
智能采集平台
福利:业内首个数据集高级清洗服务 百度EasyData智能数据服务平台免费试用中
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2020-09-07 23:30
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
业界首个高级数据集清洁服务百度EasyData智能数据服务平台正在免费试用
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
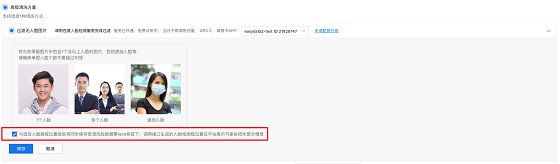
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。

清洁前的数据集收录人脸照片,风景照片和静物照片

仅保存清洁数据集的面部照片

戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。

在清洁之前的数据集中有风景图像,静物图像和人体图像。

通过数据清理和过滤保留5张人像

模板是清洁图像检测数据集后的标签

模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。

8张图片,然后再浏览类似图片

相似后保留3张图片
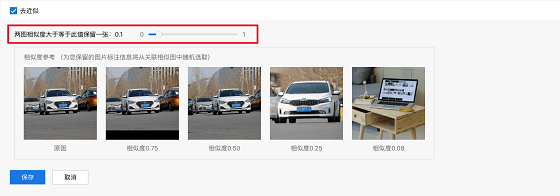
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。

去模糊前5张不同质量的图片

去模糊后保持清晰的画面
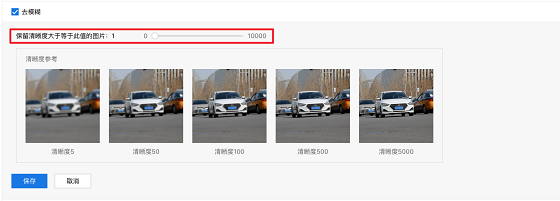
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
完整解决方案:百度推智能数据服务平台EasyData,具有高级智能数据清洗功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-09-07 13:50
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在这一步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终机密?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务(人脸检测和人体检测均可免费试用),他们可以通过简单的配置直接使用EasyData平台。使用这些功能可以自动清除数据。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人为检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二值图像转换为相应的标签。
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,对于基本的清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
百度推出具有高级智能数据清理功能的智能数据服务平台EasyData
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在这一步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终机密?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务(人脸检测和人体检测均可免费试用),他们可以通过简单的配置直接使用EasyData平台。使用这些功能可以自动清除数据。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。

对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人为检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二值图像转换为相应的标签。
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,对于基本的清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
整体解决方案:业内首个数据集高级清洗服务 百度EasyData智能数据服务平台免费试用中
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-09-04 22:40
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
业界首个高级数据集清洁服务百度EasyData智能数据服务平台正在免费试用
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。

提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。

清洁前的数据集收录人脸照片,风景照片和静物照片

仅保存清洁数据集的面部照片

戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。

在清洁之前的数据集中有风景图像,静物图像和人体图像。

通过数据清理和过滤保留5张人像

模板是清洁图像检测数据集后的标签

模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。

8张图片,然后再浏览类似图片

相似后保留3张图片

拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。

去模糊前5张不同质量的图片

去模糊后保持清晰的画面

拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
整套解决方案:业内首个数据集高级清洗服务 百度EasyData智能数据服务平台免费试用中
采集交流 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2020-09-04 12:02
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
业界首个高级数据集清洁服务百度EasyData智能数据服务平台正在免费试用
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。

提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。

清洁前的数据集收录人脸照片,风景照片和静物照片

仅保存清洁数据集的面部照片

戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。

在清洁之前的数据集中有风景图像,静物图像和人体图像。

通过数据清理和过滤保留5张人像

模板是清洁图像检测数据集后的标签

模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。

8张图片,然后再浏览类似图片

相似后保留3张图片

拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。

去模糊前5张不同质量的图片

去模糊后保持清晰的画面

拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
吉林智能数据采集 专业数据采集平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 726 次浏览 • 2020-08-29 04:01
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。
对于企业生产经营数据上的顾客数据,财务数据等保密性要求较高的数据,可以通过与数据技术服务商合作,使用特定系统插口等相关方法采集数据。比如八度云计算的数企BDSaaS,无论是数据采集技术、BI数据剖析,还是数据的安全性和保密性,都做得挺好。
‘搜客’---搜客数据采集APP的优势
一、‘搜客’是哪些?
‘搜客’是一款高智能客源信息采集平台,本质上是一款市场营销系统,能够帮助使用人确切的采集所须要搜集的会员顾客信息。
二、‘搜客’是如何的一个行业定位?
‘搜客’做为大数据营销软件,定位为垂直搜索引擎。即专注于信息采集垂直领域,搜索引擎只能调阅数据信息,不形成任何交易环节。
三、‘搜客’所提供的数据信息是否真实合法?
‘搜客’以数十家小型为搜索基础。所有数据信息皆从调阅,真实性毋庸置疑,至于所采集的信息也都是全网公开的信息,并且由本人上传,在主观意愿上是选择公开的,‘搜客’所采集的信息,属于网路公开信息,真实合法。
四、‘搜客’的采集源从何而至?
‘搜客’采集源来自于百度地图、高德地图、360网、赶集网等搜索引擎。全网搜索采集各行业类别信息,包括各类别店家的地址信息,联系方法,经营信息等公开信息,切实做到信息有效、更新及时的问题,并且具体化至区域搜索,精确到市区内采集,真实有效的提供了精准的行业布满
五、‘搜客’的功能都有什么?
搜索精确:在软件全网采集站点里输入想要的行业和地区 就可以搜索到精准的顾客信息资源。
产品推广:主要功能是可以发布广告信息,针对信息情况来选择信息分类。收录推广图片,以及文字进行详尽的描述介绍。
一键添加:搜索下来的资源信息通过一键添加可以直接导出到手机通讯录里。
同城客源:基于归属地大数据,可按照规则一键生成海量目标号码。营销宝典:搜集互联网精品的营销课程,让您用的过程中也才能学习。
一键清空:将添加的客源信息,一键删掉。只删掉从搜客软件添加的信息,不会影响任何自动保存的信息。提供精准对口行业资源信息;有针对性的做业务,提高效率;提供建立的埋点采集规范,调用 API 接收埋点数据;支持导出第三方或线下数据,丰富数据源进行剖析;提供统一的埋点指标管理平台,便捷管理埋点指标。
六、‘搜客’相比同类产品的优势?
1、搜索内容的随意性大,不用局限于软件里现有的行业,用户能想到的都可以搜索。
2、客源的区域性更细化。用户可以依照自己的需求选择区或则市区。
3、可以根据行业分类导出手机通讯录。让手机通讯录里的客源信息分类更明晰。并且可以同步陌陌和QQ软件,灵活多样的做业务推广。
4、可以根据行业分类导入execl表格。
5、短信群发功能,选择一个地区的某个行业后,用户以邮件的形式顿时发送给对方,针对性强,推广速度快。
6、推广功能,用户可以把自己的产品推广到软件里,并且可以分享到陌陌好友和朋友圈。
7、私人定制,用户可以按照自己的行业须要订做软件。
8、只须要一部手机,通过搜客系统即可开发全省市场。
七、‘搜客’系统未来会怎样优化?
目前‘搜客’仅可作为营销工具使用,但在不断建立更新的过程中,会逐渐进行除营销工具意外的调整,自身调整包括上线‘搜客’商城,系统功能在‘搜客’完善过程中通过大数据信息流调整出行业并立的搭建式系统,推广者虽然任何事情都不做,也会带来大的产品销量。
-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。 查看全部
吉林智能数据采集 专业数据采集平台
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。

对于企业生产经营数据上的顾客数据,财务数据等保密性要求较高的数据,可以通过与数据技术服务商合作,使用特定系统插口等相关方法采集数据。比如八度云计算的数企BDSaaS,无论是数据采集技术、BI数据剖析,还是数据的安全性和保密性,都做得挺好。

‘搜客’---搜客数据采集APP的优势
一、‘搜客’是哪些?
‘搜客’是一款高智能客源信息采集平台,本质上是一款市场营销系统,能够帮助使用人确切的采集所须要搜集的会员顾客信息。
二、‘搜客’是如何的一个行业定位?
‘搜客’做为大数据营销软件,定位为垂直搜索引擎。即专注于信息采集垂直领域,搜索引擎只能调阅数据信息,不形成任何交易环节。
三、‘搜客’所提供的数据信息是否真实合法?
‘搜客’以数十家小型为搜索基础。所有数据信息皆从调阅,真实性毋庸置疑,至于所采集的信息也都是全网公开的信息,并且由本人上传,在主观意愿上是选择公开的,‘搜客’所采集的信息,属于网路公开信息,真实合法。
四、‘搜客’的采集源从何而至?
‘搜客’采集源来自于百度地图、高德地图、360网、赶集网等搜索引擎。全网搜索采集各行业类别信息,包括各类别店家的地址信息,联系方法,经营信息等公开信息,切实做到信息有效、更新及时的问题,并且具体化至区域搜索,精确到市区内采集,真实有效的提供了精准的行业布满
五、‘搜客’的功能都有什么?
搜索精确:在软件全网采集站点里输入想要的行业和地区 就可以搜索到精准的顾客信息资源。
产品推广:主要功能是可以发布广告信息,针对信息情况来选择信息分类。收录推广图片,以及文字进行详尽的描述介绍。
一键添加:搜索下来的资源信息通过一键添加可以直接导出到手机通讯录里。
同城客源:基于归属地大数据,可按照规则一键生成海量目标号码。营销宝典:搜集互联网精品的营销课程,让您用的过程中也才能学习。
一键清空:将添加的客源信息,一键删掉。只删掉从搜客软件添加的信息,不会影响任何自动保存的信息。提供精准对口行业资源信息;有针对性的做业务,提高效率;提供建立的埋点采集规范,调用 API 接收埋点数据;支持导出第三方或线下数据,丰富数据源进行剖析;提供统一的埋点指标管理平台,便捷管理埋点指标。
六、‘搜客’相比同类产品的优势?
1、搜索内容的随意性大,不用局限于软件里现有的行业,用户能想到的都可以搜索。
2、客源的区域性更细化。用户可以依照自己的需求选择区或则市区。
3、可以根据行业分类导出手机通讯录。让手机通讯录里的客源信息分类更明晰。并且可以同步陌陌和QQ软件,灵活多样的做业务推广。
4、可以根据行业分类导入execl表格。
5、短信群发功能,选择一个地区的某个行业后,用户以邮件的形式顿时发送给对方,针对性强,推广速度快。
6、推广功能,用户可以把自己的产品推广到软件里,并且可以分享到陌陌好友和朋友圈。
7、私人定制,用户可以按照自己的行业须要订做软件。
8、只须要一部手机,通过搜客系统即可开发全省市场。
七、‘搜客’系统未来会怎样优化?
目前‘搜客’仅可作为营销工具使用,但在不断建立更新的过程中,会逐渐进行除营销工具意外的调整,自身调整包括上线‘搜客’商城,系统功能在‘搜客’完善过程中通过大数据信息流调整出行业并立的搭建式系统,推广者虽然任何事情都不做,也会带来大的产品销量。

-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。
Aria Insights公司借助人工智能来提供新的无人机数据采集和剖析服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-26 04:52
【据UnmannedSystemstechnology网站2019年1月22日报导】自主机器人数据采集平台开发商Aria Insights公司宣布,发起一项新的服务,将借助人工智能为顾客提供新的无人机数据采集和剖析服务,可以更有效地使用无人机搜集的数据,并确保用户在此过程中的安全。 Aria Insights 公司正在通过将人工智能和机器学习软件集成到其无人机上来扩充 CyPhy 公司系留无人机服务范围,计划为顾客提供智能、自主型无人机,这些无人机可以搜集和剖析数据,为用户提供可操作的解决方案。
关于日本Aria Insights无人机公司步入企业商铺
美国Aria Insights无人机公司提供全方位服务的无人机解决方案,结合了自主和机器学习的强悍功能,可搜集数据并为用户创建可操作的看法。
Aria Insights使用无人机和人工智能步入公共安全,石油和天然气以及其他商业领域的后勤困难和潜在危险环境,同时确保人类生命不会遭到恐吓。
Aria Insights,一家致力于提供自主,机器人队友的公司,今天早已推出。使用人工智能(AI),Aria可以更有效地借助无人机搜集的数据,并在此过程中保证用户的安全。Aria Insights由CyPhy Works团队成立,通过将AI和机器学习软件集成到无人机中,扩展了CyPhy的系留无人机传统。该公司将为顾客提供智能,自主的无人机,既可以搜集和剖析数据,也可以为用户创建可操作的看法。将重点置于人工智能上的决定来自于多年的行业经验,这些经验表明无人机的威力仅限于使用和理解她们搜集的数据。
“Aptly以一群金丝雀命名,他们过去经常努力保护矿山工人免受致命二氧化碳的侵犯,Aria Insights布署无人驾驶客机和人工智能,以便将人类从不安全的情况中移除。更智能的数据搜集和机器学习让决策者才能快速有效地解决问题或执行任务,同时确保人类生命不会遭到恐吓。通过复杂的剖析,决策者不再须要耗费数小时捕获和观看视频;相反,Aria Insights的机器人将辨识感兴趣的信息,在测量到新信息时发送警报,并最终将所有数据联接到数字3D地图。 查看全部
Aria Insights公司借助人工智能来提供新的无人机数据采集和剖析服务

【据UnmannedSystemstechnology网站2019年1月22日报导】自主机器人数据采集平台开发商Aria Insights公司宣布,发起一项新的服务,将借助人工智能为顾客提供新的无人机数据采集和剖析服务,可以更有效地使用无人机搜集的数据,并确保用户在此过程中的安全。 Aria Insights 公司正在通过将人工智能和机器学习软件集成到其无人机上来扩充 CyPhy 公司系留无人机服务范围,计划为顾客提供智能、自主型无人机,这些无人机可以搜集和剖析数据,为用户提供可操作的解决方案。

关于日本Aria Insights无人机公司步入企业商铺
美国Aria Insights无人机公司提供全方位服务的无人机解决方案,结合了自主和机器学习的强悍功能,可搜集数据并为用户创建可操作的看法。
Aria Insights使用无人机和人工智能步入公共安全,石油和天然气以及其他商业领域的后勤困难和潜在危险环境,同时确保人类生命不会遭到恐吓。
Aria Insights,一家致力于提供自主,机器人队友的公司,今天早已推出。使用人工智能(AI),Aria可以更有效地借助无人机搜集的数据,并在此过程中保证用户的安全。Aria Insights由CyPhy Works团队成立,通过将AI和机器学习软件集成到无人机中,扩展了CyPhy的系留无人机传统。该公司将为顾客提供智能,自主的无人机,既可以搜集和剖析数据,也可以为用户创建可操作的看法。将重点置于人工智能上的决定来自于多年的行业经验,这些经验表明无人机的威力仅限于使用和理解她们搜集的数据。
“Aptly以一群金丝雀命名,他们过去经常努力保护矿山工人免受致命二氧化碳的侵犯,Aria Insights布署无人驾驶客机和人工智能,以便将人类从不安全的情况中移除。更智能的数据搜集和机器学习让决策者才能快速有效地解决问题或执行任务,同时确保人类生命不会遭到恐吓。通过复杂的剖析,决策者不再须要耗费数小时捕获和观看视频;相反,Aria Insights的机器人将辨识感兴趣的信息,在测量到新信息时发送警报,并最终将所有数据联接到数字3D地图。
包头智能数据采集 专业数据采集平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2020-08-26 01:53
数据采集的设计,几乎完全取决于数据源的特点,毕竟数据源是整个大数据平台蓄水的上游,数据采集不过是获取水源的管线罢了。
大数据生命周期
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。我们明天就来瞧瞧大数据技术在数据采集方面采用了什么方式:
实时采集主要用在考虑流处理的业务场景,比如,用于记录数据源的执行的各类操作活动,比如网络监控的流量管理、金融应用的股票记账和 web 服务器记录的用户访问行为。在流处理场景,数据采集会成为Kafka的消费者,就像一个大坝通常将上游源源不断的数据拦截住,然后依照业务场景做对应的处理(例如去重、去噪、中间估算等),之后再写入到对应的数据储存中。这个过程类似传统的ETL,但它是流式的处理方法,而非定时的批处理Job,些工具均采用分布式构架,能满足每秒数百MB的日志数据采集和传输需求
数据采集–>数据储存–>数据处理–>数据凸显(可视化,报表和监控)
任何完整的大数据平台,一般包括以下的几个过程:(如果对大数据生命周期认识不够清晰,可参考还不懂哪些是大数据?大数据的生命周期求婚)
大数据环境下数据来源十分丰富且数据类型多样,存储和剖析挖掘的数据量庞大,对数据凸显的要求较高,并且太看重数据处理的高效性和可用性。(点击看懂大数据处理:大数据处理构架系列三:原来如此简单,HADOOP原理剖析)
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。
全的大数据采集方法分类,你想知道的都在这里
-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。 查看全部
包头智能数据采集 专业数据采集平台
数据采集的设计,几乎完全取决于数据源的特点,毕竟数据源是整个大数据平台蓄水的上游,数据采集不过是获取水源的管线罢了。
大数据生命周期
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。我们明天就来瞧瞧大数据技术在数据采集方面采用了什么方式:
实时采集主要用在考虑流处理的业务场景,比如,用于记录数据源的执行的各类操作活动,比如网络监控的流量管理、金融应用的股票记账和 web 服务器记录的用户访问行为。在流处理场景,数据采集会成为Kafka的消费者,就像一个大坝通常将上游源源不断的数据拦截住,然后依照业务场景做对应的处理(例如去重、去噪、中间估算等),之后再写入到对应的数据储存中。这个过程类似传统的ETL,但它是流式的处理方法,而非定时的批处理Job,些工具均采用分布式构架,能满足每秒数百MB的日志数据采集和传输需求

数据采集–>数据储存–>数据处理–>数据凸显(可视化,报表和监控)
任何完整的大数据平台,一般包括以下的几个过程:(如果对大数据生命周期认识不够清晰,可参考还不懂哪些是大数据?大数据的生命周期求婚)

大数据环境下数据来源十分丰富且数据类型多样,存储和剖析挖掘的数据量庞大,对数据凸显的要求较高,并且太看重数据处理的高效性和可用性。(点击看懂大数据处理:大数据处理构架系列三:原来如此简单,HADOOP原理剖析)
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。

全的大数据采集方法分类,你想知道的都在这里
-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。
种草爬虫利器,小白也能一键采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-26 00:41
你有没有苦恼过,如何将网页中收录的各类信息转变为有用的数据呢?
粘贴复制??太累
开发软件??太贵
写python爬虫??太难学
下载了一些工具??太难用
这里给你们介绍下采集数据的利器,优采云采集器,无需编撰代码,就可以免费采集网站数据。
01
采集神器:优采云采集器
前微软技术团队鼎力构建,基于人工智能技术,只需输入网址能够手动辨识采集内容。
优采云采集器除了才能进行数据的自动化采集,而且在采集过程中还可以对数据进行清洗。在数据源头即可实现多种内容的过滤。
这么好用的一款产品,它竟然还是免费的!免费支持100个任务,支持多任务同时运行,无数目限制。
02
采集场景和数组
场景:采集优采云采集器文档中心发布的相关文章等相关数据
字段:文章标题、文章链接、摘要、发布时间
采集步骤
1、首先须要先在页面下载安装优采云采集器,然后注册用户
2、在首页输入要爬取数据的网址,我们以采集优采云采集器文档中心的数据为例
3、点击【智能采集】,优采云采集器可以手动辨识页面内容和分页按键,生成采集字段
4、点击【深入采集】,可步入每位详情页采集数据,如手动辨识的数组不是自己想要的,可以【清空所有】,点击【添加数组】选择自己想要采集的内容。
5、点击【开始采集】和【启动】,运行完毕后【导出数据】
播放暂停步入全屏退出全屏00:0000:00重播请刷新试试
--本视频来自优采云采集器
03
这是我用优采云采集器爬取去年最火电视剧的数据场景
优采云采集器真棒,还可以过滤数据,就可以只爬取开播收录2020的数据
优采云采集器爬取去年最火电视剧的数据场景
数据剖析
用爬到的数据做了一张文字云,2020年上半年最火评分最高的就是
隐秘的角落
20202020年上半年最火评分最高的电视剧 查看全部
种草爬虫利器,小白也能一键采集数据
你有没有苦恼过,如何将网页中收录的各类信息转变为有用的数据呢?
粘贴复制??太累
开发软件??太贵
写python爬虫??太难学
下载了一些工具??太难用
这里给你们介绍下采集数据的利器,优采云采集器,无需编撰代码,就可以免费采集网站数据。
01
采集神器:优采云采集器
前微软技术团队鼎力构建,基于人工智能技术,只需输入网址能够手动辨识采集内容。
优采云采集器除了才能进行数据的自动化采集,而且在采集过程中还可以对数据进行清洗。在数据源头即可实现多种内容的过滤。
这么好用的一款产品,它竟然还是免费的!免费支持100个任务,支持多任务同时运行,无数目限制。
02
采集场景和数组
场景:采集优采云采集器文档中心发布的相关文章等相关数据
字段:文章标题、文章链接、摘要、发布时间
采集步骤
1、首先须要先在页面下载安装优采云采集器,然后注册用户
2、在首页输入要爬取数据的网址,我们以采集优采云采集器文档中心的数据为例
3、点击【智能采集】,优采云采集器可以手动辨识页面内容和分页按键,生成采集字段
4、点击【深入采集】,可步入每位详情页采集数据,如手动辨识的数组不是自己想要的,可以【清空所有】,点击【添加数组】选择自己想要采集的内容。
5、点击【开始采集】和【启动】,运行完毕后【导出数据】
播放暂停步入全屏退出全屏00:0000:00重播请刷新试试
--本视频来自优采云采集器
03
这是我用优采云采集器爬取去年最火电视剧的数据场景
优采云采集器真棒,还可以过滤数据,就可以只爬取开播收录2020的数据
优采云采集器爬取去年最火电视剧的数据场景
数据剖析
用爬到的数据做了一张文字云,2020年上半年最火评分最高的就是
隐秘的角落
20202020年上半年最火评分最高的电视剧
智能互联网信息采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2020-08-25 16:07
本系统集成网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
一、系统简介
新闻媒体、政府部门、大型企事业单位纷纷通过互联网技术搭建网路信息搜集平台:新闻媒体须要获取大量的互联网上新闻资料,充实新闻资料库;政府机关须要搜集与自身业务相关的文献资料,提升办公与决策效率;大型企事业单位须要快速获取行业宏观环境、政策动态与竞争对手信息……
天宇智能互联网信息采集系统(CGSEEK)集成了网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现了对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
二、系统结构
三、系统主要功能
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
信息借助
◆可以将采集下来的网页信息放置到本地机器指定的某个文件夹下,进行借助。
◆系统支持采集的文本内容批量上载到天宇CGRS全文数据库中,可以借助天宇采盘发系统及全文检索系统进行信息采编、审核、发布与全文检索等借助。
◆经过智能提取的文本内容,可以上载到SQLServer等主流的关系型数据库中,充实资料库,也可以借助第三方应用系统对信息进行采编、发布与检索等应用。
四、系统特征
◆网页采集内容全面
适应网站内容格式的多变性,能完整地获取须要采集的页面,遗漏少,网页采集内容的完整性在99%以上。
◆内容准确度高
能便捷地将网页中的信息提取下来,如日期,标题,作者,栏目等内容;过滤网页中的无用信息。
◆精确定义采集范围
精确描述须要采集的网站范围,可以精确到整个网站、特定栏目、特定页面。
◆使用便捷,自动化程度高
系统参数设置简单,一次设置多次使用,修改便捷、直观、快捷。
◆信息采集快
系统通过多线程处理技术,可以同时启动多个搜索器,快速高效地对目标站点或栏目进行信息采集。
五、系统性能
◆采集速度:每分钟采集数百个最新目标页面(与机器性能及网路带宽有关);
◆处理速率:每分钟提取、过滤与上载数百个网页;
◆自动分类:页面内容手动分类准确率90%以上;
◆提取效率:页面内容(标题、日期、作者、正文等)准确提取率达99%以上。
六、运行环境
◆普通PC机,512M以上显存;
◆操作系统:Windows2000/2003/XP。
七、行业应用
◆网络传媒:自动跟踪与采集国内外网路媒体信息,可以使用关键词过滤搜索或批量采集的形式,实现各种新闻的有效采集、分类、编辑、管理、发布与检索一体化;系统支持第三方应用系统,如采编系统、发布系统、检索系统。
◆党政机关:实时搜集与业务工作相关的信息资源或新闻,在外网或内网上实时动态地发布下来,满足办公人员对互联网信息的须要,提高办公与办事效率。
◆大型企事业单位:通过系统实时追踪与搜集行业新政、宏观环境、竞争对手等相关情报资料,有利于提高企业综合竞争力。 查看全部
智能互联网信息采集系统
本系统集成网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
一、系统简介
新闻媒体、政府部门、大型企事业单位纷纷通过互联网技术搭建网路信息搜集平台:新闻媒体须要获取大量的互联网上新闻资料,充实新闻资料库;政府机关须要搜集与自身业务相关的文献资料,提升办公与决策效率;大型企事业单位须要快速获取行业宏观环境、政策动态与竞争对手信息……
天宇智能互联网信息采集系统(CGSEEK)集成了网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现了对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
二、系统结构

三、系统主要功能
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
信息借助
◆可以将采集下来的网页信息放置到本地机器指定的某个文件夹下,进行借助。
◆系统支持采集的文本内容批量上载到天宇CGRS全文数据库中,可以借助天宇采盘发系统及全文检索系统进行信息采编、审核、发布与全文检索等借助。
◆经过智能提取的文本内容,可以上载到SQLServer等主流的关系型数据库中,充实资料库,也可以借助第三方应用系统对信息进行采编、发布与检索等应用。
四、系统特征
◆网页采集内容全面
适应网站内容格式的多变性,能完整地获取须要采集的页面,遗漏少,网页采集内容的完整性在99%以上。
◆内容准确度高
能便捷地将网页中的信息提取下来,如日期,标题,作者,栏目等内容;过滤网页中的无用信息。
◆精确定义采集范围
精确描述须要采集的网站范围,可以精确到整个网站、特定栏目、特定页面。
◆使用便捷,自动化程度高
系统参数设置简单,一次设置多次使用,修改便捷、直观、快捷。
◆信息采集快
系统通过多线程处理技术,可以同时启动多个搜索器,快速高效地对目标站点或栏目进行信息采集。
五、系统性能
◆采集速度:每分钟采集数百个最新目标页面(与机器性能及网路带宽有关);
◆处理速率:每分钟提取、过滤与上载数百个网页;
◆自动分类:页面内容手动分类准确率90%以上;
◆提取效率:页面内容(标题、日期、作者、正文等)准确提取率达99%以上。
六、运行环境
◆普通PC机,512M以上显存;
◆操作系统:Windows2000/2003/XP。
七、行业应用
◆网络传媒:自动跟踪与采集国内外网路媒体信息,可以使用关键词过滤搜索或批量采集的形式,实现各种新闻的有效采集、分类、编辑、管理、发布与检索一体化;系统支持第三方应用系统,如采编系统、发布系统、检索系统。
◆党政机关:实时搜集与业务工作相关的信息资源或新闻,在外网或内网上实时动态地发布下来,满足办公人员对互联网信息的须要,提高办公与办事效率。
◆大型企事业单位:通过系统实时追踪与搜集行业新政、宏观环境、竞争对手等相关情报资料,有利于提高企业综合竞争力。
亿级APP支付宝在移动端的高可用技术实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2020-08-25 07:39
亿级 APP 在可用性方面的挑战
可用性的概念
简单而言,可用性就是当用户想要使用 APP 做一个事情,这件事情弄成了就是可用,没有弄成就不可用。
为什么没有弄成?可能的诱因有很多,比如有可能使用 APP 的时侯死机了,或者使用支付宝付款的时侯,由于后台某个环节出现错误,导致了这笔支付失败了等,这些都可能导致 APP 的不可用。
如果各种各样不可用的情况都没有出现,那么对于顾客而言就是可用的。虽然每位开发人员都希望自己开发的 APP 是 100% 可用的,但是实际上这一点是不可能的。所以开发人员真正须要做的事情就是使 APP 发生不可用的情况越来越少。
亿级 APP 的可用性挑战
目前,APP 开发技术早已比较成熟了,所以好多开发人员会觉得自己的 APP 可用性应当问题不是很大,因为 APP 都经历了相关的测试流程、灰度验证等保障举措。
但是如今情况早已发生变化了,与先前相比,APP 的用户量大了好多,很多的 APP 都达到了亿级用户,所以一点点可用性问题都可能会影响大量的用户。
比如 APP 的闪退率下降了千分之一,虽然这一比列并不是很大,但是对于一亿用户而言,乘上千分之一就是 10 万人。
大家可以想像一下,如果某三天你们在使用支付宝在商场付款的时侯,其中的 10 万人出现掉帧的情况,这个影响是绝对不可以接受的。
现在开发移动端 APP 讲究动态化,业务要求实时动态地实现线上变更,可以说明天的支付宝和今天的支付宝相比就早已形成很大区别了。
每一次线上的变更虽然就会降低线上可用性的风险,而且三天中可能会发生很多次变更,在这些情况下风险也会显得很大。尤其对于作为保障 APP 可用性的一线人员而言,压力也会非常大。
正是由于面临这么多的问题和挑战,才须要通过移动端的高可用技术体系解决这个问题,保证线上客户端高可用性。
APP 线上运维的发展和变迁
如上图,是这几年来支付宝客户端在可用性运维上的发展历史,大致分为了三个阶段。随着支付宝的成长,可用性运维也仍然在演化,最后演变到了移动端高可用的状态。
第一个阶段就是简单的死机监控。绝大多数的 APP 也做过这个事情,就是本地搜集一些死机信息并进行上报,在 APP 后台对于闪退率进行监控,解决死机比较多的问题,并在 APP 的下一个版本中进行相应的更改,最后让闪退率维持在某一个指标以下。
但是现今来看,这个阶段距离实现高可用的要求相差很远,因为用户所遇见不可用问题中死机只抢占其中一部分,所以对可用性而言,解决了死机问题只是改进了一点点而已,还存在着大部分的问题没有解决。
第二个阶段,在阿里巴巴内部称作稳定性监控体系,相比于第一个阶段而言,稳定性监控体系可以说前进了特别大的一步。
首先,可以监控的问题大大丰富了,通过对多种问题的监控可以了解线上用户稳定性方面的可用情况,而不仅仅是一个用户。
第二个方面,稳定性监控体系具有相当程度的确诊能力和修补能力。当发觉问题的时侯,可以通过确诊日志等相应的方式剖析故障缘由并尝试进行修补。
稳定性监控体系在最初的时侯疗效比较不错,并且阿里巴巴内部也使用了太长的时间,但是后来问题也渐渐曝露下来。
举两个事例,曾经一个版本的 APP 在 X86 一款机器上运行时出现的问题十分多,但是那种型号的用户量太小,所以问题始终都没有被发觉,直到太晚的时侯才通过其他方法发觉了这个问题,也就是说由于只监控具体问题引起早已不能发觉局部人群的问题了。
第二个事例,在做象双 11 这样的大促值勤的技术保障的时侯,因为监控的问题比较多,运维人员须要通过不停地翻监控来发觉问题,翻来翻去最后还是不敢确定 APP 的可用性究竟有没有问题,有时候确实会遗漏一些问题。
第三个方案就是在发觉了问题以后,能否快速修补还须要碰运气,有可能很快就才能修补,也有可能修补上去不太容易,需要等到下一次发版,这就促使有些问题所影响用户数会特别多。
以上就是在 2.0 阶段所碰到的问题,这说明稳定性监控体系也早已不够用了,需要继续进行改进,这也是支付宝决定继续做 3.0 阶段的移动端高可用的动机和动力。
移动端高可用的定义、目标、核心打法
高可用在移动端的重新定义
高可用本来属于服务端的概念,阿里巴巴的服务端都在讲高可用。服务端的高可用重点讲的是停机时间短、服务不可用时间短。
移动端的高可用从服务端借鉴过来以后进行了重新定义,因为客户端不存在停机时间概念。
所以,移动端高可用的定义是指通过专门的设计,结合整套技术体系,保证用户所遇见的技术不可用总次数太低。
移动端高可用的目标
简单来说,移动端高可用的目标就是实现可用率达到 99.99%,这里的可用率是支付宝自己定义的概念,指的就是用户在使用 APP 的时侯,可用次数在使用次数当中的占比,可用率达到 99.99%。
也就意味着用户使用 1 万次支付宝中的 9999 次都必须是可用的,最多只有一次不可用。为了实现这一目标,还会将任务拆解成为不同的子目标分别攻破。
移动端高可用的核心打法
目标的实现还是比较困难的,因为使可用率达到 99.99% 是一个很高的指标。而为了才能努力实现这个目标,支付宝也自创了一套核心打法。
主要分为以下四个部份:
支付宝在移动端高可用技术实践
如上图所示,是支付宝实现的移动端高可用技术构架图,大家可以看见支付宝移动端高可用的技术构架设计也是围绕上述的四个核心打法展开的。
客户端可用性监控
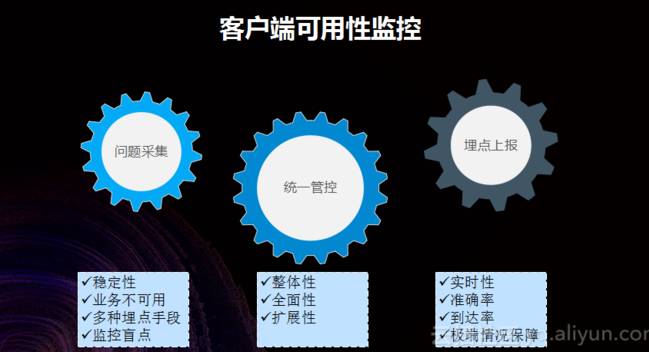
问题采集
客户端可用性监控的第一步就是问题采集,当 APP 发生不可用时必须才能感知和采集到问题,这是基础的基础,如果没有这个基础后续哪些都不能实现。
怎样确保当用户出现了不可用情况时才能采集到问题?这是比较困难的,因为我们不能保证一定可以采集到所有类型的不可用问题,但是还是会通过多种方式尽量地实现全面覆盖。
支付宝把不可用问题分为稳定性不可用和业务不可用两个方面。对于稳定性不可用而言,通过 2.0 阶段的逐步摸索以及各类反馈渠道、问题采集渠道的补充,现在早已可以把各种各样稳定性的不可用问题采集得比较全了。
比如传统的死机、卡死等以及不容易被监控的蓝屏、白屏以及非死机类型的异常退出等。
目前早已采集到了大部分的问题,当然可能就会存在遗漏,对于那些遗漏的问题,还须要通过不停地采集并补充到这个体系中。
对于业务不可用而言,在开发时会对于业务不可用问题进行埋点,只须要将业务不可用埋点列入到系统上面来,就能够基本覆盖最重要的业务不可用问题。
统一管控
当问题采集上来以后,需要通过统一管控产生客户端可用率指标。通过这个指标可以全面地评估线上某一个人群中的可用情况,而不需要象曾经那样逐一检测各个指标并在最后给一个不太确切的评估结果。通过统一管控可以设计出整体的监控和报案机制以及各类算法模型,并且其扩展性更好。
埋点上报
埋点上报这一功能是特别核心的,因为后续还要借助不可用埋点做高灵敏,所以埋点的实时性、准确性、到达率的要求非常高。
并且对于不可用埋点而言,当客户端早已发生了不可用时才须要进行上报,而在这个时侯客户端情况太可能十分恶劣,甚至此时客户端可能早已未能启动了,即便是这样也要保证埋点才能上报。
为了实现这一点,我们借助了一些小技巧,比如对于 Android 系统而言,支付宝通过独立的轻量级进程来单独上报埋点,即便主进程早已死掉了,但是埋点也就能实时上报上来。
对于 iOS 系统而言,采取在线上 hold 住进程让其报完埋点再退出去的形式,并且后续还有补偿机制,即使出现遗漏埋点的情况也才能让其最终能否上报上来。
通过问题采集、统一管控和埋点上报,基本上可以保障当用户碰到不可用问题时可以搜集问题并上报服务端,做好了第一步的基础。
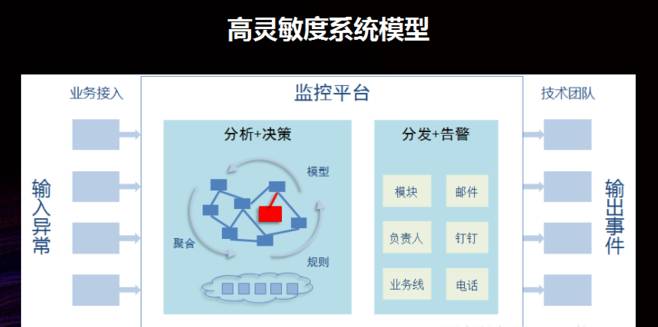
高灵敏度系统模型
在问题搜集到的情况下须要用高灵敏系统模型做监控和报案。监控和报案在 2.0 时代就早已存在了,比如当盘面上监控的闪退率出现异常情况时才会进行报案。
但是高灵敏系统模型要做的是在线上问题刚才出现端倪的时侯就可以发觉,而不是等到盘面出现波动才发觉。
所以这个模型的关键在于剖析决策的过程中,它会基于用户的人群特点、问题特点把线上采集到的不可用问题进行聚合再进行剖析,通过预制的一些算法模型和规则来判定是否形成了异常,如果最终判定的确有异常形成了则会输出一个异常风波。
举个事例,比如线上的某个业务发布了一个新的 H5 离线包版本,其中某一个页面的卡死率很高。那么使用这个页面的用户都会产生一个特点人群,这个特点人群的页面卡死率就有异常的波动,这个时侯才会输出异常风波。
但是此时盘面并没有很大波动,因为特点人群的人数并不多,但是后台可以捕获到异常风波。
当异常风波输出然后,可以通过附送信息准确地匹配到相应的负责人以及开发、测试人员,告警系统会告知负责人进行处理,并且会依照问题的严重程度采取不同的告警形式,可能会采取电邮、钉钉或则电话等方法进行告警。
在问题十分严重的情况下,如果几分钟之内没有响应就有人打电话给负责人了。通过这样的告警机制就可以保证无论哪些时间,只要线上出现异常问题就可以迅速地感知到。
高可用容灾平台
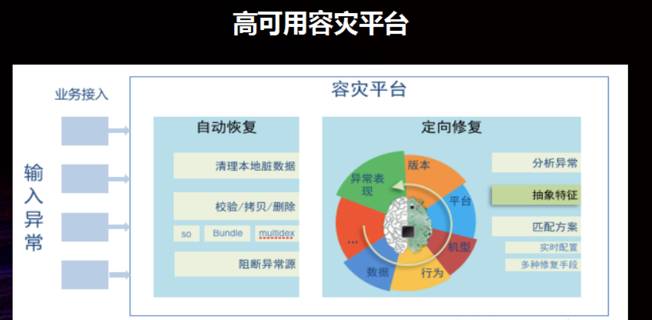
通过上述的内容,我们早已可以实现对于可用性问题的感知了。接下来分享怎样通过高可用容灾平台修补异常问题。
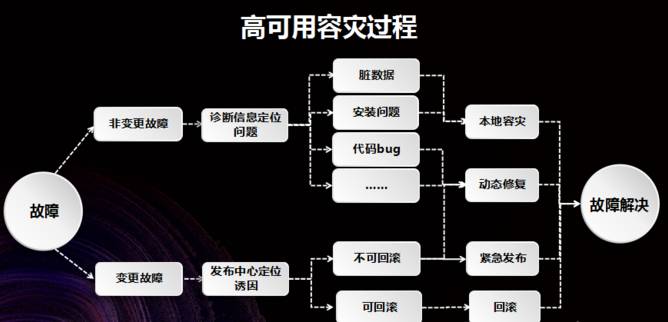
这里通过整体的故障容灾过程进行分享,如下图所示,当一个故障进来了,会向相应的负责人发出告警,这时负责人须要检测这个故障是如何形成的,到底是因为线上变更引起的,还是因为客户端本身的 Bug 导致的。
如果是由于线上变更引起的则比较好办,因为现今的系统比较灵敏,只要故障刚一发生,在短时间内负责人员就可以收到告警。
之后就可以到发布记录中检测这段时间内发生了哪几次变更,可以很快地基本了解是哪一次变更引起的故障,并采取相应的处理策略。
如果可以回滚就进行回滚操作,不能回滚就须要进行紧急发布,如果不能紧急发布就要依赖客户端进行修补。
比较麻烦的是和变更没有关系的情况,此时就须要通过异常携带的确诊信息或则通过获取一些日志来检测问题为何形成,问题的形成有时候是因为兼容性问题。
比如某个厂商灰度发布了一批和支付宝兼容性不太好的系统,导致出现了各种各样的问题,这种情况下就要通过动态修补解决。
也可能一些顾客本地出现了严重错误,比如说形成了一些脏数据,或者安装时由于市场的临时性 Bug 导致了大量安装失败,最终造成支付宝打不开。
对于这些情况而言,可以通过本地容灾做一些恢复工作,进而实现客户端的手动恢复。
总之,通过上述的过程,可以让故障得到解决。从右图中可以看出,支付宝在高可用容灾中致力于两点:
高可用的动态修补体系
移动端高可用和服务端高可用的重大区别就是移动端的发布比较困难,所以须要借助动态修补技术。
动态修补并不是新的概念,像 hotpatch 等技术都早已十分成熟了,目前也有好多可选的动态修补方案。
但是,虽然在高可用的动态修补体系中,hotpatch 属于比较重要的点,但是并不是最主要的点,因为它也存在一定的局限性,也有不适宜的时侯。目前,支付宝基于多种修补手段搭建了高可用的动态修补体系。
支付宝的高可用动态修补体系主要由以下三部份构成:
修复手段
修复手段有很多种,并且有轻有重。轻的手段在线上进行一些配置就可以解决线上不可用的问题,重的手段可以把整个模块完全重新布署下去。具体应当选择哪一种修补手段应当按照故障的情况来看,选择效率最高、风险最低的修补方法。
下发通道
这一点与埋点上报的要求有一点类似,也须要高实时性和高可靠性。当用户早已不可用了,常规方法拉不到线上的修补方案的时侯,能够解决的办法再多也是没有用的,所以须要保障无论面对多么恶劣的情况下都还能把修补方案拉出来。
下发通道的实现方法有很多种,最终实现只要才能联网一定可以将修补方案拉出来,如果暂时不能联网,那么一定要在联网以后将修补方案拉出来。
发布平台
设计动态修补的发布平台的时侯特别关注的一点就是把修补方案推送给真正须要它的用户,也就是把修补方案推给早已出现或则可能出现这个问题的用户。
这样做的缘由是每一次的动态修补虽然也是一次线上变更,本身也是存在风险的,如果对于所有用户都进行推送则须要比较长的时间进行灰度来保证安全,但是假如才能只对目标的冷门人群、特征人群推送方案,这样灰度时间会太短,修复时间也会太短。
支付宝在客户端恳求修补方案的时侯,会依照客户端的人群特点、是否发生过这个问题以及有没有发生这个问题的可能来判定是否把这个修补方案推送给她们,这样可以很快地完成推送过程。这在图中称之为“智能修补”,其实称之为“定向修补”更为确切一些。
高可用实战经验
在这里和你们分享支付宝在高可用实战中的两个案例,其中一个处理的比较成功,另外一个则不是太成功。
案例 1:一个业务营运推送了一个错误的菜单配置,而客户端没有做好保护。在营运推送配置的 10 分钟之内,相关的负责人都收到了报案,并且很快地查到是这个配置造成的。
之后营运将马上对于配置进行了回滚,这个过程所影响用户数比较少,所以是一个比较成功的案例。
这也是支付宝最期望的运维过程,实现了及时发觉、很快修补而且影响用户数极少。
案例 2:在一次大促的时侯,一个业务开启了限流,客户端弹出一个限流的页面,这个页面有 Bug,会导致死机,进而造成用户难以进行操作。
但是因为当时的可用性监控不健全,所以这个问题没有被监控到,最后是因为用户的反馈才晓得出现了问题,到问题出现的第三天,反馈量早已积累到一个显著的程度了,才发觉这个问题。
之后,我们迅速地对于这个问题进行了剖析和解决,最后定位到限流的问题,一个小时之内确定了问题所在,并暂时把限流先关闭,后来把这个 Bug 修复掉了以后再将限流打开,这样客户端才恢复正常。
虽然最终把问题建立地解决了,但是这一过程存在十分显著的缺陷。首先是发觉的很晚了,这是因为可用性问题没有覆盖到。
另外,因为没有足够的信息促使决策的过程比较慢,花了 1 个小时进行剖析能够够止血,直到现今我们也不知道这一天究竟影响了多少用户,但是这一风波肯定对支付宝的可用性导致了不小的伤害。
而如今,支付宝实现了移动端的高可用,以后象这样的事情不会再发生了,当出现故障时,支付宝可以在第一天太短的时间内就可以搞定问题。
故障演习
有这样一句话“避免故障最好的形式就是不断演习故障”,所以我们要通过可控的成本在线上真实地模拟一些故障,进行故障演习,检验高可用体系是否可靠,同时也使相应的朋友对系统、工具和流程愈发熟悉,当真正发生问题的时侯可以快速地处理。
为了更好的检验这套东西,支付宝采用了攻守对抗演习的形式,成立了一个虚拟小组,他们会想办法模拟线上可能出现的故障情况,而另外一组人则借助移动端高可用技术接招,把对方研制的问题快速地处理掉。
这样做好准备之后,当真正出现故障须要进行处理的时侯,我们也早已才能熟练地应对了。
在前进中探求
最后再谈一下对客户端可用性运维未来的思索:
智能化
前面提及了高灵敏的模型,大家可以看见在决策的过程中常常须要依赖预设的算法模型、规则以及数值等,这些都缘于长期积攒出来的经验。
但是这也存在一些缺点:一是有可能出现误报;二是为了避免误报太多,这个模型不敢做的太短,所以模型的灵敏度属于比较灵敏,而不是极其灵敏。
我们期盼通过智能化的形式,通过人工智能、机器学习的方式实现决策过程的智能化,可以做得愈加灵敏,将问题发觉的时间再提高一节,而且这目前早已不仅仅是一个看法了,在支付宝的好多场景中早已开始使用智能报案了,我们也在督查和尝试接入这个东西。
自动化
这部份主要指的是容灾过程的自动化。我们想把上面展示的容灾过程做的太顺滑,但是其中好多步骤都须要人来做,这样时间成本、决策成本会很高。
所以我们希望把尽量多的步骤转成自动化形式,至少是半自动化的方法,这样就能使容灾过程愈发顺滑,使得修补时间形成本质的飞跃。
产品化
我们希望当客户端可用性愈发成熟以后赋能给其他类似的 APP,通过这个过程积攒更多的经验,发现更多的问题。并且在未来合适的时间,或者 3.0 版本的客户端可用性不能满足需求的时侯再去建设 4.0 可用性运维体系。
作者:竹光
简介:蚂蚁金服中级技术专家。2015 年加入支付宝,主要负责客户端的稳定性和高可用,曾多次参与双 11、双 12、春节红包等大促的技术保障工作,主要负责保证活动期间支付宝客户端的稳定性以及可用性。 查看全部
亿级APP支付宝在移动端的高可用技术实践
亿级 APP 在可用性方面的挑战
可用性的概念
简单而言,可用性就是当用户想要使用 APP 做一个事情,这件事情弄成了就是可用,没有弄成就不可用。
为什么没有弄成?可能的诱因有很多,比如有可能使用 APP 的时侯死机了,或者使用支付宝付款的时侯,由于后台某个环节出现错误,导致了这笔支付失败了等,这些都可能导致 APP 的不可用。
如果各种各样不可用的情况都没有出现,那么对于顾客而言就是可用的。虽然每位开发人员都希望自己开发的 APP 是 100% 可用的,但是实际上这一点是不可能的。所以开发人员真正须要做的事情就是使 APP 发生不可用的情况越来越少。
亿级 APP 的可用性挑战

目前,APP 开发技术早已比较成熟了,所以好多开发人员会觉得自己的 APP 可用性应当问题不是很大,因为 APP 都经历了相关的测试流程、灰度验证等保障举措。
但是如今情况早已发生变化了,与先前相比,APP 的用户量大了好多,很多的 APP 都达到了亿级用户,所以一点点可用性问题都可能会影响大量的用户。
比如 APP 的闪退率下降了千分之一,虽然这一比列并不是很大,但是对于一亿用户而言,乘上千分之一就是 10 万人。
大家可以想像一下,如果某三天你们在使用支付宝在商场付款的时侯,其中的 10 万人出现掉帧的情况,这个影响是绝对不可以接受的。
现在开发移动端 APP 讲究动态化,业务要求实时动态地实现线上变更,可以说明天的支付宝和今天的支付宝相比就早已形成很大区别了。
每一次线上的变更虽然就会降低线上可用性的风险,而且三天中可能会发生很多次变更,在这些情况下风险也会显得很大。尤其对于作为保障 APP 可用性的一线人员而言,压力也会非常大。
正是由于面临这么多的问题和挑战,才须要通过移动端的高可用技术体系解决这个问题,保证线上客户端高可用性。
APP 线上运维的发展和变迁

如上图,是这几年来支付宝客户端在可用性运维上的发展历史,大致分为了三个阶段。随着支付宝的成长,可用性运维也仍然在演化,最后演变到了移动端高可用的状态。
第一个阶段就是简单的死机监控。绝大多数的 APP 也做过这个事情,就是本地搜集一些死机信息并进行上报,在 APP 后台对于闪退率进行监控,解决死机比较多的问题,并在 APP 的下一个版本中进行相应的更改,最后让闪退率维持在某一个指标以下。
但是现今来看,这个阶段距离实现高可用的要求相差很远,因为用户所遇见不可用问题中死机只抢占其中一部分,所以对可用性而言,解决了死机问题只是改进了一点点而已,还存在着大部分的问题没有解决。
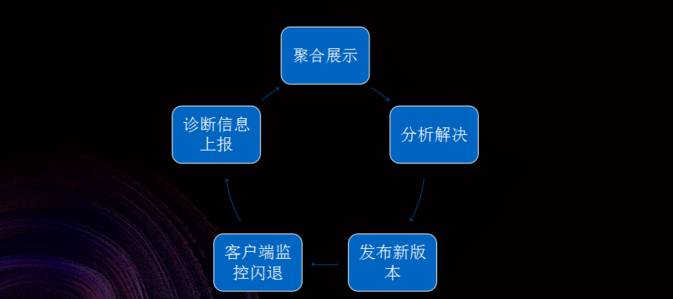
第二个阶段,在阿里巴巴内部称作稳定性监控体系,相比于第一个阶段而言,稳定性监控体系可以说前进了特别大的一步。
首先,可以监控的问题大大丰富了,通过对多种问题的监控可以了解线上用户稳定性方面的可用情况,而不仅仅是一个用户。
第二个方面,稳定性监控体系具有相当程度的确诊能力和修补能力。当发觉问题的时侯,可以通过确诊日志等相应的方式剖析故障缘由并尝试进行修补。
稳定性监控体系在最初的时侯疗效比较不错,并且阿里巴巴内部也使用了太长的时间,但是后来问题也渐渐曝露下来。
举两个事例,曾经一个版本的 APP 在 X86 一款机器上运行时出现的问题十分多,但是那种型号的用户量太小,所以问题始终都没有被发觉,直到太晚的时侯才通过其他方法发觉了这个问题,也就是说由于只监控具体问题引起早已不能发觉局部人群的问题了。
第二个事例,在做象双 11 这样的大促值勤的技术保障的时侯,因为监控的问题比较多,运维人员须要通过不停地翻监控来发觉问题,翻来翻去最后还是不敢确定 APP 的可用性究竟有没有问题,有时候确实会遗漏一些问题。
第三个方案就是在发觉了问题以后,能否快速修补还须要碰运气,有可能很快就才能修补,也有可能修补上去不太容易,需要等到下一次发版,这就促使有些问题所影响用户数会特别多。
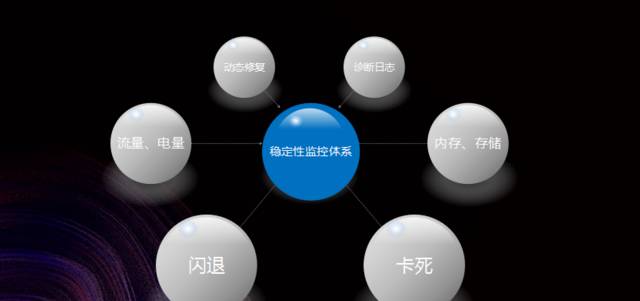
以上就是在 2.0 阶段所碰到的问题,这说明稳定性监控体系也早已不够用了,需要继续进行改进,这也是支付宝决定继续做 3.0 阶段的移动端高可用的动机和动力。
移动端高可用的定义、目标、核心打法
高可用在移动端的重新定义
高可用本来属于服务端的概念,阿里巴巴的服务端都在讲高可用。服务端的高可用重点讲的是停机时间短、服务不可用时间短。
移动端的高可用从服务端借鉴过来以后进行了重新定义,因为客户端不存在停机时间概念。
所以,移动端高可用的定义是指通过专门的设计,结合整套技术体系,保证用户所遇见的技术不可用总次数太低。

移动端高可用的目标
简单来说,移动端高可用的目标就是实现可用率达到 99.99%,这里的可用率是支付宝自己定义的概念,指的就是用户在使用 APP 的时侯,可用次数在使用次数当中的占比,可用率达到 99.99%。
也就意味着用户使用 1 万次支付宝中的 9999 次都必须是可用的,最多只有一次不可用。为了实现这一目标,还会将任务拆解成为不同的子目标分别攻破。
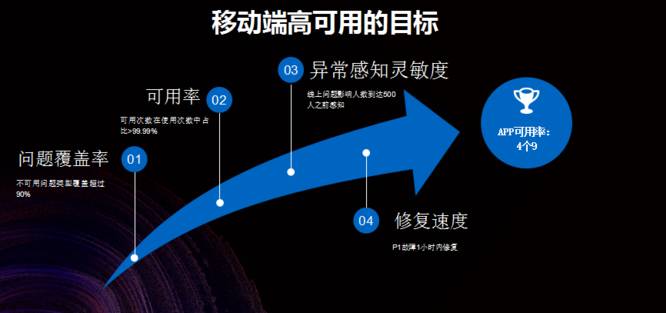
移动端高可用的核心打法
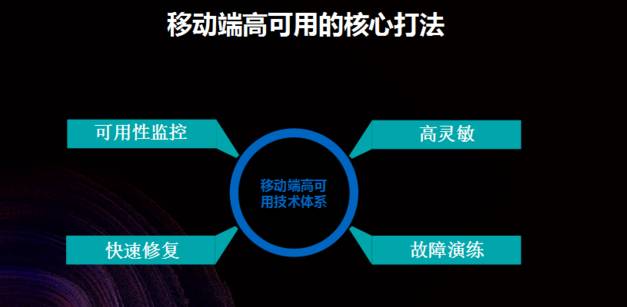
目标的实现还是比较困难的,因为使可用率达到 99.99% 是一个很高的指标。而为了才能努力实现这个目标,支付宝也自创了一套核心打法。
主要分为以下四个部份:
支付宝在移动端高可用技术实践

如上图所示,是支付宝实现的移动端高可用技术构架图,大家可以看见支付宝移动端高可用的技术构架设计也是围绕上述的四个核心打法展开的。
客户端可用性监控
问题采集
客户端可用性监控的第一步就是问题采集,当 APP 发生不可用时必须才能感知和采集到问题,这是基础的基础,如果没有这个基础后续哪些都不能实现。
怎样确保当用户出现了不可用情况时才能采集到问题?这是比较困难的,因为我们不能保证一定可以采集到所有类型的不可用问题,但是还是会通过多种方式尽量地实现全面覆盖。
支付宝把不可用问题分为稳定性不可用和业务不可用两个方面。对于稳定性不可用而言,通过 2.0 阶段的逐步摸索以及各类反馈渠道、问题采集渠道的补充,现在早已可以把各种各样稳定性的不可用问题采集得比较全了。
比如传统的死机、卡死等以及不容易被监控的蓝屏、白屏以及非死机类型的异常退出等。
目前早已采集到了大部分的问题,当然可能就会存在遗漏,对于那些遗漏的问题,还须要通过不停地采集并补充到这个体系中。
对于业务不可用而言,在开发时会对于业务不可用问题进行埋点,只须要将业务不可用埋点列入到系统上面来,就能够基本覆盖最重要的业务不可用问题。
统一管控
当问题采集上来以后,需要通过统一管控产生客户端可用率指标。通过这个指标可以全面地评估线上某一个人群中的可用情况,而不需要象曾经那样逐一检测各个指标并在最后给一个不太确切的评估结果。通过统一管控可以设计出整体的监控和报案机制以及各类算法模型,并且其扩展性更好。
埋点上报
埋点上报这一功能是特别核心的,因为后续还要借助不可用埋点做高灵敏,所以埋点的实时性、准确性、到达率的要求非常高。
并且对于不可用埋点而言,当客户端早已发生了不可用时才须要进行上报,而在这个时侯客户端情况太可能十分恶劣,甚至此时客户端可能早已未能启动了,即便是这样也要保证埋点才能上报。
为了实现这一点,我们借助了一些小技巧,比如对于 Android 系统而言,支付宝通过独立的轻量级进程来单独上报埋点,即便主进程早已死掉了,但是埋点也就能实时上报上来。
对于 iOS 系统而言,采取在线上 hold 住进程让其报完埋点再退出去的形式,并且后续还有补偿机制,即使出现遗漏埋点的情况也才能让其最终能否上报上来。
通过问题采集、统一管控和埋点上报,基本上可以保障当用户碰到不可用问题时可以搜集问题并上报服务端,做好了第一步的基础。
高灵敏度系统模型
在问题搜集到的情况下须要用高灵敏系统模型做监控和报案。监控和报案在 2.0 时代就早已存在了,比如当盘面上监控的闪退率出现异常情况时才会进行报案。
但是高灵敏系统模型要做的是在线上问题刚才出现端倪的时侯就可以发觉,而不是等到盘面出现波动才发觉。
所以这个模型的关键在于剖析决策的过程中,它会基于用户的人群特点、问题特点把线上采集到的不可用问题进行聚合再进行剖析,通过预制的一些算法模型和规则来判定是否形成了异常,如果最终判定的确有异常形成了则会输出一个异常风波。
举个事例,比如线上的某个业务发布了一个新的 H5 离线包版本,其中某一个页面的卡死率很高。那么使用这个页面的用户都会产生一个特点人群,这个特点人群的页面卡死率就有异常的波动,这个时侯才会输出异常风波。
但是此时盘面并没有很大波动,因为特点人群的人数并不多,但是后台可以捕获到异常风波。
当异常风波输出然后,可以通过附送信息准确地匹配到相应的负责人以及开发、测试人员,告警系统会告知负责人进行处理,并且会依照问题的严重程度采取不同的告警形式,可能会采取电邮、钉钉或则电话等方法进行告警。
在问题十分严重的情况下,如果几分钟之内没有响应就有人打电话给负责人了。通过这样的告警机制就可以保证无论哪些时间,只要线上出现异常问题就可以迅速地感知到。
高可用容灾平台
通过上述的内容,我们早已可以实现对于可用性问题的感知了。接下来分享怎样通过高可用容灾平台修补异常问题。
这里通过整体的故障容灾过程进行分享,如下图所示,当一个故障进来了,会向相应的负责人发出告警,这时负责人须要检测这个故障是如何形成的,到底是因为线上变更引起的,还是因为客户端本身的 Bug 导致的。
如果是由于线上变更引起的则比较好办,因为现今的系统比较灵敏,只要故障刚一发生,在短时间内负责人员就可以收到告警。
之后就可以到发布记录中检测这段时间内发生了哪几次变更,可以很快地基本了解是哪一次变更引起的故障,并采取相应的处理策略。
如果可以回滚就进行回滚操作,不能回滚就须要进行紧急发布,如果不能紧急发布就要依赖客户端进行修补。
比较麻烦的是和变更没有关系的情况,此时就须要通过异常携带的确诊信息或则通过获取一些日志来检测问题为何形成,问题的形成有时候是因为兼容性问题。
比如某个厂商灰度发布了一批和支付宝兼容性不太好的系统,导致出现了各种各样的问题,这种情况下就要通过动态修补解决。
也可能一些顾客本地出现了严重错误,比如说形成了一些脏数据,或者安装时由于市场的临时性 Bug 导致了大量安装失败,最终造成支付宝打不开。
对于这些情况而言,可以通过本地容灾做一些恢复工作,进而实现客户端的手动恢复。
总之,通过上述的过程,可以让故障得到解决。从右图中可以看出,支付宝在高可用容灾中致力于两点:
高可用的动态修补体系
移动端高可用和服务端高可用的重大区别就是移动端的发布比较困难,所以须要借助动态修补技术。
动态修补并不是新的概念,像 hotpatch 等技术都早已十分成熟了,目前也有好多可选的动态修补方案。
但是,虽然在高可用的动态修补体系中,hotpatch 属于比较重要的点,但是并不是最主要的点,因为它也存在一定的局限性,也有不适宜的时侯。目前,支付宝基于多种修补手段搭建了高可用的动态修补体系。

支付宝的高可用动态修补体系主要由以下三部份构成:
修复手段
修复手段有很多种,并且有轻有重。轻的手段在线上进行一些配置就可以解决线上不可用的问题,重的手段可以把整个模块完全重新布署下去。具体应当选择哪一种修补手段应当按照故障的情况来看,选择效率最高、风险最低的修补方法。
下发通道
这一点与埋点上报的要求有一点类似,也须要高实时性和高可靠性。当用户早已不可用了,常规方法拉不到线上的修补方案的时侯,能够解决的办法再多也是没有用的,所以须要保障无论面对多么恶劣的情况下都还能把修补方案拉出来。
下发通道的实现方法有很多种,最终实现只要才能联网一定可以将修补方案拉出来,如果暂时不能联网,那么一定要在联网以后将修补方案拉出来。
发布平台
设计动态修补的发布平台的时侯特别关注的一点就是把修补方案推送给真正须要它的用户,也就是把修补方案推给早已出现或则可能出现这个问题的用户。
这样做的缘由是每一次的动态修补虽然也是一次线上变更,本身也是存在风险的,如果对于所有用户都进行推送则须要比较长的时间进行灰度来保证安全,但是假如才能只对目标的冷门人群、特征人群推送方案,这样灰度时间会太短,修复时间也会太短。
支付宝在客户端恳求修补方案的时侯,会依照客户端的人群特点、是否发生过这个问题以及有没有发生这个问题的可能来判定是否把这个修补方案推送给她们,这样可以很快地完成推送过程。这在图中称之为“智能修补”,其实称之为“定向修补”更为确切一些。
高可用实战经验
在这里和你们分享支付宝在高可用实战中的两个案例,其中一个处理的比较成功,另外一个则不是太成功。
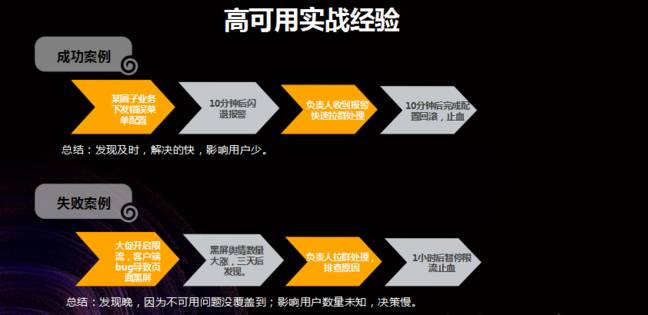
案例 1:一个业务营运推送了一个错误的菜单配置,而客户端没有做好保护。在营运推送配置的 10 分钟之内,相关的负责人都收到了报案,并且很快地查到是这个配置造成的。
之后营运将马上对于配置进行了回滚,这个过程所影响用户数比较少,所以是一个比较成功的案例。
这也是支付宝最期望的运维过程,实现了及时发觉、很快修补而且影响用户数极少。
案例 2:在一次大促的时侯,一个业务开启了限流,客户端弹出一个限流的页面,这个页面有 Bug,会导致死机,进而造成用户难以进行操作。
但是因为当时的可用性监控不健全,所以这个问题没有被监控到,最后是因为用户的反馈才晓得出现了问题,到问题出现的第三天,反馈量早已积累到一个显著的程度了,才发觉这个问题。
之后,我们迅速地对于这个问题进行了剖析和解决,最后定位到限流的问题,一个小时之内确定了问题所在,并暂时把限流先关闭,后来把这个 Bug 修复掉了以后再将限流打开,这样客户端才恢复正常。
虽然最终把问题建立地解决了,但是这一过程存在十分显著的缺陷。首先是发觉的很晚了,这是因为可用性问题没有覆盖到。
另外,因为没有足够的信息促使决策的过程比较慢,花了 1 个小时进行剖析能够够止血,直到现今我们也不知道这一天究竟影响了多少用户,但是这一风波肯定对支付宝的可用性导致了不小的伤害。
而如今,支付宝实现了移动端的高可用,以后象这样的事情不会再发生了,当出现故障时,支付宝可以在第一天太短的时间内就可以搞定问题。
故障演习

有这样一句话“避免故障最好的形式就是不断演习故障”,所以我们要通过可控的成本在线上真实地模拟一些故障,进行故障演习,检验高可用体系是否可靠,同时也使相应的朋友对系统、工具和流程愈发熟悉,当真正发生问题的时侯可以快速地处理。
为了更好的检验这套东西,支付宝采用了攻守对抗演习的形式,成立了一个虚拟小组,他们会想办法模拟线上可能出现的故障情况,而另外一组人则借助移动端高可用技术接招,把对方研制的问题快速地处理掉。
这样做好准备之后,当真正出现故障须要进行处理的时侯,我们也早已才能熟练地应对了。
在前进中探求

最后再谈一下对客户端可用性运维未来的思索:
智能化
前面提及了高灵敏的模型,大家可以看见在决策的过程中常常须要依赖预设的算法模型、规则以及数值等,这些都缘于长期积攒出来的经验。
但是这也存在一些缺点:一是有可能出现误报;二是为了避免误报太多,这个模型不敢做的太短,所以模型的灵敏度属于比较灵敏,而不是极其灵敏。
我们期盼通过智能化的形式,通过人工智能、机器学习的方式实现决策过程的智能化,可以做得愈加灵敏,将问题发觉的时间再提高一节,而且这目前早已不仅仅是一个看法了,在支付宝的好多场景中早已开始使用智能报案了,我们也在督查和尝试接入这个东西。
自动化
这部份主要指的是容灾过程的自动化。我们想把上面展示的容灾过程做的太顺滑,但是其中好多步骤都须要人来做,这样时间成本、决策成本会很高。
所以我们希望把尽量多的步骤转成自动化形式,至少是半自动化的方法,这样就能使容灾过程愈发顺滑,使得修补时间形成本质的飞跃。
产品化
我们希望当客户端可用性愈发成熟以后赋能给其他类似的 APP,通过这个过程积攒更多的经验,发现更多的问题。并且在未来合适的时间,或者 3.0 版本的客户端可用性不能满足需求的时侯再去建设 4.0 可用性运维体系。
作者:竹光
简介:蚂蚁金服中级技术专家。2015 年加入支付宝,主要负责客户端的稳定性和高可用,曾多次参与双 11、双 12、春节红包等大促的技术保障工作,主要负责保证活动期间支付宝客户端的稳定性以及可用性。
智慧中学一体化平台(技术施行方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-22 10:54
今天智慧城市大数据生态伙伴君分享一个智慧校园管理及教育资源一体化平台建设方案(小学):全文三部份,技术清单,技术要求,技术尺寸。
二、技术要求
1.1实现的功能或则目标,以及为落实政府新政需满足的要求:
1.1.1 建立智慧校园管理及教育资源一体化办公平台,能够深度融合办公交互聊天IM,日志,审批,云盘资源库,等微应用的智慧校园管理办共平台,包括作业、公告、德育、学生评价、学生考勤、固定资产、请假、报修、微官网、晨检、班级课表、教师助手、调兼课、班级故事、成长档案、教师薪资管理等模块,并就能实现根据中学实际需求自定义扩充功能;
1.1.2 建立智慧课堂服务体系,实现智慧教学的常态化使用和运行,创建一种智能的全媒体互动教学模式,配备班主任专用平板硬件辅助教学,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数;
1.1.3 建立基于中英文的智能阅卷系统,提供网阅数据采集、中英文手动评分、A3高速扫描读取试题、阅卷后大数据剖析等功能;
1.1.4构建软件硬件一体化的智慧校园,将联接中学生考勤腕带、电子班牌、A3高速扫描阅卷机,统一的认证登入系统,统一用户管理机制;
1.1.5构建统一的服务响应机制,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数。
1.2 采购标项需满足的质量、安全、技术尺寸、物理特点等要求;
1.2.1 质量要求:TC初验标准:覆盖率小于等于95%TC中必须收录但不限于场景要求:
1)输入框必须校准:长度限制,特殊字符控制
2)网络情况:WiFi,2G,3G,4G
3)机型适配:市场主流型号,如Android:(Android4.1及以上版本)htc x920e、LG G2 A8、Coolpad A6、huawei g3、Moto G、OPPO U705T Android 4.1.1、三星 s4 I9500 Android4.2.2、华为H60-L02、华为H30-L01、nexus 5 A10 5.1.1、coolpad 8720 Android 4.3、nexus 4、魅族MX4 Android 4.4.2、魅族MX4 Pro Android 4.4.4、三星Note 3 Android 4.3、Oppo813t 小屏、vivo S9t Android 4.1.2三星GT-N7100 Android 4.1.2、魅族 M1 note Android 4.4.4、华为Mate 7 5.1.1、联想A820t Android 4.1.2、iPhone:(IOS 7及以上版本)、iPhone 4s、iPhone 5、iPhone 5c、iPhone 5s、iPhone6、iPhone 6plus、iPhone 6s等。
4)图片:尺寸限制,大小限制
5)多端:PC与联通关联的功能场景
6)必须实现免登录
7)PC功能支持确认
8)不能有注册流程
9)统一的交互,统一的导航栏,问号标示,反馈入口
10)选人场景必须用系统平台提供的选人组件
11)不能出现用户填写手机号的场景
12)Critical:系统未能执行、崩溃或严重资源不足、应用模块未能启动或异常退出、无法测试、造成系统不稳定,则不通过。
13)Major:部分非主流程功能存在严重缺陷,不得影响到系统稳定性
14)Minor:界面、性能无缺陷
15)Trivial:具备易用性
1.2.2应用线上质量标准:
1)P1/P2类bug 处理 原则当日发觉当日解决不得过夜
2)P3类bug 处理 原则不得超过3天
3)P4类bug 处理 原则可在下个迭代发布中解决
1.2.3性能标准
1)服务端响应时间
2)服务端授权激活响应时间整体大于3s
3)页面大小:首屏页面大小大于200k
4)加载时间:首屏加载时间大于2s
1.2.4 安全要求:
1)开启云盾全部防御功能,开启云监控,实时监控线上服务状况保障7*24小时防治
2)代码安全标准:符合通用代码安全编程规范
1.2.5数据采集标准
1)操作用户数:指每日在应用内重要按键有操作行为的去重用户数
2)操作企业数:指每日在应用内重要按键有操作行为的用户所在企业去重统计数
3)重要按键:重要的TAB页面切换,比如 应用有5个浏览页面,每次切换页面须要记录一个操作;向服务端有数据上传的点击,比如 表单保存,提交数据,页面更改,新增内容,上传图片等
1.2.6 物理特点要求:
所提供服务需符合国家安全技术相关标准要求
查看全部
智慧中学一体化平台(技术施行方案)
今天智慧城市大数据生态伙伴君分享一个智慧校园管理及教育资源一体化平台建设方案(小学):全文三部份,技术清单,技术要求,技术尺寸。
二、技术要求
1.1实现的功能或则目标,以及为落实政府新政需满足的要求:
1.1.1 建立智慧校园管理及教育资源一体化办公平台,能够深度融合办公交互聊天IM,日志,审批,云盘资源库,等微应用的智慧校园管理办共平台,包括作业、公告、德育、学生评价、学生考勤、固定资产、请假、报修、微官网、晨检、班级课表、教师助手、调兼课、班级故事、成长档案、教师薪资管理等模块,并就能实现根据中学实际需求自定义扩充功能;
1.1.2 建立智慧课堂服务体系,实现智慧教学的常态化使用和运行,创建一种智能的全媒体互动教学模式,配备班主任专用平板硬件辅助教学,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数;
1.1.3 建立基于中英文的智能阅卷系统,提供网阅数据采集、中英文手动评分、A3高速扫描读取试题、阅卷后大数据剖析等功能;
1.1.4构建软件硬件一体化的智慧校园,将联接中学生考勤腕带、电子班牌、A3高速扫描阅卷机,统一的认证登入系统,统一用户管理机制;
1.1.5构建统一的服务响应机制,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数。
1.2 采购标项需满足的质量、安全、技术尺寸、物理特点等要求;
1.2.1 质量要求:TC初验标准:覆盖率小于等于95%TC中必须收录但不限于场景要求:
1)输入框必须校准:长度限制,特殊字符控制
2)网络情况:WiFi,2G,3G,4G
3)机型适配:市场主流型号,如Android:(Android4.1及以上版本)htc x920e、LG G2 A8、Coolpad A6、huawei g3、Moto G、OPPO U705T Android 4.1.1、三星 s4 I9500 Android4.2.2、华为H60-L02、华为H30-L01、nexus 5 A10 5.1.1、coolpad 8720 Android 4.3、nexus 4、魅族MX4 Android 4.4.2、魅族MX4 Pro Android 4.4.4、三星Note 3 Android 4.3、Oppo813t 小屏、vivo S9t Android 4.1.2三星GT-N7100 Android 4.1.2、魅族 M1 note Android 4.4.4、华为Mate 7 5.1.1、联想A820t Android 4.1.2、iPhone:(IOS 7及以上版本)、iPhone 4s、iPhone 5、iPhone 5c、iPhone 5s、iPhone6、iPhone 6plus、iPhone 6s等。
4)图片:尺寸限制,大小限制
5)多端:PC与联通关联的功能场景
6)必须实现免登录
7)PC功能支持确认
8)不能有注册流程
9)统一的交互,统一的导航栏,问号标示,反馈入口
10)选人场景必须用系统平台提供的选人组件
11)不能出现用户填写手机号的场景
12)Critical:系统未能执行、崩溃或严重资源不足、应用模块未能启动或异常退出、无法测试、造成系统不稳定,则不通过。
13)Major:部分非主流程功能存在严重缺陷,不得影响到系统稳定性
14)Minor:界面、性能无缺陷
15)Trivial:具备易用性
1.2.2应用线上质量标准:
1)P1/P2类bug 处理 原则当日发觉当日解决不得过夜
2)P3类bug 处理 原则不得超过3天
3)P4类bug 处理 原则可在下个迭代发布中解决
1.2.3性能标准
1)服务端响应时间
2)服务端授权激活响应时间整体大于3s
3)页面大小:首屏页面大小大于200k
4)加载时间:首屏加载时间大于2s
1.2.4 安全要求:
1)开启云盾全部防御功能,开启云监控,实时监控线上服务状况保障7*24小时防治
2)代码安全标准:符合通用代码安全编程规范
1.2.5数据采集标准
1)操作用户数:指每日在应用内重要按键有操作行为的去重用户数
2)操作企业数:指每日在应用内重要按键有操作行为的用户所在企业去重统计数
3)重要按键:重要的TAB页面切换,比如 应用有5个浏览页面,每次切换页面须要记录一个操作;向服务端有数据上传的点击,比如 表单保存,提交数据,页面更改,新增内容,上传图片等
1.2.6 物理特点要求:
所提供服务需符合国家安全技术相关标准要求











金融大数据信息采集挖掘系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-20 13:55
中国金融业正在进入大数据时代的中级阶段。经过多年的发展与积累,目前国外金融机构的数据量早已达到100TB以上级别,并且非结构化数据量正在以更快的速率下降。金融机构行在大数据应用方面具有天然优势:一方面,金融企业在业务举办过程中积累了包括顾客身分、资产负债情况、资金收付交易等大量高价值密度的数据,这些数据在运用专业技术挖掘和剖析以后,将形成巨大的商业价值;另一方面,金融机构具有较为充足的预算,可以吸引到施行大数据的高档人才,也有能力采用大数据的新技术。因此,金融大数据采集就十分重要了,数据采集的情况决定了后期的挖掘剖析疗效,“金融采集平台”就是按照金融大数据的快速发展研制下来的,在使用的过程中反馈非常好。“金融采集平台”是一款既可以对网站深度订制,也可以使用最简单的配置快速采集的系统平台,它采用智能匹配和先进的HTML5模块编辑工具满足动静态数组的配置;配备全面且直观的运行时监控系统;丰富多彩的开发插口和建立详尽的SDK文档;同时支持分布采集部署,调度、数据处理,可以轻松的应对大数据在采集中遇见的各类问题。“金融采集平台”数据采集首先要提出采集请求,采集系统就会按照要求,按照采集指令进行采集任务分发,然后到分布式流数据剖析平台进行数据比对、数据源设置、数据抓取、实体抽取、数据分类,最后到分布式数据储存平台进行储存。“金融采集平台”最重要的就是智能动态增减采集器。智能动态增减采集器是通过对数据ID、数据地址、采集功能添加、采集数量等功能项的设置来进行数据采集,而采集的形式有两种模式:一种是通用模式,既使用普通的功能设置来采集数据,一般这些模块采集的数据比较多但疗效相对比较差;另一种是特殊设置模式,既根据要求对采集器进行功能设置,这种采集的疗效更好,准确率高。大数据在金融行业的应用起步比互联网行业稍晚,其应用深度和广度还有很大的扩充空间。金融行业的大数据应用仍然有很多的障碍须要克服,比如建行企业内各业务的数据孤岛效应严重、大数据人才相对缺少以及缺少建行之外的外部数据的整合等问题。可喜的是,金融行业尤其是以工行的中高层对大数据渴求和注重度十分高,相信在未来的两三年内,在互联网和联通互联网的驱动下,金融行业的大数据应用将迎来突破性的发展。 查看全部
金融大数据信息采集挖掘系统
中国金融业正在进入大数据时代的中级阶段。经过多年的发展与积累,目前国外金融机构的数据量早已达到100TB以上级别,并且非结构化数据量正在以更快的速率下降。金融机构行在大数据应用方面具有天然优势:一方面,金融企业在业务举办过程中积累了包括顾客身分、资产负债情况、资金收付交易等大量高价值密度的数据,这些数据在运用专业技术挖掘和剖析以后,将形成巨大的商业价值;另一方面,金融机构具有较为充足的预算,可以吸引到施行大数据的高档人才,也有能力采用大数据的新技术。因此,金融大数据采集就十分重要了,数据采集的情况决定了后期的挖掘剖析疗效,“金融采集平台”就是按照金融大数据的快速发展研制下来的,在使用的过程中反馈非常好。“金融采集平台”是一款既可以对网站深度订制,也可以使用最简单的配置快速采集的系统平台,它采用智能匹配和先进的HTML5模块编辑工具满足动静态数组的配置;配备全面且直观的运行时监控系统;丰富多彩的开发插口和建立详尽的SDK文档;同时支持分布采集部署,调度、数据处理,可以轻松的应对大数据在采集中遇见的各类问题。“金融采集平台”数据采集首先要提出采集请求,采集系统就会按照要求,按照采集指令进行采集任务分发,然后到分布式流数据剖析平台进行数据比对、数据源设置、数据抓取、实体抽取、数据分类,最后到分布式数据储存平台进行储存。“金融采集平台”最重要的就是智能动态增减采集器。智能动态增减采集器是通过对数据ID、数据地址、采集功能添加、采集数量等功能项的设置来进行数据采集,而采集的形式有两种模式:一种是通用模式,既使用普通的功能设置来采集数据,一般这些模块采集的数据比较多但疗效相对比较差;另一种是特殊设置模式,既根据要求对采集器进行功能设置,这种采集的疗效更好,准确率高。大数据在金融行业的应用起步比互联网行业稍晚,其应用深度和广度还有很大的扩充空间。金融行业的大数据应用仍然有很多的障碍须要克服,比如建行企业内各业务的数据孤岛效应严重、大数据人才相对缺少以及缺少建行之外的外部数据的整合等问题。可喜的是,金融行业尤其是以工行的中高层对大数据渴求和注重度十分高,相信在未来的两三年内,在互联网和联通互联网的驱动下,金融行业的大数据应用将迎来突破性的发展。
美工终结者「鹿班智能设计平台」是怎样工作的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-19 08:03
@阿里巴巴UED:在去年UCAN会议开场,阿里巴巴集团UED委员会委员长杨光发布的智能设计平台——鹿班,便出自乐乘的团队。此平台是通过人工智能算法和大量数据训练机器学习设计。通过一段时间的学习,此平台从今年“双十一”前就早已在阿里内部大规模投入使用,目前其设计水平早已十分接近专业设计师设计的疗效。在会议上,乐乘介绍了阿里智能设计实验室的实践全过程。
用AI做设计
我们团队如今叫人工智能设计实验室,做的事情很简单,用AI做设计。人工智能如今这个概念很火了,有一个数据证明它有多火:去年人工智能这个领域的创业公司开张速率超过了麦当劳的开店速率。不可证实,这里一定有泡沫成份,也有好多概念的炒作。我们先抛掉高大上的词,把这个事情拆解一下。
现在讲的人工智能都是通过算法、数据和强悍的估算能力来构建服务场景,这是人工智能的四个要素。今天我们团队做的就是用算法、数据、计算、场景来解决商业领域的事情,这样促使这件事情看起来比较靠谱、容易落地。
为什么我们团队会想要做这个事情呢,这不是YY下来的看法,而是从广泛的业务场景里找到的一个机会。以一个广告Banner为例,我们把它归类为“大量低质易耗”的设计,这样的设计,设计师花三天做下来,在线上投放时间也只有三天。而且是重复的,改改字就可以了,非常适宜被机器所替代。
今年UCAN的主题是新设计x新商业,新商业里特别大的概念,是要通过新的技术、互联网的手段,完成人、货、场的构建,人是消费者,货是商品的服务,场景就是联接人和商品之间的手段。在新的时期下,需要找到一种新的方法做设计。
我们团队的使命是基于算法数据和前台业务需求,打造一个商业设计脑部。这个脑部能理解设计,能为商业的产品去服务,做出合理的设计。
商业设计脑部的三大挑战
在开始做事情之前,我们遇见了三个比较严峻的挑战。
第一个挑战,缺少标明数据。今天所有的人工智能都基于大量的结构化标明数据,设计这件事情连数据都没有完成在线化,更别说标准化、结构化的数据了。
第二个挑战,设计不确定性。设计是个太不确定的东西,比如明天你使机器设计一个高档大气的Banner广告,它就蒙圈了。
第三个挑战,无先例可循。在整个行业里过去一年做出来发觉,没有一些现成的技术或则框架可以参考。比如AlphaGo把棋类AI论文发完以后,全世界象棋AI照这个方式都可以做到先进的水平。我们过去一年来都是自己一街摸索中走过来的,这一年走来我们给人工智能做的定义是,我们做的是可控的视觉生成。可控,就是按照商业的需求、业务的需求,智能地进行控制。它解决的是视觉从无到有的问题。
可控的视觉生成过程
这是机器人从诞生的第一版到近来一版的发展历程。2016年9月,勉强完成一张图片的拼合,没有哪些美感可言。第二张是去年圣诞节前做的广告,稍微看起来精美一点,整个设计还是十分简单。第三张是两个月前的进展,基本上可以依据这个商品输入主体的气氛,找到最符合的背景气氛,整个设计细节和结构,看起来更稳定一点。
我们现今大约学会几百种常规的设计手法,并且每晚都在学习中。这是我们目前的设计能力和设计疗效,青云给它定的评级是P4,意味着它还只是个助理设计师。我们明年目标是做到P5,还有太长的街要走。
机器怎样学习设计
下面和你们详尽解释一下这个机器背后的学习设计逻辑。
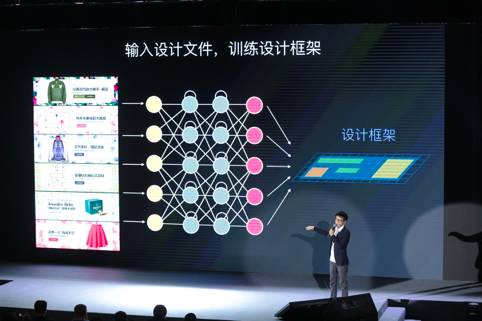
我们要使机器学习设计,首先必须要使机器理解感知设计是哪些。以这样一张十分常见的广告为例,在机器的眼中是有一堆象素点组成的。如果明天以象素为单位使机器去理解设计,对设计的可控性十分弱,所以在前期技术方案选择中没有走象素级生产,而是迈向了元素级生产。
四个组成部份:设计框架、元素中心、行动器、评估网路
组成一,设计框架。还是以这个广告为例,首先通过人工标明的方法,让机器理解这张设计有什么元素组成,比如它的商品主体,花的背景,蒙版。往上一层,我们通过设计的经验知识,定义一些设计的手法和风格。手法指的是那些元素为何可以如此构成,这个知识在设计头脑里机器是不知道的,所以会有手法这一层做输入。最前面这一层是风格,当这种元素构成以后,它从美学或则视觉角度看是一个哪些体味。让机器晓得它是用哪些组成的,为什么可以如此组成,以及它组成后的疗效。这个过程将一个设计问题转化成数据问题,这就是设计数据化。
下一步是打算设计的原创文件,比如一系列花朵和设计方式,输入到深度学习系列网路。这个网路有一个很大特征:具备一定记忆功能。因为设计是个步骤很复杂的过程,经常有好几十步能够完成一个设计。
经过这层神经网路学习以后,我们会得到一个设计框架。从技术上理解,它是一堆空间特点和视觉特点构成的模型。设计师的视角来理解的话,它相当于设计师头脑上面在做一组设计之前大约的框架印象,比如明天你接到一个任务要做一个花朵风格,思考这个设计大约会怎样做,然后从一堆文件里提取出了特点模型下来。
组成二,元素中心。因为我们做的是元素级生成,所以必须打算一个元素的库。我们会通过搜集一些版权图库,以及自己造设计元素的方法,输入到一个元素的分类器。这个分类器会把这种元素分布到各个类型里,比如背景、主体、修饰,也会完成图片库的提取。
组成三,行动器。接下来,就是设计的具体过程。比如明天我们接到一个设计任务,要为这样一件校服设计一个花朵风格的广告。这时候会有一个行动器,负责把上面打算好的底料放在设计框架里。这个过程和下象棋太象,左边是棋盘,右边是下象棋的棋子。行动器就是把元素放在棋盘里,这是整个行动器的生成原理。
它太象设计师实际在做设计的过程,如设计师要做一个花朵的时侯,也在软件上面会不断去调每位位置、每个象素、每个角度。同时,整个过程也是一个强化学习的过程,行动器会在不断试错中更智能。
组成四,评估网路。设计成品下来以后,我们要告诉机器人,从设计的角度是好还是不好。我们有一个设计评估网路,最终实现的疗效就是给它输入任何一个设计成品,它能打个分。技术原理是,我们通过人工输入大量历史上投放过的一些设计图评分,它从这儿训练出一个打分的模型下来。同时,专家也会人工干预打分,完成单向反馈。
这套框架并不是只能做Banner广告,Banner广告是我们找到的第一个最适宜落地的业务场景。我们把它定义为是一个通用的设计智能,理论上,它可以设计一切的数字内容。只要是通过元素或则象素组成的图象,理论上都是可以完成的。
预告一下我们最新的实践。前两张图是机器完成的服装搭配,根据用户输入的服装商品进行组合搭配,生成类似刊物的搭配效果图。另外,我们也正在训练机器完成页面模块的设计,比如大量的营销活动页面,我们如今正在训练它完成复杂的排版设计。
正在攻破的三个困局
目前,我们早已完成了框架搭建,以及数据的自我学习成长。接下来我们决心攻破的三个困局,也是使机器显得愈发强悍的关键突破点。
第一,让机器能否自主生成元素。我们目前的元素是靠设计师来提供,一方面是为了保证版权,另一方面,保证它的质量足够高。我们希望能做到,要求机器造一个花朵时,它自己能生成下来,这也是目前计算机视觉生成的一个十分火的话题。
第二,提高认知理解。现在机器还不太理解语义,只能按照需求或则任务生成一个结果,并不了解其中的关系。我们下一步要做的事情是,当用户输入了“清凉一夏”的文案时,机器人能理解“清凉”这个词代表了哪些意思,并且理解这张相片代表了“清凉一夏”的理念,图文之间有一定的关系。
最后一个,设计的迁移。比如明天通过大量专家数据训练了几百种常规数据手法以后,它还能完成主流的设计要求了。当这种手法很相似时,就可以完成风格迁移。我们会进一步探求AI,不再依据需求完成使命,而是通过自我学习和演变以后有新的东西下来。
AI+Design 拥抱新时代
今天人工智能设计真的来了,它不以任何意志为转移的趋势走来了,它距我们太逾。当一个新的浪潮打过来的时侯,我们应当学会的是拥抱它,而不是调头就跑,边跑边骂不靠谱。
视觉设计的四个层次
最基础的是临摹拓展。给你一个东西,照着它拓展一份下来,很明显这一定是机器第一步替代的工作。而且目前早已做到一大半了,证明这是一个无法回避的问题。
第二层,场景抒发。今天你给它一个东西,它能理解,能抒发对。比如明天你按照情人节,这些品牌才能找到一种合适的设计手段,去抒发出情人节的温情,这种手绘的形式会稍为难一点,也就是我们上面提到的语义这一层。
第三层,创意洞见。它还能有一些启发性的东西下来。天猫品牌上面时常有把猫头和品牌创意做联合的事情,这是机器不可能做到的事情,或者在我有生之年没有指望它能做到的。
最后一层,创造趋势。这通常是设计大师做的事情。它能定义今年、未来几年的设计趋势迈向,这是更高的设计能力。比如去年“三八”女王节,天猫用了一种全新的设计手段,用这些太轻的质感、很饱满的方法来抒发商品。它才能代表一个新的趋势和未来,代表一个新的手段,这件事情一定是人来做的。
回到明天机器和人之间的差别和对比,如果明天我们搞设计人机大战的话,机器最擅长的是数据、计算、学习。数据上,可以完成巨量素材库,训练成长速率,不断地完成闭环。它的学习速率之快,一个晚上可以完成几十万次的学习训练,是人不喝不吃也赶不上的。而人类设计师的特点,首先在情感层面,我们理解共情,情绪上有抒发,这是机器很难做到的。另外两层,创意和创造,设计师才能创造出一些新的东西,做组合迁移,组合创意,美学趋势。如果真正人机对战的话,设计师还是应回归创造、创意,以及理解用户的层面。
拥抱这个AI时代,对我们来说有没有哪些新的工作方式呢。比如明天有客人使你做一个设计,以前是一对一的给他一个成品,一对一的完成一个设计任务。有了设计AI以后,就可以将一个设计手段输入给机器,教会机器做执行和生成。这样,你就可以不止为一个顾客服务,而是为成千上万的顾客服务。
人工智能设计是个不可抵挡的时代,是未来。但是它也刚才来,我们也刚才走出第一步。我们还有大量的时间,希望接下来和设计同行一起努力,继续把这件事情做好。
优设目前早已约请了「鹿班智能设计平台」的负责人乐乘来优设做一期线上公开课,大家有哪些想问的可以随时反馈给主编@3年2班程远喔。
之前优设的合作伙伴「特赞」也专访过乐乘,大家可以先瞧瞧:双11期间有1.7 亿个BANNER,都来自阿里的“鹿班”AI设计系统
[关于UCAN]
UCAN是阿里巴巴的年度设计峰会,聚焦用户体验设计。4月27—28日,由阿里巴巴用户体验设计委员会举行的UCAN2017用户体验设计峰会在阿里巴巴西溪园区举办,本届主题是“新设计×新商业”。围绕“无界、融通、超距、生长”等概念,重新定义用户体验在新商业环境中的蝶变和价值,不断把设计领域、设计概念向外延伸,与技术、能源和商业形成新的化学反应。
欢迎关注阿里巴巴UED 的微信公众号:
「回顾2017 UCAN」
UCAN 2017回顾!8分钟看完设计大咖们的尖端干货阿里资深经理杨光:聊聊消费升级下的设计变化
【优设网 原创文章 投稿邮箱:】
================关于优设网================
“优设网“是国外人气最高的网页设计师学习平台,专注分享网页设计、无线端设计以及PS教程。
【特色推荐】
设计师须要读的100本书:史上最全的设计师图书导航:。
设计微博:拥有粉丝量200万的人气微博@优秀网页设计 ,欢迎关注获取网页设计资源、下载顶级设计素材。
设计导航:全球顶级设计网站推荐,设计师必备导航: 查看全部
美工终结者「鹿班智能设计平台」是怎样工作的?

@阿里巴巴UED:在去年UCAN会议开场,阿里巴巴集团UED委员会委员长杨光发布的智能设计平台——鹿班,便出自乐乘的团队。此平台是通过人工智能算法和大量数据训练机器学习设计。通过一段时间的学习,此平台从今年“双十一”前就早已在阿里内部大规模投入使用,目前其设计水平早已十分接近专业设计师设计的疗效。在会议上,乐乘介绍了阿里智能设计实验室的实践全过程。

用AI做设计
我们团队如今叫人工智能设计实验室,做的事情很简单,用AI做设计。人工智能如今这个概念很火了,有一个数据证明它有多火:去年人工智能这个领域的创业公司开张速率超过了麦当劳的开店速率。不可证实,这里一定有泡沫成份,也有好多概念的炒作。我们先抛掉高大上的词,把这个事情拆解一下。
现在讲的人工智能都是通过算法、数据和强悍的估算能力来构建服务场景,这是人工智能的四个要素。今天我们团队做的就是用算法、数据、计算、场景来解决商业领域的事情,这样促使这件事情看起来比较靠谱、容易落地。

为什么我们团队会想要做这个事情呢,这不是YY下来的看法,而是从广泛的业务场景里找到的一个机会。以一个广告Banner为例,我们把它归类为“大量低质易耗”的设计,这样的设计,设计师花三天做下来,在线上投放时间也只有三天。而且是重复的,改改字就可以了,非常适宜被机器所替代。
今年UCAN的主题是新设计x新商业,新商业里特别大的概念,是要通过新的技术、互联网的手段,完成人、货、场的构建,人是消费者,货是商品的服务,场景就是联接人和商品之间的手段。在新的时期下,需要找到一种新的方法做设计。
我们团队的使命是基于算法数据和前台业务需求,打造一个商业设计脑部。这个脑部能理解设计,能为商业的产品去服务,做出合理的设计。
商业设计脑部的三大挑战
在开始做事情之前,我们遇见了三个比较严峻的挑战。
第一个挑战,缺少标明数据。今天所有的人工智能都基于大量的结构化标明数据,设计这件事情连数据都没有完成在线化,更别说标准化、结构化的数据了。
第二个挑战,设计不确定性。设计是个太不确定的东西,比如明天你使机器设计一个高档大气的Banner广告,它就蒙圈了。
第三个挑战,无先例可循。在整个行业里过去一年做出来发觉,没有一些现成的技术或则框架可以参考。比如AlphaGo把棋类AI论文发完以后,全世界象棋AI照这个方式都可以做到先进的水平。我们过去一年来都是自己一街摸索中走过来的,这一年走来我们给人工智能做的定义是,我们做的是可控的视觉生成。可控,就是按照商业的需求、业务的需求,智能地进行控制。它解决的是视觉从无到有的问题。
可控的视觉生成过程
这是机器人从诞生的第一版到近来一版的发展历程。2016年9月,勉强完成一张图片的拼合,没有哪些美感可言。第二张是去年圣诞节前做的广告,稍微看起来精美一点,整个设计还是十分简单。第三张是两个月前的进展,基本上可以依据这个商品输入主体的气氛,找到最符合的背景气氛,整个设计细节和结构,看起来更稳定一点。

我们现今大约学会几百种常规的设计手法,并且每晚都在学习中。这是我们目前的设计能力和设计疗效,青云给它定的评级是P4,意味着它还只是个助理设计师。我们明年目标是做到P5,还有太长的街要走。
机器怎样学习设计
下面和你们详尽解释一下这个机器背后的学习设计逻辑。
我们要使机器学习设计,首先必须要使机器理解感知设计是哪些。以这样一张十分常见的广告为例,在机器的眼中是有一堆象素点组成的。如果明天以象素为单位使机器去理解设计,对设计的可控性十分弱,所以在前期技术方案选择中没有走象素级生产,而是迈向了元素级生产。

四个组成部份:设计框架、元素中心、行动器、评估网路
组成一,设计框架。还是以这个广告为例,首先通过人工标明的方法,让机器理解这张设计有什么元素组成,比如它的商品主体,花的背景,蒙版。往上一层,我们通过设计的经验知识,定义一些设计的手法和风格。手法指的是那些元素为何可以如此构成,这个知识在设计头脑里机器是不知道的,所以会有手法这一层做输入。最前面这一层是风格,当这种元素构成以后,它从美学或则视觉角度看是一个哪些体味。让机器晓得它是用哪些组成的,为什么可以如此组成,以及它组成后的疗效。这个过程将一个设计问题转化成数据问题,这就是设计数据化。
下一步是打算设计的原创文件,比如一系列花朵和设计方式,输入到深度学习系列网路。这个网路有一个很大特征:具备一定记忆功能。因为设计是个步骤很复杂的过程,经常有好几十步能够完成一个设计。
经过这层神经网路学习以后,我们会得到一个设计框架。从技术上理解,它是一堆空间特点和视觉特点构成的模型。设计师的视角来理解的话,它相当于设计师头脑上面在做一组设计之前大约的框架印象,比如明天你接到一个任务要做一个花朵风格,思考这个设计大约会怎样做,然后从一堆文件里提取出了特点模型下来。
组成二,元素中心。因为我们做的是元素级生成,所以必须打算一个元素的库。我们会通过搜集一些版权图库,以及自己造设计元素的方法,输入到一个元素的分类器。这个分类器会把这种元素分布到各个类型里,比如背景、主体、修饰,也会完成图片库的提取。

组成三,行动器。接下来,就是设计的具体过程。比如明天我们接到一个设计任务,要为这样一件校服设计一个花朵风格的广告。这时候会有一个行动器,负责把上面打算好的底料放在设计框架里。这个过程和下象棋太象,左边是棋盘,右边是下象棋的棋子。行动器就是把元素放在棋盘里,这是整个行动器的生成原理。
它太象设计师实际在做设计的过程,如设计师要做一个花朵的时侯,也在软件上面会不断去调每位位置、每个象素、每个角度。同时,整个过程也是一个强化学习的过程,行动器会在不断试错中更智能。
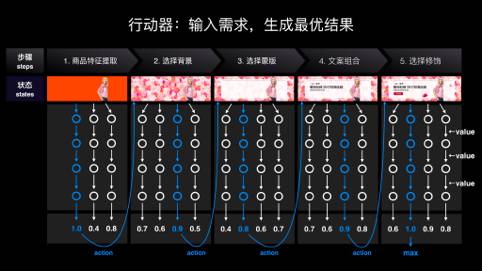
组成四,评估网路。设计成品下来以后,我们要告诉机器人,从设计的角度是好还是不好。我们有一个设计评估网路,最终实现的疗效就是给它输入任何一个设计成品,它能打个分。技术原理是,我们通过人工输入大量历史上投放过的一些设计图评分,它从这儿训练出一个打分的模型下来。同时,专家也会人工干预打分,完成单向反馈。

这套框架并不是只能做Banner广告,Banner广告是我们找到的第一个最适宜落地的业务场景。我们把它定义为是一个通用的设计智能,理论上,它可以设计一切的数字内容。只要是通过元素或则象素组成的图象,理论上都是可以完成的。
预告一下我们最新的实践。前两张图是机器完成的服装搭配,根据用户输入的服装商品进行组合搭配,生成类似刊物的搭配效果图。另外,我们也正在训练机器完成页面模块的设计,比如大量的营销活动页面,我们如今正在训练它完成复杂的排版设计。

正在攻破的三个困局
目前,我们早已完成了框架搭建,以及数据的自我学习成长。接下来我们决心攻破的三个困局,也是使机器显得愈发强悍的关键突破点。
第一,让机器能否自主生成元素。我们目前的元素是靠设计师来提供,一方面是为了保证版权,另一方面,保证它的质量足够高。我们希望能做到,要求机器造一个花朵时,它自己能生成下来,这也是目前计算机视觉生成的一个十分火的话题。
第二,提高认知理解。现在机器还不太理解语义,只能按照需求或则任务生成一个结果,并不了解其中的关系。我们下一步要做的事情是,当用户输入了“清凉一夏”的文案时,机器人能理解“清凉”这个词代表了哪些意思,并且理解这张相片代表了“清凉一夏”的理念,图文之间有一定的关系。
最后一个,设计的迁移。比如明天通过大量专家数据训练了几百种常规数据手法以后,它还能完成主流的设计要求了。当这种手法很相似时,就可以完成风格迁移。我们会进一步探求AI,不再依据需求完成使命,而是通过自我学习和演变以后有新的东西下来。
AI+Design 拥抱新时代
今天人工智能设计真的来了,它不以任何意志为转移的趋势走来了,它距我们太逾。当一个新的浪潮打过来的时侯,我们应当学会的是拥抱它,而不是调头就跑,边跑边骂不靠谱。
视觉设计的四个层次

最基础的是临摹拓展。给你一个东西,照着它拓展一份下来,很明显这一定是机器第一步替代的工作。而且目前早已做到一大半了,证明这是一个无法回避的问题。

第二层,场景抒发。今天你给它一个东西,它能理解,能抒发对。比如明天你按照情人节,这些品牌才能找到一种合适的设计手段,去抒发出情人节的温情,这种手绘的形式会稍为难一点,也就是我们上面提到的语义这一层。

第三层,创意洞见。它还能有一些启发性的东西下来。天猫品牌上面时常有把猫头和品牌创意做联合的事情,这是机器不可能做到的事情,或者在我有生之年没有指望它能做到的。

最后一层,创造趋势。这通常是设计大师做的事情。它能定义今年、未来几年的设计趋势迈向,这是更高的设计能力。比如去年“三八”女王节,天猫用了一种全新的设计手段,用这些太轻的质感、很饱满的方法来抒发商品。它才能代表一个新的趋势和未来,代表一个新的手段,这件事情一定是人来做的。
回到明天机器和人之间的差别和对比,如果明天我们搞设计人机大战的话,机器最擅长的是数据、计算、学习。数据上,可以完成巨量素材库,训练成长速率,不断地完成闭环。它的学习速率之快,一个晚上可以完成几十万次的学习训练,是人不喝不吃也赶不上的。而人类设计师的特点,首先在情感层面,我们理解共情,情绪上有抒发,这是机器很难做到的。另外两层,创意和创造,设计师才能创造出一些新的东西,做组合迁移,组合创意,美学趋势。如果真正人机对战的话,设计师还是应回归创造、创意,以及理解用户的层面。

拥抱这个AI时代,对我们来说有没有哪些新的工作方式呢。比如明天有客人使你做一个设计,以前是一对一的给他一个成品,一对一的完成一个设计任务。有了设计AI以后,就可以将一个设计手段输入给机器,教会机器做执行和生成。这样,你就可以不止为一个顾客服务,而是为成千上万的顾客服务。
人工智能设计是个不可抵挡的时代,是未来。但是它也刚才来,我们也刚才走出第一步。我们还有大量的时间,希望接下来和设计同行一起努力,继续把这件事情做好。
优设目前早已约请了「鹿班智能设计平台」的负责人乐乘来优设做一期线上公开课,大家有哪些想问的可以随时反馈给主编@3年2班程远喔。
之前优设的合作伙伴「特赞」也专访过乐乘,大家可以先瞧瞧:双11期间有1.7 亿个BANNER,都来自阿里的“鹿班”AI设计系统
[关于UCAN]
UCAN是阿里巴巴的年度设计峰会,聚焦用户体验设计。4月27—28日,由阿里巴巴用户体验设计委员会举行的UCAN2017用户体验设计峰会在阿里巴巴西溪园区举办,本届主题是“新设计×新商业”。围绕“无界、融通、超距、生长”等概念,重新定义用户体验在新商业环境中的蝶变和价值,不断把设计领域、设计概念向外延伸,与技术、能源和商业形成新的化学反应。
欢迎关注阿里巴巴UED 的微信公众号:

「回顾2017 UCAN」
UCAN 2017回顾!8分钟看完设计大咖们的尖端干货阿里资深经理杨光:聊聊消费升级下的设计变化
【优设网 原创文章 投稿邮箱:】
================关于优设网================
“优设网“是国外人气最高的网页设计师学习平台,专注分享网页设计、无线端设计以及PS教程。
【特色推荐】
设计师须要读的100本书:史上最全的设计师图书导航:。
设计微博:拥有粉丝量200万的人气微博@优秀网页设计 ,欢迎关注获取网页设计资源、下载顶级设计素材。
设计导航:全球顶级设计网站推荐,设计师必备导航:
基于大数据平台开发工作总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-13 04:35
大数据开发,有几个阶段:
1.数据采集【原创数据】
2.数据凝聚【经过清洗合并的可用数据】
3.数据转换和映射【经过分类,提取的专项主题数据】
4.数据应用 【提供api 智能系统 应用系统等】
数据采集
数据采集有线上和线下两种形式,线上通常通过爬虫、通过抓取,或者通过已有应用系统的采集,在这个阶段,我们可以做一个大数据采集平台,依托手动爬虫(使用python或则nodejs制做爬虫软件),ETL工具、或者自定义的抽取转换引擎,从文件中、数据库中、网页中专项爬取数据,如果这一步通过自动化系统来做的话,可以很方便的管理所有的原创数据,并且从数据的开始对数据进行标签采集,可以规范开发人员的工作。并且目标数据源可以更方便的管理。
数据采集的难点在于多数据源,例如mysql、postgresql、sqlserver 、 mongodb 、sqllite。还有本地文件、excel统计文档、甚至是doc文件。如何将她们规整的、有方案的整理进我们的大数据流程中也是必不可缺的一环。
数据凝聚
数据的凝聚是大数据流程最关键的一步,你可以在这里加上数据标准化,你也可以在这里做数据清洗,数据合并,还可以在这一步将数据存档,将确认可用的数据经过可监控的流程进行整理归类,这里产出的所有数据就是整个公司的数据资产了,到了一定的量就是一笔固定资产。
数据凝聚的难点在于怎样标准化数据,例如表名标准化,表的标签分类,表的用途,数据的量,是否有数据增量?,数据是否可用? 需要在业务上下很大的工夫,必要时还要引入智能化处理,例如依照内容训练结果手动打标签,自动分配推荐表名、表数组名等。还有怎样从原创数据中导出数据等。
数据转换和映射
经过数据凝聚的数据资产怎样提供给具体的使用方使用?在这一步,主要就是考虑数据怎么应用,如何将两个?三个?数据表转换成一张才能提供服务的数据。然后定期更新增量。
经过上面的那几步,在这一步难点并不太多了,如何转换数据与怎样清洗数据、标准数据无二,将两个数组的值转换成一个数组,或者按照多个可用表统计出一张图表数据等等。
数据应用
数据的应用方法好多,有对外的、有对内的,如果拥有了前期的大量数据资产,通过restful API提供给用户?或者提供流式引擎 KAFKA 给应用消费? 或者直接组成专题数据,供自己的应用查询?这里对数据资产的要求比较高,所以前期的工作做好了,这里的自由度很高。
总结:大数据开发的难点
大数据开发的难点主要是监控,怎么样规划开发人员的工作?开发人员随随便便采集了一堆垃圾数据,并且直连数据库。 短期来看,这些问题比较小,可以矫治。 但是在资产的量不断降低的时侯,这就是一颗定时炸弹,随时会引爆,然后引起一系列对数据资产的影响,例如数据混乱带来的就是数据资产的价值增长,客户信任度变低。
如何监控开发人员的开发流程?
答案只能是自动化平台,只有自动化平台才能做到使开发人员倍感舒心的同时,接受新的事务,抛弃自动时代。
这就是后端开发工程师在大数据行业中所占有的优势点,如何制做交互良好的可视化操作界面?如何将现有的工作流程、工作需求弄成一个个的可视化操作界面? 可不可以使用智能化代替一些无脑的操作?
从一定意义上来说,大数据开发中,我个人觉得后端开发工程师抢占着更重要的位置,仅次于大数据开发工程师。至于后台开发,系统开发是第三位的。好的交互至关重要,如何转换数据,如何抽取数据,一定程度上,都是有先人踩过的坑,例如kettle,再比如kafka,pipeline ,解决方案诸多。关键是怎么交互? 怎么样变现为可视化界面? 这是一个重要的课题。
现有的诸位同学的优缺不同,认为后端的角色都是可有可无,我认为是错误的,后台的确很重要,但是后台的解决方案多。 前端实际的地位更重要,但是基本无开源的解决方案,如果不够注重后端开发, 面临的问题就是交互太烂,界面烂,体验差,导致开发人员的抵触,而可视化这块的知识点诸多,对开发人员的素养要求更高。
大数据治理
大数据整治应当贯串整个大数据开发流程,它有饰演着重要的角色,浅略的介绍几点:
数据血缘
数据质量审查
全平台监控
数据血缘
从数据血缘说起,数据血缘应当是大数据整治的入口,通过一张表,能够清晰看到它的来龙去脉,字段的分拆,清洗过程,表的流转,数据的量的变化,都应当从数据血缘出发,我个人觉得,大数据整治整个的目标就是这个数据血缘,从数据血缘才能有监控全局的能力。
数据血缘是依托于大数据开发过程的,它包围着整个大数据开发过程,每一步开发的历史,数据导出的历史,都应当有相应的记录,数据血缘在数据资产有一定规模时,基本必不可少。
数据质量审查
数据开发中,每一个模型(表)创建的结束,都应当有一个数据质量审查的过程,在体系大的环境中,还应当在关键步骤添加审批,例如在数据转换和映射这一步,涉及到顾客的数据提供,应该构建一个建立的数据质量审查制度,帮助企业第一时间发觉数据存在的问题,在数据发生问题时也能第一时间听到问题的所在,并从症结解决问题,而不是盲目的通过联接数据库一遍一遍的查询sql。
全平台监控
监控呢,其实收录了好多的点,例如应用监控,数据监控,预警系统,工单系统等,对我们接管的每位数据源、数据表都须要做到实时监控,一旦发生殆机,或者发生停水,能够第一时间电话或则邮件通知到具体负责人,这里可以借鉴一些自动化运维平台的经验的,监控约等于运维,好的监控提供的数据资产的保护也是很重要的。
大数据可视化
大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,重要的事说三遍,大数据可视化归类的数据开发中,有一部分属于应用类,有一部分属于开发类。
在开发中,大数据可视化饰演的是可视化操作的角色, 如何通过可视化的模式构建模型? 如何通过拖拉拽,或者立体操作来实现数据质量的可操作性? 画两个表格加几个按键实现复杂的操作流程是不现实的。
在可视化应用中,更多的也有怎样转换数据,如何展示数据,图表是其中的一部分,平时更多的工作还是对数据的剖析,怎么样更直观的抒发数据?这须要对数据有深刻的理解,对业务有深刻的理解,才能作出合适的可视化应用。
智能的可视化平台
可视化是可以被再可视化的,例如superset,通过操作sql实现图表,有一些产品甚至能做到按照数据的内容智能分类,推荐图表类型,实时的进行可视化开发,这样的功能才是可视化现有的发展方向,我们须要大量的可视化内容来对公司发生产出,例如服饰行业,销售部门:进货出货,颜色搭配对用户的影响,季节对选择的影响 生产部门:布料价钱走势? 产能和效率的数据统计? 等等,每一个部门都可以有一个数据大屏,可以通过平台任意规划自己的大屏,所有人每晚才能关注到自己的领域动向,这才是大数据可视化应用的具体意义。
写在最后
未来的几年,希望自己继续努力工作,主业前端开发,另外,一有时间多学学大数据开发、人工智能方面的知识,这是未来,也是方向。
最后,和你们自勉,更希望你们能给一些规划建议,三人行,必有我师焉,谢谢。 查看全部
大数据开发
大数据开发,有几个阶段:
1.数据采集【原创数据】
2.数据凝聚【经过清洗合并的可用数据】
3.数据转换和映射【经过分类,提取的专项主题数据】
4.数据应用 【提供api 智能系统 应用系统等】
数据采集
数据采集有线上和线下两种形式,线上通常通过爬虫、通过抓取,或者通过已有应用系统的采集,在这个阶段,我们可以做一个大数据采集平台,依托手动爬虫(使用python或则nodejs制做爬虫软件),ETL工具、或者自定义的抽取转换引擎,从文件中、数据库中、网页中专项爬取数据,如果这一步通过自动化系统来做的话,可以很方便的管理所有的原创数据,并且从数据的开始对数据进行标签采集,可以规范开发人员的工作。并且目标数据源可以更方便的管理。
数据采集的难点在于多数据源,例如mysql、postgresql、sqlserver 、 mongodb 、sqllite。还有本地文件、excel统计文档、甚至是doc文件。如何将她们规整的、有方案的整理进我们的大数据流程中也是必不可缺的一环。
数据凝聚
数据的凝聚是大数据流程最关键的一步,你可以在这里加上数据标准化,你也可以在这里做数据清洗,数据合并,还可以在这一步将数据存档,将确认可用的数据经过可监控的流程进行整理归类,这里产出的所有数据就是整个公司的数据资产了,到了一定的量就是一笔固定资产。
数据凝聚的难点在于怎样标准化数据,例如表名标准化,表的标签分类,表的用途,数据的量,是否有数据增量?,数据是否可用? 需要在业务上下很大的工夫,必要时还要引入智能化处理,例如依照内容训练结果手动打标签,自动分配推荐表名、表数组名等。还有怎样从原创数据中导出数据等。
数据转换和映射
经过数据凝聚的数据资产怎样提供给具体的使用方使用?在这一步,主要就是考虑数据怎么应用,如何将两个?三个?数据表转换成一张才能提供服务的数据。然后定期更新增量。
经过上面的那几步,在这一步难点并不太多了,如何转换数据与怎样清洗数据、标准数据无二,将两个数组的值转换成一个数组,或者按照多个可用表统计出一张图表数据等等。
数据应用
数据的应用方法好多,有对外的、有对内的,如果拥有了前期的大量数据资产,通过restful API提供给用户?或者提供流式引擎 KAFKA 给应用消费? 或者直接组成专题数据,供自己的应用查询?这里对数据资产的要求比较高,所以前期的工作做好了,这里的自由度很高。
总结:大数据开发的难点
大数据开发的难点主要是监控,怎么样规划开发人员的工作?开发人员随随便便采集了一堆垃圾数据,并且直连数据库。 短期来看,这些问题比较小,可以矫治。 但是在资产的量不断降低的时侯,这就是一颗定时炸弹,随时会引爆,然后引起一系列对数据资产的影响,例如数据混乱带来的就是数据资产的价值增长,客户信任度变低。
如何监控开发人员的开发流程?
答案只能是自动化平台,只有自动化平台才能做到使开发人员倍感舒心的同时,接受新的事务,抛弃自动时代。
这就是后端开发工程师在大数据行业中所占有的优势点,如何制做交互良好的可视化操作界面?如何将现有的工作流程、工作需求弄成一个个的可视化操作界面? 可不可以使用智能化代替一些无脑的操作?
从一定意义上来说,大数据开发中,我个人觉得后端开发工程师抢占着更重要的位置,仅次于大数据开发工程师。至于后台开发,系统开发是第三位的。好的交互至关重要,如何转换数据,如何抽取数据,一定程度上,都是有先人踩过的坑,例如kettle,再比如kafka,pipeline ,解决方案诸多。关键是怎么交互? 怎么样变现为可视化界面? 这是一个重要的课题。
现有的诸位同学的优缺不同,认为后端的角色都是可有可无,我认为是错误的,后台的确很重要,但是后台的解决方案多。 前端实际的地位更重要,但是基本无开源的解决方案,如果不够注重后端开发, 面临的问题就是交互太烂,界面烂,体验差,导致开发人员的抵触,而可视化这块的知识点诸多,对开发人员的素养要求更高。
大数据治理
大数据整治应当贯串整个大数据开发流程,它有饰演着重要的角色,浅略的介绍几点:
数据血缘
数据质量审查
全平台监控
数据血缘
从数据血缘说起,数据血缘应当是大数据整治的入口,通过一张表,能够清晰看到它的来龙去脉,字段的分拆,清洗过程,表的流转,数据的量的变化,都应当从数据血缘出发,我个人觉得,大数据整治整个的目标就是这个数据血缘,从数据血缘才能有监控全局的能力。
数据血缘是依托于大数据开发过程的,它包围着整个大数据开发过程,每一步开发的历史,数据导出的历史,都应当有相应的记录,数据血缘在数据资产有一定规模时,基本必不可少。
数据质量审查
数据开发中,每一个模型(表)创建的结束,都应当有一个数据质量审查的过程,在体系大的环境中,还应当在关键步骤添加审批,例如在数据转换和映射这一步,涉及到顾客的数据提供,应该构建一个建立的数据质量审查制度,帮助企业第一时间发觉数据存在的问题,在数据发生问题时也能第一时间听到问题的所在,并从症结解决问题,而不是盲目的通过联接数据库一遍一遍的查询sql。
全平台监控
监控呢,其实收录了好多的点,例如应用监控,数据监控,预警系统,工单系统等,对我们接管的每位数据源、数据表都须要做到实时监控,一旦发生殆机,或者发生停水,能够第一时间电话或则邮件通知到具体负责人,这里可以借鉴一些自动化运维平台的经验的,监控约等于运维,好的监控提供的数据资产的保护也是很重要的。
大数据可视化
大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,重要的事说三遍,大数据可视化归类的数据开发中,有一部分属于应用类,有一部分属于开发类。
在开发中,大数据可视化饰演的是可视化操作的角色, 如何通过可视化的模式构建模型? 如何通过拖拉拽,或者立体操作来实现数据质量的可操作性? 画两个表格加几个按键实现复杂的操作流程是不现实的。
在可视化应用中,更多的也有怎样转换数据,如何展示数据,图表是其中的一部分,平时更多的工作还是对数据的剖析,怎么样更直观的抒发数据?这须要对数据有深刻的理解,对业务有深刻的理解,才能作出合适的可视化应用。
智能的可视化平台
可视化是可以被再可视化的,例如superset,通过操作sql实现图表,有一些产品甚至能做到按照数据的内容智能分类,推荐图表类型,实时的进行可视化开发,这样的功能才是可视化现有的发展方向,我们须要大量的可视化内容来对公司发生产出,例如服饰行业,销售部门:进货出货,颜色搭配对用户的影响,季节对选择的影响 生产部门:布料价钱走势? 产能和效率的数据统计? 等等,每一个部门都可以有一个数据大屏,可以通过平台任意规划自己的大屏,所有人每晚才能关注到自己的领域动向,这才是大数据可视化应用的具体意义。
写在最后
未来的几年,希望自己继续努力工作,主业前端开发,另外,一有时间多学学大数据开发、人工智能方面的知识,这是未来,也是方向。
最后,和你们自勉,更希望你们能给一些规划建议,三人行,必有我师焉,谢谢。
Windows系统数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 460 次浏览 • 2020-08-12 03:38
前期打算
从这儿下载最新版的logkit-pro,因为wmi与wineventlog都是windows下的组件,所以请下载windows版本的logkit-pro。
具体logkit-pro的安装可以参考logkit-pro安装手册。
安装完成后登陆logkit-pro,在数据搜集蓝筹股中选择添加搜集器->日志搜集,在添加采集器的页面就能看见如下结果,则证明安装无误,可以使用logkit进行数据搜集的操作。
使用file reader搜集windows下的数据
在数据搜集的页面见到两侧的这五个采集器是用于搜集文件类型的数据的。
具体每位采集器的使用方式和用途可以参考文件数据源
这里我们选择file模式读取文件数据,并在配置栏中填写相应配置。这里我们获取的是磁盘下名为test.txt文本文件中的数据。
点击一侧的获取数据可以在左边的文本框中见到尝试获得数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下文本数据的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
使用wineventlog reader搜集windows系统日志
进入windows系统日志的搜集界面,能看到如下所示的界面:
如图中所示,logkit-pro默认提供的搜集类别有应用程序(Application),安全(Security),系统(System)。
其他须要搜集的风波日志可以在自定义文本框中填写须要搜集的风波名称。支持填写多个风波名,中间用,分隔。
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
这里我们将数据发送到七牛的大数据平台进行剖析,发送后可以在智能日志平台中见到相应的数据信息。
还可以在搜索框中输入相应的搜索条件进行信息的快速搜索和筛选。
同时还可以借助日志平台的仪表盘进行数据的可视化剖析。以下是我们制做的数据图表。
详细的搜集操作和配置可以参考Windows Eventlog数据源
使用wmi reader搜集windows系统信息
进入通过WMI读取windows系统信息页面,能看到如下所示界面:
如图中所示,相应配置项的涵义:
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。(目前提供了Win32_Process和Win32_NTLogEvent两个实例的搜集,其中Win32_NTLogEvent实例可能因为数据较多,尝试获取数据的时侯会加载较长的时间)
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
详细的搜集操作和配置可以参考wmi数据源
windows系统审计项的配置
由于默认情况下 Windows 的审计未设或则设置项极少,因此需降低相应的审计项目。
配置成功以后的相关初审项即可在wmi reader中通过Win32_NTLogEvent实例来搜集。
注意:若配置了和防火墙有关的初审项,日志量会下降起码 10 倍,请慎重配置。 查看全部
logkit-pro支持直接采集windows下的文本数据和wineventlog信息或则通过wmi采集windows的系统信息。文本数据的搜集使用的是file reader,wineventlog信息的搜集使用的是wineventlog reader,而通过wmi搜集windows系统信息则是使用wmi reader。wineventlog reader须要将agent布署在须要采集eventlog的机器上,而wmi reader则支持远程访问的方法读取系统信息
前期打算
从这儿下载最新版的logkit-pro,因为wmi与wineventlog都是windows下的组件,所以请下载windows版本的logkit-pro。
具体logkit-pro的安装可以参考logkit-pro安装手册。
安装完成后登陆logkit-pro,在数据搜集蓝筹股中选择添加搜集器->日志搜集,在添加采集器的页面就能看见如下结果,则证明安装无误,可以使用logkit进行数据搜集的操作。
使用file reader搜集windows下的数据
在数据搜集的页面见到两侧的这五个采集器是用于搜集文件类型的数据的。
具体每位采集器的使用方式和用途可以参考文件数据源
这里我们选择file模式读取文件数据,并在配置栏中填写相应配置。这里我们获取的是磁盘下名为test.txt文本文件中的数据。
点击一侧的获取数据可以在左边的文本框中见到尝试获得数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下文本数据的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
使用wineventlog reader搜集windows系统日志
进入windows系统日志的搜集界面,能看到如下所示的界面:
如图中所示,logkit-pro默认提供的搜集类别有应用程序(Application),安全(Security),系统(System)。
其他须要搜集的风波日志可以在自定义文本框中填写须要搜集的风波名称。支持填写多个风波名,中间用,分隔。
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
这里我们将数据发送到七牛的大数据平台进行剖析,发送后可以在智能日志平台中见到相应的数据信息。
还可以在搜索框中输入相应的搜索条件进行信息的快速搜索和筛选。
同时还可以借助日志平台的仪表盘进行数据的可视化剖析。以下是我们制做的数据图表。
详细的搜集操作和配置可以参考Windows Eventlog数据源
使用wmi reader搜集windows系统信息
进入通过WMI读取windows系统信息页面,能看到如下所示界面:
如图中所示,相应配置项的涵义:
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。(目前提供了Win32_Process和Win32_NTLogEvent两个实例的搜集,其中Win32_NTLogEvent实例可能因为数据较多,尝试获取数据的时侯会加载较长的时间)
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
详细的搜集操作和配置可以参考wmi数据源
windows系统审计项的配置
由于默认情况下 Windows 的审计未设或则设置项极少,因此需降低相应的审计项目。
配置成功以后的相关初审项即可在wmi reader中通过Win32_NTLogEvent实例来搜集。
注意:若配置了和防火墙有关的初审项,日志量会下降起码 10 倍,请慎重配置。
1 无埋点采集 · 数极客
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-12 00:10
无埋点采集也称为"全埋点",系统手动采集所有元素的点击数据,通过在页面中圈选定义风波名称,即可查询相关数据。特点是无须事前埋点,减轻工程师的埋点工作量。
1. 无埋点的原理
用户在网页上添加JavaScript sdk代码(APP集成数极客SDK)后,您就可以在数极客的剖析后台里步入无埋点管理模块,系统会手动辨识出页面上所有的元素,并采集所有点击行为的数据。您在仅在须要数据时,根据剖析需求对任意的元素进行圈选。对埋点进行命名后,该指标就可以各剖析模型中查询。
参考阅读:数极客Android无埋点的技术原理解读
2. 无埋点与可视化埋点的区别
无埋点技术无需事先埋点即可采集数据。可视化埋点,需要得前通过可视化界面定义风波,然后系统就会开始采集数据,因此实用性比无埋点更弱。
3. 无埋点的优缺点
运营、产品、营销人员均可以依照自身业务的需求进行可视化圈选,自定义创建风波指标,不需麻烦技术朋友代码埋点,提高工作效率。无埋点技术只能采集点击行为,生成的指标主要是点击的人数、次数、用户数、会话数等简单指标。因此当须要采集业务相关精准指标时,还需和埋点采集相结合使用。在日常工作中,大约有80%的指标,可以通过无埋点技术获取,因此,无埋点技术对于数据采集是重大的效率突破。
4. 支持的应用平台类型
数极客目前支持WEB、H5、Android、iOS四种类型的应用的无埋点数据采集。
5. 产品演示视频 查看全部
无埋点
无埋点采集也称为"全埋点",系统手动采集所有元素的点击数据,通过在页面中圈选定义风波名称,即可查询相关数据。特点是无须事前埋点,减轻工程师的埋点工作量。
1. 无埋点的原理
用户在网页上添加JavaScript sdk代码(APP集成数极客SDK)后,您就可以在数极客的剖析后台里步入无埋点管理模块,系统会手动辨识出页面上所有的元素,并采集所有点击行为的数据。您在仅在须要数据时,根据剖析需求对任意的元素进行圈选。对埋点进行命名后,该指标就可以各剖析模型中查询。
参考阅读:数极客Android无埋点的技术原理解读
2. 无埋点与可视化埋点的区别
无埋点技术无需事先埋点即可采集数据。可视化埋点,需要得前通过可视化界面定义风波,然后系统就会开始采集数据,因此实用性比无埋点更弱。
3. 无埋点的优缺点
运营、产品、营销人员均可以依照自身业务的需求进行可视化圈选,自定义创建风波指标,不需麻烦技术朋友代码埋点,提高工作效率。无埋点技术只能采集点击行为,生成的指标主要是点击的人数、次数、用户数、会话数等简单指标。因此当须要采集业务相关精准指标时,还需和埋点采集相结合使用。在日常工作中,大约有80%的指标,可以通过无埋点技术获取,因此,无埋点技术对于数据采集是重大的效率突破。
4. 支持的应用平台类型
数极客目前支持WEB、H5、Android、iOS四种类型的应用的无埋点数据采集。
5. 产品演示视频
推荐NLPIR大数据语义智能剖析平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-11 09:08
NLPIR大数据语义智能剖析平台由北京理工大学大数据搜索与挖掘实验室( Big Data Search and Mining Lab.BDSM@BIT)张华平博士主导,最近上线了新版,这里做个推荐。张华平博士最广为人知的产品是ICTCLAS英文动词平台,相信这更有助于你们了解NLPIR大数据语义智能剖析平台,以下摘自“NLPIR大数据语义智能剖析平台新版上线”。
NLPIR大数据语义智能剖析平台针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达十八年,服务了全球四十万家机构用户,是大数据时代语义智能剖析的一大神器。
NLPIR大数据语义智能挖掘平台,针对大数据内容处理的须要,融合了网路精准采集、自然语言理解、文本挖掘和网路搜索的技术,提供了客户端工具、云服务、二次开发插口。开发平台由多个中间件组成,各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux,Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,C,C#等各种开发语言使用。
NLPIR大数据语义智能剖析平台十三大功能:
1、精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
2、文档抽取:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息抽取,信息抽取确切,效率达到大数据处理的要求。
3、新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
4、批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
5、语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的中文解释。
6、文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
7、文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
8、摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
9、智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
10、情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
11、文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
12、全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
13、编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
欢迎你们下载使用。
NLPIR大数据语义智能剖析平台蓝皮书:
(约3MB)
NLPIR大数据语义智能剖析平台:
(约160MB)
Related posts:推荐张华平老师的中文分词工具ICTCLAS2010 Python自然语言处理实践: 在NLTK中使用哈佛英文分词器 Python自然语言处理工具NLTK学习导引及相关资料 中文动词入门之字标明法全文文档 查看全部

NLPIR大数据语义智能剖析平台由北京理工大学大数据搜索与挖掘实验室( Big Data Search and Mining Lab.BDSM@BIT)张华平博士主导,最近上线了新版,这里做个推荐。张华平博士最广为人知的产品是ICTCLAS英文动词平台,相信这更有助于你们了解NLPIR大数据语义智能剖析平台,以下摘自“NLPIR大数据语义智能剖析平台新版上线”。
NLPIR大数据语义智能剖析平台针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达十八年,服务了全球四十万家机构用户,是大数据时代语义智能剖析的一大神器。

NLPIR大数据语义智能挖掘平台,针对大数据内容处理的须要,融合了网路精准采集、自然语言理解、文本挖掘和网路搜索的技术,提供了客户端工具、云服务、二次开发插口。开发平台由多个中间件组成,各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux,Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,C,C#等各种开发语言使用。
NLPIR大数据语义智能剖析平台十三大功能:
1、精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
2、文档抽取:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息抽取,信息抽取确切,效率达到大数据处理的要求。
3、新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
4、批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
5、语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的中文解释。
6、文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
7、文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
8、摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
9、智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
10、情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
11、文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
12、全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
13、编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
欢迎你们下载使用。
NLPIR大数据语义智能剖析平台蓝皮书:
(约3MB)
NLPIR大数据语义智能剖析平台:
(约160MB)
Related posts:推荐张华平老师的中文分词工具ICTCLAS2010 Python自然语言处理实践: 在NLTK中使用哈佛英文分词器 Python自然语言处理工具NLTK学习导引及相关资料 中文动词入门之字标明法全文文档
智能伪原创-采集插件(终身可用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-10 22:45
由于采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改的PHP环境。修改的方式很简单,打开网站采集软件的安装目录“System/PHP”,找到php.ini文件打开,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在插件目录
例如我本机是:D:优采云采集器V9Plugins
问:这个插件主要功能是哪些?
回答:是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后,在正常运行的基础上,选择伪原创插件。
伪原创插件使用教程
一个有效的搜集工具,可以帮助我们更快地完成竞购。
采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。 查看全部
1、修改的PHP环境
由于采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改的PHP环境。修改的方式很简单,打开网站采集软件的安装目录“System/PHP”,找到php.ini文件打开,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在插件目录
例如我本机是:D:优采云采集器V9Plugins
问:这个插件主要功能是哪些?
回答:是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后,在正常运行的基础上,选择伪原创插件。
伪原创插件使用教程
一个有效的搜集工具,可以帮助我们更快地完成竞购。
采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。
干货|国内外十大主流采集软件盘点
采集交流 • 优采云 发表了文章 • 0 个评论 • 763 次浏览 • 2020-08-10 15:09
文|优采云大数据
大数据技术用了多年时间进行演变,才从一种看起来太炫目的新技术弄成了企业在生产经营中实际布署的服务。其中,数据采集产品迎来了辽阔的市场前景,无论国内外,市面上都出现了许多技术不一、良莠不齐的采集软件。
今天,我们将对比 国内外十大主流采集软件优缺点,帮助你选择最适宜的爬虫,体验数据hunting带来的快感。
国内篇
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。它的用户定位主要是拥有一定代码基础的人群,适合编程老鸟。
采集功能健全,不限网页与内容,任意文件格式都可下载
具有智能多辨识系统以及可选的验证方法保护安全
支持PHP和C#插件扩充,方便更改处理数据
具有同义,近义词替换、参数替换,伪原创必备技能
采集难度大,对没有编程基础的用户来说存在困难
Conclusion:优采云适用于编程能手,规则编撰比较复杂,软件的定位比较专业并且精准化。
2.优采云
一款可视化免编程的网页采集软件,可以从不同网站中快速提取规范化数据,帮助用户实现数据的自动化采集、编辑以及规范化,降低工作成本。云采集是它的一大特色,相比其他采集软件,云采集能够做到愈发精准、高效和大规模。
可视化操作,无需编撰代码,制作规则采集,适用于零编程基础的用户
即将发布的7.0版本智能化,内置智能算法和既定采集规则,用户设置相应参数能够实现网站、APP的手动采集。
云采集是其主要功能,支持死机采集,并实现手动定时采集
支持多IP动态分配与验证码破解,避免IP封锁
采集数据表格化,支持多种导入方法和导出网站
Conclusion:优采云是一款适宜小白用户尝试的采集软件,云功能强悍,当然爬虫老鸟也能开拓它的中级功能。
3.集搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素。同样可通过简单可视化流程进行采集,服务于任何对数据有采集需求的人群。
可视化流程操作,与优采云不同,集搜客的流程重在定义所抓取的数据和爬虫路线,优采云的规则流程非常明晰,由用户决定软件的每一步操作
支持抓取在指数图表上漂浮显示的数据,还可以抓取手机网站上的数据
会员可以互助抓取,提升采集效率,同时还有模板资源可以套用
Conclusion:集搜客操作较简单,适用于中级用户,功能方面没有很大的特色,后续付费要求比较多。
4.优采云云爬虫
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据。
直接接入代理IP,避免IP封锁
自动登入验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富表格化方式诠释本地化隐私保护,云端采集,可隐藏用户IP
Conclusion: 优采云类似一个爬虫系统框架,具体采集还需用户自写爬虫,需要代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
支持对文章内容中的文字、链接批量替换和过滤
可以同时向网站或峰会的多个版块一起批量发帖
具备采集或发贴任务完成后自动关机功能
Conclusion: 专注峰会、博客文本内容的抓取,对于全网数据的采集通用性不高。
国外篇
1.Import.io
Import.io是一个基于Web的网页数据采集平台,用户无需编撰代码点选即可生成一个提取器。相比国外大多采集软件,Import.io较为智能,能够匹配并生成同类元素列表,用户输入网址也可一键采集数据。
提供云服务,自动分配云节点并提供SaaS平台储存数据
提供API导入插口,可导入Google Sheets, Excel, Tableau等格式
收费形式按采集词条数目,提供基础版、专业版、企业版三种版本
Conclution: Import.io智能发展,采集简便,但对于一些复杂的网页结构处理能力较为薄弱。
2.Octoparse
Octoparse是一款功能齐全互联网采集工具,内置许多高效工具,用户无需编撰代码便可从复杂网页结构中搜集结构化数据。采集页面设计简单友好,完全可视化操作,适用于菜鸟用户。
提供云采集服务,可达到4-10倍速的云采集
广告封锁功能,通过降低加载时间来提升采集效率
提供Xpath设置,精准定位网页数据的元素
支持导入多种数据格式如CSV,Excel,XML等
多版本选择,分为免费版付费版,付费版均提供云服务
Conclution: Octoparse功能健全,价格合理,能够应用于复杂网页结构,如果你想无需翻墙直采亚马逊、Facebook、Twitter等平台,Octoparse是一种选择。
3.Visual Web Ripper
Visual Web Ripper是一个自动化的Web抓取工具,支持各类功能。它适用于个别中级且采集难度较大的网页结构,用户需具备较强的编程技能。
可提取各类数据格式(列表页面)
提供IP代理,避免IP封锁
支持多种数据导入格式也可通过编程自定义输出格式
内置调试器,可帮助用户自定义采集过程和输出格式
Conclution :Visual Web Ripper功能强悍,自定义采集能力强,适用于编程经验丰富的用户。它不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber是功能最强悍的Web抓取工具之一。它更适宜具有中级编程技能的人群,提供了许多强大的脚本编辑,调试界面。允许用户编撰正则表达式,而不是使用外置的工具。
内置调试器,帮助用户进行代码调试
与一些软件开发平台对接,供用户编辑爬虫脚本
提供API导入插口并支持自定义编程插口
Conclution :Content Grabber网页适用性强,功能强悍,不完全为用户提供基础功能,适合具有中级编程技能的人群。
5.Mozenda
Mozenda是一个基于云服务的数据采集软件,为用户提供许多实用性功能包括数据云端储备功能。
能够提取各类数据格式,但对于不规则数据结构较难处理(如列表、表格)
内置正则表达式工具,需要用户自行编撰
支持多种数据导入格式但不提供自定义插口
Conclution :Mozenda提供数据云储备,但无法处理复杂网页结构,软件操作界面跳跃,用户体验不够友好,适合拥有基础爬虫经验的人群。
上述的爬虫软件早已能满足海内外用户的采集需求,其中一些工具,如优采云、优采云、Octoparse、Content Grabber提供了不少中级功能,帮助用户使用外置的Regex,XPath工具和代理服务器,从复杂网页中爬取精准数据。
没有编程基础的用户不建议选择优采云、Content Grabber等须要自定义编程的工具。当然,这完全取决于个人需求,毕竟适宜自己的就是最好的!
本文由 优采云大数据 投稿至36大数据,并经由36大数据编辑发布,转载必须获得原作者和36大数据许可,并标明来源36大数据,任何不经同意的转载均为侵权。
End. 查看全部

文|优采云大数据
大数据技术用了多年时间进行演变,才从一种看起来太炫目的新技术弄成了企业在生产经营中实际布署的服务。其中,数据采集产品迎来了辽阔的市场前景,无论国内外,市面上都出现了许多技术不一、良莠不齐的采集软件。
今天,我们将对比 国内外十大主流采集软件优缺点,帮助你选择最适宜的爬虫,体验数据hunting带来的快感。
国内篇
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。它的用户定位主要是拥有一定代码基础的人群,适合编程老鸟。

采集功能健全,不限网页与内容,任意文件格式都可下载
具有智能多辨识系统以及可选的验证方法保护安全
支持PHP和C#插件扩充,方便更改处理数据
具有同义,近义词替换、参数替换,伪原创必备技能
采集难度大,对没有编程基础的用户来说存在困难
Conclusion:优采云适用于编程能手,规则编撰比较复杂,软件的定位比较专业并且精准化。
2.优采云
一款可视化免编程的网页采集软件,可以从不同网站中快速提取规范化数据,帮助用户实现数据的自动化采集、编辑以及规范化,降低工作成本。云采集是它的一大特色,相比其他采集软件,云采集能够做到愈发精准、高效和大规模。
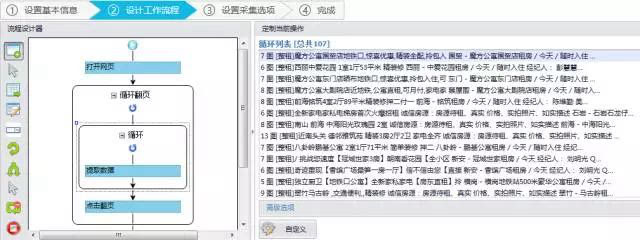
可视化操作,无需编撰代码,制作规则采集,适用于零编程基础的用户
即将发布的7.0版本智能化,内置智能算法和既定采集规则,用户设置相应参数能够实现网站、APP的手动采集。
云采集是其主要功能,支持死机采集,并实现手动定时采集
支持多IP动态分配与验证码破解,避免IP封锁
采集数据表格化,支持多种导入方法和导出网站
Conclusion:优采云是一款适宜小白用户尝试的采集软件,云功能强悍,当然爬虫老鸟也能开拓它的中级功能。
3.集搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素。同样可通过简单可视化流程进行采集,服务于任何对数据有采集需求的人群。

可视化流程操作,与优采云不同,集搜客的流程重在定义所抓取的数据和爬虫路线,优采云的规则流程非常明晰,由用户决定软件的每一步操作
支持抓取在指数图表上漂浮显示的数据,还可以抓取手机网站上的数据
会员可以互助抓取,提升采集效率,同时还有模板资源可以套用
Conclusion:集搜客操作较简单,适用于中级用户,功能方面没有很大的特色,后续付费要求比较多。
4.优采云云爬虫
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据。

直接接入代理IP,避免IP封锁
自动登入验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富表格化方式诠释本地化隐私保护,云端采集,可隐藏用户IP
Conclusion: 优采云类似一个爬虫系统框架,具体采集还需用户自写爬虫,需要代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
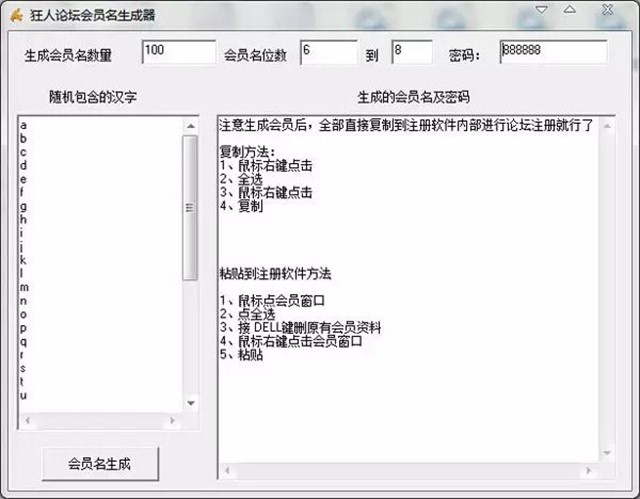
支持对文章内容中的文字、链接批量替换和过滤
可以同时向网站或峰会的多个版块一起批量发帖
具备采集或发贴任务完成后自动关机功能
Conclusion: 专注峰会、博客文本内容的抓取,对于全网数据的采集通用性不高。
国外篇
1.Import.io
Import.io是一个基于Web的网页数据采集平台,用户无需编撰代码点选即可生成一个提取器。相比国外大多采集软件,Import.io较为智能,能够匹配并生成同类元素列表,用户输入网址也可一键采集数据。
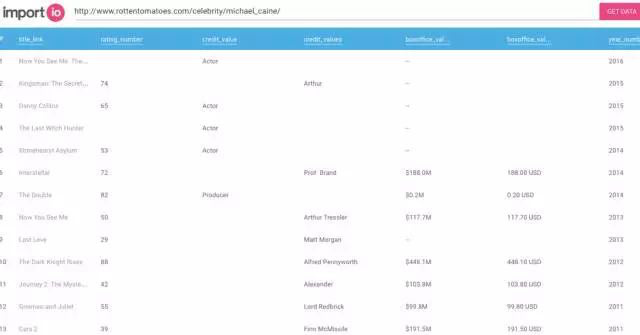
提供云服务,自动分配云节点并提供SaaS平台储存数据
提供API导入插口,可导入Google Sheets, Excel, Tableau等格式
收费形式按采集词条数目,提供基础版、专业版、企业版三种版本
Conclution: Import.io智能发展,采集简便,但对于一些复杂的网页结构处理能力较为薄弱。
2.Octoparse
Octoparse是一款功能齐全互联网采集工具,内置许多高效工具,用户无需编撰代码便可从复杂网页结构中搜集结构化数据。采集页面设计简单友好,完全可视化操作,适用于菜鸟用户。
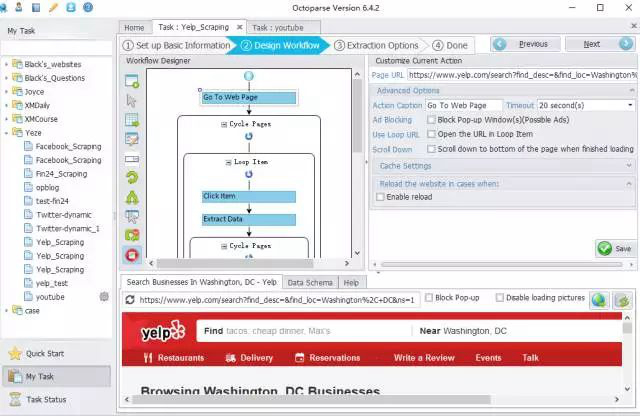
提供云采集服务,可达到4-10倍速的云采集
广告封锁功能,通过降低加载时间来提升采集效率
提供Xpath设置,精准定位网页数据的元素
支持导入多种数据格式如CSV,Excel,XML等
多版本选择,分为免费版付费版,付费版均提供云服务
Conclution: Octoparse功能健全,价格合理,能够应用于复杂网页结构,如果你想无需翻墙直采亚马逊、Facebook、Twitter等平台,Octoparse是一种选择。
3.Visual Web Ripper
Visual Web Ripper是一个自动化的Web抓取工具,支持各类功能。它适用于个别中级且采集难度较大的网页结构,用户需具备较强的编程技能。

可提取各类数据格式(列表页面)
提供IP代理,避免IP封锁
支持多种数据导入格式也可通过编程自定义输出格式
内置调试器,可帮助用户自定义采集过程和输出格式
Conclution :Visual Web Ripper功能强悍,自定义采集能力强,适用于编程经验丰富的用户。它不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber是功能最强悍的Web抓取工具之一。它更适宜具有中级编程技能的人群,提供了许多强大的脚本编辑,调试界面。允许用户编撰正则表达式,而不是使用外置的工具。
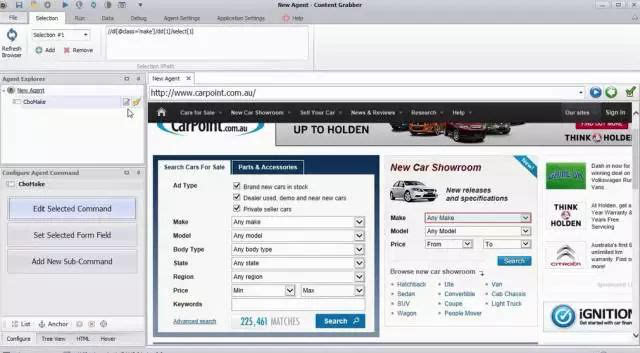
内置调试器,帮助用户进行代码调试
与一些软件开发平台对接,供用户编辑爬虫脚本
提供API导入插口并支持自定义编程插口
Conclution :Content Grabber网页适用性强,功能强悍,不完全为用户提供基础功能,适合具有中级编程技能的人群。
5.Mozenda
Mozenda是一个基于云服务的数据采集软件,为用户提供许多实用性功能包括数据云端储备功能。
能够提取各类数据格式,但对于不规则数据结构较难处理(如列表、表格)
内置正则表达式工具,需要用户自行编撰
支持多种数据导入格式但不提供自定义插口
Conclution :Mozenda提供数据云储备,但无法处理复杂网页结构,软件操作界面跳跃,用户体验不够友好,适合拥有基础爬虫经验的人群。
上述的爬虫软件早已能满足海内外用户的采集需求,其中一些工具,如优采云、优采云、Octoparse、Content Grabber提供了不少中级功能,帮助用户使用外置的Regex,XPath工具和代理服务器,从复杂网页中爬取精准数据。
没有编程基础的用户不建议选择优采云、Content Grabber等须要自定义编程的工具。当然,这完全取决于个人需求,毕竟适宜自己的就是最好的!
本文由 优采云大数据 投稿至36大数据,并经由36大数据编辑发布,转载必须获得原作者和36大数据许可,并标明来源36大数据,任何不经同意的转载均为侵权。
End.
优采云采集器软件(熊猫智能采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-07 23:37
Microsoft .NET Framework 3.5 SP1
版本: V3.5
运行平台: Microsoft Windows(32位)操作系统
运行优采云采集器软件所需的平台软件应确保运行优采云采集器软件的计算机已安装.net 3.5 SP1或更高版本.
当前的大多数Windows操作系统都有自己的.net3.5和更高版本的优采云采集器软件,除非必要,否则无需进行特殊安装.
这是平台软件的官方Microsoft网站的游戏策略地址:
如何直接玩
Microsoft Access 2010 x64数据库引擎
版本: Microsoft Office 2010 64位
运行平台: Microsoft Windows 64位操作系统
如果您需要运行64位版本的Panda软件,则需要在计算机上安装Microsoft Office 64位. 如果尚未安装,则可以直接安装驱动程序引擎.
在少数情况下,尽管已安装64位版本的Office,但在软件运行期间经常报告莫名其妙的错误. 此时,您还应该尝试再次安装该引擎.
如何直接玩
访问数据库
版本: Office 2003及更高版本
Microsoft Office系列中的一个小型数据库. 在优采云采集器软件运行期间生成的日志和其他信息均由优采云采集器软件存储和管理,这也是优采云采集器中的默认数据库.
但这不是必需的. 如果确认使用第三方数据库引擎,则优采云采集器系统仍然可以正常运行,但是此时无法打开运行日志.
Access数据库软件是Microsoft Office办公室自动化软件系列之一. 如果您的计算机上未安装此软件,请从您的Office安装盘中添加并安装Access.
您还可以从Internet搜索与游戏策略相关的软件,但不建议这样做. 查看全部

Microsoft .NET Framework 3.5 SP1
版本: V3.5
运行平台: Microsoft Windows(32位)操作系统
运行优采云采集器软件所需的平台软件应确保运行优采云采集器软件的计算机已安装.net 3.5 SP1或更高版本.
当前的大多数Windows操作系统都有自己的.net3.5和更高版本的优采云采集器软件,除非必要,否则无需进行特殊安装.
这是平台软件的官方Microsoft网站的游戏策略地址:
如何直接玩

Microsoft Access 2010 x64数据库引擎
版本: Microsoft Office 2010 64位
运行平台: Microsoft Windows 64位操作系统
如果您需要运行64位版本的Panda软件,则需要在计算机上安装Microsoft Office 64位. 如果尚未安装,则可以直接安装驱动程序引擎.
在少数情况下,尽管已安装64位版本的Office,但在软件运行期间经常报告莫名其妙的错误. 此时,您还应该尝试再次安装该引擎.
如何直接玩
访问数据库
版本: Office 2003及更高版本
Microsoft Office系列中的一个小型数据库. 在优采云采集器软件运行期间生成的日志和其他信息均由优采云采集器软件存储和管理,这也是优采云采集器中的默认数据库.
但这不是必需的. 如果确认使用第三方数据库引擎,则优采云采集器系统仍然可以正常运行,但是此时无法打开运行日志.
Access数据库软件是Microsoft Office办公室自动化软件系列之一. 如果您的计算机上未安装此软件,请从您的Office安装盘中添加并安装Access.
您还可以从Internet搜索与游戏策略相关的软件,但不建议这样做.
福利:业内首个数据集高级清洗服务 百度EasyData智能数据服务平台免费试用中
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2020-09-07 23:30
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
业界首个高级数据集清洁服务百度EasyData智能数据服务平台正在免费试用
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
完整解决方案:百度推智能数据服务平台EasyData,具有高级智能数据清洗功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-09-07 13:50
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在这一步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终机密?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务(人脸检测和人体检测均可免费试用),他们可以通过简单的配置直接使用EasyData平台。使用这些功能可以自动清除数据。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人为检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二值图像转换为相应的标签。
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,对于基本的清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
百度推出具有高级智能数据清理功能的智能数据服务平台EasyData
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在这一步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终机密?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务(人脸检测和人体检测均可免费试用),他们可以通过简单的配置直接使用EasyData平台。使用这些功能可以自动清除数据。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器将过滤掉这些没有面部的照片,并保留收录面部的照片,包括遮罩和遮挡的面部也可以被识别。
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人为检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二值图像转换为相应的标签。
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,对于基本的清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
整体解决方案:业内首个数据集高级清洗服务 百度EasyData智能数据服务平台免费试用中
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-09-04 22:40
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
业界首个高级数据集清洁服务百度EasyData智能数据服务平台正在免费试用
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
整套解决方案:业内首个数据集高级清洗服务 百度EasyData智能数据服务平台免费试用中
采集交流 • 优采云 发表了文章 • 0 个评论 • 447 次浏览 • 2020-09-04 12:02
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。 查看全部
业界首个高级数据集清洁服务百度EasyData智能数据服务平台正在免费试用
在开发AI模型时,数据的数量和质量会直接影响模型的效果。在获得现场数据采集之后,公司经常需要从大量数据中筛选出符合培训要求的相关数据,并消除质量差或不相关的数据。此步骤称为数据清除。
通常,在清理数据时,主要清理对培训任务无用的数据。例如,当培训工厂工人佩戴头盔识别模型时,希望在绘制视频帧后仅工人保留在大量图片中。用于注释训练的图像。在此步骤中,传统方法是执行手动筛选,这需要大量的人工输入,并且容易遗漏。随着人工智能的发展,诸如百度大脑AI开放平台等许多平台已经提供了用于人脸检测和人体检测的通用接口。 ,用户可以首先调用界面来处理数据,从采集到人像中过滤掉数据,然后输入特定的检测和识别步骤。那么,是否有一种解决方案可以集成各种数据处理功能,最大程度地减少人工干预,并可以自动完成视频数据采集,帧提取,数据清理和智能标记,从而有效地提取高质量的训练数据?
着眼于越来越多的用户对数据处理的强烈需求。今年4月,百度推出了新的智能数据服务平台EasyData,该平台集成了数据采集,数据清理,数据标记等功能,完成了上述工作。数据处理后,可以在EasyDL平台上进行模型训练和模型部署
对于数据清理的特定功能,EasyData当前具有五种基本的数据清理功能:类似,去模糊,旋转,修剪和镜像。那么,除了常规功能之外,EasyData在行业中还有哪些其他最终秘诀?
从应用程序开始,先进的清理功能使数据处理更加轻松高效
在公园智能管理等场景中,有必要监视是否有人闯入工厂公园或森林区域,或检查工人是否戴上安全帽。为了满足这种情况下图像清洁的需求,EasyData推出了高级清洁功能,可以在没有人脸或人体的情况下过滤数据。 EasyData与百度Brain AI开放平台提供的尖端技术功能相关联。用户只需要在百度智能云上打开相应的服务即可(面部检测和人体检测均可免费试用),他们可以通过简单的配置直接在EasyData平台上使用这些功能进行自动数据清理。
1、过滤没有脸孔的照片
如果您以前从未使用过百度智能云的面部检测服务,则第一次使用高级清洁功能时,系统会提示您“申请免费试用”,单击链接进入百度智能云面部检测页面,按照提示激活服务后,返回EasyData页面即可正常使用。
像基本的数据清洁服务一样,无人脸图像的过滤也基于数据集。在数据清理页面上,选择过滤没有人脸的图像,单击保存,然后提交任务以对其进行清理。如果选中“保留标签”,则不仅将滤除没有脸部的图片,而且脸部框架也会同步到清洁的数据集。
提交任务时检查保持脸部轮廓
例如,在下图中,除了面部图片之外,清洁之前的数据集还收录风景照片,车辆和其他物体的图片。面部过滤器可以过滤掉这些没有面部的照片,并保留收录面部的照片,包括面具和遮挡的面部也可以被识别。
清洁前的数据集收录人脸照片,风景照片和静物照片
仅保存清洁数据集的面部照片
戴口罩的脸的照片
2、过滤掉没有人体的图像
对没有人体的图像进行过滤还将使用百度智能云的人体检测功能,并且在使用之前需要在百度智能云上激活相应的服务。两个界面用于过滤没有人体的图像,即人体检测和属性分析()和人像分割()。用于图像分类和对象检测的数据集模板将调用人体检测和属性分析界面,而用于图像分割数据集的数据集模板将调用肖像分割界面。百度智能云上的人像分割界面返回与人像图像相对应的二进制图像(人像为1,背景为0),并在后端进行相应的标签转换,并将返回的二进制图像转换为相应的标签。
在清洁之前的数据集中有风景图像,静物图像和人体图像。
通过数据清理和过滤保留5张人像
模板是清洁图像检测数据集后的标签
模板是清洗图像分割数据集后的标签
关注广泛的需求并提供各种基本的数据清理功能
1、转到相似的图片
使用照相机自动[k1]照片时,即使长时间在同一场景中提取帧,仍然会有大量相似的照片。大量相似图片的数据值较低,并且占用大量存储空间。手动选择非常耗时,费力且容易出错。 EasyData平台启动的相似图片的去除,利用图片的相似检索功能,计算出图片的成对相关性,可以自动判断相似图片并保留不相似图片,具体操作也非常简单。
如下图所示,类似之前,数据集中有8张图片。根据图片的相似度,图片可分为3类。清洁后数据集中有3张图片,是清洁前3种图片之一。
8张图片,然后再浏览类似图片
相似后保留3张图片
拖动点以修改相似度得分
2、对图像进行模糊处理
相机震动和快速移动的物体会导致图像不清晰和质量低劣的图像。手动选择去除模糊图像的方法缺乏统一的标准,容易遗漏或删除多个。使用EasyData的去模糊图像,您可以轻松删除模糊的图像。
以示例图片为例。清洁之前,有5张不同质量的照片。清洁后保留两张高质量的照片。另外,如果用户认为某些模糊的图片没有被去除,或者高质量的图片没有被保留,他们可以考虑调整清晰度得分并再次对其进行清洁。
去模糊前5张不同质量的图片
去模糊后保持清晰的画面
拖动点以修改清晰度得分
对于常规清洁,您可以在清洁任务中提交多个清洁操作。例如,检查同时删除相似性和去模糊功能以同时删除相似和模糊的图片。
当前数据清理服务可以支持的最大数据集大小为50,000张图像。基于EasyData平台的大数据处理平台,为基本清洁服务,仅1小时即可清洁20,000张图片的数据集;可以在2小时内清除50,000张照片的数据集。对于高级清洁服务,还可以通过配置QPS灵活地调整清洁效率,这更加方便,快捷。
考虑到在智能公园管理等场景中,需要剪切帧并自动上传视频,EasyData平台还提供了免费的SDK供用户下载,并且该SDK可以连接到数据采集终端,在平台上设置切帧时间和间隔,并自动将原创视频数据切成图片数据,并将其上传到EasyData平台进行后续处理。
EasyData是百度Brain推出的业界首个智能数据采集和处理平台,可提供软件和硬件集成以及端云协作。它支持处理四种类型的数据:图片,文本,音频和视频,其中图片数据支持采集一站式清洁和标记处理,涵盖了模型开发中的各种数据管理要求。 EasyData处理的数据可以直接应用于EasyDL模型训练,通过EasyDL预训练模型和自动迁移学习机制可以有效地开发AI模型。
吉林智能数据采集 专业数据采集平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 726 次浏览 • 2020-08-29 04:01
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。
对于企业生产经营数据上的顾客数据,财务数据等保密性要求较高的数据,可以通过与数据技术服务商合作,使用特定系统插口等相关方法采集数据。比如八度云计算的数企BDSaaS,无论是数据采集技术、BI数据剖析,还是数据的安全性和保密性,都做得挺好。
‘搜客’---搜客数据采集APP的优势
一、‘搜客’是哪些?
‘搜客’是一款高智能客源信息采集平台,本质上是一款市场营销系统,能够帮助使用人确切的采集所须要搜集的会员顾客信息。
二、‘搜客’是如何的一个行业定位?
‘搜客’做为大数据营销软件,定位为垂直搜索引擎。即专注于信息采集垂直领域,搜索引擎只能调阅数据信息,不形成任何交易环节。
三、‘搜客’所提供的数据信息是否真实合法?
‘搜客’以数十家小型为搜索基础。所有数据信息皆从调阅,真实性毋庸置疑,至于所采集的信息也都是全网公开的信息,并且由本人上传,在主观意愿上是选择公开的,‘搜客’所采集的信息,属于网路公开信息,真实合法。
四、‘搜客’的采集源从何而至?
‘搜客’采集源来自于百度地图、高德地图、360网、赶集网等搜索引擎。全网搜索采集各行业类别信息,包括各类别店家的地址信息,联系方法,经营信息等公开信息,切实做到信息有效、更新及时的问题,并且具体化至区域搜索,精确到市区内采集,真实有效的提供了精准的行业布满
五、‘搜客’的功能都有什么?
搜索精确:在软件全网采集站点里输入想要的行业和地区 就可以搜索到精准的顾客信息资源。
产品推广:主要功能是可以发布广告信息,针对信息情况来选择信息分类。收录推广图片,以及文字进行详尽的描述介绍。
一键添加:搜索下来的资源信息通过一键添加可以直接导出到手机通讯录里。
同城客源:基于归属地大数据,可按照规则一键生成海量目标号码。营销宝典:搜集互联网精品的营销课程,让您用的过程中也才能学习。
一键清空:将添加的客源信息,一键删掉。只删掉从搜客软件添加的信息,不会影响任何自动保存的信息。提供精准对口行业资源信息;有针对性的做业务,提高效率;提供建立的埋点采集规范,调用 API 接收埋点数据;支持导出第三方或线下数据,丰富数据源进行剖析;提供统一的埋点指标管理平台,便捷管理埋点指标。
六、‘搜客’相比同类产品的优势?
1、搜索内容的随意性大,不用局限于软件里现有的行业,用户能想到的都可以搜索。
2、客源的区域性更细化。用户可以依照自己的需求选择区或则市区。
3、可以根据行业分类导出手机通讯录。让手机通讯录里的客源信息分类更明晰。并且可以同步陌陌和QQ软件,灵活多样的做业务推广。
4、可以根据行业分类导入execl表格。
5、短信群发功能,选择一个地区的某个行业后,用户以邮件的形式顿时发送给对方,针对性强,推广速度快。
6、推广功能,用户可以把自己的产品推广到软件里,并且可以分享到陌陌好友和朋友圈。
7、私人定制,用户可以按照自己的行业须要订做软件。
8、只须要一部手机,通过搜客系统即可开发全省市场。
七、‘搜客’系统未来会怎样优化?
目前‘搜客’仅可作为营销工具使用,但在不断建立更新的过程中,会逐渐进行除营销工具意外的调整,自身调整包括上线‘搜客’商城,系统功能在‘搜客’完善过程中通过大数据信息流调整出行业并立的搭建式系统,推广者虽然任何事情都不做,也会带来大的产品销量。
-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。 查看全部
吉林智能数据采集 专业数据采集平台
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。
对于企业生产经营数据上的顾客数据,财务数据等保密性要求较高的数据,可以通过与数据技术服务商合作,使用特定系统插口等相关方法采集数据。比如八度云计算的数企BDSaaS,无论是数据采集技术、BI数据剖析,还是数据的安全性和保密性,都做得挺好。
‘搜客’---搜客数据采集APP的优势
一、‘搜客’是哪些?
‘搜客’是一款高智能客源信息采集平台,本质上是一款市场营销系统,能够帮助使用人确切的采集所须要搜集的会员顾客信息。
二、‘搜客’是如何的一个行业定位?
‘搜客’做为大数据营销软件,定位为垂直搜索引擎。即专注于信息采集垂直领域,搜索引擎只能调阅数据信息,不形成任何交易环节。
三、‘搜客’所提供的数据信息是否真实合法?
‘搜客’以数十家小型为搜索基础。所有数据信息皆从调阅,真实性毋庸置疑,至于所采集的信息也都是全网公开的信息,并且由本人上传,在主观意愿上是选择公开的,‘搜客’所采集的信息,属于网路公开信息,真实合法。
四、‘搜客’的采集源从何而至?
‘搜客’采集源来自于百度地图、高德地图、360网、赶集网等搜索引擎。全网搜索采集各行业类别信息,包括各类别店家的地址信息,联系方法,经营信息等公开信息,切实做到信息有效、更新及时的问题,并且具体化至区域搜索,精确到市区内采集,真实有效的提供了精准的行业布满
五、‘搜客’的功能都有什么?
搜索精确:在软件全网采集站点里输入想要的行业和地区 就可以搜索到精准的顾客信息资源。
产品推广:主要功能是可以发布广告信息,针对信息情况来选择信息分类。收录推广图片,以及文字进行详尽的描述介绍。
一键添加:搜索下来的资源信息通过一键添加可以直接导出到手机通讯录里。
同城客源:基于归属地大数据,可按照规则一键生成海量目标号码。营销宝典:搜集互联网精品的营销课程,让您用的过程中也才能学习。
一键清空:将添加的客源信息,一键删掉。只删掉从搜客软件添加的信息,不会影响任何自动保存的信息。提供精准对口行业资源信息;有针对性的做业务,提高效率;提供建立的埋点采集规范,调用 API 接收埋点数据;支持导出第三方或线下数据,丰富数据源进行剖析;提供统一的埋点指标管理平台,便捷管理埋点指标。
六、‘搜客’相比同类产品的优势?
1、搜索内容的随意性大,不用局限于软件里现有的行业,用户能想到的都可以搜索。
2、客源的区域性更细化。用户可以依照自己的需求选择区或则市区。
3、可以根据行业分类导出手机通讯录。让手机通讯录里的客源信息分类更明晰。并且可以同步陌陌和QQ软件,灵活多样的做业务推广。
4、可以根据行业分类导入execl表格。
5、短信群发功能,选择一个地区的某个行业后,用户以邮件的形式顿时发送给对方,针对性强,推广速度快。
6、推广功能,用户可以把自己的产品推广到软件里,并且可以分享到陌陌好友和朋友圈。
7、私人定制,用户可以按照自己的行业须要订做软件。
8、只须要一部手机,通过搜客系统即可开发全省市场。
七、‘搜客’系统未来会怎样优化?
目前‘搜客’仅可作为营销工具使用,但在不断建立更新的过程中,会逐渐进行除营销工具意外的调整,自身调整包括上线‘搜客’商城,系统功能在‘搜客’完善过程中通过大数据信息流调整出行业并立的搭建式系统,推广者虽然任何事情都不做,也会带来大的产品销量。
-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。
Aria Insights公司借助人工智能来提供新的无人机数据采集和剖析服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-26 04:52
【据UnmannedSystemstechnology网站2019年1月22日报导】自主机器人数据采集平台开发商Aria Insights公司宣布,发起一项新的服务,将借助人工智能为顾客提供新的无人机数据采集和剖析服务,可以更有效地使用无人机搜集的数据,并确保用户在此过程中的安全。 Aria Insights 公司正在通过将人工智能和机器学习软件集成到其无人机上来扩充 CyPhy 公司系留无人机服务范围,计划为顾客提供智能、自主型无人机,这些无人机可以搜集和剖析数据,为用户提供可操作的解决方案。
关于日本Aria Insights无人机公司步入企业商铺
美国Aria Insights无人机公司提供全方位服务的无人机解决方案,结合了自主和机器学习的强悍功能,可搜集数据并为用户创建可操作的看法。
Aria Insights使用无人机和人工智能步入公共安全,石油和天然气以及其他商业领域的后勤困难和潜在危险环境,同时确保人类生命不会遭到恐吓。
Aria Insights,一家致力于提供自主,机器人队友的公司,今天早已推出。使用人工智能(AI),Aria可以更有效地借助无人机搜集的数据,并在此过程中保证用户的安全。Aria Insights由CyPhy Works团队成立,通过将AI和机器学习软件集成到无人机中,扩展了CyPhy的系留无人机传统。该公司将为顾客提供智能,自主的无人机,既可以搜集和剖析数据,也可以为用户创建可操作的看法。将重点置于人工智能上的决定来自于多年的行业经验,这些经验表明无人机的威力仅限于使用和理解她们搜集的数据。
“Aptly以一群金丝雀命名,他们过去经常努力保护矿山工人免受致命二氧化碳的侵犯,Aria Insights布署无人驾驶客机和人工智能,以便将人类从不安全的情况中移除。更智能的数据搜集和机器学习让决策者才能快速有效地解决问题或执行任务,同时确保人类生命不会遭到恐吓。通过复杂的剖析,决策者不再须要耗费数小时捕获和观看视频;相反,Aria Insights的机器人将辨识感兴趣的信息,在测量到新信息时发送警报,并最终将所有数据联接到数字3D地图。 查看全部
Aria Insights公司借助人工智能来提供新的无人机数据采集和剖析服务
【据UnmannedSystemstechnology网站2019年1月22日报导】自主机器人数据采集平台开发商Aria Insights公司宣布,发起一项新的服务,将借助人工智能为顾客提供新的无人机数据采集和剖析服务,可以更有效地使用无人机搜集的数据,并确保用户在此过程中的安全。 Aria Insights 公司正在通过将人工智能和机器学习软件集成到其无人机上来扩充 CyPhy 公司系留无人机服务范围,计划为顾客提供智能、自主型无人机,这些无人机可以搜集和剖析数据,为用户提供可操作的解决方案。
关于日本Aria Insights无人机公司步入企业商铺
美国Aria Insights无人机公司提供全方位服务的无人机解决方案,结合了自主和机器学习的强悍功能,可搜集数据并为用户创建可操作的看法。
Aria Insights使用无人机和人工智能步入公共安全,石油和天然气以及其他商业领域的后勤困难和潜在危险环境,同时确保人类生命不会遭到恐吓。
Aria Insights,一家致力于提供自主,机器人队友的公司,今天早已推出。使用人工智能(AI),Aria可以更有效地借助无人机搜集的数据,并在此过程中保证用户的安全。Aria Insights由CyPhy Works团队成立,通过将AI和机器学习软件集成到无人机中,扩展了CyPhy的系留无人机传统。该公司将为顾客提供智能,自主的无人机,既可以搜集和剖析数据,也可以为用户创建可操作的看法。将重点置于人工智能上的决定来自于多年的行业经验,这些经验表明无人机的威力仅限于使用和理解她们搜集的数据。
“Aptly以一群金丝雀命名,他们过去经常努力保护矿山工人免受致命二氧化碳的侵犯,Aria Insights布署无人驾驶客机和人工智能,以便将人类从不安全的情况中移除。更智能的数据搜集和机器学习让决策者才能快速有效地解决问题或执行任务,同时确保人类生命不会遭到恐吓。通过复杂的剖析,决策者不再须要耗费数小时捕获和观看视频;相反,Aria Insights的机器人将辨识感兴趣的信息,在测量到新信息时发送警报,并最终将所有数据联接到数字3D地图。
包头智能数据采集 专业数据采集平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2020-08-26 01:53
数据采集的设计,几乎完全取决于数据源的特点,毕竟数据源是整个大数据平台蓄水的上游,数据采集不过是获取水源的管线罢了。
大数据生命周期
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。我们明天就来瞧瞧大数据技术在数据采集方面采用了什么方式:
实时采集主要用在考虑流处理的业务场景,比如,用于记录数据源的执行的各类操作活动,比如网络监控的流量管理、金融应用的股票记账和 web 服务器记录的用户访问行为。在流处理场景,数据采集会成为Kafka的消费者,就像一个大坝通常将上游源源不断的数据拦截住,然后依照业务场景做对应的处理(例如去重、去噪、中间估算等),之后再写入到对应的数据储存中。这个过程类似传统的ETL,但它是流式的处理方法,而非定时的批处理Job,些工具均采用分布式构架,能满足每秒数百MB的日志数据采集和传输需求
数据采集–>数据储存–>数据处理–>数据凸显(可视化,报表和监控)
任何完整的大数据平台,一般包括以下的几个过程:(如果对大数据生命周期认识不够清晰,可参考还不懂哪些是大数据?大数据的生命周期求婚)
大数据环境下数据来源十分丰富且数据类型多样,存储和剖析挖掘的数据量庞大,对数据凸显的要求较高,并且太看重数据处理的高效性和可用性。(点击看懂大数据处理:大数据处理构架系列三:原来如此简单,HADOOP原理剖析)
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。
全的大数据采集方法分类,你想知道的都在这里
-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。 查看全部
包头智能数据采集 专业数据采集平台
数据采集的设计,几乎完全取决于数据源的特点,毕竟数据源是整个大数据平台蓄水的上游,数据采集不过是获取水源的管线罢了。
大数据生命周期
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。我们明天就来瞧瞧大数据技术在数据采集方面采用了什么方式:
实时采集主要用在考虑流处理的业务场景,比如,用于记录数据源的执行的各类操作活动,比如网络监控的流量管理、金融应用的股票记账和 web 服务器记录的用户访问行为。在流处理场景,数据采集会成为Kafka的消费者,就像一个大坝通常将上游源源不断的数据拦截住,然后依照业务场景做对应的处理(例如去重、去噪、中间估算等),之后再写入到对应的数据储存中。这个过程类似传统的ETL,但它是流式的处理方法,而非定时的批处理Job,些工具均采用分布式构架,能满足每秒数百MB的日志数据采集和传输需求
数据采集–>数据储存–>数据处理–>数据凸显(可视化,报表和监控)
任何完整的大数据平台,一般包括以下的几个过程:(如果对大数据生命周期认识不够清晰,可参考还不懂哪些是大数据?大数据的生命周期求婚)
大数据环境下数据来源十分丰富且数据类型多样,存储和剖析挖掘的数据量庞大,对数据凸显的要求较高,并且太看重数据处理的高效性和可用性。(点击看懂大数据处理:大数据处理构架系列三:原来如此简单,HADOOP原理剖析)
Scribe是Facebook开发的数据(日志)采集系统。又被称为网页蜘蛛,网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本,它支持图片、音频、视频等文件或附件的采集。
全的大数据采集方法分类,你想知道的都在这里
-/gbabjfi/-
欢迎来到河南搜客网络科技有限公司网站, 具体地址是河南省郑州市金水区兴业大厦2606,联系人是秦。
种草爬虫利器,小白也能一键采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-26 00:41
你有没有苦恼过,如何将网页中收录的各类信息转变为有用的数据呢?
粘贴复制??太累
开发软件??太贵
写python爬虫??太难学
下载了一些工具??太难用
这里给你们介绍下采集数据的利器,优采云采集器,无需编撰代码,就可以免费采集网站数据。
01
采集神器:优采云采集器
前微软技术团队鼎力构建,基于人工智能技术,只需输入网址能够手动辨识采集内容。
优采云采集器除了才能进行数据的自动化采集,而且在采集过程中还可以对数据进行清洗。在数据源头即可实现多种内容的过滤。
这么好用的一款产品,它竟然还是免费的!免费支持100个任务,支持多任务同时运行,无数目限制。
02
采集场景和数组
场景:采集优采云采集器文档中心发布的相关文章等相关数据
字段:文章标题、文章链接、摘要、发布时间
采集步骤
1、首先须要先在页面下载安装优采云采集器,然后注册用户
2、在首页输入要爬取数据的网址,我们以采集优采云采集器文档中心的数据为例
3、点击【智能采集】,优采云采集器可以手动辨识页面内容和分页按键,生成采集字段
4、点击【深入采集】,可步入每位详情页采集数据,如手动辨识的数组不是自己想要的,可以【清空所有】,点击【添加数组】选择自己想要采集的内容。
5、点击【开始采集】和【启动】,运行完毕后【导出数据】
播放暂停步入全屏退出全屏00:0000:00重播请刷新试试
--本视频来自优采云采集器
03
这是我用优采云采集器爬取去年最火电视剧的数据场景
优采云采集器真棒,还可以过滤数据,就可以只爬取开播收录2020的数据
优采云采集器爬取去年最火电视剧的数据场景
数据剖析
用爬到的数据做了一张文字云,2020年上半年最火评分最高的就是
隐秘的角落
20202020年上半年最火评分最高的电视剧 查看全部
种草爬虫利器,小白也能一键采集数据
你有没有苦恼过,如何将网页中收录的各类信息转变为有用的数据呢?
粘贴复制??太累
开发软件??太贵
写python爬虫??太难学
下载了一些工具??太难用
这里给你们介绍下采集数据的利器,优采云采集器,无需编撰代码,就可以免费采集网站数据。
01
采集神器:优采云采集器
前微软技术团队鼎力构建,基于人工智能技术,只需输入网址能够手动辨识采集内容。
优采云采集器除了才能进行数据的自动化采集,而且在采集过程中还可以对数据进行清洗。在数据源头即可实现多种内容的过滤。
这么好用的一款产品,它竟然还是免费的!免费支持100个任务,支持多任务同时运行,无数目限制。
02
采集场景和数组
场景:采集优采云采集器文档中心发布的相关文章等相关数据
字段:文章标题、文章链接、摘要、发布时间
采集步骤
1、首先须要先在页面下载安装优采云采集器,然后注册用户
2、在首页输入要爬取数据的网址,我们以采集优采云采集器文档中心的数据为例
3、点击【智能采集】,优采云采集器可以手动辨识页面内容和分页按键,生成采集字段
4、点击【深入采集】,可步入每位详情页采集数据,如手动辨识的数组不是自己想要的,可以【清空所有】,点击【添加数组】选择自己想要采集的内容。
5、点击【开始采集】和【启动】,运行完毕后【导出数据】
播放暂停步入全屏退出全屏00:0000:00重播请刷新试试
--本视频来自优采云采集器
03
这是我用优采云采集器爬取去年最火电视剧的数据场景
优采云采集器真棒,还可以过滤数据,就可以只爬取开播收录2020的数据
优采云采集器爬取去年最火电视剧的数据场景
数据剖析
用爬到的数据做了一张文字云,2020年上半年最火评分最高的就是
隐秘的角落
20202020年上半年最火评分最高的电视剧
智能互联网信息采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2020-08-25 16:07
本系统集成网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
一、系统简介
新闻媒体、政府部门、大型企事业单位纷纷通过互联网技术搭建网路信息搜集平台:新闻媒体须要获取大量的互联网上新闻资料,充实新闻资料库;政府机关须要搜集与自身业务相关的文献资料,提升办公与决策效率;大型企事业单位须要快速获取行业宏观环境、政策动态与竞争对手信息……
天宇智能互联网信息采集系统(CGSEEK)集成了网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现了对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
二、系统结构
三、系统主要功能
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
信息借助
◆可以将采集下来的网页信息放置到本地机器指定的某个文件夹下,进行借助。
◆系统支持采集的文本内容批量上载到天宇CGRS全文数据库中,可以借助天宇采盘发系统及全文检索系统进行信息采编、审核、发布与全文检索等借助。
◆经过智能提取的文本内容,可以上载到SQLServer等主流的关系型数据库中,充实资料库,也可以借助第三方应用系统对信息进行采编、发布与检索等应用。
四、系统特征
◆网页采集内容全面
适应网站内容格式的多变性,能完整地获取须要采集的页面,遗漏少,网页采集内容的完整性在99%以上。
◆内容准确度高
能便捷地将网页中的信息提取下来,如日期,标题,作者,栏目等内容;过滤网页中的无用信息。
◆精确定义采集范围
精确描述须要采集的网站范围,可以精确到整个网站、特定栏目、特定页面。
◆使用便捷,自动化程度高
系统参数设置简单,一次设置多次使用,修改便捷、直观、快捷。
◆信息采集快
系统通过多线程处理技术,可以同时启动多个搜索器,快速高效地对目标站点或栏目进行信息采集。
五、系统性能
◆采集速度:每分钟采集数百个最新目标页面(与机器性能及网路带宽有关);
◆处理速率:每分钟提取、过滤与上载数百个网页;
◆自动分类:页面内容手动分类准确率90%以上;
◆提取效率:页面内容(标题、日期、作者、正文等)准确提取率达99%以上。
六、运行环境
◆普通PC机,512M以上显存;
◆操作系统:Windows2000/2003/XP。
七、行业应用
◆网络传媒:自动跟踪与采集国内外网路媒体信息,可以使用关键词过滤搜索或批量采集的形式,实现各种新闻的有效采集、分类、编辑、管理、发布与检索一体化;系统支持第三方应用系统,如采编系统、发布系统、检索系统。
◆党政机关:实时搜集与业务工作相关的信息资源或新闻,在外网或内网上实时动态地发布下来,满足办公人员对互联网信息的须要,提高办公与办事效率。
◆大型企事业单位:通过系统实时追踪与搜集行业新政、宏观环境、竞争对手等相关情报资料,有利于提高企业综合竞争力。 查看全部
智能互联网信息采集系统
本系统集成网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
一、系统简介
新闻媒体、政府部门、大型企事业单位纷纷通过互联网技术搭建网路信息搜集平台:新闻媒体须要获取大量的互联网上新闻资料,充实新闻资料库;政府机关须要搜集与自身业务相关的文献资料,提升办公与决策效率;大型企事业单位须要快速获取行业宏观环境、政策动态与竞争对手信息……
天宇智能互联网信息采集系统(CGSEEK)集成了网页搜索、内容智能提取与过滤、自动分类、自动去重等技术,实现了对互联网信息采集、过滤、提取与批量上载的自动化与一体化。
二、系统结构
三、系统主要功能
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
◆支持各类标准格式信息资源的采集,如HTML页面、文本信息、表格、图片、声音、视频等。
◆实现对网页与内联图片的统一采集。
◆支持简体页面(BIG5码)的采集,并手动转换为标准的繁体码(GB码),支持Unicode码集。
◆支持由程序手动生成的页面内容的采集,如由JavaScript生成的页面。
◆能便捷将抓取网站上后台数据库的内容(JSP,ASP,CGI),和抓取须要通过用户身分校准的网站内容。
◆支持单篇网页及网站历史数据的批量下载。
信息借助
◆可以将采集下来的网页信息放置到本地机器指定的某个文件夹下,进行借助。
◆系统支持采集的文本内容批量上载到天宇CGRS全文数据库中,可以借助天宇采盘发系统及全文检索系统进行信息采编、审核、发布与全文检索等借助。
◆经过智能提取的文本内容,可以上载到SQLServer等主流的关系型数据库中,充实资料库,也可以借助第三方应用系统对信息进行采编、发布与检索等应用。
四、系统特征
◆网页采集内容全面
适应网站内容格式的多变性,能完整地获取须要采集的页面,遗漏少,网页采集内容的完整性在99%以上。
◆内容准确度高
能便捷地将网页中的信息提取下来,如日期,标题,作者,栏目等内容;过滤网页中的无用信息。
◆精确定义采集范围
精确描述须要采集的网站范围,可以精确到整个网站、特定栏目、特定页面。
◆使用便捷,自动化程度高
系统参数设置简单,一次设置多次使用,修改便捷、直观、快捷。
◆信息采集快
系统通过多线程处理技术,可以同时启动多个搜索器,快速高效地对目标站点或栏目进行信息采集。
五、系统性能
◆采集速度:每分钟采集数百个最新目标页面(与机器性能及网路带宽有关);
◆处理速率:每分钟提取、过滤与上载数百个网页;
◆自动分类:页面内容手动分类准确率90%以上;
◆提取效率:页面内容(标题、日期、作者、正文等)准确提取率达99%以上。
六、运行环境
◆普通PC机,512M以上显存;
◆操作系统:Windows2000/2003/XP。
七、行业应用
◆网络传媒:自动跟踪与采集国内外网路媒体信息,可以使用关键词过滤搜索或批量采集的形式,实现各种新闻的有效采集、分类、编辑、管理、发布与检索一体化;系统支持第三方应用系统,如采编系统、发布系统、检索系统。
◆党政机关:实时搜集与业务工作相关的信息资源或新闻,在外网或内网上实时动态地发布下来,满足办公人员对互联网信息的须要,提高办公与办事效率。
◆大型企事业单位:通过系统实时追踪与搜集行业新政、宏观环境、竞争对手等相关情报资料,有利于提高企业综合竞争力。
亿级APP支付宝在移动端的高可用技术实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2020-08-25 07:39
亿级 APP 在可用性方面的挑战
可用性的概念
简单而言,可用性就是当用户想要使用 APP 做一个事情,这件事情弄成了就是可用,没有弄成就不可用。
为什么没有弄成?可能的诱因有很多,比如有可能使用 APP 的时侯死机了,或者使用支付宝付款的时侯,由于后台某个环节出现错误,导致了这笔支付失败了等,这些都可能导致 APP 的不可用。
如果各种各样不可用的情况都没有出现,那么对于顾客而言就是可用的。虽然每位开发人员都希望自己开发的 APP 是 100% 可用的,但是实际上这一点是不可能的。所以开发人员真正须要做的事情就是使 APP 发生不可用的情况越来越少。
亿级 APP 的可用性挑战
目前,APP 开发技术早已比较成熟了,所以好多开发人员会觉得自己的 APP 可用性应当问题不是很大,因为 APP 都经历了相关的测试流程、灰度验证等保障举措。
但是如今情况早已发生变化了,与先前相比,APP 的用户量大了好多,很多的 APP 都达到了亿级用户,所以一点点可用性问题都可能会影响大量的用户。
比如 APP 的闪退率下降了千分之一,虽然这一比列并不是很大,但是对于一亿用户而言,乘上千分之一就是 10 万人。
大家可以想像一下,如果某三天你们在使用支付宝在商场付款的时侯,其中的 10 万人出现掉帧的情况,这个影响是绝对不可以接受的。
现在开发移动端 APP 讲究动态化,业务要求实时动态地实现线上变更,可以说明天的支付宝和今天的支付宝相比就早已形成很大区别了。
每一次线上的变更虽然就会降低线上可用性的风险,而且三天中可能会发生很多次变更,在这些情况下风险也会显得很大。尤其对于作为保障 APP 可用性的一线人员而言,压力也会非常大。
正是由于面临这么多的问题和挑战,才须要通过移动端的高可用技术体系解决这个问题,保证线上客户端高可用性。
APP 线上运维的发展和变迁
如上图,是这几年来支付宝客户端在可用性运维上的发展历史,大致分为了三个阶段。随着支付宝的成长,可用性运维也仍然在演化,最后演变到了移动端高可用的状态。
第一个阶段就是简单的死机监控。绝大多数的 APP 也做过这个事情,就是本地搜集一些死机信息并进行上报,在 APP 后台对于闪退率进行监控,解决死机比较多的问题,并在 APP 的下一个版本中进行相应的更改,最后让闪退率维持在某一个指标以下。
但是现今来看,这个阶段距离实现高可用的要求相差很远,因为用户所遇见不可用问题中死机只抢占其中一部分,所以对可用性而言,解决了死机问题只是改进了一点点而已,还存在着大部分的问题没有解决。
第二个阶段,在阿里巴巴内部称作稳定性监控体系,相比于第一个阶段而言,稳定性监控体系可以说前进了特别大的一步。
首先,可以监控的问题大大丰富了,通过对多种问题的监控可以了解线上用户稳定性方面的可用情况,而不仅仅是一个用户。
第二个方面,稳定性监控体系具有相当程度的确诊能力和修补能力。当发觉问题的时侯,可以通过确诊日志等相应的方式剖析故障缘由并尝试进行修补。
稳定性监控体系在最初的时侯疗效比较不错,并且阿里巴巴内部也使用了太长的时间,但是后来问题也渐渐曝露下来。
举两个事例,曾经一个版本的 APP 在 X86 一款机器上运行时出现的问题十分多,但是那种型号的用户量太小,所以问题始终都没有被发觉,直到太晚的时侯才通过其他方法发觉了这个问题,也就是说由于只监控具体问题引起早已不能发觉局部人群的问题了。
第二个事例,在做象双 11 这样的大促值勤的技术保障的时侯,因为监控的问题比较多,运维人员须要通过不停地翻监控来发觉问题,翻来翻去最后还是不敢确定 APP 的可用性究竟有没有问题,有时候确实会遗漏一些问题。
第三个方案就是在发觉了问题以后,能否快速修补还须要碰运气,有可能很快就才能修补,也有可能修补上去不太容易,需要等到下一次发版,这就促使有些问题所影响用户数会特别多。
以上就是在 2.0 阶段所碰到的问题,这说明稳定性监控体系也早已不够用了,需要继续进行改进,这也是支付宝决定继续做 3.0 阶段的移动端高可用的动机和动力。
移动端高可用的定义、目标、核心打法
高可用在移动端的重新定义
高可用本来属于服务端的概念,阿里巴巴的服务端都在讲高可用。服务端的高可用重点讲的是停机时间短、服务不可用时间短。
移动端的高可用从服务端借鉴过来以后进行了重新定义,因为客户端不存在停机时间概念。
所以,移动端高可用的定义是指通过专门的设计,结合整套技术体系,保证用户所遇见的技术不可用总次数太低。
移动端高可用的目标
简单来说,移动端高可用的目标就是实现可用率达到 99.99%,这里的可用率是支付宝自己定义的概念,指的就是用户在使用 APP 的时侯,可用次数在使用次数当中的占比,可用率达到 99.99%。
也就意味着用户使用 1 万次支付宝中的 9999 次都必须是可用的,最多只有一次不可用。为了实现这一目标,还会将任务拆解成为不同的子目标分别攻破。
移动端高可用的核心打法
目标的实现还是比较困难的,因为使可用率达到 99.99% 是一个很高的指标。而为了才能努力实现这个目标,支付宝也自创了一套核心打法。
主要分为以下四个部份:
支付宝在移动端高可用技术实践
如上图所示,是支付宝实现的移动端高可用技术构架图,大家可以看见支付宝移动端高可用的技术构架设计也是围绕上述的四个核心打法展开的。
客户端可用性监控
问题采集
客户端可用性监控的第一步就是问题采集,当 APP 发生不可用时必须才能感知和采集到问题,这是基础的基础,如果没有这个基础后续哪些都不能实现。
怎样确保当用户出现了不可用情况时才能采集到问题?这是比较困难的,因为我们不能保证一定可以采集到所有类型的不可用问题,但是还是会通过多种方式尽量地实现全面覆盖。
支付宝把不可用问题分为稳定性不可用和业务不可用两个方面。对于稳定性不可用而言,通过 2.0 阶段的逐步摸索以及各类反馈渠道、问题采集渠道的补充,现在早已可以把各种各样稳定性的不可用问题采集得比较全了。
比如传统的死机、卡死等以及不容易被监控的蓝屏、白屏以及非死机类型的异常退出等。
目前早已采集到了大部分的问题,当然可能就会存在遗漏,对于那些遗漏的问题,还须要通过不停地采集并补充到这个体系中。
对于业务不可用而言,在开发时会对于业务不可用问题进行埋点,只须要将业务不可用埋点列入到系统上面来,就能够基本覆盖最重要的业务不可用问题。
统一管控
当问题采集上来以后,需要通过统一管控产生客户端可用率指标。通过这个指标可以全面地评估线上某一个人群中的可用情况,而不需要象曾经那样逐一检测各个指标并在最后给一个不太确切的评估结果。通过统一管控可以设计出整体的监控和报案机制以及各类算法模型,并且其扩展性更好。
埋点上报
埋点上报这一功能是特别核心的,因为后续还要借助不可用埋点做高灵敏,所以埋点的实时性、准确性、到达率的要求非常高。
并且对于不可用埋点而言,当客户端早已发生了不可用时才须要进行上报,而在这个时侯客户端情况太可能十分恶劣,甚至此时客户端可能早已未能启动了,即便是这样也要保证埋点才能上报。
为了实现这一点,我们借助了一些小技巧,比如对于 Android 系统而言,支付宝通过独立的轻量级进程来单独上报埋点,即便主进程早已死掉了,但是埋点也就能实时上报上来。
对于 iOS 系统而言,采取在线上 hold 住进程让其报完埋点再退出去的形式,并且后续还有补偿机制,即使出现遗漏埋点的情况也才能让其最终能否上报上来。
通过问题采集、统一管控和埋点上报,基本上可以保障当用户碰到不可用问题时可以搜集问题并上报服务端,做好了第一步的基础。
高灵敏度系统模型
在问题搜集到的情况下须要用高灵敏系统模型做监控和报案。监控和报案在 2.0 时代就早已存在了,比如当盘面上监控的闪退率出现异常情况时才会进行报案。
但是高灵敏系统模型要做的是在线上问题刚才出现端倪的时侯就可以发觉,而不是等到盘面出现波动才发觉。
所以这个模型的关键在于剖析决策的过程中,它会基于用户的人群特点、问题特点把线上采集到的不可用问题进行聚合再进行剖析,通过预制的一些算法模型和规则来判定是否形成了异常,如果最终判定的确有异常形成了则会输出一个异常风波。
举个事例,比如线上的某个业务发布了一个新的 H5 离线包版本,其中某一个页面的卡死率很高。那么使用这个页面的用户都会产生一个特点人群,这个特点人群的页面卡死率就有异常的波动,这个时侯才会输出异常风波。
但是此时盘面并没有很大波动,因为特点人群的人数并不多,但是后台可以捕获到异常风波。
当异常风波输出然后,可以通过附送信息准确地匹配到相应的负责人以及开发、测试人员,告警系统会告知负责人进行处理,并且会依照问题的严重程度采取不同的告警形式,可能会采取电邮、钉钉或则电话等方法进行告警。
在问题十分严重的情况下,如果几分钟之内没有响应就有人打电话给负责人了。通过这样的告警机制就可以保证无论哪些时间,只要线上出现异常问题就可以迅速地感知到。
高可用容灾平台
通过上述的内容,我们早已可以实现对于可用性问题的感知了。接下来分享怎样通过高可用容灾平台修补异常问题。
这里通过整体的故障容灾过程进行分享,如下图所示,当一个故障进来了,会向相应的负责人发出告警,这时负责人须要检测这个故障是如何形成的,到底是因为线上变更引起的,还是因为客户端本身的 Bug 导致的。
如果是由于线上变更引起的则比较好办,因为现今的系统比较灵敏,只要故障刚一发生,在短时间内负责人员就可以收到告警。
之后就可以到发布记录中检测这段时间内发生了哪几次变更,可以很快地基本了解是哪一次变更引起的故障,并采取相应的处理策略。
如果可以回滚就进行回滚操作,不能回滚就须要进行紧急发布,如果不能紧急发布就要依赖客户端进行修补。
比较麻烦的是和变更没有关系的情况,此时就须要通过异常携带的确诊信息或则通过获取一些日志来检测问题为何形成,问题的形成有时候是因为兼容性问题。
比如某个厂商灰度发布了一批和支付宝兼容性不太好的系统,导致出现了各种各样的问题,这种情况下就要通过动态修补解决。
也可能一些顾客本地出现了严重错误,比如说形成了一些脏数据,或者安装时由于市场的临时性 Bug 导致了大量安装失败,最终造成支付宝打不开。
对于这些情况而言,可以通过本地容灾做一些恢复工作,进而实现客户端的手动恢复。
总之,通过上述的过程,可以让故障得到解决。从右图中可以看出,支付宝在高可用容灾中致力于两点:
高可用的动态修补体系
移动端高可用和服务端高可用的重大区别就是移动端的发布比较困难,所以须要借助动态修补技术。
动态修补并不是新的概念,像 hotpatch 等技术都早已十分成熟了,目前也有好多可选的动态修补方案。
但是,虽然在高可用的动态修补体系中,hotpatch 属于比较重要的点,但是并不是最主要的点,因为它也存在一定的局限性,也有不适宜的时侯。目前,支付宝基于多种修补手段搭建了高可用的动态修补体系。
支付宝的高可用动态修补体系主要由以下三部份构成:
修复手段
修复手段有很多种,并且有轻有重。轻的手段在线上进行一些配置就可以解决线上不可用的问题,重的手段可以把整个模块完全重新布署下去。具体应当选择哪一种修补手段应当按照故障的情况来看,选择效率最高、风险最低的修补方法。
下发通道
这一点与埋点上报的要求有一点类似,也须要高实时性和高可靠性。当用户早已不可用了,常规方法拉不到线上的修补方案的时侯,能够解决的办法再多也是没有用的,所以须要保障无论面对多么恶劣的情况下都还能把修补方案拉出来。
下发通道的实现方法有很多种,最终实现只要才能联网一定可以将修补方案拉出来,如果暂时不能联网,那么一定要在联网以后将修补方案拉出来。
发布平台
设计动态修补的发布平台的时侯特别关注的一点就是把修补方案推送给真正须要它的用户,也就是把修补方案推给早已出现或则可能出现这个问题的用户。
这样做的缘由是每一次的动态修补虽然也是一次线上变更,本身也是存在风险的,如果对于所有用户都进行推送则须要比较长的时间进行灰度来保证安全,但是假如才能只对目标的冷门人群、特征人群推送方案,这样灰度时间会太短,修复时间也会太短。
支付宝在客户端恳求修补方案的时侯,会依照客户端的人群特点、是否发生过这个问题以及有没有发生这个问题的可能来判定是否把这个修补方案推送给她们,这样可以很快地完成推送过程。这在图中称之为“智能修补”,其实称之为“定向修补”更为确切一些。
高可用实战经验
在这里和你们分享支付宝在高可用实战中的两个案例,其中一个处理的比较成功,另外一个则不是太成功。
案例 1:一个业务营运推送了一个错误的菜单配置,而客户端没有做好保护。在营运推送配置的 10 分钟之内,相关的负责人都收到了报案,并且很快地查到是这个配置造成的。
之后营运将马上对于配置进行了回滚,这个过程所影响用户数比较少,所以是一个比较成功的案例。
这也是支付宝最期望的运维过程,实现了及时发觉、很快修补而且影响用户数极少。
案例 2:在一次大促的时侯,一个业务开启了限流,客户端弹出一个限流的页面,这个页面有 Bug,会导致死机,进而造成用户难以进行操作。
但是因为当时的可用性监控不健全,所以这个问题没有被监控到,最后是因为用户的反馈才晓得出现了问题,到问题出现的第三天,反馈量早已积累到一个显著的程度了,才发觉这个问题。
之后,我们迅速地对于这个问题进行了剖析和解决,最后定位到限流的问题,一个小时之内确定了问题所在,并暂时把限流先关闭,后来把这个 Bug 修复掉了以后再将限流打开,这样客户端才恢复正常。
虽然最终把问题建立地解决了,但是这一过程存在十分显著的缺陷。首先是发觉的很晚了,这是因为可用性问题没有覆盖到。
另外,因为没有足够的信息促使决策的过程比较慢,花了 1 个小时进行剖析能够够止血,直到现今我们也不知道这一天究竟影响了多少用户,但是这一风波肯定对支付宝的可用性导致了不小的伤害。
而如今,支付宝实现了移动端的高可用,以后象这样的事情不会再发生了,当出现故障时,支付宝可以在第一天太短的时间内就可以搞定问题。
故障演习
有这样一句话“避免故障最好的形式就是不断演习故障”,所以我们要通过可控的成本在线上真实地模拟一些故障,进行故障演习,检验高可用体系是否可靠,同时也使相应的朋友对系统、工具和流程愈发熟悉,当真正发生问题的时侯可以快速地处理。
为了更好的检验这套东西,支付宝采用了攻守对抗演习的形式,成立了一个虚拟小组,他们会想办法模拟线上可能出现的故障情况,而另外一组人则借助移动端高可用技术接招,把对方研制的问题快速地处理掉。
这样做好准备之后,当真正出现故障须要进行处理的时侯,我们也早已才能熟练地应对了。
在前进中探求
最后再谈一下对客户端可用性运维未来的思索:
智能化
前面提及了高灵敏的模型,大家可以看见在决策的过程中常常须要依赖预设的算法模型、规则以及数值等,这些都缘于长期积攒出来的经验。
但是这也存在一些缺点:一是有可能出现误报;二是为了避免误报太多,这个模型不敢做的太短,所以模型的灵敏度属于比较灵敏,而不是极其灵敏。
我们期盼通过智能化的形式,通过人工智能、机器学习的方式实现决策过程的智能化,可以做得愈加灵敏,将问题发觉的时间再提高一节,而且这目前早已不仅仅是一个看法了,在支付宝的好多场景中早已开始使用智能报案了,我们也在督查和尝试接入这个东西。
自动化
这部份主要指的是容灾过程的自动化。我们想把上面展示的容灾过程做的太顺滑,但是其中好多步骤都须要人来做,这样时间成本、决策成本会很高。
所以我们希望把尽量多的步骤转成自动化形式,至少是半自动化的方法,这样就能使容灾过程愈发顺滑,使得修补时间形成本质的飞跃。
产品化
我们希望当客户端可用性愈发成熟以后赋能给其他类似的 APP,通过这个过程积攒更多的经验,发现更多的问题。并且在未来合适的时间,或者 3.0 版本的客户端可用性不能满足需求的时侯再去建设 4.0 可用性运维体系。
作者:竹光
简介:蚂蚁金服中级技术专家。2015 年加入支付宝,主要负责客户端的稳定性和高可用,曾多次参与双 11、双 12、春节红包等大促的技术保障工作,主要负责保证活动期间支付宝客户端的稳定性以及可用性。 查看全部
亿级APP支付宝在移动端的高可用技术实践
亿级 APP 在可用性方面的挑战
可用性的概念
简单而言,可用性就是当用户想要使用 APP 做一个事情,这件事情弄成了就是可用,没有弄成就不可用。
为什么没有弄成?可能的诱因有很多,比如有可能使用 APP 的时侯死机了,或者使用支付宝付款的时侯,由于后台某个环节出现错误,导致了这笔支付失败了等,这些都可能导致 APP 的不可用。
如果各种各样不可用的情况都没有出现,那么对于顾客而言就是可用的。虽然每位开发人员都希望自己开发的 APP 是 100% 可用的,但是实际上这一点是不可能的。所以开发人员真正须要做的事情就是使 APP 发生不可用的情况越来越少。
亿级 APP 的可用性挑战
目前,APP 开发技术早已比较成熟了,所以好多开发人员会觉得自己的 APP 可用性应当问题不是很大,因为 APP 都经历了相关的测试流程、灰度验证等保障举措。
但是如今情况早已发生变化了,与先前相比,APP 的用户量大了好多,很多的 APP 都达到了亿级用户,所以一点点可用性问题都可能会影响大量的用户。
比如 APP 的闪退率下降了千分之一,虽然这一比列并不是很大,但是对于一亿用户而言,乘上千分之一就是 10 万人。
大家可以想像一下,如果某三天你们在使用支付宝在商场付款的时侯,其中的 10 万人出现掉帧的情况,这个影响是绝对不可以接受的。
现在开发移动端 APP 讲究动态化,业务要求实时动态地实现线上变更,可以说明天的支付宝和今天的支付宝相比就早已形成很大区别了。
每一次线上的变更虽然就会降低线上可用性的风险,而且三天中可能会发生很多次变更,在这些情况下风险也会显得很大。尤其对于作为保障 APP 可用性的一线人员而言,压力也会非常大。
正是由于面临这么多的问题和挑战,才须要通过移动端的高可用技术体系解决这个问题,保证线上客户端高可用性。
APP 线上运维的发展和变迁
如上图,是这几年来支付宝客户端在可用性运维上的发展历史,大致分为了三个阶段。随着支付宝的成长,可用性运维也仍然在演化,最后演变到了移动端高可用的状态。
第一个阶段就是简单的死机监控。绝大多数的 APP 也做过这个事情,就是本地搜集一些死机信息并进行上报,在 APP 后台对于闪退率进行监控,解决死机比较多的问题,并在 APP 的下一个版本中进行相应的更改,最后让闪退率维持在某一个指标以下。
但是现今来看,这个阶段距离实现高可用的要求相差很远,因为用户所遇见不可用问题中死机只抢占其中一部分,所以对可用性而言,解决了死机问题只是改进了一点点而已,还存在着大部分的问题没有解决。
第二个阶段,在阿里巴巴内部称作稳定性监控体系,相比于第一个阶段而言,稳定性监控体系可以说前进了特别大的一步。
首先,可以监控的问题大大丰富了,通过对多种问题的监控可以了解线上用户稳定性方面的可用情况,而不仅仅是一个用户。
第二个方面,稳定性监控体系具有相当程度的确诊能力和修补能力。当发觉问题的时侯,可以通过确诊日志等相应的方式剖析故障缘由并尝试进行修补。
稳定性监控体系在最初的时侯疗效比较不错,并且阿里巴巴内部也使用了太长的时间,但是后来问题也渐渐曝露下来。
举两个事例,曾经一个版本的 APP 在 X86 一款机器上运行时出现的问题十分多,但是那种型号的用户量太小,所以问题始终都没有被发觉,直到太晚的时侯才通过其他方法发觉了这个问题,也就是说由于只监控具体问题引起早已不能发觉局部人群的问题了。
第二个事例,在做象双 11 这样的大促值勤的技术保障的时侯,因为监控的问题比较多,运维人员须要通过不停地翻监控来发觉问题,翻来翻去最后还是不敢确定 APP 的可用性究竟有没有问题,有时候确实会遗漏一些问题。
第三个方案就是在发觉了问题以后,能否快速修补还须要碰运气,有可能很快就才能修补,也有可能修补上去不太容易,需要等到下一次发版,这就促使有些问题所影响用户数会特别多。
以上就是在 2.0 阶段所碰到的问题,这说明稳定性监控体系也早已不够用了,需要继续进行改进,这也是支付宝决定继续做 3.0 阶段的移动端高可用的动机和动力。
移动端高可用的定义、目标、核心打法
高可用在移动端的重新定义
高可用本来属于服务端的概念,阿里巴巴的服务端都在讲高可用。服务端的高可用重点讲的是停机时间短、服务不可用时间短。
移动端的高可用从服务端借鉴过来以后进行了重新定义,因为客户端不存在停机时间概念。
所以,移动端高可用的定义是指通过专门的设计,结合整套技术体系,保证用户所遇见的技术不可用总次数太低。
移动端高可用的目标
简单来说,移动端高可用的目标就是实现可用率达到 99.99%,这里的可用率是支付宝自己定义的概念,指的就是用户在使用 APP 的时侯,可用次数在使用次数当中的占比,可用率达到 99.99%。
也就意味着用户使用 1 万次支付宝中的 9999 次都必须是可用的,最多只有一次不可用。为了实现这一目标,还会将任务拆解成为不同的子目标分别攻破。
移动端高可用的核心打法
目标的实现还是比较困难的,因为使可用率达到 99.99% 是一个很高的指标。而为了才能努力实现这个目标,支付宝也自创了一套核心打法。
主要分为以下四个部份:
支付宝在移动端高可用技术实践
如上图所示,是支付宝实现的移动端高可用技术构架图,大家可以看见支付宝移动端高可用的技术构架设计也是围绕上述的四个核心打法展开的。
客户端可用性监控
问题采集
客户端可用性监控的第一步就是问题采集,当 APP 发生不可用时必须才能感知和采集到问题,这是基础的基础,如果没有这个基础后续哪些都不能实现。
怎样确保当用户出现了不可用情况时才能采集到问题?这是比较困难的,因为我们不能保证一定可以采集到所有类型的不可用问题,但是还是会通过多种方式尽量地实现全面覆盖。
支付宝把不可用问题分为稳定性不可用和业务不可用两个方面。对于稳定性不可用而言,通过 2.0 阶段的逐步摸索以及各类反馈渠道、问题采集渠道的补充,现在早已可以把各种各样稳定性的不可用问题采集得比较全了。
比如传统的死机、卡死等以及不容易被监控的蓝屏、白屏以及非死机类型的异常退出等。
目前早已采集到了大部分的问题,当然可能就会存在遗漏,对于那些遗漏的问题,还须要通过不停地采集并补充到这个体系中。
对于业务不可用而言,在开发时会对于业务不可用问题进行埋点,只须要将业务不可用埋点列入到系统上面来,就能够基本覆盖最重要的业务不可用问题。
统一管控
当问题采集上来以后,需要通过统一管控产生客户端可用率指标。通过这个指标可以全面地评估线上某一个人群中的可用情况,而不需要象曾经那样逐一检测各个指标并在最后给一个不太确切的评估结果。通过统一管控可以设计出整体的监控和报案机制以及各类算法模型,并且其扩展性更好。
埋点上报
埋点上报这一功能是特别核心的,因为后续还要借助不可用埋点做高灵敏,所以埋点的实时性、准确性、到达率的要求非常高。
并且对于不可用埋点而言,当客户端早已发生了不可用时才须要进行上报,而在这个时侯客户端情况太可能十分恶劣,甚至此时客户端可能早已未能启动了,即便是这样也要保证埋点才能上报。
为了实现这一点,我们借助了一些小技巧,比如对于 Android 系统而言,支付宝通过独立的轻量级进程来单独上报埋点,即便主进程早已死掉了,但是埋点也就能实时上报上来。
对于 iOS 系统而言,采取在线上 hold 住进程让其报完埋点再退出去的形式,并且后续还有补偿机制,即使出现遗漏埋点的情况也才能让其最终能否上报上来。
通过问题采集、统一管控和埋点上报,基本上可以保障当用户碰到不可用问题时可以搜集问题并上报服务端,做好了第一步的基础。
高灵敏度系统模型
在问题搜集到的情况下须要用高灵敏系统模型做监控和报案。监控和报案在 2.0 时代就早已存在了,比如当盘面上监控的闪退率出现异常情况时才会进行报案。
但是高灵敏系统模型要做的是在线上问题刚才出现端倪的时侯就可以发觉,而不是等到盘面出现波动才发觉。
所以这个模型的关键在于剖析决策的过程中,它会基于用户的人群特点、问题特点把线上采集到的不可用问题进行聚合再进行剖析,通过预制的一些算法模型和规则来判定是否形成了异常,如果最终判定的确有异常形成了则会输出一个异常风波。
举个事例,比如线上的某个业务发布了一个新的 H5 离线包版本,其中某一个页面的卡死率很高。那么使用这个页面的用户都会产生一个特点人群,这个特点人群的页面卡死率就有异常的波动,这个时侯才会输出异常风波。
但是此时盘面并没有很大波动,因为特点人群的人数并不多,但是后台可以捕获到异常风波。
当异常风波输出然后,可以通过附送信息准确地匹配到相应的负责人以及开发、测试人员,告警系统会告知负责人进行处理,并且会依照问题的严重程度采取不同的告警形式,可能会采取电邮、钉钉或则电话等方法进行告警。
在问题十分严重的情况下,如果几分钟之内没有响应就有人打电话给负责人了。通过这样的告警机制就可以保证无论哪些时间,只要线上出现异常问题就可以迅速地感知到。
高可用容灾平台
通过上述的内容,我们早已可以实现对于可用性问题的感知了。接下来分享怎样通过高可用容灾平台修补异常问题。
这里通过整体的故障容灾过程进行分享,如下图所示,当一个故障进来了,会向相应的负责人发出告警,这时负责人须要检测这个故障是如何形成的,到底是因为线上变更引起的,还是因为客户端本身的 Bug 导致的。
如果是由于线上变更引起的则比较好办,因为现今的系统比较灵敏,只要故障刚一发生,在短时间内负责人员就可以收到告警。
之后就可以到发布记录中检测这段时间内发生了哪几次变更,可以很快地基本了解是哪一次变更引起的故障,并采取相应的处理策略。
如果可以回滚就进行回滚操作,不能回滚就须要进行紧急发布,如果不能紧急发布就要依赖客户端进行修补。
比较麻烦的是和变更没有关系的情况,此时就须要通过异常携带的确诊信息或则通过获取一些日志来检测问题为何形成,问题的形成有时候是因为兼容性问题。
比如某个厂商灰度发布了一批和支付宝兼容性不太好的系统,导致出现了各种各样的问题,这种情况下就要通过动态修补解决。
也可能一些顾客本地出现了严重错误,比如说形成了一些脏数据,或者安装时由于市场的临时性 Bug 导致了大量安装失败,最终造成支付宝打不开。
对于这些情况而言,可以通过本地容灾做一些恢复工作,进而实现客户端的手动恢复。
总之,通过上述的过程,可以让故障得到解决。从右图中可以看出,支付宝在高可用容灾中致力于两点:
高可用的动态修补体系
移动端高可用和服务端高可用的重大区别就是移动端的发布比较困难,所以须要借助动态修补技术。
动态修补并不是新的概念,像 hotpatch 等技术都早已十分成熟了,目前也有好多可选的动态修补方案。
但是,虽然在高可用的动态修补体系中,hotpatch 属于比较重要的点,但是并不是最主要的点,因为它也存在一定的局限性,也有不适宜的时侯。目前,支付宝基于多种修补手段搭建了高可用的动态修补体系。
支付宝的高可用动态修补体系主要由以下三部份构成:
修复手段
修复手段有很多种,并且有轻有重。轻的手段在线上进行一些配置就可以解决线上不可用的问题,重的手段可以把整个模块完全重新布署下去。具体应当选择哪一种修补手段应当按照故障的情况来看,选择效率最高、风险最低的修补方法。
下发通道
这一点与埋点上报的要求有一点类似,也须要高实时性和高可靠性。当用户早已不可用了,常规方法拉不到线上的修补方案的时侯,能够解决的办法再多也是没有用的,所以须要保障无论面对多么恶劣的情况下都还能把修补方案拉出来。
下发通道的实现方法有很多种,最终实现只要才能联网一定可以将修补方案拉出来,如果暂时不能联网,那么一定要在联网以后将修补方案拉出来。
发布平台
设计动态修补的发布平台的时侯特别关注的一点就是把修补方案推送给真正须要它的用户,也就是把修补方案推给早已出现或则可能出现这个问题的用户。
这样做的缘由是每一次的动态修补虽然也是一次线上变更,本身也是存在风险的,如果对于所有用户都进行推送则须要比较长的时间进行灰度来保证安全,但是假如才能只对目标的冷门人群、特征人群推送方案,这样灰度时间会太短,修复时间也会太短。
支付宝在客户端恳求修补方案的时侯,会依照客户端的人群特点、是否发生过这个问题以及有没有发生这个问题的可能来判定是否把这个修补方案推送给她们,这样可以很快地完成推送过程。这在图中称之为“智能修补”,其实称之为“定向修补”更为确切一些。
高可用实战经验
在这里和你们分享支付宝在高可用实战中的两个案例,其中一个处理的比较成功,另外一个则不是太成功。
案例 1:一个业务营运推送了一个错误的菜单配置,而客户端没有做好保护。在营运推送配置的 10 分钟之内,相关的负责人都收到了报案,并且很快地查到是这个配置造成的。
之后营运将马上对于配置进行了回滚,这个过程所影响用户数比较少,所以是一个比较成功的案例。
这也是支付宝最期望的运维过程,实现了及时发觉、很快修补而且影响用户数极少。
案例 2:在一次大促的时侯,一个业务开启了限流,客户端弹出一个限流的页面,这个页面有 Bug,会导致死机,进而造成用户难以进行操作。
但是因为当时的可用性监控不健全,所以这个问题没有被监控到,最后是因为用户的反馈才晓得出现了问题,到问题出现的第三天,反馈量早已积累到一个显著的程度了,才发觉这个问题。
之后,我们迅速地对于这个问题进行了剖析和解决,最后定位到限流的问题,一个小时之内确定了问题所在,并暂时把限流先关闭,后来把这个 Bug 修复掉了以后再将限流打开,这样客户端才恢复正常。
虽然最终把问题建立地解决了,但是这一过程存在十分显著的缺陷。首先是发觉的很晚了,这是因为可用性问题没有覆盖到。
另外,因为没有足够的信息促使决策的过程比较慢,花了 1 个小时进行剖析能够够止血,直到现今我们也不知道这一天究竟影响了多少用户,但是这一风波肯定对支付宝的可用性导致了不小的伤害。
而如今,支付宝实现了移动端的高可用,以后象这样的事情不会再发生了,当出现故障时,支付宝可以在第一天太短的时间内就可以搞定问题。
故障演习
有这样一句话“避免故障最好的形式就是不断演习故障”,所以我们要通过可控的成本在线上真实地模拟一些故障,进行故障演习,检验高可用体系是否可靠,同时也使相应的朋友对系统、工具和流程愈发熟悉,当真正发生问题的时侯可以快速地处理。
为了更好的检验这套东西,支付宝采用了攻守对抗演习的形式,成立了一个虚拟小组,他们会想办法模拟线上可能出现的故障情况,而另外一组人则借助移动端高可用技术接招,把对方研制的问题快速地处理掉。
这样做好准备之后,当真正出现故障须要进行处理的时侯,我们也早已才能熟练地应对了。
在前进中探求
最后再谈一下对客户端可用性运维未来的思索:
智能化
前面提及了高灵敏的模型,大家可以看见在决策的过程中常常须要依赖预设的算法模型、规则以及数值等,这些都缘于长期积攒出来的经验。
但是这也存在一些缺点:一是有可能出现误报;二是为了避免误报太多,这个模型不敢做的太短,所以模型的灵敏度属于比较灵敏,而不是极其灵敏。
我们期盼通过智能化的形式,通过人工智能、机器学习的方式实现决策过程的智能化,可以做得愈加灵敏,将问题发觉的时间再提高一节,而且这目前早已不仅仅是一个看法了,在支付宝的好多场景中早已开始使用智能报案了,我们也在督查和尝试接入这个东西。
自动化
这部份主要指的是容灾过程的自动化。我们想把上面展示的容灾过程做的太顺滑,但是其中好多步骤都须要人来做,这样时间成本、决策成本会很高。
所以我们希望把尽量多的步骤转成自动化形式,至少是半自动化的方法,这样就能使容灾过程愈发顺滑,使得修补时间形成本质的飞跃。
产品化
我们希望当客户端可用性愈发成熟以后赋能给其他类似的 APP,通过这个过程积攒更多的经验,发现更多的问题。并且在未来合适的时间,或者 3.0 版本的客户端可用性不能满足需求的时侯再去建设 4.0 可用性运维体系。
作者:竹光
简介:蚂蚁金服中级技术专家。2015 年加入支付宝,主要负责客户端的稳定性和高可用,曾多次参与双 11、双 12、春节红包等大促的技术保障工作,主要负责保证活动期间支付宝客户端的稳定性以及可用性。
智慧中学一体化平台(技术施行方案)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-22 10:54
今天智慧城市大数据生态伙伴君分享一个智慧校园管理及教育资源一体化平台建设方案(小学):全文三部份,技术清单,技术要求,技术尺寸。
二、技术要求
1.1实现的功能或则目标,以及为落实政府新政需满足的要求:
1.1.1 建立智慧校园管理及教育资源一体化办公平台,能够深度融合办公交互聊天IM,日志,审批,云盘资源库,等微应用的智慧校园管理办共平台,包括作业、公告、德育、学生评价、学生考勤、固定资产、请假、报修、微官网、晨检、班级课表、教师助手、调兼课、班级故事、成长档案、教师薪资管理等模块,并就能实现根据中学实际需求自定义扩充功能;
1.1.2 建立智慧课堂服务体系,实现智慧教学的常态化使用和运行,创建一种智能的全媒体互动教学模式,配备班主任专用平板硬件辅助教学,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数;
1.1.3 建立基于中英文的智能阅卷系统,提供网阅数据采集、中英文手动评分、A3高速扫描读取试题、阅卷后大数据剖析等功能;
1.1.4构建软件硬件一体化的智慧校园,将联接中学生考勤腕带、电子班牌、A3高速扫描阅卷机,统一的认证登入系统,统一用户管理机制;
1.1.5构建统一的服务响应机制,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数。
1.2 采购标项需满足的质量、安全、技术尺寸、物理特点等要求;
1.2.1 质量要求:TC初验标准:覆盖率小于等于95%TC中必须收录但不限于场景要求:
1)输入框必须校准:长度限制,特殊字符控制
2)网络情况:WiFi,2G,3G,4G
3)机型适配:市场主流型号,如Android:(Android4.1及以上版本)htc x920e、LG G2 A8、Coolpad A6、huawei g3、Moto G、OPPO U705T Android 4.1.1、三星 s4 I9500 Android4.2.2、华为H60-L02、华为H30-L01、nexus 5 A10 5.1.1、coolpad 8720 Android 4.3、nexus 4、魅族MX4 Android 4.4.2、魅族MX4 Pro Android 4.4.4、三星Note 3 Android 4.3、Oppo813t 小屏、vivo S9t Android 4.1.2三星GT-N7100 Android 4.1.2、魅族 M1 note Android 4.4.4、华为Mate 7 5.1.1、联想A820t Android 4.1.2、iPhone:(IOS 7及以上版本)、iPhone 4s、iPhone 5、iPhone 5c、iPhone 5s、iPhone6、iPhone 6plus、iPhone 6s等。
4)图片:尺寸限制,大小限制
5)多端:PC与联通关联的功能场景
6)必须实现免登录
7)PC功能支持确认
8)不能有注册流程
9)统一的交互,统一的导航栏,问号标示,反馈入口
10)选人场景必须用系统平台提供的选人组件
11)不能出现用户填写手机号的场景
12)Critical:系统未能执行、崩溃或严重资源不足、应用模块未能启动或异常退出、无法测试、造成系统不稳定,则不通过。
13)Major:部分非主流程功能存在严重缺陷,不得影响到系统稳定性
14)Minor:界面、性能无缺陷
15)Trivial:具备易用性
1.2.2应用线上质量标准:
1)P1/P2类bug 处理 原则当日发觉当日解决不得过夜
2)P3类bug 处理 原则不得超过3天
3)P4类bug 处理 原则可在下个迭代发布中解决
1.2.3性能标准
1)服务端响应时间
2)服务端授权激活响应时间整体大于3s
3)页面大小:首屏页面大小大于200k
4)加载时间:首屏加载时间大于2s
1.2.4 安全要求:
1)开启云盾全部防御功能,开启云监控,实时监控线上服务状况保障7*24小时防治
2)代码安全标准:符合通用代码安全编程规范
1.2.5数据采集标准
1)操作用户数:指每日在应用内重要按键有操作行为的去重用户数
2)操作企业数:指每日在应用内重要按键有操作行为的用户所在企业去重统计数
3)重要按键:重要的TAB页面切换,比如 应用有5个浏览页面,每次切换页面须要记录一个操作;向服务端有数据上传的点击,比如 表单保存,提交数据,页面更改,新增内容,上传图片等
1.2.6 物理特点要求:
所提供服务需符合国家安全技术相关标准要求
查看全部
智慧中学一体化平台(技术施行方案)
今天智慧城市大数据生态伙伴君分享一个智慧校园管理及教育资源一体化平台建设方案(小学):全文三部份,技术清单,技术要求,技术尺寸。
二、技术要求
1.1实现的功能或则目标,以及为落实政府新政需满足的要求:
1.1.1 建立智慧校园管理及教育资源一体化办公平台,能够深度融合办公交互聊天IM,日志,审批,云盘资源库,等微应用的智慧校园管理办共平台,包括作业、公告、德育、学生评价、学生考勤、固定资产、请假、报修、微官网、晨检、班级课表、教师助手、调兼课、班级故事、成长档案、教师薪资管理等模块,并就能实现根据中学实际需求自定义扩充功能;
1.1.2 建立智慧课堂服务体系,实现智慧教学的常态化使用和运行,创建一种智能的全媒体互动教学模式,配备班主任专用平板硬件辅助教学,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数;
1.1.3 建立基于中英文的智能阅卷系统,提供网阅数据采集、中英文手动评分、A3高速扫描读取试题、阅卷后大数据剖析等功能;
1.1.4构建软件硬件一体化的智慧校园,将联接中学生考勤腕带、电子班牌、A3高速扫描阅卷机,统一的认证登入系统,统一用户管理机制;
1.1.5构建统一的服务响应机制,提供在线技术支持、全程技术答疑、实施培训以及后期进行相关的驻点答疑。提供班主任全员集中培训每年不多于1次,每次培训时间不少于2小时,提供班主任一对一问题指导不限次数。
1.2 采购标项需满足的质量、安全、技术尺寸、物理特点等要求;
1.2.1 质量要求:TC初验标准:覆盖率小于等于95%TC中必须收录但不限于场景要求:
1)输入框必须校准:长度限制,特殊字符控制
2)网络情况:WiFi,2G,3G,4G
3)机型适配:市场主流型号,如Android:(Android4.1及以上版本)htc x920e、LG G2 A8、Coolpad A6、huawei g3、Moto G、OPPO U705T Android 4.1.1、三星 s4 I9500 Android4.2.2、华为H60-L02、华为H30-L01、nexus 5 A10 5.1.1、coolpad 8720 Android 4.3、nexus 4、魅族MX4 Android 4.4.2、魅族MX4 Pro Android 4.4.4、三星Note 3 Android 4.3、Oppo813t 小屏、vivo S9t Android 4.1.2三星GT-N7100 Android 4.1.2、魅族 M1 note Android 4.4.4、华为Mate 7 5.1.1、联想A820t Android 4.1.2、iPhone:(IOS 7及以上版本)、iPhone 4s、iPhone 5、iPhone 5c、iPhone 5s、iPhone6、iPhone 6plus、iPhone 6s等。
4)图片:尺寸限制,大小限制
5)多端:PC与联通关联的功能场景
6)必须实现免登录
7)PC功能支持确认
8)不能有注册流程
9)统一的交互,统一的导航栏,问号标示,反馈入口
10)选人场景必须用系统平台提供的选人组件
11)不能出现用户填写手机号的场景
12)Critical:系统未能执行、崩溃或严重资源不足、应用模块未能启动或异常退出、无法测试、造成系统不稳定,则不通过。
13)Major:部分非主流程功能存在严重缺陷,不得影响到系统稳定性
14)Minor:界面、性能无缺陷
15)Trivial:具备易用性
1.2.2应用线上质量标准:
1)P1/P2类bug 处理 原则当日发觉当日解决不得过夜
2)P3类bug 处理 原则不得超过3天
3)P4类bug 处理 原则可在下个迭代发布中解决
1.2.3性能标准
1)服务端响应时间
2)服务端授权激活响应时间整体大于3s
3)页面大小:首屏页面大小大于200k
4)加载时间:首屏加载时间大于2s
1.2.4 安全要求:
1)开启云盾全部防御功能,开启云监控,实时监控线上服务状况保障7*24小时防治
2)代码安全标准:符合通用代码安全编程规范
1.2.5数据采集标准
1)操作用户数:指每日在应用内重要按键有操作行为的去重用户数
2)操作企业数:指每日在应用内重要按键有操作行为的用户所在企业去重统计数
3)重要按键:重要的TAB页面切换,比如 应用有5个浏览页面,每次切换页面须要记录一个操作;向服务端有数据上传的点击,比如 表单保存,提交数据,页面更改,新增内容,上传图片等
1.2.6 物理特点要求:
所提供服务需符合国家安全技术相关标准要求
金融大数据信息采集挖掘系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-20 13:55
中国金融业正在进入大数据时代的中级阶段。经过多年的发展与积累,目前国外金融机构的数据量早已达到100TB以上级别,并且非结构化数据量正在以更快的速率下降。金融机构行在大数据应用方面具有天然优势:一方面,金融企业在业务举办过程中积累了包括顾客身分、资产负债情况、资金收付交易等大量高价值密度的数据,这些数据在运用专业技术挖掘和剖析以后,将形成巨大的商业价值;另一方面,金融机构具有较为充足的预算,可以吸引到施行大数据的高档人才,也有能力采用大数据的新技术。因此,金融大数据采集就十分重要了,数据采集的情况决定了后期的挖掘剖析疗效,“金融采集平台”就是按照金融大数据的快速发展研制下来的,在使用的过程中反馈非常好。“金融采集平台”是一款既可以对网站深度订制,也可以使用最简单的配置快速采集的系统平台,它采用智能匹配和先进的HTML5模块编辑工具满足动静态数组的配置;配备全面且直观的运行时监控系统;丰富多彩的开发插口和建立详尽的SDK文档;同时支持分布采集部署,调度、数据处理,可以轻松的应对大数据在采集中遇见的各类问题。“金融采集平台”数据采集首先要提出采集请求,采集系统就会按照要求,按照采集指令进行采集任务分发,然后到分布式流数据剖析平台进行数据比对、数据源设置、数据抓取、实体抽取、数据分类,最后到分布式数据储存平台进行储存。“金融采集平台”最重要的就是智能动态增减采集器。智能动态增减采集器是通过对数据ID、数据地址、采集功能添加、采集数量等功能项的设置来进行数据采集,而采集的形式有两种模式:一种是通用模式,既使用普通的功能设置来采集数据,一般这些模块采集的数据比较多但疗效相对比较差;另一种是特殊设置模式,既根据要求对采集器进行功能设置,这种采集的疗效更好,准确率高。大数据在金融行业的应用起步比互联网行业稍晚,其应用深度和广度还有很大的扩充空间。金融行业的大数据应用仍然有很多的障碍须要克服,比如建行企业内各业务的数据孤岛效应严重、大数据人才相对缺少以及缺少建行之外的外部数据的整合等问题。可喜的是,金融行业尤其是以工行的中高层对大数据渴求和注重度十分高,相信在未来的两三年内,在互联网和联通互联网的驱动下,金融行业的大数据应用将迎来突破性的发展。 查看全部
金融大数据信息采集挖掘系统
中国金融业正在进入大数据时代的中级阶段。经过多年的发展与积累,目前国外金融机构的数据量早已达到100TB以上级别,并且非结构化数据量正在以更快的速率下降。金融机构行在大数据应用方面具有天然优势:一方面,金融企业在业务举办过程中积累了包括顾客身分、资产负债情况、资金收付交易等大量高价值密度的数据,这些数据在运用专业技术挖掘和剖析以后,将形成巨大的商业价值;另一方面,金融机构具有较为充足的预算,可以吸引到施行大数据的高档人才,也有能力采用大数据的新技术。因此,金融大数据采集就十分重要了,数据采集的情况决定了后期的挖掘剖析疗效,“金融采集平台”就是按照金融大数据的快速发展研制下来的,在使用的过程中反馈非常好。“金融采集平台”是一款既可以对网站深度订制,也可以使用最简单的配置快速采集的系统平台,它采用智能匹配和先进的HTML5模块编辑工具满足动静态数组的配置;配备全面且直观的运行时监控系统;丰富多彩的开发插口和建立详尽的SDK文档;同时支持分布采集部署,调度、数据处理,可以轻松的应对大数据在采集中遇见的各类问题。“金融采集平台”数据采集首先要提出采集请求,采集系统就会按照要求,按照采集指令进行采集任务分发,然后到分布式流数据剖析平台进行数据比对、数据源设置、数据抓取、实体抽取、数据分类,最后到分布式数据储存平台进行储存。“金融采集平台”最重要的就是智能动态增减采集器。智能动态增减采集器是通过对数据ID、数据地址、采集功能添加、采集数量等功能项的设置来进行数据采集,而采集的形式有两种模式:一种是通用模式,既使用普通的功能设置来采集数据,一般这些模块采集的数据比较多但疗效相对比较差;另一种是特殊设置模式,既根据要求对采集器进行功能设置,这种采集的疗效更好,准确率高。大数据在金融行业的应用起步比互联网行业稍晚,其应用深度和广度还有很大的扩充空间。金融行业的大数据应用仍然有很多的障碍须要克服,比如建行企业内各业务的数据孤岛效应严重、大数据人才相对缺少以及缺少建行之外的外部数据的整合等问题。可喜的是,金融行业尤其是以工行的中高层对大数据渴求和注重度十分高,相信在未来的两三年内,在互联网和联通互联网的驱动下,金融行业的大数据应用将迎来突破性的发展。
美工终结者「鹿班智能设计平台」是怎样工作的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-19 08:03
@阿里巴巴UED:在去年UCAN会议开场,阿里巴巴集团UED委员会委员长杨光发布的智能设计平台——鹿班,便出自乐乘的团队。此平台是通过人工智能算法和大量数据训练机器学习设计。通过一段时间的学习,此平台从今年“双十一”前就早已在阿里内部大规模投入使用,目前其设计水平早已十分接近专业设计师设计的疗效。在会议上,乐乘介绍了阿里智能设计实验室的实践全过程。
用AI做设计
我们团队如今叫人工智能设计实验室,做的事情很简单,用AI做设计。人工智能如今这个概念很火了,有一个数据证明它有多火:去年人工智能这个领域的创业公司开张速率超过了麦当劳的开店速率。不可证实,这里一定有泡沫成份,也有好多概念的炒作。我们先抛掉高大上的词,把这个事情拆解一下。
现在讲的人工智能都是通过算法、数据和强悍的估算能力来构建服务场景,这是人工智能的四个要素。今天我们团队做的就是用算法、数据、计算、场景来解决商业领域的事情,这样促使这件事情看起来比较靠谱、容易落地。
为什么我们团队会想要做这个事情呢,这不是YY下来的看法,而是从广泛的业务场景里找到的一个机会。以一个广告Banner为例,我们把它归类为“大量低质易耗”的设计,这样的设计,设计师花三天做下来,在线上投放时间也只有三天。而且是重复的,改改字就可以了,非常适宜被机器所替代。
今年UCAN的主题是新设计x新商业,新商业里特别大的概念,是要通过新的技术、互联网的手段,完成人、货、场的构建,人是消费者,货是商品的服务,场景就是联接人和商品之间的手段。在新的时期下,需要找到一种新的方法做设计。
我们团队的使命是基于算法数据和前台业务需求,打造一个商业设计脑部。这个脑部能理解设计,能为商业的产品去服务,做出合理的设计。
商业设计脑部的三大挑战
在开始做事情之前,我们遇见了三个比较严峻的挑战。
第一个挑战,缺少标明数据。今天所有的人工智能都基于大量的结构化标明数据,设计这件事情连数据都没有完成在线化,更别说标准化、结构化的数据了。
第二个挑战,设计不确定性。设计是个太不确定的东西,比如明天你使机器设计一个高档大气的Banner广告,它就蒙圈了。
第三个挑战,无先例可循。在整个行业里过去一年做出来发觉,没有一些现成的技术或则框架可以参考。比如AlphaGo把棋类AI论文发完以后,全世界象棋AI照这个方式都可以做到先进的水平。我们过去一年来都是自己一街摸索中走过来的,这一年走来我们给人工智能做的定义是,我们做的是可控的视觉生成。可控,就是按照商业的需求、业务的需求,智能地进行控制。它解决的是视觉从无到有的问题。
可控的视觉生成过程
这是机器人从诞生的第一版到近来一版的发展历程。2016年9月,勉强完成一张图片的拼合,没有哪些美感可言。第二张是去年圣诞节前做的广告,稍微看起来精美一点,整个设计还是十分简单。第三张是两个月前的进展,基本上可以依据这个商品输入主体的气氛,找到最符合的背景气氛,整个设计细节和结构,看起来更稳定一点。
我们现今大约学会几百种常规的设计手法,并且每晚都在学习中。这是我们目前的设计能力和设计疗效,青云给它定的评级是P4,意味着它还只是个助理设计师。我们明年目标是做到P5,还有太长的街要走。
机器怎样学习设计
下面和你们详尽解释一下这个机器背后的学习设计逻辑。
我们要使机器学习设计,首先必须要使机器理解感知设计是哪些。以这样一张十分常见的广告为例,在机器的眼中是有一堆象素点组成的。如果明天以象素为单位使机器去理解设计,对设计的可控性十分弱,所以在前期技术方案选择中没有走象素级生产,而是迈向了元素级生产。
四个组成部份:设计框架、元素中心、行动器、评估网路
组成一,设计框架。还是以这个广告为例,首先通过人工标明的方法,让机器理解这张设计有什么元素组成,比如它的商品主体,花的背景,蒙版。往上一层,我们通过设计的经验知识,定义一些设计的手法和风格。手法指的是那些元素为何可以如此构成,这个知识在设计头脑里机器是不知道的,所以会有手法这一层做输入。最前面这一层是风格,当这种元素构成以后,它从美学或则视觉角度看是一个哪些体味。让机器晓得它是用哪些组成的,为什么可以如此组成,以及它组成后的疗效。这个过程将一个设计问题转化成数据问题,这就是设计数据化。
下一步是打算设计的原创文件,比如一系列花朵和设计方式,输入到深度学习系列网路。这个网路有一个很大特征:具备一定记忆功能。因为设计是个步骤很复杂的过程,经常有好几十步能够完成一个设计。
经过这层神经网路学习以后,我们会得到一个设计框架。从技术上理解,它是一堆空间特点和视觉特点构成的模型。设计师的视角来理解的话,它相当于设计师头脑上面在做一组设计之前大约的框架印象,比如明天你接到一个任务要做一个花朵风格,思考这个设计大约会怎样做,然后从一堆文件里提取出了特点模型下来。
组成二,元素中心。因为我们做的是元素级生成,所以必须打算一个元素的库。我们会通过搜集一些版权图库,以及自己造设计元素的方法,输入到一个元素的分类器。这个分类器会把这种元素分布到各个类型里,比如背景、主体、修饰,也会完成图片库的提取。
组成三,行动器。接下来,就是设计的具体过程。比如明天我们接到一个设计任务,要为这样一件校服设计一个花朵风格的广告。这时候会有一个行动器,负责把上面打算好的底料放在设计框架里。这个过程和下象棋太象,左边是棋盘,右边是下象棋的棋子。行动器就是把元素放在棋盘里,这是整个行动器的生成原理。
它太象设计师实际在做设计的过程,如设计师要做一个花朵的时侯,也在软件上面会不断去调每位位置、每个象素、每个角度。同时,整个过程也是一个强化学习的过程,行动器会在不断试错中更智能。
组成四,评估网路。设计成品下来以后,我们要告诉机器人,从设计的角度是好还是不好。我们有一个设计评估网路,最终实现的疗效就是给它输入任何一个设计成品,它能打个分。技术原理是,我们通过人工输入大量历史上投放过的一些设计图评分,它从这儿训练出一个打分的模型下来。同时,专家也会人工干预打分,完成单向反馈。
这套框架并不是只能做Banner广告,Banner广告是我们找到的第一个最适宜落地的业务场景。我们把它定义为是一个通用的设计智能,理论上,它可以设计一切的数字内容。只要是通过元素或则象素组成的图象,理论上都是可以完成的。
预告一下我们最新的实践。前两张图是机器完成的服装搭配,根据用户输入的服装商品进行组合搭配,生成类似刊物的搭配效果图。另外,我们也正在训练机器完成页面模块的设计,比如大量的营销活动页面,我们如今正在训练它完成复杂的排版设计。
正在攻破的三个困局
目前,我们早已完成了框架搭建,以及数据的自我学习成长。接下来我们决心攻破的三个困局,也是使机器显得愈发强悍的关键突破点。
第一,让机器能否自主生成元素。我们目前的元素是靠设计师来提供,一方面是为了保证版权,另一方面,保证它的质量足够高。我们希望能做到,要求机器造一个花朵时,它自己能生成下来,这也是目前计算机视觉生成的一个十分火的话题。
第二,提高认知理解。现在机器还不太理解语义,只能按照需求或则任务生成一个结果,并不了解其中的关系。我们下一步要做的事情是,当用户输入了“清凉一夏”的文案时,机器人能理解“清凉”这个词代表了哪些意思,并且理解这张相片代表了“清凉一夏”的理念,图文之间有一定的关系。
最后一个,设计的迁移。比如明天通过大量专家数据训练了几百种常规数据手法以后,它还能完成主流的设计要求了。当这种手法很相似时,就可以完成风格迁移。我们会进一步探求AI,不再依据需求完成使命,而是通过自我学习和演变以后有新的东西下来。
AI+Design 拥抱新时代
今天人工智能设计真的来了,它不以任何意志为转移的趋势走来了,它距我们太逾。当一个新的浪潮打过来的时侯,我们应当学会的是拥抱它,而不是调头就跑,边跑边骂不靠谱。
视觉设计的四个层次
最基础的是临摹拓展。给你一个东西,照着它拓展一份下来,很明显这一定是机器第一步替代的工作。而且目前早已做到一大半了,证明这是一个无法回避的问题。
第二层,场景抒发。今天你给它一个东西,它能理解,能抒发对。比如明天你按照情人节,这些品牌才能找到一种合适的设计手段,去抒发出情人节的温情,这种手绘的形式会稍为难一点,也就是我们上面提到的语义这一层。
第三层,创意洞见。它还能有一些启发性的东西下来。天猫品牌上面时常有把猫头和品牌创意做联合的事情,这是机器不可能做到的事情,或者在我有生之年没有指望它能做到的。
最后一层,创造趋势。这通常是设计大师做的事情。它能定义今年、未来几年的设计趋势迈向,这是更高的设计能力。比如去年“三八”女王节,天猫用了一种全新的设计手段,用这些太轻的质感、很饱满的方法来抒发商品。它才能代表一个新的趋势和未来,代表一个新的手段,这件事情一定是人来做的。
回到明天机器和人之间的差别和对比,如果明天我们搞设计人机大战的话,机器最擅长的是数据、计算、学习。数据上,可以完成巨量素材库,训练成长速率,不断地完成闭环。它的学习速率之快,一个晚上可以完成几十万次的学习训练,是人不喝不吃也赶不上的。而人类设计师的特点,首先在情感层面,我们理解共情,情绪上有抒发,这是机器很难做到的。另外两层,创意和创造,设计师才能创造出一些新的东西,做组合迁移,组合创意,美学趋势。如果真正人机对战的话,设计师还是应回归创造、创意,以及理解用户的层面。
拥抱这个AI时代,对我们来说有没有哪些新的工作方式呢。比如明天有客人使你做一个设计,以前是一对一的给他一个成品,一对一的完成一个设计任务。有了设计AI以后,就可以将一个设计手段输入给机器,教会机器做执行和生成。这样,你就可以不止为一个顾客服务,而是为成千上万的顾客服务。
人工智能设计是个不可抵挡的时代,是未来。但是它也刚才来,我们也刚才走出第一步。我们还有大量的时间,希望接下来和设计同行一起努力,继续把这件事情做好。
优设目前早已约请了「鹿班智能设计平台」的负责人乐乘来优设做一期线上公开课,大家有哪些想问的可以随时反馈给主编@3年2班程远喔。
之前优设的合作伙伴「特赞」也专访过乐乘,大家可以先瞧瞧:双11期间有1.7 亿个BANNER,都来自阿里的“鹿班”AI设计系统
[关于UCAN]
UCAN是阿里巴巴的年度设计峰会,聚焦用户体验设计。4月27—28日,由阿里巴巴用户体验设计委员会举行的UCAN2017用户体验设计峰会在阿里巴巴西溪园区举办,本届主题是“新设计×新商业”。围绕“无界、融通、超距、生长”等概念,重新定义用户体验在新商业环境中的蝶变和价值,不断把设计领域、设计概念向外延伸,与技术、能源和商业形成新的化学反应。
欢迎关注阿里巴巴UED 的微信公众号:
「回顾2017 UCAN」
UCAN 2017回顾!8分钟看完设计大咖们的尖端干货阿里资深经理杨光:聊聊消费升级下的设计变化
【优设网 原创文章 投稿邮箱:】
================关于优设网================
“优设网“是国外人气最高的网页设计师学习平台,专注分享网页设计、无线端设计以及PS教程。
【特色推荐】
设计师须要读的100本书:史上最全的设计师图书导航:。
设计微博:拥有粉丝量200万的人气微博@优秀网页设计 ,欢迎关注获取网页设计资源、下载顶级设计素材。
设计导航:全球顶级设计网站推荐,设计师必备导航: 查看全部
美工终结者「鹿班智能设计平台」是怎样工作的?
@阿里巴巴UED:在去年UCAN会议开场,阿里巴巴集团UED委员会委员长杨光发布的智能设计平台——鹿班,便出自乐乘的团队。此平台是通过人工智能算法和大量数据训练机器学习设计。通过一段时间的学习,此平台从今年“双十一”前就早已在阿里内部大规模投入使用,目前其设计水平早已十分接近专业设计师设计的疗效。在会议上,乐乘介绍了阿里智能设计实验室的实践全过程。
用AI做设计
我们团队如今叫人工智能设计实验室,做的事情很简单,用AI做设计。人工智能如今这个概念很火了,有一个数据证明它有多火:去年人工智能这个领域的创业公司开张速率超过了麦当劳的开店速率。不可证实,这里一定有泡沫成份,也有好多概念的炒作。我们先抛掉高大上的词,把这个事情拆解一下。
现在讲的人工智能都是通过算法、数据和强悍的估算能力来构建服务场景,这是人工智能的四个要素。今天我们团队做的就是用算法、数据、计算、场景来解决商业领域的事情,这样促使这件事情看起来比较靠谱、容易落地。
为什么我们团队会想要做这个事情呢,这不是YY下来的看法,而是从广泛的业务场景里找到的一个机会。以一个广告Banner为例,我们把它归类为“大量低质易耗”的设计,这样的设计,设计师花三天做下来,在线上投放时间也只有三天。而且是重复的,改改字就可以了,非常适宜被机器所替代。
今年UCAN的主题是新设计x新商业,新商业里特别大的概念,是要通过新的技术、互联网的手段,完成人、货、场的构建,人是消费者,货是商品的服务,场景就是联接人和商品之间的手段。在新的时期下,需要找到一种新的方法做设计。
我们团队的使命是基于算法数据和前台业务需求,打造一个商业设计脑部。这个脑部能理解设计,能为商业的产品去服务,做出合理的设计。
商业设计脑部的三大挑战
在开始做事情之前,我们遇见了三个比较严峻的挑战。
第一个挑战,缺少标明数据。今天所有的人工智能都基于大量的结构化标明数据,设计这件事情连数据都没有完成在线化,更别说标准化、结构化的数据了。
第二个挑战,设计不确定性。设计是个太不确定的东西,比如明天你使机器设计一个高档大气的Banner广告,它就蒙圈了。
第三个挑战,无先例可循。在整个行业里过去一年做出来发觉,没有一些现成的技术或则框架可以参考。比如AlphaGo把棋类AI论文发完以后,全世界象棋AI照这个方式都可以做到先进的水平。我们过去一年来都是自己一街摸索中走过来的,这一年走来我们给人工智能做的定义是,我们做的是可控的视觉生成。可控,就是按照商业的需求、业务的需求,智能地进行控制。它解决的是视觉从无到有的问题。
可控的视觉生成过程
这是机器人从诞生的第一版到近来一版的发展历程。2016年9月,勉强完成一张图片的拼合,没有哪些美感可言。第二张是去年圣诞节前做的广告,稍微看起来精美一点,整个设计还是十分简单。第三张是两个月前的进展,基本上可以依据这个商品输入主体的气氛,找到最符合的背景气氛,整个设计细节和结构,看起来更稳定一点。
我们现今大约学会几百种常规的设计手法,并且每晚都在学习中。这是我们目前的设计能力和设计疗效,青云给它定的评级是P4,意味着它还只是个助理设计师。我们明年目标是做到P5,还有太长的街要走。
机器怎样学习设计
下面和你们详尽解释一下这个机器背后的学习设计逻辑。
我们要使机器学习设计,首先必须要使机器理解感知设计是哪些。以这样一张十分常见的广告为例,在机器的眼中是有一堆象素点组成的。如果明天以象素为单位使机器去理解设计,对设计的可控性十分弱,所以在前期技术方案选择中没有走象素级生产,而是迈向了元素级生产。
四个组成部份:设计框架、元素中心、行动器、评估网路
组成一,设计框架。还是以这个广告为例,首先通过人工标明的方法,让机器理解这张设计有什么元素组成,比如它的商品主体,花的背景,蒙版。往上一层,我们通过设计的经验知识,定义一些设计的手法和风格。手法指的是那些元素为何可以如此构成,这个知识在设计头脑里机器是不知道的,所以会有手法这一层做输入。最前面这一层是风格,当这种元素构成以后,它从美学或则视觉角度看是一个哪些体味。让机器晓得它是用哪些组成的,为什么可以如此组成,以及它组成后的疗效。这个过程将一个设计问题转化成数据问题,这就是设计数据化。
下一步是打算设计的原创文件,比如一系列花朵和设计方式,输入到深度学习系列网路。这个网路有一个很大特征:具备一定记忆功能。因为设计是个步骤很复杂的过程,经常有好几十步能够完成一个设计。
经过这层神经网路学习以后,我们会得到一个设计框架。从技术上理解,它是一堆空间特点和视觉特点构成的模型。设计师的视角来理解的话,它相当于设计师头脑上面在做一组设计之前大约的框架印象,比如明天你接到一个任务要做一个花朵风格,思考这个设计大约会怎样做,然后从一堆文件里提取出了特点模型下来。
组成二,元素中心。因为我们做的是元素级生成,所以必须打算一个元素的库。我们会通过搜集一些版权图库,以及自己造设计元素的方法,输入到一个元素的分类器。这个分类器会把这种元素分布到各个类型里,比如背景、主体、修饰,也会完成图片库的提取。
组成三,行动器。接下来,就是设计的具体过程。比如明天我们接到一个设计任务,要为这样一件校服设计一个花朵风格的广告。这时候会有一个行动器,负责把上面打算好的底料放在设计框架里。这个过程和下象棋太象,左边是棋盘,右边是下象棋的棋子。行动器就是把元素放在棋盘里,这是整个行动器的生成原理。
它太象设计师实际在做设计的过程,如设计师要做一个花朵的时侯,也在软件上面会不断去调每位位置、每个象素、每个角度。同时,整个过程也是一个强化学习的过程,行动器会在不断试错中更智能。
组成四,评估网路。设计成品下来以后,我们要告诉机器人,从设计的角度是好还是不好。我们有一个设计评估网路,最终实现的疗效就是给它输入任何一个设计成品,它能打个分。技术原理是,我们通过人工输入大量历史上投放过的一些设计图评分,它从这儿训练出一个打分的模型下来。同时,专家也会人工干预打分,完成单向反馈。
这套框架并不是只能做Banner广告,Banner广告是我们找到的第一个最适宜落地的业务场景。我们把它定义为是一个通用的设计智能,理论上,它可以设计一切的数字内容。只要是通过元素或则象素组成的图象,理论上都是可以完成的。
预告一下我们最新的实践。前两张图是机器完成的服装搭配,根据用户输入的服装商品进行组合搭配,生成类似刊物的搭配效果图。另外,我们也正在训练机器完成页面模块的设计,比如大量的营销活动页面,我们如今正在训练它完成复杂的排版设计。
正在攻破的三个困局
目前,我们早已完成了框架搭建,以及数据的自我学习成长。接下来我们决心攻破的三个困局,也是使机器显得愈发强悍的关键突破点。
第一,让机器能否自主生成元素。我们目前的元素是靠设计师来提供,一方面是为了保证版权,另一方面,保证它的质量足够高。我们希望能做到,要求机器造一个花朵时,它自己能生成下来,这也是目前计算机视觉生成的一个十分火的话题。
第二,提高认知理解。现在机器还不太理解语义,只能按照需求或则任务生成一个结果,并不了解其中的关系。我们下一步要做的事情是,当用户输入了“清凉一夏”的文案时,机器人能理解“清凉”这个词代表了哪些意思,并且理解这张相片代表了“清凉一夏”的理念,图文之间有一定的关系。
最后一个,设计的迁移。比如明天通过大量专家数据训练了几百种常规数据手法以后,它还能完成主流的设计要求了。当这种手法很相似时,就可以完成风格迁移。我们会进一步探求AI,不再依据需求完成使命,而是通过自我学习和演变以后有新的东西下来。
AI+Design 拥抱新时代
今天人工智能设计真的来了,它不以任何意志为转移的趋势走来了,它距我们太逾。当一个新的浪潮打过来的时侯,我们应当学会的是拥抱它,而不是调头就跑,边跑边骂不靠谱。
视觉设计的四个层次
最基础的是临摹拓展。给你一个东西,照着它拓展一份下来,很明显这一定是机器第一步替代的工作。而且目前早已做到一大半了,证明这是一个无法回避的问题。
第二层,场景抒发。今天你给它一个东西,它能理解,能抒发对。比如明天你按照情人节,这些品牌才能找到一种合适的设计手段,去抒发出情人节的温情,这种手绘的形式会稍为难一点,也就是我们上面提到的语义这一层。
第三层,创意洞见。它还能有一些启发性的东西下来。天猫品牌上面时常有把猫头和品牌创意做联合的事情,这是机器不可能做到的事情,或者在我有生之年没有指望它能做到的。
最后一层,创造趋势。这通常是设计大师做的事情。它能定义今年、未来几年的设计趋势迈向,这是更高的设计能力。比如去年“三八”女王节,天猫用了一种全新的设计手段,用这些太轻的质感、很饱满的方法来抒发商品。它才能代表一个新的趋势和未来,代表一个新的手段,这件事情一定是人来做的。
回到明天机器和人之间的差别和对比,如果明天我们搞设计人机大战的话,机器最擅长的是数据、计算、学习。数据上,可以完成巨量素材库,训练成长速率,不断地完成闭环。它的学习速率之快,一个晚上可以完成几十万次的学习训练,是人不喝不吃也赶不上的。而人类设计师的特点,首先在情感层面,我们理解共情,情绪上有抒发,这是机器很难做到的。另外两层,创意和创造,设计师才能创造出一些新的东西,做组合迁移,组合创意,美学趋势。如果真正人机对战的话,设计师还是应回归创造、创意,以及理解用户的层面。
拥抱这个AI时代,对我们来说有没有哪些新的工作方式呢。比如明天有客人使你做一个设计,以前是一对一的给他一个成品,一对一的完成一个设计任务。有了设计AI以后,就可以将一个设计手段输入给机器,教会机器做执行和生成。这样,你就可以不止为一个顾客服务,而是为成千上万的顾客服务。
人工智能设计是个不可抵挡的时代,是未来。但是它也刚才来,我们也刚才走出第一步。我们还有大量的时间,希望接下来和设计同行一起努力,继续把这件事情做好。
优设目前早已约请了「鹿班智能设计平台」的负责人乐乘来优设做一期线上公开课,大家有哪些想问的可以随时反馈给主编@3年2班程远喔。
之前优设的合作伙伴「特赞」也专访过乐乘,大家可以先瞧瞧:双11期间有1.7 亿个BANNER,都来自阿里的“鹿班”AI设计系统
[关于UCAN]
UCAN是阿里巴巴的年度设计峰会,聚焦用户体验设计。4月27—28日,由阿里巴巴用户体验设计委员会举行的UCAN2017用户体验设计峰会在阿里巴巴西溪园区举办,本届主题是“新设计×新商业”。围绕“无界、融通、超距、生长”等概念,重新定义用户体验在新商业环境中的蝶变和价值,不断把设计领域、设计概念向外延伸,与技术、能源和商业形成新的化学反应。
欢迎关注阿里巴巴UED 的微信公众号:
「回顾2017 UCAN」
UCAN 2017回顾!8分钟看完设计大咖们的尖端干货阿里资深经理杨光:聊聊消费升级下的设计变化
【优设网 原创文章 投稿邮箱:】
================关于优设网================
“优设网“是国外人气最高的网页设计师学习平台,专注分享网页设计、无线端设计以及PS教程。
【特色推荐】
设计师须要读的100本书:史上最全的设计师图书导航:。
设计微博:拥有粉丝量200万的人气微博@优秀网页设计 ,欢迎关注获取网页设计资源、下载顶级设计素材。
设计导航:全球顶级设计网站推荐,设计师必备导航:
基于大数据平台开发工作总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-13 04:35
大数据开发,有几个阶段:
1.数据采集【原创数据】
2.数据凝聚【经过清洗合并的可用数据】
3.数据转换和映射【经过分类,提取的专项主题数据】
4.数据应用 【提供api 智能系统 应用系统等】
数据采集
数据采集有线上和线下两种形式,线上通常通过爬虫、通过抓取,或者通过已有应用系统的采集,在这个阶段,我们可以做一个大数据采集平台,依托手动爬虫(使用python或则nodejs制做爬虫软件),ETL工具、或者自定义的抽取转换引擎,从文件中、数据库中、网页中专项爬取数据,如果这一步通过自动化系统来做的话,可以很方便的管理所有的原创数据,并且从数据的开始对数据进行标签采集,可以规范开发人员的工作。并且目标数据源可以更方便的管理。
数据采集的难点在于多数据源,例如mysql、postgresql、sqlserver 、 mongodb 、sqllite。还有本地文件、excel统计文档、甚至是doc文件。如何将她们规整的、有方案的整理进我们的大数据流程中也是必不可缺的一环。
数据凝聚
数据的凝聚是大数据流程最关键的一步,你可以在这里加上数据标准化,你也可以在这里做数据清洗,数据合并,还可以在这一步将数据存档,将确认可用的数据经过可监控的流程进行整理归类,这里产出的所有数据就是整个公司的数据资产了,到了一定的量就是一笔固定资产。
数据凝聚的难点在于怎样标准化数据,例如表名标准化,表的标签分类,表的用途,数据的量,是否有数据增量?,数据是否可用? 需要在业务上下很大的工夫,必要时还要引入智能化处理,例如依照内容训练结果手动打标签,自动分配推荐表名、表数组名等。还有怎样从原创数据中导出数据等。
数据转换和映射
经过数据凝聚的数据资产怎样提供给具体的使用方使用?在这一步,主要就是考虑数据怎么应用,如何将两个?三个?数据表转换成一张才能提供服务的数据。然后定期更新增量。
经过上面的那几步,在这一步难点并不太多了,如何转换数据与怎样清洗数据、标准数据无二,将两个数组的值转换成一个数组,或者按照多个可用表统计出一张图表数据等等。
数据应用
数据的应用方法好多,有对外的、有对内的,如果拥有了前期的大量数据资产,通过restful API提供给用户?或者提供流式引擎 KAFKA 给应用消费? 或者直接组成专题数据,供自己的应用查询?这里对数据资产的要求比较高,所以前期的工作做好了,这里的自由度很高。
总结:大数据开发的难点
大数据开发的难点主要是监控,怎么样规划开发人员的工作?开发人员随随便便采集了一堆垃圾数据,并且直连数据库。 短期来看,这些问题比较小,可以矫治。 但是在资产的量不断降低的时侯,这就是一颗定时炸弹,随时会引爆,然后引起一系列对数据资产的影响,例如数据混乱带来的就是数据资产的价值增长,客户信任度变低。
如何监控开发人员的开发流程?
答案只能是自动化平台,只有自动化平台才能做到使开发人员倍感舒心的同时,接受新的事务,抛弃自动时代。
这就是后端开发工程师在大数据行业中所占有的优势点,如何制做交互良好的可视化操作界面?如何将现有的工作流程、工作需求弄成一个个的可视化操作界面? 可不可以使用智能化代替一些无脑的操作?
从一定意义上来说,大数据开发中,我个人觉得后端开发工程师抢占着更重要的位置,仅次于大数据开发工程师。至于后台开发,系统开发是第三位的。好的交互至关重要,如何转换数据,如何抽取数据,一定程度上,都是有先人踩过的坑,例如kettle,再比如kafka,pipeline ,解决方案诸多。关键是怎么交互? 怎么样变现为可视化界面? 这是一个重要的课题。
现有的诸位同学的优缺不同,认为后端的角色都是可有可无,我认为是错误的,后台的确很重要,但是后台的解决方案多。 前端实际的地位更重要,但是基本无开源的解决方案,如果不够注重后端开发, 面临的问题就是交互太烂,界面烂,体验差,导致开发人员的抵触,而可视化这块的知识点诸多,对开发人员的素养要求更高。
大数据治理
大数据整治应当贯串整个大数据开发流程,它有饰演着重要的角色,浅略的介绍几点:
数据血缘
数据质量审查
全平台监控
数据血缘
从数据血缘说起,数据血缘应当是大数据整治的入口,通过一张表,能够清晰看到它的来龙去脉,字段的分拆,清洗过程,表的流转,数据的量的变化,都应当从数据血缘出发,我个人觉得,大数据整治整个的目标就是这个数据血缘,从数据血缘才能有监控全局的能力。
数据血缘是依托于大数据开发过程的,它包围着整个大数据开发过程,每一步开发的历史,数据导出的历史,都应当有相应的记录,数据血缘在数据资产有一定规模时,基本必不可少。
数据质量审查
数据开发中,每一个模型(表)创建的结束,都应当有一个数据质量审查的过程,在体系大的环境中,还应当在关键步骤添加审批,例如在数据转换和映射这一步,涉及到顾客的数据提供,应该构建一个建立的数据质量审查制度,帮助企业第一时间发觉数据存在的问题,在数据发生问题时也能第一时间听到问题的所在,并从症结解决问题,而不是盲目的通过联接数据库一遍一遍的查询sql。
全平台监控
监控呢,其实收录了好多的点,例如应用监控,数据监控,预警系统,工单系统等,对我们接管的每位数据源、数据表都须要做到实时监控,一旦发生殆机,或者发生停水,能够第一时间电话或则邮件通知到具体负责人,这里可以借鉴一些自动化运维平台的经验的,监控约等于运维,好的监控提供的数据资产的保护也是很重要的。
大数据可视化
大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,重要的事说三遍,大数据可视化归类的数据开发中,有一部分属于应用类,有一部分属于开发类。
在开发中,大数据可视化饰演的是可视化操作的角色, 如何通过可视化的模式构建模型? 如何通过拖拉拽,或者立体操作来实现数据质量的可操作性? 画两个表格加几个按键实现复杂的操作流程是不现实的。
在可视化应用中,更多的也有怎样转换数据,如何展示数据,图表是其中的一部分,平时更多的工作还是对数据的剖析,怎么样更直观的抒发数据?这须要对数据有深刻的理解,对业务有深刻的理解,才能作出合适的可视化应用。
智能的可视化平台
可视化是可以被再可视化的,例如superset,通过操作sql实现图表,有一些产品甚至能做到按照数据的内容智能分类,推荐图表类型,实时的进行可视化开发,这样的功能才是可视化现有的发展方向,我们须要大量的可视化内容来对公司发生产出,例如服饰行业,销售部门:进货出货,颜色搭配对用户的影响,季节对选择的影响 生产部门:布料价钱走势? 产能和效率的数据统计? 等等,每一个部门都可以有一个数据大屏,可以通过平台任意规划自己的大屏,所有人每晚才能关注到自己的领域动向,这才是大数据可视化应用的具体意义。
写在最后
未来的几年,希望自己继续努力工作,主业前端开发,另外,一有时间多学学大数据开发、人工智能方面的知识,这是未来,也是方向。
最后,和你们自勉,更希望你们能给一些规划建议,三人行,必有我师焉,谢谢。 查看全部
大数据开发
大数据开发,有几个阶段:
1.数据采集【原创数据】
2.数据凝聚【经过清洗合并的可用数据】
3.数据转换和映射【经过分类,提取的专项主题数据】
4.数据应用 【提供api 智能系统 应用系统等】
数据采集
数据采集有线上和线下两种形式,线上通常通过爬虫、通过抓取,或者通过已有应用系统的采集,在这个阶段,我们可以做一个大数据采集平台,依托手动爬虫(使用python或则nodejs制做爬虫软件),ETL工具、或者自定义的抽取转换引擎,从文件中、数据库中、网页中专项爬取数据,如果这一步通过自动化系统来做的话,可以很方便的管理所有的原创数据,并且从数据的开始对数据进行标签采集,可以规范开发人员的工作。并且目标数据源可以更方便的管理。
数据采集的难点在于多数据源,例如mysql、postgresql、sqlserver 、 mongodb 、sqllite。还有本地文件、excel统计文档、甚至是doc文件。如何将她们规整的、有方案的整理进我们的大数据流程中也是必不可缺的一环。
数据凝聚
数据的凝聚是大数据流程最关键的一步,你可以在这里加上数据标准化,你也可以在这里做数据清洗,数据合并,还可以在这一步将数据存档,将确认可用的数据经过可监控的流程进行整理归类,这里产出的所有数据就是整个公司的数据资产了,到了一定的量就是一笔固定资产。
数据凝聚的难点在于怎样标准化数据,例如表名标准化,表的标签分类,表的用途,数据的量,是否有数据增量?,数据是否可用? 需要在业务上下很大的工夫,必要时还要引入智能化处理,例如依照内容训练结果手动打标签,自动分配推荐表名、表数组名等。还有怎样从原创数据中导出数据等。
数据转换和映射
经过数据凝聚的数据资产怎样提供给具体的使用方使用?在这一步,主要就是考虑数据怎么应用,如何将两个?三个?数据表转换成一张才能提供服务的数据。然后定期更新增量。
经过上面的那几步,在这一步难点并不太多了,如何转换数据与怎样清洗数据、标准数据无二,将两个数组的值转换成一个数组,或者按照多个可用表统计出一张图表数据等等。
数据应用
数据的应用方法好多,有对外的、有对内的,如果拥有了前期的大量数据资产,通过restful API提供给用户?或者提供流式引擎 KAFKA 给应用消费? 或者直接组成专题数据,供自己的应用查询?这里对数据资产的要求比较高,所以前期的工作做好了,这里的自由度很高。
总结:大数据开发的难点
大数据开发的难点主要是监控,怎么样规划开发人员的工作?开发人员随随便便采集了一堆垃圾数据,并且直连数据库。 短期来看,这些问题比较小,可以矫治。 但是在资产的量不断降低的时侯,这就是一颗定时炸弹,随时会引爆,然后引起一系列对数据资产的影响,例如数据混乱带来的就是数据资产的价值增长,客户信任度变低。
如何监控开发人员的开发流程?
答案只能是自动化平台,只有自动化平台才能做到使开发人员倍感舒心的同时,接受新的事务,抛弃自动时代。
这就是后端开发工程师在大数据行业中所占有的优势点,如何制做交互良好的可视化操作界面?如何将现有的工作流程、工作需求弄成一个个的可视化操作界面? 可不可以使用智能化代替一些无脑的操作?
从一定意义上来说,大数据开发中,我个人觉得后端开发工程师抢占着更重要的位置,仅次于大数据开发工程师。至于后台开发,系统开发是第三位的。好的交互至关重要,如何转换数据,如何抽取数据,一定程度上,都是有先人踩过的坑,例如kettle,再比如kafka,pipeline ,解决方案诸多。关键是怎么交互? 怎么样变现为可视化界面? 这是一个重要的课题。
现有的诸位同学的优缺不同,认为后端的角色都是可有可无,我认为是错误的,后台的确很重要,但是后台的解决方案多。 前端实际的地位更重要,但是基本无开源的解决方案,如果不够注重后端开发, 面临的问题就是交互太烂,界面烂,体验差,导致开发人员的抵触,而可视化这块的知识点诸多,对开发人员的素养要求更高。
大数据治理
大数据整治应当贯串整个大数据开发流程,它有饰演着重要的角色,浅略的介绍几点:
数据血缘
数据质量审查
全平台监控
数据血缘
从数据血缘说起,数据血缘应当是大数据整治的入口,通过一张表,能够清晰看到它的来龙去脉,字段的分拆,清洗过程,表的流转,数据的量的变化,都应当从数据血缘出发,我个人觉得,大数据整治整个的目标就是这个数据血缘,从数据血缘才能有监控全局的能力。
数据血缘是依托于大数据开发过程的,它包围着整个大数据开发过程,每一步开发的历史,数据导出的历史,都应当有相应的记录,数据血缘在数据资产有一定规模时,基本必不可少。
数据质量审查
数据开发中,每一个模型(表)创建的结束,都应当有一个数据质量审查的过程,在体系大的环境中,还应当在关键步骤添加审批,例如在数据转换和映射这一步,涉及到顾客的数据提供,应该构建一个建立的数据质量审查制度,帮助企业第一时间发觉数据存在的问题,在数据发生问题时也能第一时间听到问题的所在,并从症结解决问题,而不是盲目的通过联接数据库一遍一遍的查询sql。
全平台监控
监控呢,其实收录了好多的点,例如应用监控,数据监控,预警系统,工单系统等,对我们接管的每位数据源、数据表都须要做到实时监控,一旦发生殆机,或者发生停水,能够第一时间电话或则邮件通知到具体负责人,这里可以借鉴一些自动化运维平台的经验的,监控约等于运维,好的监控提供的数据资产的保护也是很重要的。
大数据可视化
大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,大数据可视化不仅仅是图表的诠释,重要的事说三遍,大数据可视化归类的数据开发中,有一部分属于应用类,有一部分属于开发类。
在开发中,大数据可视化饰演的是可视化操作的角色, 如何通过可视化的模式构建模型? 如何通过拖拉拽,或者立体操作来实现数据质量的可操作性? 画两个表格加几个按键实现复杂的操作流程是不现实的。
在可视化应用中,更多的也有怎样转换数据,如何展示数据,图表是其中的一部分,平时更多的工作还是对数据的剖析,怎么样更直观的抒发数据?这须要对数据有深刻的理解,对业务有深刻的理解,才能作出合适的可视化应用。
智能的可视化平台
可视化是可以被再可视化的,例如superset,通过操作sql实现图表,有一些产品甚至能做到按照数据的内容智能分类,推荐图表类型,实时的进行可视化开发,这样的功能才是可视化现有的发展方向,我们须要大量的可视化内容来对公司发生产出,例如服饰行业,销售部门:进货出货,颜色搭配对用户的影响,季节对选择的影响 生产部门:布料价钱走势? 产能和效率的数据统计? 等等,每一个部门都可以有一个数据大屏,可以通过平台任意规划自己的大屏,所有人每晚才能关注到自己的领域动向,这才是大数据可视化应用的具体意义。
写在最后
未来的几年,希望自己继续努力工作,主业前端开发,另外,一有时间多学学大数据开发、人工智能方面的知识,这是未来,也是方向。
最后,和你们自勉,更希望你们能给一些规划建议,三人行,必有我师焉,谢谢。
Windows系统数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 460 次浏览 • 2020-08-12 03:38
前期打算
从这儿下载最新版的logkit-pro,因为wmi与wineventlog都是windows下的组件,所以请下载windows版本的logkit-pro。
具体logkit-pro的安装可以参考logkit-pro安装手册。
安装完成后登陆logkit-pro,在数据搜集蓝筹股中选择添加搜集器->日志搜集,在添加采集器的页面就能看见如下结果,则证明安装无误,可以使用logkit进行数据搜集的操作。
使用file reader搜集windows下的数据
在数据搜集的页面见到两侧的这五个采集器是用于搜集文件类型的数据的。
具体每位采集器的使用方式和用途可以参考文件数据源
这里我们选择file模式读取文件数据,并在配置栏中填写相应配置。这里我们获取的是磁盘下名为test.txt文本文件中的数据。
点击一侧的获取数据可以在左边的文本框中见到尝试获得数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下文本数据的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
使用wineventlog reader搜集windows系统日志
进入windows系统日志的搜集界面,能看到如下所示的界面:
如图中所示,logkit-pro默认提供的搜集类别有应用程序(Application),安全(Security),系统(System)。
其他须要搜集的风波日志可以在自定义文本框中填写须要搜集的风波名称。支持填写多个风波名,中间用,分隔。
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
这里我们将数据发送到七牛的大数据平台进行剖析,发送后可以在智能日志平台中见到相应的数据信息。
还可以在搜索框中输入相应的搜索条件进行信息的快速搜索和筛选。
同时还可以借助日志平台的仪表盘进行数据的可视化剖析。以下是我们制做的数据图表。
详细的搜集操作和配置可以参考Windows Eventlog数据源
使用wmi reader搜集windows系统信息
进入通过WMI读取windows系统信息页面,能看到如下所示界面:
如图中所示,相应配置项的涵义:
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。(目前提供了Win32_Process和Win32_NTLogEvent两个实例的搜集,其中Win32_NTLogEvent实例可能因为数据较多,尝试获取数据的时侯会加载较长的时间)
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
详细的搜集操作和配置可以参考wmi数据源
windows系统审计项的配置
由于默认情况下 Windows 的审计未设或则设置项极少,因此需降低相应的审计项目。
配置成功以后的相关初审项即可在wmi reader中通过Win32_NTLogEvent实例来搜集。
注意:若配置了和防火墙有关的初审项,日志量会下降起码 10 倍,请慎重配置。 查看全部
logkit-pro支持直接采集windows下的文本数据和wineventlog信息或则通过wmi采集windows的系统信息。文本数据的搜集使用的是file reader,wineventlog信息的搜集使用的是wineventlog reader,而通过wmi搜集windows系统信息则是使用wmi reader。wineventlog reader须要将agent布署在须要采集eventlog的机器上,而wmi reader则支持远程访问的方法读取系统信息
前期打算
从这儿下载最新版的logkit-pro,因为wmi与wineventlog都是windows下的组件,所以请下载windows版本的logkit-pro。
具体logkit-pro的安装可以参考logkit-pro安装手册。
安装完成后登陆logkit-pro,在数据搜集蓝筹股中选择添加搜集器->日志搜集,在添加采集器的页面就能看见如下结果,则证明安装无误,可以使用logkit进行数据搜集的操作。
使用file reader搜集windows下的数据
在数据搜集的页面见到两侧的这五个采集器是用于搜集文件类型的数据的。
具体每位采集器的使用方式和用途可以参考文件数据源
这里我们选择file模式读取文件数据,并在配置栏中填写相应配置。这里我们获取的是磁盘下名为test.txt文本文件中的数据。
点击一侧的获取数据可以在左边的文本框中见到尝试获得数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下文本数据的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
使用wineventlog reader搜集windows系统日志
进入windows系统日志的搜集界面,能看到如下所示的界面:
如图中所示,logkit-pro默认提供的搜集类别有应用程序(Application),安全(Security),系统(System)。
其他须要搜集的风波日志可以在自定义文本框中填写须要搜集的风波名称。支持填写多个风波名,中间用,分隔。
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
这里我们将数据发送到七牛的大数据平台进行剖析,发送后可以在智能日志平台中见到相应的数据信息。
还可以在搜索框中输入相应的搜索条件进行信息的快速搜索和筛选。
同时还可以借助日志平台的仪表盘进行数据的可视化剖析。以下是我们制做的数据图表。
详细的搜集操作和配置可以参考Windows Eventlog数据源
使用wmi reader搜集windows系统信息
进入通过WMI读取windows系统信息页面,能看到如下所示界面:
如图中所示,相应配置项的涵义:
配置完成后点击两侧的获取数据,可以尝试获取当前配置下的数据。若配置无误,在两侧文本框中可以见到尝试获取的数据。(目前提供了Win32_Process和Win32_NTLogEvent两个实例的搜集,其中Win32_NTLogEvent实例可能因为数据较多,尝试获取数据的时侯会加载较长的时间)
后续配置相应须要的解析器(可选),转换器(可选),发送目的地,即可完成windows下系统日志的搜集。我们可以看见系统日志早已被源源不断的发送到配置的目的地了。
详细的搜集操作和配置可以参考wmi数据源
windows系统审计项的配置
由于默认情况下 Windows 的审计未设或则设置项极少,因此需降低相应的审计项目。
配置成功以后的相关初审项即可在wmi reader中通过Win32_NTLogEvent实例来搜集。
注意:若配置了和防火墙有关的初审项,日志量会下降起码 10 倍,请慎重配置。
1 无埋点采集 · 数极客
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-12 00:10
无埋点采集也称为"全埋点",系统手动采集所有元素的点击数据,通过在页面中圈选定义风波名称,即可查询相关数据。特点是无须事前埋点,减轻工程师的埋点工作量。
1. 无埋点的原理
用户在网页上添加JavaScript sdk代码(APP集成数极客SDK)后,您就可以在数极客的剖析后台里步入无埋点管理模块,系统会手动辨识出页面上所有的元素,并采集所有点击行为的数据。您在仅在须要数据时,根据剖析需求对任意的元素进行圈选。对埋点进行命名后,该指标就可以各剖析模型中查询。
参考阅读:数极客Android无埋点的技术原理解读
2. 无埋点与可视化埋点的区别
无埋点技术无需事先埋点即可采集数据。可视化埋点,需要得前通过可视化界面定义风波,然后系统就会开始采集数据,因此实用性比无埋点更弱。
3. 无埋点的优缺点
运营、产品、营销人员均可以依照自身业务的需求进行可视化圈选,自定义创建风波指标,不需麻烦技术朋友代码埋点,提高工作效率。无埋点技术只能采集点击行为,生成的指标主要是点击的人数、次数、用户数、会话数等简单指标。因此当须要采集业务相关精准指标时,还需和埋点采集相结合使用。在日常工作中,大约有80%的指标,可以通过无埋点技术获取,因此,无埋点技术对于数据采集是重大的效率突破。
4. 支持的应用平台类型
数极客目前支持WEB、H5、Android、iOS四种类型的应用的无埋点数据采集。
5. 产品演示视频 查看全部
无埋点
无埋点采集也称为"全埋点",系统手动采集所有元素的点击数据,通过在页面中圈选定义风波名称,即可查询相关数据。特点是无须事前埋点,减轻工程师的埋点工作量。
1. 无埋点的原理
用户在网页上添加JavaScript sdk代码(APP集成数极客SDK)后,您就可以在数极客的剖析后台里步入无埋点管理模块,系统会手动辨识出页面上所有的元素,并采集所有点击行为的数据。您在仅在须要数据时,根据剖析需求对任意的元素进行圈选。对埋点进行命名后,该指标就可以各剖析模型中查询。
参考阅读:数极客Android无埋点的技术原理解读
2. 无埋点与可视化埋点的区别
无埋点技术无需事先埋点即可采集数据。可视化埋点,需要得前通过可视化界面定义风波,然后系统就会开始采集数据,因此实用性比无埋点更弱。
3. 无埋点的优缺点
运营、产品、营销人员均可以依照自身业务的需求进行可视化圈选,自定义创建风波指标,不需麻烦技术朋友代码埋点,提高工作效率。无埋点技术只能采集点击行为,生成的指标主要是点击的人数、次数、用户数、会话数等简单指标。因此当须要采集业务相关精准指标时,还需和埋点采集相结合使用。在日常工作中,大约有80%的指标,可以通过无埋点技术获取,因此,无埋点技术对于数据采集是重大的效率突破。
4. 支持的应用平台类型
数极客目前支持WEB、H5、Android、iOS四种类型的应用的无埋点数据采集。
5. 产品演示视频
推荐NLPIR大数据语义智能剖析平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-11 09:08
NLPIR大数据语义智能剖析平台由北京理工大学大数据搜索与挖掘实验室( Big Data Search and Mining Lab.BDSM@BIT)张华平博士主导,最近上线了新版,这里做个推荐。张华平博士最广为人知的产品是ICTCLAS英文动词平台,相信这更有助于你们了解NLPIR大数据语义智能剖析平台,以下摘自“NLPIR大数据语义智能剖析平台新版上线”。
NLPIR大数据语义智能剖析平台针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达十八年,服务了全球四十万家机构用户,是大数据时代语义智能剖析的一大神器。
NLPIR大数据语义智能挖掘平台,针对大数据内容处理的须要,融合了网路精准采集、自然语言理解、文本挖掘和网路搜索的技术,提供了客户端工具、云服务、二次开发插口。开发平台由多个中间件组成,各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux,Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,C,C#等各种开发语言使用。
NLPIR大数据语义智能剖析平台十三大功能:
1、精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
2、文档抽取:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息抽取,信息抽取确切,效率达到大数据处理的要求。
3、新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
4、批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
5、语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的中文解释。
6、文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
7、文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
8、摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
9、智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
10、情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
11、文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
12、全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
13、编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
欢迎你们下载使用。
NLPIR大数据语义智能剖析平台蓝皮书:
(约3MB)
NLPIR大数据语义智能剖析平台:
(约160MB)
Related posts:推荐张华平老师的中文分词工具ICTCLAS2010 Python自然语言处理实践: 在NLTK中使用哈佛英文分词器 Python自然语言处理工具NLTK学习导引及相关资料 中文动词入门之字标明法全文文档 查看全部
NLPIR大数据语义智能剖析平台由北京理工大学大数据搜索与挖掘实验室( Big Data Search and Mining Lab.BDSM@BIT)张华平博士主导,最近上线了新版,这里做个推荐。张华平博士最广为人知的产品是ICTCLAS英文动词平台,相信这更有助于你们了解NLPIR大数据语义智能剖析平台,以下摘自“NLPIR大数据语义智能剖析平台新版上线”。
NLPIR大数据语义智能剖析平台针对大数据内容采编挖搜的综合需求,融合了网路精准采集、自然语言理解、文本挖掘和语义搜索的最新研究成果,先后长达十八年,服务了全球四十万家机构用户,是大数据时代语义智能剖析的一大神器。
NLPIR大数据语义智能挖掘平台,针对大数据内容处理的须要,融合了网路精准采集、自然语言理解、文本挖掘和网路搜索的技术,提供了客户端工具、云服务、二次开发插口。开发平台由多个中间件组成,各个中间件API可以无缝地融合到顾客的各种复杂应用系统之中,可兼容Windows,Linux,Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,C,C#等各种开发语言使用。
NLPIR大数据语义智能剖析平台十三大功能:
1、精准采集:对境内外互联网海量信息实时精准采集,有主题采集(按照信息需求的主题采集)与站点采集两种模式(给定网址列表的站内定点采集功能)。
2、文档抽取:对doc、excel、pdf与ppt等多种主流文档格式,进行文本信息抽取,信息抽取确切,效率达到大数据处理的要求。
3、新词发觉:从文本中挖掘出新词、新概念,用户可以用于专业辞典的编纂,还可以进一步编辑标明,导入动词辞典中,提高动词系统的准确度,并适应新的语言变化。
4、批量动词:对原创语料进行动词,自动辨识人名地名机构名等未登入词,新词标明以及动词标明。并可在剖析过程中,导入用户定义的辞典。
5、语言统计:针对切分标明结果,系统可以手动地进行一元词频统计、二元成语转移机率统计。针对常用的术语,会手动给出相应的中文解释。
6、文本降维:能够从大规模数据中手动剖析出热点风波,并提供风波话题的关键特点描述。同时适用于长文本和邮件、微博等短文本的热点剖析。
7、文本分类:根据规则或训练的方式对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等众多方面。
8、摘要实体:对单篇或多篇文章,自动提炼出内容摘要,抽取人名、地名、机构名、时间及主题关键词;方便用户快速浏览文本内容。
9、智能过滤:对文本内容的语义智能过滤审查,内置国外最全词库,智能辨识多种变种:形变、音变、繁简等多种变型,语义精准排岐。
10、情感剖析:针对事先指定的剖析对象,系统手动剖析海量文档的情感倾向:情感极性及情感值检测,并在原文中给出正负面的得分和语句样例。
11、文档去重:快速准确地判定文件集合或数据库中是否存在相同或相像内容的记录,同时找出所有的重复记录。
12、全文检索:支持文本、数字、日期、字符串等各类数据类型,多数组的高效搜索,支持AND/OR/NOT以及NEAR毗邻等查询句型,支持俄语、藏语、蒙语、阿拉伯、韩语等多种少数民族语言的检索。
13、编码转换:自动辨识内容的编码,并把编码统一转换为其他编码。
欢迎你们下载使用。
NLPIR大数据语义智能剖析平台蓝皮书:
(约3MB)
NLPIR大数据语义智能剖析平台:
(约160MB)
Related posts:推荐张华平老师的中文分词工具ICTCLAS2010 Python自然语言处理实践: 在NLTK中使用哈佛英文分词器 Python自然语言处理工具NLTK学习导引及相关资料 中文动词入门之字标明法全文文档
智能伪原创-采集插件(终身可用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-10 22:45
由于采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改的PHP环境。修改的方式很简单,打开网站采集软件的安装目录“System/PHP”,找到php.ini文件打开,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在插件目录
例如我本机是:D:优采云采集器V9Plugins
问:这个插件主要功能是哪些?
回答:是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后,在正常运行的基础上,选择伪原创插件。
伪原创插件使用教程
一个有效的搜集工具,可以帮助我们更快地完成竞购。
采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。 查看全部
1、修改的PHP环境
由于采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改的PHP环境。修改的方式很简单,打开网站采集软件的安装目录“System/PHP”,找到php.ini文件打开,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在插件目录
例如我本机是:D:优采云采集器V9Plugins
问:这个插件主要功能是哪些?
回答:是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后,在正常运行的基础上,选择伪原创插件。
伪原创插件使用教程
一个有效的搜集工具,可以帮助我们更快地完成竞购。
采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。
干货|国内外十大主流采集软件盘点
采集交流 • 优采云 发表了文章 • 0 个评论 • 763 次浏览 • 2020-08-10 15:09
文|优采云大数据
大数据技术用了多年时间进行演变,才从一种看起来太炫目的新技术弄成了企业在生产经营中实际布署的服务。其中,数据采集产品迎来了辽阔的市场前景,无论国内外,市面上都出现了许多技术不一、良莠不齐的采集软件。
今天,我们将对比 国内外十大主流采集软件优缺点,帮助你选择最适宜的爬虫,体验数据hunting带来的快感。
国内篇
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。它的用户定位主要是拥有一定代码基础的人群,适合编程老鸟。
采集功能健全,不限网页与内容,任意文件格式都可下载
具有智能多辨识系统以及可选的验证方法保护安全
支持PHP和C#插件扩充,方便更改处理数据
具有同义,近义词替换、参数替换,伪原创必备技能
采集难度大,对没有编程基础的用户来说存在困难
Conclusion:优采云适用于编程能手,规则编撰比较复杂,软件的定位比较专业并且精准化。
2.优采云
一款可视化免编程的网页采集软件,可以从不同网站中快速提取规范化数据,帮助用户实现数据的自动化采集、编辑以及规范化,降低工作成本。云采集是它的一大特色,相比其他采集软件,云采集能够做到愈发精准、高效和大规模。
可视化操作,无需编撰代码,制作规则采集,适用于零编程基础的用户
即将发布的7.0版本智能化,内置智能算法和既定采集规则,用户设置相应参数能够实现网站、APP的手动采集。
云采集是其主要功能,支持死机采集,并实现手动定时采集
支持多IP动态分配与验证码破解,避免IP封锁
采集数据表格化,支持多种导入方法和导出网站
Conclusion:优采云是一款适宜小白用户尝试的采集软件,云功能强悍,当然爬虫老鸟也能开拓它的中级功能。
3.集搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素。同样可通过简单可视化流程进行采集,服务于任何对数据有采集需求的人群。
可视化流程操作,与优采云不同,集搜客的流程重在定义所抓取的数据和爬虫路线,优采云的规则流程非常明晰,由用户决定软件的每一步操作
支持抓取在指数图表上漂浮显示的数据,还可以抓取手机网站上的数据
会员可以互助抓取,提升采集效率,同时还有模板资源可以套用
Conclusion:集搜客操作较简单,适用于中级用户,功能方面没有很大的特色,后续付费要求比较多。
4.优采云云爬虫
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据。
直接接入代理IP,避免IP封锁
自动登入验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富表格化方式诠释本地化隐私保护,云端采集,可隐藏用户IP
Conclusion: 优采云类似一个爬虫系统框架,具体采集还需用户自写爬虫,需要代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
支持对文章内容中的文字、链接批量替换和过滤
可以同时向网站或峰会的多个版块一起批量发帖
具备采集或发贴任务完成后自动关机功能
Conclusion: 专注峰会、博客文本内容的抓取,对于全网数据的采集通用性不高。
国外篇
1.Import.io
Import.io是一个基于Web的网页数据采集平台,用户无需编撰代码点选即可生成一个提取器。相比国外大多采集软件,Import.io较为智能,能够匹配并生成同类元素列表,用户输入网址也可一键采集数据。
提供云服务,自动分配云节点并提供SaaS平台储存数据
提供API导入插口,可导入Google Sheets, Excel, Tableau等格式
收费形式按采集词条数目,提供基础版、专业版、企业版三种版本
Conclution: Import.io智能发展,采集简便,但对于一些复杂的网页结构处理能力较为薄弱。
2.Octoparse
Octoparse是一款功能齐全互联网采集工具,内置许多高效工具,用户无需编撰代码便可从复杂网页结构中搜集结构化数据。采集页面设计简单友好,完全可视化操作,适用于菜鸟用户。
提供云采集服务,可达到4-10倍速的云采集
广告封锁功能,通过降低加载时间来提升采集效率
提供Xpath设置,精准定位网页数据的元素
支持导入多种数据格式如CSV,Excel,XML等
多版本选择,分为免费版付费版,付费版均提供云服务
Conclution: Octoparse功能健全,价格合理,能够应用于复杂网页结构,如果你想无需翻墙直采亚马逊、Facebook、Twitter等平台,Octoparse是一种选择。
3.Visual Web Ripper
Visual Web Ripper是一个自动化的Web抓取工具,支持各类功能。它适用于个别中级且采集难度较大的网页结构,用户需具备较强的编程技能。
可提取各类数据格式(列表页面)
提供IP代理,避免IP封锁
支持多种数据导入格式也可通过编程自定义输出格式
内置调试器,可帮助用户自定义采集过程和输出格式
Conclution :Visual Web Ripper功能强悍,自定义采集能力强,适用于编程经验丰富的用户。它不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber是功能最强悍的Web抓取工具之一。它更适宜具有中级编程技能的人群,提供了许多强大的脚本编辑,调试界面。允许用户编撰正则表达式,而不是使用外置的工具。
内置调试器,帮助用户进行代码调试
与一些软件开发平台对接,供用户编辑爬虫脚本
提供API导入插口并支持自定义编程插口
Conclution :Content Grabber网页适用性强,功能强悍,不完全为用户提供基础功能,适合具有中级编程技能的人群。
5.Mozenda
Mozenda是一个基于云服务的数据采集软件,为用户提供许多实用性功能包括数据云端储备功能。
能够提取各类数据格式,但对于不规则数据结构较难处理(如列表、表格)
内置正则表达式工具,需要用户自行编撰
支持多种数据导入格式但不提供自定义插口
Conclution :Mozenda提供数据云储备,但无法处理复杂网页结构,软件操作界面跳跃,用户体验不够友好,适合拥有基础爬虫经验的人群。
上述的爬虫软件早已能满足海内外用户的采集需求,其中一些工具,如优采云、优采云、Octoparse、Content Grabber提供了不少中级功能,帮助用户使用外置的Regex,XPath工具和代理服务器,从复杂网页中爬取精准数据。
没有编程基础的用户不建议选择优采云、Content Grabber等须要自定义编程的工具。当然,这完全取决于个人需求,毕竟适宜自己的就是最好的!
本文由 优采云大数据 投稿至36大数据,并经由36大数据编辑发布,转载必须获得原作者和36大数据许可,并标明来源36大数据,任何不经同意的转载均为侵权。
End. 查看全部
文|优采云大数据
大数据技术用了多年时间进行演变,才从一种看起来太炫目的新技术弄成了企业在生产经营中实际布署的服务。其中,数据采集产品迎来了辽阔的市场前景,无论国内外,市面上都出现了许多技术不一、良莠不齐的采集软件。
今天,我们将对比 国内外十大主流采集软件优缺点,帮助你选择最适宜的爬虫,体验数据hunting带来的快感。
国内篇
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。它的用户定位主要是拥有一定代码基础的人群,适合编程老鸟。
采集功能健全,不限网页与内容,任意文件格式都可下载
具有智能多辨识系统以及可选的验证方法保护安全
支持PHP和C#插件扩充,方便更改处理数据
具有同义,近义词替换、参数替换,伪原创必备技能
采集难度大,对没有编程基础的用户来说存在困难
Conclusion:优采云适用于编程能手,规则编撰比较复杂,软件的定位比较专业并且精准化。
2.优采云
一款可视化免编程的网页采集软件,可以从不同网站中快速提取规范化数据,帮助用户实现数据的自动化采集、编辑以及规范化,降低工作成本。云采集是它的一大特色,相比其他采集软件,云采集能够做到愈发精准、高效和大规模。
可视化操作,无需编撰代码,制作规则采集,适用于零编程基础的用户
即将发布的7.0版本智能化,内置智能算法和既定采集规则,用户设置相应参数能够实现网站、APP的手动采集。
云采集是其主要功能,支持死机采集,并实现手动定时采集
支持多IP动态分配与验证码破解,避免IP封锁
采集数据表格化,支持多种导入方法和导出网站
Conclusion:优采云是一款适宜小白用户尝试的采集软件,云功能强悍,当然爬虫老鸟也能开拓它的中级功能。
3.集搜客
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素。同样可通过简单可视化流程进行采集,服务于任何对数据有采集需求的人群。
可视化流程操作,与优采云不同,集搜客的流程重在定义所抓取的数据和爬虫路线,优采云的规则流程非常明晰,由用户决定软件的每一步操作
支持抓取在指数图表上漂浮显示的数据,还可以抓取手机网站上的数据
会员可以互助抓取,提升采集效率,同时还有模板资源可以套用
Conclusion:集搜客操作较简单,适用于中级用户,功能方面没有很大的特色,后续付费要求比较多。
4.优采云云爬虫
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据。
直接接入代理IP,避免IP封锁
自动登入验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富表格化方式诠释本地化隐私保护,云端采集,可隐藏用户IP
Conclusion: 优采云类似一个爬虫系统框架,具体采集还需用户自写爬虫,需要代码基础。
5.优采云采集器
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
支持对文章内容中的文字、链接批量替换和过滤
可以同时向网站或峰会的多个版块一起批量发帖
具备采集或发贴任务完成后自动关机功能
Conclusion: 专注峰会、博客文本内容的抓取,对于全网数据的采集通用性不高。
国外篇
1.Import.io
Import.io是一个基于Web的网页数据采集平台,用户无需编撰代码点选即可生成一个提取器。相比国外大多采集软件,Import.io较为智能,能够匹配并生成同类元素列表,用户输入网址也可一键采集数据。
提供云服务,自动分配云节点并提供SaaS平台储存数据
提供API导入插口,可导入Google Sheets, Excel, Tableau等格式
收费形式按采集词条数目,提供基础版、专业版、企业版三种版本
Conclution: Import.io智能发展,采集简便,但对于一些复杂的网页结构处理能力较为薄弱。
2.Octoparse
Octoparse是一款功能齐全互联网采集工具,内置许多高效工具,用户无需编撰代码便可从复杂网页结构中搜集结构化数据。采集页面设计简单友好,完全可视化操作,适用于菜鸟用户。
提供云采集服务,可达到4-10倍速的云采集
广告封锁功能,通过降低加载时间来提升采集效率
提供Xpath设置,精准定位网页数据的元素
支持导入多种数据格式如CSV,Excel,XML等
多版本选择,分为免费版付费版,付费版均提供云服务
Conclution: Octoparse功能健全,价格合理,能够应用于复杂网页结构,如果你想无需翻墙直采亚马逊、Facebook、Twitter等平台,Octoparse是一种选择。
3.Visual Web Ripper
Visual Web Ripper是一个自动化的Web抓取工具,支持各类功能。它适用于个别中级且采集难度较大的网页结构,用户需具备较强的编程技能。
可提取各类数据格式(列表页面)
提供IP代理,避免IP封锁
支持多种数据导入格式也可通过编程自定义输出格式
内置调试器,可帮助用户自定义采集过程和输出格式
Conclution :Visual Web Ripper功能强悍,自定义采集能力强,适用于编程经验丰富的用户。它不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber是功能最强悍的Web抓取工具之一。它更适宜具有中级编程技能的人群,提供了许多强大的脚本编辑,调试界面。允许用户编撰正则表达式,而不是使用外置的工具。
内置调试器,帮助用户进行代码调试
与一些软件开发平台对接,供用户编辑爬虫脚本
提供API导入插口并支持自定义编程插口
Conclution :Content Grabber网页适用性强,功能强悍,不完全为用户提供基础功能,适合具有中级编程技能的人群。
5.Mozenda
Mozenda是一个基于云服务的数据采集软件,为用户提供许多实用性功能包括数据云端储备功能。
能够提取各类数据格式,但对于不规则数据结构较难处理(如列表、表格)
内置正则表达式工具,需要用户自行编撰
支持多种数据导入格式但不提供自定义插口
Conclution :Mozenda提供数据云储备,但无法处理复杂网页结构,软件操作界面跳跃,用户体验不够友好,适合拥有基础爬虫经验的人群。
上述的爬虫软件早已能满足海内外用户的采集需求,其中一些工具,如优采云、优采云、Octoparse、Content Grabber提供了不少中级功能,帮助用户使用外置的Regex,XPath工具和代理服务器,从复杂网页中爬取精准数据。
没有编程基础的用户不建议选择优采云、Content Grabber等须要自定义编程的工具。当然,这完全取决于个人需求,毕竟适宜自己的就是最好的!
本文由 优采云大数据 投稿至36大数据,并经由36大数据编辑发布,转载必须获得原作者和36大数据许可,并标明来源36大数据,任何不经同意的转载均为侵权。
End.
优采云采集器软件(熊猫智能采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-07 23:37
Microsoft .NET Framework 3.5 SP1
版本: V3.5
运行平台: Microsoft Windows(32位)操作系统
运行优采云采集器软件所需的平台软件应确保运行优采云采集器软件的计算机已安装.net 3.5 SP1或更高版本.
当前的大多数Windows操作系统都有自己的.net3.5和更高版本的优采云采集器软件,除非必要,否则无需进行特殊安装.
这是平台软件的官方Microsoft网站的游戏策略地址:
如何直接玩
Microsoft Access 2010 x64数据库引擎
版本: Microsoft Office 2010 64位
运行平台: Microsoft Windows 64位操作系统
如果您需要运行64位版本的Panda软件,则需要在计算机上安装Microsoft Office 64位. 如果尚未安装,则可以直接安装驱动程序引擎.
在少数情况下,尽管已安装64位版本的Office,但在软件运行期间经常报告莫名其妙的错误. 此时,您还应该尝试再次安装该引擎.
如何直接玩
访问数据库
版本: Office 2003及更高版本
Microsoft Office系列中的一个小型数据库. 在优采云采集器软件运行期间生成的日志和其他信息均由优采云采集器软件存储和管理,这也是优采云采集器中的默认数据库.
但这不是必需的. 如果确认使用第三方数据库引擎,则优采云采集器系统仍然可以正常运行,但是此时无法打开运行日志.
Access数据库软件是Microsoft Office办公室自动化软件系列之一. 如果您的计算机上未安装此软件,请从您的Office安装盘中添加并安装Access.
您还可以从Internet搜索与游戏策略相关的软件,但不建议这样做. 查看全部
Microsoft .NET Framework 3.5 SP1
版本: V3.5
运行平台: Microsoft Windows(32位)操作系统
运行优采云采集器软件所需的平台软件应确保运行优采云采集器软件的计算机已安装.net 3.5 SP1或更高版本.
当前的大多数Windows操作系统都有自己的.net3.5和更高版本的优采云采集器软件,除非必要,否则无需进行特殊安装.
这是平台软件的官方Microsoft网站的游戏策略地址:
如何直接玩
Microsoft Access 2010 x64数据库引擎
版本: Microsoft Office 2010 64位
运行平台: Microsoft Windows 64位操作系统
如果您需要运行64位版本的Panda软件,则需要在计算机上安装Microsoft Office 64位. 如果尚未安装,则可以直接安装驱动程序引擎.
在少数情况下,尽管已安装64位版本的Office,但在软件运行期间经常报告莫名其妙的错误. 此时,您还应该尝试再次安装该引擎.
如何直接玩
访问数据库
版本: Office 2003及更高版本
Microsoft Office系列中的一个小型数据库. 在优采云采集器软件运行期间生成的日志和其他信息均由优采云采集器软件存储和管理,这也是优采云采集器中的默认数据库.
但这不是必需的. 如果确认使用第三方数据库引擎,则优采云采集器系统仍然可以正常运行,但是此时无法打开运行日志.
Access数据库软件是Microsoft Office办公室自动化软件系列之一. 如果您的计算机上未安装此软件,请从您的Office安装盘中添加并安装Access.
您还可以从Internet搜索与游戏策略相关的软件,但不建议这样做.

