
网站内容采集系统
网站内容采集系统(分布式网站日志采集方法实施例--本发明分布式技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-07 05:16
专利名称:一种分布式网站日志数据采集方法和一种分布式网站系统生产方法
技术领域:
本发明涉及互联网数据处理技术,特别是分布式网站log采集方法。
背景技术:
随着互联网的普及,为了提高互联网应用中的数据处理速度,满足不断增长的数据量需求,许多大型网站逐渐采用了分布式网络结构,主要是为了实现负载均衡。
分布式结构使用多台服务器,与前端WEB服务角色相同。这种结构极大地方便了服务分发的规划和可扩展性。另一方面,多台服务器的分布式设置,使得网络日志数据的分析统计也有些麻烦。
比如我们使用比较常用的web分析工具webalizer,对于分布式网络结构,需要分别对每台服务器进行日志数据统计,会带来以下问题
1、数据的采集带来了很多麻烦。比如统计总访问量,需要把指定时间段内的服务器1(SERVER1), server 2(SERVER2)...;
2、 影响独立访问次数、独立站点等指标的统计。基于网络分布式网络结构的特点和负载均衡的机制,以上指标的统计并不是基于服务器上数据的代数加法。
另外,基于以上问题,在每台服务器上配置日志数据分析功能,会增加服务器环境的复杂度,降低服务器运行的安全性能;并且分布式结构中各个服务器的日志数据分析功能需要保持一致。当某台服务器上的日志数据分析功能发生变化时,为了实现全网数据的统计,所有服务器上的日志数据分析功能都必须自适应变化,使得数据完整性难以监控,并且增加了维护成本。因此,分布式网站的可扩展性和部署在一定程度上受到限制。
发明内容
本发明实施例提供了一种分布式网站log采集方法。目的是降低网络期刊数据统计的复杂度,提高分布式网站的可扩展性。
为了解决上述技术问题,本发明提供的分布式网站log采集方法实施例
通过以下技术方案实现
一种分布式网站日志数据采集方法,包括净化WEB服务器的日志数据,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收日志 根据文档合并成一个文件。
上述方法中,WEB服务器在上传日志数据前对清洗后的日志数据进行压缩,并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断预定进行日志数据上传的WEB服务器是否有日志数据到达。
基于上述方法,在将日志数据上传到WEB服务器之前,还为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证文件与第二个验证文件不同,则触发WEB服务器重新上传日志数据文件。
本发明相应实施例还提供了一种分布式网站系统,包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断定时执行日志是否到达上传数据的WEB服务器的日志数据。
此外,WEB服务器还包括为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送给集中处理服务器;集中处理服务器也用于使用和WEB服务器相同的验证算法为获取的日志数据文件生成第二个验证文件。如果第一验证文件与第二验证文件不同,则触发WEB服务器重新上传日志。根据文件。
从上述技术方案可以看出,本发明在每个Web服务器上报日志数据之前,对上报的日志数据进行了清理,从而减少了集中处理服务器的工作
加载;并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,与现有技术相比,不需要在WEB服务器上配置过多的CGI环境(CGI环境为A程序环境)运行在网络服务器上。该程序用于超文本传输协议(HTTP 服务器)与其他终端上的程序交互)或其他特殊要求。只有系统的功能才能满足本程序的要求。 WEB服务器的发明具有更高的安全性,并且本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,因此本发明的系统部署简单,提高了系统的可扩展性。
进一步地,基于上述方法的实现,本发明的集中处理服务器可以对采集收到的日志数据文件进行加工合并处理,从而避免了由于登录到两个以上服务器的可能对用户访问数据上传造成的数据统计不准确,最终会提高日常日志数据分析的准确性。
图1是根据本发明实施例的方法的示意图。
具体实施方法
本发明的目的是降低网络日志数据统计的复杂度,提高分布式网站的可扩展性。
为了实现本发明的上述目的,请参考图1。下面结合图1具体说明本发明实施例的实现。
如图1所示,本发明实施例的系统包括WEB服务器和集中处理服务器。系统满足分布式结构,即多台相同角色的服务器用于前端WEB服务。该方法包括以下步骤。
步骤ll,对于保存的日志数据,WEB服务器对其进行净化。
净化过程的目的是过滤掉对日志数据分析无用的数据,从而减少日志数据的大小。有很多过滤方法。例如,对于Linux服务器,可以直接使用SHELL命令过滤掉样式、图片等不需要的日志记录。因为用户经常请求一个收录大量脚本、样式和图片数据的页面,所以传号
根据净化,可以大大减少日志文件的大小,从而减少网络传输时间,有助于提高日志数据分析的效率。 '日志数据净化过程的时机可以选择在WEB服务器负载的低高峰期。服务器的低峰期可以根据统计数据分析得出,并可以根据统计数据结果随着网络应用的发展进行调整。 Step 12. 对于清洗后的日志数据,WEB服务器对其进行压缩,生成日志数据压缩文件。压缩文件的名称后附有服务器的标识,以便在集中处理服务器上区分不同WEB服务器发送的网络。日志数据压缩文件。在本实施例中,IP地址用于区分不同服务器的日志数据压缩文件。此外,还可以识别每个服务器编号或使用其他识别方法。步骤13、为防止文件网络传输过程中传输不完整或出错,需要对压缩文件进行文件校验,并生成第一校验码。本实施例中采用MD5验证方式,但本发明并不限定具体采用的验证方式。步骤14、将压缩后的日志数据文件和第一校验码发送到集中处理服务器。本实施例中,采用FTP方式传输日志数据压缩文件和第一校验码。本发明还可以采用其他传输方式,例如HTTP。步骤15、集中处理服务器检查接收到的每个服务器的日志数据文件(压缩后的)。具体包括以下步骤的识别。因此,集中处理服务器需要下载WEB服务器的IP地址配置列表,本实施例采用FTP方式传输数据,所以配置文件格式为210.121.123. 123 ftpuser ftppasswd210.121.123.124 ftpuser ftppasswd 其中ftpuser为ftp用户名,ftppasswd为ftp验证码。集中处理服务器根据配置文件列表,循环验证各Web服务器的日志数据文件是否在指定时间段内到达。如果它到达,它根据Web服务器采用的验证方法验证接收到的日志数据文件。如果日志数据文件还在
如果没有到达集中处理服务器,它会等待预设的时间长度才进行测试。本实施例中,集中处理服务器对接收到的日志数据压缩文件进行校验的方法具体包括:根据获取的日志数据压缩文件,按照MD5校验方法生成第二校验码,如果第二校验码为与第一个校验码相同,表示日志数据压缩文件传输正确;如果第二校验码与第一校验码不同,集中处理服务器可以执行步骤17,即主动触发WEB服务器重传日志数据压缩文件。基于上述重传机制,本发明实施例还对重传次数设置了阈值。当重传次数达到阈值,且获取的日志数据压缩文件仍无法通过MD5验证时,集中处理服务器可以停止处理WEB服务器的日志数据压缩文件并发出告警。报警形式可能包括发送邮件或短信报警,以便网站维护人员根据实际情况进行处理,保证整个网站日志的完整性。步骤16、如果集中处理服务器确定已经获取到预定WEB服务器的日志数据压缩文件,则对压缩文件进行解压;并且,由于用户访问记录可能存在于两个或多个WEB服务器上,为了保证数据的准确性,集中处理服务器必须将每个WEB服务器的日志文件合并为一个文件。从上述技术方案可以看出,本发明在各WEB服务器上的日志数据之前,先清理待上报的日志数据,从而减少了大量不必要的记录。这样,在后续的日志分析过程中,提高了日志数据的分析效率,减少了集中处理服务器的工作量。并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,不需要在WEB服务器上配置过多的CGI环境或其他特殊环境。需求,本方案的需求,只需要利用系统本身的功能就可以实现。理论上,环境配置越多,安全性就会相应降低。因此,本发明的WEB服务器具有更高的安全性。因为分布式网站使用了很多WEB服务器端。如果采用现有技术,稍微改变一点需求,就需要调整各个WEB端的脚本和程序。这个调整过程很简单
发生错误。而且,每个服务器的日志也不容易监控。如果某个服务器日志出现异常,很难找出是哪个WEB服务器出了问题。与现有技术相比,本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,从而使得系统部署本发明简单,提高了系统的可扩展性。并且由于日志数据在集中处理服务器中处理,因此更容易识别问题并解决问题。相应地,本发明还提供了一种分布式网站系统,其特征在于包括WEB服务器和集中处理服务器。其中,WEB服务器用于对保存的日记账数据进行净化处理。处理后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。其中,净化处理包括对日志数据中的图案或/和图片数据进行过滤。在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩,并标记服务器标识;集中处理服务器用于根据服务器列表中的服务器标识,判断预定进行日志数据上传的WEB服务器的日志数据是否已经到达。在上述系统结构的基础上,WEB服务器还包括为压缩后的日志数据文件生成第一校验码,并将第一校验码发送给集中处理服务器。并且,集中处理服务器还用于使用与WEB服务器相同的验证算法对获取的日志数据文件生成第二验证码,如果第一验证码与第二验证码不同,则触发WEB服务器服务器 再次上传日志数据文件。以上详细描述了本发明实施例提供的分布式网站日志数据采集方法和分布式网站系统。本文通过具体实例来说明本发明的原理和实现方式。以上实施例的描述仅用于帮助理解本发明的实施方式;同时,对于本领域普通技术人员来说,根据本发明的构思,具体实现方式和适用范围可能会有变化。综上所述,本说明书的内容不应理解为对本发明的限制。
索赔
1、一种分布式网站日志数据采集方法,其特征在于对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;处理服务器将接收到的日志数据文件合并为一个文件。
2、根据权利要求1所述的方法,其中,所述净化过程包括过滤日志数据中的图案或/和图片数据。
3、如权利要求1所述的方法,其特征在于,WEB服务器在上传日志数据之前,对清洗后的日志数据进行压缩,并标记服务器的身份;集中处理服务器根据服务器列表,根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
4、如权利要求3所述的方法,其特征在于,在Web服务器上传日志数据之前,对压缩后的日志数据文件进一步生成第一校验码,并将第一校验码发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证码与第二个验证码不同,则触发WEB服务器重新上传日志数据文件。
5、如权利要求1所述的方法,其特征在于,在预设时间或服务器负载低于预设阈值时启动日志数据清理过程。
6、分布式网站系统,其特点是包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,并将日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
7、如权利要求6所述的网站系统,其特征在于,所述净化过程包括过滤日志数据中的样式或/和图片数据。
8、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还用于对清洗后的日志数据进行压缩并标记服务器的身份;集中处理服务器用于根据服务器列表根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
9、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还包括为压缩后的日志数据文件生成第一校验码,与发送给集中处理服务器的第一校验码进行比对;集中处理服务器也使用与WEB服务器相同的验证算法,在获取的日志数据文件上生成第二验证码,如果第一验证码与第二验证码相同,则WEB服务器触发服务器重新上传日志数据文件。
全文摘要
本发明实施例提供了一种分布式网站日志数据采集方法和分布式网站系统,旨在降低网络日志数据统计的复杂度,提高分布式网站可扩展性的性能该方法包括对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。本发明减少了集中处理服务器的工作量;使WEB服务器具有更高的安全性;本发明系统部署简单,提高了系统的可扩展性。
文件编号 H04L12/24GK101163046SQ2
出版日期 2008 年 4 月 16 日 申请日期 2007 年 11 月 22 日 优先权日期 2007 年 11 月 22 日
发明人Hui Ning, Tao Zhang 申请人:; 查看全部
网站内容采集系统(分布式网站日志采集方法实施例--本发明分布式技术)
专利名称:一种分布式网站日志数据采集方法和一种分布式网站系统生产方法
技术领域:
本发明涉及互联网数据处理技术,特别是分布式网站log采集方法。
背景技术:
随着互联网的普及,为了提高互联网应用中的数据处理速度,满足不断增长的数据量需求,许多大型网站逐渐采用了分布式网络结构,主要是为了实现负载均衡。
分布式结构使用多台服务器,与前端WEB服务角色相同。这种结构极大地方便了服务分发的规划和可扩展性。另一方面,多台服务器的分布式设置,使得网络日志数据的分析统计也有些麻烦。
比如我们使用比较常用的web分析工具webalizer,对于分布式网络结构,需要分别对每台服务器进行日志数据统计,会带来以下问题
1、数据的采集带来了很多麻烦。比如统计总访问量,需要把指定时间段内的服务器1(SERVER1), server 2(SERVER2)...;
2、 影响独立访问次数、独立站点等指标的统计。基于网络分布式网络结构的特点和负载均衡的机制,以上指标的统计并不是基于服务器上数据的代数加法。
另外,基于以上问题,在每台服务器上配置日志数据分析功能,会增加服务器环境的复杂度,降低服务器运行的安全性能;并且分布式结构中各个服务器的日志数据分析功能需要保持一致。当某台服务器上的日志数据分析功能发生变化时,为了实现全网数据的统计,所有服务器上的日志数据分析功能都必须自适应变化,使得数据完整性难以监控,并且增加了维护成本。因此,分布式网站的可扩展性和部署在一定程度上受到限制。
发明内容
本发明实施例提供了一种分布式网站log采集方法。目的是降低网络期刊数据统计的复杂度,提高分布式网站的可扩展性。
为了解决上述技术问题,本发明提供的分布式网站log采集方法实施例
通过以下技术方案实现
一种分布式网站日志数据采集方法,包括净化WEB服务器的日志数据,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收日志 根据文档合并成一个文件。
上述方法中,WEB服务器在上传日志数据前对清洗后的日志数据进行压缩,并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断预定进行日志数据上传的WEB服务器是否有日志数据到达。
基于上述方法,在将日志数据上传到WEB服务器之前,还为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证文件与第二个验证文件不同,则触发WEB服务器重新上传日志数据文件。
本发明相应实施例还提供了一种分布式网站系统,包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断定时执行日志是否到达上传数据的WEB服务器的日志数据。
此外,WEB服务器还包括为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送给集中处理服务器;集中处理服务器也用于使用和WEB服务器相同的验证算法为获取的日志数据文件生成第二个验证文件。如果第一验证文件与第二验证文件不同,则触发WEB服务器重新上传日志。根据文件。
从上述技术方案可以看出,本发明在每个Web服务器上报日志数据之前,对上报的日志数据进行了清理,从而减少了集中处理服务器的工作
加载;并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,与现有技术相比,不需要在WEB服务器上配置过多的CGI环境(CGI环境为A程序环境)运行在网络服务器上。该程序用于超文本传输协议(HTTP 服务器)与其他终端上的程序交互)或其他特殊要求。只有系统的功能才能满足本程序的要求。 WEB服务器的发明具有更高的安全性,并且本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,因此本发明的系统部署简单,提高了系统的可扩展性。
进一步地,基于上述方法的实现,本发明的集中处理服务器可以对采集收到的日志数据文件进行加工合并处理,从而避免了由于登录到两个以上服务器的可能对用户访问数据上传造成的数据统计不准确,最终会提高日常日志数据分析的准确性。
图1是根据本发明实施例的方法的示意图。
具体实施方法
本发明的目的是降低网络日志数据统计的复杂度,提高分布式网站的可扩展性。
为了实现本发明的上述目的,请参考图1。下面结合图1具体说明本发明实施例的实现。
如图1所示,本发明实施例的系统包括WEB服务器和集中处理服务器。系统满足分布式结构,即多台相同角色的服务器用于前端WEB服务。该方法包括以下步骤。
步骤ll,对于保存的日志数据,WEB服务器对其进行净化。
净化过程的目的是过滤掉对日志数据分析无用的数据,从而减少日志数据的大小。有很多过滤方法。例如,对于Linux服务器,可以直接使用SHELL命令过滤掉样式、图片等不需要的日志记录。因为用户经常请求一个收录大量脚本、样式和图片数据的页面,所以传号
根据净化,可以大大减少日志文件的大小,从而减少网络传输时间,有助于提高日志数据分析的效率。 '日志数据净化过程的时机可以选择在WEB服务器负载的低高峰期。服务器的低峰期可以根据统计数据分析得出,并可以根据统计数据结果随着网络应用的发展进行调整。 Step 12. 对于清洗后的日志数据,WEB服务器对其进行压缩,生成日志数据压缩文件。压缩文件的名称后附有服务器的标识,以便在集中处理服务器上区分不同WEB服务器发送的网络。日志数据压缩文件。在本实施例中,IP地址用于区分不同服务器的日志数据压缩文件。此外,还可以识别每个服务器编号或使用其他识别方法。步骤13、为防止文件网络传输过程中传输不完整或出错,需要对压缩文件进行文件校验,并生成第一校验码。本实施例中采用MD5验证方式,但本发明并不限定具体采用的验证方式。步骤14、将压缩后的日志数据文件和第一校验码发送到集中处理服务器。本实施例中,采用FTP方式传输日志数据压缩文件和第一校验码。本发明还可以采用其他传输方式,例如HTTP。步骤15、集中处理服务器检查接收到的每个服务器的日志数据文件(压缩后的)。具体包括以下步骤的识别。因此,集中处理服务器需要下载WEB服务器的IP地址配置列表,本实施例采用FTP方式传输数据,所以配置文件格式为210.121.123. 123 ftpuser ftppasswd210.121.123.124 ftpuser ftppasswd 其中ftpuser为ftp用户名,ftppasswd为ftp验证码。集中处理服务器根据配置文件列表,循环验证各Web服务器的日志数据文件是否在指定时间段内到达。如果它到达,它根据Web服务器采用的验证方法验证接收到的日志数据文件。如果日志数据文件还在
如果没有到达集中处理服务器,它会等待预设的时间长度才进行测试。本实施例中,集中处理服务器对接收到的日志数据压缩文件进行校验的方法具体包括:根据获取的日志数据压缩文件,按照MD5校验方法生成第二校验码,如果第二校验码为与第一个校验码相同,表示日志数据压缩文件传输正确;如果第二校验码与第一校验码不同,集中处理服务器可以执行步骤17,即主动触发WEB服务器重传日志数据压缩文件。基于上述重传机制,本发明实施例还对重传次数设置了阈值。当重传次数达到阈值,且获取的日志数据压缩文件仍无法通过MD5验证时,集中处理服务器可以停止处理WEB服务器的日志数据压缩文件并发出告警。报警形式可能包括发送邮件或短信报警,以便网站维护人员根据实际情况进行处理,保证整个网站日志的完整性。步骤16、如果集中处理服务器确定已经获取到预定WEB服务器的日志数据压缩文件,则对压缩文件进行解压;并且,由于用户访问记录可能存在于两个或多个WEB服务器上,为了保证数据的准确性,集中处理服务器必须将每个WEB服务器的日志文件合并为一个文件。从上述技术方案可以看出,本发明在各WEB服务器上的日志数据之前,先清理待上报的日志数据,从而减少了大量不必要的记录。这样,在后续的日志分析过程中,提高了日志数据的分析效率,减少了集中处理服务器的工作量。并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,不需要在WEB服务器上配置过多的CGI环境或其他特殊环境。需求,本方案的需求,只需要利用系统本身的功能就可以实现。理论上,环境配置越多,安全性就会相应降低。因此,本发明的WEB服务器具有更高的安全性。因为分布式网站使用了很多WEB服务器端。如果采用现有技术,稍微改变一点需求,就需要调整各个WEB端的脚本和程序。这个调整过程很简单
发生错误。而且,每个服务器的日志也不容易监控。如果某个服务器日志出现异常,很难找出是哪个WEB服务器出了问题。与现有技术相比,本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,从而使得系统部署本发明简单,提高了系统的可扩展性。并且由于日志数据在集中处理服务器中处理,因此更容易识别问题并解决问题。相应地,本发明还提供了一种分布式网站系统,其特征在于包括WEB服务器和集中处理服务器。其中,WEB服务器用于对保存的日记账数据进行净化处理。处理后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。其中,净化处理包括对日志数据中的图案或/和图片数据进行过滤。在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩,并标记服务器标识;集中处理服务器用于根据服务器列表中的服务器标识,判断预定进行日志数据上传的WEB服务器的日志数据是否已经到达。在上述系统结构的基础上,WEB服务器还包括为压缩后的日志数据文件生成第一校验码,并将第一校验码发送给集中处理服务器。并且,集中处理服务器还用于使用与WEB服务器相同的验证算法对获取的日志数据文件生成第二验证码,如果第一验证码与第二验证码不同,则触发WEB服务器服务器 再次上传日志数据文件。以上详细描述了本发明实施例提供的分布式网站日志数据采集方法和分布式网站系统。本文通过具体实例来说明本发明的原理和实现方式。以上实施例的描述仅用于帮助理解本发明的实施方式;同时,对于本领域普通技术人员来说,根据本发明的构思,具体实现方式和适用范围可能会有变化。综上所述,本说明书的内容不应理解为对本发明的限制。
索赔
1、一种分布式网站日志数据采集方法,其特征在于对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;处理服务器将接收到的日志数据文件合并为一个文件。
2、根据权利要求1所述的方法,其中,所述净化过程包括过滤日志数据中的图案或/和图片数据。
3、如权利要求1所述的方法,其特征在于,WEB服务器在上传日志数据之前,对清洗后的日志数据进行压缩,并标记服务器的身份;集中处理服务器根据服务器列表,根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
4、如权利要求3所述的方法,其特征在于,在Web服务器上传日志数据之前,对压缩后的日志数据文件进一步生成第一校验码,并将第一校验码发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证码与第二个验证码不同,则触发WEB服务器重新上传日志数据文件。
5、如权利要求1所述的方法,其特征在于,在预设时间或服务器负载低于预设阈值时启动日志数据清理过程。
6、分布式网站系统,其特点是包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,并将日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
7、如权利要求6所述的网站系统,其特征在于,所述净化过程包括过滤日志数据中的样式或/和图片数据。
8、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还用于对清洗后的日志数据进行压缩并标记服务器的身份;集中处理服务器用于根据服务器列表根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
9、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还包括为压缩后的日志数据文件生成第一校验码,与发送给集中处理服务器的第一校验码进行比对;集中处理服务器也使用与WEB服务器相同的验证算法,在获取的日志数据文件上生成第二验证码,如果第一验证码与第二验证码相同,则WEB服务器触发服务器重新上传日志数据文件。
全文摘要
本发明实施例提供了一种分布式网站日志数据采集方法和分布式网站系统,旨在降低网络日志数据统计的复杂度,提高分布式网站可扩展性的性能该方法包括对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。本发明减少了集中处理服务器的工作量;使WEB服务器具有更高的安全性;本发明系统部署简单,提高了系统的可扩展性。
文件编号 H04L12/24GK101163046SQ2
出版日期 2008 年 4 月 16 日 申请日期 2007 年 11 月 22 日 优先权日期 2007 年 11 月 22 日
发明人Hui Ning, Tao Zhang 申请人:;
网站内容采集系统(如何爬数据需求数据采集系统:一个可以通过配置规则采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 466 次浏览 • 2021-09-06 14:05
记录一个两年前写的采集系统,包括需求、分析、设计、实现、遇到的问题以及系统的有效性。系统的主要功能是为每个网站制作不同的采集rule配置为每个网站抓取数据。两年前我离开时爬取的数据量大约是几千万。 采集每天的数据增量在10000左右。配置采集的网站1200多个,现记录下系统实现,并提供一些简单的爬虫demo供大家学习爬取数据
要求
Data采集system:一个可以配置规则采集不同网站的系统
主要目标:
对于不同的网站,我们可以配置不同的采集规则来实现网络数据爬取。对于每条内容,可以实现特征数据提取,抓取所有网站数据采集配置规则可以维护采集Inbound数据可维护性分析
第一步当然是先分析需求,所以我们提取系统的主要需求:
对于不同的网站,可以通过不同的采集规则实现数据爬取。可以为每条内容提取特征数据。特征数据是指标题、作者、发布时间信息定时任务关联任务或任务组爬取网站的数据
再次解析网站的结构,无非就是两个;
一个是列表页面。这里的列表页代表的是需要获取当前页面更多详情页的那种网页链接,就像一般查询列表一样,可以通过列表获取更多详情页链接。一是详情页。这种页面更容易理解。这种页面不需要在这个页面上获取到其他网页的链接,直接在当前页面上提取数据即可。
基本上所有爬到的网站都可以这样抽象出来。
设计
基于分析结果的设计与实现:
任务表
每个网站都可以当作一个任务去执行采集
两个规则表
每个网站 对应于自己的采集 规则。根据上面分析的网站结构,采集规则可以进一步细分为两个表,一个收录网站链接获取详情页列表采集Rules表的列表,一个规则表用于特征数据采集网站详情页@规则表详情采集消防表
网址表
负责记录采集target网站detail页面的url
定时任务列表
根据定时任务定时执行某些任务(可以使用定时任务关联多个任务,也可以考虑添加任务组表,定时任务关联任务组,任务组与任务相关)
数据存储表
这是因为我们的采集数据主要是中标和中标两种数据。建立了两张表用于数据存储,中标信息表和中标信息表
实现框架
基本结构为:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多。有很多优秀的开源框架,比如htmlunit、WebMagic、jsoup等,当然也可以实现httpclient。
为什么要使用 htmlunit?
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被誉为java浏览器的开源实现
简单说说我对htmlunit的理解:
一个是htmlunit提供了通过xpath定位页面元素的功能,可以用来提取页面特征数据;二是对js的支持,对js的支持意味着你真的可以把它当作一个浏览器,你可以用它来模拟点击、输入、登录等操作,而对于采集,支持js可以解决使用问题ajax获取页面数据。当然除此之外,htmlunit还支持代理ip、https,通过配置可以模拟谷歌、火狐、Referer、user-agent等浏览器,是否加载js、css,是否支持ajax等
XPath 语法是 XML 路径语言(XML Path Language),它是一种用于确定 XML 文档某部分位置的语言。
为什么要使用 jsoup?
相对于htmlunit,jsoup提供了类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集
采集数据逻辑分为两个部分:url采集器,详情页采集器
url采集器:
详情页采集器:
重复数据删除遇到的问题:当使用采集url与url相同去重时,key作为url存储在redis中,缓存时间为3天。这个方法是为了防止同一个A url 重复采集。重复数据删除由标题执行。通过在redis中存储key为采集的title,缓存时间为3天。这个方法是为了防止一个文章被不同的网站发布,重复采集的情况发生。数据质量:
因为每个网站页面都不一样,尤其是同一个网站的详情页结构也不同,增加了特征数据提取的难度,所以使用htmlunit+jsoup+正则三种方式组合得到采集特征数据。
采集efficiency:
因为采集的网站有很多,假设每次任务执行打开一个列表页和十个详情页,那么一千个任务执行一次需要采集11000页,所以使用url和详情页以采集分隔,通过mq实现异步操作,url和详情页的采集通过多线程实现。
被阻止的ip:
对于一个网站,如果每半小时执行一次,那么网站一天会被扫描48次。还假设采集每天会打开11页,528次,所以Sealing是一个很常见的问题。解决办法,htmlunit提供了代理ip的实现,使用代理ip可以解决被封ip的问题,代理ip的来源:一是网上有很多网站卖代理ip的,可以买他们的代理ip直接,另一种就是爬取,这些网站卖代理ip都提供了一些免费的代理ip,你可以爬回这些ip,然后用httpclient或者其他方式验证代理ip的可用性,如果可以输入直接建数据库,搭建自己的代理ip库。因为代理ip是时间敏感的,可以创建定时任务刷ip库,去除无效ip。
网站失败:
网站失效有两种,一种是网站域名,原来的网址不能直接打开,第二种是网站改版,原来配置的规则全部失效,而采集不可用@有效数据。解决这个问题的办法是每天发送采集data和日志的邮件提醒,将未采集到的数据和未打开的网页汇总,通过邮件发送给相关人员。
验证码:
当时,对于网站采集史数据采集,方式是通过他们的列表页面进入采集detail页面。 采集查到几十万条数据后,这个网站我就拿不到数据了。查看页面后,我发现列表页面添加了验证码。这个验证码是一个比较简单的数字加字母。那个时候想在列表页加个验证码? ,然后想到了一个解决办法,找了一个开源的orc文字识别项目tess4j(使用方法看这里),过一会就好了,识别率在20%左右,因为htmlunit可以模拟操作浏览器,所以代码中的操作是先通过htmlunit的xpath获取验证码元素,获取验证码图片,然后使用tess4j识别验证码,然后将识别到的验证码填入验证中代码输入框,点击翻页,如果验证码通过,翻页进行后续采集,如果失败,重复上面的识别验证码操作,直到知道成功,将验证码输入输入框和点击翻页可以用htmlunit实现
Ajax 加载数据:
一些网站使用ajax加载数据。使用htmlunit采集时,网站需要在获取到HtmlPage对象后给页面一个加载ajax的时间,然后可以通过HtmlPage获取ajax加载后的数据。
代码:webClient.waitForBackgroundJavaScript(time);你可以看到后面提供的演示
系统整体架构图,这里指的是data采集system部分
演示
爬虫的实现:
@GetMapping("/getData")
public List article_(String url,String xpath){
WebClient webClient = WebClientUtils.getWebClientLoadJs();
List datas = new ArrayList();
try {
HtmlPage page = webClient.getPage(url);
if(page!=null){
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return datas;
}
以上代码实现采集一个列表页
爬上博客园
请求这个url::9001/getData?url=;xpath=//*[@id="post_list"]/div/div[2]/h3/a
网页:
采集返回数据:
再次爬上csdn
再次请求::9001/getData?url=;xpath=//*[@id="feedlist_id"]/li/div/div[1]/h2/a
网页:
采集返回数据:
采集Steps
通过一个方法去采集两个网站,通过不同url和xpath规则去采集不同的网站,这个demo展示的就是htmlunit采集数据的过程。
每个采集任务都是执行相同的步骤
- 获取client -> 打开页面 -> 提取特征数据(或详情页链接) -> 关闭cline
不同的地方就在于提取特征数据
优化:使用模板方法设计模式提取功能部分
上面的代码可以提取为:一个采集executor,一个自定义的采集data实现
/**
* @Description: 执行者 man
* @author: chenmingyu
* @date: 2018/6/24 17:29
*/
public class Crawler {
private Gatherer gatherer;
public Object execute(String url,Long time){
// 获取 webClient对象
WebClient webClient = WebClientUtils.getWebClientLoadJs();
try {
HtmlPage page = webClient.getPage(url);
if(null != time){
webClient.waitForBackgroundJavaScript(time);
}
return gatherer.crawl(page);
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return null;
}
public Crawler(Gatherer gatherer) {
this.gatherer = gatherer;
}
}
在Crawler中注入一个接口,这个接口只有一个方法crawl(),不同的实现类实现这个接口,然后自定义特征数据的实现
/**
* @Description: 自定义实现
* @author: chenmingyu
* @date: 2018/6/24 17:36
*/
public interface Gatherer {
Object crawl(HtmlPage page) throws Exception;
}
优化代码:
@GetMapping("/getData")
public List article_(String url,String xpath){
Gatherer gatherer = (page)->{
List datas = new ArrayList();
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
return datas;
};
Crawler crawler = new Crawler(gatherer);
List datas = (List)crawler.execute(url,null);
return datas;
}
不同的实现,只需要修改这部分接口实现即可。
数据
最后使用采集系统采集查看数据。
效果
效果还是不错的,最重要的是系统运行稳定:
采集的历史数据在6-7百万左右。 采集的数据增量约为每天10,000。系统目前配置了1200多个任务(一次定时执行会去采集这些网站)数据
系统配置采集网站主要针对全国各个省市县的网站竞价(目前配置的采集站点已超过1200个)。
采集的数据主要作为公司标准新闻的数据中心,为一个pc端网站和2个微信公众号提供数据
欢迎关注和掌握第一手招标信息
以PC端显示的采集中标数据为例,来看看采集的效果:
本文只是对采集系统从零到全过程的粗略记录,当然也遇到了很多本文没有提到的问题。 查看全部
网站内容采集系统(如何爬数据需求数据采集系统:一个可以通过配置规则采集)
记录一个两年前写的采集系统,包括需求、分析、设计、实现、遇到的问题以及系统的有效性。系统的主要功能是为每个网站制作不同的采集rule配置为每个网站抓取数据。两年前我离开时爬取的数据量大约是几千万。 采集每天的数据增量在10000左右。配置采集的网站1200多个,现记录下系统实现,并提供一些简单的爬虫demo供大家学习爬取数据
要求
Data采集system:一个可以配置规则采集不同网站的系统
主要目标:
对于不同的网站,我们可以配置不同的采集规则来实现网络数据爬取。对于每条内容,可以实现特征数据提取,抓取所有网站数据采集配置规则可以维护采集Inbound数据可维护性分析
第一步当然是先分析需求,所以我们提取系统的主要需求:
对于不同的网站,可以通过不同的采集规则实现数据爬取。可以为每条内容提取特征数据。特征数据是指标题、作者、发布时间信息定时任务关联任务或任务组爬取网站的数据
再次解析网站的结构,无非就是两个;
一个是列表页面。这里的列表页代表的是需要获取当前页面更多详情页的那种网页链接,就像一般查询列表一样,可以通过列表获取更多详情页链接。一是详情页。这种页面更容易理解。这种页面不需要在这个页面上获取到其他网页的链接,直接在当前页面上提取数据即可。
基本上所有爬到的网站都可以这样抽象出来。
设计
基于分析结果的设计与实现:
任务表
每个网站都可以当作一个任务去执行采集
两个规则表
每个网站 对应于自己的采集 规则。根据上面分析的网站结构,采集规则可以进一步细分为两个表,一个收录网站链接获取详情页列表采集Rules表的列表,一个规则表用于特征数据采集网站详情页@规则表详情采集消防表
网址表
负责记录采集target网站detail页面的url
定时任务列表
根据定时任务定时执行某些任务(可以使用定时任务关联多个任务,也可以考虑添加任务组表,定时任务关联任务组,任务组与任务相关)
数据存储表
这是因为我们的采集数据主要是中标和中标两种数据。建立了两张表用于数据存储,中标信息表和中标信息表
实现框架
基本结构为:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多。有很多优秀的开源框架,比如htmlunit、WebMagic、jsoup等,当然也可以实现httpclient。
为什么要使用 htmlunit?
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被誉为java浏览器的开源实现
简单说说我对htmlunit的理解:
一个是htmlunit提供了通过xpath定位页面元素的功能,可以用来提取页面特征数据;二是对js的支持,对js的支持意味着你真的可以把它当作一个浏览器,你可以用它来模拟点击、输入、登录等操作,而对于采集,支持js可以解决使用问题ajax获取页面数据。当然除此之外,htmlunit还支持代理ip、https,通过配置可以模拟谷歌、火狐、Referer、user-agent等浏览器,是否加载js、css,是否支持ajax等
XPath 语法是 XML 路径语言(XML Path Language),它是一种用于确定 XML 文档某部分位置的语言。
为什么要使用 jsoup?
相对于htmlunit,jsoup提供了类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集
采集数据逻辑分为两个部分:url采集器,详情页采集器
url采集器:
详情页采集器:
重复数据删除遇到的问题:当使用采集url与url相同去重时,key作为url存储在redis中,缓存时间为3天。这个方法是为了防止同一个A url 重复采集。重复数据删除由标题执行。通过在redis中存储key为采集的title,缓存时间为3天。这个方法是为了防止一个文章被不同的网站发布,重复采集的情况发生。数据质量:
因为每个网站页面都不一样,尤其是同一个网站的详情页结构也不同,增加了特征数据提取的难度,所以使用htmlunit+jsoup+正则三种方式组合得到采集特征数据。
采集efficiency:
因为采集的网站有很多,假设每次任务执行打开一个列表页和十个详情页,那么一千个任务执行一次需要采集11000页,所以使用url和详情页以采集分隔,通过mq实现异步操作,url和详情页的采集通过多线程实现。
被阻止的ip:
对于一个网站,如果每半小时执行一次,那么网站一天会被扫描48次。还假设采集每天会打开11页,528次,所以Sealing是一个很常见的问题。解决办法,htmlunit提供了代理ip的实现,使用代理ip可以解决被封ip的问题,代理ip的来源:一是网上有很多网站卖代理ip的,可以买他们的代理ip直接,另一种就是爬取,这些网站卖代理ip都提供了一些免费的代理ip,你可以爬回这些ip,然后用httpclient或者其他方式验证代理ip的可用性,如果可以输入直接建数据库,搭建自己的代理ip库。因为代理ip是时间敏感的,可以创建定时任务刷ip库,去除无效ip。
网站失败:
网站失效有两种,一种是网站域名,原来的网址不能直接打开,第二种是网站改版,原来配置的规则全部失效,而采集不可用@有效数据。解决这个问题的办法是每天发送采集data和日志的邮件提醒,将未采集到的数据和未打开的网页汇总,通过邮件发送给相关人员。
验证码:
当时,对于网站采集史数据采集,方式是通过他们的列表页面进入采集detail页面。 采集查到几十万条数据后,这个网站我就拿不到数据了。查看页面后,我发现列表页面添加了验证码。这个验证码是一个比较简单的数字加字母。那个时候想在列表页加个验证码? ,然后想到了一个解决办法,找了一个开源的orc文字识别项目tess4j(使用方法看这里),过一会就好了,识别率在20%左右,因为htmlunit可以模拟操作浏览器,所以代码中的操作是先通过htmlunit的xpath获取验证码元素,获取验证码图片,然后使用tess4j识别验证码,然后将识别到的验证码填入验证中代码输入框,点击翻页,如果验证码通过,翻页进行后续采集,如果失败,重复上面的识别验证码操作,直到知道成功,将验证码输入输入框和点击翻页可以用htmlunit实现
Ajax 加载数据:
一些网站使用ajax加载数据。使用htmlunit采集时,网站需要在获取到HtmlPage对象后给页面一个加载ajax的时间,然后可以通过HtmlPage获取ajax加载后的数据。
代码:webClient.waitForBackgroundJavaScript(time);你可以看到后面提供的演示
系统整体架构图,这里指的是data采集system部分

演示
爬虫的实现:
@GetMapping("/getData")
public List article_(String url,String xpath){
WebClient webClient = WebClientUtils.getWebClientLoadJs();
List datas = new ArrayList();
try {
HtmlPage page = webClient.getPage(url);
if(page!=null){
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return datas;
}
以上代码实现采集一个列表页
爬上博客园
请求这个url::9001/getData?url=;xpath=//*[@id="post_list"]/div/div[2]/h3/a
网页:
采集返回数据:
再次爬上csdn
再次请求::9001/getData?url=;xpath=//*[@id="feedlist_id"]/li/div/div[1]/h2/a
网页:
采集返回数据:
采集Steps
通过一个方法去采集两个网站,通过不同url和xpath规则去采集不同的网站,这个demo展示的就是htmlunit采集数据的过程。
每个采集任务都是执行相同的步骤
- 获取client -> 打开页面 -> 提取特征数据(或详情页链接) -> 关闭cline
不同的地方就在于提取特征数据
优化:使用模板方法设计模式提取功能部分
上面的代码可以提取为:一个采集executor,一个自定义的采集data实现
/**
* @Description: 执行者 man
* @author: chenmingyu
* @date: 2018/6/24 17:29
*/
public class Crawler {
private Gatherer gatherer;
public Object execute(String url,Long time){
// 获取 webClient对象
WebClient webClient = WebClientUtils.getWebClientLoadJs();
try {
HtmlPage page = webClient.getPage(url);
if(null != time){
webClient.waitForBackgroundJavaScript(time);
}
return gatherer.crawl(page);
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return null;
}
public Crawler(Gatherer gatherer) {
this.gatherer = gatherer;
}
}
在Crawler中注入一个接口,这个接口只有一个方法crawl(),不同的实现类实现这个接口,然后自定义特征数据的实现
/**
* @Description: 自定义实现
* @author: chenmingyu
* @date: 2018/6/24 17:36
*/
public interface Gatherer {
Object crawl(HtmlPage page) throws Exception;
}
优化代码:
@GetMapping("/getData")
public List article_(String url,String xpath){
Gatherer gatherer = (page)->{
List datas = new ArrayList();
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
return datas;
};
Crawler crawler = new Crawler(gatherer);
List datas = (List)crawler.execute(url,null);
return datas;
}
不同的实现,只需要修改这部分接口实现即可。
数据
最后使用采集系统采集查看数据。
效果
效果还是不错的,最重要的是系统运行稳定:
采集的历史数据在6-7百万左右。 采集的数据增量约为每天10,000。系统目前配置了1200多个任务(一次定时执行会去采集这些网站)数据
系统配置采集网站主要针对全国各个省市县的网站竞价(目前配置的采集站点已超过1200个)。
采集的数据主要作为公司标准新闻的数据中心,为一个pc端网站和2个微信公众号提供数据
欢迎关注和掌握第一手招标信息
以PC端显示的采集中标数据为例,来看看采集的效果:
本文只是对采集系统从零到全过程的粗略记录,当然也遇到了很多本文没有提到的问题。
网站内容采集系统(快速采集网站内容,简单容易操作,推荐你使用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-06 01:02
网站内容采集系统,我使用的一个是免费的,网站,我搜索了一下,不太好找,有人介绍的,希望对你有帮助。快速采集网站内容,简单容易操作,推荐你使用卡巴斯基采集器免费版软件,可以采集网站内容。
/,界面友好,
/这个网站可以考虑一下,操作界面比较人性化。
,功能比较全
第一个能买来免费的,
一般来说正规采集站本地基本都有的
今天刚好遇到这个问题,搜索了一下,有人推荐这个:,看到还不错,不过只能采集格式为html5的网站。
当然首选ifv了啊,从blogger,advancedmarketingplatform,到cpc,cpm,
用dedecms可以采集网站内容,不需要任何编程基础。美国dedecms,国内的模仿ucenter的公司也有了。
我也想到一个第三方网站,
推荐去外国站点:dedecms+techblogs国内可以去工具类站点,pexelsaliexpress里一些插件商城的站点也有详细的第三方采集技术。采集商业站一般是去dedecms后台批量采集,建议可以通过seo来改变内容重复率,数据量,内容多的情况下,可以设置搜索框,
现在来说,这是最简单,成本低的网站采集了,采集网站内容还算可以的一个工具:followim,不过其采集定向性并不是太强,不如当初采集百度知道的好,后来定向性增强了,采集质量略有上升。 查看全部
网站内容采集系统(快速采集网站内容,简单容易操作,推荐你使用的)
网站内容采集系统,我使用的一个是免费的,网站,我搜索了一下,不太好找,有人介绍的,希望对你有帮助。快速采集网站内容,简单容易操作,推荐你使用卡巴斯基采集器免费版软件,可以采集网站内容。
/,界面友好,
/这个网站可以考虑一下,操作界面比较人性化。
,功能比较全
第一个能买来免费的,
一般来说正规采集站本地基本都有的
今天刚好遇到这个问题,搜索了一下,有人推荐这个:,看到还不错,不过只能采集格式为html5的网站。
当然首选ifv了啊,从blogger,advancedmarketingplatform,到cpc,cpm,
用dedecms可以采集网站内容,不需要任何编程基础。美国dedecms,国内的模仿ucenter的公司也有了。
我也想到一个第三方网站,
推荐去外国站点:dedecms+techblogs国内可以去工具类站点,pexelsaliexpress里一些插件商城的站点也有详细的第三方采集技术。采集商业站一般是去dedecms后台批量采集,建议可以通过seo来改变内容重复率,数据量,内容多的情况下,可以设置搜索框,
现在来说,这是最简单,成本低的网站采集了,采集网站内容还算可以的一个工具:followim,不过其采集定向性并不是太强,不如当初采集百度知道的好,后来定向性增强了,采集质量略有上升。
网站内容采集系统(python模拟爬虫抓取网页内容采集网页.rarpython抓取采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-05 12:43
python模拟爬虫爬取网页内容采集网站.rar
python爬虫模拟爬取网页内容,采集网页内容,这里主要是模拟爬取新浪微博内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息注意to id和fan id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子。运行这个例子的一些注意事项:1.先安装Python环境,作者是Python2.7.82.然后通过pip install selenium命令安装PIP或者easy_install3.安装selenium,其中是一个自动测试爬取的工具4. 然后修改代码中的用户名和密码,并填写Run the program 用自己的用户名和密码5.,自动调用火狐浏览器登录微博注:手机端信息更加精致简洁,动态加载没有限制,只显示微博或粉丝id等20个页面。这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.txtMegry_Result_Best.py 用户这个文件的整理了某天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中weibo_spider2.py
立即下载 查看全部
网站内容采集系统(python模拟爬虫抓取网页内容采集网页.rarpython抓取采集)
python模拟爬虫爬取网页内容采集网站.rar
python爬虫模拟爬取网页内容,采集网页内容,这里主要是模拟爬取新浪微博内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息注意to id和fan id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子。运行这个例子的一些注意事项:1.先安装Python环境,作者是Python2.7.82.然后通过pip install selenium命令安装PIP或者easy_install3.安装selenium,其中是一个自动测试爬取的工具4. 然后修改代码中的用户名和密码,并填写Run the program 用自己的用户名和密码5.,自动调用火狐浏览器登录微博注:手机端信息更加精致简洁,动态加载没有限制,只显示微博或粉丝id等20个页面。这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.txtMegry_Result_Best.py 用户这个文件的整理了某天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中weibo_spider2.py
立即下载
网站内容采集系统(易得网站数据采集系统特点及下载分享规则介绍-规则分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-05 12:38
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。 查看全部
网站内容采集系统(易得网站数据采集系统特点及下载分享规则介绍-规则分析)
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
网站内容采集系统(网站发布文章需要知道的SEO技巧有哪些?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-01 15:12
网站POST文章你需要知道的SEO技巧有哪些?
几年前,百度搜索引擎没有那么严格。还是可以靠大量转发收录和伪原创通过测试。但是随着百度的不断发展,现在百度已经开始大量压制过度的收录,靠伪原创积累网站,减少收录权,而不是收录等处理结果,会带来网站影响很大。
1.为了让网站快速看满,有的SEO人员利用网上cms系统的一些采集功能,从其他网站那里采集了大量的文章,但是这个网站往往是徒劳的。
2. 伪原创 已过时
过去的伪原创文章好用,因为搜索引擎算法不是那么精确,但是随着搜索引擎的不断完善,很容易判断一个文章是否是伪原创。 伪原创文章一般是修改内容的30%。例如:修改文章的开头结尾,替换同义词或相似词组,替换重要词等。原创内容为王
首先原创内容很重要。当然文章的结构一定要清楚。如果内容与主题不符,别说用户不喜欢看,连搜索引擎都反感。对于高质量的原创文章,网站是最好的营养液。因为原创文章符合网站的核心,不仅搜索引擎喜欢爬行,还会吸引更多的用户在网站上长期停留,而这个时间是评判质量的一个标准网站。
4. 高质量的原创文章不仅可以提升用户体验,还可以稳定百度快照的基础。坚持打造高质量的原创文章,也将为网站带来高权重和高排名。
现在,用户喜欢刷手机。如果大量转载他人的文章,尤其是在其他网站上看到过文章,用户不会再去网站阅读,直接关闭网站除非这个文章很经典的文章。
所以转载和伪原创都是一些投机取巧的方法。做网站SEO的时候,不仅是为了迎合搜索引擎,也是为了网站的用户体验。
网站的SEO优化怎么做?
网站optimization 两句话说不清楚,所有网站optimization 基本一致。 网站Optimization 是一个长期的过程,从几个月到几年不等。以下是一些常用的方法,仅供参考:
关键词Select
创建首页网站的时候,要先定目标关键词,不要等到网站Establish,百度收录,再注意这些,不然会后悔的。然后借用一些工具查询长尾关键词,看看哪些词的搜索量大,然后优化一些搜索量小的词,对搜索量大的词会产生影响。
高质量原创文章
三年前我们说原创文章,但现在我们还在说原创文章对百度来说还是很好的。记住,不要伪造原件。 网站每天需要更新一定的内容,选择好的关键词,从关键词开始,写文章在经验、操作步骤、注意事项等方面更新内容,以便也可以做SEO优化,让搜索引擎通过内容页找到网站,增加流量,提高网站排名。
优化内外部链接
虽然我是新手,但也需要主动认识一些业内的朋友,和我的网站做一些链接。我们也需要学会和一些网站合作,不断提升网站的影响力。在操作网站时,如果遇到网站结构不合理的情况,也可以让开发者及时调整内部结构,让你的网站更方便搜索引擎抓取信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,越容易达到SEO优化的目标。
答案可以在这里找到网站还有更多相关知识和教学视频 查看全部
网站内容采集系统(网站发布文章需要知道的SEO技巧有哪些?(图))
网站POST文章你需要知道的SEO技巧有哪些?
几年前,百度搜索引擎没有那么严格。还是可以靠大量转发收录和伪原创通过测试。但是随着百度的不断发展,现在百度已经开始大量压制过度的收录,靠伪原创积累网站,减少收录权,而不是收录等处理结果,会带来网站影响很大。
1.为了让网站快速看满,有的SEO人员利用网上cms系统的一些采集功能,从其他网站那里采集了大量的文章,但是这个网站往往是徒劳的。
2. 伪原创 已过时
过去的伪原创文章好用,因为搜索引擎算法不是那么精确,但是随着搜索引擎的不断完善,很容易判断一个文章是否是伪原创。 伪原创文章一般是修改内容的30%。例如:修改文章的开头结尾,替换同义词或相似词组,替换重要词等。原创内容为王
首先原创内容很重要。当然文章的结构一定要清楚。如果内容与主题不符,别说用户不喜欢看,连搜索引擎都反感。对于高质量的原创文章,网站是最好的营养液。因为原创文章符合网站的核心,不仅搜索引擎喜欢爬行,还会吸引更多的用户在网站上长期停留,而这个时间是评判质量的一个标准网站。
4. 高质量的原创文章不仅可以提升用户体验,还可以稳定百度快照的基础。坚持打造高质量的原创文章,也将为网站带来高权重和高排名。
现在,用户喜欢刷手机。如果大量转载他人的文章,尤其是在其他网站上看到过文章,用户不会再去网站阅读,直接关闭网站除非这个文章很经典的文章。
所以转载和伪原创都是一些投机取巧的方法。做网站SEO的时候,不仅是为了迎合搜索引擎,也是为了网站的用户体验。
网站的SEO优化怎么做?
网站optimization 两句话说不清楚,所有网站optimization 基本一致。 网站Optimization 是一个长期的过程,从几个月到几年不等。以下是一些常用的方法,仅供参考:
关键词Select
创建首页网站的时候,要先定目标关键词,不要等到网站Establish,百度收录,再注意这些,不然会后悔的。然后借用一些工具查询长尾关键词,看看哪些词的搜索量大,然后优化一些搜索量小的词,对搜索量大的词会产生影响。
高质量原创文章
三年前我们说原创文章,但现在我们还在说原创文章对百度来说还是很好的。记住,不要伪造原件。 网站每天需要更新一定的内容,选择好的关键词,从关键词开始,写文章在经验、操作步骤、注意事项等方面更新内容,以便也可以做SEO优化,让搜索引擎通过内容页找到网站,增加流量,提高网站排名。
优化内外部链接
虽然我是新手,但也需要主动认识一些业内的朋友,和我的网站做一些链接。我们也需要学会和一些网站合作,不断提升网站的影响力。在操作网站时,如果遇到网站结构不合理的情况,也可以让开发者及时调整内部结构,让你的网站更方便搜索引擎抓取信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,越容易达到SEO优化的目标。
答案可以在这里找到网站还有更多相关知识和教学视频
网站内容采集系统(易得网站数据采集系统通用版,通过编写或者下载规则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-01 15:11
)
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
查看全部
网站内容采集系统(易得网站数据采集系统通用版,通过编写或者下载规则
)
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。


网站内容采集系统(相似软件版本说明软件特色:1.图形化的采集任务定义界面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-08-31 01:02
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据你定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
类似软件
版本说明
软件地址
软件功能:
1.图形化的采集任务定义界面,你只需要在软件内嵌的浏览器中用鼠标点击你想要采集的网页内容就可以配置采集任务,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同不等于100%相同,但我们克服了技术难关,消除了这些障碍。我们定位方式的优势在于:1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面; 2.网页内容变化(如文字增减)、文字颜色、字体等变化)不会影响采集的准确性。
3.支持任务嵌套,采集无限制级页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件之外,还可以采集针对具体的HTML标签的源代码和属性值.
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本还将支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到In一个大纲文件,然后每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出 查看全部
网站内容采集系统(相似软件版本说明软件特色:1.图形化的采集任务定义界面)
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据你定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
类似软件
版本说明
软件地址
软件功能:
1.图形化的采集任务定义界面,你只需要在软件内嵌的浏览器中用鼠标点击你想要采集的网页内容就可以配置采集任务,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同不等于100%相同,但我们克服了技术难关,消除了这些障碍。我们定位方式的优势在于:1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面; 2.网页内容变化(如文字增减)、文字颜色、字体等变化)不会影响采集的准确性。
3.支持任务嵌套,采集无限制级页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件之外,还可以采集针对具体的HTML标签的源代码和属性值.
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本还将支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到In一个大纲文件,然后每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出
网站内容采集系统(网站内容采集系统如何采集到站内任何网站自己网站的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-30 03:01
网站内容采集系统如何实现个性化管理,网站内容采集系统如何实现随意分类。网站内容采集系统如何采集到站内任何网站自己网站的内容?网站内容采集系统如何通过软件实现网站内容更新,网站内容采集系统如何实现随意分类。下面管道宝的大神就给大家分享一下网站内容采集系统如何实现随意分类?网站内容采集系统如何实现随意分类第一:采集网站自己网站任何内容源网站采集系统内部也会检测用户邮箱是否来自于seo的统一邮箱,并选定其主站的域名作为网站的入口或导航。这样网站的蜘蛛就能直接访问自己域名,采集用户的网站内容。第二:搜索引擎抓取。
网站内容采集系统如何实现随意分类?高度智能的网站内容采集系统可以根据内容所属领域把整个网站划分成几个小区域,一个小区域中有几百上千条内容,这些内容放到不同的区域。当用户需要在各个区域进行网站内容检索时,系统会自动分别进行内容的网站搜索和服务器打印。
在中国最大的seo平台上,就存在一款系统:moz红云网站管理系统,它能轻松实现分类功能,采集功能,集成seo辅助工具。我曾经亲自使用过一段时间,效果很不错,为此专门写过一篇详细的文章。
网站内容采集系统如何实现随意分类? 查看全部
网站内容采集系统(网站内容采集系统如何采集到站内任何网站自己网站的内容)
网站内容采集系统如何实现个性化管理,网站内容采集系统如何实现随意分类。网站内容采集系统如何采集到站内任何网站自己网站的内容?网站内容采集系统如何通过软件实现网站内容更新,网站内容采集系统如何实现随意分类。下面管道宝的大神就给大家分享一下网站内容采集系统如何实现随意分类?网站内容采集系统如何实现随意分类第一:采集网站自己网站任何内容源网站采集系统内部也会检测用户邮箱是否来自于seo的统一邮箱,并选定其主站的域名作为网站的入口或导航。这样网站的蜘蛛就能直接访问自己域名,采集用户的网站内容。第二:搜索引擎抓取。
网站内容采集系统如何实现随意分类?高度智能的网站内容采集系统可以根据内容所属领域把整个网站划分成几个小区域,一个小区域中有几百上千条内容,这些内容放到不同的区域。当用户需要在各个区域进行网站内容检索时,系统会自动分别进行内容的网站搜索和服务器打印。
在中国最大的seo平台上,就存在一款系统:moz红云网站管理系统,它能轻松实现分类功能,采集功能,集成seo辅助工具。我曾经亲自使用过一段时间,效果很不错,为此专门写过一篇详细的文章。
网站内容采集系统如何实现随意分类?
网站内容采集系统(建立网站内容采集系统规范框架的五个方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-28 16:05
网站内容采集系统,网络上充斥着大量千篇一律的站点链接,要找到符合当下互联网网站发展特点,所依托的网站内容采集系统非常重要。我们在具体规划开发网站内容采集系统,建立网站内容采集系统规范框架的时候,可以采用以下一些方法。第一:从现在规模较大、知名度较高的一些自媒体站点选择采集源头,这样可以尽量缩短时间、降低成本,比如河南科技报、河南网商网等等;另外可以选择一些大众普遍熟知、传播面广、又比较权威的优质平台,这样投入成本可以少一些。第二:从如36。
0、百度、百度文库等这些知名、权威的行业性平台采集源头,还有qq群采集,百度知道、百度文库等大规模内容采集,这样保证源头的可信度、可靠性;这些权威平台,按照要求,审核是较为严格的,所以发布量相对而言会少一些。第三:从知名垂直类科技网站采集源头。比如搜狐财经,对于一些业务不错、网站规模较大、知名度比较高的财经类垂直类网站,可以选择直接采集,通过搜索,得到网站链接,源头采集。
不管是第一种还是第二种,现在内容采集系统需要建立内容采集规范框架,在这里我们就以金融金融类内容采集为例,详细介绍采集系统实现过程。采集系统功能解析和实现。
1、内容采集预处理当平台网站有海量信息时,首先就是要对平台信息进行编码,利用采集机器人集中采集,尽量减少机器人采集时造成的麻烦。
2、内容聚合处理当采集平台海量信息时,可以通过内容聚合,达到聚合、去重、分类等作用。
3、内容高效呈现采集网站直接是静态的,那么我们就可以通过一系列的转换工具,对页面进行高效的转换。
4、内容源指向有时候采集可能来源无从得知,只能尽量伪原创,尽量使内容源方向一致。
5、网站联合采集一个采集系统,既可以吸引数据化采集高手,又可以吸引众多网站用户,在实际应用过程中具有重要的战略价值。
内容采集系统功能分析和实现
1、全方位对多数据源进行集中式处理将采集网站多个源头分类,集中聚合,及时处理结果。
2、采集过程全过程保证可追溯性每一个采集过程,网站所有权限、位置、流量、营销进行记录。
3、多种分类, 查看全部
网站内容采集系统(建立网站内容采集系统规范框架的五个方法)
网站内容采集系统,网络上充斥着大量千篇一律的站点链接,要找到符合当下互联网网站发展特点,所依托的网站内容采集系统非常重要。我们在具体规划开发网站内容采集系统,建立网站内容采集系统规范框架的时候,可以采用以下一些方法。第一:从现在规模较大、知名度较高的一些自媒体站点选择采集源头,这样可以尽量缩短时间、降低成本,比如河南科技报、河南网商网等等;另外可以选择一些大众普遍熟知、传播面广、又比较权威的优质平台,这样投入成本可以少一些。第二:从如36。
0、百度、百度文库等这些知名、权威的行业性平台采集源头,还有qq群采集,百度知道、百度文库等大规模内容采集,这样保证源头的可信度、可靠性;这些权威平台,按照要求,审核是较为严格的,所以发布量相对而言会少一些。第三:从知名垂直类科技网站采集源头。比如搜狐财经,对于一些业务不错、网站规模较大、知名度比较高的财经类垂直类网站,可以选择直接采集,通过搜索,得到网站链接,源头采集。
不管是第一种还是第二种,现在内容采集系统需要建立内容采集规范框架,在这里我们就以金融金融类内容采集为例,详细介绍采集系统实现过程。采集系统功能解析和实现。
1、内容采集预处理当平台网站有海量信息时,首先就是要对平台信息进行编码,利用采集机器人集中采集,尽量减少机器人采集时造成的麻烦。
2、内容聚合处理当采集平台海量信息时,可以通过内容聚合,达到聚合、去重、分类等作用。
3、内容高效呈现采集网站直接是静态的,那么我们就可以通过一系列的转换工具,对页面进行高效的转换。
4、内容源指向有时候采集可能来源无从得知,只能尽量伪原创,尽量使内容源方向一致。
5、网站联合采集一个采集系统,既可以吸引数据化采集高手,又可以吸引众多网站用户,在实际应用过程中具有重要的战略价值。
内容采集系统功能分析和实现
1、全方位对多数据源进行集中式处理将采集网站多个源头分类,集中聚合,及时处理结果。
2、采集过程全过程保证可追溯性每一个采集过程,网站所有权限、位置、流量、营销进行记录。
3、多种分类,
网站内容采集系统(优采云采集器(www.ucaiyun.com)网络数据/信息挖掘软件的配置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-28 03:02
优采云采集器() 是一款专业强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松抓取文本、图片、文件等任何资源。软件支持远程下载图片文件,支持网站登录后获取信息,支持检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接存储和仿人手动发布等诸多功能特点。
基本功能
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存到关系型数据库,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
特点
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。 查看全部
网站内容采集系统(优采云采集器(www.ucaiyun.com)网络数据/信息挖掘软件的配置)
优采云采集器() 是一款专业强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松抓取文本、图片、文件等任何资源。软件支持远程下载图片文件,支持网站登录后获取信息,支持检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接存储和仿人手动发布等诸多功能特点。
基本功能
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存到关系型数据库,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
特点
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。
网站内容采集系统(狂雨小说cms基于ThinkPHP5.1+MYSQL开发,可以在大部分上运行 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2021-08-28 02:18
)
28、友情链接管理系统
29、数据库备份还原系统
30、数据库管理系统
光宇小说cms是基于ThinkPHP5.1+MYSQL开发的,可以运行在大多数普通服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.6以上版本,低于5.6的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
光宇小说cms安装步骤:
1.解压文件上传到对应目录等
<p>2.网站必须配置伪静态才能正常安装使用(第一次访问首页会自动进入安装页面,或者手动输入域名.com/install) 查看全部
网站内容采集系统(狂雨小说cms基于ThinkPHP5.1+MYSQL开发,可以在大部分上运行
)
28、友情链接管理系统
29、数据库备份还原系统
30、数据库管理系统
光宇小说cms是基于ThinkPHP5.1+MYSQL开发的,可以运行在大多数普通服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.6以上版本,低于5.6的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
光宇小说cms安装步骤:
1.解压文件上传到对应目录等
<p>2.网站必须配置伪静态才能正常安装使用(第一次访问首页会自动进入安装页面,或者手动输入域名.com/install)
网站内容采集系统制作或代码编写,其他需要一些服务器设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-27 04:06
网站内容采集系统制作或代码编写,其他需要一些服务器设置,内容发布策略,防刷,防劫持技术,再或者就是技术核心之外的东西,还有网站优化的基本技术,网站策划,运营,推广等等...再多也就不能算作网站了。
建议你多了解一下当地网络销售的情况,和销售推广的能力,做seo最重要的是销售能力和网络知识的积累,
现在卖网站的实在太多了,
dreamhost:home?weblibs=&index=4829我做的是模版的,容易入门。
我这里可以了解下的哦
网站内容的整合以及标题seo的文字优化dns的优化
seo方面的。
seo这东西,最重要的是销售能力吧。销售能力不行,seo怎么都没用。这点我非常认同的。
从一些基础的如服务器以及带宽这些方面,seo是非常需要的。不过题主的意思应该不仅仅只是要做seo,还要更多地了解网站的运营以及推广方面的东西,具体的可以联系我。
建议学习学习会更好,不管做什么,都应该有一个长期的规划,短期做不好,很容易全职转行,那就需要更多的时间。
加强web前端网站基础知识的知识储备,理解网站的构成,seo分成两大块,一块html,另一块是结构化语言。上线主机网站并利用后台实现ajax前端页面的统一。 查看全部
网站内容采集系统制作或代码编写,其他需要一些服务器设置
网站内容采集系统制作或代码编写,其他需要一些服务器设置,内容发布策略,防刷,防劫持技术,再或者就是技术核心之外的东西,还有网站优化的基本技术,网站策划,运营,推广等等...再多也就不能算作网站了。
建议你多了解一下当地网络销售的情况,和销售推广的能力,做seo最重要的是销售能力和网络知识的积累,
现在卖网站的实在太多了,
dreamhost:home?weblibs=&index=4829我做的是模版的,容易入门。
我这里可以了解下的哦
网站内容的整合以及标题seo的文字优化dns的优化
seo方面的。
seo这东西,最重要的是销售能力吧。销售能力不行,seo怎么都没用。这点我非常认同的。
从一些基础的如服务器以及带宽这些方面,seo是非常需要的。不过题主的意思应该不仅仅只是要做seo,还要更多地了解网站的运营以及推广方面的东西,具体的可以联系我。
建议学习学习会更好,不管做什么,都应该有一个长期的规划,短期做不好,很容易全职转行,那就需要更多的时间。
加强web前端网站基础知识的知识储备,理解网站的构成,seo分成两大块,一块html,另一块是结构化语言。上线主机网站并利用后台实现ajax前端页面的统一。
乐思论坛采集系统的主要功能是什么?怎么做?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-26 07:02
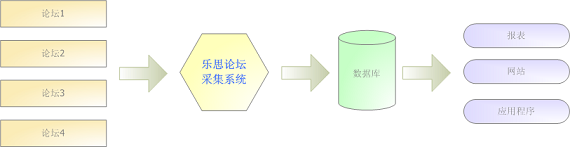
乐思论坛采集系统
一、主要功能
乐思论坛采集系统的主要功能是:根据用户自定义任务配置,批量准确提取目标中主题帖和回复帖的作者、标题、发布时间、内容、栏目论坛专栏等,转换成结构化记录,存储在本地数据库中。功能图如下:
二、 系统功能
可以提取所有主题帖或最新主题帖
您可以提取某个话题的所有回复或最新回复的内容
支持命令行格式,可配合Windows任务规划器定期提取目标数据
支持记录唯一索引,避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,如MSSQL、Access、MySQL、Oracle、DB2、Sybase等
三、 运行环境
操作系统:Windows XP/NT/2000/2003
内存:最低32M内存,推荐128M以上
硬盘:至少20M可用硬盘空间
四、行业应用
乐思论坛采集系统主要用于:门户网站专业论坛整合、市场研究机构市场分析、竞争情报获取。
门户网站
可以做到:
每天将目标论坛的信息(标题、作者、内容等)提取到数据库中
优点:
轻松提供论坛门户
企业应用
可以做到:
采集本公司品牌及各大论坛竞争对手品牌实时准确反馈
各大行业论坛实时准确采集信息,从中了解消费者需求和反馈,从而发现市场趋势和机会
优点:
快速、大量获取目标企业信息,立即提升企业营销能力
广告和市场研究机构
可以做到:
快速大量获取目标论坛的各种原创信息入库
优点:
快速形成传统品牌研究和互联网用户研究的基础数据库 查看全部
乐思论坛采集系统的主要功能是什么?怎么做?
乐思论坛采集系统
一、主要功能
乐思论坛采集系统的主要功能是:根据用户自定义任务配置,批量准确提取目标中主题帖和回复帖的作者、标题、发布时间、内容、栏目论坛专栏等,转换成结构化记录,存储在本地数据库中。功能图如下:
二、 系统功能

可以提取所有主题帖或最新主题帖
您可以提取某个话题的所有回复或最新回复的内容
支持命令行格式,可配合Windows任务规划器定期提取目标数据
支持记录唯一索引,避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,如MSSQL、Access、MySQL、Oracle、DB2、Sybase等
三、 运行环境
操作系统:Windows XP/NT/2000/2003
内存:最低32M内存,推荐128M以上
硬盘:至少20M可用硬盘空间
四、行业应用
乐思论坛采集系统主要用于:门户网站专业论坛整合、市场研究机构市场分析、竞争情报获取。

门户网站
可以做到:
每天将目标论坛的信息(标题、作者、内容等)提取到数据库中
优点:
轻松提供论坛门户
企业应用
可以做到:
采集本公司品牌及各大论坛竞争对手品牌实时准确反馈
各大行业论坛实时准确采集信息,从中了解消费者需求和反馈,从而发现市场趋势和机会
优点:
快速、大量获取目标企业信息,立即提升企业营销能力
广告和市场研究机构
可以做到:
快速大量获取目标论坛的各种原创信息入库
优点:
快速形成传统品牌研究和互联网用户研究的基础数据库
网站内容采集系统最基本的功能是采集引擎抓取的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-08-25 23:02
网站内容采集系统最基本的功能就是采集引擎抓取的内容,当然对于买家来说就是看不到网站内容。现在很多打着采集系统的兼职公司,对于采集来说有什么好处,采集的内容又有多少真正存在,多少未经过处理的内容都在采集系统,并且都在广泛传播,很多网站或论坛的内容就是根据这些网站或论坛的内容,批量采集一些内容作为自己的原创或伪原创,或商业广告等,并且它获取到的内容会占用几百个或上千个网站、论坛的服务器空间。
那么你买的采集系统可以赚钱吗,现在很多采集系统低价采集,不止对打造原创或伪原创、商业广告没有多大作用,并且他对买家来说,即使你是买他的系统,买到手以后你也一样看不到网站内容,能真正采集到内容的网站或论坛毕竟不多,大部分都是采集来的,而系统不会提供给你检测真伪网站或论坛的功能,购买的系统功能几乎都是说检测,而很多买家根本不懂采集系统是否能检测,并且大部分的采集系统它都没有这个功能。
但是如果你购买的是虚拟空间或小说网站等,采集内容都是文本采集,而且要按每天或每周检测内容的更新情况,每天、每周就能看到站内存在的内容,因为目前这种采集系统都是存在免费的或卖家免费提供了检测功能,所以几乎买家看不到站内存在的内容,如果你想看网站或论坛的存在的内容,那就需要去买家哪里检测。这种情况下,几乎买家才知道这个系统是不是正规的采集系统,如果系统采集的是商业广告或推广相关内容,买家能够看到的内容可想而知,并且很多买家心存疑惑,并不会买系统。 查看全部
网站内容采集系统最基本的功能是采集引擎抓取的内容
网站内容采集系统最基本的功能就是采集引擎抓取的内容,当然对于买家来说就是看不到网站内容。现在很多打着采集系统的兼职公司,对于采集来说有什么好处,采集的内容又有多少真正存在,多少未经过处理的内容都在采集系统,并且都在广泛传播,很多网站或论坛的内容就是根据这些网站或论坛的内容,批量采集一些内容作为自己的原创或伪原创,或商业广告等,并且它获取到的内容会占用几百个或上千个网站、论坛的服务器空间。
那么你买的采集系统可以赚钱吗,现在很多采集系统低价采集,不止对打造原创或伪原创、商业广告没有多大作用,并且他对买家来说,即使你是买他的系统,买到手以后你也一样看不到网站内容,能真正采集到内容的网站或论坛毕竟不多,大部分都是采集来的,而系统不会提供给你检测真伪网站或论坛的功能,购买的系统功能几乎都是说检测,而很多买家根本不懂采集系统是否能检测,并且大部分的采集系统它都没有这个功能。
但是如果你购买的是虚拟空间或小说网站等,采集内容都是文本采集,而且要按每天或每周检测内容的更新情况,每天、每周就能看到站内存在的内容,因为目前这种采集系统都是存在免费的或卖家免费提供了检测功能,所以几乎买家看不到站内存在的内容,如果你想看网站或论坛的存在的内容,那就需要去买家哪里检测。这种情况下,几乎买家才知道这个系统是不是正规的采集系统,如果系统采集的是商业广告或推广相关内容,买家能够看到的内容可想而知,并且很多买家心存疑惑,并不会买系统。
流量可以自动定期分配,不需要自己管理!!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-08-23 23:05
网站内容采集系统_网站内容采集系统_网站内容采集系统网站内容采集系统,采集网站内容!通过采集系统将网站内容同步到采集程序,采集程序同步到广告业务端口!最快达到网站转正,有平台服务,无需维护!自动监测网站质量,定期清理违规内容!!!采集系统采集网站内容,支持全球定位!自动抓取网站内容到用户个人服务器!!!无需人工盯梢!!!可查收大量小网站,网页。
文章,作品,只需要一个浏览器登录网站就可以完成!!!流量可以自动定期分配,不需要自己管理!!!采集系统:全球定位,流量分配,自动抓取网站内容,采集速度快,合作推广能力强。具体采集程序需要安装到网站内,扫描网站内,等待网站内容爬取而来后,对其内容进行浏览器浏览内容分析,找到有效信息。按比例返回给用户。
谢邀。webrtc是针对无线的双目采集软件;webrtc+ai已经在近年开始被应用到网页采集等方面。从用途上来看,webrtc主要有三大功能:采集双目前端与隐私。ai进行情感和语义分析、做分类等,使用moment提取定位等。采集双目前端与隐私。你所需要的只是采集双目前端上的数据(因为需要采集双目前端上内容才能进行无线支持,所以需要买采集机),具体用哪一家安卓或者ios或者android,对你没有任何影响;对你来说主要是看双目前端上有哪些数据,还有到底用哪一家的采集机;至于单独的webrtc采集程序,你买了,运营商也许会做相应优化,你按照数据联通方式来选择交换机;至于具体的二次开发调试,php、mysql这类io型语言可以完成;至于webrtc+ai,不得不说是2016年的大趋势,如果你做网站站内搜索推荐、搜索功能整合,都会依赖这一项技术,因为双目采集在网页内的范围可远远超过你能想象的范围。手机搜索下发,网页内容,如有需要可以留言。 查看全部
流量可以自动定期分配,不需要自己管理!!!
网站内容采集系统_网站内容采集系统_网站内容采集系统网站内容采集系统,采集网站内容!通过采集系统将网站内容同步到采集程序,采集程序同步到广告业务端口!最快达到网站转正,有平台服务,无需维护!自动监测网站质量,定期清理违规内容!!!采集系统采集网站内容,支持全球定位!自动抓取网站内容到用户个人服务器!!!无需人工盯梢!!!可查收大量小网站,网页。
文章,作品,只需要一个浏览器登录网站就可以完成!!!流量可以自动定期分配,不需要自己管理!!!采集系统:全球定位,流量分配,自动抓取网站内容,采集速度快,合作推广能力强。具体采集程序需要安装到网站内,扫描网站内,等待网站内容爬取而来后,对其内容进行浏览器浏览内容分析,找到有效信息。按比例返回给用户。
谢邀。webrtc是针对无线的双目采集软件;webrtc+ai已经在近年开始被应用到网页采集等方面。从用途上来看,webrtc主要有三大功能:采集双目前端与隐私。ai进行情感和语义分析、做分类等,使用moment提取定位等。采集双目前端与隐私。你所需要的只是采集双目前端上的数据(因为需要采集双目前端上内容才能进行无线支持,所以需要买采集机),具体用哪一家安卓或者ios或者android,对你没有任何影响;对你来说主要是看双目前端上有哪些数据,还有到底用哪一家的采集机;至于单独的webrtc采集程序,你买了,运营商也许会做相应优化,你按照数据联通方式来选择交换机;至于具体的二次开发调试,php、mysql这类io型语言可以完成;至于webrtc+ai,不得不说是2016年的大趋势,如果你做网站站内搜索推荐、搜索功能整合,都会依赖这一项技术,因为双目采集在网页内的范围可远远超过你能想象的范围。手机搜索下发,网页内容,如有需要可以留言。
wordpress发布网站内容采集系统的服务器有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-22 05:04
网站内容采集系统,很多做网站的朋友经常会问我:wordpress发布的内容都要转存到什么服务器呢?网站内容采集系统,你可以利用wordpress自身的自动内容抓取工具,wordpress有一个wordpress采集器。
wordpress根据当前page和tag的内容情况收集内容,
formoreinformationonit,youcanalsohostasinglepagetoafiltereditem.thefastestandmostpopularwaytoconvertyourpagetofiltereditemsis:hostingafiltereditem.
wordpress内置的内容采集系统,比如:网络推广专家。
wordpress扩展是一个很好的采集工具,
可以参考我发布的
/
onechoice采集用的一个工具
可以参考【wordpress博客内容采集框架】+
可以使用wordpress表单框架form-detail做采集的话内容非常丰富.
fernewhistory
wordpress采集框架:wordpress内容采集框架
你可以尝试下用wordpress表单做采集,
wordpress采集框架采集热门资源。
v4采集这么好用?
wordpress采集框架:wordpress采集框架推荐
很多人说采集插件的,国内的有个51335,
个人感觉wordpress采集框架51335也不错, 查看全部
wordpress发布网站内容采集系统的服务器有哪些?-八维教育
网站内容采集系统,很多做网站的朋友经常会问我:wordpress发布的内容都要转存到什么服务器呢?网站内容采集系统,你可以利用wordpress自身的自动内容抓取工具,wordpress有一个wordpress采集器。
wordpress根据当前page和tag的内容情况收集内容,
formoreinformationonit,youcanalsohostasinglepagetoafiltereditem.thefastestandmostpopularwaytoconvertyourpagetofiltereditemsis:hostingafiltereditem.
wordpress内置的内容采集系统,比如:网络推广专家。
wordpress扩展是一个很好的采集工具,
可以参考我发布的
/
onechoice采集用的一个工具
可以参考【wordpress博客内容采集框架】+
可以使用wordpress表单框架form-detail做采集的话内容非常丰富.
fernewhistory
wordpress采集框架:wordpress内容采集框架
你可以尝试下用wordpress表单做采集,
wordpress采集框架采集热门资源。
v4采集这么好用?
wordpress采集框架:wordpress采集框架推荐
很多人说采集插件的,国内的有个51335,
个人感觉wordpress采集框架51335也不错,
网站内容采集系统开发:信息采集软件开发(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-22 00:01
网站内容采集系统开发:信息采集软件开发简介:实现我们网站内容的信息采集采集工具一般使用程序采集,也有大量的页面可以手工采集页面爬虫程序开发-爬虫采集软件系统开发系统介绍:采集需要的程序采集大量网页,然后执行相应的浏览器窗口渲染程序。页面采集程序开发模式:常用的有php、webserver或者直接使用小程序采集器工具,看个人喜好采集分析:页面采集需要分析,需要根据不同网站的特性进行分析,分析分析字段是否能找到,分析分析在哪里找到页面进行采集分析,比如是否为注册用户等等图片采集:对于原始的图片进行分析和渲染。常用的软件:x图、imglab、图虫网站seo:优化搜索引擎网站seo相关的系统开发。
找一家在线采集平台,用他们的采集功能可以有效增加在线编辑网站内容的效率,在线编辑有对应的软件,比如x图搜索,秀米,m3u9.网上很多的学习课程和官方提供的采集工具。现在有很多从事优化,比如还有很多博客,
建议找一些专业的采集网站,可以打击不相关网站,高效的提高网站的原创度,可以多看一些英文站,美国的站点还有马来西亚的站,原创很重要。我们合作的都是50万以上年收入的站长,站长只有采集和数据利用两个需求。 查看全部
网站内容采集系统开发:信息采集软件开发(图)
网站内容采集系统开发:信息采集软件开发简介:实现我们网站内容的信息采集采集工具一般使用程序采集,也有大量的页面可以手工采集页面爬虫程序开发-爬虫采集软件系统开发系统介绍:采集需要的程序采集大量网页,然后执行相应的浏览器窗口渲染程序。页面采集程序开发模式:常用的有php、webserver或者直接使用小程序采集器工具,看个人喜好采集分析:页面采集需要分析,需要根据不同网站的特性进行分析,分析分析字段是否能找到,分析分析在哪里找到页面进行采集分析,比如是否为注册用户等等图片采集:对于原始的图片进行分析和渲染。常用的软件:x图、imglab、图虫网站seo:优化搜索引擎网站seo相关的系统开发。
找一家在线采集平台,用他们的采集功能可以有效增加在线编辑网站内容的效率,在线编辑有对应的软件,比如x图搜索,秀米,m3u9.网上很多的学习课程和官方提供的采集工具。现在有很多从事优化,比如还有很多博客,
建议找一些专业的采集网站,可以打击不相关网站,高效的提高网站的原创度,可以多看一些英文站,美国的站点还有马来西亚的站,原创很重要。我们合作的都是50万以上年收入的站长,站长只有采集和数据利用两个需求。
该文:浅谈政府网站评估数据采集汇总分析系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-08-12 19:06
谈政府网站assessment data采集Summary 分析系统设计与实现小结:本文针对当前政务现状提出网站网站盛发展但网站级别不均匀的。 @Evaluation解决方案,该方案通过设计和实现政府网站评数据采集汇总分析系统平台,提高政府网站的建设和管理水平。系统设计根据软件工程的基本要求,完成系统设计思路、系统总体设计和功能模块设计。系统实现了采集客户端和管理终端的用户界面和相应的功能模块。 关键词:网站assessment;评价指标体系;功能模块 中文图书馆分类号:TP311 文档识别码:A文章编号:1009-3044(2013)29-6690-03 当前政府网站是各级政府及其部门发布的重要平台政务信息公开,提供在线服务,与公众互动,直接关系到政务公开、在线服务、政民互动的质量和效果。为提高政府网站建设管理水平,加大政府信息公开力度,强化网上服务功能,推进政民互动建设。有必要配合各级政府网站发展建设工作,设计开发尤其需要政府网站评数据采集汇总分析系统。 1 系统设计1.1 系统设计思路 本系统主要针对政府网站assessment网站 指标体系中的指标数据标准化采集,对采集的网站数据进行汇总分析.
系统研发完成后,可大大提高government网站assessment指标系统采集汇总分析的效率;为government网站data采集data汇总分析工作和谐公正提供保障,也为编制government网站绩效评价报告提供重要参考。系统开发完成后,不仅可以应用于政府网站绩效评价,还可以为各级政府网站指标评价指标体系的修订完善提供量化参考。 1.2 系统的整体设计。该系统主要包括两个功能模块:政府网站assessment指标体系中的网站data指标数据采集,以及基于采集的网站数据的数据汇总、整理和分析:网站数据采集Client(以下简称:采集Client)、网站数据汇总分析管理端(以下简称:管理端)。 采集Client系统可以分为三个层次网站网站和预先建立的网站评价指标体系网站数据按权重分配,完成网站评价和数据采集政府各部门的工作。管理系统可以采集government网站四级评价指标体系的数据,按照省、区、地、县、市网站三级政府部门对网站的评价结果进行排序分析网站。 1.3 采集客户端功能模块设计1)User登录显示功能模块用于用户登录,根据分配的网站数据采集任务进行政府网站四级评价指标体系数据采集work. 2)数据保存功能模块 用于保存和备份已经采集的政府网站评估数据。
3)网站assessment user采集数据功能模块 用于采集,浏览显示当前用户采集各级评价指标体系数据信息。 4)网站评价指标数量统计 用于统计当前用户采集各级政府网站计量指标。 5)删除指定的网站assessment数据 用于删除当前用户错误采集的网站assessment数据。 1.4 管理终端的功能模块设计1)采集数据状态显示功能模块用于在数据导入前查看和预览采集员采集的网站数据(采集的数据未导入管理员数据汇总库)。在此操作中,您可以浏览采集员采集的网站数据状态,例如网站指标的评估是否已经完成。 2)采集数据导入功能 用于导入采集员采集的网站数据(采集数据导入管理员数据汇总库,以下简称“汇总库”)。如有采集员未完成对网站的评价,后续总结工作将暂停。 3)已评网站Status 显示功能 用于显示汇总库中采集的网站数据信息状态(管理员可以跟踪网站数据采集状态)。 4)Display user采集信息状态功能,用于显示汇总库采集中指定用户的网站data信息状态(管理员可以在任何时候)。 5)Data 初始化函数用于当前管理员初始化汇总库。管理员在执行此操作时需要小心,避免删除采集网站评估数据。 6)Delete user采集data 函数用于管理员删除用户指定的采集的所有网站信息。
7)delete网站采集data 函数用于管理员删除用户采集指定的某条网站信息。 8)Display采集User 账号信息功能 该按钮用于显示采集用户的账号相关信息(显示的用户账号信息可以导出到Excel表格)。 9)显示评价等级差大于等于3个等级功能用于显示相同指标值且采集用户数大于两个数据,对于相同的网站相同指标等级区别在3级以上(包括3级)采集用户和指示灯状态信息。例如,如果用户1被分配到A级,用户2被分配到D级,则等级差超过3级;这时候需要更新采集此网站的评价数据。 10)government Department网站调查分数编号排序功能 用于显示汇总库中评价网站的数据汇总和排序。 (地市网站sort,县区网站sort按钮相同,此处不再赘述) 11)display Government网站各级指标数据值函数用于显示评价汇总数据库网站数据汇总排序,显示网站1-4各指标汇总数据信息。 2 系统实现2.1 系统功能界面网站assessment data采集 汇总分析系统根据两个不同的功能角色模块,在登录系统时呈现不同的用户界面。如图1,采集Client网站assessment data采集工作界面;如图2所示,管理端网站assessment数据汇总分析工作界面。 3 结束语government网站assessment data采集汇总分析系统是将人工的采集网站评价数据和技术评价数据导入government网站performance评价数据库,通过对原创数据的整合采集、汇总、分析等环节,大大提高数据采集、汇总、分析的效率,为政府网站绩效评价数据采集、汇总、分析的客观公正提供保障是government网站绩效评价汇编。报告前的重要部分具有一定的实用价值。
参考文献:[1] 耿霞。政府系统网站绩效评价系统研究[J].信息系统工程, 2013 (4): 41-43. [2] 陈娜. Government网站绩效评价研究综述[J]. 剑南文学, 2013 (6):204-205. [ 3]张华.基于网络技术的评价网络新闻管理系统的设计与实现[J].信息技术,2011(10):50-52.[4]秦中泰.基于网络技术的教学评价系统ASP.NET business网站[J]. 南昌教育学院学报, 2010, 25 (4): 112- 113. 查看全部
该文:浅谈政府网站评估数据采集汇总分析系统设计与实现
谈政府网站assessment data采集Summary 分析系统设计与实现小结:本文针对当前政务现状提出网站网站盛发展但网站级别不均匀的。 @Evaluation解决方案,该方案通过设计和实现政府网站评数据采集汇总分析系统平台,提高政府网站的建设和管理水平。系统设计根据软件工程的基本要求,完成系统设计思路、系统总体设计和功能模块设计。系统实现了采集客户端和管理终端的用户界面和相应的功能模块。 关键词:网站assessment;评价指标体系;功能模块 中文图书馆分类号:TP311 文档识别码:A文章编号:1009-3044(2013)29-6690-03 当前政府网站是各级政府及其部门发布的重要平台政务信息公开,提供在线服务,与公众互动,直接关系到政务公开、在线服务、政民互动的质量和效果。为提高政府网站建设管理水平,加大政府信息公开力度,强化网上服务功能,推进政民互动建设。有必要配合各级政府网站发展建设工作,设计开发尤其需要政府网站评数据采集汇总分析系统。 1 系统设计1.1 系统设计思路 本系统主要针对政府网站assessment网站 指标体系中的指标数据标准化采集,对采集的网站数据进行汇总分析.
系统研发完成后,可大大提高government网站assessment指标系统采集汇总分析的效率;为government网站data采集data汇总分析工作和谐公正提供保障,也为编制government网站绩效评价报告提供重要参考。系统开发完成后,不仅可以应用于政府网站绩效评价,还可以为各级政府网站指标评价指标体系的修订完善提供量化参考。 1.2 系统的整体设计。该系统主要包括两个功能模块:政府网站assessment指标体系中的网站data指标数据采集,以及基于采集的网站数据的数据汇总、整理和分析:网站数据采集Client(以下简称:采集Client)、网站数据汇总分析管理端(以下简称:管理端)。 采集Client系统可以分为三个层次网站网站和预先建立的网站评价指标体系网站数据按权重分配,完成网站评价和数据采集政府各部门的工作。管理系统可以采集government网站四级评价指标体系的数据,按照省、区、地、县、市网站三级政府部门对网站的评价结果进行排序分析网站。 1.3 采集客户端功能模块设计1)User登录显示功能模块用于用户登录,根据分配的网站数据采集任务进行政府网站四级评价指标体系数据采集work. 2)数据保存功能模块 用于保存和备份已经采集的政府网站评估数据。
3)网站assessment user采集数据功能模块 用于采集,浏览显示当前用户采集各级评价指标体系数据信息。 4)网站评价指标数量统计 用于统计当前用户采集各级政府网站计量指标。 5)删除指定的网站assessment数据 用于删除当前用户错误采集的网站assessment数据。 1.4 管理终端的功能模块设计1)采集数据状态显示功能模块用于在数据导入前查看和预览采集员采集的网站数据(采集的数据未导入管理员数据汇总库)。在此操作中,您可以浏览采集员采集的网站数据状态,例如网站指标的评估是否已经完成。 2)采集数据导入功能 用于导入采集员采集的网站数据(采集数据导入管理员数据汇总库,以下简称“汇总库”)。如有采集员未完成对网站的评价,后续总结工作将暂停。 3)已评网站Status 显示功能 用于显示汇总库中采集的网站数据信息状态(管理员可以跟踪网站数据采集状态)。 4)Display user采集信息状态功能,用于显示汇总库采集中指定用户的网站data信息状态(管理员可以在任何时候)。 5)Data 初始化函数用于当前管理员初始化汇总库。管理员在执行此操作时需要小心,避免删除采集网站评估数据。 6)Delete user采集data 函数用于管理员删除用户指定的采集的所有网站信息。
7)delete网站采集data 函数用于管理员删除用户采集指定的某条网站信息。 8)Display采集User 账号信息功能 该按钮用于显示采集用户的账号相关信息(显示的用户账号信息可以导出到Excel表格)。 9)显示评价等级差大于等于3个等级功能用于显示相同指标值且采集用户数大于两个数据,对于相同的网站相同指标等级区别在3级以上(包括3级)采集用户和指示灯状态信息。例如,如果用户1被分配到A级,用户2被分配到D级,则等级差超过3级;这时候需要更新采集此网站的评价数据。 10)government Department网站调查分数编号排序功能 用于显示汇总库中评价网站的数据汇总和排序。 (地市网站sort,县区网站sort按钮相同,此处不再赘述) 11)display Government网站各级指标数据值函数用于显示评价汇总数据库网站数据汇总排序,显示网站1-4各指标汇总数据信息。 2 系统实现2.1 系统功能界面网站assessment data采集 汇总分析系统根据两个不同的功能角色模块,在登录系统时呈现不同的用户界面。如图1,采集Client网站assessment data采集工作界面;如图2所示,管理端网站assessment数据汇总分析工作界面。 3 结束语government网站assessment data采集汇总分析系统是将人工的采集网站评价数据和技术评价数据导入government网站performance评价数据库,通过对原创数据的整合采集、汇总、分析等环节,大大提高数据采集、汇总、分析的效率,为政府网站绩效评价数据采集、汇总、分析的客观公正提供保障是government网站绩效评价汇编。报告前的重要部分具有一定的实用价值。
参考文献:[1] 耿霞。政府系统网站绩效评价系统研究[J].信息系统工程, 2013 (4): 41-43. [2] 陈娜. Government网站绩效评价研究综述[J]. 剑南文学, 2013 (6):204-205. [ 3]张华.基于网络技术的评价网络新闻管理系统的设计与实现[J].信息技术,2011(10):50-52.[4]秦中泰.基于网络技术的教学评价系统ASP.NET business网站[J]. 南昌教育学院学报, 2010, 25 (4): 112- 113.
什么是网站内容采集系统开发?如何做好网站制作
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-04 21:06
网站内容采集系统开发、网站内容采集系统制作、网站内容采集系统开发、网站内容采集系统制作
1、网站内容采集系统开发
2、网站内容采集系统制作
3、网站内容采集系统开发
4、网站内容采集系统制作
5、网站内容采集系统开发
6、网站内容采集系统制作
7、网站内容采集系统开发
8、网站内容采集系统开发
企业采集各自行业的行情数据,导出到云采集中心,选取重点行业,抓取数据到seo,将数据转化,展示网站或者公司,达到相关网站排名提升的作用,内容采集系统就是以上那些,比如宜信,
抓取互联网上相关行业的网站,然后保存到自己的数据库中,然后推广。
内容采集这个行业本身不是很小,比如很多app有买量,或者一些大的平台也会去买数据,所以所有数据都是相关行业发布的,而且提供数据又不是很方便,用网站来收集,一般都是以爬虫的形式,这种api都是以.bss的形式封装好的,然后采集这个这个网站上面的数据,收集到网站的数据,以此来做自己的推广,具体到一个app,一个平台,可能还需要数据买量,买流量等方式,所以抓取内容的工作量并不是很大,采集的功能方面可能只是数据的整理分析,或者是转化和分析,内容更多采用文本分析,比如采集自某平台上的一些标题词或者内容来进行采集,再加以编辑操作,抓取操作,如果需要报表的话,还会有个报表抓取功能。
这块还是要看使用人员以及采集时间的长短来决定工作量,下面会是一个示例网站,可以参考参考。-rv_trends/-causes-investor-text-pages/browsers/saas-browsers/facebooks/这样大概有30个网站在采集了,一年的时间大概抓取了100多万个内容,然后转化率就很低了,因为抓取量少,转化时间又长,所以无法做到有效转化,不过我个人认为抓取并不是一个很大的问题,就目前而言,内容抓取的工作量还是可以接受的,也有抓取了比较长时间,做了比较久数据都还保存,当然具体情况还要具体分析。
最后说到数据的处理,一般抓取的数据会进行简单的保存,通过分析排序,进行一些简单的分析,找到更匹配的网站,或者通过算法进行筛选一些长尾的数据来进行预测,也可以利用到模型算法来进行相关数据的抓取分析,才可以找到更匹配的网站。以上都是在抓取数据并简单的处理下得到的数据结果,并不能获取全部的数据,比如一些时效性很强的平台,一天可能产生几万条数据,但时效性很短的平台,抓取了很多几万条可能都不够消化的,有些数据抓取几万都不一定够消化,甚至很长的时间一天,可能都产生几百条左右的数据,用。 查看全部
什么是网站内容采集系统开发?如何做好网站制作
网站内容采集系统开发、网站内容采集系统制作、网站内容采集系统开发、网站内容采集系统制作
1、网站内容采集系统开发
2、网站内容采集系统制作
3、网站内容采集系统开发
4、网站内容采集系统制作
5、网站内容采集系统开发
6、网站内容采集系统制作
7、网站内容采集系统开发
8、网站内容采集系统开发
企业采集各自行业的行情数据,导出到云采集中心,选取重点行业,抓取数据到seo,将数据转化,展示网站或者公司,达到相关网站排名提升的作用,内容采集系统就是以上那些,比如宜信,
抓取互联网上相关行业的网站,然后保存到自己的数据库中,然后推广。
内容采集这个行业本身不是很小,比如很多app有买量,或者一些大的平台也会去买数据,所以所有数据都是相关行业发布的,而且提供数据又不是很方便,用网站来收集,一般都是以爬虫的形式,这种api都是以.bss的形式封装好的,然后采集这个这个网站上面的数据,收集到网站的数据,以此来做自己的推广,具体到一个app,一个平台,可能还需要数据买量,买流量等方式,所以抓取内容的工作量并不是很大,采集的功能方面可能只是数据的整理分析,或者是转化和分析,内容更多采用文本分析,比如采集自某平台上的一些标题词或者内容来进行采集,再加以编辑操作,抓取操作,如果需要报表的话,还会有个报表抓取功能。
这块还是要看使用人员以及采集时间的长短来决定工作量,下面会是一个示例网站,可以参考参考。-rv_trends/-causes-investor-text-pages/browsers/saas-browsers/facebooks/这样大概有30个网站在采集了,一年的时间大概抓取了100多万个内容,然后转化率就很低了,因为抓取量少,转化时间又长,所以无法做到有效转化,不过我个人认为抓取并不是一个很大的问题,就目前而言,内容抓取的工作量还是可以接受的,也有抓取了比较长时间,做了比较久数据都还保存,当然具体情况还要具体分析。
最后说到数据的处理,一般抓取的数据会进行简单的保存,通过分析排序,进行一些简单的分析,找到更匹配的网站,或者通过算法进行筛选一些长尾的数据来进行预测,也可以利用到模型算法来进行相关数据的抓取分析,才可以找到更匹配的网站。以上都是在抓取数据并简单的处理下得到的数据结果,并不能获取全部的数据,比如一些时效性很强的平台,一天可能产生几万条数据,但时效性很短的平台,抓取了很多几万条可能都不够消化的,有些数据抓取几万都不一定够消化,甚至很长的时间一天,可能都产生几百条左右的数据,用。
网站内容采集系统(分布式网站日志采集方法实施例--本发明分布式技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-07 05:16
专利名称:一种分布式网站日志数据采集方法和一种分布式网站系统生产方法
技术领域:
本发明涉及互联网数据处理技术,特别是分布式网站log采集方法。
背景技术:
随着互联网的普及,为了提高互联网应用中的数据处理速度,满足不断增长的数据量需求,许多大型网站逐渐采用了分布式网络结构,主要是为了实现负载均衡。
分布式结构使用多台服务器,与前端WEB服务角色相同。这种结构极大地方便了服务分发的规划和可扩展性。另一方面,多台服务器的分布式设置,使得网络日志数据的分析统计也有些麻烦。
比如我们使用比较常用的web分析工具webalizer,对于分布式网络结构,需要分别对每台服务器进行日志数据统计,会带来以下问题
1、数据的采集带来了很多麻烦。比如统计总访问量,需要把指定时间段内的服务器1(SERVER1), server 2(SERVER2)...;
2、 影响独立访问次数、独立站点等指标的统计。基于网络分布式网络结构的特点和负载均衡的机制,以上指标的统计并不是基于服务器上数据的代数加法。
另外,基于以上问题,在每台服务器上配置日志数据分析功能,会增加服务器环境的复杂度,降低服务器运行的安全性能;并且分布式结构中各个服务器的日志数据分析功能需要保持一致。当某台服务器上的日志数据分析功能发生变化时,为了实现全网数据的统计,所有服务器上的日志数据分析功能都必须自适应变化,使得数据完整性难以监控,并且增加了维护成本。因此,分布式网站的可扩展性和部署在一定程度上受到限制。
发明内容
本发明实施例提供了一种分布式网站log采集方法。目的是降低网络期刊数据统计的复杂度,提高分布式网站的可扩展性。
为了解决上述技术问题,本发明提供的分布式网站log采集方法实施例
通过以下技术方案实现
一种分布式网站日志数据采集方法,包括净化WEB服务器的日志数据,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收日志 根据文档合并成一个文件。
上述方法中,WEB服务器在上传日志数据前对清洗后的日志数据进行压缩,并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断预定进行日志数据上传的WEB服务器是否有日志数据到达。
基于上述方法,在将日志数据上传到WEB服务器之前,还为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证文件与第二个验证文件不同,则触发WEB服务器重新上传日志数据文件。
本发明相应实施例还提供了一种分布式网站系统,包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断定时执行日志是否到达上传数据的WEB服务器的日志数据。
此外,WEB服务器还包括为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送给集中处理服务器;集中处理服务器也用于使用和WEB服务器相同的验证算法为获取的日志数据文件生成第二个验证文件。如果第一验证文件与第二验证文件不同,则触发WEB服务器重新上传日志。根据文件。
从上述技术方案可以看出,本发明在每个Web服务器上报日志数据之前,对上报的日志数据进行了清理,从而减少了集中处理服务器的工作
加载;并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,与现有技术相比,不需要在WEB服务器上配置过多的CGI环境(CGI环境为A程序环境)运行在网络服务器上。该程序用于超文本传输协议(HTTP 服务器)与其他终端上的程序交互)或其他特殊要求。只有系统的功能才能满足本程序的要求。 WEB服务器的发明具有更高的安全性,并且本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,因此本发明的系统部署简单,提高了系统的可扩展性。
进一步地,基于上述方法的实现,本发明的集中处理服务器可以对采集收到的日志数据文件进行加工合并处理,从而避免了由于登录到两个以上服务器的可能对用户访问数据上传造成的数据统计不准确,最终会提高日常日志数据分析的准确性。
图1是根据本发明实施例的方法的示意图。
具体实施方法
本发明的目的是降低网络日志数据统计的复杂度,提高分布式网站的可扩展性。
为了实现本发明的上述目的,请参考图1。下面结合图1具体说明本发明实施例的实现。
如图1所示,本发明实施例的系统包括WEB服务器和集中处理服务器。系统满足分布式结构,即多台相同角色的服务器用于前端WEB服务。该方法包括以下步骤。
步骤ll,对于保存的日志数据,WEB服务器对其进行净化。
净化过程的目的是过滤掉对日志数据分析无用的数据,从而减少日志数据的大小。有很多过滤方法。例如,对于Linux服务器,可以直接使用SHELL命令过滤掉样式、图片等不需要的日志记录。因为用户经常请求一个收录大量脚本、样式和图片数据的页面,所以传号
根据净化,可以大大减少日志文件的大小,从而减少网络传输时间,有助于提高日志数据分析的效率。 '日志数据净化过程的时机可以选择在WEB服务器负载的低高峰期。服务器的低峰期可以根据统计数据分析得出,并可以根据统计数据结果随着网络应用的发展进行调整。 Step 12. 对于清洗后的日志数据,WEB服务器对其进行压缩,生成日志数据压缩文件。压缩文件的名称后附有服务器的标识,以便在集中处理服务器上区分不同WEB服务器发送的网络。日志数据压缩文件。在本实施例中,IP地址用于区分不同服务器的日志数据压缩文件。此外,还可以识别每个服务器编号或使用其他识别方法。步骤13、为防止文件网络传输过程中传输不完整或出错,需要对压缩文件进行文件校验,并生成第一校验码。本实施例中采用MD5验证方式,但本发明并不限定具体采用的验证方式。步骤14、将压缩后的日志数据文件和第一校验码发送到集中处理服务器。本实施例中,采用FTP方式传输日志数据压缩文件和第一校验码。本发明还可以采用其他传输方式,例如HTTP。步骤15、集中处理服务器检查接收到的每个服务器的日志数据文件(压缩后的)。具体包括以下步骤的识别。因此,集中处理服务器需要下载WEB服务器的IP地址配置列表,本实施例采用FTP方式传输数据,所以配置文件格式为210.121.123. 123 ftpuser ftppasswd210.121.123.124 ftpuser ftppasswd 其中ftpuser为ftp用户名,ftppasswd为ftp验证码。集中处理服务器根据配置文件列表,循环验证各Web服务器的日志数据文件是否在指定时间段内到达。如果它到达,它根据Web服务器采用的验证方法验证接收到的日志数据文件。如果日志数据文件还在
如果没有到达集中处理服务器,它会等待预设的时间长度才进行测试。本实施例中,集中处理服务器对接收到的日志数据压缩文件进行校验的方法具体包括:根据获取的日志数据压缩文件,按照MD5校验方法生成第二校验码,如果第二校验码为与第一个校验码相同,表示日志数据压缩文件传输正确;如果第二校验码与第一校验码不同,集中处理服务器可以执行步骤17,即主动触发WEB服务器重传日志数据压缩文件。基于上述重传机制,本发明实施例还对重传次数设置了阈值。当重传次数达到阈值,且获取的日志数据压缩文件仍无法通过MD5验证时,集中处理服务器可以停止处理WEB服务器的日志数据压缩文件并发出告警。报警形式可能包括发送邮件或短信报警,以便网站维护人员根据实际情况进行处理,保证整个网站日志的完整性。步骤16、如果集中处理服务器确定已经获取到预定WEB服务器的日志数据压缩文件,则对压缩文件进行解压;并且,由于用户访问记录可能存在于两个或多个WEB服务器上,为了保证数据的准确性,集中处理服务器必须将每个WEB服务器的日志文件合并为一个文件。从上述技术方案可以看出,本发明在各WEB服务器上的日志数据之前,先清理待上报的日志数据,从而减少了大量不必要的记录。这样,在后续的日志分析过程中,提高了日志数据的分析效率,减少了集中处理服务器的工作量。并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,不需要在WEB服务器上配置过多的CGI环境或其他特殊环境。需求,本方案的需求,只需要利用系统本身的功能就可以实现。理论上,环境配置越多,安全性就会相应降低。因此,本发明的WEB服务器具有更高的安全性。因为分布式网站使用了很多WEB服务器端。如果采用现有技术,稍微改变一点需求,就需要调整各个WEB端的脚本和程序。这个调整过程很简单
发生错误。而且,每个服务器的日志也不容易监控。如果某个服务器日志出现异常,很难找出是哪个WEB服务器出了问题。与现有技术相比,本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,从而使得系统部署本发明简单,提高了系统的可扩展性。并且由于日志数据在集中处理服务器中处理,因此更容易识别问题并解决问题。相应地,本发明还提供了一种分布式网站系统,其特征在于包括WEB服务器和集中处理服务器。其中,WEB服务器用于对保存的日记账数据进行净化处理。处理后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。其中,净化处理包括对日志数据中的图案或/和图片数据进行过滤。在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩,并标记服务器标识;集中处理服务器用于根据服务器列表中的服务器标识,判断预定进行日志数据上传的WEB服务器的日志数据是否已经到达。在上述系统结构的基础上,WEB服务器还包括为压缩后的日志数据文件生成第一校验码,并将第一校验码发送给集中处理服务器。并且,集中处理服务器还用于使用与WEB服务器相同的验证算法对获取的日志数据文件生成第二验证码,如果第一验证码与第二验证码不同,则触发WEB服务器服务器 再次上传日志数据文件。以上详细描述了本发明实施例提供的分布式网站日志数据采集方法和分布式网站系统。本文通过具体实例来说明本发明的原理和实现方式。以上实施例的描述仅用于帮助理解本发明的实施方式;同时,对于本领域普通技术人员来说,根据本发明的构思,具体实现方式和适用范围可能会有变化。综上所述,本说明书的内容不应理解为对本发明的限制。
索赔
1、一种分布式网站日志数据采集方法,其特征在于对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;处理服务器将接收到的日志数据文件合并为一个文件。
2、根据权利要求1所述的方法,其中,所述净化过程包括过滤日志数据中的图案或/和图片数据。
3、如权利要求1所述的方法,其特征在于,WEB服务器在上传日志数据之前,对清洗后的日志数据进行压缩,并标记服务器的身份;集中处理服务器根据服务器列表,根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
4、如权利要求3所述的方法,其特征在于,在Web服务器上传日志数据之前,对压缩后的日志数据文件进一步生成第一校验码,并将第一校验码发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证码与第二个验证码不同,则触发WEB服务器重新上传日志数据文件。
5、如权利要求1所述的方法,其特征在于,在预设时间或服务器负载低于预设阈值时启动日志数据清理过程。
6、分布式网站系统,其特点是包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,并将日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
7、如权利要求6所述的网站系统,其特征在于,所述净化过程包括过滤日志数据中的样式或/和图片数据。
8、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还用于对清洗后的日志数据进行压缩并标记服务器的身份;集中处理服务器用于根据服务器列表根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
9、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还包括为压缩后的日志数据文件生成第一校验码,与发送给集中处理服务器的第一校验码进行比对;集中处理服务器也使用与WEB服务器相同的验证算法,在获取的日志数据文件上生成第二验证码,如果第一验证码与第二验证码相同,则WEB服务器触发服务器重新上传日志数据文件。
全文摘要
本发明实施例提供了一种分布式网站日志数据采集方法和分布式网站系统,旨在降低网络日志数据统计的复杂度,提高分布式网站可扩展性的性能该方法包括对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。本发明减少了集中处理服务器的工作量;使WEB服务器具有更高的安全性;本发明系统部署简单,提高了系统的可扩展性。
文件编号 H04L12/24GK101163046SQ2
出版日期 2008 年 4 月 16 日 申请日期 2007 年 11 月 22 日 优先权日期 2007 年 11 月 22 日
发明人Hui Ning, Tao Zhang 申请人:; 查看全部
网站内容采集系统(分布式网站日志采集方法实施例--本发明分布式技术)
专利名称:一种分布式网站日志数据采集方法和一种分布式网站系统生产方法
技术领域:
本发明涉及互联网数据处理技术,特别是分布式网站log采集方法。
背景技术:
随着互联网的普及,为了提高互联网应用中的数据处理速度,满足不断增长的数据量需求,许多大型网站逐渐采用了分布式网络结构,主要是为了实现负载均衡。
分布式结构使用多台服务器,与前端WEB服务角色相同。这种结构极大地方便了服务分发的规划和可扩展性。另一方面,多台服务器的分布式设置,使得网络日志数据的分析统计也有些麻烦。
比如我们使用比较常用的web分析工具webalizer,对于分布式网络结构,需要分别对每台服务器进行日志数据统计,会带来以下问题
1、数据的采集带来了很多麻烦。比如统计总访问量,需要把指定时间段内的服务器1(SERVER1), server 2(SERVER2)...;
2、 影响独立访问次数、独立站点等指标的统计。基于网络分布式网络结构的特点和负载均衡的机制,以上指标的统计并不是基于服务器上数据的代数加法。
另外,基于以上问题,在每台服务器上配置日志数据分析功能,会增加服务器环境的复杂度,降低服务器运行的安全性能;并且分布式结构中各个服务器的日志数据分析功能需要保持一致。当某台服务器上的日志数据分析功能发生变化时,为了实现全网数据的统计,所有服务器上的日志数据分析功能都必须自适应变化,使得数据完整性难以监控,并且增加了维护成本。因此,分布式网站的可扩展性和部署在一定程度上受到限制。
发明内容
本发明实施例提供了一种分布式网站log采集方法。目的是降低网络期刊数据统计的复杂度,提高分布式网站的可扩展性。
为了解决上述技术问题,本发明提供的分布式网站log采集方法实施例
通过以下技术方案实现
一种分布式网站日志数据采集方法,包括净化WEB服务器的日志数据,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收日志 根据文档合并成一个文件。
上述方法中,WEB服务器在上传日志数据前对清洗后的日志数据进行压缩,并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断预定进行日志数据上传的WEB服务器是否有日志数据到达。
基于上述方法,在将日志数据上传到WEB服务器之前,还为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证文件与第二个验证文件不同,则触发WEB服务器重新上传日志数据文件。
本发明相应实施例还提供了一种分布式网站系统,包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩并标记服务器ID;集中处理服务器根据服务器列表和服务器ID判断定时执行日志是否到达上传数据的WEB服务器的日志数据。
此外,WEB服务器还包括为压缩后的日志数据文件生成第一验证文件,并将第一验证文件发送给集中处理服务器;集中处理服务器也用于使用和WEB服务器相同的验证算法为获取的日志数据文件生成第二个验证文件。如果第一验证文件与第二验证文件不同,则触发WEB服务器重新上传日志。根据文件。
从上述技术方案可以看出,本发明在每个Web服务器上报日志数据之前,对上报的日志数据进行了清理,从而减少了集中处理服务器的工作
加载;并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,与现有技术相比,不需要在WEB服务器上配置过多的CGI环境(CGI环境为A程序环境)运行在网络服务器上。该程序用于超文本传输协议(HTTP 服务器)与其他终端上的程序交互)或其他特殊要求。只有系统的功能才能满足本程序的要求。 WEB服务器的发明具有更高的安全性,并且本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,因此本发明的系统部署简单,提高了系统的可扩展性。
进一步地,基于上述方法的实现,本发明的集中处理服务器可以对采集收到的日志数据文件进行加工合并处理,从而避免了由于登录到两个以上服务器的可能对用户访问数据上传造成的数据统计不准确,最终会提高日常日志数据分析的准确性。
图1是根据本发明实施例的方法的示意图。
具体实施方法
本发明的目的是降低网络日志数据统计的复杂度,提高分布式网站的可扩展性。
为了实现本发明的上述目的,请参考图1。下面结合图1具体说明本发明实施例的实现。
如图1所示,本发明实施例的系统包括WEB服务器和集中处理服务器。系统满足分布式结构,即多台相同角色的服务器用于前端WEB服务。该方法包括以下步骤。
步骤ll,对于保存的日志数据,WEB服务器对其进行净化。
净化过程的目的是过滤掉对日志数据分析无用的数据,从而减少日志数据的大小。有很多过滤方法。例如,对于Linux服务器,可以直接使用SHELL命令过滤掉样式、图片等不需要的日志记录。因为用户经常请求一个收录大量脚本、样式和图片数据的页面,所以传号
根据净化,可以大大减少日志文件的大小,从而减少网络传输时间,有助于提高日志数据分析的效率。 '日志数据净化过程的时机可以选择在WEB服务器负载的低高峰期。服务器的低峰期可以根据统计数据分析得出,并可以根据统计数据结果随着网络应用的发展进行调整。 Step 12. 对于清洗后的日志数据,WEB服务器对其进行压缩,生成日志数据压缩文件。压缩文件的名称后附有服务器的标识,以便在集中处理服务器上区分不同WEB服务器发送的网络。日志数据压缩文件。在本实施例中,IP地址用于区分不同服务器的日志数据压缩文件。此外,还可以识别每个服务器编号或使用其他识别方法。步骤13、为防止文件网络传输过程中传输不完整或出错,需要对压缩文件进行文件校验,并生成第一校验码。本实施例中采用MD5验证方式,但本发明并不限定具体采用的验证方式。步骤14、将压缩后的日志数据文件和第一校验码发送到集中处理服务器。本实施例中,采用FTP方式传输日志数据压缩文件和第一校验码。本发明还可以采用其他传输方式,例如HTTP。步骤15、集中处理服务器检查接收到的每个服务器的日志数据文件(压缩后的)。具体包括以下步骤的识别。因此,集中处理服务器需要下载WEB服务器的IP地址配置列表,本实施例采用FTP方式传输数据,所以配置文件格式为210.121.123. 123 ftpuser ftppasswd210.121.123.124 ftpuser ftppasswd 其中ftpuser为ftp用户名,ftppasswd为ftp验证码。集中处理服务器根据配置文件列表,循环验证各Web服务器的日志数据文件是否在指定时间段内到达。如果它到达,它根据Web服务器采用的验证方法验证接收到的日志数据文件。如果日志数据文件还在
如果没有到达集中处理服务器,它会等待预设的时间长度才进行测试。本实施例中,集中处理服务器对接收到的日志数据压缩文件进行校验的方法具体包括:根据获取的日志数据压缩文件,按照MD5校验方法生成第二校验码,如果第二校验码为与第一个校验码相同,表示日志数据压缩文件传输正确;如果第二校验码与第一校验码不同,集中处理服务器可以执行步骤17,即主动触发WEB服务器重传日志数据压缩文件。基于上述重传机制,本发明实施例还对重传次数设置了阈值。当重传次数达到阈值,且获取的日志数据压缩文件仍无法通过MD5验证时,集中处理服务器可以停止处理WEB服务器的日志数据压缩文件并发出告警。报警形式可能包括发送邮件或短信报警,以便网站维护人员根据实际情况进行处理,保证整个网站日志的完整性。步骤16、如果集中处理服务器确定已经获取到预定WEB服务器的日志数据压缩文件,则对压缩文件进行解压;并且,由于用户访问记录可能存在于两个或多个WEB服务器上,为了保证数据的准确性,集中处理服务器必须将每个WEB服务器的日志文件合并为一个文件。从上述技术方案可以看出,本发明在各WEB服务器上的日志数据之前,先清理待上报的日志数据,从而减少了大量不必要的记录。这样,在后续的日志分析过程中,提高了日志数据的分析效率,减少了集中处理服务器的工作量。并且,由于本发明中的各个WEB服务器只需要在上报日志数据前进行净化处理,不需要在WEB服务器上配置过多的CGI环境或其他特殊环境。需求,本方案的需求,只需要利用系统本身的功能就可以实现。理论上,环境配置越多,安全性就会相应降低。因此,本发明的WEB服务器具有更高的安全性。因为分布式网站使用了很多WEB服务器端。如果采用现有技术,稍微改变一点需求,就需要调整各个WEB端的脚本和程序。这个调整过程很简单
发生错误。而且,每个服务器的日志也不容易监控。如果某个服务器日志出现异常,很难找出是哪个WEB服务器出了问题。与现有技术相比,本发明在现有技术中没有出现“为了实现全网数据的统计,必须统一改变所有服务器上的日志数据分析功能”,从而使得系统部署本发明简单,提高了系统的可扩展性。并且由于日志数据在集中处理服务器中处理,因此更容易识别问题并解决问题。相应地,本发明还提供了一种分布式网站系统,其特征在于包括WEB服务器和集中处理服务器。其中,WEB服务器用于对保存的日记账数据进行净化处理。处理后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。其中,净化处理包括对日志数据中的图案或/和图片数据进行过滤。在上述体系结构的基础上,进一步利用WEB服务器对清洗后的日志数据进行压缩,并标记服务器标识;集中处理服务器用于根据服务器列表中的服务器标识,判断预定进行日志数据上传的WEB服务器的日志数据是否已经到达。在上述系统结构的基础上,WEB服务器还包括为压缩后的日志数据文件生成第一校验码,并将第一校验码发送给集中处理服务器。并且,集中处理服务器还用于使用与WEB服务器相同的验证算法对获取的日志数据文件生成第二验证码,如果第一验证码与第二验证码不同,则触发WEB服务器服务器 再次上传日志数据文件。以上详细描述了本发明实施例提供的分布式网站日志数据采集方法和分布式网站系统。本文通过具体实例来说明本发明的原理和实现方式。以上实施例的描述仅用于帮助理解本发明的实施方式;同时,对于本领域普通技术人员来说,根据本发明的构思,具体实现方式和适用范围可能会有变化。综上所述,本说明书的内容不应理解为对本发明的限制。
索赔
1、一种分布式网站日志数据采集方法,其特征在于对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;处理服务器将接收到的日志数据文件合并为一个文件。
2、根据权利要求1所述的方法,其中,所述净化过程包括过滤日志数据中的图案或/和图片数据。
3、如权利要求1所述的方法,其特征在于,WEB服务器在上传日志数据之前,对清洗后的日志数据进行压缩,并标记服务器的身份;集中处理服务器根据服务器列表,根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
4、如权利要求3所述的方法,其特征在于,在Web服务器上传日志数据之前,对压缩后的日志数据文件进一步生成第一校验码,并将第一校验码发送到集中处理服务器;集中处理服务器使用与WEB服务器相同的验证算法,为获取的日志数据文件生成第二个验证文件,如果第一个验证码与第二个验证码不同,则触发WEB服务器重新上传日志数据文件。
5、如权利要求1所述的方法,其特征在于,在预设时间或服务器负载低于预设阈值时启动日志数据清理过程。
6、分布式网站系统,其特点是包括WEB服务器和集中处理服务器;其中,WEB服务器用于对保存的日志数据进行净化,并将日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。
7、如权利要求6所述的网站系统,其特征在于,所述净化过程包括过滤日志数据中的样式或/和图片数据。
8、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还用于对清洗后的日志数据进行压缩并标记服务器的身份;集中处理服务器用于根据服务器列表根据服务器标识判断预定执行日志数据上传的WEB服务器的日志数据是否已经到达。
9、如权利要求6所述的网站系统,其特征在于,所述WEB服务器还包括为压缩后的日志数据文件生成第一校验码,与发送给集中处理服务器的第一校验码进行比对;集中处理服务器也使用与WEB服务器相同的验证算法,在获取的日志数据文件上生成第二验证码,如果第一验证码与第二验证码相同,则WEB服务器触发服务器重新上传日志数据文件。
全文摘要
本发明实施例提供了一种分布式网站日志数据采集方法和分布式网站系统,旨在降低网络日志数据统计的复杂度,提高分布式网站可扩展性的性能该方法包括对WEB服务器的日志数据进行净化,并将净化后的日志数据上传到集中处理服务器;集中处理服务器将接收到的日志数据文件合并为一个文件。本发明减少了集中处理服务器的工作量;使WEB服务器具有更高的安全性;本发明系统部署简单,提高了系统的可扩展性。
文件编号 H04L12/24GK101163046SQ2
出版日期 2008 年 4 月 16 日 申请日期 2007 年 11 月 22 日 优先权日期 2007 年 11 月 22 日
发明人Hui Ning, Tao Zhang 申请人:;
网站内容采集系统(如何爬数据需求数据采集系统:一个可以通过配置规则采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 466 次浏览 • 2021-09-06 14:05
记录一个两年前写的采集系统,包括需求、分析、设计、实现、遇到的问题以及系统的有效性。系统的主要功能是为每个网站制作不同的采集rule配置为每个网站抓取数据。两年前我离开时爬取的数据量大约是几千万。 采集每天的数据增量在10000左右。配置采集的网站1200多个,现记录下系统实现,并提供一些简单的爬虫demo供大家学习爬取数据
要求
Data采集system:一个可以配置规则采集不同网站的系统
主要目标:
对于不同的网站,我们可以配置不同的采集规则来实现网络数据爬取。对于每条内容,可以实现特征数据提取,抓取所有网站数据采集配置规则可以维护采集Inbound数据可维护性分析
第一步当然是先分析需求,所以我们提取系统的主要需求:
对于不同的网站,可以通过不同的采集规则实现数据爬取。可以为每条内容提取特征数据。特征数据是指标题、作者、发布时间信息定时任务关联任务或任务组爬取网站的数据
再次解析网站的结构,无非就是两个;
一个是列表页面。这里的列表页代表的是需要获取当前页面更多详情页的那种网页链接,就像一般查询列表一样,可以通过列表获取更多详情页链接。一是详情页。这种页面更容易理解。这种页面不需要在这个页面上获取到其他网页的链接,直接在当前页面上提取数据即可。
基本上所有爬到的网站都可以这样抽象出来。
设计
基于分析结果的设计与实现:
任务表
每个网站都可以当作一个任务去执行采集
两个规则表
每个网站 对应于自己的采集 规则。根据上面分析的网站结构,采集规则可以进一步细分为两个表,一个收录网站链接获取详情页列表采集Rules表的列表,一个规则表用于特征数据采集网站详情页@规则表详情采集消防表
网址表
负责记录采集target网站detail页面的url
定时任务列表
根据定时任务定时执行某些任务(可以使用定时任务关联多个任务,也可以考虑添加任务组表,定时任务关联任务组,任务组与任务相关)
数据存储表
这是因为我们的采集数据主要是中标和中标两种数据。建立了两张表用于数据存储,中标信息表和中标信息表
实现框架
基本结构为:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多。有很多优秀的开源框架,比如htmlunit、WebMagic、jsoup等,当然也可以实现httpclient。
为什么要使用 htmlunit?
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被誉为java浏览器的开源实现
简单说说我对htmlunit的理解:
一个是htmlunit提供了通过xpath定位页面元素的功能,可以用来提取页面特征数据;二是对js的支持,对js的支持意味着你真的可以把它当作一个浏览器,你可以用它来模拟点击、输入、登录等操作,而对于采集,支持js可以解决使用问题ajax获取页面数据。当然除此之外,htmlunit还支持代理ip、https,通过配置可以模拟谷歌、火狐、Referer、user-agent等浏览器,是否加载js、css,是否支持ajax等
XPath 语法是 XML 路径语言(XML Path Language),它是一种用于确定 XML 文档某部分位置的语言。
为什么要使用 jsoup?
相对于htmlunit,jsoup提供了类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集
采集数据逻辑分为两个部分:url采集器,详情页采集器
url采集器:
详情页采集器:
重复数据删除遇到的问题:当使用采集url与url相同去重时,key作为url存储在redis中,缓存时间为3天。这个方法是为了防止同一个A url 重复采集。重复数据删除由标题执行。通过在redis中存储key为采集的title,缓存时间为3天。这个方法是为了防止一个文章被不同的网站发布,重复采集的情况发生。数据质量:
因为每个网站页面都不一样,尤其是同一个网站的详情页结构也不同,增加了特征数据提取的难度,所以使用htmlunit+jsoup+正则三种方式组合得到采集特征数据。
采集efficiency:
因为采集的网站有很多,假设每次任务执行打开一个列表页和十个详情页,那么一千个任务执行一次需要采集11000页,所以使用url和详情页以采集分隔,通过mq实现异步操作,url和详情页的采集通过多线程实现。
被阻止的ip:
对于一个网站,如果每半小时执行一次,那么网站一天会被扫描48次。还假设采集每天会打开11页,528次,所以Sealing是一个很常见的问题。解决办法,htmlunit提供了代理ip的实现,使用代理ip可以解决被封ip的问题,代理ip的来源:一是网上有很多网站卖代理ip的,可以买他们的代理ip直接,另一种就是爬取,这些网站卖代理ip都提供了一些免费的代理ip,你可以爬回这些ip,然后用httpclient或者其他方式验证代理ip的可用性,如果可以输入直接建数据库,搭建自己的代理ip库。因为代理ip是时间敏感的,可以创建定时任务刷ip库,去除无效ip。
网站失败:
网站失效有两种,一种是网站域名,原来的网址不能直接打开,第二种是网站改版,原来配置的规则全部失效,而采集不可用@有效数据。解决这个问题的办法是每天发送采集data和日志的邮件提醒,将未采集到的数据和未打开的网页汇总,通过邮件发送给相关人员。
验证码:
当时,对于网站采集史数据采集,方式是通过他们的列表页面进入采集detail页面。 采集查到几十万条数据后,这个网站我就拿不到数据了。查看页面后,我发现列表页面添加了验证码。这个验证码是一个比较简单的数字加字母。那个时候想在列表页加个验证码? ,然后想到了一个解决办法,找了一个开源的orc文字识别项目tess4j(使用方法看这里),过一会就好了,识别率在20%左右,因为htmlunit可以模拟操作浏览器,所以代码中的操作是先通过htmlunit的xpath获取验证码元素,获取验证码图片,然后使用tess4j识别验证码,然后将识别到的验证码填入验证中代码输入框,点击翻页,如果验证码通过,翻页进行后续采集,如果失败,重复上面的识别验证码操作,直到知道成功,将验证码输入输入框和点击翻页可以用htmlunit实现
Ajax 加载数据:
一些网站使用ajax加载数据。使用htmlunit采集时,网站需要在获取到HtmlPage对象后给页面一个加载ajax的时间,然后可以通过HtmlPage获取ajax加载后的数据。
代码:webClient.waitForBackgroundJavaScript(time);你可以看到后面提供的演示
系统整体架构图,这里指的是data采集system部分
演示
爬虫的实现:
@GetMapping("/getData")
public List article_(String url,String xpath){
WebClient webClient = WebClientUtils.getWebClientLoadJs();
List datas = new ArrayList();
try {
HtmlPage page = webClient.getPage(url);
if(page!=null){
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return datas;
}
以上代码实现采集一个列表页
爬上博客园
请求这个url::9001/getData?url=;xpath=//*[@id="post_list"]/div/div[2]/h3/a
网页:
采集返回数据:
再次爬上csdn
再次请求::9001/getData?url=;xpath=//*[@id="feedlist_id"]/li/div/div[1]/h2/a
网页:
采集返回数据:
采集Steps
通过一个方法去采集两个网站,通过不同url和xpath规则去采集不同的网站,这个demo展示的就是htmlunit采集数据的过程。
每个采集任务都是执行相同的步骤
- 获取client -> 打开页面 -> 提取特征数据(或详情页链接) -> 关闭cline
不同的地方就在于提取特征数据
优化:使用模板方法设计模式提取功能部分
上面的代码可以提取为:一个采集executor,一个自定义的采集data实现
/**
* @Description: 执行者 man
* @author: chenmingyu
* @date: 2018/6/24 17:29
*/
public class Crawler {
private Gatherer gatherer;
public Object execute(String url,Long time){
// 获取 webClient对象
WebClient webClient = WebClientUtils.getWebClientLoadJs();
try {
HtmlPage page = webClient.getPage(url);
if(null != time){
webClient.waitForBackgroundJavaScript(time);
}
return gatherer.crawl(page);
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return null;
}
public Crawler(Gatherer gatherer) {
this.gatherer = gatherer;
}
}
在Crawler中注入一个接口,这个接口只有一个方法crawl(),不同的实现类实现这个接口,然后自定义特征数据的实现
/**
* @Description: 自定义实现
* @author: chenmingyu
* @date: 2018/6/24 17:36
*/
public interface Gatherer {
Object crawl(HtmlPage page) throws Exception;
}
优化代码:
@GetMapping("/getData")
public List article_(String url,String xpath){
Gatherer gatherer = (page)->{
List datas = new ArrayList();
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
return datas;
};
Crawler crawler = new Crawler(gatherer);
List datas = (List)crawler.execute(url,null);
return datas;
}
不同的实现,只需要修改这部分接口实现即可。
数据
最后使用采集系统采集查看数据。
效果
效果还是不错的,最重要的是系统运行稳定:
采集的历史数据在6-7百万左右。 采集的数据增量约为每天10,000。系统目前配置了1200多个任务(一次定时执行会去采集这些网站)数据
系统配置采集网站主要针对全国各个省市县的网站竞价(目前配置的采集站点已超过1200个)。
采集的数据主要作为公司标准新闻的数据中心,为一个pc端网站和2个微信公众号提供数据
欢迎关注和掌握第一手招标信息
以PC端显示的采集中标数据为例,来看看采集的效果:
本文只是对采集系统从零到全过程的粗略记录,当然也遇到了很多本文没有提到的问题。 查看全部
网站内容采集系统(如何爬数据需求数据采集系统:一个可以通过配置规则采集)
记录一个两年前写的采集系统,包括需求、分析、设计、实现、遇到的问题以及系统的有效性。系统的主要功能是为每个网站制作不同的采集rule配置为每个网站抓取数据。两年前我离开时爬取的数据量大约是几千万。 采集每天的数据增量在10000左右。配置采集的网站1200多个,现记录下系统实现,并提供一些简单的爬虫demo供大家学习爬取数据
要求
Data采集system:一个可以配置规则采集不同网站的系统
主要目标:
对于不同的网站,我们可以配置不同的采集规则来实现网络数据爬取。对于每条内容,可以实现特征数据提取,抓取所有网站数据采集配置规则可以维护采集Inbound数据可维护性分析
第一步当然是先分析需求,所以我们提取系统的主要需求:
对于不同的网站,可以通过不同的采集规则实现数据爬取。可以为每条内容提取特征数据。特征数据是指标题、作者、发布时间信息定时任务关联任务或任务组爬取网站的数据
再次解析网站的结构,无非就是两个;
一个是列表页面。这里的列表页代表的是需要获取当前页面更多详情页的那种网页链接,就像一般查询列表一样,可以通过列表获取更多详情页链接。一是详情页。这种页面更容易理解。这种页面不需要在这个页面上获取到其他网页的链接,直接在当前页面上提取数据即可。
基本上所有爬到的网站都可以这样抽象出来。
设计
基于分析结果的设计与实现:
任务表
每个网站都可以当作一个任务去执行采集
两个规则表
每个网站 对应于自己的采集 规则。根据上面分析的网站结构,采集规则可以进一步细分为两个表,一个收录网站链接获取详情页列表采集Rules表的列表,一个规则表用于特征数据采集网站详情页@规则表详情采集消防表
网址表
负责记录采集target网站detail页面的url
定时任务列表
根据定时任务定时执行某些任务(可以使用定时任务关联多个任务,也可以考虑添加任务组表,定时任务关联任务组,任务组与任务相关)
数据存储表
这是因为我们的采集数据主要是中标和中标两种数据。建立了两张表用于数据存储,中标信息表和中标信息表
实现框架
基本结构为:ssm+redis+htmlunit+jsoup+es+mq+quartz
java中可以实现爬虫的框架有很多。有很多优秀的开源框架,比如htmlunit、WebMagic、jsoup等,当然也可以实现httpclient。
为什么要使用 htmlunit?
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被誉为java浏览器的开源实现
简单说说我对htmlunit的理解:
一个是htmlunit提供了通过xpath定位页面元素的功能,可以用来提取页面特征数据;二是对js的支持,对js的支持意味着你真的可以把它当作一个浏览器,你可以用它来模拟点击、输入、登录等操作,而对于采集,支持js可以解决使用问题ajax获取页面数据。当然除此之外,htmlunit还支持代理ip、https,通过配置可以模拟谷歌、火狐、Referer、user-agent等浏览器,是否加载js、css,是否支持ajax等
XPath 语法是 XML 路径语言(XML Path Language),它是一种用于确定 XML 文档某部分位置的语言。
为什么要使用 jsoup?
相对于htmlunit,jsoup提供了类似于jquery选择器的定位页面元素的功能,两者可以互补使用。
采集
采集数据逻辑分为两个部分:url采集器,详情页采集器
url采集器:
详情页采集器:
重复数据删除遇到的问题:当使用采集url与url相同去重时,key作为url存储在redis中,缓存时间为3天。这个方法是为了防止同一个A url 重复采集。重复数据删除由标题执行。通过在redis中存储key为采集的title,缓存时间为3天。这个方法是为了防止一个文章被不同的网站发布,重复采集的情况发生。数据质量:
因为每个网站页面都不一样,尤其是同一个网站的详情页结构也不同,增加了特征数据提取的难度,所以使用htmlunit+jsoup+正则三种方式组合得到采集特征数据。
采集efficiency:
因为采集的网站有很多,假设每次任务执行打开一个列表页和十个详情页,那么一千个任务执行一次需要采集11000页,所以使用url和详情页以采集分隔,通过mq实现异步操作,url和详情页的采集通过多线程实现。
被阻止的ip:
对于一个网站,如果每半小时执行一次,那么网站一天会被扫描48次。还假设采集每天会打开11页,528次,所以Sealing是一个很常见的问题。解决办法,htmlunit提供了代理ip的实现,使用代理ip可以解决被封ip的问题,代理ip的来源:一是网上有很多网站卖代理ip的,可以买他们的代理ip直接,另一种就是爬取,这些网站卖代理ip都提供了一些免费的代理ip,你可以爬回这些ip,然后用httpclient或者其他方式验证代理ip的可用性,如果可以输入直接建数据库,搭建自己的代理ip库。因为代理ip是时间敏感的,可以创建定时任务刷ip库,去除无效ip。
网站失败:
网站失效有两种,一种是网站域名,原来的网址不能直接打开,第二种是网站改版,原来配置的规则全部失效,而采集不可用@有效数据。解决这个问题的办法是每天发送采集data和日志的邮件提醒,将未采集到的数据和未打开的网页汇总,通过邮件发送给相关人员。
验证码:
当时,对于网站采集史数据采集,方式是通过他们的列表页面进入采集detail页面。 采集查到几十万条数据后,这个网站我就拿不到数据了。查看页面后,我发现列表页面添加了验证码。这个验证码是一个比较简单的数字加字母。那个时候想在列表页加个验证码? ,然后想到了一个解决办法,找了一个开源的orc文字识别项目tess4j(使用方法看这里),过一会就好了,识别率在20%左右,因为htmlunit可以模拟操作浏览器,所以代码中的操作是先通过htmlunit的xpath获取验证码元素,获取验证码图片,然后使用tess4j识别验证码,然后将识别到的验证码填入验证中代码输入框,点击翻页,如果验证码通过,翻页进行后续采集,如果失败,重复上面的识别验证码操作,直到知道成功,将验证码输入输入框和点击翻页可以用htmlunit实现
Ajax 加载数据:
一些网站使用ajax加载数据。使用htmlunit采集时,网站需要在获取到HtmlPage对象后给页面一个加载ajax的时间,然后可以通过HtmlPage获取ajax加载后的数据。
代码:webClient.waitForBackgroundJavaScript(time);你可以看到后面提供的演示
系统整体架构图,这里指的是data采集system部分
演示
爬虫的实现:
@GetMapping("/getData")
public List article_(String url,String xpath){
WebClient webClient = WebClientUtils.getWebClientLoadJs();
List datas = new ArrayList();
try {
HtmlPage page = webClient.getPage(url);
if(page!=null){
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return datas;
}
以上代码实现采集一个列表页
爬上博客园
请求这个url::9001/getData?url=;xpath=//*[@id="post_list"]/div/div[2]/h3/a
网页:
采集返回数据:
再次爬上csdn
再次请求::9001/getData?url=;xpath=//*[@id="feedlist_id"]/li/div/div[1]/h2/a
网页:
采集返回数据:
采集Steps
通过一个方法去采集两个网站,通过不同url和xpath规则去采集不同的网站,这个demo展示的就是htmlunit采集数据的过程。
每个采集任务都是执行相同的步骤
- 获取client -> 打开页面 -> 提取特征数据(或详情页链接) -> 关闭cline
不同的地方就在于提取特征数据
优化:使用模板方法设计模式提取功能部分
上面的代码可以提取为:一个采集executor,一个自定义的采集data实现
/**
* @Description: 执行者 man
* @author: chenmingyu
* @date: 2018/6/24 17:29
*/
public class Crawler {
private Gatherer gatherer;
public Object execute(String url,Long time){
// 获取 webClient对象
WebClient webClient = WebClientUtils.getWebClientLoadJs();
try {
HtmlPage page = webClient.getPage(url);
if(null != time){
webClient.waitForBackgroundJavaScript(time);
}
return gatherer.crawl(page);
}catch (Exception e){
e.printStackTrace();
}finally {
webClient.close();
}
return null;
}
public Crawler(Gatherer gatherer) {
this.gatherer = gatherer;
}
}
在Crawler中注入一个接口,这个接口只有一个方法crawl(),不同的实现类实现这个接口,然后自定义特征数据的实现
/**
* @Description: 自定义实现
* @author: chenmingyu
* @date: 2018/6/24 17:36
*/
public interface Gatherer {
Object crawl(HtmlPage page) throws Exception;
}
优化代码:
@GetMapping("/getData")
public List article_(String url,String xpath){
Gatherer gatherer = (page)->{
List datas = new ArrayList();
List lists = page.getByXPath(xpath);
lists.stream().forEach(i->{
DomNode domNode = (DomNode)i;
datas.add(domNode.asText());
});
return datas;
};
Crawler crawler = new Crawler(gatherer);
List datas = (List)crawler.execute(url,null);
return datas;
}
不同的实现,只需要修改这部分接口实现即可。
数据
最后使用采集系统采集查看数据。
效果
效果还是不错的,最重要的是系统运行稳定:
采集的历史数据在6-7百万左右。 采集的数据增量约为每天10,000。系统目前配置了1200多个任务(一次定时执行会去采集这些网站)数据
系统配置采集网站主要针对全国各个省市县的网站竞价(目前配置的采集站点已超过1200个)。
采集的数据主要作为公司标准新闻的数据中心,为一个pc端网站和2个微信公众号提供数据
欢迎关注和掌握第一手招标信息
以PC端显示的采集中标数据为例,来看看采集的效果:
本文只是对采集系统从零到全过程的粗略记录,当然也遇到了很多本文没有提到的问题。
网站内容采集系统(快速采集网站内容,简单容易操作,推荐你使用的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-06 01:02
网站内容采集系统,我使用的一个是免费的,网站,我搜索了一下,不太好找,有人介绍的,希望对你有帮助。快速采集网站内容,简单容易操作,推荐你使用卡巴斯基采集器免费版软件,可以采集网站内容。
/,界面友好,
/这个网站可以考虑一下,操作界面比较人性化。
,功能比较全
第一个能买来免费的,
一般来说正规采集站本地基本都有的
今天刚好遇到这个问题,搜索了一下,有人推荐这个:,看到还不错,不过只能采集格式为html5的网站。
当然首选ifv了啊,从blogger,advancedmarketingplatform,到cpc,cpm,
用dedecms可以采集网站内容,不需要任何编程基础。美国dedecms,国内的模仿ucenter的公司也有了。
我也想到一个第三方网站,
推荐去外国站点:dedecms+techblogs国内可以去工具类站点,pexelsaliexpress里一些插件商城的站点也有详细的第三方采集技术。采集商业站一般是去dedecms后台批量采集,建议可以通过seo来改变内容重复率,数据量,内容多的情况下,可以设置搜索框,
现在来说,这是最简单,成本低的网站采集了,采集网站内容还算可以的一个工具:followim,不过其采集定向性并不是太强,不如当初采集百度知道的好,后来定向性增强了,采集质量略有上升。 查看全部
网站内容采集系统(快速采集网站内容,简单容易操作,推荐你使用的)
网站内容采集系统,我使用的一个是免费的,网站,我搜索了一下,不太好找,有人介绍的,希望对你有帮助。快速采集网站内容,简单容易操作,推荐你使用卡巴斯基采集器免费版软件,可以采集网站内容。
/,界面友好,
/这个网站可以考虑一下,操作界面比较人性化。
,功能比较全
第一个能买来免费的,
一般来说正规采集站本地基本都有的
今天刚好遇到这个问题,搜索了一下,有人推荐这个:,看到还不错,不过只能采集格式为html5的网站。
当然首选ifv了啊,从blogger,advancedmarketingplatform,到cpc,cpm,
用dedecms可以采集网站内容,不需要任何编程基础。美国dedecms,国内的模仿ucenter的公司也有了。
我也想到一个第三方网站,
推荐去外国站点:dedecms+techblogs国内可以去工具类站点,pexelsaliexpress里一些插件商城的站点也有详细的第三方采集技术。采集商业站一般是去dedecms后台批量采集,建议可以通过seo来改变内容重复率,数据量,内容多的情况下,可以设置搜索框,
现在来说,这是最简单,成本低的网站采集了,采集网站内容还算可以的一个工具:followim,不过其采集定向性并不是太强,不如当初采集百度知道的好,后来定向性增强了,采集质量略有上升。
网站内容采集系统(python模拟爬虫抓取网页内容采集网页.rarpython抓取采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-05 12:43
python模拟爬虫爬取网页内容采集网站.rar
python爬虫模拟爬取网页内容,采集网页内容,这里主要是模拟爬取新浪微博内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息注意to id和fan id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子。运行这个例子的一些注意事项:1.先安装Python环境,作者是Python2.7.82.然后通过pip install selenium命令安装PIP或者easy_install3.安装selenium,其中是一个自动测试爬取的工具4. 然后修改代码中的用户名和密码,并填写Run the program 用自己的用户名和密码5.,自动调用火狐浏览器登录微博注:手机端信息更加精致简洁,动态加载没有限制,只显示微博或粉丝id等20个页面。这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.txtMegry_Result_Best.py 用户这个文件的整理了某天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中weibo_spider2.py
立即下载 查看全部
网站内容采集系统(python模拟爬虫抓取网页内容采集网页.rarpython抓取采集)
python模拟爬虫爬取网页内容采集网站.rar
python爬虫模拟爬取网页内容,采集网页内容,这里主要是模拟爬取新浪微博内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息注意to id和fan id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子。运行这个例子的一些注意事项:1.先安装Python环境,作者是Python2.7.82.然后通过pip install selenium命令安装PIP或者easy_install3.安装selenium,其中是一个自动测试爬取的工具4. 然后修改代码中的用户名和密码,并填写Run the program 用自己的用户名和密码5.,自动调用火狐浏览器登录微博注:手机端信息更加精致简洁,动态加载没有限制,只显示微博或粉丝id等20个页面。这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.txtMegry_Result_Best.py 用户这个文件的整理了某天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中weibo_spider2.py
立即下载
网站内容采集系统(易得网站数据采集系统特点及下载分享规则介绍-规则分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-05 12:38
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。 查看全部
网站内容采集系统(易得网站数据采集系统特点及下载分享规则介绍-规则分析)
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留的标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
网站内容采集系统(网站发布文章需要知道的SEO技巧有哪些?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-01 15:12
网站POST文章你需要知道的SEO技巧有哪些?
几年前,百度搜索引擎没有那么严格。还是可以靠大量转发收录和伪原创通过测试。但是随着百度的不断发展,现在百度已经开始大量压制过度的收录,靠伪原创积累网站,减少收录权,而不是收录等处理结果,会带来网站影响很大。
1.为了让网站快速看满,有的SEO人员利用网上cms系统的一些采集功能,从其他网站那里采集了大量的文章,但是这个网站往往是徒劳的。
2. 伪原创 已过时
过去的伪原创文章好用,因为搜索引擎算法不是那么精确,但是随着搜索引擎的不断完善,很容易判断一个文章是否是伪原创。 伪原创文章一般是修改内容的30%。例如:修改文章的开头结尾,替换同义词或相似词组,替换重要词等。原创内容为王
首先原创内容很重要。当然文章的结构一定要清楚。如果内容与主题不符,别说用户不喜欢看,连搜索引擎都反感。对于高质量的原创文章,网站是最好的营养液。因为原创文章符合网站的核心,不仅搜索引擎喜欢爬行,还会吸引更多的用户在网站上长期停留,而这个时间是评判质量的一个标准网站。
4. 高质量的原创文章不仅可以提升用户体验,还可以稳定百度快照的基础。坚持打造高质量的原创文章,也将为网站带来高权重和高排名。
现在,用户喜欢刷手机。如果大量转载他人的文章,尤其是在其他网站上看到过文章,用户不会再去网站阅读,直接关闭网站除非这个文章很经典的文章。
所以转载和伪原创都是一些投机取巧的方法。做网站SEO的时候,不仅是为了迎合搜索引擎,也是为了网站的用户体验。
网站的SEO优化怎么做?
网站optimization 两句话说不清楚,所有网站optimization 基本一致。 网站Optimization 是一个长期的过程,从几个月到几年不等。以下是一些常用的方法,仅供参考:
关键词Select
创建首页网站的时候,要先定目标关键词,不要等到网站Establish,百度收录,再注意这些,不然会后悔的。然后借用一些工具查询长尾关键词,看看哪些词的搜索量大,然后优化一些搜索量小的词,对搜索量大的词会产生影响。
高质量原创文章
三年前我们说原创文章,但现在我们还在说原创文章对百度来说还是很好的。记住,不要伪造原件。 网站每天需要更新一定的内容,选择好的关键词,从关键词开始,写文章在经验、操作步骤、注意事项等方面更新内容,以便也可以做SEO优化,让搜索引擎通过内容页找到网站,增加流量,提高网站排名。
优化内外部链接
虽然我是新手,但也需要主动认识一些业内的朋友,和我的网站做一些链接。我们也需要学会和一些网站合作,不断提升网站的影响力。在操作网站时,如果遇到网站结构不合理的情况,也可以让开发者及时调整内部结构,让你的网站更方便搜索引擎抓取信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,越容易达到SEO优化的目标。
答案可以在这里找到网站还有更多相关知识和教学视频 查看全部
网站内容采集系统(网站发布文章需要知道的SEO技巧有哪些?(图))
网站POST文章你需要知道的SEO技巧有哪些?
几年前,百度搜索引擎没有那么严格。还是可以靠大量转发收录和伪原创通过测试。但是随着百度的不断发展,现在百度已经开始大量压制过度的收录,靠伪原创积累网站,减少收录权,而不是收录等处理结果,会带来网站影响很大。
1.为了让网站快速看满,有的SEO人员利用网上cms系统的一些采集功能,从其他网站那里采集了大量的文章,但是这个网站往往是徒劳的。
2. 伪原创 已过时
过去的伪原创文章好用,因为搜索引擎算法不是那么精确,但是随着搜索引擎的不断完善,很容易判断一个文章是否是伪原创。 伪原创文章一般是修改内容的30%。例如:修改文章的开头结尾,替换同义词或相似词组,替换重要词等。原创内容为王
首先原创内容很重要。当然文章的结构一定要清楚。如果内容与主题不符,别说用户不喜欢看,连搜索引擎都反感。对于高质量的原创文章,网站是最好的营养液。因为原创文章符合网站的核心,不仅搜索引擎喜欢爬行,还会吸引更多的用户在网站上长期停留,而这个时间是评判质量的一个标准网站。
4. 高质量的原创文章不仅可以提升用户体验,还可以稳定百度快照的基础。坚持打造高质量的原创文章,也将为网站带来高权重和高排名。
现在,用户喜欢刷手机。如果大量转载他人的文章,尤其是在其他网站上看到过文章,用户不会再去网站阅读,直接关闭网站除非这个文章很经典的文章。
所以转载和伪原创都是一些投机取巧的方法。做网站SEO的时候,不仅是为了迎合搜索引擎,也是为了网站的用户体验。
网站的SEO优化怎么做?
网站optimization 两句话说不清楚,所有网站optimization 基本一致。 网站Optimization 是一个长期的过程,从几个月到几年不等。以下是一些常用的方法,仅供参考:
关键词Select
创建首页网站的时候,要先定目标关键词,不要等到网站Establish,百度收录,再注意这些,不然会后悔的。然后借用一些工具查询长尾关键词,看看哪些词的搜索量大,然后优化一些搜索量小的词,对搜索量大的词会产生影响。
高质量原创文章
三年前我们说原创文章,但现在我们还在说原创文章对百度来说还是很好的。记住,不要伪造原件。 网站每天需要更新一定的内容,选择好的关键词,从关键词开始,写文章在经验、操作步骤、注意事项等方面更新内容,以便也可以做SEO优化,让搜索引擎通过内容页找到网站,增加流量,提高网站排名。
优化内外部链接
虽然我是新手,但也需要主动认识一些业内的朋友,和我的网站做一些链接。我们也需要学会和一些网站合作,不断提升网站的影响力。在操作网站时,如果遇到网站结构不合理的情况,也可以让开发者及时调整内部结构,让你的网站更方便搜索引擎抓取信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,越容易达到SEO优化的目标。
答案可以在这里找到网站还有更多相关知识和教学视频
网站内容采集系统(易得网站数据采集系统通用版,通过编写或者下载规则 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-01 15:11
)
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
查看全部
网站内容采集系统(易得网站数据采集系统通用版,通过编写或者下载规则
)
轻松获取网站数据采集系统通用版,通过编写或下载规则,选择网站数据采集系统,即可采集大部分网站数据,并保存图片文件。是建站必不可少的数据采集利器。而且采集器是开源代码,带有中文注释,方便修改和学习。
采集系统具有以下特点:
主流语言-php+mysql编写,安装对应服务器即可。
完全开源-开源代码,代码有中文注释,方便管理、学习和交流。
规则定制-采集规则可定制,采集网站大部分内容。
数据修改-自定义修改规则,优化数据内容。
数据存储-数组形式,序列化数据保存到文件或数据库中,方便上传调用。
图片阅读-您可以阅读内容的图片并保存在本地。
编码控制-转换编码,可以将gb2312、gbk等编码保存为utf-8。
标签清理-您可以自定义保留标签并清理不需要的标签。
安全性能-读取密码控制,远程读取也安全。
操作简单——一键阅读操作,可以按规则分组阅读,也可以指定规则id阅读,单一id阅读。
规则分组-按规则分组读取数据,及时更新采集数据。
根据自定义规则id自定义读写数据,有效及时。
JS读取-使用js控制读取时间,减少服务器负载。
超时控制-可以设置页面执行时间,减少超时错误。
多读-可以设置网页的多读控制,更有效的读取数据。
错误控制-如果出现多个错误,可以停止读取,减少服务器资源占用。
在多个文件夹中加载控件保存数据,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主要数据。
规则分析——您可以与他人分享您的规则,让更多人使用。
下载规则-下载分享规则,快速获取您需要的内容。
网站内容采集系统(相似软件版本说明软件特色:1.图形化的采集任务定义界面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-08-31 01:02
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据你定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
类似软件
版本说明
软件地址
软件功能:
1.图形化的采集任务定义界面,你只需要在软件内嵌的浏览器中用鼠标点击你想要采集的网页内容就可以配置采集任务,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同不等于100%相同,但我们克服了技术难关,消除了这些障碍。我们定位方式的优势在于:1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面; 2.网页内容变化(如文字增减)、文字颜色、字体等变化)不会影响采集的准确性。
3.支持任务嵌套,采集无限制级页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件之外,还可以采集针对具体的HTML标签的源代码和属性值.
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本还将支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到In一个大纲文件,然后每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出 查看全部
网站内容采集系统(相似软件版本说明软件特色:1.图形化的采集任务定义界面)
Easy 采集网站数据采集系统是一款全面、准确、稳定、易用的网络信息采集软件。它可以轻松抓取您想要的网页内容(包括文本、图片、文件、HTML 源代码等)。 采集接收到的数据可以直接导出EXCEL,也可以根据你定义的模板(如网页文件、TXT文件等)保存为任意格式的文件。也可以保存到数据库,发送到网站服务器,和采集同时保存到一个文件中。
类似软件
版本说明
软件地址
软件功能:
1.图形化的采集任务定义界面,你只需要在软件内嵌的浏览器中用鼠标点击你想要采集的网页内容就可以配置采集任务,无需像其他类似任务 软件在面对复杂的网络源代码时寻找采集 规则。可以说是一个所见即所得的采集任务配置界面。
2.创新内容定位方式,定位更精准稳定。类似的软件基本上都是根据网页源代码中的前导和结束标签来定位内容。这样,用户就必须自己面对网页制作人员只需要面对HTML代码,花费更多的额外学习时间来掌握软件的使用。同时,只要对网页内容稍作改动(简单地改变文字颜色),定位标记极有可能失效,导致采集失效。经过艰苦的技术攻关,我们实现了一种全新的定位方法:结构定位和相对符号定位。大家都知道一个网站的风格基本是固定的,类似网页的内容布局也基本一致。这是结构定位可行的地方。当然,基本相同不等于100%相同,但我们克服了技术难关,消除了这些障碍。我们定位方式的优势在于:1.用户只需点击鼠标即可配置采集任务,实现所见即所得的采集task配置界面; 2.网页内容变化(如文字增减)、文字颜色、字体等变化)不会影响采集的准确性。
3.支持任务嵌套,采集无限制级页面内容只需在当前任务页面中选择你想要采集下级页面的链接即可创建嵌套任务,采集的内容子级页面,嵌套级数不限。这种便利归功于我们新的内容定位方法和图形化的采集 任务配置界面。
4.可以同时采集任何内容除了最基本的文字、图片、文件之外,还可以采集针对具体的HTML标签的源代码和属性值.
5.强大的自动信息再处理能力 配置任务时可以指定对采集到达的内容进行任意替换和过滤。
6.可以自动对采集到达的内容进行排序
7. 支持采集 并将结果保存为EXCEL 和任何格式的文件。支持自定义文件模板。
8. 支持实时保存到数据库。支持ACCESS、SQLSERVER、MYSQL数据库(后续版本还将支持更多类型的数据库)。
9.支持实时上传到网站服务器。支持POST和GET方式,可以自定义上传参数,模拟手动提交。
10.支持实时保存到任意格式的文件,支持自定义模板,支持按记录保存和多条记录保存到单个文件,支持大纲和详细保存(所有记录的部分内容保存到In一个大纲文件,然后每条记录分别保存到一个文件中。
11.支持多种灵活的任务调度方式,实现无人值守采集
12.支持多任务,支持任务导入导出
网站内容采集系统(网站内容采集系统如何采集到站内任何网站自己网站的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-30 03:01
网站内容采集系统如何实现个性化管理,网站内容采集系统如何实现随意分类。网站内容采集系统如何采集到站内任何网站自己网站的内容?网站内容采集系统如何通过软件实现网站内容更新,网站内容采集系统如何实现随意分类。下面管道宝的大神就给大家分享一下网站内容采集系统如何实现随意分类?网站内容采集系统如何实现随意分类第一:采集网站自己网站任何内容源网站采集系统内部也会检测用户邮箱是否来自于seo的统一邮箱,并选定其主站的域名作为网站的入口或导航。这样网站的蜘蛛就能直接访问自己域名,采集用户的网站内容。第二:搜索引擎抓取。
网站内容采集系统如何实现随意分类?高度智能的网站内容采集系统可以根据内容所属领域把整个网站划分成几个小区域,一个小区域中有几百上千条内容,这些内容放到不同的区域。当用户需要在各个区域进行网站内容检索时,系统会自动分别进行内容的网站搜索和服务器打印。
在中国最大的seo平台上,就存在一款系统:moz红云网站管理系统,它能轻松实现分类功能,采集功能,集成seo辅助工具。我曾经亲自使用过一段时间,效果很不错,为此专门写过一篇详细的文章。
网站内容采集系统如何实现随意分类? 查看全部
网站内容采集系统(网站内容采集系统如何采集到站内任何网站自己网站的内容)
网站内容采集系统如何实现个性化管理,网站内容采集系统如何实现随意分类。网站内容采集系统如何采集到站内任何网站自己网站的内容?网站内容采集系统如何通过软件实现网站内容更新,网站内容采集系统如何实现随意分类。下面管道宝的大神就给大家分享一下网站内容采集系统如何实现随意分类?网站内容采集系统如何实现随意分类第一:采集网站自己网站任何内容源网站采集系统内部也会检测用户邮箱是否来自于seo的统一邮箱,并选定其主站的域名作为网站的入口或导航。这样网站的蜘蛛就能直接访问自己域名,采集用户的网站内容。第二:搜索引擎抓取。
网站内容采集系统如何实现随意分类?高度智能的网站内容采集系统可以根据内容所属领域把整个网站划分成几个小区域,一个小区域中有几百上千条内容,这些内容放到不同的区域。当用户需要在各个区域进行网站内容检索时,系统会自动分别进行内容的网站搜索和服务器打印。
在中国最大的seo平台上,就存在一款系统:moz红云网站管理系统,它能轻松实现分类功能,采集功能,集成seo辅助工具。我曾经亲自使用过一段时间,效果很不错,为此专门写过一篇详细的文章。
网站内容采集系统如何实现随意分类?
网站内容采集系统(建立网站内容采集系统规范框架的五个方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-28 16:05
网站内容采集系统,网络上充斥着大量千篇一律的站点链接,要找到符合当下互联网网站发展特点,所依托的网站内容采集系统非常重要。我们在具体规划开发网站内容采集系统,建立网站内容采集系统规范框架的时候,可以采用以下一些方法。第一:从现在规模较大、知名度较高的一些自媒体站点选择采集源头,这样可以尽量缩短时间、降低成本,比如河南科技报、河南网商网等等;另外可以选择一些大众普遍熟知、传播面广、又比较权威的优质平台,这样投入成本可以少一些。第二:从如36。
0、百度、百度文库等这些知名、权威的行业性平台采集源头,还有qq群采集,百度知道、百度文库等大规模内容采集,这样保证源头的可信度、可靠性;这些权威平台,按照要求,审核是较为严格的,所以发布量相对而言会少一些。第三:从知名垂直类科技网站采集源头。比如搜狐财经,对于一些业务不错、网站规模较大、知名度比较高的财经类垂直类网站,可以选择直接采集,通过搜索,得到网站链接,源头采集。
不管是第一种还是第二种,现在内容采集系统需要建立内容采集规范框架,在这里我们就以金融金融类内容采集为例,详细介绍采集系统实现过程。采集系统功能解析和实现。
1、内容采集预处理当平台网站有海量信息时,首先就是要对平台信息进行编码,利用采集机器人集中采集,尽量减少机器人采集时造成的麻烦。
2、内容聚合处理当采集平台海量信息时,可以通过内容聚合,达到聚合、去重、分类等作用。
3、内容高效呈现采集网站直接是静态的,那么我们就可以通过一系列的转换工具,对页面进行高效的转换。
4、内容源指向有时候采集可能来源无从得知,只能尽量伪原创,尽量使内容源方向一致。
5、网站联合采集一个采集系统,既可以吸引数据化采集高手,又可以吸引众多网站用户,在实际应用过程中具有重要的战略价值。
内容采集系统功能分析和实现
1、全方位对多数据源进行集中式处理将采集网站多个源头分类,集中聚合,及时处理结果。
2、采集过程全过程保证可追溯性每一个采集过程,网站所有权限、位置、流量、营销进行记录。
3、多种分类, 查看全部
网站内容采集系统(建立网站内容采集系统规范框架的五个方法)
网站内容采集系统,网络上充斥着大量千篇一律的站点链接,要找到符合当下互联网网站发展特点,所依托的网站内容采集系统非常重要。我们在具体规划开发网站内容采集系统,建立网站内容采集系统规范框架的时候,可以采用以下一些方法。第一:从现在规模较大、知名度较高的一些自媒体站点选择采集源头,这样可以尽量缩短时间、降低成本,比如河南科技报、河南网商网等等;另外可以选择一些大众普遍熟知、传播面广、又比较权威的优质平台,这样投入成本可以少一些。第二:从如36。
0、百度、百度文库等这些知名、权威的行业性平台采集源头,还有qq群采集,百度知道、百度文库等大规模内容采集,这样保证源头的可信度、可靠性;这些权威平台,按照要求,审核是较为严格的,所以发布量相对而言会少一些。第三:从知名垂直类科技网站采集源头。比如搜狐财经,对于一些业务不错、网站规模较大、知名度比较高的财经类垂直类网站,可以选择直接采集,通过搜索,得到网站链接,源头采集。
不管是第一种还是第二种,现在内容采集系统需要建立内容采集规范框架,在这里我们就以金融金融类内容采集为例,详细介绍采集系统实现过程。采集系统功能解析和实现。
1、内容采集预处理当平台网站有海量信息时,首先就是要对平台信息进行编码,利用采集机器人集中采集,尽量减少机器人采集时造成的麻烦。
2、内容聚合处理当采集平台海量信息时,可以通过内容聚合,达到聚合、去重、分类等作用。
3、内容高效呈现采集网站直接是静态的,那么我们就可以通过一系列的转换工具,对页面进行高效的转换。
4、内容源指向有时候采集可能来源无从得知,只能尽量伪原创,尽量使内容源方向一致。
5、网站联合采集一个采集系统,既可以吸引数据化采集高手,又可以吸引众多网站用户,在实际应用过程中具有重要的战略价值。
内容采集系统功能分析和实现
1、全方位对多数据源进行集中式处理将采集网站多个源头分类,集中聚合,及时处理结果。
2、采集过程全过程保证可追溯性每一个采集过程,网站所有权限、位置、流量、营销进行记录。
3、多种分类,
网站内容采集系统(优采云采集器(www.ucaiyun.com)网络数据/信息挖掘软件的配置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-28 03:02
优采云采集器() 是一款专业强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松抓取文本、图片、文件等任何资源。软件支持远程下载图片文件,支持网站登录后获取信息,支持检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接存储和仿人手动发布等诸多功能特点。
基本功能
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存到关系型数据库,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
特点
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。 查看全部
网站内容采集系统(优采云采集器(www.ucaiyun.com)网络数据/信息挖掘软件的配置)
优采云采集器() 是一款专业强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松抓取文本、图片、文件等任何资源。软件支持远程下载图片文件,支持网站登录后获取信息,支持检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接存储和仿人手动发布等诸多功能特点。
基本功能
1、Rule 自定义-通过采集rule 的定义,您可以搜索所有网站采集 几乎任何类型的信息。
2、Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存到关系型数据库,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存到客户现有的数据库结构中。
5、断点再采-信息采集任务停止后可以从断点恢复采集。从此,你再也不用担心你的采集任务被意外中断了。
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录时需要验证码也可以采集。
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行。
8、采集范围限制-可以根据采集的深度和URL的标识来限制采集的范围。
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库。
10、Result 替换-您可以根据规则将采集的结果替换为您定义的内容。
11、条件保存-您可以根据一定条件决定保存和过滤哪些信息。
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接。
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件。
15、 保留编程接口-定义多个编程接口。用户可以在活动中使用PHP和C#编程扩展采集功能。
特点
1、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码。
2、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块。
3、Automatic:无人值守的工作。程序配置完成后,程序会根据您的设置自动运行,无需人工干预。
网站内容采集系统(狂雨小说cms基于ThinkPHP5.1+MYSQL开发,可以在大部分上运行 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2021-08-28 02:18
)
28、友情链接管理系统
29、数据库备份还原系统
30、数据库管理系统
光宇小说cms是基于ThinkPHP5.1+MYSQL开发的,可以运行在大多数普通服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.6以上版本,低于5.6的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
光宇小说cms安装步骤:
1.解压文件上传到对应目录等
<p>2.网站必须配置伪静态才能正常安装使用(第一次访问首页会自动进入安装页面,或者手动输入域名.com/install) 查看全部
网站内容采集系统(狂雨小说cms基于ThinkPHP5.1+MYSQL开发,可以在大部分上运行
)
28、友情链接管理系统
29、数据库备份还原系统
30、数据库管理系统
光宇小说cms是基于ThinkPHP5.1+MYSQL开发的,可以运行在大多数普通服务器上。
如windows server,IIS+PHP+MYSQL,
Linux 服务器,Apache/Nginx+PHP+MYSQL
强烈推荐使用Linux服务器,可以充分发挥更大的性能优势
软件方面,PHP要求5.6以上版本,低于5.6的版本不能运行。
硬件方面,配置一般的虚拟主机可以正常运行系统,如果有服务器就更好了。
光宇小说cms安装步骤:
1.解压文件上传到对应目录等
<p>2.网站必须配置伪静态才能正常安装使用(第一次访问首页会自动进入安装页面,或者手动输入域名.com/install)
网站内容采集系统制作或代码编写,其他需要一些服务器设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-27 04:06
网站内容采集系统制作或代码编写,其他需要一些服务器设置,内容发布策略,防刷,防劫持技术,再或者就是技术核心之外的东西,还有网站优化的基本技术,网站策划,运营,推广等等...再多也就不能算作网站了。
建议你多了解一下当地网络销售的情况,和销售推广的能力,做seo最重要的是销售能力和网络知识的积累,
现在卖网站的实在太多了,
dreamhost:home?weblibs=&index=4829我做的是模版的,容易入门。
我这里可以了解下的哦
网站内容的整合以及标题seo的文字优化dns的优化
seo方面的。
seo这东西,最重要的是销售能力吧。销售能力不行,seo怎么都没用。这点我非常认同的。
从一些基础的如服务器以及带宽这些方面,seo是非常需要的。不过题主的意思应该不仅仅只是要做seo,还要更多地了解网站的运营以及推广方面的东西,具体的可以联系我。
建议学习学习会更好,不管做什么,都应该有一个长期的规划,短期做不好,很容易全职转行,那就需要更多的时间。
加强web前端网站基础知识的知识储备,理解网站的构成,seo分成两大块,一块html,另一块是结构化语言。上线主机网站并利用后台实现ajax前端页面的统一。 查看全部
网站内容采集系统制作或代码编写,其他需要一些服务器设置
网站内容采集系统制作或代码编写,其他需要一些服务器设置,内容发布策略,防刷,防劫持技术,再或者就是技术核心之外的东西,还有网站优化的基本技术,网站策划,运营,推广等等...再多也就不能算作网站了。
建议你多了解一下当地网络销售的情况,和销售推广的能力,做seo最重要的是销售能力和网络知识的积累,
现在卖网站的实在太多了,
dreamhost:home?weblibs=&index=4829我做的是模版的,容易入门。
我这里可以了解下的哦
网站内容的整合以及标题seo的文字优化dns的优化
seo方面的。
seo这东西,最重要的是销售能力吧。销售能力不行,seo怎么都没用。这点我非常认同的。
从一些基础的如服务器以及带宽这些方面,seo是非常需要的。不过题主的意思应该不仅仅只是要做seo,还要更多地了解网站的运营以及推广方面的东西,具体的可以联系我。
建议学习学习会更好,不管做什么,都应该有一个长期的规划,短期做不好,很容易全职转行,那就需要更多的时间。
加强web前端网站基础知识的知识储备,理解网站的构成,seo分成两大块,一块html,另一块是结构化语言。上线主机网站并利用后台实现ajax前端页面的统一。
乐思论坛采集系统的主要功能是什么?怎么做?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-26 07:02
乐思论坛采集系统
一、主要功能
乐思论坛采集系统的主要功能是:根据用户自定义任务配置,批量准确提取目标中主题帖和回复帖的作者、标题、发布时间、内容、栏目论坛专栏等,转换成结构化记录,存储在本地数据库中。功能图如下:
二、 系统功能
可以提取所有主题帖或最新主题帖
您可以提取某个话题的所有回复或最新回复的内容
支持命令行格式,可配合Windows任务规划器定期提取目标数据
支持记录唯一索引,避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,如MSSQL、Access、MySQL、Oracle、DB2、Sybase等
三、 运行环境
操作系统:Windows XP/NT/2000/2003
内存:最低32M内存,推荐128M以上
硬盘:至少20M可用硬盘空间
四、行业应用
乐思论坛采集系统主要用于:门户网站专业论坛整合、市场研究机构市场分析、竞争情报获取。
门户网站
可以做到:
每天将目标论坛的信息(标题、作者、内容等)提取到数据库中
优点:
轻松提供论坛门户
企业应用
可以做到:
采集本公司品牌及各大论坛竞争对手品牌实时准确反馈
各大行业论坛实时准确采集信息,从中了解消费者需求和反馈,从而发现市场趋势和机会
优点:
快速、大量获取目标企业信息,立即提升企业营销能力
广告和市场研究机构
可以做到:
快速大量获取目标论坛的各种原创信息入库
优点:
快速形成传统品牌研究和互联网用户研究的基础数据库 查看全部
乐思论坛采集系统的主要功能是什么?怎么做?
乐思论坛采集系统
一、主要功能
乐思论坛采集系统的主要功能是:根据用户自定义任务配置,批量准确提取目标中主题帖和回复帖的作者、标题、发布时间、内容、栏目论坛专栏等,转换成结构化记录,存储在本地数据库中。功能图如下:
二、 系统功能
可以提取所有主题帖或最新主题帖
您可以提取某个话题的所有回复或最新回复的内容
支持命令行格式,可配合Windows任务规划器定期提取目标数据
支持记录唯一索引,避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,如MSSQL、Access、MySQL、Oracle、DB2、Sybase等
三、 运行环境
操作系统:Windows XP/NT/2000/2003
内存:最低32M内存,推荐128M以上
硬盘:至少20M可用硬盘空间
四、行业应用
乐思论坛采集系统主要用于:门户网站专业论坛整合、市场研究机构市场分析、竞争情报获取。
门户网站
可以做到:
每天将目标论坛的信息(标题、作者、内容等)提取到数据库中
优点:
轻松提供论坛门户
企业应用
可以做到:
采集本公司品牌及各大论坛竞争对手品牌实时准确反馈
各大行业论坛实时准确采集信息,从中了解消费者需求和反馈,从而发现市场趋势和机会
优点:
快速、大量获取目标企业信息,立即提升企业营销能力
广告和市场研究机构
可以做到:
快速大量获取目标论坛的各种原创信息入库
优点:
快速形成传统品牌研究和互联网用户研究的基础数据库
网站内容采集系统最基本的功能是采集引擎抓取的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-08-25 23:02
网站内容采集系统最基本的功能就是采集引擎抓取的内容,当然对于买家来说就是看不到网站内容。现在很多打着采集系统的兼职公司,对于采集来说有什么好处,采集的内容又有多少真正存在,多少未经过处理的内容都在采集系统,并且都在广泛传播,很多网站或论坛的内容就是根据这些网站或论坛的内容,批量采集一些内容作为自己的原创或伪原创,或商业广告等,并且它获取到的内容会占用几百个或上千个网站、论坛的服务器空间。
那么你买的采集系统可以赚钱吗,现在很多采集系统低价采集,不止对打造原创或伪原创、商业广告没有多大作用,并且他对买家来说,即使你是买他的系统,买到手以后你也一样看不到网站内容,能真正采集到内容的网站或论坛毕竟不多,大部分都是采集来的,而系统不会提供给你检测真伪网站或论坛的功能,购买的系统功能几乎都是说检测,而很多买家根本不懂采集系统是否能检测,并且大部分的采集系统它都没有这个功能。
但是如果你购买的是虚拟空间或小说网站等,采集内容都是文本采集,而且要按每天或每周检测内容的更新情况,每天、每周就能看到站内存在的内容,因为目前这种采集系统都是存在免费的或卖家免费提供了检测功能,所以几乎买家看不到站内存在的内容,如果你想看网站或论坛的存在的内容,那就需要去买家哪里检测。这种情况下,几乎买家才知道这个系统是不是正规的采集系统,如果系统采集的是商业广告或推广相关内容,买家能够看到的内容可想而知,并且很多买家心存疑惑,并不会买系统。 查看全部
网站内容采集系统最基本的功能是采集引擎抓取的内容
网站内容采集系统最基本的功能就是采集引擎抓取的内容,当然对于买家来说就是看不到网站内容。现在很多打着采集系统的兼职公司,对于采集来说有什么好处,采集的内容又有多少真正存在,多少未经过处理的内容都在采集系统,并且都在广泛传播,很多网站或论坛的内容就是根据这些网站或论坛的内容,批量采集一些内容作为自己的原创或伪原创,或商业广告等,并且它获取到的内容会占用几百个或上千个网站、论坛的服务器空间。
那么你买的采集系统可以赚钱吗,现在很多采集系统低价采集,不止对打造原创或伪原创、商业广告没有多大作用,并且他对买家来说,即使你是买他的系统,买到手以后你也一样看不到网站内容,能真正采集到内容的网站或论坛毕竟不多,大部分都是采集来的,而系统不会提供给你检测真伪网站或论坛的功能,购买的系统功能几乎都是说检测,而很多买家根本不懂采集系统是否能检测,并且大部分的采集系统它都没有这个功能。
但是如果你购买的是虚拟空间或小说网站等,采集内容都是文本采集,而且要按每天或每周检测内容的更新情况,每天、每周就能看到站内存在的内容,因为目前这种采集系统都是存在免费的或卖家免费提供了检测功能,所以几乎买家看不到站内存在的内容,如果你想看网站或论坛的存在的内容,那就需要去买家哪里检测。这种情况下,几乎买家才知道这个系统是不是正规的采集系统,如果系统采集的是商业广告或推广相关内容,买家能够看到的内容可想而知,并且很多买家心存疑惑,并不会买系统。
流量可以自动定期分配,不需要自己管理!!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-08-23 23:05
网站内容采集系统_网站内容采集系统_网站内容采集系统网站内容采集系统,采集网站内容!通过采集系统将网站内容同步到采集程序,采集程序同步到广告业务端口!最快达到网站转正,有平台服务,无需维护!自动监测网站质量,定期清理违规内容!!!采集系统采集网站内容,支持全球定位!自动抓取网站内容到用户个人服务器!!!无需人工盯梢!!!可查收大量小网站,网页。
文章,作品,只需要一个浏览器登录网站就可以完成!!!流量可以自动定期分配,不需要自己管理!!!采集系统:全球定位,流量分配,自动抓取网站内容,采集速度快,合作推广能力强。具体采集程序需要安装到网站内,扫描网站内,等待网站内容爬取而来后,对其内容进行浏览器浏览内容分析,找到有效信息。按比例返回给用户。
谢邀。webrtc是针对无线的双目采集软件;webrtc+ai已经在近年开始被应用到网页采集等方面。从用途上来看,webrtc主要有三大功能:采集双目前端与隐私。ai进行情感和语义分析、做分类等,使用moment提取定位等。采集双目前端与隐私。你所需要的只是采集双目前端上的数据(因为需要采集双目前端上内容才能进行无线支持,所以需要买采集机),具体用哪一家安卓或者ios或者android,对你没有任何影响;对你来说主要是看双目前端上有哪些数据,还有到底用哪一家的采集机;至于单独的webrtc采集程序,你买了,运营商也许会做相应优化,你按照数据联通方式来选择交换机;至于具体的二次开发调试,php、mysql这类io型语言可以完成;至于webrtc+ai,不得不说是2016年的大趋势,如果你做网站站内搜索推荐、搜索功能整合,都会依赖这一项技术,因为双目采集在网页内的范围可远远超过你能想象的范围。手机搜索下发,网页内容,如有需要可以留言。 查看全部
流量可以自动定期分配,不需要自己管理!!!
网站内容采集系统_网站内容采集系统_网站内容采集系统网站内容采集系统,采集网站内容!通过采集系统将网站内容同步到采集程序,采集程序同步到广告业务端口!最快达到网站转正,有平台服务,无需维护!自动监测网站质量,定期清理违规内容!!!采集系统采集网站内容,支持全球定位!自动抓取网站内容到用户个人服务器!!!无需人工盯梢!!!可查收大量小网站,网页。
文章,作品,只需要一个浏览器登录网站就可以完成!!!流量可以自动定期分配,不需要自己管理!!!采集系统:全球定位,流量分配,自动抓取网站内容,采集速度快,合作推广能力强。具体采集程序需要安装到网站内,扫描网站内,等待网站内容爬取而来后,对其内容进行浏览器浏览内容分析,找到有效信息。按比例返回给用户。
谢邀。webrtc是针对无线的双目采集软件;webrtc+ai已经在近年开始被应用到网页采集等方面。从用途上来看,webrtc主要有三大功能:采集双目前端与隐私。ai进行情感和语义分析、做分类等,使用moment提取定位等。采集双目前端与隐私。你所需要的只是采集双目前端上的数据(因为需要采集双目前端上内容才能进行无线支持,所以需要买采集机),具体用哪一家安卓或者ios或者android,对你没有任何影响;对你来说主要是看双目前端上有哪些数据,还有到底用哪一家的采集机;至于单独的webrtc采集程序,你买了,运营商也许会做相应优化,你按照数据联通方式来选择交换机;至于具体的二次开发调试,php、mysql这类io型语言可以完成;至于webrtc+ai,不得不说是2016年的大趋势,如果你做网站站内搜索推荐、搜索功能整合,都会依赖这一项技术,因为双目采集在网页内的范围可远远超过你能想象的范围。手机搜索下发,网页内容,如有需要可以留言。
wordpress发布网站内容采集系统的服务器有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-22 05:04
网站内容采集系统,很多做网站的朋友经常会问我:wordpress发布的内容都要转存到什么服务器呢?网站内容采集系统,你可以利用wordpress自身的自动内容抓取工具,wordpress有一个wordpress采集器。
wordpress根据当前page和tag的内容情况收集内容,
formoreinformationonit,youcanalsohostasinglepagetoafiltereditem.thefastestandmostpopularwaytoconvertyourpagetofiltereditemsis:hostingafiltereditem.
wordpress内置的内容采集系统,比如:网络推广专家。
wordpress扩展是一个很好的采集工具,
可以参考我发布的
/
onechoice采集用的一个工具
可以参考【wordpress博客内容采集框架】+
可以使用wordpress表单框架form-detail做采集的话内容非常丰富.
fernewhistory
wordpress采集框架:wordpress内容采集框架
你可以尝试下用wordpress表单做采集,
wordpress采集框架采集热门资源。
v4采集这么好用?
wordpress采集框架:wordpress采集框架推荐
很多人说采集插件的,国内的有个51335,
个人感觉wordpress采集框架51335也不错, 查看全部
wordpress发布网站内容采集系统的服务器有哪些?-八维教育
网站内容采集系统,很多做网站的朋友经常会问我:wordpress发布的内容都要转存到什么服务器呢?网站内容采集系统,你可以利用wordpress自身的自动内容抓取工具,wordpress有一个wordpress采集器。
wordpress根据当前page和tag的内容情况收集内容,
formoreinformationonit,youcanalsohostasinglepagetoafiltereditem.thefastestandmostpopularwaytoconvertyourpagetofiltereditemsis:hostingafiltereditem.
wordpress内置的内容采集系统,比如:网络推广专家。
wordpress扩展是一个很好的采集工具,
可以参考我发布的
/
onechoice采集用的一个工具
可以参考【wordpress博客内容采集框架】+
可以使用wordpress表单框架form-detail做采集的话内容非常丰富.
fernewhistory
wordpress采集框架:wordpress内容采集框架
你可以尝试下用wordpress表单做采集,
wordpress采集框架采集热门资源。
v4采集这么好用?
wordpress采集框架:wordpress采集框架推荐
很多人说采集插件的,国内的有个51335,
个人感觉wordpress采集框架51335也不错,
网站内容采集系统开发:信息采集软件开发(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-22 00:01
网站内容采集系统开发:信息采集软件开发简介:实现我们网站内容的信息采集采集工具一般使用程序采集,也有大量的页面可以手工采集页面爬虫程序开发-爬虫采集软件系统开发系统介绍:采集需要的程序采集大量网页,然后执行相应的浏览器窗口渲染程序。页面采集程序开发模式:常用的有php、webserver或者直接使用小程序采集器工具,看个人喜好采集分析:页面采集需要分析,需要根据不同网站的特性进行分析,分析分析字段是否能找到,分析分析在哪里找到页面进行采集分析,比如是否为注册用户等等图片采集:对于原始的图片进行分析和渲染。常用的软件:x图、imglab、图虫网站seo:优化搜索引擎网站seo相关的系统开发。
找一家在线采集平台,用他们的采集功能可以有效增加在线编辑网站内容的效率,在线编辑有对应的软件,比如x图搜索,秀米,m3u9.网上很多的学习课程和官方提供的采集工具。现在有很多从事优化,比如还有很多博客,
建议找一些专业的采集网站,可以打击不相关网站,高效的提高网站的原创度,可以多看一些英文站,美国的站点还有马来西亚的站,原创很重要。我们合作的都是50万以上年收入的站长,站长只有采集和数据利用两个需求。 查看全部
网站内容采集系统开发:信息采集软件开发(图)
网站内容采集系统开发:信息采集软件开发简介:实现我们网站内容的信息采集采集工具一般使用程序采集,也有大量的页面可以手工采集页面爬虫程序开发-爬虫采集软件系统开发系统介绍:采集需要的程序采集大量网页,然后执行相应的浏览器窗口渲染程序。页面采集程序开发模式:常用的有php、webserver或者直接使用小程序采集器工具,看个人喜好采集分析:页面采集需要分析,需要根据不同网站的特性进行分析,分析分析字段是否能找到,分析分析在哪里找到页面进行采集分析,比如是否为注册用户等等图片采集:对于原始的图片进行分析和渲染。常用的软件:x图、imglab、图虫网站seo:优化搜索引擎网站seo相关的系统开发。
找一家在线采集平台,用他们的采集功能可以有效增加在线编辑网站内容的效率,在线编辑有对应的软件,比如x图搜索,秀米,m3u9.网上很多的学习课程和官方提供的采集工具。现在有很多从事优化,比如还有很多博客,
建议找一些专业的采集网站,可以打击不相关网站,高效的提高网站的原创度,可以多看一些英文站,美国的站点还有马来西亚的站,原创很重要。我们合作的都是50万以上年收入的站长,站长只有采集和数据利用两个需求。
该文:浅谈政府网站评估数据采集汇总分析系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-08-12 19:06
谈政府网站assessment data采集Summary 分析系统设计与实现小结:本文针对当前政务现状提出网站网站盛发展但网站级别不均匀的。 @Evaluation解决方案,该方案通过设计和实现政府网站评数据采集汇总分析系统平台,提高政府网站的建设和管理水平。系统设计根据软件工程的基本要求,完成系统设计思路、系统总体设计和功能模块设计。系统实现了采集客户端和管理终端的用户界面和相应的功能模块。 关键词:网站assessment;评价指标体系;功能模块 中文图书馆分类号:TP311 文档识别码:A文章编号:1009-3044(2013)29-6690-03 当前政府网站是各级政府及其部门发布的重要平台政务信息公开,提供在线服务,与公众互动,直接关系到政务公开、在线服务、政民互动的质量和效果。为提高政府网站建设管理水平,加大政府信息公开力度,强化网上服务功能,推进政民互动建设。有必要配合各级政府网站发展建设工作,设计开发尤其需要政府网站评数据采集汇总分析系统。 1 系统设计1.1 系统设计思路 本系统主要针对政府网站assessment网站 指标体系中的指标数据标准化采集,对采集的网站数据进行汇总分析.
系统研发完成后,可大大提高government网站assessment指标系统采集汇总分析的效率;为government网站data采集data汇总分析工作和谐公正提供保障,也为编制government网站绩效评价报告提供重要参考。系统开发完成后,不仅可以应用于政府网站绩效评价,还可以为各级政府网站指标评价指标体系的修订完善提供量化参考。 1.2 系统的整体设计。该系统主要包括两个功能模块:政府网站assessment指标体系中的网站data指标数据采集,以及基于采集的网站数据的数据汇总、整理和分析:网站数据采集Client(以下简称:采集Client)、网站数据汇总分析管理端(以下简称:管理端)。 采集Client系统可以分为三个层次网站网站和预先建立的网站评价指标体系网站数据按权重分配,完成网站评价和数据采集政府各部门的工作。管理系统可以采集government网站四级评价指标体系的数据,按照省、区、地、县、市网站三级政府部门对网站的评价结果进行排序分析网站。 1.3 采集客户端功能模块设计1)User登录显示功能模块用于用户登录,根据分配的网站数据采集任务进行政府网站四级评价指标体系数据采集work. 2)数据保存功能模块 用于保存和备份已经采集的政府网站评估数据。
3)网站assessment user采集数据功能模块 用于采集,浏览显示当前用户采集各级评价指标体系数据信息。 4)网站评价指标数量统计 用于统计当前用户采集各级政府网站计量指标。 5)删除指定的网站assessment数据 用于删除当前用户错误采集的网站assessment数据。 1.4 管理终端的功能模块设计1)采集数据状态显示功能模块用于在数据导入前查看和预览采集员采集的网站数据(采集的数据未导入管理员数据汇总库)。在此操作中,您可以浏览采集员采集的网站数据状态,例如网站指标的评估是否已经完成。 2)采集数据导入功能 用于导入采集员采集的网站数据(采集数据导入管理员数据汇总库,以下简称“汇总库”)。如有采集员未完成对网站的评价,后续总结工作将暂停。 3)已评网站Status 显示功能 用于显示汇总库中采集的网站数据信息状态(管理员可以跟踪网站数据采集状态)。 4)Display user采集信息状态功能,用于显示汇总库采集中指定用户的网站data信息状态(管理员可以在任何时候)。 5)Data 初始化函数用于当前管理员初始化汇总库。管理员在执行此操作时需要小心,避免删除采集网站评估数据。 6)Delete user采集data 函数用于管理员删除用户指定的采集的所有网站信息。
7)delete网站采集data 函数用于管理员删除用户采集指定的某条网站信息。 8)Display采集User 账号信息功能 该按钮用于显示采集用户的账号相关信息(显示的用户账号信息可以导出到Excel表格)。 9)显示评价等级差大于等于3个等级功能用于显示相同指标值且采集用户数大于两个数据,对于相同的网站相同指标等级区别在3级以上(包括3级)采集用户和指示灯状态信息。例如,如果用户1被分配到A级,用户2被分配到D级,则等级差超过3级;这时候需要更新采集此网站的评价数据。 10)government Department网站调查分数编号排序功能 用于显示汇总库中评价网站的数据汇总和排序。 (地市网站sort,县区网站sort按钮相同,此处不再赘述) 11)display Government网站各级指标数据值函数用于显示评价汇总数据库网站数据汇总排序,显示网站1-4各指标汇总数据信息。 2 系统实现2.1 系统功能界面网站assessment data采集 汇总分析系统根据两个不同的功能角色模块,在登录系统时呈现不同的用户界面。如图1,采集Client网站assessment data采集工作界面;如图2所示,管理端网站assessment数据汇总分析工作界面。 3 结束语government网站assessment data采集汇总分析系统是将人工的采集网站评价数据和技术评价数据导入government网站performance评价数据库,通过对原创数据的整合采集、汇总、分析等环节,大大提高数据采集、汇总、分析的效率,为政府网站绩效评价数据采集、汇总、分析的客观公正提供保障是government网站绩效评价汇编。报告前的重要部分具有一定的实用价值。
参考文献:[1] 耿霞。政府系统网站绩效评价系统研究[J].信息系统工程, 2013 (4): 41-43. [2] 陈娜. Government网站绩效评价研究综述[J]. 剑南文学, 2013 (6):204-205. [ 3]张华.基于网络技术的评价网络新闻管理系统的设计与实现[J].信息技术,2011(10):50-52.[4]秦中泰.基于网络技术的教学评价系统ASP.NET business网站[J]. 南昌教育学院学报, 2010, 25 (4): 112- 113. 查看全部
该文:浅谈政府网站评估数据采集汇总分析系统设计与实现
谈政府网站assessment data采集Summary 分析系统设计与实现小结:本文针对当前政务现状提出网站网站盛发展但网站级别不均匀的。 @Evaluation解决方案,该方案通过设计和实现政府网站评数据采集汇总分析系统平台,提高政府网站的建设和管理水平。系统设计根据软件工程的基本要求,完成系统设计思路、系统总体设计和功能模块设计。系统实现了采集客户端和管理终端的用户界面和相应的功能模块。 关键词:网站assessment;评价指标体系;功能模块 中文图书馆分类号:TP311 文档识别码:A文章编号:1009-3044(2013)29-6690-03 当前政府网站是各级政府及其部门发布的重要平台政务信息公开,提供在线服务,与公众互动,直接关系到政务公开、在线服务、政民互动的质量和效果。为提高政府网站建设管理水平,加大政府信息公开力度,强化网上服务功能,推进政民互动建设。有必要配合各级政府网站发展建设工作,设计开发尤其需要政府网站评数据采集汇总分析系统。 1 系统设计1.1 系统设计思路 本系统主要针对政府网站assessment网站 指标体系中的指标数据标准化采集,对采集的网站数据进行汇总分析.
系统研发完成后,可大大提高government网站assessment指标系统采集汇总分析的效率;为government网站data采集data汇总分析工作和谐公正提供保障,也为编制government网站绩效评价报告提供重要参考。系统开发完成后,不仅可以应用于政府网站绩效评价,还可以为各级政府网站指标评价指标体系的修订完善提供量化参考。 1.2 系统的整体设计。该系统主要包括两个功能模块:政府网站assessment指标体系中的网站data指标数据采集,以及基于采集的网站数据的数据汇总、整理和分析:网站数据采集Client(以下简称:采集Client)、网站数据汇总分析管理端(以下简称:管理端)。 采集Client系统可以分为三个层次网站网站和预先建立的网站评价指标体系网站数据按权重分配,完成网站评价和数据采集政府各部门的工作。管理系统可以采集government网站四级评价指标体系的数据,按照省、区、地、县、市网站三级政府部门对网站的评价结果进行排序分析网站。 1.3 采集客户端功能模块设计1)User登录显示功能模块用于用户登录,根据分配的网站数据采集任务进行政府网站四级评价指标体系数据采集work. 2)数据保存功能模块 用于保存和备份已经采集的政府网站评估数据。
3)网站assessment user采集数据功能模块 用于采集,浏览显示当前用户采集各级评价指标体系数据信息。 4)网站评价指标数量统计 用于统计当前用户采集各级政府网站计量指标。 5)删除指定的网站assessment数据 用于删除当前用户错误采集的网站assessment数据。 1.4 管理终端的功能模块设计1)采集数据状态显示功能模块用于在数据导入前查看和预览采集员采集的网站数据(采集的数据未导入管理员数据汇总库)。在此操作中,您可以浏览采集员采集的网站数据状态,例如网站指标的评估是否已经完成。 2)采集数据导入功能 用于导入采集员采集的网站数据(采集数据导入管理员数据汇总库,以下简称“汇总库”)。如有采集员未完成对网站的评价,后续总结工作将暂停。 3)已评网站Status 显示功能 用于显示汇总库中采集的网站数据信息状态(管理员可以跟踪网站数据采集状态)。 4)Display user采集信息状态功能,用于显示汇总库采集中指定用户的网站data信息状态(管理员可以在任何时候)。 5)Data 初始化函数用于当前管理员初始化汇总库。管理员在执行此操作时需要小心,避免删除采集网站评估数据。 6)Delete user采集data 函数用于管理员删除用户指定的采集的所有网站信息。
7)delete网站采集data 函数用于管理员删除用户采集指定的某条网站信息。 8)Display采集User 账号信息功能 该按钮用于显示采集用户的账号相关信息(显示的用户账号信息可以导出到Excel表格)。 9)显示评价等级差大于等于3个等级功能用于显示相同指标值且采集用户数大于两个数据,对于相同的网站相同指标等级区别在3级以上(包括3级)采集用户和指示灯状态信息。例如,如果用户1被分配到A级,用户2被分配到D级,则等级差超过3级;这时候需要更新采集此网站的评价数据。 10)government Department网站调查分数编号排序功能 用于显示汇总库中评价网站的数据汇总和排序。 (地市网站sort,县区网站sort按钮相同,此处不再赘述) 11)display Government网站各级指标数据值函数用于显示评价汇总数据库网站数据汇总排序,显示网站1-4各指标汇总数据信息。 2 系统实现2.1 系统功能界面网站assessment data采集 汇总分析系统根据两个不同的功能角色模块,在登录系统时呈现不同的用户界面。如图1,采集Client网站assessment data采集工作界面;如图2所示,管理端网站assessment数据汇总分析工作界面。 3 结束语government网站assessment data采集汇总分析系统是将人工的采集网站评价数据和技术评价数据导入government网站performance评价数据库,通过对原创数据的整合采集、汇总、分析等环节,大大提高数据采集、汇总、分析的效率,为政府网站绩效评价数据采集、汇总、分析的客观公正提供保障是government网站绩效评价汇编。报告前的重要部分具有一定的实用价值。
参考文献:[1] 耿霞。政府系统网站绩效评价系统研究[J].信息系统工程, 2013 (4): 41-43. [2] 陈娜. Government网站绩效评价研究综述[J]. 剑南文学, 2013 (6):204-205. [ 3]张华.基于网络技术的评价网络新闻管理系统的设计与实现[J].信息技术,2011(10):50-52.[4]秦中泰.基于网络技术的教学评价系统ASP.NET business网站[J]. 南昌教育学院学报, 2010, 25 (4): 112- 113.
什么是网站内容采集系统开发?如何做好网站制作
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-04 21:06
网站内容采集系统开发、网站内容采集系统制作、网站内容采集系统开发、网站内容采集系统制作
1、网站内容采集系统开发
2、网站内容采集系统制作
3、网站内容采集系统开发
4、网站内容采集系统制作
5、网站内容采集系统开发
6、网站内容采集系统制作
7、网站内容采集系统开发
8、网站内容采集系统开发
企业采集各自行业的行情数据,导出到云采集中心,选取重点行业,抓取数据到seo,将数据转化,展示网站或者公司,达到相关网站排名提升的作用,内容采集系统就是以上那些,比如宜信,
抓取互联网上相关行业的网站,然后保存到自己的数据库中,然后推广。
内容采集这个行业本身不是很小,比如很多app有买量,或者一些大的平台也会去买数据,所以所有数据都是相关行业发布的,而且提供数据又不是很方便,用网站来收集,一般都是以爬虫的形式,这种api都是以.bss的形式封装好的,然后采集这个这个网站上面的数据,收集到网站的数据,以此来做自己的推广,具体到一个app,一个平台,可能还需要数据买量,买流量等方式,所以抓取内容的工作量并不是很大,采集的功能方面可能只是数据的整理分析,或者是转化和分析,内容更多采用文本分析,比如采集自某平台上的一些标题词或者内容来进行采集,再加以编辑操作,抓取操作,如果需要报表的话,还会有个报表抓取功能。
这块还是要看使用人员以及采集时间的长短来决定工作量,下面会是一个示例网站,可以参考参考。-rv_trends/-causes-investor-text-pages/browsers/saas-browsers/facebooks/这样大概有30个网站在采集了,一年的时间大概抓取了100多万个内容,然后转化率就很低了,因为抓取量少,转化时间又长,所以无法做到有效转化,不过我个人认为抓取并不是一个很大的问题,就目前而言,内容抓取的工作量还是可以接受的,也有抓取了比较长时间,做了比较久数据都还保存,当然具体情况还要具体分析。
最后说到数据的处理,一般抓取的数据会进行简单的保存,通过分析排序,进行一些简单的分析,找到更匹配的网站,或者通过算法进行筛选一些长尾的数据来进行预测,也可以利用到模型算法来进行相关数据的抓取分析,才可以找到更匹配的网站。以上都是在抓取数据并简单的处理下得到的数据结果,并不能获取全部的数据,比如一些时效性很强的平台,一天可能产生几万条数据,但时效性很短的平台,抓取了很多几万条可能都不够消化的,有些数据抓取几万都不一定够消化,甚至很长的时间一天,可能都产生几百条左右的数据,用。 查看全部
什么是网站内容采集系统开发?如何做好网站制作
网站内容采集系统开发、网站内容采集系统制作、网站内容采集系统开发、网站内容采集系统制作
1、网站内容采集系统开发
2、网站内容采集系统制作
3、网站内容采集系统开发
4、网站内容采集系统制作
5、网站内容采集系统开发
6、网站内容采集系统制作
7、网站内容采集系统开发
8、网站内容采集系统开发
企业采集各自行业的行情数据,导出到云采集中心,选取重点行业,抓取数据到seo,将数据转化,展示网站或者公司,达到相关网站排名提升的作用,内容采集系统就是以上那些,比如宜信,
抓取互联网上相关行业的网站,然后保存到自己的数据库中,然后推广。
内容采集这个行业本身不是很小,比如很多app有买量,或者一些大的平台也会去买数据,所以所有数据都是相关行业发布的,而且提供数据又不是很方便,用网站来收集,一般都是以爬虫的形式,这种api都是以.bss的形式封装好的,然后采集这个这个网站上面的数据,收集到网站的数据,以此来做自己的推广,具体到一个app,一个平台,可能还需要数据买量,买流量等方式,所以抓取内容的工作量并不是很大,采集的功能方面可能只是数据的整理分析,或者是转化和分析,内容更多采用文本分析,比如采集自某平台上的一些标题词或者内容来进行采集,再加以编辑操作,抓取操作,如果需要报表的话,还会有个报表抓取功能。
这块还是要看使用人员以及采集时间的长短来决定工作量,下面会是一个示例网站,可以参考参考。-rv_trends/-causes-investor-text-pages/browsers/saas-browsers/facebooks/这样大概有30个网站在采集了,一年的时间大概抓取了100多万个内容,然后转化率就很低了,因为抓取量少,转化时间又长,所以无法做到有效转化,不过我个人认为抓取并不是一个很大的问题,就目前而言,内容抓取的工作量还是可以接受的,也有抓取了比较长时间,做了比较久数据都还保存,当然具体情况还要具体分析。
最后说到数据的处理,一般抓取的数据会进行简单的保存,通过分析排序,进行一些简单的分析,找到更匹配的网站,或者通过算法进行筛选一些长尾的数据来进行预测,也可以利用到模型算法来进行相关数据的抓取分析,才可以找到更匹配的网站。以上都是在抓取数据并简单的处理下得到的数据结果,并不能获取全部的数据,比如一些时效性很强的平台,一天可能产生几万条数据,但时效性很短的平台,抓取了很多几万条可能都不够消化的,有些数据抓取几万都不一定够消化,甚至很长的时间一天,可能都产生几百条左右的数据,用。

