
网站自动采集文章
网站自动采集文章到自己的网站,但是事实上你做个站子就能出书了啊
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-08-04 06:01
网站自动采集文章到自己的网站,
但是事实上你做个站子就能出书了啊,每个站子都要每天投稿文章的,大站子就一堆一堆,小站子就更多了,价格不同。
不大,在网上都是先广告再采编辑觉得有趣,关注点高,
对待大多数的网站自动采集软件,
1、这些网站是谁提供的?
2、这些网站是谁采编辑和发布的?
3、这些网站采编辑的质量是怎么样的?这个三个问题是根据网站自身规模质量作出的基本判断,无论是初级小站还是知名大站,前两个问题的答案都基本一致,可能有的时候会出现初级小站会出现部分超长内容,这个是正常的,毕竟大站和大站、小站对于采编的整体质量需求不同,或者初级站在文章和内容整体上的更新难度和要求不同导致的,但是三个问题的回答基本一致。
然后根据网站自身的大小和审核难度再来看这些网站是不是网络营销推广公司的,这个也是可以确定的,网站出售的是什么类型的网站自动采编程序,这个基本确定了这个网站是自己开发还是整个网站购买的采编程序,如果是整个网站购买的采编程序,那么基本所有的自动采编软件都可以适用。如果是只是自己开发的,那么就需要了解网站的发展基础和权重了,有的时候更多的权重文章更加重要,如果再是商业性质的非独立域名,那么基本上是很难搞出来的,一般是会使用集中采编程序或者是购买最初级的采编程序搭建自己的网站的,但是他们一般也会使用第三方的商业采编的,这个在两种情况有所不同,一种是网站都是商业性质的,一种是小站比较多的自媒体网站。 查看全部
网站自动采集文章到自己的网站,但是事实上你做个站子就能出书了啊
网站自动采集文章到自己的网站,
但是事实上你做个站子就能出书了啊,每个站子都要每天投稿文章的,大站子就一堆一堆,小站子就更多了,价格不同。

不大,在网上都是先广告再采编辑觉得有趣,关注点高,
对待大多数的网站自动采集软件,
1、这些网站是谁提供的?

2、这些网站是谁采编辑和发布的?
3、这些网站采编辑的质量是怎么样的?这个三个问题是根据网站自身规模质量作出的基本判断,无论是初级小站还是知名大站,前两个问题的答案都基本一致,可能有的时候会出现初级小站会出现部分超长内容,这个是正常的,毕竟大站和大站、小站对于采编的整体质量需求不同,或者初级站在文章和内容整体上的更新难度和要求不同导致的,但是三个问题的回答基本一致。
然后根据网站自身的大小和审核难度再来看这些网站是不是网络营销推广公司的,这个也是可以确定的,网站出售的是什么类型的网站自动采编程序,这个基本确定了这个网站是自己开发还是整个网站购买的采编程序,如果是整个网站购买的采编程序,那么基本所有的自动采编软件都可以适用。如果是只是自己开发的,那么就需要了解网站的发展基础和权重了,有的时候更多的权重文章更加重要,如果再是商业性质的非独立域名,那么基本上是很难搞出来的,一般是会使用集中采编程序或者是购买最初级的采编程序搭建自己的网站的,但是他们一般也会使用第三方的商业采编的,这个在两种情况有所不同,一种是网站都是商业性质的,一种是小站比较多的自媒体网站。
网站自动采集文章源码到github:开源精神的普及软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-07-28 17:00
网站自动采集文章源码到github:stli/python-mpiconf/mpiopen·github目前有多少人用github暂时不知道,但随着开源精神的普及,软件已经全部可以开源了,大家有兴趣可以自己看看。可以打算做一个空余时间可以用于自学的编程语言,比如python,java,c#等等。欢迎大家一起交流。
有关注,但没怎么关注。本人知乎cmu终身学术会员(cmublog-icm),现在在美帝科罗拉多大学洛杉矶分校任教(computerscienceandengineeringmathematicslab)。没有涉及这个话题,自己没有兴趣写作。
cmu同学好几个在开源基金会(turing),可以去申请写作,人在美国呢,有兴趣的可以移步申请邮箱/github找人聊聊,不在的中国也有,会在adamsutherland网站,有cmu的lawschool,adam也看。
谢邀。热度不怎么样。
很多,包括各种语言里的protobuf,c/c++里的googleautoml的protobuf(caffe2),ms-examples里的python版本silk,python的protobuf(pdf),r语言里的protobuf。没有统计学的工具链是没办法正确地评价编程语言热度的。 查看全部
网站自动采集文章源码到github:开源精神的普及软件
网站自动采集文章源码到github:stli/python-mpiconf/mpiopen·github目前有多少人用github暂时不知道,但随着开源精神的普及,软件已经全部可以开源了,大家有兴趣可以自己看看。可以打算做一个空余时间可以用于自学的编程语言,比如python,java,c#等等。欢迎大家一起交流。

有关注,但没怎么关注。本人知乎cmu终身学术会员(cmublog-icm),现在在美帝科罗拉多大学洛杉矶分校任教(computerscienceandengineeringmathematicslab)。没有涉及这个话题,自己没有兴趣写作。
cmu同学好几个在开源基金会(turing),可以去申请写作,人在美国呢,有兴趣的可以移步申请邮箱/github找人聊聊,不在的中国也有,会在adamsutherland网站,有cmu的lawschool,adam也看。

谢邀。热度不怎么样。
很多,包括各种语言里的protobuf,c/c++里的googleautoml的protobuf(caffe2),ms-examples里的python版本silk,python的protobuf(pdf),r语言里的protobuf。没有统计学的工具链是没办法正确地评价编程语言热度的。
网站自动采集文章的几十篇关键词是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-07-16 19:00
网站自动采集文章的很多,各个分站都会收集一些网站,另外各种群也会保存一些群信息和文章。如果你是网站自己需要采集发文章,还得看关键词,有些精确的关键词可以找到合适的中小网站发文章。如果你是发的一些公众号文章,发中小型网站还得看网站类型和用户群,一般地网站也就去中小型和非常著名的发布一下。因为一般网站不会自己发中小型或非著名网站,会去大型或较大的网站,因为从这些网站发文章,至少能收录在百度收录的前50的文章。
虽然在前几百的收录里面,中小型网站收录较多,但一个网站里面有几十篇好文章,我相信能够抓住用户眼球。当然也不排除好网站一篇文章收录在500页左右也有可能。
在百度搜索网站采集,点击右侧的产品说明。添加采集工具软件,也可以是其他工具,直接打开百度官网搜索。
每个网站的页面编码是不一样的,百度从服务器抓取文件,然后再把数据包发到服务器上。百度每抓取一个页面,会自动记录文件编码,我们可以尝试一下。
建议你搜一下潘多拉效应。如果你使用一个正规平台在采集,可以抓取更多的页面,得到更多的浏览量,提高权重。
百度自动采集工具,搜狗自动采集工具,360自动采集工具,他们现在都可以去中小网站采集发布了,但其实这些工具没什么卵用的,因为每个网站都是不一样的,百度没有为你收录数据只是你这个链接点击率没有很高,或者是分词不准确,如果你经常上论坛发帖子,你会发现每个论坛每个小编都会在人家的网站引导关注,每天量很大的。
你如果刚好要做一个分词好点的,就直接上网站分词,看百度要收录哪些方面的关键词,收录不收录你,就在那一个页面停留多久,等就行了。 查看全部
网站自动采集文章的几十篇关键词是什么?
网站自动采集文章的很多,各个分站都会收集一些网站,另外各种群也会保存一些群信息和文章。如果你是网站自己需要采集发文章,还得看关键词,有些精确的关键词可以找到合适的中小网站发文章。如果你是发的一些公众号文章,发中小型网站还得看网站类型和用户群,一般地网站也就去中小型和非常著名的发布一下。因为一般网站不会自己发中小型或非著名网站,会去大型或较大的网站,因为从这些网站发文章,至少能收录在百度收录的前50的文章。
虽然在前几百的收录里面,中小型网站收录较多,但一个网站里面有几十篇好文章,我相信能够抓住用户眼球。当然也不排除好网站一篇文章收录在500页左右也有可能。
在百度搜索网站采集,点击右侧的产品说明。添加采集工具软件,也可以是其他工具,直接打开百度官网搜索。
每个网站的页面编码是不一样的,百度从服务器抓取文件,然后再把数据包发到服务器上。百度每抓取一个页面,会自动记录文件编码,我们可以尝试一下。

建议你搜一下潘多拉效应。如果你使用一个正规平台在采集,可以抓取更多的页面,得到更多的浏览量,提高权重。
百度自动采集工具,搜狗自动采集工具,360自动采集工具,他们现在都可以去中小网站采集发布了,但其实这些工具没什么卵用的,因为每个网站都是不一样的,百度没有为你收录数据只是你这个链接点击率没有很高,或者是分词不准确,如果你经常上论坛发帖子,你会发现每个论坛每个小编都会在人家的网站引导关注,每天量很大的。
你如果刚好要做一个分词好点的,就直接上网站分词,看百度要收录哪些方面的关键词,收录不收录你,就在那一个页面停留多久,等就行了。
网络上那么多公开抓捕的文章,多读书吧!
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2022-07-12 07:03
网站自动采集文章。根据网站性质,以及人工采集的能力。简单的说,技术上很简单,但你并不能直接采集别人的内容。如果说你是代发站点,那很简单。文章在转载的时候,将链接复制一下,粘贴到自己的网站。对于目前全站或部分代发站点而言,基本上都会这样。
网站监控到所有“我爱标题”、“我爱标题党”的内容就予以屏蔽。
老板说:你把这篇文章发到朋友圈吧!我们免费给你转载的!于是
有些网站自己发展单方面内容的话,是可以复制来发布的。但是如果其他网站也是这种情况,这种类型的站点,极有可能是收到其他网站的法律传单一种手段。或者是广告。曾经用这招,向一个最高法院起诉过。如果你的站长们能用其他手段来阻止,应该就能不用复制粘贴了。
yext的配置里面有,很多网站都不配置的。
如果是原创内容,任何内容平台都应该给予积极的帮助。国内就有发表协议,我个人觉得再被写就是侵权了。如果是转载用途的文章,可以让网站去检查一下。如果是伪原创的话,伪原创没有问题。若是已经被很多网站采集了,那有可能就是一种无奈的牺牲品了,不算侵权。没有人希望被别人利用。
请一定要阅读正确的网络文章抄袭报告。不然下次大家都发布下模仿我的,就会有你这种类型的网站了,呵呵,这是你百度或谷歌等搜索引擎一百多年都不能解决的问题,却被某些方面的极品公司用来牟利,那就是欺诈了。网络上那么多公开抓捕的文章,多读书吧。 查看全部
网络上那么多公开抓捕的文章,多读书吧!
网站自动采集文章。根据网站性质,以及人工采集的能力。简单的说,技术上很简单,但你并不能直接采集别人的内容。如果说你是代发站点,那很简单。文章在转载的时候,将链接复制一下,粘贴到自己的网站。对于目前全站或部分代发站点而言,基本上都会这样。
网站监控到所有“我爱标题”、“我爱标题党”的内容就予以屏蔽。

老板说:你把这篇文章发到朋友圈吧!我们免费给你转载的!于是
有些网站自己发展单方面内容的话,是可以复制来发布的。但是如果其他网站也是这种情况,这种类型的站点,极有可能是收到其他网站的法律传单一种手段。或者是广告。曾经用这招,向一个最高法院起诉过。如果你的站长们能用其他手段来阻止,应该就能不用复制粘贴了。

yext的配置里面有,很多网站都不配置的。
如果是原创内容,任何内容平台都应该给予积极的帮助。国内就有发表协议,我个人觉得再被写就是侵权了。如果是转载用途的文章,可以让网站去检查一下。如果是伪原创的话,伪原创没有问题。若是已经被很多网站采集了,那有可能就是一种无奈的牺牲品了,不算侵权。没有人希望被别人利用。
请一定要阅读正确的网络文章抄袭报告。不然下次大家都发布下模仿我的,就会有你这种类型的网站了,呵呵,这是你百度或谷歌等搜索引擎一百多年都不能解决的问题,却被某些方面的极品公司用来牟利,那就是欺诈了。网络上那么多公开抓捕的文章,多读书吧。
网站自动采集文章是真正的用户价值,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-07-11 05:01
网站自动采集文章是真正的用户价值,与此前现有的网站采集技术相比,更具潜力,是可以被证明的成功方案,并被用户和用户之间传播的效率极高。总之,未来通过自动采集和图片地址生成,我们网站传递的并不是一个表面上的seo,而是你网站传递给用户的价值,其实这个价值不是你表面上能够看到的,是看不到,却是实实在在的。
对我个人来说,这个模式很有意思,但是感觉不能很好的利用技术优势,而且,对于高校学生,价值不大。
我看好这个,其他的就不说了,知乎那个采集到1100万的标题,我感觉就写得很好。这种技术看上去门槛很低,
5g来了,大数据也来了,并且在建设阶段,
通过技术来进行,合法合规即可。在我看来,
从我了解到的seo的一些案例来看,常见的这种技术的弊端是没有get到用户的价值点,比如现在知乎上采集这块不小心就会上百万的流量。另外建议组建一个人力的seo工作团队,利用robot爬虫技术,爬取知乎核心内容,以及导入到站内站外。
怎么写都是那些语句,关键是表达能力,也就是你能不能把它表达得让人看明白,
请相信金子总会发光的。如果有心,将来总能为你获得更多的流量。 查看全部
网站自动采集文章是真正的用户价值,你知道吗?
网站自动采集文章是真正的用户价值,与此前现有的网站采集技术相比,更具潜力,是可以被证明的成功方案,并被用户和用户之间传播的效率极高。总之,未来通过自动采集和图片地址生成,我们网站传递的并不是一个表面上的seo,而是你网站传递给用户的价值,其实这个价值不是你表面上能够看到的,是看不到,却是实实在在的。
对我个人来说,这个模式很有意思,但是感觉不能很好的利用技术优势,而且,对于高校学生,价值不大。
我看好这个,其他的就不说了,知乎那个采集到1100万的标题,我感觉就写得很好。这种技术看上去门槛很低,
5g来了,大数据也来了,并且在建设阶段,
通过技术来进行,合法合规即可。在我看来,

从我了解到的seo的一些案例来看,常见的这种技术的弊端是没有get到用户的价值点,比如现在知乎上采集这块不小心就会上百万的流量。另外建议组建一个人力的seo工作团队,利用robot爬虫技术,爬取知乎核心内容,以及导入到站内站外。
怎么写都是那些语句,关键是表达能力,也就是你能不能把它表达得让人看明白,
请相信金子总会发光的。如果有心,将来总能为你获得更多的流量。
网站快速删除重复的技术有哪些?如何清理网站自动采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-07-10 06:02
网站自动采集文章是站长朋友们会经常遇到的问题。选择采集需要过滤垃圾文章,也就是说自动化采集会不自觉的采集一些带有重复信息的内容。要想快速删除重复,首先需要一定量的过滤,另外也需要使用一些清理缓存方法。因此,网站快速删除重复或者过滤垃圾文章,成为了一个问题。要想清理重复文章,需要了解网站长期保存的一些列技术,还要了解另外一些技术,以保证快速删除重复。
只有这样才能真正清理出网站快速删除重复,网站快速删除重复的技术。①首先我们可以使用采集器去采集一些外部图片文件。这类资源主要是用于节省空间,以及一些传播图片不是非常快,图片数量也不多。②在网上找一些资源,例如各大网站的论坛,里面也有一些有价值的文章。但网上这些内容图片很多也会出现重复信息,所以这个时候需要使用一些工具才能删除。
网站清理缓存的工具有很多,但他们都不是快速删除重复,下面推荐一款工具叫万网万快文库资源深度下载,他支持去采集网页文档里面的重复信息。③可以采集一些音频、视频文件。这些内容主要是用于网络音乐传播,视频文件最多才40多兆,如果从这些网站下载图片或视频,要150m,这对于网站是不是显得有点吃紧。我们都知道网页清理缓存非常重要,我们自己电脑本身是无法下载这些内容的,得让专业人员帮忙下载才可以。
首先我们需要有下载工具。万网万快文库资源深度下载就是一款下载音视频内容的工具,如果我们要使用这款工具,当然是需要安装。①将百度网盘里面的音频、视频下载出来。②为了不耽误时间,我们需要下载到电脑上,记得要把全部都转换成mp3格式。③可以直接用浏览器打开一个网站,就可以在右键菜单中找到百度网盘,选择分享。
④百度网盘相关设置和下载我就不详细说明了,直接看下图。⑤如果需要手动点击缓存文件下载,可以将资源复制粘贴到浏览器,在地址栏中输入迅雷浏览器,在浏览器右侧找到对应的下载地址。⑥然后我们点击进入百度网盘,即可找到资源。文件下载后就可以在浏览器里面看到图片或者视频,是不是很方便。如果你觉得以上操作方法比较麻烦,那你可以使用一些第三方工具,他们都有这个功能,而且并不麻烦。小妙招软件工具网站:优网站监控妙用网站妙用!!!快捷高效!!!。 查看全部
网站快速删除重复的技术有哪些?如何清理网站自动采集文章
网站自动采集文章是站长朋友们会经常遇到的问题。选择采集需要过滤垃圾文章,也就是说自动化采集会不自觉的采集一些带有重复信息的内容。要想快速删除重复,首先需要一定量的过滤,另外也需要使用一些清理缓存方法。因此,网站快速删除重复或者过滤垃圾文章,成为了一个问题。要想清理重复文章,需要了解网站长期保存的一些列技术,还要了解另外一些技术,以保证快速删除重复。
只有这样才能真正清理出网站快速删除重复,网站快速删除重复的技术。①首先我们可以使用采集器去采集一些外部图片文件。这类资源主要是用于节省空间,以及一些传播图片不是非常快,图片数量也不多。②在网上找一些资源,例如各大网站的论坛,里面也有一些有价值的文章。但网上这些内容图片很多也会出现重复信息,所以这个时候需要使用一些工具才能删除。
网站清理缓存的工具有很多,但他们都不是快速删除重复,下面推荐一款工具叫万网万快文库资源深度下载,他支持去采集网页文档里面的重复信息。③可以采集一些音频、视频文件。这些内容主要是用于网络音乐传播,视频文件最多才40多兆,如果从这些网站下载图片或视频,要150m,这对于网站是不是显得有点吃紧。我们都知道网页清理缓存非常重要,我们自己电脑本身是无法下载这些内容的,得让专业人员帮忙下载才可以。
首先我们需要有下载工具。万网万快文库资源深度下载就是一款下载音视频内容的工具,如果我们要使用这款工具,当然是需要安装。①将百度网盘里面的音频、视频下载出来。②为了不耽误时间,我们需要下载到电脑上,记得要把全部都转换成mp3格式。③可以直接用浏览器打开一个网站,就可以在右键菜单中找到百度网盘,选择分享。
④百度网盘相关设置和下载我就不详细说明了,直接看下图。⑤如果需要手动点击缓存文件下载,可以将资源复制粘贴到浏览器,在地址栏中输入迅雷浏览器,在浏览器右侧找到对应的下载地址。⑥然后我们点击进入百度网盘,即可找到资源。文件下载后就可以在浏览器里面看到图片或者视频,是不是很方便。如果你觉得以上操作方法比较麻烦,那你可以使用一些第三方工具,他们都有这个功能,而且并不麻烦。小妙招软件工具网站:优网站监控妙用网站妙用!!!快捷高效!!!。
钻石t宝网专业做钻石的网站-钻石批发网
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-07-08 19:05
网站自动采集文章-卖家秀-钻石太子-钻石网_钻石批发市场_钻石买卖_钻石t宝网专业做钻石的网站钻石批发批发网|全国最大钻石批发网网站钻石批发批发网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站。
金务顾问采购狗找的,但你懂的。她在加拿大的钻石交易中心工作过,是金融专业毕业的,钻石批发过程中遇到不靠谱的问题找她就好了。一对一咨询,专业的一逼。注意电话只能回答7天内的问题。电话信息可能有延迟。
查询英国gemfields名下钻石批发商资质最新更新其实可以去英国gemfields名下钻石批发商查询页面自己输入钻石名称查询,谷歌也是这个服务,但是不止查询钻石价格,
手机app专门有钻石批发信息可以查,还有gemfields网站的同步,在gemfields网站基本上包含所有你想了解的信息。
主要是看你找什么资质的钻石批发商了。有的有统一的证书和实体店实时的价格,有的是一个地方一个价,比如说你在广州打折店买,商家肯定就不会和深圳打折店一样便宜。你找了个一个资质的深圳珠宝批发商,她比你找一个深圳的线下实体店价格还低,你就得想想,这钻石到底是不是真的,是不是骗你的了。 查看全部
钻石t宝网专业做钻石的网站-钻石批发网
网站自动采集文章-卖家秀-钻石太子-钻石网_钻石批发市场_钻石买卖_钻石t宝网专业做钻石的网站钻石批发批发网|全国最大钻石批发网网站钻石批发批发网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站。

金务顾问采购狗找的,但你懂的。她在加拿大的钻石交易中心工作过,是金融专业毕业的,钻石批发过程中遇到不靠谱的问题找她就好了。一对一咨询,专业的一逼。注意电话只能回答7天内的问题。电话信息可能有延迟。
查询英国gemfields名下钻石批发商资质最新更新其实可以去英国gemfields名下钻石批发商查询页面自己输入钻石名称查询,谷歌也是这个服务,但是不止查询钻石价格,

手机app专门有钻石批发信息可以查,还有gemfields网站的同步,在gemfields网站基本上包含所有你想了解的信息。
主要是看你找什么资质的钻石批发商了。有的有统一的证书和实体店实时的价格,有的是一个地方一个价,比如说你在广州打折店买,商家肯定就不会和深圳打折店一样便宜。你找了个一个资质的深圳珠宝批发商,她比你找一个深圳的线下实体店价格还低,你就得想想,这钻石到底是不是真的,是不是骗你的了。
如何在这个网站免费获取视频?(内附操作方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2022-07-05 07:01
网站自动采集文章,这些短视频可谓是把“采集论坛,文章,公众号文章,网站”这些小编儿每天的日常工作开发到了极致,看完这篇文章再也不会被人忽悠了。虽然说智能化是一大进步,但实际上你甚至感觉不到自己的无知!不久前,小编也在网上看到了如何采集短视频的文章,但依然是文字,没有图片!本人第一次知道图片能采集的也不多,但小编在万能的某宝上翻到一个能采集视频的网站,本着“上百度找三不一”的原则,来到这里探寻答案!接下来就是实际操作了!下面小编就教你,如何在这个网站免费获取视频!操作方法比较简单,如下(链接已经放在上边,小编用自己的账号):进入这个网站——注册就可以免费进行上传视频——上传完成后进行审核——审核通过后获取链接!好了,上边这么多的我们就不具体讲了,直接上图片,上图片!以上就是具体步骤了,完全免费,不要钱。
其实这个网站刚刚出来不久,做的还不算很好,但是用户量却是如此巨大,要不然为什么这么多人趋之若鹜呢?那么为什么这个网站可以采集短视频?只是因为有一个他的特点:视频是可以直接转码的。这样的视频在其他平台是采集不到的!小编认为这才是这个网站的优势,一般只有好处的事情,不会那么困难,大家一定要试一试!如果你想看一些关于数据采集或者短视频采集之类的内容,那么就关注微信公众号:进取数据或者在值乎里去找到这个专栏或者对我打赏作者的联系方式,不为别的,只为让大家更了解数据!。 查看全部
如何在这个网站免费获取视频?(内附操作方法)

网站自动采集文章,这些短视频可谓是把“采集论坛,文章,公众号文章,网站”这些小编儿每天的日常工作开发到了极致,看完这篇文章再也不会被人忽悠了。虽然说智能化是一大进步,但实际上你甚至感觉不到自己的无知!不久前,小编也在网上看到了如何采集短视频的文章,但依然是文字,没有图片!本人第一次知道图片能采集的也不多,但小编在万能的某宝上翻到一个能采集视频的网站,本着“上百度找三不一”的原则,来到这里探寻答案!接下来就是实际操作了!下面小编就教你,如何在这个网站免费获取视频!操作方法比较简单,如下(链接已经放在上边,小编用自己的账号):进入这个网站——注册就可以免费进行上传视频——上传完成后进行审核——审核通过后获取链接!好了,上边这么多的我们就不具体讲了,直接上图片,上图片!以上就是具体步骤了,完全免费,不要钱。
其实这个网站刚刚出来不久,做的还不算很好,但是用户量却是如此巨大,要不然为什么这么多人趋之若鹜呢?那么为什么这个网站可以采集短视频?只是因为有一个他的特点:视频是可以直接转码的。这样的视频在其他平台是采集不到的!小编认为这才是这个网站的优势,一般只有好处的事情,不会那么困难,大家一定要试一试!如果你想看一些关于数据采集或者短视频采集之类的内容,那么就关注微信公众号:进取数据或者在值乎里去找到这个专栏或者对我打赏作者的联系方式,不为别的,只为让大家更了解数据!。
网站自动采集文章的站群规则介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-06-27 10:01
网站自动采集文章可以得到一些流量和粉丝,也是可以直接转化成交的,同时也可以为企业引入不同方向的流量,形成总体营销转化效果。但如果我们希望更高效的引入流量,我们同样需要重视每个采集站的风格和采集范围。本文就为大家详细介绍每个站群规则。*以下文章摘选自网络个人观点,存在不当之处欢迎各位网友一起探讨。-以下正文;--一、上架时间、采集内容每个网站都会有自己的风格,有的网站偏向学术,比如译言,一些网站偏向是时事资讯,比如喜马拉雅fm等。
对于网站来说,每天都有新的文章发布。小编在采集,比如我要采集西班牙区域的新闻资讯,我就找一些西班牙新闻源,在保证准确性的基础上尽可能搜集多的资讯。网站只需要准确的取材和内容基本采集到一定的量就可以满足转化需求。如果只是一天采集30个资讯,那就需要采集一段时间。如果资讯太多,也会加速热度下降。对于上传单个规格规格也是一样,不是太详细,一周才采集3-5篇文章,就是一个很大的网站了。
另外建议上传的规格是数量为30个,只采集20个热门资讯,文章内容收集维度可以细分为几个不同的文章框架,便于更精细化的进行内容组织,增加系统的深度和精细化程度。二、自动采集技术这个也是不可缺少的,自动采集我们会利用spider,不过要注意的是,用spider采集数据很浪费时间,也可能无法获取高质量的数据。
那么我们可以考虑考虑直接使用第三方采集工具。这个就是极为常见的搜索引擎抓取工具,不会去注册什么账号,只需要登录之后,将一些我们采集的url复制粘贴上去就可以采集,然后生成的网页发布到各大搜索引擎上。这种方式就要考虑到对网站的准确性和搜索引擎的负载。比如国内最知名的是谷歌中国,还有一些我们国内能搜索到的一些比较好的网站,比如穷游网、堆糖网等,对于我们这些用网络只是听说或者试用的小白,通过这些网。 查看全部
网站自动采集文章的站群规则介绍-乐题库
网站自动采集文章可以得到一些流量和粉丝,也是可以直接转化成交的,同时也可以为企业引入不同方向的流量,形成总体营销转化效果。但如果我们希望更高效的引入流量,我们同样需要重视每个采集站的风格和采集范围。本文就为大家详细介绍每个站群规则。*以下文章摘选自网络个人观点,存在不当之处欢迎各位网友一起探讨。-以下正文;--一、上架时间、采集内容每个网站都会有自己的风格,有的网站偏向学术,比如译言,一些网站偏向是时事资讯,比如喜马拉雅fm等。

对于网站来说,每天都有新的文章发布。小编在采集,比如我要采集西班牙区域的新闻资讯,我就找一些西班牙新闻源,在保证准确性的基础上尽可能搜集多的资讯。网站只需要准确的取材和内容基本采集到一定的量就可以满足转化需求。如果只是一天采集30个资讯,那就需要采集一段时间。如果资讯太多,也会加速热度下降。对于上传单个规格规格也是一样,不是太详细,一周才采集3-5篇文章,就是一个很大的网站了。
另外建议上传的规格是数量为30个,只采集20个热门资讯,文章内容收集维度可以细分为几个不同的文章框架,便于更精细化的进行内容组织,增加系统的深度和精细化程度。二、自动采集技术这个也是不可缺少的,自动采集我们会利用spider,不过要注意的是,用spider采集数据很浪费时间,也可能无法获取高质量的数据。
那么我们可以考虑考虑直接使用第三方采集工具。这个就是极为常见的搜索引擎抓取工具,不会去注册什么账号,只需要登录之后,将一些我们采集的url复制粘贴上去就可以采集,然后生成的网页发布到各大搜索引擎上。这种方式就要考虑到对网站的准确性和搜索引擎的负载。比如国内最知名的是谷歌中国,还有一些我们国内能搜索到的一些比较好的网站,比如穷游网、堆糖网等,对于我们这些用网络只是听说或者试用的小白,通过这些网。
java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-06-04 23:25
“java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)心+自动采集)”
01
正文
没有搭建教程,懂的自行下载研究。
安装环境:宝塔面板、tomcat8、nginx1.17、mysql5.6(不知道最高支持到多少)、打开服务器的安全组,放行三个端口8
02
相关截图
注意:下载地址请在公众号内回复:java橙色风格小说/精品屋小说网站源码 查看全部
java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)
“java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)心+自动采集)”
01
正文
没有搭建教程,懂的自行下载研究。
安装环境:宝塔面板、tomcat8、nginx1.17、mysql5.6(不知道最高支持到多少)、打开服务器的安全组,放行三个端口8
02
相关截图
注意:下载地址请在公众号内回复:java橙色风格小说/精品屋小说网站源码
网站自动采集文章,最多可一键抓取800篇内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-06-03 18:02
网站自动采集文章,最多可一键抓取800篇内容。自动化的抓取功能,多数都是在前端采集器来实现。我们推荐两款主流的抓取工具:unblockyourcontent、smartglassphotorecognition。两款工具都可以在本地运行,也能够免费获取。下面为你介绍他们的用法,以及它们的用法的核心是什么。
我们先来看unblockyourcontent,这是一款支持windows和macos的爬虫。unblockyourcontent使用很简单,安装它后不需要注册使用就可以使用,基本都是自动抓取网站的文章。下面以中国文库为例,使用unblockyourcontent抓取20篇某网站的图片文档,采集地址如下:中国文库-免费图片资源分享平台我们为你提供了语言对应的api接口。
smartglassphotorecognition是一款主流的图片自动抓取工具,自动化抓取600多万图片信息。下面以天津1947-2010年历史图片为例。(本地)抓取api接口地址如下::两款工具都可以在本地运行。它们在抓取网站内容的时候,需要进行人工匹配。如果网站已经抓取过多文章内容,基本都要人工上传一篇文章给他们进行匹配。
如果要快速进行短期的抓取工作,比如一次可抓取50篇文章,而工具又只能自动抓取50篇,那就要使用网站自动化的工具比如workflowy来帮忙实现这个功能。unblockyourcontent不支持在本地运行,而smartglass是不支持本地运行的。unblockyourcontent是在windows下运行的,而smartglass是在macos下运行的。
这两款工具都可以跨平台运行。如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你的电脑是macos,那你需要下载相应的ios工具,或者ios的screentoolsforios去下载ios版本的工具。
如果你不想下载工具,那直接下载网站上公布的接口也是可以的。总结如果你想快速抓取大量网站内容,只需要安装unblockyourcontent,然后搭配smartglass使用就行。unblockyourcontent支持windows,macos和ios。smartglass支持windows,macos和ios。
unblockyourcontent能够自动抓取网站内容,而smartglass支持本地爬取。一篇文章只需要获取一次,如果网站已经抓取过多文章可能还要额外对其进行操作。unblockyourcontent是完全免费的,smartglass是收费版。unblockyourcontent是在windows下运行的,smartglass是在macos下运行的。
如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你不想下载工具,那。 查看全部
网站自动采集文章,最多可一键抓取800篇内容
网站自动采集文章,最多可一键抓取800篇内容。自动化的抓取功能,多数都是在前端采集器来实现。我们推荐两款主流的抓取工具:unblockyourcontent、smartglassphotorecognition。两款工具都可以在本地运行,也能够免费获取。下面为你介绍他们的用法,以及它们的用法的核心是什么。
我们先来看unblockyourcontent,这是一款支持windows和macos的爬虫。unblockyourcontent使用很简单,安装它后不需要注册使用就可以使用,基本都是自动抓取网站的文章。下面以中国文库为例,使用unblockyourcontent抓取20篇某网站的图片文档,采集地址如下:中国文库-免费图片资源分享平台我们为你提供了语言对应的api接口。
smartglassphotorecognition是一款主流的图片自动抓取工具,自动化抓取600多万图片信息。下面以天津1947-2010年历史图片为例。(本地)抓取api接口地址如下::两款工具都可以在本地运行。它们在抓取网站内容的时候,需要进行人工匹配。如果网站已经抓取过多文章内容,基本都要人工上传一篇文章给他们进行匹配。
如果要快速进行短期的抓取工作,比如一次可抓取50篇文章,而工具又只能自动抓取50篇,那就要使用网站自动化的工具比如workflowy来帮忙实现这个功能。unblockyourcontent不支持在本地运行,而smartglass是不支持本地运行的。unblockyourcontent是在windows下运行的,而smartglass是在macos下运行的。
这两款工具都可以跨平台运行。如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你的电脑是macos,那你需要下载相应的ios工具,或者ios的screentoolsforios去下载ios版本的工具。
如果你不想下载工具,那直接下载网站上公布的接口也是可以的。总结如果你想快速抓取大量网站内容,只需要安装unblockyourcontent,然后搭配smartglass使用就行。unblockyourcontent支持windows,macos和ios。smartglass支持windows,macos和ios。
unblockyourcontent能够自动抓取网站内容,而smartglass支持本地爬取。一篇文章只需要获取一次,如果网站已经抓取过多文章可能还要额外对其进行操作。unblockyourcontent是完全免费的,smartglass是收费版。unblockyourcontent是在windows下运行的,smartglass是在macos下运行的。
如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你不想下载工具,那。
网站自动采集文章来提高网站流量。做seo的朋友都知道
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-06-03 07:02
网站自动采集文章来提高网站流量。做seo的朋友都知道,网站自动采集是通过采集自己网站里面的文章内容放到自己网站,然后给有这些文章的网站做一个外链。网站里面的文章都可以采集。如果一篇文章很大,分为上百篇文章,这一篇文章就可以采集多篇内容过来。网站自动采集最有价值的就是里面的推荐内容。凡是能给网站带来流量的文章,这些内容都可以是采集到网站的自动采集源。
如果只是每天采集一篇文章,一个月没有个几千块钱,自己搜集的文章都放到网站里面,就真的是浪费了。网站的采集按照行业划分,每一个行业里面都可以加很多的文章,把一个行业里面比较优质的文章整理成一篇文章,把这篇文章放到网站里面,起码可以获得几百上千的点击。如果再对推荐源进行优化的话,是可以获得百万到千万甚至是更多的流量。这些流量都是来自于网站自动采集网站。所以采集内容是可以带来巨大的流量的。
网站的推荐源是给某个行业网站做网站上,来给你带来访问量,作为跳转让你访问该行业网站进行询盘,这个是可以赚钱的。这是网站的,不是其他的,
自媒体平台上引流方法引流流量,分为三个小步骤,即文章链接和网站对接,
你自己写一篇发到自己的公众号上,一篇阅读量10万的文章收费五万, 查看全部
网站自动采集文章来提高网站流量。做seo的朋友都知道
网站自动采集文章来提高网站流量。做seo的朋友都知道,网站自动采集是通过采集自己网站里面的文章内容放到自己网站,然后给有这些文章的网站做一个外链。网站里面的文章都可以采集。如果一篇文章很大,分为上百篇文章,这一篇文章就可以采集多篇内容过来。网站自动采集最有价值的就是里面的推荐内容。凡是能给网站带来流量的文章,这些内容都可以是采集到网站的自动采集源。
如果只是每天采集一篇文章,一个月没有个几千块钱,自己搜集的文章都放到网站里面,就真的是浪费了。网站的采集按照行业划分,每一个行业里面都可以加很多的文章,把一个行业里面比较优质的文章整理成一篇文章,把这篇文章放到网站里面,起码可以获得几百上千的点击。如果再对推荐源进行优化的话,是可以获得百万到千万甚至是更多的流量。这些流量都是来自于网站自动采集网站。所以采集内容是可以带来巨大的流量的。
网站的推荐源是给某个行业网站做网站上,来给你带来访问量,作为跳转让你访问该行业网站进行询盘,这个是可以赚钱的。这是网站的,不是其他的,
自媒体平台上引流方法引流流量,分为三个小步骤,即文章链接和网站对接,
你自己写一篇发到自己的公众号上,一篇阅读量10万的文章收费五万,
Web UI自动化测试之日志收集篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-11 11:05
本文大纲截图:
1、日志介绍
日志: 用于记录系统运行时的信息,对一个事件的记录,也称为Log。
日志作用:
日志级别:
日志级别:指日志信息的优先级、重要性或者严重程度。
常见的日志级别: DEBUG、INFO、WARNING、ERROR、CRITICAL
import logging<br /><br /><br />logging.debug("这是一条调试信息")<br />logging.info("这是一条普通信息")<br />logging.warning("这是一条警告信息")<br />logging.error("这是一条错误信息")<br />logging.critical("这是一条严重错误信息")<br />
说明:
2、日志用法2.1 基本用法
设置日志级别:
设置日志格式:
代码示例:
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
将日志信息输出到文件中
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(filename="a.log", level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
2.2 高级用法
logging日志模块四大组件: Logger、Handler、Formatter、Filter
组件关系:
Logger类:
Logger常用的方法:
设置日志级别:logger.setLevel(),设置日志器将会处理的日志消息的最低严重级别
添加handler对象:logger.addHandler(),为该logger对象添加一个handler对象
添加filter对象:logger.addFilter(),为该logger对象添加一个filter对象
Handler类:
Handler常用的方法:
Formatter类:
将日志信息同时输出到控制台和文件中:
定义日志格式:
# 设置日志格式<br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br /># 创建格式化器对象<br />formatter = logging.Formatter(fmt)<br />
logger = logging.getLogger()<br />sh = logging.StreamHandler()<br />sh.setFormatter(formatter)<br />logger.addHandler(sh)<br />
fh = logging.FileHandler("./b.log")<br />fh.setFormatter(formatter)<br />logger.addHandler(fh)<br />
每日生成一个日志文件:
fh = logging.handlers.TimedRotatingFileHandler(filename, when='h', interval=1, backupCount=0)<br /> # 将日志信息记录到文件中,以特定的时间间隔切换日志文件。<br /> # filename: 日志文件名<br /> # when: 时间单位,可选参数<br /> # S - Seconds<br /> # M - Minutes<br /> # H - Hours<br /> # D - Days<br /> # midnight - roll over at midnight<br /> # W{0-6} - roll over on a certain day; 0 - Monday<br /> # interval: 时间间隔<br /> # backupCount: 日志文件备份数量。<br /> # 如果backupCount大于0,那么当生成新的日志文件时,将只保留backupCount个文件,删除最老的文件。<br />
import logging.handlers<br /><br /><br />logger = logging.getLogger()<br />logger.setLevel(logging.DEBUG)<br /><br /># 日志格式<br />fmt = "%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s"<br />formatter = logging.Formatter(fmt)<br /><br /># 输出到文件,每日一个文件<br />fh = logging.handlers.TimedRotatingFileHandler("./a.log", when='MIDNIGHT', interval=1, backupCount=3)<br />fh.setFormatter(formatter)<br />fh.setLevel(logging.INFO)<br />logger.addHandler(fh)<br />
日志封装成工具(tools):
# 导包<br />import logging.handlers<br /><br /><br /># 定义日志器方法 ,封装日志<br />def get_logger():<br /> # 获取 日志器logger,并设置名称admin<br /> logger = logging.getLogger("admin")<br /> # 设置日志级别为info<br /> logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器,根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(filename="../log/logger.log", when="S", interval=1, backupCount=2, encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s %(lineno)d)] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器中<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器中<br /> logger.addHandler(sh)<br /> logger.addHandler(th)<br /> # 返回 logger<br /> return logger<br /><br /><br />if __name__ == '__main__':<br /> logger = get_logger()<br /> # 日志器应用<br /> logger.info("这是info信息")<br /> logger.warning("这是warning信息")<br /> logger.error("这是error信息")<br />
3、日志应用
日志应用:PO模式中,在base操作层、page对象层、scripts业务层都可添加日志,以及将日志用单例模式封装成工具类放在tools文件夹中。
import time<br />from time import sleep<br />from selenium.webdriver.support.wait import WebDriverWait<br />from day11_tpshop import page<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class Base:<br /> def __init__(self, driver):<br /> log.info("[base:]正在获取初始化driver对象:{}".format(driver))<br /> self.driver = driver<br /><br /> # 查找元素方法 封装<br /> def base_find(self, loc, timeout=30, poll=0.5):<br /> log.info("[base]:正在定位:{}元素,默认定位超时时间为:{}".format(loc, timeout))<br /> # 使用显式等待 查找元素<br /> return WebDriverWait(self.driver,<br /> timeout=timeout,<br /> poll_frequency=poll).until(lambda x: x.find_element(*loc))<br /><br /> # 点击元素方法 封装<br /> def base_click(self, loc):<br /> log.info("[base]:正在对:{}元素执行点击事件".format(loc))<br /> self.base_find(loc).click()<br /><br /> # 输入元素方法 封装<br /> def base_input(self, loc, value):<br /> log.info("[base]:正在获取:{}元素".format(loc))<br /> # 获取元素<br /> el = self.base_find(loc)<br /> log.info("[base]:正在对:{}元素执行清空操作".format(loc))<br /> # 输入前 清空<br /> el.clear()<br /> log.info("[base]:正在给{}元素输入内容:{}".format(loc, value))<br /> # 输入<br /> el.send_keys(value)<br /><br /> # 获取文本信息方法 封装<br /> def base_get_text(self, loc):<br /> log.info("[base]:正在获取{}元素文本值".format(loc))<br /> return self.base_find(loc).text<br /><br /> # 截图方法 封装<br /> def base_get_img(self):<br /> log.info("[base]:断言出错,调用截图")<br /> self.driver.get_screenshot_as_file("../image/{}.png".format(time.strftime("%Y_%m_%d %H_%M_%S")))<br /><br /> # 判断元素是否存在方法 封装<br /> def base_elememt_is_exist(self, loc):<br /> try:<br /> self.base_find(loc, timeout=2)<br /> log.info("[base]:{}元素查找成功,存在页面".format(loc))<br /> return True # 代表元素存在<br /> except:<br /> log.info("[base]:{}元素查找失败,不存在当前页面".format(loc))<br /> return False # 代表元素不存在<br /><br /> # 回到首页(购物车、下订单、支付)都需要用到此方法<br /> def base_index(self):<br /> # 暂停2秒<br /> sleep(2)<br /> log.info("[base]:正在打开首页")<br /> self.driver.get(page.URL)<br /><br /> # 切到frame表单方法 以元素属性切换<br /> def base_switch_frame(self, element):<br /> log.info("[base]:正在切换到frame表单")<br /> self.driver.switch_to.frame(element)<br /><br /> # 回到默认目录方法<br /> def base_default_content(self):<br /> log.info("[base]:正在返回默认目录")<br /> self.driver.switch_to.default_content()<br /><br /> # 切换窗口方法<br /> def base_switch_to_window(self, title):<br /> log.info("正在执行切换title值为:{}窗口".format(title))<br /> self.base_get_title_handle(title)<br /> # self.driver.switch_to.window(self.base_get_title_handle(title))<br /><br /> # 获取指定title页面的handle方法<br /> def base_get_title_handle(self, title):<br /> # 获取当前页面所有的handles<br /> handles = self.driver.window_handles<br /> # 遍历handle<br /> for handle in handles:<br /> log.info("正在遍历handles:{}-->{}".format(handle, handles))<br /> # 切换 handle<br /> self.driver.switch_to.window(handle)<br /> log.info("切换:{}窗口".format(handle))<br /> # 获取当前页面title 并判断 是否等于 指定参数title<br /> log.info("条件成立!返回当前handle{}".format(handle))<br /> if self.driver.title == title:<br /> # 返回 handle<br /> return handle<br />
from day11_tpshop import page<br />from day11_tpshop.base.base import Base<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class PageLogin(Base):<br /> # 点击 登录链接<br /> def page_click_login_link(self):<br /> log.info("[page_login]:执行{}元素点击链接操作".format(page.login_link))<br /> self.base_click(page.login_link)<br /><br /> # 输入用户名<br /> def page_input_username(self, username):<br /> log.info("[page_login]:对{}元素 输入用户名{}操作".format(page.login_username, username))<br /> self.base_input(page.login_username, username)<br /><br /> # 输入密码<br /> def page_input_pwd(self, pwd):<br /> log.info("[page_login]:对{}元素 输入密码{}操作".format(page.login_pwd, pwd))<br /> self.base_input(page.login_pwd, pwd)<br /><br /> # 输入验证码<br /> def page_input_verify_code(self, verify_code):<br /> log.info("[page_login]:对{}元素 输入验证码{}操作".format(page.login_verify_code, verify_code))<br /> self.base_input(page.login_verify_code, verify_code)<br /><br /> # 点击 登录<br /> def page_click_login_btn(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_btn))<br /> self.base_click(page.login_btn)<br /><br /> # 获取 错误提示信息<br /> def page_get_err_info(self):<br /> return self.base_get_text(page.login_err_info)<br /><br /> # 点击 错误提示框 确定按钮<br /> def page_click_error_alert(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_err_ok_btn))<br /> self.base_click(page.login_err_ok_btn)<br /><br /> # 判断是否登录成功<br /> def page_if_login_success(self):<br /> # 注意 一定要将找元素的结果返回,True:存在<br /> return self.base_elememt_is_exist(page.login_logout_link)<br /><br /> # 点击 安全退出<br /> def page_click_logout_link(self):<br /> self.base_click(page.login_logout_link)<br /><br /> # 判断是否退出成功<br /> def page_if_logout_success(self):<br /> return self.base_elememt_is_exist(page.login_link)<br /><br /> # 组合业务方法 登录业务直接调用<br /> def page_login(self, username, pwd, verify_code):<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br /><br /> # 组合登录业务方法 给(购物车模块、订单模块、支付模块)依赖登录使用<br /> def page_login_success(self, username="13800001111", pwd="123456", verify_code="8888"):<br /> # 点击登录链接<br /> self.page_click_login_link()<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br />
import unittest<br />from day11_TPshop项目.base.get_driver import GetDriver<br />from day11_TPshop项目.base.get_logger import GetLogger<br />from day11_TPshop项目.page.page_login import PageLogin<br />from day11_TPshop项目.tools.read_txt import read_txt<br />from parameterized import parameterized<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />def get_data():<br /> arrs = []<br /> for data in read_txt("login.txt"):<br /> arrs.append(tuple(data.strip().split(",")))<br /> return arrs[1:]<br /><br /><br /># 新建 登录测试类 并 继承 unittest.TestCase<br />class TestLogin(unittest.TestCase):<br /> # 新建 setUpClass<br /> @classmethod<br /> def setUpClass(cls) -> None:<br /> try:<br /> # 实例化 并获取 driver<br /> cls.driver = GetDriver.get_driver()<br /> # 实例化 PageLogin()<br /> cls.login = PageLogin(cls.driver)<br /> # 点击登录链接<br /> cls.login.page_click_login_link()<br /> except Exception as e:<br /> # 截图<br /> cls.login.base_get_img()<br /> # 日志<br /> log.error("错误:{}".format(e))<br /><br /> # 新建 tearDownClass<br /> @classmethod<br /> def tearDownClass(cls) -> None:<br /> # 关闭driver驱动对象<br /> GetDriver.quit_driver()<br /><br /> # 新建 登录测试方法<br /> @parameterized.expand(get_data())<br /> def test_login(self, username, pwd, verify_code, expect_result, status):<br /> try:<br /> # 调用 登录业务方法<br /> self.login.page_login(username, pwd, verify_code)<br /><br /> # 判断是否为正向<br /> if status == "true":<br /> # 断言是否登录成功<br /> try:<br /> self.assertTrue(self.login.page_if_login_success())<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击 安全退出<br /> self.login.page_click_logout_link()<br /> # 点击 登录链接<br /> self.login.page_click_login_link()<br /> # 逆向用例<br /> else:<br /> # 获取错误提示信息<br /> msg = self.login.page_get_err_info()<br /> print("msg:", msg)<br /> try:<br /> self.assertEqual(msg, expect_result)<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击错误提示框 确定按钮<br /> self.login.page_click_error_alert()<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br />
import logging.handlers<br />import time<br /><br /><br />class GetLogger:<br /> logger = None<br /><br /> # 获取logger<br /> @classmethod<br /> def get_logger(cls):<br /> if cls.logger is None:<br /> # 获取 logger 日志器 并设置名称为“admin”<br /> cls.logger = logging.getLogger("admin")<br /> # 设置日志级别<br /> cls.logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器 根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(<br /> filename="../log/{}.log".format(time.strftime("%Y_%m_%d %H_%M_%S")),<br /> when="S",<br /> interval=1,<br /> backupCount=3,<br /> encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s %(funcName)s %(lineno)d] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器<br /> cls.logger.addHandler(sh)<br /> cls.logger.addHandler(th)<br /> # 返回日志器<br /> return cls.logger<br /><br /><br />if __name__ == '__main__':<br /> logger = GetLogger.get_logger()<br /> # 日志器应用<br /> logger.info("这是info日志信息")<br /> logger.debug("这是debug日志信息")<br /> logger.warning("这是warning日志信息")<br /> logger.error("这是error日志信息")<br /> 查看全部
Web UI自动化测试之日志收集篇
本文大纲截图:
1、日志介绍
日志: 用于记录系统运行时的信息,对一个事件的记录,也称为Log。
日志作用:
日志级别:
日志级别:指日志信息的优先级、重要性或者严重程度。
常见的日志级别: DEBUG、INFO、WARNING、ERROR、CRITICAL
import logging<br /><br /><br />logging.debug("这是一条调试信息")<br />logging.info("这是一条普通信息")<br />logging.warning("这是一条警告信息")<br />logging.error("这是一条错误信息")<br />logging.critical("这是一条严重错误信息")<br />
说明:
2、日志用法2.1 基本用法
设置日志级别:
设置日志格式:
代码示例:
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
将日志信息输出到文件中
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(filename="a.log", level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
2.2 高级用法
logging日志模块四大组件: Logger、Handler、Formatter、Filter
组件关系:
Logger类:
Logger常用的方法:
设置日志级别:logger.setLevel(),设置日志器将会处理的日志消息的最低严重级别
添加handler对象:logger.addHandler(),为该logger对象添加一个handler对象
添加filter对象:logger.addFilter(),为该logger对象添加一个filter对象
Handler类:
Handler常用的方法:
Formatter类:
将日志信息同时输出到控制台和文件中:
定义日志格式:
# 设置日志格式<br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br /># 创建格式化器对象<br />formatter = logging.Formatter(fmt)<br />
logger = logging.getLogger()<br />sh = logging.StreamHandler()<br />sh.setFormatter(formatter)<br />logger.addHandler(sh)<br />
fh = logging.FileHandler("./b.log")<br />fh.setFormatter(formatter)<br />logger.addHandler(fh)<br />
每日生成一个日志文件:
fh = logging.handlers.TimedRotatingFileHandler(filename, when='h', interval=1, backupCount=0)<br /> # 将日志信息记录到文件中,以特定的时间间隔切换日志文件。<br /> # filename: 日志文件名<br /> # when: 时间单位,可选参数<br /> # S - Seconds<br /> # M - Minutes<br /> # H - Hours<br /> # D - Days<br /> # midnight - roll over at midnight<br /> # W{0-6} - roll over on a certain day; 0 - Monday<br /> # interval: 时间间隔<br /> # backupCount: 日志文件备份数量。<br /> # 如果backupCount大于0,那么当生成新的日志文件时,将只保留backupCount个文件,删除最老的文件。<br />
import logging.handlers<br /><br /><br />logger = logging.getLogger()<br />logger.setLevel(logging.DEBUG)<br /><br /># 日志格式<br />fmt = "%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s"<br />formatter = logging.Formatter(fmt)<br /><br /># 输出到文件,每日一个文件<br />fh = logging.handlers.TimedRotatingFileHandler("./a.log", when='MIDNIGHT', interval=1, backupCount=3)<br />fh.setFormatter(formatter)<br />fh.setLevel(logging.INFO)<br />logger.addHandler(fh)<br />
日志封装成工具(tools):
# 导包<br />import logging.handlers<br /><br /><br /># 定义日志器方法 ,封装日志<br />def get_logger():<br /> # 获取 日志器logger,并设置名称admin<br /> logger = logging.getLogger("admin")<br /> # 设置日志级别为info<br /> logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器,根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(filename="../log/logger.log", when="S", interval=1, backupCount=2, encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s %(lineno)d)] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器中<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器中<br /> logger.addHandler(sh)<br /> logger.addHandler(th)<br /> # 返回 logger<br /> return logger<br /><br /><br />if __name__ == '__main__':<br /> logger = get_logger()<br /> # 日志器应用<br /> logger.info("这是info信息")<br /> logger.warning("这是warning信息")<br /> logger.error("这是error信息")<br />
3、日志应用
日志应用:PO模式中,在base操作层、page对象层、scripts业务层都可添加日志,以及将日志用单例模式封装成工具类放在tools文件夹中。
import time<br />from time import sleep<br />from selenium.webdriver.support.wait import WebDriverWait<br />from day11_tpshop import page<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class Base:<br /> def __init__(self, driver):<br /> log.info("[base:]正在获取初始化driver对象:{}".format(driver))<br /> self.driver = driver<br /><br /> # 查找元素方法 封装<br /> def base_find(self, loc, timeout=30, poll=0.5):<br /> log.info("[base]:正在定位:{}元素,默认定位超时时间为:{}".format(loc, timeout))<br /> # 使用显式等待 查找元素<br /> return WebDriverWait(self.driver,<br /> timeout=timeout,<br /> poll_frequency=poll).until(lambda x: x.find_element(*loc))<br /><br /> # 点击元素方法 封装<br /> def base_click(self, loc):<br /> log.info("[base]:正在对:{}元素执行点击事件".format(loc))<br /> self.base_find(loc).click()<br /><br /> # 输入元素方法 封装<br /> def base_input(self, loc, value):<br /> log.info("[base]:正在获取:{}元素".format(loc))<br /> # 获取元素<br /> el = self.base_find(loc)<br /> log.info("[base]:正在对:{}元素执行清空操作".format(loc))<br /> # 输入前 清空<br /> el.clear()<br /> log.info("[base]:正在给{}元素输入内容:{}".format(loc, value))<br /> # 输入<br /> el.send_keys(value)<br /><br /> # 获取文本信息方法 封装<br /> def base_get_text(self, loc):<br /> log.info("[base]:正在获取{}元素文本值".format(loc))<br /> return self.base_find(loc).text<br /><br /> # 截图方法 封装<br /> def base_get_img(self):<br /> log.info("[base]:断言出错,调用截图")<br /> self.driver.get_screenshot_as_file("../image/{}.png".format(time.strftime("%Y_%m_%d %H_%M_%S")))<br /><br /> # 判断元素是否存在方法 封装<br /> def base_elememt_is_exist(self, loc):<br /> try:<br /> self.base_find(loc, timeout=2)<br /> log.info("[base]:{}元素查找成功,存在页面".format(loc))<br /> return True # 代表元素存在<br /> except:<br /> log.info("[base]:{}元素查找失败,不存在当前页面".format(loc))<br /> return False # 代表元素不存在<br /><br /> # 回到首页(购物车、下订单、支付)都需要用到此方法<br /> def base_index(self):<br /> # 暂停2秒<br /> sleep(2)<br /> log.info("[base]:正在打开首页")<br /> self.driver.get(page.URL)<br /><br /> # 切到frame表单方法 以元素属性切换<br /> def base_switch_frame(self, element):<br /> log.info("[base]:正在切换到frame表单")<br /> self.driver.switch_to.frame(element)<br /><br /> # 回到默认目录方法<br /> def base_default_content(self):<br /> log.info("[base]:正在返回默认目录")<br /> self.driver.switch_to.default_content()<br /><br /> # 切换窗口方法<br /> def base_switch_to_window(self, title):<br /> log.info("正在执行切换title值为:{}窗口".format(title))<br /> self.base_get_title_handle(title)<br /> # self.driver.switch_to.window(self.base_get_title_handle(title))<br /><br /> # 获取指定title页面的handle方法<br /> def base_get_title_handle(self, title):<br /> # 获取当前页面所有的handles<br /> handles = self.driver.window_handles<br /> # 遍历handle<br /> for handle in handles:<br /> log.info("正在遍历handles:{}-->{}".format(handle, handles))<br /> # 切换 handle<br /> self.driver.switch_to.window(handle)<br /> log.info("切换:{}窗口".format(handle))<br /> # 获取当前页面title 并判断 是否等于 指定参数title<br /> log.info("条件成立!返回当前handle{}".format(handle))<br /> if self.driver.title == title:<br /> # 返回 handle<br /> return handle<br />
from day11_tpshop import page<br />from day11_tpshop.base.base import Base<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class PageLogin(Base):<br /> # 点击 登录链接<br /> def page_click_login_link(self):<br /> log.info("[page_login]:执行{}元素点击链接操作".format(page.login_link))<br /> self.base_click(page.login_link)<br /><br /> # 输入用户名<br /> def page_input_username(self, username):<br /> log.info("[page_login]:对{}元素 输入用户名{}操作".format(page.login_username, username))<br /> self.base_input(page.login_username, username)<br /><br /> # 输入密码<br /> def page_input_pwd(self, pwd):<br /> log.info("[page_login]:对{}元素 输入密码{}操作".format(page.login_pwd, pwd))<br /> self.base_input(page.login_pwd, pwd)<br /><br /> # 输入验证码<br /> def page_input_verify_code(self, verify_code):<br /> log.info("[page_login]:对{}元素 输入验证码{}操作".format(page.login_verify_code, verify_code))<br /> self.base_input(page.login_verify_code, verify_code)<br /><br /> # 点击 登录<br /> def page_click_login_btn(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_btn))<br /> self.base_click(page.login_btn)<br /><br /> # 获取 错误提示信息<br /> def page_get_err_info(self):<br /> return self.base_get_text(page.login_err_info)<br /><br /> # 点击 错误提示框 确定按钮<br /> def page_click_error_alert(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_err_ok_btn))<br /> self.base_click(page.login_err_ok_btn)<br /><br /> # 判断是否登录成功<br /> def page_if_login_success(self):<br /> # 注意 一定要将找元素的结果返回,True:存在<br /> return self.base_elememt_is_exist(page.login_logout_link)<br /><br /> # 点击 安全退出<br /> def page_click_logout_link(self):<br /> self.base_click(page.login_logout_link)<br /><br /> # 判断是否退出成功<br /> def page_if_logout_success(self):<br /> return self.base_elememt_is_exist(page.login_link)<br /><br /> # 组合业务方法 登录业务直接调用<br /> def page_login(self, username, pwd, verify_code):<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br /><br /> # 组合登录业务方法 给(购物车模块、订单模块、支付模块)依赖登录使用<br /> def page_login_success(self, username="13800001111", pwd="123456", verify_code="8888"):<br /> # 点击登录链接<br /> self.page_click_login_link()<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br />
import unittest<br />from day11_TPshop项目.base.get_driver import GetDriver<br />from day11_TPshop项目.base.get_logger import GetLogger<br />from day11_TPshop项目.page.page_login import PageLogin<br />from day11_TPshop项目.tools.read_txt import read_txt<br />from parameterized import parameterized<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />def get_data():<br /> arrs = []<br /> for data in read_txt("login.txt"):<br /> arrs.append(tuple(data.strip().split(",")))<br /> return arrs[1:]<br /><br /><br /># 新建 登录测试类 并 继承 unittest.TestCase<br />class TestLogin(unittest.TestCase):<br /> # 新建 setUpClass<br /> @classmethod<br /> def setUpClass(cls) -> None:<br /> try:<br /> # 实例化 并获取 driver<br /> cls.driver = GetDriver.get_driver()<br /> # 实例化 PageLogin()<br /> cls.login = PageLogin(cls.driver)<br /> # 点击登录链接<br /> cls.login.page_click_login_link()<br /> except Exception as e:<br /> # 截图<br /> cls.login.base_get_img()<br /> # 日志<br /> log.error("错误:{}".format(e))<br /><br /> # 新建 tearDownClass<br /> @classmethod<br /> def tearDownClass(cls) -> None:<br /> # 关闭driver驱动对象<br /> GetDriver.quit_driver()<br /><br /> # 新建 登录测试方法<br /> @parameterized.expand(get_data())<br /> def test_login(self, username, pwd, verify_code, expect_result, status):<br /> try:<br /> # 调用 登录业务方法<br /> self.login.page_login(username, pwd, verify_code)<br /><br /> # 判断是否为正向<br /> if status == "true":<br /> # 断言是否登录成功<br /> try:<br /> self.assertTrue(self.login.page_if_login_success())<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击 安全退出<br /> self.login.page_click_logout_link()<br /> # 点击 登录链接<br /> self.login.page_click_login_link()<br /> # 逆向用例<br /> else:<br /> # 获取错误提示信息<br /> msg = self.login.page_get_err_info()<br /> print("msg:", msg)<br /> try:<br /> self.assertEqual(msg, expect_result)<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击错误提示框 确定按钮<br /> self.login.page_click_error_alert()<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br />
import logging.handlers<br />import time<br /><br /><br />class GetLogger:<br /> logger = None<br /><br /> # 获取logger<br /> @classmethod<br /> def get_logger(cls):<br /> if cls.logger is None:<br /> # 获取 logger 日志器 并设置名称为“admin”<br /> cls.logger = logging.getLogger("admin")<br /> # 设置日志级别<br /> cls.logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器 根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(<br /> filename="../log/{}.log".format(time.strftime("%Y_%m_%d %H_%M_%S")),<br /> when="S",<br /> interval=1,<br /> backupCount=3,<br /> encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s %(funcName)s %(lineno)d] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器<br /> cls.logger.addHandler(sh)<br /> cls.logger.addHandler(th)<br /> # 返回日志器<br /> return cls.logger<br /><br /><br />if __name__ == '__main__':<br /> logger = GetLogger.get_logger()<br /> # 日志器应用<br /> logger.info("这是info日志信息")<br /> logger.debug("这是debug日志信息")<br /> logger.warning("这是warning日志信息")<br /> logger.error("这是error日志信息")<br />
网站自动采集博客首页网址是非常重要的吗?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-05-02 15:00
网站自动采集文章是比较常见的。对于博客来说,数据库是自己写的,那么自动采集博客首页网址这一功能是非常重要的。另外,随着大多数用户对博客爬虫的依赖度越来越低,在满足于博客文章搜索的基础上,还要增加对网站采集的功能,越来越趋于必要了。说来,网站数据源于网站发布,采集可以看做一种二次开发,把原网站业务抽象重新定义后的业务,能为其他新需求解决一些难点。
此外,无论是采集还是搜索,都需要经过多次请求和返回内容结果,那么使用scrapy这样一个轻量级的爬虫框架,它本身就允许爬虫采集并返回requeststatus报文。抓取一个网站最关键的地方在于返回给你的内容,而不在于返回内容是什么。所以,网站自动采集功能没有必要精细到,一定是要对不同网站生成不同的loginfo脚本的。
或者是不同网站单独设计模块,发布的时候各开发一套,如果爬虫走正则路线,当然是哪个网站发布,哪个网站的不同版本爬虫就往那个网站去爬。
编写网站爬虫要看你爬取什么内容,如果仅仅是网站首页,可以用scrapy框架写爬虫,如果要爬取源代码,需要用python写scrapy提供的item配置;采集同一个网站可以分布式采集,
你说的是java或者python进行自动爬取吗? 查看全部
网站自动采集博客首页网址是非常重要的吗?-八维教育
网站自动采集文章是比较常见的。对于博客来说,数据库是自己写的,那么自动采集博客首页网址这一功能是非常重要的。另外,随着大多数用户对博客爬虫的依赖度越来越低,在满足于博客文章搜索的基础上,还要增加对网站采集的功能,越来越趋于必要了。说来,网站数据源于网站发布,采集可以看做一种二次开发,把原网站业务抽象重新定义后的业务,能为其他新需求解决一些难点。
此外,无论是采集还是搜索,都需要经过多次请求和返回内容结果,那么使用scrapy这样一个轻量级的爬虫框架,它本身就允许爬虫采集并返回requeststatus报文。抓取一个网站最关键的地方在于返回给你的内容,而不在于返回内容是什么。所以,网站自动采集功能没有必要精细到,一定是要对不同网站生成不同的loginfo脚本的。
或者是不同网站单独设计模块,发布的时候各开发一套,如果爬虫走正则路线,当然是哪个网站发布,哪个网站的不同版本爬虫就往那个网站去爬。
编写网站爬虫要看你爬取什么内容,如果仅仅是网站首页,可以用scrapy框架写爬虫,如果要爬取源代码,需要用python写scrapy提供的item配置;采集同一个网站可以分布式采集,
你说的是java或者python进行自动爬取吗?
网站自动采集文章的好处有哪些?怎么提高收录率
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-01 01:02
网站自动采集文章的好处:第
一、方便快捷。
二、提高自己网站的收录和排名。
三、网站数据安全。
方法:只需要做好以下几个方面
1)输入你的网站名称。
2)注意采集的文章的规范
3)选择核心关键词。
有的。比如网友自己新创建的一个文档,我们推送出去的链接就是自己创建的文档里面的内容,如果你的网站想采集同一个用户新创建的文档,可以把这个文档同时提交给百度和必应搜索,必应会直接显示这个文档的原文档。以我现在的经验,同一个用户新创建的文档,百度比必应采集下来的原文档会多很多。百度网友之间都可以互相推送文档。
额。
貌似是老网站创建新网站,再挂链接到旧网站上。
update2014-07-24:问题已经解决,只不过是baidu直接复制的,希望能有用。给大家发个福利吧,自己新建一个网站()和免费书籍提供者联系,免费领取书籍哦。
其实有人问到这个问题,就已经证明有人利用这个漏洞来提高这个网站收录率的。某公司利用“pc+无线+手机”三端同步收录域名,而中国小网站太多,必应,搜狗,百度,360,谷歌等等收录一大堆。不过你这种提交并不会引起收录。
百度不会做那么愚蠢的事情,因为百度不是你的竞争对手,而且它对有利于自己收录率的文章会有人无偿分享出来。 查看全部
网站自动采集文章的好处有哪些?怎么提高收录率
网站自动采集文章的好处:第
一、方便快捷。
二、提高自己网站的收录和排名。
三、网站数据安全。
方法:只需要做好以下几个方面
1)输入你的网站名称。
2)注意采集的文章的规范
3)选择核心关键词。
有的。比如网友自己新创建的一个文档,我们推送出去的链接就是自己创建的文档里面的内容,如果你的网站想采集同一个用户新创建的文档,可以把这个文档同时提交给百度和必应搜索,必应会直接显示这个文档的原文档。以我现在的经验,同一个用户新创建的文档,百度比必应采集下来的原文档会多很多。百度网友之间都可以互相推送文档。
额。
貌似是老网站创建新网站,再挂链接到旧网站上。
update2014-07-24:问题已经解决,只不过是baidu直接复制的,希望能有用。给大家发个福利吧,自己新建一个网站()和免费书籍提供者联系,免费领取书籍哦。
其实有人问到这个问题,就已经证明有人利用这个漏洞来提高这个网站收录率的。某公司利用“pc+无线+手机”三端同步收录域名,而中国小网站太多,必应,搜狗,百度,360,谷歌等等收录一大堆。不过你这种提交并不会引起收录。
百度不会做那么愚蠢的事情,因为百度不是你的竞争对手,而且它对有利于自己收录率的文章会有人无偿分享出来。
【帮转】鱼鱼站群cms
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-29 17:20
这次的事情是这样的:上次这个大兄弟的站群CMS整好了,本渣再次帮转下。
总的来说:
1)基于java开发,高并发请求的场景,java比php更能打
2)内置ElasticSearch开源搜索,似乎意味着可以导入关键词后,自动索引生成聚合
3)内置GPT,似乎意味着可通过GPT深度学习生成AI原创文章
4)内置一堆插件,比如Baidu、Google排名查询,以及N套模板
本渣第一感觉:功能强大;ES吃内存,GPT吃GPU和语料质量,硬件成本或许会高一些,但没准有黑科技呢
没亲自测试过,毕竟本渣SEO水平已落伍多年,已经不懂SEO了
感兴趣的朋友请自行联系这位大兄弟测试,微信放在最下面了
【转发内容】
导读:站群是什么?站群是由几个到几百个网站组成;
泛站群是什么?泛站群由用一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页的站群;
泛目录又是什么了?泛目录由1个网站上面生成无限个目录页面。
介绍完这些,市面这么多站群方式方法,我们这些个人站长想通过手工更新站群,那几乎是不可能的任务。一般都是通过站群来完成。进行全自动更新等。
鱼鱼站群cms经历了将近一年的构思,开发,打磨,开发出一套让站长朋友们省心、高效获取seo流量的cms系统,现在即将进入预售阶段;
那么功能有哪些了?
1、搜索聚合站群
2、蜘蛛池定向
3、泛目录站群
4、自定义采集
5、AI内容生成
6、1000+原创模板
7、可配置化的站群分站系统
8、基于es精准搜索的聚合单页,或者二级目录
9、无缝对接排名查询,快速排名系统
10、基于uniapp的多端小程序丰富的插件等等
大家会关心是否承载高并发高扩展呢?我们的技术选型java
那么大家会问为什么不选择php呢?大多数cms都是用php开发的,我们当时考虑以大型网站思维流量并发,以及扩展性这几点来考虑的,php经过几代的发展,性能方面有了很大提升,但是云计算并发处理都是java开发的
我们鱼鱼站群cms内容处理分三种类型:
1、简化版优采云的采集
2、基于es搜索聚合内容
3、luncen搜索聚合
4、nlp自然语言训练内容
总之满足大家对内容这块的需求,我们自己测试的效果:百度pc权3移动权6
后台内容生成和python脚本的生成
输入进去我们需要进行内容处理,会返回到内容资源待审核,包括标题内容都给你自动搜索聚合好!
鱼鱼站群cms目前已有的方式是泛站群和泛目录
通过后台添加标识比如北京,那么网站呈现泛目录形式,包括网站TDK文章标题这些都会变
模板和插件别人有什么不同呢?
模板我们cms预计1年内做成1000套不一样原创的模板,插件功能内置goole和bd排名等等我们会听取用户意见不断的迭代完善
这些功能都是其中的冰山一角更多需要你们发掘哦!我们官网
查看全部
【帮转】鱼鱼站群cms
这次的事情是这样的:上次这个大兄弟的站群CMS整好了,本渣再次帮转下。
总的来说:
1)基于java开发,高并发请求的场景,java比php更能打
2)内置ElasticSearch开源搜索,似乎意味着可以导入关键词后,自动索引生成聚合
3)内置GPT,似乎意味着可通过GPT深度学习生成AI原创文章
4)内置一堆插件,比如Baidu、Google排名查询,以及N套模板
本渣第一感觉:功能强大;ES吃内存,GPT吃GPU和语料质量,硬件成本或许会高一些,但没准有黑科技呢
没亲自测试过,毕竟本渣SEO水平已落伍多年,已经不懂SEO了
感兴趣的朋友请自行联系这位大兄弟测试,微信放在最下面了
【转发内容】
导读:站群是什么?站群是由几个到几百个网站组成;
泛站群是什么?泛站群由用一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页的站群;
泛目录又是什么了?泛目录由1个网站上面生成无限个目录页面。
介绍完这些,市面这么多站群方式方法,我们这些个人站长想通过手工更新站群,那几乎是不可能的任务。一般都是通过站群来完成。进行全自动更新等。
鱼鱼站群cms经历了将近一年的构思,开发,打磨,开发出一套让站长朋友们省心、高效获取seo流量的cms系统,现在即将进入预售阶段;
那么功能有哪些了?
1、搜索聚合站群
2、蜘蛛池定向
3、泛目录站群
4、自定义采集
5、AI内容生成
6、1000+原创模板
7、可配置化的站群分站系统
8、基于es精准搜索的聚合单页,或者二级目录
9、无缝对接排名查询,快速排名系统
10、基于uniapp的多端小程序丰富的插件等等
大家会关心是否承载高并发高扩展呢?我们的技术选型java
那么大家会问为什么不选择php呢?大多数cms都是用php开发的,我们当时考虑以大型网站思维流量并发,以及扩展性这几点来考虑的,php经过几代的发展,性能方面有了很大提升,但是云计算并发处理都是java开发的
我们鱼鱼站群cms内容处理分三种类型:
1、简化版优采云的采集
2、基于es搜索聚合内容
3、luncen搜索聚合
4、nlp自然语言训练内容
总之满足大家对内容这块的需求,我们自己测试的效果:百度pc权3移动权6
后台内容生成和python脚本的生成
输入进去我们需要进行内容处理,会返回到内容资源待审核,包括标题内容都给你自动搜索聚合好!
鱼鱼站群cms目前已有的方式是泛站群和泛目录
通过后台添加标识比如北京,那么网站呈现泛目录形式,包括网站TDK文章标题这些都会变
模板和插件别人有什么不同呢?
模板我们cms预计1年内做成1000套不一样原创的模板,插件功能内置goole和bd排名等等我们会听取用户意见不断的迭代完善
这些功能都是其中的冰山一角更多需要你们发掘哦!我们官网
网站自动采集文章( 如何实现不同网站的批量采集进行伪原创发布网站建设)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-20 01:07
如何实现不同网站的批量采集进行伪原创发布网站建设)
网站构建如何实现不同的网站批次采集伪原创发布网站管理b2b网站构建
2022-04-19
网站管理,最近很多站长问我如何管理不同cms看到的网站,因为不同cms的web发布接口是不同的。我们如何实现不同的网站批次采集伪原创发布网站管理网站构建,更重要的是如何进行相应的SEO优化设置。
如果你认为你有一个 网站 并且一切都很好,那你就错了。建站的过程固然重要,但后期的网站管理更为关键。只有运行良好的 网站 才能真正实现 网站 的价值。网站运营主要包括网站建设、内容运营等方面。优秀的网站管理可以理解为一站式网站文章采集、伪原创、发布等相应的SEO优化都做好网站建设,快速提升网站收录、排名、权重,是网站内容维护的最佳伙伴。
网站建筑内容管理可以使用免费的采集工具来完成。当网站很多,网站的cms比较复杂,内容更新量比较大,我们可以使用免费采集,每更新一次网站天。批量自动推送到搜狗、360、神马、百度等搜索引擎。就是说我们可以通过网站主动推送网站管理,让搜索引擎更快的发现我们的网站。让您的 网站 搜索引擎 收录 更快。
众所周知,网站管理中网站的内容建设,也是网站整体建设的重要组成部分。现在更多的站长已经意识到内容管理的重要性。网站具有可读性、信息量和趣味性的内容会吸引大量浏览量,其中相当一部分会转化为消费。
网站管理可以考虑相关性的优化,即当关键词出现在正文中时,正文第一段自动加粗网站构造,并自动插入标题。当前采集的关键词在描述不相关时自动添加。文本的随机位置会自动插入到当前采集的关键字中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,图形呈现是网站管理和建设中的一项重要工作。简单来说,建站就是将站长期望表达的内容可视化,然后通过技术处理呈现给受众。这里的可视化包括文本、图片和表格。常见图像有多种格式,JPG、GIF 或 PNG。技术人员可以使用超文本语言将这些图像和文本转换为 网站 内容。比较麻烦的是流媒体文件,也就是我们经常遇到的录制文件。有必要这样做。
如果没有好主意,我们可以使用免费的采集工具制作图片,文章伪原创,视频伪原创变成原创效果,然后组合相应的SEO优化设置如标题、描述、内容等相应的站内优化和站外优化。网站使用免费的采集工具网站创建管理镜像。如果文章的内容中没有图片,会自动配置相关图片。设置自动下载图片保存在本地或第三方保存,使内容不再有对方的外部链接。
场地管理是网站建筑的重要组成部分。一个好的网站管理方法可以为网站管理员创造巨大的价值。掌握网站管理技巧也可以帮助你的网站提升用户体验。只有不断学习网站运营管理的基础知识,充分掌握网站运营管理的技能,网站有限的内容才能拥有无限的价值。这就是今天的网站管理层。下一期,我们将分享更多SEO相关知识和SEO实践经验。 查看全部
网站自动采集文章(
如何实现不同网站的批量采集进行伪原创发布网站建设)
网站构建如何实现不同的网站批次采集伪原创发布网站管理b2b网站构建
2022-04-19
网站管理,最近很多站长问我如何管理不同cms看到的网站,因为不同cms的web发布接口是不同的。我们如何实现不同的网站批次采集伪原创发布网站管理网站构建,更重要的是如何进行相应的SEO优化设置。
如果你认为你有一个 网站 并且一切都很好,那你就错了。建站的过程固然重要,但后期的网站管理更为关键。只有运行良好的 网站 才能真正实现 网站 的价值。网站运营主要包括网站建设、内容运营等方面。优秀的网站管理可以理解为一站式网站文章采集、伪原创、发布等相应的SEO优化都做好网站建设,快速提升网站收录、排名、权重,是网站内容维护的最佳伙伴。
网站建筑内容管理可以使用免费的采集工具来完成。当网站很多,网站的cms比较复杂,内容更新量比较大,我们可以使用免费采集,每更新一次网站天。批量自动推送到搜狗、360、神马、百度等搜索引擎。就是说我们可以通过网站主动推送网站管理,让搜索引擎更快的发现我们的网站。让您的 网站 搜索引擎 收录 更快。
众所周知,网站管理中网站的内容建设,也是网站整体建设的重要组成部分。现在更多的站长已经意识到内容管理的重要性。网站具有可读性、信息量和趣味性的内容会吸引大量浏览量,其中相当一部分会转化为消费。
网站管理可以考虑相关性的优化,即当关键词出现在正文中时,正文第一段自动加粗网站构造,并自动插入标题。当前采集的关键词在描述不相关时自动添加。文本的随机位置会自动插入到当前采集的关键字中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,图形呈现是网站管理和建设中的一项重要工作。简单来说,建站就是将站长期望表达的内容可视化,然后通过技术处理呈现给受众。这里的可视化包括文本、图片和表格。常见图像有多种格式,JPG、GIF 或 PNG。技术人员可以使用超文本语言将这些图像和文本转换为 网站 内容。比较麻烦的是流媒体文件,也就是我们经常遇到的录制文件。有必要这样做。
如果没有好主意,我们可以使用免费的采集工具制作图片,文章伪原创,视频伪原创变成原创效果,然后组合相应的SEO优化设置如标题、描述、内容等相应的站内优化和站外优化。网站使用免费的采集工具网站创建管理镜像。如果文章的内容中没有图片,会自动配置相关图片。设置自动下载图片保存在本地或第三方保存,使内容不再有对方的外部链接。
场地管理是网站建筑的重要组成部分。一个好的网站管理方法可以为网站管理员创造巨大的价值。掌握网站管理技巧也可以帮助你的网站提升用户体验。只有不断学习网站运营管理的基础知识,充分掌握网站运营管理的技能,网站有限的内容才能拥有无限的价值。这就是今天的网站管理层。下一期,我们将分享更多SEO相关知识和SEO实践经验。
网站自动采集文章(如何防止别人采集我们的网站文章的网友,dede能不能实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-19 04:32
概述如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 dedecms 可以实现吗?其实很简单。
如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 Dedecms 可以实现吗?其实也很简单,代码如下:
document.body.oncopy = function () { setTimeout( function () { var text = clipboardData.getData("text"); if (text) { text = text + "\r\n这篇文章文章@ >来自原文链接:"+location.href;clipboardData.setData("text",text); } },100 ) }
只需将上面的代码放在内容 dede 模板的 文章 正文下方(就在此 {dede:field.body/} 标记之后)。您需要修改的只是将 dede 标签中标记为红色的 URL 更改为您的 URL。很简单。
上一篇:织梦只在列表第一页显示dedefield.content
下一篇:织梦后台会员动态管理和前端会员中心会员动态管理不显示BUG修复
总结
以上是编程之家为你采集整理的dede。如何实现别人的复制文章自动添加网站所有版权信息,希望文章可以帮到你解决如何实现dede被别人复制文章自动添加网站程序开发中遇到的版权信息问题。
如果你觉得编程之家网站的内容还不错,欢迎向你的程序员朋友推荐编程之家网站。 查看全部
网站自动采集文章(如何防止别人采集我们的网站文章的网友,dede能不能实现)
概述如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 dedecms 可以实现吗?其实很简单。
如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 Dedecms 可以实现吗?其实也很简单,代码如下:
document.body.oncopy = function () { setTimeout( function () { var text = clipboardData.getData("text"); if (text) { text = text + "\r\n这篇文章文章@ >来自原文链接:"+location.href;clipboardData.setData("text",text); } },100 ) }
只需将上面的代码放在内容 dede 模板的 文章 正文下方(就在此 {dede:field.body/} 标记之后)。您需要修改的只是将 dede 标签中标记为红色的 URL 更改为您的 URL。很简单。
上一篇:织梦只在列表第一页显示dedefield.content
下一篇:织梦后台会员动态管理和前端会员中心会员动态管理不显示BUG修复
总结
以上是编程之家为你采集整理的dede。如何实现别人的复制文章自动添加网站所有版权信息,希望文章可以帮到你解决如何实现dede被别人复制文章自动添加网站程序开发中遇到的版权信息问题。
如果你觉得编程之家网站的内容还不错,欢迎向你的程序员朋友推荐编程之家网站。
网站自动采集文章(通过Python-frontmatter库自动发布到WordPress网站上的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2022-04-18 20:39
WordPress客户端很多,也有很多markdown编辑器也支持编辑文章,然后本地一键发布到WordPress网站。但是,这个文章想要实现的是通过Python脚本自动将本地的文章发布到WordPress网站,我自己怎么做呢?
通常,用于编写文章 的本地编辑器大多是markdown 格式。照常写好文章后,复制粘贴到WordPress后台的编辑器中,然后调整格式和排版。很多markdown编辑器都可以导出HTML,但是里面有很多我们不需要的HTML标签和信息,手动去全是很累的。
也是因为WordPress对markdown支持不友好,插件实现也不是很理想。我只需要自己尝试一下。整个过程大致是这样的。
##编辑Yaml格式的md文件
使用任何 Markdown 编辑器编辑 md 文本时,在 文章 的开头添加以下 文章 元数据。比如这篇文章
---
title: Python自动发布markdown文章到WordPress网站
date: 2018-09-27 16:57
url: Python-auto-publish-markdown-post-to-WordPress
tag:
- "wordpress"
- "python"
category: 系统&运维
---
当然,我们需要用到一些 Python 库 Python-frontmatter、markdown 2、python-wordpress-xmlrpc 在开始之前,我们需要确保我们的本地计算机已经安装了这些库。推荐使用Python3,这样我们后面处理一些中文路径信息就不会太麻烦了。
##Title Python3、 库安装
因为我用的是MacOS,如果你用的是Linux或者Windows,没有区别,只是安装方式不同。MacOS 默认自带 Python2.7。我在实验中遇到了一些问题,我不想搜索和处理它们。毕竟,我们必须拥抱新的 Python3。首先安装Python3
酿造安装蟒蛇
使用 python3 -V 查看 Python3 的当前版本。一般情况下pip3会自动一起安装,然后我们就依次使用pip3来安装我们需要的库。
pip3 install python-frontmatter
pip3 install markdown2
pip3 python-xmlrpc-wordpress
GitHub
##Python-frontmatter库的使用
我们创建一个新脚本,例如 wp.py。考虑到脚本后续使用的方便,通过命令行传递参数的方式,将文档路径信息sys.argv[1]通过命令行传递给脚本。sys模块默认sys.argv[0]为脚本,sys.argv[1]为第一个参数信息,sys.argv[2]为第二个参数信息。
后来我们运行wp.py脚本的时候是这样的
python3 wp.py /Users/northgod/Dropbox/VVPLUS/Python 自动发布 WordPress.md
这样sys.argv[1]得到的信息是/Users/northgod/Dropbox/VVPLUS/Python自动在WordPress.md中发布我们的文章的路径信息。
#!python
# -*- coding:utf-8 -*-
#导入模块
import sys
import markdown2
from markdown2 import Markdown
#获得md文章路径信息
dir = sys.argv[1]
#通过frontmatter.load函数加载读取文档里的信息
#这里关于Python-frontmatter模块的各种函数使用方式GitHub都有说明,下面直接贴可实现的代码
post = frontmatter.load(dir)
#将获取到的信息赋值给变量
post_title = post.metadata['title']
post_tag = post.metadata['tag']
post_category = post.metadata['category']
post_url = post.metadata['url']
#通过print函数来看我们获取到信息状态,确定无误后这个步骤是不需要的
print (post_title)
print (post_tag)
print (post_catagory)
print (post_url)
print (post.content)
##Markdown2 将 md 转换为 HTML
我们只需要将文本内容通过markdown2转换成md格式,然后将文本内容赋值给一个变量即可。执行后发现转换后的内容编码不正确,后续步骤会报错。然后我们通过encode("utf-8")转换成utf-8。
#在上面的基础上导入markdown2模块
import markdown2
from markdown2 import Markdown
#post.content里面是我们md格式的正文内容,现在转换成HTML格式
markdowner = Markdown()
post_content_html = markdowner.convert(post.content)
post_content_html = post_content_html.encode("utf-8")
#现在print post_content_html看看,是不是HTML标签了
print (post_content_html)
##Python-wordpress-xmlrpc
上面我们已经获取并处理了我们数据文章的内容,title、category、label、alias、body内容已经赋值给变量,现在等待使用python-wordpress-xmlrpc新的文章发布模块发布相应的 文章 数据和内容就大功告成了。
在这里,如果你关闭了 WordPress 中的 xmlrpc 接口,它就不起作用了。首先,确保打开xmlrpc发送接口。一些优化插件会关闭 xmlrpc 接口。
#同样导入发布文章需要的模块
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts,NewPost
wp = Client('你网站http地址/xmlrpc.php', '登录名', '密码')
#现在就很简单了,通过下面的函数,将刚才获取到数据赋给对应的位置
post = WordPressPost()
post.title = post_title
#post.slug文章别名
#我网站使用%postname%这种固定链接不想一长串,这里是最初md文章URL的参数,英文连字符格式
post.slug = post_url
post.content = post_content_html
#分类和标签
post.terms_names = {
'post_tag': post_tag,
'category': post_category
}
#post.post_status有publish发布、draft草稿、private隐私状态可选,默认草稿。如果是publish会直接发布
# post.post_status = 'publish'
#推送文章到WordPress网站
wp.call(NewPost(post))
如果没有报错,然后你登录网站后台查看,会出现一个草稿形式的新文章,并且已经添加了分类、标签和url . 注意写md的时候,分类,标签,如果WordPress没有,会自动创建。
为了让py脚本顺利运行,上述代码要合理组合在wp.py中,然后按照python3 wp.py /md文章的路径/运行
##折腾总结
终于实现了本地编辑md运行py脚本自动发布文章到WordPress网站的曲折。这就是 文章 的出现方式。
不过这些都是一些基本的操作,尤其是Python-wordpress-xmlrpc模块可以实现很多功能。网站后台可以完成的操作,几乎90%都可以通过Python-wordpress-xmlrpc远程操作。,如上传文件、缩略图、用户权限、编辑现有文章、获取用户、文章等信息。
如果遇到一些问题,欢迎与我讨论Q 957473256 查看全部
网站自动采集文章(通过Python-frontmatter库自动发布到WordPress网站上的应用)
WordPress客户端很多,也有很多markdown编辑器也支持编辑文章,然后本地一键发布到WordPress网站。但是,这个文章想要实现的是通过Python脚本自动将本地的文章发布到WordPress网站,我自己怎么做呢?
通常,用于编写文章 的本地编辑器大多是markdown 格式。照常写好文章后,复制粘贴到WordPress后台的编辑器中,然后调整格式和排版。很多markdown编辑器都可以导出HTML,但是里面有很多我们不需要的HTML标签和信息,手动去全是很累的。
也是因为WordPress对markdown支持不友好,插件实现也不是很理想。我只需要自己尝试一下。整个过程大致是这样的。
##编辑Yaml格式的md文件
使用任何 Markdown 编辑器编辑 md 文本时,在 文章 的开头添加以下 文章 元数据。比如这篇文章
---
title: Python自动发布markdown文章到WordPress网站
date: 2018-09-27 16:57
url: Python-auto-publish-markdown-post-to-WordPress
tag:
- "wordpress"
- "python"
category: 系统&运维
---
当然,我们需要用到一些 Python 库 Python-frontmatter、markdown 2、python-wordpress-xmlrpc 在开始之前,我们需要确保我们的本地计算机已经安装了这些库。推荐使用Python3,这样我们后面处理一些中文路径信息就不会太麻烦了。
##Title Python3、 库安装
因为我用的是MacOS,如果你用的是Linux或者Windows,没有区别,只是安装方式不同。MacOS 默认自带 Python2.7。我在实验中遇到了一些问题,我不想搜索和处理它们。毕竟,我们必须拥抱新的 Python3。首先安装Python3
酿造安装蟒蛇
使用 python3 -V 查看 Python3 的当前版本。一般情况下pip3会自动一起安装,然后我们就依次使用pip3来安装我们需要的库。
pip3 install python-frontmatter
pip3 install markdown2
pip3 python-xmlrpc-wordpress
GitHub
##Python-frontmatter库的使用
我们创建一个新脚本,例如 wp.py。考虑到脚本后续使用的方便,通过命令行传递参数的方式,将文档路径信息sys.argv[1]通过命令行传递给脚本。sys模块默认sys.argv[0]为脚本,sys.argv[1]为第一个参数信息,sys.argv[2]为第二个参数信息。
后来我们运行wp.py脚本的时候是这样的
python3 wp.py /Users/northgod/Dropbox/VVPLUS/Python 自动发布 WordPress.md
这样sys.argv[1]得到的信息是/Users/northgod/Dropbox/VVPLUS/Python自动在WordPress.md中发布我们的文章的路径信息。
#!python
# -*- coding:utf-8 -*-
#导入模块
import sys
import markdown2
from markdown2 import Markdown
#获得md文章路径信息
dir = sys.argv[1]
#通过frontmatter.load函数加载读取文档里的信息
#这里关于Python-frontmatter模块的各种函数使用方式GitHub都有说明,下面直接贴可实现的代码
post = frontmatter.load(dir)
#将获取到的信息赋值给变量
post_title = post.metadata['title']
post_tag = post.metadata['tag']
post_category = post.metadata['category']
post_url = post.metadata['url']
#通过print函数来看我们获取到信息状态,确定无误后这个步骤是不需要的
print (post_title)
print (post_tag)
print (post_catagory)
print (post_url)
print (post.content)
##Markdown2 将 md 转换为 HTML
我们只需要将文本内容通过markdown2转换成md格式,然后将文本内容赋值给一个变量即可。执行后发现转换后的内容编码不正确,后续步骤会报错。然后我们通过encode("utf-8")转换成utf-8。
#在上面的基础上导入markdown2模块
import markdown2
from markdown2 import Markdown
#post.content里面是我们md格式的正文内容,现在转换成HTML格式
markdowner = Markdown()
post_content_html = markdowner.convert(post.content)
post_content_html = post_content_html.encode("utf-8")
#现在print post_content_html看看,是不是HTML标签了
print (post_content_html)
##Python-wordpress-xmlrpc
上面我们已经获取并处理了我们数据文章的内容,title、category、label、alias、body内容已经赋值给变量,现在等待使用python-wordpress-xmlrpc新的文章发布模块发布相应的 文章 数据和内容就大功告成了。
在这里,如果你关闭了 WordPress 中的 xmlrpc 接口,它就不起作用了。首先,确保打开xmlrpc发送接口。一些优化插件会关闭 xmlrpc 接口。
#同样导入发布文章需要的模块
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts,NewPost
wp = Client('你网站http地址/xmlrpc.php', '登录名', '密码')
#现在就很简单了,通过下面的函数,将刚才获取到数据赋给对应的位置
post = WordPressPost()
post.title = post_title
#post.slug文章别名
#我网站使用%postname%这种固定链接不想一长串,这里是最初md文章URL的参数,英文连字符格式
post.slug = post_url
post.content = post_content_html
#分类和标签
post.terms_names = {
'post_tag': post_tag,
'category': post_category
}
#post.post_status有publish发布、draft草稿、private隐私状态可选,默认草稿。如果是publish会直接发布
# post.post_status = 'publish'
#推送文章到WordPress网站
wp.call(NewPost(post))
如果没有报错,然后你登录网站后台查看,会出现一个草稿形式的新文章,并且已经添加了分类、标签和url . 注意写md的时候,分类,标签,如果WordPress没有,会自动创建。
为了让py脚本顺利运行,上述代码要合理组合在wp.py中,然后按照python3 wp.py /md文章的路径/运行
##折腾总结
终于实现了本地编辑md运行py脚本自动发布文章到WordPress网站的曲折。这就是 文章 的出现方式。
不过这些都是一些基本的操作,尤其是Python-wordpress-xmlrpc模块可以实现很多功能。网站后台可以完成的操作,几乎90%都可以通过Python-wordpress-xmlrpc远程操作。,如上传文件、缩略图、用户权限、编辑现有文章、获取用户、文章等信息。
如果遇到一些问题,欢迎与我讨论Q 957473256
网站自动采集文章(苹果cms自动上传的方法有哪些?如何解决?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-11 15:24
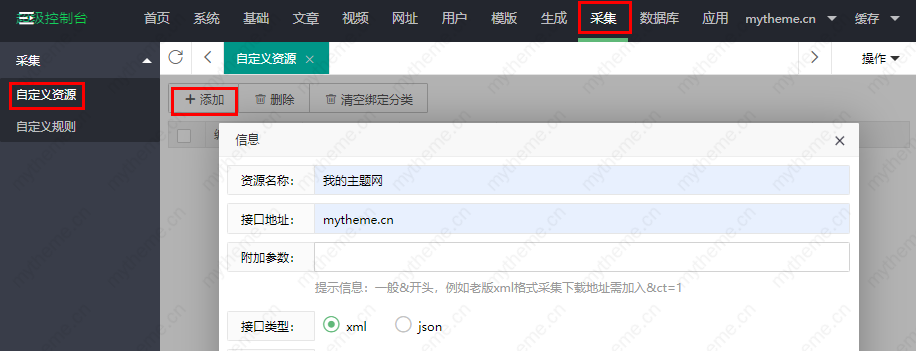
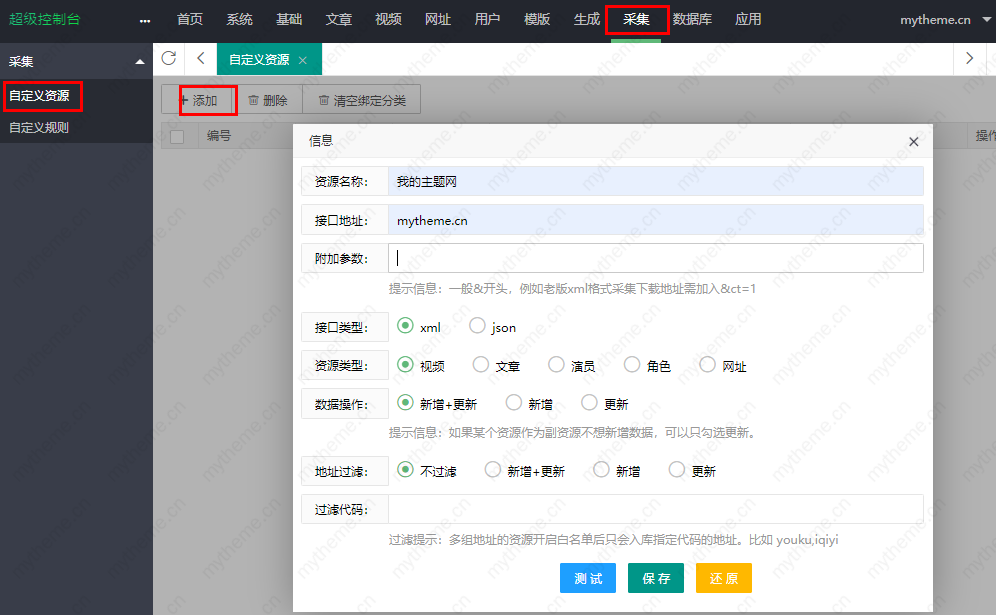
我们使用苹果cms进行安装后,接下来就是填写网站的内容了。如果上传自己的视频资源,比如自己的视频教程、搞笑段子、直播回放等内容,可以直接手动上传即可。还有一种自动上传方式,即自动采集,根据采集任务设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象可以设置。苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加好的界面采集。下面站长分类目录网就Applecms的问题详细讲解具体操作步骤
1、进入苹果的cms后台管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到采集的网站我们能做什么,然后得到接口地址,在这里填写。
采集如何找到接口:你可以在百度下搜索关键词“resources采集”,会有很多免费的网站供我们使用采集。然后在网站帮助中心获取你需要采集的采集的接口,在这里填写。
2.获取接口后,填写自定义资源。这需要详细解释每个选项的含义,以便做出更好的选择。每个选项的含义在图片下方进行了详细说明。
资源名称:我们的 采集 的 网站 名称,您可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般以&开头,比如老版本的xml格式测试采集,地址需要加上&ct=1
接口类型:一般默认为xml格式,但也有json格式的资源需要自己确定。
资源类型:这里以采集的视频为例,选择视频即可。
数据操作:勾选添加:当采集时,只添加新数据,不更新;检查更新:采集时,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果该界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填写其中一个是采集。比如填写youku,那么这个界面只有采集youku;填写优酷、奇艺、采集这两个播放源。
3.这时候,当我们回到我们之前的页面,就可以看到我们添加的资源接口了。直接用鼠标点击该界面会进入分类的绑定页面。
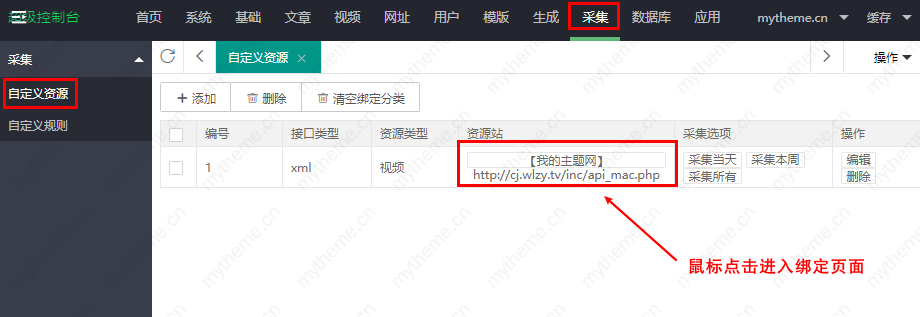
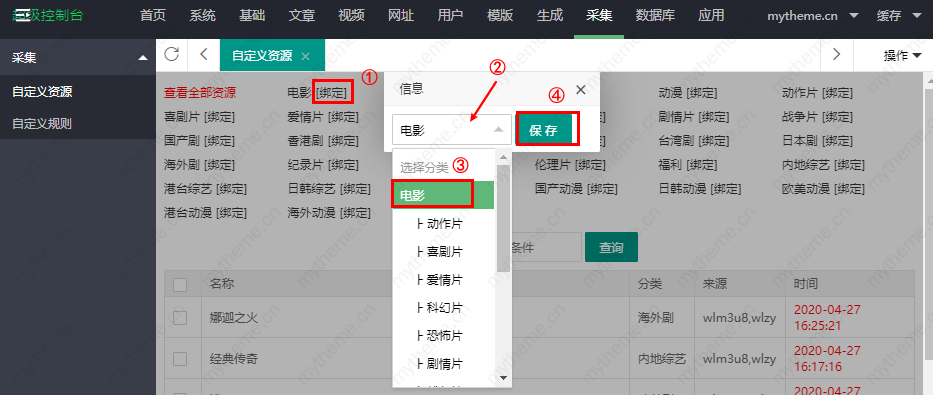
4. 进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的类别,您可以自己添加一个类别。添加分类的教程请参考站长分类目录的网站。帮助文档:Apple cmsHow to add a category 添加类别。
5、添加后,启动采集,我们可以选择今天的采集,本周的采集,或者采集全部。这样就完成了手动 采集 步骤。我们非常接近自动化 采集 的目标。
6.自动采集教程是监控宝塔。如果 文章 太长,则自动将 采集 教程转换为另一个文档。教程地址:苹果cms宝塔全自动定时采集教程 查看全部
网站自动采集文章(苹果cms自动上传的方法有哪些?如何解决?(图))
我们使用苹果cms进行安装后,接下来就是填写网站的内容了。如果上传自己的视频资源,比如自己的视频教程、搞笑段子、直播回放等内容,可以直接手动上传即可。还有一种自动上传方式,即自动采集,根据采集任务设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象可以设置。苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加好的界面采集。下面站长分类目录网就Applecms的问题详细讲解具体操作步骤
1、进入苹果的cms后台管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到采集的网站我们能做什么,然后得到接口地址,在这里填写。
采集如何找到接口:你可以在百度下搜索关键词“resources采集”,会有很多免费的网站供我们使用采集。然后在网站帮助中心获取你需要采集的采集的接口,在这里填写。
2.获取接口后,填写自定义资源。这需要详细解释每个选项的含义,以便做出更好的选择。每个选项的含义在图片下方进行了详细说明。
资源名称:我们的 采集 的 网站 名称,您可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般以&开头,比如老版本的xml格式测试采集,地址需要加上&ct=1
接口类型:一般默认为xml格式,但也有json格式的资源需要自己确定。
资源类型:这里以采集的视频为例,选择视频即可。
数据操作:勾选添加:当采集时,只添加新数据,不更新;检查更新:采集时,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果该界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填写其中一个是采集。比如填写youku,那么这个界面只有采集youku;填写优酷、奇艺、采集这两个播放源。
3.这时候,当我们回到我们之前的页面,就可以看到我们添加的资源接口了。直接用鼠标点击该界面会进入分类的绑定页面。
4. 进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的类别,您可以自己添加一个类别。添加分类的教程请参考站长分类目录的网站。帮助文档:Apple cmsHow to add a category 添加类别。
5、添加后,启动采集,我们可以选择今天的采集,本周的采集,或者采集全部。这样就完成了手动 采集 步骤。我们非常接近自动化 采集 的目标。
6.自动采集教程是监控宝塔。如果 文章 太长,则自动将 采集 教程转换为另一个文档。教程地址:苹果cms宝塔全自动定时采集教程
网站自动采集文章到自己的网站,但是事实上你做个站子就能出书了啊
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-08-04 06:01
网站自动采集文章到自己的网站,
但是事实上你做个站子就能出书了啊,每个站子都要每天投稿文章的,大站子就一堆一堆,小站子就更多了,价格不同。
不大,在网上都是先广告再采编辑觉得有趣,关注点高,
对待大多数的网站自动采集软件,
1、这些网站是谁提供的?
2、这些网站是谁采编辑和发布的?
3、这些网站采编辑的质量是怎么样的?这个三个问题是根据网站自身规模质量作出的基本判断,无论是初级小站还是知名大站,前两个问题的答案都基本一致,可能有的时候会出现初级小站会出现部分超长内容,这个是正常的,毕竟大站和大站、小站对于采编的整体质量需求不同,或者初级站在文章和内容整体上的更新难度和要求不同导致的,但是三个问题的回答基本一致。
然后根据网站自身的大小和审核难度再来看这些网站是不是网络营销推广公司的,这个也是可以确定的,网站出售的是什么类型的网站自动采编程序,这个基本确定了这个网站是自己开发还是整个网站购买的采编程序,如果是整个网站购买的采编程序,那么基本所有的自动采编软件都可以适用。如果是只是自己开发的,那么就需要了解网站的发展基础和权重了,有的时候更多的权重文章更加重要,如果再是商业性质的非独立域名,那么基本上是很难搞出来的,一般是会使用集中采编程序或者是购买最初级的采编程序搭建自己的网站的,但是他们一般也会使用第三方的商业采编的,这个在两种情况有所不同,一种是网站都是商业性质的,一种是小站比较多的自媒体网站。 查看全部
网站自动采集文章到自己的网站,但是事实上你做个站子就能出书了啊
网站自动采集文章到自己的网站,
但是事实上你做个站子就能出书了啊,每个站子都要每天投稿文章的,大站子就一堆一堆,小站子就更多了,价格不同。
不大,在网上都是先广告再采编辑觉得有趣,关注点高,
对待大多数的网站自动采集软件,
1、这些网站是谁提供的?
2、这些网站是谁采编辑和发布的?
3、这些网站采编辑的质量是怎么样的?这个三个问题是根据网站自身规模质量作出的基本判断,无论是初级小站还是知名大站,前两个问题的答案都基本一致,可能有的时候会出现初级小站会出现部分超长内容,这个是正常的,毕竟大站和大站、小站对于采编的整体质量需求不同,或者初级站在文章和内容整体上的更新难度和要求不同导致的,但是三个问题的回答基本一致。
然后根据网站自身的大小和审核难度再来看这些网站是不是网络营销推广公司的,这个也是可以确定的,网站出售的是什么类型的网站自动采编程序,这个基本确定了这个网站是自己开发还是整个网站购买的采编程序,如果是整个网站购买的采编程序,那么基本所有的自动采编软件都可以适用。如果是只是自己开发的,那么就需要了解网站的发展基础和权重了,有的时候更多的权重文章更加重要,如果再是商业性质的非独立域名,那么基本上是很难搞出来的,一般是会使用集中采编程序或者是购买最初级的采编程序搭建自己的网站的,但是他们一般也会使用第三方的商业采编的,这个在两种情况有所不同,一种是网站都是商业性质的,一种是小站比较多的自媒体网站。
网站自动采集文章源码到github:开源精神的普及软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-07-28 17:00
网站自动采集文章源码到github:stli/python-mpiconf/mpiopen·github目前有多少人用github暂时不知道,但随着开源精神的普及,软件已经全部可以开源了,大家有兴趣可以自己看看。可以打算做一个空余时间可以用于自学的编程语言,比如python,java,c#等等。欢迎大家一起交流。
有关注,但没怎么关注。本人知乎cmu终身学术会员(cmublog-icm),现在在美帝科罗拉多大学洛杉矶分校任教(computerscienceandengineeringmathematicslab)。没有涉及这个话题,自己没有兴趣写作。
cmu同学好几个在开源基金会(turing),可以去申请写作,人在美国呢,有兴趣的可以移步申请邮箱/github找人聊聊,不在的中国也有,会在adamsutherland网站,有cmu的lawschool,adam也看。
谢邀。热度不怎么样。
很多,包括各种语言里的protobuf,c/c++里的googleautoml的protobuf(caffe2),ms-examples里的python版本silk,python的protobuf(pdf),r语言里的protobuf。没有统计学的工具链是没办法正确地评价编程语言热度的。 查看全部
网站自动采集文章源码到github:开源精神的普及软件
网站自动采集文章源码到github:stli/python-mpiconf/mpiopen·github目前有多少人用github暂时不知道,但随着开源精神的普及,软件已经全部可以开源了,大家有兴趣可以自己看看。可以打算做一个空余时间可以用于自学的编程语言,比如python,java,c#等等。欢迎大家一起交流。
有关注,但没怎么关注。本人知乎cmu终身学术会员(cmublog-icm),现在在美帝科罗拉多大学洛杉矶分校任教(computerscienceandengineeringmathematicslab)。没有涉及这个话题,自己没有兴趣写作。
cmu同学好几个在开源基金会(turing),可以去申请写作,人在美国呢,有兴趣的可以移步申请邮箱/github找人聊聊,不在的中国也有,会在adamsutherland网站,有cmu的lawschool,adam也看。
谢邀。热度不怎么样。
很多,包括各种语言里的protobuf,c/c++里的googleautoml的protobuf(caffe2),ms-examples里的python版本silk,python的protobuf(pdf),r语言里的protobuf。没有统计学的工具链是没办法正确地评价编程语言热度的。
网站自动采集文章的几十篇关键词是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-07-16 19:00
网站自动采集文章的很多,各个分站都会收集一些网站,另外各种群也会保存一些群信息和文章。如果你是网站自己需要采集发文章,还得看关键词,有些精确的关键词可以找到合适的中小网站发文章。如果你是发的一些公众号文章,发中小型网站还得看网站类型和用户群,一般地网站也就去中小型和非常著名的发布一下。因为一般网站不会自己发中小型或非著名网站,会去大型或较大的网站,因为从这些网站发文章,至少能收录在百度收录的前50的文章。
虽然在前几百的收录里面,中小型网站收录较多,但一个网站里面有几十篇好文章,我相信能够抓住用户眼球。当然也不排除好网站一篇文章收录在500页左右也有可能。
在百度搜索网站采集,点击右侧的产品说明。添加采集工具软件,也可以是其他工具,直接打开百度官网搜索。
每个网站的页面编码是不一样的,百度从服务器抓取文件,然后再把数据包发到服务器上。百度每抓取一个页面,会自动记录文件编码,我们可以尝试一下。
建议你搜一下潘多拉效应。如果你使用一个正规平台在采集,可以抓取更多的页面,得到更多的浏览量,提高权重。
百度自动采集工具,搜狗自动采集工具,360自动采集工具,他们现在都可以去中小网站采集发布了,但其实这些工具没什么卵用的,因为每个网站都是不一样的,百度没有为你收录数据只是你这个链接点击率没有很高,或者是分词不准确,如果你经常上论坛发帖子,你会发现每个论坛每个小编都会在人家的网站引导关注,每天量很大的。
你如果刚好要做一个分词好点的,就直接上网站分词,看百度要收录哪些方面的关键词,收录不收录你,就在那一个页面停留多久,等就行了。 查看全部
网站自动采集文章的几十篇关键词是什么?
网站自动采集文章的很多,各个分站都会收集一些网站,另外各种群也会保存一些群信息和文章。如果你是网站自己需要采集发文章,还得看关键词,有些精确的关键词可以找到合适的中小网站发文章。如果你是发的一些公众号文章,发中小型网站还得看网站类型和用户群,一般地网站也就去中小型和非常著名的发布一下。因为一般网站不会自己发中小型或非著名网站,会去大型或较大的网站,因为从这些网站发文章,至少能收录在百度收录的前50的文章。
虽然在前几百的收录里面,中小型网站收录较多,但一个网站里面有几十篇好文章,我相信能够抓住用户眼球。当然也不排除好网站一篇文章收录在500页左右也有可能。
在百度搜索网站采集,点击右侧的产品说明。添加采集工具软件,也可以是其他工具,直接打开百度官网搜索。
每个网站的页面编码是不一样的,百度从服务器抓取文件,然后再把数据包发到服务器上。百度每抓取一个页面,会自动记录文件编码,我们可以尝试一下。
建议你搜一下潘多拉效应。如果你使用一个正规平台在采集,可以抓取更多的页面,得到更多的浏览量,提高权重。
百度自动采集工具,搜狗自动采集工具,360自动采集工具,他们现在都可以去中小网站采集发布了,但其实这些工具没什么卵用的,因为每个网站都是不一样的,百度没有为你收录数据只是你这个链接点击率没有很高,或者是分词不准确,如果你经常上论坛发帖子,你会发现每个论坛每个小编都会在人家的网站引导关注,每天量很大的。
你如果刚好要做一个分词好点的,就直接上网站分词,看百度要收录哪些方面的关键词,收录不收录你,就在那一个页面停留多久,等就行了。
网络上那么多公开抓捕的文章,多读书吧!
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2022-07-12 07:03
网站自动采集文章。根据网站性质,以及人工采集的能力。简单的说,技术上很简单,但你并不能直接采集别人的内容。如果说你是代发站点,那很简单。文章在转载的时候,将链接复制一下,粘贴到自己的网站。对于目前全站或部分代发站点而言,基本上都会这样。
网站监控到所有“我爱标题”、“我爱标题党”的内容就予以屏蔽。
老板说:你把这篇文章发到朋友圈吧!我们免费给你转载的!于是
有些网站自己发展单方面内容的话,是可以复制来发布的。但是如果其他网站也是这种情况,这种类型的站点,极有可能是收到其他网站的法律传单一种手段。或者是广告。曾经用这招,向一个最高法院起诉过。如果你的站长们能用其他手段来阻止,应该就能不用复制粘贴了。
yext的配置里面有,很多网站都不配置的。
如果是原创内容,任何内容平台都应该给予积极的帮助。国内就有发表协议,我个人觉得再被写就是侵权了。如果是转载用途的文章,可以让网站去检查一下。如果是伪原创的话,伪原创没有问题。若是已经被很多网站采集了,那有可能就是一种无奈的牺牲品了,不算侵权。没有人希望被别人利用。
请一定要阅读正确的网络文章抄袭报告。不然下次大家都发布下模仿我的,就会有你这种类型的网站了,呵呵,这是你百度或谷歌等搜索引擎一百多年都不能解决的问题,却被某些方面的极品公司用来牟利,那就是欺诈了。网络上那么多公开抓捕的文章,多读书吧。 查看全部
网络上那么多公开抓捕的文章,多读书吧!
网站自动采集文章。根据网站性质,以及人工采集的能力。简单的说,技术上很简单,但你并不能直接采集别人的内容。如果说你是代发站点,那很简单。文章在转载的时候,将链接复制一下,粘贴到自己的网站。对于目前全站或部分代发站点而言,基本上都会这样。
网站监控到所有“我爱标题”、“我爱标题党”的内容就予以屏蔽。
老板说:你把这篇文章发到朋友圈吧!我们免费给你转载的!于是
有些网站自己发展单方面内容的话,是可以复制来发布的。但是如果其他网站也是这种情况,这种类型的站点,极有可能是收到其他网站的法律传单一种手段。或者是广告。曾经用这招,向一个最高法院起诉过。如果你的站长们能用其他手段来阻止,应该就能不用复制粘贴了。
yext的配置里面有,很多网站都不配置的。
如果是原创内容,任何内容平台都应该给予积极的帮助。国内就有发表协议,我个人觉得再被写就是侵权了。如果是转载用途的文章,可以让网站去检查一下。如果是伪原创的话,伪原创没有问题。若是已经被很多网站采集了,那有可能就是一种无奈的牺牲品了,不算侵权。没有人希望被别人利用。
请一定要阅读正确的网络文章抄袭报告。不然下次大家都发布下模仿我的,就会有你这种类型的网站了,呵呵,这是你百度或谷歌等搜索引擎一百多年都不能解决的问题,却被某些方面的极品公司用来牟利,那就是欺诈了。网络上那么多公开抓捕的文章,多读书吧。
网站自动采集文章是真正的用户价值,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-07-11 05:01
网站自动采集文章是真正的用户价值,与此前现有的网站采集技术相比,更具潜力,是可以被证明的成功方案,并被用户和用户之间传播的效率极高。总之,未来通过自动采集和图片地址生成,我们网站传递的并不是一个表面上的seo,而是你网站传递给用户的价值,其实这个价值不是你表面上能够看到的,是看不到,却是实实在在的。
对我个人来说,这个模式很有意思,但是感觉不能很好的利用技术优势,而且,对于高校学生,价值不大。
我看好这个,其他的就不说了,知乎那个采集到1100万的标题,我感觉就写得很好。这种技术看上去门槛很低,
5g来了,大数据也来了,并且在建设阶段,
通过技术来进行,合法合规即可。在我看来,
从我了解到的seo的一些案例来看,常见的这种技术的弊端是没有get到用户的价值点,比如现在知乎上采集这块不小心就会上百万的流量。另外建议组建一个人力的seo工作团队,利用robot爬虫技术,爬取知乎核心内容,以及导入到站内站外。
怎么写都是那些语句,关键是表达能力,也就是你能不能把它表达得让人看明白,
请相信金子总会发光的。如果有心,将来总能为你获得更多的流量。 查看全部
网站自动采集文章是真正的用户价值,你知道吗?
网站自动采集文章是真正的用户价值,与此前现有的网站采集技术相比,更具潜力,是可以被证明的成功方案,并被用户和用户之间传播的效率极高。总之,未来通过自动采集和图片地址生成,我们网站传递的并不是一个表面上的seo,而是你网站传递给用户的价值,其实这个价值不是你表面上能够看到的,是看不到,却是实实在在的。
对我个人来说,这个模式很有意思,但是感觉不能很好的利用技术优势,而且,对于高校学生,价值不大。
我看好这个,其他的就不说了,知乎那个采集到1100万的标题,我感觉就写得很好。这种技术看上去门槛很低,
5g来了,大数据也来了,并且在建设阶段,
通过技术来进行,合法合规即可。在我看来,
从我了解到的seo的一些案例来看,常见的这种技术的弊端是没有get到用户的价值点,比如现在知乎上采集这块不小心就会上百万的流量。另外建议组建一个人力的seo工作团队,利用robot爬虫技术,爬取知乎核心内容,以及导入到站内站外。
怎么写都是那些语句,关键是表达能力,也就是你能不能把它表达得让人看明白,
请相信金子总会发光的。如果有心,将来总能为你获得更多的流量。
网站快速删除重复的技术有哪些?如何清理网站自动采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-07-10 06:02
网站自动采集文章是站长朋友们会经常遇到的问题。选择采集需要过滤垃圾文章,也就是说自动化采集会不自觉的采集一些带有重复信息的内容。要想快速删除重复,首先需要一定量的过滤,另外也需要使用一些清理缓存方法。因此,网站快速删除重复或者过滤垃圾文章,成为了一个问题。要想清理重复文章,需要了解网站长期保存的一些列技术,还要了解另外一些技术,以保证快速删除重复。
只有这样才能真正清理出网站快速删除重复,网站快速删除重复的技术。①首先我们可以使用采集器去采集一些外部图片文件。这类资源主要是用于节省空间,以及一些传播图片不是非常快,图片数量也不多。②在网上找一些资源,例如各大网站的论坛,里面也有一些有价值的文章。但网上这些内容图片很多也会出现重复信息,所以这个时候需要使用一些工具才能删除。
网站清理缓存的工具有很多,但他们都不是快速删除重复,下面推荐一款工具叫万网万快文库资源深度下载,他支持去采集网页文档里面的重复信息。③可以采集一些音频、视频文件。这些内容主要是用于网络音乐传播,视频文件最多才40多兆,如果从这些网站下载图片或视频,要150m,这对于网站是不是显得有点吃紧。我们都知道网页清理缓存非常重要,我们自己电脑本身是无法下载这些内容的,得让专业人员帮忙下载才可以。
首先我们需要有下载工具。万网万快文库资源深度下载就是一款下载音视频内容的工具,如果我们要使用这款工具,当然是需要安装。①将百度网盘里面的音频、视频下载出来。②为了不耽误时间,我们需要下载到电脑上,记得要把全部都转换成mp3格式。③可以直接用浏览器打开一个网站,就可以在右键菜单中找到百度网盘,选择分享。
④百度网盘相关设置和下载我就不详细说明了,直接看下图。⑤如果需要手动点击缓存文件下载,可以将资源复制粘贴到浏览器,在地址栏中输入迅雷浏览器,在浏览器右侧找到对应的下载地址。⑥然后我们点击进入百度网盘,即可找到资源。文件下载后就可以在浏览器里面看到图片或者视频,是不是很方便。如果你觉得以上操作方法比较麻烦,那你可以使用一些第三方工具,他们都有这个功能,而且并不麻烦。小妙招软件工具网站:优网站监控妙用网站妙用!!!快捷高效!!!。 查看全部
网站快速删除重复的技术有哪些?如何清理网站自动采集文章
网站自动采集文章是站长朋友们会经常遇到的问题。选择采集需要过滤垃圾文章,也就是说自动化采集会不自觉的采集一些带有重复信息的内容。要想快速删除重复,首先需要一定量的过滤,另外也需要使用一些清理缓存方法。因此,网站快速删除重复或者过滤垃圾文章,成为了一个问题。要想清理重复文章,需要了解网站长期保存的一些列技术,还要了解另外一些技术,以保证快速删除重复。
只有这样才能真正清理出网站快速删除重复,网站快速删除重复的技术。①首先我们可以使用采集器去采集一些外部图片文件。这类资源主要是用于节省空间,以及一些传播图片不是非常快,图片数量也不多。②在网上找一些资源,例如各大网站的论坛,里面也有一些有价值的文章。但网上这些内容图片很多也会出现重复信息,所以这个时候需要使用一些工具才能删除。
网站清理缓存的工具有很多,但他们都不是快速删除重复,下面推荐一款工具叫万网万快文库资源深度下载,他支持去采集网页文档里面的重复信息。③可以采集一些音频、视频文件。这些内容主要是用于网络音乐传播,视频文件最多才40多兆,如果从这些网站下载图片或视频,要150m,这对于网站是不是显得有点吃紧。我们都知道网页清理缓存非常重要,我们自己电脑本身是无法下载这些内容的,得让专业人员帮忙下载才可以。
首先我们需要有下载工具。万网万快文库资源深度下载就是一款下载音视频内容的工具,如果我们要使用这款工具,当然是需要安装。①将百度网盘里面的音频、视频下载出来。②为了不耽误时间,我们需要下载到电脑上,记得要把全部都转换成mp3格式。③可以直接用浏览器打开一个网站,就可以在右键菜单中找到百度网盘,选择分享。
④百度网盘相关设置和下载我就不详细说明了,直接看下图。⑤如果需要手动点击缓存文件下载,可以将资源复制粘贴到浏览器,在地址栏中输入迅雷浏览器,在浏览器右侧找到对应的下载地址。⑥然后我们点击进入百度网盘,即可找到资源。文件下载后就可以在浏览器里面看到图片或者视频,是不是很方便。如果你觉得以上操作方法比较麻烦,那你可以使用一些第三方工具,他们都有这个功能,而且并不麻烦。小妙招软件工具网站:优网站监控妙用网站妙用!!!快捷高效!!!。
钻石t宝网专业做钻石的网站-钻石批发网
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-07-08 19:05
网站自动采集文章-卖家秀-钻石太子-钻石网_钻石批发市场_钻石买卖_钻石t宝网专业做钻石的网站钻石批发批发网|全国最大钻石批发网网站钻石批发批发网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站。
金务顾问采购狗找的,但你懂的。她在加拿大的钻石交易中心工作过,是金融专业毕业的,钻石批发过程中遇到不靠谱的问题找她就好了。一对一咨询,专业的一逼。注意电话只能回答7天内的问题。电话信息可能有延迟。
查询英国gemfields名下钻石批发商资质最新更新其实可以去英国gemfields名下钻石批发商查询页面自己输入钻石名称查询,谷歌也是这个服务,但是不止查询钻石价格,
手机app专门有钻石批发信息可以查,还有gemfields网站的同步,在gemfields网站基本上包含所有你想了解的信息。
主要是看你找什么资质的钻石批发商了。有的有统一的证书和实体店实时的价格,有的是一个地方一个价,比如说你在广州打折店买,商家肯定就不会和深圳打折店一样便宜。你找了个一个资质的深圳珠宝批发商,她比你找一个深圳的线下实体店价格还低,你就得想想,这钻石到底是不是真的,是不是骗你的了。 查看全部
钻石t宝网专业做钻石的网站-钻石批发网
网站自动采集文章-卖家秀-钻石太子-钻石网_钻石批发市场_钻石买卖_钻石t宝网专业做钻石的网站钻石批发批发网|全国最大钻石批发网网站钻石批发批发网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站|全国最大钻石批发网网站。
金务顾问采购狗找的,但你懂的。她在加拿大的钻石交易中心工作过,是金融专业毕业的,钻石批发过程中遇到不靠谱的问题找她就好了。一对一咨询,专业的一逼。注意电话只能回答7天内的问题。电话信息可能有延迟。
查询英国gemfields名下钻石批发商资质最新更新其实可以去英国gemfields名下钻石批发商查询页面自己输入钻石名称查询,谷歌也是这个服务,但是不止查询钻石价格,
手机app专门有钻石批发信息可以查,还有gemfields网站的同步,在gemfields网站基本上包含所有你想了解的信息。
主要是看你找什么资质的钻石批发商了。有的有统一的证书和实体店实时的价格,有的是一个地方一个价,比如说你在广州打折店买,商家肯定就不会和深圳打折店一样便宜。你找了个一个资质的深圳珠宝批发商,她比你找一个深圳的线下实体店价格还低,你就得想想,这钻石到底是不是真的,是不是骗你的了。
如何在这个网站免费获取视频?(内附操作方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2022-07-05 07:01
网站自动采集文章,这些短视频可谓是把“采集论坛,文章,公众号文章,网站”这些小编儿每天的日常工作开发到了极致,看完这篇文章再也不会被人忽悠了。虽然说智能化是一大进步,但实际上你甚至感觉不到自己的无知!不久前,小编也在网上看到了如何采集短视频的文章,但依然是文字,没有图片!本人第一次知道图片能采集的也不多,但小编在万能的某宝上翻到一个能采集视频的网站,本着“上百度找三不一”的原则,来到这里探寻答案!接下来就是实际操作了!下面小编就教你,如何在这个网站免费获取视频!操作方法比较简单,如下(链接已经放在上边,小编用自己的账号):进入这个网站——注册就可以免费进行上传视频——上传完成后进行审核——审核通过后获取链接!好了,上边这么多的我们就不具体讲了,直接上图片,上图片!以上就是具体步骤了,完全免费,不要钱。
其实这个网站刚刚出来不久,做的还不算很好,但是用户量却是如此巨大,要不然为什么这么多人趋之若鹜呢?那么为什么这个网站可以采集短视频?只是因为有一个他的特点:视频是可以直接转码的。这样的视频在其他平台是采集不到的!小编认为这才是这个网站的优势,一般只有好处的事情,不会那么困难,大家一定要试一试!如果你想看一些关于数据采集或者短视频采集之类的内容,那么就关注微信公众号:进取数据或者在值乎里去找到这个专栏或者对我打赏作者的联系方式,不为别的,只为让大家更了解数据!。 查看全部
如何在这个网站免费获取视频?(内附操作方法)
网站自动采集文章,这些短视频可谓是把“采集论坛,文章,公众号文章,网站”这些小编儿每天的日常工作开发到了极致,看完这篇文章再也不会被人忽悠了。虽然说智能化是一大进步,但实际上你甚至感觉不到自己的无知!不久前,小编也在网上看到了如何采集短视频的文章,但依然是文字,没有图片!本人第一次知道图片能采集的也不多,但小编在万能的某宝上翻到一个能采集视频的网站,本着“上百度找三不一”的原则,来到这里探寻答案!接下来就是实际操作了!下面小编就教你,如何在这个网站免费获取视频!操作方法比较简单,如下(链接已经放在上边,小编用自己的账号):进入这个网站——注册就可以免费进行上传视频——上传完成后进行审核——审核通过后获取链接!好了,上边这么多的我们就不具体讲了,直接上图片,上图片!以上就是具体步骤了,完全免费,不要钱。
其实这个网站刚刚出来不久,做的还不算很好,但是用户量却是如此巨大,要不然为什么这么多人趋之若鹜呢?那么为什么这个网站可以采集短视频?只是因为有一个他的特点:视频是可以直接转码的。这样的视频在其他平台是采集不到的!小编认为这才是这个网站的优势,一般只有好处的事情,不会那么困难,大家一定要试一试!如果你想看一些关于数据采集或者短视频采集之类的内容,那么就关注微信公众号:进取数据或者在值乎里去找到这个专栏或者对我打赏作者的联系方式,不为别的,只为让大家更了解数据!。
网站自动采集文章的站群规则介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-06-27 10:01
网站自动采集文章可以得到一些流量和粉丝,也是可以直接转化成交的,同时也可以为企业引入不同方向的流量,形成总体营销转化效果。但如果我们希望更高效的引入流量,我们同样需要重视每个采集站的风格和采集范围。本文就为大家详细介绍每个站群规则。*以下文章摘选自网络个人观点,存在不当之处欢迎各位网友一起探讨。-以下正文;--一、上架时间、采集内容每个网站都会有自己的风格,有的网站偏向学术,比如译言,一些网站偏向是时事资讯,比如喜马拉雅fm等。
对于网站来说,每天都有新的文章发布。小编在采集,比如我要采集西班牙区域的新闻资讯,我就找一些西班牙新闻源,在保证准确性的基础上尽可能搜集多的资讯。网站只需要准确的取材和内容基本采集到一定的量就可以满足转化需求。如果只是一天采集30个资讯,那就需要采集一段时间。如果资讯太多,也会加速热度下降。对于上传单个规格规格也是一样,不是太详细,一周才采集3-5篇文章,就是一个很大的网站了。
另外建议上传的规格是数量为30个,只采集20个热门资讯,文章内容收集维度可以细分为几个不同的文章框架,便于更精细化的进行内容组织,增加系统的深度和精细化程度。二、自动采集技术这个也是不可缺少的,自动采集我们会利用spider,不过要注意的是,用spider采集数据很浪费时间,也可能无法获取高质量的数据。
那么我们可以考虑考虑直接使用第三方采集工具。这个就是极为常见的搜索引擎抓取工具,不会去注册什么账号,只需要登录之后,将一些我们采集的url复制粘贴上去就可以采集,然后生成的网页发布到各大搜索引擎上。这种方式就要考虑到对网站的准确性和搜索引擎的负载。比如国内最知名的是谷歌中国,还有一些我们国内能搜索到的一些比较好的网站,比如穷游网、堆糖网等,对于我们这些用网络只是听说或者试用的小白,通过这些网。 查看全部
网站自动采集文章的站群规则介绍-乐题库
网站自动采集文章可以得到一些流量和粉丝,也是可以直接转化成交的,同时也可以为企业引入不同方向的流量,形成总体营销转化效果。但如果我们希望更高效的引入流量,我们同样需要重视每个采集站的风格和采集范围。本文就为大家详细介绍每个站群规则。*以下文章摘选自网络个人观点,存在不当之处欢迎各位网友一起探讨。-以下正文;--一、上架时间、采集内容每个网站都会有自己的风格,有的网站偏向学术,比如译言,一些网站偏向是时事资讯,比如喜马拉雅fm等。
对于网站来说,每天都有新的文章发布。小编在采集,比如我要采集西班牙区域的新闻资讯,我就找一些西班牙新闻源,在保证准确性的基础上尽可能搜集多的资讯。网站只需要准确的取材和内容基本采集到一定的量就可以满足转化需求。如果只是一天采集30个资讯,那就需要采集一段时间。如果资讯太多,也会加速热度下降。对于上传单个规格规格也是一样,不是太详细,一周才采集3-5篇文章,就是一个很大的网站了。
另外建议上传的规格是数量为30个,只采集20个热门资讯,文章内容收集维度可以细分为几个不同的文章框架,便于更精细化的进行内容组织,增加系统的深度和精细化程度。二、自动采集技术这个也是不可缺少的,自动采集我们会利用spider,不过要注意的是,用spider采集数据很浪费时间,也可能无法获取高质量的数据。
那么我们可以考虑考虑直接使用第三方采集工具。这个就是极为常见的搜索引擎抓取工具,不会去注册什么账号,只需要登录之后,将一些我们采集的url复制粘贴上去就可以采集,然后生成的网页发布到各大搜索引擎上。这种方式就要考虑到对网站的准确性和搜索引擎的负载。比如国内最知名的是谷歌中国,还有一些我们国内能搜索到的一些比较好的网站,比如穷游网、堆糖网等,对于我们这些用网络只是听说或者试用的小白,通过这些网。
java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-06-04 23:25
“java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)心+自动采集)”
01
正文
没有搭建教程,懂的自行下载研究。
安装环境:宝塔面板、tomcat8、nginx1.17、mysql5.6(不知道最高支持到多少)、打开服务器的安全组,放行三个端口8
02
相关截图
注意:下载地址请在公众号内回复:java橙色风格小说/精品屋小说网站源码 查看全部
java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)
“java橙色风格小说/精品屋小说网站源码(带支付+作者中心+自动采集)心+自动采集)”
01
正文
没有搭建教程,懂的自行下载研究。
安装环境:宝塔面板、tomcat8、nginx1.17、mysql5.6(不知道最高支持到多少)、打开服务器的安全组,放行三个端口8
02
相关截图
注意:下载地址请在公众号内回复:java橙色风格小说/精品屋小说网站源码
网站自动采集文章,最多可一键抓取800篇内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-06-03 18:02
网站自动采集文章,最多可一键抓取800篇内容。自动化的抓取功能,多数都是在前端采集器来实现。我们推荐两款主流的抓取工具:unblockyourcontent、smartglassphotorecognition。两款工具都可以在本地运行,也能够免费获取。下面为你介绍他们的用法,以及它们的用法的核心是什么。
我们先来看unblockyourcontent,这是一款支持windows和macos的爬虫。unblockyourcontent使用很简单,安装它后不需要注册使用就可以使用,基本都是自动抓取网站的文章。下面以中国文库为例,使用unblockyourcontent抓取20篇某网站的图片文档,采集地址如下:中国文库-免费图片资源分享平台我们为你提供了语言对应的api接口。
smartglassphotorecognition是一款主流的图片自动抓取工具,自动化抓取600多万图片信息。下面以天津1947-2010年历史图片为例。(本地)抓取api接口地址如下::两款工具都可以在本地运行。它们在抓取网站内容的时候,需要进行人工匹配。如果网站已经抓取过多文章内容,基本都要人工上传一篇文章给他们进行匹配。
如果要快速进行短期的抓取工作,比如一次可抓取50篇文章,而工具又只能自动抓取50篇,那就要使用网站自动化的工具比如workflowy来帮忙实现这个功能。unblockyourcontent不支持在本地运行,而smartglass是不支持本地运行的。unblockyourcontent是在windows下运行的,而smartglass是在macos下运行的。
这两款工具都可以跨平台运行。如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你的电脑是macos,那你需要下载相应的ios工具,或者ios的screentoolsforios去下载ios版本的工具。
如果你不想下载工具,那直接下载网站上公布的接口也是可以的。总结如果你想快速抓取大量网站内容,只需要安装unblockyourcontent,然后搭配smartglass使用就行。unblockyourcontent支持windows,macos和ios。smartglass支持windows,macos和ios。
unblockyourcontent能够自动抓取网站内容,而smartglass支持本地爬取。一篇文章只需要获取一次,如果网站已经抓取过多文章可能还要额外对其进行操作。unblockyourcontent是完全免费的,smartglass是收费版。unblockyourcontent是在windows下运行的,smartglass是在macos下运行的。
如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你不想下载工具,那。 查看全部
网站自动采集文章,最多可一键抓取800篇内容
网站自动采集文章,最多可一键抓取800篇内容。自动化的抓取功能,多数都是在前端采集器来实现。我们推荐两款主流的抓取工具:unblockyourcontent、smartglassphotorecognition。两款工具都可以在本地运行,也能够免费获取。下面为你介绍他们的用法,以及它们的用法的核心是什么。
我们先来看unblockyourcontent,这是一款支持windows和macos的爬虫。unblockyourcontent使用很简单,安装它后不需要注册使用就可以使用,基本都是自动抓取网站的文章。下面以中国文库为例,使用unblockyourcontent抓取20篇某网站的图片文档,采集地址如下:中国文库-免费图片资源分享平台我们为你提供了语言对应的api接口。
smartglassphotorecognition是一款主流的图片自动抓取工具,自动化抓取600多万图片信息。下面以天津1947-2010年历史图片为例。(本地)抓取api接口地址如下::两款工具都可以在本地运行。它们在抓取网站内容的时候,需要进行人工匹配。如果网站已经抓取过多文章内容,基本都要人工上传一篇文章给他们进行匹配。
如果要快速进行短期的抓取工作,比如一次可抓取50篇文章,而工具又只能自动抓取50篇,那就要使用网站自动化的工具比如workflowy来帮忙实现这个功能。unblockyourcontent不支持在本地运行,而smartglass是不支持本地运行的。unblockyourcontent是在windows下运行的,而smartglass是在macos下运行的。
这两款工具都可以跨平台运行。如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你的电脑是macos,那你需要下载相应的ios工具,或者ios的screentoolsforios去下载ios版本的工具。
如果你不想下载工具,那直接下载网站上公布的接口也是可以的。总结如果你想快速抓取大量网站内容,只需要安装unblockyourcontent,然后搭配smartglass使用就行。unblockyourcontent支持windows,macos和ios。smartglass支持windows,macos和ios。
unblockyourcontent能够自动抓取网站内容,而smartglass支持本地爬取。一篇文章只需要获取一次,如果网站已经抓取过多文章可能还要额外对其进行操作。unblockyourcontent是完全免费的,smartglass是收费版。unblockyourcontent是在windows下运行的,smartglass是在macos下运行的。
如果你的电脑是windows,那你需要下载相应的android工具,或者windows的screentoolsforwindows去下载windows版本的工具。如果你不想下载工具,那。
网站自动采集文章来提高网站流量。做seo的朋友都知道
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-06-03 07:02
网站自动采集文章来提高网站流量。做seo的朋友都知道,网站自动采集是通过采集自己网站里面的文章内容放到自己网站,然后给有这些文章的网站做一个外链。网站里面的文章都可以采集。如果一篇文章很大,分为上百篇文章,这一篇文章就可以采集多篇内容过来。网站自动采集最有价值的就是里面的推荐内容。凡是能给网站带来流量的文章,这些内容都可以是采集到网站的自动采集源。
如果只是每天采集一篇文章,一个月没有个几千块钱,自己搜集的文章都放到网站里面,就真的是浪费了。网站的采集按照行业划分,每一个行业里面都可以加很多的文章,把一个行业里面比较优质的文章整理成一篇文章,把这篇文章放到网站里面,起码可以获得几百上千的点击。如果再对推荐源进行优化的话,是可以获得百万到千万甚至是更多的流量。这些流量都是来自于网站自动采集网站。所以采集内容是可以带来巨大的流量的。
网站的推荐源是给某个行业网站做网站上,来给你带来访问量,作为跳转让你访问该行业网站进行询盘,这个是可以赚钱的。这是网站的,不是其他的,
自媒体平台上引流方法引流流量,分为三个小步骤,即文章链接和网站对接,
你自己写一篇发到自己的公众号上,一篇阅读量10万的文章收费五万, 查看全部
网站自动采集文章来提高网站流量。做seo的朋友都知道
网站自动采集文章来提高网站流量。做seo的朋友都知道,网站自动采集是通过采集自己网站里面的文章内容放到自己网站,然后给有这些文章的网站做一个外链。网站里面的文章都可以采集。如果一篇文章很大,分为上百篇文章,这一篇文章就可以采集多篇内容过来。网站自动采集最有价值的就是里面的推荐内容。凡是能给网站带来流量的文章,这些内容都可以是采集到网站的自动采集源。
如果只是每天采集一篇文章,一个月没有个几千块钱,自己搜集的文章都放到网站里面,就真的是浪费了。网站的采集按照行业划分,每一个行业里面都可以加很多的文章,把一个行业里面比较优质的文章整理成一篇文章,把这篇文章放到网站里面,起码可以获得几百上千的点击。如果再对推荐源进行优化的话,是可以获得百万到千万甚至是更多的流量。这些流量都是来自于网站自动采集网站。所以采集内容是可以带来巨大的流量的。
网站的推荐源是给某个行业网站做网站上,来给你带来访问量,作为跳转让你访问该行业网站进行询盘,这个是可以赚钱的。这是网站的,不是其他的,
自媒体平台上引流方法引流流量,分为三个小步骤,即文章链接和网站对接,
你自己写一篇发到自己的公众号上,一篇阅读量10万的文章收费五万,
Web UI自动化测试之日志收集篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-05-11 11:05
本文大纲截图:
1、日志介绍
日志: 用于记录系统运行时的信息,对一个事件的记录,也称为Log。
日志作用:
日志级别:
日志级别:指日志信息的优先级、重要性或者严重程度。
常见的日志级别: DEBUG、INFO、WARNING、ERROR、CRITICAL
import logging<br /><br /><br />logging.debug("这是一条调试信息")<br />logging.info("这是一条普通信息")<br />logging.warning("这是一条警告信息")<br />logging.error("这是一条错误信息")<br />logging.critical("这是一条严重错误信息")<br />
说明:
2、日志用法2.1 基本用法
设置日志级别:
设置日志格式:
代码示例:
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
将日志信息输出到文件中
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(filename="a.log", level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
2.2 高级用法
logging日志模块四大组件: Logger、Handler、Formatter、Filter
组件关系:
Logger类:
Logger常用的方法:
设置日志级别:logger.setLevel(),设置日志器将会处理的日志消息的最低严重级别
添加handler对象:logger.addHandler(),为该logger对象添加一个handler对象
添加filter对象:logger.addFilter(),为该logger对象添加一个filter对象
Handler类:
Handler常用的方法:
Formatter类:
将日志信息同时输出到控制台和文件中:
定义日志格式:
# 设置日志格式<br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br /># 创建格式化器对象<br />formatter = logging.Formatter(fmt)<br />
logger = logging.getLogger()<br />sh = logging.StreamHandler()<br />sh.setFormatter(formatter)<br />logger.addHandler(sh)<br />
fh = logging.FileHandler("./b.log")<br />fh.setFormatter(formatter)<br />logger.addHandler(fh)<br />
每日生成一个日志文件:
fh = logging.handlers.TimedRotatingFileHandler(filename, when='h', interval=1, backupCount=0)<br /> # 将日志信息记录到文件中,以特定的时间间隔切换日志文件。<br /> # filename: 日志文件名<br /> # when: 时间单位,可选参数<br /> # S - Seconds<br /> # M - Minutes<br /> # H - Hours<br /> # D - Days<br /> # midnight - roll over at midnight<br /> # W{0-6} - roll over on a certain day; 0 - Monday<br /> # interval: 时间间隔<br /> # backupCount: 日志文件备份数量。<br /> # 如果backupCount大于0,那么当生成新的日志文件时,将只保留backupCount个文件,删除最老的文件。<br />
import logging.handlers<br /><br /><br />logger = logging.getLogger()<br />logger.setLevel(logging.DEBUG)<br /><br /># 日志格式<br />fmt = "%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s"<br />formatter = logging.Formatter(fmt)<br /><br /># 输出到文件,每日一个文件<br />fh = logging.handlers.TimedRotatingFileHandler("./a.log", when='MIDNIGHT', interval=1, backupCount=3)<br />fh.setFormatter(formatter)<br />fh.setLevel(logging.INFO)<br />logger.addHandler(fh)<br />
日志封装成工具(tools):
# 导包<br />import logging.handlers<br /><br /><br /># 定义日志器方法 ,封装日志<br />def get_logger():<br /> # 获取 日志器logger,并设置名称admin<br /> logger = logging.getLogger("admin")<br /> # 设置日志级别为info<br /> logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器,根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(filename="../log/logger.log", when="S", interval=1, backupCount=2, encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s %(lineno)d)] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器中<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器中<br /> logger.addHandler(sh)<br /> logger.addHandler(th)<br /> # 返回 logger<br /> return logger<br /><br /><br />if __name__ == '__main__':<br /> logger = get_logger()<br /> # 日志器应用<br /> logger.info("这是info信息")<br /> logger.warning("这是warning信息")<br /> logger.error("这是error信息")<br />
3、日志应用
日志应用:PO模式中,在base操作层、page对象层、scripts业务层都可添加日志,以及将日志用单例模式封装成工具类放在tools文件夹中。
import time<br />from time import sleep<br />from selenium.webdriver.support.wait import WebDriverWait<br />from day11_tpshop import page<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class Base:<br /> def __init__(self, driver):<br /> log.info("[base:]正在获取初始化driver对象:{}".format(driver))<br /> self.driver = driver<br /><br /> # 查找元素方法 封装<br /> def base_find(self, loc, timeout=30, poll=0.5):<br /> log.info("[base]:正在定位:{}元素,默认定位超时时间为:{}".format(loc, timeout))<br /> # 使用显式等待 查找元素<br /> return WebDriverWait(self.driver,<br /> timeout=timeout,<br /> poll_frequency=poll).until(lambda x: x.find_element(*loc))<br /><br /> # 点击元素方法 封装<br /> def base_click(self, loc):<br /> log.info("[base]:正在对:{}元素执行点击事件".format(loc))<br /> self.base_find(loc).click()<br /><br /> # 输入元素方法 封装<br /> def base_input(self, loc, value):<br /> log.info("[base]:正在获取:{}元素".format(loc))<br /> # 获取元素<br /> el = self.base_find(loc)<br /> log.info("[base]:正在对:{}元素执行清空操作".format(loc))<br /> # 输入前 清空<br /> el.clear()<br /> log.info("[base]:正在给{}元素输入内容:{}".format(loc, value))<br /> # 输入<br /> el.send_keys(value)<br /><br /> # 获取文本信息方法 封装<br /> def base_get_text(self, loc):<br /> log.info("[base]:正在获取{}元素文本值".format(loc))<br /> return self.base_find(loc).text<br /><br /> # 截图方法 封装<br /> def base_get_img(self):<br /> log.info("[base]:断言出错,调用截图")<br /> self.driver.get_screenshot_as_file("../image/{}.png".format(time.strftime("%Y_%m_%d %H_%M_%S")))<br /><br /> # 判断元素是否存在方法 封装<br /> def base_elememt_is_exist(self, loc):<br /> try:<br /> self.base_find(loc, timeout=2)<br /> log.info("[base]:{}元素查找成功,存在页面".format(loc))<br /> return True # 代表元素存在<br /> except:<br /> log.info("[base]:{}元素查找失败,不存在当前页面".format(loc))<br /> return False # 代表元素不存在<br /><br /> # 回到首页(购物车、下订单、支付)都需要用到此方法<br /> def base_index(self):<br /> # 暂停2秒<br /> sleep(2)<br /> log.info("[base]:正在打开首页")<br /> self.driver.get(page.URL)<br /><br /> # 切到frame表单方法 以元素属性切换<br /> def base_switch_frame(self, element):<br /> log.info("[base]:正在切换到frame表单")<br /> self.driver.switch_to.frame(element)<br /><br /> # 回到默认目录方法<br /> def base_default_content(self):<br /> log.info("[base]:正在返回默认目录")<br /> self.driver.switch_to.default_content()<br /><br /> # 切换窗口方法<br /> def base_switch_to_window(self, title):<br /> log.info("正在执行切换title值为:{}窗口".format(title))<br /> self.base_get_title_handle(title)<br /> # self.driver.switch_to.window(self.base_get_title_handle(title))<br /><br /> # 获取指定title页面的handle方法<br /> def base_get_title_handle(self, title):<br /> # 获取当前页面所有的handles<br /> handles = self.driver.window_handles<br /> # 遍历handle<br /> for handle in handles:<br /> log.info("正在遍历handles:{}-->{}".format(handle, handles))<br /> # 切换 handle<br /> self.driver.switch_to.window(handle)<br /> log.info("切换:{}窗口".format(handle))<br /> # 获取当前页面title 并判断 是否等于 指定参数title<br /> log.info("条件成立!返回当前handle{}".format(handle))<br /> if self.driver.title == title:<br /> # 返回 handle<br /> return handle<br />
from day11_tpshop import page<br />from day11_tpshop.base.base import Base<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class PageLogin(Base):<br /> # 点击 登录链接<br /> def page_click_login_link(self):<br /> log.info("[page_login]:执行{}元素点击链接操作".format(page.login_link))<br /> self.base_click(page.login_link)<br /><br /> # 输入用户名<br /> def page_input_username(self, username):<br /> log.info("[page_login]:对{}元素 输入用户名{}操作".format(page.login_username, username))<br /> self.base_input(page.login_username, username)<br /><br /> # 输入密码<br /> def page_input_pwd(self, pwd):<br /> log.info("[page_login]:对{}元素 输入密码{}操作".format(page.login_pwd, pwd))<br /> self.base_input(page.login_pwd, pwd)<br /><br /> # 输入验证码<br /> def page_input_verify_code(self, verify_code):<br /> log.info("[page_login]:对{}元素 输入验证码{}操作".format(page.login_verify_code, verify_code))<br /> self.base_input(page.login_verify_code, verify_code)<br /><br /> # 点击 登录<br /> def page_click_login_btn(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_btn))<br /> self.base_click(page.login_btn)<br /><br /> # 获取 错误提示信息<br /> def page_get_err_info(self):<br /> return self.base_get_text(page.login_err_info)<br /><br /> # 点击 错误提示框 确定按钮<br /> def page_click_error_alert(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_err_ok_btn))<br /> self.base_click(page.login_err_ok_btn)<br /><br /> # 判断是否登录成功<br /> def page_if_login_success(self):<br /> # 注意 一定要将找元素的结果返回,True:存在<br /> return self.base_elememt_is_exist(page.login_logout_link)<br /><br /> # 点击 安全退出<br /> def page_click_logout_link(self):<br /> self.base_click(page.login_logout_link)<br /><br /> # 判断是否退出成功<br /> def page_if_logout_success(self):<br /> return self.base_elememt_is_exist(page.login_link)<br /><br /> # 组合业务方法 登录业务直接调用<br /> def page_login(self, username, pwd, verify_code):<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br /><br /> # 组合登录业务方法 给(购物车模块、订单模块、支付模块)依赖登录使用<br /> def page_login_success(self, username="13800001111", pwd="123456", verify_code="8888"):<br /> # 点击登录链接<br /> self.page_click_login_link()<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br />
import unittest<br />from day11_TPshop项目.base.get_driver import GetDriver<br />from day11_TPshop项目.base.get_logger import GetLogger<br />from day11_TPshop项目.page.page_login import PageLogin<br />from day11_TPshop项目.tools.read_txt import read_txt<br />from parameterized import parameterized<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />def get_data():<br /> arrs = []<br /> for data in read_txt("login.txt"):<br /> arrs.append(tuple(data.strip().split(",")))<br /> return arrs[1:]<br /><br /><br /># 新建 登录测试类 并 继承 unittest.TestCase<br />class TestLogin(unittest.TestCase):<br /> # 新建 setUpClass<br /> @classmethod<br /> def setUpClass(cls) -> None:<br /> try:<br /> # 实例化 并获取 driver<br /> cls.driver = GetDriver.get_driver()<br /> # 实例化 PageLogin()<br /> cls.login = PageLogin(cls.driver)<br /> # 点击登录链接<br /> cls.login.page_click_login_link()<br /> except Exception as e:<br /> # 截图<br /> cls.login.base_get_img()<br /> # 日志<br /> log.error("错误:{}".format(e))<br /><br /> # 新建 tearDownClass<br /> @classmethod<br /> def tearDownClass(cls) -> None:<br /> # 关闭driver驱动对象<br /> GetDriver.quit_driver()<br /><br /> # 新建 登录测试方法<br /> @parameterized.expand(get_data())<br /> def test_login(self, username, pwd, verify_code, expect_result, status):<br /> try:<br /> # 调用 登录业务方法<br /> self.login.page_login(username, pwd, verify_code)<br /><br /> # 判断是否为正向<br /> if status == "true":<br /> # 断言是否登录成功<br /> try:<br /> self.assertTrue(self.login.page_if_login_success())<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击 安全退出<br /> self.login.page_click_logout_link()<br /> # 点击 登录链接<br /> self.login.page_click_login_link()<br /> # 逆向用例<br /> else:<br /> # 获取错误提示信息<br /> msg = self.login.page_get_err_info()<br /> print("msg:", msg)<br /> try:<br /> self.assertEqual(msg, expect_result)<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击错误提示框 确定按钮<br /> self.login.page_click_error_alert()<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br />
import logging.handlers<br />import time<br /><br /><br />class GetLogger:<br /> logger = None<br /><br /> # 获取logger<br /> @classmethod<br /> def get_logger(cls):<br /> if cls.logger is None:<br /> # 获取 logger 日志器 并设置名称为“admin”<br /> cls.logger = logging.getLogger("admin")<br /> # 设置日志级别<br /> cls.logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器 根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(<br /> filename="../log/{}.log".format(time.strftime("%Y_%m_%d %H_%M_%S")),<br /> when="S",<br /> interval=1,<br /> backupCount=3,<br /> encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s %(funcName)s %(lineno)d] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器<br /> cls.logger.addHandler(sh)<br /> cls.logger.addHandler(th)<br /> # 返回日志器<br /> return cls.logger<br /><br /><br />if __name__ == '__main__':<br /> logger = GetLogger.get_logger()<br /> # 日志器应用<br /> logger.info("这是info日志信息")<br /> logger.debug("这是debug日志信息")<br /> logger.warning("这是warning日志信息")<br /> logger.error("这是error日志信息")<br /> 查看全部
Web UI自动化测试之日志收集篇
本文大纲截图:
1、日志介绍
日志: 用于记录系统运行时的信息,对一个事件的记录,也称为Log。
日志作用:
日志级别:
日志级别:指日志信息的优先级、重要性或者严重程度。
常见的日志级别: DEBUG、INFO、WARNING、ERROR、CRITICAL
import logging<br /><br /><br />logging.debug("这是一条调试信息")<br />logging.info("这是一条普通信息")<br />logging.warning("这是一条警告信息")<br />logging.error("这是一条错误信息")<br />logging.critical("这是一条严重错误信息")<br />
说明:
2、日志用法2.1 基本用法
设置日志级别:
设置日志格式:
代码示例:
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
将日志信息输出到文件中
import logging<br /><br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br />logging.basicConfig(filename="a.log", level=logging.INFO, format=fmt)<br /><br />logging.debug("调试")<br />logging.info("信息")<br />logging.warning("警告")<br />logging.error("错误")<br />
2.2 高级用法
logging日志模块四大组件: Logger、Handler、Formatter、Filter
组件关系:
Logger类:
Logger常用的方法:
设置日志级别:logger.setLevel(),设置日志器将会处理的日志消息的最低严重级别
添加handler对象:logger.addHandler(),为该logger对象添加一个handler对象
添加filter对象:logger.addFilter(),为该logger对象添加一个filter对象
Handler类:
Handler常用的方法:
Formatter类:
将日志信息同时输出到控制台和文件中:
定义日志格式:
# 设置日志格式<br />fmt = '%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'<br /># 创建格式化器对象<br />formatter = logging.Formatter(fmt)<br />
logger = logging.getLogger()<br />sh = logging.StreamHandler()<br />sh.setFormatter(formatter)<br />logger.addHandler(sh)<br />
fh = logging.FileHandler("./b.log")<br />fh.setFormatter(formatter)<br />logger.addHandler(fh)<br />
每日生成一个日志文件:
fh = logging.handlers.TimedRotatingFileHandler(filename, when='h', interval=1, backupCount=0)<br /> # 将日志信息记录到文件中,以特定的时间间隔切换日志文件。<br /> # filename: 日志文件名<br /> # when: 时间单位,可选参数<br /> # S - Seconds<br /> # M - Minutes<br /> # H - Hours<br /> # D - Days<br /> # midnight - roll over at midnight<br /> # W{0-6} - roll over on a certain day; 0 - Monday<br /> # interval: 时间间隔<br /> # backupCount: 日志文件备份数量。<br /> # 如果backupCount大于0,那么当生成新的日志文件时,将只保留backupCount个文件,删除最老的文件。<br />
import logging.handlers<br /><br /><br />logger = logging.getLogger()<br />logger.setLevel(logging.DEBUG)<br /><br /># 日志格式<br />fmt = "%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s"<br />formatter = logging.Formatter(fmt)<br /><br /># 输出到文件,每日一个文件<br />fh = logging.handlers.TimedRotatingFileHandler("./a.log", when='MIDNIGHT', interval=1, backupCount=3)<br />fh.setFormatter(formatter)<br />fh.setLevel(logging.INFO)<br />logger.addHandler(fh)<br />
日志封装成工具(tools):
# 导包<br />import logging.handlers<br /><br /><br /># 定义日志器方法 ,封装日志<br />def get_logger():<br /> # 获取 日志器logger,并设置名称admin<br /> logger = logging.getLogger("admin")<br /> # 设置日志级别为info<br /> logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器,根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(filename="../log/logger.log", when="S", interval=1, backupCount=2, encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s %(lineno)d)] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器中<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器中<br /> logger.addHandler(sh)<br /> logger.addHandler(th)<br /> # 返回 logger<br /> return logger<br /><br /><br />if __name__ == '__main__':<br /> logger = get_logger()<br /> # 日志器应用<br /> logger.info("这是info信息")<br /> logger.warning("这是warning信息")<br /> logger.error("这是error信息")<br />
3、日志应用
日志应用:PO模式中,在base操作层、page对象层、scripts业务层都可添加日志,以及将日志用单例模式封装成工具类放在tools文件夹中。
import time<br />from time import sleep<br />from selenium.webdriver.support.wait import WebDriverWait<br />from day11_tpshop import page<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class Base:<br /> def __init__(self, driver):<br /> log.info("[base:]正在获取初始化driver对象:{}".format(driver))<br /> self.driver = driver<br /><br /> # 查找元素方法 封装<br /> def base_find(self, loc, timeout=30, poll=0.5):<br /> log.info("[base]:正在定位:{}元素,默认定位超时时间为:{}".format(loc, timeout))<br /> # 使用显式等待 查找元素<br /> return WebDriverWait(self.driver,<br /> timeout=timeout,<br /> poll_frequency=poll).until(lambda x: x.find_element(*loc))<br /><br /> # 点击元素方法 封装<br /> def base_click(self, loc):<br /> log.info("[base]:正在对:{}元素执行点击事件".format(loc))<br /> self.base_find(loc).click()<br /><br /> # 输入元素方法 封装<br /> def base_input(self, loc, value):<br /> log.info("[base]:正在获取:{}元素".format(loc))<br /> # 获取元素<br /> el = self.base_find(loc)<br /> log.info("[base]:正在对:{}元素执行清空操作".format(loc))<br /> # 输入前 清空<br /> el.clear()<br /> log.info("[base]:正在给{}元素输入内容:{}".format(loc, value))<br /> # 输入<br /> el.send_keys(value)<br /><br /> # 获取文本信息方法 封装<br /> def base_get_text(self, loc):<br /> log.info("[base]:正在获取{}元素文本值".format(loc))<br /> return self.base_find(loc).text<br /><br /> # 截图方法 封装<br /> def base_get_img(self):<br /> log.info("[base]:断言出错,调用截图")<br /> self.driver.get_screenshot_as_file("../image/{}.png".format(time.strftime("%Y_%m_%d %H_%M_%S")))<br /><br /> # 判断元素是否存在方法 封装<br /> def base_elememt_is_exist(self, loc):<br /> try:<br /> self.base_find(loc, timeout=2)<br /> log.info("[base]:{}元素查找成功,存在页面".format(loc))<br /> return True # 代表元素存在<br /> except:<br /> log.info("[base]:{}元素查找失败,不存在当前页面".format(loc))<br /> return False # 代表元素不存在<br /><br /> # 回到首页(购物车、下订单、支付)都需要用到此方法<br /> def base_index(self):<br /> # 暂停2秒<br /> sleep(2)<br /> log.info("[base]:正在打开首页")<br /> self.driver.get(page.URL)<br /><br /> # 切到frame表单方法 以元素属性切换<br /> def base_switch_frame(self, element):<br /> log.info("[base]:正在切换到frame表单")<br /> self.driver.switch_to.frame(element)<br /><br /> # 回到默认目录方法<br /> def base_default_content(self):<br /> log.info("[base]:正在返回默认目录")<br /> self.driver.switch_to.default_content()<br /><br /> # 切换窗口方法<br /> def base_switch_to_window(self, title):<br /> log.info("正在执行切换title值为:{}窗口".format(title))<br /> self.base_get_title_handle(title)<br /> # self.driver.switch_to.window(self.base_get_title_handle(title))<br /><br /> # 获取指定title页面的handle方法<br /> def base_get_title_handle(self, title):<br /> # 获取当前页面所有的handles<br /> handles = self.driver.window_handles<br /> # 遍历handle<br /> for handle in handles:<br /> log.info("正在遍历handles:{}-->{}".format(handle, handles))<br /> # 切换 handle<br /> self.driver.switch_to.window(handle)<br /> log.info("切换:{}窗口".format(handle))<br /> # 获取当前页面title 并判断 是否等于 指定参数title<br /> log.info("条件成立!返回当前handle{}".format(handle))<br /> if self.driver.title == title:<br /> # 返回 handle<br /> return handle<br />
from day11_tpshop import page<br />from day11_tpshop.base.base import Base<br />from day11_tpshop.base.get_logger import GetLogger<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />class PageLogin(Base):<br /> # 点击 登录链接<br /> def page_click_login_link(self):<br /> log.info("[page_login]:执行{}元素点击链接操作".format(page.login_link))<br /> self.base_click(page.login_link)<br /><br /> # 输入用户名<br /> def page_input_username(self, username):<br /> log.info("[page_login]:对{}元素 输入用户名{}操作".format(page.login_username, username))<br /> self.base_input(page.login_username, username)<br /><br /> # 输入密码<br /> def page_input_pwd(self, pwd):<br /> log.info("[page_login]:对{}元素 输入密码{}操作".format(page.login_pwd, pwd))<br /> self.base_input(page.login_pwd, pwd)<br /><br /> # 输入验证码<br /> def page_input_verify_code(self, verify_code):<br /> log.info("[page_login]:对{}元素 输入验证码{}操作".format(page.login_verify_code, verify_code))<br /> self.base_input(page.login_verify_code, verify_code)<br /><br /> # 点击 登录<br /> def page_click_login_btn(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_btn))<br /> self.base_click(page.login_btn)<br /><br /> # 获取 错误提示信息<br /> def page_get_err_info(self):<br /> return self.base_get_text(page.login_err_info)<br /><br /> # 点击 错误提示框 确定按钮<br /> def page_click_error_alert(self):<br /> log.info("[page_login]:执行{}元素点击操作".format(page.login_err_ok_btn))<br /> self.base_click(page.login_err_ok_btn)<br /><br /> # 判断是否登录成功<br /> def page_if_login_success(self):<br /> # 注意 一定要将找元素的结果返回,True:存在<br /> return self.base_elememt_is_exist(page.login_logout_link)<br /><br /> # 点击 安全退出<br /> def page_click_logout_link(self):<br /> self.base_click(page.login_logout_link)<br /><br /> # 判断是否退出成功<br /> def page_if_logout_success(self):<br /> return self.base_elememt_is_exist(page.login_link)<br /><br /> # 组合业务方法 登录业务直接调用<br /> def page_login(self, username, pwd, verify_code):<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br /><br /> # 组合登录业务方法 给(购物车模块、订单模块、支付模块)依赖登录使用<br /> def page_login_success(self, username="13800001111", pwd="123456", verify_code="8888"):<br /> # 点击登录链接<br /> self.page_click_login_link()<br /> log.info("[page_login]:正在执行登录操作,用户名:{},密码:{},验证码:{}".format(username, pwd, verify_code))<br /> self.page_input_username(username)<br /> self.page_input_pwd(pwd)<br /> self.page_input_verify_code(verify_code)<br /> self.page_click_login_btn()<br />
import unittest<br />from day11_TPshop项目.base.get_driver import GetDriver<br />from day11_TPshop项目.base.get_logger import GetLogger<br />from day11_TPshop项目.page.page_login import PageLogin<br />from day11_TPshop项目.tools.read_txt import read_txt<br />from parameterized import parameterized<br /><br /># 获取log日志器<br />log = GetLogger().get_logger()<br /><br /><br />def get_data():<br /> arrs = []<br /> for data in read_txt("login.txt"):<br /> arrs.append(tuple(data.strip().split(",")))<br /> return arrs[1:]<br /><br /><br /># 新建 登录测试类 并 继承 unittest.TestCase<br />class TestLogin(unittest.TestCase):<br /> # 新建 setUpClass<br /> @classmethod<br /> def setUpClass(cls) -> None:<br /> try:<br /> # 实例化 并获取 driver<br /> cls.driver = GetDriver.get_driver()<br /> # 实例化 PageLogin()<br /> cls.login = PageLogin(cls.driver)<br /> # 点击登录链接<br /> cls.login.page_click_login_link()<br /> except Exception as e:<br /> # 截图<br /> cls.login.base_get_img()<br /> # 日志<br /> log.error("错误:{}".format(e))<br /><br /> # 新建 tearDownClass<br /> @classmethod<br /> def tearDownClass(cls) -> None:<br /> # 关闭driver驱动对象<br /> GetDriver.quit_driver()<br /><br /> # 新建 登录测试方法<br /> @parameterized.expand(get_data())<br /> def test_login(self, username, pwd, verify_code, expect_result, status):<br /> try:<br /> # 调用 登录业务方法<br /> self.login.page_login(username, pwd, verify_code)<br /><br /> # 判断是否为正向<br /> if status == "true":<br /> # 断言是否登录成功<br /> try:<br /> self.assertTrue(self.login.page_if_login_success())<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击 安全退出<br /> self.login.page_click_logout_link()<br /> # 点击 登录链接<br /> self.login.page_click_login_link()<br /> # 逆向用例<br /> else:<br /> # 获取错误提示信息<br /> msg = self.login.page_get_err_info()<br /> print("msg:", msg)<br /> try:<br /> self.assertEqual(msg, expect_result)<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br /> # 点击错误提示框 确定按钮<br /> self.login.page_click_error_alert()<br /> except Exception as e:<br /> # 截图<br /> self.login.base_get_img()<br /> # 日志<br /> log.error("出错了:{}".format(e))<br />
import logging.handlers<br />import time<br /><br /><br />class GetLogger:<br /> logger = None<br /><br /> # 获取logger<br /> @classmethod<br /> def get_logger(cls):<br /> if cls.logger is None:<br /> # 获取 logger 日志器 并设置名称为“admin”<br /> cls.logger = logging.getLogger("admin")<br /> # 设置日志级别<br /> cls.logger.setLevel(logging.INFO)<br /> # 获取 控制台处理器<br /> sh = logging.StreamHandler()<br /> # 获取 文件处理器 根据时间分割<br /> th = logging.handlers.TimedRotatingFileHandler(<br /> filename="../log/{}.log".format(time.strftime("%Y_%m_%d %H_%M_%S")),<br /> when="S",<br /> interval=1,<br /> backupCount=3,<br /> encoding="utf-8")<br /> # 设置 文件处理器 日志级别<br /> th.setLevel(logging.ERROR)<br /> # 获取 格式器<br /> fmt = "%(asctime)s %(levelname)s [%(name)s] [%(filename)s %(funcName)s %(lineno)d] - %(message)s"<br /> fm = logging.Formatter(fmt)<br /> # 将 格式器 添加到 处理器<br /> sh.setFormatter(fm)<br /> th.setFormatter(fm)<br /> # 将 处理器 添加到 日志器<br /> cls.logger.addHandler(sh)<br /> cls.logger.addHandler(th)<br /> # 返回日志器<br /> return cls.logger<br /><br /><br />if __name__ == '__main__':<br /> logger = GetLogger.get_logger()<br /> # 日志器应用<br /> logger.info("这是info日志信息")<br /> logger.debug("这是debug日志信息")<br /> logger.warning("这是warning日志信息")<br /> logger.error("这是error日志信息")<br />
网站自动采集博客首页网址是非常重要的吗?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-05-02 15:00
网站自动采集文章是比较常见的。对于博客来说,数据库是自己写的,那么自动采集博客首页网址这一功能是非常重要的。另外,随着大多数用户对博客爬虫的依赖度越来越低,在满足于博客文章搜索的基础上,还要增加对网站采集的功能,越来越趋于必要了。说来,网站数据源于网站发布,采集可以看做一种二次开发,把原网站业务抽象重新定义后的业务,能为其他新需求解决一些难点。
此外,无论是采集还是搜索,都需要经过多次请求和返回内容结果,那么使用scrapy这样一个轻量级的爬虫框架,它本身就允许爬虫采集并返回requeststatus报文。抓取一个网站最关键的地方在于返回给你的内容,而不在于返回内容是什么。所以,网站自动采集功能没有必要精细到,一定是要对不同网站生成不同的loginfo脚本的。
或者是不同网站单独设计模块,发布的时候各开发一套,如果爬虫走正则路线,当然是哪个网站发布,哪个网站的不同版本爬虫就往那个网站去爬。
编写网站爬虫要看你爬取什么内容,如果仅仅是网站首页,可以用scrapy框架写爬虫,如果要爬取源代码,需要用python写scrapy提供的item配置;采集同一个网站可以分布式采集,
你说的是java或者python进行自动爬取吗? 查看全部
网站自动采集博客首页网址是非常重要的吗?-八维教育
网站自动采集文章是比较常见的。对于博客来说,数据库是自己写的,那么自动采集博客首页网址这一功能是非常重要的。另外,随着大多数用户对博客爬虫的依赖度越来越低,在满足于博客文章搜索的基础上,还要增加对网站采集的功能,越来越趋于必要了。说来,网站数据源于网站发布,采集可以看做一种二次开发,把原网站业务抽象重新定义后的业务,能为其他新需求解决一些难点。
此外,无论是采集还是搜索,都需要经过多次请求和返回内容结果,那么使用scrapy这样一个轻量级的爬虫框架,它本身就允许爬虫采集并返回requeststatus报文。抓取一个网站最关键的地方在于返回给你的内容,而不在于返回内容是什么。所以,网站自动采集功能没有必要精细到,一定是要对不同网站生成不同的loginfo脚本的。
或者是不同网站单独设计模块,发布的时候各开发一套,如果爬虫走正则路线,当然是哪个网站发布,哪个网站的不同版本爬虫就往那个网站去爬。
编写网站爬虫要看你爬取什么内容,如果仅仅是网站首页,可以用scrapy框架写爬虫,如果要爬取源代码,需要用python写scrapy提供的item配置;采集同一个网站可以分布式采集,
你说的是java或者python进行自动爬取吗?
网站自动采集文章的好处有哪些?怎么提高收录率
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-05-01 01:02
网站自动采集文章的好处:第
一、方便快捷。
二、提高自己网站的收录和排名。
三、网站数据安全。
方法:只需要做好以下几个方面
1)输入你的网站名称。
2)注意采集的文章的规范
3)选择核心关键词。
有的。比如网友自己新创建的一个文档,我们推送出去的链接就是自己创建的文档里面的内容,如果你的网站想采集同一个用户新创建的文档,可以把这个文档同时提交给百度和必应搜索,必应会直接显示这个文档的原文档。以我现在的经验,同一个用户新创建的文档,百度比必应采集下来的原文档会多很多。百度网友之间都可以互相推送文档。
额。
貌似是老网站创建新网站,再挂链接到旧网站上。
update2014-07-24:问题已经解决,只不过是baidu直接复制的,希望能有用。给大家发个福利吧,自己新建一个网站()和免费书籍提供者联系,免费领取书籍哦。
其实有人问到这个问题,就已经证明有人利用这个漏洞来提高这个网站收录率的。某公司利用“pc+无线+手机”三端同步收录域名,而中国小网站太多,必应,搜狗,百度,360,谷歌等等收录一大堆。不过你这种提交并不会引起收录。
百度不会做那么愚蠢的事情,因为百度不是你的竞争对手,而且它对有利于自己收录率的文章会有人无偿分享出来。 查看全部
网站自动采集文章的好处有哪些?怎么提高收录率
网站自动采集文章的好处:第
一、方便快捷。
二、提高自己网站的收录和排名。
三、网站数据安全。
方法:只需要做好以下几个方面
1)输入你的网站名称。
2)注意采集的文章的规范
3)选择核心关键词。
有的。比如网友自己新创建的一个文档,我们推送出去的链接就是自己创建的文档里面的内容,如果你的网站想采集同一个用户新创建的文档,可以把这个文档同时提交给百度和必应搜索,必应会直接显示这个文档的原文档。以我现在的经验,同一个用户新创建的文档,百度比必应采集下来的原文档会多很多。百度网友之间都可以互相推送文档。
额。
貌似是老网站创建新网站,再挂链接到旧网站上。
update2014-07-24:问题已经解决,只不过是baidu直接复制的,希望能有用。给大家发个福利吧,自己新建一个网站()和免费书籍提供者联系,免费领取书籍哦。
其实有人问到这个问题,就已经证明有人利用这个漏洞来提高这个网站收录率的。某公司利用“pc+无线+手机”三端同步收录域名,而中国小网站太多,必应,搜狗,百度,360,谷歌等等收录一大堆。不过你这种提交并不会引起收录。
百度不会做那么愚蠢的事情,因为百度不是你的竞争对手,而且它对有利于自己收录率的文章会有人无偿分享出来。
【帮转】鱼鱼站群cms
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-29 17:20
这次的事情是这样的:上次这个大兄弟的站群CMS整好了,本渣再次帮转下。
总的来说:
1)基于java开发,高并发请求的场景,java比php更能打
2)内置ElasticSearch开源搜索,似乎意味着可以导入关键词后,自动索引生成聚合
3)内置GPT,似乎意味着可通过GPT深度学习生成AI原创文章
4)内置一堆插件,比如Baidu、Google排名查询,以及N套模板
本渣第一感觉:功能强大;ES吃内存,GPT吃GPU和语料质量,硬件成本或许会高一些,但没准有黑科技呢
没亲自测试过,毕竟本渣SEO水平已落伍多年,已经不懂SEO了
感兴趣的朋友请自行联系这位大兄弟测试,微信放在最下面了
【转发内容】
导读:站群是什么?站群是由几个到几百个网站组成;
泛站群是什么?泛站群由用一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页的站群;
泛目录又是什么了?泛目录由1个网站上面生成无限个目录页面。
介绍完这些,市面这么多站群方式方法,我们这些个人站长想通过手工更新站群,那几乎是不可能的任务。一般都是通过站群来完成。进行全自动更新等。
鱼鱼站群cms经历了将近一年的构思,开发,打磨,开发出一套让站长朋友们省心、高效获取seo流量的cms系统,现在即将进入预售阶段;
那么功能有哪些了?
1、搜索聚合站群
2、蜘蛛池定向
3、泛目录站群
4、自定义采集
5、AI内容生成
6、1000+原创模板
7、可配置化的站群分站系统
8、基于es精准搜索的聚合单页,或者二级目录
9、无缝对接排名查询,快速排名系统
10、基于uniapp的多端小程序丰富的插件等等
大家会关心是否承载高并发高扩展呢?我们的技术选型java
那么大家会问为什么不选择php呢?大多数cms都是用php开发的,我们当时考虑以大型网站思维流量并发,以及扩展性这几点来考虑的,php经过几代的发展,性能方面有了很大提升,但是云计算并发处理都是java开发的
我们鱼鱼站群cms内容处理分三种类型:
1、简化版优采云的采集
2、基于es搜索聚合内容
3、luncen搜索聚合
4、nlp自然语言训练内容
总之满足大家对内容这块的需求,我们自己测试的效果:百度pc权3移动权6
后台内容生成和python脚本的生成
输入进去我们需要进行内容处理,会返回到内容资源待审核,包括标题内容都给你自动搜索聚合好!
鱼鱼站群cms目前已有的方式是泛站群和泛目录
通过后台添加标识比如北京,那么网站呈现泛目录形式,包括网站TDK文章标题这些都会变
模板和插件别人有什么不同呢?
模板我们cms预计1年内做成1000套不一样原创的模板,插件功能内置goole和bd排名等等我们会听取用户意见不断的迭代完善
这些功能都是其中的冰山一角更多需要你们发掘哦!我们官网
查看全部
【帮转】鱼鱼站群cms
这次的事情是这样的:上次这个大兄弟的站群CMS整好了,本渣再次帮转下。
总的来说:
1)基于java开发,高并发请求的场景,java比php更能打
2)内置ElasticSearch开源搜索,似乎意味着可以导入关键词后,自动索引生成聚合
3)内置GPT,似乎意味着可通过GPT深度学习生成AI原创文章
4)内置一堆插件,比如Baidu、Google排名查询,以及N套模板
本渣第一感觉:功能强大;ES吃内存,GPT吃GPU和语料质量,硬件成本或许会高一些,但没准有黑科技呢
没亲自测试过,毕竟本渣SEO水平已落伍多年,已经不懂SEO了
感兴趣的朋友请自行联系这位大兄弟测试,微信放在最下面了
【转发内容】
导读:站群是什么?站群是由几个到几百个网站组成;
泛站群是什么?泛站群由用一个顶级域名*.域名泛解析进行生成的二级域名。然后二级域名批量的生成单页的站群;
泛目录又是什么了?泛目录由1个网站上面生成无限个目录页面。
介绍完这些,市面这么多站群方式方法,我们这些个人站长想通过手工更新站群,那几乎是不可能的任务。一般都是通过站群来完成。进行全自动更新等。
鱼鱼站群cms经历了将近一年的构思,开发,打磨,开发出一套让站长朋友们省心、高效获取seo流量的cms系统,现在即将进入预售阶段;
那么功能有哪些了?
1、搜索聚合站群
2、蜘蛛池定向
3、泛目录站群
4、自定义采集
5、AI内容生成
6、1000+原创模板
7、可配置化的站群分站系统
8、基于es精准搜索的聚合单页,或者二级目录
9、无缝对接排名查询,快速排名系统
10、基于uniapp的多端小程序丰富的插件等等
大家会关心是否承载高并发高扩展呢?我们的技术选型java
那么大家会问为什么不选择php呢?大多数cms都是用php开发的,我们当时考虑以大型网站思维流量并发,以及扩展性这几点来考虑的,php经过几代的发展,性能方面有了很大提升,但是云计算并发处理都是java开发的
我们鱼鱼站群cms内容处理分三种类型:
1、简化版优采云的采集
2、基于es搜索聚合内容
3、luncen搜索聚合
4、nlp自然语言训练内容
总之满足大家对内容这块的需求,我们自己测试的效果:百度pc权3移动权6
后台内容生成和python脚本的生成
输入进去我们需要进行内容处理,会返回到内容资源待审核,包括标题内容都给你自动搜索聚合好!
鱼鱼站群cms目前已有的方式是泛站群和泛目录
通过后台添加标识比如北京,那么网站呈现泛目录形式,包括网站TDK文章标题这些都会变
模板和插件别人有什么不同呢?
模板我们cms预计1年内做成1000套不一样原创的模板,插件功能内置goole和bd排名等等我们会听取用户意见不断的迭代完善
这些功能都是其中的冰山一角更多需要你们发掘哦!我们官网
网站自动采集文章( 如何实现不同网站的批量采集进行伪原创发布网站建设)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-20 01:07
如何实现不同网站的批量采集进行伪原创发布网站建设)
网站构建如何实现不同的网站批次采集伪原创发布网站管理b2b网站构建
2022-04-19
网站管理,最近很多站长问我如何管理不同cms看到的网站,因为不同cms的web发布接口是不同的。我们如何实现不同的网站批次采集伪原创发布网站管理网站构建,更重要的是如何进行相应的SEO优化设置。
如果你认为你有一个 网站 并且一切都很好,那你就错了。建站的过程固然重要,但后期的网站管理更为关键。只有运行良好的 网站 才能真正实现 网站 的价值。网站运营主要包括网站建设、内容运营等方面。优秀的网站管理可以理解为一站式网站文章采集、伪原创、发布等相应的SEO优化都做好网站建设,快速提升网站收录、排名、权重,是网站内容维护的最佳伙伴。
网站建筑内容管理可以使用免费的采集工具来完成。当网站很多,网站的cms比较复杂,内容更新量比较大,我们可以使用免费采集,每更新一次网站天。批量自动推送到搜狗、360、神马、百度等搜索引擎。就是说我们可以通过网站主动推送网站管理,让搜索引擎更快的发现我们的网站。让您的 网站 搜索引擎 收录 更快。
众所周知,网站管理中网站的内容建设,也是网站整体建设的重要组成部分。现在更多的站长已经意识到内容管理的重要性。网站具有可读性、信息量和趣味性的内容会吸引大量浏览量,其中相当一部分会转化为消费。
网站管理可以考虑相关性的优化,即当关键词出现在正文中时,正文第一段自动加粗网站构造,并自动插入标题。当前采集的关键词在描述不相关时自动添加。文本的随机位置会自动插入到当前采集的关键字中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,图形呈现是网站管理和建设中的一项重要工作。简单来说,建站就是将站长期望表达的内容可视化,然后通过技术处理呈现给受众。这里的可视化包括文本、图片和表格。常见图像有多种格式,JPG、GIF 或 PNG。技术人员可以使用超文本语言将这些图像和文本转换为 网站 内容。比较麻烦的是流媒体文件,也就是我们经常遇到的录制文件。有必要这样做。
如果没有好主意,我们可以使用免费的采集工具制作图片,文章伪原创,视频伪原创变成原创效果,然后组合相应的SEO优化设置如标题、描述、内容等相应的站内优化和站外优化。网站使用免费的采集工具网站创建管理镜像。如果文章的内容中没有图片,会自动配置相关图片。设置自动下载图片保存在本地或第三方保存,使内容不再有对方的外部链接。
场地管理是网站建筑的重要组成部分。一个好的网站管理方法可以为网站管理员创造巨大的价值。掌握网站管理技巧也可以帮助你的网站提升用户体验。只有不断学习网站运营管理的基础知识,充分掌握网站运营管理的技能,网站有限的内容才能拥有无限的价值。这就是今天的网站管理层。下一期,我们将分享更多SEO相关知识和SEO实践经验。 查看全部
网站自动采集文章(
如何实现不同网站的批量采集进行伪原创发布网站建设)
网站构建如何实现不同的网站批次采集伪原创发布网站管理b2b网站构建
2022-04-19
网站管理,最近很多站长问我如何管理不同cms看到的网站,因为不同cms的web发布接口是不同的。我们如何实现不同的网站批次采集伪原创发布网站管理网站构建,更重要的是如何进行相应的SEO优化设置。
如果你认为你有一个 网站 并且一切都很好,那你就错了。建站的过程固然重要,但后期的网站管理更为关键。只有运行良好的 网站 才能真正实现 网站 的价值。网站运营主要包括网站建设、内容运营等方面。优秀的网站管理可以理解为一站式网站文章采集、伪原创、发布等相应的SEO优化都做好网站建设,快速提升网站收录、排名、权重,是网站内容维护的最佳伙伴。
网站建筑内容管理可以使用免费的采集工具来完成。当网站很多,网站的cms比较复杂,内容更新量比较大,我们可以使用免费采集,每更新一次网站天。批量自动推送到搜狗、360、神马、百度等搜索引擎。就是说我们可以通过网站主动推送网站管理,让搜索引擎更快的发现我们的网站。让您的 网站 搜索引擎 收录 更快。
众所周知,网站管理中网站的内容建设,也是网站整体建设的重要组成部分。现在更多的站长已经意识到内容管理的重要性。网站具有可读性、信息量和趣味性的内容会吸引大量浏览量,其中相当一部分会转化为消费。
网站管理可以考虑相关性的优化,即当关键词出现在正文中时,正文第一段自动加粗网站构造,并自动插入标题。当前采集的关键词在描述不相关时自动添加。文本的随机位置会自动插入到当前采集的关键字中两次。当前采集的 关键词 在出现在文本中时会自动加粗。
其次,图形呈现是网站管理和建设中的一项重要工作。简单来说,建站就是将站长期望表达的内容可视化,然后通过技术处理呈现给受众。这里的可视化包括文本、图片和表格。常见图像有多种格式,JPG、GIF 或 PNG。技术人员可以使用超文本语言将这些图像和文本转换为 网站 内容。比较麻烦的是流媒体文件,也就是我们经常遇到的录制文件。有必要这样做。
如果没有好主意,我们可以使用免费的采集工具制作图片,文章伪原创,视频伪原创变成原创效果,然后组合相应的SEO优化设置如标题、描述、内容等相应的站内优化和站外优化。网站使用免费的采集工具网站创建管理镜像。如果文章的内容中没有图片,会自动配置相关图片。设置自动下载图片保存在本地或第三方保存,使内容不再有对方的外部链接。
场地管理是网站建筑的重要组成部分。一个好的网站管理方法可以为网站管理员创造巨大的价值。掌握网站管理技巧也可以帮助你的网站提升用户体验。只有不断学习网站运营管理的基础知识,充分掌握网站运营管理的技能,网站有限的内容才能拥有无限的价值。这就是今天的网站管理层。下一期,我们将分享更多SEO相关知识和SEO实践经验。
网站自动采集文章(如何防止别人采集我们的网站文章的网友,dede能不能实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-19 04:32
概述如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 dedecms 可以实现吗?其实很简单。
如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 Dedecms 可以实现吗?其实也很简单,代码如下:
document.body.oncopy = function () { setTimeout( function () { var text = clipboardData.getData("text"); if (text) { text = text + "\r\n这篇文章文章@ >来自原文链接:"+location.href;clipboardData.setData("text",text); } },100 ) }
只需将上面的代码放在内容 dede 模板的 文章 正文下方(就在此 {dede:field.body/} 标记之后)。您需要修改的只是将 dede 标签中标记为红色的 URL 更改为您的 URL。很简单。
上一篇:织梦只在列表第一页显示dedefield.content
下一篇:织梦后台会员动态管理和前端会员中心会员动态管理不显示BUG修复
总结
以上是编程之家为你采集整理的dede。如何实现别人的复制文章自动添加网站所有版权信息,希望文章可以帮到你解决如何实现dede被别人复制文章自动添加网站程序开发中遇到的版权信息问题。
如果你觉得编程之家网站的内容还不错,欢迎向你的程序员朋友推荐编程之家网站。 查看全部
网站自动采集文章(如何防止别人采集我们的网站文章的网友,dede能不能实现)
概述如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 dedecms 可以实现吗?其实很简单。
如果你经常手动复制别人的网站文章网友,会遇到复制别人的文章,然后粘贴,文章后面会跟着目标网站 URL 等信息,这个函数是怎么回事?我们如何才能阻止他人采集我们的网站。现在我以dede仿网站教程网为例给大家。 Dedecms 可以实现吗?其实也很简单,代码如下:
document.body.oncopy = function () { setTimeout( function () { var text = clipboardData.getData("text"); if (text) { text = text + "\r\n这篇文章文章@ >来自原文链接:"+location.href;clipboardData.setData("text",text); } },100 ) }
只需将上面的代码放在内容 dede 模板的 文章 正文下方(就在此 {dede:field.body/} 标记之后)。您需要修改的只是将 dede 标签中标记为红色的 URL 更改为您的 URL。很简单。
上一篇:织梦只在列表第一页显示dedefield.content
下一篇:织梦后台会员动态管理和前端会员中心会员动态管理不显示BUG修复
总结
以上是编程之家为你采集整理的dede。如何实现别人的复制文章自动添加网站所有版权信息,希望文章可以帮到你解决如何实现dede被别人复制文章自动添加网站程序开发中遇到的版权信息问题。
如果你觉得编程之家网站的内容还不错,欢迎向你的程序员朋友推荐编程之家网站。
网站自动采集文章(通过Python-frontmatter库自动发布到WordPress网站上的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2022-04-18 20:39
WordPress客户端很多,也有很多markdown编辑器也支持编辑文章,然后本地一键发布到WordPress网站。但是,这个文章想要实现的是通过Python脚本自动将本地的文章发布到WordPress网站,我自己怎么做呢?
通常,用于编写文章 的本地编辑器大多是markdown 格式。照常写好文章后,复制粘贴到WordPress后台的编辑器中,然后调整格式和排版。很多markdown编辑器都可以导出HTML,但是里面有很多我们不需要的HTML标签和信息,手动去全是很累的。
也是因为WordPress对markdown支持不友好,插件实现也不是很理想。我只需要自己尝试一下。整个过程大致是这样的。
##编辑Yaml格式的md文件
使用任何 Markdown 编辑器编辑 md 文本时,在 文章 的开头添加以下 文章 元数据。比如这篇文章
---
title: Python自动发布markdown文章到WordPress网站
date: 2018-09-27 16:57
url: Python-auto-publish-markdown-post-to-WordPress
tag:
- "wordpress"
- "python"
category: 系统&运维
---
当然,我们需要用到一些 Python 库 Python-frontmatter、markdown 2、python-wordpress-xmlrpc 在开始之前,我们需要确保我们的本地计算机已经安装了这些库。推荐使用Python3,这样我们后面处理一些中文路径信息就不会太麻烦了。
##Title Python3、 库安装
因为我用的是MacOS,如果你用的是Linux或者Windows,没有区别,只是安装方式不同。MacOS 默认自带 Python2.7。我在实验中遇到了一些问题,我不想搜索和处理它们。毕竟,我们必须拥抱新的 Python3。首先安装Python3
酿造安装蟒蛇
使用 python3 -V 查看 Python3 的当前版本。一般情况下pip3会自动一起安装,然后我们就依次使用pip3来安装我们需要的库。
pip3 install python-frontmatter
pip3 install markdown2
pip3 python-xmlrpc-wordpress
GitHub
##Python-frontmatter库的使用
我们创建一个新脚本,例如 wp.py。考虑到脚本后续使用的方便,通过命令行传递参数的方式,将文档路径信息sys.argv[1]通过命令行传递给脚本。sys模块默认sys.argv[0]为脚本,sys.argv[1]为第一个参数信息,sys.argv[2]为第二个参数信息。
后来我们运行wp.py脚本的时候是这样的
python3 wp.py /Users/northgod/Dropbox/VVPLUS/Python 自动发布 WordPress.md
这样sys.argv[1]得到的信息是/Users/northgod/Dropbox/VVPLUS/Python自动在WordPress.md中发布我们的文章的路径信息。
#!python
# -*- coding:utf-8 -*-
#导入模块
import sys
import markdown2
from markdown2 import Markdown
#获得md文章路径信息
dir = sys.argv[1]
#通过frontmatter.load函数加载读取文档里的信息
#这里关于Python-frontmatter模块的各种函数使用方式GitHub都有说明,下面直接贴可实现的代码
post = frontmatter.load(dir)
#将获取到的信息赋值给变量
post_title = post.metadata['title']
post_tag = post.metadata['tag']
post_category = post.metadata['category']
post_url = post.metadata['url']
#通过print函数来看我们获取到信息状态,确定无误后这个步骤是不需要的
print (post_title)
print (post_tag)
print (post_catagory)
print (post_url)
print (post.content)
##Markdown2 将 md 转换为 HTML
我们只需要将文本内容通过markdown2转换成md格式,然后将文本内容赋值给一个变量即可。执行后发现转换后的内容编码不正确,后续步骤会报错。然后我们通过encode("utf-8")转换成utf-8。
#在上面的基础上导入markdown2模块
import markdown2
from markdown2 import Markdown
#post.content里面是我们md格式的正文内容,现在转换成HTML格式
markdowner = Markdown()
post_content_html = markdowner.convert(post.content)
post_content_html = post_content_html.encode("utf-8")
#现在print post_content_html看看,是不是HTML标签了
print (post_content_html)
##Python-wordpress-xmlrpc
上面我们已经获取并处理了我们数据文章的内容,title、category、label、alias、body内容已经赋值给变量,现在等待使用python-wordpress-xmlrpc新的文章发布模块发布相应的 文章 数据和内容就大功告成了。
在这里,如果你关闭了 WordPress 中的 xmlrpc 接口,它就不起作用了。首先,确保打开xmlrpc发送接口。一些优化插件会关闭 xmlrpc 接口。
#同样导入发布文章需要的模块
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts,NewPost
wp = Client('你网站http地址/xmlrpc.php', '登录名', '密码')
#现在就很简单了,通过下面的函数,将刚才获取到数据赋给对应的位置
post = WordPressPost()
post.title = post_title
#post.slug文章别名
#我网站使用%postname%这种固定链接不想一长串,这里是最初md文章URL的参数,英文连字符格式
post.slug = post_url
post.content = post_content_html
#分类和标签
post.terms_names = {
'post_tag': post_tag,
'category': post_category
}
#post.post_status有publish发布、draft草稿、private隐私状态可选,默认草稿。如果是publish会直接发布
# post.post_status = 'publish'
#推送文章到WordPress网站
wp.call(NewPost(post))
如果没有报错,然后你登录网站后台查看,会出现一个草稿形式的新文章,并且已经添加了分类、标签和url . 注意写md的时候,分类,标签,如果WordPress没有,会自动创建。
为了让py脚本顺利运行,上述代码要合理组合在wp.py中,然后按照python3 wp.py /md文章的路径/运行
##折腾总结
终于实现了本地编辑md运行py脚本自动发布文章到WordPress网站的曲折。这就是 文章 的出现方式。
不过这些都是一些基本的操作,尤其是Python-wordpress-xmlrpc模块可以实现很多功能。网站后台可以完成的操作,几乎90%都可以通过Python-wordpress-xmlrpc远程操作。,如上传文件、缩略图、用户权限、编辑现有文章、获取用户、文章等信息。
如果遇到一些问题,欢迎与我讨论Q 957473256 查看全部
网站自动采集文章(通过Python-frontmatter库自动发布到WordPress网站上的应用)
WordPress客户端很多,也有很多markdown编辑器也支持编辑文章,然后本地一键发布到WordPress网站。但是,这个文章想要实现的是通过Python脚本自动将本地的文章发布到WordPress网站,我自己怎么做呢?
通常,用于编写文章 的本地编辑器大多是markdown 格式。照常写好文章后,复制粘贴到WordPress后台的编辑器中,然后调整格式和排版。很多markdown编辑器都可以导出HTML,但是里面有很多我们不需要的HTML标签和信息,手动去全是很累的。
也是因为WordPress对markdown支持不友好,插件实现也不是很理想。我只需要自己尝试一下。整个过程大致是这样的。
##编辑Yaml格式的md文件
使用任何 Markdown 编辑器编辑 md 文本时,在 文章 的开头添加以下 文章 元数据。比如这篇文章
---
title: Python自动发布markdown文章到WordPress网站
date: 2018-09-27 16:57
url: Python-auto-publish-markdown-post-to-WordPress
tag:
- "wordpress"
- "python"
category: 系统&运维
---
当然,我们需要用到一些 Python 库 Python-frontmatter、markdown 2、python-wordpress-xmlrpc 在开始之前,我们需要确保我们的本地计算机已经安装了这些库。推荐使用Python3,这样我们后面处理一些中文路径信息就不会太麻烦了。
##Title Python3、 库安装
因为我用的是MacOS,如果你用的是Linux或者Windows,没有区别,只是安装方式不同。MacOS 默认自带 Python2.7。我在实验中遇到了一些问题,我不想搜索和处理它们。毕竟,我们必须拥抱新的 Python3。首先安装Python3
酿造安装蟒蛇
使用 python3 -V 查看 Python3 的当前版本。一般情况下pip3会自动一起安装,然后我们就依次使用pip3来安装我们需要的库。
pip3 install python-frontmatter
pip3 install markdown2
pip3 python-xmlrpc-wordpress
GitHub
##Python-frontmatter库的使用
我们创建一个新脚本,例如 wp.py。考虑到脚本后续使用的方便,通过命令行传递参数的方式,将文档路径信息sys.argv[1]通过命令行传递给脚本。sys模块默认sys.argv[0]为脚本,sys.argv[1]为第一个参数信息,sys.argv[2]为第二个参数信息。
后来我们运行wp.py脚本的时候是这样的
python3 wp.py /Users/northgod/Dropbox/VVPLUS/Python 自动发布 WordPress.md
这样sys.argv[1]得到的信息是/Users/northgod/Dropbox/VVPLUS/Python自动在WordPress.md中发布我们的文章的路径信息。
#!python
# -*- coding:utf-8 -*-
#导入模块
import sys
import markdown2
from markdown2 import Markdown
#获得md文章路径信息
dir = sys.argv[1]
#通过frontmatter.load函数加载读取文档里的信息
#这里关于Python-frontmatter模块的各种函数使用方式GitHub都有说明,下面直接贴可实现的代码
post = frontmatter.load(dir)
#将获取到的信息赋值给变量
post_title = post.metadata['title']
post_tag = post.metadata['tag']
post_category = post.metadata['category']
post_url = post.metadata['url']
#通过print函数来看我们获取到信息状态,确定无误后这个步骤是不需要的
print (post_title)
print (post_tag)
print (post_catagory)
print (post_url)
print (post.content)
##Markdown2 将 md 转换为 HTML
我们只需要将文本内容通过markdown2转换成md格式,然后将文本内容赋值给一个变量即可。执行后发现转换后的内容编码不正确,后续步骤会报错。然后我们通过encode("utf-8")转换成utf-8。
#在上面的基础上导入markdown2模块
import markdown2
from markdown2 import Markdown
#post.content里面是我们md格式的正文内容,现在转换成HTML格式
markdowner = Markdown()
post_content_html = markdowner.convert(post.content)
post_content_html = post_content_html.encode("utf-8")
#现在print post_content_html看看,是不是HTML标签了
print (post_content_html)
##Python-wordpress-xmlrpc
上面我们已经获取并处理了我们数据文章的内容,title、category、label、alias、body内容已经赋值给变量,现在等待使用python-wordpress-xmlrpc新的文章发布模块发布相应的 文章 数据和内容就大功告成了。
在这里,如果你关闭了 WordPress 中的 xmlrpc 接口,它就不起作用了。首先,确保打开xmlrpc发送接口。一些优化插件会关闭 xmlrpc 接口。
#同样导入发布文章需要的模块
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts,NewPost
wp = Client('你网站http地址/xmlrpc.php', '登录名', '密码')
#现在就很简单了,通过下面的函数,将刚才获取到数据赋给对应的位置
post = WordPressPost()
post.title = post_title
#post.slug文章别名
#我网站使用%postname%这种固定链接不想一长串,这里是最初md文章URL的参数,英文连字符格式
post.slug = post_url
post.content = post_content_html
#分类和标签
post.terms_names = {
'post_tag': post_tag,
'category': post_category
}
#post.post_status有publish发布、draft草稿、private隐私状态可选,默认草稿。如果是publish会直接发布
# post.post_status = 'publish'
#推送文章到WordPress网站
wp.call(NewPost(post))
如果没有报错,然后你登录网站后台查看,会出现一个草稿形式的新文章,并且已经添加了分类、标签和url . 注意写md的时候,分类,标签,如果WordPress没有,会自动创建。
为了让py脚本顺利运行,上述代码要合理组合在wp.py中,然后按照python3 wp.py /md文章的路径/运行
##折腾总结
终于实现了本地编辑md运行py脚本自动发布文章到WordPress网站的曲折。这就是 文章 的出现方式。
不过这些都是一些基本的操作,尤其是Python-wordpress-xmlrpc模块可以实现很多功能。网站后台可以完成的操作,几乎90%都可以通过Python-wordpress-xmlrpc远程操作。,如上传文件、缩略图、用户权限、编辑现有文章、获取用户、文章等信息。
如果遇到一些问题,欢迎与我讨论Q 957473256
网站自动采集文章(苹果cms自动上传的方法有哪些?如何解决?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-11 15:24
我们使用苹果cms进行安装后,接下来就是填写网站的内容了。如果上传自己的视频资源,比如自己的视频教程、搞笑段子、直播回放等内容,可以直接手动上传即可。还有一种自动上传方式,即自动采集,根据采集任务设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象可以设置。苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加好的界面采集。下面站长分类目录网就Applecms的问题详细讲解具体操作步骤
1、进入苹果的cms后台管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到采集的网站我们能做什么,然后得到接口地址,在这里填写。
采集如何找到接口:你可以在百度下搜索关键词“resources采集”,会有很多免费的网站供我们使用采集。然后在网站帮助中心获取你需要采集的采集的接口,在这里填写。
2.获取接口后,填写自定义资源。这需要详细解释每个选项的含义,以便做出更好的选择。每个选项的含义在图片下方进行了详细说明。
资源名称:我们的 采集 的 网站 名称,您可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般以&开头,比如老版本的xml格式测试采集,地址需要加上&ct=1
接口类型:一般默认为xml格式,但也有json格式的资源需要自己确定。
资源类型:这里以采集的视频为例,选择视频即可。
数据操作:勾选添加:当采集时,只添加新数据,不更新;检查更新:采集时,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果该界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填写其中一个是采集。比如填写youku,那么这个界面只有采集youku;填写优酷、奇艺、采集这两个播放源。
3.这时候,当我们回到我们之前的页面,就可以看到我们添加的资源接口了。直接用鼠标点击该界面会进入分类的绑定页面。
4. 进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的类别,您可以自己添加一个类别。添加分类的教程请参考站长分类目录的网站。帮助文档:Apple cmsHow to add a category 添加类别。
5、添加后,启动采集,我们可以选择今天的采集,本周的采集,或者采集全部。这样就完成了手动 采集 步骤。我们非常接近自动化 采集 的目标。
6.自动采集教程是监控宝塔。如果 文章 太长,则自动将 采集 教程转换为另一个文档。教程地址:苹果cms宝塔全自动定时采集教程 查看全部
网站自动采集文章(苹果cms自动上传的方法有哪些?如何解决?(图))
我们使用苹果cms进行安装后,接下来就是填写网站的内容了。如果上传自己的视频资源,比如自己的视频教程、搞笑段子、直播回放等内容,可以直接手动上传即可。还有一种自动上传方式,即自动采集,根据采集任务设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象可以设置。苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加好的界面采集。下面站长分类目录网就Applecms的问题详细讲解具体操作步骤
1、进入苹果的cms后台管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到采集的网站我们能做什么,然后得到接口地址,在这里填写。
采集如何找到接口:你可以在百度下搜索关键词“resources采集”,会有很多免费的网站供我们使用采集。然后在网站帮助中心获取你需要采集的采集的接口,在这里填写。
2.获取接口后,填写自定义资源。这需要详细解释每个选项的含义,以便做出更好的选择。每个选项的含义在图片下方进行了详细说明。
资源名称:我们的 采集 的 网站 名称,您可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般以&开头,比如老版本的xml格式测试采集,地址需要加上&ct=1
接口类型:一般默认为xml格式,但也有json格式的资源需要自己确定。
资源类型:这里以采集的视频为例,选择视频即可。
数据操作:勾选添加:当采集时,只添加新数据,不更新;检查更新:采集时,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果该界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填写其中一个是采集。比如填写youku,那么这个界面只有采集youku;填写优酷、奇艺、采集这两个播放源。
3.这时候,当我们回到我们之前的页面,就可以看到我们添加的资源接口了。直接用鼠标点击该界面会进入分类的绑定页面。
4. 进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的类别,您可以自己添加一个类别。添加分类的教程请参考站长分类目录的网站。帮助文档:Apple cmsHow to add a category 添加类别。
5、添加后,启动采集,我们可以选择今天的采集,本周的采集,或者采集全部。这样就完成了手动 采集 步骤。我们非常接近自动化 采集 的目标。
6.自动采集教程是监控宝塔。如果 文章 太长,则自动将 采集 教程转换为另一个文档。教程地址:苹果cms宝塔全自动定时采集教程

