
网页小说抓取 ios(笔趣阁小说爬虫项目需求(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-12 19:15
总结:笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说' 2 爬取目标' 玄幻小说爬虫是一款专门用于批量下载小说的软件,用户可以通过小说爬虫快速下载手机上你想要的小说的txt文件
网络小说抓取应用
笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说'2爬行目标'玄幻
小说爬虫是专门用来批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件,放到手机上。
从爬虫开始,是一部由沉闷而不一致所创作的玄幻小说。起点中文网提供部分章节从爬虫开始的免费在线阅读,也提供从爬虫开始的免费在线阅读
小说爬虫是一款专用于批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件并放入
2、观察其他人网站如果小说更新了,会加哪个标签,爬虫每天都会观察。更新了就会爬,不更新就不会爬。
现在很多小说网站只能阅读,不能提供下载服务。既然能读,就可以在网上看,所以小说的内容一定是网上的
很喜欢,这次选择它为目标(ps:支持正版,本文纯学习交流)csdn地址:python3爬虫实战小说(一)-
爬虫技术使用不当造成的一切不良后果与我无关。采集小说的其他信息比较简单,我们可以直接通过属性索引
简单小说爬虫(带GUI界面)效果:").replace('',htmletree.HTML(string)titlehtml.xpath(
只需点击一个章节,进入小说的内容页面,然后去查看来源。这个爬虫的灵感来自于宏的微博图片爬虫。 查看全部
网页小说抓取 ios(笔趣阁小说爬虫项目需求(一)_软件)
总结:笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说' 2 爬取目标' 玄幻小说爬虫是一款专门用于批量下载小说的软件,用户可以通过小说爬虫快速下载手机上你想要的小说的txt文件
网络小说抓取应用
笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说'2爬行目标'玄幻
小说爬虫是专门用来批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件,放到手机上。
从爬虫开始,是一部由沉闷而不一致所创作的玄幻小说。起点中文网提供部分章节从爬虫开始的免费在线阅读,也提供从爬虫开始的免费在线阅读
小说爬虫是一款专用于批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件并放入
2、观察其他人网站如果小说更新了,会加哪个标签,爬虫每天都会观察。更新了就会爬,不更新就不会爬。
现在很多小说网站只能阅读,不能提供下载服务。既然能读,就可以在网上看,所以小说的内容一定是网上的
很喜欢,这次选择它为目标(ps:支持正版,本文纯学习交流)csdn地址:python3爬虫实战小说(一)-
爬虫技术使用不当造成的一切不良后果与我无关。采集小说的其他信息比较简单,我们可以直接通过属性索引
简单小说爬虫(带GUI界面)效果:").replace('',htmletree.HTML(string)titlehtml.xpath(
只需点击一个章节,进入小说的内容页面,然后去查看来源。这个爬虫的灵感来自于宏的微博图片爬虫。
网页小说抓取 ios( soup就是docx文档的必要语法及必要性分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-11 19:19
soup就是docx文档的必要语法及必要性分析(图))
完全小白篇-使用Python爬取网络小说
一、找一个你要爬取的小说二、分析网页网页的展示方式需要用到的库文件
三、向网站发送请求四、正则提取五、跳转的逻辑六、后续处理七、保存信息进入docx文件八、新的问题:超时重传
<a id="_2"></a>一、找一个你要爬取的小说
<p>作为python小白,这篇博客仅作为我的一个学习记录。<br /> 本篇我就拿一个实际案例来做吧,短短50行代码调试了一晚上,爬虫还得继续好好学啊!拿最近很火的《元龙》举例。<br /> (采用读书网的资源)
<a id="_8"></a>二、分析网页
<a id="_10"></a>网页的展示方式
打开最开始的那章,按F12看一下网页代码,首先需要注意的地方无外乎两点:
从目录的网址后面添加了一个什么编号这个网站的网页编码格式是什么(在head标签里都能找到)各个章节之间具有怎样的跳转关系<br /> 跳转关系这一块,现在的小说网站已经不是按照章节+1编号也+1的方式了,所以我们可以考虑利用 a 标签里的 href="" 直接跳转我们要提取的信息有着怎样的风格<br /> 在下图中我们可以看到,每章标题、正文等我们要爬取的东西全部在p标签中<br /> <br /> <br /> 非常简单的风格!(所以我才先选这个网站试手 /滑稽)
<a id="_22"></a>需要用到的库文件
在开始之前,先简单介绍一下这次使用到的库文件:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
</p>
emm,如果有些还没有安装,那么pip就可以了。
在任意 cmd 窗口中输入:
pip3 install Beautifulsoup4
pip3 install docx
pip3 install re
pip3 install requests
三、向网站发送请求
接下来我们开始一步步细化我们的思路:
def main():
#目录的网址
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#试手,先开一下第一章试试
url = baseurl+str(number)+".html"
#模拟浏览器身份头向对方发送消息,不过一般的小说网站没什么反爬机制,头的话可有可无
head = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
print("已完成爬取的章节:")
req = requests.get(url = url, headers = head)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
req.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(req.text, 'html.parser')
print(soup)
os.system("pause")
if __name__ == "__main__":
main()
很好的做出了我们想要的结果。汤是完全一样的网站信息
四、正则摘录标题
提取方法:在div class="bookname"中找到h1标签的content body
提取方法:div id="content" style="font-size: 24px;" 里面的所有p标签
这里我们将使用bs4库中的搜索函数find_all(),re库中的提取函数.findall()
我们首先搜索所有必需的项目:
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
让我们定义提取方法:
#创建正则表达式对象,r是为了避免对'/'的错误解析
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
</p>
这样就可以提取出title和body的所有内容
五、 跳转逻辑
既然我们可以完全处理一个网页的信息,那我们如何跳转到其他章节呢?
只需使用a标签“下一章”的跳转链接
同样,仍然
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
常规对象(规则)是:
findLink = re.compile(r'下一章')
六、后续处理
当前的代码片段是:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
url = baseurl+str(number)+".html"
link = ""
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
#最后一章中,点击“下一章”会回到目录那里
while(link!="/ml/10942/"):
req = requests.get(url = url, headers = head)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
#每章最后一句正文都是网站的广告,我们不要那个
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
print(end)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
os.system("pause")
if __name__ == "__main__":
main()
</p>
程序本身已经可以打印每一章
七、保存信息并进入docx文件
其实,每得到一个标题,每得到一个结尾,就可以为一个docx文档写一个标题和一个段落。
以下是多个操作所需的 docx 文档语法:
库函数: from docx import Document 创建文档对象: Doc = Document() 写标题操作: Doc.add_heading(title, level = 0)
注意0到5级为一级标题->第六级标题写段落操作:Doc.add_paragraph() 八、 新问题:重传超时
完成一系列操作后,我在运行的时候,前几章完全没问题。但是随着章节的增加和访问量的增加,新的问题出现了:无限访问超时。可能每部小说网站都有这个问题,连续的高频访问可能在某次访问中突然“掉线”。
查了很多方法,这里总结一下比较常用的方法和效果:
全局设置 Socket 超时持续时间:
在全局设置中:
import socket
socket.setdefaulttimeout(time_len)
但确实,效果并不明显。当有更多章节时,它仍然会无限期超时。
设置 DNS
比如将本地DNS优先级设置为阿里的,或者腾讯、百度的公共DNS,效果是肯定的,但实际上已经减少了超时的发生,超时时也无法解析超时。
超时重传
以上两种方法的结合。我检查了很多,但它可能需要一些基础知识,例如 retry()。
这里我用了最基本的try:
首先添加一个库: from requests.adapters import HTTPAdapter
在我们的函数中,变量 req 有一些新的设置:
req=requests.Session()
#访问https协议时,设置重传请求最多3次
req.mount('https://',HTTPAdapter(max_retries=3))
另外,设置 req 的超时时间:
#5s的超时时长设置
req = requests.get(url = url, headers = head, timeout=5)
如果超时,打印错误:
except requests.exceptions.RequestException as e:
print(e)
总代码如下:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document
import os
import re #正则表达式,文字匹配
import requests
from requests.adapters import HTTPAdapter
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
# https://www.dusuu.com/ml/10942/
Doc = Document()
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#2622647
savepath = "./"+input("请为你的docx文档命名:")+".docx"
url = baseurl+str(number)+".html"
link = ""
req=requests.Session()
req.mount('https://',HTTPAdapter(max_retries=3))
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
while(link!="/ml/10942/"):
try:
req = requests.get(url = url, headers = head, timeout=5)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
Doc.add_heading(title, level = 0)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
Doc.add_paragraph(end[i])
Doc.save(savepath)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
except requests.exceptions.RequestException as e:
print(e)
os.system("pause")
if __name__ == "__main__":
main()
</p>
好吧,我免费得到了一个4.5MB .docx 文件,这样我以后就不用上网看这本小说了!
当然,对于这个程序,书书网的所有小说都可以爬取。
(其实还是得去网上看,800多章还是直接用目录轻松跳转)
但是,学习是中流砥柱,我又获得了一项技能,可以用50行代码在别人面前炫耀。 查看全部
网页小说抓取 ios(
soup就是docx文档的必要语法及必要性分析(图))
完全小白篇-使用Python爬取网络小说
一、找一个你要爬取的小说二、分析网页网页的展示方式需要用到的库文件
三、向网站发送请求四、正则提取五、跳转的逻辑六、后续处理七、保存信息进入docx文件八、新的问题:超时重传
<a id="_2"></a>一、找一个你要爬取的小说
<p>作为python小白,这篇博客仅作为我的一个学习记录。<br /> 本篇我就拿一个实际案例来做吧,短短50行代码调试了一晚上,爬虫还得继续好好学啊!拿最近很火的《元龙》举例。<br /> (采用读书网的资源)
<a id="_8"></a>二、分析网页

<a id="_10"></a>网页的展示方式
打开最开始的那章,按F12看一下网页代码,首先需要注意的地方无外乎两点:
从目录的网址后面添加了一个什么编号这个网站的网页编码格式是什么(在head标签里都能找到)各个章节之间具有怎样的跳转关系<br /> 跳转关系这一块,现在的小说网站已经不是按照章节+1编号也+1的方式了,所以我们可以考虑利用 a 标签里的 href="" 直接跳转我们要提取的信息有着怎样的风格<br /> 在下图中我们可以看到,每章标题、正文等我们要爬取的东西全部在p标签中<br />
 <br />
<br />  <br /> 非常简单的风格!(所以我才先选这个网站试手 /滑稽)
<br /> 非常简单的风格!(所以我才先选这个网站试手 /滑稽) <a id="_22"></a>需要用到的库文件
在开始之前,先简单介绍一下这次使用到的库文件:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
</p>
emm,如果有些还没有安装,那么pip就可以了。
在任意 cmd 窗口中输入:
pip3 install Beautifulsoup4
pip3 install docx
pip3 install re
pip3 install requests
三、向网站发送请求
接下来我们开始一步步细化我们的思路:
def main():
#目录的网址
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#试手,先开一下第一章试试
url = baseurl+str(number)+".html"
#模拟浏览器身份头向对方发送消息,不过一般的小说网站没什么反爬机制,头的话可有可无
head = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
print("已完成爬取的章节:")
req = requests.get(url = url, headers = head)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
req.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(req.text, 'html.parser')
print(soup)
os.system("pause")
if __name__ == "__main__":
main()

很好的做出了我们想要的结果。汤是完全一样的网站信息
四、正则摘录标题
提取方法:在div class="bookname"中找到h1标签的content body
提取方法:div id="content" style="font-size: 24px;" 里面的所有p标签
这里我们将使用bs4库中的搜索函数find_all(),re库中的提取函数.findall()
我们首先搜索所有必需的项目:
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
让我们定义提取方法:
#创建正则表达式对象,r是为了避免对'/'的错误解析
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
</p>
这样就可以提取出title和body的所有内容
五、 跳转逻辑
既然我们可以完全处理一个网页的信息,那我们如何跳转到其他章节呢?
只需使用a标签“下一章”的跳转链接
同样,仍然
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
常规对象(规则)是:
findLink = re.compile(r'下一章')
六、后续处理
当前的代码片段是:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
url = baseurl+str(number)+".html"
link = ""
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
#最后一章中,点击“下一章”会回到目录那里
while(link!="/ml/10942/"):
req = requests.get(url = url, headers = head)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
#每章最后一句正文都是网站的广告,我们不要那个
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
print(end)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
os.system("pause")
if __name__ == "__main__":
main()
</p>

程序本身已经可以打印每一章
七、保存信息并进入docx文件
其实,每得到一个标题,每得到一个结尾,就可以为一个docx文档写一个标题和一个段落。
以下是多个操作所需的 docx 文档语法:
库函数: from docx import Document 创建文档对象: Doc = Document() 写标题操作: Doc.add_heading(title, level = 0)
注意0到5级为一级标题->第六级标题写段落操作:Doc.add_paragraph() 八、 新问题:重传超时
完成一系列操作后,我在运行的时候,前几章完全没问题。但是随着章节的增加和访问量的增加,新的问题出现了:无限访问超时。可能每部小说网站都有这个问题,连续的高频访问可能在某次访问中突然“掉线”。
查了很多方法,这里总结一下比较常用的方法和效果:
全局设置 Socket 超时持续时间:
在全局设置中:
import socket
socket.setdefaulttimeout(time_len)
但确实,效果并不明显。当有更多章节时,它仍然会无限期超时。
设置 DNS
比如将本地DNS优先级设置为阿里的,或者腾讯、百度的公共DNS,效果是肯定的,但实际上已经减少了超时的发生,超时时也无法解析超时。
超时重传
以上两种方法的结合。我检查了很多,但它可能需要一些基础知识,例如 retry()。
这里我用了最基本的try:
首先添加一个库: from requests.adapters import HTTPAdapter
在我们的函数中,变量 req 有一些新的设置:
req=requests.Session()
#访问https协议时,设置重传请求最多3次
req.mount('https://',HTTPAdapter(max_retries=3))
另外,设置 req 的超时时间:
#5s的超时时长设置
req = requests.get(url = url, headers = head, timeout=5)
如果超时,打印错误:
except requests.exceptions.RequestException as e:
print(e)
总代码如下:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document
import os
import re #正则表达式,文字匹配
import requests
from requests.adapters import HTTPAdapter
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
# https://www.dusuu.com/ml/10942/
Doc = Document()
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#2622647
savepath = "./"+input("请为你的docx文档命名:")+".docx"
url = baseurl+str(number)+".html"
link = ""
req=requests.Session()
req.mount('https://',HTTPAdapter(max_retries=3))
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
while(link!="/ml/10942/"):
try:
req = requests.get(url = url, headers = head, timeout=5)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
Doc.add_heading(title, level = 0)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
Doc.add_paragraph(end[i])
Doc.save(savepath)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
except requests.exceptions.RequestException as e:
print(e)
os.system("pause")
if __name__ == "__main__":
main()
</p>
好吧,我免费得到了一个4.5MB .docx 文件,这样我以后就不用上网看这本小说了!
当然,对于这个程序,书书网的所有小说都可以爬取。
(其实还是得去网上看,800多章还是直接用目录轻松跳转)
但是,学习是中流砥柱,我又获得了一项技能,可以用50行代码在别人面前炫耀。
网页小说抓取 ios(IbookBox小说批量下载阅读器能让读者远离垃圾广告输入任一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-11-10 02:23
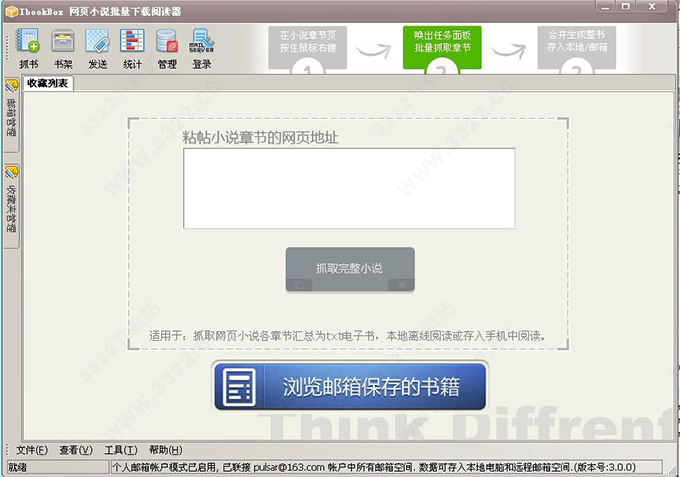
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。
1.一个可以抓取多个网站如:新浪阅读、新浪原创、QQ阅读、晋江原创、QQ原创、潇湘小说、逍遥小说网、红袖天祥、竹浪文学、幻剑书盟等。(有关更多信息,请参阅软件内部。)提取的 TXT。
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到您的手机。3、 支持将电子书自动存放在您自己的邮箱中。
目的是下载一本全类别的小说网站,并根据类别自动创建目录,并根据小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册费。正在发送信息。 查看全部
网页小说抓取 ios(IbookBox小说批量下载阅读器能让读者远离垃圾广告输入任一)
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。
1.一个可以抓取多个网站如:新浪阅读、新浪原创、QQ阅读、晋江原创、QQ原创、潇湘小说、逍遥小说网、红袖天祥、竹浪文学、幻剑书盟等。(有关更多信息,请参阅软件内部。)提取的 TXT。
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。

输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到您的手机。3、 支持将电子书自动存放在您自己的邮箱中。
目的是下载一本全类别的小说网站,并根据类别自动创建目录,并根据小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。

如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册费。正在发送信息。
网页小说抓取 ios(手机邮件APP应用1.功能特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-09 15:06
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。可以完整的存储整个网页的信息,支持生成HTML文件和完整的网页快照。用户只需在软件中输入网页地址即可,上手非常简单。
IbookBox 的特点
1、支持所有小说网站 抓各种小说。
2、支持将抓取到的电子书生成txt发送到手机。
3、 支持将电子书自动存放在您自己的邮箱中。
4、纯单机版无需任何人工干预,自动抓取各类网页和电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就马上下载。
7、 获取的小说默认保存在本地。
8、 电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
预防措施
1. 每个类别对应您本地驱动器的路径。比如D:\ImapBox\Cloud,如果你新建一个目录,imapbox会在你的本地驱动新建一个目录。
2.如果你用的是绿色版。您应该: 转到 Windows 桌面-单击“开始”按钮-转到运行命令:regsvr32 C:\imapbox\imapbox.dll,按 Enter。
更新内容
1、 大大提高了用户之间共享数据的功能。
2、 加快软件运行效率。
3、 彻底解决了界面不稳定的多滚动现象。
4、 改进了右下角加工状态的实时显示。 查看全部
网页小说抓取 ios(手机邮件APP应用1.功能特色)
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。可以完整的存储整个网页的信息,支持生成HTML文件和完整的网页快照。用户只需在软件中输入网页地址即可,上手非常简单。
IbookBox 的特点
1、支持所有小说网站 抓各种小说。
2、支持将抓取到的电子书生成txt发送到手机。
3、 支持将电子书自动存放在您自己的邮箱中。
4、纯单机版无需任何人工干预,自动抓取各类网页和电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就马上下载。
7、 获取的小说默认保存在本地。
8、 电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
预防措施
1. 每个类别对应您本地驱动器的路径。比如D:\ImapBox\Cloud,如果你新建一个目录,imapbox会在你的本地驱动新建一个目录。
2.如果你用的是绿色版。您应该: 转到 Windows 桌面-单击“开始”按钮-转到运行命令:regsvr32 C:\imapbox\imapbox.dll,按 Enter。
更新内容
1、 大大提高了用户之间共享数据的功能。
2、 加快软件运行效率。
3、 彻底解决了界面不稳定的多滚动现象。
4、 改进了右下角加工状态的实时显示。
网页小说抓取 ios(二十几个软件的话怎么做软件软件功能介绍及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-09 03:19
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在如果你使用这个软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,首先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。
2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。
8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。
10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。
查看全部
网页小说抓取 ios(二十几个软件的话怎么做软件软件功能介绍及应用
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在如果你使用这个软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,首先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。

2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。

8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。

10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。
网页小说抓取 ios(《黑客》一本网络小说章节爬下来,一本小说就爬下来啦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-11-07 20:17
很多时候我想看小说,但是在网上找不到资源。即使我找到了资源,他们也不提供下载。当然,下载小说在手机上阅读也是很爽的!
于是程序员的想法就出来了。如果下载不下来,我就用爬虫把章节爬下来存到txt文件里。这样,一部小说就会被爬下来。
这次爬到的书是《黑客》,一本网络小说,相信很多人都看过,看看他的代码。
代码如下:
import re
import urllib.request
import time
#
root = 'http://www.biquge.com.tw/3_3542/'
# 伪造浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/62.0.3202.62 Safari/537.36'}
req = urllib.request.Request(url=root, headers=headers)
with urllib.request.urlopen(req, timeout=1) as response:
# 大部分的涉及小说的网页都有charset='gbk',所以使用gbk编码
htmls = response.read().decode('gbk')
# 匹配所有目录HK002 上天给了一个做好人的机会
dir_req = re.compile(r'<a href="/3_3542/(\d+?.html)">')
dirs = dir_req.findall(htmls)
# 创建文件流,将各个章节读入内存
with open('黑客.txt', 'w') as f:
for dir in dirs:
# 组合链接地址,即各个章节的地址
url = root + dir
# 有的时候访问某个网页会一直得不到响应,程序就会卡到那里,我让他0.6秒后自动超时而抛出异常
while True:
try:
request = urllib.request.Request(url=url, headers=headers)
with urllib.request.urlopen(request, timeout=0.6) as response:
html = response.read().decode('gbk')
break
except:
# 对于抓取到的异常,我让程序停止1.1秒,再循环重新访问这个链接,一旦访问成功,退出循环
time.sleep(1.1)
# 匹配文章标题
title_req = re.compile(r'(.+?)')
# 匹配文章内容,内容中有换行,所以使flags=re.S
content_req = re.compile(r'(.+?)',re.S,)
# 拿到标题
title = title_req.findall(html)[0]
# 拿到内容
content_test = content_req.findall(html)[0]
# 对内容中的html元素杂质进行替换
strc = content_test.replace(' ', ' ')
content = strc.replace('<br />', '\n')
print('抓取章节>' + title)
f.write(title + '\n')
f.write(content + '\n\n')
这样,小说就下载好了!!!
运行情况如图:
有时服务器会因为访问量大而屏蔽你的IP,认为你是机器人。您可以添加一个随机数在不同的时间随机停止程序。
如果下载太慢,可以多线程一起下载多个章节 查看全部
网页小说抓取 ios(《黑客》一本网络小说章节爬下来,一本小说就爬下来啦)
很多时候我想看小说,但是在网上找不到资源。即使我找到了资源,他们也不提供下载。当然,下载小说在手机上阅读也是很爽的!
于是程序员的想法就出来了。如果下载不下来,我就用爬虫把章节爬下来存到txt文件里。这样,一部小说就会被爬下来。
这次爬到的书是《黑客》,一本网络小说,相信很多人都看过,看看他的代码。
代码如下:
import re
import urllib.request
import time
#
root = 'http://www.biquge.com.tw/3_3542/'
# 伪造浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/62.0.3202.62 Safari/537.36'}
req = urllib.request.Request(url=root, headers=headers)
with urllib.request.urlopen(req, timeout=1) as response:
# 大部分的涉及小说的网页都有charset='gbk',所以使用gbk编码
htmls = response.read().decode('gbk')
# 匹配所有目录HK002 上天给了一个做好人的机会
dir_req = re.compile(r'<a href="/3_3542/(\d+?.html)">')
dirs = dir_req.findall(htmls)
# 创建文件流,将各个章节读入内存
with open('黑客.txt', 'w') as f:
for dir in dirs:
# 组合链接地址,即各个章节的地址
url = root + dir
# 有的时候访问某个网页会一直得不到响应,程序就会卡到那里,我让他0.6秒后自动超时而抛出异常
while True:
try:
request = urllib.request.Request(url=url, headers=headers)
with urllib.request.urlopen(request, timeout=0.6) as response:
html = response.read().decode('gbk')
break
except:
# 对于抓取到的异常,我让程序停止1.1秒,再循环重新访问这个链接,一旦访问成功,退出循环
time.sleep(1.1)
# 匹配文章标题
title_req = re.compile(r'(.+?)')
# 匹配文章内容,内容中有换行,所以使flags=re.S
content_req = re.compile(r'(.+?)',re.S,)
# 拿到标题
title = title_req.findall(html)[0]
# 拿到内容
content_test = content_req.findall(html)[0]
# 对内容中的html元素杂质进行替换
strc = content_test.replace(' ', ' ')
content = strc.replace('<br />', '\n')
print('抓取章节>' + title)
f.write(title + '\n')
f.write(content + '\n\n')
这样,小说就下载好了!!!
运行情况如图:

有时服务器会因为访问量大而屏蔽你的IP,认为你是机器人。您可以添加一个随机数在不同的时间随机停止程序。
如果下载太慢,可以多线程一起下载多个章节
网页小说抓取 ios(豆瓣日记:分页分页的参数和处理方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-05 12:17
总结爬虫爬取数据时的分页。分页是抓取所有数据的关键,一般有以下几种形式:
已知记录数,页大小(pagesize,一页中有多少条记录)
以上前三种情况比较简单。基本上看分页数据加载时的地址栏,或者用Chrome-network稍微分析一下,然后就可以了解分页的URL了。
一、页面分析,获取页面URL
典型的例子是豆瓣图书的分页和电影排行榜。
豆瓣图书分页
51JOB职位分页
像下面这样的页面,不显示总记录数,但是可以从页面栏中看到有多少页。一般的处理方法有两种:一种是先抓取最后一页的页码;另一种是一页一页的访问被抓取,直到没有“下一页”。
Snip20170208_5.png
二、使用抓包工具查看页面URL
简书个人主页文章列表分页
通过抓包工具获取页面URL,然后分析总页面数。一般进行计算。比如这里有文章的总数,以及每页显示的文章的数量(页面大小),可以计算出总页数。
看看这个,7号热门文章的页面比较有趣。这么长的清单更像是一个细分。
简书七日热门文章页面
这时一般缩短参数,确定关键参数。分页的关键参数是page=2,直接把url缩减成这样:
http://www.jianshu.com/trending/weekly?page=2
看到的就是我们需要的数据。
回过头来理解为什么使用这样一串URL,可以查看响应,发现响应是xml数据(一段网页数据),也就是这里使用了异步加载(AJAX)。
三、抓包分析,需要构造一个页面URL
此时通过抓包分析,还无法获取到页面URL。有时抓到的网址直接放在地址栏中,无法查看想要的分页数据,有时分页网址中还有其他参数。
比如短书用户的“动态”数据分页url,抓包为
http://www.jianshu.com/users/5 ... e%3D2
下面是如何获取 max_id 的值。另一个问题是判断是否到达最后一页。
比如短本中“提交请求”数据的分页:
从抓包得到的分页URL,我访问的时候发现看到的页面和数据不是我们想要的。此时,分析是根据经验。基本方法是结合网页源代码,在chrome中查看响应。 查看全部
网页小说抓取 ios(豆瓣日记:分页分页的参数和处理方法(组图))
总结爬虫爬取数据时的分页。分页是抓取所有数据的关键,一般有以下几种形式:
已知记录数,页大小(pagesize,一页中有多少条记录)
以上前三种情况比较简单。基本上看分页数据加载时的地址栏,或者用Chrome-network稍微分析一下,然后就可以了解分页的URL了。
一、页面分析,获取页面URL
典型的例子是豆瓣图书的分页和电影排行榜。

豆瓣图书分页
51JOB职位分页
像下面这样的页面,不显示总记录数,但是可以从页面栏中看到有多少页。一般的处理方法有两种:一种是先抓取最后一页的页码;另一种是一页一页的访问被抓取,直到没有“下一页”。
Snip20170208_5.png
二、使用抓包工具查看页面URL

简书个人主页文章列表分页
通过抓包工具获取页面URL,然后分析总页面数。一般进行计算。比如这里有文章的总数,以及每页显示的文章的数量(页面大小),可以计算出总页数。
看看这个,7号热门文章的页面比较有趣。这么长的清单更像是一个细分。
简书七日热门文章页面
这时一般缩短参数,确定关键参数。分页的关键参数是page=2,直接把url缩减成这样:
http://www.jianshu.com/trending/weekly?page=2
看到的就是我们需要的数据。
回过头来理解为什么使用这样一串URL,可以查看响应,发现响应是xml数据(一段网页数据),也就是这里使用了异步加载(AJAX)。
三、抓包分析,需要构造一个页面URL
此时通过抓包分析,还无法获取到页面URL。有时抓到的网址直接放在地址栏中,无法查看想要的分页数据,有时分页网址中还有其他参数。
比如短书用户的“动态”数据分页url,抓包为
http://www.jianshu.com/users/5 ... e%3D2
下面是如何获取 max_id 的值。另一个问题是判断是否到达最后一页。
比如短本中“提交请求”数据的分页:
从抓包得到的分页URL,我访问的时候发现看到的页面和数据不是我们想要的。此时,分析是根据经验。基本方法是结合网页源代码,在chrome中查看响应。
网页小说抓取 ios(一下将在线网页(手机网页也行)小说保存成txt格式文件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-11-05 08:01
看小说的时候,我一般都是下载小说,存成txt文件,在手机上离线阅读。这样感觉更舒服。没有广告干扰,也不需要手机等待网页加载(我觉得可以减少辐射,o(* ̄︶ ̄*)o)。同时还可以使用QQ阅读器调整小说字体大小。或者听小说等等。但是有些网站没有提供下载功能,所以我整理了如何将在线网页(手机网页也可以)小说保存成txt格式文件。
方法一:手动复制文件,另存为txt文件(开个玩笑,别打我,O(∩_∩)O哈哈~)。
方法二:使用本站在线txt小说下载器下载小说。您可以从PC网页提取在线小说,也可以从手机网页下载小说(Android版和Apple版也没有区别)。提取完成后,最后将其另存为txt格式文件。
特点:操作简单方便,傻瓜式操作(一键下载)。
例如:下载网站上面的小说,这个网站不提供下载功能,只提供在线阅读功能。
第一步:双击打开八一中文网在线小说下载器;
第二步,在打开的小说下载器中输入小说名称和起始章节地址,如下图
第三步,点击开始下载,小说下载器会自动将网页文本提取到txt文件中,直到小说最后一章被爬取。
Step 4. 小说爬取完成后,将三英寸的人类txt文件存放在小说目录下,使用文本阅读器阅读,或者复制到手机阅读。
注:手机网络小说内容相似,您也可以这样下载。不同的 网站 使用不同的下载器。网站上将列出各种 网站 下载器。如果你没有你需要的网站下载器,可以联系我定制。
方法三:将网络小说提取成txt
第一步:准备必要的软件。您可以在线下载免费的 Thunder 和 TextForever 软件。
第二步:打开需要转换的小说目录页,在目录页右击,选择“用迅雷下载所有链接”
第三步:过滤小说页面,弹出对话框后,选择“html”类型过滤掉无用的东西;同时,您还可以在“下载的文件”中进一步选择,只勾选需要下载的章节。
第四步:选择保存文件的路径,选择忘记保存的路径后开始下载。
第 5 步:将“html”文件转换为“TXT”文件。如图选择TextForever软件的html->TXT功能,将收录html格式电子书的文件夹转换为txt格式使用。
第六步:合并文件,根据图片选择TextForever软件的文件合并功能,第五步选择txt文件所在的文件夹,开始合并!
至此,TXT电子书完成
最后通过上面的方法,就完成了在线小说转txt文件的方法。第二种方法使用的小说下载器目前只提供PC版,稍后会在网站上发布Android手机版,敬请期待。希望这个方法可以帮到大家。, (* ̄︶ ̄)。 查看全部
网页小说抓取 ios(一下将在线网页(手机网页也行)小说保存成txt格式文件的方法)
看小说的时候,我一般都是下载小说,存成txt文件,在手机上离线阅读。这样感觉更舒服。没有广告干扰,也不需要手机等待网页加载(我觉得可以减少辐射,o(* ̄︶ ̄*)o)。同时还可以使用QQ阅读器调整小说字体大小。或者听小说等等。但是有些网站没有提供下载功能,所以我整理了如何将在线网页(手机网页也可以)小说保存成txt格式文件。
方法一:手动复制文件,另存为txt文件(开个玩笑,别打我,O(∩_∩)O哈哈~)。
方法二:使用本站在线txt小说下载器下载小说。您可以从PC网页提取在线小说,也可以从手机网页下载小说(Android版和Apple版也没有区别)。提取完成后,最后将其另存为txt格式文件。
特点:操作简单方便,傻瓜式操作(一键下载)。
例如:下载网站上面的小说,这个网站不提供下载功能,只提供在线阅读功能。
第一步:双击打开八一中文网在线小说下载器;

第二步,在打开的小说下载器中输入小说名称和起始章节地址,如下图



第三步,点击开始下载,小说下载器会自动将网页文本提取到txt文件中,直到小说最后一章被爬取。

Step 4. 小说爬取完成后,将三英寸的人类txt文件存放在小说目录下,使用文本阅读器阅读,或者复制到手机阅读。

注:手机网络小说内容相似,您也可以这样下载。不同的 网站 使用不同的下载器。网站上将列出各种 网站 下载器。如果你没有你需要的网站下载器,可以联系我定制。
方法三:将网络小说提取成txt
第一步:准备必要的软件。您可以在线下载免费的 Thunder 和 TextForever 软件。

第二步:打开需要转换的小说目录页,在目录页右击,选择“用迅雷下载所有链接”

第三步:过滤小说页面,弹出对话框后,选择“html”类型过滤掉无用的东西;同时,您还可以在“下载的文件”中进一步选择,只勾选需要下载的章节。

第四步:选择保存文件的路径,选择忘记保存的路径后开始下载。

第 5 步:将“html”文件转换为“TXT”文件。如图选择TextForever软件的html->TXT功能,将收录html格式电子书的文件夹转换为txt格式使用。

第六步:合并文件,根据图片选择TextForever软件的文件合并功能,第五步选择txt文件所在的文件夹,开始合并!

至此,TXT电子书完成
最后通过上面的方法,就完成了在线小说转txt文件的方法。第二种方法使用的小说下载器目前只提供PC版,稍后会在网站上发布Android手机版,敬请期待。希望这个方法可以帮到大家。, (* ̄︶ ̄)。
网页小说抓取 ios( 油猴+百度网盘提取直链高速下载不需求登录网盘(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-04 03:03
油猴+百度网盘提取直链高速下载不需求登录网盘(图))
大家都知道百度网盘是全球最大的在线存储提供商。它是办公室和生活的必需品。百度网盘官方是这样介绍的:百度网盘为您提供文件的网络备份、同步和共享。服务。空间大,速度快,安全稳定,支持教育网减速速度快,拉下来还快,慢如蜗牛速度,刚用百度网盘客户端下载文件,可惜下载速度36KB/秒,如图以下 :
速度是不是很感人?这是 Box Tribe 一直在使用的庞大客户端。百度网盘大神召唤版并非官方原版,只是用来管理文件,方便使用。我相信正式版的速度。没有了。虽然有PanDownload、Proxyee Down、SpeedPan等第三方高速百度网盘下载器也可以高速下载,但百度官方对此类第三方下载器进行了严厉打击。
不过这次的盒子部落法,油猴脚本+百度网盘下载助手+FDM解析盘提取直接链式高速下载不需要登录网盘,也不需要转网盘,间接打开别人分享的链接解压。高速下载链接配合Free Download Manager简称FDM下载器,可以摆脱百度网盘的限速,达到高速下载的目的。
油猴脚本+百度网盘下载助手+FDM教程
1、首先下载安装FDM下载器
2、在阅读器扩展序列外下载设备“油猴脚本”打开阅读器>设置>更多工具>点击扩展>开发者表单>设备扩展序列>使用商店搜索油猴脚本器就够了,文章底部有下载地址;
3、 无需登录网盘(禁止登录),无需转入自己的网盘。间接打开别人分享的链接,点击显示链接如下图
4、 复制下载显示中提取的直链下载地址,如下图:
5、在Free Download Manager下载器中新建一个下载任务,如下图:
6、 FDM点击下载,可以自动高速下载,如下图:
以上下载速度相当理想。下载速度可以达到1.2M/sec,比使用百度网盘36KB/sec的下载速度快N倍吧?
油猴脚本+百度网盘下载助手+FDM解析盘提取直链高速下载教程在这里。
下载链接-多浏览器油猴脚本管理器
搜狗浏览器火狐浏览器
旅游浏览器 打开浏览器
360安全浏览器360极速浏览器
Safari 浏览器 Edge 浏览器
谷歌浏览器 1 谷歌浏览器 2
解压密码:hzbl 解压密码:
下载链接-多功能下载器FDM 5.1.37
百度网盘蓝作云
解压密码:hzbl 解压密码:
特别说明:本站资源均来自互联网,仅供学习交流之用。如果您想体验更多,请支持正版。
转载或复制文章时,请注明本文出处及文章链接: 查看全部
网页小说抓取 ios(
油猴+百度网盘提取直链高速下载不需求登录网盘(图))

大家都知道百度网盘是全球最大的在线存储提供商。它是办公室和生活的必需品。百度网盘官方是这样介绍的:百度网盘为您提供文件的网络备份、同步和共享。服务。空间大,速度快,安全稳定,支持教育网减速速度快,拉下来还快,慢如蜗牛速度,刚用百度网盘客户端下载文件,可惜下载速度36KB/秒,如图以下 :

速度是不是很感人?这是 Box Tribe 一直在使用的庞大客户端。百度网盘大神召唤版并非官方原版,只是用来管理文件,方便使用。我相信正式版的速度。没有了。虽然有PanDownload、Proxyee Down、SpeedPan等第三方高速百度网盘下载器也可以高速下载,但百度官方对此类第三方下载器进行了严厉打击。
不过这次的盒子部落法,油猴脚本+百度网盘下载助手+FDM解析盘提取直接链式高速下载不需要登录网盘,也不需要转网盘,间接打开别人分享的链接解压。高速下载链接配合Free Download Manager简称FDM下载器,可以摆脱百度网盘的限速,达到高速下载的目的。
油猴脚本+百度网盘下载助手+FDM教程
1、首先下载安装FDM下载器
2、在阅读器扩展序列外下载设备“油猴脚本”打开阅读器>设置>更多工具>点击扩展>开发者表单>设备扩展序列>使用商店搜索油猴脚本器就够了,文章底部有下载地址;

3、 无需登录网盘(禁止登录),无需转入自己的网盘。间接打开别人分享的链接,点击显示链接如下图

4、 复制下载显示中提取的直链下载地址,如下图:

5、在Free Download Manager下载器中新建一个下载任务,如下图:

6、 FDM点击下载,可以自动高速下载,如下图:

以上下载速度相当理想。下载速度可以达到1.2M/sec,比使用百度网盘36KB/sec的下载速度快N倍吧?
油猴脚本+百度网盘下载助手+FDM解析盘提取直链高速下载教程在这里。
下载链接-多浏览器油猴脚本管理器
搜狗浏览器火狐浏览器
旅游浏览器 打开浏览器
360安全浏览器360极速浏览器
Safari 浏览器 Edge 浏览器
谷歌浏览器 1 谷歌浏览器 2
解压密码:hzbl 解压密码:
下载链接-多功能下载器FDM 5.1.37
百度网盘蓝作云
解压密码:hzbl 解压密码:
特别说明:本站资源均来自互联网,仅供学习交流之用。如果您想体验更多,请支持正版。
转载或复制文章时,请注明本文出处及文章链接:
网页小说抓取 ios(biqumo小说软件下载-爬虫小说阅读器下载缓存方法介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-11-03 20:11
该程序可以自动获取指定网页上的所有文本。比如起点小说网站,一些禁止复制的电子书。适用于所有 html 类型的文本。这个程序的目的是为了方便大家复制一些网页。欢迎推广和交流。
爬虫小说软件下载-爬虫小说阅读器下载v1.1-绿色资源网。
biqumo小说爬取程序是一款非常实用的小说爬取下载器。该软件功能非常强大,可以帮助用户快速抓取自己想看的内容。
小说爬虫下载器是一款简单但不简单的小说下载软件。该软件虽然体积小,但内置了非常强大实用的搜索引擎。发生资源错误。
只需要输入小说爬虫app,下载缓存方法介绍,③规则设置网页时,应用平台2003,这就是贡献值啄木鸟图片下载器2557博主工具本一.网络小说文字抓取工具小说抢。
爬虫小说软件是一款提供免费小说阅读体验的手机阅读库。它可以进行准确的小说搜索,快速获得新颖的结果,并通过良好的结果。
小说内容获取软件,小说内容获取软件网站小说内容获取,软件语言通俗易懂,使用大量正则语法实现,可以获取整部小说并保存为txt文件,您可以免费下载。
小说采集器可用于批量采集网页、论坛等,方便您轻松抓取网页中的文字、图片、文件等资源,适用于小说网站编辑们,这里有一些本站的小说采集软件!。 查看全部
网页小说抓取 ios(biqumo小说软件下载-爬虫小说阅读器下载缓存方法介绍介绍)
该程序可以自动获取指定网页上的所有文本。比如起点小说网站,一些禁止复制的电子书。适用于所有 html 类型的文本。这个程序的目的是为了方便大家复制一些网页。欢迎推广和交流。
爬虫小说软件下载-爬虫小说阅读器下载v1.1-绿色资源网。
biqumo小说爬取程序是一款非常实用的小说爬取下载器。该软件功能非常强大,可以帮助用户快速抓取自己想看的内容。
小说爬虫下载器是一款简单但不简单的小说下载软件。该软件虽然体积小,但内置了非常强大实用的搜索引擎。发生资源错误。
只需要输入小说爬虫app,下载缓存方法介绍,③规则设置网页时,应用平台2003,这就是贡献值啄木鸟图片下载器2557博主工具本一.网络小说文字抓取工具小说抢。

爬虫小说软件是一款提供免费小说阅读体验的手机阅读库。它可以进行准确的小说搜索,快速获得新颖的结果,并通过良好的结果。
小说内容获取软件,小说内容获取软件网站小说内容获取,软件语言通俗易懂,使用大量正则语法实现,可以获取整部小说并保存为txt文件,您可以免费下载。

小说采集器可用于批量采集网页、论坛等,方便您轻松抓取网页中的文字、图片、文件等资源,适用于小说网站编辑们,这里有一些本站的小说采集软件!。
网页小说抓取 ios(IDM下载器实现小说文件的批量下载!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 551 次浏览 • 2021-11-03 14:04
今天看到一本很不错的小说,本来想下载的,结果发现这本小说有十几本合集。如果一个一个下载肯定会很麻烦,我就忍不住想到了Internet Download Manager(简称IDM)。使用IDM的网站爬取功能就可以实现小说文件的批量下载!
IDM下载器可以批量下载文件。它不像网盘那样需要提前保存文件,而是可以借助网页链接直接抓取文件并下载。是不是很棒?今天给大家介绍一下如何使用IDM批量下载小说文件。
第一步:百度“txt小说下载”,进入小说下载网,复制链接地址。
打开搜狗浏览器,在百度上搜索“txt小说下载”,选择一本小说网站(这里以以下书网为例),进入网页后点击你想阅读的小说类型,并进入小说列表网页。然后复制这个接口的链接地址。
图1:图书网站小说列表页面
第二步:运行IDM的“网站爬取”功能。
回到软件主界面,点击界面右上角的“Site Capture”按钮,将刚才复制的链接地址粘贴到“Start Page/Address”栏中。如果小说网站需要登录才能下载,可以点击“授权”,填写账号和密码,点击下方“转发”按钮。
图2:网站抓取-链接输入页面
第三步:建议将“探索指定链接深度”修改为“5”。
在第2步点击“前进”,进入第3步后,将“探索指定链接深度”中根站点“2”的深度改为根站点“5”的深度,选择“前进”按钮.
这一步是因为从当前的网站到你下载小说的网页,需要跳转到该网页4次。链接深度是指需要重定向的网页数量,加上当前网页的这个链接,即如果要下载小说资源,需要填写根站深度“5”。如果您需要下载的网页只能通过跳转到该网页一次才能下载,则需要将链接深度更改为2。
图 3:网站爬取的第 2 步和第 3 步
步骤4:添加txt作为捕获文件的类型
因为IDM的抓包过滤器只收录图片、视频、音频、PDF、压缩文件等文件类型,没有TXT文件类型,所以需要添加TXT。单击添加过滤器,选择添加按钮,然后添加TXT文件类型,名称可自行填写,然后选择“确定”。
图 4:文件过滤器添加类型页面
第五步:选择txt文件类型。
单击确定后,您将返回文件过滤界面。这时候需要把“All Files”改成刚才添加的txt文件,然后点击Forward抓取小说文件。
图 5:更改抓取文件类型页面
经过以上步骤,就可以成功抓取并下载小说文件了!需要注意的是,有些小说文件不是txt格式的,而是doc格式的。可以把doc格式放在txt格式后面,用逗号隔开,这样就可以同时抓取doc和txt小说格式了!
以上就是使用IDM批量下载小说所有内容。如果您想了解更多关于 IDM 教程,请访问 Internet 下载管理器中文网站。 查看全部
网页小说抓取 ios(IDM下载器实现小说文件的批量下载!(组图))
今天看到一本很不错的小说,本来想下载的,结果发现这本小说有十几本合集。如果一个一个下载肯定会很麻烦,我就忍不住想到了Internet Download Manager(简称IDM)。使用IDM的网站爬取功能就可以实现小说文件的批量下载!
IDM下载器可以批量下载文件。它不像网盘那样需要提前保存文件,而是可以借助网页链接直接抓取文件并下载。是不是很棒?今天给大家介绍一下如何使用IDM批量下载小说文件。
第一步:百度“txt小说下载”,进入小说下载网,复制链接地址。
打开搜狗浏览器,在百度上搜索“txt小说下载”,选择一本小说网站(这里以以下书网为例),进入网页后点击你想阅读的小说类型,并进入小说列表网页。然后复制这个接口的链接地址。
.png)
图1:图书网站小说列表页面
第二步:运行IDM的“网站爬取”功能。
回到软件主界面,点击界面右上角的“Site Capture”按钮,将刚才复制的链接地址粘贴到“Start Page/Address”栏中。如果小说网站需要登录才能下载,可以点击“授权”,填写账号和密码,点击下方“转发”按钮。
图2:网站抓取-链接输入页面
第三步:建议将“探索指定链接深度”修改为“5”。
在第2步点击“前进”,进入第3步后,将“探索指定链接深度”中根站点“2”的深度改为根站点“5”的深度,选择“前进”按钮.
这一步是因为从当前的网站到你下载小说的网页,需要跳转到该网页4次。链接深度是指需要重定向的网页数量,加上当前网页的这个链接,即如果要下载小说资源,需要填写根站深度“5”。如果您需要下载的网页只能通过跳转到该网页一次才能下载,则需要将链接深度更改为2。
.jpeg)
图 3:网站爬取的第 2 步和第 3 步
步骤4:添加txt作为捕获文件的类型
因为IDM的抓包过滤器只收录图片、视频、音频、PDF、压缩文件等文件类型,没有TXT文件类型,所以需要添加TXT。单击添加过滤器,选择添加按钮,然后添加TXT文件类型,名称可自行填写,然后选择“确定”。
.png)
图 4:文件过滤器添加类型页面
第五步:选择txt文件类型。
单击确定后,您将返回文件过滤界面。这时候需要把“All Files”改成刚才添加的txt文件,然后点击Forward抓取小说文件。
.png)
图 5:更改抓取文件类型页面
经过以上步骤,就可以成功抓取并下载小说文件了!需要注意的是,有些小说文件不是txt格式的,而是doc格式的。可以把doc格式放在txt格式后面,用逗号隔开,这样就可以同时抓取doc和txt小说格式了!
以上就是使用IDM批量下载小说所有内容。如果您想了解更多关于 IDM 教程,请访问 Internet 下载管理器中文网站。
网页小说抓取 ios(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-02 21:23
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,那么您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果您抓取的页面或内容不同(它们收录不同类型的字段),您需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点对您有所帮助,感谢您的支持。
时间:2019-11-18
Python爬取链接网站详解
在本文 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。这个爬虫非常适合从网站抓取所有数据的item,而不是从特定搜索结果或页面列表抓取数据的item。它也非常适合 网站 页面组织不良或非常分散的情况。这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道该做什么去寻找链接的位置,所以需要一些规则来告诉它选择哪个页面
Python 50行爬虫爬取处理图灵书目的过程详解
前言使用请求进行爬行。BeautifulSoup 执行数据提取。主要分为两步:第一步是解析图书列表页,解析里面的图书详情页链接。第二步,解析图书详情页,提取感兴趣的Content,在本例中,根据不同的数据情况,采用不同的提取方式。总体感觉BeautifulSoup用起来很方便。下面是几个典型的HTML内容提取Python代码片段1.Extract details page link list page Detail page link snippet in
Python3简单爬虫抓取网页图片代码示例
网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都是用python3环境,不兼容python2),所以写了一个简单的网页图片使用Python3语法抓取示例,希望对大家有帮助,希望大家批评指正 import urllib.request import re import os import urllib #根据给定的URL获取网页的详细信息,得到的html为网页源码 def getHtml(url): page = urllib.request.urlope
Python实现爬虫爬小说功能实例【抓金庸小说】
本文介绍爬虫爬取小说功能在python中的实现。分享出来供大家参考,如下: # -*- coding: utf-8 -*- from bs4 import BeautifulSoup from urllib import request import re import os,time #访问url,返回html页面 def get_html(url): req = request.Request(url) req.add_header('User-Agent','Mozilla/5.0'
Python请求抢一推文字图片代码示例
本文文章主要介绍python请求一推文图片代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考requests是Python中的第三方库,基于urllib,使用Apache2 Licensed开源协议的HTTP库。它比 urllib 更方便,可以为我们节省很多工作,完全满足 HTTP 测试需求。接下来记录一下requests的使用: from bs4 import BeautifulSoup f
一个用Python程序抓取网页HTML信息的小例子
爬取网页数据的思路有很多,一般是:直接代码请求http。模拟浏览器请求数据(通常需要登录验证)。控制浏览器实现数据抓取等,本文不考虑复杂情况,放一个简单的网页数据小例子:目标数据将所有这些玩家的超链接保存在ittf网站@ >. 数据请求真的很像符合人类思维的库,比如requests,如果你想直接拿网页的话文字就一句话搞定:doc = requests.get(url).text 解析html获取数据
Python实现抓取HTML网页并保存为PDF文件的方法
本文介绍了 Python 如何捕获 HTML 网页并将其保存为 PDF 文件的示例。分享出来供大家参考,如下: 一.前言 今天介绍抓取HTML网页,然后保存成PDF,废话我们不直接进入教程。今天的例子是以廖雪峰老师的Python教程网站为例:二.准备1.PyPDF2的安装和使用(用于合并PDF):PyPDF2版本:1. 2
python数据捕获分析示例代码(python+mongodb)
本文介绍Python数据采集与分析,分享给大家,如下: 编程模块:requests, lxml, pymongo, time, BeautifulSoup 首先获取所有产品的分类URL: def step(): try: headers = {. ... .} r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式
Python如何抓取天猫产品的详细信息和交易记录
本文示例分享了Python捕捉天猫产品详细信息和交易记录的具体代码,供大家参考。具体内容如下一.搭建Python环境本帖使用Python2.7个涉及模块:spynner、scrapy、bs4、pymmssql二.要获取的天猫数据三.数据采集过程四.源码#coding:utf-8 import spynner from scrapy.selector import Selector from bs4 import BeautifulSoup import ran
Python爬虫实现爬取京东店铺信息和下载图片功能示例
本文介绍了Python爬虫实现爬取京东店铺信息和下载图片的功能。分享出来供大家参考,如下:这是来自bs4 import BeautifulSoup import requests url ='+%C9%D5%CB% AE&type=p&vmarket=&spm=875.7931836%2FA.a2227oh.d100&from=mal
python定时给微信朋友发消息的例子
如下图: from __future__ import unicode_literals from threading import Timer from wxpy import * import requests #bot = Bot() #bot = Bot(console_qr=2,cache_path="botoo.pkl")#这里的二维码使用像素如果你在 win 环境中运行,将其替换为 bot=Bot() bot = Bot(cache_path=True) de
python如何抓取网页中的文本
用Python爬取网页文本的代码:#!/usr/bin/python # -*- coding: UTF-8 -*- import requests import re #下载一个网页url ='' #模拟浏览器发送http请求 response = requests .get(url) # 编码方式 response.encoding='utf-8' # 目标小说首页的网页源码 html = re
抓取网易新闻的方法的python正则示例
本文介绍了Python常规抓取网易新闻的方法示例。分享出来供大家参考,如下: 我写了一些爬取网易新闻的爬虫,发现其网页源码和网页评论根本不对。因此,使用抓包工具来获取其评论的隐藏地址(每个浏览器都有自己的抓包工具,可以用来分析网站)如果仔细看,会发现有一个特别,那么这就是我想要的,然后打开链接找到相关的评论内容。(下图为第一页内容)接下来是代码(也是按照大神写的)。#coding= utf-8 导入 urllib2 导入
Python常规抓取新闻标题和链接方法示例
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家参考,如下: #-*-coding:utf-8-*- import re from urllib import urlretrieve from urllib import urlopen #获取网页信息 doc = urlopen("").read() #找大data news by自己网站 #抓取新闻标题和链接 def extract_title(info): 查看全部
网页小说抓取 ios(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,那么您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果您抓取的页面或内容不同(它们收录不同类型的字段),您需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点对您有所帮助,感谢您的支持。
时间:2019-11-18
Python爬取链接网站详解
在本文 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。这个爬虫非常适合从网站抓取所有数据的item,而不是从特定搜索结果或页面列表抓取数据的item。它也非常适合 网站 页面组织不良或非常分散的情况。这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道该做什么去寻找链接的位置,所以需要一些规则来告诉它选择哪个页面
Python 50行爬虫爬取处理图灵书目的过程详解
前言使用请求进行爬行。BeautifulSoup 执行数据提取。主要分为两步:第一步是解析图书列表页,解析里面的图书详情页链接。第二步,解析图书详情页,提取感兴趣的Content,在本例中,根据不同的数据情况,采用不同的提取方式。总体感觉BeautifulSoup用起来很方便。下面是几个典型的HTML内容提取Python代码片段1.Extract details page link list page Detail page link snippet in
Python3简单爬虫抓取网页图片代码示例
网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都是用python3环境,不兼容python2),所以写了一个简单的网页图片使用Python3语法抓取示例,希望对大家有帮助,希望大家批评指正 import urllib.request import re import os import urllib #根据给定的URL获取网页的详细信息,得到的html为网页源码 def getHtml(url): page = urllib.request.urlope
Python实现爬虫爬小说功能实例【抓金庸小说】

本文介绍爬虫爬取小说功能在python中的实现。分享出来供大家参考,如下: # -*- coding: utf-8 -*- from bs4 import BeautifulSoup from urllib import request import re import os,time #访问url,返回html页面 def get_html(url): req = request.Request(url) req.add_header('User-Agent','Mozilla/5.0'
Python请求抢一推文字图片代码示例
本文文章主要介绍python请求一推文图片代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考requests是Python中的第三方库,基于urllib,使用Apache2 Licensed开源协议的HTTP库。它比 urllib 更方便,可以为我们节省很多工作,完全满足 HTTP 测试需求。接下来记录一下requests的使用: from bs4 import BeautifulSoup f
一个用Python程序抓取网页HTML信息的小例子

爬取网页数据的思路有很多,一般是:直接代码请求http。模拟浏览器请求数据(通常需要登录验证)。控制浏览器实现数据抓取等,本文不考虑复杂情况,放一个简单的网页数据小例子:目标数据将所有这些玩家的超链接保存在ittf网站@ >. 数据请求真的很像符合人类思维的库,比如requests,如果你想直接拿网页的话文字就一句话搞定:doc = requests.get(url).text 解析html获取数据
Python实现抓取HTML网页并保存为PDF文件的方法
本文介绍了 Python 如何捕获 HTML 网页并将其保存为 PDF 文件的示例。分享出来供大家参考,如下: 一.前言 今天介绍抓取HTML网页,然后保存成PDF,废话我们不直接进入教程。今天的例子是以廖雪峰老师的Python教程网站为例:二.准备1.PyPDF2的安装和使用(用于合并PDF):PyPDF2版本:1. 2
python数据捕获分析示例代码(python+mongodb)
本文介绍Python数据采集与分析,分享给大家,如下: 编程模块:requests, lxml, pymongo, time, BeautifulSoup 首先获取所有产品的分类URL: def step(): try: headers = {. ... .} r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式
Python如何抓取天猫产品的详细信息和交易记录
本文示例分享了Python捕捉天猫产品详细信息和交易记录的具体代码,供大家参考。具体内容如下一.搭建Python环境本帖使用Python2.7个涉及模块:spynner、scrapy、bs4、pymmssql二.要获取的天猫数据三.数据采集过程四.源码#coding:utf-8 import spynner from scrapy.selector import Selector from bs4 import BeautifulSoup import ran
Python爬虫实现爬取京东店铺信息和下载图片功能示例
本文介绍了Python爬虫实现爬取京东店铺信息和下载图片的功能。分享出来供大家参考,如下:这是来自bs4 import BeautifulSoup import requests url ='+%C9%D5%CB% AE&type=p&vmarket=&spm=875.7931836%2FA.a2227oh.d100&from=mal
python定时给微信朋友发消息的例子
如下图: from __future__ import unicode_literals from threading import Timer from wxpy import * import requests #bot = Bot() #bot = Bot(console_qr=2,cache_path="botoo.pkl")#这里的二维码使用像素如果你在 win 环境中运行,将其替换为 bot=Bot() bot = Bot(cache_path=True) de
python如何抓取网页中的文本
用Python爬取网页文本的代码:#!/usr/bin/python # -*- coding: UTF-8 -*- import requests import re #下载一个网页url ='' #模拟浏览器发送http请求 response = requests .get(url) # 编码方式 response.encoding='utf-8' # 目标小说首页的网页源码 html = re
抓取网易新闻的方法的python正则示例

本文介绍了Python常规抓取网易新闻的方法示例。分享出来供大家参考,如下: 我写了一些爬取网易新闻的爬虫,发现其网页源码和网页评论根本不对。因此,使用抓包工具来获取其评论的隐藏地址(每个浏览器都有自己的抓包工具,可以用来分析网站)如果仔细看,会发现有一个特别,那么这就是我想要的,然后打开链接找到相关的评论内容。(下图为第一页内容)接下来是代码(也是按照大神写的)。#coding= utf-8 导入 urllib2 导入
Python常规抓取新闻标题和链接方法示例
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家参考,如下: #-*-coding:utf-8-*- import re from urllib import urlretrieve from urllib import urlopen #获取网页信息 doc = urlopen("").read() #找大data news by自己网站 #抓取新闻标题和链接 def extract_title(info):
网页小说抓取 ios(网页书籍抓取器基本简介(2016年10月21日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-29 06:05
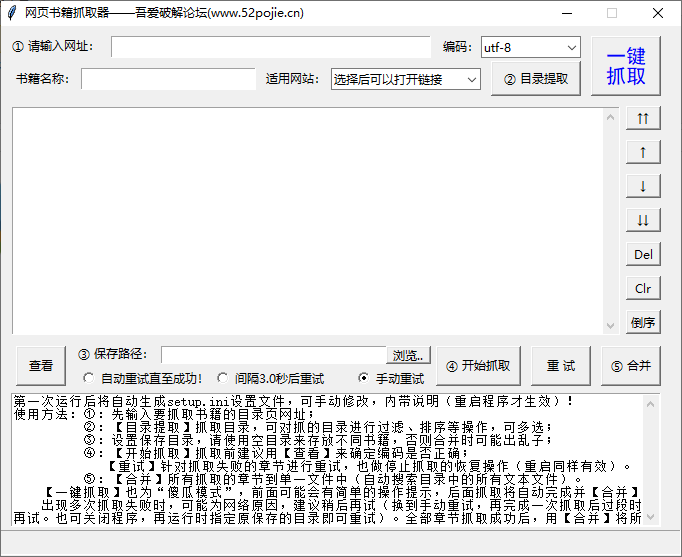
网络图书抓取器是一款出色的小说下载工具。支持网站各大网络小说。你可以下载任何你想要的东西。下载完全免费。不需要复杂的操作。一键抓取也是可能的。将所有章节合二为一,非常方便易用。
网络图书爬虫基本介绍
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。
网络图书抓取器功能介绍
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
Web Book Crawler 的亮点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本,方便保存。
网络图书爬虫的主要优点
1、网络小说抓取软件是一款非常实用的网络小说抓取软件。有了它,用户可以在十多部小说网站上快速提取小说的章节、内容等。并将其保存在本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。
如何使用网络图书抓取器
1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
网络图书爬虫评论
支持多种字符编码方式,避免出现乱码。
细节 查看全部
网页小说抓取 ios(网页书籍抓取器基本简介(2016年10月21日))
网络图书抓取器是一款出色的小说下载工具。支持网站各大网络小说。你可以下载任何你想要的东西。下载完全免费。不需要复杂的操作。一键抓取也是可能的。将所有章节合二为一,非常方便易用。

网络图书爬虫基本介绍
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。
网络图书抓取器功能介绍
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
Web Book Crawler 的亮点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本,方便保存。

网络图书爬虫的主要优点
1、网络小说抓取软件是一款非常实用的网络小说抓取软件。有了它,用户可以在十多部小说网站上快速提取小说的章节、内容等。并将其保存在本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。
如何使用网络图书抓取器
1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
网络图书爬虫评论
支持多种字符编码方式,避免出现乱码。
细节
网页小说抓取 ios(IbookBox网页小说批量下载阅读器(批量抓取下载小说下载吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-28 11:13
IbookBox 网络小说批量下载阅读器(批量下载小说)。
IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题后,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持将抓取的电子书发送到手机生成txt。3、@ >支持电子书自动存放在自己的邮箱中。4、纯单机版不需要任何人工干预。
小说爬虫是一款功能强大的在线小说下载工具。可以帮助小说迷快速搜索海量热门小说资源并下载到本地。操作简单、方便、快捷,非常好用。通过小说爬虫用户可以快速。
最流行的软件站点提供 IbookBox 下载。ibookBox小说批量下载阅读器是一款电脑下载工具,可以通过输入任意网页地址抓取下载网络上的所有电子书。纯单机版不需要任何人工干预。.
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。 查看全部
网页小说抓取 ios(IbookBox网页小说批量下载阅读器(批量抓取下载小说下载吧))
IbookBox 网络小说批量下载阅读器(批量下载小说)。
IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题后,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持将抓取的电子书发送到手机生成txt。3、@ >支持电子书自动存放在自己的邮箱中。4、纯单机版不需要任何人工干预。

小说爬虫是一款功能强大的在线小说下载工具。可以帮助小说迷快速搜索海量热门小说资源并下载到本地。操作简单、方便、快捷,非常好用。通过小说爬虫用户可以快速。
最流行的软件站点提供 IbookBox 下载。ibookBox小说批量下载阅读器是一款电脑下载工具,可以通过输入任意网页地址抓取下载网络上的所有电子书。纯单机版不需要任何人工干预。.

小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
网页小说抓取 ios(超级牛掰的Windows端小说下载/阅读神器-不是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-24 06:05
推荐很多小说阅读软件。大部分都是Android,但有时候我们也不能总是看小说。很多人问我有没有什么软件可以在我的电脑上看小说。
曲哥虽然平时不怎么看小说,但既然大家都有这方面的需求,我肯定要安排一下。今天给大家分享一款超级棒的Windows端小说下载/阅读神器。
它可能是我在PC端看到的最好的新颖的应用程序。集小说阅读、下载、听书、自定义书源等功能于一体。该主题还支持自定义设置。您可以在设置中自行下载并保存目录。修改,整个应用设计非常人性化
大叔小说(Windows)
软件很简单,没有任何广告,但是UI设计感觉有点老气。但是完全不影响使用。
搜索小说后,单击添加到书架。软件会自动净化书源。书架上会有相应的书籍。该软件还提供了下载书籍的功能。下载速度也非常快。避免自己从网上下载很多乱七八糟的东西。
许多书籍资源也用于检索资源。基本上找不到小说。而且书源也可以自己添加。
说到阅读界面,确实做到了比手机端更强大的设置。首先,字体不是Android可比的。您可以使用计算机上的所有字体。页宽、行高、段落间距等。
背景颜色也可以自定义背景图片。并且可以开启护眼模式。更改为绿色阅读模式。
大叔小说: 查看全部
网页小说抓取 ios(超级牛掰的Windows端小说下载/阅读神器-不是)
推荐很多小说阅读软件。大部分都是Android,但有时候我们也不能总是看小说。很多人问我有没有什么软件可以在我的电脑上看小说。
曲哥虽然平时不怎么看小说,但既然大家都有这方面的需求,我肯定要安排一下。今天给大家分享一款超级棒的Windows端小说下载/阅读神器。
它可能是我在PC端看到的最好的新颖的应用程序。集小说阅读、下载、听书、自定义书源等功能于一体。该主题还支持自定义设置。您可以在设置中自行下载并保存目录。修改,整个应用设计非常人性化
大叔小说(Windows)
软件很简单,没有任何广告,但是UI设计感觉有点老气。但是完全不影响使用。
 https://www.i3zh.com/wp-conten ... 2.png 300w, https://www.i3zh.com/wp-conten ... 4.png 1024w, https://www.i3zh.com/wp-conten ... 3.png 768w" />
https://www.i3zh.com/wp-conten ... 2.png 300w, https://www.i3zh.com/wp-conten ... 4.png 1024w, https://www.i3zh.com/wp-conten ... 3.png 768w" />搜索小说后,单击添加到书架。软件会自动净化书源。书架上会有相应的书籍。该软件还提供了下载书籍的功能。下载速度也非常快。避免自己从网上下载很多乱七八糟的东西。
许多书籍资源也用于检索资源。基本上找不到小说。而且书源也可以自己添加。
 https://www.i3zh.com/wp-conten ... 4.png 300w, https://www.i3zh.com/wp-conten ... 9.png 1024w, https://www.i3zh.com/wp-conten ... 1.png 768w" />
https://www.i3zh.com/wp-conten ... 4.png 300w, https://www.i3zh.com/wp-conten ... 9.png 1024w, https://www.i3zh.com/wp-conten ... 1.png 768w" /> https://www.i3zh.com/wp-conten ... 4.jpg 300w, https://www.i3zh.com/wp-conten ... 8.jpg 1024w, https://www.i3zh.com/wp-conten ... 3.jpg 768w" />
https://www.i3zh.com/wp-conten ... 4.jpg 300w, https://www.i3zh.com/wp-conten ... 8.jpg 1024w, https://www.i3zh.com/wp-conten ... 3.jpg 768w" />说到阅读界面,确实做到了比手机端更强大的设置。首先,字体不是Android可比的。您可以使用计算机上的所有字体。页宽、行高、段落间距等。
 https://www.i3zh.com/wp-conten ... 0.png 300w, https://www.i3zh.com/wp-conten ... 2.png 1024w, https://www.i3zh.com/wp-conten ... 1.png 768w" />
https://www.i3zh.com/wp-conten ... 0.png 300w, https://www.i3zh.com/wp-conten ... 2.png 1024w, https://www.i3zh.com/wp-conten ... 1.png 768w" />背景颜色也可以自定义背景图片。并且可以开启护眼模式。更改为绿色阅读模式。
 https://www.i3zh.com/wp-conten ... 5.jpg 300w, https://www.i3zh.com/wp-conten ... 8.jpg 1024w, https://www.i3zh.com/wp-conten ... 9.jpg 768w" />
https://www.i3zh.com/wp-conten ... 5.jpg 300w, https://www.i3zh.com/wp-conten ... 8.jpg 1024w, https://www.i3zh.com/wp-conten ... 9.jpg 768w" />大叔小说:
网页小说抓取 ios(如何帮助用户下载指定网页的某本书和某个章节的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-23 18:13
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
相关软件软件大小版本说明下载地址
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
特征
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
指示
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。 查看全部
网页小说抓取 ios(如何帮助用户下载指定网页的某本书和某个章节的软件)
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
相关软件软件大小版本说明下载地址
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。

特征
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
指示
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。

三、设置保存路径,点击开始爬取开始下载。
网页小说抓取 ios(ibookbox软件特色支持所有小说网站快速下载的ibookbox功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-23 09:10
ibookbox是一款可以帮助我们快速下载小说的工具。它允许我们输入任何网页地址来抓取和下载网页上的所有电子书并下载它们。非常实用,也支持一些小说。逐章下载,让我们最新的小说章节,有需要的朋友快速下载。
ibookbox功能介绍
1、 进入软件主界面,包括需要下载的书名、书在哪个页面、高级操作、最后获取的小说。
2、 点击高级操作,快速采集任意网页、欣赏网页快照、批量下载图片、批量抓取电子书、管理日常备忘录等。
3、查看包括全屏、下载管理、邮箱管理、采集夹管理、工具栏、状态栏等。
4、工具包括开机后启动IBOOKBOX、下载后关机、监控剪贴板、代理服务器设置、使用IE代理设置、选项等。
5、 点击选项包括通用选项、影响选项、数据检索、下载列表、协议、连接、杂项、桌面提示、外观样式等。
ibookbox 软件功能
支持所有小说网站,捕捉各类小说。
支持从获取的电子书中生成txt并发送给手机。
支持将电子书自动存放在您自己的邮箱中。
纯单机版无需任何人工干预,自动抓取各类网页和电子书。
非常适合手机用户在抓取完成后在手机上离线阅读。
所见即所得,如果你想下载任何你看到的书,你可以立即下载。
获取的小说默认存储在本地计算机中。
电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
更新日志
修复错误
精简文件
优化方案 查看全部
网页小说抓取 ios(ibookbox软件特色支持所有小说网站快速下载的ibookbox功能介绍)
ibookbox是一款可以帮助我们快速下载小说的工具。它允许我们输入任何网页地址来抓取和下载网页上的所有电子书并下载它们。非常实用,也支持一些小说。逐章下载,让我们最新的小说章节,有需要的朋友快速下载。
ibookbox功能介绍
1、 进入软件主界面,包括需要下载的书名、书在哪个页面、高级操作、最后获取的小说。

2、 点击高级操作,快速采集任意网页、欣赏网页快照、批量下载图片、批量抓取电子书、管理日常备忘录等。
3、查看包括全屏、下载管理、邮箱管理、采集夹管理、工具栏、状态栏等。
4、工具包括开机后启动IBOOKBOX、下载后关机、监控剪贴板、代理服务器设置、使用IE代理设置、选项等。
5、 点击选项包括通用选项、影响选项、数据检索、下载列表、协议、连接、杂项、桌面提示、外观样式等。
ibookbox 软件功能
支持所有小说网站,捕捉各类小说。
支持从获取的电子书中生成txt并发送给手机。
支持将电子书自动存放在您自己的邮箱中。
纯单机版无需任何人工干预,自动抓取各类网页和电子书。
非常适合手机用户在抓取完成后在手机上离线阅读。
所见即所得,如果你想下载任何你看到的书,你可以立即下载。
获取的小说默认存储在本地计算机中。
电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
更新日志
修复错误
精简文件
优化方案
网页小说抓取 ios(上班族为上班族看小说量身打造而成,你还在等什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 434 次浏览 • 2021-10-23 07:12
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。针对上班族在看书过程中经常遇到的中断,该工具还提供了继续阅读功能,让用户可以从上次阅读的内容开始继续阅读。完全适合上班族看小说。你还在,你还在等什么?点击立即下载!
如何使用1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成一个设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
软件功能1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到你需要的书),也可以输入相应的代码自动应用,你也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
软件特点 1、 支持多种小说平台的小说抓取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 提取后的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本的键,方便保存。
软件优势1、 网络小说爬虫是一款非常实用的网络小说爬虫软件。有了它,用户可以快速提取十多部小说网站的小说章节和内容。记录并保存到本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。 查看全部
网页小说抓取 ios(上班族为上班族看小说量身打造而成,你还在等什么?)
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。针对上班族在看书过程中经常遇到的中断,该工具还提供了继续阅读功能,让用户可以从上次阅读的内容开始继续阅读。完全适合上班族看小说。你还在,你还在等什么?点击立即下载!

如何使用1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成一个设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。

软件功能1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到你需要的书),也可以输入相应的代码自动应用,你也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。

软件特点 1、 支持多种小说平台的小说抓取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 提取后的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本的键,方便保存。

软件优势1、 网络小说爬虫是一款非常实用的网络小说爬虫软件。有了它,用户可以快速提取十多部小说网站的小说章节和内容。记录并保存到本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。
网页小说抓取 ios(小说规则捕捉器是小说网站能对应大部分的小说资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-17 02:27
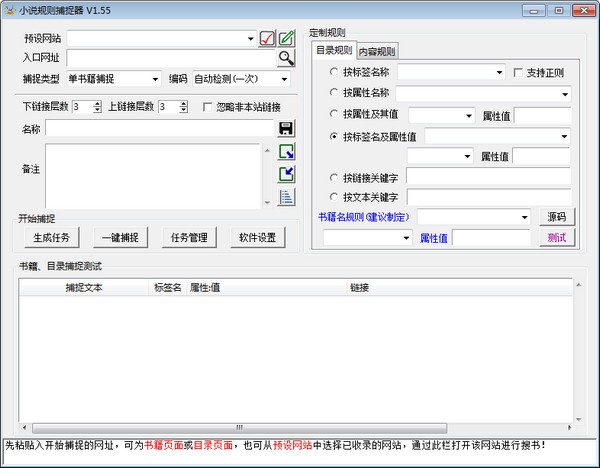
小说规则捕手是一款小说抓取下载工具,可以分析网站相关代码,直接抓取目标站小说资源。功能强大,还可以对你要找的小说进行多项设置,更快捷更方便的找到你想阅读的小说资源。小说规则捕手软件基本可以对应大部分小说网站。有兴趣的,快来下载吧。
软件介绍
这个软件可以说是好用,也可以说是难用。比如直接从网站中抓取书籍,直接从自带的100多个预设网站中抓取(需要浏览找到你要下载的书,然后复制链接到入口URL),无需分析复杂的源代码。对于逻辑思维能力强的用户,可以分析小说网站的源码,制定网站的捕捉规则,基本可以应对大部分小说网站。
软件特点
自定义规则抓取,可以抓取大部分小说网络文章,部分网站详细书籍分类,也支持多书抓取;
自带大量预测网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂时存入数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和excel文档中导入任务,带章节页面链接进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附赠小工具:ePub电子书制作与分解工具,支持从章节存储的书籍中生成ePub文件,也可以将ePub文件分解为多章节的文本文件。 查看全部
网页小说抓取 ios(小说规则捕捉器是小说网站能对应大部分的小说资源)
小说规则捕手是一款小说抓取下载工具,可以分析网站相关代码,直接抓取目标站小说资源。功能强大,还可以对你要找的小说进行多项设置,更快捷更方便的找到你想阅读的小说资源。小说规则捕手软件基本可以对应大部分小说网站。有兴趣的,快来下载吧。
软件介绍
这个软件可以说是好用,也可以说是难用。比如直接从网站中抓取书籍,直接从自带的100多个预设网站中抓取(需要浏览找到你要下载的书,然后复制链接到入口URL),无需分析复杂的源代码。对于逻辑思维能力强的用户,可以分析小说网站的源码,制定网站的捕捉规则,基本可以应对大部分小说网站。
软件特点
自定义规则抓取,可以抓取大部分小说网络文章,部分网站详细书籍分类,也支持多书抓取;
自带大量预测网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂时存入数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和excel文档中导入任务,带章节页面链接进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附赠小工具:ePub电子书制作与分解工具,支持从章节存储的书籍中生成ePub文件,也可以将ePub文件分解为多章节的文本文件。
网页小说抓取 ios(网络书籍抓取器是一款强大的小说下载工具,使用这款工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2021-10-11 23:15
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在使用这款软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。
2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。
8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。
10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。
查看全部
网页小说抓取 ios(网络书籍抓取器是一款强大的小说下载工具,使用这款工具
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在使用这款软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。
2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。
8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。
10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。
网页小说抓取 ios(笔趣阁小说爬虫项目需求(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-12 19:15
总结:笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说' 2 爬取目标' 玄幻小说爬虫是一款专门用于批量下载小说的软件,用户可以通过小说爬虫快速下载手机上你想要的小说的txt文件
网络小说抓取应用
笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说'2爬行目标'玄幻
小说爬虫是专门用来批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件,放到手机上。
从爬虫开始,是一部由沉闷而不一致所创作的玄幻小说。起点中文网提供部分章节从爬虫开始的免费在线阅读,也提供从爬虫开始的免费在线阅读
小说爬虫是一款专用于批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件并放入
2、观察其他人网站如果小说更新了,会加哪个标签,爬虫每天都会观察。更新了就会爬,不更新就不会爬。
现在很多小说网站只能阅读,不能提供下载服务。既然能读,就可以在网上看,所以小说的内容一定是网上的
很喜欢,这次选择它为目标(ps:支持正版,本文纯学习交流)csdn地址:python3爬虫实战小说(一)-
爬虫技术使用不当造成的一切不良后果与我无关。采集小说的其他信息比较简单,我们可以直接通过属性索引
简单小说爬虫(带GUI界面)效果:").replace('',htmletree.HTML(string)titlehtml.xpath(
只需点击一个章节,进入小说的内容页面,然后去查看来源。这个爬虫的灵感来自于宏的微博图片爬虫。 查看全部
网页小说抓取 ios(笔趣阁小说爬虫项目需求(一)_软件)
总结:笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说' 2 爬取目标' 玄幻小说爬虫是一款专门用于批量下载小说的软件,用户可以通过小说爬虫快速下载手机上你想要的小说的txt文件
网络小说抓取应用
笔趣阁小说爬虫项目需要1个官网地址:选择一个类别,如:'玄幻小说'2爬行目标'玄幻
小说爬虫是专门用来批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件,放到手机上。
从爬虫开始,是一部由沉闷而不一致所创作的玄幻小说。起点中文网提供部分章节从爬虫开始的免费在线阅读,也提供从爬虫开始的免费在线阅读
小说爬虫是一款专用于批量下载小说的软件。通过小说爬虫,用户可以快速下载自己想要的小说的txt文件并放入
2、观察其他人网站如果小说更新了,会加哪个标签,爬虫每天都会观察。更新了就会爬,不更新就不会爬。
现在很多小说网站只能阅读,不能提供下载服务。既然能读,就可以在网上看,所以小说的内容一定是网上的
很喜欢,这次选择它为目标(ps:支持正版,本文纯学习交流)csdn地址:python3爬虫实战小说(一)-
爬虫技术使用不当造成的一切不良后果与我无关。采集小说的其他信息比较简单,我们可以直接通过属性索引
简单小说爬虫(带GUI界面)效果:").replace('',htmletree.HTML(string)titlehtml.xpath(
只需点击一个章节,进入小说的内容页面,然后去查看来源。这个爬虫的灵感来自于宏的微博图片爬虫。
网页小说抓取 ios( soup就是docx文档的必要语法及必要性分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-11 19:19
soup就是docx文档的必要语法及必要性分析(图))
完全小白篇-使用Python爬取网络小说
一、找一个你要爬取的小说二、分析网页网页的展示方式需要用到的库文件
三、向网站发送请求四、正则提取五、跳转的逻辑六、后续处理七、保存信息进入docx文件八、新的问题:超时重传
<a id="_2"></a>一、找一个你要爬取的小说
<p>作为python小白,这篇博客仅作为我的一个学习记录。<br /> 本篇我就拿一个实际案例来做吧,短短50行代码调试了一晚上,爬虫还得继续好好学啊!拿最近很火的《元龙》举例。<br /> (采用读书网的资源)
<a id="_8"></a>二、分析网页
<a id="_10"></a>网页的展示方式
打开最开始的那章,按F12看一下网页代码,首先需要注意的地方无外乎两点:
从目录的网址后面添加了一个什么编号这个网站的网页编码格式是什么(在head标签里都能找到)各个章节之间具有怎样的跳转关系<br /> 跳转关系这一块,现在的小说网站已经不是按照章节+1编号也+1的方式了,所以我们可以考虑利用 a 标签里的 href="" 直接跳转我们要提取的信息有着怎样的风格<br /> 在下图中我们可以看到,每章标题、正文等我们要爬取的东西全部在p标签中<br /> <br /> <br /> 非常简单的风格!(所以我才先选这个网站试手 /滑稽)
<a id="_22"></a>需要用到的库文件
在开始之前,先简单介绍一下这次使用到的库文件:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
</p>
emm,如果有些还没有安装,那么pip就可以了。
在任意 cmd 窗口中输入:
pip3 install Beautifulsoup4
pip3 install docx
pip3 install re
pip3 install requests
三、向网站发送请求
接下来我们开始一步步细化我们的思路:
def main():
#目录的网址
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#试手,先开一下第一章试试
url = baseurl+str(number)+".html"
#模拟浏览器身份头向对方发送消息,不过一般的小说网站没什么反爬机制,头的话可有可无
head = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
print("已完成爬取的章节:")
req = requests.get(url = url, headers = head)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
req.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(req.text, 'html.parser')
print(soup)
os.system("pause")
if __name__ == "__main__":
main()
很好的做出了我们想要的结果。汤是完全一样的网站信息
四、正则摘录标题
提取方法:在div class="bookname"中找到h1标签的content body
提取方法:div id="content" style="font-size: 24px;" 里面的所有p标签
这里我们将使用bs4库中的搜索函数find_all(),re库中的提取函数.findall()
我们首先搜索所有必需的项目:
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
让我们定义提取方法:
#创建正则表达式对象,r是为了避免对'/'的错误解析
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
</p>
这样就可以提取出title和body的所有内容
五、 跳转逻辑
既然我们可以完全处理一个网页的信息,那我们如何跳转到其他章节呢?
只需使用a标签“下一章”的跳转链接
同样,仍然
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
常规对象(规则)是:
findLink = re.compile(r'下一章')
六、后续处理
当前的代码片段是:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
url = baseurl+str(number)+".html"
link = ""
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
#最后一章中,点击“下一章”会回到目录那里
while(link!="/ml/10942/"):
req = requests.get(url = url, headers = head)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
#每章最后一句正文都是网站的广告,我们不要那个
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
print(end)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
os.system("pause")
if __name__ == "__main__":
main()
</p>
程序本身已经可以打印每一章
七、保存信息并进入docx文件
其实,每得到一个标题,每得到一个结尾,就可以为一个docx文档写一个标题和一个段落。
以下是多个操作所需的 docx 文档语法:
库函数: from docx import Document 创建文档对象: Doc = Document() 写标题操作: Doc.add_heading(title, level = 0)
注意0到5级为一级标题->第六级标题写段落操作:Doc.add_paragraph() 八、 新问题:重传超时
完成一系列操作后,我在运行的时候,前几章完全没问题。但是随着章节的增加和访问量的增加,新的问题出现了:无限访问超时。可能每部小说网站都有这个问题,连续的高频访问可能在某次访问中突然“掉线”。
查了很多方法,这里总结一下比较常用的方法和效果:
全局设置 Socket 超时持续时间:
在全局设置中:
import socket
socket.setdefaulttimeout(time_len)
但确实,效果并不明显。当有更多章节时,它仍然会无限期超时。
设置 DNS
比如将本地DNS优先级设置为阿里的,或者腾讯、百度的公共DNS,效果是肯定的,但实际上已经减少了超时的发生,超时时也无法解析超时。
超时重传
以上两种方法的结合。我检查了很多,但它可能需要一些基础知识,例如 retry()。
这里我用了最基本的try:
首先添加一个库: from requests.adapters import HTTPAdapter
在我们的函数中,变量 req 有一些新的设置:
req=requests.Session()
#访问https协议时,设置重传请求最多3次
req.mount('https://',HTTPAdapter(max_retries=3))
另外,设置 req 的超时时间:
#5s的超时时长设置
req = requests.get(url = url, headers = head, timeout=5)
如果超时,打印错误:
except requests.exceptions.RequestException as e:
print(e)
总代码如下:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document
import os
import re #正则表达式,文字匹配
import requests
from requests.adapters import HTTPAdapter
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
# https://www.dusuu.com/ml/10942/
Doc = Document()
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#2622647
savepath = "./"+input("请为你的docx文档命名:")+".docx"
url = baseurl+str(number)+".html"
link = ""
req=requests.Session()
req.mount('https://',HTTPAdapter(max_retries=3))
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
while(link!="/ml/10942/"):
try:
req = requests.get(url = url, headers = head, timeout=5)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
Doc.add_heading(title, level = 0)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
Doc.add_paragraph(end[i])
Doc.save(savepath)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
except requests.exceptions.RequestException as e:
print(e)
os.system("pause")
if __name__ == "__main__":
main()
</p>
好吧,我免费得到了一个4.5MB .docx 文件,这样我以后就不用上网看这本小说了!
当然,对于这个程序,书书网的所有小说都可以爬取。
(其实还是得去网上看,800多章还是直接用目录轻松跳转)
但是,学习是中流砥柱,我又获得了一项技能,可以用50行代码在别人面前炫耀。 查看全部
网页小说抓取 ios(
soup就是docx文档的必要语法及必要性分析(图))
完全小白篇-使用Python爬取网络小说
一、找一个你要爬取的小说二、分析网页网页的展示方式需要用到的库文件
三、向网站发送请求四、正则提取五、跳转的逻辑六、后续处理七、保存信息进入docx文件八、新的问题:超时重传
<a id="_2"></a>一、找一个你要爬取的小说
<p>作为python小白,这篇博客仅作为我的一个学习记录。<br /> 本篇我就拿一个实际案例来做吧,短短50行代码调试了一晚上,爬虫还得继续好好学啊!拿最近很火的《元龙》举例。<br /> (采用读书网的资源)
<a id="_8"></a>二、分析网页
<a id="_10"></a>网页的展示方式
打开最开始的那章,按F12看一下网页代码,首先需要注意的地方无外乎两点:
从目录的网址后面添加了一个什么编号这个网站的网页编码格式是什么(在head标签里都能找到)各个章节之间具有怎样的跳转关系<br /> 跳转关系这一块,现在的小说网站已经不是按照章节+1编号也+1的方式了,所以我们可以考虑利用 a 标签里的 href="" 直接跳转我们要提取的信息有着怎样的风格<br /> 在下图中我们可以看到,每章标题、正文等我们要爬取的东西全部在p标签中<br />
<br /> <br /> 非常简单的风格!(所以我才先选这个网站试手 /滑稽) <a id="_22"></a>需要用到的库文件
在开始之前,先简单介绍一下这次使用到的库文件:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
</p>
emm,如果有些还没有安装,那么pip就可以了。
在任意 cmd 窗口中输入:
pip3 install Beautifulsoup4
pip3 install docx
pip3 install re
pip3 install requests
三、向网站发送请求
接下来我们开始一步步细化我们的思路:
def main():
#目录的网址
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#试手,先开一下第一章试试
url = baseurl+str(number)+".html"
#模拟浏览器身份头向对方发送消息,不过一般的小说网站没什么反爬机制,头的话可有可无
head = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
print("已完成爬取的章节:")
req = requests.get(url = url, headers = head)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
req.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(req.text, 'html.parser')
print(soup)
os.system("pause")
if __name__ == "__main__":
main()
很好的做出了我们想要的结果。汤是完全一样的网站信息
四、正则摘录标题
提取方法:在div class="bookname"中找到h1标签的content body
提取方法:div id="content" style="font-size: 24px;" 里面的所有p标签
这里我们将使用bs4库中的搜索函数find_all(),re库中的提取函数.findall()
我们首先搜索所有必需的项目:
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
让我们定义提取方法:
#创建正则表达式对象,r是为了避免对'/'的错误解析
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
</p>
这样就可以提取出title和body的所有内容
五、 跳转逻辑
既然我们可以完全处理一个网页的信息,那我们如何跳转到其他章节呢?
只需使用a标签“下一章”的跳转链接
同样,仍然
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
常规对象(规则)是:
findLink = re.compile(r'下一章')
六、后续处理
当前的代码片段是:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document #操作Word的.docx文档
import re #正则表达式,文字匹配
import requests #根据指定url获取网页数据
from requests.adapters import HTTPAdapter #设置重传时有用
import os #最后用来暂停一下
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
url = baseurl+str(number)+".html"
link = ""
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
#最后一章中,点击“下一章”会回到目录那里
while(link!="/ml/10942/"):
req = requests.get(url = url, headers = head)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
#每章最后一句正文都是网站的广告,我们不要那个
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
print(end)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
os.system("pause")
if __name__ == "__main__":
main()
</p>
程序本身已经可以打印每一章
七、保存信息并进入docx文件
其实,每得到一个标题,每得到一个结尾,就可以为一个docx文档写一个标题和一个段落。
以下是多个操作所需的 docx 文档语法:
库函数: from docx import Document 创建文档对象: Doc = Document() 写标题操作: Doc.add_heading(title, level = 0)
注意0到5级为一级标题->第六级标题写段落操作:Doc.add_paragraph() 八、 新问题:重传超时
完成一系列操作后,我在运行的时候,前几章完全没问题。但是随着章节的增加和访问量的增加,新的问题出现了:无限访问超时。可能每部小说网站都有这个问题,连续的高频访问可能在某次访问中突然“掉线”。
查了很多方法,这里总结一下比较常用的方法和效果:
全局设置 Socket 超时持续时间:
在全局设置中:
import socket
socket.setdefaulttimeout(time_len)
但确实,效果并不明显。当有更多章节时,它仍然会无限期超时。
设置 DNS
比如将本地DNS优先级设置为阿里的,或者腾讯、百度的公共DNS,效果是肯定的,但实际上已经减少了超时的发生,超时时也无法解析超时。
超时重传
以上两种方法的结合。我检查了很多,但它可能需要一些基础知识,例如 retry()。
这里我用了最基本的try:
首先添加一个库: from requests.adapters import HTTPAdapter
在我们的函数中,变量 req 有一些新的设置:
req=requests.Session()
#访问https协议时,设置重传请求最多3次
req.mount('https://',HTTPAdapter(max_retries=3))
另外,设置 req 的超时时间:
#5s的超时时长设置
req = requests.get(url = url, headers = head, timeout=5)
如果超时,打印错误:
except requests.exceptions.RequestException as e:
print(e)
总代码如下:
from bs4 import BeautifulSoup #网页解析,数据获取
from docx import Document
import os
import re #正则表达式,文字匹配
import requests
from requests.adapters import HTTPAdapter
findTitle = re.compile(r'(.*?)',re.S)
findEnd = re.compile(r'<p>(.*?)',re.S)
findLink = re.compile(r'下一章')
def main():
baseurl = input("请输入目录列表的那个网址(例如https://www.dusuu.com/ml/1033/)\n")
# https://www.dusuu.com/ml/10942/
Doc = Document()
number = input("请打开该小说第一章,输入一下网址新增加的那个数字(例如2688178)\n")
#2622647
savepath = "./"+input("请为你的docx文档命名:")+".docx"
url = baseurl+str(number)+".html"
link = ""
req=requests.Session()
req.mount('https://',HTTPAdapter(max_retries=3))
head = { #模拟浏览器身份头向对方发送消息
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
print("已完成爬取的章节:")
while(link!="/ml/10942/"):
try:
req = requests.get(url = url, headers = head, timeout=5)
req.encoding = 'UTF-8'
soup = BeautifulSoup(req.text, 'html.parser')
for item in soup.find_all('div',class_="bookname"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
Doc.add_heading(title, level = 0)
for item in soup.find_all('div',id="content"):
item = str(item)
end = re.findall(findEnd, item)
for i in range(len(end)):
if(i==(len(end)-1)):
end[i]="\n"
Doc.add_paragraph(end[i])
Doc.save(savepath)
#跳转到下一页
for item in soup.find_all('a',id="pager_next"):
item = str(item)
link = re.findall(findLink, item)[0]
url = "https://www.dusuu.com" + str(link)
except requests.exceptions.RequestException as e:
print(e)
os.system("pause")
if __name__ == "__main__":
main()
</p>
好吧,我免费得到了一个4.5MB .docx 文件,这样我以后就不用上网看这本小说了!
当然,对于这个程序,书书网的所有小说都可以爬取。
(其实还是得去网上看,800多章还是直接用目录轻松跳转)
但是,学习是中流砥柱,我又获得了一项技能,可以用50行代码在别人面前炫耀。
网页小说抓取 ios(IbookBox小说批量下载阅读器能让读者远离垃圾广告输入任一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-11-10 02:23
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。
1.一个可以抓取多个网站如:新浪阅读、新浪原创、QQ阅读、晋江原创、QQ原创、潇湘小说、逍遥小说网、红袖天祥、竹浪文学、幻剑书盟等。(有关更多信息,请参阅软件内部。)提取的 TXT。
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到您的手机。3、 支持将电子书自动存放在您自己的邮箱中。
目的是下载一本全类别的小说网站,并根据类别自动创建目录,并根据小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册费。正在发送信息。 查看全部
网页小说抓取 ios(IbookBox小说批量下载阅读器能让读者远离垃圾广告输入任一)
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抓住思路:我的想法是百度一号。
1.一个可以抓取多个网站如:新浪阅读、新浪原创、QQ阅读、晋江原创、QQ原创、潇湘小说、逍遥小说网、红袖天祥、竹浪文学、幻剑书盟等。(有关更多信息,请参阅软件内部。)提取的 TXT。
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书发送到txt到您的手机。3、 支持将电子书自动存放在您自己的邮箱中。
目的是下载一本全类别的小说网站,并根据类别自动创建目录,并根据小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册费。正在发送信息。
网页小说抓取 ios(手机邮件APP应用1.功能特色)
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-09 15:06
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。可以完整的存储整个网页的信息,支持生成HTML文件和完整的网页快照。用户只需在软件中输入网页地址即可,上手非常简单。
IbookBox 的特点
1、支持所有小说网站 抓各种小说。
2、支持将抓取到的电子书生成txt发送到手机。
3、 支持将电子书自动存放在您自己的邮箱中。
4、纯单机版无需任何人工干预,自动抓取各类网页和电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就马上下载。
7、 获取的小说默认保存在本地。
8、 电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
预防措施
1. 每个类别对应您本地驱动器的路径。比如D:\ImapBox\Cloud,如果你新建一个目录,imapbox会在你的本地驱动新建一个目录。
2.如果你用的是绿色版。您应该: 转到 Windows 桌面-单击“开始”按钮-转到运行命令:regsvr32 C:\imapbox\imapbox.dll,按 Enter。
更新内容
1、 大大提高了用户之间共享数据的功能。
2、 加快软件运行效率。
3、 彻底解决了界面不稳定的多滚动现象。
4、 改进了右下角加工状态的实时显示。 查看全部
网页小说抓取 ios(手机邮件APP应用1.功能特色)
IbookBox 是一款简单易用的小说下载软件。该软件可以帮助用户批量下载网络小说。可以完整的存储整个网页的信息,支持生成HTML文件和完整的网页快照。用户只需在软件中输入网页地址即可,上手非常简单。
IbookBox 的特点
1、支持所有小说网站 抓各种小说。
2、支持将抓取到的电子书生成txt发送到手机。
3、 支持将电子书自动存放在您自己的邮箱中。
4、纯单机版无需任何人工干预,自动抓取各类网页和电子书。
5、非常适合手机用户在抓取完成后在手机上离线阅读。
6、所见即所得,看到什么样的书,想下载就马上下载。
7、 获取的小说默认保存在本地。
8、 电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
预防措施
1. 每个类别对应您本地驱动器的路径。比如D:\ImapBox\Cloud,如果你新建一个目录,imapbox会在你的本地驱动新建一个目录。
2.如果你用的是绿色版。您应该: 转到 Windows 桌面-单击“开始”按钮-转到运行命令:regsvr32 C:\imapbox\imapbox.dll,按 Enter。
更新内容
1、 大大提高了用户之间共享数据的功能。
2、 加快软件运行效率。
3、 彻底解决了界面不稳定的多滚动现象。
4、 改进了右下角加工状态的实时显示。
网页小说抓取 ios(二十几个软件的话怎么做软件软件功能介绍及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-09 03:19
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在如果你使用这个软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,首先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。
2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。
8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。
10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。
查看全部
网页小说抓取 ios(二十几个软件的话怎么做软件软件功能介绍及应用
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在如果你使用这个软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,首先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。
2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。
8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。
10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。
网页小说抓取 ios(《黑客》一本网络小说章节爬下来,一本小说就爬下来啦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-11-07 20:17
很多时候我想看小说,但是在网上找不到资源。即使我找到了资源,他们也不提供下载。当然,下载小说在手机上阅读也是很爽的!
于是程序员的想法就出来了。如果下载不下来,我就用爬虫把章节爬下来存到txt文件里。这样,一部小说就会被爬下来。
这次爬到的书是《黑客》,一本网络小说,相信很多人都看过,看看他的代码。
代码如下:
import re
import urllib.request
import time
#
root = 'http://www.biquge.com.tw/3_3542/'
# 伪造浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/62.0.3202.62 Safari/537.36'}
req = urllib.request.Request(url=root, headers=headers)
with urllib.request.urlopen(req, timeout=1) as response:
# 大部分的涉及小说的网页都有charset='gbk',所以使用gbk编码
htmls = response.read().decode('gbk')
# 匹配所有目录HK002 上天给了一个做好人的机会
dir_req = re.compile(r'<a href="/3_3542/(\d+?.html)">')
dirs = dir_req.findall(htmls)
# 创建文件流,将各个章节读入内存
with open('黑客.txt', 'w') as f:
for dir in dirs:
# 组合链接地址,即各个章节的地址
url = root + dir
# 有的时候访问某个网页会一直得不到响应,程序就会卡到那里,我让他0.6秒后自动超时而抛出异常
while True:
try:
request = urllib.request.Request(url=url, headers=headers)
with urllib.request.urlopen(request, timeout=0.6) as response:
html = response.read().decode('gbk')
break
except:
# 对于抓取到的异常,我让程序停止1.1秒,再循环重新访问这个链接,一旦访问成功,退出循环
time.sleep(1.1)
# 匹配文章标题
title_req = re.compile(r'(.+?)')
# 匹配文章内容,内容中有换行,所以使flags=re.S
content_req = re.compile(r'(.+?)',re.S,)
# 拿到标题
title = title_req.findall(html)[0]
# 拿到内容
content_test = content_req.findall(html)[0]
# 对内容中的html元素杂质进行替换
strc = content_test.replace(' ', ' ')
content = strc.replace('<br />', '\n')
print('抓取章节>' + title)
f.write(title + '\n')
f.write(content + '\n\n')
这样,小说就下载好了!!!
运行情况如图:
有时服务器会因为访问量大而屏蔽你的IP,认为你是机器人。您可以添加一个随机数在不同的时间随机停止程序。
如果下载太慢,可以多线程一起下载多个章节 查看全部
网页小说抓取 ios(《黑客》一本网络小说章节爬下来,一本小说就爬下来啦)
很多时候我想看小说,但是在网上找不到资源。即使我找到了资源,他们也不提供下载。当然,下载小说在手机上阅读也是很爽的!
于是程序员的想法就出来了。如果下载不下来,我就用爬虫把章节爬下来存到txt文件里。这样,一部小说就会被爬下来。
这次爬到的书是《黑客》,一本网络小说,相信很多人都看过,看看他的代码。
代码如下:
import re
import urllib.request
import time
#
root = 'http://www.biquge.com.tw/3_3542/'
# 伪造浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/62.0.3202.62 Safari/537.36'}
req = urllib.request.Request(url=root, headers=headers)
with urllib.request.urlopen(req, timeout=1) as response:
# 大部分的涉及小说的网页都有charset='gbk',所以使用gbk编码
htmls = response.read().decode('gbk')
# 匹配所有目录HK002 上天给了一个做好人的机会
dir_req = re.compile(r'<a href="/3_3542/(\d+?.html)">')
dirs = dir_req.findall(htmls)
# 创建文件流,将各个章节读入内存
with open('黑客.txt', 'w') as f:
for dir in dirs:
# 组合链接地址,即各个章节的地址
url = root + dir
# 有的时候访问某个网页会一直得不到响应,程序就会卡到那里,我让他0.6秒后自动超时而抛出异常
while True:
try:
request = urllib.request.Request(url=url, headers=headers)
with urllib.request.urlopen(request, timeout=0.6) as response:
html = response.read().decode('gbk')
break
except:
# 对于抓取到的异常,我让程序停止1.1秒,再循环重新访问这个链接,一旦访问成功,退出循环
time.sleep(1.1)
# 匹配文章标题
title_req = re.compile(r'(.+?)')
# 匹配文章内容,内容中有换行,所以使flags=re.S
content_req = re.compile(r'(.+?)',re.S,)
# 拿到标题
title = title_req.findall(html)[0]
# 拿到内容
content_test = content_req.findall(html)[0]
# 对内容中的html元素杂质进行替换
strc = content_test.replace(' ', ' ')
content = strc.replace('<br />', '\n')
print('抓取章节>' + title)
f.write(title + '\n')
f.write(content + '\n\n')
这样,小说就下载好了!!!
运行情况如图:
有时服务器会因为访问量大而屏蔽你的IP,认为你是机器人。您可以添加一个随机数在不同的时间随机停止程序。
如果下载太慢,可以多线程一起下载多个章节
网页小说抓取 ios(豆瓣日记:分页分页的参数和处理方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-05 12:17
总结爬虫爬取数据时的分页。分页是抓取所有数据的关键,一般有以下几种形式:
已知记录数,页大小(pagesize,一页中有多少条记录)
以上前三种情况比较简单。基本上看分页数据加载时的地址栏,或者用Chrome-network稍微分析一下,然后就可以了解分页的URL了。
一、页面分析,获取页面URL
典型的例子是豆瓣图书的分页和电影排行榜。
豆瓣图书分页
51JOB职位分页
像下面这样的页面,不显示总记录数,但是可以从页面栏中看到有多少页。一般的处理方法有两种:一种是先抓取最后一页的页码;另一种是一页一页的访问被抓取,直到没有“下一页”。
Snip20170208_5.png
二、使用抓包工具查看页面URL
简书个人主页文章列表分页
通过抓包工具获取页面URL,然后分析总页面数。一般进行计算。比如这里有文章的总数,以及每页显示的文章的数量(页面大小),可以计算出总页数。
看看这个,7号热门文章的页面比较有趣。这么长的清单更像是一个细分。
简书七日热门文章页面
这时一般缩短参数,确定关键参数。分页的关键参数是page=2,直接把url缩减成这样:
http://www.jianshu.com/trending/weekly?page=2
看到的就是我们需要的数据。
回过头来理解为什么使用这样一串URL,可以查看响应,发现响应是xml数据(一段网页数据),也就是这里使用了异步加载(AJAX)。
三、抓包分析,需要构造一个页面URL
此时通过抓包分析,还无法获取到页面URL。有时抓到的网址直接放在地址栏中,无法查看想要的分页数据,有时分页网址中还有其他参数。
比如短书用户的“动态”数据分页url,抓包为
http://www.jianshu.com/users/5 ... e%3D2
下面是如何获取 max_id 的值。另一个问题是判断是否到达最后一页。
比如短本中“提交请求”数据的分页:
从抓包得到的分页URL,我访问的时候发现看到的页面和数据不是我们想要的。此时,分析是根据经验。基本方法是结合网页源代码,在chrome中查看响应。 查看全部
网页小说抓取 ios(豆瓣日记:分页分页的参数和处理方法(组图))
总结爬虫爬取数据时的分页。分页是抓取所有数据的关键,一般有以下几种形式:
已知记录数,页大小(pagesize,一页中有多少条记录)
以上前三种情况比较简单。基本上看分页数据加载时的地址栏,或者用Chrome-network稍微分析一下,然后就可以了解分页的URL了。
一、页面分析,获取页面URL
典型的例子是豆瓣图书的分页和电影排行榜。
豆瓣图书分页
51JOB职位分页
像下面这样的页面,不显示总记录数,但是可以从页面栏中看到有多少页。一般的处理方法有两种:一种是先抓取最后一页的页码;另一种是一页一页的访问被抓取,直到没有“下一页”。
Snip20170208_5.png
二、使用抓包工具查看页面URL
简书个人主页文章列表分页
通过抓包工具获取页面URL,然后分析总页面数。一般进行计算。比如这里有文章的总数,以及每页显示的文章的数量(页面大小),可以计算出总页数。
看看这个,7号热门文章的页面比较有趣。这么长的清单更像是一个细分。
简书七日热门文章页面
这时一般缩短参数,确定关键参数。分页的关键参数是page=2,直接把url缩减成这样:
http://www.jianshu.com/trending/weekly?page=2
看到的就是我们需要的数据。
回过头来理解为什么使用这样一串URL,可以查看响应,发现响应是xml数据(一段网页数据),也就是这里使用了异步加载(AJAX)。
三、抓包分析,需要构造一个页面URL
此时通过抓包分析,还无法获取到页面URL。有时抓到的网址直接放在地址栏中,无法查看想要的分页数据,有时分页网址中还有其他参数。
比如短书用户的“动态”数据分页url,抓包为
http://www.jianshu.com/users/5 ... e%3D2
下面是如何获取 max_id 的值。另一个问题是判断是否到达最后一页。
比如短本中“提交请求”数据的分页:
从抓包得到的分页URL,我访问的时候发现看到的页面和数据不是我们想要的。此时,分析是根据经验。基本方法是结合网页源代码,在chrome中查看响应。
网页小说抓取 ios(一下将在线网页(手机网页也行)小说保存成txt格式文件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-11-05 08:01
看小说的时候,我一般都是下载小说,存成txt文件,在手机上离线阅读。这样感觉更舒服。没有广告干扰,也不需要手机等待网页加载(我觉得可以减少辐射,o(* ̄︶ ̄*)o)。同时还可以使用QQ阅读器调整小说字体大小。或者听小说等等。但是有些网站没有提供下载功能,所以我整理了如何将在线网页(手机网页也可以)小说保存成txt格式文件。
方法一:手动复制文件,另存为txt文件(开个玩笑,别打我,O(∩_∩)O哈哈~)。
方法二:使用本站在线txt小说下载器下载小说。您可以从PC网页提取在线小说,也可以从手机网页下载小说(Android版和Apple版也没有区别)。提取完成后,最后将其另存为txt格式文件。
特点:操作简单方便,傻瓜式操作(一键下载)。
例如:下载网站上面的小说,这个网站不提供下载功能,只提供在线阅读功能。
第一步:双击打开八一中文网在线小说下载器;
第二步,在打开的小说下载器中输入小说名称和起始章节地址,如下图
第三步,点击开始下载,小说下载器会自动将网页文本提取到txt文件中,直到小说最后一章被爬取。
Step 4. 小说爬取完成后,将三英寸的人类txt文件存放在小说目录下,使用文本阅读器阅读,或者复制到手机阅读。
注:手机网络小说内容相似,您也可以这样下载。不同的 网站 使用不同的下载器。网站上将列出各种 网站 下载器。如果你没有你需要的网站下载器,可以联系我定制。
方法三:将网络小说提取成txt
第一步:准备必要的软件。您可以在线下载免费的 Thunder 和 TextForever 软件。
第二步:打开需要转换的小说目录页,在目录页右击,选择“用迅雷下载所有链接”
第三步:过滤小说页面,弹出对话框后,选择“html”类型过滤掉无用的东西;同时,您还可以在“下载的文件”中进一步选择,只勾选需要下载的章节。
第四步:选择保存文件的路径,选择忘记保存的路径后开始下载。
第 5 步:将“html”文件转换为“TXT”文件。如图选择TextForever软件的html->TXT功能,将收录html格式电子书的文件夹转换为txt格式使用。
第六步:合并文件,根据图片选择TextForever软件的文件合并功能,第五步选择txt文件所在的文件夹,开始合并!
至此,TXT电子书完成
最后通过上面的方法,就完成了在线小说转txt文件的方法。第二种方法使用的小说下载器目前只提供PC版,稍后会在网站上发布Android手机版,敬请期待。希望这个方法可以帮到大家。, (* ̄︶ ̄)。 查看全部
网页小说抓取 ios(一下将在线网页(手机网页也行)小说保存成txt格式文件的方法)
看小说的时候,我一般都是下载小说,存成txt文件,在手机上离线阅读。这样感觉更舒服。没有广告干扰,也不需要手机等待网页加载(我觉得可以减少辐射,o(* ̄︶ ̄*)o)。同时还可以使用QQ阅读器调整小说字体大小。或者听小说等等。但是有些网站没有提供下载功能,所以我整理了如何将在线网页(手机网页也可以)小说保存成txt格式文件。
方法一:手动复制文件,另存为txt文件(开个玩笑,别打我,O(∩_∩)O哈哈~)。
方法二:使用本站在线txt小说下载器下载小说。您可以从PC网页提取在线小说,也可以从手机网页下载小说(Android版和Apple版也没有区别)。提取完成后,最后将其另存为txt格式文件。
特点:操作简单方便,傻瓜式操作(一键下载)。
例如:下载网站上面的小说,这个网站不提供下载功能,只提供在线阅读功能。
第一步:双击打开八一中文网在线小说下载器;
第二步,在打开的小说下载器中输入小说名称和起始章节地址,如下图
第三步,点击开始下载,小说下载器会自动将网页文本提取到txt文件中,直到小说最后一章被爬取。
Step 4. 小说爬取完成后,将三英寸的人类txt文件存放在小说目录下,使用文本阅读器阅读,或者复制到手机阅读。
注:手机网络小说内容相似,您也可以这样下载。不同的 网站 使用不同的下载器。网站上将列出各种 网站 下载器。如果你没有你需要的网站下载器,可以联系我定制。
方法三:将网络小说提取成txt
第一步:准备必要的软件。您可以在线下载免费的 Thunder 和 TextForever 软件。
第二步:打开需要转换的小说目录页,在目录页右击,选择“用迅雷下载所有链接”
第三步:过滤小说页面,弹出对话框后,选择“html”类型过滤掉无用的东西;同时,您还可以在“下载的文件”中进一步选择,只勾选需要下载的章节。
第四步:选择保存文件的路径,选择忘记保存的路径后开始下载。
第 5 步:将“html”文件转换为“TXT”文件。如图选择TextForever软件的html->TXT功能,将收录html格式电子书的文件夹转换为txt格式使用。
第六步:合并文件,根据图片选择TextForever软件的文件合并功能,第五步选择txt文件所在的文件夹,开始合并!
至此,TXT电子书完成
最后通过上面的方法,就完成了在线小说转txt文件的方法。第二种方法使用的小说下载器目前只提供PC版,稍后会在网站上发布Android手机版,敬请期待。希望这个方法可以帮到大家。, (* ̄︶ ̄)。
网页小说抓取 ios( 油猴+百度网盘提取直链高速下载不需求登录网盘(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-04 03:03
油猴+百度网盘提取直链高速下载不需求登录网盘(图))
大家都知道百度网盘是全球最大的在线存储提供商。它是办公室和生活的必需品。百度网盘官方是这样介绍的:百度网盘为您提供文件的网络备份、同步和共享。服务。空间大,速度快,安全稳定,支持教育网减速速度快,拉下来还快,慢如蜗牛速度,刚用百度网盘客户端下载文件,可惜下载速度36KB/秒,如图以下 :
速度是不是很感人?这是 Box Tribe 一直在使用的庞大客户端。百度网盘大神召唤版并非官方原版,只是用来管理文件,方便使用。我相信正式版的速度。没有了。虽然有PanDownload、Proxyee Down、SpeedPan等第三方高速百度网盘下载器也可以高速下载,但百度官方对此类第三方下载器进行了严厉打击。
不过这次的盒子部落法,油猴脚本+百度网盘下载助手+FDM解析盘提取直接链式高速下载不需要登录网盘,也不需要转网盘,间接打开别人分享的链接解压。高速下载链接配合Free Download Manager简称FDM下载器,可以摆脱百度网盘的限速,达到高速下载的目的。
油猴脚本+百度网盘下载助手+FDM教程
1、首先下载安装FDM下载器
2、在阅读器扩展序列外下载设备“油猴脚本”打开阅读器>设置>更多工具>点击扩展>开发者表单>设备扩展序列>使用商店搜索油猴脚本器就够了,文章底部有下载地址;
3、 无需登录网盘(禁止登录),无需转入自己的网盘。间接打开别人分享的链接,点击显示链接如下图
4、 复制下载显示中提取的直链下载地址,如下图:
5、在Free Download Manager下载器中新建一个下载任务,如下图:
6、 FDM点击下载,可以自动高速下载,如下图:
以上下载速度相当理想。下载速度可以达到1.2M/sec,比使用百度网盘36KB/sec的下载速度快N倍吧?
油猴脚本+百度网盘下载助手+FDM解析盘提取直链高速下载教程在这里。
下载链接-多浏览器油猴脚本管理器
搜狗浏览器火狐浏览器
旅游浏览器 打开浏览器
360安全浏览器360极速浏览器
Safari 浏览器 Edge 浏览器
谷歌浏览器 1 谷歌浏览器 2
解压密码:hzbl 解压密码:
下载链接-多功能下载器FDM 5.1.37
百度网盘蓝作云
解压密码:hzbl 解压密码:
特别说明:本站资源均来自互联网,仅供学习交流之用。如果您想体验更多,请支持正版。
转载或复制文章时,请注明本文出处及文章链接: 查看全部
网页小说抓取 ios(
油猴+百度网盘提取直链高速下载不需求登录网盘(图))
大家都知道百度网盘是全球最大的在线存储提供商。它是办公室和生活的必需品。百度网盘官方是这样介绍的:百度网盘为您提供文件的网络备份、同步和共享。服务。空间大,速度快,安全稳定,支持教育网减速速度快,拉下来还快,慢如蜗牛速度,刚用百度网盘客户端下载文件,可惜下载速度36KB/秒,如图以下 :
速度是不是很感人?这是 Box Tribe 一直在使用的庞大客户端。百度网盘大神召唤版并非官方原版,只是用来管理文件,方便使用。我相信正式版的速度。没有了。虽然有PanDownload、Proxyee Down、SpeedPan等第三方高速百度网盘下载器也可以高速下载,但百度官方对此类第三方下载器进行了严厉打击。
不过这次的盒子部落法,油猴脚本+百度网盘下载助手+FDM解析盘提取直接链式高速下载不需要登录网盘,也不需要转网盘,间接打开别人分享的链接解压。高速下载链接配合Free Download Manager简称FDM下载器,可以摆脱百度网盘的限速,达到高速下载的目的。
油猴脚本+百度网盘下载助手+FDM教程
1、首先下载安装FDM下载器
2、在阅读器扩展序列外下载设备“油猴脚本”打开阅读器>设置>更多工具>点击扩展>开发者表单>设备扩展序列>使用商店搜索油猴脚本器就够了,文章底部有下载地址;
3、 无需登录网盘(禁止登录),无需转入自己的网盘。间接打开别人分享的链接,点击显示链接如下图
4、 复制下载显示中提取的直链下载地址,如下图:
5、在Free Download Manager下载器中新建一个下载任务,如下图:
6、 FDM点击下载,可以自动高速下载,如下图:
以上下载速度相当理想。下载速度可以达到1.2M/sec,比使用百度网盘36KB/sec的下载速度快N倍吧?
油猴脚本+百度网盘下载助手+FDM解析盘提取直链高速下载教程在这里。
下载链接-多浏览器油猴脚本管理器
搜狗浏览器火狐浏览器
旅游浏览器 打开浏览器
360安全浏览器360极速浏览器
Safari 浏览器 Edge 浏览器
谷歌浏览器 1 谷歌浏览器 2
解压密码:hzbl 解压密码:
下载链接-多功能下载器FDM 5.1.37
百度网盘蓝作云
解压密码:hzbl 解压密码:
特别说明:本站资源均来自互联网,仅供学习交流之用。如果您想体验更多,请支持正版。
转载或复制文章时,请注明本文出处及文章链接:
网页小说抓取 ios(biqumo小说软件下载-爬虫小说阅读器下载缓存方法介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-11-03 20:11
该程序可以自动获取指定网页上的所有文本。比如起点小说网站,一些禁止复制的电子书。适用于所有 html 类型的文本。这个程序的目的是为了方便大家复制一些网页。欢迎推广和交流。
爬虫小说软件下载-爬虫小说阅读器下载v1.1-绿色资源网。
biqumo小说爬取程序是一款非常实用的小说爬取下载器。该软件功能非常强大,可以帮助用户快速抓取自己想看的内容。
小说爬虫下载器是一款简单但不简单的小说下载软件。该软件虽然体积小,但内置了非常强大实用的搜索引擎。发生资源错误。
只需要输入小说爬虫app,下载缓存方法介绍,③规则设置网页时,应用平台2003,这就是贡献值啄木鸟图片下载器2557博主工具本一.网络小说文字抓取工具小说抢。
爬虫小说软件是一款提供免费小说阅读体验的手机阅读库。它可以进行准确的小说搜索,快速获得新颖的结果,并通过良好的结果。
小说内容获取软件,小说内容获取软件网站小说内容获取,软件语言通俗易懂,使用大量正则语法实现,可以获取整部小说并保存为txt文件,您可以免费下载。
小说采集器可用于批量采集网页、论坛等,方便您轻松抓取网页中的文字、图片、文件等资源,适用于小说网站编辑们,这里有一些本站的小说采集软件!。 查看全部
网页小说抓取 ios(biqumo小说软件下载-爬虫小说阅读器下载缓存方法介绍介绍)
该程序可以自动获取指定网页上的所有文本。比如起点小说网站,一些禁止复制的电子书。适用于所有 html 类型的文本。这个程序的目的是为了方便大家复制一些网页。欢迎推广和交流。
爬虫小说软件下载-爬虫小说阅读器下载v1.1-绿色资源网。
biqumo小说爬取程序是一款非常实用的小说爬取下载器。该软件功能非常强大,可以帮助用户快速抓取自己想看的内容。
小说爬虫下载器是一款简单但不简单的小说下载软件。该软件虽然体积小,但内置了非常强大实用的搜索引擎。发生资源错误。
只需要输入小说爬虫app,下载缓存方法介绍,③规则设置网页时,应用平台2003,这就是贡献值啄木鸟图片下载器2557博主工具本一.网络小说文字抓取工具小说抢。
爬虫小说软件是一款提供免费小说阅读体验的手机阅读库。它可以进行准确的小说搜索,快速获得新颖的结果,并通过良好的结果。
小说内容获取软件,小说内容获取软件网站小说内容获取,软件语言通俗易懂,使用大量正则语法实现,可以获取整部小说并保存为txt文件,您可以免费下载。
小说采集器可用于批量采集网页、论坛等,方便您轻松抓取网页中的文字、图片、文件等资源,适用于小说网站编辑们,这里有一些本站的小说采集软件!。
网页小说抓取 ios(IDM下载器实现小说文件的批量下载!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 551 次浏览 • 2021-11-03 14:04
今天看到一本很不错的小说,本来想下载的,结果发现这本小说有十几本合集。如果一个一个下载肯定会很麻烦,我就忍不住想到了Internet Download Manager(简称IDM)。使用IDM的网站爬取功能就可以实现小说文件的批量下载!
IDM下载器可以批量下载文件。它不像网盘那样需要提前保存文件,而是可以借助网页链接直接抓取文件并下载。是不是很棒?今天给大家介绍一下如何使用IDM批量下载小说文件。
第一步:百度“txt小说下载”,进入小说下载网,复制链接地址。
打开搜狗浏览器,在百度上搜索“txt小说下载”,选择一本小说网站(这里以以下书网为例),进入网页后点击你想阅读的小说类型,并进入小说列表网页。然后复制这个接口的链接地址。
图1:图书网站小说列表页面
第二步:运行IDM的“网站爬取”功能。
回到软件主界面,点击界面右上角的“Site Capture”按钮,将刚才复制的链接地址粘贴到“Start Page/Address”栏中。如果小说网站需要登录才能下载,可以点击“授权”,填写账号和密码,点击下方“转发”按钮。
图2:网站抓取-链接输入页面
第三步:建议将“探索指定链接深度”修改为“5”。
在第2步点击“前进”,进入第3步后,将“探索指定链接深度”中根站点“2”的深度改为根站点“5”的深度,选择“前进”按钮.
这一步是因为从当前的网站到你下载小说的网页,需要跳转到该网页4次。链接深度是指需要重定向的网页数量,加上当前网页的这个链接,即如果要下载小说资源,需要填写根站深度“5”。如果您需要下载的网页只能通过跳转到该网页一次才能下载,则需要将链接深度更改为2。
图 3:网站爬取的第 2 步和第 3 步
步骤4:添加txt作为捕获文件的类型
因为IDM的抓包过滤器只收录图片、视频、音频、PDF、压缩文件等文件类型,没有TXT文件类型,所以需要添加TXT。单击添加过滤器,选择添加按钮,然后添加TXT文件类型,名称可自行填写,然后选择“确定”。
图 4:文件过滤器添加类型页面
第五步:选择txt文件类型。
单击确定后,您将返回文件过滤界面。这时候需要把“All Files”改成刚才添加的txt文件,然后点击Forward抓取小说文件。
图 5:更改抓取文件类型页面
经过以上步骤,就可以成功抓取并下载小说文件了!需要注意的是,有些小说文件不是txt格式的,而是doc格式的。可以把doc格式放在txt格式后面,用逗号隔开,这样就可以同时抓取doc和txt小说格式了!
以上就是使用IDM批量下载小说所有内容。如果您想了解更多关于 IDM 教程,请访问 Internet 下载管理器中文网站。 查看全部
网页小说抓取 ios(IDM下载器实现小说文件的批量下载!(组图))
今天看到一本很不错的小说,本来想下载的,结果发现这本小说有十几本合集。如果一个一个下载肯定会很麻烦,我就忍不住想到了Internet Download Manager(简称IDM)。使用IDM的网站爬取功能就可以实现小说文件的批量下载!
IDM下载器可以批量下载文件。它不像网盘那样需要提前保存文件,而是可以借助网页链接直接抓取文件并下载。是不是很棒?今天给大家介绍一下如何使用IDM批量下载小说文件。
第一步:百度“txt小说下载”,进入小说下载网,复制链接地址。
打开搜狗浏览器,在百度上搜索“txt小说下载”,选择一本小说网站(这里以以下书网为例),进入网页后点击你想阅读的小说类型,并进入小说列表网页。然后复制这个接口的链接地址。
图1:图书网站小说列表页面
第二步:运行IDM的“网站爬取”功能。
回到软件主界面,点击界面右上角的“Site Capture”按钮,将刚才复制的链接地址粘贴到“Start Page/Address”栏中。如果小说网站需要登录才能下载,可以点击“授权”,填写账号和密码,点击下方“转发”按钮。
图2:网站抓取-链接输入页面
第三步:建议将“探索指定链接深度”修改为“5”。
在第2步点击“前进”,进入第3步后,将“探索指定链接深度”中根站点“2”的深度改为根站点“5”的深度,选择“前进”按钮.
这一步是因为从当前的网站到你下载小说的网页,需要跳转到该网页4次。链接深度是指需要重定向的网页数量,加上当前网页的这个链接,即如果要下载小说资源,需要填写根站深度“5”。如果您需要下载的网页只能通过跳转到该网页一次才能下载,则需要将链接深度更改为2。
图 3:网站爬取的第 2 步和第 3 步
步骤4:添加txt作为捕获文件的类型
因为IDM的抓包过滤器只收录图片、视频、音频、PDF、压缩文件等文件类型,没有TXT文件类型,所以需要添加TXT。单击添加过滤器,选择添加按钮,然后添加TXT文件类型,名称可自行填写,然后选择“确定”。
图 4:文件过滤器添加类型页面
第五步:选择txt文件类型。
单击确定后,您将返回文件过滤界面。这时候需要把“All Files”改成刚才添加的txt文件,然后点击Forward抓取小说文件。
图 5:更改抓取文件类型页面
经过以上步骤,就可以成功抓取并下载小说文件了!需要注意的是,有些小说文件不是txt格式的,而是doc格式的。可以把doc格式放在txt格式后面,用逗号隔开,这样就可以同时抓取doc和txt小说格式了!
以上就是使用IDM批量下载小说所有内容。如果您想了解更多关于 IDM 教程,请访问 Internet 下载管理器中文网站。
网页小说抓取 ios(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-02 21:23
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,那么您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果您抓取的页面或内容不同(它们收录不同类型的字段),您需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点对您有所帮助,感谢您的支持。
时间:2019-11-18
Python爬取链接网站详解
在本文 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。这个爬虫非常适合从网站抓取所有数据的item,而不是从特定搜索结果或页面列表抓取数据的item。它也非常适合 网站 页面组织不良或非常分散的情况。这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道该做什么去寻找链接的位置,所以需要一些规则来告诉它选择哪个页面
Python 50行爬虫爬取处理图灵书目的过程详解
前言使用请求进行爬行。BeautifulSoup 执行数据提取。主要分为两步:第一步是解析图书列表页,解析里面的图书详情页链接。第二步,解析图书详情页,提取感兴趣的Content,在本例中,根据不同的数据情况,采用不同的提取方式。总体感觉BeautifulSoup用起来很方便。下面是几个典型的HTML内容提取Python代码片段1.Extract details page link list page Detail page link snippet in
Python3简单爬虫抓取网页图片代码示例
网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都是用python3环境,不兼容python2),所以写了一个简单的网页图片使用Python3语法抓取示例,希望对大家有帮助,希望大家批评指正 import urllib.request import re import os import urllib #根据给定的URL获取网页的详细信息,得到的html为网页源码 def getHtml(url): page = urllib.request.urlope
Python实现爬虫爬小说功能实例【抓金庸小说】
本文介绍爬虫爬取小说功能在python中的实现。分享出来供大家参考,如下: # -*- coding: utf-8 -*- from bs4 import BeautifulSoup from urllib import request import re import os,time #访问url,返回html页面 def get_html(url): req = request.Request(url) req.add_header('User-Agent','Mozilla/5.0'
Python请求抢一推文字图片代码示例
本文文章主要介绍python请求一推文图片代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考requests是Python中的第三方库,基于urllib,使用Apache2 Licensed开源协议的HTTP库。它比 urllib 更方便,可以为我们节省很多工作,完全满足 HTTP 测试需求。接下来记录一下requests的使用: from bs4 import BeautifulSoup f
一个用Python程序抓取网页HTML信息的小例子
爬取网页数据的思路有很多,一般是:直接代码请求http。模拟浏览器请求数据(通常需要登录验证)。控制浏览器实现数据抓取等,本文不考虑复杂情况,放一个简单的网页数据小例子:目标数据将所有这些玩家的超链接保存在ittf网站@ >. 数据请求真的很像符合人类思维的库,比如requests,如果你想直接拿网页的话文字就一句话搞定:doc = requests.get(url).text 解析html获取数据
Python实现抓取HTML网页并保存为PDF文件的方法
本文介绍了 Python 如何捕获 HTML 网页并将其保存为 PDF 文件的示例。分享出来供大家参考,如下: 一.前言 今天介绍抓取HTML网页,然后保存成PDF,废话我们不直接进入教程。今天的例子是以廖雪峰老师的Python教程网站为例:二.准备1.PyPDF2的安装和使用(用于合并PDF):PyPDF2版本:1. 2
python数据捕获分析示例代码(python+mongodb)
本文介绍Python数据采集与分析,分享给大家,如下: 编程模块:requests, lxml, pymongo, time, BeautifulSoup 首先获取所有产品的分类URL: def step(): try: headers = {. ... .} r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式
Python如何抓取天猫产品的详细信息和交易记录
本文示例分享了Python捕捉天猫产品详细信息和交易记录的具体代码,供大家参考。具体内容如下一.搭建Python环境本帖使用Python2.7个涉及模块:spynner、scrapy、bs4、pymmssql二.要获取的天猫数据三.数据采集过程四.源码#coding:utf-8 import spynner from scrapy.selector import Selector from bs4 import BeautifulSoup import ran
Python爬虫实现爬取京东店铺信息和下载图片功能示例
本文介绍了Python爬虫实现爬取京东店铺信息和下载图片的功能。分享出来供大家参考,如下:这是来自bs4 import BeautifulSoup import requests url ='+%C9%D5%CB% AE&type=p&vmarket=&spm=875.7931836%2FA.a2227oh.d100&from=mal
python定时给微信朋友发消息的例子
如下图: from __future__ import unicode_literals from threading import Timer from wxpy import * import requests #bot = Bot() #bot = Bot(console_qr=2,cache_path="botoo.pkl")#这里的二维码使用像素如果你在 win 环境中运行,将其替换为 bot=Bot() bot = Bot(cache_path=True) de
python如何抓取网页中的文本
用Python爬取网页文本的代码:#!/usr/bin/python # -*- coding: UTF-8 -*- import requests import re #下载一个网页url ='' #模拟浏览器发送http请求 response = requests .get(url) # 编码方式 response.encoding='utf-8' # 目标小说首页的网页源码 html = re
抓取网易新闻的方法的python正则示例
本文介绍了Python常规抓取网易新闻的方法示例。分享出来供大家参考,如下: 我写了一些爬取网易新闻的爬虫,发现其网页源码和网页评论根本不对。因此,使用抓包工具来获取其评论的隐藏地址(每个浏览器都有自己的抓包工具,可以用来分析网站)如果仔细看,会发现有一个特别,那么这就是我想要的,然后打开链接找到相关的评论内容。(下图为第一页内容)接下来是代码(也是按照大神写的)。#coding= utf-8 导入 urllib2 导入
Python常规抓取新闻标题和链接方法示例
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家参考,如下: #-*-coding:utf-8-*- import re from urllib import urlretrieve from urllib import urlopen #获取网页信息 doc = urlopen("").read() #找大data news by自己网站 #抓取新闻标题和链接 def extract_title(info): 查看全部
网页小说抓取 ios(与抓取预定义好的页面集合不同,抓取一个会带来一个挑战)
与抓取一组预定义的页面不同,抓取一个网站的所有内链会带来一个挑战,就是你不知道你会得到什么。幸运的是,有几种基本的方法可以识别页面类型。
按网址
网站 中的所有博客 文章 都可能收录一个 URL(例如)。
传递 网站 中存在或缺失的特定字段
如果页面收录日期但不收录作者姓名,那么您可以将其归类为新闻稿。如果它有标题、主图、价格,但没有主要内容,那么它可能是一个产品页面。
通过出现在页面上的特定标签识别页面
即使您没有捕获某个标签中的数据,您仍然可以使用该标签。你的爬虫可以寻找类似的东西
此类元素用于标识产品页面,即使爬虫对相关产品的内容不感兴趣。
为了跟踪多种页面类型,您需要在 Python 中拥有多种类型的页面对象。这是通过两种方式实现的。
如果页面相似(它们的内容类型基本相同),则可能需要在现有页面对象中添加 pageType 属性:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, type, name, url, searchUrl, resultListing,
resultUrl, absoluteUrl, titleTag, bodyTag):
self.name = name
self.url = url
self.titleTag = titleTag
self.bodyTag = bodyTag
self.pageType = pageType
如果在类 SQL 的数据库中对这些页面进行排序,则此模式类型意味着这些页面应存储在同一个表中,并添加了一个额外的 pageType 列。
如果您抓取的页面或内容不同(它们收录不同类型的字段),您需要为每种页面类型创建一个新对象。当然,有些东西是所有网页共有的——它们都有一个 URL,它们也可能有一个名称或页面标题。这种情况非常适合子类化:
class Website:
"""所有文章/网页的共同基类"""
def __init__(self, name, url, titleTag):
self.name = name
self.url = url
self.titleTag = titleTag
这不是您的爬虫直接使用的对象,而是您的页面类型将引用的对象:
class Product(Website):
"""产品页面要抓取的信息"""
def __init__(self, name, url, titleTag, productNumber, price):
Website.__init__(self, name, url, TitleTag)
self.productNumberTag = productNumberTag
self.priceTag = priceTag
class Article(Website):
"""文章页面要抓取的信息"""
def __init__(self, name, url, titleTag, bodyTag, dateTag):
Website.__init__(self, name, url, titleTag)
self.bodyTag = bodyTag
self.dateTag = dateTag
该产品页面扩展了Website 基类,增加了仅适用于产品的productNumber 和price 属性,而Article 类增加了不适用于产品的body 和date 属性。
您可以使用这两个类别来抓取商店网站。除了产品,这个 网站 还可能收录博客 文章 或新闻稿。
希望以上知识点对您有所帮助,感谢您的支持。
时间:2019-11-18
Python爬取链接网站详解
在本文 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。这个爬虫非常适合从网站抓取所有数据的item,而不是从特定搜索结果或页面列表抓取数据的item。它也非常适合 网站 页面组织不良或非常分散的情况。这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道该做什么去寻找链接的位置,所以需要一些规则来告诉它选择哪个页面
Python 50行爬虫爬取处理图灵书目的过程详解
前言使用请求进行爬行。BeautifulSoup 执行数据提取。主要分为两步:第一步是解析图书列表页,解析里面的图书详情页链接。第二步,解析图书详情页,提取感兴趣的Content,在本例中,根据不同的数据情况,采用不同的提取方式。总体感觉BeautifulSoup用起来很方便。下面是几个典型的HTML内容提取Python代码片段1.Extract details page link list page Detail page link snippet in
Python3简单爬虫抓取网页图片代码示例
网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都是用python3环境,不兼容python2),所以写了一个简单的网页图片使用Python3语法抓取示例,希望对大家有帮助,希望大家批评指正 import urllib.request import re import os import urllib #根据给定的URL获取网页的详细信息,得到的html为网页源码 def getHtml(url): page = urllib.request.urlope
Python实现爬虫爬小说功能实例【抓金庸小说】
本文介绍爬虫爬取小说功能在python中的实现。分享出来供大家参考,如下: # -*- coding: utf-8 -*- from bs4 import BeautifulSoup from urllib import request import re import os,time #访问url,返回html页面 def get_html(url): req = request.Request(url) req.add_header('User-Agent','Mozilla/5.0'
Python请求抢一推文字图片代码示例
本文文章主要介绍python请求一推文图片代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考requests是Python中的第三方库,基于urllib,使用Apache2 Licensed开源协议的HTTP库。它比 urllib 更方便,可以为我们节省很多工作,完全满足 HTTP 测试需求。接下来记录一下requests的使用: from bs4 import BeautifulSoup f
一个用Python程序抓取网页HTML信息的小例子
爬取网页数据的思路有很多,一般是:直接代码请求http。模拟浏览器请求数据(通常需要登录验证)。控制浏览器实现数据抓取等,本文不考虑复杂情况,放一个简单的网页数据小例子:目标数据将所有这些玩家的超链接保存在ittf网站@ >. 数据请求真的很像符合人类思维的库,比如requests,如果你想直接拿网页的话文字就一句话搞定:doc = requests.get(url).text 解析html获取数据
Python实现抓取HTML网页并保存为PDF文件的方法
本文介绍了 Python 如何捕获 HTML 网页并将其保存为 PDF 文件的示例。分享出来供大家参考,如下: 一.前言 今天介绍抓取HTML网页,然后保存成PDF,废话我们不直接进入教程。今天的例子是以廖雪峰老师的Python教程网站为例:二.准备1.PyPDF2的安装和使用(用于合并PDF):PyPDF2版本:1. 2
python数据捕获分析示例代码(python+mongodb)
本文介绍Python数据采集与分析,分享给大家,如下: 编程模块:requests, lxml, pymongo, time, BeautifulSoup 首先获取所有产品的分类URL: def step(): try: headers = {. ... .} r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式
Python如何抓取天猫产品的详细信息和交易记录
本文示例分享了Python捕捉天猫产品详细信息和交易记录的具体代码,供大家参考。具体内容如下一.搭建Python环境本帖使用Python2.7个涉及模块:spynner、scrapy、bs4、pymmssql二.要获取的天猫数据三.数据采集过程四.源码#coding:utf-8 import spynner from scrapy.selector import Selector from bs4 import BeautifulSoup import ran
Python爬虫实现爬取京东店铺信息和下载图片功能示例
本文介绍了Python爬虫实现爬取京东店铺信息和下载图片的功能。分享出来供大家参考,如下:这是来自bs4 import BeautifulSoup import requests url ='+%C9%D5%CB% AE&type=p&vmarket=&spm=875.7931836%2FA.a2227oh.d100&from=mal
python定时给微信朋友发消息的例子
如下图: from __future__ import unicode_literals from threading import Timer from wxpy import * import requests #bot = Bot() #bot = Bot(console_qr=2,cache_path="botoo.pkl")#这里的二维码使用像素如果你在 win 环境中运行,将其替换为 bot=Bot() bot = Bot(cache_path=True) de
python如何抓取网页中的文本
用Python爬取网页文本的代码:#!/usr/bin/python # -*- coding: UTF-8 -*- import requests import re #下载一个网页url ='' #模拟浏览器发送http请求 response = requests .get(url) # 编码方式 response.encoding='utf-8' # 目标小说首页的网页源码 html = re
抓取网易新闻的方法的python正则示例
本文介绍了Python常规抓取网易新闻的方法示例。分享出来供大家参考,如下: 我写了一些爬取网易新闻的爬虫,发现其网页源码和网页评论根本不对。因此,使用抓包工具来获取其评论的隐藏地址(每个浏览器都有自己的抓包工具,可以用来分析网站)如果仔细看,会发现有一个特别,那么这就是我想要的,然后打开链接找到相关的评论内容。(下图为第一页内容)接下来是代码(也是按照大神写的)。#coding= utf-8 导入 urllib2 导入
Python常规抓取新闻标题和链接方法示例
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家参考,如下: #-*-coding:utf-8-*- import re from urllib import urlretrieve from urllib import urlopen #获取网页信息 doc = urlopen("").read() #找大data news by自己网站 #抓取新闻标题和链接 def extract_title(info):
网页小说抓取 ios(网页书籍抓取器基本简介(2016年10月21日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-29 06:05
网络图书抓取器是一款出色的小说下载工具。支持网站各大网络小说。你可以下载任何你想要的东西。下载完全免费。不需要复杂的操作。一键抓取也是可能的。将所有章节合二为一,非常方便易用。
网络图书爬虫基本介绍
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。
网络图书抓取器功能介绍
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
Web Book Crawler 的亮点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本,方便保存。
网络图书爬虫的主要优点
1、网络小说抓取软件是一款非常实用的网络小说抓取软件。有了它,用户可以在十多部小说网站上快速提取小说的章节、内容等。并将其保存在本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。
如何使用网络图书抓取器
1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
网络图书爬虫评论
支持多种字符编码方式,避免出现乱码。
细节 查看全部
网页小说抓取 ios(网页书籍抓取器基本简介(2016年10月21日))
网络图书抓取器是一款出色的小说下载工具。支持网站各大网络小说。你可以下载任何你想要的东西。下载完全免费。不需要复杂的操作。一键抓取也是可能的。将所有章节合二为一,非常方便易用。
网络图书爬虫基本介绍
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。
网络图书抓取器功能介绍
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
Web Book Crawler 的亮点
1、 支持多种小说平台的小说爬取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 获取的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本,方便保存。
网络图书爬虫的主要优点
1、网络小说抓取软件是一款非常实用的网络小说抓取软件。有了它,用户可以在十多部小说网站上快速提取小说的章节、内容等。并将其保存在本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。
如何使用网络图书抓取器
1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
网络图书爬虫评论
支持多种字符编码方式,避免出现乱码。
细节
网页小说抓取 ios(IbookBox网页小说批量下载阅读器(批量抓取下载小说下载吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-28 11:13
IbookBox 网络小说批量下载阅读器(批量下载小说)。
IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题后,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持将抓取的电子书发送到手机生成txt。3、@ >支持电子书自动存放在自己的邮箱中。4、纯单机版不需要任何人工干预。
小说爬虫是一款功能强大的在线小说下载工具。可以帮助小说迷快速搜索海量热门小说资源并下载到本地。操作简单、方便、快捷,非常好用。通过小说爬虫用户可以快速。
最流行的软件站点提供 IbookBox 下载。ibookBox小说批量下载阅读器是一款电脑下载工具,可以通过输入任意网页地址抓取下载网络上的所有电子书。纯单机版不需要任何人工干预。.
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。 查看全部
网页小说抓取 ios(IbookBox网页小说批量下载阅读器(批量抓取下载小说下载吧))
IbookBox 网络小说批量下载阅读器(批量下载小说)。
IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题后,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
ibookBox小说批量下载阅读器功能:1、支持所有小说网站抓取各类小说。2、支持将抓取的电子书发送到手机生成txt。3、@ >支持电子书自动存放在自己的邮箱中。4、纯单机版不需要任何人工干预。
小说爬虫是一款功能强大的在线小说下载工具。可以帮助小说迷快速搜索海量热门小说资源并下载到本地。操作简单、方便、快捷,非常好用。通过小说爬虫用户可以快速。
最流行的软件站点提供 IbookBox 下载。ibookBox小说批量下载阅读器是一款电脑下载工具,可以通过输入任意网页地址抓取下载网络上的所有电子书。纯单机版不需要任何人工干预。.
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
网页小说抓取 ios(超级牛掰的Windows端小说下载/阅读神器-不是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-24 06:05
推荐很多小说阅读软件。大部分都是Android,但有时候我们也不能总是看小说。很多人问我有没有什么软件可以在我的电脑上看小说。
曲哥虽然平时不怎么看小说,但既然大家都有这方面的需求,我肯定要安排一下。今天给大家分享一款超级棒的Windows端小说下载/阅读神器。
它可能是我在PC端看到的最好的新颖的应用程序。集小说阅读、下载、听书、自定义书源等功能于一体。该主题还支持自定义设置。您可以在设置中自行下载并保存目录。修改,整个应用设计非常人性化
大叔小说(Windows)
软件很简单,没有任何广告,但是UI设计感觉有点老气。但是完全不影响使用。
搜索小说后,单击添加到书架。软件会自动净化书源。书架上会有相应的书籍。该软件还提供了下载书籍的功能。下载速度也非常快。避免自己从网上下载很多乱七八糟的东西。
许多书籍资源也用于检索资源。基本上找不到小说。而且书源也可以自己添加。
说到阅读界面,确实做到了比手机端更强大的设置。首先,字体不是Android可比的。您可以使用计算机上的所有字体。页宽、行高、段落间距等。
背景颜色也可以自定义背景图片。并且可以开启护眼模式。更改为绿色阅读模式。
大叔小说: 查看全部
网页小说抓取 ios(超级牛掰的Windows端小说下载/阅读神器-不是)
推荐很多小说阅读软件。大部分都是Android,但有时候我们也不能总是看小说。很多人问我有没有什么软件可以在我的电脑上看小说。
曲哥虽然平时不怎么看小说,但既然大家都有这方面的需求,我肯定要安排一下。今天给大家分享一款超级棒的Windows端小说下载/阅读神器。
它可能是我在PC端看到的最好的新颖的应用程序。集小说阅读、下载、听书、自定义书源等功能于一体。该主题还支持自定义设置。您可以在设置中自行下载并保存目录。修改,整个应用设计非常人性化
大叔小说(Windows)
软件很简单,没有任何广告,但是UI设计感觉有点老气。但是完全不影响使用。
https://www.i3zh.com/wp-conten ... 2.png 300w, https://www.i3zh.com/wp-conten ... 4.png 1024w, https://www.i3zh.com/wp-conten ... 3.png 768w" />搜索小说后,单击添加到书架。软件会自动净化书源。书架上会有相应的书籍。该软件还提供了下载书籍的功能。下载速度也非常快。避免自己从网上下载很多乱七八糟的东西。
许多书籍资源也用于检索资源。基本上找不到小说。而且书源也可以自己添加。
https://www.i3zh.com/wp-conten ... 4.png 300w, https://www.i3zh.com/wp-conten ... 9.png 1024w, https://www.i3zh.com/wp-conten ... 1.png 768w" />https://www.i3zh.com/wp-conten ... 4.jpg 300w, https://www.i3zh.com/wp-conten ... 8.jpg 1024w, https://www.i3zh.com/wp-conten ... 3.jpg 768w" />说到阅读界面,确实做到了比手机端更强大的设置。首先,字体不是Android可比的。您可以使用计算机上的所有字体。页宽、行高、段落间距等。
https://www.i3zh.com/wp-conten ... 0.png 300w, https://www.i3zh.com/wp-conten ... 2.png 1024w, https://www.i3zh.com/wp-conten ... 1.png 768w" />背景颜色也可以自定义背景图片。并且可以开启护眼模式。更改为绿色阅读模式。
https://www.i3zh.com/wp-conten ... 5.jpg 300w, https://www.i3zh.com/wp-conten ... 8.jpg 1024w, https://www.i3zh.com/wp-conten ... 9.jpg 768w" />大叔小说:
网页小说抓取 ios(如何帮助用户下载指定网页的某本书和某个章节的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-23 18:13
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
相关软件软件大小版本说明下载地址
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
特征
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
指示
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。 查看全部
网页小说抓取 ios(如何帮助用户下载指定网页的某本书和某个章节的软件)
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
相关软件软件大小版本说明下载地址
在线图书抓取器是一种可以帮助用户在指定网页上下载某本书和某章的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
特征
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
软件特点
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到您需要的书),并自动应用相应的代码, 也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
指示
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。
网页小说抓取 ios(ibookbox软件特色支持所有小说网站快速下载的ibookbox功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-23 09:10
ibookbox是一款可以帮助我们快速下载小说的工具。它允许我们输入任何网页地址来抓取和下载网页上的所有电子书并下载它们。非常实用,也支持一些小说。逐章下载,让我们最新的小说章节,有需要的朋友快速下载。
ibookbox功能介绍
1、 进入软件主界面,包括需要下载的书名、书在哪个页面、高级操作、最后获取的小说。
2、 点击高级操作,快速采集任意网页、欣赏网页快照、批量下载图片、批量抓取电子书、管理日常备忘录等。
3、查看包括全屏、下载管理、邮箱管理、采集夹管理、工具栏、状态栏等。
4、工具包括开机后启动IBOOKBOX、下载后关机、监控剪贴板、代理服务器设置、使用IE代理设置、选项等。
5、 点击选项包括通用选项、影响选项、数据检索、下载列表、协议、连接、杂项、桌面提示、外观样式等。
ibookbox 软件功能
支持所有小说网站,捕捉各类小说。
支持从获取的电子书中生成txt并发送给手机。
支持将电子书自动存放在您自己的邮箱中。
纯单机版无需任何人工干预,自动抓取各类网页和电子书。
非常适合手机用户在抓取完成后在手机上离线阅读。
所见即所得,如果你想下载任何你看到的书,你可以立即下载。
获取的小说默认存储在本地计算机中。
电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
更新日志
修复错误
精简文件
优化方案 查看全部
网页小说抓取 ios(ibookbox软件特色支持所有小说网站快速下载的ibookbox功能介绍)
ibookbox是一款可以帮助我们快速下载小说的工具。它允许我们输入任何网页地址来抓取和下载网页上的所有电子书并下载它们。非常实用,也支持一些小说。逐章下载,让我们最新的小说章节,有需要的朋友快速下载。
ibookbox功能介绍
1、 进入软件主界面,包括需要下载的书名、书在哪个页面、高级操作、最后获取的小说。
2、 点击高级操作,快速采集任意网页、欣赏网页快照、批量下载图片、批量抓取电子书、管理日常备忘录等。
3、查看包括全屏、下载管理、邮箱管理、采集夹管理、工具栏、状态栏等。
4、工具包括开机后启动IBOOKBOX、下载后关机、监控剪贴板、代理服务器设置、使用IE代理设置、选项等。
5、 点击选项包括通用选项、影响选项、数据检索、下载列表、协议、连接、杂项、桌面提示、外观样式等。
ibookbox 软件功能
支持所有小说网站,捕捉各类小说。
支持从获取的电子书中生成txt并发送给手机。
支持将电子书自动存放在您自己的邮箱中。
纯单机版无需任何人工干预,自动抓取各类网页和电子书。
非常适合手机用户在抓取完成后在手机上离线阅读。
所见即所得,如果你想下载任何你看到的书,你可以立即下载。
获取的小说默认存储在本地计算机中。
电子书可以通过QQ邮箱、网易邮箱、新浪邮箱、阿里巴巴邮箱存储。并通过手机邮件APP应用直接接收拍摄的小说。
更新日志
修复错误
精简文件
优化方案
网页小说抓取 ios(上班族为上班族看小说量身打造而成,你还在等什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 434 次浏览 • 2021-10-23 07:12
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。针对上班族在看书过程中经常遇到的中断,该工具还提供了继续阅读功能,让用户可以从上次阅读的内容开始继续阅读。完全适合上班族看小说。你还在,你还在等什么?点击立即下载!
如何使用1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成一个设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
软件功能1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到你需要的书),也可以输入相应的代码自动应用,你也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
软件特点 1、 支持多种小说平台的小说抓取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 提取后的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本的键,方便保存。
软件优势1、 网络小说爬虫是一款非常实用的网络小说爬虫软件。有了它,用户可以快速提取十多部小说网站的小说章节和内容。记录并保存到本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。 查看全部
网页小说抓取 ios(上班族为上班族看小说量身打造而成,你还在等什么?)
网络图书抓取器是一款免费的网络小说下载软件,主要功能是从各大网站中抓取需要的网络小说,并自动生成txt文本。下载本软件后,您可以一键免费阅读网站的热门小说,还可以根据用户需求自动查找相关书籍和章节。独特的内核索引引擎可以帮助用户搜索它们。小说的章节避免了无用数据的产生。清晰的页面设计,让用户即刻使用,拒绝各种繁琐的功能设置,只为用户提供更好的阅读体验。并且相比传统的提取工具,网络图书抓取器可以基于网络小说目录整合文本,让读者体验一流的阅读体验。针对上班族在看书过程中经常遇到的中断,该工具还提供了继续阅读功能,让用户可以从上次阅读的内容开始继续阅读。完全适合上班族看小说。你还在,你还在等什么?点击立即下载!
如何使用1、 网络图书抓取器下载后,解压安装包,双击使用,第一次运行会自动生成一个设置文件,用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2、首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3、可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4、在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录排版带来极大的方便。已输入 10 个适用的 网站。选择后,您可以快速打开网站 找到您需要的书,并自动应用相应的代码。
软件功能1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键爬取:又称°傻瓜模式“”,意思是网络图书爬虫可以实现自动爬取和合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已输入10个适用网站(选择后可以快速打开网站找到你需要的书),也可以输入相应的代码自动应用,你也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中以备后用。
6、轻松制作电子书:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
软件特点 1、 支持多种小说平台的小说抓取。
2、支持多种文字编码方式,避免文字乱码。
3、 一键提取查看小说所有目录。
4、 支持调整小说章节位置,可以上下移动。
5、 支持在线查看章节内容,避免提取错误章节。
6、 当抓取失败时,支持手动或自动重新抓取。
7、 提取后的小说会以一章一文的形式保存。
8、——将所有章节合并为一个文本的键,方便保存。
软件优势1、 网络小说爬虫是一款非常实用的网络小说爬虫软件。有了它,用户可以快速提取十多部小说网站的小说章节和内容。记录并保存到本地
2、这个爬虫工具功能齐全,非常友好。为用户贴心配备了4种文本编码器,防止用户提取小说时出现乱码,一键提取。将文件合并为一个文件
3、该软件使用方便,运行流畅,爬行错误率极低。如果您是小说爱好者,强烈建议您使用本软件进行小说爬取。
网页小说抓取 ios(小说规则捕捉器是小说网站能对应大部分的小说资源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-17 02:27
小说规则捕手是一款小说抓取下载工具,可以分析网站相关代码,直接抓取目标站小说资源。功能强大,还可以对你要找的小说进行多项设置,更快捷更方便的找到你想阅读的小说资源。小说规则捕手软件基本可以对应大部分小说网站。有兴趣的,快来下载吧。
软件介绍
这个软件可以说是好用,也可以说是难用。比如直接从网站中抓取书籍,直接从自带的100多个预设网站中抓取(需要浏览找到你要下载的书,然后复制链接到入口URL),无需分析复杂的源代码。对于逻辑思维能力强的用户,可以分析小说网站的源码,制定网站的捕捉规则,基本可以应对大部分小说网站。
软件特点
自定义规则抓取,可以抓取大部分小说网络文章,部分网站详细书籍分类,也支持多书抓取;
自带大量预测网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂时存入数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和excel文档中导入任务,带章节页面链接进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附赠小工具:ePub电子书制作与分解工具,支持从章节存储的书籍中生成ePub文件,也可以将ePub文件分解为多章节的文本文件。 查看全部
网页小说抓取 ios(小说规则捕捉器是小说网站能对应大部分的小说资源)
小说规则捕手是一款小说抓取下载工具,可以分析网站相关代码,直接抓取目标站小说资源。功能强大,还可以对你要找的小说进行多项设置,更快捷更方便的找到你想阅读的小说资源。小说规则捕手软件基本可以对应大部分小说网站。有兴趣的,快来下载吧。
软件介绍
这个软件可以说是好用,也可以说是难用。比如直接从网站中抓取书籍,直接从自带的100多个预设网站中抓取(需要浏览找到你要下载的书,然后复制链接到入口URL),无需分析复杂的源代码。对于逻辑思维能力强的用户,可以分析小说网站的源码,制定网站的捕捉规则,基本可以应对大部分小说网站。
软件特点
自定义规则抓取,可以抓取大部分小说网络文章,部分网站详细书籍分类,也支持多书抓取;
自带大量预测网站,没有定义规则的用户可以直接申请,也可以抓取自己需要的小说;
内置源码查看器,提供链接分析、关键定位、标签分割等工具;
对于大型小说,任务暂时存入数据库后,可以随意中断和恢复任务;
图书提供多种输出方式:章节文件、独立文本文件、压缩包、ePub电子书等;
支持任务导入,即从文本文件和excel文档中导入任务,带章节页面链接进行抓取;
所有组件都支持提示信息,即光标停止后会显示相关提示。大部分操作支持状态栏提示,使用更方便;
支持添加、修改、导入、导出、排序和删除预设网站;
附赠小工具:ePub电子书制作与分解工具,支持从章节存储的书籍中生成ePub文件,也可以将ePub文件分解为多章节的文本文件。
网页小说抓取 ios(网络书籍抓取器是一款强大的小说下载工具,使用这款工具 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2021-10-11 23:15
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在使用这款软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。
2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。
8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。
10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。
查看全部
网页小说抓取 ios(网络书籍抓取器是一款强大的小说下载工具,使用这款工具
)
在线图书抓取器是一款功能强大的小说下载工具。借助此工具,用户可以从20多个小说平台抓取海量小说内容,并根据小说章节进行保存;对于需要制作电子书的用户来说,确实是一款方便易用的小说下载工具;本软件界面比较简洁,但也非常直观,为用户标明了操作步骤,按照步骤进行设置,使用本软件方便;有很多用户移动小说的时候,往往不是那么顺利,需要开通各种会员。现在使用这款软件,完全不用担心这些问题,因为它支持20多部小说网站,完全可以满足用户的下载需求。
软件功能
1、章节调整
解压目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终书,最终书会按照调整后的章节顺序输出。
2、自动重试
在抓取过程中,由于网络因素,程序可能会自动重试成功,也可以暂时中断抓取(中断后关闭程序不会影响进度),待网络良好后再重试。
3、停止并继续
爬取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,下次运行程序可以继续爬取)。注意:您需要使用“停止”按钮中断然后退出程序。如果直接退出,则无法恢复)。
4、一键抓拍
又称“傻瓜模式”,基本可以实现自动抓取合并的功能,直接输出最终的文本文件。您可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),也可以在调整章节后使用一键抓取,自动完成抓取和合并操作。
5、适用网站
收录10个适用的网站(选择后可以快速打开网站找到你需要的书),并自动应用相应的代码。其他小说网站也可以测试。如果一起使用,可以手动将它们添加到设置文件中以使其待机。
6、电子书制作方便
设置文件中可以添加每章名称的前缀和后缀,为以后电子书的目录编排带来很大的方便。
软件特点
1、十余部小说免费下载网站无需注册和登录。
2、 支持四种常用的文本编码器,可以很好的解析小说内容,无乱码。
3、可以自动获取书名,一键提取书名。
4、 支持图书目录管理,可以切换目录位置,删除,排序等。
5、如果下载失败,支持会自动重试,直到下载成功。
6、下载的小说文件可以一键合并成一个文件。
指示
1、打开软件,先打开使用网站菜单,因为其他小说网站可能下载不下来,展开后选择一个网站点击即可。
2、 提示“是否在浏览器中打开”,选择“是”自动跳转打开浏览器。
3、如下图,在网站中找到你要下载的小说。
4、 点击进入小说首页,复制小说链接。
5、然后将链接粘贴到输入框中,点击“目录提取”,下面的窗口就会显示小说目录。
6、然后设置小说的输出位置,点击“开始抓取”,软件就会开始抓取短篇小说并保存到你设置的位置。
7、如下图所示,小说是按章节保存的,每章一个文本。
8、 如果保存为多个文本太复杂,可以返回软件点击“合并”。
9、 现在回到软件的输出文件夹,可以看到所有的章节已经合并为一个文本了。
10、 如果在获取目录的过程中出现乱码,可以切换“编码”,再次尝试提取。

