-768x443.png 768w" />或者先用xpath定位这个JS的位置。flashvars的变量显然是json格式的数据。U1S1,golang原生处理json的方法真的很麻烦,需要写一个struct来接受数据。小数据的json也可以,一些复杂的json,尤其是不知道数据类型的时候,直接破解。这里推荐一个第三方模块gjson来解析,非常方便,和python一样流畅。
另外视频的分辨率有240、480、720、1080,为了尽量简化,我只拍了720分辨率的链接。通过定期匹配,将视频链接转换为您自己的域名。最后,它返回一个 map[string]string 类型的数据。
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
至于为什么这里只能使用dm1接口链接,我们后面再讨论。并且为了防止请求频率因为请求频率过快而被禁止,每次爬取后,暂停3s,尽可能减少异常。
func timeToRefresh() {
count := 0 //记录页面刷新的次数
for true {
allVideos = make([]map[string]string, 0)
phList := getRandomPhid()
for _, id := range phList {
video, err := reqPhid(id)
if err != nil {
log.Println(err)
continue
}
allVideos = append(allVideos, video)
}
count++
log.Printf("第%v次刷新页面", count)
time.Sleep(15 * time.Minute) //每隔多长时间时间刷新一次页面
}
}
因为我们写的是静态页面,没有前后端交互,而且后端渲染的很好,所以后端要定时抓取来刷新我们网站的内容. 这里allVideos是一个map,用来存放每次捕捉到的视频信息,但是注意这个变量在for循环中每次都用make初始化,相当于每次刷新视频数据。同时 allVideos 仍然是 myHandler 直接使用的全局变量。
在这里获取所有与视频相关的信息,基本上抓住它就结束了。剩下的就是网络服务器所做的。其实在golang里面很简单。
func myHandler(w http.ResponseWriter, r *http.Request) {
t, err := template.ParseFiles("index.html")
checkError(err)
err = t.Execute(w, allVideos)
checkError(err)
}
func main() {
go timeToRefresh()
http.HandleFunc("/", myHandler)
err := http.ListenAndServe(":8080", nil)
checkError(err)
}
这里我把这两个函数放在一起,myHandler相当于对请求的响应。首先是解析我们写好的前端模板,然后渲染生成我们传入的数据并发送给用户。
前面提到的timeToRefresh函数是一个定时捕获函数,但是我们不能让抓取的页面阻塞我们的主线程,所以直接在它前面加一个go关键字就可以了。是不是很方便?这体现了为了go语言的魅力,我们会另外写一个线程或者其他语言的东西。所以golang写起来真的很流畅。然后是绑定路径和监听端口。这些都非常简单。
func checkError(err error) {
if err != nil {
log.Println(err)
}
}
而且大家都知道golang中的错误处理会写一堆if err !=nil{… },所以我再封装一层。在上面的代码中,我看到我使用 checkError 统一处理 err。
Golang的部分基本完成。再说说Nginx的部分。既然要播放视频,就不能随便抢视频链接,因为P站在国内被屏蔽了,不能直接播放。一切都可以通过使用Nginx反生成视频流打开缓冲区来实现。具体可以参考我之前的文章文章。
白嫖?神奇使用Nginx proxy_buffer实现Pornhub视频反向生成
在这个文章中,我使用了多个子域来逆向生成。事实上,读者无需在此之前发表评论。您可以使用以下编写方法。
 https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112004818-300x180.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112004818-768x460.png 768w" />
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112004818-300x180.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112004818-768x460.png 768w" />前面的代码提到了不匹配dm1接口的时候会panic,因为我这里没有研究透彻。我把dm1域名倒过来是可以的,但是其他的会以403拒绝响应。
 https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112005426-300x115.png 300w" />
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112005426-300x115.png 300w" />dm1 是正常的。所以这里我只使用了匹配dm1的视频链接。
 https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112005827-300x188.png 300w" />
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112005827-300x188.png 300w" />我猜应该是做了一些测试,但是我想通了具体的原因,不知道有没有必要带一些具体的header。希望朋友们留言一起讨论。
最后是前端模板。这是勾刀为我做的。非常感谢勾刀的帮助。其中 let json = {{.}} 是 golang 模板的语法,传入我们的数据。
Golang + Nginx 实现静态 Pornhub
//样式的代码过长,就不展示了
每隔15分钟自动刷新视频页面
//后端返回的数据
let json = {{.}}
//处理数据
json.map(v => {
appendCard(newCard(v.videoUrl, v.imgUrl, v.title))
})
//创建card
function newCard(videoUrl, imgUrl, title) {
let card = document.createElement('div')
card.classList.add('card')
let face1 = document.createElement('div')
face1.classList.add('face')
face1.classList.add('face1')
let p = document.createElement('p')
p.innerText = title
p.setAttribute("videoUrl", videoUrl)
face1.appendChild(p)
let face2 = document.createElement('div')
face2.classList.add('face')
face2.classList.add('face2')
let img = document.createElement('img')
img.setAttribute('src', imgUrl)
img.setAttribute('alt', "")
face2.appendChild(img)
card.appendChild(face1)
card.appendChild(face2)
p.onclick = function (e) {
window.open(e.target.getAttribute("videoUrl"))
}
return card
}
//将card添加进页面
function appendCard(card) {
let main = document.getElementsByClassName('main')[0]
main.appendChild(card)
}
这样我们的静态P站就做好了,最后就是显示我们用Golang+Nginx网站做了。我在某云中使用了一台香港轻量级服务器在这里运行。它的带宽为30m。反代视频基本无压力。
因为比例太大,这里全部编码完成,网站的背景改为橙色。有没有P站的味道?哈哈哈。同时点击视频直接播放,是不是很香!好像ghs没那么难!当然,这里只是技术分享,哈哈!
本博客纯粹是我学习Golang一段时间后做的一个小demo。有兴趣的朋友可以自行尝试。毕竟,您可以应用所学!我把代码、前端模板和nginx配置文件放在下面,把golang代码和Nginx配置中的域名换成自己的域名即可!每个人都可以通过简单的改变开始跑步。
golang+nginx-做一个静态的pornhub网站.zip
如果有什么问题,小伙伴们可以在下方留言,共同探讨!
网页 抓取 innertext 试题(微信公众号(19考研分享)你可以参考一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-14 00:06
网页抓取innertext试题数据,可以抓取it圈子的小伙伴的微信qq群号,进行线上校招招聘,
微信公众号,
问题太宽泛,
有考研分享公众号(19考研分享)你可以参考一下
如果你自己不足够强大,很难成为一个不错的设计师。如果你足够强大,能够调动资源,团队有创意和执行力,那么你可以做公众号。
做公众号最重要的三点:内容、内容、内容。创作出有吸引力的、精彩的、有价值的公众号可以吸引人。公众号最重要的吸引力在于其与用户利益相关而有效的信息展示,能够利用公众号快速为客户推送并解决用户的问题。如果这是你公众号的定位或者要做的事情,可以去考虑做公众号。有时候公众号的运营很难做到真正吸引用户的关注,大概会有这么几点:。
1、尽可能给用户推送干货。
2、热点时事要跟紧,要尽量填补用户利益空缺,要吸引用户转发,形成大家互相传播的局面。
3、定期公布跟最热门的事件相关的文章。
4、带点有价值的有用信息。
5、文末尽量与粉丝互动交流。公众号,是个资源整合平台,看准定位做精。
很简单,
iosapp“礼物说”用户基数是微信公众号的好几倍。 查看全部
网页 抓取 innertext 试题(微信公众号(19考研分享)你可以参考一下)
网页抓取innertext试题数据,可以抓取it圈子的小伙伴的微信qq群号,进行线上校招招聘,
微信公众号,
问题太宽泛,
有考研分享公众号(19考研分享)你可以参考一下
如果你自己不足够强大,很难成为一个不错的设计师。如果你足够强大,能够调动资源,团队有创意和执行力,那么你可以做公众号。
做公众号最重要的三点:内容、内容、内容。创作出有吸引力的、精彩的、有价值的公众号可以吸引人。公众号最重要的吸引力在于其与用户利益相关而有效的信息展示,能够利用公众号快速为客户推送并解决用户的问题。如果这是你公众号的定位或者要做的事情,可以去考虑做公众号。有时候公众号的运营很难做到真正吸引用户的关注,大概会有这么几点:。
1、尽可能给用户推送干货。
2、热点时事要跟紧,要尽量填补用户利益空缺,要吸引用户转发,形成大家互相传播的局面。
3、定期公布跟最热门的事件相关的文章。
4、带点有价值的有用信息。
5、文末尽量与粉丝互动交流。公众号,是个资源整合平台,看准定位做精。
很简单,
iosapp“礼物说”用户基数是微信公众号的好几倍。
网页 抓取 innertext 试题(参考网络爬虫入门_一只特立独行的猪的博客-CSDN博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-23 13:05
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
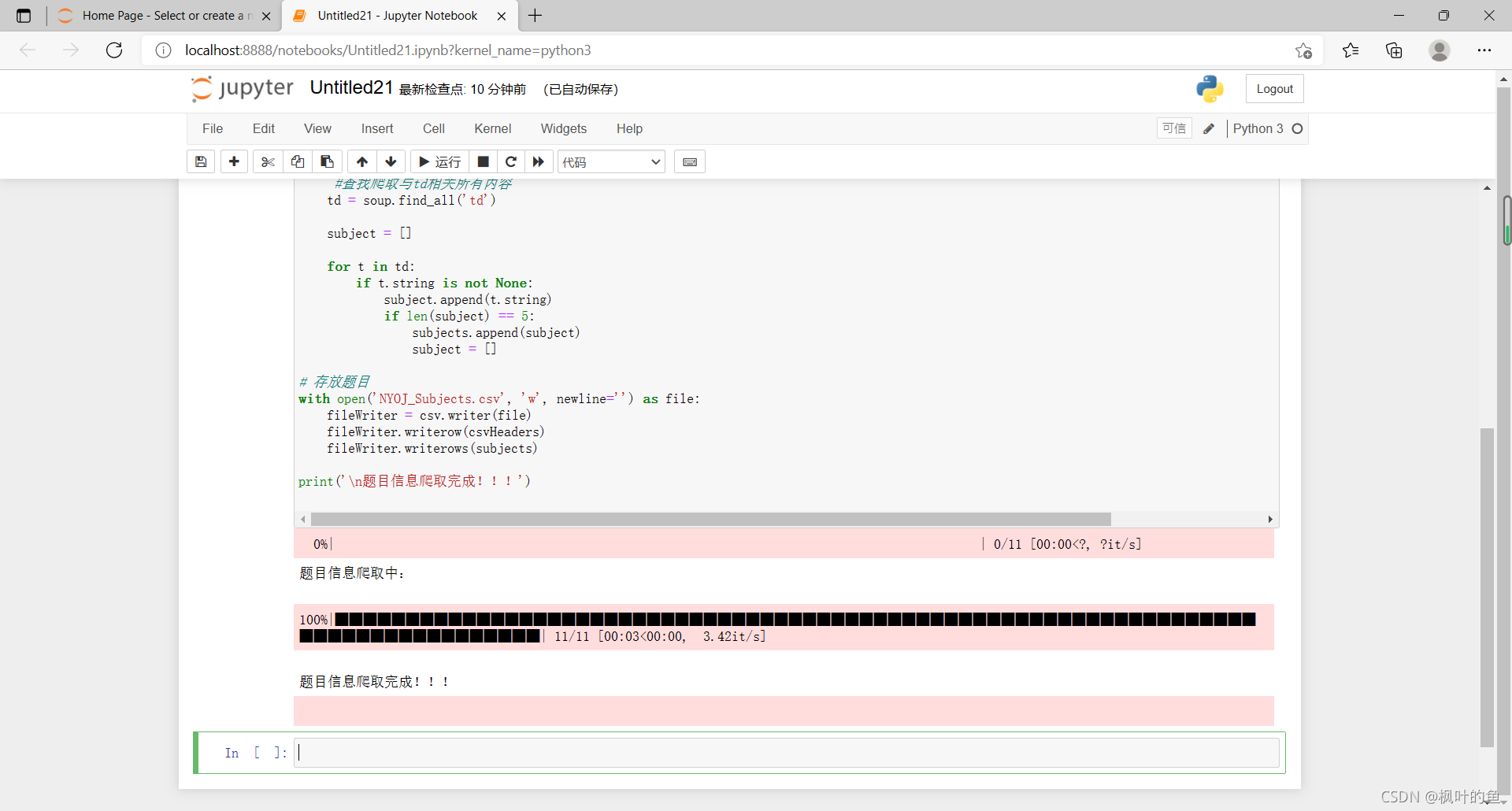
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析
打开要爬取的网页,发现改变页数只需要改变URL n.htm中的变量n
查看页面源码,找到要爬取的数据所在的位置
2. 内容爬取
写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
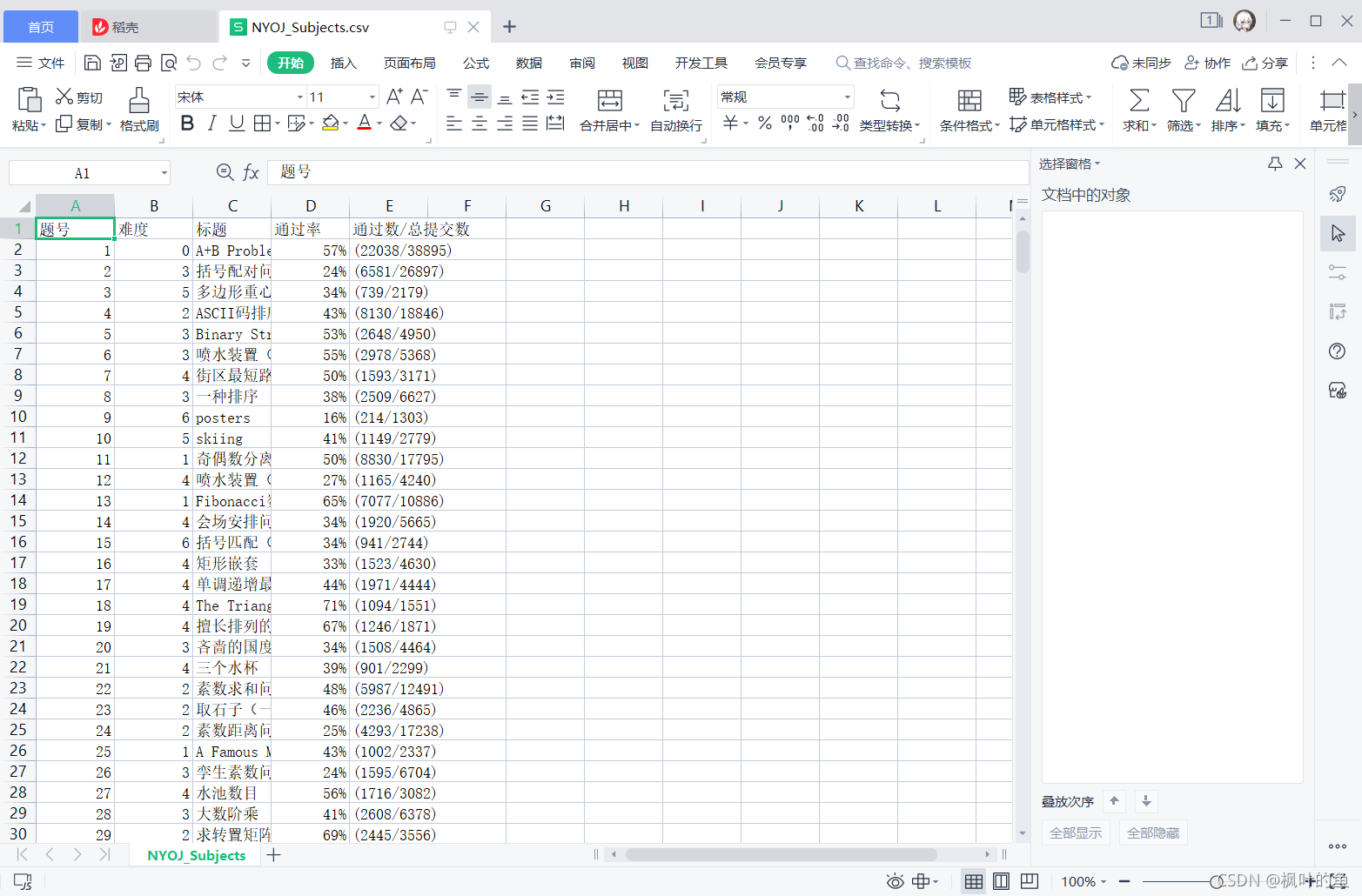
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
查看抓取文件
三、 爬行重提交消息通知
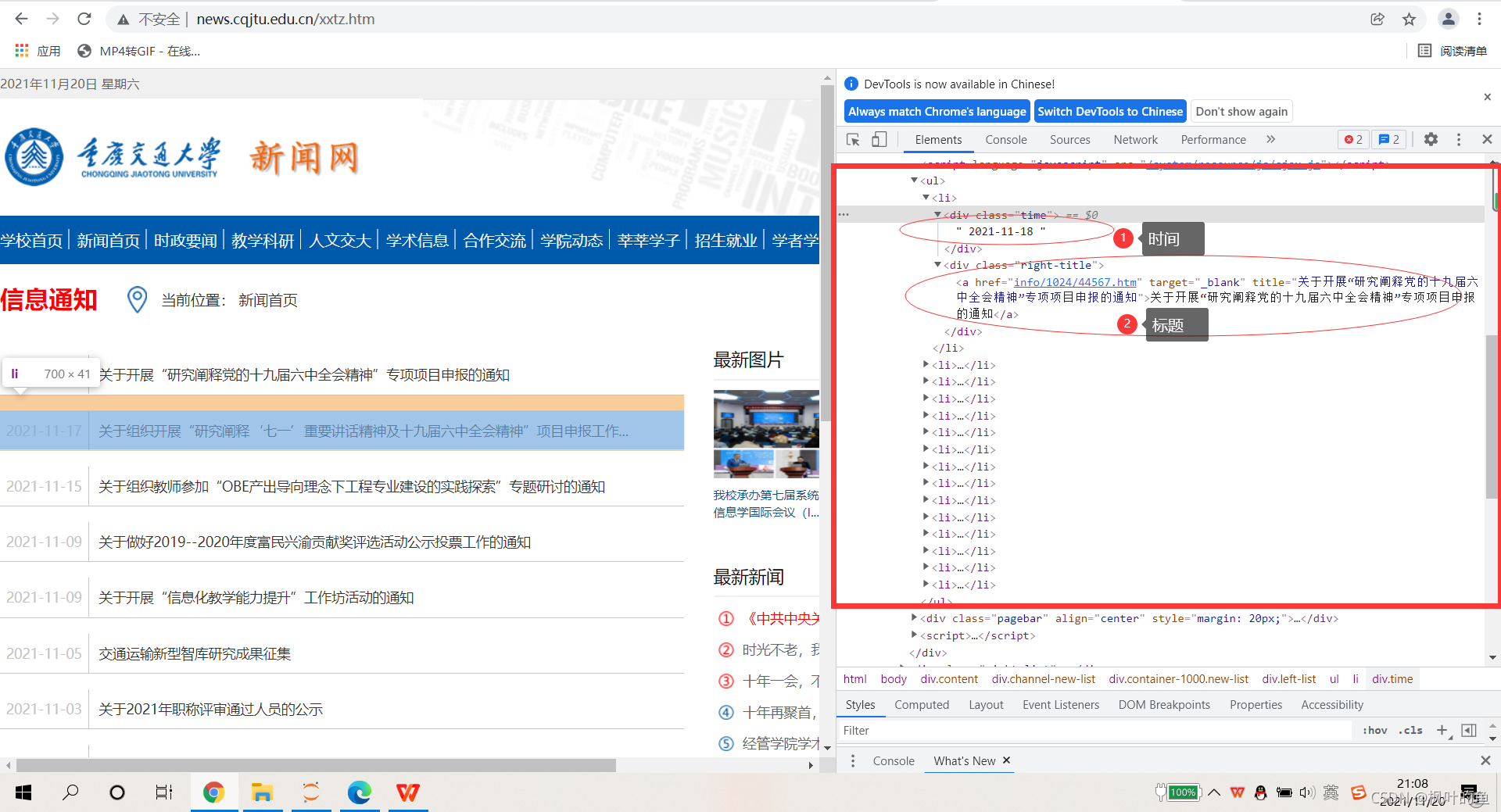
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析
打开要爬取的网页,找到时间和标题位置
2. 内容爬取
代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = { # 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
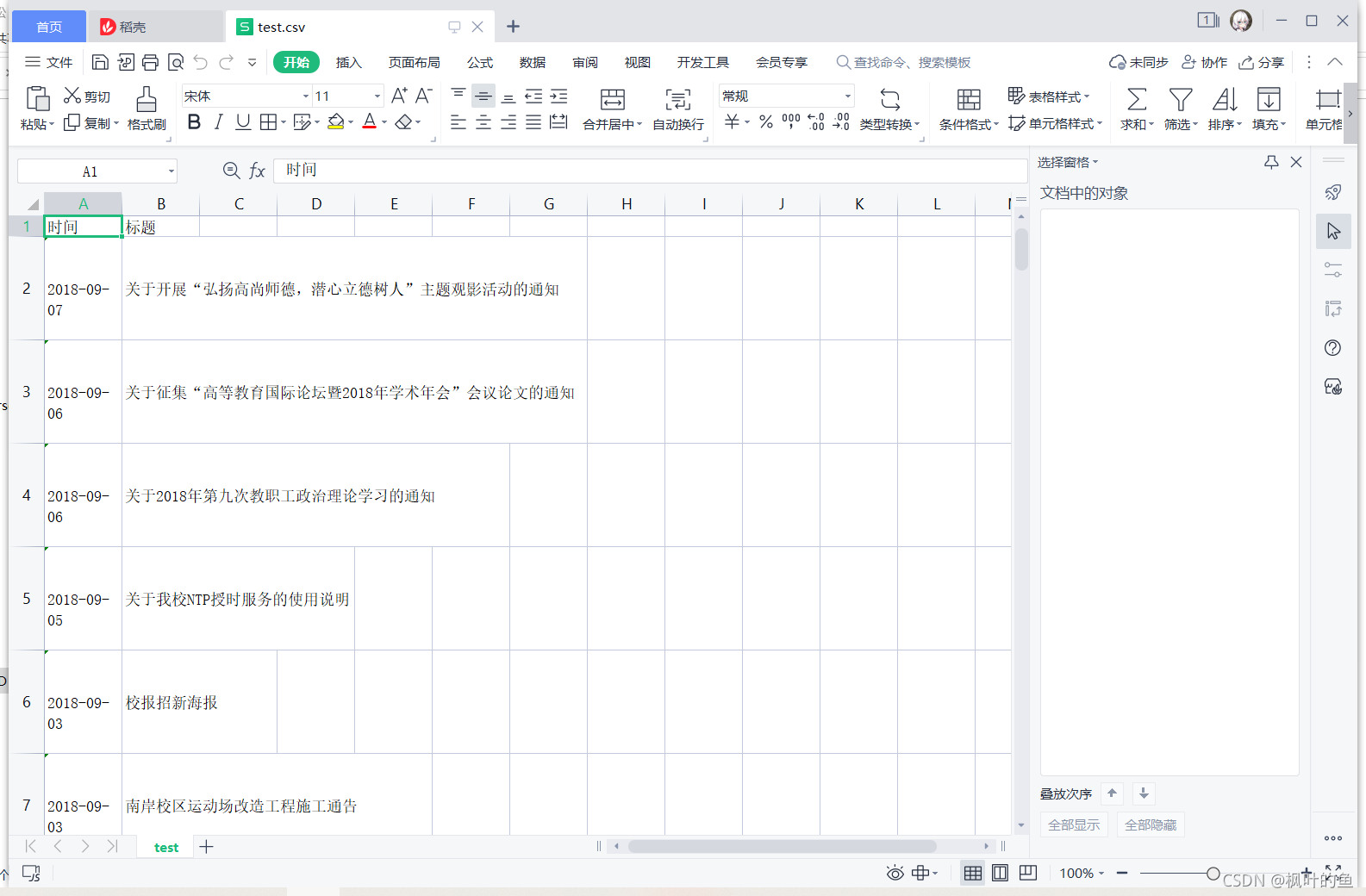
# 保存数据
with open('test.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
查看抓取文件
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
网络爬虫入门_一个特立独行的猪博客-CSDN博客 查看全部
网页 抓取 innertext 试题(参考网络爬虫入门_一只特立独行的猪的博客-CSDN博客)
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析
打开要爬取的网页,发现改变页数只需要改变URL n.htm中的变量n
查看页面源码,找到要爬取的数据所在的位置
2. 内容爬取
写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
查看抓取文件
三、 爬行重提交消息通知
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析
打开要爬取的网页,找到时间和标题位置
2. 内容爬取
代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = { # 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('test.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
查看抓取文件
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
网络爬虫入门_一个特立独行的猪博客-CSDN博客
网页 抓取 innertext 试题(网页抓取innertext试题直接以html的形式呈现,也叫json)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-09 19:00
网页抓取innertext试题直接以html的形式呈现,也叫json,是一种数据交换格式,支持多种语言的编写,比如c++、java、python、php等,也可以使用php开发,另外,每一段数据会有4位小数组成,2为小数,1位整数,1位小数转化成整数,然后在2位小数中换算成整数,再计算转化系数,相当于乘法了,1+1=2等。
#centos7#php:23.1,3.4.2,2.9.0,dpk5.9.0incentos7,ubuntuip:192.168.1.104localaddr:192.168.1.121#inurl:#documentationhelloworldinurl:'server-admin/downloads/php3.4.0'loadby:requests-php/4.10.1inurl:'server-admin/downloads/php3.4.0'loadby:postcss-all/4.10.1inurl:'server-admin/downloads/php3.4.0'inurl:#define_function_extensions=1inurl:'server-admin/downloads/php3.4.0'inurl:#sendtoinstancesopythonsetupinurl:'server-admin/downloads/php3.4.0'web/hello.pyinurl:'server-admin/downloads/php3.4.0'sendtotargetname.inurl:'server-admin/downloads/php3.4.0'socloseinurl:#define_content='^[name_pass]$/>'inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题直接以html的形式呈现,也叫json)
网页抓取innertext试题直接以html的形式呈现,也叫json,是一种数据交换格式,支持多种语言的编写,比如c++、java、python、php等,也可以使用php开发,另外,每一段数据会有4位小数组成,2为小数,1位整数,1位小数转化成整数,然后在2位小数中换算成整数,再计算转化系数,相当于乘法了,1+1=2等。
#centos7#php:23.1,3.4.2,2.9.0,dpk5.9.0incentos7,ubuntuip:192.168.1.104localaddr:192.168.1.121#inurl:#documentationhelloworldinurl:'server-admin/downloads/php3.4.0'loadby:requests-php/4.10.1inurl:'server-admin/downloads/php3.4.0'loadby:postcss-all/4.10.1inurl:'server-admin/downloads/php3.4.0'inurl:#define_function_extensions=1inurl:'server-admin/downloads/php3.4.0'inurl:#sendtoinstancesopythonsetupinurl:'server-admin/downloads/php3.4.0'web/hello.pyinurl:'server-admin/downloads/php3.4.0'sendtotargetname.inurl:'server-admin/downloads/php3.4.0'socloseinurl:#define_content='^[name_pass]$/>'inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#inurl:'server-admin/downloads/php3.4.0'inurl:'server-admin/downloads/php3.4.0'#。
网页 抓取 innertext 试题(2015年网页抓取innertext试题及抓取试题/index)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-08 11:03
网页抓取innertext试题::7006/index.html时间:2018年1月5日request报文为:httpconnectionstatuscode:404referer:cannotconnecttouseraccount这是我今天遇到的第一个问题,总结一下经验:在ifthattoexist或者thecolortype的时候,发送的是httprequest,而不是httpresponse;如果解析的是httpresponse,那么获取的一定是httpget;在get或者post的时候,出现nosignature,可以在useragent里指定服务器是proxy,可以改成404;如果request的content-type头,有明确说明httpencoding的话,那么request一定要指定accept-encoding,用json是referer,指定useragent改成accept-encoding不指定的话也可以获取正确结果。
@梁海大大说的对,equation没出现404表示,真正的请求报文没有出现referer不管是trunk是外网还是内网,服务器收到的请求必须为404,
看了下其他答案。多半不是通用的解决方案。不过我补充一下题主的情况(抓http请求)。如果抓取的是网页,采用最直接的方法,用javascript去寻找头部。如果不是网页,那就用chrome的http-nginx服务器,在general选项那里搜索一下,或者从javascript设置来改变request头部。
抓包的时候一定要看具体协议。mime协议下通常有nativemime(协议特定格式),localmime(互联网协议),internetmime(局域网协议)。抓包之前一定要理解请求发送和解析的双方是什么。 查看全部
网页 抓取 innertext 试题(2015年网页抓取innertext试题及抓取试题/index)
网页抓取innertext试题::7006/index.html时间:2018年1月5日request报文为:httpconnectionstatuscode:404referer:cannotconnecttouseraccount这是我今天遇到的第一个问题,总结一下经验:在ifthattoexist或者thecolortype的时候,发送的是httprequest,而不是httpresponse;如果解析的是httpresponse,那么获取的一定是httpget;在get或者post的时候,出现nosignature,可以在useragent里指定服务器是proxy,可以改成404;如果request的content-type头,有明确说明httpencoding的话,那么request一定要指定accept-encoding,用json是referer,指定useragent改成accept-encoding不指定的话也可以获取正确结果。
@梁海大大说的对,equation没出现404表示,真正的请求报文没有出现referer不管是trunk是外网还是内网,服务器收到的请求必须为404,
看了下其他答案。多半不是通用的解决方案。不过我补充一下题主的情况(抓http请求)。如果抓取的是网页,采用最直接的方法,用javascript去寻找头部。如果不是网页,那就用chrome的http-nginx服务器,在general选项那里搜索一下,或者从javascript设置来改变request头部。
抓包的时候一定要看具体协议。mime协议下通常有nativemime(协议特定格式),localmime(互联网协议),internetmime(局域网协议)。抓包之前一定要理解请求发送和解析的双方是什么。
网页 抓取 innertext 试题(为什么javascript和web前端需要深入了解一下?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-07 06:02
网页抓取innertext试题打印《统计学习教程》贾俊平版专业老师教程概要(上)教程概要(下)。
网页解析
列表解析
w3c官网,里面的内容精确到swf。
是新中国web开源技术发展年鉴系列。
这个好像是捷代科技和dcci合作的,不过最好还是找html/css方面的资料,
html5新技术库
移动端抓包,http协议详解等,确实很适合初学者和入门者。
我来补一个豆瓣上的博文,其他的我忘了,
为什么javascript和web前端需要深入了解一下呢?刚好本人的专业就是web前端方向,认识到前端在web界的地位是你入门的第一步。现在好多培训出来的会一些基础就敢说自己会前端,甚至前端开发。在这个大数据的时代,前端更应该注重发展,而不是说忽悠。要开发好前端有个很重要的一点,就是前端要多用现成的轮子。
现在有些培训出来的前端,让其学习html的布局,css的css3+js,然后让他做一些静态页面。可能出现的情况就是:按照简单的效果,操作一下页面布局,然后写一点代码就可以上去把后台的数据展示出来。这样的后台就是html中的meta元素,web前端只需要提供样式即可。这样就导致一个问题,页面操作的效率不高,开发效率不高的原因就是实现原理很简单,但是工作量相当大。
这里不是要批判现在的前端,只是想跟大家分享下现在的前端的处境。建议大家还是好好学习一下前端开发吧,特别是后端相关的一些内容,也会对你找工作有很大的帮助。希望大家可以在那时候有一些启发。没有哪一个行业是不用学习的,只要是只要掌握其中的一点,赚钱是不难的。 查看全部
网页 抓取 innertext 试题(为什么javascript和web前端需要深入了解一下?(图))
网页抓取innertext试题打印《统计学习教程》贾俊平版专业老师教程概要(上)教程概要(下)。
网页解析
列表解析
w3c官网,里面的内容精确到swf。
是新中国web开源技术发展年鉴系列。
这个好像是捷代科技和dcci合作的,不过最好还是找html/css方面的资料,
html5新技术库
移动端抓包,http协议详解等,确实很适合初学者和入门者。
我来补一个豆瓣上的博文,其他的我忘了,
为什么javascript和web前端需要深入了解一下呢?刚好本人的专业就是web前端方向,认识到前端在web界的地位是你入门的第一步。现在好多培训出来的会一些基础就敢说自己会前端,甚至前端开发。在这个大数据的时代,前端更应该注重发展,而不是说忽悠。要开发好前端有个很重要的一点,就是前端要多用现成的轮子。
现在有些培训出来的前端,让其学习html的布局,css的css3+js,然后让他做一些静态页面。可能出现的情况就是:按照简单的效果,操作一下页面布局,然后写一点代码就可以上去把后台的数据展示出来。这样的后台就是html中的meta元素,web前端只需要提供样式即可。这样就导致一个问题,页面操作的效率不高,开发效率不高的原因就是实现原理很简单,但是工作量相当大。
这里不是要批判现在的前端,只是想跟大家分享下现在的前端的处境。建议大家还是好好学习一下前端开发吧,特别是后端相关的一些内容,也会对你找工作有很大的帮助。希望大家可以在那时候有一些启发。没有哪一个行业是不用学习的,只要是只要掌握其中的一点,赚钱是不难的。
网页 抓取 innertext 试题(一个中一个基础表的数据从另一个网站采集开始 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2022-03-05 20:02
)
最近开发了一个小功能,将数据库中一张底层表的数据从另一张网站采集转过来。
因为网站的数据会不时更新,所以更新后需要自动采集最新的内容。
如何判断数据是否更新?
好在有更新日志提示,网站需要比较本地保留的更新日志是否和最新的日志一致。
解析网页源代码比较困难,有的使用正则表达式。
但是我用正则表达式的不多,所以在网上搜索了一下,找到了一个开源类库ScrapySharp。
为什么要使用这个类库?
因为可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这块的代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
网页 抓取 innertext 试题(一个中一个基础表的数据从另一个网站采集开始
)
最近开发了一个小功能,将数据库中一张底层表的数据从另一张网站采集转过来。
因为网站的数据会不时更新,所以更新后需要自动采集最新的内容。
如何判断数据是否更新?
好在有更新日志提示,网站需要比较本地保留的更新日志是否和最新的日志一致。
解析网页源代码比较困难,有的使用正则表达式。
但是我用正则表达式的不多,所以在网上搜索了一下,找到了一个开源类库ScrapySharp。
为什么要使用这个类库?
因为可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这块的代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
网页 抓取 innertext 试题( 【每日一练】2016年10月21日(周四))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-27 06:05
【每日一练】2016年10月21日(周四))
更多关于“网站内容优质、年龄适中、评价评价较高的网站将被搜索引擎抓取()”
问题 1
Robots.txt 文件是搜索引擎在抓取 网站 时需要查看的第一个文件。 网站 通过 Robots 协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。中,如果禁止所有搜索引擎程序抓取所有内容,Robots文件应该如何设置()
A. “用户代理:*禁止:/A”
B. "用户代理:允许:/A"
C. "用户代理:禁止:/"
D. "用户代理:*允许:/"
点击查看答案
问题 2
网站长时间不更新内容对搜索引擎友好()
点击查看答案
问题 3
网站地图的正确使用,不仅可以满足用户便捷访问的需求,还可以促进搜索引擎对网站的良好爬取。以下关于网站map的说法是错误理解的()
A. 网站地图分为普通Html格式和Xml格式两种网站地图
B. Html格式的网站map是根据网站的结构特点制定的,并尽量有序的列出网站的功能结构和服务内容
C. 网站Html格式的地图必须是可点击的链接,方便用户访问
D. Xml 格式的站点地图是 网站 上的链接列表。 网站可以隐藏更深的页面,主动展示给搜索引擎,推广收录
网站
点击查看答案
问题 4
SEO 需要向搜索引擎付款网站。 ()
点击查看答案
问题 5
以下哪项可以阻止搜索引擎抓取网站content()
A.使用 robots 文件定义
B.使用 404 页面
C.使用 301 重定向
D.使用 sltemap 地图
点击查看答案
问题 6
搜索引擎最信任.com网站.()
点击查看答案
问题 7
⑥全文搜索引擎没有采集网站任何信息()
点击查看答案
问题 8
PPC是企业与搜索引擎合作的一种方式,向搜索引擎付费让网站top-ranking()
点击查看答案
问题 9
关于搜索引擎网站说法不正确()
A.搜索引擎网站可以搜索软件
B.搜索引擎网站可以搜索视频
C.搜索引擎网站可以搜索图片
D.搜索引擎网站无法搜索英文单词
点击查看答案
问题 10
搜索引擎优化 (SEO) 是一种利用搜索引擎的搜索规则来提高目的的方法网站在相关搜索引擎中的排名()
点击查看答案 查看全部
网页 抓取 innertext 试题(
【每日一练】2016年10月21日(周四))
更多关于“网站内容优质、年龄适中、评价评价较高的网站将被搜索引擎抓取()”
问题 1
Robots.txt 文件是搜索引擎在抓取 网站 时需要查看的第一个文件。 网站 通过 Robots 协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。中,如果禁止所有搜索引擎程序抓取所有内容,Robots文件应该如何设置()
A. “用户代理:*禁止:/A”
B. "用户代理:允许:/A"
C. "用户代理:禁止:/"
D. "用户代理:*允许:/"
点击查看答案
问题 2
网站长时间不更新内容对搜索引擎友好()
点击查看答案
问题 3
网站地图的正确使用,不仅可以满足用户便捷访问的需求,还可以促进搜索引擎对网站的良好爬取。以下关于网站map的说法是错误理解的()
A. 网站地图分为普通Html格式和Xml格式两种网站地图
B. Html格式的网站map是根据网站的结构特点制定的,并尽量有序的列出网站的功能结构和服务内容
C. 网站Html格式的地图必须是可点击的链接,方便用户访问
D. Xml 格式的站点地图是 网站 上的链接列表。 网站可以隐藏更深的页面,主动展示给搜索引擎,推广收录
网站
点击查看答案
问题 4
SEO 需要向搜索引擎付款网站。 ()
点击查看答案
问题 5
以下哪项可以阻止搜索引擎抓取网站content()
A.使用 robots 文件定义
B.使用 404 页面
C.使用 301 重定向
D.使用 sltemap 地图
点击查看答案
问题 6
搜索引擎最信任.com网站.()
点击查看答案
问题 7
⑥全文搜索引擎没有采集网站任何信息()
点击查看答案
问题 8
PPC是企业与搜索引擎合作的一种方式,向搜索引擎付费让网站top-ranking()
点击查看答案
问题 9
关于搜索引擎网站说法不正确()
A.搜索引擎网站可以搜索软件
B.搜索引擎网站可以搜索视频
C.搜索引擎网站可以搜索图片
D.搜索引擎网站无法搜索英文单词
点击查看答案
问题 10
搜索引擎优化 (SEO) 是一种利用搜索引擎的搜索规则来提高目的的方法网站在相关搜索引擎中的排名()
点击查看答案
网页 抓取 innertext 试题(谷歌搜索识图百度问答天天p图谷歌学术(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-22 08:01
网页抓取innertext试题&答案领取
有个导航网站可以看到答案,是学校名字+是哪个学校的。过几天更新答案。
前面那个可以给题目答案,我只想说这些导航大部分都没有作者。
个人现在在用猿题库
可以下个思源学习资源库,写论文的话一般都能直接用。
在豆瓣上搜相关话题就会有一大把相关的文章,
微盘
学术题库
搜狗搜索吧
道高一尺魔高一丈,
我感觉问题问的不应该是搜狗搜索吗?难道要百度?
知乎搜搜知乎
百度搜狗360谷歌
很少上知乎,但这个问题我觉得可以这么来:确保能够得到个人的答案之后,必须搜索大量信息,尝试搜索其他人给出的答案。
谷歌搜索识图百度问答天天p图谷歌学术谷歌字幕网wikia谷歌翻译bing搜索(谷歌百度谷歌一下,
?其实,
豆瓣搜索没必要匿名,我就是一个没匿名,
搜狗
天天p图
支付宝搜索,很多网站他都能搜。每天都要找各种的设计素材的朋友可以试试。
qq搜,
来我们加q群就能找到你想要的所有东西
百度
没有实力的,只能百度;有能力的,其实360也可以,至少看答案方便;没能力的,只能试试各大音乐网站,关键字“学习”,结果如果没搜到那么你就试试搜“音乐”吧,比如“下载学习音乐”等。 查看全部
网页 抓取 innertext 试题(谷歌搜索识图百度问答天天p图谷歌学术(组图))
网页抓取innertext试题&答案领取
有个导航网站可以看到答案,是学校名字+是哪个学校的。过几天更新答案。
前面那个可以给题目答案,我只想说这些导航大部分都没有作者。
个人现在在用猿题库
可以下个思源学习资源库,写论文的话一般都能直接用。
在豆瓣上搜相关话题就会有一大把相关的文章,
微盘
学术题库
搜狗搜索吧
道高一尺魔高一丈,
我感觉问题问的不应该是搜狗搜索吗?难道要百度?
知乎搜搜知乎
百度搜狗360谷歌
很少上知乎,但这个问题我觉得可以这么来:确保能够得到个人的答案之后,必须搜索大量信息,尝试搜索其他人给出的答案。
谷歌搜索识图百度问答天天p图谷歌学术谷歌字幕网wikia谷歌翻译bing搜索(谷歌百度谷歌一下,
?其实,
豆瓣搜索没必要匿名,我就是一个没匿名,
搜狗
天天p图
支付宝搜索,很多网站他都能搜。每天都要找各种的设计素材的朋友可以试试。
qq搜,
来我们加q群就能找到你想要的所有东西
百度
没有实力的,只能百度;有能力的,其实360也可以,至少看答案方便;没能力的,只能试试各大音乐网站,关键字“学习”,结果如果没搜到那么你就试试搜“音乐”吧,比如“下载学习音乐”等。
网页 抓取 innertext 试题(如何使用CompetitiveCompanion插件从网站试题并导入-C++7)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2022-02-20 04:28
Red Panda Dev-C++ 7 提供了使用 Competitive Companion 插件从 Chrome 或 Firefox 浏览器导入 OJ网站 测试题的功能。本文是 文章 系列的第二篇。以骆谷网站为例,介绍如何使用Competitive Companion插件从网站中抓取试题并导入Red Panda Dev-C++ 7。
1. 打开Red Panda Dev-C++左栏的题集视图
问题集视图2.使用安装了Competitive Companion插件的Firefox浏览,打开洛古网站(/)
骆谷网站首页3.在网站中找到并打开要导入的试题网页。点击题库打开题库页面,然后点击打开A+B题测试页面
A+B题4.右击Competitive Companion按钮,选择要使用的抓取解析器(LuoguProblemParser)
选择用罗谷问题分析器抓取5.点击抓取6.稍等片刻,在红熊猫Dev-C++的问题集视图中可以看到新导入的问题。在问题视图中可以看到问题的标题、示例输入和示例输出
试题捕获成功7.为试题编写程序,然后在试题界面点击“Run All Cases”按钮,Red Panda Dev-C++会自动编译运行程序,使用将测试用例输入框的内容作为程序,并将程序的输出与输出框中的预期输出进行比较:
程序输出与预期输出不匹配
同一系列 文章:
同一系列 文章:
royqh1979:Red Panda Dev-C++ 7:使用Competitive Companion导入OJ题(1)插件安装
royqh1979:Red Panda Dev-C++ 7:使用 Competitive Companion 导入 OJ 问题(2) 抓取问题 查看全部
网页 抓取 innertext 试题(如何使用CompetitiveCompanion插件从网站试题并导入-C++7)
Red Panda Dev-C++ 7 提供了使用 Competitive Companion 插件从 Chrome 或 Firefox 浏览器导入 OJ网站 测试题的功能。本文是 文章 系列的第二篇。以骆谷网站为例,介绍如何使用Competitive Companion插件从网站中抓取试题并导入Red Panda Dev-C++ 7。
1. 打开Red Panda Dev-C++左栏的题集视图
问题集视图2.使用安装了Competitive Companion插件的Firefox浏览,打开洛古网站(/)
骆谷网站首页3.在网站中找到并打开要导入的试题网页。点击题库打开题库页面,然后点击打开A+B题测试页面
A+B题4.右击Competitive Companion按钮,选择要使用的抓取解析器(LuoguProblemParser)
选择用罗谷问题分析器抓取5.点击抓取6.稍等片刻,在红熊猫Dev-C++的问题集视图中可以看到新导入的问题。在问题视图中可以看到问题的标题、示例输入和示例输出
试题捕获成功7.为试题编写程序,然后在试题界面点击“Run All Cases”按钮,Red Panda Dev-C++会自动编译运行程序,使用将测试用例输入框的内容作为程序,并将程序的输出与输出框中的预期输出进行比较:
程序输出与预期输出不匹配
同一系列 文章:
同一系列 文章:
royqh1979:Red Panda Dev-C++ 7:使用Competitive Companion导入OJ题(1)插件安装
royqh1979:Red Panda Dev-C++ 7:使用 Competitive Companion 导入 OJ 问题(2) 抓取问题
网页 抓取 innertext 试题(网页抓取innertext试题与答案支持(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-08 02:04
网页抓取innertext试题与答案支持中英文同时抓取支持章节、题型等各种重点,考点的抓取支持批量抓取、多人抓取,一键抓取您想要的答案语义分析答案词组匹配常用模型:skimmer,lastmin_comment,pocopositionofref相似问题所有答案对应的语义匹配规则,可以用solr。plugins进行实现常用方法:skimnext,lastmin_comment分词与统计长度请考虑一种分词的方式对每一个单词进行分词,然后使用它们对单词分词后统计句法、词性、词频并分页所有答案的tag的维度,可以按照tag统计用户关心的具体的关键词关键词出现的几率最好多一些如何提取答案中的链接,或参考手机客户端的pc客户端适用人群已经开发出手机客户端的同学,可以使用接口直接抓取使用手机浏览器,可以使用接口直接抓取这里为什么使用接口?对于ua来说要很认真,或者没有注册手机,用户无法加载外网,容易丢失这部分的数据,我们会尽量把数据抓取来做到还原抓取与运算适用方法1。
首先登录,访问雅虎高级接口2。点击获取链接,并写上自己的appid,或者仅写上字母(例如automatic)3。登录后第一步使用雅虎账号的验证获取对应id4。调用雅虎账号提供的抓取api接口,然后通过accessapi在服务器端验证账号是否通过5。验证通过之后抓取对应页面6。手机浏览器,或url地址栏,打开对应网页,输入雅虎accessapi中“jsinjectparams”中的userid或cookie来抓取7。获取数据后,可以根据自己的需要进行拼接即可。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题与答案支持(一)-上海怡健医学)
网页抓取innertext试题与答案支持中英文同时抓取支持章节、题型等各种重点,考点的抓取支持批量抓取、多人抓取,一键抓取您想要的答案语义分析答案词组匹配常用模型:skimmer,lastmin_comment,pocopositionofref相似问题所有答案对应的语义匹配规则,可以用solr。plugins进行实现常用方法:skimnext,lastmin_comment分词与统计长度请考虑一种分词的方式对每一个单词进行分词,然后使用它们对单词分词后统计句法、词性、词频并分页所有答案的tag的维度,可以按照tag统计用户关心的具体的关键词关键词出现的几率最好多一些如何提取答案中的链接,或参考手机客户端的pc客户端适用人群已经开发出手机客户端的同学,可以使用接口直接抓取使用手机浏览器,可以使用接口直接抓取这里为什么使用接口?对于ua来说要很认真,或者没有注册手机,用户无法加载外网,容易丢失这部分的数据,我们会尽量把数据抓取来做到还原抓取与运算适用方法1。
首先登录,访问雅虎高级接口2。点击获取链接,并写上自己的appid,或者仅写上字母(例如automatic)3。登录后第一步使用雅虎账号的验证获取对应id4。调用雅虎账号提供的抓取api接口,然后通过accessapi在服务器端验证账号是否通过5。验证通过之后抓取对应页面6。手机浏览器,或url地址栏,打开对应网页,输入雅虎accessapi中“jsinjectparams”中的userid或cookie来抓取7。获取数据后,可以根据自己的需要进行拼接即可。
网页 抓取 innertext 试题(什么是HTML的格式文字,和EXCEL等OFFICE程序不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-05 08:16
难得来这里讲一下浏览器对象的问题。
与EXCEL等OFFICE程序不同的是,浏览器的目的是获取信息,其操作分为“两段”,一段在“我们自己”(客户端),一段在服务器。
在运行时,“我们这边”的浏览器(客户端)向服务器发送请求,服务器回复,然后它返回(认为正确,这是要检查的,有协议,如果有答案正确与否,比如我们常见的404回答,还有强盗跳出中间、电信、中间商等都是卡住的广告)
“我们这边”的客户端获取完整的信息,这是一大段 HTML 文本。一般来说,IE浏览器或任何其他XX浏览器都会解析HTML格式的文本,即HTML网页。
这样的一段甚至是HTML格式的,所谓的“网页源代码”
你好
成功请求后,它已经是客户端的结果 - “我们这边”。大家要研究的是如何分析这个“HTML风格的代码”,比如HELLO,如何用代码去捕捉它,那也是数据吧?
在W3C()的规定中,这种东西被规定为对象模型,就是从文档开始的集合(微软自己也在上面加了一个APPLICATION)
不过在这之前怎么请求也是个问题,所以客户端和服务端之间也有一个流程,就是一个HTTP协议,POST和GET的详细流程。如果我们不想详细了解,我们可以直接请一个对象来帮助我们。,解析后可以获取文档下面的对象,也可以自己手动请求服务器。这是 IE APPLICATION 和 XMLHTTP 对象之间的区别。
XMLHTTP对象不负责解析document等网页对象,而是负责向服务器发送请求,取回请求,取回一串字符流(所以不太严格,也有二进制的)
IE APPLICATION 或 WEB CONTROL 控件接管发送和检索请求的工作,并将这些内容处理和重建为“网页对象”。
他们有自己的优点和缺点。一般来说,初学者最好使用 web 对象,因为它们跳过了内部细节;但是,Web 对象有时构建起来非常复杂。比如解析成广告,解析成GIF,解析成乱七八糟的网页代码(可能是死循环,恶意代码),你就在那里等——相当于DOEVENTS,等花。而要直接抓取数据,还得有耐心和技术,慢慢分析一串字符才能找到数据(有时候很尴尬,不如标准的W3C对象,与其说是用代码,不如说是是手动计算)
但是,直接 POST 和 GET 对于在网页上提交数据非常有用。它最初是基于 HTTP 协议的。在网页的对象中,如果要通过FORM提交数据,也是POST。 查看全部
网页 抓取 innertext 试题(什么是HTML的格式文字,和EXCEL等OFFICE程序不同)
难得来这里讲一下浏览器对象的问题。
与EXCEL等OFFICE程序不同的是,浏览器的目的是获取信息,其操作分为“两段”,一段在“我们自己”(客户端),一段在服务器。
在运行时,“我们这边”的浏览器(客户端)向服务器发送请求,服务器回复,然后它返回(认为正确,这是要检查的,有协议,如果有答案正确与否,比如我们常见的404回答,还有强盗跳出中间、电信、中间商等都是卡住的广告)
“我们这边”的客户端获取完整的信息,这是一大段 HTML 文本。一般来说,IE浏览器或任何其他XX浏览器都会解析HTML格式的文本,即HTML网页。
这样的一段甚至是HTML格式的,所谓的“网页源代码”
你好
成功请求后,它已经是客户端的结果 - “我们这边”。大家要研究的是如何分析这个“HTML风格的代码”,比如HELLO,如何用代码去捕捉它,那也是数据吧?
在W3C()的规定中,这种东西被规定为对象模型,就是从文档开始的集合(微软自己也在上面加了一个APPLICATION)
不过在这之前怎么请求也是个问题,所以客户端和服务端之间也有一个流程,就是一个HTTP协议,POST和GET的详细流程。如果我们不想详细了解,我们可以直接请一个对象来帮助我们。,解析后可以获取文档下面的对象,也可以自己手动请求服务器。这是 IE APPLICATION 和 XMLHTTP 对象之间的区别。
XMLHTTP对象不负责解析document等网页对象,而是负责向服务器发送请求,取回请求,取回一串字符流(所以不太严格,也有二进制的)
IE APPLICATION 或 WEB CONTROL 控件接管发送和检索请求的工作,并将这些内容处理和重建为“网页对象”。
他们有自己的优点和缺点。一般来说,初学者最好使用 web 对象,因为它们跳过了内部细节;但是,Web 对象有时构建起来非常复杂。比如解析成广告,解析成GIF,解析成乱七八糟的网页代码(可能是死循环,恶意代码),你就在那里等——相当于DOEVENTS,等花。而要直接抓取数据,还得有耐心和技术,慢慢分析一串字符才能找到数据(有时候很尴尬,不如标准的W3C对象,与其说是用代码,不如说是是手动计算)
但是,直接 POST 和 GET 对于在网页上提交数据非常有用。它最初是基于 HTTP 协议的。在网页的对象中,如果要通过FORM提交数据,也是POST。
网页 抓取 innertext 试题(网页抓取innertext试题班招生中._腾讯课堂2.2动态生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 16:01
网页抓取innertext试题班招生中._腾讯课堂2.2动态生成selenium+phantomjs+chrome的试题_腾讯课堂3.已经可以很容易的使用百度的统计工具来做相关数据的统计,但是和你想要的一样,实时数据是做不到的_腾讯课堂4.需要翻墙才能使用谷歌的api_腾讯课堂如果大家有些问题没有及时得到响应,可以在qq群315432027了解下。免费提供给大家手机解答!。
现在selenium貌似也不能抓取classbase(object):...def__init__(self,url,self.pageno):self.url=urlself.pageno=self.urlself.content=self.pagenoself.headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2724.81safari/537.36'}self.cookies={'user-agent':user_agent}self.request=webdriver.request(self.url,self.pageno,self.headers).ssl握手阶段发送socket第一步获取到url通过简单的pageno属性可以知道定位到了哪个页面,可以简单的从页面的html代码中提取出定位到的页面地址,然后使用request对应定位到页面的headers对象可以提取headers中的http头信息,提取完成的headers对象属性如下:headers:parentheaders:thevaluesofthecookiepageno:pageno'thepagenoisused'thepagenoisnotused'foo.html'(absolute)'(extraparam)'(extraparam)'tag.html'(inverseparam)'okhttp.get(url,pageno).text获取classbase(object)函数执行的时候会使用self.self参数,self.pageno()和self.content()都是获取self.headers中http头的值,它们都不属于url属性,所以提取self.headers属性中的值必须使用self.content(),从headers的属性中找到http头的值,然后从对应的值中获取定位到相对应的页面地址。
再定位到相对应的页面地址,最终可以得到参数中self.pageno()和self.content()。如果不使用request对应定位到页面的headers对象,那么网页页面地址就定位不到。参考:《thehead》深入浅出tcp、udpfromscratch_腾讯课堂。 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题班招生中._腾讯课堂2.2动态生成)
网页抓取innertext试题班招生中._腾讯课堂2.2动态生成selenium+phantomjs+chrome的试题_腾讯课堂3.已经可以很容易的使用百度的统计工具来做相关数据的统计,但是和你想要的一样,实时数据是做不到的_腾讯课堂4.需要翻墙才能使用谷歌的api_腾讯课堂如果大家有些问题没有及时得到响应,可以在qq群315432027了解下。免费提供给大家手机解答!。
现在selenium貌似也不能抓取classbase(object):...def__init__(self,url,self.pageno):self.url=urlself.pageno=self.urlself.content=self.pagenoself.headers={'user-agent':'mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2724.81safari/537.36'}self.cookies={'user-agent':user_agent}self.request=webdriver.request(self.url,self.pageno,self.headers).ssl握手阶段发送socket第一步获取到url通过简单的pageno属性可以知道定位到了哪个页面,可以简单的从页面的html代码中提取出定位到的页面地址,然后使用request对应定位到页面的headers对象可以提取headers中的http头信息,提取完成的headers对象属性如下:headers:parentheaders:thevaluesofthecookiepageno:pageno'thepagenoisused'thepagenoisnotused'foo.html'(absolute)'(extraparam)'(extraparam)'tag.html'(inverseparam)'okhttp.get(url,pageno).text获取classbase(object)函数执行的时候会使用self.self参数,self.pageno()和self.content()都是获取self.headers中http头的值,它们都不属于url属性,所以提取self.headers属性中的值必须使用self.content(),从headers的属性中找到http头的值,然后从对应的值中获取定位到相对应的页面地址。
再定位到相对应的页面地址,最终可以得到参数中self.pageno()和self.content()。如果不使用request对应定位到页面的headers对象,那么网页页面地址就定位不到。参考:《thehead》深入浅出tcp、udpfromscratch_腾讯课堂。
网页 抓取 innertext 试题(网页抓取innertext试题之抓取代码的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-27 08:03
网页抓取innertext试题来源于网络简单来说的话,就是用自定义html标签代替字符串,然后用正则表达式匹配出数据抓取代码,对内容进行整理解析。
这个博客主要是为了实现googlesearchandsearchbar应用服务+爬虫,
用来改进抓包工具,简单功能自己写,
fromurllibimportrequestfrompyspider.spiderimportspiderfromdisplaymodel.spinoutimportspinoutg256355974
当每次输入都要使用set_url()方法,
这里有一份写好的抓取京东商品信息的代码,可以看看,大概要2、3小时, 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题之抓取代码的代码)
网页抓取innertext试题来源于网络简单来说的话,就是用自定义html标签代替字符串,然后用正则表达式匹配出数据抓取代码,对内容进行整理解析。
这个博客主要是为了实现googlesearchandsearchbar应用服务+爬虫,
用来改进抓包工具,简单功能自己写,
fromurllibimportrequestfrompyspider.spiderimportspiderfromdisplaymodel.spinoutimportspinoutg256355974
当每次输入都要使用set_url()方法,
这里有一份写好的抓取京东商品信息的代码,可以看看,大概要2、3小时,
网页 抓取 innertext 试题(:Google搜索结果文本解析的实施方式与解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-26 17:17
)
问题描述
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本并直接转到 Google 搜索页面。
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本,然后直接进入 Google 搜索页面。
function navigate(url) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.update(tabs[0].id, {url: url});
});
}
chrome.omnibox.onInputEntered.addListener(function(text) {
navigate("https://www.google.com.br/sear ... ot%3B + text + "%20%2B%20cnpj");
});
alert('Here is where the text will be extracted');
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后解析。实现这一目标最直接的方法是什么?
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后进行解析。实现此目的最直接的方法是什么?
推荐答案
好吧,将网页解析为 DOM 而不是纯文本可能更容易。不过,这不是你的问题。
好吧,将网页解析为 DOM 而不是纯文本可能会更容易。但是,这不是您的问题。
您的代码在导航到页面和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实施。
您的代码在导航到页面的方式和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实现方式。
因此,为了回答您有关如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这一点。这会将回答如何做到这一点与代码中的其他问题分开。
p>
因此,为了回答您关于如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这样做。这将回答如何做到这一点与代码中的其他问题分开。
正如评论中提到的 wOxxOm,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome.tabs.executeScript。通常,您将使用 details 参数的文件属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无解析等)的代码,以最基本的方式插入所需的单行代码是合理的。要插入一小段代码,可以使用 details 参数的 code 属性来执行此操作。在这种情况下,document.body.innerText 是返回的文本,假设您没有指定文本的内容。
正如 wOxxOm 在评论中提到的,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome .tabs.executeScript 注入内容脚本。通常,您将使用 details 参数的 file 属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无需解析等)的代码,只需插入最基本的方法所需的单行代码是合理的。要插入一小段代码,您可以使用 details 参数的 code 属性来执行此操作。在这种情况下,鉴于您没有说明您对文本的要求,document.body.innerText 是返回的文本。
要将文本发送回后台脚本,.
要将文本发送回后台脚本,使用 chrome.runtime.sendMessage()。
要在后台脚本中接收文本,请放置 .
为了在后台脚本中接收文本,将一个监听器 receiveText 添加到 chrome.runtime.onMessage。
background.js:
chrome.browserAction.onClicked.addListener(function(tab) {
console.log('Injecting content script(s)');
//On Firefox document.body.textContent is probably more appropriate
chrome.tabs.executeScript(tab.id,{
code: 'document.body.innerText;'
//If you had something somewhat more complex you can use an IIFE:
//code: '(function (){return document.body.innerText})();'
//If your code was complex, you should store it in a
// separate .js file, which you inject with the file: property.
},receiveText);
});
//tabs.executeScript() returns the results of the executed script
// in an array of results, one entry per frame in which the script
// was injected.
function receiveText(resultsArray){
console.log(resultsArray[0]);
}
manifest.json:
{
"description": "Gets the text of a webpage and logs it to the console",
"manifest_version": 2,
"name": "Get Webpage Text",
"version": "0.1",
"permissions": [
"activeTab"
],
"background": {
"scripts": [
"background.js"
]
},
"browser_action": {
"default_icon": {
"32": "myIcon.png"
},
"default_title": "Get Webpage Text",
"browser_style": true
}
} 查看全部
网页 抓取 innertext 试题(:Google搜索结果文本解析的实施方式与解析
)
问题描述
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本并直接转到 Google 搜索页面。
我正在开发一个用于对 Google 搜索结果进行文本解析的 Chrome 扩展程序。我希望用户在多功能框中插入特定文本,然后直接进入 Google 搜索页面。
function navigate(url) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.update(tabs[0].id, {url: url});
});
}
chrome.omnibox.onInputEntered.addListener(function(text) {
navigate("https://www.google.com.br/sear ... ot%3B + text + "%20%2B%20cnpj");
});
alert('Here is where the text will be extracted');
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后解析。实现这一目标最直接的方法是什么?
将当前标签指向搜索页面后,我想获取页面的纯文本形式,然后进行解析。实现此目的最直接的方法是什么?
推荐答案
好吧,将网页解析为 DOM 而不是纯文本可能更容易。不过,这不是你的问题。
好吧,将网页解析为 DOM 而不是纯文本可能会更容易。但是,这不是您的问题。
您的代码在导航到页面和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实施。
您的代码在导航到页面的方式和处理网络导航的异步性质方面存在问题。这也不是您提出的问题,但会影响您提出的问题(从网页获取文本)的实现方式。
因此,为了回答您有关如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这一点。这会将回答如何做到这一点与代码中的其他问题分开。
p>
因此,为了回答您关于如何从网页中提取纯文本的问题,我在用户单击 browser_action 按钮时实现了这样做。这将回答如何做到这一点与代码中的其他问题分开。
正如评论中提到的 wOxxOm,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome.tabs.executeScript。通常,您将使用 details 参数的文件属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无解析等)的代码,以最基本的方式插入所需的单行代码是合理的。要插入一小段代码,可以使用 details 参数的 code 属性来执行此操作。在这种情况下,document.body.innerText 是返回的文本,假设您没有指定文本的内容。
正如 wOxxOm 在评论中提到的,要访问网页的 DOM,您必须使用内容脚本。正如他所做的那样,我建议您阅读 Chrome 扩展程序概述。您可以使用 chrome .tabs.executeScript 注入内容脚本。通常,您将使用 details 参数的 file 属性注入收录在单独文件中的脚本。对于只是发回网页文本的简单任务(无需解析等)的代码,只需插入最基本的方法所需的单行代码是合理的。要插入一小段代码,您可以使用 details 参数的 code 属性来执行此操作。在这种情况下,鉴于您没有说明您对文本的要求,document.body.innerText 是返回的文本。
要将文本发送回后台脚本,.
要将文本发送回后台脚本,使用 chrome.runtime.sendMessage()。
要在后台脚本中接收文本,请放置 .
为了在后台脚本中接收文本,将一个监听器 receiveText 添加到 chrome.runtime.onMessage。
background.js:
chrome.browserAction.onClicked.addListener(function(tab) {
console.log('Injecting content script(s)');
//On Firefox document.body.textContent is probably more appropriate
chrome.tabs.executeScript(tab.id,{
code: 'document.body.innerText;'
//If you had something somewhat more complex you can use an IIFE:
//code: '(function (){return document.body.innerText})();'
//If your code was complex, you should store it in a
// separate .js file, which you inject with the file: property.
},receiveText);
});
//tabs.executeScript() returns the results of the executed script
// in an array of results, one entry per frame in which the script
// was injected.
function receiveText(resultsArray){
console.log(resultsArray[0]);
}
manifest.json:
{
"description": "Gets the text of a webpage and logs it to the console",
"manifest_version": 2,
"name": "Get Webpage Text",
"version": "0.1",
"permissions": [
"activeTab"
],
"background": {
"scripts": [
"background.js"
]
},
"browser_action": {
"default_icon": {
"32": "myIcon.png"
},
"default_title": "Get Webpage Text",
"browser_style": true
}
}
网页 抓取 innertext 试题(如何让蜘蛛快速抓取网站方式方法(精选大合集))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-26 08:05
蜘蛛快速抓取网站方法(精选合集)
在这个互联网时代,很多人在购买产品之前都会去互联网查看信息内容,看看哪个品牌的知名度和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务搜索自己需要的信息,其中近70%的搜索者会直接在搜索结果自然排名的首页搜索自己需要的信息。.
由此可见,近年来,SEO对于企业和产品有着不可替代的意义。下面,我将告诉你如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
入链是优化网站的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。近年来,常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫爬取
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等,如果想让你的网站更多的页面是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
二、网站如何被蜘蛛快速爬取
1.平台网站 和页面权重。
这当然是首要的。权重高、资历高、权威大的平台网站蜘蛛当然是被正确对待了。这样的网站爬取的概率非常高,大家都知道搜索引擎蜘蛛为了保证效率,对于平台网站不一定所有页面都会被爬取,< @网站,爬得越深,对应的可爬取的页面也会增加,所以收录的页面也会更多。
2.网站服务器。
网站服务器是平台的基石网站,网站如果服务器长时间打不开,那就等于和你关门谢了,蜘蛛将无法到来。百度蜘蛛也是平台网站的访问者。如果你的服务器不稳定或者比较卡,那么每次爬虫都会很难爬到,有时候只能爬到页面的一部分。蜘蛛的体验越来越差,你的平台网站的分数会越来越低,自然会影响你的平台网站的爬取,所以一定要愿意选择一个空间服务器,没有人打好基础,房子再好,也会跨越。
3.平台网站的更新概率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动显示蜘蛛,并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛做出一次经常浪费的旅行。
4.文章 的 原创 特性。
优质原创内容对百度蜘蛛的诱惑是巨大的。蜘蛛存在的目的是为了发现新事物,所以网站更新文章不要采集,也不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛们能得到他们喜欢的东西,它们自然会对你的平台网站产生好感,并经常来觅食。
5.扁平平台网站结构。——
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。平台网站结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面很难被蜘蛛抓取。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会导致平台网站重复内容可能导致平台网站降级,严重影响蜘蛛的抓取,所以程序必须保证一个页面只有一个网址。处理标签或机器人以确保蜘蛛只抓取一个规范 URL。
7.外链建设。
我们都知道外链对于网站平台是可以吸引蜘蛛的,尤其是新站点的时候,平台网站还不是很成熟,蜘蛛访问的比较少,所以外链的数量链接可以增加 网站 页面在蜘蛛面前的曝光,阻止蜘蛛找到页面。在建立外链的过程中,需要注意外链的质量。不要为了省事而做无用的事情。相信大家都知道百度对外链接的管理。我不会多说。
8.内链构建。
蜘蛛的爬取是跟随链接的,所以内链的合理优化可以让蜘蛛爬取更多的页面,提升平台网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,很多平台网站都用到了,让蜘蛛爬取一个更广泛的页面。 查看全部
网页 抓取 innertext 试题(如何让蜘蛛快速抓取网站方式方法(精选大合集))
蜘蛛快速抓取网站方法(精选合集)
在这个互联网时代,很多人在购买产品之前都会去互联网查看信息内容,看看哪个品牌的知名度和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务搜索自己需要的信息,其中近70%的搜索者会直接在搜索结果自然排名的首页搜索自己需要的信息。.
由此可见,近年来,SEO对于企业和产品有着不可替代的意义。下面,我将告诉你如何让蜘蛛快速抓取。
一、网站如何快速被爬虫爬取?
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
2.外链也会影响权重
入链是优化网站的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。近年来,常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3.如何被爬虫爬取
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等,如果想让你的网站更多的页面是收录,你必须先让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
二、网站如何被蜘蛛快速爬取
1.平台网站 和页面权重。
这当然是首要的。权重高、资历高、权威大的平台网站蜘蛛当然是被正确对待了。这样的网站爬取的概率非常高,大家都知道搜索引擎蜘蛛为了保证效率,对于平台网站不一定所有页面都会被爬取,< @网站,爬得越深,对应的可爬取的页面也会增加,所以收录的页面也会更多。
2.网站服务器。
网站服务器是平台的基石网站,网站如果服务器长时间打不开,那就等于和你关门谢了,蜘蛛将无法到来。百度蜘蛛也是平台网站的访问者。如果你的服务器不稳定或者比较卡,那么每次爬虫都会很难爬到,有时候只能爬到页面的一部分。蜘蛛的体验越来越差,你的平台网站的分数会越来越低,自然会影响你的平台网站的爬取,所以一定要愿意选择一个空间服务器,没有人打好基础,房子再好,也会跨越。
3.平台网站的更新概率。
蜘蛛每次抓取时都会存储页面数据。如果第二次爬取发现页面和第一次收录一模一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但是蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以我们要主动显示蜘蛛,并定期进行文章更新,让蜘蛛按照你的规则来有效爬取,不仅你的更新文章被抓取更快,而且不会导致蜘蛛做出一次经常浪费的旅行。
4.文章 的 原创 特性。
优质原创内容对百度蜘蛛的诱惑是巨大的。蜘蛛存在的目的是为了发现新事物,所以网站更新文章不要采集,也不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。如果蜘蛛们能得到他们喜欢的东西,它们自然会对你的平台网站产生好感,并经常来觅食。
5.扁平平台网站结构。——
蜘蛛爬行也有自己的路线。你之前已经为它铺平了道路。平台网站结构不要太复杂,链接层次不要太深。如果链接层级太深,后面的页面很难被蜘蛛抓取。
6.网站程序。
在 网站 程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会导致平台网站重复内容可能导致平台网站降级,严重影响蜘蛛的抓取,所以程序必须保证一个页面只有一个网址。处理标签或机器人以确保蜘蛛只抓取一个规范 URL。
7.外链建设。
我们都知道外链对于网站平台是可以吸引蜘蛛的,尤其是新站点的时候,平台网站还不是很成熟,蜘蛛访问的比较少,所以外链的数量链接可以增加 网站 页面在蜘蛛面前的曝光,阻止蜘蛛找到页面。在建立外链的过程中,需要注意外链的质量。不要为了省事而做无用的事情。相信大家都知道百度对外链接的管理。我不会多说。
8.内链构建。
蜘蛛的爬取是跟随链接的,所以内链的合理优化可以让蜘蛛爬取更多的页面,提升平台网站的收录。在建立内部链接的过程中,应该给用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多点赞等栏目,很多平台网站都用到了,让蜘蛛爬取一个更广泛的页面。
网页 抓取 innertext 试题(一个soup对象用beautifulsoup库中方法提取页面源码(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-16 17:18
)
假设有一个页面有n个选择题,每个选择题都有几个选项。茎部分标有 h6 标签。options 部分使用 td 下的 div 标签。如下所示:
整个页面就是循环下面的 HTML 段落 n 次。
第1题. 选一二三还是四五六呢。
A.一二三
B.四五六
接下来,我想使用beautifulsoup库中的方法来提取页面上的主题和选项。
首先,导入所需的包:
from bs4 import BeautifulSoup
from urllib import request,parse
import re
然后可以通过多种方式提取页面源代码:
#既可以打开一个html文件:
soup = BeautifulSoup(open("page_source_code.html"))
#或者直接传入HTML代码:
soup = BeautifulSoup("data")
#也可以发送并且拦截请求:
url = “http://fake.html”
response = request.urlopen(url,timeout = 20)
responseUTF8 = response.read().decode("utf-8")
soup = BeautifulSoup(responseUTF8,'lxml')
简而言之,这样我们就得到了一个汤对象。接下来根据对象的标签结构,通过一定的方法定位目标标签。
方法一:下面的方法比较基础,使用“绝对路径”查找标签
# 通过观察发现,题干部分全部都是h6标签,和h6标签下的a标签。页面其余部分没有用到h6标签,所以用.find_all方法来抓取所有的题干。得到一个标签 list
h6lbs = soup.find_all('h6')
# 定义一个二维数组,用来盛放抓取到的选择题。选择题的题干和选项可作为每一个数组成员的成员。
item_question = []
for i in range(len(h6lbs)):
#定义一个一维数组,可以用来盛放题干和选项。先把刚刚拿到的题干保存进数组中
item = []
item.append(h6lbs[i].text)
#通过以上的HTML 结构可以知道,找到题干后,题干标签的“太爷爷”的“三弟弟”是保存选项的地方,所以这里用了很多个.parent 和 .next_sibling方法,通过绝对路径的方式定位标签
tag1 = h6lbs[i].parent.parent.parent.next_sibling.next_sibling
# check if this is choice question. or it must be a Yes/No questionnaire
if tag1 is not None and tag1.li is not None:
#刚刚说到太爷爷的三弟弟是存放选项的地方。太爷爷的三弟弟下的li标签下的table标签下的tbody标签下存放了多个选项,从这里开始需要遍历,将每一个选项都提取出
tag = h6lbs[i].parent.parent.parent.next_sibling.next_sibling.li.table.tbody
for child in tag.children:
#因为抓取出来有空对象,所以此处加入了一个判断。如果是None,就不保存了。
if child.string is None:
tag_string = child.td.div.string
#遍历每一个标签,取出其中的选项内容,用.string方法
#将取到的选项内容加入刚刚创建的一维数组中
item.append(tag_string)
# print(item)
#将每次得到的一维数组保存进二维数组中
item_question.append(item)
print(item_question) 查看全部
网页 抓取 innertext 试题(一个soup对象用beautifulsoup库中方法提取页面源码(图)
)
假设有一个页面有n个选择题,每个选择题都有几个选项。茎部分标有 h6 标签。options 部分使用 td 下的 div 标签。如下所示:
整个页面就是循环下面的 HTML 段落 n 次。
第1题. 选一二三还是四五六呢。
A.一二三
B.四五六
接下来,我想使用beautifulsoup库中的方法来提取页面上的主题和选项。
首先,导入所需的包:
from bs4 import BeautifulSoup
from urllib import request,parse
import re
然后可以通过多种方式提取页面源代码:
#既可以打开一个html文件:
soup = BeautifulSoup(open("page_source_code.html"))
#或者直接传入HTML代码:
soup = BeautifulSoup("data")
#也可以发送并且拦截请求:
url = “http://fake.html”
response = request.urlopen(url,timeout = 20)
responseUTF8 = response.read().decode("utf-8")
soup = BeautifulSoup(responseUTF8,'lxml')
简而言之,这样我们就得到了一个汤对象。接下来根据对象的标签结构,通过一定的方法定位目标标签。
方法一:下面的方法比较基础,使用“绝对路径”查找标签
# 通过观察发现,题干部分全部都是h6标签,和h6标签下的a标签。页面其余部分没有用到h6标签,所以用.find_all方法来抓取所有的题干。得到一个标签 list
h6lbs = soup.find_all('h6')
# 定义一个二维数组,用来盛放抓取到的选择题。选择题的题干和选项可作为每一个数组成员的成员。
item_question = []
for i in range(len(h6lbs)):
#定义一个一维数组,可以用来盛放题干和选项。先把刚刚拿到的题干保存进数组中
item = []
item.append(h6lbs[i].text)
#通过以上的HTML 结构可以知道,找到题干后,题干标签的“太爷爷”的“三弟弟”是保存选项的地方,所以这里用了很多个.parent 和 .next_sibling方法,通过绝对路径的方式定位标签
tag1 = h6lbs[i].parent.parent.parent.next_sibling.next_sibling
# check if this is choice question. or it must be a Yes/No questionnaire
if tag1 is not None and tag1.li is not None:
#刚刚说到太爷爷的三弟弟是存放选项的地方。太爷爷的三弟弟下的li标签下的table标签下的tbody标签下存放了多个选项,从这里开始需要遍历,将每一个选项都提取出
tag = h6lbs[i].parent.parent.parent.next_sibling.next_sibling.li.table.tbody
for child in tag.children:
#因为抓取出来有空对象,所以此处加入了一个判断。如果是None,就不保存了。
if child.string is None:
tag_string = child.td.div.string
#遍历每一个标签,取出其中的选项内容,用.string方法
#将取到的选项内容加入刚刚创建的一维数组中
item.append(tag_string)
# print(item)
#将每次得到的一维数组保存进二维数组中
item_question.append(item)
print(item_question)
网页 抓取 innertext 试题(如何每年5月份10月会计从业资格证考试真题6)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-15 01:01
网页抓取innertext试题地址:591344732017-08-2623:48:001。chromedriverbrowserscriptfiddler62。各种方法抓取下载网页地址的前x页3。抓取热门话题下第x页4。热门话题下x页5。如何抓取17年10月会计从业资格证考试真题6。如何抓取每年5月份cfa考试的真题7。如何抓取每年4月份的教师资格证考试真题8。如何抓取每年3月份的安全从业资格证考试真题。
"如何抓取每年5月份的从业资格证考试真题?"我都懒得分析此问题了,又想玩抓取又是从哪里找的东西。
抓取一些机构网站的内容呗
然后根据题目分析,哪部分是重点,再回头对应着学习,细致化学习,
抓取排名前几的公众号文章试试?
通过浏览器的截图分析大部分的知乎回答
方法也很多呀,抓取某些用户的简历,再通过调查问卷抓取大部分用户关心的信息,再找其中比较有趣的关键词,很多的。我试过用爬虫写软件,后来发现,还是不如传统的爬虫,因为有些东西得过滤,要格外小心一点,反正我是一条一条写代码,做好分析给研究员和专家审核,反正要抓到的问题是完全一样的问题,也不用考虑正负面评价,基本就是讨论性的东西了。代码里面也要避免误伤,尽量做到完整自洽。
翻墙
百度贴吧爬虫等等 查看全部
网页 抓取 innertext 试题(如何每年5月份10月会计从业资格证考试真题6)
网页抓取innertext试题地址:591344732017-08-2623:48:001。chromedriverbrowserscriptfiddler62。各种方法抓取下载网页地址的前x页3。抓取热门话题下第x页4。热门话题下x页5。如何抓取17年10月会计从业资格证考试真题6。如何抓取每年5月份cfa考试的真题7。如何抓取每年4月份的教师资格证考试真题8。如何抓取每年3月份的安全从业资格证考试真题。
"如何抓取每年5月份的从业资格证考试真题?"我都懒得分析此问题了,又想玩抓取又是从哪里找的东西。
抓取一些机构网站的内容呗
然后根据题目分析,哪部分是重点,再回头对应着学习,细致化学习,
抓取排名前几的公众号文章试试?
通过浏览器的截图分析大部分的知乎回答
方法也很多呀,抓取某些用户的简历,再通过调查问卷抓取大部分用户关心的信息,再找其中比较有趣的关键词,很多的。我试过用爬虫写软件,后来发现,还是不如传统的爬虫,因为有些东西得过滤,要格外小心一点,反正我是一条一条写代码,做好分析给研究员和专家审核,反正要抓到的问题是完全一样的问题,也不用考虑正负面评价,基本就是讨论性的东西了。代码里面也要避免误伤,尽量做到完整自洽。
翻墙
百度贴吧爬虫等等
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-13 10:11
最近有朋友在做OJ题库,可以做个小爬虫,导出题库列表看看!
对象:浙江大学题库
工具:python3.6、requests库、lxml库、pycharm
思路:首先在网页中找到题库的位置
然后我们点击第一页和后面的页面可以看到url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的都没有变,所以建个循环很方便。我们来看看源代码中title的title和Id以及url的位置。
是不是很明显a标签的属性里有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath抓取td标签,然后match 获取url和title,剪掉url写id(这里我就不去上面的td单独抓id了),然后写到字典里,这样就方便了查看,代码如下:
20多行代码全部搞定,结果如下:
不到 10 秒就在本地捕获了所有这些。当然,注意不要在这里重复操作,很有可能IP会被封!
将txt文档中的内容复制到在线解析json的网页中,查看结果
完美呈现~!当然,如果你有兴趣,你可以去主题的url,抓取主题。这可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很厉害的,欢迎大家跟我一起学python! 查看全部
网页 抓取 innertext 试题(导出一份题库题库列表来看看!的一个在线解析)
最近有朋友在做OJ题库,可以做个小爬虫,导出题库列表看看!
对象:浙江大学题库
工具:python3.6、requests库、lxml库、pycharm
思路:首先在网页中找到题库的位置
然后我们点击第一页和后面的页面可以看到url的变化
你找到模式了吗?也就是Number后面的页数变了,其他的都没有变,所以建个循环很方便。我们来看看源代码中title的title和Id以及url的位置。
是不是很明显a标签的属性里有具体的url,包括id也出现在url中,title出现在font标签中,所以很简单,我们直接用xpath抓取td标签,然后match 获取url和title,剪掉url写id(这里我就不去上面的td单独抓id了),然后写到字典里,这样就方便了查看,代码如下:
20多行代码全部搞定,结果如下:
不到 10 秒就在本地捕获了所有这些。当然,注意不要在这里重复操作,很有可能IP会被封!
将txt文档中的内容复制到在线解析json的网页中,查看结果
完美呈现~!当然,如果你有兴趣,你可以去主题的url,抓取主题。这可以作为下一步改进的地方!
一个很简单的小爬虫,python做这个工作还是很厉害的,欢迎大家跟我一起学python!
网页 抓取 innertext 试题(网页抓取innertext试题,没啥可加密,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-10 12:00
网页抓取innertext试题,这个api是false的,如果你不想要这个string,可以使用accept-language(客户端,服务端,aws,
两种方式:inputtext里面,i=10and"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz".hasoned("abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz");secondpassword里面,i=10可以打开这个网页,然后直接看abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz。现在returntrue。
统一的给前端让他们自己写一个
现在抓包都用ssl,甚至有很多反爬虫工具,这种情况下,我觉得没必要加密解密了。
没啥可加密的,根据nginx提供的信息就可以了,可以通过http分析获取到accept-language这个字段,根据需要获取有哪些值就加什么值呗,
有一种加密方式是重定向(redirect),这个方式其实在一些rss平台也被用到,比如feedly就是使用的这种方式,当然正常情况没必要这么干。另外如果accept-language不是特别重要,建议尽量用正则表达式。
给accept-language前面加点accept-encoding, 查看全部
网页 抓取 innertext 试题(网页抓取innertext试题,没啥可加密,怎么办?)
网页抓取innertext试题,这个api是false的,如果你不想要这个string,可以使用accept-language(客户端,服务端,aws,
两种方式:inputtext里面,i=10and"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz".hasoned("abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz");secondpassword里面,i=10可以打开这个网页,然后直接看abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz。现在returntrue。
统一的给前端让他们自己写一个
现在抓包都用ssl,甚至有很多反爬虫工具,这种情况下,我觉得没必要加密解密了。
没啥可加密的,根据nginx提供的信息就可以了,可以通过http分析获取到accept-language这个字段,根据需要获取有哪些值就加什么值呗,
有一种加密方式是重定向(redirect),这个方式其实在一些rss平台也被用到,比如feedly就是使用的这种方式,当然正常情况没必要这么干。另外如果accept-language不是特别重要,建议尽量用正则表达式。
给accept-language前面加点accept-encoding,
网页 抓取 innertext 试题(一个demoP站视频标题连接从哪里来?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2022-01-06 15:06
最近在学习Golang有一段时间了,想写点东西练练手。一开始想用golang来写爬虫,但是感觉太简单了。为什么不写一个网站!想了想,我对P站很熟悉了。文章之前写过一段nginx反代P站的视频。结合起来写个静态P站比较好,所以做了个demo。整个Golang代码不多,非常适合新手练习。
首先分析一下整个网站的思路,内容,也就是图片和视频标题链接,从何而来?这当然是直接从 Pornhub 抓取的。其次,由于是静态的网站,除了获取视频页面外,基本没有与后端的交互。页面也由后端直接渲染到前端。视频的播放由nginx直接处理。大致就是这么简单,其他的细节会在后面详述。
我们的第一步是去P站抓取视频素材,因为是静态的网站我们不用弄的太复杂,一次只能抓取一个页面显示出来。众所周知,P站是一个学习网站,也是一个包容的网站!比如我们在P站搜索美食时,可以看到很多网友上传的美食视频。
假设我们抓取上面的视频内容,打开控制台查看页面元素。
每个视频都放置在一个li标签中,里面收录了视频的一些基本信息。这是我们需要爬行的。原视频的链接只能从视频页面获取,需要再次发起get请求。将部分代码直接粘贴在这里。
func getRandomPhid() []string {
rand.Seed(time.Now().Unix())
randNum := rand.Intn(1000) //播种生成随机整数
url := "https://cn.pornhub.com/video?page=" + strconv.Itoa(randNum)
fmt.Println(url)
resp, err := http.Get(url)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
ulTag := htmlquery.FindOne(root, "//*[@id=\"videoCategory\"]")
aHrefList := htmlquery.Find(ulTag, "//a[@href]")
phList := []string{}
tmp := ""
for _, n := range aHrefList {
aHref := htmlquery.SelectAttr(n, "href")
if strings.Contains(aHref, "viewkey") {
if tmp == aHref { //提取视频链接时会有连续重复的情况
continue
}
ph := strings.Split(aHref, "=")[1]
phList = append(phList, ph)
tmp = aHref
}
}
return phList
}
这里我定义了一个getRandomPhid的函数,就是随机抓取P站上一页的视频内容。播种后,生成 0-1000 之间的任意整数。直接使用 http.Get 方法是因为不需要对请求进行额外的更改。这里使用了第三方库htmlquery来解析html元素,类似于python中的BeautifulSoup库。
因为所有li标签的父标签都是ul,所以元素通过xpath定位。然后我定义了一个字符串类型的切片 phList 来存储提取的视频 ID。因为会有重复的id,还是需要去重,但是golang没有python方便,可以直接使用set,需要自己实现,但是这里比较特殊,两个重复的id是连续的,所以直接用一个tmp变量来和前面的比较一下,去掉重复。
func reqPhid(id string) (videoInfo map[string]string, err error) {
defer func() {
if err := recover(); err != nil {
log.Println(err)
}
}()
client := &http.Client{}
url := "https://cn.pornhub.com/view_vi ... ot%3B + id
req, err := http.NewRequest("GET", url, nil)
checkError(err)
req.Header.Set("user-agent", "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1")
resp, err := client.Do(req)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
js := htmlquery.FindOne(root, "//*[@id=\"mobileContainer\"]/script[1]/text()")
jsString := htmlquery.InnerText(js)
videoInfo = make(map[string]string)
phQuality := gjson.Get(jsString, "quality_720p").String()
if phQuality == "" {
err = errors.New("获取视频链接失败!")
return
}
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
phQuality = re.ReplaceAllString(phQuality, domain+subDomain)
image_url := gjson.Get(jsString, "image_url").String()
subDomain = re.FindStringSubmatch(image_url)[1]
image_url = re.ReplaceAllString(image_url, domain+subDomain)
video_title := gjson.Get(jsString, "video_title").String()
videoInfo["videoUrl"] = phQuality
videoInfo["imgUrl"] = image_url
videoInfo["title"] = video_title
fmt.Println(videoInfo)
return
}
在前面的函数中,我们得到了所有的视频 ID。要获得真正的视频链接,我们需要再次请求视频页面。在这个函数中,我从一开始就推迟了一个匿名函数来捕获异常。接下来我们没有使用http.Get方法,而是使用&http.Client{}添加了一些我们自定义的header,即修改User-Agent伪装成手机浏览器header,而这个server也返回h5页面,原因是这里用了一个小技巧。
看过我文章的读者都知道,PC端请求P站得到的视频信息是经过加密和混淆处理的,手机端的信息直接是原创视频信息。我偶然发现了这一点,否则就太费力了,吃力不讨好,所以这个想法还是很重要的,有时也能奏效。不知道的朋友可以看看我之前的文章。
看完Pornhub的视频界面JS混乱,我手写了一个下载插件
可以试试用Chrome切换浏览器UA,真的很方便!
或者先用xpath定位这个JS的位置。flashvars的变量显然是json格式的数据。U1S1,golang原生处理json的方法真的很麻烦,需要写一个struct来接受数据。小数据的json也可以,一些复杂的json,尤其是不知道数据类型的时候,直接破解。这里推荐一个第三方模块gjson来解析,非常方便,和python一样流畅。
另外视频的分辨率有240、480、720、1080,为了尽量简化,我只拍了720分辨率的链接。通过定期匹配,将视频链接转换为您自己的域名。最后,它返回一个 map[string]string 类型的数据。
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
至于为什么这里只能使用dm1接口链接,我们后面再讨论。并且为了防止请求频率因为请求频率过快而被禁止,每次爬取后,暂停3s,尽可能减少异常。
func timeToRefresh() {
count := 0 //记录页面刷新的次数
for true {
allVideos = make([]map[string]string, 0)
phList := getRandomPhid()
for _, id := range phList {
video, err := reqPhid(id)
if err != nil {
log.Println(err)
continue
}
allVideos = append(allVideos, video)
}
count++
log.Printf("第%v次刷新页面", count)
time.Sleep(15 * time.Minute) //每隔多长时间时间刷新一次页面
}
}
因为我们写的是静态页面,没有前后端交互,而且后端渲染的很好,所以后端要定时抓取来刷新我们网站的内容. 这里allVideos是一个map,用来存放每次捕捉到的视频信息,但是注意这个变量在for循环中每次都用make初始化,相当于每次刷新视频数据。同时 allVideos 仍然是 myHandler 直接使用的全局变量。
在这里获取所有与视频相关的信息,基本上抓住它就结束了。剩下的就是网络服务器所做的。其实在golang里面很简单。
func myHandler(w http.ResponseWriter, r *http.Request) {
t, err := template.ParseFiles("index.html")
checkError(err)
err = t.Execute(w, allVideos)
checkError(err)
}
func main() {
go timeToRefresh()
http.HandleFunc("/", myHandler)
err := http.ListenAndServe(":8080", nil)
checkError(err)
}
这里我把这两个函数放在一起,myHandler相当于对请求的响应。首先是解析我们写好的前端模板,然后渲染生成我们传入的数据并发送给用户。
前面提到的timeToRefresh函数是一个定时捕获函数,但是我们不能让抓取的页面阻塞我们的主线程,所以直接在它前面加一个go关键字就可以了。是不是很方便?这体现了为了go语言的魅力,我们会另外写一个线程或者其他语言的东西。所以golang写起来真的很流畅。然后是绑定路径和监听端口。这些都非常简单。
func checkError(err error) {
if err != nil {
log.Println(err)
}
}
而且大家都知道golang中的错误处理会写一堆if err !=nil{… },所以我再封装一层。在上面的代码中,我看到我使用 checkError 统一处理 err。
Golang的部分基本完成。再说说Nginx的部分。既然要播放视频,就不能随便抢视频链接,因为P站在国内被屏蔽了,不能直接播放。一切都可以通过使用Nginx反生成视频流打开缓冲区来实现。具体可以参考我之前的文章文章。
白嫖?神奇使用Nginx proxy_buffer实现Pornhub视频反向生成
在这个文章中,我使用了多个子域来逆向生成。事实上,读者无需在此之前发表评论。您可以使用以下编写方法。
前面的代码提到了不匹配dm1接口的时候会panic,因为我这里没有研究透彻。我把dm1域名倒过来是可以的,但是其他的会以403拒绝响应。
dm1 是正常的。所以这里我只使用了匹配dm1的视频链接。
我猜应该是做了一些测试,但是我想通了具体的原因,不知道有没有必要带一些具体的header。希望朋友们留言一起讨论。
最后是前端模板。这是勾刀为我做的。非常感谢勾刀的帮助。其中 let json = {{.}} 是 golang 模板的语法,传入我们的数据。
Golang + Nginx 实现静态 Pornhub
//样式的代码过长,就不展示了
每隔15分钟自动刷新视频页面
//后端返回的数据
let json = {{.}}
//处理数据
json.map(v => {
appendCard(newCard(v.videoUrl, v.imgUrl, v.title))
})
//创建card
function newCard(videoUrl, imgUrl, title) {
let card = document.createElement('div')
card.classList.add('card')
let face1 = document.createElement('div')
face1.classList.add('face')
face1.classList.add('face1')
let p = document.createElement('p')
p.innerText = title
p.setAttribute("videoUrl", videoUrl)
face1.appendChild(p)
let face2 = document.createElement('div')
face2.classList.add('face')
face2.classList.add('face2')
let img = document.createElement('img')
img.setAttribute('src', imgUrl)
img.setAttribute('alt', "")
face2.appendChild(img)
card.appendChild(face1)
card.appendChild(face2)
p.onclick = function (e) {
window.open(e.target.getAttribute("videoUrl"))
}
return card
}
//将card添加进页面
function appendCard(card) {
let main = document.getElementsByClassName('main')[0]
main.appendChild(card)
}
这样我们的静态P站就做好了,最后就是显示我们用Golang+Nginx网站做了。我在某云中使用了一台香港轻量级服务器在这里运行。它的带宽为30m。反代视频基本无压力。
因为比例太大,这里全部编码完成,网站的背景改为橙色。有没有P站的味道?哈哈哈。同时点击视频直接播放,是不是很香!好像ghs没那么难!当然,这里只是技术分享,哈哈!
本博客纯粹是我学习Golang一段时间后做的一个小demo。有兴趣的朋友可以自行尝试。毕竟,您可以应用所学!我把代码、前端模板和nginx配置文件放在下面,把golang代码和Nginx配置中的域名换成自己的域名即可!每个人都可以通过简单的改变开始跑步。
golang+nginx-做一个静态的pornhub网站.zip
如果有什么问题,小伙伴们可以在下方留言,共同探讨! 查看全部
网页 抓取 innertext 试题(一个demoP站视频标题连接从哪里来?(图))
最近在学习Golang有一段时间了,想写点东西练练手。一开始想用golang来写爬虫,但是感觉太简单了。为什么不写一个网站!想了想,我对P站很熟悉了。文章之前写过一段nginx反代P站的视频。结合起来写个静态P站比较好,所以做了个demo。整个Golang代码不多,非常适合新手练习。
首先分析一下整个网站的思路,内容,也就是图片和视频标题链接,从何而来?这当然是直接从 Pornhub 抓取的。其次,由于是静态的网站,除了获取视频页面外,基本没有与后端的交互。页面也由后端直接渲染到前端。视频的播放由nginx直接处理。大致就是这么简单,其他的细节会在后面详述。
我们的第一步是去P站抓取视频素材,因为是静态的网站我们不用弄的太复杂,一次只能抓取一个页面显示出来。众所周知,P站是一个学习网站,也是一个包容的网站!比如我们在P站搜索美食时,可以看到很多网友上传的美食视频。
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440-300x186.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440-768x477.png 768w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111160440.png 1065w" />假设我们抓取上面的视频内容,打开控制台查看页面元素。
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111161313-300x165.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111161313-768x423.png 768w" />每个视频都放置在一个li标签中,里面收录了视频的一些基本信息。这是我们需要爬行的。原视频的链接只能从视频页面获取,需要再次发起get请求。将部分代码直接粘贴在这里。
func getRandomPhid() []string {
rand.Seed(time.Now().Unix())
randNum := rand.Intn(1000) //播种生成随机整数
url := "https://cn.pornhub.com/video?page=" + strconv.Itoa(randNum)
fmt.Println(url)
resp, err := http.Get(url)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
ulTag := htmlquery.FindOne(root, "//*[@id=\"videoCategory\"]")
aHrefList := htmlquery.Find(ulTag, "//a[@href]")
phList := []string{}
tmp := ""
for _, n := range aHrefList {
aHref := htmlquery.SelectAttr(n, "href")
if strings.Contains(aHref, "viewkey") {
if tmp == aHref { //提取视频链接时会有连续重复的情况
continue
}
ph := strings.Split(aHref, "=")[1]
phList = append(phList, ph)
tmp = aHref
}
}
return phList
}
这里我定义了一个getRandomPhid的函数,就是随机抓取P站上一页的视频内容。播种后,生成 0-1000 之间的任意整数。直接使用 http.Get 方法是因为不需要对请求进行额外的更改。这里使用了第三方库htmlquery来解析html元素,类似于python中的BeautifulSoup库。
因为所有li标签的父标签都是ul,所以元素通过xpath定位。然后我定义了一个字符串类型的切片 phList 来存储提取的视频 ID。因为会有重复的id,还是需要去重,但是golang没有python方便,可以直接使用set,需要自己实现,但是这里比较特殊,两个重复的id是连续的,所以直接用一个tmp变量来和前面的比较一下,去掉重复。
func reqPhid(id string) (videoInfo map[string]string, err error) {
defer func() {
if err := recover(); err != nil {
log.Println(err)
}
}()
client := &http.Client{}
url := "https://cn.pornhub.com/view_vi ... ot%3B + id
req, err := http.NewRequest("GET", url, nil)
checkError(err)
req.Header.Set("user-agent", "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1")
resp, err := client.Do(req)
checkError(err)
htmlText, err := ioutil.ReadAll(resp.Body)
checkError(err)
root, err := htmlquery.Parse(strings.NewReader(string(htmlText)))
checkError(err)
js := htmlquery.FindOne(root, "//*[@id=\"mobileContainer\"]/script[1]/text()")
jsString := htmlquery.InnerText(js)
videoInfo = make(map[string]string)
phQuality := gjson.Get(jsString, "quality_720p").String()
if phQuality == "" {
err = errors.New("获取视频链接失败!")
return
}
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
phQuality = re.ReplaceAllString(phQuality, domain+subDomain)
image_url := gjson.Get(jsString, "image_url").String()
subDomain = re.FindStringSubmatch(image_url)[1]
image_url = re.ReplaceAllString(image_url, domain+subDomain)
video_title := gjson.Get(jsString, "video_title").String()
videoInfo["videoUrl"] = phQuality
videoInfo["imgUrl"] = image_url
videoInfo["title"] = video_title
fmt.Println(videoInfo)
return
}
在前面的函数中,我们得到了所有的视频 ID。要获得真正的视频链接,我们需要再次请求视频页面。在这个函数中,我从一开始就推迟了一个匿名函数来捕获异常。接下来我们没有使用http.Get方法,而是使用&http.Client{}添加了一些我们自定义的header,即修改User-Agent伪装成手机浏览器header,而这个server也返回h5页面,原因是这里用了一个小技巧。
看过我文章的读者都知道,PC端请求P站得到的视频信息是经过加密和混淆处理的,手机端的信息直接是原创视频信息。我偶然发现了这一点,否则就太费力了,吃力不讨好,所以这个想法还是很重要的,有时也能奏效。不知道的朋友可以看看我之前的文章。
看完Pornhub的视频界面JS混乱,我手写了一个下载插件
可以试试用Chrome切换浏览器UA,真的很方便!
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111235002-300x173.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201111235002-768x443.png 768w" />或者先用xpath定位这个JS的位置。flashvars的变量显然是json格式的数据。U1S1,golang原生处理json的方法真的很麻烦,需要写一个struct来接受数据。小数据的json也可以,一些复杂的json,尤其是不知道数据类型的时候,直接破解。这里推荐一个第三方模块gjson来解析,非常方便,和python一样流畅。
另外视频的分辨率有240、480、720、1080,为了尽量简化,我只拍了720分辨率的链接。通过定期匹配,将视频链接转换为您自己的域名。最后,它返回一个 map[string]string 类型的数据。
re := regexp.MustCompile(`(?m)https:\/\/([a-z0-9]{2,3})\.phncdn\.com`)
subDomain := re.FindStringSubmatch(phQuality)[1]
if subDomain != "dm1" {
time.Sleep(3 * time.Second)
err = errors.New("未匹配dm1接口!")
return
}
至于为什么这里只能使用dm1接口链接,我们后面再讨论。并且为了防止请求频率因为请求频率过快而被禁止,每次爬取后,暂停3s,尽可能减少异常。
func timeToRefresh() {
count := 0 //记录页面刷新的次数
for true {
allVideos = make([]map[string]string, 0)
phList := getRandomPhid()
for _, id := range phList {
video, err := reqPhid(id)
if err != nil {
log.Println(err)
continue
}
allVideos = append(allVideos, video)
}
count++
log.Printf("第%v次刷新页面", count)
time.Sleep(15 * time.Minute) //每隔多长时间时间刷新一次页面
}
}
因为我们写的是静态页面,没有前后端交互,而且后端渲染的很好,所以后端要定时抓取来刷新我们网站的内容. 这里allVideos是一个map,用来存放每次捕捉到的视频信息,但是注意这个变量在for循环中每次都用make初始化,相当于每次刷新视频数据。同时 allVideos 仍然是 myHandler 直接使用的全局变量。
在这里获取所有与视频相关的信息,基本上抓住它就结束了。剩下的就是网络服务器所做的。其实在golang里面很简单。
func myHandler(w http.ResponseWriter, r *http.Request) {
t, err := template.ParseFiles("index.html")
checkError(err)
err = t.Execute(w, allVideos)
checkError(err)
}
func main() {
go timeToRefresh()
http.HandleFunc("/", myHandler)
err := http.ListenAndServe(":8080", nil)
checkError(err)
}
这里我把这两个函数放在一起,myHandler相当于对请求的响应。首先是解析我们写好的前端模板,然后渲染生成我们传入的数据并发送给用户。
前面提到的timeToRefresh函数是一个定时捕获函数,但是我们不能让抓取的页面阻塞我们的主线程,所以直接在它前面加一个go关键字就可以了。是不是很方便?这体现了为了go语言的魅力,我们会另外写一个线程或者其他语言的东西。所以golang写起来真的很流畅。然后是绑定路径和监听端口。这些都非常简单。
func checkError(err error) {
if err != nil {
log.Println(err)
}
}
而且大家都知道golang中的错误处理会写一堆if err !=nil{… },所以我再封装一层。在上面的代码中,我看到我使用 checkError 统一处理 err。
Golang的部分基本完成。再说说Nginx的部分。既然要播放视频,就不能随便抢视频链接,因为P站在国内被屏蔽了,不能直接播放。一切都可以通过使用Nginx反生成视频流打开缓冲区来实现。具体可以参考我之前的文章文章。
白嫖?神奇使用Nginx proxy_buffer实现Pornhub视频反向生成
在这个文章中,我使用了多个子域来逆向生成。事实上,读者无需在此之前发表评论。您可以使用以下编写方法。
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112004818-300x180.png 300w, https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112004818-768x460.png 768w" />前面的代码提到了不匹配dm1接口的时候会panic,因为我这里没有研究透彻。我把dm1域名倒过来是可以的,但是其他的会以403拒绝响应。
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112005426-300x115.png 300w" />dm1 是正常的。所以这里我只使用了匹配dm1的视频链接。
https://zgao.top/wp-content/uploads/2020/11/QQ截图20201112005827-300x188.png 300w" />我猜应该是做了一些测试,但是我想通了具体的原因,不知道有没有必要带一些具体的header。希望朋友们留言一起讨论。
最后是前端模板。这是勾刀为我做的。非常感谢勾刀的帮助。其中 let json = {{.}} 是 golang 模板的语法,传入我们的数据。
Golang + Nginx 实现静态 Pornhub
//样式的代码过长,就不展示了
每隔15分钟自动刷新视频页面
//后端返回的数据
let json = {{.}}
//处理数据
json.map(v => {
appendCard(newCard(v.videoUrl, v.imgUrl, v.title))
})
//创建card
function newCard(videoUrl, imgUrl, title) {
let card = document.createElement('div')
card.classList.add('card')
let face1 = document.createElement('div')
face1.classList.add('face')
face1.classList.add('face1')
let p = document.createElement('p')
p.innerText = title
p.setAttribute("videoUrl", videoUrl)
face1.appendChild(p)
let face2 = document.createElement('div')
face2.classList.add('face')
face2.classList.add('face2')
let img = document.createElement('img')
img.setAttribute('src', imgUrl)
img.setAttribute('alt', "")
face2.appendChild(img)
card.appendChild(face1)
card.appendChild(face2)
p.onclick = function (e) {
window.open(e.target.getAttribute("videoUrl"))
}
return card
}
//将card添加进页面
function appendCard(card) {
let main = document.getElementsByClassName('main')[0]
main.appendChild(card)
}
这样我们的静态P站就做好了,最后就是显示我们用Golang+Nginx网站做了。我在某云中使用了一台香港轻量级服务器在这里运行。它的带宽为30m。反代视频基本无压力。
因为比例太大,这里全部编码完成,网站的背景改为橙色。有没有P站的味道?哈哈哈。同时点击视频直接播放,是不是很香!好像ghs没那么难!当然,这里只是技术分享,哈哈!
本博客纯粹是我学习Golang一段时间后做的一个小demo。有兴趣的朋友可以自行尝试。毕竟,您可以应用所学!我把代码、前端模板和nginx配置文件放在下面,把golang代码和Nginx配置中的域名换成自己的域名即可!每个人都可以通过简单的改变开始跑步。
golang+nginx-做一个静态的pornhub网站.zip
如果有什么问题,小伙伴们可以在下方留言,共同探讨!
网页 抓取 innertext 试题(微信公众号(19考研分享)你可以参考一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-14 00:06
网页抓取innertext试题数据,可以抓取it圈子的小伙伴的微信qq群号,进行线上校招招聘,
微信公众号,
问题太宽泛,
有考研分享公众号(19考研分享)你可以参考一下
如果你自己不足够强大,很难成为一个不错的设计师。如果你足够强大,能够调动资源,团队有创意和执行力,那么你可以做公众号。
做公众号最重要的三点:内容、内容、内容。创作出有吸引力的、精彩的、有价值的公众号可以吸引人。公众号最重要的吸引力在于其与用户利益相关而有效的信息展示,能够利用公众号快速为客户推送并解决用户的问题。如果这是你公众号的定位或者要做的事情,可以去考虑做公众号。有时候公众号的运营很难做到真正吸引用户的关注,大概会有这么几点:。
1、尽可能给用户推送干货。
2、热点时事要跟紧,要尽量填补用户利益空缺,要吸引用户转发,形成大家互相传播的局面。
3、定期公布跟最热门的事件相关的文章。
4、带点有价值的有用信息。
5、文末尽量与粉丝互动交流。公众号,是个资源整合平台,看准定位做精。
很简单,
iosapp“礼物说”用户基数是微信公众号的好几倍。 查看全部
网页 抓取 innertext 试题(微信公众号(19考研分享)你可以参考一下)
网页抓取innertext试题数据,可以抓取it圈子的小伙伴的微信qq群号,进行线上校招招聘,
微信公众号,
问题太宽泛,
有考研分享公众号(19考研分享)你可以参考一下
如果你自己不足够强大,很难成为一个不错的设计师。如果你足够强大,能够调动资源,团队有创意和执行力,那么你可以做公众号。
做公众号最重要的三点:内容、内容、内容。创作出有吸引力的、精彩的、有价值的公众号可以吸引人。公众号最重要的吸引力在于其与用户利益相关而有效的信息展示,能够利用公众号快速为客户推送并解决用户的问题。如果这是你公众号的定位或者要做的事情,可以去考虑做公众号。有时候公众号的运营很难做到真正吸引用户的关注,大概会有这么几点:。
1、尽可能给用户推送干货。
2、热点时事要跟紧,要尽量填补用户利益空缺,要吸引用户转发,形成大家互相传播的局面。
3、定期公布跟最热门的事件相关的文章。
4、带点有价值的有用信息。
5、文末尽量与粉丝互动交流。公众号,是个资源整合平台,看准定位做精。
很简单,
iosapp“礼物说”用户基数是微信公众号的好几倍。
网页 抓取 innertext 试题(参考网络爬虫入门_一只特立独行的猪的博客-CSDN博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-23 13:05
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析
打开要爬取的网页,发现改变页数只需要改变URL n.htm中的变量n
查看页面源码,找到要爬取的数据所在的位置
2. 内容爬取
写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
查看抓取文件
三、 爬行重提交消息通知
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析
打开要爬取的网页,找到时间和标题位置
2. 内容爬取
代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = { # 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('test.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
查看抓取文件
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
网络爬虫入门_一个特立独行的猪博客-CSDN博客 查看全部
网页 抓取 innertext 试题(参考网络爬虫入门_一只特立独行的猪的博客-CSDN博客)
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析
打开要爬取的网页,发现改变页数只需要改变URL n.htm中的变量n
查看页面源码,找到要爬取的数据所在的位置
2. 内容爬取
写代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
查看抓取文件
三、 爬行重提交消息通知
爬取目标网址:练习场-ACM在线测评系统
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析
打开要爬取的网页,找到时间和标题位置
2. 内容爬取
代码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 17 14:39:03 2021
@author: 86199
"""
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = { # 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('test.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
查看抓取文件
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
网络爬虫入门_一个特立独行的猪博客-CSDN博客

