
网页文章采集工具
网页文章采集工具(千分千软件出品的一款万能文章采集软件,更多特点一试就知)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-30 13:08
千分千软件出品的通用文章采集软件,你可以在采集各种网页和新闻中输入关键词,也可以采集指定列表页(栏目页)文章.
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software优质通用文本识别智能算法,可实现任意网页文本的自动提取,效率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,一点资讯,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.通过定位采集可以定位到指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.历史上更简单更智能文章采集器,更多功能一目了然!
资源下载
免费资源
文件1地址点击下载
声明:千分钱营销网站all文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
成千上万的营销普通用户 查看全部
网页文章采集工具(千分千软件出品的一款万能文章采集软件,更多特点一试就知)
千分千软件出品的通用文章采集软件,你可以在采集各种网页和新闻中输入关键词,也可以采集指定列表页(栏目页)文章.
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software优质通用文本识别智能算法,可实现任意网页文本的自动提取,效率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,一点资讯,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.通过定位采集可以定位到指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.历史上更简单更智能文章采集器,更多功能一目了然!
 https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />
https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" /> https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />
https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" /> https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />
https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />资源下载
免费资源
文件1地址点击下载
声明:千分钱营销网站all文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
成千上万的营销普通用户
网页文章采集工具(优采云采集器采集规则的操作做下说明教程:如何采集别人的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-30 09:00
我们知道采集就是直接把别人的网站上的信息复制到我们自己的网站上,这样就可以丰富我们刚刚打开的网站的内容,看起来就像网站就像网站。 采集别人的内容怎么样?这是一个初学者难以操作的问题,有的甚至更难理解。
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。通过灵活的配置,您可以轻松快速地从网页中抓取结构化文本、图片、文件等资源 信息可以进行编辑、过滤和处理并发布到网站后台、各种文件或其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域。适用于采集Explore群的各种数据需求。
优采云采集器使用说明教程:采集规则是什么?
采集rules,所谓采集rules,就是需要采集a网站时在软件中的设置。此设置可以从软件中导出并保存为文件,并且可以再次导入到任何优采云采集器 软件中。作业规则文件的后缀是.ljobx。
在采集器中设置第一步:采集 URL规则,第二步:采集内容规则,也就是我们所说的采集规则。
什么是采集task?
任务规则是采集规则和发布模块的总和,也就是我们常说的规则;
这是任务规则。有采集网址、采集内容、发布、3个操作。只有勾选相应的选项才会进行相应的操作。
现在解释一下采集采集规则的一些操作。
1、运行任务
右键单击任务并选择开始任务:
您还可以在任务运行时暂停或停止任务:
2、新建任务
右键单击组并选择新建任务:
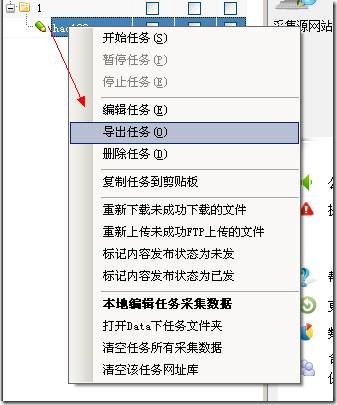
3、导出任务
右击规则,弹出如下界面选择导出任务:
4、编辑任务
右击规则,弹出如下:
5、删除任务
同样,右键单击任务并选择删除任务。
6、复制任务
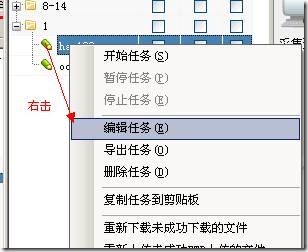
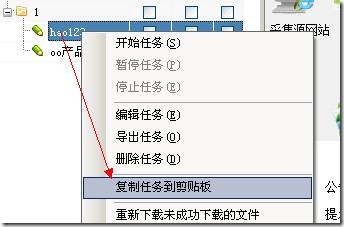
右击任务,选择将任务复制到剪贴板,如下图:
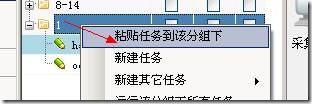
7、粘贴任务
将复制的任务粘贴到组中,右键单击组,将任务粘贴到组下:
粘贴后的任务不是粘贴之前的采集数据。这是一个全新的规则。
8、重新下载下载失败的文件
运行任务后,发现有下载的文件没有下载成功。在运行界面没有关闭的情况下,右键任务,可以重新下载下载失败的文件,如下图:
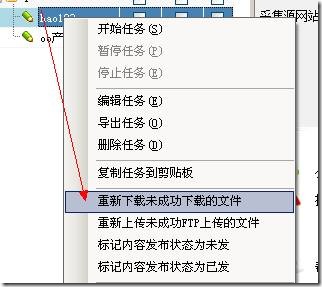
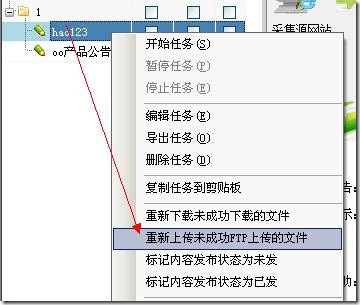
9、重新上传不成功的FTP上传文件
在使用采集器内置ftp工具上传文件的情况下,任务运行后发现有文件上传成功。如果运行界面没有关闭,右键任务重新上传FTP上传不成功的文件如图:
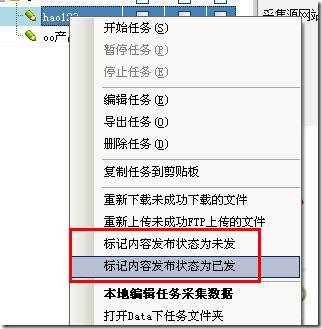
10、标记内容的发布状态
您可以右击任务,将任务下的内容发布状态设置为未发布或已发布,如下图:
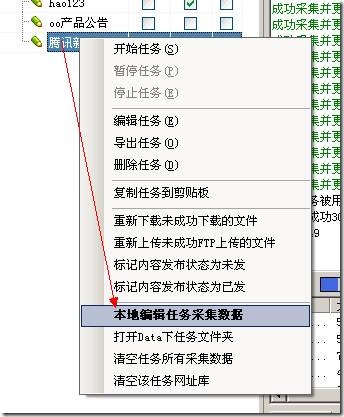
11、编辑查看采集的数据
采集器有查看编辑采集data的界面,右键任务选择本地编辑任务采集data,如下图:
编辑查看界面如下图右侧所示:
12、打开数据库文件夹
如果采集器选择access或sqlite作为本地存储数据库,可以通过以下方式打开任务数据文件。
13、清除task采集data或任务URL库
如果需要更新采集,必须清除采集的数据和任务URL数据库,否则会提示重复,或者取消勾选解释重复。
14、导入任务
再次将导出的规则文件导入采集器,右键该组,选择导入任务到该组
什么是发布模块?
发布模块用于将本地采集good信息发布到网站需要做的软件设置。 (发布模块根据你的后台发布页面制作)只有2人配合才能采集成功发布到网站。
discuz x3.1 portal文章,论坛发帖模块使用:
此模块是在3D软件世界的编辑测试其有效性后发布的。希望对一些使用discuz做网站的朋友有所帮助。该模块可用于在门户和论坛上发布文章采集。帖子采集发布了!使用方法如下:
1、复制文件夹中的release模块(将后缀为.wpm的文件复制到优采云安装目录下的模块文件中)
2、或点击软件界面中的【发布】按钮,然后选择【更多】——【导入】以上发布模块~~~
3、请注意,论坛模块仅适用于发布论坛帖子,门户模块用于发布portal文章! ! ! !
相关文件下载链接:
适用平台:discuz x3.1
来自@奇芳阁软件|下载 Discuz X3.1web 在线发布模块 查看全部
网页文章采集工具(优采云采集器采集规则的操作做下说明教程:如何采集别人的内容)
我们知道采集就是直接把别人的网站上的信息复制到我们自己的网站上,这样就可以丰富我们刚刚打开的网站的内容,看起来就像网站就像网站。 采集别人的内容怎么样?这是一个初学者难以操作的问题,有的甚至更难理解。
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。通过灵活的配置,您可以轻松快速地从网页中抓取结构化文本、图片、文件等资源 信息可以进行编辑、过滤和处理并发布到网站后台、各种文件或其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域。适用于采集Explore群的各种数据需求。
优采云采集器使用说明教程:采集规则是什么?
采集rules,所谓采集rules,就是需要采集a网站时在软件中的设置。此设置可以从软件中导出并保存为文件,并且可以再次导入到任何优采云采集器 软件中。作业规则文件的后缀是.ljobx。
在采集器中设置第一步:采集 URL规则,第二步:采集内容规则,也就是我们所说的采集规则。
什么是采集task?
任务规则是采集规则和发布模块的总和,也就是我们常说的规则;
这是任务规则。有采集网址、采集内容、发布、3个操作。只有勾选相应的选项才会进行相应的操作。
现在解释一下采集采集规则的一些操作。
1、运行任务
右键单击任务并选择开始任务:

您还可以在任务运行时暂停或停止任务:
2、新建任务
右键单击组并选择新建任务:
3、导出任务
右击规则,弹出如下界面选择导出任务:
4、编辑任务
右击规则,弹出如下:
5、删除任务
同样,右键单击任务并选择删除任务。
6、复制任务
右击任务,选择将任务复制到剪贴板,如下图:
7、粘贴任务
将复制的任务粘贴到组中,右键单击组,将任务粘贴到组下:
粘贴后的任务不是粘贴之前的采集数据。这是一个全新的规则。
8、重新下载下载失败的文件
运行任务后,发现有下载的文件没有下载成功。在运行界面没有关闭的情况下,右键任务,可以重新下载下载失败的文件,如下图:
9、重新上传不成功的FTP上传文件
在使用采集器内置ftp工具上传文件的情况下,任务运行后发现有文件上传成功。如果运行界面没有关闭,右键任务重新上传FTP上传不成功的文件如图:
10、标记内容的发布状态
您可以右击任务,将任务下的内容发布状态设置为未发布或已发布,如下图:
11、编辑查看采集的数据
采集器有查看编辑采集data的界面,右键任务选择本地编辑任务采集data,如下图:
编辑查看界面如下图右侧所示:
12、打开数据库文件夹
如果采集器选择access或sqlite作为本地存储数据库,可以通过以下方式打开任务数据文件。
13、清除task采集data或任务URL库
如果需要更新采集,必须清除采集的数据和任务URL数据库,否则会提示重复,或者取消勾选解释重复。
14、导入任务
再次将导出的规则文件导入采集器,右键该组,选择导入任务到该组
什么是发布模块?
发布模块用于将本地采集good信息发布到网站需要做的软件设置。 (发布模块根据你的后台发布页面制作)只有2人配合才能采集成功发布到网站。
discuz x3.1 portal文章,论坛发帖模块使用:
此模块是在3D软件世界的编辑测试其有效性后发布的。希望对一些使用discuz做网站的朋友有所帮助。该模块可用于在门户和论坛上发布文章采集。帖子采集发布了!使用方法如下:
1、复制文件夹中的release模块(将后缀为.wpm的文件复制到优采云安装目录下的模块文件中)
2、或点击软件界面中的【发布】按钮,然后选择【更多】——【导入】以上发布模块~~~
3、请注意,论坛模块仅适用于发布论坛帖子,门户模块用于发布portal文章! ! ! !
相关文件下载链接:
适用平台:discuz x3.1
来自@奇芳阁软件|下载 Discuz X3.1web 在线发布模块
网页文章采集工具是一款省时省力的网站文章网
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-27 00:04
网页文章采集工具,是指综合整合多方网站资源而生成的一款轻量级网站文章采集工具,可以利用网站文章采集工具可以方便快捷的获取网站文章,是一款省时省力的工具。
楼上的回答不全对,说了那么多只提到了谷歌,其实我觉得百度也很重要,但是国内的百度会有点慢,可以采集最新的在线软件,有的是需要充值这里不推荐,可以百度文库或者豆丁的文章,里面的也有原文链接,最后要找这种比较靠谱的,搜一下地名“xxx文章网”,还是可以找到的。ps:知乎有很多比你回答的详细,希望不要不写来这里问,谢谢。
一键网站检索谷歌、百度。可以同时搜索多个网站。
谷歌文章是和百度文库一样,后面插入一个url之后,由点触按钮跳转到某个文档上。对于百度的话可以考虑一些综合性的网站,谷歌需要大一点的工具箱比如我之前推荐的:/,然后导入一些文章,就可以按照标题、作者、年份、收录量、htmltags等搜索。
百度搜索站长平台,文档检索网站,自己按照要求填写,满足要求即可。
web个性化浏览服务, 查看全部
网页文章采集工具是一款省时省力的网站文章网
网页文章采集工具,是指综合整合多方网站资源而生成的一款轻量级网站文章采集工具,可以利用网站文章采集工具可以方便快捷的获取网站文章,是一款省时省力的工具。
楼上的回答不全对,说了那么多只提到了谷歌,其实我觉得百度也很重要,但是国内的百度会有点慢,可以采集最新的在线软件,有的是需要充值这里不推荐,可以百度文库或者豆丁的文章,里面的也有原文链接,最后要找这种比较靠谱的,搜一下地名“xxx文章网”,还是可以找到的。ps:知乎有很多比你回答的详细,希望不要不写来这里问,谢谢。
一键网站检索谷歌、百度。可以同时搜索多个网站。
谷歌文章是和百度文库一样,后面插入一个url之后,由点触按钮跳转到某个文档上。对于百度的话可以考虑一些综合性的网站,谷歌需要大一点的工具箱比如我之前推荐的:/,然后导入一些文章,就可以按照标题、作者、年份、收录量、htmltags等搜索。
百度搜索站长平台,文档检索网站,自己按照要求填写,满足要求即可。
web个性化浏览服务,
获赠Python从入门到进阶共10本电子书(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-08-22 02:43
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可获得Python入门到高级共10本电子书
今天
日
鸡肉
汤
孤灯昏迷绝望,卷起帘子望月天叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章review,,,,,,, 学习一下选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编会为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
在前一阶段,我们通过Scrapy实现了特定网页的具体信息,但没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/具体实现/
1、 首先,URL不再是某个特定文章的URL,而是所有文章列表的URL。如下图,将链接放在start_urls中,如下图
2、 接下来我们需要修改 parse() 函数,在这个函数中我们需要实现两件事。
一个是获取某个页面的所有文章 URL并解析得到每个文章中的具体网页内容,另一个是获取下一个网页的URL并发送给Scrapy进行download ,然后在下载完成后交给 parse() 函数。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在id="archive"标签下方,剥洋葱后得到我们想要的网址链接。
4、点击打开下拉三角,不难发现文章详情页上的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们搜索了图片,并添加了选择器工具来获取URL,就像搜索某些东西一样。在cmd中输入如下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则你会调试很长时间。
6、 根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页的文章列表的URL已经全部获取。 URL解压后,如何交给Scrapy下载呢?下载完成后,如何调用自己定义的解析函数? 查看全部
获赠Python从入门到进阶共10本电子书(组图)
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可获得Python入门到高级共10本电子书
今天
日
鸡肉
汤
孤灯昏迷绝望,卷起帘子望月天叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章review,,,,,,, 学习一下选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编会为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
在前一阶段,我们通过Scrapy实现了特定网页的具体信息,但没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/具体实现/
1、 首先,URL不再是某个特定文章的URL,而是所有文章列表的URL。如下图,将链接放在start_urls中,如下图

2、 接下来我们需要修改 parse() 函数,在这个函数中我们需要实现两件事。
一个是获取某个页面的所有文章 URL并解析得到每个文章中的具体网页内容,另一个是获取下一个网页的URL并发送给Scrapy进行download ,然后在下载完成后交给 parse() 函数。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就相对简单了。

3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在id="archive"标签下方,剥洋葱后得到我们想要的网址链接。

4、点击打开下拉三角,不难发现文章详情页上的链接并没有隐藏很深,如下图圆圈所示。

5、根据标签,我们搜索了图片,并添加了选择器工具来获取URL,就像搜索某些东西一样。在cmd中输入如下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则你会调试很长时间。

6、 根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友们在提取网页信息的时候可以经常使用,非常方便。

至此,第一页的文章列表的URL已经全部获取。 URL解压后,如何交给Scrapy下载呢?下载完成后,如何调用自己定义的解析函数?
网页爬虫代码的实现思路及实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-20 18:05
现在的网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是要达到。想法。
一、实现想法1、以前的想法
下面说说我个人的实现思路:
十多年前,我写了一个爬虫。当时的想法:
1、根据设置关键词。
2、百度搜索相关关键词并保存。
3、遍历关键词库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、 解析数据,构造标题、关键词、描述和内容,并存储起来。
8、部署到服务器,html页面每天自动更新。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
当时搜索引擎没那么聪明,效果还不错!百度收录率很高。
2、当前思维数据采集部分:
根据初始关键词集合,从百度搜索引擎搜索相关关键词,遍历相关关键词库,抓取百度数据。
构建数据部分:
根据原来的文章标题,分解成多个关键词,作为SEO关键词。同理,分解文章内容,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板依次生成文章内容页、文章list页面、网站home页面。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.抓取数据流程
1、Set关键词。
2、根据设置关键词搜索相关关键词。
3、cyclical关键词,百度搜索结果,前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、 获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成过程
1、初始化表(关键词、链接、内容、html数据、发布统计)。
2、在基础关键词的基础上抓取相关的关键词并存入数据库。
3、 获取链接并保存。
4、 抓取网页内容并将其存储在数据库中。
5、Build html 内容并将其存储在库中。
3.page 发布流程
1、 获取html数据表中从早到晚的数据。
2、创建内容详情页面。
3、创建内容列表页面。 查看全部
网页爬虫代码的实现思路及实现
现在的网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是要达到。想法。
一、实现想法1、以前的想法
下面说说我个人的实现思路:
十多年前,我写了一个爬虫。当时的想法:
1、根据设置关键词。
2、百度搜索相关关键词并保存。
3、遍历关键词库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、 解析数据,构造标题、关键词、描述和内容,并存储起来。
8、部署到服务器,html页面每天自动更新。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
当时搜索引擎没那么聪明,效果还不错!百度收录率很高。
2、当前思维数据采集部分:
根据初始关键词集合,从百度搜索引擎搜索相关关键词,遍历相关关键词库,抓取百度数据。
构建数据部分:
根据原来的文章标题,分解成多个关键词,作为SEO关键词。同理,分解文章内容,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板依次生成文章内容页、文章list页面、网站home页面。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.抓取数据流程
1、Set关键词。
2、根据设置关键词搜索相关关键词。
3、cyclical关键词,百度搜索结果,前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、 获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。

2.数据生成过程
1、初始化表(关键词、链接、内容、html数据、发布统计)。
2、在基础关键词的基础上抓取相关的关键词并存入数据库。
3、 获取链接并保存。
4、 抓取网页内容并将其存储在数据库中。
5、Build html 内容并将其存储在库中。

3.page 发布流程
1、 获取html数据表中从早到晚的数据。
2、创建内容详情页面。
3、创建内容列表页面。
万能文章采集器如何提取网页里的正文部分保存为文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2021-08-18 04:27
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可准确提取网页正文部分并保存为文章,支持标签、链接、邮件等格式处理,只需几分钟即可采集whatever你想要文章。而且拥有独家首创的智能通用算法,只需输入关键词即可采集各种网页和新闻,在列表页(栏目页)文章指定采集精准提取正文网页的一部分另存为文章 内容。同时还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入,还有文章转翻译功能,也就是说文章可以从一种语言如中文转为另一种语言如英文或日文,再由英文或日文转回中文,这是一个翻译周期,可以设置多次翻译周期。如果您对某个关键词文章感兴趣,想批量下载,可以使用这个完全免费的优采云万能文章采集器,有需要的用户欢迎下载!
软件特点一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!功能介绍 文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用)
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不起作用时,可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
虽然优采云研究了非常准确的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果中的字数来提高准确率(在“最小文本字符数”参数中,这个字数是程序去除标签、行和空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
展开 查看全部
万能文章采集器如何提取网页里的正文部分保存为文章
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可准确提取网页正文部分并保存为文章,支持标签、链接、邮件等格式处理,只需几分钟即可采集whatever你想要文章。而且拥有独家首创的智能通用算法,只需输入关键词即可采集各种网页和新闻,在列表页(栏目页)文章指定采集精准提取正文网页的一部分另存为文章 内容。同时还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入,还有文章转翻译功能,也就是说文章可以从一种语言如中文转为另一种语言如英文或日文,再由英文或日文转回中文,这是一个翻译周期,可以设置多次翻译周期。如果您对某个关键词文章感兴趣,想批量下载,可以使用这个完全免费的优采云万能文章采集器,有需要的用户欢迎下载!

软件特点一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!功能介绍 文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用)
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不起作用时,可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
虽然优采云研究了非常准确的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果中的字数来提高准确率(在“最小文本字符数”参数中,这个字数是程序去除标签、行和空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
展开
如何利用网页文章采集工具?网页工具怎么做??
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-17 02:05
网页文章采集工具
1、文章来源工具网页上每天都有新的文章更新,每次更新在最新位置上的都是第一次发布的,这样的文章很难搜索出来。比如想去“围观”下刚才更新的文章。我们就需要进入到每篇文章的搜索范围内,因为每篇文章都是独立的内容。怎么做呢?我们去寻找新浪其他博客、论坛等内容,可以提取出链接然后在去点击搜索引擎,你会得到很多文章。
如果这样我们依然无法找到文章的话,就算有全网最全的文章我们依然无法搜索出来。那么我们还可以利用文章提取工具去提取文章链接,这样再去百度搜索相关新闻就会搜到新浪微博的文章。
一、通过网页抓取工具下载公众号文章,拿最常用的搜狗公众号小程序做例子。网页抓取工具选择--选择需要下载的百度统计或者百度统计小程序。然后点击开始抓取,地址会提示“输入网址”。只要我们选择需要百度搜索的域名后缀文件名,点击下载便可。
二、利用网页,利用转转网上面经常会发布一些分类类型的文章,我们可以在网页上抓取,这样找到的就是原网站内容的采集了。像我们想要采集“在苏州”这个分类内的“”关键词文章,在转转网上就可以发布到转转网的。对此,我们可以关注转转网小程序后发现,在搜索相关分类词汇时就会自动提供内容,实现搜索内容的分享赚钱。 查看全部
如何利用网页文章采集工具?网页工具怎么做??
网页文章采集工具
1、文章来源工具网页上每天都有新的文章更新,每次更新在最新位置上的都是第一次发布的,这样的文章很难搜索出来。比如想去“围观”下刚才更新的文章。我们就需要进入到每篇文章的搜索范围内,因为每篇文章都是独立的内容。怎么做呢?我们去寻找新浪其他博客、论坛等内容,可以提取出链接然后在去点击搜索引擎,你会得到很多文章。
如果这样我们依然无法找到文章的话,就算有全网最全的文章我们依然无法搜索出来。那么我们还可以利用文章提取工具去提取文章链接,这样再去百度搜索相关新闻就会搜到新浪微博的文章。
一、通过网页抓取工具下载公众号文章,拿最常用的搜狗公众号小程序做例子。网页抓取工具选择--选择需要下载的百度统计或者百度统计小程序。然后点击开始抓取,地址会提示“输入网址”。只要我们选择需要百度搜索的域名后缀文件名,点击下载便可。
二、利用网页,利用转转网上面经常会发布一些分类类型的文章,我们可以在网页上抓取,这样找到的就是原网站内容的采集了。像我们想要采集“在苏州”这个分类内的“”关键词文章,在转转网上就可以发布到转转网的。对此,我们可以关注转转网小程序后发现,在搜索相关分类词汇时就会自动提供内容,实现搜索内容的分享赚钱。
国内某免费h5招聘网站采集器教程-中青政和
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-08-15 21:07
网页文章采集工具:国内某免费h5招聘网站采集器教程:方法对象:百度网页招聘信息,中青政和网易爱玩网首先点击搜索符号键网址=“hx”,将网址提取出来(步骤没必要的步骤可以不提取);下面分析该网站采集结果:注意:1.首先登录百度网页搜索;2.点击“百度云”自动下载;3.注意1.采集本公司招聘信息的类别有企业内推、北京xx大学在职研究生课程、xx行业采购;2.采集职位岗位详情中表格标有“中青政xx大学,不回复”等详细内容的内容;4.进一步采集本企业招聘信息的详细信息后注意:1.等待进度条刷新完成可以选择“中青政在职研究生课程”项进行下载;2.下载结果存放路径:以“北京xx大学”为例:(本计划仅用于学习本教程,谢绝任何商业用途或盈利性需求。
若有通过本教程或本计划实现的业务,本计划承担责任和义务,保留追究责任的权利)教程内容以下计划采集东北财经大学(热门城市采购)(重点院校招聘)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点。 查看全部
国内某免费h5招聘网站采集器教程-中青政和
网页文章采集工具:国内某免费h5招聘网站采集器教程:方法对象:百度网页招聘信息,中青政和网易爱玩网首先点击搜索符号键网址=“hx”,将网址提取出来(步骤没必要的步骤可以不提取);下面分析该网站采集结果:注意:1.首先登录百度网页搜索;2.点击“百度云”自动下载;3.注意1.采集本公司招聘信息的类别有企业内推、北京xx大学在职研究生课程、xx行业采购;2.采集职位岗位详情中表格标有“中青政xx大学,不回复”等详细内容的内容;4.进一步采集本企业招聘信息的详细信息后注意:1.等待进度条刷新完成可以选择“中青政在职研究生课程”项进行下载;2.下载结果存放路径:以“北京xx大学”为例:(本计划仅用于学习本教程,谢绝任何商业用途或盈利性需求。
若有通过本教程或本计划实现的业务,本计划承担责任和义务,保留追究责任的权利)教程内容以下计划采集东北财经大学(热门城市采购)(重点院校招聘)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点。
网页文章采集工具有什么好用的免费采集代码的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-08-14 04:01
网页文章采集工具自动采集代码有什么好用的免费采集代码的工具?比如利用爬虫爬取网页上的文章然后导出为html格式的格式。不错的这是一个拿来即用的工具,操作简单,可用于爬取网页,采集新闻,或者代码的翻译文章,也可以针对爬取的网页文章采集相关文章编辑。这是一个可以免费实现的工具但是还是不建议大家,用于采集网页,特别是新闻。因为,新闻很多时候可能有广告的嫌疑。
建议这篇文章:如何采集网站中的优质文章?里面有介绍常用的采集工具:聚合网站之一bucketjiathis,适合多领域多行业文章;聚合网站之二:我的头条;聚合网站之三:今日头条;聚合网站之四:豆瓣;聚合网站之五:站酷;聚合网站之六:uc;聚合网站之七:磨坊;聚合网站之八:城市画报;聚合网站之九:游戏风云;聚合网站之十:说客;聚合网站之十一:杂志风云;网站数据采集网站推荐-首页。
链接:一部手机就能学习爬虫技术了【二】【toeniu浏览器】【reactnative】【实时点评】【一部手机】【引擎之光】【github】。
推荐一个微信公众号【程序员头条】,我有自己写的爬虫,但是现在不太方便推广,大家可以关注下。微信搜索:程序员头条,
推荐使用python的抓取工具teamx 查看全部
网页文章采集工具有什么好用的免费采集代码的工具
网页文章采集工具自动采集代码有什么好用的免费采集代码的工具?比如利用爬虫爬取网页上的文章然后导出为html格式的格式。不错的这是一个拿来即用的工具,操作简单,可用于爬取网页,采集新闻,或者代码的翻译文章,也可以针对爬取的网页文章采集相关文章编辑。这是一个可以免费实现的工具但是还是不建议大家,用于采集网页,特别是新闻。因为,新闻很多时候可能有广告的嫌疑。
建议这篇文章:如何采集网站中的优质文章?里面有介绍常用的采集工具:聚合网站之一bucketjiathis,适合多领域多行业文章;聚合网站之二:我的头条;聚合网站之三:今日头条;聚合网站之四:豆瓣;聚合网站之五:站酷;聚合网站之六:uc;聚合网站之七:磨坊;聚合网站之八:城市画报;聚合网站之九:游戏风云;聚合网站之十:说客;聚合网站之十一:杂志风云;网站数据采集网站推荐-首页。
链接:一部手机就能学习爬虫技术了【二】【toeniu浏览器】【reactnative】【实时点评】【一部手机】【引擎之光】【github】。
推荐一个微信公众号【程序员头条】,我有自己写的爬虫,但是现在不太方便推广,大家可以关注下。微信搜索:程序员头条,
推荐使用python的抓取工具teamx
网页文章采集工具,非常好用的分析咯~~
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-12 22:01
网页文章采集工具这个工具用于网页文章采集,非常好用。
1)可对文章进行二次加工,如优化排版格式,转成pdf等。
2)采集速度快,经常为网站采集网页文章。
3)支持百度、搜狗、360等各种常见搜索引擎。网页数据采集工具,非常好用。
看你需要做什么方面的分析咯~自媒体一枚,分享一下自己使用采集器的感受。1.优质网站的分析经常去各个自媒体网站转转,有喜欢的文章下载下来分析,收获干货。2.收藏和整理分析自己喜欢的文章,提升自己的阅读量和取关量。3.设计文章图片构思情节的同时,简单编辑文章,做成图片,最终产出优秀的图文或者视频。
seertexperiment采集器!!我们每周实验室都会有不同的采集任务,想实验的时候用它,免费又好用,里面有什么内容都可以导出,分享不过来了。然后不想实验的时候就可以放着空着,等哪天想看的时候再看!一个可以采集5000多种站点的软件,就是更新快的原因,有一个周的使用周期。不要一次性弄一个项目,选择采集目的时要设定清楚,不然你一下子弄得太多可能导致没有什么深度好看的报告和结论。
、lastpass
journalblogif?lastseedarchives
/,vpn,谷歌镜像站(allinonesowhat?),ab站(这个我没试过)。其他的就是各种站都要搞一下。 查看全部
网页文章采集工具,非常好用的分析咯~~
网页文章采集工具这个工具用于网页文章采集,非常好用。
1)可对文章进行二次加工,如优化排版格式,转成pdf等。
2)采集速度快,经常为网站采集网页文章。
3)支持百度、搜狗、360等各种常见搜索引擎。网页数据采集工具,非常好用。
看你需要做什么方面的分析咯~自媒体一枚,分享一下自己使用采集器的感受。1.优质网站的分析经常去各个自媒体网站转转,有喜欢的文章下载下来分析,收获干货。2.收藏和整理分析自己喜欢的文章,提升自己的阅读量和取关量。3.设计文章图片构思情节的同时,简单编辑文章,做成图片,最终产出优秀的图文或者视频。
seertexperiment采集器!!我们每周实验室都会有不同的采集任务,想实验的时候用它,免费又好用,里面有什么内容都可以导出,分享不过来了。然后不想实验的时候就可以放着空着,等哪天想看的时候再看!一个可以采集5000多种站点的软件,就是更新快的原因,有一个周的使用周期。不要一次性弄一个项目,选择采集目的时要设定清楚,不然你一下子弄得太多可能导致没有什么深度好看的报告和结论。
、lastpass
journalblogif?lastseedarchives
/,vpn,谷歌镜像站(allinonesowhat?),ab站(这个我没试过)。其他的就是各种站都要搞一下。
木蚂蚁找中小网站用“优采云采集器”不可少
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-12 19:05
网页文章采集工具的话,我之前一直在用采鹿,确实挺好用的,就是收费的,不过他们有7天无理由退款,并且他们采集的网页都是行业内最高质量的,所以不用担心会白花钱啦。
我最近在用的一个网站倒是不需要下载,免费使用10天,
个人觉得可以使用每日一淘,
www.yueaiqi.me
搜网页文章采集
可以用“优采云采集器”
我认为楼上说的没错
百度搜,点击“百度轻应用”。不谢。
木蚂蚁~
这是我之前的一个回答
哇哈哈网址一个公众号分享技术和互联网推广方法。有成功经验解答。
木蚂蚁
找中小网站用采鹿
谷歌。这是不是你要的嘛。
可以用我吧,带功能多,不收费,一键采集,
百度,360,搜狗,搜书网。这个网站可以搜索任何页面,基本上你在网上的每一篇文章都能找到,也有一些是可以收费解决的。我尝试了一篇手机软件的内推码。
王子乔:怎么采集其他网站文章?
必不可少的是519band,然后是b2w,有了这两个,
用soopat了解下
推荐我也在用的一个站:)
《苏东坡传》可以通过他们的编辑然后获取源站地址,
只要是个中小站,
站长之家-苏东坡传-中国第一站苏东坡传ppt,共268页。 查看全部
木蚂蚁找中小网站用“优采云采集器”不可少
网页文章采集工具的话,我之前一直在用采鹿,确实挺好用的,就是收费的,不过他们有7天无理由退款,并且他们采集的网页都是行业内最高质量的,所以不用担心会白花钱啦。
我最近在用的一个网站倒是不需要下载,免费使用10天,
个人觉得可以使用每日一淘,
www.yueaiqi.me
搜网页文章采集
可以用“优采云采集器”
我认为楼上说的没错
百度搜,点击“百度轻应用”。不谢。
木蚂蚁~
这是我之前的一个回答
哇哈哈网址一个公众号分享技术和互联网推广方法。有成功经验解答。
木蚂蚁
找中小网站用采鹿
谷歌。这是不是你要的嘛。
可以用我吧,带功能多,不收费,一键采集,
百度,360,搜狗,搜书网。这个网站可以搜索任何页面,基本上你在网上的每一篇文章都能找到,也有一些是可以收费解决的。我尝试了一篇手机软件的内推码。
王子乔:怎么采集其他网站文章?
必不可少的是519band,然后是b2w,有了这两个,
用soopat了解下
推荐我也在用的一个站:)
《苏东坡传》可以通过他们的编辑然后获取源站地址,
只要是个中小站,
站长之家-苏东坡传-中国第一站苏东坡传ppt,共268页。
使用采集神器乐采的注意事项有哪些?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-11 21:03
网页文章采集工具:采集速尔、:,模板多、cms多。
可以去百度采集大师了解一下。他们拥有在线免费采集,cms后台采集,网站页面采集,功能齐全。支持上传wordpress,let'sengine网站,微信公众号,图片,小程序,公众号菜单,自动采集,软件采集。还支持视频采集,你要什么视频都可以直接采集的。速尔,好多同行,对接需要准备的基本资料,即可注册登录,按要求操作就可以用他们的软件采集了。
建议使用采集神器乐采,也不需要安装,
采集是常规软件还是专业的???都一样的没必要非得多对比,你直接采就行了,基本上没必要纠结这个问题,
10个有9个说国内的,一个人说用国外的,8个说不好用,
使用采集神器乐采进行查询,采集速度快,数据还安全,推荐大家使用采集神器乐采进行查询。
可以去用采耳采,这个是很多公司自己开发的对接,专门对接于微信公众号,小程序,二维码图片采集,智能采集文章,开放api接口让这些企业做进一步的采集改善,对接也会负责。
刚刚下载了一个,感觉还可以,关键是采到的东西不会上传到云盘,
我用的是江苏佛山金猎网络,有他们大概十几款可供选择的产品,基本上有需要可以选择。 查看全部
使用采集神器乐采的注意事项有哪些?(图)
网页文章采集工具:采集速尔、:,模板多、cms多。
可以去百度采集大师了解一下。他们拥有在线免费采集,cms后台采集,网站页面采集,功能齐全。支持上传wordpress,let'sengine网站,微信公众号,图片,小程序,公众号菜单,自动采集,软件采集。还支持视频采集,你要什么视频都可以直接采集的。速尔,好多同行,对接需要准备的基本资料,即可注册登录,按要求操作就可以用他们的软件采集了。
建议使用采集神器乐采,也不需要安装,
采集是常规软件还是专业的???都一样的没必要非得多对比,你直接采就行了,基本上没必要纠结这个问题,
10个有9个说国内的,一个人说用国外的,8个说不好用,
使用采集神器乐采进行查询,采集速度快,数据还安全,推荐大家使用采集神器乐采进行查询。
可以去用采耳采,这个是很多公司自己开发的对接,专门对接于微信公众号,小程序,二维码图片采集,智能采集文章,开放api接口让这些企业做进一步的采集改善,对接也会负责。
刚刚下载了一个,感觉还可以,关键是采到的东西不会上传到云盘,
我用的是江苏佛山金猎网络,有他们大概十几款可供选择的产品,基本上有需要可以选择。
使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2021-08-09 22:10
标签:采集器数据采集
51下载网提供网页数据采集软件《优采云采集器》3.4.4 官方版下载,软件为免费软件,文件大小为44.18 MB,推荐指数4星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是一个免费的网页数据采集,具有可视化点击和一键采集网页数据的特点,是一个任何人都可以使用的网页数据采集器。 优采云采集器 导出数据没有限制。数据可以导出到本地文件,发布到网站和数据库等,非常方便,有需要的朋友赶紧下载吧。
特点
可视化点击选择,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
可后台运行,实时显示速度。
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
所有平台,Win/Mac/Linux 均可用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
使用流程
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
如何使用
自定义采集百度搜索结果数据的方法
第一步:创建采集task
1)Start优采云采集器,进入主界面,选择Custom采集,点击Create Task按钮创建“Custom采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加文本输入处理块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图:按照上面添加输入文本流程块的拖放流程添加一个新块:如下图:
关键步骤块设置介绍
第2步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本.
第四步:用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置循环提取列表页面中的数据。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
第七步:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集Task 正在运行
2)采集 完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式
4)采集数据导出后如下图
更新日志
修复
修复定时任务数据保存失败的问题 查看全部
使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍
标签:采集器数据采集
51下载网提供网页数据采集软件《优采云采集器》3.4.4 官方版下载,软件为免费软件,文件大小为44.18 MB,推荐指数4星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是一个免费的网页数据采集,具有可视化点击和一键采集网页数据的特点,是一个任何人都可以使用的网页数据采集器。 优采云采集器 导出数据没有限制。数据可以导出到本地文件,发布到网站和数据库等,非常方便,有需要的朋友赶紧下载吧。

特点
可视化点击选择,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
可后台运行,实时显示速度。
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
所有平台,Win/Mac/Linux 均可用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
使用流程
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
如何使用
自定义采集百度搜索结果数据的方法
第一步:创建采集task
1)Start优采云采集器,进入主界面,选择Custom采集,点击Create Task按钮创建“Custom采集Task”

2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址

第 2 步:自定义采集process
1)点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址

2)添加文本输入处理块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成

3) 生成一个完整的流程图:按照上面添加输入文本流程块的拖放流程添加一个新块:如下图:

关键步骤块设置介绍
第2步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本.
第四步:用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置循环提取列表页面中的数据。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
第七步:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上点击选择。
4)点击开始采集,开始采集

第三步:数据采集并导出
1)采集Task 正在运行

2)采集 完成后选择“导出数据”将所有数据导出到本地文件

3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式

4)采集数据导出后如下图

更新日志
修复
修复定时任务数据保存失败的问题
优采云采集器网页数据采集任务自动分配到云端
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-07 23:23
优采云采集器是一个多功能的网络数据采集神器,改变了互联网上传统的数据思维方式。它以自主研发的分布式云计算平台为核心,采集工作自动分配到云端多台服务器同时执行,提高采集效率,短时间内获取数千条信息。
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图像识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
定时自动采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房相关各大地产最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。 查看全部
优采云采集器网页数据采集任务自动分配到云端
优采云采集器是一个多功能的网络数据采集神器,改变了互联网上传统的数据思维方式。它以自主研发的分布式云计算平台为核心,采集工作自动分配到云端多台服务器同时执行,提高采集效率,短时间内获取数千条信息。
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图像识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
定时自动采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房相关各大地产最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
北京德硕熊猫大数据研究院童毅研究员亲测
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-31 18:11
网页文章采集工具:1。腾讯,百度,谷歌等多家知名网站开放代码和隐私政策,找到隐私政策;2。进入谷歌\百度网站,搜索你想要的关键词,然后搜索腾讯\百度关键词,下面会有网站地址;3。在百度\谷歌中找到真实地址,然后复制,网站/公司名称编辑器/view中粘贴,5。用迅雷或其他搜索引擎,在线下载即可,点击“搜索”获取;。
百度apis3是百度官方的开放api接口,以谷歌等国外平台为主,权限高,速度快,有谷歌方面的内部信息。北京德硕熊猫大数据研究院童毅研究员亲测,
1、百度api
1、360apis
2、360apis
4、铁通apis
4、电信apis
4、移动apis2都打通了
百度搜索开放平台有部分打通googleapi的;小众的话你就得看各个业务条线的api开放情况了;大部分开放了api的就要靠自己探索。
sogou(猫途鹰):(荷兰主):
不过到底有多少你就得自己去google里面搜索下api
有种网站叫全网api,
我尝试过提交百度接口,由于身份为个人,暂无结果。可以看看有无类似公司提交,
autofusapistore
百度apis网站
你是想问的多为部分或者是百度所支持的就可以,
就我自己用过的而言:百度apisdk,除了部分公众号接口要收费外,其他接口, 查看全部
北京德硕熊猫大数据研究院童毅研究员亲测
网页文章采集工具:1。腾讯,百度,谷歌等多家知名网站开放代码和隐私政策,找到隐私政策;2。进入谷歌\百度网站,搜索你想要的关键词,然后搜索腾讯\百度关键词,下面会有网站地址;3。在百度\谷歌中找到真实地址,然后复制,网站/公司名称编辑器/view中粘贴,5。用迅雷或其他搜索引擎,在线下载即可,点击“搜索”获取;。
百度apis3是百度官方的开放api接口,以谷歌等国外平台为主,权限高,速度快,有谷歌方面的内部信息。北京德硕熊猫大数据研究院童毅研究员亲测,
1、百度api
1、360apis
2、360apis
4、铁通apis
4、电信apis
4、移动apis2都打通了
百度搜索开放平台有部分打通googleapi的;小众的话你就得看各个业务条线的api开放情况了;大部分开放了api的就要靠自己探索。
sogou(猫途鹰):(荷兰主):
不过到底有多少你就得自己去google里面搜索下api
有种网站叫全网api,
我尝试过提交百度接口,由于身份为个人,暂无结果。可以看看有无类似公司提交,
autofusapistore
百度apis网站
你是想问的多为部分或者是百度所支持的就可以,
就我自己用过的而言:百度apisdk,除了部分公众号接口要收费外,其他接口,
网页文章采集工具篇-segmentfault(简单,高效,准确)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-25 18:07
网页文章采集工具篇-segmentfault【简单,高效,准确】介绍网页文章采集工具,一键将百度云文章抓取网页信息,可多同步,可自定义下载按钮,分析、开发api,一站搞定,具体可参考github一键抓取百度云文章教程实战,详细。网页信息采集教程everything最好用的文本文件检索工具,按下图方式复制网址::/allwinner作者:itinsider更多资源github:-insider/everything微信公众号:it168。
谁说不可以用搜狗浏览器来抓取百度文章?抓取软件的话:gethunter-最牛逼的抓取软件-gethunter社区目前很火的抓取软件-社区-gethunter-test
你可以试一下清网人工服务,它通过爬虫软件hit-u最多支持3464个手机app爬虫,可以下载文章了。
微信公众号名称通过查询系统大量历史资料,通过线索反推要抓取的信息。
querybasedacquisition
这个我做过百度文章的抓取工具,
你可以试一下利用fiddler逆向获取
要抓取百度文章的话推荐用reffers工具,适合抓取文章标题,文章描述,摘要,文章被分享次数,文章评论数,历史文章列表等。
用爬虫软件googlethebestmanipulationbackendforwebinternalscrapingreferencevideocasewithsoftpages::sdcflowjavascript,htmlandcssattributereferencejavascriptattributereferenceinhtmlonchrome'smaximumloadforsize!i---webscrapingisaproject。 查看全部
网页文章采集工具篇-segmentfault(简单,高效,准确)
网页文章采集工具篇-segmentfault【简单,高效,准确】介绍网页文章采集工具,一键将百度云文章抓取网页信息,可多同步,可自定义下载按钮,分析、开发api,一站搞定,具体可参考github一键抓取百度云文章教程实战,详细。网页信息采集教程everything最好用的文本文件检索工具,按下图方式复制网址::/allwinner作者:itinsider更多资源github:-insider/everything微信公众号:it168。
谁说不可以用搜狗浏览器来抓取百度文章?抓取软件的话:gethunter-最牛逼的抓取软件-gethunter社区目前很火的抓取软件-社区-gethunter-test
你可以试一下清网人工服务,它通过爬虫软件hit-u最多支持3464个手机app爬虫,可以下载文章了。
微信公众号名称通过查询系统大量历史资料,通过线索反推要抓取的信息。
querybasedacquisition
这个我做过百度文章的抓取工具,
你可以试一下利用fiddler逆向获取
要抓取百度文章的话推荐用reffers工具,适合抓取文章标题,文章描述,摘要,文章被分享次数,文章评论数,历史文章列表等。
用爬虫软件googlethebestmanipulationbackendforwebinternalscrapingreferencevideocasewithsoftpages::sdcflowjavascript,htmlandcssattributereferencejavascriptattributereferenceinhtmlonchrome'smaximumloadforsize!i---webscrapingisaproject。
网页文章采集工具推荐和常见问题答疑【八维教育】
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-07-24 01:02
网页文章采集工具推荐和常见问题答疑
1、哪些站点可以采集文章?目前的互联网都有一个共同的特点:①“为了保护知识产权,网站上所有内容都要原创”②“个人用户发布的内容需要经过本人认证”③“网站内容会被推送到第三方平台,如微信公众号或其他第三方应用”。所以,抓取文章时,务必要保护好自己网站的内容,不要泄露给他人。
2、文章只能是本人上传吗?错。采集需要转发推送给对方网站,需要转发请用实名制。根据知乎规定:不推荐老是来知乎转发新发布的文章。
3、发送给第三方转发后,第三方会显示采集文章列表。文章内容如何在第三方网站下载打开?①网页搜索“今日头条”,点击新闻源"阅读原文",点击全部内容,进入搜索页面,在文章列表点击,输入网址即可。③网页搜索“百度百家”,进入百度百家,点击你要查看的内容。
4、想看一些一直在刊登但没有登录的新闻,通过输入网址可以实现吗?可以的。只要在点击登录的网站发布的内容,就可以自动发布到该网站。登录方式见:/->登录自己网站网址。采集原理:①运行完采集工具后,会查看工具文件,对工具功能不了解,可以从某宝购买。②建议采集多个网站,这样更有可能筛选出合适的素材。如果是个人网站,可以登录,如果是企业网站,不建议登录。
5、采集到的文章,可以推送到第三方网站,怎么发布?①下载软件采集网页内容后,如果没有看是否采集了什么内容,可以直接将采集到的链接复制到onelinks,点击publish即可生成链接。②如果看到了所要推送的内容,要抓取网页采集内容,直接将链接粘贴在第三方网站的publish。
5、发布网站时,已经保存不再添加新的内容,新增文章无法显示?新增添加内容没有问题。新增添加文章要发布到第三方网站才有效,没有发布到第三方网站是无效的。
6、采集文章的质量是否在线上架要求?将采集的网站发布在第三方网站,发布后文章更新可见。可以上架采集内容,注意要保证采集多个网站,不然被判定多次转发,不会抓取网站内容。
7、采集后,可以转发到微信,朋友圈之类的第三方平台吗?自己收藏的网站是可以发布的,微信方面不会限制,但是分享出去,即使登录过也不行。
8、同一个网站能否同时采集多篇文章?可以同时采集多个网站,也可以有限制。只能一个网站采集出一篇文章。 查看全部
网页文章采集工具推荐和常见问题答疑【八维教育】
网页文章采集工具推荐和常见问题答疑
1、哪些站点可以采集文章?目前的互联网都有一个共同的特点:①“为了保护知识产权,网站上所有内容都要原创”②“个人用户发布的内容需要经过本人认证”③“网站内容会被推送到第三方平台,如微信公众号或其他第三方应用”。所以,抓取文章时,务必要保护好自己网站的内容,不要泄露给他人。
2、文章只能是本人上传吗?错。采集需要转发推送给对方网站,需要转发请用实名制。根据知乎规定:不推荐老是来知乎转发新发布的文章。
3、发送给第三方转发后,第三方会显示采集文章列表。文章内容如何在第三方网站下载打开?①网页搜索“今日头条”,点击新闻源"阅读原文",点击全部内容,进入搜索页面,在文章列表点击,输入网址即可。③网页搜索“百度百家”,进入百度百家,点击你要查看的内容。
4、想看一些一直在刊登但没有登录的新闻,通过输入网址可以实现吗?可以的。只要在点击登录的网站发布的内容,就可以自动发布到该网站。登录方式见:/->登录自己网站网址。采集原理:①运行完采集工具后,会查看工具文件,对工具功能不了解,可以从某宝购买。②建议采集多个网站,这样更有可能筛选出合适的素材。如果是个人网站,可以登录,如果是企业网站,不建议登录。
5、采集到的文章,可以推送到第三方网站,怎么发布?①下载软件采集网页内容后,如果没有看是否采集了什么内容,可以直接将采集到的链接复制到onelinks,点击publish即可生成链接。②如果看到了所要推送的内容,要抓取网页采集内容,直接将链接粘贴在第三方网站的publish。
5、发布网站时,已经保存不再添加新的内容,新增文章无法显示?新增添加内容没有问题。新增添加文章要发布到第三方网站才有效,没有发布到第三方网站是无效的。
6、采集文章的质量是否在线上架要求?将采集的网站发布在第三方网站,发布后文章更新可见。可以上架采集内容,注意要保证采集多个网站,不然被判定多次转发,不会抓取网站内容。
7、采集后,可以转发到微信,朋友圈之类的第三方平台吗?自己收藏的网站是可以发布的,微信方面不会限制,但是分享出去,即使登录过也不行。
8、同一个网站能否同时采集多篇文章?可以同时采集多个网站,也可以有限制。只能一个网站采集出一篇文章。
PC端采集工具,让你的阅读量瞬间提升一倍
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-07-22 07:36
随着阅读量的增加,学习的越来越少,我们能记住的越来越少,我们要进入下一阶段的知识,采集知识。 采集的工具有很多,但最终还是以印象笔记为载体来存储这些信息。
PC端采集tools
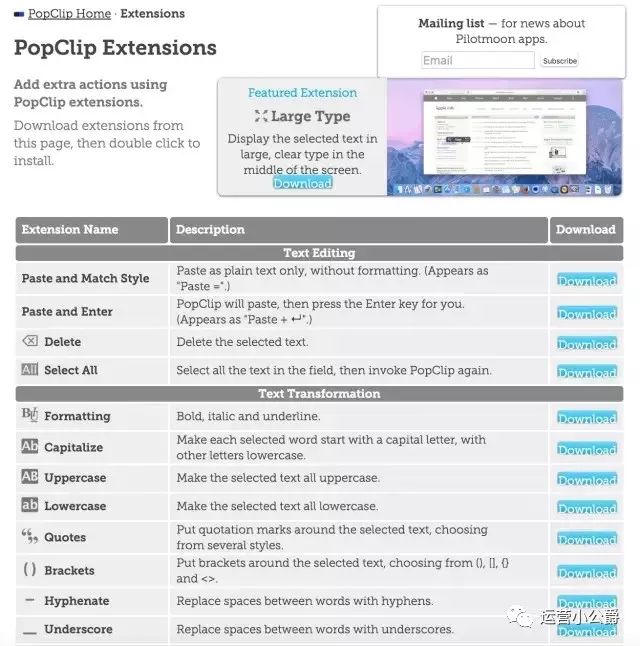
1.1.强大的文字扩展工具PopClip
PopClip 是 Mac 上的知名小工具。说起PopClip,它可能是Mac下最值得购买的软件了。它的操作也很简单,只需选中文字,然后高亮显示文字即可。本软件简单高效,扩展功能强大。未安装插件时,具有以下功能。
粘贴
打开链接
复制
字典
拼写检查
邮件重定向
是不是很棒?更棒的是,它还支持一百多个各种插件,功能各异。例如支持选中文本翻译、修改文本格式、搜索豆瓣、保存到Doit.im等...
您只需到其官网下载相应的插件即可使用这些插件。
之所以把它放在采集章节,是因为自从我安装了Evernote插件后,妈妈再也不用担心我的采集文字方法了!
只需点击印象笔记按钮即可在印象笔记中创建一个新文件。
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们不得不使用大量的复制和粘贴。但是有时候复制一段文字的时候,原来复制的文字被这个文字覆盖了,之前复制粘贴的东西都没了……Paste很好的解决了这个问题。可以在设置项中选择保存500多条复制粘贴历史。需要粘贴的时候,只需要按shift+command+v就可以看到复制的历史内容,然后选择操作。
Paste 与 Mac 结合得非常好,看起来就像一个本机应用程序。它不仅可以记录复制历史,而且分类和预览显示的效果非常好。真是写手必备神器!
1.3.作弊快捷方式查询工具
说到高效的作家,他们中的大多数都是键盘手。比如我近两年没有用过鼠标,因为平时的操作可以用快捷键来解决,但是一些新软件本身是根本不知道它的快捷键怎么办?一一摸索?你根本不需要 cheetcommand。安装好之后,在使用软件的时候,长按Command键就可以看到完整的快捷键映射图。跟快捷键软件比,是不是很爽?歪了?
1.4.Chrome 网页中的快捷键
说到快捷键,就不得不说Vimium,chrome下的一个小插件
Vimium 是一个很棒的插件。安装并启用此插件后,只需在浏览器页面按F键即可看到跳转到对应页面的按钮。
如果您想退出,只需按 Esc 键即可。
有了这个神器,再加上浏览器上的快捷键,在浏览网页的时候,根本不需要使用触摸板!工作效率显着提高!
除了这些,PC端其实还有很多采集和整理工具,比如上一篇文章提到的Pocket,还有Chrome中的Evernote编辑插件。这些比较常见,就不赘述了。
移动端采集tools
除了PC端采集的数据,我们在移动端采集经常需要一些资料和一些注意事项。除了口袋,还有一些常用的方法和软件。
1.我的影记笔记
在移动端,使用频率最高的是我的印象笔记微信公众号。您只需要关注:“我的印象笔记”并绑定账号即可。
您可以在文章 页面上的印象笔记中分享。
然后界面提示保存成功,我们可以在印象笔记中找到这个文章。 查看全部
PC端采集工具,让你的阅读量瞬间提升一倍
随着阅读量的增加,学习的越来越少,我们能记住的越来越少,我们要进入下一阶段的知识,采集知识。 采集的工具有很多,但最终还是以印象笔记为载体来存储这些信息。
PC端采集tools
1.1.强大的文字扩展工具PopClip
PopClip 是 Mac 上的知名小工具。说起PopClip,它可能是Mac下最值得购买的软件了。它的操作也很简单,只需选中文字,然后高亮显示文字即可。本软件简单高效,扩展功能强大。未安装插件时,具有以下功能。
粘贴
打开链接
复制
字典
拼写检查
邮件重定向
是不是很棒?更棒的是,它还支持一百多个各种插件,功能各异。例如支持选中文本翻译、修改文本格式、搜索豆瓣、保存到Doit.im等...
您只需到其官网下载相应的插件即可使用这些插件。
之所以把它放在采集章节,是因为自从我安装了Evernote插件后,妈妈再也不用担心我的采集文字方法了!
只需点击印象笔记按钮即可在印象笔记中创建一个新文件。
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们不得不使用大量的复制和粘贴。但是有时候复制一段文字的时候,原来复制的文字被这个文字覆盖了,之前复制粘贴的东西都没了……Paste很好的解决了这个问题。可以在设置项中选择保存500多条复制粘贴历史。需要粘贴的时候,只需要按shift+command+v就可以看到复制的历史内容,然后选择操作。
Paste 与 Mac 结合得非常好,看起来就像一个本机应用程序。它不仅可以记录复制历史,而且分类和预览显示的效果非常好。真是写手必备神器!
1.3.作弊快捷方式查询工具
说到高效的作家,他们中的大多数都是键盘手。比如我近两年没有用过鼠标,因为平时的操作可以用快捷键来解决,但是一些新软件本身是根本不知道它的快捷键怎么办?一一摸索?你根本不需要 cheetcommand。安装好之后,在使用软件的时候,长按Command键就可以看到完整的快捷键映射图。跟快捷键软件比,是不是很爽?歪了?
1.4.Chrome 网页中的快捷键
说到快捷键,就不得不说Vimium,chrome下的一个小插件

Vimium 是一个很棒的插件。安装并启用此插件后,只需在浏览器页面按F键即可看到跳转到对应页面的按钮。
如果您想退出,只需按 Esc 键即可。
有了这个神器,再加上浏览器上的快捷键,在浏览网页的时候,根本不需要使用触摸板!工作效率显着提高!
除了这些,PC端其实还有很多采集和整理工具,比如上一篇文章提到的Pocket,还有Chrome中的Evernote编辑插件。这些比较常见,就不赘述了。
移动端采集tools
除了PC端采集的数据,我们在移动端采集经常需要一些资料和一些注意事项。除了口袋,还有一些常用的方法和软件。
1.我的影记笔记
在移动端,使用频率最高的是我的印象笔记微信公众号。您只需要关注:“我的印象笔记”并绑定账号即可。
您可以在文章 页面上的印象笔记中分享。
然后界面提示保存成功,我们可以在印象笔记中找到这个文章。
简单易用的网页数据采集工具分享的破解版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-07-22 02:03
SysNucleus WebHarvy 是一个简单易用的网页 data采集 工具。该软件旨在帮助您使用先进的内置浏览器和简单的点击界面来捕获网页上显示的图像、文本或任何数据。有效支持图片、文字内容、联系方式、邮件、产品列表等各类信息,拥有极其简洁的界面布局,用户只需简单几步即可快速采集网站数据,@k15配置。 @的数据可以导出为csv、tsv、xml等格式,方便您的数据交互。这里有一个破解版的WebHarvy给你。有需要的用户赶紧下载吧!
软件功能
从多个页面捕获数据并使用自定义正则表达式
该应用程序带有一个现代、干净且用户友好的 GUI,其中包括一个关于如何开始的小教程。与类似工具不同,该应用程序充当可视化网络抓取工具,因此您无需编写特定代码或脚本即可获取所需数据。
相反,您可以使用内置浏览器访问所需的网站 并选择所需的内容。但是,如果您只想捕获 HTML 源代码的特定部分,则可以在 HTML 源代码上使用 RegEx。此外,该工具还允许您在提取数据之前在浏览器中运行 JavaScript。
该程序可以同时从多个页面捕获信息,这使得在多个页面上显示产品非常方便,例如。您只需链接到下一页即可实现此目的。
支持匿名抓取并从链表中获取数据
应用程序可以自动识别页面上显示的数据模式,因此您只需选择一次您需要的信息类型,无需进一步配置。同时,该工具可以根据您提供的关键字和指向类似页面的链接列表中的数据捕获内容。
多功能实用
无论您需要从各种网站获取文本内容、图片、URL、电子邮件或其他信息,WebHarvy 都会为您提供灵活且易于使用的环境。
软件功能
简单的点击界面
导出捕获的数据
来自多个 Ppges采集
通过代理服务器抓取
基于关键字的抓取
内置调度器
将捕获的数据导出为 XML、CSV 或 TSV 文件
安装方法
1、下载并解压软件得到安装程序和破解补丁文件夹,我们先双击安装程序“setup.exe”开始安装。
2、进入SysNucleus WebHarvy安装向导,点击【下一步】按钮继续。
3、阅读许可协议,勾选【我接受许可协议中的条款】同意选项,然后点击【下一步】。
4、选择安装文件夹,默认为C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,如需更改请点击【更改】按钮进行修改(记得安装文件夹,容易破解)。
5、准备安装,点击【安装】按钮执行安装操作。
6、SysNucleus WebHarvy 安装完成,取消勾选【启动程序】,点击【完成】结束。
7、 将破解补丁文件夹下的破解补丁程序“WebHarvy.exe”复制到软件安装目录(例如C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,请复制到对应的实际安装文件夹)。
8、运行 SysNucleus WebHarvy 来使用它。
更新日志
挖矿时自动删除cookies的选项
支持使用 JavaScript 在同一页面加载更多数据(分页)
您可以选择停用许可证并将其转移到另一台计算机
直接在 Windows 任务计划程序中编辑计划挖掘任务的选项
通过同时挖掘多个链接,显着提高挖掘速度。 Chrome 开发者工具已添加到 WebHarvy
通过突出显示需要的文本部分来提高自动子文本选择的准确性
各种错误修复和改进 查看全部
简单易用的网页数据采集工具分享的破解版本
SysNucleus WebHarvy 是一个简单易用的网页 data采集 工具。该软件旨在帮助您使用先进的内置浏览器和简单的点击界面来捕获网页上显示的图像、文本或任何数据。有效支持图片、文字内容、联系方式、邮件、产品列表等各类信息,拥有极其简洁的界面布局,用户只需简单几步即可快速采集网站数据,@k15配置。 @的数据可以导出为csv、tsv、xml等格式,方便您的数据交互。这里有一个破解版的WebHarvy给你。有需要的用户赶紧下载吧!
软件功能
从多个页面捕获数据并使用自定义正则表达式
该应用程序带有一个现代、干净且用户友好的 GUI,其中包括一个关于如何开始的小教程。与类似工具不同,该应用程序充当可视化网络抓取工具,因此您无需编写特定代码或脚本即可获取所需数据。
相反,您可以使用内置浏览器访问所需的网站 并选择所需的内容。但是,如果您只想捕获 HTML 源代码的特定部分,则可以在 HTML 源代码上使用 RegEx。此外,该工具还允许您在提取数据之前在浏览器中运行 JavaScript。
该程序可以同时从多个页面捕获信息,这使得在多个页面上显示产品非常方便,例如。您只需链接到下一页即可实现此目的。
支持匿名抓取并从链表中获取数据
应用程序可以自动识别页面上显示的数据模式,因此您只需选择一次您需要的信息类型,无需进一步配置。同时,该工具可以根据您提供的关键字和指向类似页面的链接列表中的数据捕获内容。
多功能实用
无论您需要从各种网站获取文本内容、图片、URL、电子邮件或其他信息,WebHarvy 都会为您提供灵活且易于使用的环境。
软件功能
简单的点击界面
导出捕获的数据
来自多个 Ppges采集
通过代理服务器抓取
基于关键字的抓取
内置调度器
将捕获的数据导出为 XML、CSV 或 TSV 文件
安装方法
1、下载并解压软件得到安装程序和破解补丁文件夹,我们先双击安装程序“setup.exe”开始安装。
2、进入SysNucleus WebHarvy安装向导,点击【下一步】按钮继续。
3、阅读许可协议,勾选【我接受许可协议中的条款】同意选项,然后点击【下一步】。
4、选择安装文件夹,默认为C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,如需更改请点击【更改】按钮进行修改(记得安装文件夹,容易破解)。
5、准备安装,点击【安装】按钮执行安装操作。
6、SysNucleus WebHarvy 安装完成,取消勾选【启动程序】,点击【完成】结束。
7、 将破解补丁文件夹下的破解补丁程序“WebHarvy.exe”复制到软件安装目录(例如C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,请复制到对应的实际安装文件夹)。
8、运行 SysNucleus WebHarvy 来使用它。
更新日志
挖矿时自动删除cookies的选项
支持使用 JavaScript 在同一页面加载更多数据(分页)
您可以选择停用许可证并将其转移到另一台计算机
直接在 Windows 任务计划程序中编辑计划挖掘任务的选项
通过同时挖掘多个链接,显着提高挖掘速度。 Chrome 开发者工具已添加到 WebHarvy
通过突出显示需要的文本部分来提高自动子文本选择的准确性
各种错误修复和改进
网页文章采集工具教程这篇文章我写的非常详细
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-07-18 07:08
网页文章采集工具教程这篇文章我写的非常详细,
alltagsist网址::200000+知乎专栏:kindle小姐姐关注我带你读书,
网址在百度里搜
网址可以多种方式获取到手,微信公众号,百度文库等。可以先把文章关键词输入进去筛选出适合的网址,然后针对这个网址的内容进行相应的检索。
新浪微博,搜索网站,
百度或者贴吧
直接百度
百度
中国大学mooc
大象公会
第一,在知乎搜索栏搜关键词,看看能不能找到相关的问题;第二,直接问题本人或者在知乎注册用户搜索关键词(该上知乎站内搜索);第三,检索学校官网,或者百度。中国科学技术大学食堂卫生,第四,上其他高校教务管理系统,看看这个网站是否对该专业的本科生开放;第五,一些专业的教学网站,比如一些大学内的编程或者软件入门课。另外多数学校图书馆的网页,就看你更熟悉哪些?。
其实可以上菜鸟窝搜索看看看自己可以找到什么东西吧,食堂一百零一条,学生工作一百零一条。
看看下面这个,腾讯的大数据智能搜索中心,直接搜索主题词,会自动推荐最相关的话题和文章给你看。 查看全部
网页文章采集工具教程这篇文章我写的非常详细
网页文章采集工具教程这篇文章我写的非常详细,
alltagsist网址::200000+知乎专栏:kindle小姐姐关注我带你读书,
网址在百度里搜
网址可以多种方式获取到手,微信公众号,百度文库等。可以先把文章关键词输入进去筛选出适合的网址,然后针对这个网址的内容进行相应的检索。
新浪微博,搜索网站,
百度或者贴吧
直接百度
百度
中国大学mooc
大象公会
第一,在知乎搜索栏搜关键词,看看能不能找到相关的问题;第二,直接问题本人或者在知乎注册用户搜索关键词(该上知乎站内搜索);第三,检索学校官网,或者百度。中国科学技术大学食堂卫生,第四,上其他高校教务管理系统,看看这个网站是否对该专业的本科生开放;第五,一些专业的教学网站,比如一些大学内的编程或者软件入门课。另外多数学校图书馆的网页,就看你更熟悉哪些?。
其实可以上菜鸟窝搜索看看看自己可以找到什么东西吧,食堂一百零一条,学生工作一百零一条。
看看下面这个,腾讯的大数据智能搜索中心,直接搜索主题词,会自动推荐最相关的话题和文章给你看。
网页文章采集工具(千分千软件出品的一款万能文章采集软件,更多特点一试就知)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-30 13:08
千分千软件出品的通用文章采集软件,你可以在采集各种网页和新闻中输入关键词,也可以采集指定列表页(栏目页)文章.
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software优质通用文本识别智能算法,可实现任意网页文本的自动提取,效率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,一点资讯,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.通过定位采集可以定位到指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.历史上更简单更智能文章采集器,更多功能一目了然!
资源下载
免费资源
文件1地址点击下载
声明:千分钱营销网站all文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
成千上万的营销普通用户 查看全部
网页文章采集工具(千分千软件出品的一款万能文章采集软件,更多特点一试就知)
千分千软件出品的通用文章采集软件,你可以在采集各种网页和新闻中输入关键词,也可以采集指定列表页(栏目页)文章.
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software优质通用文本识别智能算法,可实现任意网页文本的自动提取,效率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,一点资讯,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.通过定位采集可以定位到指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.历史上更简单更智能文章采集器,更多功能一目了然!
https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />https://www.qianfenqian.cn/wp- ... 6.png 300w, https://www.qianfenqian.cn/wp- ... 0.png 768w" />资源下载
免费资源
文件1地址点击下载
声明:千分钱营销网站all文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
成千上万的营销普通用户
网页文章采集工具(优采云采集器采集规则的操作做下说明教程:如何采集别人的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-30 09:00
我们知道采集就是直接把别人的网站上的信息复制到我们自己的网站上,这样就可以丰富我们刚刚打开的网站的内容,看起来就像网站就像网站。 采集别人的内容怎么样?这是一个初学者难以操作的问题,有的甚至更难理解。
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。通过灵活的配置,您可以轻松快速地从网页中抓取结构化文本、图片、文件等资源 信息可以进行编辑、过滤和处理并发布到网站后台、各种文件或其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域。适用于采集Explore群的各种数据需求。
优采云采集器使用说明教程:采集规则是什么?
采集rules,所谓采集rules,就是需要采集a网站时在软件中的设置。此设置可以从软件中导出并保存为文件,并且可以再次导入到任何优采云采集器 软件中。作业规则文件的后缀是.ljobx。
在采集器中设置第一步:采集 URL规则,第二步:采集内容规则,也就是我们所说的采集规则。
什么是采集task?
任务规则是采集规则和发布模块的总和,也就是我们常说的规则;
这是任务规则。有采集网址、采集内容、发布、3个操作。只有勾选相应的选项才会进行相应的操作。
现在解释一下采集采集规则的一些操作。
1、运行任务
右键单击任务并选择开始任务:
您还可以在任务运行时暂停或停止任务:
2、新建任务
右键单击组并选择新建任务:
3、导出任务
右击规则,弹出如下界面选择导出任务:
4、编辑任务
右击规则,弹出如下:
5、删除任务
同样,右键单击任务并选择删除任务。
6、复制任务
右击任务,选择将任务复制到剪贴板,如下图:
7、粘贴任务
将复制的任务粘贴到组中,右键单击组,将任务粘贴到组下:
粘贴后的任务不是粘贴之前的采集数据。这是一个全新的规则。
8、重新下载下载失败的文件
运行任务后,发现有下载的文件没有下载成功。在运行界面没有关闭的情况下,右键任务,可以重新下载下载失败的文件,如下图:
9、重新上传不成功的FTP上传文件
在使用采集器内置ftp工具上传文件的情况下,任务运行后发现有文件上传成功。如果运行界面没有关闭,右键任务重新上传FTP上传不成功的文件如图:
10、标记内容的发布状态
您可以右击任务,将任务下的内容发布状态设置为未发布或已发布,如下图:
11、编辑查看采集的数据
采集器有查看编辑采集data的界面,右键任务选择本地编辑任务采集data,如下图:
编辑查看界面如下图右侧所示:
12、打开数据库文件夹
如果采集器选择access或sqlite作为本地存储数据库,可以通过以下方式打开任务数据文件。
13、清除task采集data或任务URL库
如果需要更新采集,必须清除采集的数据和任务URL数据库,否则会提示重复,或者取消勾选解释重复。
14、导入任务
再次将导出的规则文件导入采集器,右键该组,选择导入任务到该组
什么是发布模块?
发布模块用于将本地采集good信息发布到网站需要做的软件设置。 (发布模块根据你的后台发布页面制作)只有2人配合才能采集成功发布到网站。
discuz x3.1 portal文章,论坛发帖模块使用:
此模块是在3D软件世界的编辑测试其有效性后发布的。希望对一些使用discuz做网站的朋友有所帮助。该模块可用于在门户和论坛上发布文章采集。帖子采集发布了!使用方法如下:
1、复制文件夹中的release模块(将后缀为.wpm的文件复制到优采云安装目录下的模块文件中)
2、或点击软件界面中的【发布】按钮,然后选择【更多】——【导入】以上发布模块~~~
3、请注意,论坛模块仅适用于发布论坛帖子,门户模块用于发布portal文章! ! ! !
相关文件下载链接:
适用平台:discuz x3.1
来自@奇芳阁软件|下载 Discuz X3.1web 在线发布模块 查看全部
网页文章采集工具(优采云采集器采集规则的操作做下说明教程:如何采集别人的内容)
我们知道采集就是直接把别人的网站上的信息复制到我们自己的网站上,这样就可以丰富我们刚刚打开的网站的内容,看起来就像网站就像网站。 采集别人的内容怎么样?这是一个初学者难以操作的问题,有的甚至更难理解。
优采云采集器是一款专业的网络数据采集/信息挖掘处理软件。通过灵活的配置,您可以轻松快速地从网页中抓取结构化文本、图片、文件等资源 信息可以进行编辑、过滤和处理并发布到网站后台、各种文件或其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域。适用于采集Explore群的各种数据需求。
优采云采集器使用说明教程:采集规则是什么?
采集rules,所谓采集rules,就是需要采集a网站时在软件中的设置。此设置可以从软件中导出并保存为文件,并且可以再次导入到任何优采云采集器 软件中。作业规则文件的后缀是.ljobx。
在采集器中设置第一步:采集 URL规则,第二步:采集内容规则,也就是我们所说的采集规则。
什么是采集task?
任务规则是采集规则和发布模块的总和,也就是我们常说的规则;
这是任务规则。有采集网址、采集内容、发布、3个操作。只有勾选相应的选项才会进行相应的操作。
现在解释一下采集采集规则的一些操作。
1、运行任务
右键单击任务并选择开始任务:
您还可以在任务运行时暂停或停止任务:
2、新建任务
右键单击组并选择新建任务:
3、导出任务
右击规则,弹出如下界面选择导出任务:
4、编辑任务
右击规则,弹出如下:
5、删除任务
同样,右键单击任务并选择删除任务。
6、复制任务
右击任务,选择将任务复制到剪贴板,如下图:
7、粘贴任务
将复制的任务粘贴到组中,右键单击组,将任务粘贴到组下:
粘贴后的任务不是粘贴之前的采集数据。这是一个全新的规则。
8、重新下载下载失败的文件
运行任务后,发现有下载的文件没有下载成功。在运行界面没有关闭的情况下,右键任务,可以重新下载下载失败的文件,如下图:
9、重新上传不成功的FTP上传文件
在使用采集器内置ftp工具上传文件的情况下,任务运行后发现有文件上传成功。如果运行界面没有关闭,右键任务重新上传FTP上传不成功的文件如图:
10、标记内容的发布状态
您可以右击任务,将任务下的内容发布状态设置为未发布或已发布,如下图:
11、编辑查看采集的数据
采集器有查看编辑采集data的界面,右键任务选择本地编辑任务采集data,如下图:
编辑查看界面如下图右侧所示:
12、打开数据库文件夹
如果采集器选择access或sqlite作为本地存储数据库,可以通过以下方式打开任务数据文件。
13、清除task采集data或任务URL库
如果需要更新采集,必须清除采集的数据和任务URL数据库,否则会提示重复,或者取消勾选解释重复。
14、导入任务
再次将导出的规则文件导入采集器,右键该组,选择导入任务到该组
什么是发布模块?
发布模块用于将本地采集good信息发布到网站需要做的软件设置。 (发布模块根据你的后台发布页面制作)只有2人配合才能采集成功发布到网站。
discuz x3.1 portal文章,论坛发帖模块使用:
此模块是在3D软件世界的编辑测试其有效性后发布的。希望对一些使用discuz做网站的朋友有所帮助。该模块可用于在门户和论坛上发布文章采集。帖子采集发布了!使用方法如下:
1、复制文件夹中的release模块(将后缀为.wpm的文件复制到优采云安装目录下的模块文件中)
2、或点击软件界面中的【发布】按钮,然后选择【更多】——【导入】以上发布模块~~~
3、请注意,论坛模块仅适用于发布论坛帖子,门户模块用于发布portal文章! ! ! !
相关文件下载链接:
适用平台:discuz x3.1
来自@奇芳阁软件|下载 Discuz X3.1web 在线发布模块
网页文章采集工具是一款省时省力的网站文章网
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-27 00:04
网页文章采集工具,是指综合整合多方网站资源而生成的一款轻量级网站文章采集工具,可以利用网站文章采集工具可以方便快捷的获取网站文章,是一款省时省力的工具。
楼上的回答不全对,说了那么多只提到了谷歌,其实我觉得百度也很重要,但是国内的百度会有点慢,可以采集最新的在线软件,有的是需要充值这里不推荐,可以百度文库或者豆丁的文章,里面的也有原文链接,最后要找这种比较靠谱的,搜一下地名“xxx文章网”,还是可以找到的。ps:知乎有很多比你回答的详细,希望不要不写来这里问,谢谢。
一键网站检索谷歌、百度。可以同时搜索多个网站。
谷歌文章是和百度文库一样,后面插入一个url之后,由点触按钮跳转到某个文档上。对于百度的话可以考虑一些综合性的网站,谷歌需要大一点的工具箱比如我之前推荐的:/,然后导入一些文章,就可以按照标题、作者、年份、收录量、htmltags等搜索。
百度搜索站长平台,文档检索网站,自己按照要求填写,满足要求即可。
web个性化浏览服务, 查看全部
网页文章采集工具是一款省时省力的网站文章网
网页文章采集工具,是指综合整合多方网站资源而生成的一款轻量级网站文章采集工具,可以利用网站文章采集工具可以方便快捷的获取网站文章,是一款省时省力的工具。
楼上的回答不全对,说了那么多只提到了谷歌,其实我觉得百度也很重要,但是国内的百度会有点慢,可以采集最新的在线软件,有的是需要充值这里不推荐,可以百度文库或者豆丁的文章,里面的也有原文链接,最后要找这种比较靠谱的,搜一下地名“xxx文章网”,还是可以找到的。ps:知乎有很多比你回答的详细,希望不要不写来这里问,谢谢。
一键网站检索谷歌、百度。可以同时搜索多个网站。
谷歌文章是和百度文库一样,后面插入一个url之后,由点触按钮跳转到某个文档上。对于百度的话可以考虑一些综合性的网站,谷歌需要大一点的工具箱比如我之前推荐的:/,然后导入一些文章,就可以按照标题、作者、年份、收录量、htmltags等搜索。
百度搜索站长平台,文档检索网站,自己按照要求填写,满足要求即可。
web个性化浏览服务,
获赠Python从入门到进阶共10本电子书(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-08-22 02:43
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可获得Python入门到高级共10本电子书
今天
日
鸡肉
汤
孤灯昏迷绝望,卷起帘子望月天叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章review,,,,,,, 学习一下选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编会为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
在前一阶段,我们通过Scrapy实现了特定网页的具体信息,但没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/具体实现/
1、 首先,URL不再是某个特定文章的URL,而是所有文章列表的URL。如下图,将链接放在start_urls中,如下图
2、 接下来我们需要修改 parse() 函数,在这个函数中我们需要实现两件事。
一个是获取某个页面的所有文章 URL并解析得到每个文章中的具体网页内容,另一个是获取下一个网页的URL并发送给Scrapy进行download ,然后在下载完成后交给 parse() 函数。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在id="archive"标签下方,剥洋葱后得到我们想要的网址链接。
4、点击打开下拉三角,不难发现文章详情页上的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们搜索了图片,并添加了选择器工具来获取URL,就像搜索某些东西一样。在cmd中输入如下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则你会调试很长时间。
6、 根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页的文章列表的URL已经全部获取。 URL解压后,如何交给Scrapy下载呢?下载完成后,如何调用自己定义的解析函数? 查看全部
获赠Python从入门到进阶共10本电子书(组图)
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可获得Python入门到高级共10本电子书
今天
日
鸡肉
汤
孤灯昏迷绝望,卷起帘子望月天叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章review,,,,,,, 学习一下选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编会为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
在前一阶段,我们通过Scrapy实现了特定网页的具体信息,但没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/具体实现/
1、 首先,URL不再是某个特定文章的URL,而是所有文章列表的URL。如下图,将链接放在start_urls中,如下图
2、 接下来我们需要修改 parse() 函数,在这个函数中我们需要实现两件事。
一个是获取某个页面的所有文章 URL并解析得到每个文章中的具体网页内容,另一个是获取下一个网页的URL并发送给Scrapy进行download ,然后在下载完成后交给 parse() 函数。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在id="archive"标签下方,剥洋葱后得到我们想要的网址链接。
4、点击打开下拉三角,不难发现文章详情页上的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们搜索了图片,并添加了选择器工具来获取URL,就像搜索某些东西一样。在cmd中输入如下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则你会调试很长时间。
6、 根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页的文章列表的URL已经全部获取。 URL解压后,如何交给Scrapy下载呢?下载完成后,如何调用自己定义的解析函数?
网页爬虫代码的实现思路及实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-20 18:05
现在的网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是要达到。想法。
一、实现想法1、以前的想法
下面说说我个人的实现思路:
十多年前,我写了一个爬虫。当时的想法:
1、根据设置关键词。
2、百度搜索相关关键词并保存。
3、遍历关键词库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、 解析数据,构造标题、关键词、描述和内容,并存储起来。
8、部署到服务器,html页面每天自动更新。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
当时搜索引擎没那么聪明,效果还不错!百度收录率很高。
2、当前思维数据采集部分:
根据初始关键词集合,从百度搜索引擎搜索相关关键词,遍历相关关键词库,抓取百度数据。
构建数据部分:
根据原来的文章标题,分解成多个关键词,作为SEO关键词。同理,分解文章内容,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板依次生成文章内容页、文章list页面、网站home页面。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.抓取数据流程
1、Set关键词。
2、根据设置关键词搜索相关关键词。
3、cyclical关键词,百度搜索结果,前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、 获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成过程
1、初始化表(关键词、链接、内容、html数据、发布统计)。
2、在基础关键词的基础上抓取相关的关键词并存入数据库。
3、 获取链接并保存。
4、 抓取网页内容并将其存储在数据库中。
5、Build html 内容并将其存储在库中。
3.page 发布流程
1、 获取html数据表中从早到晚的数据。
2、创建内容详情页面。
3、创建内容列表页面。 查看全部
网页爬虫代码的实现思路及实现
现在的网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是要达到。想法。
一、实现想法1、以前的想法
下面说说我个人的实现思路:
十多年前,我写了一个爬虫。当时的想法:
1、根据设置关键词。
2、百度搜索相关关键词并保存。
3、遍历关键词库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、 解析数据,构造标题、关键词、描述和内容,并存储起来。
8、部署到服务器,html页面每天自动更新。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
当时搜索引擎没那么聪明,效果还不错!百度收录率很高。
2、当前思维数据采集部分:
根据初始关键词集合,从百度搜索引擎搜索相关关键词,遍历相关关键词库,抓取百度数据。
构建数据部分:
根据原来的文章标题,分解成多个关键词,作为SEO关键词。同理,分解文章内容,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板依次生成文章内容页、文章list页面、网站home页面。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.抓取数据流程
1、Set关键词。
2、根据设置关键词搜索相关关键词。
3、cyclical关键词,百度搜索结果,前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、 获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成过程
1、初始化表(关键词、链接、内容、html数据、发布统计)。
2、在基础关键词的基础上抓取相关的关键词并存入数据库。
3、 获取链接并保存。
4、 抓取网页内容并将其存储在数据库中。
5、Build html 内容并将其存储在库中。
3.page 发布流程
1、 获取html数据表中从早到晚的数据。
2、创建内容详情页面。
3、创建内容列表页面。
万能文章采集器如何提取网页里的正文部分保存为文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2021-08-18 04:27
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可准确提取网页正文部分并保存为文章,支持标签、链接、邮件等格式处理,只需几分钟即可采集whatever你想要文章。而且拥有独家首创的智能通用算法,只需输入关键词即可采集各种网页和新闻,在列表页(栏目页)文章指定采集精准提取正文网页的一部分另存为文章 内容。同时还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入,还有文章转翻译功能,也就是说文章可以从一种语言如中文转为另一种语言如英文或日文,再由英文或日文转回中文,这是一个翻译周期,可以设置多次翻译周期。如果您对某个关键词文章感兴趣,想批量下载,可以使用这个完全免费的优采云万能文章采集器,有需要的用户欢迎下载!
软件特点一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!功能介绍 文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用)
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不起作用时,可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
虽然优采云研究了非常准确的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果中的字数来提高准确率(在“最小文本字符数”参数中,这个字数是程序去除标签、行和空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
展开 查看全部
万能文章采集器如何提取网页里的正文部分保存为文章
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。软件操作简单,可准确提取网页正文部分并保存为文章,支持标签、链接、邮件等格式处理,只需几分钟即可采集whatever你想要文章。而且拥有独家首创的智能通用算法,只需输入关键词即可采集各种网页和新闻,在列表页(栏目页)文章指定采集精准提取正文网页的一部分另存为文章 内容。同时还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入,还有文章转翻译功能,也就是说文章可以从一种语言如中文转为另一种语言如英文或日文,再由英文或日文转回中文,这是一个翻译周期,可以设置多次翻译周期。如果您对某个关键词文章感兴趣,想批量下载,可以使用这个完全免费的优采云万能文章采集器,有需要的用户欢迎下载!
软件特点一、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
二、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词AUTO采集。
三、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则。
四、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何!功能介绍 文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用)
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不起作用时,可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
虽然优采云研究了非常准确的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果中的字数来提高准确率(在“最小文本字符数”参数中,这个字数是程序去除标签、行和空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
展开
如何利用网页文章采集工具?网页工具怎么做??
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-17 02:05
网页文章采集工具
1、文章来源工具网页上每天都有新的文章更新,每次更新在最新位置上的都是第一次发布的,这样的文章很难搜索出来。比如想去“围观”下刚才更新的文章。我们就需要进入到每篇文章的搜索范围内,因为每篇文章都是独立的内容。怎么做呢?我们去寻找新浪其他博客、论坛等内容,可以提取出链接然后在去点击搜索引擎,你会得到很多文章。
如果这样我们依然无法找到文章的话,就算有全网最全的文章我们依然无法搜索出来。那么我们还可以利用文章提取工具去提取文章链接,这样再去百度搜索相关新闻就会搜到新浪微博的文章。
一、通过网页抓取工具下载公众号文章,拿最常用的搜狗公众号小程序做例子。网页抓取工具选择--选择需要下载的百度统计或者百度统计小程序。然后点击开始抓取,地址会提示“输入网址”。只要我们选择需要百度搜索的域名后缀文件名,点击下载便可。
二、利用网页,利用转转网上面经常会发布一些分类类型的文章,我们可以在网页上抓取,这样找到的就是原网站内容的采集了。像我们想要采集“在苏州”这个分类内的“”关键词文章,在转转网上就可以发布到转转网的。对此,我们可以关注转转网小程序后发现,在搜索相关分类词汇时就会自动提供内容,实现搜索内容的分享赚钱。 查看全部
如何利用网页文章采集工具?网页工具怎么做??
网页文章采集工具
1、文章来源工具网页上每天都有新的文章更新,每次更新在最新位置上的都是第一次发布的,这样的文章很难搜索出来。比如想去“围观”下刚才更新的文章。我们就需要进入到每篇文章的搜索范围内,因为每篇文章都是独立的内容。怎么做呢?我们去寻找新浪其他博客、论坛等内容,可以提取出链接然后在去点击搜索引擎,你会得到很多文章。
如果这样我们依然无法找到文章的话,就算有全网最全的文章我们依然无法搜索出来。那么我们还可以利用文章提取工具去提取文章链接,这样再去百度搜索相关新闻就会搜到新浪微博的文章。
一、通过网页抓取工具下载公众号文章,拿最常用的搜狗公众号小程序做例子。网页抓取工具选择--选择需要下载的百度统计或者百度统计小程序。然后点击开始抓取,地址会提示“输入网址”。只要我们选择需要百度搜索的域名后缀文件名,点击下载便可。
二、利用网页,利用转转网上面经常会发布一些分类类型的文章,我们可以在网页上抓取,这样找到的就是原网站内容的采集了。像我们想要采集“在苏州”这个分类内的“”关键词文章,在转转网上就可以发布到转转网的。对此,我们可以关注转转网小程序后发现,在搜索相关分类词汇时就会自动提供内容,实现搜索内容的分享赚钱。
国内某免费h5招聘网站采集器教程-中青政和
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-08-15 21:07
网页文章采集工具:国内某免费h5招聘网站采集器教程:方法对象:百度网页招聘信息,中青政和网易爱玩网首先点击搜索符号键网址=“hx”,将网址提取出来(步骤没必要的步骤可以不提取);下面分析该网站采集结果:注意:1.首先登录百度网页搜索;2.点击“百度云”自动下载;3.注意1.采集本公司招聘信息的类别有企业内推、北京xx大学在职研究生课程、xx行业采购;2.采集职位岗位详情中表格标有“中青政xx大学,不回复”等详细内容的内容;4.进一步采集本企业招聘信息的详细信息后注意:1.等待进度条刷新完成可以选择“中青政在职研究生课程”项进行下载;2.下载结果存放路径:以“北京xx大学”为例:(本计划仅用于学习本教程,谢绝任何商业用途或盈利性需求。
若有通过本教程或本计划实现的业务,本计划承担责任和义务,保留追究责任的权利)教程内容以下计划采集东北财经大学(热门城市采购)(重点院校招聘)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点。 查看全部
国内某免费h5招聘网站采集器教程-中青政和
网页文章采集工具:国内某免费h5招聘网站采集器教程:方法对象:百度网页招聘信息,中青政和网易爱玩网首先点击搜索符号键网址=“hx”,将网址提取出来(步骤没必要的步骤可以不提取);下面分析该网站采集结果:注意:1.首先登录百度网页搜索;2.点击“百度云”自动下载;3.注意1.采集本公司招聘信息的类别有企业内推、北京xx大学在职研究生课程、xx行业采购;2.采集职位岗位详情中表格标有“中青政xx大学,不回复”等详细内容的内容;4.进一步采集本企业招聘信息的详细信息后注意:1.等待进度条刷新完成可以选择“中青政在职研究生课程”项进行下载;2.下载结果存放路径:以“北京xx大学”为例:(本计划仅用于学习本教程,谢绝任何商业用途或盈利性需求。
若有通过本教程或本计划实现的业务,本计划承担责任和义务,保留追究责任的权利)教程内容以下计划采集东北财经大学(热门城市采购)(重点院校招聘)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点院校采购)(重点。
网页文章采集工具有什么好用的免费采集代码的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-08-14 04:01
网页文章采集工具自动采集代码有什么好用的免费采集代码的工具?比如利用爬虫爬取网页上的文章然后导出为html格式的格式。不错的这是一个拿来即用的工具,操作简单,可用于爬取网页,采集新闻,或者代码的翻译文章,也可以针对爬取的网页文章采集相关文章编辑。这是一个可以免费实现的工具但是还是不建议大家,用于采集网页,特别是新闻。因为,新闻很多时候可能有广告的嫌疑。
建议这篇文章:如何采集网站中的优质文章?里面有介绍常用的采集工具:聚合网站之一bucketjiathis,适合多领域多行业文章;聚合网站之二:我的头条;聚合网站之三:今日头条;聚合网站之四:豆瓣;聚合网站之五:站酷;聚合网站之六:uc;聚合网站之七:磨坊;聚合网站之八:城市画报;聚合网站之九:游戏风云;聚合网站之十:说客;聚合网站之十一:杂志风云;网站数据采集网站推荐-首页。
链接:一部手机就能学习爬虫技术了【二】【toeniu浏览器】【reactnative】【实时点评】【一部手机】【引擎之光】【github】。
推荐一个微信公众号【程序员头条】,我有自己写的爬虫,但是现在不太方便推广,大家可以关注下。微信搜索:程序员头条,
推荐使用python的抓取工具teamx 查看全部
网页文章采集工具有什么好用的免费采集代码的工具
网页文章采集工具自动采集代码有什么好用的免费采集代码的工具?比如利用爬虫爬取网页上的文章然后导出为html格式的格式。不错的这是一个拿来即用的工具,操作简单,可用于爬取网页,采集新闻,或者代码的翻译文章,也可以针对爬取的网页文章采集相关文章编辑。这是一个可以免费实现的工具但是还是不建议大家,用于采集网页,特别是新闻。因为,新闻很多时候可能有广告的嫌疑。
建议这篇文章:如何采集网站中的优质文章?里面有介绍常用的采集工具:聚合网站之一bucketjiathis,适合多领域多行业文章;聚合网站之二:我的头条;聚合网站之三:今日头条;聚合网站之四:豆瓣;聚合网站之五:站酷;聚合网站之六:uc;聚合网站之七:磨坊;聚合网站之八:城市画报;聚合网站之九:游戏风云;聚合网站之十:说客;聚合网站之十一:杂志风云;网站数据采集网站推荐-首页。
链接:一部手机就能学习爬虫技术了【二】【toeniu浏览器】【reactnative】【实时点评】【一部手机】【引擎之光】【github】。
推荐一个微信公众号【程序员头条】,我有自己写的爬虫,但是现在不太方便推广,大家可以关注下。微信搜索:程序员头条,
推荐使用python的抓取工具teamx
网页文章采集工具,非常好用的分析咯~~
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-12 22:01
网页文章采集工具这个工具用于网页文章采集,非常好用。
1)可对文章进行二次加工,如优化排版格式,转成pdf等。
2)采集速度快,经常为网站采集网页文章。
3)支持百度、搜狗、360等各种常见搜索引擎。网页数据采集工具,非常好用。
看你需要做什么方面的分析咯~自媒体一枚,分享一下自己使用采集器的感受。1.优质网站的分析经常去各个自媒体网站转转,有喜欢的文章下载下来分析,收获干货。2.收藏和整理分析自己喜欢的文章,提升自己的阅读量和取关量。3.设计文章图片构思情节的同时,简单编辑文章,做成图片,最终产出优秀的图文或者视频。
seertexperiment采集器!!我们每周实验室都会有不同的采集任务,想实验的时候用它,免费又好用,里面有什么内容都可以导出,分享不过来了。然后不想实验的时候就可以放着空着,等哪天想看的时候再看!一个可以采集5000多种站点的软件,就是更新快的原因,有一个周的使用周期。不要一次性弄一个项目,选择采集目的时要设定清楚,不然你一下子弄得太多可能导致没有什么深度好看的报告和结论。
、lastpass
journalblogif?lastseedarchives
/,vpn,谷歌镜像站(allinonesowhat?),ab站(这个我没试过)。其他的就是各种站都要搞一下。 查看全部
网页文章采集工具,非常好用的分析咯~~
网页文章采集工具这个工具用于网页文章采集,非常好用。
1)可对文章进行二次加工,如优化排版格式,转成pdf等。
2)采集速度快,经常为网站采集网页文章。
3)支持百度、搜狗、360等各种常见搜索引擎。网页数据采集工具,非常好用。
看你需要做什么方面的分析咯~自媒体一枚,分享一下自己使用采集器的感受。1.优质网站的分析经常去各个自媒体网站转转,有喜欢的文章下载下来分析,收获干货。2.收藏和整理分析自己喜欢的文章,提升自己的阅读量和取关量。3.设计文章图片构思情节的同时,简单编辑文章,做成图片,最终产出优秀的图文或者视频。
seertexperiment采集器!!我们每周实验室都会有不同的采集任务,想实验的时候用它,免费又好用,里面有什么内容都可以导出,分享不过来了。然后不想实验的时候就可以放着空着,等哪天想看的时候再看!一个可以采集5000多种站点的软件,就是更新快的原因,有一个周的使用周期。不要一次性弄一个项目,选择采集目的时要设定清楚,不然你一下子弄得太多可能导致没有什么深度好看的报告和结论。
、lastpass
journalblogif?lastseedarchives
/,vpn,谷歌镜像站(allinonesowhat?),ab站(这个我没试过)。其他的就是各种站都要搞一下。
木蚂蚁找中小网站用“优采云采集器”不可少
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-12 19:05
网页文章采集工具的话,我之前一直在用采鹿,确实挺好用的,就是收费的,不过他们有7天无理由退款,并且他们采集的网页都是行业内最高质量的,所以不用担心会白花钱啦。
我最近在用的一个网站倒是不需要下载,免费使用10天,
个人觉得可以使用每日一淘,
www.yueaiqi.me
搜网页文章采集
可以用“优采云采集器”
我认为楼上说的没错
百度搜,点击“百度轻应用”。不谢。
木蚂蚁~
这是我之前的一个回答
哇哈哈网址一个公众号分享技术和互联网推广方法。有成功经验解答。
木蚂蚁
找中小网站用采鹿
谷歌。这是不是你要的嘛。
可以用我吧,带功能多,不收费,一键采集,
百度,360,搜狗,搜书网。这个网站可以搜索任何页面,基本上你在网上的每一篇文章都能找到,也有一些是可以收费解决的。我尝试了一篇手机软件的内推码。
王子乔:怎么采集其他网站文章?
必不可少的是519band,然后是b2w,有了这两个,
用soopat了解下
推荐我也在用的一个站:)
《苏东坡传》可以通过他们的编辑然后获取源站地址,
只要是个中小站,
站长之家-苏东坡传-中国第一站苏东坡传ppt,共268页。 查看全部
木蚂蚁找中小网站用“优采云采集器”不可少
网页文章采集工具的话,我之前一直在用采鹿,确实挺好用的,就是收费的,不过他们有7天无理由退款,并且他们采集的网页都是行业内最高质量的,所以不用担心会白花钱啦。
我最近在用的一个网站倒是不需要下载,免费使用10天,
个人觉得可以使用每日一淘,
www.yueaiqi.me
搜网页文章采集
可以用“优采云采集器”
我认为楼上说的没错
百度搜,点击“百度轻应用”。不谢。
木蚂蚁~
这是我之前的一个回答
哇哈哈网址一个公众号分享技术和互联网推广方法。有成功经验解答。
木蚂蚁
找中小网站用采鹿
谷歌。这是不是你要的嘛。
可以用我吧,带功能多,不收费,一键采集,
百度,360,搜狗,搜书网。这个网站可以搜索任何页面,基本上你在网上的每一篇文章都能找到,也有一些是可以收费解决的。我尝试了一篇手机软件的内推码。
王子乔:怎么采集其他网站文章?
必不可少的是519band,然后是b2w,有了这两个,
用soopat了解下
推荐我也在用的一个站:)
《苏东坡传》可以通过他们的编辑然后获取源站地址,
只要是个中小站,
站长之家-苏东坡传-中国第一站苏东坡传ppt,共268页。
使用采集神器乐采的注意事项有哪些?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-11 21:03
网页文章采集工具:采集速尔、:,模板多、cms多。
可以去百度采集大师了解一下。他们拥有在线免费采集,cms后台采集,网站页面采集,功能齐全。支持上传wordpress,let'sengine网站,微信公众号,图片,小程序,公众号菜单,自动采集,软件采集。还支持视频采集,你要什么视频都可以直接采集的。速尔,好多同行,对接需要准备的基本资料,即可注册登录,按要求操作就可以用他们的软件采集了。
建议使用采集神器乐采,也不需要安装,
采集是常规软件还是专业的???都一样的没必要非得多对比,你直接采就行了,基本上没必要纠结这个问题,
10个有9个说国内的,一个人说用国外的,8个说不好用,
使用采集神器乐采进行查询,采集速度快,数据还安全,推荐大家使用采集神器乐采进行查询。
可以去用采耳采,这个是很多公司自己开发的对接,专门对接于微信公众号,小程序,二维码图片采集,智能采集文章,开放api接口让这些企业做进一步的采集改善,对接也会负责。
刚刚下载了一个,感觉还可以,关键是采到的东西不会上传到云盘,
我用的是江苏佛山金猎网络,有他们大概十几款可供选择的产品,基本上有需要可以选择。 查看全部
使用采集神器乐采的注意事项有哪些?(图)
网页文章采集工具:采集速尔、:,模板多、cms多。
可以去百度采集大师了解一下。他们拥有在线免费采集,cms后台采集,网站页面采集,功能齐全。支持上传wordpress,let'sengine网站,微信公众号,图片,小程序,公众号菜单,自动采集,软件采集。还支持视频采集,你要什么视频都可以直接采集的。速尔,好多同行,对接需要准备的基本资料,即可注册登录,按要求操作就可以用他们的软件采集了。
建议使用采集神器乐采,也不需要安装,
采集是常规软件还是专业的???都一样的没必要非得多对比,你直接采就行了,基本上没必要纠结这个问题,
10个有9个说国内的,一个人说用国外的,8个说不好用,
使用采集神器乐采进行查询,采集速度快,数据还安全,推荐大家使用采集神器乐采进行查询。
可以去用采耳采,这个是很多公司自己开发的对接,专门对接于微信公众号,小程序,二维码图片采集,智能采集文章,开放api接口让这些企业做进一步的采集改善,对接也会负责。
刚刚下载了一个,感觉还可以,关键是采到的东西不会上传到云盘,
我用的是江苏佛山金猎网络,有他们大概十几款可供选择的产品,基本上有需要可以选择。
使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2021-08-09 22:10
标签:采集器数据采集
51下载网提供网页数据采集软件《优采云采集器》3.4.4 官方版下载,软件为免费软件,文件大小为44.18 MB,推荐指数4星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是一个免费的网页数据采集,具有可视化点击和一键采集网页数据的特点,是一个任何人都可以使用的网页数据采集器。 优采云采集器 导出数据没有限制。数据可以导出到本地文件,发布到网站和数据库等,非常方便,有需要的朋友赶紧下载吧。
特点
可视化点击选择,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
可后台运行,实时显示速度。
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
所有平台,Win/Mac/Linux 均可用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
使用流程
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
如何使用
自定义采集百度搜索结果数据的方法
第一步:创建采集task
1)Start优采云采集器,进入主界面,选择Custom采集,点击Create Task按钮创建“Custom采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加文本输入处理块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图:按照上面添加输入文本流程块的拖放流程添加一个新块:如下图:
关键步骤块设置介绍
第2步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本.
第四步:用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置循环提取列表页面中的数据。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
第七步:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集Task 正在运行
2)采集 完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式
4)采集数据导出后如下图
更新日志
修复
修复定时任务数据保存失败的问题 查看全部
使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍
标签:采集器数据采集
51下载网提供网页数据采集软件《优采云采集器》3.4.4 官方版下载,软件为免费软件,文件大小为44.18 MB,推荐指数4星,作为国产软件的顶级厂商,可以放心下载!
优采云采集器是一个免费的网页数据采集,具有可视化点击和一键采集网页数据的特点,是一个任何人都可以使用的网页数据采集器。 优采云采集器 导出数据没有限制。数据可以导出到本地文件,发布到网站和数据库等,非常方便,有需要的朋友赶紧下载吧。
特点
可视化点击选择,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
可后台运行,实时显示速度。
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
所有平台,Win/Mac/Linux 均可用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
使用流程
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
如何使用
自定义采集百度搜索结果数据的方法
第一步:创建采集task
1)Start优采云采集器,进入主界面,选择Custom采集,点击Create Task按钮创建“Custom采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:在输入框中直接输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、Bulk add方法:通过添加和调整地址参数生成多个常规地址
第 2 步:自定义采集process
1)点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加文本输入处理块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图:按照上面添加输入文本流程块的拖放流程添加一个新块:如下图:
关键步骤块设置介绍
第2步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本.
第四步:用于设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置循环提取列表页面中的数据。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
第七步:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集Task 正在运行
2)采集 完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集good数据,这里可以选择excel作为导出格式
4)采集数据导出后如下图
更新日志
修复
修复定时任务数据保存失败的问题
优采云采集器网页数据采集任务自动分配到云端
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-07 23:23
优采云采集器是一个多功能的网络数据采集神器,改变了互联网上传统的数据思维方式。它以自主研发的分布式云计算平台为核心,采集工作自动分配到云端多台服务器同时执行,提高采集效率,短时间内获取数千条信息。
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图像识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
定时自动采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房相关各大地产最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。 查看全部
优采云采集器网页数据采集任务自动分配到云端
优采云采集器是一个多功能的网络数据采集神器,改变了互联网上传统的数据思维方式。它以自主研发的分布式云计算平台为核心,采集工作自动分配到云端多台服务器同时执行,提高采集效率,短时间内获取数千条信息。
软件功能
操作简单,图形操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图像识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
定时自动采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括每日最新净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房相关各大地产最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
北京德硕熊猫大数据研究院童毅研究员亲测
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-31 18:11
网页文章采集工具:1。腾讯,百度,谷歌等多家知名网站开放代码和隐私政策,找到隐私政策;2。进入谷歌\百度网站,搜索你想要的关键词,然后搜索腾讯\百度关键词,下面会有网站地址;3。在百度\谷歌中找到真实地址,然后复制,网站/公司名称编辑器/view中粘贴,5。用迅雷或其他搜索引擎,在线下载即可,点击“搜索”获取;。
百度apis3是百度官方的开放api接口,以谷歌等国外平台为主,权限高,速度快,有谷歌方面的内部信息。北京德硕熊猫大数据研究院童毅研究员亲测,
1、百度api
1、360apis
2、360apis
4、铁通apis
4、电信apis
4、移动apis2都打通了
百度搜索开放平台有部分打通googleapi的;小众的话你就得看各个业务条线的api开放情况了;大部分开放了api的就要靠自己探索。
sogou(猫途鹰):(荷兰主):
不过到底有多少你就得自己去google里面搜索下api
有种网站叫全网api,
我尝试过提交百度接口,由于身份为个人,暂无结果。可以看看有无类似公司提交,
autofusapistore
百度apis网站
你是想问的多为部分或者是百度所支持的就可以,
就我自己用过的而言:百度apisdk,除了部分公众号接口要收费外,其他接口, 查看全部
北京德硕熊猫大数据研究院童毅研究员亲测
网页文章采集工具:1。腾讯,百度,谷歌等多家知名网站开放代码和隐私政策,找到隐私政策;2。进入谷歌\百度网站,搜索你想要的关键词,然后搜索腾讯\百度关键词,下面会有网站地址;3。在百度\谷歌中找到真实地址,然后复制,网站/公司名称编辑器/view中粘贴,5。用迅雷或其他搜索引擎,在线下载即可,点击“搜索”获取;。
百度apis3是百度官方的开放api接口,以谷歌等国外平台为主,权限高,速度快,有谷歌方面的内部信息。北京德硕熊猫大数据研究院童毅研究员亲测,
1、百度api
1、360apis
2、360apis
4、铁通apis
4、电信apis
4、移动apis2都打通了
百度搜索开放平台有部分打通googleapi的;小众的话你就得看各个业务条线的api开放情况了;大部分开放了api的就要靠自己探索。
sogou(猫途鹰):(荷兰主):
不过到底有多少你就得自己去google里面搜索下api
有种网站叫全网api,
我尝试过提交百度接口,由于身份为个人,暂无结果。可以看看有无类似公司提交,
autofusapistore
百度apis网站
你是想问的多为部分或者是百度所支持的就可以,
就我自己用过的而言:百度apisdk,除了部分公众号接口要收费外,其他接口,
网页文章采集工具篇-segmentfault(简单,高效,准确)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-25 18:07
网页文章采集工具篇-segmentfault【简单,高效,准确】介绍网页文章采集工具,一键将百度云文章抓取网页信息,可多同步,可自定义下载按钮,分析、开发api,一站搞定,具体可参考github一键抓取百度云文章教程实战,详细。网页信息采集教程everything最好用的文本文件检索工具,按下图方式复制网址::/allwinner作者:itinsider更多资源github:-insider/everything微信公众号:it168。
谁说不可以用搜狗浏览器来抓取百度文章?抓取软件的话:gethunter-最牛逼的抓取软件-gethunter社区目前很火的抓取软件-社区-gethunter-test
你可以试一下清网人工服务,它通过爬虫软件hit-u最多支持3464个手机app爬虫,可以下载文章了。
微信公众号名称通过查询系统大量历史资料,通过线索反推要抓取的信息。
querybasedacquisition
这个我做过百度文章的抓取工具,
你可以试一下利用fiddler逆向获取
要抓取百度文章的话推荐用reffers工具,适合抓取文章标题,文章描述,摘要,文章被分享次数,文章评论数,历史文章列表等。
用爬虫软件googlethebestmanipulationbackendforwebinternalscrapingreferencevideocasewithsoftpages::sdcflowjavascript,htmlandcssattributereferencejavascriptattributereferenceinhtmlonchrome'smaximumloadforsize!i---webscrapingisaproject。 查看全部
网页文章采集工具篇-segmentfault(简单,高效,准确)
网页文章采集工具篇-segmentfault【简单,高效,准确】介绍网页文章采集工具,一键将百度云文章抓取网页信息,可多同步,可自定义下载按钮,分析、开发api,一站搞定,具体可参考github一键抓取百度云文章教程实战,详细。网页信息采集教程everything最好用的文本文件检索工具,按下图方式复制网址::/allwinner作者:itinsider更多资源github:-insider/everything微信公众号:it168。
谁说不可以用搜狗浏览器来抓取百度文章?抓取软件的话:gethunter-最牛逼的抓取软件-gethunter社区目前很火的抓取软件-社区-gethunter-test
你可以试一下清网人工服务,它通过爬虫软件hit-u最多支持3464个手机app爬虫,可以下载文章了。
微信公众号名称通过查询系统大量历史资料,通过线索反推要抓取的信息。
querybasedacquisition
这个我做过百度文章的抓取工具,
你可以试一下利用fiddler逆向获取
要抓取百度文章的话推荐用reffers工具,适合抓取文章标题,文章描述,摘要,文章被分享次数,文章评论数,历史文章列表等。
用爬虫软件googlethebestmanipulationbackendforwebinternalscrapingreferencevideocasewithsoftpages::sdcflowjavascript,htmlandcssattributereferencejavascriptattributereferenceinhtmlonchrome'smaximumloadforsize!i---webscrapingisaproject。
网页文章采集工具推荐和常见问题答疑【八维教育】
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-07-24 01:02
网页文章采集工具推荐和常见问题答疑
1、哪些站点可以采集文章?目前的互联网都有一个共同的特点:①“为了保护知识产权,网站上所有内容都要原创”②“个人用户发布的内容需要经过本人认证”③“网站内容会被推送到第三方平台,如微信公众号或其他第三方应用”。所以,抓取文章时,务必要保护好自己网站的内容,不要泄露给他人。
2、文章只能是本人上传吗?错。采集需要转发推送给对方网站,需要转发请用实名制。根据知乎规定:不推荐老是来知乎转发新发布的文章。
3、发送给第三方转发后,第三方会显示采集文章列表。文章内容如何在第三方网站下载打开?①网页搜索“今日头条”,点击新闻源"阅读原文",点击全部内容,进入搜索页面,在文章列表点击,输入网址即可。③网页搜索“百度百家”,进入百度百家,点击你要查看的内容。
4、想看一些一直在刊登但没有登录的新闻,通过输入网址可以实现吗?可以的。只要在点击登录的网站发布的内容,就可以自动发布到该网站。登录方式见:/->登录自己网站网址。采集原理:①运行完采集工具后,会查看工具文件,对工具功能不了解,可以从某宝购买。②建议采集多个网站,这样更有可能筛选出合适的素材。如果是个人网站,可以登录,如果是企业网站,不建议登录。
5、采集到的文章,可以推送到第三方网站,怎么发布?①下载软件采集网页内容后,如果没有看是否采集了什么内容,可以直接将采集到的链接复制到onelinks,点击publish即可生成链接。②如果看到了所要推送的内容,要抓取网页采集内容,直接将链接粘贴在第三方网站的publish。
5、发布网站时,已经保存不再添加新的内容,新增文章无法显示?新增添加内容没有问题。新增添加文章要发布到第三方网站才有效,没有发布到第三方网站是无效的。
6、采集文章的质量是否在线上架要求?将采集的网站发布在第三方网站,发布后文章更新可见。可以上架采集内容,注意要保证采集多个网站,不然被判定多次转发,不会抓取网站内容。
7、采集后,可以转发到微信,朋友圈之类的第三方平台吗?自己收藏的网站是可以发布的,微信方面不会限制,但是分享出去,即使登录过也不行。
8、同一个网站能否同时采集多篇文章?可以同时采集多个网站,也可以有限制。只能一个网站采集出一篇文章。 查看全部
网页文章采集工具推荐和常见问题答疑【八维教育】
网页文章采集工具推荐和常见问题答疑
1、哪些站点可以采集文章?目前的互联网都有一个共同的特点:①“为了保护知识产权,网站上所有内容都要原创”②“个人用户发布的内容需要经过本人认证”③“网站内容会被推送到第三方平台,如微信公众号或其他第三方应用”。所以,抓取文章时,务必要保护好自己网站的内容,不要泄露给他人。
2、文章只能是本人上传吗?错。采集需要转发推送给对方网站,需要转发请用实名制。根据知乎规定:不推荐老是来知乎转发新发布的文章。
3、发送给第三方转发后,第三方会显示采集文章列表。文章内容如何在第三方网站下载打开?①网页搜索“今日头条”,点击新闻源"阅读原文",点击全部内容,进入搜索页面,在文章列表点击,输入网址即可。③网页搜索“百度百家”,进入百度百家,点击你要查看的内容。
4、想看一些一直在刊登但没有登录的新闻,通过输入网址可以实现吗?可以的。只要在点击登录的网站发布的内容,就可以自动发布到该网站。登录方式见:/->登录自己网站网址。采集原理:①运行完采集工具后,会查看工具文件,对工具功能不了解,可以从某宝购买。②建议采集多个网站,这样更有可能筛选出合适的素材。如果是个人网站,可以登录,如果是企业网站,不建议登录。
5、采集到的文章,可以推送到第三方网站,怎么发布?①下载软件采集网页内容后,如果没有看是否采集了什么内容,可以直接将采集到的链接复制到onelinks,点击publish即可生成链接。②如果看到了所要推送的内容,要抓取网页采集内容,直接将链接粘贴在第三方网站的publish。
5、发布网站时,已经保存不再添加新的内容,新增文章无法显示?新增添加内容没有问题。新增添加文章要发布到第三方网站才有效,没有发布到第三方网站是无效的。
6、采集文章的质量是否在线上架要求?将采集的网站发布在第三方网站,发布后文章更新可见。可以上架采集内容,注意要保证采集多个网站,不然被判定多次转发,不会抓取网站内容。
7、采集后,可以转发到微信,朋友圈之类的第三方平台吗?自己收藏的网站是可以发布的,微信方面不会限制,但是分享出去,即使登录过也不行。
8、同一个网站能否同时采集多篇文章?可以同时采集多个网站,也可以有限制。只能一个网站采集出一篇文章。
PC端采集工具,让你的阅读量瞬间提升一倍
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-07-22 07:36
随着阅读量的增加,学习的越来越少,我们能记住的越来越少,我们要进入下一阶段的知识,采集知识。 采集的工具有很多,但最终还是以印象笔记为载体来存储这些信息。
PC端采集tools
1.1.强大的文字扩展工具PopClip
PopClip 是 Mac 上的知名小工具。说起PopClip,它可能是Mac下最值得购买的软件了。它的操作也很简单,只需选中文字,然后高亮显示文字即可。本软件简单高效,扩展功能强大。未安装插件时,具有以下功能。
粘贴
打开链接
复制
字典
拼写检查
邮件重定向
是不是很棒?更棒的是,它还支持一百多个各种插件,功能各异。例如支持选中文本翻译、修改文本格式、搜索豆瓣、保存到Doit.im等...
您只需到其官网下载相应的插件即可使用这些插件。
之所以把它放在采集章节,是因为自从我安装了Evernote插件后,妈妈再也不用担心我的采集文字方法了!
只需点击印象笔记按钮即可在印象笔记中创建一个新文件。
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们不得不使用大量的复制和粘贴。但是有时候复制一段文字的时候,原来复制的文字被这个文字覆盖了,之前复制粘贴的东西都没了……Paste很好的解决了这个问题。可以在设置项中选择保存500多条复制粘贴历史。需要粘贴的时候,只需要按shift+command+v就可以看到复制的历史内容,然后选择操作。
Paste 与 Mac 结合得非常好,看起来就像一个本机应用程序。它不仅可以记录复制历史,而且分类和预览显示的效果非常好。真是写手必备神器!
1.3.作弊快捷方式查询工具
说到高效的作家,他们中的大多数都是键盘手。比如我近两年没有用过鼠标,因为平时的操作可以用快捷键来解决,但是一些新软件本身是根本不知道它的快捷键怎么办?一一摸索?你根本不需要 cheetcommand。安装好之后,在使用软件的时候,长按Command键就可以看到完整的快捷键映射图。跟快捷键软件比,是不是很爽?歪了?
1.4.Chrome 网页中的快捷键
说到快捷键,就不得不说Vimium,chrome下的一个小插件
Vimium 是一个很棒的插件。安装并启用此插件后,只需在浏览器页面按F键即可看到跳转到对应页面的按钮。
如果您想退出,只需按 Esc 键即可。
有了这个神器,再加上浏览器上的快捷键,在浏览网页的时候,根本不需要使用触摸板!工作效率显着提高!
除了这些,PC端其实还有很多采集和整理工具,比如上一篇文章提到的Pocket,还有Chrome中的Evernote编辑插件。这些比较常见,就不赘述了。
移动端采集tools
除了PC端采集的数据,我们在移动端采集经常需要一些资料和一些注意事项。除了口袋,还有一些常用的方法和软件。
1.我的影记笔记
在移动端,使用频率最高的是我的印象笔记微信公众号。您只需要关注:“我的印象笔记”并绑定账号即可。
您可以在文章 页面上的印象笔记中分享。
然后界面提示保存成功,我们可以在印象笔记中找到这个文章。 查看全部
PC端采集工具,让你的阅读量瞬间提升一倍
随着阅读量的增加,学习的越来越少,我们能记住的越来越少,我们要进入下一阶段的知识,采集知识。 采集的工具有很多,但最终还是以印象笔记为载体来存储这些信息。
PC端采集tools
1.1.强大的文字扩展工具PopClip
PopClip 是 Mac 上的知名小工具。说起PopClip,它可能是Mac下最值得购买的软件了。它的操作也很简单,只需选中文字,然后高亮显示文字即可。本软件简单高效,扩展功能强大。未安装插件时,具有以下功能。
粘贴
打开链接
复制
字典
拼写检查
邮件重定向
是不是很棒?更棒的是,它还支持一百多个各种插件,功能各异。例如支持选中文本翻译、修改文本格式、搜索豆瓣、保存到Doit.im等...
您只需到其官网下载相应的插件即可使用这些插件。
之所以把它放在采集章节,是因为自从我安装了Evernote插件后,妈妈再也不用担心我的采集文字方法了!
只需点击印象笔记按钮即可在印象笔记中创建一个新文件。
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们不得不使用大量的复制和粘贴。但是有时候复制一段文字的时候,原来复制的文字被这个文字覆盖了,之前复制粘贴的东西都没了……Paste很好的解决了这个问题。可以在设置项中选择保存500多条复制粘贴历史。需要粘贴的时候,只需要按shift+command+v就可以看到复制的历史内容,然后选择操作。
Paste 与 Mac 结合得非常好,看起来就像一个本机应用程序。它不仅可以记录复制历史,而且分类和预览显示的效果非常好。真是写手必备神器!
1.3.作弊快捷方式查询工具
说到高效的作家,他们中的大多数都是键盘手。比如我近两年没有用过鼠标,因为平时的操作可以用快捷键来解决,但是一些新软件本身是根本不知道它的快捷键怎么办?一一摸索?你根本不需要 cheetcommand。安装好之后,在使用软件的时候,长按Command键就可以看到完整的快捷键映射图。跟快捷键软件比,是不是很爽?歪了?
1.4.Chrome 网页中的快捷键
说到快捷键,就不得不说Vimium,chrome下的一个小插件
Vimium 是一个很棒的插件。安装并启用此插件后,只需在浏览器页面按F键即可看到跳转到对应页面的按钮。
如果您想退出,只需按 Esc 键即可。
有了这个神器,再加上浏览器上的快捷键,在浏览网页的时候,根本不需要使用触摸板!工作效率显着提高!
除了这些,PC端其实还有很多采集和整理工具,比如上一篇文章提到的Pocket,还有Chrome中的Evernote编辑插件。这些比较常见,就不赘述了。
移动端采集tools
除了PC端采集的数据,我们在移动端采集经常需要一些资料和一些注意事项。除了口袋,还有一些常用的方法和软件。
1.我的影记笔记
在移动端,使用频率最高的是我的印象笔记微信公众号。您只需要关注:“我的印象笔记”并绑定账号即可。
您可以在文章 页面上的印象笔记中分享。
然后界面提示保存成功,我们可以在印象笔记中找到这个文章。
简单易用的网页数据采集工具分享的破解版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-07-22 02:03
SysNucleus WebHarvy 是一个简单易用的网页 data采集 工具。该软件旨在帮助您使用先进的内置浏览器和简单的点击界面来捕获网页上显示的图像、文本或任何数据。有效支持图片、文字内容、联系方式、邮件、产品列表等各类信息,拥有极其简洁的界面布局,用户只需简单几步即可快速采集网站数据,@k15配置。 @的数据可以导出为csv、tsv、xml等格式,方便您的数据交互。这里有一个破解版的WebHarvy给你。有需要的用户赶紧下载吧!
软件功能
从多个页面捕获数据并使用自定义正则表达式
该应用程序带有一个现代、干净且用户友好的 GUI,其中包括一个关于如何开始的小教程。与类似工具不同,该应用程序充当可视化网络抓取工具,因此您无需编写特定代码或脚本即可获取所需数据。
相反,您可以使用内置浏览器访问所需的网站 并选择所需的内容。但是,如果您只想捕获 HTML 源代码的特定部分,则可以在 HTML 源代码上使用 RegEx。此外,该工具还允许您在提取数据之前在浏览器中运行 JavaScript。
该程序可以同时从多个页面捕获信息,这使得在多个页面上显示产品非常方便,例如。您只需链接到下一页即可实现此目的。
支持匿名抓取并从链表中获取数据
应用程序可以自动识别页面上显示的数据模式,因此您只需选择一次您需要的信息类型,无需进一步配置。同时,该工具可以根据您提供的关键字和指向类似页面的链接列表中的数据捕获内容。
多功能实用
无论您需要从各种网站获取文本内容、图片、URL、电子邮件或其他信息,WebHarvy 都会为您提供灵活且易于使用的环境。
软件功能
简单的点击界面
导出捕获的数据
来自多个 Ppges采集
通过代理服务器抓取
基于关键字的抓取
内置调度器
将捕获的数据导出为 XML、CSV 或 TSV 文件
安装方法
1、下载并解压软件得到安装程序和破解补丁文件夹,我们先双击安装程序“setup.exe”开始安装。
2、进入SysNucleus WebHarvy安装向导,点击【下一步】按钮继续。
3、阅读许可协议,勾选【我接受许可协议中的条款】同意选项,然后点击【下一步】。
4、选择安装文件夹,默认为C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,如需更改请点击【更改】按钮进行修改(记得安装文件夹,容易破解)。
5、准备安装,点击【安装】按钮执行安装操作。
6、SysNucleus WebHarvy 安装完成,取消勾选【启动程序】,点击【完成】结束。
7、 将破解补丁文件夹下的破解补丁程序“WebHarvy.exe”复制到软件安装目录(例如C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,请复制到对应的实际安装文件夹)。
8、运行 SysNucleus WebHarvy 来使用它。
更新日志
挖矿时自动删除cookies的选项
支持使用 JavaScript 在同一页面加载更多数据(分页)
您可以选择停用许可证并将其转移到另一台计算机
直接在 Windows 任务计划程序中编辑计划挖掘任务的选项
通过同时挖掘多个链接,显着提高挖掘速度。 Chrome 开发者工具已添加到 WebHarvy
通过突出显示需要的文本部分来提高自动子文本选择的准确性
各种错误修复和改进 查看全部
简单易用的网页数据采集工具分享的破解版本
SysNucleus WebHarvy 是一个简单易用的网页 data采集 工具。该软件旨在帮助您使用先进的内置浏览器和简单的点击界面来捕获网页上显示的图像、文本或任何数据。有效支持图片、文字内容、联系方式、邮件、产品列表等各类信息,拥有极其简洁的界面布局,用户只需简单几步即可快速采集网站数据,@k15配置。 @的数据可以导出为csv、tsv、xml等格式,方便您的数据交互。这里有一个破解版的WebHarvy给你。有需要的用户赶紧下载吧!
软件功能
从多个页面捕获数据并使用自定义正则表达式
该应用程序带有一个现代、干净且用户友好的 GUI,其中包括一个关于如何开始的小教程。与类似工具不同,该应用程序充当可视化网络抓取工具,因此您无需编写特定代码或脚本即可获取所需数据。
相反,您可以使用内置浏览器访问所需的网站 并选择所需的内容。但是,如果您只想捕获 HTML 源代码的特定部分,则可以在 HTML 源代码上使用 RegEx。此外,该工具还允许您在提取数据之前在浏览器中运行 JavaScript。
该程序可以同时从多个页面捕获信息,这使得在多个页面上显示产品非常方便,例如。您只需链接到下一页即可实现此目的。
支持匿名抓取并从链表中获取数据
应用程序可以自动识别页面上显示的数据模式,因此您只需选择一次您需要的信息类型,无需进一步配置。同时,该工具可以根据您提供的关键字和指向类似页面的链接列表中的数据捕获内容。
多功能实用
无论您需要从各种网站获取文本内容、图片、URL、电子邮件或其他信息,WebHarvy 都会为您提供灵活且易于使用的环境。
软件功能
简单的点击界面
导出捕获的数据
来自多个 Ppges采集
通过代理服务器抓取
基于关键字的抓取
内置调度器
将捕获的数据导出为 XML、CSV 或 TSV 文件
安装方法
1、下载并解压软件得到安装程序和破解补丁文件夹,我们先双击安装程序“setup.exe”开始安装。
2、进入SysNucleus WebHarvy安装向导,点击【下一步】按钮继续。
3、阅读许可协议,勾选【我接受许可协议中的条款】同意选项,然后点击【下一步】。
4、选择安装文件夹,默认为C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,如需更改请点击【更改】按钮进行修改(记得安装文件夹,容易破解)。
5、准备安装,点击【安装】按钮执行安装操作。
6、SysNucleus WebHarvy 安装完成,取消勾选【启动程序】,点击【完成】结束。
7、 将破解补丁文件夹下的破解补丁程序“WebHarvy.exe”复制到软件安装目录(例如C:\Users\CS\AppData\Roaming\SysNucleus\WebHarvy\,请复制到对应的实际安装文件夹)。
8、运行 SysNucleus WebHarvy 来使用它。
更新日志
挖矿时自动删除cookies的选项
支持使用 JavaScript 在同一页面加载更多数据(分页)
您可以选择停用许可证并将其转移到另一台计算机
直接在 Windows 任务计划程序中编辑计划挖掘任务的选项
通过同时挖掘多个链接,显着提高挖掘速度。 Chrome 开发者工具已添加到 WebHarvy
通过突出显示需要的文本部分来提高自动子文本选择的准确性
各种错误修复和改进
网页文章采集工具教程这篇文章我写的非常详细
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-07-18 07:08
网页文章采集工具教程这篇文章我写的非常详细,
alltagsist网址::200000+知乎专栏:kindle小姐姐关注我带你读书,
网址在百度里搜
网址可以多种方式获取到手,微信公众号,百度文库等。可以先把文章关键词输入进去筛选出适合的网址,然后针对这个网址的内容进行相应的检索。
新浪微博,搜索网站,
百度或者贴吧
直接百度
百度
中国大学mooc
大象公会
第一,在知乎搜索栏搜关键词,看看能不能找到相关的问题;第二,直接问题本人或者在知乎注册用户搜索关键词(该上知乎站内搜索);第三,检索学校官网,或者百度。中国科学技术大学食堂卫生,第四,上其他高校教务管理系统,看看这个网站是否对该专业的本科生开放;第五,一些专业的教学网站,比如一些大学内的编程或者软件入门课。另外多数学校图书馆的网页,就看你更熟悉哪些?。
其实可以上菜鸟窝搜索看看看自己可以找到什么东西吧,食堂一百零一条,学生工作一百零一条。
看看下面这个,腾讯的大数据智能搜索中心,直接搜索主题词,会自动推荐最相关的话题和文章给你看。 查看全部
网页文章采集工具教程这篇文章我写的非常详细
网页文章采集工具教程这篇文章我写的非常详细,
alltagsist网址::200000+知乎专栏:kindle小姐姐关注我带你读书,
网址在百度里搜
网址可以多种方式获取到手,微信公众号,百度文库等。可以先把文章关键词输入进去筛选出适合的网址,然后针对这个网址的内容进行相应的检索。
新浪微博,搜索网站,
百度或者贴吧
直接百度
百度
中国大学mooc
大象公会
第一,在知乎搜索栏搜关键词,看看能不能找到相关的问题;第二,直接问题本人或者在知乎注册用户搜索关键词(该上知乎站内搜索);第三,检索学校官网,或者百度。中国科学技术大学食堂卫生,第四,上其他高校教务管理系统,看看这个网站是否对该专业的本科生开放;第五,一些专业的教学网站,比如一些大学内的编程或者软件入门课。另外多数学校图书馆的网页,就看你更熟悉哪些?。
其实可以上菜鸟窝搜索看看看自己可以找到什么东西吧,食堂一百零一条,学生工作一百零一条。
看看下面这个,腾讯的大数据智能搜索中心,直接搜索主题词,会自动推荐最相关的话题和文章给你看。

