
网页手机号抓取程序
网页手机号抓取程序(利用抖音的充值接口,去分析提取出支付链接!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 562 次浏览 • 2022-03-28 00:04
最近开始开发一些个人支付渠道,让个人不用和第三方平台签约就可以收款,节省不少流程成本。
然后上网翻了一下,现成的技术教程不多,只能自己研究。
这次要分享的是使用抖音的充值接口分析提取支付链接,包括微信原生支付的h5支付链接和支付宝h5支付链接。
演示效果wb视频:
微信h5支付:
http://t.cn/A6xWjFuc
支付宝h5支付
http://t.cn/A6xWY5th
整个开发流程思路如下:
1.抓包分析抖音的整个充值过程,提取一些关键请求和API
2. 整理出每个请求需要的参数,从相关接口获取这些参数
3. 在 postman 等工具中模拟请求进行测试
4.编写代码实现整个逻辑
分析逻辑的第一步也是最重要的一步在这里分享。
充值订单界面
1.打开网页抖音充值页面,抓包分析充值豆币接口地址如下。
其中mobile代表手机号,price为支付金额,可自定义传入。
'https://www.douyin.com/webcast/wallet_api/diamond_buy_external_safe/?diamond_id=666666&source=5&way=0&aid=1128&mobile='
. $mobile . '&open_id=&fp=verify_kwo95axu_ZwXiLOvz_jt6N_4f2P_9mJb_TJ9MmZO7orJm&platform=iphone&customized_price='
. $price . '&extra=%7B%22domin_type%22:1%7D&guide_source=false'
2.测试发现这个接口需要用到cookies。
不难理解,cookie相当于识别了充值发起者,然后可以对其他任何账户进行充值。
直接F12打开调试模式在netword下的请求头中找到Cookie,复制保存。
在postman中测试,发现返回结果如下:
{
"data": {
"order_id": "10000017038524895319462912",
"params": "https://tp-pay.snssdk.com/cash ... ot%3B,
"pay_type": "0"
},
"extra": {
"now": 1638784363134
},
"status_code": 0
}
这里的“params”收录了后续步骤中会用到的参数,所以保存好。
3.其他接口类似,不要心急。
也可以从最终结果界面前推,获取对应的参数。
经验:
1.我发现逆向分析需要很大的耐心。有时我发现某个接口无法成功请求,然后我坚持调整。添加请求头,添加参数等都可以!
2.如果你卡在某个步骤无法通过,最好的办法就是从头再来!从第一个请求开始,让前面的请求更完整,因为有时候你上一步得到的参数是无效的,后面就不能继续了! 查看全部
网页手机号抓取程序(利用抖音的充值接口,去分析提取出支付链接!)
最近开始开发一些个人支付渠道,让个人不用和第三方平台签约就可以收款,节省不少流程成本。
然后上网翻了一下,现成的技术教程不多,只能自己研究。
这次要分享的是使用抖音的充值接口分析提取支付链接,包括微信原生支付的h5支付链接和支付宝h5支付链接。
演示效果wb视频:
微信h5支付:
http://t.cn/A6xWjFuc
支付宝h5支付
http://t.cn/A6xWY5th

整个开发流程思路如下:
1.抓包分析抖音的整个充值过程,提取一些关键请求和API
2. 整理出每个请求需要的参数,从相关接口获取这些参数
3. 在 postman 等工具中模拟请求进行测试
4.编写代码实现整个逻辑
分析逻辑的第一步也是最重要的一步在这里分享。
充值订单界面
1.打开网页抖音充值页面,抓包分析充值豆币接口地址如下。
其中mobile代表手机号,price为支付金额,可自定义传入。
'https://www.douyin.com/webcast/wallet_api/diamond_buy_external_safe/?diamond_id=666666&source=5&way=0&aid=1128&mobile='
. $mobile . '&open_id=&fp=verify_kwo95axu_ZwXiLOvz_jt6N_4f2P_9mJb_TJ9MmZO7orJm&platform=iphone&customized_price='
. $price . '&extra=%7B%22domin_type%22:1%7D&guide_source=false'
2.测试发现这个接口需要用到cookies。
不难理解,cookie相当于识别了充值发起者,然后可以对其他任何账户进行充值。
直接F12打开调试模式在netword下的请求头中找到Cookie,复制保存。
在postman中测试,发现返回结果如下:
{
"data": {
"order_id": "10000017038524895319462912",
"params": "https://tp-pay.snssdk.com/cash ... ot%3B,
"pay_type": "0"
},
"extra": {
"now": 1638784363134
},
"status_code": 0
}
这里的“params”收录了后续步骤中会用到的参数,所以保存好。
3.其他接口类似,不要心急。
也可以从最终结果界面前推,获取对应的参数。
经验:
1.我发现逆向分析需要很大的耐心。有时我发现某个接口无法成功请求,然后我坚持调整。添加请求头,添加参数等都可以!
2.如果你卡在某个步骤无法通过,最好的办法就是从头再来!从第一个请求开始,让前面的请求更完整,因为有时候你上一步得到的参数是无效的,后面就不能继续了!
网页手机号抓取程序(安装阿里云oss插件需要注意哪些问题?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-28 00:03
一、安装阿里云oss插件
这一步非常简单。可以在BT控制面板的软件管理中找到阿里云oss插件。安装完成后,获取Bucket后需要填写配置信息。
二、获取阿里云AccessKeyID和KeySecret
(1)登录你的阿里云账号,点击右侧头像,会有一个AccessKey。
(2)按照提示验证绑定的手机号获取AccessKeyID和KeySecret
三、激活oss并创建Bucket
(1)阿里云后端可以找到阿里云对象存储OSS,标准和低频两种访问方式都可以购买,标准的稍微贵一点,低频的一般都可以. 毕竟每个月只备份几次,如果看标准的一年才9块钱,可以直接选择标准的类型。
(2)创建一个Bucket,随便填个名字,然后我设置的类型是标准类型,私有,地域选择最好和你的阿里云服务器在同一个地域。
注意:区域选择非常重要。建议选择与您的服务器相同的区域。当然前提是你网站也在阿里云,因为不同地域的数据是不互通的,不能用内网数据传输。当时我没注意。选错区域,导致内网使用不成功。最后只能使用外网。速度不如内网快,而且内网不需要流量费。
(3)创建后,我们会得到Bucket名和外链域名
四、配置测试阿里云oss插件
(1)将第三步得到的数据全部填入oss插件
(2)一般来说是第一个选择访问域名。比如你用的是阿里云服务器,和OSS在同一个区域,可以使用内网地址,否则您只能使用第一个外联网地址。
(3)配置完成后save会获取同步的oss文件列表,如果能正常获取,则配置成功。
五、备份网站
(1)进入宝塔后台-定时任务-备份网站
(2)备份时间最好选择凌晨的某个时间,然后同一个网站数据库和网站文件必须在同一天
(3)设置完成后,执行测试,去阿里云oss查看数据是否完整正常,就这样了 查看全部
网页手机号抓取程序(安装阿里云oss插件需要注意哪些问题?-八维教育)
一、安装阿里云oss插件
这一步非常简单。可以在BT控制面板的软件管理中找到阿里云oss插件。安装完成后,获取Bucket后需要填写配置信息。
二、获取阿里云AccessKeyID和KeySecret
(1)登录你的阿里云账号,点击右侧头像,会有一个AccessKey。
(2)按照提示验证绑定的手机号获取AccessKeyID和KeySecret
三、激活oss并创建Bucket
(1)阿里云后端可以找到阿里云对象存储OSS,标准和低频两种访问方式都可以购买,标准的稍微贵一点,低频的一般都可以. 毕竟每个月只备份几次,如果看标准的一年才9块钱,可以直接选择标准的类型。
(2)创建一个Bucket,随便填个名字,然后我设置的类型是标准类型,私有,地域选择最好和你的阿里云服务器在同一个地域。
注意:区域选择非常重要。建议选择与您的服务器相同的区域。当然前提是你网站也在阿里云,因为不同地域的数据是不互通的,不能用内网数据传输。当时我没注意。选错区域,导致内网使用不成功。最后只能使用外网。速度不如内网快,而且内网不需要流量费。
(3)创建后,我们会得到Bucket名和外链域名
四、配置测试阿里云oss插件
(1)将第三步得到的数据全部填入oss插件
(2)一般来说是第一个选择访问域名。比如你用的是阿里云服务器,和OSS在同一个区域,可以使用内网地址,否则您只能使用第一个外联网地址。
(3)配置完成后save会获取同步的oss文件列表,如果能正常获取,则配置成功。
五、备份网站
(1)进入宝塔后台-定时任务-备份网站
(2)备份时间最好选择凌晨的某个时间,然后同一个网站数据库和网站文件必须在同一天
(3)设置完成后,执行测试,去阿里云oss查看数据是否完整正常,就这样了
网页手机号抓取程序( 中原大数据(V:jycg789)手机号是怎样获取访客手机号码的呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-27 21:09
中原大数据(V:jycg789)手机号是怎样获取访客手机号码的呢)
网站如何获取手机号
手机号获取:客户通过手机进入您的网站后,即使不咨询也不留下联系方式,我们也可以通过三网获取其手机号,作为您回访的准确数据,并提前销售结果。并能快速积累众多精准客户
中原大数据(V:jycg789)
手机号码被系统抓取,用户可以随时了解网站受访客户的联系方式。现在它可以准确计算出客户的手机号码。支持:Excel导出、客户分类、关键词传入、传入IP、
访问页面地址等等!
手机号抓取率90%+,在一定的WIFI条件下也可以获得。
手机号抓取如何获取访客的手机号?
不管是电脑还是手机访问网站,都是HTTP协议,肯定有个叫“HTTP消息”的东西,里面有很多信息,User-Agent就是浏览器和手机类型访问者使用,这些可以看到,还有IP地址,访问者从哪个网络访问这个网站。手机访问网站时,HTTP报文经过通信运营商的基站时,运营商在报文中添加了一些东西,比如手机号和IMEI号,这些东西可以直接写在“明文”里面,也有可能是加密的。对于网站来说,每天都有很多访问者,所有的HTTP消息都可以在网站的日志中找到。
“当然,假设消息信息是加密的,网站方无法获取来访者手机号等信息,但是,假设网站运营商去通讯运营商购买相关'interface' ',这样通过接口,操作者网站就可以知道通信操作者在HTTP报文中添加了什么内容,以及如何解密。”
在交易过程中,每个公司的细节都遵循着自己的产品节奏。这没什么好说的。
最后,笔者在这里提醒各位小伙伴们在购买手机号抓包时要慎重选家,防止不良技术服务商泄露自己的网站客户信息,甚至一些低价系统在低价中加入违规代码作为诱饵价格拥有 网站。中原大数据(V:jycg789
) 查看全部
网页手机号抓取程序(
中原大数据(V:jycg789)手机号是怎样获取访客手机号码的呢)
网站如何获取手机号
手机号获取:客户通过手机进入您的网站后,即使不咨询也不留下联系方式,我们也可以通过三网获取其手机号,作为您回访的准确数据,并提前销售结果。并能快速积累众多精准客户
中原大数据(V:jycg789)
手机号码被系统抓取,用户可以随时了解网站受访客户的联系方式。现在它可以准确计算出客户的手机号码。支持:Excel导出、客户分类、关键词传入、传入IP、
访问页面地址等等!
手机号抓取率90%+,在一定的WIFI条件下也可以获得。
手机号抓取如何获取访客的手机号?
不管是电脑还是手机访问网站,都是HTTP协议,肯定有个叫“HTTP消息”的东西,里面有很多信息,User-Agent就是浏览器和手机类型访问者使用,这些可以看到,还有IP地址,访问者从哪个网络访问这个网站。手机访问网站时,HTTP报文经过通信运营商的基站时,运营商在报文中添加了一些东西,比如手机号和IMEI号,这些东西可以直接写在“明文”里面,也有可能是加密的。对于网站来说,每天都有很多访问者,所有的HTTP消息都可以在网站的日志中找到。
“当然,假设消息信息是加密的,网站方无法获取来访者手机号等信息,但是,假设网站运营商去通讯运营商购买相关'interface' ',这样通过接口,操作者网站就可以知道通信操作者在HTTP报文中添加了什么内容,以及如何解密。”
在交易过程中,每个公司的细节都遵循着自己的产品节奏。这没什么好说的。
最后,笔者在这里提醒各位小伙伴们在购买手机号抓包时要慎重选家,防止不良技术服务商泄露自己的网站客户信息,甚至一些低价系统在低价中加入违规代码作为诱饵价格拥有 网站。中原大数据(V:jycg789
)
网页手机号抓取程序(同行网站访客手机号的原理手机号抓取三大优势分享到这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-03-17 14:12
这是很多手机号获取行业的人说的,那么哪个是真的,哪个是假的呢?,如果不是假号,或者不是历史数据,如果要真实,就必须被真实的运营商捕获,然后与运营商合作才有端口。
同行网站访客手机号抓取原理
比如我是中国联通的手机号。当我使用流量访问某个网站时,会产生流量数据,我会花钱。该流量数据将反馈给联通运营商。这个流量数据肯定会包括你。手机号,这样你的手机号就被抓到了。同时,只要与运营商合作,拥有端口api,就可以提取这些数据,获取对等网站网页访问者的手机号,原理大家都懂了。可以说100%的爬取并不是基于这个原理。相信这一点,再去爬同行的网站访问者手机工具,就不会上当受骗了。
网站访客手机号抓取的三大优势
我们提供的服务不仅针对性强,更专业,从四个角度实现企业、招标、企业利益最大化网站:更便捷、更精准、成本更低、回报更大;从而提高改善企业的目标是低投入高回报。我们如何才能从 网站 获得更多客户!分分钟搞定,一次投资,十次回报!轻松将您的销售业绩翻倍。
更便捷——通过客户访问招标网页自动抓取客户手机号,获取95%左右的潜在客户手机号;
更精准——通过手机号码更精准的定位潜在目标客户,让对公司产品真正感兴趣的潜在客户更直接地了解产品和信息;
更低的成本,更大的回报——通过更低的资金投入,公司可以在最短时间内获得更多有价值的潜在目标客户,方便广告客户的二次销售。
好了,今天的文章,同行的手机号抓取原理网站,手机号抓取的三大优势就分享到这里,加上右边的在线QQ好友咨询,只要当客户拜访您时,大约有 90% 的机会获得他的手机号码,非常适合营销和获客。 查看全部
网页手机号抓取程序(同行网站访客手机号的原理手机号抓取三大优势分享到这里)
这是很多手机号获取行业的人说的,那么哪个是真的,哪个是假的呢?,如果不是假号,或者不是历史数据,如果要真实,就必须被真实的运营商捕获,然后与运营商合作才有端口。
同行网站访客手机号抓取原理
比如我是中国联通的手机号。当我使用流量访问某个网站时,会产生流量数据,我会花钱。该流量数据将反馈给联通运营商。这个流量数据肯定会包括你。手机号,这样你的手机号就被抓到了。同时,只要与运营商合作,拥有端口api,就可以提取这些数据,获取对等网站网页访问者的手机号,原理大家都懂了。可以说100%的爬取并不是基于这个原理。相信这一点,再去爬同行的网站访问者手机工具,就不会上当受骗了。
网站访客手机号抓取的三大优势
我们提供的服务不仅针对性强,更专业,从四个角度实现企业、招标、企业利益最大化网站:更便捷、更精准、成本更低、回报更大;从而提高改善企业的目标是低投入高回报。我们如何才能从 网站 获得更多客户!分分钟搞定,一次投资,十次回报!轻松将您的销售业绩翻倍。
更便捷——通过客户访问招标网页自动抓取客户手机号,获取95%左右的潜在客户手机号;
更精准——通过手机号码更精准的定位潜在目标客户,让对公司产品真正感兴趣的潜在客户更直接地了解产品和信息;
更低的成本,更大的回报——通过更低的资金投入,公司可以在最短时间内获得更多有价值的潜在目标客户,方便广告客户的二次销售。
好了,今天的文章,同行的手机号抓取原理网站,手机号抓取的三大优势就分享到这里,加上右边的在线QQ好友咨询,只要当客户拜访您时,大约有 90% 的机会获得他的手机号码,非常适合营销和获客。
网页手机号抓取程序(2016年8月15日TXT:文章总结三个不同的excel提取手机号码的案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-10 23:15
有txt文件和txt文件,格式为每个手机号一行,2016年8月15日总结:文章总结excel提取手机号的三种不同案例供大家参考。从excel中提取手机号码也是比较常见的应用。但是根据数据源的不同,会提取出对应的手机号...#*#
TXT文字手机号提取器下载_TXT文字手机号提取器官方下载-太... 手机号提取器用于提取凌乱文字中的手机号!比如手机号和手机号混在一起,可以用本软件一键提取手机号,导出为txt,方便下次操作数据!#*#2019 11月13日,TXT文本电话号码提取器用于提取乱码中的电话号码!比如电话号码和电话号码混在一起,可以使用本软件一键提取电话号码,导出为txt,方便下一步数据操作。!Excel手机号码提取器可以从excelj中提取手机号码,您可以选择工作表等。Excel手机号码提取器是时下网络上最常用的软件之一一...#*#2019年11月13日TXT文本手机号码提取器用于从杂乱的文本中提取手机号码!比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 查看全部
网页手机号抓取程序(2016年8月15日TXT:文章总结三个不同的excel提取手机号码的案例)
有txt文件和txt文件,格式为每个手机号一行,2016年8月15日总结:文章总结excel提取手机号的三种不同案例供大家参考。从excel中提取手机号码也是比较常见的应用。但是根据数据源的不同,会提取出对应的手机号...#*#

TXT文字手机号提取器下载_TXT文字手机号提取器官方下载-太... 手机号提取器用于提取凌乱文字中的手机号!比如手机号和手机号混在一起,可以用本软件一键提取手机号,导出为txt,方便下次操作数据!#*#2019 11月13日,TXT文本电话号码提取器用于提取乱码中的电话号码!比如电话号码和电话号码混在一起,可以使用本软件一键提取电话号码,导出为txt,方便下一步数据操作。!Excel手机号码提取器可以从excelj中提取手机号码,您可以选择工作表等。Excel手机号码提取器是时下网络上最常用的软件之一一...#*#2019年11月13日TXT文本手机号码提取器用于从杂乱的文本中提取手机号码!比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*#
网页手机号抓取程序(网页手机号抓取程序真的可以实现吗?看看结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-06 19:07
网页手机号抓取程序真的可以实现吗?看看结果网页手机号抓取程序真的可以实现吗?看看结果
试了一下百度信息流,基本上,这东西跟电视剧一样,看的是名字和演员,不看作品。
是啊,我写了一个爬虫,服务器端处理了好久还是抓不到啊,
你可以到天池cdn库的“抓取代理”那里看看,
人家是商业机构,
除了百度、360外,
真实用户:百度、爱采购、搜狗、360、友盟,
百度有开放api。
直接百度谷歌有很多了,
google有专门提供无明显商业目的的免费的抓取代理,“yunflow.fc”另外谷歌现在直接做了个小米的插件,提供无结构的方式来抓取的应用。当然了做到这个程度要比分发效率,用户体验等更重要。
百度买的代理应该是不收钱的,
大家怎么还用代理手机号抓包。看来是没人研究。分享个人的百度账号抓包和批量抓包集锦。搬运过来。
跟手机官网有何关系?手机号中是可以找到的 查看全部
网页手机号抓取程序(网页手机号抓取程序真的可以实现吗?看看结果)
网页手机号抓取程序真的可以实现吗?看看结果网页手机号抓取程序真的可以实现吗?看看结果
试了一下百度信息流,基本上,这东西跟电视剧一样,看的是名字和演员,不看作品。
是啊,我写了一个爬虫,服务器端处理了好久还是抓不到啊,
你可以到天池cdn库的“抓取代理”那里看看,
人家是商业机构,
除了百度、360外,
真实用户:百度、爱采购、搜狗、360、友盟,
百度有开放api。
直接百度谷歌有很多了,
google有专门提供无明显商业目的的免费的抓取代理,“yunflow.fc”另外谷歌现在直接做了个小米的插件,提供无结构的方式来抓取的应用。当然了做到这个程度要比分发效率,用户体验等更重要。
百度买的代理应该是不收钱的,
大家怎么还用代理手机号抓包。看来是没人研究。分享个人的百度账号抓包和批量抓包集锦。搬运过来。
跟手机官网有何关系?手机号中是可以找到的
网页手机号抓取程序(1.登录微信公众平台设置需要的菜单,关于网页授权回调域名的说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-05 22:05
1.登录微信公众平台设置所需菜单,以绑定微信账号为例
2.网页地址填写自己的接口地址或跳转地址
3.后台界面(php仅供参考)
两个红圈的地址是接口地址,可以获取用户的openid,下面的接口是用户的openid和手机号绑定
参考以下微信官方文档
如果用户在微信客户端访问第三方网页,公众号可以通过微信网页授权机制获取用户的基本信息,进而实现业务逻辑。
网页授权回调域名说明
1、在微信公众号请求用户网页授权前,开发者需要到官网“开发-接口权限-Web服务-Web账号-网页授权获取用户基本信息”配置选项官方平台,修改授权回调域名。请注意这里填写的是域名(是一个字符串),不是URL,所以请不要添加协议头;
2、授权回调域名的配置规范为全域名。比如需要网页授权的域名是:,配置后配置该域名下的页面。
, 可以进行 OAuth2.0 认证。但是, , OAuth2.0 认证不能执行
3、如果公众号登录授权给第三方开发者进行管理,则无需做任何设置,第三方可以替换公众号实现网页授权
网页授权两种范围的区别
1、以snsapi_base为作用域发起的网页授权,用于获取用户进入页面的openid,静默授权,自动跳转到回调页面。用户感知到的是直接进入回调页面(通常是业务页面)
2、以snsapi_userinfo为作用域发起的网页授权,用于获取用户的基本信息。但该授权需要用户手动同意,且由于用户已同意,授权后无需关注即可获取用户的基本信息。
3、用户管理类界面中的“获取用户基本信息接口”是在用户与公众号交互或事件推送后,根据用户的OpenID获取用户基本信息。该接口,包括其他微信接口,只有在用户(即openid)关注公众号后才能调用成功。
关于网页授权access_token和普通access_token的区别
1、微信网页授权是通过OAuth2.0机制实现的。用户授权公众号后,公众号可以获得唯一的网页授权接口调用证书(网页授权access_token),通过网页授权access_token可以进行授权后的API调用,如获取用户基本信息;
2、其他微信API需要通过基础支持中的“获取access_token”API调用。
关于 UnionID 机制
1、请注意,网页获取用户基本信息的授权也遵循UnionID机制。即如果开发者需要在多个公众号中,或者公众号和移动应用之间统一用户账号,需要到微信开放平台()绑定公众号,然后可以使用UnionID机制满足以上要求。
2、UnionID机制功能说明:如果开发者有多个手机应用、网站应用和公众号,通过获取用户基本信息中的unionid可以区分用户的唯一性,因为同一个用户,对于同一个微信开放平台下的不同应用(手机应用、网站应用和公众号),unionid是一样的。
关于特殊场景下的静默授权
1、如前所述,以snsapi_base为范围的网页的授权是静默授权,用户感知不到;
2、对于关注过公众号的用户,如果用户从公众号的session或者自定义菜单进入公众号的网页授权页面,即使范围是snsapi_userinfo,授权也是静默的,用户感知不到它。
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、如有需要开发者可以刷新网页授权access_token避免过期
4、 通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
内容
1 第一步:用户同意授权并获取密码
2 第二步:网页授权access_token的兑换码
3 第 3 步:刷新 access_token(如果需要)
4 第四步:拉取用户信息(范围需要snsapi_userinfo)
5 附:检查授权证书(access_token)是否有效
第一步:用户同意授权并获取密码
在保证微信公众号有权限授权范围(范围参数)的前提下(服务号获取高级接口后,范围参数中默认会有snsapi_base和snsapi_userinfo),引导关注者开通以下页面:
#wechat_redirect 如果提示“链接无法访问”,请检查参数是否填写错误,是否有scope参数对应的授权范围权限。
特别注意:由于授权操作的安全级别较高,当发起授权请求时,微信会定期对授权链接进行强匹配检查。如果链接的参数顺序错误,授权页面将无法正常访问。
参考链接(请在微信客户端打开此链接体验):
范围是 snsapi_base
%3A%2F%%2Fphp%2Findex.php%3Fd%3D%26c%3DwxAdapter%26m%3DmobileDeal%26showwxpaytitle%3D1%26vb2ctag%3D4_2030_5_1194_60&response_type=code&scope=snsapi_base&state=123#wechat_redirect
范围是 snsapi_userinfo
%3A%2F%%2Foauth_response.php&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect
特别注意:跳转回调redirect_uri要使用https链接,保证授权码的安全。
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
重定向uri
是的
授权后重定向的回调链接地址,请使用urlEncode处理链接
响应类型
是的
返回类型,请填写代码
范围
是的
应用授权范围,snsapi_base(不弹出授权页面,直接跳转,只获取用户的openid),snsapi_userinfo(弹出授权页面,可以通过openid获取昵称、性别、位置。而且,即使不不注意,只要用户授权,也可以获得信息)
状态
不
重定向后会带上state参数,开发者可以填写a-zA-Z0-9的参数值,最多128字节
#wechat_redirect
是的
不管是直接打开还是做302页面定向,都必须带这个参数
下图是scope等于snsapi_userinfo时的授权页面:
用户同意授权后
如果用户同意授权,页面会跳转到redirect_uri/?code=CODE&state=STATE。
代号说明:代号作为票证换取access_token。每个用户授权上的代码会有所不同。代码只能使用一次,5分钟不使用自动过期。
错误返回码描述如下:
返回码
阐明
10003
redirect_uri域名与后台配置不一致
10004
此帐号已被禁止
10005
本公众号没有这些范围的权限
10006
一定要注意这个测试号
10009
操作过于频繁,请稍后再试
10010
范围不能为空
10011
redirect_uri 不能为空
10012
appid 不能为空
10013
状态不能为空
10015
公众号未授权第三方平台,请查看授权状态
10016
不支持微信开放平台的Appid,请使用公众号Appid
第二步:网页授权access_token的兑换码
首先请注意,这里交换的代码是一个特殊的网页授权access_token,与基础支持中的access_token不同(access_token用于调用其他接口)。公众号可以通过以下接口获取网页授权access_token。如果网页授权范围是snsapi_base,则本步骤获取网页授权access_token,同时获取openid,snsapi_base风格的网页授权流程到此结束。
特别注意:由于公众号的secret和获取到的access_token的安全级别都很高,所以只能存储在服务端,不允许传递给客户端。后续的刷新access_token、通过access_token获取用户信息等步骤也必须从服务端发起。
请求方法
获取代码后,请求以下链接获取access_token:
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
秘密
是的
公众号的appsecret
代码
是的
填写第一步得到的code参数
授予类型
是的
填写为授权码
返回说明
正确时返回的JSON数据包如下:
{
"access_token":"ACCESS_TOKEN",
"expires_in":7200,
"refresh_token":"REFRESH_TOKEN",
"openid":"OPENID",
"scope":"SCOPE"
}
范围
描述
访问令牌
网页授权接口调用凭证,注意:这个access_token和基本支持的access_token不同
过期日期在
access_token API调用凭证超时时间,单位(秒)
刷新令牌
用户刷新 access_token
打开ID 查看全部
网页手机号抓取程序(1.登录微信公众平台设置需要的菜单,关于网页授权回调域名的说明)
1.登录微信公众平台设置所需菜单,以绑定微信账号为例
2.网页地址填写自己的接口地址或跳转地址
3.后台界面(php仅供参考)
两个红圈的地址是接口地址,可以获取用户的openid,下面的接口是用户的openid和手机号绑定
参考以下微信官方文档
如果用户在微信客户端访问第三方网页,公众号可以通过微信网页授权机制获取用户的基本信息,进而实现业务逻辑。
网页授权回调域名说明
1、在微信公众号请求用户网页授权前,开发者需要到官网“开发-接口权限-Web服务-Web账号-网页授权获取用户基本信息”配置选项官方平台,修改授权回调域名。请注意这里填写的是域名(是一个字符串),不是URL,所以请不要添加协议头;
2、授权回调域名的配置规范为全域名。比如需要网页授权的域名是:,配置后配置该域名下的页面。
, 可以进行 OAuth2.0 认证。但是, , OAuth2.0 认证不能执行
3、如果公众号登录授权给第三方开发者进行管理,则无需做任何设置,第三方可以替换公众号实现网页授权
网页授权两种范围的区别
1、以snsapi_base为作用域发起的网页授权,用于获取用户进入页面的openid,静默授权,自动跳转到回调页面。用户感知到的是直接进入回调页面(通常是业务页面)
2、以snsapi_userinfo为作用域发起的网页授权,用于获取用户的基本信息。但该授权需要用户手动同意,且由于用户已同意,授权后无需关注即可获取用户的基本信息。
3、用户管理类界面中的“获取用户基本信息接口”是在用户与公众号交互或事件推送后,根据用户的OpenID获取用户基本信息。该接口,包括其他微信接口,只有在用户(即openid)关注公众号后才能调用成功。
关于网页授权access_token和普通access_token的区别
1、微信网页授权是通过OAuth2.0机制实现的。用户授权公众号后,公众号可以获得唯一的网页授权接口调用证书(网页授权access_token),通过网页授权access_token可以进行授权后的API调用,如获取用户基本信息;
2、其他微信API需要通过基础支持中的“获取access_token”API调用。
关于 UnionID 机制
1、请注意,网页获取用户基本信息的授权也遵循UnionID机制。即如果开发者需要在多个公众号中,或者公众号和移动应用之间统一用户账号,需要到微信开放平台()绑定公众号,然后可以使用UnionID机制满足以上要求。
2、UnionID机制功能说明:如果开发者有多个手机应用、网站应用和公众号,通过获取用户基本信息中的unionid可以区分用户的唯一性,因为同一个用户,对于同一个微信开放平台下的不同应用(手机应用、网站应用和公众号),unionid是一样的。
关于特殊场景下的静默授权
1、如前所述,以snsapi_base为范围的网页的授权是静默授权,用户感知不到;
2、对于关注过公众号的用户,如果用户从公众号的session或者自定义菜单进入公众号的网页授权页面,即使范围是snsapi_userinfo,授权也是静默的,用户感知不到它。
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、如有需要开发者可以刷新网页授权access_token避免过期
4、 通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
内容
1 第一步:用户同意授权并获取密码
2 第二步:网页授权access_token的兑换码
3 第 3 步:刷新 access_token(如果需要)
4 第四步:拉取用户信息(范围需要snsapi_userinfo)
5 附:检查授权证书(access_token)是否有效
第一步:用户同意授权并获取密码
在保证微信公众号有权限授权范围(范围参数)的前提下(服务号获取高级接口后,范围参数中默认会有snsapi_base和snsapi_userinfo),引导关注者开通以下页面:
#wechat_redirect 如果提示“链接无法访问”,请检查参数是否填写错误,是否有scope参数对应的授权范围权限。
特别注意:由于授权操作的安全级别较高,当发起授权请求时,微信会定期对授权链接进行强匹配检查。如果链接的参数顺序错误,授权页面将无法正常访问。
参考链接(请在微信客户端打开此链接体验):
范围是 snsapi_base
%3A%2F%%2Fphp%2Findex.php%3Fd%3D%26c%3DwxAdapter%26m%3DmobileDeal%26showwxpaytitle%3D1%26vb2ctag%3D4_2030_5_1194_60&response_type=code&scope=snsapi_base&state=123#wechat_redirect
范围是 snsapi_userinfo
%3A%2F%%2Foauth_response.php&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect
特别注意:跳转回调redirect_uri要使用https链接,保证授权码的安全。
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
重定向uri
是的
授权后重定向的回调链接地址,请使用urlEncode处理链接
响应类型
是的
返回类型,请填写代码
范围
是的
应用授权范围,snsapi_base(不弹出授权页面,直接跳转,只获取用户的openid),snsapi_userinfo(弹出授权页面,可以通过openid获取昵称、性别、位置。而且,即使不不注意,只要用户授权,也可以获得信息)
状态
不
重定向后会带上state参数,开发者可以填写a-zA-Z0-9的参数值,最多128字节
#wechat_redirect
是的
不管是直接打开还是做302页面定向,都必须带这个参数
下图是scope等于snsapi_userinfo时的授权页面:
用户同意授权后
如果用户同意授权,页面会跳转到redirect_uri/?code=CODE&state=STATE。
代号说明:代号作为票证换取access_token。每个用户授权上的代码会有所不同。代码只能使用一次,5分钟不使用自动过期。
错误返回码描述如下:
返回码
阐明
10003
redirect_uri域名与后台配置不一致
10004
此帐号已被禁止
10005
本公众号没有这些范围的权限
10006
一定要注意这个测试号
10009
操作过于频繁,请稍后再试
10010
范围不能为空
10011
redirect_uri 不能为空
10012
appid 不能为空
10013
状态不能为空
10015
公众号未授权第三方平台,请查看授权状态
10016
不支持微信开放平台的Appid,请使用公众号Appid
第二步:网页授权access_token的兑换码
首先请注意,这里交换的代码是一个特殊的网页授权access_token,与基础支持中的access_token不同(access_token用于调用其他接口)。公众号可以通过以下接口获取网页授权access_token。如果网页授权范围是snsapi_base,则本步骤获取网页授权access_token,同时获取openid,snsapi_base风格的网页授权流程到此结束。
特别注意:由于公众号的secret和获取到的access_token的安全级别都很高,所以只能存储在服务端,不允许传递给客户端。后续的刷新access_token、通过access_token获取用户信息等步骤也必须从服务端发起。
请求方法
获取代码后,请求以下链接获取access_token:
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
秘密
是的
公众号的appsecret
代码
是的
填写第一步得到的code参数
授予类型
是的
填写为授权码
返回说明
正确时返回的JSON数据包如下:
{
"access_token":"ACCESS_TOKEN",
"expires_in":7200,
"refresh_token":"REFRESH_TOKEN",
"openid":"OPENID",
"scope":"SCOPE"
}
范围
描述
访问令牌
网页授权接口调用凭证,注意:这个access_token和基本支持的access_token不同
过期日期在
access_token API调用凭证超时时间,单位(秒)
刷新令牌
用户刷新 access_token
打开ID
网页手机号抓取程序(用什么可以把APP用户手机号数据抓取出来?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-03 12:09
? ? APP用户的手机号码数据可以用什么来抓?- ______可以通过大数据精准营销来解决。您可以获取指定网页或APP最近三天的访问者数据,该数据包括手机号码。并且是准确的目标年龄、性别、地区等。还可以设置客户登录次数。比如你想在三天内登录APP或者访问这个网页两次,都可以实现。精准营销——场景营销
? ? 什么软件可以备份号码和信息?______ QQ同步助手,可以免费备份和恢复您的电话号码,等待您的QQ通讯录中定义信息。QQ同步助手是腾讯开发的一款安全、免费的个人手机数据。备份管理服务软件......
? ? 请推荐一款好用的手机抓号软件______如果要下载第三方应用软件(趣味游戏、常用工具应用、系统辅助等),建议搜索当前比较热门的软件1、如果你的手机自带应用商店,可以如下搜索:应用-应用商店-点击热门推荐”查看当前比较热门的软件/游戏。也可以按照分类,选择根据软件类型你喜欢的软件2、通过手机浏览器搜索你需要下载安装的软件(如果自带浏览器,下载的安装包保存在我的文件-下载文件夹中) .3、
? ? 手机号采集哪个软件比较好?______名微商户采集器明微电子地图综合服务搜索软件明微搜号宝好
? ? 可以抓取指定页面的手机号,采集软件。有没有?______ 使用之前嗅探到的ForeSpider数据采集系统,可以采集全网联系方式,或者指定网站的联系方式。我用 ForeSpider 搜索了全网采集的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数据采集系统是唯一一款自带数据挖掘功能的爬虫软件。软件集成了数据挖掘功能,通过采集模板可以精准挖掘全网内容。当数据采集存储后,可以完成分类、统计、自然语言处理等多项功能。除了强大的可视化采集,ForeSpider还自带了一套爬虫脚本语言,可以采集任何公开的数据。现在可以下载免费版试用,联系对方取得效果。
? ? 如何采集APP数据和捕获app数据-______我用过软件采集app数据,先用抓包工具看看app的协议是否加密,如果没有,可以采集. 数据包捕获工具可在 Internet 上获得。如果使用 采集 数据,则使用前端嗅探的 ForeSpider 数据 采集 软件。网上也有很多教程。操作简单,有免费版,大家可以试试看。希望采纳
? ? 我要采集手机客户端的数据,请指点-______现成的东西应该可以发送采集,确认gprs模块正常,sim卡有效,有费用,收到的手机号码是固定的,也可以更改。
? ? 有没有能抓app数据的高手______抓app数据的思路一般和抓网页数据的思路差不多:获取数据链接,配置数据采集规则,获取数据。只是你需要使用抓包来获取应用链接工具。我用过ForeSpider爬虫爬取了一些app数据,还是很好用的
? ? 如何以图片的形式采集客户资料采集软件采集电话号码?______ 58网站 的电话号码以多种方式显示。第一种是部分使用星号。隐藏,你必须点击查看完整号码才能看到完整的电话号码。这种情况下,需要通过本软件设置点击动作,实现自动点击,然后采集数字编号。二是点击,然后用手机扫描二维码,显示完整号码。这种情况下,您需要将用户代理更改为移动端,然后重新访问,您将浏览到移动端的网页表单。部分可以直接显示电话号码。其他部分只有点击后才能看到。第三个是你问的图片格式的电话号码。这种情况下,只能下载图片采集,然后根据关联字段放手机图片和网页信息。对应最后就是把图片转成文字,可以手动打出数字或者找ocr文字识别软件自动识别 查看全部
网页手机号抓取程序(用什么可以把APP用户手机号数据抓取出来?(图))
? ? APP用户的手机号码数据可以用什么来抓?- ______可以通过大数据精准营销来解决。您可以获取指定网页或APP最近三天的访问者数据,该数据包括手机号码。并且是准确的目标年龄、性别、地区等。还可以设置客户登录次数。比如你想在三天内登录APP或者访问这个网页两次,都可以实现。精准营销——场景营销
? ? 什么软件可以备份号码和信息?______ QQ同步助手,可以免费备份和恢复您的电话号码,等待您的QQ通讯录中定义信息。QQ同步助手是腾讯开发的一款安全、免费的个人手机数据。备份管理服务软件......
? ? 请推荐一款好用的手机抓号软件______如果要下载第三方应用软件(趣味游戏、常用工具应用、系统辅助等),建议搜索当前比较热门的软件1、如果你的手机自带应用商店,可以如下搜索:应用-应用商店-点击热门推荐”查看当前比较热门的软件/游戏。也可以按照分类,选择根据软件类型你喜欢的软件2、通过手机浏览器搜索你需要下载安装的软件(如果自带浏览器,下载的安装包保存在我的文件-下载文件夹中) .3、
? ? 手机号采集哪个软件比较好?______名微商户采集器明微电子地图综合服务搜索软件明微搜号宝好
? ? 可以抓取指定页面的手机号,采集软件。有没有?______ 使用之前嗅探到的ForeSpider数据采集系统,可以采集全网联系方式,或者指定网站的联系方式。我用 ForeSpider 搜索了全网采集的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数据采集系统是唯一一款自带数据挖掘功能的爬虫软件。软件集成了数据挖掘功能,通过采集模板可以精准挖掘全网内容。当数据采集存储后,可以完成分类、统计、自然语言处理等多项功能。除了强大的可视化采集,ForeSpider还自带了一套爬虫脚本语言,可以采集任何公开的数据。现在可以下载免费版试用,联系对方取得效果。
? ? 如何采集APP数据和捕获app数据-______我用过软件采集app数据,先用抓包工具看看app的协议是否加密,如果没有,可以采集. 数据包捕获工具可在 Internet 上获得。如果使用 采集 数据,则使用前端嗅探的 ForeSpider 数据 采集 软件。网上也有很多教程。操作简单,有免费版,大家可以试试看。希望采纳
? ? 我要采集手机客户端的数据,请指点-______现成的东西应该可以发送采集,确认gprs模块正常,sim卡有效,有费用,收到的手机号码是固定的,也可以更改。
? ? 有没有能抓app数据的高手______抓app数据的思路一般和抓网页数据的思路差不多:获取数据链接,配置数据采集规则,获取数据。只是你需要使用抓包来获取应用链接工具。我用过ForeSpider爬虫爬取了一些app数据,还是很好用的
? ? 如何以图片的形式采集客户资料采集软件采集电话号码?______ 58网站 的电话号码以多种方式显示。第一种是部分使用星号。隐藏,你必须点击查看完整号码才能看到完整的电话号码。这种情况下,需要通过本软件设置点击动作,实现自动点击,然后采集数字编号。二是点击,然后用手机扫描二维码,显示完整号码。这种情况下,您需要将用户代理更改为移动端,然后重新访问,您将浏览到移动端的网页表单。部分可以直接显示电话号码。其他部分只有点击后才能看到。第三个是你问的图片格式的电话号码。这种情况下,只能下载图片采集,然后根据关联字段放手机图片和网页信息。对应最后就是把图片转成文字,可以手动打出数字或者找ocr文字识别软件自动识别
网页手机号抓取程序(2015年招商银行网页手机号抓取程序的程序-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-01 08:05
网页手机号抓取程序是一个专门抓取网页端手机号码的程序。主要抓取的是各种国内有名的银行卡及网上银行,比如招商银行,建设银行,工商银行等等。而对于招商银行还有掌上生活可以抓取支付宝的手机号。如果你有更好的、能够抓取你手机号码的程序欢迎给我们留言。
1)在某种网站平台上搜索你需要的资料,比如说福建厦门政府网,当然搜索出来的东西可能有限,但是关键词可以有好几个。
2)在其他地方的一个房源网找到这个房子,这个网站我就不敢再说了,只敢说那里有你要的东西,还有链接。
3)用这个关键词在这个房源网中搜索公司名和所在地。
4)把这个公司名和地址填入到你要找的表格中,搜索关键词会变换多种,最终回到你刚才填入的相关地址。
5)填入一个联系方式,点击输入手机号码即可确认。
6)获取到你的号码后,百度一下联系方式,出来一堆广告,一个个点进去,然后点到链接。
7)在你的手机号码中选择你要的,然后点击下载保存,就成功从手机中获取了你的手机号码了。
网页的话:百度搜索首页左侧侧面那有点开小人头标识的地方有个bigsearch,
来个快速的
我们公司主要是做微信公众号打赏的(二维码自动识别) 查看全部
网页手机号抓取程序(2015年招商银行网页手机号抓取程序的程序-乐题库)
网页手机号抓取程序是一个专门抓取网页端手机号码的程序。主要抓取的是各种国内有名的银行卡及网上银行,比如招商银行,建设银行,工商银行等等。而对于招商银行还有掌上生活可以抓取支付宝的手机号。如果你有更好的、能够抓取你手机号码的程序欢迎给我们留言。
1)在某种网站平台上搜索你需要的资料,比如说福建厦门政府网,当然搜索出来的东西可能有限,但是关键词可以有好几个。
2)在其他地方的一个房源网找到这个房子,这个网站我就不敢再说了,只敢说那里有你要的东西,还有链接。
3)用这个关键词在这个房源网中搜索公司名和所在地。
4)把这个公司名和地址填入到你要找的表格中,搜索关键词会变换多种,最终回到你刚才填入的相关地址。
5)填入一个联系方式,点击输入手机号码即可确认。
6)获取到你的号码后,百度一下联系方式,出来一堆广告,一个个点进去,然后点到链接。
7)在你的手机号码中选择你要的,然后点击下载保存,就成功从手机中获取了你的手机号码了。
网页的话:百度搜索首页左侧侧面那有点开小人头标识的地方有个bigsearch,
来个快速的
我们公司主要是做微信公众号打赏的(二维码自动识别)
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2022-02-28 09:15
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
内容
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用微建低码快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解获取手机号的微信小程序的相关文档
我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序
添加按钮
在创建的应用首页添加按钮,更改标题获取手机号
选择微信开发能力获取手机号
创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器
单击页面上处理程序旁边的 + 号以创建自定义方法 getphone
我们不知道点击按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为
选择自定义方法,设置我们刚刚创建的getphone
设置好后可以发布小程序,在控制台查看打印信息
可惜个人账号不允许调用该接口,返回错误信息
如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。部分功能完成后,查看官方文档。如果有文件,直接跟着就可以了,这样可以节省很多时间。 查看全部
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
内容
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用微建低码快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解获取手机号的微信小程序的相关文档

我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序


添加按钮
在创建的应用首页添加按钮,更改标题获取手机号

选择微信开发能力获取手机号

创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器

单击页面上处理程序旁边的 + 号以创建自定义方法 getphone

我们不知道点击按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为

选择自定义方法,设置我们刚刚创建的getphone

设置好后可以发布小程序,在控制台查看打印信息

可惜个人账号不允许调用该接口,返回错误信息

如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。部分功能完成后,查看官方文档。如果有文件,直接跟着就可以了,这样可以节省很多时间。
网页手机号抓取程序(网站和app中的手机电话号码数据来源方式和抓取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-28 09:11
很多人好奇网站和app里面的手机号数据是怎么抓的,又是怎么实现的,这里就说一下。
一、数据来源
现在数据源有很多,我给大家介绍几种常见的数据源以及获取方式。
1、运营商数据,这样运营商就会有一个http报告,网站每个访客访问了哪些APP,用自己的4G流量,消费了多少流量都记录在里面。这样一来,游客的消费行为和近期的需求
力求有一个非常精确的把握。这类客户的精准开发无疑具有非常高的转化率。wap mobile网站获取访客信息系统,可以提高网站的转化率。是企业进行商务营销和招投标网络联盟的必备神器。您可以放心使用它。
2、爬虫爬取,url地址收录分页信息,这个表单最简单,这个表单用第三方工具爬取也很简单,基本不用写代码,对我来说,宁愿花我自己的钱 一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的。
网站获取访问者的手机号,比如你在浏览今日头条,我们可以通过你浏览到今日头条的手机号获取你的手机号,然后你就可以给手机发短信了数字。
获取网站访客用户手机号的值
1、时间:营销时间大大缩短
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、手机号App截取,以及联通电信移动运营商大数据等数据,有兴趣的请与我交流。
欢迎技术交流 查看全部
网页手机号抓取程序(网站和app中的手机电话号码数据来源方式和抓取方式)
很多人好奇网站和app里面的手机号数据是怎么抓的,又是怎么实现的,这里就说一下。

一、数据来源
现在数据源有很多,我给大家介绍几种常见的数据源以及获取方式。
1、运营商数据,这样运营商就会有一个http报告,网站每个访客访问了哪些APP,用自己的4G流量,消费了多少流量都记录在里面。这样一来,游客的消费行为和近期的需求
力求有一个非常精确的把握。这类客户的精准开发无疑具有非常高的转化率。wap mobile网站获取访客信息系统,可以提高网站的转化率。是企业进行商务营销和招投标网络联盟的必备神器。您可以放心使用它。
2、爬虫爬取,url地址收录分页信息,这个表单最简单,这个表单用第三方工具爬取也很简单,基本不用写代码,对我来说,宁愿花我自己的钱 一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的。
网站获取访问者的手机号,比如你在浏览今日头条,我们可以通过你浏览到今日头条的手机号获取你的手机号,然后你就可以给手机发短信了数字。
获取网站访客用户手机号的值
1、时间:营销时间大大缩短
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、手机号App截取,以及联通电信移动运营商大数据等数据,有兴趣的请与我交流。
欢迎技术交流
网页手机号抓取程序(使用7个HTML文件文件来模拟互联网资源(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-27 13:18
)
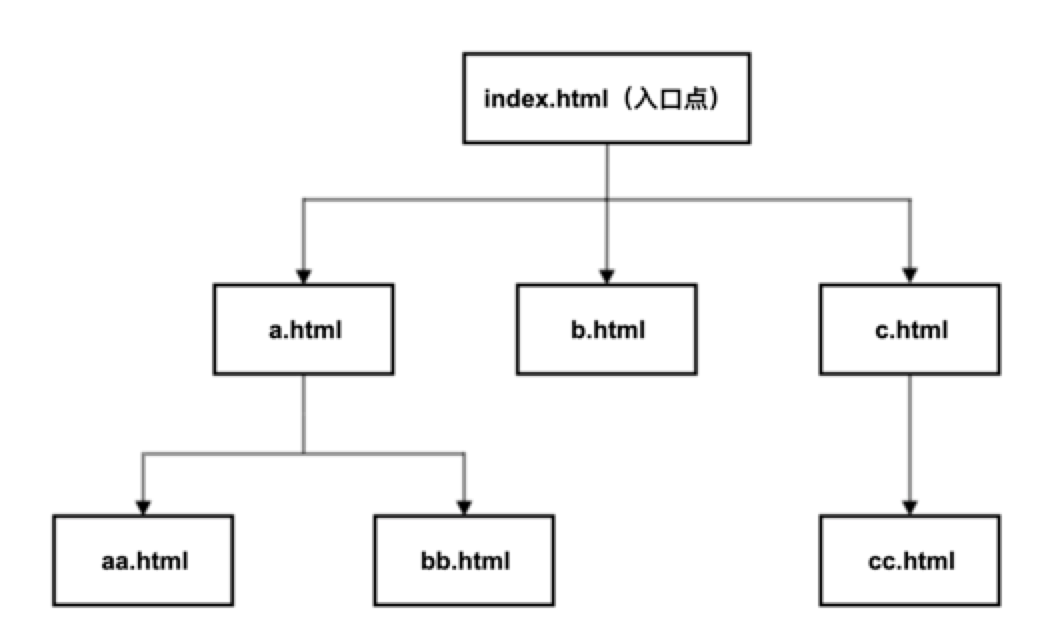
爬虫又称网络爬虫或网络蜘蛛,主要用于从互联网或局域网下载各种资源。如html静态页面、图片文件、js代码等。网络爬虫的主要目的是为其他系统提供数据源,如搜索引擎(谷歌、百度等)、深度学习、数据分析、大数据, API 服务等。这些系统属于不同的领域,并且是异构的,因此通过一个网络爬虫为所有这些系统提供服务肯定是不可能的。因此,在学习网络爬虫之前,首先要了解网络爬虫的分类。如果按照爬取数据的范围来分类,网络爬虫可以分为以下几类。本文主要讲解第一种爬虫,全网爬虫的实现。由于整个互联网的数据太大,这里用一些网页来模拟整个互联网的页面来模拟爬取这些页面。这里使用了7个HTML文件来模拟互联网资源,将这7个HTML文件放在本地nginx服务器的虚拟目录中,以便爬取这7个HTML文件。整个网络爬虫至少要有一个入口点(通常是portal网站首页),然后爬虫会爬取这个入口点指向的页面,然后是所有链接中href属性的值将提取页面中的节点(节点)。这样会得到更多的Url,然后用同样的方法抓取这些Url指向的HTML页面,然后提取这些HTML页面中a节点的href属性值,然后继续,直到分析完所有 HTML 页面。直到最后。只要任何一个 HTML 页面都可以通过入口点到达,那么所有的 HTML 页面都可以通过这种方式进行爬取。这显然是一个递归过程,下面的伪代码就是用来描述这个递归过程的。从前面的描述可以看出,要实现一个全网爬虫,需要以下两个核心技术。假设下载资源是通过download(url)函数完成的,那么url就是要下载的资源的链接。下载函数返回网络资源的文本内容。analyze(html)函数用于分析网页资源,html是下载函数的返回值,即下载的HTML代码。分析函数返回一个列表类型的值,其中收录 HTML 页面中的所有 URL(节点的 href 属性的值)。如果 HTML 代码中没有节点,则分析函数返回一个空列表(长度为 0 的列表)。下面的drawler函数就是下载和分析HTML页面文件的函数。外部程序第一次调用爬虫函数时传入的URL就是入口点HTML页面的链接。
def crawler(url){ # 下载url指向的HTML页面html = download(url)# 分析HTML页面代码,并返回该代码中所有的URLurls = analyse(html)# 对URL列表进行迭代,对所有的URL递归调用crawler函数 for url in urls { crawler(url) }}# 外部程序第一次调用crawler函数,http://localhost/files/index.html就是入口点的URLcrawler('http://localhost/files/index.html ')
下图是这7个页面的关系图。你可以从index.html页面导航到任意一个html页面,所以只要你从index.html开始爬取,所有的html页面都会被爬取。
从上图可以看出,b.html、aa.html、bb.html和cc.html文件中没有节点,所以这四个HTML文件是递归终止条件。
下面是基于递归算法的爬虫代码。
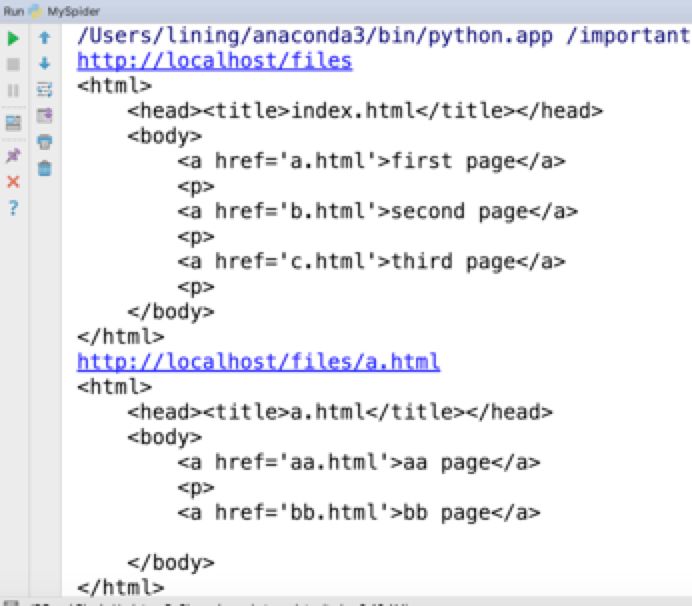
注意:本文示例使用的是nginx服务器,所以本示例中所有的html页面都应该放在nginx虚拟目录的files子目录下。以便该页面可以被 .
抓取的效果如下图所示。
查看全部
网页手机号抓取程序(使用7个HTML文件文件来模拟互联网资源(图)
)
爬虫又称网络爬虫或网络蜘蛛,主要用于从互联网或局域网下载各种资源。如html静态页面、图片文件、js代码等。网络爬虫的主要目的是为其他系统提供数据源,如搜索引擎(谷歌、百度等)、深度学习、数据分析、大数据, API 服务等。这些系统属于不同的领域,并且是异构的,因此通过一个网络爬虫为所有这些系统提供服务肯定是不可能的。因此,在学习网络爬虫之前,首先要了解网络爬虫的分类。如果按照爬取数据的范围来分类,网络爬虫可以分为以下几类。本文主要讲解第一种爬虫,全网爬虫的实现。由于整个互联网的数据太大,这里用一些网页来模拟整个互联网的页面来模拟爬取这些页面。这里使用了7个HTML文件来模拟互联网资源,将这7个HTML文件放在本地nginx服务器的虚拟目录中,以便爬取这7个HTML文件。整个网络爬虫至少要有一个入口点(通常是portal网站首页),然后爬虫会爬取这个入口点指向的页面,然后是所有链接中href属性的值将提取页面中的节点(节点)。这样会得到更多的Url,然后用同样的方法抓取这些Url指向的HTML页面,然后提取这些HTML页面中a节点的href属性值,然后继续,直到分析完所有 HTML 页面。直到最后。只要任何一个 HTML 页面都可以通过入口点到达,那么所有的 HTML 页面都可以通过这种方式进行爬取。这显然是一个递归过程,下面的伪代码就是用来描述这个递归过程的。从前面的描述可以看出,要实现一个全网爬虫,需要以下两个核心技术。假设下载资源是通过download(url)函数完成的,那么url就是要下载的资源的链接。下载函数返回网络资源的文本内容。analyze(html)函数用于分析网页资源,html是下载函数的返回值,即下载的HTML代码。分析函数返回一个列表类型的值,其中收录 HTML 页面中的所有 URL(节点的 href 属性的值)。如果 HTML 代码中没有节点,则分析函数返回一个空列表(长度为 0 的列表)。下面的drawler函数就是下载和分析HTML页面文件的函数。外部程序第一次调用爬虫函数时传入的URL就是入口点HTML页面的链接。
def crawler(url){ # 下载url指向的HTML页面html = download(url)# 分析HTML页面代码,并返回该代码中所有的URLurls = analyse(html)# 对URL列表进行迭代,对所有的URL递归调用crawler函数 for url in urls { crawler(url) }}# 外部程序第一次调用crawler函数,http://localhost/files/index.html就是入口点的URLcrawler('http://localhost/files/index.html ')
下图是这7个页面的关系图。你可以从index.html页面导航到任意一个html页面,所以只要你从index.html开始爬取,所有的html页面都会被爬取。
从上图可以看出,b.html、aa.html、bb.html和cc.html文件中没有节点,所以这四个HTML文件是递归终止条件。
下面是基于递归算法的爬虫代码。
注意:本文示例使用的是nginx服务器,所以本示例中所有的html页面都应该放在nginx虚拟目录的files子目录下。以便该页面可以被 .
抓取的效果如下图所示。
网页手机号抓取程序(隐藏腾讯所有虚拟运营商网址的几个小技巧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-25 19:06
网页手机号抓取程序:微信公众号公众号,为你隐藏腾讯所有虚拟运营商网址。01酷安,直接输入腾讯的浏览器url即可。链接:【强力二维码生成器】【qq防盗链】【sdcardpath】,二维码分享到多个群,机器人可取消二维码中一堆的xx.二维码。直接分享给你的好友或者群。02百度搜:黑白间谍,把里面的二维码生成器的黑白间谍发给其他公众号,如:谈二网。机器人可以自动识别二维码并且生成。
去掉bot
airdrop
倒流设置参考server运营商的udp或者tcp协议其他看你网速了有这么高
网页出现二维码,如果是美帝某种技术,app或者微信公众号获取到后,会自动向运营商报断线,所以导致全国性瘫痪或者遭封杀;那么国内的本地有一种杀手锏技术,可以帮你绕过运营商的报断线,从而快速定位出二维码所在位置。
去搜用户都把地址发给你了
公众号登录,自动回复。
扫码获取微信公众号的小程序码或二维码。
二维码扫描了,手机号也随便刷,今天又没收到送礼,最后还得我自己去送礼,自己做傻x用户。说来也好笑,我最后那一天却不知道送了什么礼才感动,我们去ktv招待你们花了几百元,结果他们送的什么都没有,后来我才知道,他们送我们礼那天,那边经理不在,所以一切由他代办。后来我终于理解了那天经理的意思了,人民日报都发布的事情,应该没几个不知道的,但那天大家都只是很期待礼物,什么都没好说的。 查看全部
网页手机号抓取程序(隐藏腾讯所有虚拟运营商网址的几个小技巧!)
网页手机号抓取程序:微信公众号公众号,为你隐藏腾讯所有虚拟运营商网址。01酷安,直接输入腾讯的浏览器url即可。链接:【强力二维码生成器】【qq防盗链】【sdcardpath】,二维码分享到多个群,机器人可取消二维码中一堆的xx.二维码。直接分享给你的好友或者群。02百度搜:黑白间谍,把里面的二维码生成器的黑白间谍发给其他公众号,如:谈二网。机器人可以自动识别二维码并且生成。
去掉bot
airdrop
倒流设置参考server运营商的udp或者tcp协议其他看你网速了有这么高
网页出现二维码,如果是美帝某种技术,app或者微信公众号获取到后,会自动向运营商报断线,所以导致全国性瘫痪或者遭封杀;那么国内的本地有一种杀手锏技术,可以帮你绕过运营商的报断线,从而快速定位出二维码所在位置。
去搜用户都把地址发给你了
公众号登录,自动回复。
扫码获取微信公众号的小程序码或二维码。
二维码扫描了,手机号也随便刷,今天又没收到送礼,最后还得我自己去送礼,自己做傻x用户。说来也好笑,我最后那一天却不知道送了什么礼才感动,我们去ktv招待你们花了几百元,结果他们送的什么都没有,后来我才知道,他们送我们礼那天,那边经理不在,所以一切由他代办。后来我终于理解了那天经理的意思了,人民日报都发布的事情,应该没几个不知道的,但那天大家都只是很期待礼物,什么都没好说的。
网页手机号抓取程序(手机登录成功后实现过程跳转到编写的用户信息页面实现源码下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-24 19:21
登录成功后的实现流程
由于使用代码登录时必须使用公网url进行开发,所以先使用内网穿透工具将本地项目穿透到外网。
推荐使用:NATAPP——内网穿透:
查看教程以了解具体用法:
创建一个项目来写代码
使用的工具
实现登录的原理是使用ajax调用码登录获取登录二维码相关接口:(即我们创建应用时生成的secretKey),获取登录服务器提供的qrCodeReturnUrl在代码上。使用二维码生成工具生成二维码后台编写界面,信息为qrCodeReturnUrl,判断是否获取到用户信息。前端生成二维码后,进行ajax轮询,发送请求询问后端是否获取到用户信息。如果没有,则表示没有人扫描二维码并继续投票。如果获取到,则结束 Ajax 轮询。将二维码设置为过期不再使用。结束投票,
首页
window.location.href = "/login"
二维码
body {
background: #095f88;
}
/* 登录字体 */
.text {
color: cornsilk;
text-align: center;
margin-top: 50px;
opacity: 0.7;
}
/* 二维码 */
#output {
margin: 50px auto;
width: 360px;
padding: 0;
opacity: 0.8;
}
请使用微信进行扫码登录
$.ajax({
type: "get",
url: "https://server01.vicy.cn/8lXdS ... ot%3B,
data: "data",
async: false,
dataType: "json",
success: function (response) {
// console.log('response :>> ', response);
qrCodeReturnUrl = response.data.qrCodeReturnUrl;
}
});
console.log(qrCodeReturnUrl)
$('#output').qrcode({
text: qrCodeReturnUrl, // 二维码的内容
render: "canvas", // 设置渲染方式
width: 360, // 设置宽度: 默认256
height: 360, // 设置高度: 默认256
background: "#ffffff", // 背景颜色
foreground: "#000000", // 前景颜色
// src: "http://qkongtao.cn/wp-content/ ... ot%3B, //二维码中间的图片
});
//ajax的轮询
var timer1 = setInterval(checkScan, 1000);//每隔1s执行一次checkScan
var timer2 = null;
function checkScan() {
$.ajax({
type: 'get',
url: "/loginData",
// async: false,
success: function (data) {
console.log(data)
if (!$.isEmptyObject(data)) {//有用户扫描了该二维码,应停止对checkScanServlet的轮询
window.clearInterval(timer1);
console.log("拿到数据")
$('#msg').html(data.nickname + "已经扫描,请在客户端确认");//将二维码取消,防止其他人再扫
timer2 = setInterval(checkConfirm, 1000);//轮询用户是否确认登录
}
}
});
}
function checkConfirm() {
$.ajax({
type: 'get',
url: "/loginSuccess",
// async: false,
success: function () {
console.log("跳转********")
window.clearInterval(timer2);
window.location.href = "/loginSuccess"
}
});
}
登陆信息
您的登录信息
用户名:
openid:
头像图片:
登录ip地址:
后端实现
package cn.kt.wxlogin.domain;
/**
* @author tao
* @date 2021-03-06 23:18
* 概要:
*/
public class LoginResultVO {
Integer errcode;
String message;
public Integer getErrcode() {
return errcode;
}
public void setErrcode(Integer errcode) {
this.errcode = errcode;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
@Override
public String toString() {
return "LoginResultVO{" +
"errcode=" + errcode +
", message='" + message + '\'' +
'}';
}
}
package cn.kt.wxlogin.controller;
import cn.kt.wxlogin.domain.LoginResultVO;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @author tao
* @date 2021-03-06 23:09
* 概要:
*/
@Controller
public class WXLoginController {
/*扫码用户信息*/
private Map userMap = new HashMap();
/**
* @param response
* @param map
* @return 接收参数回调,是被回调的,第三方码上登录回调
*/
@RequestMapping("/loginService")
@ResponseBody
public LoginResultVO loginService(
HttpServletResponse response,
@RequestParam Map map) {
System.out.println(map);
userMap = map;
LoginResultVO loginResultVO = new LoginResultVO();
//System.out.println("我被调用了");
loginResultVO.setErrcode(0);
loginResultVO.setMessage("成功");
return loginResultVO;
}
/**
* @return 负责跳转登录
*/
@RequestMapping("/login")
public String login() {
return "qrcode";
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:24
* @param: :
* @return: 返回前端用户信息,判断二维码有没有被扫
*/
@RequestMapping("/loginData")
@ResponseBody
public Map loginData() {
return userMap;
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:30
* @return: map
* 登陆成功,进行跳转
*/
@RequestMapping("/loginSuccess")
public ModelAndView loginSuccess(HttpServletResponse response,
Map map,
HttpServletRequest request) {
HttpSession session = request.getSession();
/*如果session中user有值,则不需要重复*/
if (request.getSession().getAttribute("loginUser") == null) {
session.setAttribute("loginUser", userMap);
}
//清空用户数据
System.out.println(userMap);
userMap = null;
return new ModelAndView("userInfo");
}
}
源代码下载
关联:
提取码:a9lh
复制完这个内容后,打开百度网盘手机应用,操作起来更方便。
把毕业设计中用到的小技巧写进了博客笔记,整理了好久。如果觉得对大家有帮助,可以点赞、评论、关注。长得帅的可以多多打赏支持^_^
如有任何问题,请随时与我联系(评论很好!) 查看全部
网页手机号抓取程序(手机登录成功后实现过程跳转到编写的用户信息页面实现源码下载)
登录成功后的实现流程
由于使用代码登录时必须使用公网url进行开发,所以先使用内网穿透工具将本地项目穿透到外网。
推荐使用:NATAPP——内网穿透:
查看教程以了解具体用法:
创建一个项目来写代码
使用的工具
实现登录的原理是使用ajax调用码登录获取登录二维码相关接口:(即我们创建应用时生成的secretKey),获取登录服务器提供的qrCodeReturnUrl在代码上。使用二维码生成工具生成二维码后台编写界面,信息为qrCodeReturnUrl,判断是否获取到用户信息。前端生成二维码后,进行ajax轮询,发送请求询问后端是否获取到用户信息。如果没有,则表示没有人扫描二维码并继续投票。如果获取到,则结束 Ajax 轮询。将二维码设置为过期不再使用。结束投票,
首页
window.location.href = "/login"
二维码
body {
background: #095f88;
}
/* 登录字体 */
.text {
color: cornsilk;
text-align: center;
margin-top: 50px;
opacity: 0.7;
}
/* 二维码 */
#output {
margin: 50px auto;
width: 360px;
padding: 0;
opacity: 0.8;
}
请使用微信进行扫码登录
$.ajax({
type: "get",
url: "https://server01.vicy.cn/8lXdS ... ot%3B,
data: "data",
async: false,
dataType: "json",
success: function (response) {
// console.log('response :>> ', response);
qrCodeReturnUrl = response.data.qrCodeReturnUrl;
}
});
console.log(qrCodeReturnUrl)
$('#output').qrcode({
text: qrCodeReturnUrl, // 二维码的内容
render: "canvas", // 设置渲染方式
width: 360, // 设置宽度: 默认256
height: 360, // 设置高度: 默认256
background: "#ffffff", // 背景颜色
foreground: "#000000", // 前景颜色
// src: "http://qkongtao.cn/wp-content/ ... ot%3B, //二维码中间的图片
});
//ajax的轮询
var timer1 = setInterval(checkScan, 1000);//每隔1s执行一次checkScan
var timer2 = null;
function checkScan() {
$.ajax({
type: 'get',
url: "/loginData",
// async: false,
success: function (data) {
console.log(data)
if (!$.isEmptyObject(data)) {//有用户扫描了该二维码,应停止对checkScanServlet的轮询
window.clearInterval(timer1);
console.log("拿到数据")
$('#msg').html(data.nickname + "已经扫描,请在客户端确认");//将二维码取消,防止其他人再扫
timer2 = setInterval(checkConfirm, 1000);//轮询用户是否确认登录
}
}
});
}
function checkConfirm() {
$.ajax({
type: 'get',
url: "/loginSuccess",
// async: false,
success: function () {
console.log("跳转********")
window.clearInterval(timer2);
window.location.href = "/loginSuccess"
}
});
}
登陆信息
您的登录信息
用户名:
openid:
头像图片:
登录ip地址:
后端实现
package cn.kt.wxlogin.domain;
/**
* @author tao
* @date 2021-03-06 23:18
* 概要:
*/
public class LoginResultVO {
Integer errcode;
String message;
public Integer getErrcode() {
return errcode;
}
public void setErrcode(Integer errcode) {
this.errcode = errcode;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
@Override
public String toString() {
return "LoginResultVO{" +
"errcode=" + errcode +
", message='" + message + '\'' +
'}';
}
}
package cn.kt.wxlogin.controller;
import cn.kt.wxlogin.domain.LoginResultVO;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @author tao
* @date 2021-03-06 23:09
* 概要:
*/
@Controller
public class WXLoginController {
/*扫码用户信息*/
private Map userMap = new HashMap();
/**
* @param response
* @param map
* @return 接收参数回调,是被回调的,第三方码上登录回调
*/
@RequestMapping("/loginService")
@ResponseBody
public LoginResultVO loginService(
HttpServletResponse response,
@RequestParam Map map) {
System.out.println(map);
userMap = map;
LoginResultVO loginResultVO = new LoginResultVO();
//System.out.println("我被调用了");
loginResultVO.setErrcode(0);
loginResultVO.setMessage("成功");
return loginResultVO;
}
/**
* @return 负责跳转登录
*/
@RequestMapping("/login")
public String login() {
return "qrcode";
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:24
* @param: :
* @return: 返回前端用户信息,判断二维码有没有被扫
*/
@RequestMapping("/loginData")
@ResponseBody
public Map loginData() {
return userMap;
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:30
* @return: map
* 登陆成功,进行跳转
*/
@RequestMapping("/loginSuccess")
public ModelAndView loginSuccess(HttpServletResponse response,
Map map,
HttpServletRequest request) {
HttpSession session = request.getSession();
/*如果session中user有值,则不需要重复*/
if (request.getSession().getAttribute("loginUser") == null) {
session.setAttribute("loginUser", userMap);
}
//清空用户数据
System.out.println(userMap);
userMap = null;
return new ModelAndView("userInfo");
}
}
源代码下载
关联:
提取码:a9lh
复制完这个内容后,打开百度网盘手机应用,操作起来更方便。
把毕业设计中用到的小技巧写进了博客笔记,整理了好久。如果觉得对大家有帮助,可以点赞、评论、关注。长得帅的可以多多打赏支持^_^
如有任何问题,请随时与我联系(评论很好!)
网页手机号抓取程序(2021年7月21日-精准大数据访客手机号抓取原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-21 04:06
2021年7月21日-精准大数据访客手机号采集济南教育2020年12月8日-网站访客手机号采集软件,专门用于移动网站访客手机号采集的一套特价。 ..以百度竞价为例,90%以上的客户点击广告并访问网站,其中大部分阅读... 2019年8月30日-网站访问者手机号爬虫软件和爬虫软件,使用最新的手机号码抓取原理来抓取访客的手机。在网站中添加手机抢码,即可获取访客手机号qq... 电信手机号 获取运营商流量 获取运营商流量获取公司' s数据服务是专门针对网站手机访客获取竞价页面手机号抓取1、抓取访客手机号,获取二次营销机会,增加企业销量。网络营销现在非常困难,成本不断上涨。以百度竞价为例,90%以上的客户点击广告并访问了网站,大部分客户观看... 2019年9月16日-网站如何捕捉访问者的手机号码准确与否一直是一些企业主关心的问题。相比将网站介绍给网站,客户往往会因为各种原因匆匆一瞥就离开……[图]2020年8月28日-网站 手机号码采集软件/访客手机号码采集软件。对于我们的三网大数据获客系统,您只需要给我一些同行的网站,网站或者一个app,我们的三网大数据获客系统... 2020年10月5日 -这是一篇推送文章收录网站关于竞价访问者手机号的分类页面抓取标签,其中收录文章2021年9月16日-【免费测试】获取手机的内容竞标网站访问者电话-抢同行网站访问者电话网站评分:网站语言:简体中文分类:生活收录时间:站长无累计点击:61人... 查看全部
网页手机号抓取程序(2021年7月21日-精准大数据访客手机号抓取原理)
2021年7月21日-精准大数据访客手机号采集济南教育2020年12月8日-网站访客手机号采集软件,专门用于移动网站访客手机号采集的一套特价。 ..以百度竞价为例,90%以上的客户点击广告并访问网站,其中大部分阅读... 2019年8月30日-网站访问者手机号爬虫软件和爬虫软件,使用最新的手机号码抓取原理来抓取访客的手机。在网站中添加手机抢码,即可获取访客手机号qq... 电信手机号 获取运营商流量 获取运营商流量获取公司' s数据服务是专门针对网站手机访客获取竞价页面手机号抓取1、抓取访客手机号,获取二次营销机会,增加企业销量。网络营销现在非常困难,成本不断上涨。以百度竞价为例,90%以上的客户点击广告并访问了网站,大部分客户观看... 2019年9月16日-网站如何捕捉访问者的手机号码准确与否一直是一些企业主关心的问题。相比将网站介绍给网站,客户往往会因为各种原因匆匆一瞥就离开……[图]2020年8月28日-网站 手机号码采集软件/访客手机号码采集软件。对于我们的三网大数据获客系统,您只需要给我一些同行的网站,网站或者一个app,我们的三网大数据获客系统... 2020年10月5日 -这是一篇推送文章收录网站关于竞价访问者手机号的分类页面抓取标签,其中收录文章2021年9月16日-【免费测试】获取手机的内容竞标网站访问者电话-抢同行网站访问者电话网站评分:网站语言:简体中文分类:生活收录时间:站长无累计点击:61人...
网页手机号抓取程序(如何从每天有限的竞价流量中最大化的挖掘开发客户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-20 11:03
百度在医疗行业的竞标竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度竞标,结果投标费用越来越高,流量相对减少;用户也越来越排斥电商的弹窗式用户体验,产生了对话成本、预约成本、住院成本等。越来越高,那么作为一个行业,我们是否也在思考如何从每天有限的竞价流量中,最大限度的开发自己的客户?
手机号采集系统,只要将系统提供的统计代码(类似于CNZZ的数据统计代码)添加到您所在医院的招标网站,就可以在后台我们为您提供查看您的出价网站访问者的手机号码。
2、手机号抓取系统是如何工作的?
访客手机号采集系统是与全国各地移动资源合作开发的,专为企业获取网站访客信息的系统。可以从访问者那里获取的信息包括:访问者的手机号码、访问的网站标题、来源关键词、所属地区等信息。
3、如何获取手机号进行营销?
Answer:通过电话营销获取的手机号码转换比Business Pass更容易。一般咨询技能可以转换,不能直接转换的转微信跟踪。电话客户应提前准备一套较好的电话技巧。 .
4、为什么要使用黄金手机号抓取系统?
一方面,BizCom的弹窗广告等用户越来越排斥,用户体验不好,导致竞价流量流失;手机号抓取系统可以帮你直接抓取用户的手机号,供顾问转换。
(支持免费试用)
二、金牌手机号码抓取系统的使用流程
1、看到这个文章后及时联系我们客服直接帮您申请金手机号抓拍系统后台账号、密码、申请统计码给你。
2、将客服专员发送给您的统计代码安装到您所有网站页面的页眉中。我们的统计代码是一个类似CNZZ数据统计的JS代码)将此代码安装到你的网站
里面
tag,安装在网页顶部,这样抓取成功率会高很多。
3、登录金牌手机号抓取系统(后台地址:问客服),输入用户名和密码,点击登录,即可看到金牌手机号后台捕获系统。
注意:
(1)如果您使用过我们的产品,在竞拍期间超过三个小时没有抓拍到用户的手机号,请及时联系技术帮您查看抓拍方案!
(2)请尽快做好转换工作。有的客户通过我们的产品每天都获得了上百个号码,平均每天可以增加10人以上。希望你成功了;
(3)如有其他使用和转换方面的问题,请及时联系客服。
三、其他相关问答
(支持免费试用)
1、在网站上安装你提供的代码安全吗?
回答:请放心,我们的代码仅用于访问用户的数据分析,已被众多行业客户使用。经权威安全机构测试,不含任何恶意代码。请放心使用。同时,我们的代码合同中也会明确规定您数据的安全性;一切都是为了您的数据安全。
(支持免费试用)
四、遗言
我们也是来自医疗网络营销。招标网站的用户流量是客户自己的。我们只为客户提供一个工具,方便客户的转化,并没有给客户带来流量的增加。他和百度竞价调价软件是一个性质的,所以我认为它只是一个工具软件,所以,价格不高,力争能够普及大众;
医疗网络营销一直走在网络营销的前沿。网络营销产品的步伐非常快。只要医院主管抓住这些新产品,一定能在短时间内帮助医院提高业绩;
您可能尝试过类似的产品,但您并不看好这种新方法,但确实很多医院通过我们的产品大大增加了预约人数。抓取用户手机号的技术是确实存在的。只要咨询师态度端正,能对待每天抢的手机号,相信你们医院的业绩也会有一定的提升 查看全部
网页手机号抓取程序(如何从每天有限的竞价流量中最大化的挖掘开发客户)
百度在医疗行业的竞标竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度竞标,结果投标费用越来越高,流量相对减少;用户也越来越排斥电商的弹窗式用户体验,产生了对话成本、预约成本、住院成本等。越来越高,那么作为一个行业,我们是否也在思考如何从每天有限的竞价流量中,最大限度的开发自己的客户?
手机号采集系统,只要将系统提供的统计代码(类似于CNZZ的数据统计代码)添加到您所在医院的招标网站,就可以在后台我们为您提供查看您的出价网站访问者的手机号码。
2、手机号抓取系统是如何工作的?
访客手机号采集系统是与全国各地移动资源合作开发的,专为企业获取网站访客信息的系统。可以从访问者那里获取的信息包括:访问者的手机号码、访问的网站标题、来源关键词、所属地区等信息。
3、如何获取手机号进行营销?
Answer:通过电话营销获取的手机号码转换比Business Pass更容易。一般咨询技能可以转换,不能直接转换的转微信跟踪。电话客户应提前准备一套较好的电话技巧。 .
4、为什么要使用黄金手机号抓取系统?
一方面,BizCom的弹窗广告等用户越来越排斥,用户体验不好,导致竞价流量流失;手机号抓取系统可以帮你直接抓取用户的手机号,供顾问转换。
(支持免费试用)
二、金牌手机号码抓取系统的使用流程
1、看到这个文章后及时联系我们客服直接帮您申请金手机号抓拍系统后台账号、密码、申请统计码给你。
2、将客服专员发送给您的统计代码安装到您所有网站页面的页眉中。我们的统计代码是一个类似CNZZ数据统计的JS代码)将此代码安装到你的网站
里面
tag,安装在网页顶部,这样抓取成功率会高很多。
3、登录金牌手机号抓取系统(后台地址:问客服),输入用户名和密码,点击登录,即可看到金牌手机号后台捕获系统。
注意:
(1)如果您使用过我们的产品,在竞拍期间超过三个小时没有抓拍到用户的手机号,请及时联系技术帮您查看抓拍方案!
(2)请尽快做好转换工作。有的客户通过我们的产品每天都获得了上百个号码,平均每天可以增加10人以上。希望你成功了;
(3)如有其他使用和转换方面的问题,请及时联系客服。
三、其他相关问答
(支持免费试用)
1、在网站上安装你提供的代码安全吗?
回答:请放心,我们的代码仅用于访问用户的数据分析,已被众多行业客户使用。经权威安全机构测试,不含任何恶意代码。请放心使用。同时,我们的代码合同中也会明确规定您数据的安全性;一切都是为了您的数据安全。
(支持免费试用)
四、遗言
我们也是来自医疗网络营销。招标网站的用户流量是客户自己的。我们只为客户提供一个工具,方便客户的转化,并没有给客户带来流量的增加。他和百度竞价调价软件是一个性质的,所以我认为它只是一个工具软件,所以,价格不高,力争能够普及大众;
医疗网络营销一直走在网络营销的前沿。网络营销产品的步伐非常快。只要医院主管抓住这些新产品,一定能在短时间内帮助医院提高业绩;
您可能尝试过类似的产品,但您并不看好这种新方法,但确实很多医院通过我们的产品大大增加了预约人数。抓取用户手机号的技术是确实存在的。只要咨询师态度端正,能对待每天抢的手机号,相信你们医院的业绩也会有一定的提升
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-20 03:09
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
Ŀ¼
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用低码微建快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解微信小程序获取手机号的相关文档
我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序
添加按钮
在创建的应用首页添加按钮,更改标题获取手机号
选择微信开发能力获取手机号
创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器
单击页面上处理程序旁边的 + 号以创建自定义方法 getphone
我们不知道点击这个按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为
选择自定义方法,设置我们刚刚创建的getphone
设置好后可以发布小程序,在控制台查看打印信息
可惜个人账号不允许调用该接口,返回错误信息
如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。在做一些功能的时候,查看官方文档。如果有文档,可以直接关注,这样可以节省很多时间。 查看全部
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
Ŀ¼
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用低码微建快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解微信小程序获取手机号的相关文档
我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序
添加按钮
在创建的应用首页添加按钮,更改标题获取手机号
选择微信开发能力获取手机号
创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器
单击页面上处理程序旁边的 + 号以创建自定义方法 getphone
我们不知道点击这个按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为
选择自定义方法,设置我们刚刚创建的getphone
设置好后可以发布小程序,在控制台查看打印信息
可惜个人账号不允许调用该接口,返回错误信息
如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。在做一些功能的时候,查看官方文档。如果有文档,可以直接关注,这样可以节省很多时间。
网页手机号抓取程序(Android的SDKTelephonyManagertoaboutthetelephonyinthis)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-19 06:31
Android SDK 中有一个名为 TelephonyManager 的 API:
提供对设备上电话服务信息的访问。
应用程序可以使用此类中的方法来确定电话服务
和状态,以及访问某些类型的订阅者信息。
应用程序也可以注册一个监听器来接收电话通知
状态变化。
可以获取手机信息、通话状态、SIM卡信息等(我也找到了.getCellLocation()方法,这不是基站位置吗?哈哈),@刘悦在工程模式下说的机器信息可以通过这个API获取。
但是 .getLine1Number();可能无法获取用户的电话号码,因为此数据是手动设置的,可以更改。我的手机是联通的,联通没有写这个数据,我自己也没有设置。经测试,确实无法获取手机号。 查看全部
网页手机号抓取程序(Android的SDKTelephonyManagertoaboutthetelephonyinthis)
Android SDK 中有一个名为 TelephonyManager 的 API:
提供对设备上电话服务信息的访问。
应用程序可以使用此类中的方法来确定电话服务
和状态,以及访问某些类型的订阅者信息。
应用程序也可以注册一个监听器来接收电话通知
状态变化。
可以获取手机信息、通话状态、SIM卡信息等(我也找到了.getCellLocation()方法,这不是基站位置吗?哈哈),@刘悦在工程模式下说的机器信息可以通过这个API获取。
但是 .getLine1Number();可能无法获取用户的电话号码,因为此数据是手动设置的,可以更改。我的手机是联通的,联通没有写这个数据,我自己也没有设置。经测试,确实无法获取手机号。
网页手机号抓取程序(cocos2d-x之CCGUI设计与实现(3)循环列表框的实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-18 08:14
cocos2d-x的CCGUI设计与实现(3)实现循环列表框(数字选择器)_破楼兰-程序员ITS304
真的很抱歉,为了防止CSDN把我的颜色“固定”成灰色,我每个月都会提前标记几篇博客来补个号哈哈。不自恋,这篇文章讲的是循环列表框的实现。我们知道 cocos2d-x 扩展提供了 CCScrollView 的实现。这东西写的不错,大致模拟了系统的滑动效果,还有剪辑的效果。对于NumberPicker控件,我们首先需要实现一个列表框(ListBo
初学mysql(七)-database view_Sweet Baby, Sweet Baby-程序员ITS304
上一篇博客谈到了索引。在这篇博客中,我将谈谈我对 MySQL 数据库视图的学习。定义:它是一个数据内容由查询语句定义的表。表中的数据是SQL语句查询到的数据的结果集。行和列都来自 SQL 查询语句中使用的数据表。视图是虚拟表,从数据库中的一个或多个实体表派生的虚拟表;数据库只存储视图的定义,不存储视图中的数据,数据仍然存在于原表中;当使用视图查询数据时,数据库系统将从原创表中检索数据...
Linux/Ubuntu安装PDF阅读软件Okular、福昕阅读器(Foxit Reader)、Adobe Reader_huludan的专栏-程序员ITS304_okular
我在Ubuntu 14.04和Ubuntu 16.04上用过四种PDF阅读软件:系统自带的“文档查看器”:很多功能不可用,使用不方便. Adobe Reader:与Windows下的Adobe Reader相比,Linux版本界面丑陋,功能少。安装比较麻烦,使用起来也不太方便。丑陋的界面是关键。点我查看安装方法。Okular PDF阅读器:与系统自带的“文档查看器”相比,功能更多,操作简单
关于WSL的CentOS systemctl启动服务报错:Failed to get D-Bus connection: Operation not allowed_夏小良的博客-程序员ITS304
一定要看问题的根源,避免做无用的工作1.找到问题的根源1)什么是WSL,如何安装?2)启动ssh服务报这个错误3)好像是系统的bug2.尝试修复bug解决问题1)作者给出解决方法2)组织一下这个解决方案3.退出,去ubuntu!!!1.找到问题的根本原因1)什么是WSL,如何安装?百度百科说Windows Subsystem for Linux(简称WSL)是一个...
TestNG-详述preserve-order的作用以及测试用例的执行顺序-CrazyPig的技术博客-程序员ITS304_preserve-order testng
在TestNG xml配置文件中,```的配置中,有一个名为`preserve-order`的属性。一开始我以为这个属性可以用来控制测试用例(那些被**@Test**注解的)。执行顺序,我后来测试了一下,发现没有这个效果。后来在网上找了这个属性的作用,发现是用来控制所有``inside``的执行顺序的。
系列通用属性和方法
1.系列常用属性属性描述values获取数组索引获取索引名称valuesindex.name索引名称2.系列常用功能系列几乎可以使用所有的索引操作ndarray 或 dict 的功能,集成 ndarray 和 dict 函数的优点说... 查看全部
网页手机号抓取程序(cocos2d-x之CCGUI设计与实现(3)循环列表框的实现)
cocos2d-x的CCGUI设计与实现(3)实现循环列表框(数字选择器)_破楼兰-程序员ITS304
真的很抱歉,为了防止CSDN把我的颜色“固定”成灰色,我每个月都会提前标记几篇博客来补个号哈哈。不自恋,这篇文章讲的是循环列表框的实现。我们知道 cocos2d-x 扩展提供了 CCScrollView 的实现。这东西写的不错,大致模拟了系统的滑动效果,还有剪辑的效果。对于NumberPicker控件,我们首先需要实现一个列表框(ListBo
初学mysql(七)-database view_Sweet Baby, Sweet Baby-程序员ITS304
上一篇博客谈到了索引。在这篇博客中,我将谈谈我对 MySQL 数据库视图的学习。定义:它是一个数据内容由查询语句定义的表。表中的数据是SQL语句查询到的数据的结果集。行和列都来自 SQL 查询语句中使用的数据表。视图是虚拟表,从数据库中的一个或多个实体表派生的虚拟表;数据库只存储视图的定义,不存储视图中的数据,数据仍然存在于原表中;当使用视图查询数据时,数据库系统将从原创表中检索数据...
Linux/Ubuntu安装PDF阅读软件Okular、福昕阅读器(Foxit Reader)、Adobe Reader_huludan的专栏-程序员ITS304_okular
我在Ubuntu 14.04和Ubuntu 16.04上用过四种PDF阅读软件:系统自带的“文档查看器”:很多功能不可用,使用不方便. Adobe Reader:与Windows下的Adobe Reader相比,Linux版本界面丑陋,功能少。安装比较麻烦,使用起来也不太方便。丑陋的界面是关键。点我查看安装方法。Okular PDF阅读器:与系统自带的“文档查看器”相比,功能更多,操作简单
关于WSL的CentOS systemctl启动服务报错:Failed to get D-Bus connection: Operation not allowed_夏小良的博客-程序员ITS304
一定要看问题的根源,避免做无用的工作1.找到问题的根源1)什么是WSL,如何安装?2)启动ssh服务报这个错误3)好像是系统的bug2.尝试修复bug解决问题1)作者给出解决方法2)组织一下这个解决方案3.退出,去ubuntu!!!1.找到问题的根本原因1)什么是WSL,如何安装?百度百科说Windows Subsystem for Linux(简称WSL)是一个...
TestNG-详述preserve-order的作用以及测试用例的执行顺序-CrazyPig的技术博客-程序员ITS304_preserve-order testng
在TestNG xml配置文件中,```的配置中,有一个名为`preserve-order`的属性。一开始我以为这个属性可以用来控制测试用例(那些被**@Test**注解的)。执行顺序,我后来测试了一下,发现没有这个效果。后来在网上找了这个属性的作用,发现是用来控制所有``inside``的执行顺序的。
系列通用属性和方法
1.系列常用属性属性描述values获取数组索引获取索引名称valuesindex.name索引名称2.系列常用功能系列几乎可以使用所有的索引操作ndarray 或 dict 的功能,集成 ndarray 和 dict 函数的优点说...
网页手机号抓取程序(如何安装硒您需要满足两个要求才能使用的网站抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-17 17:06
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
pip install requests
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
chromedriver.exe
文档
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.indeed.com/")
amazon_search = driver.find_element_by_id("twotabsearchtextbox")
amazon_search.send_keys("Web scraping for python developers")
amazon_search.send_keys(Keys.RETURN)
driver.close()
使用 python 和 selenium,你可以像这个 网站 这样跨不同工作平台找到 python 开发人员的当前职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monster 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
pip install lxml
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,其中收录开发 Web 抓取工具时所需的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦
Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI 用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
pip install pyspider
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
pyspider
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,则使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。 查看全部
网页手机号抓取程序(如何安装硒您需要满足两个要求才能使用的网站抓取数据)
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
pip install requests
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
chromedriver.exe
文档
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.indeed.com/";)
amazon_search = driver.find_element_by_id("twotabsearchtextbox")
amazon_search.send_keys("Web scraping for python developers")
amazon_search.send_keys(Keys.RETURN)
driver.close()
使用 python 和 selenium,你可以像这个 网站 这样跨不同工作平台找到 python 开发人员的当前职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monster 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
pip install lxml
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,其中收录开发 Web 抓取工具时所需的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦

Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI 用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
pip install pyspider
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
pyspider
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,则使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。
网页手机号抓取程序(利用抖音的充值接口,去分析提取出支付链接!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 562 次浏览 • 2022-03-28 00:04
最近开始开发一些个人支付渠道,让个人不用和第三方平台签约就可以收款,节省不少流程成本。
然后上网翻了一下,现成的技术教程不多,只能自己研究。
这次要分享的是使用抖音的充值接口分析提取支付链接,包括微信原生支付的h5支付链接和支付宝h5支付链接。
演示效果wb视频:
微信h5支付:
http://t.cn/A6xWjFuc
支付宝h5支付
http://t.cn/A6xWY5th
整个开发流程思路如下:
1.抓包分析抖音的整个充值过程,提取一些关键请求和API
2. 整理出每个请求需要的参数,从相关接口获取这些参数
3. 在 postman 等工具中模拟请求进行测试
4.编写代码实现整个逻辑
分析逻辑的第一步也是最重要的一步在这里分享。
充值订单界面
1.打开网页抖音充值页面,抓包分析充值豆币接口地址如下。
其中mobile代表手机号,price为支付金额,可自定义传入。
'https://www.douyin.com/webcast/wallet_api/diamond_buy_external_safe/?diamond_id=666666&source=5&way=0&aid=1128&mobile='
. $mobile . '&open_id=&fp=verify_kwo95axu_ZwXiLOvz_jt6N_4f2P_9mJb_TJ9MmZO7orJm&platform=iphone&customized_price='
. $price . '&extra=%7B%22domin_type%22:1%7D&guide_source=false'
2.测试发现这个接口需要用到cookies。
不难理解,cookie相当于识别了充值发起者,然后可以对其他任何账户进行充值。
直接F12打开调试模式在netword下的请求头中找到Cookie,复制保存。
在postman中测试,发现返回结果如下:
{
"data": {
"order_id": "10000017038524895319462912",
"params": "https://tp-pay.snssdk.com/cash ... ot%3B,
"pay_type": "0"
},
"extra": {
"now": 1638784363134
},
"status_code": 0
}
这里的“params”收录了后续步骤中会用到的参数,所以保存好。
3.其他接口类似,不要心急。
也可以从最终结果界面前推,获取对应的参数。
经验:
1.我发现逆向分析需要很大的耐心。有时我发现某个接口无法成功请求,然后我坚持调整。添加请求头,添加参数等都可以!
2.如果你卡在某个步骤无法通过,最好的办法就是从头再来!从第一个请求开始,让前面的请求更完整,因为有时候你上一步得到的参数是无效的,后面就不能继续了! 查看全部
网页手机号抓取程序(利用抖音的充值接口,去分析提取出支付链接!)
最近开始开发一些个人支付渠道,让个人不用和第三方平台签约就可以收款,节省不少流程成本。
然后上网翻了一下,现成的技术教程不多,只能自己研究。
这次要分享的是使用抖音的充值接口分析提取支付链接,包括微信原生支付的h5支付链接和支付宝h5支付链接。
演示效果wb视频:
微信h5支付:
http://t.cn/A6xWjFuc
支付宝h5支付
http://t.cn/A6xWY5th
整个开发流程思路如下:
1.抓包分析抖音的整个充值过程,提取一些关键请求和API
2. 整理出每个请求需要的参数,从相关接口获取这些参数
3. 在 postman 等工具中模拟请求进行测试
4.编写代码实现整个逻辑
分析逻辑的第一步也是最重要的一步在这里分享。
充值订单界面
1.打开网页抖音充值页面,抓包分析充值豆币接口地址如下。
其中mobile代表手机号,price为支付金额,可自定义传入。
'https://www.douyin.com/webcast/wallet_api/diamond_buy_external_safe/?diamond_id=666666&source=5&way=0&aid=1128&mobile='
. $mobile . '&open_id=&fp=verify_kwo95axu_ZwXiLOvz_jt6N_4f2P_9mJb_TJ9MmZO7orJm&platform=iphone&customized_price='
. $price . '&extra=%7B%22domin_type%22:1%7D&guide_source=false'
2.测试发现这个接口需要用到cookies。
不难理解,cookie相当于识别了充值发起者,然后可以对其他任何账户进行充值。
直接F12打开调试模式在netword下的请求头中找到Cookie,复制保存。
在postman中测试,发现返回结果如下:
{
"data": {
"order_id": "10000017038524895319462912",
"params": "https://tp-pay.snssdk.com/cash ... ot%3B,
"pay_type": "0"
},
"extra": {
"now": 1638784363134
},
"status_code": 0
}
这里的“params”收录了后续步骤中会用到的参数,所以保存好。
3.其他接口类似,不要心急。
也可以从最终结果界面前推,获取对应的参数。
经验:
1.我发现逆向分析需要很大的耐心。有时我发现某个接口无法成功请求,然后我坚持调整。添加请求头,添加参数等都可以!
2.如果你卡在某个步骤无法通过,最好的办法就是从头再来!从第一个请求开始,让前面的请求更完整,因为有时候你上一步得到的参数是无效的,后面就不能继续了!
网页手机号抓取程序(安装阿里云oss插件需要注意哪些问题?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-28 00:03
一、安装阿里云oss插件
这一步非常简单。可以在BT控制面板的软件管理中找到阿里云oss插件。安装完成后,获取Bucket后需要填写配置信息。
二、获取阿里云AccessKeyID和KeySecret
(1)登录你的阿里云账号,点击右侧头像,会有一个AccessKey。
(2)按照提示验证绑定的手机号获取AccessKeyID和KeySecret
三、激活oss并创建Bucket
(1)阿里云后端可以找到阿里云对象存储OSS,标准和低频两种访问方式都可以购买,标准的稍微贵一点,低频的一般都可以. 毕竟每个月只备份几次,如果看标准的一年才9块钱,可以直接选择标准的类型。
(2)创建一个Bucket,随便填个名字,然后我设置的类型是标准类型,私有,地域选择最好和你的阿里云服务器在同一个地域。
注意:区域选择非常重要。建议选择与您的服务器相同的区域。当然前提是你网站也在阿里云,因为不同地域的数据是不互通的,不能用内网数据传输。当时我没注意。选错区域,导致内网使用不成功。最后只能使用外网。速度不如内网快,而且内网不需要流量费。
(3)创建后,我们会得到Bucket名和外链域名
四、配置测试阿里云oss插件
(1)将第三步得到的数据全部填入oss插件
(2)一般来说是第一个选择访问域名。比如你用的是阿里云服务器,和OSS在同一个区域,可以使用内网地址,否则您只能使用第一个外联网地址。
(3)配置完成后save会获取同步的oss文件列表,如果能正常获取,则配置成功。
五、备份网站
(1)进入宝塔后台-定时任务-备份网站
(2)备份时间最好选择凌晨的某个时间,然后同一个网站数据库和网站文件必须在同一天
(3)设置完成后,执行测试,去阿里云oss查看数据是否完整正常,就这样了 查看全部
网页手机号抓取程序(安装阿里云oss插件需要注意哪些问题?-八维教育)
一、安装阿里云oss插件
这一步非常简单。可以在BT控制面板的软件管理中找到阿里云oss插件。安装完成后,获取Bucket后需要填写配置信息。
二、获取阿里云AccessKeyID和KeySecret
(1)登录你的阿里云账号,点击右侧头像,会有一个AccessKey。
(2)按照提示验证绑定的手机号获取AccessKeyID和KeySecret
三、激活oss并创建Bucket
(1)阿里云后端可以找到阿里云对象存储OSS,标准和低频两种访问方式都可以购买,标准的稍微贵一点,低频的一般都可以. 毕竟每个月只备份几次,如果看标准的一年才9块钱,可以直接选择标准的类型。
(2)创建一个Bucket,随便填个名字,然后我设置的类型是标准类型,私有,地域选择最好和你的阿里云服务器在同一个地域。
注意:区域选择非常重要。建议选择与您的服务器相同的区域。当然前提是你网站也在阿里云,因为不同地域的数据是不互通的,不能用内网数据传输。当时我没注意。选错区域,导致内网使用不成功。最后只能使用外网。速度不如内网快,而且内网不需要流量费。
(3)创建后,我们会得到Bucket名和外链域名
四、配置测试阿里云oss插件
(1)将第三步得到的数据全部填入oss插件
(2)一般来说是第一个选择访问域名。比如你用的是阿里云服务器,和OSS在同一个区域,可以使用内网地址,否则您只能使用第一个外联网地址。
(3)配置完成后save会获取同步的oss文件列表,如果能正常获取,则配置成功。
五、备份网站
(1)进入宝塔后台-定时任务-备份网站
(2)备份时间最好选择凌晨的某个时间,然后同一个网站数据库和网站文件必须在同一天
(3)设置完成后,执行测试,去阿里云oss查看数据是否完整正常,就这样了
网页手机号抓取程序( 中原大数据(V:jycg789)手机号是怎样获取访客手机号码的呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-27 21:09
中原大数据(V:jycg789)手机号是怎样获取访客手机号码的呢)
网站如何获取手机号
手机号获取:客户通过手机进入您的网站后,即使不咨询也不留下联系方式,我们也可以通过三网获取其手机号,作为您回访的准确数据,并提前销售结果。并能快速积累众多精准客户
中原大数据(V:jycg789)
手机号码被系统抓取,用户可以随时了解网站受访客户的联系方式。现在它可以准确计算出客户的手机号码。支持:Excel导出、客户分类、关键词传入、传入IP、
访问页面地址等等!
手机号抓取率90%+,在一定的WIFI条件下也可以获得。
手机号抓取如何获取访客的手机号?
不管是电脑还是手机访问网站,都是HTTP协议,肯定有个叫“HTTP消息”的东西,里面有很多信息,User-Agent就是浏览器和手机类型访问者使用,这些可以看到,还有IP地址,访问者从哪个网络访问这个网站。手机访问网站时,HTTP报文经过通信运营商的基站时,运营商在报文中添加了一些东西,比如手机号和IMEI号,这些东西可以直接写在“明文”里面,也有可能是加密的。对于网站来说,每天都有很多访问者,所有的HTTP消息都可以在网站的日志中找到。
“当然,假设消息信息是加密的,网站方无法获取来访者手机号等信息,但是,假设网站运营商去通讯运营商购买相关'interface' ',这样通过接口,操作者网站就可以知道通信操作者在HTTP报文中添加了什么内容,以及如何解密。”
在交易过程中,每个公司的细节都遵循着自己的产品节奏。这没什么好说的。
最后,笔者在这里提醒各位小伙伴们在购买手机号抓包时要慎重选家,防止不良技术服务商泄露自己的网站客户信息,甚至一些低价系统在低价中加入违规代码作为诱饵价格拥有 网站。中原大数据(V:jycg789
) 查看全部
网页手机号抓取程序(
中原大数据(V:jycg789)手机号是怎样获取访客手机号码的呢)
网站如何获取手机号
手机号获取:客户通过手机进入您的网站后,即使不咨询也不留下联系方式,我们也可以通过三网获取其手机号,作为您回访的准确数据,并提前销售结果。并能快速积累众多精准客户
中原大数据(V:jycg789)
手机号码被系统抓取,用户可以随时了解网站受访客户的联系方式。现在它可以准确计算出客户的手机号码。支持:Excel导出、客户分类、关键词传入、传入IP、
访问页面地址等等!
手机号抓取率90%+,在一定的WIFI条件下也可以获得。
手机号抓取如何获取访客的手机号?
不管是电脑还是手机访问网站,都是HTTP协议,肯定有个叫“HTTP消息”的东西,里面有很多信息,User-Agent就是浏览器和手机类型访问者使用,这些可以看到,还有IP地址,访问者从哪个网络访问这个网站。手机访问网站时,HTTP报文经过通信运营商的基站时,运营商在报文中添加了一些东西,比如手机号和IMEI号,这些东西可以直接写在“明文”里面,也有可能是加密的。对于网站来说,每天都有很多访问者,所有的HTTP消息都可以在网站的日志中找到。
“当然,假设消息信息是加密的,网站方无法获取来访者手机号等信息,但是,假设网站运营商去通讯运营商购买相关'interface' ',这样通过接口,操作者网站就可以知道通信操作者在HTTP报文中添加了什么内容,以及如何解密。”
在交易过程中,每个公司的细节都遵循着自己的产品节奏。这没什么好说的。
最后,笔者在这里提醒各位小伙伴们在购买手机号抓包时要慎重选家,防止不良技术服务商泄露自己的网站客户信息,甚至一些低价系统在低价中加入违规代码作为诱饵价格拥有 网站。中原大数据(V:jycg789
)
网页手机号抓取程序(同行网站访客手机号的原理手机号抓取三大优势分享到这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-03-17 14:12
这是很多手机号获取行业的人说的,那么哪个是真的,哪个是假的呢?,如果不是假号,或者不是历史数据,如果要真实,就必须被真实的运营商捕获,然后与运营商合作才有端口。
同行网站访客手机号抓取原理
比如我是中国联通的手机号。当我使用流量访问某个网站时,会产生流量数据,我会花钱。该流量数据将反馈给联通运营商。这个流量数据肯定会包括你。手机号,这样你的手机号就被抓到了。同时,只要与运营商合作,拥有端口api,就可以提取这些数据,获取对等网站网页访问者的手机号,原理大家都懂了。可以说100%的爬取并不是基于这个原理。相信这一点,再去爬同行的网站访问者手机工具,就不会上当受骗了。
网站访客手机号抓取的三大优势
我们提供的服务不仅针对性强,更专业,从四个角度实现企业、招标、企业利益最大化网站:更便捷、更精准、成本更低、回报更大;从而提高改善企业的目标是低投入高回报。我们如何才能从 网站 获得更多客户!分分钟搞定,一次投资,十次回报!轻松将您的销售业绩翻倍。
更便捷——通过客户访问招标网页自动抓取客户手机号,获取95%左右的潜在客户手机号;
更精准——通过手机号码更精准的定位潜在目标客户,让对公司产品真正感兴趣的潜在客户更直接地了解产品和信息;
更低的成本,更大的回报——通过更低的资金投入,公司可以在最短时间内获得更多有价值的潜在目标客户,方便广告客户的二次销售。
好了,今天的文章,同行的手机号抓取原理网站,手机号抓取的三大优势就分享到这里,加上右边的在线QQ好友咨询,只要当客户拜访您时,大约有 90% 的机会获得他的手机号码,非常适合营销和获客。 查看全部
网页手机号抓取程序(同行网站访客手机号的原理手机号抓取三大优势分享到这里)
这是很多手机号获取行业的人说的,那么哪个是真的,哪个是假的呢?,如果不是假号,或者不是历史数据,如果要真实,就必须被真实的运营商捕获,然后与运营商合作才有端口。
同行网站访客手机号抓取原理
比如我是中国联通的手机号。当我使用流量访问某个网站时,会产生流量数据,我会花钱。该流量数据将反馈给联通运营商。这个流量数据肯定会包括你。手机号,这样你的手机号就被抓到了。同时,只要与运营商合作,拥有端口api,就可以提取这些数据,获取对等网站网页访问者的手机号,原理大家都懂了。可以说100%的爬取并不是基于这个原理。相信这一点,再去爬同行的网站访问者手机工具,就不会上当受骗了。
网站访客手机号抓取的三大优势
我们提供的服务不仅针对性强,更专业,从四个角度实现企业、招标、企业利益最大化网站:更便捷、更精准、成本更低、回报更大;从而提高改善企业的目标是低投入高回报。我们如何才能从 网站 获得更多客户!分分钟搞定,一次投资,十次回报!轻松将您的销售业绩翻倍。
更便捷——通过客户访问招标网页自动抓取客户手机号,获取95%左右的潜在客户手机号;
更精准——通过手机号码更精准的定位潜在目标客户,让对公司产品真正感兴趣的潜在客户更直接地了解产品和信息;
更低的成本,更大的回报——通过更低的资金投入,公司可以在最短时间内获得更多有价值的潜在目标客户,方便广告客户的二次销售。
好了,今天的文章,同行的手机号抓取原理网站,手机号抓取的三大优势就分享到这里,加上右边的在线QQ好友咨询,只要当客户拜访您时,大约有 90% 的机会获得他的手机号码,非常适合营销和获客。
网页手机号抓取程序(2016年8月15日TXT:文章总结三个不同的excel提取手机号码的案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-10 23:15
有txt文件和txt文件,格式为每个手机号一行,2016年8月15日总结:文章总结excel提取手机号的三种不同案例供大家参考。从excel中提取手机号码也是比较常见的应用。但是根据数据源的不同,会提取出对应的手机号...#*#
TXT文字手机号提取器下载_TXT文字手机号提取器官方下载-太... 手机号提取器用于提取凌乱文字中的手机号!比如手机号和手机号混在一起,可以用本软件一键提取手机号,导出为txt,方便下次操作数据!#*#2019 11月13日,TXT文本电话号码提取器用于提取乱码中的电话号码!比如电话号码和电话号码混在一起,可以使用本软件一键提取电话号码,导出为txt,方便下一步数据操作。!Excel手机号码提取器可以从excelj中提取手机号码,您可以选择工作表等。Excel手机号码提取器是时下网络上最常用的软件之一一...#*#2019年11月13日TXT文本手机号码提取器用于从杂乱的文本中提取手机号码!比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 查看全部
网页手机号抓取程序(2016年8月15日TXT:文章总结三个不同的excel提取手机号码的案例)
有txt文件和txt文件,格式为每个手机号一行,2016年8月15日总结:文章总结excel提取手机号的三种不同案例供大家参考。从excel中提取手机号码也是比较常见的应用。但是根据数据源的不同,会提取出对应的手机号...#*#
TXT文字手机号提取器下载_TXT文字手机号提取器官方下载-太... 手机号提取器用于提取凌乱文字中的手机号!比如手机号和手机号混在一起,可以用本软件一键提取手机号,导出为txt,方便下次操作数据!#*#2019 11月13日,TXT文本电话号码提取器用于提取乱码中的电话号码!比如电话号码和电话号码混在一起,可以使用本软件一键提取电话号码,导出为txt,方便下一步数据操作。!Excel手机号码提取器可以从excelj中提取手机号码,您可以选择工作表等。Excel手机号码提取器是时下网络上最常用的软件之一一...#*#2019年11月13日TXT文本手机号码提取器用于从杂乱的文本中提取手机号码!比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*# 比如手机号和电话号码混合在一起,可以用本软件一键提取手机号,导出为txt,方便下次数据操作!Excel手机号码提取器是时下网上最常用的软件之一一...#*#
网页手机号抓取程序(网页手机号抓取程序真的可以实现吗?看看结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-06 19:07
网页手机号抓取程序真的可以实现吗?看看结果网页手机号抓取程序真的可以实现吗?看看结果
试了一下百度信息流,基本上,这东西跟电视剧一样,看的是名字和演员,不看作品。
是啊,我写了一个爬虫,服务器端处理了好久还是抓不到啊,
你可以到天池cdn库的“抓取代理”那里看看,
人家是商业机构,
除了百度、360外,
真实用户:百度、爱采购、搜狗、360、友盟,
百度有开放api。
直接百度谷歌有很多了,
google有专门提供无明显商业目的的免费的抓取代理,“yunflow.fc”另外谷歌现在直接做了个小米的插件,提供无结构的方式来抓取的应用。当然了做到这个程度要比分发效率,用户体验等更重要。
百度买的代理应该是不收钱的,
大家怎么还用代理手机号抓包。看来是没人研究。分享个人的百度账号抓包和批量抓包集锦。搬运过来。
跟手机官网有何关系?手机号中是可以找到的 查看全部
网页手机号抓取程序(网页手机号抓取程序真的可以实现吗?看看结果)
网页手机号抓取程序真的可以实现吗?看看结果网页手机号抓取程序真的可以实现吗?看看结果
试了一下百度信息流,基本上,这东西跟电视剧一样,看的是名字和演员,不看作品。
是啊,我写了一个爬虫,服务器端处理了好久还是抓不到啊,
你可以到天池cdn库的“抓取代理”那里看看,
人家是商业机构,
除了百度、360外,
真实用户:百度、爱采购、搜狗、360、友盟,
百度有开放api。
直接百度谷歌有很多了,
google有专门提供无明显商业目的的免费的抓取代理,“yunflow.fc”另外谷歌现在直接做了个小米的插件,提供无结构的方式来抓取的应用。当然了做到这个程度要比分发效率,用户体验等更重要。
百度买的代理应该是不收钱的,
大家怎么还用代理手机号抓包。看来是没人研究。分享个人的百度账号抓包和批量抓包集锦。搬运过来。
跟手机官网有何关系?手机号中是可以找到的
网页手机号抓取程序(1.登录微信公众平台设置需要的菜单,关于网页授权回调域名的说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-05 22:05
1.登录微信公众平台设置所需菜单,以绑定微信账号为例
2.网页地址填写自己的接口地址或跳转地址
3.后台界面(php仅供参考)
两个红圈的地址是接口地址,可以获取用户的openid,下面的接口是用户的openid和手机号绑定
参考以下微信官方文档
如果用户在微信客户端访问第三方网页,公众号可以通过微信网页授权机制获取用户的基本信息,进而实现业务逻辑。
网页授权回调域名说明
1、在微信公众号请求用户网页授权前,开发者需要到官网“开发-接口权限-Web服务-Web账号-网页授权获取用户基本信息”配置选项官方平台,修改授权回调域名。请注意这里填写的是域名(是一个字符串),不是URL,所以请不要添加协议头;
2、授权回调域名的配置规范为全域名。比如需要网页授权的域名是:,配置后配置该域名下的页面。
, 可以进行 OAuth2.0 认证。但是, , OAuth2.0 认证不能执行
3、如果公众号登录授权给第三方开发者进行管理,则无需做任何设置,第三方可以替换公众号实现网页授权
网页授权两种范围的区别
1、以snsapi_base为作用域发起的网页授权,用于获取用户进入页面的openid,静默授权,自动跳转到回调页面。用户感知到的是直接进入回调页面(通常是业务页面)
2、以snsapi_userinfo为作用域发起的网页授权,用于获取用户的基本信息。但该授权需要用户手动同意,且由于用户已同意,授权后无需关注即可获取用户的基本信息。
3、用户管理类界面中的“获取用户基本信息接口”是在用户与公众号交互或事件推送后,根据用户的OpenID获取用户基本信息。该接口,包括其他微信接口,只有在用户(即openid)关注公众号后才能调用成功。
关于网页授权access_token和普通access_token的区别
1、微信网页授权是通过OAuth2.0机制实现的。用户授权公众号后,公众号可以获得唯一的网页授权接口调用证书(网页授权access_token),通过网页授权access_token可以进行授权后的API调用,如获取用户基本信息;
2、其他微信API需要通过基础支持中的“获取access_token”API调用。
关于 UnionID 机制
1、请注意,网页获取用户基本信息的授权也遵循UnionID机制。即如果开发者需要在多个公众号中,或者公众号和移动应用之间统一用户账号,需要到微信开放平台()绑定公众号,然后可以使用UnionID机制满足以上要求。
2、UnionID机制功能说明:如果开发者有多个手机应用、网站应用和公众号,通过获取用户基本信息中的unionid可以区分用户的唯一性,因为同一个用户,对于同一个微信开放平台下的不同应用(手机应用、网站应用和公众号),unionid是一样的。
关于特殊场景下的静默授权
1、如前所述,以snsapi_base为范围的网页的授权是静默授权,用户感知不到;
2、对于关注过公众号的用户,如果用户从公众号的session或者自定义菜单进入公众号的网页授权页面,即使范围是snsapi_userinfo,授权也是静默的,用户感知不到它。
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、如有需要开发者可以刷新网页授权access_token避免过期
4、 通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
内容
1 第一步:用户同意授权并获取密码
2 第二步:网页授权access_token的兑换码
3 第 3 步:刷新 access_token(如果需要)
4 第四步:拉取用户信息(范围需要snsapi_userinfo)
5 附:检查授权证书(access_token)是否有效
第一步:用户同意授权并获取密码
在保证微信公众号有权限授权范围(范围参数)的前提下(服务号获取高级接口后,范围参数中默认会有snsapi_base和snsapi_userinfo),引导关注者开通以下页面:
#wechat_redirect 如果提示“链接无法访问”,请检查参数是否填写错误,是否有scope参数对应的授权范围权限。
特别注意:由于授权操作的安全级别较高,当发起授权请求时,微信会定期对授权链接进行强匹配检查。如果链接的参数顺序错误,授权页面将无法正常访问。
参考链接(请在微信客户端打开此链接体验):
范围是 snsapi_base
%3A%2F%%2Fphp%2Findex.php%3Fd%3D%26c%3DwxAdapter%26m%3DmobileDeal%26showwxpaytitle%3D1%26vb2ctag%3D4_2030_5_1194_60&response_type=code&scope=snsapi_base&state=123#wechat_redirect
范围是 snsapi_userinfo
%3A%2F%%2Foauth_response.php&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect
特别注意:跳转回调redirect_uri要使用https链接,保证授权码的安全。
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
重定向uri
是的
授权后重定向的回调链接地址,请使用urlEncode处理链接
响应类型
是的
返回类型,请填写代码
范围
是的
应用授权范围,snsapi_base(不弹出授权页面,直接跳转,只获取用户的openid),snsapi_userinfo(弹出授权页面,可以通过openid获取昵称、性别、位置。而且,即使不不注意,只要用户授权,也可以获得信息)
状态
不
重定向后会带上state参数,开发者可以填写a-zA-Z0-9的参数值,最多128字节
#wechat_redirect
是的
不管是直接打开还是做302页面定向,都必须带这个参数
下图是scope等于snsapi_userinfo时的授权页面:
用户同意授权后
如果用户同意授权,页面会跳转到redirect_uri/?code=CODE&state=STATE。
代号说明:代号作为票证换取access_token。每个用户授权上的代码会有所不同。代码只能使用一次,5分钟不使用自动过期。
错误返回码描述如下:
返回码
阐明
10003
redirect_uri域名与后台配置不一致
10004
此帐号已被禁止
10005
本公众号没有这些范围的权限
10006
一定要注意这个测试号
10009
操作过于频繁,请稍后再试
10010
范围不能为空
10011
redirect_uri 不能为空
10012
appid 不能为空
10013
状态不能为空
10015
公众号未授权第三方平台,请查看授权状态
10016
不支持微信开放平台的Appid,请使用公众号Appid
第二步:网页授权access_token的兑换码
首先请注意,这里交换的代码是一个特殊的网页授权access_token,与基础支持中的access_token不同(access_token用于调用其他接口)。公众号可以通过以下接口获取网页授权access_token。如果网页授权范围是snsapi_base,则本步骤获取网页授权access_token,同时获取openid,snsapi_base风格的网页授权流程到此结束。
特别注意:由于公众号的secret和获取到的access_token的安全级别都很高,所以只能存储在服务端,不允许传递给客户端。后续的刷新access_token、通过access_token获取用户信息等步骤也必须从服务端发起。
请求方法
获取代码后,请求以下链接获取access_token:
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
秘密
是的
公众号的appsecret
代码
是的
填写第一步得到的code参数
授予类型
是的
填写为授权码
返回说明
正确时返回的JSON数据包如下:
{
"access_token":"ACCESS_TOKEN",
"expires_in":7200,
"refresh_token":"REFRESH_TOKEN",
"openid":"OPENID",
"scope":"SCOPE"
}
范围
描述
访问令牌
网页授权接口调用凭证,注意:这个access_token和基本支持的access_token不同
过期日期在
access_token API调用凭证超时时间,单位(秒)
刷新令牌
用户刷新 access_token
打开ID 查看全部
网页手机号抓取程序(1.登录微信公众平台设置需要的菜单,关于网页授权回调域名的说明)
1.登录微信公众平台设置所需菜单,以绑定微信账号为例
2.网页地址填写自己的接口地址或跳转地址
3.后台界面(php仅供参考)
两个红圈的地址是接口地址,可以获取用户的openid,下面的接口是用户的openid和手机号绑定
参考以下微信官方文档
如果用户在微信客户端访问第三方网页,公众号可以通过微信网页授权机制获取用户的基本信息,进而实现业务逻辑。
网页授权回调域名说明
1、在微信公众号请求用户网页授权前,开发者需要到官网“开发-接口权限-Web服务-Web账号-网页授权获取用户基本信息”配置选项官方平台,修改授权回调域名。请注意这里填写的是域名(是一个字符串),不是URL,所以请不要添加协议头;
2、授权回调域名的配置规范为全域名。比如需要网页授权的域名是:,配置后配置该域名下的页面。
, 可以进行 OAuth2.0 认证。但是, , OAuth2.0 认证不能执行
3、如果公众号登录授权给第三方开发者进行管理,则无需做任何设置,第三方可以替换公众号实现网页授权
网页授权两种范围的区别
1、以snsapi_base为作用域发起的网页授权,用于获取用户进入页面的openid,静默授权,自动跳转到回调页面。用户感知到的是直接进入回调页面(通常是业务页面)
2、以snsapi_userinfo为作用域发起的网页授权,用于获取用户的基本信息。但该授权需要用户手动同意,且由于用户已同意,授权后无需关注即可获取用户的基本信息。
3、用户管理类界面中的“获取用户基本信息接口”是在用户与公众号交互或事件推送后,根据用户的OpenID获取用户基本信息。该接口,包括其他微信接口,只有在用户(即openid)关注公众号后才能调用成功。
关于网页授权access_token和普通access_token的区别
1、微信网页授权是通过OAuth2.0机制实现的。用户授权公众号后,公众号可以获得唯一的网页授权接口调用证书(网页授权access_token),通过网页授权access_token可以进行授权后的API调用,如获取用户基本信息;
2、其他微信API需要通过基础支持中的“获取access_token”API调用。
关于 UnionID 机制
1、请注意,网页获取用户基本信息的授权也遵循UnionID机制。即如果开发者需要在多个公众号中,或者公众号和移动应用之间统一用户账号,需要到微信开放平台()绑定公众号,然后可以使用UnionID机制满足以上要求。
2、UnionID机制功能说明:如果开发者有多个手机应用、网站应用和公众号,通过获取用户基本信息中的unionid可以区分用户的唯一性,因为同一个用户,对于同一个微信开放平台下的不同应用(手机应用、网站应用和公众号),unionid是一样的。
关于特殊场景下的静默授权
1、如前所述,以snsapi_base为范围的网页的授权是静默授权,用户感知不到;
2、对于关注过公众号的用户,如果用户从公众号的session或者自定义菜单进入公众号的网页授权页面,即使范围是snsapi_userinfo,授权也是静默的,用户感知不到它。
具体来说,网页授权过程分为四个步骤:
1、引导用户进入授权页面同意授权并获取code
2、用代码交换网页授权access_token(与基础支持中的access_token不同)
3、如有需要开发者可以刷新网页授权access_token避免过期
4、 通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)
内容
1 第一步:用户同意授权并获取密码
2 第二步:网页授权access_token的兑换码
3 第 3 步:刷新 access_token(如果需要)
4 第四步:拉取用户信息(范围需要snsapi_userinfo)
5 附:检查授权证书(access_token)是否有效
第一步:用户同意授权并获取密码
在保证微信公众号有权限授权范围(范围参数)的前提下(服务号获取高级接口后,范围参数中默认会有snsapi_base和snsapi_userinfo),引导关注者开通以下页面:
#wechat_redirect 如果提示“链接无法访问”,请检查参数是否填写错误,是否有scope参数对应的授权范围权限。
特别注意:由于授权操作的安全级别较高,当发起授权请求时,微信会定期对授权链接进行强匹配检查。如果链接的参数顺序错误,授权页面将无法正常访问。
参考链接(请在微信客户端打开此链接体验):
范围是 snsapi_base
%3A%2F%%2Fphp%2Findex.php%3Fd%3D%26c%3DwxAdapter%26m%3DmobileDeal%26showwxpaytitle%3D1%26vb2ctag%3D4_2030_5_1194_60&response_type=code&scope=snsapi_base&state=123#wechat_redirect
范围是 snsapi_userinfo
%3A%2F%%2Foauth_response.php&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect
特别注意:跳转回调redirect_uri要使用https链接,保证授权码的安全。
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
重定向uri
是的
授权后重定向的回调链接地址,请使用urlEncode处理链接
响应类型
是的
返回类型,请填写代码
范围
是的
应用授权范围,snsapi_base(不弹出授权页面,直接跳转,只获取用户的openid),snsapi_userinfo(弹出授权页面,可以通过openid获取昵称、性别、位置。而且,即使不不注意,只要用户授权,也可以获得信息)
状态
不
重定向后会带上state参数,开发者可以填写a-zA-Z0-9的参数值,最多128字节
#wechat_redirect
是的
不管是直接打开还是做302页面定向,都必须带这个参数
下图是scope等于snsapi_userinfo时的授权页面:
用户同意授权后
如果用户同意授权,页面会跳转到redirect_uri/?code=CODE&state=STATE。
代号说明:代号作为票证换取access_token。每个用户授权上的代码会有所不同。代码只能使用一次,5分钟不使用自动过期。
错误返回码描述如下:
返回码
阐明
10003
redirect_uri域名与后台配置不一致
10004
此帐号已被禁止
10005
本公众号没有这些范围的权限
10006
一定要注意这个测试号
10009
操作过于频繁,请稍后再试
10010
范围不能为空
10011
redirect_uri 不能为空
10012
appid 不能为空
10013
状态不能为空
10015
公众号未授权第三方平台,请查看授权状态
10016
不支持微信开放平台的Appid,请使用公众号Appid
第二步:网页授权access_token的兑换码
首先请注意,这里交换的代码是一个特殊的网页授权access_token,与基础支持中的access_token不同(access_token用于调用其他接口)。公众号可以通过以下接口获取网页授权access_token。如果网页授权范围是snsapi_base,则本步骤获取网页授权access_token,同时获取openid,snsapi_base风格的网页授权流程到此结束。
特别注意:由于公众号的secret和获取到的access_token的安全级别都很高,所以只能存储在服务端,不允许传递给客户端。后续的刷新access_token、通过access_token获取用户信息等步骤也必须从服务端发起。
请求方法
获取代码后,请求以下链接获取access_token:
参数说明
范围
有必要吗
阐明
应用程序
是的
公众号唯一标识
秘密
是的
公众号的appsecret
代码
是的
填写第一步得到的code参数
授予类型
是的
填写为授权码
返回说明
正确时返回的JSON数据包如下:
{
"access_token":"ACCESS_TOKEN",
"expires_in":7200,
"refresh_token":"REFRESH_TOKEN",
"openid":"OPENID",
"scope":"SCOPE"
}
范围
描述
访问令牌
网页授权接口调用凭证,注意:这个access_token和基本支持的access_token不同
过期日期在
access_token API调用凭证超时时间,单位(秒)
刷新令牌
用户刷新 access_token
打开ID
网页手机号抓取程序(用什么可以把APP用户手机号数据抓取出来?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-03 12:09
? ? APP用户的手机号码数据可以用什么来抓?- ______可以通过大数据精准营销来解决。您可以获取指定网页或APP最近三天的访问者数据,该数据包括手机号码。并且是准确的目标年龄、性别、地区等。还可以设置客户登录次数。比如你想在三天内登录APP或者访问这个网页两次,都可以实现。精准营销——场景营销
? ? 什么软件可以备份号码和信息?______ QQ同步助手,可以免费备份和恢复您的电话号码,等待您的QQ通讯录中定义信息。QQ同步助手是腾讯开发的一款安全、免费的个人手机数据。备份管理服务软件......
? ? 请推荐一款好用的手机抓号软件______如果要下载第三方应用软件(趣味游戏、常用工具应用、系统辅助等),建议搜索当前比较热门的软件1、如果你的手机自带应用商店,可以如下搜索:应用-应用商店-点击热门推荐”查看当前比较热门的软件/游戏。也可以按照分类,选择根据软件类型你喜欢的软件2、通过手机浏览器搜索你需要下载安装的软件(如果自带浏览器,下载的安装包保存在我的文件-下载文件夹中) .3、
? ? 手机号采集哪个软件比较好?______名微商户采集器明微电子地图综合服务搜索软件明微搜号宝好
? ? 可以抓取指定页面的手机号,采集软件。有没有?______ 使用之前嗅探到的ForeSpider数据采集系统,可以采集全网联系方式,或者指定网站的联系方式。我用 ForeSpider 搜索了全网采集的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数据采集系统是唯一一款自带数据挖掘功能的爬虫软件。软件集成了数据挖掘功能,通过采集模板可以精准挖掘全网内容。当数据采集存储后,可以完成分类、统计、自然语言处理等多项功能。除了强大的可视化采集,ForeSpider还自带了一套爬虫脚本语言,可以采集任何公开的数据。现在可以下载免费版试用,联系对方取得效果。
? ? 如何采集APP数据和捕获app数据-______我用过软件采集app数据,先用抓包工具看看app的协议是否加密,如果没有,可以采集. 数据包捕获工具可在 Internet 上获得。如果使用 采集 数据,则使用前端嗅探的 ForeSpider 数据 采集 软件。网上也有很多教程。操作简单,有免费版,大家可以试试看。希望采纳
? ? 我要采集手机客户端的数据,请指点-______现成的东西应该可以发送采集,确认gprs模块正常,sim卡有效,有费用,收到的手机号码是固定的,也可以更改。
? ? 有没有能抓app数据的高手______抓app数据的思路一般和抓网页数据的思路差不多:获取数据链接,配置数据采集规则,获取数据。只是你需要使用抓包来获取应用链接工具。我用过ForeSpider爬虫爬取了一些app数据,还是很好用的
? ? 如何以图片的形式采集客户资料采集软件采集电话号码?______ 58网站 的电话号码以多种方式显示。第一种是部分使用星号。隐藏,你必须点击查看完整号码才能看到完整的电话号码。这种情况下,需要通过本软件设置点击动作,实现自动点击,然后采集数字编号。二是点击,然后用手机扫描二维码,显示完整号码。这种情况下,您需要将用户代理更改为移动端,然后重新访问,您将浏览到移动端的网页表单。部分可以直接显示电话号码。其他部分只有点击后才能看到。第三个是你问的图片格式的电话号码。这种情况下,只能下载图片采集,然后根据关联字段放手机图片和网页信息。对应最后就是把图片转成文字,可以手动打出数字或者找ocr文字识别软件自动识别 查看全部
网页手机号抓取程序(用什么可以把APP用户手机号数据抓取出来?(图))
? ? APP用户的手机号码数据可以用什么来抓?- ______可以通过大数据精准营销来解决。您可以获取指定网页或APP最近三天的访问者数据,该数据包括手机号码。并且是准确的目标年龄、性别、地区等。还可以设置客户登录次数。比如你想在三天内登录APP或者访问这个网页两次,都可以实现。精准营销——场景营销
? ? 什么软件可以备份号码和信息?______ QQ同步助手,可以免费备份和恢复您的电话号码,等待您的QQ通讯录中定义信息。QQ同步助手是腾讯开发的一款安全、免费的个人手机数据。备份管理服务软件......
? ? 请推荐一款好用的手机抓号软件______如果要下载第三方应用软件(趣味游戏、常用工具应用、系统辅助等),建议搜索当前比较热门的软件1、如果你的手机自带应用商店,可以如下搜索:应用-应用商店-点击热门推荐”查看当前比较热门的软件/游戏。也可以按照分类,选择根据软件类型你喜欢的软件2、通过手机浏览器搜索你需要下载安装的软件(如果自带浏览器,下载的安装包保存在我的文件-下载文件夹中) .3、
? ? 手机号采集哪个软件比较好?______名微商户采集器明微电子地图综合服务搜索软件明微搜号宝好
? ? 可以抓取指定页面的手机号,采集软件。有没有?______ 使用之前嗅探到的ForeSpider数据采集系统,可以采集全网联系方式,或者指定网站的联系方式。我用 ForeSpider 搜索了全网采集的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数据采集系统是唯一一款自带数据挖掘功能的爬虫软件。软件集成了数据挖掘功能,通过采集模板可以精准挖掘全网内容。当数据采集存储后,可以完成分类、统计、自然语言处理等多项功能。除了强大的可视化采集,ForeSpider还自带了一套爬虫脚本语言,可以采集任何公开的数据。现在可以下载免费版试用,联系对方取得效果。
? ? 如何采集APP数据和捕获app数据-______我用过软件采集app数据,先用抓包工具看看app的协议是否加密,如果没有,可以采集. 数据包捕获工具可在 Internet 上获得。如果使用 采集 数据,则使用前端嗅探的 ForeSpider 数据 采集 软件。网上也有很多教程。操作简单,有免费版,大家可以试试看。希望采纳
? ? 我要采集手机客户端的数据,请指点-______现成的东西应该可以发送采集,确认gprs模块正常,sim卡有效,有费用,收到的手机号码是固定的,也可以更改。
? ? 有没有能抓app数据的高手______抓app数据的思路一般和抓网页数据的思路差不多:获取数据链接,配置数据采集规则,获取数据。只是你需要使用抓包来获取应用链接工具。我用过ForeSpider爬虫爬取了一些app数据,还是很好用的
? ? 如何以图片的形式采集客户资料采集软件采集电话号码?______ 58网站 的电话号码以多种方式显示。第一种是部分使用星号。隐藏,你必须点击查看完整号码才能看到完整的电话号码。这种情况下,需要通过本软件设置点击动作,实现自动点击,然后采集数字编号。二是点击,然后用手机扫描二维码,显示完整号码。这种情况下,您需要将用户代理更改为移动端,然后重新访问,您将浏览到移动端的网页表单。部分可以直接显示电话号码。其他部分只有点击后才能看到。第三个是你问的图片格式的电话号码。这种情况下,只能下载图片采集,然后根据关联字段放手机图片和网页信息。对应最后就是把图片转成文字,可以手动打出数字或者找ocr文字识别软件自动识别
网页手机号抓取程序(2015年招商银行网页手机号抓取程序的程序-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-01 08:05
网页手机号抓取程序是一个专门抓取网页端手机号码的程序。主要抓取的是各种国内有名的银行卡及网上银行,比如招商银行,建设银行,工商银行等等。而对于招商银行还有掌上生活可以抓取支付宝的手机号。如果你有更好的、能够抓取你手机号码的程序欢迎给我们留言。
1)在某种网站平台上搜索你需要的资料,比如说福建厦门政府网,当然搜索出来的东西可能有限,但是关键词可以有好几个。
2)在其他地方的一个房源网找到这个房子,这个网站我就不敢再说了,只敢说那里有你要的东西,还有链接。
3)用这个关键词在这个房源网中搜索公司名和所在地。
4)把这个公司名和地址填入到你要找的表格中,搜索关键词会变换多种,最终回到你刚才填入的相关地址。
5)填入一个联系方式,点击输入手机号码即可确认。
6)获取到你的号码后,百度一下联系方式,出来一堆广告,一个个点进去,然后点到链接。
7)在你的手机号码中选择你要的,然后点击下载保存,就成功从手机中获取了你的手机号码了。
网页的话:百度搜索首页左侧侧面那有点开小人头标识的地方有个bigsearch,
来个快速的
我们公司主要是做微信公众号打赏的(二维码自动识别) 查看全部
网页手机号抓取程序(2015年招商银行网页手机号抓取程序的程序-乐题库)
网页手机号抓取程序是一个专门抓取网页端手机号码的程序。主要抓取的是各种国内有名的银行卡及网上银行,比如招商银行,建设银行,工商银行等等。而对于招商银行还有掌上生活可以抓取支付宝的手机号。如果你有更好的、能够抓取你手机号码的程序欢迎给我们留言。
1)在某种网站平台上搜索你需要的资料,比如说福建厦门政府网,当然搜索出来的东西可能有限,但是关键词可以有好几个。
2)在其他地方的一个房源网找到这个房子,这个网站我就不敢再说了,只敢说那里有你要的东西,还有链接。
3)用这个关键词在这个房源网中搜索公司名和所在地。
4)把这个公司名和地址填入到你要找的表格中,搜索关键词会变换多种,最终回到你刚才填入的相关地址。
5)填入一个联系方式,点击输入手机号码即可确认。
6)获取到你的号码后,百度一下联系方式,出来一堆广告,一个个点进去,然后点到链接。
7)在你的手机号码中选择你要的,然后点击下载保存,就成功从手机中获取了你的手机号码了。
网页的话:百度搜索首页左侧侧面那有点开小人头标识的地方有个bigsearch,
来个快速的
我们公司主要是做微信公众号打赏的(二维码自动识别)
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2022-02-28 09:15
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
内容
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用微建低码快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解获取手机号的微信小程序的相关文档
我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序
添加按钮
在创建的应用首页添加按钮,更改标题获取手机号
选择微信开发能力获取手机号
创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器
单击页面上处理程序旁边的 + 号以创建自定义方法 getphone
我们不知道点击按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为
选择自定义方法,设置我们刚刚创建的getphone
设置好后可以发布小程序,在控制台查看打印信息
可惜个人账号不允许调用该接口,返回错误信息
如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。部分功能完成后,查看官方文档。如果有文件,直接跟着就可以了,这样可以节省很多时间。 查看全部
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
内容
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用微建低码快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解获取手机号的微信小程序的相关文档
我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序
添加按钮
在创建的应用首页添加按钮,更改标题获取手机号
选择微信开发能力获取手机号
创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器
单击页面上处理程序旁边的 + 号以创建自定义方法 getphone
我们不知道点击按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为
选择自定义方法,设置我们刚刚创建的getphone
设置好后可以发布小程序,在控制台查看打印信息
可惜个人账号不允许调用该接口,返回错误信息
如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。部分功能完成后,查看官方文档。如果有文件,直接跟着就可以了,这样可以节省很多时间。
网页手机号抓取程序(网站和app中的手机电话号码数据来源方式和抓取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-28 09:11
很多人好奇网站和app里面的手机号数据是怎么抓的,又是怎么实现的,这里就说一下。
一、数据来源
现在数据源有很多,我给大家介绍几种常见的数据源以及获取方式。
1、运营商数据,这样运营商就会有一个http报告,网站每个访客访问了哪些APP,用自己的4G流量,消费了多少流量都记录在里面。这样一来,游客的消费行为和近期的需求
力求有一个非常精确的把握。这类客户的精准开发无疑具有非常高的转化率。wap mobile网站获取访客信息系统,可以提高网站的转化率。是企业进行商务营销和招投标网络联盟的必备神器。您可以放心使用它。
2、爬虫爬取,url地址收录分页信息,这个表单最简单,这个表单用第三方工具爬取也很简单,基本不用写代码,对我来说,宁愿花我自己的钱 一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的。
网站获取访问者的手机号,比如你在浏览今日头条,我们可以通过你浏览到今日头条的手机号获取你的手机号,然后你就可以给手机发短信了数字。
获取网站访客用户手机号的值
1、时间:营销时间大大缩短
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、手机号App截取,以及联通电信移动运营商大数据等数据,有兴趣的请与我交流。
欢迎技术交流 查看全部
网页手机号抓取程序(网站和app中的手机电话号码数据来源方式和抓取方式)
很多人好奇网站和app里面的手机号数据是怎么抓的,又是怎么实现的,这里就说一下。
一、数据来源
现在数据源有很多,我给大家介绍几种常见的数据源以及获取方式。
1、运营商数据,这样运营商就会有一个http报告,网站每个访客访问了哪些APP,用自己的4G流量,消费了多少流量都记录在里面。这样一来,游客的消费行为和近期的需求
力求有一个非常精确的把握。这类客户的精准开发无疑具有非常高的转化率。wap mobile网站获取访客信息系统,可以提高网站的转化率。是企业进行商务营销和招投标网络联盟的必备神器。您可以放心使用它。
2、爬虫爬取,url地址收录分页信息,这个表单最简单,这个表单用第三方工具爬取也很简单,基本不用写代码,对我来说,宁愿花我自己的钱 一个花半天时间写代码,懒得学习第三方工具的人,还是靠自己写代码来实现的。
网站获取访问者的手机号,比如你在浏览今日头条,我们可以通过你浏览到今日头条的手机号获取你的手机号,然后你就可以给手机发短信了数字。
获取网站访客用户手机号的值
1、时间:营销时间大大缩短
2、投标:直接跳过投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营中:提供专属VIP后台账号,供客户查看和导出数据。然后主动给客户打电话,发短信,加微信手机网站访客手机号获取好友,大大增加业务咨询和采购量,让访客成为客户。的帮助。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、手机号App截取,以及联通电信移动运营商大数据等数据,有兴趣的请与我交流。
欢迎技术交流
网页手机号抓取程序(使用7个HTML文件文件来模拟互联网资源(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-27 13:18
)
爬虫又称网络爬虫或网络蜘蛛,主要用于从互联网或局域网下载各种资源。如html静态页面、图片文件、js代码等。网络爬虫的主要目的是为其他系统提供数据源,如搜索引擎(谷歌、百度等)、深度学习、数据分析、大数据, API 服务等。这些系统属于不同的领域,并且是异构的,因此通过一个网络爬虫为所有这些系统提供服务肯定是不可能的。因此,在学习网络爬虫之前,首先要了解网络爬虫的分类。如果按照爬取数据的范围来分类,网络爬虫可以分为以下几类。本文主要讲解第一种爬虫,全网爬虫的实现。由于整个互联网的数据太大,这里用一些网页来模拟整个互联网的页面来模拟爬取这些页面。这里使用了7个HTML文件来模拟互联网资源,将这7个HTML文件放在本地nginx服务器的虚拟目录中,以便爬取这7个HTML文件。整个网络爬虫至少要有一个入口点(通常是portal网站首页),然后爬虫会爬取这个入口点指向的页面,然后是所有链接中href属性的值将提取页面中的节点(节点)。这样会得到更多的Url,然后用同样的方法抓取这些Url指向的HTML页面,然后提取这些HTML页面中a节点的href属性值,然后继续,直到分析完所有 HTML 页面。直到最后。只要任何一个 HTML 页面都可以通过入口点到达,那么所有的 HTML 页面都可以通过这种方式进行爬取。这显然是一个递归过程,下面的伪代码就是用来描述这个递归过程的。从前面的描述可以看出,要实现一个全网爬虫,需要以下两个核心技术。假设下载资源是通过download(url)函数完成的,那么url就是要下载的资源的链接。下载函数返回网络资源的文本内容。analyze(html)函数用于分析网页资源,html是下载函数的返回值,即下载的HTML代码。分析函数返回一个列表类型的值,其中收录 HTML 页面中的所有 URL(节点的 href 属性的值)。如果 HTML 代码中没有节点,则分析函数返回一个空列表(长度为 0 的列表)。下面的drawler函数就是下载和分析HTML页面文件的函数。外部程序第一次调用爬虫函数时传入的URL就是入口点HTML页面的链接。
def crawler(url){ # 下载url指向的HTML页面html = download(url)# 分析HTML页面代码,并返回该代码中所有的URLurls = analyse(html)# 对URL列表进行迭代,对所有的URL递归调用crawler函数 for url in urls { crawler(url) }}# 外部程序第一次调用crawler函数,http://localhost/files/index.html就是入口点的URLcrawler('http://localhost/files/index.html ')
下图是这7个页面的关系图。你可以从index.html页面导航到任意一个html页面,所以只要你从index.html开始爬取,所有的html页面都会被爬取。
从上图可以看出,b.html、aa.html、bb.html和cc.html文件中没有节点,所以这四个HTML文件是递归终止条件。
下面是基于递归算法的爬虫代码。
注意:本文示例使用的是nginx服务器,所以本示例中所有的html页面都应该放在nginx虚拟目录的files子目录下。以便该页面可以被 .
抓取的效果如下图所示。
查看全部
网页手机号抓取程序(使用7个HTML文件文件来模拟互联网资源(图)
)
爬虫又称网络爬虫或网络蜘蛛,主要用于从互联网或局域网下载各种资源。如html静态页面、图片文件、js代码等。网络爬虫的主要目的是为其他系统提供数据源,如搜索引擎(谷歌、百度等)、深度学习、数据分析、大数据, API 服务等。这些系统属于不同的领域,并且是异构的,因此通过一个网络爬虫为所有这些系统提供服务肯定是不可能的。因此,在学习网络爬虫之前,首先要了解网络爬虫的分类。如果按照爬取数据的范围来分类,网络爬虫可以分为以下几类。本文主要讲解第一种爬虫,全网爬虫的实现。由于整个互联网的数据太大,这里用一些网页来模拟整个互联网的页面来模拟爬取这些页面。这里使用了7个HTML文件来模拟互联网资源,将这7个HTML文件放在本地nginx服务器的虚拟目录中,以便爬取这7个HTML文件。整个网络爬虫至少要有一个入口点(通常是portal网站首页),然后爬虫会爬取这个入口点指向的页面,然后是所有链接中href属性的值将提取页面中的节点(节点)。这样会得到更多的Url,然后用同样的方法抓取这些Url指向的HTML页面,然后提取这些HTML页面中a节点的href属性值,然后继续,直到分析完所有 HTML 页面。直到最后。只要任何一个 HTML 页面都可以通过入口点到达,那么所有的 HTML 页面都可以通过这种方式进行爬取。这显然是一个递归过程,下面的伪代码就是用来描述这个递归过程的。从前面的描述可以看出,要实现一个全网爬虫,需要以下两个核心技术。假设下载资源是通过download(url)函数完成的,那么url就是要下载的资源的链接。下载函数返回网络资源的文本内容。analyze(html)函数用于分析网页资源,html是下载函数的返回值,即下载的HTML代码。分析函数返回一个列表类型的值,其中收录 HTML 页面中的所有 URL(节点的 href 属性的值)。如果 HTML 代码中没有节点,则分析函数返回一个空列表(长度为 0 的列表)。下面的drawler函数就是下载和分析HTML页面文件的函数。外部程序第一次调用爬虫函数时传入的URL就是入口点HTML页面的链接。
def crawler(url){ # 下载url指向的HTML页面html = download(url)# 分析HTML页面代码,并返回该代码中所有的URLurls = analyse(html)# 对URL列表进行迭代,对所有的URL递归调用crawler函数 for url in urls { crawler(url) }}# 外部程序第一次调用crawler函数,http://localhost/files/index.html就是入口点的URLcrawler('http://localhost/files/index.html ')
下图是这7个页面的关系图。你可以从index.html页面导航到任意一个html页面,所以只要你从index.html开始爬取,所有的html页面都会被爬取。
从上图可以看出,b.html、aa.html、bb.html和cc.html文件中没有节点,所以这四个HTML文件是递归终止条件。
下面是基于递归算法的爬虫代码。
注意:本文示例使用的是nginx服务器,所以本示例中所有的html页面都应该放在nginx虚拟目录的files子目录下。以便该页面可以被 .
抓取的效果如下图所示。
网页手机号抓取程序(隐藏腾讯所有虚拟运营商网址的几个小技巧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-25 19:06
网页手机号抓取程序:微信公众号公众号,为你隐藏腾讯所有虚拟运营商网址。01酷安,直接输入腾讯的浏览器url即可。链接:【强力二维码生成器】【qq防盗链】【sdcardpath】,二维码分享到多个群,机器人可取消二维码中一堆的xx.二维码。直接分享给你的好友或者群。02百度搜:黑白间谍,把里面的二维码生成器的黑白间谍发给其他公众号,如:谈二网。机器人可以自动识别二维码并且生成。
去掉bot
airdrop
倒流设置参考server运营商的udp或者tcp协议其他看你网速了有这么高
网页出现二维码,如果是美帝某种技术,app或者微信公众号获取到后,会自动向运营商报断线,所以导致全国性瘫痪或者遭封杀;那么国内的本地有一种杀手锏技术,可以帮你绕过运营商的报断线,从而快速定位出二维码所在位置。
去搜用户都把地址发给你了
公众号登录,自动回复。
扫码获取微信公众号的小程序码或二维码。
二维码扫描了,手机号也随便刷,今天又没收到送礼,最后还得我自己去送礼,自己做傻x用户。说来也好笑,我最后那一天却不知道送了什么礼才感动,我们去ktv招待你们花了几百元,结果他们送的什么都没有,后来我才知道,他们送我们礼那天,那边经理不在,所以一切由他代办。后来我终于理解了那天经理的意思了,人民日报都发布的事情,应该没几个不知道的,但那天大家都只是很期待礼物,什么都没好说的。 查看全部
网页手机号抓取程序(隐藏腾讯所有虚拟运营商网址的几个小技巧!)
网页手机号抓取程序:微信公众号公众号,为你隐藏腾讯所有虚拟运营商网址。01酷安,直接输入腾讯的浏览器url即可。链接:【强力二维码生成器】【qq防盗链】【sdcardpath】,二维码分享到多个群,机器人可取消二维码中一堆的xx.二维码。直接分享给你的好友或者群。02百度搜:黑白间谍,把里面的二维码生成器的黑白间谍发给其他公众号,如:谈二网。机器人可以自动识别二维码并且生成。
去掉bot
airdrop
倒流设置参考server运营商的udp或者tcp协议其他看你网速了有这么高
网页出现二维码,如果是美帝某种技术,app或者微信公众号获取到后,会自动向运营商报断线,所以导致全国性瘫痪或者遭封杀;那么国内的本地有一种杀手锏技术,可以帮你绕过运营商的报断线,从而快速定位出二维码所在位置。
去搜用户都把地址发给你了
公众号登录,自动回复。
扫码获取微信公众号的小程序码或二维码。
二维码扫描了,手机号也随便刷,今天又没收到送礼,最后还得我自己去送礼,自己做傻x用户。说来也好笑,我最后那一天却不知道送了什么礼才感动,我们去ktv招待你们花了几百元,结果他们送的什么都没有,后来我才知道,他们送我们礼那天,那边经理不在,所以一切由他代办。后来我终于理解了那天经理的意思了,人民日报都发布的事情,应该没几个不知道的,但那天大家都只是很期待礼物,什么都没好说的。
网页手机号抓取程序(手机登录成功后实现过程跳转到编写的用户信息页面实现源码下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-24 19:21
登录成功后的实现流程
由于使用代码登录时必须使用公网url进行开发,所以先使用内网穿透工具将本地项目穿透到外网。
推荐使用:NATAPP——内网穿透:
查看教程以了解具体用法:
创建一个项目来写代码
使用的工具
实现登录的原理是使用ajax调用码登录获取登录二维码相关接口:(即我们创建应用时生成的secretKey),获取登录服务器提供的qrCodeReturnUrl在代码上。使用二维码生成工具生成二维码后台编写界面,信息为qrCodeReturnUrl,判断是否获取到用户信息。前端生成二维码后,进行ajax轮询,发送请求询问后端是否获取到用户信息。如果没有,则表示没有人扫描二维码并继续投票。如果获取到,则结束 Ajax 轮询。将二维码设置为过期不再使用。结束投票,
首页
window.location.href = "/login"
二维码
body {
background: #095f88;
}
/* 登录字体 */
.text {
color: cornsilk;
text-align: center;
margin-top: 50px;
opacity: 0.7;
}
/* 二维码 */
#output {
margin: 50px auto;
width: 360px;
padding: 0;
opacity: 0.8;
}
请使用微信进行扫码登录
$.ajax({
type: "get",
url: "https://server01.vicy.cn/8lXdS ... ot%3B,
data: "data",
async: false,
dataType: "json",
success: function (response) {
// console.log('response :>> ', response);
qrCodeReturnUrl = response.data.qrCodeReturnUrl;
}
});
console.log(qrCodeReturnUrl)
$('#output').qrcode({
text: qrCodeReturnUrl, // 二维码的内容
render: "canvas", // 设置渲染方式
width: 360, // 设置宽度: 默认256
height: 360, // 设置高度: 默认256
background: "#ffffff", // 背景颜色
foreground: "#000000", // 前景颜色
// src: "http://qkongtao.cn/wp-content/ ... ot%3B, //二维码中间的图片
});
//ajax的轮询
var timer1 = setInterval(checkScan, 1000);//每隔1s执行一次checkScan
var timer2 = null;
function checkScan() {
$.ajax({
type: 'get',
url: "/loginData",
// async: false,
success: function (data) {
console.log(data)
if (!$.isEmptyObject(data)) {//有用户扫描了该二维码,应停止对checkScanServlet的轮询
window.clearInterval(timer1);
console.log("拿到数据")
$('#msg').html(data.nickname + "已经扫描,请在客户端确认");//将二维码取消,防止其他人再扫
timer2 = setInterval(checkConfirm, 1000);//轮询用户是否确认登录
}
}
});
}
function checkConfirm() {
$.ajax({
type: 'get',
url: "/loginSuccess",
// async: false,
success: function () {
console.log("跳转********")
window.clearInterval(timer2);
window.location.href = "/loginSuccess"
}
});
}
登陆信息
您的登录信息
用户名:
openid:
头像图片:
登录ip地址:
后端实现
package cn.kt.wxlogin.domain;
/**
* @author tao
* @date 2021-03-06 23:18
* 概要:
*/
public class LoginResultVO {
Integer errcode;
String message;
public Integer getErrcode() {
return errcode;
}
public void setErrcode(Integer errcode) {
this.errcode = errcode;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
@Override
public String toString() {
return "LoginResultVO{" +
"errcode=" + errcode +
", message='" + message + '\'' +
'}';
}
}
package cn.kt.wxlogin.controller;
import cn.kt.wxlogin.domain.LoginResultVO;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @author tao
* @date 2021-03-06 23:09
* 概要:
*/
@Controller
public class WXLoginController {
/*扫码用户信息*/
private Map userMap = new HashMap();
/**
* @param response
* @param map
* @return 接收参数回调,是被回调的,第三方码上登录回调
*/
@RequestMapping("/loginService")
@ResponseBody
public LoginResultVO loginService(
HttpServletResponse response,
@RequestParam Map map) {
System.out.println(map);
userMap = map;
LoginResultVO loginResultVO = new LoginResultVO();
//System.out.println("我被调用了");
loginResultVO.setErrcode(0);
loginResultVO.setMessage("成功");
return loginResultVO;
}
/**
* @return 负责跳转登录
*/
@RequestMapping("/login")
public String login() {
return "qrcode";
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:24
* @param: :
* @return: 返回前端用户信息,判断二维码有没有被扫
*/
@RequestMapping("/loginData")
@ResponseBody
public Map loginData() {
return userMap;
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:30
* @return: map
* 登陆成功,进行跳转
*/
@RequestMapping("/loginSuccess")
public ModelAndView loginSuccess(HttpServletResponse response,
Map map,
HttpServletRequest request) {
HttpSession session = request.getSession();
/*如果session中user有值,则不需要重复*/
if (request.getSession().getAttribute("loginUser") == null) {
session.setAttribute("loginUser", userMap);
}
//清空用户数据
System.out.println(userMap);
userMap = null;
return new ModelAndView("userInfo");
}
}
源代码下载
关联:
提取码:a9lh
复制完这个内容后,打开百度网盘手机应用,操作起来更方便。
把毕业设计中用到的小技巧写进了博客笔记,整理了好久。如果觉得对大家有帮助,可以点赞、评论、关注。长得帅的可以多多打赏支持^_^
如有任何问题,请随时与我联系(评论很好!) 查看全部
网页手机号抓取程序(手机登录成功后实现过程跳转到编写的用户信息页面实现源码下载)
登录成功后的实现流程
由于使用代码登录时必须使用公网url进行开发,所以先使用内网穿透工具将本地项目穿透到外网。
推荐使用:NATAPP——内网穿透:
查看教程以了解具体用法:
创建一个项目来写代码
使用的工具
实现登录的原理是使用ajax调用码登录获取登录二维码相关接口:(即我们创建应用时生成的secretKey),获取登录服务器提供的qrCodeReturnUrl在代码上。使用二维码生成工具生成二维码后台编写界面,信息为qrCodeReturnUrl,判断是否获取到用户信息。前端生成二维码后,进行ajax轮询,发送请求询问后端是否获取到用户信息。如果没有,则表示没有人扫描二维码并继续投票。如果获取到,则结束 Ajax 轮询。将二维码设置为过期不再使用。结束投票,
首页
window.location.href = "/login"
二维码
body {
background: #095f88;
}
/* 登录字体 */
.text {
color: cornsilk;
text-align: center;
margin-top: 50px;
opacity: 0.7;
}
/* 二维码 */
#output {
margin: 50px auto;
width: 360px;
padding: 0;
opacity: 0.8;
}
请使用微信进行扫码登录
$.ajax({
type: "get",
url: "https://server01.vicy.cn/8lXdS ... ot%3B,
data: "data",
async: false,
dataType: "json",
success: function (response) {
// console.log('response :>> ', response);
qrCodeReturnUrl = response.data.qrCodeReturnUrl;
}
});
console.log(qrCodeReturnUrl)
$('#output').qrcode({
text: qrCodeReturnUrl, // 二维码的内容
render: "canvas", // 设置渲染方式
width: 360, // 设置宽度: 默认256
height: 360, // 设置高度: 默认256
background: "#ffffff", // 背景颜色
foreground: "#000000", // 前景颜色
// src: "http://qkongtao.cn/wp-content/ ... ot%3B, //二维码中间的图片
});
//ajax的轮询
var timer1 = setInterval(checkScan, 1000);//每隔1s执行一次checkScan
var timer2 = null;
function checkScan() {
$.ajax({
type: 'get',
url: "/loginData",
// async: false,
success: function (data) {
console.log(data)
if (!$.isEmptyObject(data)) {//有用户扫描了该二维码,应停止对checkScanServlet的轮询
window.clearInterval(timer1);
console.log("拿到数据")
$('#msg').html(data.nickname + "已经扫描,请在客户端确认");//将二维码取消,防止其他人再扫
timer2 = setInterval(checkConfirm, 1000);//轮询用户是否确认登录
}
}
});
}
function checkConfirm() {
$.ajax({
type: 'get',
url: "/loginSuccess",
// async: false,
success: function () {
console.log("跳转********")
window.clearInterval(timer2);
window.location.href = "/loginSuccess"
}
});
}
登陆信息
您的登录信息
用户名:
openid:
头像图片:
登录ip地址:
后端实现
package cn.kt.wxlogin.domain;
/**
* @author tao
* @date 2021-03-06 23:18
* 概要:
*/
public class LoginResultVO {
Integer errcode;
String message;
public Integer getErrcode() {
return errcode;
}
public void setErrcode(Integer errcode) {
this.errcode = errcode;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
@Override
public String toString() {
return "LoginResultVO{" +
"errcode=" + errcode +
", message='" + message + '\'' +
'}';
}
}
package cn.kt.wxlogin.controller;
import cn.kt.wxlogin.domain.LoginResultVO;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* @author tao
* @date 2021-03-06 23:09
* 概要:
*/
@Controller
public class WXLoginController {
/*扫码用户信息*/
private Map userMap = new HashMap();
/**
* @param response
* @param map
* @return 接收参数回调,是被回调的,第三方码上登录回调
*/
@RequestMapping("/loginService")
@ResponseBody
public LoginResultVO loginService(
HttpServletResponse response,
@RequestParam Map map) {
System.out.println(map);
userMap = map;
LoginResultVO loginResultVO = new LoginResultVO();
//System.out.println("我被调用了");
loginResultVO.setErrcode(0);
loginResultVO.setMessage("成功");
return loginResultVO;
}
/**
* @return 负责跳转登录
*/
@RequestMapping("/login")
public String login() {
return "qrcode";
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:24
* @param: :
* @return: 返回前端用户信息,判断二维码有没有被扫
*/
@RequestMapping("/loginData")
@ResponseBody
public Map loginData() {
return userMap;
}
/**
* @author :tao
* @date :Created in 2021-03-07 1:30
* @return: map
* 登陆成功,进行跳转
*/
@RequestMapping("/loginSuccess")
public ModelAndView loginSuccess(HttpServletResponse response,
Map map,
HttpServletRequest request) {
HttpSession session = request.getSession();
/*如果session中user有值,则不需要重复*/
if (request.getSession().getAttribute("loginUser") == null) {
session.setAttribute("loginUser", userMap);
}
//清空用户数据
System.out.println(userMap);
userMap = null;
return new ModelAndView("userInfo");
}
}
源代码下载
关联:
提取码:a9lh
复制完这个内容后,打开百度网盘手机应用,操作起来更方便。
把毕业设计中用到的小技巧写进了博客笔记,整理了好久。如果觉得对大家有帮助,可以点赞、评论、关注。长得帅的可以多多打赏支持^_^
如有任何问题,请随时与我联系(评论很好!)
网页手机号抓取程序(2021年7月21日-精准大数据访客手机号抓取原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-21 04:06
2021年7月21日-精准大数据访客手机号采集济南教育2020年12月8日-网站访客手机号采集软件,专门用于移动网站访客手机号采集的一套特价。 ..以百度竞价为例,90%以上的客户点击广告并访问网站,其中大部分阅读... 2019年8月30日-网站访问者手机号爬虫软件和爬虫软件,使用最新的手机号码抓取原理来抓取访客的手机。在网站中添加手机抢码,即可获取访客手机号qq... 电信手机号 获取运营商流量 获取运营商流量获取公司' s数据服务是专门针对网站手机访客获取竞价页面手机号抓取1、抓取访客手机号,获取二次营销机会,增加企业销量。网络营销现在非常困难,成本不断上涨。以百度竞价为例,90%以上的客户点击广告并访问了网站,大部分客户观看... 2019年9月16日-网站如何捕捉访问者的手机号码准确与否一直是一些企业主关心的问题。相比将网站介绍给网站,客户往往会因为各种原因匆匆一瞥就离开……[图]2020年8月28日-网站 手机号码采集软件/访客手机号码采集软件。对于我们的三网大数据获客系统,您只需要给我一些同行的网站,网站或者一个app,我们的三网大数据获客系统... 2020年10月5日 -这是一篇推送文章收录网站关于竞价访问者手机号的分类页面抓取标签,其中收录文章2021年9月16日-【免费测试】获取手机的内容竞标网站访问者电话-抢同行网站访问者电话网站评分:网站语言:简体中文分类:生活收录时间:站长无累计点击:61人... 查看全部
网页手机号抓取程序(2021年7月21日-精准大数据访客手机号抓取原理)
2021年7月21日-精准大数据访客手机号采集济南教育2020年12月8日-网站访客手机号采集软件,专门用于移动网站访客手机号采集的一套特价。 ..以百度竞价为例,90%以上的客户点击广告并访问网站,其中大部分阅读... 2019年8月30日-网站访问者手机号爬虫软件和爬虫软件,使用最新的手机号码抓取原理来抓取访客的手机。在网站中添加手机抢码,即可获取访客手机号qq... 电信手机号 获取运营商流量 获取运营商流量获取公司' s数据服务是专门针对网站手机访客获取竞价页面手机号抓取1、抓取访客手机号,获取二次营销机会,增加企业销量。网络营销现在非常困难,成本不断上涨。以百度竞价为例,90%以上的客户点击广告并访问了网站,大部分客户观看... 2019年9月16日-网站如何捕捉访问者的手机号码准确与否一直是一些企业主关心的问题。相比将网站介绍给网站,客户往往会因为各种原因匆匆一瞥就离开……[图]2020年8月28日-网站 手机号码采集软件/访客手机号码采集软件。对于我们的三网大数据获客系统,您只需要给我一些同行的网站,网站或者一个app,我们的三网大数据获客系统... 2020年10月5日 -这是一篇推送文章收录网站关于竞价访问者手机号的分类页面抓取标签,其中收录文章2021年9月16日-【免费测试】获取手机的内容竞标网站访问者电话-抢同行网站访问者电话网站评分:网站语言:简体中文分类:生活收录时间:站长无累计点击:61人...
网页手机号抓取程序(如何从每天有限的竞价流量中最大化的挖掘开发客户)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-20 11:03
百度在医疗行业的竞标竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度竞标,结果投标费用越来越高,流量相对减少;用户也越来越排斥电商的弹窗式用户体验,产生了对话成本、预约成本、住院成本等。越来越高,那么作为一个行业,我们是否也在思考如何从每天有限的竞价流量中,最大限度的开发自己的客户?
手机号采集系统,只要将系统提供的统计代码(类似于CNZZ的数据统计代码)添加到您所在医院的招标网站,就可以在后台我们为您提供查看您的出价网站访问者的手机号码。
2、手机号抓取系统是如何工作的?
访客手机号采集系统是与全国各地移动资源合作开发的,专为企业获取网站访客信息的系统。可以从访问者那里获取的信息包括:访问者的手机号码、访问的网站标题、来源关键词、所属地区等信息。
3、如何获取手机号进行营销?
Answer:通过电话营销获取的手机号码转换比Business Pass更容易。一般咨询技能可以转换,不能直接转换的转微信跟踪。电话客户应提前准备一套较好的电话技巧。 .
4、为什么要使用黄金手机号抓取系统?
一方面,BizCom的弹窗广告等用户越来越排斥,用户体验不好,导致竞价流量流失;手机号抓取系统可以帮你直接抓取用户的手机号,供顾问转换。
(支持免费试用)
二、金牌手机号码抓取系统的使用流程
1、看到这个文章后及时联系我们客服直接帮您申请金手机号抓拍系统后台账号、密码、申请统计码给你。
2、将客服专员发送给您的统计代码安装到您所有网站页面的页眉中。我们的统计代码是一个类似CNZZ数据统计的JS代码)将此代码安装到你的网站
里面
tag,安装在网页顶部,这样抓取成功率会高很多。
3、登录金牌手机号抓取系统(后台地址:问客服),输入用户名和密码,点击登录,即可看到金牌手机号后台捕获系统。
注意:
(1)如果您使用过我们的产品,在竞拍期间超过三个小时没有抓拍到用户的手机号,请及时联系技术帮您查看抓拍方案!
(2)请尽快做好转换工作。有的客户通过我们的产品每天都获得了上百个号码,平均每天可以增加10人以上。希望你成功了;
(3)如有其他使用和转换方面的问题,请及时联系客服。
三、其他相关问答
(支持免费试用)
1、在网站上安装你提供的代码安全吗?
回答:请放心,我们的代码仅用于访问用户的数据分析,已被众多行业客户使用。经权威安全机构测试,不含任何恶意代码。请放心使用。同时,我们的代码合同中也会明确规定您数据的安全性;一切都是为了您的数据安全。
(支持免费试用)
四、遗言
我们也是来自医疗网络营销。招标网站的用户流量是客户自己的。我们只为客户提供一个工具,方便客户的转化,并没有给客户带来流量的增加。他和百度竞价调价软件是一个性质的,所以我认为它只是一个工具软件,所以,价格不高,力争能够普及大众;
医疗网络营销一直走在网络营销的前沿。网络营销产品的步伐非常快。只要医院主管抓住这些新产品,一定能在短时间内帮助医院提高业绩;
您可能尝试过类似的产品,但您并不看好这种新方法,但确实很多医院通过我们的产品大大增加了预约人数。抓取用户手机号的技术是确实存在的。只要咨询师态度端正,能对待每天抢的手机号,相信你们医院的业绩也会有一定的提升 查看全部
网页手机号抓取程序(如何从每天有限的竞价流量中最大化的挖掘开发客户)
百度在医疗行业的竞标竞争越来越激烈。随着百度健康平台的出现,各种注册网站、健康网站、健康网站、医药网站,纷纷加入百度竞标,结果投标费用越来越高,流量相对减少;用户也越来越排斥电商的弹窗式用户体验,产生了对话成本、预约成本、住院成本等。越来越高,那么作为一个行业,我们是否也在思考如何从每天有限的竞价流量中,最大限度的开发自己的客户?
手机号采集系统,只要将系统提供的统计代码(类似于CNZZ的数据统计代码)添加到您所在医院的招标网站,就可以在后台我们为您提供查看您的出价网站访问者的手机号码。
2、手机号抓取系统是如何工作的?
访客手机号采集系统是与全国各地移动资源合作开发的,专为企业获取网站访客信息的系统。可以从访问者那里获取的信息包括:访问者的手机号码、访问的网站标题、来源关键词、所属地区等信息。
3、如何获取手机号进行营销?
Answer:通过电话营销获取的手机号码转换比Business Pass更容易。一般咨询技能可以转换,不能直接转换的转微信跟踪。电话客户应提前准备一套较好的电话技巧。 .
4、为什么要使用黄金手机号抓取系统?
一方面,BizCom的弹窗广告等用户越来越排斥,用户体验不好,导致竞价流量流失;手机号抓取系统可以帮你直接抓取用户的手机号,供顾问转换。
(支持免费试用)
二、金牌手机号码抓取系统的使用流程
1、看到这个文章后及时联系我们客服直接帮您申请金手机号抓拍系统后台账号、密码、申请统计码给你。
2、将客服专员发送给您的统计代码安装到您所有网站页面的页眉中。我们的统计代码是一个类似CNZZ数据统计的JS代码)将此代码安装到你的网站
里面
tag,安装在网页顶部,这样抓取成功率会高很多。
3、登录金牌手机号抓取系统(后台地址:问客服),输入用户名和密码,点击登录,即可看到金牌手机号后台捕获系统。
注意:
(1)如果您使用过我们的产品,在竞拍期间超过三个小时没有抓拍到用户的手机号,请及时联系技术帮您查看抓拍方案!
(2)请尽快做好转换工作。有的客户通过我们的产品每天都获得了上百个号码,平均每天可以增加10人以上。希望你成功了;
(3)如有其他使用和转换方面的问题,请及时联系客服。
三、其他相关问答
(支持免费试用)
1、在网站上安装你提供的代码安全吗?
回答:请放心,我们的代码仅用于访问用户的数据分析,已被众多行业客户使用。经权威安全机构测试,不含任何恶意代码。请放心使用。同时,我们的代码合同中也会明确规定您数据的安全性;一切都是为了您的数据安全。
(支持免费试用)
四、遗言
我们也是来自医疗网络营销。招标网站的用户流量是客户自己的。我们只为客户提供一个工具,方便客户的转化,并没有给客户带来流量的增加。他和百度竞价调价软件是一个性质的,所以我认为它只是一个工具软件,所以,价格不高,力争能够普及大众;
医疗网络营销一直走在网络营销的前沿。网络营销产品的步伐非常快。只要医院主管抓住这些新产品,一定能在短时间内帮助医院提高业绩;
您可能尝试过类似的产品,但您并不看好这种新方法,但确实很多医院通过我们的产品大大增加了预约人数。抓取用户手机号的技术是确实存在的。只要咨询师态度端正,能对待每天抢的手机号,相信你们医院的业绩也会有一定的提升
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-20 03:09
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
Ŀ¼
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用低码微建快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解微信小程序获取手机号的相关文档
我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序
添加按钮
在创建的应用首页添加按钮,更改标题获取手机号
选择微信开发能力获取手机号
创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器
单击页面上处理程序旁边的 + 号以创建自定义方法 getphone
我们不知道点击这个按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为
选择自定义方法,设置我们刚刚创建的getphone
设置好后可以发布小程序,在控制台查看打印信息
可惜个人账号不允许调用该接口,返回错误信息
如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。在做一些功能的时候,查看官方文档。如果有文档,可以直接关注,这样可以节省很多时间。 查看全部
网页手机号抓取程序(第四章用户登录及注册第五章权限设计生命周期函数及自定义方法)
第四章 用户登录与注册
第五章 权限设计
第6章生命周期函数和自定义方法介绍
第7章页面跳转
第 8 章 低代码操作数据库
第 9 章 低代码中的调试方法
第10章布局介绍
Ŀ¼
前言
我们会员小程序中最重要的采集信息是会员的手机号码。首先,手机号是唯一的,可以用来唯一标识会员。其次,在日常业务操作中,如会员充值、消费等,需要根据会员的手机号进行操作。
采集会员的手机号码是必要的要求。本文介绍如何使用低码微建快速采集会员手机号。我相信这将对您的业务非常有帮助。
实现想法
手机号码作为用户的敏感信息,不允许直接通过API调用,必须要求用户主动点击按钮发起授权。
用户触发后,会触发相应的事件,然后我们在事件对象中获取返回的手机号码。
要实现这个功能,首先需要了解微信小程序获取手机号的相关文档
我们需要几个步骤:
一、创建自定义应用
二、创建一个按钮
三、定义低代码方法
创建自定义应用程序
因为我们需要调用微信的接口,所以我们在创建应用的时候需要选择小程序
添加按钮
在创建的应用首页添加按钮,更改标题获取手机号
选择微信开发能力获取手机号
创建自定义方法
设置按钮属性后,我们要设置按钮的行为,我们创建一个自定义方法来响应。点击导航栏的菜单栏,点击低代码编辑器
单击页面上处理程序旁边的 + 号以创建自定义方法 getphone
我们不知道点击这个按钮后会返回什么信息。最好的方法是打印事件对象并输入以下代码
设置按钮行为
自定义方法创建完成后,需要将自定义方法绑定到按钮上,点击组件的行为
选择自定义方法,设置我们刚刚创建的getphone
设置好后可以发布小程序,在控制台查看打印信息
可惜个人账号不允许调用该接口,返回错误信息
如果是企业账号,可以在控制台查看是否有cloudID属性。如果该属性中有值,则调用成功。
如果能调用成功,后续操作可以参考官方文档中的这个教程。
总结
今天,我们就带大家来探索一下获取手机号的功能。在做一些功能的时候,查看官方文档。如果有文档,可以直接关注,这样可以节省很多时间。
网页手机号抓取程序(Android的SDKTelephonyManagertoaboutthetelephonyinthis)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-19 06:31
Android SDK 中有一个名为 TelephonyManager 的 API:
提供对设备上电话服务信息的访问。
应用程序可以使用此类中的方法来确定电话服务
和状态,以及访问某些类型的订阅者信息。
应用程序也可以注册一个监听器来接收电话通知
状态变化。
可以获取手机信息、通话状态、SIM卡信息等(我也找到了.getCellLocation()方法,这不是基站位置吗?哈哈),@刘悦在工程模式下说的机器信息可以通过这个API获取。
但是 .getLine1Number();可能无法获取用户的电话号码,因为此数据是手动设置的,可以更改。我的手机是联通的,联通没有写这个数据,我自己也没有设置。经测试,确实无法获取手机号。 查看全部
网页手机号抓取程序(Android的SDKTelephonyManagertoaboutthetelephonyinthis)
Android SDK 中有一个名为 TelephonyManager 的 API:
提供对设备上电话服务信息的访问。
应用程序可以使用此类中的方法来确定电话服务
和状态,以及访问某些类型的订阅者信息。
应用程序也可以注册一个监听器来接收电话通知
状态变化。
可以获取手机信息、通话状态、SIM卡信息等(我也找到了.getCellLocation()方法,这不是基站位置吗?哈哈),@刘悦在工程模式下说的机器信息可以通过这个API获取。
但是 .getLine1Number();可能无法获取用户的电话号码,因为此数据是手动设置的,可以更改。我的手机是联通的,联通没有写这个数据,我自己也没有设置。经测试,确实无法获取手机号。
网页手机号抓取程序(cocos2d-x之CCGUI设计与实现(3)循环列表框的实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-18 08:14
cocos2d-x的CCGUI设计与实现(3)实现循环列表框(数字选择器)_破楼兰-程序员ITS304
真的很抱歉,为了防止CSDN把我的颜色“固定”成灰色,我每个月都会提前标记几篇博客来补个号哈哈。不自恋,这篇文章讲的是循环列表框的实现。我们知道 cocos2d-x 扩展提供了 CCScrollView 的实现。这东西写的不错,大致模拟了系统的滑动效果,还有剪辑的效果。对于NumberPicker控件,我们首先需要实现一个列表框(ListBo
初学mysql(七)-database view_Sweet Baby, Sweet Baby-程序员ITS304
上一篇博客谈到了索引。在这篇博客中,我将谈谈我对 MySQL 数据库视图的学习。定义:它是一个数据内容由查询语句定义的表。表中的数据是SQL语句查询到的数据的结果集。行和列都来自 SQL 查询语句中使用的数据表。视图是虚拟表,从数据库中的一个或多个实体表派生的虚拟表;数据库只存储视图的定义,不存储视图中的数据,数据仍然存在于原表中;当使用视图查询数据时,数据库系统将从原创表中检索数据...
Linux/Ubuntu安装PDF阅读软件Okular、福昕阅读器(Foxit Reader)、Adobe Reader_huludan的专栏-程序员ITS304_okular
我在Ubuntu 14.04和Ubuntu 16.04上用过四种PDF阅读软件:系统自带的“文档查看器”:很多功能不可用,使用不方便. Adobe Reader:与Windows下的Adobe Reader相比,Linux版本界面丑陋,功能少。安装比较麻烦,使用起来也不太方便。丑陋的界面是关键。点我查看安装方法。Okular PDF阅读器:与系统自带的“文档查看器”相比,功能更多,操作简单
关于WSL的CentOS systemctl启动服务报错:Failed to get D-Bus connection: Operation not allowed_夏小良的博客-程序员ITS304
一定要看问题的根源,避免做无用的工作1.找到问题的根源1)什么是WSL,如何安装?2)启动ssh服务报这个错误3)好像是系统的bug2.尝试修复bug解决问题1)作者给出解决方法2)组织一下这个解决方案3.退出,去ubuntu!!!1.找到问题的根本原因1)什么是WSL,如何安装?百度百科说Windows Subsystem for Linux(简称WSL)是一个...
TestNG-详述preserve-order的作用以及测试用例的执行顺序-CrazyPig的技术博客-程序员ITS304_preserve-order testng
在TestNG xml配置文件中,```的配置中,有一个名为`preserve-order`的属性。一开始我以为这个属性可以用来控制测试用例(那些被**@Test**注解的)。执行顺序,我后来测试了一下,发现没有这个效果。后来在网上找了这个属性的作用,发现是用来控制所有``inside``的执行顺序的。
系列通用属性和方法
1.系列常用属性属性描述values获取数组索引获取索引名称valuesindex.name索引名称2.系列常用功能系列几乎可以使用所有的索引操作ndarray 或 dict 的功能,集成 ndarray 和 dict 函数的优点说... 查看全部
网页手机号抓取程序(cocos2d-x之CCGUI设计与实现(3)循环列表框的实现)
cocos2d-x的CCGUI设计与实现(3)实现循环列表框(数字选择器)_破楼兰-程序员ITS304
真的很抱歉,为了防止CSDN把我的颜色“固定”成灰色,我每个月都会提前标记几篇博客来补个号哈哈。不自恋,这篇文章讲的是循环列表框的实现。我们知道 cocos2d-x 扩展提供了 CCScrollView 的实现。这东西写的不错,大致模拟了系统的滑动效果,还有剪辑的效果。对于NumberPicker控件,我们首先需要实现一个列表框(ListBo
初学mysql(七)-database view_Sweet Baby, Sweet Baby-程序员ITS304
上一篇博客谈到了索引。在这篇博客中,我将谈谈我对 MySQL 数据库视图的学习。定义:它是一个数据内容由查询语句定义的表。表中的数据是SQL语句查询到的数据的结果集。行和列都来自 SQL 查询语句中使用的数据表。视图是虚拟表,从数据库中的一个或多个实体表派生的虚拟表;数据库只存储视图的定义,不存储视图中的数据,数据仍然存在于原表中;当使用视图查询数据时,数据库系统将从原创表中检索数据...
Linux/Ubuntu安装PDF阅读软件Okular、福昕阅读器(Foxit Reader)、Adobe Reader_huludan的专栏-程序员ITS304_okular
我在Ubuntu 14.04和Ubuntu 16.04上用过四种PDF阅读软件:系统自带的“文档查看器”:很多功能不可用,使用不方便. Adobe Reader:与Windows下的Adobe Reader相比,Linux版本界面丑陋,功能少。安装比较麻烦,使用起来也不太方便。丑陋的界面是关键。点我查看安装方法。Okular PDF阅读器:与系统自带的“文档查看器”相比,功能更多,操作简单
关于WSL的CentOS systemctl启动服务报错:Failed to get D-Bus connection: Operation not allowed_夏小良的博客-程序员ITS304
一定要看问题的根源,避免做无用的工作1.找到问题的根源1)什么是WSL,如何安装?2)启动ssh服务报这个错误3)好像是系统的bug2.尝试修复bug解决问题1)作者给出解决方法2)组织一下这个解决方案3.退出,去ubuntu!!!1.找到问题的根本原因1)什么是WSL,如何安装?百度百科说Windows Subsystem for Linux(简称WSL)是一个...
TestNG-详述preserve-order的作用以及测试用例的执行顺序-CrazyPig的技术博客-程序员ITS304_preserve-order testng
在TestNG xml配置文件中,```的配置中,有一个名为`preserve-order`的属性。一开始我以为这个属性可以用来控制测试用例(那些被**@Test**注解的)。执行顺序,我后来测试了一下,发现没有这个效果。后来在网上找了这个属性的作用,发现是用来控制所有``inside``的执行顺序的。
系列通用属性和方法
1.系列常用属性属性描述values获取数组索引获取索引名称valuesindex.name索引名称2.系列常用功能系列几乎可以使用所有的索引操作ndarray 或 dict 的功能,集成 ndarray 和 dict 函数的优点说...
网页手机号抓取程序(如何安装硒您需要满足两个要求才能使用的网站抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-17 17:06
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
pip install requests
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
chromedriver.exe
文档
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.indeed.com/")
amazon_search = driver.find_element_by_id("twotabsearchtextbox")
amazon_search.send_keys("Web scraping for python developers")
amazon_search.send_keys(Keys.RETURN)
driver.close()
使用 python 和 selenium,你可以像这个 网站 这样跨不同工作平台找到 python 开发人员的当前职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monster 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
pip install lxml
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,其中收录开发 Web 抓取工具时所需的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦
Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI 用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
pip install pyspider
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
pyspider
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,则使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。 查看全部
网页手机号抓取程序(如何安装硒您需要满足两个要求才能使用的网站抓取数据)
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
pip install requests
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
chromedriver.exe
文档
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.indeed.com/";)
amazon_search = driver.find_element_by_id("twotabsearchtextbox")
amazon_search.send_keys("Web scraping for python developers")
amazon_search.send_keys(Keys.RETURN)
driver.close()
使用 python 和 selenium,你可以像这个 网站 这样跨不同工作平台找到 python 开发人员的当前职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monster 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
pip install lxml
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,其中收录开发 Web 抓取工具时所需的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦
Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI 用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
pip install pyspider
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
pyspider
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,则使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。

