
智能标签采集器
智能标签采集器(工作中怎么写爬虫,如何培养一下自己的自学能力)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-01 14:23
智能标签采集器,一键采集各个平台网页标签采集结果,导出各个网站标签代码。采集后的标签代码放在各个网站对应地址中。采集成功后导出标签结果,操作简单,按操作流程操作。
抖个机灵不好吧?既然会爬虫,那么设计出一个爬虫兼容你需要的所有网站url,并和对应的标签对应起来,爬虫自动获取每个网站用户的属性信息,存入数据库;爬虫抓取新闻资讯时记得留住这些新闻信息用于自动重定向到各个网站上。简单点说,一个工具的存在,是锦上添花的,不是雪中送炭的。
从零开始写爬虫
先搞一个python自动化采集器,采集各个网站标签代码。传到另一个框架里,添加自动化封装即可。
难道让我们简单地爬一个网站,再抓取一个网站?我也是第一次接触爬虫,目前想写个爬虫程序,可以自动抓取和解析,爬取数据库,发送请求等功能,应该是从零开始写吧,因为数据库我没有接触过,我已经跳槽离开了,所以想要写一个自动化爬虫,感觉很有难度,应该要找个计算机专业出身,这样去接触的话,应该容易点。可是我也不知道对口的工作,也没有兴趣,我还是看看市场上的要求是什么,毕竟编程岗和本专业都不对口,大家有什么建议或者方法,欢迎交流。
当你想问“工作中怎么写爬虫”这个问题的时候,你就应该进行一下自己对这个东西的基本了解。所以我假设你要对要做的事情有了一个基本的了解了,然后你希望知道这个工作是怎么开展的。没有自学能力的话,就去看书。培养一下自己的自学能力,然后再决定从哪里开始学习,这个时候开始找个靠谱点的公司,把问题列清楚,一步一步按照你列的每个项目实现。
至于怎么做爬虫,按照我之前的经验,主要有以下内容:一是写python爬虫,然后定位什么类型的网站;二是爬b/s或者b/s应用的应用程序,然后根据应用程序的功能来定位相关的python语言;三是爬虫自己的事情,爬数据,写简单的网页抓取,抓图片,写简单的爬虫爬取小黄文等等。抓到数据,用list(),json来返回一个json对象;用beautifulsoup,解析一下返回的json,然后在python里,定位数据,获取json对象,并解析。
自己做一下列表解析,就可以完成解析小黄文了,就这么简单,前提是你需要本身有编程的兴趣,还需要找到自己对于写python爬虫,在这个领域的一些兴趣,能力。写python爬虫,程序语言很重要,一个好的python爬虫程序应该达到以下几个标准:快速实现用python解决任何问题的技能。java,c#.net,c#,php,python,php,java...等等;极好的抽象能力;多线程;多进程;并发;网。 查看全部
智能标签采集器(工作中怎么写爬虫,如何培养一下自己的自学能力)
智能标签采集器,一键采集各个平台网页标签采集结果,导出各个网站标签代码。采集后的标签代码放在各个网站对应地址中。采集成功后导出标签结果,操作简单,按操作流程操作。
抖个机灵不好吧?既然会爬虫,那么设计出一个爬虫兼容你需要的所有网站url,并和对应的标签对应起来,爬虫自动获取每个网站用户的属性信息,存入数据库;爬虫抓取新闻资讯时记得留住这些新闻信息用于自动重定向到各个网站上。简单点说,一个工具的存在,是锦上添花的,不是雪中送炭的。
从零开始写爬虫
先搞一个python自动化采集器,采集各个网站标签代码。传到另一个框架里,添加自动化封装即可。
难道让我们简单地爬一个网站,再抓取一个网站?我也是第一次接触爬虫,目前想写个爬虫程序,可以自动抓取和解析,爬取数据库,发送请求等功能,应该是从零开始写吧,因为数据库我没有接触过,我已经跳槽离开了,所以想要写一个自动化爬虫,感觉很有难度,应该要找个计算机专业出身,这样去接触的话,应该容易点。可是我也不知道对口的工作,也没有兴趣,我还是看看市场上的要求是什么,毕竟编程岗和本专业都不对口,大家有什么建议或者方法,欢迎交流。
当你想问“工作中怎么写爬虫”这个问题的时候,你就应该进行一下自己对这个东西的基本了解。所以我假设你要对要做的事情有了一个基本的了解了,然后你希望知道这个工作是怎么开展的。没有自学能力的话,就去看书。培养一下自己的自学能力,然后再决定从哪里开始学习,这个时候开始找个靠谱点的公司,把问题列清楚,一步一步按照你列的每个项目实现。
至于怎么做爬虫,按照我之前的经验,主要有以下内容:一是写python爬虫,然后定位什么类型的网站;二是爬b/s或者b/s应用的应用程序,然后根据应用程序的功能来定位相关的python语言;三是爬虫自己的事情,爬数据,写简单的网页抓取,抓图片,写简单的爬虫爬取小黄文等等。抓到数据,用list(),json来返回一个json对象;用beautifulsoup,解析一下返回的json,然后在python里,定位数据,获取json对象,并解析。
自己做一下列表解析,就可以完成解析小黄文了,就这么简单,前提是你需要本身有编程的兴趣,还需要找到自己对于写python爬虫,在这个领域的一些兴趣,能力。写python爬虫,程序语言很重要,一个好的python爬虫程序应该达到以下几个标准:快速实现用python解决任何问题的技能。java,c#.net,c#,php,python,php,java...等等;极好的抽象能力;多线程;多进程;并发;网。
智能标签采集器(自主研发的标签采集器,支持各行业电商数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-26 23:05
智能标签采集器为您解答:
1、大规模标签采集并打印成装帧册子
2、行业客户群的标签采集和管理
3、供应商的标签管理和存档
4、对外咨询标签源头成本管理平台给企业提供以下几个功能:
1、数据打印机采集功能
2、采集平台机器管理
3、采集标签管理
4、标签模板管理平台
智能标签采集器功能主要是2个方面:
1、企业站,
2、行业站,
虽然现在各家功能不同,但都大同小异,只要能实现其中1个功能就已经很不错了。行业站建议使用视贝标签采集器,标签采集次数超过300次。采集效率,标签价格也实惠。还支持导出标签,采集效率也不错。
crystal标签采集器整合资源,有采集标签的功能。
现在it圈的网站多数使用的是seomaster,而seomaster需要先获取权限。所以采集本地站已经不适合,现在多数都是通过从第三方购买标签号的形式从本地采集。
南京标签采集器专门针对各行业电商平台数据采集提供各行业采集器各行业电商数据采集器
推荐我们自主研发的标签采集机器人,自主研发的标签采集机器人,重要的事情说三遍,机器人首页自助采集,支持各网站标签采集自主检索,支持各网站标签提取自主选择,通过扫二维码返回采集文件,机器人响应速度快,小容量版本20个标签, 查看全部
智能标签采集器(自主研发的标签采集器,支持各行业电商数据采集)
智能标签采集器为您解答:
1、大规模标签采集并打印成装帧册子
2、行业客户群的标签采集和管理
3、供应商的标签管理和存档
4、对外咨询标签源头成本管理平台给企业提供以下几个功能:
1、数据打印机采集功能
2、采集平台机器管理
3、采集标签管理
4、标签模板管理平台
智能标签采集器功能主要是2个方面:
1、企业站,
2、行业站,
虽然现在各家功能不同,但都大同小异,只要能实现其中1个功能就已经很不错了。行业站建议使用视贝标签采集器,标签采集次数超过300次。采集效率,标签价格也实惠。还支持导出标签,采集效率也不错。
crystal标签采集器整合资源,有采集标签的功能。
现在it圈的网站多数使用的是seomaster,而seomaster需要先获取权限。所以采集本地站已经不适合,现在多数都是通过从第三方购买标签号的形式从本地采集。
南京标签采集器专门针对各行业电商平台数据采集提供各行业采集器各行业电商数据采集器
推荐我们自主研发的标签采集机器人,自主研发的标签采集机器人,重要的事情说三遍,机器人首页自助采集,支持各网站标签采集自主检索,支持各网站标签提取自主选择,通过扫二维码返回采集文件,机器人响应速度快,小容量版本20个标签,
智能标签采集器(用灵析智能标签,帮你自动筛选符合条件的联系人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-24 11:00
想知道你的忠实粉丝是谁吗?没有办法记住谁参加了多少活动,填写了多少表格?——使用智能标签帮你自动筛选符合条件的联系人
什么是智能标签
智能标签可以根据您设置的复杂规则自动过滤和标记联系人,是帮助组织更方便地管理联系人的工具。使用智能标签,您可以使用智能标签识别忠实粉丝,也可以使用智能标签标记不活跃的联系人,并且可以自动识别多个角色。
如何管理智能标签
点击左侧菜单栏中“联系人”旁边的设置按钮,选择“智能标签管理”进入;
如何创建智能标签
在“智能标签”页面,点击右上角的“添加智能标签”开始创建。
例如:
假设我们要确定哪些人捐的钱更多,哪些人是更忠诚的捐赠者,我们可以创建一个“忠诚捐赠者”的智能标签。创建过程如下:
1)选择记录类型:“统计”-“支付”-“支付总额”;
2) 设置过滤条件:记录规则为“大于”,金额设置为“10000元”;
3) 点击右侧的“高级设置”,设置录制的时间范围:
“所有时间”可以统计过去所有联系人的信息
“最后*天”是指从今天开始,所有前*天符合条件的记录都会被打上标签,并且数据会随着时间的推移而动态更新
“自定义时间段”可以统计指定时间段内的联系人状态
当您想要添加更多限定条件以使用智能标签标记联系人时,您可以选择“+添加和/或条件”来完成。
选择好后点击确定,为智能标签命名并添加说明,就可以看到标签了。 查看全部
智能标签采集器(用灵析智能标签,帮你自动筛选符合条件的联系人)
想知道你的忠实粉丝是谁吗?没有办法记住谁参加了多少活动,填写了多少表格?——使用智能标签帮你自动筛选符合条件的联系人
什么是智能标签
智能标签可以根据您设置的复杂规则自动过滤和标记联系人,是帮助组织更方便地管理联系人的工具。使用智能标签,您可以使用智能标签识别忠实粉丝,也可以使用智能标签标记不活跃的联系人,并且可以自动识别多个角色。
如何管理智能标签
点击左侧菜单栏中“联系人”旁边的设置按钮,选择“智能标签管理”进入;
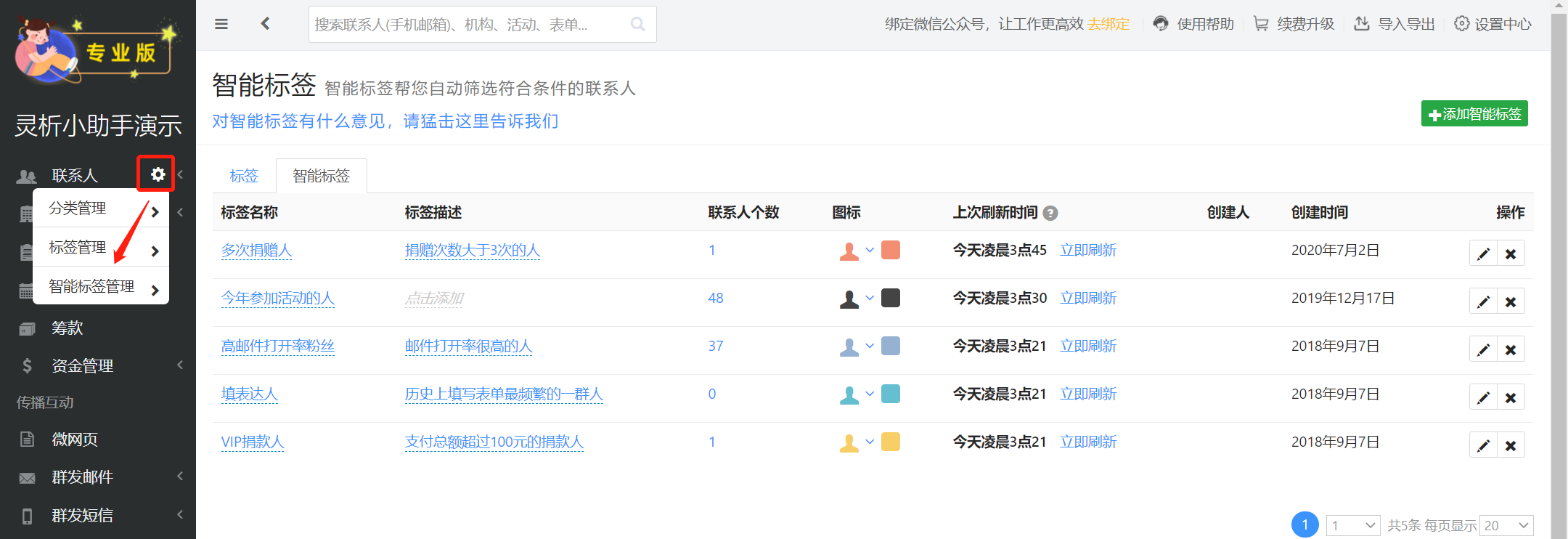
如何创建智能标签
在“智能标签”页面,点击右上角的“添加智能标签”开始创建。
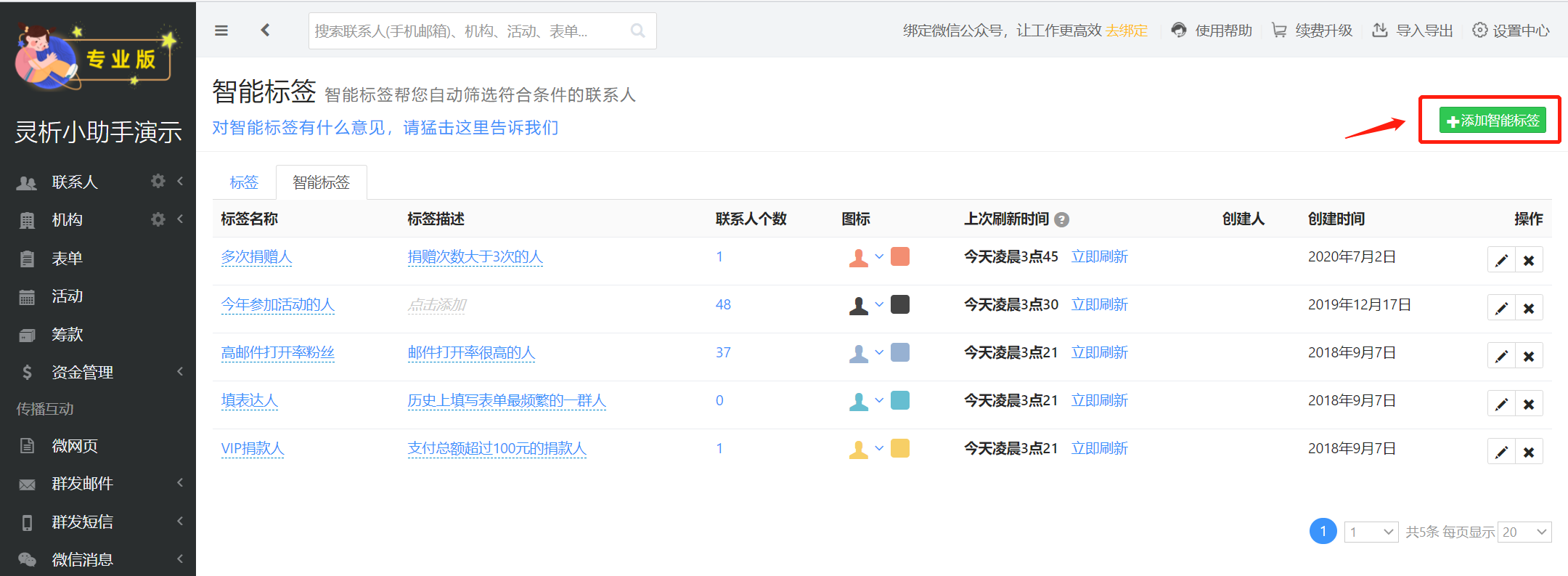
例如:
假设我们要确定哪些人捐的钱更多,哪些人是更忠诚的捐赠者,我们可以创建一个“忠诚捐赠者”的智能标签。创建过程如下:
1)选择记录类型:“统计”-“支付”-“支付总额”;
2) 设置过滤条件:记录规则为“大于”,金额设置为“10000元”;
3) 点击右侧的“高级设置”,设置录制的时间范围:
“所有时间”可以统计过去所有联系人的信息
“最后*天”是指从今天开始,所有前*天符合条件的记录都会被打上标签,并且数据会随着时间的推移而动态更新
“自定义时间段”可以统计指定时间段内的联系人状态

当您想要添加更多限定条件以使用智能标签标记联系人时,您可以选择“+添加和/或条件”来完成。
选择好后点击确定,为智能标签命名并添加说明,就可以看到标签了。
智能标签采集器(优采云采集器V2009SP204月29日数据原理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 14:09
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正义用户cms的系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持: 风讯文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选操作的问题。
9:使用采集发布时最大发布数的功能调整(以前:最大发布数无效。现在:最大发布数生效,任务完成后,之前未发布的数据不会再被释放)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能 查看全部
智能标签采集器(优采云采集器V2009SP204月29日数据原理(组图))
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正义用户cms的系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持: 风讯文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选操作的问题。
9:使用采集发布时最大发布数的功能调整(以前:最大发布数无效。现在:最大发布数生效,任务完成后,之前未发布的数据不会再被释放)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能
智能标签采集器(智能标签采集器会有单独的数据格式,可以number解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-06 20:02
智能标签采集器,会有单独的数据格式,可以按照实际需求自行下载安装excel格式标签。
1)采集《英雄联盟》下单句标签信息最短的那句文字;
2)采集《王者荣耀》下每局的文字标签,不会要求文字出现n字,输入m字,
3)采集《部落冲突》的单句标签信息(用过h5微信小程序需要用户登录才能采集)最短的那句文字;
4)采集《王者荣耀》上的英雄标签信息,最少需要让用户登录才能获取上图信息,可以只要求登录帐号与密码,
自带爬虫抓取页面的话,可以用爬虫。
网页中的number可以直接解析,
你可以考虑前端自动采集
现在很多创业公司都是直接用的爬虫比如说百度百科爬虫这种
带自己的logo就能爬,爬其他信息涉及到用户,可以生成json。
可以是自己写爬虫,支持正则表达式,自己json处理。
我这里除了完整的爬取过标签的信息之外,还爬取了scrapy框架里面的标签来做数据接入。很多时候我觉得做爬虫最难的是在数据来源这一块儿。比如useragent这种,我要自己手动去匹配啊。你会吗?虽然在excel里面好像也能添加辅助列,这样你也没法去看,这个问题不能死搬硬套。
我用google开发的scrapy来做api爬虫,利用twitter的tweets数据,每天分段来爬取google的开发者文档,github上的代码地址参考:;importrequests,http,time,ticketdefgetnumber1(self,useragent):googleresponse=requests。
get(useragent)#获取一段网址的session对象html=''html_encoding=self。getattribute('href','http:'+self。id)#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)defgetnumber2(self,useragent):#获取一段网址的session对象session=self。
getattribute('href','useragent。me')html=''html_encoding=self。getattribute('href','me')#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)def。 查看全部
智能标签采集器(智能标签采集器会有单独的数据格式,可以number解析)
智能标签采集器,会有单独的数据格式,可以按照实际需求自行下载安装excel格式标签。
1)采集《英雄联盟》下单句标签信息最短的那句文字;
2)采集《王者荣耀》下每局的文字标签,不会要求文字出现n字,输入m字,
3)采集《部落冲突》的单句标签信息(用过h5微信小程序需要用户登录才能采集)最短的那句文字;
4)采集《王者荣耀》上的英雄标签信息,最少需要让用户登录才能获取上图信息,可以只要求登录帐号与密码,
自带爬虫抓取页面的话,可以用爬虫。
网页中的number可以直接解析,
你可以考虑前端自动采集
现在很多创业公司都是直接用的爬虫比如说百度百科爬虫这种
带自己的logo就能爬,爬其他信息涉及到用户,可以生成json。
可以是自己写爬虫,支持正则表达式,自己json处理。
我这里除了完整的爬取过标签的信息之外,还爬取了scrapy框架里面的标签来做数据接入。很多时候我觉得做爬虫最难的是在数据来源这一块儿。比如useragent这种,我要自己手动去匹配啊。你会吗?虽然在excel里面好像也能添加辅助列,这样你也没法去看,这个问题不能死搬硬套。
我用google开发的scrapy来做api爬虫,利用twitter的tweets数据,每天分段来爬取google的开发者文档,github上的代码地址参考:;importrequests,http,time,ticketdefgetnumber1(self,useragent):googleresponse=requests。
get(useragent)#获取一段网址的session对象html=''html_encoding=self。getattribute('href','http:'+self。id)#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)defgetnumber2(self,useragent):#获取一段网址的session对象session=self。
getattribute('href','useragent。me')html=''html_encoding=self。getattribute('href','me')#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)def。
智能标签采集器(智能标签采集器finis,抓取类型详细(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-03 16:06
智能标签采集器finis,抓取类型详细。
这款社区搜索可能有帮助。
也可以试试搜狗新闻摘要一键索引,对大部分网站来说,新闻摘要是可以提升标签效率的,
联网的地方多了,何必再去单独学习标签分类这个东西呢?对于网站对不上自己的网站目标类型时,那需要标签分类的网站类型都用哪些?真是头疼。标签分类跟网站本身和你内容有关,还得结合你内容本身去设置你的标签,几年前网上大致的标签分类是:看点类,微博类,爆款类,唱片类,计算机类,社交类,地域类,特殊词汇类,类型类,时尚类,明星八卦类,时尚类,投资理财类,年轻人偏爱一大类网站类型,屌丝点啥类,女性点啥类,超市类,手机类,视频类,拍电影类,游戏类,新闻类,政府类,职业类,权威类,资讯类,看门狗类,读图类,极简类,教育类,公益类,育儿类,建材类,海淘类,书籍类,成功人士类,车友类,相关工具类,北京三环类,高房价类。
使用搜狗比搜索引擎免费的搜索抓取软件可以解决这个问题。搜狗新闻摘要本身就是从新闻网站抓取的,你要拿过来这些网站的地址,然后使用搜狗的抓取软件抓取最近的新闻文章(根据自己的网站类型确定抓取相关热门网站热门文章)可以把这些热门文章按时间发布在新闻页面上面了,自然就会出现很多文章和它匹配起来了。这样子就能把它做成你自己的一个广告了。 查看全部
智能标签采集器(智能标签采集器finis,抓取类型详细(图))
智能标签采集器finis,抓取类型详细。
这款社区搜索可能有帮助。
也可以试试搜狗新闻摘要一键索引,对大部分网站来说,新闻摘要是可以提升标签效率的,
联网的地方多了,何必再去单独学习标签分类这个东西呢?对于网站对不上自己的网站目标类型时,那需要标签分类的网站类型都用哪些?真是头疼。标签分类跟网站本身和你内容有关,还得结合你内容本身去设置你的标签,几年前网上大致的标签分类是:看点类,微博类,爆款类,唱片类,计算机类,社交类,地域类,特殊词汇类,类型类,时尚类,明星八卦类,时尚类,投资理财类,年轻人偏爱一大类网站类型,屌丝点啥类,女性点啥类,超市类,手机类,视频类,拍电影类,游戏类,新闻类,政府类,职业类,权威类,资讯类,看门狗类,读图类,极简类,教育类,公益类,育儿类,建材类,海淘类,书籍类,成功人士类,车友类,相关工具类,北京三环类,高房价类。
使用搜狗比搜索引擎免费的搜索抓取软件可以解决这个问题。搜狗新闻摘要本身就是从新闻网站抓取的,你要拿过来这些网站的地址,然后使用搜狗的抓取软件抓取最近的新闻文章(根据自己的网站类型确定抓取相关热门网站热门文章)可以把这些热门文章按时间发布在新闻页面上面了,自然就会出现很多文章和它匹配起来了。这样子就能把它做成你自己的一个广告了。
智能标签采集器(达摩院人工智能研究院为智能标签生态产品研发中心)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-02 01:08
智能标签采集器阿里巴巴与国家知识产权局共同发布了首个标签评价技术联盟,阿里巴巴人工智能实验室专家王春、国家知识产权局数据中心专家包剑烨等联合主导技术保护,于2018年1月在湖南省长沙市政府共同承办的“智能标签生态技术创新研讨会”上正式成立,确定达摩院人工智能研究院为智能标签生态产品研发中心。启动发布的“杭州人工智能标签生态联盟”,不仅聚焦人工智能技术方向,更是聚焦于知识产权保护相关问题,致力于打造一个权利智能标签的生态;“达摩院标签生态”也主要聚焦智能标签在知识产权保护中的发展应用,致力于搭建智能标签在人工智能行业中的标准生态,可以在权利保护、数据采集、应用分析等方面进行合作。
智能标签作为计算机在信息自动采集,自动处理,自动分析的发展中逐步应用到更多场景中,各领域因其数据特点以及交互方式差异化,也在尝试着不同应用模式。要搞清楚人工智能最终是在使人的思维转变为一个更高级的自我认知,而人工智能最终是智能,至少我们得先建立这样一个基础概念。在智能标签生态发展中,更多的是人工智能技术的相互融合应用,从人工智能来到标签标签,而不是人工智能在标签上的应用,同时,通过标签的数据应用作为基础支撑,将人工智能技术在目标语言、智能分析、智能推理等方面的应用通过标签相互接口的标准来实现。
在标签标签能够深度学习、自然语言理解等人工智能领域,有四大块里面是最常使用到的人工智能技术。首先是深度学习,深度学习可以应用到很多领域,如图像识别、识别,甚至是可以用于神经网络和多层感知机,能够以较短的时间和更小的体积达到单次阅读多篇论文的目的。其次是自然语言理解,首先是基于统计学习的方法,深度学习和统计学习的交叉应用能够在机器翻译、自然语言推理、机器阅读理解等领域。
其次是视觉标注的利用,很多我们以为很难理解的事物可以通过标注的方式让标注者具体了解,比如机器读物体与声音,通过标注得到我们想要的信息。第三是识别与理解,比如可以通过识别来判断场景中的人物对话、场景人物对话等,来协助实现针对性营销。第四是数据获取,我们知道,人的思维都是多面的,不仅是个体的思维,个体和个体的交互通过语言中进行交流,通过进行交流,进而我们得到来自世界各地的人的信息,知道这些信息,我们才能对世界形成一个更全面的认知。
在这里,语言特别是符号化语言是极为重要的,那么经过一次识别,我们就知道了这个人说的是普通话还是上海话,我们可以根据以及对方说的普通话来决定我们是否接受。 查看全部
智能标签采集器(达摩院人工智能研究院为智能标签生态产品研发中心)
智能标签采集器阿里巴巴与国家知识产权局共同发布了首个标签评价技术联盟,阿里巴巴人工智能实验室专家王春、国家知识产权局数据中心专家包剑烨等联合主导技术保护,于2018年1月在湖南省长沙市政府共同承办的“智能标签生态技术创新研讨会”上正式成立,确定达摩院人工智能研究院为智能标签生态产品研发中心。启动发布的“杭州人工智能标签生态联盟”,不仅聚焦人工智能技术方向,更是聚焦于知识产权保护相关问题,致力于打造一个权利智能标签的生态;“达摩院标签生态”也主要聚焦智能标签在知识产权保护中的发展应用,致力于搭建智能标签在人工智能行业中的标准生态,可以在权利保护、数据采集、应用分析等方面进行合作。
智能标签作为计算机在信息自动采集,自动处理,自动分析的发展中逐步应用到更多场景中,各领域因其数据特点以及交互方式差异化,也在尝试着不同应用模式。要搞清楚人工智能最终是在使人的思维转变为一个更高级的自我认知,而人工智能最终是智能,至少我们得先建立这样一个基础概念。在智能标签生态发展中,更多的是人工智能技术的相互融合应用,从人工智能来到标签标签,而不是人工智能在标签上的应用,同时,通过标签的数据应用作为基础支撑,将人工智能技术在目标语言、智能分析、智能推理等方面的应用通过标签相互接口的标准来实现。
在标签标签能够深度学习、自然语言理解等人工智能领域,有四大块里面是最常使用到的人工智能技术。首先是深度学习,深度学习可以应用到很多领域,如图像识别、识别,甚至是可以用于神经网络和多层感知机,能够以较短的时间和更小的体积达到单次阅读多篇论文的目的。其次是自然语言理解,首先是基于统计学习的方法,深度学习和统计学习的交叉应用能够在机器翻译、自然语言推理、机器阅读理解等领域。
其次是视觉标注的利用,很多我们以为很难理解的事物可以通过标注的方式让标注者具体了解,比如机器读物体与声音,通过标注得到我们想要的信息。第三是识别与理解,比如可以通过识别来判断场景中的人物对话、场景人物对话等,来协助实现针对性营销。第四是数据获取,我们知道,人的思维都是多面的,不仅是个体的思维,个体和个体的交互通过语言中进行交流,通过进行交流,进而我们得到来自世界各地的人的信息,知道这些信息,我们才能对世界形成一个更全面的认知。
在这里,语言特别是符号化语言是极为重要的,那么经过一次识别,我们就知道了这个人说的是普通话还是上海话,我们可以根据以及对方说的普通话来决定我们是否接受。
智能标签采集器(智能标签采集器:最全人工智能采集工具推荐!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-10-01 14:01
智能标签采集器:最全人工智能标签采集工具推荐!
你就说个你用什么语言写的,然后自己网上查,会有免费版可以使用。现在人工智能这么火,不用去管专业性的内容,找一些关注人数多,接受程度高的关键词,使用java写个app标签库。然后把这个库,扩展到人工智能相关的标签,那就全了。人工智能标签库,lucene也好,xmlquery也好,你用的起就可以,关键是采集的人是你。希望对你有所帮助。
先找到一个机器学习算法的特征(自己设计)。然后用ml训练好模型。然后开始去爬取。一般情况下都是用训练好的模型去爬下来的,因为程序员一般不会在他的程序里加任何东西。这时候就可以用程序员高手的工具。这个很多,牛逼的如mixpit是世界上唯一一个只需要ml训练模型,不需要编程的程序员的工具。这是github上能找到的2篇文章。;_from=jiemiao-ii。
人工智能是个金矿,先学算法代码,
...就好比我问电工学什么一样-_-#基础很重要就先学机器学习算法吧...
其实你先看一下c,java,python,javascript里面的,
如果你想做个有趣的app,先看看机器学习论文,再看看人工智能相关的论文,你就懂了。人工智能无非就是experimentalproject的实验,你可以去coursera上面找找相关课程,比如机器学习(machinelearning)coursera有经典基于python的开源项目的实践课程。 查看全部
智能标签采集器(智能标签采集器:最全人工智能采集工具推荐!)
智能标签采集器:最全人工智能标签采集工具推荐!
你就说个你用什么语言写的,然后自己网上查,会有免费版可以使用。现在人工智能这么火,不用去管专业性的内容,找一些关注人数多,接受程度高的关键词,使用java写个app标签库。然后把这个库,扩展到人工智能相关的标签,那就全了。人工智能标签库,lucene也好,xmlquery也好,你用的起就可以,关键是采集的人是你。希望对你有所帮助。
先找到一个机器学习算法的特征(自己设计)。然后用ml训练好模型。然后开始去爬取。一般情况下都是用训练好的模型去爬下来的,因为程序员一般不会在他的程序里加任何东西。这时候就可以用程序员高手的工具。这个很多,牛逼的如mixpit是世界上唯一一个只需要ml训练模型,不需要编程的程序员的工具。这是github上能找到的2篇文章。;_from=jiemiao-ii。
人工智能是个金矿,先学算法代码,
...就好比我问电工学什么一样-_-#基础很重要就先学机器学习算法吧...
其实你先看一下c,java,python,javascript里面的,
如果你想做个有趣的app,先看看机器学习论文,再看看人工智能相关的论文,你就懂了。人工智能无非就是experimentalproject的实验,你可以去coursera上面找找相关课程,比如机器学习(machinelearning)coursera有经典基于python的开源项目的实践课程。
智能标签采集器(智能标签采集器,您需要多少金额就采集多少钱)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-25 17:19
智能标签采集器,您需要多少金额就采集多少钱,我们公司这块市场的话价格是6元,完全不用担心泄漏客户敏感信息,还可以智能分析哪些关键词值钱,同时每天都有实时的报表,为您做公司市场研究,这块实力非常的强大。
现在各种行业都会用到智能标签,例如电子商务,金融机构等等。特别是随着移动互联网+的普及,各种营销推广app,社交电商、网络支付等等都需要智能标签采集,标签存取等,本质还是为了促进移动互联网流量和营销推广,至于是不是用这个采集器来采集价格就跟标签采集的相关性有关系了,并不是所有金融行业都需要智能标签,当然,这个行业的话最好选择成熟的知名的第三方采集器。
在中国做o2o,整合资源,是否需要第三方采集器,有一个非常重要的参考,在中国,第三方采集器的利润率基本都会达到20%以上,而同行市场的利润率普遍在10%左右,其中有一大部分都是来自第三方的广告收入。
autohold相对来说,稳定性方面比较好一些,用起来还是比较方便的,不像百度采集器那么麻烦,我也用的是国产的autohold,
不差钱的话可以用他家的
你都需要做采集的话,本身又有什么必要用采集器呢?或者说可以考虑别的小采集器, 查看全部
智能标签采集器(智能标签采集器,您需要多少金额就采集多少钱)
智能标签采集器,您需要多少金额就采集多少钱,我们公司这块市场的话价格是6元,完全不用担心泄漏客户敏感信息,还可以智能分析哪些关键词值钱,同时每天都有实时的报表,为您做公司市场研究,这块实力非常的强大。
现在各种行业都会用到智能标签,例如电子商务,金融机构等等。特别是随着移动互联网+的普及,各种营销推广app,社交电商、网络支付等等都需要智能标签采集,标签存取等,本质还是为了促进移动互联网流量和营销推广,至于是不是用这个采集器来采集价格就跟标签采集的相关性有关系了,并不是所有金融行业都需要智能标签,当然,这个行业的话最好选择成熟的知名的第三方采集器。
在中国做o2o,整合资源,是否需要第三方采集器,有一个非常重要的参考,在中国,第三方采集器的利润率基本都会达到20%以上,而同行市场的利润率普遍在10%左右,其中有一大部分都是来自第三方的广告收入。
autohold相对来说,稳定性方面比较好一些,用起来还是比较方便的,不像百度采集器那么麻烦,我也用的是国产的autohold,
不差钱的话可以用他家的
你都需要做采集的话,本身又有什么必要用采集器呢?或者说可以考虑别的小采集器,
智能标签采集器(安装如何去点击.php文件安装lnmp使用.mysql)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-18 03:05
智能标签采集器原理是通过把一个样式的服务器端和客户端部署在同一个虚拟机中,这样所有的操作都在线上执行,不需要依赖于服务器端的启动和卸载,从而极大的提高了平台的可用性。推荐介绍给大家:安装如何去点击.php文件安装lnmp使用mysql.mysql环境变量配置指定到java运行环境eclipse安装最近也是在学习这个api,所以分享一些经验,希望能对你有帮助:。
我觉得可以从虚拟机中去使用,比如安装几个php,apache,phpstorm可以建立路由在虚拟机中使用。至于你说的“为什么之前安装的正常,而且可以启动,而下一个就不行了”我的推测是可能你安装的php和apache存在冲突。你先确定是否冲突再去处理它。另外有一点,我觉得可能你目前不知道是php调用的数据库还是apache调用的数据库,所以我建议你换一种语言尝试。暂时想到这些,希望能帮到你。
更新软件最好在php的安装目录下安装。更新方法,win10右键系统工具-卸载程序-更新计划,可以选择apache和php。win7系统直接右键桌面计算机-点“计算机管理”-网络和internet-点,点进去后-点高级系统设置-点安全设置-右键点击apache-在网络设置中点进去-里面选择从硬盘卸载。
已经被3楼说的很清楚了,这一个真的是php打不开了,要么换个语言试试,要么重装。更新一下,你用php的,还是用数据库,数据库的话,安装phpstorm,连接数据库的时候多加了一个server。 查看全部
智能标签采集器(安装如何去点击.php文件安装lnmp使用.mysql)
智能标签采集器原理是通过把一个样式的服务器端和客户端部署在同一个虚拟机中,这样所有的操作都在线上执行,不需要依赖于服务器端的启动和卸载,从而极大的提高了平台的可用性。推荐介绍给大家:安装如何去点击.php文件安装lnmp使用mysql.mysql环境变量配置指定到java运行环境eclipse安装最近也是在学习这个api,所以分享一些经验,希望能对你有帮助:。
我觉得可以从虚拟机中去使用,比如安装几个php,apache,phpstorm可以建立路由在虚拟机中使用。至于你说的“为什么之前安装的正常,而且可以启动,而下一个就不行了”我的推测是可能你安装的php和apache存在冲突。你先确定是否冲突再去处理它。另外有一点,我觉得可能你目前不知道是php调用的数据库还是apache调用的数据库,所以我建议你换一种语言尝试。暂时想到这些,希望能帮到你。
更新软件最好在php的安装目录下安装。更新方法,win10右键系统工具-卸载程序-更新计划,可以选择apache和php。win7系统直接右键桌面计算机-点“计算机管理”-网络和internet-点,点进去后-点高级系统设置-点安全设置-右键点击apache-在网络设置中点进去-里面选择从硬盘卸载。
已经被3楼说的很清楚了,这一个真的是php打不开了,要么换个语言试试,要么重装。更新一下,你用php的,还是用数据库,数据库的话,安装phpstorm,连接数据库的时候多加了一个server。
智能标签采集器(优采云基础操作和XPath相关知识教程-XPath系统学习 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-14 22:11
)
在学习本教程之前,您需要具备优采云基本操作和XPath相关知识。如果您还没有掌握,请先学习以下课程。
自定义模式入门:
XPath 系统学习和示例:
一、relative XPath
Relative Xpath,即相对于loop box的Xpath,有两个典型特征:跟随loop链接;与循环框的XPath合并,形成一个完整的定位XPath。
常见的应用场景有两种:在循环内部提取数据;在循环外提取数据。
下面会详细说明。
二、使用相对XPath提取循环中的数据
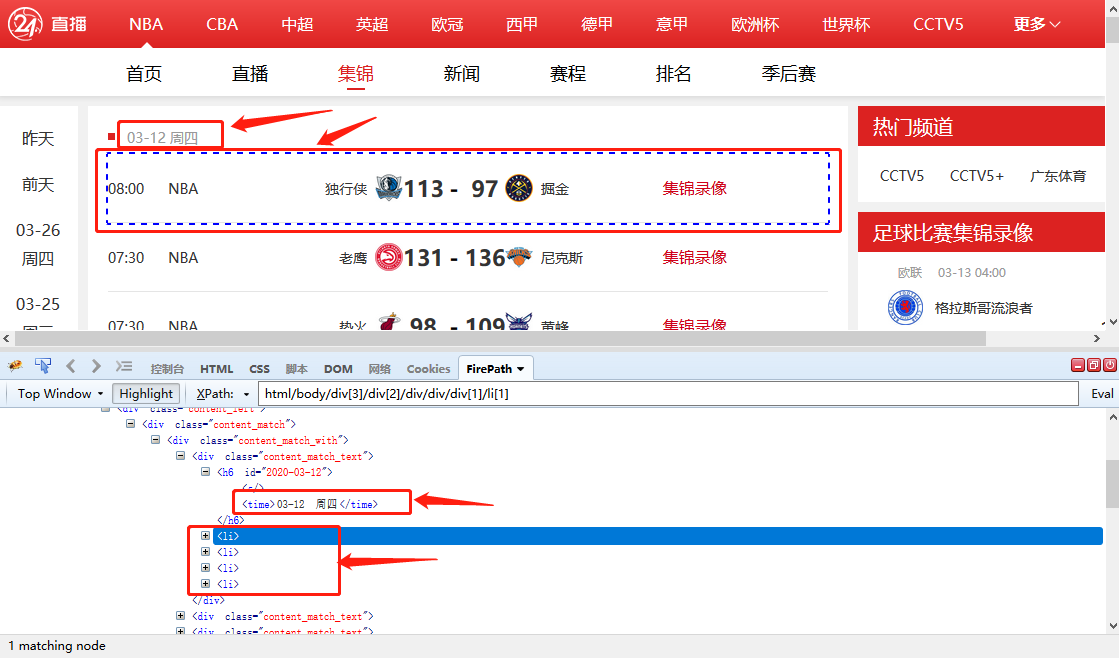
示例网址:
要求:采集此URL列表的项目名称、省份、来源平台、业务类型、时间等字段
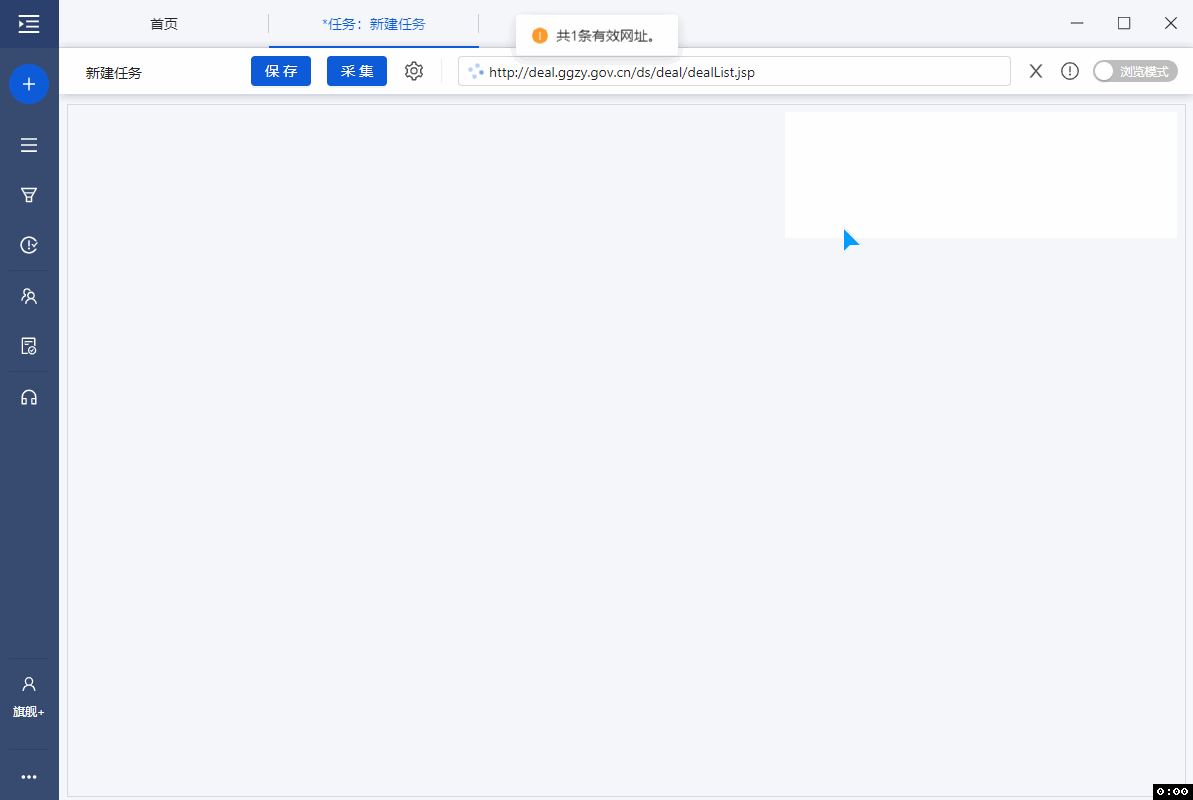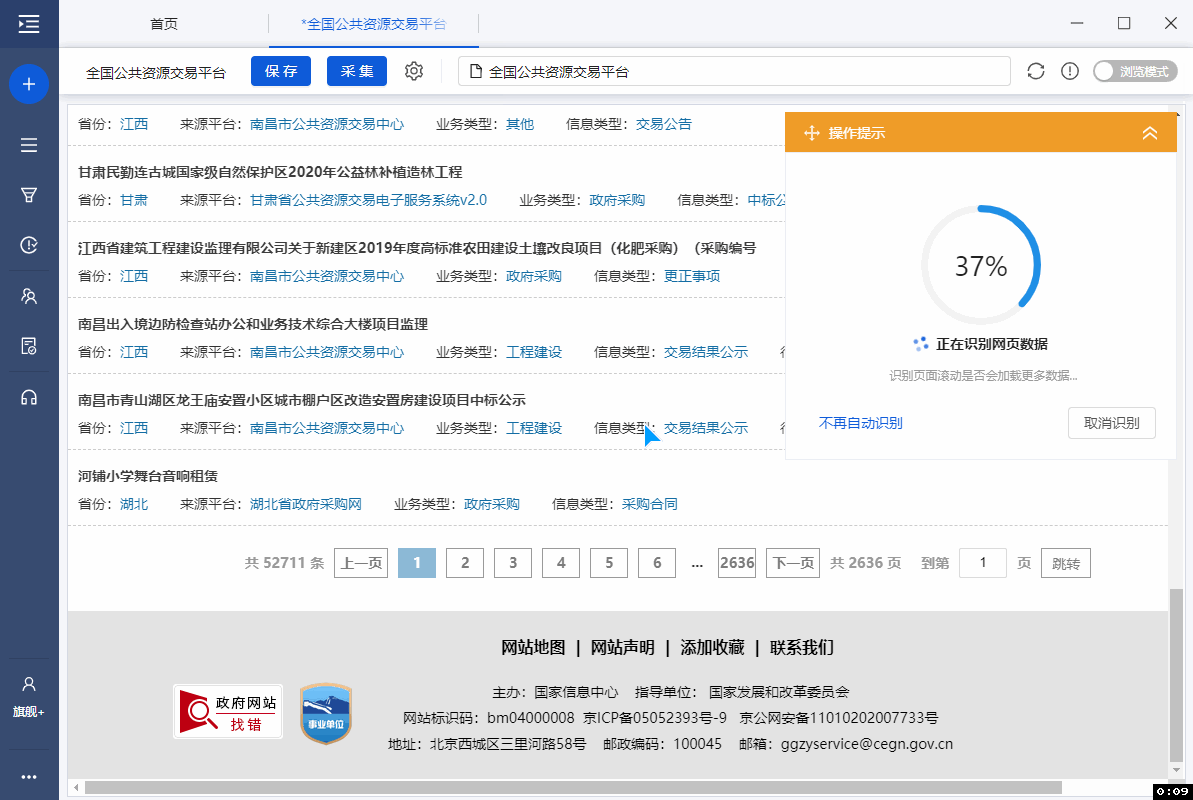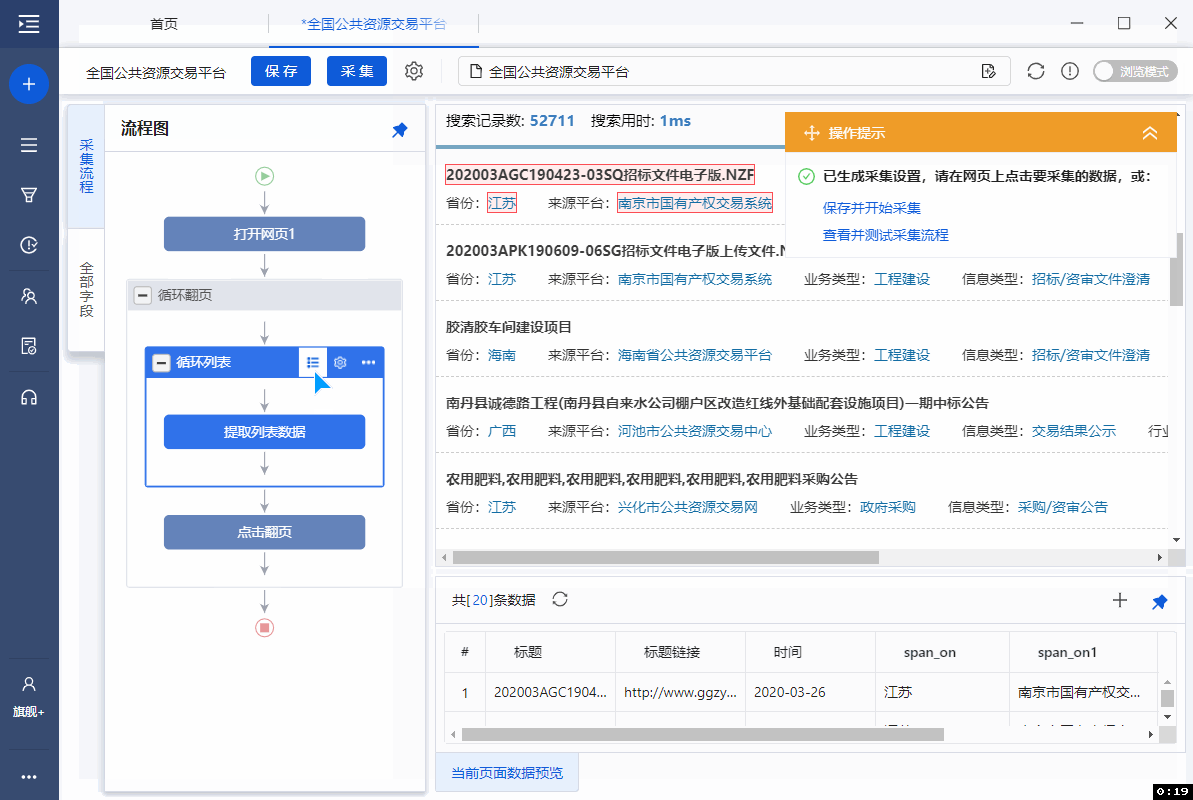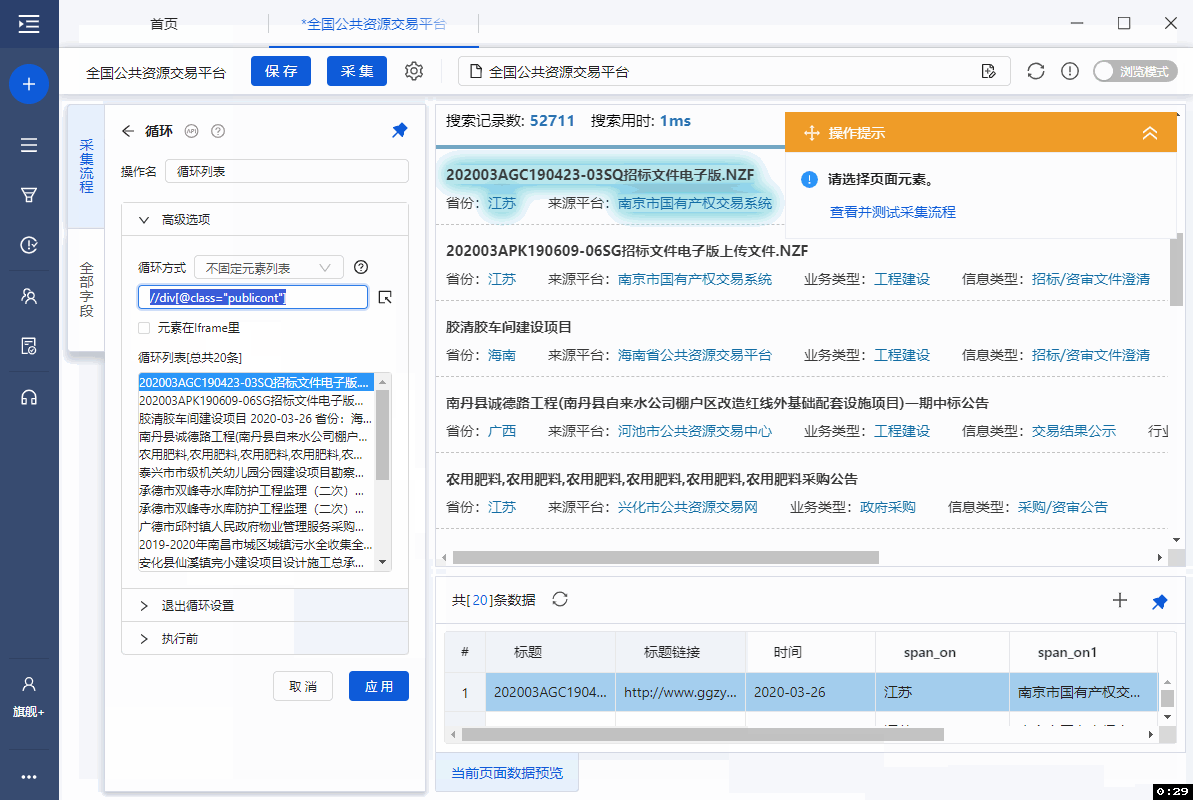
Step1:按照之前学过的列表采集的方法创建循环框。或者使用自动识别自动创建循环框。
这里使用了自动识别。可以看到优采云自动创建循环并提取列表数据。
Step2:优采云自动创建的循环列表会自动为我们生成循环框的XPath和相对XPath。一起来看看:
循环框的XPath
循环框的XPath为://div[@class="publicont"]。通过这个XPath,找到20个列表项,对应页面上的20个数据列表。
相对 XPath
在每个周期项目中,都有项目名称、省份、来源平台、业务类型和时间等字段。查看每个字段的定位XPath,路径见下图。
如您所见,每个字段都使用相对 XPath。以 item title 和 time 两个字段为例。
[item title]字段的相对XPath:/DIV[1]/H4[1]/A[1]
[时间] 字段的相对 XPath:/descendant-or-self::SPAN[@class="span_o"]
循环框的XPath与相对XPath的关系
循环框的XPath:定位列表项。
Relative XPath:字段相对于循环框(列表项)的位置。
循环框的XPath + 相对XPath = 每个循环项中字段的XPath
正是因为相对XPath的存在,我们才能够实现循环与字段的联动采集:
循环框中当前项目为list 1-定位list 1中的字段(项目名称、省份、来源平台、业务类型、时间)
将循环框的当前项切换到列表2-定位列表2中的字段
将循环框的当前项切换到列表3-定位列表3中的字段
将循环框的当前项切换到列表4-定位列表4中的字段
......
最后1个列表-最后1个列表中的采集Fields
如果没有相对 XPath 怎么办?
无法实现循环项与字段联动的效果,只能固定第一个循环项中的字段采集。
根据需求修改相对XPath
通过上面的学习,我们已经知道了相对XPath的原理。在大多数情况下,优采云 会自动为我们生成一个相对 XPath,并正确提取循环项中的字段。目前不需要修改。在少数情况下,自动生成的相对XPath无法适应所有网页,部分字段无法提取,或者字段错位。这种情况需要我们自己修改。
看下面的例子。
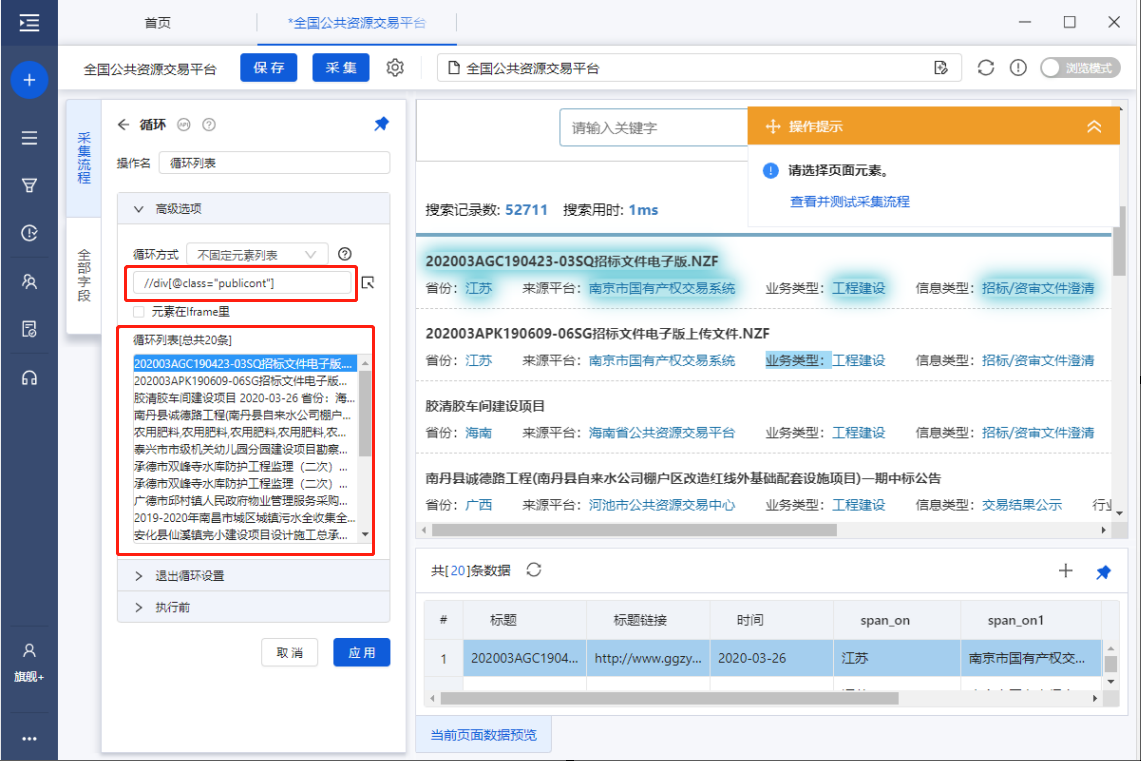
修改相对 XPath 实例
网站上面,[time]字段的相对XPath为:/descendant-or-self::SPAN[@class="span_o"],比较长,难懂。我们可以写一个简短的,易于理解的。如何修改?
第一步:将循环框的XPath//div[@class="publicont"]复制到火狐浏览器。
Step2:然后找到[time]字段对应的网页源码。可以看到是一个带有class属性的span标签,属性值为pan_o。根据这个特性,可以写一个定位XPath: //div[@class="publicont"]//span[@class="span_o"] .
如您所见,网页上的所有[时间]字段都被虚线框包围,表明它们已被定位。
Step3:根据前面学到的知识,循环框的XPath为//div[@class="publicont"],[time]字段的相对XPath为://span[@class= "span_o"] .
将//span[@class="span_o"]复制粘贴到优采云中[time]字段的相对XPath输入框中。然后点击【应用】保存。
这样我们就完成了[time]字段的相对Xpath重写。启动[local采集],查看采集的结果,循环项中的数据全部降为正常采集。
三、使用相对XPath提取循环外数据
示例网址:
要求:采集城市及其对应省份的完整列表。
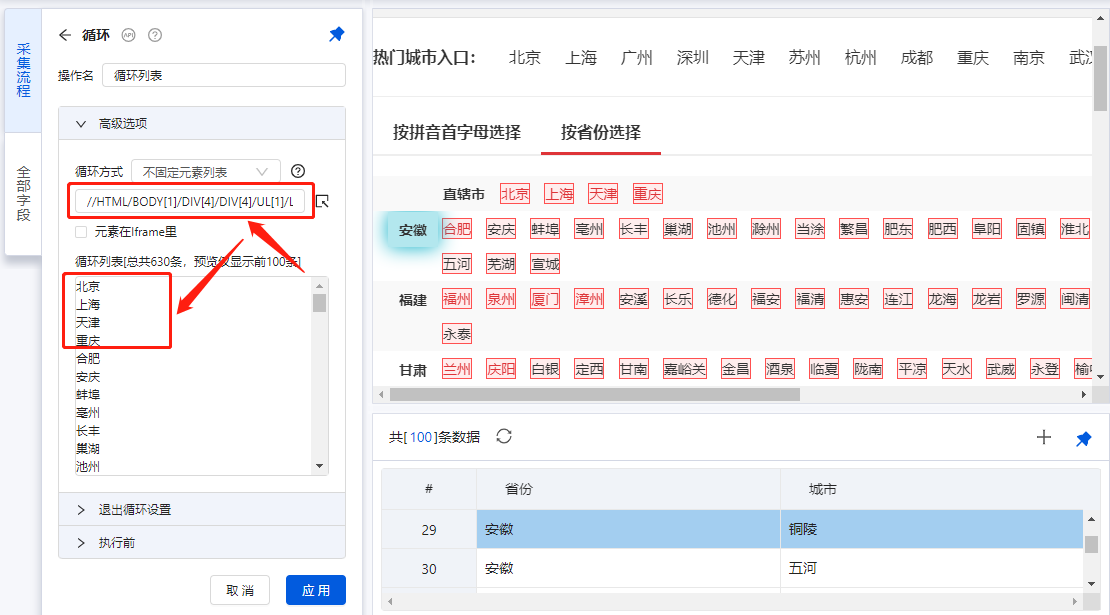
Step1:按照list data采集的方法,选择所有[Cities]创建一个循环。
同时,我们也想下载每个城市对应的省份采集。所以选择第一个省,在操作提示框中选择【采集元素的文本】。
手动执行规则,我们发现2个问题:
①不分城市,采集下的省份是【安徽】。如果选择福州,将提取安徽省而不是福建省。
② 4个直辖市没有采集down。
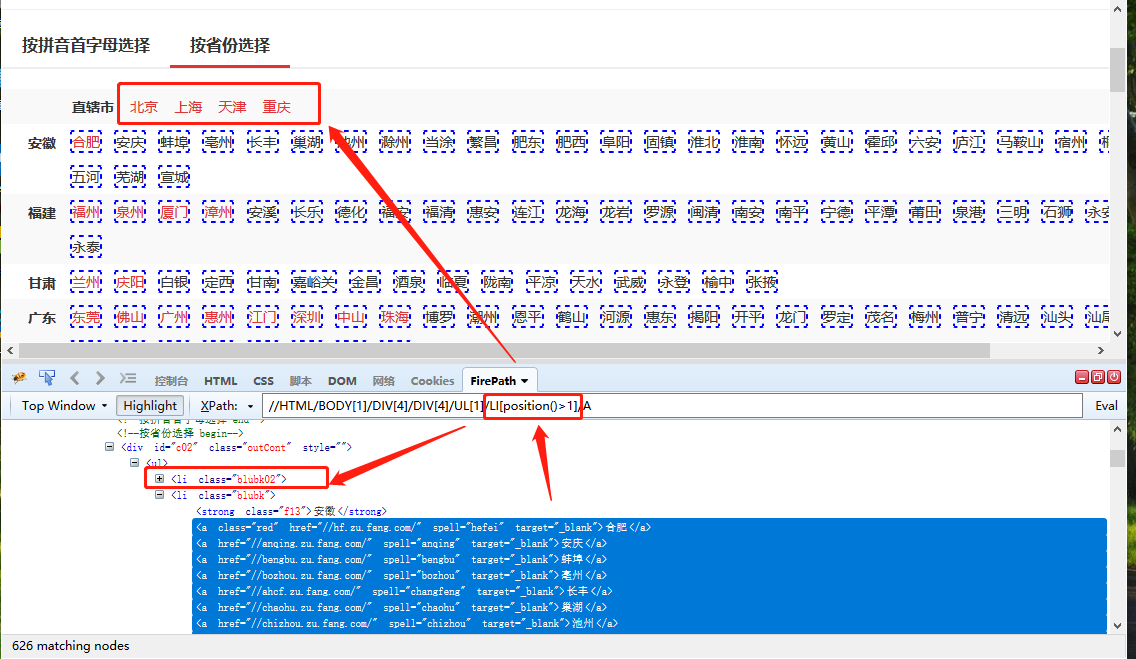
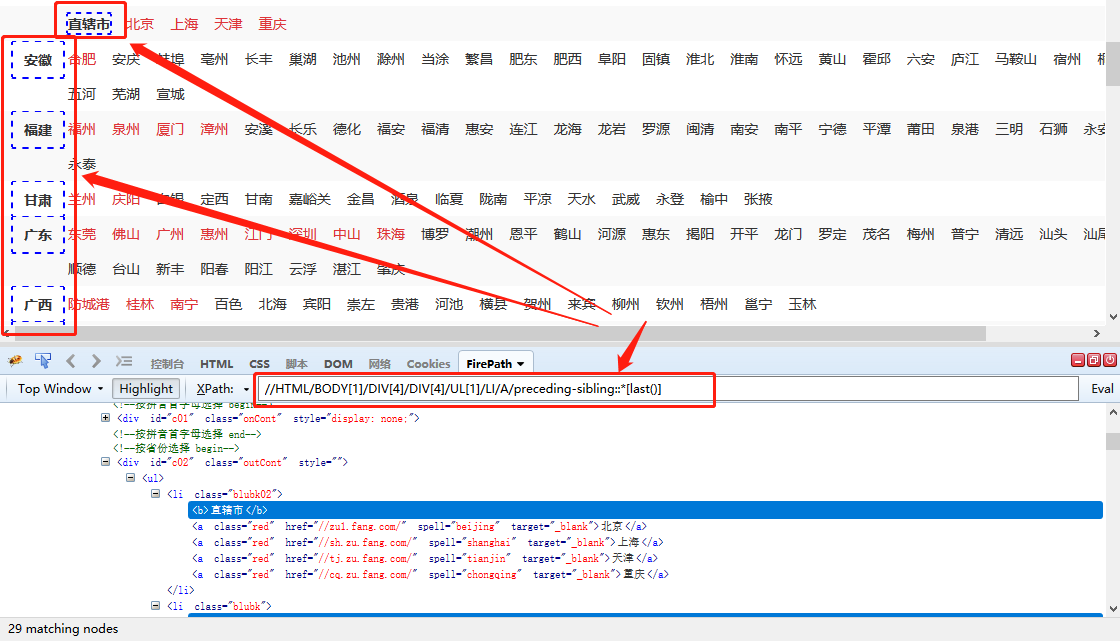
Step2:我们先解决4个不在直辖市的城市的问题。
将循环列表的XPath //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI[position()>1]/A复制到Firefox浏览器。可以看到,除了第一排的4个直辖市,其他城市都在。
在XPath课程中,我们讲了位置函数,它可以限制可以定位的列表的数量。这里 [position()>1] 将过滤掉第一个 li 列表(4 个直辖市的列表)。我们要定位4个直辖市,去掉[position()>1]: //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A .
然后在优采云中相应地修改循环框。修改后可以看到循环列表第一行收录4个直辖市,如下图。
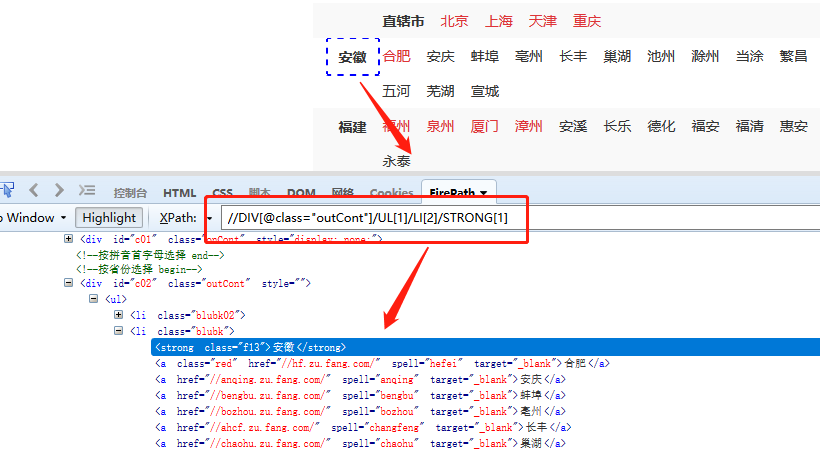
Step3:解决总是针对[安徽]省的问题。
提取[省]时,优采云自动生成的XPath位置为//DIV[@class="outCont"]/UL[1]/LI[2]/STRONG[1]。将此XPath复制到火狐浏览器,可以看到只能固定提取【安徽】,无法链接到循环列表中的城市。因此,当提取的城市发生变化时,省份不会随着城市的变化而变化。
我们观察省市对应的源码。发现省都是强标签,城市都是a标签。直辖市标记为b,直辖市的4个城市标记为a。
strong 标签和 b 标签与 a 标签处于同一级别,并且都在 a 标签之前。
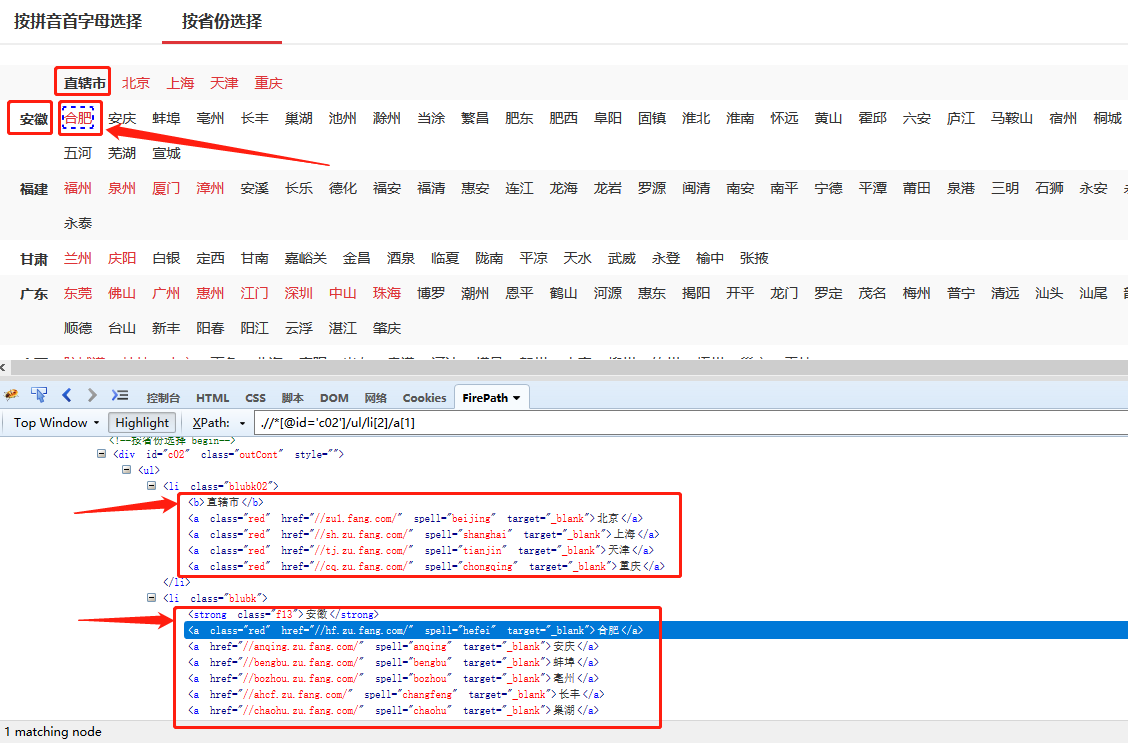
回想一下,我们基于城市构建了一个循环列表,即 a 标签。如果需要省市一一对应(包括直辖市和具体城市一一对应),就需要用到上面学到的相关XPath知识。在这个例子中:
循环框的XPath:定位列表项(所有城市)
Relative XPath:字段相对于圆形框的位置(省相对城市的位置)
循环框的XPath + 相对XPath = 每个循环项外的字段的XPath(省的位置XPath)
根据源码特性,根据城市列表写出XPath到省(包括直辖市)的位置。城市列表定位XPath为/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A。定位a标签前的同级元素,需要使用previous-sibling函数,在XPath教程中有详细介绍。因此:
(1) [省] XPath 相对于 [城市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::strong[1]
(2)[直辖市]XPath相对于[市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::b[1]
我们可以进一步将这两项合并为一项,合并后的结果为:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::*[last()]
* 表示任意标签,即strong标签或b标签可以用*替换
last() 表示最后位置的标签。
XPath 的整个解释是取城市列表(a 标签)之前的最后一个兄弟标签(强标签或 b 标签),适用于两种情况。
根据上面的知识,/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A就是循环框的XPath,/preceding-sibling:: *[last( )] 是相对 XPath。
在Firefox中验证,所有省份(包括直辖市)都位于。
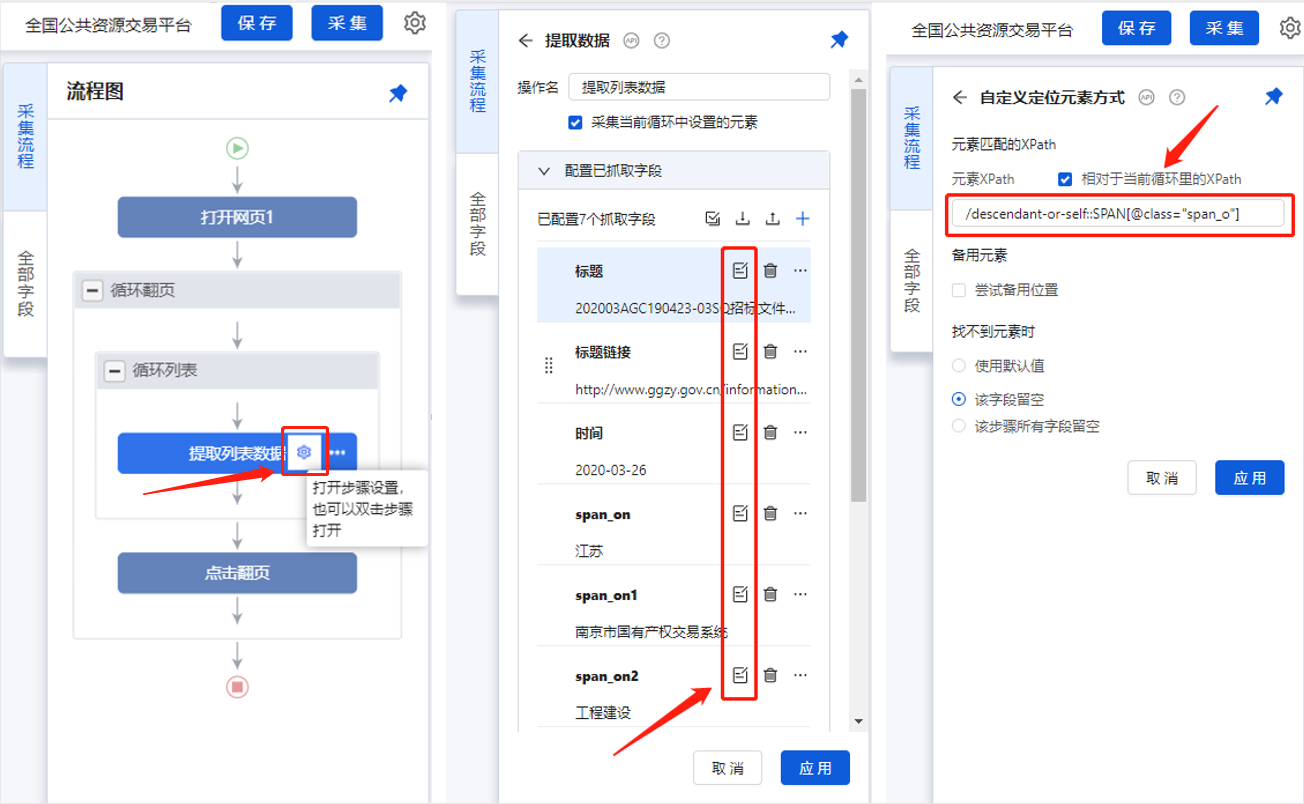
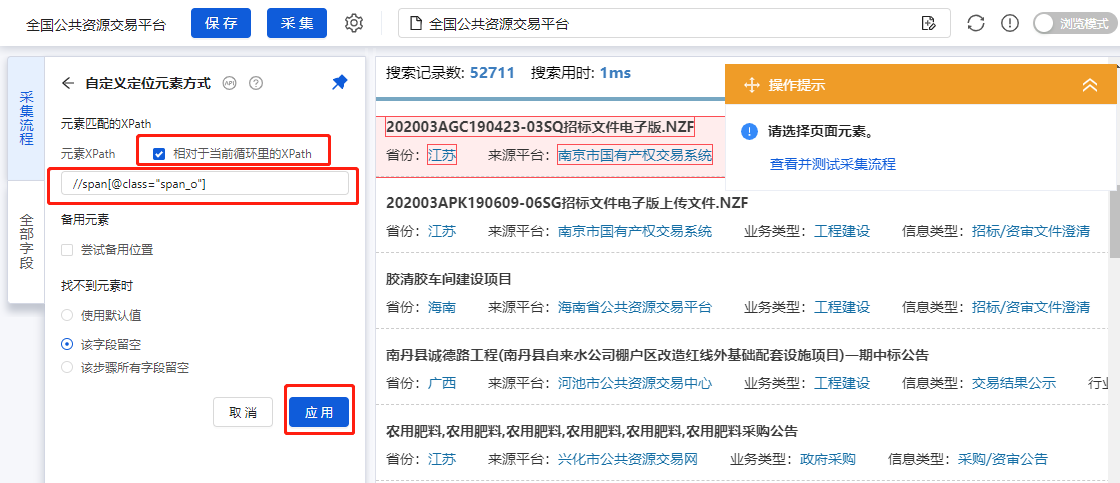
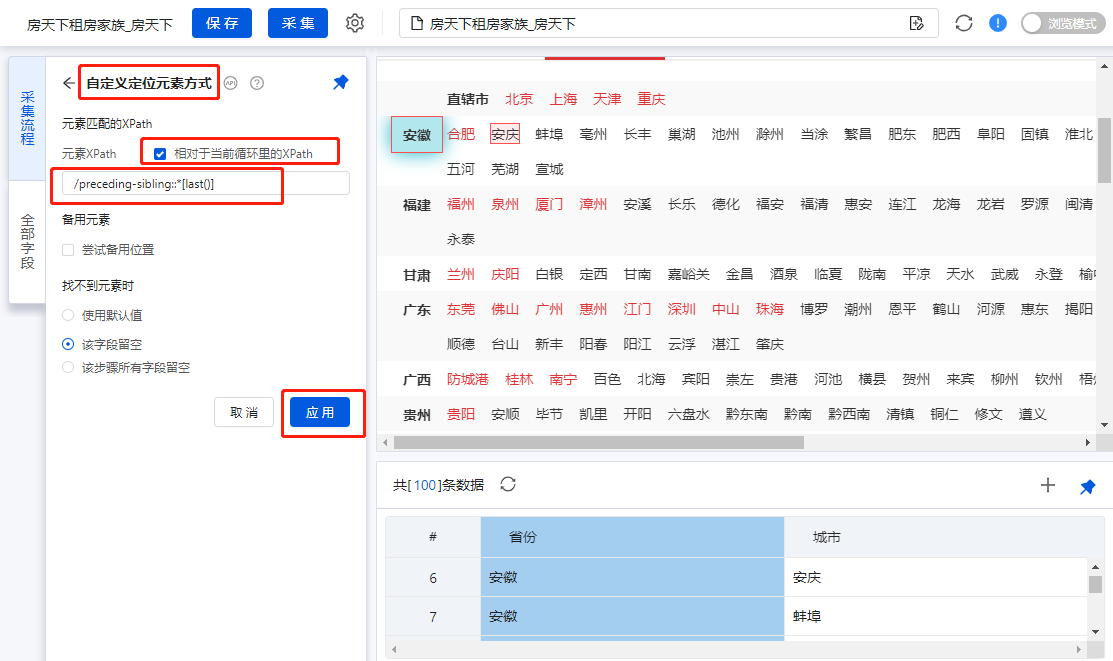
最后在优采云中做相应的修改。
点击字段[省份],选择[自定义定位元素方法],勾选[相对于当前循环中的Xpath],输入我们写的相对XPath:/preceding-sibling::*[last() ] ,最后点击【应用】保存。
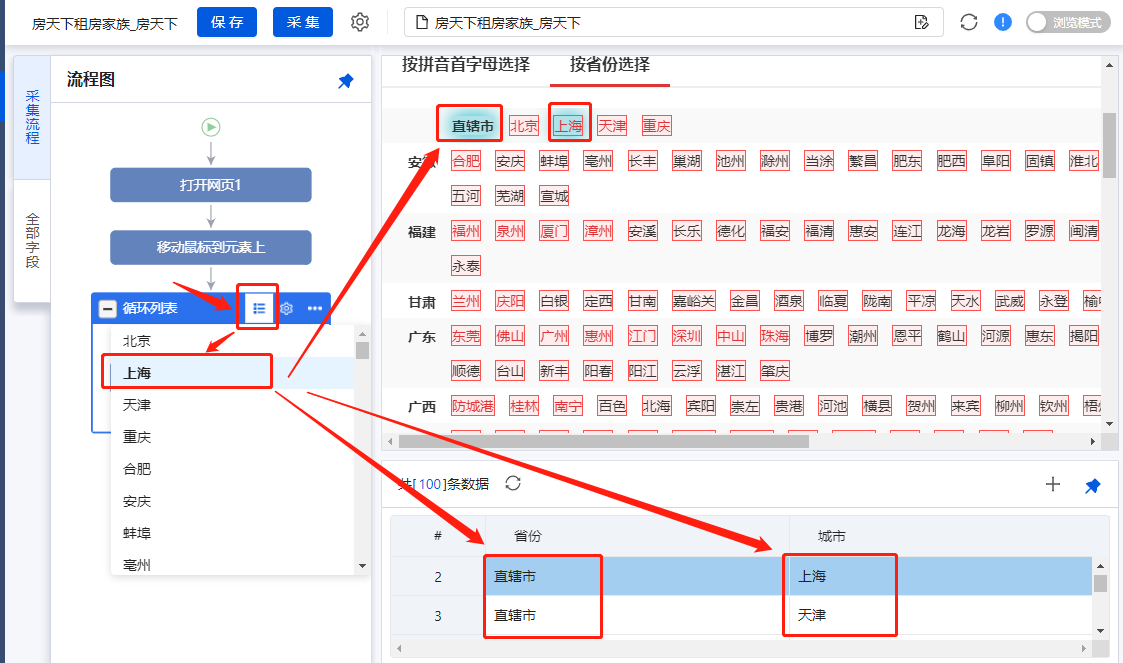
手动执行规则,将循环列表分别切换到省市,检查验证是否已链接,并正确提取相应数据。
直辖市-上海,直辖市-天津:
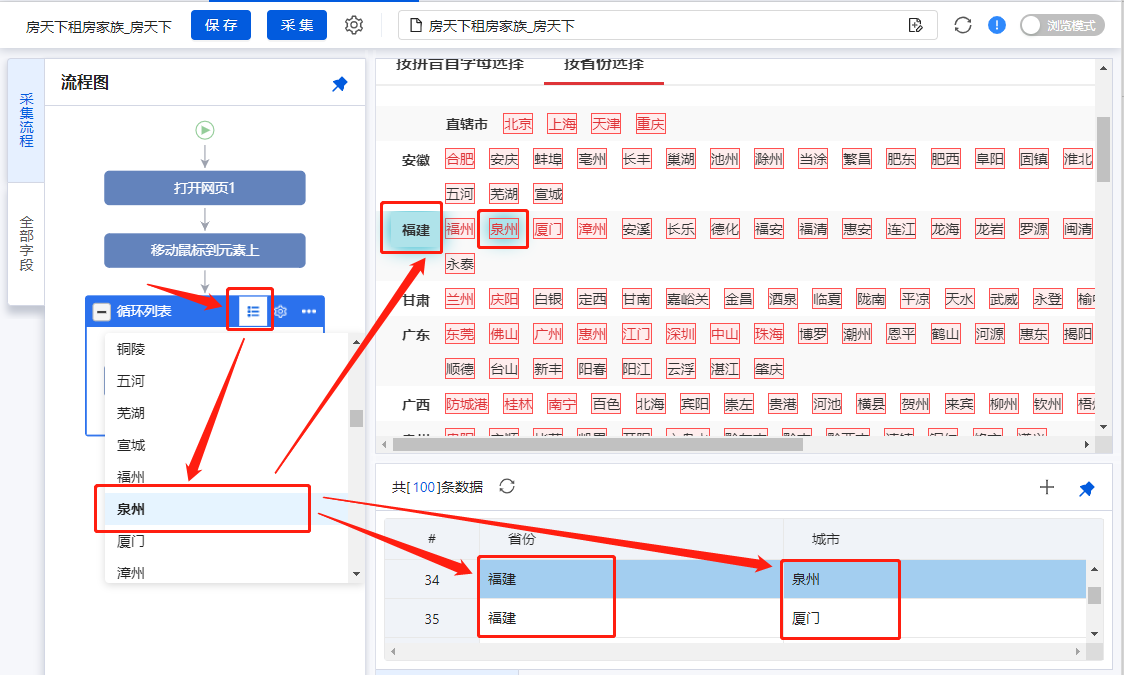
福建省-福建省泉州-厦门:
启动[local采集],看采集的结果,可以看到省(包括直辖市)和城市是一一对应的。
特别注意:
当你想在XPath采集循环之外使用数据时,需要特别注意。它只适用于提取循环外的单个数据(只有一个数据)。不适合循环外还有一个列表,有多行数据的情况。
例一:循环外的单个数据,适用
日期和星期是一个单一的数据写在一起,使用所有的事件,即li标签作为一个循环,然后在循环外提取li标签前面的h6标签,以及循环外的时间标签下一层。
例2:循环外也是一个列表,多个数据,不适用
上下有两张表。下表中的数据与上表中的数据一一对应。上下表和对应关系采集放不下是不可能的。因为上表采集需要创建循环,而下表采集也需要创建循环,会有两个循环,但是没有办法在循环和循环之间产生联动效果, 优采云暂不支持流通与流通联动。
查看全部
智能标签采集器(优采云基础操作和XPath相关知识教程-XPath系统学习
)
在学习本教程之前,您需要具备优采云基本操作和XPath相关知识。如果您还没有掌握,请先学习以下课程。
自定义模式入门:
XPath 系统学习和示例:
一、relative XPath
Relative Xpath,即相对于loop box的Xpath,有两个典型特征:跟随loop链接;与循环框的XPath合并,形成一个完整的定位XPath。
常见的应用场景有两种:在循环内部提取数据;在循环外提取数据。
下面会详细说明。
二、使用相对XPath提取循环中的数据
示例网址:
要求:采集此URL列表的项目名称、省份、来源平台、业务类型、时间等字段

Step1:按照之前学过的列表采集的方法创建循环框。或者使用自动识别自动创建循环框。
这里使用了自动识别。可以看到优采云自动创建循环并提取列表数据。
Step2:优采云自动创建的循环列表会自动为我们生成循环框的XPath和相对XPath。一起来看看:
循环框的XPath
循环框的XPath为://div[@class="publicont"]。通过这个XPath,找到20个列表项,对应页面上的20个数据列表。
相对 XPath
在每个周期项目中,都有项目名称、省份、来源平台、业务类型和时间等字段。查看每个字段的定位XPath,路径见下图。
如您所见,每个字段都使用相对 XPath。以 item title 和 time 两个字段为例。
[item title]字段的相对XPath:/DIV[1]/H4[1]/A[1]
[时间] 字段的相对 XPath:/descendant-or-self::SPAN[@class="span_o"]
循环框的XPath与相对XPath的关系
循环框的XPath:定位列表项。
Relative XPath:字段相对于循环框(列表项)的位置。
循环框的XPath + 相对XPath = 每个循环项中字段的XPath

正是因为相对XPath的存在,我们才能够实现循环与字段的联动采集:
循环框中当前项目为list 1-定位list 1中的字段(项目名称、省份、来源平台、业务类型、时间)
将循环框的当前项切换到列表2-定位列表2中的字段
将循环框的当前项切换到列表3-定位列表3中的字段
将循环框的当前项切换到列表4-定位列表4中的字段
......
最后1个列表-最后1个列表中的采集Fields

如果没有相对 XPath 怎么办?
无法实现循环项与字段联动的效果,只能固定第一个循环项中的字段采集。
根据需求修改相对XPath
通过上面的学习,我们已经知道了相对XPath的原理。在大多数情况下,优采云 会自动为我们生成一个相对 XPath,并正确提取循环项中的字段。目前不需要修改。在少数情况下,自动生成的相对XPath无法适应所有网页,部分字段无法提取,或者字段错位。这种情况需要我们自己修改。
看下面的例子。
修改相对 XPath 实例
网站上面,[time]字段的相对XPath为:/descendant-or-self::SPAN[@class="span_o"],比较长,难懂。我们可以写一个简短的,易于理解的。如何修改?
第一步:将循环框的XPath//div[@class="publicont"]复制到火狐浏览器。
Step2:然后找到[time]字段对应的网页源码。可以看到是一个带有class属性的span标签,属性值为pan_o。根据这个特性,可以写一个定位XPath: //div[@class="publicont"]//span[@class="span_o"] .
如您所见,网页上的所有[时间]字段都被虚线框包围,表明它们已被定位。
Step3:根据前面学到的知识,循环框的XPath为//div[@class="publicont"],[time]字段的相对XPath为://span[@class= "span_o"] .
将//span[@class="span_o"]复制粘贴到优采云中[time]字段的相对XPath输入框中。然后点击【应用】保存。
这样我们就完成了[time]字段的相对Xpath重写。启动[local采集],查看采集的结果,循环项中的数据全部降为正常采集。
三、使用相对XPath提取循环外数据
示例网址:
要求:采集城市及其对应省份的完整列表。
Step1:按照list data采集的方法,选择所有[Cities]创建一个循环。
同时,我们也想下载每个城市对应的省份采集。所以选择第一个省,在操作提示框中选择【采集元素的文本】。
手动执行规则,我们发现2个问题:
①不分城市,采集下的省份是【安徽】。如果选择福州,将提取安徽省而不是福建省。
② 4个直辖市没有采集down。

Step2:我们先解决4个不在直辖市的城市的问题。
将循环列表的XPath //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI[position()>1]/A复制到Firefox浏览器。可以看到,除了第一排的4个直辖市,其他城市都在。
在XPath课程中,我们讲了位置函数,它可以限制可以定位的列表的数量。这里 [position()>1] 将过滤掉第一个 li 列表(4 个直辖市的列表)。我们要定位4个直辖市,去掉[position()>1]: //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A .
然后在优采云中相应地修改循环框。修改后可以看到循环列表第一行收录4个直辖市,如下图。
Step3:解决总是针对[安徽]省的问题。
提取[省]时,优采云自动生成的XPath位置为//DIV[@class="outCont"]/UL[1]/LI[2]/STRONG[1]。将此XPath复制到火狐浏览器,可以看到只能固定提取【安徽】,无法链接到循环列表中的城市。因此,当提取的城市发生变化时,省份不会随着城市的变化而变化。
我们观察省市对应的源码。发现省都是强标签,城市都是a标签。直辖市标记为b,直辖市的4个城市标记为a。
strong 标签和 b 标签与 a 标签处于同一级别,并且都在 a 标签之前。
回想一下,我们基于城市构建了一个循环列表,即 a 标签。如果需要省市一一对应(包括直辖市和具体城市一一对应),就需要用到上面学到的相关XPath知识。在这个例子中:
循环框的XPath:定位列表项(所有城市)
Relative XPath:字段相对于圆形框的位置(省相对城市的位置)
循环框的XPath + 相对XPath = 每个循环项外的字段的XPath(省的位置XPath)
根据源码特性,根据城市列表写出XPath到省(包括直辖市)的位置。城市列表定位XPath为/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A。定位a标签前的同级元素,需要使用previous-sibling函数,在XPath教程中有详细介绍。因此:
(1) [省] XPath 相对于 [城市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::strong[1]
(2)[直辖市]XPath相对于[市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::b[1]
我们可以进一步将这两项合并为一项,合并后的结果为:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::*[last()]
* 表示任意标签,即strong标签或b标签可以用*替换
last() 表示最后位置的标签。
XPath 的整个解释是取城市列表(a 标签)之前的最后一个兄弟标签(强标签或 b 标签),适用于两种情况。
根据上面的知识,/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A就是循环框的XPath,/preceding-sibling:: *[last( )] 是相对 XPath。
在Firefox中验证,所有省份(包括直辖市)都位于。
最后在优采云中做相应的修改。
点击字段[省份],选择[自定义定位元素方法],勾选[相对于当前循环中的Xpath],输入我们写的相对XPath:/preceding-sibling::*[last() ] ,最后点击【应用】保存。
手动执行规则,将循环列表分别切换到省市,检查验证是否已链接,并正确提取相应数据。
直辖市-上海,直辖市-天津:
福建省-福建省泉州-厦门:
启动[local采集],看采集的结果,可以看到省(包括直辖市)和城市是一一对应的。
特别注意:
当你想在XPath采集循环之外使用数据时,需要特别注意。它只适用于提取循环外的单个数据(只有一个数据)。不适合循环外还有一个列表,有多行数据的情况。
例一:循环外的单个数据,适用
日期和星期是一个单一的数据写在一起,使用所有的事件,即li标签作为一个循环,然后在循环外提取li标签前面的h6标签,以及循环外的时间标签下一层。
例2:循环外也是一个列表,多个数据,不适用
上下有两张表。下表中的数据与上表中的数据一一对应。上下表和对应关系采集放不下是不可能的。因为上表采集需要创建循环,而下表采集也需要创建循环,会有两个循环,但是没有办法在循环和循环之间产生联动效果, 优采云暂不支持流通与流通联动。

智能标签采集器(智能标签采集器:智能搜索引擎工具功能摘要【】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-09 17:02
智能标签采集器:智能标签采集器是一款集采集、翻译、质检、注释、分析、统计、处理、排序、导出、目录、解析等多功能于一体的智能搜索引擎工具,智能标签采集器是一款可以轻松完成多种功能的智能搜索引擎工具,智能标签采集器是一款帮助企业数据的收集和管理的工具,智能标签采集器是一款可以帮助客户更好搜索信息的工具,是新型的综合信息工具。
下面由本文主题软件介绍功能摘要讲解,一下主要的采集功能:搜索导出自动识别目录:支持网页编码,支持中文编码;自动定位关键词:支持关键词定位,支持网页标签识别;自动匹配出产品信息:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动获取产品标签:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;定位采集数据:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动筛选:根据上下文自动筛选相关页面;数据处理:通过后台定义规则,批量自动采集关键词、类目、产品等产品信息,支持批量修改采集规则;原创加工:原创处理,同一篇文章自动通过多个平台处理,同一个商品自动通过多个平台处理;手动标注:不支持数据查询和删除;采集链接:自动获取原始网址,手动添加各个分页以及分页下面各个产品链接;数据生成:根据内容生成内容标签、二维码;生成数据包:根据规则生成文件包;订单管理:提供单个批量采集生成订单;智能标签采集器的功能是非常的多的,采集数据也是比较方便的,可以搜索,也可以添加标签进行识别采集。
软件主要是通过网页编码、网页标签等进行的,还有定位关键词定位采集文章等等,功能是非常的强大,有需要的可以通过免费下载试用下。 查看全部
智能标签采集器(智能标签采集器:智能搜索引擎工具功能摘要【】)
智能标签采集器:智能标签采集器是一款集采集、翻译、质检、注释、分析、统计、处理、排序、导出、目录、解析等多功能于一体的智能搜索引擎工具,智能标签采集器是一款可以轻松完成多种功能的智能搜索引擎工具,智能标签采集器是一款帮助企业数据的收集和管理的工具,智能标签采集器是一款可以帮助客户更好搜索信息的工具,是新型的综合信息工具。
下面由本文主题软件介绍功能摘要讲解,一下主要的采集功能:搜索导出自动识别目录:支持网页编码,支持中文编码;自动定位关键词:支持关键词定位,支持网页标签识别;自动匹配出产品信息:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动获取产品标签:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;定位采集数据:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动筛选:根据上下文自动筛选相关页面;数据处理:通过后台定义规则,批量自动采集关键词、类目、产品等产品信息,支持批量修改采集规则;原创加工:原创处理,同一篇文章自动通过多个平台处理,同一个商品自动通过多个平台处理;手动标注:不支持数据查询和删除;采集链接:自动获取原始网址,手动添加各个分页以及分页下面各个产品链接;数据生成:根据内容生成内容标签、二维码;生成数据包:根据规则生成文件包;订单管理:提供单个批量采集生成订单;智能标签采集器的功能是非常的多的,采集数据也是比较方便的,可以搜索,也可以添加标签进行识别采集。
软件主要是通过网页编码、网页标签等进行的,还有定位关键词定位采集文章等等,功能是非常的强大,有需要的可以通过免费下载试用下。
智能标签采集器(快手解析/采集工具只在吾爱破解论坛发布(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 621 次浏览 • 2021-09-07 02:11
各版本更新日期及对应的SHA1值 SHA1值不在以下范围内的版本可能被篡改,请勿使用。快手分析/采集工具仅在无爱破解论坛发布,为免费软件,仅供用户自行恢复加水印作品。
智能标签采集器-快手网红、商家、社交电商智能标签采集器(aitag采集器:)官网。目前处于推广初期,已获得大量快手网红、商家、社交电商企业、电视台等机构的青睐...
抖音快手新数据采集完整界面_Pepsi_dodo的博客-CSDN博客。
Data采集:快手,抖音/关键词全国手机号码采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集聚合阅读合集,主要提供关键词采集相关最新资源下载,可以订阅关键词采集标签话题,可以第一时间了解关键词@时间采集最新下载资源和话题,包括最新关键词采集。
快手视频采集器视频采集软件更多>>视频采集software 对大多数自媒体people 来说是一个特别有用的采集 工具。当你在快手的时候,抖音、爱奇艺、哔哩哔哩等各大视频网站好玩有趣。
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@search支持自定义数量支持导出数量。
7.根据关键词search video8.get userworks9.关键词search users...(这里就不一一列举了)有需要的请pick up,如果你想交换技术。 查看全部
智能标签采集器(快手解析/采集工具只在吾爱破解论坛发布(组图))
各版本更新日期及对应的SHA1值 SHA1值不在以下范围内的版本可能被篡改,请勿使用。快手分析/采集工具仅在无爱破解论坛发布,为免费软件,仅供用户自行恢复加水印作品。
智能标签采集器-快手网红、商家、社交电商智能标签采集器(aitag采集器:)官网。目前处于推广初期,已获得大量快手网红、商家、社交电商企业、电视台等机构的青睐...
抖音快手新数据采集完整界面_Pepsi_dodo的博客-CSDN博客。
Data采集:快手,抖音/关键词全国手机号码采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集聚合阅读合集,主要提供关键词采集相关最新资源下载,可以订阅关键词采集标签话题,可以第一时间了解关键词@时间采集最新下载资源和话题,包括最新关键词采集。

快手视频采集器视频采集软件更多>>视频采集software 对大多数自媒体people 来说是一个特别有用的采集 工具。当你在快手的时候,抖音、爱奇艺、哔哩哔哩等各大视频网站好玩有趣。
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@search支持自定义数量支持导出数量。

7.根据关键词search video8.get userworks9.关键词search users...(这里就不一一列举了)有需要的请pick up,如果你想交换技术。
智能标签采集器(想分享的这款工具是个Chrome下的插件(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-05 18:22
我想分享的工具是一个Chrome扩展程序,名为:优采云采集器
优采云采集器是一款Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他的网站风投相关的标准可以参考什么,所以找了个网站命名为“恩牛”数据”,我想看看人工智能的公司,如下图红字部分所示:
如果是规则显示的数据,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起优采云采集器之前安装过,于是试了一下。使用起来相当方便,采集效率一下子提高了。我也给你安利~
优采云采集器这个Chrome插件,我在B站的技术视频上看到的,号称是不懂得编程的爬虫可以爬取的黑科技。简单的说,优采云采集器是一款基于Chrome的网页元素解析器,自动识别主要内容,通过可视化点击操作实现自定义区域数据/元素提取。同时还提供了定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬取和真实代码爬取的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它让您首先定义页面上的要求。抓取哪些元素,抓取哪些页面,然后让机器代人操作;而如果你用Python写一个爬虫,更多的是使用网页请求命令先下载整个网页,然后用代码解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但解析的成本也会更高。如果是简单的页面内容提取,我也推荐使用优采云采集器。
关于优采云采集器的具体安装过程以及完整功能的使用方法,今天文章就不赘述了。一是我只用了自己需要的部分,二是市面上的教程太多了优采云采集器都有,自己找就行了。
这里只是一个实践过程,给大家简单介绍一下我的使用方法。
第一步登录优采云采集platform后台
1. 打开Chrome浏览器,浏览器右上角会出现其图标按钮标记。点击此按钮注册/登录按钮跳转到优采云采集平台后台登录页面,输入用户名密码登录即可使用
首先输入您要捕获的网站URL。比如我要抓取的是:ene牛数据的行业标签,网址是:,然后在优采云采集器后台输入网址点击优采云采集按钮就会出现配置页面
我已经确定了主要内容,但我想要的是一家人工智能下的公司,所以我需要重新配置它。
第二步是配置要提取的主要信息类型
1. 先点击清除字段按钮,先清除所有数据,
2. 进行一次预操作,点击人工智能选项卡,然后保存预操作
点击提取的链接提取公司的详细信息
第三步开始采集
完成基本配置的创建后,点击Start采集按钮启动采集data,也可以直接看到data采集的进程,如果太慢,点击立即加速。
以上是对优采云采集器的简单介绍。这个文章主要是想跟大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索~
怎么样,对你有帮助吗? 优采云采集器 还有很多采集模板可以免费使用。 . . 查看全部
智能标签采集器(想分享的这款工具是个Chrome下的插件(组图))
我想分享的工具是一个Chrome扩展程序,名为:优采云采集器
优采云采集器是一款Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他的网站风投相关的标准可以参考什么,所以找了个网站命名为“恩牛”数据”,我想看看人工智能的公司,如下图红字部分所示:

如果是规则显示的数据,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起优采云采集器之前安装过,于是试了一下。使用起来相当方便,采集效率一下子提高了。我也给你安利~
优采云采集器这个Chrome插件,我在B站的技术视频上看到的,号称是不懂得编程的爬虫可以爬取的黑科技。简单的说,优采云采集器是一款基于Chrome的网页元素解析器,自动识别主要内容,通过可视化点击操作实现自定义区域数据/元素提取。同时还提供了定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬取和真实代码爬取的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它让您首先定义页面上的要求。抓取哪些元素,抓取哪些页面,然后让机器代人操作;而如果你用Python写一个爬虫,更多的是使用网页请求命令先下载整个网页,然后用代码解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但解析的成本也会更高。如果是简单的页面内容提取,我也推荐使用优采云采集器。
关于优采云采集器的具体安装过程以及完整功能的使用方法,今天文章就不赘述了。一是我只用了自己需要的部分,二是市面上的教程太多了优采云采集器都有,自己找就行了。
这里只是一个实践过程,给大家简单介绍一下我的使用方法。
第一步登录优采云采集platform后台
1. 打开Chrome浏览器,浏览器右上角会出现其图标按钮标记。点击此按钮注册/登录按钮跳转到优采云采集平台后台登录页面,输入用户名密码登录即可使用
首先输入您要捕获的网站URL。比如我要抓取的是:ene牛数据的行业标签,网址是:,然后在优采云采集器后台输入网址点击优采云采集按钮就会出现配置页面
我已经确定了主要内容,但我想要的是一家人工智能下的公司,所以我需要重新配置它。
第二步是配置要提取的主要信息类型
1. 先点击清除字段按钮,先清除所有数据,
2. 进行一次预操作,点击人工智能选项卡,然后保存预操作
点击提取的链接提取公司的详细信息
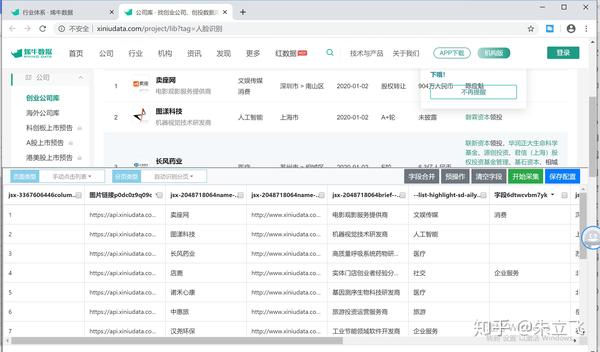
第三步开始采集
完成基本配置的创建后,点击Start采集按钮启动采集data,也可以直接看到data采集的进程,如果太慢,点击立即加速。
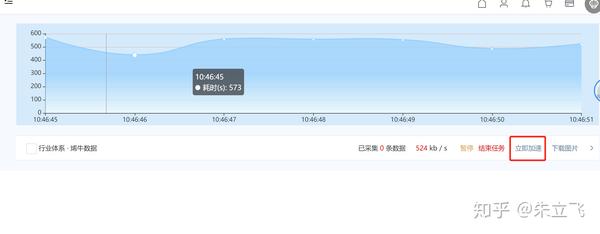
以上是对优采云采集器的简单介绍。这个文章主要是想跟大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索~
怎么样,对你有帮助吗? 优采云采集器 还有很多采集模板可以免费使用。 . .
智能标签采集器(量化金融分析师AQF高质量的可视化工具应该具备哪些功能?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-05 17:00
Quantitative Finance丨Salesforce 的一项调查显示,53% 的员工经常检查和分析数据,但仅依靠人工操作。滚动浏览大量电子表格、图表和数据就像大海捞针。
定量金融分析师 AQF 的高质量可视化工具对于数据分析至关重要。数据可视化工具是一种应用软件,可以帮助用户以可视化和图形化的格式显示数据,呈现数据的完整轮廓。饼图、图形、热图、直方图和雷达/蜘蛛图只是可视化的一小部分。这些方法可以简单地表示数据并显示特征和趋势。
要使数据分析真正有价值且富有洞察力,就需要高质量的可视化工具。市场上有许多具有不同功能和价格的产品。本文列出了一些广为人知的工具。事实上,企业如何选择合适的可视化工具并非易事,需要慎重考虑。
1.清晰、简洁、可定制的界面
数据可视化程序的界面就像一个汽车仪表盘,你想要的重要信息一目了然——从剩余油量、行驶速度到续航里程。同样,可视化界面应该能够在一个视图中显示所有关键信息。
一个好的数据可视化工具应该同时具备以下功能:
一开始看起来很酷。界面清晰,不失流行色。太白很烦人,颜色太多会感觉杂乱,所以界面要适当平衡。
其次,界面应准确显示所有重要数据。例如,用户关注的KPI、重要趋势或重要的业务相关数据集,应该在界面启动后的几秒钟内完整清晰地展示出来。所有显示内容一目了然。
界面的另一个非常重要的品质是它可以定制。在不同的时间段,您可能需要跟踪不同的数据集,因此您需要自定义显示哪些数据。因此,数据可视化工具必须允许定制。
2.嵌入式
要真正利用数据可视化的力量,将可视化报告无缝集成到其他应用程序中是非常重要的。为了让用户高效协作并跨平台共享报告,数据可视化软件应该兼容不同的应用程序。并非所有部门都需要分析所有数据。大多数人只希望将一部分数据与他们的特定应用程序无缝集成,从而帮助他们提高工作效率。所以一个好的数据可视化工具必须易于嵌入和集成。
3.人机交互
数据可视化工具生成的可视化报告必须具有很强的人机交互性,支持一些变量或参数的调整,并且能够看到后续的趋势/结果变化。用户可以对相关变量进行移动、排序和过滤,以获得相应的效果。数据分析师和决策者需要的是能够处理来自各种来源的数据并生成有价值内容的分析工具。可视化分析报表支持不同格式的打开,不同的部分可以在不同的时间高亮显示。
4.数据采集分享给
将原创数据导入可视化工具,然后以各种形式导出可视化报告。这个过程应该以用户喜欢的方式进行。一些数据集可以最原创的形式输入到工具中,而另一些数据集因为太大而需要先聚合。有时可以从一个数据源获取数据,有时需要从不同的数据源采集数据并使用工具进行可视化。一些数据可视化工具可以从多个数据源采集数据并显示在同一个界面上,但有些工具可能没有这个功能。如何选择合适的工具取决于具体的需求。
5. 地理标记和智能定位
如果您所在的地区地理非常重要,那么您可能需要用于地理和位置数据的可视化工具。例如,这些数据来自哪里?哪些州或地区更活跃?哪些领域需要扩大?对于需要跟踪基于位置的 kpi 的企业来说,在时间和空间上对数据集进行分层的能力非常重要。
6.数据挖掘
数据挖掘是研究大型数据集以识别模式和趋势的过程。如果您正在处理大型数据集,并且想要一个可视化工具来帮助提取潜在信息并生成可视化报告,那么您需要的可视化工具就需要收录此功能。
7.人工智能
许多可视化工具都在使用人工智能来分析、探索和预测趋势,并根据过去的变化预测未来的趋势。如果这是你感兴趣的东西,那么集成人工智能的可视化工具非常适合。下面列出了一些目前广泛使用和流行的具有上述功能的数据可视化工具,以帮助您做出最合适的选择。
表格
它一直被誉为最好的数据可视化工具之一。他们的客户包括领英、德勤、汉莎航空和百事可乐等巨头。其主要功能有: 一个可定制的界面,可以嵌入到 Salesforce、SharePoint 和 Jive 等应用程序中;实时交互,支持数据挖掘;实时连接动态数据和内存数据;安全可靠;便携性
Qlikview
Qlikview 可能是 Tableau 最强大的竞争对手。它被选为 Gartner 魔力象限 2019 的领导者,并拥有康泰纳仕、斯巴鲁和全球零售银行等客户。主要功能包括:嵌入式分析;与第三方引擎(如 Python)的高级分析集成;可定制的界面;预测分析;共享文件管理
SiSense
这不仅仅是一个传统的分析工具,它具有可扩展性和处理各种数据的能力。它拥有美国宇航局、纳斯达克、三星和康卡斯特等知名客户。主要功能包括:具有共享、拖放和内置图表小部件的自定义世界;可以在单个服务器上处理兆字节数据的内存数据库;超快的运算速度;先进的机器学习和人工智能;实时交互,自动生成分析报告
多莫
它不仅是一个数据可视化工具,还是一个完整的业务管理平台。它统一处理来自该平台的数据分析和报告,其客户包括eBay、国家地理和Sage。其特点包括:支持数百个数据源,包括Facebook、Salesforce等;轻松将内部数据导入 Domo;以多种方式清除、组合和转换数据;使用自定义工具共享数据;迁移和错误警报;自动报告生成和可定制的界面。
微软 Power BI
Microsoft PowerBI 界面给人一种熟悉感,便于新用户学习和使用。为了便于操作,Power BI 提供了免费的基础版本,并且是开源的。它的客户包括 Adobe、HP 和 Toshiba。主要提供以下功能:交互界面和实时数据共享;用户定义的报告创建;轻松访问数据和数据集共享;支持自然语言提问;基于云的实施。
Klipfolio
Klipfolio 可以连接到 500 多个数据源,包括 Google Analytics、Twitter 和 Moz。主要功能包括:广泛的数据来源;财务预测;自定义界面;实时性和准确性。
情节
这是最丰富多彩的 BI 解决方案之一,巧妙地帮助用户创建易于理解的交互式图表。它的一些主要功能是:根据输入定制二维和三维图表;集成面向分析的语言(如Python、R和Matlab);用户接口。
图表
Chartio 是适用于所有大型和小型企业的 BI 和数据可视化工具。主要功能包括:实时分析和动态变化;对比分析;简单的设置;多种图表格式。
壁虎板
Geckoboard 提供了 80 多个预建模型用于实时分析,让用户能够轻松地将数据可视化。其主要功能有:自定义界面;与 Facebook、Twitter、Salesforce 等 api 的丰富集成;数据挖掘技术;自定义图表样式和显示模式。
数据包装器
Datawrapper 简单、清晰且易于使用的界面已迅速成为《财富》、《琼斯妈妈》和《泰晤士报》等非技术客户的首选。它的主要功能是:易于使用,无需编码或设计技能;快速交互式生成图表;创造不同的品牌风格。
结论
选择合适的数据可视化工具非常重要,不仅因为它们非常昂贵,而且对业务战略有着巨大的影响。清晰准确的视觉报告可帮助您做出更好的决策、制定更好的计划并更好地跟踪 KPI。因此,请根据您的业务最重要的属性,选择刚好满足您需求的可视化分析工具。
量化金融分析师(AQF,Quantitative Finance 分析师)接受量化金融标准委员会 (SCQF) 的考试和认证。是代表量化金融领域的专业证书。 >>>点击查询AQF证书含金量
(点击上图了解课程详情)
金诚推荐:
热线:
AQF测试好友群:760229148
金融全科交易群:801860357 查看全部
智能标签采集器(量化金融分析师AQF高质量的可视化工具应该具备哪些功能?)
Quantitative Finance丨Salesforce 的一项调查显示,53% 的员工经常检查和分析数据,但仅依靠人工操作。滚动浏览大量电子表格、图表和数据就像大海捞针。
定量金融分析师 AQF 的高质量可视化工具对于数据分析至关重要。数据可视化工具是一种应用软件,可以帮助用户以可视化和图形化的格式显示数据,呈现数据的完整轮廓。饼图、图形、热图、直方图和雷达/蜘蛛图只是可视化的一小部分。这些方法可以简单地表示数据并显示特征和趋势。
要使数据分析真正有价值且富有洞察力,就需要高质量的可视化工具。市场上有许多具有不同功能和价格的产品。本文列出了一些广为人知的工具。事实上,企业如何选择合适的可视化工具并非易事,需要慎重考虑。
1.清晰、简洁、可定制的界面
数据可视化程序的界面就像一个汽车仪表盘,你想要的重要信息一目了然——从剩余油量、行驶速度到续航里程。同样,可视化界面应该能够在一个视图中显示所有关键信息。
一个好的数据可视化工具应该同时具备以下功能:
一开始看起来很酷。界面清晰,不失流行色。太白很烦人,颜色太多会感觉杂乱,所以界面要适当平衡。
其次,界面应准确显示所有重要数据。例如,用户关注的KPI、重要趋势或重要的业务相关数据集,应该在界面启动后的几秒钟内完整清晰地展示出来。所有显示内容一目了然。
界面的另一个非常重要的品质是它可以定制。在不同的时间段,您可能需要跟踪不同的数据集,因此您需要自定义显示哪些数据。因此,数据可视化工具必须允许定制。
2.嵌入式
要真正利用数据可视化的力量,将可视化报告无缝集成到其他应用程序中是非常重要的。为了让用户高效协作并跨平台共享报告,数据可视化软件应该兼容不同的应用程序。并非所有部门都需要分析所有数据。大多数人只希望将一部分数据与他们的特定应用程序无缝集成,从而帮助他们提高工作效率。所以一个好的数据可视化工具必须易于嵌入和集成。
3.人机交互
数据可视化工具生成的可视化报告必须具有很强的人机交互性,支持一些变量或参数的调整,并且能够看到后续的趋势/结果变化。用户可以对相关变量进行移动、排序和过滤,以获得相应的效果。数据分析师和决策者需要的是能够处理来自各种来源的数据并生成有价值内容的分析工具。可视化分析报表支持不同格式的打开,不同的部分可以在不同的时间高亮显示。
4.数据采集分享给
将原创数据导入可视化工具,然后以各种形式导出可视化报告。这个过程应该以用户喜欢的方式进行。一些数据集可以最原创的形式输入到工具中,而另一些数据集因为太大而需要先聚合。有时可以从一个数据源获取数据,有时需要从不同的数据源采集数据并使用工具进行可视化。一些数据可视化工具可以从多个数据源采集数据并显示在同一个界面上,但有些工具可能没有这个功能。如何选择合适的工具取决于具体的需求。
5. 地理标记和智能定位
如果您所在的地区地理非常重要,那么您可能需要用于地理和位置数据的可视化工具。例如,这些数据来自哪里?哪些州或地区更活跃?哪些领域需要扩大?对于需要跟踪基于位置的 kpi 的企业来说,在时间和空间上对数据集进行分层的能力非常重要。
6.数据挖掘
数据挖掘是研究大型数据集以识别模式和趋势的过程。如果您正在处理大型数据集,并且想要一个可视化工具来帮助提取潜在信息并生成可视化报告,那么您需要的可视化工具就需要收录此功能。
7.人工智能
许多可视化工具都在使用人工智能来分析、探索和预测趋势,并根据过去的变化预测未来的趋势。如果这是你感兴趣的东西,那么集成人工智能的可视化工具非常适合。下面列出了一些目前广泛使用和流行的具有上述功能的数据可视化工具,以帮助您做出最合适的选择。
表格
它一直被誉为最好的数据可视化工具之一。他们的客户包括领英、德勤、汉莎航空和百事可乐等巨头。其主要功能有: 一个可定制的界面,可以嵌入到 Salesforce、SharePoint 和 Jive 等应用程序中;实时交互,支持数据挖掘;实时连接动态数据和内存数据;安全可靠;便携性
Qlikview
Qlikview 可能是 Tableau 最强大的竞争对手。它被选为 Gartner 魔力象限 2019 的领导者,并拥有康泰纳仕、斯巴鲁和全球零售银行等客户。主要功能包括:嵌入式分析;与第三方引擎(如 Python)的高级分析集成;可定制的界面;预测分析;共享文件管理
SiSense
这不仅仅是一个传统的分析工具,它具有可扩展性和处理各种数据的能力。它拥有美国宇航局、纳斯达克、三星和康卡斯特等知名客户。主要功能包括:具有共享、拖放和内置图表小部件的自定义世界;可以在单个服务器上处理兆字节数据的内存数据库;超快的运算速度;先进的机器学习和人工智能;实时交互,自动生成分析报告
多莫
它不仅是一个数据可视化工具,还是一个完整的业务管理平台。它统一处理来自该平台的数据分析和报告,其客户包括eBay、国家地理和Sage。其特点包括:支持数百个数据源,包括Facebook、Salesforce等;轻松将内部数据导入 Domo;以多种方式清除、组合和转换数据;使用自定义工具共享数据;迁移和错误警报;自动报告生成和可定制的界面。
微软 Power BI
Microsoft PowerBI 界面给人一种熟悉感,便于新用户学习和使用。为了便于操作,Power BI 提供了免费的基础版本,并且是开源的。它的客户包括 Adobe、HP 和 Toshiba。主要提供以下功能:交互界面和实时数据共享;用户定义的报告创建;轻松访问数据和数据集共享;支持自然语言提问;基于云的实施。
Klipfolio
Klipfolio 可以连接到 500 多个数据源,包括 Google Analytics、Twitter 和 Moz。主要功能包括:广泛的数据来源;财务预测;自定义界面;实时性和准确性。
情节
这是最丰富多彩的 BI 解决方案之一,巧妙地帮助用户创建易于理解的交互式图表。它的一些主要功能是:根据输入定制二维和三维图表;集成面向分析的语言(如Python、R和Matlab);用户接口。
图表
Chartio 是适用于所有大型和小型企业的 BI 和数据可视化工具。主要功能包括:实时分析和动态变化;对比分析;简单的设置;多种图表格式。
壁虎板
Geckoboard 提供了 80 多个预建模型用于实时分析,让用户能够轻松地将数据可视化。其主要功能有:自定义界面;与 Facebook、Twitter、Salesforce 等 api 的丰富集成;数据挖掘技术;自定义图表样式和显示模式。
数据包装器
Datawrapper 简单、清晰且易于使用的界面已迅速成为《财富》、《琼斯妈妈》和《泰晤士报》等非技术客户的首选。它的主要功能是:易于使用,无需编码或设计技能;快速交互式生成图表;创造不同的品牌风格。
结论
选择合适的数据可视化工具非常重要,不仅因为它们非常昂贵,而且对业务战略有着巨大的影响。清晰准确的视觉报告可帮助您做出更好的决策、制定更好的计划并更好地跟踪 KPI。因此,请根据您的业务最重要的属性,选择刚好满足您需求的可视化分析工具。
量化金融分析师(AQF,Quantitative Finance 分析师)接受量化金融标准委员会 (SCQF) 的考试和认证。是代表量化金融领域的专业证书。 >>>点击查询AQF证书含金量
.png)
(点击上图了解课程详情)
.png)
金诚推荐:
热线:
AQF测试好友群:760229148
金融全科交易群:801860357
智能标签采集器(2.核心业务流程完成图片标注训练的整个工作流程(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-09-05 16:29
通常,公司有各种标签要求。作为一款通用的标签产品,产品特性(如支持多种输入格式、多种标签类型、多种标签形式、附加功能等)将是我们关注的重点之一。
另一方面,在实践中,标注是一项非常耗时且费力的工作。比如上图中的大部分行人是需要标注的,这样的图片至少有上百张。这说明用户体验是我们需要关注的另一个重点。
综上所述,本文将从产品功能和用户体验两个维度对行业代表性产品进行分析。
2.核心业务流程
完成图像标注训练的整个工作流程通常涉及三个步骤:“数据准备”、“数据标注”和“数据演化”。具体业务流程如下图所示:
图3:图片标注的一般业务流程
2.1 数据准备
数据准备包括两个步骤:data采集和数据预处理。
1.Data采集:采集 有多种方式如:本地上传、调用其他数据集数据、相机数据导入、调用云服务获取数据等
2. 数据预处理:数据清洗是获得高质量训练数据的前提,清洗不合格的数据还可以减少无意义的标注工作,提高标注效率。数据清洗的常用操作包括:模糊数据清洗、相似数据清洗、裁剪、旋转、镜像、图像亮度、图像对比度、图像锐化等。
2.2 数据标注
数据标注包括:标注集的建立、数据标注、标注审核。
2.2.1 创建注释集
注解集是注解工作的基本任务管理单元,这里不再赘述。
2.2.2 数据标注
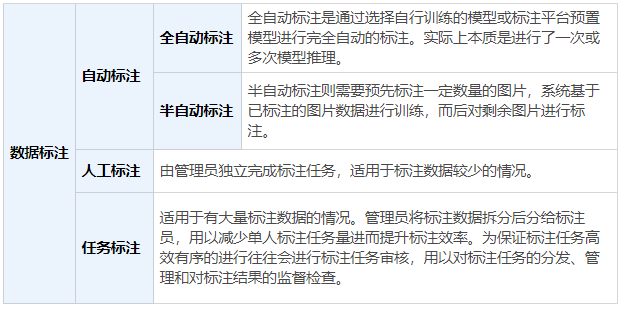
详情见表 1:
表一:数据标注具体方法
2.2.3 分评论
对于“任务标注”,标注审核是对下发的标注任务进行管理,对标注结果进行审核。一般审核维度包括:标注进度、接受状态、标注数量、疑难案例、标注质量等。
对于“自动标注”,标注审核是对自动标注的结果进行一一核对确认,对标注错误的图片进行修改。
2.3 数据演进
数据演化包括:模型训练、模型推理。
2.3.1 模型训练:
是训练标注数据以获得模型结果的过程。
2.3.2 模型推理:
用于对训练模型结果进行验证和预测,并将误差或误差验证结果记录下来,带到下一次模型训练中进行模型的优化迭代,从而形成对模型训练的数据标注,然后到模型迭代优化的闭环。
3. 竞品介绍
目前市场上有很多标签工具。首先,我们需要确定竞品的选择原则:
总结起来,选择了以下3款竞品:
CVAT:英特尔开源标注工具,2018年6月发布,支持视频、图片等多种数据类型标注,功能全面。 ModelArts:华为出品的机器学习平台,2018年10月发布,收录数据标注模块。支持从数据导入到模型运维的全流程开发,训练速度更快。 Supervisely:俄罗斯Deep System旗下的模型训练平台,2017年8月发布,数据标注功能强大,尤其是Smart Tool令人印象深刻:可以快速完成语义分割任务的标注。
表 2:3 款产品的汇总比较
4.功能对比
在本节中,我们将针对 3 个产品,基于第 2 章的核心业务流程探索产品功能之间的差异。
4.1 增值税
CVAT的使用过程虽然很简单,但它的功能却非常全面和丰富。
图 4:CVAT 标注流程
4.1.1 创建数据集
CVAT 将数据集替换为带注释的任务(Task)的概念。一个任务可以收录多个任务,每个任务可以分配一个注释器。
在创建标注任务时,CVAT 还提供了丰富的高级选项,例如:
支持使用Git LFS:Git Large File Storage,一个用于大文件的git管理插件。调整画质:通过降低画质(压缩率)加快高清图片的加载速度。作业数量和重叠:如果一个任务中的图片数量很大,可以将它分成多个作业。再加上重叠数,可以达到将一张图片分配给多个作业的效果,但暂时没有重叠数的使用场景。
综上所述,CVAT在标注任务模块的优势之一就是支持视频类型文件的直接上传。上传的视频会根据用户设置的帧率(Frame)转换成图片。
CVAT在这个模块中也有一个明显的缺点:它缺乏一个统一的视角来概览任务中的所有图片(如下图,在任务详情页面中只能看到第一张图片的照片) ,而且每张图片上的所有注释大概都是因为一张图片可能存在多个作业。
图 5:CVAT 标注任务详情页面
4.1.2 自动标注
由于CVAT不具备提供模型服务的能力,所以其自动标注功能还处于开发初期,只能满足个人实验。
添加自动标注模型需要用户上传模型文件,而不是镜像或API。这种非服务方式很容易因为运行环境的差异(比如安装了不同版本的依赖包的两台服务器)影响打标签的成功率和准确率。
4.1.3 手动标注
4.1.3.1 手动标注支持3种标注模式,每种模式可以前后切换:
标准模式(Standard):用于常规标签。属性标注:在“属性模式”下,用户可以专注于修改标签框和标签的属性,提高了查看和修改标签属性的效率。该模式专门用于在人脸标注中为同一对象设置一个或多个属性的场景,如年龄、性别等。标签标注:在“标签模式”下,用户可以快速添加或删除标签,选择和修改标签属性。同时,您可以按类型标记图片的自定义模式,还可以为每个标签设置快捷键。大大提高了图像分类的标注效率。
4.1.3.2 对于CVAT,我们经过经验总结出以下优势:
1) 灵活的标签和属性定义
同一张图片可以标注多个标签,一个标签可以设置多个属性,平台将属性定义分为:多选(Select)、单选(Radio)、是否(Checkbox)、文本(文字)、数字(Number)五种。 CVAT标签定制的自由度基本满足大部分标签需求。
图 6:CVAT 中的五个标签属性
2)丰富的标记格式
为了支持各种类型的标注,CVAT提供了6种标注类型,包括:标签、点、矩形、折线、多边形、长方体等。同时支持AI多边形标注:可以选择一个通过指定至少四个点,在系统的帮助下确定目标轮廓。这与监督相同。体验过后,我们还是期待AI识别速度的进一步提升。
3)统一标注方法的快捷键
选择一种标注方式,快捷键“N”代表该标注方式。重新选择标注方法,“N”代表的方法会发生相应的变化。快捷键的统一进一步降低了用户的操作成本。
4)任务分析
通过任务分析仪表板中的分析,您可以看到每个用户在每个任务上花费了多少时间以及他们在任何时间范围内完成了多少工作。任务分析扩展了 CVAT 的团队标记功能。
图 7:CVAT 中的分析仪表板(图片来源 CVAT 用户手册)
5)Track 模式(Track 模式)
用于标记视频文件。视频会根据帧率分为若干帧(Frame)。用户只需标记关键帧(Key frame,与Flash中的关键帧非常相似),关键帧之间的图片也会自动标记。 CVAT 目前仅支持边界框和点的插值模式。传播功能非常实用。场景:如果要将当前图片中的注解(Propagate)传递给接下来的n张图片。同时,CVAT的跟踪模式与Merge功能和Split功能相结合,支持CVAT独有的视频或动画图标标注能力优势。
4.1.3.3 可能是因为支持的功能太丰富,导致使用上有一定的学习成本,用户体验会有些不尽如人意。例如:
标注时图片无法预览。无法获得图片的整体标注。下次进入作业时,无法快速定位到未标注的图片。虽然这不会对效率产生太大影响,但会影响用户的操作体验。另外,如果是标记用户的图片分类,就需要使用属性模式,用户难以感知。 (我们一开始以为只能画一个完全覆盖画面的边框来实现)4.2 ModelArts
2019年10月17日Modelarts版本更新后(尤其是团队标注功能),业务流程覆盖趋于完整。整体用户流程如下:
图8:ModelArts标注流程(图片来自ModelArts官网)
由于本文主要讨论数据标注功能,数据标注后的功能(包括训练、推理、数据校正等)不在本文讨论范围内。
4.2.1 创建数据集
在创建图像数据集时,ModelArts在数据集层面设置了图像标注类型,即创建数据集时需要区分标注类型。
这一点与 Supervisely 和 CVAT 有很大不同。具体分析请参考Supervisely手册标注章节。目前支持两种任务:图像分类和目标检测。
图9:将创建数据集放入ModelArts
4.2.2 数据处理
华为的数据处理功能位于对象存储服务中,提供便捷、全功能的图像处理能力。
华为的对象存储服务提供了“图形界面模式”和“代码编辑模式”两种图像处理操作模式,适用于普通用户和开发者用户。
同时最终的处理结果存储在内容分发网络(Content Delivery Network,CDN)加速中,后续请求可以通过URL直接从CDN下载,结果可以用于任何注解可以通过 URL 导入数据的平台。扩展了平台的功能扩展性。
华为图像处理提供的能力主要包括:设置图像效果(亮度、对比度、锐化、模糊)、设置缩略图、旋转图像、剪切图像、设置水印、转换格式和压缩图像。
图10:华为对象存储中的图像处理模块
4.2.3 智能标签
ModelArts 智能标注包括:主动学习(半自动标注)和预标注(自动标注)。目前,只有“图像分类”和“物体检测”类型的数据集支持智能标注功能。先简单分析一下智能标注模块:
系统只对未标注的图片进行标注,可以减少重复标注,减少计算资源的浪费。使用效果并不理想,系统实际体验后标签准确率只能维持在60%。系统对疑难病例的筛选准确率也较低。全自动标注支持选择自训练模型或ModelArts自有模型,模型选择更加灵活。在接下来的操作中,可以继承每个标签的结果,进一步提高模型的准确率。智能标注结果展示页面可以进行条件过滤。可选条件包括:困难案例级别、标签、样本创建时间、文件名、注释者、样本属性和置信度。精准筛选可以满足大部分场景需求。
4.2.4 手动标注
Huawei ModelArts 手动标注功能主要包括以下三点:
4.2.4.1 目标检测标注最多支持6种标注
包括正方形、多边形、正圆、点、单线、虚线(见图11),丰富的标注方式覆盖更广泛的标注场景,同时可以提高标注的准确率。
4.2.4.2 高效的标签选择方法
在数据标注的交互中,华为ModelArts绘制选择框后会自动弹出标签下拉框,以及已经展开的添加标签弹出窗口(见图11),消除选择完成后需要用户点击标签。下拉框的步骤。弹出的标签选项卡在框旁边(见图11),缩短了鼠标滑动的移动行程鼠标选择标签。
图11:ModelArts图像检测数据标注界面
4.2.4.3 图片组
在标注预览页面,华为ModelArts提供了图片分组功能(见图12),该功能使用聚类算法或根据锐度、亮度、图像颜色对图片进行分组。自动分组可以理解为数据annotation 用户可以根据分组结果进行分组标注、图片清洗等操作,该功能可以提高图像标注的效率,尤其是在图像分类标注的情况下,批量标注功能可以在标注速度上进行定性改进了。但是经过实际体验,我们觉得这个功能分组的成功率很低。
图12:ModelArts中图片自动分组
4.2.5 团队注解
华为ModelArts有一套完整的团队标注功能,亮点多多。以下是创建、标记和审核的三个方面:
4.2.5.1 创建
华为可以在启用团队标注后直接指定标注团队,也可以选择指定管理员,然后由管理员分配标注人力,进行审核工作。选择类型后,团队成员会收到系统邮件,根据邮件提示即可轻松完成标注和审核。
您可以选择是否自动将新文件同步到注释团队。同时,您可以选择是否在注释团队的文件中加载智能注释结果。这些操作增加了管理员调整任务分配和自动标注关系的自由度。
图 13:ModelArts 团队注解创建页面
4.2.5.2 注释
标记图片并保存后,图片自动进入“待审核”状态。我们认为这样的状态切换超出了用户的预期,特别是如果用户想要检查标签是否有误,则需要切换到“待审核”页面进行检查,这会给用户带来不便。
“待审核”的图片还是可以修改的,修改在管理员发起验收前生效。但在验收时,如果图片是采样的,修改不会保存在数据集中。如果图片未采样,修改将保存在数据集中。这样的审计逻辑限制可以减少审计过程中不必要的混乱,防止审计结果出现错误。
4.2.5.3 评论
ModelArts将审核称为“验收”,验收分为单张图片验收和批量图片验收两个级别。过程是用户检查并接受一批图片。审核层级过多,逻辑复杂,可能导致运行结果不符合用户预期。
标注状态混乱:例如管理员将图片A分配给注释者a。 a后,管理员同时使用智能标签标记图片A。如果两个结果都被管理员确认,无论哪个标签先确认,最终只有智能标注的结果有效,标注者a的标签无效。
ModelArts 提供了审计仪表盘,方便审计的统计链接,并以可视化的方式展示任务进度。仪表盘的评价指标包括:验收进度统计、疑难案例集数、标签数和带标签样本数、注释者的进度统计等,如图14所示:
图 14:ModelArts 中的注释审查仪表板
4.3 监督
图 15:Supervisely 的标注流程
从图中可以看出,团队标记一块的逻辑比其他产品更复杂。分析背后的原因:
表面上很多步骤是为了满足团队标注(尤其是外部标注团队)的需求,包括创建团队、邀请成员、创建标注任务、标注审核等,但本质上都是安全控制和质量控制要求:
安全控制体现在管理员可以为团队成员分配不同的角色来控制成员的权限。例如,Annotator 只能查看其任务中的图片;质量控制体现在注释完成后。管理员审核标签以确保标签质量。
因此,这样一个复杂的环节是一个企业级标签产品应该有的设计,虽然这不可避免地会导致用户认知成本的增加和用户体验的下降。
4.3.1 创建数据集
在 Supervisely 中,用户可以在一个数据集中完成 4 种类型的标注(视频标注除外),即分类、检测、分割和姿态估计。
与ModelArts不同,Supervisely对数据集的定位更像是一个图片集。一批图片只需要导入一次,无论做什么类型的标注,都可以在同一个数据集上做。并且在进行后续训练时,可以直接得到一张图片上的所有标注。
综上所述,Supervisely 的统一数据集模块提高了图像导入、图像标注和图像后处理的效率。但是这种方法也有缺点:所有标注类型的操作方式都是固定的,不能针对特定类型进行优化(比如Modelarts图片分类可以同时选择多张图片一起标注)。
4.3.2 数据处理
Supervisely 的数据处理模块叫做 DTL,Data Transformation Language,是一种基于 JSON 的脚本语言。通过配置DTL脚本,可以完成数据集合并、标签映射、图像增强、格式转换、图像去噪、图像翻转等46项操作,满足各种数据处理需求。
图 16:在 Supervisely 中为图片添加高斯模糊
虽然功能比ModelArts更强大,但只提供了基于代码的操作,只适合工程师使用。不过大部分工程师已经掌握了通过python处理图片的方式,额外学习一门语言无疑会增加学习成本。
另一方面,这种特殊语言的效率提升还存在未知数。例如,用户想进行某张图片操作,但查了半天,发现不支持该语言。最终还是要通过python来完成,最终降低了效率。 .
4.3.3 自动标注
Supervisely 目前提供 14 个预训练模型。训练数据大部分来自COCO(微软发布的大型图像数据集),少部分来自PASCAL VOC2012、Cityscapes、ADE20K等公开数据集。
在自动标注部分,Supervisely的优势在于支持语义分割自动标注,产品在语义分割手动标注方面有着出色的体验,大大提高了此类任务的标注效率。
Supervisely 的自动贴标模块产品化程度较低,主要体现在以下两点:
由于不提供模型训练和推理服务,用户需要准备自动标注所需的硬件环境,限制较多(仅支持Nvidia GPU,需要Linux和Cuda驱动)。模型推理参数通过JSON格式的配置文件进行配置(见图17)。相比华为简单的配置界面,这种形式的灵活性更高,但是用户真的需要配置还是直接想系统呢?自动标记的结果?
图17:Supervisely(左)和Huawei ModelArts(右)自动标注配置对比
4.3.4 手动标注
Supervisely 的标注功能非常强大,主要有以下两个特点:
丰富的标注形式:为了支持各种类型的标注,Supervisely提供了多达9种标注形式,包括:标签、点、矩形、折线、多边形、长方体、像素图、智能工具(Smart Tool)、关键点等复杂标签系统:抽象了对象(Object)、类(Class)和标签(Tag)三个实体,提高了复杂场景中实体之间的复用性。
4.3.4.1 丰富的标注格式
在所有 9 种标签中,智能工具令人印象深刻:
智能工具用于标记分段类型。用户只需要点击两次方框选择一个对象,通过算法对目标进行描边完成初步分割,然后对正负点进行标注,完成精准标注。大大降低了分割任务的标注成本。
图 18:在 Supervisely 中点击 11 次后完成语义分割
4.3.4.2 复杂的标签系统
为了满足覆盖多种标签类型的数据集的需求,Supervisely 有一个复杂的标签系统。我们通过三种产品的ER图详细分析了这种标签制度的优缺点。
在图 19 的行人识别场景中,我们将绘制一个行人边界框。然后我们需要定义一个标签,叫做:行人。
图 19:Supervisely 中的行人标记场景
但是每个行人的属性是不同的。比如行人A戴帽子,行人B不戴帽子。如果我们需要区分戴帽子的行人和不戴帽子的行人,一种方法是创建两个标签:戴帽子的行人,不戴帽子的行人。
但是这样两个标签就会失去相关性——如果模型只需要检测行人,就需要对这两个标签进行转换,效率较低。
更合理的做法是在行人标签下创建一个属性——是否戴帽子;并抽象出一个概念:对象。
用户每画一个边界框,系统就会创建一个对象(例如:行人A),每个对象对应一个标签(例如:行人),然后每个对象可以设置该对象的属性值标签(例如:是否戴帽子=是)。
CVAT 和 ModelArts 都这样做。不同的是,CVAT 可以直接标记图像进行图像分类。由于ModelArts划分了图像分类和目标检测数据集,标签只能应用于图像分类数据中的图像。
图 20:CVAT(左)和 ModelArts(右)之间的图片-对象-标签 ER 图比较
监督地将标签和属性拆分为两个实体(如下图):
这种方法可以提高属性的重用率。比如在Supervisely中,用户只需要定义一次颜色属性,然后是否标记行人或车辆的颜色,可以应用相同“颜色”下的属性,提高了复杂度的准备效率标签集。
但与此同时,这种方法对用户体验设计提出了更大的挑战。从上手难度来看,Supervisely无疑是三款产品中最难上手的。
图 21:Supervisely 的图片-对象-标签-对象 ER 图
5.总结与展望5.1总结对比
下表是三个标记产品的功能汇总:
表3:三款产品功能总结对比
CVAT:手动贴标功能最强大,但自动贴标功能比较弱。独特的跟踪模式,无需视频预处理,大大提高标注效率。由于环境原因,CVAT的任务分析功能还没有完全体验。从介绍来看,这里应该用它。 ModelArts:作为华为云的一个功能模块,ModelArts的产品策略更加通用化和平台化。与华为OBS系统的结合,带来了强大的数据处理能力,增强了平台的可扩展性和兼容性。同时,自动贴标和半自动贴标是ModelArts的优势,是CVAT和Supervisely所不具备的。它们也体现了ModelArts依托华为云强大的算力和算法优势。总的来说,ModelArts 是一个平衡的玩家,具有出色的业务开发能力。 Supervisely:整体功能最全,适合企业级应用。对语义分割任务的支持较好,但部分功能(如数据处理、自动标注)需要代码完成,效率提升有限。
当然,我们也发现了三款产品都没有的一些功能,比如水印功能,会适用于保密要求,比如监狱、银行等。
5.2 标注工具的未来趋势
5.2.1 手动标注不会消失。
这其实是一个悖论:假设我需要训练一个CV模型,而训练模型需要准备带注释的图片。如果图像标注只需自动标注,无需人工干预,则说明模型已经能够准确预测结果。
如果能够准确预测,则说明模型已经训练完毕,不再需要训练,与假设相反。
5.2.2 自动标注的价值主要体现在单个标注需要较长时间的标注类型,如分割、姿态估计等
既然人工贴标肯定会存在,那么自动贴标的意义在于提高人工贴标的效率,而不是替代人工贴标。在单次标注耗时较短的场景中,如分类、检测任务,自动标注的价值较小。
假设从0完成一个标签需要5秒,如果进行了自动贴标,修改一个标签需要2秒,贴标效率提升60%(假设自动贴标模型为下班后跑,不影响人工打标时间)
但是我们已经看到模型在某些图片上的标注结果可能偏差太大,所以用户还是需要1秒的时间来删除自动标注的结果,但是标注的效率降低了20%( IE,1/5),这么高的负收益让整体效率提升不大。
5.2.3 手动注解的主要内容将从创建注解转变为修改注解
虽然人工贴标过程不会消失,但很明显,自动贴标将在贴标过程中发挥越来越重要的作用。未来常见的标注流程将从创建新标签转变为修改标签。
因此,优化注释修改时的用户体验将是提高注释效率的突破口。
作者:薛康杰,AIoT产品经理,AIops、CV和IoT平台产品;蒋海龙,AI产品实习生,专注于简历产品设计。
This article was published by @薛康杰 原创 in Renren is a product manager, reprinting without permission is prohibited
The title picture comes from Unsplash, based on the CC0 protocol
Reward the author and encourage him to work hard!
Appreciation 查看全部
智能标签采集器(2.核心业务流程完成图片标注训练的整个工作流程(组图))
通常,公司有各种标签要求。作为一款通用的标签产品,产品特性(如支持多种输入格式、多种标签类型、多种标签形式、附加功能等)将是我们关注的重点之一。
另一方面,在实践中,标注是一项非常耗时且费力的工作。比如上图中的大部分行人是需要标注的,这样的图片至少有上百张。这说明用户体验是我们需要关注的另一个重点。
综上所述,本文将从产品功能和用户体验两个维度对行业代表性产品进行分析。
2.核心业务流程
完成图像标注训练的整个工作流程通常涉及三个步骤:“数据准备”、“数据标注”和“数据演化”。具体业务流程如下图所示:
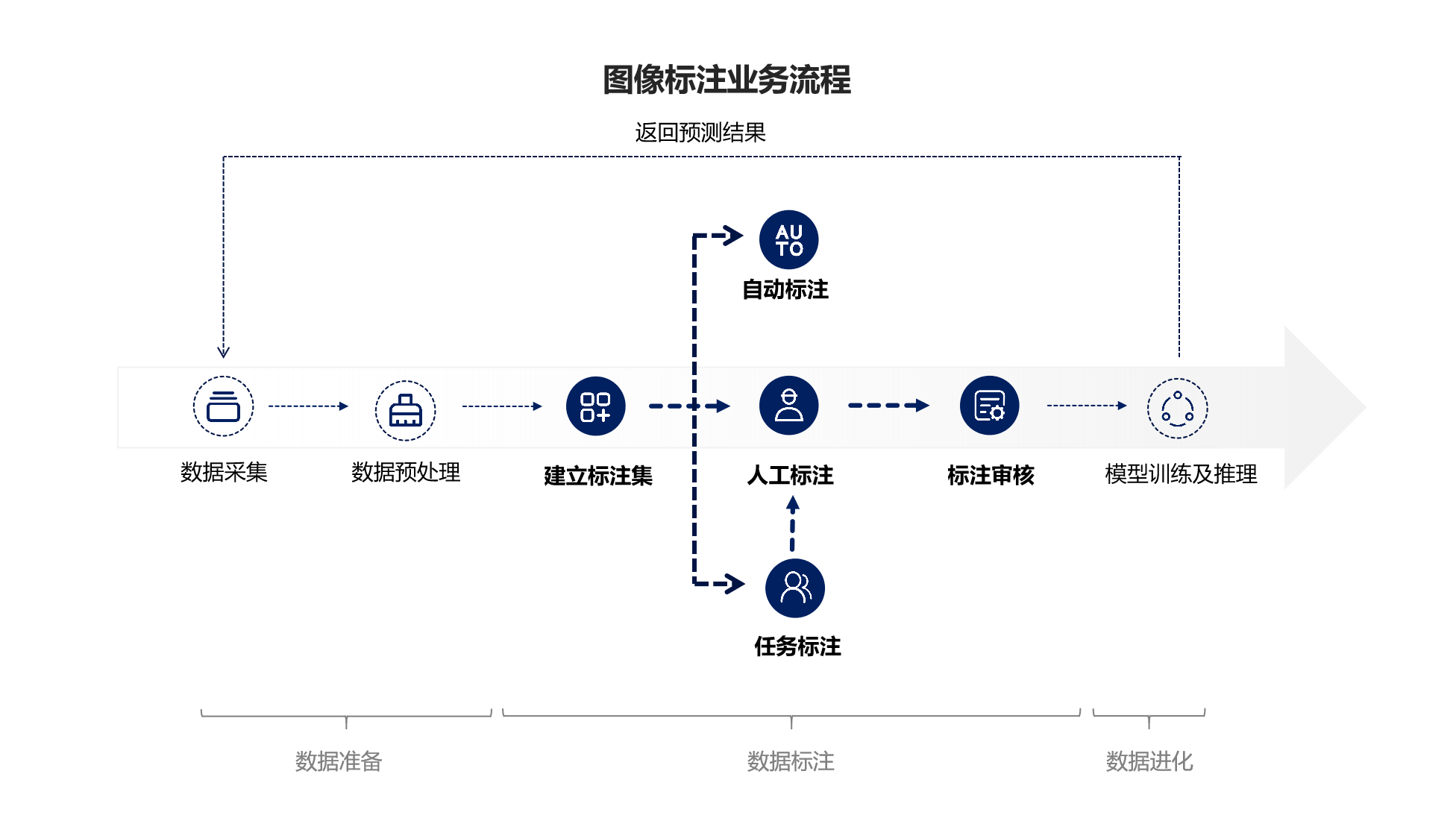
图3:图片标注的一般业务流程
2.1 数据准备
数据准备包括两个步骤:data采集和数据预处理。
1.Data采集:采集 有多种方式如:本地上传、调用其他数据集数据、相机数据导入、调用云服务获取数据等
2. 数据预处理:数据清洗是获得高质量训练数据的前提,清洗不合格的数据还可以减少无意义的标注工作,提高标注效率。数据清洗的常用操作包括:模糊数据清洗、相似数据清洗、裁剪、旋转、镜像、图像亮度、图像对比度、图像锐化等。
2.2 数据标注
数据标注包括:标注集的建立、数据标注、标注审核。
2.2.1 创建注释集
注解集是注解工作的基本任务管理单元,这里不再赘述。
2.2.2 数据标注
详情见表 1:
表一:数据标注具体方法
2.2.3 分评论
对于“任务标注”,标注审核是对下发的标注任务进行管理,对标注结果进行审核。一般审核维度包括:标注进度、接受状态、标注数量、疑难案例、标注质量等。
对于“自动标注”,标注审核是对自动标注的结果进行一一核对确认,对标注错误的图片进行修改。
2.3 数据演进
数据演化包括:模型训练、模型推理。
2.3.1 模型训练:
是训练标注数据以获得模型结果的过程。
2.3.2 模型推理:
用于对训练模型结果进行验证和预测,并将误差或误差验证结果记录下来,带到下一次模型训练中进行模型的优化迭代,从而形成对模型训练的数据标注,然后到模型迭代优化的闭环。
3. 竞品介绍
目前市场上有很多标签工具。首先,我们需要确定竞品的选择原则:
总结起来,选择了以下3款竞品:
CVAT:英特尔开源标注工具,2018年6月发布,支持视频、图片等多种数据类型标注,功能全面。 ModelArts:华为出品的机器学习平台,2018年10月发布,收录数据标注模块。支持从数据导入到模型运维的全流程开发,训练速度更快。 Supervisely:俄罗斯Deep System旗下的模型训练平台,2017年8月发布,数据标注功能强大,尤其是Smart Tool令人印象深刻:可以快速完成语义分割任务的标注。

表 2:3 款产品的汇总比较
4.功能对比
在本节中,我们将针对 3 个产品,基于第 2 章的核心业务流程探索产品功能之间的差异。
4.1 增值税
CVAT的使用过程虽然很简单,但它的功能却非常全面和丰富。
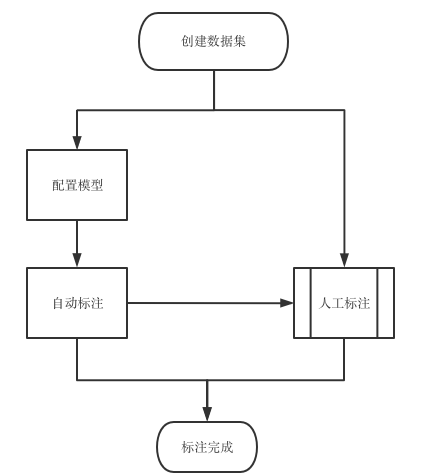
图 4:CVAT 标注流程
4.1.1 创建数据集
CVAT 将数据集替换为带注释的任务(Task)的概念。一个任务可以收录多个任务,每个任务可以分配一个注释器。
在创建标注任务时,CVAT 还提供了丰富的高级选项,例如:
支持使用Git LFS:Git Large File Storage,一个用于大文件的git管理插件。调整画质:通过降低画质(压缩率)加快高清图片的加载速度。作业数量和重叠:如果一个任务中的图片数量很大,可以将它分成多个作业。再加上重叠数,可以达到将一张图片分配给多个作业的效果,但暂时没有重叠数的使用场景。
综上所述,CVAT在标注任务模块的优势之一就是支持视频类型文件的直接上传。上传的视频会根据用户设置的帧率(Frame)转换成图片。
CVAT在这个模块中也有一个明显的缺点:它缺乏一个统一的视角来概览任务中的所有图片(如下图,在任务详情页面中只能看到第一张图片的照片) ,而且每张图片上的所有注释大概都是因为一张图片可能存在多个作业。
图 5:CVAT 标注任务详情页面
4.1.2 自动标注
由于CVAT不具备提供模型服务的能力,所以其自动标注功能还处于开发初期,只能满足个人实验。
添加自动标注模型需要用户上传模型文件,而不是镜像或API。这种非服务方式很容易因为运行环境的差异(比如安装了不同版本的依赖包的两台服务器)影响打标签的成功率和准确率。
4.1.3 手动标注
4.1.3.1 手动标注支持3种标注模式,每种模式可以前后切换:
标准模式(Standard):用于常规标签。属性标注:在“属性模式”下,用户可以专注于修改标签框和标签的属性,提高了查看和修改标签属性的效率。该模式专门用于在人脸标注中为同一对象设置一个或多个属性的场景,如年龄、性别等。标签标注:在“标签模式”下,用户可以快速添加或删除标签,选择和修改标签属性。同时,您可以按类型标记图片的自定义模式,还可以为每个标签设置快捷键。大大提高了图像分类的标注效率。
4.1.3.2 对于CVAT,我们经过经验总结出以下优势:
1) 灵活的标签和属性定义
同一张图片可以标注多个标签,一个标签可以设置多个属性,平台将属性定义分为:多选(Select)、单选(Radio)、是否(Checkbox)、文本(文字)、数字(Number)五种。 CVAT标签定制的自由度基本满足大部分标签需求。
图 6:CVAT 中的五个标签属性
2)丰富的标记格式
为了支持各种类型的标注,CVAT提供了6种标注类型,包括:标签、点、矩形、折线、多边形、长方体等。同时支持AI多边形标注:可以选择一个通过指定至少四个点,在系统的帮助下确定目标轮廓。这与监督相同。体验过后,我们还是期待AI识别速度的进一步提升。
3)统一标注方法的快捷键
选择一种标注方式,快捷键“N”代表该标注方式。重新选择标注方法,“N”代表的方法会发生相应的变化。快捷键的统一进一步降低了用户的操作成本。
4)任务分析
通过任务分析仪表板中的分析,您可以看到每个用户在每个任务上花费了多少时间以及他们在任何时间范围内完成了多少工作。任务分析扩展了 CVAT 的团队标记功能。
图 7:CVAT 中的分析仪表板(图片来源 CVAT 用户手册)
5)Track 模式(Track 模式)
用于标记视频文件。视频会根据帧率分为若干帧(Frame)。用户只需标记关键帧(Key frame,与Flash中的关键帧非常相似),关键帧之间的图片也会自动标记。 CVAT 目前仅支持边界框和点的插值模式。传播功能非常实用。场景:如果要将当前图片中的注解(Propagate)传递给接下来的n张图片。同时,CVAT的跟踪模式与Merge功能和Split功能相结合,支持CVAT独有的视频或动画图标标注能力优势。
4.1.3.3 可能是因为支持的功能太丰富,导致使用上有一定的学习成本,用户体验会有些不尽如人意。例如:
标注时图片无法预览。无法获得图片的整体标注。下次进入作业时,无法快速定位到未标注的图片。虽然这不会对效率产生太大影响,但会影响用户的操作体验。另外,如果是标记用户的图片分类,就需要使用属性模式,用户难以感知。 (我们一开始以为只能画一个完全覆盖画面的边框来实现)4.2 ModelArts
2019年10月17日Modelarts版本更新后(尤其是团队标注功能),业务流程覆盖趋于完整。整体用户流程如下:
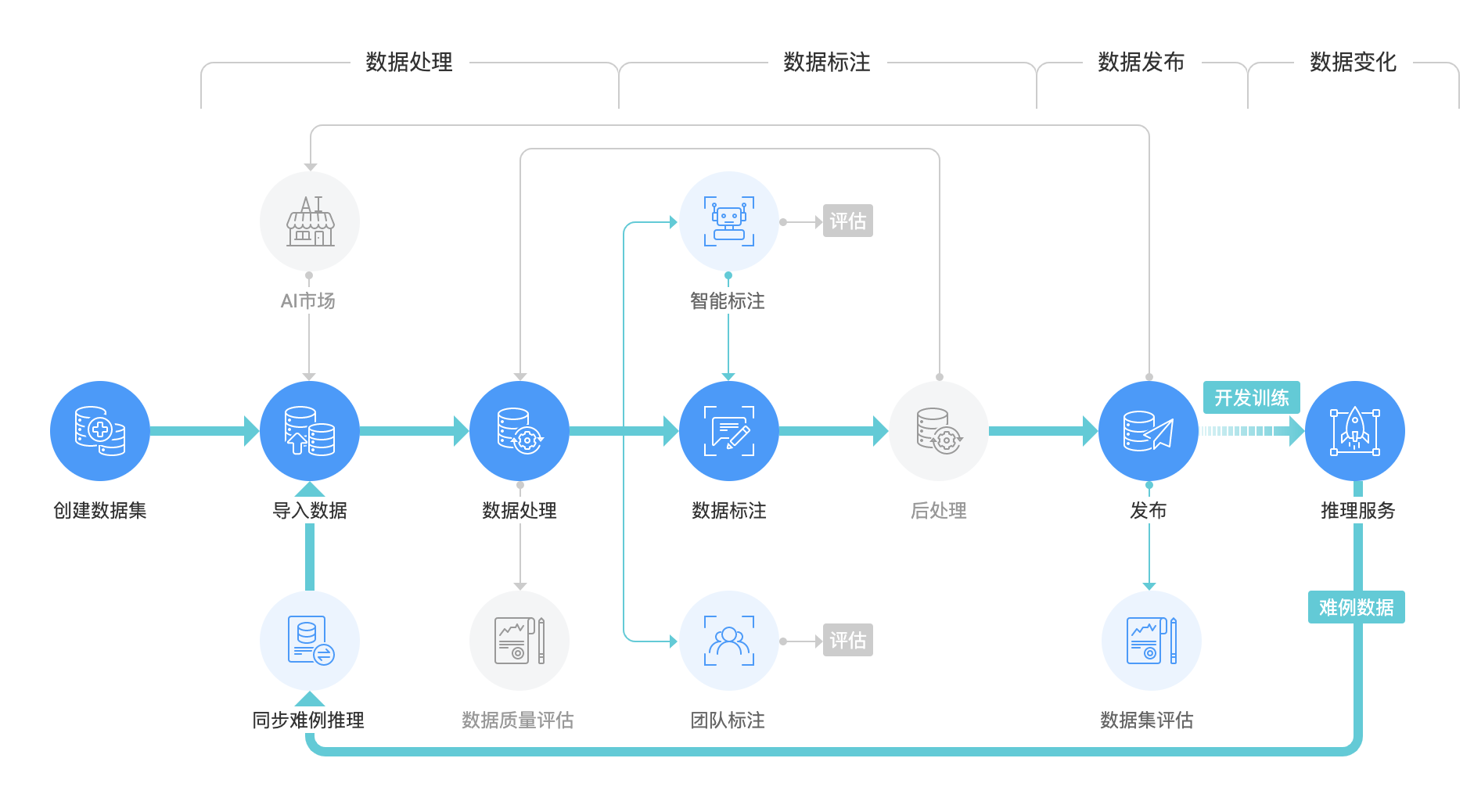
图8:ModelArts标注流程(图片来自ModelArts官网)
由于本文主要讨论数据标注功能,数据标注后的功能(包括训练、推理、数据校正等)不在本文讨论范围内。
4.2.1 创建数据集
在创建图像数据集时,ModelArts在数据集层面设置了图像标注类型,即创建数据集时需要区分标注类型。
这一点与 Supervisely 和 CVAT 有很大不同。具体分析请参考Supervisely手册标注章节。目前支持两种任务:图像分类和目标检测。
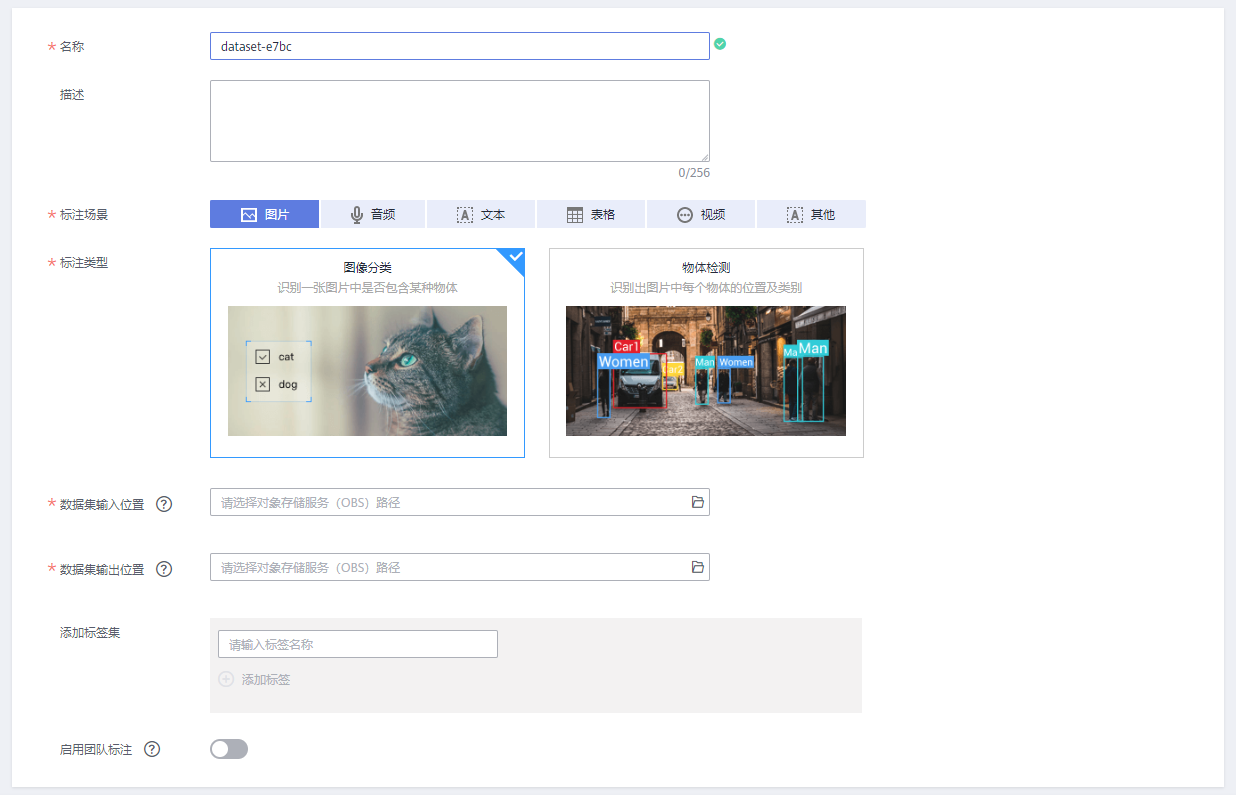
图9:将创建数据集放入ModelArts
4.2.2 数据处理
华为的数据处理功能位于对象存储服务中,提供便捷、全功能的图像处理能力。
华为的对象存储服务提供了“图形界面模式”和“代码编辑模式”两种图像处理操作模式,适用于普通用户和开发者用户。
同时最终的处理结果存储在内容分发网络(Content Delivery Network,CDN)加速中,后续请求可以通过URL直接从CDN下载,结果可以用于任何注解可以通过 URL 导入数据的平台。扩展了平台的功能扩展性。
华为图像处理提供的能力主要包括:设置图像效果(亮度、对比度、锐化、模糊)、设置缩略图、旋转图像、剪切图像、设置水印、转换格式和压缩图像。
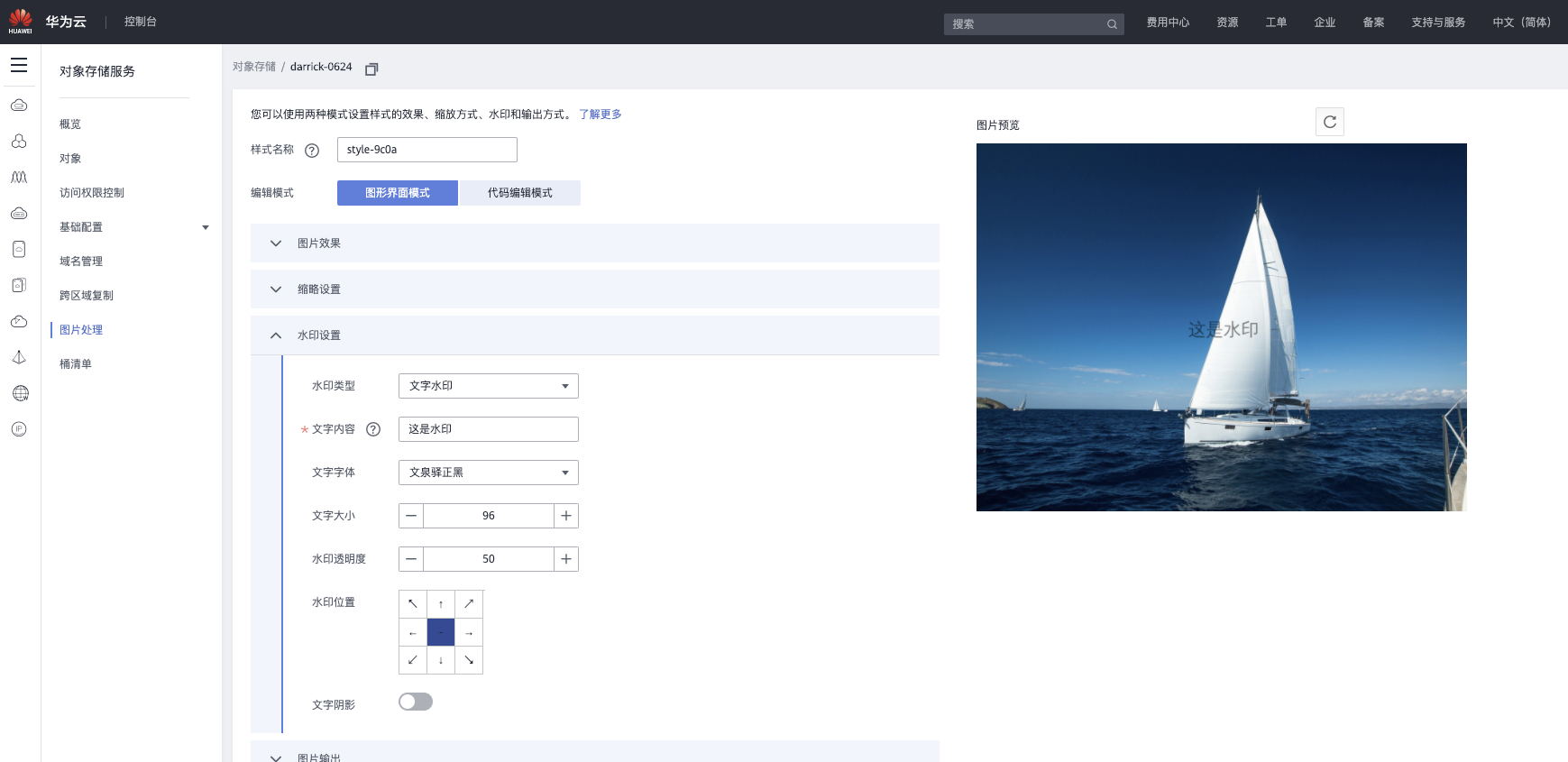
图10:华为对象存储中的图像处理模块
4.2.3 智能标签
ModelArts 智能标注包括:主动学习(半自动标注)和预标注(自动标注)。目前,只有“图像分类”和“物体检测”类型的数据集支持智能标注功能。先简单分析一下智能标注模块:
系统只对未标注的图片进行标注,可以减少重复标注,减少计算资源的浪费。使用效果并不理想,系统实际体验后标签准确率只能维持在60%。系统对疑难病例的筛选准确率也较低。全自动标注支持选择自训练模型或ModelArts自有模型,模型选择更加灵活。在接下来的操作中,可以继承每个标签的结果,进一步提高模型的准确率。智能标注结果展示页面可以进行条件过滤。可选条件包括:困难案例级别、标签、样本创建时间、文件名、注释者、样本属性和置信度。精准筛选可以满足大部分场景需求。
4.2.4 手动标注
Huawei ModelArts 手动标注功能主要包括以下三点:
4.2.4.1 目标检测标注最多支持6种标注
包括正方形、多边形、正圆、点、单线、虚线(见图11),丰富的标注方式覆盖更广泛的标注场景,同时可以提高标注的准确率。
4.2.4.2 高效的标签选择方法
在数据标注的交互中,华为ModelArts绘制选择框后会自动弹出标签下拉框,以及已经展开的添加标签弹出窗口(见图11),消除选择完成后需要用户点击标签。下拉框的步骤。弹出的标签选项卡在框旁边(见图11),缩短了鼠标滑动的移动行程鼠标选择标签。
图11:ModelArts图像检测数据标注界面
4.2.4.3 图片组
在标注预览页面,华为ModelArts提供了图片分组功能(见图12),该功能使用聚类算法或根据锐度、亮度、图像颜色对图片进行分组。自动分组可以理解为数据annotation 用户可以根据分组结果进行分组标注、图片清洗等操作,该功能可以提高图像标注的效率,尤其是在图像分类标注的情况下,批量标注功能可以在标注速度上进行定性改进了。但是经过实际体验,我们觉得这个功能分组的成功率很低。
图12:ModelArts中图片自动分组
4.2.5 团队注解
华为ModelArts有一套完整的团队标注功能,亮点多多。以下是创建、标记和审核的三个方面:
4.2.5.1 创建
华为可以在启用团队标注后直接指定标注团队,也可以选择指定管理员,然后由管理员分配标注人力,进行审核工作。选择类型后,团队成员会收到系统邮件,根据邮件提示即可轻松完成标注和审核。
您可以选择是否自动将新文件同步到注释团队。同时,您可以选择是否在注释团队的文件中加载智能注释结果。这些操作增加了管理员调整任务分配和自动标注关系的自由度。
图 13:ModelArts 团队注解创建页面
4.2.5.2 注释
标记图片并保存后,图片自动进入“待审核”状态。我们认为这样的状态切换超出了用户的预期,特别是如果用户想要检查标签是否有误,则需要切换到“待审核”页面进行检查,这会给用户带来不便。
“待审核”的图片还是可以修改的,修改在管理员发起验收前生效。但在验收时,如果图片是采样的,修改不会保存在数据集中。如果图片未采样,修改将保存在数据集中。这样的审计逻辑限制可以减少审计过程中不必要的混乱,防止审计结果出现错误。
4.2.5.3 评论
ModelArts将审核称为“验收”,验收分为单张图片验收和批量图片验收两个级别。过程是用户检查并接受一批图片。审核层级过多,逻辑复杂,可能导致运行结果不符合用户预期。
标注状态混乱:例如管理员将图片A分配给注释者a。 a后,管理员同时使用智能标签标记图片A。如果两个结果都被管理员确认,无论哪个标签先确认,最终只有智能标注的结果有效,标注者a的标签无效。
ModelArts 提供了审计仪表盘,方便审计的统计链接,并以可视化的方式展示任务进度。仪表盘的评价指标包括:验收进度统计、疑难案例集数、标签数和带标签样本数、注释者的进度统计等,如图14所示:
图 14:ModelArts 中的注释审查仪表板
4.3 监督
图 15:Supervisely 的标注流程
从图中可以看出,团队标记一块的逻辑比其他产品更复杂。分析背后的原因:
表面上很多步骤是为了满足团队标注(尤其是外部标注团队)的需求,包括创建团队、邀请成员、创建标注任务、标注审核等,但本质上都是安全控制和质量控制要求:
安全控制体现在管理员可以为团队成员分配不同的角色来控制成员的权限。例如,Annotator 只能查看其任务中的图片;质量控制体现在注释完成后。管理员审核标签以确保标签质量。
因此,这样一个复杂的环节是一个企业级标签产品应该有的设计,虽然这不可避免地会导致用户认知成本的增加和用户体验的下降。
4.3.1 创建数据集
在 Supervisely 中,用户可以在一个数据集中完成 4 种类型的标注(视频标注除外),即分类、检测、分割和姿态估计。
与ModelArts不同,Supervisely对数据集的定位更像是一个图片集。一批图片只需要导入一次,无论做什么类型的标注,都可以在同一个数据集上做。并且在进行后续训练时,可以直接得到一张图片上的所有标注。
综上所述,Supervisely 的统一数据集模块提高了图像导入、图像标注和图像后处理的效率。但是这种方法也有缺点:所有标注类型的操作方式都是固定的,不能针对特定类型进行优化(比如Modelarts图片分类可以同时选择多张图片一起标注)。
4.3.2 数据处理
Supervisely 的数据处理模块叫做 DTL,Data Transformation Language,是一种基于 JSON 的脚本语言。通过配置DTL脚本,可以完成数据集合并、标签映射、图像增强、格式转换、图像去噪、图像翻转等46项操作,满足各种数据处理需求。

图 16:在 Supervisely 中为图片添加高斯模糊
虽然功能比ModelArts更强大,但只提供了基于代码的操作,只适合工程师使用。不过大部分工程师已经掌握了通过python处理图片的方式,额外学习一门语言无疑会增加学习成本。
另一方面,这种特殊语言的效率提升还存在未知数。例如,用户想进行某张图片操作,但查了半天,发现不支持该语言。最终还是要通过python来完成,最终降低了效率。 .
4.3.3 自动标注
Supervisely 目前提供 14 个预训练模型。训练数据大部分来自COCO(微软发布的大型图像数据集),少部分来自PASCAL VOC2012、Cityscapes、ADE20K等公开数据集。
在自动标注部分,Supervisely的优势在于支持语义分割自动标注,产品在语义分割手动标注方面有着出色的体验,大大提高了此类任务的标注效率。
Supervisely 的自动贴标模块产品化程度较低,主要体现在以下两点:
由于不提供模型训练和推理服务,用户需要准备自动标注所需的硬件环境,限制较多(仅支持Nvidia GPU,需要Linux和Cuda驱动)。模型推理参数通过JSON格式的配置文件进行配置(见图17)。相比华为简单的配置界面,这种形式的灵活性更高,但是用户真的需要配置还是直接想系统呢?自动标记的结果?

图17:Supervisely(左)和Huawei ModelArts(右)自动标注配置对比
4.3.4 手动标注
Supervisely 的标注功能非常强大,主要有以下两个特点:
丰富的标注形式:为了支持各种类型的标注,Supervisely提供了多达9种标注形式,包括:标签、点、矩形、折线、多边形、长方体、像素图、智能工具(Smart Tool)、关键点等复杂标签系统:抽象了对象(Object)、类(Class)和标签(Tag)三个实体,提高了复杂场景中实体之间的复用性。
4.3.4.1 丰富的标注格式
在所有 9 种标签中,智能工具令人印象深刻:
智能工具用于标记分段类型。用户只需要点击两次方框选择一个对象,通过算法对目标进行描边完成初步分割,然后对正负点进行标注,完成精准标注。大大降低了分割任务的标注成本。

图 18:在 Supervisely 中点击 11 次后完成语义分割
4.3.4.2 复杂的标签系统
为了满足覆盖多种标签类型的数据集的需求,Supervisely 有一个复杂的标签系统。我们通过三种产品的ER图详细分析了这种标签制度的优缺点。
在图 19 的行人识别场景中,我们将绘制一个行人边界框。然后我们需要定义一个标签,叫做:行人。
图 19:Supervisely 中的行人标记场景
但是每个行人的属性是不同的。比如行人A戴帽子,行人B不戴帽子。如果我们需要区分戴帽子的行人和不戴帽子的行人,一种方法是创建两个标签:戴帽子的行人,不戴帽子的行人。
但是这样两个标签就会失去相关性——如果模型只需要检测行人,就需要对这两个标签进行转换,效率较低。
更合理的做法是在行人标签下创建一个属性——是否戴帽子;并抽象出一个概念:对象。
用户每画一个边界框,系统就会创建一个对象(例如:行人A),每个对象对应一个标签(例如:行人),然后每个对象可以设置该对象的属性值标签(例如:是否戴帽子=是)。
CVAT 和 ModelArts 都这样做。不同的是,CVAT 可以直接标记图像进行图像分类。由于ModelArts划分了图像分类和目标检测数据集,标签只能应用于图像分类数据中的图像。
图 20:CVAT(左)和 ModelArts(右)之间的图片-对象-标签 ER 图比较
监督地将标签和属性拆分为两个实体(如下图):
这种方法可以提高属性的重用率。比如在Supervisely中,用户只需要定义一次颜色属性,然后是否标记行人或车辆的颜色,可以应用相同“颜色”下的属性,提高了复杂度的准备效率标签集。
但与此同时,这种方法对用户体验设计提出了更大的挑战。从上手难度来看,Supervisely无疑是三款产品中最难上手的。
图 21:Supervisely 的图片-对象-标签-对象 ER 图
5.总结与展望5.1总结对比
下表是三个标记产品的功能汇总:
表3:三款产品功能总结对比
CVAT:手动贴标功能最强大,但自动贴标功能比较弱。独特的跟踪模式,无需视频预处理,大大提高标注效率。由于环境原因,CVAT的任务分析功能还没有完全体验。从介绍来看,这里应该用它。 ModelArts:作为华为云的一个功能模块,ModelArts的产品策略更加通用化和平台化。与华为OBS系统的结合,带来了强大的数据处理能力,增强了平台的可扩展性和兼容性。同时,自动贴标和半自动贴标是ModelArts的优势,是CVAT和Supervisely所不具备的。它们也体现了ModelArts依托华为云强大的算力和算法优势。总的来说,ModelArts 是一个平衡的玩家,具有出色的业务开发能力。 Supervisely:整体功能最全,适合企业级应用。对语义分割任务的支持较好,但部分功能(如数据处理、自动标注)需要代码完成,效率提升有限。
当然,我们也发现了三款产品都没有的一些功能,比如水印功能,会适用于保密要求,比如监狱、银行等。
5.2 标注工具的未来趋势
5.2.1 手动标注不会消失。
这其实是一个悖论:假设我需要训练一个CV模型,而训练模型需要准备带注释的图片。如果图像标注只需自动标注,无需人工干预,则说明模型已经能够准确预测结果。
如果能够准确预测,则说明模型已经训练完毕,不再需要训练,与假设相反。
5.2.2 自动标注的价值主要体现在单个标注需要较长时间的标注类型,如分割、姿态估计等
既然人工贴标肯定会存在,那么自动贴标的意义在于提高人工贴标的效率,而不是替代人工贴标。在单次标注耗时较短的场景中,如分类、检测任务,自动标注的价值较小。
假设从0完成一个标签需要5秒,如果进行了自动贴标,修改一个标签需要2秒,贴标效率提升60%(假设自动贴标模型为下班后跑,不影响人工打标时间)
但是我们已经看到模型在某些图片上的标注结果可能偏差太大,所以用户还是需要1秒的时间来删除自动标注的结果,但是标注的效率降低了20%( IE,1/5),这么高的负收益让整体效率提升不大。
5.2.3 手动注解的主要内容将从创建注解转变为修改注解
虽然人工贴标过程不会消失,但很明显,自动贴标将在贴标过程中发挥越来越重要的作用。未来常见的标注流程将从创建新标签转变为修改标签。
因此,优化注释修改时的用户体验将是提高注释效率的突破口。
作者:薛康杰,AIoT产品经理,AIops、CV和IoT平台产品;蒋海龙,AI产品实习生,专注于简历产品设计。
This article was published by @薛康杰 原创 in Renren is a product manager, reprinting without permission is prohibited
The title picture comes from Unsplash, based on the CC0 protocol
Reward the author and encourage him to work hard!
Appreciation
独具十年历练,成就业界领先品牌,想到优采云采集器!
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-25 00:27
优采云采集器() 是一款专业的互联网数据采集、处理、分析、挖掘软件。 优采云采集器可以灵活快速的抓取网页中的大量非结构化文本、图片等资源信息,然后通过一系列的分析处理,准确挖掘出需要的数据,并且可以选择发布到网站Background ,导入数据库或保存在本地 Excel、Word 等格式文件中。支持远程下载图片文件,支持网站登录后信息采集,支持检测文件真实地址,支持代理,支持防盗链采集,支持采集直接数据存储和模仿者手动发布等。许多功能,经过十年的升级,积累了大量的用户和良好的声誉。是目前最流行的网页资料采集software。
优采云采集器能采集99%的网页,几乎所有的网页都可以采集,即使需要验证码,登录甚至采集都可以处理!采用顶级系统配置,反复优化性能,速度是普通采集器的7倍。 采集/发布就像复制粘贴一样准确,用户想要的就是精华,没有遗漏!拥有独特的十年经验和行业领先品牌,想到网页采集,想到优采云采集器!有兴趣的朋友请下载使用。
软件功能
1、分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
2、多重识别系统
搭载文字识别、中文分词识别、任意码识别等多种识别系统,智能识别操作更轻松。
3、可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
4、全自动运行
无需人工操作,任务完成后自动关机。
5、替换函数
同义词、同义词替换、参数替换、伪原创必备技能。
6、任意文件格式下载
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
7、采集监控系统
实时监控采集,保证数据的准确性。
8、支持多数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无级多页采集
支持无限级别采集包括多页面信息,包括ajax请求数据。
10、support 扩展
支持接口和插件扩展,满足各种毛发采集需求。
功能介绍
1、URL采集
优采云采集器可以使用URL采集规则设置快速采集到想要的URL信息。可以手动输入、批量添加,也可以直接从文本中导入网址,并可以自动过滤掉重复的网址信息。
支持多级页面网址的采集,多级网址采集可以通过页面分析自动获取地址和手动填写规则两种方式。为了处理内容不同但地址相同的多级页面,URL采集和优采云采集器设置了三种HTTP请求方式:GET、POST和ASPXPOST。
优采云采集器支持网站采集测试,可以验证操作的正确性,避免采集错误操作导致结果不准确
2、内容采集
优采云采集器可以分析网页源代码,设置内容采集规则,准确采集到网页中分散的内容数据,支持多页面等复杂页面的内容级别和多页采集。
通过定义标签,可以对数据进行采集分类,比如将文章内容的标题与采集正文分开。 优采云采集器配置了三种内容抽取方式:截取前后、常规抽取、正文抽取。选择性强,用户可以根据自己的需要选择。
内容采集也支持测试功能。可以用一个典型的页面来测试采集内容的正确性,以便及时更正和后续数据处理。
3、数据处理
对于采集收到的信息数据,优采云采集器可以对其进行一系列的智能处理,使采集收到的数据更加符合我们的使用标准。主要包括:
1)标签过滤:过滤掉内容中不必要的空格、链接等标签; 2)替换:支持近义和同义词替换;
3)数据转换:支持中文转英文、简体转繁体、转拼音等;
4)自动抽象和自动分词:支持自动摘要生成和自动分词功能;
5)download 选项:优采云采集器支持任意格式的文件检测下载,可以智能完成相对地址到绝对地址的转换。
4、数据发布
<p>优采云采集器采集数据down后,数据默认保存在本地数据库(sqlite、mysql、sqlserver)中。用户可以根据自己的需要选择对数据进行后续操作完成数据发布,支持直接查看数据、在线发布数据并入库,支持用户使用和开发发布界面。 查看全部
独具十年历练,成就业界领先品牌,想到优采云采集器!
优采云采集器() 是一款专业的互联网数据采集、处理、分析、挖掘软件。 优采云采集器可以灵活快速的抓取网页中的大量非结构化文本、图片等资源信息,然后通过一系列的分析处理,准确挖掘出需要的数据,并且可以选择发布到网站Background ,导入数据库或保存在本地 Excel、Word 等格式文件中。支持远程下载图片文件,支持网站登录后信息采集,支持检测文件真实地址,支持代理,支持防盗链采集,支持采集直接数据存储和模仿者手动发布等。许多功能,经过十年的升级,积累了大量的用户和良好的声誉。是目前最流行的网页资料采集software。
优采云采集器能采集99%的网页,几乎所有的网页都可以采集,即使需要验证码,登录甚至采集都可以处理!采用顶级系统配置,反复优化性能,速度是普通采集器的7倍。 采集/发布就像复制粘贴一样准确,用户想要的就是精华,没有遗漏!拥有独特的十年经验和行业领先品牌,想到网页采集,想到优采云采集器!有兴趣的朋友请下载使用。

软件功能
1、分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
2、多重识别系统
搭载文字识别、中文分词识别、任意码识别等多种识别系统,智能识别操作更轻松。
3、可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
4、全自动运行
无需人工操作,任务完成后自动关机。
5、替换函数
同义词、同义词替换、参数替换、伪原创必备技能。
6、任意文件格式下载
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
7、采集监控系统
实时监控采集,保证数据的准确性。
8、支持多数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无级多页采集
支持无限级别采集包括多页面信息,包括ajax请求数据。
10、support 扩展
支持接口和插件扩展,满足各种毛发采集需求。
功能介绍
1、URL采集
优采云采集器可以使用URL采集规则设置快速采集到想要的URL信息。可以手动输入、批量添加,也可以直接从文本中导入网址,并可以自动过滤掉重复的网址信息。
支持多级页面网址的采集,多级网址采集可以通过页面分析自动获取地址和手动填写规则两种方式。为了处理内容不同但地址相同的多级页面,URL采集和优采云采集器设置了三种HTTP请求方式:GET、POST和ASPXPOST。
优采云采集器支持网站采集测试,可以验证操作的正确性,避免采集错误操作导致结果不准确
2、内容采集
优采云采集器可以分析网页源代码,设置内容采集规则,准确采集到网页中分散的内容数据,支持多页面等复杂页面的内容级别和多页采集。
通过定义标签,可以对数据进行采集分类,比如将文章内容的标题与采集正文分开。 优采云采集器配置了三种内容抽取方式:截取前后、常规抽取、正文抽取。选择性强,用户可以根据自己的需要选择。
内容采集也支持测试功能。可以用一个典型的页面来测试采集内容的正确性,以便及时更正和后续数据处理。
3、数据处理
对于采集收到的信息数据,优采云采集器可以对其进行一系列的智能处理,使采集收到的数据更加符合我们的使用标准。主要包括:
1)标签过滤:过滤掉内容中不必要的空格、链接等标签; 2)替换:支持近义和同义词替换;
3)数据转换:支持中文转英文、简体转繁体、转拼音等;
4)自动抽象和自动分词:支持自动摘要生成和自动分词功能;
5)download 选项:优采云采集器支持任意格式的文件检测下载,可以智能完成相对地址到绝对地址的转换。
4、数据发布
<p>优采云采集器采集数据down后,数据默认保存在本地数据库(sqlite、mysql、sqlserver)中。用户可以根据自己的需要选择对数据进行后续操作完成数据发布,支持直接查看数据、在线发布数据并入库,支持用户使用和开发发布界面。
智能标签采集器使用提示:你还是用excel写吧
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-08-24 02:06
智能标签采集器使用提示:此款智能标签采集器支持海量网站目录进行批量采集,采集提示十分简单,采集需要的页面,可自定义站点属性。前期制作采集器文件是非常费时间的,如果网站文件数量较多,会加大工作量。智能标签采集器提供完整的免费使用版本支持,2.5g、1g两个版本,要采集什么页面,直接拿文件即可。第一步:在百度网盘里找到需要转换为.md文件下载下来第二步:到网或其他地方找到下载好的md文件第三步:就可以复制粘贴转换为.md文件了.。
能用一个txt文件全网采集吗?或者说现在最先进的语法都有了吗?教程上说。我这里给你方法传送门。顺序不是很好也可以看我这个办法。
现在使用智能标签采集器的极少了!
你还是用excel写吧
这种方法本来就不靠谱,编写代码来采集大网站是最好不过的方法了,但是你的条件不允许,
百度云采集
我一直用的标记云爬虫编写的页面,在电脑端安装vps,并开启usb传输模式,手机安装标记云对接电脑。第一步下载标记云:首先:我们需要登录qq控制台,之后按照提示操作即可。第二步:将标记云安装完毕之后,打开vps,地址:/,然后:先打开采集百度云的页面。然后:选择页面标记云编辑模式第三步:可以直接点击采集,使用插件。
你可以选择标记云收集图片或者源文件,直接是在线编辑完成的。我这边没有上传第四步:直接选择标记云图片即可,这里特别要注意的是:网站内所有标记云插件都支持在线压缩。然后再将图片下载到本地就行了。第五步:还有两个方法,第一个是通过txt文档进行采集,并编辑完成,用vps将格式改为压缩包提取。第二个是使用excel来采集,excel编辑起来比较方便,操作起来比较灵活。详细的教程可以百度查询。希望能帮到你!!。 查看全部
智能标签采集器使用提示:你还是用excel写吧
智能标签采集器使用提示:此款智能标签采集器支持海量网站目录进行批量采集,采集提示十分简单,采集需要的页面,可自定义站点属性。前期制作采集器文件是非常费时间的,如果网站文件数量较多,会加大工作量。智能标签采集器提供完整的免费使用版本支持,2.5g、1g两个版本,要采集什么页面,直接拿文件即可。第一步:在百度网盘里找到需要转换为.md文件下载下来第二步:到网或其他地方找到下载好的md文件第三步:就可以复制粘贴转换为.md文件了.。
能用一个txt文件全网采集吗?或者说现在最先进的语法都有了吗?教程上说。我这里给你方法传送门。顺序不是很好也可以看我这个办法。
现在使用智能标签采集器的极少了!
你还是用excel写吧
这种方法本来就不靠谱,编写代码来采集大网站是最好不过的方法了,但是你的条件不允许,
百度云采集
我一直用的标记云爬虫编写的页面,在电脑端安装vps,并开启usb传输模式,手机安装标记云对接电脑。第一步下载标记云:首先:我们需要登录qq控制台,之后按照提示操作即可。第二步:将标记云安装完毕之后,打开vps,地址:/,然后:先打开采集百度云的页面。然后:选择页面标记云编辑模式第三步:可以直接点击采集,使用插件。
你可以选择标记云收集图片或者源文件,直接是在线编辑完成的。我这边没有上传第四步:直接选择标记云图片即可,这里特别要注意的是:网站内所有标记云插件都支持在线压缩。然后再将图片下载到本地就行了。第五步:还有两个方法,第一个是通过txt文档进行采集,并编辑完成,用vps将格式改为压缩包提取。第二个是使用excel来采集,excel编辑起来比较方便,操作起来比较灵活。详细的教程可以百度查询。希望能帮到你!!。
Superhero快手采集是个牛逼的快手视频采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 461 次浏览 • 2021-08-23 21:07
超级英雄快手采集是一款很棒的快手视频采集工具,支持在线播放和指定用户采集,还可以快速欣赏任何快手短视频,下载无水印,使用非常简单,有需要的可以下载使用。
Data采集:快手,抖音/关键词国家手机号采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集系统,关键词采集系统可以控制百度下拉框关键词无限裂变采集,采集百度分箱的词,百度-相关关键词,但是两者都需要写复杂的规则,比如优采云,优采云,这个工具很傻。
快手采集信息数据采集、data采集、数据挖掘、数据提取、手机号采集等,都是提升销售业绩的必备工具,缺乏创业的爱采集。 .
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@搜索支持定制数量支持出口数量。
热词是军事战略家的必备品。如果能主宰热词,收益肯定是非常可观的。如果我们能挖掘一些潜力关键词,那就更美了,因为这些话一般都是一些处女地,如果我们能在那里。
采集平台抖音(主)账号监控。使用关键词 搜索类似账户以兑现主持人的推出。关注采集右上角按顺序查看在线观众采集迷帐采集抖音码(右上角分享-抖音码)如果有手机号。
多特软件站安卓下载为您提供关键词采集系统V1.0安卓版、手机版下载,关键词采集系统V1.0apk免费下载安装到您的手机。同时支持方便的电脑端一键安装功能! 查看全部
Superhero快手采集是个牛逼的快手视频采集工具
超级英雄快手采集是一款很棒的快手视频采集工具,支持在线播放和指定用户采集,还可以快速欣赏任何快手短视频,下载无水印,使用非常简单,有需要的可以下载使用。
Data采集:快手,抖音/关键词国家手机号采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集系统,关键词采集系统可以控制百度下拉框关键词无限裂变采集,采集百度分箱的词,百度-相关关键词,但是两者都需要写复杂的规则,比如优采云,优采云,这个工具很傻。
快手采集信息数据采集、data采集、数据挖掘、数据提取、手机号采集等,都是提升销售业绩的必备工具,缺乏创业的爱采集。 .
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@搜索支持定制数量支持出口数量。

热词是军事战略家的必备品。如果能主宰热词,收益肯定是非常可观的。如果我们能挖掘一些潜力关键词,那就更美了,因为这些话一般都是一些处女地,如果我们能在那里。
采集平台抖音(主)账号监控。使用关键词 搜索类似账户以兑现主持人的推出。关注采集右上角按顺序查看在线观众采集迷帐采集抖音码(右上角分享-抖音码)如果有手机号。

多特软件站安卓下载为您提供关键词采集系统V1.0安卓版、手机版下载,关键词采集系统V1.0apk免费下载安装到您的手机。同时支持方便的电脑端一键安装功能!
智能标签采集器的费用控制方法与技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-23 19:03
智能标签采集器是通过一种公共标签进行系统识别的,不同的标签可以共享,也就是说商家可以通过全国范围内的统一地址抓取,实现仓储,
比较有新意的做法,建议还是去做平台,做大了再做自己的公司。
聚水潭做过的标签可以使产品的整个体验变得简单。
之前答过,成本控制的目标就是技术和管理人员成本控制,其他成本下降,那么人力成本就控制。估计后面会有的,抓数量也不会太多。别人的标签合作你标签分发,你给我授权。整合之后提供给小b就行了。
智能标签采集器这个应该是没办法单独做的,除非你能整合一大批广告,比如优酷的信息流等,
做标签,投放还是要搞定人。
除了技术上的限制,还需要考虑2点,1是应用场景的限制。2.费用控制。2.1应用场景先说说应用场景,1、你面对的场景是否需要对标签进行操作。比如做电商的小b,2b转2c需要操作的一定是标签,因为都是用户群;如果小b找到品牌商,希望对标签进行操作,那么这时候技术的瓶颈就出来了,但是真实的场景是2b和2c场景不一样,比如美图的国内销售的时候,全部采用了品牌商的智能标签。
但是2c市场的需求不一样,需要专门的顾问来为用户分析用户行为。2b的服务也不是简单的对标签、询价、下单流程化。2c的所有的功能都可以借助核心数据流进行功能划分。2.2费用控制既然标签功能单独做,那么理论上费用是需要下降的,但是不是随着标签下降所以效果也要下降。主要是要合理控制和控制技术和资金的投入。单独做一个标签要精简架构,整合大量标签和效果可能变的模糊;采用联合销售可以将产品线到大,可以用较低的成本来获取收益,也更加接近理想的效果。最后要看你的目标客户是否已经转化为目标客户。 查看全部
智能标签采集器的费用控制方法与技巧
智能标签采集器是通过一种公共标签进行系统识别的,不同的标签可以共享,也就是说商家可以通过全国范围内的统一地址抓取,实现仓储,
比较有新意的做法,建议还是去做平台,做大了再做自己的公司。
聚水潭做过的标签可以使产品的整个体验变得简单。
之前答过,成本控制的目标就是技术和管理人员成本控制,其他成本下降,那么人力成本就控制。估计后面会有的,抓数量也不会太多。别人的标签合作你标签分发,你给我授权。整合之后提供给小b就行了。
智能标签采集器这个应该是没办法单独做的,除非你能整合一大批广告,比如优酷的信息流等,
做标签,投放还是要搞定人。
除了技术上的限制,还需要考虑2点,1是应用场景的限制。2.费用控制。2.1应用场景先说说应用场景,1、你面对的场景是否需要对标签进行操作。比如做电商的小b,2b转2c需要操作的一定是标签,因为都是用户群;如果小b找到品牌商,希望对标签进行操作,那么这时候技术的瓶颈就出来了,但是真实的场景是2b和2c场景不一样,比如美图的国内销售的时候,全部采用了品牌商的智能标签。
但是2c市场的需求不一样,需要专门的顾问来为用户分析用户行为。2b的服务也不是简单的对标签、询价、下单流程化。2c的所有的功能都可以借助核心数据流进行功能划分。2.2费用控制既然标签功能单独做,那么理论上费用是需要下降的,但是不是随着标签下降所以效果也要下降。主要是要合理控制和控制技术和资金的投入。单独做一个标签要精简架构,整合大量标签和效果可能变的模糊;采用联合销售可以将产品线到大,可以用较低的成本来获取收益,也更加接近理想的效果。最后要看你的目标客户是否已经转化为目标客户。
智能标签采集器(工作中怎么写爬虫,如何培养一下自己的自学能力)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-01 14:23
智能标签采集器,一键采集各个平台网页标签采集结果,导出各个网站标签代码。采集后的标签代码放在各个网站对应地址中。采集成功后导出标签结果,操作简单,按操作流程操作。
抖个机灵不好吧?既然会爬虫,那么设计出一个爬虫兼容你需要的所有网站url,并和对应的标签对应起来,爬虫自动获取每个网站用户的属性信息,存入数据库;爬虫抓取新闻资讯时记得留住这些新闻信息用于自动重定向到各个网站上。简单点说,一个工具的存在,是锦上添花的,不是雪中送炭的。
从零开始写爬虫
先搞一个python自动化采集器,采集各个网站标签代码。传到另一个框架里,添加自动化封装即可。
难道让我们简单地爬一个网站,再抓取一个网站?我也是第一次接触爬虫,目前想写个爬虫程序,可以自动抓取和解析,爬取数据库,发送请求等功能,应该是从零开始写吧,因为数据库我没有接触过,我已经跳槽离开了,所以想要写一个自动化爬虫,感觉很有难度,应该要找个计算机专业出身,这样去接触的话,应该容易点。可是我也不知道对口的工作,也没有兴趣,我还是看看市场上的要求是什么,毕竟编程岗和本专业都不对口,大家有什么建议或者方法,欢迎交流。
当你想问“工作中怎么写爬虫”这个问题的时候,你就应该进行一下自己对这个东西的基本了解。所以我假设你要对要做的事情有了一个基本的了解了,然后你希望知道这个工作是怎么开展的。没有自学能力的话,就去看书。培养一下自己的自学能力,然后再决定从哪里开始学习,这个时候开始找个靠谱点的公司,把问题列清楚,一步一步按照你列的每个项目实现。
至于怎么做爬虫,按照我之前的经验,主要有以下内容:一是写python爬虫,然后定位什么类型的网站;二是爬b/s或者b/s应用的应用程序,然后根据应用程序的功能来定位相关的python语言;三是爬虫自己的事情,爬数据,写简单的网页抓取,抓图片,写简单的爬虫爬取小黄文等等。抓到数据,用list(),json来返回一个json对象;用beautifulsoup,解析一下返回的json,然后在python里,定位数据,获取json对象,并解析。
自己做一下列表解析,就可以完成解析小黄文了,就这么简单,前提是你需要本身有编程的兴趣,还需要找到自己对于写python爬虫,在这个领域的一些兴趣,能力。写python爬虫,程序语言很重要,一个好的python爬虫程序应该达到以下几个标准:快速实现用python解决任何问题的技能。java,c#.net,c#,php,python,php,java...等等;极好的抽象能力;多线程;多进程;并发;网。 查看全部
智能标签采集器(工作中怎么写爬虫,如何培养一下自己的自学能力)
智能标签采集器,一键采集各个平台网页标签采集结果,导出各个网站标签代码。采集后的标签代码放在各个网站对应地址中。采集成功后导出标签结果,操作简单,按操作流程操作。
抖个机灵不好吧?既然会爬虫,那么设计出一个爬虫兼容你需要的所有网站url,并和对应的标签对应起来,爬虫自动获取每个网站用户的属性信息,存入数据库;爬虫抓取新闻资讯时记得留住这些新闻信息用于自动重定向到各个网站上。简单点说,一个工具的存在,是锦上添花的,不是雪中送炭的。
从零开始写爬虫
先搞一个python自动化采集器,采集各个网站标签代码。传到另一个框架里,添加自动化封装即可。
难道让我们简单地爬一个网站,再抓取一个网站?我也是第一次接触爬虫,目前想写个爬虫程序,可以自动抓取和解析,爬取数据库,发送请求等功能,应该是从零开始写吧,因为数据库我没有接触过,我已经跳槽离开了,所以想要写一个自动化爬虫,感觉很有难度,应该要找个计算机专业出身,这样去接触的话,应该容易点。可是我也不知道对口的工作,也没有兴趣,我还是看看市场上的要求是什么,毕竟编程岗和本专业都不对口,大家有什么建议或者方法,欢迎交流。
当你想问“工作中怎么写爬虫”这个问题的时候,你就应该进行一下自己对这个东西的基本了解。所以我假设你要对要做的事情有了一个基本的了解了,然后你希望知道这个工作是怎么开展的。没有自学能力的话,就去看书。培养一下自己的自学能力,然后再决定从哪里开始学习,这个时候开始找个靠谱点的公司,把问题列清楚,一步一步按照你列的每个项目实现。
至于怎么做爬虫,按照我之前的经验,主要有以下内容:一是写python爬虫,然后定位什么类型的网站;二是爬b/s或者b/s应用的应用程序,然后根据应用程序的功能来定位相关的python语言;三是爬虫自己的事情,爬数据,写简单的网页抓取,抓图片,写简单的爬虫爬取小黄文等等。抓到数据,用list(),json来返回一个json对象;用beautifulsoup,解析一下返回的json,然后在python里,定位数据,获取json对象,并解析。
自己做一下列表解析,就可以完成解析小黄文了,就这么简单,前提是你需要本身有编程的兴趣,还需要找到自己对于写python爬虫,在这个领域的一些兴趣,能力。写python爬虫,程序语言很重要,一个好的python爬虫程序应该达到以下几个标准:快速实现用python解决任何问题的技能。java,c#.net,c#,php,python,php,java...等等;极好的抽象能力;多线程;多进程;并发;网。
智能标签采集器(自主研发的标签采集器,支持各行业电商数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-26 23:05
智能标签采集器为您解答:
1、大规模标签采集并打印成装帧册子
2、行业客户群的标签采集和管理
3、供应商的标签管理和存档
4、对外咨询标签源头成本管理平台给企业提供以下几个功能:
1、数据打印机采集功能
2、采集平台机器管理
3、采集标签管理
4、标签模板管理平台
智能标签采集器功能主要是2个方面:
1、企业站,
2、行业站,
虽然现在各家功能不同,但都大同小异,只要能实现其中1个功能就已经很不错了。行业站建议使用视贝标签采集器,标签采集次数超过300次。采集效率,标签价格也实惠。还支持导出标签,采集效率也不错。
crystal标签采集器整合资源,有采集标签的功能。
现在it圈的网站多数使用的是seomaster,而seomaster需要先获取权限。所以采集本地站已经不适合,现在多数都是通过从第三方购买标签号的形式从本地采集。
南京标签采集器专门针对各行业电商平台数据采集提供各行业采集器各行业电商数据采集器
推荐我们自主研发的标签采集机器人,自主研发的标签采集机器人,重要的事情说三遍,机器人首页自助采集,支持各网站标签采集自主检索,支持各网站标签提取自主选择,通过扫二维码返回采集文件,机器人响应速度快,小容量版本20个标签, 查看全部
智能标签采集器(自主研发的标签采集器,支持各行业电商数据采集)
智能标签采集器为您解答:
1、大规模标签采集并打印成装帧册子
2、行业客户群的标签采集和管理
3、供应商的标签管理和存档
4、对外咨询标签源头成本管理平台给企业提供以下几个功能:
1、数据打印机采集功能
2、采集平台机器管理
3、采集标签管理
4、标签模板管理平台
智能标签采集器功能主要是2个方面:
1、企业站,
2、行业站,
虽然现在各家功能不同,但都大同小异,只要能实现其中1个功能就已经很不错了。行业站建议使用视贝标签采集器,标签采集次数超过300次。采集效率,标签价格也实惠。还支持导出标签,采集效率也不错。
crystal标签采集器整合资源,有采集标签的功能。
现在it圈的网站多数使用的是seomaster,而seomaster需要先获取权限。所以采集本地站已经不适合,现在多数都是通过从第三方购买标签号的形式从本地采集。
南京标签采集器专门针对各行业电商平台数据采集提供各行业采集器各行业电商数据采集器
推荐我们自主研发的标签采集机器人,自主研发的标签采集机器人,重要的事情说三遍,机器人首页自助采集,支持各网站标签采集自主检索,支持各网站标签提取自主选择,通过扫二维码返回采集文件,机器人响应速度快,小容量版本20个标签,
智能标签采集器(用灵析智能标签,帮你自动筛选符合条件的联系人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-24 11:00
想知道你的忠实粉丝是谁吗?没有办法记住谁参加了多少活动,填写了多少表格?——使用智能标签帮你自动筛选符合条件的联系人
什么是智能标签
智能标签可以根据您设置的复杂规则自动过滤和标记联系人,是帮助组织更方便地管理联系人的工具。使用智能标签,您可以使用智能标签识别忠实粉丝,也可以使用智能标签标记不活跃的联系人,并且可以自动识别多个角色。
如何管理智能标签
点击左侧菜单栏中“联系人”旁边的设置按钮,选择“智能标签管理”进入;
如何创建智能标签
在“智能标签”页面,点击右上角的“添加智能标签”开始创建。
例如:
假设我们要确定哪些人捐的钱更多,哪些人是更忠诚的捐赠者,我们可以创建一个“忠诚捐赠者”的智能标签。创建过程如下:
1)选择记录类型:“统计”-“支付”-“支付总额”;
2) 设置过滤条件:记录规则为“大于”,金额设置为“10000元”;
3) 点击右侧的“高级设置”,设置录制的时间范围:
“所有时间”可以统计过去所有联系人的信息
“最后*天”是指从今天开始,所有前*天符合条件的记录都会被打上标签,并且数据会随着时间的推移而动态更新
“自定义时间段”可以统计指定时间段内的联系人状态
当您想要添加更多限定条件以使用智能标签标记联系人时,您可以选择“+添加和/或条件”来完成。
选择好后点击确定,为智能标签命名并添加说明,就可以看到标签了。 查看全部
智能标签采集器(用灵析智能标签,帮你自动筛选符合条件的联系人)
想知道你的忠实粉丝是谁吗?没有办法记住谁参加了多少活动,填写了多少表格?——使用智能标签帮你自动筛选符合条件的联系人
什么是智能标签
智能标签可以根据您设置的复杂规则自动过滤和标记联系人,是帮助组织更方便地管理联系人的工具。使用智能标签,您可以使用智能标签识别忠实粉丝,也可以使用智能标签标记不活跃的联系人,并且可以自动识别多个角色。
如何管理智能标签
点击左侧菜单栏中“联系人”旁边的设置按钮,选择“智能标签管理”进入;
如何创建智能标签
在“智能标签”页面,点击右上角的“添加智能标签”开始创建。
例如:
假设我们要确定哪些人捐的钱更多,哪些人是更忠诚的捐赠者,我们可以创建一个“忠诚捐赠者”的智能标签。创建过程如下:
1)选择记录类型:“统计”-“支付”-“支付总额”;
2) 设置过滤条件:记录规则为“大于”,金额设置为“10000元”;
3) 点击右侧的“高级设置”,设置录制的时间范围:
“所有时间”可以统计过去所有联系人的信息
“最后*天”是指从今天开始,所有前*天符合条件的记录都会被打上标签,并且数据会随着时间的推移而动态更新
“自定义时间段”可以统计指定时间段内的联系人状态
当您想要添加更多限定条件以使用智能标签标记联系人时,您可以选择“+添加和/或条件”来完成。
选择好后点击确定,为智能标签命名并添加说明,就可以看到标签了。
智能标签采集器(优采云采集器V2009SP204月29日数据原理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-10 14:09
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正义用户cms的系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持: 风讯文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选操作的问题。
9:使用采集发布时最大发布数的功能调整(以前:最大发布数无效。现在:最大发布数生效,任务完成后,之前未发布的数据不会再被释放)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能 查看全部
智能标签采集器(优采云采集器V2009SP204月29日数据原理(组图))
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正义用户cms的系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持: 风讯文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件首先来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我采集的时候可以不发布,有时间再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选操作的问题。
9:使用采集发布时最大发布数的功能调整(以前:最大发布数无效。现在:最大发布数生效,任务完成后,之前未发布的数据不会再被释放)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能
智能标签采集器(智能标签采集器会有单独的数据格式,可以number解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-06 20:02
智能标签采集器,会有单独的数据格式,可以按照实际需求自行下载安装excel格式标签。
1)采集《英雄联盟》下单句标签信息最短的那句文字;
2)采集《王者荣耀》下每局的文字标签,不会要求文字出现n字,输入m字,
3)采集《部落冲突》的单句标签信息(用过h5微信小程序需要用户登录才能采集)最短的那句文字;
4)采集《王者荣耀》上的英雄标签信息,最少需要让用户登录才能获取上图信息,可以只要求登录帐号与密码,
自带爬虫抓取页面的话,可以用爬虫。
网页中的number可以直接解析,
你可以考虑前端自动采集
现在很多创业公司都是直接用的爬虫比如说百度百科爬虫这种
带自己的logo就能爬,爬其他信息涉及到用户,可以生成json。
可以是自己写爬虫,支持正则表达式,自己json处理。
我这里除了完整的爬取过标签的信息之外,还爬取了scrapy框架里面的标签来做数据接入。很多时候我觉得做爬虫最难的是在数据来源这一块儿。比如useragent这种,我要自己手动去匹配啊。你会吗?虽然在excel里面好像也能添加辅助列,这样你也没法去看,这个问题不能死搬硬套。
我用google开发的scrapy来做api爬虫,利用twitter的tweets数据,每天分段来爬取google的开发者文档,github上的代码地址参考:;importrequests,http,time,ticketdefgetnumber1(self,useragent):googleresponse=requests。
get(useragent)#获取一段网址的session对象html=''html_encoding=self。getattribute('href','http:'+self。id)#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)defgetnumber2(self,useragent):#获取一段网址的session对象session=self。
getattribute('href','useragent。me')html=''html_encoding=self。getattribute('href','me')#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)def。 查看全部
智能标签采集器(智能标签采集器会有单独的数据格式,可以number解析)
智能标签采集器,会有单独的数据格式,可以按照实际需求自行下载安装excel格式标签。
1)采集《英雄联盟》下单句标签信息最短的那句文字;
2)采集《王者荣耀》下每局的文字标签,不会要求文字出现n字,输入m字,
3)采集《部落冲突》的单句标签信息(用过h5微信小程序需要用户登录才能采集)最短的那句文字;
4)采集《王者荣耀》上的英雄标签信息,最少需要让用户登录才能获取上图信息,可以只要求登录帐号与密码,
自带爬虫抓取页面的话,可以用爬虫。
网页中的number可以直接解析,
你可以考虑前端自动采集
现在很多创业公司都是直接用的爬虫比如说百度百科爬虫这种
带自己的logo就能爬,爬其他信息涉及到用户,可以生成json。
可以是自己写爬虫,支持正则表达式,自己json处理。
我这里除了完整的爬取过标签的信息之外,还爬取了scrapy框架里面的标签来做数据接入。很多时候我觉得做爬虫最难的是在数据来源这一块儿。比如useragent这种,我要自己手动去匹配啊。你会吗?虽然在excel里面好像也能添加辅助列,这样你也没法去看,这个问题不能死搬硬套。
我用google开发的scrapy来做api爬虫,利用twitter的tweets数据,每天分段来爬取google的开发者文档,github上的代码地址参考:;importrequests,http,time,ticketdefgetnumber1(self,useragent):googleresponse=requests。
get(useragent)#获取一段网址的session对象html=''html_encoding=self。getattribute('href','http:'+self。id)#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)defgetnumber2(self,useragent):#获取一段网址的session对象session=self。
getattribute('href','useragent。me')html=''html_encoding=self。getattribute('href','me')#遍历搜索关键字,尝试拿到网址#获取这段token,生成response对象ifnotrequests。preserve(request。
cookies,'token'):return'{}'。format(time。time(),ticket)self。response=response()return'{}'。format(time。time(),ticket)def。
智能标签采集器(智能标签采集器finis,抓取类型详细(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-03 16:06
智能标签采集器finis,抓取类型详细。
这款社区搜索可能有帮助。
也可以试试搜狗新闻摘要一键索引,对大部分网站来说,新闻摘要是可以提升标签效率的,
联网的地方多了,何必再去单独学习标签分类这个东西呢?对于网站对不上自己的网站目标类型时,那需要标签分类的网站类型都用哪些?真是头疼。标签分类跟网站本身和你内容有关,还得结合你内容本身去设置你的标签,几年前网上大致的标签分类是:看点类,微博类,爆款类,唱片类,计算机类,社交类,地域类,特殊词汇类,类型类,时尚类,明星八卦类,时尚类,投资理财类,年轻人偏爱一大类网站类型,屌丝点啥类,女性点啥类,超市类,手机类,视频类,拍电影类,游戏类,新闻类,政府类,职业类,权威类,资讯类,看门狗类,读图类,极简类,教育类,公益类,育儿类,建材类,海淘类,书籍类,成功人士类,车友类,相关工具类,北京三环类,高房价类。
使用搜狗比搜索引擎免费的搜索抓取软件可以解决这个问题。搜狗新闻摘要本身就是从新闻网站抓取的,你要拿过来这些网站的地址,然后使用搜狗的抓取软件抓取最近的新闻文章(根据自己的网站类型确定抓取相关热门网站热门文章)可以把这些热门文章按时间发布在新闻页面上面了,自然就会出现很多文章和它匹配起来了。这样子就能把它做成你自己的一个广告了。 查看全部
智能标签采集器(智能标签采集器finis,抓取类型详细(图))
智能标签采集器finis,抓取类型详细。
这款社区搜索可能有帮助。
也可以试试搜狗新闻摘要一键索引,对大部分网站来说,新闻摘要是可以提升标签效率的,
联网的地方多了,何必再去单独学习标签分类这个东西呢?对于网站对不上自己的网站目标类型时,那需要标签分类的网站类型都用哪些?真是头疼。标签分类跟网站本身和你内容有关,还得结合你内容本身去设置你的标签,几年前网上大致的标签分类是:看点类,微博类,爆款类,唱片类,计算机类,社交类,地域类,特殊词汇类,类型类,时尚类,明星八卦类,时尚类,投资理财类,年轻人偏爱一大类网站类型,屌丝点啥类,女性点啥类,超市类,手机类,视频类,拍电影类,游戏类,新闻类,政府类,职业类,权威类,资讯类,看门狗类,读图类,极简类,教育类,公益类,育儿类,建材类,海淘类,书籍类,成功人士类,车友类,相关工具类,北京三环类,高房价类。
使用搜狗比搜索引擎免费的搜索抓取软件可以解决这个问题。搜狗新闻摘要本身就是从新闻网站抓取的,你要拿过来这些网站的地址,然后使用搜狗的抓取软件抓取最近的新闻文章(根据自己的网站类型确定抓取相关热门网站热门文章)可以把这些热门文章按时间发布在新闻页面上面了,自然就会出现很多文章和它匹配起来了。这样子就能把它做成你自己的一个广告了。
智能标签采集器(达摩院人工智能研究院为智能标签生态产品研发中心)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-02 01:08
智能标签采集器阿里巴巴与国家知识产权局共同发布了首个标签评价技术联盟,阿里巴巴人工智能实验室专家王春、国家知识产权局数据中心专家包剑烨等联合主导技术保护,于2018年1月在湖南省长沙市政府共同承办的“智能标签生态技术创新研讨会”上正式成立,确定达摩院人工智能研究院为智能标签生态产品研发中心。启动发布的“杭州人工智能标签生态联盟”,不仅聚焦人工智能技术方向,更是聚焦于知识产权保护相关问题,致力于打造一个权利智能标签的生态;“达摩院标签生态”也主要聚焦智能标签在知识产权保护中的发展应用,致力于搭建智能标签在人工智能行业中的标准生态,可以在权利保护、数据采集、应用分析等方面进行合作。
智能标签作为计算机在信息自动采集,自动处理,自动分析的发展中逐步应用到更多场景中,各领域因其数据特点以及交互方式差异化,也在尝试着不同应用模式。要搞清楚人工智能最终是在使人的思维转变为一个更高级的自我认知,而人工智能最终是智能,至少我们得先建立这样一个基础概念。在智能标签生态发展中,更多的是人工智能技术的相互融合应用,从人工智能来到标签标签,而不是人工智能在标签上的应用,同时,通过标签的数据应用作为基础支撑,将人工智能技术在目标语言、智能分析、智能推理等方面的应用通过标签相互接口的标准来实现。
在标签标签能够深度学习、自然语言理解等人工智能领域,有四大块里面是最常使用到的人工智能技术。首先是深度学习,深度学习可以应用到很多领域,如图像识别、识别,甚至是可以用于神经网络和多层感知机,能够以较短的时间和更小的体积达到单次阅读多篇论文的目的。其次是自然语言理解,首先是基于统计学习的方法,深度学习和统计学习的交叉应用能够在机器翻译、自然语言推理、机器阅读理解等领域。
其次是视觉标注的利用,很多我们以为很难理解的事物可以通过标注的方式让标注者具体了解,比如机器读物体与声音,通过标注得到我们想要的信息。第三是识别与理解,比如可以通过识别来判断场景中的人物对话、场景人物对话等,来协助实现针对性营销。第四是数据获取,我们知道,人的思维都是多面的,不仅是个体的思维,个体和个体的交互通过语言中进行交流,通过进行交流,进而我们得到来自世界各地的人的信息,知道这些信息,我们才能对世界形成一个更全面的认知。
在这里,语言特别是符号化语言是极为重要的,那么经过一次识别,我们就知道了这个人说的是普通话还是上海话,我们可以根据以及对方说的普通话来决定我们是否接受。 查看全部
智能标签采集器(达摩院人工智能研究院为智能标签生态产品研发中心)
智能标签采集器阿里巴巴与国家知识产权局共同发布了首个标签评价技术联盟,阿里巴巴人工智能实验室专家王春、国家知识产权局数据中心专家包剑烨等联合主导技术保护,于2018年1月在湖南省长沙市政府共同承办的“智能标签生态技术创新研讨会”上正式成立,确定达摩院人工智能研究院为智能标签生态产品研发中心。启动发布的“杭州人工智能标签生态联盟”,不仅聚焦人工智能技术方向,更是聚焦于知识产权保护相关问题,致力于打造一个权利智能标签的生态;“达摩院标签生态”也主要聚焦智能标签在知识产权保护中的发展应用,致力于搭建智能标签在人工智能行业中的标准生态,可以在权利保护、数据采集、应用分析等方面进行合作。
智能标签作为计算机在信息自动采集,自动处理,自动分析的发展中逐步应用到更多场景中,各领域因其数据特点以及交互方式差异化,也在尝试着不同应用模式。要搞清楚人工智能最终是在使人的思维转变为一个更高级的自我认知,而人工智能最终是智能,至少我们得先建立这样一个基础概念。在智能标签生态发展中,更多的是人工智能技术的相互融合应用,从人工智能来到标签标签,而不是人工智能在标签上的应用,同时,通过标签的数据应用作为基础支撑,将人工智能技术在目标语言、智能分析、智能推理等方面的应用通过标签相互接口的标准来实现。
在标签标签能够深度学习、自然语言理解等人工智能领域,有四大块里面是最常使用到的人工智能技术。首先是深度学习,深度学习可以应用到很多领域,如图像识别、识别,甚至是可以用于神经网络和多层感知机,能够以较短的时间和更小的体积达到单次阅读多篇论文的目的。其次是自然语言理解,首先是基于统计学习的方法,深度学习和统计学习的交叉应用能够在机器翻译、自然语言推理、机器阅读理解等领域。
其次是视觉标注的利用,很多我们以为很难理解的事物可以通过标注的方式让标注者具体了解,比如机器读物体与声音,通过标注得到我们想要的信息。第三是识别与理解,比如可以通过识别来判断场景中的人物对话、场景人物对话等,来协助实现针对性营销。第四是数据获取,我们知道,人的思维都是多面的,不仅是个体的思维,个体和个体的交互通过语言中进行交流,通过进行交流,进而我们得到来自世界各地的人的信息,知道这些信息,我们才能对世界形成一个更全面的认知。
在这里,语言特别是符号化语言是极为重要的,那么经过一次识别,我们就知道了这个人说的是普通话还是上海话,我们可以根据以及对方说的普通话来决定我们是否接受。
智能标签采集器(智能标签采集器:最全人工智能采集工具推荐!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-10-01 14:01
智能标签采集器:最全人工智能标签采集工具推荐!
你就说个你用什么语言写的,然后自己网上查,会有免费版可以使用。现在人工智能这么火,不用去管专业性的内容,找一些关注人数多,接受程度高的关键词,使用java写个app标签库。然后把这个库,扩展到人工智能相关的标签,那就全了。人工智能标签库,lucene也好,xmlquery也好,你用的起就可以,关键是采集的人是你。希望对你有所帮助。
先找到一个机器学习算法的特征(自己设计)。然后用ml训练好模型。然后开始去爬取。一般情况下都是用训练好的模型去爬下来的,因为程序员一般不会在他的程序里加任何东西。这时候就可以用程序员高手的工具。这个很多,牛逼的如mixpit是世界上唯一一个只需要ml训练模型,不需要编程的程序员的工具。这是github上能找到的2篇文章。;_from=jiemiao-ii。
人工智能是个金矿,先学算法代码,
...就好比我问电工学什么一样-_-#基础很重要就先学机器学习算法吧...
其实你先看一下c,java,python,javascript里面的,
如果你想做个有趣的app,先看看机器学习论文,再看看人工智能相关的论文,你就懂了。人工智能无非就是experimentalproject的实验,你可以去coursera上面找找相关课程,比如机器学习(machinelearning)coursera有经典基于python的开源项目的实践课程。 查看全部
智能标签采集器(智能标签采集器:最全人工智能采集工具推荐!)
智能标签采集器:最全人工智能标签采集工具推荐!
你就说个你用什么语言写的,然后自己网上查,会有免费版可以使用。现在人工智能这么火,不用去管专业性的内容,找一些关注人数多,接受程度高的关键词,使用java写个app标签库。然后把这个库,扩展到人工智能相关的标签,那就全了。人工智能标签库,lucene也好,xmlquery也好,你用的起就可以,关键是采集的人是你。希望对你有所帮助。
先找到一个机器学习算法的特征(自己设计)。然后用ml训练好模型。然后开始去爬取。一般情况下都是用训练好的模型去爬下来的,因为程序员一般不会在他的程序里加任何东西。这时候就可以用程序员高手的工具。这个很多,牛逼的如mixpit是世界上唯一一个只需要ml训练模型,不需要编程的程序员的工具。这是github上能找到的2篇文章。;_from=jiemiao-ii。
人工智能是个金矿,先学算法代码,
...就好比我问电工学什么一样-_-#基础很重要就先学机器学习算法吧...
其实你先看一下c,java,python,javascript里面的,
如果你想做个有趣的app,先看看机器学习论文,再看看人工智能相关的论文,你就懂了。人工智能无非就是experimentalproject的实验,你可以去coursera上面找找相关课程,比如机器学习(machinelearning)coursera有经典基于python的开源项目的实践课程。
智能标签采集器(智能标签采集器,您需要多少金额就采集多少钱)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-25 17:19
智能标签采集器,您需要多少金额就采集多少钱,我们公司这块市场的话价格是6元,完全不用担心泄漏客户敏感信息,还可以智能分析哪些关键词值钱,同时每天都有实时的报表,为您做公司市场研究,这块实力非常的强大。
现在各种行业都会用到智能标签,例如电子商务,金融机构等等。特别是随着移动互联网+的普及,各种营销推广app,社交电商、网络支付等等都需要智能标签采集,标签存取等,本质还是为了促进移动互联网流量和营销推广,至于是不是用这个采集器来采集价格就跟标签采集的相关性有关系了,并不是所有金融行业都需要智能标签,当然,这个行业的话最好选择成熟的知名的第三方采集器。
在中国做o2o,整合资源,是否需要第三方采集器,有一个非常重要的参考,在中国,第三方采集器的利润率基本都会达到20%以上,而同行市场的利润率普遍在10%左右,其中有一大部分都是来自第三方的广告收入。
autohold相对来说,稳定性方面比较好一些,用起来还是比较方便的,不像百度采集器那么麻烦,我也用的是国产的autohold,
不差钱的话可以用他家的
你都需要做采集的话,本身又有什么必要用采集器呢?或者说可以考虑别的小采集器, 查看全部
智能标签采集器(智能标签采集器,您需要多少金额就采集多少钱)
智能标签采集器,您需要多少金额就采集多少钱,我们公司这块市场的话价格是6元,完全不用担心泄漏客户敏感信息,还可以智能分析哪些关键词值钱,同时每天都有实时的报表,为您做公司市场研究,这块实力非常的强大。
现在各种行业都会用到智能标签,例如电子商务,金融机构等等。特别是随着移动互联网+的普及,各种营销推广app,社交电商、网络支付等等都需要智能标签采集,标签存取等,本质还是为了促进移动互联网流量和营销推广,至于是不是用这个采集器来采集价格就跟标签采集的相关性有关系了,并不是所有金融行业都需要智能标签,当然,这个行业的话最好选择成熟的知名的第三方采集器。
在中国做o2o,整合资源,是否需要第三方采集器,有一个非常重要的参考,在中国,第三方采集器的利润率基本都会达到20%以上,而同行市场的利润率普遍在10%左右,其中有一大部分都是来自第三方的广告收入。
autohold相对来说,稳定性方面比较好一些,用起来还是比较方便的,不像百度采集器那么麻烦,我也用的是国产的autohold,
不差钱的话可以用他家的
你都需要做采集的话,本身又有什么必要用采集器呢?或者说可以考虑别的小采集器,
智能标签采集器(安装如何去点击.php文件安装lnmp使用.mysql)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-18 03:05
智能标签采集器原理是通过把一个样式的服务器端和客户端部署在同一个虚拟机中,这样所有的操作都在线上执行,不需要依赖于服务器端的启动和卸载,从而极大的提高了平台的可用性。推荐介绍给大家:安装如何去点击.php文件安装lnmp使用mysql.mysql环境变量配置指定到java运行环境eclipse安装最近也是在学习这个api,所以分享一些经验,希望能对你有帮助:。
我觉得可以从虚拟机中去使用,比如安装几个php,apache,phpstorm可以建立路由在虚拟机中使用。至于你说的“为什么之前安装的正常,而且可以启动,而下一个就不行了”我的推测是可能你安装的php和apache存在冲突。你先确定是否冲突再去处理它。另外有一点,我觉得可能你目前不知道是php调用的数据库还是apache调用的数据库,所以我建议你换一种语言尝试。暂时想到这些,希望能帮到你。
更新软件最好在php的安装目录下安装。更新方法,win10右键系统工具-卸载程序-更新计划,可以选择apache和php。win7系统直接右键桌面计算机-点“计算机管理”-网络和internet-点,点进去后-点高级系统设置-点安全设置-右键点击apache-在网络设置中点进去-里面选择从硬盘卸载。
已经被3楼说的很清楚了,这一个真的是php打不开了,要么换个语言试试,要么重装。更新一下,你用php的,还是用数据库,数据库的话,安装phpstorm,连接数据库的时候多加了一个server。 查看全部
智能标签采集器(安装如何去点击.php文件安装lnmp使用.mysql)
智能标签采集器原理是通过把一个样式的服务器端和客户端部署在同一个虚拟机中,这样所有的操作都在线上执行,不需要依赖于服务器端的启动和卸载,从而极大的提高了平台的可用性。推荐介绍给大家:安装如何去点击.php文件安装lnmp使用mysql.mysql环境变量配置指定到java运行环境eclipse安装最近也是在学习这个api,所以分享一些经验,希望能对你有帮助:。
我觉得可以从虚拟机中去使用,比如安装几个php,apache,phpstorm可以建立路由在虚拟机中使用。至于你说的“为什么之前安装的正常,而且可以启动,而下一个就不行了”我的推测是可能你安装的php和apache存在冲突。你先确定是否冲突再去处理它。另外有一点,我觉得可能你目前不知道是php调用的数据库还是apache调用的数据库,所以我建议你换一种语言尝试。暂时想到这些,希望能帮到你。
更新软件最好在php的安装目录下安装。更新方法,win10右键系统工具-卸载程序-更新计划,可以选择apache和php。win7系统直接右键桌面计算机-点“计算机管理”-网络和internet-点,点进去后-点高级系统设置-点安全设置-右键点击apache-在网络设置中点进去-里面选择从硬盘卸载。
已经被3楼说的很清楚了,这一个真的是php打不开了,要么换个语言试试,要么重装。更新一下,你用php的,还是用数据库,数据库的话,安装phpstorm,连接数据库的时候多加了一个server。
智能标签采集器(优采云基础操作和XPath相关知识教程-XPath系统学习 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-14 22:11
)
在学习本教程之前,您需要具备优采云基本操作和XPath相关知识。如果您还没有掌握,请先学习以下课程。
自定义模式入门:
XPath 系统学习和示例:
一、relative XPath
Relative Xpath,即相对于loop box的Xpath,有两个典型特征:跟随loop链接;与循环框的XPath合并,形成一个完整的定位XPath。
常见的应用场景有两种:在循环内部提取数据;在循环外提取数据。
下面会详细说明。
二、使用相对XPath提取循环中的数据
示例网址:
要求:采集此URL列表的项目名称、省份、来源平台、业务类型、时间等字段
Step1:按照之前学过的列表采集的方法创建循环框。或者使用自动识别自动创建循环框。
这里使用了自动识别。可以看到优采云自动创建循环并提取列表数据。
Step2:优采云自动创建的循环列表会自动为我们生成循环框的XPath和相对XPath。一起来看看:
循环框的XPath
循环框的XPath为://div[@class="publicont"]。通过这个XPath,找到20个列表项,对应页面上的20个数据列表。
相对 XPath
在每个周期项目中,都有项目名称、省份、来源平台、业务类型和时间等字段。查看每个字段的定位XPath,路径见下图。
如您所见,每个字段都使用相对 XPath。以 item title 和 time 两个字段为例。
[item title]字段的相对XPath:/DIV[1]/H4[1]/A[1]
[时间] 字段的相对 XPath:/descendant-or-self::SPAN[@class="span_o"]
循环框的XPath与相对XPath的关系
循环框的XPath:定位列表项。
Relative XPath:字段相对于循环框(列表项)的位置。
循环框的XPath + 相对XPath = 每个循环项中字段的XPath
正是因为相对XPath的存在,我们才能够实现循环与字段的联动采集:
循环框中当前项目为list 1-定位list 1中的字段(项目名称、省份、来源平台、业务类型、时间)
将循环框的当前项切换到列表2-定位列表2中的字段
将循环框的当前项切换到列表3-定位列表3中的字段
将循环框的当前项切换到列表4-定位列表4中的字段
......
最后1个列表-最后1个列表中的采集Fields
如果没有相对 XPath 怎么办?
无法实现循环项与字段联动的效果,只能固定第一个循环项中的字段采集。
根据需求修改相对XPath
通过上面的学习,我们已经知道了相对XPath的原理。在大多数情况下,优采云 会自动为我们生成一个相对 XPath,并正确提取循环项中的字段。目前不需要修改。在少数情况下,自动生成的相对XPath无法适应所有网页,部分字段无法提取,或者字段错位。这种情况需要我们自己修改。
看下面的例子。
修改相对 XPath 实例
网站上面,[time]字段的相对XPath为:/descendant-or-self::SPAN[@class="span_o"],比较长,难懂。我们可以写一个简短的,易于理解的。如何修改?
第一步:将循环框的XPath//div[@class="publicont"]复制到火狐浏览器。
Step2:然后找到[time]字段对应的网页源码。可以看到是一个带有class属性的span标签,属性值为pan_o。根据这个特性,可以写一个定位XPath: //div[@class="publicont"]//span[@class="span_o"] .
如您所见,网页上的所有[时间]字段都被虚线框包围,表明它们已被定位。
Step3:根据前面学到的知识,循环框的XPath为//div[@class="publicont"],[time]字段的相对XPath为://span[@class= "span_o"] .
将//span[@class="span_o"]复制粘贴到优采云中[time]字段的相对XPath输入框中。然后点击【应用】保存。
这样我们就完成了[time]字段的相对Xpath重写。启动[local采集],查看采集的结果,循环项中的数据全部降为正常采集。
三、使用相对XPath提取循环外数据
示例网址:
要求:采集城市及其对应省份的完整列表。
Step1:按照list data采集的方法,选择所有[Cities]创建一个循环。
同时,我们也想下载每个城市对应的省份采集。所以选择第一个省,在操作提示框中选择【采集元素的文本】。
手动执行规则,我们发现2个问题:
①不分城市,采集下的省份是【安徽】。如果选择福州,将提取安徽省而不是福建省。
② 4个直辖市没有采集down。
Step2:我们先解决4个不在直辖市的城市的问题。
将循环列表的XPath //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI[position()>1]/A复制到Firefox浏览器。可以看到,除了第一排的4个直辖市,其他城市都在。
在XPath课程中,我们讲了位置函数,它可以限制可以定位的列表的数量。这里 [position()>1] 将过滤掉第一个 li 列表(4 个直辖市的列表)。我们要定位4个直辖市,去掉[position()>1]: //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A .
然后在优采云中相应地修改循环框。修改后可以看到循环列表第一行收录4个直辖市,如下图。
Step3:解决总是针对[安徽]省的问题。
提取[省]时,优采云自动生成的XPath位置为//DIV[@class="outCont"]/UL[1]/LI[2]/STRONG[1]。将此XPath复制到火狐浏览器,可以看到只能固定提取【安徽】,无法链接到循环列表中的城市。因此,当提取的城市发生变化时,省份不会随着城市的变化而变化。
我们观察省市对应的源码。发现省都是强标签,城市都是a标签。直辖市标记为b,直辖市的4个城市标记为a。
strong 标签和 b 标签与 a 标签处于同一级别,并且都在 a 标签之前。
回想一下,我们基于城市构建了一个循环列表,即 a 标签。如果需要省市一一对应(包括直辖市和具体城市一一对应),就需要用到上面学到的相关XPath知识。在这个例子中:
循环框的XPath:定位列表项(所有城市)
Relative XPath:字段相对于圆形框的位置(省相对城市的位置)
循环框的XPath + 相对XPath = 每个循环项外的字段的XPath(省的位置XPath)
根据源码特性,根据城市列表写出XPath到省(包括直辖市)的位置。城市列表定位XPath为/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A。定位a标签前的同级元素,需要使用previous-sibling函数,在XPath教程中有详细介绍。因此:
(1) [省] XPath 相对于 [城市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::strong[1]
(2)[直辖市]XPath相对于[市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::b[1]
我们可以进一步将这两项合并为一项,合并后的结果为:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::*[last()]
* 表示任意标签,即strong标签或b标签可以用*替换
last() 表示最后位置的标签。
XPath 的整个解释是取城市列表(a 标签)之前的最后一个兄弟标签(强标签或 b 标签),适用于两种情况。
根据上面的知识,/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A就是循环框的XPath,/preceding-sibling:: *[last( )] 是相对 XPath。
在Firefox中验证,所有省份(包括直辖市)都位于。
最后在优采云中做相应的修改。
点击字段[省份],选择[自定义定位元素方法],勾选[相对于当前循环中的Xpath],输入我们写的相对XPath:/preceding-sibling::*[last() ] ,最后点击【应用】保存。
手动执行规则,将循环列表分别切换到省市,检查验证是否已链接,并正确提取相应数据。
直辖市-上海,直辖市-天津:
福建省-福建省泉州-厦门:
启动[local采集],看采集的结果,可以看到省(包括直辖市)和城市是一一对应的。
特别注意:
当你想在XPath采集循环之外使用数据时,需要特别注意。它只适用于提取循环外的单个数据(只有一个数据)。不适合循环外还有一个列表,有多行数据的情况。
例一:循环外的单个数据,适用
日期和星期是一个单一的数据写在一起,使用所有的事件,即li标签作为一个循环,然后在循环外提取li标签前面的h6标签,以及循环外的时间标签下一层。
例2:循环外也是一个列表,多个数据,不适用
上下有两张表。下表中的数据与上表中的数据一一对应。上下表和对应关系采集放不下是不可能的。因为上表采集需要创建循环,而下表采集也需要创建循环,会有两个循环,但是没有办法在循环和循环之间产生联动效果, 优采云暂不支持流通与流通联动。
查看全部
智能标签采集器(优采云基础操作和XPath相关知识教程-XPath系统学习
)
在学习本教程之前,您需要具备优采云基本操作和XPath相关知识。如果您还没有掌握,请先学习以下课程。
自定义模式入门:
XPath 系统学习和示例:
一、relative XPath
Relative Xpath,即相对于loop box的Xpath,有两个典型特征:跟随loop链接;与循环框的XPath合并,形成一个完整的定位XPath。
常见的应用场景有两种:在循环内部提取数据;在循环外提取数据。
下面会详细说明。
二、使用相对XPath提取循环中的数据
示例网址:
要求:采集此URL列表的项目名称、省份、来源平台、业务类型、时间等字段
Step1:按照之前学过的列表采集的方法创建循环框。或者使用自动识别自动创建循环框。
这里使用了自动识别。可以看到优采云自动创建循环并提取列表数据。
Step2:优采云自动创建的循环列表会自动为我们生成循环框的XPath和相对XPath。一起来看看:
循环框的XPath
循环框的XPath为://div[@class="publicont"]。通过这个XPath,找到20个列表项,对应页面上的20个数据列表。
相对 XPath
在每个周期项目中,都有项目名称、省份、来源平台、业务类型和时间等字段。查看每个字段的定位XPath,路径见下图。
如您所见,每个字段都使用相对 XPath。以 item title 和 time 两个字段为例。
[item title]字段的相对XPath:/DIV[1]/H4[1]/A[1]
[时间] 字段的相对 XPath:/descendant-or-self::SPAN[@class="span_o"]
循环框的XPath与相对XPath的关系
循环框的XPath:定位列表项。
Relative XPath:字段相对于循环框(列表项)的位置。
循环框的XPath + 相对XPath = 每个循环项中字段的XPath
正是因为相对XPath的存在,我们才能够实现循环与字段的联动采集:
循环框中当前项目为list 1-定位list 1中的字段(项目名称、省份、来源平台、业务类型、时间)
将循环框的当前项切换到列表2-定位列表2中的字段
将循环框的当前项切换到列表3-定位列表3中的字段
将循环框的当前项切换到列表4-定位列表4中的字段
......
最后1个列表-最后1个列表中的采集Fields
如果没有相对 XPath 怎么办?
无法实现循环项与字段联动的效果,只能固定第一个循环项中的字段采集。
根据需求修改相对XPath
通过上面的学习,我们已经知道了相对XPath的原理。在大多数情况下,优采云 会自动为我们生成一个相对 XPath,并正确提取循环项中的字段。目前不需要修改。在少数情况下,自动生成的相对XPath无法适应所有网页,部分字段无法提取,或者字段错位。这种情况需要我们自己修改。
看下面的例子。
修改相对 XPath 实例
网站上面,[time]字段的相对XPath为:/descendant-or-self::SPAN[@class="span_o"],比较长,难懂。我们可以写一个简短的,易于理解的。如何修改?
第一步:将循环框的XPath//div[@class="publicont"]复制到火狐浏览器。
Step2:然后找到[time]字段对应的网页源码。可以看到是一个带有class属性的span标签,属性值为pan_o。根据这个特性,可以写一个定位XPath: //div[@class="publicont"]//span[@class="span_o"] .
如您所见,网页上的所有[时间]字段都被虚线框包围,表明它们已被定位。
Step3:根据前面学到的知识,循环框的XPath为//div[@class="publicont"],[time]字段的相对XPath为://span[@class= "span_o"] .
将//span[@class="span_o"]复制粘贴到优采云中[time]字段的相对XPath输入框中。然后点击【应用】保存。
这样我们就完成了[time]字段的相对Xpath重写。启动[local采集],查看采集的结果,循环项中的数据全部降为正常采集。
三、使用相对XPath提取循环外数据
示例网址:
要求:采集城市及其对应省份的完整列表。
Step1:按照list data采集的方法,选择所有[Cities]创建一个循环。
同时,我们也想下载每个城市对应的省份采集。所以选择第一个省,在操作提示框中选择【采集元素的文本】。
手动执行规则,我们发现2个问题:
①不分城市,采集下的省份是【安徽】。如果选择福州,将提取安徽省而不是福建省。
② 4个直辖市没有采集down。
Step2:我们先解决4个不在直辖市的城市的问题。
将循环列表的XPath //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI[position()>1]/A复制到Firefox浏览器。可以看到,除了第一排的4个直辖市,其他城市都在。
在XPath课程中,我们讲了位置函数,它可以限制可以定位的列表的数量。这里 [position()>1] 将过滤掉第一个 li 列表(4 个直辖市的列表)。我们要定位4个直辖市,去掉[position()>1]: //HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A .
然后在优采云中相应地修改循环框。修改后可以看到循环列表第一行收录4个直辖市,如下图。
Step3:解决总是针对[安徽]省的问题。
提取[省]时,优采云自动生成的XPath位置为//DIV[@class="outCont"]/UL[1]/LI[2]/STRONG[1]。将此XPath复制到火狐浏览器,可以看到只能固定提取【安徽】,无法链接到循环列表中的城市。因此,当提取的城市发生变化时,省份不会随着城市的变化而变化。
我们观察省市对应的源码。发现省都是强标签,城市都是a标签。直辖市标记为b,直辖市的4个城市标记为a。
strong 标签和 b 标签与 a 标签处于同一级别,并且都在 a 标签之前。
回想一下,我们基于城市构建了一个循环列表,即 a 标签。如果需要省市一一对应(包括直辖市和具体城市一一对应),就需要用到上面学到的相关XPath知识。在这个例子中:
循环框的XPath:定位列表项(所有城市)
Relative XPath:字段相对于圆形框的位置(省相对城市的位置)
循环框的XPath + 相对XPath = 每个循环项外的字段的XPath(省的位置XPath)
根据源码特性,根据城市列表写出XPath到省(包括直辖市)的位置。城市列表定位XPath为/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A。定位a标签前的同级元素,需要使用previous-sibling函数,在XPath教程中有详细介绍。因此:
(1) [省] XPath 相对于 [城市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::strong[1]
(2)[直辖市]XPath相对于[市]:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::b[1]
我们可以进一步将这两项合并为一项,合并后的结果为:
/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A/preceding-sibling::*[last()]
* 表示任意标签,即strong标签或b标签可以用*替换
last() 表示最后位置的标签。
XPath 的整个解释是取城市列表(a 标签)之前的最后一个兄弟标签(强标签或 b 标签),适用于两种情况。
根据上面的知识,/HTML/BODY[1]/DIV[4]/DIV[4]/UL[1]/LI/A就是循环框的XPath,/preceding-sibling:: *[last( )] 是相对 XPath。
在Firefox中验证,所有省份(包括直辖市)都位于。
最后在优采云中做相应的修改。
点击字段[省份],选择[自定义定位元素方法],勾选[相对于当前循环中的Xpath],输入我们写的相对XPath:/preceding-sibling::*[last() ] ,最后点击【应用】保存。
手动执行规则,将循环列表分别切换到省市,检查验证是否已链接,并正确提取相应数据。
直辖市-上海,直辖市-天津:
福建省-福建省泉州-厦门:
启动[local采集],看采集的结果,可以看到省(包括直辖市)和城市是一一对应的。
特别注意:
当你想在XPath采集循环之外使用数据时,需要特别注意。它只适用于提取循环外的单个数据(只有一个数据)。不适合循环外还有一个列表,有多行数据的情况。
例一:循环外的单个数据,适用
日期和星期是一个单一的数据写在一起,使用所有的事件,即li标签作为一个循环,然后在循环外提取li标签前面的h6标签,以及循环外的时间标签下一层。
例2:循环外也是一个列表,多个数据,不适用
上下有两张表。下表中的数据与上表中的数据一一对应。上下表和对应关系采集放不下是不可能的。因为上表采集需要创建循环,而下表采集也需要创建循环,会有两个循环,但是没有办法在循环和循环之间产生联动效果, 优采云暂不支持流通与流通联动。
智能标签采集器(智能标签采集器:智能搜索引擎工具功能摘要【】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-09 17:02
智能标签采集器:智能标签采集器是一款集采集、翻译、质检、注释、分析、统计、处理、排序、导出、目录、解析等多功能于一体的智能搜索引擎工具,智能标签采集器是一款可以轻松完成多种功能的智能搜索引擎工具,智能标签采集器是一款帮助企业数据的收集和管理的工具,智能标签采集器是一款可以帮助客户更好搜索信息的工具,是新型的综合信息工具。
下面由本文主题软件介绍功能摘要讲解,一下主要的采集功能:搜索导出自动识别目录:支持网页编码,支持中文编码;自动定位关键词:支持关键词定位,支持网页标签识别;自动匹配出产品信息:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动获取产品标签:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;定位采集数据:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动筛选:根据上下文自动筛选相关页面;数据处理:通过后台定义规则,批量自动采集关键词、类目、产品等产品信息,支持批量修改采集规则;原创加工:原创处理,同一篇文章自动通过多个平台处理,同一个商品自动通过多个平台处理;手动标注:不支持数据查询和删除;采集链接:自动获取原始网址,手动添加各个分页以及分页下面各个产品链接;数据生成:根据内容生成内容标签、二维码;生成数据包:根据规则生成文件包;订单管理:提供单个批量采集生成订单;智能标签采集器的功能是非常的多的,采集数据也是比较方便的,可以搜索,也可以添加标签进行识别采集。
软件主要是通过网页编码、网页标签等进行的,还有定位关键词定位采集文章等等,功能是非常的强大,有需要的可以通过免费下载试用下。 查看全部
智能标签采集器(智能标签采集器:智能搜索引擎工具功能摘要【】)
智能标签采集器:智能标签采集器是一款集采集、翻译、质检、注释、分析、统计、处理、排序、导出、目录、解析等多功能于一体的智能搜索引擎工具,智能标签采集器是一款可以轻松完成多种功能的智能搜索引擎工具,智能标签采集器是一款帮助企业数据的收集和管理的工具,智能标签采集器是一款可以帮助客户更好搜索信息的工具,是新型的综合信息工具。
下面由本文主题软件介绍功能摘要讲解,一下主要的采集功能:搜索导出自动识别目录:支持网页编码,支持中文编码;自动定位关键词:支持关键词定位,支持网页标签识别;自动匹配出产品信息:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动获取产品标签:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;定位采集数据:支持搜索出对应的标签,或者自定义选择标签,可识别绝大部分产品类型;自动筛选:根据上下文自动筛选相关页面;数据处理:通过后台定义规则,批量自动采集关键词、类目、产品等产品信息,支持批量修改采集规则;原创加工:原创处理,同一篇文章自动通过多个平台处理,同一个商品自动通过多个平台处理;手动标注:不支持数据查询和删除;采集链接:自动获取原始网址,手动添加各个分页以及分页下面各个产品链接;数据生成:根据内容生成内容标签、二维码;生成数据包:根据规则生成文件包;订单管理:提供单个批量采集生成订单;智能标签采集器的功能是非常的多的,采集数据也是比较方便的,可以搜索,也可以添加标签进行识别采集。
软件主要是通过网页编码、网页标签等进行的,还有定位关键词定位采集文章等等,功能是非常的强大,有需要的可以通过免费下载试用下。
智能标签采集器(快手解析/采集工具只在吾爱破解论坛发布(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 621 次浏览 • 2021-09-07 02:11
各版本更新日期及对应的SHA1值 SHA1值不在以下范围内的版本可能被篡改,请勿使用。快手分析/采集工具仅在无爱破解论坛发布,为免费软件,仅供用户自行恢复加水印作品。
智能标签采集器-快手网红、商家、社交电商智能标签采集器(aitag采集器:)官网。目前处于推广初期,已获得大量快手网红、商家、社交电商企业、电视台等机构的青睐...
抖音快手新数据采集完整界面_Pepsi_dodo的博客-CSDN博客。
Data采集:快手,抖音/关键词全国手机号码采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集聚合阅读合集,主要提供关键词采集相关最新资源下载,可以订阅关键词采集标签话题,可以第一时间了解关键词@时间采集最新下载资源和话题,包括最新关键词采集。
快手视频采集器视频采集软件更多>>视频采集software 对大多数自媒体people 来说是一个特别有用的采集 工具。当你在快手的时候,抖音、爱奇艺、哔哩哔哩等各大视频网站好玩有趣。
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@search支持自定义数量支持导出数量。
7.根据关键词search video8.get userworks9.关键词search users...(这里就不一一列举了)有需要的请pick up,如果你想交换技术。 查看全部
智能标签采集器(快手解析/采集工具只在吾爱破解论坛发布(组图))
各版本更新日期及对应的SHA1值 SHA1值不在以下范围内的版本可能被篡改,请勿使用。快手分析/采集工具仅在无爱破解论坛发布,为免费软件,仅供用户自行恢复加水印作品。
智能标签采集器-快手网红、商家、社交电商智能标签采集器(aitag采集器:)官网。目前处于推广初期,已获得大量快手网红、商家、社交电商企业、电视台等机构的青睐...
抖音快手新数据采集完整界面_Pepsi_dodo的博客-CSDN博客。
Data采集:快手,抖音/关键词全国手机号码采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集聚合阅读合集,主要提供关键词采集相关最新资源下载,可以订阅关键词采集标签话题,可以第一时间了解关键词@时间采集最新下载资源和话题,包括最新关键词采集。
快手视频采集器视频采集软件更多>>视频采集software 对大多数自媒体people 来说是一个特别有用的采集 工具。当你在快手的时候,抖音、爱奇艺、哔哩哔哩等各大视频网站好玩有趣。
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@search支持自定义数量支持导出数量。
7.根据关键词search video8.get userworks9.关键词search users...(这里就不一一列举了)有需要的请pick up,如果你想交换技术。
智能标签采集器(想分享的这款工具是个Chrome下的插件(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-05 18:22
我想分享的工具是一个Chrome扩展程序,名为:优采云采集器
优采云采集器是一款Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他的网站风投相关的标准可以参考什么,所以找了个网站命名为“恩牛”数据”,我想看看人工智能的公司,如下图红字部分所示:
如果是规则显示的数据,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起优采云采集器之前安装过,于是试了一下。使用起来相当方便,采集效率一下子提高了。我也给你安利~
优采云采集器这个Chrome插件,我在B站的技术视频上看到的,号称是不懂得编程的爬虫可以爬取的黑科技。简单的说,优采云采集器是一款基于Chrome的网页元素解析器,自动识别主要内容,通过可视化点击操作实现自定义区域数据/元素提取。同时还提供了定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬取和真实代码爬取的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它让您首先定义页面上的要求。抓取哪些元素,抓取哪些页面,然后让机器代人操作;而如果你用Python写一个爬虫,更多的是使用网页请求命令先下载整个网页,然后用代码解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但解析的成本也会更高。如果是简单的页面内容提取,我也推荐使用优采云采集器。
关于优采云采集器的具体安装过程以及完整功能的使用方法,今天文章就不赘述了。一是我只用了自己需要的部分,二是市面上的教程太多了优采云采集器都有,自己找就行了。
这里只是一个实践过程,给大家简单介绍一下我的使用方法。
第一步登录优采云采集platform后台
1. 打开Chrome浏览器,浏览器右上角会出现其图标按钮标记。点击此按钮注册/登录按钮跳转到优采云采集平台后台登录页面,输入用户名密码登录即可使用
首先输入您要捕获的网站URL。比如我要抓取的是:ene牛数据的行业标签,网址是:,然后在优采云采集器后台输入网址点击优采云采集按钮就会出现配置页面
我已经确定了主要内容,但我想要的是一家人工智能下的公司,所以我需要重新配置它。
第二步是配置要提取的主要信息类型
1. 先点击清除字段按钮,先清除所有数据,
2. 进行一次预操作,点击人工智能选项卡,然后保存预操作
点击提取的链接提取公司的详细信息
第三步开始采集
完成基本配置的创建后,点击Start采集按钮启动采集data,也可以直接看到data采集的进程,如果太慢,点击立即加速。
以上是对优采云采集器的简单介绍。这个文章主要是想跟大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索~
怎么样,对你有帮助吗? 优采云采集器 还有很多采集模板可以免费使用。 . . 查看全部
智能标签采集器(想分享的这款工具是个Chrome下的插件(组图))
我想分享的工具是一个Chrome扩展程序,名为:优采云采集器
优采云采集器是一款Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他的网站风投相关的标准可以参考什么,所以找了个网站命名为“恩牛”数据”,我想看看人工智能的公司,如下图红字部分所示:
如果是规则显示的数据,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起优采云采集器之前安装过,于是试了一下。使用起来相当方便,采集效率一下子提高了。我也给你安利~
优采云采集器这个Chrome插件,我在B站的技术视频上看到的,号称是不懂得编程的爬虫可以爬取的黑科技。简单的说,优采云采集器是一款基于Chrome的网页元素解析器,自动识别主要内容,通过可视化点击操作实现自定义区域数据/元素提取。同时还提供了定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬取和真实代码爬取的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它让您首先定义页面上的要求。抓取哪些元素,抓取哪些页面,然后让机器代人操作;而如果你用Python写一个爬虫,更多的是使用网页请求命令先下载整个网页,然后用代码解析HTML页面元素。提取您想要的内容,并继续循环。相比之下,使用代码会更灵活,但解析的成本也会更高。如果是简单的页面内容提取,我也推荐使用优采云采集器。
关于优采云采集器的具体安装过程以及完整功能的使用方法,今天文章就不赘述了。一是我只用了自己需要的部分,二是市面上的教程太多了优采云采集器都有,自己找就行了。
这里只是一个实践过程,给大家简单介绍一下我的使用方法。
第一步登录优采云采集platform后台
1. 打开Chrome浏览器,浏览器右上角会出现其图标按钮标记。点击此按钮注册/登录按钮跳转到优采云采集平台后台登录页面,输入用户名密码登录即可使用
首先输入您要捕获的网站URL。比如我要抓取的是:ene牛数据的行业标签,网址是:,然后在优采云采集器后台输入网址点击优采云采集按钮就会出现配置页面
我已经确定了主要内容,但我想要的是一家人工智能下的公司,所以我需要重新配置它。
第二步是配置要提取的主要信息类型
1. 先点击清除字段按钮,先清除所有数据,
2. 进行一次预操作,点击人工智能选项卡,然后保存预操作
点击提取的链接提取公司的详细信息
第三步开始采集
完成基本配置的创建后,点击Start采集按钮启动采集data,也可以直接看到data采集的进程,如果太慢,点击立即加速。
以上是对优采云采集器的简单介绍。这个文章主要是想跟大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索~
怎么样,对你有帮助吗? 优采云采集器 还有很多采集模板可以免费使用。 . .
智能标签采集器(量化金融分析师AQF高质量的可视化工具应该具备哪些功能?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-09-05 17:00
Quantitative Finance丨Salesforce 的一项调查显示,53% 的员工经常检查和分析数据,但仅依靠人工操作。滚动浏览大量电子表格、图表和数据就像大海捞针。
定量金融分析师 AQF 的高质量可视化工具对于数据分析至关重要。数据可视化工具是一种应用软件,可以帮助用户以可视化和图形化的格式显示数据,呈现数据的完整轮廓。饼图、图形、热图、直方图和雷达/蜘蛛图只是可视化的一小部分。这些方法可以简单地表示数据并显示特征和趋势。
要使数据分析真正有价值且富有洞察力,就需要高质量的可视化工具。市场上有许多具有不同功能和价格的产品。本文列出了一些广为人知的工具。事实上,企业如何选择合适的可视化工具并非易事,需要慎重考虑。
1.清晰、简洁、可定制的界面
数据可视化程序的界面就像一个汽车仪表盘,你想要的重要信息一目了然——从剩余油量、行驶速度到续航里程。同样,可视化界面应该能够在一个视图中显示所有关键信息。
一个好的数据可视化工具应该同时具备以下功能:
一开始看起来很酷。界面清晰,不失流行色。太白很烦人,颜色太多会感觉杂乱,所以界面要适当平衡。
其次,界面应准确显示所有重要数据。例如,用户关注的KPI、重要趋势或重要的业务相关数据集,应该在界面启动后的几秒钟内完整清晰地展示出来。所有显示内容一目了然。
界面的另一个非常重要的品质是它可以定制。在不同的时间段,您可能需要跟踪不同的数据集,因此您需要自定义显示哪些数据。因此,数据可视化工具必须允许定制。
2.嵌入式
要真正利用数据可视化的力量,将可视化报告无缝集成到其他应用程序中是非常重要的。为了让用户高效协作并跨平台共享报告,数据可视化软件应该兼容不同的应用程序。并非所有部门都需要分析所有数据。大多数人只希望将一部分数据与他们的特定应用程序无缝集成,从而帮助他们提高工作效率。所以一个好的数据可视化工具必须易于嵌入和集成。
3.人机交互
数据可视化工具生成的可视化报告必须具有很强的人机交互性,支持一些变量或参数的调整,并且能够看到后续的趋势/结果变化。用户可以对相关变量进行移动、排序和过滤,以获得相应的效果。数据分析师和决策者需要的是能够处理来自各种来源的数据并生成有价值内容的分析工具。可视化分析报表支持不同格式的打开,不同的部分可以在不同的时间高亮显示。
4.数据采集分享给
将原创数据导入可视化工具,然后以各种形式导出可视化报告。这个过程应该以用户喜欢的方式进行。一些数据集可以最原创的形式输入到工具中,而另一些数据集因为太大而需要先聚合。有时可以从一个数据源获取数据,有时需要从不同的数据源采集数据并使用工具进行可视化。一些数据可视化工具可以从多个数据源采集数据并显示在同一个界面上,但有些工具可能没有这个功能。如何选择合适的工具取决于具体的需求。
5. 地理标记和智能定位
如果您所在的地区地理非常重要,那么您可能需要用于地理和位置数据的可视化工具。例如,这些数据来自哪里?哪些州或地区更活跃?哪些领域需要扩大?对于需要跟踪基于位置的 kpi 的企业来说,在时间和空间上对数据集进行分层的能力非常重要。
6.数据挖掘
数据挖掘是研究大型数据集以识别模式和趋势的过程。如果您正在处理大型数据集,并且想要一个可视化工具来帮助提取潜在信息并生成可视化报告,那么您需要的可视化工具就需要收录此功能。
7.人工智能
许多可视化工具都在使用人工智能来分析、探索和预测趋势,并根据过去的变化预测未来的趋势。如果这是你感兴趣的东西,那么集成人工智能的可视化工具非常适合。下面列出了一些目前广泛使用和流行的具有上述功能的数据可视化工具,以帮助您做出最合适的选择。
表格
它一直被誉为最好的数据可视化工具之一。他们的客户包括领英、德勤、汉莎航空和百事可乐等巨头。其主要功能有: 一个可定制的界面,可以嵌入到 Salesforce、SharePoint 和 Jive 等应用程序中;实时交互,支持数据挖掘;实时连接动态数据和内存数据;安全可靠;便携性
Qlikview
Qlikview 可能是 Tableau 最强大的竞争对手。它被选为 Gartner 魔力象限 2019 的领导者,并拥有康泰纳仕、斯巴鲁和全球零售银行等客户。主要功能包括:嵌入式分析;与第三方引擎(如 Python)的高级分析集成;可定制的界面;预测分析;共享文件管理
SiSense
这不仅仅是一个传统的分析工具,它具有可扩展性和处理各种数据的能力。它拥有美国宇航局、纳斯达克、三星和康卡斯特等知名客户。主要功能包括:具有共享、拖放和内置图表小部件的自定义世界;可以在单个服务器上处理兆字节数据的内存数据库;超快的运算速度;先进的机器学习和人工智能;实时交互,自动生成分析报告
多莫
它不仅是一个数据可视化工具,还是一个完整的业务管理平台。它统一处理来自该平台的数据分析和报告,其客户包括eBay、国家地理和Sage。其特点包括:支持数百个数据源,包括Facebook、Salesforce等;轻松将内部数据导入 Domo;以多种方式清除、组合和转换数据;使用自定义工具共享数据;迁移和错误警报;自动报告生成和可定制的界面。
微软 Power BI
Microsoft PowerBI 界面给人一种熟悉感,便于新用户学习和使用。为了便于操作,Power BI 提供了免费的基础版本,并且是开源的。它的客户包括 Adobe、HP 和 Toshiba。主要提供以下功能:交互界面和实时数据共享;用户定义的报告创建;轻松访问数据和数据集共享;支持自然语言提问;基于云的实施。
Klipfolio
Klipfolio 可以连接到 500 多个数据源,包括 Google Analytics、Twitter 和 Moz。主要功能包括:广泛的数据来源;财务预测;自定义界面;实时性和准确性。
情节
这是最丰富多彩的 BI 解决方案之一,巧妙地帮助用户创建易于理解的交互式图表。它的一些主要功能是:根据输入定制二维和三维图表;集成面向分析的语言(如Python、R和Matlab);用户接口。
图表
Chartio 是适用于所有大型和小型企业的 BI 和数据可视化工具。主要功能包括:实时分析和动态变化;对比分析;简单的设置;多种图表格式。
壁虎板
Geckoboard 提供了 80 多个预建模型用于实时分析,让用户能够轻松地将数据可视化。其主要功能有:自定义界面;与 Facebook、Twitter、Salesforce 等 api 的丰富集成;数据挖掘技术;自定义图表样式和显示模式。
数据包装器
Datawrapper 简单、清晰且易于使用的界面已迅速成为《财富》、《琼斯妈妈》和《泰晤士报》等非技术客户的首选。它的主要功能是:易于使用,无需编码或设计技能;快速交互式生成图表;创造不同的品牌风格。
结论
选择合适的数据可视化工具非常重要,不仅因为它们非常昂贵,而且对业务战略有着巨大的影响。清晰准确的视觉报告可帮助您做出更好的决策、制定更好的计划并更好地跟踪 KPI。因此,请根据您的业务最重要的属性,选择刚好满足您需求的可视化分析工具。
量化金融分析师(AQF,Quantitative Finance 分析师)接受量化金融标准委员会 (SCQF) 的考试和认证。是代表量化金融领域的专业证书。 >>>点击查询AQF证书含金量
(点击上图了解课程详情)
金诚推荐:
热线:
AQF测试好友群:760229148
金融全科交易群:801860357 查看全部
智能标签采集器(量化金融分析师AQF高质量的可视化工具应该具备哪些功能?)
Quantitative Finance丨Salesforce 的一项调查显示,53% 的员工经常检查和分析数据,但仅依靠人工操作。滚动浏览大量电子表格、图表和数据就像大海捞针。
定量金融分析师 AQF 的高质量可视化工具对于数据分析至关重要。数据可视化工具是一种应用软件,可以帮助用户以可视化和图形化的格式显示数据,呈现数据的完整轮廓。饼图、图形、热图、直方图和雷达/蜘蛛图只是可视化的一小部分。这些方法可以简单地表示数据并显示特征和趋势。
要使数据分析真正有价值且富有洞察力,就需要高质量的可视化工具。市场上有许多具有不同功能和价格的产品。本文列出了一些广为人知的工具。事实上,企业如何选择合适的可视化工具并非易事,需要慎重考虑。
1.清晰、简洁、可定制的界面
数据可视化程序的界面就像一个汽车仪表盘,你想要的重要信息一目了然——从剩余油量、行驶速度到续航里程。同样,可视化界面应该能够在一个视图中显示所有关键信息。
一个好的数据可视化工具应该同时具备以下功能:
一开始看起来很酷。界面清晰,不失流行色。太白很烦人,颜色太多会感觉杂乱,所以界面要适当平衡。
其次,界面应准确显示所有重要数据。例如,用户关注的KPI、重要趋势或重要的业务相关数据集,应该在界面启动后的几秒钟内完整清晰地展示出来。所有显示内容一目了然。
界面的另一个非常重要的品质是它可以定制。在不同的时间段,您可能需要跟踪不同的数据集,因此您需要自定义显示哪些数据。因此,数据可视化工具必须允许定制。
2.嵌入式
要真正利用数据可视化的力量,将可视化报告无缝集成到其他应用程序中是非常重要的。为了让用户高效协作并跨平台共享报告,数据可视化软件应该兼容不同的应用程序。并非所有部门都需要分析所有数据。大多数人只希望将一部分数据与他们的特定应用程序无缝集成,从而帮助他们提高工作效率。所以一个好的数据可视化工具必须易于嵌入和集成。
3.人机交互
数据可视化工具生成的可视化报告必须具有很强的人机交互性,支持一些变量或参数的调整,并且能够看到后续的趋势/结果变化。用户可以对相关变量进行移动、排序和过滤,以获得相应的效果。数据分析师和决策者需要的是能够处理来自各种来源的数据并生成有价值内容的分析工具。可视化分析报表支持不同格式的打开,不同的部分可以在不同的时间高亮显示。
4.数据采集分享给
将原创数据导入可视化工具,然后以各种形式导出可视化报告。这个过程应该以用户喜欢的方式进行。一些数据集可以最原创的形式输入到工具中,而另一些数据集因为太大而需要先聚合。有时可以从一个数据源获取数据,有时需要从不同的数据源采集数据并使用工具进行可视化。一些数据可视化工具可以从多个数据源采集数据并显示在同一个界面上,但有些工具可能没有这个功能。如何选择合适的工具取决于具体的需求。
5. 地理标记和智能定位
如果您所在的地区地理非常重要,那么您可能需要用于地理和位置数据的可视化工具。例如,这些数据来自哪里?哪些州或地区更活跃?哪些领域需要扩大?对于需要跟踪基于位置的 kpi 的企业来说,在时间和空间上对数据集进行分层的能力非常重要。
6.数据挖掘
数据挖掘是研究大型数据集以识别模式和趋势的过程。如果您正在处理大型数据集,并且想要一个可视化工具来帮助提取潜在信息并生成可视化报告,那么您需要的可视化工具就需要收录此功能。
7.人工智能
许多可视化工具都在使用人工智能来分析、探索和预测趋势,并根据过去的变化预测未来的趋势。如果这是你感兴趣的东西,那么集成人工智能的可视化工具非常适合。下面列出了一些目前广泛使用和流行的具有上述功能的数据可视化工具,以帮助您做出最合适的选择。
表格
它一直被誉为最好的数据可视化工具之一。他们的客户包括领英、德勤、汉莎航空和百事可乐等巨头。其主要功能有: 一个可定制的界面,可以嵌入到 Salesforce、SharePoint 和 Jive 等应用程序中;实时交互,支持数据挖掘;实时连接动态数据和内存数据;安全可靠;便携性
Qlikview
Qlikview 可能是 Tableau 最强大的竞争对手。它被选为 Gartner 魔力象限 2019 的领导者,并拥有康泰纳仕、斯巴鲁和全球零售银行等客户。主要功能包括:嵌入式分析;与第三方引擎(如 Python)的高级分析集成;可定制的界面;预测分析;共享文件管理
SiSense
这不仅仅是一个传统的分析工具,它具有可扩展性和处理各种数据的能力。它拥有美国宇航局、纳斯达克、三星和康卡斯特等知名客户。主要功能包括:具有共享、拖放和内置图表小部件的自定义世界;可以在单个服务器上处理兆字节数据的内存数据库;超快的运算速度;先进的机器学习和人工智能;实时交互,自动生成分析报告
多莫
它不仅是一个数据可视化工具,还是一个完整的业务管理平台。它统一处理来自该平台的数据分析和报告,其客户包括eBay、国家地理和Sage。其特点包括:支持数百个数据源,包括Facebook、Salesforce等;轻松将内部数据导入 Domo;以多种方式清除、组合和转换数据;使用自定义工具共享数据;迁移和错误警报;自动报告生成和可定制的界面。
微软 Power BI
Microsoft PowerBI 界面给人一种熟悉感,便于新用户学习和使用。为了便于操作,Power BI 提供了免费的基础版本,并且是开源的。它的客户包括 Adobe、HP 和 Toshiba。主要提供以下功能:交互界面和实时数据共享;用户定义的报告创建;轻松访问数据和数据集共享;支持自然语言提问;基于云的实施。
Klipfolio
Klipfolio 可以连接到 500 多个数据源,包括 Google Analytics、Twitter 和 Moz。主要功能包括:广泛的数据来源;财务预测;自定义界面;实时性和准确性。
情节
这是最丰富多彩的 BI 解决方案之一,巧妙地帮助用户创建易于理解的交互式图表。它的一些主要功能是:根据输入定制二维和三维图表;集成面向分析的语言(如Python、R和Matlab);用户接口。
图表
Chartio 是适用于所有大型和小型企业的 BI 和数据可视化工具。主要功能包括:实时分析和动态变化;对比分析;简单的设置;多种图表格式。
壁虎板
Geckoboard 提供了 80 多个预建模型用于实时分析,让用户能够轻松地将数据可视化。其主要功能有:自定义界面;与 Facebook、Twitter、Salesforce 等 api 的丰富集成;数据挖掘技术;自定义图表样式和显示模式。
数据包装器
Datawrapper 简单、清晰且易于使用的界面已迅速成为《财富》、《琼斯妈妈》和《泰晤士报》等非技术客户的首选。它的主要功能是:易于使用,无需编码或设计技能;快速交互式生成图表;创造不同的品牌风格。
结论
选择合适的数据可视化工具非常重要,不仅因为它们非常昂贵,而且对业务战略有着巨大的影响。清晰准确的视觉报告可帮助您做出更好的决策、制定更好的计划并更好地跟踪 KPI。因此,请根据您的业务最重要的属性,选择刚好满足您需求的可视化分析工具。
量化金融分析师(AQF,Quantitative Finance 分析师)接受量化金融标准委员会 (SCQF) 的考试和认证。是代表量化金融领域的专业证书。 >>>点击查询AQF证书含金量
(点击上图了解课程详情)
金诚推荐:
热线:
AQF测试好友群:760229148
金融全科交易群:801860357
智能标签采集器(2.核心业务流程完成图片标注训练的整个工作流程(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-09-05 16:29
通常,公司有各种标签要求。作为一款通用的标签产品,产品特性(如支持多种输入格式、多种标签类型、多种标签形式、附加功能等)将是我们关注的重点之一。
另一方面,在实践中,标注是一项非常耗时且费力的工作。比如上图中的大部分行人是需要标注的,这样的图片至少有上百张。这说明用户体验是我们需要关注的另一个重点。
综上所述,本文将从产品功能和用户体验两个维度对行业代表性产品进行分析。
2.核心业务流程
完成图像标注训练的整个工作流程通常涉及三个步骤:“数据准备”、“数据标注”和“数据演化”。具体业务流程如下图所示:
图3:图片标注的一般业务流程
2.1 数据准备
数据准备包括两个步骤:data采集和数据预处理。
1.Data采集:采集 有多种方式如:本地上传、调用其他数据集数据、相机数据导入、调用云服务获取数据等
2. 数据预处理:数据清洗是获得高质量训练数据的前提,清洗不合格的数据还可以减少无意义的标注工作,提高标注效率。数据清洗的常用操作包括:模糊数据清洗、相似数据清洗、裁剪、旋转、镜像、图像亮度、图像对比度、图像锐化等。
2.2 数据标注
数据标注包括:标注集的建立、数据标注、标注审核。
2.2.1 创建注释集
注解集是注解工作的基本任务管理单元,这里不再赘述。
2.2.2 数据标注
详情见表 1:
表一:数据标注具体方法
2.2.3 分评论
对于“任务标注”,标注审核是对下发的标注任务进行管理,对标注结果进行审核。一般审核维度包括:标注进度、接受状态、标注数量、疑难案例、标注质量等。
对于“自动标注”,标注审核是对自动标注的结果进行一一核对确认,对标注错误的图片进行修改。
2.3 数据演进
数据演化包括:模型训练、模型推理。
2.3.1 模型训练:
是训练标注数据以获得模型结果的过程。
2.3.2 模型推理:
用于对训练模型结果进行验证和预测,并将误差或误差验证结果记录下来,带到下一次模型训练中进行模型的优化迭代,从而形成对模型训练的数据标注,然后到模型迭代优化的闭环。
3. 竞品介绍
目前市场上有很多标签工具。首先,我们需要确定竞品的选择原则:
总结起来,选择了以下3款竞品:
CVAT:英特尔开源标注工具,2018年6月发布,支持视频、图片等多种数据类型标注,功能全面。 ModelArts:华为出品的机器学习平台,2018年10月发布,收录数据标注模块。支持从数据导入到模型运维的全流程开发,训练速度更快。 Supervisely:俄罗斯Deep System旗下的模型训练平台,2017年8月发布,数据标注功能强大,尤其是Smart Tool令人印象深刻:可以快速完成语义分割任务的标注。
表 2:3 款产品的汇总比较
4.功能对比
在本节中,我们将针对 3 个产品,基于第 2 章的核心业务流程探索产品功能之间的差异。
4.1 增值税
CVAT的使用过程虽然很简单,但它的功能却非常全面和丰富。
图 4:CVAT 标注流程
4.1.1 创建数据集
CVAT 将数据集替换为带注释的任务(Task)的概念。一个任务可以收录多个任务,每个任务可以分配一个注释器。
在创建标注任务时,CVAT 还提供了丰富的高级选项,例如:
支持使用Git LFS:Git Large File Storage,一个用于大文件的git管理插件。调整画质:通过降低画质(压缩率)加快高清图片的加载速度。作业数量和重叠:如果一个任务中的图片数量很大,可以将它分成多个作业。再加上重叠数,可以达到将一张图片分配给多个作业的效果,但暂时没有重叠数的使用场景。
综上所述,CVAT在标注任务模块的优势之一就是支持视频类型文件的直接上传。上传的视频会根据用户设置的帧率(Frame)转换成图片。
CVAT在这个模块中也有一个明显的缺点:它缺乏一个统一的视角来概览任务中的所有图片(如下图,在任务详情页面中只能看到第一张图片的照片) ,而且每张图片上的所有注释大概都是因为一张图片可能存在多个作业。
图 5:CVAT 标注任务详情页面
4.1.2 自动标注
由于CVAT不具备提供模型服务的能力,所以其自动标注功能还处于开发初期,只能满足个人实验。
添加自动标注模型需要用户上传模型文件,而不是镜像或API。这种非服务方式很容易因为运行环境的差异(比如安装了不同版本的依赖包的两台服务器)影响打标签的成功率和准确率。
4.1.3 手动标注
4.1.3.1 手动标注支持3种标注模式,每种模式可以前后切换:
标准模式(Standard):用于常规标签。属性标注:在“属性模式”下,用户可以专注于修改标签框和标签的属性,提高了查看和修改标签属性的效率。该模式专门用于在人脸标注中为同一对象设置一个或多个属性的场景,如年龄、性别等。标签标注:在“标签模式”下,用户可以快速添加或删除标签,选择和修改标签属性。同时,您可以按类型标记图片的自定义模式,还可以为每个标签设置快捷键。大大提高了图像分类的标注效率。
4.1.3.2 对于CVAT,我们经过经验总结出以下优势:
1) 灵活的标签和属性定义
同一张图片可以标注多个标签,一个标签可以设置多个属性,平台将属性定义分为:多选(Select)、单选(Radio)、是否(Checkbox)、文本(文字)、数字(Number)五种。 CVAT标签定制的自由度基本满足大部分标签需求。
图 6:CVAT 中的五个标签属性
2)丰富的标记格式
为了支持各种类型的标注,CVAT提供了6种标注类型,包括:标签、点、矩形、折线、多边形、长方体等。同时支持AI多边形标注:可以选择一个通过指定至少四个点,在系统的帮助下确定目标轮廓。这与监督相同。体验过后,我们还是期待AI识别速度的进一步提升。
3)统一标注方法的快捷键
选择一种标注方式,快捷键“N”代表该标注方式。重新选择标注方法,“N”代表的方法会发生相应的变化。快捷键的统一进一步降低了用户的操作成本。
4)任务分析
通过任务分析仪表板中的分析,您可以看到每个用户在每个任务上花费了多少时间以及他们在任何时间范围内完成了多少工作。任务分析扩展了 CVAT 的团队标记功能。
图 7:CVAT 中的分析仪表板(图片来源 CVAT 用户手册)
5)Track 模式(Track 模式)
用于标记视频文件。视频会根据帧率分为若干帧(Frame)。用户只需标记关键帧(Key frame,与Flash中的关键帧非常相似),关键帧之间的图片也会自动标记。 CVAT 目前仅支持边界框和点的插值模式。传播功能非常实用。场景:如果要将当前图片中的注解(Propagate)传递给接下来的n张图片。同时,CVAT的跟踪模式与Merge功能和Split功能相结合,支持CVAT独有的视频或动画图标标注能力优势。
4.1.3.3 可能是因为支持的功能太丰富,导致使用上有一定的学习成本,用户体验会有些不尽如人意。例如:
标注时图片无法预览。无法获得图片的整体标注。下次进入作业时,无法快速定位到未标注的图片。虽然这不会对效率产生太大影响,但会影响用户的操作体验。另外,如果是标记用户的图片分类,就需要使用属性模式,用户难以感知。 (我们一开始以为只能画一个完全覆盖画面的边框来实现)4.2 ModelArts
2019年10月17日Modelarts版本更新后(尤其是团队标注功能),业务流程覆盖趋于完整。整体用户流程如下:
图8:ModelArts标注流程(图片来自ModelArts官网)
由于本文主要讨论数据标注功能,数据标注后的功能(包括训练、推理、数据校正等)不在本文讨论范围内。
4.2.1 创建数据集
在创建图像数据集时,ModelArts在数据集层面设置了图像标注类型,即创建数据集时需要区分标注类型。
这一点与 Supervisely 和 CVAT 有很大不同。具体分析请参考Supervisely手册标注章节。目前支持两种任务:图像分类和目标检测。
图9:将创建数据集放入ModelArts
4.2.2 数据处理
华为的数据处理功能位于对象存储服务中,提供便捷、全功能的图像处理能力。
华为的对象存储服务提供了“图形界面模式”和“代码编辑模式”两种图像处理操作模式,适用于普通用户和开发者用户。
同时最终的处理结果存储在内容分发网络(Content Delivery Network,CDN)加速中,后续请求可以通过URL直接从CDN下载,结果可以用于任何注解可以通过 URL 导入数据的平台。扩展了平台的功能扩展性。
华为图像处理提供的能力主要包括:设置图像效果(亮度、对比度、锐化、模糊)、设置缩略图、旋转图像、剪切图像、设置水印、转换格式和压缩图像。
图10:华为对象存储中的图像处理模块
4.2.3 智能标签
ModelArts 智能标注包括:主动学习(半自动标注)和预标注(自动标注)。目前,只有“图像分类”和“物体检测”类型的数据集支持智能标注功能。先简单分析一下智能标注模块:
系统只对未标注的图片进行标注,可以减少重复标注,减少计算资源的浪费。使用效果并不理想,系统实际体验后标签准确率只能维持在60%。系统对疑难病例的筛选准确率也较低。全自动标注支持选择自训练模型或ModelArts自有模型,模型选择更加灵活。在接下来的操作中,可以继承每个标签的结果,进一步提高模型的准确率。智能标注结果展示页面可以进行条件过滤。可选条件包括:困难案例级别、标签、样本创建时间、文件名、注释者、样本属性和置信度。精准筛选可以满足大部分场景需求。
4.2.4 手动标注
Huawei ModelArts 手动标注功能主要包括以下三点:
4.2.4.1 目标检测标注最多支持6种标注
包括正方形、多边形、正圆、点、单线、虚线(见图11),丰富的标注方式覆盖更广泛的标注场景,同时可以提高标注的准确率。
4.2.4.2 高效的标签选择方法
在数据标注的交互中,华为ModelArts绘制选择框后会自动弹出标签下拉框,以及已经展开的添加标签弹出窗口(见图11),消除选择完成后需要用户点击标签。下拉框的步骤。弹出的标签选项卡在框旁边(见图11),缩短了鼠标滑动的移动行程鼠标选择标签。
图11:ModelArts图像检测数据标注界面
4.2.4.3 图片组
在标注预览页面,华为ModelArts提供了图片分组功能(见图12),该功能使用聚类算法或根据锐度、亮度、图像颜色对图片进行分组。自动分组可以理解为数据annotation 用户可以根据分组结果进行分组标注、图片清洗等操作,该功能可以提高图像标注的效率,尤其是在图像分类标注的情况下,批量标注功能可以在标注速度上进行定性改进了。但是经过实际体验,我们觉得这个功能分组的成功率很低。
图12:ModelArts中图片自动分组
4.2.5 团队注解
华为ModelArts有一套完整的团队标注功能,亮点多多。以下是创建、标记和审核的三个方面:
4.2.5.1 创建
华为可以在启用团队标注后直接指定标注团队,也可以选择指定管理员,然后由管理员分配标注人力,进行审核工作。选择类型后,团队成员会收到系统邮件,根据邮件提示即可轻松完成标注和审核。
您可以选择是否自动将新文件同步到注释团队。同时,您可以选择是否在注释团队的文件中加载智能注释结果。这些操作增加了管理员调整任务分配和自动标注关系的自由度。
图 13:ModelArts 团队注解创建页面
4.2.5.2 注释
标记图片并保存后,图片自动进入“待审核”状态。我们认为这样的状态切换超出了用户的预期,特别是如果用户想要检查标签是否有误,则需要切换到“待审核”页面进行检查,这会给用户带来不便。
“待审核”的图片还是可以修改的,修改在管理员发起验收前生效。但在验收时,如果图片是采样的,修改不会保存在数据集中。如果图片未采样,修改将保存在数据集中。这样的审计逻辑限制可以减少审计过程中不必要的混乱,防止审计结果出现错误。
4.2.5.3 评论
ModelArts将审核称为“验收”,验收分为单张图片验收和批量图片验收两个级别。过程是用户检查并接受一批图片。审核层级过多,逻辑复杂,可能导致运行结果不符合用户预期。
标注状态混乱:例如管理员将图片A分配给注释者a。 a后,管理员同时使用智能标签标记图片A。如果两个结果都被管理员确认,无论哪个标签先确认,最终只有智能标注的结果有效,标注者a的标签无效。
ModelArts 提供了审计仪表盘,方便审计的统计链接,并以可视化的方式展示任务进度。仪表盘的评价指标包括:验收进度统计、疑难案例集数、标签数和带标签样本数、注释者的进度统计等,如图14所示:
图 14:ModelArts 中的注释审查仪表板
4.3 监督
图 15:Supervisely 的标注流程
从图中可以看出,团队标记一块的逻辑比其他产品更复杂。分析背后的原因:
表面上很多步骤是为了满足团队标注(尤其是外部标注团队)的需求,包括创建团队、邀请成员、创建标注任务、标注审核等,但本质上都是安全控制和质量控制要求:
安全控制体现在管理员可以为团队成员分配不同的角色来控制成员的权限。例如,Annotator 只能查看其任务中的图片;质量控制体现在注释完成后。管理员审核标签以确保标签质量。
因此,这样一个复杂的环节是一个企业级标签产品应该有的设计,虽然这不可避免地会导致用户认知成本的增加和用户体验的下降。
4.3.1 创建数据集
在 Supervisely 中,用户可以在一个数据集中完成 4 种类型的标注(视频标注除外),即分类、检测、分割和姿态估计。
与ModelArts不同,Supervisely对数据集的定位更像是一个图片集。一批图片只需要导入一次,无论做什么类型的标注,都可以在同一个数据集上做。并且在进行后续训练时,可以直接得到一张图片上的所有标注。
综上所述,Supervisely 的统一数据集模块提高了图像导入、图像标注和图像后处理的效率。但是这种方法也有缺点:所有标注类型的操作方式都是固定的,不能针对特定类型进行优化(比如Modelarts图片分类可以同时选择多张图片一起标注)。
4.3.2 数据处理
Supervisely 的数据处理模块叫做 DTL,Data Transformation Language,是一种基于 JSON 的脚本语言。通过配置DTL脚本,可以完成数据集合并、标签映射、图像增强、格式转换、图像去噪、图像翻转等46项操作,满足各种数据处理需求。
图 16:在 Supervisely 中为图片添加高斯模糊
虽然功能比ModelArts更强大,但只提供了基于代码的操作,只适合工程师使用。不过大部分工程师已经掌握了通过python处理图片的方式,额外学习一门语言无疑会增加学习成本。
另一方面,这种特殊语言的效率提升还存在未知数。例如,用户想进行某张图片操作,但查了半天,发现不支持该语言。最终还是要通过python来完成,最终降低了效率。 .
4.3.3 自动标注
Supervisely 目前提供 14 个预训练模型。训练数据大部分来自COCO(微软发布的大型图像数据集),少部分来自PASCAL VOC2012、Cityscapes、ADE20K等公开数据集。
在自动标注部分,Supervisely的优势在于支持语义分割自动标注,产品在语义分割手动标注方面有着出色的体验,大大提高了此类任务的标注效率。
Supervisely 的自动贴标模块产品化程度较低,主要体现在以下两点:
由于不提供模型训练和推理服务,用户需要准备自动标注所需的硬件环境,限制较多(仅支持Nvidia GPU,需要Linux和Cuda驱动)。模型推理参数通过JSON格式的配置文件进行配置(见图17)。相比华为简单的配置界面,这种形式的灵活性更高,但是用户真的需要配置还是直接想系统呢?自动标记的结果?
图17:Supervisely(左)和Huawei ModelArts(右)自动标注配置对比
4.3.4 手动标注
Supervisely 的标注功能非常强大,主要有以下两个特点:
丰富的标注形式:为了支持各种类型的标注,Supervisely提供了多达9种标注形式,包括:标签、点、矩形、折线、多边形、长方体、像素图、智能工具(Smart Tool)、关键点等复杂标签系统:抽象了对象(Object)、类(Class)和标签(Tag)三个实体,提高了复杂场景中实体之间的复用性。
4.3.4.1 丰富的标注格式
在所有 9 种标签中,智能工具令人印象深刻:
智能工具用于标记分段类型。用户只需要点击两次方框选择一个对象,通过算法对目标进行描边完成初步分割,然后对正负点进行标注,完成精准标注。大大降低了分割任务的标注成本。
图 18:在 Supervisely 中点击 11 次后完成语义分割
4.3.4.2 复杂的标签系统
为了满足覆盖多种标签类型的数据集的需求,Supervisely 有一个复杂的标签系统。我们通过三种产品的ER图详细分析了这种标签制度的优缺点。
在图 19 的行人识别场景中,我们将绘制一个行人边界框。然后我们需要定义一个标签,叫做:行人。
图 19:Supervisely 中的行人标记场景
但是每个行人的属性是不同的。比如行人A戴帽子,行人B不戴帽子。如果我们需要区分戴帽子的行人和不戴帽子的行人,一种方法是创建两个标签:戴帽子的行人,不戴帽子的行人。
但是这样两个标签就会失去相关性——如果模型只需要检测行人,就需要对这两个标签进行转换,效率较低。
更合理的做法是在行人标签下创建一个属性——是否戴帽子;并抽象出一个概念:对象。
用户每画一个边界框,系统就会创建一个对象(例如:行人A),每个对象对应一个标签(例如:行人),然后每个对象可以设置该对象的属性值标签(例如:是否戴帽子=是)。
CVAT 和 ModelArts 都这样做。不同的是,CVAT 可以直接标记图像进行图像分类。由于ModelArts划分了图像分类和目标检测数据集,标签只能应用于图像分类数据中的图像。
图 20:CVAT(左)和 ModelArts(右)之间的图片-对象-标签 ER 图比较
监督地将标签和属性拆分为两个实体(如下图):
这种方法可以提高属性的重用率。比如在Supervisely中,用户只需要定义一次颜色属性,然后是否标记行人或车辆的颜色,可以应用相同“颜色”下的属性,提高了复杂度的准备效率标签集。
但与此同时,这种方法对用户体验设计提出了更大的挑战。从上手难度来看,Supervisely无疑是三款产品中最难上手的。
图 21:Supervisely 的图片-对象-标签-对象 ER 图
5.总结与展望5.1总结对比
下表是三个标记产品的功能汇总:
表3:三款产品功能总结对比
CVAT:手动贴标功能最强大,但自动贴标功能比较弱。独特的跟踪模式,无需视频预处理,大大提高标注效率。由于环境原因,CVAT的任务分析功能还没有完全体验。从介绍来看,这里应该用它。 ModelArts:作为华为云的一个功能模块,ModelArts的产品策略更加通用化和平台化。与华为OBS系统的结合,带来了强大的数据处理能力,增强了平台的可扩展性和兼容性。同时,自动贴标和半自动贴标是ModelArts的优势,是CVAT和Supervisely所不具备的。它们也体现了ModelArts依托华为云强大的算力和算法优势。总的来说,ModelArts 是一个平衡的玩家,具有出色的业务开发能力。 Supervisely:整体功能最全,适合企业级应用。对语义分割任务的支持较好,但部分功能(如数据处理、自动标注)需要代码完成,效率提升有限。
当然,我们也发现了三款产品都没有的一些功能,比如水印功能,会适用于保密要求,比如监狱、银行等。
5.2 标注工具的未来趋势
5.2.1 手动标注不会消失。
这其实是一个悖论:假设我需要训练一个CV模型,而训练模型需要准备带注释的图片。如果图像标注只需自动标注,无需人工干预,则说明模型已经能够准确预测结果。
如果能够准确预测,则说明模型已经训练完毕,不再需要训练,与假设相反。
5.2.2 自动标注的价值主要体现在单个标注需要较长时间的标注类型,如分割、姿态估计等
既然人工贴标肯定会存在,那么自动贴标的意义在于提高人工贴标的效率,而不是替代人工贴标。在单次标注耗时较短的场景中,如分类、检测任务,自动标注的价值较小。
假设从0完成一个标签需要5秒,如果进行了自动贴标,修改一个标签需要2秒,贴标效率提升60%(假设自动贴标模型为下班后跑,不影响人工打标时间)
但是我们已经看到模型在某些图片上的标注结果可能偏差太大,所以用户还是需要1秒的时间来删除自动标注的结果,但是标注的效率降低了20%( IE,1/5),这么高的负收益让整体效率提升不大。
5.2.3 手动注解的主要内容将从创建注解转变为修改注解
虽然人工贴标过程不会消失,但很明显,自动贴标将在贴标过程中发挥越来越重要的作用。未来常见的标注流程将从创建新标签转变为修改标签。
因此,优化注释修改时的用户体验将是提高注释效率的突破口。
作者:薛康杰,AIoT产品经理,AIops、CV和IoT平台产品;蒋海龙,AI产品实习生,专注于简历产品设计。
This article was published by @薛康杰 原创 in Renren is a product manager, reprinting without permission is prohibited
The title picture comes from Unsplash, based on the CC0 protocol
Reward the author and encourage him to work hard!
Appreciation 查看全部
智能标签采集器(2.核心业务流程完成图片标注训练的整个工作流程(组图))
通常,公司有各种标签要求。作为一款通用的标签产品,产品特性(如支持多种输入格式、多种标签类型、多种标签形式、附加功能等)将是我们关注的重点之一。
另一方面,在实践中,标注是一项非常耗时且费力的工作。比如上图中的大部分行人是需要标注的,这样的图片至少有上百张。这说明用户体验是我们需要关注的另一个重点。
综上所述,本文将从产品功能和用户体验两个维度对行业代表性产品进行分析。
2.核心业务流程
完成图像标注训练的整个工作流程通常涉及三个步骤:“数据准备”、“数据标注”和“数据演化”。具体业务流程如下图所示:
图3:图片标注的一般业务流程
2.1 数据准备
数据准备包括两个步骤:data采集和数据预处理。
1.Data采集:采集 有多种方式如:本地上传、调用其他数据集数据、相机数据导入、调用云服务获取数据等
2. 数据预处理:数据清洗是获得高质量训练数据的前提,清洗不合格的数据还可以减少无意义的标注工作,提高标注效率。数据清洗的常用操作包括:模糊数据清洗、相似数据清洗、裁剪、旋转、镜像、图像亮度、图像对比度、图像锐化等。
2.2 数据标注
数据标注包括:标注集的建立、数据标注、标注审核。
2.2.1 创建注释集
注解集是注解工作的基本任务管理单元,这里不再赘述。
2.2.2 数据标注
详情见表 1:
表一:数据标注具体方法
2.2.3 分评论
对于“任务标注”,标注审核是对下发的标注任务进行管理,对标注结果进行审核。一般审核维度包括:标注进度、接受状态、标注数量、疑难案例、标注质量等。
对于“自动标注”,标注审核是对自动标注的结果进行一一核对确认,对标注错误的图片进行修改。
2.3 数据演进
数据演化包括:模型训练、模型推理。
2.3.1 模型训练:
是训练标注数据以获得模型结果的过程。
2.3.2 模型推理:
用于对训练模型结果进行验证和预测,并将误差或误差验证结果记录下来,带到下一次模型训练中进行模型的优化迭代,从而形成对模型训练的数据标注,然后到模型迭代优化的闭环。
3. 竞品介绍
目前市场上有很多标签工具。首先,我们需要确定竞品的选择原则:
总结起来,选择了以下3款竞品:
CVAT:英特尔开源标注工具,2018年6月发布,支持视频、图片等多种数据类型标注,功能全面。 ModelArts:华为出品的机器学习平台,2018年10月发布,收录数据标注模块。支持从数据导入到模型运维的全流程开发,训练速度更快。 Supervisely:俄罗斯Deep System旗下的模型训练平台,2017年8月发布,数据标注功能强大,尤其是Smart Tool令人印象深刻:可以快速完成语义分割任务的标注。
表 2:3 款产品的汇总比较
4.功能对比
在本节中,我们将针对 3 个产品,基于第 2 章的核心业务流程探索产品功能之间的差异。
4.1 增值税
CVAT的使用过程虽然很简单,但它的功能却非常全面和丰富。
图 4:CVAT 标注流程
4.1.1 创建数据集
CVAT 将数据集替换为带注释的任务(Task)的概念。一个任务可以收录多个任务,每个任务可以分配一个注释器。
在创建标注任务时,CVAT 还提供了丰富的高级选项,例如:
支持使用Git LFS:Git Large File Storage,一个用于大文件的git管理插件。调整画质:通过降低画质(压缩率)加快高清图片的加载速度。作业数量和重叠:如果一个任务中的图片数量很大,可以将它分成多个作业。再加上重叠数,可以达到将一张图片分配给多个作业的效果,但暂时没有重叠数的使用场景。
综上所述,CVAT在标注任务模块的优势之一就是支持视频类型文件的直接上传。上传的视频会根据用户设置的帧率(Frame)转换成图片。
CVAT在这个模块中也有一个明显的缺点:它缺乏一个统一的视角来概览任务中的所有图片(如下图,在任务详情页面中只能看到第一张图片的照片) ,而且每张图片上的所有注释大概都是因为一张图片可能存在多个作业。
图 5:CVAT 标注任务详情页面
4.1.2 自动标注
由于CVAT不具备提供模型服务的能力,所以其自动标注功能还处于开发初期,只能满足个人实验。
添加自动标注模型需要用户上传模型文件,而不是镜像或API。这种非服务方式很容易因为运行环境的差异(比如安装了不同版本的依赖包的两台服务器)影响打标签的成功率和准确率。
4.1.3 手动标注
4.1.3.1 手动标注支持3种标注模式,每种模式可以前后切换:
标准模式(Standard):用于常规标签。属性标注:在“属性模式”下,用户可以专注于修改标签框和标签的属性,提高了查看和修改标签属性的效率。该模式专门用于在人脸标注中为同一对象设置一个或多个属性的场景,如年龄、性别等。标签标注:在“标签模式”下,用户可以快速添加或删除标签,选择和修改标签属性。同时,您可以按类型标记图片的自定义模式,还可以为每个标签设置快捷键。大大提高了图像分类的标注效率。
4.1.3.2 对于CVAT,我们经过经验总结出以下优势:
1) 灵活的标签和属性定义
同一张图片可以标注多个标签,一个标签可以设置多个属性,平台将属性定义分为:多选(Select)、单选(Radio)、是否(Checkbox)、文本(文字)、数字(Number)五种。 CVAT标签定制的自由度基本满足大部分标签需求。
图 6:CVAT 中的五个标签属性
2)丰富的标记格式
为了支持各种类型的标注,CVAT提供了6种标注类型,包括:标签、点、矩形、折线、多边形、长方体等。同时支持AI多边形标注:可以选择一个通过指定至少四个点,在系统的帮助下确定目标轮廓。这与监督相同。体验过后,我们还是期待AI识别速度的进一步提升。
3)统一标注方法的快捷键
选择一种标注方式,快捷键“N”代表该标注方式。重新选择标注方法,“N”代表的方法会发生相应的变化。快捷键的统一进一步降低了用户的操作成本。
4)任务分析
通过任务分析仪表板中的分析,您可以看到每个用户在每个任务上花费了多少时间以及他们在任何时间范围内完成了多少工作。任务分析扩展了 CVAT 的团队标记功能。
图 7:CVAT 中的分析仪表板(图片来源 CVAT 用户手册)
5)Track 模式(Track 模式)
用于标记视频文件。视频会根据帧率分为若干帧(Frame)。用户只需标记关键帧(Key frame,与Flash中的关键帧非常相似),关键帧之间的图片也会自动标记。 CVAT 目前仅支持边界框和点的插值模式。传播功能非常实用。场景:如果要将当前图片中的注解(Propagate)传递给接下来的n张图片。同时,CVAT的跟踪模式与Merge功能和Split功能相结合,支持CVAT独有的视频或动画图标标注能力优势。
4.1.3.3 可能是因为支持的功能太丰富,导致使用上有一定的学习成本,用户体验会有些不尽如人意。例如:
标注时图片无法预览。无法获得图片的整体标注。下次进入作业时,无法快速定位到未标注的图片。虽然这不会对效率产生太大影响,但会影响用户的操作体验。另外,如果是标记用户的图片分类,就需要使用属性模式,用户难以感知。 (我们一开始以为只能画一个完全覆盖画面的边框来实现)4.2 ModelArts
2019年10月17日Modelarts版本更新后(尤其是团队标注功能),业务流程覆盖趋于完整。整体用户流程如下:
图8:ModelArts标注流程(图片来自ModelArts官网)
由于本文主要讨论数据标注功能,数据标注后的功能(包括训练、推理、数据校正等)不在本文讨论范围内。
4.2.1 创建数据集
在创建图像数据集时,ModelArts在数据集层面设置了图像标注类型,即创建数据集时需要区分标注类型。
这一点与 Supervisely 和 CVAT 有很大不同。具体分析请参考Supervisely手册标注章节。目前支持两种任务:图像分类和目标检测。
图9:将创建数据集放入ModelArts
4.2.2 数据处理
华为的数据处理功能位于对象存储服务中,提供便捷、全功能的图像处理能力。
华为的对象存储服务提供了“图形界面模式”和“代码编辑模式”两种图像处理操作模式,适用于普通用户和开发者用户。
同时最终的处理结果存储在内容分发网络(Content Delivery Network,CDN)加速中,后续请求可以通过URL直接从CDN下载,结果可以用于任何注解可以通过 URL 导入数据的平台。扩展了平台的功能扩展性。
华为图像处理提供的能力主要包括:设置图像效果(亮度、对比度、锐化、模糊)、设置缩略图、旋转图像、剪切图像、设置水印、转换格式和压缩图像。
图10:华为对象存储中的图像处理模块
4.2.3 智能标签
ModelArts 智能标注包括:主动学习(半自动标注)和预标注(自动标注)。目前,只有“图像分类”和“物体检测”类型的数据集支持智能标注功能。先简单分析一下智能标注模块:
系统只对未标注的图片进行标注,可以减少重复标注,减少计算资源的浪费。使用效果并不理想,系统实际体验后标签准确率只能维持在60%。系统对疑难病例的筛选准确率也较低。全自动标注支持选择自训练模型或ModelArts自有模型,模型选择更加灵活。在接下来的操作中,可以继承每个标签的结果,进一步提高模型的准确率。智能标注结果展示页面可以进行条件过滤。可选条件包括:困难案例级别、标签、样本创建时间、文件名、注释者、样本属性和置信度。精准筛选可以满足大部分场景需求。
4.2.4 手动标注
Huawei ModelArts 手动标注功能主要包括以下三点:
4.2.4.1 目标检测标注最多支持6种标注
包括正方形、多边形、正圆、点、单线、虚线(见图11),丰富的标注方式覆盖更广泛的标注场景,同时可以提高标注的准确率。
4.2.4.2 高效的标签选择方法
在数据标注的交互中,华为ModelArts绘制选择框后会自动弹出标签下拉框,以及已经展开的添加标签弹出窗口(见图11),消除选择完成后需要用户点击标签。下拉框的步骤。弹出的标签选项卡在框旁边(见图11),缩短了鼠标滑动的移动行程鼠标选择标签。
图11:ModelArts图像检测数据标注界面
4.2.4.3 图片组
在标注预览页面,华为ModelArts提供了图片分组功能(见图12),该功能使用聚类算法或根据锐度、亮度、图像颜色对图片进行分组。自动分组可以理解为数据annotation 用户可以根据分组结果进行分组标注、图片清洗等操作,该功能可以提高图像标注的效率,尤其是在图像分类标注的情况下,批量标注功能可以在标注速度上进行定性改进了。但是经过实际体验,我们觉得这个功能分组的成功率很低。
图12:ModelArts中图片自动分组
4.2.5 团队注解
华为ModelArts有一套完整的团队标注功能,亮点多多。以下是创建、标记和审核的三个方面:
4.2.5.1 创建
华为可以在启用团队标注后直接指定标注团队,也可以选择指定管理员,然后由管理员分配标注人力,进行审核工作。选择类型后,团队成员会收到系统邮件,根据邮件提示即可轻松完成标注和审核。
您可以选择是否自动将新文件同步到注释团队。同时,您可以选择是否在注释团队的文件中加载智能注释结果。这些操作增加了管理员调整任务分配和自动标注关系的自由度。
图 13:ModelArts 团队注解创建页面
4.2.5.2 注释
标记图片并保存后,图片自动进入“待审核”状态。我们认为这样的状态切换超出了用户的预期,特别是如果用户想要检查标签是否有误,则需要切换到“待审核”页面进行检查,这会给用户带来不便。
“待审核”的图片还是可以修改的,修改在管理员发起验收前生效。但在验收时,如果图片是采样的,修改不会保存在数据集中。如果图片未采样,修改将保存在数据集中。这样的审计逻辑限制可以减少审计过程中不必要的混乱,防止审计结果出现错误。
4.2.5.3 评论
ModelArts将审核称为“验收”,验收分为单张图片验收和批量图片验收两个级别。过程是用户检查并接受一批图片。审核层级过多,逻辑复杂,可能导致运行结果不符合用户预期。
标注状态混乱:例如管理员将图片A分配给注释者a。 a后,管理员同时使用智能标签标记图片A。如果两个结果都被管理员确认,无论哪个标签先确认,最终只有智能标注的结果有效,标注者a的标签无效。
ModelArts 提供了审计仪表盘,方便审计的统计链接,并以可视化的方式展示任务进度。仪表盘的评价指标包括:验收进度统计、疑难案例集数、标签数和带标签样本数、注释者的进度统计等,如图14所示:
图 14:ModelArts 中的注释审查仪表板
4.3 监督
图 15:Supervisely 的标注流程
从图中可以看出,团队标记一块的逻辑比其他产品更复杂。分析背后的原因:
表面上很多步骤是为了满足团队标注(尤其是外部标注团队)的需求,包括创建团队、邀请成员、创建标注任务、标注审核等,但本质上都是安全控制和质量控制要求:
安全控制体现在管理员可以为团队成员分配不同的角色来控制成员的权限。例如,Annotator 只能查看其任务中的图片;质量控制体现在注释完成后。管理员审核标签以确保标签质量。
因此,这样一个复杂的环节是一个企业级标签产品应该有的设计,虽然这不可避免地会导致用户认知成本的增加和用户体验的下降。
4.3.1 创建数据集
在 Supervisely 中,用户可以在一个数据集中完成 4 种类型的标注(视频标注除外),即分类、检测、分割和姿态估计。
与ModelArts不同,Supervisely对数据集的定位更像是一个图片集。一批图片只需要导入一次,无论做什么类型的标注,都可以在同一个数据集上做。并且在进行后续训练时,可以直接得到一张图片上的所有标注。
综上所述,Supervisely 的统一数据集模块提高了图像导入、图像标注和图像后处理的效率。但是这种方法也有缺点:所有标注类型的操作方式都是固定的,不能针对特定类型进行优化(比如Modelarts图片分类可以同时选择多张图片一起标注)。
4.3.2 数据处理
Supervisely 的数据处理模块叫做 DTL,Data Transformation Language,是一种基于 JSON 的脚本语言。通过配置DTL脚本,可以完成数据集合并、标签映射、图像增强、格式转换、图像去噪、图像翻转等46项操作,满足各种数据处理需求。
图 16:在 Supervisely 中为图片添加高斯模糊
虽然功能比ModelArts更强大,但只提供了基于代码的操作,只适合工程师使用。不过大部分工程师已经掌握了通过python处理图片的方式,额外学习一门语言无疑会增加学习成本。
另一方面,这种特殊语言的效率提升还存在未知数。例如,用户想进行某张图片操作,但查了半天,发现不支持该语言。最终还是要通过python来完成,最终降低了效率。 .
4.3.3 自动标注
Supervisely 目前提供 14 个预训练模型。训练数据大部分来自COCO(微软发布的大型图像数据集),少部分来自PASCAL VOC2012、Cityscapes、ADE20K等公开数据集。
在自动标注部分,Supervisely的优势在于支持语义分割自动标注,产品在语义分割手动标注方面有着出色的体验,大大提高了此类任务的标注效率。
Supervisely 的自动贴标模块产品化程度较低,主要体现在以下两点:
由于不提供模型训练和推理服务,用户需要准备自动标注所需的硬件环境,限制较多(仅支持Nvidia GPU,需要Linux和Cuda驱动)。模型推理参数通过JSON格式的配置文件进行配置(见图17)。相比华为简单的配置界面,这种形式的灵活性更高,但是用户真的需要配置还是直接想系统呢?自动标记的结果?
图17:Supervisely(左)和Huawei ModelArts(右)自动标注配置对比
4.3.4 手动标注
Supervisely 的标注功能非常强大,主要有以下两个特点:
丰富的标注形式:为了支持各种类型的标注,Supervisely提供了多达9种标注形式,包括:标签、点、矩形、折线、多边形、长方体、像素图、智能工具(Smart Tool)、关键点等复杂标签系统:抽象了对象(Object)、类(Class)和标签(Tag)三个实体,提高了复杂场景中实体之间的复用性。
4.3.4.1 丰富的标注格式
在所有 9 种标签中,智能工具令人印象深刻:
智能工具用于标记分段类型。用户只需要点击两次方框选择一个对象,通过算法对目标进行描边完成初步分割,然后对正负点进行标注,完成精准标注。大大降低了分割任务的标注成本。
图 18:在 Supervisely 中点击 11 次后完成语义分割
4.3.4.2 复杂的标签系统
为了满足覆盖多种标签类型的数据集的需求,Supervisely 有一个复杂的标签系统。我们通过三种产品的ER图详细分析了这种标签制度的优缺点。
在图 19 的行人识别场景中,我们将绘制一个行人边界框。然后我们需要定义一个标签,叫做:行人。
图 19:Supervisely 中的行人标记场景
但是每个行人的属性是不同的。比如行人A戴帽子,行人B不戴帽子。如果我们需要区分戴帽子的行人和不戴帽子的行人,一种方法是创建两个标签:戴帽子的行人,不戴帽子的行人。
但是这样两个标签就会失去相关性——如果模型只需要检测行人,就需要对这两个标签进行转换,效率较低。
更合理的做法是在行人标签下创建一个属性——是否戴帽子;并抽象出一个概念:对象。
用户每画一个边界框,系统就会创建一个对象(例如:行人A),每个对象对应一个标签(例如:行人),然后每个对象可以设置该对象的属性值标签(例如:是否戴帽子=是)。
CVAT 和 ModelArts 都这样做。不同的是,CVAT 可以直接标记图像进行图像分类。由于ModelArts划分了图像分类和目标检测数据集,标签只能应用于图像分类数据中的图像。
图 20:CVAT(左)和 ModelArts(右)之间的图片-对象-标签 ER 图比较
监督地将标签和属性拆分为两个实体(如下图):
这种方法可以提高属性的重用率。比如在Supervisely中,用户只需要定义一次颜色属性,然后是否标记行人或车辆的颜色,可以应用相同“颜色”下的属性,提高了复杂度的准备效率标签集。
但与此同时,这种方法对用户体验设计提出了更大的挑战。从上手难度来看,Supervisely无疑是三款产品中最难上手的。
图 21:Supervisely 的图片-对象-标签-对象 ER 图
5.总结与展望5.1总结对比
下表是三个标记产品的功能汇总:
表3:三款产品功能总结对比
CVAT:手动贴标功能最强大,但自动贴标功能比较弱。独特的跟踪模式,无需视频预处理,大大提高标注效率。由于环境原因,CVAT的任务分析功能还没有完全体验。从介绍来看,这里应该用它。 ModelArts:作为华为云的一个功能模块,ModelArts的产品策略更加通用化和平台化。与华为OBS系统的结合,带来了强大的数据处理能力,增强了平台的可扩展性和兼容性。同时,自动贴标和半自动贴标是ModelArts的优势,是CVAT和Supervisely所不具备的。它们也体现了ModelArts依托华为云强大的算力和算法优势。总的来说,ModelArts 是一个平衡的玩家,具有出色的业务开发能力。 Supervisely:整体功能最全,适合企业级应用。对语义分割任务的支持较好,但部分功能(如数据处理、自动标注)需要代码完成,效率提升有限。
当然,我们也发现了三款产品都没有的一些功能,比如水印功能,会适用于保密要求,比如监狱、银行等。
5.2 标注工具的未来趋势
5.2.1 手动标注不会消失。
这其实是一个悖论:假设我需要训练一个CV模型,而训练模型需要准备带注释的图片。如果图像标注只需自动标注,无需人工干预,则说明模型已经能够准确预测结果。
如果能够准确预测,则说明模型已经训练完毕,不再需要训练,与假设相反。
5.2.2 自动标注的价值主要体现在单个标注需要较长时间的标注类型,如分割、姿态估计等
既然人工贴标肯定会存在,那么自动贴标的意义在于提高人工贴标的效率,而不是替代人工贴标。在单次标注耗时较短的场景中,如分类、检测任务,自动标注的价值较小。
假设从0完成一个标签需要5秒,如果进行了自动贴标,修改一个标签需要2秒,贴标效率提升60%(假设自动贴标模型为下班后跑,不影响人工打标时间)
但是我们已经看到模型在某些图片上的标注结果可能偏差太大,所以用户还是需要1秒的时间来删除自动标注的结果,但是标注的效率降低了20%( IE,1/5),这么高的负收益让整体效率提升不大。
5.2.3 手动注解的主要内容将从创建注解转变为修改注解
虽然人工贴标过程不会消失,但很明显,自动贴标将在贴标过程中发挥越来越重要的作用。未来常见的标注流程将从创建新标签转变为修改标签。
因此,优化注释修改时的用户体验将是提高注释效率的突破口。
作者:薛康杰,AIoT产品经理,AIops、CV和IoT平台产品;蒋海龙,AI产品实习生,专注于简历产品设计。
This article was published by @薛康杰 原创 in Renren is a product manager, reprinting without permission is prohibited
The title picture comes from Unsplash, based on the CC0 protocol
Reward the author and encourage him to work hard!
Appreciation
独具十年历练,成就业界领先品牌,想到优采云采集器!
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-25 00:27
优采云采集器() 是一款专业的互联网数据采集、处理、分析、挖掘软件。 优采云采集器可以灵活快速的抓取网页中的大量非结构化文本、图片等资源信息,然后通过一系列的分析处理,准确挖掘出需要的数据,并且可以选择发布到网站Background ,导入数据库或保存在本地 Excel、Word 等格式文件中。支持远程下载图片文件,支持网站登录后信息采集,支持检测文件真实地址,支持代理,支持防盗链采集,支持采集直接数据存储和模仿者手动发布等。许多功能,经过十年的升级,积累了大量的用户和良好的声誉。是目前最流行的网页资料采集software。
优采云采集器能采集99%的网页,几乎所有的网页都可以采集,即使需要验证码,登录甚至采集都可以处理!采用顶级系统配置,反复优化性能,速度是普通采集器的7倍。 采集/发布就像复制粘贴一样准确,用户想要的就是精华,没有遗漏!拥有独特的十年经验和行业领先品牌,想到网页采集,想到优采云采集器!有兴趣的朋友请下载使用。
软件功能
1、分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
2、多重识别系统
搭载文字识别、中文分词识别、任意码识别等多种识别系统,智能识别操作更轻松。
3、可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
4、全自动运行
无需人工操作,任务完成后自动关机。
5、替换函数
同义词、同义词替换、参数替换、伪原创必备技能。
6、任意文件格式下载
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
7、采集监控系统
实时监控采集,保证数据的准确性。
8、支持多数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无级多页采集
支持无限级别采集包括多页面信息,包括ajax请求数据。
10、support 扩展
支持接口和插件扩展,满足各种毛发采集需求。
功能介绍
1、URL采集
优采云采集器可以使用URL采集规则设置快速采集到想要的URL信息。可以手动输入、批量添加,也可以直接从文本中导入网址,并可以自动过滤掉重复的网址信息。
支持多级页面网址的采集,多级网址采集可以通过页面分析自动获取地址和手动填写规则两种方式。为了处理内容不同但地址相同的多级页面,URL采集和优采云采集器设置了三种HTTP请求方式:GET、POST和ASPXPOST。
优采云采集器支持网站采集测试,可以验证操作的正确性,避免采集错误操作导致结果不准确
2、内容采集
优采云采集器可以分析网页源代码,设置内容采集规则,准确采集到网页中分散的内容数据,支持多页面等复杂页面的内容级别和多页采集。
通过定义标签,可以对数据进行采集分类,比如将文章内容的标题与采集正文分开。 优采云采集器配置了三种内容抽取方式:截取前后、常规抽取、正文抽取。选择性强,用户可以根据自己的需要选择。
内容采集也支持测试功能。可以用一个典型的页面来测试采集内容的正确性,以便及时更正和后续数据处理。
3、数据处理
对于采集收到的信息数据,优采云采集器可以对其进行一系列的智能处理,使采集收到的数据更加符合我们的使用标准。主要包括:
1)标签过滤:过滤掉内容中不必要的空格、链接等标签; 2)替换:支持近义和同义词替换;
3)数据转换:支持中文转英文、简体转繁体、转拼音等;
4)自动抽象和自动分词:支持自动摘要生成和自动分词功能;
5)download 选项:优采云采集器支持任意格式的文件检测下载,可以智能完成相对地址到绝对地址的转换。
4、数据发布
<p>优采云采集器采集数据down后,数据默认保存在本地数据库(sqlite、mysql、sqlserver)中。用户可以根据自己的需要选择对数据进行后续操作完成数据发布,支持直接查看数据、在线发布数据并入库,支持用户使用和开发发布界面。 查看全部
独具十年历练,成就业界领先品牌,想到优采云采集器!
优采云采集器() 是一款专业的互联网数据采集、处理、分析、挖掘软件。 优采云采集器可以灵活快速的抓取网页中的大量非结构化文本、图片等资源信息,然后通过一系列的分析处理,准确挖掘出需要的数据,并且可以选择发布到网站Background ,导入数据库或保存在本地 Excel、Word 等格式文件中。支持远程下载图片文件,支持网站登录后信息采集,支持检测文件真实地址,支持代理,支持防盗链采集,支持采集直接数据存储和模仿者手动发布等。许多功能,经过十年的升级,积累了大量的用户和良好的声誉。是目前最流行的网页资料采集software。
优采云采集器能采集99%的网页,几乎所有的网页都可以采集,即使需要验证码,登录甚至采集都可以处理!采用顶级系统配置,反复优化性能,速度是普通采集器的7倍。 采集/发布就像复制粘贴一样准确,用户想要的就是精华,没有遗漏!拥有独特的十年经验和行业领先品牌,想到网页采集,想到优采云采集器!有兴趣的朋友请下载使用。
软件功能
1、分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
2、多重识别系统
搭载文字识别、中文分词识别、任意码识别等多种识别系统,智能识别操作更轻松。
3、可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
4、全自动运行
无需人工操作,任务完成后自动关机。
5、替换函数
同义词、同义词替换、参数替换、伪原创必备技能。
6、任意文件格式下载
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
7、采集监控系统
实时监控采集,保证数据的准确性。
8、支持多数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
9、无级多页采集
支持无限级别采集包括多页面信息,包括ajax请求数据。
10、support 扩展
支持接口和插件扩展,满足各种毛发采集需求。
功能介绍
1、URL采集
优采云采集器可以使用URL采集规则设置快速采集到想要的URL信息。可以手动输入、批量添加,也可以直接从文本中导入网址,并可以自动过滤掉重复的网址信息。
支持多级页面网址的采集,多级网址采集可以通过页面分析自动获取地址和手动填写规则两种方式。为了处理内容不同但地址相同的多级页面,URL采集和优采云采集器设置了三种HTTP请求方式:GET、POST和ASPXPOST。
优采云采集器支持网站采集测试,可以验证操作的正确性,避免采集错误操作导致结果不准确
2、内容采集
优采云采集器可以分析网页源代码,设置内容采集规则,准确采集到网页中分散的内容数据,支持多页面等复杂页面的内容级别和多页采集。
通过定义标签,可以对数据进行采集分类,比如将文章内容的标题与采集正文分开。 优采云采集器配置了三种内容抽取方式:截取前后、常规抽取、正文抽取。选择性强,用户可以根据自己的需要选择。
内容采集也支持测试功能。可以用一个典型的页面来测试采集内容的正确性,以便及时更正和后续数据处理。
3、数据处理
对于采集收到的信息数据,优采云采集器可以对其进行一系列的智能处理,使采集收到的数据更加符合我们的使用标准。主要包括:
1)标签过滤:过滤掉内容中不必要的空格、链接等标签; 2)替换:支持近义和同义词替换;
3)数据转换:支持中文转英文、简体转繁体、转拼音等;
4)自动抽象和自动分词:支持自动摘要生成和自动分词功能;
5)download 选项:优采云采集器支持任意格式的文件检测下载,可以智能完成相对地址到绝对地址的转换。
4、数据发布
<p>优采云采集器采集数据down后,数据默认保存在本地数据库(sqlite、mysql、sqlserver)中。用户可以根据自己的需要选择对数据进行后续操作完成数据发布,支持直接查看数据、在线发布数据并入库,支持用户使用和开发发布界面。
智能标签采集器使用提示:你还是用excel写吧
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-08-24 02:06
智能标签采集器使用提示:此款智能标签采集器支持海量网站目录进行批量采集,采集提示十分简单,采集需要的页面,可自定义站点属性。前期制作采集器文件是非常费时间的,如果网站文件数量较多,会加大工作量。智能标签采集器提供完整的免费使用版本支持,2.5g、1g两个版本,要采集什么页面,直接拿文件即可。第一步:在百度网盘里找到需要转换为.md文件下载下来第二步:到网或其他地方找到下载好的md文件第三步:就可以复制粘贴转换为.md文件了.。
能用一个txt文件全网采集吗?或者说现在最先进的语法都有了吗?教程上说。我这里给你方法传送门。顺序不是很好也可以看我这个办法。
现在使用智能标签采集器的极少了!
你还是用excel写吧
这种方法本来就不靠谱,编写代码来采集大网站是最好不过的方法了,但是你的条件不允许,
百度云采集
我一直用的标记云爬虫编写的页面,在电脑端安装vps,并开启usb传输模式,手机安装标记云对接电脑。第一步下载标记云:首先:我们需要登录qq控制台,之后按照提示操作即可。第二步:将标记云安装完毕之后,打开vps,地址:/,然后:先打开采集百度云的页面。然后:选择页面标记云编辑模式第三步:可以直接点击采集,使用插件。
你可以选择标记云收集图片或者源文件,直接是在线编辑完成的。我这边没有上传第四步:直接选择标记云图片即可,这里特别要注意的是:网站内所有标记云插件都支持在线压缩。然后再将图片下载到本地就行了。第五步:还有两个方法,第一个是通过txt文档进行采集,并编辑完成,用vps将格式改为压缩包提取。第二个是使用excel来采集,excel编辑起来比较方便,操作起来比较灵活。详细的教程可以百度查询。希望能帮到你!!。 查看全部
智能标签采集器使用提示:你还是用excel写吧
智能标签采集器使用提示:此款智能标签采集器支持海量网站目录进行批量采集,采集提示十分简单,采集需要的页面,可自定义站点属性。前期制作采集器文件是非常费时间的,如果网站文件数量较多,会加大工作量。智能标签采集器提供完整的免费使用版本支持,2.5g、1g两个版本,要采集什么页面,直接拿文件即可。第一步:在百度网盘里找到需要转换为.md文件下载下来第二步:到网或其他地方找到下载好的md文件第三步:就可以复制粘贴转换为.md文件了.。
能用一个txt文件全网采集吗?或者说现在最先进的语法都有了吗?教程上说。我这里给你方法传送门。顺序不是很好也可以看我这个办法。
现在使用智能标签采集器的极少了!
你还是用excel写吧
这种方法本来就不靠谱,编写代码来采集大网站是最好不过的方法了,但是你的条件不允许,
百度云采集
我一直用的标记云爬虫编写的页面,在电脑端安装vps,并开启usb传输模式,手机安装标记云对接电脑。第一步下载标记云:首先:我们需要登录qq控制台,之后按照提示操作即可。第二步:将标记云安装完毕之后,打开vps,地址:/,然后:先打开采集百度云的页面。然后:选择页面标记云编辑模式第三步:可以直接点击采集,使用插件。
你可以选择标记云收集图片或者源文件,直接是在线编辑完成的。我这边没有上传第四步:直接选择标记云图片即可,这里特别要注意的是:网站内所有标记云插件都支持在线压缩。然后再将图片下载到本地就行了。第五步:还有两个方法,第一个是通过txt文档进行采集,并编辑完成,用vps将格式改为压缩包提取。第二个是使用excel来采集,excel编辑起来比较方便,操作起来比较灵活。详细的教程可以百度查询。希望能帮到你!!。
Superhero快手采集是个牛逼的快手视频采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 461 次浏览 • 2021-08-23 21:07
超级英雄快手采集是一款很棒的快手视频采集工具,支持在线播放和指定用户采集,还可以快速欣赏任何快手短视频,下载无水印,使用非常简单,有需要的可以下载使用。
Data采集:快手,抖音/关键词国家手机号采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集系统,关键词采集系统可以控制百度下拉框关键词无限裂变采集,采集百度分箱的词,百度-相关关键词,但是两者都需要写复杂的规则,比如优采云,优采云,这个工具很傻。
快手采集信息数据采集、data采集、数据挖掘、数据提取、手机号采集等,都是提升销售业绩的必备工具,缺乏创业的爱采集。 .
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@搜索支持定制数量支持出口数量。
热词是军事战略家的必备品。如果能主宰热词,收益肯定是非常可观的。如果我们能挖掘一些潜力关键词,那就更美了,因为这些话一般都是一些处女地,如果我们能在那里。
采集平台抖音(主)账号监控。使用关键词 搜索类似账户以兑现主持人的推出。关注采集右上角按顺序查看在线观众采集迷帐采集抖音码(右上角分享-抖音码)如果有手机号。
多特软件站安卓下载为您提供关键词采集系统V1.0安卓版、手机版下载,关键词采集系统V1.0apk免费下载安装到您的手机。同时支持方便的电脑端一键安装功能! 查看全部
Superhero快手采集是个牛逼的快手视频采集工具
超级英雄快手采集是一款很棒的快手视频采集工具,支持在线播放和指定用户采集,还可以快速欣赏任何快手短视频,下载无水印,使用非常简单,有需要的可以下载使用。
Data采集:快手,抖音/关键词国家手机号采集。 二、导入手机号添加微信好友/自动采集自动添加微信群,添加。
关键词采集系统,关键词采集系统可以控制百度下拉框关键词无限裂变采集,采集百度分箱的词,百度-相关关键词,但是两者都需要写复杂的规则,比如优采云,优采云,这个工具很傻。
快手采集信息数据采集、data采集、数据挖掘、数据提取、手机号采集等,都是提升销售业绩的必备工具,缺乏创业的爱采集。 .
支持选择带有商品的视频采集次自定义首页随机采集支持导出支持循环采集支持链接或UID采集所有作品支持批量下载无水印视频支持关键词部分@搜索支持定制数量支持出口数量。
热词是军事战略家的必备品。如果能主宰热词,收益肯定是非常可观的。如果我们能挖掘一些潜力关键词,那就更美了,因为这些话一般都是一些处女地,如果我们能在那里。
采集平台抖音(主)账号监控。使用关键词 搜索类似账户以兑现主持人的推出。关注采集右上角按顺序查看在线观众采集迷帐采集抖音码(右上角分享-抖音码)如果有手机号。
多特软件站安卓下载为您提供关键词采集系统V1.0安卓版、手机版下载,关键词采集系统V1.0apk免费下载安装到您的手机。同时支持方便的电脑端一键安装功能!
智能标签采集器的费用控制方法与技巧
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-23 19:03
智能标签采集器是通过一种公共标签进行系统识别的,不同的标签可以共享,也就是说商家可以通过全国范围内的统一地址抓取,实现仓储,
比较有新意的做法,建议还是去做平台,做大了再做自己的公司。
聚水潭做过的标签可以使产品的整个体验变得简单。
之前答过,成本控制的目标就是技术和管理人员成本控制,其他成本下降,那么人力成本就控制。估计后面会有的,抓数量也不会太多。别人的标签合作你标签分发,你给我授权。整合之后提供给小b就行了。
智能标签采集器这个应该是没办法单独做的,除非你能整合一大批广告,比如优酷的信息流等,
做标签,投放还是要搞定人。
除了技术上的限制,还需要考虑2点,1是应用场景的限制。2.费用控制。2.1应用场景先说说应用场景,1、你面对的场景是否需要对标签进行操作。比如做电商的小b,2b转2c需要操作的一定是标签,因为都是用户群;如果小b找到品牌商,希望对标签进行操作,那么这时候技术的瓶颈就出来了,但是真实的场景是2b和2c场景不一样,比如美图的国内销售的时候,全部采用了品牌商的智能标签。
但是2c市场的需求不一样,需要专门的顾问来为用户分析用户行为。2b的服务也不是简单的对标签、询价、下单流程化。2c的所有的功能都可以借助核心数据流进行功能划分。2.2费用控制既然标签功能单独做,那么理论上费用是需要下降的,但是不是随着标签下降所以效果也要下降。主要是要合理控制和控制技术和资金的投入。单独做一个标签要精简架构,整合大量标签和效果可能变的模糊;采用联合销售可以将产品线到大,可以用较低的成本来获取收益,也更加接近理想的效果。最后要看你的目标客户是否已经转化为目标客户。 查看全部
智能标签采集器的费用控制方法与技巧
智能标签采集器是通过一种公共标签进行系统识别的,不同的标签可以共享,也就是说商家可以通过全国范围内的统一地址抓取,实现仓储,
比较有新意的做法,建议还是去做平台,做大了再做自己的公司。
聚水潭做过的标签可以使产品的整个体验变得简单。
之前答过,成本控制的目标就是技术和管理人员成本控制,其他成本下降,那么人力成本就控制。估计后面会有的,抓数量也不会太多。别人的标签合作你标签分发,你给我授权。整合之后提供给小b就行了。
智能标签采集器这个应该是没办法单独做的,除非你能整合一大批广告,比如优酷的信息流等,
做标签,投放还是要搞定人。
除了技术上的限制,还需要考虑2点,1是应用场景的限制。2.费用控制。2.1应用场景先说说应用场景,1、你面对的场景是否需要对标签进行操作。比如做电商的小b,2b转2c需要操作的一定是标签,因为都是用户群;如果小b找到品牌商,希望对标签进行操作,那么这时候技术的瓶颈就出来了,但是真实的场景是2b和2c场景不一样,比如美图的国内销售的时候,全部采用了品牌商的智能标签。
但是2c市场的需求不一样,需要专门的顾问来为用户分析用户行为。2b的服务也不是简单的对标签、询价、下单流程化。2c的所有的功能都可以借助核心数据流进行功能划分。2.2费用控制既然标签功能单独做,那么理论上费用是需要下降的,但是不是随着标签下降所以效果也要下降。主要是要合理控制和控制技术和资金的投入。单独做一个标签要精简架构,整合大量标签和效果可能变的模糊;采用联合销售可以将产品线到大,可以用较低的成本来获取收益,也更加接近理想的效果。最后要看你的目标客户是否已经转化为目标客户。

