[申精]淘宝网爬虫引擎设计构架图等
优采云 发布时间: 2020-05-05 08:03
更多贴子
猪孩子啊啊大大
本版专家分:0
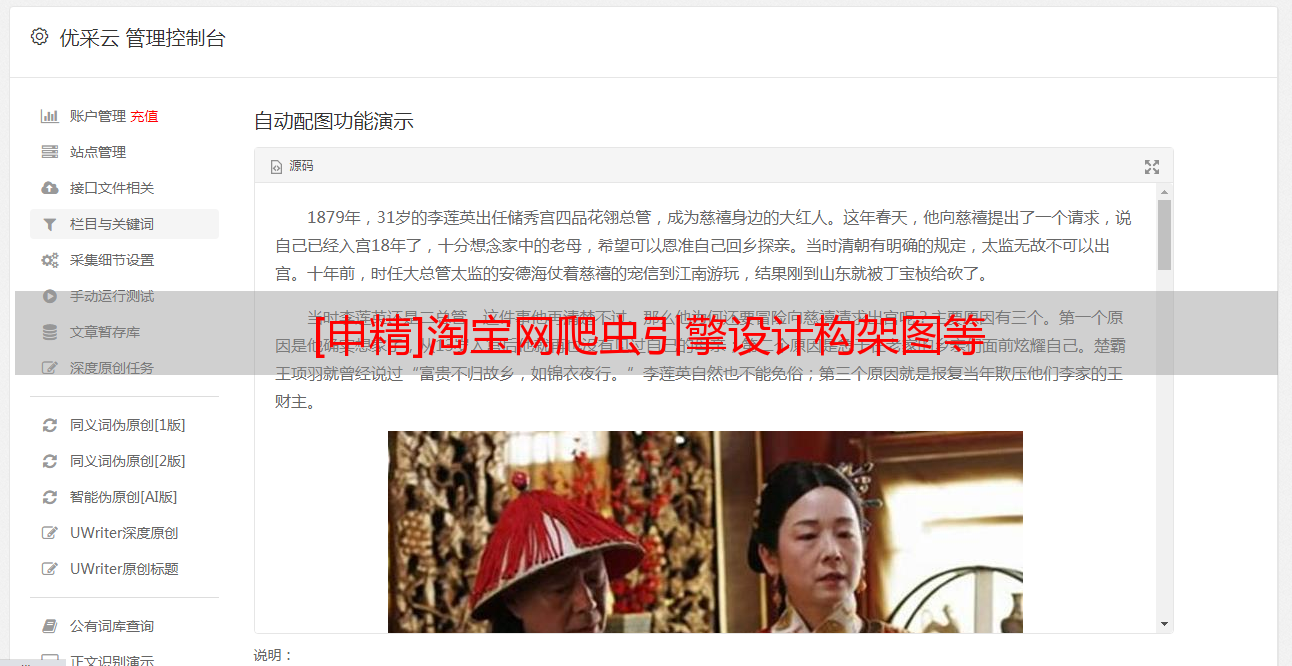
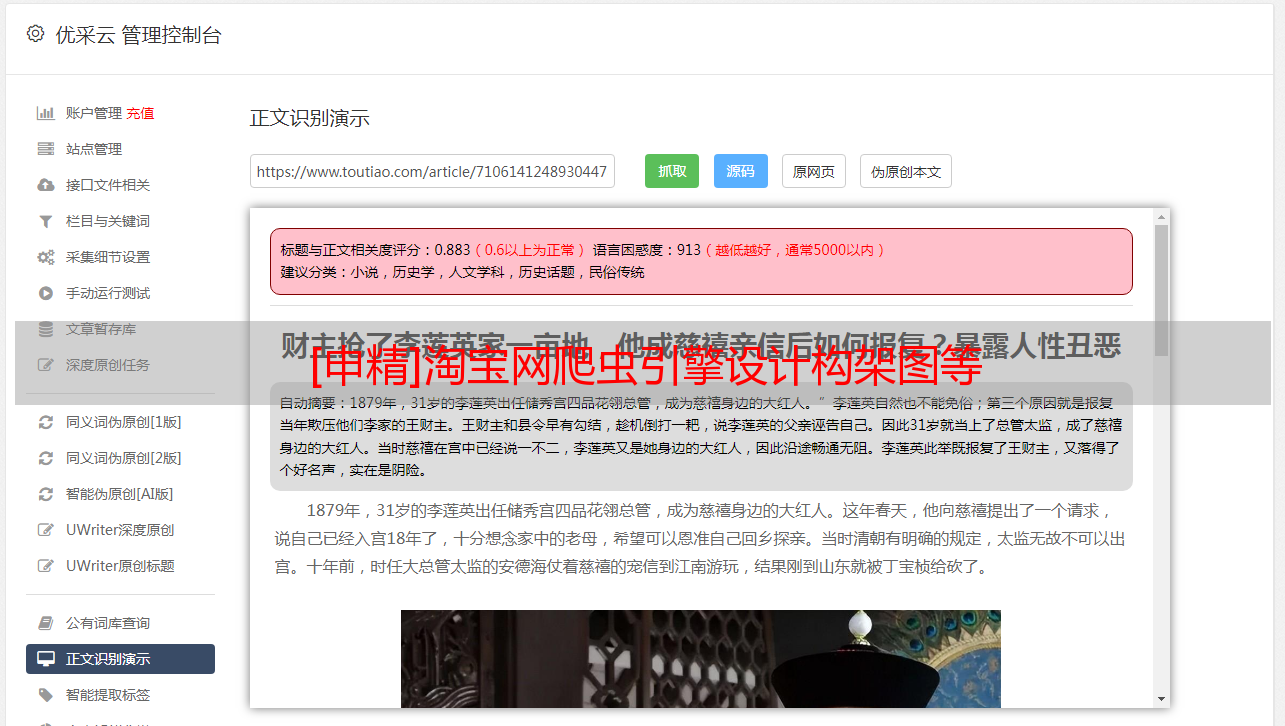
在《淘宝网》购物时爬虫框架设计,顾客最关心的就是这两个页面(这两个页面的网址sample分别为
;item_num_id=3899429723&cm_cat=50010388和),因此这两个页面的信息对于客户至关重要,这也是我的搜索引擎信息搜集的地方。由于有成千上万的这样格式的页面,所以我的目标就是设计出一个爬虫引擎在《淘宝网》上不断地爬,以零下载为条件,直接将目标信息数据导出我创建的数据库中,再进行搜索。
综合剖析这两个典型页面,我们可以得到这样的信息:大部分《淘宝网》的商品和商家信息都是根据这两个页面的格式方式存在的。所以借此便可以写出程序推算出整个《淘宝网》的数据。
页面HTML源码关键点
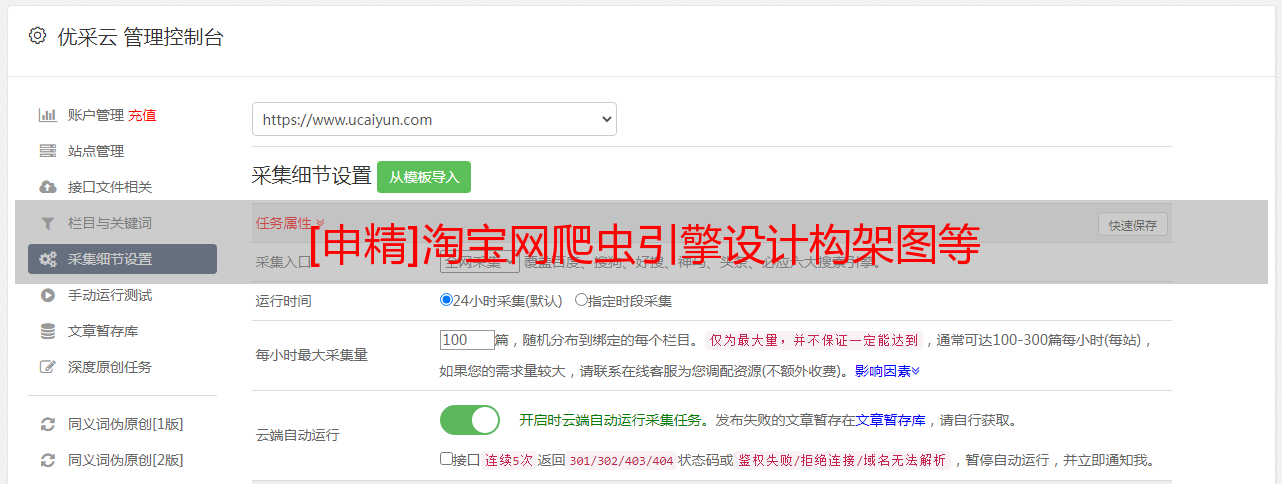
我在网上详尽查阅了有关爬虫引擎的资料和仔细选购了开源框架后。决定使用以下几个框架作为我的爬虫引擎的主要框架。
1.HtmlParser
这个开源框架主要用于解析Html格式的页面,这个框架的目的就是从当前页面将关键数据提取下来,从而在零下载的情况下得到数据。由于这个框架时间比较早,未免有些比较陈旧的做法,比如NodeList类没有实现Iterator插口爬虫框架设计,没有借助类库等。以后的项目中可以替换为较新较成熟的框架。
2.ApacheCommonsChain
在网页提取过程中,每个不同页面究竟该用那个类来负责解析呢?仔细剖析后,我个人认为使用【设计模式】中的责任链模式可以极大地减少代码耦合性,达到【软件工程】中开闭原则的疗效。减少ifelse繁杂的判定,使代码更清晰。
3.iBatis
我经过对比,选择了iBatis作为DAO层的数据储存框架,由于其可以灵活的配置SQL句子,以及轻量级设计,可以使我使用一些数据库存储过程等维持字段的约束。
4.ApacheCommonsBeanutils
这个框架的BeanMap是一个挺好的东西,它采用了一个反射的做法给我提供了一个可以将Map属性通配符对转化为bean类的方式,利用这个类可以让页面提取出的Map中包含的数据用一个统一的方式转化为实体类,再存入数据库。

爬虫引擎程序流程图
最终,得到了大量的《淘宝网》的商品和店家的数据库表中的数据,由于这个爬虫引擎借助“责任链模式”解析数据,可以灵活地扩充到其他不同结构的网页中去提取数据,在此基础上再实现搜索。(很抱歉,由于我下班后业余时间之作,时间匆忙,全文搜索这部份未完成,考虑计划使用ApacheLucene开源框架做智能全文搜索框架)

