
网站自动采集系统
解决方案:网站采集工具 - 超级采集 5.058
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-12-29 11:18
[网站采集Tools-Super采集]是一款智能的采集软件。 Super采集的最大特点是您不需要定义任何采集规则,只需选择您即可。如果您对关键词感兴趣,那么Super采集会自动搜索您和采集的相关信息然后通过WEB发布模块将其直接发布到您的网站。 Super采集当前支持大多数主流cms,一般博客和论坛系统,包括织梦Dede,Dongyi,Discuz,Phpwind,Php cms,Php168、SuperSite,Empire E cms,Very cms ],Hb cms,Fengxun,Kexun,Wordpress,Z-blog,Joomla等,如果现有发布模块不能支持您的网站,我们还可以为标准版和专业版用户提供免费的自定义发布模块来支持您的网站发布。
1、傻瓜式使用模式
超级采集非常易于使用。您不需要具备有关网站采集的任何专业知识和经验。 super采集的核心是智能搜索和采集引擎。根据您对采集相关信息感兴趣的内容,并将其自动发布到网站。
2、超级强大的关键词挖掘工具
选择正确的关键词可以为您的网站带来更高的流量和更大的广告价值。 Super采集提供的关键词挖掘工具为您提供关键词的每日搜索量,Google广告的每次点击估算价格以及关键词广告受欢迎程度信息,最合适的关键词可以根据这些信息的排名进行选择。
3、内容,标题伪原创
Super采集提供了最新的伪原创引擎,该引擎可以进行同义词替换,段落重新排列,多个文章混合等。您可以选择处理从采集到伪原创的信息以增加搜索数量由引擎获取网站内容中的收录。 查看全部
解决方案:网站采集工具 - 超级采集 5.058
[网站采集Tools-Super采集]是一款智能的采集软件。 Super采集的最大特点是您不需要定义任何采集规则,只需选择您即可。如果您对关键词感兴趣,那么Super采集会自动搜索您和采集的相关信息然后通过WEB发布模块将其直接发布到您的网站。 Super采集当前支持大多数主流cms,一般博客和论坛系统,包括织梦Dede,Dongyi,Discuz,Phpwind,Php cms,Php168、SuperSite,Empire E cms,Very cms ],Hb cms,Fengxun,Kexun,Wordpress,Z-blog,Joomla等,如果现有发布模块不能支持您的网站,我们还可以为标准版和专业版用户提供免费的自定义发布模块来支持您的网站发布。
1、傻瓜式使用模式
超级采集非常易于使用。您不需要具备有关网站采集的任何专业知识和经验。 super采集的核心是智能搜索和采集引擎。根据您对采集相关信息感兴趣的内容,并将其自动发布到网站。
2、超级强大的关键词挖掘工具
选择正确的关键词可以为您的网站带来更高的流量和更大的广告价值。 Super采集提供的关键词挖掘工具为您提供关键词的每日搜索量,Google广告的每次点击估算价格以及关键词广告受欢迎程度信息,最合适的关键词可以根据这些信息的排名进行选择。
3、内容,标题伪原创
Super采集提供了最新的伪原创引擎,该引擎可以进行同义词替换,段落重新排列,多个文章混合等。您可以选择处理从采集到伪原创的信息以增加搜索数量由引擎获取网站内容中的收录。
详细数据:网站流量日志数据自定义采集实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 916 次浏览 • 2020-12-19 11:17
为什么需要对网站个流量数据进行统计分析?
随着大数据时代的到来,各行各业所生成的数据爆炸了。大数据技术已从以前的``虚无''变为可能,人们逐渐发现由数据产生的各种潜在价值。用于各行各业。例如,对网站流量数据的统计分析可以帮助网站管理员,操作员,发起人等获取实时网站流量信息,并从流量来源,网站内容等各个方面提供信息,以及网站访问者特征网站分析的数据基础。这将有助于增加网站的访问量并改善网站的用户体验,使更多的访客成为会员或客户,并以较少的投资获得最大的收益。
网站交通记录数据采集原理分析
首先,用户的行为将触发浏览器对正在计数的页面的http请求,例如打开某个网页。打开网页后,将执行页面中嵌入的javascript代码。
埋点是指:在网页中预先添加一小段javascript代码。此代码段通常将动态创建脚本标签,并将src属性指向单独的js文件。此时,浏览器将请求并执行此单独的js文件(图中的绿色节点)。该js通常是真正的数据采集脚本。
数据采集完成后,js将请求后端数据采集脚本(图中的后端)。该脚本通常是伪装成图片的动态脚本程序。 js将通过http参数传递采集的数据。对于后端脚本,后端脚本解析参数并以固定格式记录访问日志。同时,它可能会在http响应中为客户端植入一些跟踪cookie。
设计与实现
基于原理分析并结合Google Analytics(分析),如果您要构建自定义日志数据采集系统,则需要执行以下操作:
确认采集信息
确定掩埋点代码
埋点是用于网站分析的常用data 采集方法。核心是在需要数据采集来执行数据采集的关键点植入统计代码。例如,在Google Analytics(分析)原型中,需要将其提供的javascript片段插入页面。该片段通常称为嵌入式代码。 (以Google的嵌入式代码为例)
var _maq = _maq || [];
_maq.push(['_setAccount', 'UA-XXXXX-X']);
(function() {
var ma = document.createElement('script'); ma.type =
'text/javascript'; ma.async = true;
ma.src = ('https:' == document.location.protocol ?
'https://ssl' : 'http://www') + '.google-analytics.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore( m a, s);
})();
其中_maq是一个全局数组,用于放置各种配置,每种配置的格式为:
_maq.push(['Action','param1','param2',...]);
_maq的机制不是焦点,而是焦点在于后面的匿名函数代码。该代码的主要目的是通过通过document.createElement方法创建脚本并遵循协议(http或https)将src指向相应的ma.js来引入外部js文件(ma.js),最后将其插入元素放入页面的dom树中。
请注意,ma.async = true表示外部js文件是异步调用的,即,它不会阻止浏览器的解析,并且将在外部js下载完成后异步执行。此属性是HTML5中新引入的。
前端数据采集脚本
数据采集脚本(ma.js)将在请求后执行。通常,应执行以下操作:
通过浏览器的内置javascript对象采集信息,例如页面标题(通过document.title),引荐来源网址(最后一个URL,通过document.referrer),用户显示分辨率(通过windows.screen),cookie信息(通过document.cookie)等。解析_maq数组并采集配置信息。这可能包括用户定义的事件跟踪,业务数据(例如电子商务网站产品编号等)。以上两个步骤中采集的数据将以预定义的格式进行解析和拼接(获取请求参数)。请求后端脚本,然后将http请求参数中的信息放入后端脚本。
这里唯一的问题是第4步。javascript请求后端脚本的常用方法是ajax,但是无法跨域请求ajax。一种常见的方法是使用js脚本创建Image对象,将Image对象的src属性指向后端脚本并携带参数。此时,实现了跨域请求后端。这就是为什么后端脚本通常伪装成gif文件的原因。
示例代码
(function () {
var params = {};
//Document 对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window 对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator 对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq 配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过 Image 对象请求后端脚本
var img = new Image(1, 1);
img.src = ' http://xxx.xxxxx.xxxxx/log.gif? ' + args;
})();
将整个脚本放置在一个匿名函数中,以确保它不会污染全局环境。其中log.gif是后端脚本。
后端脚本
log.gif是后端脚本,该脚本伪装成gif图片。后端脚本通常需要完成以下操作:
分析http请求参数以获取信息。获取客户端无法从Web服务器获取的某些信息,例如visitor ip。以日志格式写入信息。生成1×1的空白gif图像作为响应内容,并将响应头的Content-type设置为image / gif。通过响应标头中的Set-cookie设置一些必需的cookie信息。
设置cookie的原因是因为如果您要跟踪唯一的访问者,通常的做法是根据规则生成一个全局唯一的cookie,如果发现客户端没有该cookie,则将其植入用户。在请求时指定跟踪cookie,否则Set-cookie放置获取的跟踪cookie以保持相同的用户cookie不变。尽管这种方法并不完美(例如,清除cookie或更改浏览器的用户将被视为两个用户),但目前已广泛使用。
我们使用nginx的access_log进行日志采集,但是存在一个问题,即nginx配置本身具有有限的逻辑表达能力,因此我们选择OpenResty来实现。
OpenResty是基于Nginx的高性能应用程序开发平台。它集成了许多有用的模块,其核心是通过ngx_lua模块将Lua集成在一起,因此Lua可用于在nginx配置文件中表达业务。
Lua是一种轻量级且紧凑的脚本语言,用标准C语言编写,并以源代码形式开放。其设计目的是嵌入到应用程序中,从而为应用程序提供灵活的扩展和自定义功能。
首先,您需要在nginx配置文件中定义日志格式:
log_format tick
"$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url|
|$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_ag
ent||$u_account";
请注意,此处以u_开头的变量是我们稍后将定义的变量,其他变量是nginx的内置变量。然后是两个核心位置:
location / log.gif {
#伪装成 gif 文件
default_type image/gif;
#本身关闭 access_log,通过 subrequest 记录 log
access_log off;
access_by_lua "
-- 用户跟踪 cookie 名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪 cookie,算法为
md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() ..
ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid ..
'; path=/'}
if ngx.var.arg_domain then
-- 通过 subrequest 子请求 到/i-log 记录日志,
将参数和用户跟踪 cookie 带过去
ngx.location.capture('/i-log?' ..
ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-
revalidate";
#返回一个 1×1 的空 gif 图片
empty_gif;
}
location /i-log {
#内部 location,不允许外部直接访问
internal;
#设置变量,注意需要 unescape,来自 ngx_set_misc 模块
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开日志
log_subrequest on;
#记录日志到 ma.log 格式为 tick
access_log /path/to/logs/directory/ma.log tick;
#输出空字符串
echo '';
}
此脚本使用许多第三方ngxin模块(全部收录在OpenResty中),关键点带有注释。只要您在完成我们提到的End逻辑就可以了之后,就不需要完全了解每一行的含义。
日志格式
日志格式主要考虑日志分隔符,通常有以下选项:
固定数量的字符,制表符,空格,一个或多个其他字符,特定的开始和结束文本。
日志细分
只要日志采集系统访问日志,文件就会变得很大,并且很难在一个文件中管理日志。通常有必要根据时间段拆分日志,例如每天或每小时一个日志。它是通过定期通过crontab调用shell脚本来实现的,如下所示:
_prefix="/path/to/nginx"
time=`date +%Y%m%d%H`
mv ${_prefix}/logs/ma.log ${_prefix}/logs/ma/ma-${time}.log
kill -USR1 `cat ${_prefix}/logs/nginx.pid `
此脚本将ma.log移至指定的文件夹,并将其重命名为ma- {yyyymmddhh} .log,然后将USR1信号发送给nginx以重新打开日志文件。
USR1通常用于通知应用程序重新加载配置文件。向服务器发送USR1信号将导致执行以下步骤:停止接受新连接,等待当前连接停止,重新加载配置文件,然后重新打开日志文件,重新启动服务器以实现相对平稳的更改而不关闭
cat $ {_ prefix} /logs/nginx.pid接受nginx的进程号
然后在/ etc / crontab中添加一行:
59 * * * *根/path/to/directory/rotatelog.sh
每小时59分钟启动此脚本以执行日志轮换操作。 查看全部
详细数据:网站流量日志数据自定义采集实现
为什么需要对网站个流量数据进行统计分析?
随着大数据时代的到来,各行各业所生成的数据爆炸了。大数据技术已从以前的``虚无''变为可能,人们逐渐发现由数据产生的各种潜在价值。用于各行各业。例如,对网站流量数据的统计分析可以帮助网站管理员,操作员,发起人等获取实时网站流量信息,并从流量来源,网站内容等各个方面提供信息,以及网站访问者特征网站分析的数据基础。这将有助于增加网站的访问量并改善网站的用户体验,使更多的访客成为会员或客户,并以较少的投资获得最大的收益。
网站交通记录数据采集原理分析
首先,用户的行为将触发浏览器对正在计数的页面的http请求,例如打开某个网页。打开网页后,将执行页面中嵌入的javascript代码。
埋点是指:在网页中预先添加一小段javascript代码。此代码段通常将动态创建脚本标签,并将src属性指向单独的js文件。此时,浏览器将请求并执行此单独的js文件(图中的绿色节点)。该js通常是真正的数据采集脚本。
数据采集完成后,js将请求后端数据采集脚本(图中的后端)。该脚本通常是伪装成图片的动态脚本程序。 js将通过http参数传递采集的数据。对于后端脚本,后端脚本解析参数并以固定格式记录访问日志。同时,它可能会在http响应中为客户端植入一些跟踪cookie。
设计与实现
基于原理分析并结合Google Analytics(分析),如果您要构建自定义日志数据采集系统,则需要执行以下操作:
确认采集信息
确定掩埋点代码
埋点是用于网站分析的常用data 采集方法。核心是在需要数据采集来执行数据采集的关键点植入统计代码。例如,在Google Analytics(分析)原型中,需要将其提供的javascript片段插入页面。该片段通常称为嵌入式代码。 (以Google的嵌入式代码为例)
var _maq = _maq || [];
_maq.push(['_setAccount', 'UA-XXXXX-X']);
(function() {
var ma = document.createElement('script'); ma.type =
'text/javascript'; ma.async = true;
ma.src = ('https:' == document.location.protocol ?
'https://ssl' : 'http://www') + '.google-analytics.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore( m a, s);
})();
其中_maq是一个全局数组,用于放置各种配置,每种配置的格式为:
_maq.push(['Action','param1','param2',...]);
_maq的机制不是焦点,而是焦点在于后面的匿名函数代码。该代码的主要目的是通过通过document.createElement方法创建脚本并遵循协议(http或https)将src指向相应的ma.js来引入外部js文件(ma.js),最后将其插入元素放入页面的dom树中。
请注意,ma.async = true表示外部js文件是异步调用的,即,它不会阻止浏览器的解析,并且将在外部js下载完成后异步执行。此属性是HTML5中新引入的。
前端数据采集脚本
数据采集脚本(ma.js)将在请求后执行。通常,应执行以下操作:
通过浏览器的内置javascript对象采集信息,例如页面标题(通过document.title),引荐来源网址(最后一个URL,通过document.referrer),用户显示分辨率(通过windows.screen),cookie信息(通过document.cookie)等。解析_maq数组并采集配置信息。这可能包括用户定义的事件跟踪,业务数据(例如电子商务网站产品编号等)。以上两个步骤中采集的数据将以预定义的格式进行解析和拼接(获取请求参数)。请求后端脚本,然后将http请求参数中的信息放入后端脚本。
这里唯一的问题是第4步。javascript请求后端脚本的常用方法是ajax,但是无法跨域请求ajax。一种常见的方法是使用js脚本创建Image对象,将Image对象的src属性指向后端脚本并携带参数。此时,实现了跨域请求后端。这就是为什么后端脚本通常伪装成gif文件的原因。
示例代码
(function () {
var params = {};
//Document 对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window 对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator 对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq 配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过 Image 对象请求后端脚本
var img = new Image(1, 1);
img.src = ' http://xxx.xxxxx.xxxxx/log.gif? ' + args;
})();
将整个脚本放置在一个匿名函数中,以确保它不会污染全局环境。其中log.gif是后端脚本。
后端脚本
log.gif是后端脚本,该脚本伪装成gif图片。后端脚本通常需要完成以下操作:
分析http请求参数以获取信息。获取客户端无法从Web服务器获取的某些信息,例如visitor ip。以日志格式写入信息。生成1×1的空白gif图像作为响应内容,并将响应头的Content-type设置为image / gif。通过响应标头中的Set-cookie设置一些必需的cookie信息。
设置cookie的原因是因为如果您要跟踪唯一的访问者,通常的做法是根据规则生成一个全局唯一的cookie,如果发现客户端没有该cookie,则将其植入用户。在请求时指定跟踪cookie,否则Set-cookie放置获取的跟踪cookie以保持相同的用户cookie不变。尽管这种方法并不完美(例如,清除cookie或更改浏览器的用户将被视为两个用户),但目前已广泛使用。
我们使用nginx的access_log进行日志采集,但是存在一个问题,即nginx配置本身具有有限的逻辑表达能力,因此我们选择OpenResty来实现。
OpenResty是基于Nginx的高性能应用程序开发平台。它集成了许多有用的模块,其核心是通过ngx_lua模块将Lua集成在一起,因此Lua可用于在nginx配置文件中表达业务。
Lua是一种轻量级且紧凑的脚本语言,用标准C语言编写,并以源代码形式开放。其设计目的是嵌入到应用程序中,从而为应用程序提供灵活的扩展和自定义功能。
首先,您需要在nginx配置文件中定义日志格式:
log_format tick
"$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url|
|$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_ag
ent||$u_account";
请注意,此处以u_开头的变量是我们稍后将定义的变量,其他变量是nginx的内置变量。然后是两个核心位置:
location / log.gif {
#伪装成 gif 文件
default_type image/gif;
#本身关闭 access_log,通过 subrequest 记录 log
access_log off;
access_by_lua "
-- 用户跟踪 cookie 名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪 cookie,算法为
md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() ..
ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid ..
'; path=/'}
if ngx.var.arg_domain then
-- 通过 subrequest 子请求 到/i-log 记录日志,
将参数和用户跟踪 cookie 带过去
ngx.location.capture('/i-log?' ..
ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-
revalidate";
#返回一个 1×1 的空 gif 图片
empty_gif;
}
location /i-log {
#内部 location,不允许外部直接访问
internal;
#设置变量,注意需要 unescape,来自 ngx_set_misc 模块
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开日志
log_subrequest on;
#记录日志到 ma.log 格式为 tick
access_log /path/to/logs/directory/ma.log tick;
#输出空字符串
echo '';
}
此脚本使用许多第三方ngxin模块(全部收录在OpenResty中),关键点带有注释。只要您在完成我们提到的End逻辑就可以了之后,就不需要完全了解每一行的含义。
日志格式
日志格式主要考虑日志分隔符,通常有以下选项:
固定数量的字符,制表符,空格,一个或多个其他字符,特定的开始和结束文本。
日志细分
只要日志采集系统访问日志,文件就会变得很大,并且很难在一个文件中管理日志。通常有必要根据时间段拆分日志,例如每天或每小时一个日志。它是通过定期通过crontab调用shell脚本来实现的,如下所示:
_prefix="/path/to/nginx"
time=`date +%Y%m%d%H`
mv ${_prefix}/logs/ma.log ${_prefix}/logs/ma/ma-${time}.log
kill -USR1 `cat ${_prefix}/logs/nginx.pid `
此脚本将ma.log移至指定的文件夹,并将其重命名为ma- {yyyymmddhh} .log,然后将USR1信号发送给nginx以重新打开日志文件。
USR1通常用于通知应用程序重新加载配置文件。向服务器发送USR1信号将导致执行以下步骤:停止接受新连接,等待当前连接停止,重新加载配置文件,然后重新打开日志文件,重新启动服务器以实现相对平稳的更改而不关闭
cat $ {_ prefix} /logs/nginx.pid接受nginx的进程号
然后在/ etc / crontab中添加一行:
59 * * * *根/path/to/directory/rotatelog.sh
每小时59分钟启动此脚本以执行日志轮换操作。
操作方法:一种能识别网页信息自动采集的系统与方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-10-06 12:00
专利名称:一种可以自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,尤其属于一种可以识别网页信息的自动系统和方法。
背景技术:
随着Internet的发展,越来越多的Internet网站出现了,形式无穷无尽,包括新闻,博客,论坛,SNS,微博等。根据CNNIC今年的最新统计,中国现在有85亿网民4.和超过130万个各种站点域名。随着Internet信息的爆炸式增长,搜索引擎已成为人们查找Internet信息的最重要工具。搜索引擎主要自动抓取网站信息,对其进行预处理,并在分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经相对成熟,并且由于可以成功使用的商业模式,吸引了许多互联网公司进入。比较有名的有百度,谷歌,搜搜,搜狗,有道,奇虎360等。此外,在某些垂直领域(例如旅行,机票,价格比较等)中也有搜索引擎,已有上千家制造商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体过程如图1所示。URL DB存储所有要爬网的URL。 URL调度模块从URL DB中选择最重要的URL,并将它们放入URL下载队列中。页面下载模块下载队列中的URL。下载完成后,提取模块提取下载的页面代码的文本和URL,并将提取的文本发送到索引模块以进行单词分割和索引,然后将URL放入URL DB。信息采集流程是将其他人网站的信息放入您自己的信息数据库的过程,这会遇到一些问题。
1、Internet信息每时每刻都在不断增加,因此信息爬网是7 * 24小时不间断的过程。频繁的爬网将给目标网站带来巨大的访问压力,从而形成DDOS拒绝服务攻击,从而导致无法为普通用户提供访问权限。这在中小型企业中尤为明显网站。这些网站硬件资源相对贫乏,技术力量不强,并且超过90%的Internet都是这种类型网站。例如:一个著名的搜索引擎由于频繁抓取某个网站而要求用户投诉。2、某些网站信息具有隐私权或版权。许多网页收录后台数据库,用户隐私,密码和其他信息。网站发起人不希望将此信息公开或免费使用。 Dianping.com曾经对Aibang.com提起诉讼,要求其对网站进行评论并将其发布在自身网站上。目前,网页反搜索引擎采集采用的主流方法是漫游器协议协议,网站使用漫游器txt协议控制搜索引擎收录是否愿意搜索内容,以及搜索引擎允许收录,并指定可用于收录和禁止的收录。同时,搜索引擎将根据为每个网站 Robots协议赋予的权限自觉地进行爬网。该方法假定搜索引擎的爬取过程如下:下载网站机器人文件-根据机器人协议解析文件-获取要下载的URL-确定URL的访问权限-确定是否进行爬网确定的结果。机器人协议是绅士协议,没有任何限制。搜寻计划仍然完全由搜索引擎控制,完全有可能在不遵循协议的情况下进行搜寻。
例如,在2012年8月,一个著名的国内搜索引擎未遵循该协议来抓取百度网站内容,并被百度指控。另一种反采集方法主要使用动态技术来构建要禁止爬网的网页。该方法使用客户端脚本语言(例如JS,VBScript,AJAX)动态生成网页显示信息,从而实现信息隐藏,并使传统的搜索引擎难以获取URL和正文内容。动态网页构建技术仅增加了网页解析和提取的难度,不能从根本上禁止网页信息的采集解析。当前,一些高级搜索引擎可以模拟浏览器来实现所有脚本代码分析。获取所有信息的网络URL,从而获得存储在服务器中的动态信息。当前,存在成熟的网页动态分析技术,主要是通过解析网页中所有脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)来实现的。实际的实现过程以开源脚本代码分析引擎(如Rhino,V8等)为基础,以构建网页脚本分析环境,然后从网页中提取脚本代码段,并将将提取的代码段提取到网页脚本分析环境中,以执行以返回动态信息。解析过程如图2所示,因此使用动态技术构建动态网页的方法只会增加网页采集和分析的难度,而不会从根本上消除搜索引擎采集。
发明内容
本发明的目的是提供一种可以自动识别网页信息的系统和方法,从而克服了现有技术的缺点。系统通过分析网站的历史网页访问行为来建立自动采集。 ]分类器,可识别机器人的自动采集,并通过自动机器人采集的识别来实现网页的防爬网。本发明采用的技术方案如下:一种能够自动采集识别网页信息的系统和方法,包括anti 采集分类器构建模块,auto 采集识别模块和anti 采集 ]在线处理模块,anti 采集 k15]分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块,此模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将采集程序的已标识IP段添加到黑名单中,黑名单中用于后续的在线拦截对于自动采集行为,如果访问者的IP已经在IP段中,则反采集在线处理模块主要用于自动在线判断和处理访问的用户;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志解析子模块通过对站点访问日志的自动分析,包括用户对网站的访问,获得用户的访问行为信息。 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内同一IP段中访问频率最高的数据记录,在步骤I中选择解析的数据记录样本采集;访问统计子模块对选定的样本数据进行统计,并计算同一IP段的平均页面停留时间,站点访问的页面总数,采集网页附件信息,第采集页的频率;(6)使用IP段作为主要关键字,将以上信息存储在样品库中并将其标记为未标记;(7)在步骤(I)中标记未标记的样品确定d。样品自动加工采集,标记为I;如果是用户浏览器的正常访问,则将其标记为0,并将所有标记的样本更新到数据库中; (8)计算机程序会自动学习样本库,并为稍后阶段的采集自动识别生成分类模型。
[p15]中所述的采集自动识别模块的实现方法
包括以下步骤:(5)识别程序的初始化阶段,完成分类器模型的加载,该模型可以确定自动的采集行为;(6)日志分析该程序解析最新的[网站访问日志,并将解析后的数据发送到访问统计模块; [7)访问统计模块计算相同IP段的平均页面停留时间,无论是采集 Web附件信息,网页采集频率;([ 8)分类器根据分类模型判断IP段的访问行为,并将判断为程序自动采集行为的IP段添加到黑名单中;反采集在线处理模块的实现方法包括:步骤:(I)为Web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单数据库中的IP信息(如果IP已在黑名单中),在这种情况下,将通知Web服务器拒绝IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下:本发明的系统分析网站网页访问行为的历史,建立自动采集分类器,识别自动采集分类器。机器人,通过自动识别机器人采集来实现网页的防抓取,自动发现搜索引擎网页采集的行为,并对其进行处理采集行为被屏蔽以从根本上消除采集个搜索引擎。
图1是现有技术搜索引擎的信息捕获过程的示意图。图2是现有技术的第二分析过程的示意图;图3是本发明的anti 采集分类器的框图。图4是本发明的自动采集识别模块图;图5是本发明的抗采集在线处理模块。
<p>有关具体实施例,请参考附图。可以识别网页信息的反抓取系统和方法包括反采集分类器构建模块,自动采集识别模块和反采集在线处理模块。 采集分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器以自动识别搜索引擎程序的自动采集行为,并将识别的采集程序的IP段添加到黑名单中。该列表用于后续的自动采集行为的在线拦截。 anti- 采集在线处理模块主要用于自动在线判断和处理访问的用户。如果访问者的IP已经在IP中。在细分黑名单中,该IP被拒绝访问;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(9)日志解析子模块通过自动分析站点访问日志来获取用户访问行为信息,包括用户访问网站 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内相同IP段中访问频率最高的数据记录,作为候选数据样本采集,选择步骤I中的解析数据记录。访问统计子模块对所选样本数据进行统计,并计算相同IP段的平均页面停留时间,访问的页面总数,采集个网页附件信息,采集个网页 查看全部
可以自动识别网页信息的系统和方法采集
专利名称:一种可以自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,尤其属于一种可以识别网页信息的自动系统和方法。
背景技术:
随着Internet的发展,越来越多的Internet网站出现了,形式无穷无尽,包括新闻,博客,论坛,SNS,微博等。根据CNNIC今年的最新统计,中国现在有85亿网民4.和超过130万个各种站点域名。随着Internet信息的爆炸式增长,搜索引擎已成为人们查找Internet信息的最重要工具。搜索引擎主要自动抓取网站信息,对其进行预处理,并在分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经相对成熟,并且由于可以成功使用的商业模式,吸引了许多互联网公司进入。比较有名的有百度,谷歌,搜搜,搜狗,有道,奇虎360等。此外,在某些垂直领域(例如旅行,机票,价格比较等)中也有搜索引擎,已有上千家制造商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体过程如图1所示。URL DB存储所有要爬网的URL。 URL调度模块从URL DB中选择最重要的URL,并将它们放入URL下载队列中。页面下载模块下载队列中的URL。下载完成后,提取模块提取下载的页面代码的文本和URL,并将提取的文本发送到索引模块以进行单词分割和索引,然后将URL放入URL DB。信息采集流程是将其他人网站的信息放入您自己的信息数据库的过程,这会遇到一些问题。
1、Internet信息每时每刻都在不断增加,因此信息爬网是7 * 24小时不间断的过程。频繁的爬网将给目标网站带来巨大的访问压力,从而形成DDOS拒绝服务攻击,从而导致无法为普通用户提供访问权限。这在中小型企业中尤为明显网站。这些网站硬件资源相对贫乏,技术力量不强,并且超过90%的Internet都是这种类型网站。例如:一个著名的搜索引擎由于频繁抓取某个网站而要求用户投诉。2、某些网站信息具有隐私权或版权。许多网页收录后台数据库,用户隐私,密码和其他信息。网站发起人不希望将此信息公开或免费使用。 Dianping.com曾经对Aibang.com提起诉讼,要求其对网站进行评论并将其发布在自身网站上。目前,网页反搜索引擎采集采用的主流方法是漫游器协议协议,网站使用漫游器txt协议控制搜索引擎收录是否愿意搜索内容,以及搜索引擎允许收录,并指定可用于收录和禁止的收录。同时,搜索引擎将根据为每个网站 Robots协议赋予的权限自觉地进行爬网。该方法假定搜索引擎的爬取过程如下:下载网站机器人文件-根据机器人协议解析文件-获取要下载的URL-确定URL的访问权限-确定是否进行爬网确定的结果。机器人协议是绅士协议,没有任何限制。搜寻计划仍然完全由搜索引擎控制,完全有可能在不遵循协议的情况下进行搜寻。
例如,在2012年8月,一个著名的国内搜索引擎未遵循该协议来抓取百度网站内容,并被百度指控。另一种反采集方法主要使用动态技术来构建要禁止爬网的网页。该方法使用客户端脚本语言(例如JS,VBScript,AJAX)动态生成网页显示信息,从而实现信息隐藏,并使传统的搜索引擎难以获取URL和正文内容。动态网页构建技术仅增加了网页解析和提取的难度,不能从根本上禁止网页信息的采集解析。当前,一些高级搜索引擎可以模拟浏览器来实现所有脚本代码分析。获取所有信息的网络URL,从而获得存储在服务器中的动态信息。当前,存在成熟的网页动态分析技术,主要是通过解析网页中所有脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)来实现的。实际的实现过程以开源脚本代码分析引擎(如Rhino,V8等)为基础,以构建网页脚本分析环境,然后从网页中提取脚本代码段,并将将提取的代码段提取到网页脚本分析环境中,以执行以返回动态信息。解析过程如图2所示,因此使用动态技术构建动态网页的方法只会增加网页采集和分析的难度,而不会从根本上消除搜索引擎采集。
发明内容
本发明的目的是提供一种可以自动识别网页信息的系统和方法,从而克服了现有技术的缺点。系统通过分析网站的历史网页访问行为来建立自动采集。 ]分类器,可识别机器人的自动采集,并通过自动机器人采集的识别来实现网页的防爬网。本发明采用的技术方案如下:一种能够自动采集识别网页信息的系统和方法,包括anti 采集分类器构建模块,auto 采集识别模块和anti 采集 ]在线处理模块,anti 采集 k15]分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块,此模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将采集程序的已标识IP段添加到黑名单中,黑名单中用于后续的在线拦截对于自动采集行为,如果访问者的IP已经在IP段中,则反采集在线处理模块主要用于自动在线判断和处理访问的用户;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志解析子模块通过对站点访问日志的自动分析,包括用户对网站的访问,获得用户的访问行为信息。 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内同一IP段中访问频率最高的数据记录,在步骤I中选择解析的数据记录样本采集;访问统计子模块对选定的样本数据进行统计,并计算同一IP段的平均页面停留时间,站点访问的页面总数,采集网页附件信息,第采集页的频率;(6)使用IP段作为主要关键字,将以上信息存储在样品库中并将其标记为未标记;(7)在步骤(I)中标记未标记的样品确定d。样品自动加工采集,标记为I;如果是用户浏览器的正常访问,则将其标记为0,并将所有标记的样本更新到数据库中; (8)计算机程序会自动学习样本库,并为稍后阶段的采集自动识别生成分类模型。
[p15]中所述的采集自动识别模块的实现方法
包括以下步骤:(5)识别程序的初始化阶段,完成分类器模型的加载,该模型可以确定自动的采集行为;(6)日志分析该程序解析最新的[网站访问日志,并将解析后的数据发送到访问统计模块; [7)访问统计模块计算相同IP段的平均页面停留时间,无论是采集 Web附件信息,网页采集频率;([ 8)分类器根据分类模型判断IP段的访问行为,并将判断为程序自动采集行为的IP段添加到黑名单中;反采集在线处理模块的实现方法包括:步骤:(I)为Web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单数据库中的IP信息(如果IP已在黑名单中),在这种情况下,将通知Web服务器拒绝IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下:本发明的系统分析网站网页访问行为的历史,建立自动采集分类器,识别自动采集分类器。机器人,通过自动识别机器人采集来实现网页的防抓取,自动发现搜索引擎网页采集的行为,并对其进行处理采集行为被屏蔽以从根本上消除采集个搜索引擎。
图1是现有技术搜索引擎的信息捕获过程的示意图。图2是现有技术的第二分析过程的示意图;图3是本发明的anti 采集分类器的框图。图4是本发明的自动采集识别模块图;图5是本发明的抗采集在线处理模块。
<p>有关具体实施例,请参考附图。可以识别网页信息的反抓取系统和方法包括反采集分类器构建模块,自动采集识别模块和反采集在线处理模块。 采集分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器以自动识别搜索引擎程序的自动采集行为,并将识别的采集程序的IP段添加到黑名单中。该列表用于后续的自动采集行为的在线拦截。 anti- 采集在线处理模块主要用于自动在线判断和处理访问的用户。如果访问者的IP已经在IP中。在细分黑名单中,该IP被拒绝访问;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(9)日志解析子模块通过自动分析站点访问日志来获取用户访问行为信息,包括用户访问网站 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内相同IP段中访问频率最高的数据记录,作为候选数据样本采集,选择步骤I中的解析数据记录。访问统计子模块对所选样本数据进行统计,并计算相同IP段的平均页面停留时间,访问的页面总数,采集个网页附件信息,采集个网页
直观:中文网页自动采集与分类系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-09-21 13:03
中文网页自动分类系统的设计与实现:保密期限:本人声明结果。据我介绍,该学位已申请其他学术机构的学术和贡献。我已经签署了我正在攻读学位的学位。有关部门可以出版学位保存和学位理论汇编。我已经签署了老师的签名。自动中文网页采集摘要随着科学技术的飞速发展,我们已经进入了数字信息时代。作为当今世界上最大的信息数据库,互联网也已成为人们获取信息的最重要手段。如何从Internet上的海量信息资源中快速准确地找到他们所需的信息已成为网络用户迫切需要解决的主要问题。因此,基于网络的网络信息的采集和分类已经成为研究的重点。传统Web信息采集的目标是制作尽可能多的采集信息页,甚至制作整个Web上的资源。在此过程中,它并不关心采集页的顺序和采集页的顺序。相关的主要混乱和重复的发生。同时,也非常有必要对采集中的网页进行自动分类以创建更有效的搜索引擎。网页分类是组织和管理信息的有效手段。它可以更大程度地解决信息混乱问题,并帮助用户准确确定他们所需的信息。传统的操作方式是在手动分类之后对它们进行组织和管理。
随着Internet上各种信息的迅速增加,手动处理它是不切实际的。因此,网页的自动分类是一种具有较大实用价值的方法,是一种组织和管理数据的有效手段。这也是本文的重要内容。本文首先介绍了课题的背景,研究目的以及国内外的研究现状。在解释了网页采集和网页分类的相关理论,主要技术和算法,包括几种典型的Web爬行技术和重复数据删除技术算法之后,本文选择了主题采集器方法和出色的KNN方法进行分类,并结合结合重复数据删除,分词和特征提取等相关技术,分析了中文网页的结构和特征,提出了中文网页采集,最终通过编程语言实现了分类和分类的设计与实现方法。在本文结尾处,对该系统进行了测试。测试结果符合系统设计要求,应用效果显着。关键词:Web信息采集网页分类信息提取单词分割特征提取OFSEHINESEANDIMPLE转N1:信息设计wEBPAGEAUT0〜IATIC采集和CLASSICATIONATION摘要随着科学的发展,并进入了开发技术,我们迅速地将信息信息化了世界的信息数字时代。 Intemet,其中最大的是maint001信息。 ItiS数据库。成为主要问题已解决了如何从用户那里迅速准确地关联信息资源,因为用户需要信息网络来查找信息的缺乏特征,以及庞大的,动态的,异构的,半结构化的基于信息的统一采集管理组织。研究和分类成为热点。信息采集的信息作为目标,是采集所有资源,例如订单和尽可能多的页面,或者内容不涉及采集的主题。在页面混乱的情况下,浪费了大部分SO资源,很少使用系统采集方法来减少采集的数据。 TIliSeff需要分类整齐的网页并自动创建页面重复页面。 Web有效管理页面引擎的研究。组织可以解决范围广泛的分类信息(i种有效的小信息),这种大的杂乱信息有助于用户准确地表达信息模式。借助传统信息。但是,要处理所有种类的互联网,手动快速增加方式分类的操作信息,并不是一种方法论,也不是一种有效的数据手段。 Ttisanvalue,但组织管理这一重要部分的研究。首先介绍了网络采集理论的背景,目的,主题和分类,描述了包括网页爬虫网络分解在内的技术算法页面,其中技术,重复页面词提取分割,特征技术,中文技术,信息网络分类提取页面技术。几种履带和KNNmade的综合技术,局部比较的典型算法已被分类,因为它们具有出色的性能。提出了111种拟议的中文网站,并结合了中文的已设计实现的获取结构和特征的分类,并对技术网页进行了编码并实现了语言页面的分析。最后,它的编程结果就是该语言。测试系统设计要求和应用程序完成。许多信息分类,关键词:网页采集,网页信息提取,分割,字符方法。„„„„„„„„„„„„„„„„„„„„。 484.7.2 KNN结„„„„„„„„„„„„„„„„„„„„„„„ 5253„„„„„„„„„„。
63北京邮电大学软件工程硕士学位论文第1章引言1.1项目背景和研究现状1.1.1项目背景和研究目标随着Internet的普及和网络技术的飞速发展,Internet信息资源日益丰富。为了从Internet获得越来越多的信息,包括文本,数字,图形,图像,声音和视频,需要使用指数形式。但是,随着网络信息的迅速发展,如何快速,准确地从庞大的信息资源中找到他们所需的信息已成为大多数网络用户的主要问题。它基于Internet 采集和搜索引擎上的信息。这些搜索引擎通常使用一个或多个采集器从Internet采集FTP,电子邮件,新闻等各种数据,然后在本地服务器上为这些数据建立索引,然后用户根据索引数据库从索引数据库中进行搜索。用户提交的搜索条件。快速找到您需要的信息。网络信息采集作为这些搜索引擎的基础和组成部分,起着举足轻重的作用。 Web信息采集是指通过Web页面之间的链接关系从Web自动获取页面信息,并随着链接不断扩展到所需Web页面的过程。传统的W歌曲信息采集的目标是要有尽可能多的采集信息页,甚至是整个Web上的资源,这样,集中精力于采集的速度和数量,并且实现是比较简单。但是,这种传统的采集方法存在很多缺陷。
由于采集需要基于整个Web信息的采集页,因此部分利用率非常低。用户通常只关心很少的页面,采集器 采集的大多数页面对他们来说都是无用的。显然,这是对系统资源和网络资源的巨大开销。随着网页数量的快速增长,非常有必要使用固定标题采集技术来构造固定标题类别,以创建一个更有效,更快速的搜索引擎。传统的操作模式是分类后组织和管理其工作。该分类方法更准确,分类质量更高。随着Internet上各种信息的迅速增加,手动处理是不切实际的。对网页进行分类可以在很大程度上解决网页上的混乱信息,并方便用户准确定位所需信息。因此,自动网页分类是一种具有很大实用价值的方法,也是一种组织和管理数据的方法。有效手段。这也是本文的重要内容。北京邮电大学软件工程硕士学位论文1.1.2主题网页的国内外研究现状采集技术发展的现状互联网正在不断改变着我们的生活。 Intemet已成为当今世界上最大的信息资源库。对于网络用户来说,从庞大的信息资源数据库中准确找到所需信息已经成为一个大问题。无论是某些通用搜索引擎(例如Google,百度等)还是用于特定主题的专用网页采集系统,它们都离不开网页采集,因此基于网络的信息采集和处理方式越来越多成为关注的焦点。
传统Web信息采集的采集中的页面数太大,采集的内容太乱,这会占用大量系统资源和网络资源。同时,互联网信息的分散状态和动态变化也是困扰信息的主要问题采集。为了解决这些问题,搜索引擎。这些搜索引擎通常通过一个或多个采集器从Internet采集各种数据,然后在用户根据用户提交的需求检索它们时,在本地服务器上为这些数据建立索引。即使是大规模的信息采集系统,其Web覆盖率也仅为30“ -40%。即使使用处理能力更强的计算机系统,其性价比也不是很高。相对较好的满意度可以满足人们其次,互联网信息的分散状态和动态变化也是影响信息采集的原因,由于信息源随时可能在变化,因此信息采集器必须经常刷新数据,但这仍然不能对于传统信息采集,由于需要刷新的页面数是采集所到达页面的很大一部分,因此利用率很低,因为用户经常只关心很少的页面,而且这些页面通常集中在一个或几个主题上,采集器浪费了大量的网络资源,这些问题主要是由大量传统Web信息引起的采集 ]和采集页。 采集页面的内容太乱。如果信息检索仅限于特定主题领域,并且基于与主题相关的信息提供检索服务,则采集所需的网页数量将大大减少,北京邮电大学的主要软件工程硕士和电信最后一篇论文。
这种类型的Web信息采集被称为固定主题Web信息采集。由于固定主题采集的搜索范围较大,因此准确性和召回率较高。但是,随着Internet的快速发展和网页数量的爆炸性增长,即使使用固定主题采集技术构建固定主题的搜索引擎,同一主题上的网页数量与广泛的主题相比仍然很大。因此,如何根据给定的模式有效地对同一主题上的网页进行分类以创建更有效,更快的搜索引擎是一个非常重要的主题。网页分类技术的发展现状基于文本分类算法并结合HTML语言的结构特点,开发了网页自动分类技术。自动文本分类最初是为了满足信息检索InformationRetrieval和IR系统的需求而开发的。信息检索系统必须处理大量数据,并且其文本信息数据库占据大部分内容。同时,用于表示文本内容的单词数为数千。在这种情况下,如果可以提供组织良好的结构化文本集合,则可以大大简化文本的访问和操作。自动文本分类系统的目的是以有序的方式组织文本集合,并将相似和相关的文本组织在一起。作为知识组织工具,它为信息检索提供了更有效的搜索策略和更准确的查询结果。自动文本分类的研究始于1950年代后期,H。RLulm在这一领域进行了开创性研究。
网页的自动分类在国外经历了三个发展阶段:第一阶段是1958年。1964年,进行了自动分类的可行性研究,第二阶段是1965.1974年,进行了自动分类的实验研究,第三阶段是阶段是1975年。它已经进入实用阶段[l_]。国内对自动分类的研究相对较晚,始于1980年代初期。关于中文文本分类的研究相对较少。国内外的研究基本上是以英文文本的分类为基础,结合中文文本和中文的特点,采取相应的策略,再将其应用于中文,形成中文文本。分类研究系统。 1981年,侯汉清讨论了计算机在文档分类中的应用。早期系统的主要特征是结合主题词汇进行分析和分类,并且人工干预的组成部分非常庞大。林等。将KNN方法与线性分类器相结合,取得了良好的效果。香港中文大学的围观回报率接近90%。准确率超过t31的80%。 C.K.P Wong等。研究了使用混合关键词进行文本分类的方法,召回率和准确率分别为72%和62%。复旦大学和富士通研究与发展中心的黄守,吴立德和石崎阳幸研究了独立语言的文本分类,并将单词类别的互信息用作评分功能。单分类器和多分类器用于分隔中文和日语。经过测试,最佳结果召回率为88.87%[5'。
上海交通大学的刁倩和王永成结合了词权重和分类算法进行分类,采用VSM方法N97%t71在封闭测试中分类正确。从那时起,基于统计的思想以及分词,语料库和其他技术一直被连续应用于分类。万维网收录大约115亿个可索引网页,并且每天添加数千万或更多的网页。如何组织这些大量有效的信息网络资源是一个很大的实际问题。网页数实现网页采集的功能子系统。二、比较了网页信息提取技术,中文分词技术,特征提取技术和网页分类技术的分析与比较,采用了优秀的KNN分类算法来实现网页分类功能。三、使用最大匹配算法来分割文本。清洁网页,删除网页中的一些垃圾邮件,然后将网页转换为文本格式。四、网页的预处理部分结合网页的模型特征,基于HTML标签对网页的无关文本进行加权。通过以上几方面的工作,终于完成了网页自动采集和分类系统的实现,并通过实验对上述算法进行了验证。 1.3论文的结构本文共分为6章,内容安排如下:第1章绪论,介绍了本课题的含义,国内外的现状和任务。第二章介绍网页采集和与分类有关的技术。本章介绍采集以及将用于分类的北京邮电大学软件工程硕士学位论文的原理和方法。包括常用的Web爬虫技术,网页到页面分类技术。
第3章网页采集和分类系统设计。本章首先进行系统分析,然后进行系统轮廓设计,功能模块设计,系统流程设计,系统逻辑设计和数据设计。第4章Web页面采集和分类系统的实现。本章详细介绍了每个模块的实现过程,包括页面采集模块,信息提取模块,网页重复数据删除模块,中文分词模块,特征向量提取模块,训练语料库模块和分类模块。第5章网页采集和分类系统测试。本章首先介绍了系统的操作界面,然后给出了实验评估标准并分析了实验结果。第六章结束语,本章对本文的工作进行了全面总结,给出了本文所取得的成果,并指出了现有的不足和改进的方向。北京第2章网页2.1 Web爬虫技术该程序也是搜索引擎的核心组件。搜索引擎的性能,规模和扩展能力在很大程度上取决于Web采集器的处理能力。网络爬虫Crawler也称为网络蜘蛛或网络机器人Robot。 Web爬网程序的系统结构如图2-1所示:下载模块用于存储从爬网的网页提取的URL。图2.1 Web爬网程序的结构图Web爬网程序从给定的URL开始并遵循网页上的出站链接。根据设置的网络搜索策略(例如,广度优先策略,深度优先策略或最佳优先级策略)链接采集 URL队列中的高优先级网页,然后使用网页分类器确定是否是主题网页,如果是,保存,否则丢弃;对于采集网页,请提取其中收录的URL,然后通过相应的位置将其插入URL队列。
2.1.1通用Web爬网程序通用Web爬网程序将基于预先设置的一个或几个初始种子URL进行启动,并且下载模块将不断从URL队列中获取URL,并访问和下载页面。页面解析器删除页面上的HTML标记以获取页面内容,将摘要,URL和其他信息保存在Web数据库中,同时提取当前页面上的新URL并将其保存到UURL队列中,直到很满意 查看全部
中文网页自动采集和分类系统的设计与实现
中文网页自动分类系统的设计与实现:保密期限:本人声明结果。据我介绍,该学位已申请其他学术机构的学术和贡献。我已经签署了我正在攻读学位的学位。有关部门可以出版学位保存和学位理论汇编。我已经签署了老师的签名。自动中文网页采集摘要随着科学技术的飞速发展,我们已经进入了数字信息时代。作为当今世界上最大的信息数据库,互联网也已成为人们获取信息的最重要手段。如何从Internet上的海量信息资源中快速准确地找到他们所需的信息已成为网络用户迫切需要解决的主要问题。因此,基于网络的网络信息的采集和分类已经成为研究的重点。传统Web信息采集的目标是制作尽可能多的采集信息页,甚至制作整个Web上的资源。在此过程中,它并不关心采集页的顺序和采集页的顺序。相关的主要混乱和重复的发生。同时,也非常有必要对采集中的网页进行自动分类以创建更有效的搜索引擎。网页分类是组织和管理信息的有效手段。它可以更大程度地解决信息混乱问题,并帮助用户准确确定他们所需的信息。传统的操作方式是在手动分类之后对它们进行组织和管理。
随着Internet上各种信息的迅速增加,手动处理它是不切实际的。因此,网页的自动分类是一种具有较大实用价值的方法,是一种组织和管理数据的有效手段。这也是本文的重要内容。本文首先介绍了课题的背景,研究目的以及国内外的研究现状。在解释了网页采集和网页分类的相关理论,主要技术和算法,包括几种典型的Web爬行技术和重复数据删除技术算法之后,本文选择了主题采集器方法和出色的KNN方法进行分类,并结合结合重复数据删除,分词和特征提取等相关技术,分析了中文网页的结构和特征,提出了中文网页采集,最终通过编程语言实现了分类和分类的设计与实现方法。在本文结尾处,对该系统进行了测试。测试结果符合系统设计要求,应用效果显着。关键词:Web信息采集网页分类信息提取单词分割特征提取OFSEHINESEANDIMPLE转N1:信息设计wEBPAGEAUT0〜IATIC采集和CLASSICATIONATION摘要随着科学的发展,并进入了开发技术,我们迅速地将信息信息化了世界的信息数字时代。 Intemet,其中最大的是maint001信息。 ItiS数据库。成为主要问题已解决了如何从用户那里迅速准确地关联信息资源,因为用户需要信息网络来查找信息的缺乏特征,以及庞大的,动态的,异构的,半结构化的基于信息的统一采集管理组织。研究和分类成为热点。信息采集的信息作为目标,是采集所有资源,例如订单和尽可能多的页面,或者内容不涉及采集的主题。在页面混乱的情况下,浪费了大部分SO资源,很少使用系统采集方法来减少采集的数据。 TIliSeff需要分类整齐的网页并自动创建页面重复页面。 Web有效管理页面引擎的研究。组织可以解决范围广泛的分类信息(i种有效的小信息),这种大的杂乱信息有助于用户准确地表达信息模式。借助传统信息。但是,要处理所有种类的互联网,手动快速增加方式分类的操作信息,并不是一种方法论,也不是一种有效的数据手段。 Ttisanvalue,但组织管理这一重要部分的研究。首先介绍了网络采集理论的背景,目的,主题和分类,描述了包括网页爬虫网络分解在内的技术算法页面,其中技术,重复页面词提取分割,特征技术,中文技术,信息网络分类提取页面技术。几种履带和KNNmade的综合技术,局部比较的典型算法已被分类,因为它们具有出色的性能。提出了111种拟议的中文网站,并结合了中文的已设计实现的获取结构和特征的分类,并对技术网页进行了编码并实现了语言页面的分析。最后,它的编程结果就是该语言。测试系统设计要求和应用程序完成。许多信息分类,关键词:网页采集,网页信息提取,分割,字符方法。„„„„„„„„„„„„„„„„„„„„。 484.7.2 KNN结„„„„„„„„„„„„„„„„„„„„„„„ 5253„„„„„„„„„„。
63北京邮电大学软件工程硕士学位论文第1章引言1.1项目背景和研究现状1.1.1项目背景和研究目标随着Internet的普及和网络技术的飞速发展,Internet信息资源日益丰富。为了从Internet获得越来越多的信息,包括文本,数字,图形,图像,声音和视频,需要使用指数形式。但是,随着网络信息的迅速发展,如何快速,准确地从庞大的信息资源中找到他们所需的信息已成为大多数网络用户的主要问题。它基于Internet 采集和搜索引擎上的信息。这些搜索引擎通常使用一个或多个采集器从Internet采集FTP,电子邮件,新闻等各种数据,然后在本地服务器上为这些数据建立索引,然后用户根据索引数据库从索引数据库中进行搜索。用户提交的搜索条件。快速找到您需要的信息。网络信息采集作为这些搜索引擎的基础和组成部分,起着举足轻重的作用。 Web信息采集是指通过Web页面之间的链接关系从Web自动获取页面信息,并随着链接不断扩展到所需Web页面的过程。传统的W歌曲信息采集的目标是要有尽可能多的采集信息页,甚至是整个Web上的资源,这样,集中精力于采集的速度和数量,并且实现是比较简单。但是,这种传统的采集方法存在很多缺陷。
由于采集需要基于整个Web信息的采集页,因此部分利用率非常低。用户通常只关心很少的页面,采集器 采集的大多数页面对他们来说都是无用的。显然,这是对系统资源和网络资源的巨大开销。随着网页数量的快速增长,非常有必要使用固定标题采集技术来构造固定标题类别,以创建一个更有效,更快速的搜索引擎。传统的操作模式是分类后组织和管理其工作。该分类方法更准确,分类质量更高。随着Internet上各种信息的迅速增加,手动处理是不切实际的。对网页进行分类可以在很大程度上解决网页上的混乱信息,并方便用户准确定位所需信息。因此,自动网页分类是一种具有很大实用价值的方法,也是一种组织和管理数据的方法。有效手段。这也是本文的重要内容。北京邮电大学软件工程硕士学位论文1.1.2主题网页的国内外研究现状采集技术发展的现状互联网正在不断改变着我们的生活。 Intemet已成为当今世界上最大的信息资源库。对于网络用户来说,从庞大的信息资源数据库中准确找到所需信息已经成为一个大问题。无论是某些通用搜索引擎(例如Google,百度等)还是用于特定主题的专用网页采集系统,它们都离不开网页采集,因此基于网络的信息采集和处理方式越来越多成为关注的焦点。
传统Web信息采集的采集中的页面数太大,采集的内容太乱,这会占用大量系统资源和网络资源。同时,互联网信息的分散状态和动态变化也是困扰信息的主要问题采集。为了解决这些问题,搜索引擎。这些搜索引擎通常通过一个或多个采集器从Internet采集各种数据,然后在用户根据用户提交的需求检索它们时,在本地服务器上为这些数据建立索引。即使是大规模的信息采集系统,其Web覆盖率也仅为30“ -40%。即使使用处理能力更强的计算机系统,其性价比也不是很高。相对较好的满意度可以满足人们其次,互联网信息的分散状态和动态变化也是影响信息采集的原因,由于信息源随时可能在变化,因此信息采集器必须经常刷新数据,但这仍然不能对于传统信息采集,由于需要刷新的页面数是采集所到达页面的很大一部分,因此利用率很低,因为用户经常只关心很少的页面,而且这些页面通常集中在一个或几个主题上,采集器浪费了大量的网络资源,这些问题主要是由大量传统Web信息引起的采集 ]和采集页。 采集页面的内容太乱。如果信息检索仅限于特定主题领域,并且基于与主题相关的信息提供检索服务,则采集所需的网页数量将大大减少,北京邮电大学的主要软件工程硕士和电信最后一篇论文。
这种类型的Web信息采集被称为固定主题Web信息采集。由于固定主题采集的搜索范围较大,因此准确性和召回率较高。但是,随着Internet的快速发展和网页数量的爆炸性增长,即使使用固定主题采集技术构建固定主题的搜索引擎,同一主题上的网页数量与广泛的主题相比仍然很大。因此,如何根据给定的模式有效地对同一主题上的网页进行分类以创建更有效,更快的搜索引擎是一个非常重要的主题。网页分类技术的发展现状基于文本分类算法并结合HTML语言的结构特点,开发了网页自动分类技术。自动文本分类最初是为了满足信息检索InformationRetrieval和IR系统的需求而开发的。信息检索系统必须处理大量数据,并且其文本信息数据库占据大部分内容。同时,用于表示文本内容的单词数为数千。在这种情况下,如果可以提供组织良好的结构化文本集合,则可以大大简化文本的访问和操作。自动文本分类系统的目的是以有序的方式组织文本集合,并将相似和相关的文本组织在一起。作为知识组织工具,它为信息检索提供了更有效的搜索策略和更准确的查询结果。自动文本分类的研究始于1950年代后期,H。RLulm在这一领域进行了开创性研究。
网页的自动分类在国外经历了三个发展阶段:第一阶段是1958年。1964年,进行了自动分类的可行性研究,第二阶段是1965.1974年,进行了自动分类的实验研究,第三阶段是阶段是1975年。它已经进入实用阶段[l_]。国内对自动分类的研究相对较晚,始于1980年代初期。关于中文文本分类的研究相对较少。国内外的研究基本上是以英文文本的分类为基础,结合中文文本和中文的特点,采取相应的策略,再将其应用于中文,形成中文文本。分类研究系统。 1981年,侯汉清讨论了计算机在文档分类中的应用。早期系统的主要特征是结合主题词汇进行分析和分类,并且人工干预的组成部分非常庞大。林等。将KNN方法与线性分类器相结合,取得了良好的效果。香港中文大学的围观回报率接近90%。准确率超过t31的80%。 C.K.P Wong等。研究了使用混合关键词进行文本分类的方法,召回率和准确率分别为72%和62%。复旦大学和富士通研究与发展中心的黄守,吴立德和石崎阳幸研究了独立语言的文本分类,并将单词类别的互信息用作评分功能。单分类器和多分类器用于分隔中文和日语。经过测试,最佳结果召回率为88.87%[5'。
上海交通大学的刁倩和王永成结合了词权重和分类算法进行分类,采用VSM方法N97%t71在封闭测试中分类正确。从那时起,基于统计的思想以及分词,语料库和其他技术一直被连续应用于分类。万维网收录大约115亿个可索引网页,并且每天添加数千万或更多的网页。如何组织这些大量有效的信息网络资源是一个很大的实际问题。网页数实现网页采集的功能子系统。二、比较了网页信息提取技术,中文分词技术,特征提取技术和网页分类技术的分析与比较,采用了优秀的KNN分类算法来实现网页分类功能。三、使用最大匹配算法来分割文本。清洁网页,删除网页中的一些垃圾邮件,然后将网页转换为文本格式。四、网页的预处理部分结合网页的模型特征,基于HTML标签对网页的无关文本进行加权。通过以上几方面的工作,终于完成了网页自动采集和分类系统的实现,并通过实验对上述算法进行了验证。 1.3论文的结构本文共分为6章,内容安排如下:第1章绪论,介绍了本课题的含义,国内外的现状和任务。第二章介绍网页采集和与分类有关的技术。本章介绍采集以及将用于分类的北京邮电大学软件工程硕士学位论文的原理和方法。包括常用的Web爬虫技术,网页到页面分类技术。
第3章网页采集和分类系统设计。本章首先进行系统分析,然后进行系统轮廓设计,功能模块设计,系统流程设计,系统逻辑设计和数据设计。第4章Web页面采集和分类系统的实现。本章详细介绍了每个模块的实现过程,包括页面采集模块,信息提取模块,网页重复数据删除模块,中文分词模块,特征向量提取模块,训练语料库模块和分类模块。第5章网页采集和分类系统测试。本章首先介绍了系统的操作界面,然后给出了实验评估标准并分析了实验结果。第六章结束语,本章对本文的工作进行了全面总结,给出了本文所取得的成果,并指出了现有的不足和改进的方向。北京第2章网页2.1 Web爬虫技术该程序也是搜索引擎的核心组件。搜索引擎的性能,规模和扩展能力在很大程度上取决于Web采集器的处理能力。网络爬虫Crawler也称为网络蜘蛛或网络机器人Robot。 Web爬网程序的系统结构如图2-1所示:下载模块用于存储从爬网的网页提取的URL。图2.1 Web爬网程序的结构图Web爬网程序从给定的URL开始并遵循网页上的出站链接。根据设置的网络搜索策略(例如,广度优先策略,深度优先策略或最佳优先级策略)链接采集 URL队列中的高优先级网页,然后使用网页分类器确定是否是主题网页,如果是,保存,否则丢弃;对于采集网页,请提取其中收录的URL,然后通过相应的位置将其插入URL队列。
2.1.1通用Web爬网程序通用Web爬网程序将基于预先设置的一个或几个初始种子URL进行启动,并且下载模块将不断从URL队列中获取URL,并访问和下载页面。页面解析器删除页面上的HTML标记以获取页面内容,将摘要,URL和其他信息保存在Web数据库中,同时提取当前页面上的新URL并将其保存到UURL队列中,直到很满意
汇总:网站新闻自动采集系统设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-09-02 01:34
摘要现在,许多传统媒体已经建立了自己的新闻网站,除了及时发布自己的新闻外,他们还需要采集其他专业新闻网站新闻作为补充,文章通过ASPHTTP组件实现网站新闻远程批量自动采集,提高网络编辑的发布效率,并为相关应用提供快速可行的思路和设计方案. 现在,许多传统媒体都建立了自己的新闻站点. 除了立即发布自己的新闻外,他们还需要从其他分类新闻网站采集新闻作为补充,带有ASPHTTP组件的文章可实现该网站的自动新闻采集,提高Web编辑器的发布效率,并提供快速且相关应用的可行方法和设计. 查看全部
网站新闻自动采集系统设计
摘要现在,许多传统媒体已经建立了自己的新闻网站,除了及时发布自己的新闻外,他们还需要采集其他专业新闻网站新闻作为补充,文章通过ASPHTTP组件实现网站新闻远程批量自动采集,提高网络编辑的发布效率,并为相关应用提供快速可行的思路和设计方案. 现在,许多传统媒体都建立了自己的新闻站点. 除了立即发布自己的新闻外,他们还需要从其他分类新闻网站采集新闻作为补充,带有ASPHTTP组件的文章可实现该网站的自动新闻采集,提高Web编辑器的发布效率,并提供快速且相关应用的可行方法和设计.
大数据采集系统靠谱吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-26 04:58
大数据智能营销系统究竟可靠吗,首先在问这个问题之前,我想先请你们想一下,你们觉得智能营销系统应当有怎么样的功能,能把顾客直接带到你的身边吗?
大数据智能营销系统是一共有45款软件,300多个功能,大致有三块功能,信息采集,智能营销和引流,三大蓝筹股都是模拟人工去操作的,很多破解版都是按照这一点来愚弄消费者,把自己的功能吹的神乎其神,今天小编就带给你们解密这种骗子!正版大数据采集笔记本联系,
首先看一下信息采集,这个功能就是说借助网路爬虫技术在网上实时抓取数据,这个网路爬虫虽然也是模拟人工的,就是说采集信息就是快速的把信息采集过来,但是采集的信息都是你自己能从网上找到的公开信息,也就是说这个功能可以看成一个全网信息快速整合工具,但是现今破解版智能营销系统给消费者说可以按照关键词采集私人信息,网站的浏览痕迹或则直接说可以采集到须要大家产品的人,这种居然还有人信,那我是真的服了,稍微懂点互联网的都晓得这是找不到的,而且这是属于私人信息,是违规的,说实话假如一个几千块的工具可以直接把意向顾客送到你手上,那须要她们系统的顾客也许要绕月球300圈了。
智能营销包括的功能也比较多,比如说陌陌,QQ,短信,电话等等,这里的操作也是一样都是由人工操作的,今天就讲一个陌陌,比如说陌陌加人,智能营销系统的陌陌加人和你自己加熟练更是差不多的,但是就是说智能营销系统比较便捷一点,而且是可以同时登录几十个陌陌帐号手动循环添加的,但是破解版的如何给顾客承诺呢,强制加人,不需要经过对方同意等等,这种超出腾讯规则的事,你觉得她们公司能比腾讯更厉害吗?
最后讲一下引流,同样的引流也是模拟人工操作的,都是借助真实的帐号(自己订购,成本低),然后模拟真人去顶贴回帖的,现在最可怕的是现今还有破解版智能营销系统给顾客说可以做网站优化,这个你们可以自行去百度搜索惊雷算法,做网站排名的软件2017年就不能再用了,现在跟本没有网站优化的功能,还有什么上万个防封ip,都是不存在的!
大数据智能营销系统究竟可靠吗,这些破解版的智能营销系统都是不管更新和售后的,所以总是爱给顾客夸耀自己的功能多么的强悍,诱骗消费者,客户订购以后就找都不到她们了,希望广大消费者可以看清这种骗子,可靠的智能营销系统其实也是有的,鹰眼大数据智能营销系统(133,838,41381)是最早研制智能营销系统的公司,公司创立六年了,也仍然在做软件研制,现在又是大品牌,值得信赖 查看全部
大数据采集系统靠谱吗
大数据智能营销系统究竟可靠吗,首先在问这个问题之前,我想先请你们想一下,你们觉得智能营销系统应当有怎么样的功能,能把顾客直接带到你的身边吗?
大数据智能营销系统是一共有45款软件,300多个功能,大致有三块功能,信息采集,智能营销和引流,三大蓝筹股都是模拟人工去操作的,很多破解版都是按照这一点来愚弄消费者,把自己的功能吹的神乎其神,今天小编就带给你们解密这种骗子!正版大数据采集笔记本联系,
首先看一下信息采集,这个功能就是说借助网路爬虫技术在网上实时抓取数据,这个网路爬虫虽然也是模拟人工的,就是说采集信息就是快速的把信息采集过来,但是采集的信息都是你自己能从网上找到的公开信息,也就是说这个功能可以看成一个全网信息快速整合工具,但是现今破解版智能营销系统给消费者说可以按照关键词采集私人信息,网站的浏览痕迹或则直接说可以采集到须要大家产品的人,这种居然还有人信,那我是真的服了,稍微懂点互联网的都晓得这是找不到的,而且这是属于私人信息,是违规的,说实话假如一个几千块的工具可以直接把意向顾客送到你手上,那须要她们系统的顾客也许要绕月球300圈了。

智能营销包括的功能也比较多,比如说陌陌,QQ,短信,电话等等,这里的操作也是一样都是由人工操作的,今天就讲一个陌陌,比如说陌陌加人,智能营销系统的陌陌加人和你自己加熟练更是差不多的,但是就是说智能营销系统比较便捷一点,而且是可以同时登录几十个陌陌帐号手动循环添加的,但是破解版的如何给顾客承诺呢,强制加人,不需要经过对方同意等等,这种超出腾讯规则的事,你觉得她们公司能比腾讯更厉害吗?
最后讲一下引流,同样的引流也是模拟人工操作的,都是借助真实的帐号(自己订购,成本低),然后模拟真人去顶贴回帖的,现在最可怕的是现今还有破解版智能营销系统给顾客说可以做网站优化,这个你们可以自行去百度搜索惊雷算法,做网站排名的软件2017年就不能再用了,现在跟本没有网站优化的功能,还有什么上万个防封ip,都是不存在的!
大数据智能营销系统究竟可靠吗,这些破解版的智能营销系统都是不管更新和售后的,所以总是爱给顾客夸耀自己的功能多么的强悍,诱骗消费者,客户订购以后就找都不到她们了,希望广大消费者可以看清这种骗子,可靠的智能营销系统其实也是有的,鹰眼大数据智能营销系统(133,838,41381)是最早研制智能营销系统的公司,公司创立六年了,也仍然在做软件研制,现在又是大品牌,值得信赖
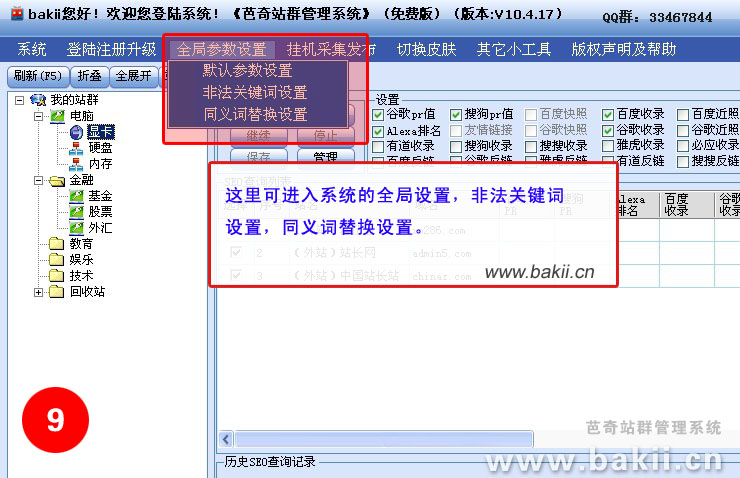
芭奇站群管理系统使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-13 21:42
芭奇站群管理系统说明:所有版本,支持无限网站,傻瓜式操作,无须编撰采集规则,无限采集新数据,无限发布数据,可永久免费升级,可任意笔记本(收录vps)使用挂机采集发布,可多帐号多开同时使用,无绑定机器硬件,无须订购加密狗,不受空间商程序限制,基本不消耗空间cpu与显存(适合更多的美国空间),支持发布数据到各类流行cms中去(目前没有的会尽早降低起来),也可独立网站程序订制发布插口。只需下载软件,只需订购相应的序列号升级即可(当然,免费版本也是可以使用的)!
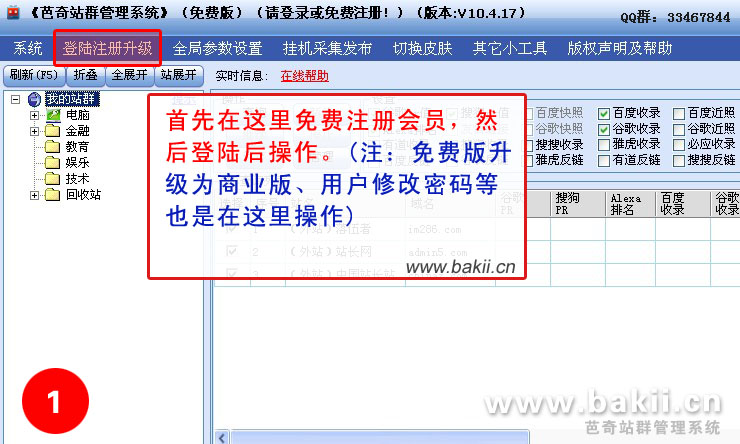
第一次根据它一步一步来,以后就就会了,每站只须要设置一次就可以永久使用
注意:记得要在软件上面先注册一个新帐号才按下边的操作进行哦!
基本流程:注册-->登陆-->新建网站分类-->新建网站栏目-->采集关键字-->采集文章-->设置发布插口-->全部发布
视频教程免费下载,适合菜鸟使用: [千脑快速下载] 大小:13.68MB (强烈推荐)
千脑下载网址:
站群构建步骤:
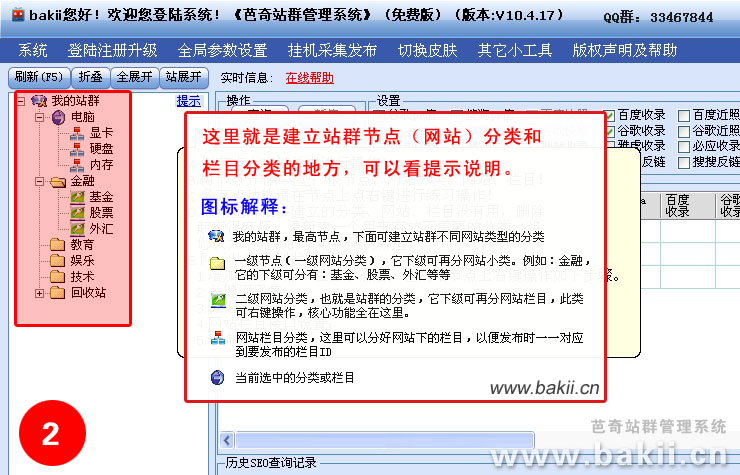
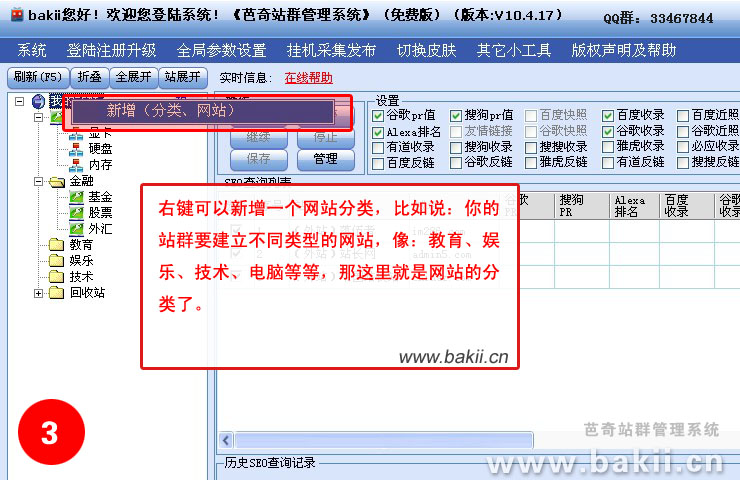
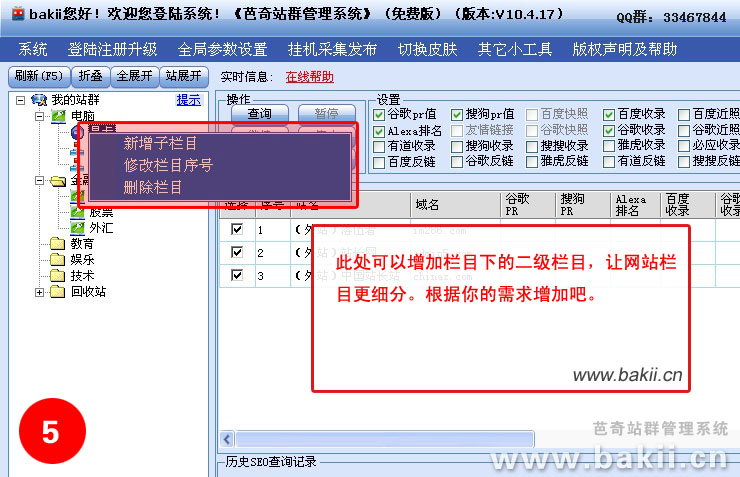
1、在“我的站群”右键,选择“新增(网站、分类)”,填写“节点名称”和选择“节点类型”。
具体作用看下边详尽解释:
①“节点名称”:你的节点命名,例如:“芭奇站”(注:以下我都以“芭奇站”这个名称作为说明);
②“节点顺序号”:可以默认不改动,这只是做为排序作用;
③“节点类型”:这里分有两种类型“网站分类”和“网站”,一般可以选“网站”就好,以下是详尽解释:
---“网站分类”的意思是一个大的分类,作用象一个文件夹,这个文件夹下有很多不同类型的网站,如果是做上几百个网站,这个网站分类是太有必要构建的,方便管理。此功能右键菜单只有:“新增(网站、分类)”,“修改分类”,“移动分类”;
---“网站”的意思是网站的类型,它归类到“网站分类”下,一般大型个人站群,类型直接选这个就好。它的下级可以新建网站栏目。右键菜单有多个功能。
2、在“芭奇站”下右键,选择“新增栏目”,填写栏目名称,例如:“网站优化”;
注意,这个不一定是和你的网站栏目一样,这个将会作为一个“关键字”去采集它的一些“长尾关键字”,所以定位要好一点。
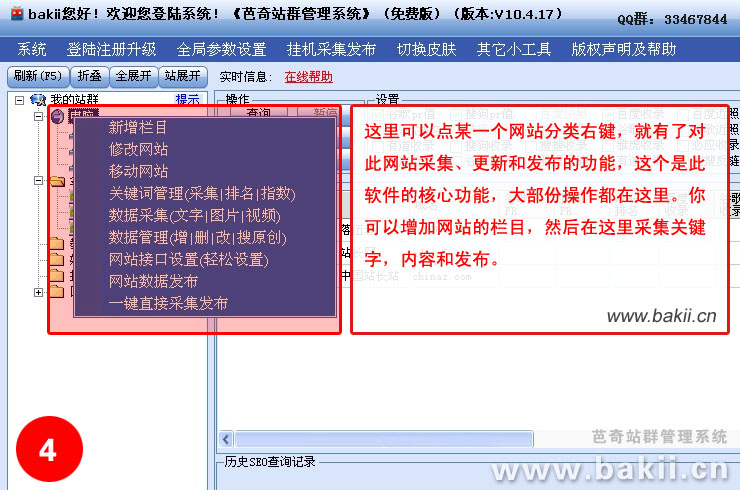
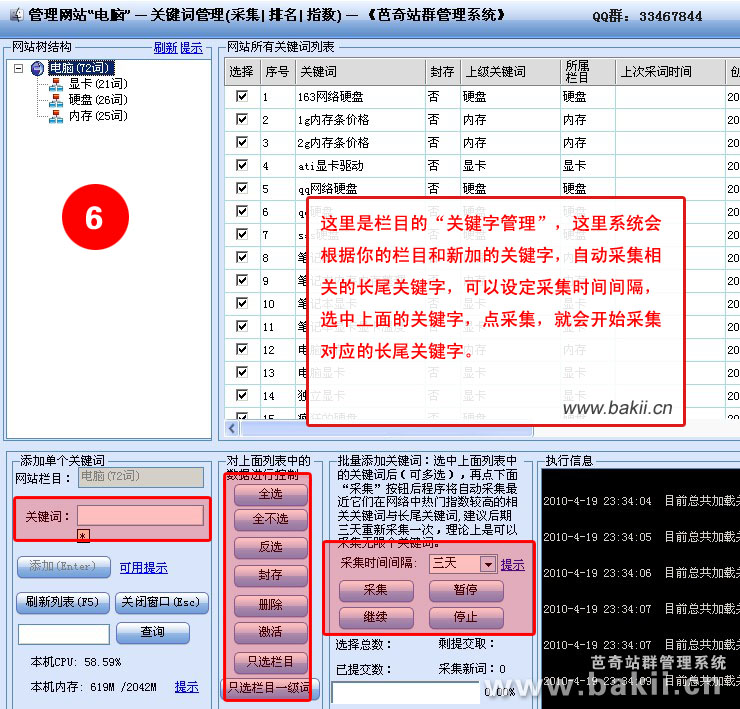
3、在“芭奇站”右键,进入“关键字管理”,采集关键字;
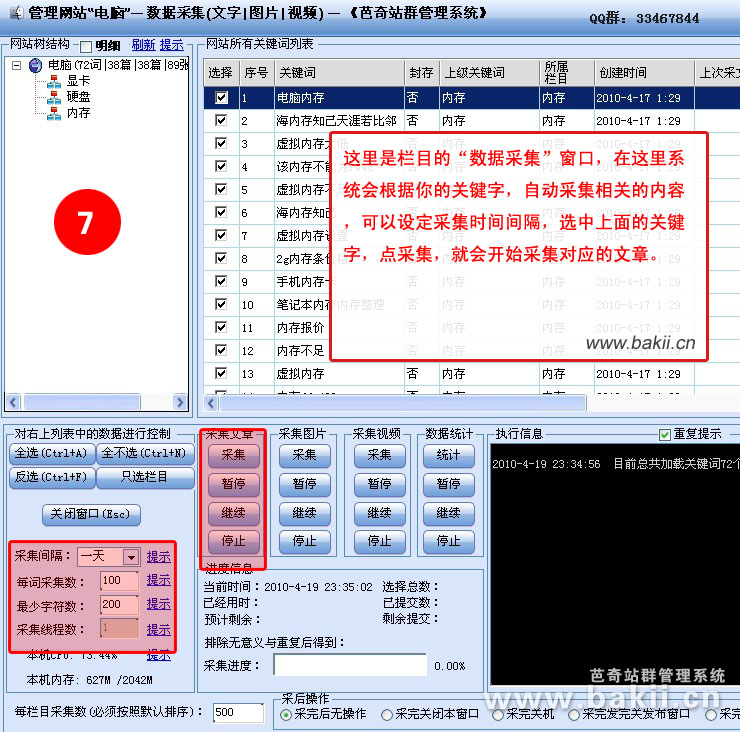
4、在“芭奇站”右键,进入“数据采集”,采集文章;
5、在“芭奇站”右键,进入“数据管理”,检查已采集的文章,根据个人要求可删可改;
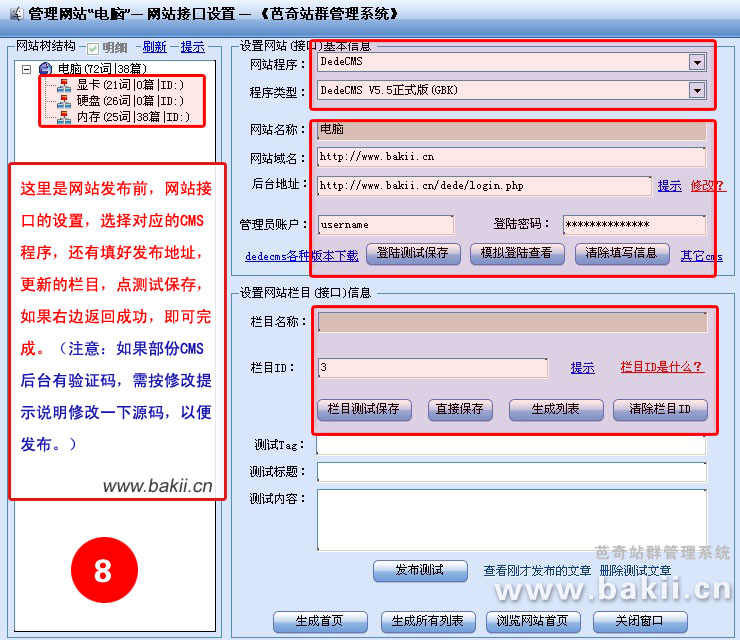
6、在“芭奇站”右键,进入“网站接口设置”,按提示填写网站地址;
7、在“芭奇站”右键,进入“网站数据发布”,根据个人需求设置,然后开始发布;
芭奇站群系统图片说明:
查看全部
芭奇站群管理系统使用教程
芭奇站群管理系统说明:所有版本,支持无限网站,傻瓜式操作,无须编撰采集规则,无限采集新数据,无限发布数据,可永久免费升级,可任意笔记本(收录vps)使用挂机采集发布,可多帐号多开同时使用,无绑定机器硬件,无须订购加密狗,不受空间商程序限制,基本不消耗空间cpu与显存(适合更多的美国空间),支持发布数据到各类流行cms中去(目前没有的会尽早降低起来),也可独立网站程序订制发布插口。只需下载软件,只需订购相应的序列号升级即可(当然,免费版本也是可以使用的)!
第一次根据它一步一步来,以后就就会了,每站只须要设置一次就可以永久使用
注意:记得要在软件上面先注册一个新帐号才按下边的操作进行哦!
基本流程:注册-->登陆-->新建网站分类-->新建网站栏目-->采集关键字-->采集文章-->设置发布插口-->全部发布
视频教程免费下载,适合菜鸟使用: [千脑快速下载] 大小:13.68MB (强烈推荐)
千脑下载网址:
站群构建步骤:
1、在“我的站群”右键,选择“新增(网站、分类)”,填写“节点名称”和选择“节点类型”。
具体作用看下边详尽解释:
①“节点名称”:你的节点命名,例如:“芭奇站”(注:以下我都以“芭奇站”这个名称作为说明);
②“节点顺序号”:可以默认不改动,这只是做为排序作用;
③“节点类型”:这里分有两种类型“网站分类”和“网站”,一般可以选“网站”就好,以下是详尽解释:
---“网站分类”的意思是一个大的分类,作用象一个文件夹,这个文件夹下有很多不同类型的网站,如果是做上几百个网站,这个网站分类是太有必要构建的,方便管理。此功能右键菜单只有:“新增(网站、分类)”,“修改分类”,“移动分类”;
---“网站”的意思是网站的类型,它归类到“网站分类”下,一般大型个人站群,类型直接选这个就好。它的下级可以新建网站栏目。右键菜单有多个功能。
2、在“芭奇站”下右键,选择“新增栏目”,填写栏目名称,例如:“网站优化”;
注意,这个不一定是和你的网站栏目一样,这个将会作为一个“关键字”去采集它的一些“长尾关键字”,所以定位要好一点。
3、在“芭奇站”右键,进入“关键字管理”,采集关键字;
4、在“芭奇站”右键,进入“数据采集”,采集文章;
5、在“芭奇站”右键,进入“数据管理”,检查已采集的文章,根据个人要求可删可改;
6、在“芭奇站”右键,进入“网站接口设置”,按提示填写网站地址;
7、在“芭奇站”右键,进入“网站数据发布”,根据个人需求设置,然后开始发布;
芭奇站群系统图片说明:
问问搜搜百科网站内容系统源码,自动伪原创SEO完美优化功能,自动采集更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2020-08-13 21:31
安装环境
商品介绍
自动更新问问搜搜百科站系统 自动伪原创seo完美优化 自动采集 网络挣钱神器 必备!
2016.4.4号 升级版本
演示地址1: 2015年12月上线站
该套源码对360搜索优化的比较好,演示站点是2015年12月上线,360搜索收录了大约400万页面,网站域名是老域名,360和百度收录排行都挺好,并且这个网站的不需要任何操作,每天手动更新,自动采集,自动伪原创,完全做到全手动。
这套网站源码特性:
,360搜索完美收录,后期完全可以做到秒收。
第二,解放右手,完全做到全手动更新网站内容。
赚钱思路:
这套源码的挣钱思路很简单,纯靠360搜索流量挣钱,这种网站全是长尾关键词,收录量越大,长尾关键词越多,流量越大,挂广告联盟挣钱。真正做到躺下都挣钱。
网站环境配置要求:必须要求web服务是IIS6,支持语言是ASP,支持httpd.ini伪静态。建议使用最低512M显存的win2003 vps云服务器。
温馨提示:由于源码具有可复制性,一经拍下,只要环境无问题,直接上传源码,打开cj.html页面,即可手动采集更新网站内容。恶意侵吞源码的,拒绝退货。如果是源码的相关问题,联系我的QQ,帮助解决。另外,关于在其他店订购盗版源码的不要来找我,给你植入木马侧门吃亏的是你,购买我站源码转让的,一经发觉,以后不再提供更新版本,出现侧门木马不要来找我,切记,切记!!!
再说一遍,骗取源码的,请自重,不要拍~~
查看全部
商品属性
安装环境
商品介绍
自动更新问问搜搜百科站系统 自动伪原创seo完美优化 自动采集 网络挣钱神器 必备!
2016.4.4号 升级版本
演示地址1: 2015年12月上线站
该套源码对360搜索优化的比较好,演示站点是2015年12月上线,360搜索收录了大约400万页面,网站域名是老域名,360和百度收录排行都挺好,并且这个网站的不需要任何操作,每天手动更新,自动采集,自动伪原创,完全做到全手动。
这套网站源码特性:
,360搜索完美收录,后期完全可以做到秒收。
第二,解放右手,完全做到全手动更新网站内容。
赚钱思路:
这套源码的挣钱思路很简单,纯靠360搜索流量挣钱,这种网站全是长尾关键词,收录量越大,长尾关键词越多,流量越大,挂广告联盟挣钱。真正做到躺下都挣钱。
网站环境配置要求:必须要求web服务是IIS6,支持语言是ASP,支持httpd.ini伪静态。建议使用最低512M显存的win2003 vps云服务器。
温馨提示:由于源码具有可复制性,一经拍下,只要环境无问题,直接上传源码,打开cj.html页面,即可手动采集更新网站内容。恶意侵吞源码的,拒绝退货。如果是源码的相关问题,联系我的QQ,帮助解决。另外,关于在其他店订购盗版源码的不要来找我,给你植入木马侧门吃亏的是你,购买我站源码转让的,一经发觉,以后不再提供更新版本,出现侧门木马不要来找我,切记,切记!!!
再说一遍,骗取源码的,请自重,不要拍~~

YGBOOK小说采集系统 php版 v1.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 577 次浏览 • 2020-08-11 19:46
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取 查看全部
YGBOOK小说内容管理系统(以下简称YGBOOK)提供一个轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取
小说网站源码 697小说网源码 自动采集小说系统隆重推出 全手动无人值守采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2020-08-11 14:10
1、源码类型:整站源码
2、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
3、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
4、原创程序:织梦DEDECMS 5.7SP1
5、编码类型:GBK
6、可否采集:全手动采集,赠送三条规则
7、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
查看全部
源码编号:A70小说网站源码 697小说网源码 自动采集小说系统隆重推出 全手动无人值守采集,PC+手机
1、源码类型:整站源码
2、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
3、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
4、原创程序:织梦DEDECMS 5.7SP1
5、编码类型:GBK
6、可否采集:全手动采集,赠送三条规则
7、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。

网站测试自动化系统—采集测试结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 529 次浏览 • 2020-08-10 11:01
一般来说,测试报告须要收录以下几个信息:
1. 测试用例的通过率,通过率代表产品的稳定程度,当然这是在排除了测试用例本身的问题导致的测试失败(Test Failure)得到的通过率。前面执行测试用例里提及到的MsTest.exe生成的结果文件.trx文件就早已保存了这个信息,在资源管理器上面双击这个文件,就能见到类似右图的结果:
在上图上面,可能会有悉心的读者发觉上面只有3个用例,但是红圈上面标出的文字却说:“6/6 passed”,这是因为这3个用例当中有数据驱动的用例,VSTT把每一行数据都当成一个独立的测试用例。关于数据驱动测试,可以参看我的这篇文章:网站自动化测试系统—数据驱动测试。
2. 代码覆盖率信息,代码覆盖率告诉测试团队有什么产品代码没有被覆盖到,没有覆盖到的产品代码意味着有一些用户场景我们没有考虑到,或者说测试覆盖面上有一些漏洞(Testing Hole)。如果是从VSTT用户界面上执行测试用例的话,VSTT早已手动集成了搜集代码覆盖率的功能,做法请参看我的文章软件自动化测试—代码覆盖率。在这篇文章里,我将告诉你怎样使用命令行做到搜集代码覆盖率。
至少有两种方式将搜集代码覆盖率的功能整合到自动化测试系统当中,一种是通过直接编辑.testrunconfig文件,这也是我们在VSTT用户界面操作时,VSTT背地里帮我们做的事情,使用.testrunconfig文件的方式请参考文章执行测试用例。
另外一种方式,是更深入的分解,实际上Visual Studio搜集代码覆盖率是通过一个称作VsPerfMon.exe的程序来搜集的,这个程序坐落C:\Program Files\Microsoft Visual Studio 9.0\Team Tools\Performance Tools(假设VSTT安装在磁盘)。当你根据软件自动化测试—代码覆盖率里介绍的步骤执行自动化测试的时侯,VSTT背地里做了下边几件事情:
1. 注入用于统计代码覆盖率的代码(instrument),注入的代码在文章软件自动化测试—代码覆盖率里早已有过讲解,这里不再说了。代码注入是通过vsinstr.exe来实现的,下面是使用它进行代码注入最简化的命令(接受任何.Net程序—即.dll和.exe文件,是否支持原生C++程序我还没有尝试过):
Vsinstr.exe –coverage image.dll
Vsinstr.exe不仅在程序上面注入代码以外,还要更改程序的符号文件(.pdb文件),之所以这样做,是因为程序被注入代码之后,就不和注入前的符号文件匹配了。使用不匹配的符号文件,将会造成前面浏览代码覆盖率结果时,我们没有办法查看详尽的代码覆盖信息—即什么行的代码被覆盖了,哪些代码没有覆盖。符号文件的作用请参考文章Visual Studio调试之符号文件。
如果要给网站 bin文件夹上面所有的程序执行代码注入操作的话,可以使用下边这个简单的命令来完成:
for %f in (*.dll) do vsinstr.exe –nowarn –coverage “%f”
for命令的用法,请查看Windows帮助文件上面的批处理一章;%f使用冒号括上去是防止%f代码的文件路径收录空格的情况;-nowarn这个参数告诉vsinstr不要输出警告信息了,因为懒得看, :)
2. 代码注入完成之后,启动vsperfmon.exe。在整个执行测试用例的过程中,vsperfmon.exe会在后台持续运行,采集代码覆盖率信息。你可能会奇怪,这个程序的名子如何称作perfmon?而不是使用哪些covermon之类的名子,这是因为vsperfmon.exe原本就是拿来做性能测试的,只不过是兼职搜集代码覆盖率罢了。
启动vsperfmon.exe的命令很简单:
vsperfmon.exe /START:COVERAGE /OUTPUT:result.coverage /CS
上面的参数解释一下:
参数
说明
/START:COVERAGE
告诉vsperfmon进行代码覆盖率的搜集。
/OUTPUT
保存结果的文件路径,可以是绝对路径或则相对路径,最好将后缀名设置为.coverage,这样你可以直接通过资源管理器上面双击在Visual studio中打开这个文件。
/CS
CS是CrossSession的缩写。
Session的意思有必要解释一下,Windows 从Windows 2000之后是一个多用户,多任务的操作系统(不知道NT是不是)。而Windows 95/98/Me不是多用户多任务操作系统,它们只是单用户多任务操作系统。多用户的意思是多个用户可以同时登陆同一台主机(通过远程登陆系统,mstsc.exe),操作系统会在这多个同时进行独立操作的用户当中执行有效的进程分离。虽然你可以在Windows 95/98/Me设置多个用户,但是这多个用户不能同时登陆同一台机器,必须要等另外一个用户注销(LogOff)才能登入这台机器。
每个用户登入到Windows操作系统时,Windows以Session(会话)的概念来描述它,一个用户可以有多个Session,例如这个用户可以从数学上直接登陆主机,这个Session称作Console Session;这个用户同时也可以通过远程登陆来操作这台主机,这又是另外一个Session。
之所以要在这里花很大的篇幅去描述Session,是因为假如我们在IIS上面启动网站时,IIS的应用程序池(Application Pool)需要你指定一个用户用于访问数据库、文件系统等资源,这个会话(Session)不会使用控制台会话(Console Session),因此一般来说,即使IIS的应用程序池使用的用户与当前执行测试用例的用户是同一个用户,也是在使用不同的会话。
在Windows Vista和Windows Server 2008之后,大部分Windows服务(当然也包括IIS提供的W3C服务)都是在第0会话(Session 0)当中运行,目的是为了更好地将Windows服务与其他进程分隔开来。而第一个登陆Windows Vista或Windows Server 2008的用户的会话标示号是1,而不像先前那样是0了。如下图所示:
在Vista之前,Windows服务(比如运行Asp.Net网站的IIS的W3C服务)和普通用户的进程(比如vsperfmon.exe)是运行在同一个会话里,两个进程之间交流消息只要用SendMessage或则PostMessage这个API就可以了。
但是在Vista以后,由于服务进程和普通用户进程不是在同一个会话里,所以就须要用命名管线(Named Pipeline)等IPC机制来执行交互了。/CS选项就是告诉vsperfmon.exe关注在其他会话里执行的进程的代码覆盖率信息。
3. 当所有的测试用例都执行完毕之后,VSTT关掉被测试的进程。因为在搜集代码覆盖率信息时,vsperfmon是和被统计的进程直接进行交互的;在保存覆盖率信息时,它须要等被搜集的进程关掉之后,才能执行保存操作。如果测试时,你的网站是运行在IIS里的,你须要使用下边的命令关掉IIS:
iisreset /stop
(启动iis的命令时iisreset /start)
如果你没有安装IIS,但是你会发觉在VSTS直接按下F5运行网站时,网站照样能运行,那是因为VSTS自带了一个支持Asp.Net的Web服务器WebDev.WebServer.EXE。这个程序保存在文件夹C:\Program Files\Common Files\microsoft shared\DevServer\9.0(假设你的系统盘是C,并且安装的是VSTS 2008版本)里面。
当你在VSTS上面运行网站的时侯,Visual Studio采用下边的命令启动网站:
Webdev.webserver /path: /port: /vpath:/
如果是使用webdev.webserver运行网站的话,在命令行关掉这个程序的命令是(实际上是杀死这个程序):
taskkill /im WebDev.WebServer.EXE
4. VSTT执行下边的命令关掉vsperfmon.exe,vsperfmon.exe将采集到的代码覆盖率保存到指定的文件当中。
vsperfmon.exe /shutdown
备注:vsperfmon.exe默认情况下只能搜集同一个用户运行的进程的代码覆盖率信息,如果你是将网站放在iis上面进行测试,默认情况下,运行这个网站的应用程序池(application pool)的用户是NetworkService,这种情况下,要么用vsperfmon.exe的/USER选项指定NetworkService这个用户。要么将应用程序池的用户改成执行vsperfmon.exe的那种用户。 查看全部
在后面的文章执行测试用例里,已经解释了怎样通过命令行来编译和执行测试用例,这样我们才有机会通过批处理的方法来将执行测试用例自动化。而我在文章系统应当有的功能里,也提到了一个完整的自动化系统应当是能否手动搜集测试结果的—毕竟我们的远景是,测试人员在夜晚上班前将用例执行上去,然后在第二天上午就可以直接看测试报告了。
一般来说,测试报告须要收录以下几个信息:
1. 测试用例的通过率,通过率代表产品的稳定程度,当然这是在排除了测试用例本身的问题导致的测试失败(Test Failure)得到的通过率。前面执行测试用例里提及到的MsTest.exe生成的结果文件.trx文件就早已保存了这个信息,在资源管理器上面双击这个文件,就能见到类似右图的结果:

在上图上面,可能会有悉心的读者发觉上面只有3个用例,但是红圈上面标出的文字却说:“6/6 passed”,这是因为这3个用例当中有数据驱动的用例,VSTT把每一行数据都当成一个独立的测试用例。关于数据驱动测试,可以参看我的这篇文章:网站自动化测试系统—数据驱动测试。
2. 代码覆盖率信息,代码覆盖率告诉测试团队有什么产品代码没有被覆盖到,没有覆盖到的产品代码意味着有一些用户场景我们没有考虑到,或者说测试覆盖面上有一些漏洞(Testing Hole)。如果是从VSTT用户界面上执行测试用例的话,VSTT早已手动集成了搜集代码覆盖率的功能,做法请参看我的文章软件自动化测试—代码覆盖率。在这篇文章里,我将告诉你怎样使用命令行做到搜集代码覆盖率。
至少有两种方式将搜集代码覆盖率的功能整合到自动化测试系统当中,一种是通过直接编辑.testrunconfig文件,这也是我们在VSTT用户界面操作时,VSTT背地里帮我们做的事情,使用.testrunconfig文件的方式请参考文章执行测试用例。
另外一种方式,是更深入的分解,实际上Visual Studio搜集代码覆盖率是通过一个称作VsPerfMon.exe的程序来搜集的,这个程序坐落C:\Program Files\Microsoft Visual Studio 9.0\Team Tools\Performance Tools(假设VSTT安装在磁盘)。当你根据软件自动化测试—代码覆盖率里介绍的步骤执行自动化测试的时侯,VSTT背地里做了下边几件事情:
1. 注入用于统计代码覆盖率的代码(instrument),注入的代码在文章软件自动化测试—代码覆盖率里早已有过讲解,这里不再说了。代码注入是通过vsinstr.exe来实现的,下面是使用它进行代码注入最简化的命令(接受任何.Net程序—即.dll和.exe文件,是否支持原生C++程序我还没有尝试过):
Vsinstr.exe –coverage image.dll
Vsinstr.exe不仅在程序上面注入代码以外,还要更改程序的符号文件(.pdb文件),之所以这样做,是因为程序被注入代码之后,就不和注入前的符号文件匹配了。使用不匹配的符号文件,将会造成前面浏览代码覆盖率结果时,我们没有办法查看详尽的代码覆盖信息—即什么行的代码被覆盖了,哪些代码没有覆盖。符号文件的作用请参考文章Visual Studio调试之符号文件。
如果要给网站 bin文件夹上面所有的程序执行代码注入操作的话,可以使用下边这个简单的命令来完成:
for %f in (*.dll) do vsinstr.exe –nowarn –coverage “%f”
for命令的用法,请查看Windows帮助文件上面的批处理一章;%f使用冒号括上去是防止%f代码的文件路径收录空格的情况;-nowarn这个参数告诉vsinstr不要输出警告信息了,因为懒得看, :)
2. 代码注入完成之后,启动vsperfmon.exe。在整个执行测试用例的过程中,vsperfmon.exe会在后台持续运行,采集代码覆盖率信息。你可能会奇怪,这个程序的名子如何称作perfmon?而不是使用哪些covermon之类的名子,这是因为vsperfmon.exe原本就是拿来做性能测试的,只不过是兼职搜集代码覆盖率罢了。
启动vsperfmon.exe的命令很简单:
vsperfmon.exe /START:COVERAGE /OUTPUT:result.coverage /CS
上面的参数解释一下:
参数
说明
/START:COVERAGE
告诉vsperfmon进行代码覆盖率的搜集。
/OUTPUT
保存结果的文件路径,可以是绝对路径或则相对路径,最好将后缀名设置为.coverage,这样你可以直接通过资源管理器上面双击在Visual studio中打开这个文件。
/CS
CS是CrossSession的缩写。
Session的意思有必要解释一下,Windows 从Windows 2000之后是一个多用户,多任务的操作系统(不知道NT是不是)。而Windows 95/98/Me不是多用户多任务操作系统,它们只是单用户多任务操作系统。多用户的意思是多个用户可以同时登陆同一台主机(通过远程登陆系统,mstsc.exe),操作系统会在这多个同时进行独立操作的用户当中执行有效的进程分离。虽然你可以在Windows 95/98/Me设置多个用户,但是这多个用户不能同时登陆同一台机器,必须要等另外一个用户注销(LogOff)才能登入这台机器。
每个用户登入到Windows操作系统时,Windows以Session(会话)的概念来描述它,一个用户可以有多个Session,例如这个用户可以从数学上直接登陆主机,这个Session称作Console Session;这个用户同时也可以通过远程登陆来操作这台主机,这又是另外一个Session。
之所以要在这里花很大的篇幅去描述Session,是因为假如我们在IIS上面启动网站时,IIS的应用程序池(Application Pool)需要你指定一个用户用于访问数据库、文件系统等资源,这个会话(Session)不会使用控制台会话(Console Session),因此一般来说,即使IIS的应用程序池使用的用户与当前执行测试用例的用户是同一个用户,也是在使用不同的会话。
在Windows Vista和Windows Server 2008之后,大部分Windows服务(当然也包括IIS提供的W3C服务)都是在第0会话(Session 0)当中运行,目的是为了更好地将Windows服务与其他进程分隔开来。而第一个登陆Windows Vista或Windows Server 2008的用户的会话标示号是1,而不像先前那样是0了。如下图所示:

在Vista之前,Windows服务(比如运行Asp.Net网站的IIS的W3C服务)和普通用户的进程(比如vsperfmon.exe)是运行在同一个会话里,两个进程之间交流消息只要用SendMessage或则PostMessage这个API就可以了。
但是在Vista以后,由于服务进程和普通用户进程不是在同一个会话里,所以就须要用命名管线(Named Pipeline)等IPC机制来执行交互了。/CS选项就是告诉vsperfmon.exe关注在其他会话里执行的进程的代码覆盖率信息。
3. 当所有的测试用例都执行完毕之后,VSTT关掉被测试的进程。因为在搜集代码覆盖率信息时,vsperfmon是和被统计的进程直接进行交互的;在保存覆盖率信息时,它须要等被搜集的进程关掉之后,才能执行保存操作。如果测试时,你的网站是运行在IIS里的,你须要使用下边的命令关掉IIS:
iisreset /stop
(启动iis的命令时iisreset /start)
如果你没有安装IIS,但是你会发觉在VSTS直接按下F5运行网站时,网站照样能运行,那是因为VSTS自带了一个支持Asp.Net的Web服务器WebDev.WebServer.EXE。这个程序保存在文件夹C:\Program Files\Common Files\microsoft shared\DevServer\9.0(假设你的系统盘是C,并且安装的是VSTS 2008版本)里面。
当你在VSTS上面运行网站的时侯,Visual Studio采用下边的命令启动网站:
Webdev.webserver /path: /port: /vpath:/
如果是使用webdev.webserver运行网站的话,在命令行关掉这个程序的命令是(实际上是杀死这个程序):
taskkill /im WebDev.WebServer.EXE
4. VSTT执行下边的命令关掉vsperfmon.exe,vsperfmon.exe将采集到的代码覆盖率保存到指定的文件当中。
vsperfmon.exe /shutdown
备注:vsperfmon.exe默认情况下只能搜集同一个用户运行的进程的代码覆盖率信息,如果你是将网站放在iis上面进行测试,默认情况下,运行这个网站的应用程序池(application pool)的用户是NetworkService,这种情况下,要么用vsperfmon.exe的/USER选项指定NetworkService这个用户。要么将应用程序池的用户改成执行vsperfmon.exe的那种用户。
网上新闻资源手动采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-10 09:26
采集的困 联程度要略高与WAP 网站。因WWW 网站面内容相 而且 更加丰富,最重要的是它没有似XML 在抓取的候可能会遇到好多解析 比如符号的失,不能匹配等等, 于采集系 重要的是能匹配到想要抓取的内容,如果不能 不能构建完整的目,也就是 构不完整将太可能导致我 在采集特定内容的 偏差或则采集不成功。所以,于采集WWW的网站不光须要采集程序的 面。但是,在的情况是常常用 大量的,所以会 真正的 一个的讯号 自己的面没有 范,如果出不能匹配 是个好消息,将大大的增加 的成本,加快 目的提出也奠定了一定的基。当然,随着手机上网的普及和 3G 手机来取信息, 一个,可能在未来 代替有的 抓住个方式,将要 基于手机器平台的 内容,我 采集的 象也是WAP 嵌入到有的 目中,真正 即抓即用。 研究的基本内容,解决的主要 采集系的运行 程是个依据任 列表不断 候须要一个 面订制一套,用来解析 附加参数:内容的地址附加的一些参数(比如: 示全文) 用于替列表中不需要的字符 条目(收录:接和地址) :用于文章内容的 :用于文章内容的 片的采集不同与新的采集, 而且在整个抓取程中的操作都接近相同,但 是在格式上要。
文字主要是存在 在网上抓取到 片以后下 到本地须要保持格式的一致性。 由于JPG和GIF 的配置是整个系中最重要的部份,新 采集 能正常工作的首要前提就是须要个采集任 配置包括有目地址以及 ,力求可以将用的文本定 表达式,以保采集内容的正确性。 采集的程主要是剖析 源,并加入到我 正确和程的透明性。 需要采集 可以采集的 掌握采集源的状况,如果 研究、方法及举措 程序的运行和须要一系列的配置, 于整个 都是至重要的。配置人 需要一定的 可能在不同的数据境中来使 用,所以我了数据 框架, 将大大便捷系 数据等情况。系 中使用了ibatis 也是一个源的框架,相 于hibernate 一个采集目都是 由于网的不确定诱因特别多,常常会 致程序出 需要一个大的日志系 也须要剖析日志来判定的缘由。 有一个建立的机制,用以 。如果须要制订效考核方 将会提供一份完整的可性的文档。 ,可以取当前入 管理可以 内容 管理系的后台,可以 抓取的信息 行有效的控制。 采集系构架 08/12/11-09/01/1210. 背景11.2 12. 09/01/13-09/02/19 13. 15.09/02/20-09/02/27 16. 18.09/02/28-09/03/15 19. 21.09/03/16-09/04/03 22. 完成程序23. 24.09/04/04-09/04/10 25. 中期26. 27.09/04/11-09/05/01 28. 完成相文档 30.09/05/02-09/05/22 31. 撰写文定稿 32. 33.09/05/23-09/05/29 34. 35.10 36. 09/05/30-09/06/05 37. 38.主要参考文献 QuickStart[EB/OL]. ml HttpclientUser Documentation.[EB/OL]. JavaUser Guide.[EB/OL]. 人民出版社 型手册》委会 O’ReillyJava 系列 Java联程思想(第4 机械工出版社 EffectiveJava 机械工出版社 2007-6-110. 中国道出版社 同学就网上新 源自 采集系 性的文献、分析和理解,基本明晰了本 体需求和具体任,基本提出了系 思想 告内容完整,内容和格式基本符合要求。
.完善后通;3.未通 杭州子科技大学 采集系以其高效和低廉的成本仍然遭到太 个信息爆燃的代,能及 是一个用,但是互 采集的主要工作不在采集的 的管理以及内容的分。主要 程,数据程以及正 表达式的 程的能力是评判一个程序能力的重要 下,能将系的性能全部 出来须要程序 充分的 使用无疑能提升程序的行效率和提供更好的用 生以来,一革命性的技 世界 来翻天覆地的 化,不能想像假如没有网 提出,未来的所有用可能 无非是十分考JAVA 表达式的史可以溯源到十九世 四十年代, 算机科学和自控制理 和方式 述或则匹配一系列符合某个复句的字符串的 个字符串。一 表达式一般被称一个模式,用来匹配一 系列符合某个复句的字符串。在好多文本 它工具里,正表达式一般被拿来 的文本内容。多程序 言都支持借助正 表达式 大概就可以了解到,正抒发 式是拿来理字符串用的,而且它的使用十分便捷和广泛。[3] 多少听起来有些和晦涩,但是在我 的日常生 中会太不意的须要使用它。比如在 常会有找符合个别 的字符 候就须要正表达式了。正如我 想要 一个新采集系 ,那第一 就是须要将目 面解析 将文档化,并根据我 正确无的提取我 需要的数据,如果没有正 起来肯定会相当的困。
另外, 一个 的反例。可能你在 WINDOWS 或者DOS 平台下找文件, 里会提及一个通配 字符,而星号拿来匹配任意 度的字符串。其 如果想正确的使用正表达式来 工作 来便利和减 :匹配任何个字符, 是它只能匹配 个字符。 :匹配入字符串的 束位置。 :匹配入字符串的 始位置。 “*”:匹配上面的子表达式零次或多次。 但是它匹配最少一次。 字符,即将下一个字符特殊字符或一个原 字符。 “[]”:匹配收录在括弧中的任意字符。 “x|y”:匹配X或则Y中的一个字符。 “?”:匹配零个或一个刚好在它之前的字符。 :匹配制订数量的字符,些字符是定 在此表达式之前的。[5] 非常广泛,在我一些WEB 用程序的候须要 繁的使用到它。比如我需要 提交和入的数据做一 就可以在客端使用JAVASCRIPT 做可以来好多的好 。一是在客 数据的安全性,网本身是不安全的,我 需要 入的数据行限制, 程序来未能 料的后果, 件的格式,一功能 使用正表达式来提取网 文档中的元素。在我 行剖析和解,找出我 需要的 具体内容,比如文章的,作者,内容和附 等等, 些内容的提 正是它的大指强 出,就是文本的操控。如果没有 些特点,我 需要做大量的判定以确保我找到的数据即将我 需要的, 往往的方式不是万能可靠的,而正 表达式正 点。
另外我一般也会碰到 ,当我须要 入大量数据的 格式不是我想要的,一般情况下我 会使用正 达式来解析些数据, 其根据我 定的格式来排列, 程只要我好正 表达式,如果 采集系中使用MYSQL 数据,MYSQL 管理系,它的主要特征是体 小,速度快, 一特征,在多中小型网站中 了增加网站的成本而 网站数据。MYSQL 中也支持正表达式在, 一特点可以和使用者 来特别大的便利和挺好 数据再通后台 理的方式在效率上一定没有在数 中直接要高,而且可以愈发明晰 和数 据存取的功能次,也增加了一定程度上的耦合。MYSQL 表达式的格式SELECT 字符串REGEXP 如果你有一定的正表达式 那你将可以很快的把握在MYSQL 达式一技能。 就是正 表达式 来的便利。[7] 采集系的使用是非常广泛的。想 一个 的事情,特是须要考 的情况。同你须要把握多 天气前提是你必 熟悉各个方面的特性以及其中 采集系的效率始 也是评判系 性能的一 个重要指,在相同的硬件 境下,如果采用多 可以正常的工作。《Athread monitoring system multithreadedJava programs 》一文中推荐了一使用 器起到一个管理的作用,是一个 得推荐的方式。
核心技卷II 机械工出版社 2008-12-1 SOCKET-BasedNetwork Programing 基于正表达式技 的数据 科技横>>2006 WebpageCleaning System Exploiting Static Regular Expression 杜冬梅,联彩欣, RegularExpression Websystem 算机系用>>2007 人民出版社 2006-12-1 Chang,BM threadmonitoring system multithreadedJava programs SIGPLANNotices 2006 vol.41(no.5) 刘邦桂,李正凡,LIUBang-gui,LI Zheng-fan SocketStream Communication EASTCHINA JIAOTONG UNIVERSITY 卷(期):2007 24(5) 10. Xing Bo PERFORMANCEPROMOTION DATABASERETRIEVAL COMPUTERAPPLICATIONS 200724(12) 11. 瓦特 2008-10-112. 佛瑞德(Friedl,J.E.F. 精通正表达式(第3 2007-7-113. 中国力出版社 文献述考核表 同学网上新 源自 采集系 文献行了适当的理 解剖析和整理,完成的文献 杭州子科技大学 文)外文文献翻HTTP 文件的相信息 联个文件是从HttpClient 里所表示的概念同地适用于HttpComponents,或是SUN的 HttpURLConnectiong, 又或是其它任何程序 即使你不在使用Java和HttpClient, 得它很有用。
警告 可以在任何刻被重新 同的文件,器都会 示新的内容。 送信息。个HTTP 是来历自服器的新文件所特定的。如果你的 只是模仿器的将会被终止。 如果你想行一个可靠的 用程序,你只能用这些 已公布的用程序 接口中。比如 商索要POP或则IMAP 搜索一下来自供商的RSS feed 用程序。HTTP Client HttpClient 联行HTTP 求。既然HttpClient没有与 文件那述内容,那 它就不允 的运行中可以允一些 ,但是它 HttpClient 可以理的误差是有限定的。 部分介了一些必 了解的重要的 助我了解 个文件剩下来的部份。 HTTP信息 由一个和一个任意的 形式的信息,求和回 第一行的形不同,但 都有一个部份和一个任意的 体部份。 HTTP毕求 送的缘由--URI 行的一个程序。HTTP 它的第一行包括一个数据,它表明了 求的成功或失 。HTTP 联联了一系列的数据代 联,像200 表示成功的代和404 个表示未找到的代。其它构建在HTTP 查看全部
随着互网技 的迅猛 或者。更多的人 上网 或者是 手机取。相比上面的两 方式,后者更具 量的工作人来支撑,本文将通 源采集系 构建一个低成本的信息共享平台提供建 可以愈发松的更新站点的内容信息。 采集系也在哪个 版本到在的多样化 言的版本, 采集来降低人工入所降低的成本。 如今,新采集系 非常成熟。市的需求量也十分大。在百度中 采集系可以搜到逾393,000 是一些新的站点,主要以广告赢利 目的,如果使用新 采集系 那可以 不用去操劳怎么更新网站内容,一但架好就几乎可以 或者小型的网站,都 的成本。新采集系 (手机 用版)用于在 采集和源的共享。 一方面可以保信息更及 更有效,另一方面可以 主流系的剖析 目前的新采集系 采集系基本上可以 以下功能: 网站行信息自 抓取,支持HTML 数据的采集,如文本信息,URL 信息自定来源与分 支持惟一索引,避免相同信息重 支持智能替功能,可以将内容中嵌入的所有的无 部分如广告消除 支持多面文章内容自 抽取与合并 数据直接入数据 而不是文件中,因此与借助 些数据的网站程序或则桌面程序之没有任何耦合 构完全自定,充分利用 信息的完整性与准确性,不会出 支持各主流数据 ,如MSSQL、Access、MySQL、Oracle、DB2、Sybase 采集系与本文所 的略有不同, 采集系都是基于WWW网站。
采集的困 联程度要略高与WAP 网站。因WWW 网站面内容相 而且 更加丰富,最重要的是它没有似XML 在抓取的候可能会遇到好多解析 比如符号的失,不能匹配等等, 于采集系 重要的是能匹配到想要抓取的内容,如果不能 不能构建完整的目,也就是 构不完整将太可能导致我 在采集特定内容的 偏差或则采集不成功。所以,于采集WWW的网站不光须要采集程序的 面。但是,在的情况是常常用 大量的,所以会 真正的 一个的讯号 自己的面没有 范,如果出不能匹配 是个好消息,将大大的增加 的成本,加快 目的提出也奠定了一定的基。当然,随着手机上网的普及和 3G 手机来取信息, 一个,可能在未来 代替有的 抓住个方式,将要 基于手机器平台的 内容,我 采集的 象也是WAP 嵌入到有的 目中,真正 即抓即用。 研究的基本内容,解决的主要 采集系的运行 程是个依据任 列表不断 候须要一个 面订制一套,用来解析 附加参数:内容的地址附加的一些参数(比如: 示全文) 用于替列表中不需要的字符 条目(收录:接和地址) :用于文章内容的 :用于文章内容的 片的采集不同与新的采集, 而且在整个抓取程中的操作都接近相同,但 是在格式上要。
文字主要是存在 在网上抓取到 片以后下 到本地须要保持格式的一致性。 由于JPG和GIF 的配置是整个系中最重要的部份,新 采集 能正常工作的首要前提就是须要个采集任 配置包括有目地址以及 ,力求可以将用的文本定 表达式,以保采集内容的正确性。 采集的程主要是剖析 源,并加入到我 正确和程的透明性。 需要采集 可以采集的 掌握采集源的状况,如果 研究、方法及举措 程序的运行和须要一系列的配置, 于整个 都是至重要的。配置人 需要一定的 可能在不同的数据境中来使 用,所以我了数据 框架, 将大大便捷系 数据等情况。系 中使用了ibatis 也是一个源的框架,相 于hibernate 一个采集目都是 由于网的不确定诱因特别多,常常会 致程序出 需要一个大的日志系 也须要剖析日志来判定的缘由。 有一个建立的机制,用以 。如果须要制订效考核方 将会提供一份完整的可性的文档。 ,可以取当前入 管理可以 内容 管理系的后台,可以 抓取的信息 行有效的控制。 采集系构架 08/12/11-09/01/1210. 背景11.2 12. 09/01/13-09/02/19 13. 15.09/02/20-09/02/27 16. 18.09/02/28-09/03/15 19. 21.09/03/16-09/04/03 22. 完成程序23. 24.09/04/04-09/04/10 25. 中期26. 27.09/04/11-09/05/01 28. 完成相文档 30.09/05/02-09/05/22 31. 撰写文定稿 32. 33.09/05/23-09/05/29 34. 35.10 36. 09/05/30-09/06/05 37. 38.主要参考文献 QuickStart[EB/OL]. ml HttpclientUser Documentation.[EB/OL]. JavaUser Guide.[EB/OL]. 人民出版社 型手册》委会 O’ReillyJava 系列 Java联程思想(第4 机械工出版社 EffectiveJava 机械工出版社 2007-6-110. 中国道出版社 同学就网上新 源自 采集系 性的文献、分析和理解,基本明晰了本 体需求和具体任,基本提出了系 思想 告内容完整,内容和格式基本符合要求。
.完善后通;3.未通 杭州子科技大学 采集系以其高效和低廉的成本仍然遭到太 个信息爆燃的代,能及 是一个用,但是互 采集的主要工作不在采集的 的管理以及内容的分。主要 程,数据程以及正 表达式的 程的能力是评判一个程序能力的重要 下,能将系的性能全部 出来须要程序 充分的 使用无疑能提升程序的行效率和提供更好的用 生以来,一革命性的技 世界 来翻天覆地的 化,不能想像假如没有网 提出,未来的所有用可能 无非是十分考JAVA 表达式的史可以溯源到十九世 四十年代, 算机科学和自控制理 和方式 述或则匹配一系列符合某个复句的字符串的 个字符串。一 表达式一般被称一个模式,用来匹配一 系列符合某个复句的字符串。在好多文本 它工具里,正表达式一般被拿来 的文本内容。多程序 言都支持借助正 表达式 大概就可以了解到,正抒发 式是拿来理字符串用的,而且它的使用十分便捷和广泛。[3] 多少听起来有些和晦涩,但是在我 的日常生 中会太不意的须要使用它。比如在 常会有找符合个别 的字符 候就须要正表达式了。正如我 想要 一个新采集系 ,那第一 就是须要将目 面解析 将文档化,并根据我 正确无的提取我 需要的数据,如果没有正 起来肯定会相当的困。
另外, 一个 的反例。可能你在 WINDOWS 或者DOS 平台下找文件, 里会提及一个通配 字符,而星号拿来匹配任意 度的字符串。其 如果想正确的使用正表达式来 工作 来便利和减 :匹配任何个字符, 是它只能匹配 个字符。 :匹配入字符串的 束位置。 :匹配入字符串的 始位置。 “*”:匹配上面的子表达式零次或多次。 但是它匹配最少一次。 字符,即将下一个字符特殊字符或一个原 字符。 “[]”:匹配收录在括弧中的任意字符。 “x|y”:匹配X或则Y中的一个字符。 “?”:匹配零个或一个刚好在它之前的字符。 :匹配制订数量的字符,些字符是定 在此表达式之前的。[5] 非常广泛,在我一些WEB 用程序的候须要 繁的使用到它。比如我需要 提交和入的数据做一 就可以在客端使用JAVASCRIPT 做可以来好多的好 。一是在客 数据的安全性,网本身是不安全的,我 需要 入的数据行限制, 程序来未能 料的后果, 件的格式,一功能 使用正表达式来提取网 文档中的元素。在我 行剖析和解,找出我 需要的 具体内容,比如文章的,作者,内容和附 等等, 些内容的提 正是它的大指强 出,就是文本的操控。如果没有 些特点,我 需要做大量的判定以确保我找到的数据即将我 需要的, 往往的方式不是万能可靠的,而正 表达式正 点。
另外我一般也会碰到 ,当我须要 入大量数据的 格式不是我想要的,一般情况下我 会使用正 达式来解析些数据, 其根据我 定的格式来排列, 程只要我好正 表达式,如果 采集系中使用MYSQL 数据,MYSQL 管理系,它的主要特征是体 小,速度快, 一特征,在多中小型网站中 了增加网站的成本而 网站数据。MYSQL 中也支持正表达式在, 一特点可以和使用者 来特别大的便利和挺好 数据再通后台 理的方式在效率上一定没有在数 中直接要高,而且可以愈发明晰 和数 据存取的功能次,也增加了一定程度上的耦合。MYSQL 表达式的格式SELECT 字符串REGEXP 如果你有一定的正表达式 那你将可以很快的把握在MYSQL 达式一技能。 就是正 表达式 来的便利。[7] 采集系的使用是非常广泛的。想 一个 的事情,特是须要考 的情况。同你须要把握多 天气前提是你必 熟悉各个方面的特性以及其中 采集系的效率始 也是评判系 性能的一 个重要指,在相同的硬件 境下,如果采用多 可以正常的工作。《Athread monitoring system multithreadedJava programs 》一文中推荐了一使用 器起到一个管理的作用,是一个 得推荐的方式。
核心技卷II 机械工出版社 2008-12-1 SOCKET-BasedNetwork Programing 基于正表达式技 的数据 科技横>>2006 WebpageCleaning System Exploiting Static Regular Expression 杜冬梅,联彩欣, RegularExpression Websystem 算机系用>>2007 人民出版社 2006-12-1 Chang,BM threadmonitoring system multithreadedJava programs SIGPLANNotices 2006 vol.41(no.5) 刘邦桂,李正凡,LIUBang-gui,LI Zheng-fan SocketStream Communication EASTCHINA JIAOTONG UNIVERSITY 卷(期):2007 24(5) 10. Xing Bo PERFORMANCEPROMOTION DATABASERETRIEVAL COMPUTERAPPLICATIONS 200724(12) 11. 瓦特 2008-10-112. 佛瑞德(Friedl,J.E.F. 精通正表达式(第3 2007-7-113. 中国力出版社 文献述考核表 同学网上新 源自 采集系 文献行了适当的理 解剖析和整理,完成的文献 杭州子科技大学 文)外文文献翻HTTP 文件的相信息 联个文件是从HttpClient 里所表示的概念同地适用于HttpComponents,或是SUN的 HttpURLConnectiong, 又或是其它任何程序 即使你不在使用Java和HttpClient, 得它很有用。
警告 可以在任何刻被重新 同的文件,器都会 示新的内容。 送信息。个HTTP 是来历自服器的新文件所特定的。如果你的 只是模仿器的将会被终止。 如果你想行一个可靠的 用程序,你只能用这些 已公布的用程序 接口中。比如 商索要POP或则IMAP 搜索一下来自供商的RSS feed 用程序。HTTP Client HttpClient 联行HTTP 求。既然HttpClient没有与 文件那述内容,那 它就不允 的运行中可以允一些 ,但是它 HttpClient 可以理的误差是有限定的。 部分介了一些必 了解的重要的 助我了解 个文件剩下来的部份。 HTTP信息 由一个和一个任意的 形式的信息,求和回 第一行的形不同,但 都有一个部份和一个任意的 体部份。 HTTP毕求 送的缘由--URI 行的一个程序。HTTP 它的第一行包括一个数据,它表明了 求的成功或失 。HTTP 联联了一系列的数据代 联,像200 表示成功的代和404 个表示未找到的代。其它构建在HTTP
优采云网路信息手动采集系统2016官方下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2020-08-09 17:05
它与其他采集系统的优势在于:
A、 理论上可采集任何网站的信息,实现“想采就采”。由于信息来源网站的结构各不相同,目前市面上大多数采集系统均只绑定了某一家或几家网站的资源(同种模板的网站)进行采集,如果须要指定其他模板的网站,则需再度付费进行订制;“网络信息手动采集系统”模块化的方法,将采集信息须要的方式进行封装,并以广大站长熟悉的脚本语言为插口诠释下来,您只须要短短的几十行代码,即可实现一个新类型网站的采集工作。如果您不懂编程也不要紧,您可以直接使用预设的采集/发布向导工具,通过简单的设置参数实现一定类型模板网站的采集。而且“网络信息手动采集系统”还支持项目保存、共享,您可以从我们的网站下载其他用户上传的采集方案,来实现诸多网站的采集、发布工作。
B、 同样的,理论上可以发布采集到的信息到任何类型的您的网站。目前市面上其他的采集系统,要么不支持发布采集的信息,要么只能发布到某一种模板的网站上。“网络信息手动采集系统”采用递交表单的形式发布信息,FTP传输方法发布文件,模拟了您的自动发布过程,因此只要您在网站上放置一个表单接受页面,即可将信息发布到任何类型的网站上。同时我们也提供小型网站(如动易等)的发布页面,您可以直接使用。
C、 价格优势,这是最不用声明的优势,请诸位用户自行对比市面上的同类产品。 查看全部
网络信息手动采集系统(优采云)是一款面向大型网站站长、网站编辑的以采集网络信息,并发布到自己网站为天职的共享软件。
它与其他采集系统的优势在于:
A、 理论上可采集任何网站的信息,实现“想采就采”。由于信息来源网站的结构各不相同,目前市面上大多数采集系统均只绑定了某一家或几家网站的资源(同种模板的网站)进行采集,如果须要指定其他模板的网站,则需再度付费进行订制;“网络信息手动采集系统”模块化的方法,将采集信息须要的方式进行封装,并以广大站长熟悉的脚本语言为插口诠释下来,您只须要短短的几十行代码,即可实现一个新类型网站的采集工作。如果您不懂编程也不要紧,您可以直接使用预设的采集/发布向导工具,通过简单的设置参数实现一定类型模板网站的采集。而且“网络信息手动采集系统”还支持项目保存、共享,您可以从我们的网站下载其他用户上传的采集方案,来实现诸多网站的采集、发布工作。
B、 同样的,理论上可以发布采集到的信息到任何类型的您的网站。目前市面上其他的采集系统,要么不支持发布采集的信息,要么只能发布到某一种模板的网站上。“网络信息手动采集系统”采用递交表单的形式发布信息,FTP传输方法发布文件,模拟了您的自动发布过程,因此只要您在网站上放置一个表单接受页面,即可将信息发布到任何类型的网站上。同时我们也提供小型网站(如动易等)的发布页面,您可以直接使用。
C、 价格优势,这是最不用声明的优势,请诸位用户自行对比市面上的同类产品。
优采云网钛发布插口|网钛文章管理系统采集代写|网钛CMS发布插口
采集交流 • 优采云 发表了文章 • 0 个评论 • 599 次浏览 • 2020-08-09 16:05
网钛文章管理系统(OTCMS)以简单、实用、傻瓜式操作而著称,是国外最热门ASP开源网站管理系统之一,也是用户增速最快的ASP类CMS系统之一,目前的版本无论在功能,人性化,还是易用性方面,都有了长足的发展,OTCMS的主要目标用户锁定在草根型中小个人站长,让这些对网路不是太熟悉,对网站建设不是太懂又想做网站的人可以很快搭建起一个功能实用又强悍,操作人性又易用。OTCMS更专注于个人网站或中小型门户的建立,当然也不乏有企业用户等在使用本系统,使用过OTCMS的用户就会它好评不断。
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。
雨过天晴工作室提供优采云网钛发布插口及网钛文章管理系统采集代写
该插口为免登录插口,上传好文件,配置好规则和插口就可以马上采集发布,效果很好!
如果你是菜鸟,我可以直接将配置好的优采云软件带采集规则和发布插口一起发你,你可以直接采集发布
如果你是大神,可以只要求发插口文件和发布模块,自己导出使用!
需要采集规则代写和优采云采集发布插口 采集规则的同学都可以联系我!
规则编撰:1条10元,发布插口一个100元!
不成功不收费
特别说明: 查看全部
优采云网钛发布插口|网钛文章管理系统采集代写|网钛CMS发布插口otcms优采云发布插口
网钛文章管理系统(OTCMS)以简单、实用、傻瓜式操作而著称,是国外最热门ASP开源网站管理系统之一,也是用户增速最快的ASP类CMS系统之一,目前的版本无论在功能,人性化,还是易用性方面,都有了长足的发展,OTCMS的主要目标用户锁定在草根型中小个人站长,让这些对网路不是太熟悉,对网站建设不是太懂又想做网站的人可以很快搭建起一个功能实用又强悍,操作人性又易用。OTCMS更专注于个人网站或中小型门户的建立,当然也不乏有企业用户等在使用本系统,使用过OTCMS的用户就会它好评不断。
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。

雨过天晴工作室提供优采云网钛发布插口及网钛文章管理系统采集代写
该插口为免登录插口,上传好文件,配置好规则和插口就可以马上采集发布,效果很好!
如果你是菜鸟,我可以直接将配置好的优采云软件带采集规则和发布插口一起发你,你可以直接采集发布
如果你是大神,可以只要求发插口文件和发布模块,自己导出使用!
需要采集规则代写和优采云采集发布插口 采集规则的同学都可以联系我!
规则编撰:1条10元,发布插口一个100元!
不成功不收费


特别说明:
【python】打造一款手动扫描全网漏洞的扫描器
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2020-08-09 14:08
早在17年11月份的时侯就有这个看法,可是仍然没有去做,后来快到春节前几天才即将开始整个软件工程的设计。当时的想实现的功能比较简单,就是能做到无限采集到网站使用的CMS,比如www。xx。com使用的是DEDECMS,那么我就把www。xx。com|dedecms这样的数据存到数据库上面,如果上次dedecms爆出新的漏洞后,我能在第一时间内发觉什么网站存在这个漏洞。那么这个软件工程的核心功能就必须满足以下的需求。
能无限爬行采集互联网上存活的网址链接 能对采集到的链接进行扫描验证 Mysql数据库和服务器的负载均衡处理
当然若果只是只检查CMS类型之后保存到数据库肯定是不够的,这样简单的功能并没有多大的优势,于是我选择了加入下述漏洞的扫描验证。
添加备份文件扫描功能 添加SVN/GIT/源码泄露扫描功能,其中包括webinfo信息扫描 添加编辑器漏洞扫描功能 添加SQL注入漏洞的手动检查功能 添加使用Struts2框架的网站验证功能(居心叵测) 添加xss扫描检查功能(暂未实现) 添加扫描网站IP而且扫描危险端口功能 添加外链解析漏洞检查功能(暂未实现) 暂时想不到别的了,如果你有好的建议请联系我~ 结果展示
如图展示的都是扫描到的备份文件,敏感信息泄露,注入,cms类型辨识,st2框架,端口开放等等,挂机刷洞,基本上只要漏洞报告写得详尽一点,勤快多写点,都可以通过初审,刷洞小意思,刷排行之类的都不在 查看全部
这是一款和刘老师一起写的网安类别扫描器。基本原理是由Python+Mysql搭建的扫描器,实现手动无限永久爬行采集网站链接,自动化漏洞扫描检查。目的是挂机能够实现自动化开掘敏感情报,亦或是发觉网站的漏洞或则隐藏可借助的漏洞。
早在17年11月份的时侯就有这个看法,可是仍然没有去做,后来快到春节前几天才即将开始整个软件工程的设计。当时的想实现的功能比较简单,就是能做到无限采集到网站使用的CMS,比如www。xx。com使用的是DEDECMS,那么我就把www。xx。com|dedecms这样的数据存到数据库上面,如果上次dedecms爆出新的漏洞后,我能在第一时间内发觉什么网站存在这个漏洞。那么这个软件工程的核心功能就必须满足以下的需求。
能无限爬行采集互联网上存活的网址链接 能对采集到的链接进行扫描验证 Mysql数据库和服务器的负载均衡处理
当然若果只是只检查CMS类型之后保存到数据库肯定是不够的,这样简单的功能并没有多大的优势,于是我选择了加入下述漏洞的扫描验证。
添加备份文件扫描功能 添加SVN/GIT/源码泄露扫描功能,其中包括webinfo信息扫描 添加编辑器漏洞扫描功能 添加SQL注入漏洞的手动检查功能 添加使用Struts2框架的网站验证功能(居心叵测) 添加xss扫描检查功能(暂未实现) 添加扫描网站IP而且扫描危险端口功能 添加外链解析漏洞检查功能(暂未实现) 暂时想不到别的了,如果你有好的建议请联系我~ 结果展示
如图展示的都是扫描到的备份文件,敏感信息泄露,注入,cms类型辨识,st2框架,端口开放等等,挂机刷洞,基本上只要漏洞报告写得详尽一点,勤快多写点,都可以通过初审,刷洞小意思,刷排行之类的都不在
E客影片系统EKVOD免费下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2020-08-09 11:53
一键安装,一键采集,一键生成的PHP影片系统
01.支持所有主流FLV视频站及P2P
全面支持优酷,新浪,土豆,56,六间房,qq,youtube等flv资源,天线高清,新浪高清,土豆高清等高清flv采集!支持qvod【快播】,gvod【迅播】,pps,远古等高清资源,支持media,real,flv,swf等格式文件!更多支持的格式还在相继降低中。
02.丰富的模板及强悍易用的标签
独创的HTML方式的标签机制,使得做模板特别简单,只要你会HTML就可以制做精致的模板皮肤。自定义模板系统满足你个性化的需求,使你的网站更独具一格!自定义标签和IF标签等更是强悍!标签向导可以教你灵活的运用标签!
03.影视资源管理系统
系统外置的编辑器,使得添加电影介绍愈发得心应手为广大影片站长推动。资源管理系统可以便捷的添加,删除电影,设置推荐,设置专题,支持批量操作,支持无限极电影分类!后台添加更改电影集成web采集助手,支持youku、sina、tudou、天线、ku6、56、youtube、qq播客等数十个视频站的专辑及视频及高清大片的采集!
04.模板管理系统
先进的在线模板编辑系统,可以很方便的编辑模板文件!
05.网站地图系统
强大的网站地图可以便捷的生成google,百度,rss,有利于搜索引擎的快速收录,在最短的时间提高贵站的流量!
06.网页生成系统
网站运营模式可以在后台一键切换(php动态/HTML静态2中目录结构),一键生成全站、一键生成分类等等,让静态生成愈发智能,只需一次点击全部搞定,生成速率飞快、更快更节约资源。征对搜索引擎特点制做的多种生成路径方法。
07.广告管理系统
先进的广告管理系统打破传统模式,完全可以在线自定义广告内容,更方便添加!
08.友情链接系统
简单而实用的友情链接系统可以便捷的为您的网站添加图片链接,文字链接,各种式样可以通过标签完美的调出,并且运用!
09.管理员分级管理系统
独立开发的管理员管理系统,可以对管理员进行多个级别的分级,更能人性化的管理网站! 查看全部
EkVod影视系统是一套采用PHP+MYSQL数据库形式运行的全新且健全的强悍影视系统。
一键安装,一键采集,一键生成的PHP影片系统
01.支持所有主流FLV视频站及P2P
全面支持优酷,新浪,土豆,56,六间房,qq,youtube等flv资源,天线高清,新浪高清,土豆高清等高清flv采集!支持qvod【快播】,gvod【迅播】,pps,远古等高清资源,支持media,real,flv,swf等格式文件!更多支持的格式还在相继降低中。
02.丰富的模板及强悍易用的标签
独创的HTML方式的标签机制,使得做模板特别简单,只要你会HTML就可以制做精致的模板皮肤。自定义模板系统满足你个性化的需求,使你的网站更独具一格!自定义标签和IF标签等更是强悍!标签向导可以教你灵活的运用标签!
03.影视资源管理系统
系统外置的编辑器,使得添加电影介绍愈发得心应手为广大影片站长推动。资源管理系统可以便捷的添加,删除电影,设置推荐,设置专题,支持批量操作,支持无限极电影分类!后台添加更改电影集成web采集助手,支持youku、sina、tudou、天线、ku6、56、youtube、qq播客等数十个视频站的专辑及视频及高清大片的采集!
04.模板管理系统
先进的在线模板编辑系统,可以很方便的编辑模板文件!
05.网站地图系统
强大的网站地图可以便捷的生成google,百度,rss,有利于搜索引擎的快速收录,在最短的时间提高贵站的流量!
06.网页生成系统
网站运营模式可以在后台一键切换(php动态/HTML静态2中目录结构),一键生成全站、一键生成分类等等,让静态生成愈发智能,只需一次点击全部搞定,生成速率飞快、更快更节约资源。征对搜索引擎特点制做的多种生成路径方法。
07.广告管理系统
先进的广告管理系统打破传统模式,完全可以在线自定义广告内容,更方便添加!
08.友情链接系统
简单而实用的友情链接系统可以便捷的为您的网站添加图片链接,文字链接,各种式样可以通过标签完美的调出,并且运用!
09.管理员分级管理系统
独立开发的管理员管理系统,可以对管理员进行多个级别的分级,更能人性化的管理网站!
帝国CMS7.5模仿土豪漫画网站模板,具有手机和自动采集功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-08-08 21:39
漫画网站系统是使用Empire cms7.5开发的. 团队制定的具体细节尚不清楚. 由于程序+数据太大,因此尚未执行测试. 您需要自己测试源代码,因为漫画网站的源代码未知. 已经散发了多少手,因此,网站程序的安全性需要重点检查是否有后门.
漫画网站的源代码程序的安装说明:
1. 将程序上传到网站的根目录,该过程与普通的Empire安装过程相同.
2. 安装完成后,登录网站后台以还原漫画和网站模板数据. 后台的登录帐户为管理员密码admin888
3. 从右到左生成和更新网站缓存的顺序,单击以全部生成;
4. 找到系统设置→展开变量→用您自己的信息全部替换
5. 修改系统文件\ m \ e \ config并找到$ ecms_config ['sets'] ['txtpath'] ='D: // manhua / d / txt /';修改到您自己的服务器目录
完成上述操作后,您已经完成了,网站将被更改,地图将被更改,微调,并且将正式运行!
点击下载
帝国CMS7.5模仿土豪漫画网站模板,具有手机和自动采集功能
大小: 238MB |下载次数: 0次|文件类型: 压缩文件 查看全部
Empire CMS7.5模仿本地漫画网站模板,是在线漫画网站的网站源代码,该程序自带手机网站和采集功能,非常易于操作,如果操作正确,几乎是在撒谎靠赚钱,漫画的流量尤其是在线漫画近年来,漫画一直在突飞猛进地发展,现在很少有人在做漫画网站. 这是个很好的机会.
漫画网站系统是使用Empire cms7.5开发的. 团队制定的具体细节尚不清楚. 由于程序+数据太大,因此尚未执行测试. 您需要自己测试源代码,因为漫画网站的源代码未知. 已经散发了多少手,因此,网站程序的安全性需要重点检查是否有后门.
漫画网站的源代码程序的安装说明:
1. 将程序上传到网站的根目录,该过程与普通的Empire安装过程相同.
2. 安装完成后,登录网站后台以还原漫画和网站模板数据. 后台的登录帐户为管理员密码admin888
3. 从右到左生成和更新网站缓存的顺序,单击以全部生成;
4. 找到系统设置→展开变量→用您自己的信息全部替换
5. 修改系统文件\ m \ e \ config并找到$ ecms_config ['sets'] ['txtpath'] ='D: // manhua / d / txt /';修改到您自己的服务器目录
完成上述操作后,您已经完成了,网站将被更改,地图将被更改,微调,并且将正式运行!

点击下载
帝国CMS7.5模仿土豪漫画网站模板,具有手机和自动采集功能
大小: 238MB |下载次数: 0次|文件类型: 压缩文件
googlebot如何抓取网页?
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-08 19:27
服务器将采集的信息分类并将其组织到一个巨大的数据库中. 数据库之一用于存储网站域名. 只要域名被搜索引擎索引,它们就会自动存储在该数据库中. 该数据库排名第一. 蜘蛛网的核心. 它的内部分为10个每个级别的PR的小型数据库. 尽管数据库很小,但它们又很大又可怕.
10级数据库的周期也不同. 基本上,对于pr = 4的网站,蜘蛛爬网的可能性也是每7天一次. 因此,基本上,您会发现7天之内的某一天也是大范围的收录. 细心的网站管理员会发现有时7天是非常准确的,但仅适用于pr = 4. pr越高,周期越短,pr越低,周期越长
当然,这些网站管理员中有许多人对此表示怀疑. 我认为蜘蛛有时每天都会包括他的驻地. 这是我接下来要谈的第二个蜘蛛. 第二只蜘蛛通常是第一只蜘蛛. 在抓取过程中发布,主要用于由第一蜘蛛抓取的网站的外部链接.
ps: 因为据说它是2号蜘蛛,所以它的爬行力必须比1号蜘蛛小得多.
当然,不仅有2号蜘蛛,而且还有3号蜘蛛. 所谓3号,是指a站的1号蜘蛛爬到B站,b站的2号蜘蛛爬到C站. 目前,Google试图限制其无限循环. 分为蜘蛛的这三个级别. 其级别的爬网速率有一个非常明确的标准,并且蜘蛛网2和3具有基本上按时间顺序爬网的爬网功能.
例如: 第a蜘蛛对网站a进行爬网之后,文章的最后一次发布时间是2008-6-1,那么当第2蜘蛛从另一个网站对a进行爬网时,该网站可能会首先被定位为有几篇最近发表的文章,例如: 2008-5-31、2008-5-30和其他文章将第二次执行,并且在第三次访问之后,将抓取2008-6-1之后的信息. 如果您的网站没有任何更新,它将在过去一个月内两次检索其更改.
如果从外面有更多的蜘蛛2和3,则同一文章可能会被抓取几次. 以下是Google提供的官方数据
蜘蛛1号
基本爬网率为5%〜10%
基于pr = 0,没有导入链接,提交时可检索的时间范围为6到12个月.
基于pr = 1,没有导入链接,提交时每个爬网的期限可能从4到8个月不等.
基于pr = 2,没有导入链接,提交时可能的爬网时间为2到4个月.
基于pr = 3,没有导入链接,提交时可检索的时间为1到2个月.
基于pr = 4,没有导入链接,提交时可能捕获的期限从1周到1个月不等.
当然,没有任何导入链接的网站无法达到pr = 4
最高只有pr = 3
以上数据仅是Google正式提供的基数.
这意味着蜘蛛#1主动抓取您的网站的周期数.
要让蜘蛛2或蜘蛛3抓取您的网站,取决于您的导入链接.
因此,您会发现您的网站有时每天都在更新.
蜘蛛#2
基本爬网率为2.5%〜5%
3号蜘蛛
基本抓取率为1.25%〜2.5%
Google当前具有三个级别的蜘蛛
蜘蛛当然有不同的蜘蛛
这里唯一的一个是网络蜘蛛. 因为我只对此感兴趣.
googlebot如何抓取网页?相关文章:
·SEO优化的六个常见误解,让您无法伤害站点组系统
·SEOer如何分析竞争对手网站组工具
·PS制作PS制作数字笔划文本工作站群组软件
·成功赢得外贸订单的6个步骤. 什么是站组?
·6种有用的在线商店推广技术,流量飙升站群系统
·10条使您在下订单时变得柔软的提示!站群软件
本文标题: googlebot如何抓取网页?
本文的地址: 查看全部
要了解Google蜘蛛如何爬网以收录网页,我们首先需要了解Google蜘蛛的起源. 最初建立Google搜索引擎时,它拥有非常强大的服务器. 它每天释放大量蜘蛛. 我们称其为第一蜘蛛. 它的爬网速度非常快. 对于信息采集,我们可以看到服务器有多快. 实际上,最重要的是Google在后来将服务器扩展到了许多城市,因此现在您可以发现Google的计算速度领先.
服务器将采集的信息分类并将其组织到一个巨大的数据库中. 数据库之一用于存储网站域名. 只要域名被搜索引擎索引,它们就会自动存储在该数据库中. 该数据库排名第一. 蜘蛛网的核心. 它的内部分为10个每个级别的PR的小型数据库. 尽管数据库很小,但它们又很大又可怕.
10级数据库的周期也不同. 基本上,对于pr = 4的网站,蜘蛛爬网的可能性也是每7天一次. 因此,基本上,您会发现7天之内的某一天也是大范围的收录. 细心的网站管理员会发现有时7天是非常准确的,但仅适用于pr = 4. pr越高,周期越短,pr越低,周期越长
当然,这些网站管理员中有许多人对此表示怀疑. 我认为蜘蛛有时每天都会包括他的驻地. 这是我接下来要谈的第二个蜘蛛. 第二只蜘蛛通常是第一只蜘蛛. 在抓取过程中发布,主要用于由第一蜘蛛抓取的网站的外部链接.
ps: 因为据说它是2号蜘蛛,所以它的爬行力必须比1号蜘蛛小得多.
当然,不仅有2号蜘蛛,而且还有3号蜘蛛. 所谓3号,是指a站的1号蜘蛛爬到B站,b站的2号蜘蛛爬到C站. 目前,Google试图限制其无限循环. 分为蜘蛛的这三个级别. 其级别的爬网速率有一个非常明确的标准,并且蜘蛛网2和3具有基本上按时间顺序爬网的爬网功能.
例如: 第a蜘蛛对网站a进行爬网之后,文章的最后一次发布时间是2008-6-1,那么当第2蜘蛛从另一个网站对a进行爬网时,该网站可能会首先被定位为有几篇最近发表的文章,例如: 2008-5-31、2008-5-30和其他文章将第二次执行,并且在第三次访问之后,将抓取2008-6-1之后的信息. 如果您的网站没有任何更新,它将在过去一个月内两次检索其更改.
如果从外面有更多的蜘蛛2和3,则同一文章可能会被抓取几次. 以下是Google提供的官方数据
蜘蛛1号
基本爬网率为5%〜10%
基于pr = 0,没有导入链接,提交时可检索的时间范围为6到12个月.
基于pr = 1,没有导入链接,提交时每个爬网的期限可能从4到8个月不等.
基于pr = 2,没有导入链接,提交时可能的爬网时间为2到4个月.
基于pr = 3,没有导入链接,提交时可检索的时间为1到2个月.
基于pr = 4,没有导入链接,提交时可能捕获的期限从1周到1个月不等.
当然,没有任何导入链接的网站无法达到pr = 4
最高只有pr = 3
以上数据仅是Google正式提供的基数.
这意味着蜘蛛#1主动抓取您的网站的周期数.
要让蜘蛛2或蜘蛛3抓取您的网站,取决于您的导入链接.
因此,您会发现您的网站有时每天都在更新.
蜘蛛#2
基本爬网率为2.5%〜5%
3号蜘蛛
基本抓取率为1.25%〜2.5%
Google当前具有三个级别的蜘蛛
蜘蛛当然有不同的蜘蛛
这里唯一的一个是网络蜘蛛. 因为我只对此感兴趣.
googlebot如何抓取网页?相关文章:
·SEO优化的六个常见误解,让您无法伤害站点组系统
·SEOer如何分析竞争对手网站组工具
·PS制作PS制作数字笔划文本工作站群组软件
·成功赢得外贸订单的6个步骤. 什么是站组?
·6种有用的在线商店推广技术,流量飙升站群系统
·10条使您在下订单时变得柔软的提示!站群软件
本文标题: googlebot如何抓取网页?
本文的地址:
网站测试自动化系统-采集测试结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2020-08-08 15:52
通常来说,测试报告需要收录以下信息:
1. 测试用例的通过率. 通过率表示产品的稳定性. 当然,这是排除由测试用例本身问题引起的测试失败后的通过率. 在上一个执行测试用例中提到的MsTest.exe生成的结果文件.trx文件已经保存了此信息. 在资源管理器中双击此文件,您将看到类似于下图的结果:
在上面的图片中,一些细心的读者可能会发现只有3个用例,但是红色圆圈中的文字表示: “ 6/6通过了”. 这是因为这3个用例是数据驱动的用例,因此VSTT将每行数据视为一个独立的测试用例. 对于数据驱动的测试,您可以参考我的文章: 网站自动测试系统-数据驱动的测试.
2. 代码覆盖率信息. 代码覆盖率告诉测试团队哪些产品代码未被覆盖. 未发现的产品代码意味着有些我们尚未考虑的用户场景,或者测试范围中存在一些漏洞. (测试孔). 如果从VSTT用户界面执行测试用例,则VSTT将自动集成采集代码覆盖率的功能. 有关详细信息,请参阅我的文章《软件自动化测试-代码覆盖率》. 在本文中,我将向您展示如何使用命令行来采集代码覆盖率.
至少有两种方法可以将采集代码覆盖率的功能集成到自动化测试系统中. 一种是直接编辑.testrunconfig文件. 当我们在VSTT用户界面上操作时,这就是VSTT在后台为我们所做的. ,请参阅本文以执行测试用例,以了解使用.testrunconfig文件的方法.
另一种方法是更深入的分解. 实际上,Visual Studio通过名为VsPerfMon.exe的程序采集代码覆盖率,该程序位于C: \ Program Files \ Microsoft Visual Studio 9.0 \ Team Tools \ Performance Tools(假定VSTT安装在C驱动器上). 当您按照软件自动化测试代码覆盖率中介绍的步骤执行自动化测试时,VSTT会秘密执行以下操作:
<p>1. 注入用于计算代码覆盖率(仪器)的代码. 注入的代码已经在“软件自动化测试代码覆盖率”一文中进行了说明,因此在此不再赘述. 通过vsinstr.exe实现代码注入. 以下是将其用于代码注入的最简化命令(接受任何.Net程序,即.dll和.exe文件,无论它是否支持本机C ++程序,我都还没有尝试过): 查看全部
在上一篇文章“执行测试用例”中,我们介绍了如何通过命令行编译和执行测试用例,以便我们有机会通过批处理自动执行测试用例. 在文章系统应具有的功能中,我还提到了一个完整的自动化系统应该能够自动采集测试结果-毕竟,我们的目标是测试人员在晚上下班之前执行用例,然后在晚上离开. 第二天早上,您可以直接阅读测试报告.
通常来说,测试报告需要收录以下信息:
1. 测试用例的通过率. 通过率表示产品的稳定性. 当然,这是排除由测试用例本身问题引起的测试失败后的通过率. 在上一个执行测试用例中提到的MsTest.exe生成的结果文件.trx文件已经保存了此信息. 在资源管理器中双击此文件,您将看到类似于下图的结果:
在上面的图片中,一些细心的读者可能会发现只有3个用例,但是红色圆圈中的文字表示: “ 6/6通过了”. 这是因为这3个用例是数据驱动的用例,因此VSTT将每行数据视为一个独立的测试用例. 对于数据驱动的测试,您可以参考我的文章: 网站自动测试系统-数据驱动的测试.
2. 代码覆盖率信息. 代码覆盖率告诉测试团队哪些产品代码未被覆盖. 未发现的产品代码意味着有些我们尚未考虑的用户场景,或者测试范围中存在一些漏洞. (测试孔). 如果从VSTT用户界面执行测试用例,则VSTT将自动集成采集代码覆盖率的功能. 有关详细信息,请参阅我的文章《软件自动化测试-代码覆盖率》. 在本文中,我将向您展示如何使用命令行来采集代码覆盖率.
至少有两种方法可以将采集代码覆盖率的功能集成到自动化测试系统中. 一种是直接编辑.testrunconfig文件. 当我们在VSTT用户界面上操作时,这就是VSTT在后台为我们所做的. ,请参阅本文以执行测试用例,以了解使用.testrunconfig文件的方法.
另一种方法是更深入的分解. 实际上,Visual Studio通过名为VsPerfMon.exe的程序采集代码覆盖率,该程序位于C: \ Program Files \ Microsoft Visual Studio 9.0 \ Team Tools \ Performance Tools(假定VSTT安装在C驱动器上). 当您按照软件自动化测试代码覆盖率中介绍的步骤执行自动化测试时,VSTT会秘密执行以下操作:
<p>1. 注入用于计算代码覆盖率(仪器)的代码. 注入的代码已经在“软件自动化测试代码覆盖率”一文中进行了说明,因此在此不再赘述. 通过vsinstr.exe实现代码注入. 以下是将其用于代码注入的最简化命令(接受任何.Net程序,即.dll和.exe文件,无论它是否支持本机C ++程序,我都还没有尝试过):
舆论系统网站采集的优雅采集系统模板配置-资本主义公牛的羊毛
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-08 10:22
自动分析: 分为两种: 傻瓜式分析和具有神经网络功能的智能分析. 前者是找出主要网页内容页面的特征并遍历网页节点以获得所谓的标题. 正文的最佳解决方案;后者是通过机器学习(通常是各种搜索公司)来进行的. 我在这里建议您了解diffbot关于diffbot的报告. 公司的网站就是公司的主页.
模板配置: 什么是模板?以爬虫框架webmagic为例. 采集器程序不知道如何格式化下载的Web html数据. 这时,我们需要使用xpath和CSS路径来告诉程序. 该节点是有用的数据,需要检索. 当前的公众舆论公司的方法是找一个专门的人来配置模板,并且为了方便配置,专门开发了相应的系统来方便配置.
那我今天要说什么?是的,我说的是资本主义的毛毛. 作为舆论爬虫开发人员,我将教您如何使用diffbot的羊毛.
让我们看看diffbot如何首先格式化网页:
很大,对吧?并不是使用神经网络训练来进行100%格式化的,但是处理国内外新闻网站则可以100%进行格式化. 当然,此页面用于交流. 您可以使用它而无需加密. 然后,我开始展示我所做的工作.
这次,我使用开发的这些接口来反转diffbot智能解析的数据. 首先介绍第一个界面:
接口1: 使用starttxt,endtxt反转内容的节点,如图所示:
在这里,我输入“ starttxt”: “北京新华社,4月2日”,“ endtxt”: “版本01,2018年4月3日”,让我们看一下该页面的内容并编写链接内容在这里
如您所见,本文的开头是: 新华社北京,4月2日,结尾内容可能是: 2018年4月3日01版. 让我们看一下我的界面的输出:
如图所示,在页面上输出路径: #root: 0 | html: 0 | body: 0 | div: 4 | div: 0 | div: 0,此路径既不是xpath也不是css路径,但是自定义html框架路径. 然后验证输出:
接口2: 通过所选路径获取相应节点下的文本内容
分析结果如下:
因此,通过这两个界面,我们起到了替换手动配置模板的功能,并且可以通过摆脱diffbot程序的程序为新闻站点生成模板. 毕竟,并不是每个人都可以开发类似于diffbot的人工智能程序,该程序可以根据视觉效果分析网络数据.
剩下的就是改进其他事情,例如获取发布时间节点. 上述方法是不可行的. 因此,我专门开发了一个提取时间节点的程序:
接口3: 通过选定的txt获得最佳路径解决方案,适合提取释放时间的路径
Pubtimetxt只需要是页面中的发布时间,格式类似于2018年4月3日04:36的格式,并且可以同时匹配到对应的节点. 查看输出数据:
验证此节点的内容: 查看全部
在中国,不论大小,都有数百家专注于发展民意体系的公司,与民意相对应,如何构建采集到的数据是非常重要的. 如果网页上的数据不能很好地进行结构化,则后续数据的情感分析,关键词分析将难以执行. 一般公司格式化网页时,大多数是自动分析+模板配置;
自动分析: 分为两种: 傻瓜式分析和具有神经网络功能的智能分析. 前者是找出主要网页内容页面的特征并遍历网页节点以获得所谓的标题. 正文的最佳解决方案;后者是通过机器学习(通常是各种搜索公司)来进行的. 我在这里建议您了解diffbot关于diffbot的报告. 公司的网站就是公司的主页.
模板配置: 什么是模板?以爬虫框架webmagic为例. 采集器程序不知道如何格式化下载的Web html数据. 这时,我们需要使用xpath和CSS路径来告诉程序. 该节点是有用的数据,需要检索. 当前的公众舆论公司的方法是找一个专门的人来配置模板,并且为了方便配置,专门开发了相应的系统来方便配置.
那我今天要说什么?是的,我说的是资本主义的毛毛. 作为舆论爬虫开发人员,我将教您如何使用diffbot的羊毛.
让我们看看diffbot如何首先格式化网页:

很大,对吧?并不是使用神经网络训练来进行100%格式化的,但是处理国内外新闻网站则可以100%进行格式化. 当然,此页面用于交流. 您可以使用它而无需加密. 然后,我开始展示我所做的工作.

这次,我使用开发的这些接口来反转diffbot智能解析的数据. 首先介绍第一个界面:
接口1: 使用starttxt,endtxt反转内容的节点,如图所示:

在这里,我输入“ starttxt”: “北京新华社,4月2日”,“ endtxt”: “版本01,2018年4月3日”,让我们看一下该页面的内容并编写链接内容在这里
如您所见,本文的开头是: 新华社北京,4月2日,结尾内容可能是: 2018年4月3日01版. 让我们看一下我的界面的输出:

如图所示,在页面上输出路径: #root: 0 | html: 0 | body: 0 | div: 4 | div: 0 | div: 0,此路径既不是xpath也不是css路径,但是自定义html框架路径. 然后验证输出:
接口2: 通过所选路径获取相应节点下的文本内容

分析结果如下:

因此,通过这两个界面,我们起到了替换手动配置模板的功能,并且可以通过摆脱diffbot程序的程序为新闻站点生成模板. 毕竟,并不是每个人都可以开发类似于diffbot的人工智能程序,该程序可以根据视觉效果分析网络数据.
剩下的就是改进其他事情,例如获取发布时间节点. 上述方法是不可行的. 因此,我专门开发了一个提取时间节点的程序:
接口3: 通过选定的txt获得最佳路径解决方案,适合提取释放时间的路径

Pubtimetxt只需要是页面中的发布时间,格式类似于2018年4月3日04:36的格式,并且可以同时匹配到对应的节点. 查看输出数据:

验证此节点的内容:
解决方案:网站采集工具 - 超级采集 5.058
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-12-29 11:18
[网站采集Tools-Super采集]是一款智能的采集软件。 Super采集的最大特点是您不需要定义任何采集规则,只需选择您即可。如果您对关键词感兴趣,那么Super采集会自动搜索您和采集的相关信息然后通过WEB发布模块将其直接发布到您的网站。 Super采集当前支持大多数主流cms,一般博客和论坛系统,包括织梦Dede,Dongyi,Discuz,Phpwind,Php cms,Php168、SuperSite,Empire E cms,Very cms ],Hb cms,Fengxun,Kexun,Wordpress,Z-blog,Joomla等,如果现有发布模块不能支持您的网站,我们还可以为标准版和专业版用户提供免费的自定义发布模块来支持您的网站发布。
1、傻瓜式使用模式
超级采集非常易于使用。您不需要具备有关网站采集的任何专业知识和经验。 super采集的核心是智能搜索和采集引擎。根据您对采集相关信息感兴趣的内容,并将其自动发布到网站。
2、超级强大的关键词挖掘工具
选择正确的关键词可以为您的网站带来更高的流量和更大的广告价值。 Super采集提供的关键词挖掘工具为您提供关键词的每日搜索量,Google广告的每次点击估算价格以及关键词广告受欢迎程度信息,最合适的关键词可以根据这些信息的排名进行选择。
3、内容,标题伪原创
Super采集提供了最新的伪原创引擎,该引擎可以进行同义词替换,段落重新排列,多个文章混合等。您可以选择处理从采集到伪原创的信息以增加搜索数量由引擎获取网站内容中的收录。 查看全部
解决方案:网站采集工具 - 超级采集 5.058
[网站采集Tools-Super采集]是一款智能的采集软件。 Super采集的最大特点是您不需要定义任何采集规则,只需选择您即可。如果您对关键词感兴趣,那么Super采集会自动搜索您和采集的相关信息然后通过WEB发布模块将其直接发布到您的网站。 Super采集当前支持大多数主流cms,一般博客和论坛系统,包括织梦Dede,Dongyi,Discuz,Phpwind,Php cms,Php168、SuperSite,Empire E cms,Very cms ],Hb cms,Fengxun,Kexun,Wordpress,Z-blog,Joomla等,如果现有发布模块不能支持您的网站,我们还可以为标准版和专业版用户提供免费的自定义发布模块来支持您的网站发布。
1、傻瓜式使用模式
超级采集非常易于使用。您不需要具备有关网站采集的任何专业知识和经验。 super采集的核心是智能搜索和采集引擎。根据您对采集相关信息感兴趣的内容,并将其自动发布到网站。
2、超级强大的关键词挖掘工具
选择正确的关键词可以为您的网站带来更高的流量和更大的广告价值。 Super采集提供的关键词挖掘工具为您提供关键词的每日搜索量,Google广告的每次点击估算价格以及关键词广告受欢迎程度信息,最合适的关键词可以根据这些信息的排名进行选择。
3、内容,标题伪原创
Super采集提供了最新的伪原创引擎,该引擎可以进行同义词替换,段落重新排列,多个文章混合等。您可以选择处理从采集到伪原创的信息以增加搜索数量由引擎获取网站内容中的收录。
详细数据:网站流量日志数据自定义采集实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 916 次浏览 • 2020-12-19 11:17
为什么需要对网站个流量数据进行统计分析?
随着大数据时代的到来,各行各业所生成的数据爆炸了。大数据技术已从以前的``虚无''变为可能,人们逐渐发现由数据产生的各种潜在价值。用于各行各业。例如,对网站流量数据的统计分析可以帮助网站管理员,操作员,发起人等获取实时网站流量信息,并从流量来源,网站内容等各个方面提供信息,以及网站访问者特征网站分析的数据基础。这将有助于增加网站的访问量并改善网站的用户体验,使更多的访客成为会员或客户,并以较少的投资获得最大的收益。
网站交通记录数据采集原理分析
首先,用户的行为将触发浏览器对正在计数的页面的http请求,例如打开某个网页。打开网页后,将执行页面中嵌入的javascript代码。
埋点是指:在网页中预先添加一小段javascript代码。此代码段通常将动态创建脚本标签,并将src属性指向单独的js文件。此时,浏览器将请求并执行此单独的js文件(图中的绿色节点)。该js通常是真正的数据采集脚本。
数据采集完成后,js将请求后端数据采集脚本(图中的后端)。该脚本通常是伪装成图片的动态脚本程序。 js将通过http参数传递采集的数据。对于后端脚本,后端脚本解析参数并以固定格式记录访问日志。同时,它可能会在http响应中为客户端植入一些跟踪cookie。
设计与实现
基于原理分析并结合Google Analytics(分析),如果您要构建自定义日志数据采集系统,则需要执行以下操作:
确认采集信息
确定掩埋点代码
埋点是用于网站分析的常用data 采集方法。核心是在需要数据采集来执行数据采集的关键点植入统计代码。例如,在Google Analytics(分析)原型中,需要将其提供的javascript片段插入页面。该片段通常称为嵌入式代码。 (以Google的嵌入式代码为例)
var _maq = _maq || [];
_maq.push(['_setAccount', 'UA-XXXXX-X']);
(function() {
var ma = document.createElement('script'); ma.type =
'text/javascript'; ma.async = true;
ma.src = ('https:' == document.location.protocol ?
'https://ssl' : 'http://www') + '.google-analytics.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore( m a, s);
})();
其中_maq是一个全局数组,用于放置各种配置,每种配置的格式为:
_maq.push(['Action','param1','param2',...]);
_maq的机制不是焦点,而是焦点在于后面的匿名函数代码。该代码的主要目的是通过通过document.createElement方法创建脚本并遵循协议(http或https)将src指向相应的ma.js来引入外部js文件(ma.js),最后将其插入元素放入页面的dom树中。
请注意,ma.async = true表示外部js文件是异步调用的,即,它不会阻止浏览器的解析,并且将在外部js下载完成后异步执行。此属性是HTML5中新引入的。
前端数据采集脚本
数据采集脚本(ma.js)将在请求后执行。通常,应执行以下操作:
通过浏览器的内置javascript对象采集信息,例如页面标题(通过document.title),引荐来源网址(最后一个URL,通过document.referrer),用户显示分辨率(通过windows.screen),cookie信息(通过document.cookie)等。解析_maq数组并采集配置信息。这可能包括用户定义的事件跟踪,业务数据(例如电子商务网站产品编号等)。以上两个步骤中采集的数据将以预定义的格式进行解析和拼接(获取请求参数)。请求后端脚本,然后将http请求参数中的信息放入后端脚本。
这里唯一的问题是第4步。javascript请求后端脚本的常用方法是ajax,但是无法跨域请求ajax。一种常见的方法是使用js脚本创建Image对象,将Image对象的src属性指向后端脚本并携带参数。此时,实现了跨域请求后端。这就是为什么后端脚本通常伪装成gif文件的原因。
示例代码
(function () {
var params = {};
//Document 对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window 对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator 对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq 配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过 Image 对象请求后端脚本
var img = new Image(1, 1);
img.src = ' http://xxx.xxxxx.xxxxx/log.gif? ' + args;
})();
将整个脚本放置在一个匿名函数中,以确保它不会污染全局环境。其中log.gif是后端脚本。
后端脚本
log.gif是后端脚本,该脚本伪装成gif图片。后端脚本通常需要完成以下操作:
分析http请求参数以获取信息。获取客户端无法从Web服务器获取的某些信息,例如visitor ip。以日志格式写入信息。生成1×1的空白gif图像作为响应内容,并将响应头的Content-type设置为image / gif。通过响应标头中的Set-cookie设置一些必需的cookie信息。
设置cookie的原因是因为如果您要跟踪唯一的访问者,通常的做法是根据规则生成一个全局唯一的cookie,如果发现客户端没有该cookie,则将其植入用户。在请求时指定跟踪cookie,否则Set-cookie放置获取的跟踪cookie以保持相同的用户cookie不变。尽管这种方法并不完美(例如,清除cookie或更改浏览器的用户将被视为两个用户),但目前已广泛使用。
我们使用nginx的access_log进行日志采集,但是存在一个问题,即nginx配置本身具有有限的逻辑表达能力,因此我们选择OpenResty来实现。
OpenResty是基于Nginx的高性能应用程序开发平台。它集成了许多有用的模块,其核心是通过ngx_lua模块将Lua集成在一起,因此Lua可用于在nginx配置文件中表达业务。
Lua是一种轻量级且紧凑的脚本语言,用标准C语言编写,并以源代码形式开放。其设计目的是嵌入到应用程序中,从而为应用程序提供灵活的扩展和自定义功能。
首先,您需要在nginx配置文件中定义日志格式:
log_format tick
"$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url|
|$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_ag
ent||$u_account";
请注意,此处以u_开头的变量是我们稍后将定义的变量,其他变量是nginx的内置变量。然后是两个核心位置:
location / log.gif {
#伪装成 gif 文件
default_type image/gif;
#本身关闭 access_log,通过 subrequest 记录 log
access_log off;
access_by_lua "
-- 用户跟踪 cookie 名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪 cookie,算法为
md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() ..
ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid ..
'; path=/'}
if ngx.var.arg_domain then
-- 通过 subrequest 子请求 到/i-log 记录日志,
将参数和用户跟踪 cookie 带过去
ngx.location.capture('/i-log?' ..
ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-
revalidate";
#返回一个 1×1 的空 gif 图片
empty_gif;
}
location /i-log {
#内部 location,不允许外部直接访问
internal;
#设置变量,注意需要 unescape,来自 ngx_set_misc 模块
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开日志
log_subrequest on;
#记录日志到 ma.log 格式为 tick
access_log /path/to/logs/directory/ma.log tick;
#输出空字符串
echo '';
}
此脚本使用许多第三方ngxin模块(全部收录在OpenResty中),关键点带有注释。只要您在完成我们提到的End逻辑就可以了之后,就不需要完全了解每一行的含义。
日志格式
日志格式主要考虑日志分隔符,通常有以下选项:
固定数量的字符,制表符,空格,一个或多个其他字符,特定的开始和结束文本。
日志细分
只要日志采集系统访问日志,文件就会变得很大,并且很难在一个文件中管理日志。通常有必要根据时间段拆分日志,例如每天或每小时一个日志。它是通过定期通过crontab调用shell脚本来实现的,如下所示:
_prefix="/path/to/nginx"
time=`date +%Y%m%d%H`
mv ${_prefix}/logs/ma.log ${_prefix}/logs/ma/ma-${time}.log
kill -USR1 `cat ${_prefix}/logs/nginx.pid `
此脚本将ma.log移至指定的文件夹,并将其重命名为ma- {yyyymmddhh} .log,然后将USR1信号发送给nginx以重新打开日志文件。
USR1通常用于通知应用程序重新加载配置文件。向服务器发送USR1信号将导致执行以下步骤:停止接受新连接,等待当前连接停止,重新加载配置文件,然后重新打开日志文件,重新启动服务器以实现相对平稳的更改而不关闭
cat $ {_ prefix} /logs/nginx.pid接受nginx的进程号
然后在/ etc / crontab中添加一行:
59 * * * *根/path/to/directory/rotatelog.sh
每小时59分钟启动此脚本以执行日志轮换操作。 查看全部
详细数据:网站流量日志数据自定义采集实现
为什么需要对网站个流量数据进行统计分析?
随着大数据时代的到来,各行各业所生成的数据爆炸了。大数据技术已从以前的``虚无''变为可能,人们逐渐发现由数据产生的各种潜在价值。用于各行各业。例如,对网站流量数据的统计分析可以帮助网站管理员,操作员,发起人等获取实时网站流量信息,并从流量来源,网站内容等各个方面提供信息,以及网站访问者特征网站分析的数据基础。这将有助于增加网站的访问量并改善网站的用户体验,使更多的访客成为会员或客户,并以较少的投资获得最大的收益。
网站交通记录数据采集原理分析
首先,用户的行为将触发浏览器对正在计数的页面的http请求,例如打开某个网页。打开网页后,将执行页面中嵌入的javascript代码。
埋点是指:在网页中预先添加一小段javascript代码。此代码段通常将动态创建脚本标签,并将src属性指向单独的js文件。此时,浏览器将请求并执行此单独的js文件(图中的绿色节点)。该js通常是真正的数据采集脚本。
数据采集完成后,js将请求后端数据采集脚本(图中的后端)。该脚本通常是伪装成图片的动态脚本程序。 js将通过http参数传递采集的数据。对于后端脚本,后端脚本解析参数并以固定格式记录访问日志。同时,它可能会在http响应中为客户端植入一些跟踪cookie。
设计与实现
基于原理分析并结合Google Analytics(分析),如果您要构建自定义日志数据采集系统,则需要执行以下操作:
确认采集信息
确定掩埋点代码
埋点是用于网站分析的常用data 采集方法。核心是在需要数据采集来执行数据采集的关键点植入统计代码。例如,在Google Analytics(分析)原型中,需要将其提供的javascript片段插入页面。该片段通常称为嵌入式代码。 (以Google的嵌入式代码为例)
var _maq = _maq || [];
_maq.push(['_setAccount', 'UA-XXXXX-X']);
(function() {
var ma = document.createElement('script'); ma.type =
'text/javascript'; ma.async = true;
ma.src = ('https:' == document.location.protocol ?
'https://ssl' : 'http://www') + '.google-analytics.com/ma.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore( m a, s);
})();
其中_maq是一个全局数组,用于放置各种配置,每种配置的格式为:
_maq.push(['Action','param1','param2',...]);
_maq的机制不是焦点,而是焦点在于后面的匿名函数代码。该代码的主要目的是通过通过document.createElement方法创建脚本并遵循协议(http或https)将src指向相应的ma.js来引入外部js文件(ma.js),最后将其插入元素放入页面的dom树中。
请注意,ma.async = true表示外部js文件是异步调用的,即,它不会阻止浏览器的解析,并且将在外部js下载完成后异步执行。此属性是HTML5中新引入的。
前端数据采集脚本
数据采集脚本(ma.js)将在请求后执行。通常,应执行以下操作:
通过浏览器的内置javascript对象采集信息,例如页面标题(通过document.title),引荐来源网址(最后一个URL,通过document.referrer),用户显示分辨率(通过windows.screen),cookie信息(通过document.cookie)等。解析_maq数组并采集配置信息。这可能包括用户定义的事件跟踪,业务数据(例如电子商务网站产品编号等)。以上两个步骤中采集的数据将以预定义的格式进行解析和拼接(获取请求参数)。请求后端脚本,然后将http请求参数中的信息放入后端脚本。
这里唯一的问题是第4步。javascript请求后端脚本的常用方法是ajax,但是无法跨域请求ajax。一种常见的方法是使用js脚本创建Image对象,将Image对象的src属性指向后端脚本并携带参数。此时,实现了跨域请求后端。这就是为什么后端脚本通常伪装成gif文件的原因。
示例代码
(function () {
var params = {};
//Document 对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window 对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator 对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq 配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过 Image 对象请求后端脚本
var img = new Image(1, 1);
img.src = ' http://xxx.xxxxx.xxxxx/log.gif? ' + args;
})();
将整个脚本放置在一个匿名函数中,以确保它不会污染全局环境。其中log.gif是后端脚本。
后端脚本
log.gif是后端脚本,该脚本伪装成gif图片。后端脚本通常需要完成以下操作:
分析http请求参数以获取信息。获取客户端无法从Web服务器获取的某些信息,例如visitor ip。以日志格式写入信息。生成1×1的空白gif图像作为响应内容,并将响应头的Content-type设置为image / gif。通过响应标头中的Set-cookie设置一些必需的cookie信息。
设置cookie的原因是因为如果您要跟踪唯一的访问者,通常的做法是根据规则生成一个全局唯一的cookie,如果发现客户端没有该cookie,则将其植入用户。在请求时指定跟踪cookie,否则Set-cookie放置获取的跟踪cookie以保持相同的用户cookie不变。尽管这种方法并不完美(例如,清除cookie或更改浏览器的用户将被视为两个用户),但目前已广泛使用。
我们使用nginx的access_log进行日志采集,但是存在一个问题,即nginx配置本身具有有限的逻辑表达能力,因此我们选择OpenResty来实现。
OpenResty是基于Nginx的高性能应用程序开发平台。它集成了许多有用的模块,其核心是通过ngx_lua模块将Lua集成在一起,因此Lua可用于在nginx配置文件中表达业务。
Lua是一种轻量级且紧凑的脚本语言,用标准C语言编写,并以源代码形式开放。其设计目的是嵌入到应用程序中,从而为应用程序提供灵活的扩展和自定义功能。
首先,您需要在nginx配置文件中定义日志格式:
log_format tick
"$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url|
|$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_ag
ent||$u_account";
请注意,此处以u_开头的变量是我们稍后将定义的变量,其他变量是nginx的内置变量。然后是两个核心位置:
location / log.gif {
#伪装成 gif 文件
default_type image/gif;
#本身关闭 access_log,通过 subrequest 记录 log
access_log off;
access_by_lua "
-- 用户跟踪 cookie 名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪 cookie,算法为
md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() ..
ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid ..
'; path=/'}
if ngx.var.arg_domain then
-- 通过 subrequest 子请求 到/i-log 记录日志,
将参数和用户跟踪 cookie 带过去
ngx.location.capture('/i-log?' ..
ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求资源本地不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-
revalidate";
#返回一个 1×1 的空 gif 图片
empty_gif;
}
location /i-log {
#内部 location,不允许外部直接访问
internal;
#设置变量,注意需要 unescape,来自 ngx_set_misc 模块
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_account $arg_account;
#打开日志
log_subrequest on;
#记录日志到 ma.log 格式为 tick
access_log /path/to/logs/directory/ma.log tick;
#输出空字符串
echo '';
}
此脚本使用许多第三方ngxin模块(全部收录在OpenResty中),关键点带有注释。只要您在完成我们提到的End逻辑就可以了之后,就不需要完全了解每一行的含义。
日志格式
日志格式主要考虑日志分隔符,通常有以下选项:
固定数量的字符,制表符,空格,一个或多个其他字符,特定的开始和结束文本。
日志细分
只要日志采集系统访问日志,文件就会变得很大,并且很难在一个文件中管理日志。通常有必要根据时间段拆分日志,例如每天或每小时一个日志。它是通过定期通过crontab调用shell脚本来实现的,如下所示:
_prefix="/path/to/nginx"
time=`date +%Y%m%d%H`
mv ${_prefix}/logs/ma.log ${_prefix}/logs/ma/ma-${time}.log
kill -USR1 `cat ${_prefix}/logs/nginx.pid `
此脚本将ma.log移至指定的文件夹,并将其重命名为ma- {yyyymmddhh} .log,然后将USR1信号发送给nginx以重新打开日志文件。
USR1通常用于通知应用程序重新加载配置文件。向服务器发送USR1信号将导致执行以下步骤:停止接受新连接,等待当前连接停止,重新加载配置文件,然后重新打开日志文件,重新启动服务器以实现相对平稳的更改而不关闭
cat $ {_ prefix} /logs/nginx.pid接受nginx的进程号
然后在/ etc / crontab中添加一行:
59 * * * *根/path/to/directory/rotatelog.sh
每小时59分钟启动此脚本以执行日志轮换操作。
操作方法:一种能识别网页信息自动采集的系统与方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-10-06 12:00
专利名称:一种可以自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,尤其属于一种可以识别网页信息的自动系统和方法。
背景技术:
随着Internet的发展,越来越多的Internet网站出现了,形式无穷无尽,包括新闻,博客,论坛,SNS,微博等。根据CNNIC今年的最新统计,中国现在有85亿网民4.和超过130万个各种站点域名。随着Internet信息的爆炸式增长,搜索引擎已成为人们查找Internet信息的最重要工具。搜索引擎主要自动抓取网站信息,对其进行预处理,并在分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经相对成熟,并且由于可以成功使用的商业模式,吸引了许多互联网公司进入。比较有名的有百度,谷歌,搜搜,搜狗,有道,奇虎360等。此外,在某些垂直领域(例如旅行,机票,价格比较等)中也有搜索引擎,已有上千家制造商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体过程如图1所示。URL DB存储所有要爬网的URL。 URL调度模块从URL DB中选择最重要的URL,并将它们放入URL下载队列中。页面下载模块下载队列中的URL。下载完成后,提取模块提取下载的页面代码的文本和URL,并将提取的文本发送到索引模块以进行单词分割和索引,然后将URL放入URL DB。信息采集流程是将其他人网站的信息放入您自己的信息数据库的过程,这会遇到一些问题。
1、Internet信息每时每刻都在不断增加,因此信息爬网是7 * 24小时不间断的过程。频繁的爬网将给目标网站带来巨大的访问压力,从而形成DDOS拒绝服务攻击,从而导致无法为普通用户提供访问权限。这在中小型企业中尤为明显网站。这些网站硬件资源相对贫乏,技术力量不强,并且超过90%的Internet都是这种类型网站。例如:一个著名的搜索引擎由于频繁抓取某个网站而要求用户投诉。2、某些网站信息具有隐私权或版权。许多网页收录后台数据库,用户隐私,密码和其他信息。网站发起人不希望将此信息公开或免费使用。 Dianping.com曾经对Aibang.com提起诉讼,要求其对网站进行评论并将其发布在自身网站上。目前,网页反搜索引擎采集采用的主流方法是漫游器协议协议,网站使用漫游器txt协议控制搜索引擎收录是否愿意搜索内容,以及搜索引擎允许收录,并指定可用于收录和禁止的收录。同时,搜索引擎将根据为每个网站 Robots协议赋予的权限自觉地进行爬网。该方法假定搜索引擎的爬取过程如下:下载网站机器人文件-根据机器人协议解析文件-获取要下载的URL-确定URL的访问权限-确定是否进行爬网确定的结果。机器人协议是绅士协议,没有任何限制。搜寻计划仍然完全由搜索引擎控制,完全有可能在不遵循协议的情况下进行搜寻。
例如,在2012年8月,一个著名的国内搜索引擎未遵循该协议来抓取百度网站内容,并被百度指控。另一种反采集方法主要使用动态技术来构建要禁止爬网的网页。该方法使用客户端脚本语言(例如JS,VBScript,AJAX)动态生成网页显示信息,从而实现信息隐藏,并使传统的搜索引擎难以获取URL和正文内容。动态网页构建技术仅增加了网页解析和提取的难度,不能从根本上禁止网页信息的采集解析。当前,一些高级搜索引擎可以模拟浏览器来实现所有脚本代码分析。获取所有信息的网络URL,从而获得存储在服务器中的动态信息。当前,存在成熟的网页动态分析技术,主要是通过解析网页中所有脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)来实现的。实际的实现过程以开源脚本代码分析引擎(如Rhino,V8等)为基础,以构建网页脚本分析环境,然后从网页中提取脚本代码段,并将将提取的代码段提取到网页脚本分析环境中,以执行以返回动态信息。解析过程如图2所示,因此使用动态技术构建动态网页的方法只会增加网页采集和分析的难度,而不会从根本上消除搜索引擎采集。
发明内容
本发明的目的是提供一种可以自动识别网页信息的系统和方法,从而克服了现有技术的缺点。系统通过分析网站的历史网页访问行为来建立自动采集。 ]分类器,可识别机器人的自动采集,并通过自动机器人采集的识别来实现网页的防爬网。本发明采用的技术方案如下:一种能够自动采集识别网页信息的系统和方法,包括anti 采集分类器构建模块,auto 采集识别模块和anti 采集 ]在线处理模块,anti 采集 k15]分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块,此模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将采集程序的已标识IP段添加到黑名单中,黑名单中用于后续的在线拦截对于自动采集行为,如果访问者的IP已经在IP段中,则反采集在线处理模块主要用于自动在线判断和处理访问的用户;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志解析子模块通过对站点访问日志的自动分析,包括用户对网站的访问,获得用户的访问行为信息。 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内同一IP段中访问频率最高的数据记录,在步骤I中选择解析的数据记录样本采集;访问统计子模块对选定的样本数据进行统计,并计算同一IP段的平均页面停留时间,站点访问的页面总数,采集网页附件信息,第采集页的频率;(6)使用IP段作为主要关键字,将以上信息存储在样品库中并将其标记为未标记;(7)在步骤(I)中标记未标记的样品确定d。样品自动加工采集,标记为I;如果是用户浏览器的正常访问,则将其标记为0,并将所有标记的样本更新到数据库中; (8)计算机程序会自动学习样本库,并为稍后阶段的采集自动识别生成分类模型。
[p15]中所述的采集自动识别模块的实现方法
包括以下步骤:(5)识别程序的初始化阶段,完成分类器模型的加载,该模型可以确定自动的采集行为;(6)日志分析该程序解析最新的[网站访问日志,并将解析后的数据发送到访问统计模块; [7)访问统计模块计算相同IP段的平均页面停留时间,无论是采集 Web附件信息,网页采集频率;([ 8)分类器根据分类模型判断IP段的访问行为,并将判断为程序自动采集行为的IP段添加到黑名单中;反采集在线处理模块的实现方法包括:步骤:(I)为Web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单数据库中的IP信息(如果IP已在黑名单中),在这种情况下,将通知Web服务器拒绝IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下:本发明的系统分析网站网页访问行为的历史,建立自动采集分类器,识别自动采集分类器。机器人,通过自动识别机器人采集来实现网页的防抓取,自动发现搜索引擎网页采集的行为,并对其进行处理采集行为被屏蔽以从根本上消除采集个搜索引擎。
图1是现有技术搜索引擎的信息捕获过程的示意图。图2是现有技术的第二分析过程的示意图;图3是本发明的anti 采集分类器的框图。图4是本发明的自动采集识别模块图;图5是本发明的抗采集在线处理模块。
<p>有关具体实施例,请参考附图。可以识别网页信息的反抓取系统和方法包括反采集分类器构建模块,自动采集识别模块和反采集在线处理模块。 采集分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器以自动识别搜索引擎程序的自动采集行为,并将识别的采集程序的IP段添加到黑名单中。该列表用于后续的自动采集行为的在线拦截。 anti- 采集在线处理模块主要用于自动在线判断和处理访问的用户。如果访问者的IP已经在IP中。在细分黑名单中,该IP被拒绝访问;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(9)日志解析子模块通过自动分析站点访问日志来获取用户访问行为信息,包括用户访问网站 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内相同IP段中访问频率最高的数据记录,作为候选数据样本采集,选择步骤I中的解析数据记录。访问统计子模块对所选样本数据进行统计,并计算相同IP段的平均页面停留时间,访问的页面总数,采集个网页附件信息,采集个网页 查看全部
可以自动识别网页信息的系统和方法采集
专利名称:一种可以自动识别网页信息的系统和方法采集
技术领域:
本发明涉及网页动态分析技术领域,尤其属于一种可以识别网页信息的自动系统和方法。
背景技术:
随着Internet的发展,越来越多的Internet网站出现了,形式无穷无尽,包括新闻,博客,论坛,SNS,微博等。根据CNNIC今年的最新统计,中国现在有85亿网民4.和超过130万个各种站点域名。随着Internet信息的爆炸式增长,搜索引擎已成为人们查找Internet信息的最重要工具。搜索引擎主要自动抓取网站信息,对其进行预处理,并在分词后建立索引。输入搜索词后,搜索引擎可以自动为用户找到最相关的结果。经过十多年的发展,搜索引擎技术已经相对成熟,并且由于可以成功使用的商业模式,吸引了许多互联网公司进入。比较有名的有百度,谷歌,搜搜,搜狗,有道,奇虎360等。此外,在某些垂直领域(例如旅行,机票,价格比较等)中也有搜索引擎,已有上千家制造商进入。搜索引擎的第一步也是最重要的一步是信息捕获,这是搜索引擎的数据准备过程。具体过程如图1所示。URL DB存储所有要爬网的URL。 URL调度模块从URL DB中选择最重要的URL,并将它们放入URL下载队列中。页面下载模块下载队列中的URL。下载完成后,提取模块提取下载的页面代码的文本和URL,并将提取的文本发送到索引模块以进行单词分割和索引,然后将URL放入URL DB。信息采集流程是将其他人网站的信息放入您自己的信息数据库的过程,这会遇到一些问题。
1、Internet信息每时每刻都在不断增加,因此信息爬网是7 * 24小时不间断的过程。频繁的爬网将给目标网站带来巨大的访问压力,从而形成DDOS拒绝服务攻击,从而导致无法为普通用户提供访问权限。这在中小型企业中尤为明显网站。这些网站硬件资源相对贫乏,技术力量不强,并且超过90%的Internet都是这种类型网站。例如:一个著名的搜索引擎由于频繁抓取某个网站而要求用户投诉。2、某些网站信息具有隐私权或版权。许多网页收录后台数据库,用户隐私,密码和其他信息。网站发起人不希望将此信息公开或免费使用。 Dianping.com曾经对Aibang.com提起诉讼,要求其对网站进行评论并将其发布在自身网站上。目前,网页反搜索引擎采集采用的主流方法是漫游器协议协议,网站使用漫游器txt协议控制搜索引擎收录是否愿意搜索内容,以及搜索引擎允许收录,并指定可用于收录和禁止的收录。同时,搜索引擎将根据为每个网站 Robots协议赋予的权限自觉地进行爬网。该方法假定搜索引擎的爬取过程如下:下载网站机器人文件-根据机器人协议解析文件-获取要下载的URL-确定URL的访问权限-确定是否进行爬网确定的结果。机器人协议是绅士协议,没有任何限制。搜寻计划仍然完全由搜索引擎控制,完全有可能在不遵循协议的情况下进行搜寻。
例如,在2012年8月,一个著名的国内搜索引擎未遵循该协议来抓取百度网站内容,并被百度指控。另一种反采集方法主要使用动态技术来构建要禁止爬网的网页。该方法使用客户端脚本语言(例如JS,VBScript,AJAX)动态生成网页显示信息,从而实现信息隐藏,并使传统的搜索引擎难以获取URL和正文内容。动态网页构建技术仅增加了网页解析和提取的难度,不能从根本上禁止网页信息的采集解析。当前,一些高级搜索引擎可以模拟浏览器来实现所有脚本代码分析。获取所有信息的网络URL,从而获得存储在服务器中的动态信息。当前,存在成熟的网页动态分析技术,主要是通过解析网页中所有脚本代码段,然后获取网页的所有动态信息(包括有用信息和垃圾信息)来实现的。实际的实现过程以开源脚本代码分析引擎(如Rhino,V8等)为基础,以构建网页脚本分析环境,然后从网页中提取脚本代码段,并将将提取的代码段提取到网页脚本分析环境中,以执行以返回动态信息。解析过程如图2所示,因此使用动态技术构建动态网页的方法只会增加网页采集和分析的难度,而不会从根本上消除搜索引擎采集。
发明内容
本发明的目的是提供一种可以自动识别网页信息的系统和方法,从而克服了现有技术的缺点。系统通过分析网站的历史网页访问行为来建立自动采集。 ]分类器,可识别机器人的自动采集,并通过自动机器人采集的识别来实现网页的防爬网。本发明采用的技术方案如下:一种能够自动采集识别网页信息的系统和方法,包括anti 采集分类器构建模块,auto 采集识别模块和anti 采集 ]在线处理模块,anti 采集 k15]分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块,此模块通过加载自动分类器自动识别搜索引擎程序的自动采集行为,并将采集程序的已标识IP段添加到黑名单中,黑名单中用于后续的在线拦截对于自动采集行为,如果访问者的IP已经在IP段中,则反采集在线处理模块主要用于自动在线判断和处理访问的用户;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(5)日志解析子模块通过对站点访问日志的自动分析,包括用户对网站的访问,获得用户的访问行为信息。 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内同一IP段中访问频率最高的数据记录,在步骤I中选择解析的数据记录样本采集;访问统计子模块对选定的样本数据进行统计,并计算同一IP段的平均页面停留时间,站点访问的页面总数,采集网页附件信息,第采集页的频率;(6)使用IP段作为主要关键字,将以上信息存储在样品库中并将其标记为未标记;(7)在步骤(I)中标记未标记的样品确定d。样品自动加工采集,标记为I;如果是用户浏览器的正常访问,则将其标记为0,并将所有标记的样本更新到数据库中; (8)计算机程序会自动学习样本库,并为稍后阶段的采集自动识别生成分类模型。
[p15]中所述的采集自动识别模块的实现方法
包括以下步骤:(5)识别程序的初始化阶段,完成分类器模型的加载,该模型可以确定自动的采集行为;(6)日志分析该程序解析最新的[网站访问日志,并将解析后的数据发送到访问统计模块; [7)访问统计模块计算相同IP段的平均页面停留时间,无论是采集 Web附件信息,网页采集频率;([ 8)分类器根据分类模型判断IP段的访问行为,并将判断为程序自动采集行为的IP段添加到黑名单中;反采集在线处理模块的实现方法包括:步骤:(I)为Web服务器转发的访问请求提取访问者的IP信息;(2)比较黑名单数据库中的IP信息(如果IP已在黑名单中),在这种情况下,将通知Web服务器拒绝IP的访问;否则,通知Web服务器正常处理访问请求。与现有技术相比,本发明的有益效果如下:本发明的系统分析网站网页访问行为的历史,建立自动采集分类器,识别自动采集分类器。机器人,通过自动识别机器人采集来实现网页的防抓取,自动发现搜索引擎网页采集的行为,并对其进行处理采集行为被屏蔽以从根本上消除采集个搜索引擎。
图1是现有技术搜索引擎的信息捕获过程的示意图。图2是现有技术的第二分析过程的示意图;图3是本发明的anti 采集分类器的框图。图4是本发明的自动采集识别模块图;图5是本发明的抗采集在线处理模块。
<p>有关具体实施例,请参考附图。可以识别网页信息的反抓取系统和方法包括反采集分类器构建模块,自动采集识别模块和反采集在线处理模块。 采集分类器构建模块,此模块主要用于使用计算机程序来学习并区分自动采集历史Web信息和正常Web页面访问行为。该模块提供了用于自动采集识别的训练模型。自动采集识别模块主要用于加载自动分类器以自动识别搜索引擎程序的自动采集行为,并将识别的采集程序的IP段添加到黑名单中。该列表用于后续的自动采集行为的在线拦截。 anti- 采集在线处理模块主要用于自动在线判断和处理访问的用户。如果访问者的IP已经在IP中。在细分黑名单中,该IP被拒绝访问;否则,将访问请求转发到Web服务器以进行进一步处理。反采集分类器构建模块的实现方法具体包括以下步骤:(9)日志解析子模块通过自动分析站点访问日志来获取用户访问行为信息,包括用户访问网站 IP,访问时间,访问URL,源URL;样本选择子模块基于连续一段时间内相同IP段中访问频率最高的数据记录,作为候选数据样本采集,选择步骤I中的解析数据记录。访问统计子模块对所选样本数据进行统计,并计算相同IP段的平均页面停留时间,访问的页面总数,采集个网页附件信息,采集个网页
直观:中文网页自动采集与分类系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-09-21 13:03
中文网页自动分类系统的设计与实现:保密期限:本人声明结果。据我介绍,该学位已申请其他学术机构的学术和贡献。我已经签署了我正在攻读学位的学位。有关部门可以出版学位保存和学位理论汇编。我已经签署了老师的签名。自动中文网页采集摘要随着科学技术的飞速发展,我们已经进入了数字信息时代。作为当今世界上最大的信息数据库,互联网也已成为人们获取信息的最重要手段。如何从Internet上的海量信息资源中快速准确地找到他们所需的信息已成为网络用户迫切需要解决的主要问题。因此,基于网络的网络信息的采集和分类已经成为研究的重点。传统Web信息采集的目标是制作尽可能多的采集信息页,甚至制作整个Web上的资源。在此过程中,它并不关心采集页的顺序和采集页的顺序。相关的主要混乱和重复的发生。同时,也非常有必要对采集中的网页进行自动分类以创建更有效的搜索引擎。网页分类是组织和管理信息的有效手段。它可以更大程度地解决信息混乱问题,并帮助用户准确确定他们所需的信息。传统的操作方式是在手动分类之后对它们进行组织和管理。
随着Internet上各种信息的迅速增加,手动处理它是不切实际的。因此,网页的自动分类是一种具有较大实用价值的方法,是一种组织和管理数据的有效手段。这也是本文的重要内容。本文首先介绍了课题的背景,研究目的以及国内外的研究现状。在解释了网页采集和网页分类的相关理论,主要技术和算法,包括几种典型的Web爬行技术和重复数据删除技术算法之后,本文选择了主题采集器方法和出色的KNN方法进行分类,并结合结合重复数据删除,分词和特征提取等相关技术,分析了中文网页的结构和特征,提出了中文网页采集,最终通过编程语言实现了分类和分类的设计与实现方法。在本文结尾处,对该系统进行了测试。测试结果符合系统设计要求,应用效果显着。关键词:Web信息采集网页分类信息提取单词分割特征提取OFSEHINESEANDIMPLE转N1:信息设计wEBPAGEAUT0〜IATIC采集和CLASSICATIONATION摘要随着科学的发展,并进入了开发技术,我们迅速地将信息信息化了世界的信息数字时代。 Intemet,其中最大的是maint001信息。 ItiS数据库。成为主要问题已解决了如何从用户那里迅速准确地关联信息资源,因为用户需要信息网络来查找信息的缺乏特征,以及庞大的,动态的,异构的,半结构化的基于信息的统一采集管理组织。研究和分类成为热点。信息采集的信息作为目标,是采集所有资源,例如订单和尽可能多的页面,或者内容不涉及采集的主题。在页面混乱的情况下,浪费了大部分SO资源,很少使用系统采集方法来减少采集的数据。 TIliSeff需要分类整齐的网页并自动创建页面重复页面。 Web有效管理页面引擎的研究。组织可以解决范围广泛的分类信息(i种有效的小信息),这种大的杂乱信息有助于用户准确地表达信息模式。借助传统信息。但是,要处理所有种类的互联网,手动快速增加方式分类的操作信息,并不是一种方法论,也不是一种有效的数据手段。 Ttisanvalue,但组织管理这一重要部分的研究。首先介绍了网络采集理论的背景,目的,主题和分类,描述了包括网页爬虫网络分解在内的技术算法页面,其中技术,重复页面词提取分割,特征技术,中文技术,信息网络分类提取页面技术。几种履带和KNNmade的综合技术,局部比较的典型算法已被分类,因为它们具有出色的性能。提出了111种拟议的中文网站,并结合了中文的已设计实现的获取结构和特征的分类,并对技术网页进行了编码并实现了语言页面的分析。最后,它的编程结果就是该语言。测试系统设计要求和应用程序完成。许多信息分类,关键词:网页采集,网页信息提取,分割,字符方法。„„„„„„„„„„„„„„„„„„„„。 484.7.2 KNN结„„„„„„„„„„„„„„„„„„„„„„„ 5253„„„„„„„„„„。
63北京邮电大学软件工程硕士学位论文第1章引言1.1项目背景和研究现状1.1.1项目背景和研究目标随着Internet的普及和网络技术的飞速发展,Internet信息资源日益丰富。为了从Internet获得越来越多的信息,包括文本,数字,图形,图像,声音和视频,需要使用指数形式。但是,随着网络信息的迅速发展,如何快速,准确地从庞大的信息资源中找到他们所需的信息已成为大多数网络用户的主要问题。它基于Internet 采集和搜索引擎上的信息。这些搜索引擎通常使用一个或多个采集器从Internet采集FTP,电子邮件,新闻等各种数据,然后在本地服务器上为这些数据建立索引,然后用户根据索引数据库从索引数据库中进行搜索。用户提交的搜索条件。快速找到您需要的信息。网络信息采集作为这些搜索引擎的基础和组成部分,起着举足轻重的作用。 Web信息采集是指通过Web页面之间的链接关系从Web自动获取页面信息,并随着链接不断扩展到所需Web页面的过程。传统的W歌曲信息采集的目标是要有尽可能多的采集信息页,甚至是整个Web上的资源,这样,集中精力于采集的速度和数量,并且实现是比较简单。但是,这种传统的采集方法存在很多缺陷。
由于采集需要基于整个Web信息的采集页,因此部分利用率非常低。用户通常只关心很少的页面,采集器 采集的大多数页面对他们来说都是无用的。显然,这是对系统资源和网络资源的巨大开销。随着网页数量的快速增长,非常有必要使用固定标题采集技术来构造固定标题类别,以创建一个更有效,更快速的搜索引擎。传统的操作模式是分类后组织和管理其工作。该分类方法更准确,分类质量更高。随着Internet上各种信息的迅速增加,手动处理是不切实际的。对网页进行分类可以在很大程度上解决网页上的混乱信息,并方便用户准确定位所需信息。因此,自动网页分类是一种具有很大实用价值的方法,也是一种组织和管理数据的方法。有效手段。这也是本文的重要内容。北京邮电大学软件工程硕士学位论文1.1.2主题网页的国内外研究现状采集技术发展的现状互联网正在不断改变着我们的生活。 Intemet已成为当今世界上最大的信息资源库。对于网络用户来说,从庞大的信息资源数据库中准确找到所需信息已经成为一个大问题。无论是某些通用搜索引擎(例如Google,百度等)还是用于特定主题的专用网页采集系统,它们都离不开网页采集,因此基于网络的信息采集和处理方式越来越多成为关注的焦点。
传统Web信息采集的采集中的页面数太大,采集的内容太乱,这会占用大量系统资源和网络资源。同时,互联网信息的分散状态和动态变化也是困扰信息的主要问题采集。为了解决这些问题,搜索引擎。这些搜索引擎通常通过一个或多个采集器从Internet采集各种数据,然后在用户根据用户提交的需求检索它们时,在本地服务器上为这些数据建立索引。即使是大规模的信息采集系统,其Web覆盖率也仅为30“ -40%。即使使用处理能力更强的计算机系统,其性价比也不是很高。相对较好的满意度可以满足人们其次,互联网信息的分散状态和动态变化也是影响信息采集的原因,由于信息源随时可能在变化,因此信息采集器必须经常刷新数据,但这仍然不能对于传统信息采集,由于需要刷新的页面数是采集所到达页面的很大一部分,因此利用率很低,因为用户经常只关心很少的页面,而且这些页面通常集中在一个或几个主题上,采集器浪费了大量的网络资源,这些问题主要是由大量传统Web信息引起的采集 ]和采集页。 采集页面的内容太乱。如果信息检索仅限于特定主题领域,并且基于与主题相关的信息提供检索服务,则采集所需的网页数量将大大减少,北京邮电大学的主要软件工程硕士和电信最后一篇论文。
这种类型的Web信息采集被称为固定主题Web信息采集。由于固定主题采集的搜索范围较大,因此准确性和召回率较高。但是,随着Internet的快速发展和网页数量的爆炸性增长,即使使用固定主题采集技术构建固定主题的搜索引擎,同一主题上的网页数量与广泛的主题相比仍然很大。因此,如何根据给定的模式有效地对同一主题上的网页进行分类以创建更有效,更快的搜索引擎是一个非常重要的主题。网页分类技术的发展现状基于文本分类算法并结合HTML语言的结构特点,开发了网页自动分类技术。自动文本分类最初是为了满足信息检索InformationRetrieval和IR系统的需求而开发的。信息检索系统必须处理大量数据,并且其文本信息数据库占据大部分内容。同时,用于表示文本内容的单词数为数千。在这种情况下,如果可以提供组织良好的结构化文本集合,则可以大大简化文本的访问和操作。自动文本分类系统的目的是以有序的方式组织文本集合,并将相似和相关的文本组织在一起。作为知识组织工具,它为信息检索提供了更有效的搜索策略和更准确的查询结果。自动文本分类的研究始于1950年代后期,H。RLulm在这一领域进行了开创性研究。
网页的自动分类在国外经历了三个发展阶段:第一阶段是1958年。1964年,进行了自动分类的可行性研究,第二阶段是1965.1974年,进行了自动分类的实验研究,第三阶段是阶段是1975年。它已经进入实用阶段[l_]。国内对自动分类的研究相对较晚,始于1980年代初期。关于中文文本分类的研究相对较少。国内外的研究基本上是以英文文本的分类为基础,结合中文文本和中文的特点,采取相应的策略,再将其应用于中文,形成中文文本。分类研究系统。 1981年,侯汉清讨论了计算机在文档分类中的应用。早期系统的主要特征是结合主题词汇进行分析和分类,并且人工干预的组成部分非常庞大。林等。将KNN方法与线性分类器相结合,取得了良好的效果。香港中文大学的围观回报率接近90%。准确率超过t31的80%。 C.K.P Wong等。研究了使用混合关键词进行文本分类的方法,召回率和准确率分别为72%和62%。复旦大学和富士通研究与发展中心的黄守,吴立德和石崎阳幸研究了独立语言的文本分类,并将单词类别的互信息用作评分功能。单分类器和多分类器用于分隔中文和日语。经过测试,最佳结果召回率为88.87%[5'。
上海交通大学的刁倩和王永成结合了词权重和分类算法进行分类,采用VSM方法N97%t71在封闭测试中分类正确。从那时起,基于统计的思想以及分词,语料库和其他技术一直被连续应用于分类。万维网收录大约115亿个可索引网页,并且每天添加数千万或更多的网页。如何组织这些大量有效的信息网络资源是一个很大的实际问题。网页数实现网页采集的功能子系统。二、比较了网页信息提取技术,中文分词技术,特征提取技术和网页分类技术的分析与比较,采用了优秀的KNN分类算法来实现网页分类功能。三、使用最大匹配算法来分割文本。清洁网页,删除网页中的一些垃圾邮件,然后将网页转换为文本格式。四、网页的预处理部分结合网页的模型特征,基于HTML标签对网页的无关文本进行加权。通过以上几方面的工作,终于完成了网页自动采集和分类系统的实现,并通过实验对上述算法进行了验证。 1.3论文的结构本文共分为6章,内容安排如下:第1章绪论,介绍了本课题的含义,国内外的现状和任务。第二章介绍网页采集和与分类有关的技术。本章介绍采集以及将用于分类的北京邮电大学软件工程硕士学位论文的原理和方法。包括常用的Web爬虫技术,网页到页面分类技术。
第3章网页采集和分类系统设计。本章首先进行系统分析,然后进行系统轮廓设计,功能模块设计,系统流程设计,系统逻辑设计和数据设计。第4章Web页面采集和分类系统的实现。本章详细介绍了每个模块的实现过程,包括页面采集模块,信息提取模块,网页重复数据删除模块,中文分词模块,特征向量提取模块,训练语料库模块和分类模块。第5章网页采集和分类系统测试。本章首先介绍了系统的操作界面,然后给出了实验评估标准并分析了实验结果。第六章结束语,本章对本文的工作进行了全面总结,给出了本文所取得的成果,并指出了现有的不足和改进的方向。北京第2章网页2.1 Web爬虫技术该程序也是搜索引擎的核心组件。搜索引擎的性能,规模和扩展能力在很大程度上取决于Web采集器的处理能力。网络爬虫Crawler也称为网络蜘蛛或网络机器人Robot。 Web爬网程序的系统结构如图2-1所示:下载模块用于存储从爬网的网页提取的URL。图2.1 Web爬网程序的结构图Web爬网程序从给定的URL开始并遵循网页上的出站链接。根据设置的网络搜索策略(例如,广度优先策略,深度优先策略或最佳优先级策略)链接采集 URL队列中的高优先级网页,然后使用网页分类器确定是否是主题网页,如果是,保存,否则丢弃;对于采集网页,请提取其中收录的URL,然后通过相应的位置将其插入URL队列。
2.1.1通用Web爬网程序通用Web爬网程序将基于预先设置的一个或几个初始种子URL进行启动,并且下载模块将不断从URL队列中获取URL,并访问和下载页面。页面解析器删除页面上的HTML标记以获取页面内容,将摘要,URL和其他信息保存在Web数据库中,同时提取当前页面上的新URL并将其保存到UURL队列中,直到很满意 查看全部
中文网页自动采集和分类系统的设计与实现
中文网页自动分类系统的设计与实现:保密期限:本人声明结果。据我介绍,该学位已申请其他学术机构的学术和贡献。我已经签署了我正在攻读学位的学位。有关部门可以出版学位保存和学位理论汇编。我已经签署了老师的签名。自动中文网页采集摘要随着科学技术的飞速发展,我们已经进入了数字信息时代。作为当今世界上最大的信息数据库,互联网也已成为人们获取信息的最重要手段。如何从Internet上的海量信息资源中快速准确地找到他们所需的信息已成为网络用户迫切需要解决的主要问题。因此,基于网络的网络信息的采集和分类已经成为研究的重点。传统Web信息采集的目标是制作尽可能多的采集信息页,甚至制作整个Web上的资源。在此过程中,它并不关心采集页的顺序和采集页的顺序。相关的主要混乱和重复的发生。同时,也非常有必要对采集中的网页进行自动分类以创建更有效的搜索引擎。网页分类是组织和管理信息的有效手段。它可以更大程度地解决信息混乱问题,并帮助用户准确确定他们所需的信息。传统的操作方式是在手动分类之后对它们进行组织和管理。
随着Internet上各种信息的迅速增加,手动处理它是不切实际的。因此,网页的自动分类是一种具有较大实用价值的方法,是一种组织和管理数据的有效手段。这也是本文的重要内容。本文首先介绍了课题的背景,研究目的以及国内外的研究现状。在解释了网页采集和网页分类的相关理论,主要技术和算法,包括几种典型的Web爬行技术和重复数据删除技术算法之后,本文选择了主题采集器方法和出色的KNN方法进行分类,并结合结合重复数据删除,分词和特征提取等相关技术,分析了中文网页的结构和特征,提出了中文网页采集,最终通过编程语言实现了分类和分类的设计与实现方法。在本文结尾处,对该系统进行了测试。测试结果符合系统设计要求,应用效果显着。关键词:Web信息采集网页分类信息提取单词分割特征提取OFSEHINESEANDIMPLE转N1:信息设计wEBPAGEAUT0〜IATIC采集和CLASSICATIONATION摘要随着科学的发展,并进入了开发技术,我们迅速地将信息信息化了世界的信息数字时代。 Intemet,其中最大的是maint001信息。 ItiS数据库。成为主要问题已解决了如何从用户那里迅速准确地关联信息资源,因为用户需要信息网络来查找信息的缺乏特征,以及庞大的,动态的,异构的,半结构化的基于信息的统一采集管理组织。研究和分类成为热点。信息采集的信息作为目标,是采集所有资源,例如订单和尽可能多的页面,或者内容不涉及采集的主题。在页面混乱的情况下,浪费了大部分SO资源,很少使用系统采集方法来减少采集的数据。 TIliSeff需要分类整齐的网页并自动创建页面重复页面。 Web有效管理页面引擎的研究。组织可以解决范围广泛的分类信息(i种有效的小信息),这种大的杂乱信息有助于用户准确地表达信息模式。借助传统信息。但是,要处理所有种类的互联网,手动快速增加方式分类的操作信息,并不是一种方法论,也不是一种有效的数据手段。 Ttisanvalue,但组织管理这一重要部分的研究。首先介绍了网络采集理论的背景,目的,主题和分类,描述了包括网页爬虫网络分解在内的技术算法页面,其中技术,重复页面词提取分割,特征技术,中文技术,信息网络分类提取页面技术。几种履带和KNNmade的综合技术,局部比较的典型算法已被分类,因为它们具有出色的性能。提出了111种拟议的中文网站,并结合了中文的已设计实现的获取结构和特征的分类,并对技术网页进行了编码并实现了语言页面的分析。最后,它的编程结果就是该语言。测试系统设计要求和应用程序完成。许多信息分类,关键词:网页采集,网页信息提取,分割,字符方法。„„„„„„„„„„„„„„„„„„„„。 484.7.2 KNN结„„„„„„„„„„„„„„„„„„„„„„„ 5253„„„„„„„„„„。
63北京邮电大学软件工程硕士学位论文第1章引言1.1项目背景和研究现状1.1.1项目背景和研究目标随着Internet的普及和网络技术的飞速发展,Internet信息资源日益丰富。为了从Internet获得越来越多的信息,包括文本,数字,图形,图像,声音和视频,需要使用指数形式。但是,随着网络信息的迅速发展,如何快速,准确地从庞大的信息资源中找到他们所需的信息已成为大多数网络用户的主要问题。它基于Internet 采集和搜索引擎上的信息。这些搜索引擎通常使用一个或多个采集器从Internet采集FTP,电子邮件,新闻等各种数据,然后在本地服务器上为这些数据建立索引,然后用户根据索引数据库从索引数据库中进行搜索。用户提交的搜索条件。快速找到您需要的信息。网络信息采集作为这些搜索引擎的基础和组成部分,起着举足轻重的作用。 Web信息采集是指通过Web页面之间的链接关系从Web自动获取页面信息,并随着链接不断扩展到所需Web页面的过程。传统的W歌曲信息采集的目标是要有尽可能多的采集信息页,甚至是整个Web上的资源,这样,集中精力于采集的速度和数量,并且实现是比较简单。但是,这种传统的采集方法存在很多缺陷。
由于采集需要基于整个Web信息的采集页,因此部分利用率非常低。用户通常只关心很少的页面,采集器 采集的大多数页面对他们来说都是无用的。显然,这是对系统资源和网络资源的巨大开销。随着网页数量的快速增长,非常有必要使用固定标题采集技术来构造固定标题类别,以创建一个更有效,更快速的搜索引擎。传统的操作模式是分类后组织和管理其工作。该分类方法更准确,分类质量更高。随着Internet上各种信息的迅速增加,手动处理是不切实际的。对网页进行分类可以在很大程度上解决网页上的混乱信息,并方便用户准确定位所需信息。因此,自动网页分类是一种具有很大实用价值的方法,也是一种组织和管理数据的方法。有效手段。这也是本文的重要内容。北京邮电大学软件工程硕士学位论文1.1.2主题网页的国内外研究现状采集技术发展的现状互联网正在不断改变着我们的生活。 Intemet已成为当今世界上最大的信息资源库。对于网络用户来说,从庞大的信息资源数据库中准确找到所需信息已经成为一个大问题。无论是某些通用搜索引擎(例如Google,百度等)还是用于特定主题的专用网页采集系统,它们都离不开网页采集,因此基于网络的信息采集和处理方式越来越多成为关注的焦点。
传统Web信息采集的采集中的页面数太大,采集的内容太乱,这会占用大量系统资源和网络资源。同时,互联网信息的分散状态和动态变化也是困扰信息的主要问题采集。为了解决这些问题,搜索引擎。这些搜索引擎通常通过一个或多个采集器从Internet采集各种数据,然后在用户根据用户提交的需求检索它们时,在本地服务器上为这些数据建立索引。即使是大规模的信息采集系统,其Web覆盖率也仅为30“ -40%。即使使用处理能力更强的计算机系统,其性价比也不是很高。相对较好的满意度可以满足人们其次,互联网信息的分散状态和动态变化也是影响信息采集的原因,由于信息源随时可能在变化,因此信息采集器必须经常刷新数据,但这仍然不能对于传统信息采集,由于需要刷新的页面数是采集所到达页面的很大一部分,因此利用率很低,因为用户经常只关心很少的页面,而且这些页面通常集中在一个或几个主题上,采集器浪费了大量的网络资源,这些问题主要是由大量传统Web信息引起的采集 ]和采集页。 采集页面的内容太乱。如果信息检索仅限于特定主题领域,并且基于与主题相关的信息提供检索服务,则采集所需的网页数量将大大减少,北京邮电大学的主要软件工程硕士和电信最后一篇论文。
这种类型的Web信息采集被称为固定主题Web信息采集。由于固定主题采集的搜索范围较大,因此准确性和召回率较高。但是,随着Internet的快速发展和网页数量的爆炸性增长,即使使用固定主题采集技术构建固定主题的搜索引擎,同一主题上的网页数量与广泛的主题相比仍然很大。因此,如何根据给定的模式有效地对同一主题上的网页进行分类以创建更有效,更快的搜索引擎是一个非常重要的主题。网页分类技术的发展现状基于文本分类算法并结合HTML语言的结构特点,开发了网页自动分类技术。自动文本分类最初是为了满足信息检索InformationRetrieval和IR系统的需求而开发的。信息检索系统必须处理大量数据,并且其文本信息数据库占据大部分内容。同时,用于表示文本内容的单词数为数千。在这种情况下,如果可以提供组织良好的结构化文本集合,则可以大大简化文本的访问和操作。自动文本分类系统的目的是以有序的方式组织文本集合,并将相似和相关的文本组织在一起。作为知识组织工具,它为信息检索提供了更有效的搜索策略和更准确的查询结果。自动文本分类的研究始于1950年代后期,H。RLulm在这一领域进行了开创性研究。
网页的自动分类在国外经历了三个发展阶段:第一阶段是1958年。1964年,进行了自动分类的可行性研究,第二阶段是1965.1974年,进行了自动分类的实验研究,第三阶段是阶段是1975年。它已经进入实用阶段[l_]。国内对自动分类的研究相对较晚,始于1980年代初期。关于中文文本分类的研究相对较少。国内外的研究基本上是以英文文本的分类为基础,结合中文文本和中文的特点,采取相应的策略,再将其应用于中文,形成中文文本。分类研究系统。 1981年,侯汉清讨论了计算机在文档分类中的应用。早期系统的主要特征是结合主题词汇进行分析和分类,并且人工干预的组成部分非常庞大。林等。将KNN方法与线性分类器相结合,取得了良好的效果。香港中文大学的围观回报率接近90%。准确率超过t31的80%。 C.K.P Wong等。研究了使用混合关键词进行文本分类的方法,召回率和准确率分别为72%和62%。复旦大学和富士通研究与发展中心的黄守,吴立德和石崎阳幸研究了独立语言的文本分类,并将单词类别的互信息用作评分功能。单分类器和多分类器用于分隔中文和日语。经过测试,最佳结果召回率为88.87%[5'。
上海交通大学的刁倩和王永成结合了词权重和分类算法进行分类,采用VSM方法N97%t71在封闭测试中分类正确。从那时起,基于统计的思想以及分词,语料库和其他技术一直被连续应用于分类。万维网收录大约115亿个可索引网页,并且每天添加数千万或更多的网页。如何组织这些大量有效的信息网络资源是一个很大的实际问题。网页数实现网页采集的功能子系统。二、比较了网页信息提取技术,中文分词技术,特征提取技术和网页分类技术的分析与比较,采用了优秀的KNN分类算法来实现网页分类功能。三、使用最大匹配算法来分割文本。清洁网页,删除网页中的一些垃圾邮件,然后将网页转换为文本格式。四、网页的预处理部分结合网页的模型特征,基于HTML标签对网页的无关文本进行加权。通过以上几方面的工作,终于完成了网页自动采集和分类系统的实现,并通过实验对上述算法进行了验证。 1.3论文的结构本文共分为6章,内容安排如下:第1章绪论,介绍了本课题的含义,国内外的现状和任务。第二章介绍网页采集和与分类有关的技术。本章介绍采集以及将用于分类的北京邮电大学软件工程硕士学位论文的原理和方法。包括常用的Web爬虫技术,网页到页面分类技术。
第3章网页采集和分类系统设计。本章首先进行系统分析,然后进行系统轮廓设计,功能模块设计,系统流程设计,系统逻辑设计和数据设计。第4章Web页面采集和分类系统的实现。本章详细介绍了每个模块的实现过程,包括页面采集模块,信息提取模块,网页重复数据删除模块,中文分词模块,特征向量提取模块,训练语料库模块和分类模块。第5章网页采集和分类系统测试。本章首先介绍了系统的操作界面,然后给出了实验评估标准并分析了实验结果。第六章结束语,本章对本文的工作进行了全面总结,给出了本文所取得的成果,并指出了现有的不足和改进的方向。北京第2章网页2.1 Web爬虫技术该程序也是搜索引擎的核心组件。搜索引擎的性能,规模和扩展能力在很大程度上取决于Web采集器的处理能力。网络爬虫Crawler也称为网络蜘蛛或网络机器人Robot。 Web爬网程序的系统结构如图2-1所示:下载模块用于存储从爬网的网页提取的URL。图2.1 Web爬网程序的结构图Web爬网程序从给定的URL开始并遵循网页上的出站链接。根据设置的网络搜索策略(例如,广度优先策略,深度优先策略或最佳优先级策略)链接采集 URL队列中的高优先级网页,然后使用网页分类器确定是否是主题网页,如果是,保存,否则丢弃;对于采集网页,请提取其中收录的URL,然后通过相应的位置将其插入URL队列。
2.1.1通用Web爬网程序通用Web爬网程序将基于预先设置的一个或几个初始种子URL进行启动,并且下载模块将不断从URL队列中获取URL,并访问和下载页面。页面解析器删除页面上的HTML标记以获取页面内容,将摘要,URL和其他信息保存在Web数据库中,同时提取当前页面上的新URL并将其保存到UURL队列中,直到很满意
汇总:网站新闻自动采集系统设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-09-02 01:34
摘要现在,许多传统媒体已经建立了自己的新闻网站,除了及时发布自己的新闻外,他们还需要采集其他专业新闻网站新闻作为补充,文章通过ASPHTTP组件实现网站新闻远程批量自动采集,提高网络编辑的发布效率,并为相关应用提供快速可行的思路和设计方案. 现在,许多传统媒体都建立了自己的新闻站点. 除了立即发布自己的新闻外,他们还需要从其他分类新闻网站采集新闻作为补充,带有ASPHTTP组件的文章可实现该网站的自动新闻采集,提高Web编辑器的发布效率,并提供快速且相关应用的可行方法和设计. 查看全部
网站新闻自动采集系统设计
摘要现在,许多传统媒体已经建立了自己的新闻网站,除了及时发布自己的新闻外,他们还需要采集其他专业新闻网站新闻作为补充,文章通过ASPHTTP组件实现网站新闻远程批量自动采集,提高网络编辑的发布效率,并为相关应用提供快速可行的思路和设计方案. 现在,许多传统媒体都建立了自己的新闻站点. 除了立即发布自己的新闻外,他们还需要从其他分类新闻网站采集新闻作为补充,带有ASPHTTP组件的文章可实现该网站的自动新闻采集,提高Web编辑器的发布效率,并提供快速且相关应用的可行方法和设计.
大数据采集系统靠谱吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-26 04:58
大数据智能营销系统究竟可靠吗,首先在问这个问题之前,我想先请你们想一下,你们觉得智能营销系统应当有怎么样的功能,能把顾客直接带到你的身边吗?
大数据智能营销系统是一共有45款软件,300多个功能,大致有三块功能,信息采集,智能营销和引流,三大蓝筹股都是模拟人工去操作的,很多破解版都是按照这一点来愚弄消费者,把自己的功能吹的神乎其神,今天小编就带给你们解密这种骗子!正版大数据采集笔记本联系,
首先看一下信息采集,这个功能就是说借助网路爬虫技术在网上实时抓取数据,这个网路爬虫虽然也是模拟人工的,就是说采集信息就是快速的把信息采集过来,但是采集的信息都是你自己能从网上找到的公开信息,也就是说这个功能可以看成一个全网信息快速整合工具,但是现今破解版智能营销系统给消费者说可以按照关键词采集私人信息,网站的浏览痕迹或则直接说可以采集到须要大家产品的人,这种居然还有人信,那我是真的服了,稍微懂点互联网的都晓得这是找不到的,而且这是属于私人信息,是违规的,说实话假如一个几千块的工具可以直接把意向顾客送到你手上,那须要她们系统的顾客也许要绕月球300圈了。
智能营销包括的功能也比较多,比如说陌陌,QQ,短信,电话等等,这里的操作也是一样都是由人工操作的,今天就讲一个陌陌,比如说陌陌加人,智能营销系统的陌陌加人和你自己加熟练更是差不多的,但是就是说智能营销系统比较便捷一点,而且是可以同时登录几十个陌陌帐号手动循环添加的,但是破解版的如何给顾客承诺呢,强制加人,不需要经过对方同意等等,这种超出腾讯规则的事,你觉得她们公司能比腾讯更厉害吗?
最后讲一下引流,同样的引流也是模拟人工操作的,都是借助真实的帐号(自己订购,成本低),然后模拟真人去顶贴回帖的,现在最可怕的是现今还有破解版智能营销系统给顾客说可以做网站优化,这个你们可以自行去百度搜索惊雷算法,做网站排名的软件2017年就不能再用了,现在跟本没有网站优化的功能,还有什么上万个防封ip,都是不存在的!
大数据智能营销系统究竟可靠吗,这些破解版的智能营销系统都是不管更新和售后的,所以总是爱给顾客夸耀自己的功能多么的强悍,诱骗消费者,客户订购以后就找都不到她们了,希望广大消费者可以看清这种骗子,可靠的智能营销系统其实也是有的,鹰眼大数据智能营销系统(133,838,41381)是最早研制智能营销系统的公司,公司创立六年了,也仍然在做软件研制,现在又是大品牌,值得信赖 查看全部
大数据采集系统靠谱吗
大数据智能营销系统究竟可靠吗,首先在问这个问题之前,我想先请你们想一下,你们觉得智能营销系统应当有怎么样的功能,能把顾客直接带到你的身边吗?
大数据智能营销系统是一共有45款软件,300多个功能,大致有三块功能,信息采集,智能营销和引流,三大蓝筹股都是模拟人工去操作的,很多破解版都是按照这一点来愚弄消费者,把自己的功能吹的神乎其神,今天小编就带给你们解密这种骗子!正版大数据采集笔记本联系,
首先看一下信息采集,这个功能就是说借助网路爬虫技术在网上实时抓取数据,这个网路爬虫虽然也是模拟人工的,就是说采集信息就是快速的把信息采集过来,但是采集的信息都是你自己能从网上找到的公开信息,也就是说这个功能可以看成一个全网信息快速整合工具,但是现今破解版智能营销系统给消费者说可以按照关键词采集私人信息,网站的浏览痕迹或则直接说可以采集到须要大家产品的人,这种居然还有人信,那我是真的服了,稍微懂点互联网的都晓得这是找不到的,而且这是属于私人信息,是违规的,说实话假如一个几千块的工具可以直接把意向顾客送到你手上,那须要她们系统的顾客也许要绕月球300圈了。
智能营销包括的功能也比较多,比如说陌陌,QQ,短信,电话等等,这里的操作也是一样都是由人工操作的,今天就讲一个陌陌,比如说陌陌加人,智能营销系统的陌陌加人和你自己加熟练更是差不多的,但是就是说智能营销系统比较便捷一点,而且是可以同时登录几十个陌陌帐号手动循环添加的,但是破解版的如何给顾客承诺呢,强制加人,不需要经过对方同意等等,这种超出腾讯规则的事,你觉得她们公司能比腾讯更厉害吗?
最后讲一下引流,同样的引流也是模拟人工操作的,都是借助真实的帐号(自己订购,成本低),然后模拟真人去顶贴回帖的,现在最可怕的是现今还有破解版智能营销系统给顾客说可以做网站优化,这个你们可以自行去百度搜索惊雷算法,做网站排名的软件2017年就不能再用了,现在跟本没有网站优化的功能,还有什么上万个防封ip,都是不存在的!
大数据智能营销系统究竟可靠吗,这些破解版的智能营销系统都是不管更新和售后的,所以总是爱给顾客夸耀自己的功能多么的强悍,诱骗消费者,客户订购以后就找都不到她们了,希望广大消费者可以看清这种骗子,可靠的智能营销系统其实也是有的,鹰眼大数据智能营销系统(133,838,41381)是最早研制智能营销系统的公司,公司创立六年了,也仍然在做软件研制,现在又是大品牌,值得信赖
芭奇站群管理系统使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-13 21:42
芭奇站群管理系统说明:所有版本,支持无限网站,傻瓜式操作,无须编撰采集规则,无限采集新数据,无限发布数据,可永久免费升级,可任意笔记本(收录vps)使用挂机采集发布,可多帐号多开同时使用,无绑定机器硬件,无须订购加密狗,不受空间商程序限制,基本不消耗空间cpu与显存(适合更多的美国空间),支持发布数据到各类流行cms中去(目前没有的会尽早降低起来),也可独立网站程序订制发布插口。只需下载软件,只需订购相应的序列号升级即可(当然,免费版本也是可以使用的)!
第一次根据它一步一步来,以后就就会了,每站只须要设置一次就可以永久使用
注意:记得要在软件上面先注册一个新帐号才按下边的操作进行哦!
基本流程:注册-->登陆-->新建网站分类-->新建网站栏目-->采集关键字-->采集文章-->设置发布插口-->全部发布
视频教程免费下载,适合菜鸟使用: [千脑快速下载] 大小:13.68MB (强烈推荐)
千脑下载网址:
站群构建步骤:
1、在“我的站群”右键,选择“新增(网站、分类)”,填写“节点名称”和选择“节点类型”。
具体作用看下边详尽解释:
①“节点名称”:你的节点命名,例如:“芭奇站”(注:以下我都以“芭奇站”这个名称作为说明);
②“节点顺序号”:可以默认不改动,这只是做为排序作用;
③“节点类型”:这里分有两种类型“网站分类”和“网站”,一般可以选“网站”就好,以下是详尽解释:
---“网站分类”的意思是一个大的分类,作用象一个文件夹,这个文件夹下有很多不同类型的网站,如果是做上几百个网站,这个网站分类是太有必要构建的,方便管理。此功能右键菜单只有:“新增(网站、分类)”,“修改分类”,“移动分类”;
---“网站”的意思是网站的类型,它归类到“网站分类”下,一般大型个人站群,类型直接选这个就好。它的下级可以新建网站栏目。右键菜单有多个功能。
2、在“芭奇站”下右键,选择“新增栏目”,填写栏目名称,例如:“网站优化”;
注意,这个不一定是和你的网站栏目一样,这个将会作为一个“关键字”去采集它的一些“长尾关键字”,所以定位要好一点。
3、在“芭奇站”右键,进入“关键字管理”,采集关键字;
4、在“芭奇站”右键,进入“数据采集”,采集文章;
5、在“芭奇站”右键,进入“数据管理”,检查已采集的文章,根据个人要求可删可改;
6、在“芭奇站”右键,进入“网站接口设置”,按提示填写网站地址;
7、在“芭奇站”右键,进入“网站数据发布”,根据个人需求设置,然后开始发布;
芭奇站群系统图片说明:
查看全部
芭奇站群管理系统使用教程
芭奇站群管理系统说明:所有版本,支持无限网站,傻瓜式操作,无须编撰采集规则,无限采集新数据,无限发布数据,可永久免费升级,可任意笔记本(收录vps)使用挂机采集发布,可多帐号多开同时使用,无绑定机器硬件,无须订购加密狗,不受空间商程序限制,基本不消耗空间cpu与显存(适合更多的美国空间),支持发布数据到各类流行cms中去(目前没有的会尽早降低起来),也可独立网站程序订制发布插口。只需下载软件,只需订购相应的序列号升级即可(当然,免费版本也是可以使用的)!
第一次根据它一步一步来,以后就就会了,每站只须要设置一次就可以永久使用
注意:记得要在软件上面先注册一个新帐号才按下边的操作进行哦!
基本流程:注册-->登陆-->新建网站分类-->新建网站栏目-->采集关键字-->采集文章-->设置发布插口-->全部发布
视频教程免费下载,适合菜鸟使用: [千脑快速下载] 大小:13.68MB (强烈推荐)
千脑下载网址:
站群构建步骤:
1、在“我的站群”右键,选择“新增(网站、分类)”,填写“节点名称”和选择“节点类型”。
具体作用看下边详尽解释:
①“节点名称”:你的节点命名,例如:“芭奇站”(注:以下我都以“芭奇站”这个名称作为说明);
②“节点顺序号”:可以默认不改动,这只是做为排序作用;
③“节点类型”:这里分有两种类型“网站分类”和“网站”,一般可以选“网站”就好,以下是详尽解释:
---“网站分类”的意思是一个大的分类,作用象一个文件夹,这个文件夹下有很多不同类型的网站,如果是做上几百个网站,这个网站分类是太有必要构建的,方便管理。此功能右键菜单只有:“新增(网站、分类)”,“修改分类”,“移动分类”;
---“网站”的意思是网站的类型,它归类到“网站分类”下,一般大型个人站群,类型直接选这个就好。它的下级可以新建网站栏目。右键菜单有多个功能。
2、在“芭奇站”下右键,选择“新增栏目”,填写栏目名称,例如:“网站优化”;
注意,这个不一定是和你的网站栏目一样,这个将会作为一个“关键字”去采集它的一些“长尾关键字”,所以定位要好一点。
3、在“芭奇站”右键,进入“关键字管理”,采集关键字;
4、在“芭奇站”右键,进入“数据采集”,采集文章;
5、在“芭奇站”右键,进入“数据管理”,检查已采集的文章,根据个人要求可删可改;
6、在“芭奇站”右键,进入“网站接口设置”,按提示填写网站地址;
7、在“芭奇站”右键,进入“网站数据发布”,根据个人需求设置,然后开始发布;
芭奇站群系统图片说明:
问问搜搜百科网站内容系统源码,自动伪原创SEO完美优化功能,自动采集更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2020-08-13 21:31
安装环境
商品介绍
自动更新问问搜搜百科站系统 自动伪原创seo完美优化 自动采集 网络挣钱神器 必备!
2016.4.4号 升级版本
演示地址1: 2015年12月上线站
该套源码对360搜索优化的比较好,演示站点是2015年12月上线,360搜索收录了大约400万页面,网站域名是老域名,360和百度收录排行都挺好,并且这个网站的不需要任何操作,每天手动更新,自动采集,自动伪原创,完全做到全手动。
这套网站源码特性:
,360搜索完美收录,后期完全可以做到秒收。
第二,解放右手,完全做到全手动更新网站内容。
赚钱思路:
这套源码的挣钱思路很简单,纯靠360搜索流量挣钱,这种网站全是长尾关键词,收录量越大,长尾关键词越多,流量越大,挂广告联盟挣钱。真正做到躺下都挣钱。
网站环境配置要求:必须要求web服务是IIS6,支持语言是ASP,支持httpd.ini伪静态。建议使用最低512M显存的win2003 vps云服务器。
温馨提示:由于源码具有可复制性,一经拍下,只要环境无问题,直接上传源码,打开cj.html页面,即可手动采集更新网站内容。恶意侵吞源码的,拒绝退货。如果是源码的相关问题,联系我的QQ,帮助解决。另外,关于在其他店订购盗版源码的不要来找我,给你植入木马侧门吃亏的是你,购买我站源码转让的,一经发觉,以后不再提供更新版本,出现侧门木马不要来找我,切记,切记!!!
再说一遍,骗取源码的,请自重,不要拍~~
查看全部
商品属性
安装环境
商品介绍
自动更新问问搜搜百科站系统 自动伪原创seo完美优化 自动采集 网络挣钱神器 必备!
2016.4.4号 升级版本
演示地址1: 2015年12月上线站
该套源码对360搜索优化的比较好,演示站点是2015年12月上线,360搜索收录了大约400万页面,网站域名是老域名,360和百度收录排行都挺好,并且这个网站的不需要任何操作,每天手动更新,自动采集,自动伪原创,完全做到全手动。
这套网站源码特性:
,360搜索完美收录,后期完全可以做到秒收。
第二,解放右手,完全做到全手动更新网站内容。
赚钱思路:
这套源码的挣钱思路很简单,纯靠360搜索流量挣钱,这种网站全是长尾关键词,收录量越大,长尾关键词越多,流量越大,挂广告联盟挣钱。真正做到躺下都挣钱。
网站环境配置要求:必须要求web服务是IIS6,支持语言是ASP,支持httpd.ini伪静态。建议使用最低512M显存的win2003 vps云服务器。
温馨提示:由于源码具有可复制性,一经拍下,只要环境无问题,直接上传源码,打开cj.html页面,即可手动采集更新网站内容。恶意侵吞源码的,拒绝退货。如果是源码的相关问题,联系我的QQ,帮助解决。另外,关于在其他店订购盗版源码的不要来找我,给你植入木马侧门吃亏的是你,购买我站源码转让的,一经发觉,以后不再提供更新版本,出现侧门木马不要来找我,切记,切记!!!
再说一遍,骗取源码的,请自重,不要拍~~
YGBOOK小说采集系统 php版 v1.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 577 次浏览 • 2020-08-11 19:46
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取 查看全部
YGBOOK小说内容管理系统(以下简称YGBOOK)提供一个轻量级小说网站解决方案,基于ThinkPHP+MySQL的技术开发。
YGBOOK是介于CMS和扒手网站之间的一款新型网站系统,批量采集目标网站数据,并进行数据入库。不仅URL完全不同,模板不同,数据也属于自己,完全为解放站长右手,只需搭建好网站,即可手动采集+自动更新。
本软件以SEO性能极好的笔趣阁模板为基础,进行了大量优化,呈送给你们一款SEO优秀,不失美观大方的小说网站系统。
YGBOOK免费版本提供了基础小说功能,包括:
1.全手动采集2345导航小说的数据,内置采集规则,无需自己设置管理
2.数据入库,不必担忧目标站改版或死掉
3.网站本身进提供小说简介和章节列表的展示,章节阅读采用跳转到原站模式,以规避版权问题
4.自带伪静态功能,但未能自由订制,无手机版本、无站内搜索、无sitemap、无结构化数据
YGBOOK基于ThinkPHP+MYSQL开发,可以在大部分常见的服务器上运行。
如windows服务器,IIS+PHP+MYSQL,
Linux服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以发挥更大性能优势
软件方面,PHP要求5.3版本以上,低于5.3版本未能运行。
硬件方面,一般配置的虚拟主机即可正常运行本系统,如果有服务器会更好。
伪静态配置参见压缩包中txt文件,针对不同环境的有不同配置说明(自带.htacess文件重新优化了兼容性,解决了apache+nts模式下可能出现的“No input file specified.”问题)
安装步骤:
1.将文件解压后上传至相应目录等
2.网站必须配置好伪静态(参考上一步配置),才能正常进行安装和使用(初次访问首页会手动步入安装页面,或自动输入//www.域名.com/install)
3.同意使用合同步入下一步检查目录权限
4.检测通过后,填写常规数据库配置项,填写正确即可安装成功,安装成功后会手动步入后台页面//www.域名.com/admin,填写安装时输入的后台管理员和密码即可登入
5.在后台文章列表页面,可以进行自动采集文章,和批量采集文章数据。初次安装完毕建议采集一些数据填充网站内容。网站在运行过程中,会手动执行采集操作(需前台访问触发,蜘蛛亦可触发采集),无须人工干预。
YGBOOK小说采集系统 更新日志:
v1.4
增加了百度sitemap功能
安装1.4版本后,您的sitemap地址即为“//您的域名/home/sitemap/baidu.xml”
您将域名替换成自己的域名后,访问查看无误,即可递交到百度站长平台
利于百度蜘蛛的爬取
小说网站源码 697小说网源码 自动采集小说系统隆重推出 全手动无人值守采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2020-08-11 14:10
1、源码类型:整站源码
2、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
3、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
4、原创程序:织梦DEDECMS 5.7SP1
5、编码类型:GBK
6、可否采集:全手动采集,赠送三条规则
7、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
查看全部
源码编号:A70小说网站源码 697小说网源码 自动采集小说系统隆重推出 全手动无人值守采集,PC+手机
1、源码类型:整站源码
2、环境要求:PHP5.2/5.3/5.4/5.5+MYSQL5(URLrewrite)
3、服务器要求:建议用40G数据盘以上的VPS或则独立服务器,系统建议用Windows而不建议用Linux,99%的小说站服务器是用Windows系统,方便文件管理以及备份等(目前演示站空间使用情况:6.5G数据库+5G网页空间,经群内站友网站证实:4核CPU+4G显存的xen构架VPS能承受日5万IP、50万PV流量毫无压力,每天收入700元以上)
4、原创程序:织梦DEDECMS 5.7SP1
5、编码类型:GBK
6、可否采集:全手动采集,赠送三条规则
7、其他特征:
(1)自动生成首页、分类、目录、作者、排行榜、sitemap页面静态html。
(2)全站拼音目录化(可自定义URL格式),章节页面伪静态。
(3)支持下载功能,可以手动生成对应文本文件,可在文件中设置广告。
(4)自动生成关键词及关键词手动内链。
(5)自动伪原创成语替换(采集、输出时都可以替换)。
(6)配合CNZZ的统计插件,能便捷实现下载明细统计和被采集的明细统计等。
(7)本程序的手动采集并非市面上常见的优采云、关关、采集侠等,而是在DEDE原有采集功能的基础上二次开发的采集模块,可以有效的保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量能达到25~30万章节。
网站测试自动化系统—采集测试结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 529 次浏览 • 2020-08-10 11:01
一般来说,测试报告须要收录以下几个信息:
1. 测试用例的通过率,通过率代表产品的稳定程度,当然这是在排除了测试用例本身的问题导致的测试失败(Test Failure)得到的通过率。前面执行测试用例里提及到的MsTest.exe生成的结果文件.trx文件就早已保存了这个信息,在资源管理器上面双击这个文件,就能见到类似右图的结果:
在上图上面,可能会有悉心的读者发觉上面只有3个用例,但是红圈上面标出的文字却说:“6/6 passed”,这是因为这3个用例当中有数据驱动的用例,VSTT把每一行数据都当成一个独立的测试用例。关于数据驱动测试,可以参看我的这篇文章:网站自动化测试系统—数据驱动测试。
2. 代码覆盖率信息,代码覆盖率告诉测试团队有什么产品代码没有被覆盖到,没有覆盖到的产品代码意味着有一些用户场景我们没有考虑到,或者说测试覆盖面上有一些漏洞(Testing Hole)。如果是从VSTT用户界面上执行测试用例的话,VSTT早已手动集成了搜集代码覆盖率的功能,做法请参看我的文章软件自动化测试—代码覆盖率。在这篇文章里,我将告诉你怎样使用命令行做到搜集代码覆盖率。
至少有两种方式将搜集代码覆盖率的功能整合到自动化测试系统当中,一种是通过直接编辑.testrunconfig文件,这也是我们在VSTT用户界面操作时,VSTT背地里帮我们做的事情,使用.testrunconfig文件的方式请参考文章执行测试用例。
另外一种方式,是更深入的分解,实际上Visual Studio搜集代码覆盖率是通过一个称作VsPerfMon.exe的程序来搜集的,这个程序坐落C:\Program Files\Microsoft Visual Studio 9.0\Team Tools\Performance Tools(假设VSTT安装在磁盘)。当你根据软件自动化测试—代码覆盖率里介绍的步骤执行自动化测试的时侯,VSTT背地里做了下边几件事情:
1. 注入用于统计代码覆盖率的代码(instrument),注入的代码在文章软件自动化测试—代码覆盖率里早已有过讲解,这里不再说了。代码注入是通过vsinstr.exe来实现的,下面是使用它进行代码注入最简化的命令(接受任何.Net程序—即.dll和.exe文件,是否支持原生C++程序我还没有尝试过):
Vsinstr.exe –coverage image.dll
Vsinstr.exe不仅在程序上面注入代码以外,还要更改程序的符号文件(.pdb文件),之所以这样做,是因为程序被注入代码之后,就不和注入前的符号文件匹配了。使用不匹配的符号文件,将会造成前面浏览代码覆盖率结果时,我们没有办法查看详尽的代码覆盖信息—即什么行的代码被覆盖了,哪些代码没有覆盖。符号文件的作用请参考文章Visual Studio调试之符号文件。
如果要给网站 bin文件夹上面所有的程序执行代码注入操作的话,可以使用下边这个简单的命令来完成:
for %f in (*.dll) do vsinstr.exe –nowarn –coverage “%f”
for命令的用法,请查看Windows帮助文件上面的批处理一章;%f使用冒号括上去是防止%f代码的文件路径收录空格的情况;-nowarn这个参数告诉vsinstr不要输出警告信息了,因为懒得看, :)
2. 代码注入完成之后,启动vsperfmon.exe。在整个执行测试用例的过程中,vsperfmon.exe会在后台持续运行,采集代码覆盖率信息。你可能会奇怪,这个程序的名子如何称作perfmon?而不是使用哪些covermon之类的名子,这是因为vsperfmon.exe原本就是拿来做性能测试的,只不过是兼职搜集代码覆盖率罢了。
启动vsperfmon.exe的命令很简单:
vsperfmon.exe /START:COVERAGE /OUTPUT:result.coverage /CS
上面的参数解释一下:
参数
说明
/START:COVERAGE
告诉vsperfmon进行代码覆盖率的搜集。
/OUTPUT
保存结果的文件路径,可以是绝对路径或则相对路径,最好将后缀名设置为.coverage,这样你可以直接通过资源管理器上面双击在Visual studio中打开这个文件。
/CS
CS是CrossSession的缩写。
Session的意思有必要解释一下,Windows 从Windows 2000之后是一个多用户,多任务的操作系统(不知道NT是不是)。而Windows 95/98/Me不是多用户多任务操作系统,它们只是单用户多任务操作系统。多用户的意思是多个用户可以同时登陆同一台主机(通过远程登陆系统,mstsc.exe),操作系统会在这多个同时进行独立操作的用户当中执行有效的进程分离。虽然你可以在Windows 95/98/Me设置多个用户,但是这多个用户不能同时登陆同一台机器,必须要等另外一个用户注销(LogOff)才能登入这台机器。
每个用户登入到Windows操作系统时,Windows以Session(会话)的概念来描述它,一个用户可以有多个Session,例如这个用户可以从数学上直接登陆主机,这个Session称作Console Session;这个用户同时也可以通过远程登陆来操作这台主机,这又是另外一个Session。
之所以要在这里花很大的篇幅去描述Session,是因为假如我们在IIS上面启动网站时,IIS的应用程序池(Application Pool)需要你指定一个用户用于访问数据库、文件系统等资源,这个会话(Session)不会使用控制台会话(Console Session),因此一般来说,即使IIS的应用程序池使用的用户与当前执行测试用例的用户是同一个用户,也是在使用不同的会话。
在Windows Vista和Windows Server 2008之后,大部分Windows服务(当然也包括IIS提供的W3C服务)都是在第0会话(Session 0)当中运行,目的是为了更好地将Windows服务与其他进程分隔开来。而第一个登陆Windows Vista或Windows Server 2008的用户的会话标示号是1,而不像先前那样是0了。如下图所示:
在Vista之前,Windows服务(比如运行Asp.Net网站的IIS的W3C服务)和普通用户的进程(比如vsperfmon.exe)是运行在同一个会话里,两个进程之间交流消息只要用SendMessage或则PostMessage这个API就可以了。
但是在Vista以后,由于服务进程和普通用户进程不是在同一个会话里,所以就须要用命名管线(Named Pipeline)等IPC机制来执行交互了。/CS选项就是告诉vsperfmon.exe关注在其他会话里执行的进程的代码覆盖率信息。
3. 当所有的测试用例都执行完毕之后,VSTT关掉被测试的进程。因为在搜集代码覆盖率信息时,vsperfmon是和被统计的进程直接进行交互的;在保存覆盖率信息时,它须要等被搜集的进程关掉之后,才能执行保存操作。如果测试时,你的网站是运行在IIS里的,你须要使用下边的命令关掉IIS:
iisreset /stop
(启动iis的命令时iisreset /start)
如果你没有安装IIS,但是你会发觉在VSTS直接按下F5运行网站时,网站照样能运行,那是因为VSTS自带了一个支持Asp.Net的Web服务器WebDev.WebServer.EXE。这个程序保存在文件夹C:\Program Files\Common Files\microsoft shared\DevServer\9.0(假设你的系统盘是C,并且安装的是VSTS 2008版本)里面。
当你在VSTS上面运行网站的时侯,Visual Studio采用下边的命令启动网站:
Webdev.webserver /path: /port: /vpath:/
如果是使用webdev.webserver运行网站的话,在命令行关掉这个程序的命令是(实际上是杀死这个程序):
taskkill /im WebDev.WebServer.EXE
4. VSTT执行下边的命令关掉vsperfmon.exe,vsperfmon.exe将采集到的代码覆盖率保存到指定的文件当中。
vsperfmon.exe /shutdown
备注:vsperfmon.exe默认情况下只能搜集同一个用户运行的进程的代码覆盖率信息,如果你是将网站放在iis上面进行测试,默认情况下,运行这个网站的应用程序池(application pool)的用户是NetworkService,这种情况下,要么用vsperfmon.exe的/USER选项指定NetworkService这个用户。要么将应用程序池的用户改成执行vsperfmon.exe的那种用户。 查看全部
在后面的文章执行测试用例里,已经解释了怎样通过命令行来编译和执行测试用例,这样我们才有机会通过批处理的方法来将执行测试用例自动化。而我在文章系统应当有的功能里,也提到了一个完整的自动化系统应当是能否手动搜集测试结果的—毕竟我们的远景是,测试人员在夜晚上班前将用例执行上去,然后在第二天上午就可以直接看测试报告了。
一般来说,测试报告须要收录以下几个信息:
1. 测试用例的通过率,通过率代表产品的稳定程度,当然这是在排除了测试用例本身的问题导致的测试失败(Test Failure)得到的通过率。前面执行测试用例里提及到的MsTest.exe生成的结果文件.trx文件就早已保存了这个信息,在资源管理器上面双击这个文件,就能见到类似右图的结果:
在上图上面,可能会有悉心的读者发觉上面只有3个用例,但是红圈上面标出的文字却说:“6/6 passed”,这是因为这3个用例当中有数据驱动的用例,VSTT把每一行数据都当成一个独立的测试用例。关于数据驱动测试,可以参看我的这篇文章:网站自动化测试系统—数据驱动测试。
2. 代码覆盖率信息,代码覆盖率告诉测试团队有什么产品代码没有被覆盖到,没有覆盖到的产品代码意味着有一些用户场景我们没有考虑到,或者说测试覆盖面上有一些漏洞(Testing Hole)。如果是从VSTT用户界面上执行测试用例的话,VSTT早已手动集成了搜集代码覆盖率的功能,做法请参看我的文章软件自动化测试—代码覆盖率。在这篇文章里,我将告诉你怎样使用命令行做到搜集代码覆盖率。
至少有两种方式将搜集代码覆盖率的功能整合到自动化测试系统当中,一种是通过直接编辑.testrunconfig文件,这也是我们在VSTT用户界面操作时,VSTT背地里帮我们做的事情,使用.testrunconfig文件的方式请参考文章执行测试用例。
另外一种方式,是更深入的分解,实际上Visual Studio搜集代码覆盖率是通过一个称作VsPerfMon.exe的程序来搜集的,这个程序坐落C:\Program Files\Microsoft Visual Studio 9.0\Team Tools\Performance Tools(假设VSTT安装在磁盘)。当你根据软件自动化测试—代码覆盖率里介绍的步骤执行自动化测试的时侯,VSTT背地里做了下边几件事情:
1. 注入用于统计代码覆盖率的代码(instrument),注入的代码在文章软件自动化测试—代码覆盖率里早已有过讲解,这里不再说了。代码注入是通过vsinstr.exe来实现的,下面是使用它进行代码注入最简化的命令(接受任何.Net程序—即.dll和.exe文件,是否支持原生C++程序我还没有尝试过):
Vsinstr.exe –coverage image.dll
Vsinstr.exe不仅在程序上面注入代码以外,还要更改程序的符号文件(.pdb文件),之所以这样做,是因为程序被注入代码之后,就不和注入前的符号文件匹配了。使用不匹配的符号文件,将会造成前面浏览代码覆盖率结果时,我们没有办法查看详尽的代码覆盖信息—即什么行的代码被覆盖了,哪些代码没有覆盖。符号文件的作用请参考文章Visual Studio调试之符号文件。
如果要给网站 bin文件夹上面所有的程序执行代码注入操作的话,可以使用下边这个简单的命令来完成:
for %f in (*.dll) do vsinstr.exe –nowarn –coverage “%f”
for命令的用法,请查看Windows帮助文件上面的批处理一章;%f使用冒号括上去是防止%f代码的文件路径收录空格的情况;-nowarn这个参数告诉vsinstr不要输出警告信息了,因为懒得看, :)
2. 代码注入完成之后,启动vsperfmon.exe。在整个执行测试用例的过程中,vsperfmon.exe会在后台持续运行,采集代码覆盖率信息。你可能会奇怪,这个程序的名子如何称作perfmon?而不是使用哪些covermon之类的名子,这是因为vsperfmon.exe原本就是拿来做性能测试的,只不过是兼职搜集代码覆盖率罢了。
启动vsperfmon.exe的命令很简单:
vsperfmon.exe /START:COVERAGE /OUTPUT:result.coverage /CS
上面的参数解释一下:
参数
说明
/START:COVERAGE
告诉vsperfmon进行代码覆盖率的搜集。
/OUTPUT
保存结果的文件路径,可以是绝对路径或则相对路径,最好将后缀名设置为.coverage,这样你可以直接通过资源管理器上面双击在Visual studio中打开这个文件。
/CS
CS是CrossSession的缩写。
Session的意思有必要解释一下,Windows 从Windows 2000之后是一个多用户,多任务的操作系统(不知道NT是不是)。而Windows 95/98/Me不是多用户多任务操作系统,它们只是单用户多任务操作系统。多用户的意思是多个用户可以同时登陆同一台主机(通过远程登陆系统,mstsc.exe),操作系统会在这多个同时进行独立操作的用户当中执行有效的进程分离。虽然你可以在Windows 95/98/Me设置多个用户,但是这多个用户不能同时登陆同一台机器,必须要等另外一个用户注销(LogOff)才能登入这台机器。
每个用户登入到Windows操作系统时,Windows以Session(会话)的概念来描述它,一个用户可以有多个Session,例如这个用户可以从数学上直接登陆主机,这个Session称作Console Session;这个用户同时也可以通过远程登陆来操作这台主机,这又是另外一个Session。
之所以要在这里花很大的篇幅去描述Session,是因为假如我们在IIS上面启动网站时,IIS的应用程序池(Application Pool)需要你指定一个用户用于访问数据库、文件系统等资源,这个会话(Session)不会使用控制台会话(Console Session),因此一般来说,即使IIS的应用程序池使用的用户与当前执行测试用例的用户是同一个用户,也是在使用不同的会话。
在Windows Vista和Windows Server 2008之后,大部分Windows服务(当然也包括IIS提供的W3C服务)都是在第0会话(Session 0)当中运行,目的是为了更好地将Windows服务与其他进程分隔开来。而第一个登陆Windows Vista或Windows Server 2008的用户的会话标示号是1,而不像先前那样是0了。如下图所示:
在Vista之前,Windows服务(比如运行Asp.Net网站的IIS的W3C服务)和普通用户的进程(比如vsperfmon.exe)是运行在同一个会话里,两个进程之间交流消息只要用SendMessage或则PostMessage这个API就可以了。
但是在Vista以后,由于服务进程和普通用户进程不是在同一个会话里,所以就须要用命名管线(Named Pipeline)等IPC机制来执行交互了。/CS选项就是告诉vsperfmon.exe关注在其他会话里执行的进程的代码覆盖率信息。
3. 当所有的测试用例都执行完毕之后,VSTT关掉被测试的进程。因为在搜集代码覆盖率信息时,vsperfmon是和被统计的进程直接进行交互的;在保存覆盖率信息时,它须要等被搜集的进程关掉之后,才能执行保存操作。如果测试时,你的网站是运行在IIS里的,你须要使用下边的命令关掉IIS:
iisreset /stop
(启动iis的命令时iisreset /start)
如果你没有安装IIS,但是你会发觉在VSTS直接按下F5运行网站时,网站照样能运行,那是因为VSTS自带了一个支持Asp.Net的Web服务器WebDev.WebServer.EXE。这个程序保存在文件夹C:\Program Files\Common Files\microsoft shared\DevServer\9.0(假设你的系统盘是C,并且安装的是VSTS 2008版本)里面。
当你在VSTS上面运行网站的时侯,Visual Studio采用下边的命令启动网站:
Webdev.webserver /path: /port: /vpath:/
如果是使用webdev.webserver运行网站的话,在命令行关掉这个程序的命令是(实际上是杀死这个程序):
taskkill /im WebDev.WebServer.EXE
4. VSTT执行下边的命令关掉vsperfmon.exe,vsperfmon.exe将采集到的代码覆盖率保存到指定的文件当中。
vsperfmon.exe /shutdown
备注:vsperfmon.exe默认情况下只能搜集同一个用户运行的进程的代码覆盖率信息,如果你是将网站放在iis上面进行测试,默认情况下,运行这个网站的应用程序池(application pool)的用户是NetworkService,这种情况下,要么用vsperfmon.exe的/USER选项指定NetworkService这个用户。要么将应用程序池的用户改成执行vsperfmon.exe的那种用户。
网上新闻资源手动采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-10 09:26
采集的困 联程度要略高与WAP 网站。因WWW 网站面内容相 而且 更加丰富,最重要的是它没有似XML 在抓取的候可能会遇到好多解析 比如符号的失,不能匹配等等, 于采集系 重要的是能匹配到想要抓取的内容,如果不能 不能构建完整的目,也就是 构不完整将太可能导致我 在采集特定内容的 偏差或则采集不成功。所以,于采集WWW的网站不光须要采集程序的 面。但是,在的情况是常常用 大量的,所以会 真正的 一个的讯号 自己的面没有 范,如果出不能匹配 是个好消息,将大大的增加 的成本,加快 目的提出也奠定了一定的基。当然,随着手机上网的普及和 3G 手机来取信息, 一个,可能在未来 代替有的 抓住个方式,将要 基于手机器平台的 内容,我 采集的 象也是WAP 嵌入到有的 目中,真正 即抓即用。 研究的基本内容,解决的主要 采集系的运行 程是个依据任 列表不断 候须要一个 面订制一套,用来解析 附加参数:内容的地址附加的一些参数(比如: 示全文) 用于替列表中不需要的字符 条目(收录:接和地址) :用于文章内容的 :用于文章内容的 片的采集不同与新的采集, 而且在整个抓取程中的操作都接近相同,但 是在格式上要。
文字主要是存在 在网上抓取到 片以后下 到本地须要保持格式的一致性。 由于JPG和GIF 的配置是整个系中最重要的部份,新 采集 能正常工作的首要前提就是须要个采集任 配置包括有目地址以及 ,力求可以将用的文本定 表达式,以保采集内容的正确性。 采集的程主要是剖析 源,并加入到我 正确和程的透明性。 需要采集 可以采集的 掌握采集源的状况,如果 研究、方法及举措 程序的运行和须要一系列的配置, 于整个 都是至重要的。配置人 需要一定的 可能在不同的数据境中来使 用,所以我了数据 框架, 将大大便捷系 数据等情况。系 中使用了ibatis 也是一个源的框架,相 于hibernate 一个采集目都是 由于网的不确定诱因特别多,常常会 致程序出 需要一个大的日志系 也须要剖析日志来判定的缘由。 有一个建立的机制,用以 。如果须要制订效考核方 将会提供一份完整的可性的文档。 ,可以取当前入 管理可以 内容 管理系的后台,可以 抓取的信息 行有效的控制。 采集系构架 08/12/11-09/01/1210. 背景11.2 12. 09/01/13-09/02/19 13. 15.09/02/20-09/02/27 16. 18.09/02/28-09/03/15 19. 21.09/03/16-09/04/03 22. 完成程序23. 24.09/04/04-09/04/10 25. 中期26. 27.09/04/11-09/05/01 28. 完成相文档 30.09/05/02-09/05/22 31. 撰写文定稿 32. 33.09/05/23-09/05/29 34. 35.10 36. 09/05/30-09/06/05 37. 38.主要参考文献 QuickStart[EB/OL]. ml HttpclientUser Documentation.[EB/OL]. JavaUser Guide.[EB/OL]. 人民出版社 型手册》委会 O’ReillyJava 系列 Java联程思想(第4 机械工出版社 EffectiveJava 机械工出版社 2007-6-110. 中国道出版社 同学就网上新 源自 采集系 性的文献、分析和理解,基本明晰了本 体需求和具体任,基本提出了系 思想 告内容完整,内容和格式基本符合要求。
.完善后通;3.未通 杭州子科技大学 采集系以其高效和低廉的成本仍然遭到太 个信息爆燃的代,能及 是一个用,但是互 采集的主要工作不在采集的 的管理以及内容的分。主要 程,数据程以及正 表达式的 程的能力是评判一个程序能力的重要 下,能将系的性能全部 出来须要程序 充分的 使用无疑能提升程序的行效率和提供更好的用 生以来,一革命性的技 世界 来翻天覆地的 化,不能想像假如没有网 提出,未来的所有用可能 无非是十分考JAVA 表达式的史可以溯源到十九世 四十年代, 算机科学和自控制理 和方式 述或则匹配一系列符合某个复句的字符串的 个字符串。一 表达式一般被称一个模式,用来匹配一 系列符合某个复句的字符串。在好多文本 它工具里,正表达式一般被拿来 的文本内容。多程序 言都支持借助正 表达式 大概就可以了解到,正抒发 式是拿来理字符串用的,而且它的使用十分便捷和广泛。[3] 多少听起来有些和晦涩,但是在我 的日常生 中会太不意的须要使用它。比如在 常会有找符合个别 的字符 候就须要正表达式了。正如我 想要 一个新采集系 ,那第一 就是须要将目 面解析 将文档化,并根据我 正确无的提取我 需要的数据,如果没有正 起来肯定会相当的困。
另外, 一个 的反例。可能你在 WINDOWS 或者DOS 平台下找文件, 里会提及一个通配 字符,而星号拿来匹配任意 度的字符串。其 如果想正确的使用正表达式来 工作 来便利和减 :匹配任何个字符, 是它只能匹配 个字符。 :匹配入字符串的 束位置。 :匹配入字符串的 始位置。 “*”:匹配上面的子表达式零次或多次。 但是它匹配最少一次。 字符,即将下一个字符特殊字符或一个原 字符。 “[]”:匹配收录在括弧中的任意字符。 “x|y”:匹配X或则Y中的一个字符。 “?”:匹配零个或一个刚好在它之前的字符。 :匹配制订数量的字符,些字符是定 在此表达式之前的。[5] 非常广泛,在我一些WEB 用程序的候须要 繁的使用到它。比如我需要 提交和入的数据做一 就可以在客端使用JAVASCRIPT 做可以来好多的好 。一是在客 数据的安全性,网本身是不安全的,我 需要 入的数据行限制, 程序来未能 料的后果, 件的格式,一功能 使用正表达式来提取网 文档中的元素。在我 行剖析和解,找出我 需要的 具体内容,比如文章的,作者,内容和附 等等, 些内容的提 正是它的大指强 出,就是文本的操控。如果没有 些特点,我 需要做大量的判定以确保我找到的数据即将我 需要的, 往往的方式不是万能可靠的,而正 表达式正 点。
另外我一般也会碰到 ,当我须要 入大量数据的 格式不是我想要的,一般情况下我 会使用正 达式来解析些数据, 其根据我 定的格式来排列, 程只要我好正 表达式,如果 采集系中使用MYSQL 数据,MYSQL 管理系,它的主要特征是体 小,速度快, 一特征,在多中小型网站中 了增加网站的成本而 网站数据。MYSQL 中也支持正表达式在, 一特点可以和使用者 来特别大的便利和挺好 数据再通后台 理的方式在效率上一定没有在数 中直接要高,而且可以愈发明晰 和数 据存取的功能次,也增加了一定程度上的耦合。MYSQL 表达式的格式SELECT 字符串REGEXP 如果你有一定的正表达式 那你将可以很快的把握在MYSQL 达式一技能。 就是正 表达式 来的便利。[7] 采集系的使用是非常广泛的。想 一个 的事情,特是须要考 的情况。同你须要把握多 天气前提是你必 熟悉各个方面的特性以及其中 采集系的效率始 也是评判系 性能的一 个重要指,在相同的硬件 境下,如果采用多 可以正常的工作。《Athread monitoring system multithreadedJava programs 》一文中推荐了一使用 器起到一个管理的作用,是一个 得推荐的方式。
核心技卷II 机械工出版社 2008-12-1 SOCKET-BasedNetwork Programing 基于正表达式技 的数据 科技横>>2006 WebpageCleaning System Exploiting Static Regular Expression 杜冬梅,联彩欣, RegularExpression Websystem 算机系用>>2007 人民出版社 2006-12-1 Chang,BM threadmonitoring system multithreadedJava programs SIGPLANNotices 2006 vol.41(no.5) 刘邦桂,李正凡,LIUBang-gui,LI Zheng-fan SocketStream Communication EASTCHINA JIAOTONG UNIVERSITY 卷(期):2007 24(5) 10. Xing Bo PERFORMANCEPROMOTION DATABASERETRIEVAL COMPUTERAPPLICATIONS 200724(12) 11. 瓦特 2008-10-112. 佛瑞德(Friedl,J.E.F. 精通正表达式(第3 2007-7-113. 中国力出版社 文献述考核表 同学网上新 源自 采集系 文献行了适当的理 解剖析和整理,完成的文献 杭州子科技大学 文)外文文献翻HTTP 文件的相信息 联个文件是从HttpClient 里所表示的概念同地适用于HttpComponents,或是SUN的 HttpURLConnectiong, 又或是其它任何程序 即使你不在使用Java和HttpClient, 得它很有用。
警告 可以在任何刻被重新 同的文件,器都会 示新的内容。 送信息。个HTTP 是来历自服器的新文件所特定的。如果你的 只是模仿器的将会被终止。 如果你想行一个可靠的 用程序,你只能用这些 已公布的用程序 接口中。比如 商索要POP或则IMAP 搜索一下来自供商的RSS feed 用程序。HTTP Client HttpClient 联行HTTP 求。既然HttpClient没有与 文件那述内容,那 它就不允 的运行中可以允一些 ,但是它 HttpClient 可以理的误差是有限定的。 部分介了一些必 了解的重要的 助我了解 个文件剩下来的部份。 HTTP信息 由一个和一个任意的 形式的信息,求和回 第一行的形不同,但 都有一个部份和一个任意的 体部份。 HTTP毕求 送的缘由--URI 行的一个程序。HTTP 它的第一行包括一个数据,它表明了 求的成功或失 。HTTP 联联了一系列的数据代 联,像200 表示成功的代和404 个表示未找到的代。其它构建在HTTP 查看全部
随着互网技 的迅猛 或者。更多的人 上网 或者是 手机取。相比上面的两 方式,后者更具 量的工作人来支撑,本文将通 源采集系 构建一个低成本的信息共享平台提供建 可以愈发松的更新站点的内容信息。 采集系也在哪个 版本到在的多样化 言的版本, 采集来降低人工入所降低的成本。 如今,新采集系 非常成熟。市的需求量也十分大。在百度中 采集系可以搜到逾393,000 是一些新的站点,主要以广告赢利 目的,如果使用新 采集系 那可以 不用去操劳怎么更新网站内容,一但架好就几乎可以 或者小型的网站,都 的成本。新采集系 (手机 用版)用于在 采集和源的共享。 一方面可以保信息更及 更有效,另一方面可以 主流系的剖析 目前的新采集系 采集系基本上可以 以下功能: 网站行信息自 抓取,支持HTML 数据的采集,如文本信息,URL 信息自定来源与分 支持惟一索引,避免相同信息重 支持智能替功能,可以将内容中嵌入的所有的无 部分如广告消除 支持多面文章内容自 抽取与合并 数据直接入数据 而不是文件中,因此与借助 些数据的网站程序或则桌面程序之没有任何耦合 构完全自定,充分利用 信息的完整性与准确性,不会出 支持各主流数据 ,如MSSQL、Access、MySQL、Oracle、DB2、Sybase 采集系与本文所 的略有不同, 采集系都是基于WWW网站。
采集的困 联程度要略高与WAP 网站。因WWW 网站面内容相 而且 更加丰富,最重要的是它没有似XML 在抓取的候可能会遇到好多解析 比如符号的失,不能匹配等等, 于采集系 重要的是能匹配到想要抓取的内容,如果不能 不能构建完整的目,也就是 构不完整将太可能导致我 在采集特定内容的 偏差或则采集不成功。所以,于采集WWW的网站不光须要采集程序的 面。但是,在的情况是常常用 大量的,所以会 真正的 一个的讯号 自己的面没有 范,如果出不能匹配 是个好消息,将大大的增加 的成本,加快 目的提出也奠定了一定的基。当然,随着手机上网的普及和 3G 手机来取信息, 一个,可能在未来 代替有的 抓住个方式,将要 基于手机器平台的 内容,我 采集的 象也是WAP 嵌入到有的 目中,真正 即抓即用。 研究的基本内容,解决的主要 采集系的运行 程是个依据任 列表不断 候须要一个 面订制一套,用来解析 附加参数:内容的地址附加的一些参数(比如: 示全文) 用于替列表中不需要的字符 条目(收录:接和地址) :用于文章内容的 :用于文章内容的 片的采集不同与新的采集, 而且在整个抓取程中的操作都接近相同,但 是在格式上要。
文字主要是存在 在网上抓取到 片以后下 到本地须要保持格式的一致性。 由于JPG和GIF 的配置是整个系中最重要的部份,新 采集 能正常工作的首要前提就是须要个采集任 配置包括有目地址以及 ,力求可以将用的文本定 表达式,以保采集内容的正确性。 采集的程主要是剖析 源,并加入到我 正确和程的透明性。 需要采集 可以采集的 掌握采集源的状况,如果 研究、方法及举措 程序的运行和须要一系列的配置, 于整个 都是至重要的。配置人 需要一定的 可能在不同的数据境中来使 用,所以我了数据 框架, 将大大便捷系 数据等情况。系 中使用了ibatis 也是一个源的框架,相 于hibernate 一个采集目都是 由于网的不确定诱因特别多,常常会 致程序出 需要一个大的日志系 也须要剖析日志来判定的缘由。 有一个建立的机制,用以 。如果须要制订效考核方 将会提供一份完整的可性的文档。 ,可以取当前入 管理可以 内容 管理系的后台,可以 抓取的信息 行有效的控制。 采集系构架 08/12/11-09/01/1210. 背景11.2 12. 09/01/13-09/02/19 13. 15.09/02/20-09/02/27 16. 18.09/02/28-09/03/15 19. 21.09/03/16-09/04/03 22. 完成程序23. 24.09/04/04-09/04/10 25. 中期26. 27.09/04/11-09/05/01 28. 完成相文档 30.09/05/02-09/05/22 31. 撰写文定稿 32. 33.09/05/23-09/05/29 34. 35.10 36. 09/05/30-09/06/05 37. 38.主要参考文献 QuickStart[EB/OL]. ml HttpclientUser Documentation.[EB/OL]. JavaUser Guide.[EB/OL]. 人民出版社 型手册》委会 O’ReillyJava 系列 Java联程思想(第4 机械工出版社 EffectiveJava 机械工出版社 2007-6-110. 中国道出版社 同学就网上新 源自 采集系 性的文献、分析和理解,基本明晰了本 体需求和具体任,基本提出了系 思想 告内容完整,内容和格式基本符合要求。
.完善后通;3.未通 杭州子科技大学 采集系以其高效和低廉的成本仍然遭到太 个信息爆燃的代,能及 是一个用,但是互 采集的主要工作不在采集的 的管理以及内容的分。主要 程,数据程以及正 表达式的 程的能力是评判一个程序能力的重要 下,能将系的性能全部 出来须要程序 充分的 使用无疑能提升程序的行效率和提供更好的用 生以来,一革命性的技 世界 来翻天覆地的 化,不能想像假如没有网 提出,未来的所有用可能 无非是十分考JAVA 表达式的史可以溯源到十九世 四十年代, 算机科学和自控制理 和方式 述或则匹配一系列符合某个复句的字符串的 个字符串。一 表达式一般被称一个模式,用来匹配一 系列符合某个复句的字符串。在好多文本 它工具里,正表达式一般被拿来 的文本内容。多程序 言都支持借助正 表达式 大概就可以了解到,正抒发 式是拿来理字符串用的,而且它的使用十分便捷和广泛。[3] 多少听起来有些和晦涩,但是在我 的日常生 中会太不意的须要使用它。比如在 常会有找符合个别 的字符 候就须要正表达式了。正如我 想要 一个新采集系 ,那第一 就是须要将目 面解析 将文档化,并根据我 正确无的提取我 需要的数据,如果没有正 起来肯定会相当的困。
另外, 一个 的反例。可能你在 WINDOWS 或者DOS 平台下找文件, 里会提及一个通配 字符,而星号拿来匹配任意 度的字符串。其 如果想正确的使用正表达式来 工作 来便利和减 :匹配任何个字符, 是它只能匹配 个字符。 :匹配入字符串的 束位置。 :匹配入字符串的 始位置。 “*”:匹配上面的子表达式零次或多次。 但是它匹配最少一次。 字符,即将下一个字符特殊字符或一个原 字符。 “[]”:匹配收录在括弧中的任意字符。 “x|y”:匹配X或则Y中的一个字符。 “?”:匹配零个或一个刚好在它之前的字符。 :匹配制订数量的字符,些字符是定 在此表达式之前的。[5] 非常广泛,在我一些WEB 用程序的候须要 繁的使用到它。比如我需要 提交和入的数据做一 就可以在客端使用JAVASCRIPT 做可以来好多的好 。一是在客 数据的安全性,网本身是不安全的,我 需要 入的数据行限制, 程序来未能 料的后果, 件的格式,一功能 使用正表达式来提取网 文档中的元素。在我 行剖析和解,找出我 需要的 具体内容,比如文章的,作者,内容和附 等等, 些内容的提 正是它的大指强 出,就是文本的操控。如果没有 些特点,我 需要做大量的判定以确保我找到的数据即将我 需要的, 往往的方式不是万能可靠的,而正 表达式正 点。
另外我一般也会碰到 ,当我须要 入大量数据的 格式不是我想要的,一般情况下我 会使用正 达式来解析些数据, 其根据我 定的格式来排列, 程只要我好正 表达式,如果 采集系中使用MYSQL 数据,MYSQL 管理系,它的主要特征是体 小,速度快, 一特征,在多中小型网站中 了增加网站的成本而 网站数据。MYSQL 中也支持正表达式在, 一特点可以和使用者 来特别大的便利和挺好 数据再通后台 理的方式在效率上一定没有在数 中直接要高,而且可以愈发明晰 和数 据存取的功能次,也增加了一定程度上的耦合。MYSQL 表达式的格式SELECT 字符串REGEXP 如果你有一定的正表达式 那你将可以很快的把握在MYSQL 达式一技能。 就是正 表达式 来的便利。[7] 采集系的使用是非常广泛的。想 一个 的事情,特是须要考 的情况。同你须要把握多 天气前提是你必 熟悉各个方面的特性以及其中 采集系的效率始 也是评判系 性能的一 个重要指,在相同的硬件 境下,如果采用多 可以正常的工作。《Athread monitoring system multithreadedJava programs 》一文中推荐了一使用 器起到一个管理的作用,是一个 得推荐的方式。
核心技卷II 机械工出版社 2008-12-1 SOCKET-BasedNetwork Programing 基于正表达式技 的数据 科技横>>2006 WebpageCleaning System Exploiting Static Regular Expression 杜冬梅,联彩欣, RegularExpression Websystem 算机系用>>2007 人民出版社 2006-12-1 Chang,BM threadmonitoring system multithreadedJava programs SIGPLANNotices 2006 vol.41(no.5) 刘邦桂,李正凡,LIUBang-gui,LI Zheng-fan SocketStream Communication EASTCHINA JIAOTONG UNIVERSITY 卷(期):2007 24(5) 10. Xing Bo PERFORMANCEPROMOTION DATABASERETRIEVAL COMPUTERAPPLICATIONS 200724(12) 11. 瓦特 2008-10-112. 佛瑞德(Friedl,J.E.F. 精通正表达式(第3 2007-7-113. 中国力出版社 文献述考核表 同学网上新 源自 采集系 文献行了适当的理 解剖析和整理,完成的文献 杭州子科技大学 文)外文文献翻HTTP 文件的相信息 联个文件是从HttpClient 里所表示的概念同地适用于HttpComponents,或是SUN的 HttpURLConnectiong, 又或是其它任何程序 即使你不在使用Java和HttpClient, 得它很有用。
警告 可以在任何刻被重新 同的文件,器都会 示新的内容。 送信息。个HTTP 是来历自服器的新文件所特定的。如果你的 只是模仿器的将会被终止。 如果你想行一个可靠的 用程序,你只能用这些 已公布的用程序 接口中。比如 商索要POP或则IMAP 搜索一下来自供商的RSS feed 用程序。HTTP Client HttpClient 联行HTTP 求。既然HttpClient没有与 文件那述内容,那 它就不允 的运行中可以允一些 ,但是它 HttpClient 可以理的误差是有限定的。 部分介了一些必 了解的重要的 助我了解 个文件剩下来的部份。 HTTP信息 由一个和一个任意的 形式的信息,求和回 第一行的形不同,但 都有一个部份和一个任意的 体部份。 HTTP毕求 送的缘由--URI 行的一个程序。HTTP 它的第一行包括一个数据,它表明了 求的成功或失 。HTTP 联联了一系列的数据代 联,像200 表示成功的代和404 个表示未找到的代。其它构建在HTTP
优采云网路信息手动采集系统2016官方下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2020-08-09 17:05
它与其他采集系统的优势在于:
A、 理论上可采集任何网站的信息,实现“想采就采”。由于信息来源网站的结构各不相同,目前市面上大多数采集系统均只绑定了某一家或几家网站的资源(同种模板的网站)进行采集,如果须要指定其他模板的网站,则需再度付费进行订制;“网络信息手动采集系统”模块化的方法,将采集信息须要的方式进行封装,并以广大站长熟悉的脚本语言为插口诠释下来,您只须要短短的几十行代码,即可实现一个新类型网站的采集工作。如果您不懂编程也不要紧,您可以直接使用预设的采集/发布向导工具,通过简单的设置参数实现一定类型模板网站的采集。而且“网络信息手动采集系统”还支持项目保存、共享,您可以从我们的网站下载其他用户上传的采集方案,来实现诸多网站的采集、发布工作。
B、 同样的,理论上可以发布采集到的信息到任何类型的您的网站。目前市面上其他的采集系统,要么不支持发布采集的信息,要么只能发布到某一种模板的网站上。“网络信息手动采集系统”采用递交表单的形式发布信息,FTP传输方法发布文件,模拟了您的自动发布过程,因此只要您在网站上放置一个表单接受页面,即可将信息发布到任何类型的网站上。同时我们也提供小型网站(如动易等)的发布页面,您可以直接使用。
C、 价格优势,这是最不用声明的优势,请诸位用户自行对比市面上的同类产品。 查看全部
网络信息手动采集系统(优采云)是一款面向大型网站站长、网站编辑的以采集网络信息,并发布到自己网站为天职的共享软件。
它与其他采集系统的优势在于:
A、 理论上可采集任何网站的信息,实现“想采就采”。由于信息来源网站的结构各不相同,目前市面上大多数采集系统均只绑定了某一家或几家网站的资源(同种模板的网站)进行采集,如果须要指定其他模板的网站,则需再度付费进行订制;“网络信息手动采集系统”模块化的方法,将采集信息须要的方式进行封装,并以广大站长熟悉的脚本语言为插口诠释下来,您只须要短短的几十行代码,即可实现一个新类型网站的采集工作。如果您不懂编程也不要紧,您可以直接使用预设的采集/发布向导工具,通过简单的设置参数实现一定类型模板网站的采集。而且“网络信息手动采集系统”还支持项目保存、共享,您可以从我们的网站下载其他用户上传的采集方案,来实现诸多网站的采集、发布工作。
B、 同样的,理论上可以发布采集到的信息到任何类型的您的网站。目前市面上其他的采集系统,要么不支持发布采集的信息,要么只能发布到某一种模板的网站上。“网络信息手动采集系统”采用递交表单的形式发布信息,FTP传输方法发布文件,模拟了您的自动发布过程,因此只要您在网站上放置一个表单接受页面,即可将信息发布到任何类型的网站上。同时我们也提供小型网站(如动易等)的发布页面,您可以直接使用。
C、 价格优势,这是最不用声明的优势,请诸位用户自行对比市面上的同类产品。
优采云网钛发布插口|网钛文章管理系统采集代写|网钛CMS发布插口
采集交流 • 优采云 发表了文章 • 0 个评论 • 599 次浏览 • 2020-08-09 16:05
网钛文章管理系统(OTCMS)以简单、实用、傻瓜式操作而著称,是国外最热门ASP开源网站管理系统之一,也是用户增速最快的ASP类CMS系统之一,目前的版本无论在功能,人性化,还是易用性方面,都有了长足的发展,OTCMS的主要目标用户锁定在草根型中小个人站长,让这些对网路不是太熟悉,对网站建设不是太懂又想做网站的人可以很快搭建起一个功能实用又强悍,操作人性又易用。OTCMS更专注于个人网站或中小型门户的建立,当然也不乏有企业用户等在使用本系统,使用过OTCMS的用户就会它好评不断。
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。
雨过天晴工作室提供优采云网钛发布插口及网钛文章管理系统采集代写
该插口为免登录插口,上传好文件,配置好规则和插口就可以马上采集发布,效果很好!
如果你是菜鸟,我可以直接将配置好的优采云软件带采集规则和发布插口一起发你,你可以直接采集发布
如果你是大神,可以只要求发插口文件和发布模块,自己导出使用!
需要采集规则代写和优采云采集发布插口 采集规则的同学都可以联系我!
规则编撰:1条10元,发布插口一个100元!
不成功不收费
特别说明: 查看全部
优采云网钛发布插口|网钛文章管理系统采集代写|网钛CMS发布插口otcms优采云发布插口
网钛文章管理系统(OTCMS)以简单、实用、傻瓜式操作而著称,是国外最热门ASP开源网站管理系统之一,也是用户增速最快的ASP类CMS系统之一,目前的版本无论在功能,人性化,还是易用性方面,都有了长足的发展,OTCMS的主要目标用户锁定在草根型中小个人站长,让这些对网路不是太熟悉,对网站建设不是太懂又想做网站的人可以很快搭建起一个功能实用又强悍,操作人性又易用。OTCMS更专注于个人网站或中小型门户的建立,当然也不乏有企业用户等在使用本系统,使用过OTCMS的用户就会它好评不断。
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。
雨过天晴工作室提供优采云网钛发布插口及网钛文章管理系统采集代写
该插口为免登录插口,上传好文件,配置好规则和插口就可以马上采集发布,效果很好!
如果你是菜鸟,我可以直接将配置好的优采云软件带采集规则和发布插口一起发你,你可以直接采集发布
如果你是大神,可以只要求发插口文件和发布模块,自己导出使用!
需要采集规则代写和优采云采集发布插口 采集规则的同学都可以联系我!
规则编撰:1条10元,发布插口一个100元!
不成功不收费
特别说明:
【python】打造一款手动扫描全网漏洞的扫描器
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2020-08-09 14:08
早在17年11月份的时侯就有这个看法,可是仍然没有去做,后来快到春节前几天才即将开始整个软件工程的设计。当时的想实现的功能比较简单,就是能做到无限采集到网站使用的CMS,比如www。xx。com使用的是DEDECMS,那么我就把www。xx。com|dedecms这样的数据存到数据库上面,如果上次dedecms爆出新的漏洞后,我能在第一时间内发觉什么网站存在这个漏洞。那么这个软件工程的核心功能就必须满足以下的需求。
能无限爬行采集互联网上存活的网址链接 能对采集到的链接进行扫描验证 Mysql数据库和服务器的负载均衡处理
当然若果只是只检查CMS类型之后保存到数据库肯定是不够的,这样简单的功能并没有多大的优势,于是我选择了加入下述漏洞的扫描验证。
添加备份文件扫描功能 添加SVN/GIT/源码泄露扫描功能,其中包括webinfo信息扫描 添加编辑器漏洞扫描功能 添加SQL注入漏洞的手动检查功能 添加使用Struts2框架的网站验证功能(居心叵测) 添加xss扫描检查功能(暂未实现) 添加扫描网站IP而且扫描危险端口功能 添加外链解析漏洞检查功能(暂未实现) 暂时想不到别的了,如果你有好的建议请联系我~ 结果展示
如图展示的都是扫描到的备份文件,敏感信息泄露,注入,cms类型辨识,st2框架,端口开放等等,挂机刷洞,基本上只要漏洞报告写得详尽一点,勤快多写点,都可以通过初审,刷洞小意思,刷排行之类的都不在 查看全部
这是一款和刘老师一起写的网安类别扫描器。基本原理是由Python+Mysql搭建的扫描器,实现手动无限永久爬行采集网站链接,自动化漏洞扫描检查。目的是挂机能够实现自动化开掘敏感情报,亦或是发觉网站的漏洞或则隐藏可借助的漏洞。
早在17年11月份的时侯就有这个看法,可是仍然没有去做,后来快到春节前几天才即将开始整个软件工程的设计。当时的想实现的功能比较简单,就是能做到无限采集到网站使用的CMS,比如www。xx。com使用的是DEDECMS,那么我就把www。xx。com|dedecms这样的数据存到数据库上面,如果上次dedecms爆出新的漏洞后,我能在第一时间内发觉什么网站存在这个漏洞。那么这个软件工程的核心功能就必须满足以下的需求。
能无限爬行采集互联网上存活的网址链接 能对采集到的链接进行扫描验证 Mysql数据库和服务器的负载均衡处理
当然若果只是只检查CMS类型之后保存到数据库肯定是不够的,这样简单的功能并没有多大的优势,于是我选择了加入下述漏洞的扫描验证。
添加备份文件扫描功能 添加SVN/GIT/源码泄露扫描功能,其中包括webinfo信息扫描 添加编辑器漏洞扫描功能 添加SQL注入漏洞的手动检查功能 添加使用Struts2框架的网站验证功能(居心叵测) 添加xss扫描检查功能(暂未实现) 添加扫描网站IP而且扫描危险端口功能 添加外链解析漏洞检查功能(暂未实现) 暂时想不到别的了,如果你有好的建议请联系我~ 结果展示
如图展示的都是扫描到的备份文件,敏感信息泄露,注入,cms类型辨识,st2框架,端口开放等等,挂机刷洞,基本上只要漏洞报告写得详尽一点,勤快多写点,都可以通过初审,刷洞小意思,刷排行之类的都不在
E客影片系统EKVOD免费下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2020-08-09 11:53
一键安装,一键采集,一键生成的PHP影片系统
01.支持所有主流FLV视频站及P2P
全面支持优酷,新浪,土豆,56,六间房,qq,youtube等flv资源,天线高清,新浪高清,土豆高清等高清flv采集!支持qvod【快播】,gvod【迅播】,pps,远古等高清资源,支持media,real,flv,swf等格式文件!更多支持的格式还在相继降低中。
02.丰富的模板及强悍易用的标签
独创的HTML方式的标签机制,使得做模板特别简单,只要你会HTML就可以制做精致的模板皮肤。自定义模板系统满足你个性化的需求,使你的网站更独具一格!自定义标签和IF标签等更是强悍!标签向导可以教你灵活的运用标签!
03.影视资源管理系统
系统外置的编辑器,使得添加电影介绍愈发得心应手为广大影片站长推动。资源管理系统可以便捷的添加,删除电影,设置推荐,设置专题,支持批量操作,支持无限极电影分类!后台添加更改电影集成web采集助手,支持youku、sina、tudou、天线、ku6、56、youtube、qq播客等数十个视频站的专辑及视频及高清大片的采集!
04.模板管理系统
先进的在线模板编辑系统,可以很方便的编辑模板文件!
05.网站地图系统
强大的网站地图可以便捷的生成google,百度,rss,有利于搜索引擎的快速收录,在最短的时间提高贵站的流量!
06.网页生成系统
网站运营模式可以在后台一键切换(php动态/HTML静态2中目录结构),一键生成全站、一键生成分类等等,让静态生成愈发智能,只需一次点击全部搞定,生成速率飞快、更快更节约资源。征对搜索引擎特点制做的多种生成路径方法。
07.广告管理系统
先进的广告管理系统打破传统模式,完全可以在线自定义广告内容,更方便添加!
08.友情链接系统
简单而实用的友情链接系统可以便捷的为您的网站添加图片链接,文字链接,各种式样可以通过标签完美的调出,并且运用!
09.管理员分级管理系统
独立开发的管理员管理系统,可以对管理员进行多个级别的分级,更能人性化的管理网站! 查看全部
EkVod影视系统是一套采用PHP+MYSQL数据库形式运行的全新且健全的强悍影视系统。
一键安装,一键采集,一键生成的PHP影片系统
01.支持所有主流FLV视频站及P2P
全面支持优酷,新浪,土豆,56,六间房,qq,youtube等flv资源,天线高清,新浪高清,土豆高清等高清flv采集!支持qvod【快播】,gvod【迅播】,pps,远古等高清资源,支持media,real,flv,swf等格式文件!更多支持的格式还在相继降低中。
02.丰富的模板及强悍易用的标签
独创的HTML方式的标签机制,使得做模板特别简单,只要你会HTML就可以制做精致的模板皮肤。自定义模板系统满足你个性化的需求,使你的网站更独具一格!自定义标签和IF标签等更是强悍!标签向导可以教你灵活的运用标签!
03.影视资源管理系统
系统外置的编辑器,使得添加电影介绍愈发得心应手为广大影片站长推动。资源管理系统可以便捷的添加,删除电影,设置推荐,设置专题,支持批量操作,支持无限极电影分类!后台添加更改电影集成web采集助手,支持youku、sina、tudou、天线、ku6、56、youtube、qq播客等数十个视频站的专辑及视频及高清大片的采集!
04.模板管理系统
先进的在线模板编辑系统,可以很方便的编辑模板文件!
05.网站地图系统
强大的网站地图可以便捷的生成google,百度,rss,有利于搜索引擎的快速收录,在最短的时间提高贵站的流量!
06.网页生成系统
网站运营模式可以在后台一键切换(php动态/HTML静态2中目录结构),一键生成全站、一键生成分类等等,让静态生成愈发智能,只需一次点击全部搞定,生成速率飞快、更快更节约资源。征对搜索引擎特点制做的多种生成路径方法。
07.广告管理系统
先进的广告管理系统打破传统模式,完全可以在线自定义广告内容,更方便添加!
08.友情链接系统
简单而实用的友情链接系统可以便捷的为您的网站添加图片链接,文字链接,各种式样可以通过标签完美的调出,并且运用!
09.管理员分级管理系统
独立开发的管理员管理系统,可以对管理员进行多个级别的分级,更能人性化的管理网站!
帝国CMS7.5模仿土豪漫画网站模板,具有手机和自动采集功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-08-08 21:39
漫画网站系统是使用Empire cms7.5开发的. 团队制定的具体细节尚不清楚. 由于程序+数据太大,因此尚未执行测试. 您需要自己测试源代码,因为漫画网站的源代码未知. 已经散发了多少手,因此,网站程序的安全性需要重点检查是否有后门.
漫画网站的源代码程序的安装说明:
1. 将程序上传到网站的根目录,该过程与普通的Empire安装过程相同.
2. 安装完成后,登录网站后台以还原漫画和网站模板数据. 后台的登录帐户为管理员密码admin888
3. 从右到左生成和更新网站缓存的顺序,单击以全部生成;
4. 找到系统设置→展开变量→用您自己的信息全部替换
5. 修改系统文件\ m \ e \ config并找到$ ecms_config ['sets'] ['txtpath'] ='D: // manhua / d / txt /';修改到您自己的服务器目录
完成上述操作后,您已经完成了,网站将被更改,地图将被更改,微调,并且将正式运行!
点击下载
帝国CMS7.5模仿土豪漫画网站模板,具有手机和自动采集功能
大小: 238MB |下载次数: 0次|文件类型: 压缩文件 查看全部
Empire CMS7.5模仿本地漫画网站模板,是在线漫画网站的网站源代码,该程序自带手机网站和采集功能,非常易于操作,如果操作正确,几乎是在撒谎靠赚钱,漫画的流量尤其是在线漫画近年来,漫画一直在突飞猛进地发展,现在很少有人在做漫画网站. 这是个很好的机会.
漫画网站系统是使用Empire cms7.5开发的. 团队制定的具体细节尚不清楚. 由于程序+数据太大,因此尚未执行测试. 您需要自己测试源代码,因为漫画网站的源代码未知. 已经散发了多少手,因此,网站程序的安全性需要重点检查是否有后门.
漫画网站的源代码程序的安装说明:
1. 将程序上传到网站的根目录,该过程与普通的Empire安装过程相同.
2. 安装完成后,登录网站后台以还原漫画和网站模板数据. 后台的登录帐户为管理员密码admin888
3. 从右到左生成和更新网站缓存的顺序,单击以全部生成;
4. 找到系统设置→展开变量→用您自己的信息全部替换
5. 修改系统文件\ m \ e \ config并找到$ ecms_config ['sets'] ['txtpath'] ='D: // manhua / d / txt /';修改到您自己的服务器目录
完成上述操作后,您已经完成了,网站将被更改,地图将被更改,微调,并且将正式运行!
点击下载
帝国CMS7.5模仿土豪漫画网站模板,具有手机和自动采集功能
大小: 238MB |下载次数: 0次|文件类型: 压缩文件
googlebot如何抓取网页?
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-08 19:27
服务器将采集的信息分类并将其组织到一个巨大的数据库中. 数据库之一用于存储网站域名. 只要域名被搜索引擎索引,它们就会自动存储在该数据库中. 该数据库排名第一. 蜘蛛网的核心. 它的内部分为10个每个级别的PR的小型数据库. 尽管数据库很小,但它们又很大又可怕.
10级数据库的周期也不同. 基本上,对于pr = 4的网站,蜘蛛爬网的可能性也是每7天一次. 因此,基本上,您会发现7天之内的某一天也是大范围的收录. 细心的网站管理员会发现有时7天是非常准确的,但仅适用于pr = 4. pr越高,周期越短,pr越低,周期越长
当然,这些网站管理员中有许多人对此表示怀疑. 我认为蜘蛛有时每天都会包括他的驻地. 这是我接下来要谈的第二个蜘蛛. 第二只蜘蛛通常是第一只蜘蛛. 在抓取过程中发布,主要用于由第一蜘蛛抓取的网站的外部链接.
ps: 因为据说它是2号蜘蛛,所以它的爬行力必须比1号蜘蛛小得多.
当然,不仅有2号蜘蛛,而且还有3号蜘蛛. 所谓3号,是指a站的1号蜘蛛爬到B站,b站的2号蜘蛛爬到C站. 目前,Google试图限制其无限循环. 分为蜘蛛的这三个级别. 其级别的爬网速率有一个非常明确的标准,并且蜘蛛网2和3具有基本上按时间顺序爬网的爬网功能.
例如: 第a蜘蛛对网站a进行爬网之后,文章的最后一次发布时间是2008-6-1,那么当第2蜘蛛从另一个网站对a进行爬网时,该网站可能会首先被定位为有几篇最近发表的文章,例如: 2008-5-31、2008-5-30和其他文章将第二次执行,并且在第三次访问之后,将抓取2008-6-1之后的信息. 如果您的网站没有任何更新,它将在过去一个月内两次检索其更改.
如果从外面有更多的蜘蛛2和3,则同一文章可能会被抓取几次. 以下是Google提供的官方数据
蜘蛛1号
基本爬网率为5%〜10%
基于pr = 0,没有导入链接,提交时可检索的时间范围为6到12个月.
基于pr = 1,没有导入链接,提交时每个爬网的期限可能从4到8个月不等.
基于pr = 2,没有导入链接,提交时可能的爬网时间为2到4个月.
基于pr = 3,没有导入链接,提交时可检索的时间为1到2个月.
基于pr = 4,没有导入链接,提交时可能捕获的期限从1周到1个月不等.
当然,没有任何导入链接的网站无法达到pr = 4
最高只有pr = 3
以上数据仅是Google正式提供的基数.
这意味着蜘蛛#1主动抓取您的网站的周期数.
要让蜘蛛2或蜘蛛3抓取您的网站,取决于您的导入链接.
因此,您会发现您的网站有时每天都在更新.
蜘蛛#2
基本爬网率为2.5%〜5%
3号蜘蛛
基本抓取率为1.25%〜2.5%
Google当前具有三个级别的蜘蛛
蜘蛛当然有不同的蜘蛛
这里唯一的一个是网络蜘蛛. 因为我只对此感兴趣.
googlebot如何抓取网页?相关文章:
·SEO优化的六个常见误解,让您无法伤害站点组系统
·SEOer如何分析竞争对手网站组工具
·PS制作PS制作数字笔划文本工作站群组软件
·成功赢得外贸订单的6个步骤. 什么是站组?
·6种有用的在线商店推广技术,流量飙升站群系统
·10条使您在下订单时变得柔软的提示!站群软件
本文标题: googlebot如何抓取网页?
本文的地址: 查看全部
要了解Google蜘蛛如何爬网以收录网页,我们首先需要了解Google蜘蛛的起源. 最初建立Google搜索引擎时,它拥有非常强大的服务器. 它每天释放大量蜘蛛. 我们称其为第一蜘蛛. 它的爬网速度非常快. 对于信息采集,我们可以看到服务器有多快. 实际上,最重要的是Google在后来将服务器扩展到了许多城市,因此现在您可以发现Google的计算速度领先.
服务器将采集的信息分类并将其组织到一个巨大的数据库中. 数据库之一用于存储网站域名. 只要域名被搜索引擎索引,它们就会自动存储在该数据库中. 该数据库排名第一. 蜘蛛网的核心. 它的内部分为10个每个级别的PR的小型数据库. 尽管数据库很小,但它们又很大又可怕.
10级数据库的周期也不同. 基本上,对于pr = 4的网站,蜘蛛爬网的可能性也是每7天一次. 因此,基本上,您会发现7天之内的某一天也是大范围的收录. 细心的网站管理员会发现有时7天是非常准确的,但仅适用于pr = 4. pr越高,周期越短,pr越低,周期越长
当然,这些网站管理员中有许多人对此表示怀疑. 我认为蜘蛛有时每天都会包括他的驻地. 这是我接下来要谈的第二个蜘蛛. 第二只蜘蛛通常是第一只蜘蛛. 在抓取过程中发布,主要用于由第一蜘蛛抓取的网站的外部链接.
ps: 因为据说它是2号蜘蛛,所以它的爬行力必须比1号蜘蛛小得多.
当然,不仅有2号蜘蛛,而且还有3号蜘蛛. 所谓3号,是指a站的1号蜘蛛爬到B站,b站的2号蜘蛛爬到C站. 目前,Google试图限制其无限循环. 分为蜘蛛的这三个级别. 其级别的爬网速率有一个非常明确的标准,并且蜘蛛网2和3具有基本上按时间顺序爬网的爬网功能.
例如: 第a蜘蛛对网站a进行爬网之后,文章的最后一次发布时间是2008-6-1,那么当第2蜘蛛从另一个网站对a进行爬网时,该网站可能会首先被定位为有几篇最近发表的文章,例如: 2008-5-31、2008-5-30和其他文章将第二次执行,并且在第三次访问之后,将抓取2008-6-1之后的信息. 如果您的网站没有任何更新,它将在过去一个月内两次检索其更改.
如果从外面有更多的蜘蛛2和3,则同一文章可能会被抓取几次. 以下是Google提供的官方数据
蜘蛛1号
基本爬网率为5%〜10%
基于pr = 0,没有导入链接,提交时可检索的时间范围为6到12个月.
基于pr = 1,没有导入链接,提交时每个爬网的期限可能从4到8个月不等.
基于pr = 2,没有导入链接,提交时可能的爬网时间为2到4个月.
基于pr = 3,没有导入链接,提交时可检索的时间为1到2个月.
基于pr = 4,没有导入链接,提交时可能捕获的期限从1周到1个月不等.
当然,没有任何导入链接的网站无法达到pr = 4
最高只有pr = 3
以上数据仅是Google正式提供的基数.
这意味着蜘蛛#1主动抓取您的网站的周期数.
要让蜘蛛2或蜘蛛3抓取您的网站,取决于您的导入链接.
因此,您会发现您的网站有时每天都在更新.
蜘蛛#2
基本爬网率为2.5%〜5%
3号蜘蛛
基本抓取率为1.25%〜2.5%
Google当前具有三个级别的蜘蛛
蜘蛛当然有不同的蜘蛛
这里唯一的一个是网络蜘蛛. 因为我只对此感兴趣.
googlebot如何抓取网页?相关文章:
·SEO优化的六个常见误解,让您无法伤害站点组系统
·SEOer如何分析竞争对手网站组工具
·PS制作PS制作数字笔划文本工作站群组软件
·成功赢得外贸订单的6个步骤. 什么是站组?
·6种有用的在线商店推广技术,流量飙升站群系统
·10条使您在下订单时变得柔软的提示!站群软件
本文标题: googlebot如何抓取网页?
本文的地址:
网站测试自动化系统-采集测试结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2020-08-08 15:52
通常来说,测试报告需要收录以下信息:
1. 测试用例的通过率. 通过率表示产品的稳定性. 当然,这是排除由测试用例本身问题引起的测试失败后的通过率. 在上一个执行测试用例中提到的MsTest.exe生成的结果文件.trx文件已经保存了此信息. 在资源管理器中双击此文件,您将看到类似于下图的结果:
在上面的图片中,一些细心的读者可能会发现只有3个用例,但是红色圆圈中的文字表示: “ 6/6通过了”. 这是因为这3个用例是数据驱动的用例,因此VSTT将每行数据视为一个独立的测试用例. 对于数据驱动的测试,您可以参考我的文章: 网站自动测试系统-数据驱动的测试.
2. 代码覆盖率信息. 代码覆盖率告诉测试团队哪些产品代码未被覆盖. 未发现的产品代码意味着有些我们尚未考虑的用户场景,或者测试范围中存在一些漏洞. (测试孔). 如果从VSTT用户界面执行测试用例,则VSTT将自动集成采集代码覆盖率的功能. 有关详细信息,请参阅我的文章《软件自动化测试-代码覆盖率》. 在本文中,我将向您展示如何使用命令行来采集代码覆盖率.
至少有两种方法可以将采集代码覆盖率的功能集成到自动化测试系统中. 一种是直接编辑.testrunconfig文件. 当我们在VSTT用户界面上操作时,这就是VSTT在后台为我们所做的. ,请参阅本文以执行测试用例,以了解使用.testrunconfig文件的方法.
另一种方法是更深入的分解. 实际上,Visual Studio通过名为VsPerfMon.exe的程序采集代码覆盖率,该程序位于C: \ Program Files \ Microsoft Visual Studio 9.0 \ Team Tools \ Performance Tools(假定VSTT安装在C驱动器上). 当您按照软件自动化测试代码覆盖率中介绍的步骤执行自动化测试时,VSTT会秘密执行以下操作:
<p>1. 注入用于计算代码覆盖率(仪器)的代码. 注入的代码已经在“软件自动化测试代码覆盖率”一文中进行了说明,因此在此不再赘述. 通过vsinstr.exe实现代码注入. 以下是将其用于代码注入的最简化命令(接受任何.Net程序,即.dll和.exe文件,无论它是否支持本机C ++程序,我都还没有尝试过): 查看全部
在上一篇文章“执行测试用例”中,我们介绍了如何通过命令行编译和执行测试用例,以便我们有机会通过批处理自动执行测试用例. 在文章系统应具有的功能中,我还提到了一个完整的自动化系统应该能够自动采集测试结果-毕竟,我们的目标是测试人员在晚上下班之前执行用例,然后在晚上离开. 第二天早上,您可以直接阅读测试报告.
通常来说,测试报告需要收录以下信息:
1. 测试用例的通过率. 通过率表示产品的稳定性. 当然,这是排除由测试用例本身问题引起的测试失败后的通过率. 在上一个执行测试用例中提到的MsTest.exe生成的结果文件.trx文件已经保存了此信息. 在资源管理器中双击此文件,您将看到类似于下图的结果:
在上面的图片中,一些细心的读者可能会发现只有3个用例,但是红色圆圈中的文字表示: “ 6/6通过了”. 这是因为这3个用例是数据驱动的用例,因此VSTT将每行数据视为一个独立的测试用例. 对于数据驱动的测试,您可以参考我的文章: 网站自动测试系统-数据驱动的测试.
2. 代码覆盖率信息. 代码覆盖率告诉测试团队哪些产品代码未被覆盖. 未发现的产品代码意味着有些我们尚未考虑的用户场景,或者测试范围中存在一些漏洞. (测试孔). 如果从VSTT用户界面执行测试用例,则VSTT将自动集成采集代码覆盖率的功能. 有关详细信息,请参阅我的文章《软件自动化测试-代码覆盖率》. 在本文中,我将向您展示如何使用命令行来采集代码覆盖率.
至少有两种方法可以将采集代码覆盖率的功能集成到自动化测试系统中. 一种是直接编辑.testrunconfig文件. 当我们在VSTT用户界面上操作时,这就是VSTT在后台为我们所做的. ,请参阅本文以执行测试用例,以了解使用.testrunconfig文件的方法.
另一种方法是更深入的分解. 实际上,Visual Studio通过名为VsPerfMon.exe的程序采集代码覆盖率,该程序位于C: \ Program Files \ Microsoft Visual Studio 9.0 \ Team Tools \ Performance Tools(假定VSTT安装在C驱动器上). 当您按照软件自动化测试代码覆盖率中介绍的步骤执行自动化测试时,VSTT会秘密执行以下操作:
<p>1. 注入用于计算代码覆盖率(仪器)的代码. 注入的代码已经在“软件自动化测试代码覆盖率”一文中进行了说明,因此在此不再赘述. 通过vsinstr.exe实现代码注入. 以下是将其用于代码注入的最简化命令(接受任何.Net程序,即.dll和.exe文件,无论它是否支持本机C ++程序,我都还没有尝试过):
舆论系统网站采集的优雅采集系统模板配置-资本主义公牛的羊毛
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-08-08 10:22
自动分析: 分为两种: 傻瓜式分析和具有神经网络功能的智能分析. 前者是找出主要网页内容页面的特征并遍历网页节点以获得所谓的标题. 正文的最佳解决方案;后者是通过机器学习(通常是各种搜索公司)来进行的. 我在这里建议您了解diffbot关于diffbot的报告. 公司的网站就是公司的主页.
模板配置: 什么是模板?以爬虫框架webmagic为例. 采集器程序不知道如何格式化下载的Web html数据. 这时,我们需要使用xpath和CSS路径来告诉程序. 该节点是有用的数据,需要检索. 当前的公众舆论公司的方法是找一个专门的人来配置模板,并且为了方便配置,专门开发了相应的系统来方便配置.
那我今天要说什么?是的,我说的是资本主义的毛毛. 作为舆论爬虫开发人员,我将教您如何使用diffbot的羊毛.
让我们看看diffbot如何首先格式化网页:
很大,对吧?并不是使用神经网络训练来进行100%格式化的,但是处理国内外新闻网站则可以100%进行格式化. 当然,此页面用于交流. 您可以使用它而无需加密. 然后,我开始展示我所做的工作.
这次,我使用开发的这些接口来反转diffbot智能解析的数据. 首先介绍第一个界面:
接口1: 使用starttxt,endtxt反转内容的节点,如图所示:
在这里,我输入“ starttxt”: “北京新华社,4月2日”,“ endtxt”: “版本01,2018年4月3日”,让我们看一下该页面的内容并编写链接内容在这里
如您所见,本文的开头是: 新华社北京,4月2日,结尾内容可能是: 2018年4月3日01版. 让我们看一下我的界面的输出:
如图所示,在页面上输出路径: #root: 0 | html: 0 | body: 0 | div: 4 | div: 0 | div: 0,此路径既不是xpath也不是css路径,但是自定义html框架路径. 然后验证输出:
接口2: 通过所选路径获取相应节点下的文本内容
分析结果如下:
因此,通过这两个界面,我们起到了替换手动配置模板的功能,并且可以通过摆脱diffbot程序的程序为新闻站点生成模板. 毕竟,并不是每个人都可以开发类似于diffbot的人工智能程序,该程序可以根据视觉效果分析网络数据.
剩下的就是改进其他事情,例如获取发布时间节点. 上述方法是不可行的. 因此,我专门开发了一个提取时间节点的程序:
接口3: 通过选定的txt获得最佳路径解决方案,适合提取释放时间的路径
Pubtimetxt只需要是页面中的发布时间,格式类似于2018年4月3日04:36的格式,并且可以同时匹配到对应的节点. 查看输出数据:
验证此节点的内容: 查看全部
在中国,不论大小,都有数百家专注于发展民意体系的公司,与民意相对应,如何构建采集到的数据是非常重要的. 如果网页上的数据不能很好地进行结构化,则后续数据的情感分析,关键词分析将难以执行. 一般公司格式化网页时,大多数是自动分析+模板配置;
自动分析: 分为两种: 傻瓜式分析和具有神经网络功能的智能分析. 前者是找出主要网页内容页面的特征并遍历网页节点以获得所谓的标题. 正文的最佳解决方案;后者是通过机器学习(通常是各种搜索公司)来进行的. 我在这里建议您了解diffbot关于diffbot的报告. 公司的网站就是公司的主页.
模板配置: 什么是模板?以爬虫框架webmagic为例. 采集器程序不知道如何格式化下载的Web html数据. 这时,我们需要使用xpath和CSS路径来告诉程序. 该节点是有用的数据,需要检索. 当前的公众舆论公司的方法是找一个专门的人来配置模板,并且为了方便配置,专门开发了相应的系统来方便配置.
那我今天要说什么?是的,我说的是资本主义的毛毛. 作为舆论爬虫开发人员,我将教您如何使用diffbot的羊毛.
让我们看看diffbot如何首先格式化网页:
很大,对吧?并不是使用神经网络训练来进行100%格式化的,但是处理国内外新闻网站则可以100%进行格式化. 当然,此页面用于交流. 您可以使用它而无需加密. 然后,我开始展示我所做的工作.
这次,我使用开发的这些接口来反转diffbot智能解析的数据. 首先介绍第一个界面:
接口1: 使用starttxt,endtxt反转内容的节点,如图所示:
在这里,我输入“ starttxt”: “北京新华社,4月2日”,“ endtxt”: “版本01,2018年4月3日”,让我们看一下该页面的内容并编写链接内容在这里
如您所见,本文的开头是: 新华社北京,4月2日,结尾内容可能是: 2018年4月3日01版. 让我们看一下我的界面的输出:
如图所示,在页面上输出路径: #root: 0 | html: 0 | body: 0 | div: 4 | div: 0 | div: 0,此路径既不是xpath也不是css路径,但是自定义html框架路径. 然后验证输出:
接口2: 通过所选路径获取相应节点下的文本内容
分析结果如下:
因此,通过这两个界面,我们起到了替换手动配置模板的功能,并且可以通过摆脱diffbot程序的程序为新闻站点生成模板. 毕竟,并不是每个人都可以开发类似于diffbot的人工智能程序,该程序可以根据视觉效果分析网络数据.
剩下的就是改进其他事情,例如获取发布时间节点. 上述方法是不可行的. 因此,我专门开发了一个提取时间节点的程序:
接口3: 通过选定的txt获得最佳路径解决方案,适合提取释放时间的路径
Pubtimetxt只需要是页面中的发布时间,格式类似于2018年4月3日04:36的格式,并且可以同时匹配到对应的节点. 查看输出数据:
验证此节点的内容:

