
框架网页
推荐10款流行的java开源的网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-06-29 08:03
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫 查看全部
1:JAVA爬虫WebCollector(Star:1345)
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫
干货丨推荐八款高效率的爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-05-24 08:01
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。 查看全部

Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。
网络爬虫 c++
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-05-22 08:01
广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。
c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...
互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...
这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...
b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...
说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...
所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...
nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...
很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...
requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...
本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先... 查看全部

广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。

c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...

互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...

这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...

rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...

b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...

说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...

所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...

nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...

很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...

requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...

本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先...
Go语言网络爬虫概述
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-05-13 08:03
简单来说,网络爬虫是互联网终端用户的模仿者。它模仿的主要对象有两个,一个是坐在计算器前使用网络浏览器访问网路内容的人类用户,另一个就是网络浏览器。
网络爬虫会模仿人类用户输入某个网站的网路地址,并企图访问该网站上的内容,还会模仿网路浏览器按照给定的网路地址去下载相应的内容。这里所说的内容可以是 HTML 页面、图片文件、音视频数据流,等等。
在下载到对应的内容以后,网络爬虫会按照预设的规则对它进行剖析和筛选。这些筛选岀的部份会马上得到特定的处理。与此同时,网络爬虫都会象人类用户点击网页中某个他感兴趣的链接那样,继续访问和下载相关联的其他内容,然后再重复上述步骤,直到满足停止的条件。
如上所述,网络爬虫应当按照使用者的意愿手动下载、分析、筛选、统计以及储存指定的网路内容。注意,这里的关键词是“自动”和“根据意愿”。“自动”的涵义是,网络爬虫在启动后自己完成整个爬取过程而无需人工干预,并且能够够在过程结束以后手动停止。而“根据意愿”则是说,网络爬虫最大限度地准许使用者对其爬取过程进行订制。
乍一看,要做到手动爬取其实并不困难。我们只需使网路爬虫依据相关的网路地址不断地下载对应的内容即可。但是,窥探其中就可以发觉,这里有很多细节须要我们进行非常处理,如下所示。
在这种细节当中,有的是比较容易处理的,而有的则须要额外的解决方案。例如,我们都晓得,基于 HTML 的网页中可以包含代表按键的 button 标签。
让网络浏览器在终端用户点击按键的时侯加载并显示另一个网页可以有很多种方式,其中,非常常用的一种方式就是为该标签添加 onclick 属性并把一些 JavaScript 语言的代码作为它的值。
虽然这个方式这么常用,但是我们要想使网络爬虫可以从中提取出有效的网路地址却是比较 困难的,因为这涉及对JavaScript程序的理解。JavaScript代码的编撰方式繁杂,要想使 网络爬虫完全理解它们,恐怕就须要用到某个JavaScript程序解析器的 Go语言实现了。
另一方面,由于互联网对人们生活和工作的全面渗透,我们可以通过各类途径找到各式各样的网路爬虫实现,它们几乎都有着复杂而又奇特的逻辑。这些复杂的逻辑主要针对如下几个方面。
这些逻辑绝大多数都与网路爬虫使用者当时的意愿有关。换句话说,它们都与具体的使用目的有着紧密的联系。也许它们并不应当是网路爬虫的核心功能,而应当作为扩充功能或可订制的功能存在。
因此,我想我们更应当编撰一个容易被订制和扩充的网路爬虫框架,而非一个满足特定爬取目的的网路爬虫,这样就能让这个程序成为一个可适用于不同应用场景的通用工具。
既然这么,接下来我们就要搞清楚该程序应当或可以做什么事,这也就能使我们进一步明晰它的功能、用途和意义。
功能需求和剖析概括来讲,网络爬虫框架会反复执行如下步骤直到触遇到停止条件。
1) “下载器”下载与给定网路地址相对应的内容。其中,在下载“请求”的组装方面,网络爬虫框架为使用者尽量预留出订制插口。使用者可以使用这种插口自定义“请求”的组装方式。
2) “分析器”分析下载到的内容,并从中筛选出可用的部份(以下称为“条目”)和须要访问的新网路地址。其中,在用于剖析和筛选内容的规则和策略方面,应该由网路爬虫框架提供灵活的订制插口。
换句话说,由于只有使用者自己才晓得她们真正想要的是哪些,所以应当准许她们对这种规则和策略进行深入的订制。网络爬虫框架仅须要规定好订制的方法即可。
3) “分析器”把筛选出的“条目”发送给“条目处理管线”。同时,它会把发觉的新网路地址和其他一些信息组装成新的下载“请求”,然后把这种恳求发送给“下载器”。在此步骤中,我们会过滤掉一些不符合要求的网路地址,比如忽视超出有效边界的网路地址。
你可能早已注意到,在这几个步骤中,我使用冒号突出展示了几个名词,即下载器、请求、分析器、条目和条目处理管线,其中,请求和条目都代表了某类数据,而其他 3 个名词则代表了处理数据的子程序(可称为处理模块或组件)。
它们与上面早已提及过的网路内容(或称对恳求的响应)共同描述了数据在网路爬虫程序中的流转形式。下图演示了起始于首次恳求的数据流程图。
图:起始于首次恳求的数据流程图
从上图中,我们可以清晰地看见每一个处理模块才能接受的输入和可以形成的输出。实际上,我们即将编撰的网路爬虫框架都会借此为根据产生几个相对独立的子程序。
当然,为了维护它们的运行和协作的有效性,框架中都会存在其他一些子程序。关于它们,我会在旁边相继给以说明。
这里,我再度指出一下网路爬虫框架与网路爬虫实现的区别。作为一个框架,该程序在每位处理模块中给与使用者尽量多的订制技巧,而不去涉及各个处理步骤的实现细节。
另外,框架更多地考虑使用者自定义的处理步骤在执行期间可能发生的各类情况和问题,并注意对这种问题的处理方法,这样就能在便于扩充的同时保证框架的稳定性。这方面的思索和策略会彰显在该网路爬虫框架的各阶段设计和编码实现之中。
下面我就依照上述剖析对这一程序进行总体设计。
总体设计通过上图可知,网络爬虫框架的处理模块有 3 个:下载器、分析器和条目处理管线。再加上调度和协调那些处理模块运行的控制模块,我们就可以明确该框架的模块界定了。我把这儿提及的控制模块称为调度器。下面是这 4 个模块各自承当的职责。
1) 下载器接受恳求类型的数据,并根据该恳求获得 HTTP 请求;将 HTTP 请求发送至与指定的网路地址对应的远程服务器;在 HTTP 请求发送完毕以后,立即等待相应的 HTTP 响应的到来;在收到 HTTP 响应以后,将其封装成响应并作为输出返回给下载器的调用方。
其中,HTTP 客户端程序可以由网路爬虫框架的使用方自行定义。另外,若在该子流程执行期间发生了错误,应该立刻以适当的方法告知使用方。对于其他模块来讲,也是这样。
2) 分析器接受响应类型的数据,并根据该响应获得 HTTP 响应;对该 HTTP 响应的内容进行检测,并按照给定的规则进行剖析、筛选以及生成新的恳求或条目;将生成的恳求或条目作为输出返回给分析器的调用方。
在分析器的职责中,我可以想到的才能留给网路爬虫框架的使用方自定义的部份并不少。例如,对 HTTP 响应的前期检测、对内容的筛选,以及生成恳求和条目的方法,等等。不过,我在前面会对那些可以自定义的部份进行一些抉择。
3) 条目处理管线接受条目类型的数据,并对其执行若干步骤的处理;条目处理管线中可以产出最终的数据;这个最终的数据可以在其中的某个处理步骤中被持久化(不论是本地储存还是发送给远程的储存服务器)以备后用。
我们可以把这种处理步骤的具体实现留给网路爬虫框架的使用方自行定义。这样,网络爬虫框架就可以真正地与条目处理的细节脱离开来。网络爬虫框架丝毫不关心那些条目如何被处理和持久化,它仅仅负责控制整体的处理流程。我把负责单个处理步骤的程序称为条目处理器。
条目处理器接受条目类型的数据,并把处理完成的条目返回给条目处理管线。条目处理管线会紧接着把该条目传递给下一个条目处理器,直至给定的条目处理器列表中的每位条目处理器都处理过该条目为止。
4) 调度器调度器在启动时仅接受首次恳求,并且不会形成任何输出。调度器的主要职责是调度各个处理模块的运行。其中包括维护各个处理模块的实例、在不同的处理模块实例之间传递数据(包括恳求、响应和条目),以及监控所有那些被调度者的状态,等等。
有了调度器的维护,各个处理模块得以保持其职责的简约和专情。由于调度器是网路爬虫框架中最重要的一个模块,所以还须要再编撰出一些工具来支撑起它的功能。
在弄清楚网路爬虫框架中各个模块的职责以后网络爬虫 语言,你晓得它是以调度器为核心的。此外,为了并发执行的须要,除调度器之外的其他模块都可以是多实例的,它们由调度器持有、维护和调用。反过来讲,这些处理模块的实例会从调度器那儿接受输入,并在进行相应的处理后将输出返回给调度器。
最后,与另外两个处理模块相比,条目处理管线是比较特殊的。顾名思义,它是以流式处理为基础的,其设计灵感来自于我之前讲过的 Linux 系统中的管线。
我们可以不断地向该管线发送条目,而该管线则会使其中的若干个条目处理器依次处理每一个条目。我们可以挺轻易地使用一些同步方式来保证条目处理管线的并发安全性,因此虽然调度器只持有该管线的一个实例,也不会有任何问题。
下图展示了调度器与各个处理模块之间的关系,图中加入了一个新的元素——工具箱网络爬虫 语言,之前所说的用于支撑调度器功能的这些工具就是工具箱的一部分。顾名思义,工具箱不是一个完整的模块,而是一些工具的集合,这些工具是调度器与所有处理模块之间的桥梁。
图:调度器与各处理模块的关系
至此,大家对网路爬虫框架的设计有了一个宏观上的认识。不过,我还未提到在这个总体设计之下包含的大量设计方法和决策。这些方法和决策不但与一些通用的程序设计原则有关,还涉及好多依赖于 Go语言的编程风格和形式技巧。
这也从侧面说明,由于几乎所有语言都有着十分鲜明的特征和比较擅长的领域,所以在设计一个须要由特定语言实现的软件或程序时,多多少少会考虑到这门语言自身的特点。也就是说,软件设计不是与具体的语言毫不相关的。反过来讲,总会有一门或几门语言十分适宜实现某一类软件或程序。 查看全部

简单来说,网络爬虫是互联网终端用户的模仿者。它模仿的主要对象有两个,一个是坐在计算器前使用网络浏览器访问网路内容的人类用户,另一个就是网络浏览器。
网络爬虫会模仿人类用户输入某个网站的网路地址,并企图访问该网站上的内容,还会模仿网路浏览器按照给定的网路地址去下载相应的内容。这里所说的内容可以是 HTML 页面、图片文件、音视频数据流,等等。
在下载到对应的内容以后,网络爬虫会按照预设的规则对它进行剖析和筛选。这些筛选岀的部份会马上得到特定的处理。与此同时,网络爬虫都会象人类用户点击网页中某个他感兴趣的链接那样,继续访问和下载相关联的其他内容,然后再重复上述步骤,直到满足停止的条件。
如上所述,网络爬虫应当按照使用者的意愿手动下载、分析、筛选、统计以及储存指定的网路内容。注意,这里的关键词是“自动”和“根据意愿”。“自动”的涵义是,网络爬虫在启动后自己完成整个爬取过程而无需人工干预,并且能够够在过程结束以后手动停止。而“根据意愿”则是说,网络爬虫最大限度地准许使用者对其爬取过程进行订制。
乍一看,要做到手动爬取其实并不困难。我们只需使网路爬虫依据相关的网路地址不断地下载对应的内容即可。但是,窥探其中就可以发觉,这里有很多细节须要我们进行非常处理,如下所示。
在这种细节当中,有的是比较容易处理的,而有的则须要额外的解决方案。例如,我们都晓得,基于 HTML 的网页中可以包含代表按键的 button 标签。
让网络浏览器在终端用户点击按键的时侯加载并显示另一个网页可以有很多种方式,其中,非常常用的一种方式就是为该标签添加 onclick 属性并把一些 JavaScript 语言的代码作为它的值。
虽然这个方式这么常用,但是我们要想使网络爬虫可以从中提取出有效的网路地址却是比较 困难的,因为这涉及对JavaScript程序的理解。JavaScript代码的编撰方式繁杂,要想使 网络爬虫完全理解它们,恐怕就须要用到某个JavaScript程序解析器的 Go语言实现了。
另一方面,由于互联网对人们生活和工作的全面渗透,我们可以通过各类途径找到各式各样的网路爬虫实现,它们几乎都有着复杂而又奇特的逻辑。这些复杂的逻辑主要针对如下几个方面。
这些逻辑绝大多数都与网路爬虫使用者当时的意愿有关。换句话说,它们都与具体的使用目的有着紧密的联系。也许它们并不应当是网路爬虫的核心功能,而应当作为扩充功能或可订制的功能存在。
因此,我想我们更应当编撰一个容易被订制和扩充的网路爬虫框架,而非一个满足特定爬取目的的网路爬虫,这样就能让这个程序成为一个可适用于不同应用场景的通用工具。
既然这么,接下来我们就要搞清楚该程序应当或可以做什么事,这也就能使我们进一步明晰它的功能、用途和意义。
功能需求和剖析概括来讲,网络爬虫框架会反复执行如下步骤直到触遇到停止条件。
1) “下载器”下载与给定网路地址相对应的内容。其中,在下载“请求”的组装方面,网络爬虫框架为使用者尽量预留出订制插口。使用者可以使用这种插口自定义“请求”的组装方式。
2) “分析器”分析下载到的内容,并从中筛选出可用的部份(以下称为“条目”)和须要访问的新网路地址。其中,在用于剖析和筛选内容的规则和策略方面,应该由网路爬虫框架提供灵活的订制插口。
换句话说,由于只有使用者自己才晓得她们真正想要的是哪些,所以应当准许她们对这种规则和策略进行深入的订制。网络爬虫框架仅须要规定好订制的方法即可。
3) “分析器”把筛选出的“条目”发送给“条目处理管线”。同时,它会把发觉的新网路地址和其他一些信息组装成新的下载“请求”,然后把这种恳求发送给“下载器”。在此步骤中,我们会过滤掉一些不符合要求的网路地址,比如忽视超出有效边界的网路地址。
你可能早已注意到,在这几个步骤中,我使用冒号突出展示了几个名词,即下载器、请求、分析器、条目和条目处理管线,其中,请求和条目都代表了某类数据,而其他 3 个名词则代表了处理数据的子程序(可称为处理模块或组件)。
它们与上面早已提及过的网路内容(或称对恳求的响应)共同描述了数据在网路爬虫程序中的流转形式。下图演示了起始于首次恳求的数据流程图。
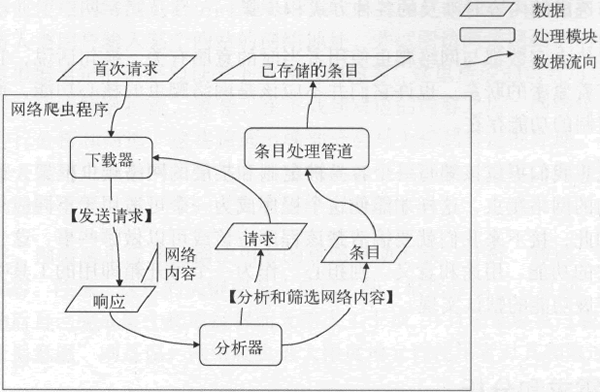
图:起始于首次恳求的数据流程图
从上图中,我们可以清晰地看见每一个处理模块才能接受的输入和可以形成的输出。实际上,我们即将编撰的网路爬虫框架都会借此为根据产生几个相对独立的子程序。
当然,为了维护它们的运行和协作的有效性,框架中都会存在其他一些子程序。关于它们,我会在旁边相继给以说明。
这里,我再度指出一下网路爬虫框架与网路爬虫实现的区别。作为一个框架,该程序在每位处理模块中给与使用者尽量多的订制技巧,而不去涉及各个处理步骤的实现细节。
另外,框架更多地考虑使用者自定义的处理步骤在执行期间可能发生的各类情况和问题,并注意对这种问题的处理方法,这样就能在便于扩充的同时保证框架的稳定性。这方面的思索和策略会彰显在该网路爬虫框架的各阶段设计和编码实现之中。
下面我就依照上述剖析对这一程序进行总体设计。
总体设计通过上图可知,网络爬虫框架的处理模块有 3 个:下载器、分析器和条目处理管线。再加上调度和协调那些处理模块运行的控制模块,我们就可以明确该框架的模块界定了。我把这儿提及的控制模块称为调度器。下面是这 4 个模块各自承当的职责。
1) 下载器接受恳求类型的数据,并根据该恳求获得 HTTP 请求;将 HTTP 请求发送至与指定的网路地址对应的远程服务器;在 HTTP 请求发送完毕以后,立即等待相应的 HTTP 响应的到来;在收到 HTTP 响应以后,将其封装成响应并作为输出返回给下载器的调用方。
其中,HTTP 客户端程序可以由网路爬虫框架的使用方自行定义。另外,若在该子流程执行期间发生了错误,应该立刻以适当的方法告知使用方。对于其他模块来讲,也是这样。
2) 分析器接受响应类型的数据,并根据该响应获得 HTTP 响应;对该 HTTP 响应的内容进行检测,并按照给定的规则进行剖析、筛选以及生成新的恳求或条目;将生成的恳求或条目作为输出返回给分析器的调用方。
在分析器的职责中,我可以想到的才能留给网路爬虫框架的使用方自定义的部份并不少。例如,对 HTTP 响应的前期检测、对内容的筛选,以及生成恳求和条目的方法,等等。不过,我在前面会对那些可以自定义的部份进行一些抉择。
3) 条目处理管线接受条目类型的数据,并对其执行若干步骤的处理;条目处理管线中可以产出最终的数据;这个最终的数据可以在其中的某个处理步骤中被持久化(不论是本地储存还是发送给远程的储存服务器)以备后用。
我们可以把这种处理步骤的具体实现留给网路爬虫框架的使用方自行定义。这样,网络爬虫框架就可以真正地与条目处理的细节脱离开来。网络爬虫框架丝毫不关心那些条目如何被处理和持久化,它仅仅负责控制整体的处理流程。我把负责单个处理步骤的程序称为条目处理器。
条目处理器接受条目类型的数据,并把处理完成的条目返回给条目处理管线。条目处理管线会紧接着把该条目传递给下一个条目处理器,直至给定的条目处理器列表中的每位条目处理器都处理过该条目为止。
4) 调度器调度器在启动时仅接受首次恳求,并且不会形成任何输出。调度器的主要职责是调度各个处理模块的运行。其中包括维护各个处理模块的实例、在不同的处理模块实例之间传递数据(包括恳求、响应和条目),以及监控所有那些被调度者的状态,等等。
有了调度器的维护,各个处理模块得以保持其职责的简约和专情。由于调度器是网路爬虫框架中最重要的一个模块,所以还须要再编撰出一些工具来支撑起它的功能。
在弄清楚网路爬虫框架中各个模块的职责以后网络爬虫 语言,你晓得它是以调度器为核心的。此外,为了并发执行的须要,除调度器之外的其他模块都可以是多实例的,它们由调度器持有、维护和调用。反过来讲,这些处理模块的实例会从调度器那儿接受输入,并在进行相应的处理后将输出返回给调度器。
最后,与另外两个处理模块相比,条目处理管线是比较特殊的。顾名思义,它是以流式处理为基础的,其设计灵感来自于我之前讲过的 Linux 系统中的管线。
我们可以不断地向该管线发送条目,而该管线则会使其中的若干个条目处理器依次处理每一个条目。我们可以挺轻易地使用一些同步方式来保证条目处理管线的并发安全性,因此虽然调度器只持有该管线的一个实例,也不会有任何问题。
下图展示了调度器与各个处理模块之间的关系,图中加入了一个新的元素——工具箱网络爬虫 语言,之前所说的用于支撑调度器功能的这些工具就是工具箱的一部分。顾名思义,工具箱不是一个完整的模块,而是一些工具的集合,这些工具是调度器与所有处理模块之间的桥梁。
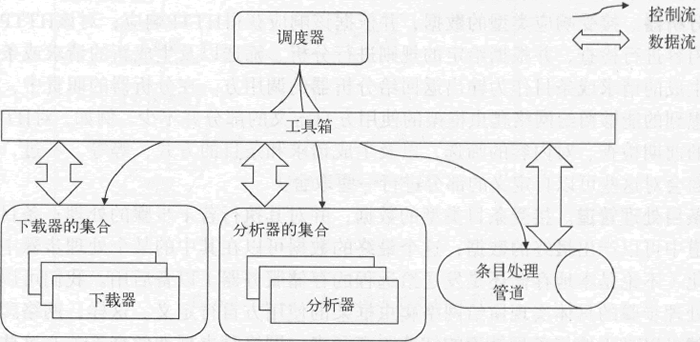
图:调度器与各处理模块的关系
至此,大家对网路爬虫框架的设计有了一个宏观上的认识。不过,我还未提到在这个总体设计之下包含的大量设计方法和决策。这些方法和决策不但与一些通用的程序设计原则有关,还涉及好多依赖于 Go语言的编程风格和形式技巧。
这也从侧面说明,由于几乎所有语言都有着十分鲜明的特征和比较擅长的领域,所以在设计一个须要由特定语言实现的软件或程序时,多多少少会考虑到这门语言自身的特点。也就是说,软件设计不是与具体的语言毫不相关的。反过来讲,总会有一门或几门语言十分适宜实现某一类软件或程序。
设计和实现一款轻量级的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-05-05 08:05
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。
关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图
整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图
项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献 查看全部
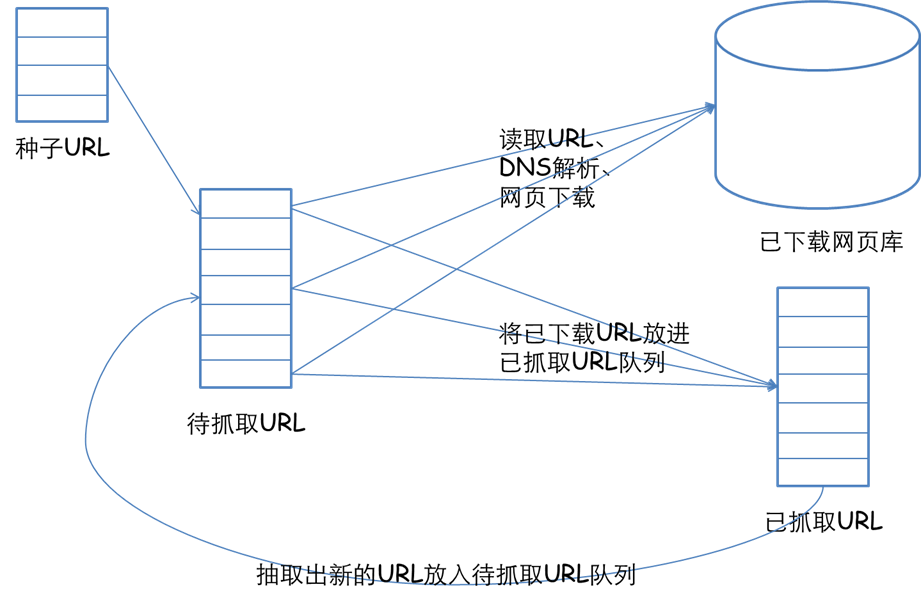
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。

关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图

整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图

项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献
[申精]淘宝网爬虫引擎设计构架图等
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-05 08:03
更多贴子
猪孩子啊啊大大
本版专家分:0
在《淘宝网》购物时爬虫框架设计,顾客最关心的就是这两个页面(这两个页面的网址sample分别为
;item_num_id=3899429723&cm_cat=50010388和),因此这两个页面的信息对于客户至关重要,这也是我的搜索引擎信息搜集的地方。由于有成千上万的这样格式的页面,所以我的目标就是设计出一个爬虫引擎在《淘宝网》上不断地爬,以零下载为条件,直接将目标信息数据导出我创建的数据库中,再进行搜索。
综合剖析这两个典型页面,我们可以得到这样的信息:大部分《淘宝网》的商品和商家信息都是根据这两个页面的格式方式存在的。所以借此便可以写出程序推算出整个《淘宝网》的数据。
页面HTML源码关键点
我在网上详尽查阅了有关爬虫引擎的资料和仔细选购了开源框架后。决定使用以下几个框架作为我的爬虫引擎的主要框架。
1.HtmlParser
这个开源框架主要用于解析Html格式的页面,这个框架的目的就是从当前页面将关键数据提取下来,从而在零下载的情况下得到数据。由于这个框架时间比较早,未免有些比较陈旧的做法,比如NodeList类没有实现Iterator插口爬虫框架设计,没有借助类库等。以后的项目中可以替换为较新较成熟的框架。
2.ApacheCommonsChain
在网页提取过程中,每个不同页面究竟该用那个类来负责解析呢?仔细剖析后,我个人认为使用【设计模式】中的责任链模式可以极大地减少代码耦合性,达到【软件工程】中开闭原则的疗效。减少ifelse繁杂的判定,使代码更清晰。
3.iBatis
我经过对比,选择了iBatis作为DAO层的数据储存框架,由于其可以灵活的配置SQL句子,以及轻量级设计,可以使我使用一些数据库存储过程等维持字段的约束。
4.ApacheCommonsBeanutils
这个框架的BeanMap是一个挺好的东西,它采用了一个反射的做法给我提供了一个可以将Map属性通配符对转化为bean类的方式,利用这个类可以让页面提取出的Map中包含的数据用一个统一的方式转化为实体类,再存入数据库。
爬虫引擎程序流程图
最终,得到了大量的《淘宝网》的商品和店家的数据库表中的数据,由于这个爬虫引擎借助“责任链模式”解析数据,可以灵活地扩充到其他不同结构的网页中去提取数据,在此基础上再实现搜索。(很抱歉,由于我下班后业余时间之作,时间匆忙,全文搜索这部份未完成,考虑计划使用ApacheLucene开源框架做智能全文搜索框架) 查看全部


更多贴子
猪孩子啊啊大大

本版专家分:0
在《淘宝网》购物时爬虫框架设计,顾客最关心的就是这两个页面(这两个页面的网址sample分别为
;item_num_id=3899429723&cm_cat=50010388和),因此这两个页面的信息对于客户至关重要,这也是我的搜索引擎信息搜集的地方。由于有成千上万的这样格式的页面,所以我的目标就是设计出一个爬虫引擎在《淘宝网》上不断地爬,以零下载为条件,直接将目标信息数据导出我创建的数据库中,再进行搜索。
综合剖析这两个典型页面,我们可以得到这样的信息:大部分《淘宝网》的商品和商家信息都是根据这两个页面的格式方式存在的。所以借此便可以写出程序推算出整个《淘宝网》的数据。

页面HTML源码关键点
我在网上详尽查阅了有关爬虫引擎的资料和仔细选购了开源框架后。决定使用以下几个框架作为我的爬虫引擎的主要框架。
1.HtmlParser
这个开源框架主要用于解析Html格式的页面,这个框架的目的就是从当前页面将关键数据提取下来,从而在零下载的情况下得到数据。由于这个框架时间比较早,未免有些比较陈旧的做法,比如NodeList类没有实现Iterator插口爬虫框架设计,没有借助类库等。以后的项目中可以替换为较新较成熟的框架。
2.ApacheCommonsChain
在网页提取过程中,每个不同页面究竟该用那个类来负责解析呢?仔细剖析后,我个人认为使用【设计模式】中的责任链模式可以极大地减少代码耦合性,达到【软件工程】中开闭原则的疗效。减少ifelse繁杂的判定,使代码更清晰。
3.iBatis
我经过对比,选择了iBatis作为DAO层的数据储存框架,由于其可以灵活的配置SQL句子,以及轻量级设计,可以使我使用一些数据库存储过程等维持字段的约束。
4.ApacheCommonsBeanutils
这个框架的BeanMap是一个挺好的东西,它采用了一个反射的做法给我提供了一个可以将Map属性通配符对转化为bean类的方式,利用这个类可以让页面提取出的Map中包含的数据用一个统一的方式转化为实体类,再存入数据库。

爬虫引擎程序流程图
最终,得到了大量的《淘宝网》的商品和店家的数据库表中的数据,由于这个爬虫引擎借助“责任链模式”解析数据,可以灵活地扩充到其他不同结构的网页中去提取数据,在此基础上再实现搜索。(很抱歉,由于我下班后业余时间之作,时间匆忙,全文搜索这部份未完成,考虑计划使用ApacheLucene开源框架做智能全文搜索框架)
爬虫框架是哪些?常见的Python爬虫框架有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-05-02 08:09
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。
推荐10款流行的java开源的网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-06-29 08:03
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫 查看全部
1:JAVA爬虫WebCollector(Star:1345)
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫
干货丨推荐八款高效率的爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-05-24 08:01
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。 查看全部
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。
网络爬虫 c++
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-05-22 08:01
广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。
c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...
互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...
这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...
b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...
说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...
所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...
nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...
很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...
requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...
本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先... 查看全部
广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。
c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...
互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...
这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...
b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...
说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...
所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...
nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...
很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...
requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...
本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先...
Go语言网络爬虫概述
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-05-13 08:03
简单来说,网络爬虫是互联网终端用户的模仿者。它模仿的主要对象有两个,一个是坐在计算器前使用网络浏览器访问网路内容的人类用户,另一个就是网络浏览器。
网络爬虫会模仿人类用户输入某个网站的网路地址,并企图访问该网站上的内容,还会模仿网路浏览器按照给定的网路地址去下载相应的内容。这里所说的内容可以是 HTML 页面、图片文件、音视频数据流,等等。
在下载到对应的内容以后,网络爬虫会按照预设的规则对它进行剖析和筛选。这些筛选岀的部份会马上得到特定的处理。与此同时,网络爬虫都会象人类用户点击网页中某个他感兴趣的链接那样,继续访问和下载相关联的其他内容,然后再重复上述步骤,直到满足停止的条件。
如上所述,网络爬虫应当按照使用者的意愿手动下载、分析、筛选、统计以及储存指定的网路内容。注意,这里的关键词是“自动”和“根据意愿”。“自动”的涵义是,网络爬虫在启动后自己完成整个爬取过程而无需人工干预,并且能够够在过程结束以后手动停止。而“根据意愿”则是说,网络爬虫最大限度地准许使用者对其爬取过程进行订制。
乍一看,要做到手动爬取其实并不困难。我们只需使网路爬虫依据相关的网路地址不断地下载对应的内容即可。但是,窥探其中就可以发觉,这里有很多细节须要我们进行非常处理,如下所示。
在这种细节当中,有的是比较容易处理的,而有的则须要额外的解决方案。例如,我们都晓得,基于 HTML 的网页中可以包含代表按键的 button 标签。
让网络浏览器在终端用户点击按键的时侯加载并显示另一个网页可以有很多种方式,其中,非常常用的一种方式就是为该标签添加 onclick 属性并把一些 JavaScript 语言的代码作为它的值。
虽然这个方式这么常用,但是我们要想使网络爬虫可以从中提取出有效的网路地址却是比较 困难的,因为这涉及对JavaScript程序的理解。JavaScript代码的编撰方式繁杂,要想使 网络爬虫完全理解它们,恐怕就须要用到某个JavaScript程序解析器的 Go语言实现了。
另一方面,由于互联网对人们生活和工作的全面渗透,我们可以通过各类途径找到各式各样的网路爬虫实现,它们几乎都有着复杂而又奇特的逻辑。这些复杂的逻辑主要针对如下几个方面。
这些逻辑绝大多数都与网路爬虫使用者当时的意愿有关。换句话说,它们都与具体的使用目的有着紧密的联系。也许它们并不应当是网路爬虫的核心功能,而应当作为扩充功能或可订制的功能存在。
因此,我想我们更应当编撰一个容易被订制和扩充的网路爬虫框架,而非一个满足特定爬取目的的网路爬虫,这样就能让这个程序成为一个可适用于不同应用场景的通用工具。
既然这么,接下来我们就要搞清楚该程序应当或可以做什么事,这也就能使我们进一步明晰它的功能、用途和意义。
功能需求和剖析概括来讲,网络爬虫框架会反复执行如下步骤直到触遇到停止条件。
1) “下载器”下载与给定网路地址相对应的内容。其中,在下载“请求”的组装方面,网络爬虫框架为使用者尽量预留出订制插口。使用者可以使用这种插口自定义“请求”的组装方式。
2) “分析器”分析下载到的内容,并从中筛选出可用的部份(以下称为“条目”)和须要访问的新网路地址。其中,在用于剖析和筛选内容的规则和策略方面,应该由网路爬虫框架提供灵活的订制插口。
换句话说,由于只有使用者自己才晓得她们真正想要的是哪些,所以应当准许她们对这种规则和策略进行深入的订制。网络爬虫框架仅须要规定好订制的方法即可。
3) “分析器”把筛选出的“条目”发送给“条目处理管线”。同时,它会把发觉的新网路地址和其他一些信息组装成新的下载“请求”,然后把这种恳求发送给“下载器”。在此步骤中,我们会过滤掉一些不符合要求的网路地址,比如忽视超出有效边界的网路地址。
你可能早已注意到,在这几个步骤中,我使用冒号突出展示了几个名词,即下载器、请求、分析器、条目和条目处理管线,其中,请求和条目都代表了某类数据,而其他 3 个名词则代表了处理数据的子程序(可称为处理模块或组件)。
它们与上面早已提及过的网路内容(或称对恳求的响应)共同描述了数据在网路爬虫程序中的流转形式。下图演示了起始于首次恳求的数据流程图。
图:起始于首次恳求的数据流程图
从上图中,我们可以清晰地看见每一个处理模块才能接受的输入和可以形成的输出。实际上,我们即将编撰的网路爬虫框架都会借此为根据产生几个相对独立的子程序。
当然,为了维护它们的运行和协作的有效性,框架中都会存在其他一些子程序。关于它们,我会在旁边相继给以说明。
这里,我再度指出一下网路爬虫框架与网路爬虫实现的区别。作为一个框架,该程序在每位处理模块中给与使用者尽量多的订制技巧,而不去涉及各个处理步骤的实现细节。
另外,框架更多地考虑使用者自定义的处理步骤在执行期间可能发生的各类情况和问题,并注意对这种问题的处理方法,这样就能在便于扩充的同时保证框架的稳定性。这方面的思索和策略会彰显在该网路爬虫框架的各阶段设计和编码实现之中。
下面我就依照上述剖析对这一程序进行总体设计。
总体设计通过上图可知,网络爬虫框架的处理模块有 3 个:下载器、分析器和条目处理管线。再加上调度和协调那些处理模块运行的控制模块,我们就可以明确该框架的模块界定了。我把这儿提及的控制模块称为调度器。下面是这 4 个模块各自承当的职责。
1) 下载器接受恳求类型的数据,并根据该恳求获得 HTTP 请求;将 HTTP 请求发送至与指定的网路地址对应的远程服务器;在 HTTP 请求发送完毕以后,立即等待相应的 HTTP 响应的到来;在收到 HTTP 响应以后,将其封装成响应并作为输出返回给下载器的调用方。
其中,HTTP 客户端程序可以由网路爬虫框架的使用方自行定义。另外,若在该子流程执行期间发生了错误,应该立刻以适当的方法告知使用方。对于其他模块来讲,也是这样。
2) 分析器接受响应类型的数据,并根据该响应获得 HTTP 响应;对该 HTTP 响应的内容进行检测,并按照给定的规则进行剖析、筛选以及生成新的恳求或条目;将生成的恳求或条目作为输出返回给分析器的调用方。
在分析器的职责中,我可以想到的才能留给网路爬虫框架的使用方自定义的部份并不少。例如,对 HTTP 响应的前期检测、对内容的筛选,以及生成恳求和条目的方法,等等。不过,我在前面会对那些可以自定义的部份进行一些抉择。
3) 条目处理管线接受条目类型的数据,并对其执行若干步骤的处理;条目处理管线中可以产出最终的数据;这个最终的数据可以在其中的某个处理步骤中被持久化(不论是本地储存还是发送给远程的储存服务器)以备后用。
我们可以把这种处理步骤的具体实现留给网路爬虫框架的使用方自行定义。这样,网络爬虫框架就可以真正地与条目处理的细节脱离开来。网络爬虫框架丝毫不关心那些条目如何被处理和持久化,它仅仅负责控制整体的处理流程。我把负责单个处理步骤的程序称为条目处理器。
条目处理器接受条目类型的数据,并把处理完成的条目返回给条目处理管线。条目处理管线会紧接着把该条目传递给下一个条目处理器,直至给定的条目处理器列表中的每位条目处理器都处理过该条目为止。
4) 调度器调度器在启动时仅接受首次恳求,并且不会形成任何输出。调度器的主要职责是调度各个处理模块的运行。其中包括维护各个处理模块的实例、在不同的处理模块实例之间传递数据(包括恳求、响应和条目),以及监控所有那些被调度者的状态,等等。
有了调度器的维护,各个处理模块得以保持其职责的简约和专情。由于调度器是网路爬虫框架中最重要的一个模块,所以还须要再编撰出一些工具来支撑起它的功能。
在弄清楚网路爬虫框架中各个模块的职责以后网络爬虫 语言,你晓得它是以调度器为核心的。此外,为了并发执行的须要,除调度器之外的其他模块都可以是多实例的,它们由调度器持有、维护和调用。反过来讲,这些处理模块的实例会从调度器那儿接受输入,并在进行相应的处理后将输出返回给调度器。
最后,与另外两个处理模块相比,条目处理管线是比较特殊的。顾名思义,它是以流式处理为基础的,其设计灵感来自于我之前讲过的 Linux 系统中的管线。
我们可以不断地向该管线发送条目,而该管线则会使其中的若干个条目处理器依次处理每一个条目。我们可以挺轻易地使用一些同步方式来保证条目处理管线的并发安全性,因此虽然调度器只持有该管线的一个实例,也不会有任何问题。
下图展示了调度器与各个处理模块之间的关系,图中加入了一个新的元素——工具箱网络爬虫 语言,之前所说的用于支撑调度器功能的这些工具就是工具箱的一部分。顾名思义,工具箱不是一个完整的模块,而是一些工具的集合,这些工具是调度器与所有处理模块之间的桥梁。
图:调度器与各处理模块的关系
至此,大家对网路爬虫框架的设计有了一个宏观上的认识。不过,我还未提到在这个总体设计之下包含的大量设计方法和决策。这些方法和决策不但与一些通用的程序设计原则有关,还涉及好多依赖于 Go语言的编程风格和形式技巧。
这也从侧面说明,由于几乎所有语言都有着十分鲜明的特征和比较擅长的领域,所以在设计一个须要由特定语言实现的软件或程序时,多多少少会考虑到这门语言自身的特点。也就是说,软件设计不是与具体的语言毫不相关的。反过来讲,总会有一门或几门语言十分适宜实现某一类软件或程序。 查看全部
简单来说,网络爬虫是互联网终端用户的模仿者。它模仿的主要对象有两个,一个是坐在计算器前使用网络浏览器访问网路内容的人类用户,另一个就是网络浏览器。
网络爬虫会模仿人类用户输入某个网站的网路地址,并企图访问该网站上的内容,还会模仿网路浏览器按照给定的网路地址去下载相应的内容。这里所说的内容可以是 HTML 页面、图片文件、音视频数据流,等等。
在下载到对应的内容以后,网络爬虫会按照预设的规则对它进行剖析和筛选。这些筛选岀的部份会马上得到特定的处理。与此同时,网络爬虫都会象人类用户点击网页中某个他感兴趣的链接那样,继续访问和下载相关联的其他内容,然后再重复上述步骤,直到满足停止的条件。
如上所述,网络爬虫应当按照使用者的意愿手动下载、分析、筛选、统计以及储存指定的网路内容。注意,这里的关键词是“自动”和“根据意愿”。“自动”的涵义是,网络爬虫在启动后自己完成整个爬取过程而无需人工干预,并且能够够在过程结束以后手动停止。而“根据意愿”则是说,网络爬虫最大限度地准许使用者对其爬取过程进行订制。
乍一看,要做到手动爬取其实并不困难。我们只需使网路爬虫依据相关的网路地址不断地下载对应的内容即可。但是,窥探其中就可以发觉,这里有很多细节须要我们进行非常处理,如下所示。
在这种细节当中,有的是比较容易处理的,而有的则须要额外的解决方案。例如,我们都晓得,基于 HTML 的网页中可以包含代表按键的 button 标签。
让网络浏览器在终端用户点击按键的时侯加载并显示另一个网页可以有很多种方式,其中,非常常用的一种方式就是为该标签添加 onclick 属性并把一些 JavaScript 语言的代码作为它的值。
虽然这个方式这么常用,但是我们要想使网络爬虫可以从中提取出有效的网路地址却是比较 困难的,因为这涉及对JavaScript程序的理解。JavaScript代码的编撰方式繁杂,要想使 网络爬虫完全理解它们,恐怕就须要用到某个JavaScript程序解析器的 Go语言实现了。
另一方面,由于互联网对人们生活和工作的全面渗透,我们可以通过各类途径找到各式各样的网路爬虫实现,它们几乎都有着复杂而又奇特的逻辑。这些复杂的逻辑主要针对如下几个方面。
这些逻辑绝大多数都与网路爬虫使用者当时的意愿有关。换句话说,它们都与具体的使用目的有着紧密的联系。也许它们并不应当是网路爬虫的核心功能,而应当作为扩充功能或可订制的功能存在。
因此,我想我们更应当编撰一个容易被订制和扩充的网路爬虫框架,而非一个满足特定爬取目的的网路爬虫,这样就能让这个程序成为一个可适用于不同应用场景的通用工具。
既然这么,接下来我们就要搞清楚该程序应当或可以做什么事,这也就能使我们进一步明晰它的功能、用途和意义。
功能需求和剖析概括来讲,网络爬虫框架会反复执行如下步骤直到触遇到停止条件。
1) “下载器”下载与给定网路地址相对应的内容。其中,在下载“请求”的组装方面,网络爬虫框架为使用者尽量预留出订制插口。使用者可以使用这种插口自定义“请求”的组装方式。
2) “分析器”分析下载到的内容,并从中筛选出可用的部份(以下称为“条目”)和须要访问的新网路地址。其中,在用于剖析和筛选内容的规则和策略方面,应该由网路爬虫框架提供灵活的订制插口。
换句话说,由于只有使用者自己才晓得她们真正想要的是哪些,所以应当准许她们对这种规则和策略进行深入的订制。网络爬虫框架仅须要规定好订制的方法即可。
3) “分析器”把筛选出的“条目”发送给“条目处理管线”。同时,它会把发觉的新网路地址和其他一些信息组装成新的下载“请求”,然后把这种恳求发送给“下载器”。在此步骤中,我们会过滤掉一些不符合要求的网路地址,比如忽视超出有效边界的网路地址。
你可能早已注意到,在这几个步骤中,我使用冒号突出展示了几个名词,即下载器、请求、分析器、条目和条目处理管线,其中,请求和条目都代表了某类数据,而其他 3 个名词则代表了处理数据的子程序(可称为处理模块或组件)。
它们与上面早已提及过的网路内容(或称对恳求的响应)共同描述了数据在网路爬虫程序中的流转形式。下图演示了起始于首次恳求的数据流程图。
图:起始于首次恳求的数据流程图
从上图中,我们可以清晰地看见每一个处理模块才能接受的输入和可以形成的输出。实际上,我们即将编撰的网路爬虫框架都会借此为根据产生几个相对独立的子程序。
当然,为了维护它们的运行和协作的有效性,框架中都会存在其他一些子程序。关于它们,我会在旁边相继给以说明。
这里,我再度指出一下网路爬虫框架与网路爬虫实现的区别。作为一个框架,该程序在每位处理模块中给与使用者尽量多的订制技巧,而不去涉及各个处理步骤的实现细节。
另外,框架更多地考虑使用者自定义的处理步骤在执行期间可能发生的各类情况和问题,并注意对这种问题的处理方法,这样就能在便于扩充的同时保证框架的稳定性。这方面的思索和策略会彰显在该网路爬虫框架的各阶段设计和编码实现之中。
下面我就依照上述剖析对这一程序进行总体设计。
总体设计通过上图可知,网络爬虫框架的处理模块有 3 个:下载器、分析器和条目处理管线。再加上调度和协调那些处理模块运行的控制模块,我们就可以明确该框架的模块界定了。我把这儿提及的控制模块称为调度器。下面是这 4 个模块各自承当的职责。
1) 下载器接受恳求类型的数据,并根据该恳求获得 HTTP 请求;将 HTTP 请求发送至与指定的网路地址对应的远程服务器;在 HTTP 请求发送完毕以后,立即等待相应的 HTTP 响应的到来;在收到 HTTP 响应以后,将其封装成响应并作为输出返回给下载器的调用方。
其中,HTTP 客户端程序可以由网路爬虫框架的使用方自行定义。另外,若在该子流程执行期间发生了错误,应该立刻以适当的方法告知使用方。对于其他模块来讲,也是这样。
2) 分析器接受响应类型的数据,并根据该响应获得 HTTP 响应;对该 HTTP 响应的内容进行检测,并按照给定的规则进行剖析、筛选以及生成新的恳求或条目;将生成的恳求或条目作为输出返回给分析器的调用方。
在分析器的职责中,我可以想到的才能留给网路爬虫框架的使用方自定义的部份并不少。例如,对 HTTP 响应的前期检测、对内容的筛选,以及生成恳求和条目的方法,等等。不过,我在前面会对那些可以自定义的部份进行一些抉择。
3) 条目处理管线接受条目类型的数据,并对其执行若干步骤的处理;条目处理管线中可以产出最终的数据;这个最终的数据可以在其中的某个处理步骤中被持久化(不论是本地储存还是发送给远程的储存服务器)以备后用。
我们可以把这种处理步骤的具体实现留给网路爬虫框架的使用方自行定义。这样,网络爬虫框架就可以真正地与条目处理的细节脱离开来。网络爬虫框架丝毫不关心那些条目如何被处理和持久化,它仅仅负责控制整体的处理流程。我把负责单个处理步骤的程序称为条目处理器。
条目处理器接受条目类型的数据,并把处理完成的条目返回给条目处理管线。条目处理管线会紧接着把该条目传递给下一个条目处理器,直至给定的条目处理器列表中的每位条目处理器都处理过该条目为止。
4) 调度器调度器在启动时仅接受首次恳求,并且不会形成任何输出。调度器的主要职责是调度各个处理模块的运行。其中包括维护各个处理模块的实例、在不同的处理模块实例之间传递数据(包括恳求、响应和条目),以及监控所有那些被调度者的状态,等等。
有了调度器的维护,各个处理模块得以保持其职责的简约和专情。由于调度器是网路爬虫框架中最重要的一个模块,所以还须要再编撰出一些工具来支撑起它的功能。
在弄清楚网路爬虫框架中各个模块的职责以后网络爬虫 语言,你晓得它是以调度器为核心的。此外,为了并发执行的须要,除调度器之外的其他模块都可以是多实例的,它们由调度器持有、维护和调用。反过来讲,这些处理模块的实例会从调度器那儿接受输入,并在进行相应的处理后将输出返回给调度器。
最后,与另外两个处理模块相比,条目处理管线是比较特殊的。顾名思义,它是以流式处理为基础的,其设计灵感来自于我之前讲过的 Linux 系统中的管线。
我们可以不断地向该管线发送条目,而该管线则会使其中的若干个条目处理器依次处理每一个条目。我们可以挺轻易地使用一些同步方式来保证条目处理管线的并发安全性,因此虽然调度器只持有该管线的一个实例,也不会有任何问题。
下图展示了调度器与各个处理模块之间的关系,图中加入了一个新的元素——工具箱网络爬虫 语言,之前所说的用于支撑调度器功能的这些工具就是工具箱的一部分。顾名思义,工具箱不是一个完整的模块,而是一些工具的集合,这些工具是调度器与所有处理模块之间的桥梁。
图:调度器与各处理模块的关系
至此,大家对网路爬虫框架的设计有了一个宏观上的认识。不过,我还未提到在这个总体设计之下包含的大量设计方法和决策。这些方法和决策不但与一些通用的程序设计原则有关,还涉及好多依赖于 Go语言的编程风格和形式技巧。
这也从侧面说明,由于几乎所有语言都有着十分鲜明的特征和比较擅长的领域,所以在设计一个须要由特定语言实现的软件或程序时,多多少少会考虑到这门语言自身的特点。也就是说,软件设计不是与具体的语言毫不相关的。反过来讲,总会有一门或几门语言十分适宜实现某一类软件或程序。
设计和实现一款轻量级的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-05-05 08:05
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。
关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图
整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图
项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献 查看全部
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。
关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图
整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图
项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献
[申精]淘宝网爬虫引擎设计构架图等
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-05 08:03
更多贴子
猪孩子啊啊大大
本版专家分:0
在《淘宝网》购物时爬虫框架设计,顾客最关心的就是这两个页面(这两个页面的网址sample分别为
;item_num_id=3899429723&cm_cat=50010388和),因此这两个页面的信息对于客户至关重要,这也是我的搜索引擎信息搜集的地方。由于有成千上万的这样格式的页面,所以我的目标就是设计出一个爬虫引擎在《淘宝网》上不断地爬,以零下载为条件,直接将目标信息数据导出我创建的数据库中,再进行搜索。
综合剖析这两个典型页面,我们可以得到这样的信息:大部分《淘宝网》的商品和商家信息都是根据这两个页面的格式方式存在的。所以借此便可以写出程序推算出整个《淘宝网》的数据。
页面HTML源码关键点
我在网上详尽查阅了有关爬虫引擎的资料和仔细选购了开源框架后。决定使用以下几个框架作为我的爬虫引擎的主要框架。
1.HtmlParser
这个开源框架主要用于解析Html格式的页面,这个框架的目的就是从当前页面将关键数据提取下来,从而在零下载的情况下得到数据。由于这个框架时间比较早,未免有些比较陈旧的做法,比如NodeList类没有实现Iterator插口爬虫框架设计,没有借助类库等。以后的项目中可以替换为较新较成熟的框架。
2.ApacheCommonsChain
在网页提取过程中,每个不同页面究竟该用那个类来负责解析呢?仔细剖析后,我个人认为使用【设计模式】中的责任链模式可以极大地减少代码耦合性,达到【软件工程】中开闭原则的疗效。减少ifelse繁杂的判定,使代码更清晰。
3.iBatis
我经过对比,选择了iBatis作为DAO层的数据储存框架,由于其可以灵活的配置SQL句子,以及轻量级设计,可以使我使用一些数据库存储过程等维持字段的约束。
4.ApacheCommonsBeanutils
这个框架的BeanMap是一个挺好的东西,它采用了一个反射的做法给我提供了一个可以将Map属性通配符对转化为bean类的方式,利用这个类可以让页面提取出的Map中包含的数据用一个统一的方式转化为实体类,再存入数据库。
爬虫引擎程序流程图
最终,得到了大量的《淘宝网》的商品和店家的数据库表中的数据,由于这个爬虫引擎借助“责任链模式”解析数据,可以灵活地扩充到其他不同结构的网页中去提取数据,在此基础上再实现搜索。(很抱歉,由于我下班后业余时间之作,时间匆忙,全文搜索这部份未完成,考虑计划使用ApacheLucene开源框架做智能全文搜索框架) 查看全部
更多贴子
猪孩子啊啊大大
本版专家分:0
在《淘宝网》购物时爬虫框架设计,顾客最关心的就是这两个页面(这两个页面的网址sample分别为
;item_num_id=3899429723&cm_cat=50010388和),因此这两个页面的信息对于客户至关重要,这也是我的搜索引擎信息搜集的地方。由于有成千上万的这样格式的页面,所以我的目标就是设计出一个爬虫引擎在《淘宝网》上不断地爬,以零下载为条件,直接将目标信息数据导出我创建的数据库中,再进行搜索。
综合剖析这两个典型页面,我们可以得到这样的信息:大部分《淘宝网》的商品和商家信息都是根据这两个页面的格式方式存在的。所以借此便可以写出程序推算出整个《淘宝网》的数据。
页面HTML源码关键点
我在网上详尽查阅了有关爬虫引擎的资料和仔细选购了开源框架后。决定使用以下几个框架作为我的爬虫引擎的主要框架。
1.HtmlParser
这个开源框架主要用于解析Html格式的页面,这个框架的目的就是从当前页面将关键数据提取下来,从而在零下载的情况下得到数据。由于这个框架时间比较早,未免有些比较陈旧的做法,比如NodeList类没有实现Iterator插口爬虫框架设计,没有借助类库等。以后的项目中可以替换为较新较成熟的框架。
2.ApacheCommonsChain
在网页提取过程中,每个不同页面究竟该用那个类来负责解析呢?仔细剖析后,我个人认为使用【设计模式】中的责任链模式可以极大地减少代码耦合性,达到【软件工程】中开闭原则的疗效。减少ifelse繁杂的判定,使代码更清晰。
3.iBatis
我经过对比,选择了iBatis作为DAO层的数据储存框架,由于其可以灵活的配置SQL句子,以及轻量级设计,可以使我使用一些数据库存储过程等维持字段的约束。
4.ApacheCommonsBeanutils
这个框架的BeanMap是一个挺好的东西,它采用了一个反射的做法给我提供了一个可以将Map属性通配符对转化为bean类的方式,利用这个类可以让页面提取出的Map中包含的数据用一个统一的方式转化为实体类,再存入数据库。
爬虫引擎程序流程图
最终,得到了大量的《淘宝网》的商品和店家的数据库表中的数据,由于这个爬虫引擎借助“责任链模式”解析数据,可以灵活地扩充到其他不同结构的网页中去提取数据,在此基础上再实现搜索。(很抱歉,由于我下班后业余时间之作,时间匆忙,全文搜索这部份未完成,考虑计划使用ApacheLucene开源框架做智能全文搜索框架)
爬虫框架是哪些?常见的Python爬虫框架有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-05-02 08:09
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。

