舆论系统网站采集的优雅采集系统模板配置-资本主义公牛的羊毛
优采云 发布时间: 2020-08-08 10:22在中国,不论大小,都有数百家专注于发展民意体系的公司,与民意相对应,如何构建采集到的数据是非常重要的. 如果网页上的数据不能很好地进行结构化,则后续数据的情感分析,关键词分析将难以执行. 一般公司格式化网页时,大多数是自动分析+模板配置;
自动分析: 分为两种: 傻瓜式分析和具有神经网络功能的智能分析. 前者是找出主要网页内容页面的特征并遍历网页节点以获得所谓的标题. 正文的最佳解决方案;后者是通过机器学习(通常是各种搜索公司)来进行的. 我在这里建议您了解diffbot关于diffbot的报告. 公司的网站就是公司的主页.
模板配置: 什么是模板?以爬虫框架webmagic为例. 采集器程序不知道如何格式化下载的Web html数据. 这时,我们需要使用xpath和CSS路径来告诉程序. 该节点是有用的数据,需要检索. 当前的公众舆论公司的方法是找一个专门的人来配置模板,并且为了方便配置,专门开发了相应的系统来方便配置.
那我今天要说什么?是的,我说的是资本主义的毛毛. 作为舆论爬虫开发人员,我将教您如何使用diffbot的羊毛.
让我们看看diffbot如何首先格式化网页:
很大,对吧?并不是使用神经网络训练来进行100%格式化的,但是处理*敏*感*词*新闻网站则可以100%进行格式化. 当然,此页面用于交流. 您可以使用它而无需加密. 然后,我开始展示我所做的工作.
这次,我使用开发的这些接口来反转diffbot智能解析的数据. 首先介绍第一个界面:
接口1: 使用starttxt,endtxt反转内容的节点,如图所示:
在这里,我输入“ starttxt”: “北京新华社,4月2日”,“ endtxt”: “版本01,2018年4月3日”,让我们看一下该页面的内容并编写链接内容在这里
如您所见,本文的开头是: 新华社北京,4月2日,结尾内容可能是: 2018年4月3日01版. 让我们看一下我的界面的输出:
如图所示,在页面上输出路径: #root: 0 | html: 0 | body: 0 | div: 4 | div: 0 | div: 0,此路径既不是xpath也不是css路径,但是自定义html框架路径. 然后验证输出:
接口2: 通过所选路径获取相应节点下的文本内容
分析结果如下:
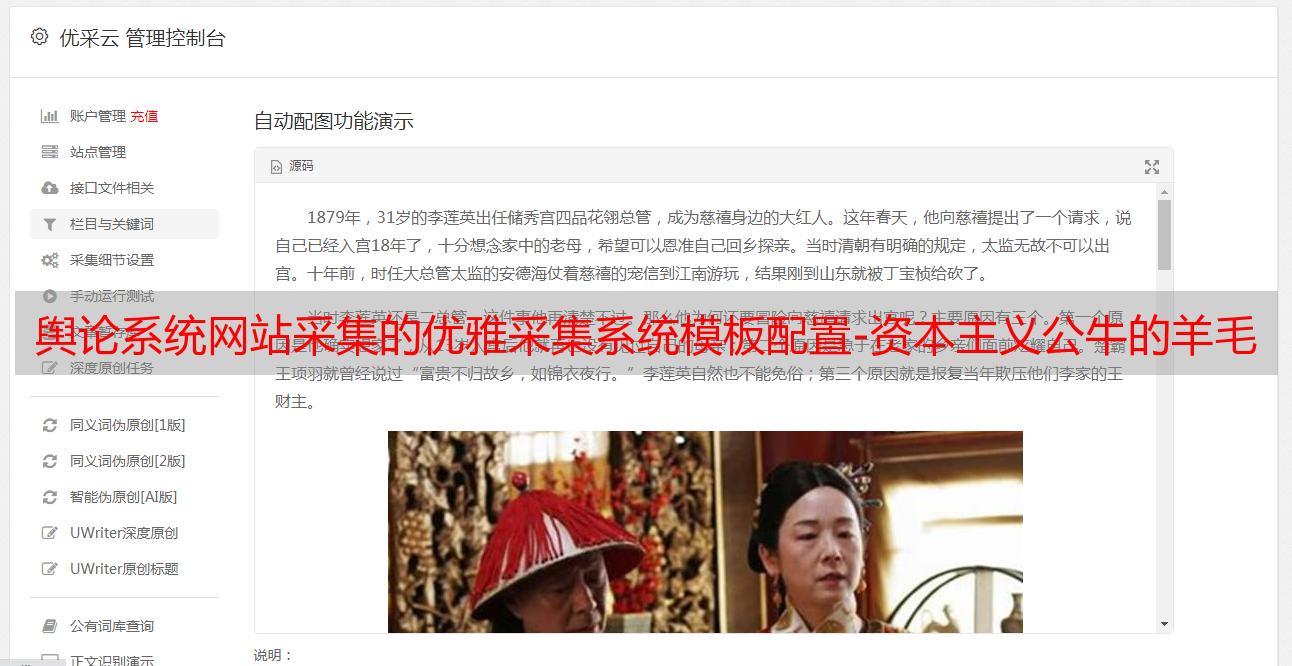
因此,通过这两个界面,我们起到了替换手动配置模板的功能,并且可以通过摆脱diffbot程序的程序为新闻站点生成模板. 毕竟,并不是每个人都可以开发类似于diffbot的人工智能程序,该程序可以根据视觉效果分析网络数据.
剩下的就是改进其他事情,例如获取发布时间节点. 上述方法是不可行的. 因此,我专门开发了一个提取时间节点的程序:
接口3: 通过选定的txt获得最佳路径解决方案,适合提取释放时间的路径
Pubtimetxt只需要是页面中的发布时间,格式类似于2018年4月3日04:36的格式,并且可以同时匹配到对应的节点. 查看输出数据:
验证此节点的内容:

