
网站调用新浪微博内容
网站调用新浪微博内容(OAuth2.0协议授权流程查看/access_token获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-08 17:12
一、OAuth2.0概览
大多数 API 访问,例如发布微博、获取私人消息和关注,都需要用户身份。目前新浪微博开放平台用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发Debugging接口),新版接口也仅支持这两种方式。 OAuth2.0比1.0的整个授权验证过程更简单、更安全,也是未来最重要的用户认证和授权方式。 OAuth2.0协议授权流程见OAuth2.0授权流程,其中Client指第三方应用,Resource Owner指用户,Authorization Server是我们的授权服务器,Resource Server是API 服务器。
参考链接:以及新浪微博开放平台和新浪微博CodeProject开源项目
开发者可以先浏览OAuth2.0的接口文档,熟悉OAuth2接口和参数的含义,然后根据应用讲解如何使用OAuth2.0场景。
OAuth2 接口文档
接口说明
OAuth2/授权
请求用户授权令牌
OAuth2/access_token
获取授权访问令牌
OAuth2/get_token_info
授权信息查询界面
OAuth2/revokeoauth2
授权恢复接口
OAuth2/get_oauth2_token
OAuth1.0的Access Token替换为OAuth2.0的Access Token
二、OAuth2.0 新浪授权页面
1、 首先获取appKey和appSecret。这种获取方式可以在新浪微博新手指南中一步步获取。这里的回调地址使用默认的:网站访问方式。以下是 C# 示例源代码(控制台应用程序):
01.using System;
02.using System.Collections.Generic;
03.using System.Linq;
04.using System.Text;
05.using NetDimension.Weibo;
06.using System.Net;
07.
08.namespace SinaWeiboTestApp
09.{
10. class Program
11. {
12.
13. static void Main(string[] args)
14. {
15.
16. string appkey = "124543453288";
17. string appsecret = "3a456c5332fd2cb1178338fccb9fa51c";
18. //string callBack = "http://127.0.0.1:3170/WebSite2/Default.aspx";
19. string callBack = "https://api.weibo.com/oauth2/default.html";
20. var oauth = new NetDimension.Weibo.OAuth(appkey,appsecret,callBack);
21.
22. ////模拟登录
23. //string username = "[email protected]";
24. //string password = "xxxxxxx";
25. //oauth.ClientLogin(username, password); //模拟登录下,没啥好说的,你也可以改成标准登录。
26.
27. //标准登录
28. var authUrl = oauth.GetAuthorizeURL();
29. //string redirectUrl;
30. //HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(authUrl);
31. //request.Referer = authUrl;
32. //request.AllowAutoRedirect = false;
33. //using (WebResponse response = request.GetResponse())
34. //{
35. // redirectUrl = response.Headers["Location"];
36. // redirectUrl = response.ResponseUri.AbsolutePath;
37. //}
38. System.Diagnostics.Process.Start(authUrl);
39. Console.WriteLine("填写浏览器地址中的Code参数:");
40. var code = Console.ReadLine();
41. var accessToken = oauth.GetAccessTokenByAuthorizationCode(code);
42. if (!string.IsNullOrEmpty(accessToken.Token))
43. {
44. var sina = new NetDimension.Weibo.Client(oauth);
45. var uid = sina.API.Dynamic.Account.GetUID(); //调用API中获取UID的方法
46. Console.WriteLine(uid);
47. }
48.
49. var Sina = new Client(oauth);
50. Console.WriteLine("开始发送异步请求...");
51.
52. //例子1:异步获取用户的ID
53. //demo的运行环境是.net 4.0,下面展示的这种方法在2.0及以上版本环境下有效,3.0以上可以用lambda表达式来简化delegate的蛋疼写法,请看下面的例子。
54. Sina.AsyncInvoke(
55. //第一个代理中编写调用API接口的相关逻辑
56. delegate()
57. {
58. Console.WriteLine("发送请求来获得用户ID...");
59. System.Threading.Thread.Sleep(8000); //等待8秒
60. return Sina.API.Entity.Account.GetUID();
61. },
62. //第二个代理为回调函数,异步完成后将自动调用这个函数来处理结果。
63. delegate(AsyncCallback callback)
64. {
65. if (callback.IsSuccess)
66. {
67. Console.WriteLine("获取用户ID成功,ID:{0}", callback.Data);
68. }
69. else
70. {
71. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
72. }
73. }
74. );
75.
76. //列子2:获取公共微博列表
77. //2.0以上用lambda来写,方便不是一点点
78. Sina.AsyncInvoke(() =>
79. {
80. //获取微博,接口调用,返回值是个NetDimension.Weibo.Entities.status.Collection,所以泛型T为NetDimension.Weibo.Entities.status.Collection
81. Console.WriteLine("发送请求来获得公共微博列表...");
82. return Sina.API.Entity.Statuses.PublicTimeline();
83. //return Sina.API.Entity.Statuses.RepostTimeline;
84. }, (callback) =>
85. {
86. if (callback.IsSuccess)
87. {
88. //异步完成后处理结果,result就是返回的结果,类型就是泛型所指定的NetDimension.Weibo.Entities.status.Collection
89. Console.WriteLine("获得公共微博列表成功,现在公共频道发微博的人都是他们:");
90. foreach (var status in callback.Data.Statuses)
91. {
92. if (status.User != null)
93. Console.WriteLine(status.User.ScreenName + " ");//打印公共微博发起人的姓名
94. }
95. Console.WriteLine();
96. }
97. else
98. {
99. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
100. }
101.
102. });
103.
104.
105. Console.WriteLine("已发送所有异步请求。等待异步执行完成...");
106.
107. Console.ReadKey(); //阻塞,等待异步调用执行完成
108.
109. }
110.
111. }
112.}
MVC 中的代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using Myself.Models;
using Myself.Code;
using BLL;
using Lib;
using SpeexToWavToMp3;
using System.Web.Http.Filters;
using Models;
using Webdiyer.WebControls.Mvc;
using System.IO;
namespace Myself.Controllers
{
public class MySelfController : Controller
{
public ActionResult LoginSina()
{
var oauth = new NetDimension.Weibo.OAuth(appKey,appSecret,Url.Action("LoginSinaResult", "MySelf", null, "http"));
//第一步获取新浪授权页面的地址
var oauthUrl = oauth.GetAuthorizeURL();
return Redirect(oauthUrl);
}
public ActionResult LoginSinaResult(string code)
{
var oauth = new NetDimension.Weibo.OAuth(appKey, appSecret, Url.Action("LoginSinaResult", "MySelf", null, "http"));
var oauthToken = oauth.GetAccessTokenByAuthorizationCode(code);
var model = UserHelper.GetAuthorizeInfo(oauthToken.UID, 1);
if (model != null)
{
if (LoginHelper.UserLogin(model.UserID, 1, oauthToken.UID, Request.UserAgent, Request.UserHostAddress, "1", "web"))
{
return RedirectToAction("Index", "Home");
}
else
{
return Content("登录失败");
}
}
return Content("您尚未注册");
}
}
}
要运行上述程序,需要替换Appkey和Appsecret。
2、授权页面
以下是微博登录的界面,登录后第三方网站授权访问您新浪微博上的资源
将提供。
3、授权访问页面
4、新浪官方网站提供API测试工具来测试客户端构造的参数是否正确
5、Oauth2.0 操作流程图
第一步:首先直接跳转到用户授权地址,即图标Request User Url,提示用户登录,授权相关资源获取唯一Auth code。这里注意代码的有效期只有10分钟出于安全考虑,相比OAuth1.0,它节省了一步获取临时token的时间,而且有效期也有控制,比1.0简单多了,安全多了@1.0 认证;第二步:获取代码授权后,这一步是请求访问令牌,使用图标请求访问url生成数据令牌;第三步:通过Access Token请求一个OpenID,即用户在本平台的唯一标识,通过图标Request info url请求,然后得到OpenID;第四步:利用第二步获取的数据Token、第三步获取的OpenID及相关API请求获取用户授权资源信息 查看全部
网站调用新浪微博内容(OAuth2.0协议授权流程查看/access_token获取)
一、OAuth2.0概览
大多数 API 访问,例如发布微博、获取私人消息和关注,都需要用户身份。目前新浪微博开放平台用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发Debugging接口),新版接口也仅支持这两种方式。 OAuth2.0比1.0的整个授权验证过程更简单、更安全,也是未来最重要的用户认证和授权方式。 OAuth2.0协议授权流程见OAuth2.0授权流程,其中Client指第三方应用,Resource Owner指用户,Authorization Server是我们的授权服务器,Resource Server是API 服务器。
参考链接:以及新浪微博开放平台和新浪微博CodeProject开源项目
开发者可以先浏览OAuth2.0的接口文档,熟悉OAuth2接口和参数的含义,然后根据应用讲解如何使用OAuth2.0场景。
OAuth2 接口文档
接口说明
OAuth2/授权
请求用户授权令牌
OAuth2/access_token
获取授权访问令牌
OAuth2/get_token_info
授权信息查询界面
OAuth2/revokeoauth2
授权恢复接口
OAuth2/get_oauth2_token
OAuth1.0的Access Token替换为OAuth2.0的Access Token
二、OAuth2.0 新浪授权页面
1、 首先获取appKey和appSecret。这种获取方式可以在新浪微博新手指南中一步步获取。这里的回调地址使用默认的:网站访问方式。以下是 C# 示例源代码(控制台应用程序):
01.using System;
02.using System.Collections.Generic;
03.using System.Linq;
04.using System.Text;
05.using NetDimension.Weibo;
06.using System.Net;
07.
08.namespace SinaWeiboTestApp
09.{
10. class Program
11. {
12.
13. static void Main(string[] args)
14. {
15.
16. string appkey = "124543453288";
17. string appsecret = "3a456c5332fd2cb1178338fccb9fa51c";
18. //string callBack = "http://127.0.0.1:3170/WebSite2/Default.aspx";
19. string callBack = "https://api.weibo.com/oauth2/default.html";
20. var oauth = new NetDimension.Weibo.OAuth(appkey,appsecret,callBack);
21.
22. ////模拟登录
23. //string username = "[email protected]";
24. //string password = "xxxxxxx";
25. //oauth.ClientLogin(username, password); //模拟登录下,没啥好说的,你也可以改成标准登录。
26.
27. //标准登录
28. var authUrl = oauth.GetAuthorizeURL();
29. //string redirectUrl;
30. //HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(authUrl);
31. //request.Referer = authUrl;
32. //request.AllowAutoRedirect = false;
33. //using (WebResponse response = request.GetResponse())
34. //{
35. // redirectUrl = response.Headers["Location"];
36. // redirectUrl = response.ResponseUri.AbsolutePath;
37. //}
38. System.Diagnostics.Process.Start(authUrl);
39. Console.WriteLine("填写浏览器地址中的Code参数:");
40. var code = Console.ReadLine();
41. var accessToken = oauth.GetAccessTokenByAuthorizationCode(code);
42. if (!string.IsNullOrEmpty(accessToken.Token))
43. {
44. var sina = new NetDimension.Weibo.Client(oauth);
45. var uid = sina.API.Dynamic.Account.GetUID(); //调用API中获取UID的方法
46. Console.WriteLine(uid);
47. }
48.
49. var Sina = new Client(oauth);
50. Console.WriteLine("开始发送异步请求...");
51.
52. //例子1:异步获取用户的ID
53. //demo的运行环境是.net 4.0,下面展示的这种方法在2.0及以上版本环境下有效,3.0以上可以用lambda表达式来简化delegate的蛋疼写法,请看下面的例子。
54. Sina.AsyncInvoke(
55. //第一个代理中编写调用API接口的相关逻辑
56. delegate()
57. {
58. Console.WriteLine("发送请求来获得用户ID...");
59. System.Threading.Thread.Sleep(8000); //等待8秒
60. return Sina.API.Entity.Account.GetUID();
61. },
62. //第二个代理为回调函数,异步完成后将自动调用这个函数来处理结果。
63. delegate(AsyncCallback callback)
64. {
65. if (callback.IsSuccess)
66. {
67. Console.WriteLine("获取用户ID成功,ID:{0}", callback.Data);
68. }
69. else
70. {
71. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
72. }
73. }
74. );
75.
76. //列子2:获取公共微博列表
77. //2.0以上用lambda来写,方便不是一点点
78. Sina.AsyncInvoke(() =>
79. {
80. //获取微博,接口调用,返回值是个NetDimension.Weibo.Entities.status.Collection,所以泛型T为NetDimension.Weibo.Entities.status.Collection
81. Console.WriteLine("发送请求来获得公共微博列表...");
82. return Sina.API.Entity.Statuses.PublicTimeline();
83. //return Sina.API.Entity.Statuses.RepostTimeline;
84. }, (callback) =>
85. {
86. if (callback.IsSuccess)
87. {
88. //异步完成后处理结果,result就是返回的结果,类型就是泛型所指定的NetDimension.Weibo.Entities.status.Collection
89. Console.WriteLine("获得公共微博列表成功,现在公共频道发微博的人都是他们:");
90. foreach (var status in callback.Data.Statuses)
91. {
92. if (status.User != null)
93. Console.WriteLine(status.User.ScreenName + " ");//打印公共微博发起人的姓名
94. }
95. Console.WriteLine();
96. }
97. else
98. {
99. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
100. }
101.
102. });
103.
104.
105. Console.WriteLine("已发送所有异步请求。等待异步执行完成...");
106.
107. Console.ReadKey(); //阻塞,等待异步调用执行完成
108.
109. }
110.
111. }
112.}
MVC 中的代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using Myself.Models;
using Myself.Code;
using BLL;
using Lib;
using SpeexToWavToMp3;
using System.Web.Http.Filters;
using Models;
using Webdiyer.WebControls.Mvc;
using System.IO;
namespace Myself.Controllers
{
public class MySelfController : Controller
{
public ActionResult LoginSina()
{
var oauth = new NetDimension.Weibo.OAuth(appKey,appSecret,Url.Action("LoginSinaResult", "MySelf", null, "http"));
//第一步获取新浪授权页面的地址
var oauthUrl = oauth.GetAuthorizeURL();
return Redirect(oauthUrl);
}
public ActionResult LoginSinaResult(string code)
{
var oauth = new NetDimension.Weibo.OAuth(appKey, appSecret, Url.Action("LoginSinaResult", "MySelf", null, "http"));
var oauthToken = oauth.GetAccessTokenByAuthorizationCode(code);
var model = UserHelper.GetAuthorizeInfo(oauthToken.UID, 1);
if (model != null)
{
if (LoginHelper.UserLogin(model.UserID, 1, oauthToken.UID, Request.UserAgent, Request.UserHostAddress, "1", "web"))
{
return RedirectToAction("Index", "Home");
}
else
{
return Content("登录失败");
}
}
return Content("您尚未注册");
}
}
}
要运行上述程序,需要替换Appkey和Appsecret。
2、授权页面
以下是微博登录的界面,登录后第三方网站授权访问您新浪微博上的资源
将提供。

3、授权访问页面
4、新浪官方网站提供API测试工具来测试客户端构造的参数是否正确

5、Oauth2.0 操作流程图

第一步:首先直接跳转到用户授权地址,即图标Request User Url,提示用户登录,授权相关资源获取唯一Auth code。这里注意代码的有效期只有10分钟出于安全考虑,相比OAuth1.0,它节省了一步获取临时token的时间,而且有效期也有控制,比1.0简单多了,安全多了@1.0 认证;第二步:获取代码授权后,这一步是请求访问令牌,使用图标请求访问url生成数据令牌;第三步:通过Access Token请求一个OpenID,即用户在本平台的唯一标识,通过图标Request info url请求,然后得到OpenID;第四步:利用第二步获取的数据Token、第三步获取的OpenID及相关API请求获取用户授权资源信息
网站调用新浪微博内容(微博登录访问第三方网站,分享内容,同步信息。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-05 05:09
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
如果用户同意授权,页面跳转到your_registered_redirect_uri/?code=code:
2、 接下来,我们需要根据上面得到的代码换取访问令牌:
返回值:
json
{
"access_token": "slav32hkkg",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的oauth2.0 access token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = null )
{
$curl = curl_init();
//curl_setopt ( $curl, curlopt_safe_upload, false);
if( stripos($url, 'https://') !==false )
{
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
}
curl_setopt($curl, curlopt_url, $url);
curl_setopt($curl, curlopt_header, 0);
curl_setopt($curl, curlopt_returntransfer, 1);
if ( $_header != null )
{
curl_setopt($curl, curlopt_httpheader, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$ocurl = curl_init ();
curl_setopt ( $ocurl, curlopt_safe_upload, false);
if (stripos ( $url, "https://" ) !== false) {
curl_setopt ( $ocurl, curlopt_ssl_verifypeer, false );
curl_setopt ( $ocurl, curlopt_ssl_verifyhost, false );
}
curl_setopt ( $ocurl, curlopt_url, $url );
curl_setopt ( $ocurl, curlopt_returntransfer, 1 );
curl_setopt ( $ocurl, curlopt_post, true );
curl_setopt ( $ocurl, curlopt_postfields, $param );
$scontent = curl_exec ( $ocurl );
$astatus = curl_getinfo ( $ocurl );
curl_close ( $ocurl );
if (intval ( $astatus ["http_code"] ) == 200) {
return $scontent;
} else {
return false;
}
}
控制器处理代码login.php:
class login extends \think\controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/weblogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function weblogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取access token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。 查看全部
网站调用新浪微博内容(微博登录访问第三方网站,分享内容,同步信息。。)
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
如果用户同意授权,页面跳转到your_registered_redirect_uri/?code=code:
2、 接下来,我们需要根据上面得到的代码换取访问令牌:
返回值:
json
{
"access_token": "slav32hkkg",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的oauth2.0 access token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = null )
{
$curl = curl_init();
//curl_setopt ( $curl, curlopt_safe_upload, false);
if( stripos($url, 'https://') !==false )
{
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
}
curl_setopt($curl, curlopt_url, $url);
curl_setopt($curl, curlopt_header, 0);
curl_setopt($curl, curlopt_returntransfer, 1);
if ( $_header != null )
{
curl_setopt($curl, curlopt_httpheader, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$ocurl = curl_init ();
curl_setopt ( $ocurl, curlopt_safe_upload, false);
if (stripos ( $url, "https://" ) !== false) {
curl_setopt ( $ocurl, curlopt_ssl_verifypeer, false );
curl_setopt ( $ocurl, curlopt_ssl_verifyhost, false );
}
curl_setopt ( $ocurl, curlopt_url, $url );
curl_setopt ( $ocurl, curlopt_returntransfer, 1 );
curl_setopt ( $ocurl, curlopt_post, true );
curl_setopt ( $ocurl, curlopt_postfields, $param );
$scontent = curl_exec ( $ocurl );
$astatus = curl_getinfo ( $ocurl );
curl_close ( $ocurl );
if (intval ( $astatus ["http_code"] ) == 200) {
return $scontent;
} else {
return false;
}
}
控制器处理代码login.php:
class login extends \think\controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/weblogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function weblogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取access token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:



以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。
网站调用新浪微博内容(QQ和新浪微博登录门槛的降低就已经做到了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-02 16:18
网站引入QQ和新浪微博登录后,实现了网站登录门槛的降低,因为这两个基本上所有网名都可以使用,尤其是QQ。下载这两种登录方式的详细说明。
1.QQ需要申请认证,创建应用申请。如下所示:
点击网站,填写网站信息,如下图:
点击创建应用,等待审核。审核通过后,我们就可以使用基本的API了。以下是QQ互联API列表。
这是调用代码:
//引入JS脚本
QC.Login({
btnId: "qq_login_btn",
scope: "all",
},
function() {
QC.api("get_user_info").success(function(s) {
var paras = {
format: "json"
};
QC.api("get_info", paras).success(function(w) {
var data = eval(w.data);
var weiboUrl = "http://t.qq.com/" data.data.name;
var lc = data.data.location;
}).error(function(e) {
}).complete(function(c) { //完成请求回调
var nickName = s.data.nickname; //称谓
var userQQSmallImage = s.data.figureurl_qq_1; //大小为40×40像素的QQ头像URL。
userQQLargeImage = s.data.figureurl_qq_2; //大小为100×100像素的QQ头像URL。
var userQQZoneImage = s.data.figureurl_1; //大小为50×50像素的QQ空间头像URL
});
});
});
" _ue_custom_node_="true">
演示地址:
2.新浪微博:
登录新浪微博开放平台,点击进入管理中心,点击添加网站,先验证网站的所有权,验证后会添加到我的网站,不是我们刚刚填写的在线专栏网站,那么您需要提交审核。审核后就可以拿到APPID了,就可以使用了。
详细接口信息:
%E5%BE%AE%E5%8D%9AAPI
登录按钮介绍及代码:
function login(o) {
//
$.ajax({
type: "Get",
url: "https://api.weibo.com/2/users/ ... ot%3B + o.screen_name + "",
dataType: "jsonp",
success: function(data) {
var lc = data.data.location;
var nickName = o.screen_name;
var userQQLargeImage = o.avatar_large;
var weiboUrl = "http://weibo.com/u/" + o.idstr;
// document.getElementById("Friend").style.display = "block";
// document.getElementById("LoginA").style.display = "none";
// document.getElementById("FriendImg").src = o.avatar_large;
// document.getElementById("FriendName").innerHTML = o.screen_name + "(来自新浪微博登录)";
},
error: function(xhr, msg, e) {
alert(msg);
}
});
}
function logout() {
alert('logout');
}
QQ登录和新浪微博登录方式非常相似,步骤也一样。一般是申请认证,导入code,接收回调,注销。如果您需要使用一些更高级的API,我们需要单独申请。这里就不介绍了。 查看全部
网站调用新浪微博内容(QQ和新浪微博登录门槛的降低就已经做到了!)
网站引入QQ和新浪微博登录后,实现了网站登录门槛的降低,因为这两个基本上所有网名都可以使用,尤其是QQ。下载这两种登录方式的详细说明。
1.QQ需要申请认证,创建应用申请。如下所示:

点击网站,填写网站信息,如下图:
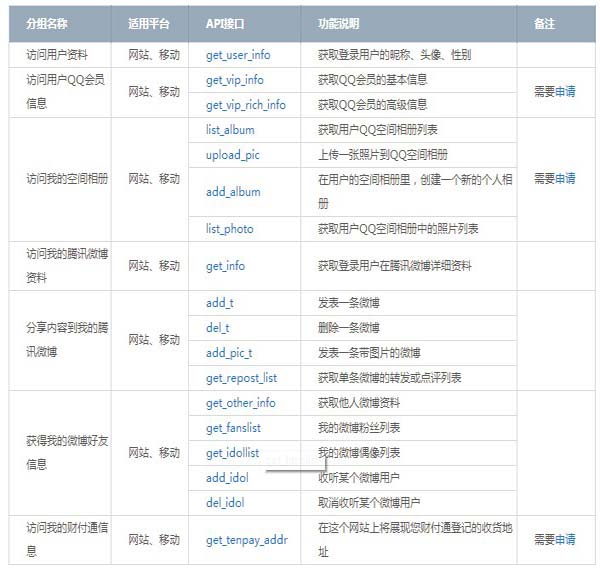
点击创建应用,等待审核。审核通过后,我们就可以使用基本的API了。以下是QQ互联API列表。
这是调用代码:
//引入JS脚本
QC.Login({
btnId: "qq_login_btn",
scope: "all",
},
function() {
QC.api("get_user_info").success(function(s) {
var paras = {
format: "json"
};
QC.api("get_info", paras).success(function(w) {
var data = eval(w.data);
var weiboUrl = "http://t.qq.com/" data.data.name;
var lc = data.data.location;
}).error(function(e) {
}).complete(function(c) { //完成请求回调
var nickName = s.data.nickname; //称谓
var userQQSmallImage = s.data.figureurl_qq_1; //大小为40×40像素的QQ头像URL。
userQQLargeImage = s.data.figureurl_qq_2; //大小为100×100像素的QQ头像URL。
var userQQZoneImage = s.data.figureurl_1; //大小为50×50像素的QQ空间头像URL
});
});
});
" _ue_custom_node_="true">
演示地址:
2.新浪微博:
登录新浪微博开放平台,点击进入管理中心,点击添加网站,先验证网站的所有权,验证后会添加到我的网站,不是我们刚刚填写的在线专栏网站,那么您需要提交审核。审核后就可以拿到APPID了,就可以使用了。

详细接口信息:
%E5%BE%AE%E5%8D%9AAPI
登录按钮介绍及代码:
function login(o) {
//
$.ajax({
type: "Get",
url: "https://api.weibo.com/2/users/ ... ot%3B + o.screen_name + "",
dataType: "jsonp",
success: function(data) {
var lc = data.data.location;
var nickName = o.screen_name;
var userQQLargeImage = o.avatar_large;
var weiboUrl = "http://weibo.com/u/" + o.idstr;
// document.getElementById("Friend").style.display = "block";
// document.getElementById("LoginA").style.display = "none";
// document.getElementById("FriendImg").src = o.avatar_large;
// document.getElementById("FriendName").innerHTML = o.screen_name + "(来自新浪微博登录)";
},
error: function(xhr, msg, e) {
alert(msg);
}
});
}
function logout() {
alert('logout');
}
QQ登录和新浪微博登录方式非常相似,步骤也一样。一般是申请认证,导入code,接收回调,注销。如果您需要使用一些更高级的API,我们需要单独申请。这里就不介绍了。
网站调用新浪微博内容(批量删除新浪微博的原理分析(图)JS代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-01 21:20
)
新浪微博开放平台删除接口已关闭。目前没有其他方法可以有效删除微博。网页版微博可以通过AJAX请求删除。唯一的参数是mid,我们可以理解为唯一的微博。ID,那么我们只需要获取这个ID并发起请求即可。
新浪微博的翻页使用直接嵌套的HTML代码,里面收录了你看到的所有信息,然后我们可以模拟用户操作,批量删除微博。
原理分析
首先,构建一个 curl 方法。为了识别登录用户,我们首先要设置cookie:
function post($url, $post_data, $method = 'post', $location = 0, $reffer = null, $origin = null, $host = null){
$header = array(
'Host: weibo.com',
'User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept: */*',
'Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding: gzip, deflate, br',
'Connection: keep-alive',
'Referer: https://weibo.com/p/1006061848 ... ll%3D1',
'Cookie: SUB=_2A25Nei59DeRhGedG71oW8SfIyz6IHXVuDhi1rDV8PUNbmtANLWTxkW9NUTJhgRrUko8Y3kcSMy2qik69SLr5cWOz; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5hXoza0gdfeO6EFBAyGQ6P5JpX5KzhUgL.Fo2RShnNeK.Xehz2dJLoIpjLxK.L1KMLB--LxKnLB-qLBoBLxKMLB.BL1K2t; login_sid_t=d86405009f566cd57c8b433b74b96be8; cross_origin_proto=SSL; WBStorage=8daec78e6a891122|undefined; _s_tentry=passport.weibo.com; Apache=2936390402941.201.1618894353597; SINAGLOBAL=2936390402941.201.1618894353597; ULV=1618894353599:1:1:1:2936390402941.201.1618894353597:; wb_view_log=1920*10801; ALF=1650430381; SSOLoginState=1618894382; wb_view_log_1848719402=1920*10801; webim_unReadCount=%7B%22time%22%3A1618894400887%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A0%2C%22msgbox%22%3A0%7D',
'X-Requested-With: XMLHttpRequest',
);
$curl = curl_init(); // 这里并没有带参数初始化
curl_setopt($curl, CURLOPT_URL, $url); // 这里传入url
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查,不开启次功能
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 2); // 从证书中检测 SSL 加密算法
curl_setopt($curl, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36");
curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
curl_setopt($curl, CURLOPT_POST, $method == 'post'?true:false); // 开启 post
curl_setopt($curl, CURLOPT_ENCODING, "gzip, deflate" );
curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data); // 要传送的数据
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制,防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$tmpInfo = curl_exec($curl);
return $tmpInfo;
}
通过浏览器调试工具,我们可以找到翻页的URL地址:
%2Fp%2F19402%2Fhome%3Ffrom%3Dpage_100606%26mod%3DTAB%26is_all%3D1%23place&_t=FM_9555
page 参数是页码。这个请求得到的是一段JS代码,在页面上执行可以加载更多的微博内容,但是我们只需要里面的mid参数即可。
您可以使用常规匹配来:
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
同样,删除的url是:
参数为中。如果请求成功,您将获得:
{"code":"100000","msg":"","data":{}}
完整代码
至此,我们已经基本分析清楚了,完整的代码如下:
include_once('curl_post.php');
while(1){
$url = "https://weibo.com/p/1006061848 ... 3B%3B
$res = post($url, null, 'get');
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
print_r($match[1]);
foreach($match[1] as $key => $mid){
echo "start del ".$mid." ==============\r\n";
$res = post('https://weibo.com/aj/mblog/del?ajwvr=6', array('mid' => $mid));
echo $res."\r\n";
echo 'await 5s ================='."\r\n";
sleep(5);
}
if(count($match[1]) < 10) break;
}
执行php delWeibo.php,结果如下:
如果觉得等待时间太长,可以自行修改。建议不要太频繁地调用它。
这个调用可以批量删除微博,但是不方便。例如,如果你想保留一些内容,这是不够的。推荐使用我开发的另一个软件:可以手动选择一个键进行删除,精确控制删除动作。
'PHP' 不是内部或外部命令,也不是可执行程序或批处理文件。
将PHP的安装路径添加到环境变量中,就可以在命令行执行PHP文件了。
查看全部
网站调用新浪微博内容(批量删除新浪微博的原理分析(图)JS代码
)
新浪微博开放平台删除接口已关闭。目前没有其他方法可以有效删除微博。网页版微博可以通过AJAX请求删除。唯一的参数是mid,我们可以理解为唯一的微博。ID,那么我们只需要获取这个ID并发起请求即可。
新浪微博的翻页使用直接嵌套的HTML代码,里面收录了你看到的所有信息,然后我们可以模拟用户操作,批量删除微博。
原理分析
首先,构建一个 curl 方法。为了识别登录用户,我们首先要设置cookie:
function post($url, $post_data, $method = 'post', $location = 0, $reffer = null, $origin = null, $host = null){
$header = array(
'Host: weibo.com',
'User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept: */*',
'Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding: gzip, deflate, br',
'Connection: keep-alive',
'Referer: https://weibo.com/p/1006061848 ... ll%3D1',
'Cookie: SUB=_2A25Nei59DeRhGedG71oW8SfIyz6IHXVuDhi1rDV8PUNbmtANLWTxkW9NUTJhgRrUko8Y3kcSMy2qik69SLr5cWOz; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5hXoza0gdfeO6EFBAyGQ6P5JpX5KzhUgL.Fo2RShnNeK.Xehz2dJLoIpjLxK.L1KMLB--LxKnLB-qLBoBLxKMLB.BL1K2t; login_sid_t=d86405009f566cd57c8b433b74b96be8; cross_origin_proto=SSL; WBStorage=8daec78e6a891122|undefined; _s_tentry=passport.weibo.com; Apache=2936390402941.201.1618894353597; SINAGLOBAL=2936390402941.201.1618894353597; ULV=1618894353599:1:1:1:2936390402941.201.1618894353597:; wb_view_log=1920*10801; ALF=1650430381; SSOLoginState=1618894382; wb_view_log_1848719402=1920*10801; webim_unReadCount=%7B%22time%22%3A1618894400887%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A0%2C%22msgbox%22%3A0%7D',
'X-Requested-With: XMLHttpRequest',
);
$curl = curl_init(); // 这里并没有带参数初始化
curl_setopt($curl, CURLOPT_URL, $url); // 这里传入url
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查,不开启次功能
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 2); // 从证书中检测 SSL 加密算法
curl_setopt($curl, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36");
curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
curl_setopt($curl, CURLOPT_POST, $method == 'post'?true:false); // 开启 post
curl_setopt($curl, CURLOPT_ENCODING, "gzip, deflate" );
curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data); // 要传送的数据
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制,防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$tmpInfo = curl_exec($curl);
return $tmpInfo;
}
通过浏览器调试工具,我们可以找到翻页的URL地址:
%2Fp%2F19402%2Fhome%3Ffrom%3Dpage_100606%26mod%3DTAB%26is_all%3D1%23place&_t=FM_9555
page 参数是页码。这个请求得到的是一段JS代码,在页面上执行可以加载更多的微博内容,但是我们只需要里面的mid参数即可。
您可以使用常规匹配来:
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
同样,删除的url是:
参数为中。如果请求成功,您将获得:
{"code":"100000","msg":"","data":{}}
完整代码
至此,我们已经基本分析清楚了,完整的代码如下:
include_once('curl_post.php');
while(1){
$url = "https://weibo.com/p/1006061848 ... 3B%3B
$res = post($url, null, 'get');
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
print_r($match[1]);
foreach($match[1] as $key => $mid){
echo "start del ".$mid." ==============\r\n";
$res = post('https://weibo.com/aj/mblog/del?ajwvr=6', array('mid' => $mid));
echo $res."\r\n";
echo 'await 5s ================='."\r\n";
sleep(5);
}
if(count($match[1]) < 10) break;
}
执行php delWeibo.php,结果如下:

如果觉得等待时间太长,可以自行修改。建议不要太频繁地调用它。
这个调用可以批量删除微博,但是不方便。例如,如果你想保留一些内容,这是不够的。推荐使用我开发的另一个软件:可以手动选择一个键进行删除,精确控制删除动作。
'PHP' 不是内部或外部命令,也不是可执行程序或批处理文件。
将PHP的安装路径添加到环境变量中,就可以在命令行执行PHP文件了。

网站调用新浪微博内容(使用新浪微博API:创建SDK中的Web应用准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-31 13:04
在《使用新浪微博API:创建SDK》一文中,我们准备了用于编写Web应用程序的SDK,可以在命令行上测试成功。现在,我们可以在Web网站中集成和调用新浪微博的API。
微博登录
使用新浪微博API的第一步是允许用户通过微博登录。在您的网站上放置一个“用微博账号登录”链接,指向一个网站的URL,例如/signin。代码显示如下:
/static/i/signin.png
效果如图:
在URL映射处理函数签名中,创建一个APIClient实例,然后调用get_authorize_url()方法获取新浪微博认证的URL,并将用户重定向到该URL。代码显示如下:
def _create_client():
_APP_ID = '12345'
_APP_SECRET = 'abc123xyz'
_REDIRECT_URI = 'http://example.com/callback'
return APIClient(_APP_ID, _APP_SECRET, _REDIRECT_URI)
@get('/signin')
def signin():
client = _create_client()
# 重定向到新浪微博登陆页:
raise seeother(client.get_authorize_url())
用户在新浪微博的认证页面完成登录后,新浪微博会将用户重定向到我们指定的redirect_uri,并附加参数code。处理redirect_uri的函数会提取参数代码,然后获取登录用户的访问令牌。代码显示如下:
@get('/callback')
def callback():
client = _create_client()
r = client.request_access_token(ctx.request['code'])
access_token, expires_in, uid = r.access_token, r.expires_in, r.uid
在获取access token的同时,新浪微博也会返回access token的过期时间和用户ID。SDK 将过期时间转换为 UNIX 时间戳并返回。
获取到的访问令牌,然后可以使用登录用户的身份调用 API 以进一步获取用户详细信息。代码显示如下:
@get('/callback')
def callback():
...
client.set_access_token(access_token, expires_in)
user = client.users.show.get(uid=uid)
logging.info(json.dump(user)) # { "uid": 1234, "screen_name": "Michael", … }
紧接着,网站必须判断该用户是否是第一次访问,如果是,则在数据库中创建一条记录,如果该用户已经存在,则更新该用户的相关信息。由于uid是用户在新浪微博上的唯一ID号,因此可以作为主键来存储用户信息。同时,访问令牌和过期时间一起存储在数据库中。代码显示如下:
@get('/callback')
def callback():
...
if (_is_user_exist(uid)):
_update_user(user, access_token, expires_in)
else:
_create_user(user, access_token, expires_in)
最后一步是在您的 网站 上使用会话或 cookie 来识别用户已登录。然后,该用户可以作为登录名访问您的 网站。
调用接口
获得用户授权后,即可调用API。例如,列出用户关注的微博列表,代码如下:
@get('/list')
def list_weibo():
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.home_timeline.get()
return Template('list.html', statuses = r.statuses)
在HTML模板中,可以将JSON格式的状态列表转成HTML,代码如下:
L = []
for st in statuses:
L.append('''
%s
%s
%s
''' % (st.user.profile_image_url, st.user.screen_name, st.text)
print ''.join(L)
CSS处理后的最终HTML效果如下:
不过仔细观察,我们输出的微博和新浪微博官网是不一样的。官网会把@和http和#topic#开头的文字改成超链接。如何处理@某某某、#主题#和链接?下面是一个JavaScript正则匹配方案,代码如下:
var g_all = /(\@[^\s\&\:\)\uff09\uff1a\@]+)|(\#[^\#]+\#)|(http\:\/\/[a-zA-Z0-9\_\/\.\-]+)/g;
var g_at = /^\@[^\s\&\:\)\uff09\uff1a\@]+$/;
var g_topic = /^\#[^\#]+\#$/;
var g_link = /^http\:\/\/[a-zA-Z0-9\_\/\.\-]+$/;
function format_text(t) {
ss = t.replace('').split(g_all);
L = []
$.each(ss, function(index, s) {
if (s===undefined)
return;
if (g_at.test(s)) {
L.push('' + s + '');
}
else if (g_topic.test(s)) {
L.push('' + s + '');
}
else if (g_link.test(s)) {
L.push('' + s + '');
}
else {
L.push(s);
}
});
return L.join('');
}
在微博上发帖
发布微博的API是status/update,需要通过POST调用。发布微博代码如下:
@post('/update')
def statuses_update():
text = ctx.request['text']
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.update.post(status=text)
return True
本文演示了网站:
本文源代码可从GitHub下载: 查看全部
网站调用新浪微博内容(使用新浪微博API:创建SDK中的Web应用准备)
在《使用新浪微博API:创建SDK》一文中,我们准备了用于编写Web应用程序的SDK,可以在命令行上测试成功。现在,我们可以在Web网站中集成和调用新浪微博的API。
微博登录
使用新浪微博API的第一步是允许用户通过微博登录。在您的网站上放置一个“用微博账号登录”链接,指向一个网站的URL,例如/signin。代码显示如下:
/static/i/signin.png
效果如图:
在URL映射处理函数签名中,创建一个APIClient实例,然后调用get_authorize_url()方法获取新浪微博认证的URL,并将用户重定向到该URL。代码显示如下:
def _create_client():
_APP_ID = '12345'
_APP_SECRET = 'abc123xyz'
_REDIRECT_URI = 'http://example.com/callback'
return APIClient(_APP_ID, _APP_SECRET, _REDIRECT_URI)
@get('/signin')
def signin():
client = _create_client()
# 重定向到新浪微博登陆页:
raise seeother(client.get_authorize_url())
用户在新浪微博的认证页面完成登录后,新浪微博会将用户重定向到我们指定的redirect_uri,并附加参数code。处理redirect_uri的函数会提取参数代码,然后获取登录用户的访问令牌。代码显示如下:
@get('/callback')
def callback():
client = _create_client()
r = client.request_access_token(ctx.request['code'])
access_token, expires_in, uid = r.access_token, r.expires_in, r.uid
在获取access token的同时,新浪微博也会返回access token的过期时间和用户ID。SDK 将过期时间转换为 UNIX 时间戳并返回。
获取到的访问令牌,然后可以使用登录用户的身份调用 API 以进一步获取用户详细信息。代码显示如下:
@get('/callback')
def callback():
...
client.set_access_token(access_token, expires_in)
user = client.users.show.get(uid=uid)
logging.info(json.dump(user)) # { "uid": 1234, "screen_name": "Michael", … }
紧接着,网站必须判断该用户是否是第一次访问,如果是,则在数据库中创建一条记录,如果该用户已经存在,则更新该用户的相关信息。由于uid是用户在新浪微博上的唯一ID号,因此可以作为主键来存储用户信息。同时,访问令牌和过期时间一起存储在数据库中。代码显示如下:
@get('/callback')
def callback():
...
if (_is_user_exist(uid)):
_update_user(user, access_token, expires_in)
else:
_create_user(user, access_token, expires_in)
最后一步是在您的 网站 上使用会话或 cookie 来识别用户已登录。然后,该用户可以作为登录名访问您的 网站。
调用接口
获得用户授权后,即可调用API。例如,列出用户关注的微博列表,代码如下:
@get('/list')
def list_weibo():
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.home_timeline.get()
return Template('list.html', statuses = r.statuses)
在HTML模板中,可以将JSON格式的状态列表转成HTML,代码如下:
L = []
for st in statuses:
L.append('''
%s
%s
%s
''' % (st.user.profile_image_url, st.user.screen_name, st.text)
print ''.join(L)
CSS处理后的最终HTML效果如下:
不过仔细观察,我们输出的微博和新浪微博官网是不一样的。官网会把@和http和#topic#开头的文字改成超链接。如何处理@某某某、#主题#和链接?下面是一个JavaScript正则匹配方案,代码如下:
var g_all = /(\@[^\s\&\:\)\uff09\uff1a\@]+)|(\#[^\#]+\#)|(http\:\/\/[a-zA-Z0-9\_\/\.\-]+)/g;
var g_at = /^\@[^\s\&\:\)\uff09\uff1a\@]+$/;
var g_topic = /^\#[^\#]+\#$/;
var g_link = /^http\:\/\/[a-zA-Z0-9\_\/\.\-]+$/;
function format_text(t) {
ss = t.replace('').split(g_all);
L = []
$.each(ss, function(index, s) {
if (s===undefined)
return;
if (g_at.test(s)) {
L.push('' + s + '');
}
else if (g_topic.test(s)) {
L.push('' + s + '');
}
else if (g_link.test(s)) {
L.push('' + s + '');
}
else {
L.push(s);
}
});
return L.join('');
}
在微博上发帖
发布微博的API是status/update,需要通过POST调用。发布微博代码如下:
@post('/update')
def statuses_update():
text = ctx.request['text']
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.update.post(status=text)
return True
本文演示了网站:
本文源代码可从GitHub下载:
网站调用新浪微博内容( 【C#小蜗牛】C#调用微博API的相关知识点内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-31 13:04
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#Invoke 新浪微博 API 示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗
本文文章,小编为大家整理的一篇关于C#调用微博API相关知识点的文章,有需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();
上面的代码示例非常简单。您可以在本地进行测试。感谢您阅读和支持脚本之家。 查看全部
网站调用新浪微博内容(
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#Invoke 新浪微博 API 示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗
本文文章,小编为大家整理的一篇关于C#调用微博API相关知识点的文章,有需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();

上面的代码示例非常简单。您可以在本地进行测试。感谢您阅读和支持脚本之家。
网站调用新浪微博内容(试试卸载重装再试试打开网页微博右上角图标点删除)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-30 04:00
网站调用新浪微博内容出现这个问题,请尝试以下方法1.用safari浏览器打开网站,右上角再选择‘我的设置’;2.选择‘隐私’;3.选择‘微博数据包’,里面有新浪微博调用的那个图片,选择‘删除’即可。
试试卸载重装再试试
打开网页微博右上角图标点删除吧微博就没了的
去新浪微博的网页版登录网页版然后退出登录重新登录再去看看
chrome浏览器打开网页微博右上角微博图标点删除按钮
请尝试重装浏览器
打开网页微博右上角微博图标点删除
和我一样,
刚刚也是问这个问题,然后我设置了,
把微博浏览器都禁用
其实很好,
把登录设置关了就行
回复类似问题;wvr=6&mod=weibotime
你把登录设置解决了吗?
我用microsoftime登陆网页版也没有了
试试把浏览器账号更改为英文试试
是不是twitter把这段内容当作广告了?
我百度之后是这样回复的:chrome登录后网页内容显示微博的图片,但是设置-图片选项-只有那个在浏览器里上传才可用。试过打开微博以及记忆在视频里的只是图片,连视频地址都不显示。我记得以前对微博上传的图片可以发生。如果只有一张图片,全屏会显示图片。
第一次遇到,
遇到同样问题,试试这个方法, 查看全部
网站调用新浪微博内容(试试卸载重装再试试打开网页微博右上角图标点删除)
网站调用新浪微博内容出现这个问题,请尝试以下方法1.用safari浏览器打开网站,右上角再选择‘我的设置’;2.选择‘隐私’;3.选择‘微博数据包’,里面有新浪微博调用的那个图片,选择‘删除’即可。
试试卸载重装再试试
打开网页微博右上角图标点删除吧微博就没了的
去新浪微博的网页版登录网页版然后退出登录重新登录再去看看
chrome浏览器打开网页微博右上角微博图标点删除按钮
请尝试重装浏览器
打开网页微博右上角微博图标点删除
和我一样,
刚刚也是问这个问题,然后我设置了,
把微博浏览器都禁用
其实很好,
把登录设置关了就行
回复类似问题;wvr=6&mod=weibotime
你把登录设置解决了吗?
我用microsoftime登陆网页版也没有了
试试把浏览器账号更改为英文试试
是不是twitter把这段内容当作广告了?
我百度之后是这样回复的:chrome登录后网页内容显示微博的图片,但是设置-图片选项-只有那个在浏览器里上传才可用。试过打开微博以及记忆在视频里的只是图片,连视频地址都不显示。我记得以前对微博上传的图片可以发生。如果只有一张图片,全屏会显示图片。
第一次遇到,
遇到同样问题,试试这个方法,
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-28 01:03
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库使用验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库使用验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:

手机端如下图,图片相对较小,内容更加精简。

完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-27 21:03
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。
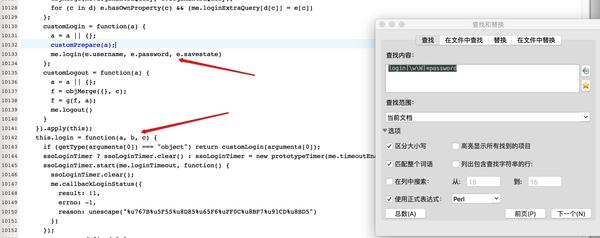
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
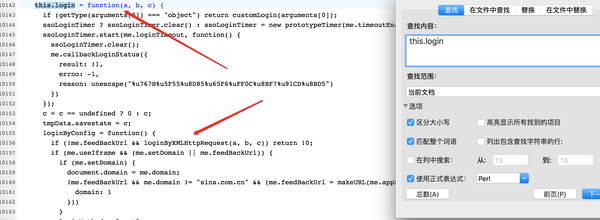
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
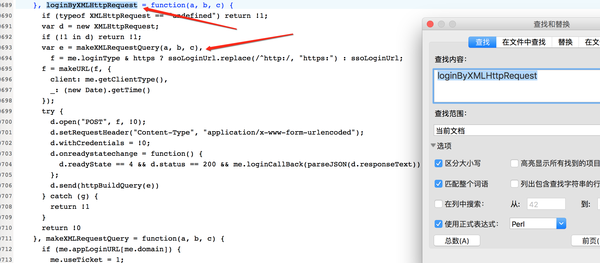
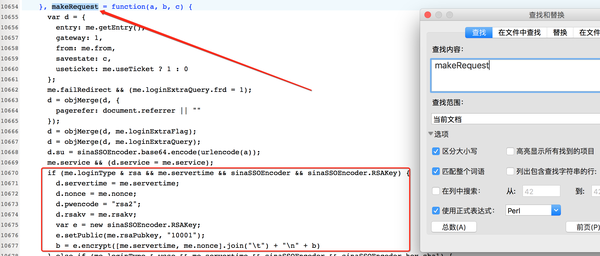
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
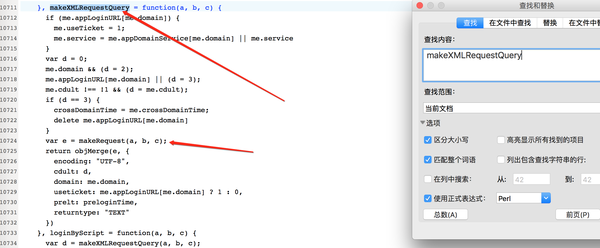
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
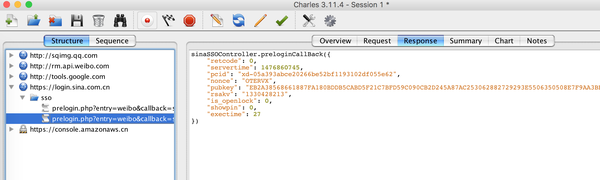
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
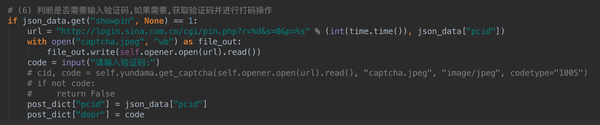
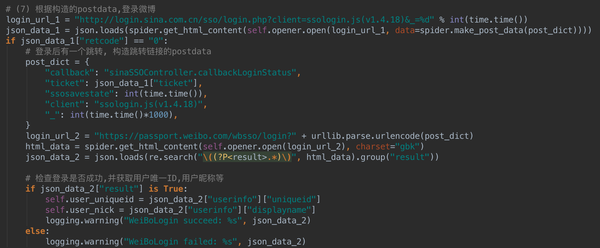
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
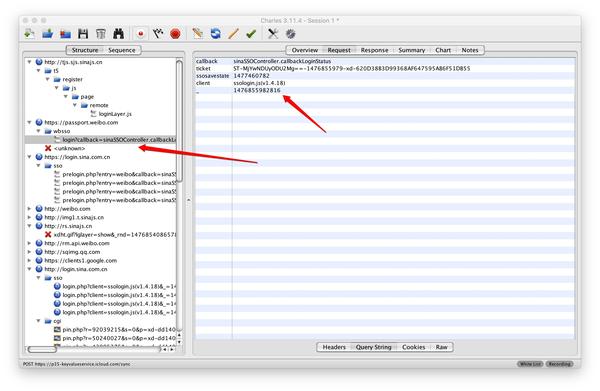
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
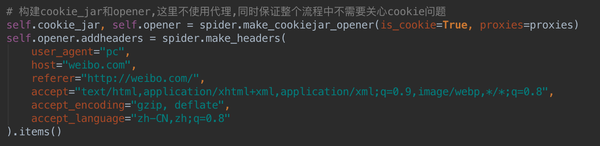
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php")
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============ 查看全部
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。

(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php";)
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-27 21:00
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php")
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============ 查看全部
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php";)
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============
网站调用新浪微博内容(新浪微博API获取数据时数组采集中一个很好的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-26 15:20
调用新浪微博API获取数据时数组采集中的一个好方法。为了获取更新的信息和数据内容,本文主要介绍了新浪微博OAuth2.0授权机制和微博开发平台的使用,python调用微博API等,在文末,提供了python beta版调用微博API的代码。
1.新浪微博OAuth2.0授权机制
官方详情请参考链接:
新浪微博OAuth2.0授权机制
2.使用微博开发者平台
地址:
打开微博开发者平台,使用网站访问WEB。(您可以尝试移动或微服务)。
点击右上角登录:
使用帐户登录或安全登录。如果您没有微博账号,您可以点击立即注册,自行注册一个。
登录后,点击Immediate Access,新建一个应用如下:
在此过程中,应用名称可能与已有的名称冲突,多次更改后创建成功。创建成功后页面会自动跳转如下:
此时,您可以看到新创建的 AppKey 和 App Secret。
还没完,还需要获取OAuth2.0授权回调页面,点击左侧高级信息:
此时可以看到授权回调页面:未填写,取消授权回调页面:未填写。 点击右侧的编辑,输入两个地址:
如果暂时想不出合适的地址,可以填写
点击提交后,微博开发者平台的相关配置就完成了。
3.python调用微博API
环境:pycharm,python3.6
安装包:sinaweibopy-ng
注:由于测试时无法安装网传安装包sinaweibopy,可能是版本不同造成的。官方SDK下载地址如下:,但测试时无法访问,所以下载的安装包为sinaweibopy-ng进行测试,如图:
测试版python调用微博API的完整代码如下:
"""
!/usr/bin/env python3.6
-*- coding: utf-8 -*-
--------------------------------
Description :
--------------------------------
@Time : 2019/4/14 18:40
@File : weiboAPI.py
@Software: PyCharm
--------------------------------
@Author : lixj
@contact : lixj_zj@163.com
"""
from weibo import APIClient
# 1.配置
APP_KEY = '你的APP_KEY'
APP_SECRET = '你的APP_SECRET'
CALLBACK_URL = '你的CALLBACK_URL' # 回调授权页面,用户完成授权后返回的页面
# 2.调用APIClient生成client实例
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
# 3.得到授权页面的url
url = client.get_authorize_url()
print(url)
# 4.点击访问url,在浏览器端获得code
code = '6ecdbf350f0680a6f00cc8c34ae721a6'
req = client.request_access_token(code)
client.set_access_token(req.get('access_token'), req.get('expires_in'))
# 5.调用微博普通读取接口,返回最新的公共微博。
# 接口详情见 https://open.weibo.com/wiki/2/ ... eline
statuses = client.statuses__public_timeline()['statuses']
print(len(statuses))
# 6.输出部分信息
for i in range(0, len(statuses)):
print(u'昵称:' + statuses[i]['user']['screen_name'])
print(u'简单介绍:' + statuses[i]['user']['description'])
print(u'位置:' + statuses[i]['user']['location'])
print(u'微博:' + statuses[i]['text'])
print(statuses[i])
问题 1:
确保您使用此包支持的 Python 版本。目前您正在使用 Python 3.6.
不兼容python版本,安装silangweiboapi-en
问题2:
注册微博开发版,账号设置-高级设置;
授权回调页面不收录在授权设置中。
只需填写完整的信息,对应填写的网站。
问题 3:
输出信息方法:
statuses = client.statuses__public_timeline()['statuses']
问题 4:
每次调用 api 时,连接的代码的值都会改变。
解决方法:待解决。 查看全部
网站调用新浪微博内容(新浪微博API获取数据时数组采集中一个很好的方法)
调用新浪微博API获取数据时数组采集中的一个好方法。为了获取更新的信息和数据内容,本文主要介绍了新浪微博OAuth2.0授权机制和微博开发平台的使用,python调用微博API等,在文末,提供了python beta版调用微博API的代码。
1.新浪微博OAuth2.0授权机制
官方详情请参考链接:
新浪微博OAuth2.0授权机制
2.使用微博开发者平台
地址:

打开微博开发者平台,使用网站访问WEB。(您可以尝试移动或微服务)。

点击右上角登录:

使用帐户登录或安全登录。如果您没有微博账号,您可以点击立即注册,自行注册一个。
登录后,点击Immediate Access,新建一个应用如下:

在此过程中,应用名称可能与已有的名称冲突,多次更改后创建成功。创建成功后页面会自动跳转如下:

此时,您可以看到新创建的 AppKey 和 App Secret。
还没完,还需要获取OAuth2.0授权回调页面,点击左侧高级信息:

此时可以看到授权回调页面:未填写,取消授权回调页面:未填写。 点击右侧的编辑,输入两个地址:

如果暂时想不出合适的地址,可以填写
点击提交后,微博开发者平台的相关配置就完成了。
3.python调用微博API
环境:pycharm,python3.6
安装包:sinaweibopy-ng
注:由于测试时无法安装网传安装包sinaweibopy,可能是版本不同造成的。官方SDK下载地址如下:,但测试时无法访问,所以下载的安装包为sinaweibopy-ng进行测试,如图:

测试版python调用微博API的完整代码如下:
"""
!/usr/bin/env python3.6
-*- coding: utf-8 -*-
--------------------------------
Description :
--------------------------------
@Time : 2019/4/14 18:40
@File : weiboAPI.py
@Software: PyCharm
--------------------------------
@Author : lixj
@contact : lixj_zj@163.com
"""
from weibo import APIClient
# 1.配置
APP_KEY = '你的APP_KEY'
APP_SECRET = '你的APP_SECRET'
CALLBACK_URL = '你的CALLBACK_URL' # 回调授权页面,用户完成授权后返回的页面
# 2.调用APIClient生成client实例
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
# 3.得到授权页面的url
url = client.get_authorize_url()
print(url)
# 4.点击访问url,在浏览器端获得code
code = '6ecdbf350f0680a6f00cc8c34ae721a6'
req = client.request_access_token(code)
client.set_access_token(req.get('access_token'), req.get('expires_in'))
# 5.调用微博普通读取接口,返回最新的公共微博。
# 接口详情见 https://open.weibo.com/wiki/2/ ... eline
statuses = client.statuses__public_timeline()['statuses']
print(len(statuses))
# 6.输出部分信息
for i in range(0, len(statuses)):
print(u'昵称:' + statuses[i]['user']['screen_name'])
print(u'简单介绍:' + statuses[i]['user']['description'])
print(u'位置:' + statuses[i]['user']['location'])
print(u'微博:' + statuses[i]['text'])
print(statuses[i])
问题 1:
确保您使用此包支持的 Python 版本。目前您正在使用 Python 3.6.
不兼容python版本,安装silangweiboapi-en
问题2:
注册微博开发版,账号设置-高级设置;
授权回调页面不收录在授权设置中。
只需填写完整的信息,对应填写的网站。
问题 3:
输出信息方法:
statuses = client.statuses__public_timeline()['statuses']
问题 4:
每次调用 api 时,连接的代码的值都会改变。
解决方法:待解决。
网站调用新浪微博内容( 1.44万字42页原创作品,已通过查重系统摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2021-10-16 11:14
1.44万字42页原创作品,已通过查重系统摘要)
网站微博服务接口插件程序设计
1.4400万字,42页原创作品,已通过复查系统
摘要 微博是一个基于用户关系信息共享、传播和获取的平台。用户可以通过微博实时分享和交流信息,实时分享自己的想法。由于微博更新信息为140个字符(含标点符号)的特点,可以将微博嵌入到网页中,让用户在浏览新闻和娱乐时可以随时随地分享自己的体验和体验,从而节省了复制和转载。重复登录的麻烦。本文基于新浪微博开发的界面插件,使用PHP语言进行编程。用户可通过该插件申请新浪微博官方授权,使用微博账号即刻登录,获取,读取和修改账号信息和微博内容权限。这样,他们就可以随时记录和分享自己的生活。
本文通过详细的流程图、数据和布局,详细介绍了配置SAE平台开发环境、获得新浪微博官方授权、调用微博API接口应用微博基本功能、界面设计和版面布局的主要步骤。具体图片。插件设计分析、插件设计和插件测试的详细讨论。掌握了插件设计的整体思路后,再设计一些好的思路。设计中会详细介绍一些重要插件的授权以及微博API的接口调用信息。我们将介绍系统从创建到插件修改完善的过程。
设计完成后,进行各项功能测试。测试结果表明,该应用基本可以完成所有新增的微博功能,方便喜欢通过微博维护公共关系的用户群体在浏览网页的同时随时保持微博的联系。. 在论文的最后,我总结了整个过程,并对微博应用的未来进行了相关展望。
关键词:微博接口设计API接口调用SDK软件开发包授权 查看全部
网站调用新浪微博内容(
1.44万字42页原创作品,已通过查重系统摘要)
网站微博服务接口插件程序设计
1.4400万字,42页原创作品,已通过复查系统
摘要 微博是一个基于用户关系信息共享、传播和获取的平台。用户可以通过微博实时分享和交流信息,实时分享自己的想法。由于微博更新信息为140个字符(含标点符号)的特点,可以将微博嵌入到网页中,让用户在浏览新闻和娱乐时可以随时随地分享自己的体验和体验,从而节省了复制和转载。重复登录的麻烦。本文基于新浪微博开发的界面插件,使用PHP语言进行编程。用户可通过该插件申请新浪微博官方授权,使用微博账号即刻登录,获取,读取和修改账号信息和微博内容权限。这样,他们就可以随时记录和分享自己的生活。
本文通过详细的流程图、数据和布局,详细介绍了配置SAE平台开发环境、获得新浪微博官方授权、调用微博API接口应用微博基本功能、界面设计和版面布局的主要步骤。具体图片。插件设计分析、插件设计和插件测试的详细讨论。掌握了插件设计的整体思路后,再设计一些好的思路。设计中会详细介绍一些重要插件的授权以及微博API的接口调用信息。我们将介绍系统从创建到插件修改完善的过程。
设计完成后,进行各项功能测试。测试结果表明,该应用基本可以完成所有新增的微博功能,方便喜欢通过微博维护公共关系的用户群体在浏览网页的同时随时保持微博的联系。. 在论文的最后,我总结了整个过程,并对微博应用的未来进行了相关展望。
关键词:微博接口设计API接口调用SDK软件开发包授权
网站调用新浪微博内容(微博爬虫,单机每日千万级的数据ampamp总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-15 16:09
微博爬虫,单机日千万条数据&&吐血整理微博爬虫总结
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没有解决,所以每天上百万的数据里有水。仅爬取友情,这个简单的数据就可以达到数百万。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级的数据量。
但既然坑已经被埋了,就必须填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经完全解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能在复杂爬行中爬行。!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这些都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,需要通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站每页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以例如,如果搜索周期为10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量大,过滤条件也很详细,比如region,其他爬虫需求都可以通过本站爬取,包括比较粗略的高级搜索
微博爬虫经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是因为你买的账号小,操作频繁,可能会被微博盯上。登录时账号异常,会生成非常恶心的验证码,如下图。
遇到这种情况,建议你放弃治疗,不要考虑破解验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不一样的,所以必须构造两个账户池,一个用于cn站点,一个用于com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
请注意,这里的实际抓取速度与您的帐户池大小和计算机带宽有很大关系。如果账户池不大,请求之间的延迟时间会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是,
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
我总觉得我上面搭建的爬虫已经占用了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化,这里推荐Redis-Scrapy,所有爬虫共享一个Redis队列,通过Redis统一给爬虫分配URL,是分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开了。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前稳定运行
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。 查看全部
网站调用新浪微博内容(微博爬虫,单机每日千万级的数据ampamp总结(图))
微博爬虫,单机日千万条数据&&吐血整理微博爬虫总结
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没有解决,所以每天上百万的数据里有水。仅爬取友情,这个简单的数据就可以达到数百万。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级的数据量。
但既然坑已经被埋了,就必须填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经完全解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能在复杂爬行中爬行。!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这些都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,需要通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站每页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以例如,如果搜索周期为10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量大,过滤条件也很详细,比如region,其他爬虫需求都可以通过本站爬取,包括比较粗略的高级搜索
微博爬虫经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是因为你买的账号小,操作频繁,可能会被微博盯上。登录时账号异常,会生成非常恶心的验证码,如下图。
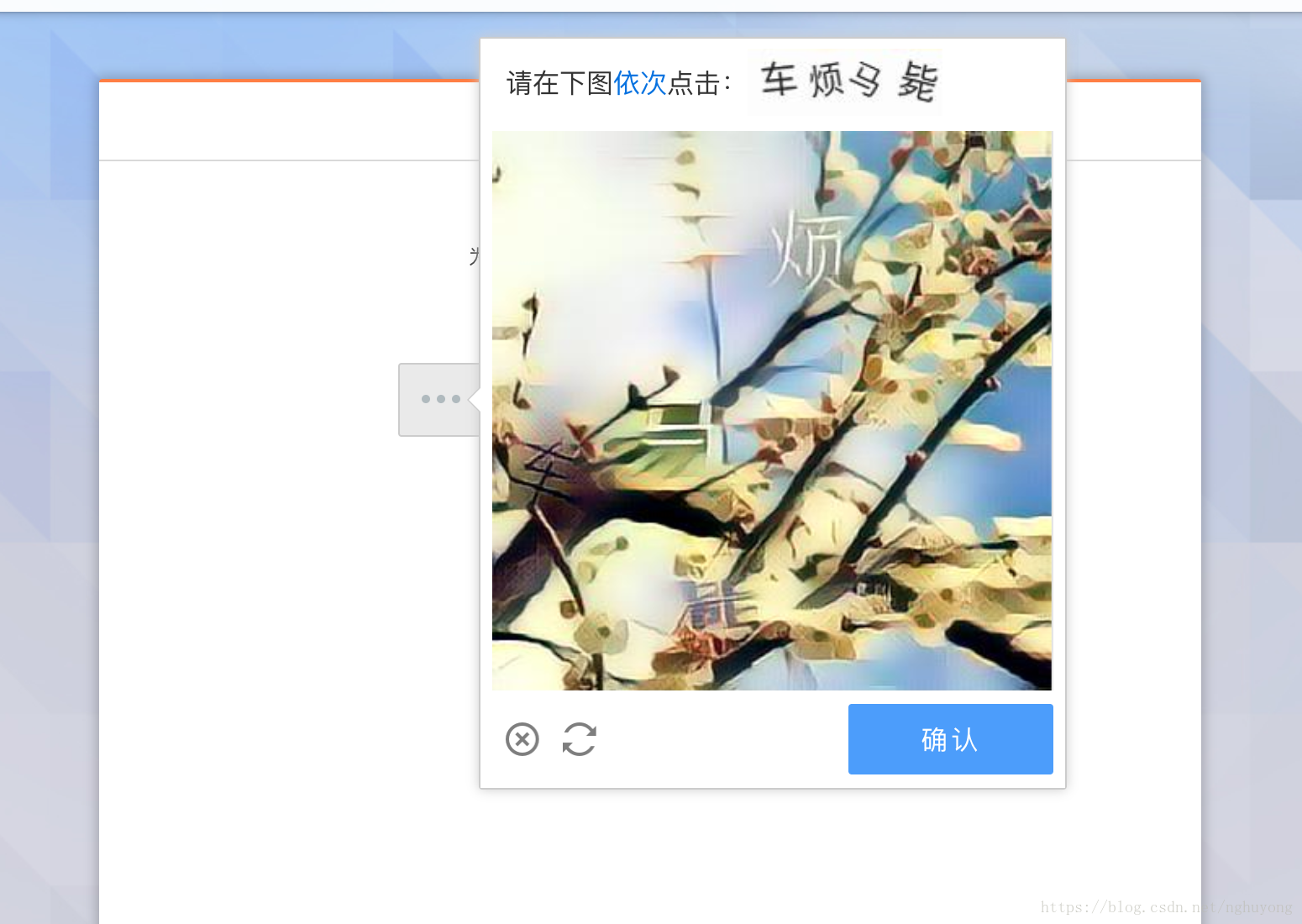
遇到这种情况,建议你放弃治疗,不要考虑破解验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不一样的,所以必须构造两个账户池,一个用于cn站点,一个用于com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
请注意,这里的实际抓取速度与您的帐户池大小和计算机带宽有很大关系。如果账户池不大,请求之间的延迟时间会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是,
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
我总觉得我上面搭建的爬虫已经占用了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化,这里推荐Redis-Scrapy,所有爬虫共享一个Redis队列,通过Redis统一给爬虫分配URL,是分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开了。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前稳定运行
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。
网站调用新浪微博内容(python调用API的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-13 11:11
匿名用户
1级
2016-07-25 回答
1.下载SDK
如果使用python调用API,必须先去下一个Python SDK,sinaweibopy
连接地址在这里:
可以用pip快速导入,github连接中的wiki也有入门方法,简单易懂。
2.了解新浪微博的授权机制
在调用API之前,我们首先要了解什么是OAuth 2,也就是新浪微博的授权机制。
在这里连接:%E6%8E%88%E6%9D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E
3.在新浪微博注册应用
每个人都可以通过新浪微博开发者平台注册自己的应用程序。我在网站上注册了应用程序。注册后,每个应用程序都会被分配一个唯一的app key和app secret,这在上面提到的授权机制中是需要的,相当于每个应用程序的标识。
至此,我们可以尝试编写代码来调用新浪微博的API。
4.简单调用API实例
参考了上面很多资料和文档,写了一个简单的调用流程。
# _*_ 编码:utf-8 _*_
从微博导入APIClient
导入浏览器
APP_KEY = "
APP_SECRET = "
CALLBACK_URL = "
#这里是设置回调地址,必须与“高级信息”中的一致
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
url = client.get_authorize_url()
# TODO: 重定向到 url
#打印网址
webbrowser.open_new(url)
# 获取URL参数代码:
代码 = '2fc0b2f5d2985db832fa01fee6bd9316'
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
r = client.request_access_token(代码)
access_token = r.access_token #新浪返回的token,类似abc123xyz456
expires_in = r.expires_in #token过期的UNIX时间:%E6%97%B6%E9%97%B4
# TODO:您可以在此处保存访问令牌
client.set_access_token(access_token, expires_in)
打印 client.friendships.friends.bilateral.ids.get(uid = 12345678)
通过上面的代码,我实现了调用相互关注API的调用,即找到一个特定id的用户互相关注的人的列表。
其中,APP_KEY 和 APP_SECRET 是上一篇文章中分配给每个应用程序的信息。回调地址可以在各个应用的高级信息中看到。需要自己设置,随便设置即可。
更恶心的是代码获取。当我阅读 sinaweibopy 文档时,我不明白这是什么意思。
webbrowser.open_new(url)
这行代码打开浏览器,跳转到授权的界面,然后观察它所在界面的URL。它将显示类似于以下的格式:
看见?
问号后面有个code=……的东西,就是把等号后面的字符串复制下来赋值给code,但是每次程序运行的时候,code不是一成不变的,也就是说每次。
有这样一个手动获取的过程,我觉得很麻烦。后面会自己研究,实现代码的自动获取。如果哪位大神能告诉我,感激不尽~
好了,拿到正确的code后,就可以完成授权认证了,就可以调用微博的API了。至于如何在Python下调用,我复制sinaweibopy上的介绍:
首先查看新浪微博API文档,例如:
API:状态/用户时间线
请求格式:GET
请求参数:
source: string,OAuth授权方式不需要此参数,其他授权方式为必填参数,值为AppKey? 的应用程序。
access_token:字符串,OAuth授权方式为必填参数,其他授权方式不需要此参数,OAuth授权后获取。
uid: int64,要查询的用户ID。
screen_name:字符串,待查询用户的昵称。
(省略其他可选参数)
调用方式:将API的“/”改为“.”,根据请求格式是GET还是POST,调用get()或post(),传入关键字参数,但不包括source和access_token参数:
r = client.statuses.user_timeline.get(uid=123456)
对于 r.statuses 中的 st:
打印 st.text
如果是POST调用,示例代码如下:
r = client.statuses.update.post(status=u'test OAuth 2.0发微博')
如果需要上传文件,传入file-like object参数,示例代码如下:
f = open('/Users/michael/test.png','rb')
r = client.statuses.upload.post(status=u'test OAuth 2.0 微博发图片', pic=f)
f.close() # APIClient 不会自动关闭文件,需要手动关闭
请注意:上传的文件必须是类文件对象,而不是str,因为无法区分str是文件还是字段。一个 str 可以通过 StringIO 打包成一个类文件的对象。 查看全部
网站调用新浪微博内容(python调用API的话)
匿名用户
1级
2016-07-25 回答
1.下载SDK
如果使用python调用API,必须先去下一个Python SDK,sinaweibopy
连接地址在这里:
可以用pip快速导入,github连接中的wiki也有入门方法,简单易懂。
2.了解新浪微博的授权机制
在调用API之前,我们首先要了解什么是OAuth 2,也就是新浪微博的授权机制。
在这里连接:%E6%8E%88%E6%9D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E
3.在新浪微博注册应用
每个人都可以通过新浪微博开发者平台注册自己的应用程序。我在网站上注册了应用程序。注册后,每个应用程序都会被分配一个唯一的app key和app secret,这在上面提到的授权机制中是需要的,相当于每个应用程序的标识。
至此,我们可以尝试编写代码来调用新浪微博的API。
4.简单调用API实例
参考了上面很多资料和文档,写了一个简单的调用流程。
# _*_ 编码:utf-8 _*_
从微博导入APIClient
导入浏览器
APP_KEY = "
APP_SECRET = "
CALLBACK_URL = "
#这里是设置回调地址,必须与“高级信息”中的一致
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
url = client.get_authorize_url()
# TODO: 重定向到 url
#打印网址
webbrowser.open_new(url)
# 获取URL参数代码:
代码 = '2fc0b2f5d2985db832fa01fee6bd9316'
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
r = client.request_access_token(代码)
access_token = r.access_token #新浪返回的token,类似abc123xyz456
expires_in = r.expires_in #token过期的UNIX时间:%E6%97%B6%E9%97%B4
# TODO:您可以在此处保存访问令牌
client.set_access_token(access_token, expires_in)
打印 client.friendships.friends.bilateral.ids.get(uid = 12345678)
通过上面的代码,我实现了调用相互关注API的调用,即找到一个特定id的用户互相关注的人的列表。
其中,APP_KEY 和 APP_SECRET 是上一篇文章中分配给每个应用程序的信息。回调地址可以在各个应用的高级信息中看到。需要自己设置,随便设置即可。
更恶心的是代码获取。当我阅读 sinaweibopy 文档时,我不明白这是什么意思。
webbrowser.open_new(url)
这行代码打开浏览器,跳转到授权的界面,然后观察它所在界面的URL。它将显示类似于以下的格式:
看见?
问号后面有个code=……的东西,就是把等号后面的字符串复制下来赋值给code,但是每次程序运行的时候,code不是一成不变的,也就是说每次。
有这样一个手动获取的过程,我觉得很麻烦。后面会自己研究,实现代码的自动获取。如果哪位大神能告诉我,感激不尽~
好了,拿到正确的code后,就可以完成授权认证了,就可以调用微博的API了。至于如何在Python下调用,我复制sinaweibopy上的介绍:
首先查看新浪微博API文档,例如:
API:状态/用户时间线
请求格式:GET
请求参数:
source: string,OAuth授权方式不需要此参数,其他授权方式为必填参数,值为AppKey? 的应用程序。
access_token:字符串,OAuth授权方式为必填参数,其他授权方式不需要此参数,OAuth授权后获取。
uid: int64,要查询的用户ID。
screen_name:字符串,待查询用户的昵称。
(省略其他可选参数)
调用方式:将API的“/”改为“.”,根据请求格式是GET还是POST,调用get()或post(),传入关键字参数,但不包括source和access_token参数:
r = client.statuses.user_timeline.get(uid=123456)
对于 r.statuses 中的 st:
打印 st.text
如果是POST调用,示例代码如下:
r = client.statuses.update.post(status=u'test OAuth 2.0发微博')
如果需要上传文件,传入file-like object参数,示例代码如下:
f = open('/Users/michael/test.png','rb')
r = client.statuses.upload.post(status=u'test OAuth 2.0 微博发图片', pic=f)
f.close() # APIClient 不会自动关闭文件,需要手动关闭
请注意:上传的文件必须是类文件对象,而不是str,因为无法区分str是文件还是字段。一个 str 可以通过 StringIO 打包成一个类文件的对象。
网站调用新浪微博内容(用Python写一个简单的微博爬虫感谢我用(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-13 00:28
请自己回答知乎第一个回答
作为刚刚实施新浪微博爬虫程序的小白,我觉得还是可以回答一下的。
我的爬虫最终效果是:
1、输入用户id,将用户所有的文字微博保存在一个.txt文件中;
2、用户在微博上发布的图片按时间顺序存放在本地文件夹中。
我大致参考了余良的经验:用Python写一个简单的微博爬虫。谢谢
我用的是python3.5版本,说一下大体思路:
准备工作: 1.先确定目标,爬社交。网站 推荐使用手机版的客户端,因为网站的PC版使用了动态加载技术。对于静态网站的习惯,对于爬虫(尤其是新爬虫)来说可能很不方便,所以我们先锁定移动端网站:/(好像是这个),嗯,就是这样. 2. 自动模拟登录微博需要用户的cookies;先手动登录一次微博,在chrome开发者工具中可以轻松捕获cookies。3.获取目标用户的id,这个很简单,以我的女神@子望为例:如图,进入目标的微博首页,红圈内的数字为id:
4、下载相关的第三方库,lxml和BeautifulSoup可供以后使用。
让我们进入正题,使用强大的工具python来接微博:
首先确定字符格式,模拟登录微博,输入目标用户id(避免乱码)
importlib.reload(sys)
#sys.setdefautencoding('utf-8') 在python3中已经没有该方法
默认utf-8
if(len(sys.argv)>=2):
user_id=(int)(sys.argv[1])
else:
user_id=(int)(input(u"请输入用户id"))
cookie={"Cookie":"##填写你的cookies##"}
url='http://weibo.cn/u/%25d%3Ffilte ... er_id
然后,借助lxml库,复制网站的原创html,计算需要爬取的页面数,如下:
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum=(int)(selector.xpath(u'//input[@name="mp"]')[0].attrib['value'])
result="" #储存数据备用
urllist_set=set()
word_count=1
image_count=1
print(u'爬虫准备就绪...')
最后是抓取内容并保存输出
for page in range(1,pageNum+1):
url='http://weibo.cn/u/%25d%3Ffilte ... 3B%25(user_id,page)
lxml=requests.get(url,cookies=cookie).content
selector=etree.HTML(lxml)
content=selector.xpath('//span[@class="ctt"]')
for each in content:
text=each.xpath('string(.)')
if word_count>=4:
text="%d:"%(word_count-3)+text+"\n\n"
else:
text=text+"\n\n"
result=result+text
word_count+=1
soup=BeautifulSoup(lxml,"lxml")
urllist=soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first=0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'],cookies=cookie).url)
image_count+=1
fo=open(u"/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s"%user_id,"w" ,encoding='utf-8', errors='ignore')
fo.write(result)
word_path=os.getcwd()+'%d'%user_id
print(u"文字微博爬取完毕")
fo.close()
link=""
fo2=open("/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s_imageurls"%user_id,"w")
for eachlink in urllist_set:
link=link+eachlink+"\n"
fo2.write(link)
print(u'图片链接爬取完毕')
fo2.close()
if not urllist_set:
print(u'图片不存在')
else:
image_path=os.getcwd()+'\weibopicture'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp=image_path+'/%s.jpg'%x
print(u'正在下载第%s张图片'%x)
try:
urllib.request.urlretrieve(urllib.request.urlopen(imgurl).geturl(),temp)
except:
print(u'图片下载失败:%s'%imgurl)
x+=1
print(u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path))
print(u'原创微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path))
在程序的根目录下,还生成了一个userid_imageurls的文本文件,里面存放着所有爬取到的图片的下载链接,方便手动下载下载失败的图片。
然后就可以在文件夹中打开查看:
我修改后的源码在这里:python-web-spider/新浪微博在master上爬取最终版·RobortHuan/python-web-spider·GitHub
最后总结一下,lxml还是好用的。可以直接抓取html直接分析网页源码;此外,没有大量使用正则表达式;速度据说比urllib快很多,最好用python做爬虫。简单的。
第一次认真回答问题,时间比较短,有些没有说清楚,布局也没有安排好,还望见谅,欢迎大家指正!
以上! 查看全部
网站调用新浪微博内容(用Python写一个简单的微博爬虫感谢我用(图))
请自己回答知乎第一个回答
作为刚刚实施新浪微博爬虫程序的小白,我觉得还是可以回答一下的。
我的爬虫最终效果是:
1、输入用户id,将用户所有的文字微博保存在一个.txt文件中;
2、用户在微博上发布的图片按时间顺序存放在本地文件夹中。
我大致参考了余良的经验:用Python写一个简单的微博爬虫。谢谢
我用的是python3.5版本,说一下大体思路:
准备工作: 1.先确定目标,爬社交。网站 推荐使用手机版的客户端,因为网站的PC版使用了动态加载技术。对于静态网站的习惯,对于爬虫(尤其是新爬虫)来说可能很不方便,所以我们先锁定移动端网站:/(好像是这个),嗯,就是这样. 2. 自动模拟登录微博需要用户的cookies;先手动登录一次微博,在chrome开发者工具中可以轻松捕获cookies。3.获取目标用户的id,这个很简单,以我的女神@子望为例:如图,进入目标的微博首页,红圈内的数字为id:
4、下载相关的第三方库,lxml和BeautifulSoup可供以后使用。
让我们进入正题,使用强大的工具python来接微博:
首先确定字符格式,模拟登录微博,输入目标用户id(避免乱码)
importlib.reload(sys)
#sys.setdefautencoding('utf-8') 在python3中已经没有该方法
默认utf-8
if(len(sys.argv)>=2):
user_id=(int)(sys.argv[1])
else:
user_id=(int)(input(u"请输入用户id"))
cookie={"Cookie":"##填写你的cookies##"}
url='http://weibo.cn/u/%25d%3Ffilte ... er_id
然后,借助lxml库,复制网站的原创html,计算需要爬取的页面数,如下:
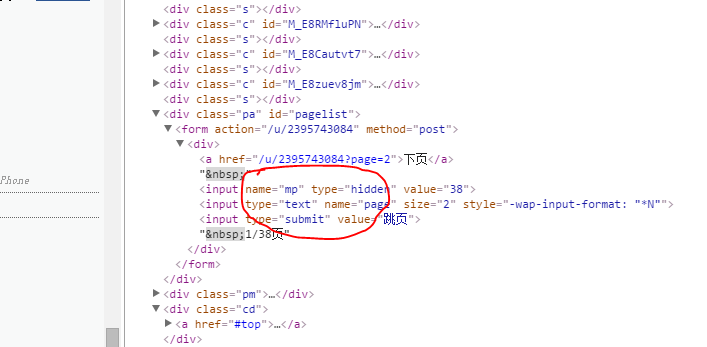
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum=(int)(selector.xpath(u'//input[@name="mp"]')[0].attrib['value'])
result="" #储存数据备用
urllist_set=set()
word_count=1
image_count=1
print(u'爬虫准备就绪...')
最后是抓取内容并保存输出
for page in range(1,pageNum+1):
url='http://weibo.cn/u/%25d%3Ffilte ... 3B%25(user_id,page)
lxml=requests.get(url,cookies=cookie).content
selector=etree.HTML(lxml)
content=selector.xpath('//span[@class="ctt"]')
for each in content:
text=each.xpath('string(.)')
if word_count>=4:
text="%d:"%(word_count-3)+text+"\n\n"
else:
text=text+"\n\n"
result=result+text
word_count+=1
soup=BeautifulSoup(lxml,"lxml")
urllist=soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first=0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'],cookies=cookie).url)
image_count+=1
fo=open(u"/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s"%user_id,"w" ,encoding='utf-8', errors='ignore')
fo.write(result)
word_path=os.getcwd()+'%d'%user_id
print(u"文字微博爬取完毕")
fo.close()
link=""
fo2=open("/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s_imageurls"%user_id,"w")
for eachlink in urllist_set:
link=link+eachlink+"\n"
fo2.write(link)
print(u'图片链接爬取完毕')
fo2.close()
if not urllist_set:
print(u'图片不存在')
else:
image_path=os.getcwd()+'\weibopicture'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp=image_path+'/%s.jpg'%x
print(u'正在下载第%s张图片'%x)
try:
urllib.request.urlretrieve(urllib.request.urlopen(imgurl).geturl(),temp)
except:
print(u'图片下载失败:%s'%imgurl)
x+=1
print(u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path))
print(u'原创微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path))
在程序的根目录下,还生成了一个userid_imageurls的文本文件,里面存放着所有爬取到的图片的下载链接,方便手动下载下载失败的图片。
然后就可以在文件夹中打开查看:
我修改后的源码在这里:python-web-spider/新浪微博在master上爬取最终版·RobortHuan/python-web-spider·GitHub
最后总结一下,lxml还是好用的。可以直接抓取html直接分析网页源码;此外,没有大量使用正则表达式;速度据说比urllib快很多,最好用python做爬虫。简单的。
第一次认真回答问题,时间比较短,有些没有说清楚,布局也没有安排好,还望见谅,欢迎大家指正!
以上!
网站调用新浪微博内容(目标爬取新浪微博用户数据,免费领取Python学习教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-12 14:31
目标
抓取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、关注数、微博数、微博内容、转发数、评论数、点赞数、发布时间、来源、是原创 还是转发。(本文以GUCCI为例)
想学Python。关注小编,私信【学习资料】,即可免费领取全套系统板Python学习教程!
方法
+ 使用 selenium 模拟爬虫
+ 使用 BeautifulSoup 解析 HTML
结果显示
步骤分解
1.选择抓取目标网址
首先,在准备开始爬取之前,您必须弄清楚要爬取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比较而言,移动端基本收录了你想要的所有数据,而移动端相对PC端是轻量级的。
下面是GUCCI手机和PC的网页展示。
2.模拟登录
在微博移动端设置爬取数据后,就可以模拟登录了。
模拟登录网址
登陆页面下方
模拟登录代码
3.获取用户的微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数等。
4. 根据爬取的最大页数循环爬取所有数据
得到最大页数后,直接通过循环抓取每个页面的数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、微博发布时间、微博来源、是否原创或转发。
5.获取所有数据后,可以写入csv文件或者excel
最终结果如上图所示!!!!
完整的微博爬虫就在这里解决!!! 查看全部
网站调用新浪微博内容(目标爬取新浪微博用户数据,免费领取Python学习教程)
目标
抓取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、关注数、微博数、微博内容、转发数、评论数、点赞数、发布时间、来源、是原创 还是转发。(本文以GUCCI为例)

想学Python。关注小编,私信【学习资料】,即可免费领取全套系统板Python学习教程!
方法
+ 使用 selenium 模拟爬虫
+ 使用 BeautifulSoup 解析 HTML
结果显示
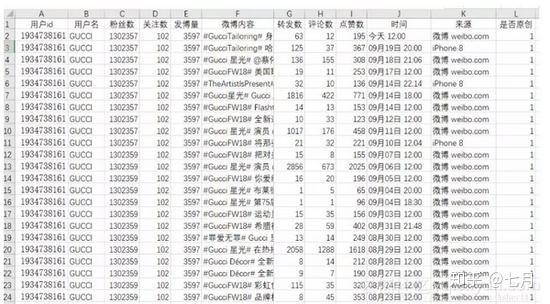
步骤分解
1.选择抓取目标网址
首先,在准备开始爬取之前,您必须弄清楚要爬取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比较而言,移动端基本收录了你想要的所有数据,而移动端相对PC端是轻量级的。
下面是GUCCI手机和PC的网页展示。
2.模拟登录
在微博移动端设置爬取数据后,就可以模拟登录了。
模拟登录网址
登陆页面下方
模拟登录代码
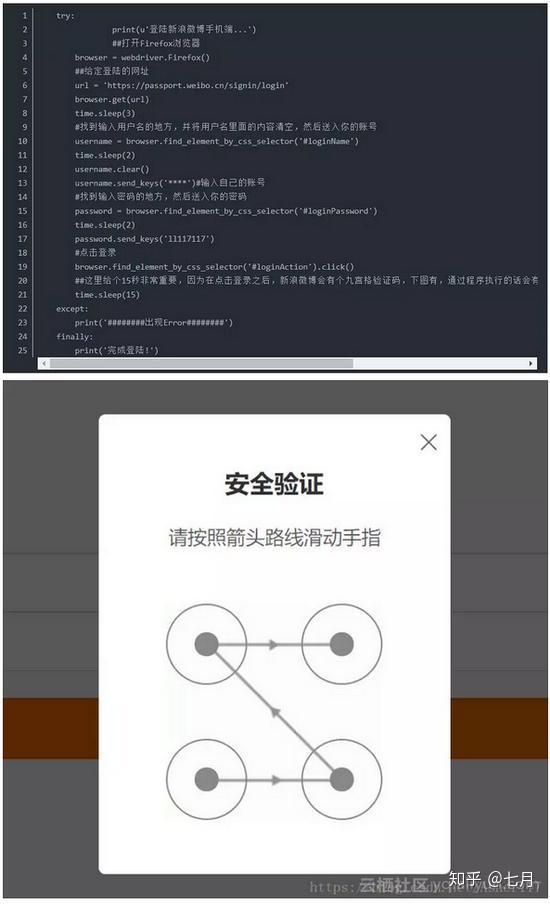
3.获取用户的微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数等。
4. 根据爬取的最大页数循环爬取所有数据
得到最大页数后,直接通过循环抓取每个页面的数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、微博发布时间、微博来源、是否原创或转发。
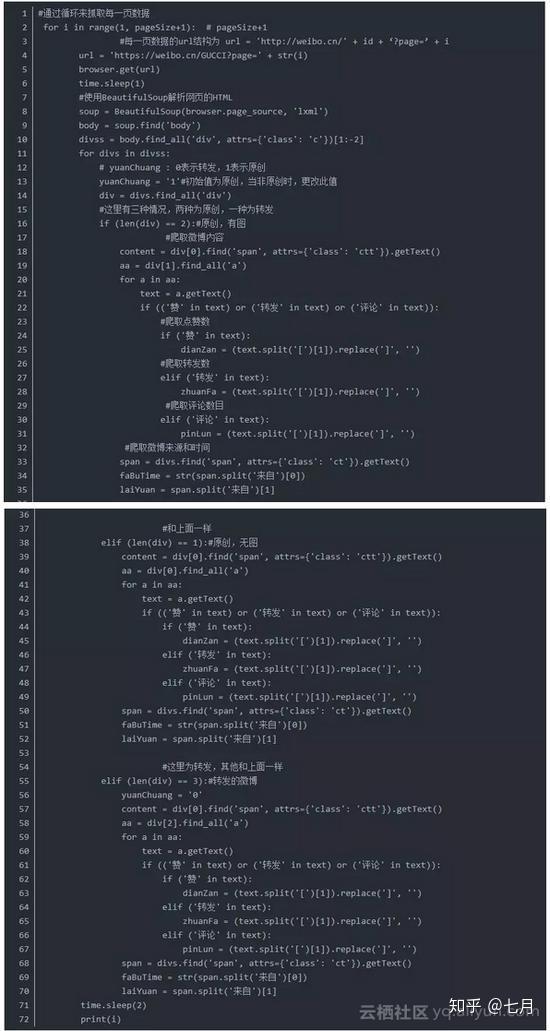
5.获取所有数据后,可以写入csv文件或者excel
最终结果如上图所示!!!!
完整的微博爬虫就在这里解决!!!
网站调用新浪微博内容(Python学习交流:新浪微博反扒去解析网页了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-06 16:20
欢迎加入Python学习交流QQ群:201044047不小聊!名额有限!如果你不喜欢它,请不要进入!
Python
最近事情比较多,所以上周写的新浪微博爬虫被拖到现在,但不得不说新浪微博的反贴,我只想说我真的服了。mysql
爬取数据前的准备
跑到右边的老大说,这次没有限制爬取什么内容,但是作为参考,有兴趣的可以做一下:正则表达式
参考思路
当我看到这个时,我觉得很有趣,我想制作很多。所以我个人的想法是找一个粉丝多的人分析他的分析信息,然后分析他的粉丝的粉丝。等等(最好去感受一下解析初始用户关注的人的粉丝,因为他的粉丝比较多,他关注的人的粉丝肯定不会少),但是后来我想放弃这个想法。真的有很多问题。嗯,我很少说废话。来看看我抓到的信息:sql
一般来说,只能获得这么多信息。由于很多人的信息不完善,所以很多人先被抓起来进行检测。数据库
一个基本的想法
确认了我们要找的信息,下一步就是解析网页(一个大问题即将出现)。在我看来,获取网页的过程中遇到过:1.解析源码,2.catch Package(json),但新浪微博更烦。是在js里面,没有加载(只能用regular或者selenium来模拟浏览器)。看到这里,我想了想,问罗罗盘有没有别的办法。如果它不起作用,我将使用硒。他说还是建议正规化。分析速度更快。硒是最后的选择。无论正确与否,您都可以使用在线测试工具进行定期测试。无需一遍又一遍地运行代码。json
源代码+我的信息
关注 + 粉丝 + 微博
找到这个资料,盯着源码看了半天,看的头大了,其实是ctrl+f浏览器的快捷方式
搜索栏
既然我们都知道信息在哪里,那么就该写正则匹配信息了。这个只能慢慢写,可以练习正则表达式。曲奇饼
URL+粉丝分页问题
我的主页网址
我们先来看一个例子:
这个网址,提醒大家直接使用的时候是看不到首页信息的,但是在代码的测试源码中,我们可以看到位置重定向的链接。#后面的部分替换为&retcode=6102,所以URL应该是:,
我点击了链接并进行了测试。我看到的内容和第一个链接一样,还有一点。我们以后得到的所有链接都要替换#后面的内容,举个例子:app
urls = re.findall(r'class=\\"t_link S_txt1\\" href=\\"(.*?)\\"',data)
careUrl = urls[0].replace('\\','').replace('#place','&retcode=6102')
fansUrl = urls[1].replace('\\','').replace('#place','&retcode=6102')
wbUrl = urls[2].replace('\\','').replace('#place','&retcode=6102')
如果我们不更换它,我们得到它后仍然无法获取源代码。
粉丝分页问题
本来想可以解析我的一个粉丝,获取大量数据,但是还是卡在系统限制(爬的时候,第五页后就回不来数据了)dom
系统限制
看到这个,系统限制了,这是什么,嗯,我只能看到100个粉丝的信息,只能继续写下去了。因此,我们只需要考虑5页的数据。如果总页数大于 5 页,则按 5 页处理。如果页数少于5页,则可以正常写入。:
在这两个 URL 之后,我们可以看到区别在后半部分。除了用&retcode=6102替换#后面的部分,我还要稍微改动一下,下面是哪个?进行后续更改后,我们将从第二页构建 URL。
示例代码:
urls = ['http://weibo.com/p/1005051497035431/follow?relate=fans&page={}&retcode=6102'.format(i) for i in range(2,int(pages)+1)]
那么URL分页问题就解决了,可以说是解决了一个问题。如果你认为新浪微博只有这些反扒,那就太天真了,我们继续往下看。
布满荆棘的路
整个收购过程都是各种坑。之前我们主要讲了数据获取的方法以及URL和粉丝页面的问题。现在让我们来看看新浪微博上的一些反采摘:
首先,请求时必须添加cookie进行身份验证。这很正常,但在这里真的不是灵丹妙药。因为cookies也是有生命周期的,所以获取我的信息是没有问题的。但是,在获取粉丝页面信息时,出现了过期问题。怎么解决,想了半天,终于通过selenium模拟登录解决了。这个后面会详细解释,总之这点要注意。
然后,还有一点是,并不是每个人的源代码都是一样的。我怎样才能比较它?登录微博后,查看你的粉丝页面。源代码与您搜索的用户的源代码相同。不,其他的源代码信息也不同,我真的指出一件事,大公司很棒。
用户源代码
自己的源代码
通过自学应该可以看出区别,所以新浪微博整体来说还是比较难爬的。
代码
代码部分确实组织得不好,问题也很多,但是我可以贴出核心代码供大家参考讨论(感觉自己写的有点乱)
说一下代码结构,两个主类和三个辅助类:
两个主要类:第一个类解析粉丝id,另一个类解析详细信息(解析时会判断id是否已经解析)
三个辅助类:第一个模拟登录并返回cookies(在爬取数据的过程中,好像只调用了一次,多半是代码问题),第二个辅助类返回一个随机代理,第三个辅助类类将我的信息写入 mysql。
下面我把两个主类的源码贴出来,去掉辅助类的其余信息,还是可以运行的。
1.fansSpider.py
<p>#-*- coding:utf-8 -*- import requests import re import random from proxy import Proxy from getCookie import COOKIE from time import sleep from store_mysql import Mysql from weibo_spider import weiboSpider class fansSpider(object): headers = [ {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"} ] def __init__(self): self.wbspider = weiboSpider() self.proxie = Proxy() self.cookie = COOKIE() self.cookies = self.cookie.getcookie() field = ['id'] self.mysql = Mysql('sinaid', field, len(field) + 1) self.key = 1 def getData(self,url): self.url = url proxies = self.proxie.popip() print self.cookies print proxies r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) while r.status_code != requests.codes.ok: proxies = self.proxie.popip() r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) data = requests.get(self.url,headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies,timeout=20).text #print data infos = re.findall(r'fnick=(.+?)&f=1\\',data) if infos is None: self.cookies = self.cookie.getcookie() data = requests.get(self.url, headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies, timeout=20).text infos = re.findall(r'fnick=(.+?)&f=1\\', data) fans = [] for info in infos: fans.append(info.split('&')[0]) try: totalpage = re.findall(r'Pl_Official_HisRelation__6\d+\\">(\d+)(\d+)(.*?)(.+?)(\d*)(.+?)(.+?) 查看全部
网站调用新浪微博内容(Python学习交流:新浪微博反扒去解析网页了)
欢迎加入Python学习交流QQ群:201044047不小聊!名额有限!如果你不喜欢它,请不要进入!
Python
最近事情比较多,所以上周写的新浪微博爬虫被拖到现在,但不得不说新浪微博的反贴,我只想说我真的服了。mysql
爬取数据前的准备
跑到右边的老大说,这次没有限制爬取什么内容,但是作为参考,有兴趣的可以做一下:正则表达式

参考思路
当我看到这个时,我觉得很有趣,我想制作很多。所以我个人的想法是找一个粉丝多的人分析他的分析信息,然后分析他的粉丝的粉丝。等等(最好去感受一下解析初始用户关注的人的粉丝,因为他的粉丝比较多,他关注的人的粉丝肯定不会少),但是后来我想放弃这个想法。真的有很多问题。嗯,我很少说废话。来看看我抓到的信息:sql
一般来说,只能获得这么多信息。由于很多人的信息不完善,所以很多人先被抓起来进行检测。数据库
一个基本的想法
确认了我们要找的信息,下一步就是解析网页(一个大问题即将出现)。在我看来,获取网页的过程中遇到过:1.解析源码,2.catch Package(json),但新浪微博更烦。是在js里面,没有加载(只能用regular或者selenium来模拟浏览器)。看到这里,我想了想,问罗罗盘有没有别的办法。如果它不起作用,我将使用硒。他说还是建议正规化。分析速度更快。硒是最后的选择。无论正确与否,您都可以使用在线测试工具进行定期测试。无需一遍又一遍地运行代码。json
源代码+我的信息
关注 + 粉丝 + 微博
找到这个资料,盯着源码看了半天,看的头大了,其实是ctrl+f浏览器的快捷方式
搜索栏
既然我们都知道信息在哪里,那么就该写正则匹配信息了。这个只能慢慢写,可以练习正则表达式。曲奇饼
URL+粉丝分页问题
我的主页网址
我们先来看一个例子:
这个网址,提醒大家直接使用的时候是看不到首页信息的,但是在代码的测试源码中,我们可以看到位置重定向的链接。#后面的部分替换为&retcode=6102,所以URL应该是:,
我点击了链接并进行了测试。我看到的内容和第一个链接一样,还有一点。我们以后得到的所有链接都要替换#后面的内容,举个例子:app
urls = re.findall(r'class=\\"t_link S_txt1\\" href=\\"(.*?)\\"',data)
careUrl = urls[0].replace('\\','').replace('#place','&retcode=6102')
fansUrl = urls[1].replace('\\','').replace('#place','&retcode=6102')
wbUrl = urls[2].replace('\\','').replace('#place','&retcode=6102')
如果我们不更换它,我们得到它后仍然无法获取源代码。
粉丝分页问题
本来想可以解析我的一个粉丝,获取大量数据,但是还是卡在系统限制(爬的时候,第五页后就回不来数据了)dom
系统限制
看到这个,系统限制了,这是什么,嗯,我只能看到100个粉丝的信息,只能继续写下去了。因此,我们只需要考虑5页的数据。如果总页数大于 5 页,则按 5 页处理。如果页数少于5页,则可以正常写入。:
在这两个 URL 之后,我们可以看到区别在后半部分。除了用&retcode=6102替换#后面的部分,我还要稍微改动一下,下面是哪个?进行后续更改后,我们将从第二页构建 URL。
示例代码:
urls = ['http://weibo.com/p/1005051497035431/follow?relate=fans&page={}&retcode=6102'.format(i) for i in range(2,int(pages)+1)]
那么URL分页问题就解决了,可以说是解决了一个问题。如果你认为新浪微博只有这些反扒,那就太天真了,我们继续往下看。
布满荆棘的路
整个收购过程都是各种坑。之前我们主要讲了数据获取的方法以及URL和粉丝页面的问题。现在让我们来看看新浪微博上的一些反采摘:
首先,请求时必须添加cookie进行身份验证。这很正常,但在这里真的不是灵丹妙药。因为cookies也是有生命周期的,所以获取我的信息是没有问题的。但是,在获取粉丝页面信息时,出现了过期问题。怎么解决,想了半天,终于通过selenium模拟登录解决了。这个后面会详细解释,总之这点要注意。
然后,还有一点是,并不是每个人的源代码都是一样的。我怎样才能比较它?登录微博后,查看你的粉丝页面。源代码与您搜索的用户的源代码相同。不,其他的源代码信息也不同,我真的指出一件事,大公司很棒。
用户源代码
自己的源代码
通过自学应该可以看出区别,所以新浪微博整体来说还是比较难爬的。
代码
代码部分确实组织得不好,问题也很多,但是我可以贴出核心代码供大家参考讨论(感觉自己写的有点乱)
说一下代码结构,两个主类和三个辅助类:
两个主要类:第一个类解析粉丝id,另一个类解析详细信息(解析时会判断id是否已经解析)
三个辅助类:第一个模拟登录并返回cookies(在爬取数据的过程中,好像只调用了一次,多半是代码问题),第二个辅助类返回一个随机代理,第三个辅助类类将我的信息写入 mysql。
下面我把两个主类的源码贴出来,去掉辅助类的其余信息,还是可以运行的。
1.fansSpider.py
<p>#-*- coding:utf-8 -*- import requests import re import random from proxy import Proxy from getCookie import COOKIE from time import sleep from store_mysql import Mysql from weibo_spider import weiboSpider class fansSpider(object): headers = [ {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"} ] def __init__(self): self.wbspider = weiboSpider() self.proxie = Proxy() self.cookie = COOKIE() self.cookies = self.cookie.getcookie() field = ['id'] self.mysql = Mysql('sinaid', field, len(field) + 1) self.key = 1 def getData(self,url): self.url = url proxies = self.proxie.popip() print self.cookies print proxies r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) while r.status_code != requests.codes.ok: proxies = self.proxie.popip() r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) data = requests.get(self.url,headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies,timeout=20).text #print data infos = re.findall(r'fnick=(.+?)&f=1\\',data) if infos is None: self.cookies = self.cookie.getcookie() data = requests.get(self.url, headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies, timeout=20).text infos = re.findall(r'fnick=(.+?)&f=1\\', data) fans = [] for info in infos: fans.append(info.split('&')[0]) try: totalpage = re.findall(r'Pl_Official_HisRelation__6\d+\\">(\d+)(\d+)(.*?)(.+?)(\d*)(.+?)(.+?)
网站调用新浪微博内容(博客回复改版的事件、研究了新浪的web.api成功调用的新浪表情组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-02 10:33
最近在准备博客响应改版事件,研究了新浪的web.api成功调用新浪的表情。
给大家分享一个很实用的东西,希望对大家有帮助
一起来享受手术的效果吧
是不是很耀眼?让我们来看看如何实现它。
JS自定义hashtable代码如下
//自定义hashtable
function Hashtable() {
this._hash = new Object();
this.put = function(key, value) {
if (typeof (key) != "undefined") {
if (this.containsKey(key) == false) {
this._hash[key] = typeof (value) == "undefined" ? null : value;
return true;
} else {
return false;
}
} else {
return false;
}
}
this.remove = function(key) { delete this._hash[key]; }
this.size =
function() { var i = 0; for (var k in this._hash) { i ; } return i; }
this.get = function(key) { return this._hash[key]; }
this.containsKey =
function(key) { return typeof (this._hash[key]) != "undefined"; }
this.clear =
function() { for (var k in this._hash) { delete this._hash[k]; } }
}
初始化缓存并只加载一次页面
$(function() {
$.ajax( {
dataType : ´json´,
url : ´json/jquery.sinaEmotion.json´,
success : function(response) {
var data = response.data;
for ( var i in data) {
if (data[i].category == ´´) {
data[i].category = ´默认´;
}
if (emotions[data[i].category] == undefined) {
emotions[data[i].category] = new Array();
categorys.push(data[i].category);
}
emotions[data[i].category].push( {
name : data[i].phrase,
icon : data[i].icon
});
uSinaEmotionsHt.put(data[i].phrase, data[i].icon);
}
}
});
});
代替
function AnalyticEmotion(s) {
if(typeof (s) != "undefined") {
var sArr = s.match(/[.*?]/g);
for(var i = 0; i < sArr.length; i ){
if(uSinaEmotionsHt.containsKey(sArr[i])) {
var reStr = "";
s = s.replace(sArr[i], reStr);
}
}
}
return s;
}
显示类别
function showCategorys(){
var page = arguments[0]?arguments[0]:0;
if(page < 0 || page >= categorys.length / 5){
return;
}
$(´#emotions .categorys´).html(´´);
cat_page = page;
for(var i = page * 5; i < (page 1) * 5 && i < categorys.length; i){
$(´#emotions .categorys´)
.append($(´´
categorys[i] ´´));
}
$(´#emotions .categorys a´).click(function(){
showEmotions($(this).text());
});
$(´#emotions .categorys a´).each(function(){
if($(this).text() == cat_current){
$(this).addClass(´current´);
}
});
}
显示表情
function showEmotions(){
var category = arguments[0]?arguments[0]:´默认´;
var page = arguments[1]?arguments[1] - 1:0;
$(´#emotions .containersina´).html(´´);
$(´#emotions .page´).html(´´);
cat_current = category;
for(var i = page * 72; i < (page 1) * 72 && i < emotions[category].length; i){
$(´#emotions .containersina´)
.append($(´´
emotions[category][i].icon ´´));
}
$(´#emotions .containersina a´).click(function(){
target.insertText($(this).attr(´title´));
$(´#emotions´).remove();
});
for(var i = 1; i < emotions[category].length / 72 1; i){
$(´#emotions .page´).append($(´´ i ´´));
}
$(´#emotions .page a´).click(function(){
showEmotions(category, $(this).text());
});
$(´#emotions .categorys a.current´).removeClass(´current´);
$(´#emotions .categorys a´).each(function(){
if($(this).text() == category){
$(this).addClass(´current´);
}
});
}
HTML代码如下
JQuery新浪1630个表情插件(带解析方法)
完美兼容IE6 所有浏览器
<br />
<br />
当然,在整个代码实现之前,还得引入对应的JS和CSS文件,对应的文件在源码中。
最后给大家提供一个源码下载链接:密码:6xe9
还有一个本地版本:密码:6s3r
如果资源对你有帮助,浏览后收获很多,何乐而不为,你的鼓励是我继续写博客的最大动力 查看全部
网站调用新浪微博内容(博客回复改版的事件、研究了新浪的web.api成功调用的新浪表情组件)
最近在准备博客响应改版事件,研究了新浪的web.api成功调用新浪的表情。
给大家分享一个很实用的东西,希望对大家有帮助
一起来享受手术的效果吧

是不是很耀眼?让我们来看看如何实现它。
JS自定义hashtable代码如下
//自定义hashtable
function Hashtable() {
this._hash = new Object();
this.put = function(key, value) {
if (typeof (key) != "undefined") {
if (this.containsKey(key) == false) {
this._hash[key] = typeof (value) == "undefined" ? null : value;
return true;
} else {
return false;
}
} else {
return false;
}
}
this.remove = function(key) { delete this._hash[key]; }
this.size =
function() { var i = 0; for (var k in this._hash) { i ; } return i; }
this.get = function(key) { return this._hash[key]; }
this.containsKey =
function(key) { return typeof (this._hash[key]) != "undefined"; }
this.clear =
function() { for (var k in this._hash) { delete this._hash[k]; } }
}
初始化缓存并只加载一次页面
$(function() {
$.ajax( {
dataType : ´json´,
url : ´json/jquery.sinaEmotion.json´,
success : function(response) {
var data = response.data;
for ( var i in data) {
if (data[i].category == ´´) {
data[i].category = ´默认´;
}
if (emotions[data[i].category] == undefined) {
emotions[data[i].category] = new Array();
categorys.push(data[i].category);
}
emotions[data[i].category].push( {
name : data[i].phrase,
icon : data[i].icon
});
uSinaEmotionsHt.put(data[i].phrase, data[i].icon);
}
}
});
});
代替
function AnalyticEmotion(s) {
if(typeof (s) != "undefined") {
var sArr = s.match(/[.*?]/g);
for(var i = 0; i < sArr.length; i ){
if(uSinaEmotionsHt.containsKey(sArr[i])) {
var reStr = "";
s = s.replace(sArr[i], reStr);
}
}
}
return s;
}
显示类别
function showCategorys(){
var page = arguments[0]?arguments[0]:0;
if(page < 0 || page >= categorys.length / 5){
return;
}
$(´#emotions .categorys´).html(´´);
cat_page = page;
for(var i = page * 5; i < (page 1) * 5 && i < categorys.length; i){
$(´#emotions .categorys´)
.append($(´´
categorys[i] ´´));
}
$(´#emotions .categorys a´).click(function(){
showEmotions($(this).text());
});
$(´#emotions .categorys a´).each(function(){
if($(this).text() == cat_current){
$(this).addClass(´current´);
}
});
}
显示表情
function showEmotions(){
var category = arguments[0]?arguments[0]:´默认´;
var page = arguments[1]?arguments[1] - 1:0;
$(´#emotions .containersina´).html(´´);
$(´#emotions .page´).html(´´);
cat_current = category;
for(var i = page * 72; i < (page 1) * 72 && i < emotions[category].length; i){
$(´#emotions .containersina´)
.append($(´´
emotions[category][i].icon ´´));
}
$(´#emotions .containersina a´).click(function(){
target.insertText($(this).attr(´title´));
$(´#emotions´).remove();
});
for(var i = 1; i < emotions[category].length / 72 1; i){
$(´#emotions .page´).append($(´´ i ´´));
}
$(´#emotions .page a´).click(function(){
showEmotions(category, $(this).text());
});
$(´#emotions .categorys a.current´).removeClass(´current´);
$(´#emotions .categorys a´).each(function(){
if($(this).text() == category){
$(this).addClass(´current´);
}
});
}
HTML代码如下
JQuery新浪1630个表情插件(带解析方法)
完美兼容IE6 所有浏览器
<br />
<br />
当然,在整个代码实现之前,还得引入对应的JS和CSS文件,对应的文件在源码中。
最后给大家提供一个源码下载链接:密码:6xe9
还有一个本地版本:密码:6s3r
如果资源对你有帮助,浏览后收获很多,何乐而不为,你的鼓励是我继续写博客的最大动力
网站调用新浪微博内容(百度、A5站长网等多个使用com域名大站解析出现问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-01 14:15
项目招商找A5快速获取精准代理商名单
A5站长网站1月21日消息:今天下午15点20分左右,大量网友反映新浪、百度等知名网站无法访问,A5站长也收到多位站长反馈网站打不开,A5下的很多网站包括等也打不开。根据ping结果,很多使用com域名的主要网站,包括新浪微博、百度、A5站长等,似乎都解析为65.49.2.178案件。DNSPod在其官方微博上表示,国内所有gTLD的根都异常,已联系相关机构协调处理。(杨洋)
DNSPoD 相关公告
ping 百度结果
pingA5站点长网显示结果
之前在新浪微博上显示的ping结果
新浪微博已恢复正常
据了解,国内三分之二使用com域名的网站DNS解析存在问题。目前新浪微博DNS已恢复正常,但百度仍解析为65.49.2.178无法访问,目前正在逐步恢复。笔者提醒网友,如果网站因DNS解析问题无法访问,可将网络连接属性中的DNS设置为8.8.8.8,正常访问是可能的。
最新消息,根据百度速乐从电信部门获得的信息,各地区DNS故障已经恢复,运营商清除了各地区递归DNS上的DNS缓存。
提示:
什么是 DNS
DNS是Domain Name System的缩写,是互联网的核心服务。作为一个可以将域名和IP地址相互映射的分布式数据库,它可以让人们更轻松地访问互联网,而无需记住一串机器可以直接读取的IP号码。
人们习惯于记住域名,但机器只能识别 IP 地址。域名和IP地址是一一对应的。它们之间的转换称为域名解析。域名解析需要由专门的域名解析服务器完成。该过程是自动的。当您的网站完成上传到您的虚拟主机后,您可以直接在浏览器中输入IP地址浏览您的网站,或者输入域名查询您的网站虽然获取的内容相同,调用过程不同。输入IP地址是直接从主机调用内容,输入的域名是通过域名解析服务器指向对应主机的IP地址,然后调用<
更多信息请关注A5站长官方微信公众号。可搜索微信“iadmin5”或扫描下方二维码
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网站调用新浪微博内容(百度、A5站长网等多个使用com域名大站解析出现问题)
项目招商找A5快速获取精准代理商名单
A5站长网站1月21日消息:今天下午15点20分左右,大量网友反映新浪、百度等知名网站无法访问,A5站长也收到多位站长反馈网站打不开,A5下的很多网站包括等也打不开。根据ping结果,很多使用com域名的主要网站,包括新浪微博、百度、A5站长等,似乎都解析为65.49.2.178案件。DNSPod在其官方微博上表示,国内所有gTLD的根都异常,已联系相关机构协调处理。(杨洋)
DNSPoD 相关公告
ping 百度结果
pingA5站点长网显示结果
之前在新浪微博上显示的ping结果
新浪微博已恢复正常
据了解,国内三分之二使用com域名的网站DNS解析存在问题。目前新浪微博DNS已恢复正常,但百度仍解析为65.49.2.178无法访问,目前正在逐步恢复。笔者提醒网友,如果网站因DNS解析问题无法访问,可将网络连接属性中的DNS设置为8.8.8.8,正常访问是可能的。
最新消息,根据百度速乐从电信部门获得的信息,各地区DNS故障已经恢复,运营商清除了各地区递归DNS上的DNS缓存。
提示:
什么是 DNS
DNS是Domain Name System的缩写,是互联网的核心服务。作为一个可以将域名和IP地址相互映射的分布式数据库,它可以让人们更轻松地访问互联网,而无需记住一串机器可以直接读取的IP号码。
人们习惯于记住域名,但机器只能识别 IP 地址。域名和IP地址是一一对应的。它们之间的转换称为域名解析。域名解析需要由专门的域名解析服务器完成。该过程是自动的。当您的网站完成上传到您的虚拟主机后,您可以直接在浏览器中输入IP地址浏览您的网站,或者输入域名查询您的网站虽然获取的内容相同,调用过程不同。输入IP地址是直接从主机调用内容,输入的域名是通过域名解析服务器指向对应主机的IP地址,然后调用<
更多信息请关注A5站长官方微信公众号。可搜索微信“iadmin5”或扫描下方二维码
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-01 05:02
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用方法。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,我原本是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php")
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者的GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============ 查看全部
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用方法。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,我原本是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php";)
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者的GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============
网站调用新浪微博内容(OAuth2.0协议授权流程查看/access_token获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-08 17:12
一、OAuth2.0概览
大多数 API 访问,例如发布微博、获取私人消息和关注,都需要用户身份。目前新浪微博开放平台用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发Debugging接口),新版接口也仅支持这两种方式。 OAuth2.0比1.0的整个授权验证过程更简单、更安全,也是未来最重要的用户认证和授权方式。 OAuth2.0协议授权流程见OAuth2.0授权流程,其中Client指第三方应用,Resource Owner指用户,Authorization Server是我们的授权服务器,Resource Server是API 服务器。
参考链接:以及新浪微博开放平台和新浪微博CodeProject开源项目
开发者可以先浏览OAuth2.0的接口文档,熟悉OAuth2接口和参数的含义,然后根据应用讲解如何使用OAuth2.0场景。
OAuth2 接口文档
接口说明
OAuth2/授权
请求用户授权令牌
OAuth2/access_token
获取授权访问令牌
OAuth2/get_token_info
授权信息查询界面
OAuth2/revokeoauth2
授权恢复接口
OAuth2/get_oauth2_token
OAuth1.0的Access Token替换为OAuth2.0的Access Token
二、OAuth2.0 新浪授权页面
1、 首先获取appKey和appSecret。这种获取方式可以在新浪微博新手指南中一步步获取。这里的回调地址使用默认的:网站访问方式。以下是 C# 示例源代码(控制台应用程序):
01.using System;
02.using System.Collections.Generic;
03.using System.Linq;
04.using System.Text;
05.using NetDimension.Weibo;
06.using System.Net;
07.
08.namespace SinaWeiboTestApp
09.{
10. class Program
11. {
12.
13. static void Main(string[] args)
14. {
15.
16. string appkey = "124543453288";
17. string appsecret = "3a456c5332fd2cb1178338fccb9fa51c";
18. //string callBack = "http://127.0.0.1:3170/WebSite2/Default.aspx";
19. string callBack = "https://api.weibo.com/oauth2/default.html";
20. var oauth = new NetDimension.Weibo.OAuth(appkey,appsecret,callBack);
21.
22. ////模拟登录
23. //string username = "[email protected]";
24. //string password = "xxxxxxx";
25. //oauth.ClientLogin(username, password); //模拟登录下,没啥好说的,你也可以改成标准登录。
26.
27. //标准登录
28. var authUrl = oauth.GetAuthorizeURL();
29. //string redirectUrl;
30. //HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(authUrl);
31. //request.Referer = authUrl;
32. //request.AllowAutoRedirect = false;
33. //using (WebResponse response = request.GetResponse())
34. //{
35. // redirectUrl = response.Headers["Location"];
36. // redirectUrl = response.ResponseUri.AbsolutePath;
37. //}
38. System.Diagnostics.Process.Start(authUrl);
39. Console.WriteLine("填写浏览器地址中的Code参数:");
40. var code = Console.ReadLine();
41. var accessToken = oauth.GetAccessTokenByAuthorizationCode(code);
42. if (!string.IsNullOrEmpty(accessToken.Token))
43. {
44. var sina = new NetDimension.Weibo.Client(oauth);
45. var uid = sina.API.Dynamic.Account.GetUID(); //调用API中获取UID的方法
46. Console.WriteLine(uid);
47. }
48.
49. var Sina = new Client(oauth);
50. Console.WriteLine("开始发送异步请求...");
51.
52. //例子1:异步获取用户的ID
53. //demo的运行环境是.net 4.0,下面展示的这种方法在2.0及以上版本环境下有效,3.0以上可以用lambda表达式来简化delegate的蛋疼写法,请看下面的例子。
54. Sina.AsyncInvoke(
55. //第一个代理中编写调用API接口的相关逻辑
56. delegate()
57. {
58. Console.WriteLine("发送请求来获得用户ID...");
59. System.Threading.Thread.Sleep(8000); //等待8秒
60. return Sina.API.Entity.Account.GetUID();
61. },
62. //第二个代理为回调函数,异步完成后将自动调用这个函数来处理结果。
63. delegate(AsyncCallback callback)
64. {
65. if (callback.IsSuccess)
66. {
67. Console.WriteLine("获取用户ID成功,ID:{0}", callback.Data);
68. }
69. else
70. {
71. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
72. }
73. }
74. );
75.
76. //列子2:获取公共微博列表
77. //2.0以上用lambda来写,方便不是一点点
78. Sina.AsyncInvoke(() =>
79. {
80. //获取微博,接口调用,返回值是个NetDimension.Weibo.Entities.status.Collection,所以泛型T为NetDimension.Weibo.Entities.status.Collection
81. Console.WriteLine("发送请求来获得公共微博列表...");
82. return Sina.API.Entity.Statuses.PublicTimeline();
83. //return Sina.API.Entity.Statuses.RepostTimeline;
84. }, (callback) =>
85. {
86. if (callback.IsSuccess)
87. {
88. //异步完成后处理结果,result就是返回的结果,类型就是泛型所指定的NetDimension.Weibo.Entities.status.Collection
89. Console.WriteLine("获得公共微博列表成功,现在公共频道发微博的人都是他们:");
90. foreach (var status in callback.Data.Statuses)
91. {
92. if (status.User != null)
93. Console.WriteLine(status.User.ScreenName + " ");//打印公共微博发起人的姓名
94. }
95. Console.WriteLine();
96. }
97. else
98. {
99. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
100. }
101.
102. });
103.
104.
105. Console.WriteLine("已发送所有异步请求。等待异步执行完成...");
106.
107. Console.ReadKey(); //阻塞,等待异步调用执行完成
108.
109. }
110.
111. }
112.}
MVC 中的代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using Myself.Models;
using Myself.Code;
using BLL;
using Lib;
using SpeexToWavToMp3;
using System.Web.Http.Filters;
using Models;
using Webdiyer.WebControls.Mvc;
using System.IO;
namespace Myself.Controllers
{
public class MySelfController : Controller
{
public ActionResult LoginSina()
{
var oauth = new NetDimension.Weibo.OAuth(appKey,appSecret,Url.Action("LoginSinaResult", "MySelf", null, "http"));
//第一步获取新浪授权页面的地址
var oauthUrl = oauth.GetAuthorizeURL();
return Redirect(oauthUrl);
}
public ActionResult LoginSinaResult(string code)
{
var oauth = new NetDimension.Weibo.OAuth(appKey, appSecret, Url.Action("LoginSinaResult", "MySelf", null, "http"));
var oauthToken = oauth.GetAccessTokenByAuthorizationCode(code);
var model = UserHelper.GetAuthorizeInfo(oauthToken.UID, 1);
if (model != null)
{
if (LoginHelper.UserLogin(model.UserID, 1, oauthToken.UID, Request.UserAgent, Request.UserHostAddress, "1", "web"))
{
return RedirectToAction("Index", "Home");
}
else
{
return Content("登录失败");
}
}
return Content("您尚未注册");
}
}
}
要运行上述程序,需要替换Appkey和Appsecret。
2、授权页面
以下是微博登录的界面,登录后第三方网站授权访问您新浪微博上的资源
将提供。
3、授权访问页面
4、新浪官方网站提供API测试工具来测试客户端构造的参数是否正确
5、Oauth2.0 操作流程图
第一步:首先直接跳转到用户授权地址,即图标Request User Url,提示用户登录,授权相关资源获取唯一Auth code。这里注意代码的有效期只有10分钟出于安全考虑,相比OAuth1.0,它节省了一步获取临时token的时间,而且有效期也有控制,比1.0简单多了,安全多了@1.0 认证;第二步:获取代码授权后,这一步是请求访问令牌,使用图标请求访问url生成数据令牌;第三步:通过Access Token请求一个OpenID,即用户在本平台的唯一标识,通过图标Request info url请求,然后得到OpenID;第四步:利用第二步获取的数据Token、第三步获取的OpenID及相关API请求获取用户授权资源信息 查看全部
网站调用新浪微博内容(OAuth2.0协议授权流程查看/access_token获取)
一、OAuth2.0概览
大多数 API 访问,例如发布微博、获取私人消息和关注,都需要用户身份。目前新浪微博开放平台用户身份认证包括OAuth2.0和Basic Auth(仅用于应用开发Debugging接口),新版接口也仅支持这两种方式。 OAuth2.0比1.0的整个授权验证过程更简单、更安全,也是未来最重要的用户认证和授权方式。 OAuth2.0协议授权流程见OAuth2.0授权流程,其中Client指第三方应用,Resource Owner指用户,Authorization Server是我们的授权服务器,Resource Server是API 服务器。
参考链接:以及新浪微博开放平台和新浪微博CodeProject开源项目
开发者可以先浏览OAuth2.0的接口文档,熟悉OAuth2接口和参数的含义,然后根据应用讲解如何使用OAuth2.0场景。
OAuth2 接口文档
接口说明
OAuth2/授权
请求用户授权令牌
OAuth2/access_token
获取授权访问令牌
OAuth2/get_token_info
授权信息查询界面
OAuth2/revokeoauth2
授权恢复接口
OAuth2/get_oauth2_token
OAuth1.0的Access Token替换为OAuth2.0的Access Token
二、OAuth2.0 新浪授权页面
1、 首先获取appKey和appSecret。这种获取方式可以在新浪微博新手指南中一步步获取。这里的回调地址使用默认的:网站访问方式。以下是 C# 示例源代码(控制台应用程序):
01.using System;
02.using System.Collections.Generic;
03.using System.Linq;
04.using System.Text;
05.using NetDimension.Weibo;
06.using System.Net;
07.
08.namespace SinaWeiboTestApp
09.{
10. class Program
11. {
12.
13. static void Main(string[] args)
14. {
15.
16. string appkey = "124543453288";
17. string appsecret = "3a456c5332fd2cb1178338fccb9fa51c";
18. //string callBack = "http://127.0.0.1:3170/WebSite2/Default.aspx";
19. string callBack = "https://api.weibo.com/oauth2/default.html";
20. var oauth = new NetDimension.Weibo.OAuth(appkey,appsecret,callBack);
21.
22. ////模拟登录
23. //string username = "[email protected]";
24. //string password = "xxxxxxx";
25. //oauth.ClientLogin(username, password); //模拟登录下,没啥好说的,你也可以改成标准登录。
26.
27. //标准登录
28. var authUrl = oauth.GetAuthorizeURL();
29. //string redirectUrl;
30. //HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(authUrl);
31. //request.Referer = authUrl;
32. //request.AllowAutoRedirect = false;
33. //using (WebResponse response = request.GetResponse())
34. //{
35. // redirectUrl = response.Headers["Location"];
36. // redirectUrl = response.ResponseUri.AbsolutePath;
37. //}
38. System.Diagnostics.Process.Start(authUrl);
39. Console.WriteLine("填写浏览器地址中的Code参数:");
40. var code = Console.ReadLine();
41. var accessToken = oauth.GetAccessTokenByAuthorizationCode(code);
42. if (!string.IsNullOrEmpty(accessToken.Token))
43. {
44. var sina = new NetDimension.Weibo.Client(oauth);
45. var uid = sina.API.Dynamic.Account.GetUID(); //调用API中获取UID的方法
46. Console.WriteLine(uid);
47. }
48.
49. var Sina = new Client(oauth);
50. Console.WriteLine("开始发送异步请求...");
51.
52. //例子1:异步获取用户的ID
53. //demo的运行环境是.net 4.0,下面展示的这种方法在2.0及以上版本环境下有效,3.0以上可以用lambda表达式来简化delegate的蛋疼写法,请看下面的例子。
54. Sina.AsyncInvoke(
55. //第一个代理中编写调用API接口的相关逻辑
56. delegate()
57. {
58. Console.WriteLine("发送请求来获得用户ID...");
59. System.Threading.Thread.Sleep(8000); //等待8秒
60. return Sina.API.Entity.Account.GetUID();
61. },
62. //第二个代理为回调函数,异步完成后将自动调用这个函数来处理结果。
63. delegate(AsyncCallback callback)
64. {
65. if (callback.IsSuccess)
66. {
67. Console.WriteLine("获取用户ID成功,ID:{0}", callback.Data);
68. }
69. else
70. {
71. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
72. }
73. }
74. );
75.
76. //列子2:获取公共微博列表
77. //2.0以上用lambda来写,方便不是一点点
78. Sina.AsyncInvoke(() =>
79. {
80. //获取微博,接口调用,返回值是个NetDimension.Weibo.Entities.status.Collection,所以泛型T为NetDimension.Weibo.Entities.status.Collection
81. Console.WriteLine("发送请求来获得公共微博列表...");
82. return Sina.API.Entity.Statuses.PublicTimeline();
83. //return Sina.API.Entity.Statuses.RepostTimeline;
84. }, (callback) =>
85. {
86. if (callback.IsSuccess)
87. {
88. //异步完成后处理结果,result就是返回的结果,类型就是泛型所指定的NetDimension.Weibo.Entities.status.Collection
89. Console.WriteLine("获得公共微博列表成功,现在公共频道发微博的人都是他们:");
90. foreach (var status in callback.Data.Statuses)
91. {
92. if (status.User != null)
93. Console.WriteLine(status.User.ScreenName + " ");//打印公共微博发起人的姓名
94. }
95. Console.WriteLine();
96. }
97. else
98. {
99. Console.WriteLine("获取用户ID失败,异常:{0}", callback.Error);
100. }
101.
102. });
103.
104.
105. Console.WriteLine("已发送所有异步请求。等待异步执行完成...");
106.
107. Console.ReadKey(); //阻塞,等待异步调用执行完成
108.
109. }
110.
111. }
112.}
MVC 中的代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using Myself.Models;
using Myself.Code;
using BLL;
using Lib;
using SpeexToWavToMp3;
using System.Web.Http.Filters;
using Models;
using Webdiyer.WebControls.Mvc;
using System.IO;
namespace Myself.Controllers
{
public class MySelfController : Controller
{
public ActionResult LoginSina()
{
var oauth = new NetDimension.Weibo.OAuth(appKey,appSecret,Url.Action("LoginSinaResult", "MySelf", null, "http"));
//第一步获取新浪授权页面的地址
var oauthUrl = oauth.GetAuthorizeURL();
return Redirect(oauthUrl);
}
public ActionResult LoginSinaResult(string code)
{
var oauth = new NetDimension.Weibo.OAuth(appKey, appSecret, Url.Action("LoginSinaResult", "MySelf", null, "http"));
var oauthToken = oauth.GetAccessTokenByAuthorizationCode(code);
var model = UserHelper.GetAuthorizeInfo(oauthToken.UID, 1);
if (model != null)
{
if (LoginHelper.UserLogin(model.UserID, 1, oauthToken.UID, Request.UserAgent, Request.UserHostAddress, "1", "web"))
{
return RedirectToAction("Index", "Home");
}
else
{
return Content("登录失败");
}
}
return Content("您尚未注册");
}
}
}
要运行上述程序,需要替换Appkey和Appsecret。
2、授权页面
以下是微博登录的界面,登录后第三方网站授权访问您新浪微博上的资源
将提供。
3、授权访问页面
4、新浪官方网站提供API测试工具来测试客户端构造的参数是否正确
5、Oauth2.0 操作流程图
第一步:首先直接跳转到用户授权地址,即图标Request User Url,提示用户登录,授权相关资源获取唯一Auth code。这里注意代码的有效期只有10分钟出于安全考虑,相比OAuth1.0,它节省了一步获取临时token的时间,而且有效期也有控制,比1.0简单多了,安全多了@1.0 认证;第二步:获取代码授权后,这一步是请求访问令牌,使用图标请求访问url生成数据令牌;第三步:通过Access Token请求一个OpenID,即用户在本平台的唯一标识,通过图标Request info url请求,然后得到OpenID;第四步:利用第二步获取的数据Token、第三步获取的OpenID及相关API请求获取用户授权资源信息
网站调用新浪微博内容(微博登录访问第三方网站,分享内容,同步信息。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-05 05:09
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
如果用户同意授权,页面跳转到your_registered_redirect_uri/?code=code:
2、 接下来,我们需要根据上面得到的代码换取访问令牌:
返回值:
json
{
"access_token": "slav32hkkg",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的oauth2.0 access token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = null )
{
$curl = curl_init();
//curl_setopt ( $curl, curlopt_safe_upload, false);
if( stripos($url, 'https://') !==false )
{
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
}
curl_setopt($curl, curlopt_url, $url);
curl_setopt($curl, curlopt_header, 0);
curl_setopt($curl, curlopt_returntransfer, 1);
if ( $_header != null )
{
curl_setopt($curl, curlopt_httpheader, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$ocurl = curl_init ();
curl_setopt ( $ocurl, curlopt_safe_upload, false);
if (stripos ( $url, "https://" ) !== false) {
curl_setopt ( $ocurl, curlopt_ssl_verifypeer, false );
curl_setopt ( $ocurl, curlopt_ssl_verifyhost, false );
}
curl_setopt ( $ocurl, curlopt_url, $url );
curl_setopt ( $ocurl, curlopt_returntransfer, 1 );
curl_setopt ( $ocurl, curlopt_post, true );
curl_setopt ( $ocurl, curlopt_postfields, $param );
$scontent = curl_exec ( $ocurl );
$astatus = curl_getinfo ( $ocurl );
curl_close ( $ocurl );
if (intval ( $astatus ["http_code"] ) == 200) {
return $scontent;
} else {
return false;
}
}
控制器处理代码login.php:
class login extends \think\controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/weblogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function weblogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取access token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。 查看全部
网站调用新浪微博内容(微博登录访问第三方网站,分享内容,同步信息。。)
在平时的项目开发过程中,除了注册这个网站账号登录外,还可以调用第三方接口登录网站。这里我们以微博登录为例。微博登录包括身份认证、用户关系和内容传播。允许用户使用微博账号登录访问第三方网站,分享内容,同步信息。
1、首先需要将需要授权的用户引导到以下地址:
如果用户同意授权,页面跳转到your_registered_redirect_uri/?code=code:
2、 接下来,我们需要根据上面得到的代码换取访问令牌:
返回值:
json
{
"access_token": "slav32hkkg",
"remind_in": 3600,
"expires_in": 3600
}
3、最后使用获取到的oauth2.0 access token调用API获取用户身份,完成用户登录。
话不多说,直接上代码:
为方便起见,我们先将get和post封装到application下的common.php中:
应用公用文件common.php:
function get( $url, $_header = null )
{
$curl = curl_init();
//curl_setopt ( $curl, curlopt_safe_upload, false);
if( stripos($url, 'https://') !==false )
{
curl_setopt($curl, curlopt_ssl_verifypeer, false);
curl_setopt($curl, curlopt_ssl_verifyhost, false);
}
curl_setopt($curl, curlopt_url, $url);
curl_setopt($curl, curlopt_header, 0);
curl_setopt($curl, curlopt_returntransfer, 1);
if ( $_header != null )
{
curl_setopt($curl, curlopt_httpheader, $_header);
}
$ret = curl_exec($curl);
$info = curl_getinfo($curl);
curl_close($curl);
if( intval( $info["http_code"] ) == 200 )
{
return $ret;
}
return false;
}
/*
* post method
*/
function post( $url, $param )
{
$ocurl = curl_init ();
curl_setopt ( $ocurl, curlopt_safe_upload, false);
if (stripos ( $url, "https://" ) !== false) {
curl_setopt ( $ocurl, curlopt_ssl_verifypeer, false );
curl_setopt ( $ocurl, curlopt_ssl_verifyhost, false );
}
curl_setopt ( $ocurl, curlopt_url, $url );
curl_setopt ( $ocurl, curlopt_returntransfer, 1 );
curl_setopt ( $ocurl, curlopt_post, true );
curl_setopt ( $ocurl, curlopt_postfields, $param );
$scontent = curl_exec ( $ocurl );
$astatus = curl_getinfo ( $ocurl );
curl_close ( $ocurl );
if (intval ( $astatus ["http_code"] ) == 200) {
return $scontent;
} else {
return false;
}
}
控制器处理代码login.php:
class login extends \think\controller
{
public function index()
{
$key = "****";
$redirect_uri = "***微博应用安全域名***/?backurl=***项目本地域名***/home/login/weblogin?";
//授权后将页面重定向到本地项目
$redirect_uri = urlencode($redirect_uri);
$wb_url = "https://api.weibo.com/oauth2/authorize?client_id={$key}&response_type=code&redirect_uri={$redirect_uri}";
$this -> assign('wb_url',$wb_url);
return view('login');
}
public function weblogin(){
$key = "*****";
//接收code值
$code = input('get.code');
//换取access token: post方式请求 替换参数: client_id, client_secret,redirect_uri, code
$secret = "********";
$redirect_uri = "********";
$url = "https://api.weibo.com/oauth2/a ... id%3D{$key}&client_secret={$secret}&grant_type=authorization_code&redirect_uri={$redirect_uri}&code={$code}";
$token = post($url, array());
$token = json_decode($token, true);
//获取用户信息 : get方法,替换参数: access_token, uid
$url = "https://api.weibo.com/2/users/ ... en%3D{$token['access_token']}&uid={$token['uid']}";
$info = get($url);
if($info){
echo "<p>登录成功";
}
}
}</p>
模板代码 login.html:
微博登录
点击这里进行微博登录
效果图:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。
网站调用新浪微博内容(QQ和新浪微博登录门槛的降低就已经做到了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-02 16:18
网站引入QQ和新浪微博登录后,实现了网站登录门槛的降低,因为这两个基本上所有网名都可以使用,尤其是QQ。下载这两种登录方式的详细说明。
1.QQ需要申请认证,创建应用申请。如下所示:
点击网站,填写网站信息,如下图:
点击创建应用,等待审核。审核通过后,我们就可以使用基本的API了。以下是QQ互联API列表。
这是调用代码:
//引入JS脚本
QC.Login({
btnId: "qq_login_btn",
scope: "all",
},
function() {
QC.api("get_user_info").success(function(s) {
var paras = {
format: "json"
};
QC.api("get_info", paras).success(function(w) {
var data = eval(w.data);
var weiboUrl = "http://t.qq.com/" data.data.name;
var lc = data.data.location;
}).error(function(e) {
}).complete(function(c) { //完成请求回调
var nickName = s.data.nickname; //称谓
var userQQSmallImage = s.data.figureurl_qq_1; //大小为40×40像素的QQ头像URL。
userQQLargeImage = s.data.figureurl_qq_2; //大小为100×100像素的QQ头像URL。
var userQQZoneImage = s.data.figureurl_1; //大小为50×50像素的QQ空间头像URL
});
});
});
" _ue_custom_node_="true">
演示地址:
2.新浪微博:
登录新浪微博开放平台,点击进入管理中心,点击添加网站,先验证网站的所有权,验证后会添加到我的网站,不是我们刚刚填写的在线专栏网站,那么您需要提交审核。审核后就可以拿到APPID了,就可以使用了。
详细接口信息:
%E5%BE%AE%E5%8D%9AAPI
登录按钮介绍及代码:
function login(o) {
//
$.ajax({
type: "Get",
url: "https://api.weibo.com/2/users/ ... ot%3B + o.screen_name + "",
dataType: "jsonp",
success: function(data) {
var lc = data.data.location;
var nickName = o.screen_name;
var userQQLargeImage = o.avatar_large;
var weiboUrl = "http://weibo.com/u/" + o.idstr;
// document.getElementById("Friend").style.display = "block";
// document.getElementById("LoginA").style.display = "none";
// document.getElementById("FriendImg").src = o.avatar_large;
// document.getElementById("FriendName").innerHTML = o.screen_name + "(来自新浪微博登录)";
},
error: function(xhr, msg, e) {
alert(msg);
}
});
}
function logout() {
alert('logout');
}
QQ登录和新浪微博登录方式非常相似,步骤也一样。一般是申请认证,导入code,接收回调,注销。如果您需要使用一些更高级的API,我们需要单独申请。这里就不介绍了。 查看全部
网站调用新浪微博内容(QQ和新浪微博登录门槛的降低就已经做到了!)
网站引入QQ和新浪微博登录后,实现了网站登录门槛的降低,因为这两个基本上所有网名都可以使用,尤其是QQ。下载这两种登录方式的详细说明。
1.QQ需要申请认证,创建应用申请。如下所示:
点击网站,填写网站信息,如下图:
点击创建应用,等待审核。审核通过后,我们就可以使用基本的API了。以下是QQ互联API列表。
这是调用代码:
//引入JS脚本
QC.Login({
btnId: "qq_login_btn",
scope: "all",
},
function() {
QC.api("get_user_info").success(function(s) {
var paras = {
format: "json"
};
QC.api("get_info", paras).success(function(w) {
var data = eval(w.data);
var weiboUrl = "http://t.qq.com/" data.data.name;
var lc = data.data.location;
}).error(function(e) {
}).complete(function(c) { //完成请求回调
var nickName = s.data.nickname; //称谓
var userQQSmallImage = s.data.figureurl_qq_1; //大小为40×40像素的QQ头像URL。
userQQLargeImage = s.data.figureurl_qq_2; //大小为100×100像素的QQ头像URL。
var userQQZoneImage = s.data.figureurl_1; //大小为50×50像素的QQ空间头像URL
});
});
});
" _ue_custom_node_="true">
演示地址:
2.新浪微博:
登录新浪微博开放平台,点击进入管理中心,点击添加网站,先验证网站的所有权,验证后会添加到我的网站,不是我们刚刚填写的在线专栏网站,那么您需要提交审核。审核后就可以拿到APPID了,就可以使用了。
详细接口信息:
%E5%BE%AE%E5%8D%9AAPI
登录按钮介绍及代码:
function login(o) {
//
$.ajax({
type: "Get",
url: "https://api.weibo.com/2/users/ ... ot%3B + o.screen_name + "",
dataType: "jsonp",
success: function(data) {
var lc = data.data.location;
var nickName = o.screen_name;
var userQQLargeImage = o.avatar_large;
var weiboUrl = "http://weibo.com/u/" + o.idstr;
// document.getElementById("Friend").style.display = "block";
// document.getElementById("LoginA").style.display = "none";
// document.getElementById("FriendImg").src = o.avatar_large;
// document.getElementById("FriendName").innerHTML = o.screen_name + "(来自新浪微博登录)";
},
error: function(xhr, msg, e) {
alert(msg);
}
});
}
function logout() {
alert('logout');
}
QQ登录和新浪微博登录方式非常相似,步骤也一样。一般是申请认证,导入code,接收回调,注销。如果您需要使用一些更高级的API,我们需要单独申请。这里就不介绍了。
网站调用新浪微博内容(批量删除新浪微博的原理分析(图)JS代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-01 21:20
)
新浪微博开放平台删除接口已关闭。目前没有其他方法可以有效删除微博。网页版微博可以通过AJAX请求删除。唯一的参数是mid,我们可以理解为唯一的微博。ID,那么我们只需要获取这个ID并发起请求即可。
新浪微博的翻页使用直接嵌套的HTML代码,里面收录了你看到的所有信息,然后我们可以模拟用户操作,批量删除微博。
原理分析
首先,构建一个 curl 方法。为了识别登录用户,我们首先要设置cookie:
function post($url, $post_data, $method = 'post', $location = 0, $reffer = null, $origin = null, $host = null){
$header = array(
'Host: weibo.com',
'User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept: */*',
'Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding: gzip, deflate, br',
'Connection: keep-alive',
'Referer: https://weibo.com/p/1006061848 ... ll%3D1',
'Cookie: SUB=_2A25Nei59DeRhGedG71oW8SfIyz6IHXVuDhi1rDV8PUNbmtANLWTxkW9NUTJhgRrUko8Y3kcSMy2qik69SLr5cWOz; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5hXoza0gdfeO6EFBAyGQ6P5JpX5KzhUgL.Fo2RShnNeK.Xehz2dJLoIpjLxK.L1KMLB--LxKnLB-qLBoBLxKMLB.BL1K2t; login_sid_t=d86405009f566cd57c8b433b74b96be8; cross_origin_proto=SSL; WBStorage=8daec78e6a891122|undefined; _s_tentry=passport.weibo.com; Apache=2936390402941.201.1618894353597; SINAGLOBAL=2936390402941.201.1618894353597; ULV=1618894353599:1:1:1:2936390402941.201.1618894353597:; wb_view_log=1920*10801; ALF=1650430381; SSOLoginState=1618894382; wb_view_log_1848719402=1920*10801; webim_unReadCount=%7B%22time%22%3A1618894400887%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A0%2C%22msgbox%22%3A0%7D',
'X-Requested-With: XMLHttpRequest',
);
$curl = curl_init(); // 这里并没有带参数初始化
curl_setopt($curl, CURLOPT_URL, $url); // 这里传入url
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查,不开启次功能
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 2); // 从证书中检测 SSL 加密算法
curl_setopt($curl, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36");
curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
curl_setopt($curl, CURLOPT_POST, $method == 'post'?true:false); // 开启 post
curl_setopt($curl, CURLOPT_ENCODING, "gzip, deflate" );
curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data); // 要传送的数据
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制,防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$tmpInfo = curl_exec($curl);
return $tmpInfo;
}
通过浏览器调试工具,我们可以找到翻页的URL地址:
%2Fp%2F19402%2Fhome%3Ffrom%3Dpage_100606%26mod%3DTAB%26is_all%3D1%23place&_t=FM_9555
page 参数是页码。这个请求得到的是一段JS代码,在页面上执行可以加载更多的微博内容,但是我们只需要里面的mid参数即可。
您可以使用常规匹配来:
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
同样,删除的url是:
参数为中。如果请求成功,您将获得:
{"code":"100000","msg":"","data":{}}
完整代码
至此,我们已经基本分析清楚了,完整的代码如下:
include_once('curl_post.php');
while(1){
$url = "https://weibo.com/p/1006061848 ... 3B%3B
$res = post($url, null, 'get');
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
print_r($match[1]);
foreach($match[1] as $key => $mid){
echo "start del ".$mid." ==============\r\n";
$res = post('https://weibo.com/aj/mblog/del?ajwvr=6', array('mid' => $mid));
echo $res."\r\n";
echo 'await 5s ================='."\r\n";
sleep(5);
}
if(count($match[1]) < 10) break;
}
执行php delWeibo.php,结果如下:
如果觉得等待时间太长,可以自行修改。建议不要太频繁地调用它。
这个调用可以批量删除微博,但是不方便。例如,如果你想保留一些内容,这是不够的。推荐使用我开发的另一个软件:可以手动选择一个键进行删除,精确控制删除动作。
'PHP' 不是内部或外部命令,也不是可执行程序或批处理文件。
将PHP的安装路径添加到环境变量中,就可以在命令行执行PHP文件了。
查看全部
网站调用新浪微博内容(批量删除新浪微博的原理分析(图)JS代码
)
新浪微博开放平台删除接口已关闭。目前没有其他方法可以有效删除微博。网页版微博可以通过AJAX请求删除。唯一的参数是mid,我们可以理解为唯一的微博。ID,那么我们只需要获取这个ID并发起请求即可。
新浪微博的翻页使用直接嵌套的HTML代码,里面收录了你看到的所有信息,然后我们可以模拟用户操作,批量删除微博。
原理分析
首先,构建一个 curl 方法。为了识别登录用户,我们首先要设置cookie:
function post($url, $post_data, $method = 'post', $location = 0, $reffer = null, $origin = null, $host = null){
$header = array(
'Host: weibo.com',
'User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept: */*',
'Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding: gzip, deflate, br',
'Connection: keep-alive',
'Referer: https://weibo.com/p/1006061848 ... ll%3D1',
'Cookie: SUB=_2A25Nei59DeRhGedG71oW8SfIyz6IHXVuDhi1rDV8PUNbmtANLWTxkW9NUTJhgRrUko8Y3kcSMy2qik69SLr5cWOz; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5hXoza0gdfeO6EFBAyGQ6P5JpX5KzhUgL.Fo2RShnNeK.Xehz2dJLoIpjLxK.L1KMLB--LxKnLB-qLBoBLxKMLB.BL1K2t; login_sid_t=d86405009f566cd57c8b433b74b96be8; cross_origin_proto=SSL; WBStorage=8daec78e6a891122|undefined; _s_tentry=passport.weibo.com; Apache=2936390402941.201.1618894353597; SINAGLOBAL=2936390402941.201.1618894353597; ULV=1618894353599:1:1:1:2936390402941.201.1618894353597:; wb_view_log=1920*10801; ALF=1650430381; SSOLoginState=1618894382; wb_view_log_1848719402=1920*10801; webim_unReadCount=%7B%22time%22%3A1618894400887%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A0%2C%22msgbox%22%3A0%7D',
'X-Requested-With: XMLHttpRequest',
);
$curl = curl_init(); // 这里并没有带参数初始化
curl_setopt($curl, CURLOPT_URL, $url); // 这里传入url
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0); // 对认证证书来源的检查,不开启次功能
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 2); // 从证书中检测 SSL 加密算法
curl_setopt($curl, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36");
curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
curl_setopt($curl, CURLOPT_POST, $method == 'post'?true:false); // 开启 post
curl_setopt($curl, CURLOPT_ENCODING, "gzip, deflate" );
curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data); // 要传送的数据
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制,防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$tmpInfo = curl_exec($curl);
return $tmpInfo;
}
通过浏览器调试工具,我们可以找到翻页的URL地址:
%2Fp%2F19402%2Fhome%3Ffrom%3Dpage_100606%26mod%3DTAB%26is_all%3D1%23place&_t=FM_9555
page 参数是页码。这个请求得到的是一段JS代码,在页面上执行可以加载更多的微博内容,但是我们只需要里面的mid参数即可。
您可以使用常规匹配来:
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
同样,删除的url是:
参数为中。如果请求成功,您将获得:
{"code":"100000","msg":"","data":{}}
完整代码
至此,我们已经基本分析清楚了,完整的代码如下:
include_once('curl_post.php');
while(1){
$url = "https://weibo.com/p/1006061848 ... 3B%3B
$res = post($url, null, 'get');
preg_match_all('/mid=\\\"(.+?)\\\"/', $res, $match);
print_r($match[1]);
foreach($match[1] as $key => $mid){
echo "start del ".$mid." ==============\r\n";
$res = post('https://weibo.com/aj/mblog/del?ajwvr=6', array('mid' => $mid));
echo $res."\r\n";
echo 'await 5s ================='."\r\n";
sleep(5);
}
if(count($match[1]) < 10) break;
}
执行php delWeibo.php,结果如下:
如果觉得等待时间太长,可以自行修改。建议不要太频繁地调用它。
这个调用可以批量删除微博,但是不方便。例如,如果你想保留一些内容,这是不够的。推荐使用我开发的另一个软件:可以手动选择一个键进行删除,精确控制删除动作。
'PHP' 不是内部或外部命令,也不是可执行程序或批处理文件。
将PHP的安装路径添加到环境变量中,就可以在命令行执行PHP文件了。
网站调用新浪微博内容(使用新浪微博API:创建SDK中的Web应用准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-31 13:04
在《使用新浪微博API:创建SDK》一文中,我们准备了用于编写Web应用程序的SDK,可以在命令行上测试成功。现在,我们可以在Web网站中集成和调用新浪微博的API。
微博登录
使用新浪微博API的第一步是允许用户通过微博登录。在您的网站上放置一个“用微博账号登录”链接,指向一个网站的URL,例如/signin。代码显示如下:
/static/i/signin.png
效果如图:
在URL映射处理函数签名中,创建一个APIClient实例,然后调用get_authorize_url()方法获取新浪微博认证的URL,并将用户重定向到该URL。代码显示如下:
def _create_client():
_APP_ID = '12345'
_APP_SECRET = 'abc123xyz'
_REDIRECT_URI = 'http://example.com/callback'
return APIClient(_APP_ID, _APP_SECRET, _REDIRECT_URI)
@get('/signin')
def signin():
client = _create_client()
# 重定向到新浪微博登陆页:
raise seeother(client.get_authorize_url())
用户在新浪微博的认证页面完成登录后,新浪微博会将用户重定向到我们指定的redirect_uri,并附加参数code。处理redirect_uri的函数会提取参数代码,然后获取登录用户的访问令牌。代码显示如下:
@get('/callback')
def callback():
client = _create_client()
r = client.request_access_token(ctx.request['code'])
access_token, expires_in, uid = r.access_token, r.expires_in, r.uid
在获取access token的同时,新浪微博也会返回access token的过期时间和用户ID。SDK 将过期时间转换为 UNIX 时间戳并返回。
获取到的访问令牌,然后可以使用登录用户的身份调用 API 以进一步获取用户详细信息。代码显示如下:
@get('/callback')
def callback():
...
client.set_access_token(access_token, expires_in)
user = client.users.show.get(uid=uid)
logging.info(json.dump(user)) # { "uid": 1234, "screen_name": "Michael", … }
紧接着,网站必须判断该用户是否是第一次访问,如果是,则在数据库中创建一条记录,如果该用户已经存在,则更新该用户的相关信息。由于uid是用户在新浪微博上的唯一ID号,因此可以作为主键来存储用户信息。同时,访问令牌和过期时间一起存储在数据库中。代码显示如下:
@get('/callback')
def callback():
...
if (_is_user_exist(uid)):
_update_user(user, access_token, expires_in)
else:
_create_user(user, access_token, expires_in)
最后一步是在您的 网站 上使用会话或 cookie 来识别用户已登录。然后,该用户可以作为登录名访问您的 网站。
调用接口
获得用户授权后,即可调用API。例如,列出用户关注的微博列表,代码如下:
@get('/list')
def list_weibo():
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.home_timeline.get()
return Template('list.html', statuses = r.statuses)
在HTML模板中,可以将JSON格式的状态列表转成HTML,代码如下:
L = []
for st in statuses:
L.append('''
%s
%s
%s
''' % (st.user.profile_image_url, st.user.screen_name, st.text)
print ''.join(L)
CSS处理后的最终HTML效果如下:
不过仔细观察,我们输出的微博和新浪微博官网是不一样的。官网会把@和http和#topic#开头的文字改成超链接。如何处理@某某某、#主题#和链接?下面是一个JavaScript正则匹配方案,代码如下:
var g_all = /(\@[^\s\&\:\)\uff09\uff1a\@]+)|(\#[^\#]+\#)|(http\:\/\/[a-zA-Z0-9\_\/\.\-]+)/g;
var g_at = /^\@[^\s\&\:\)\uff09\uff1a\@]+$/;
var g_topic = /^\#[^\#]+\#$/;
var g_link = /^http\:\/\/[a-zA-Z0-9\_\/\.\-]+$/;
function format_text(t) {
ss = t.replace('').split(g_all);
L = []
$.each(ss, function(index, s) {
if (s===undefined)
return;
if (g_at.test(s)) {
L.push('' + s + '');
}
else if (g_topic.test(s)) {
L.push('' + s + '');
}
else if (g_link.test(s)) {
L.push('' + s + '');
}
else {
L.push(s);
}
});
return L.join('');
}
在微博上发帖
发布微博的API是status/update,需要通过POST调用。发布微博代码如下:
@post('/update')
def statuses_update():
text = ctx.request['text']
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.update.post(status=text)
return True
本文演示了网站:
本文源代码可从GitHub下载: 查看全部
网站调用新浪微博内容(使用新浪微博API:创建SDK中的Web应用准备)
在《使用新浪微博API:创建SDK》一文中,我们准备了用于编写Web应用程序的SDK,可以在命令行上测试成功。现在,我们可以在Web网站中集成和调用新浪微博的API。
微博登录
使用新浪微博API的第一步是允许用户通过微博登录。在您的网站上放置一个“用微博账号登录”链接,指向一个网站的URL,例如/signin。代码显示如下:
/static/i/signin.png
效果如图:
在URL映射处理函数签名中,创建一个APIClient实例,然后调用get_authorize_url()方法获取新浪微博认证的URL,并将用户重定向到该URL。代码显示如下:
def _create_client():
_APP_ID = '12345'
_APP_SECRET = 'abc123xyz'
_REDIRECT_URI = 'http://example.com/callback'
return APIClient(_APP_ID, _APP_SECRET, _REDIRECT_URI)
@get('/signin')
def signin():
client = _create_client()
# 重定向到新浪微博登陆页:
raise seeother(client.get_authorize_url())
用户在新浪微博的认证页面完成登录后,新浪微博会将用户重定向到我们指定的redirect_uri,并附加参数code。处理redirect_uri的函数会提取参数代码,然后获取登录用户的访问令牌。代码显示如下:
@get('/callback')
def callback():
client = _create_client()
r = client.request_access_token(ctx.request['code'])
access_token, expires_in, uid = r.access_token, r.expires_in, r.uid
在获取access token的同时,新浪微博也会返回access token的过期时间和用户ID。SDK 将过期时间转换为 UNIX 时间戳并返回。
获取到的访问令牌,然后可以使用登录用户的身份调用 API 以进一步获取用户详细信息。代码显示如下:
@get('/callback')
def callback():
...
client.set_access_token(access_token, expires_in)
user = client.users.show.get(uid=uid)
logging.info(json.dump(user)) # { "uid": 1234, "screen_name": "Michael", … }
紧接着,网站必须判断该用户是否是第一次访问,如果是,则在数据库中创建一条记录,如果该用户已经存在,则更新该用户的相关信息。由于uid是用户在新浪微博上的唯一ID号,因此可以作为主键来存储用户信息。同时,访问令牌和过期时间一起存储在数据库中。代码显示如下:
@get('/callback')
def callback():
...
if (_is_user_exist(uid)):
_update_user(user, access_token, expires_in)
else:
_create_user(user, access_token, expires_in)
最后一步是在您的 网站 上使用会话或 cookie 来识别用户已登录。然后,该用户可以作为登录名访问您的 网站。
调用接口
获得用户授权后,即可调用API。例如,列出用户关注的微博列表,代码如下:
@get('/list')
def list_weibo():
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.home_timeline.get()
return Template('list.html', statuses = r.statuses)
在HTML模板中,可以将JSON格式的状态列表转成HTML,代码如下:
L = []
for st in statuses:
L.append('''
%s
%s
%s
''' % (st.user.profile_image_url, st.user.screen_name, st.text)
print ''.join(L)
CSS处理后的最终HTML效果如下:
不过仔细观察,我们输出的微博和新浪微博官网是不一样的。官网会把@和http和#topic#开头的文字改成超链接。如何处理@某某某、#主题#和链接?下面是一个JavaScript正则匹配方案,代码如下:
var g_all = /(\@[^\s\&\:\)\uff09\uff1a\@]+)|(\#[^\#]+\#)|(http\:\/\/[a-zA-Z0-9\_\/\.\-]+)/g;
var g_at = /^\@[^\s\&\:\)\uff09\uff1a\@]+$/;
var g_topic = /^\#[^\#]+\#$/;
var g_link = /^http\:\/\/[a-zA-Z0-9\_\/\.\-]+$/;
function format_text(t) {
ss = t.replace('').split(g_all);
L = []
$.each(ss, function(index, s) {
if (s===undefined)
return;
if (g_at.test(s)) {
L.push('' + s + '');
}
else if (g_topic.test(s)) {
L.push('' + s + '');
}
else if (g_link.test(s)) {
L.push('' + s + '');
}
else {
L.push(s);
}
});
return L.join('');
}
在微博上发帖
发布微博的API是status/update,需要通过POST调用。发布微博代码如下:
@post('/update')
def statuses_update():
text = ctx.request['text']
user = _user_from_session()
client = _create_client()
client.set_access_token(user.auth_token, user.expired_time)
r = client.statuses.update.post(status=text)
return True
本文演示了网站:
本文源代码可从GitHub下载:
网站调用新浪微博内容( 【C#小蜗牛】C#调用微博API的相关知识点内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-31 13:04
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#Invoke 新浪微博 API 示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗
本文文章,小编为大家整理的一篇关于C#调用微博API相关知识点的文章,有需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();
上面的代码示例非常简单。您可以在本地进行测试。感谢您阅读和支持脚本之家。 查看全部
网站调用新浪微博内容(
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#Invoke 新浪微博 API 示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗
本文文章,小编为大家整理的一篇关于C#调用微博API相关知识点的文章,有需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();
上面的代码示例非常简单。您可以在本地进行测试。感谢您阅读和支持脚本之家。
网站调用新浪微博内容(试试卸载重装再试试打开网页微博右上角图标点删除)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-30 04:00
网站调用新浪微博内容出现这个问题,请尝试以下方法1.用safari浏览器打开网站,右上角再选择‘我的设置’;2.选择‘隐私’;3.选择‘微博数据包’,里面有新浪微博调用的那个图片,选择‘删除’即可。
试试卸载重装再试试
打开网页微博右上角图标点删除吧微博就没了的
去新浪微博的网页版登录网页版然后退出登录重新登录再去看看
chrome浏览器打开网页微博右上角微博图标点删除按钮
请尝试重装浏览器
打开网页微博右上角微博图标点删除
和我一样,
刚刚也是问这个问题,然后我设置了,
把微博浏览器都禁用
其实很好,
把登录设置关了就行
回复类似问题;wvr=6&mod=weibotime
你把登录设置解决了吗?
我用microsoftime登陆网页版也没有了
试试把浏览器账号更改为英文试试
是不是twitter把这段内容当作广告了?
我百度之后是这样回复的:chrome登录后网页内容显示微博的图片,但是设置-图片选项-只有那个在浏览器里上传才可用。试过打开微博以及记忆在视频里的只是图片,连视频地址都不显示。我记得以前对微博上传的图片可以发生。如果只有一张图片,全屏会显示图片。
第一次遇到,
遇到同样问题,试试这个方法, 查看全部
网站调用新浪微博内容(试试卸载重装再试试打开网页微博右上角图标点删除)
网站调用新浪微博内容出现这个问题,请尝试以下方法1.用safari浏览器打开网站,右上角再选择‘我的设置’;2.选择‘隐私’;3.选择‘微博数据包’,里面有新浪微博调用的那个图片,选择‘删除’即可。
试试卸载重装再试试
打开网页微博右上角图标点删除吧微博就没了的
去新浪微博的网页版登录网页版然后退出登录重新登录再去看看
chrome浏览器打开网页微博右上角微博图标点删除按钮
请尝试重装浏览器
打开网页微博右上角微博图标点删除
和我一样,
刚刚也是问这个问题,然后我设置了,
把微博浏览器都禁用
其实很好,
把登录设置关了就行
回复类似问题;wvr=6&mod=weibotime
你把登录设置解决了吗?
我用microsoftime登陆网页版也没有了
试试把浏览器账号更改为英文试试
是不是twitter把这段内容当作广告了?
我百度之后是这样回复的:chrome登录后网页内容显示微博的图片,但是设置-图片选项-只有那个在浏览器里上传才可用。试过打开微博以及记忆在视频里的只是图片,连视频地址都不显示。我记得以前对微博上传的图片可以发生。如果只有一张图片,全屏会显示图片。
第一次遇到,
遇到同样问题,试试这个方法,
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-28 01:03
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库使用验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过我个人推荐使用手机微博入口:
对应主界面:
原因是手机数据比较轻,基础数据齐全。可能缺少一些基本的个人信息,如“个人资料补全”、“个人等级”等,同时粉丝ID和关注者ID只能显示20页,但可以作为大部分的语料库使用验证。
通过对比下面两张图,在PC端和手机端,可以发现内容基本一致:
手机端如下图,图片相对较小,内容更加精简。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名,密码) 登录微博
2.VisitPersonPage(user_id) 访问人物网站获取个人信息
3.翻页获取微博内容
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-27 21:03
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php")
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============ 查看全部
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php";)
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-27 21:00
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php")
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============ 查看全部
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟一个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,本来是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码的形式。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php";)
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============
网站调用新浪微博内容(新浪微博API获取数据时数组采集中一个很好的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-26 15:20
调用新浪微博API获取数据时数组采集中的一个好方法。为了获取更新的信息和数据内容,本文主要介绍了新浪微博OAuth2.0授权机制和微博开发平台的使用,python调用微博API等,在文末,提供了python beta版调用微博API的代码。
1.新浪微博OAuth2.0授权机制
官方详情请参考链接:
新浪微博OAuth2.0授权机制
2.使用微博开发者平台
地址:
打开微博开发者平台,使用网站访问WEB。(您可以尝试移动或微服务)。
点击右上角登录:
使用帐户登录或安全登录。如果您没有微博账号,您可以点击立即注册,自行注册一个。
登录后,点击Immediate Access,新建一个应用如下:
在此过程中,应用名称可能与已有的名称冲突,多次更改后创建成功。创建成功后页面会自动跳转如下:
此时,您可以看到新创建的 AppKey 和 App Secret。
还没完,还需要获取OAuth2.0授权回调页面,点击左侧高级信息:
此时可以看到授权回调页面:未填写,取消授权回调页面:未填写。 点击右侧的编辑,输入两个地址:
如果暂时想不出合适的地址,可以填写
点击提交后,微博开发者平台的相关配置就完成了。
3.python调用微博API
环境:pycharm,python3.6
安装包:sinaweibopy-ng
注:由于测试时无法安装网传安装包sinaweibopy,可能是版本不同造成的。官方SDK下载地址如下:,但测试时无法访问,所以下载的安装包为sinaweibopy-ng进行测试,如图:
测试版python调用微博API的完整代码如下:
"""
!/usr/bin/env python3.6
-*- coding: utf-8 -*-
--------------------------------
Description :
--------------------------------
@Time : 2019/4/14 18:40
@File : weiboAPI.py
@Software: PyCharm
--------------------------------
@Author : lixj
@contact : lixj_zj@163.com
"""
from weibo import APIClient
# 1.配置
APP_KEY = '你的APP_KEY'
APP_SECRET = '你的APP_SECRET'
CALLBACK_URL = '你的CALLBACK_URL' # 回调授权页面,用户完成授权后返回的页面
# 2.调用APIClient生成client实例
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
# 3.得到授权页面的url
url = client.get_authorize_url()
print(url)
# 4.点击访问url,在浏览器端获得code
code = '6ecdbf350f0680a6f00cc8c34ae721a6'
req = client.request_access_token(code)
client.set_access_token(req.get('access_token'), req.get('expires_in'))
# 5.调用微博普通读取接口,返回最新的公共微博。
# 接口详情见 https://open.weibo.com/wiki/2/ ... eline
statuses = client.statuses__public_timeline()['statuses']
print(len(statuses))
# 6.输出部分信息
for i in range(0, len(statuses)):
print(u'昵称:' + statuses[i]['user']['screen_name'])
print(u'简单介绍:' + statuses[i]['user']['description'])
print(u'位置:' + statuses[i]['user']['location'])
print(u'微博:' + statuses[i]['text'])
print(statuses[i])
问题 1:
确保您使用此包支持的 Python 版本。目前您正在使用 Python 3.6.
不兼容python版本,安装silangweiboapi-en
问题2:
注册微博开发版,账号设置-高级设置;
授权回调页面不收录在授权设置中。
只需填写完整的信息,对应填写的网站。
问题 3:
输出信息方法:
statuses = client.statuses__public_timeline()['statuses']
问题 4:
每次调用 api 时,连接的代码的值都会改变。
解决方法:待解决。 查看全部
网站调用新浪微博内容(新浪微博API获取数据时数组采集中一个很好的方法)
调用新浪微博API获取数据时数组采集中的一个好方法。为了获取更新的信息和数据内容,本文主要介绍了新浪微博OAuth2.0授权机制和微博开发平台的使用,python调用微博API等,在文末,提供了python beta版调用微博API的代码。
1.新浪微博OAuth2.0授权机制
官方详情请参考链接:
新浪微博OAuth2.0授权机制
2.使用微博开发者平台
地址:
打开微博开发者平台,使用网站访问WEB。(您可以尝试移动或微服务)。
点击右上角登录:
使用帐户登录或安全登录。如果您没有微博账号,您可以点击立即注册,自行注册一个。
登录后,点击Immediate Access,新建一个应用如下:
在此过程中,应用名称可能与已有的名称冲突,多次更改后创建成功。创建成功后页面会自动跳转如下:
此时,您可以看到新创建的 AppKey 和 App Secret。
还没完,还需要获取OAuth2.0授权回调页面,点击左侧高级信息:
此时可以看到授权回调页面:未填写,取消授权回调页面:未填写。 点击右侧的编辑,输入两个地址:
如果暂时想不出合适的地址,可以填写
点击提交后,微博开发者平台的相关配置就完成了。
3.python调用微博API
环境:pycharm,python3.6
安装包:sinaweibopy-ng
注:由于测试时无法安装网传安装包sinaweibopy,可能是版本不同造成的。官方SDK下载地址如下:,但测试时无法访问,所以下载的安装包为sinaweibopy-ng进行测试,如图:
测试版python调用微博API的完整代码如下:
"""
!/usr/bin/env python3.6
-*- coding: utf-8 -*-
--------------------------------
Description :
--------------------------------
@Time : 2019/4/14 18:40
@File : weiboAPI.py
@Software: PyCharm
--------------------------------
@Author : lixj
@contact : lixj_zj@163.com
"""
from weibo import APIClient
# 1.配置
APP_KEY = '你的APP_KEY'
APP_SECRET = '你的APP_SECRET'
CALLBACK_URL = '你的CALLBACK_URL' # 回调授权页面,用户完成授权后返回的页面
# 2.调用APIClient生成client实例
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
# 3.得到授权页面的url
url = client.get_authorize_url()
print(url)
# 4.点击访问url,在浏览器端获得code
code = '6ecdbf350f0680a6f00cc8c34ae721a6'
req = client.request_access_token(code)
client.set_access_token(req.get('access_token'), req.get('expires_in'))
# 5.调用微博普通读取接口,返回最新的公共微博。
# 接口详情见 https://open.weibo.com/wiki/2/ ... eline
statuses = client.statuses__public_timeline()['statuses']
print(len(statuses))
# 6.输出部分信息
for i in range(0, len(statuses)):
print(u'昵称:' + statuses[i]['user']['screen_name'])
print(u'简单介绍:' + statuses[i]['user']['description'])
print(u'位置:' + statuses[i]['user']['location'])
print(u'微博:' + statuses[i]['text'])
print(statuses[i])
问题 1:
确保您使用此包支持的 Python 版本。目前您正在使用 Python 3.6.
不兼容python版本,安装silangweiboapi-en
问题2:
注册微博开发版,账号设置-高级设置;
授权回调页面不收录在授权设置中。
只需填写完整的信息,对应填写的网站。
问题 3:
输出信息方法:
statuses = client.statuses__public_timeline()['statuses']
问题 4:
每次调用 api 时,连接的代码的值都会改变。
解决方法:待解决。
网站调用新浪微博内容( 1.44万字42页原创作品,已通过查重系统摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2021-10-16 11:14
1.44万字42页原创作品,已通过查重系统摘要)
网站微博服务接口插件程序设计
1.4400万字,42页原创作品,已通过复查系统
摘要 微博是一个基于用户关系信息共享、传播和获取的平台。用户可以通过微博实时分享和交流信息,实时分享自己的想法。由于微博更新信息为140个字符(含标点符号)的特点,可以将微博嵌入到网页中,让用户在浏览新闻和娱乐时可以随时随地分享自己的体验和体验,从而节省了复制和转载。重复登录的麻烦。本文基于新浪微博开发的界面插件,使用PHP语言进行编程。用户可通过该插件申请新浪微博官方授权,使用微博账号即刻登录,获取,读取和修改账号信息和微博内容权限。这样,他们就可以随时记录和分享自己的生活。
本文通过详细的流程图、数据和布局,详细介绍了配置SAE平台开发环境、获得新浪微博官方授权、调用微博API接口应用微博基本功能、界面设计和版面布局的主要步骤。具体图片。插件设计分析、插件设计和插件测试的详细讨论。掌握了插件设计的整体思路后,再设计一些好的思路。设计中会详细介绍一些重要插件的授权以及微博API的接口调用信息。我们将介绍系统从创建到插件修改完善的过程。
设计完成后,进行各项功能测试。测试结果表明,该应用基本可以完成所有新增的微博功能,方便喜欢通过微博维护公共关系的用户群体在浏览网页的同时随时保持微博的联系。. 在论文的最后,我总结了整个过程,并对微博应用的未来进行了相关展望。
关键词:微博接口设计API接口调用SDK软件开发包授权 查看全部
网站调用新浪微博内容(
1.44万字42页原创作品,已通过查重系统摘要)
网站微博服务接口插件程序设计
1.4400万字,42页原创作品,已通过复查系统
摘要 微博是一个基于用户关系信息共享、传播和获取的平台。用户可以通过微博实时分享和交流信息,实时分享自己的想法。由于微博更新信息为140个字符(含标点符号)的特点,可以将微博嵌入到网页中,让用户在浏览新闻和娱乐时可以随时随地分享自己的体验和体验,从而节省了复制和转载。重复登录的麻烦。本文基于新浪微博开发的界面插件,使用PHP语言进行编程。用户可通过该插件申请新浪微博官方授权,使用微博账号即刻登录,获取,读取和修改账号信息和微博内容权限。这样,他们就可以随时记录和分享自己的生活。
本文通过详细的流程图、数据和布局,详细介绍了配置SAE平台开发环境、获得新浪微博官方授权、调用微博API接口应用微博基本功能、界面设计和版面布局的主要步骤。具体图片。插件设计分析、插件设计和插件测试的详细讨论。掌握了插件设计的整体思路后,再设计一些好的思路。设计中会详细介绍一些重要插件的授权以及微博API的接口调用信息。我们将介绍系统从创建到插件修改完善的过程。
设计完成后,进行各项功能测试。测试结果表明,该应用基本可以完成所有新增的微博功能,方便喜欢通过微博维护公共关系的用户群体在浏览网页的同时随时保持微博的联系。. 在论文的最后,我总结了整个过程,并对微博应用的未来进行了相关展望。
关键词:微博接口设计API接口调用SDK软件开发包授权
网站调用新浪微博内容(微博爬虫,单机每日千万级的数据ampamp总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-15 16:09
微博爬虫,单机日千万条数据&&吐血整理微博爬虫总结
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没有解决,所以每天上百万的数据里有水。仅爬取友情,这个简单的数据就可以达到数百万。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级的数据量。
但既然坑已经被埋了,就必须填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经完全解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能在复杂爬行中爬行。!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这些都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,需要通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站每页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以例如,如果搜索周期为10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量大,过滤条件也很详细,比如region,其他爬虫需求都可以通过本站爬取,包括比较粗略的高级搜索
微博爬虫经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是因为你买的账号小,操作频繁,可能会被微博盯上。登录时账号异常,会生成非常恶心的验证码,如下图。
遇到这种情况,建议你放弃治疗,不要考虑破解验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不一样的,所以必须构造两个账户池,一个用于cn站点,一个用于com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
请注意,这里的实际抓取速度与您的帐户池大小和计算机带宽有很大关系。如果账户池不大,请求之间的延迟时间会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是,
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
我总觉得我上面搭建的爬虫已经占用了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化,这里推荐Redis-Scrapy,所有爬虫共享一个Redis队列,通过Redis统一给爬虫分配URL,是分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开了。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前稳定运行
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。 查看全部
网站调用新浪微博内容(微博爬虫,单机每日千万级的数据ampamp总结(图))
微博爬虫,单机日千万条数据&&吐血整理微博爬虫总结
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没有解决,所以每天上百万的数据里有水。仅爬取友情,这个简单的数据就可以达到数百万。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级的数据量。
但既然坑已经被埋了,就必须填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经完全解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能在复杂爬行中爬行。!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这些都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这样的需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,需要通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站每页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以例如,如果搜索周期为10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量大,过滤条件也很详细,比如region,其他爬虫需求都可以通过本站爬取,包括比较粗略的高级搜索
微博爬虫经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是因为你买的账号小,操作频繁,可能会被微博盯上。登录时账号异常,会生成非常恶心的验证码,如下图。
遇到这种情况,建议你放弃治疗,不要考虑破解验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不一样的,所以必须构造两个账户池,一个用于cn站点,一个用于com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
请注意,这里的实际抓取速度与您的帐户池大小和计算机带宽有很大关系。如果账户池不大,请求之间的延迟时间会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是,
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
我总觉得我上面搭建的爬虫已经占用了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化,这里推荐Redis-Scrapy,所有爬虫共享一个Redis队列,通过Redis统一给爬虫分配URL,是分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开了。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前稳定运行
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。
网站调用新浪微博内容(python调用API的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-13 11:11
匿名用户
1级
2016-07-25 回答
1.下载SDK
如果使用python调用API,必须先去下一个Python SDK,sinaweibopy
连接地址在这里:
可以用pip快速导入,github连接中的wiki也有入门方法,简单易懂。
2.了解新浪微博的授权机制
在调用API之前,我们首先要了解什么是OAuth 2,也就是新浪微博的授权机制。
在这里连接:%E6%8E%88%E6%9D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E
3.在新浪微博注册应用
每个人都可以通过新浪微博开发者平台注册自己的应用程序。我在网站上注册了应用程序。注册后,每个应用程序都会被分配一个唯一的app key和app secret,这在上面提到的授权机制中是需要的,相当于每个应用程序的标识。
至此,我们可以尝试编写代码来调用新浪微博的API。
4.简单调用API实例
参考了上面很多资料和文档,写了一个简单的调用流程。
# _*_ 编码:utf-8 _*_
从微博导入APIClient
导入浏览器
APP_KEY = "
APP_SECRET = "
CALLBACK_URL = "
#这里是设置回调地址,必须与“高级信息”中的一致
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
url = client.get_authorize_url()
# TODO: 重定向到 url
#打印网址
webbrowser.open_new(url)
# 获取URL参数代码:
代码 = '2fc0b2f5d2985db832fa01fee6bd9316'
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
r = client.request_access_token(代码)
access_token = r.access_token #新浪返回的token,类似abc123xyz456
expires_in = r.expires_in #token过期的UNIX时间:%E6%97%B6%E9%97%B4
# TODO:您可以在此处保存访问令牌
client.set_access_token(access_token, expires_in)
打印 client.friendships.friends.bilateral.ids.get(uid = 12345678)
通过上面的代码,我实现了调用相互关注API的调用,即找到一个特定id的用户互相关注的人的列表。
其中,APP_KEY 和 APP_SECRET 是上一篇文章中分配给每个应用程序的信息。回调地址可以在各个应用的高级信息中看到。需要自己设置,随便设置即可。
更恶心的是代码获取。当我阅读 sinaweibopy 文档时,我不明白这是什么意思。
webbrowser.open_new(url)
这行代码打开浏览器,跳转到授权的界面,然后观察它所在界面的URL。它将显示类似于以下的格式:
看见?
问号后面有个code=……的东西,就是把等号后面的字符串复制下来赋值给code,但是每次程序运行的时候,code不是一成不变的,也就是说每次。
有这样一个手动获取的过程,我觉得很麻烦。后面会自己研究,实现代码的自动获取。如果哪位大神能告诉我,感激不尽~
好了,拿到正确的code后,就可以完成授权认证了,就可以调用微博的API了。至于如何在Python下调用,我复制sinaweibopy上的介绍:
首先查看新浪微博API文档,例如:
API:状态/用户时间线
请求格式:GET
请求参数:
source: string,OAuth授权方式不需要此参数,其他授权方式为必填参数,值为AppKey? 的应用程序。
access_token:字符串,OAuth授权方式为必填参数,其他授权方式不需要此参数,OAuth授权后获取。
uid: int64,要查询的用户ID。
screen_name:字符串,待查询用户的昵称。
(省略其他可选参数)
调用方式:将API的“/”改为“.”,根据请求格式是GET还是POST,调用get()或post(),传入关键字参数,但不包括source和access_token参数:
r = client.statuses.user_timeline.get(uid=123456)
对于 r.statuses 中的 st:
打印 st.text
如果是POST调用,示例代码如下:
r = client.statuses.update.post(status=u'test OAuth 2.0发微博')
如果需要上传文件,传入file-like object参数,示例代码如下:
f = open('/Users/michael/test.png','rb')
r = client.statuses.upload.post(status=u'test OAuth 2.0 微博发图片', pic=f)
f.close() # APIClient 不会自动关闭文件,需要手动关闭
请注意:上传的文件必须是类文件对象,而不是str,因为无法区分str是文件还是字段。一个 str 可以通过 StringIO 打包成一个类文件的对象。 查看全部
网站调用新浪微博内容(python调用API的话)
匿名用户
1级
2016-07-25 回答
1.下载SDK
如果使用python调用API,必须先去下一个Python SDK,sinaweibopy
连接地址在这里:
可以用pip快速导入,github连接中的wiki也有入门方法,简单易懂。
2.了解新浪微博的授权机制
在调用API之前,我们首先要了解什么是OAuth 2,也就是新浪微博的授权机制。
在这里连接:%E6%8E%88%E6%9D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E
3.在新浪微博注册应用
每个人都可以通过新浪微博开发者平台注册自己的应用程序。我在网站上注册了应用程序。注册后,每个应用程序都会被分配一个唯一的app key和app secret,这在上面提到的授权机制中是需要的,相当于每个应用程序的标识。
至此,我们可以尝试编写代码来调用新浪微博的API。
4.简单调用API实例
参考了上面很多资料和文档,写了一个简单的调用流程。
# _*_ 编码:utf-8 _*_
从微博导入APIClient
导入浏览器
APP_KEY = "
APP_SECRET = "
CALLBACK_URL = "
#这里是设置回调地址,必须与“高级信息”中的一致
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
url = client.get_authorize_url()
# TODO: 重定向到 url
#打印网址
webbrowser.open_new(url)
# 获取URL参数代码:
代码 = '2fc0b2f5d2985db832fa01fee6bd9316'
客户端 = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
r = client.request_access_token(代码)
access_token = r.access_token #新浪返回的token,类似abc123xyz456
expires_in = r.expires_in #token过期的UNIX时间:%E6%97%B6%E9%97%B4
# TODO:您可以在此处保存访问令牌
client.set_access_token(access_token, expires_in)
打印 client.friendships.friends.bilateral.ids.get(uid = 12345678)
通过上面的代码,我实现了调用相互关注API的调用,即找到一个特定id的用户互相关注的人的列表。
其中,APP_KEY 和 APP_SECRET 是上一篇文章中分配给每个应用程序的信息。回调地址可以在各个应用的高级信息中看到。需要自己设置,随便设置即可。
更恶心的是代码获取。当我阅读 sinaweibopy 文档时,我不明白这是什么意思。
webbrowser.open_new(url)
这行代码打开浏览器,跳转到授权的界面,然后观察它所在界面的URL。它将显示类似于以下的格式:
看见?
问号后面有个code=……的东西,就是把等号后面的字符串复制下来赋值给code,但是每次程序运行的时候,code不是一成不变的,也就是说每次。
有这样一个手动获取的过程,我觉得很麻烦。后面会自己研究,实现代码的自动获取。如果哪位大神能告诉我,感激不尽~
好了,拿到正确的code后,就可以完成授权认证了,就可以调用微博的API了。至于如何在Python下调用,我复制sinaweibopy上的介绍:
首先查看新浪微博API文档,例如:
API:状态/用户时间线
请求格式:GET
请求参数:
source: string,OAuth授权方式不需要此参数,其他授权方式为必填参数,值为AppKey? 的应用程序。
access_token:字符串,OAuth授权方式为必填参数,其他授权方式不需要此参数,OAuth授权后获取。
uid: int64,要查询的用户ID。
screen_name:字符串,待查询用户的昵称。
(省略其他可选参数)
调用方式:将API的“/”改为“.”,根据请求格式是GET还是POST,调用get()或post(),传入关键字参数,但不包括source和access_token参数:
r = client.statuses.user_timeline.get(uid=123456)
对于 r.statuses 中的 st:
打印 st.text
如果是POST调用,示例代码如下:
r = client.statuses.update.post(status=u'test OAuth 2.0发微博')
如果需要上传文件,传入file-like object参数,示例代码如下:
f = open('/Users/michael/test.png','rb')
r = client.statuses.upload.post(status=u'test OAuth 2.0 微博发图片', pic=f)
f.close() # APIClient 不会自动关闭文件,需要手动关闭
请注意:上传的文件必须是类文件对象,而不是str,因为无法区分str是文件还是字段。一个 str 可以通过 StringIO 打包成一个类文件的对象。
网站调用新浪微博内容(用Python写一个简单的微博爬虫感谢我用(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-13 00:28
请自己回答知乎第一个回答
作为刚刚实施新浪微博爬虫程序的小白,我觉得还是可以回答一下的。
我的爬虫最终效果是:
1、输入用户id,将用户所有的文字微博保存在一个.txt文件中;
2、用户在微博上发布的图片按时间顺序存放在本地文件夹中。
我大致参考了余良的经验:用Python写一个简单的微博爬虫。谢谢
我用的是python3.5版本,说一下大体思路:
准备工作: 1.先确定目标,爬社交。网站 推荐使用手机版的客户端,因为网站的PC版使用了动态加载技术。对于静态网站的习惯,对于爬虫(尤其是新爬虫)来说可能很不方便,所以我们先锁定移动端网站:/(好像是这个),嗯,就是这样. 2. 自动模拟登录微博需要用户的cookies;先手动登录一次微博,在chrome开发者工具中可以轻松捕获cookies。3.获取目标用户的id,这个很简单,以我的女神@子望为例:如图,进入目标的微博首页,红圈内的数字为id:
4、下载相关的第三方库,lxml和BeautifulSoup可供以后使用。
让我们进入正题,使用强大的工具python来接微博:
首先确定字符格式,模拟登录微博,输入目标用户id(避免乱码)
importlib.reload(sys)
#sys.setdefautencoding('utf-8') 在python3中已经没有该方法
默认utf-8
if(len(sys.argv)>=2):
user_id=(int)(sys.argv[1])
else:
user_id=(int)(input(u"请输入用户id"))
cookie={"Cookie":"##填写你的cookies##"}
url='http://weibo.cn/u/%25d%3Ffilte ... er_id
然后,借助lxml库,复制网站的原创html,计算需要爬取的页面数,如下:
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum=(int)(selector.xpath(u'//input[@name="mp"]')[0].attrib['value'])
result="" #储存数据备用
urllist_set=set()
word_count=1
image_count=1
print(u'爬虫准备就绪...')
最后是抓取内容并保存输出
for page in range(1,pageNum+1):
url='http://weibo.cn/u/%25d%3Ffilte ... 3B%25(user_id,page)
lxml=requests.get(url,cookies=cookie).content
selector=etree.HTML(lxml)
content=selector.xpath('//span[@class="ctt"]')
for each in content:
text=each.xpath('string(.)')
if word_count>=4:
text="%d:"%(word_count-3)+text+"\n\n"
else:
text=text+"\n\n"
result=result+text
word_count+=1
soup=BeautifulSoup(lxml,"lxml")
urllist=soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first=0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'],cookies=cookie).url)
image_count+=1
fo=open(u"/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s"%user_id,"w" ,encoding='utf-8', errors='ignore')
fo.write(result)
word_path=os.getcwd()+'%d'%user_id
print(u"文字微博爬取完毕")
fo.close()
link=""
fo2=open("/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s_imageurls"%user_id,"w")
for eachlink in urllist_set:
link=link+eachlink+"\n"
fo2.write(link)
print(u'图片链接爬取完毕')
fo2.close()
if not urllist_set:
print(u'图片不存在')
else:
image_path=os.getcwd()+'\weibopicture'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp=image_path+'/%s.jpg'%x
print(u'正在下载第%s张图片'%x)
try:
urllib.request.urlretrieve(urllib.request.urlopen(imgurl).geturl(),temp)
except:
print(u'图片下载失败:%s'%imgurl)
x+=1
print(u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path))
print(u'原创微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path))
在程序的根目录下,还生成了一个userid_imageurls的文本文件,里面存放着所有爬取到的图片的下载链接,方便手动下载下载失败的图片。
然后就可以在文件夹中打开查看:
我修改后的源码在这里:python-web-spider/新浪微博在master上爬取最终版·RobortHuan/python-web-spider·GitHub
最后总结一下,lxml还是好用的。可以直接抓取html直接分析网页源码;此外,没有大量使用正则表达式;速度据说比urllib快很多,最好用python做爬虫。简单的。
第一次认真回答问题,时间比较短,有些没有说清楚,布局也没有安排好,还望见谅,欢迎大家指正!
以上! 查看全部
网站调用新浪微博内容(用Python写一个简单的微博爬虫感谢我用(图))
请自己回答知乎第一个回答
作为刚刚实施新浪微博爬虫程序的小白,我觉得还是可以回答一下的。
我的爬虫最终效果是:
1、输入用户id,将用户所有的文字微博保存在一个.txt文件中;
2、用户在微博上发布的图片按时间顺序存放在本地文件夹中。
我大致参考了余良的经验:用Python写一个简单的微博爬虫。谢谢
我用的是python3.5版本,说一下大体思路:
准备工作: 1.先确定目标,爬社交。网站 推荐使用手机版的客户端,因为网站的PC版使用了动态加载技术。对于静态网站的习惯,对于爬虫(尤其是新爬虫)来说可能很不方便,所以我们先锁定移动端网站:/(好像是这个),嗯,就是这样. 2. 自动模拟登录微博需要用户的cookies;先手动登录一次微博,在chrome开发者工具中可以轻松捕获cookies。3.获取目标用户的id,这个很简单,以我的女神@子望为例:如图,进入目标的微博首页,红圈内的数字为id:
4、下载相关的第三方库,lxml和BeautifulSoup可供以后使用。
让我们进入正题,使用强大的工具python来接微博:
首先确定字符格式,模拟登录微博,输入目标用户id(避免乱码)
importlib.reload(sys)
#sys.setdefautencoding('utf-8') 在python3中已经没有该方法
默认utf-8
if(len(sys.argv)>=2):
user_id=(int)(sys.argv[1])
else:
user_id=(int)(input(u"请输入用户id"))
cookie={"Cookie":"##填写你的cookies##"}
url='http://weibo.cn/u/%25d%3Ffilte ... er_id
然后,借助lxml库,复制网站的原创html,计算需要爬取的页面数,如下:
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum=(int)(selector.xpath(u'//input[@name="mp"]')[0].attrib['value'])
result="" #储存数据备用
urllist_set=set()
word_count=1
image_count=1
print(u'爬虫准备就绪...')
最后是抓取内容并保存输出
for page in range(1,pageNum+1):
url='http://weibo.cn/u/%25d%3Ffilte ... 3B%25(user_id,page)
lxml=requests.get(url,cookies=cookie).content
selector=etree.HTML(lxml)
content=selector.xpath('//span[@class="ctt"]')
for each in content:
text=each.xpath('string(.)')
if word_count>=4:
text="%d:"%(word_count-3)+text+"\n\n"
else:
text=text+"\n\n"
result=result+text
word_count+=1
soup=BeautifulSoup(lxml,"lxml")
urllist=soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first=0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'],cookies=cookie).url)
image_count+=1
fo=open(u"/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s"%user_id,"w" ,encoding='utf-8', errors='ignore')
fo.write(result)
word_path=os.getcwd()+'%d'%user_id
print(u"文字微博爬取完毕")
fo.close()
link=""
fo2=open("/Users/wanghuan/AppData/Local/Programs/Python/Python35/爬虫/%s_imageurls"%user_id,"w")
for eachlink in urllist_set:
link=link+eachlink+"\n"
fo2.write(link)
print(u'图片链接爬取完毕')
fo2.close()
if not urllist_set:
print(u'图片不存在')
else:
image_path=os.getcwd()+'\weibopicture'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp=image_path+'/%s.jpg'%x
print(u'正在下载第%s张图片'%x)
try:
urllib.request.urlretrieve(urllib.request.urlopen(imgurl).geturl(),temp)
except:
print(u'图片下载失败:%s'%imgurl)
x+=1
print(u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path))
print(u'原创微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path))
在程序的根目录下,还生成了一个userid_imageurls的文本文件,里面存放着所有爬取到的图片的下载链接,方便手动下载下载失败的图片。
然后就可以在文件夹中打开查看:
我修改后的源码在这里:python-web-spider/新浪微博在master上爬取最终版·RobortHuan/python-web-spider·GitHub
最后总结一下,lxml还是好用的。可以直接抓取html直接分析网页源码;此外,没有大量使用正则表达式;速度据说比urllib快很多,最好用python做爬虫。简单的。
第一次认真回答问题,时间比较短,有些没有说清楚,布局也没有安排好,还望见谅,欢迎大家指正!
以上!
网站调用新浪微博内容(目标爬取新浪微博用户数据,免费领取Python学习教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-12 14:31
目标
抓取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、关注数、微博数、微博内容、转发数、评论数、点赞数、发布时间、来源、是原创 还是转发。(本文以GUCCI为例)
想学Python。关注小编,私信【学习资料】,即可免费领取全套系统板Python学习教程!
方法
+ 使用 selenium 模拟爬虫
+ 使用 BeautifulSoup 解析 HTML
结果显示
步骤分解
1.选择抓取目标网址
首先,在准备开始爬取之前,您必须弄清楚要爬取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比较而言,移动端基本收录了你想要的所有数据,而移动端相对PC端是轻量级的。
下面是GUCCI手机和PC的网页展示。
2.模拟登录
在微博移动端设置爬取数据后,就可以模拟登录了。
模拟登录网址
登陆页面下方
模拟登录代码
3.获取用户的微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数等。
4. 根据爬取的最大页数循环爬取所有数据
得到最大页数后,直接通过循环抓取每个页面的数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、微博发布时间、微博来源、是否原创或转发。
5.获取所有数据后,可以写入csv文件或者excel
最终结果如上图所示!!!!
完整的微博爬虫就在这里解决!!! 查看全部
网站调用新浪微博内容(目标爬取新浪微博用户数据,免费领取Python学习教程)
目标
抓取新浪微博用户数据,包括以下字段:id、昵称、粉丝数、关注数、微博数、微博内容、转发数、评论数、点赞数、发布时间、来源、是原创 还是转发。(本文以GUCCI为例)
想学Python。关注小编,私信【学习资料】,即可免费领取全套系统板Python学习教程!
方法
+ 使用 selenium 模拟爬虫
+ 使用 BeautifulSoup 解析 HTML
结果显示
步骤分解
1.选择抓取目标网址
首先,在准备开始爬取之前,您必须弄清楚要爬取哪个网址。新浪微博网站分为网页版和手机版两种。大部分微博数据抓取都会选择抓取移动端,因为相比较而言,移动端基本收录了你想要的所有数据,而移动端相对PC端是轻量级的。
下面是GUCCI手机和PC的网页展示。
2.模拟登录
在微博移动端设置爬取数据后,就可以模拟登录了。
模拟登录网址
登陆页面下方
模拟登录代码
3.获取用户的微博页码
登录后,您可以输入您要抓取的商家信息。因为每个商家的微博数量不同,对应的微博页码也不同。这里先抓取商家的微博页码。同时,爬取那些公开的信息,比如用户uid、用户名、微博数、关注数、粉丝数等。
4. 根据爬取的最大页数循环爬取所有数据
得到最大页数后,直接通过循环抓取每个页面的数据。抓取到的数据包括微博内容、转发数、评论数、点赞数、微博发布时间、微博来源、是否原创或转发。
5.获取所有数据后,可以写入csv文件或者excel
最终结果如上图所示!!!!
完整的微博爬虫就在这里解决!!!
网站调用新浪微博内容(Python学习交流:新浪微博反扒去解析网页了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-06 16:20
欢迎加入Python学习交流QQ群:201044047不小聊!名额有限!如果你不喜欢它,请不要进入!
Python
最近事情比较多,所以上周写的新浪微博爬虫被拖到现在,但不得不说新浪微博的反贴,我只想说我真的服了。mysql
爬取数据前的准备
跑到右边的老大说,这次没有限制爬取什么内容,但是作为参考,有兴趣的可以做一下:正则表达式
参考思路
当我看到这个时,我觉得很有趣,我想制作很多。所以我个人的想法是找一个粉丝多的人分析他的分析信息,然后分析他的粉丝的粉丝。等等(最好去感受一下解析初始用户关注的人的粉丝,因为他的粉丝比较多,他关注的人的粉丝肯定不会少),但是后来我想放弃这个想法。真的有很多问题。嗯,我很少说废话。来看看我抓到的信息:sql
一般来说,只能获得这么多信息。由于很多人的信息不完善,所以很多人先被抓起来进行检测。数据库
一个基本的想法
确认了我们要找的信息,下一步就是解析网页(一个大问题即将出现)。在我看来,获取网页的过程中遇到过:1.解析源码,2.catch Package(json),但新浪微博更烦。是在js里面,没有加载(只能用regular或者selenium来模拟浏览器)。看到这里,我想了想,问罗罗盘有没有别的办法。如果它不起作用,我将使用硒。他说还是建议正规化。分析速度更快。硒是最后的选择。无论正确与否,您都可以使用在线测试工具进行定期测试。无需一遍又一遍地运行代码。json
源代码+我的信息
关注 + 粉丝 + 微博
找到这个资料,盯着源码看了半天,看的头大了,其实是ctrl+f浏览器的快捷方式
搜索栏
既然我们都知道信息在哪里,那么就该写正则匹配信息了。这个只能慢慢写,可以练习正则表达式。曲奇饼
URL+粉丝分页问题
我的主页网址
我们先来看一个例子:
这个网址,提醒大家直接使用的时候是看不到首页信息的,但是在代码的测试源码中,我们可以看到位置重定向的链接。#后面的部分替换为&retcode=6102,所以URL应该是:,
我点击了链接并进行了测试。我看到的内容和第一个链接一样,还有一点。我们以后得到的所有链接都要替换#后面的内容,举个例子:app
urls = re.findall(r'class=\\"t_link S_txt1\\" href=\\"(.*?)\\"',data)
careUrl = urls[0].replace('\\','').replace('#place','&retcode=6102')
fansUrl = urls[1].replace('\\','').replace('#place','&retcode=6102')
wbUrl = urls[2].replace('\\','').replace('#place','&retcode=6102')
如果我们不更换它,我们得到它后仍然无法获取源代码。
粉丝分页问题
本来想可以解析我的一个粉丝,获取大量数据,但是还是卡在系统限制(爬的时候,第五页后就回不来数据了)dom
系统限制
看到这个,系统限制了,这是什么,嗯,我只能看到100个粉丝的信息,只能继续写下去了。因此,我们只需要考虑5页的数据。如果总页数大于 5 页,则按 5 页处理。如果页数少于5页,则可以正常写入。:
在这两个 URL 之后,我们可以看到区别在后半部分。除了用&retcode=6102替换#后面的部分,我还要稍微改动一下,下面是哪个?进行后续更改后,我们将从第二页构建 URL。
示例代码:
urls = ['http://weibo.com/p/1005051497035431/follow?relate=fans&page={}&retcode=6102'.format(i) for i in range(2,int(pages)+1)]
那么URL分页问题就解决了,可以说是解决了一个问题。如果你认为新浪微博只有这些反扒,那就太天真了,我们继续往下看。
布满荆棘的路
整个收购过程都是各种坑。之前我们主要讲了数据获取的方法以及URL和粉丝页面的问题。现在让我们来看看新浪微博上的一些反采摘:
首先,请求时必须添加cookie进行身份验证。这很正常,但在这里真的不是灵丹妙药。因为cookies也是有生命周期的,所以获取我的信息是没有问题的。但是,在获取粉丝页面信息时,出现了过期问题。怎么解决,想了半天,终于通过selenium模拟登录解决了。这个后面会详细解释,总之这点要注意。
然后,还有一点是,并不是每个人的源代码都是一样的。我怎样才能比较它?登录微博后,查看你的粉丝页面。源代码与您搜索的用户的源代码相同。不,其他的源代码信息也不同,我真的指出一件事,大公司很棒。
用户源代码
自己的源代码
通过自学应该可以看出区别,所以新浪微博整体来说还是比较难爬的。
代码
代码部分确实组织得不好,问题也很多,但是我可以贴出核心代码供大家参考讨论(感觉自己写的有点乱)
说一下代码结构,两个主类和三个辅助类:
两个主要类:第一个类解析粉丝id,另一个类解析详细信息(解析时会判断id是否已经解析)
三个辅助类:第一个模拟登录并返回cookies(在爬取数据的过程中,好像只调用了一次,多半是代码问题),第二个辅助类返回一个随机代理,第三个辅助类类将我的信息写入 mysql。
下面我把两个主类的源码贴出来,去掉辅助类的其余信息,还是可以运行的。
1.fansSpider.py
<p>#-*- coding:utf-8 -*- import requests import re import random from proxy import Proxy from getCookie import COOKIE from time import sleep from store_mysql import Mysql from weibo_spider import weiboSpider class fansSpider(object): headers = [ {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"} ] def __init__(self): self.wbspider = weiboSpider() self.proxie = Proxy() self.cookie = COOKIE() self.cookies = self.cookie.getcookie() field = ['id'] self.mysql = Mysql('sinaid', field, len(field) + 1) self.key = 1 def getData(self,url): self.url = url proxies = self.proxie.popip() print self.cookies print proxies r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) while r.status_code != requests.codes.ok: proxies = self.proxie.popip() r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) data = requests.get(self.url,headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies,timeout=20).text #print data infos = re.findall(r'fnick=(.+?)&f=1\\',data) if infos is None: self.cookies = self.cookie.getcookie() data = requests.get(self.url, headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies, timeout=20).text infos = re.findall(r'fnick=(.+?)&f=1\\', data) fans = [] for info in infos: fans.append(info.split('&')[0]) try: totalpage = re.findall(r'Pl_Official_HisRelation__6\d+\\">(\d+)(\d+)(.*?)(.+?)(\d*)(.+?)(.+?) 查看全部
网站调用新浪微博内容(Python学习交流:新浪微博反扒去解析网页了)
欢迎加入Python学习交流QQ群:201044047不小聊!名额有限!如果你不喜欢它,请不要进入!
Python
最近事情比较多,所以上周写的新浪微博爬虫被拖到现在,但不得不说新浪微博的反贴,我只想说我真的服了。mysql
爬取数据前的准备
跑到右边的老大说,这次没有限制爬取什么内容,但是作为参考,有兴趣的可以做一下:正则表达式
参考思路
当我看到这个时,我觉得很有趣,我想制作很多。所以我个人的想法是找一个粉丝多的人分析他的分析信息,然后分析他的粉丝的粉丝。等等(最好去感受一下解析初始用户关注的人的粉丝,因为他的粉丝比较多,他关注的人的粉丝肯定不会少),但是后来我想放弃这个想法。真的有很多问题。嗯,我很少说废话。来看看我抓到的信息:sql
一般来说,只能获得这么多信息。由于很多人的信息不完善,所以很多人先被抓起来进行检测。数据库
一个基本的想法
确认了我们要找的信息,下一步就是解析网页(一个大问题即将出现)。在我看来,获取网页的过程中遇到过:1.解析源码,2.catch Package(json),但新浪微博更烦。是在js里面,没有加载(只能用regular或者selenium来模拟浏览器)。看到这里,我想了想,问罗罗盘有没有别的办法。如果它不起作用,我将使用硒。他说还是建议正规化。分析速度更快。硒是最后的选择。无论正确与否,您都可以使用在线测试工具进行定期测试。无需一遍又一遍地运行代码。json
源代码+我的信息
关注 + 粉丝 + 微博
找到这个资料,盯着源码看了半天,看的头大了,其实是ctrl+f浏览器的快捷方式
搜索栏
既然我们都知道信息在哪里,那么就该写正则匹配信息了。这个只能慢慢写,可以练习正则表达式。曲奇饼
URL+粉丝分页问题
我的主页网址
我们先来看一个例子:
这个网址,提醒大家直接使用的时候是看不到首页信息的,但是在代码的测试源码中,我们可以看到位置重定向的链接。#后面的部分替换为&retcode=6102,所以URL应该是:,
我点击了链接并进行了测试。我看到的内容和第一个链接一样,还有一点。我们以后得到的所有链接都要替换#后面的内容,举个例子:app
urls = re.findall(r'class=\\"t_link S_txt1\\" href=\\"(.*?)\\"',data)
careUrl = urls[0].replace('\\','').replace('#place','&retcode=6102')
fansUrl = urls[1].replace('\\','').replace('#place','&retcode=6102')
wbUrl = urls[2].replace('\\','').replace('#place','&retcode=6102')
如果我们不更换它,我们得到它后仍然无法获取源代码。
粉丝分页问题
本来想可以解析我的一个粉丝,获取大量数据,但是还是卡在系统限制(爬的时候,第五页后就回不来数据了)dom
系统限制
看到这个,系统限制了,这是什么,嗯,我只能看到100个粉丝的信息,只能继续写下去了。因此,我们只需要考虑5页的数据。如果总页数大于 5 页,则按 5 页处理。如果页数少于5页,则可以正常写入。:
在这两个 URL 之后,我们可以看到区别在后半部分。除了用&retcode=6102替换#后面的部分,我还要稍微改动一下,下面是哪个?进行后续更改后,我们将从第二页构建 URL。
示例代码:
urls = ['http://weibo.com/p/1005051497035431/follow?relate=fans&page={}&retcode=6102'.format(i) for i in range(2,int(pages)+1)]
那么URL分页问题就解决了,可以说是解决了一个问题。如果你认为新浪微博只有这些反扒,那就太天真了,我们继续往下看。
布满荆棘的路
整个收购过程都是各种坑。之前我们主要讲了数据获取的方法以及URL和粉丝页面的问题。现在让我们来看看新浪微博上的一些反采摘:
首先,请求时必须添加cookie进行身份验证。这很正常,但在这里真的不是灵丹妙药。因为cookies也是有生命周期的,所以获取我的信息是没有问题的。但是,在获取粉丝页面信息时,出现了过期问题。怎么解决,想了半天,终于通过selenium模拟登录解决了。这个后面会详细解释,总之这点要注意。
然后,还有一点是,并不是每个人的源代码都是一样的。我怎样才能比较它?登录微博后,查看你的粉丝页面。源代码与您搜索的用户的源代码相同。不,其他的源代码信息也不同,我真的指出一件事,大公司很棒。
用户源代码
自己的源代码
通过自学应该可以看出区别,所以新浪微博整体来说还是比较难爬的。
代码
代码部分确实组织得不好,问题也很多,但是我可以贴出核心代码供大家参考讨论(感觉自己写的有点乱)
说一下代码结构,两个主类和三个辅助类:
两个主要类:第一个类解析粉丝id,另一个类解析详细信息(解析时会判断id是否已经解析)
三个辅助类:第一个模拟登录并返回cookies(在爬取数据的过程中,好像只调用了一次,多半是代码问题),第二个辅助类返回一个随机代理,第三个辅助类类将我的信息写入 mysql。
下面我把两个主类的源码贴出来,去掉辅助类的其余信息,还是可以运行的。
1.fansSpider.py
<p>#-*- coding:utf-8 -*- import requests import re import random from proxy import Proxy from getCookie import COOKIE from time import sleep from store_mysql import Mysql from weibo_spider import weiboSpider class fansSpider(object): headers = [ {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3"}, {"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"}, {"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"} ] def __init__(self): self.wbspider = weiboSpider() self.proxie = Proxy() self.cookie = COOKIE() self.cookies = self.cookie.getcookie() field = ['id'] self.mysql = Mysql('sinaid', field, len(field) + 1) self.key = 1 def getData(self,url): self.url = url proxies = self.proxie.popip() print self.cookies print proxies r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) while r.status_code != requests.codes.ok: proxies = self.proxie.popip() r = requests.get("https://www.baidu.com", headers=random.choice(self.headers), proxies=proxies) data = requests.get(self.url,headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies,timeout=20).text #print data infos = re.findall(r'fnick=(.+?)&f=1\\',data) if infos is None: self.cookies = self.cookie.getcookie() data = requests.get(self.url, headers=random.choice(self.headers), cookies=self.cookies, proxies=proxies, timeout=20).text infos = re.findall(r'fnick=(.+?)&f=1\\', data) fans = [] for info in infos: fans.append(info.split('&')[0]) try: totalpage = re.findall(r'Pl_Official_HisRelation__6\d+\\">(\d+)(\d+)(.*?)(.+?)(\d*)(.+?)(.+?)
网站调用新浪微博内容(博客回复改版的事件、研究了新浪的web.api成功调用的新浪表情组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-02 10:33
最近在准备博客响应改版事件,研究了新浪的web.api成功调用新浪的表情。
给大家分享一个很实用的东西,希望对大家有帮助
一起来享受手术的效果吧
是不是很耀眼?让我们来看看如何实现它。
JS自定义hashtable代码如下
//自定义hashtable
function Hashtable() {
this._hash = new Object();
this.put = function(key, value) {
if (typeof (key) != "undefined") {
if (this.containsKey(key) == false) {
this._hash[key] = typeof (value) == "undefined" ? null : value;
return true;
} else {
return false;
}
} else {
return false;
}
}
this.remove = function(key) { delete this._hash[key]; }
this.size =
function() { var i = 0; for (var k in this._hash) { i ; } return i; }
this.get = function(key) { return this._hash[key]; }
this.containsKey =
function(key) { return typeof (this._hash[key]) != "undefined"; }
this.clear =
function() { for (var k in this._hash) { delete this._hash[k]; } }
}
初始化缓存并只加载一次页面
$(function() {
$.ajax( {
dataType : ´json´,
url : ´json/jquery.sinaEmotion.json´,
success : function(response) {
var data = response.data;
for ( var i in data) {
if (data[i].category == ´´) {
data[i].category = ´默认´;
}
if (emotions[data[i].category] == undefined) {
emotions[data[i].category] = new Array();
categorys.push(data[i].category);
}
emotions[data[i].category].push( {
name : data[i].phrase,
icon : data[i].icon
});
uSinaEmotionsHt.put(data[i].phrase, data[i].icon);
}
}
});
});
代替
function AnalyticEmotion(s) {
if(typeof (s) != "undefined") {
var sArr = s.match(/[.*?]/g);
for(var i = 0; i < sArr.length; i ){
if(uSinaEmotionsHt.containsKey(sArr[i])) {
var reStr = "";
s = s.replace(sArr[i], reStr);
}
}
}
return s;
}
显示类别
function showCategorys(){
var page = arguments[0]?arguments[0]:0;
if(page < 0 || page >= categorys.length / 5){
return;
}
$(´#emotions .categorys´).html(´´);
cat_page = page;
for(var i = page * 5; i < (page 1) * 5 && i < categorys.length; i){
$(´#emotions .categorys´)
.append($(´´
categorys[i] ´´));
}
$(´#emotions .categorys a´).click(function(){
showEmotions($(this).text());
});
$(´#emotions .categorys a´).each(function(){
if($(this).text() == cat_current){
$(this).addClass(´current´);
}
});
}
显示表情
function showEmotions(){
var category = arguments[0]?arguments[0]:´默认´;
var page = arguments[1]?arguments[1] - 1:0;
$(´#emotions .containersina´).html(´´);
$(´#emotions .page´).html(´´);
cat_current = category;
for(var i = page * 72; i < (page 1) * 72 && i < emotions[category].length; i){
$(´#emotions .containersina´)
.append($(´´
emotions[category][i].icon ´´));
}
$(´#emotions .containersina a´).click(function(){
target.insertText($(this).attr(´title´));
$(´#emotions´).remove();
});
for(var i = 1; i < emotions[category].length / 72 1; i){
$(´#emotions .page´).append($(´´ i ´´));
}
$(´#emotions .page a´).click(function(){
showEmotions(category, $(this).text());
});
$(´#emotions .categorys a.current´).removeClass(´current´);
$(´#emotions .categorys a´).each(function(){
if($(this).text() == category){
$(this).addClass(´current´);
}
});
}
HTML代码如下
JQuery新浪1630个表情插件(带解析方法)
完美兼容IE6 所有浏览器
<br />
<br />
当然,在整个代码实现之前,还得引入对应的JS和CSS文件,对应的文件在源码中。
最后给大家提供一个源码下载链接:密码:6xe9
还有一个本地版本:密码:6s3r
如果资源对你有帮助,浏览后收获很多,何乐而不为,你的鼓励是我继续写博客的最大动力 查看全部
网站调用新浪微博内容(博客回复改版的事件、研究了新浪的web.api成功调用的新浪表情组件)
最近在准备博客响应改版事件,研究了新浪的web.api成功调用新浪的表情。
给大家分享一个很实用的东西,希望对大家有帮助
一起来享受手术的效果吧
是不是很耀眼?让我们来看看如何实现它。
JS自定义hashtable代码如下
//自定义hashtable
function Hashtable() {
this._hash = new Object();
this.put = function(key, value) {
if (typeof (key) != "undefined") {
if (this.containsKey(key) == false) {
this._hash[key] = typeof (value) == "undefined" ? null : value;
return true;
} else {
return false;
}
} else {
return false;
}
}
this.remove = function(key) { delete this._hash[key]; }
this.size =
function() { var i = 0; for (var k in this._hash) { i ; } return i; }
this.get = function(key) { return this._hash[key]; }
this.containsKey =
function(key) { return typeof (this._hash[key]) != "undefined"; }
this.clear =
function() { for (var k in this._hash) { delete this._hash[k]; } }
}
初始化缓存并只加载一次页面
$(function() {
$.ajax( {
dataType : ´json´,
url : ´json/jquery.sinaEmotion.json´,
success : function(response) {
var data = response.data;
for ( var i in data) {
if (data[i].category == ´´) {
data[i].category = ´默认´;
}
if (emotions[data[i].category] == undefined) {
emotions[data[i].category] = new Array();
categorys.push(data[i].category);
}
emotions[data[i].category].push( {
name : data[i].phrase,
icon : data[i].icon
});
uSinaEmotionsHt.put(data[i].phrase, data[i].icon);
}
}
});
});
代替
function AnalyticEmotion(s) {
if(typeof (s) != "undefined") {
var sArr = s.match(/[.*?]/g);
for(var i = 0; i < sArr.length; i ){
if(uSinaEmotionsHt.containsKey(sArr[i])) {
var reStr = "";
s = s.replace(sArr[i], reStr);
}
}
}
return s;
}
显示类别
function showCategorys(){
var page = arguments[0]?arguments[0]:0;
if(page < 0 || page >= categorys.length / 5){
return;
}
$(´#emotions .categorys´).html(´´);
cat_page = page;
for(var i = page * 5; i < (page 1) * 5 && i < categorys.length; i){
$(´#emotions .categorys´)
.append($(´´
categorys[i] ´´));
}
$(´#emotions .categorys a´).click(function(){
showEmotions($(this).text());
});
$(´#emotions .categorys a´).each(function(){
if($(this).text() == cat_current){
$(this).addClass(´current´);
}
});
}
显示表情
function showEmotions(){
var category = arguments[0]?arguments[0]:´默认´;
var page = arguments[1]?arguments[1] - 1:0;
$(´#emotions .containersina´).html(´´);
$(´#emotions .page´).html(´´);
cat_current = category;
for(var i = page * 72; i < (page 1) * 72 && i < emotions[category].length; i){
$(´#emotions .containersina´)
.append($(´´
emotions[category][i].icon ´´));
}
$(´#emotions .containersina a´).click(function(){
target.insertText($(this).attr(´title´));
$(´#emotions´).remove();
});
for(var i = 1; i < emotions[category].length / 72 1; i){
$(´#emotions .page´).append($(´´ i ´´));
}
$(´#emotions .page a´).click(function(){
showEmotions(category, $(this).text());
});
$(´#emotions .categorys a.current´).removeClass(´current´);
$(´#emotions .categorys a´).each(function(){
if($(this).text() == category){
$(this).addClass(´current´);
}
});
}
HTML代码如下
JQuery新浪1630个表情插件(带解析方法)
完美兼容IE6 所有浏览器
<br />
<br />
当然,在整个代码实现之前,还得引入对应的JS和CSS文件,对应的文件在源码中。
最后给大家提供一个源码下载链接:密码:6xe9
还有一个本地版本:密码:6s3r
如果资源对你有帮助,浏览后收获很多,何乐而不为,你的鼓励是我继续写博客的最大动力
网站调用新浪微博内容(百度、A5站长网等多个使用com域名大站解析出现问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-01 14:15
项目招商找A5快速获取精准代理商名单
A5站长网站1月21日消息:今天下午15点20分左右,大量网友反映新浪、百度等知名网站无法访问,A5站长也收到多位站长反馈网站打不开,A5下的很多网站包括等也打不开。根据ping结果,很多使用com域名的主要网站,包括新浪微博、百度、A5站长等,似乎都解析为65.49.2.178案件。DNSPod在其官方微博上表示,国内所有gTLD的根都异常,已联系相关机构协调处理。(杨洋)
DNSPoD 相关公告
ping 百度结果
pingA5站点长网显示结果
之前在新浪微博上显示的ping结果
新浪微博已恢复正常
据了解,国内三分之二使用com域名的网站DNS解析存在问题。目前新浪微博DNS已恢复正常,但百度仍解析为65.49.2.178无法访问,目前正在逐步恢复。笔者提醒网友,如果网站因DNS解析问题无法访问,可将网络连接属性中的DNS设置为8.8.8.8,正常访问是可能的。
最新消息,根据百度速乐从电信部门获得的信息,各地区DNS故障已经恢复,运营商清除了各地区递归DNS上的DNS缓存。
提示:
什么是 DNS
DNS是Domain Name System的缩写,是互联网的核心服务。作为一个可以将域名和IP地址相互映射的分布式数据库,它可以让人们更轻松地访问互联网,而无需记住一串机器可以直接读取的IP号码。
人们习惯于记住域名,但机器只能识别 IP 地址。域名和IP地址是一一对应的。它们之间的转换称为域名解析。域名解析需要由专门的域名解析服务器完成。该过程是自动的。当您的网站完成上传到您的虚拟主机后,您可以直接在浏览器中输入IP地址浏览您的网站,或者输入域名查询您的网站虽然获取的内容相同,调用过程不同。输入IP地址是直接从主机调用内容,输入的域名是通过域名解析服务器指向对应主机的IP地址,然后调用<
更多信息请关注A5站长官方微信公众号。可搜索微信“iadmin5”或扫描下方二维码
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网站调用新浪微博内容(百度、A5站长网等多个使用com域名大站解析出现问题)
项目招商找A5快速获取精准代理商名单
A5站长网站1月21日消息:今天下午15点20分左右,大量网友反映新浪、百度等知名网站无法访问,A5站长也收到多位站长反馈网站打不开,A5下的很多网站包括等也打不开。根据ping结果,很多使用com域名的主要网站,包括新浪微博、百度、A5站长等,似乎都解析为65.49.2.178案件。DNSPod在其官方微博上表示,国内所有gTLD的根都异常,已联系相关机构协调处理。(杨洋)
DNSPoD 相关公告
ping 百度结果
pingA5站点长网显示结果
之前在新浪微博上显示的ping结果
新浪微博已恢复正常
据了解,国内三分之二使用com域名的网站DNS解析存在问题。目前新浪微博DNS已恢复正常,但百度仍解析为65.49.2.178无法访问,目前正在逐步恢复。笔者提醒网友,如果网站因DNS解析问题无法访问,可将网络连接属性中的DNS设置为8.8.8.8,正常访问是可能的。
最新消息,根据百度速乐从电信部门获得的信息,各地区DNS故障已经恢复,运营商清除了各地区递归DNS上的DNS缓存。
提示:
什么是 DNS
DNS是Domain Name System的缩写,是互联网的核心服务。作为一个可以将域名和IP地址相互映射的分布式数据库,它可以让人们更轻松地访问互联网,而无需记住一串机器可以直接读取的IP号码。
人们习惯于记住域名,但机器只能识别 IP 地址。域名和IP地址是一一对应的。它们之间的转换称为域名解析。域名解析需要由专门的域名解析服务器完成。该过程是自动的。当您的网站完成上传到您的虚拟主机后,您可以直接在浏览器中输入IP地址浏览您的网站,或者输入域名查询您的网站虽然获取的内容相同,调用过程不同。输入IP地址是直接从主机调用内容,输入的域名是通过域名解析服务器指向对应主机的IP地址,然后调用<
更多信息请关注A5站长官方微信公众号。可搜索微信“iadmin5”或扫描下方二维码
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-01 05:02
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用方法。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,我原本是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php")
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者的GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============ 查看全部
网站调用新浪微博内容(如果你想用Python模拟登陆新浪微博,这篇文章绝对你!)
更新:上一版本使用了自用框架PSpider的部分功能。更新后的版本只使用requests库,改写成Class的形式,方便大家运行调试。
-------------------------------------------------- -------------------------------------------------- ----
干货来了,想学Python模拟登录,想知道如何使用抓包工具一步步搞定网站登录流程,想破解网站@ > 登录加密算法,那么这篇文章文章绝对值得你!
标题随意开头,不喜欢,但是这个文章真的很详细的分析了新浪微博的登录过程,包括各种加密算法分析、验证码分析、跳转分析等等。还有登录代码供参考。代码在文章末尾给出,同时上传到GitHub。你可以参考一下。
登录代码地址:GitHub-xianhu/LearnPython:以代码的形式学习Python。
代码中用到了爬虫框架PSpider中的一些功能。看框架:一个非常简洁的Python爬虫框架。
如果你需要学习爬虫的基础知识,请移步:一个很“水”的Python爬虫入门代码文件。
如果想用Python模拟登录新浪微博,首先得去百度了解一些相关知识,了解前人做过一些工作。通过这里搜索,可以知道新浪微博在登录时对用户名和密码进行了加密,也知道了加密算法(b64encode、rsa等)。这是一个总体印象。我会一步一步告诉你如何发现新浪微博的加密算法。毕竟教人钓鱼不如教人钓鱼!
这里用到的工具是Charles,Mac下的抓包工具。Windows 下对应的是 Fiddler。如果您不知道如何使用它或不熟悉它,建议先安装一个并熟悉该软件的使用方法。
好了,准备工作完成,废话不多说,开始干货!
(1)打开Charles后,打开新浪微博的登录页面,输入用户名、密码和验证码,再次登录。此时Charles将把整个登录过程留给后面分析。
(2)分析的第一步就是要知道如何加密用户名。在Charles中搜索“username”。为什么要这样搜索?如果做网站,估计90%的用户都会给name这个变量命名为username!搜索后发现只有loginLayers.js这个文件收录username,这个文件的命名也说明跟这个文件有关,凭经验应该可以判断这个文件很重要。
(3)复制这个文件的内容,放到一个文本文件中,搜索username,你会发现下图中这几行代码,然后就知道用户名的加密方法了。user name加密方法很简单,encode后跟个base64就可以了。具体怎么写Python,自己看代码。
(4)用户名是加密的,密码应该是加密的。继续在这个文件中搜索密码,得到:
可以推断,this.login中的参数b应该是password。查看登录功能,可以得到:
这里调用loginByXMLHttpRequest函数,传入参数b,即password,于是我们继续搜索loginByXMLHttpRequest,得到:
这里调用了makeXMLRequestQuery函数,传入了参数b,即password,于是我们继续搜索makeXMLRequestQuery,得到:
这里调用makeRequest函数,传入参数b,即password,于是我们继续搜索makeRequest,得到:
在这里可以清晰的看到密码加密的过程。具体如何实现Python,还是自己看代码。但是这里有一个问题。密码加密的时候,有几个参数需要传入,比如nonce,servertime,rsakv等等,这是什么鬼?继续往下看。
(5)在Charles中搜索servertime,会得到一个prelogin请求,返回servertime,nonce,pubkey等参数,这里返回的是一个json字符串。
查看请求的请求,可以看到他需要对用户名su进行加密。根据这里的参数,可以对密码进行加密。下面稍微回忆一下,总结一下整个过程:
(6)在Charles中可以找到login.php请求,根据经验,可以大致判断这是一个登录请求,结果确实如此,根据请求的请求,您可以自己构建postdata并发送请求。
这里需要说明一下验证码问题。有些帐户需要验证码才能登录,有些则不需要。这个跟账号设置有关,有登录保护的需要输入验证码。也可以从上面得到的json字符串中的showpin参数得知(详见上图)。如果需要验证码,只需要找到验证码地址,获取图片即可:
将此图片保存到本地进行手动编码,或访问编码平台,即可获取验证码内容。在我的代码中,我原本是封装了云编码平台的接口,直接调用就可以了,但是为了大家测试的方便,我改成了手工编码。详情见代码:
(7) 构造postdata,发送请求,即使请求成功,也登录不成功。因为新浪微博还有一步跳转,麻烦吗?别急,胜利就在眼前我们仔细检查Charles后,会发现在上一个请求之后,还有下一个请求wbsso.login,这是跳转,如下图所示。
跳转请求的请求是怎么构造的,看代码就可以了,这里就不讲了。代码显示如下:
代码还会检查是否登录成功,这里就不多说了。至此,新浪微博已成功登录。
还有一个问题这里没有提到,就是cookie问题。Cookie 在本文中没有提及,因为 Python 中的 Cookiejar 会帮助我们自动处理所有 cookie 问题。您只需要在模拟登录前声明一个 cookiejar 和 opener。这两个东西的具体用法请自行百度。代码显示如下:
微博的模拟登录真的很麻烦,确实需要一定的经验。每个人都练习了很多,并掌握了这一点。相信在模拟登录其他网站的时候,也可以类比破解登录过程。有什么问题可以在评论里指出,有时间我会帮你解答的。
总代码如下:
# _*_ coding: utf-8 _*_
import re
import rsa
import time
import json
import base64
import logging
import binascii
import requests
import urllib.parse
class WeiBoLogin(object):
"""
class of WeiBoLogin, to login weibo.com
"""
def __init__(self):
"""
constructor
"""
self.user_name = None
self.pass_word = None
self.user_uniqueid = None
self.user_nick = None
self.session = requests.Session()
self.session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"})
self.session.get("http://weibo.com/login.php";)
return
def login(self, user_name, pass_word):
"""
login weibo.com, return True or False
"""
self.user_name = user_name
self.pass_word = pass_word
self.user_uniqueid = None
self.user_nick = None
# get json data
s_user_name = self.get_username()
json_data = self.get_json_data(su_value=s_user_name)
if not json_data:
return False
s_pass_word = self.get_password(json_data["servertime"], json_data["nonce"], json_data["pubkey"])
# make post_data
post_data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"userticket": "1",
"vsnf": "1",
"service": "miniblog",
"encoding": "UTF-8",
"pwencode": "rsa2",
"sr": "1280*800",
"prelt": "529",
"url": "http://weibo.com/ajaxlogin.php ... ot%3B,
"rsakv": json_data["rsakv"],
"servertime": json_data["servertime"],
"nonce": json_data["nonce"],
"su": s_user_name,
"sp": s_pass_word,
"returntype": "TEXT",
}
# get captcha code
if json_data["showpin"] == 1:
url = "http://login.sina.com.cn/cgi/p ... ot%3B % (int(time.time()), json_data["pcid"])
with open("captcha.jpeg", "wb") as file_out:
file_out.write(self.session.get(url).content)
code = input("请输入验证码:")
post_data["pcid"] = json_data["pcid"]
post_data["door"] = code
# login weibo.com
login_url_1 = "http://login.sina.com.cn/sso/l ... in.js(v1.4.18)&_=%d" % int(time.time())
json_data_1 = self.session.post(login_url_1, data=post_data).json()
if json_data_1["retcode"] == "0":
params = {
"callback": "sinaSSOController.callbackLoginStatus",
"client": "ssologin.js(v1.4.18)",
"ticket": json_data_1["ticket"],
"ssosavestate": int(time.time()),
"_": int(time.time()*1000),
}
response = self.session.get("https://passport.weibo.com/wbsso/login", params=params)
json_data_2 = json.loads(re.search(r"\((?P.*)\)", response.text).group("result"))
if json_data_2["result"] is True:
self.user_uniqueid = json_data_2["userinfo"]["uniqueid"]
self.user_nick = json_data_2["userinfo"]["displayname"]
logging.warning("WeiBoLogin succeed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_2)
else:
logging.warning("WeiBoLogin failed: %s", json_data_1)
return True if self.user_uniqueid and self.user_nick else False
def get_username(self):
"""
get legal username
"""
username_quote = urllib.parse.quote_plus(self.user_name)
username_base64 = base64.b64encode(username_quote.encode("utf-8"))
return username_base64.decode("utf-8")
def get_json_data(self, su_value):
"""
get the value of "servertime", "nonce", "pubkey", "rsakv" and "showpin", etc
"""
params = {
"entry": "weibo",
"callback": "sinaSSOController.preloginCallBack",
"rsakt": "mod",
"checkpin": "1",
"client": "ssologin.js(v1.4.18)",
"su": su_value,
"_": int(time.time()*1000),
}
try:
response = self.session.get("http://login.sina.com.cn/sso/prelogin.php", params=params)
json_data = json.loads(re.search(r"\((?P.*)\)", response.text).group("data"))
except Exception as excep:
json_data = {}
logging.error("WeiBoLogin get_json_data error: %s", excep)
logging.debug("WeiBoLogin get_json_data: %s", json_data)
return json_data
def get_password(self, servertime, nonce, pubkey):
"""
get legal password
"""
string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.pass_word)).encode("utf-8")
public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16))
password = rsa.encrypt(string, public_key)
password = binascii.b2a_hex(password)
return password.decode()
if __name__ == "__main__":
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s\t%(levelname)s\t%(message)s")
weibo = WeiBoLogin()
weibo.login("username", "password")
================================================== ============
作者主页:小虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏首页:代码,学习知识-知乎专栏
作者的GitHub主页:代码,学习知识-GitHub
欢迎大家发表评论和评论。相互交流,共同进步!
================================================== ============

