
网站调用新浪微博内容
PC登录新浪微博模拟登录(人人网)(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-06-11 06:22
PC登录新浪微博时,用户名和密码在客户端用js进行了预加密,POST前会先GET一组参数,也会是POST_DATA的一部分。这样就不能用通常的简单方法来模拟POST登录(如人人网)。
通过爬虫获取新浪微博数据,模拟登录必不可少。
1、 在提交 POST 请求之前,需要通过 GET 获取四个参数(servertime、nonce、pubkey 和 rsakv)。这不仅仅是之前提到的简单的服务器时间和随机数。这主要是因为js有了用户名,密码加密方式发生了变化。
1.1 由于加密方式的变化,这里我们将使用RSA模块。 RSA公钥加密算法的介绍请参考网络中的相关内容。下载并安装 rsa 模块:
下载:
rsa 模块文档地址:
根据你的Python版本选择适合你的rsa安装包(.egg)。 win下安装需要通过命令行使用easy_install.exe(win下安装setuptool,从这里下载:setuptools-0.6c11.win32-py2.6.exe安装文件)安装,例如:easy_install rsa-3.1.1-py2.6.egg,在最后的命令行下测试import rsa,如果没有报错则安装成功。
1.2 获取并查看新浪微博登录js文件
查看新浪通url()的源码,在那里可以找到js地址,但是里面的内容打开后是加密的,可以在网上找一个在线解密站点解密,查看最终用户名和密码加密方式。
1.3 登录
第一步登录,添加自己的用户名(username),并请求prelogin_url链接地址:
prelogin_url =';callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&client=ssologin.js(v1.4.4)'% username
使用get方法获取如下类似内容:
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1362041092, “PCID”: “GZ-6664c3dea2bfdaa3c94e8734c9ec2c9e6a1f”, “随机数”: “IRYP4N”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: "1330428213","exectime":1})
然后从中提取我们想要的servertime、nonce、pubkey和rsakv。当然,pubkey和rsakv的值可以写在代码里,都是固定值。
2、在用户名由BASE64计算之前:
复制代码代码如下:
用户名_ = urllib.quote(用户名)
username = base64.encodestring(username)[:-1]
密码是SHA1加密3次,加上servertime和nonce值来干扰。即:经过两次SHA1加密,结果加上servertime和nonce的值,然后SHA1算一次。
在最新的rsa加密方式中,username还是像以前一样处理;
密码加密方式与原来不同:
2.1 首先创建一个rsa公钥。公钥的两个参数在新浪微博上都是固定值,但都是16进制字符串。第一个是第一步登录的公钥,第二个是js加密文件中的'10001'。
这两个值需要从十六进制转换为十进制,但也可以写在代码中。这里10001直接写成65537,代码如下:
复制代码代码如下:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) +'\t' + str(nonce) +'\n' + str(password) #从拼接明文js加密文件中获取
passwd = rsa.encrypt(message, key) #encryption
passwd = binascii.b2a_hex(passwd) #将加密后的信息转换为十六进制。
2.2 请求pass url: login_url =‘(v1.4.4)'
要发送的头信息
复制代码代码如下:
postPara = {
'entry':'微博',
'网关': '1',
'来自':'',
'savestate': '7',
'用户票':'1',
'ssosimplelogin': '1',
'vsnf': '1',
'vsnval':'',
'su': 编码用户名,
'service':'miniblog',
'servertime': serverTime,
'nonce':随机数,
'pwencode':'rsa2',
'sp': 编码密码,
'encoding':'UTF-8',
'prelt': '115',
'rsakv': rsakv,
'url':';callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype':'META'
}
在请求的内容中加入RSakv,pwencode的值改为rsa2,其他和之前一样。
整理参数,POST请求。检查是否登录成功,可以参考一句location.replace(";callback=parent.sinaSSOController.feedBackUrlCallBack&retcode=101&reason=%B5%C7%C2%BC%C3%FB%BB%F2%C3% in POST DC%C2%EB%B4%ED%CE%F3后得到的内容");
如果retcode=101,表示登录失败。登录成功后的结果类似,只是retcode的值为0。
3、登录成功后,body中替换信息中的url就是我们下一步要使用的url。然后对上面的URL使用GET方法向服务器发送一个请求,并保存这个请求的cookie信息,也就是我们需要的登录cookie。 查看全部
PC登录新浪微博模拟登录(人人网)(组图)
PC登录新浪微博时,用户名和密码在客户端用js进行了预加密,POST前会先GET一组参数,也会是POST_DATA的一部分。这样就不能用通常的简单方法来模拟POST登录(如人人网)。
通过爬虫获取新浪微博数据,模拟登录必不可少。
1、 在提交 POST 请求之前,需要通过 GET 获取四个参数(servertime、nonce、pubkey 和 rsakv)。这不仅仅是之前提到的简单的服务器时间和随机数。这主要是因为js有了用户名,密码加密方式发生了变化。
1.1 由于加密方式的变化,这里我们将使用RSA模块。 RSA公钥加密算法的介绍请参考网络中的相关内容。下载并安装 rsa 模块:
下载:
rsa 模块文档地址:
根据你的Python版本选择适合你的rsa安装包(.egg)。 win下安装需要通过命令行使用easy_install.exe(win下安装setuptool,从这里下载:setuptools-0.6c11.win32-py2.6.exe安装文件)安装,例如:easy_install rsa-3.1.1-py2.6.egg,在最后的命令行下测试import rsa,如果没有报错则安装成功。
1.2 获取并查看新浪微博登录js文件
查看新浪通url()的源码,在那里可以找到js地址,但是里面的内容打开后是加密的,可以在网上找一个在线解密站点解密,查看最终用户名和密码加密方式。
1.3 登录
第一步登录,添加自己的用户名(username),并请求prelogin_url链接地址:
prelogin_url =';callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&client=ssologin.js(v1.4.4)'% username
使用get方法获取如下类似内容:
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1362041092, “PCID”: “GZ-6664c3dea2bfdaa3c94e8734c9ec2c9e6a1f”, “随机数”: “IRYP4N”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: "1330428213","exectime":1})
然后从中提取我们想要的servertime、nonce、pubkey和rsakv。当然,pubkey和rsakv的值可以写在代码里,都是固定值。
2、在用户名由BASE64计算之前:
复制代码代码如下:
用户名_ = urllib.quote(用户名)
username = base64.encodestring(username)[:-1]
密码是SHA1加密3次,加上servertime和nonce值来干扰。即:经过两次SHA1加密,结果加上servertime和nonce的值,然后SHA1算一次。
在最新的rsa加密方式中,username还是像以前一样处理;
密码加密方式与原来不同:
2.1 首先创建一个rsa公钥。公钥的两个参数在新浪微博上都是固定值,但都是16进制字符串。第一个是第一步登录的公钥,第二个是js加密文件中的'10001'。
这两个值需要从十六进制转换为十进制,但也可以写在代码中。这里10001直接写成65537,代码如下:
复制代码代码如下:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) +'\t' + str(nonce) +'\n' + str(password) #从拼接明文js加密文件中获取
passwd = rsa.encrypt(message, key) #encryption
passwd = binascii.b2a_hex(passwd) #将加密后的信息转换为十六进制。
2.2 请求pass url: login_url =‘(v1.4.4)'
要发送的头信息
复制代码代码如下:
postPara = {
'entry':'微博',
'网关': '1',
'来自':'',
'savestate': '7',
'用户票':'1',
'ssosimplelogin': '1',
'vsnf': '1',
'vsnval':'',
'su': 编码用户名,
'service':'miniblog',
'servertime': serverTime,
'nonce':随机数,
'pwencode':'rsa2',
'sp': 编码密码,
'encoding':'UTF-8',
'prelt': '115',
'rsakv': rsakv,
'url':';callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype':'META'
}
在请求的内容中加入RSakv,pwencode的值改为rsa2,其他和之前一样。
整理参数,POST请求。检查是否登录成功,可以参考一句location.replace(";callback=parent.sinaSSOController.feedBackUrlCallBack&retcode=101&reason=%B5%C7%C2%BC%C3%FB%BB%F2%C3% in POST DC%C2%EB%B4%ED%CE%F3后得到的内容");
如果retcode=101,表示登录失败。登录成功后的结果类似,只是retcode的值为0。
3、登录成功后,body中替换信息中的url就是我们下一步要使用的url。然后对上面的URL使用GET方法向服务器发送一个请求,并保存这个请求的cookie信息,也就是我们需要的登录cookie。
盘点国内首款多用户PHP+Mysql开源微博客系统
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-06-10 03:40
国外的微博程序,虽然有StateusNet等所有功能,但可能不适合国内的特殊环境。既然如此,再来算一下国内的微博产品。详情请关注相关报道。
微博
Xweibo v2.0 正式版下载
界面预览
新浪X微博基于新浪开放API,通过绑定新浪微博账号即可与新浪微博无缝对接。 Xweibo 是完全免费和开源的。如果不能完全满足客户的需求,客户可以自由修改。 Xweibo支持与原站账号系统对接。 1.1版本内置了Discuz!的账号适配器,可以连接Discuz!和 Xweibo 帐户只需几个操作。微博支持换肤机制。除了默认提供的六套皮肤外,您还可以开发自己的自定义皮肤。
微博
i微博 v1.0 下载
界面预览
腾讯i微博系统是基于腾讯微博开放平台API开发的免费微博系统。收录完整的微博功能,可轻松接入腾讯微博。
PageCookery
PageCookery 微博系统 v0.9.8 下载
界面预览
PageCookery 是中国第一个公开发布的单用户开源微博程序。基于PHP+MySQL架构,以“分享”和“发现”为理念的安全、高效、稳定的Web2.0微博解决方案。
注意狗
Notes Dog v3.6.6.20120829 UTF-8 升级包下载
界面预览
健视狗微博系统是一套业界领先的开源PHP微博程序。支持网页、手机、QQ机器人、站外分享等多种方式发布内容,可通过QQ、微博秀场外呼、同步到新浪微博(可以使用新浪微博账号登录) 、注册和绑定)等传播内容,是目前最流行、最流行的交互系统。
EasyTalk
EasyTalk v5.0.1 build 20100801 下载
界面预览
EasyTalk 是国内第一个多用户 PHP+Mysql 开源微博系统。支持网页、手机等多种方式发布和接收信息。 EasyTalk 完全符合中国人的上网习惯。它真正轻便且易于使用。 ,便于管理员安装部署,管理方便。 EasyTalk 功能强大,二次开发度高,人性化的模板定制功能大大提升了用户体验,相比国内其他微博软件,EasyTalk 具有绝对优势! 查看全部
盘点国内首款多用户PHP+Mysql开源微博客系统
国外的微博程序,虽然有StateusNet等所有功能,但可能不适合国内的特殊环境。既然如此,再来算一下国内的微博产品。详情请关注相关报道。
微博
Xweibo v2.0 正式版下载


界面预览
新浪X微博基于新浪开放API,通过绑定新浪微博账号即可与新浪微博无缝对接。 Xweibo 是完全免费和开源的。如果不能完全满足客户的需求,客户可以自由修改。 Xweibo支持与原站账号系统对接。 1.1版本内置了Discuz!的账号适配器,可以连接Discuz!和 Xweibo 帐户只需几个操作。微博支持换肤机制。除了默认提供的六套皮肤外,您还可以开发自己的自定义皮肤。
微博
i微博 v1.0 下载
界面预览
腾讯i微博系统是基于腾讯微博开放平台API开发的免费微博系统。收录完整的微博功能,可轻松接入腾讯微博。
PageCookery
PageCookery 微博系统 v0.9.8 下载
界面预览
PageCookery 是中国第一个公开发布的单用户开源微博程序。基于PHP+MySQL架构,以“分享”和“发现”为理念的安全、高效、稳定的Web2.0微博解决方案。
注意狗
Notes Dog v3.6.6.20120829 UTF-8 升级包下载
界面预览
健视狗微博系统是一套业界领先的开源PHP微博程序。支持网页、手机、QQ机器人、站外分享等多种方式发布内容,可通过QQ、微博秀场外呼、同步到新浪微博(可以使用新浪微博账号登录) 、注册和绑定)等传播内容,是目前最流行、最流行的交互系统。
EasyTalk
EasyTalk v5.0.1 build 20100801 下载
界面预览
EasyTalk 是国内第一个多用户 PHP+Mysql 开源微博系统。支持网页、手机等多种方式发布和接收信息。 EasyTalk 完全符合中国人的上网习惯。它真正轻便且易于使用。 ,便于管理员安装部署,管理方便。 EasyTalk 功能强大,二次开发度高,人性化的模板定制功能大大提升了用户体验,相比国内其他微博软件,EasyTalk 具有绝对优势!
Twitter全面改用OAuth认证新浪微博接口的人~~
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-06 20:12
由于 Twitter 近期只支持 OAuth 认证方式,各大应用纷纷转向 OAuth 认证方式,新浪微博开放平台也将在近期停止 Base OAuth 认证方式。
为了继续使用新浪微博的开放平台,我开始研究OAuth认证方式。经过一段时间的实践,对新浪微博开放平台的OAuth认证方式有了一定的体会。鉴于网上这个平台的OAuth相关资料比较少,在这里分享一下过程中积累的经验,希望能帮助到一些想使用OAuth认证的人调用新浪微博界面~ ~
1.关于 OAuth:
OAUth认证方式相比Base OAuth认证方式最大的特点是应用端不需要保存用户的账号和密码,只需要用户授权的Key和Secret组合即可使用平台上的接口资源访问,在传输过程中,也可以避免恶意人员通过截包分析获取用户的账号和密码。 (有一种说法,推特之所以完全切换到OAuth认证,是为了防止GFW通过截包的方式获取一些相关名人的账号和密码)。具体定义可以阅读OAuth规范定义:OAuth规范。
2.新浪微博开放平台:
新浪微博开放平台的基本界面、参数、返回格式均参考推特模型。当然,国内其他一些开放平台也大量借鉴了推特的模式,所以基本是一样的。要使用新浪微博的开放平台,当然要先到其网站注册:新浪微博API。
注册后,会得到两个关键字段Consumer Key和Consumer Secret。保存它们。
新浪微博的开发平台有足够的文档,可以快速调用这些接口。除了一些较难的接口,我们将在下面讨论。
3.使用 OAuth 到新浪:
要使用 OAuth,用户必须先获得授权。一般来说,授权流程如下:
(1)应用向新浪开发平台发送请求,获取未授权的Request Token和Request Secret。此时Request Secret暂时不用,请妥善保管。
(2)以上一步获取的Request Token为参数,引导用户浏览器跳转到新浪微博授权页面,用户进入该页面登录新浪微博进行token授权.如果你在(1)如果浏览器的回调地址已经设置到服务器中,用户的浏览器会被重定向到这个地址,并且会在地址中增加一个新的参数:oauth_verifier。这个参数会稍后使用并保存。
(3)OAuth是认证过程的最后一步,向服务器请求真实的Token,将(1))中得到的Request Token、Request Secret和oauth_verifier作为参数传递给新浪微博服务器,服务端会返回真实的Access Token和Access Secret,新浪微博也会返回用户在新浪微博中的userid。有了用户的Access Token和Access Secret,就可以自由方便的调用新浪微博界面的开通。
每次调用都必须收录 OAuth 身份验证信息。作为OAuth认证信息,添加到请求包中基本上有两种方式:
(1)最推荐的方法是使用HTTP Authorization Header。这个header的定义在RFC2617中定义。
例如:
Authorization: OAuth realm="http://photos.example.net/",
oauth_consumer_key="dpf43f3p2l4k3l03",
oauth_token="nnch734d00sl2jdk",
oauth_signature_method="HMAC-SHA1",
oauth_signature="tR3%2BTy81lMeYAr%2FFid0kMTYa%2FWM%3D",
oauth_timestamp="1191242096", oauth_nonce="kllo9940pd9333jh",
oauth_version="1.0"
(2)或者你可以使用参数传递的方法,把OAuth参数像普通参数一样放在Get的URL中,或者放在POST的body内容中,都是可以的,
但是,在某些特殊情况下,解决这个问题会比较困难。
4.OAuth 认证参数分析:
如上所示,正常的 OAuth 身份验证收录以下参数:
(1)oauth_consumer_key:这是新浪在注册时给你的conusmer key,纯文本传输
(2)oauth_token:这是用户完成OAuth认证后的Access Token。在OAuth认证的第三步,就是Request Token,第一步不需要这个参数
(3)oauth_signature_method:加密方法,提供HMAC-SHA1、RSA-SHA1、PLAINTEXT几种方法
(4)oauth_signature:所有参数的加密字符串,包括消费者秘密和访问秘密
(5)oauth_timestamp:请求的时间戳
(6)oauth_version:可选参数,基本设置为1.0,否则会报错。
(7)oauth_nonce:防止重复调用的随机值
5.OAuth上传图片的痛苦:
使用上面的方法,基本上所有的接口调用都可以解决。但是当你遇到上传图片等困难的请求时,你需要一些技巧。
新浪微博开放平台要求上传图片时使用multipart/form-data。但是,当定义 OAuth 协议时,Content-Type 被描述为 application/x-www-form-urlencoded。没有提到如何在 multipart/form-data 中使用它。
在新浪微博的开放平台上,基本上网上找不到任何地方提到通过OAuth上传图片。在 Twitter 上尝试和学习了一晚之后,
终于找到解决办法了。
基本上,协议中没有规定的内容,必须由私营部门以更直观的方式解决。在新浪微博界面上传图片,必须使用multipart/form-data作为Content-Type,OAuth认证参数不能放在form-data中,必须通过Authorization Header进行处理。这时候就必须除了file参数之外,在这个界面,status是加到oauth的加密里面的,但是没有出现在Authorization Header里面,而是后面加到了fom-data中,这样图片可以正常上传,可以发布微博。通过这个简单又麻烦的方法,我终于可以安全的上传图片到新浪微博了。
6.last
到目前为止,我已经成功调用了新浪微博的大部分接口,并开始覆盖搜狐微博、网易微博等开放平台。希望可以通过这个文章记录一些经验和教训。
7.参考资料
[RFC5849]E。哈默拉哈夫,埃德。 《OAuth 1.0 协议》,RFC5849
[RFC1867] E. Nebel,L. Masinter,“HTML 中基于表单的文件上传”,RFC1867
[RFC2616] Fielding,R.,Gettys,J,e "超文本传输协议 - HTTP/1.1", RFC2616
[RFC2617] Franks,J.“HTTP 身份验证:基本和摘要式访问身份验证”,RFC2617
新浪微博开放平台: 查看全部
Twitter全面改用OAuth认证新浪微博接口的人~~
由于 Twitter 近期只支持 OAuth 认证方式,各大应用纷纷转向 OAuth 认证方式,新浪微博开放平台也将在近期停止 Base OAuth 认证方式。
为了继续使用新浪微博的开放平台,我开始研究OAuth认证方式。经过一段时间的实践,对新浪微博开放平台的OAuth认证方式有了一定的体会。鉴于网上这个平台的OAuth相关资料比较少,在这里分享一下过程中积累的经验,希望能帮助到一些想使用OAuth认证的人调用新浪微博界面~ ~
1.关于 OAuth:
OAUth认证方式相比Base OAuth认证方式最大的特点是应用端不需要保存用户的账号和密码,只需要用户授权的Key和Secret组合即可使用平台上的接口资源访问,在传输过程中,也可以避免恶意人员通过截包分析获取用户的账号和密码。 (有一种说法,推特之所以完全切换到OAuth认证,是为了防止GFW通过截包的方式获取一些相关名人的账号和密码)。具体定义可以阅读OAuth规范定义:OAuth规范。
2.新浪微博开放平台:
新浪微博开放平台的基本界面、参数、返回格式均参考推特模型。当然,国内其他一些开放平台也大量借鉴了推特的模式,所以基本是一样的。要使用新浪微博的开放平台,当然要先到其网站注册:新浪微博API。
注册后,会得到两个关键字段Consumer Key和Consumer Secret。保存它们。
新浪微博的开发平台有足够的文档,可以快速调用这些接口。除了一些较难的接口,我们将在下面讨论。
3.使用 OAuth 到新浪:

要使用 OAuth,用户必须先获得授权。一般来说,授权流程如下:
(1)应用向新浪开发平台发送请求,获取未授权的Request Token和Request Secret。此时Request Secret暂时不用,请妥善保管。
(2)以上一步获取的Request Token为参数,引导用户浏览器跳转到新浪微博授权页面,用户进入该页面登录新浪微博进行token授权.如果你在(1)如果浏览器的回调地址已经设置到服务器中,用户的浏览器会被重定向到这个地址,并且会在地址中增加一个新的参数:oauth_verifier。这个参数会稍后使用并保存。
(3)OAuth是认证过程的最后一步,向服务器请求真实的Token,将(1))中得到的Request Token、Request Secret和oauth_verifier作为参数传递给新浪微博服务器,服务端会返回真实的Access Token和Access Secret,新浪微博也会返回用户在新浪微博中的userid。有了用户的Access Token和Access Secret,就可以自由方便的调用新浪微博界面的开通。
每次调用都必须收录 OAuth 身份验证信息。作为OAuth认证信息,添加到请求包中基本上有两种方式:
(1)最推荐的方法是使用HTTP Authorization Header。这个header的定义在RFC2617中定义。
例如:
Authorization: OAuth realm="http://photos.example.net/",
oauth_consumer_key="dpf43f3p2l4k3l03",
oauth_token="nnch734d00sl2jdk",
oauth_signature_method="HMAC-SHA1",
oauth_signature="tR3%2BTy81lMeYAr%2FFid0kMTYa%2FWM%3D",
oauth_timestamp="1191242096", oauth_nonce="kllo9940pd9333jh",
oauth_version="1.0"
(2)或者你可以使用参数传递的方法,把OAuth参数像普通参数一样放在Get的URL中,或者放在POST的body内容中,都是可以的,
但是,在某些特殊情况下,解决这个问题会比较困难。
4.OAuth 认证参数分析:
如上所示,正常的 OAuth 身份验证收录以下参数:
(1)oauth_consumer_key:这是新浪在注册时给你的conusmer key,纯文本传输
(2)oauth_token:这是用户完成OAuth认证后的Access Token。在OAuth认证的第三步,就是Request Token,第一步不需要这个参数
(3)oauth_signature_method:加密方法,提供HMAC-SHA1、RSA-SHA1、PLAINTEXT几种方法
(4)oauth_signature:所有参数的加密字符串,包括消费者秘密和访问秘密
(5)oauth_timestamp:请求的时间戳
(6)oauth_version:可选参数,基本设置为1.0,否则会报错。
(7)oauth_nonce:防止重复调用的随机值
5.OAuth上传图片的痛苦:
使用上面的方法,基本上所有的接口调用都可以解决。但是当你遇到上传图片等困难的请求时,你需要一些技巧。
新浪微博开放平台要求上传图片时使用multipart/form-data。但是,当定义 OAuth 协议时,Content-Type 被描述为 application/x-www-form-urlencoded。没有提到如何在 multipart/form-data 中使用它。
在新浪微博的开放平台上,基本上网上找不到任何地方提到通过OAuth上传图片。在 Twitter 上尝试和学习了一晚之后,
终于找到解决办法了。
基本上,协议中没有规定的内容,必须由私营部门以更直观的方式解决。在新浪微博界面上传图片,必须使用multipart/form-data作为Content-Type,OAuth认证参数不能放在form-data中,必须通过Authorization Header进行处理。这时候就必须除了file参数之外,在这个界面,status是加到oauth的加密里面的,但是没有出现在Authorization Header里面,而是后面加到了fom-data中,这样图片可以正常上传,可以发布微博。通过这个简单又麻烦的方法,我终于可以安全的上传图片到新浪微博了。
6.last
到目前为止,我已经成功调用了新浪微博的大部分接口,并开始覆盖搜狐微博、网易微博等开放平台。希望可以通过这个文章记录一些经验和教训。
7.参考资料
[RFC5849]E。哈默拉哈夫,埃德。 《OAuth 1.0 协议》,RFC5849
[RFC1867] E. Nebel,L. Masinter,“HTML 中基于表单的文件上传”,RFC1867
[RFC2616] Fielding,R.,Gettys,J,e "超文本传输协议 - HTTP/1.1", RFC2616
[RFC2617] Franks,J.“HTTP 身份验证:基本和摘要式访问身份验证”,RFC2617
新浪微博开放平台:
新浪微博登录常用接口:对应主界面:但是个人建议
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-06-03 07:02
登录入口
新浪微博登录常用界面:
对应主界面:
但我个人推荐使用手机微博入口:
对应主界面:
原因是手机上的数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
对比下面两张PC端和手机端的图片,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(username, password) 登录微博
2.VisitPersonPage(user_id)访问people网站获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
新浪微博登录常用接口:对应主界面:但是个人建议
登录入口
新浪微博登录常用界面:
对应主界面:
但我个人推荐使用手机微博入口:
对应主界面:
原因是手机上的数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
对比下面两张PC端和手机端的图片,可以发现内容基本一致:

手机端如下图,图片相对较小,内容更加精简。
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(username, password) 登录微博
2.VisitPersonPage(user_id)访问people网站获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
PC站是你的首选:爬虫爬取网站m站
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-06-03 06:39
相关github地址:
一般做爬虫爬网站时,m站是首选,wap站次之,PC站最后考虑,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备工作
1、环境配置
2、Proxyip
使用代理ip爬虫是反爬虫方法之一。很多网站会检测某个时间段内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。但是一般这个只适合个人爬虫需求,因为很多免费的代理ip可能会被多人同时使用,使用时间短,速度慢,匿名性低,所以需要专业的爬虫工程师或者爬虫公司要使用更高品质的隐私代理,通常这类代理需要找专门的供应商购买,然后使用用户名/密码授权使用。
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = ''+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果
查看全部
PC站是你的首选:爬虫爬取网站m站
相关github地址:
一般做爬虫爬网站时,m站是首选,wap站次之,PC站最后考虑,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备工作
1、环境配置
2、Proxyip
使用代理ip爬虫是反爬虫方法之一。很多网站会检测某个时间段内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。但是一般这个只适合个人爬虫需求,因为很多免费的代理ip可能会被多人同时使用,使用时间短,速度慢,匿名性低,所以需要专业的爬虫工程师或者爬虫公司要使用更高品质的隐私代理,通常这类代理需要找专门的供应商购买,然后使用用户名/密码授权使用。
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = ''+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果

2018年2月赖敬之(东南大学信息科学与工程学院)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-06-03 06:37
2018年2月,建立基于网络爬虫的新浪微博数据分析网站赖景智(东南大学信息科学与工程学院,南京211189)[摘要]新浪微博作为中国最大的社交网络中国网站,内容丰富,本文实现了一个微博数据分析网站,网站后端使用爬虫实时抓取数据存入redis数据库,前端使用ajax轮询技术和数据可视化 该技术将统计分析后的数据展示在网页上,相比直接调用新浪微博的API,网络爬虫获取数据的方式具有更大的灵活性,能够获取的数据量也比较大,但也有一定的局限性,最大的障碍之一是新浪微博的反爬虫技术,本文也将讨论如何突破反爬虫的限制。[关键词]新浪;爬虫;数据分析[CL] C号] TP391.3 [文档识别码] A [文章号] 1006-4222 (2018)02-0073-02 1 简介 新浪微博是一种新兴的以关注和分享为一种模式,内容少,发布快,形式多样 正好迎合了人们对信息实时、准确、多样的分享和交流的需求,因此受到广大用户的欢迎和喜爱,而微博本身也有成为当代互联网领域的一颗冉冉升起的新星。人们热衷于在微博上获取信息 最新信息,发表您的观点,分享您喜欢的东西。因此,微博收录了丰富的数据,具有重要的数据挖掘意义。
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。使用爬虫,您可以轻松、自动、灵活地获取海量数据。本文首先介绍了新浪微博数据分析网站的整体思路,然后介绍了如何使用爬虫获取新浪微博上的数据。它还介绍了所使用的反爬虫技术。最后,本文讨论了如何实时显示数据。前端,并一一演示了可视化方法。 2 总体架构 整个网站分为三个部分:微博数据的抓取、微博数据的存储、微博数据的展示。用户首先在前端输入需要爬取的URL地址和cook-ie。点击开始爬取后,后端会向爬虫服务器发送爬虫请求,并将用户传入的cookie作为redis数据的key。将爬取到的数据存储在redis数据库中。这时候前端页面会向后端发起ajax轮询,希望能够获取到爬取到的数据,后端会从redis中取出数据封装成json发送给前端。这时候前端就可以使用数据进行可视化绘制了。 3 微博数据爬取方法3.1 通过自动化测试框架selenium抓取 由于电脑版微博是js动态生成的,无法通过简单的GET请求获取,需要js渲染引擎。
所以我们使用selenium的phatomjs来驱动。在个人主页上,随着滑块向下滚动,微博数据会不断更新,所以我们可以使用phatomjs来模拟这个过程,就在scrapy爬虫框架的中间文件中配置代码。 3.2 通过对ajax接口微博评论数据和转发数据接口的分析,通过抓包获取。使用浏览器自带的调试工具可以捕获数据包。 URL接口可以看成: /v6/comment/big?ajwvr=6&id=42153647 85782495&root_comment_max_i =9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0=42153647 85782495&root_comment_max_i=9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0d=42153647经过观察分析,可以发现大部分参数核心url为:https:// 查看全部
2018年2月赖敬之(东南大学信息科学与工程学院)
2018年2月,建立基于网络爬虫的新浪微博数据分析网站赖景智(东南大学信息科学与工程学院,南京211189)[摘要]新浪微博作为中国最大的社交网络中国网站,内容丰富,本文实现了一个微博数据分析网站,网站后端使用爬虫实时抓取数据存入redis数据库,前端使用ajax轮询技术和数据可视化 该技术将统计分析后的数据展示在网页上,相比直接调用新浪微博的API,网络爬虫获取数据的方式具有更大的灵活性,能够获取的数据量也比较大,但也有一定的局限性,最大的障碍之一是新浪微博的反爬虫技术,本文也将讨论如何突破反爬虫的限制。[关键词]新浪;爬虫;数据分析[CL] C号] TP391.3 [文档识别码] A [文章号] 1006-4222 (2018)02-0073-02 1 简介 新浪微博是一种新兴的以关注和分享为一种模式,内容少,发布快,形式多样 正好迎合了人们对信息实时、准确、多样的分享和交流的需求,因此受到广大用户的欢迎和喜爱,而微博本身也有成为当代互联网领域的一颗冉冉升起的新星。人们热衷于在微博上获取信息 最新信息,发表您的观点,分享您喜欢的东西。因此,微博收录了丰富的数据,具有重要的数据挖掘意义。
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。使用爬虫,您可以轻松、自动、灵活地获取海量数据。本文首先介绍了新浪微博数据分析网站的整体思路,然后介绍了如何使用爬虫获取新浪微博上的数据。它还介绍了所使用的反爬虫技术。最后,本文讨论了如何实时显示数据。前端,并一一演示了可视化方法。 2 总体架构 整个网站分为三个部分:微博数据的抓取、微博数据的存储、微博数据的展示。用户首先在前端输入需要爬取的URL地址和cook-ie。点击开始爬取后,后端会向爬虫服务器发送爬虫请求,并将用户传入的cookie作为redis数据的key。将爬取到的数据存储在redis数据库中。这时候前端页面会向后端发起ajax轮询,希望能够获取到爬取到的数据,后端会从redis中取出数据封装成json发送给前端。这时候前端就可以使用数据进行可视化绘制了。 3 微博数据爬取方法3.1 通过自动化测试框架selenium抓取 由于电脑版微博是js动态生成的,无法通过简单的GET请求获取,需要js渲染引擎。
所以我们使用selenium的phatomjs来驱动。在个人主页上,随着滑块向下滚动,微博数据会不断更新,所以我们可以使用phatomjs来模拟这个过程,就在scrapy爬虫框架的中间文件中配置代码。 3.2 通过对ajax接口微博评论数据和转发数据接口的分析,通过抓包获取。使用浏览器自带的调试工具可以捕获数据包。 URL接口可以看成: /v6/comment/big?ajwvr=6&id=42153647 85782495&root_comment_max_i =9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0=42153647 85782495&root_comment_max_i=9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0d=42153647经过观察分析,可以发现大部分参数核心url为:https://
新浪微博如何实现微博同步的功能?(一)_
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-06-03 05:19
最近遇到一个项目,需要用户的微博信息和他的网站项目同步。好在新浪微博提供了API。我大概查了一下。需要调用信息同步:需要验证用户登录,返回的数据为JSON格式。
在授权机制的描述中,新浪微博的API有两种认证机制,分别是:OAuth和Basic Auth。 OAuth 没有仔细看,所以忽略它们。在Basic Auth授权介绍部分,在cnblogs上有提到。 文章的一篇文章,这个文章展示了如何以GET方式提交http请求,并给出返回内容的代码,我在这个文章文章的公园团队中找到了另一个博客:这个文章实现站外发微博功能。结合这两个文章,就实现了新浪微博的同步功能。
下面介绍实现微博同步的步骤:
1. 首先,为了实现http请求,使用System.Net;需要引入命名空间。同时,在后面转换字符集和获取返回内容的过程中,还需要另外两个命名空间:using System.Text;并使用系统。 .IO;
接下来就可以开始写代码获取json数据了。
(1)准备用户验证数据
string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
(2)准备API URL,URL中的参数是通过GET直接附在URL上的。一开始博客园里的文章也没仔细看,直接贴出代码,给数据追加参数,返回400错误,后来查msdn,发现HttpWebRequest的默认请求方式是GET,既然是GET,就应该通过URL传递参数。
string url = "https://api.weibo.com/2/status ... 3B%3B
以上apikey是作为新浪微博用户的开发者申请的,应该是唯一的。博客园的文章zhong 说需要邮件审核。我没有发邮件,直接申请就收到了。一个APIKEY,信息也可以同步,但是在站外发送微博信息时,来源部分会是:未审核的应用。还有uid、screen_name等参数,具体参数API文档中有说明。 查看全部
新浪微博如何实现微博同步的功能?(一)_
最近遇到一个项目,需要用户的微博信息和他的网站项目同步。好在新浪微博提供了API。我大概查了一下。需要调用信息同步:需要验证用户登录,返回的数据为JSON格式。
在授权机制的描述中,新浪微博的API有两种认证机制,分别是:OAuth和Basic Auth。 OAuth 没有仔细看,所以忽略它们。在Basic Auth授权介绍部分,在cnblogs上有提到。 文章的一篇文章,这个文章展示了如何以GET方式提交http请求,并给出返回内容的代码,我在这个文章文章的公园团队中找到了另一个博客:这个文章实现站外发微博功能。结合这两个文章,就实现了新浪微博的同步功能。
下面介绍实现微博同步的步骤:
1. 首先,为了实现http请求,使用System.Net;需要引入命名空间。同时,在后面转换字符集和获取返回内容的过程中,还需要另外两个命名空间:using System.Text;并使用系统。 .IO;
接下来就可以开始写代码获取json数据了。
(1)准备用户验证数据
string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
(2)准备API URL,URL中的参数是通过GET直接附在URL上的。一开始博客园里的文章也没仔细看,直接贴出代码,给数据追加参数,返回400错误,后来查msdn,发现HttpWebRequest的默认请求方式是GET,既然是GET,就应该通过URL传递参数。
string url = "https://api.weibo.com/2/status ... 3B%3B
以上apikey是作为新浪微博用户的开发者申请的,应该是唯一的。博客园的文章zhong 说需要邮件审核。我没有发邮件,直接申请就收到了。一个APIKEY,信息也可以同步,但是在站外发送微博信息时,来源部分会是:未审核的应用。还有uid、screen_name等参数,具体参数API文档中有说明。
新浪微博开放接口调用微博API怎么样?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-06-01 01:29
因为最近接触到调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载链接:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的应用,然后你就可以得到应用密钥和应用秘钥,这是应用获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看新浪微博链接的说明。除了app key和app secret外,OAuth2授权参数还需要网站回调地址redirect_uri,而且这个回调地址不允许在局域网内(不管localhost,127.0.0. ]1 好像不行),这个真的让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写道可以改用该地址,我尝试了一下,这样就可以了,这对Diosi来说是个好消息。
我们先来一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
1 api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
2 authorize_url = api.get_authorize_url()
3 print(authorize_url)
4 webbrowser.open_new(authorize_url)
登录后会转成一个连接代码=92cc6accecfb5b2176adf58f4c
key是code值,是认证的关键。手动输入code值模拟认证
1 request = api.request_access_token(code, REDIRECT_URL)
2 access_token = request.access_token
3 expires_in = request.expires_in
4 api.set_access_token(access_token, expires_in)
5 api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token就是获得的token,expires_in是授权的过期时间 (UNIX时间)
用set_access_token保存授权。往下就可以调用微博接口了。测试发了一条微博
但是,这样的手动代码输入方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,对程序进行如下改进,可以自动获取并保存代码,方便程序服务调用。
访问微博
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
重试.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff 0:
if rv == True or type(rv) == str: # Done on success ..
return rv
mtries -= 1 # consume an attempt
time.sleep(mdelay) # wait...
mdelay *= backoff # make future wait longer
rv = f(*args, **kwargs) # Try again
return False # Ran out of tries :-(
return f_retry # true decorator -> decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
查看全部
新浪微博开放接口调用微博API怎么样?(图)
因为最近接触到调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载链接:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的应用,然后你就可以得到应用密钥和应用秘钥,这是应用获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看新浪微博链接的说明。除了app key和app secret外,OAuth2授权参数还需要网站回调地址redirect_uri,而且这个回调地址不允许在局域网内(不管localhost,127.0.0. ]1 好像不行),这个真的让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写道可以改用该地址,我尝试了一下,这样就可以了,这对Diosi来说是个好消息。
我们先来一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
1 api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
2 authorize_url = api.get_authorize_url()
3 print(authorize_url)
4 webbrowser.open_new(authorize_url)
登录后会转成一个连接代码=92cc6accecfb5b2176adf58f4c
key是code值,是认证的关键。手动输入code值模拟认证
1 request = api.request_access_token(code, REDIRECT_URL)
2 access_token = request.access_token
3 expires_in = request.expires_in
4 api.set_access_token(access_token, expires_in)
5 api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token就是获得的token,expires_in是授权的过期时间 (UNIX时间)
用set_access_token保存授权。往下就可以调用微博接口了。测试发了一条微博
但是,这样的手动代码输入方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,对程序进行如下改进,可以自动获取并保存代码,方便程序服务调用。


访问微博
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
重试.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff 0:
if rv == True or type(rv) == str: # Done on success ..
return rv
mtries -= 1 # consume an attempt
time.sleep(mdelay) # wait...
mdelay *= backoff # make future wait longer
rv = f(*args, **kwargs) # Try again
return False # Ran out of tries :-(
return f_retry # true decorator -> decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
注意修改sinarss2.文件文件中的用户名1.2新浪草根用户的调用方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-01 01:22
注意修改sinarss2.文件文件中的用户名1.2新浪草根用户的调用方法
本文介绍了WordPress博客网站与新浪微博的互操作应用,同时实现了WordPress网站中新浪微博文章列表和WordPress发布文章到新浪的自动同步微博。
1、调用新浪微博列表文章
首先给大家介绍一下WordPress博客【k14】中不用插件调用新浪微博的应用。由于新浪微博还没有开发提供RSS功能,我们使用知名的月光博主开发了新浪微博RSS功能。 ,主要用途是数据交换。本程序目前支持新浪微博认证用户和草根用户,但两者的调用方式略有不同。所以,根据你的微博用户级别,选择正确使用(认证用户使用sinarss.php;草根用户使用sinarss2.php)。以下使用方法参考月光博客文章。
1.1 如何调用新浪认证用户:
首先找到你访问新浪微博的地址,例如,然后取出如下地址作为参数调用:sinarss.php?username=williamlong,其中username中的数据就是你个人姓名后面的地址.
*注意修改sinarss.php文件中的用户名
1.2 如何给新浪草根用户打电话:
首先找到您访问新浪微博的身份证号码。具体方法是登录新浪微博,点击用户的关注、粉丝页面,你会在地址栏中间看到一串数字。取出中间的数字。然后用这个号码作为id参数调用一个地址,类似于:sinarss2.php?id=1494759712,其中id是草根用户的新浪微博id号。
* 注意修改sinarss2.php文件中的用户ID
1.3 微博文章页面调用:
完成上述文件设置后,下面介绍如何使用WordPress自带的feed捕获功能来显示文章列表页面。
方法一:
get_item_quantity(5);
//从元素0(第一个元素)开始,构建所有项目的数组。
$rss_items = $rss->get_items(0, $maxitems);
endif;
方法二:
get_items(0,5);
foreach($items as $item) {
echo ''.$item->get_title().' '.$item->get_date('Y-m-j G:i').'';
}
?>
2、将WordPress文章同步到新浪微博
2.1 博客微博
lloydsheng 开发的一款基于新浪微博 API 的 Wordpress 插件。当您发布博文时,您可以自动向新浪微博发送消息,标签将转换为主题。同时支持消息模板,可以自定义消息内容。
2.2 U2S
MG.Core.Team 开发的WordPress插件在保存博客文章时,会自动将分类、标题、摘要、图片等相关信息同步到新浪微博指定账号。 WordPress官方下载地址(或直接从WordPress后台搜索安装)。
2.3 WordPress 微博插件
由kedy开发,基于新浪微博和WordPress,可以在WordPress中快速发布微博的功能。同时当用户在Wordpress文章上发帖时,会自动及时将消息发到新浪微博上,节省人工同步的成本。 (部分自建博客用户可能无法直接同步关联博客文章) 查看全部
注意修改sinarss2.文件文件中的用户名1.2新浪草根用户的调用方法

本文介绍了WordPress博客网站与新浪微博的互操作应用,同时实现了WordPress网站中新浪微博文章列表和WordPress发布文章到新浪的自动同步微博。
1、调用新浪微博列表文章
首先给大家介绍一下WordPress博客【k14】中不用插件调用新浪微博的应用。由于新浪微博还没有开发提供RSS功能,我们使用知名的月光博主开发了新浪微博RSS功能。 ,主要用途是数据交换。本程序目前支持新浪微博认证用户和草根用户,但两者的调用方式略有不同。所以,根据你的微博用户级别,选择正确使用(认证用户使用sinarss.php;草根用户使用sinarss2.php)。以下使用方法参考月光博客文章。
1.1 如何调用新浪认证用户:
首先找到你访问新浪微博的地址,例如,然后取出如下地址作为参数调用:sinarss.php?username=williamlong,其中username中的数据就是你个人姓名后面的地址.
*注意修改sinarss.php文件中的用户名
1.2 如何给新浪草根用户打电话:
首先找到您访问新浪微博的身份证号码。具体方法是登录新浪微博,点击用户的关注、粉丝页面,你会在地址栏中间看到一串数字。取出中间的数字。然后用这个号码作为id参数调用一个地址,类似于:sinarss2.php?id=1494759712,其中id是草根用户的新浪微博id号。
* 注意修改sinarss2.php文件中的用户ID
1.3 微博文章页面调用:
完成上述文件设置后,下面介绍如何使用WordPress自带的feed捕获功能来显示文章列表页面。
方法一:
get_item_quantity(5);
//从元素0(第一个元素)开始,构建所有项目的数组。
$rss_items = $rss->get_items(0, $maxitems);
endif;
方法二:
get_items(0,5);
foreach($items as $item) {
echo ''.$item->get_title().' '.$item->get_date('Y-m-j G:i').'';
}
?>
2、将WordPress文章同步到新浪微博
2.1 博客微博
lloydsheng 开发的一款基于新浪微博 API 的 Wordpress 插件。当您发布博文时,您可以自动向新浪微博发送消息,标签将转换为主题。同时支持消息模板,可以自定义消息内容。
2.2 U2S
MG.Core.Team 开发的WordPress插件在保存博客文章时,会自动将分类、标题、摘要、图片等相关信息同步到新浪微博指定账号。 WordPress官方下载地址(或直接从WordPress后台搜索安装)。
2.3 WordPress 微博插件
由kedy开发,基于新浪微博和WordPress,可以在WordPress中快速发布微博的功能。同时当用户在Wordpress文章上发帖时,会自动及时将消息发到新浪微博上,节省人工同步的成本。 (部分自建博客用户可能无法直接同步关联博客文章)
E5B7发微博未审核应用未通过审核或未影响
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-05-27 06:04
任务
发布博客后,希望提取摘要并自动自动同步发布微博;
准备工作
作为新浪微博的开发者,需要身份验证;
对个人身份认证的审查通常需要一个工作日;
下一步是提交网站进行审查,而国内的则是提交记录号。向海外提交网站地方的海外证书就足够了;也大约是一个工作日;
通过个人身份审核后,您可以创建应用程序和呼叫接口,此时获得的权限相对较低;
网站如果您不提交审核或审核失败,则对微博发布没有影响;只是“未审核的应用”将显示在发布的微博下方;
网站应用名称在审核后显示:
通话界面
微博开放平台提供测试工具;
在进行开发和访问之前,必须首先确保可以通过此测试工具发送测试微博;
%E5%BE%AE%E5%8D%9A%E6%9D%A5%E8%87%AAAPI%E6%B5%8B%E8%AF%95%E5%B7%A5%E5%85% B7
微博的api参考文档为:
所有微博接口都需要授权认证;认证后,将获得一个access_token(访问密钥);密钥的有效期因用户级别而异;
对于那些未通过网络审核的人,
1天;通过审核的普通用户7天;
在有效期内,无需与Sina服务器进行交互以进行权限认证。只要令牌存储在本地,它就可以用于调用各种微博API(读取,写入,获取观众信息等)
授权
共有三种身份验证方式:
通过用户名和密码;
这是最容易理解的。在程序中输入微博帐号的用户名和密码,并使用api调用进行身份验证;但应注意,提供此界面是为了开发要使用的应用程序,并且不能使用Web应用程序;
通过网络回调;
需要与sina服务器进行交互并提供回调地址;在回调地址中获取access_token;
第三个方法是代码方法。我没有仔细阅读,因此请跳过;
Web应用程序仅支持第二种授权方法;下面详细介绍第二种方法的使用:
下载Sina提供的SDK,其中收录演示和api打包类;
访问页面:
call.php:
include_once( 'sina_config.php' );
include_once( 'saetv2.ex.class.php' );
//获取到授权的url
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
$code_url = $o->getAuthorizeURL( WB_CALLBACK_URL );
//post或get方式调用该url,取得授权;授权完成后,新浪会调用我们这边传过去的回调地址:WB_CALLBACK_URL
request()->redirect($code_url);
回调地址页面(WB_CALLBACK_URL):
callback.php
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
if (isset($_REQUEST['code'])) {
$keys = array();
$keys['code'] = $_REQUEST['code'];
$keys['redirect_uri'] = WB_CALLBACK_URL;
try {
$token = $o->getAccessToken( 'code', $keys ) ;
} catch (OAuthException $e) {
echo "weibo.com get access token err.";
LOG_ERR("weibo.com get access token err.");
return ;
}
}
if ($token) {
//取到授权后的api调用密钥,可用存起来,在有效期内多次调用api接口就不用再授权了
$_SESSION['token'] = $token;
$c = new SaeTClientV2( WB_AKEY , WB_SKEY , $_SESSION['token']['access_token'] );
$ret = $c->update( $weiboStr ); //发送微博
if ( isset($ret['error_code']) && $ret['error_code'] > 0 ) {
$str = "Weibo.com Send failed. err info:" . $ret['error_code'] . '/' . $ret['error'];
LOG_ERR($str);
} else {
LOG_INFO("Weibo.com Send Success.");
}
}
博客摘要摘录
微博中的字符数为140个字符;其中,汉字为1个字符;我们必须选择一个计数功能;对于一个汉字,strlen()计为3个字符,多字节统计函数mb_strlen()为1个字,符合我们的要求;
最后,您需要清除html标签和&nbsp; etc。
//获取当前微博内容(140字)
public function getWeibo()
{
$titleLen = mb_strlen($this->title, 'UTF-8');
//140字除去链接的20个字和省略符;剩115字左右,需要说明的是链接:无论文章的链接多长,在微博里都会被替换成短链接,按短链接的长度来计算字数;
$summaryLen = 115 - $titleLen ;
$pubPaper = cutstr_html($this->summary);
if(mb_strlen($pubPaper, 'UTF-8') >= $summaryLen)
$pubPaper = mb_substr($pubPaper,0,$summaryLen,'UTF-8');
$pubPaper = sprintf('【%s】%s...%s', $this->title , $pubPaper , aurl('post/show', array('id' => $this->id)));
return $pubPaper;
}
//完全的去除html标记
function cutstr_html($string)
{
$string = strip_tags($string);
$string = preg_replace ('/n/is', '', $string);
$string = preg_replace ('/ | /is', '', $string);
$string = preg_replace ('/ /is', '', $string);
return $string;
}
结束。
发布者:Big CC | 2013年11月30日
博客:
微博:新浪微博 查看全部
E5B7发微博未审核应用未通过审核或未影响
任务
发布博客后,希望提取摘要并自动自动同步发布微博;
准备工作
作为新浪微博的开发者,需要身份验证;
对个人身份认证的审查通常需要一个工作日;
下一步是提交网站进行审查,而国内的则是提交记录号。向海外提交网站地方的海外证书就足够了;也大约是一个工作日;
通过个人身份审核后,您可以创建应用程序和呼叫接口,此时获得的权限相对较低;
网站如果您不提交审核或审核失败,则对微博发布没有影响;只是“未审核的应用”将显示在发布的微博下方;
网站应用名称在审核后显示:

通话界面
微博开放平台提供测试工具;
在进行开发和访问之前,必须首先确保可以通过此测试工具发送测试微博;
%E5%BE%AE%E5%8D%9A%E6%9D%A5%E8%87%AAAPI%E6%B5%8B%E8%AF%95%E5%B7%A5%E5%85% B7
微博的api参考文档为:
所有微博接口都需要授权认证;认证后,将获得一个access_token(访问密钥);密钥的有效期因用户级别而异;
对于那些未通过网络审核的人,
1天;通过审核的普通用户7天;
在有效期内,无需与Sina服务器进行交互以进行权限认证。只要令牌存储在本地,它就可以用于调用各种微博API(读取,写入,获取观众信息等)
授权
共有三种身份验证方式:
通过用户名和密码;
这是最容易理解的。在程序中输入微博帐号的用户名和密码,并使用api调用进行身份验证;但应注意,提供此界面是为了开发要使用的应用程序,并且不能使用Web应用程序;
通过网络回调;
需要与sina服务器进行交互并提供回调地址;在回调地址中获取access_token;
第三个方法是代码方法。我没有仔细阅读,因此请跳过;
Web应用程序仅支持第二种授权方法;下面详细介绍第二种方法的使用:
下载Sina提供的SDK,其中收录演示和api打包类;
访问页面:
call.php:
include_once( 'sina_config.php' );
include_once( 'saetv2.ex.class.php' );
//获取到授权的url
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
$code_url = $o->getAuthorizeURL( WB_CALLBACK_URL );
//post或get方式调用该url,取得授权;授权完成后,新浪会调用我们这边传过去的回调地址:WB_CALLBACK_URL
request()->redirect($code_url);
回调地址页面(WB_CALLBACK_URL):
callback.php
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
if (isset($_REQUEST['code'])) {
$keys = array();
$keys['code'] = $_REQUEST['code'];
$keys['redirect_uri'] = WB_CALLBACK_URL;
try {
$token = $o->getAccessToken( 'code', $keys ) ;
} catch (OAuthException $e) {
echo "weibo.com get access token err.";
LOG_ERR("weibo.com get access token err.");
return ;
}
}
if ($token) {
//取到授权后的api调用密钥,可用存起来,在有效期内多次调用api接口就不用再授权了
$_SESSION['token'] = $token;
$c = new SaeTClientV2( WB_AKEY , WB_SKEY , $_SESSION['token']['access_token'] );
$ret = $c->update( $weiboStr ); //发送微博
if ( isset($ret['error_code']) && $ret['error_code'] > 0 ) {
$str = "Weibo.com Send failed. err info:" . $ret['error_code'] . '/' . $ret['error'];
LOG_ERR($str);
} else {
LOG_INFO("Weibo.com Send Success.");
}
}
博客摘要摘录
微博中的字符数为140个字符;其中,汉字为1个字符;我们必须选择一个计数功能;对于一个汉字,strlen()计为3个字符,多字节统计函数mb_strlen()为1个字,符合我们的要求;
最后,您需要清除html标签和&nbsp; etc。
//获取当前微博内容(140字)
public function getWeibo()
{
$titleLen = mb_strlen($this->title, 'UTF-8');
//140字除去链接的20个字和省略符;剩115字左右,需要说明的是链接:无论文章的链接多长,在微博里都会被替换成短链接,按短链接的长度来计算字数;
$summaryLen = 115 - $titleLen ;
$pubPaper = cutstr_html($this->summary);
if(mb_strlen($pubPaper, 'UTF-8') >= $summaryLen)
$pubPaper = mb_substr($pubPaper,0,$summaryLen,'UTF-8');
$pubPaper = sprintf('【%s】%s...%s', $this->title , $pubPaper , aurl('post/show', array('id' => $this->id)));
return $pubPaper;
}
//完全的去除html标记
function cutstr_html($string)
{
$string = strip_tags($string);
$string = preg_replace ('/n/is', '', $string);
$string = preg_replace ('/ | /is', '', $string);
$string = preg_replace ('/ /is', '', $string);
return $string;
}
结束。
发布者:Big CC | 2013年11月30日
博客:
微博:新浪微博
之前客户要隐藏新浪微博的所有内容,临时写了一段代码
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-05-26 00:33
之前,客户希望隐藏新浪微博的所有内容,并临时编写一段代码。现在分享。
公共课程HiddenWeiBo {
复制代码 隐藏代码
public static void main(String[] args) throws HttpProcessException, FileNotFoundException, InterruptedException {
HiddenWeiBo demo = new HiddenWeiBo();
while (true) {
List mid = demo.getMid(demo.getIndex());
for (String string : mid) {
demo.postwb(string);
Thread.sleep(500);
}
}
}
public String getIndex() throws HttpProcessException{
String url = "https://weibo.com/p/#####自己的ID######/home?from=page_100505_profile&wvr=6&mod=data&is_all=1";
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://passport.weibo.com/vis ... 23%23自己的ID#####%2Fhome%3Ffrom%3Dpage_100505_profile%26wvr%3D6%26mod%3Ddata%26is_hot%3D1&domain=.weibo.com&ua=php-sso_sdk_client-0.6.28&_rand=1534310854.1213")
.contentType("application/x-www-form-urlencoded")
.cookie("YF-Page-G0=b58533766541bcc934acef7f6116c26d1; _s_tentry=passport.weibo.com; Apache=2482346697449.5763.1534310855544; SINAGLOBAL=2482346629749.5763.1534310855544; ULV=1534310855679:1:1:1:248234669749.5763.1534310855544:; YF-Ugrow-G0=b02489d329584fca03ad6347fc915997; YF-V5-G0=cd5d86283b86b0d5506628aedd6f8896e; WBtopGlobal_register_version=2b2691ab11833cbd; wb_view_log_5175311215=1920*10801; login_sid_t=6e3af2ce0d487e764cc21551bd64ee61; cross_origin_proto=SSL; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; UOR=,,login.sina.com.cn; SSOLoginState=1534317576; SCF=An380Z_lJI4Er6AG9v5XU6ULsCZ8EswRdbTEUE52u4sKz4mbINDT8lL8v-FgZhuYiwV_2kWCPJORBMVpowD5Sl4.; SUB=_2A252d6RYDeRhGeNP7FcS8S_OyjmIHXVVBJKQrDV8PUNbmtAKLWz6kW9NTnyOtWRIAjuzxoDWBNFsiOTo4QS08kaw; SUBP=0033WrSXqPxfM6725Ws9jqgMF55529P9D9WWWbMZ3lYrAgORyMlPl1Ni15JpX5K2hUgL.Fo-pS0-0eK2EeK-2dJLoI74kPfYLxKqLBK5LB.SAIBtt; SUHB=0YhhvX2IYso1ka; ALF=1565853576; un=; wvr=6")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client);
String result2 = HttpClientUtil.get(config); //post请求
return result2;
}
public List getMid(String html){
List mid = new ArrayList();
String patt = "name=[0-9]{16}";
Pattern r = Pattern.compile(patt);
Matcher m = r.matcher(html);
while (m.find()) {
mid.add(m.group(0).replace("name=", ""));
}
return mid;
}
public void postwb(String mid) throws HttpProcessException{
String url = "https://weibo.com/p/aj/v6/mblo ... illis();
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://weibo.com/p/#####自己的ID#####/home?is_all=1&stat_date=201212")
.contentType("application/x-www-form-urlencoded")
.cookie("SINAGLOBAL=8635537446547.301.1507198819218; UM_distinctid=161cc50123d26d1fa-02fcbe6e2eda04-4a541326-1fa400-161cc50d26e510; un=1231233123; login_sid_t=2c011620a31237dd2c973a420f7bf48e4d8; YF-Ugrow-G0=ea90f703b7694b74b62d38420b5273df; YF-V5-G0=c99031715427fe982b79bf287ae448f6; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; _s_tentry=-; Apache=9255634056765.951.1534307466102; ULV=1534307466128:24:3:1:9255634056765.951.1534307466102:1533893011406; SSOLoginState=1534307540; SCF=AhJ5a4l55u6Ym2tu3123rWNWWaszjwG-_9f_3HstU3vWd69GnSGQXqXDKe2GVorlKGqk-3Erg3lfS6XH6V9anNWwUPk.; SUB=_2A252d9yFDeRhGeRJ7lMV9C_OyjiIHXVVBUlNrDV8PUNbmtANLVmikW9NUpanwG_uVHqh5x7c1lnw8hThtgc8AgTY; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5D6Yv-_WaN-LU2mIXhSYxE5JpX5KzhUgL.FozNSK2XSh2EeKB2dJLoI0qLxK-L12eL1KMLxKBLB.2LB-eLxKqL1K.LB--LxKnLBoBLBKBLxKnL12-LBozLxKMLBKBLB.-t; SUHB=02M-sImmDLEWQ_; ALF=1565843540; wvr=6; YF-Page-G0=734c07cbfd1a4ed44f254d8b9173a162eb; wb_view_log_2751441214=1920*10801; UOR=cas.baidu.com,widget.weibo.com,login.sina.com.cn; cross_origin_proto=SSL")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
System.out.println("----");
Map map = new HashMap();
map.put("visible", "1");
map.put("mid", mid);
map.put("_t", "0");
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.map(map) //设置请求参数,没有则无需设置
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client) ;
String result2 = HttpClientUtil.post(config); //post请求
System.out.println(result2);
}
}
谈论一般原则。
有两个数字A(任何数字或没有登录号,只需要Cookie),B(您需要删除或隐藏微博号码)
过程A ------在主页上获取所有微博的ID -----“删除到B
getIndex()-----》 getMid(String html)----》 postwb(String mid)
代码是隐藏的,删除也是如此
如果需要使用它,则需要更改Cookie
使用的框架
com.arronlong 查看全部
之前客户要隐藏新浪微博的所有内容,临时写了一段代码
之前,客户希望隐藏新浪微博的所有内容,并临时编写一段代码。现在分享。
公共课程HiddenWeiBo {
复制代码 隐藏代码
public static void main(String[] args) throws HttpProcessException, FileNotFoundException, InterruptedException {
HiddenWeiBo demo = new HiddenWeiBo();
while (true) {
List mid = demo.getMid(demo.getIndex());
for (String string : mid) {
demo.postwb(string);
Thread.sleep(500);
}
}
}
public String getIndex() throws HttpProcessException{
String url = "https://weibo.com/p/#####自己的ID######/home?from=page_100505_profile&wvr=6&mod=data&is_all=1";
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://passport.weibo.com/vis ... 23%23自己的ID#####%2Fhome%3Ffrom%3Dpage_100505_profile%26wvr%3D6%26mod%3Ddata%26is_hot%3D1&domain=.weibo.com&ua=php-sso_sdk_client-0.6.28&_rand=1534310854.1213")
.contentType("application/x-www-form-urlencoded")
.cookie("YF-Page-G0=b58533766541bcc934acef7f6116c26d1; _s_tentry=passport.weibo.com; Apache=2482346697449.5763.1534310855544; SINAGLOBAL=2482346629749.5763.1534310855544; ULV=1534310855679:1:1:1:248234669749.5763.1534310855544:; YF-Ugrow-G0=b02489d329584fca03ad6347fc915997; YF-V5-G0=cd5d86283b86b0d5506628aedd6f8896e; WBtopGlobal_register_version=2b2691ab11833cbd; wb_view_log_5175311215=1920*10801; login_sid_t=6e3af2ce0d487e764cc21551bd64ee61; cross_origin_proto=SSL; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; UOR=,,login.sina.com.cn; SSOLoginState=1534317576; SCF=An380Z_lJI4Er6AG9v5XU6ULsCZ8EswRdbTEUE52u4sKz4mbINDT8lL8v-FgZhuYiwV_2kWCPJORBMVpowD5Sl4.; SUB=_2A252d6RYDeRhGeNP7FcS8S_OyjmIHXVVBJKQrDV8PUNbmtAKLWz6kW9NTnyOtWRIAjuzxoDWBNFsiOTo4QS08kaw; SUBP=0033WrSXqPxfM6725Ws9jqgMF55529P9D9WWWbMZ3lYrAgORyMlPl1Ni15JpX5K2hUgL.Fo-pS0-0eK2EeK-2dJLoI74kPfYLxKqLBK5LB.SAIBtt; SUHB=0YhhvX2IYso1ka; ALF=1565853576; un=; wvr=6")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client);
String result2 = HttpClientUtil.get(config); //post请求
return result2;
}
public List getMid(String html){
List mid = new ArrayList();
String patt = "name=[0-9]{16}";
Pattern r = Pattern.compile(patt);
Matcher m = r.matcher(html);
while (m.find()) {
mid.add(m.group(0).replace("name=", ""));
}
return mid;
}
public void postwb(String mid) throws HttpProcessException{
String url = "https://weibo.com/p/aj/v6/mblo ... illis();
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://weibo.com/p/#####自己的ID#####/home?is_all=1&stat_date=201212")
.contentType("application/x-www-form-urlencoded")
.cookie("SINAGLOBAL=8635537446547.301.1507198819218; UM_distinctid=161cc50123d26d1fa-02fcbe6e2eda04-4a541326-1fa400-161cc50d26e510; un=1231233123; login_sid_t=2c011620a31237dd2c973a420f7bf48e4d8; YF-Ugrow-G0=ea90f703b7694b74b62d38420b5273df; YF-V5-G0=c99031715427fe982b79bf287ae448f6; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; _s_tentry=-; Apache=9255634056765.951.1534307466102; ULV=1534307466128:24:3:1:9255634056765.951.1534307466102:1533893011406; SSOLoginState=1534307540; SCF=AhJ5a4l55u6Ym2tu3123rWNWWaszjwG-_9f_3HstU3vWd69GnSGQXqXDKe2GVorlKGqk-3Erg3lfS6XH6V9anNWwUPk.; SUB=_2A252d9yFDeRhGeRJ7lMV9C_OyjiIHXVVBUlNrDV8PUNbmtANLVmikW9NUpanwG_uVHqh5x7c1lnw8hThtgc8AgTY; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5D6Yv-_WaN-LU2mIXhSYxE5JpX5KzhUgL.FozNSK2XSh2EeKB2dJLoI0qLxK-L12eL1KMLxKBLB.2LB-eLxKqL1K.LB--LxKnLBoBLBKBLxKnL12-LBozLxKMLBKBLB.-t; SUHB=02M-sImmDLEWQ_; ALF=1565843540; wvr=6; YF-Page-G0=734c07cbfd1a4ed44f254d8b9173a162eb; wb_view_log_2751441214=1920*10801; UOR=cas.baidu.com,widget.weibo.com,login.sina.com.cn; cross_origin_proto=SSL")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
System.out.println("----");
Map map = new HashMap();
map.put("visible", "1");
map.put("mid", mid);
map.put("_t", "0");
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.map(map) //设置请求参数,没有则无需设置
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client) ;
String result2 = HttpClientUtil.post(config); //post请求
System.out.println(result2);
}
}
谈论一般原则。
有两个数字A(任何数字或没有登录号,只需要Cookie),B(您需要删除或隐藏微博号码)
过程A ------在主页上获取所有微博的ID -----“删除到B
getIndex()-----》 getMid(String html)----》 postwb(String mid)
代码是隐藏的,删除也是如此
如果需要使用它,则需要更改Cookie
使用的框架
com.arronlong
新浪微博开放平台使用账户登录的注意不要点击【微连接】
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-05-25 21:15
新浪微博网站访问应用程序教程(包括本地测试)织梦无忧网站管理员的文章2020-09-21 13:59
摘要:进入新浪微博开放平台并使用您的帐户登录。单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用这些组件。要申请微连接appKey,请单击[开始访问]按钮。在这里
进入新浪微博开放平台并使用您的帐户登录。
单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。
左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用。
要申请微连接appKey,请单击[开始访问]按钮。
此处应注意以下两点:
1要以这种方式申请appKey,前提是您的网站必须使用域名并且正在Internet上运行。如果您处于本地测试阶段,则此方法将不起作用。稍后将介绍如何申请本地测试阶段。
2 网站提供了两种验证方法,以验证您具有网站的管理员权限。请注意这两种方法之间的区别。
没有自动重定向的网站
具有自动重定向功能的网站或WAP网站
在网站主页上添加验证码后,单击下面的[验证并添加]按钮。按照提示进行操作。
注意:如果此步骤失败,请仔细分析新浪提供的信息。如果您确实找不到问题,则不妨尝试上述两种验证方法。
从这一步开始,如何在本地调试阶段进行应用。
由于没有用于本地调试的域名,因此无法直接访问网站。需要使用Web应用程序来实现本地调试。
许多人在申请时找不到Web应用程序的选项。这是一个解释:
([1)在开放平台的主页上,直接单击[微连接]菜单。
请注意不要在[微连接]菜单下单击该站点上的应用程序,单击该站点上的应用程序后的页面将不是同一页面。
转到如下所示的页面:
([2)这时,单击[创建应用程序]按钮,将弹出各种应用程序类型,并显示Web应用程序。
单击[Web应用程序]进入应用程序页面。
此处的申请地址可以填写IP地址,方便我们测试。
创建Web应用程序后,它尚未完成。单击[管理中心]进入我们刚刚申请的应用程序。单击左侧的应用程序信息中的基本信息。
单击以在右侧进行编辑,请注意下图中突出显示的位置。
申请地址是指微博发布时显示的源地址(未经批准将无法正确显示)。
需要安全域名,因为新浪微博的Api需要通过域名进行访问,否则将报告错误。所以下一步就是关键。
设置本地环境域名映射。
([1)在操作系统主机文件中添加本地域名映射。
([2)在上述安全域名中配置本地自定义域名。
单击[高级信息]进行设置。
授权设置是成功调用api后将返回的页面。
安全设置指定应用程序部署的IP地址。
此时,新浪微博appKey的应用程序被认为是成功的,您可以启动本地调试路径。 查看全部
新浪微博开放平台使用账户登录的注意不要点击【微连接】
新浪微博网站访问应用程序教程(包括本地测试)织梦无忧网站管理员的文章2020-09-21 13:59
摘要:进入新浪微博开放平台并使用您的帐户登录。单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用这些组件。要申请微连接appKey,请单击[开始访问]按钮。在这里
进入新浪微博开放平台并使用您的帐户登录。

单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。

左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用。

要申请微连接appKey,请单击[开始访问]按钮。

此处应注意以下两点:
1要以这种方式申请appKey,前提是您的网站必须使用域名并且正在Internet上运行。如果您处于本地测试阶段,则此方法将不起作用。稍后将介绍如何申请本地测试阶段。
2 网站提供了两种验证方法,以验证您具有网站的管理员权限。请注意这两种方法之间的区别。
没有自动重定向的网站

具有自动重定向功能的网站或WAP网站

在网站主页上添加验证码后,单击下面的[验证并添加]按钮。按照提示进行操作。
注意:如果此步骤失败,请仔细分析新浪提供的信息。如果您确实找不到问题,则不妨尝试上述两种验证方法。
从这一步开始,如何在本地调试阶段进行应用。
由于没有用于本地调试的域名,因此无法直接访问网站。需要使用Web应用程序来实现本地调试。
许多人在申请时找不到Web应用程序的选项。这是一个解释:
([1)在开放平台的主页上,直接单击[微连接]菜单。

请注意不要在[微连接]菜单下单击该站点上的应用程序,单击该站点上的应用程序后的页面将不是同一页面。

转到如下所示的页面:

([2)这时,单击[创建应用程序]按钮,将弹出各种应用程序类型,并显示Web应用程序。

单击[Web应用程序]进入应用程序页面。

此处的申请地址可以填写IP地址,方便我们测试。

创建Web应用程序后,它尚未完成。单击[管理中心]进入我们刚刚申请的应用程序。单击左侧的应用程序信息中的基本信息。

单击以在右侧进行编辑,请注意下图中突出显示的位置。

申请地址是指微博发布时显示的源地址(未经批准将无法正确显示)。
需要安全域名,因为新浪微博的Api需要通过域名进行访问,否则将报告错误。所以下一步就是关键。
设置本地环境域名映射。
([1)在操作系统主机文件中添加本地域名映射。

([2)在上述安全域名中配置本地自定义域名。
单击[高级信息]进行设置。

授权设置是成功调用api后将返回的页面。
安全设置指定应用程序部署的IP地址。
此时,新浪微博appKey的应用程序被认为是成功的,您可以启动本地调试路径。
跨域读取Twitter微博的代码,是这样写的博文
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-05-21 21:18
我最近才刚开始学习JavaScript,我在教程中看到了有关跨域阅读Twitter微博的代码,其编写方式如下
window.onload = init;
function init() {
var interval = setInterval(handleRefresh, 3000);
handleRefresh();
}
function handleRefresh() {
console.log("here");
var url = "http://gumball.wickedlysmart.com" +
"?callback=updateSales" + //利用callback回调updateSales
//"&lastreporttime=" + lastReportTime +
"&random=" + (new Date()).getTime();
var newScriptElement = document.createElement("script");
newScriptElement.setAttribute("src", url);
newScriptElement.setAttribute("id", "jsonp");
var oldScriptElement = document.getElementById("jsonp");
var head = document.getElementsByTagName("head")[0];
if (oldScriptElement == null) {
head.appendChild(newScriptElement);
}
else {
head.replaceChild(newScriptElement, oldScriptElement);
}
}
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
for (var i = 0; i < jsonp_sales.length; i++) {
var sale = jsonp_sales[i];
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sale.name + " sold " + jsonp_sale.sales + " gumballs";
//salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
if (sales.length > 0) {
lastReportTime = jsonp_[jsonp_sales.length-1].time;
}
}
所以我想当然我会尝试更改为新浪微博的API,当然您必须先申请它
更换后,我得到了此链接(新浪微博的API接口,现在仅允许读取我的微博帐户的内容,并且只能读取5个微博=-=以后我会努力学习,我自己,让我们抓取数据...)
var url = "https://api.weibo.com/2/status ... id%3D你的ID可以从自己微博链接地址查,是一串数字&access_token=这里是token&callback=updateSales" ;
我尝试了一下,发现没有成功,所以我使用Firefox进行调试,发现jsonp_sales可能有问题,如下所示
展开,找到
换句话说,博客文章存储在jsonp_sales.data.statuses [i] .text中,因此请修改代码
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
var length=jsonp_sales.data.statuses.length;
for (var i = 0; i < length; i++) {
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sales.data.statuses[i].text;
salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
}
最终成功,以下是在网页上阅读的原创博客文章,尚未处理
从开始学习JavaScript以来,我发现Firefox的调试工具大有帮助。我的技能有限,我仍然需要继续学习
我希望它对所有人都有帮助 查看全部
跨域读取Twitter微博的代码,是这样写的博文
我最近才刚开始学习JavaScript,我在教程中看到了有关跨域阅读Twitter微博的代码,其编写方式如下
window.onload = init;
function init() {
var interval = setInterval(handleRefresh, 3000);
handleRefresh();
}
function handleRefresh() {
console.log("here");
var url = "http://gumball.wickedlysmart.com" +
"?callback=updateSales" + //利用callback回调updateSales
//"&lastreporttime=" + lastReportTime +
"&random=" + (new Date()).getTime();
var newScriptElement = document.createElement("script");
newScriptElement.setAttribute("src", url);
newScriptElement.setAttribute("id", "jsonp");
var oldScriptElement = document.getElementById("jsonp");
var head = document.getElementsByTagName("head")[0];
if (oldScriptElement == null) {
head.appendChild(newScriptElement);
}
else {
head.replaceChild(newScriptElement, oldScriptElement);
}
}
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
for (var i = 0; i < jsonp_sales.length; i++) {
var sale = jsonp_sales[i];
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sale.name + " sold " + jsonp_sale.sales + " gumballs";
//salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
if (sales.length > 0) {
lastReportTime = jsonp_[jsonp_sales.length-1].time;
}
}
所以我想当然我会尝试更改为新浪微博的API,当然您必须先申请它

更换后,我得到了此链接(新浪微博的API接口,现在仅允许读取我的微博帐户的内容,并且只能读取5个微博=-=以后我会努力学习,我自己,让我们抓取数据...)
var url = "https://api.weibo.com/2/status ... id%3D你的ID可以从自己微博链接地址查,是一串数字&access_token=这里是token&callback=updateSales" ;
我尝试了一下,发现没有成功,所以我使用Firefox进行调试,发现jsonp_sales可能有问题,如下所示

展开,找到


换句话说,博客文章存储在jsonp_sales.data.statuses [i] .text中,因此请修改代码
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
var length=jsonp_sales.data.statuses.length;
for (var i = 0; i < length; i++) {
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sales.data.statuses[i].text;
salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
}
最终成功,以下是在网页上阅读的原创博客文章,尚未处理

从开始学习JavaScript以来,我发现Firefox的调试工具大有帮助。我的技能有限,我仍然需要继续学习
我希望它对所有人都有帮助
Python3下用Tornado调用新浪微博API.0认证的顺序
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-21 21:17
Python3下用Tornado调用新浪微博API.0认证的顺序
使用Tornado试用新浪微博开放平台API
Tornado作为Python异步无阻塞服务器和轻量级Web框架,非常吸引人。为了体验OAuth 2. 0身份验证,我使用了Tornado构建了网站并调用了新浪微博API。新浪微博的OAuth 2. 0身份验证序列如下:
以下内容简要说明了如何在Python 3下使用Tornado完成上述四个步骤。
将用户带到新浪认证页面
假设我们要开发的客户端的域名是,在Sina中创建一个新应用程序,然后在设置中填写此安全域名,以便我们可以跨站点请求XMLRequests。
此步骤是编写html页面,在Tornado中则是编写模板。假设我们在客户端上放置了一个名为“使用新浪微博登录”的按钮,代码如下:
Login
通过这种方式,您只需单击此按钮即可转到新浪的身份验证页面。用户通过身份验证后,新浪会将用户转到您提供的redirect_uri地址,这里是
因此,我们需要使用Tornado来处理身份验证服务器发送给我们的代码。
龙卷风在后台使用代码交换access_token
这部分有两个步骤:
配置Tornado的路由表,然后让r'/ auth_code'路由到AuthCodeHandler处理程序。然后,我们可以重写此处理程序的get方法以获取代码。然后我们使用POST方法将代码发送到Sina,这是它可以反映Tornado的异步和非阻塞功能的强大之处。龙卷风的AsyncHTTPClient可以发起异步请求。 @ gen.coroutine装饰器可用于编写异步(如同步)。代码如下:
from urllib.parse import urlencode
import json
import tornado.web
from tornado import gen
from tornado.httpclient import AsyncHTTPClient
from handlers.token import TokenBaseHandler
class AuthCodeHandler(TokenBaseHandler):
"""
已经获得用户授权, 向API服务器获取Token
"""
@gen.coroutine
def get(self):
auth_code = self.get_argument("code", "No code")
post_data = {
"client_id": "你的App Key",
"client_secret": "你的App Secret",
"grant_type": "authorization_code",
"code": auth_code,
"redirect_uri": "http://dropthej.com"
}
http_client = AsyncHTTPClient()
response = "init"
body = urlencode(post_data)
try:
response = yield http_client.fetch(
"https://api.weibo.com/oauth2/access_token",
method="POST",
body=body
)
except Exception as e:
self.write(str(e))
return;
token_json = json.loads(str(response.body, encoding='utf-8'))
# set token_json
self.application.token_json = token_json
self.write("
" + str(token_json['access_token']))
url = "http://dropthej.com/?tk=" + token_json['access_token']
self.redirect(url)
由于我们仅使用它来与他的API一起使用,因此我们不会在cookie中编写access_token,而是使用一种简单的方法将其放入URL中。这样,应用程序的每个页面都会被带入。tk参数可以保留用户的登录状态。在这里,我们返回到此页面,因此我们在html中收到此tk并使用它来调用Sina API。
为什么发送GET和POST请求?应该使用龙卷风在后台发送此消息吗?前端的javascript无法完成吗?由于应将“应用程序秘密”发送到此处,因此称为“秘密”,您仍然可以将其发送到前端。遍历用户计算机是非常不安全的。 Secret旨在验证这是真实客户端发送的请求,因此必须在后台发送,并且必须由客户端而不是用户完成。
使用jQuery调用Sina API以获取用户的最新主页微博
这不是重点。我不会再说了。效果非常好,也很高兴。主要代码如下:
var xyz;
$(function() {
$.ajax({
url: "https://api.weibo.com/2/status ... ot%3B,
type: "GET",
dataType: "jsonp",
data: {
"access_token": ac_tk
},
success: function(result) {
xyz = result.data.statuses;
for (x in xyz) {
$("#tbody").append("" + xyz[x].user.name + "" + xyz[x].text + "");
}
}
});
});
效果如图所示:
链接到本文 查看全部
Python3下用Tornado调用新浪微博API.0认证的顺序
使用Tornado试用新浪微博开放平台API
Tornado作为Python异步无阻塞服务器和轻量级Web框架,非常吸引人。为了体验OAuth 2. 0身份验证,我使用了Tornado构建了网站并调用了新浪微博API。新浪微博的OAuth 2. 0身份验证序列如下:
以下内容简要说明了如何在Python 3下使用Tornado完成上述四个步骤。
将用户带到新浪认证页面
假设我们要开发的客户端的域名是,在Sina中创建一个新应用程序,然后在设置中填写此安全域名,以便我们可以跨站点请求XMLRequests。
此步骤是编写html页面,在Tornado中则是编写模板。假设我们在客户端上放置了一个名为“使用新浪微博登录”的按钮,代码如下:
Login
通过这种方式,您只需单击此按钮即可转到新浪的身份验证页面。用户通过身份验证后,新浪会将用户转到您提供的redirect_uri地址,这里是
因此,我们需要使用Tornado来处理身份验证服务器发送给我们的代码。
龙卷风在后台使用代码交换access_token
这部分有两个步骤:
配置Tornado的路由表,然后让r'/ auth_code'路由到AuthCodeHandler处理程序。然后,我们可以重写此处理程序的get方法以获取代码。然后我们使用POST方法将代码发送到Sina,这是它可以反映Tornado的异步和非阻塞功能的强大之处。龙卷风的AsyncHTTPClient可以发起异步请求。 @ gen.coroutine装饰器可用于编写异步(如同步)。代码如下:
from urllib.parse import urlencode
import json
import tornado.web
from tornado import gen
from tornado.httpclient import AsyncHTTPClient
from handlers.token import TokenBaseHandler
class AuthCodeHandler(TokenBaseHandler):
"""
已经获得用户授权, 向API服务器获取Token
"""
@gen.coroutine
def get(self):
auth_code = self.get_argument("code", "No code")
post_data = {
"client_id": "你的App Key",
"client_secret": "你的App Secret",
"grant_type": "authorization_code",
"code": auth_code,
"redirect_uri": "http://dropthej.com"
}
http_client = AsyncHTTPClient()
response = "init"
body = urlencode(post_data)
try:
response = yield http_client.fetch(
"https://api.weibo.com/oauth2/access_token",
method="POST",
body=body
)
except Exception as e:
self.write(str(e))
return;
token_json = json.loads(str(response.body, encoding='utf-8'))
# set token_json
self.application.token_json = token_json
self.write("
" + str(token_json['access_token']))
url = "http://dropthej.com/?tk=" + token_json['access_token']
self.redirect(url)
由于我们仅使用它来与他的API一起使用,因此我们不会在cookie中编写access_token,而是使用一种简单的方法将其放入URL中。这样,应用程序的每个页面都会被带入。tk参数可以保留用户的登录状态。在这里,我们返回到此页面,因此我们在html中收到此tk并使用它来调用Sina API。
为什么发送GET和POST请求?应该使用龙卷风在后台发送此消息吗?前端的javascript无法完成吗?由于应将“应用程序秘密”发送到此处,因此称为“秘密”,您仍然可以将其发送到前端。遍历用户计算机是非常不安全的。 Secret旨在验证这是真实客户端发送的请求,因此必须在后台发送,并且必须由客户端而不是用户完成。
使用jQuery调用Sina API以获取用户的最新主页微博
这不是重点。我不会再说了。效果非常好,也很高兴。主要代码如下:
var xyz;
$(function() {
$.ajax({
url: "https://api.weibo.com/2/status ... ot%3B,
type: "GET",
dataType: "jsonp",
data: {
"access_token": ac_tk
},
success: function(result) {
xyz = result.data.statuses;
for (x in xyz) {
$("#tbody").append("" + xyz[x].user.name + "" + xyz[x].text + "");
}
}
});
});
效果如图所示:
 https://jecvay.com/wp-content/ ... 0.png 254w" />
https://jecvay.com/wp-content/ ... 0.png 254w" />链接到本文
NET调用新浪微博开放平台接口之旅(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-05-20 19:18
要使用新浪微博开放平台界面,您需要先申请一个帐户。申请方法:向@微博开平台发送私信,或发送收录您的电子邮件,微博个人主页,电话号码和简介的电子邮件。
发送申请电子邮件后,我们在不到1小时的时间内收到了申请批准电子邮件。然后进入新浪微博开放平台,查看相关文档。在该文档(使用Basic Auth进行用户身份验证)中,发现新浪微博开发团队在花园中推荐了Q.Lee.lulu撰写的博客文章:访问需要HTTP Basic Authentication实现各种资源语言。本文文章已成为我们的重要参考,但本文仅适用于“ GET”请求,而新浪微博开放平台接口要求HTTP请求方法为“ POST”,并且在本文中也引用了黑鱼。花园。 Tang撰写的另一篇博客文章:使用HttpWebRequest发送自定义POST请求。谢谢两位园丁的分享!
接下来,我们开始.NET的旅程,即调用新浪微博开放平台接口。
1.首先,我们需要获取一个应用程序密钥,并在新浪微博开放平台的“我的应用程序”中创建一个应用程序,并假设该应用程序密钥为123456,将生成该应用程序密钥。
2.在新浪微博API文档中找到您要调用的API。在这里,我们假设调用发布微博的API状态/更新。网址是POST参数:source = appkey&status = Weibo content。 appkey是先前获得的应用程序密钥。
3.准备数据
1)准备用户验证数据:
string username = "t@cnblogs.com";<br />string password = "cnblogs.com";<br />string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
2)要调用的URL和要发布的数据:
string url = "http://api.t.sina.com.cn/statu ... %3Bbr /> string news_title = "VS2010网剧合集:讲述程序员的爱情故事";<br />int news_id = 62747;<br /> string t_news = string.Format("{0},http://news.cnblogs.com/n/{1}/", news_title, news_id );<br /> string data = "source=123456&status=" + System.Web.HttpUtility.UrlEncode(t_news);
4.准备用于发起请求的HttpWebRequest对象:
System.Net.WebRequest webRequest = System.Net.WebRequest.Create(url);<br /> System.Net.HttpWebRequest httpRequest = webRequest as System.Net.HttpWebRequest;
5.准备用于用户身份验证的凭据:
6.发起POST请求:
httpRequest.Method = "POST";<br /> httpRequest.ContentType = "application/x-www-form-urlencoded";<br /> System.Text.Encoding encoding = System.Text.Encoding.ASCII;<br />byte[] bytesToPost = encoding.GetBytes(data); <br /> httpRequest.ContentLength = bytesToPost.Length;<br /> System.IO.Stream requestStream = httpRequest.GetRequestStream();<br /> requestStream.Write(bytesToPost, 0, bytesToPost.Length);<br /> requestStream.Close();
上述代码成功执行后,内容将发布到您的微博上。
7.从服务器获取响应内容:
System.Net.WebResponse wr = httpRequest.GetResponse();<br /> System.IO.Stream receiveStream = wr.GetResponseStream();<br />using (System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8))<br /> {<br />string responseContent = reader.ReadToEnd();<br /> }
好的,.NET调用新浪微博开放平台接口的过程已经完成,非常简单。
如果您没有Q.Lee.lulu和鱼汤的文章作为参考,那么对我们而言,这并非易事。这也许是分享的价值,但是您的小经验可能会给其他人带来很大的帮助。
所以,我们也分享一下。尽管这不是一种体验,但它只是一种整理,但对有需要的人可能会有所帮助。 查看全部
NET调用新浪微博开放平台接口之旅(图)
要使用新浪微博开放平台界面,您需要先申请一个帐户。申请方法:向@微博开平台发送私信,或发送收录您的电子邮件,微博个人主页,电话号码和简介的电子邮件。
发送申请电子邮件后,我们在不到1小时的时间内收到了申请批准电子邮件。然后进入新浪微博开放平台,查看相关文档。在该文档(使用Basic Auth进行用户身份验证)中,发现新浪微博开发团队在花园中推荐了Q.Lee.lulu撰写的博客文章:访问需要HTTP Basic Authentication实现各种资源语言。本文文章已成为我们的重要参考,但本文仅适用于“ GET”请求,而新浪微博开放平台接口要求HTTP请求方法为“ POST”,并且在本文中也引用了黑鱼。花园。 Tang撰写的另一篇博客文章:使用HttpWebRequest发送自定义POST请求。谢谢两位园丁的分享!
接下来,我们开始.NET的旅程,即调用新浪微博开放平台接口。
1.首先,我们需要获取一个应用程序密钥,并在新浪微博开放平台的“我的应用程序”中创建一个应用程序,并假设该应用程序密钥为123456,将生成该应用程序密钥。
2.在新浪微博API文档中找到您要调用的API。在这里,我们假设调用发布微博的API状态/更新。网址是POST参数:source = appkey&status = Weibo content。 appkey是先前获得的应用程序密钥。
3.准备数据
1)准备用户验证数据:
string username = "t@cnblogs.com";<br />string password = "cnblogs.com";<br />string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
2)要调用的URL和要发布的数据:
string url = "http://api.t.sina.com.cn/statu ... %3Bbr /> string news_title = "VS2010网剧合集:讲述程序员的爱情故事";<br />int news_id = 62747;<br /> string t_news = string.Format("{0},http://news.cnblogs.com/n/{1}/", news_title, news_id );<br /> string data = "source=123456&status=" + System.Web.HttpUtility.UrlEncode(t_news);
4.准备用于发起请求的HttpWebRequest对象:
System.Net.WebRequest webRequest = System.Net.WebRequest.Create(url);<br /> System.Net.HttpWebRequest httpRequest = webRequest as System.Net.HttpWebRequest;
5.准备用于用户身份验证的凭据:
6.发起POST请求:
httpRequest.Method = "POST";<br /> httpRequest.ContentType = "application/x-www-form-urlencoded";<br /> System.Text.Encoding encoding = System.Text.Encoding.ASCII;<br />byte[] bytesToPost = encoding.GetBytes(data); <br /> httpRequest.ContentLength = bytesToPost.Length;<br /> System.IO.Stream requestStream = httpRequest.GetRequestStream();<br /> requestStream.Write(bytesToPost, 0, bytesToPost.Length);<br /> requestStream.Close();
上述代码成功执行后,内容将发布到您的微博上。
7.从服务器获取响应内容:
System.Net.WebResponse wr = httpRequest.GetResponse();<br /> System.IO.Stream receiveStream = wr.GetResponseStream();<br />using (System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8))<br /> {<br />string responseContent = reader.ReadToEnd();<br /> }
好的,.NET调用新浪微博开放平台接口的过程已经完成,非常简单。
如果您没有Q.Lee.lulu和鱼汤的文章作为参考,那么对我们而言,这并非易事。这也许是分享的价值,但是您的小经验可能会给其他人带来很大的帮助。
所以,我们也分享一下。尽管这不是一种体验,但它只是一种整理,但对有需要的人可能会有所帮助。
第三方开发者可免费接入新浪微博位置服务平台上线
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-18 19:00
最近,新浪微博的“位置服务接口”正式启动,第三方开发人员可以免费访问新浪的位置服务平台。
新浪微博位置服务平台的启动意味着LBS应用程序将退出简单的“签入”模式。我相信在不久的将来,定位功能将作为移动应用程序的标准配置存在。
新浪微博位置服务平台的功能在于,它为第三方开发人员提供了最丰富,最实用的功能界面。通过访问基于用户,活动,位置,邻居等的界面,开发人员可以自由获取微博上一个人的时间表和社交动态,并按兴趣和标签对其进行分类。通过动态和附近的界面,开发人员可以获得单个用户的所有关注者信息,并且可以根据距离,时间和体重等各种参数对结果列表进行排序。
开发人员获取特定位置的微博用户的照片,信息和用户行为后,可以根据这些用户的位置行为,微博内容和其他多维信息全面分析用户的真实兴趣,并建立一种“真实的用户行为”而不是“单纯的内容分析”,真正的“兴趣图”是探索用户的实际需求,并根据产品功能满足他们的需求。
在新浪微博定位平台正式启动不到三天的时间里,已有30多家应用程序开发商与新浪公司签署了合作协议,其中包括优秀的行业应用程序,如桃边,酒店管家,公开点评,订购秘书等。
“位置服务接口”总共提供六种类型的接口,包括21个普通接口和7个高级接口。第三方开发人员现在可以通过新浪微博开放平台()直接调用上述界面。
1.第三方调用位置服务接口的必要条件:
调用通用接口的条件:开发人员Appkey必须首先通过对微博开放平台的审查。
(如何申请微博开放平台:)
高级界面申请方法:通过“高级界面申请流程”
%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7
如有任何疑问,请联系@微博位置服务平台
2.位置服务接口(“位置服务接口”类别)的详细说明:
%E6%96%87%E6%A1%A3_V2
3.位置服务平台访问案例和详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD% AE%E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附件1:位置服务界面概述
附件2:应用案例演示-淘宝
[周围的人]
1.呼叫界面
a)获取附近的位置界面(已签署隐私协议的界面)
b)POI数据写入接口
2.实现功能 查看全部
第三方开发者可免费接入新浪微博位置服务平台上线
最近,新浪微博的“位置服务接口”正式启动,第三方开发人员可以免费访问新浪的位置服务平台。
新浪微博位置服务平台的启动意味着LBS应用程序将退出简单的“签入”模式。我相信在不久的将来,定位功能将作为移动应用程序的标准配置存在。
新浪微博位置服务平台的功能在于,它为第三方开发人员提供了最丰富,最实用的功能界面。通过访问基于用户,活动,位置,邻居等的界面,开发人员可以自由获取微博上一个人的时间表和社交动态,并按兴趣和标签对其进行分类。通过动态和附近的界面,开发人员可以获得单个用户的所有关注者信息,并且可以根据距离,时间和体重等各种参数对结果列表进行排序。
开发人员获取特定位置的微博用户的照片,信息和用户行为后,可以根据这些用户的位置行为,微博内容和其他多维信息全面分析用户的真实兴趣,并建立一种“真实的用户行为”而不是“单纯的内容分析”,真正的“兴趣图”是探索用户的实际需求,并根据产品功能满足他们的需求。
在新浪微博定位平台正式启动不到三天的时间里,已有30多家应用程序开发商与新浪公司签署了合作协议,其中包括优秀的行业应用程序,如桃边,酒店管家,公开点评,订购秘书等。
“位置服务接口”总共提供六种类型的接口,包括21个普通接口和7个高级接口。第三方开发人员现在可以通过新浪微博开放平台()直接调用上述界面。
1.第三方调用位置服务接口的必要条件:
调用通用接口的条件:开发人员Appkey必须首先通过对微博开放平台的审查。
(如何申请微博开放平台:)
高级界面申请方法:通过“高级界面申请流程”
%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7
如有任何疑问,请联系@微博位置服务平台
2.位置服务接口(“位置服务接口”类别)的详细说明:
%E6%96%87%E6%A1%A3_V2
3.位置服务平台访问案例和详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD% AE%E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附件1:位置服务界面概述

附件2:应用案例演示-淘宝
[周围的人]
1.呼叫界面
a)获取附近的位置界面(已签署隐私协议的界面)
b)POI数据写入接口
2.实现功能
网上的博客网站推广提高网站流量的各种方法,效果很明显
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-05-18 18:12
在线博客网站推广的各种方法中,增加网站的流量,很多作者提到使用微博推广方法,效果也非常明显。博客栏这次我们介绍一个与新浪微博同步更新的WordPress博客插件wp-tsina。使用此插件可以节省博客作者大量的晋升时间。当然,很多博客都没有在微博上推广。更新。
wp-tsina插件简介:
WP-tsina是专门为新浪微博用户开发的插件,可以自动将新发布的WordPress博客文章与新浪微博同步。
Wp-tsina插件的安装和使用:
下载博客插件wp-tsina,并将其上传到wp-content / plugins /目录(您也可以在博客背景中使用添加新插件功能)来启用wp-tsina插件,在插件列表中,然后在插件选项卡下,还有两个选项“ Sina Weibo Configuration”和“ Sina Weibo Backup”。点击“新浪微博配置”选项,进入插件设置界面
这里需要说明的是备份。选择将发布设置另存为草稿。从微博备份到WordPress博客的内容将作为草稿保存在文章列表中,自动发布将以文章的形式发布;标题前缀可以自由修改;是否将备份发布到微博,如果是,备份成功后,备份的URL 文章将发布在新浪微博上。单击“新浪微博备份”将自动将新浪微博的所有内容备份到WordPress博客,然后使用“另存为草稿”或“自动发布”集对其进行处理。
提醒:此插件需要网站主机的PHP配置来支持curl。在使用之前,请检查空间是否支持curl可以使用的phpinfo()函数。
除非特别说明,文章将由Blog Bar组织和发布,欢迎转载。 查看全部
网上的博客网站推广提高网站流量的各种方法,效果很明显
在线博客网站推广的各种方法中,增加网站的流量,很多作者提到使用微博推广方法,效果也非常明显。博客栏这次我们介绍一个与新浪微博同步更新的WordPress博客插件wp-tsina。使用此插件可以节省博客作者大量的晋升时间。当然,很多博客都没有在微博上推广。更新。
wp-tsina插件简介:
WP-tsina是专门为新浪微博用户开发的插件,可以自动将新发布的WordPress博客文章与新浪微博同步。

Wp-tsina插件的安装和使用:
下载博客插件wp-tsina,并将其上传到wp-content / plugins /目录(您也可以在博客背景中使用添加新插件功能)来启用wp-tsina插件,在插件列表中,然后在插件选项卡下,还有两个选项“ Sina Weibo Configuration”和“ Sina Weibo Backup”。点击“新浪微博配置”选项,进入插件设置界面
这里需要说明的是备份。选择将发布设置另存为草稿。从微博备份到WordPress博客的内容将作为草稿保存在文章列表中,自动发布将以文章的形式发布;标题前缀可以自由修改;是否将备份发布到微博,如果是,备份成功后,备份的URL 文章将发布在新浪微博上。单击“新浪微博备份”将自动将新浪微博的所有内容备份到WordPress博客,然后使用“另存为草稿”或“自动发布”集对其进行处理。
提醒:此插件需要网站主机的PHP配置来支持curl。在使用之前,请检查空间是否支持curl可以使用的phpinfo()函数。
除非特别说明,文章将由Blog Bar组织和发布,欢迎转载。
利用PHP进行新浪微博API开发的内容进行一个整理和说明
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-05-18 18:02
现在,玩微博的人越来越多,有关微博的第三方应用程序开发也越来越多。我不小心开始接触新浪微博API开发,新浪微博API开发资源更多,新浪微博为开发人员提供了平台。该网站是:它收录有关新浪微博开发的全面信息,包括开发人员的使用和介绍,各种语言的API函数介绍文档,SDK等。各种材料。
在发展和学习的过程中,我觉得尽管这不太困难,但仍有一些问题需要我们注意。今天,在开发和学习过程中,我仅使用PHP进行新浪微博来组织和解释API开发的内容,
新浪微博API开发之前的准备工作
首先进入新浪微博开放平台,下载基于PHP的SDK开发包。下载地址为:?name = weibo-oauth-class-with-image-avatar-06-2 9. zip
下载完成后,将其放置在您自己的开发环境中并解压缩。演示程序也包括在内。我们可以参考其示例程序进行编写。
新浪微博API开发中最重要的用户授权过程
实际上,开发过程中的许多问题都集中在用户授权阶段。我开发的第三方应用程序使用OAuth授权。在新浪微博开放平台中,OAuth授权过程非常清晰且完整。简介,我们可以检查一下,我将从示例开发的角度进行介绍和解释。
1.首先获取未经授权的请求令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,WB_SKEY);
$ keys = $ o-> getRequestToken();
// echo($ keys ['oauth_token']。':'。$ keys ['oauth_token_secret']);
我们需要在新浪微博开放平台上注册一个帐户,或直接使用我们的新浪微博帐户登录,输入我的应用程序,然后按照提示创建我们自己的第三方应用程序。创建完成后,我们可以获得两个授权的App Key和App Secret值,这两个值是我们应用程序开发的关键。
获取授权值后,我们可以使用上述代码获取未经授权的请求令牌值,该值将存储在$ key数组变量中。
2.然后请求用户授权令牌
复制代码,代码如下:
$ _ SESSION ['keys'] = $ keys;
aurl = $ o-> getAuthorizeURL($ keys ['oauth_token'],false,'');
获得未授权的请求令牌值后,我们可以使用上面的代码准备进入新浪微博授权页面进行授权。 $ aurl是授权链接页面。得到$ aurl后,可以使用header()直接跳转到授权页面,然后用户输入新浪微博帐户和密码进行授权。授权完成后,它将自动跳回到您在上一个参数中设置的回调页面:此链接可以设置为上一页,并且授权完成后,它将自动再次跳回。
应注意,有必要设置会话密钥的值。在下面获得的授权访问令牌中需要它。许多朋友可能会参考开放平台上的说明进行授权,但是他们发现总是存在错误。这通常是问题所在。您尚未设置会话的键值。当然,您不能在下面获取访问令牌的值。必须记住这一点。
3.最后是用户授权的访问令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,
WB_SKEY
$ _ SESSION ['keys'] ['oauth_token'],
$ _ SESSION ['keys'] ['oauth_token_secret']);
$ last_key = $ o-> getAccessToken($ _REQUEST ['oauth_verifier']);
echo($ last_key ['oauth_token']);
以上代码最终获得了用户授权的访问令牌。总共有两个值,它们存储在$ last_key数组变量中。我们还可以看到最后两个参数是我们之前设置的会话值。至此,基本完成。这是新浪微博用户授权的完整过程。
授权完成后的工作
授权完成后,我们可以开始调用新浪微博提供的各种API函数接口,以进行实际的应用程序开发。在这里,我将简要介绍获取最新微博记录的界面。其他都差不多。
获取新浪微博最新信息的API接口函数为:public_timeline(),示例代码如下:
复制代码,代码如下:
///获取前20条最新更新的公共微博消息
$ c =新的WeiboClient(WB_AKEY,
WB_SKEY
$ oauth_token
$ oauth_token_secret);
$ msg = $ c-> public_timeline();
if($ msg === false || $ msg === null){
回显“发生错误”;
返回假;
}
if(isset($ msg ['error_code'])&& isset($ msg ['error'])){
echo('Error_code:'。$ msg ['error_code']。'; Error:'。$ msg ['error']);
返回假;
}
print_r($ msg);
通常,在获得用户授权的访问令牌值之后,我们将其保存在用户表中并与我们应用程序中的帐户相对应。之后,我们不必每次都调用每个新浪微博API接口。我一直都在申请认证。
上面的代码非常简单,实例化WeiboClient对象,然后如果没有错误,则直接调用接口函数public_timeline以获取返回的信息。通常,新浪微博api接口返回的数据格式通常为Json格式或xml格式,我们在此处使用php开发,如果您以Json格式返回数据,则使用Json格式具有固有的优势。直接php函数json_decode()可以转换为PHP常用的数组格式。 查看全部
利用PHP进行新浪微博API开发的内容进行一个整理和说明
现在,玩微博的人越来越多,有关微博的第三方应用程序开发也越来越多。我不小心开始接触新浪微博API开发,新浪微博API开发资源更多,新浪微博为开发人员提供了平台。该网站是:它收录有关新浪微博开发的全面信息,包括开发人员的使用和介绍,各种语言的API函数介绍文档,SDK等。各种材料。
在发展和学习的过程中,我觉得尽管这不太困难,但仍有一些问题需要我们注意。今天,在开发和学习过程中,我仅使用PHP进行新浪微博来组织和解释API开发的内容,
新浪微博API开发之前的准备工作
首先进入新浪微博开放平台,下载基于PHP的SDK开发包。下载地址为:?name = weibo-oauth-class-with-image-avatar-06-2 9. zip
下载完成后,将其放置在您自己的开发环境中并解压缩。演示程序也包括在内。我们可以参考其示例程序进行编写。
新浪微博API开发中最重要的用户授权过程
实际上,开发过程中的许多问题都集中在用户授权阶段。我开发的第三方应用程序使用OAuth授权。在新浪微博开放平台中,OAuth授权过程非常清晰且完整。简介,我们可以检查一下,我将从示例开发的角度进行介绍和解释。
1.首先获取未经授权的请求令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,WB_SKEY);
$ keys = $ o-> getRequestToken();
// echo($ keys ['oauth_token']。':'。$ keys ['oauth_token_secret']);
我们需要在新浪微博开放平台上注册一个帐户,或直接使用我们的新浪微博帐户登录,输入我的应用程序,然后按照提示创建我们自己的第三方应用程序。创建完成后,我们可以获得两个授权的App Key和App Secret值,这两个值是我们应用程序开发的关键。
获取授权值后,我们可以使用上述代码获取未经授权的请求令牌值,该值将存储在$ key数组变量中。
2.然后请求用户授权令牌
复制代码,代码如下:
$ _ SESSION ['keys'] = $ keys;
aurl = $ o-> getAuthorizeURL($ keys ['oauth_token'],false,'');
获得未授权的请求令牌值后,我们可以使用上面的代码准备进入新浪微博授权页面进行授权。 $ aurl是授权链接页面。得到$ aurl后,可以使用header()直接跳转到授权页面,然后用户输入新浪微博帐户和密码进行授权。授权完成后,它将自动跳回到您在上一个参数中设置的回调页面:此链接可以设置为上一页,并且授权完成后,它将自动再次跳回。
应注意,有必要设置会话密钥的值。在下面获得的授权访问令牌中需要它。许多朋友可能会参考开放平台上的说明进行授权,但是他们发现总是存在错误。这通常是问题所在。您尚未设置会话的键值。当然,您不能在下面获取访问令牌的值。必须记住这一点。
3.最后是用户授权的访问令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,
WB_SKEY
$ _ SESSION ['keys'] ['oauth_token'],
$ _ SESSION ['keys'] ['oauth_token_secret']);
$ last_key = $ o-> getAccessToken($ _REQUEST ['oauth_verifier']);
echo($ last_key ['oauth_token']);
以上代码最终获得了用户授权的访问令牌。总共有两个值,它们存储在$ last_key数组变量中。我们还可以看到最后两个参数是我们之前设置的会话值。至此,基本完成。这是新浪微博用户授权的完整过程。
授权完成后的工作
授权完成后,我们可以开始调用新浪微博提供的各种API函数接口,以进行实际的应用程序开发。在这里,我将简要介绍获取最新微博记录的界面。其他都差不多。
获取新浪微博最新信息的API接口函数为:public_timeline(),示例代码如下:
复制代码,代码如下:
///获取前20条最新更新的公共微博消息
$ c =新的WeiboClient(WB_AKEY,
WB_SKEY
$ oauth_token
$ oauth_token_secret);
$ msg = $ c-> public_timeline();
if($ msg === false || $ msg === null){
回显“发生错误”;
返回假;
}
if(isset($ msg ['error_code'])&& isset($ msg ['error'])){
echo('Error_code:'。$ msg ['error_code']。'; Error:'。$ msg ['error']);
返回假;
}
print_r($ msg);
通常,在获得用户授权的访问令牌值之后,我们将其保存在用户表中并与我们应用程序中的帐户相对应。之后,我们不必每次都调用每个新浪微博API接口。我一直都在申请认证。
上面的代码非常简单,实例化WeiboClient对象,然后如果没有错误,则直接调用接口函数public_timeline以获取返回的信息。通常,新浪微博api接口返回的数据格式通常为Json格式或xml格式,我们在此处使用php开发,如果您以Json格式返回数据,则使用Json格式具有固有的优势。直接php函数json_decode()可以转换为PHP常用的数组格式。
零基础建站教程之同步新浪微博Wordpress代码(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 528 次浏览 • 2021-05-16 19:13
1、在学习从零开始的网站构建教程时,许多朋友提到博客正在使用社交评论插件。第一个是由于跨博客回复提醒功能,第二个是它附带的。与社交平台同步文章;也就是本文要实现的功能。首先两张图片
2、不难看出两张图片之间的区别:除了内容不同外,还有来自XXX的位置,即用红色框标记的位置;图2显示了以前使用Dushuo插件同步的效果,图1显示了此Blog中的实现。功能网站生产过程后的效果。
3、为什么您要“独立”开发一个将Wordpress自动同步到新浪微博的应用程序?第一:减少流量并为您自己的博客优化SEO 网站;第二:改善引人入胜的风格,突出我根据网站模仿站的步骤做出的网站高气质;因此,我们必须自己实现功能,而无需插件。
4、要实现此功能,请在新浪微博开发人员中心申请许可并创建网站访问应用程序。使用您的新浪微博帐户登录微博开放平台,网址:
5、单击页面导航中的[编辑开发者信息]或访问:,根据页面表单的内容填写信息,然后等待新浪审核后提交。 (下图是基本过程)
6、新浪审查通常需要大约1项工作。通过审核后,可以创建应用程序。在微博开放平台的主页上,单击橙色的[立即创建微连接]-> [网站 Access]或访问
7、完成申请信息后,将其提交以供审核。此处的审核时间将更长。我忘记了要花多长时间。在此期间,您可以使用Sina的开放端口进行开发,但是在通过审核之前,源位置会显示未审核一词,但这不会影响开发和使用。
二、同步新浪微博Wordpress代码
1、新浪微博具有许多供开发人员调用的界面。有兴趣的朋友可以认真学习。但是,一些有关学习的书籍网站也介绍了“ 2 / statuss / update”界面(开发文档:)。
2、根据开发文档()中的介绍,我们可以知道:
3、基于以上信息,我们编写的代码如下(appkey,用户名和userpassword替换为您自己的代码):
function post_to_sina_weibo($post_ID) {<br />
if (wp_is_post_revision($post_ID)) return;//修订版本(更新)不发微博<br />
$get_post_info = get_post($post_ID);<br />
$get_post_centent = get_post($post_ID)->post_content;<br />
$get_post_title = get_post($post_ID)->post_title;<br />
if ($get_post_info->post_status == \'publish\' && $_POST[\'original_post_status\'] != \'publish\') {<br />
$appkey=\'3838258703\';<br />
$username=\'微博用户名\';<br />
$userpassword=\'微博密码\';<br />
$request = new WP_Http;<br />
$status = \'【\' . strip_tags($get_post_title) . \'】 \' . mb_strimwidth(strip_tags(apply_filters(\'the_content\', $get_post_centent)) , 0, 132, \'...\') . \' 全文地址:\' . get_permalink($post_ID);<br />
$api_url = \'https://api.weibo.com/2/statuses/update.json\';<br />
$body = array(\'status\' => $status,\'source\' => $appkey);<br />
$headers = array(\'Authorization\' => \'Basic \' . base64_encode("$username:$userpassword"));<br />
$result = $request->post($api_url, array(\'body\' => $body,\'headers\' => $headers));<br />
}<br />
}<br />
add_action(\'publish_post\', \'post_to_sina_weibo\', 0);//给发布文章增加一个分享微博的动作 查看全部
零基础建站教程之同步新浪微博Wordpress代码(图)
1、在学习从零开始的网站构建教程时,许多朋友提到博客正在使用社交评论插件。第一个是由于跨博客回复提醒功能,第二个是它附带的。与社交平台同步文章;也就是本文要实现的功能。首先两张图片
2、不难看出两张图片之间的区别:除了内容不同外,还有来自XXX的位置,即用红色框标记的位置;图2显示了以前使用Dushuo插件同步的效果,图1显示了此Blog中的实现。功能网站生产过程后的效果。
3、为什么您要“独立”开发一个将Wordpress自动同步到新浪微博的应用程序?第一:减少流量并为您自己的博客优化SEO 网站;第二:改善引人入胜的风格,突出我根据网站模仿站的步骤做出的网站高气质;因此,我们必须自己实现功能,而无需插件。
4、要实现此功能,请在新浪微博开发人员中心申请许可并创建网站访问应用程序。使用您的新浪微博帐户登录微博开放平台,网址:
5、单击页面导航中的[编辑开发者信息]或访问:,根据页面表单的内容填写信息,然后等待新浪审核后提交。 (下图是基本过程)
6、新浪审查通常需要大约1项工作。通过审核后,可以创建应用程序。在微博开放平台的主页上,单击橙色的[立即创建微连接]-> [网站 Access]或访问
7、完成申请信息后,将其提交以供审核。此处的审核时间将更长。我忘记了要花多长时间。在此期间,您可以使用Sina的开放端口进行开发,但是在通过审核之前,源位置会显示未审核一词,但这不会影响开发和使用。
二、同步新浪微博Wordpress代码
1、新浪微博具有许多供开发人员调用的界面。有兴趣的朋友可以认真学习。但是,一些有关学习的书籍网站也介绍了“ 2 / statuss / update”界面(开发文档:)。
2、根据开发文档()中的介绍,我们可以知道:
3、基于以上信息,我们编写的代码如下(appkey,用户名和userpassword替换为您自己的代码):
function post_to_sina_weibo($post_ID) {<br />
if (wp_is_post_revision($post_ID)) return;//修订版本(更新)不发微博<br />
$get_post_info = get_post($post_ID);<br />
$get_post_centent = get_post($post_ID)->post_content;<br />
$get_post_title = get_post($post_ID)->post_title;<br />
if ($get_post_info->post_status == \'publish\' && $_POST[\'original_post_status\'] != \'publish\') {<br />
$appkey=\'3838258703\';<br />
$username=\'微博用户名\';<br />
$userpassword=\'微博密码\';<br />
$request = new WP_Http;<br />
$status = \'【\' . strip_tags($get_post_title) . \'】 \' . mb_strimwidth(strip_tags(apply_filters(\'the_content\', $get_post_centent)) , 0, 132, \'...\') . \' 全文地址:\' . get_permalink($post_ID);<br />
$api_url = \'https://api.weibo.com/2/statuses/update.json\';<br />
$body = array(\'status\' => $status,\'source\' => $appkey);<br />
$headers = array(\'Authorization\' => \'Basic \' . base64_encode("$username:$userpassword"));<br />
$result = $request->post($api_url, array(\'body\' => $body,\'headers\' => $headers));<br />
}<br />
}<br />
add_action(\'publish_post\', \'post_to_sina_weibo\', 0);//给发布文章增加一个分享微博的动作
如何用python登录新浪获取code值,解决如何自动登录code
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-05-16 18:13
我之前编写了有关调用新浪微博api的教程,包括如何使用python登录到新浪并获取调用api所需的代码。在此处发布此段:如果要自动获取代码值,则必须解决它。授权界面后如何获取登录问题,这个问题也困扰了我很长时间
首先,我是第一次手动登录,然后直接使用chrome查看发送的请求,复制其中的cookie,然后每次发送一个get请求以获取回调网页的代码值,如下所示:如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,此方法非常方便,无需分析太多的Sina登录方法,但是当我调用api的次数有限时,此方法不起作用
当应用程序的调用api受限制时,我们可以创建多个新浪帐户和多个应用程序,获取多个App密钥和App Secrets以重复调用,因此必须解决如何自动登录新浪获取的问题。代码
首先,我们需要分析新浪微博的登录过程。我无法完全使用chrome,edge(即fiddler4)捕获完整的登录过程。最后,我尝试使用firefox成功捕获整个登录过程
虽然我只输入了一次帐户密码,但我发送了两个帖子请求
让我们按请求分析它:
base64加密后的用户名,我将在稍后讨论如何实现,只要您知道含义,我都会随便更改它
请求成功后,服务器将向我们返回一条信息,包括我们稍后将使用的参数
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “ 1330428213”,“ is_openlock”:0,“ showpin”:0,“ exectime”:18})
稍后将需要servertime,nonce,pubket和rsakv的值,我们需要将它们解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
接下来,让我们看看第二个发帖请求
第二个请求是将表格发送到新浪通行证
servertime,nonce,pubket和rsakv是我们在最后一个get请求中获得的。 su是加密的帐户,sp是加密的密码。
su的加密方法是base64,首先安装一个base64库,然后调用以下函数:
su=base64.encodestring(username)[:-1]
密码的加密方法稍微复杂一点,还使用了servertime,nonce,pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要使用binascii库和rsa库
发送此请求后,服务器将返回JSON数据,包括我们稍后将使用的票证
请求并获取票证代码,如下所示:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
第三个请求仍然是发布请求,该请求已发送到具有授权错误的第三方。表单的内容直接在html代码中给出。
其中client_id是我们的APP_KEY; redirect_url是我们的回调页面,它是在我们首次创建应用程序时设置的;我不知道regCallback的来源,但是有两个变量,一个是APP_KEY,另一个是我们设置的回调页面。其他表格内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后,分析成功响应的get_code_url中的代码值。
code=get_code_url.url[47:]
通过这种方式,我们成功并自动获得了代码值。原创地址:python模拟登录新浪微博并自动获取调用新浪api所需的代码 查看全部
如何用python登录新浪获取code值,解决如何自动登录code
我之前编写了有关调用新浪微博api的教程,包括如何使用python登录到新浪并获取调用api所需的代码。在此处发布此段:如果要自动获取代码值,则必须解决它。授权界面后如何获取登录问题,这个问题也困扰了我很长时间
首先,我是第一次手动登录,然后直接使用chrome查看发送的请求,复制其中的cookie,然后每次发送一个get请求以获取回调网页的代码值,如下所示:如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,此方法非常方便,无需分析太多的Sina登录方法,但是当我调用api的次数有限时,此方法不起作用
当应用程序的调用api受限制时,我们可以创建多个新浪帐户和多个应用程序,获取多个App密钥和App Secrets以重复调用,因此必须解决如何自动登录新浪获取的问题。代码
首先,我们需要分析新浪微博的登录过程。我无法完全使用chrome,edge(即fiddler4)捕获完整的登录过程。最后,我尝试使用firefox成功捕获整个登录过程


虽然我只输入了一次帐户密码,但我发送了两个帖子请求
让我们按请求分析它:
base64加密后的用户名,我将在稍后讨论如何实现,只要您知道含义,我都会随便更改它
请求成功后,服务器将向我们返回一条信息,包括我们稍后将使用的参数


sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “ 1330428213”,“ is_openlock”:0,“ showpin”:0,“ exectime”:18})
稍后将需要servertime,nonce,pubket和rsakv的值,我们需要将它们解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
接下来,让我们看看第二个发帖请求
第二个请求是将表格发送到新浪通行证
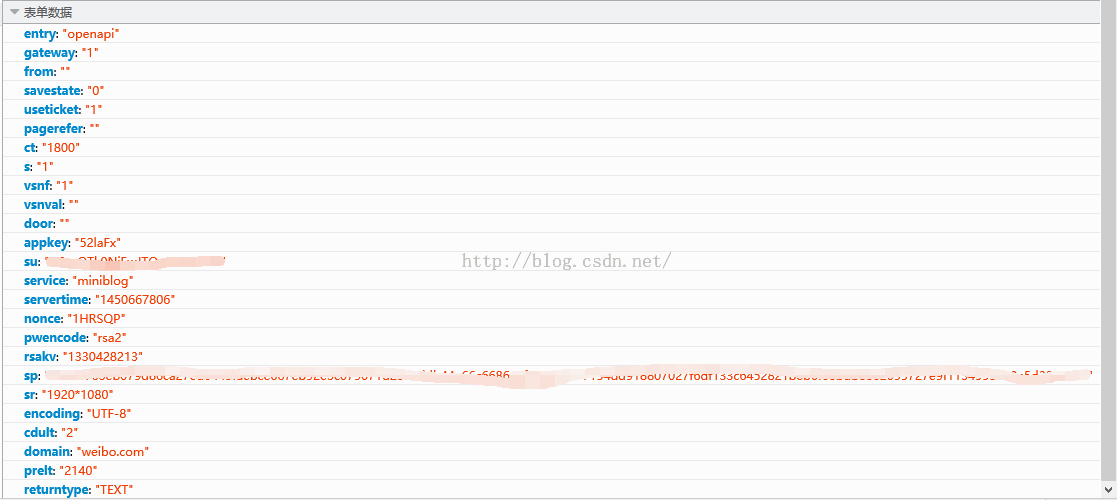
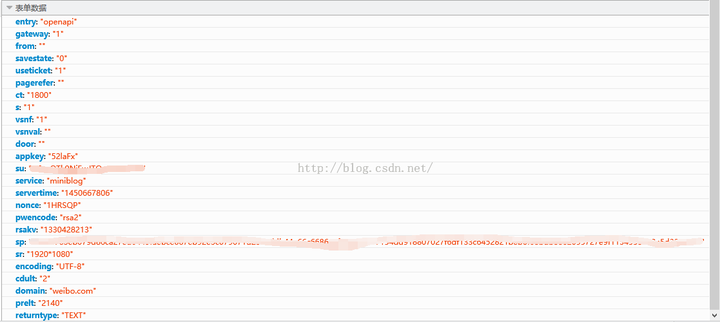
servertime,nonce,pubket和rsakv是我们在最后一个get请求中获得的。 su是加密的帐户,sp是加密的密码。
su的加密方法是base64,首先安装一个base64库,然后调用以下函数:
su=base64.encodestring(username)[:-1]
密码的加密方法稍微复杂一点,还使用了servertime,nonce,pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要使用binascii库和rsa库
发送此请求后,服务器将返回JSON数据,包括我们稍后将使用的票证


请求并获取票证代码,如下所示:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
第三个请求仍然是发布请求,该请求已发送到具有授权错误的第三方。表单的内容直接在html代码中给出。
其中client_id是我们的APP_KEY; redirect_url是我们的回调页面,它是在我们首次创建应用程序时设置的;我不知道regCallback的来源,但是有两个变量,一个是APP_KEY,另一个是我们设置的回调页面。其他表格内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后,分析成功响应的get_code_url中的代码值。
code=get_code_url.url[47:]
通过这种方式,我们成功并自动获得了代码值。原创地址:python模拟登录新浪微博并自动获取调用新浪api所需的代码
PC登录新浪微博模拟登录(人人网)(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-06-11 06:22
PC登录新浪微博时,用户名和密码在客户端用js进行了预加密,POST前会先GET一组参数,也会是POST_DATA的一部分。这样就不能用通常的简单方法来模拟POST登录(如人人网)。
通过爬虫获取新浪微博数据,模拟登录必不可少。
1、 在提交 POST 请求之前,需要通过 GET 获取四个参数(servertime、nonce、pubkey 和 rsakv)。这不仅仅是之前提到的简单的服务器时间和随机数。这主要是因为js有了用户名,密码加密方式发生了变化。
1.1 由于加密方式的变化,这里我们将使用RSA模块。 RSA公钥加密算法的介绍请参考网络中的相关内容。下载并安装 rsa 模块:
下载:
rsa 模块文档地址:
根据你的Python版本选择适合你的rsa安装包(.egg)。 win下安装需要通过命令行使用easy_install.exe(win下安装setuptool,从这里下载:setuptools-0.6c11.win32-py2.6.exe安装文件)安装,例如:easy_install rsa-3.1.1-py2.6.egg,在最后的命令行下测试import rsa,如果没有报错则安装成功。
1.2 获取并查看新浪微博登录js文件
查看新浪通url()的源码,在那里可以找到js地址,但是里面的内容打开后是加密的,可以在网上找一个在线解密站点解密,查看最终用户名和密码加密方式。
1.3 登录
第一步登录,添加自己的用户名(username),并请求prelogin_url链接地址:
prelogin_url =';callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&client=ssologin.js(v1.4.4)'% username
使用get方法获取如下类似内容:
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1362041092, “PCID”: “GZ-6664c3dea2bfdaa3c94e8734c9ec2c9e6a1f”, “随机数”: “IRYP4N”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: "1330428213","exectime":1})
然后从中提取我们想要的servertime、nonce、pubkey和rsakv。当然,pubkey和rsakv的值可以写在代码里,都是固定值。
2、在用户名由BASE64计算之前:
复制代码代码如下:
用户名_ = urllib.quote(用户名)
username = base64.encodestring(username)[:-1]
密码是SHA1加密3次,加上servertime和nonce值来干扰。即:经过两次SHA1加密,结果加上servertime和nonce的值,然后SHA1算一次。
在最新的rsa加密方式中,username还是像以前一样处理;
密码加密方式与原来不同:
2.1 首先创建一个rsa公钥。公钥的两个参数在新浪微博上都是固定值,但都是16进制字符串。第一个是第一步登录的公钥,第二个是js加密文件中的'10001'。
这两个值需要从十六进制转换为十进制,但也可以写在代码中。这里10001直接写成65537,代码如下:
复制代码代码如下:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) +'\t' + str(nonce) +'\n' + str(password) #从拼接明文js加密文件中获取
passwd = rsa.encrypt(message, key) #encryption
passwd = binascii.b2a_hex(passwd) #将加密后的信息转换为十六进制。
2.2 请求pass url: login_url =‘(v1.4.4)'
要发送的头信息
复制代码代码如下:
postPara = {
'entry':'微博',
'网关': '1',
'来自':'',
'savestate': '7',
'用户票':'1',
'ssosimplelogin': '1',
'vsnf': '1',
'vsnval':'',
'su': 编码用户名,
'service':'miniblog',
'servertime': serverTime,
'nonce':随机数,
'pwencode':'rsa2',
'sp': 编码密码,
'encoding':'UTF-8',
'prelt': '115',
'rsakv': rsakv,
'url':';callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype':'META'
}
在请求的内容中加入RSakv,pwencode的值改为rsa2,其他和之前一样。
整理参数,POST请求。检查是否登录成功,可以参考一句location.replace(";callback=parent.sinaSSOController.feedBackUrlCallBack&retcode=101&reason=%B5%C7%C2%BC%C3%FB%BB%F2%C3% in POST DC%C2%EB%B4%ED%CE%F3后得到的内容");
如果retcode=101,表示登录失败。登录成功后的结果类似,只是retcode的值为0。
3、登录成功后,body中替换信息中的url就是我们下一步要使用的url。然后对上面的URL使用GET方法向服务器发送一个请求,并保存这个请求的cookie信息,也就是我们需要的登录cookie。 查看全部
PC登录新浪微博模拟登录(人人网)(组图)
PC登录新浪微博时,用户名和密码在客户端用js进行了预加密,POST前会先GET一组参数,也会是POST_DATA的一部分。这样就不能用通常的简单方法来模拟POST登录(如人人网)。
通过爬虫获取新浪微博数据,模拟登录必不可少。
1、 在提交 POST 请求之前,需要通过 GET 获取四个参数(servertime、nonce、pubkey 和 rsakv)。这不仅仅是之前提到的简单的服务器时间和随机数。这主要是因为js有了用户名,密码加密方式发生了变化。
1.1 由于加密方式的变化,这里我们将使用RSA模块。 RSA公钥加密算法的介绍请参考网络中的相关内容。下载并安装 rsa 模块:
下载:
rsa 模块文档地址:
根据你的Python版本选择适合你的rsa安装包(.egg)。 win下安装需要通过命令行使用easy_install.exe(win下安装setuptool,从这里下载:setuptools-0.6c11.win32-py2.6.exe安装文件)安装,例如:easy_install rsa-3.1.1-py2.6.egg,在最后的命令行下测试import rsa,如果没有报错则安装成功。
1.2 获取并查看新浪微博登录js文件
查看新浪通url()的源码,在那里可以找到js地址,但是里面的内容打开后是加密的,可以在网上找一个在线解密站点解密,查看最终用户名和密码加密方式。
1.3 登录
第一步登录,添加自己的用户名(username),并请求prelogin_url链接地址:
prelogin_url =';callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&client=ssologin.js(v1.4.4)'% username
使用get方法获取如下类似内容:
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1362041092, “PCID”: “GZ-6664c3dea2bfdaa3c94e8734c9ec2c9e6a1f”, “随机数”: “IRYP4N”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: "1330428213","exectime":1})
然后从中提取我们想要的servertime、nonce、pubkey和rsakv。当然,pubkey和rsakv的值可以写在代码里,都是固定值。
2、在用户名由BASE64计算之前:
复制代码代码如下:
用户名_ = urllib.quote(用户名)
username = base64.encodestring(username)[:-1]
密码是SHA1加密3次,加上servertime和nonce值来干扰。即:经过两次SHA1加密,结果加上servertime和nonce的值,然后SHA1算一次。
在最新的rsa加密方式中,username还是像以前一样处理;
密码加密方式与原来不同:
2.1 首先创建一个rsa公钥。公钥的两个参数在新浪微博上都是固定值,但都是16进制字符串。第一个是第一步登录的公钥,第二个是js加密文件中的'10001'。
这两个值需要从十六进制转换为十进制,但也可以写在代码中。这里10001直接写成65537,代码如下:
复制代码代码如下:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) +'\t' + str(nonce) +'\n' + str(password) #从拼接明文js加密文件中获取
passwd = rsa.encrypt(message, key) #encryption
passwd = binascii.b2a_hex(passwd) #将加密后的信息转换为十六进制。
2.2 请求pass url: login_url =‘(v1.4.4)'
要发送的头信息
复制代码代码如下:
postPara = {
'entry':'微博',
'网关': '1',
'来自':'',
'savestate': '7',
'用户票':'1',
'ssosimplelogin': '1',
'vsnf': '1',
'vsnval':'',
'su': 编码用户名,
'service':'miniblog',
'servertime': serverTime,
'nonce':随机数,
'pwencode':'rsa2',
'sp': 编码密码,
'encoding':'UTF-8',
'prelt': '115',
'rsakv': rsakv,
'url':';callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype':'META'
}
在请求的内容中加入RSakv,pwencode的值改为rsa2,其他和之前一样。
整理参数,POST请求。检查是否登录成功,可以参考一句location.replace(";callback=parent.sinaSSOController.feedBackUrlCallBack&retcode=101&reason=%B5%C7%C2%BC%C3%FB%BB%F2%C3% in POST DC%C2%EB%B4%ED%CE%F3后得到的内容");
如果retcode=101,表示登录失败。登录成功后的结果类似,只是retcode的值为0。
3、登录成功后,body中替换信息中的url就是我们下一步要使用的url。然后对上面的URL使用GET方法向服务器发送一个请求,并保存这个请求的cookie信息,也就是我们需要的登录cookie。
盘点国内首款多用户PHP+Mysql开源微博客系统
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-06-10 03:40
国外的微博程序,虽然有StateusNet等所有功能,但可能不适合国内的特殊环境。既然如此,再来算一下国内的微博产品。详情请关注相关报道。
微博
Xweibo v2.0 正式版下载
界面预览
新浪X微博基于新浪开放API,通过绑定新浪微博账号即可与新浪微博无缝对接。 Xweibo 是完全免费和开源的。如果不能完全满足客户的需求,客户可以自由修改。 Xweibo支持与原站账号系统对接。 1.1版本内置了Discuz!的账号适配器,可以连接Discuz!和 Xweibo 帐户只需几个操作。微博支持换肤机制。除了默认提供的六套皮肤外,您还可以开发自己的自定义皮肤。
微博
i微博 v1.0 下载
界面预览
腾讯i微博系统是基于腾讯微博开放平台API开发的免费微博系统。收录完整的微博功能,可轻松接入腾讯微博。
PageCookery
PageCookery 微博系统 v0.9.8 下载
界面预览
PageCookery 是中国第一个公开发布的单用户开源微博程序。基于PHP+MySQL架构,以“分享”和“发现”为理念的安全、高效、稳定的Web2.0微博解决方案。
注意狗
Notes Dog v3.6.6.20120829 UTF-8 升级包下载
界面预览
健视狗微博系统是一套业界领先的开源PHP微博程序。支持网页、手机、QQ机器人、站外分享等多种方式发布内容,可通过QQ、微博秀场外呼、同步到新浪微博(可以使用新浪微博账号登录) 、注册和绑定)等传播内容,是目前最流行、最流行的交互系统。
EasyTalk
EasyTalk v5.0.1 build 20100801 下载
界面预览
EasyTalk 是国内第一个多用户 PHP+Mysql 开源微博系统。支持网页、手机等多种方式发布和接收信息。 EasyTalk 完全符合中国人的上网习惯。它真正轻便且易于使用。 ,便于管理员安装部署,管理方便。 EasyTalk 功能强大,二次开发度高,人性化的模板定制功能大大提升了用户体验,相比国内其他微博软件,EasyTalk 具有绝对优势! 查看全部
盘点国内首款多用户PHP+Mysql开源微博客系统
国外的微博程序,虽然有StateusNet等所有功能,但可能不适合国内的特殊环境。既然如此,再来算一下国内的微博产品。详情请关注相关报道。
微博
Xweibo v2.0 正式版下载
界面预览
新浪X微博基于新浪开放API,通过绑定新浪微博账号即可与新浪微博无缝对接。 Xweibo 是完全免费和开源的。如果不能完全满足客户的需求,客户可以自由修改。 Xweibo支持与原站账号系统对接。 1.1版本内置了Discuz!的账号适配器,可以连接Discuz!和 Xweibo 帐户只需几个操作。微博支持换肤机制。除了默认提供的六套皮肤外,您还可以开发自己的自定义皮肤。
微博
i微博 v1.0 下载
界面预览
腾讯i微博系统是基于腾讯微博开放平台API开发的免费微博系统。收录完整的微博功能,可轻松接入腾讯微博。
PageCookery
PageCookery 微博系统 v0.9.8 下载
界面预览
PageCookery 是中国第一个公开发布的单用户开源微博程序。基于PHP+MySQL架构,以“分享”和“发现”为理念的安全、高效、稳定的Web2.0微博解决方案。
注意狗
Notes Dog v3.6.6.20120829 UTF-8 升级包下载
界面预览
健视狗微博系统是一套业界领先的开源PHP微博程序。支持网页、手机、QQ机器人、站外分享等多种方式发布内容,可通过QQ、微博秀场外呼、同步到新浪微博(可以使用新浪微博账号登录) 、注册和绑定)等传播内容,是目前最流行、最流行的交互系统。
EasyTalk
EasyTalk v5.0.1 build 20100801 下载
界面预览
EasyTalk 是国内第一个多用户 PHP+Mysql 开源微博系统。支持网页、手机等多种方式发布和接收信息。 EasyTalk 完全符合中国人的上网习惯。它真正轻便且易于使用。 ,便于管理员安装部署,管理方便。 EasyTalk 功能强大,二次开发度高,人性化的模板定制功能大大提升了用户体验,相比国内其他微博软件,EasyTalk 具有绝对优势!
Twitter全面改用OAuth认证新浪微博接口的人~~
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-06 20:12
由于 Twitter 近期只支持 OAuth 认证方式,各大应用纷纷转向 OAuth 认证方式,新浪微博开放平台也将在近期停止 Base OAuth 认证方式。
为了继续使用新浪微博的开放平台,我开始研究OAuth认证方式。经过一段时间的实践,对新浪微博开放平台的OAuth认证方式有了一定的体会。鉴于网上这个平台的OAuth相关资料比较少,在这里分享一下过程中积累的经验,希望能帮助到一些想使用OAuth认证的人调用新浪微博界面~ ~
1.关于 OAuth:
OAUth认证方式相比Base OAuth认证方式最大的特点是应用端不需要保存用户的账号和密码,只需要用户授权的Key和Secret组合即可使用平台上的接口资源访问,在传输过程中,也可以避免恶意人员通过截包分析获取用户的账号和密码。 (有一种说法,推特之所以完全切换到OAuth认证,是为了防止GFW通过截包的方式获取一些相关名人的账号和密码)。具体定义可以阅读OAuth规范定义:OAuth规范。
2.新浪微博开放平台:
新浪微博开放平台的基本界面、参数、返回格式均参考推特模型。当然,国内其他一些开放平台也大量借鉴了推特的模式,所以基本是一样的。要使用新浪微博的开放平台,当然要先到其网站注册:新浪微博API。
注册后,会得到两个关键字段Consumer Key和Consumer Secret。保存它们。
新浪微博的开发平台有足够的文档,可以快速调用这些接口。除了一些较难的接口,我们将在下面讨论。
3.使用 OAuth 到新浪:
要使用 OAuth,用户必须先获得授权。一般来说,授权流程如下:
(1)应用向新浪开发平台发送请求,获取未授权的Request Token和Request Secret。此时Request Secret暂时不用,请妥善保管。
(2)以上一步获取的Request Token为参数,引导用户浏览器跳转到新浪微博授权页面,用户进入该页面登录新浪微博进行token授权.如果你在(1)如果浏览器的回调地址已经设置到服务器中,用户的浏览器会被重定向到这个地址,并且会在地址中增加一个新的参数:oauth_verifier。这个参数会稍后使用并保存。
(3)OAuth是认证过程的最后一步,向服务器请求真实的Token,将(1))中得到的Request Token、Request Secret和oauth_verifier作为参数传递给新浪微博服务器,服务端会返回真实的Access Token和Access Secret,新浪微博也会返回用户在新浪微博中的userid。有了用户的Access Token和Access Secret,就可以自由方便的调用新浪微博界面的开通。
每次调用都必须收录 OAuth 身份验证信息。作为OAuth认证信息,添加到请求包中基本上有两种方式:
(1)最推荐的方法是使用HTTP Authorization Header。这个header的定义在RFC2617中定义。
例如:
Authorization: OAuth realm="http://photos.example.net/",
oauth_consumer_key="dpf43f3p2l4k3l03",
oauth_token="nnch734d00sl2jdk",
oauth_signature_method="HMAC-SHA1",
oauth_signature="tR3%2BTy81lMeYAr%2FFid0kMTYa%2FWM%3D",
oauth_timestamp="1191242096", oauth_nonce="kllo9940pd9333jh",
oauth_version="1.0"
(2)或者你可以使用参数传递的方法,把OAuth参数像普通参数一样放在Get的URL中,或者放在POST的body内容中,都是可以的,
但是,在某些特殊情况下,解决这个问题会比较困难。
4.OAuth 认证参数分析:
如上所示,正常的 OAuth 身份验证收录以下参数:
(1)oauth_consumer_key:这是新浪在注册时给你的conusmer key,纯文本传输
(2)oauth_token:这是用户完成OAuth认证后的Access Token。在OAuth认证的第三步,就是Request Token,第一步不需要这个参数
(3)oauth_signature_method:加密方法,提供HMAC-SHA1、RSA-SHA1、PLAINTEXT几种方法
(4)oauth_signature:所有参数的加密字符串,包括消费者秘密和访问秘密
(5)oauth_timestamp:请求的时间戳
(6)oauth_version:可选参数,基本设置为1.0,否则会报错。
(7)oauth_nonce:防止重复调用的随机值
5.OAuth上传图片的痛苦:
使用上面的方法,基本上所有的接口调用都可以解决。但是当你遇到上传图片等困难的请求时,你需要一些技巧。
新浪微博开放平台要求上传图片时使用multipart/form-data。但是,当定义 OAuth 协议时,Content-Type 被描述为 application/x-www-form-urlencoded。没有提到如何在 multipart/form-data 中使用它。
在新浪微博的开放平台上,基本上网上找不到任何地方提到通过OAuth上传图片。在 Twitter 上尝试和学习了一晚之后,
终于找到解决办法了。
基本上,协议中没有规定的内容,必须由私营部门以更直观的方式解决。在新浪微博界面上传图片,必须使用multipart/form-data作为Content-Type,OAuth认证参数不能放在form-data中,必须通过Authorization Header进行处理。这时候就必须除了file参数之外,在这个界面,status是加到oauth的加密里面的,但是没有出现在Authorization Header里面,而是后面加到了fom-data中,这样图片可以正常上传,可以发布微博。通过这个简单又麻烦的方法,我终于可以安全的上传图片到新浪微博了。
6.last
到目前为止,我已经成功调用了新浪微博的大部分接口,并开始覆盖搜狐微博、网易微博等开放平台。希望可以通过这个文章记录一些经验和教训。
7.参考资料
[RFC5849]E。哈默拉哈夫,埃德。 《OAuth 1.0 协议》,RFC5849
[RFC1867] E. Nebel,L. Masinter,“HTML 中基于表单的文件上传”,RFC1867
[RFC2616] Fielding,R.,Gettys,J,e "超文本传输协议 - HTTP/1.1", RFC2616
[RFC2617] Franks,J.“HTTP 身份验证:基本和摘要式访问身份验证”,RFC2617
新浪微博开放平台: 查看全部
Twitter全面改用OAuth认证新浪微博接口的人~~
由于 Twitter 近期只支持 OAuth 认证方式,各大应用纷纷转向 OAuth 认证方式,新浪微博开放平台也将在近期停止 Base OAuth 认证方式。
为了继续使用新浪微博的开放平台,我开始研究OAuth认证方式。经过一段时间的实践,对新浪微博开放平台的OAuth认证方式有了一定的体会。鉴于网上这个平台的OAuth相关资料比较少,在这里分享一下过程中积累的经验,希望能帮助到一些想使用OAuth认证的人调用新浪微博界面~ ~
1.关于 OAuth:
OAUth认证方式相比Base OAuth认证方式最大的特点是应用端不需要保存用户的账号和密码,只需要用户授权的Key和Secret组合即可使用平台上的接口资源访问,在传输过程中,也可以避免恶意人员通过截包分析获取用户的账号和密码。 (有一种说法,推特之所以完全切换到OAuth认证,是为了防止GFW通过截包的方式获取一些相关名人的账号和密码)。具体定义可以阅读OAuth规范定义:OAuth规范。
2.新浪微博开放平台:
新浪微博开放平台的基本界面、参数、返回格式均参考推特模型。当然,国内其他一些开放平台也大量借鉴了推特的模式,所以基本是一样的。要使用新浪微博的开放平台,当然要先到其网站注册:新浪微博API。
注册后,会得到两个关键字段Consumer Key和Consumer Secret。保存它们。
新浪微博的开发平台有足够的文档,可以快速调用这些接口。除了一些较难的接口,我们将在下面讨论。
3.使用 OAuth 到新浪:
要使用 OAuth,用户必须先获得授权。一般来说,授权流程如下:
(1)应用向新浪开发平台发送请求,获取未授权的Request Token和Request Secret。此时Request Secret暂时不用,请妥善保管。
(2)以上一步获取的Request Token为参数,引导用户浏览器跳转到新浪微博授权页面,用户进入该页面登录新浪微博进行token授权.如果你在(1)如果浏览器的回调地址已经设置到服务器中,用户的浏览器会被重定向到这个地址,并且会在地址中增加一个新的参数:oauth_verifier。这个参数会稍后使用并保存。
(3)OAuth是认证过程的最后一步,向服务器请求真实的Token,将(1))中得到的Request Token、Request Secret和oauth_verifier作为参数传递给新浪微博服务器,服务端会返回真实的Access Token和Access Secret,新浪微博也会返回用户在新浪微博中的userid。有了用户的Access Token和Access Secret,就可以自由方便的调用新浪微博界面的开通。
每次调用都必须收录 OAuth 身份验证信息。作为OAuth认证信息,添加到请求包中基本上有两种方式:
(1)最推荐的方法是使用HTTP Authorization Header。这个header的定义在RFC2617中定义。
例如:
Authorization: OAuth realm="http://photos.example.net/",
oauth_consumer_key="dpf43f3p2l4k3l03",
oauth_token="nnch734d00sl2jdk",
oauth_signature_method="HMAC-SHA1",
oauth_signature="tR3%2BTy81lMeYAr%2FFid0kMTYa%2FWM%3D",
oauth_timestamp="1191242096", oauth_nonce="kllo9940pd9333jh",
oauth_version="1.0"
(2)或者你可以使用参数传递的方法,把OAuth参数像普通参数一样放在Get的URL中,或者放在POST的body内容中,都是可以的,
但是,在某些特殊情况下,解决这个问题会比较困难。
4.OAuth 认证参数分析:
如上所示,正常的 OAuth 身份验证收录以下参数:
(1)oauth_consumer_key:这是新浪在注册时给你的conusmer key,纯文本传输
(2)oauth_token:这是用户完成OAuth认证后的Access Token。在OAuth认证的第三步,就是Request Token,第一步不需要这个参数
(3)oauth_signature_method:加密方法,提供HMAC-SHA1、RSA-SHA1、PLAINTEXT几种方法
(4)oauth_signature:所有参数的加密字符串,包括消费者秘密和访问秘密
(5)oauth_timestamp:请求的时间戳
(6)oauth_version:可选参数,基本设置为1.0,否则会报错。
(7)oauth_nonce:防止重复调用的随机值
5.OAuth上传图片的痛苦:
使用上面的方法,基本上所有的接口调用都可以解决。但是当你遇到上传图片等困难的请求时,你需要一些技巧。
新浪微博开放平台要求上传图片时使用multipart/form-data。但是,当定义 OAuth 协议时,Content-Type 被描述为 application/x-www-form-urlencoded。没有提到如何在 multipart/form-data 中使用它。
在新浪微博的开放平台上,基本上网上找不到任何地方提到通过OAuth上传图片。在 Twitter 上尝试和学习了一晚之后,
终于找到解决办法了。
基本上,协议中没有规定的内容,必须由私营部门以更直观的方式解决。在新浪微博界面上传图片,必须使用multipart/form-data作为Content-Type,OAuth认证参数不能放在form-data中,必须通过Authorization Header进行处理。这时候就必须除了file参数之外,在这个界面,status是加到oauth的加密里面的,但是没有出现在Authorization Header里面,而是后面加到了fom-data中,这样图片可以正常上传,可以发布微博。通过这个简单又麻烦的方法,我终于可以安全的上传图片到新浪微博了。
6.last
到目前为止,我已经成功调用了新浪微博的大部分接口,并开始覆盖搜狐微博、网易微博等开放平台。希望可以通过这个文章记录一些经验和教训。
7.参考资料
[RFC5849]E。哈默拉哈夫,埃德。 《OAuth 1.0 协议》,RFC5849
[RFC1867] E. Nebel,L. Masinter,“HTML 中基于表单的文件上传”,RFC1867
[RFC2616] Fielding,R.,Gettys,J,e "超文本传输协议 - HTTP/1.1", RFC2616
[RFC2617] Franks,J.“HTTP 身份验证:基本和摘要式访问身份验证”,RFC2617
新浪微博开放平台:
新浪微博登录常用接口:对应主界面:但是个人建议
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-06-03 07:02
登录入口
新浪微博登录常用界面:
对应主界面:
但我个人推荐使用手机微博入口:
对应主界面:
原因是手机上的数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
对比下面两张PC端和手机端的图片,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(username, password) 登录微博
2.VisitPersonPage(user_id)访问people网站获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
新浪微博登录常用接口:对应主界面:但是个人建议
登录入口
新浪微博登录常用界面:
对应主界面:
但我个人推荐使用手机微博入口:
对应主界面:
原因是手机上的数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库验证。
对比下面两张PC端和手机端的图片,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
以下代码主要分为三部分:
1.LoginWeibo(username, password) 登录微博
2.VisitPersonPage(user_id)访问people网站获取个人信息
3.获取微博内容,同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
PC站是你的首选:爬虫爬取网站m站
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-06-03 06:39
相关github地址:
一般做爬虫爬网站时,m站是首选,wap站次之,PC站最后考虑,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备工作
1、环境配置
2、Proxyip
使用代理ip爬虫是反爬虫方法之一。很多网站会检测某个时间段内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。但是一般这个只适合个人爬虫需求,因为很多免费的代理ip可能会被多人同时使用,使用时间短,速度慢,匿名性低,所以需要专业的爬虫工程师或者爬虫公司要使用更高品质的隐私代理,通常这类代理需要找专门的供应商购买,然后使用用户名/密码授权使用。
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = ''+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果
查看全部
PC站是你的首选:爬虫爬取网站m站
相关github地址:
一般做爬虫爬网站时,m站是首选,wap站次之,PC站最后考虑,因为PC站的各种验证最多。当然,这不是绝对的。有时PC站的信息最全,而您只需要所有的信息,那么PC站就是您的首选。一般m站以m开头,后跟域名。这次我们来分析一下微博的HTTP请求。
准备工作
1、环境配置
2、Proxyip
使用代理ip爬虫是反爬虫方法之一。很多网站会检测某个时间段内某个ip的访问次数。如果访问次数过多,会禁止ip访问(例如防止刷票)。所以爬取的时候可以设置多个agent,每次都可以换一个。如果其中一个被及时拦截,也可以调用其他ip来完成爬取任务。在 urllib.request 库中,代理服务器是通过 ProxyHandler 设置的。网上有很多免费代理IP池,比如Xspur免费代理IP,可以根据自己的需要选择。但是一般这个只适合个人爬虫需求,因为很多免费的代理ip可能会被多人同时使用,使用时间短,速度慢,匿名性低,所以需要专业的爬虫工程师或者爬虫公司要使用更高品质的隐私代理,通常这类代理需要找专门的供应商购买,然后使用用户名/密码授权使用。
单代理ip调用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url = "https://www.douban.com/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http": "61.135.217.7:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True # 定义一个代理开关
# 通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request(url, headers=header)
# 方法1、只有使用opener.open()方法发送请求才使用自定义的代理,而使用urlopen()函数则不使用自定义代理。
response = opener.open(request)
# 方法2、urllib.request.install_opener(opener)函数就是将opener应用到全局,之后所有的,
# 不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
随机选择多个代理ip列表
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
import random
url ="https://www.douban.com/"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
# 代理IP列表随机抽取
proxy_list = [{"http" : "220.168.52.245:55255"},
{"http" : "124.193.135.242:54219"},
{"http" : "36.7.128.146:52222"},
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
print(proxy)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url, headers=header)
response = opener.open(request)
data = response.read().decode('utf-8', 'ignore')
print(data)
完整代码
'''
抓取并保存 正文、图片、发布时间、点赞数、评论数、转发数
抓取的微博id:
洋葱故事会 https://m.weibo.cn/u/1806732505
'''
# -*-coding:utf8-*-
# 需要的模块
import os
import urllib
import urllib.request
import time
import json
import xlwt
# 定义要爬取的微博大V的微博ID
id='1806732505'
# 设置代理IP
proxy_addr="122.241.72.191:808"
# 定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
# 获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
# 获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:" + name + "\n" + "微博主页地址:" + profile_url + "\n" + "微博头像地址:" + profile_image_url + "\n" + "是否认证:" + str(verified) + "\n" + "微博说明:" + description + "\n" + "关注人数:" + str(guanzhu) + "\n" + "粉丝数:" + str(fensi) + "\n" + "性别:" + gender + "\n" + "微博等级:" + str(urank) + "\n")
return name
# 保存图片
def savepic(pic_urls, created_at, page, num):
pic_num = len(pic_urls)
srcpath = 'weibo_img/洋葱故事会/'
if not os.path.exists(srcpath):
os.makedirs(srcpath)
picpath = str(created_at) + 'page' + str(page) + 'num' + str(num) + 'pic'
for i in range(len(pic_urls)):
picpathi = picpath + str(i)
path = srcpath + picpathi + ".jpg"
urllib.request.urlretrieve(pic_urls[i], path)
# 获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id
weibo_url='https://m.weibo.cn/api/container/getIndex?type=uid&value='+id+'&containerid='+get_containerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count') # 点赞数
comments_count=mblog.get('comments_count') # 评论数
created_at=mblog.get('created_at') # 发布时间
reposts_count=mblog.get('reposts_count') # 转发数
scheme=cards[j].get('scheme') # 微博地址
text=mblog.get('text') # 微博内容
pictures=mblog.get('pics') # 正文配图,返回list
pic_urls = [] # 存储图片url地址
if pictures:
for picture in pictures:
pic_url = picture.get('large').get('url')
pic_urls.append(pic_url)
# print(pic_urls)
# 保存文本
with open(file,'a',encoding='utf-8') as fh:
if len(str(created_at)) < 6:
created_at = ''+ str(created_at)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数、图片链接
fh.write(str(i)+'\t'+str(j)+'\t'+str(scheme)+'\t'+str(created_at)+'\t'+text+'\t'+str(attitudes_count)+'\t'+str(comments_count)+'\t'+str(reposts_count)+'\t'+str(pic_urls)+'\n')
# 保存图片
savepic(pic_urls, created_at, i, j)
i+=1
'''休眠1s以免给服务器造成严重负担'''
time.sleep(1)
else:
break
except Exception as e:
print(e)
pass
def txt_xls(filename,xlsname):
"""
:文本转换成xls的函数
:param filename txt文本文件名称、
:param xlsname 表示转换后的excel文件名
"""
try:
with open(filename,'r',encoding='utf-8') as f:
xls=xlwt.Workbook()
#生成excel的方法,声明excel
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
# 页数、条数、微博地址、发布时间、微博内容、点赞数、评论数、转发数
sheet.write(0, 0, '爬取页数')
sheet.write(0, 1, '爬取当前页数的条数')
sheet.write(0, 2, '微博地址')
sheet.write(0, 3, '发布时间')
sheet.write(0, 4, '微博内容')
sheet.write(0, 5, '点赞数')
sheet.write(0, 6, '评论数')
sheet.write(0, 7, '转发数')
sheet.write(0, 8, '图片链接')
x = 1
while True:
#按行循环,读取文本文件
line = f.readline()
if not line:
break #如果没有内容,则退出循环
for i in range(0, len(line.split('\t'))):
item=line.split('\t')[i]
sheet.write(x,i,item) # x单元格行,i 单元格列
x += 1 #excel另起一行
xls.save(xlsname) #保存xls文件
except:
raise
if __name__=="__main__":
name = get_userInfo(id)
file = str(name) + id+".txt"
get_weibo(id,file)
txtname = file
xlsname = str(name) + id + ".xls"
txt_xls(txtname, xlsname)
print('finish')
爬虫结果
2018年2月赖敬之(东南大学信息科学与工程学院)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-06-03 06:37
2018年2月,建立基于网络爬虫的新浪微博数据分析网站赖景智(东南大学信息科学与工程学院,南京211189)[摘要]新浪微博作为中国最大的社交网络中国网站,内容丰富,本文实现了一个微博数据分析网站,网站后端使用爬虫实时抓取数据存入redis数据库,前端使用ajax轮询技术和数据可视化 该技术将统计分析后的数据展示在网页上,相比直接调用新浪微博的API,网络爬虫获取数据的方式具有更大的灵活性,能够获取的数据量也比较大,但也有一定的局限性,最大的障碍之一是新浪微博的反爬虫技术,本文也将讨论如何突破反爬虫的限制。[关键词]新浪;爬虫;数据分析[CL] C号] TP391.3 [文档识别码] A [文章号] 1006-4222 (2018)02-0073-02 1 简介 新浪微博是一种新兴的以关注和分享为一种模式,内容少,发布快,形式多样 正好迎合了人们对信息实时、准确、多样的分享和交流的需求,因此受到广大用户的欢迎和喜爱,而微博本身也有成为当代互联网领域的一颗冉冉升起的新星。人们热衷于在微博上获取信息 最新信息,发表您的观点,分享您喜欢的东西。因此,微博收录了丰富的数据,具有重要的数据挖掘意义。
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。使用爬虫,您可以轻松、自动、灵活地获取海量数据。本文首先介绍了新浪微博数据分析网站的整体思路,然后介绍了如何使用爬虫获取新浪微博上的数据。它还介绍了所使用的反爬虫技术。最后,本文讨论了如何实时显示数据。前端,并一一演示了可视化方法。 2 总体架构 整个网站分为三个部分:微博数据的抓取、微博数据的存储、微博数据的展示。用户首先在前端输入需要爬取的URL地址和cook-ie。点击开始爬取后,后端会向爬虫服务器发送爬虫请求,并将用户传入的cookie作为redis数据的key。将爬取到的数据存储在redis数据库中。这时候前端页面会向后端发起ajax轮询,希望能够获取到爬取到的数据,后端会从redis中取出数据封装成json发送给前端。这时候前端就可以使用数据进行可视化绘制了。 3 微博数据爬取方法3.1 通过自动化测试框架selenium抓取 由于电脑版微博是js动态生成的,无法通过简单的GET请求获取,需要js渲染引擎。
所以我们使用selenium的phatomjs来驱动。在个人主页上,随着滑块向下滚动,微博数据会不断更新,所以我们可以使用phatomjs来模拟这个过程,就在scrapy爬虫框架的中间文件中配置代码。 3.2 通过对ajax接口微博评论数据和转发数据接口的分析,通过抓包获取。使用浏览器自带的调试工具可以捕获数据包。 URL接口可以看成: /v6/comment/big?ajwvr=6&id=42153647 85782495&root_comment_max_i =9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0=42153647 85782495&root_comment_max_i=9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0d=42153647经过观察分析,可以发现大部分参数核心url为:https:// 查看全部
2018年2月赖敬之(东南大学信息科学与工程学院)
2018年2月,建立基于网络爬虫的新浪微博数据分析网站赖景智(东南大学信息科学与工程学院,南京211189)[摘要]新浪微博作为中国最大的社交网络中国网站,内容丰富,本文实现了一个微博数据分析网站,网站后端使用爬虫实时抓取数据存入redis数据库,前端使用ajax轮询技术和数据可视化 该技术将统计分析后的数据展示在网页上,相比直接调用新浪微博的API,网络爬虫获取数据的方式具有更大的灵活性,能够获取的数据量也比较大,但也有一定的局限性,最大的障碍之一是新浪微博的反爬虫技术,本文也将讨论如何突破反爬虫的限制。[关键词]新浪;爬虫;数据分析[CL] C号] TP391.3 [文档识别码] A [文章号] 1006-4222 (2018)02-0073-02 1 简介 新浪微博是一种新兴的以关注和分享为一种模式,内容少,发布快,形式多样 正好迎合了人们对信息实时、准确、多样的分享和交流的需求,因此受到广大用户的欢迎和喜爱,而微博本身也有成为当代互联网领域的一颗冉冉升起的新星。人们热衷于在微博上获取信息 最新信息,发表您的观点,分享您喜欢的东西。因此,微博收录了丰富的数据,具有重要的数据挖掘意义。
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。使用爬虫,您可以轻松、自动、灵活地获取海量数据。本文首先介绍了新浪微博数据分析网站的整体思路,然后介绍了如何使用爬虫获取新浪微博上的数据。它还介绍了所使用的反爬虫技术。最后,本文讨论了如何实时显示数据。前端,并一一演示了可视化方法。 2 总体架构 整个网站分为三个部分:微博数据的抓取、微博数据的存储、微博数据的展示。用户首先在前端输入需要爬取的URL地址和cook-ie。点击开始爬取后,后端会向爬虫服务器发送爬虫请求,并将用户传入的cookie作为redis数据的key。将爬取到的数据存储在redis数据库中。这时候前端页面会向后端发起ajax轮询,希望能够获取到爬取到的数据,后端会从redis中取出数据封装成json发送给前端。这时候前端就可以使用数据进行可视化绘制了。 3 微博数据爬取方法3.1 通过自动化测试框架selenium抓取 由于电脑版微博是js动态生成的,无法通过简单的GET请求获取,需要js渲染引擎。
所以我们使用selenium的phatomjs来驱动。在个人主页上,随着滑块向下滚动,微博数据会不断更新,所以我们可以使用phatomjs来模拟这个过程,就在scrapy爬虫框架的中间文件中配置代码。 3.2 通过对ajax接口微博评论数据和转发数据接口的分析,通过抓包获取。使用浏览器自带的调试工具可以捕获数据包。 URL接口可以看成: /v6/comment/big?ajwvr=6&id=42153647 85782495&root_comment_max_i =9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0=42153647 85782495&root_comment_max_i=9221&root_com-ment_max_id_type=0&root_comment_ext_param=&page=2&fil-terbefore_filteri0d=42153647经过观察分析,可以发现大部分参数核心url为:https://
新浪微博如何实现微博同步的功能?(一)_
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-06-03 05:19
最近遇到一个项目,需要用户的微博信息和他的网站项目同步。好在新浪微博提供了API。我大概查了一下。需要调用信息同步:需要验证用户登录,返回的数据为JSON格式。
在授权机制的描述中,新浪微博的API有两种认证机制,分别是:OAuth和Basic Auth。 OAuth 没有仔细看,所以忽略它们。在Basic Auth授权介绍部分,在cnblogs上有提到。 文章的一篇文章,这个文章展示了如何以GET方式提交http请求,并给出返回内容的代码,我在这个文章文章的公园团队中找到了另一个博客:这个文章实现站外发微博功能。结合这两个文章,就实现了新浪微博的同步功能。
下面介绍实现微博同步的步骤:
1. 首先,为了实现http请求,使用System.Net;需要引入命名空间。同时,在后面转换字符集和获取返回内容的过程中,还需要另外两个命名空间:using System.Text;并使用系统。 .IO;
接下来就可以开始写代码获取json数据了。
(1)准备用户验证数据
string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
(2)准备API URL,URL中的参数是通过GET直接附在URL上的。一开始博客园里的文章也没仔细看,直接贴出代码,给数据追加参数,返回400错误,后来查msdn,发现HttpWebRequest的默认请求方式是GET,既然是GET,就应该通过URL传递参数。
string url = "https://api.weibo.com/2/status ... 3B%3B
以上apikey是作为新浪微博用户的开发者申请的,应该是唯一的。博客园的文章zhong 说需要邮件审核。我没有发邮件,直接申请就收到了。一个APIKEY,信息也可以同步,但是在站外发送微博信息时,来源部分会是:未审核的应用。还有uid、screen_name等参数,具体参数API文档中有说明。 查看全部
新浪微博如何实现微博同步的功能?(一)_
最近遇到一个项目,需要用户的微博信息和他的网站项目同步。好在新浪微博提供了API。我大概查了一下。需要调用信息同步:需要验证用户登录,返回的数据为JSON格式。
在授权机制的描述中,新浪微博的API有两种认证机制,分别是:OAuth和Basic Auth。 OAuth 没有仔细看,所以忽略它们。在Basic Auth授权介绍部分,在cnblogs上有提到。 文章的一篇文章,这个文章展示了如何以GET方式提交http请求,并给出返回内容的代码,我在这个文章文章的公园团队中找到了另一个博客:这个文章实现站外发微博功能。结合这两个文章,就实现了新浪微博的同步功能。
下面介绍实现微博同步的步骤:
1. 首先,为了实现http请求,使用System.Net;需要引入命名空间。同时,在后面转换字符集和获取返回内容的过程中,还需要另外两个命名空间:using System.Text;并使用系统。 .IO;
接下来就可以开始写代码获取json数据了。
(1)准备用户验证数据
string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
(2)准备API URL,URL中的参数是通过GET直接附在URL上的。一开始博客园里的文章也没仔细看,直接贴出代码,给数据追加参数,返回400错误,后来查msdn,发现HttpWebRequest的默认请求方式是GET,既然是GET,就应该通过URL传递参数。
string url = "https://api.weibo.com/2/status ... 3B%3B
以上apikey是作为新浪微博用户的开发者申请的,应该是唯一的。博客园的文章zhong 说需要邮件审核。我没有发邮件,直接申请就收到了。一个APIKEY,信息也可以同步,但是在站外发送微博信息时,来源部分会是:未审核的应用。还有uid、screen_name等参数,具体参数API文档中有说明。
新浪微博开放接口调用微博API怎么样?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-06-01 01:29
因为最近接触到调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载链接:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的应用,然后你就可以得到应用密钥和应用秘钥,这是应用获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看新浪微博链接的说明。除了app key和app secret外,OAuth2授权参数还需要网站回调地址redirect_uri,而且这个回调地址不允许在局域网内(不管localhost,127.0.0. ]1 好像不行),这个真的让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写道可以改用该地址,我尝试了一下,这样就可以了,这对Diosi来说是个好消息。
我们先来一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
1 api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
2 authorize_url = api.get_authorize_url()
3 print(authorize_url)
4 webbrowser.open_new(authorize_url)
登录后会转成一个连接代码=92cc6accecfb5b2176adf58f4c
key是code值,是认证的关键。手动输入code值模拟认证
1 request = api.request_access_token(code, REDIRECT_URL)
2 access_token = request.access_token
3 expires_in = request.expires_in
4 api.set_access_token(access_token, expires_in)
5 api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token就是获得的token,expires_in是授权的过期时间 (UNIX时间)
用set_access_token保存授权。往下就可以调用微博接口了。测试发了一条微博
但是,这样的手动代码输入方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,对程序进行如下改进,可以自动获取并保存代码,方便程序服务调用。
访问微博
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
重试.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff 0:
if rv == True or type(rv) == str: # Done on success ..
return rv
mtries -= 1 # consume an attempt
time.sleep(mdelay) # wait...
mdelay *= backoff # make future wait longer
rv = f(*args, **kwargs) # Try again
return False # Ran out of tries :-(
return f_retry # true decorator -> decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
查看全部
新浪微博开放接口调用微博API怎么样?(图)
因为最近接触到调用新浪微博开放接口的项目,想尝试用python调用微博API。
SDK下载链接:代码不超过十几K,完全可以理解。
如果你有微博账号,你可以创建一个新的应用,然后你就可以得到应用密钥和应用秘钥,这是应用获得OAuth2.0授权所必需的。
要了解OAuth2,可以查看新浪微博链接的说明。除了app key和app secret外,OAuth2授权参数还需要网站回调地址redirect_uri,而且这个回调地址不允许在局域网内(不管localhost,127.0.0. ]1 好像不行),这个真的让我着急了好久。我没有使用API调用网站,所以查了很多。看到有人写道可以改用该地址,我尝试了一下,这样就可以了,这对Diosi来说是个好消息。
我们先来一个简单的程序来感受一下:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第二行,用默认浏览器打开后,会要求登录微博,用需要授权的账号登录,如下图
1 api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
2 authorize_url = api.get_authorize_url()
3 print(authorize_url)
4 webbrowser.open_new(authorize_url)
登录后会转成一个连接代码=92cc6accecfb5b2176adf58f4c
key是code值,是认证的关键。手动输入code值模拟认证
1 request = api.request_access_token(code, REDIRECT_URL)
2 access_token = request.access_token
3 expires_in = request.expires_in
4 api.set_access_token(access_token, expires_in)
5 api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token就是获得的token,expires_in是授权的过期时间 (UNIX时间)
用set_access_token保存授权。往下就可以调用微博接口了。测试发了一条微博
但是,这样的手动代码输入方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,对程序进行如下改进,可以自动获取并保存代码,方便程序服务调用。
访问微博
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
重试.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff 0:
if rv == True or type(rv) == str: # Done on success ..
return rv
mtries -= 1 # consume an attempt
time.sleep(mdelay) # wait...
mdelay *= backoff # make future wait longer
rv = f(*args, **kwargs) # Try again
return False # Ran out of tries :-(
return f_retry # true decorator -> decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
注意修改sinarss2.文件文件中的用户名1.2新浪草根用户的调用方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-01 01:22
注意修改sinarss2.文件文件中的用户名1.2新浪草根用户的调用方法
本文介绍了WordPress博客网站与新浪微博的互操作应用,同时实现了WordPress网站中新浪微博文章列表和WordPress发布文章到新浪的自动同步微博。
1、调用新浪微博列表文章
首先给大家介绍一下WordPress博客【k14】中不用插件调用新浪微博的应用。由于新浪微博还没有开发提供RSS功能,我们使用知名的月光博主开发了新浪微博RSS功能。 ,主要用途是数据交换。本程序目前支持新浪微博认证用户和草根用户,但两者的调用方式略有不同。所以,根据你的微博用户级别,选择正确使用(认证用户使用sinarss.php;草根用户使用sinarss2.php)。以下使用方法参考月光博客文章。
1.1 如何调用新浪认证用户:
首先找到你访问新浪微博的地址,例如,然后取出如下地址作为参数调用:sinarss.php?username=williamlong,其中username中的数据就是你个人姓名后面的地址.
*注意修改sinarss.php文件中的用户名
1.2 如何给新浪草根用户打电话:
首先找到您访问新浪微博的身份证号码。具体方法是登录新浪微博,点击用户的关注、粉丝页面,你会在地址栏中间看到一串数字。取出中间的数字。然后用这个号码作为id参数调用一个地址,类似于:sinarss2.php?id=1494759712,其中id是草根用户的新浪微博id号。
* 注意修改sinarss2.php文件中的用户ID
1.3 微博文章页面调用:
完成上述文件设置后,下面介绍如何使用WordPress自带的feed捕获功能来显示文章列表页面。
方法一:
get_item_quantity(5);
//从元素0(第一个元素)开始,构建所有项目的数组。
$rss_items = $rss->get_items(0, $maxitems);
endif;
方法二:
get_items(0,5);
foreach($items as $item) {
echo ''.$item->get_title().' '.$item->get_date('Y-m-j G:i').'';
}
?>
2、将WordPress文章同步到新浪微博
2.1 博客微博
lloydsheng 开发的一款基于新浪微博 API 的 Wordpress 插件。当您发布博文时,您可以自动向新浪微博发送消息,标签将转换为主题。同时支持消息模板,可以自定义消息内容。
2.2 U2S
MG.Core.Team 开发的WordPress插件在保存博客文章时,会自动将分类、标题、摘要、图片等相关信息同步到新浪微博指定账号。 WordPress官方下载地址(或直接从WordPress后台搜索安装)。
2.3 WordPress 微博插件
由kedy开发,基于新浪微博和WordPress,可以在WordPress中快速发布微博的功能。同时当用户在Wordpress文章上发帖时,会自动及时将消息发到新浪微博上,节省人工同步的成本。 (部分自建博客用户可能无法直接同步关联博客文章) 查看全部
注意修改sinarss2.文件文件中的用户名1.2新浪草根用户的调用方法
本文介绍了WordPress博客网站与新浪微博的互操作应用,同时实现了WordPress网站中新浪微博文章列表和WordPress发布文章到新浪的自动同步微博。
1、调用新浪微博列表文章
首先给大家介绍一下WordPress博客【k14】中不用插件调用新浪微博的应用。由于新浪微博还没有开发提供RSS功能,我们使用知名的月光博主开发了新浪微博RSS功能。 ,主要用途是数据交换。本程序目前支持新浪微博认证用户和草根用户,但两者的调用方式略有不同。所以,根据你的微博用户级别,选择正确使用(认证用户使用sinarss.php;草根用户使用sinarss2.php)。以下使用方法参考月光博客文章。
1.1 如何调用新浪认证用户:
首先找到你访问新浪微博的地址,例如,然后取出如下地址作为参数调用:sinarss.php?username=williamlong,其中username中的数据就是你个人姓名后面的地址.
*注意修改sinarss.php文件中的用户名
1.2 如何给新浪草根用户打电话:
首先找到您访问新浪微博的身份证号码。具体方法是登录新浪微博,点击用户的关注、粉丝页面,你会在地址栏中间看到一串数字。取出中间的数字。然后用这个号码作为id参数调用一个地址,类似于:sinarss2.php?id=1494759712,其中id是草根用户的新浪微博id号。
* 注意修改sinarss2.php文件中的用户ID
1.3 微博文章页面调用:
完成上述文件设置后,下面介绍如何使用WordPress自带的feed捕获功能来显示文章列表页面。
方法一:
get_item_quantity(5);
//从元素0(第一个元素)开始,构建所有项目的数组。
$rss_items = $rss->get_items(0, $maxitems);
endif;
方法二:
get_items(0,5);
foreach($items as $item) {
echo ''.$item->get_title().' '.$item->get_date('Y-m-j G:i').'';
}
?>
2、将WordPress文章同步到新浪微博
2.1 博客微博
lloydsheng 开发的一款基于新浪微博 API 的 Wordpress 插件。当您发布博文时,您可以自动向新浪微博发送消息,标签将转换为主题。同时支持消息模板,可以自定义消息内容。
2.2 U2S
MG.Core.Team 开发的WordPress插件在保存博客文章时,会自动将分类、标题、摘要、图片等相关信息同步到新浪微博指定账号。 WordPress官方下载地址(或直接从WordPress后台搜索安装)。
2.3 WordPress 微博插件
由kedy开发,基于新浪微博和WordPress,可以在WordPress中快速发布微博的功能。同时当用户在Wordpress文章上发帖时,会自动及时将消息发到新浪微博上,节省人工同步的成本。 (部分自建博客用户可能无法直接同步关联博客文章)
E5B7发微博未审核应用未通过审核或未影响
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-05-27 06:04
任务
发布博客后,希望提取摘要并自动自动同步发布微博;
准备工作
作为新浪微博的开发者,需要身份验证;
对个人身份认证的审查通常需要一个工作日;
下一步是提交网站进行审查,而国内的则是提交记录号。向海外提交网站地方的海外证书就足够了;也大约是一个工作日;
通过个人身份审核后,您可以创建应用程序和呼叫接口,此时获得的权限相对较低;
网站如果您不提交审核或审核失败,则对微博发布没有影响;只是“未审核的应用”将显示在发布的微博下方;
网站应用名称在审核后显示:
通话界面
微博开放平台提供测试工具;
在进行开发和访问之前,必须首先确保可以通过此测试工具发送测试微博;
%E5%BE%AE%E5%8D%9A%E6%9D%A5%E8%87%AAAPI%E6%B5%8B%E8%AF%95%E5%B7%A5%E5%85% B7
微博的api参考文档为:
所有微博接口都需要授权认证;认证后,将获得一个access_token(访问密钥);密钥的有效期因用户级别而异;
对于那些未通过网络审核的人,
1天;通过审核的普通用户7天;
在有效期内,无需与Sina服务器进行交互以进行权限认证。只要令牌存储在本地,它就可以用于调用各种微博API(读取,写入,获取观众信息等)
授权
共有三种身份验证方式:
通过用户名和密码;
这是最容易理解的。在程序中输入微博帐号的用户名和密码,并使用api调用进行身份验证;但应注意,提供此界面是为了开发要使用的应用程序,并且不能使用Web应用程序;
通过网络回调;
需要与sina服务器进行交互并提供回调地址;在回调地址中获取access_token;
第三个方法是代码方法。我没有仔细阅读,因此请跳过;
Web应用程序仅支持第二种授权方法;下面详细介绍第二种方法的使用:
下载Sina提供的SDK,其中收录演示和api打包类;
访问页面:
call.php:
include_once( 'sina_config.php' );
include_once( 'saetv2.ex.class.php' );
//获取到授权的url
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
$code_url = $o->getAuthorizeURL( WB_CALLBACK_URL );
//post或get方式调用该url,取得授权;授权完成后,新浪会调用我们这边传过去的回调地址:WB_CALLBACK_URL
request()->redirect($code_url);
回调地址页面(WB_CALLBACK_URL):
callback.php
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
if (isset($_REQUEST['code'])) {
$keys = array();
$keys['code'] = $_REQUEST['code'];
$keys['redirect_uri'] = WB_CALLBACK_URL;
try {
$token = $o->getAccessToken( 'code', $keys ) ;
} catch (OAuthException $e) {
echo "weibo.com get access token err.";
LOG_ERR("weibo.com get access token err.");
return ;
}
}
if ($token) {
//取到授权后的api调用密钥,可用存起来,在有效期内多次调用api接口就不用再授权了
$_SESSION['token'] = $token;
$c = new SaeTClientV2( WB_AKEY , WB_SKEY , $_SESSION['token']['access_token'] );
$ret = $c->update( $weiboStr ); //发送微博
if ( isset($ret['error_code']) && $ret['error_code'] > 0 ) {
$str = "Weibo.com Send failed. err info:" . $ret['error_code'] . '/' . $ret['error'];
LOG_ERR($str);
} else {
LOG_INFO("Weibo.com Send Success.");
}
}
博客摘要摘录
微博中的字符数为140个字符;其中,汉字为1个字符;我们必须选择一个计数功能;对于一个汉字,strlen()计为3个字符,多字节统计函数mb_strlen()为1个字,符合我们的要求;
最后,您需要清除html标签和&nbsp; etc。
//获取当前微博内容(140字)
public function getWeibo()
{
$titleLen = mb_strlen($this->title, 'UTF-8');
//140字除去链接的20个字和省略符;剩115字左右,需要说明的是链接:无论文章的链接多长,在微博里都会被替换成短链接,按短链接的长度来计算字数;
$summaryLen = 115 - $titleLen ;
$pubPaper = cutstr_html($this->summary);
if(mb_strlen($pubPaper, 'UTF-8') >= $summaryLen)
$pubPaper = mb_substr($pubPaper,0,$summaryLen,'UTF-8');
$pubPaper = sprintf('【%s】%s...%s', $this->title , $pubPaper , aurl('post/show', array('id' => $this->id)));
return $pubPaper;
}
//完全的去除html标记
function cutstr_html($string)
{
$string = strip_tags($string);
$string = preg_replace ('/n/is', '', $string);
$string = preg_replace ('/ | /is', '', $string);
$string = preg_replace ('/ /is', '', $string);
return $string;
}
结束。
发布者:Big CC | 2013年11月30日
博客:
微博:新浪微博 查看全部
E5B7发微博未审核应用未通过审核或未影响
任务
发布博客后,希望提取摘要并自动自动同步发布微博;
准备工作
作为新浪微博的开发者,需要身份验证;
对个人身份认证的审查通常需要一个工作日;
下一步是提交网站进行审查,而国内的则是提交记录号。向海外提交网站地方的海外证书就足够了;也大约是一个工作日;
通过个人身份审核后,您可以创建应用程序和呼叫接口,此时获得的权限相对较低;
网站如果您不提交审核或审核失败,则对微博发布没有影响;只是“未审核的应用”将显示在发布的微博下方;
网站应用名称在审核后显示:
通话界面
微博开放平台提供测试工具;
在进行开发和访问之前,必须首先确保可以通过此测试工具发送测试微博;
%E5%BE%AE%E5%8D%9A%E6%9D%A5%E8%87%AAAPI%E6%B5%8B%E8%AF%95%E5%B7%A5%E5%85% B7
微博的api参考文档为:
所有微博接口都需要授权认证;认证后,将获得一个access_token(访问密钥);密钥的有效期因用户级别而异;
对于那些未通过网络审核的人,
1天;通过审核的普通用户7天;
在有效期内,无需与Sina服务器进行交互以进行权限认证。只要令牌存储在本地,它就可以用于调用各种微博API(读取,写入,获取观众信息等)
授权
共有三种身份验证方式:
通过用户名和密码;
这是最容易理解的。在程序中输入微博帐号的用户名和密码,并使用api调用进行身份验证;但应注意,提供此界面是为了开发要使用的应用程序,并且不能使用Web应用程序;
通过网络回调;
需要与sina服务器进行交互并提供回调地址;在回调地址中获取access_token;
第三个方法是代码方法。我没有仔细阅读,因此请跳过;
Web应用程序仅支持第二种授权方法;下面详细介绍第二种方法的使用:
下载Sina提供的SDK,其中收录演示和api打包类;
访问页面:
call.php:
include_once( 'sina_config.php' );
include_once( 'saetv2.ex.class.php' );
//获取到授权的url
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
$code_url = $o->getAuthorizeURL( WB_CALLBACK_URL );
//post或get方式调用该url,取得授权;授权完成后,新浪会调用我们这边传过去的回调地址:WB_CALLBACK_URL
request()->redirect($code_url);
回调地址页面(WB_CALLBACK_URL):
callback.php
$o = new SaeTOAuthV2( WB_AKEY , WB_SKEY );
if (isset($_REQUEST['code'])) {
$keys = array();
$keys['code'] = $_REQUEST['code'];
$keys['redirect_uri'] = WB_CALLBACK_URL;
try {
$token = $o->getAccessToken( 'code', $keys ) ;
} catch (OAuthException $e) {
echo "weibo.com get access token err.";
LOG_ERR("weibo.com get access token err.");
return ;
}
}
if ($token) {
//取到授权后的api调用密钥,可用存起来,在有效期内多次调用api接口就不用再授权了
$_SESSION['token'] = $token;
$c = new SaeTClientV2( WB_AKEY , WB_SKEY , $_SESSION['token']['access_token'] );
$ret = $c->update( $weiboStr ); //发送微博
if ( isset($ret['error_code']) && $ret['error_code'] > 0 ) {
$str = "Weibo.com Send failed. err info:" . $ret['error_code'] . '/' . $ret['error'];
LOG_ERR($str);
} else {
LOG_INFO("Weibo.com Send Success.");
}
}
博客摘要摘录
微博中的字符数为140个字符;其中,汉字为1个字符;我们必须选择一个计数功能;对于一个汉字,strlen()计为3个字符,多字节统计函数mb_strlen()为1个字,符合我们的要求;
最后,您需要清除html标签和&nbsp; etc。
//获取当前微博内容(140字)
public function getWeibo()
{
$titleLen = mb_strlen($this->title, 'UTF-8');
//140字除去链接的20个字和省略符;剩115字左右,需要说明的是链接:无论文章的链接多长,在微博里都会被替换成短链接,按短链接的长度来计算字数;
$summaryLen = 115 - $titleLen ;
$pubPaper = cutstr_html($this->summary);
if(mb_strlen($pubPaper, 'UTF-8') >= $summaryLen)
$pubPaper = mb_substr($pubPaper,0,$summaryLen,'UTF-8');
$pubPaper = sprintf('【%s】%s...%s', $this->title , $pubPaper , aurl('post/show', array('id' => $this->id)));
return $pubPaper;
}
//完全的去除html标记
function cutstr_html($string)
{
$string = strip_tags($string);
$string = preg_replace ('/n/is', '', $string);
$string = preg_replace ('/ | /is', '', $string);
$string = preg_replace ('/ /is', '', $string);
return $string;
}
结束。
发布者:Big CC | 2013年11月30日
博客:
微博:新浪微博
之前客户要隐藏新浪微博的所有内容,临时写了一段代码
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-05-26 00:33
之前,客户希望隐藏新浪微博的所有内容,并临时编写一段代码。现在分享。
公共课程HiddenWeiBo {
复制代码 隐藏代码
public static void main(String[] args) throws HttpProcessException, FileNotFoundException, InterruptedException {
HiddenWeiBo demo = new HiddenWeiBo();
while (true) {
List mid = demo.getMid(demo.getIndex());
for (String string : mid) {
demo.postwb(string);
Thread.sleep(500);
}
}
}
public String getIndex() throws HttpProcessException{
String url = "https://weibo.com/p/#####自己的ID######/home?from=page_100505_profile&wvr=6&mod=data&is_all=1";
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://passport.weibo.com/vis ... 23%23自己的ID#####%2Fhome%3Ffrom%3Dpage_100505_profile%26wvr%3D6%26mod%3Ddata%26is_hot%3D1&domain=.weibo.com&ua=php-sso_sdk_client-0.6.28&_rand=1534310854.1213")
.contentType("application/x-www-form-urlencoded")
.cookie("YF-Page-G0=b58533766541bcc934acef7f6116c26d1; _s_tentry=passport.weibo.com; Apache=2482346697449.5763.1534310855544; SINAGLOBAL=2482346629749.5763.1534310855544; ULV=1534310855679:1:1:1:248234669749.5763.1534310855544:; YF-Ugrow-G0=b02489d329584fca03ad6347fc915997; YF-V5-G0=cd5d86283b86b0d5506628aedd6f8896e; WBtopGlobal_register_version=2b2691ab11833cbd; wb_view_log_5175311215=1920*10801; login_sid_t=6e3af2ce0d487e764cc21551bd64ee61; cross_origin_proto=SSL; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; UOR=,,login.sina.com.cn; SSOLoginState=1534317576; SCF=An380Z_lJI4Er6AG9v5XU6ULsCZ8EswRdbTEUE52u4sKz4mbINDT8lL8v-FgZhuYiwV_2kWCPJORBMVpowD5Sl4.; SUB=_2A252d6RYDeRhGeNP7FcS8S_OyjmIHXVVBJKQrDV8PUNbmtAKLWz6kW9NTnyOtWRIAjuzxoDWBNFsiOTo4QS08kaw; SUBP=0033WrSXqPxfM6725Ws9jqgMF55529P9D9WWWbMZ3lYrAgORyMlPl1Ni15JpX5K2hUgL.Fo-pS0-0eK2EeK-2dJLoI74kPfYLxKqLBK5LB.SAIBtt; SUHB=0YhhvX2IYso1ka; ALF=1565853576; un=; wvr=6")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client);
String result2 = HttpClientUtil.get(config); //post请求
return result2;
}
public List getMid(String html){
List mid = new ArrayList();
String patt = "name=[0-9]{16}";
Pattern r = Pattern.compile(patt);
Matcher m = r.matcher(html);
while (m.find()) {
mid.add(m.group(0).replace("name=", ""));
}
return mid;
}
public void postwb(String mid) throws HttpProcessException{
String url = "https://weibo.com/p/aj/v6/mblo ... illis();
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://weibo.com/p/#####自己的ID#####/home?is_all=1&stat_date=201212")
.contentType("application/x-www-form-urlencoded")
.cookie("SINAGLOBAL=8635537446547.301.1507198819218; UM_distinctid=161cc50123d26d1fa-02fcbe6e2eda04-4a541326-1fa400-161cc50d26e510; un=1231233123; login_sid_t=2c011620a31237dd2c973a420f7bf48e4d8; YF-Ugrow-G0=ea90f703b7694b74b62d38420b5273df; YF-V5-G0=c99031715427fe982b79bf287ae448f6; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; _s_tentry=-; Apache=9255634056765.951.1534307466102; ULV=1534307466128:24:3:1:9255634056765.951.1534307466102:1533893011406; SSOLoginState=1534307540; SCF=AhJ5a4l55u6Ym2tu3123rWNWWaszjwG-_9f_3HstU3vWd69GnSGQXqXDKe2GVorlKGqk-3Erg3lfS6XH6V9anNWwUPk.; SUB=_2A252d9yFDeRhGeRJ7lMV9C_OyjiIHXVVBUlNrDV8PUNbmtANLVmikW9NUpanwG_uVHqh5x7c1lnw8hThtgc8AgTY; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5D6Yv-_WaN-LU2mIXhSYxE5JpX5KzhUgL.FozNSK2XSh2EeKB2dJLoI0qLxK-L12eL1KMLxKBLB.2LB-eLxKqL1K.LB--LxKnLBoBLBKBLxKnL12-LBozLxKMLBKBLB.-t; SUHB=02M-sImmDLEWQ_; ALF=1565843540; wvr=6; YF-Page-G0=734c07cbfd1a4ed44f254d8b9173a162eb; wb_view_log_2751441214=1920*10801; UOR=cas.baidu.com,widget.weibo.com,login.sina.com.cn; cross_origin_proto=SSL")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
System.out.println("----");
Map map = new HashMap();
map.put("visible", "1");
map.put("mid", mid);
map.put("_t", "0");
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.map(map) //设置请求参数,没有则无需设置
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client) ;
String result2 = HttpClientUtil.post(config); //post请求
System.out.println(result2);
}
}
谈论一般原则。
有两个数字A(任何数字或没有登录号,只需要Cookie),B(您需要删除或隐藏微博号码)
过程A ------在主页上获取所有微博的ID -----“删除到B
getIndex()-----》 getMid(String html)----》 postwb(String mid)
代码是隐藏的,删除也是如此
如果需要使用它,则需要更改Cookie
使用的框架
com.arronlong 查看全部
之前客户要隐藏新浪微博的所有内容,临时写了一段代码
之前,客户希望隐藏新浪微博的所有内容,并临时编写一段代码。现在分享。
公共课程HiddenWeiBo {
复制代码 隐藏代码
public static void main(String[] args) throws HttpProcessException, FileNotFoundException, InterruptedException {
HiddenWeiBo demo = new HiddenWeiBo();
while (true) {
List mid = demo.getMid(demo.getIndex());
for (String string : mid) {
demo.postwb(string);
Thread.sleep(500);
}
}
}
public String getIndex() throws HttpProcessException{
String url = "https://weibo.com/p/#####自己的ID######/home?from=page_100505_profile&wvr=6&mod=data&is_all=1";
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://passport.weibo.com/vis ... 23%23自己的ID#####%2Fhome%3Ffrom%3Dpage_100505_profile%26wvr%3D6%26mod%3Ddata%26is_hot%3D1&domain=.weibo.com&ua=php-sso_sdk_client-0.6.28&_rand=1534310854.1213")
.contentType("application/x-www-form-urlencoded")
.cookie("YF-Page-G0=b58533766541bcc934acef7f6116c26d1; _s_tentry=passport.weibo.com; Apache=2482346697449.5763.1534310855544; SINAGLOBAL=2482346629749.5763.1534310855544; ULV=1534310855679:1:1:1:248234669749.5763.1534310855544:; YF-Ugrow-G0=b02489d329584fca03ad6347fc915997; YF-V5-G0=cd5d86283b86b0d5506628aedd6f8896e; WBtopGlobal_register_version=2b2691ab11833cbd; wb_view_log_5175311215=1920*10801; login_sid_t=6e3af2ce0d487e764cc21551bd64ee61; cross_origin_proto=SSL; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; UOR=,,login.sina.com.cn; SSOLoginState=1534317576; SCF=An380Z_lJI4Er6AG9v5XU6ULsCZ8EswRdbTEUE52u4sKz4mbINDT8lL8v-FgZhuYiwV_2kWCPJORBMVpowD5Sl4.; SUB=_2A252d6RYDeRhGeNP7FcS8S_OyjmIHXVVBJKQrDV8PUNbmtAKLWz6kW9NTnyOtWRIAjuzxoDWBNFsiOTo4QS08kaw; SUBP=0033WrSXqPxfM6725Ws9jqgMF55529P9D9WWWbMZ3lYrAgORyMlPl1Ni15JpX5K2hUgL.Fo-pS0-0eK2EeK-2dJLoI74kPfYLxKqLBK5LB.SAIBtt; SUHB=0YhhvX2IYso1ka; ALF=1565853576; un=; wvr=6")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client);
String result2 = HttpClientUtil.get(config); //post请求
return result2;
}
public List getMid(String html){
List mid = new ArrayList();
String patt = "name=[0-9]{16}";
Pattern r = Pattern.compile(patt);
Matcher m = r.matcher(html);
while (m.find()) {
mid.add(m.group(0).replace("name=", ""));
}
return mid;
}
public void postwb(String mid) throws HttpProcessException{
String url = "https://weibo.com/p/aj/v6/mblo ... illis();
//插件式配置Header(各种header信息、自定义header)
Header[] headers = HttpHeader.custom()
.host("weibo.com")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36")
.referer("https://weibo.com/p/#####自己的ID#####/home?is_all=1&stat_date=201212")
.contentType("application/x-www-form-urlencoded")
.cookie("SINAGLOBAL=8635537446547.301.1507198819218; UM_distinctid=161cc50123d26d1fa-02fcbe6e2eda04-4a541326-1fa400-161cc50d26e510; un=1231233123; login_sid_t=2c011620a31237dd2c973a420f7bf48e4d8; YF-Ugrow-G0=ea90f703b7694b74b62d38420b5273df; YF-V5-G0=c99031715427fe982b79bf287ae448f6; WBStorage=e8781eb7dee3fd7f|undefined; wb_view_log=1920*10801; _s_tentry=-; Apache=9255634056765.951.1534307466102; ULV=1534307466128:24:3:1:9255634056765.951.1534307466102:1533893011406; SSOLoginState=1534307540; SCF=AhJ5a4l55u6Ym2tu3123rWNWWaszjwG-_9f_3HstU3vWd69GnSGQXqXDKe2GVorlKGqk-3Erg3lfS6XH6V9anNWwUPk.; SUB=_2A252d9yFDeRhGeRJ7lMV9C_OyjiIHXVVBUlNrDV8PUNbmtANLVmikW9NUpanwG_uVHqh5x7c1lnw8hThtgc8AgTY; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5D6Yv-_WaN-LU2mIXhSYxE5JpX5KzhUgL.FozNSK2XSh2EeKB2dJLoI0qLxK-L12eL1KMLxKBLB.2LB-eLxKqL1K.LB--LxKnLBoBLBKBLxKnL12-LBozLxKMLBKBLB.-t; SUHB=02M-sImmDLEWQ_; ALF=1565843540; wvr=6; YF-Page-G0=734c07cbfd1a4ed44f254d8b9173a162eb; wb_view_log_2751441214=1920*10801; UOR=cas.baidu.com,widget.weibo.com,login.sina.com.cn; cross_origin_proto=SSL")
.build();
//插件式配置生成HttpClient时所需参数(超时、连接池、ssl、重试)
HCB hcb = HCB.custom()
.timeout(10000) //超时
.pool(100, 10) //启用连接池,每个路由最大创建10个链接,总连接数限制为100个
.sslpv(SSLProtocolVersion.TLSv1_2) //可设置ssl版本号,默认SSLv3,用于ssl,也可以调用sslpv("TLSv1.2")
.ssl() //https,支持自定义ssl证书路径和密码,ssl(String keyStorePath, String keyStorepass)
.retry(5) //重试5次
;
HttpClient client = hcb.build();
System.out.println("----");
Map map = new HashMap();
map.put("visible", "1");
map.put("mid", mid);
map.put("_t", "0");
//插件式配置请求参数(网址、请求参数、编码、client)
HttpConfig config = HttpConfig.custom()
.headers(headers) //设置headers,不需要时则无需设置
.url(url) //设置请求的url
.map(map) //设置请求参数,没有则无需设置
.encoding("utf-8") //设置请求和返回编码,默认就是Charset.defaultCharset()
.client(client) ;
String result2 = HttpClientUtil.post(config); //post请求
System.out.println(result2);
}
}
谈论一般原则。
有两个数字A(任何数字或没有登录号,只需要Cookie),B(您需要删除或隐藏微博号码)
过程A ------在主页上获取所有微博的ID -----“删除到B
getIndex()-----》 getMid(String html)----》 postwb(String mid)
代码是隐藏的,删除也是如此
如果需要使用它,则需要更改Cookie
使用的框架
com.arronlong
新浪微博开放平台使用账户登录的注意不要点击【微连接】
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-05-25 21:15
新浪微博网站访问应用程序教程(包括本地测试)织梦无忧网站管理员的文章2020-09-21 13:59
摘要:进入新浪微博开放平台并使用您的帐户登录。单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用这些组件。要申请微连接appKey,请单击[开始访问]按钮。在这里
进入新浪微博开放平台并使用您的帐户登录。
单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。
左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用。
要申请微连接appKey,请单击[开始访问]按钮。
此处应注意以下两点:
1要以这种方式申请appKey,前提是您的网站必须使用域名并且正在Internet上运行。如果您处于本地测试阶段,则此方法将不起作用。稍后将介绍如何申请本地测试阶段。
2 网站提供了两种验证方法,以验证您具有网站的管理员权限。请注意这两种方法之间的区别。
没有自动重定向的网站
具有自动重定向功能的网站或WAP网站
在网站主页上添加验证码后,单击下面的[验证并添加]按钮。按照提示进行操作。
注意:如果此步骤失败,请仔细分析新浪提供的信息。如果您确实找不到问题,则不妨尝试上述两种验证方法。
从这一步开始,如何在本地调试阶段进行应用。
由于没有用于本地调试的域名,因此无法直接访问网站。需要使用Web应用程序来实现本地调试。
许多人在申请时找不到Web应用程序的选项。这是一个解释:
([1)在开放平台的主页上,直接单击[微连接]菜单。
请注意不要在[微连接]菜单下单击该站点上的应用程序,单击该站点上的应用程序后的页面将不是同一页面。
转到如下所示的页面:
([2)这时,单击[创建应用程序]按钮,将弹出各种应用程序类型,并显示Web应用程序。
单击[Web应用程序]进入应用程序页面。
此处的申请地址可以填写IP地址,方便我们测试。
创建Web应用程序后,它尚未完成。单击[管理中心]进入我们刚刚申请的应用程序。单击左侧的应用程序信息中的基本信息。
单击以在右侧进行编辑,请注意下图中突出显示的位置。
申请地址是指微博发布时显示的源地址(未经批准将无法正确显示)。
需要安全域名,因为新浪微博的Api需要通过域名进行访问,否则将报告错误。所以下一步就是关键。
设置本地环境域名映射。
([1)在操作系统主机文件中添加本地域名映射。
([2)在上述安全域名中配置本地自定义域名。
单击[高级信息]进行设置。
授权设置是成功调用api后将返回的页面。
安全设置指定应用程序部署的IP地址。
此时,新浪微博appKey的应用程序被认为是成功的,您可以启动本地调试路径。 查看全部
新浪微博开放平台使用账户登录的注意不要点击【微连接】
新浪微博网站访问应用程序教程(包括本地测试)织梦无忧网站管理员的文章2020-09-21 13:59
摘要:进入新浪微博开放平台并使用您的帐户登录。单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用这些组件。要申请微连接appKey,请单击[开始访问]按钮。在这里
进入新浪微博开放平台并使用您的帐户登录。
单击[网站访问]或在顶部菜单[微连接]中选择以进入网站访问页面。
左侧提供了开放平台的一系列公共组件,可以在您的网站中直接引用。
要申请微连接appKey,请单击[开始访问]按钮。
此处应注意以下两点:
1要以这种方式申请appKey,前提是您的网站必须使用域名并且正在Internet上运行。如果您处于本地测试阶段,则此方法将不起作用。稍后将介绍如何申请本地测试阶段。
2 网站提供了两种验证方法,以验证您具有网站的管理员权限。请注意这两种方法之间的区别。
没有自动重定向的网站
具有自动重定向功能的网站或WAP网站
在网站主页上添加验证码后,单击下面的[验证并添加]按钮。按照提示进行操作。
注意:如果此步骤失败,请仔细分析新浪提供的信息。如果您确实找不到问题,则不妨尝试上述两种验证方法。
从这一步开始,如何在本地调试阶段进行应用。
由于没有用于本地调试的域名,因此无法直接访问网站。需要使用Web应用程序来实现本地调试。
许多人在申请时找不到Web应用程序的选项。这是一个解释:
([1)在开放平台的主页上,直接单击[微连接]菜单。
请注意不要在[微连接]菜单下单击该站点上的应用程序,单击该站点上的应用程序后的页面将不是同一页面。
转到如下所示的页面:
([2)这时,单击[创建应用程序]按钮,将弹出各种应用程序类型,并显示Web应用程序。
单击[Web应用程序]进入应用程序页面。
此处的申请地址可以填写IP地址,方便我们测试。
创建Web应用程序后,它尚未完成。单击[管理中心]进入我们刚刚申请的应用程序。单击左侧的应用程序信息中的基本信息。
单击以在右侧进行编辑,请注意下图中突出显示的位置。
申请地址是指微博发布时显示的源地址(未经批准将无法正确显示)。
需要安全域名,因为新浪微博的Api需要通过域名进行访问,否则将报告错误。所以下一步就是关键。
设置本地环境域名映射。
([1)在操作系统主机文件中添加本地域名映射。
([2)在上述安全域名中配置本地自定义域名。
单击[高级信息]进行设置。
授权设置是成功调用api后将返回的页面。
安全设置指定应用程序部署的IP地址。
此时,新浪微博appKey的应用程序被认为是成功的,您可以启动本地调试路径。
跨域读取Twitter微博的代码,是这样写的博文
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-05-21 21:18
我最近才刚开始学习JavaScript,我在教程中看到了有关跨域阅读Twitter微博的代码,其编写方式如下
window.onload = init;
function init() {
var interval = setInterval(handleRefresh, 3000);
handleRefresh();
}
function handleRefresh() {
console.log("here");
var url = "http://gumball.wickedlysmart.com" +
"?callback=updateSales" + //利用callback回调updateSales
//"&lastreporttime=" + lastReportTime +
"&random=" + (new Date()).getTime();
var newScriptElement = document.createElement("script");
newScriptElement.setAttribute("src", url);
newScriptElement.setAttribute("id", "jsonp");
var oldScriptElement = document.getElementById("jsonp");
var head = document.getElementsByTagName("head")[0];
if (oldScriptElement == null) {
head.appendChild(newScriptElement);
}
else {
head.replaceChild(newScriptElement, oldScriptElement);
}
}
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
for (var i = 0; i < jsonp_sales.length; i++) {
var sale = jsonp_sales[i];
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sale.name + " sold " + jsonp_sale.sales + " gumballs";
//salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
if (sales.length > 0) {
lastReportTime = jsonp_[jsonp_sales.length-1].time;
}
}
所以我想当然我会尝试更改为新浪微博的API,当然您必须先申请它
更换后,我得到了此链接(新浪微博的API接口,现在仅允许读取我的微博帐户的内容,并且只能读取5个微博=-=以后我会努力学习,我自己,让我们抓取数据...)
var url = "https://api.weibo.com/2/status ... id%3D你的ID可以从自己微博链接地址查,是一串数字&access_token=这里是token&callback=updateSales" ;
我尝试了一下,发现没有成功,所以我使用Firefox进行调试,发现jsonp_sales可能有问题,如下所示
展开,找到
换句话说,博客文章存储在jsonp_sales.data.statuses [i] .text中,因此请修改代码
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
var length=jsonp_sales.data.statuses.length;
for (var i = 0; i < length; i++) {
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sales.data.statuses[i].text;
salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
}
最终成功,以下是在网页上阅读的原创博客文章,尚未处理
从开始学习JavaScript以来,我发现Firefox的调试工具大有帮助。我的技能有限,我仍然需要继续学习
我希望它对所有人都有帮助 查看全部
跨域读取Twitter微博的代码,是这样写的博文
我最近才刚开始学习JavaScript,我在教程中看到了有关跨域阅读Twitter微博的代码,其编写方式如下
window.onload = init;
function init() {
var interval = setInterval(handleRefresh, 3000);
handleRefresh();
}
function handleRefresh() {
console.log("here");
var url = "http://gumball.wickedlysmart.com" +
"?callback=updateSales" + //利用callback回调updateSales
//"&lastreporttime=" + lastReportTime +
"&random=" + (new Date()).getTime();
var newScriptElement = document.createElement("script");
newScriptElement.setAttribute("src", url);
newScriptElement.setAttribute("id", "jsonp");
var oldScriptElement = document.getElementById("jsonp");
var head = document.getElementsByTagName("head")[0];
if (oldScriptElement == null) {
head.appendChild(newScriptElement);
}
else {
head.replaceChild(newScriptElement, oldScriptElement);
}
}
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
for (var i = 0; i < jsonp_sales.length; i++) {
var sale = jsonp_sales[i];
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sale.name + " sold " + jsonp_sale.sales + " gumballs";
//salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
if (sales.length > 0) {
lastReportTime = jsonp_[jsonp_sales.length-1].time;
}
}
所以我想当然我会尝试更改为新浪微博的API,当然您必须先申请它
更换后,我得到了此链接(新浪微博的API接口,现在仅允许读取我的微博帐户的内容,并且只能读取5个微博=-=以后我会努力学习,我自己,让我们抓取数据...)
var url = "https://api.weibo.com/2/status ... id%3D你的ID可以从自己微博链接地址查,是一串数字&access_token=这里是token&callback=updateSales" ;
我尝试了一下,发现没有成功,所以我使用Firefox进行调试,发现jsonp_sales可能有问题,如下所示
展开,找到
换句话说,博客文章存储在jsonp_sales.data.statuses [i] .text中,因此请修改代码
function updateSales(jsonp_sales) {
var salesDiv = document.getElementById("sales");
var length=jsonp_sales.data.statuses.length;
for (var i = 0; i < length; i++) {
var div = document.createElement("div");
div.setAttribute("class", "saleItem");
div.innerHTML = jsonp_sales.data.statuses[i].text;
salesDiv.appendChild(div);
if (salesDiv.childElementCount == 0) {
salesDiv.appendChild(div);
}
else {
salesDiv.insertBefore(div, salesDiv.firstChild);
}
}
}
最终成功,以下是在网页上阅读的原创博客文章,尚未处理
从开始学习JavaScript以来,我发现Firefox的调试工具大有帮助。我的技能有限,我仍然需要继续学习
我希望它对所有人都有帮助
Python3下用Tornado调用新浪微博API.0认证的顺序
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-05-21 21:17
Python3下用Tornado调用新浪微博API.0认证的顺序
使用Tornado试用新浪微博开放平台API
Tornado作为Python异步无阻塞服务器和轻量级Web框架,非常吸引人。为了体验OAuth 2. 0身份验证,我使用了Tornado构建了网站并调用了新浪微博API。新浪微博的OAuth 2. 0身份验证序列如下:
以下内容简要说明了如何在Python 3下使用Tornado完成上述四个步骤。
将用户带到新浪认证页面
假设我们要开发的客户端的域名是,在Sina中创建一个新应用程序,然后在设置中填写此安全域名,以便我们可以跨站点请求XMLRequests。
此步骤是编写html页面,在Tornado中则是编写模板。假设我们在客户端上放置了一个名为“使用新浪微博登录”的按钮,代码如下:
Login
通过这种方式,您只需单击此按钮即可转到新浪的身份验证页面。用户通过身份验证后,新浪会将用户转到您提供的redirect_uri地址,这里是
因此,我们需要使用Tornado来处理身份验证服务器发送给我们的代码。
龙卷风在后台使用代码交换access_token
这部分有两个步骤:
配置Tornado的路由表,然后让r'/ auth_code'路由到AuthCodeHandler处理程序。然后,我们可以重写此处理程序的get方法以获取代码。然后我们使用POST方法将代码发送到Sina,这是它可以反映Tornado的异步和非阻塞功能的强大之处。龙卷风的AsyncHTTPClient可以发起异步请求。 @ gen.coroutine装饰器可用于编写异步(如同步)。代码如下:
from urllib.parse import urlencode
import json
import tornado.web
from tornado import gen
from tornado.httpclient import AsyncHTTPClient
from handlers.token import TokenBaseHandler
class AuthCodeHandler(TokenBaseHandler):
"""
已经获得用户授权, 向API服务器获取Token
"""
@gen.coroutine
def get(self):
auth_code = self.get_argument("code", "No code")
post_data = {
"client_id": "你的App Key",
"client_secret": "你的App Secret",
"grant_type": "authorization_code",
"code": auth_code,
"redirect_uri": "http://dropthej.com"
}
http_client = AsyncHTTPClient()
response = "init"
body = urlencode(post_data)
try:
response = yield http_client.fetch(
"https://api.weibo.com/oauth2/access_token",
method="POST",
body=body
)
except Exception as e:
self.write(str(e))
return;
token_json = json.loads(str(response.body, encoding='utf-8'))
# set token_json
self.application.token_json = token_json
self.write("
" + str(token_json['access_token']))
url = "http://dropthej.com/?tk=" + token_json['access_token']
self.redirect(url)
由于我们仅使用它来与他的API一起使用,因此我们不会在cookie中编写access_token,而是使用一种简单的方法将其放入URL中。这样,应用程序的每个页面都会被带入。tk参数可以保留用户的登录状态。在这里,我们返回到此页面,因此我们在html中收到此tk并使用它来调用Sina API。
为什么发送GET和POST请求?应该使用龙卷风在后台发送此消息吗?前端的javascript无法完成吗?由于应将“应用程序秘密”发送到此处,因此称为“秘密”,您仍然可以将其发送到前端。遍历用户计算机是非常不安全的。 Secret旨在验证这是真实客户端发送的请求,因此必须在后台发送,并且必须由客户端而不是用户完成。
使用jQuery调用Sina API以获取用户的最新主页微博
这不是重点。我不会再说了。效果非常好,也很高兴。主要代码如下:
var xyz;
$(function() {
$.ajax({
url: "https://api.weibo.com/2/status ... ot%3B,
type: "GET",
dataType: "jsonp",
data: {
"access_token": ac_tk
},
success: function(result) {
xyz = result.data.statuses;
for (x in xyz) {
$("#tbody").append("" + xyz[x].user.name + "" + xyz[x].text + "");
}
}
});
});
效果如图所示:
链接到本文 查看全部
Python3下用Tornado调用新浪微博API.0认证的顺序
使用Tornado试用新浪微博开放平台API
Tornado作为Python异步无阻塞服务器和轻量级Web框架,非常吸引人。为了体验OAuth 2. 0身份验证,我使用了Tornado构建了网站并调用了新浪微博API。新浪微博的OAuth 2. 0身份验证序列如下:
以下内容简要说明了如何在Python 3下使用Tornado完成上述四个步骤。
将用户带到新浪认证页面
假设我们要开发的客户端的域名是,在Sina中创建一个新应用程序,然后在设置中填写此安全域名,以便我们可以跨站点请求XMLRequests。
此步骤是编写html页面,在Tornado中则是编写模板。假设我们在客户端上放置了一个名为“使用新浪微博登录”的按钮,代码如下:
Login
通过这种方式,您只需单击此按钮即可转到新浪的身份验证页面。用户通过身份验证后,新浪会将用户转到您提供的redirect_uri地址,这里是
因此,我们需要使用Tornado来处理身份验证服务器发送给我们的代码。
龙卷风在后台使用代码交换access_token
这部分有两个步骤:
配置Tornado的路由表,然后让r'/ auth_code'路由到AuthCodeHandler处理程序。然后,我们可以重写此处理程序的get方法以获取代码。然后我们使用POST方法将代码发送到Sina,这是它可以反映Tornado的异步和非阻塞功能的强大之处。龙卷风的AsyncHTTPClient可以发起异步请求。 @ gen.coroutine装饰器可用于编写异步(如同步)。代码如下:
from urllib.parse import urlencode
import json
import tornado.web
from tornado import gen
from tornado.httpclient import AsyncHTTPClient
from handlers.token import TokenBaseHandler
class AuthCodeHandler(TokenBaseHandler):
"""
已经获得用户授权, 向API服务器获取Token
"""
@gen.coroutine
def get(self):
auth_code = self.get_argument("code", "No code")
post_data = {
"client_id": "你的App Key",
"client_secret": "你的App Secret",
"grant_type": "authorization_code",
"code": auth_code,
"redirect_uri": "http://dropthej.com"
}
http_client = AsyncHTTPClient()
response = "init"
body = urlencode(post_data)
try:
response = yield http_client.fetch(
"https://api.weibo.com/oauth2/access_token",
method="POST",
body=body
)
except Exception as e:
self.write(str(e))
return;
token_json = json.loads(str(response.body, encoding='utf-8'))
# set token_json
self.application.token_json = token_json
self.write("
" + str(token_json['access_token']))
url = "http://dropthej.com/?tk=" + token_json['access_token']
self.redirect(url)
由于我们仅使用它来与他的API一起使用,因此我们不会在cookie中编写access_token,而是使用一种简单的方法将其放入URL中。这样,应用程序的每个页面都会被带入。tk参数可以保留用户的登录状态。在这里,我们返回到此页面,因此我们在html中收到此tk并使用它来调用Sina API。
为什么发送GET和POST请求?应该使用龙卷风在后台发送此消息吗?前端的javascript无法完成吗?由于应将“应用程序秘密”发送到此处,因此称为“秘密”,您仍然可以将其发送到前端。遍历用户计算机是非常不安全的。 Secret旨在验证这是真实客户端发送的请求,因此必须在后台发送,并且必须由客户端而不是用户完成。
使用jQuery调用Sina API以获取用户的最新主页微博
这不是重点。我不会再说了。效果非常好,也很高兴。主要代码如下:
var xyz;
$(function() {
$.ajax({
url: "https://api.weibo.com/2/status ... ot%3B,
type: "GET",
dataType: "jsonp",
data: {
"access_token": ac_tk
},
success: function(result) {
xyz = result.data.statuses;
for (x in xyz) {
$("#tbody").append("" + xyz[x].user.name + "" + xyz[x].text + "");
}
}
});
});
效果如图所示:
https://jecvay.com/wp-content/ ... 0.png 254w" />链接到本文
NET调用新浪微博开放平台接口之旅(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-05-20 19:18
要使用新浪微博开放平台界面,您需要先申请一个帐户。申请方法:向@微博开平台发送私信,或发送收录您的电子邮件,微博个人主页,电话号码和简介的电子邮件。
发送申请电子邮件后,我们在不到1小时的时间内收到了申请批准电子邮件。然后进入新浪微博开放平台,查看相关文档。在该文档(使用Basic Auth进行用户身份验证)中,发现新浪微博开发团队在花园中推荐了Q.Lee.lulu撰写的博客文章:访问需要HTTP Basic Authentication实现各种资源语言。本文文章已成为我们的重要参考,但本文仅适用于“ GET”请求,而新浪微博开放平台接口要求HTTP请求方法为“ POST”,并且在本文中也引用了黑鱼。花园。 Tang撰写的另一篇博客文章:使用HttpWebRequest发送自定义POST请求。谢谢两位园丁的分享!
接下来,我们开始.NET的旅程,即调用新浪微博开放平台接口。
1.首先,我们需要获取一个应用程序密钥,并在新浪微博开放平台的“我的应用程序”中创建一个应用程序,并假设该应用程序密钥为123456,将生成该应用程序密钥。
2.在新浪微博API文档中找到您要调用的API。在这里,我们假设调用发布微博的API状态/更新。网址是POST参数:source = appkey&status = Weibo content。 appkey是先前获得的应用程序密钥。
3.准备数据
1)准备用户验证数据:
string username = "t@cnblogs.com";<br />string password = "cnblogs.com";<br />string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
2)要调用的URL和要发布的数据:
string url = "http://api.t.sina.com.cn/statu ... %3Bbr /> string news_title = "VS2010网剧合集:讲述程序员的爱情故事";<br />int news_id = 62747;<br /> string t_news = string.Format("{0},http://news.cnblogs.com/n/{1}/", news_title, news_id );<br /> string data = "source=123456&status=" + System.Web.HttpUtility.UrlEncode(t_news);
4.准备用于发起请求的HttpWebRequest对象:
System.Net.WebRequest webRequest = System.Net.WebRequest.Create(url);<br /> System.Net.HttpWebRequest httpRequest = webRequest as System.Net.HttpWebRequest;
5.准备用于用户身份验证的凭据:
6.发起POST请求:
httpRequest.Method = "POST";<br /> httpRequest.ContentType = "application/x-www-form-urlencoded";<br /> System.Text.Encoding encoding = System.Text.Encoding.ASCII;<br />byte[] bytesToPost = encoding.GetBytes(data); <br /> httpRequest.ContentLength = bytesToPost.Length;<br /> System.IO.Stream requestStream = httpRequest.GetRequestStream();<br /> requestStream.Write(bytesToPost, 0, bytesToPost.Length);<br /> requestStream.Close();
上述代码成功执行后,内容将发布到您的微博上。
7.从服务器获取响应内容:
System.Net.WebResponse wr = httpRequest.GetResponse();<br /> System.IO.Stream receiveStream = wr.GetResponseStream();<br />using (System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8))<br /> {<br />string responseContent = reader.ReadToEnd();<br /> }
好的,.NET调用新浪微博开放平台接口的过程已经完成,非常简单。
如果您没有Q.Lee.lulu和鱼汤的文章作为参考,那么对我们而言,这并非易事。这也许是分享的价值,但是您的小经验可能会给其他人带来很大的帮助。
所以,我们也分享一下。尽管这不是一种体验,但它只是一种整理,但对有需要的人可能会有所帮助。 查看全部
NET调用新浪微博开放平台接口之旅(图)
要使用新浪微博开放平台界面,您需要先申请一个帐户。申请方法:向@微博开平台发送私信,或发送收录您的电子邮件,微博个人主页,电话号码和简介的电子邮件。
发送申请电子邮件后,我们在不到1小时的时间内收到了申请批准电子邮件。然后进入新浪微博开放平台,查看相关文档。在该文档(使用Basic Auth进行用户身份验证)中,发现新浪微博开发团队在花园中推荐了Q.Lee.lulu撰写的博客文章:访问需要HTTP Basic Authentication实现各种资源语言。本文文章已成为我们的重要参考,但本文仅适用于“ GET”请求,而新浪微博开放平台接口要求HTTP请求方法为“ POST”,并且在本文中也引用了黑鱼。花园。 Tang撰写的另一篇博客文章:使用HttpWebRequest发送自定义POST请求。谢谢两位园丁的分享!
接下来,我们开始.NET的旅程,即调用新浪微博开放平台接口。
1.首先,我们需要获取一个应用程序密钥,并在新浪微博开放平台的“我的应用程序”中创建一个应用程序,并假设该应用程序密钥为123456,将生成该应用程序密钥。
2.在新浪微博API文档中找到您要调用的API。在这里,我们假设调用发布微博的API状态/更新。网址是POST参数:source = appkey&status = Weibo content。 appkey是先前获得的应用程序密钥。
3.准备数据
1)准备用户验证数据:
string username = "t@cnblogs.com";<br />string password = "cnblogs.com";<br />string usernamePassword = username + ":" + password;
用户名是您的微博登录用户名,密码是您的博客密码。
2)要调用的URL和要发布的数据:
string url = "http://api.t.sina.com.cn/statu ... %3Bbr /> string news_title = "VS2010网剧合集:讲述程序员的爱情故事";<br />int news_id = 62747;<br /> string t_news = string.Format("{0},http://news.cnblogs.com/n/{1}/", news_title, news_id );<br /> string data = "source=123456&status=" + System.Web.HttpUtility.UrlEncode(t_news);
4.准备用于发起请求的HttpWebRequest对象:
System.Net.WebRequest webRequest = System.Net.WebRequest.Create(url);<br /> System.Net.HttpWebRequest httpRequest = webRequest as System.Net.HttpWebRequest;
5.准备用于用户身份验证的凭据:
6.发起POST请求:
httpRequest.Method = "POST";<br /> httpRequest.ContentType = "application/x-www-form-urlencoded";<br /> System.Text.Encoding encoding = System.Text.Encoding.ASCII;<br />byte[] bytesToPost = encoding.GetBytes(data); <br /> httpRequest.ContentLength = bytesToPost.Length;<br /> System.IO.Stream requestStream = httpRequest.GetRequestStream();<br /> requestStream.Write(bytesToPost, 0, bytesToPost.Length);<br /> requestStream.Close();
上述代码成功执行后,内容将发布到您的微博上。
7.从服务器获取响应内容:
System.Net.WebResponse wr = httpRequest.GetResponse();<br /> System.IO.Stream receiveStream = wr.GetResponseStream();<br />using (System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8))<br /> {<br />string responseContent = reader.ReadToEnd();<br /> }
好的,.NET调用新浪微博开放平台接口的过程已经完成,非常简单。
如果您没有Q.Lee.lulu和鱼汤的文章作为参考,那么对我们而言,这并非易事。这也许是分享的价值,但是您的小经验可能会给其他人带来很大的帮助。
所以,我们也分享一下。尽管这不是一种体验,但它只是一种整理,但对有需要的人可能会有所帮助。
第三方开发者可免费接入新浪微博位置服务平台上线
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-18 19:00
最近,新浪微博的“位置服务接口”正式启动,第三方开发人员可以免费访问新浪的位置服务平台。
新浪微博位置服务平台的启动意味着LBS应用程序将退出简单的“签入”模式。我相信在不久的将来,定位功能将作为移动应用程序的标准配置存在。
新浪微博位置服务平台的功能在于,它为第三方开发人员提供了最丰富,最实用的功能界面。通过访问基于用户,活动,位置,邻居等的界面,开发人员可以自由获取微博上一个人的时间表和社交动态,并按兴趣和标签对其进行分类。通过动态和附近的界面,开发人员可以获得单个用户的所有关注者信息,并且可以根据距离,时间和体重等各种参数对结果列表进行排序。
开发人员获取特定位置的微博用户的照片,信息和用户行为后,可以根据这些用户的位置行为,微博内容和其他多维信息全面分析用户的真实兴趣,并建立一种“真实的用户行为”而不是“单纯的内容分析”,真正的“兴趣图”是探索用户的实际需求,并根据产品功能满足他们的需求。
在新浪微博定位平台正式启动不到三天的时间里,已有30多家应用程序开发商与新浪公司签署了合作协议,其中包括优秀的行业应用程序,如桃边,酒店管家,公开点评,订购秘书等。
“位置服务接口”总共提供六种类型的接口,包括21个普通接口和7个高级接口。第三方开发人员现在可以通过新浪微博开放平台()直接调用上述界面。
1.第三方调用位置服务接口的必要条件:
调用通用接口的条件:开发人员Appkey必须首先通过对微博开放平台的审查。
(如何申请微博开放平台:)
高级界面申请方法:通过“高级界面申请流程”
%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7
如有任何疑问,请联系@微博位置服务平台
2.位置服务接口(“位置服务接口”类别)的详细说明:
%E6%96%87%E6%A1%A3_V2
3.位置服务平台访问案例和详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD% AE%E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附件1:位置服务界面概述
附件2:应用案例演示-淘宝
[周围的人]
1.呼叫界面
a)获取附近的位置界面(已签署隐私协议的界面)
b)POI数据写入接口
2.实现功能 查看全部
第三方开发者可免费接入新浪微博位置服务平台上线
最近,新浪微博的“位置服务接口”正式启动,第三方开发人员可以免费访问新浪的位置服务平台。
新浪微博位置服务平台的启动意味着LBS应用程序将退出简单的“签入”模式。我相信在不久的将来,定位功能将作为移动应用程序的标准配置存在。
新浪微博位置服务平台的功能在于,它为第三方开发人员提供了最丰富,最实用的功能界面。通过访问基于用户,活动,位置,邻居等的界面,开发人员可以自由获取微博上一个人的时间表和社交动态,并按兴趣和标签对其进行分类。通过动态和附近的界面,开发人员可以获得单个用户的所有关注者信息,并且可以根据距离,时间和体重等各种参数对结果列表进行排序。
开发人员获取特定位置的微博用户的照片,信息和用户行为后,可以根据这些用户的位置行为,微博内容和其他多维信息全面分析用户的真实兴趣,并建立一种“真实的用户行为”而不是“单纯的内容分析”,真正的“兴趣图”是探索用户的实际需求,并根据产品功能满足他们的需求。
在新浪微博定位平台正式启动不到三天的时间里,已有30多家应用程序开发商与新浪公司签署了合作协议,其中包括优秀的行业应用程序,如桃边,酒店管家,公开点评,订购秘书等。
“位置服务接口”总共提供六种类型的接口,包括21个普通接口和7个高级接口。第三方开发人员现在可以通过新浪微博开放平台()直接调用上述界面。
1.第三方调用位置服务接口的必要条件:
调用通用接口的条件:开发人员Appkey必须首先通过对微博开放平台的审查。
(如何申请微博开放平台:)
高级界面申请方法:通过“高级界面申请流程”
%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7
如有任何疑问,请联系@微博位置服务平台
2.位置服务接口(“位置服务接口”类别)的详细说明:
%E6%96%87%E6%A1%A3_V2
3.位置服务平台访问案例和详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD% AE%E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附件1:位置服务界面概述
附件2:应用案例演示-淘宝
[周围的人]
1.呼叫界面
a)获取附近的位置界面(已签署隐私协议的界面)
b)POI数据写入接口
2.实现功能
网上的博客网站推广提高网站流量的各种方法,效果很明显
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-05-18 18:12
在线博客网站推广的各种方法中,增加网站的流量,很多作者提到使用微博推广方法,效果也非常明显。博客栏这次我们介绍一个与新浪微博同步更新的WordPress博客插件wp-tsina。使用此插件可以节省博客作者大量的晋升时间。当然,很多博客都没有在微博上推广。更新。
wp-tsina插件简介:
WP-tsina是专门为新浪微博用户开发的插件,可以自动将新发布的WordPress博客文章与新浪微博同步。
Wp-tsina插件的安装和使用:
下载博客插件wp-tsina,并将其上传到wp-content / plugins /目录(您也可以在博客背景中使用添加新插件功能)来启用wp-tsina插件,在插件列表中,然后在插件选项卡下,还有两个选项“ Sina Weibo Configuration”和“ Sina Weibo Backup”。点击“新浪微博配置”选项,进入插件设置界面
这里需要说明的是备份。选择将发布设置另存为草稿。从微博备份到WordPress博客的内容将作为草稿保存在文章列表中,自动发布将以文章的形式发布;标题前缀可以自由修改;是否将备份发布到微博,如果是,备份成功后,备份的URL 文章将发布在新浪微博上。单击“新浪微博备份”将自动将新浪微博的所有内容备份到WordPress博客,然后使用“另存为草稿”或“自动发布”集对其进行处理。
提醒:此插件需要网站主机的PHP配置来支持curl。在使用之前,请检查空间是否支持curl可以使用的phpinfo()函数。
除非特别说明,文章将由Blog Bar组织和发布,欢迎转载。 查看全部
网上的博客网站推广提高网站流量的各种方法,效果很明显
在线博客网站推广的各种方法中,增加网站的流量,很多作者提到使用微博推广方法,效果也非常明显。博客栏这次我们介绍一个与新浪微博同步更新的WordPress博客插件wp-tsina。使用此插件可以节省博客作者大量的晋升时间。当然,很多博客都没有在微博上推广。更新。
wp-tsina插件简介:
WP-tsina是专门为新浪微博用户开发的插件,可以自动将新发布的WordPress博客文章与新浪微博同步。
Wp-tsina插件的安装和使用:
下载博客插件wp-tsina,并将其上传到wp-content / plugins /目录(您也可以在博客背景中使用添加新插件功能)来启用wp-tsina插件,在插件列表中,然后在插件选项卡下,还有两个选项“ Sina Weibo Configuration”和“ Sina Weibo Backup”。点击“新浪微博配置”选项,进入插件设置界面
这里需要说明的是备份。选择将发布设置另存为草稿。从微博备份到WordPress博客的内容将作为草稿保存在文章列表中,自动发布将以文章的形式发布;标题前缀可以自由修改;是否将备份发布到微博,如果是,备份成功后,备份的URL 文章将发布在新浪微博上。单击“新浪微博备份”将自动将新浪微博的所有内容备份到WordPress博客,然后使用“另存为草稿”或“自动发布”集对其进行处理。
提醒:此插件需要网站主机的PHP配置来支持curl。在使用之前,请检查空间是否支持curl可以使用的phpinfo()函数。
除非特别说明,文章将由Blog Bar组织和发布,欢迎转载。
利用PHP进行新浪微博API开发的内容进行一个整理和说明
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-05-18 18:02
现在,玩微博的人越来越多,有关微博的第三方应用程序开发也越来越多。我不小心开始接触新浪微博API开发,新浪微博API开发资源更多,新浪微博为开发人员提供了平台。该网站是:它收录有关新浪微博开发的全面信息,包括开发人员的使用和介绍,各种语言的API函数介绍文档,SDK等。各种材料。
在发展和学习的过程中,我觉得尽管这不太困难,但仍有一些问题需要我们注意。今天,在开发和学习过程中,我仅使用PHP进行新浪微博来组织和解释API开发的内容,
新浪微博API开发之前的准备工作
首先进入新浪微博开放平台,下载基于PHP的SDK开发包。下载地址为:?name = weibo-oauth-class-with-image-avatar-06-2 9. zip
下载完成后,将其放置在您自己的开发环境中并解压缩。演示程序也包括在内。我们可以参考其示例程序进行编写。
新浪微博API开发中最重要的用户授权过程
实际上,开发过程中的许多问题都集中在用户授权阶段。我开发的第三方应用程序使用OAuth授权。在新浪微博开放平台中,OAuth授权过程非常清晰且完整。简介,我们可以检查一下,我将从示例开发的角度进行介绍和解释。
1.首先获取未经授权的请求令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,WB_SKEY);
$ keys = $ o-> getRequestToken();
// echo($ keys ['oauth_token']。':'。$ keys ['oauth_token_secret']);
我们需要在新浪微博开放平台上注册一个帐户,或直接使用我们的新浪微博帐户登录,输入我的应用程序,然后按照提示创建我们自己的第三方应用程序。创建完成后,我们可以获得两个授权的App Key和App Secret值,这两个值是我们应用程序开发的关键。
获取授权值后,我们可以使用上述代码获取未经授权的请求令牌值,该值将存储在$ key数组变量中。
2.然后请求用户授权令牌
复制代码,代码如下:
$ _ SESSION ['keys'] = $ keys;
aurl = $ o-> getAuthorizeURL($ keys ['oauth_token'],false,'');
获得未授权的请求令牌值后,我们可以使用上面的代码准备进入新浪微博授权页面进行授权。 $ aurl是授权链接页面。得到$ aurl后,可以使用header()直接跳转到授权页面,然后用户输入新浪微博帐户和密码进行授权。授权完成后,它将自动跳回到您在上一个参数中设置的回调页面:此链接可以设置为上一页,并且授权完成后,它将自动再次跳回。
应注意,有必要设置会话密钥的值。在下面获得的授权访问令牌中需要它。许多朋友可能会参考开放平台上的说明进行授权,但是他们发现总是存在错误。这通常是问题所在。您尚未设置会话的键值。当然,您不能在下面获取访问令牌的值。必须记住这一点。
3.最后是用户授权的访问令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,
WB_SKEY
$ _ SESSION ['keys'] ['oauth_token'],
$ _ SESSION ['keys'] ['oauth_token_secret']);
$ last_key = $ o-> getAccessToken($ _REQUEST ['oauth_verifier']);
echo($ last_key ['oauth_token']);
以上代码最终获得了用户授权的访问令牌。总共有两个值,它们存储在$ last_key数组变量中。我们还可以看到最后两个参数是我们之前设置的会话值。至此,基本完成。这是新浪微博用户授权的完整过程。
授权完成后的工作
授权完成后,我们可以开始调用新浪微博提供的各种API函数接口,以进行实际的应用程序开发。在这里,我将简要介绍获取最新微博记录的界面。其他都差不多。
获取新浪微博最新信息的API接口函数为:public_timeline(),示例代码如下:
复制代码,代码如下:
///获取前20条最新更新的公共微博消息
$ c =新的WeiboClient(WB_AKEY,
WB_SKEY
$ oauth_token
$ oauth_token_secret);
$ msg = $ c-> public_timeline();
if($ msg === false || $ msg === null){
回显“发生错误”;
返回假;
}
if(isset($ msg ['error_code'])&& isset($ msg ['error'])){
echo('Error_code:'。$ msg ['error_code']。'; Error:'。$ msg ['error']);
返回假;
}
print_r($ msg);
通常,在获得用户授权的访问令牌值之后,我们将其保存在用户表中并与我们应用程序中的帐户相对应。之后,我们不必每次都调用每个新浪微博API接口。我一直都在申请认证。
上面的代码非常简单,实例化WeiboClient对象,然后如果没有错误,则直接调用接口函数public_timeline以获取返回的信息。通常,新浪微博api接口返回的数据格式通常为Json格式或xml格式,我们在此处使用php开发,如果您以Json格式返回数据,则使用Json格式具有固有的优势。直接php函数json_decode()可以转换为PHP常用的数组格式。 查看全部
利用PHP进行新浪微博API开发的内容进行一个整理和说明
现在,玩微博的人越来越多,有关微博的第三方应用程序开发也越来越多。我不小心开始接触新浪微博API开发,新浪微博API开发资源更多,新浪微博为开发人员提供了平台。该网站是:它收录有关新浪微博开发的全面信息,包括开发人员的使用和介绍,各种语言的API函数介绍文档,SDK等。各种材料。
在发展和学习的过程中,我觉得尽管这不太困难,但仍有一些问题需要我们注意。今天,在开发和学习过程中,我仅使用PHP进行新浪微博来组织和解释API开发的内容,
新浪微博API开发之前的准备工作
首先进入新浪微博开放平台,下载基于PHP的SDK开发包。下载地址为:?name = weibo-oauth-class-with-image-avatar-06-2 9. zip
下载完成后,将其放置在您自己的开发环境中并解压缩。演示程序也包括在内。我们可以参考其示例程序进行编写。
新浪微博API开发中最重要的用户授权过程
实际上,开发过程中的许多问题都集中在用户授权阶段。我开发的第三方应用程序使用OAuth授权。在新浪微博开放平台中,OAuth授权过程非常清晰且完整。简介,我们可以检查一下,我将从示例开发的角度进行介绍和解释。
1.首先获取未经授权的请求令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,WB_SKEY);
$ keys = $ o-> getRequestToken();
// echo($ keys ['oauth_token']。':'。$ keys ['oauth_token_secret']);
我们需要在新浪微博开放平台上注册一个帐户,或直接使用我们的新浪微博帐户登录,输入我的应用程序,然后按照提示创建我们自己的第三方应用程序。创建完成后,我们可以获得两个授权的App Key和App Secret值,这两个值是我们应用程序开发的关键。
获取授权值后,我们可以使用上述代码获取未经授权的请求令牌值,该值将存储在$ key数组变量中。
2.然后请求用户授权令牌
复制代码,代码如下:
$ _ SESSION ['keys'] = $ keys;
aurl = $ o-> getAuthorizeURL($ keys ['oauth_token'],false,'');
获得未授权的请求令牌值后,我们可以使用上面的代码准备进入新浪微博授权页面进行授权。 $ aurl是授权链接页面。得到$ aurl后,可以使用header()直接跳转到授权页面,然后用户输入新浪微博帐户和密码进行授权。授权完成后,它将自动跳回到您在上一个参数中设置的回调页面:此链接可以设置为上一页,并且授权完成后,它将自动再次跳回。
应注意,有必要设置会话密钥的值。在下面获得的授权访问令牌中需要它。许多朋友可能会参考开放平台上的说明进行授权,但是他们发现总是存在错误。这通常是问题所在。您尚未设置会话的键值。当然,您不能在下面获取访问令牌的值。必须记住这一点。
3.最后是用户授权的访问令牌
复制代码,代码如下:
$ o =新的WeiboOAuth(WB_AKEY,
WB_SKEY
$ _ SESSION ['keys'] ['oauth_token'],
$ _ SESSION ['keys'] ['oauth_token_secret']);
$ last_key = $ o-> getAccessToken($ _REQUEST ['oauth_verifier']);
echo($ last_key ['oauth_token']);
以上代码最终获得了用户授权的访问令牌。总共有两个值,它们存储在$ last_key数组变量中。我们还可以看到最后两个参数是我们之前设置的会话值。至此,基本完成。这是新浪微博用户授权的完整过程。
授权完成后的工作
授权完成后,我们可以开始调用新浪微博提供的各种API函数接口,以进行实际的应用程序开发。在这里,我将简要介绍获取最新微博记录的界面。其他都差不多。
获取新浪微博最新信息的API接口函数为:public_timeline(),示例代码如下:
复制代码,代码如下:
///获取前20条最新更新的公共微博消息
$ c =新的WeiboClient(WB_AKEY,
WB_SKEY
$ oauth_token
$ oauth_token_secret);
$ msg = $ c-> public_timeline();
if($ msg === false || $ msg === null){
回显“发生错误”;
返回假;
}
if(isset($ msg ['error_code'])&& isset($ msg ['error'])){
echo('Error_code:'。$ msg ['error_code']。'; Error:'。$ msg ['error']);
返回假;
}
print_r($ msg);
通常,在获得用户授权的访问令牌值之后,我们将其保存在用户表中并与我们应用程序中的帐户相对应。之后,我们不必每次都调用每个新浪微博API接口。我一直都在申请认证。
上面的代码非常简单,实例化WeiboClient对象,然后如果没有错误,则直接调用接口函数public_timeline以获取返回的信息。通常,新浪微博api接口返回的数据格式通常为Json格式或xml格式,我们在此处使用php开发,如果您以Json格式返回数据,则使用Json格式具有固有的优势。直接php函数json_decode()可以转换为PHP常用的数组格式。
零基础建站教程之同步新浪微博Wordpress代码(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 528 次浏览 • 2021-05-16 19:13
1、在学习从零开始的网站构建教程时,许多朋友提到博客正在使用社交评论插件。第一个是由于跨博客回复提醒功能,第二个是它附带的。与社交平台同步文章;也就是本文要实现的功能。首先两张图片
2、不难看出两张图片之间的区别:除了内容不同外,还有来自XXX的位置,即用红色框标记的位置;图2显示了以前使用Dushuo插件同步的效果,图1显示了此Blog中的实现。功能网站生产过程后的效果。
3、为什么您要“独立”开发一个将Wordpress自动同步到新浪微博的应用程序?第一:减少流量并为您自己的博客优化SEO 网站;第二:改善引人入胜的风格,突出我根据网站模仿站的步骤做出的网站高气质;因此,我们必须自己实现功能,而无需插件。
4、要实现此功能,请在新浪微博开发人员中心申请许可并创建网站访问应用程序。使用您的新浪微博帐户登录微博开放平台,网址:
5、单击页面导航中的[编辑开发者信息]或访问:,根据页面表单的内容填写信息,然后等待新浪审核后提交。 (下图是基本过程)
6、新浪审查通常需要大约1项工作。通过审核后,可以创建应用程序。在微博开放平台的主页上,单击橙色的[立即创建微连接]-> [网站 Access]或访问
7、完成申请信息后,将其提交以供审核。此处的审核时间将更长。我忘记了要花多长时间。在此期间,您可以使用Sina的开放端口进行开发,但是在通过审核之前,源位置会显示未审核一词,但这不会影响开发和使用。
二、同步新浪微博Wordpress代码
1、新浪微博具有许多供开发人员调用的界面。有兴趣的朋友可以认真学习。但是,一些有关学习的书籍网站也介绍了“ 2 / statuss / update”界面(开发文档:)。
2、根据开发文档()中的介绍,我们可以知道:
3、基于以上信息,我们编写的代码如下(appkey,用户名和userpassword替换为您自己的代码):
function post_to_sina_weibo($post_ID) {<br />
if (wp_is_post_revision($post_ID)) return;//修订版本(更新)不发微博<br />
$get_post_info = get_post($post_ID);<br />
$get_post_centent = get_post($post_ID)->post_content;<br />
$get_post_title = get_post($post_ID)->post_title;<br />
if ($get_post_info->post_status == \'publish\' && $_POST[\'original_post_status\'] != \'publish\') {<br />
$appkey=\'3838258703\';<br />
$username=\'微博用户名\';<br />
$userpassword=\'微博密码\';<br />
$request = new WP_Http;<br />
$status = \'【\' . strip_tags($get_post_title) . \'】 \' . mb_strimwidth(strip_tags(apply_filters(\'the_content\', $get_post_centent)) , 0, 132, \'...\') . \' 全文地址:\' . get_permalink($post_ID);<br />
$api_url = \'https://api.weibo.com/2/statuses/update.json\';<br />
$body = array(\'status\' => $status,\'source\' => $appkey);<br />
$headers = array(\'Authorization\' => \'Basic \' . base64_encode("$username:$userpassword"));<br />
$result = $request->post($api_url, array(\'body\' => $body,\'headers\' => $headers));<br />
}<br />
}<br />
add_action(\'publish_post\', \'post_to_sina_weibo\', 0);//给发布文章增加一个分享微博的动作 查看全部
零基础建站教程之同步新浪微博Wordpress代码(图)
1、在学习从零开始的网站构建教程时,许多朋友提到博客正在使用社交评论插件。第一个是由于跨博客回复提醒功能,第二个是它附带的。与社交平台同步文章;也就是本文要实现的功能。首先两张图片
2、不难看出两张图片之间的区别:除了内容不同外,还有来自XXX的位置,即用红色框标记的位置;图2显示了以前使用Dushuo插件同步的效果,图1显示了此Blog中的实现。功能网站生产过程后的效果。
3、为什么您要“独立”开发一个将Wordpress自动同步到新浪微博的应用程序?第一:减少流量并为您自己的博客优化SEO 网站;第二:改善引人入胜的风格,突出我根据网站模仿站的步骤做出的网站高气质;因此,我们必须自己实现功能,而无需插件。
4、要实现此功能,请在新浪微博开发人员中心申请许可并创建网站访问应用程序。使用您的新浪微博帐户登录微博开放平台,网址:
5、单击页面导航中的[编辑开发者信息]或访问:,根据页面表单的内容填写信息,然后等待新浪审核后提交。 (下图是基本过程)
6、新浪审查通常需要大约1项工作。通过审核后,可以创建应用程序。在微博开放平台的主页上,单击橙色的[立即创建微连接]-> [网站 Access]或访问
7、完成申请信息后,将其提交以供审核。此处的审核时间将更长。我忘记了要花多长时间。在此期间,您可以使用Sina的开放端口进行开发,但是在通过审核之前,源位置会显示未审核一词,但这不会影响开发和使用。
二、同步新浪微博Wordpress代码
1、新浪微博具有许多供开发人员调用的界面。有兴趣的朋友可以认真学习。但是,一些有关学习的书籍网站也介绍了“ 2 / statuss / update”界面(开发文档:)。
2、根据开发文档()中的介绍,我们可以知道:
3、基于以上信息,我们编写的代码如下(appkey,用户名和userpassword替换为您自己的代码):
function post_to_sina_weibo($post_ID) {<br />
if (wp_is_post_revision($post_ID)) return;//修订版本(更新)不发微博<br />
$get_post_info = get_post($post_ID);<br />
$get_post_centent = get_post($post_ID)->post_content;<br />
$get_post_title = get_post($post_ID)->post_title;<br />
if ($get_post_info->post_status == \'publish\' && $_POST[\'original_post_status\'] != \'publish\') {<br />
$appkey=\'3838258703\';<br />
$username=\'微博用户名\';<br />
$userpassword=\'微博密码\';<br />
$request = new WP_Http;<br />
$status = \'【\' . strip_tags($get_post_title) . \'】 \' . mb_strimwidth(strip_tags(apply_filters(\'the_content\', $get_post_centent)) , 0, 132, \'...\') . \' 全文地址:\' . get_permalink($post_ID);<br />
$api_url = \'https://api.weibo.com/2/statuses/update.json\';<br />
$body = array(\'status\' => $status,\'source\' => $appkey);<br />
$headers = array(\'Authorization\' => \'Basic \' . base64_encode("$username:$userpassword"));<br />
$result = $request->post($api_url, array(\'body\' => $body,\'headers\' => $headers));<br />
}<br />
}<br />
add_action(\'publish_post\', \'post_to_sina_weibo\', 0);//给发布文章增加一个分享微博的动作
如何用python登录新浪获取code值,解决如何自动登录code
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-05-16 18:13
我之前编写了有关调用新浪微博api的教程,包括如何使用python登录到新浪并获取调用api所需的代码。在此处发布此段:如果要自动获取代码值,则必须解决它。授权界面后如何获取登录问题,这个问题也困扰了我很长时间
首先,我是第一次手动登录,然后直接使用chrome查看发送的请求,复制其中的cookie,然后每次发送一个get请求以获取回调网页的代码值,如下所示:如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,此方法非常方便,无需分析太多的Sina登录方法,但是当我调用api的次数有限时,此方法不起作用
当应用程序的调用api受限制时,我们可以创建多个新浪帐户和多个应用程序,获取多个App密钥和App Secrets以重复调用,因此必须解决如何自动登录新浪获取的问题。代码
首先,我们需要分析新浪微博的登录过程。我无法完全使用chrome,edge(即fiddler4)捕获完整的登录过程。最后,我尝试使用firefox成功捕获整个登录过程
虽然我只输入了一次帐户密码,但我发送了两个帖子请求
让我们按请求分析它:
base64加密后的用户名,我将在稍后讨论如何实现,只要您知道含义,我都会随便更改它
请求成功后,服务器将向我们返回一条信息,包括我们稍后将使用的参数
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “ 1330428213”,“ is_openlock”:0,“ showpin”:0,“ exectime”:18})
稍后将需要servertime,nonce,pubket和rsakv的值,我们需要将它们解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
接下来,让我们看看第二个发帖请求
第二个请求是将表格发送到新浪通行证
servertime,nonce,pubket和rsakv是我们在最后一个get请求中获得的。 su是加密的帐户,sp是加密的密码。
su的加密方法是base64,首先安装一个base64库,然后调用以下函数:
su=base64.encodestring(username)[:-1]
密码的加密方法稍微复杂一点,还使用了servertime,nonce,pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要使用binascii库和rsa库
发送此请求后,服务器将返回JSON数据,包括我们稍后将使用的票证
请求并获取票证代码,如下所示:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
第三个请求仍然是发布请求,该请求已发送到具有授权错误的第三方。表单的内容直接在html代码中给出。
其中client_id是我们的APP_KEY; redirect_url是我们的回调页面,它是在我们首次创建应用程序时设置的;我不知道regCallback的来源,但是有两个变量,一个是APP_KEY,另一个是我们设置的回调页面。其他表格内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后,分析成功响应的get_code_url中的代码值。
code=get_code_url.url[47:]
通过这种方式,我们成功并自动获得了代码值。原创地址:python模拟登录新浪微博并自动获取调用新浪api所需的代码 查看全部
如何用python登录新浪获取code值,解决如何自动登录code
我之前编写了有关调用新浪微博api的教程,包括如何使用python登录到新浪并获取调用api所需的代码。在此处发布此段:如果要自动获取代码值,则必须解决它。授权界面后如何获取登录问题,这个问题也困扰了我很长时间
首先,我是第一次手动登录,然后直接使用chrome查看发送的请求,复制其中的cookie,然后每次发送一个get请求以获取回调网页的代码值,如下所示:如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,此方法非常方便,无需分析太多的Sina登录方法,但是当我调用api的次数有限时,此方法不起作用
当应用程序的调用api受限制时,我们可以创建多个新浪帐户和多个应用程序,获取多个App密钥和App Secrets以重复调用,因此必须解决如何自动登录新浪获取的问题。代码
首先,我们需要分析新浪微博的登录过程。我无法完全使用chrome,edge(即fiddler4)捕获完整的登录过程。最后,我尝试使用firefox成功捕获整个登录过程
虽然我只输入了一次帐户密码,但我发送了两个帖子请求
让我们按请求分析它:
base64加密后的用户名,我将在稍后讨论如何实现,只要您知道含义,我都会随便更改它
请求成功后,服务器将向我们返回一条信息,包括我们稍后将使用的参数
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “ 1330428213”,“ is_openlock”:0,“ showpin”:0,“ exectime”:18})
稍后将需要servertime,nonce,pubket和rsakv的值,我们需要将它们解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
接下来,让我们看看第二个发帖请求
第二个请求是将表格发送到新浪通行证
servertime,nonce,pubket和rsakv是我们在最后一个get请求中获得的。 su是加密的帐户,sp是加密的密码。
su的加密方法是base64,首先安装一个base64库,然后调用以下函数:
su=base64.encodestring(username)[:-1]
密码的加密方法稍微复杂一点,还使用了servertime,nonce,pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要使用binascii库和rsa库
发送此请求后,服务器将返回JSON数据,包括我们稍后将使用的票证
请求并获取票证代码,如下所示:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
第三个请求仍然是发布请求,该请求已发送到具有授权错误的第三方。表单的内容直接在html代码中给出。
其中client_id是我们的APP_KEY; redirect_url是我们的回调页面,它是在我们首次创建应用程序时设置的;我不知道regCallback的来源,但是有两个变量,一个是APP_KEY,另一个是我们设置的回调页面。其他表格内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后,分析成功响应的get_code_url中的代码值。
code=get_code_url.url[47:]
通过这种方式,我们成功并自动获得了代码值。原创地址:python模拟登录新浪微博并自动获取调用新浪api所需的代码

