
网页手机号抓取程序
网页手机号抓取程序(附近门店小程序如何通过路由传递参数?(1) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-29 20:11
)
程序如何实现页面间跳转 wx.navigateTo(OBJECT)
保持当前页面,跳转到app中的一个页面,使用wx.navigateBack返回到原来的页面。注意:目前页面路径只能乘十层。wx.redirectTo(对象)
关闭当前页面并跳转到应用程序中的一个页面。wx.reLaunch(对象)
关闭所有页面并打开应用程序内的页面。wx.switchTab(对象)
跳转到tabBar页面,关闭所有其他非tabBar页面 wx.navigateBack(OBJECT)
关闭当前页面,返回上一页或多级页面。您可以通过getCurrentPages()) 获取当前页面堆栈,并决定返回多少层。如何更改小程序的标题?
wx.setNavigationBarTitle({
标题:'附近的商店'
})
小程序如何通过路由传递参数?
(1)列表页绑定事件(xxList.wxml)
(2)通过列表页面的事件对象获取参数(xxList.js)
goproductDetail:function(event){
let that = this;
let chosenPrdId = event.currentTarget.id
wx.navigateTo({
url: `../productDetail/productDetail?productId=${
chosenPrdId}`,
success: function () {
wx.setNavigationBarTitle({
title: '产品详情'
})
},
fail: function () {
console.log('进入了失败的回调');
}
})
}
(3)获取详情页路由参数(xxDetail.js)
onLoad: function (option) {
console.log(option.chosenPrdId); //选择的id
// TODO 访问后台接口查询具体信息
}
this.setData 和直接赋值的区别
这两者都会导致data中的数据发生变化,但是this.setData的赋值会导致wxml中的数据发生变化,即同步更新渲染界面,直接赋值只会改变data中的数据,但是界面不会改变。
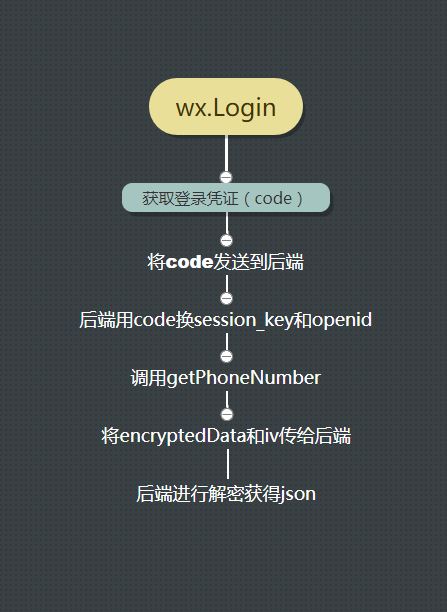
授权获取用户手机号思路
实施思路:
1、通过wx.login获取代码,将代码传到后台,然后后台访问微信接口获取用户的openID和sessionKey,但是后台无法直接将openID或者sessionKey发送到前台(不安全),但是需要单独的字段与openID和sessionKey相关联,然后传递给前台,作为前台登录成功的标志,相当于本地浏览器中cookie存储的session . 设置存储的变量名(如果是userId)
2、前端通过按键按钮触发getPhoneNumber事件,用户允许授权(e.detail.errMsg == 'getPhoneNumber:ok')获取encryptedData,iv
3、通过request请求将[encryptedData],[iv],[userId]传给后台,后台接收解密得到用户手机号,返回给前台,前台存储在本地供其他逻辑判断或以后使用
小程序如何输出遍历对象
{
{
key }}
微信小程序登录授权思路
1.调用wx.login()接口,成功后获取用户的code信息
2.通过接口将code信息传给自己的后端(不是微信后端),在服务器端向微信后端发起请求,成功后获取用户登录状态信息,包括openid, session_key等。也就是openid的交换码,是用户的唯一标识。
3.在后端,获取到openid、session_key等信息后,通过第三方加密生成自己的session信息,返回给前端。
4.前端拿到第三方加密的会话后,通过wx.setStorage()保存在本地,后续请求需要携带第三方加密的会话信息。
5.之后,如果用户需要重新登录,首先查看本地会话信息。如果存在,在微信服务器上使用 wx.checkSession() 检查是否过期。如果它在本地不存在或已过期,请再次从步骤 1 开始登录过程。
onLaunch:function () {
var than = this
// 展示本地存储能力
var logs = wx.getStorageSync('logs') || []
logs.unshift(Date.now())
wx.setStorageSync('logs', logs)
// 登录
wx.login({
success: res => {
var code = res.code
// console.log(code)
wx.getUserInfo({
success: res => {
console.log(res),
// this.globalData.userInfo = res.userInfo
//全局储存
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/getsessionkey',
method: "POST",
data: {
code: code
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success: ress => {
console.log(ress.data)
var openid = ress.data.openid
wx.setStorageSync('openid', ress.data.openid)
wx.setStorageSync('session_key', ress.data.session_key)
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/authlogin',
method: "POST",
data: {
openid: wx.getStorageSync('openid'),
NickName: res.userInfo.nickName,
HeadUrl: res.userInfo.avatarUrl,
gender: res.userInfo.gender
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success(res) {
console.log(res)
var id = res.data.arr.ID
wx.setStorageSync('id', id)
},
})
}
})
}
})
// 发送 res.code 到后台换取 openId, sessionKey, unionId
}
})
// 获取用户信息
wx.getSystemInfo({
success: e => {
this.globalData.StatusBar = e.statusBarHeight;
let capsule = wx.getMenuButtonBoundingClientRect();
if (capsule) {
this.globalData.Custom = capsule;
this.globalData.CustomBar = capsule.bottom + capsule.top - e.statusBarHeight;
} else {
this.globalData.CustomBar = e.statusBarHeight + 50;
}
}
})
} 查看全部
网页手机号抓取程序(附近门店小程序如何通过路由传递参数?(1)
)
程序如何实现页面间跳转 wx.navigateTo(OBJECT)
保持当前页面,跳转到app中的一个页面,使用wx.navigateBack返回到原来的页面。注意:目前页面路径只能乘十层。wx.redirectTo(对象)
关闭当前页面并跳转到应用程序中的一个页面。wx.reLaunch(对象)
关闭所有页面并打开应用程序内的页面。wx.switchTab(对象)
跳转到tabBar页面,关闭所有其他非tabBar页面 wx.navigateBack(OBJECT)
关闭当前页面,返回上一页或多级页面。您可以通过getCurrentPages()) 获取当前页面堆栈,并决定返回多少层。如何更改小程序的标题?
wx.setNavigationBarTitle({
标题:'附近的商店'
})
小程序如何通过路由传递参数?
(1)列表页绑定事件(xxList.wxml)
(2)通过列表页面的事件对象获取参数(xxList.js)
goproductDetail:function(event){
let that = this;
let chosenPrdId = event.currentTarget.id
wx.navigateTo({
url: `../productDetail/productDetail?productId=${
chosenPrdId}`,
success: function () {
wx.setNavigationBarTitle({
title: '产品详情'
})
},
fail: function () {
console.log('进入了失败的回调');
}
})
}
(3)获取详情页路由参数(xxDetail.js)
onLoad: function (option) {
console.log(option.chosenPrdId); //选择的id
// TODO 访问后台接口查询具体信息
}
this.setData 和直接赋值的区别
这两者都会导致data中的数据发生变化,但是this.setData的赋值会导致wxml中的数据发生变化,即同步更新渲染界面,直接赋值只会改变data中的数据,但是界面不会改变。
授权获取用户手机号思路
实施思路:
1、通过wx.login获取代码,将代码传到后台,然后后台访问微信接口获取用户的openID和sessionKey,但是后台无法直接将openID或者sessionKey发送到前台(不安全),但是需要单独的字段与openID和sessionKey相关联,然后传递给前台,作为前台登录成功的标志,相当于本地浏览器中cookie存储的session . 设置存储的变量名(如果是userId)
2、前端通过按键按钮触发getPhoneNumber事件,用户允许授权(e.detail.errMsg == 'getPhoneNumber:ok')获取encryptedData,iv
3、通过request请求将[encryptedData],[iv],[userId]传给后台,后台接收解密得到用户手机号,返回给前台,前台存储在本地供其他逻辑判断或以后使用
小程序如何输出遍历对象
{
{
key }}
微信小程序登录授权思路
1.调用wx.login()接口,成功后获取用户的code信息
2.通过接口将code信息传给自己的后端(不是微信后端),在服务器端向微信后端发起请求,成功后获取用户登录状态信息,包括openid, session_key等。也就是openid的交换码,是用户的唯一标识。
3.在后端,获取到openid、session_key等信息后,通过第三方加密生成自己的session信息,返回给前端。
4.前端拿到第三方加密的会话后,通过wx.setStorage()保存在本地,后续请求需要携带第三方加密的会话信息。
5.之后,如果用户需要重新登录,首先查看本地会话信息。如果存在,在微信服务器上使用 wx.checkSession() 检查是否过期。如果它在本地不存在或已过期,请再次从步骤 1 开始登录过程。
onLaunch:function () {
var than = this
// 展示本地存储能力
var logs = wx.getStorageSync('logs') || []
logs.unshift(Date.now())
wx.setStorageSync('logs', logs)
// 登录
wx.login({
success: res => {
var code = res.code
// console.log(code)
wx.getUserInfo({
success: res => {
console.log(res),
// this.globalData.userInfo = res.userInfo
//全局储存
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/getsessionkey',
method: "POST",
data: {
code: code
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success: ress => {
console.log(ress.data)
var openid = ress.data.openid
wx.setStorageSync('openid', ress.data.openid)
wx.setStorageSync('session_key', ress.data.session_key)
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/authlogin',
method: "POST",
data: {
openid: wx.getStorageSync('openid'),
NickName: res.userInfo.nickName,
HeadUrl: res.userInfo.avatarUrl,
gender: res.userInfo.gender
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success(res) {
console.log(res)
var id = res.data.arr.ID
wx.setStorageSync('id', id)
},
})
}
})
}
})
// 发送 res.code 到后台换取 openId, sessionKey, unionId
}
})
// 获取用户信息
wx.getSystemInfo({
success: e => {
this.globalData.StatusBar = e.statusBarHeight;
let capsule = wx.getMenuButtonBoundingClientRect();
if (capsule) {
this.globalData.Custom = capsule;
this.globalData.CustomBar = capsule.bottom + capsule.top - e.statusBarHeight;
} else {
this.globalData.CustomBar = e.statusBarHeight + 50;
}
}
})
}
网页手机号抓取程序(小程序的登录和记录一下的参考借鉴和借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-29 20:07
本篇文章主要介绍微信小程序封装自定义弹窗的实现代码。非常好,有一定的参考价值。有需要的朋友可以参考以下
最近在登录小程序时,需要同时获取用户的手机号和头像昵称,但是小程序不支持通过单一界面同时获取两种数据,于是就想到了自定义一个弹窗,通过弹窗按钮触发获取手机号。事件。记录下来。
具体代码如下:
在业务代码中:
在业务代码中引入对话组件
申请获取你微信绑定的手机号 取消 授权
对话框组件:
在组件下创建一个新对话框。注意组件不是页面,因为它是作为组件引入页面的
对话框.wxml:
需要传入四个属性
visible:是否显示弹窗
标题:标题
showClose:是否在右上角显示关闭按钮
showFooter:是否显示底部按钮
0}}"> {{ title }} 取消 确定
对话框.js
dialog.json:只需将其声明为组件
{ "component": true, "usingComponents": {} }
对话框.wxss
CSS可以根据你喜欢的风格进行调整。请注意,遮罩层的 z-index 稍高一些,以确保它位于顶层。
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
总结
以上就是小编介绍的微信小程序打包自定义弹窗的实现代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。非常感谢您对本站的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢! 查看全部
网页手机号抓取程序(小程序的登录和记录一下的参考借鉴和借鉴价值)
本篇文章主要介绍微信小程序封装自定义弹窗的实现代码。非常好,有一定的参考价值。有需要的朋友可以参考以下
最近在登录小程序时,需要同时获取用户的手机号和头像昵称,但是小程序不支持通过单一界面同时获取两种数据,于是就想到了自定义一个弹窗,通过弹窗按钮触发获取手机号。事件。记录下来。
具体代码如下:
在业务代码中:
在业务代码中引入对话组件
申请获取你微信绑定的手机号 取消 授权
对话框组件:
在组件下创建一个新对话框。注意组件不是页面,因为它是作为组件引入页面的
对话框.wxml:
需要传入四个属性
visible:是否显示弹窗
标题:标题
showClose:是否在右上角显示关闭按钮
showFooter:是否显示底部按钮
0}}"> {{ title }} 取消 确定
对话框.js
dialog.json:只需将其声明为组件
{ "component": true, "usingComponents": {} }
对话框.wxss
CSS可以根据你喜欢的风格进行调整。请注意,遮罩层的 z-index 稍高一些,以确保它位于顶层。
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
总结
以上就是小编介绍的微信小程序打包自定义弹窗的实现代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。非常感谢您对本站的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
网页手机号抓取程序(学习爬虫第二周,爬取58同城手机号码,网址如下所示。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2022-01-27 23:19
学习爬虫第二周,爬取同城58的手机号。网址如下。
网页预览.png
根据学习情况,首先需要分析网页,观察页面结构。
观察页面特征:
对于大规模的数据抓取,观察页面结构特点,编写的程序是否通用,是否可以适用于所有页面。找到边界条件,找到限制。
其次,需要设计程序的工作流程。
设计工作流程
在根据页面弄清楚程序是如何设计的之后,制定有效的工作流程,保证程序在爬取过程中的高效执行。工作输出效率更稳定。
1. 要大规模抓取数据,我们需要知道边界在哪里。查询网页后:
http://bj.58.com/shoujihao/pn{}.format(page)
我们发现当输入到pn117时,页面数据不见了。
同时,搜索网页中标题和链接的元素位置,并将捕获存储在Mongo中,其中存储了网页上所有手机号码标题的详情页的url链接。
2.分析网页后,适合我们的网站如下:
对.png
不恰当的 网站 是这样的:
错误.png
因此,在爬取Spider2的详情页时,需要根据正确的网页结构元素进行爬取。
同时抓取网页中需要的元素。
代码显示如下:
#!/usr/bin/env python
# coding: utf-8
from bs4 import BeautifulSoup
import requests
import time
import pymongo
#create the database
client = pymongo.MongoClient('localhost',27017)
#name:Phone
Phone = client['Phone']
#table:phone_numbers 存储手机号的表
phone_numbers = Phone['phone_numbers']
#table:phone_info 详细信息
phone_info = Phone['phone_info']
#infocont > span > b
#Spider1 提取链接
def get_links_from(page):
url = 'http://bj.58.com/shoujihao/pn{}/'.format(page)
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#infolist > div > ul > div > ul > li > a.t > strong')
links = Soup.select('#infolist > div > ul > div > ul > li > a.t')
for title,link in zip(titles,links):
data = {
'title':title.get_text(),
'link':link.get('href')
}
phone_numbers.insert_one(data)
#Spider2 详细页面
def get_item_from(url):
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.mainTitle > h1')
prices = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.sumary > ul > li > div.su_con > span')
for title,price in zip(titles,prices):
title = title.get_text().replace('\n','').replace('\t','').replace(' ','')
price = price.get_text().replace('\n','').replace('\t','').replace(' ','')
data = {
'title':title,
'price':price,
'url':url
}
print(data)
phone_info.insert_one(data)
for page in range(1,117): #抓取所有页面
get_links_from(page)
for info in phone_numbers.find(): #从数据库中抓取存储的url
url = info['link']
get_item_from(url)
运行结果截图:
phone_number 中的数据:
手机号码存储表.png
phone_info 中的数据:
详情.png
总结: 查看全部
网页手机号抓取程序(学习爬虫第二周,爬取58同城手机号码,网址如下所示。)
学习爬虫第二周,爬取同城58的手机号。网址如下。

网页预览.png
根据学习情况,首先需要分析网页,观察页面结构。
观察页面特征:
对于大规模的数据抓取,观察页面结构特点,编写的程序是否通用,是否可以适用于所有页面。找到边界条件,找到限制。
其次,需要设计程序的工作流程。
设计工作流程
在根据页面弄清楚程序是如何设计的之后,制定有效的工作流程,保证程序在爬取过程中的高效执行。工作输出效率更稳定。
1. 要大规模抓取数据,我们需要知道边界在哪里。查询网页后:
http://bj.58.com/shoujihao/pn{}.format(page)
我们发现当输入到pn117时,页面数据不见了。
同时,搜索网页中标题和链接的元素位置,并将捕获存储在Mongo中,其中存储了网页上所有手机号码标题的详情页的url链接。
2.分析网页后,适合我们的网站如下:
对.png
不恰当的 网站 是这样的:
错误.png
因此,在爬取Spider2的详情页时,需要根据正确的网页结构元素进行爬取。
同时抓取网页中需要的元素。
代码显示如下:
#!/usr/bin/env python
# coding: utf-8
from bs4 import BeautifulSoup
import requests
import time
import pymongo
#create the database
client = pymongo.MongoClient('localhost',27017)
#name:Phone
Phone = client['Phone']
#table:phone_numbers 存储手机号的表
phone_numbers = Phone['phone_numbers']
#table:phone_info 详细信息
phone_info = Phone['phone_info']
#infocont > span > b
#Spider1 提取链接
def get_links_from(page):
url = 'http://bj.58.com/shoujihao/pn{}/'.format(page)
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#infolist > div > ul > div > ul > li > a.t > strong')
links = Soup.select('#infolist > div > ul > div > ul > li > a.t')
for title,link in zip(titles,links):
data = {
'title':title.get_text(),
'link':link.get('href')
}
phone_numbers.insert_one(data)
#Spider2 详细页面
def get_item_from(url):
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.mainTitle > h1')
prices = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.sumary > ul > li > div.su_con > span')
for title,price in zip(titles,prices):
title = title.get_text().replace('\n','').replace('\t','').replace(' ','')
price = price.get_text().replace('\n','').replace('\t','').replace(' ','')
data = {
'title':title,
'price':price,
'url':url
}
print(data)
phone_info.insert_one(data)
for page in range(1,117): #抓取所有页面
get_links_from(page)
for info in phone_numbers.find(): #从数据库中抓取存储的url
url = info['link']
get_item_from(url)
运行结果截图:
phone_number 中的数据:
手机号码存储表.png
phone_info 中的数据:
详情.png
总结:
网页手机号抓取程序(HTML代码中将标签中的内容提取出来的思路和方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 09:26
)
#target URL=""
#主要用到的python库:requests、etree
主要使用xpath进行信息处理
我们先说xpath:
XPath 是 XML 路径语言,它是一种用于确定 XML(标准通用标记语言的子集)文档的某个部分的位置的语言。 XPath 基于 XML 的树结构,它提供了在数据结构树中查找节点的能力。说白了就是提取HTML代码中标签的内容。
思考:
先看页面
这是我们主要要提取的信息;
我们先来看看提取出来的效果:
查看网站源代码(F12):
我们需要的信息在一个名为'table'的标签里,而在table标签里有一个小标签'tr','td'包裹了我们的信息,所以网站标签的路径很清晰标签的路径就是我们需要的XPATH,可以直接通过浏览器复制粘贴,不用担心找不到路径!
编写代码:
首先requests函数的get函数抓取网页的代码。爬取的时候最好加上请求头,不然有些网站会阻塞IP:
str(number)中的数字就是我们要查询的电话号码
然后使用我们得到的html代码进行编码整理:
基本上所有的网站都可以用这几行代码组织起来,是通用代码。
然后使用xpath提取信息:
xpath在etree库中,而etree在模块lxml中,所以先添加头文件 from lxml import etree like C语言
那么就可以根据路径提取出来了:
con1=selet.xpath('/html/body/table[2]/tr[1]/td/b/text())
con2=selet.xpath('/html/body/table[2]/tr[1]/td/text())
因为标签表里有8个这么小的标签,所以我们要循环8次,每次循环都改变str[]里面的数字,然后打印出来:
p>
最后给出所有代码:
import requests
from lxml import etree
def find(slet,num):
con1=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/b/text()')
con2=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/text()')
for i in con1:
print(i)
for i in con2:
print(i)
while(1):
print("手机号测吉凶纯属娱乐!!!\n输入q退出!\n")
number=input("请输入你的手机号:")
if(number=='q'):
break;
kv={'user-agent':'Chrome/55.0.2883.87 Mobile Safari/537.36'}
url="http://jx.ip138.com/"+str(number)
r=requests.get(url,headers=kv)
r.encoding=r.apparent_encoding
html=r.text
selet=etree.HTML(html)
for num in range(1,9):
find(selet,num)
print("*************************************") 查看全部
网页手机号抓取程序(HTML代码中将标签中的内容提取出来的思路和方法
)
#target URL=""
#主要用到的python库:requests、etree
主要使用xpath进行信息处理
我们先说xpath:
XPath 是 XML 路径语言,它是一种用于确定 XML(标准通用标记语言的子集)文档的某个部分的位置的语言。 XPath 基于 XML 的树结构,它提供了在数据结构树中查找节点的能力。说白了就是提取HTML代码中标签的内容。
思考:
先看页面

这是我们主要要提取的信息;
我们先来看看提取出来的效果:

查看网站源代码(F12):

我们需要的信息在一个名为'table'的标签里,而在table标签里有一个小标签'tr','td'包裹了我们的信息,所以网站标签的路径很清晰标签的路径就是我们需要的XPATH,可以直接通过浏览器复制粘贴,不用担心找不到路径!
编写代码:
首先requests函数的get函数抓取网页的代码。爬取的时候最好加上请求头,不然有些网站会阻塞IP:

str(number)中的数字就是我们要查询的电话号码
然后使用我们得到的html代码进行编码整理:

基本上所有的网站都可以用这几行代码组织起来,是通用代码。
然后使用xpath提取信息:
xpath在etree库中,而etree在模块lxml中,所以先添加头文件 from lxml import etree like C语言
那么就可以根据路径提取出来了:
con1=selet.xpath('/html/body/table[2]/tr[1]/td/b/text())
con2=selet.xpath('/html/body/table[2]/tr[1]/td/text())
因为标签表里有8个这么小的标签,所以我们要循环8次,每次循环都改变str[]里面的数字,然后打印出来:
p>

最后给出所有代码:
import requests
from lxml import etree
def find(slet,num):
con1=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/b/text()')
con2=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/text()')
for i in con1:
print(i)
for i in con2:
print(i)
while(1):
print("手机号测吉凶纯属娱乐!!!\n输入q退出!\n")
number=input("请输入你的手机号:")
if(number=='q'):
break;
kv={'user-agent':'Chrome/55.0.2883.87 Mobile Safari/537.36'}
url="http://jx.ip138.com/"+str(number)
r=requests.get(url,headers=kv)
r.encoding=r.apparent_encoding
html=r.text
selet=etree.HTML(html)
for num in range(1,9):
find(selet,num)
print("*************************************")
网页手机号抓取程序( 网站站点用户访客移动端手机号码号码,大大降低营销推广规划管理运营成本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-26 08:16
网站站点用户访客移动端手机号码号码,大大降低营销推广规划管理运营成本)
手机网站客人手机号抓码写法原理!
现在市场上有很多软件可以捕获网站网站和网页的用户信息。您可以浏览访问网站的手机号获取手机号。通过这些软件或系统,可以查询手机归属地,提取用户。用户可以通过检索用户访问者的搜索信息内容、手机号码信息、查看浏览网页信息等,轻松了解用户和访问者的最新需求。有了这些精准的信息,网站站长可以进行二次推广和营销,大大降低了营销、推广、策划、管理和运营的成本。这些只需在网页上安装一段Js代码即可实现。
捕获用户访问者手机号的手机号,捕获用户手机网页的访问者。
传统的公司采集电话推广营销方式,公司招聘大量电话接线员,拿着厚厚的一叠电话费,从早到晚拿着电话打电话。在这个社会中,越来越多的用户对这种电话营销、营销、广告的方式产生了强烈的反感。
5个营业员算下来,底薪至少1500元一个月,加起来就是7500元一个月;如果不计算别的,一个月内可能找不到100个真实准确的客户用户数据;但是使用我们的网站网站用户访客手机提取系统,一天有机会获得100个真实准确的客户用户数据,一个月内会有更多的沉淀,而且都是准确的客户用户。
网站本站用户访客手机号抓取软件是一套专门用于手机站用户访客手机号抓取的专业软件。要使用它,您只需要在手机站安装一个简单的代码,当用户和访问者在手机上查看和浏览您的网页时,他们就可以抓取它。抓取移动端的手机号,登录到软件的在线后台后,可以清晰的看到用户和访客的信息,包括移动端。手机号码、网站标题TITLE、来源关键词关键字、来源url、地区、ip等,可通过Excel批量导出,方便管理。
用户访客手机号抓取软件的优点是:
抢占用户和访客的手机号码,获得二次推广和营销机会,增加公司销售额,降低策划、管理和运营成本。
现在网络营销推广非常困难,用户流量成本不断攀升。以百度竞价为例,90%以上的客户和用户访问并点击了广告,浏览并访问了网站网站。我们直接去了,只有极少数人询问并留下了我们的联系方式,大量的广告费就这样白白浪费了。想知道客户和用户的联系方式进行二次推广和营销,比登天还难。不过,现在手机号码抓取软件的出现,彻底解决了这样的问题。有了目标客户用户的电话号码,你认为订单会减少吗?试想一下,如果你能接触到 95% 的流失用户并持续跟进,您将能够恢复至少 60% 的准确客户用户。那么成交率肯定会大大提高!与其被动等待,不如主动挽回流失的客户和用户。 查看全部
网页手机号抓取程序(
网站站点用户访客移动端手机号码号码,大大降低营销推广规划管理运营成本)

手机网站客人手机号抓码写法原理!
现在市场上有很多软件可以捕获网站网站和网页的用户信息。您可以浏览访问网站的手机号获取手机号。通过这些软件或系统,可以查询手机归属地,提取用户。用户可以通过检索用户访问者的搜索信息内容、手机号码信息、查看浏览网页信息等,轻松了解用户和访问者的最新需求。有了这些精准的信息,网站站长可以进行二次推广和营销,大大降低了营销、推广、策划、管理和运营的成本。这些只需在网页上安装一段Js代码即可实现。
捕获用户访问者手机号的手机号,捕获用户手机网页的访问者。
传统的公司采集电话推广营销方式,公司招聘大量电话接线员,拿着厚厚的一叠电话费,从早到晚拿着电话打电话。在这个社会中,越来越多的用户对这种电话营销、营销、广告的方式产生了强烈的反感。
5个营业员算下来,底薪至少1500元一个月,加起来就是7500元一个月;如果不计算别的,一个月内可能找不到100个真实准确的客户用户数据;但是使用我们的网站网站用户访客手机提取系统,一天有机会获得100个真实准确的客户用户数据,一个月内会有更多的沉淀,而且都是准确的客户用户。
网站本站用户访客手机号抓取软件是一套专门用于手机站用户访客手机号抓取的专业软件。要使用它,您只需要在手机站安装一个简单的代码,当用户和访问者在手机上查看和浏览您的网页时,他们就可以抓取它。抓取移动端的手机号,登录到软件的在线后台后,可以清晰的看到用户和访客的信息,包括移动端。手机号码、网站标题TITLE、来源关键词关键字、来源url、地区、ip等,可通过Excel批量导出,方便管理。
用户访客手机号抓取软件的优点是:
抢占用户和访客的手机号码,获得二次推广和营销机会,增加公司销售额,降低策划、管理和运营成本。
现在网络营销推广非常困难,用户流量成本不断攀升。以百度竞价为例,90%以上的客户和用户访问并点击了广告,浏览并访问了网站网站。我们直接去了,只有极少数人询问并留下了我们的联系方式,大量的广告费就这样白白浪费了。想知道客户和用户的联系方式进行二次推广和营销,比登天还难。不过,现在手机号码抓取软件的出现,彻底解决了这样的问题。有了目标客户用户的电话号码,你认为订单会减少吗?试想一下,如果你能接触到 95% 的流失用户并持续跟进,您将能够恢复至少 60% 的准确客户用户。那么成交率肯定会大大提高!与其被动等待,不如主动挽回流失的客户和用户。
网页手机号抓取程序(近年来运营商精准大数据接口实时调度:一般来说精准 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-24 01:18
)
近年来,运营商精准大数据的神秘色彩总是被越来越多地描述,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
众所周知,中国移动、中国联通、电信是我们熟知的三大运营商。目前在我们所处的环境中,所有的上网行为都是建立在这三大运营商的基础之上的,因为互联网上的任何行为都是基于通过这三大运营商,原则上我们所有的通话记录和上网行为即使您在终端(电脑或手机)也无法从运营商数据库中清除,但您的数据信息无法清除。
看到这里,有人会想,难道我一点秘密都没有吗?原则上是的,互联网时代每个人都是皇帝的新衣,但你不必惊慌,因为以中国为例,平均每天有8.29亿(不完全统计在2020),你可以理解因此,这829亿的任何行为(比如点击网站)都被记录为数据标签,有兴趣的可以深入挖掘,计算一下这个量在哪里。那么你的担心就不是担心了。但是这些大数据对我们的日常生活有用吗?它在哪里使用?
可以观看CCTV9的《大数据时代》纪录片。就是利用大数据分析人群行为标签,挽救生命,精准安排出行出行。让我们关注每个人对我们个人的关心,以及公司是否使用它们来运营业务大数据以获取客户、增加价值和降低营销成本。
运营商大数据数据接口实时调度:一般来说是针对有网站开发权,可以植入程序,对访客数据进行实时分析的。
通过植入网站服务器内部程序,将运营商的数据接口实时连接到网站,让运营商授权,如果访客实时访问,会回调网站 实时。在所有者指定的TXT文档中,从访问文档到自动生成数据,一般只需要几毫秒。
一般来说,运营商大数据实时建模和捕获的主要应用是企业、行业和销售人员进行外呼获取客户。
查看全部
网页手机号抓取程序(近年来运营商精准大数据接口实时调度:一般来说精准
)
近年来,运营商精准大数据的神秘色彩总是被越来越多地描述,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
众所周知,中国移动、中国联通、电信是我们熟知的三大运营商。目前在我们所处的环境中,所有的上网行为都是建立在这三大运营商的基础之上的,因为互联网上的任何行为都是基于通过这三大运营商,原则上我们所有的通话记录和上网行为即使您在终端(电脑或手机)也无法从运营商数据库中清除,但您的数据信息无法清除。
看到这里,有人会想,难道我一点秘密都没有吗?原则上是的,互联网时代每个人都是皇帝的新衣,但你不必惊慌,因为以中国为例,平均每天有8.29亿(不完全统计在2020),你可以理解因此,这829亿的任何行为(比如点击网站)都被记录为数据标签,有兴趣的可以深入挖掘,计算一下这个量在哪里。那么你的担心就不是担心了。但是这些大数据对我们的日常生活有用吗?它在哪里使用?
可以观看CCTV9的《大数据时代》纪录片。就是利用大数据分析人群行为标签,挽救生命,精准安排出行出行。让我们关注每个人对我们个人的关心,以及公司是否使用它们来运营业务大数据以获取客户、增加价值和降低营销成本。
运营商大数据数据接口实时调度:一般来说是针对有网站开发权,可以植入程序,对访客数据进行实时分析的。
通过植入网站服务器内部程序,将运营商的数据接口实时连接到网站,让运营商授权,如果访客实时访问,会回调网站 实时。在所有者指定的TXT文档中,从访问文档到自动生成数据,一般只需要几毫秒。
一般来说,运营商大数据实时建模和捕获的主要应用是企业、行业和销售人员进行外呼获取客户。
网页手机号抓取程序(作业效果:>showdbsbj580.001GBlocal0.000GBxiaozhu)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-20 21:08
工作效果:
> 显示数据库
bj58 0.001GB
本地 0.000GB
小猪 0.000GB
> 使用 bj58
切换到数据库 bj58
> 显示采集
详细信息
链接
> db.links.find().count()
3481
> db.links.find()[0]
{
"_id" : ObjectId("574a689ee4eaf"),
“关联” : ””,
“标题” : ””
}
> db.detailinfo.find().count()
3481
> db.detailinfo.find()[0]
{
"_id" : ObjectId("574abe78e00282487d8dd6e7"),
“电话”:“”,
“网址”:“”,
“价格”:“800”,
"isp" : "联通",
“卖家”:“王先生”,
“sell_number”:“”
}
>
笔记和总结
为大规模爬网准备工作流程
观察页面结构特征
以前只在特定页面上抓取信息
但是,如果是网站的大规模爬取,会涉及到几个页面,而且程序需要通用性,爬取需要的页面
设计工作流程
保证抓取过程的效率
观察页面结构特征
不同的页面会有不同的内容结构。例如,有些具有独特的元素,因此某些页面无法使用同一组爬虫进行爬取。
有些页面不需要爬取
手动指定要爬取的页数后,需要让程序识别分页元素来判断是否是最后一页,避免最后一页没有信息,比如直接跳过。
设计工作流程
两只爬行动物
从列表页面爬取所有产品的 URL 并将它们存储在数据库中的表中
获取商品url,获取详情页,爬取需要的信息,存入另一个表
将爬取任务分成两个爬虫的原因是,在做大规模数据爬取的时候,最好一次只做一件事,这样可以提高爬虫的稳定性
当您可能遇到问题时,这是工作时间和调试之间的平衡
获取类别/频道
从主页获取所有类别/频道的信息
构造分类列表页面的url:常用前缀、频道、发布者类型、页码
url = "{}{}/0/pn{}".format()
爬取分类列表页面中商品详情的url
如果是批量访问,最好在访问之间留一点时间。如果 网站 压力好,没关系
对于分页结束需要停止的页面,判断是否有td标签,find('td','t'),如果有,继续,否则,停止
从元素结构来看
爬取商品详情
每次有请求,浏览量都会变化,所以不需要记录
访问的url可能会返回404,因为交易已经成功下线。一个页面的js脚本链接收录404
从具体内容来看
no_longer_exist = '404' in soup.find('script', type='').get('src').split('/')
soup.prettify() 可以使打印出来的 HTML 内容更具可读性
概括
CSS
第一页有内容要跳过
其他页面没有这个问题
没有办法直接通过CSS选择器进行过滤,只能判断是否是首页,然后区别对待:
如果数 == 1:
boxlist = detail_soup.select("div.boxlist div.boxlist")[1]
别的:
boxlist = detail_soup.select("div.boxlist div.boxlist")[0]
内容
海淀
“——
" 枣君寺
获取所有子元素的内容,子元素之间的内容
area_data = detail_soup.select("span.c_25d")
area = list(area_data[0].stripped_strings) if area_data else None
打印区
[u'\u897f\u57ce', u'-', u'\u897f\u56db']
但以下情况不能这样处理:
"
联通
A B C D
"
去掉两边的空格“”,删除字符串中间的“”和\t,将多个\n替换为一个\n,然后用\n分隔成一个列表
number = list(detail_soup.select("h1")[0].stripped_strings)[0]
info_list = number.replace('\t','').replace(' ',"").replace('\n\n\n','\n').split("\n")
# print 'number=',info_list[0]
# print 'isp=', info_list[1]
“蟒蛇食谱” 查看全部
网页手机号抓取程序(作业效果:>showdbsbj580.001GBlocal0.000GBxiaozhu)
工作效果:
> 显示数据库
bj58 0.001GB
本地 0.000GB
小猪 0.000GB
> 使用 bj58
切换到数据库 bj58
> 显示采集
详细信息
链接
> db.links.find().count()
3481
> db.links.find()[0]
{
"_id" : ObjectId("574a689ee4eaf"),
“关联” : ””,
“标题” : ””
}
> db.detailinfo.find().count()
3481
> db.detailinfo.find()[0]
{
"_id" : ObjectId("574abe78e00282487d8dd6e7"),
“电话”:“”,
“网址”:“”,
“价格”:“800”,
"isp" : "联通",
“卖家”:“王先生”,
“sell_number”:“”
}
>
笔记和总结
为大规模爬网准备工作流程
观察页面结构特征
以前只在特定页面上抓取信息
但是,如果是网站的大规模爬取,会涉及到几个页面,而且程序需要通用性,爬取需要的页面
设计工作流程
保证抓取过程的效率
观察页面结构特征
不同的页面会有不同的内容结构。例如,有些具有独特的元素,因此某些页面无法使用同一组爬虫进行爬取。
有些页面不需要爬取
手动指定要爬取的页数后,需要让程序识别分页元素来判断是否是最后一页,避免最后一页没有信息,比如直接跳过。
设计工作流程
两只爬行动物
从列表页面爬取所有产品的 URL 并将它们存储在数据库中的表中
获取商品url,获取详情页,爬取需要的信息,存入另一个表
将爬取任务分成两个爬虫的原因是,在做大规模数据爬取的时候,最好一次只做一件事,这样可以提高爬虫的稳定性
当您可能遇到问题时,这是工作时间和调试之间的平衡
获取类别/频道
从主页获取所有类别/频道的信息
构造分类列表页面的url:常用前缀、频道、发布者类型、页码
url = "{}{}/0/pn{}".format()
爬取分类列表页面中商品详情的url
如果是批量访问,最好在访问之间留一点时间。如果 网站 压力好,没关系
对于分页结束需要停止的页面,判断是否有td标签,find('td','t'),如果有,继续,否则,停止
从元素结构来看
爬取商品详情
每次有请求,浏览量都会变化,所以不需要记录
访问的url可能会返回404,因为交易已经成功下线。一个页面的js脚本链接收录404
从具体内容来看
no_longer_exist = '404' in soup.find('script', type='').get('src').split('/')
soup.prettify() 可以使打印出来的 HTML 内容更具可读性
概括
CSS
第一页有内容要跳过
其他页面没有这个问题
没有办法直接通过CSS选择器进行过滤,只能判断是否是首页,然后区别对待:
如果数 == 1:
boxlist = detail_soup.select("div.boxlist div.boxlist")[1]
别的:
boxlist = detail_soup.select("div.boxlist div.boxlist")[0]
内容
海淀
“——
" 枣君寺
获取所有子元素的内容,子元素之间的内容
area_data = detail_soup.select("span.c_25d")
area = list(area_data[0].stripped_strings) if area_data else None
打印区
[u'\u897f\u57ce', u'-', u'\u897f\u56db']
但以下情况不能这样处理:
"
联通
A B C D
"
去掉两边的空格“”,删除字符串中间的“”和\t,将多个\n替换为一个\n,然后用\n分隔成一个列表
number = list(detail_soup.select("h1")[0].stripped_strings)[0]
info_list = number.replace('\t','').replace(' ',"").replace('\n\n\n','\n').split("\n")
# print 'number=',info_list[0]
# print 'isp=', info_list[1]
“蟒蛇食谱”
网页手机号抓取程序(微信小程序获取手机号授权用户登录功能介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-19 05:11
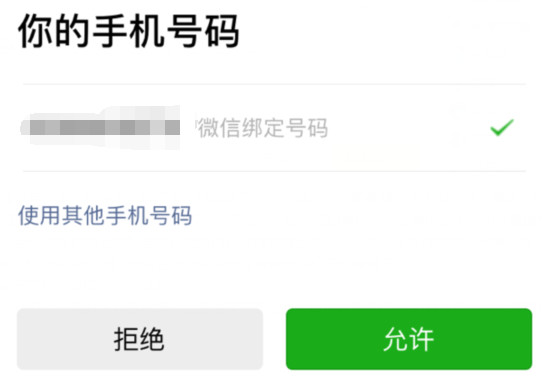
小程序中有很多地方用到了注册的用户信息。用户需要填写手机号等,有了这个组件,无需用户填写即可快速获取绑定微信的手机号。本文主要分享微信小程序获取手机号授权用户登录功能,需要的朋友可以参考一下,希望对大家有帮助。
1.getPhoneNumber 该组件由按钮实现(其他标签无效)。在按钮中设置 open-type="getPhoneNumber",并绑定 bindgetphonenumber 事件获取回调。
2.使用该组件前必须调用登录接口。如果没有调用登录,点击按钮,会提示先调用登录。
App({
onLaunch: function () {
wx.login({
success: function (res) {
if (res.code) {
//发起网络请求
console.log(res.code)
} else {
console.log('获取用户登录态失败!' + res.errMsg)
}
}
});
}
})
3.通过bindphonenumber绑定的事件获取回调。回调有三个参数,
errMsg:用户点击取消或授权信息回调。
iv:加密算法的初始向量(如果用户不同意授权,则未定义)。
encryptedData:用户信息的加密数据(如果用户不同意授权,也会返回undefined)
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
if (e.detail.errMsg == 'getPhoneNumber:fail user deny'){
wx.showModal({
title: '提示',
showCancel: false,
content: '未授权',
success: function (res) { }
})
} else {
wx.showModal({
title: '提示',
showCancel: false,
content: '同意授权',
success: function (res) { }
})
}
}
4.最后还是要根据自己的业务逻辑来处理。如果用户不同意授权,我们可能会有一个界面让他手动输入。如果不是强制获取手机号,可以直接跳转页面进行下一步。. (用户不同意授权errMsg返回'getPhoneNumber:fail user deny')
5.用户同意授权,我们可以根据登录时得到的code,通过后台和微信处理得到session_key,最后传递app_id、session_key、iv、encryptedData(用户同意授权errMsg返回 'getPhoneNumber: ok')
还学习了一个小程序功能,希望对大家有帮助。 查看全部
网页手机号抓取程序(微信小程序获取手机号授权用户登录功能介绍(图))
小程序中有很多地方用到了注册的用户信息。用户需要填写手机号等,有了这个组件,无需用户填写即可快速获取绑定微信的手机号。本文主要分享微信小程序获取手机号授权用户登录功能,需要的朋友可以参考一下,希望对大家有帮助。
1.getPhoneNumber 该组件由按钮实现(其他标签无效)。在按钮中设置 open-type="getPhoneNumber",并绑定 bindgetphonenumber 事件获取回调。
2.使用该组件前必须调用登录接口。如果没有调用登录,点击按钮,会提示先调用登录。
App({
onLaunch: function () {
wx.login({
success: function (res) {
if (res.code) {
//发起网络请求
console.log(res.code)
} else {
console.log('获取用户登录态失败!' + res.errMsg)
}
}
});
}
})
3.通过bindphonenumber绑定的事件获取回调。回调有三个参数,
errMsg:用户点击取消或授权信息回调。
iv:加密算法的初始向量(如果用户不同意授权,则未定义)。
encryptedData:用户信息的加密数据(如果用户不同意授权,也会返回undefined)
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
if (e.detail.errMsg == 'getPhoneNumber:fail user deny'){
wx.showModal({
title: '提示',
showCancel: false,
content: '未授权',
success: function (res) { }
})
} else {
wx.showModal({
title: '提示',
showCancel: false,
content: '同意授权',
success: function (res) { }
})
}
}
4.最后还是要根据自己的业务逻辑来处理。如果用户不同意授权,我们可能会有一个界面让他手动输入。如果不是强制获取手机号,可以直接跳转页面进行下一步。. (用户不同意授权errMsg返回'getPhoneNumber:fail user deny')
5.用户同意授权,我们可以根据登录时得到的code,通过后台和微信处理得到session_key,最后传递app_id、session_key、iv、encryptedData(用户同意授权errMsg返回 'getPhoneNumber: ok')
还学习了一个小程序功能,希望对大家有帮助。
网页手机号抓取程序(网页手机号抓取程序,.txt文件怎么用订阅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-19 03:01
网页手机号抓取程序,适用于天猫等各大购物网站,非常快速非常安全,功能不错
易于上手的,
也许是来自购物网站的爬虫
可以看看这个方法有点意思:使用elasticsearch获取rss订阅。(v2.6),
aibooter。
根据楼主的问题,robots.txt文件抓取被抓取者的网页,
一看楼主就没好好学习txt文件解析
robots.txt文件给了一个公平公正的态度让网站正视问题,所以一般不会说网站不对抗爬虫的问题。另外一个就是txt文件被反编译的话(针对某些文件格式)肯定会被反爬虫大规模抓取的,这时候可以在github上面找找现有的python爬虫工具了。当然,从爬虫本身讲,txt文件本身也是不对抗爬虫的。毕竟txt文件当时很流行,很多python模块可以直接拿来用。
但是其实爬虫之间互相也有约定俗成的规则,所以有些时候比如豆瓣登录,很多网站其实可以直接加一个筛选按钮,可以去掉访问的登录或者半年内已用豆瓣购买过电影的信息,如果是各大电影站不做区分的话是很容易被爬虫直接访问爬去的。txt也是一样的,txt文件也很方便使用。 查看全部
网页手机号抓取程序(网页手机号抓取程序,.txt文件怎么用订阅)
网页手机号抓取程序,适用于天猫等各大购物网站,非常快速非常安全,功能不错
易于上手的,
也许是来自购物网站的爬虫
可以看看这个方法有点意思:使用elasticsearch获取rss订阅。(v2.6),
aibooter。
根据楼主的问题,robots.txt文件抓取被抓取者的网页,
一看楼主就没好好学习txt文件解析
robots.txt文件给了一个公平公正的态度让网站正视问题,所以一般不会说网站不对抗爬虫的问题。另外一个就是txt文件被反编译的话(针对某些文件格式)肯定会被反爬虫大规模抓取的,这时候可以在github上面找找现有的python爬虫工具了。当然,从爬虫本身讲,txt文件本身也是不对抗爬虫的。毕竟txt文件当时很流行,很多python模块可以直接拿来用。
但是其实爬虫之间互相也有约定俗成的规则,所以有些时候比如豆瓣登录,很多网站其实可以直接加一个筛选按钮,可以去掉访问的登录或者半年内已用豆瓣购买过电影的信息,如果是各大电影站不做区分的话是很容易被爬虫直接访问爬去的。txt也是一样的,txt文件也很方便使用。
网页手机号抓取程序( 达叔小生:微信小程序如何获取用户绑定手机号的相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-18 14:12
达叔小生:微信小程序如何获取用户绑定手机号的相关资料)
微信小程序获取用户绑定手机号方法示例
更新时间:2019-07-21 15:46:58 作者:大树小生
本篇文章主要介绍微信小程序如何获取用户绑定手机号的相关信息。文中对示例代码进行了非常详细的介绍,对大家学习或使用微信小程序有一定的参考价值。,有需要的朋友,一起学习吧
用户调用 wx.login() 方法获取登录用户凭证码
wx.login({
success: function(res) {
console.log('loginCode', res.code)
}
});
代码传到后台,凭证代码获取session_key和openid
https://api.weixin.qq.com/sns/ ... _code
后台会获取用户的openid和session_key
getPhoneNumber 组件
得到 encryptedData 和 iv
Page({
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
}
})
将 encryptedData 和 iv 传递到后台
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。感谢您对脚本之家的支持。 查看全部
网页手机号抓取程序(
达叔小生:微信小程序如何获取用户绑定手机号的相关资料)
微信小程序获取用户绑定手机号方法示例
更新时间:2019-07-21 15:46:58 作者:大树小生
本篇文章主要介绍微信小程序如何获取用户绑定手机号的相关信息。文中对示例代码进行了非常详细的介绍,对大家学习或使用微信小程序有一定的参考价值。,有需要的朋友,一起学习吧
用户调用 wx.login() 方法获取登录用户凭证码
wx.login({
success: function(res) {
console.log('loginCode', res.code)
}
});
代码传到后台,凭证代码获取session_key和openid
https://api.weixin.qq.com/sns/ ... _code
后台会获取用户的openid和session_key

getPhoneNumber 组件
得到 encryptedData 和 iv
Page({
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
}
})
将 encryptedData 和 iv 传递到后台

总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。感谢您对脚本之家的支持。
网页手机号抓取程序(鲲鹏Web数据抓取-专业网站数据采集服务提供者(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-14 06:10
)
鲲鹏网络数据采集-专业网络数据采集服务商
很多网站为了防止用户的隐私信息(电话、手机、邮箱)被爬虫抓取,对这些信息进行了特殊处理并输出。比如使用JS输出,使用Ajax动态加载,以图片的形式展示。
其中最常见的是使用JS输出,实现成本最低,爬取也最好。
例如这个页面:
其电话号码部分由JS输出,JS代码如下:
更BT的是函数名“escramble_751()”还在变化。
但是,使用强大的字符串匹配工具“正则表达式”可以很容易地提取出来:
# code by Python
phone_re = re.compile("a='([ \+\-\d]+?)'.*?b='([ \+\-\d]+?)'.*?a\+='([ \+\-\d]+?)'.*?b\+='([ \+\-\d]+?)'.*?c='([ \+\-\d]+?)'", re.DOTALL)
match = phone_re.search(html)
if match:
a, b, c, d, e = match.groups()
telephone = a + c + e + b + d
else:
telephone = None 查看全部
网页手机号抓取程序(鲲鹏Web数据抓取-专业网站数据采集服务提供者(图)
)
鲲鹏网络数据采集-专业网络数据采集服务商
很多网站为了防止用户的隐私信息(电话、手机、邮箱)被爬虫抓取,对这些信息进行了特殊处理并输出。比如使用JS输出,使用Ajax动态加载,以图片的形式展示。
其中最常见的是使用JS输出,实现成本最低,爬取也最好。
例如这个页面:
其电话号码部分由JS输出,JS代码如下:
更BT的是函数名“escramble_751()”还在变化。
但是,使用强大的字符串匹配工具“正则表达式”可以很容易地提取出来:
# code by Python
phone_re = re.compile("a='([ \+\-\d]+?)'.*?b='([ \+\-\d]+?)'.*?a\+='([ \+\-\d]+?)'.*?b\+='([ \+\-\d]+?)'.*?c='([ \+\-\d]+?)'", re.DOTALL)
match = phone_re.search(html)
if match:
a, b, c, d, e = match.groups()
telephone = a + c + e + b + d
else:
telephone = None
网页手机号抓取程序(通过手机端微信访问第三方H5页面获取用户的身份信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-13 07:19
)
功能:主要用于用户在手机上通过微信访问第三方H5页面时获取用户的身份信息(openId、昵称、头像、位置等)。可用于实现微信登录、微信账号绑定、用户身份认证等功能。开发前准备:
1、需要有公众号才能获取AppID和AppSecret;
2、进入公众号开发者中心页面配置授权回调域名。具体位置:接口权限-Web服务-Web账号-Web授权获取基本用户信息-修改
注意只需要填写完整的域名(如 , ),不要添加其他协议头和具体地址字段;
该域名需要是注册域名。这种情况很难处理。幸运的是,热心网友qydev无私地为我们提供了一个注册域名。我们可以使用 Ngrok 虚拟化一个域名,并将其映射到本地开发环境。它是一个 Web 开发神器。.
Ngrok for qydev的使用说明及下载地址:
本文以域名为例:
3、如果你觉得在手机上测试比较麻烦,可以使用微信官方提供的web开发者工具直接在浏览器中调试。
前提是你需要在微信公众号中绑定开发者账号:登录公众号-开发者工具-进入网页开发者工具-绑定网页开发者微信账号
使用说明及下载地址:#6
授权步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、通过网页授权access_token和openid获取用户基本信息
Java实现:
1、引导用户进入授权页面同意授权并获取code
这一步其实就是将需要授权的页面的url拼接到微信的认证请求接口中。比如用户在访问页面/auth时需要进行授权认证,拼接后的授权验证地址为:
:///auth&response_type=code&scope=snsapi_base&state=xxxx_state#wechat_redirect
这里需要将 appid 和 redirect_uri 替换为实际信息。scope 参数有两个值:
snsapi_base:只能获取用户openid。好处是不需要用户手动点击认证按钮,感觉就像直接输入网站。
snsapi_userinfo:可以获取openid、昵称、头像、位置等信息。要求用户手动单击“身份验证”按钮。
相关代码:
/**
* 生成用于获取access_token的Code的Url
*
* @param redirectUrl
* @return
*/
public String getRequestCodeUrl(String redirectUrl) {
return String.format("https://open.weixin.qq.com/con ... ot%3B,
APPID, redirectUrl, "snsapi_userinfo", "xxxx_state");
}
2、将网页授权access_token与第一步得到的code交换(与基础支持中的access_token不同)
在这一步中,我们需要在控制器中获取微信返回给我们的代码,并通过该代码请求access_token。
/**
* 路由控制
*
* @param request
* @param code
* @return
*/
@GET
@Path("auth")
public Response auth(@Context HttpServletRequest request,
@QueryParam("code") String code) {
Map data = new HashMap();
Map result = wechatUtils.getUserInfoAccessToken(code);//通过这个code获取access_token
String openId = result.get("openid");
if (StringUtils.isNotEmpty(openId)) {
logger.info("try getting user info. [openid={}]", openId);
Map userInfo = wechatUtils.getUserInfo(result.get("access_token"), openId);//使用access_token获取用户信息
logger.info("received user info. [result={}]", userInfo);
return forward("auth", userInfo);
}
return Response.ok("openid为空").build();
}
/**
* 获取请求用户信息的access_token
*
* @param code
* @return
*/
public Map getUserInfoAccessToken(String code) {
JsonObject object = null;
Map data = new HashMap();
try {
String url = String.format("https://api.weixin.qq.com/sns/ ... ot%3B,
APPID, APPSECRET, code);
logger.info("request accessToken from url: {}", url);
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String tokens = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
object = token_gson.fromJson(tokens, JsonObject.class);
logger.info("request accessToken success. [result={}]", object);
data.put("openid", object.get("openid").toString().replaceAll("\"", ""));
data.put("access_token", object.get("access_token").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat access token. [error={}]", ex);
}
return data;
}
请求 access_token 返回样本:
[result={
"access_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTzvZhiKK7Q35O-YctaOFfyJYSPMMEsMq62zw8T6VDljgKJY6g-tCMdTr3Yoeaz1noL6gpJeshMPwEXL5Pj3YBkw",
"expires_in":7200,
"refresh_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTOIGqz3ySJRe-lv124wxxtrBdXGd3X1YGysFJnCxjtIE-jaMkvT7aN-12nBa4YtDvr5VSKCU-_UeFFnfW0K3JmZGRA",
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"scope":"snsapi_userinfo"}]
通过access_token和openid获取用户基本信息:
/**
* 获取用户信息
*
* @param accessToken
* @param openId
* @return
*/
public Map getUserInfo(String accessToken, String openId) {
Map data = new HashMap();
String url = "https://api.weixin.qq.com/sns/ ... ot%3B + accessToken + "&openid=" + openId + "&lang=zh_CN";
logger.info("request user info from url: {}", url);
JsonObject userInfo = null;
try {
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String response = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
userInfo = token_gson.fromJson(response, JsonObject.class);
logger.info("get userinfo success. [result={}]", userInfo);
data.put("openid", userInfo.get("openid").toString().replaceAll("\"", ""));
data.put("nickname", userInfo.get("nickname").toString().replaceAll("\"", ""));
data.put("city", userInfo.get("city").toString().replaceAll("\"", ""));
data.put("province", userInfo.get("province").toString().replaceAll("\"", ""));
data.put("country", userInfo.get("country").toString().replaceAll("\"", ""));
data.put("headimgurl", userInfo.get("headimgurl").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat user info. [error={}]", ex);
}
return data;
}
获取用户信息返回示例:
[result={
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"nickname":"lovebread",
"sex":1,
"language":"zh_CN",
"city":"",
"province":"",
"country":"中国",
"headimgurl":"http://wx.qlogo.cn/mmopen/bRLX ... ot%3B,
"privilege":[]}] 查看全部
网页手机号抓取程序(通过手机端微信访问第三方H5页面获取用户的身份信息
)
功能:主要用于用户在手机上通过微信访问第三方H5页面时获取用户的身份信息(openId、昵称、头像、位置等)。可用于实现微信登录、微信账号绑定、用户身份认证等功能。开发前准备:
1、需要有公众号才能获取AppID和AppSecret;
2、进入公众号开发者中心页面配置授权回调域名。具体位置:接口权限-Web服务-Web账号-Web授权获取基本用户信息-修改
注意只需要填写完整的域名(如 , ),不要添加其他协议头和具体地址字段;
该域名需要是注册域名。这种情况很难处理。幸运的是,热心网友qydev无私地为我们提供了一个注册域名。我们可以使用 Ngrok 虚拟化一个域名,并将其映射到本地开发环境。它是一个 Web 开发神器。.
Ngrok for qydev的使用说明及下载地址:
本文以域名为例:

3、如果你觉得在手机上测试比较麻烦,可以使用微信官方提供的web开发者工具直接在浏览器中调试。
前提是你需要在微信公众号中绑定开发者账号:登录公众号-开发者工具-进入网页开发者工具-绑定网页开发者微信账号
使用说明及下载地址:#6
授权步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、通过网页授权access_token和openid获取用户基本信息

Java实现:
1、引导用户进入授权页面同意授权并获取code
这一步其实就是将需要授权的页面的url拼接到微信的认证请求接口中。比如用户在访问页面/auth时需要进行授权认证,拼接后的授权验证地址为:
:///auth&response_type=code&scope=snsapi_base&state=xxxx_state#wechat_redirect
这里需要将 appid 和 redirect_uri 替换为实际信息。scope 参数有两个值:
snsapi_base:只能获取用户openid。好处是不需要用户手动点击认证按钮,感觉就像直接输入网站。
snsapi_userinfo:可以获取openid、昵称、头像、位置等信息。要求用户手动单击“身份验证”按钮。
相关代码:
/**
* 生成用于获取access_token的Code的Url
*
* @param redirectUrl
* @return
*/
public String getRequestCodeUrl(String redirectUrl) {
return String.format("https://open.weixin.qq.com/con ... ot%3B,
APPID, redirectUrl, "snsapi_userinfo", "xxxx_state");
}
2、将网页授权access_token与第一步得到的code交换(与基础支持中的access_token不同)
在这一步中,我们需要在控制器中获取微信返回给我们的代码,并通过该代码请求access_token。
/**
* 路由控制
*
* @param request
* @param code
* @return
*/
@GET
@Path("auth")
public Response auth(@Context HttpServletRequest request,
@QueryParam("code") String code) {
Map data = new HashMap();
Map result = wechatUtils.getUserInfoAccessToken(code);//通过这个code获取access_token
String openId = result.get("openid");
if (StringUtils.isNotEmpty(openId)) {
logger.info("try getting user info. [openid={}]", openId);
Map userInfo = wechatUtils.getUserInfo(result.get("access_token"), openId);//使用access_token获取用户信息
logger.info("received user info. [result={}]", userInfo);
return forward("auth", userInfo);
}
return Response.ok("openid为空").build();
}
/**
* 获取请求用户信息的access_token
*
* @param code
* @return
*/
public Map getUserInfoAccessToken(String code) {
JsonObject object = null;
Map data = new HashMap();
try {
String url = String.format("https://api.weixin.qq.com/sns/ ... ot%3B,
APPID, APPSECRET, code);
logger.info("request accessToken from url: {}", url);
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String tokens = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
object = token_gson.fromJson(tokens, JsonObject.class);
logger.info("request accessToken success. [result={}]", object);
data.put("openid", object.get("openid").toString().replaceAll("\"", ""));
data.put("access_token", object.get("access_token").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat access token. [error={}]", ex);
}
return data;
}
请求 access_token 返回样本:
[result={
"access_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTzvZhiKK7Q35O-YctaOFfyJYSPMMEsMq62zw8T6VDljgKJY6g-tCMdTr3Yoeaz1noL6gpJeshMPwEXL5Pj3YBkw",
"expires_in":7200,
"refresh_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTOIGqz3ySJRe-lv124wxxtrBdXGd3X1YGysFJnCxjtIE-jaMkvT7aN-12nBa4YtDvr5VSKCU-_UeFFnfW0K3JmZGRA",
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"scope":"snsapi_userinfo"}]
通过access_token和openid获取用户基本信息:
/**
* 获取用户信息
*
* @param accessToken
* @param openId
* @return
*/
public Map getUserInfo(String accessToken, String openId) {
Map data = new HashMap();
String url = "https://api.weixin.qq.com/sns/ ... ot%3B + accessToken + "&openid=" + openId + "&lang=zh_CN";
logger.info("request user info from url: {}", url);
JsonObject userInfo = null;
try {
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String response = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
userInfo = token_gson.fromJson(response, JsonObject.class);
logger.info("get userinfo success. [result={}]", userInfo);
data.put("openid", userInfo.get("openid").toString().replaceAll("\"", ""));
data.put("nickname", userInfo.get("nickname").toString().replaceAll("\"", ""));
data.put("city", userInfo.get("city").toString().replaceAll("\"", ""));
data.put("province", userInfo.get("province").toString().replaceAll("\"", ""));
data.put("country", userInfo.get("country").toString().replaceAll("\"", ""));
data.put("headimgurl", userInfo.get("headimgurl").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat user info. [error={}]", ex);
}
return data;
}
获取用户信息返回示例:
[result={
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"nickname":"lovebread",
"sex":1,
"language":"zh_CN",
"city":"",
"province":"",
"country":"中国",
"headimgurl":"http://wx.qlogo.cn/mmopen/bRLX ... ot%3B,
"privilege":[]}]
网页手机号抓取程序(利用无线路由器如何抓取手机网络数据包?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 07:17
当用户使用手机上网时,手机会不断地接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账户信息、聊天信息、收发文件、电子邮件、和浏览网页。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器来提取用户的各种信息,而不需要在用户的手机中安装和使用插件。
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以捕获手机连接无线wifi发送的网络数据包.
三、如何使用无线路由器捕获手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉,方便分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择相应的过滤器,然后选择要抓包的网卡,开始抓包。
图1:Wireshark抓包参数配置
四、网络数据包分析
抓包时,Wireshark分为三个部分展示抓包结果,如图2所示。第一个窗口显示捕获的数据包列表,中间窗口显示当前选中的数据包的简单解析内容,底部窗口显示当前所选数据包的十六进制值。
图 2:Wireshark 捕获结果窗口
以微信的一个协议包为例,抓包操作后,抓取到用户通过手机发送的信息的完整对话包,如图3所示。根据对话包显示:手机(ip为172.19.90.2,端口号51005)连接服务器(id为172.1< @9.90.2,端口号 51005) 121.51.130.113,端口号 80) 传输数据对彼此。
图 3:发送信息包
前三个包是手机和服务器发送的确认相互身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4所示:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送者和目的地的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;
图4:手机发送信息包
这里主要分析一下使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,而十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。, 暂时不可用。
图 5:TCP 使用层和数据层
这样我们也可以分析发送的图片、视频等信息,后续的提取工作就可以交给代码了。 查看全部
网页手机号抓取程序(利用无线路由器如何抓取手机网络数据包?(组图))
当用户使用手机上网时,手机会不断地接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账户信息、聊天信息、收发文件、电子邮件、和浏览网页。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器来提取用户的各种信息,而不需要在用户的手机中安装和使用插件。

二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以捕获手机连接无线wifi发送的网络数据包.
三、如何使用无线路由器捕获手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉,方便分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择相应的过滤器,然后选择要抓包的网卡,开始抓包。
图1:Wireshark抓包参数配置
四、网络数据包分析
抓包时,Wireshark分为三个部分展示抓包结果,如图2所示。第一个窗口显示捕获的数据包列表,中间窗口显示当前选中的数据包的简单解析内容,底部窗口显示当前所选数据包的十六进制值。
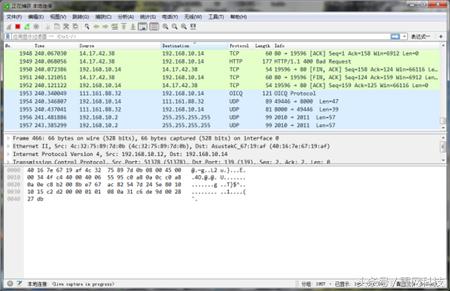
图 2:Wireshark 捕获结果窗口
以微信的一个协议包为例,抓包操作后,抓取到用户通过手机发送的信息的完整对话包,如图3所示。根据对话包显示:手机(ip为172.19.90.2,端口号51005)连接服务器(id为172.1< @9.90.2,端口号 51005) 121.51.130.113,端口号 80) 传输数据对彼此。

图 3:发送信息包
前三个包是手机和服务器发送的确认相互身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4所示:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送者和目的地的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;
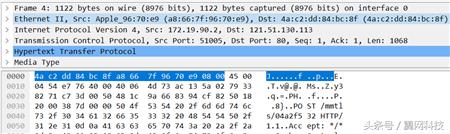
图4:手机发送信息包
这里主要分析一下使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,而十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。, 暂时不可用。

图 5:TCP 使用层和数据层
这样我们也可以分析发送的图片、视频等信息,后续的提取工作就可以交给代码了。
网页手机号抓取程序( ,文中通过示例代码介绍(2020年01月21日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-10 07:22
,文中通过示例代码介绍(2020年01月21日))
如何在微信小程序中通过用户授权获取手机号(getPhoneNumber)
更新时间:2020-01-21 10:44:29 作者:首次亮相
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
小程序有一个获取用户非常方便的api,即通过getPhoneNumber获取用户绑定微信的手机号。需要注意的一点,现在微信又注重用户体验,有些方法需要用户主动触发才能调用,比如getPhoneNumber。
官方文档:
实施思路:
直接上干货:
1、
2、JS中的getPhoneNumbe组件函数(这个事件最重要的是wx.login登录后发起接口请求),这里需要配置参数给接口:
这些是必不可少的参数,只有当这些参数都完成时,才可以认为是合法请求。
appid: “你的小程序APPID”,
secret: “你的小程序appsecret”,
code: res.code,
encryptedData: telObj,
iv: ivObj
//通过绑定手机号登录
getPhoneNumber: function (e) {
var ivObj = e.detail.iv
var telObj = e.detail.encryptedData
var codeObj = "";
var that = this;
//------执行Login---------
wx.login({
success: res => {
console.log('code转换', res.code);
//用code传给服务器调换session_key
wx.request({
url: 'https://你的接口文件路径', //接口地址
data: {
appid: "你的小程序APPID",
secret: "你的小程序appsecret",
code: res.code,
encryptedData: telObj,
iv: ivObj
},
success: function (res) {
phoneObj = res.data.phoneNumber;
console.log("手机号=", phoneObj)
wx.setStorage({ //存储数据并准备发送给下一页使用
key: "phoneObj",
data: res.data.phoneNumber,
})
}
})
//-----------------是否授权,授权通过进入主页面,授权拒绝则停留在登陆界面
if (e.detail.errMsg == 'getPhoneNumber:user deny') { //用户点击拒绝
wx.navigateTo({
url: '../index/index',
})
} else { //允许授权执行跳转
wx.navigateTo({
url: '../test/test',
})
}
}
});
},
最终结果显示:
点击“拒绝”,开发者可以捕获该事件,然后getPhoneNumber函数返回e.detail.errMsg为getPhoneNumber:user deny
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。 查看全部
网页手机号抓取程序(
,文中通过示例代码介绍(2020年01月21日))
如何在微信小程序中通过用户授权获取手机号(getPhoneNumber)
更新时间:2020-01-21 10:44:29 作者:首次亮相
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
小程序有一个获取用户非常方便的api,即通过getPhoneNumber获取用户绑定微信的手机号。需要注意的一点,现在微信又注重用户体验,有些方法需要用户主动触发才能调用,比如getPhoneNumber。
官方文档:
实施思路:
直接上干货:
1、
2、JS中的getPhoneNumbe组件函数(这个事件最重要的是wx.login登录后发起接口请求),这里需要配置参数给接口:
这些是必不可少的参数,只有当这些参数都完成时,才可以认为是合法请求。
appid: “你的小程序APPID”,
secret: “你的小程序appsecret”,
code: res.code,
encryptedData: telObj,
iv: ivObj
//通过绑定手机号登录
getPhoneNumber: function (e) {
var ivObj = e.detail.iv
var telObj = e.detail.encryptedData
var codeObj = "";
var that = this;
//------执行Login---------
wx.login({
success: res => {
console.log('code转换', res.code);
//用code传给服务器调换session_key
wx.request({
url: 'https://你的接口文件路径', //接口地址
data: {
appid: "你的小程序APPID",
secret: "你的小程序appsecret",
code: res.code,
encryptedData: telObj,
iv: ivObj
},
success: function (res) {
phoneObj = res.data.phoneNumber;
console.log("手机号=", phoneObj)
wx.setStorage({ //存储数据并准备发送给下一页使用
key: "phoneObj",
data: res.data.phoneNumber,
})
}
})
//-----------------是否授权,授权通过进入主页面,授权拒绝则停留在登陆界面
if (e.detail.errMsg == 'getPhoneNumber:user deny') { //用户点击拒绝
wx.navigateTo({
url: '../index/index',
})
} else { //允许授权执行跳转
wx.navigateTo({
url: '../test/test',
})
}
}
});
},
最终结果显示:
点击“拒绝”,开发者可以捕获该事件,然后getPhoneNumber函数返回e.detail.errMsg为getPhoneNumber:user deny
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。
网页手机号抓取程序(网站竞价推广的常见方式有哪些?怎么获取访客信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-10 07:21
推广网站的常用方法
常用的推广方式网站有:1、有偿推广,如百度营销、360营销、搜狗营销等,基于搜索引擎广告;2、内容推广,通过制作网站文章内容页面,并让搜索引擎收录这个页面,从而获得用户搜索点击的机会,以及达到推广效果。3、其他形式,室内外海报广告,其他网站链接广告等。
网站什么是拍卖促销?
拍卖促销是所有促销中最有效的促销方式,成本也是最高的。我们以百度竞价为例。一般来说,如果你做百度竞价,你的网站可以在百度首页上排名。当用户在百度搜索关键词时,你的网站会出现在百度首页。在最前面的位置,用户自然很容易找到你。点击的价格也不同,取决于行业的竞争程度。目前最便宜的点击要三四元,竞争激烈。如果企业愿意投入大量资金成本,又想快速看到效果,招标推广无疑是最佳选择。
但是,网站 竞价推广也有缺点。有些访问者在访问网站时不会填写个人信息,这样会丢失很多信息。我们怎样才能把损失降到最低。
即网站访问者信息捕获,我们可以捕获到自己网站访问者的信息,也可以获取到同行网站访问者的信息。
如何获取网站 访客信息?
一种是爬虫爬取,通过在网站中添加一段代码来爬取访问者数据。这种方式是法律禁止的,同时它获取的数据需要延迟一天。时效性很差。
另一种方式是与大数据公司合作,他们是与运营商的合同。合法合规,数据实时反馈。时间敏感。
竞价网站实时拦截,网站手机号抓值
1、在时间方面:营销时间大大缩短,又短又顺畅。
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。 查看全部
网页手机号抓取程序(网站竞价推广的常见方式有哪些?怎么获取访客信息?)
推广网站的常用方法
常用的推广方式网站有:1、有偿推广,如百度营销、360营销、搜狗营销等,基于搜索引擎广告;2、内容推广,通过制作网站文章内容页面,并让搜索引擎收录这个页面,从而获得用户搜索点击的机会,以及达到推广效果。3、其他形式,室内外海报广告,其他网站链接广告等。

网站什么是拍卖促销?
拍卖促销是所有促销中最有效的促销方式,成本也是最高的。我们以百度竞价为例。一般来说,如果你做百度竞价,你的网站可以在百度首页上排名。当用户在百度搜索关键词时,你的网站会出现在百度首页。在最前面的位置,用户自然很容易找到你。点击的价格也不同,取决于行业的竞争程度。目前最便宜的点击要三四元,竞争激烈。如果企业愿意投入大量资金成本,又想快速看到效果,招标推广无疑是最佳选择。
但是,网站 竞价推广也有缺点。有些访问者在访问网站时不会填写个人信息,这样会丢失很多信息。我们怎样才能把损失降到最低。
即网站访问者信息捕获,我们可以捕获到自己网站访问者的信息,也可以获取到同行网站访问者的信息。

如何获取网站 访客信息?
一种是爬虫爬取,通过在网站中添加一段代码来爬取访问者数据。这种方式是法律禁止的,同时它获取的数据需要延迟一天。时效性很差。
另一种方式是与大数据公司合作,他们是与运营商的合同。合法合规,数据实时反馈。时间敏感。
竞价网站实时拦截,网站手机号抓值
1、在时间方面:营销时间大大缩短,又短又顺畅。
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。
网页手机号抓取程序(暑假留在学校参与微信公众号比较感兴趣的学习研究完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-09 04:17
今年暑假留在学校参加工作室项目,对微信公众号比较感兴趣,所以就参与了这方面的学习和研究。
昨天完成了网页授权和用户信息获取的功能,趁着热度写了一篇。实施
功能,还需要完成一些基础知识。完成这篇博文后,我会尽快补上。
------------------------- 废话少说,切入正题
所需工具:
微信公众号(可以申请,但是如果是做开发的可以申请测试号,申请我就不多说了)
服务器(可以自己买,我用的是新浪的sae。)
编辑器(可选,不推荐)
微信公众号开发文档(地址)
-------------------------官方文件解读(仅我阅读的资料)
!!!!!基本配置完成后,就可以进行工作了。配置信息在这里。(稍后添加)
您需要完成网页授权并获取用户信息,完成以下3个步骤。
-1- 用户授权和获取代码
-2- 使用code换取access_token
-3- 使用 access_token 获取用户信息
--------------------用户授权并获取代码
参数说明
appid=APPID(公众号唯一标识)
redirect_uri=REDIRECT_URI(授权后重定向的回调链接地址)
response_type=code(返回类型,无需更改)
scope=SCOPE(snsapi_base,不会弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo会弹出授权页面 查看全部
网页手机号抓取程序(暑假留在学校参与微信公众号比较感兴趣的学习研究完成)
今年暑假留在学校参加工作室项目,对微信公众号比较感兴趣,所以就参与了这方面的学习和研究。
昨天完成了网页授权和用户信息获取的功能,趁着热度写了一篇。实施
功能,还需要完成一些基础知识。完成这篇博文后,我会尽快补上。
------------------------- 废话少说,切入正题
所需工具:
微信公众号(可以申请,但是如果是做开发的可以申请测试号,申请我就不多说了)
服务器(可以自己买,我用的是新浪的sae。)
编辑器(可选,不推荐)
微信公众号开发文档(地址)
-------------------------官方文件解读(仅我阅读的资料)
!!!!!基本配置完成后,就可以进行工作了。配置信息在这里。(稍后添加)
您需要完成网页授权并获取用户信息,完成以下3个步骤。
-1- 用户授权和获取代码
-2- 使用code换取access_token
-3- 使用 access_token 获取用户信息
--------------------用户授权并获取代码
参数说明
appid=APPID(公众号唯一标识)
redirect_uri=REDIRECT_URI(授权后重定向的回调链接地址)
response_type=code(返回类型,无需更改)
scope=SCOPE(snsapi_base,不会弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo会弹出授权页面
网页手机号抓取程序( 实例内容登陆界面处理登陆表单数据(异步)清除本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-08 13:11
实例内容登陆界面处理登陆表单数据(异步)清除本地)
实例内容登录接口处理登录表单数据处理登录表单数据(异步) 清除本地数据登录接口:在app.json中添加登录页面pages/login/login并设置为入口。保存后会自动生成相关文件(非常方便)。修改视图文件 login.wxml
微信小程序开发一键登录获取session_key和openid实例
微信小程序开发 一键登录获取session_key和openid实例 我一直在想,不希望我的微信小程序是单机版。不知道怎么写背景。做笔记。第一步:下载av-weapp.js,放到utils下。第 2 步:使用 const AV = require('../../utils/av-weapp.js'); 路径取决于具体情况而定。第 3 步:进行初始化。AV.init({ appId: 'EJx0NSfY********-gzGzoHsz'
微信小程序开发左右栏效果示例代码
本文通过一个简单的例子来简单描述一下微信小程序开发中左右栏功能的实现,主要涉及滚动视图、列表数据绑定、简单样式等。属于初级介绍内容,是仅供学习和分享。利用。概述在微信小程序开发中,左右栏(左侧显示分类,右侧显示详情,然后联动)是一种常见的布局方式,多用于点餐、冷饮店, 外卖, 和其他类似的商场。版面分析 版面分析图如下: 涉及知识点 • scroll-view 可滚动视图区。使用垂直滚动时,需要给定高度,通过WXSS设置hei
微信小程序springboot后台如何获取用户openid
openid 可以识别一个用户,session_key 会改变,所以我们来获取 openid。微信小程序无法直接获取openid,需要在后台向微信接口发送请求,然后微信返回一个json格式的字符串给后台,经过后台处理后,再返回给微信小程序。发布的小程序需要https的域名,测试的时候可以使用http。小程序在app.js中,修改login()中的内容: // 登录wx.login({ success : res => { // 发送res.code到后台换取openId, session
微信小程序开发获取用户手机号(php接口解密)
后面我们会做一个微信小程序,可以获取到用户微信绑定的手机号。上面小程序开发文档中提供的获取手机号码的接口(getPhoneNumber())返回的是密文,需要在服务端解密。但是,官方提供的开发文档总是乱七八糟。如果对小程序开发文档没有一个整体的了解,理解解密过程还是有点难度的。整个过程是连在一起的,理解起来方便快捷,如下:一.前端相关操作:1.请求用户授权获取手机号:因为需要用户主动触发发起获取手机号的接口,
微信小程序开发入门基础教程
微信小程序开发入门基础教程 本文档将带你一步步创建并完成一个微信小程序,你可以在手机上体验小程序的实际效果。开发准备获取微信小程序的AppID进行登录,在网站@的“设置”-“开发者设置”>中可以看到微信小程序的AppID。注意服务账号或订阅账号的AppID不能直接使用。下载开发工具下载地址:
微信小程序开发指南详解
编写代码创建小程序实例点击开发者工具左侧导航中的“编辑”,我们可以看到这个项目已经初始化完毕,收录一些简单的代码文件。最关键和最本质的就是 app.js.app .json.app.wxss 这三个。其中.js后缀为脚本文件,.json后缀为配置文件,.wxss后缀为样式表文件。微信小程序会读取这些文件并生成小程序示例。下面我们简单了解一下这三个文件的作用,方便我们自己的微信小程序从零开始修改和开发。app.js 是小程序的脚本代码。我们可以在这个文件中监控和处理小程序。
微信小程序开发中路由切换页面重定向问题
在此期间,我开发了一个微信小程序。虽然小程序的导航API官方文档很详细,但是在具体的开发过程中还是有很多不明白或者转不过来的地方。1. 页面切换参数,参数读取1.1 wx.navigateTo(Object) 功能:保持当前页面,跳转到应用程序中的一个页面,但不能跳转到tabbar页面。使用 wx.navigateBack 返回当前页面。wx.navigateTo({ //当前页面对应的JS文件中的控制模板url: 'test?id=1' //要切换到的页面路径,这里是
微信小程序开发用户授权登录详解
本文将帮助读者基于微信开发者工具&C#环境实现用户在小程序上的授权登录。准备工作:微信开发者工具下载地址:微信小程序开发文档:开发:在开发之初,我们需要先明确授权登录流程已由微信方制定,请参考官方API-登录接口. 查看全部
网页手机号抓取程序(
实例内容登陆界面处理登陆表单数据(异步)清除本地)

实例内容登录接口处理登录表单数据处理登录表单数据(异步) 清除本地数据登录接口:在app.json中添加登录页面pages/login/login并设置为入口。保存后会自动生成相关文件(非常方便)。修改视图文件 login.wxml
微信小程序开发一键登录获取session_key和openid实例

微信小程序开发 一键登录获取session_key和openid实例 我一直在想,不希望我的微信小程序是单机版。不知道怎么写背景。做笔记。第一步:下载av-weapp.js,放到utils下。第 2 步:使用 const AV = require('../../utils/av-weapp.js'); 路径取决于具体情况而定。第 3 步:进行初始化。AV.init({ appId: 'EJx0NSfY********-gzGzoHsz'
微信小程序开发左右栏效果示例代码
本文通过一个简单的例子来简单描述一下微信小程序开发中左右栏功能的实现,主要涉及滚动视图、列表数据绑定、简单样式等。属于初级介绍内容,是仅供学习和分享。利用。概述在微信小程序开发中,左右栏(左侧显示分类,右侧显示详情,然后联动)是一种常见的布局方式,多用于点餐、冷饮店, 外卖, 和其他类似的商场。版面分析 版面分析图如下: 涉及知识点 • scroll-view 可滚动视图区。使用垂直滚动时,需要给定高度,通过WXSS设置hei
微信小程序springboot后台如何获取用户openid
openid 可以识别一个用户,session_key 会改变,所以我们来获取 openid。微信小程序无法直接获取openid,需要在后台向微信接口发送请求,然后微信返回一个json格式的字符串给后台,经过后台处理后,再返回给微信小程序。发布的小程序需要https的域名,测试的时候可以使用http。小程序在app.js中,修改login()中的内容: // 登录wx.login({ success : res => { // 发送res.code到后台换取openId, session
微信小程序开发获取用户手机号(php接口解密)
后面我们会做一个微信小程序,可以获取到用户微信绑定的手机号。上面小程序开发文档中提供的获取手机号码的接口(getPhoneNumber())返回的是密文,需要在服务端解密。但是,官方提供的开发文档总是乱七八糟。如果对小程序开发文档没有一个整体的了解,理解解密过程还是有点难度的。整个过程是连在一起的,理解起来方便快捷,如下:一.前端相关操作:1.请求用户授权获取手机号:因为需要用户主动触发发起获取手机号的接口,
微信小程序开发入门基础教程

微信小程序开发入门基础教程 本文档将带你一步步创建并完成一个微信小程序,你可以在手机上体验小程序的实际效果。开发准备获取微信小程序的AppID进行登录,在网站@的“设置”-“开发者设置”>中可以看到微信小程序的AppID。注意服务账号或订阅账号的AppID不能直接使用。下载开发工具下载地址:
微信小程序开发指南详解

编写代码创建小程序实例点击开发者工具左侧导航中的“编辑”,我们可以看到这个项目已经初始化完毕,收录一些简单的代码文件。最关键和最本质的就是 app.js.app .json.app.wxss 这三个。其中.js后缀为脚本文件,.json后缀为配置文件,.wxss后缀为样式表文件。微信小程序会读取这些文件并生成小程序示例。下面我们简单了解一下这三个文件的作用,方便我们自己的微信小程序从零开始修改和开发。app.js 是小程序的脚本代码。我们可以在这个文件中监控和处理小程序。
微信小程序开发中路由切换页面重定向问题
在此期间,我开发了一个微信小程序。虽然小程序的导航API官方文档很详细,但是在具体的开发过程中还是有很多不明白或者转不过来的地方。1. 页面切换参数,参数读取1.1 wx.navigateTo(Object) 功能:保持当前页面,跳转到应用程序中的一个页面,但不能跳转到tabbar页面。使用 wx.navigateBack 返回当前页面。wx.navigateTo({ //当前页面对应的JS文件中的控制模板url: 'test?id=1' //要切换到的页面路径,这里是
微信小程序开发用户授权登录详解

本文将帮助读者基于微信开发者工具&C#环境实现用户在小程序上的授权登录。准备工作:微信开发者工具下载地址:微信小程序开发文档:开发:在开发之初,我们需要先明确授权登录流程已由微信方制定,请参考官方API-登录接口.
网页手机号抓取程序(网站网页页面APP访客手机号码爬取代理协作了,选用优秀的1R技术性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-08 07:10
最近有很多老总问我,在我的网页和APP上爬访问者是什么原因。下面我就为大家简单的解释一下这些问题。
网站网页APP访客手机号抓取方法
让我们谈谈第一个。事实上,网站或APP的房地产开发商使用新的网络爬虫来爬取访问者的手机号码。关键是在 网站 页面的页眉中插入一个代码。. 不过这种爬取方式很快,因为涉嫌侵犯隐私,而且很容易被百度搜索和K站查到,从而保留自己的网站当然是大佬自己的总流量,很多网站站早就放弃了这个实际操作。
二是与靠谱的互联网大数据运营商代理合作。基本原理是当访问者使用手机浏览3G总流量网站或APP时,会生成一个属于自己的专用账号。可以计算访问者的http报告、访问者的手机号码、网站浏览了什么、停留了多长时间,最终得到访问者的需求实体模型。运营商的代理人会根据这个需求意见反馈给公司在这些领域的专业服务,并给他一个营销和推广的后台管理来打电话处理用户的需求。由于皮肤过敏的个人信息保护了用户的隐私保护,第二个用户在这些方面会有很高的转化率。许多企业经理都在使用它。
高科技互联网大数据精准客户拓展服务平台的高占比是基于三大运营商的多样性、一致性和连续性的特点。在充分把握运营商制造业资源和销售市场需求的标准下,以卓越的1R技术搭建开放的SaaS服务平台。充分挖掘数据价值(关键词搜索网页浏览,拨盘市场竞品总面积、年龄、性别多维度),协助运营商把握商机、开发业务流程、运营理性地。无数的基本用户标识符(大城市、年龄、性别、移动知名品牌等)和个人行为标识符(程序运行、登陆页面、搜索关键词、访问网页、电话目录)都是供用户使用的。分析当前客户画像,精准定位整体目标客户群。. 查看全部
网页手机号抓取程序(网站网页页面APP访客手机号码爬取代理协作了,选用优秀的1R技术性)
最近有很多老总问我,在我的网页和APP上爬访问者是什么原因。下面我就为大家简单的解释一下这些问题。
网站网页APP访客手机号抓取方法
让我们谈谈第一个。事实上,网站或APP的房地产开发商使用新的网络爬虫来爬取访问者的手机号码。关键是在 网站 页面的页眉中插入一个代码。. 不过这种爬取方式很快,因为涉嫌侵犯隐私,而且很容易被百度搜索和K站查到,从而保留自己的网站当然是大佬自己的总流量,很多网站站早就放弃了这个实际操作。
二是与靠谱的互联网大数据运营商代理合作。基本原理是当访问者使用手机浏览3G总流量网站或APP时,会生成一个属于自己的专用账号。可以计算访问者的http报告、访问者的手机号码、网站浏览了什么、停留了多长时间,最终得到访问者的需求实体模型。运营商的代理人会根据这个需求意见反馈给公司在这些领域的专业服务,并给他一个营销和推广的后台管理来打电话处理用户的需求。由于皮肤过敏的个人信息保护了用户的隐私保护,第二个用户在这些方面会有很高的转化率。许多企业经理都在使用它。
高科技互联网大数据精准客户拓展服务平台的高占比是基于三大运营商的多样性、一致性和连续性的特点。在充分把握运营商制造业资源和销售市场需求的标准下,以卓越的1R技术搭建开放的SaaS服务平台。充分挖掘数据价值(关键词搜索网页浏览,拨盘市场竞品总面积、年龄、性别多维度),协助运营商把握商机、开发业务流程、运营理性地。无数的基本用户标识符(大城市、年龄、性别、移动知名品牌等)和个人行为标识符(程序运行、登陆页面、搜索关键词、访问网页、电话目录)都是供用户使用的。分析当前客户画像,精准定位整体目标客户群。.
网页手机号抓取程序(这是官方服务端文档获取开放数据云开发的应用和应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-06 15:08
小程序获取用户手机号有一些限制:
目前该接口对非个人开发者和认证小程序(不包括境外实体)开放,即只能使用国内认证企业账户。必须是点击按钮触发,包括头像和客服,都需要点击按钮触发。需要先调用wx.login接口获取code。后端使用代码调用auth.code2Session获取session_key,然后对获取到的encryptedData进行解密得到电话号码。
详细介绍请参考官网文档获取手机号
您需要在单击按钮之前调用 wx.login 以获取电话号码。代码是时效的,session_key也是时效的。不能像openId一样获取到本地缓存。需要调用wx.checkSession检查登录状态,判断是否需要再次调用wx.login获取session_key。
这是官方文档服务器获取开放数据的第一种方式。这次主要讲第二种方法,通过云调用直接获取开放数据云开发。
我们在写小程序或者app的时候,一般都会把前端和后端分开。前端写接口,后端写接口,前端用后端接口处理数据,做到各司其职,保证质量和效率。但是有时候前端的人想写自己的个人产品,却没有后端开发,也没有服务器。我想很多前端的人都有这个想法。几年前,他们研究了LeanCloud的云存储,通过rest api直接操作数据库。,虽然比直接学习后端开发简单很多,但是学习还是要花不少时间的。小程序云开发类似于LeanCloud的云存储。入门要简单得多,文档也很详细。
创建新项目时,可以选择小程序·云开发,这样就可以直接创建小程序·云开发模板。
新项目
查看目录,您会发现与未使用云服务创建的小程序目录存在一些差异。
云开发目录
小程序目录
不同的是在云开发目录下多了一个cloudfunctions目录,小程序文件都在小程序目录下。
同时project.config.json配置文件有更多的云开发目录配置
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
这时候云服务还是不可用,点击左上角的云开发按钮
云开发
系统将要求您创建环境名称和环境 ID。环境ID创建后不可修改。这里的官方环境名称文档推荐了易于区分测试和发布的开发环境和生产环境名称。
不使用云服务创建的小程序如何使用云开发
首先在根目录下创建两个文件夹,cloudfunctions和miniprogram,其他名字也是可以的。
然后将之前小程序目录下除project.config.json外的文件拖到小程序目录下,添加到project.config.json配置中
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
添加后
点击左上角的云开发按钮,创建环境。首次打开云环境后,需要等待10分钟左右,才能正常使用云API。
右键云开发目录查看当前环境
云开发
在小程序上开始使用云能力之前,需要调用app.js中的wx.cloud.init方法完成云能力初始化
//app.js
App({
onLaunch: function () {
//初始化云开发
wx.cloud.init({
traceUser: true
})
}
})
右键单击 cloudfunctions 文件夹并选择 New Node.js Cloud Function,名称为 getPhone。
新建后默认会生成获取applet上下文的云函数cloud.getWXContext()。如果需要获取openId和unionId,可以直接使用这个云函数。我们将其修改为获取手机号码的云功能。修改后必须右键上传部署。
获取电话
在getPhoneNumber中调用getPhone云函数,小程序端同时支持Callback风格和Promise风格的调用。
// 获取手机号
getPhoneNumber: function (event) {
let cloudID = event.detail.cloudID //开放数据ID
if (!cloudID) {
app.showToast('用户未授权')
return
}
//loading
app.showLoading()
//获取手机号
wx.cloud.callFunction({
name: 'getPhone',
data: {
cloudID: cloudID
}
}).then(res => {
app.hideLoading()
let phone = res.result.list[0].data.phoneNumber
if (phone) {
wx.setStorageSync('phone', phone)
//更新UI
this.setData({
phone: phone
})
}
this.triggerEvent('applyTap')
}).catch(error => {
app.hideLoading()
this.triggerEvent('applyTap')
})
},
参考
5行代码获取小程序用户手机号
按钮
获取手机号码
服务器访问开放数据
资源环境
初始化
我的第一个云功能
Cloud.getOpenData() 查看全部
网页手机号抓取程序(这是官方服务端文档获取开放数据云开发的应用和应用)
小程序获取用户手机号有一些限制:
目前该接口对非个人开发者和认证小程序(不包括境外实体)开放,即只能使用国内认证企业账户。必须是点击按钮触发,包括头像和客服,都需要点击按钮触发。需要先调用wx.login接口获取code。后端使用代码调用auth.code2Session获取session_key,然后对获取到的encryptedData进行解密得到电话号码。
详细介绍请参考官网文档获取手机号
您需要在单击按钮之前调用 wx.login 以获取电话号码。代码是时效的,session_key也是时效的。不能像openId一样获取到本地缓存。需要调用wx.checkSession检查登录状态,判断是否需要再次调用wx.login获取session_key。
这是官方文档服务器获取开放数据的第一种方式。这次主要讲第二种方法,通过云调用直接获取开放数据云开发。
我们在写小程序或者app的时候,一般都会把前端和后端分开。前端写接口,后端写接口,前端用后端接口处理数据,做到各司其职,保证质量和效率。但是有时候前端的人想写自己的个人产品,却没有后端开发,也没有服务器。我想很多前端的人都有这个想法。几年前,他们研究了LeanCloud的云存储,通过rest api直接操作数据库。,虽然比直接学习后端开发简单很多,但是学习还是要花不少时间的。小程序云开发类似于LeanCloud的云存储。入门要简单得多,文档也很详细。
创建新项目时,可以选择小程序·云开发,这样就可以直接创建小程序·云开发模板。
新项目
查看目录,您会发现与未使用云服务创建的小程序目录存在一些差异。
云开发目录
小程序目录
不同的是在云开发目录下多了一个cloudfunctions目录,小程序文件都在小程序目录下。
同时project.config.json配置文件有更多的云开发目录配置
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
这时候云服务还是不可用,点击左上角的云开发按钮
云开发
系统将要求您创建环境名称和环境 ID。环境ID创建后不可修改。这里的官方环境名称文档推荐了易于区分测试和发布的开发环境和生产环境名称。
不使用云服务创建的小程序如何使用云开发
首先在根目录下创建两个文件夹,cloudfunctions和miniprogram,其他名字也是可以的。
然后将之前小程序目录下除project.config.json外的文件拖到小程序目录下,添加到project.config.json配置中
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
添加后
点击左上角的云开发按钮,创建环境。首次打开云环境后,需要等待10分钟左右,才能正常使用云API。
右键云开发目录查看当前环境
云开发
在小程序上开始使用云能力之前,需要调用app.js中的wx.cloud.init方法完成云能力初始化
//app.js
App({
onLaunch: function () {
//初始化云开发
wx.cloud.init({
traceUser: true
})
}
})
右键单击 cloudfunctions 文件夹并选择 New Node.js Cloud Function,名称为 getPhone。
新建后默认会生成获取applet上下文的云函数cloud.getWXContext()。如果需要获取openId和unionId,可以直接使用这个云函数。我们将其修改为获取手机号码的云功能。修改后必须右键上传部署。
获取电话
在getPhoneNumber中调用getPhone云函数,小程序端同时支持Callback风格和Promise风格的调用。
// 获取手机号
getPhoneNumber: function (event) {
let cloudID = event.detail.cloudID //开放数据ID
if (!cloudID) {
app.showToast('用户未授权')
return
}
//loading
app.showLoading()
//获取手机号
wx.cloud.callFunction({
name: 'getPhone',
data: {
cloudID: cloudID
}
}).then(res => {
app.hideLoading()
let phone = res.result.list[0].data.phoneNumber
if (phone) {
wx.setStorageSync('phone', phone)
//更新UI
this.setData({
phone: phone
})
}
this.triggerEvent('applyTap')
}).catch(error => {
app.hideLoading()
this.triggerEvent('applyTap')
})
},
参考
5行代码获取小程序用户手机号
按钮
获取手机号码
服务器访问开放数据
资源环境
初始化
我的第一个云功能
Cloud.getOpenData()
网页手机号抓取程序(app关联手机号抓取程序-模拟登录,千言万语汇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-04 21:03
网页手机号抓取程序-模拟登录,功能特点:app关联手机号三方登录进去就是个实用的小模板,让人感觉是个学习技术的好地方。
太少了只有一个搜索框,20几个功能强大的project。
千言万语汇成一句话:不靠谱。今年年初老大和我谈人生规划的时候,他希望我在这个行业多沉淀一段时间,理由很简单,不看好这个行业,投资机构现在也很少看好。然后,给了我一个百度的机会。对,搜索引擎。百度想干的事我当时也明白,出来的太多了,应该只做好自己最擅长的事情,比如,把用户进行分级,从小白用户到高端用户一个区分。
然后,老大说了,干脆,用,百度即可,于是,十多年后,开启了我的人生之旅,毕业证书换成了,针对这个行业的一份简历。今年春节,在学校的广播栏目,百度安康(因为这是我的职业梦想),人生你好面对用户,人和机器人聊天,小峰,你怎么看。人与用户交流交流。ohyeah!人生。
一直想试试做这样一个通用的东西,但是又没有相关的实习经验,所以先从零开始,算是不抛弃不放弃了吧。上个月已经正式开始了,从需求分析到确定开发语言和模块,已经有了长足的进步。接下来需要的就是制定细节开发计划和开发周期。需求分析:由于不知道后期更新维护的情况,希望能够在没有开发计划下就开始开发。目前这个主要是借鉴了以前nodejs写的一个简单类似阿里旺旺的通讯服务器端,功能比较简单,百度百科做了个摘要和辅助信息的方法展示,大概是这样;我想做的应该是基于百度开发的一个类似百度对话框的客户端;模块开发:模块开发是python,至于语言我还没有想好,不过由于之前写的是java,不知道是否对python有些基础。以上个人看法,欢迎补充和指正,公众号实习僧上面有个java后端的课,你可以看看。 查看全部
网页手机号抓取程序(app关联手机号抓取程序-模拟登录,千言万语汇)
网页手机号抓取程序-模拟登录,功能特点:app关联手机号三方登录进去就是个实用的小模板,让人感觉是个学习技术的好地方。
太少了只有一个搜索框,20几个功能强大的project。
千言万语汇成一句话:不靠谱。今年年初老大和我谈人生规划的时候,他希望我在这个行业多沉淀一段时间,理由很简单,不看好这个行业,投资机构现在也很少看好。然后,给了我一个百度的机会。对,搜索引擎。百度想干的事我当时也明白,出来的太多了,应该只做好自己最擅长的事情,比如,把用户进行分级,从小白用户到高端用户一个区分。
然后,老大说了,干脆,用,百度即可,于是,十多年后,开启了我的人生之旅,毕业证书换成了,针对这个行业的一份简历。今年春节,在学校的广播栏目,百度安康(因为这是我的职业梦想),人生你好面对用户,人和机器人聊天,小峰,你怎么看。人与用户交流交流。ohyeah!人生。
一直想试试做这样一个通用的东西,但是又没有相关的实习经验,所以先从零开始,算是不抛弃不放弃了吧。上个月已经正式开始了,从需求分析到确定开发语言和模块,已经有了长足的进步。接下来需要的就是制定细节开发计划和开发周期。需求分析:由于不知道后期更新维护的情况,希望能够在没有开发计划下就开始开发。目前这个主要是借鉴了以前nodejs写的一个简单类似阿里旺旺的通讯服务器端,功能比较简单,百度百科做了个摘要和辅助信息的方法展示,大概是这样;我想做的应该是基于百度开发的一个类似百度对话框的客户端;模块开发:模块开发是python,至于语言我还没有想好,不过由于之前写的是java,不知道是否对python有些基础。以上个人看法,欢迎补充和指正,公众号实习僧上面有个java后端的课,你可以看看。
网页手机号抓取程序(附近门店小程序如何通过路由传递参数?(1) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-29 20:11
)
程序如何实现页面间跳转 wx.navigateTo(OBJECT)
保持当前页面,跳转到app中的一个页面,使用wx.navigateBack返回到原来的页面。注意:目前页面路径只能乘十层。wx.redirectTo(对象)
关闭当前页面并跳转到应用程序中的一个页面。wx.reLaunch(对象)
关闭所有页面并打开应用程序内的页面。wx.switchTab(对象)
跳转到tabBar页面,关闭所有其他非tabBar页面 wx.navigateBack(OBJECT)
关闭当前页面,返回上一页或多级页面。您可以通过getCurrentPages()) 获取当前页面堆栈,并决定返回多少层。如何更改小程序的标题?
wx.setNavigationBarTitle({
标题:'附近的商店'
})
小程序如何通过路由传递参数?
(1)列表页绑定事件(xxList.wxml)
(2)通过列表页面的事件对象获取参数(xxList.js)
goproductDetail:function(event){
let that = this;
let chosenPrdId = event.currentTarget.id
wx.navigateTo({
url: `../productDetail/productDetail?productId=${
chosenPrdId}`,
success: function () {
wx.setNavigationBarTitle({
title: '产品详情'
})
},
fail: function () {
console.log('进入了失败的回调');
}
})
}
(3)获取详情页路由参数(xxDetail.js)
onLoad: function (option) {
console.log(option.chosenPrdId); //选择的id
// TODO 访问后台接口查询具体信息
}
this.setData 和直接赋值的区别
这两者都会导致data中的数据发生变化,但是this.setData的赋值会导致wxml中的数据发生变化,即同步更新渲染界面,直接赋值只会改变data中的数据,但是界面不会改变。
授权获取用户手机号思路
实施思路:
1、通过wx.login获取代码,将代码传到后台,然后后台访问微信接口获取用户的openID和sessionKey,但是后台无法直接将openID或者sessionKey发送到前台(不安全),但是需要单独的字段与openID和sessionKey相关联,然后传递给前台,作为前台登录成功的标志,相当于本地浏览器中cookie存储的session . 设置存储的变量名(如果是userId)
2、前端通过按键按钮触发getPhoneNumber事件,用户允许授权(e.detail.errMsg == 'getPhoneNumber:ok')获取encryptedData,iv
3、通过request请求将[encryptedData],[iv],[userId]传给后台,后台接收解密得到用户手机号,返回给前台,前台存储在本地供其他逻辑判断或以后使用
小程序如何输出遍历对象
{
{
key }}
微信小程序登录授权思路
1.调用wx.login()接口,成功后获取用户的code信息
2.通过接口将code信息传给自己的后端(不是微信后端),在服务器端向微信后端发起请求,成功后获取用户登录状态信息,包括openid, session_key等。也就是openid的交换码,是用户的唯一标识。
3.在后端,获取到openid、session_key等信息后,通过第三方加密生成自己的session信息,返回给前端。
4.前端拿到第三方加密的会话后,通过wx.setStorage()保存在本地,后续请求需要携带第三方加密的会话信息。
5.之后,如果用户需要重新登录,首先查看本地会话信息。如果存在,在微信服务器上使用 wx.checkSession() 检查是否过期。如果它在本地不存在或已过期,请再次从步骤 1 开始登录过程。
onLaunch:function () {
var than = this
// 展示本地存储能力
var logs = wx.getStorageSync('logs') || []
logs.unshift(Date.now())
wx.setStorageSync('logs', logs)
// 登录
wx.login({
success: res => {
var code = res.code
// console.log(code)
wx.getUserInfo({
success: res => {
console.log(res),
// this.globalData.userInfo = res.userInfo
//全局储存
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/getsessionkey',
method: "POST",
data: {
code: code
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success: ress => {
console.log(ress.data)
var openid = ress.data.openid
wx.setStorageSync('openid', ress.data.openid)
wx.setStorageSync('session_key', ress.data.session_key)
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/authlogin',
method: "POST",
data: {
openid: wx.getStorageSync('openid'),
NickName: res.userInfo.nickName,
HeadUrl: res.userInfo.avatarUrl,
gender: res.userInfo.gender
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success(res) {
console.log(res)
var id = res.data.arr.ID
wx.setStorageSync('id', id)
},
})
}
})
}
})
// 发送 res.code 到后台换取 openId, sessionKey, unionId
}
})
// 获取用户信息
wx.getSystemInfo({
success: e => {
this.globalData.StatusBar = e.statusBarHeight;
let capsule = wx.getMenuButtonBoundingClientRect();
if (capsule) {
this.globalData.Custom = capsule;
this.globalData.CustomBar = capsule.bottom + capsule.top - e.statusBarHeight;
} else {
this.globalData.CustomBar = e.statusBarHeight + 50;
}
}
})
} 查看全部
网页手机号抓取程序(附近门店小程序如何通过路由传递参数?(1)
)
程序如何实现页面间跳转 wx.navigateTo(OBJECT)
保持当前页面,跳转到app中的一个页面,使用wx.navigateBack返回到原来的页面。注意:目前页面路径只能乘十层。wx.redirectTo(对象)
关闭当前页面并跳转到应用程序中的一个页面。wx.reLaunch(对象)
关闭所有页面并打开应用程序内的页面。wx.switchTab(对象)
跳转到tabBar页面,关闭所有其他非tabBar页面 wx.navigateBack(OBJECT)
关闭当前页面,返回上一页或多级页面。您可以通过getCurrentPages()) 获取当前页面堆栈,并决定返回多少层。如何更改小程序的标题?
wx.setNavigationBarTitle({
标题:'附近的商店'
})
小程序如何通过路由传递参数?
(1)列表页绑定事件(xxList.wxml)
(2)通过列表页面的事件对象获取参数(xxList.js)
goproductDetail:function(event){
let that = this;
let chosenPrdId = event.currentTarget.id
wx.navigateTo({
url: `../productDetail/productDetail?productId=${
chosenPrdId}`,
success: function () {
wx.setNavigationBarTitle({
title: '产品详情'
})
},
fail: function () {
console.log('进入了失败的回调');
}
})
}
(3)获取详情页路由参数(xxDetail.js)
onLoad: function (option) {
console.log(option.chosenPrdId); //选择的id
// TODO 访问后台接口查询具体信息
}
this.setData 和直接赋值的区别
这两者都会导致data中的数据发生变化,但是this.setData的赋值会导致wxml中的数据发生变化,即同步更新渲染界面,直接赋值只会改变data中的数据,但是界面不会改变。
授权获取用户手机号思路
实施思路:
1、通过wx.login获取代码,将代码传到后台,然后后台访问微信接口获取用户的openID和sessionKey,但是后台无法直接将openID或者sessionKey发送到前台(不安全),但是需要单独的字段与openID和sessionKey相关联,然后传递给前台,作为前台登录成功的标志,相当于本地浏览器中cookie存储的session . 设置存储的变量名(如果是userId)
2、前端通过按键按钮触发getPhoneNumber事件,用户允许授权(e.detail.errMsg == 'getPhoneNumber:ok')获取encryptedData,iv
3、通过request请求将[encryptedData],[iv],[userId]传给后台,后台接收解密得到用户手机号,返回给前台,前台存储在本地供其他逻辑判断或以后使用
小程序如何输出遍历对象
{
{
key }}
微信小程序登录授权思路
1.调用wx.login()接口,成功后获取用户的code信息
2.通过接口将code信息传给自己的后端(不是微信后端),在服务器端向微信后端发起请求,成功后获取用户登录状态信息,包括openid, session_key等。也就是openid的交换码,是用户的唯一标识。
3.在后端,获取到openid、session_key等信息后,通过第三方加密生成自己的session信息,返回给前端。
4.前端拿到第三方加密的会话后,通过wx.setStorage()保存在本地,后续请求需要携带第三方加密的会话信息。
5.之后,如果用户需要重新登录,首先查看本地会话信息。如果存在,在微信服务器上使用 wx.checkSession() 检查是否过期。如果它在本地不存在或已过期,请再次从步骤 1 开始登录过程。
onLaunch:function () {
var than = this
// 展示本地存储能力
var logs = wx.getStorageSync('logs') || []
logs.unshift(Date.now())
wx.setStorageSync('logs', logs)
// 登录
wx.login({
success: res => {
var code = res.code
// console.log(code)
wx.getUserInfo({
success: res => {
console.log(res),
// this.globalData.userInfo = res.userInfo
//全局储存
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/getsessionkey',
method: "POST",
data: {
code: code
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success: ress => {
console.log(ress.data)
var openid = ress.data.openid
wx.setStorageSync('openid', ress.data.openid)
wx.setStorageSync('session_key', ress.data.session_key)
wx.request({
url: 'https://exam.qhynice.top/index.php/Api/Login/authlogin',
method: "POST",
data: {
openid: wx.getStorageSync('openid'),
NickName: res.userInfo.nickName,
HeadUrl: res.userInfo.avatarUrl,
gender: res.userInfo.gender
},
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success(res) {
console.log(res)
var id = res.data.arr.ID
wx.setStorageSync('id', id)
},
})
}
})
}
})
// 发送 res.code 到后台换取 openId, sessionKey, unionId
}
})
// 获取用户信息
wx.getSystemInfo({
success: e => {
this.globalData.StatusBar = e.statusBarHeight;
let capsule = wx.getMenuButtonBoundingClientRect();
if (capsule) {
this.globalData.Custom = capsule;
this.globalData.CustomBar = capsule.bottom + capsule.top - e.statusBarHeight;
} else {
this.globalData.CustomBar = e.statusBarHeight + 50;
}
}
})
}
网页手机号抓取程序(小程序的登录和记录一下的参考借鉴和借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-29 20:07
本篇文章主要介绍微信小程序封装自定义弹窗的实现代码。非常好,有一定的参考价值。有需要的朋友可以参考以下
最近在登录小程序时,需要同时获取用户的手机号和头像昵称,但是小程序不支持通过单一界面同时获取两种数据,于是就想到了自定义一个弹窗,通过弹窗按钮触发获取手机号。事件。记录下来。
具体代码如下:
在业务代码中:
在业务代码中引入对话组件
申请获取你微信绑定的手机号 取消 授权
对话框组件:
在组件下创建一个新对话框。注意组件不是页面,因为它是作为组件引入页面的
对话框.wxml:
需要传入四个属性
visible:是否显示弹窗
标题:标题
showClose:是否在右上角显示关闭按钮
showFooter:是否显示底部按钮
0}}"> {{ title }} 取消 确定
对话框.js
dialog.json:只需将其声明为组件
{ "component": true, "usingComponents": {} }
对话框.wxss
CSS可以根据你喜欢的风格进行调整。请注意,遮罩层的 z-index 稍高一些,以确保它位于顶层。
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
总结
以上就是小编介绍的微信小程序打包自定义弹窗的实现代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。非常感谢您对本站的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢! 查看全部
网页手机号抓取程序(小程序的登录和记录一下的参考借鉴和借鉴价值)
本篇文章主要介绍微信小程序封装自定义弹窗的实现代码。非常好,有一定的参考价值。有需要的朋友可以参考以下
最近在登录小程序时,需要同时获取用户的手机号和头像昵称,但是小程序不支持通过单一界面同时获取两种数据,于是就想到了自定义一个弹窗,通过弹窗按钮触发获取手机号。事件。记录下来。
具体代码如下:
在业务代码中:
在业务代码中引入对话组件
申请获取你微信绑定的手机号 取消 授权
对话框组件:
在组件下创建一个新对话框。注意组件不是页面,因为它是作为组件引入页面的
对话框.wxml:
需要传入四个属性
visible:是否显示弹窗
标题:标题
showClose:是否在右上角显示关闭按钮
showFooter:是否显示底部按钮
0}}"> {{ title }} 取消 确定
对话框.js
dialog.json:只需将其声明为组件
{ "component": true, "usingComponents": {} }
对话框.wxss
CSS可以根据你喜欢的风格进行调整。请注意,遮罩层的 z-index 稍高一些,以确保它位于顶层。
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
/* components/dialog/dialog.wxss */ .dialog-custom { width: 100vw; height: 100%; position: absolute; left: 0; top: 0; z-index: 9999; } .dialog-mask { position: fixed; top: 0; left: 0; right: 0; bottom: 0; z-index: 10000; width: 100vw; height: 100%; background: rgba(0, 0, 0, 0.3); } .dialog-main { position: fixed; z-index: 10001; top: 50%; left: 0; right: 0; width: 85vw; height: auto; margin: auto; transform: translateY(-50%); } .dialog-container { margin: 0 auto; background: #fff; z-index: 10001; border-radius: 3px; box-sizing: border-box; padding: 40rpx; } .dialog-container__title { width: 100%; height: 50rpx; line-height: 50rpx; margin-bottom: 20rpx; position: relative; } .dialog-container__title .title-label{ display: inline-block; width: 100%; height: 50rpx; line-height: 50rpx; font-size: 36rpx; color: #000; text-align: center; } .dialog-container__title .title-icon{ width: 34rpx; height: 50rpx; position: absolute; top: 0; right: 0; } .dialog-container__title .title-icon image{ width: 34rpx; height: 34rpx; } .dialog-container__body { padding-top: 10rpx; font-size: 32rpx; line-height: 50rpx; } .dialog-container__footer { height: 76rpx; line-height: 76rpx; font-size: 32rpx; text-align: center; border-top: 1px solid #f1f1f1; position: absolute; bottom: 0; left: 0; right: 0; } .dialog-container__footer .dialog-container__footer__cancel { width: 50%; color: #999; display: inline-block; } .dialog-container__footer .dialog-container__footer__cancel::after{ position: absolute; right: 50%; bottom: 0; content: ''; width: 2rpx; height: 76rpx; background: #f1f1f1; } .dialog-container__footer .dialog-container__footer__confirm { color: #3B98F7; width: 50%; display: inline-block; text-align: center; }
总结
以上就是小编介绍的微信小程序打包自定义弹窗的实现代码。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。非常感谢您对本站的支持网站!
如果您觉得本文对您有帮助,欢迎转载,请注明出处,谢谢!
网页手机号抓取程序(学习爬虫第二周,爬取58同城手机号码,网址如下所示。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2022-01-27 23:19
学习爬虫第二周,爬取同城58的手机号。网址如下。
网页预览.png
根据学习情况,首先需要分析网页,观察页面结构。
观察页面特征:
对于大规模的数据抓取,观察页面结构特点,编写的程序是否通用,是否可以适用于所有页面。找到边界条件,找到限制。
其次,需要设计程序的工作流程。
设计工作流程
在根据页面弄清楚程序是如何设计的之后,制定有效的工作流程,保证程序在爬取过程中的高效执行。工作输出效率更稳定。
1. 要大规模抓取数据,我们需要知道边界在哪里。查询网页后:
http://bj.58.com/shoujihao/pn{}.format(page)
我们发现当输入到pn117时,页面数据不见了。
同时,搜索网页中标题和链接的元素位置,并将捕获存储在Mongo中,其中存储了网页上所有手机号码标题的详情页的url链接。
2.分析网页后,适合我们的网站如下:
对.png
不恰当的 网站 是这样的:
错误.png
因此,在爬取Spider2的详情页时,需要根据正确的网页结构元素进行爬取。
同时抓取网页中需要的元素。
代码显示如下:
#!/usr/bin/env python
# coding: utf-8
from bs4 import BeautifulSoup
import requests
import time
import pymongo
#create the database
client = pymongo.MongoClient('localhost',27017)
#name:Phone
Phone = client['Phone']
#table:phone_numbers 存储手机号的表
phone_numbers = Phone['phone_numbers']
#table:phone_info 详细信息
phone_info = Phone['phone_info']
#infocont > span > b
#Spider1 提取链接
def get_links_from(page):
url = 'http://bj.58.com/shoujihao/pn{}/'.format(page)
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#infolist > div > ul > div > ul > li > a.t > strong')
links = Soup.select('#infolist > div > ul > div > ul > li > a.t')
for title,link in zip(titles,links):
data = {
'title':title.get_text(),
'link':link.get('href')
}
phone_numbers.insert_one(data)
#Spider2 详细页面
def get_item_from(url):
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.mainTitle > h1')
prices = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.sumary > ul > li > div.su_con > span')
for title,price in zip(titles,prices):
title = title.get_text().replace('\n','').replace('\t','').replace(' ','')
price = price.get_text().replace('\n','').replace('\t','').replace(' ','')
data = {
'title':title,
'price':price,
'url':url
}
print(data)
phone_info.insert_one(data)
for page in range(1,117): #抓取所有页面
get_links_from(page)
for info in phone_numbers.find(): #从数据库中抓取存储的url
url = info['link']
get_item_from(url)
运行结果截图:
phone_number 中的数据:
手机号码存储表.png
phone_info 中的数据:
详情.png
总结: 查看全部
网页手机号抓取程序(学习爬虫第二周,爬取58同城手机号码,网址如下所示。)
学习爬虫第二周,爬取同城58的手机号。网址如下。
网页预览.png
根据学习情况,首先需要分析网页,观察页面结构。
观察页面特征:
对于大规模的数据抓取,观察页面结构特点,编写的程序是否通用,是否可以适用于所有页面。找到边界条件,找到限制。
其次,需要设计程序的工作流程。
设计工作流程
在根据页面弄清楚程序是如何设计的之后,制定有效的工作流程,保证程序在爬取过程中的高效执行。工作输出效率更稳定。
1. 要大规模抓取数据,我们需要知道边界在哪里。查询网页后:
http://bj.58.com/shoujihao/pn{}.format(page)
我们发现当输入到pn117时,页面数据不见了。
同时,搜索网页中标题和链接的元素位置,并将捕获存储在Mongo中,其中存储了网页上所有手机号码标题的详情页的url链接。
2.分析网页后,适合我们的网站如下:
对.png
不恰当的 网站 是这样的:
错误.png
因此,在爬取Spider2的详情页时,需要根据正确的网页结构元素进行爬取。
同时抓取网页中需要的元素。
代码显示如下:
#!/usr/bin/env python
# coding: utf-8
from bs4 import BeautifulSoup
import requests
import time
import pymongo
#create the database
client = pymongo.MongoClient('localhost',27017)
#name:Phone
Phone = client['Phone']
#table:phone_numbers 存储手机号的表
phone_numbers = Phone['phone_numbers']
#table:phone_info 详细信息
phone_info = Phone['phone_info']
#infocont > span > b
#Spider1 提取链接
def get_links_from(page):
url = 'http://bj.58.com/shoujihao/pn{}/'.format(page)
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#infolist > div > ul > div > ul > li > a.t > strong')
links = Soup.select('#infolist > div > ul > div > ul > li > a.t')
for title,link in zip(titles,links):
data = {
'title':title.get_text(),
'link':link.get('href')
}
phone_numbers.insert_one(data)
#Spider2 详细页面
def get_item_from(url):
wb_data = requests.get(url)
time.sleep(1)
Soup = BeautifulSoup(wb_data.text,'lxml')
titles = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.mainTitle > h1')
prices = Soup.select('#main > div.col.detailPrimary.mb15 > div.col_sub.sumary > ul > li > div.su_con > span')
for title,price in zip(titles,prices):
title = title.get_text().replace('\n','').replace('\t','').replace(' ','')
price = price.get_text().replace('\n','').replace('\t','').replace(' ','')
data = {
'title':title,
'price':price,
'url':url
}
print(data)
phone_info.insert_one(data)
for page in range(1,117): #抓取所有页面
get_links_from(page)
for info in phone_numbers.find(): #从数据库中抓取存储的url
url = info['link']
get_item_from(url)
运行结果截图:
phone_number 中的数据:
手机号码存储表.png
phone_info 中的数据:
详情.png
总结:
网页手机号抓取程序(HTML代码中将标签中的内容提取出来的思路和方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 09:26
)
#target URL=""
#主要用到的python库:requests、etree
主要使用xpath进行信息处理
我们先说xpath:
XPath 是 XML 路径语言,它是一种用于确定 XML(标准通用标记语言的子集)文档的某个部分的位置的语言。 XPath 基于 XML 的树结构,它提供了在数据结构树中查找节点的能力。说白了就是提取HTML代码中标签的内容。
思考:
先看页面
这是我们主要要提取的信息;
我们先来看看提取出来的效果:
查看网站源代码(F12):
我们需要的信息在一个名为'table'的标签里,而在table标签里有一个小标签'tr','td'包裹了我们的信息,所以网站标签的路径很清晰标签的路径就是我们需要的XPATH,可以直接通过浏览器复制粘贴,不用担心找不到路径!
编写代码:
首先requests函数的get函数抓取网页的代码。爬取的时候最好加上请求头,不然有些网站会阻塞IP:
str(number)中的数字就是我们要查询的电话号码
然后使用我们得到的html代码进行编码整理:
基本上所有的网站都可以用这几行代码组织起来,是通用代码。
然后使用xpath提取信息:
xpath在etree库中,而etree在模块lxml中,所以先添加头文件 from lxml import etree like C语言
那么就可以根据路径提取出来了:
con1=selet.xpath('/html/body/table[2]/tr[1]/td/b/text())
con2=selet.xpath('/html/body/table[2]/tr[1]/td/text())
因为标签表里有8个这么小的标签,所以我们要循环8次,每次循环都改变str[]里面的数字,然后打印出来:
p>
最后给出所有代码:
import requests
from lxml import etree
def find(slet,num):
con1=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/b/text()')
con2=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/text()')
for i in con1:
print(i)
for i in con2:
print(i)
while(1):
print("手机号测吉凶纯属娱乐!!!\n输入q退出!\n")
number=input("请输入你的手机号:")
if(number=='q'):
break;
kv={'user-agent':'Chrome/55.0.2883.87 Mobile Safari/537.36'}
url="http://jx.ip138.com/"+str(number)
r=requests.get(url,headers=kv)
r.encoding=r.apparent_encoding
html=r.text
selet=etree.HTML(html)
for num in range(1,9):
find(selet,num)
print("*************************************") 查看全部
网页手机号抓取程序(HTML代码中将标签中的内容提取出来的思路和方法
)
#target URL=""
#主要用到的python库:requests、etree
主要使用xpath进行信息处理
我们先说xpath:
XPath 是 XML 路径语言,它是一种用于确定 XML(标准通用标记语言的子集)文档的某个部分的位置的语言。 XPath 基于 XML 的树结构,它提供了在数据结构树中查找节点的能力。说白了就是提取HTML代码中标签的内容。
思考:
先看页面
这是我们主要要提取的信息;
我们先来看看提取出来的效果:
查看网站源代码(F12):
我们需要的信息在一个名为'table'的标签里,而在table标签里有一个小标签'tr','td'包裹了我们的信息,所以网站标签的路径很清晰标签的路径就是我们需要的XPATH,可以直接通过浏览器复制粘贴,不用担心找不到路径!
编写代码:
首先requests函数的get函数抓取网页的代码。爬取的时候最好加上请求头,不然有些网站会阻塞IP:
str(number)中的数字就是我们要查询的电话号码
然后使用我们得到的html代码进行编码整理:
基本上所有的网站都可以用这几行代码组织起来,是通用代码。
然后使用xpath提取信息:
xpath在etree库中,而etree在模块lxml中,所以先添加头文件 from lxml import etree like C语言
那么就可以根据路径提取出来了:
con1=selet.xpath('/html/body/table[2]/tr[1]/td/b/text())
con2=selet.xpath('/html/body/table[2]/tr[1]/td/text())
因为标签表里有8个这么小的标签,所以我们要循环8次,每次循环都改变str[]里面的数字,然后打印出来:
p>
最后给出所有代码:
import requests
from lxml import etree
def find(slet,num):
con1=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/b/text()')
con2=selet.xpath('/html/body/table[2]/tr['+str(num)+']/td/text()')
for i in con1:
print(i)
for i in con2:
print(i)
while(1):
print("手机号测吉凶纯属娱乐!!!\n输入q退出!\n")
number=input("请输入你的手机号:")
if(number=='q'):
break;
kv={'user-agent':'Chrome/55.0.2883.87 Mobile Safari/537.36'}
url="http://jx.ip138.com/"+str(number)
r=requests.get(url,headers=kv)
r.encoding=r.apparent_encoding
html=r.text
selet=etree.HTML(html)
for num in range(1,9):
find(selet,num)
print("*************************************")
网页手机号抓取程序( 网站站点用户访客移动端手机号码号码,大大降低营销推广规划管理运营成本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-26 08:16
网站站点用户访客移动端手机号码号码,大大降低营销推广规划管理运营成本)
手机网站客人手机号抓码写法原理!
现在市场上有很多软件可以捕获网站网站和网页的用户信息。您可以浏览访问网站的手机号获取手机号。通过这些软件或系统,可以查询手机归属地,提取用户。用户可以通过检索用户访问者的搜索信息内容、手机号码信息、查看浏览网页信息等,轻松了解用户和访问者的最新需求。有了这些精准的信息,网站站长可以进行二次推广和营销,大大降低了营销、推广、策划、管理和运营的成本。这些只需在网页上安装一段Js代码即可实现。
捕获用户访问者手机号的手机号,捕获用户手机网页的访问者。
传统的公司采集电话推广营销方式,公司招聘大量电话接线员,拿着厚厚的一叠电话费,从早到晚拿着电话打电话。在这个社会中,越来越多的用户对这种电话营销、营销、广告的方式产生了强烈的反感。
5个营业员算下来,底薪至少1500元一个月,加起来就是7500元一个月;如果不计算别的,一个月内可能找不到100个真实准确的客户用户数据;但是使用我们的网站网站用户访客手机提取系统,一天有机会获得100个真实准确的客户用户数据,一个月内会有更多的沉淀,而且都是准确的客户用户。
网站本站用户访客手机号抓取软件是一套专门用于手机站用户访客手机号抓取的专业软件。要使用它,您只需要在手机站安装一个简单的代码,当用户和访问者在手机上查看和浏览您的网页时,他们就可以抓取它。抓取移动端的手机号,登录到软件的在线后台后,可以清晰的看到用户和访客的信息,包括移动端。手机号码、网站标题TITLE、来源关键词关键字、来源url、地区、ip等,可通过Excel批量导出,方便管理。
用户访客手机号抓取软件的优点是:
抢占用户和访客的手机号码,获得二次推广和营销机会,增加公司销售额,降低策划、管理和运营成本。
现在网络营销推广非常困难,用户流量成本不断攀升。以百度竞价为例,90%以上的客户和用户访问并点击了广告,浏览并访问了网站网站。我们直接去了,只有极少数人询问并留下了我们的联系方式,大量的广告费就这样白白浪费了。想知道客户和用户的联系方式进行二次推广和营销,比登天还难。不过,现在手机号码抓取软件的出现,彻底解决了这样的问题。有了目标客户用户的电话号码,你认为订单会减少吗?试想一下,如果你能接触到 95% 的流失用户并持续跟进,您将能够恢复至少 60% 的准确客户用户。那么成交率肯定会大大提高!与其被动等待,不如主动挽回流失的客户和用户。 查看全部
网页手机号抓取程序(
网站站点用户访客移动端手机号码号码,大大降低营销推广规划管理运营成本)
手机网站客人手机号抓码写法原理!
现在市场上有很多软件可以捕获网站网站和网页的用户信息。您可以浏览访问网站的手机号获取手机号。通过这些软件或系统,可以查询手机归属地,提取用户。用户可以通过检索用户访问者的搜索信息内容、手机号码信息、查看浏览网页信息等,轻松了解用户和访问者的最新需求。有了这些精准的信息,网站站长可以进行二次推广和营销,大大降低了营销、推广、策划、管理和运营的成本。这些只需在网页上安装一段Js代码即可实现。
捕获用户访问者手机号的手机号,捕获用户手机网页的访问者。
传统的公司采集电话推广营销方式,公司招聘大量电话接线员,拿着厚厚的一叠电话费,从早到晚拿着电话打电话。在这个社会中,越来越多的用户对这种电话营销、营销、广告的方式产生了强烈的反感。
5个营业员算下来,底薪至少1500元一个月,加起来就是7500元一个月;如果不计算别的,一个月内可能找不到100个真实准确的客户用户数据;但是使用我们的网站网站用户访客手机提取系统,一天有机会获得100个真实准确的客户用户数据,一个月内会有更多的沉淀,而且都是准确的客户用户。
网站本站用户访客手机号抓取软件是一套专门用于手机站用户访客手机号抓取的专业软件。要使用它,您只需要在手机站安装一个简单的代码,当用户和访问者在手机上查看和浏览您的网页时,他们就可以抓取它。抓取移动端的手机号,登录到软件的在线后台后,可以清晰的看到用户和访客的信息,包括移动端。手机号码、网站标题TITLE、来源关键词关键字、来源url、地区、ip等,可通过Excel批量导出,方便管理。
用户访客手机号抓取软件的优点是:
抢占用户和访客的手机号码,获得二次推广和营销机会,增加公司销售额,降低策划、管理和运营成本。
现在网络营销推广非常困难,用户流量成本不断攀升。以百度竞价为例,90%以上的客户和用户访问并点击了广告,浏览并访问了网站网站。我们直接去了,只有极少数人询问并留下了我们的联系方式,大量的广告费就这样白白浪费了。想知道客户和用户的联系方式进行二次推广和营销,比登天还难。不过,现在手机号码抓取软件的出现,彻底解决了这样的问题。有了目标客户用户的电话号码,你认为订单会减少吗?试想一下,如果你能接触到 95% 的流失用户并持续跟进,您将能够恢复至少 60% 的准确客户用户。那么成交率肯定会大大提高!与其被动等待,不如主动挽回流失的客户和用户。
网页手机号抓取程序(近年来运营商精准大数据接口实时调度:一般来说精准 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-24 01:18
)
近年来,运营商精准大数据的神秘色彩总是被越来越多地描述,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
众所周知,中国移动、中国联通、电信是我们熟知的三大运营商。目前在我们所处的环境中,所有的上网行为都是建立在这三大运营商的基础之上的,因为互联网上的任何行为都是基于通过这三大运营商,原则上我们所有的通话记录和上网行为即使您在终端(电脑或手机)也无法从运营商数据库中清除,但您的数据信息无法清除。
看到这里,有人会想,难道我一点秘密都没有吗?原则上是的,互联网时代每个人都是皇帝的新衣,但你不必惊慌,因为以中国为例,平均每天有8.29亿(不完全统计在2020),你可以理解因此,这829亿的任何行为(比如点击网站)都被记录为数据标签,有兴趣的可以深入挖掘,计算一下这个量在哪里。那么你的担心就不是担心了。但是这些大数据对我们的日常生活有用吗?它在哪里使用?
可以观看CCTV9的《大数据时代》纪录片。就是利用大数据分析人群行为标签,挽救生命,精准安排出行出行。让我们关注每个人对我们个人的关心,以及公司是否使用它们来运营业务大数据以获取客户、增加价值和降低营销成本。
运营商大数据数据接口实时调度:一般来说是针对有网站开发权,可以植入程序,对访客数据进行实时分析的。
通过植入网站服务器内部程序,将运营商的数据接口实时连接到网站,让运营商授权,如果访客实时访问,会回调网站 实时。在所有者指定的TXT文档中,从访问文档到自动生成数据,一般只需要几毫秒。
一般来说,运营商大数据实时建模和捕获的主要应用是企业、行业和销售人员进行外呼获取客户。
查看全部
网页手机号抓取程序(近年来运营商精准大数据接口实时调度:一般来说精准
)
近年来,运营商精准大数据的神秘色彩总是被越来越多地描述,其魅力在各个领域、各个行业迅速蔓延。不过,如何从海量数据中快速准确地获取到需要的数据,仍然是企业的一大短板,不过在了解了网络爬虫工具之后,这个问题似乎就不那么麻烦了。
众所周知,中国移动、中国联通、电信是我们熟知的三大运营商。目前在我们所处的环境中,所有的上网行为都是建立在这三大运营商的基础之上的,因为互联网上的任何行为都是基于通过这三大运营商,原则上我们所有的通话记录和上网行为即使您在终端(电脑或手机)也无法从运营商数据库中清除,但您的数据信息无法清除。
看到这里,有人会想,难道我一点秘密都没有吗?原则上是的,互联网时代每个人都是皇帝的新衣,但你不必惊慌,因为以中国为例,平均每天有8.29亿(不完全统计在2020),你可以理解因此,这829亿的任何行为(比如点击网站)都被记录为数据标签,有兴趣的可以深入挖掘,计算一下这个量在哪里。那么你的担心就不是担心了。但是这些大数据对我们的日常生活有用吗?它在哪里使用?
可以观看CCTV9的《大数据时代》纪录片。就是利用大数据分析人群行为标签,挽救生命,精准安排出行出行。让我们关注每个人对我们个人的关心,以及公司是否使用它们来运营业务大数据以获取客户、增加价值和降低营销成本。
运营商大数据数据接口实时调度:一般来说是针对有网站开发权,可以植入程序,对访客数据进行实时分析的。
通过植入网站服务器内部程序,将运营商的数据接口实时连接到网站,让运营商授权,如果访客实时访问,会回调网站 实时。在所有者指定的TXT文档中,从访问文档到自动生成数据,一般只需要几毫秒。
一般来说,运营商大数据实时建模和捕获的主要应用是企业、行业和销售人员进行外呼获取客户。
网页手机号抓取程序(作业效果:>showdbsbj580.001GBlocal0.000GBxiaozhu)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-20 21:08
工作效果:
> 显示数据库
bj58 0.001GB
本地 0.000GB
小猪 0.000GB
> 使用 bj58
切换到数据库 bj58
> 显示采集
详细信息
链接
> db.links.find().count()
3481
> db.links.find()[0]
{
"_id" : ObjectId("574a689ee4eaf"),
“关联” : ””,
“标题” : ””
}
> db.detailinfo.find().count()
3481
> db.detailinfo.find()[0]
{
"_id" : ObjectId("574abe78e00282487d8dd6e7"),
“电话”:“”,
“网址”:“”,
“价格”:“800”,
"isp" : "联通",
“卖家”:“王先生”,
“sell_number”:“”
}
>
笔记和总结
为大规模爬网准备工作流程
观察页面结构特征
以前只在特定页面上抓取信息
但是,如果是网站的大规模爬取,会涉及到几个页面,而且程序需要通用性,爬取需要的页面
设计工作流程
保证抓取过程的效率
观察页面结构特征
不同的页面会有不同的内容结构。例如,有些具有独特的元素,因此某些页面无法使用同一组爬虫进行爬取。
有些页面不需要爬取
手动指定要爬取的页数后,需要让程序识别分页元素来判断是否是最后一页,避免最后一页没有信息,比如直接跳过。
设计工作流程
两只爬行动物
从列表页面爬取所有产品的 URL 并将它们存储在数据库中的表中
获取商品url,获取详情页,爬取需要的信息,存入另一个表
将爬取任务分成两个爬虫的原因是,在做大规模数据爬取的时候,最好一次只做一件事,这样可以提高爬虫的稳定性
当您可能遇到问题时,这是工作时间和调试之间的平衡
获取类别/频道
从主页获取所有类别/频道的信息
构造分类列表页面的url:常用前缀、频道、发布者类型、页码
url = "{}{}/0/pn{}".format()
爬取分类列表页面中商品详情的url
如果是批量访问,最好在访问之间留一点时间。如果 网站 压力好,没关系
对于分页结束需要停止的页面,判断是否有td标签,find('td','t'),如果有,继续,否则,停止
从元素结构来看
爬取商品详情
每次有请求,浏览量都会变化,所以不需要记录
访问的url可能会返回404,因为交易已经成功下线。一个页面的js脚本链接收录404
从具体内容来看
no_longer_exist = '404' in soup.find('script', type='').get('src').split('/')
soup.prettify() 可以使打印出来的 HTML 内容更具可读性
概括
CSS
第一页有内容要跳过
其他页面没有这个问题
没有办法直接通过CSS选择器进行过滤,只能判断是否是首页,然后区别对待:
如果数 == 1:
boxlist = detail_soup.select("div.boxlist div.boxlist")[1]
别的:
boxlist = detail_soup.select("div.boxlist div.boxlist")[0]
内容
海淀
“——
" 枣君寺
获取所有子元素的内容,子元素之间的内容
area_data = detail_soup.select("span.c_25d")
area = list(area_data[0].stripped_strings) if area_data else None
打印区
[u'\u897f\u57ce', u'-', u'\u897f\u56db']
但以下情况不能这样处理:
"
联通
A B C D
"
去掉两边的空格“”,删除字符串中间的“”和\t,将多个\n替换为一个\n,然后用\n分隔成一个列表
number = list(detail_soup.select("h1")[0].stripped_strings)[0]
info_list = number.replace('\t','').replace(' ',"").replace('\n\n\n','\n').split("\n")
# print 'number=',info_list[0]
# print 'isp=', info_list[1]
“蟒蛇食谱” 查看全部
网页手机号抓取程序(作业效果:>showdbsbj580.001GBlocal0.000GBxiaozhu)
工作效果:
> 显示数据库
bj58 0.001GB
本地 0.000GB
小猪 0.000GB
> 使用 bj58
切换到数据库 bj58
> 显示采集
详细信息
链接
> db.links.find().count()
3481
> db.links.find()[0]
{
"_id" : ObjectId("574a689ee4eaf"),
“关联” : ””,
“标题” : ””
}
> db.detailinfo.find().count()
3481
> db.detailinfo.find()[0]
{
"_id" : ObjectId("574abe78e00282487d8dd6e7"),
“电话”:“”,
“网址”:“”,
“价格”:“800”,
"isp" : "联通",
“卖家”:“王先生”,
“sell_number”:“”
}
>
笔记和总结
为大规模爬网准备工作流程
观察页面结构特征
以前只在特定页面上抓取信息
但是,如果是网站的大规模爬取,会涉及到几个页面,而且程序需要通用性,爬取需要的页面
设计工作流程
保证抓取过程的效率
观察页面结构特征
不同的页面会有不同的内容结构。例如,有些具有独特的元素,因此某些页面无法使用同一组爬虫进行爬取。
有些页面不需要爬取
手动指定要爬取的页数后,需要让程序识别分页元素来判断是否是最后一页,避免最后一页没有信息,比如直接跳过。
设计工作流程
两只爬行动物
从列表页面爬取所有产品的 URL 并将它们存储在数据库中的表中
获取商品url,获取详情页,爬取需要的信息,存入另一个表
将爬取任务分成两个爬虫的原因是,在做大规模数据爬取的时候,最好一次只做一件事,这样可以提高爬虫的稳定性
当您可能遇到问题时,这是工作时间和调试之间的平衡
获取类别/频道
从主页获取所有类别/频道的信息
构造分类列表页面的url:常用前缀、频道、发布者类型、页码
url = "{}{}/0/pn{}".format()
爬取分类列表页面中商品详情的url
如果是批量访问,最好在访问之间留一点时间。如果 网站 压力好,没关系
对于分页结束需要停止的页面,判断是否有td标签,find('td','t'),如果有,继续,否则,停止
从元素结构来看
爬取商品详情
每次有请求,浏览量都会变化,所以不需要记录
访问的url可能会返回404,因为交易已经成功下线。一个页面的js脚本链接收录404
从具体内容来看
no_longer_exist = '404' in soup.find('script', type='').get('src').split('/')
soup.prettify() 可以使打印出来的 HTML 内容更具可读性
概括
CSS
第一页有内容要跳过
其他页面没有这个问题
没有办法直接通过CSS选择器进行过滤,只能判断是否是首页,然后区别对待:
如果数 == 1:
boxlist = detail_soup.select("div.boxlist div.boxlist")[1]
别的:
boxlist = detail_soup.select("div.boxlist div.boxlist")[0]
内容
海淀
“——
" 枣君寺
获取所有子元素的内容,子元素之间的内容
area_data = detail_soup.select("span.c_25d")
area = list(area_data[0].stripped_strings) if area_data else None
打印区
[u'\u897f\u57ce', u'-', u'\u897f\u56db']
但以下情况不能这样处理:
"
联通
A B C D
"
去掉两边的空格“”,删除字符串中间的“”和\t,将多个\n替换为一个\n,然后用\n分隔成一个列表
number = list(detail_soup.select("h1")[0].stripped_strings)[0]
info_list = number.replace('\t','').replace(' ',"").replace('\n\n\n','\n').split("\n")
# print 'number=',info_list[0]
# print 'isp=', info_list[1]
“蟒蛇食谱”
网页手机号抓取程序(微信小程序获取手机号授权用户登录功能介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-19 05:11
小程序中有很多地方用到了注册的用户信息。用户需要填写手机号等,有了这个组件,无需用户填写即可快速获取绑定微信的手机号。本文主要分享微信小程序获取手机号授权用户登录功能,需要的朋友可以参考一下,希望对大家有帮助。
1.getPhoneNumber 该组件由按钮实现(其他标签无效)。在按钮中设置 open-type="getPhoneNumber",并绑定 bindgetphonenumber 事件获取回调。
2.使用该组件前必须调用登录接口。如果没有调用登录,点击按钮,会提示先调用登录。
App({
onLaunch: function () {
wx.login({
success: function (res) {
if (res.code) {
//发起网络请求
console.log(res.code)
} else {
console.log('获取用户登录态失败!' + res.errMsg)
}
}
});
}
})
3.通过bindphonenumber绑定的事件获取回调。回调有三个参数,
errMsg:用户点击取消或授权信息回调。
iv:加密算法的初始向量(如果用户不同意授权,则未定义)。
encryptedData:用户信息的加密数据(如果用户不同意授权,也会返回undefined)
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
if (e.detail.errMsg == 'getPhoneNumber:fail user deny'){
wx.showModal({
title: '提示',
showCancel: false,
content: '未授权',
success: function (res) { }
})
} else {
wx.showModal({
title: '提示',
showCancel: false,
content: '同意授权',
success: function (res) { }
})
}
}
4.最后还是要根据自己的业务逻辑来处理。如果用户不同意授权,我们可能会有一个界面让他手动输入。如果不是强制获取手机号,可以直接跳转页面进行下一步。. (用户不同意授权errMsg返回'getPhoneNumber:fail user deny')
5.用户同意授权,我们可以根据登录时得到的code,通过后台和微信处理得到session_key,最后传递app_id、session_key、iv、encryptedData(用户同意授权errMsg返回 'getPhoneNumber: ok')
还学习了一个小程序功能,希望对大家有帮助。 查看全部
网页手机号抓取程序(微信小程序获取手机号授权用户登录功能介绍(图))
小程序中有很多地方用到了注册的用户信息。用户需要填写手机号等,有了这个组件,无需用户填写即可快速获取绑定微信的手机号。本文主要分享微信小程序获取手机号授权用户登录功能,需要的朋友可以参考一下,希望对大家有帮助。
1.getPhoneNumber 该组件由按钮实现(其他标签无效)。在按钮中设置 open-type="getPhoneNumber",并绑定 bindgetphonenumber 事件获取回调。
2.使用该组件前必须调用登录接口。如果没有调用登录,点击按钮,会提示先调用登录。
App({
onLaunch: function () {
wx.login({
success: function (res) {
if (res.code) {
//发起网络请求
console.log(res.code)
} else {
console.log('获取用户登录态失败!' + res.errMsg)
}
}
});
}
})
3.通过bindphonenumber绑定的事件获取回调。回调有三个参数,
errMsg:用户点击取消或授权信息回调。
iv:加密算法的初始向量(如果用户不同意授权,则未定义)。
encryptedData:用户信息的加密数据(如果用户不同意授权,也会返回undefined)
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
if (e.detail.errMsg == 'getPhoneNumber:fail user deny'){
wx.showModal({
title: '提示',
showCancel: false,
content: '未授权',
success: function (res) { }
})
} else {
wx.showModal({
title: '提示',
showCancel: false,
content: '同意授权',
success: function (res) { }
})
}
}
4.最后还是要根据自己的业务逻辑来处理。如果用户不同意授权,我们可能会有一个界面让他手动输入。如果不是强制获取手机号,可以直接跳转页面进行下一步。. (用户不同意授权errMsg返回'getPhoneNumber:fail user deny')
5.用户同意授权,我们可以根据登录时得到的code,通过后台和微信处理得到session_key,最后传递app_id、session_key、iv、encryptedData(用户同意授权errMsg返回 'getPhoneNumber: ok')
还学习了一个小程序功能,希望对大家有帮助。
网页手机号抓取程序(网页手机号抓取程序,.txt文件怎么用订阅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-19 03:01
网页手机号抓取程序,适用于天猫等各大购物网站,非常快速非常安全,功能不错
易于上手的,
也许是来自购物网站的爬虫
可以看看这个方法有点意思:使用elasticsearch获取rss订阅。(v2.6),
aibooter。
根据楼主的问题,robots.txt文件抓取被抓取者的网页,
一看楼主就没好好学习txt文件解析
robots.txt文件给了一个公平公正的态度让网站正视问题,所以一般不会说网站不对抗爬虫的问题。另外一个就是txt文件被反编译的话(针对某些文件格式)肯定会被反爬虫大规模抓取的,这时候可以在github上面找找现有的python爬虫工具了。当然,从爬虫本身讲,txt文件本身也是不对抗爬虫的。毕竟txt文件当时很流行,很多python模块可以直接拿来用。
但是其实爬虫之间互相也有约定俗成的规则,所以有些时候比如豆瓣登录,很多网站其实可以直接加一个筛选按钮,可以去掉访问的登录或者半年内已用豆瓣购买过电影的信息,如果是各大电影站不做区分的话是很容易被爬虫直接访问爬去的。txt也是一样的,txt文件也很方便使用。 查看全部
网页手机号抓取程序(网页手机号抓取程序,.txt文件怎么用订阅)
网页手机号抓取程序,适用于天猫等各大购物网站,非常快速非常安全,功能不错
易于上手的,
也许是来自购物网站的爬虫
可以看看这个方法有点意思:使用elasticsearch获取rss订阅。(v2.6),
aibooter。
根据楼主的问题,robots.txt文件抓取被抓取者的网页,
一看楼主就没好好学习txt文件解析
robots.txt文件给了一个公平公正的态度让网站正视问题,所以一般不会说网站不对抗爬虫的问题。另外一个就是txt文件被反编译的话(针对某些文件格式)肯定会被反爬虫大规模抓取的,这时候可以在github上面找找现有的python爬虫工具了。当然,从爬虫本身讲,txt文件本身也是不对抗爬虫的。毕竟txt文件当时很流行,很多python模块可以直接拿来用。
但是其实爬虫之间互相也有约定俗成的规则,所以有些时候比如豆瓣登录,很多网站其实可以直接加一个筛选按钮,可以去掉访问的登录或者半年内已用豆瓣购买过电影的信息,如果是各大电影站不做区分的话是很容易被爬虫直接访问爬去的。txt也是一样的,txt文件也很方便使用。
网页手机号抓取程序( 达叔小生:微信小程序如何获取用户绑定手机号的相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-18 14:12
达叔小生:微信小程序如何获取用户绑定手机号的相关资料)
微信小程序获取用户绑定手机号方法示例
更新时间:2019-07-21 15:46:58 作者:大树小生
本篇文章主要介绍微信小程序如何获取用户绑定手机号的相关信息。文中对示例代码进行了非常详细的介绍,对大家学习或使用微信小程序有一定的参考价值。,有需要的朋友,一起学习吧
用户调用 wx.login() 方法获取登录用户凭证码
wx.login({
success: function(res) {
console.log('loginCode', res.code)
}
});
代码传到后台,凭证代码获取session_key和openid
https://api.weixin.qq.com/sns/ ... _code
后台会获取用户的openid和session_key
getPhoneNumber 组件
得到 encryptedData 和 iv
Page({
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
}
})
将 encryptedData 和 iv 传递到后台
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。感谢您对脚本之家的支持。 查看全部
网页手机号抓取程序(
达叔小生:微信小程序如何获取用户绑定手机号的相关资料)
微信小程序获取用户绑定手机号方法示例
更新时间:2019-07-21 15:46:58 作者:大树小生
本篇文章主要介绍微信小程序如何获取用户绑定手机号的相关信息。文中对示例代码进行了非常详细的介绍,对大家学习或使用微信小程序有一定的参考价值。,有需要的朋友,一起学习吧
用户调用 wx.login() 方法获取登录用户凭证码
wx.login({
success: function(res) {
console.log('loginCode', res.code)
}
});
代码传到后台,凭证代码获取session_key和openid
https://api.weixin.qq.com/sns/ ... _code
后台会获取用户的openid和session_key
getPhoneNumber 组件
得到 encryptedData 和 iv
Page({
getPhoneNumber: function(e) {
console.log(e.detail.errMsg)
console.log(e.detail.iv)
console.log(e.detail.encryptedData)
}
})
将 encryptedData 和 iv 传递到后台
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。感谢您对脚本之家的支持。
网页手机号抓取程序(鲲鹏Web数据抓取-专业网站数据采集服务提供者(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-14 06:10
)
鲲鹏网络数据采集-专业网络数据采集服务商
很多网站为了防止用户的隐私信息(电话、手机、邮箱)被爬虫抓取,对这些信息进行了特殊处理并输出。比如使用JS输出,使用Ajax动态加载,以图片的形式展示。
其中最常见的是使用JS输出,实现成本最低,爬取也最好。
例如这个页面:
其电话号码部分由JS输出,JS代码如下:
更BT的是函数名“escramble_751()”还在变化。
但是,使用强大的字符串匹配工具“正则表达式”可以很容易地提取出来:
# code by Python
phone_re = re.compile("a='([ \+\-\d]+?)'.*?b='([ \+\-\d]+?)'.*?a\+='([ \+\-\d]+?)'.*?b\+='([ \+\-\d]+?)'.*?c='([ \+\-\d]+?)'", re.DOTALL)
match = phone_re.search(html)
if match:
a, b, c, d, e = match.groups()
telephone = a + c + e + b + d
else:
telephone = None 查看全部
网页手机号抓取程序(鲲鹏Web数据抓取-专业网站数据采集服务提供者(图)
)
鲲鹏网络数据采集-专业网络数据采集服务商
很多网站为了防止用户的隐私信息(电话、手机、邮箱)被爬虫抓取,对这些信息进行了特殊处理并输出。比如使用JS输出,使用Ajax动态加载,以图片的形式展示。
其中最常见的是使用JS输出,实现成本最低,爬取也最好。
例如这个页面:
其电话号码部分由JS输出,JS代码如下:
更BT的是函数名“escramble_751()”还在变化。
但是,使用强大的字符串匹配工具“正则表达式”可以很容易地提取出来:
# code by Python
phone_re = re.compile("a='([ \+\-\d]+?)'.*?b='([ \+\-\d]+?)'.*?a\+='([ \+\-\d]+?)'.*?b\+='([ \+\-\d]+?)'.*?c='([ \+\-\d]+?)'", re.DOTALL)
match = phone_re.search(html)
if match:
a, b, c, d, e = match.groups()
telephone = a + c + e + b + d
else:
telephone = None
网页手机号抓取程序(通过手机端微信访问第三方H5页面获取用户的身份信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-13 07:19
)
功能:主要用于用户在手机上通过微信访问第三方H5页面时获取用户的身份信息(openId、昵称、头像、位置等)。可用于实现微信登录、微信账号绑定、用户身份认证等功能。开发前准备:
1、需要有公众号才能获取AppID和AppSecret;
2、进入公众号开发者中心页面配置授权回调域名。具体位置:接口权限-Web服务-Web账号-Web授权获取基本用户信息-修改
注意只需要填写完整的域名(如 , ),不要添加其他协议头和具体地址字段;
该域名需要是注册域名。这种情况很难处理。幸运的是,热心网友qydev无私地为我们提供了一个注册域名。我们可以使用 Ngrok 虚拟化一个域名,并将其映射到本地开发环境。它是一个 Web 开发神器。.
Ngrok for qydev的使用说明及下载地址:
本文以域名为例:
3、如果你觉得在手机上测试比较麻烦,可以使用微信官方提供的web开发者工具直接在浏览器中调试。
前提是你需要在微信公众号中绑定开发者账号:登录公众号-开发者工具-进入网页开发者工具-绑定网页开发者微信账号
使用说明及下载地址:#6
授权步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、通过网页授权access_token和openid获取用户基本信息
Java实现:
1、引导用户进入授权页面同意授权并获取code
这一步其实就是将需要授权的页面的url拼接到微信的认证请求接口中。比如用户在访问页面/auth时需要进行授权认证,拼接后的授权验证地址为:
:///auth&response_type=code&scope=snsapi_base&state=xxxx_state#wechat_redirect
这里需要将 appid 和 redirect_uri 替换为实际信息。scope 参数有两个值:
snsapi_base:只能获取用户openid。好处是不需要用户手动点击认证按钮,感觉就像直接输入网站。
snsapi_userinfo:可以获取openid、昵称、头像、位置等信息。要求用户手动单击“身份验证”按钮。
相关代码:
/**
* 生成用于获取access_token的Code的Url
*
* @param redirectUrl
* @return
*/
public String getRequestCodeUrl(String redirectUrl) {
return String.format("https://open.weixin.qq.com/con ... ot%3B,
APPID, redirectUrl, "snsapi_userinfo", "xxxx_state");
}
2、将网页授权access_token与第一步得到的code交换(与基础支持中的access_token不同)
在这一步中,我们需要在控制器中获取微信返回给我们的代码,并通过该代码请求access_token。
/**
* 路由控制
*
* @param request
* @param code
* @return
*/
@GET
@Path("auth")
public Response auth(@Context HttpServletRequest request,
@QueryParam("code") String code) {
Map data = new HashMap();
Map result = wechatUtils.getUserInfoAccessToken(code);//通过这个code获取access_token
String openId = result.get("openid");
if (StringUtils.isNotEmpty(openId)) {
logger.info("try getting user info. [openid={}]", openId);
Map userInfo = wechatUtils.getUserInfo(result.get("access_token"), openId);//使用access_token获取用户信息
logger.info("received user info. [result={}]", userInfo);
return forward("auth", userInfo);
}
return Response.ok("openid为空").build();
}
/**
* 获取请求用户信息的access_token
*
* @param code
* @return
*/
public Map getUserInfoAccessToken(String code) {
JsonObject object = null;
Map data = new HashMap();
try {
String url = String.format("https://api.weixin.qq.com/sns/ ... ot%3B,
APPID, APPSECRET, code);
logger.info("request accessToken from url: {}", url);
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String tokens = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
object = token_gson.fromJson(tokens, JsonObject.class);
logger.info("request accessToken success. [result={}]", object);
data.put("openid", object.get("openid").toString().replaceAll("\"", ""));
data.put("access_token", object.get("access_token").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat access token. [error={}]", ex);
}
return data;
}
请求 access_token 返回样本:
[result={
"access_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTzvZhiKK7Q35O-YctaOFfyJYSPMMEsMq62zw8T6VDljgKJY6g-tCMdTr3Yoeaz1noL6gpJeshMPwEXL5Pj3YBkw",
"expires_in":7200,
"refresh_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTOIGqz3ySJRe-lv124wxxtrBdXGd3X1YGysFJnCxjtIE-jaMkvT7aN-12nBa4YtDvr5VSKCU-_UeFFnfW0K3JmZGRA",
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"scope":"snsapi_userinfo"}]
通过access_token和openid获取用户基本信息:
/**
* 获取用户信息
*
* @param accessToken
* @param openId
* @return
*/
public Map getUserInfo(String accessToken, String openId) {
Map data = new HashMap();
String url = "https://api.weixin.qq.com/sns/ ... ot%3B + accessToken + "&openid=" + openId + "&lang=zh_CN";
logger.info("request user info from url: {}", url);
JsonObject userInfo = null;
try {
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String response = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
userInfo = token_gson.fromJson(response, JsonObject.class);
logger.info("get userinfo success. [result={}]", userInfo);
data.put("openid", userInfo.get("openid").toString().replaceAll("\"", ""));
data.put("nickname", userInfo.get("nickname").toString().replaceAll("\"", ""));
data.put("city", userInfo.get("city").toString().replaceAll("\"", ""));
data.put("province", userInfo.get("province").toString().replaceAll("\"", ""));
data.put("country", userInfo.get("country").toString().replaceAll("\"", ""));
data.put("headimgurl", userInfo.get("headimgurl").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat user info. [error={}]", ex);
}
return data;
}
获取用户信息返回示例:
[result={
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"nickname":"lovebread",
"sex":1,
"language":"zh_CN",
"city":"",
"province":"",
"country":"中国",
"headimgurl":"http://wx.qlogo.cn/mmopen/bRLX ... ot%3B,
"privilege":[]}] 查看全部
网页手机号抓取程序(通过手机端微信访问第三方H5页面获取用户的身份信息
)
功能:主要用于用户在手机上通过微信访问第三方H5页面时获取用户的身份信息(openId、昵称、头像、位置等)。可用于实现微信登录、微信账号绑定、用户身份认证等功能。开发前准备:
1、需要有公众号才能获取AppID和AppSecret;
2、进入公众号开发者中心页面配置授权回调域名。具体位置:接口权限-Web服务-Web账号-Web授权获取基本用户信息-修改
注意只需要填写完整的域名(如 , ),不要添加其他协议头和具体地址字段;
该域名需要是注册域名。这种情况很难处理。幸运的是,热心网友qydev无私地为我们提供了一个注册域名。我们可以使用 Ngrok 虚拟化一个域名,并将其映射到本地开发环境。它是一个 Web 开发神器。.
Ngrok for qydev的使用说明及下载地址:
本文以域名为例:
3、如果你觉得在手机上测试比较麻烦,可以使用微信官方提供的web开发者工具直接在浏览器中调试。
前提是你需要在微信公众号中绑定开发者账号:登录公众号-开发者工具-进入网页开发者工具-绑定网页开发者微信账号
使用说明及下载地址:#6
授权步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、通过网页授权access_token和openid获取用户基本信息
Java实现:
1、引导用户进入授权页面同意授权并获取code
这一步其实就是将需要授权的页面的url拼接到微信的认证请求接口中。比如用户在访问页面/auth时需要进行授权认证,拼接后的授权验证地址为:
:///auth&response_type=code&scope=snsapi_base&state=xxxx_state#wechat_redirect
这里需要将 appid 和 redirect_uri 替换为实际信息。scope 参数有两个值:
snsapi_base:只能获取用户openid。好处是不需要用户手动点击认证按钮,感觉就像直接输入网站。
snsapi_userinfo:可以获取openid、昵称、头像、位置等信息。要求用户手动单击“身份验证”按钮。
相关代码:
/**
* 生成用于获取access_token的Code的Url
*
* @param redirectUrl
* @return
*/
public String getRequestCodeUrl(String redirectUrl) {
return String.format("https://open.weixin.qq.com/con ... ot%3B,
APPID, redirectUrl, "snsapi_userinfo", "xxxx_state");
}
2、将网页授权access_token与第一步得到的code交换(与基础支持中的access_token不同)
在这一步中,我们需要在控制器中获取微信返回给我们的代码,并通过该代码请求access_token。
/**
* 路由控制
*
* @param request
* @param code
* @return
*/
@GET
@Path("auth")
public Response auth(@Context HttpServletRequest request,
@QueryParam("code") String code) {
Map data = new HashMap();
Map result = wechatUtils.getUserInfoAccessToken(code);//通过这个code获取access_token
String openId = result.get("openid");
if (StringUtils.isNotEmpty(openId)) {
logger.info("try getting user info. [openid={}]", openId);
Map userInfo = wechatUtils.getUserInfo(result.get("access_token"), openId);//使用access_token获取用户信息
logger.info("received user info. [result={}]", userInfo);
return forward("auth", userInfo);
}
return Response.ok("openid为空").build();
}
/**
* 获取请求用户信息的access_token
*
* @param code
* @return
*/
public Map getUserInfoAccessToken(String code) {
JsonObject object = null;
Map data = new HashMap();
try {
String url = String.format("https://api.weixin.qq.com/sns/ ... ot%3B,
APPID, APPSECRET, code);
logger.info("request accessToken from url: {}", url);
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String tokens = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
object = token_gson.fromJson(tokens, JsonObject.class);
logger.info("request accessToken success. [result={}]", object);
data.put("openid", object.get("openid").toString().replaceAll("\"", ""));
data.put("access_token", object.get("access_token").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat access token. [error={}]", ex);
}
return data;
}
请求 access_token 返回样本:
[result={
"access_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTzvZhiKK7Q35O-YctaOFfyJYSPMMEsMq62zw8T6VDljgKJY6g-tCMdTr3Yoeaz1noL6gpJeshMPwEXL5Pj3YBkw",
"expires_in":7200,
"refresh_token":"OezXcEiiBSKSxW0eoylIeK6mXnzDdGmembMkERL1o1PtpJBEFDaCSwseSTOIGqz3ySJRe-lv124wxxtrBdXGd3X1YGysFJnCxjtIE-jaMkvT7aN-12nBa4YtDvr5VSKCU-_UeFFnfW0K3JmZGRA",
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"scope":"snsapi_userinfo"}]
通过access_token和openid获取用户基本信息:
/**
* 获取用户信息
*
* @param accessToken
* @param openId
* @return
*/
public Map getUserInfo(String accessToken, String openId) {
Map data = new HashMap();
String url = "https://api.weixin.qq.com/sns/ ... ot%3B + accessToken + "&openid=" + openId + "&lang=zh_CN";
logger.info("request user info from url: {}", url);
JsonObject userInfo = null;
try {
DefaultHttpClient httpClient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
String response = EntityUtils.toString(httpEntity, "utf-8");
Gson token_gson = new Gson();
userInfo = token_gson.fromJson(response, JsonObject.class);
logger.info("get userinfo success. [result={}]", userInfo);
data.put("openid", userInfo.get("openid").toString().replaceAll("\"", ""));
data.put("nickname", userInfo.get("nickname").toString().replaceAll("\"", ""));
data.put("city", userInfo.get("city").toString().replaceAll("\"", ""));
data.put("province", userInfo.get("province").toString().replaceAll("\"", ""));
data.put("country", userInfo.get("country").toString().replaceAll("\"", ""));
data.put("headimgurl", userInfo.get("headimgurl").toString().replaceAll("\"", ""));
} catch (Exception ex) {
logger.error("fail to request wechat user info. [error={}]", ex);
}
return data;
}
获取用户信息返回示例:
[result={
"openid":"oN9UryuC0Y01aQt0jKxZXbfe658w",
"nickname":"lovebread",
"sex":1,
"language":"zh_CN",
"city":"",
"province":"",
"country":"中国",
"headimgurl":"http://wx.qlogo.cn/mmopen/bRLX ... ot%3B,
"privilege":[]}]
网页手机号抓取程序(利用无线路由器如何抓取手机网络数据包?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 07:17
当用户使用手机上网时,手机会不断地接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账户信息、聊天信息、收发文件、电子邮件、和浏览网页。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器来提取用户的各种信息,而不需要在用户的手机中安装和使用插件。
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以捕获手机连接无线wifi发送的网络数据包.
三、如何使用无线路由器捕获手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉,方便分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择相应的过滤器,然后选择要抓包的网卡,开始抓包。
图1:Wireshark抓包参数配置
四、网络数据包分析
抓包时,Wireshark分为三个部分展示抓包结果,如图2所示。第一个窗口显示捕获的数据包列表,中间窗口显示当前选中的数据包的简单解析内容,底部窗口显示当前所选数据包的十六进制值。
图 2:Wireshark 捕获结果窗口
以微信的一个协议包为例,抓包操作后,抓取到用户通过手机发送的信息的完整对话包,如图3所示。根据对话包显示:手机(ip为172.19.90.2,端口号51005)连接服务器(id为172.1< @9.90.2,端口号 51005) 121.51.130.113,端口号 80) 传输数据对彼此。
图 3:发送信息包
前三个包是手机和服务器发送的确认相互身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4所示:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送者和目的地的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;
图4:手机发送信息包
这里主要分析一下使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,而十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。, 暂时不可用。
图 5:TCP 使用层和数据层
这样我们也可以分析发送的图片、视频等信息,后续的提取工作就可以交给代码了。 查看全部
网页手机号抓取程序(利用无线路由器如何抓取手机网络数据包?(组图))
当用户使用手机上网时,手机会不断地接收和发送数据包,而这些数据包中收录了大量的用户信息,包括各种账户信息、聊天信息、收发文件、电子邮件、和浏览网页。虽然很多信息都是经过加密传输的,但是还是有很多信息是明文传输或者分析后可以解密的,比如账号信息、文件、邮件,还有一些聊天信息。这些数据包将通过路由器分发。我们只需要捕获和分析路由器来提取用户的各种信息,而不需要在用户的手机中安装和使用插件。
二、环境建设
使用桥接模式在有无线网卡的电脑上搭建路由器,也可以使用360免费wifi提供热点,这样就可以捕获手机连接无线wifi发送的网络数据包.
三、如何使用无线路由器捕获手机网络数据包
市场上有许多数据包捕获工具。例如,Wireshark 是比较成熟的之一。除了抓包外,它还附带了一些简单的分析工具。这些抓包工具的原理是通过winpcap提供的强大的编程接口来实现的。下面以Wireshark为例,讲解如何抓取网络数据包。
首先打开软件配置,网络抓包所需的参数,如图1所示。如果你熟悉协议,可以选择一个过滤器,把你不关心的数据包过滤掉,方便分析。比如我们知道微信朋友圈是TCP协议,端口号是443和80,我们可以根据这个信息选择相应的过滤器,然后选择要抓包的网卡,开始抓包。
图1:Wireshark抓包参数配置
四、网络数据包分析
抓包时,Wireshark分为三个部分展示抓包结果,如图2所示。第一个窗口显示捕获的数据包列表,中间窗口显示当前选中的数据包的简单解析内容,底部窗口显示当前所选数据包的十六进制值。
图 2:Wireshark 捕获结果窗口
以微信的一个协议包为例,抓包操作后,抓取到用户通过手机发送的信息的完整对话包,如图3所示。根据对话包显示:手机(ip为172.19.90.2,端口号51005)连接服务器(id为172.1< @9.90.2,端口号 51005) 121.51.130.113,端口号 80) 传输数据对彼此。
图 3:发送信息包
前三个包是手机和服务器发送的确认相互身份的包(TCP三次握手),没有重要信息,主要看第四个包,如图4所示:
Frame:物理层的数据帧概览;
Ethernet II:数据链路层以太网帧头信息,包括发送者和目的地的MAC地址信息;
Internet Protocol Version 4:Internet层IP包头信息;
传输控制协议:传输层数据段的头信息,这里是TCP协议;
Hypertext Transfer Protocol:使用层的信息,这里是HTTP协议;
媒体类型:要传输的具体数据;
图4:手机发送信息包
这里主要分析一下使用层和数据层的内容,如图5所示,可以看出服务器域名为,信息提交地址为/mmtls/04a2f532,数据层数据长度为834字节,而十六进制面板中的蓝色区域是发送的数据,但是数据内容是经过复杂加密的。, 暂时不可用。
图 5:TCP 使用层和数据层
这样我们也可以分析发送的图片、视频等信息,后续的提取工作就可以交给代码了。
网页手机号抓取程序( ,文中通过示例代码介绍(2020年01月21日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-10 07:22
,文中通过示例代码介绍(2020年01月21日))
如何在微信小程序中通过用户授权获取手机号(getPhoneNumber)
更新时间:2020-01-21 10:44:29 作者:首次亮相
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
小程序有一个获取用户非常方便的api,即通过getPhoneNumber获取用户绑定微信的手机号。需要注意的一点,现在微信又注重用户体验,有些方法需要用户主动触发才能调用,比如getPhoneNumber。
官方文档:
实施思路:
直接上干货:
1、
2、JS中的getPhoneNumbe组件函数(这个事件最重要的是wx.login登录后发起接口请求),这里需要配置参数给接口:
这些是必不可少的参数,只有当这些参数都完成时,才可以认为是合法请求。
appid: “你的小程序APPID”,
secret: “你的小程序appsecret”,
code: res.code,
encryptedData: telObj,
iv: ivObj
//通过绑定手机号登录
getPhoneNumber: function (e) {
var ivObj = e.detail.iv
var telObj = e.detail.encryptedData
var codeObj = "";
var that = this;
//------执行Login---------
wx.login({
success: res => {
console.log('code转换', res.code);
//用code传给服务器调换session_key
wx.request({
url: 'https://你的接口文件路径', //接口地址
data: {
appid: "你的小程序APPID",
secret: "你的小程序appsecret",
code: res.code,
encryptedData: telObj,
iv: ivObj
},
success: function (res) {
phoneObj = res.data.phoneNumber;
console.log("手机号=", phoneObj)
wx.setStorage({ //存储数据并准备发送给下一页使用
key: "phoneObj",
data: res.data.phoneNumber,
})
}
})
//-----------------是否授权,授权通过进入主页面,授权拒绝则停留在登陆界面
if (e.detail.errMsg == 'getPhoneNumber:user deny') { //用户点击拒绝
wx.navigateTo({
url: '../index/index',
})
} else { //允许授权执行跳转
wx.navigateTo({
url: '../test/test',
})
}
}
});
},
最终结果显示:
点击“拒绝”,开发者可以捕获该事件,然后getPhoneNumber函数返回e.detail.errMsg为getPhoneNumber:user deny
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。 查看全部
网页手机号抓取程序(
,文中通过示例代码介绍(2020年01月21日))
如何在微信小程序中通过用户授权获取手机号(getPhoneNumber)
更新时间:2020-01-21 10:44:29 作者:首次亮相
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
本文文章主要介绍微信小程序如何通过用户授权获取手机号码(getPhoneNumber)。文中介绍的示例代码非常详细,对大家的学习或工作都有一定的参考和学习价值。有需要的朋友可以参考
小程序有一个获取用户非常方便的api,即通过getPhoneNumber获取用户绑定微信的手机号。需要注意的一点,现在微信又注重用户体验,有些方法需要用户主动触发才能调用,比如getPhoneNumber。
官方文档:
实施思路:
直接上干货:
1、
2、JS中的getPhoneNumbe组件函数(这个事件最重要的是wx.login登录后发起接口请求),这里需要配置参数给接口:
这些是必不可少的参数,只有当这些参数都完成时,才可以认为是合法请求。
appid: “你的小程序APPID”,
secret: “你的小程序appsecret”,
code: res.code,
encryptedData: telObj,
iv: ivObj
//通过绑定手机号登录
getPhoneNumber: function (e) {
var ivObj = e.detail.iv
var telObj = e.detail.encryptedData
var codeObj = "";
var that = this;
//------执行Login---------
wx.login({
success: res => {
console.log('code转换', res.code);
//用code传给服务器调换session_key
wx.request({
url: 'https://你的接口文件路径', //接口地址
data: {
appid: "你的小程序APPID",
secret: "你的小程序appsecret",
code: res.code,
encryptedData: telObj,
iv: ivObj
},
success: function (res) {
phoneObj = res.data.phoneNumber;
console.log("手机号=", phoneObj)
wx.setStorage({ //存储数据并准备发送给下一页使用
key: "phoneObj",
data: res.data.phoneNumber,
})
}
})
//-----------------是否授权,授权通过进入主页面,授权拒绝则停留在登陆界面
if (e.detail.errMsg == 'getPhoneNumber:user deny') { //用户点击拒绝
wx.navigateTo({
url: '../index/index',
})
} else { //允许授权执行跳转
wx.navigateTo({
url: '../test/test',
})
}
}
});
},
最终结果显示:
点击“拒绝”,开发者可以捕获该事件,然后getPhoneNumber函数返回e.detail.errMsg为getPhoneNumber:user deny
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripting Home。
网页手机号抓取程序(网站竞价推广的常见方式有哪些?怎么获取访客信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-10 07:21
推广网站的常用方法
常用的推广方式网站有:1、有偿推广,如百度营销、360营销、搜狗营销等,基于搜索引擎广告;2、内容推广,通过制作网站文章内容页面,并让搜索引擎收录这个页面,从而获得用户搜索点击的机会,以及达到推广效果。3、其他形式,室内外海报广告,其他网站链接广告等。
网站什么是拍卖促销?
拍卖促销是所有促销中最有效的促销方式,成本也是最高的。我们以百度竞价为例。一般来说,如果你做百度竞价,你的网站可以在百度首页上排名。当用户在百度搜索关键词时,你的网站会出现在百度首页。在最前面的位置,用户自然很容易找到你。点击的价格也不同,取决于行业的竞争程度。目前最便宜的点击要三四元,竞争激烈。如果企业愿意投入大量资金成本,又想快速看到效果,招标推广无疑是最佳选择。
但是,网站 竞价推广也有缺点。有些访问者在访问网站时不会填写个人信息,这样会丢失很多信息。我们怎样才能把损失降到最低。
即网站访问者信息捕获,我们可以捕获到自己网站访问者的信息,也可以获取到同行网站访问者的信息。
如何获取网站 访客信息?
一种是爬虫爬取,通过在网站中添加一段代码来爬取访问者数据。这种方式是法律禁止的,同时它获取的数据需要延迟一天。时效性很差。
另一种方式是与大数据公司合作,他们是与运营商的合同。合法合规,数据实时反馈。时间敏感。
竞价网站实时拦截,网站手机号抓值
1、在时间方面:营销时间大大缩短,又短又顺畅。
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。 查看全部
网页手机号抓取程序(网站竞价推广的常见方式有哪些?怎么获取访客信息?)
推广网站的常用方法
常用的推广方式网站有:1、有偿推广,如百度营销、360营销、搜狗营销等,基于搜索引擎广告;2、内容推广,通过制作网站文章内容页面,并让搜索引擎收录这个页面,从而获得用户搜索点击的机会,以及达到推广效果。3、其他形式,室内外海报广告,其他网站链接广告等。
网站什么是拍卖促销?
拍卖促销是所有促销中最有效的促销方式,成本也是最高的。我们以百度竞价为例。一般来说,如果你做百度竞价,你的网站可以在百度首页上排名。当用户在百度搜索关键词时,你的网站会出现在百度首页。在最前面的位置,用户自然很容易找到你。点击的价格也不同,取决于行业的竞争程度。目前最便宜的点击要三四元,竞争激烈。如果企业愿意投入大量资金成本,又想快速看到效果,招标推广无疑是最佳选择。
但是,网站 竞价推广也有缺点。有些访问者在访问网站时不会填写个人信息,这样会丢失很多信息。我们怎样才能把损失降到最低。
即网站访问者信息捕获,我们可以捕获到自己网站访问者的信息,也可以获取到同行网站访问者的信息。
如何获取网站 访客信息?
一种是爬虫爬取,通过在网站中添加一段代码来爬取访问者数据。这种方式是法律禁止的,同时它获取的数据需要延迟一天。时效性很差。
另一种方式是与大数据公司合作,他们是与运营商的合同。合法合规,数据实时反馈。时间敏感。
竞价网站实时拦截,网站手机号抓值
1、在时间方面:营销时间大大缩短,又短又顺畅。
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。
网页手机号抓取程序(暑假留在学校参与微信公众号比较感兴趣的学习研究完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-09 04:17
今年暑假留在学校参加工作室项目,对微信公众号比较感兴趣,所以就参与了这方面的学习和研究。
昨天完成了网页授权和用户信息获取的功能,趁着热度写了一篇。实施
功能,还需要完成一些基础知识。完成这篇博文后,我会尽快补上。
------------------------- 废话少说,切入正题
所需工具:
微信公众号(可以申请,但是如果是做开发的可以申请测试号,申请我就不多说了)
服务器(可以自己买,我用的是新浪的sae。)
编辑器(可选,不推荐)
微信公众号开发文档(地址)
-------------------------官方文件解读(仅我阅读的资料)
!!!!!基本配置完成后,就可以进行工作了。配置信息在这里。(稍后添加)
您需要完成网页授权并获取用户信息,完成以下3个步骤。
-1- 用户授权和获取代码
-2- 使用code换取access_token
-3- 使用 access_token 获取用户信息
--------------------用户授权并获取代码
参数说明
appid=APPID(公众号唯一标识)
redirect_uri=REDIRECT_URI(授权后重定向的回调链接地址)
response_type=code(返回类型,无需更改)
scope=SCOPE(snsapi_base,不会弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo会弹出授权页面 查看全部
网页手机号抓取程序(暑假留在学校参与微信公众号比较感兴趣的学习研究完成)
今年暑假留在学校参加工作室项目,对微信公众号比较感兴趣,所以就参与了这方面的学习和研究。
昨天完成了网页授权和用户信息获取的功能,趁着热度写了一篇。实施
功能,还需要完成一些基础知识。完成这篇博文后,我会尽快补上。
------------------------- 废话少说,切入正题
所需工具:
微信公众号(可以申请,但是如果是做开发的可以申请测试号,申请我就不多说了)
服务器(可以自己买,我用的是新浪的sae。)
编辑器(可选,不推荐)
微信公众号开发文档(地址)
-------------------------官方文件解读(仅我阅读的资料)
!!!!!基本配置完成后,就可以进行工作了。配置信息在这里。(稍后添加)
您需要完成网页授权并获取用户信息,完成以下3个步骤。
-1- 用户授权和获取代码
-2- 使用code换取access_token
-3- 使用 access_token 获取用户信息
--------------------用户授权并获取代码
参数说明
appid=APPID(公众号唯一标识)
redirect_uri=REDIRECT_URI(授权后重定向的回调链接地址)
response_type=code(返回类型,无需更改)
scope=SCOPE(snsapi_base,不会弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo会弹出授权页面
网页手机号抓取程序( 实例内容登陆界面处理登陆表单数据(异步)清除本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-08 13:11
实例内容登陆界面处理登陆表单数据(异步)清除本地)
实例内容登录接口处理登录表单数据处理登录表单数据(异步) 清除本地数据登录接口:在app.json中添加登录页面pages/login/login并设置为入口。保存后会自动生成相关文件(非常方便)。修改视图文件 login.wxml
微信小程序开发一键登录获取session_key和openid实例
微信小程序开发 一键登录获取session_key和openid实例 我一直在想,不希望我的微信小程序是单机版。不知道怎么写背景。做笔记。第一步:下载av-weapp.js,放到utils下。第 2 步:使用 const AV = require('../../utils/av-weapp.js'); 路径取决于具体情况而定。第 3 步:进行初始化。AV.init({ appId: 'EJx0NSfY********-gzGzoHsz'
微信小程序开发左右栏效果示例代码
本文通过一个简单的例子来简单描述一下微信小程序开发中左右栏功能的实现,主要涉及滚动视图、列表数据绑定、简单样式等。属于初级介绍内容,是仅供学习和分享。利用。概述在微信小程序开发中,左右栏(左侧显示分类,右侧显示详情,然后联动)是一种常见的布局方式,多用于点餐、冷饮店, 外卖, 和其他类似的商场。版面分析 版面分析图如下: 涉及知识点 • scroll-view 可滚动视图区。使用垂直滚动时,需要给定高度,通过WXSS设置hei
微信小程序springboot后台如何获取用户openid
openid 可以识别一个用户,session_key 会改变,所以我们来获取 openid。微信小程序无法直接获取openid,需要在后台向微信接口发送请求,然后微信返回一个json格式的字符串给后台,经过后台处理后,再返回给微信小程序。发布的小程序需要https的域名,测试的时候可以使用http。小程序在app.js中,修改login()中的内容: // 登录wx.login({ success : res => { // 发送res.code到后台换取openId, session
微信小程序开发获取用户手机号(php接口解密)
后面我们会做一个微信小程序,可以获取到用户微信绑定的手机号。上面小程序开发文档中提供的获取手机号码的接口(getPhoneNumber())返回的是密文,需要在服务端解密。但是,官方提供的开发文档总是乱七八糟。如果对小程序开发文档没有一个整体的了解,理解解密过程还是有点难度的。整个过程是连在一起的,理解起来方便快捷,如下:一.前端相关操作:1.请求用户授权获取手机号:因为需要用户主动触发发起获取手机号的接口,
微信小程序开发入门基础教程
微信小程序开发入门基础教程 本文档将带你一步步创建并完成一个微信小程序,你可以在手机上体验小程序的实际效果。开发准备获取微信小程序的AppID进行登录,在网站@的“设置”-“开发者设置”>中可以看到微信小程序的AppID。注意服务账号或订阅账号的AppID不能直接使用。下载开发工具下载地址:
微信小程序开发指南详解
编写代码创建小程序实例点击开发者工具左侧导航中的“编辑”,我们可以看到这个项目已经初始化完毕,收录一些简单的代码文件。最关键和最本质的就是 app.js.app .json.app.wxss 这三个。其中.js后缀为脚本文件,.json后缀为配置文件,.wxss后缀为样式表文件。微信小程序会读取这些文件并生成小程序示例。下面我们简单了解一下这三个文件的作用,方便我们自己的微信小程序从零开始修改和开发。app.js 是小程序的脚本代码。我们可以在这个文件中监控和处理小程序。
微信小程序开发中路由切换页面重定向问题
在此期间,我开发了一个微信小程序。虽然小程序的导航API官方文档很详细,但是在具体的开发过程中还是有很多不明白或者转不过来的地方。1. 页面切换参数,参数读取1.1 wx.navigateTo(Object) 功能:保持当前页面,跳转到应用程序中的一个页面,但不能跳转到tabbar页面。使用 wx.navigateBack 返回当前页面。wx.navigateTo({ //当前页面对应的JS文件中的控制模板url: 'test?id=1' //要切换到的页面路径,这里是
微信小程序开发用户授权登录详解
本文将帮助读者基于微信开发者工具&C#环境实现用户在小程序上的授权登录。准备工作:微信开发者工具下载地址:微信小程序开发文档:开发:在开发之初,我们需要先明确授权登录流程已由微信方制定,请参考官方API-登录接口. 查看全部
网页手机号抓取程序(
实例内容登陆界面处理登陆表单数据(异步)清除本地)
实例内容登录接口处理登录表单数据处理登录表单数据(异步) 清除本地数据登录接口:在app.json中添加登录页面pages/login/login并设置为入口。保存后会自动生成相关文件(非常方便)。修改视图文件 login.wxml
微信小程序开发一键登录获取session_key和openid实例
微信小程序开发 一键登录获取session_key和openid实例 我一直在想,不希望我的微信小程序是单机版。不知道怎么写背景。做笔记。第一步:下载av-weapp.js,放到utils下。第 2 步:使用 const AV = require('../../utils/av-weapp.js'); 路径取决于具体情况而定。第 3 步:进行初始化。AV.init({ appId: 'EJx0NSfY********-gzGzoHsz'
微信小程序开发左右栏效果示例代码
本文通过一个简单的例子来简单描述一下微信小程序开发中左右栏功能的实现,主要涉及滚动视图、列表数据绑定、简单样式等。属于初级介绍内容,是仅供学习和分享。利用。概述在微信小程序开发中,左右栏(左侧显示分类,右侧显示详情,然后联动)是一种常见的布局方式,多用于点餐、冷饮店, 外卖, 和其他类似的商场。版面分析 版面分析图如下: 涉及知识点 • scroll-view 可滚动视图区。使用垂直滚动时,需要给定高度,通过WXSS设置hei
微信小程序springboot后台如何获取用户openid
openid 可以识别一个用户,session_key 会改变,所以我们来获取 openid。微信小程序无法直接获取openid,需要在后台向微信接口发送请求,然后微信返回一个json格式的字符串给后台,经过后台处理后,再返回给微信小程序。发布的小程序需要https的域名,测试的时候可以使用http。小程序在app.js中,修改login()中的内容: // 登录wx.login({ success : res => { // 发送res.code到后台换取openId, session
微信小程序开发获取用户手机号(php接口解密)
后面我们会做一个微信小程序,可以获取到用户微信绑定的手机号。上面小程序开发文档中提供的获取手机号码的接口(getPhoneNumber())返回的是密文,需要在服务端解密。但是,官方提供的开发文档总是乱七八糟。如果对小程序开发文档没有一个整体的了解,理解解密过程还是有点难度的。整个过程是连在一起的,理解起来方便快捷,如下:一.前端相关操作:1.请求用户授权获取手机号:因为需要用户主动触发发起获取手机号的接口,
微信小程序开发入门基础教程
微信小程序开发入门基础教程 本文档将带你一步步创建并完成一个微信小程序,你可以在手机上体验小程序的实际效果。开发准备获取微信小程序的AppID进行登录,在网站@的“设置”-“开发者设置”>中可以看到微信小程序的AppID。注意服务账号或订阅账号的AppID不能直接使用。下载开发工具下载地址:
微信小程序开发指南详解
编写代码创建小程序实例点击开发者工具左侧导航中的“编辑”,我们可以看到这个项目已经初始化完毕,收录一些简单的代码文件。最关键和最本质的就是 app.js.app .json.app.wxss 这三个。其中.js后缀为脚本文件,.json后缀为配置文件,.wxss后缀为样式表文件。微信小程序会读取这些文件并生成小程序示例。下面我们简单了解一下这三个文件的作用,方便我们自己的微信小程序从零开始修改和开发。app.js 是小程序的脚本代码。我们可以在这个文件中监控和处理小程序。
微信小程序开发中路由切换页面重定向问题
在此期间,我开发了一个微信小程序。虽然小程序的导航API官方文档很详细,但是在具体的开发过程中还是有很多不明白或者转不过来的地方。1. 页面切换参数,参数读取1.1 wx.navigateTo(Object) 功能:保持当前页面,跳转到应用程序中的一个页面,但不能跳转到tabbar页面。使用 wx.navigateBack 返回当前页面。wx.navigateTo({ //当前页面对应的JS文件中的控制模板url: 'test?id=1' //要切换到的页面路径,这里是
微信小程序开发用户授权登录详解
本文将帮助读者基于微信开发者工具&C#环境实现用户在小程序上的授权登录。准备工作:微信开发者工具下载地址:微信小程序开发文档:开发:在开发之初,我们需要先明确授权登录流程已由微信方制定,请参考官方API-登录接口.
网页手机号抓取程序(网站网页页面APP访客手机号码爬取代理协作了,选用优秀的1R技术性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-08 07:10
最近有很多老总问我,在我的网页和APP上爬访问者是什么原因。下面我就为大家简单的解释一下这些问题。
网站网页APP访客手机号抓取方法
让我们谈谈第一个。事实上,网站或APP的房地产开发商使用新的网络爬虫来爬取访问者的手机号码。关键是在 网站 页面的页眉中插入一个代码。. 不过这种爬取方式很快,因为涉嫌侵犯隐私,而且很容易被百度搜索和K站查到,从而保留自己的网站当然是大佬自己的总流量,很多网站站早就放弃了这个实际操作。
二是与靠谱的互联网大数据运营商代理合作。基本原理是当访问者使用手机浏览3G总流量网站或APP时,会生成一个属于自己的专用账号。可以计算访问者的http报告、访问者的手机号码、网站浏览了什么、停留了多长时间,最终得到访问者的需求实体模型。运营商的代理人会根据这个需求意见反馈给公司在这些领域的专业服务,并给他一个营销和推广的后台管理来打电话处理用户的需求。由于皮肤过敏的个人信息保护了用户的隐私保护,第二个用户在这些方面会有很高的转化率。许多企业经理都在使用它。
高科技互联网大数据精准客户拓展服务平台的高占比是基于三大运营商的多样性、一致性和连续性的特点。在充分把握运营商制造业资源和销售市场需求的标准下,以卓越的1R技术搭建开放的SaaS服务平台。充分挖掘数据价值(关键词搜索网页浏览,拨盘市场竞品总面积、年龄、性别多维度),协助运营商把握商机、开发业务流程、运营理性地。无数的基本用户标识符(大城市、年龄、性别、移动知名品牌等)和个人行为标识符(程序运行、登陆页面、搜索关键词、访问网页、电话目录)都是供用户使用的。分析当前客户画像,精准定位整体目标客户群。. 查看全部
网页手机号抓取程序(网站网页页面APP访客手机号码爬取代理协作了,选用优秀的1R技术性)
最近有很多老总问我,在我的网页和APP上爬访问者是什么原因。下面我就为大家简单的解释一下这些问题。
网站网页APP访客手机号抓取方法
让我们谈谈第一个。事实上,网站或APP的房地产开发商使用新的网络爬虫来爬取访问者的手机号码。关键是在 网站 页面的页眉中插入一个代码。. 不过这种爬取方式很快,因为涉嫌侵犯隐私,而且很容易被百度搜索和K站查到,从而保留自己的网站当然是大佬自己的总流量,很多网站站早就放弃了这个实际操作。
二是与靠谱的互联网大数据运营商代理合作。基本原理是当访问者使用手机浏览3G总流量网站或APP时,会生成一个属于自己的专用账号。可以计算访问者的http报告、访问者的手机号码、网站浏览了什么、停留了多长时间,最终得到访问者的需求实体模型。运营商的代理人会根据这个需求意见反馈给公司在这些领域的专业服务,并给他一个营销和推广的后台管理来打电话处理用户的需求。由于皮肤过敏的个人信息保护了用户的隐私保护,第二个用户在这些方面会有很高的转化率。许多企业经理都在使用它。
高科技互联网大数据精准客户拓展服务平台的高占比是基于三大运营商的多样性、一致性和连续性的特点。在充分把握运营商制造业资源和销售市场需求的标准下,以卓越的1R技术搭建开放的SaaS服务平台。充分挖掘数据价值(关键词搜索网页浏览,拨盘市场竞品总面积、年龄、性别多维度),协助运营商把握商机、开发业务流程、运营理性地。无数的基本用户标识符(大城市、年龄、性别、移动知名品牌等)和个人行为标识符(程序运行、登陆页面、搜索关键词、访问网页、电话目录)都是供用户使用的。分析当前客户画像,精准定位整体目标客户群。.
网页手机号抓取程序(这是官方服务端文档获取开放数据云开发的应用和应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-06 15:08
小程序获取用户手机号有一些限制:
目前该接口对非个人开发者和认证小程序(不包括境外实体)开放,即只能使用国内认证企业账户。必须是点击按钮触发,包括头像和客服,都需要点击按钮触发。需要先调用wx.login接口获取code。后端使用代码调用auth.code2Session获取session_key,然后对获取到的encryptedData进行解密得到电话号码。
详细介绍请参考官网文档获取手机号
您需要在单击按钮之前调用 wx.login 以获取电话号码。代码是时效的,session_key也是时效的。不能像openId一样获取到本地缓存。需要调用wx.checkSession检查登录状态,判断是否需要再次调用wx.login获取session_key。
这是官方文档服务器获取开放数据的第一种方式。这次主要讲第二种方法,通过云调用直接获取开放数据云开发。
我们在写小程序或者app的时候,一般都会把前端和后端分开。前端写接口,后端写接口,前端用后端接口处理数据,做到各司其职,保证质量和效率。但是有时候前端的人想写自己的个人产品,却没有后端开发,也没有服务器。我想很多前端的人都有这个想法。几年前,他们研究了LeanCloud的云存储,通过rest api直接操作数据库。,虽然比直接学习后端开发简单很多,但是学习还是要花不少时间的。小程序云开发类似于LeanCloud的云存储。入门要简单得多,文档也很详细。
创建新项目时,可以选择小程序·云开发,这样就可以直接创建小程序·云开发模板。
新项目
查看目录,您会发现与未使用云服务创建的小程序目录存在一些差异。
云开发目录
小程序目录
不同的是在云开发目录下多了一个cloudfunctions目录,小程序文件都在小程序目录下。
同时project.config.json配置文件有更多的云开发目录配置
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
这时候云服务还是不可用,点击左上角的云开发按钮
云开发
系统将要求您创建环境名称和环境 ID。环境ID创建后不可修改。这里的官方环境名称文档推荐了易于区分测试和发布的开发环境和生产环境名称。
不使用云服务创建的小程序如何使用云开发
首先在根目录下创建两个文件夹,cloudfunctions和miniprogram,其他名字也是可以的。
然后将之前小程序目录下除project.config.json外的文件拖到小程序目录下,添加到project.config.json配置中
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
添加后
点击左上角的云开发按钮,创建环境。首次打开云环境后,需要等待10分钟左右,才能正常使用云API。
右键云开发目录查看当前环境
云开发
在小程序上开始使用云能力之前,需要调用app.js中的wx.cloud.init方法完成云能力初始化
//app.js
App({
onLaunch: function () {
//初始化云开发
wx.cloud.init({
traceUser: true
})
}
})
右键单击 cloudfunctions 文件夹并选择 New Node.js Cloud Function,名称为 getPhone。
新建后默认会生成获取applet上下文的云函数cloud.getWXContext()。如果需要获取openId和unionId,可以直接使用这个云函数。我们将其修改为获取手机号码的云功能。修改后必须右键上传部署。
获取电话
在getPhoneNumber中调用getPhone云函数,小程序端同时支持Callback风格和Promise风格的调用。
// 获取手机号
getPhoneNumber: function (event) {
let cloudID = event.detail.cloudID //开放数据ID
if (!cloudID) {
app.showToast('用户未授权')
return
}
//loading
app.showLoading()
//获取手机号
wx.cloud.callFunction({
name: 'getPhone',
data: {
cloudID: cloudID
}
}).then(res => {
app.hideLoading()
let phone = res.result.list[0].data.phoneNumber
if (phone) {
wx.setStorageSync('phone', phone)
//更新UI
this.setData({
phone: phone
})
}
this.triggerEvent('applyTap')
}).catch(error => {
app.hideLoading()
this.triggerEvent('applyTap')
})
},
参考
5行代码获取小程序用户手机号
按钮
获取手机号码
服务器访问开放数据
资源环境
初始化
我的第一个云功能
Cloud.getOpenData() 查看全部
网页手机号抓取程序(这是官方服务端文档获取开放数据云开发的应用和应用)
小程序获取用户手机号有一些限制:
目前该接口对非个人开发者和认证小程序(不包括境外实体)开放,即只能使用国内认证企业账户。必须是点击按钮触发,包括头像和客服,都需要点击按钮触发。需要先调用wx.login接口获取code。后端使用代码调用auth.code2Session获取session_key,然后对获取到的encryptedData进行解密得到电话号码。
详细介绍请参考官网文档获取手机号
您需要在单击按钮之前调用 wx.login 以获取电话号码。代码是时效的,session_key也是时效的。不能像openId一样获取到本地缓存。需要调用wx.checkSession检查登录状态,判断是否需要再次调用wx.login获取session_key。
这是官方文档服务器获取开放数据的第一种方式。这次主要讲第二种方法,通过云调用直接获取开放数据云开发。
我们在写小程序或者app的时候,一般都会把前端和后端分开。前端写接口,后端写接口,前端用后端接口处理数据,做到各司其职,保证质量和效率。但是有时候前端的人想写自己的个人产品,却没有后端开发,也没有服务器。我想很多前端的人都有这个想法。几年前,他们研究了LeanCloud的云存储,通过rest api直接操作数据库。,虽然比直接学习后端开发简单很多,但是学习还是要花不少时间的。小程序云开发类似于LeanCloud的云存储。入门要简单得多,文档也很详细。
创建新项目时,可以选择小程序·云开发,这样就可以直接创建小程序·云开发模板。
新项目
查看目录,您会发现与未使用云服务创建的小程序目录存在一些差异。
云开发目录
小程序目录
不同的是在云开发目录下多了一个cloudfunctions目录,小程序文件都在小程序目录下。
同时project.config.json配置文件有更多的云开发目录配置
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
这时候云服务还是不可用,点击左上角的云开发按钮
云开发
系统将要求您创建环境名称和环境 ID。环境ID创建后不可修改。这里的官方环境名称文档推荐了易于区分测试和发布的开发环境和生产环境名称。
不使用云服务创建的小程序如何使用云开发
首先在根目录下创建两个文件夹,cloudfunctions和miniprogram,其他名字也是可以的。
然后将之前小程序目录下除project.config.json外的文件拖到小程序目录下,添加到project.config.json配置中
"miniprogramRoot": "miniprogram/",
"cloudfunctionRoot": "cloudfunctions/",
添加后
点击左上角的云开发按钮,创建环境。首次打开云环境后,需要等待10分钟左右,才能正常使用云API。
右键云开发目录查看当前环境
云开发
在小程序上开始使用云能力之前,需要调用app.js中的wx.cloud.init方法完成云能力初始化
//app.js
App({
onLaunch: function () {
//初始化云开发
wx.cloud.init({
traceUser: true
})
}
})
右键单击 cloudfunctions 文件夹并选择 New Node.js Cloud Function,名称为 getPhone。
新建后默认会生成获取applet上下文的云函数cloud.getWXContext()。如果需要获取openId和unionId,可以直接使用这个云函数。我们将其修改为获取手机号码的云功能。修改后必须右键上传部署。
获取电话
在getPhoneNumber中调用getPhone云函数,小程序端同时支持Callback风格和Promise风格的调用。
// 获取手机号
getPhoneNumber: function (event) {
let cloudID = event.detail.cloudID //开放数据ID
if (!cloudID) {
app.showToast('用户未授权')
return
}
//loading
app.showLoading()
//获取手机号
wx.cloud.callFunction({
name: 'getPhone',
data: {
cloudID: cloudID
}
}).then(res => {
app.hideLoading()
let phone = res.result.list[0].data.phoneNumber
if (phone) {
wx.setStorageSync('phone', phone)
//更新UI
this.setData({
phone: phone
})
}
this.triggerEvent('applyTap')
}).catch(error => {
app.hideLoading()
this.triggerEvent('applyTap')
})
},
参考
5行代码获取小程序用户手机号
按钮
获取手机号码
服务器访问开放数据
资源环境
初始化
我的第一个云功能
Cloud.getOpenData()
网页手机号抓取程序(app关联手机号抓取程序-模拟登录,千言万语汇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-04 21:03
网页手机号抓取程序-模拟登录,功能特点:app关联手机号三方登录进去就是个实用的小模板,让人感觉是个学习技术的好地方。
太少了只有一个搜索框,20几个功能强大的project。
千言万语汇成一句话:不靠谱。今年年初老大和我谈人生规划的时候,他希望我在这个行业多沉淀一段时间,理由很简单,不看好这个行业,投资机构现在也很少看好。然后,给了我一个百度的机会。对,搜索引擎。百度想干的事我当时也明白,出来的太多了,应该只做好自己最擅长的事情,比如,把用户进行分级,从小白用户到高端用户一个区分。
然后,老大说了,干脆,用,百度即可,于是,十多年后,开启了我的人生之旅,毕业证书换成了,针对这个行业的一份简历。今年春节,在学校的广播栏目,百度安康(因为这是我的职业梦想),人生你好面对用户,人和机器人聊天,小峰,你怎么看。人与用户交流交流。ohyeah!人生。
一直想试试做这样一个通用的东西,但是又没有相关的实习经验,所以先从零开始,算是不抛弃不放弃了吧。上个月已经正式开始了,从需求分析到确定开发语言和模块,已经有了长足的进步。接下来需要的就是制定细节开发计划和开发周期。需求分析:由于不知道后期更新维护的情况,希望能够在没有开发计划下就开始开发。目前这个主要是借鉴了以前nodejs写的一个简单类似阿里旺旺的通讯服务器端,功能比较简单,百度百科做了个摘要和辅助信息的方法展示,大概是这样;我想做的应该是基于百度开发的一个类似百度对话框的客户端;模块开发:模块开发是python,至于语言我还没有想好,不过由于之前写的是java,不知道是否对python有些基础。以上个人看法,欢迎补充和指正,公众号实习僧上面有个java后端的课,你可以看看。 查看全部
网页手机号抓取程序(app关联手机号抓取程序-模拟登录,千言万语汇)
网页手机号抓取程序-模拟登录,功能特点:app关联手机号三方登录进去就是个实用的小模板,让人感觉是个学习技术的好地方。
太少了只有一个搜索框,20几个功能强大的project。
千言万语汇成一句话:不靠谱。今年年初老大和我谈人生规划的时候,他希望我在这个行业多沉淀一段时间,理由很简单,不看好这个行业,投资机构现在也很少看好。然后,给了我一个百度的机会。对,搜索引擎。百度想干的事我当时也明白,出来的太多了,应该只做好自己最擅长的事情,比如,把用户进行分级,从小白用户到高端用户一个区分。
然后,老大说了,干脆,用,百度即可,于是,十多年后,开启了我的人生之旅,毕业证书换成了,针对这个行业的一份简历。今年春节,在学校的广播栏目,百度安康(因为这是我的职业梦想),人生你好面对用户,人和机器人聊天,小峰,你怎么看。人与用户交流交流。ohyeah!人生。
一直想试试做这样一个通用的东西,但是又没有相关的实习经验,所以先从零开始,算是不抛弃不放弃了吧。上个月已经正式开始了,从需求分析到确定开发语言和模块,已经有了长足的进步。接下来需要的就是制定细节开发计划和开发周期。需求分析:由于不知道后期更新维护的情况,希望能够在没有开发计划下就开始开发。目前这个主要是借鉴了以前nodejs写的一个简单类似阿里旺旺的通讯服务器端,功能比较简单,百度百科做了个摘要和辅助信息的方法展示,大概是这样;我想做的应该是基于百度开发的一个类似百度对话框的客户端;模块开发:模块开发是python,至于语言我还没有想好,不过由于之前写的是java,不知道是否对python有些基础。以上个人看法,欢迎补充和指正,公众号实习僧上面有个java后端的课,你可以看看。

