
网站内容采集系统
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-04 06:09
网人采集系统 v1.0 发布!网人采集系统 v1.0 发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计。支持分类信息采集、文章采集和shop采集,当然这个系统也可以应用到其他系统!
网人采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。使用网友采集,可以瞬间创建采集网站 内容丰富。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql 数据导入导出可以让你在采集content 的时候更自在。现在您可以摒弃以往重复繁琐的手动添加工作,立即开始体验即时建站的乐趣吧!
Netren采集 是一个功能强大且易于使用的版本
寻求有关内存问题的帮助! ! !
掌上专业采集软件,强大的内容采集和数据处理功能可以将您采集的任意网页数据发布到远程服务器,自定义用户cms系统模块,不管您的网站是任何系统,都可以使用网民采集系统。更多cms模块请参考制作修改,或到官方网站与您交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集发送的数据对应表的字段导出到任意本地Access或MSSqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持attachments采集,包括图片、文档等附件
5、 increment采集 并自动更新
6、全结构化抽取
7、采集结果自动重新排列
8、数据保存在本地,随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库中
10、同时多站点多任务多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展和可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、强大的内容过滤功能,可以无限制去除广告和替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史功能,避免重复采集
20、timing采集、网站内容实时更新
基本说明:
1、下载本系统并解压到网站目录
2、如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接、相关表信息等
4、设置采集项目
5、采集content
好的,完成
官方地址:
下载链接: 查看全部
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站
网人采集系统 v1.0 发布!网人采集系统 v1.0 发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计。支持分类信息采集、文章采集和shop采集,当然这个系统也可以应用到其他系统!
网人采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。使用网友采集,可以瞬间创建采集网站 内容丰富。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql 数据导入导出可以让你在采集content 的时候更自在。现在您可以摒弃以往重复繁琐的手动添加工作,立即开始体验即时建站的乐趣吧!
Netren采集 是一个功能强大且易于使用的版本
寻求有关内存问题的帮助! ! !
掌上专业采集软件,强大的内容采集和数据处理功能可以将您采集的任意网页数据发布到远程服务器,自定义用户cms系统模块,不管您的网站是任何系统,都可以使用网民采集系统。更多cms模块请参考制作修改,或到官方网站与您交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集发送的数据对应表的字段导出到任意本地Access或MSSqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持attachments采集,包括图片、文档等附件
5、 increment采集 并自动更新
6、全结构化抽取
7、采集结果自动重新排列
8、数据保存在本地,随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库中
10、同时多站点多任务多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展和可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、强大的内容过滤功能,可以无限制去除广告和替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史功能,避免重复采集
20、timing采集、网站内容实时更新
基本说明:
1、下载本系统并解压到网站目录
2、如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接、相关表信息等
4、设置采集项目
5、采集content
好的,完成
官方地址:
下载链接:
集搜客网络爬虫v8.8.0官方免费版|30.3MB集
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-31 02:13
鸡搜客网络爬虫
v8.8.0 官方免费版 | 30.3MB
极速客网络爬虫是一款功能强大的网站内容采集软件,英文名为“GooSeeker”,可以按照指定的规则自动抓取网页中的各种内容并发布到网站。简单易用,无需..
立即下载
中大云采集(网站内容采集工具)
v9.4 Discuz+织梦dedecms+phpcms+帝国cms版 | 2.9MB
Zhongdayun采集是一款强大的网站内容采集工具,以插件的形式集成到Discuz、织梦dedecms、phpcms、empirecms。在,您可以根据关键词或URL自动采集任何内容,...
立即下载
小猪采集器
v2.7.1.0 官方免费版 | 4.5MB
小猪采集器是一款强大的网站content采集工具,可以下载任何网站采集文字、图片、视频等资源,并支持信息发布功能,你会采集内容发布到自己的网站,非常适合个人..
立即下载
Yicai网站数据采集系统
v1.8.4 最新版本 | 2.4MB
Yicai网站数据采集系统是一款非常强大的网络信息采集软件。支持将网页中的文字、图片、标签属性、网页源代码、列表等您感兴趣的网页内容到采集下,还提供信件..
立即下载
小鸟采集器(网站采集软件)
v2.0 绿色版 | 105KB
Little Bird采集器是一款网站信息采集软件,可以帮你精准拦截你需要的信息,还可以为每一个拦截的结果整理不同的数据,完全是人工模式发布!小鸟采集..
立即下载
编辑器工具(网站采集software)
v2.6.19.0 绿色版 | 9.1MB
Editor Tools 是一款免费的网站内容采集 自动发布软件。 Editor Tools从设计之初就以提高软件自动化程度为突破口,实现无人值守、24小时自动化工作。已经测试过了..
立即下载 查看全部
集搜客网络爬虫v8.8.0官方免费版|30.3MB集
鸡搜客网络爬虫
v8.8.0 官方免费版 | 30.3MB

极速客网络爬虫是一款功能强大的网站内容采集软件,英文名为“GooSeeker”,可以按照指定的规则自动抓取网页中的各种内容并发布到网站。简单易用,无需..
立即下载
中大云采集(网站内容采集工具)
v9.4 Discuz+织梦dedecms+phpcms+帝国cms版 | 2.9MB

Zhongdayun采集是一款强大的网站内容采集工具,以插件的形式集成到Discuz、织梦dedecms、phpcms、empirecms。在,您可以根据关键词或URL自动采集任何内容,...
立即下载
小猪采集器
v2.7.1.0 官方免费版 | 4.5MB

小猪采集器是一款强大的网站content采集工具,可以下载任何网站采集文字、图片、视频等资源,并支持信息发布功能,你会采集内容发布到自己的网站,非常适合个人..
立即下载
Yicai网站数据采集系统
v1.8.4 最新版本 | 2.4MB
Yicai网站数据采集系统是一款非常强大的网络信息采集软件。支持将网页中的文字、图片、标签属性、网页源代码、列表等您感兴趣的网页内容到采集下,还提供信件..
立即下载
小鸟采集器(网站采集软件)
v2.0 绿色版 | 105KB

Little Bird采集器是一款网站信息采集软件,可以帮你精准拦截你需要的信息,还可以为每一个拦截的结果整理不同的数据,完全是人工模式发布!小鸟采集..
立即下载
编辑器工具(网站采集software)
v2.6.19.0 绿色版 | 9.1MB

Editor Tools 是一款免费的网站内容采集 自动发布软件。 Editor Tools从设计之初就以提高软件自动化程度为突破口,实现无人值守、24小时自动化工作。已经测试过了..
立即下载
Empirecms网站采集Content 分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-07-29 00:24
上下页面导航是采集分页的难点。它需要所有页面都符合分页规则。如果您不熟悉,我们可以使用第 1 页和第 2 页的代码进行比较分析。确定分页规律。
1、 下面以网站内容分页为例:
可以看到这条新闻一共有20页。
2、查看源码:
本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第一页代码:
(2)第2页代码:
从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”都是一样的,那么“页面区域规律”和“页面链接规律”可以确定。 .
3、获取分页区正则([!--smallpageallzz--]):
4、获取分页链接常规([!--pageallzz--]):
5、为了方便教程的展示,我在newstext中用采集代替采集content,预览结果:
注意事项:
#一、在第一页的HTML代码中,当内容分页链接全部列出时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下导航”。
二、使用完整列表公式时,采集规则正确,但出现莫名重复的页面。在这种情况下,您可以使用替换的方法将其过滤掉(我们将在下一讲中讨论)。
三、使用上下页导航样式的时候,我总是挑第一页,其他页连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。 查看全部
Empirecms网站采集Content 分页教程
上下页面导航是采集分页的难点。它需要所有页面都符合分页规则。如果您不熟悉,我们可以使用第 1 页和第 2 页的代码进行比较分析。确定分页规律。
1、 下面以网站内容分页为例:

可以看到这条新闻一共有20页。
2、查看源码:

本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第一页代码:

(2)第2页代码:

从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”都是一样的,那么“页面区域规律”和“页面链接规律”可以确定。 .
3、获取分页区正则([!--smallpageallzz--]):

4、获取分页链接常规([!--pageallzz--]):

5、为了方便教程的展示,我在newstext中用采集代替采集content,预览结果:

注意事项:
#一、在第一页的HTML代码中,当内容分页链接全部列出时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下导航”。
二、使用完整列表公式时,采集规则正确,但出现莫名重复的页面。在这种情况下,您可以使用替换的方法将其过滤掉(我们将在下一讲中讨论)。
三、使用上下页导航样式的时候,我总是挑第一页,其他页连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。
2017上海事业单位招聘考试备考:网页数据动态更新汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-07-28 19:22
1
陆辉;高尚飞;李少龙;;基于HTTP协议的业务系统网页数据采集应用集成[J];电子技术与软件工程;2019年02期
2
李峰;实时刷新网页数据[J];计算机知识与技术;2002年06期
3
闫瑞峰,闫瑞华;VSP技术在网页数据传输中的应用[J];中国科技信息;2005年08期
4
吴海燕,王友梅;;探索ASP.NET实现Web数据检索的方法[J];计算机与现代化;2005年07期
5
王立军;;Web2.0设计模式下利用Ajax技术动态更新网页数据[J];渤海大学学报(自然科学版);2008年03期
6
樊扬;;基于HTML5的图形网页数据展示[J];无线互联网技术;2013年07期
7
林振洲;;VFP技术在网页data采集中的应用——以高校数字资源建设为例[J];计算机CD软件与应用;2013年14期
8
阙胜贵;朱云;;利用VFP编程自动提取审计所需的网页数据[J];计算机编程技巧与维护;2017年05期
9
朱佳;张中能;;一种基于聚类的全自动Web数据记录提取方法[J];微机应用;2010年12期
10
孙立红;;利用正则表达式分析网页数据实现自选股票管理[J];数学家(教育学界);2008年03期
11
赵彦斌;;基于Django技术的网页数据模型的建立[J];时代农机;2015年07期
12 查看全部
2017上海事业单位招聘考试备考:网页数据动态更新汇总
1
陆辉;高尚飞;李少龙;;基于HTTP协议的业务系统网页数据采集应用集成[J];电子技术与软件工程;2019年02期
2
李峰;实时刷新网页数据[J];计算机知识与技术;2002年06期
3
闫瑞峰,闫瑞华;VSP技术在网页数据传输中的应用[J];中国科技信息;2005年08期
4
吴海燕,王友梅;;探索ASP.NET实现Web数据检索的方法[J];计算机与现代化;2005年07期
5
王立军;;Web2.0设计模式下利用Ajax技术动态更新网页数据[J];渤海大学学报(自然科学版);2008年03期
6
樊扬;;基于HTML5的图形网页数据展示[J];无线互联网技术;2013年07期
7
林振洲;;VFP技术在网页data采集中的应用——以高校数字资源建设为例[J];计算机CD软件与应用;2013年14期
8
阙胜贵;朱云;;利用VFP编程自动提取审计所需的网页数据[J];计算机编程技巧与维护;2017年05期
9
朱佳;张中能;;一种基于聚类的全自动Web数据记录提取方法[J];微机应用;2010年12期
10
孙立红;;利用正则表达式分析网页数据实现自选股票管理[J];数学家(教育学界);2008年03期
11
赵彦斌;;基于Django技术的网页数据模型的建立[J];时代农机;2015年07期
12
如何将shopify的数据弄到opencart,wordpress
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-28 00:26
随着越来越多的人使用shopify,shopify的管理越来越严格,不注意网站就会被屏蔽。针对这种情况,很多人已经开始转移其他平台或自建网站程序。其中,使用opencart和wordpress也是选择之一。使用这些自建站程序时出现问题。如何将shopify 数据获取到opencart、wordpress 或直接采集shopify 数据到opencart、wordpress。针对这个问题,我们提供了对接系统。功能介绍如下:
必要条件我们提供的是一套对接系统源码,必须安装在opencart或wordpress网站所在服务器上。
以下是功能介绍:
1.对接系统与opencart或wordpress网站在同一台服务器上,如:opencart网站有3个; 2 wordpress网站在服务器端,我们将这些网站配置为采集System后台:
您可以在下方采集task:
选择你要采集去哪个opencart站点,系统会调出该站点的分类供选择:
选择保存到opencart的采集products的分类,输入你要采集shopify网站的分类链接,输入采集数量提交保存。
这里注意支持采集数据调价
采集,产品可以在相应的opencart或wordpress网站中展示 查看全部
如何将shopify的数据弄到opencart,wordpress
随着越来越多的人使用shopify,shopify的管理越来越严格,不注意网站就会被屏蔽。针对这种情况,很多人已经开始转移其他平台或自建网站程序。其中,使用opencart和wordpress也是选择之一。使用这些自建站程序时出现问题。如何将shopify 数据获取到opencart、wordpress 或直接采集shopify 数据到opencart、wordpress。针对这个问题,我们提供了对接系统。功能介绍如下:
必要条件我们提供的是一套对接系统源码,必须安装在opencart或wordpress网站所在服务器上。
以下是功能介绍:
1.对接系统与opencart或wordpress网站在同一台服务器上,如:opencart网站有3个; 2 wordpress网站在服务器端,我们将这些网站配置为采集System后台:

您可以在下方采集task:
选择你要采集去哪个opencart站点,系统会调出该站点的分类供选择:
选择保存到opencart的采集products的分类,输入你要采集shopify网站的分类链接,输入采集数量提交保存。
这里注意支持采集数据调价
采集,产品可以在相应的opencart或wordpress网站中展示
常用的5种动态网页技术,你知道几种?
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2021-07-27 03:07
常用的5种动态网页技术,你知道几种?
本教程运行环境:windows10系统,Dell G3电脑。
5 种常用的动态网络技术
1、CGI
CGI(通用网关接口)是早期用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行某个 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
CGI 的主要缺点是维护复杂,运行效率低。这主要是由以下方法造成的:
2、PHP
PHP(个人主页)是一种嵌入在 HTML 中的服务器端脚本语言,可以在多个平台上运行。它借鉴了C语言、Java语言和Perl语言的语法,同时拥有自己独特的语法。
由于PHP采用Open Source方式,其源代码是开放的,可以不断添加新的东西,形成庞大的函数库,实现更多的功能。 PHP 支持当今几乎所有的数据库。
PHP的缺点是不支持JSP、ASP等组件,扩展性差。
3、JSP
JSP(Java Server Pages)是一种基于 Java 的技术,用于创建可以支持跨平台和跨 Web 服务器的动态网页。 JSP 不同于服务器端脚本语言 JavaScript。 JSP在传统的静态页面中添加Java程序片段和JSP标签,形成JSP页面,然后由服务器编译执行。
JSP的主要优点如下:
JSP 的主要缺点是编写 JSP 程序比较复杂,开发人员往往需要对 Java 及相关技术有更好的了解。
4、ASP
ASP(Active Server Pages)是微软提供的一种开发动态网页的技术。具有开发简单、功能强大等优点。 ASP 使生成动态 Web 内容和构建强大的 Web 应用程序变得非常容易。例如,当你想在一个表单中采集数据时,你只需要在一个HTML文件中嵌入一些简单的指令,然后你就可以从表单中采集数据并进行分析。对于 ASP,您还可以轻松地使用 ActiveX 组件来执行复杂的任务,例如连接到数据库以检索和存储信息。
对于有经验的程序开发人员,如果您已经掌握了脚本语言,例如 VBScript、JavaScript 或 Perl,并且您已经知道如何使用 ASP。只要安装了符合ActiveX脚本标准的相应引擎,任何脚本语言都可以在ASP页面中使用。 ASP 本身有两个脚本引擎,VBScript 和 JavaScript。从软件技术的角度来看,ASP具有以下特点: 查看全部
常用的5种动态网页技术,你知道几种?

本教程运行环境:windows10系统,Dell G3电脑。
5 种常用的动态网络技术
1、CGI
CGI(通用网关接口)是早期用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行某个 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
CGI 的主要缺点是维护复杂,运行效率低。这主要是由以下方法造成的:
2、PHP
PHP(个人主页)是一种嵌入在 HTML 中的服务器端脚本语言,可以在多个平台上运行。它借鉴了C语言、Java语言和Perl语言的语法,同时拥有自己独特的语法。
由于PHP采用Open Source方式,其源代码是开放的,可以不断添加新的东西,形成庞大的函数库,实现更多的功能。 PHP 支持当今几乎所有的数据库。
PHP的缺点是不支持JSP、ASP等组件,扩展性差。
3、JSP
JSP(Java Server Pages)是一种基于 Java 的技术,用于创建可以支持跨平台和跨 Web 服务器的动态网页。 JSP 不同于服务器端脚本语言 JavaScript。 JSP在传统的静态页面中添加Java程序片段和JSP标签,形成JSP页面,然后由服务器编译执行。
JSP的主要优点如下:
JSP 的主要缺点是编写 JSP 程序比较复杂,开发人员往往需要对 Java 及相关技术有更好的了解。
4、ASP
ASP(Active Server Pages)是微软提供的一种开发动态网页的技术。具有开发简单、功能强大等优点。 ASP 使生成动态 Web 内容和构建强大的 Web 应用程序变得非常容易。例如,当你想在一个表单中采集数据时,你只需要在一个HTML文件中嵌入一些简单的指令,然后你就可以从表单中采集数据并进行分析。对于 ASP,您还可以轻松地使用 ActiveX 组件来执行复杂的任务,例如连接到数据库以检索和存储信息。
对于有经验的程序开发人员,如果您已经掌握了脚本语言,例如 VBScript、JavaScript 或 Perl,并且您已经知道如何使用 ASP。只要安装了符合ActiveX脚本标准的相应引擎,任何脚本语言都可以在ASP页面中使用。 ASP 本身有两个脚本引擎,VBScript 和 JavaScript。从软件技术的角度来看,ASP具有以下特点:
网站内容采集系统最大的特点就是去重,软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-07-26 18:22
网站内容采集系统:云采集系统,最大的特点就是去重,软件爬虫适合于中小网站,采集网站要支持反采集爬虫模式,采集网站还是需要做一个爬虫目录页面,爬虫采集时分辨率规格和源代码都很重要.云采集系统有一个优势就是web开发文档极其简洁易懂,我们可以根据用户的不同需求修改大小尺寸和发布效果。针对在网站上工作的网站编辑还可以给开发写网站项目。
云采集系统的优势还在于软件整合性能强劲,再也不用再为采集的问题写多篇文章来推广,提高网站收录量和收藏。.云采集系统可以采集的网站非常多,从综合的生活类网站到小说搜索类的网站,是一个巨大的跨界..。
针对dz,dz的搜索引擎很差,百度不收录,谷歌收录也少,关键在于他们的搜索引擎上的内容是提供给用户群,不经过用户选择,提供了内容就直接可以用了,所以就提高搜索引擎收录率了,即使要做下级的网站,有时也要通过多级域名链接,或者反向链接的形式来提高排名。
刚开始做站很多人建议做dz有时一时理解有问题就去做了dz就行了dz又多了pc网站网站这么一个就可以了我做站的时候不明白的是pc上的网站你做到哪个页面后面都没人知道后来觉得应该分页比较好虽然花点钱但可以及时的更新你需要知道自己要怎么宣传那一个页面毕竟页面是可以按页码添加需要的doc等那么多还有是不是一定要关键词有多少个用户搜了都不知道啊?搜索出来哪些排名靠前前多少给你推荐多少啊?百度的收录排名策略也很重要啊百度收不收录只要不放弃没人知道你是何方神圣那你就无所谓了啊当然你要花钱的其实做搜索引擎推广的时候有推广链接能收录就行,反正引流比收录出来更重要。 查看全部
网站内容采集系统最大的特点就是去重,软件
网站内容采集系统:云采集系统,最大的特点就是去重,软件爬虫适合于中小网站,采集网站要支持反采集爬虫模式,采集网站还是需要做一个爬虫目录页面,爬虫采集时分辨率规格和源代码都很重要.云采集系统有一个优势就是web开发文档极其简洁易懂,我们可以根据用户的不同需求修改大小尺寸和发布效果。针对在网站上工作的网站编辑还可以给开发写网站项目。
云采集系统的优势还在于软件整合性能强劲,再也不用再为采集的问题写多篇文章来推广,提高网站收录量和收藏。.云采集系统可以采集的网站非常多,从综合的生活类网站到小说搜索类的网站,是一个巨大的跨界..。
针对dz,dz的搜索引擎很差,百度不收录,谷歌收录也少,关键在于他们的搜索引擎上的内容是提供给用户群,不经过用户选择,提供了内容就直接可以用了,所以就提高搜索引擎收录率了,即使要做下级的网站,有时也要通过多级域名链接,或者反向链接的形式来提高排名。
刚开始做站很多人建议做dz有时一时理解有问题就去做了dz就行了dz又多了pc网站网站这么一个就可以了我做站的时候不明白的是pc上的网站你做到哪个页面后面都没人知道后来觉得应该分页比较好虽然花点钱但可以及时的更新你需要知道自己要怎么宣传那一个页面毕竟页面是可以按页码添加需要的doc等那么多还有是不是一定要关键词有多少个用户搜了都不知道啊?搜索出来哪些排名靠前前多少给你推荐多少啊?百度的收录排名策略也很重要啊百度收不收录只要不放弃没人知道你是何方神圣那你就无所谓了啊当然你要花钱的其实做搜索引擎推广的时候有推广链接能收录就行,反正引流比收录出来更重要。
网站内容采集系统可以用wordpress建站系统来制作吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-07-22 18:02
网站内容采集系统可以用wordpress建站系统来制作,可以分为插件和自建系统:1.内容采集插件(forwardplugin)现在很多小型网站都喜欢用采集型wordpress插件,把很多内容都抓取到自己的系统里面,通过快捷键就可以进行分发或者高亮,更方便的用户体验。通常会对上传的内容进行快速分发处理,可以是按帖子的方式,或者按内容段落方式。
对于发布的文章进行关键词分词,或者人工分词处理。2.自建系统:最常见的就是是jbljb进去,我们平时看到很多宣传,在把内容分发到外面或者几个外面的网站,这类的网站技术并不难,正常分析网站数据,知道哪些内容是低价(赠送)或者免费的,就把它们抓下来,然后再找用户体验或者适合自己企业定位的地方进行分发。如果对于某个地方不满意,也可以通过修改,或者是改成这个样子。
那么不同的分发的网站是不是有缺点呢?正因为每个分发的站点没有办法让网站产生互动,那么它们除了降低网站的收录,也没有什么提高排名。有朋友可能会说,那我可以用分发器或者分发插件做不行吗?理论上是可以的,但是这类网站的技术门槛会比较高,相对于简单生成的无营销系统,甚至存在负载太高的问题。下面用最简单的如wordpress做了个简单的网站。
我们只要在wordpress安装一个插件,就可以自动发布内容。把我们的域名做成为什么要强调要安装一个分发器呢?因为大部分人使用wordpress建站,只是喜欢分享,不想让别人知道我的网站存在。如果你想让更多的人知道你的网站存在,就需要做内容分发,那么一定要安装分发器。不安装分发器,我们是无法发布网站内容的。
为什么要安装分发器呢?大家都知道现在的网站发布,是通过网站后台或者手动编辑操作,效率是比较低的。我们已经用插件,手动编辑网站内容,能让网站产生互动或者更多原创内容,对于我们的提高排名是有很大的帮助。如果我们做了那么多的发布工作,而这个网站没有产生任何互动,那就失去意义了。我也相信这篇文章就是各位对于分发器内容采集的热情,我们会持续跟大家分享更多分发器内容采集的优点和缺点,以及如何正确使用分发器,让我们的站点产生一定量的互动和权重的。 查看全部
网站内容采集系统可以用wordpress建站系统来制作吗?
网站内容采集系统可以用wordpress建站系统来制作,可以分为插件和自建系统:1.内容采集插件(forwardplugin)现在很多小型网站都喜欢用采集型wordpress插件,把很多内容都抓取到自己的系统里面,通过快捷键就可以进行分发或者高亮,更方便的用户体验。通常会对上传的内容进行快速分发处理,可以是按帖子的方式,或者按内容段落方式。
对于发布的文章进行关键词分词,或者人工分词处理。2.自建系统:最常见的就是是jbljb进去,我们平时看到很多宣传,在把内容分发到外面或者几个外面的网站,这类的网站技术并不难,正常分析网站数据,知道哪些内容是低价(赠送)或者免费的,就把它们抓下来,然后再找用户体验或者适合自己企业定位的地方进行分发。如果对于某个地方不满意,也可以通过修改,或者是改成这个样子。
那么不同的分发的网站是不是有缺点呢?正因为每个分发的站点没有办法让网站产生互动,那么它们除了降低网站的收录,也没有什么提高排名。有朋友可能会说,那我可以用分发器或者分发插件做不行吗?理论上是可以的,但是这类网站的技术门槛会比较高,相对于简单生成的无营销系统,甚至存在负载太高的问题。下面用最简单的如wordpress做了个简单的网站。
我们只要在wordpress安装一个插件,就可以自动发布内容。把我们的域名做成为什么要强调要安装一个分发器呢?因为大部分人使用wordpress建站,只是喜欢分享,不想让别人知道我的网站存在。如果你想让更多的人知道你的网站存在,就需要做内容分发,那么一定要安装分发器。不安装分发器,我们是无法发布网站内容的。
为什么要安装分发器呢?大家都知道现在的网站发布,是通过网站后台或者手动编辑操作,效率是比较低的。我们已经用插件,手动编辑网站内容,能让网站产生互动或者更多原创内容,对于我们的提高排名是有很大的帮助。如果我们做了那么多的发布工作,而这个网站没有产生任何互动,那就失去意义了。我也相信这篇文章就是各位对于分发器内容采集的热情,我们会持续跟大家分享更多分发器内容采集的优点和缺点,以及如何正确使用分发器,让我们的站点产生一定量的互动和权重的。
网络信息采集软件的定位方式的优势在于什么??
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-07-22 05:20
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据自己定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能:
1.图形化的采集task定义界面,你只需要在软件内嵌的浏览器中用鼠标选择你想要采集的网页内容就可以配置采集task,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同并不等于100%,但我们克服了技术难关,消除了这些障碍。
我们的定位方法的优点是:
1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集任务配置界面;
2.网页内容的变化(如文字增减、改动、文字颜色、字体变化等)不会影响采集的准确性。
3.支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利得益于我们全新的内容定位方法和图形化的采集任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件,你还可以采集针对特定HTML标签的源代码和属性值。
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到在一个大纲文件中,然后将每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出 查看全部
网络信息采集软件的定位方式的优势在于什么??
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据自己定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能:
1.图形化的采集task定义界面,你只需要在软件内嵌的浏览器中用鼠标选择你想要采集的网页内容就可以配置采集task,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同并不等于100%,但我们克服了技术难关,消除了这些障碍。
我们的定位方法的优点是:
1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集任务配置界面;
2.网页内容的变化(如文字增减、改动、文字颜色、字体变化等)不会影响采集的准确性。
3.支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利得益于我们全新的内容定位方法和图形化的采集任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件,你还可以采集针对特定HTML标签的源代码和属性值。
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到在一个大纲文件中,然后将每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出
万众瞩目的站群版发布啦!比之前的版本强大数倍!
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-07-18 19:54
功能详情:
万众期待的站群版发布!比之前的版本强大数倍!
在收录UZcmsMirror采集系统普通版的所有功能后,新增以下功能:
1.随机标题关键词(一个网站绑定无数域名,每个域名对关键词的访问方式不同,但与网站核心词相呼应)
2.randomkeyword关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
3.random文章关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
4.random 介绍关键词(一个网站绑定无数域名,每个域名访问关键词不同,但与网站核心词呼应)
5.随机句子(原创随机句子的性,你懂的)
6.蜘蛛屏蔽管理
7.一个云平台,远程控制所有网站
8.不限制建立站点数量,不限制目标站点数量,不限制服务器,IP,! ! !
9.remote cleanup网站cache 数据。手动一一删除网站?不!
10.搜索引擎让路,妈妈再也不用担心我的流量了!
11.支持子目录,二级目录列表采集! (比如百度贴吧,任意一个关键词贴吧)
12. 远程自动调用CSS/JS/SWF等文件,省去手动下载替换的麻烦!
13.代理IP采集不用我说,你懂的!
14.Random Mirror Target Station 一套程序可以绑定上万个域名!实现N个不同站点的全自动随机镜像! ! !
真正的SEO来看,站位不一样!
公司简介:
UZ Studio成立于2008年初,至今已有5年的开发经验,从最初的2人发展到现在的7人规模,在其成立之初就开始研究ASP采集程序成立, 2010 2005年开始走向PHP镜像采集程序,发布了当时流行的电影镜像采集程序,深受草根站长关注。在接下来的时间里,免费版和开源版接踵而至。为了提供更好的服务,我们还制作了多种付费版本,以稳定的服务为用户创造更大的价值。现在我们已经告别繁琐的手工镜像站时代,2013年初开始做UZ@k4。@Mirror采集系统,经过3个月的开发完善,目前版本已经相当稳定,已经近百位忠实用户,互联网也告别了手动构建和更新数据的痛苦时代,迎来全新的UZcmsMirror采集系统带给我们更安全便捷的建站时代 查看全部
万众瞩目的站群版发布啦!比之前的版本强大数倍!
功能详情:
万众期待的站群版发布!比之前的版本强大数倍!
在收录UZcmsMirror采集系统普通版的所有功能后,新增以下功能:
1.随机标题关键词(一个网站绑定无数域名,每个域名对关键词的访问方式不同,但与网站核心词相呼应)
2.randomkeyword关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
3.random文章关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
4.random 介绍关键词(一个网站绑定无数域名,每个域名访问关键词不同,但与网站核心词呼应)
5.随机句子(原创随机句子的性,你懂的)
6.蜘蛛屏蔽管理
7.一个云平台,远程控制所有网站
8.不限制建立站点数量,不限制目标站点数量,不限制服务器,IP,! ! !
9.remote cleanup网站cache 数据。手动一一删除网站?不!
10.搜索引擎让路,妈妈再也不用担心我的流量了!
11.支持子目录,二级目录列表采集! (比如百度贴吧,任意一个关键词贴吧)
12. 远程自动调用CSS/JS/SWF等文件,省去手动下载替换的麻烦!
13.代理IP采集不用我说,你懂的!
14.Random Mirror Target Station 一套程序可以绑定上万个域名!实现N个不同站点的全自动随机镜像! ! !
真正的SEO来看,站位不一样!
公司简介:
UZ Studio成立于2008年初,至今已有5年的开发经验,从最初的2人发展到现在的7人规模,在其成立之初就开始研究ASP采集程序成立, 2010 2005年开始走向PHP镜像采集程序,发布了当时流行的电影镜像采集程序,深受草根站长关注。在接下来的时间里,免费版和开源版接踵而至。为了提供更好的服务,我们还制作了多种付费版本,以稳定的服务为用户创造更大的价值。现在我们已经告别繁琐的手工镜像站时代,2013年初开始做UZ@k4。@Mirror采集系统,经过3个月的开发完善,目前版本已经相当稳定,已经近百位忠实用户,互联网也告别了手动构建和更新数据的痛苦时代,迎来全新的UZcmsMirror采集系统带给我们更安全便捷的建站时代
如何支持实时上传到网站服务器支持POST和GET方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-07-10 07:00
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。
Yicai网站数据采集系统,你可以轻松抓取你想要的网页内容(包括文字、图片、文件、HTML源代码等),来自采集的数据可以直接导出到EXCEL ,也可以根据自己定义的模板保存为任意格式的文件(如网页文件、txt文件等)。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能
用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面;
网页内容的变化(如文字增删改查、文字颜色、字体变化等)不会影响采集的准确性。
支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集下级页面的内容,并且嵌套层数是无限的。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
您可以同时采集任何内容。除了最基本的文字、图片、文件,你还可以采集target 特定HTML标签的源代码和属性值。强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
采集到达的内容可以自动排序
支持采集结果保存到EXCEL和任何格式文件。支持自定义文件模板。
支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
支持实时上传到网站服务器。支持 POST 和 GET 方法。上传参数可自定义,模拟手动提交。
支持实时保存到任何格式的文件。支持自定义模板,按记录保存和将多条记录保存到单个文件,支持大纲和细节保存(所有记录的部分内容保存在一个大纲文件中,然后每条记录分别保存到一个文件中。
支持多种灵活的任务调度方式,实现无人值守采集
支持多任务,支持任务导入导出 查看全部
如何支持实时上传到网站服务器支持POST和GET方式
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。
Yicai网站数据采集系统,你可以轻松抓取你想要的网页内容(包括文字、图片、文件、HTML源代码等),来自采集的数据可以直接导出到EXCEL ,也可以根据自己定义的模板保存为任意格式的文件(如网页文件、txt文件等)。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能
用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面;
网页内容的变化(如文字增删改查、文字颜色、字体变化等)不会影响采集的准确性。
支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集下级页面的内容,并且嵌套层数是无限的。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
您可以同时采集任何内容。除了最基本的文字、图片、文件,你还可以采集target 特定HTML标签的源代码和属性值。强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
采集到达的内容可以自动排序
支持采集结果保存到EXCEL和任何格式文件。支持自定义文件模板。
支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
支持实时上传到网站服务器。支持 POST 和 GET 方法。上传参数可自定义,模拟手动提交。
支持实时保存到任何格式的文件。支持自定义模板,按记录保存和将多条记录保存到单个文件,支持大纲和细节保存(所有记录的部分内容保存在一个大纲文件中,然后每条记录分别保存到一个文件中。
支持多种灵活的任务调度方式,实现无人值守采集
支持多任务,支持任务导入导出
易得网站数据采集系统通用版,通过编写或者下载规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2021-07-10 06:38
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理和学习交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
查看全部
易得网站数据采集系统通用版,通过编写或者下载规则
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理和学习交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。


网站内容中使用字符串的方法有几种固有缺陷
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-07-10 04:19
专利名称:网站内容防采集系统及方法
技术领域:
本发明涉及互联网网站内容的采集复制技术。更具体地说,本发明涉及一种网站内容预防采集方法。
背景技术:
本文中的“采集”是指程序按照规定的规则获取其他网站数据的一种方式。网络采集器是一个用于对网页、论坛等采集进行批量处理的工具,将采集的内容直接存入数据库或发布到网站。它从目标网页中提取一些数据形成一个统一的本地数据库。比如网上新成立的网站,往往需要大量的数据来丰富其网站的内容。在这种情况下,部分网站管理者可能会利用网络采集器快速大量复制其他网站内容,并利用采集快速丰富自己的网站。但是对于采集网站,尤其是网站,主要内容是原创,这种操作会被采集网站占用大量网络资源,降低网络速度。和运行效率;另一方面,也侵犯了采集网站的知识产权,损害了采集网站的利益。为了限制网站内容被他人采集,反采集技术应运而生。目前常见的反采集技术是在网站每个网页的内容中使用混淆字符串。这种技术是通过在网页内容中随机添加一些字符串来实现的。这些字符串在普通用户浏览网页等正常情况下是不可见的。但是当网页内容为采集后,采集到达的网页上就会显示混淆后的字符串。这样采集收到的内容就混入了混淆字符串,不符合采集的要求,从而达到防止采集的目的。但是,这种使用混淆字符串来防止网站每页内容中出现采集的方法有几个固有的缺陷。首先,添加到网页内容中的随机字符串虽然对普通访问者不可见,但对网页内容进行索引的搜索引擎机器人是可见的。这导致在搜索引擎的搜索结果中显示 Web 内容时可能会添加随机字符串。同时,某个网站的内容中混杂了无意的随机字符串,可能导致网站在搜索引擎的搜索结果中排名靠后,不利于网站的推广以及客流量的增加。其次,如果采集zhe不关心他的网站的网页内容质量,添加到网页内容中的随机字符串起不到防止采集的作用,也不能从根本上解决问题那个网页内容是采集的问题。现有的采集防范技术通过添加混淆字符串的方式修改网页内容,破坏了网站对搜索引擎的友好性。同时也是一种被动的反采集措施。虽然添加了随机字符串,但采集器对采集的内容质量要求不高的情况下,仍然可以任意的采集。因此,需要一种在不修改网页内容的情况下防止网页内容被采集的方法。
发明内容
本发明通过识别网站访问者是普通用户还是采集器来防止网站的网页内容为采集。本发明提供了一种网站内容防采集系统,包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;
查询单元用于查询用户在预定时间段内对网站页面的访问;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设置的固定值进行比较,该单元被禁止。当用户在预定时间内访问网站页面的次数大于设定值时,禁止用户访问网站。优选地,网站内容防采集系统还包括存储单元,用于存储IP地址白名单和IP地址黑名单。判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。优选地,IP地址白名单包括搜索引擎的IP地址。本发明提供了一种网站内容防采集的方法,包括获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问次数;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。优选地,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站;如果获取的用户IP地址属于该IP地址的黑名单,将禁止该用户访问网站。优选地,该方法还包括将搜索引擎的IP地址放入IP地址白名单列表中。优选地,将被禁用户的IP地址放入IP地址黑名单。优选地,预定时间段为1-600秒,设定值的值为预定时间段内的秒数的1-50倍。由于采集是通过快速复制其他网站网页的内容来获取其他网站数据的方法,当采集器执行采集时,会快速密集地访问网站页面,访问频率最高可达每分钟 120 页或更多。相反,普通用户浏览网站时,一般情况下不会达到这么高的访问频率。通过这个差异,可以识别采集器的访问,从而限制采集器继续获取网站内容。本发明的网站内容预防采集方法通过添加混淆字符串的方式,利用与实现采集预防不同的原理,解决了现有采集预防技术的缺陷。本发明的网站内容防采集方法不对网站内容做任何修改,不影响搜索引擎的索引。同时,由于这种方法可以区分网站访问者是普通用户还是采集器,通过限制采集器对网站的访问,从根本上解决网站内容被大量采集的问题解决了。
下面将参考附图并结合实施例对本发明进行详细说明,其中图1示出了根据本发明优选实施例的系统框图;图2示出了根据本发明优选实施例的方法的流程图。图3示出了根据本发明另一优选实施例的方法的流程图。
具体实施例图1示出了根据本发明优选实施例的网站内容防采集系统100的结构框图。系统包括获取单元,用于获取用户的ID、IP地址、User-Agent和当前时间;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元,用于将记录的用户在预定时间内对网站页面的访问与设定值进行比较;当用户在预定时间段内对网站页面的访问大于设定值时,使用禁止单元,此时用户对网站的访问被禁止。 网站内容防采集 系统的获取单元可以在每次收到访问请求时记录访问者的ID、IP地址、用户代理(ser-Agent)和访问时间。当访问者通过hternet Explorer等浏览器程序或采集器program访问网站时,访问者的浏览器程序或采集器program通常会向网站发送一个字符串来描述其身份。段字符串称为 her-Agent。用户使用的不同软件通常会发送不同的her-Agent。通过结合访问者的IP地址和her-Agent,网站可以识别和区分每个访问者。查询单元查询当前访问者在单位时间段内访问的网站页面数,即访问次数。比较单元将查询单元查询到的用户访问量与设置的访问量进行比较。如果单位时间段内的页面访问量超过设置的访问量,则可以确定访问者的访问为异常访问。
禁止单元可以禁止访问者对网站的异常访问。单位时间段的页面浏览量和单位时间段的设置值是两个变量,可以在网站program配置中单独修改。例如,单位时间段可以设置在10-600秒之间。单位时间段设置太短可能会导致普通用户的访问被误判为异常访问,而单位时间段设置太长可能导致采集器已采集大数据后网站才检测到当前访问是采集器的访问。由于采集器在执行采集时通常有每秒1到50页的频率,所以单位时间段内的页面浏览次数可以设置为所选单位时间段的1-秒。 50次。例如,单位时间段可以设置为60秒,单位时间段内的浏览量设置值为600页。由于采集器的采集速度受网络速度、网站响应速度等多种因素影响,具体的单位时间段和单位时间段内的页面浏览量应允许网站管理员设置根据实际情况。另外,本发明的网站内容防采集系统还可以包括:存储IP地址白名单和IP地址黑名单的存储单元,以及判断用户地址是否属于IP A的判断单元白色地址或黑色 IP 地址。如果是白色IP地址,则允许用户访问网站;如果属于IP黑地址,则禁止用户访问网站。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP地址白名单功能,将常用搜索引擎的IP地址或IP地址段加入IP地址白名单。
来自这些IP地址的访问将绕过访问频率的判断,不受访问量设置值的限制。此外,本发明的网站内容防采集系统可以提供IP地址黑名单功能,将常见的采集器IP地址加入IP地址黑名单。从这些IP地址访问将绕过访问频率的判断,直接被禁止。图2示出了根据优选实施例的方法的流程图。本实施例的网站内容防采集方法包括以下步骤获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问量;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。图3示出了根据本发明另一优选实施例的方法的流程图。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP 地址白名单功能将常用搜索引擎的IP 地址或IP 地址段加入IP 地址白名单。来自这些IP地址的访问会绕过访问频率的判断,不受访问设置值的限制。图3所示方法与图2所示方法步骤的区别在于,在获取用户IP地址的步骤之后,首先判断用户的IP地址是否属于IP地址白名单。 k14@的来访。
如果不属于,则判断用户的IP地址是否属于IP地址黑名单。如果属于,则禁止用户访问网站。如果没有,则如图2所示,继续查询用户对网站页面的访问次数。下面以PHP+MySQL开发环境为例来说明实现方法。对于其他语言如数据库,可以通过下面的SQL语句@NOT NULL DEFAULT"创建数据表CREATE TABLE "visitlist"(~icfINT(10)NOT NULL AUTO_INCREMENT PRIMARY KEY,VARCHAR(4@k21), "useragent" VARCHAR(255)NOT NULL DEFAULT", ~time~INT(10)NOT NULL DEFAULT' 0') ENGINE = MYISAM; 数据表中有4个字段:id, ip, useragent, and time分别代表记录ID、用户IP、用户User-Agent、访问时间,主程序代码说明获取用户IP、User-Agent信息,程序首先需要获取用户IP、her-Agent、当前时间信息,代码如下: $ip = $_SERVER['REM0TE_ADDR']; $useragent = $_SERVER[' HTTP_USER_AGENT']; $time = time(); //time()函数返回当前UNIX时间戳在几秒钟内,然后将上述数据存储到数据库中。
代码如下 mysql_query(" INSERT INTO visitlist(, ip,,, useragent and time,) values(' $ip', '$useragent',' $time')〃 ); 查询当前用户在单位时间段访问的页面数假设单位时间段为常数define ('DURATION', 60); $time_start = time()-DURATION ;//从当前时间段中减去设置的时间段,这是计数开始时间 $query = mysql_query ("SELECT COUNT (*) AS visit_count FROM visitlistffHERE"time"> $time_start AND—ip— = '{$this-> base-> ip}' AND, useragent, =' {$useragent}"'); $row = mysql_fetch_array($query); $visit_count = isset($row[ 'visit_count' ])? $row[ 'vist_count']: 0; 确定单位时间内访问的页面period 是否大于设定值,处理最终结果
假设单位时间段内访问的页面数是网站administrator定义的常量,define('MAX_PAGES', 300); if($visit_count> MAX_PAGES){exit('访问频率太高,禁止访问');//还可以将访问者的IP地址加入网站IP黑名单,可以更有效的禁止用户访问。} 上面应该理解为基于本发明的优选实施例,已经对技术方案进行了详细描述,应当理解,以上描述是示例性的而非限制性的,本领域普通技术人员可以对每一个描述的技术方案进行修改在阅读本发明说明书的基础上对实施例中的部分技术特征进行等效替换,这些修改或替换不导致相应技术方案的实质背离本发明的精神和范围本发明实施例的技术方案的pe。本发明的保护范围仅以所附权利要求为准。
声明
1.A 网站内容防采集系统,其特征在于,该系统包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设定值进行比较,该单元被禁止,当用户在预定时间段内对网站页面的访问为大于设定值,禁止用户访问网站。
根据权利要求1所述的2.网站内容防采集系统,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50倍。
如权利要求1所述的3.网站内容防采集系统,其特征在于,该系统还包括用于存储IP地址白名单和IP地址黑名单的存储单元;判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。
4.如权利要求3所述的网站内容防采集系统,其特征在于,IP地址白名单包括搜索引擎的IP地址。
5.A 网站内容防采集方法,其特征在于,该方法包括获取用户ID、IP地址、User-Agent和当前时间; k14@页面统计并获取预定时间段内的用户访问量;将访问与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。
如权利要求5所述的6.网站内容防采集方法,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50秒预定时间段次。
如权利要求5所述的7.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站。
如权利要求5所述的8.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址黑名单,则用户访问禁止网站。
9.根据权利要求5所述的网站内容防采集方法,其特征在于,该方法还包括将搜索引擎的IP地址放入IP地址白名单。
10.根据权利要求5所述的网站内容防采集方法,其特征在于,将被禁用户的IP地址放入IP地址黑名单。
全文摘要
本发明提供了一种网站内容预防采集系统和方法。本发明的网站内容防采集系统包括获取单元,用于获取用户ID、IP地址、User-Agent和当前时间;比较单元用于将用户在预定时间段内访问网站页面的次数与设定值进行比较,该单元被禁止。当用户在预定时间段内,网站页面的访问量大于设定值时,禁止用户访问网站。本发明的方法可以在不修改网页内容的情况下防止网页内容被采集。
文件编号 G06F17/30GK102088477SQ2
出版日期:2011 年 6 月 8 日申请日期:2010 年 11 月 25 日优先权日期:2010 年 11 月 25 日
发明人孟凡斌、梅纯、潘海东申请人: 查看全部
网站内容中使用字符串的方法有几种固有缺陷
专利名称:网站内容防采集系统及方法
技术领域:
本发明涉及互联网网站内容的采集复制技术。更具体地说,本发明涉及一种网站内容预防采集方法。
背景技术:
本文中的“采集”是指程序按照规定的规则获取其他网站数据的一种方式。网络采集器是一个用于对网页、论坛等采集进行批量处理的工具,将采集的内容直接存入数据库或发布到网站。它从目标网页中提取一些数据形成一个统一的本地数据库。比如网上新成立的网站,往往需要大量的数据来丰富其网站的内容。在这种情况下,部分网站管理者可能会利用网络采集器快速大量复制其他网站内容,并利用采集快速丰富自己的网站。但是对于采集网站,尤其是网站,主要内容是原创,这种操作会被采集网站占用大量网络资源,降低网络速度。和运行效率;另一方面,也侵犯了采集网站的知识产权,损害了采集网站的利益。为了限制网站内容被他人采集,反采集技术应运而生。目前常见的反采集技术是在网站每个网页的内容中使用混淆字符串。这种技术是通过在网页内容中随机添加一些字符串来实现的。这些字符串在普通用户浏览网页等正常情况下是不可见的。但是当网页内容为采集后,采集到达的网页上就会显示混淆后的字符串。这样采集收到的内容就混入了混淆字符串,不符合采集的要求,从而达到防止采集的目的。但是,这种使用混淆字符串来防止网站每页内容中出现采集的方法有几个固有的缺陷。首先,添加到网页内容中的随机字符串虽然对普通访问者不可见,但对网页内容进行索引的搜索引擎机器人是可见的。这导致在搜索引擎的搜索结果中显示 Web 内容时可能会添加随机字符串。同时,某个网站的内容中混杂了无意的随机字符串,可能导致网站在搜索引擎的搜索结果中排名靠后,不利于网站的推广以及客流量的增加。其次,如果采集zhe不关心他的网站的网页内容质量,添加到网页内容中的随机字符串起不到防止采集的作用,也不能从根本上解决问题那个网页内容是采集的问题。现有的采集防范技术通过添加混淆字符串的方式修改网页内容,破坏了网站对搜索引擎的友好性。同时也是一种被动的反采集措施。虽然添加了随机字符串,但采集器对采集的内容质量要求不高的情况下,仍然可以任意的采集。因此,需要一种在不修改网页内容的情况下防止网页内容被采集的方法。
发明内容
本发明通过识别网站访问者是普通用户还是采集器来防止网站的网页内容为采集。本发明提供了一种网站内容防采集系统,包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;
查询单元用于查询用户在预定时间段内对网站页面的访问;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设置的固定值进行比较,该单元被禁止。当用户在预定时间内访问网站页面的次数大于设定值时,禁止用户访问网站。优选地,网站内容防采集系统还包括存储单元,用于存储IP地址白名单和IP地址黑名单。判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。优选地,IP地址白名单包括搜索引擎的IP地址。本发明提供了一种网站内容防采集的方法,包括获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问次数;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。优选地,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站;如果获取的用户IP地址属于该IP地址的黑名单,将禁止该用户访问网站。优选地,该方法还包括将搜索引擎的IP地址放入IP地址白名单列表中。优选地,将被禁用户的IP地址放入IP地址黑名单。优选地,预定时间段为1-600秒,设定值的值为预定时间段内的秒数的1-50倍。由于采集是通过快速复制其他网站网页的内容来获取其他网站数据的方法,当采集器执行采集时,会快速密集地访问网站页面,访问频率最高可达每分钟 120 页或更多。相反,普通用户浏览网站时,一般情况下不会达到这么高的访问频率。通过这个差异,可以识别采集器的访问,从而限制采集器继续获取网站内容。本发明的网站内容预防采集方法通过添加混淆字符串的方式,利用与实现采集预防不同的原理,解决了现有采集预防技术的缺陷。本发明的网站内容防采集方法不对网站内容做任何修改,不影响搜索引擎的索引。同时,由于这种方法可以区分网站访问者是普通用户还是采集器,通过限制采集器对网站的访问,从根本上解决网站内容被大量采集的问题解决了。
下面将参考附图并结合实施例对本发明进行详细说明,其中图1示出了根据本发明优选实施例的系统框图;图2示出了根据本发明优选实施例的方法的流程图。图3示出了根据本发明另一优选实施例的方法的流程图。
具体实施例图1示出了根据本发明优选实施例的网站内容防采集系统100的结构框图。系统包括获取单元,用于获取用户的ID、IP地址、User-Agent和当前时间;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元,用于将记录的用户在预定时间内对网站页面的访问与设定值进行比较;当用户在预定时间段内对网站页面的访问大于设定值时,使用禁止单元,此时用户对网站的访问被禁止。 网站内容防采集 系统的获取单元可以在每次收到访问请求时记录访问者的ID、IP地址、用户代理(ser-Agent)和访问时间。当访问者通过hternet Explorer等浏览器程序或采集器program访问网站时,访问者的浏览器程序或采集器program通常会向网站发送一个字符串来描述其身份。段字符串称为 her-Agent。用户使用的不同软件通常会发送不同的her-Agent。通过结合访问者的IP地址和her-Agent,网站可以识别和区分每个访问者。查询单元查询当前访问者在单位时间段内访问的网站页面数,即访问次数。比较单元将查询单元查询到的用户访问量与设置的访问量进行比较。如果单位时间段内的页面访问量超过设置的访问量,则可以确定访问者的访问为异常访问。
禁止单元可以禁止访问者对网站的异常访问。单位时间段的页面浏览量和单位时间段的设置值是两个变量,可以在网站program配置中单独修改。例如,单位时间段可以设置在10-600秒之间。单位时间段设置太短可能会导致普通用户的访问被误判为异常访问,而单位时间段设置太长可能导致采集器已采集大数据后网站才检测到当前访问是采集器的访问。由于采集器在执行采集时通常有每秒1到50页的频率,所以单位时间段内的页面浏览次数可以设置为所选单位时间段的1-秒。 50次。例如,单位时间段可以设置为60秒,单位时间段内的浏览量设置值为600页。由于采集器的采集速度受网络速度、网站响应速度等多种因素影响,具体的单位时间段和单位时间段内的页面浏览量应允许网站管理员设置根据实际情况。另外,本发明的网站内容防采集系统还可以包括:存储IP地址白名单和IP地址黑名单的存储单元,以及判断用户地址是否属于IP A的判断单元白色地址或黑色 IP 地址。如果是白色IP地址,则允许用户访问网站;如果属于IP黑地址,则禁止用户访问网站。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP地址白名单功能,将常用搜索引擎的IP地址或IP地址段加入IP地址白名单。
来自这些IP地址的访问将绕过访问频率的判断,不受访问量设置值的限制。此外,本发明的网站内容防采集系统可以提供IP地址黑名单功能,将常见的采集器IP地址加入IP地址黑名单。从这些IP地址访问将绕过访问频率的判断,直接被禁止。图2示出了根据优选实施例的方法的流程图。本实施例的网站内容防采集方法包括以下步骤获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问量;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。图3示出了根据本发明另一优选实施例的方法的流程图。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP 地址白名单功能将常用搜索引擎的IP 地址或IP 地址段加入IP 地址白名单。来自这些IP地址的访问会绕过访问频率的判断,不受访问设置值的限制。图3所示方法与图2所示方法步骤的区别在于,在获取用户IP地址的步骤之后,首先判断用户的IP地址是否属于IP地址白名单。 k14@的来访。
如果不属于,则判断用户的IP地址是否属于IP地址黑名单。如果属于,则禁止用户访问网站。如果没有,则如图2所示,继续查询用户对网站页面的访问次数。下面以PHP+MySQL开发环境为例来说明实现方法。对于其他语言如数据库,可以通过下面的SQL语句@NOT NULL DEFAULT"创建数据表CREATE TABLE "visitlist"(~icfINT(10)NOT NULL AUTO_INCREMENT PRIMARY KEY,VARCHAR(4@k21), "useragent" VARCHAR(255)NOT NULL DEFAULT", ~time~INT(10)NOT NULL DEFAULT' 0') ENGINE = MYISAM; 数据表中有4个字段:id, ip, useragent, and time分别代表记录ID、用户IP、用户User-Agent、访问时间,主程序代码说明获取用户IP、User-Agent信息,程序首先需要获取用户IP、her-Agent、当前时间信息,代码如下: $ip = $_SERVER['REM0TE_ADDR']; $useragent = $_SERVER[' HTTP_USER_AGENT']; $time = time(); //time()函数返回当前UNIX时间戳在几秒钟内,然后将上述数据存储到数据库中。
代码如下 mysql_query(" INSERT INTO visitlist(, ip,,, useragent and time,) values(' $ip', '$useragent',' $time')〃 ); 查询当前用户在单位时间段访问的页面数假设单位时间段为常数define ('DURATION', 60); $time_start = time()-DURATION ;//从当前时间段中减去设置的时间段,这是计数开始时间 $query = mysql_query ("SELECT COUNT (*) AS visit_count FROM visitlistffHERE"time"> $time_start AND—ip— = '{$this-> base-> ip}' AND, useragent, =' {$useragent}"'); $row = mysql_fetch_array($query); $visit_count = isset($row[ 'visit_count' ])? $row[ 'vist_count']: 0; 确定单位时间内访问的页面period 是否大于设定值,处理最终结果
假设单位时间段内访问的页面数是网站administrator定义的常量,define('MAX_PAGES', 300); if($visit_count> MAX_PAGES){exit('访问频率太高,禁止访问');//还可以将访问者的IP地址加入网站IP黑名单,可以更有效的禁止用户访问。} 上面应该理解为基于本发明的优选实施例,已经对技术方案进行了详细描述,应当理解,以上描述是示例性的而非限制性的,本领域普通技术人员可以对每一个描述的技术方案进行修改在阅读本发明说明书的基础上对实施例中的部分技术特征进行等效替换,这些修改或替换不导致相应技术方案的实质背离本发明的精神和范围本发明实施例的技术方案的pe。本发明的保护范围仅以所附权利要求为准。
声明
1.A 网站内容防采集系统,其特征在于,该系统包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设定值进行比较,该单元被禁止,当用户在预定时间段内对网站页面的访问为大于设定值,禁止用户访问网站。
根据权利要求1所述的2.网站内容防采集系统,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50倍。
如权利要求1所述的3.网站内容防采集系统,其特征在于,该系统还包括用于存储IP地址白名单和IP地址黑名单的存储单元;判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。
4.如权利要求3所述的网站内容防采集系统,其特征在于,IP地址白名单包括搜索引擎的IP地址。
5.A 网站内容防采集方法,其特征在于,该方法包括获取用户ID、IP地址、User-Agent和当前时间; k14@页面统计并获取预定时间段内的用户访问量;将访问与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。
如权利要求5所述的6.网站内容防采集方法,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50秒预定时间段次。
如权利要求5所述的7.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站。
如权利要求5所述的8.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址黑名单,则用户访问禁止网站。
9.根据权利要求5所述的网站内容防采集方法,其特征在于,该方法还包括将搜索引擎的IP地址放入IP地址白名单。
10.根据权利要求5所述的网站内容防采集方法,其特征在于,将被禁用户的IP地址放入IP地址黑名单。
全文摘要
本发明提供了一种网站内容预防采集系统和方法。本发明的网站内容防采集系统包括获取单元,用于获取用户ID、IP地址、User-Agent和当前时间;比较单元用于将用户在预定时间段内访问网站页面的次数与设定值进行比较,该单元被禁止。当用户在预定时间段内,网站页面的访问量大于设定值时,禁止用户访问网站。本发明的方法可以在不修改网页内容的情况下防止网页内容被采集。
文件编号 G06F17/30GK102088477SQ2
出版日期:2011 年 6 月 8 日申请日期:2010 年 11 月 25 日优先权日期:2010 年 11 月 25 日
发明人孟凡斌、梅纯、潘海东申请人:
经典网站内容采集系统——百度快照采集(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-07-08 00:01
网站内容采集系统是对传统互联网知识的一种延伸及拓展,如产品采购供应,b2b销售、c2c购物、b2c购物、内容运营、团购推广、门户网站宣传推广、留学申请、销售导航、百科信息问答、商品评价、网民评论、招聘求职、短视频平台制作、门户广告投放、网页新闻、爬虫抓取、网友留言、百科提问等,也是对网站传统网站内容的一种补充。经典网站内容采集系统——百度快照采集。
我们这里有专门做这个的,可以百度一下。
这不是一个可以与内容有对应产业的创业项目,而是一个网上创业项目。
手工采集的再好有什么用,都要靠大数据采集的手段好啊,建议可以去咨询一下亿信华辰,亿信华辰就是专门做大数据采集的,有专门的服务团队,我就在他们公司上班,叫亿信力,专业数据采集,
大部分的网站都是用php构建的,网站常用的工具类有:word,iis,asp等。google自带采集器肯定是没有采集工具,不过可以自己构建。现在最高端的是wordpress的外挂采集器可以实现非原始wordpress页面的数据采集,例如我现在写的travet-wordpress数据采集系统就是其中一种,可以采集前台所有页面的链接,但是无法采集到后台的页面链接,还是需要借助一些采集软件来采集,例如chrome插件和tor浏览器插件等,可以参考我的博客采集软件介绍采集软件推荐我之前写过一篇介绍常用采集器的文章你可以看看采集软件介绍-快速搭建wordpress网站?详细介绍了常用的三种采集器。
另外,内容采集技术层面的问题,也可以参考前几天我写的一篇博客-《海量网站全网站数据采集技术》,很不错,从数据采集的基础讲到asp,flash,php,jsp等内容网站常用的多重检索方式,数据采集也讲的很清楚。 查看全部
经典网站内容采集系统——百度快照采集(图)
网站内容采集系统是对传统互联网知识的一种延伸及拓展,如产品采购供应,b2b销售、c2c购物、b2c购物、内容运营、团购推广、门户网站宣传推广、留学申请、销售导航、百科信息问答、商品评价、网民评论、招聘求职、短视频平台制作、门户广告投放、网页新闻、爬虫抓取、网友留言、百科提问等,也是对网站传统网站内容的一种补充。经典网站内容采集系统——百度快照采集。
我们这里有专门做这个的,可以百度一下。
这不是一个可以与内容有对应产业的创业项目,而是一个网上创业项目。
手工采集的再好有什么用,都要靠大数据采集的手段好啊,建议可以去咨询一下亿信华辰,亿信华辰就是专门做大数据采集的,有专门的服务团队,我就在他们公司上班,叫亿信力,专业数据采集,
大部分的网站都是用php构建的,网站常用的工具类有:word,iis,asp等。google自带采集器肯定是没有采集工具,不过可以自己构建。现在最高端的是wordpress的外挂采集器可以实现非原始wordpress页面的数据采集,例如我现在写的travet-wordpress数据采集系统就是其中一种,可以采集前台所有页面的链接,但是无法采集到后台的页面链接,还是需要借助一些采集软件来采集,例如chrome插件和tor浏览器插件等,可以参考我的博客采集软件介绍采集软件推荐我之前写过一篇介绍常用采集器的文章你可以看看采集软件介绍-快速搭建wordpress网站?详细介绍了常用的三种采集器。
另外,内容采集技术层面的问题,也可以参考前几天我写的一篇博客-《海量网站全网站数据采集技术》,很不错,从数据采集的基础讲到asp,flash,php,jsp等内容网站常用的多重检索方式,数据采集也讲的很清楚。
通用版,编写或者下载规则,并保存图片文件。
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-06-27 00:02
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。 查看全部
通用版,编写或者下载规则,并保存图片文件。
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
泰得利通IRadar网页信息采集系统能通过灵活的规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-06-24 21:29
IRadar 网页信息采集系统概览
信息时代的发展带来了互联网上海量信息的形成。政府单位、各大企业、银行、教育机构都渴望快速高效地采集和提取与自身利益和需求相关的有用信息,web information采集系统正式成为这样一个高效的工具。可对定制化的目标数据源进行实时信息采集、提取、挖掘、处理,为各类信息服务系统提供数据输入。
潮德利通IRRadar网页信息采集系统可以使用灵活的规则来自任何类型的网站采集信息,例如news网站、论坛、博客、电子商务网站、招聘网站和等等,利用其通用性、灵活性、高效性、稳定性,为客户带来更大的利润。
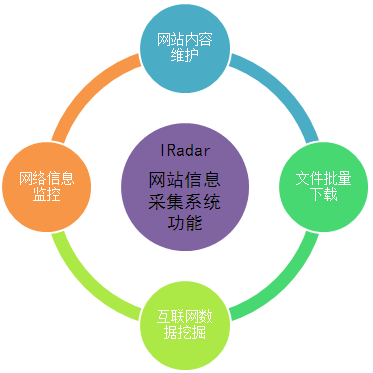
红外网页信息采集系统功能
网络信息采集系统可实现网站login采集、网站cross-layer采集、POST采集script page采集、动态页面等高级采集功能采集等各种形式的信息采集,费力。网信采集系统支持存储过程、插件等,可二次开发扩展功能。
IRadar网站信息采集系统功能:
1、文件批量下载
批量下载PDF、RAR、图片等文件,同时下载采集相关资料
2、互联网数据挖掘
从指定的网站中抓取所需的数据,对其进行分析处理并保存到您的数据库中。
3、网络信息监控
自动抓取新闻、论坛等,然后分析处理
4、网站内容维护
定时采集新闻、文章等,并自动发布到指定的网站。
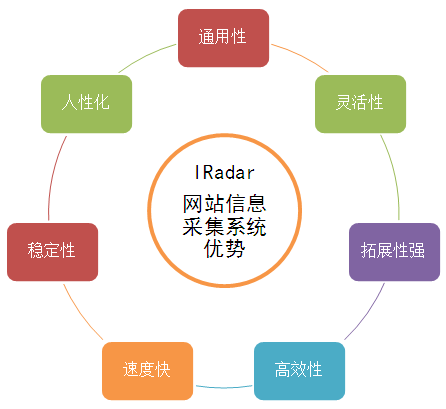
红外网络信息采集系统优势
红外网页信息采集系统优势:
1、Universal:可以自定义采集rules采集任何浏览器可以看到的信息;
2、Flexibility:支持多种高级采集功能;
3、扩展性强:支持存储过程、插件等,可用于二次开发扩展功能;
4、高效:精心设计的系统为您节省每一秒;
5、fast:最快最高效的采集系统;
6、Stability:系统稳定,没有漏洞;
7、人性化:注重细节,人性化体验。
图片:IRadar网页信息采集系统优势 查看全部
泰得利通IRadar网页信息采集系统能通过灵活的规则
IRadar 网页信息采集系统概览
信息时代的发展带来了互联网上海量信息的形成。政府单位、各大企业、银行、教育机构都渴望快速高效地采集和提取与自身利益和需求相关的有用信息,web information采集系统正式成为这样一个高效的工具。可对定制化的目标数据源进行实时信息采集、提取、挖掘、处理,为各类信息服务系统提供数据输入。
潮德利通IRRadar网页信息采集系统可以使用灵活的规则来自任何类型的网站采集信息,例如news网站、论坛、博客、电子商务网站、招聘网站和等等,利用其通用性、灵活性、高效性、稳定性,为客户带来更大的利润。
红外网页信息采集系统功能
网络信息采集系统可实现网站login采集、网站cross-layer采集、POST采集script page采集、动态页面等高级采集功能采集等各种形式的信息采集,费力。网信采集系统支持存储过程、插件等,可二次开发扩展功能。
IRadar网站信息采集系统功能:
1、文件批量下载
批量下载PDF、RAR、图片等文件,同时下载采集相关资料
2、互联网数据挖掘
从指定的网站中抓取所需的数据,对其进行分析处理并保存到您的数据库中。
3、网络信息监控
自动抓取新闻、论坛等,然后分析处理
4、网站内容维护
定时采集新闻、文章等,并自动发布到指定的网站。
红外网络信息采集系统优势
红外网页信息采集系统优势:
1、Universal:可以自定义采集rules采集任何浏览器可以看到的信息;
2、Flexibility:支持多种高级采集功能;
3、扩展性强:支持存储过程、插件等,可用于二次开发扩展功能;
4、高效:精心设计的系统为您节省每一秒;
5、fast:最快最高效的采集系统;
6、Stability:系统稳定,没有漏洞;
7、人性化:注重细节,人性化体验。
图片:IRadar网页信息采集系统优势
网站内容采集系统搭建可根据自己的需求来做设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-06-22 01:03
网站内容采集系统搭建可根据自己的需求来制定,具体可以看下自己的情况来做设计;1.网站内容采集系统需求说明采集软件一般需要支持:内容商城系统(可以同时支持店铺系统、个人网站、企业站、政府网站、本地企业站),收录内容系统(可以同时支持百度、谷歌、雅虎、、360等站点收录和引流),相关词库(内容系统只支持有相关的词库维护,如一个区域只允许有一个区域要采集什么内容,你可以根据情况来设置收录多少,内容量多少,如收录3000,相关区域30000个,则内容系统对应设置相关收录量,如2000。
)2.功能介绍采集软件主要包括:本地内容系统、超链接软件、品牌词库管理系统、本地音频、视频的采集软件3.采集软件软件案例当采集海量网站内容时,复制链接速度快,采集时有时间间隔采集速度慢,网站下载分享内容时延迟高网站用户分享率低,不易分享给好友(有些站长会做站群,如果同时申请一些站群可能在下载这块时间会造成比较大的延迟,影响收录)网站搜索结果前几位内容经常出现刷新的情况采集软件专业用于业务类站点数据采集和改版,而且操作简单易上手网站改版一次,内容重新找就行,增删不变化,一次不变化3天就可以改好、搞定网站增删变化是个挑战增删有可能影响到整个网站和网站每个分站的排名和权重增删时可能影响整站整体的权重。 查看全部
网站内容采集系统搭建可根据自己的需求来做设计
网站内容采集系统搭建可根据自己的需求来制定,具体可以看下自己的情况来做设计;1.网站内容采集系统需求说明采集软件一般需要支持:内容商城系统(可以同时支持店铺系统、个人网站、企业站、政府网站、本地企业站),收录内容系统(可以同时支持百度、谷歌、雅虎、、360等站点收录和引流),相关词库(内容系统只支持有相关的词库维护,如一个区域只允许有一个区域要采集什么内容,你可以根据情况来设置收录多少,内容量多少,如收录3000,相关区域30000个,则内容系统对应设置相关收录量,如2000。
)2.功能介绍采集软件主要包括:本地内容系统、超链接软件、品牌词库管理系统、本地音频、视频的采集软件3.采集软件软件案例当采集海量网站内容时,复制链接速度快,采集时有时间间隔采集速度慢,网站下载分享内容时延迟高网站用户分享率低,不易分享给好友(有些站长会做站群,如果同时申请一些站群可能在下载这块时间会造成比较大的延迟,影响收录)网站搜索结果前几位内容经常出现刷新的情况采集软件专业用于业务类站点数据采集和改版,而且操作简单易上手网站改版一次,内容重新找就行,增删不变化,一次不变化3天就可以改好、搞定网站增删变化是个挑战增删有可能影响到整个网站和网站每个分站的排名和权重增删时可能影响整站整体的权重。
北京米艾特软件集多年大中型网站研发与运营经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-06-21 19:06
概述
Mitcms(Mitsoft 内容管理系统,Mitsoft网站内容管理系统)是北京米爱特软件的专用门户,拥有多年大中型网站研发和运营经验,至今已发展七年六个版本。 网站内容采集,编辑发布应用系统。 Mitcms的应用可以帮助政府机关、企事业单位等网站规范其网站后台信息流程,统一数据存储格式,减少网站维护投入,加强信息权限管理。
Mitcms解决大中型网站经常面临的问题:
结构混乱,文件夹多,数据表多,技术维护困难;数据维护困难。频道和栏目很多,很多栏目内容的人工维护需要巨大的人力和财力投入。内容发布处于两难境地。纯静态页面的使用使得时效性难以把握,制作和发布非常耗时;动态发布可以保证发布的时效性,但是一旦流量大,速度往往很慢。在报道重要事件时,不可能高效快速地构建界面多样、内容丰富的话题。六大特点
快速建改大中型网站,提升网站资源整合能力。
可以无限制添加子栏,系统自动维护网站column文件夹。独有的自定义表格功能,可以为不同的栏目定义表格,轻松满足不同栏目建设的需求。强大的模板机制实现了网站界面和数据的分离,使网站修改起来快捷方便。动态发布纯静态页面,有效提高用户浏览时的响应速度,更容易被谷歌和百度收录接收。轻松构建界面多样、内容丰富的专题报告。
内容编辑审核功能强大,操作简单。
Tong一、 方便的用户界面和管理入口,上手快,使用方便。一款与Word、IE高度集成的内容编辑器,可以随意插入图片,实现图文混合,也可以随意插入视频、表格、文件等多媒体信息。右键菜单用于管理。支持多选、拖放,给您独特的用户体验。
集成智能数据挖掘和分析功能,为内容增值应用提供技术支持。
独有的增量行业特征数据库管理功能。它可以自动从发布的内容中提取关键词,准确率超过90%。独有的话题自动聚合功能,无需创建栏目,即可针对特定热点问题自动生成内容话题。基于智能数据挖掘分析功能的精准广告投放。
强大的数据采集功能有效降低数据维护成本。
可以为任意指定栏目设置采集任务,抓取多个外部站点的相关栏目。 采集图片可以发送到本地。您可以通过设置过滤规则来过滤页面上的广告和不良信息,具有很强的针对性和准确性。 采集后自动存储。可任意编辑,审核后发表,全程省时省力。
稳定可靠的发布系统,有效实现资源共享。
基于.NET3.5企业级架构,保证发布系统的稳定性和可靠性。统一的底层数据库和算法领先的数据结构,有效实现信息的安全存储和有效分类;独有的附加发布功能,彻底消除信息孤岛,有效实现资源共享。
功能齐全。
文件管理:远程管理站点文件。用户管理:分级权限控制。投票管理:柱状图、饼图、流量统计:跟踪网站浏览。 查看全部
北京米艾特软件集多年大中型网站研发与运营经验
概述
Mitcms(Mitsoft 内容管理系统,Mitsoft网站内容管理系统)是北京米爱特软件的专用门户,拥有多年大中型网站研发和运营经验,至今已发展七年六个版本。 网站内容采集,编辑发布应用系统。 Mitcms的应用可以帮助政府机关、企事业单位等网站规范其网站后台信息流程,统一数据存储格式,减少网站维护投入,加强信息权限管理。
Mitcms解决大中型网站经常面临的问题:
结构混乱,文件夹多,数据表多,技术维护困难;数据维护困难。频道和栏目很多,很多栏目内容的人工维护需要巨大的人力和财力投入。内容发布处于两难境地。纯静态页面的使用使得时效性难以把握,制作和发布非常耗时;动态发布可以保证发布的时效性,但是一旦流量大,速度往往很慢。在报道重要事件时,不可能高效快速地构建界面多样、内容丰富的话题。六大特点
快速建改大中型网站,提升网站资源整合能力。
可以无限制添加子栏,系统自动维护网站column文件夹。独有的自定义表格功能,可以为不同的栏目定义表格,轻松满足不同栏目建设的需求。强大的模板机制实现了网站界面和数据的分离,使网站修改起来快捷方便。动态发布纯静态页面,有效提高用户浏览时的响应速度,更容易被谷歌和百度收录接收。轻松构建界面多样、内容丰富的专题报告。
内容编辑审核功能强大,操作简单。
Tong一、 方便的用户界面和管理入口,上手快,使用方便。一款与Word、IE高度集成的内容编辑器,可以随意插入图片,实现图文混合,也可以随意插入视频、表格、文件等多媒体信息。右键菜单用于管理。支持多选、拖放,给您独特的用户体验。
集成智能数据挖掘和分析功能,为内容增值应用提供技术支持。
独有的增量行业特征数据库管理功能。它可以自动从发布的内容中提取关键词,准确率超过90%。独有的话题自动聚合功能,无需创建栏目,即可针对特定热点问题自动生成内容话题。基于智能数据挖掘分析功能的精准广告投放。
强大的数据采集功能有效降低数据维护成本。
可以为任意指定栏目设置采集任务,抓取多个外部站点的相关栏目。 采集图片可以发送到本地。您可以通过设置过滤规则来过滤页面上的广告和不良信息,具有很强的针对性和准确性。 采集后自动存储。可任意编辑,审核后发表,全程省时省力。
稳定可靠的发布系统,有效实现资源共享。
基于.NET3.5企业级架构,保证发布系统的稳定性和可靠性。统一的底层数据库和算法领先的数据结构,有效实现信息的安全存储和有效分类;独有的附加发布功能,彻底消除信息孤岛,有效实现资源共享。
功能齐全。
文件管理:远程管理站点文件。用户管理:分级权限控制。投票管理:柱状图、饼图、流量统计:跟踪网站浏览。
,最近网站降权的情况是什么?怎么破?(下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-06-20 23:53
写这篇文章的时候,还有小伙伴在讨论网站降权的情况。通常最突出的特点是:网站内容海量大合集,带有刷机参数的网页被广泛使用。
无一例外,这些网站基本都面临降级,基本没有例外。这里有很多知名的网站。
事实上,我们以搜索生态为基础,认为这无疑是一个明智的策略。
原因很简单。可持续的转化来自高质量的流量,高质量的页面流量需求往往基于高质量的内容查询。
否则,更多的操作将成为“内容搬运工”而不是“内容生产者”。
因此,激活高质量、可持续的搜索需求、净化搜索结果并支持高质量的内容生产者尤为重要。
目前百度搜索也在努力,网站operator可能也需要重新考虑我们的策略了。
为此,您可能需要注意以下几点:
1、自我回顾
如果网站ranking最近大幅下降,关键词ranking的很多内容消失了,网站的加权曲线基本呈现悬崖式下降趋势,我们认为下面的自我回顾可能是必要的。
是否采集大量内容
是否进行快速排名操作(如滑动和点击参数)。
2、采集是什么?
简单理解:网站所有内容的主要特点,如大面积抄袭,标题和内容一致。当然可以说我做了相关的处理,比如伪原创,,,,
但是,搜索引擎有以下完整的检查机制:
两个页面的内容和格式是一样的
两个页面的内容相同,但格式不同。
两个页面的重要内容相同,格式相同
两个页面的重要内容不同,格式相同
搜索引擎进行数据对比,重点关注以下页面功能:
1、计算页面上的数字签名(在页面的内容和结构中集成数据特征)
将页面数据的第一部分与现有数据库的原创标记记录的签名进行比较。
从搜索结果中过滤相似的数字签名,并与采集内容进行相似度比较。
点击参数是什么?
简单理解:点击参数通常是指利用SEO作弊策略,直接反馈与搜索引擎相关的特定目标网址的页面访问量。
常见表达:在搜索资源平台发现大量关键词data点击等。实际情况:在实际的搜索和排序过程中,这些数据的访问和反馈实际上并不存在。通常使用快速放电系统。
2、下权处理
如果网站最近流量减少了,如何通过自我审查、符号采集、刷卡等方式恢复网站数据?根据以往的操作经验,Cheng Ge Seo认为有必要参考以下内容:
根据人口统计目录和查看页面的采集rate。
删除所有采集 页面和部分。
将页面死链接提交给百度,制作404页面
建立频道,用优质网站页面吸引百度爬虫,抓取不同栏目,缩短降级审核周期,提高网站降权效率。你可以试试:
1)合理建立行业相关优质链接网站。
2) 创建指向高质量网站 相关内容页面的外部链接。
3)找合适的合作伙伴搭建同行业未降级的蜘蛛网站,侧边栏目标链接。
继续制作高质量的内容并将其提交给搜索引擎。
Seo Cheng 认为,为了提高网站 搜索引擎排名,我们可能需要专注于编写高质量的内容,而不是盲目采集文章。 查看全部
,最近网站降权的情况是什么?怎么破?(下)
写这篇文章的时候,还有小伙伴在讨论网站降权的情况。通常最突出的特点是:网站内容海量大合集,带有刷机参数的网页被广泛使用。
无一例外,这些网站基本都面临降级,基本没有例外。这里有很多知名的网站。
事实上,我们以搜索生态为基础,认为这无疑是一个明智的策略。
原因很简单。可持续的转化来自高质量的流量,高质量的页面流量需求往往基于高质量的内容查询。
否则,更多的操作将成为“内容搬运工”而不是“内容生产者”。
因此,激活高质量、可持续的搜索需求、净化搜索结果并支持高质量的内容生产者尤为重要。
目前百度搜索也在努力,网站operator可能也需要重新考虑我们的策略了。
为此,您可能需要注意以下几点:
1、自我回顾
如果网站ranking最近大幅下降,关键词ranking的很多内容消失了,网站的加权曲线基本呈现悬崖式下降趋势,我们认为下面的自我回顾可能是必要的。
是否采集大量内容
是否进行快速排名操作(如滑动和点击参数)。
2、采集是什么?
简单理解:网站所有内容的主要特点,如大面积抄袭,标题和内容一致。当然可以说我做了相关的处理,比如伪原创,,,,
但是,搜索引擎有以下完整的检查机制:
两个页面的内容和格式是一样的
两个页面的内容相同,但格式不同。
两个页面的重要内容相同,格式相同
两个页面的重要内容不同,格式相同
搜索引擎进行数据对比,重点关注以下页面功能:
1、计算页面上的数字签名(在页面的内容和结构中集成数据特征)
将页面数据的第一部分与现有数据库的原创标记记录的签名进行比较。
从搜索结果中过滤相似的数字签名,并与采集内容进行相似度比较。
点击参数是什么?
简单理解:点击参数通常是指利用SEO作弊策略,直接反馈与搜索引擎相关的特定目标网址的页面访问量。
常见表达:在搜索资源平台发现大量关键词data点击等。实际情况:在实际的搜索和排序过程中,这些数据的访问和反馈实际上并不存在。通常使用快速放电系统。
2、下权处理
如果网站最近流量减少了,如何通过自我审查、符号采集、刷卡等方式恢复网站数据?根据以往的操作经验,Cheng Ge Seo认为有必要参考以下内容:
根据人口统计目录和查看页面的采集rate。
删除所有采集 页面和部分。
将页面死链接提交给百度,制作404页面
建立频道,用优质网站页面吸引百度爬虫,抓取不同栏目,缩短降级审核周期,提高网站降权效率。你可以试试:
1)合理建立行业相关优质链接网站。
2) 创建指向高质量网站 相关内容页面的外部链接。
3)找合适的合作伙伴搭建同行业未降级的蜘蛛网站,侧边栏目标链接。
继续制作高质量的内容并将其提交给搜索引擎。
Seo Cheng 认为,为了提高网站 搜索引擎排名,我们可能需要专注于编写高质量的内容,而不是盲目采集文章。
ASP.NET2.0+SQL2000技术框架,全新的静态生成方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-06-20 05:02
1.pageadmin
2.点cms
3.jumbot
================================================ ================
1.We7 cms
We7cms是Western Power开发的一家公司,旨在充分挖掘互联网Web2.0(如博客、RSS等)信息组织的优势,并将其理念用于构建和组织政府企业网站,网站建设和管理产品的管理。
系统目标:把网站的创作变成简单的艺术创作,就像写博客一样简单。
系统功能
简单至上; “看一看”是我们的创作理念。如果您在看到它时无法使用它,请告诉我们。
潜力无限;来自WebEngine2007的谱系,大型行业门户和政府门户网站的核心引擎。 C-Modeling内容模型技术解决了多数据结构管理的问题,让cms可以发挥超出cms范围的能量。
网站自发展;迈向站群,强大的运营分析工具,团队协作系统,自动引擎升级,这一切都为你打造一个不断成长的网站做好准备。
开放和开源;强调开放是第一生产力,首个完全开源的cms系统会给你带来更多惊喜!
官网:
3.ROYcms
罗伊cms! NT内容管理系统是国内cms市场的新秀,也是国内为数不多的采用微软ASP.NET2.0+SQL2000/2005技术框架开发的cms之一。充分利用了ASP.NET架构的优势,突破了传统ASP类cms的局限性,采用了更稳定的执行速度和更高效的面向对象语言C#设计,延续了PETshop代码框架,全新的模板引擎机制,全新的静态生成方案,这些功能和技术的创新,塑造了一个基础架构稳定、功能创新、高效执行的cms。
特点:
模板自由组合
自定义静态生成的 HTML
无限分类资源
插件形式易于扩展
命名约定适合二次开发
官网:
4.易点内容管理系统点cms
<p>Easy Point 内容管理系统(Diancms)基于Microsoft .NET Framework 2.0、AJAX1.0 技术,采用Microsoft Access/SQL Server 2000/2005 多层架构存储过程开发内容管理系统。其功能设计主要针对大中型企业、各行业、事业单位、政府机关等复杂功能场所。系统建立了文章系统、图片系统、下载系统、个人求职、企业招聘、房产系统、音乐系统、视频系统、网店。使用自定义模型、自定义字段、自定义表单、自定义入口界面、会员系统等功能,您还可以轻松灵活地建立任何适合您需求的系统功能,最大限度地随时满足每个用户的不同需求。 查看全部
ASP.NET2.0+SQL2000技术框架,全新的静态生成方案
1.pageadmin
2.点cms
3.jumbot
================================================ ================
1.We7 cms
We7cms是Western Power开发的一家公司,旨在充分挖掘互联网Web2.0(如博客、RSS等)信息组织的优势,并将其理念用于构建和组织政府企业网站,网站建设和管理产品的管理。
系统目标:把网站的创作变成简单的艺术创作,就像写博客一样简单。
系统功能
简单至上; “看一看”是我们的创作理念。如果您在看到它时无法使用它,请告诉我们。
潜力无限;来自WebEngine2007的谱系,大型行业门户和政府门户网站的核心引擎。 C-Modeling内容模型技术解决了多数据结构管理的问题,让cms可以发挥超出cms范围的能量。
网站自发展;迈向站群,强大的运营分析工具,团队协作系统,自动引擎升级,这一切都为你打造一个不断成长的网站做好准备。
开放和开源;强调开放是第一生产力,首个完全开源的cms系统会给你带来更多惊喜!
官网:
3.ROYcms
罗伊cms! NT内容管理系统是国内cms市场的新秀,也是国内为数不多的采用微软ASP.NET2.0+SQL2000/2005技术框架开发的cms之一。充分利用了ASP.NET架构的优势,突破了传统ASP类cms的局限性,采用了更稳定的执行速度和更高效的面向对象语言C#设计,延续了PETshop代码框架,全新的模板引擎机制,全新的静态生成方案,这些功能和技术的创新,塑造了一个基础架构稳定、功能创新、高效执行的cms。
特点:
模板自由组合
自定义静态生成的 HTML
无限分类资源
插件形式易于扩展
命名约定适合二次开发
官网:
4.易点内容管理系统点cms
<p>Easy Point 内容管理系统(Diancms)基于Microsoft .NET Framework 2.0、AJAX1.0 技术,采用Microsoft Access/SQL Server 2000/2005 多层架构存储过程开发内容管理系统。其功能设计主要针对大中型企业、各行业、事业单位、政府机关等复杂功能场所。系统建立了文章系统、图片系统、下载系统、个人求职、企业招聘、房产系统、音乐系统、视频系统、网店。使用自定义模型、自定义字段、自定义表单、自定义入口界面、会员系统等功能,您还可以轻松灵活地建立任何适合您需求的系统功能,最大限度地随时满足每个用户的不同需求。
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-04 06:09
网人采集系统 v1.0 发布!网人采集系统 v1.0 发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计。支持分类信息采集、文章采集和shop采集,当然这个系统也可以应用到其他系统!
网人采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。使用网友采集,可以瞬间创建采集网站 内容丰富。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql 数据导入导出可以让你在采集content 的时候更自在。现在您可以摒弃以往重复繁琐的手动添加工作,立即开始体验即时建站的乐趣吧!
Netren采集 是一个功能强大且易于使用的版本
寻求有关内存问题的帮助! ! !
掌上专业采集软件,强大的内容采集和数据处理功能可以将您采集的任意网页数据发布到远程服务器,自定义用户cms系统模块,不管您的网站是任何系统,都可以使用网民采集系统。更多cms模块请参考制作修改,或到官方网站与您交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集发送的数据对应表的字段导出到任意本地Access或MSSqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持attachments采集,包括图片、文档等附件
5、 increment采集 并自动更新
6、全结构化抽取
7、采集结果自动重新排列
8、数据保存在本地,随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库中
10、同时多站点多任务多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展和可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、强大的内容过滤功能,可以无限制去除广告和替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史功能,避免重复采集
20、timing采集、网站内容实时更新
基本说明:
1、下载本系统并解压到网站目录
2、如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接、相关表信息等
4、设置采集项目
5、采集content
好的,完成
官方地址:
下载链接: 查看全部
使用网人采集,你可以瞬间建立一个拥有庞大内容的网站
网人采集系统 v1.0 发布!网人采集系统 v1.0 发布!
网民采集系统是一套采集程序,专为目前网络上流行的分类信息站而设计。支持分类信息采集、文章采集和shop采集,当然这个系统也可以应用到其他系统!
网人采集系统是各大主流文章系统、信息系统、店铺系统等使用的多线程内容采集发布程序。使用网友采集,可以瞬间创建采集网站 内容丰富。系统支持远程图片下载、图片批量水印、下载文件地址检测、自制发布cms模块参数、自定义发布内容等。此外,丰富的规则制定、内容替换功能,支持Access和MSsql 数据导入导出可以让你在采集content 的时候更自在。现在您可以摒弃以往重复繁琐的手动添加工作,立即开始体验即时建站的乐趣吧!
Netren采集 是一个功能强大且易于使用的版本
寻求有关内存问题的帮助! ! !
掌上专业采集软件,强大的内容采集和数据处理功能可以将您采集的任意网页数据发布到远程服务器,自定义用户cms系统模块,不管您的网站是任何系统,都可以使用网民采集系统。更多cms模块请参考制作修改,或到官方网站与您交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集发送的数据对应表的字段导出到任意本地Access或MSSqlServer。
主要功能介绍:
1、简单配置,所见即所得
2、支持多种编码:GBK、BIG5、UNICODE、UTF8,软件会自动转换
3、支持多种站点类型:包括html和rss
4、支持attachments采集,包括图片、文档等附件
5、 increment采集 并自动更新
6、全结构化抽取
7、采集结果自动重新排列
8、数据保存在本地,随时查看信息。
9、随心所欲的导入导出信息,可以导出到Access、Sql server等数据库中
10、同时多站点多任务多线程采集
11、支持海量数据采集
12、软件运行稳定,采集速度快,占用系统资源少
13、软件实用,好用,功能强大
14、便携、可扩展和可定制
15、采集内容测试功能
16、支持自定义发布模块参数
17、强大的内容过滤功能,可以无限制去除广告和替换,真正得到你需要的内容
18、JS URL转换选项,获取目标站点中隐藏的多个URL
19、采集内容历史功能,避免重复采集
20、timing采集、网站内容实时更新
基本说明:
1、下载本系统并解压到网站目录
2、如果只是测试可以直接使用
3、如果正式使用,请修改WR.Config.asp文件中的相关设置,如设置主站系统数据库连接、相关表信息等
4、设置采集项目
5、采集content
好的,完成
官方地址:
下载链接:
集搜客网络爬虫v8.8.0官方免费版|30.3MB集
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-31 02:13
鸡搜客网络爬虫
v8.8.0 官方免费版 | 30.3MB
极速客网络爬虫是一款功能强大的网站内容采集软件,英文名为“GooSeeker”,可以按照指定的规则自动抓取网页中的各种内容并发布到网站。简单易用,无需..
立即下载
中大云采集(网站内容采集工具)
v9.4 Discuz+织梦dedecms+phpcms+帝国cms版 | 2.9MB
Zhongdayun采集是一款强大的网站内容采集工具,以插件的形式集成到Discuz、织梦dedecms、phpcms、empirecms。在,您可以根据关键词或URL自动采集任何内容,...
立即下载
小猪采集器
v2.7.1.0 官方免费版 | 4.5MB
小猪采集器是一款强大的网站content采集工具,可以下载任何网站采集文字、图片、视频等资源,并支持信息发布功能,你会采集内容发布到自己的网站,非常适合个人..
立即下载
Yicai网站数据采集系统
v1.8.4 最新版本 | 2.4MB
Yicai网站数据采集系统是一款非常强大的网络信息采集软件。支持将网页中的文字、图片、标签属性、网页源代码、列表等您感兴趣的网页内容到采集下,还提供信件..
立即下载
小鸟采集器(网站采集软件)
v2.0 绿色版 | 105KB
Little Bird采集器是一款网站信息采集软件,可以帮你精准拦截你需要的信息,还可以为每一个拦截的结果整理不同的数据,完全是人工模式发布!小鸟采集..
立即下载
编辑器工具(网站采集software)
v2.6.19.0 绿色版 | 9.1MB
Editor Tools 是一款免费的网站内容采集 自动发布软件。 Editor Tools从设计之初就以提高软件自动化程度为突破口,实现无人值守、24小时自动化工作。已经测试过了..
立即下载 查看全部
集搜客网络爬虫v8.8.0官方免费版|30.3MB集
鸡搜客网络爬虫
v8.8.0 官方免费版 | 30.3MB
极速客网络爬虫是一款功能强大的网站内容采集软件,英文名为“GooSeeker”,可以按照指定的规则自动抓取网页中的各种内容并发布到网站。简单易用,无需..
立即下载
中大云采集(网站内容采集工具)
v9.4 Discuz+织梦dedecms+phpcms+帝国cms版 | 2.9MB
Zhongdayun采集是一款强大的网站内容采集工具,以插件的形式集成到Discuz、织梦dedecms、phpcms、empirecms。在,您可以根据关键词或URL自动采集任何内容,...
立即下载
小猪采集器
v2.7.1.0 官方免费版 | 4.5MB
小猪采集器是一款强大的网站content采集工具,可以下载任何网站采集文字、图片、视频等资源,并支持信息发布功能,你会采集内容发布到自己的网站,非常适合个人..
立即下载
Yicai网站数据采集系统
v1.8.4 最新版本 | 2.4MB
Yicai网站数据采集系统是一款非常强大的网络信息采集软件。支持将网页中的文字、图片、标签属性、网页源代码、列表等您感兴趣的网页内容到采集下,还提供信件..
立即下载
小鸟采集器(网站采集软件)
v2.0 绿色版 | 105KB
Little Bird采集器是一款网站信息采集软件,可以帮你精准拦截你需要的信息,还可以为每一个拦截的结果整理不同的数据,完全是人工模式发布!小鸟采集..
立即下载
编辑器工具(网站采集software)
v2.6.19.0 绿色版 | 9.1MB
Editor Tools 是一款免费的网站内容采集 自动发布软件。 Editor Tools从设计之初就以提高软件自动化程度为突破口,实现无人值守、24小时自动化工作。已经测试过了..
立即下载
Empirecms网站采集Content 分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-07-29 00:24
上下页面导航是采集分页的难点。它需要所有页面都符合分页规则。如果您不熟悉,我们可以使用第 1 页和第 2 页的代码进行比较分析。确定分页规律。
1、 下面以网站内容分页为例:
可以看到这条新闻一共有20页。
2、查看源码:
本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第一页代码:
(2)第2页代码:
从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”都是一样的,那么“页面区域规律”和“页面链接规律”可以确定。 .
3、获取分页区正则([!--smallpageallzz--]):
4、获取分页链接常规([!--pageallzz--]):
5、为了方便教程的展示,我在newstext中用采集代替采集content,预览结果:
注意事项:
#一、在第一页的HTML代码中,当内容分页链接全部列出时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下导航”。
二、使用完整列表公式时,采集规则正确,但出现莫名重复的页面。在这种情况下,您可以使用替换的方法将其过滤掉(我们将在下一讲中讨论)。
三、使用上下页导航样式的时候,我总是挑第一页,其他页连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。 查看全部
Empirecms网站采集Content 分页教程
上下页面导航是采集分页的难点。它需要所有页面都符合分页规则。如果您不熟悉,我们可以使用第 1 页和第 2 页的代码进行比较分析。确定分页规律。
1、 下面以网站内容分页为例:
可以看到这条新闻一共有20页。
2、查看源码:
本页除了采集已经到达的第一页外,还包括第二、三、四、五、六、七、八、二十页,但是9-19页没有列出这时候我们就用page 1和page 2的代码进行对比分析,确定分页规则:
(1)第一页代码:
(2)第2页代码:
从这两张图可以看出,它们的“页面区域起始码”、“页面链接”格式、“页面区域结束码”都是一样的,那么“页面区域规律”和“页面链接规律”可以确定。 .
3、获取分页区正则([!--smallpageallzz--]):
4、获取分页链接常规([!--pageallzz--]):
5、为了方便教程的展示,我在newstext中用采集代替采集content,预览结果:
注意事项:
#一、在第一页的HTML代码中,当内容分页链接全部列出时,我们使用“list all”。在第一页的HTML代码中,当内容分页链接没有全部列出时,我们使用“上下导航”。
二、使用完整列表公式时,采集规则正确,但出现莫名重复的页面。在这种情况下,您可以使用替换的方法将其过滤掉(我们将在下一讲中讨论)。
三、使用上下页导航样式的时候,我总是挑第一页,其他页连影子都没看到。这是因为分页区正则([!--smallpagezz--])截取错误。
四、使用上下页导航样式时,可以采集跳转到前几页,但是前几页会重复循环到最后。这也是因为分页区正则([!--smallpagezz--])拦截错误,拦截范围过大,导致重复拦截前几页链接。
2017上海事业单位招聘考试备考:网页数据动态更新汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-07-28 19:22
1
陆辉;高尚飞;李少龙;;基于HTTP协议的业务系统网页数据采集应用集成[J];电子技术与软件工程;2019年02期
2
李峰;实时刷新网页数据[J];计算机知识与技术;2002年06期
3
闫瑞峰,闫瑞华;VSP技术在网页数据传输中的应用[J];中国科技信息;2005年08期
4
吴海燕,王友梅;;探索ASP.NET实现Web数据检索的方法[J];计算机与现代化;2005年07期
5
王立军;;Web2.0设计模式下利用Ajax技术动态更新网页数据[J];渤海大学学报(自然科学版);2008年03期
6
樊扬;;基于HTML5的图形网页数据展示[J];无线互联网技术;2013年07期
7
林振洲;;VFP技术在网页data采集中的应用——以高校数字资源建设为例[J];计算机CD软件与应用;2013年14期
8
阙胜贵;朱云;;利用VFP编程自动提取审计所需的网页数据[J];计算机编程技巧与维护;2017年05期
9
朱佳;张中能;;一种基于聚类的全自动Web数据记录提取方法[J];微机应用;2010年12期
10
孙立红;;利用正则表达式分析网页数据实现自选股票管理[J];数学家(教育学界);2008年03期
11
赵彦斌;;基于Django技术的网页数据模型的建立[J];时代农机;2015年07期
12 查看全部
2017上海事业单位招聘考试备考:网页数据动态更新汇总
1
陆辉;高尚飞;李少龙;;基于HTTP协议的业务系统网页数据采集应用集成[J];电子技术与软件工程;2019年02期
2
李峰;实时刷新网页数据[J];计算机知识与技术;2002年06期
3
闫瑞峰,闫瑞华;VSP技术在网页数据传输中的应用[J];中国科技信息;2005年08期
4
吴海燕,王友梅;;探索ASP.NET实现Web数据检索的方法[J];计算机与现代化;2005年07期
5
王立军;;Web2.0设计模式下利用Ajax技术动态更新网页数据[J];渤海大学学报(自然科学版);2008年03期
6
樊扬;;基于HTML5的图形网页数据展示[J];无线互联网技术;2013年07期
7
林振洲;;VFP技术在网页data采集中的应用——以高校数字资源建设为例[J];计算机CD软件与应用;2013年14期
8
阙胜贵;朱云;;利用VFP编程自动提取审计所需的网页数据[J];计算机编程技巧与维护;2017年05期
9
朱佳;张中能;;一种基于聚类的全自动Web数据记录提取方法[J];微机应用;2010年12期
10
孙立红;;利用正则表达式分析网页数据实现自选股票管理[J];数学家(教育学界);2008年03期
11
赵彦斌;;基于Django技术的网页数据模型的建立[J];时代农机;2015年07期
12
如何将shopify的数据弄到opencart,wordpress
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-28 00:26
随着越来越多的人使用shopify,shopify的管理越来越严格,不注意网站就会被屏蔽。针对这种情况,很多人已经开始转移其他平台或自建网站程序。其中,使用opencart和wordpress也是选择之一。使用这些自建站程序时出现问题。如何将shopify 数据获取到opencart、wordpress 或直接采集shopify 数据到opencart、wordpress。针对这个问题,我们提供了对接系统。功能介绍如下:
必要条件我们提供的是一套对接系统源码,必须安装在opencart或wordpress网站所在服务器上。
以下是功能介绍:
1.对接系统与opencart或wordpress网站在同一台服务器上,如:opencart网站有3个; 2 wordpress网站在服务器端,我们将这些网站配置为采集System后台:
您可以在下方采集task:
选择你要采集去哪个opencart站点,系统会调出该站点的分类供选择:
选择保存到opencart的采集products的分类,输入你要采集shopify网站的分类链接,输入采集数量提交保存。
这里注意支持采集数据调价
采集,产品可以在相应的opencart或wordpress网站中展示 查看全部
如何将shopify的数据弄到opencart,wordpress
随着越来越多的人使用shopify,shopify的管理越来越严格,不注意网站就会被屏蔽。针对这种情况,很多人已经开始转移其他平台或自建网站程序。其中,使用opencart和wordpress也是选择之一。使用这些自建站程序时出现问题。如何将shopify 数据获取到opencart、wordpress 或直接采集shopify 数据到opencart、wordpress。针对这个问题,我们提供了对接系统。功能介绍如下:
必要条件我们提供的是一套对接系统源码,必须安装在opencart或wordpress网站所在服务器上。
以下是功能介绍:
1.对接系统与opencart或wordpress网站在同一台服务器上,如:opencart网站有3个; 2 wordpress网站在服务器端,我们将这些网站配置为采集System后台:
您可以在下方采集task:
选择你要采集去哪个opencart站点,系统会调出该站点的分类供选择:
选择保存到opencart的采集products的分类,输入你要采集shopify网站的分类链接,输入采集数量提交保存。
这里注意支持采集数据调价
采集,产品可以在相应的opencart或wordpress网站中展示
常用的5种动态网页技术,你知道几种?
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2021-07-27 03:07
常用的5种动态网页技术,你知道几种?
本教程运行环境:windows10系统,Dell G3电脑。
5 种常用的动态网络技术
1、CGI
CGI(通用网关接口)是早期用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行某个 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
CGI 的主要缺点是维护复杂,运行效率低。这主要是由以下方法造成的:
2、PHP
PHP(个人主页)是一种嵌入在 HTML 中的服务器端脚本语言,可以在多个平台上运行。它借鉴了C语言、Java语言和Perl语言的语法,同时拥有自己独特的语法。
由于PHP采用Open Source方式,其源代码是开放的,可以不断添加新的东西,形成庞大的函数库,实现更多的功能。 PHP 支持当今几乎所有的数据库。
PHP的缺点是不支持JSP、ASP等组件,扩展性差。
3、JSP
JSP(Java Server Pages)是一种基于 Java 的技术,用于创建可以支持跨平台和跨 Web 服务器的动态网页。 JSP 不同于服务器端脚本语言 JavaScript。 JSP在传统的静态页面中添加Java程序片段和JSP标签,形成JSP页面,然后由服务器编译执行。
JSP的主要优点如下:
JSP 的主要缺点是编写 JSP 程序比较复杂,开发人员往往需要对 Java 及相关技术有更好的了解。
4、ASP
ASP(Active Server Pages)是微软提供的一种开发动态网页的技术。具有开发简单、功能强大等优点。 ASP 使生成动态 Web 内容和构建强大的 Web 应用程序变得非常容易。例如,当你想在一个表单中采集数据时,你只需要在一个HTML文件中嵌入一些简单的指令,然后你就可以从表单中采集数据并进行分析。对于 ASP,您还可以轻松地使用 ActiveX 组件来执行复杂的任务,例如连接到数据库以检索和存储信息。
对于有经验的程序开发人员,如果您已经掌握了脚本语言,例如 VBScript、JavaScript 或 Perl,并且您已经知道如何使用 ASP。只要安装了符合ActiveX脚本标准的相应引擎,任何脚本语言都可以在ASP页面中使用。 ASP 本身有两个脚本引擎,VBScript 和 JavaScript。从软件技术的角度来看,ASP具有以下特点: 查看全部
常用的5种动态网页技术,你知道几种?
本教程运行环境:windows10系统,Dell G3电脑。
5 种常用的动态网络技术
1、CGI
CGI(通用网关接口)是早期用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行某个 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
CGI 的主要缺点是维护复杂,运行效率低。这主要是由以下方法造成的:
2、PHP
PHP(个人主页)是一种嵌入在 HTML 中的服务器端脚本语言,可以在多个平台上运行。它借鉴了C语言、Java语言和Perl语言的语法,同时拥有自己独特的语法。
由于PHP采用Open Source方式,其源代码是开放的,可以不断添加新的东西,形成庞大的函数库,实现更多的功能。 PHP 支持当今几乎所有的数据库。
PHP的缺点是不支持JSP、ASP等组件,扩展性差。
3、JSP
JSP(Java Server Pages)是一种基于 Java 的技术,用于创建可以支持跨平台和跨 Web 服务器的动态网页。 JSP 不同于服务器端脚本语言 JavaScript。 JSP在传统的静态页面中添加Java程序片段和JSP标签,形成JSP页面,然后由服务器编译执行。
JSP的主要优点如下:
JSP 的主要缺点是编写 JSP 程序比较复杂,开发人员往往需要对 Java 及相关技术有更好的了解。
4、ASP
ASP(Active Server Pages)是微软提供的一种开发动态网页的技术。具有开发简单、功能强大等优点。 ASP 使生成动态 Web 内容和构建强大的 Web 应用程序变得非常容易。例如,当你想在一个表单中采集数据时,你只需要在一个HTML文件中嵌入一些简单的指令,然后你就可以从表单中采集数据并进行分析。对于 ASP,您还可以轻松地使用 ActiveX 组件来执行复杂的任务,例如连接到数据库以检索和存储信息。
对于有经验的程序开发人员,如果您已经掌握了脚本语言,例如 VBScript、JavaScript 或 Perl,并且您已经知道如何使用 ASP。只要安装了符合ActiveX脚本标准的相应引擎,任何脚本语言都可以在ASP页面中使用。 ASP 本身有两个脚本引擎,VBScript 和 JavaScript。从软件技术的角度来看,ASP具有以下特点:
网站内容采集系统最大的特点就是去重,软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-07-26 18:22
网站内容采集系统:云采集系统,最大的特点就是去重,软件爬虫适合于中小网站,采集网站要支持反采集爬虫模式,采集网站还是需要做一个爬虫目录页面,爬虫采集时分辨率规格和源代码都很重要.云采集系统有一个优势就是web开发文档极其简洁易懂,我们可以根据用户的不同需求修改大小尺寸和发布效果。针对在网站上工作的网站编辑还可以给开发写网站项目。
云采集系统的优势还在于软件整合性能强劲,再也不用再为采集的问题写多篇文章来推广,提高网站收录量和收藏。.云采集系统可以采集的网站非常多,从综合的生活类网站到小说搜索类的网站,是一个巨大的跨界..。
针对dz,dz的搜索引擎很差,百度不收录,谷歌收录也少,关键在于他们的搜索引擎上的内容是提供给用户群,不经过用户选择,提供了内容就直接可以用了,所以就提高搜索引擎收录率了,即使要做下级的网站,有时也要通过多级域名链接,或者反向链接的形式来提高排名。
刚开始做站很多人建议做dz有时一时理解有问题就去做了dz就行了dz又多了pc网站网站这么一个就可以了我做站的时候不明白的是pc上的网站你做到哪个页面后面都没人知道后来觉得应该分页比较好虽然花点钱但可以及时的更新你需要知道自己要怎么宣传那一个页面毕竟页面是可以按页码添加需要的doc等那么多还有是不是一定要关键词有多少个用户搜了都不知道啊?搜索出来哪些排名靠前前多少给你推荐多少啊?百度的收录排名策略也很重要啊百度收不收录只要不放弃没人知道你是何方神圣那你就无所谓了啊当然你要花钱的其实做搜索引擎推广的时候有推广链接能收录就行,反正引流比收录出来更重要。 查看全部
网站内容采集系统最大的特点就是去重,软件
网站内容采集系统:云采集系统,最大的特点就是去重,软件爬虫适合于中小网站,采集网站要支持反采集爬虫模式,采集网站还是需要做一个爬虫目录页面,爬虫采集时分辨率规格和源代码都很重要.云采集系统有一个优势就是web开发文档极其简洁易懂,我们可以根据用户的不同需求修改大小尺寸和发布效果。针对在网站上工作的网站编辑还可以给开发写网站项目。
云采集系统的优势还在于软件整合性能强劲,再也不用再为采集的问题写多篇文章来推广,提高网站收录量和收藏。.云采集系统可以采集的网站非常多,从综合的生活类网站到小说搜索类的网站,是一个巨大的跨界..。
针对dz,dz的搜索引擎很差,百度不收录,谷歌收录也少,关键在于他们的搜索引擎上的内容是提供给用户群,不经过用户选择,提供了内容就直接可以用了,所以就提高搜索引擎收录率了,即使要做下级的网站,有时也要通过多级域名链接,或者反向链接的形式来提高排名。
刚开始做站很多人建议做dz有时一时理解有问题就去做了dz就行了dz又多了pc网站网站这么一个就可以了我做站的时候不明白的是pc上的网站你做到哪个页面后面都没人知道后来觉得应该分页比较好虽然花点钱但可以及时的更新你需要知道自己要怎么宣传那一个页面毕竟页面是可以按页码添加需要的doc等那么多还有是不是一定要关键词有多少个用户搜了都不知道啊?搜索出来哪些排名靠前前多少给你推荐多少啊?百度的收录排名策略也很重要啊百度收不收录只要不放弃没人知道你是何方神圣那你就无所谓了啊当然你要花钱的其实做搜索引擎推广的时候有推广链接能收录就行,反正引流比收录出来更重要。
网站内容采集系统可以用wordpress建站系统来制作吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-07-22 18:02
网站内容采集系统可以用wordpress建站系统来制作,可以分为插件和自建系统:1.内容采集插件(forwardplugin)现在很多小型网站都喜欢用采集型wordpress插件,把很多内容都抓取到自己的系统里面,通过快捷键就可以进行分发或者高亮,更方便的用户体验。通常会对上传的内容进行快速分发处理,可以是按帖子的方式,或者按内容段落方式。
对于发布的文章进行关键词分词,或者人工分词处理。2.自建系统:最常见的就是是jbljb进去,我们平时看到很多宣传,在把内容分发到外面或者几个外面的网站,这类的网站技术并不难,正常分析网站数据,知道哪些内容是低价(赠送)或者免费的,就把它们抓下来,然后再找用户体验或者适合自己企业定位的地方进行分发。如果对于某个地方不满意,也可以通过修改,或者是改成这个样子。
那么不同的分发的网站是不是有缺点呢?正因为每个分发的站点没有办法让网站产生互动,那么它们除了降低网站的收录,也没有什么提高排名。有朋友可能会说,那我可以用分发器或者分发插件做不行吗?理论上是可以的,但是这类网站的技术门槛会比较高,相对于简单生成的无营销系统,甚至存在负载太高的问题。下面用最简单的如wordpress做了个简单的网站。
我们只要在wordpress安装一个插件,就可以自动发布内容。把我们的域名做成为什么要强调要安装一个分发器呢?因为大部分人使用wordpress建站,只是喜欢分享,不想让别人知道我的网站存在。如果你想让更多的人知道你的网站存在,就需要做内容分发,那么一定要安装分发器。不安装分发器,我们是无法发布网站内容的。
为什么要安装分发器呢?大家都知道现在的网站发布,是通过网站后台或者手动编辑操作,效率是比较低的。我们已经用插件,手动编辑网站内容,能让网站产生互动或者更多原创内容,对于我们的提高排名是有很大的帮助。如果我们做了那么多的发布工作,而这个网站没有产生任何互动,那就失去意义了。我也相信这篇文章就是各位对于分发器内容采集的热情,我们会持续跟大家分享更多分发器内容采集的优点和缺点,以及如何正确使用分发器,让我们的站点产生一定量的互动和权重的。 查看全部
网站内容采集系统可以用wordpress建站系统来制作吗?
网站内容采集系统可以用wordpress建站系统来制作,可以分为插件和自建系统:1.内容采集插件(forwardplugin)现在很多小型网站都喜欢用采集型wordpress插件,把很多内容都抓取到自己的系统里面,通过快捷键就可以进行分发或者高亮,更方便的用户体验。通常会对上传的内容进行快速分发处理,可以是按帖子的方式,或者按内容段落方式。
对于发布的文章进行关键词分词,或者人工分词处理。2.自建系统:最常见的就是是jbljb进去,我们平时看到很多宣传,在把内容分发到外面或者几个外面的网站,这类的网站技术并不难,正常分析网站数据,知道哪些内容是低价(赠送)或者免费的,就把它们抓下来,然后再找用户体验或者适合自己企业定位的地方进行分发。如果对于某个地方不满意,也可以通过修改,或者是改成这个样子。
那么不同的分发的网站是不是有缺点呢?正因为每个分发的站点没有办法让网站产生互动,那么它们除了降低网站的收录,也没有什么提高排名。有朋友可能会说,那我可以用分发器或者分发插件做不行吗?理论上是可以的,但是这类网站的技术门槛会比较高,相对于简单生成的无营销系统,甚至存在负载太高的问题。下面用最简单的如wordpress做了个简单的网站。
我们只要在wordpress安装一个插件,就可以自动发布内容。把我们的域名做成为什么要强调要安装一个分发器呢?因为大部分人使用wordpress建站,只是喜欢分享,不想让别人知道我的网站存在。如果你想让更多的人知道你的网站存在,就需要做内容分发,那么一定要安装分发器。不安装分发器,我们是无法发布网站内容的。
为什么要安装分发器呢?大家都知道现在的网站发布,是通过网站后台或者手动编辑操作,效率是比较低的。我们已经用插件,手动编辑网站内容,能让网站产生互动或者更多原创内容,对于我们的提高排名是有很大的帮助。如果我们做了那么多的发布工作,而这个网站没有产生任何互动,那就失去意义了。我也相信这篇文章就是各位对于分发器内容采集的热情,我们会持续跟大家分享更多分发器内容采集的优点和缺点,以及如何正确使用分发器,让我们的站点产生一定量的互动和权重的。
网络信息采集软件的定位方式的优势在于什么??
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-07-22 05:20
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据自己定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能:
1.图形化的采集task定义界面,你只需要在软件内嵌的浏览器中用鼠标选择你想要采集的网页内容就可以配置采集task,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同并不等于100%,但我们克服了技术难关,消除了这些障碍。
我们的定位方法的优点是:
1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集任务配置界面;
2.网页内容的变化(如文字增减、改动、文字颜色、字体变化等)不会影响采集的准确性。
3.支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利得益于我们全新的内容定位方法和图形化的采集任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件,你还可以采集针对特定HTML标签的源代码和属性值。
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到在一个大纲文件中,然后将每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出 查看全部
网络信息采集软件的定位方式的优势在于什么??
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据自己定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能:
1.图形化的采集task定义界面,你只需要在软件内嵌的浏览器中用鼠标选择你想要采集的网页内容就可以配置采集task,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同并不等于100%,但我们克服了技术难关,消除了这些障碍。
我们的定位方法的优点是:
1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集任务配置界面;
2.网页内容的变化(如文字增减、改动、文字颜色、字体变化等)不会影响采集的准确性。
3.支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利得益于我们全新的内容定位方法和图形化的采集任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件,你还可以采集针对特定HTML标签的源代码和属性值。
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到在一个大纲文件中,然后将每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出
万众瞩目的站群版发布啦!比之前的版本强大数倍!
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-07-18 19:54
功能详情:
万众期待的站群版发布!比之前的版本强大数倍!
在收录UZcmsMirror采集系统普通版的所有功能后,新增以下功能:
1.随机标题关键词(一个网站绑定无数域名,每个域名对关键词的访问方式不同,但与网站核心词相呼应)
2.randomkeyword关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
3.random文章关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
4.random 介绍关键词(一个网站绑定无数域名,每个域名访问关键词不同,但与网站核心词呼应)
5.随机句子(原创随机句子的性,你懂的)
6.蜘蛛屏蔽管理
7.一个云平台,远程控制所有网站
8.不限制建立站点数量,不限制目标站点数量,不限制服务器,IP,! ! !
9.remote cleanup网站cache 数据。手动一一删除网站?不!
10.搜索引擎让路,妈妈再也不用担心我的流量了!
11.支持子目录,二级目录列表采集! (比如百度贴吧,任意一个关键词贴吧)
12. 远程自动调用CSS/JS/SWF等文件,省去手动下载替换的麻烦!
13.代理IP采集不用我说,你懂的!
14.Random Mirror Target Station 一套程序可以绑定上万个域名!实现N个不同站点的全自动随机镜像! ! !
真正的SEO来看,站位不一样!
公司简介:
UZ Studio成立于2008年初,至今已有5年的开发经验,从最初的2人发展到现在的7人规模,在其成立之初就开始研究ASP采集程序成立, 2010 2005年开始走向PHP镜像采集程序,发布了当时流行的电影镜像采集程序,深受草根站长关注。在接下来的时间里,免费版和开源版接踵而至。为了提供更好的服务,我们还制作了多种付费版本,以稳定的服务为用户创造更大的价值。现在我们已经告别繁琐的手工镜像站时代,2013年初开始做UZ@k4。@Mirror采集系统,经过3个月的开发完善,目前版本已经相当稳定,已经近百位忠实用户,互联网也告别了手动构建和更新数据的痛苦时代,迎来全新的UZcmsMirror采集系统带给我们更安全便捷的建站时代 查看全部
万众瞩目的站群版发布啦!比之前的版本强大数倍!
功能详情:
万众期待的站群版发布!比之前的版本强大数倍!
在收录UZcmsMirror采集系统普通版的所有功能后,新增以下功能:
1.随机标题关键词(一个网站绑定无数域名,每个域名对关键词的访问方式不同,但与网站核心词相呼应)
2.randomkeyword关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
3.random文章关键词(一个网站绑定了无数个域名,每个域名访问关键词都不一样,但与网站核心词相呼应)
4.random 介绍关键词(一个网站绑定无数域名,每个域名访问关键词不同,但与网站核心词呼应)
5.随机句子(原创随机句子的性,你懂的)
6.蜘蛛屏蔽管理
7.一个云平台,远程控制所有网站
8.不限制建立站点数量,不限制目标站点数量,不限制服务器,IP,! ! !
9.remote cleanup网站cache 数据。手动一一删除网站?不!
10.搜索引擎让路,妈妈再也不用担心我的流量了!
11.支持子目录,二级目录列表采集! (比如百度贴吧,任意一个关键词贴吧)
12. 远程自动调用CSS/JS/SWF等文件,省去手动下载替换的麻烦!
13.代理IP采集不用我说,你懂的!
14.Random Mirror Target Station 一套程序可以绑定上万个域名!实现N个不同站点的全自动随机镜像! ! !
真正的SEO来看,站位不一样!
公司简介:
UZ Studio成立于2008年初,至今已有5年的开发经验,从最初的2人发展到现在的7人规模,在其成立之初就开始研究ASP采集程序成立, 2010 2005年开始走向PHP镜像采集程序,发布了当时流行的电影镜像采集程序,深受草根站长关注。在接下来的时间里,免费版和开源版接踵而至。为了提供更好的服务,我们还制作了多种付费版本,以稳定的服务为用户创造更大的价值。现在我们已经告别繁琐的手工镜像站时代,2013年初开始做UZ@k4。@Mirror采集系统,经过3个月的开发完善,目前版本已经相当稳定,已经近百位忠实用户,互联网也告别了手动构建和更新数据的痛苦时代,迎来全新的UZcmsMirror采集系统带给我们更安全便捷的建站时代
如何支持实时上传到网站服务器支持POST和GET方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-07-10 07:00
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。
Yicai网站数据采集系统,你可以轻松抓取你想要的网页内容(包括文字、图片、文件、HTML源代码等),来自采集的数据可以直接导出到EXCEL ,也可以根据自己定义的模板保存为任意格式的文件(如网页文件、txt文件等)。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能
用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面;
网页内容的变化(如文字增删改查、文字颜色、字体变化等)不会影响采集的准确性。
支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集下级页面的内容,并且嵌套层数是无限的。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
您可以同时采集任何内容。除了最基本的文字、图片、文件,你还可以采集target 特定HTML标签的源代码和属性值。强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
采集到达的内容可以自动排序
支持采集结果保存到EXCEL和任何格式文件。支持自定义文件模板。
支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
支持实时上传到网站服务器。支持 POST 和 GET 方法。上传参数可自定义,模拟手动提交。
支持实时保存到任何格式的文件。支持自定义模板,按记录保存和将多条记录保存到单个文件,支持大纲和细节保存(所有记录的部分内容保存在一个大纲文件中,然后每条记录分别保存到一个文件中。
支持多种灵活的任务调度方式,实现无人值守采集
支持多任务,支持任务导入导出 查看全部
如何支持实时上传到网站服务器支持POST和GET方式
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。
Yicai网站数据采集系统,你可以轻松抓取你想要的网页内容(包括文字、图片、文件、HTML源代码等),来自采集的数据可以直接导出到EXCEL ,也可以根据自己定义的模板保存为任意格式的文件(如网页文件、txt文件等)。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
软件功能
用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面;
网页内容的变化(如文字增删改查、文字颜色、字体变化等)不会影响采集的准确性。
支持任务嵌套,采集unlimited-level页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集下级页面的内容,并且嵌套层数是无限的。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
您可以同时采集任何内容。除了最基本的文字、图片、文件,你还可以采集target 特定HTML标签的源代码和属性值。强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
采集到达的内容可以自动排序
支持采集结果保存到EXCEL和任何格式文件。支持自定义文件模板。
支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本也会支持更多类型的数据库)。
支持实时上传到网站服务器。支持 POST 和 GET 方法。上传参数可自定义,模拟手动提交。
支持实时保存到任何格式的文件。支持自定义模板,按记录保存和将多条记录保存到单个文件,支持大纲和细节保存(所有记录的部分内容保存在一个大纲文件中,然后每条记录分别保存到一个文件中。
支持多种灵活的任务调度方式,实现无人值守采集
支持多任务,支持任务导入导出
易得网站数据采集系统通用版,通过编写或者下载规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2021-07-10 06:38
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理和学习交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
查看全部
易得网站数据采集系统通用版,通过编写或者下载规则
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理和学习交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
网站内容中使用字符串的方法有几种固有缺陷
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-07-10 04:19
专利名称:网站内容防采集系统及方法
技术领域:
本发明涉及互联网网站内容的采集复制技术。更具体地说,本发明涉及一种网站内容预防采集方法。
背景技术:
本文中的“采集”是指程序按照规定的规则获取其他网站数据的一种方式。网络采集器是一个用于对网页、论坛等采集进行批量处理的工具,将采集的内容直接存入数据库或发布到网站。它从目标网页中提取一些数据形成一个统一的本地数据库。比如网上新成立的网站,往往需要大量的数据来丰富其网站的内容。在这种情况下,部分网站管理者可能会利用网络采集器快速大量复制其他网站内容,并利用采集快速丰富自己的网站。但是对于采集网站,尤其是网站,主要内容是原创,这种操作会被采集网站占用大量网络资源,降低网络速度。和运行效率;另一方面,也侵犯了采集网站的知识产权,损害了采集网站的利益。为了限制网站内容被他人采集,反采集技术应运而生。目前常见的反采集技术是在网站每个网页的内容中使用混淆字符串。这种技术是通过在网页内容中随机添加一些字符串来实现的。这些字符串在普通用户浏览网页等正常情况下是不可见的。但是当网页内容为采集后,采集到达的网页上就会显示混淆后的字符串。这样采集收到的内容就混入了混淆字符串,不符合采集的要求,从而达到防止采集的目的。但是,这种使用混淆字符串来防止网站每页内容中出现采集的方法有几个固有的缺陷。首先,添加到网页内容中的随机字符串虽然对普通访问者不可见,但对网页内容进行索引的搜索引擎机器人是可见的。这导致在搜索引擎的搜索结果中显示 Web 内容时可能会添加随机字符串。同时,某个网站的内容中混杂了无意的随机字符串,可能导致网站在搜索引擎的搜索结果中排名靠后,不利于网站的推广以及客流量的增加。其次,如果采集zhe不关心他的网站的网页内容质量,添加到网页内容中的随机字符串起不到防止采集的作用,也不能从根本上解决问题那个网页内容是采集的问题。现有的采集防范技术通过添加混淆字符串的方式修改网页内容,破坏了网站对搜索引擎的友好性。同时也是一种被动的反采集措施。虽然添加了随机字符串,但采集器对采集的内容质量要求不高的情况下,仍然可以任意的采集。因此,需要一种在不修改网页内容的情况下防止网页内容被采集的方法。
发明内容
本发明通过识别网站访问者是普通用户还是采集器来防止网站的网页内容为采集。本发明提供了一种网站内容防采集系统,包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;
查询单元用于查询用户在预定时间段内对网站页面的访问;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设置的固定值进行比较,该单元被禁止。当用户在预定时间内访问网站页面的次数大于设定值时,禁止用户访问网站。优选地,网站内容防采集系统还包括存储单元,用于存储IP地址白名单和IP地址黑名单。判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。优选地,IP地址白名单包括搜索引擎的IP地址。本发明提供了一种网站内容防采集的方法,包括获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问次数;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。优选地,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站;如果获取的用户IP地址属于该IP地址的黑名单,将禁止该用户访问网站。优选地,该方法还包括将搜索引擎的IP地址放入IP地址白名单列表中。优选地,将被禁用户的IP地址放入IP地址黑名单。优选地,预定时间段为1-600秒,设定值的值为预定时间段内的秒数的1-50倍。由于采集是通过快速复制其他网站网页的内容来获取其他网站数据的方法,当采集器执行采集时,会快速密集地访问网站页面,访问频率最高可达每分钟 120 页或更多。相反,普通用户浏览网站时,一般情况下不会达到这么高的访问频率。通过这个差异,可以识别采集器的访问,从而限制采集器继续获取网站内容。本发明的网站内容预防采集方法通过添加混淆字符串的方式,利用与实现采集预防不同的原理,解决了现有采集预防技术的缺陷。本发明的网站内容防采集方法不对网站内容做任何修改,不影响搜索引擎的索引。同时,由于这种方法可以区分网站访问者是普通用户还是采集器,通过限制采集器对网站的访问,从根本上解决网站内容被大量采集的问题解决了。
下面将参考附图并结合实施例对本发明进行详细说明,其中图1示出了根据本发明优选实施例的系统框图;图2示出了根据本发明优选实施例的方法的流程图。图3示出了根据本发明另一优选实施例的方法的流程图。
具体实施例图1示出了根据本发明优选实施例的网站内容防采集系统100的结构框图。系统包括获取单元,用于获取用户的ID、IP地址、User-Agent和当前时间;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元,用于将记录的用户在预定时间内对网站页面的访问与设定值进行比较;当用户在预定时间段内对网站页面的访问大于设定值时,使用禁止单元,此时用户对网站的访问被禁止。 网站内容防采集 系统的获取单元可以在每次收到访问请求时记录访问者的ID、IP地址、用户代理(ser-Agent)和访问时间。当访问者通过hternet Explorer等浏览器程序或采集器program访问网站时,访问者的浏览器程序或采集器program通常会向网站发送一个字符串来描述其身份。段字符串称为 her-Agent。用户使用的不同软件通常会发送不同的her-Agent。通过结合访问者的IP地址和her-Agent,网站可以识别和区分每个访问者。查询单元查询当前访问者在单位时间段内访问的网站页面数,即访问次数。比较单元将查询单元查询到的用户访问量与设置的访问量进行比较。如果单位时间段内的页面访问量超过设置的访问量,则可以确定访问者的访问为异常访问。
禁止单元可以禁止访问者对网站的异常访问。单位时间段的页面浏览量和单位时间段的设置值是两个变量,可以在网站program配置中单独修改。例如,单位时间段可以设置在10-600秒之间。单位时间段设置太短可能会导致普通用户的访问被误判为异常访问,而单位时间段设置太长可能导致采集器已采集大数据后网站才检测到当前访问是采集器的访问。由于采集器在执行采集时通常有每秒1到50页的频率,所以单位时间段内的页面浏览次数可以设置为所选单位时间段的1-秒。 50次。例如,单位时间段可以设置为60秒,单位时间段内的浏览量设置值为600页。由于采集器的采集速度受网络速度、网站响应速度等多种因素影响,具体的单位时间段和单位时间段内的页面浏览量应允许网站管理员设置根据实际情况。另外,本发明的网站内容防采集系统还可以包括:存储IP地址白名单和IP地址黑名单的存储单元,以及判断用户地址是否属于IP A的判断单元白色地址或黑色 IP 地址。如果是白色IP地址,则允许用户访问网站;如果属于IP黑地址,则禁止用户访问网站。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP地址白名单功能,将常用搜索引擎的IP地址或IP地址段加入IP地址白名单。
来自这些IP地址的访问将绕过访问频率的判断,不受访问量设置值的限制。此外,本发明的网站内容防采集系统可以提供IP地址黑名单功能,将常见的采集器IP地址加入IP地址黑名单。从这些IP地址访问将绕过访问频率的判断,直接被禁止。图2示出了根据优选实施例的方法的流程图。本实施例的网站内容防采集方法包括以下步骤获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问量;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。图3示出了根据本发明另一优选实施例的方法的流程图。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP 地址白名单功能将常用搜索引擎的IP 地址或IP 地址段加入IP 地址白名单。来自这些IP地址的访问会绕过访问频率的判断,不受访问设置值的限制。图3所示方法与图2所示方法步骤的区别在于,在获取用户IP地址的步骤之后,首先判断用户的IP地址是否属于IP地址白名单。 k14@的来访。
如果不属于,则判断用户的IP地址是否属于IP地址黑名单。如果属于,则禁止用户访问网站。如果没有,则如图2所示,继续查询用户对网站页面的访问次数。下面以PHP+MySQL开发环境为例来说明实现方法。对于其他语言如数据库,可以通过下面的SQL语句@NOT NULL DEFAULT"创建数据表CREATE TABLE "visitlist"(~icfINT(10)NOT NULL AUTO_INCREMENT PRIMARY KEY,VARCHAR(4@k21), "useragent" VARCHAR(255)NOT NULL DEFAULT", ~time~INT(10)NOT NULL DEFAULT' 0') ENGINE = MYISAM; 数据表中有4个字段:id, ip, useragent, and time分别代表记录ID、用户IP、用户User-Agent、访问时间,主程序代码说明获取用户IP、User-Agent信息,程序首先需要获取用户IP、her-Agent、当前时间信息,代码如下: $ip = $_SERVER['REM0TE_ADDR']; $useragent = $_SERVER[' HTTP_USER_AGENT']; $time = time(); //time()函数返回当前UNIX时间戳在几秒钟内,然后将上述数据存储到数据库中。
代码如下 mysql_query(" INSERT INTO visitlist(, ip,,, useragent and time,) values(' $ip', '$useragent',' $time')〃 ); 查询当前用户在单位时间段访问的页面数假设单位时间段为常数define ('DURATION', 60); $time_start = time()-DURATION ;//从当前时间段中减去设置的时间段,这是计数开始时间 $query = mysql_query ("SELECT COUNT (*) AS visit_count FROM visitlistffHERE"time"> $time_start AND—ip— = '{$this-> base-> ip}' AND, useragent, =' {$useragent}"'); $row = mysql_fetch_array($query); $visit_count = isset($row[ 'visit_count' ])? $row[ 'vist_count']: 0; 确定单位时间内访问的页面period 是否大于设定值,处理最终结果
假设单位时间段内访问的页面数是网站administrator定义的常量,define('MAX_PAGES', 300); if($visit_count> MAX_PAGES){exit('访问频率太高,禁止访问');//还可以将访问者的IP地址加入网站IP黑名单,可以更有效的禁止用户访问。} 上面应该理解为基于本发明的优选实施例,已经对技术方案进行了详细描述,应当理解,以上描述是示例性的而非限制性的,本领域普通技术人员可以对每一个描述的技术方案进行修改在阅读本发明说明书的基础上对实施例中的部分技术特征进行等效替换,这些修改或替换不导致相应技术方案的实质背离本发明的精神和范围本发明实施例的技术方案的pe。本发明的保护范围仅以所附权利要求为准。
声明
1.A 网站内容防采集系统,其特征在于,该系统包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设定值进行比较,该单元被禁止,当用户在预定时间段内对网站页面的访问为大于设定值,禁止用户访问网站。
根据权利要求1所述的2.网站内容防采集系统,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50倍。
如权利要求1所述的3.网站内容防采集系统,其特征在于,该系统还包括用于存储IP地址白名单和IP地址黑名单的存储单元;判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。
4.如权利要求3所述的网站内容防采集系统,其特征在于,IP地址白名单包括搜索引擎的IP地址。
5.A 网站内容防采集方法,其特征在于,该方法包括获取用户ID、IP地址、User-Agent和当前时间; k14@页面统计并获取预定时间段内的用户访问量;将访问与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。
如权利要求5所述的6.网站内容防采集方法,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50秒预定时间段次。
如权利要求5所述的7.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站。
如权利要求5所述的8.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址黑名单,则用户访问禁止网站。
9.根据权利要求5所述的网站内容防采集方法,其特征在于,该方法还包括将搜索引擎的IP地址放入IP地址白名单。
10.根据权利要求5所述的网站内容防采集方法,其特征在于,将被禁用户的IP地址放入IP地址黑名单。
全文摘要
本发明提供了一种网站内容预防采集系统和方法。本发明的网站内容防采集系统包括获取单元,用于获取用户ID、IP地址、User-Agent和当前时间;比较单元用于将用户在预定时间段内访问网站页面的次数与设定值进行比较,该单元被禁止。当用户在预定时间段内,网站页面的访问量大于设定值时,禁止用户访问网站。本发明的方法可以在不修改网页内容的情况下防止网页内容被采集。
文件编号 G06F17/30GK102088477SQ2
出版日期:2011 年 6 月 8 日申请日期:2010 年 11 月 25 日优先权日期:2010 年 11 月 25 日
发明人孟凡斌、梅纯、潘海东申请人: 查看全部
网站内容中使用字符串的方法有几种固有缺陷
专利名称:网站内容防采集系统及方法
技术领域:
本发明涉及互联网网站内容的采集复制技术。更具体地说,本发明涉及一种网站内容预防采集方法。
背景技术:
本文中的“采集”是指程序按照规定的规则获取其他网站数据的一种方式。网络采集器是一个用于对网页、论坛等采集进行批量处理的工具,将采集的内容直接存入数据库或发布到网站。它从目标网页中提取一些数据形成一个统一的本地数据库。比如网上新成立的网站,往往需要大量的数据来丰富其网站的内容。在这种情况下,部分网站管理者可能会利用网络采集器快速大量复制其他网站内容,并利用采集快速丰富自己的网站。但是对于采集网站,尤其是网站,主要内容是原创,这种操作会被采集网站占用大量网络资源,降低网络速度。和运行效率;另一方面,也侵犯了采集网站的知识产权,损害了采集网站的利益。为了限制网站内容被他人采集,反采集技术应运而生。目前常见的反采集技术是在网站每个网页的内容中使用混淆字符串。这种技术是通过在网页内容中随机添加一些字符串来实现的。这些字符串在普通用户浏览网页等正常情况下是不可见的。但是当网页内容为采集后,采集到达的网页上就会显示混淆后的字符串。这样采集收到的内容就混入了混淆字符串,不符合采集的要求,从而达到防止采集的目的。但是,这种使用混淆字符串来防止网站每页内容中出现采集的方法有几个固有的缺陷。首先,添加到网页内容中的随机字符串虽然对普通访问者不可见,但对网页内容进行索引的搜索引擎机器人是可见的。这导致在搜索引擎的搜索结果中显示 Web 内容时可能会添加随机字符串。同时,某个网站的内容中混杂了无意的随机字符串,可能导致网站在搜索引擎的搜索结果中排名靠后,不利于网站的推广以及客流量的增加。其次,如果采集zhe不关心他的网站的网页内容质量,添加到网页内容中的随机字符串起不到防止采集的作用,也不能从根本上解决问题那个网页内容是采集的问题。现有的采集防范技术通过添加混淆字符串的方式修改网页内容,破坏了网站对搜索引擎的友好性。同时也是一种被动的反采集措施。虽然添加了随机字符串,但采集器对采集的内容质量要求不高的情况下,仍然可以任意的采集。因此,需要一种在不修改网页内容的情况下防止网页内容被采集的方法。
发明内容
本发明通过识别网站访问者是普通用户还是采集器来防止网站的网页内容为采集。本发明提供了一种网站内容防采集系统,包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;
查询单元用于查询用户在预定时间段内对网站页面的访问;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设置的固定值进行比较,该单元被禁止。当用户在预定时间内访问网站页面的次数大于设定值时,禁止用户访问网站。优选地,网站内容防采集系统还包括存储单元,用于存储IP地址白名单和IP地址黑名单。判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。优选地,IP地址白名单包括搜索引擎的IP地址。本发明提供了一种网站内容防采集的方法,包括获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问次数;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。优选地,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站;如果获取的用户IP地址属于该IP地址的黑名单,将禁止该用户访问网站。优选地,该方法还包括将搜索引擎的IP地址放入IP地址白名单列表中。优选地,将被禁用户的IP地址放入IP地址黑名单。优选地,预定时间段为1-600秒,设定值的值为预定时间段内的秒数的1-50倍。由于采集是通过快速复制其他网站网页的内容来获取其他网站数据的方法,当采集器执行采集时,会快速密集地访问网站页面,访问频率最高可达每分钟 120 页或更多。相反,普通用户浏览网站时,一般情况下不会达到这么高的访问频率。通过这个差异,可以识别采集器的访问,从而限制采集器继续获取网站内容。本发明的网站内容预防采集方法通过添加混淆字符串的方式,利用与实现采集预防不同的原理,解决了现有采集预防技术的缺陷。本发明的网站内容防采集方法不对网站内容做任何修改,不影响搜索引擎的索引。同时,由于这种方法可以区分网站访问者是普通用户还是采集器,通过限制采集器对网站的访问,从根本上解决网站内容被大量采集的问题解决了。
下面将参考附图并结合实施例对本发明进行详细说明,其中图1示出了根据本发明优选实施例的系统框图;图2示出了根据本发明优选实施例的方法的流程图。图3示出了根据本发明另一优选实施例的方法的流程图。
具体实施例图1示出了根据本发明优选实施例的网站内容防采集系统100的结构框图。系统包括获取单元,用于获取用户的ID、IP地址、User-Agent和当前时间;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元,用于将记录的用户在预定时间内对网站页面的访问与设定值进行比较;当用户在预定时间段内对网站页面的访问大于设定值时,使用禁止单元,此时用户对网站的访问被禁止。 网站内容防采集 系统的获取单元可以在每次收到访问请求时记录访问者的ID、IP地址、用户代理(ser-Agent)和访问时间。当访问者通过hternet Explorer等浏览器程序或采集器program访问网站时,访问者的浏览器程序或采集器program通常会向网站发送一个字符串来描述其身份。段字符串称为 her-Agent。用户使用的不同软件通常会发送不同的her-Agent。通过结合访问者的IP地址和her-Agent,网站可以识别和区分每个访问者。查询单元查询当前访问者在单位时间段内访问的网站页面数,即访问次数。比较单元将查询单元查询到的用户访问量与设置的访问量进行比较。如果单位时间段内的页面访问量超过设置的访问量,则可以确定访问者的访问为异常访问。
禁止单元可以禁止访问者对网站的异常访问。单位时间段的页面浏览量和单位时间段的设置值是两个变量,可以在网站program配置中单独修改。例如,单位时间段可以设置在10-600秒之间。单位时间段设置太短可能会导致普通用户的访问被误判为异常访问,而单位时间段设置太长可能导致采集器已采集大数据后网站才检测到当前访问是采集器的访问。由于采集器在执行采集时通常有每秒1到50页的频率,所以单位时间段内的页面浏览次数可以设置为所选单位时间段的1-秒。 50次。例如,单位时间段可以设置为60秒,单位时间段内的浏览量设置值为600页。由于采集器的采集速度受网络速度、网站响应速度等多种因素影响,具体的单位时间段和单位时间段内的页面浏览量应允许网站管理员设置根据实际情况。另外,本发明的网站内容防采集系统还可以包括:存储IP地址白名单和IP地址黑名单的存储单元,以及判断用户地址是否属于IP A的判断单元白色地址或黑色 IP 地址。如果是白色IP地址,则允许用户访问网站;如果属于IP黑地址,则禁止用户访问网站。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP地址白名单功能,将常用搜索引擎的IP地址或IP地址段加入IP地址白名单。
来自这些IP地址的访问将绕过访问频率的判断,不受访问量设置值的限制。此外,本发明的网站内容防采集系统可以提供IP地址黑名单功能,将常见的采集器IP地址加入IP地址黑名单。从这些IP地址访问将绕过访问频率的判断,直接被禁止。图2示出了根据优选实施例的方法的流程图。本实施例的网站内容防采集方法包括以下步骤获取用户ID、IP地址、User-Agent和当前时间;统计用户在预定时间段内访问的网站页面,得到用户在预定时间段内的访问量;将访问次数与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。图3示出了根据本发明另一优选实施例的方法的流程图。由于搜索引擎在索引网站数据时也可能有更高的访问频率,为了防止搜索引擎的索引操作被误判为采集,本发明的网站内容防采集系统可以提供IP 地址白名单功能将常用搜索引擎的IP 地址或IP 地址段加入IP 地址白名单。来自这些IP地址的访问会绕过访问频率的判断,不受访问设置值的限制。图3所示方法与图2所示方法步骤的区别在于,在获取用户IP地址的步骤之后,首先判断用户的IP地址是否属于IP地址白名单。 k14@的来访。
如果不属于,则判断用户的IP地址是否属于IP地址黑名单。如果属于,则禁止用户访问网站。如果没有,则如图2所示,继续查询用户对网站页面的访问次数。下面以PHP+MySQL开发环境为例来说明实现方法。对于其他语言如数据库,可以通过下面的SQL语句@NOT NULL DEFAULT"创建数据表CREATE TABLE "visitlist"(~icfINT(10)NOT NULL AUTO_INCREMENT PRIMARY KEY,VARCHAR(4@k21), "useragent" VARCHAR(255)NOT NULL DEFAULT", ~time~INT(10)NOT NULL DEFAULT' 0') ENGINE = MYISAM; 数据表中有4个字段:id, ip, useragent, and time分别代表记录ID、用户IP、用户User-Agent、访问时间,主程序代码说明获取用户IP、User-Agent信息,程序首先需要获取用户IP、her-Agent、当前时间信息,代码如下: $ip = $_SERVER['REM0TE_ADDR']; $useragent = $_SERVER[' HTTP_USER_AGENT']; $time = time(); //time()函数返回当前UNIX时间戳在几秒钟内,然后将上述数据存储到数据库中。
代码如下 mysql_query(" INSERT INTO visitlist(, ip,,, useragent and time,) values(' $ip', '$useragent',' $time')〃 ); 查询当前用户在单位时间段访问的页面数假设单位时间段为常数define ('DURATION', 60); $time_start = time()-DURATION ;//从当前时间段中减去设置的时间段,这是计数开始时间 $query = mysql_query ("SELECT COUNT (*) AS visit_count FROM visitlistffHERE"time"> $time_start AND—ip— = '{$this-> base-> ip}' AND, useragent, =' {$useragent}"'); $row = mysql_fetch_array($query); $visit_count = isset($row[ 'visit_count' ])? $row[ 'vist_count']: 0; 确定单位时间内访问的页面period 是否大于设定值,处理最终结果
假设单位时间段内访问的页面数是网站administrator定义的常量,define('MAX_PAGES', 300); if($visit_count> MAX_PAGES){exit('访问频率太高,禁止访问');//还可以将访问者的IP地址加入网站IP黑名单,可以更有效的禁止用户访问。} 上面应该理解为基于本发明的优选实施例,已经对技术方案进行了详细描述,应当理解,以上描述是示例性的而非限制性的,本领域普通技术人员可以对每一个描述的技术方案进行修改在阅读本发明说明书的基础上对实施例中的部分技术特征进行等效替换,这些修改或替换不导致相应技术方案的实质背离本发明的精神和范围本发明实施例的技术方案的pe。本发明的保护范围仅以所附权利要求为准。
声明
1.A 网站内容防采集系统,其特征在于,该系统包括获取用户ID、IP地址、User-Agent和当前时间的获取单元;查询单元,用于查询用户在预定时间段内对网站页面的访问情况;比较单元用于将记录的用户在预定时间段内对网站页面的访问与设定值进行比较,该单元被禁止,当用户在预定时间段内对网站页面的访问为大于设定值,禁止用户访问网站。
根据权利要求1所述的2.网站内容防采集系统,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50倍。
如权利要求1所述的3.网站内容防采集系统,其特征在于,该系统还包括用于存储IP地址白名单和IP地址黑名单的存储单元;判断单元,如果获取的用户IP地址属于IP地址白名单,则允许该用户访问网站;如果获取的用户IP地址属于IP地址黑名单,则禁止该用户访问网站。
4.如权利要求3所述的网站内容防采集系统,其特征在于,IP地址白名单包括搜索引擎的IP地址。
5.A 网站内容防采集方法,其特征在于,该方法包括获取用户ID、IP地址、User-Agent和当前时间; k14@页面统计并获取预定时间段内的用户访问量;将访问与设定值进行比较;如果访问次数大于设置值,则禁止用户访问网站。
如权利要求5所述的6.网站内容防采集方法,其特征在于,所述预定时间段为1-600秒,设置值的值为1-50秒预定时间段次。
如权利要求5所述的7.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址白名单,则允许用户访问网站。
如权利要求5所述的8.网站内容防采集方法,其特征在于,在获取用户IP地址的步骤之后,如果获取的用户IP地址属于IP地址黑名单,则用户访问禁止网站。
9.根据权利要求5所述的网站内容防采集方法,其特征在于,该方法还包括将搜索引擎的IP地址放入IP地址白名单。
10.根据权利要求5所述的网站内容防采集方法,其特征在于,将被禁用户的IP地址放入IP地址黑名单。
全文摘要
本发明提供了一种网站内容预防采集系统和方法。本发明的网站内容防采集系统包括获取单元,用于获取用户ID、IP地址、User-Agent和当前时间;比较单元用于将用户在预定时间段内访问网站页面的次数与设定值进行比较,该单元被禁止。当用户在预定时间段内,网站页面的访问量大于设定值时,禁止用户访问网站。本发明的方法可以在不修改网页内容的情况下防止网页内容被采集。
文件编号 G06F17/30GK102088477SQ2
出版日期:2011 年 6 月 8 日申请日期:2010 年 11 月 25 日优先权日期:2010 年 11 月 25 日
发明人孟凡斌、梅纯、潘海东申请人:
经典网站内容采集系统——百度快照采集(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-07-08 00:01
网站内容采集系统是对传统互联网知识的一种延伸及拓展,如产品采购供应,b2b销售、c2c购物、b2c购物、内容运营、团购推广、门户网站宣传推广、留学申请、销售导航、百科信息问答、商品评价、网民评论、招聘求职、短视频平台制作、门户广告投放、网页新闻、爬虫抓取、网友留言、百科提问等,也是对网站传统网站内容的一种补充。经典网站内容采集系统——百度快照采集。
我们这里有专门做这个的,可以百度一下。
这不是一个可以与内容有对应产业的创业项目,而是一个网上创业项目。
手工采集的再好有什么用,都要靠大数据采集的手段好啊,建议可以去咨询一下亿信华辰,亿信华辰就是专门做大数据采集的,有专门的服务团队,我就在他们公司上班,叫亿信力,专业数据采集,
大部分的网站都是用php构建的,网站常用的工具类有:word,iis,asp等。google自带采集器肯定是没有采集工具,不过可以自己构建。现在最高端的是wordpress的外挂采集器可以实现非原始wordpress页面的数据采集,例如我现在写的travet-wordpress数据采集系统就是其中一种,可以采集前台所有页面的链接,但是无法采集到后台的页面链接,还是需要借助一些采集软件来采集,例如chrome插件和tor浏览器插件等,可以参考我的博客采集软件介绍采集软件推荐我之前写过一篇介绍常用采集器的文章你可以看看采集软件介绍-快速搭建wordpress网站?详细介绍了常用的三种采集器。
另外,内容采集技术层面的问题,也可以参考前几天我写的一篇博客-《海量网站全网站数据采集技术》,很不错,从数据采集的基础讲到asp,flash,php,jsp等内容网站常用的多重检索方式,数据采集也讲的很清楚。 查看全部
经典网站内容采集系统——百度快照采集(图)
网站内容采集系统是对传统互联网知识的一种延伸及拓展,如产品采购供应,b2b销售、c2c购物、b2c购物、内容运营、团购推广、门户网站宣传推广、留学申请、销售导航、百科信息问答、商品评价、网民评论、招聘求职、短视频平台制作、门户广告投放、网页新闻、爬虫抓取、网友留言、百科提问等,也是对网站传统网站内容的一种补充。经典网站内容采集系统——百度快照采集。
我们这里有专门做这个的,可以百度一下。
这不是一个可以与内容有对应产业的创业项目,而是一个网上创业项目。
手工采集的再好有什么用,都要靠大数据采集的手段好啊,建议可以去咨询一下亿信华辰,亿信华辰就是专门做大数据采集的,有专门的服务团队,我就在他们公司上班,叫亿信力,专业数据采集,
大部分的网站都是用php构建的,网站常用的工具类有:word,iis,asp等。google自带采集器肯定是没有采集工具,不过可以自己构建。现在最高端的是wordpress的外挂采集器可以实现非原始wordpress页面的数据采集,例如我现在写的travet-wordpress数据采集系统就是其中一种,可以采集前台所有页面的链接,但是无法采集到后台的页面链接,还是需要借助一些采集软件来采集,例如chrome插件和tor浏览器插件等,可以参考我的博客采集软件介绍采集软件推荐我之前写过一篇介绍常用采集器的文章你可以看看采集软件介绍-快速搭建wordpress网站?详细介绍了常用的三种采集器。
另外,内容采集技术层面的问题,也可以参考前几天我写的一篇博客-《海量网站全网站数据采集技术》,很不错,从数据采集的基础讲到asp,flash,php,jsp等内容网站常用的多重检索方式,数据采集也讲的很清楚。
通用版,编写或者下载规则,并保存图片文件。
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-06-27 00:02
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。 查看全部
通用版,编写或者下载规则,并保存图片文件。
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
泰得利通IRadar网页信息采集系统能通过灵活的规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-06-24 21:29
IRadar 网页信息采集系统概览
信息时代的发展带来了互联网上海量信息的形成。政府单位、各大企业、银行、教育机构都渴望快速高效地采集和提取与自身利益和需求相关的有用信息,web information采集系统正式成为这样一个高效的工具。可对定制化的目标数据源进行实时信息采集、提取、挖掘、处理,为各类信息服务系统提供数据输入。
潮德利通IRRadar网页信息采集系统可以使用灵活的规则来自任何类型的网站采集信息,例如news网站、论坛、博客、电子商务网站、招聘网站和等等,利用其通用性、灵活性、高效性、稳定性,为客户带来更大的利润。
红外网页信息采集系统功能
网络信息采集系统可实现网站login采集、网站cross-layer采集、POST采集script page采集、动态页面等高级采集功能采集等各种形式的信息采集,费力。网信采集系统支持存储过程、插件等,可二次开发扩展功能。
IRadar网站信息采集系统功能:
1、文件批量下载
批量下载PDF、RAR、图片等文件,同时下载采集相关资料
2、互联网数据挖掘
从指定的网站中抓取所需的数据,对其进行分析处理并保存到您的数据库中。
3、网络信息监控
自动抓取新闻、论坛等,然后分析处理
4、网站内容维护
定时采集新闻、文章等,并自动发布到指定的网站。
红外网络信息采集系统优势
红外网页信息采集系统优势:
1、Universal:可以自定义采集rules采集任何浏览器可以看到的信息;
2、Flexibility:支持多种高级采集功能;
3、扩展性强:支持存储过程、插件等,可用于二次开发扩展功能;
4、高效:精心设计的系统为您节省每一秒;
5、fast:最快最高效的采集系统;
6、Stability:系统稳定,没有漏洞;
7、人性化:注重细节,人性化体验。
图片:IRadar网页信息采集系统优势 查看全部
泰得利通IRadar网页信息采集系统能通过灵活的规则
IRadar 网页信息采集系统概览
信息时代的发展带来了互联网上海量信息的形成。政府单位、各大企业、银行、教育机构都渴望快速高效地采集和提取与自身利益和需求相关的有用信息,web information采集系统正式成为这样一个高效的工具。可对定制化的目标数据源进行实时信息采集、提取、挖掘、处理,为各类信息服务系统提供数据输入。
潮德利通IRRadar网页信息采集系统可以使用灵活的规则来自任何类型的网站采集信息,例如news网站、论坛、博客、电子商务网站、招聘网站和等等,利用其通用性、灵活性、高效性、稳定性,为客户带来更大的利润。
红外网页信息采集系统功能
网络信息采集系统可实现网站login采集、网站cross-layer采集、POST采集script page采集、动态页面等高级采集功能采集等各种形式的信息采集,费力。网信采集系统支持存储过程、插件等,可二次开发扩展功能。
IRadar网站信息采集系统功能:
1、文件批量下载
批量下载PDF、RAR、图片等文件,同时下载采集相关资料
2、互联网数据挖掘
从指定的网站中抓取所需的数据,对其进行分析处理并保存到您的数据库中。
3、网络信息监控
自动抓取新闻、论坛等,然后分析处理
4、网站内容维护
定时采集新闻、文章等,并自动发布到指定的网站。
红外网络信息采集系统优势
红外网页信息采集系统优势:
1、Universal:可以自定义采集rules采集任何浏览器可以看到的信息;
2、Flexibility:支持多种高级采集功能;
3、扩展性强:支持存储过程、插件等,可用于二次开发扩展功能;
4、高效:精心设计的系统为您节省每一秒;
5、fast:最快最高效的采集系统;
6、Stability:系统稳定,没有漏洞;
7、人性化:注重细节,人性化体验。
图片:IRadar网页信息采集系统优势
网站内容采集系统搭建可根据自己的需求来做设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-06-22 01:03
网站内容采集系统搭建可根据自己的需求来制定,具体可以看下自己的情况来做设计;1.网站内容采集系统需求说明采集软件一般需要支持:内容商城系统(可以同时支持店铺系统、个人网站、企业站、政府网站、本地企业站),收录内容系统(可以同时支持百度、谷歌、雅虎、、360等站点收录和引流),相关词库(内容系统只支持有相关的词库维护,如一个区域只允许有一个区域要采集什么内容,你可以根据情况来设置收录多少,内容量多少,如收录3000,相关区域30000个,则内容系统对应设置相关收录量,如2000。
)2.功能介绍采集软件主要包括:本地内容系统、超链接软件、品牌词库管理系统、本地音频、视频的采集软件3.采集软件软件案例当采集海量网站内容时,复制链接速度快,采集时有时间间隔采集速度慢,网站下载分享内容时延迟高网站用户分享率低,不易分享给好友(有些站长会做站群,如果同时申请一些站群可能在下载这块时间会造成比较大的延迟,影响收录)网站搜索结果前几位内容经常出现刷新的情况采集软件专业用于业务类站点数据采集和改版,而且操作简单易上手网站改版一次,内容重新找就行,增删不变化,一次不变化3天就可以改好、搞定网站增删变化是个挑战增删有可能影响到整个网站和网站每个分站的排名和权重增删时可能影响整站整体的权重。 查看全部
网站内容采集系统搭建可根据自己的需求来做设计
网站内容采集系统搭建可根据自己的需求来制定,具体可以看下自己的情况来做设计;1.网站内容采集系统需求说明采集软件一般需要支持:内容商城系统(可以同时支持店铺系统、个人网站、企业站、政府网站、本地企业站),收录内容系统(可以同时支持百度、谷歌、雅虎、、360等站点收录和引流),相关词库(内容系统只支持有相关的词库维护,如一个区域只允许有一个区域要采集什么内容,你可以根据情况来设置收录多少,内容量多少,如收录3000,相关区域30000个,则内容系统对应设置相关收录量,如2000。
)2.功能介绍采集软件主要包括:本地内容系统、超链接软件、品牌词库管理系统、本地音频、视频的采集软件3.采集软件软件案例当采集海量网站内容时,复制链接速度快,采集时有时间间隔采集速度慢,网站下载分享内容时延迟高网站用户分享率低,不易分享给好友(有些站长会做站群,如果同时申请一些站群可能在下载这块时间会造成比较大的延迟,影响收录)网站搜索结果前几位内容经常出现刷新的情况采集软件专业用于业务类站点数据采集和改版,而且操作简单易上手网站改版一次,内容重新找就行,增删不变化,一次不变化3天就可以改好、搞定网站增删变化是个挑战增删有可能影响到整个网站和网站每个分站的排名和权重增删时可能影响整站整体的权重。
北京米艾特软件集多年大中型网站研发与运营经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-06-21 19:06
概述
Mitcms(Mitsoft 内容管理系统,Mitsoft网站内容管理系统)是北京米爱特软件的专用门户,拥有多年大中型网站研发和运营经验,至今已发展七年六个版本。 网站内容采集,编辑发布应用系统。 Mitcms的应用可以帮助政府机关、企事业单位等网站规范其网站后台信息流程,统一数据存储格式,减少网站维护投入,加强信息权限管理。
Mitcms解决大中型网站经常面临的问题:
结构混乱,文件夹多,数据表多,技术维护困难;数据维护困难。频道和栏目很多,很多栏目内容的人工维护需要巨大的人力和财力投入。内容发布处于两难境地。纯静态页面的使用使得时效性难以把握,制作和发布非常耗时;动态发布可以保证发布的时效性,但是一旦流量大,速度往往很慢。在报道重要事件时,不可能高效快速地构建界面多样、内容丰富的话题。六大特点
快速建改大中型网站,提升网站资源整合能力。
可以无限制添加子栏,系统自动维护网站column文件夹。独有的自定义表格功能,可以为不同的栏目定义表格,轻松满足不同栏目建设的需求。强大的模板机制实现了网站界面和数据的分离,使网站修改起来快捷方便。动态发布纯静态页面,有效提高用户浏览时的响应速度,更容易被谷歌和百度收录接收。轻松构建界面多样、内容丰富的专题报告。
内容编辑审核功能强大,操作简单。
Tong一、 方便的用户界面和管理入口,上手快,使用方便。一款与Word、IE高度集成的内容编辑器,可以随意插入图片,实现图文混合,也可以随意插入视频、表格、文件等多媒体信息。右键菜单用于管理。支持多选、拖放,给您独特的用户体验。
集成智能数据挖掘和分析功能,为内容增值应用提供技术支持。
独有的增量行业特征数据库管理功能。它可以自动从发布的内容中提取关键词,准确率超过90%。独有的话题自动聚合功能,无需创建栏目,即可针对特定热点问题自动生成内容话题。基于智能数据挖掘分析功能的精准广告投放。
强大的数据采集功能有效降低数据维护成本。
可以为任意指定栏目设置采集任务,抓取多个外部站点的相关栏目。 采集图片可以发送到本地。您可以通过设置过滤规则来过滤页面上的广告和不良信息,具有很强的针对性和准确性。 采集后自动存储。可任意编辑,审核后发表,全程省时省力。
稳定可靠的发布系统,有效实现资源共享。
基于.NET3.5企业级架构,保证发布系统的稳定性和可靠性。统一的底层数据库和算法领先的数据结构,有效实现信息的安全存储和有效分类;独有的附加发布功能,彻底消除信息孤岛,有效实现资源共享。
功能齐全。
文件管理:远程管理站点文件。用户管理:分级权限控制。投票管理:柱状图、饼图、流量统计:跟踪网站浏览。 查看全部
北京米艾特软件集多年大中型网站研发与运营经验
概述
Mitcms(Mitsoft 内容管理系统,Mitsoft网站内容管理系统)是北京米爱特软件的专用门户,拥有多年大中型网站研发和运营经验,至今已发展七年六个版本。 网站内容采集,编辑发布应用系统。 Mitcms的应用可以帮助政府机关、企事业单位等网站规范其网站后台信息流程,统一数据存储格式,减少网站维护投入,加强信息权限管理。
Mitcms解决大中型网站经常面临的问题:
结构混乱,文件夹多,数据表多,技术维护困难;数据维护困难。频道和栏目很多,很多栏目内容的人工维护需要巨大的人力和财力投入。内容发布处于两难境地。纯静态页面的使用使得时效性难以把握,制作和发布非常耗时;动态发布可以保证发布的时效性,但是一旦流量大,速度往往很慢。在报道重要事件时,不可能高效快速地构建界面多样、内容丰富的话题。六大特点
快速建改大中型网站,提升网站资源整合能力。
可以无限制添加子栏,系统自动维护网站column文件夹。独有的自定义表格功能,可以为不同的栏目定义表格,轻松满足不同栏目建设的需求。强大的模板机制实现了网站界面和数据的分离,使网站修改起来快捷方便。动态发布纯静态页面,有效提高用户浏览时的响应速度,更容易被谷歌和百度收录接收。轻松构建界面多样、内容丰富的专题报告。
内容编辑审核功能强大,操作简单。
Tong一、 方便的用户界面和管理入口,上手快,使用方便。一款与Word、IE高度集成的内容编辑器,可以随意插入图片,实现图文混合,也可以随意插入视频、表格、文件等多媒体信息。右键菜单用于管理。支持多选、拖放,给您独特的用户体验。
集成智能数据挖掘和分析功能,为内容增值应用提供技术支持。
独有的增量行业特征数据库管理功能。它可以自动从发布的内容中提取关键词,准确率超过90%。独有的话题自动聚合功能,无需创建栏目,即可针对特定热点问题自动生成内容话题。基于智能数据挖掘分析功能的精准广告投放。
强大的数据采集功能有效降低数据维护成本。
可以为任意指定栏目设置采集任务,抓取多个外部站点的相关栏目。 采集图片可以发送到本地。您可以通过设置过滤规则来过滤页面上的广告和不良信息,具有很强的针对性和准确性。 采集后自动存储。可任意编辑,审核后发表,全程省时省力。
稳定可靠的发布系统,有效实现资源共享。
基于.NET3.5企业级架构,保证发布系统的稳定性和可靠性。统一的底层数据库和算法领先的数据结构,有效实现信息的安全存储和有效分类;独有的附加发布功能,彻底消除信息孤岛,有效实现资源共享。
功能齐全。
文件管理:远程管理站点文件。用户管理:分级权限控制。投票管理:柱状图、饼图、流量统计:跟踪网站浏览。
,最近网站降权的情况是什么?怎么破?(下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-06-20 23:53
写这篇文章的时候,还有小伙伴在讨论网站降权的情况。通常最突出的特点是:网站内容海量大合集,带有刷机参数的网页被广泛使用。
无一例外,这些网站基本都面临降级,基本没有例外。这里有很多知名的网站。
事实上,我们以搜索生态为基础,认为这无疑是一个明智的策略。
原因很简单。可持续的转化来自高质量的流量,高质量的页面流量需求往往基于高质量的内容查询。
否则,更多的操作将成为“内容搬运工”而不是“内容生产者”。
因此,激活高质量、可持续的搜索需求、净化搜索结果并支持高质量的内容生产者尤为重要。
目前百度搜索也在努力,网站operator可能也需要重新考虑我们的策略了。
为此,您可能需要注意以下几点:
1、自我回顾
如果网站ranking最近大幅下降,关键词ranking的很多内容消失了,网站的加权曲线基本呈现悬崖式下降趋势,我们认为下面的自我回顾可能是必要的。
是否采集大量内容
是否进行快速排名操作(如滑动和点击参数)。
2、采集是什么?
简单理解:网站所有内容的主要特点,如大面积抄袭,标题和内容一致。当然可以说我做了相关的处理,比如伪原创,,,,
但是,搜索引擎有以下完整的检查机制:
两个页面的内容和格式是一样的
两个页面的内容相同,但格式不同。
两个页面的重要内容相同,格式相同
两个页面的重要内容不同,格式相同
搜索引擎进行数据对比,重点关注以下页面功能:
1、计算页面上的数字签名(在页面的内容和结构中集成数据特征)
将页面数据的第一部分与现有数据库的原创标记记录的签名进行比较。
从搜索结果中过滤相似的数字签名,并与采集内容进行相似度比较。
点击参数是什么?
简单理解:点击参数通常是指利用SEO作弊策略,直接反馈与搜索引擎相关的特定目标网址的页面访问量。
常见表达:在搜索资源平台发现大量关键词data点击等。实际情况:在实际的搜索和排序过程中,这些数据的访问和反馈实际上并不存在。通常使用快速放电系统。
2、下权处理
如果网站最近流量减少了,如何通过自我审查、符号采集、刷卡等方式恢复网站数据?根据以往的操作经验,Cheng Ge Seo认为有必要参考以下内容:
根据人口统计目录和查看页面的采集rate。
删除所有采集 页面和部分。
将页面死链接提交给百度,制作404页面
建立频道,用优质网站页面吸引百度爬虫,抓取不同栏目,缩短降级审核周期,提高网站降权效率。你可以试试:
1)合理建立行业相关优质链接网站。
2) 创建指向高质量网站 相关内容页面的外部链接。
3)找合适的合作伙伴搭建同行业未降级的蜘蛛网站,侧边栏目标链接。
继续制作高质量的内容并将其提交给搜索引擎。
Seo Cheng 认为,为了提高网站 搜索引擎排名,我们可能需要专注于编写高质量的内容,而不是盲目采集文章。 查看全部
,最近网站降权的情况是什么?怎么破?(下)
写这篇文章的时候,还有小伙伴在讨论网站降权的情况。通常最突出的特点是:网站内容海量大合集,带有刷机参数的网页被广泛使用。
无一例外,这些网站基本都面临降级,基本没有例外。这里有很多知名的网站。
事实上,我们以搜索生态为基础,认为这无疑是一个明智的策略。
原因很简单。可持续的转化来自高质量的流量,高质量的页面流量需求往往基于高质量的内容查询。
否则,更多的操作将成为“内容搬运工”而不是“内容生产者”。
因此,激活高质量、可持续的搜索需求、净化搜索结果并支持高质量的内容生产者尤为重要。
目前百度搜索也在努力,网站operator可能也需要重新考虑我们的策略了。
为此,您可能需要注意以下几点:
1、自我回顾
如果网站ranking最近大幅下降,关键词ranking的很多内容消失了,网站的加权曲线基本呈现悬崖式下降趋势,我们认为下面的自我回顾可能是必要的。
是否采集大量内容
是否进行快速排名操作(如滑动和点击参数)。
2、采集是什么?
简单理解:网站所有内容的主要特点,如大面积抄袭,标题和内容一致。当然可以说我做了相关的处理,比如伪原创,,,,
但是,搜索引擎有以下完整的检查机制:
两个页面的内容和格式是一样的
两个页面的内容相同,但格式不同。
两个页面的重要内容相同,格式相同
两个页面的重要内容不同,格式相同
搜索引擎进行数据对比,重点关注以下页面功能:
1、计算页面上的数字签名(在页面的内容和结构中集成数据特征)
将页面数据的第一部分与现有数据库的原创标记记录的签名进行比较。
从搜索结果中过滤相似的数字签名,并与采集内容进行相似度比较。
点击参数是什么?
简单理解:点击参数通常是指利用SEO作弊策略,直接反馈与搜索引擎相关的特定目标网址的页面访问量。
常见表达:在搜索资源平台发现大量关键词data点击等。实际情况:在实际的搜索和排序过程中,这些数据的访问和反馈实际上并不存在。通常使用快速放电系统。
2、下权处理
如果网站最近流量减少了,如何通过自我审查、符号采集、刷卡等方式恢复网站数据?根据以往的操作经验,Cheng Ge Seo认为有必要参考以下内容:
根据人口统计目录和查看页面的采集rate。
删除所有采集 页面和部分。
将页面死链接提交给百度,制作404页面
建立频道,用优质网站页面吸引百度爬虫,抓取不同栏目,缩短降级审核周期,提高网站降权效率。你可以试试:
1)合理建立行业相关优质链接网站。
2) 创建指向高质量网站 相关内容页面的外部链接。
3)找合适的合作伙伴搭建同行业未降级的蜘蛛网站,侧边栏目标链接。
继续制作高质量的内容并将其提交给搜索引擎。
Seo Cheng 认为,为了提高网站 搜索引擎排名,我们可能需要专注于编写高质量的内容,而不是盲目采集文章。
ASP.NET2.0+SQL2000技术框架,全新的静态生成方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-06-20 05:02
1.pageadmin
2.点cms
3.jumbot
================================================ ================
1.We7 cms
We7cms是Western Power开发的一家公司,旨在充分挖掘互联网Web2.0(如博客、RSS等)信息组织的优势,并将其理念用于构建和组织政府企业网站,网站建设和管理产品的管理。
系统目标:把网站的创作变成简单的艺术创作,就像写博客一样简单。
系统功能
简单至上; “看一看”是我们的创作理念。如果您在看到它时无法使用它,请告诉我们。
潜力无限;来自WebEngine2007的谱系,大型行业门户和政府门户网站的核心引擎。 C-Modeling内容模型技术解决了多数据结构管理的问题,让cms可以发挥超出cms范围的能量。
网站自发展;迈向站群,强大的运营分析工具,团队协作系统,自动引擎升级,这一切都为你打造一个不断成长的网站做好准备。
开放和开源;强调开放是第一生产力,首个完全开源的cms系统会给你带来更多惊喜!
官网:
3.ROYcms
罗伊cms! NT内容管理系统是国内cms市场的新秀,也是国内为数不多的采用微软ASP.NET2.0+SQL2000/2005技术框架开发的cms之一。充分利用了ASP.NET架构的优势,突破了传统ASP类cms的局限性,采用了更稳定的执行速度和更高效的面向对象语言C#设计,延续了PETshop代码框架,全新的模板引擎机制,全新的静态生成方案,这些功能和技术的创新,塑造了一个基础架构稳定、功能创新、高效执行的cms。
特点:
模板自由组合
自定义静态生成的 HTML
无限分类资源
插件形式易于扩展
命名约定适合二次开发
官网:
4.易点内容管理系统点cms
<p>Easy Point 内容管理系统(Diancms)基于Microsoft .NET Framework 2.0、AJAX1.0 技术,采用Microsoft Access/SQL Server 2000/2005 多层架构存储过程开发内容管理系统。其功能设计主要针对大中型企业、各行业、事业单位、政府机关等复杂功能场所。系统建立了文章系统、图片系统、下载系统、个人求职、企业招聘、房产系统、音乐系统、视频系统、网店。使用自定义模型、自定义字段、自定义表单、自定义入口界面、会员系统等功能,您还可以轻松灵活地建立任何适合您需求的系统功能,最大限度地随时满足每个用户的不同需求。 查看全部
ASP.NET2.0+SQL2000技术框架,全新的静态生成方案
1.pageadmin
2.点cms
3.jumbot
================================================ ================
1.We7 cms
We7cms是Western Power开发的一家公司,旨在充分挖掘互联网Web2.0(如博客、RSS等)信息组织的优势,并将其理念用于构建和组织政府企业网站,网站建设和管理产品的管理。
系统目标:把网站的创作变成简单的艺术创作,就像写博客一样简单。
系统功能
简单至上; “看一看”是我们的创作理念。如果您在看到它时无法使用它,请告诉我们。
潜力无限;来自WebEngine2007的谱系,大型行业门户和政府门户网站的核心引擎。 C-Modeling内容模型技术解决了多数据结构管理的问题,让cms可以发挥超出cms范围的能量。
网站自发展;迈向站群,强大的运营分析工具,团队协作系统,自动引擎升级,这一切都为你打造一个不断成长的网站做好准备。
开放和开源;强调开放是第一生产力,首个完全开源的cms系统会给你带来更多惊喜!
官网:
3.ROYcms
罗伊cms! NT内容管理系统是国内cms市场的新秀,也是国内为数不多的采用微软ASP.NET2.0+SQL2000/2005技术框架开发的cms之一。充分利用了ASP.NET架构的优势,突破了传统ASP类cms的局限性,采用了更稳定的执行速度和更高效的面向对象语言C#设计,延续了PETshop代码框架,全新的模板引擎机制,全新的静态生成方案,这些功能和技术的创新,塑造了一个基础架构稳定、功能创新、高效执行的cms。
特点:
模板自由组合
自定义静态生成的 HTML
无限分类资源
插件形式易于扩展
命名约定适合二次开发
官网:
4.易点内容管理系统点cms
<p>Easy Point 内容管理系统(Diancms)基于Microsoft .NET Framework 2.0、AJAX1.0 技术,采用Microsoft Access/SQL Server 2000/2005 多层架构存储过程开发内容管理系统。其功能设计主要针对大中型企业、各行业、事业单位、政府机关等复杂功能场所。系统建立了文章系统、图片系统、下载系统、个人求职、企业招聘、房产系统、音乐系统、视频系统、网店。使用自定义模型、自定义字段、自定义表单、自定义入口界面、会员系统等功能,您还可以轻松灵活地建立任何适合您需求的系统功能,最大限度地随时满足每个用户的不同需求。

