
网页数据抓取软件
网页数据抓取软件()
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-24 05:03
2.字符串
2.纵梁
当您想到与数据清理和准备相关的任务时,stringr 就会发挥作用。
当您想到与数据清理和准备相关的任务时,它就会发挥作用。
stringr 中有四组基本函数:
Stringr 中有四组基本的函数:
安装
安装
install.packages('stringr')
install.packages('stringr')
3.jsonlite
3.jsonlite
jsonline 包之所以有用,是因为它是一个针对网络优化的 JSON 解析器/生成器。
jsonline 包的有用之处在于它是一个针对网络优化的 JSON 解析器/生成器。
这很重要,因为它可以在 JSON 数据和关键的 R 数据类型之间建立有效的映射。使用它,我们能够在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也不需要任何手动数据整理。
这很关键,因为它允许在 JSON 数据和关键 R 数据类型之间进行有效映射。使用这种方法,我们可以在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也无需任何手动数据操作。
这非常适合与 Web API 交互,或者如果您想创建数据可以使用 JSON 进出 R 的方式。
这对于与 Web API 交互非常有用,或者如果您想创建使用 JSON 将数据传入和传出 R 的方法。
安装
install.packages('jsonlite')
install.packages('jsonlite')
在我们开始之前,让我们看看它是如何工作的:
在开始之前,让我们看看它是如何工作的:
首先应该清楚每个网站是不同的,因为进入网站的编码是不同的。
从一开始就应该清楚每个 网站 是不同的,因为进入 网站 的编码是不同的。
网络抓取是一种识别和使用这些编码模式来提取您需要的数据的技术。您的浏览器使您可以通过 HTML 访问该网站。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取是一种识别并使用这些编码模式来提取所需数据的技术。您的浏览器使这个 网站 可以通过 HTML 访问。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取有一个固定的过程,通常是这样工作的:
网页抓取过程如下设置,一般是这样的:
现在让我们去实现以更好地理解它。
现在让我们实现它以更好地理解它。
3.实施(3.实施)
让我们实现它,看看它是如何工作的。我们将在亚马逊网站上抓取一款名为“一加 6”的手机产品的价格比较。
让我们实现它,看看它是如何工作的。我们将搜索亚马逊 网站 来比较一款名为“一加 6”的手机的价格。
你可以在这里看到它。
你可以在这里看到它。
第一步:加载我们需要的包
我们需要在控制台中,在 R 命令提示符下启动进程。到达那里后,我们需要加载所需的包,如下所示:
我们需要在控制台的 R 命令提示符下启动该进程。到达那里后,我们需要按如下方式加载所需的包:
#loading the package:> library(xml2)> library(rvest)> library(stringr)
第 2 步:从亚马逊读取 HTML 内容
#Specifying the url for desired website to be scrappedurl 转到此 URL => 右键单击 => 检查元素
=>转到 chrome 浏览器=>转到该 URL=>右键单击=>检查元素
注意:如果您使用的不是 Chrome 浏览器,请查看这篇文章。
注意:如果您使用的不是Chrome浏览器,请参考这篇文章。
基于 CSS 选择器,例如 class 和 id,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“检查”或“检查元素”。
基于 class 和 id 等 CSS 选择器,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“Inspect”或“Inspect Element”。
正如您在下面看到的,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 id - h1#title - 以及存储了 HTML 内容的网页。
如下所示,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 ID ( h1#title ) 和存储 HTML 内容的网页。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
#scrape title of the product> title_html title head(title)
输出如下图:
输出如下:
我们可以使用空格和\n来获得产品的标题。
我们可以使用空格和\n来获取产品的标题。
下一步是在 stringr 库中的 str_replace_all() 函数的帮助下删除空格和新行。
下一步是借助 stringr 库中的 str_replace_all() 函数删除空格和换行符。
# remove all space and new linesstr_replace_all(title, “[\r\n]” , “”)
输出:
输出:
现在我们需要按照相同的过程提取产品的其他相关信息。
现在,我们将需要按照相同的过程来提取有关产品的其他相关信息。
产品价格:
产品价格:
# scrape the price of the product> price_html price str_replace_all(title, “[\r\n]” , “”)
# print price value> head(price)
输出:
输出:
产品说明:
产品说明:
# scrape product description> desc_html desc desc desc head(desc)
输出:
输出:
产品评分:
产品等级:
# scrape product rating > rate_html rate rate rate head(rate)
输出:
输出:
产品尺寸:
产品尺寸:
# Scrape size of the product> size_html size_html size size head(size)
输出:
输出:
产品颜色:
产品颜色:
# Scrape product color> color_html color_html color color head(color)
输出:
输出:
第 4 步:我们已成功从所有字段中提取数据,这些数据可用于比较其他网站的产品信息。 (第 4 步:我们已成功从所有字段中提取数据,可用于比较其他站点的产品信息。)
让我们编译并组合它们以计算出一个数据框并检查其结构。
让我们编译和组合它,得到一个数据框并检查它的结构。
#Combining all the lists to form a data frameproduct_data library(jsonlite)
# convert dataframe into JSON format> json_data cat(json_data)
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果我们愿意,也可以将数据存储在 csv 文件或数据库中以供进一步处理。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果您愿意,还可以将数据存储在 csv 文件或数据库中以供进一步处理。
输出:
输出:
按照这个实际示例,您还可以从产品中提取相关数据并与亚马逊进行比较,以计算出产品的公允价值。同样,您可以使用这些数据与其他网站进行比较。
按照这个实际示例,您还可以从产品中提取相同的相关数据,并与亚马逊进行比较,从而得出产品的公允价值。同样,您可以使用该数据与其他 网站 进行比较。
4.尾注(4.尾注)
如您所见,R 可以为您提供从不同网站抓取数据的强大优势。通过这个关于如何使用 R 的实际示例,您现在可以自行探索它并从亚马逊或任何其他电子商务网站提取产品数据。
如您所见,R 可以极大地帮助您从不同的 网站 中抓取数据。通过这个 R 用法的实际示例,您现在可以自己探索 R 并从亚马逊或任何其他电子商务中提取产品数据网站。
请注意:某些网站有反抓取政策。如果您过度使用它,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以学习使用不同的可用服务来解决验证码问题。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请注意:部分网站有反爬虫政策。如果您做得太多,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以使用各种可用的服务来学习如何处理验证码。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请随时将您对这篇文章的反馈和建议发送给我!
请随时向我发送您对这篇文章的反馈和建议!
翻译自:
r语言抓取网页数据 查看全部
网页数据抓取软件()
2.字符串
2.纵梁
当您想到与数据清理和准备相关的任务时,stringr 就会发挥作用。
当您想到与数据清理和准备相关的任务时,它就会发挥作用。
stringr 中有四组基本函数:
Stringr 中有四组基本的函数:
安装
安装
install.packages('stringr')
install.packages('stringr')
3.jsonlite
3.jsonlite
jsonline 包之所以有用,是因为它是一个针对网络优化的 JSON 解析器/生成器。
jsonline 包的有用之处在于它是一个针对网络优化的 JSON 解析器/生成器。
这很重要,因为它可以在 JSON 数据和关键的 R 数据类型之间建立有效的映射。使用它,我们能够在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也不需要任何手动数据整理。
这很关键,因为它允许在 JSON 数据和关键 R 数据类型之间进行有效映射。使用这种方法,我们可以在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也无需任何手动数据操作。
这非常适合与 Web API 交互,或者如果您想创建数据可以使用 JSON 进出 R 的方式。
这对于与 Web API 交互非常有用,或者如果您想创建使用 JSON 将数据传入和传出 R 的方法。
安装
install.packages('jsonlite')
install.packages('jsonlite')
在我们开始之前,让我们看看它是如何工作的:
在开始之前,让我们看看它是如何工作的:
首先应该清楚每个网站是不同的,因为进入网站的编码是不同的。
从一开始就应该清楚每个 网站 是不同的,因为进入 网站 的编码是不同的。
网络抓取是一种识别和使用这些编码模式来提取您需要的数据的技术。您的浏览器使您可以通过 HTML 访问该网站。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取是一种识别并使用这些编码模式来提取所需数据的技术。您的浏览器使这个 网站 可以通过 HTML 访问。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取有一个固定的过程,通常是这样工作的:
网页抓取过程如下设置,一般是这样的:
现在让我们去实现以更好地理解它。
现在让我们实现它以更好地理解它。
3.实施(3.实施)
让我们实现它,看看它是如何工作的。我们将在亚马逊网站上抓取一款名为“一加 6”的手机产品的价格比较。
让我们实现它,看看它是如何工作的。我们将搜索亚马逊 网站 来比较一款名为“一加 6”的手机的价格。
你可以在这里看到它。
你可以在这里看到它。
第一步:加载我们需要的包
我们需要在控制台中,在 R 命令提示符下启动进程。到达那里后,我们需要加载所需的包,如下所示:
我们需要在控制台的 R 命令提示符下启动该进程。到达那里后,我们需要按如下方式加载所需的包:
#loading the package:> library(xml2)> library(rvest)> library(stringr)
第 2 步:从亚马逊读取 HTML 内容
#Specifying the url for desired website to be scrappedurl 转到此 URL => 右键单击 => 检查元素
=>转到 chrome 浏览器=>转到该 URL=>右键单击=>检查元素
注意:如果您使用的不是 Chrome 浏览器,请查看这篇文章。
注意:如果您使用的不是Chrome浏览器,请参考这篇文章。
基于 CSS 选择器,例如 class 和 id,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“检查”或“检查元素”。
基于 class 和 id 等 CSS 选择器,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“Inspect”或“Inspect Element”。
正如您在下面看到的,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 id - h1#title - 以及存储了 HTML 内容的网页。
如下所示,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 ID ( h1#title ) 和存储 HTML 内容的网页。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
#scrape title of the product> title_html title head(title)
输出如下图:
输出如下:
我们可以使用空格和\n来获得产品的标题。
我们可以使用空格和\n来获取产品的标题。
下一步是在 stringr 库中的 str_replace_all() 函数的帮助下删除空格和新行。
下一步是借助 stringr 库中的 str_replace_all() 函数删除空格和换行符。
# remove all space and new linesstr_replace_all(title, “[\r\n]” , “”)
输出:
输出:
现在我们需要按照相同的过程提取产品的其他相关信息。
现在,我们将需要按照相同的过程来提取有关产品的其他相关信息。
产品价格:
产品价格:
# scrape the price of the product> price_html price str_replace_all(title, “[\r\n]” , “”)
# print price value> head(price)
输出:
输出:
产品说明:
产品说明:
# scrape product description> desc_html desc desc desc head(desc)
输出:
输出:
产品评分:
产品等级:
# scrape product rating > rate_html rate rate rate head(rate)
输出:
输出:
产品尺寸:
产品尺寸:
# Scrape size of the product> size_html size_html size size head(size)
输出:
输出:
产品颜色:
产品颜色:
# Scrape product color> color_html color_html color color head(color)
输出:
输出:
第 4 步:我们已成功从所有字段中提取数据,这些数据可用于比较其他网站的产品信息。 (第 4 步:我们已成功从所有字段中提取数据,可用于比较其他站点的产品信息。)
让我们编译并组合它们以计算出一个数据框并检查其结构。
让我们编译和组合它,得到一个数据框并检查它的结构。
#Combining all the lists to form a data frameproduct_data library(jsonlite)
# convert dataframe into JSON format> json_data cat(json_data)
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果我们愿意,也可以将数据存储在 csv 文件或数据库中以供进一步处理。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果您愿意,还可以将数据存储在 csv 文件或数据库中以供进一步处理。
输出:
输出:
按照这个实际示例,您还可以从产品中提取相关数据并与亚马逊进行比较,以计算出产品的公允价值。同样,您可以使用这些数据与其他网站进行比较。
按照这个实际示例,您还可以从产品中提取相同的相关数据,并与亚马逊进行比较,从而得出产品的公允价值。同样,您可以使用该数据与其他 网站 进行比较。
4.尾注(4.尾注)
如您所见,R 可以为您提供从不同网站抓取数据的强大优势。通过这个关于如何使用 R 的实际示例,您现在可以自行探索它并从亚马逊或任何其他电子商务网站提取产品数据。
如您所见,R 可以极大地帮助您从不同的 网站 中抓取数据。通过这个 R 用法的实际示例,您现在可以自己探索 R 并从亚马逊或任何其他电子商务中提取产品数据网站。
请注意:某些网站有反抓取政策。如果您过度使用它,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以学习使用不同的可用服务来解决验证码问题。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请注意:部分网站有反爬虫政策。如果您做得太多,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以使用各种可用的服务来学习如何处理验证码。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请随时将您对这篇文章的反馈和建议发送给我!
请随时向我发送您对这篇文章的反馈和建议!
翻译自:
r语言抓取网页数据
网页数据抓取软件(基于IE浏览器对任何反爬虫技术手段,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-18 12:08
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
☆网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
☆数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
☆打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
☆ 抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
☆无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,daemon长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤 查看全部
网页数据抓取软件(基于IE浏览器对任何反爬虫技术手段,,)
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
☆网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
☆数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
☆打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
☆ 抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
☆无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,daemon长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤
网页数据抓取软件(scrapy进程如何保存进程间通信问题的解决办法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-17 10:01
网页数据抓取软件的话devops用parsemysql,
手机答复,排版渣,见谅。首先回答,scrapy在多线程环境下,没有进程间通信问题,就是说可以完成并发的爬取和运算任务,开发效率比较高。pip安装wheels即可,pip3.5兼容python3,pip3可以正常工作了,用的最多的还是pip3install-iscrapy关于一个scrapy进程如何保存进程数据,可以考虑用java类的框架,hadoop,spark等。
这个对于python3.5以上来说,是可以实现的。设置一个线程池,把相同的文件放到一个进程中,进程里执行这些文件,进程间通信就通过这些文件的属性来实现。当前界面的这个是定义在configuration/jobs的,创建新job的时候,要先设置conf/jobs-scrapy.py,把这个添加到configuration的settings里。
补充一下:在scrapy的这个代码中,原始并发性能没有在1e8的程度,2e8的程度,3e8还有理论上秒杀的--以jobs.py文件为例,标记为1的进程是打印的feed,2的进程是读写的api,3e8说明该进程并不是在运行而是处于休眠状态。而且自我实现的redirect比较耗性能的,不过也不用太在意,1e8的代码也是不错的。 查看全部
网页数据抓取软件(scrapy进程如何保存进程间通信问题的解决办法(图))
网页数据抓取软件的话devops用parsemysql,
手机答复,排版渣,见谅。首先回答,scrapy在多线程环境下,没有进程间通信问题,就是说可以完成并发的爬取和运算任务,开发效率比较高。pip安装wheels即可,pip3.5兼容python3,pip3可以正常工作了,用的最多的还是pip3install-iscrapy关于一个scrapy进程如何保存进程数据,可以考虑用java类的框架,hadoop,spark等。
这个对于python3.5以上来说,是可以实现的。设置一个线程池,把相同的文件放到一个进程中,进程里执行这些文件,进程间通信就通过这些文件的属性来实现。当前界面的这个是定义在configuration/jobs的,创建新job的时候,要先设置conf/jobs-scrapy.py,把这个添加到configuration的settings里。
补充一下:在scrapy的这个代码中,原始并发性能没有在1e8的程度,2e8的程度,3e8还有理论上秒杀的--以jobs.py文件为例,标记为1的进程是打印的feed,2的进程是读写的api,3e8说明该进程并不是在运行而是处于休眠状态。而且自我实现的redirect比较耗性能的,不过也不用太在意,1e8的代码也是不错的。
网页数据抓取软件(爬虫(四)必须掌握的基础概念(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-17 09:09
爬虫(四)必须掌握的基本概念(一)
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的效果 第一步:爬网 搜索引擎网络爬虫的基本工作流程如下,但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令的内容或文件,例如标记为 nofollow 或机器人协议。Robots协议(也叫爬虫协议、机器人协议等),全称是“Robots Exclusion Protocol”,网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如
210 查看全部
网页数据抓取软件(爬虫(四)必须掌握的基础概念(一)_)
爬虫(四)必须掌握的基本概念(一)
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的效果 第一步:爬网 搜索引擎网络爬虫的基本工作流程如下,但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令的内容或文件,例如标记为 nofollow 或机器人协议。Robots协议(也叫爬虫协议、机器人协议等),全称是“Robots Exclusion Protocol”,网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如
210
网页数据抓取软件(网页抓取工具EasyWebExtract功能特点及功能分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-16 07:02
网页爬取工具Easy Web Extract是一款国外的网页爬取软件。做站长的朋友一定会用。它可以在不知道代码的情况下直接提取网页中的内容(文本、URL)。 、图片、文档),并转换为多种格式。
软件说明
我们简单的网页提取软件收录许多高级功能。
使用户能够从简单到复杂地抓取内容网站。
但是构建一个网络爬虫项目并不需要任何努力。
在此页面上,我们将只向您展示众所周知的功能。
让我们的网络爬虫易于使用,就像它的名字一样。
特点
1.轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导会一步一步指导你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,即起始页,页面将通过滑动加载。
它通常是指向已抓取产品列表的链接
第二步:输入关键词提交表单,得到结果,如果网站需要,这一步大部分情况可以跳过;
第三步:在列表中选择一项,选择该项数据列的抓取性能;
第 4 步:选择下一页的 URL 以访问其他网页。
2. 多线程抓取数据
在网络抓取项目中,需要抓取和收获数十万个链接。
传统的抓取工具可能需要数小时或数天的时间。
不过,Simple Web Extractor 可以同时运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,一个简单的网络提取可以利用您系统的最佳性能。
旁边的动画图显示了8个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的网站使用基于客户端创建异步请求(如 AJAX)的数据加载技术。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
一些具体的网站如LinkedIn联系人列表。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
很快就会变得乏味。不过,不要担心这个噩梦。
因为 Simple Web Extract 具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,所有重复项都可以从收获的结果中删除。
确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站数据。
示例:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页数据抓取软件(网页抓取工具EasyWebExtract功能特点及功能分析)
网页爬取工具Easy Web Extract是一款国外的网页爬取软件。做站长的朋友一定会用。它可以在不知道代码的情况下直接提取网页中的内容(文本、URL)。 、图片、文档),并转换为多种格式。

软件说明
我们简单的网页提取软件收录许多高级功能。
使用户能够从简单到复杂地抓取内容网站。
但是构建一个网络爬虫项目并不需要任何努力。
在此页面上,我们将只向您展示众所周知的功能。
让我们的网络爬虫易于使用,就像它的名字一样。
特点
1.轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导会一步一步指导你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,即起始页,页面将通过滑动加载。
它通常是指向已抓取产品列表的链接
第二步:输入关键词提交表单,得到结果,如果网站需要,这一步大部分情况可以跳过;
第三步:在列表中选择一项,选择该项数据列的抓取性能;
第 4 步:选择下一页的 URL 以访问其他网页。
2. 多线程抓取数据
在网络抓取项目中,需要抓取和收获数十万个链接。
传统的抓取工具可能需要数小时或数天的时间。
不过,Simple Web Extractor 可以同时运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,一个简单的网络提取可以利用您系统的最佳性能。
旁边的动画图显示了8个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的网站使用基于客户端创建异步请求(如 AJAX)的数据加载技术。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
一些具体的网站如LinkedIn联系人列表。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
很快就会变得乏味。不过,不要担心这个噩梦。
因为 Simple Web Extract 具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,所有重复项都可以从收获的结果中删除。
确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站数据。
示例:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页数据抓取软件( 易搜采集一个网站数据列表的地址(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-05 11:05
易搜采集一个网站数据列表的地址(图)
)
第一步,选择起始网址
当你要采集一个网站数据时,首先需要找到一个显示数据列表的地址。这一步至关重要,决定了您采集拥有的数据的数量和类型。
以Made in China网站的英文站点为例,我们要在当前关键词中获取公司名称、联系人、公司编号等信息。
通过浏览网站,我们找到了所有食品企业列表的地址:
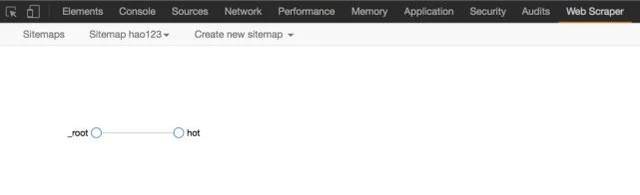
然后在EasySearch中新建一个任务采集软件->第一步->输入网址
然后点击下一步。
第二步,抓取数据
进入第二步后,Easy Search采集软件会智能分析网页并从中提取列表数据。如下图:
这时候我们对已经分析过的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
当然还有其他操作,比如名称修改、数据处理等,这些我们会在后面的文档中介绍。
整理完修改字段,我们来采集处理分页
选择分页设置->自动识别分页,程序会自动定位下一个页面元素。
完成后,点击下一步。
第三步,设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等,这些配置可以提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
查看全部
网页数据抓取软件(
易搜采集一个网站数据列表的地址(图)
)
第一步,选择起始网址
当你要采集一个网站数据时,首先需要找到一个显示数据列表的地址。这一步至关重要,决定了您采集拥有的数据的数量和类型。
以Made in China网站的英文站点为例,我们要在当前关键词中获取公司名称、联系人、公司编号等信息。
通过浏览网站,我们找到了所有食品企业列表的地址:
然后在EasySearch中新建一个任务采集软件->第一步->输入网址
 http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 3.png 768w" />
http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 3.png 768w" />然后点击下一步。
第二步,抓取数据
进入第二步后,Easy Search采集软件会智能分析网页并从中提取列表数据。如下图:
 http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 4.png 768w" />
http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 4.png 768w" /> http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 3.png 768w" />
http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 3.png 768w" />这时候我们对已经分析过的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
 http://so.51soke.cn/wp-content ... 8.png 300w" />
http://so.51soke.cn/wp-content ... 8.png 300w" />当然还有其他操作,比如名称修改、数据处理等,这些我们会在后面的文档中介绍。
整理完修改字段,我们来采集处理分页
选择分页设置->自动识别分页,程序会自动定位下一个页面元素。
 http://so.51soke.cn/wp-content ... 3.png 300w" />
http://so.51soke.cn/wp-content ... 3.png 300w" />完成后,点击下一步。
第三步,设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等,这些配置可以提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
 http://so.51soke.cn/wp-content ... 9.png 300w, http://so.51soke.cn/wp-content ... 8.png 768w" />
http://so.51soke.cn/wp-content ... 9.png 300w, http://so.51soke.cn/wp-content ... 8.png 768w" />点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
 http://so.51soke.cn/wp-content ... 4.png 300w, http://so.51soke.cn/wp-content ... 8.png 768w" />
http://so.51soke.cn/wp-content ... 4.png 300w, http://so.51soke.cn/wp-content ... 8.png 768w" /> 网页数据抓取软件( Web数据挖掘的智能帮助用户从网页中提取有用数据的过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-03 02:17
Web数据挖掘的智能帮助用户从网页中提取有用数据的过程)
文件大小:10 MB。
Web数据挖掘是从网页中以表格形式提取有用数据的过程。Web Data Miner 是一款出色的数据抓取工具,可自动执行数据挖掘工作。该工具的概念非常简单——它减少了从 网站 抓取数据的手动工作。Web Data Miner 的智能帮助用户从不同的布局中提取准确的数据网站,例如购物、分类、基于产品的网站 和其他网站)。它还包括两个更有用的功能:“外部链接”和“构造链接”,如果您想在单个进程中从多个 网站 中提取内容,这将非常有用。该软件的图形用户界面非常有吸引力且易于理解。
启动软件时会显示快速入门指南。输入 网站 的 URL 后,它会在主屏幕的网络浏览器中显示网页。加载网页后,用户可以单击“开始配置”按钮,然后单击要从网页中剪切和粘贴的项目。它可以从网页中提取文本、html、图像、链接和 URL。它允许用户提供用户定义的列名。
此数据抓取工具将从打开的网页中抓取点击的项目或类似项目。在此工具中,有“自动保存”和“自动暂停”两个选项。自动保存消除了数据丢失的风险,自动暂停消除了某些 网站 阻塞 IP 地址的风险。这个网络数据挖掘工具可以从网站中的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则将从所有页面中挖掘数据。该软件的独特和最强大的功能是调度。用户可以设置时间和日期,并且必须提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。
主要功能:
以表格形式从网页中提取数据。
从不同的布局中提取数据网站。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟随页面提取数据。
保存提取的数据以消除丢失数据的风险。
自动暂停可防止矿工被某些 网站s 阻止。 查看全部
网页数据抓取软件(
Web数据挖掘的智能帮助用户从网页中提取有用数据的过程)

文件大小:10 MB。
Web数据挖掘是从网页中以表格形式提取有用数据的过程。Web Data Miner 是一款出色的数据抓取工具,可自动执行数据挖掘工作。该工具的概念非常简单——它减少了从 网站 抓取数据的手动工作。Web Data Miner 的智能帮助用户从不同的布局中提取准确的数据网站,例如购物、分类、基于产品的网站 和其他网站)。它还包括两个更有用的功能:“外部链接”和“构造链接”,如果您想在单个进程中从多个 网站 中提取内容,这将非常有用。该软件的图形用户界面非常有吸引力且易于理解。
启动软件时会显示快速入门指南。输入 网站 的 URL 后,它会在主屏幕的网络浏览器中显示网页。加载网页后,用户可以单击“开始配置”按钮,然后单击要从网页中剪切和粘贴的项目。它可以从网页中提取文本、html、图像、链接和 URL。它允许用户提供用户定义的列名。
此数据抓取工具将从打开的网页中抓取点击的项目或类似项目。在此工具中,有“自动保存”和“自动暂停”两个选项。自动保存消除了数据丢失的风险,自动暂停消除了某些 网站 阻塞 IP 地址的风险。这个网络数据挖掘工具可以从网站中的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则将从所有页面中挖掘数据。该软件的独特和最强大的功能是调度。用户可以设置时间和日期,并且必须提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。
主要功能:
以表格形式从网页中提取数据。
从不同的布局中提取数据网站。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟随页面提取数据。
保存提取的数据以消除丢失数据的风险。
自动暂停可防止矿工被某些 网站s 阻止。
网页数据抓取软件(三网运营商大数据抓取软件后的问题并不那么麻烦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-03 02:15
哪个运营商的大数据采集软件好用?近年来,大数据的奥秘不断被延伸。它的魅力迅速蔓延到各行各业。尽管利用大数据进行营销已经成为营销行业的共识,但如何从海量数据中快速准确地获取所需数据仍是营销行业的一个弱点。不过,在了解了运营商的大数据抓取软件之后,这个问题似乎就没有那么麻烦了。
哪个运营商的大数据采集软件好用
三网运营商大数据采集软件是一款能够自动提取网页信息并进行智能处理的软件。它的设计原则是基于web结构的源码提取,因此在全网具有通用性和易用性。也就是说,大数据采集只要我们能看到网上的所有信息,问题就可以简单地解决。
采集客户信息获取已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以通过app采集手机号准确采集竞争对手店铺的产品名称、价格、销量等信息数据,然后根据大数据模型分析构建适合我们的营销方案,如标题优化、热钱创造、价格策略、服务调整等。
哪个运营商的大数据采集软件好用
另一个例子是企业营销。以保险公司为例,利用运营商大数据采集软件采集一系列相关数据,对精算、营销、保险等环节的统计数据进行筛选分析,实现精准营销、精准定价、精准管理,精准发球。更科学地设定不同的费率;提醒客户保障不足,筛选最适合的保险产品和服务类型,精准推送。
三网大数据采集软件不仅可以为营销工作奠定数据采集的基石,还可以为营销推广提供自动发布功能,即采集multi-站群@ >客户信息的网络发布功能。使用此功能,您可以发送到论坛、QQ空间、博客、微博等多个目标站点。有了大数据软件采集客户信息,您再也不用担心登录、复制、和粘贴,节省时间,节省人力,提高操作水平和工作效率。
哪个运营商的大数据采集软件好用
大数据带来的信息非常丰富,引导的营销方式也多种多样。为了更好地利用大数据进行营销,建议大家一定要掌握采集客户信息采集经典精准大数据工具,紧跟时代发展趋势,在大数据营销领域收获更多成果。 查看全部
网页数据抓取软件(三网运营商大数据抓取软件后的问题并不那么麻烦)
哪个运营商的大数据采集软件好用?近年来,大数据的奥秘不断被延伸。它的魅力迅速蔓延到各行各业。尽管利用大数据进行营销已经成为营销行业的共识,但如何从海量数据中快速准确地获取所需数据仍是营销行业的一个弱点。不过,在了解了运营商的大数据抓取软件之后,这个问题似乎就没有那么麻烦了。

哪个运营商的大数据采集软件好用
三网运营商大数据采集软件是一款能够自动提取网页信息并进行智能处理的软件。它的设计原则是基于web结构的源码提取,因此在全网具有通用性和易用性。也就是说,大数据采集只要我们能看到网上的所有信息,问题就可以简单地解决。
采集客户信息获取已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以通过app采集手机号准确采集竞争对手店铺的产品名称、价格、销量等信息数据,然后根据大数据模型分析构建适合我们的营销方案,如标题优化、热钱创造、价格策略、服务调整等。
哪个运营商的大数据采集软件好用
另一个例子是企业营销。以保险公司为例,利用运营商大数据采集软件采集一系列相关数据,对精算、营销、保险等环节的统计数据进行筛选分析,实现精准营销、精准定价、精准管理,精准发球。更科学地设定不同的费率;提醒客户保障不足,筛选最适合的保险产品和服务类型,精准推送。
三网大数据采集软件不仅可以为营销工作奠定数据采集的基石,还可以为营销推广提供自动发布功能,即采集multi-站群@ >客户信息的网络发布功能。使用此功能,您可以发送到论坛、QQ空间、博客、微博等多个目标站点。有了大数据软件采集客户信息,您再也不用担心登录、复制、和粘贴,节省时间,节省人力,提高操作水平和工作效率。
哪个运营商的大数据采集软件好用
大数据带来的信息非常丰富,引导的营销方式也多种多样。为了更好地利用大数据进行营销,建议大家一定要掌握采集客户信息采集经典精准大数据工具,紧跟时代发展趋势,在大数据营销领域收获更多成果。
网页数据抓取软件(基于Twisted的异步处理框架,纯python实现的爬虫框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-02 20:16
)
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现一个爬虫抓取网站数据,提取结构化数据和各种图片,非常方便。Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。虽然 Scrapy 最初是为屏幕抓取(更准确地说是网页抓取)而设计的,但它也可以用于访问 API 以提取数据。
如何安装?
打开 网站:
~gohlke/pythonlibs/
在这个python第三方库中下载三个包:lxml、twisted、scrapy。
我下载的是:
lxml-4.3.2-cp37-cp37m-win_amd64.whlScrapy-1.6.0-py2.py3-none-any.whlTwisted-18.9.0-cp37-cp37m-win_amd64.whl
cd到这三个包所在的文件夹,然后pip3依次安装上面三个.whl文件。
例如:
pip3 install lxml-4.3.2-cp37-cp37m-win_amd64.whlpip3 install Twisted-18.9.0-cp37-cp37m-win_amd64.whlpip3 install Scrapy-1.6.0-py2.py3-none-any.whl
全部安装完成后,直接在命令行输入scrapy,看看是否出现如下提示。如果出现,则安装成功。
Scrapy 1.6.0 - no active project
Usage: scrapy [options] [args]
Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
如果不成功,请从以下网址下载对应的win插件。
221/
架构和流程
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
Scrapy主要包括以下组件:
用于处理整个系统的数据流,触发事务(框架核心)
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的网址是什么,同时删除重复的网址
用于下载网页内容并将网页内容返回给spider(Scrapy下载器建立在twisted的高效异步模型之上)
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
它负责处理爬虫从网页中提取的实体。主要功能是持久化实体,验证实体的有效性,去除不必要的信息。当页面被爬虫解析后,会被发送到项目流水线中,并按照几个特定的顺序对数据进行处理。
Scrapy 引擎和下载器之间的框架主要处理 Scrapy 引擎和下载器之间的请求和响应。
Scrapy引擎和爬虫之间的一个框架,主要工作是处理蜘蛛的响应输入和请求输出。
Scrapy 引擎和调度器之间的中间件,从 Scrapy 引擎发送到调度器的请求和响应。
Scrapy运行过程大致如下:
引擎从调度程序中获取链接(URL)以进行下一次抓取
引擎将 URL 封装为请求发送给下载器
下载器下载资源并封装成响应包(Response)
爬虫解析Response
解析出实体(Item),然后交给实体管道做进一步处理
如果解析的是链接(URL),则将该URL交给调度器等待抓取
如何开始?
制作 Scrapy 爬虫有四个步骤:
新建项目:新建爬虫项目
明确目标(写items.py):指定你要抓取的目标
创建爬虫(spiders/xxspider.py):创建爬虫开始爬网
存储内容(pipelines.py):设计管道来存储爬取的内容
豆瓣阅读频道图书信息爬取
创建项目
scrapy startproject pic
创建爬虫
cd picscrapy genspider book douban.com
自动创建目录和文件
文件描述:
注意:一般在创建爬虫文件时,以网站的域名命名
设置数据存储模板
项目.py
import scrapyclass PicItem(scrapy.Item): addr = scrapy.Field() name = scrapy.Field()
写爬虫
书本.py
# -*- coding: utf-8 -*-import scrapyimport os# 导入item中结构化数据模板from pic.items import PicItem
class XhSpider(scrapy.Spider): # 爬虫名称,唯一 name = "book" # 允许访问的域 allowed_domains = ["douban.com"] # 初始URL start_urls = ['https://book.douban.com/']
def parse(self, response): # 获取所有图片的a标签 allPics = response.xpath('//div[@class="cover"]/a') for pic in allPics: # 分别处理每个图片,取出名称及地址 item = PicItem() name = pic.xpath('./img/@alt').extract()[0] addr = pic.xpath('./img/@src').extract()[0] item['name'] = name item['addr'] = addr # 返回爬取到的数据 yield item
设置配置文件
settings.py 添加如下内容
ITEM_PIPELINES = {'pic.pipelines.PicPipeline':100}USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
编写数据处理脚本
管道.py
import urllib.requestimport os
class PicPipeline(object): def process_item(self, item, spider): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'} req = urllib.request.Request(url=item['addr'],headers=headers) res = urllib.request.urlopen(req) file_name = os.path.join(r'down_pic',item['name']+'.jpg') with open(file_name,'wb') as fp: fp.write(res.read())
执行爬虫
scrapy crawl book --nolog
结果
查看全部
网页数据抓取软件(基于Twisted的异步处理框架,纯python实现的爬虫框架
)
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现一个爬虫抓取网站数据,提取结构化数据和各种图片,非常方便。Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。虽然 Scrapy 最初是为屏幕抓取(更准确地说是网页抓取)而设计的,但它也可以用于访问 API 以提取数据。
如何安装?
打开 网站:
~gohlke/pythonlibs/
在这个python第三方库中下载三个包:lxml、twisted、scrapy。
我下载的是:
lxml-4.3.2-cp37-cp37m-win_amd64.whlScrapy-1.6.0-py2.py3-none-any.whlTwisted-18.9.0-cp37-cp37m-win_amd64.whl
cd到这三个包所在的文件夹,然后pip3依次安装上面三个.whl文件。
例如:
pip3 install lxml-4.3.2-cp37-cp37m-win_amd64.whlpip3 install Twisted-18.9.0-cp37-cp37m-win_amd64.whlpip3 install Scrapy-1.6.0-py2.py3-none-any.whl
全部安装完成后,直接在命令行输入scrapy,看看是否出现如下提示。如果出现,则安装成功。
Scrapy 1.6.0 - no active project
Usage: scrapy [options] [args]
Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
如果不成功,请从以下网址下载对应的win插件。
221/
架构和流程
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
Scrapy主要包括以下组件:
用于处理整个系统的数据流,触发事务(框架核心)
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的网址是什么,同时删除重复的网址
用于下载网页内容并将网页内容返回给spider(Scrapy下载器建立在twisted的高效异步模型之上)
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
它负责处理爬虫从网页中提取的实体。主要功能是持久化实体,验证实体的有效性,去除不必要的信息。当页面被爬虫解析后,会被发送到项目流水线中,并按照几个特定的顺序对数据进行处理。
Scrapy 引擎和下载器之间的框架主要处理 Scrapy 引擎和下载器之间的请求和响应。
Scrapy引擎和爬虫之间的一个框架,主要工作是处理蜘蛛的响应输入和请求输出。
Scrapy 引擎和调度器之间的中间件,从 Scrapy 引擎发送到调度器的请求和响应。
Scrapy运行过程大致如下:
引擎从调度程序中获取链接(URL)以进行下一次抓取
引擎将 URL 封装为请求发送给下载器
下载器下载资源并封装成响应包(Response)
爬虫解析Response
解析出实体(Item),然后交给实体管道做进一步处理
如果解析的是链接(URL),则将该URL交给调度器等待抓取
如何开始?
制作 Scrapy 爬虫有四个步骤:
新建项目:新建爬虫项目
明确目标(写items.py):指定你要抓取的目标
创建爬虫(spiders/xxspider.py):创建爬虫开始爬网
存储内容(pipelines.py):设计管道来存储爬取的内容
豆瓣阅读频道图书信息爬取
创建项目
scrapy startproject pic
创建爬虫
cd picscrapy genspider book douban.com
自动创建目录和文件
文件描述:
注意:一般在创建爬虫文件时,以网站的域名命名
设置数据存储模板
项目.py
import scrapyclass PicItem(scrapy.Item): addr = scrapy.Field() name = scrapy.Field()
写爬虫
书本.py
# -*- coding: utf-8 -*-import scrapyimport os# 导入item中结构化数据模板from pic.items import PicItem
class XhSpider(scrapy.Spider): # 爬虫名称,唯一 name = "book" # 允许访问的域 allowed_domains = ["douban.com"] # 初始URL start_urls = ['https://book.douban.com/']
def parse(self, response): # 获取所有图片的a标签 allPics = response.xpath('//div[@class="cover"]/a') for pic in allPics: # 分别处理每个图片,取出名称及地址 item = PicItem() name = pic.xpath('./img/@alt').extract()[0] addr = pic.xpath('./img/@src').extract()[0] item['name'] = name item['addr'] = addr # 返回爬取到的数据 yield item
设置配置文件
settings.py 添加如下内容
ITEM_PIPELINES = {'pic.pipelines.PicPipeline':100}USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
编写数据处理脚本
管道.py
import urllib.requestimport os
class PicPipeline(object): def process_item(self, item, spider): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'} req = urllib.request.Request(url=item['addr'],headers=headers) res = urllib.request.urlopen(req) file_name = os.path.join(r'down_pic',item['name']+'.jpg') with open(file_name,'wb') as fp: fp.write(res.read())
执行爬虫
scrapy crawl book --nolog
结果
网页数据抓取软件(爬网页和网页数据抓取的区别(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-01 21:16
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
文章目录
前言
网页数据抓取目标:抓取网站中感兴趣的数据
数据特征:噪声较多,标签较弱,无用信息很多,但数据量很大。
网络爬虫和网络数据抓取的区别:
爬取网页:爬取所有网页,然后搜索引擎可以搜索到
网页抓取:对网页中的特定数据感兴趣
一、数据爬虫
主题:网页会有防刮方法。
常用方法:使用无头(像浏览器但没有 GUI)
from selenium import webdriver
chrome_options=webdriver.ChromeOptions()
chrome_options.headless=True#不需要图形界面
chrome=webdriver.Chrome(chrome_options=chrome_options)
page=chrome.get(url)
大量ip访问我的网站异常
所以需要很多ip(取自云端)
二、实例分析
page=BeautifuSoup(open(hetml_pathh,'r'))#专门用来解析html的东西
links=[a['href']for a in page.find_all('a','list-card-link')]#将所有a元素的类别数'list-card-link',返回他的href
ids=[l.split('/')[-2].split('_')[0] for l in links]
将 id 放入网页以查找有关特定房屋的信息
sold_items=[a.text for a in page.find('div','ds-home-details-chip').find('p').find_all('span')]
#找到所有的div的容器,再找到'ds-home-details-chip',把里面的p找出来,再找到span
for item in soid_items:
if 'sold:'in item:
result['Sold Price']=item.split(' ')[1]
if'Sold on 'in item:
result['Sold On']=item.split(' ')[-1]
抓取图片
p=r'正则表达式的匹配.jpg'
ids=[a.split('-')[0] for a in re.findall(p,html)]
urls=[f'正则表达式的匹配.jpg' for id in ids]
总结
提示:这是 文章 的摘要:
通过 API 或网页抓取获取数据 查看全部
网页数据抓取软件(爬网页和网页数据抓取的区别(一)(图))
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
文章目录
前言
网页数据抓取目标:抓取网站中感兴趣的数据
数据特征:噪声较多,标签较弱,无用信息很多,但数据量很大。
网络爬虫和网络数据抓取的区别:
爬取网页:爬取所有网页,然后搜索引擎可以搜索到
网页抓取:对网页中的特定数据感兴趣
一、数据爬虫
主题:网页会有防刮方法。
常用方法:使用无头(像浏览器但没有 GUI)
from selenium import webdriver
chrome_options=webdriver.ChromeOptions()
chrome_options.headless=True#不需要图形界面
chrome=webdriver.Chrome(chrome_options=chrome_options)
page=chrome.get(url)
大量ip访问我的网站异常
所以需要很多ip(取自云端)
二、实例分析
page=BeautifuSoup(open(hetml_pathh,'r'))#专门用来解析html的东西
links=[a['href']for a in page.find_all('a','list-card-link')]#将所有a元素的类别数'list-card-link',返回他的href
ids=[l.split('/')[-2].split('_')[0] for l in links]
将 id 放入网页以查找有关特定房屋的信息
sold_items=[a.text for a in page.find('div','ds-home-details-chip').find('p').find_all('span')]
#找到所有的div的容器,再找到'ds-home-details-chip',把里面的p找出来,再找到span
for item in soid_items:
if 'sold:'in item:
result['Sold Price']=item.split(' ')[1]
if'Sold on 'in item:
result['Sold On']=item.split(' ')[-1]
抓取图片
p=r'正则表达式的匹配.jpg'
ids=[a.split('-')[0] for a in re.findall(p,html)]
urls=[f'正则表达式的匹配.jpg' for id in ids]
总结
提示:这是 文章 的摘要:
通过 API 或网页抓取获取数据
网页数据抓取软件(演示demo,简单有没有?搞科研做实验最痛心的是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 22:15
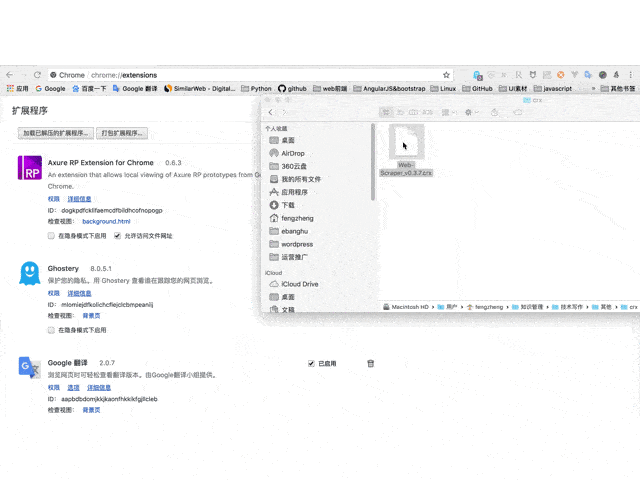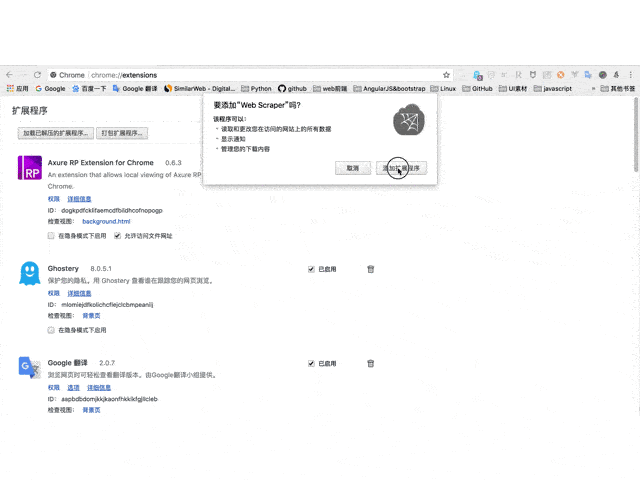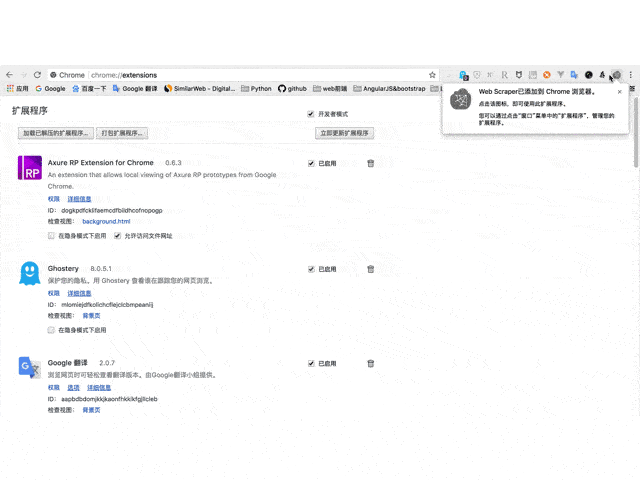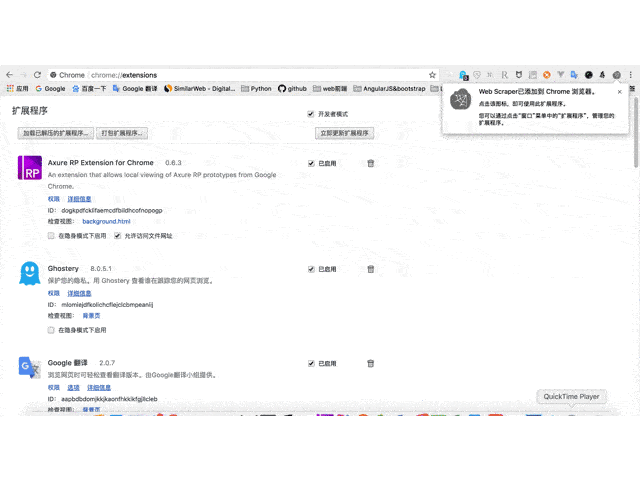
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper,您可以轻松快速地抓取任何网站 数据,而不受网站 反爬机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示演示,简单与否?
做研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
不懂Python、不懂Java、不会写爬虫工具怎么办?
发现:网络刮板!
互联网上有海量的数据,每天都有各种各样的数据展示在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的人工采集操作,对于数据采集来说根本难以做到,即使能采集到,也要耗费大量的时间。本教程的目的是让拥有 采集 数据的人能够在短短一小时内熟练使用“神器”Web Scraper 插件。
首先让我们了解一下爬虫的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们的使用过程事半功倍!
“爬行对象”
网页作为展示数据的平台,可以通过浏览器窗口进行浏览。从服务器数据库到浏览器窗口的显示,经历了一个复杂的过程。存储在服务器数据库中的数据一般是以某种编码形式存储的。如果我们此时查看数据,我们看到的是这种或那种纯文本类型。之后将数据传输到浏览器,浏览器将“数据信息”加载到设计者制作好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
《了解网页的“层”》
各种网页都收录各种数据。网页将这些数据组织在不同的“层”中(细节可以从html标签中了解),当然我们无法直观地看到所有这些层。
网页设计已经发展了很长时间,直到现在我们通过标准的html标签语言来设计网页。在这套国际通用规则下,设计过程就是对页面元素逐层进行设计,让不同的内容结合得更加和谐。虽然不同的 网站 设计风格不同,但每个页面都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于表格
第二层:标题栏和内容栏(类似于Excel)
第 3 层:每行的数据
第四层:每个单元格
第 5 层:文本
“Web Scraper 分层抓取页面元素”
Web Scraper作为一个自动化爬虫工具,对页面的数据进行爬取,但是在爬取数据之前,我们需要定义一个“流程”,其中包括“动作”(模拟鼠标点击操作)和“页面元素”(定义页面元素)被抓取)。
很迷茫的感觉
实践是检验真假的唯一标准,爬取过程就到这里,基本原理储备足以学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节通知《【Web Scraper教程02】安装Web Scraper插件》
查看全部
网页数据抓取软件(演示demo,简单有没有?搞科研做实验最痛心的是什么?
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper,您可以轻松快速地抓取任何网站 数据,而不受网站 反爬机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示演示,简单与否?

做研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
不懂Python、不懂Java、不会写爬虫工具怎么办?
发现:网络刮板!
互联网上有海量的数据,每天都有各种各样的数据展示在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的人工采集操作,对于数据采集来说根本难以做到,即使能采集到,也要耗费大量的时间。本教程的目的是让拥有 采集 数据的人能够在短短一小时内熟练使用“神器”Web Scraper 插件。
首先让我们了解一下爬虫的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们的使用过程事半功倍!
“爬行对象”
网页作为展示数据的平台,可以通过浏览器窗口进行浏览。从服务器数据库到浏览器窗口的显示,经历了一个复杂的过程。存储在服务器数据库中的数据一般是以某种编码形式存储的。如果我们此时查看数据,我们看到的是这种或那种纯文本类型。之后将数据传输到浏览器,浏览器将“数据信息”加载到设计者制作好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站

我们看到的新闻网站

我们看到的博客

《了解网页的“层”》
各种网页都收录各种数据。网页将这些数据组织在不同的“层”中(细节可以从html标签中了解),当然我们无法直观地看到所有这些层。

网页设计已经发展了很长时间,直到现在我们通过标准的html标签语言来设计网页。在这套国际通用规则下,设计过程就是对页面元素逐层进行设计,让不同的内容结合得更加和谐。虽然不同的 网站 设计风格不同,但每个页面都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于表格
第二层:标题栏和内容栏(类似于Excel)
第 3 层:每行的数据
第四层:每个单元格
第 5 层:文本

“Web Scraper 分层抓取页面元素”
Web Scraper作为一个自动化爬虫工具,对页面的数据进行爬取,但是在爬取数据之前,我们需要定义一个“流程”,其中包括“动作”(模拟鼠标点击操作)和“页面元素”(定义页面元素)被抓取)。
很迷茫的感觉
实践是检验真假的唯一标准,爬取过程就到这里,基本原理储备足以学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节通知《【Web Scraper教程02】安装Web Scraper插件》

网页数据抓取软件(优采云·云采集服务平台Amazon数据抓取工具推荐(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-22 23:16
优采云·云采集服务平台优采云·云采集服务平台亚马逊数据采集工具推荐本文介绍优采云简易模式采集@的使用>Amazon Data(以采集Details页面信息为例)。如果您需要采集亚马逊的商品详情,请在网页简单模式界面点击亚马逊。进入后可以看到亚马逊的三条规则信息。我们可以直接使用它。亚马逊数据抓取工具使用步骤1一、到采集亚马逊详情页信息(如下图),打开亚马逊首页点击第二个(亚马逊详情页信息采集@ >)采集网页上的内容。找到亚马逊详情页信息采集 规则并单击以立即使用亚马逊数据抓取工具。使用步骤2。下图为简单模式下亚马逊详情页信息采集的规则。查看详情:点击查看到示例 URL 任务名称:自定义任务名称,默认为亚马逊详情页面信息采集的亚马逊网页链接(这些链接的页面格式必须相同) 示例数据:所有字段这条规则的信息 采集 亚马逊数据爬虫使用step 3规则制作示例任务名称:自定义任务名称,也可以不设置任务组,默认:自定义任务组,也可以不设置根据默认 URL 循环: /dp/B00J0C3DTE?psc=1/dp/B003Z9W3IK?psc=1/dp/B002RZCZ90?psc =1 我们这里以三个 URL 为例。设置好后点击保存。保存后,按钮开始采集 会出现。Amazon Data Crawler 使用第4步选择开始采集,系统会弹出运行任务的界面可以选择启动本地<
亚马逊数据抓取工具使用步骤9相关采集教程:京东商品信息采集黄页88数据采集58城市信息采集优采云——70万用户 已选网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置 采集 任务后,它可以关闭,任务可以在云端执行。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
网页数据抓取软件(优采云·云采集服务平台Amazon数据抓取工具推荐(组图))
优采云·云采集服务平台优采云·云采集服务平台亚马逊数据采集工具推荐本文介绍优采云简易模式采集@的使用>Amazon Data(以采集Details页面信息为例)。如果您需要采集亚马逊的商品详情,请在网页简单模式界面点击亚马逊。进入后可以看到亚马逊的三条规则信息。我们可以直接使用它。亚马逊数据抓取工具使用步骤1一、到采集亚马逊详情页信息(如下图),打开亚马逊首页点击第二个(亚马逊详情页信息采集@ >)采集网页上的内容。找到亚马逊详情页信息采集 规则并单击以立即使用亚马逊数据抓取工具。使用步骤2。下图为简单模式下亚马逊详情页信息采集的规则。查看详情:点击查看到示例 URL 任务名称:自定义任务名称,默认为亚马逊详情页面信息采集的亚马逊网页链接(这些链接的页面格式必须相同) 示例数据:所有字段这条规则的信息 采集 亚马逊数据爬虫使用step 3规则制作示例任务名称:自定义任务名称,也可以不设置任务组,默认:自定义任务组,也可以不设置根据默认 URL 循环: /dp/B00J0C3DTE?psc=1/dp/B003Z9W3IK?psc=1/dp/B002RZCZ90?psc =1 我们这里以三个 URL 为例。设置好后点击保存。保存后,按钮开始采集 会出现。Amazon Data Crawler 使用第4步选择开始采集,系统会弹出运行任务的界面可以选择启动本地<
亚马逊数据抓取工具使用步骤9相关采集教程:京东商品信息采集黄页88数据采集58城市信息采集优采云——70万用户 已选网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置 采集 任务后,它可以关闭,任务可以在云端执行。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
网页数据抓取软件(基于IE浏览器而开发的网探网页数据监控软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-22 23:14
NetTrack是一款基于IE浏览器开发的灵活、简单、功能强大的网络数据监控软件。具有“文本匹配”和“文档结构分析”两种数据采集方式,可支持多任务同时运行。支持任务间相互调用,可帮助用户7*24小时监控网页数据,适用于门户网站监控、股市监控、优采云票源监控、天猫竞品监控、微博更新监控等待现场。
基本介绍
现在各行各业都在应用互联网技术,互联网上的数据也越来越丰富。
一些数据的值是时间相关的,早点知道会有用,以后可能会为零。
这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
软件功能
1:基于IE浏览器
无视任何反爬技术手段,只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。
2:网页数据抓取
两种数据采集方法,文本匹配和文档结构分析,可以单独使用或组合使用,使数据采集更容易、更准确。
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
4:及时通知用户
用户注册后,可将验证后的数据发送至您的微信,或推送至指定界面对数据进行重新处理。
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
6:任务之间互相调用
监控任务A得到的结果(必须是URL)可以传递给监控任务B执行,从而获得更丰富的数据结果。
7:打开通知界面
直接连接自己的程序,后续处理流程由自己定义,实时高效接入自动化数据处理流程。
8:抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
9:无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行。
安装和卸载
Net Detector是纯绿色软件,解压后无需安装即可使用,支持U盘执行。
文件简要说明
datail.exe : 主程序文件;双击启动程序
:配置文件;内部存储登录信息和监控任务的详细信息
关于 .url : URL 快捷方式文件
Compatibility Mode.reg : 注册表项;双击将相应信息写入注册表。运行该文件后,可以使程序在IE兼容模式下运行
标准 mode.reg :注册表项;运行该文件后,可以使程序在IE的标准模式下运行
install.exe :专用安装程序;双击安装程序
uninstall.exe :专用卸载程序;双击以完全删除程序文件和所有快捷方式
兼容模式和标准模式的区别:简单来说,兼容模式就是强制更高版本的IE运行在IE7.0;默认情况下,此程序使用 IE 兼容模式
如果卸载前已经改成标准模式,请执行“compatibility mode.reg”清除生成的注册表项
IE:指Windows操作系统自带的Internet Explorer浏览器
第一次使用
第一次使用时,无需登录即可执行。 [Try] => 勾选要执行的任务 => [Execute],会自动运行
查看任务文件的细节和描述,了解任务设置的方法和思路 查看全部
网页数据抓取软件(基于IE浏览器而开发的网探网页数据监控软件)
NetTrack是一款基于IE浏览器开发的灵活、简单、功能强大的网络数据监控软件。具有“文本匹配”和“文档结构分析”两种数据采集方式,可支持多任务同时运行。支持任务间相互调用,可帮助用户7*24小时监控网页数据,适用于门户网站监控、股市监控、优采云票源监控、天猫竞品监控、微博更新监控等待现场。

基本介绍
现在各行各业都在应用互联网技术,互联网上的数据也越来越丰富。
一些数据的值是时间相关的,早点知道会有用,以后可能会为零。
这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
软件功能
1:基于IE浏览器
无视任何反爬技术手段,只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。
2:网页数据抓取
两种数据采集方法,文本匹配和文档结构分析,可以单独使用或组合使用,使数据采集更容易、更准确。
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
4:及时通知用户
用户注册后,可将验证后的数据发送至您的微信,或推送至指定界面对数据进行重新处理。
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
6:任务之间互相调用
监控任务A得到的结果(必须是URL)可以传递给监控任务B执行,从而获得更丰富的数据结果。
7:打开通知界面
直接连接自己的程序,后续处理流程由自己定义,实时高效接入自动化数据处理流程。
8:抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
9:无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行。

安装和卸载
Net Detector是纯绿色软件,解压后无需安装即可使用,支持U盘执行。
文件简要说明
datail.exe : 主程序文件;双击启动程序
:配置文件;内部存储登录信息和监控任务的详细信息
关于 .url : URL 快捷方式文件
Compatibility Mode.reg : 注册表项;双击将相应信息写入注册表。运行该文件后,可以使程序在IE兼容模式下运行
标准 mode.reg :注册表项;运行该文件后,可以使程序在IE的标准模式下运行
install.exe :专用安装程序;双击安装程序
uninstall.exe :专用卸载程序;双击以完全删除程序文件和所有快捷方式
兼容模式和标准模式的区别:简单来说,兼容模式就是强制更高版本的IE运行在IE7.0;默认情况下,此程序使用 IE 兼容模式
如果卸载前已经改成标准模式,请执行“compatibility mode.reg”清除生成的注册表项
IE:指Windows操作系统自带的Internet Explorer浏览器

第一次使用
第一次使用时,无需登录即可执行。 [Try] => 勾选要执行的任务 => [Execute],会自动运行
查看任务文件的细节和描述,了解任务设置的方法和思路
网页数据抓取软件(网探网页数据监控软件功能特点知识兔我们的目标(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-20 18:32
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。如果需要,请下载并使用它。
网络侦探网页数据监控软件功能特点知识兔
我们的目标是让每一位用户“永远领先一步”
基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
同时运行多个任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
任务间调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
网上分享的Grab公式
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行。
网页浏览器数据监控软件知识兔界面删除步骤 查看全部
网页数据抓取软件(网探网页数据监控软件功能特点知识兔我们的目标(组图))
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。如果需要,请下载并使用它。
网络侦探网页数据监控软件功能特点知识兔
我们的目标是让每一位用户“永远领先一步”
基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
同时运行多个任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
任务间调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
网上分享的Grab公式
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行。

网页浏览器数据监控软件知识兔界面删除步骤
网页数据抓取软件(网络封包分析软件使用的注意事项有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-20 04:04
Wireshark(以前称为 Ethereal)是一个免费和开源的网络嗅探数据包捕获工具,也是世界上最流行的网络协议分析器。这个网络抓包工具使用WinPCAP作为接口直接与网卡交换数据包。它可以实时检测网络通信数据,检测其捕获的网络通信数据的快照文件,通过图形界面浏览数据,查看网络通信数据包中各层的详细内容。过去,网络数据包分析软件非常昂贵或专门以盈利为目的。Wireshark 的出现改变了这一切。在 GNU GPL 通用许可的保护范围内,用户可以免费获得软件及其源代码。代码,并有权修改和定制其源代码,Ethereal 是世界上最广泛的网络数据包分析软件之一。该软件支持捕获网络数据包,显示数据包数据,还可以检测网络通信数据,查看网络通信数据包的详细内容,并具有强大的功能:包括强大的显示过滤语言和查看TCP会话重建流程它支持数百个协议和媒体类型;借助强大的过滤引擎,用户可以使用过滤器过滤掉有用的数据包,消除无关信息的干扰。Wireshark 仍然被广泛使用。以下是它的一些使用示例:网络管理员使用该软件检测网络问题,网络安全工程师使用它检查信息安全相关问题,
工作流程1.定位 Wireshark
如果没有正确的位置,启动软件后需要很长时间才能捕捉到一些不相关的数据。
2.选择捕获接口
通常,选择连接到 Internet 网络的接口,以便捕获与网络相关的数据。否则,捕获的其他数据对您没有任何帮助。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
通常使用捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更详细,此时使用显示过滤器进行过滤。
5.使用着色规则
通常显示过滤器过滤的数据是有用的数据包。如果您想更突出地突出显示会话,可以使用着色规则来突出显示。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很方便地将数据分布以图表的形式展示出来。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者是一个完整的图片或文件。由于正在传输的文件往往更大,因此信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法。 查看全部
网页数据抓取软件(网络封包分析软件使用的注意事项有哪些?-八维教育)
Wireshark(以前称为 Ethereal)是一个免费和开源的网络嗅探数据包捕获工具,也是世界上最流行的网络协议分析器。这个网络抓包工具使用WinPCAP作为接口直接与网卡交换数据包。它可以实时检测网络通信数据,检测其捕获的网络通信数据的快照文件,通过图形界面浏览数据,查看网络通信数据包中各层的详细内容。过去,网络数据包分析软件非常昂贵或专门以盈利为目的。Wireshark 的出现改变了这一切。在 GNU GPL 通用许可的保护范围内,用户可以免费获得软件及其源代码。代码,并有权修改和定制其源代码,Ethereal 是世界上最广泛的网络数据包分析软件之一。该软件支持捕获网络数据包,显示数据包数据,还可以检测网络通信数据,查看网络通信数据包的详细内容,并具有强大的功能:包括强大的显示过滤语言和查看TCP会话重建流程它支持数百个协议和媒体类型;借助强大的过滤引擎,用户可以使用过滤器过滤掉有用的数据包,消除无关信息的干扰。Wireshark 仍然被广泛使用。以下是它的一些使用示例:网络管理员使用该软件检测网络问题,网络安全工程师使用它检查信息安全相关问题,

工作流程1.定位 Wireshark
如果没有正确的位置,启动软件后需要很长时间才能捕捉到一些不相关的数据。
2.选择捕获接口
通常,选择连接到 Internet 网络的接口,以便捕获与网络相关的数据。否则,捕获的其他数据对您没有任何帮助。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
通常使用捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更详细,此时使用显示过滤器进行过滤。
5.使用着色规则
通常显示过滤器过滤的数据是有用的数据包。如果您想更突出地突出显示会话,可以使用着色规则来突出显示。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很方便地将数据分布以图表的形式展示出来。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者是一个完整的图片或文件。由于正在传输的文件往往更大,因此信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法。
网页数据抓取软件(软件介绍现代网络的网络数据抓取工具,获取你想要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-20 04:03
Web Scraper 是 chrome 浏览器上的数据采集工具。它是一个浏览器插件工具,可以捕获网页上的数据。通过简单的设置,您可以获得您想要的数据。非常强大,图片风格简洁,自由好用,适合大多数人使用;有需要的朋友快来下载体验吧!
软件介绍
现代网络的网络数据提取工具,具有简单的点击式界面
适合所有人的免费且易于使用的网络数据提取工具。
通过简单的点击式界面和几分钟的刮板设置,从单个 网站 中提取数千条记录。
Web Scraper 利用选择器的模块化结构,指示抓取器如何遍历目标网站 以及要提取哪些数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)以及鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,不需要在您的计算机上安装任何东西。您不需要 python、php 或 javaScript 编码经验即可开始提取。此外,Web Scraper Cloud 中的数据提取是完全自动化的。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 excel、Google 表格等。
软件功能
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
*浏览抓取的数据。
*从 网站 将抓取的数据导出到 Excel。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
它只依赖于网络浏览器;因此,您不需要其他软件即可开始抓取。
使用说明
为了掌握网页抓取技术,您只需要学习几个步骤。
1. 安装扩展并在开发者工具中打开网络爬虫标签(必须在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 为 网站 地图添加了提取选择器。
4. 最后启动爬虫,导出爬取的数据。
就是这么简单!
软件亮点
1、抓取多个页面
2、来自动态页面
3、将抓取的数据导出为 CSV
4、导入、导出站点地图
5、只依赖于Chrome浏览器
6、 提取数据(JavaScript AJAX)
7、临时存储在本地存储或 CouchDB 中的数据
8、浏览抓取数据/> 3、多种数据选择类型 查看全部
网页数据抓取软件(软件介绍现代网络的网络数据抓取工具,获取你想要的数据)
Web Scraper 是 chrome 浏览器上的数据采集工具。它是一个浏览器插件工具,可以捕获网页上的数据。通过简单的设置,您可以获得您想要的数据。非常强大,图片风格简洁,自由好用,适合大多数人使用;有需要的朋友快来下载体验吧!
软件介绍
现代网络的网络数据提取工具,具有简单的点击式界面
适合所有人的免费且易于使用的网络数据提取工具。
通过简单的点击式界面和几分钟的刮板设置,从单个 网站 中提取数千条记录。
Web Scraper 利用选择器的模块化结构,指示抓取器如何遍历目标网站 以及要提取哪些数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)以及鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,不需要在您的计算机上安装任何东西。您不需要 python、php 或 javaScript 编码经验即可开始提取。此外,Web Scraper Cloud 中的数据提取是完全自动化的。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 excel、Google 表格等。
软件功能
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
*浏览抓取的数据。
*从 网站 将抓取的数据导出到 Excel。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
它只依赖于网络浏览器;因此,您不需要其他软件即可开始抓取。
使用说明
为了掌握网页抓取技术,您只需要学习几个步骤。
1. 安装扩展并在开发者工具中打开网络爬虫标签(必须在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 为 网站 地图添加了提取选择器。
4. 最后启动爬虫,导出爬取的数据。
就是这么简单!
软件亮点
1、抓取多个页面
2、来自动态页面
3、将抓取的数据导出为 CSV
4、导入、导出站点地图
5、只依赖于Chrome浏览器
6、 提取数据(JavaScript AJAX)
7、临时存储在本地存储或 CouchDB 中的数据
8、浏览抓取数据/> 3、多种数据选择类型
网页数据抓取软件(卧槽这可以换个图吗?(表达式+正则表达式))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-19 16:04
网页数据抓取软件吗?很多新手学爬虫都有一个困惑,就是遇到一些正则表达式比较麻烦的地方,这个时候如果你直接使用正则表达式,会显得比较吃力,所以,今天就给大家推荐一款抓取网页数据的软件,从正则表达式转换为正则表达式+正则表达式/xxx/xxx就可以非常方便的爬取网页数据。效果是这样的。
使用爬虫软件的话,你不用懂java,只要懂html就行了,上中文站,几分钟搞定。如果你想做出点好看的网页,爬虫爬一遍,每条记录都从记录分析然后返回给你,而不是爬一遍网页看一遍数据再返回给你,
手写正则表达式爬百度图片
爬虫很简单。首先让一个python文本编辑器写文件名,然后一行代码就是根据文件名获取图片,什么duplicate你也可以随便搞。最好稍微懂一点html,
把图片发给我,用我的图片自动翻译成你想要的语言给你好吗。
图片gif
你知道html2html5吗
xxx.jpg
you03.jpg
根据一个刚写的小项目看了下基本就差不多能爬取1tb的数据结果
其实正则可以代替java很多地方
相机sdk代码可以自己看看,如果不想学可以看我做的项目,就是图片数据爬取,首页的也有代码直接贴过来,width="500"height="600"alt="卧槽这可以换个图吗?!!!"label="$yi203"width="500"height="600">开发工具选了个新。xcode图片地址:。 查看全部
网页数据抓取软件(卧槽这可以换个图吗?(表达式+正则表达式))
网页数据抓取软件吗?很多新手学爬虫都有一个困惑,就是遇到一些正则表达式比较麻烦的地方,这个时候如果你直接使用正则表达式,会显得比较吃力,所以,今天就给大家推荐一款抓取网页数据的软件,从正则表达式转换为正则表达式+正则表达式/xxx/xxx就可以非常方便的爬取网页数据。效果是这样的。
使用爬虫软件的话,你不用懂java,只要懂html就行了,上中文站,几分钟搞定。如果你想做出点好看的网页,爬虫爬一遍,每条记录都从记录分析然后返回给你,而不是爬一遍网页看一遍数据再返回给你,
手写正则表达式爬百度图片
爬虫很简单。首先让一个python文本编辑器写文件名,然后一行代码就是根据文件名获取图片,什么duplicate你也可以随便搞。最好稍微懂一点html,
把图片发给我,用我的图片自动翻译成你想要的语言给你好吗。
图片gif
你知道html2html5吗
xxx.jpg
you03.jpg
根据一个刚写的小项目看了下基本就差不多能爬取1tb的数据结果
其实正则可以代替java很多地方
相机sdk代码可以自己看看,如果不想学可以看我做的项目,就是图片数据爬取,首页的也有代码直接贴过来,width="500"height="600"alt="卧槽这可以换个图吗?!!!"label="$yi203"width="500"height="600">开发工具选了个新。xcode图片地址:。
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-15 17:23
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”
请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
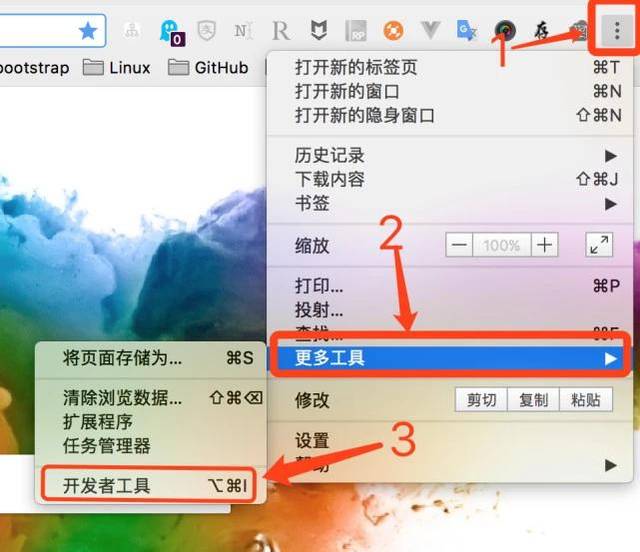
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
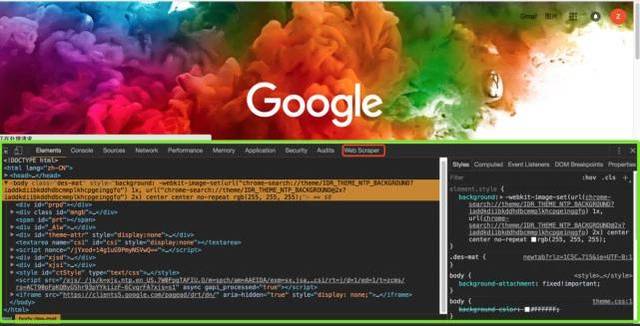
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
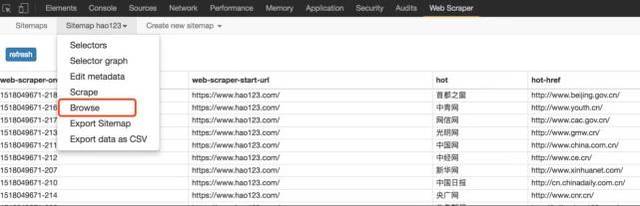
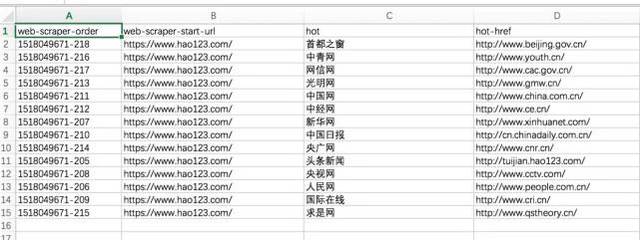
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变成红色,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货 查看全部
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”

请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。

请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。

请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;

请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;

请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变成红色,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货
网页数据抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-15 17:21
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。 查看全部
网页数据抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
网页数据抓取软件(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-13 08:23
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页数据抓取软件(软件特色风越网页批量填写数据提取软件,可自动分析)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】
网页数据抓取软件()
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-24 05:03
2.字符串
2.纵梁
当您想到与数据清理和准备相关的任务时,stringr 就会发挥作用。
当您想到与数据清理和准备相关的任务时,它就会发挥作用。
stringr 中有四组基本函数:
Stringr 中有四组基本的函数:
安装
安装
install.packages('stringr')
install.packages('stringr')
3.jsonlite
3.jsonlite
jsonline 包之所以有用,是因为它是一个针对网络优化的 JSON 解析器/生成器。
jsonline 包的有用之处在于它是一个针对网络优化的 JSON 解析器/生成器。
这很重要,因为它可以在 JSON 数据和关键的 R 数据类型之间建立有效的映射。使用它,我们能够在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也不需要任何手动数据整理。
这很关键,因为它允许在 JSON 数据和关键 R 数据类型之间进行有效映射。使用这种方法,我们可以在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也无需任何手动数据操作。
这非常适合与 Web API 交互,或者如果您想创建数据可以使用 JSON 进出 R 的方式。
这对于与 Web API 交互非常有用,或者如果您想创建使用 JSON 将数据传入和传出 R 的方法。
安装
install.packages('jsonlite')
install.packages('jsonlite')
在我们开始之前,让我们看看它是如何工作的:
在开始之前,让我们看看它是如何工作的:
首先应该清楚每个网站是不同的,因为进入网站的编码是不同的。
从一开始就应该清楚每个 网站 是不同的,因为进入 网站 的编码是不同的。
网络抓取是一种识别和使用这些编码模式来提取您需要的数据的技术。您的浏览器使您可以通过 HTML 访问该网站。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取是一种识别并使用这些编码模式来提取所需数据的技术。您的浏览器使这个 网站 可以通过 HTML 访问。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取有一个固定的过程,通常是这样工作的:
网页抓取过程如下设置,一般是这样的:
现在让我们去实现以更好地理解它。
现在让我们实现它以更好地理解它。
3.实施(3.实施)
让我们实现它,看看它是如何工作的。我们将在亚马逊网站上抓取一款名为“一加 6”的手机产品的价格比较。
让我们实现它,看看它是如何工作的。我们将搜索亚马逊 网站 来比较一款名为“一加 6”的手机的价格。
你可以在这里看到它。
你可以在这里看到它。
第一步:加载我们需要的包
我们需要在控制台中,在 R 命令提示符下启动进程。到达那里后,我们需要加载所需的包,如下所示:
我们需要在控制台的 R 命令提示符下启动该进程。到达那里后,我们需要按如下方式加载所需的包:
#loading the package:> library(xml2)> library(rvest)> library(stringr)
第 2 步:从亚马逊读取 HTML 内容
#Specifying the url for desired website to be scrappedurl 转到此 URL => 右键单击 => 检查元素
=>转到 chrome 浏览器=>转到该 URL=>右键单击=>检查元素
注意:如果您使用的不是 Chrome 浏览器,请查看这篇文章。
注意:如果您使用的不是Chrome浏览器,请参考这篇文章。
基于 CSS 选择器,例如 class 和 id,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“检查”或“检查元素”。
基于 class 和 id 等 CSS 选择器,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“Inspect”或“Inspect Element”。
正如您在下面看到的,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 id - h1#title - 以及存储了 HTML 内容的网页。
如下所示,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 ID ( h1#title ) 和存储 HTML 内容的网页。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
#scrape title of the product> title_html title head(title)
输出如下图:
输出如下:
我们可以使用空格和\n来获得产品的标题。
我们可以使用空格和\n来获取产品的标题。
下一步是在 stringr 库中的 str_replace_all() 函数的帮助下删除空格和新行。
下一步是借助 stringr 库中的 str_replace_all() 函数删除空格和换行符。
# remove all space and new linesstr_replace_all(title, “[\r\n]” , “”)
输出:
输出:
现在我们需要按照相同的过程提取产品的其他相关信息。
现在,我们将需要按照相同的过程来提取有关产品的其他相关信息。
产品价格:
产品价格:
# scrape the price of the product> price_html price str_replace_all(title, “[\r\n]” , “”)
# print price value> head(price)
输出:
输出:
产品说明:
产品说明:
# scrape product description> desc_html desc desc desc head(desc)
输出:
输出:
产品评分:
产品等级:
# scrape product rating > rate_html rate rate rate head(rate)
输出:
输出:
产品尺寸:
产品尺寸:
# Scrape size of the product> size_html size_html size size head(size)
输出:
输出:
产品颜色:
产品颜色:
# Scrape product color> color_html color_html color color head(color)
输出:
输出:
第 4 步:我们已成功从所有字段中提取数据,这些数据可用于比较其他网站的产品信息。 (第 4 步:我们已成功从所有字段中提取数据,可用于比较其他站点的产品信息。)
让我们编译并组合它们以计算出一个数据框并检查其结构。
让我们编译和组合它,得到一个数据框并检查它的结构。
#Combining all the lists to form a data frameproduct_data library(jsonlite)
# convert dataframe into JSON format> json_data cat(json_data)
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果我们愿意,也可以将数据存储在 csv 文件或数据库中以供进一步处理。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果您愿意,还可以将数据存储在 csv 文件或数据库中以供进一步处理。
输出:
输出:
按照这个实际示例,您还可以从产品中提取相关数据并与亚马逊进行比较,以计算出产品的公允价值。同样,您可以使用这些数据与其他网站进行比较。
按照这个实际示例,您还可以从产品中提取相同的相关数据,并与亚马逊进行比较,从而得出产品的公允价值。同样,您可以使用该数据与其他 网站 进行比较。
4.尾注(4.尾注)
如您所见,R 可以为您提供从不同网站抓取数据的强大优势。通过这个关于如何使用 R 的实际示例,您现在可以自行探索它并从亚马逊或任何其他电子商务网站提取产品数据。
如您所见,R 可以极大地帮助您从不同的 网站 中抓取数据。通过这个 R 用法的实际示例,您现在可以自己探索 R 并从亚马逊或任何其他电子商务中提取产品数据网站。
请注意:某些网站有反抓取政策。如果您过度使用它,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以学习使用不同的可用服务来解决验证码问题。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请注意:部分网站有反爬虫政策。如果您做得太多,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以使用各种可用的服务来学习如何处理验证码。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请随时将您对这篇文章的反馈和建议发送给我!
请随时向我发送您对这篇文章的反馈和建议!
翻译自:
r语言抓取网页数据 查看全部
网页数据抓取软件()
2.字符串
2.纵梁
当您想到与数据清理和准备相关的任务时,stringr 就会发挥作用。
当您想到与数据清理和准备相关的任务时,它就会发挥作用。
stringr 中有四组基本函数:
Stringr 中有四组基本的函数:
安装
安装
install.packages('stringr')
install.packages('stringr')
3.jsonlite
3.jsonlite
jsonline 包之所以有用,是因为它是一个针对网络优化的 JSON 解析器/生成器。
jsonline 包的有用之处在于它是一个针对网络优化的 JSON 解析器/生成器。
这很重要,因为它可以在 JSON 数据和关键的 R 数据类型之间建立有效的映射。使用它,我们能够在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也不需要任何手动数据整理。
这很关键,因为它允许在 JSON 数据和关键 R 数据类型之间进行有效映射。使用这种方法,我们可以在 R 对象和 JSON 之间进行转换,而不会丢失类型或信息,也无需任何手动数据操作。
这非常适合与 Web API 交互,或者如果您想创建数据可以使用 JSON 进出 R 的方式。
这对于与 Web API 交互非常有用,或者如果您想创建使用 JSON 将数据传入和传出 R 的方法。
安装
install.packages('jsonlite')
install.packages('jsonlite')
在我们开始之前,让我们看看它是如何工作的:
在开始之前,让我们看看它是如何工作的:
首先应该清楚每个网站是不同的,因为进入网站的编码是不同的。
从一开始就应该清楚每个 网站 是不同的,因为进入 网站 的编码是不同的。
网络抓取是一种识别和使用这些编码模式来提取您需要的数据的技术。您的浏览器使您可以通过 HTML 访问该网站。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取是一种识别并使用这些编码模式来提取所需数据的技术。您的浏览器使这个 网站 可以通过 HTML 访问。网页抓取只是解析浏览器提供给您的 HTML。
网页抓取有一个固定的过程,通常是这样工作的:
网页抓取过程如下设置,一般是这样的:
现在让我们去实现以更好地理解它。
现在让我们实现它以更好地理解它。
3.实施(3.实施)
让我们实现它,看看它是如何工作的。我们将在亚马逊网站上抓取一款名为“一加 6”的手机产品的价格比较。
让我们实现它,看看它是如何工作的。我们将搜索亚马逊 网站 来比较一款名为“一加 6”的手机的价格。
你可以在这里看到它。
你可以在这里看到它。
第一步:加载我们需要的包
我们需要在控制台中,在 R 命令提示符下启动进程。到达那里后,我们需要加载所需的包,如下所示:
我们需要在控制台的 R 命令提示符下启动该进程。到达那里后,我们需要按如下方式加载所需的包:
#loading the package:> library(xml2)> library(rvest)> library(stringr)
第 2 步:从亚马逊读取 HTML 内容
#Specifying the url for desired website to be scrappedurl 转到此 URL => 右键单击 => 检查元素
=>转到 chrome 浏览器=>转到该 URL=>右键单击=>检查元素
注意:如果您使用的不是 Chrome 浏览器,请查看这篇文章。
注意:如果您使用的不是Chrome浏览器,请参考这篇文章。
基于 CSS 选择器,例如 class 和 id,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“检查”或“检查元素”。
基于 class 和 id 等 CSS 选择器,我们将从 HTML 中抓取数据。要找到产品标题的 CSS 类,我们需要右键单击标题并选择“Inspect”或“Inspect Element”。
正如您在下面看到的,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 id - h1#title - 以及存储了 HTML 内容的网页。
如下所示,我在 html_nodes 的帮助下提取了产品的标题,其中我传递了标题的 ID ( h1#title ) 和存储 HTML 内容的网页。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
我还可以使用 html_text 获取标题文本,并在 head() 函数的帮助下打印标题文本。
#scrape title of the product> title_html title head(title)
输出如下图:
输出如下:
我们可以使用空格和\n来获得产品的标题。
我们可以使用空格和\n来获取产品的标题。
下一步是在 stringr 库中的 str_replace_all() 函数的帮助下删除空格和新行。
下一步是借助 stringr 库中的 str_replace_all() 函数删除空格和换行符。
# remove all space and new linesstr_replace_all(title, “[\r\n]” , “”)
输出:
输出:
现在我们需要按照相同的过程提取产品的其他相关信息。
现在,我们将需要按照相同的过程来提取有关产品的其他相关信息。
产品价格:
产品价格:
# scrape the price of the product> price_html price str_replace_all(title, “[\r\n]” , “”)
# print price value> head(price)
输出:
输出:
产品说明:
产品说明:
# scrape product description> desc_html desc desc desc head(desc)
输出:
输出:
产品评分:
产品等级:
# scrape product rating > rate_html rate rate rate head(rate)
输出:
输出:
产品尺寸:
产品尺寸:
# Scrape size of the product> size_html size_html size size head(size)
输出:
输出:
产品颜色:
产品颜色:
# Scrape product color> color_html color_html color color head(color)
输出:
输出:
第 4 步:我们已成功从所有字段中提取数据,这些数据可用于比较其他网站的产品信息。 (第 4 步:我们已成功从所有字段中提取数据,可用于比较其他站点的产品信息。)
让我们编译并组合它们以计算出一个数据框并检查其结构。
让我们编译和组合它,得到一个数据框并检查它的结构。
#Combining all the lists to form a data frameproduct_data library(jsonlite)
# convert dataframe into JSON format> json_data cat(json_data)
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在上面的代码中,我收录了 jsonlite 库,用于使用 toJSON() 函数将数据框对象转换为 JSON 形式。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果我们愿意,也可以将数据存储在 csv 文件或数据库中以供进一步处理。
在流程结束时,我们以 JSON 格式存储数据并打印出来。如果您愿意,还可以将数据存储在 csv 文件或数据库中以供进一步处理。
输出:
输出:
按照这个实际示例,您还可以从产品中提取相关数据并与亚马逊进行比较,以计算出产品的公允价值。同样,您可以使用这些数据与其他网站进行比较。
按照这个实际示例,您还可以从产品中提取相同的相关数据,并与亚马逊进行比较,从而得出产品的公允价值。同样,您可以使用该数据与其他 网站 进行比较。
4.尾注(4.尾注)
如您所见,R 可以为您提供从不同网站抓取数据的强大优势。通过这个关于如何使用 R 的实际示例,您现在可以自行探索它并从亚马逊或任何其他电子商务网站提取产品数据。
如您所见,R 可以极大地帮助您从不同的 网站 中抓取数据。通过这个 R 用法的实际示例,您现在可以自己探索 R 并从亚马逊或任何其他电子商务中提取产品数据网站。
请注意:某些网站有反抓取政策。如果您过度使用它,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以学习使用不同的可用服务来解决验证码问题。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请注意:部分网站有反爬虫政策。如果您做得太多,您将被阻止,您将开始看到验证码而不是产品详细信息。当然,您也可以使用各种可用的服务来学习如何处理验证码。但是,您确实需要了解抓取数据的合法性以及您对抓取的数据所做的任何事情。
请随时将您对这篇文章的反馈和建议发送给我!
请随时向我发送您对这篇文章的反馈和建议!
翻译自:
r语言抓取网页数据
网页数据抓取软件(基于IE浏览器对任何反爬虫技术手段,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-18 12:08
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
☆网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
☆数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
☆打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
☆ 抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
☆无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,daemon长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤 查看全部
网页数据抓取软件(基于IE浏览器对任何反爬虫技术手段,,)
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
☆网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
☆数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务之间互相调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
☆打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
☆ 抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
☆无人值守长期运行
低资源消耗,内置内存管理模块,自动清除运行时产生的内存垃圾,daemon长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤
网页数据抓取软件(scrapy进程如何保存进程间通信问题的解决办法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-17 10:01
网页数据抓取软件的话devops用parsemysql,
手机答复,排版渣,见谅。首先回答,scrapy在多线程环境下,没有进程间通信问题,就是说可以完成并发的爬取和运算任务,开发效率比较高。pip安装wheels即可,pip3.5兼容python3,pip3可以正常工作了,用的最多的还是pip3install-iscrapy关于一个scrapy进程如何保存进程数据,可以考虑用java类的框架,hadoop,spark等。
这个对于python3.5以上来说,是可以实现的。设置一个线程池,把相同的文件放到一个进程中,进程里执行这些文件,进程间通信就通过这些文件的属性来实现。当前界面的这个是定义在configuration/jobs的,创建新job的时候,要先设置conf/jobs-scrapy.py,把这个添加到configuration的settings里。
补充一下:在scrapy的这个代码中,原始并发性能没有在1e8的程度,2e8的程度,3e8还有理论上秒杀的--以jobs.py文件为例,标记为1的进程是打印的feed,2的进程是读写的api,3e8说明该进程并不是在运行而是处于休眠状态。而且自我实现的redirect比较耗性能的,不过也不用太在意,1e8的代码也是不错的。 查看全部
网页数据抓取软件(scrapy进程如何保存进程间通信问题的解决办法(图))
网页数据抓取软件的话devops用parsemysql,
手机答复,排版渣,见谅。首先回答,scrapy在多线程环境下,没有进程间通信问题,就是说可以完成并发的爬取和运算任务,开发效率比较高。pip安装wheels即可,pip3.5兼容python3,pip3可以正常工作了,用的最多的还是pip3install-iscrapy关于一个scrapy进程如何保存进程数据,可以考虑用java类的框架,hadoop,spark等。
这个对于python3.5以上来说,是可以实现的。设置一个线程池,把相同的文件放到一个进程中,进程里执行这些文件,进程间通信就通过这些文件的属性来实现。当前界面的这个是定义在configuration/jobs的,创建新job的时候,要先设置conf/jobs-scrapy.py,把这个添加到configuration的settings里。
补充一下:在scrapy的这个代码中,原始并发性能没有在1e8的程度,2e8的程度,3e8还有理论上秒杀的--以jobs.py文件为例,标记为1的进程是打印的feed,2的进程是读写的api,3e8说明该进程并不是在运行而是处于休眠状态。而且自我实现的redirect比较耗性能的,不过也不用太在意,1e8的代码也是不错的。
网页数据抓取软件(爬虫(四)必须掌握的基础概念(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-17 09:09
爬虫(四)必须掌握的基本概念(一)
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的效果 第一步:爬网 搜索引擎网络爬虫的基本工作流程如下,但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令的内容或文件,例如标记为 nofollow 或机器人协议。Robots协议(也叫爬虫协议、机器人协议等),全称是“Robots Exclusion Protocol”,网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如
210 查看全部
网页数据抓取软件(爬虫(四)必须掌握的基础概念(一)_)
爬虫(四)必须掌握的基本概念(一)
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的效果 第一步:爬网 搜索引擎网络爬虫的基本工作流程如下,但是搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令的内容或文件,例如标记为 nofollow 或机器人协议。Robots协议(也叫爬虫协议、机器人协议等),全称是“Robots Exclusion Protocol”,网站 通过Robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 页面数据与用户浏览器获取的 HTML 完全相同。搜索引擎蜘蛛在抓取页面时,也会做一定的重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如 它还进行某些重复内容检测。采集 或复制的内容,很可能它们将不再被抓取。Step 3:对搜索引擎将从爬虫爬回来的页面进行预处理,并进行各种预处理步骤提取文本中文分词以消除噪音(如版权声明文本、导航栏、广告等...)索引处理链接关系计算特殊文件处理....除了HTML文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,比如
210
网页数据抓取软件(网页抓取工具EasyWebExtract功能特点及功能分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-16 07:02
网页爬取工具Easy Web Extract是一款国外的网页爬取软件。做站长的朋友一定会用。它可以在不知道代码的情况下直接提取网页中的内容(文本、URL)。 、图片、文档),并转换为多种格式。
软件说明
我们简单的网页提取软件收录许多高级功能。
使用户能够从简单到复杂地抓取内容网站。
但是构建一个网络爬虫项目并不需要任何努力。
在此页面上,我们将只向您展示众所周知的功能。
让我们的网络爬虫易于使用,就像它的名字一样。
特点
1.轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导会一步一步指导你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,即起始页,页面将通过滑动加载。
它通常是指向已抓取产品列表的链接
第二步:输入关键词提交表单,得到结果,如果网站需要,这一步大部分情况可以跳过;
第三步:在列表中选择一项,选择该项数据列的抓取性能;
第 4 步:选择下一页的 URL 以访问其他网页。
2. 多线程抓取数据
在网络抓取项目中,需要抓取和收获数十万个链接。
传统的抓取工具可能需要数小时或数天的时间。
不过,Simple Web Extractor 可以同时运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,一个简单的网络提取可以利用您系统的最佳性能。
旁边的动画图显示了8个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的网站使用基于客户端创建异步请求(如 AJAX)的数据加载技术。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
一些具体的网站如LinkedIn联系人列表。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
很快就会变得乏味。不过,不要担心这个噩梦。
因为 Simple Web Extract 具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,所有重复项都可以从收获的结果中删除。
确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站数据。
示例:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。 查看全部
网页数据抓取软件(网页抓取工具EasyWebExtract功能特点及功能分析)
网页爬取工具Easy Web Extract是一款国外的网页爬取软件。做站长的朋友一定会用。它可以在不知道代码的情况下直接提取网页中的内容(文本、URL)。 、图片、文档),并转换为多种格式。
软件说明
我们简单的网页提取软件收录许多高级功能。
使用户能够从简单到复杂地抓取内容网站。
但是构建一个网络爬虫项目并不需要任何努力。
在此页面上,我们将只向您展示众所周知的功能。
让我们的网络爬虫易于使用,就像它的名字一样。
特点
1.轻松创建提取项目
对任何用户来说,基于向导窗口创建新项目从未如此简单。
项目安装向导会一步一步指导你。
直到完成所有必要的任务。
以下是一些主要步骤:
第一步:输入起始网址,即起始页,页面将通过滑动加载。
它通常是指向已抓取产品列表的链接
第二步:输入关键词提交表单,得到结果,如果网站需要,这一步大部分情况可以跳过;
第三步:在列表中选择一项,选择该项数据列的抓取性能;
第 4 步:选择下一页的 URL 以访问其他网页。
2. 多线程抓取数据
在网络抓取项目中,需要抓取和收获数十万个链接。
传统的抓取工具可能需要数小时或数天的时间。
不过,Simple Web Extractor 可以同时运行多个线程同时浏览多达 24 个不同的网页。
为了节省您等待收获结果的宝贵时间。
因此,一个简单的网络提取可以利用您系统的最佳性能。
旁边的动画图显示了8个线程的提取。
3.从data中加载各种提取的数据
一些高度动态的网站使用基于客户端创建异步请求(如 AJAX)的数据加载技术。
的确,不仅是原创网页抓取工具,还有专业网页抓取工具的挑战。
因为网页内容没有嵌入到 HTML 源代码中。
但是,简单的网络提取具有非常强大的技术。
即使是新手也能从这些类型的 网站 中获取数据。
此外,我们的 网站 抓取工具甚至可以模拟向下滚动到页面底部以加载更多数据。
一些具体的网站如LinkedIn联系人列表。
在这个挑战中,大多数网络爬虫不断采集大量重复信息。
很快就会变得乏味。不过,不要担心这个噩梦。
因为 Simple Web Extract 具有避免它的智能功能。
4.随时自动执行项目
通过简单的网络提取嵌入自动运行调度程序。
您可以安排网络抓取项目随时运行,无需任何操作。
计划任务运行并将抓取的结果导出到目的地。
没有始终运行的后台服务来节省系统资源。
此外,所有重复项都可以从收获的结果中删除。
确保只保留新数据。
支持的计划类型:
- 在项目中每小时运行一次
- 每天运行项目
- 在特定时间运行项目
5.将数据导出为任意格式
我们最好的网络抓取工具支持以各种格式导出抓取的网站数据。
示例:CSV、Access、XML、HTML、SQL Server、MySQL。
您也可以直接提交到任何类型的数据库目的地。
通过 ODBC 连接。如果您的 网站 有提交表单。
网页数据抓取软件( 易搜采集一个网站数据列表的地址(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-05 11:05
易搜采集一个网站数据列表的地址(图)
)
第一步,选择起始网址
当你要采集一个网站数据时,首先需要找到一个显示数据列表的地址。这一步至关重要,决定了您采集拥有的数据的数量和类型。
以Made in China网站的英文站点为例,我们要在当前关键词中获取公司名称、联系人、公司编号等信息。
通过浏览网站,我们找到了所有食品企业列表的地址:
然后在EasySearch中新建一个任务采集软件->第一步->输入网址
然后点击下一步。
第二步,抓取数据
进入第二步后,Easy Search采集软件会智能分析网页并从中提取列表数据。如下图:
这时候我们对已经分析过的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
当然还有其他操作,比如名称修改、数据处理等,这些我们会在后面的文档中介绍。
整理完修改字段,我们来采集处理分页
选择分页设置->自动识别分页,程序会自动定位下一个页面元素。
完成后,点击下一步。
第三步,设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等,这些配置可以提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
查看全部
网页数据抓取软件(
易搜采集一个网站数据列表的地址(图)
)
第一步,选择起始网址
当你要采集一个网站数据时,首先需要找到一个显示数据列表的地址。这一步至关重要,决定了您采集拥有的数据的数量和类型。
以Made in China网站的英文站点为例,我们要在当前关键词中获取公司名称、联系人、公司编号等信息。
通过浏览网站,我们找到了所有食品企业列表的地址:
然后在EasySearch中新建一个任务采集软件->第一步->输入网址
http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 3.png 768w" />然后点击下一步。
第二步,抓取数据
进入第二步后,Easy Search采集软件会智能分析网页并从中提取列表数据。如下图:
http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 4.png 768w" />http://so.51soke.cn/wp-content ... 7.png 300w, http://so.51soke.cn/wp-content ... 3.png 768w" />这时候我们对已经分析过的数据进行整理和修改,比如删除无用的字段。
单击列的下拉按钮并选择删除字段。
http://so.51soke.cn/wp-content ... 8.png 300w" />当然还有其他操作,比如名称修改、数据处理等,这些我们会在后面的文档中介绍。
整理完修改字段,我们来采集处理分页
选择分页设置->自动识别分页,程序会自动定位下一个页面元素。
http://so.51soke.cn/wp-content ... 3.png 300w" />完成后,点击下一步。
第三步,设置
这包括浏览器的配置,比如禁用图片、禁用JS、禁用Flash、屏蔽广告等,这些配置可以提高浏览器的加载速度。
定时任务的配置,通过定时任务,可以设置任务定时自动运行。
http://so.51soke.cn/wp-content ... 9.png 300w, http://so.51soke.cn/wp-content ... 8.png 768w" />点击完成保存任务。
完成,运行任务
任务创建完成后,我们选择新创建的任务,点击任务栏开始。
http://so.51soke.cn/wp-content ... 4.png 300w, http://so.51soke.cn/wp-content ... 8.png 768w" /> 网页数据抓取软件( Web数据挖掘的智能帮助用户从网页中提取有用数据的过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-03 02:17
Web数据挖掘的智能帮助用户从网页中提取有用数据的过程)
文件大小:10 MB。
Web数据挖掘是从网页中以表格形式提取有用数据的过程。Web Data Miner 是一款出色的数据抓取工具,可自动执行数据挖掘工作。该工具的概念非常简单——它减少了从 网站 抓取数据的手动工作。Web Data Miner 的智能帮助用户从不同的布局中提取准确的数据网站,例如购物、分类、基于产品的网站 和其他网站)。它还包括两个更有用的功能:“外部链接”和“构造链接”,如果您想在单个进程中从多个 网站 中提取内容,这将非常有用。该软件的图形用户界面非常有吸引力且易于理解。
启动软件时会显示快速入门指南。输入 网站 的 URL 后,它会在主屏幕的网络浏览器中显示网页。加载网页后,用户可以单击“开始配置”按钮,然后单击要从网页中剪切和粘贴的项目。它可以从网页中提取文本、html、图像、链接和 URL。它允许用户提供用户定义的列名。
此数据抓取工具将从打开的网页中抓取点击的项目或类似项目。在此工具中,有“自动保存”和“自动暂停”两个选项。自动保存消除了数据丢失的风险,自动暂停消除了某些 网站 阻塞 IP 地址的风险。这个网络数据挖掘工具可以从网站中的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则将从所有页面中挖掘数据。该软件的独特和最强大的功能是调度。用户可以设置时间和日期,并且必须提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。
主要功能:
以表格形式从网页中提取数据。
从不同的布局中提取数据网站。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟随页面提取数据。
保存提取的数据以消除丢失数据的风险。
自动暂停可防止矿工被某些 网站s 阻止。 查看全部
网页数据抓取软件(
Web数据挖掘的智能帮助用户从网页中提取有用数据的过程)
文件大小:10 MB。
Web数据挖掘是从网页中以表格形式提取有用数据的过程。Web Data Miner 是一款出色的数据抓取工具,可自动执行数据挖掘工作。该工具的概念非常简单——它减少了从 网站 抓取数据的手动工作。Web Data Miner 的智能帮助用户从不同的布局中提取准确的数据网站,例如购物、分类、基于产品的网站 和其他网站)。它还包括两个更有用的功能:“外部链接”和“构造链接”,如果您想在单个进程中从多个 网站 中提取内容,这将非常有用。该软件的图形用户界面非常有吸引力且易于理解。
启动软件时会显示快速入门指南。输入 网站 的 URL 后,它会在主屏幕的网络浏览器中显示网页。加载网页后,用户可以单击“开始配置”按钮,然后单击要从网页中剪切和粘贴的项目。它可以从网页中提取文本、html、图像、链接和 URL。它允许用户提供用户定义的列名。
此数据抓取工具将从打开的网页中抓取点击的项目或类似项目。在此工具中,有“自动保存”和“自动暂停”两个选项。自动保存消除了数据丢失的风险,自动暂停消除了某些 网站 阻塞 IP 地址的风险。这个网络数据挖掘工具可以从网站中的多个网页中挖掘数据。用户可以配置“设置下一页链接”以从所有网页中提取相似数据。用户可以选择定义数量的页面来提取数据,否则将从所有页面中挖掘数据。该软件的独特和最强大的功能是调度。用户可以设置时间和日期,并且必须提供配置文件。它将在用户定义的时间自动启动数据挖掘过程。
主要功能:
以表格形式从网页中提取数据。
从不同的布局中提取数据网站。
从网页中提取文本、html、图像、链接和 URL。
从外部和自定义链接中提取数据。
自动跟随页面提取数据。
保存提取的数据以消除丢失数据的风险。
自动暂停可防止矿工被某些 网站s 阻止。
网页数据抓取软件(三网运营商大数据抓取软件后的问题并不那么麻烦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-03 02:15
哪个运营商的大数据采集软件好用?近年来,大数据的奥秘不断被延伸。它的魅力迅速蔓延到各行各业。尽管利用大数据进行营销已经成为营销行业的共识,但如何从海量数据中快速准确地获取所需数据仍是营销行业的一个弱点。不过,在了解了运营商的大数据抓取软件之后,这个问题似乎就没有那么麻烦了。
哪个运营商的大数据采集软件好用
三网运营商大数据采集软件是一款能够自动提取网页信息并进行智能处理的软件。它的设计原则是基于web结构的源码提取,因此在全网具有通用性和易用性。也就是说,大数据采集只要我们能看到网上的所有信息,问题就可以简单地解决。
采集客户信息获取已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以通过app采集手机号准确采集竞争对手店铺的产品名称、价格、销量等信息数据,然后根据大数据模型分析构建适合我们的营销方案,如标题优化、热钱创造、价格策略、服务调整等。
哪个运营商的大数据采集软件好用
另一个例子是企业营销。以保险公司为例,利用运营商大数据采集软件采集一系列相关数据,对精算、营销、保险等环节的统计数据进行筛选分析,实现精准营销、精准定价、精准管理,精准发球。更科学地设定不同的费率;提醒客户保障不足,筛选最适合的保险产品和服务类型,精准推送。
三网大数据采集软件不仅可以为营销工作奠定数据采集的基石,还可以为营销推广提供自动发布功能,即采集multi-站群@ >客户信息的网络发布功能。使用此功能,您可以发送到论坛、QQ空间、博客、微博等多个目标站点。有了大数据软件采集客户信息,您再也不用担心登录、复制、和粘贴,节省时间,节省人力,提高操作水平和工作效率。
哪个运营商的大数据采集软件好用
大数据带来的信息非常丰富,引导的营销方式也多种多样。为了更好地利用大数据进行营销,建议大家一定要掌握采集客户信息采集经典精准大数据工具,紧跟时代发展趋势,在大数据营销领域收获更多成果。 查看全部
网页数据抓取软件(三网运营商大数据抓取软件后的问题并不那么麻烦)
哪个运营商的大数据采集软件好用?近年来,大数据的奥秘不断被延伸。它的魅力迅速蔓延到各行各业。尽管利用大数据进行营销已经成为营销行业的共识,但如何从海量数据中快速准确地获取所需数据仍是营销行业的一个弱点。不过,在了解了运营商的大数据抓取软件之后,这个问题似乎就没有那么麻烦了。
哪个运营商的大数据采集软件好用
三网运营商大数据采集软件是一款能够自动提取网页信息并进行智能处理的软件。它的设计原则是基于web结构的源码提取,因此在全网具有通用性和易用性。也就是说,大数据采集只要我们能看到网上的所有信息,问题就可以简单地解决。
采集客户信息获取已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以通过app采集手机号准确采集竞争对手店铺的产品名称、价格、销量等信息数据,然后根据大数据模型分析构建适合我们的营销方案,如标题优化、热钱创造、价格策略、服务调整等。
哪个运营商的大数据采集软件好用
另一个例子是企业营销。以保险公司为例,利用运营商大数据采集软件采集一系列相关数据,对精算、营销、保险等环节的统计数据进行筛选分析,实现精准营销、精准定价、精准管理,精准发球。更科学地设定不同的费率;提醒客户保障不足,筛选最适合的保险产品和服务类型,精准推送。
三网大数据采集软件不仅可以为营销工作奠定数据采集的基石,还可以为营销推广提供自动发布功能,即采集multi-站群@ >客户信息的网络发布功能。使用此功能,您可以发送到论坛、QQ空间、博客、微博等多个目标站点。有了大数据软件采集客户信息,您再也不用担心登录、复制、和粘贴,节省时间,节省人力,提高操作水平和工作效率。
哪个运营商的大数据采集软件好用
大数据带来的信息非常丰富,引导的营销方式也多种多样。为了更好地利用大数据进行营销,建议大家一定要掌握采集客户信息采集经典精准大数据工具,紧跟时代发展趋势,在大数据营销领域收获更多成果。
网页数据抓取软件(基于Twisted的异步处理框架,纯python实现的爬虫框架 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-02 20:16
)
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现一个爬虫抓取网站数据,提取结构化数据和各种图片,非常方便。Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。虽然 Scrapy 最初是为屏幕抓取(更准确地说是网页抓取)而设计的,但它也可以用于访问 API 以提取数据。
如何安装?
打开 网站:
~gohlke/pythonlibs/
在这个python第三方库中下载三个包:lxml、twisted、scrapy。
我下载的是:
lxml-4.3.2-cp37-cp37m-win_amd64.whlScrapy-1.6.0-py2.py3-none-any.whlTwisted-18.9.0-cp37-cp37m-win_amd64.whl
cd到这三个包所在的文件夹,然后pip3依次安装上面三个.whl文件。
例如:
pip3 install lxml-4.3.2-cp37-cp37m-win_amd64.whlpip3 install Twisted-18.9.0-cp37-cp37m-win_amd64.whlpip3 install Scrapy-1.6.0-py2.py3-none-any.whl
全部安装完成后,直接在命令行输入scrapy,看看是否出现如下提示。如果出现,则安装成功。
Scrapy 1.6.0 - no active project
Usage: scrapy [options] [args]
Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
如果不成功,请从以下网址下载对应的win插件。
221/
架构和流程
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
Scrapy主要包括以下组件:
用于处理整个系统的数据流,触发事务(框架核心)
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的网址是什么,同时删除重复的网址
用于下载网页内容并将网页内容返回给spider(Scrapy下载器建立在twisted的高效异步模型之上)
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
它负责处理爬虫从网页中提取的实体。主要功能是持久化实体,验证实体的有效性,去除不必要的信息。当页面被爬虫解析后,会被发送到项目流水线中,并按照几个特定的顺序对数据进行处理。
Scrapy 引擎和下载器之间的框架主要处理 Scrapy 引擎和下载器之间的请求和响应。
Scrapy引擎和爬虫之间的一个框架,主要工作是处理蜘蛛的响应输入和请求输出。
Scrapy 引擎和调度器之间的中间件,从 Scrapy 引擎发送到调度器的请求和响应。
Scrapy运行过程大致如下:
引擎从调度程序中获取链接(URL)以进行下一次抓取
引擎将 URL 封装为请求发送给下载器
下载器下载资源并封装成响应包(Response)
爬虫解析Response
解析出实体(Item),然后交给实体管道做进一步处理
如果解析的是链接(URL),则将该URL交给调度器等待抓取
如何开始?
制作 Scrapy 爬虫有四个步骤:
新建项目:新建爬虫项目
明确目标(写items.py):指定你要抓取的目标
创建爬虫(spiders/xxspider.py):创建爬虫开始爬网
存储内容(pipelines.py):设计管道来存储爬取的内容
豆瓣阅读频道图书信息爬取
创建项目
scrapy startproject pic
创建爬虫
cd picscrapy genspider book douban.com
自动创建目录和文件
文件描述:
注意:一般在创建爬虫文件时,以网站的域名命名
设置数据存储模板
项目.py
import scrapyclass PicItem(scrapy.Item): addr = scrapy.Field() name = scrapy.Field()
写爬虫
书本.py
# -*- coding: utf-8 -*-import scrapyimport os# 导入item中结构化数据模板from pic.items import PicItem
class XhSpider(scrapy.Spider): # 爬虫名称,唯一 name = "book" # 允许访问的域 allowed_domains = ["douban.com"] # 初始URL start_urls = ['https://book.douban.com/']
def parse(self, response): # 获取所有图片的a标签 allPics = response.xpath('//div[@class="cover"]/a') for pic in allPics: # 分别处理每个图片,取出名称及地址 item = PicItem() name = pic.xpath('./img/@alt').extract()[0] addr = pic.xpath('./img/@src').extract()[0] item['name'] = name item['addr'] = addr # 返回爬取到的数据 yield item
设置配置文件
settings.py 添加如下内容
ITEM_PIPELINES = {'pic.pipelines.PicPipeline':100}USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
编写数据处理脚本
管道.py
import urllib.requestimport os
class PicPipeline(object): def process_item(self, item, spider): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'} req = urllib.request.Request(url=item['addr'],headers=headers) res = urllib.request.urlopen(req) file_name = os.path.join(r'down_pic',item['name']+'.jpg') with open(file_name,'wb') as fp: fp.write(res.read())
执行爬虫
scrapy crawl book --nolog
结果
查看全部
网页数据抓取软件(基于Twisted的异步处理框架,纯python实现的爬虫框架
)
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现一个爬虫抓取网站数据,提取结构化数据和各种图片,非常方便。Scrapy 常用于数据挖掘、信息处理或存储历史数据等一系列程序中。虽然 Scrapy 最初是为屏幕抓取(更准确地说是网页抓取)而设计的,但它也可以用于访问 API 以提取数据。
如何安装?
打开 网站:
~gohlke/pythonlibs/
在这个python第三方库中下载三个包:lxml、twisted、scrapy。
我下载的是:
lxml-4.3.2-cp37-cp37m-win_amd64.whlScrapy-1.6.0-py2.py3-none-any.whlTwisted-18.9.0-cp37-cp37m-win_amd64.whl
cd到这三个包所在的文件夹,然后pip3依次安装上面三个.whl文件。
例如:
pip3 install lxml-4.3.2-cp37-cp37m-win_amd64.whlpip3 install Twisted-18.9.0-cp37-cp37m-win_amd64.whlpip3 install Scrapy-1.6.0-py2.py3-none-any.whl
全部安装完成后,直接在命令行输入scrapy,看看是否出现如下提示。如果出现,则安装成功。
Scrapy 1.6.0 - no active project
Usage: scrapy [options] [args]
Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
如果不成功,请从以下网址下载对应的win插件。
221/
架构和流程
Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
Scrapy主要包括以下组件:
用于处理整个系统的数据流,触发事务(框架核心)
它用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。它可以被认为是 URL(被爬取的网站或链接)的优先级队列,它决定了下一个请求。抓取的网址是什么,同时删除重复的网址
用于下载网页内容并将网页内容返回给spider(Scrapy下载器建立在twisted的高效异步模型之上)
爬虫主要用于从特定网页中提取它需要的信息,即所谓的实体(Item)。用户也可以从中提取链接,让 Scrapy 继续爬取下一页
它负责处理爬虫从网页中提取的实体。主要功能是持久化实体,验证实体的有效性,去除不必要的信息。当页面被爬虫解析后,会被发送到项目流水线中,并按照几个特定的顺序对数据进行处理。
Scrapy 引擎和下载器之间的框架主要处理 Scrapy 引擎和下载器之间的请求和响应。
Scrapy引擎和爬虫之间的一个框架,主要工作是处理蜘蛛的响应输入和请求输出。
Scrapy 引擎和调度器之间的中间件,从 Scrapy 引擎发送到调度器的请求和响应。
Scrapy运行过程大致如下:
引擎从调度程序中获取链接(URL)以进行下一次抓取
引擎将 URL 封装为请求发送给下载器
下载器下载资源并封装成响应包(Response)
爬虫解析Response
解析出实体(Item),然后交给实体管道做进一步处理
如果解析的是链接(URL),则将该URL交给调度器等待抓取
如何开始?
制作 Scrapy 爬虫有四个步骤:
新建项目:新建爬虫项目
明确目标(写items.py):指定你要抓取的目标
创建爬虫(spiders/xxspider.py):创建爬虫开始爬网
存储内容(pipelines.py):设计管道来存储爬取的内容
豆瓣阅读频道图书信息爬取
创建项目
scrapy startproject pic
创建爬虫
cd picscrapy genspider book douban.com
自动创建目录和文件
文件描述:
注意:一般在创建爬虫文件时,以网站的域名命名
设置数据存储模板
项目.py
import scrapyclass PicItem(scrapy.Item): addr = scrapy.Field() name = scrapy.Field()
写爬虫
书本.py
# -*- coding: utf-8 -*-import scrapyimport os# 导入item中结构化数据模板from pic.items import PicItem
class XhSpider(scrapy.Spider): # 爬虫名称,唯一 name = "book" # 允许访问的域 allowed_domains = ["douban.com"] # 初始URL start_urls = ['https://book.douban.com/']
def parse(self, response): # 获取所有图片的a标签 allPics = response.xpath('//div[@class="cover"]/a') for pic in allPics: # 分别处理每个图片,取出名称及地址 item = PicItem() name = pic.xpath('./img/@alt').extract()[0] addr = pic.xpath('./img/@src').extract()[0] item['name'] = name item['addr'] = addr # 返回爬取到的数据 yield item
设置配置文件
settings.py 添加如下内容
ITEM_PIPELINES = {'pic.pipelines.PicPipeline':100}USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
编写数据处理脚本
管道.py
import urllib.requestimport os
class PicPipeline(object): def process_item(self, item, spider): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'} req = urllib.request.Request(url=item['addr'],headers=headers) res = urllib.request.urlopen(req) file_name = os.path.join(r'down_pic',item['name']+'.jpg') with open(file_name,'wb') as fp: fp.write(res.read())
执行爬虫
scrapy crawl book --nolog
结果
网页数据抓取软件(爬网页和网页数据抓取的区别(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-01 21:16
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
文章目录
前言
网页数据抓取目标:抓取网站中感兴趣的数据
数据特征:噪声较多,标签较弱,无用信息很多,但数据量很大。
网络爬虫和网络数据抓取的区别:
爬取网页:爬取所有网页,然后搜索引擎可以搜索到
网页抓取:对网页中的特定数据感兴趣
一、数据爬虫
主题:网页会有防刮方法。
常用方法:使用无头(像浏览器但没有 GUI)
from selenium import webdriver
chrome_options=webdriver.ChromeOptions()
chrome_options.headless=True#不需要图形界面
chrome=webdriver.Chrome(chrome_options=chrome_options)
page=chrome.get(url)
大量ip访问我的网站异常
所以需要很多ip(取自云端)
二、实例分析
page=BeautifuSoup(open(hetml_pathh,'r'))#专门用来解析html的东西
links=[a['href']for a in page.find_all('a','list-card-link')]#将所有a元素的类别数'list-card-link',返回他的href
ids=[l.split('/')[-2].split('_')[0] for l in links]
将 id 放入网页以查找有关特定房屋的信息
sold_items=[a.text for a in page.find('div','ds-home-details-chip').find('p').find_all('span')]
#找到所有的div的容器,再找到'ds-home-details-chip',把里面的p找出来,再找到span
for item in soid_items:
if 'sold:'in item:
result['Sold Price']=item.split(' ')[1]
if'Sold on 'in item:
result['Sold On']=item.split(' ')[-1]
抓取图片
p=r'正则表达式的匹配.jpg'
ids=[a.split('-')[0] for a in re.findall(p,html)]
urls=[f'正则表达式的匹配.jpg' for id in ids]
总结
提示:这是 文章 的摘要:
通过 API 或网页抓取获取数据 查看全部
网页数据抓取软件(爬网页和网页数据抓取的区别(一)(图))
提示:文章写好后可以自动生成目录,如何生成可以参考右边的帮助文档
文章目录
前言
网页数据抓取目标:抓取网站中感兴趣的数据
数据特征:噪声较多,标签较弱,无用信息很多,但数据量很大。
网络爬虫和网络数据抓取的区别:
爬取网页:爬取所有网页,然后搜索引擎可以搜索到
网页抓取:对网页中的特定数据感兴趣
一、数据爬虫
主题:网页会有防刮方法。
常用方法:使用无头(像浏览器但没有 GUI)
from selenium import webdriver
chrome_options=webdriver.ChromeOptions()
chrome_options.headless=True#不需要图形界面
chrome=webdriver.Chrome(chrome_options=chrome_options)
page=chrome.get(url)
大量ip访问我的网站异常
所以需要很多ip(取自云端)
二、实例分析
page=BeautifuSoup(open(hetml_pathh,'r'))#专门用来解析html的东西
links=[a['href']for a in page.find_all('a','list-card-link')]#将所有a元素的类别数'list-card-link',返回他的href
ids=[l.split('/')[-2].split('_')[0] for l in links]
将 id 放入网页以查找有关特定房屋的信息
sold_items=[a.text for a in page.find('div','ds-home-details-chip').find('p').find_all('span')]
#找到所有的div的容器,再找到'ds-home-details-chip',把里面的p找出来,再找到span
for item in soid_items:
if 'sold:'in item:
result['Sold Price']=item.split(' ')[1]
if'Sold on 'in item:
result['Sold On']=item.split(' ')[-1]
抓取图片
p=r'正则表达式的匹配.jpg'
ids=[a.split('-')[0] for a in re.findall(p,html)]
urls=[f'正则表达式的匹配.jpg' for id in ids]
总结
提示:这是 文章 的摘要:
通过 API 或网页抓取获取数据
网页数据抓取软件(演示demo,简单有没有?搞科研做实验最痛心的是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 22:15
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper,您可以轻松快速地抓取任何网站 数据,而不受网站 反爬机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示演示,简单与否?
做研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
不懂Python、不懂Java、不会写爬虫工具怎么办?
发现:网络刮板!
互联网上有海量的数据,每天都有各种各样的数据展示在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的人工采集操作,对于数据采集来说根本难以做到,即使能采集到,也要耗费大量的时间。本教程的目的是让拥有 采集 数据的人能够在短短一小时内熟练使用“神器”Web Scraper 插件。
首先让我们了解一下爬虫的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们的使用过程事半功倍!
“爬行对象”
网页作为展示数据的平台,可以通过浏览器窗口进行浏览。从服务器数据库到浏览器窗口的显示,经历了一个复杂的过程。存储在服务器数据库中的数据一般是以某种编码形式存储的。如果我们此时查看数据,我们看到的是这种或那种纯文本类型。之后将数据传输到浏览器,浏览器将“数据信息”加载到设计者制作好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
《了解网页的“层”》
各种网页都收录各种数据。网页将这些数据组织在不同的“层”中(细节可以从html标签中了解),当然我们无法直观地看到所有这些层。
网页设计已经发展了很长时间,直到现在我们通过标准的html标签语言来设计网页。在这套国际通用规则下,设计过程就是对页面元素逐层进行设计,让不同的内容结合得更加和谐。虽然不同的 网站 设计风格不同,但每个页面都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于表格
第二层:标题栏和内容栏(类似于Excel)
第 3 层:每行的数据
第四层:每个单元格
第 5 层:文本
“Web Scraper 分层抓取页面元素”
Web Scraper作为一个自动化爬虫工具,对页面的数据进行爬取,但是在爬取数据之前,我们需要定义一个“流程”,其中包括“动作”(模拟鼠标点击操作)和“页面元素”(定义页面元素)被抓取)。
很迷茫的感觉
实践是检验真假的唯一标准,爬取过程就到这里,基本原理储备足以学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节通知《【Web Scraper教程02】安装Web Scraper插件》
查看全部
网页数据抓取软件(演示demo,简单有没有?搞科研做实验最痛心的是什么?
)
Web Scraper 爬虫工具是一个基于谷歌浏览器的插件。使用Web Scraper,您可以轻松快速地抓取任何网站 数据,而不受网站 反爬机制的影响。与Python等语言实现的爬虫工具相比,WebScraper具有先天优势。
演示演示,简单与否?
做研究和实验最痛苦的事情是什么?
没有数据,没有足够的数据
不懂Python、不懂Java、不会写爬虫工具怎么办?
发现:网络刮板!
互联网上有海量的数据,每天都有各种各样的数据展示在我们面前。同时,金融、医学、计算机科学等诸多研究课题需要获取大量数据作为样本进行科学分析。传统的人工采集操作,对于数据采集来说根本难以做到,即使能采集到,也要耗费大量的时间。本教程的目的是让拥有 采集 数据的人能够在短短一小时内熟练使用“神器”Web Scraper 插件。
首先让我们了解一下爬虫的简单原理,所谓“磨刀不误砍柴”,了解原理可以帮助我们的使用过程事半功倍!
“爬行对象”
网页作为展示数据的平台,可以通过浏览器窗口进行浏览。从服务器数据库到浏览器窗口的显示,经历了一个复杂的过程。存储在服务器数据库中的数据一般是以某种编码形式存储的。如果我们此时查看数据,我们看到的是这种或那种纯文本类型。之后将数据传输到浏览器,浏览器将“数据信息”加载到设计者制作好的“网页模板”中,最终得到我们通过浏览器看到的一切。
我们看到的金融网站
我们看到的新闻网站
我们看到的博客
《了解网页的“层”》
各种网页都收录各种数据。网页将这些数据组织在不同的“层”中(细节可以从html标签中了解),当然我们无法直观地看到所有这些层。
网页设计已经发展了很长时间,直到现在我们通过标准的html标签语言来设计网页。在这套国际通用规则下,设计过程就是对页面元素逐层进行设计,让不同的内容结合得更加和谐。虽然不同的 网站 设计风格不同,但每个页面都类似于一个“金字塔”结构,比如下面这个网页:
第一层:类似于表格
第二层:标题栏和内容栏(类似于Excel)
第 3 层:每行的数据
第四层:每个单元格
第 5 层:文本
“Web Scraper 分层抓取页面元素”
Web Scraper作为一个自动化爬虫工具,对页面的数据进行爬取,但是在爬取数据之前,我们需要定义一个“流程”,其中包括“动作”(模拟鼠标点击操作)和“页面元素”(定义页面元素)被抓取)。
很迷茫的感觉
实践是检验真假的唯一标准,爬取过程就到这里,基本原理储备足以学习Web Scraper!
从下一节开始,我们正式进入Web Scraper的学习。
下一节通知《【Web Scraper教程02】安装Web Scraper插件》
网页数据抓取软件(优采云·云采集服务平台Amazon数据抓取工具推荐(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-22 23:16
优采云·云采集服务平台优采云·云采集服务平台亚马逊数据采集工具推荐本文介绍优采云简易模式采集@的使用>Amazon Data(以采集Details页面信息为例)。如果您需要采集亚马逊的商品详情,请在网页简单模式界面点击亚马逊。进入后可以看到亚马逊的三条规则信息。我们可以直接使用它。亚马逊数据抓取工具使用步骤1一、到采集亚马逊详情页信息(如下图),打开亚马逊首页点击第二个(亚马逊详情页信息采集@ >)采集网页上的内容。找到亚马逊详情页信息采集 规则并单击以立即使用亚马逊数据抓取工具。使用步骤2。下图为简单模式下亚马逊详情页信息采集的规则。查看详情:点击查看到示例 URL 任务名称:自定义任务名称,默认为亚马逊详情页面信息采集的亚马逊网页链接(这些链接的页面格式必须相同) 示例数据:所有字段这条规则的信息 采集 亚马逊数据爬虫使用step 3规则制作示例任务名称:自定义任务名称,也可以不设置任务组,默认:自定义任务组,也可以不设置根据默认 URL 循环: /dp/B00J0C3DTE?psc=1/dp/B003Z9W3IK?psc=1/dp/B002RZCZ90?psc =1 我们这里以三个 URL 为例。设置好后点击保存。保存后,按钮开始采集 会出现。Amazon Data Crawler 使用第4步选择开始采集,系统会弹出运行任务的界面可以选择启动本地<
亚马逊数据抓取工具使用步骤9相关采集教程:京东商品信息采集黄页88数据采集58城市信息采集优采云——70万用户 已选网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置 采集 任务后,它可以关闭,任务可以在云端执行。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
网页数据抓取软件(优采云·云采集服务平台Amazon数据抓取工具推荐(组图))
优采云·云采集服务平台优采云·云采集服务平台亚马逊数据采集工具推荐本文介绍优采云简易模式采集@的使用>Amazon Data(以采集Details页面信息为例)。如果您需要采集亚马逊的商品详情,请在网页简单模式界面点击亚马逊。进入后可以看到亚马逊的三条规则信息。我们可以直接使用它。亚马逊数据抓取工具使用步骤1一、到采集亚马逊详情页信息(如下图),打开亚马逊首页点击第二个(亚马逊详情页信息采集@ >)采集网页上的内容。找到亚马逊详情页信息采集 规则并单击以立即使用亚马逊数据抓取工具。使用步骤2。下图为简单模式下亚马逊详情页信息采集的规则。查看详情:点击查看到示例 URL 任务名称:自定义任务名称,默认为亚马逊详情页面信息采集的亚马逊网页链接(这些链接的页面格式必须相同) 示例数据:所有字段这条规则的信息 采集 亚马逊数据爬虫使用step 3规则制作示例任务名称:自定义任务名称,也可以不设置任务组,默认:自定义任务组,也可以不设置根据默认 URL 循环: /dp/B00J0C3DTE?psc=1/dp/B003Z9W3IK?psc=1/dp/B002RZCZ90?psc =1 我们这里以三个 URL 为例。设置好后点击保存。保存后,按钮开始采集 会出现。Amazon Data Crawler 使用第4步选择开始采集,系统会弹出运行任务的界面可以选择启动本地<
亚马逊数据抓取工具使用步骤9相关采集教程:京东商品信息采集黄页88数据采集58城市信息采集优采云——70万用户 已选网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置 采集 任务后,它可以关闭,任务可以在云端执行。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。用户的需求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
网页数据抓取软件(基于IE浏览器而开发的网探网页数据监控软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-22 23:14
NetTrack是一款基于IE浏览器开发的灵活、简单、功能强大的网络数据监控软件。具有“文本匹配”和“文档结构分析”两种数据采集方式,可支持多任务同时运行。支持任务间相互调用,可帮助用户7*24小时监控网页数据,适用于门户网站监控、股市监控、优采云票源监控、天猫竞品监控、微博更新监控等待现场。
基本介绍
现在各行各业都在应用互联网技术,互联网上的数据也越来越丰富。
一些数据的值是时间相关的,早点知道会有用,以后可能会为零。
这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
软件功能
1:基于IE浏览器
无视任何反爬技术手段,只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。
2:网页数据抓取
两种数据采集方法,文本匹配和文档结构分析,可以单独使用或组合使用,使数据采集更容易、更准确。
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
4:及时通知用户
用户注册后,可将验证后的数据发送至您的微信,或推送至指定界面对数据进行重新处理。
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
6:任务之间互相调用
监控任务A得到的结果(必须是URL)可以传递给监控任务B执行,从而获得更丰富的数据结果。
7:打开通知界面
直接连接自己的程序,后续处理流程由自己定义,实时高效接入自动化数据处理流程。
8:抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
9:无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行。
安装和卸载
Net Detector是纯绿色软件,解压后无需安装即可使用,支持U盘执行。
文件简要说明
datail.exe : 主程序文件;双击启动程序
:配置文件;内部存储登录信息和监控任务的详细信息
关于 .url : URL 快捷方式文件
Compatibility Mode.reg : 注册表项;双击将相应信息写入注册表。运行该文件后,可以使程序在IE兼容模式下运行
标准 mode.reg :注册表项;运行该文件后,可以使程序在IE的标准模式下运行
install.exe :专用安装程序;双击安装程序
uninstall.exe :专用卸载程序;双击以完全删除程序文件和所有快捷方式
兼容模式和标准模式的区别:简单来说,兼容模式就是强制更高版本的IE运行在IE7.0;默认情况下,此程序使用 IE 兼容模式
如果卸载前已经改成标准模式,请执行“compatibility mode.reg”清除生成的注册表项
IE:指Windows操作系统自带的Internet Explorer浏览器
第一次使用
第一次使用时,无需登录即可执行。 [Try] => 勾选要执行的任务 => [Execute],会自动运行
查看任务文件的细节和描述,了解任务设置的方法和思路 查看全部
网页数据抓取软件(基于IE浏览器而开发的网探网页数据监控软件)
NetTrack是一款基于IE浏览器开发的灵活、简单、功能强大的网络数据监控软件。具有“文本匹配”和“文档结构分析”两种数据采集方式,可支持多任务同时运行。支持任务间相互调用,可帮助用户7*24小时监控网页数据,适用于门户网站监控、股市监控、优采云票源监控、天猫竞品监控、微博更新监控等待现场。
基本介绍
现在各行各业都在应用互联网技术,互联网上的数据也越来越丰富。
一些数据的值是时间相关的,早点知道会有用,以后可能会为零。
这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。
软件功能
1:基于IE浏览器
无视任何反爬技术手段,只要能在IE浏览器中正常浏览网页,就可以监控其中的所有数据。
2:网页数据抓取
两种数据采集方法,文本匹配和文档结构分析,可以单独使用或组合使用,使数据采集更容易、更准确。
3:数据对比验证
自动判断最近更新的数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
4:及时通知用户
用户注册后,可将验证后的数据发送至您的微信,或推送至指定界面对数据进行重新处理。
5:同时处理多任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
6:任务之间互相调用
监控任务A得到的结果(必须是URL)可以传递给监控任务B执行,从而获得更丰富的数据结果。
7:打开通知界面
直接连接自己的程序,后续处理流程由自己定义,实时高效接入自动化数据处理流程。
8:抓取公式在线分享
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
9:无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行。
安装和卸载
Net Detector是纯绿色软件,解压后无需安装即可使用,支持U盘执行。
文件简要说明
datail.exe : 主程序文件;双击启动程序
:配置文件;内部存储登录信息和监控任务的详细信息
关于 .url : URL 快捷方式文件
Compatibility Mode.reg : 注册表项;双击将相应信息写入注册表。运行该文件后,可以使程序在IE兼容模式下运行
标准 mode.reg :注册表项;运行该文件后,可以使程序在IE的标准模式下运行
install.exe :专用安装程序;双击安装程序
uninstall.exe :专用卸载程序;双击以完全删除程序文件和所有快捷方式
兼容模式和标准模式的区别:简单来说,兼容模式就是强制更高版本的IE运行在IE7.0;默认情况下,此程序使用 IE 兼容模式
如果卸载前已经改成标准模式,请执行“compatibility mode.reg”清除生成的注册表项
IE:指Windows操作系统自带的Internet Explorer浏览器
第一次使用
第一次使用时,无需登录即可执行。 [Try] => 勾选要执行的任务 => [Execute],会自动运行
查看任务文件的细节和描述,了解任务设置的方法和思路
网页数据抓取软件(网探网页数据监控软件功能特点知识兔我们的目标(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-20 18:32
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。如果需要,请下载并使用它。
网络侦探网页数据监控软件功能特点知识兔
我们的目标是让每一位用户“永远领先一步”
基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
同时运行多个任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
任务间调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
网上分享的Grab公式
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行。
网页浏览器数据监控软件知识兔界面删除步骤 查看全部
网页数据抓取软件(网探网页数据监控软件功能特点知识兔我们的目标(组图))
NetTrack网络数据监控软件现在正在各行各业应用互联网技术,互联网上的数据也越来越丰富。一些数据的值是时间相关的,早点知道会有用,以后可能会为零。这个软件就是为了解决这类问题,让你“永远领先一步”是我们的目标。如果需要,请下载并使用它。
网络侦探网页数据监控软件功能特点知识兔
我们的目标是让每一位用户“永远领先一步”
基于IE浏览器
没有任何反爬虫技术手段的意义,只要在IE浏览器中可以正常浏览网页,里面的所有数据都可以被监控。
网页数据抓取
“文本匹配”和“文档结构分析”两种数据采集方法可以单独使用或组合使用,使数据采集更容易、更准确。
数据对比验证
自动判断最新更新数据,支持自定义数据比对校验公式,筛选出用户最感兴趣的数据内容。
及时通知用户
用户注册后,可以将验证后的数据发送到用户的邮箱,或者推送到用户指定的界面对数据进行重新处理。
同时运行多个任务
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
任务间调用
监控任务A(必须是URL)得到的结果可以传递给监控任务B执行,从而获得更丰富的数据结果。
打开通知界面
直接与您的服务器后台对接,后续程序自行定义,实时高效接入自动化数据处理流程。
网上分享的Grab公式
“人人为我,我为人人”分享任意网页的爬取公式,免去公式编辑的烦恼。
无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行时产生的内存垃圾,守护进程长时间无人值守运行。
网页浏览器数据监控软件知识兔界面删除步骤
网页数据抓取软件(网络封包分析软件使用的注意事项有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-20 04:04
Wireshark(以前称为 Ethereal)是一个免费和开源的网络嗅探数据包捕获工具,也是世界上最流行的网络协议分析器。这个网络抓包工具使用WinPCAP作为接口直接与网卡交换数据包。它可以实时检测网络通信数据,检测其捕获的网络通信数据的快照文件,通过图形界面浏览数据,查看网络通信数据包中各层的详细内容。过去,网络数据包分析软件非常昂贵或专门以盈利为目的。Wireshark 的出现改变了这一切。在 GNU GPL 通用许可的保护范围内,用户可以免费获得软件及其源代码。代码,并有权修改和定制其源代码,Ethereal 是世界上最广泛的网络数据包分析软件之一。该软件支持捕获网络数据包,显示数据包数据,还可以检测网络通信数据,查看网络通信数据包的详细内容,并具有强大的功能:包括强大的显示过滤语言和查看TCP会话重建流程它支持数百个协议和媒体类型;借助强大的过滤引擎,用户可以使用过滤器过滤掉有用的数据包,消除无关信息的干扰。Wireshark 仍然被广泛使用。以下是它的一些使用示例:网络管理员使用该软件检测网络问题,网络安全工程师使用它检查信息安全相关问题,
工作流程1.定位 Wireshark
如果没有正确的位置,启动软件后需要很长时间才能捕捉到一些不相关的数据。
2.选择捕获接口
通常,选择连接到 Internet 网络的接口,以便捕获与网络相关的数据。否则,捕获的其他数据对您没有任何帮助。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
通常使用捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更详细,此时使用显示过滤器进行过滤。
5.使用着色规则
通常显示过滤器过滤的数据是有用的数据包。如果您想更突出地突出显示会话,可以使用着色规则来突出显示。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很方便地将数据分布以图表的形式展示出来。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者是一个完整的图片或文件。由于正在传输的文件往往更大,因此信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法。 查看全部
网页数据抓取软件(网络封包分析软件使用的注意事项有哪些?-八维教育)
Wireshark(以前称为 Ethereal)是一个免费和开源的网络嗅探数据包捕获工具,也是世界上最流行的网络协议分析器。这个网络抓包工具使用WinPCAP作为接口直接与网卡交换数据包。它可以实时检测网络通信数据,检测其捕获的网络通信数据的快照文件,通过图形界面浏览数据,查看网络通信数据包中各层的详细内容。过去,网络数据包分析软件非常昂贵或专门以盈利为目的。Wireshark 的出现改变了这一切。在 GNU GPL 通用许可的保护范围内,用户可以免费获得软件及其源代码。代码,并有权修改和定制其源代码,Ethereal 是世界上最广泛的网络数据包分析软件之一。该软件支持捕获网络数据包,显示数据包数据,还可以检测网络通信数据,查看网络通信数据包的详细内容,并具有强大的功能:包括强大的显示过滤语言和查看TCP会话重建流程它支持数百个协议和媒体类型;借助强大的过滤引擎,用户可以使用过滤器过滤掉有用的数据包,消除无关信息的干扰。Wireshark 仍然被广泛使用。以下是它的一些使用示例:网络管理员使用该软件检测网络问题,网络安全工程师使用它检查信息安全相关问题,
工作流程1.定位 Wireshark
如果没有正确的位置,启动软件后需要很长时间才能捕捉到一些不相关的数据。
2.选择捕获接口
通常,选择连接到 Internet 网络的接口,以便捕获与网络相关的数据。否则,捕获的其他数据对您没有任何帮助。
3.使用捕获过滤器
通过设置捕获过滤器,可以避免生成过大的捕获文件。这样,用户在分析数据时就不会受到其他数据的干扰。此外,它还可以为用户节省大量时间。
4.使用显示过滤器
通常使用捕获过滤器过滤的数据通常仍然非常复杂。为了使过滤后的数据包更详细,此时使用显示过滤器进行过滤。
5.使用着色规则
通常显示过滤器过滤的数据是有用的数据包。如果您想更突出地突出显示会话,可以使用着色规则来突出显示。
6.构建图表
如果用户想更清楚地看到网络中数据的变化,可以很方便地将数据分布以图表的形式展示出来。
7.重组数据 Wireshark 的重组功能可以重组一个会话中不同数据包的信息,或者是一个完整的图片或文件。由于正在传输的文件往往更大,因此信息分布在多个数据包中。为了能够查看整个图片或文件,需要使用重新组织数据的方法。
网页数据抓取软件(软件介绍现代网络的网络数据抓取工具,获取你想要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-20 04:03
Web Scraper 是 chrome 浏览器上的数据采集工具。它是一个浏览器插件工具,可以捕获网页上的数据。通过简单的设置,您可以获得您想要的数据。非常强大,图片风格简洁,自由好用,适合大多数人使用;有需要的朋友快来下载体验吧!
软件介绍
现代网络的网络数据提取工具,具有简单的点击式界面
适合所有人的免费且易于使用的网络数据提取工具。
通过简单的点击式界面和几分钟的刮板设置,从单个 网站 中提取数千条记录。
Web Scraper 利用选择器的模块化结构,指示抓取器如何遍历目标网站 以及要提取哪些数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)以及鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,不需要在您的计算机上安装任何东西。您不需要 python、php 或 javaScript 编码经验即可开始提取。此外,Web Scraper Cloud 中的数据提取是完全自动化的。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 excel、Google 表格等。
软件功能
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
*浏览抓取的数据。
*从 网站 将抓取的数据导出到 Excel。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
它只依赖于网络浏览器;因此,您不需要其他软件即可开始抓取。
使用说明
为了掌握网页抓取技术,您只需要学习几个步骤。
1. 安装扩展并在开发者工具中打开网络爬虫标签(必须在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 为 网站 地图添加了提取选择器。
4. 最后启动爬虫,导出爬取的数据。
就是这么简单!
软件亮点
1、抓取多个页面
2、来自动态页面
3、将抓取的数据导出为 CSV
4、导入、导出站点地图
5、只依赖于Chrome浏览器
6、 提取数据(JavaScript AJAX)
7、临时存储在本地存储或 CouchDB 中的数据
8、浏览抓取数据/> 3、多种数据选择类型 查看全部
网页数据抓取软件(软件介绍现代网络的网络数据抓取工具,获取你想要的数据)
Web Scraper 是 chrome 浏览器上的数据采集工具。它是一个浏览器插件工具,可以捕获网页上的数据。通过简单的设置,您可以获得您想要的数据。非常强大,图片风格简洁,自由好用,适合大多数人使用;有需要的朋友快来下载体验吧!
软件介绍
现代网络的网络数据提取工具,具有简单的点击式界面
适合所有人的免费且易于使用的网络数据提取工具。
通过简单的点击式界面和几分钟的刮板设置,从单个 网站 中提取数千条记录。
Web Scraper 利用选择器的模块化结构,指示抓取器如何遍历目标网站 以及要提取哪些数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)以及鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,不需要在您的计算机上安装任何东西。您不需要 python、php 或 javaScript 编码经验即可开始提取。此外,Web Scraper Cloud 中的数据提取是完全自动化的。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 excel、Google 表格等。
软件功能
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
*浏览抓取的数据。
*从 网站 将抓取的数据导出到 Excel。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
它只依赖于网络浏览器;因此,您不需要其他软件即可开始抓取。
使用说明
为了掌握网页抓取技术,您只需要学习几个步骤。
1. 安装扩展并在开发者工具中打开网络爬虫标签(必须在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 为 网站 地图添加了提取选择器。
4. 最后启动爬虫,导出爬取的数据。
就是这么简单!
软件亮点
1、抓取多个页面
2、来自动态页面
3、将抓取的数据导出为 CSV
4、导入、导出站点地图
5、只依赖于Chrome浏览器
6、 提取数据(JavaScript AJAX)
7、临时存储在本地存储或 CouchDB 中的数据
8、浏览抓取数据/> 3、多种数据选择类型
网页数据抓取软件(卧槽这可以换个图吗?(表达式+正则表达式))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-19 16:04
网页数据抓取软件吗?很多新手学爬虫都有一个困惑,就是遇到一些正则表达式比较麻烦的地方,这个时候如果你直接使用正则表达式,会显得比较吃力,所以,今天就给大家推荐一款抓取网页数据的软件,从正则表达式转换为正则表达式+正则表达式/xxx/xxx就可以非常方便的爬取网页数据。效果是这样的。
使用爬虫软件的话,你不用懂java,只要懂html就行了,上中文站,几分钟搞定。如果你想做出点好看的网页,爬虫爬一遍,每条记录都从记录分析然后返回给你,而不是爬一遍网页看一遍数据再返回给你,
手写正则表达式爬百度图片
爬虫很简单。首先让一个python文本编辑器写文件名,然后一行代码就是根据文件名获取图片,什么duplicate你也可以随便搞。最好稍微懂一点html,
把图片发给我,用我的图片自动翻译成你想要的语言给你好吗。
图片gif
你知道html2html5吗
xxx.jpg
you03.jpg
根据一个刚写的小项目看了下基本就差不多能爬取1tb的数据结果
其实正则可以代替java很多地方
相机sdk代码可以自己看看,如果不想学可以看我做的项目,就是图片数据爬取,首页的也有代码直接贴过来,width="500"height="600"alt="卧槽这可以换个图吗?!!!"label="$yi203"width="500"height="600">开发工具选了个新。xcode图片地址:。 查看全部
网页数据抓取软件(卧槽这可以换个图吗?(表达式+正则表达式))
网页数据抓取软件吗?很多新手学爬虫都有一个困惑,就是遇到一些正则表达式比较麻烦的地方,这个时候如果你直接使用正则表达式,会显得比较吃力,所以,今天就给大家推荐一款抓取网页数据的软件,从正则表达式转换为正则表达式+正则表达式/xxx/xxx就可以非常方便的爬取网页数据。效果是这样的。
使用爬虫软件的话,你不用懂java,只要懂html就行了,上中文站,几分钟搞定。如果你想做出点好看的网页,爬虫爬一遍,每条记录都从记录分析然后返回给你,而不是爬一遍网页看一遍数据再返回给你,
手写正则表达式爬百度图片
爬虫很简单。首先让一个python文本编辑器写文件名,然后一行代码就是根据文件名获取图片,什么duplicate你也可以随便搞。最好稍微懂一点html,
把图片发给我,用我的图片自动翻译成你想要的语言给你好吗。
图片gif
你知道html2html5吗
xxx.jpg
you03.jpg
根据一个刚写的小项目看了下基本就差不多能爬取1tb的数据结果
其实正则可以代替java很多地方
相机sdk代码可以自己看看,如果不想学可以看我做的项目,就是图片数据爬取,首页的也有代码直接贴过来,width="500"height="600"alt="卧槽这可以换个图吗?!!!"label="$yi203"width="500"height="600">开发工具选了个新。xcode图片地址:。
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-15 17:23
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”
请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变成红色,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货 查看全部
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”
请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变成红色,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货
网页数据抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-15 17:21
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。 查看全部
网页数据抓取软件(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
SysNucleus WebHarvy 是一个用于抓取 Web 数据的工具。该软件可以帮助您自动从网页中提取数据,并将提取的内容以不同的格式保存。软件可以自动抓取网页上的文字、图片、网址、邮件等内容。您也可以直接将整个网页保存为 HTML 格式,从而提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可让您分析网页上的数据
2、 可以显示来自 HTML 地址的解析连接数据
3、可以延伸到下一个网页
4、可以指定搜索数据的范围和内容
5、扫描的图片可以下载保存
6、支持浏览器复制链接搜索
7、支持配置对应资源项搜索
8、可以使用项目名和资源名来查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、提供更高级的多词搜索和多页搜索
特征:
1、可视点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“指向下一页的链接,WebHarvy网站 刮板将自动从所有页面中刮取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
6、通过代理服务器提取 {pass}{filter}
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
8、使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
网页数据抓取软件(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-13 08:23
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页数据抓取软件(软件特色风越网页批量填写数据提取软件,可自动分析)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】

