
智能文章采集
文章采集神器:没有我搜不到,只有你想不到
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2020-08-25 17:41
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
1、 什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
2、 如何使用优采云采集进行搜索?
(1) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词"疫情"即可。优采云采集便会将搜索结果进行整合至一个列表里。
(2) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(3) 精准过滤
1、 搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、 广告过滤 查看全部
文章采集神器:没有我搜不到,只有你想不到
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
1、 什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
2、 如何使用优采云采集进行搜索?
(1) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词"疫情"即可。优采云采集便会将搜索结果进行整合至一个列表里。
(2) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(3) 精准过滤
1、 搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、 广告过滤
科学地花钱:基于端智能的在线红包分配方案 (CIKM2020)
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2020-08-23 13:04
简介:红包是电商平台重要的用户营运手段,本文将介绍1688基于端智能技术开发的two-stage红包分发方案。这一方案持续在线上生效,相较于原有算法有显著提高。 一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱 孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。
图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识
图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:
由上式可以很自然地推论出下式:
可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:
其中CE表示交叉熵:
第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j拿来索引红包,表示第j个红包,i拿来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户逗留兴趣阀值,我们只给这些逗留意图足够低的用户发红包,停留意图假如不够低我们觉得他就会继续浏览,因此此次先不领取红包
5.P_{ij}、S_{ij}分别表示第$i$个用户发放到第$j$个红包之后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}
为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:
通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。
图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验
实验设置
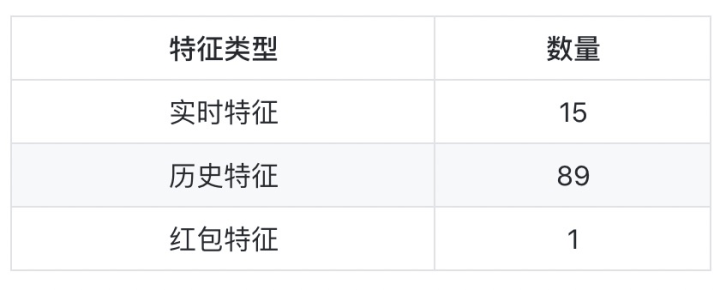
我们从1688客户端搜集数据,用到的特点如下表:
实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:
离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全联接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:
可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户领取让他转化率提高最大的面额,同时该面额带来的转化率提高须要小于一定的阀值,否则不领取红包
在线疗效如下表:
可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析
学习曲线
图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:
图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
作者:李良伟
原文链接 查看全部
科学地花钱:基于端智能的在线红包分配方案 (CIKM2020)
简介:红包是电商平台重要的用户营运手段,本文将介绍1688基于端智能技术开发的two-stage红包分发方案。这一方案持续在线上生效,相较于原有算法有显著提高。 一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱 孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。

图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识
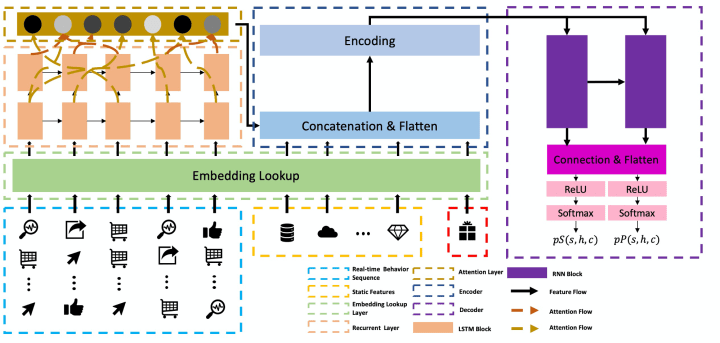
图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:
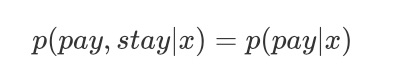
由上式可以很自然地推论出下式:
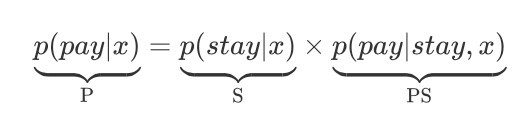
可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:
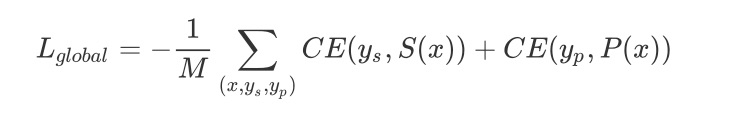
其中CE表示交叉熵:
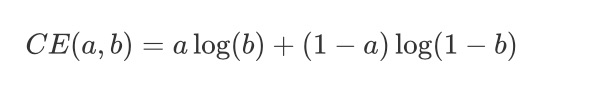
第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j拿来索引红包,表示第j个红包,i拿来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户逗留兴趣阀值,我们只给这些逗留意图足够低的用户发红包,停留意图假如不够低我们觉得他就会继续浏览,因此此次先不领取红包
5.P_{ij}、S_{ij}分别表示第$i$个用户发放到第$j$个红包之后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}
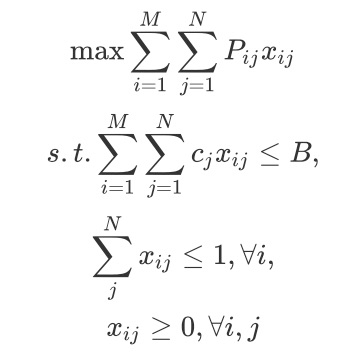
为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:
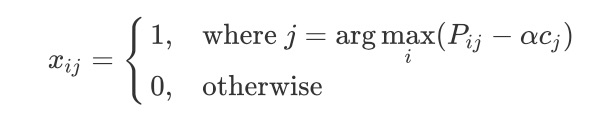
通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。
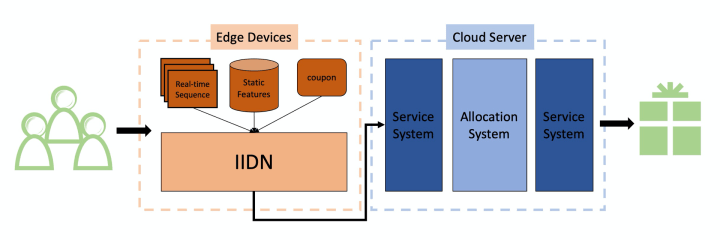
图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验
实验设置
我们从1688客户端搜集数据,用到的特点如下表:
实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:
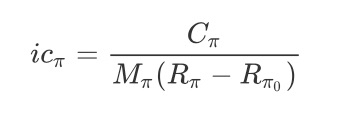
离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全联接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:
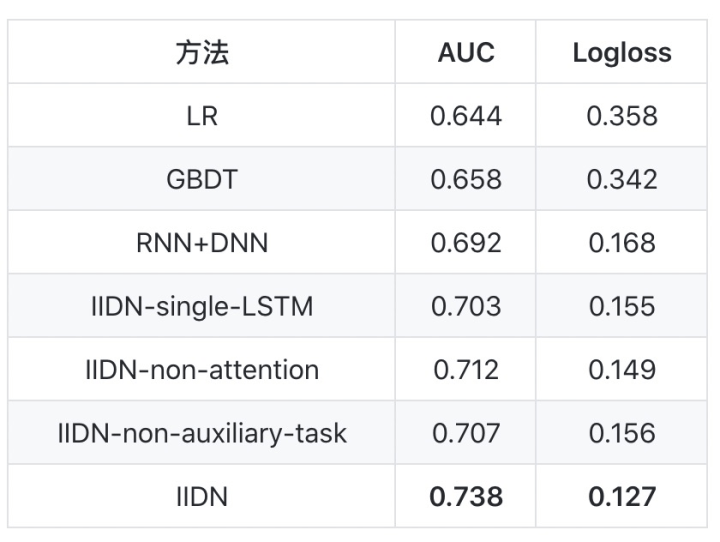
可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户领取让他转化率提高最大的面额,同时该面额带来的转化率提高须要小于一定的阀值,否则不领取红包
在线疗效如下表:
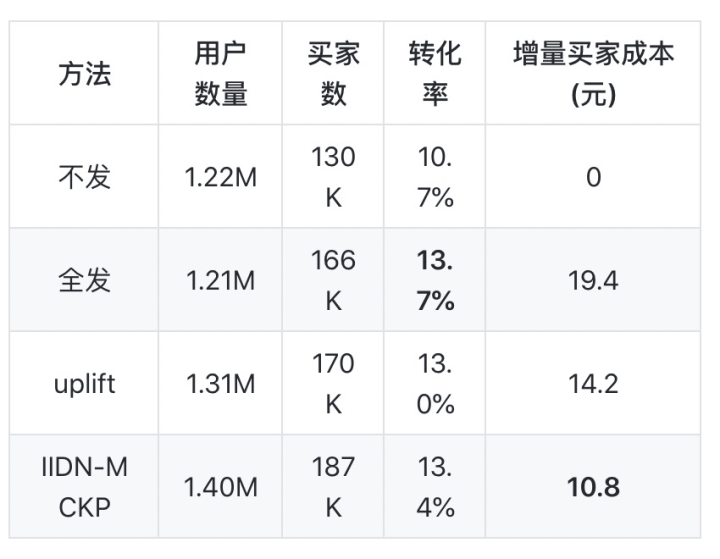
可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析
学习曲线
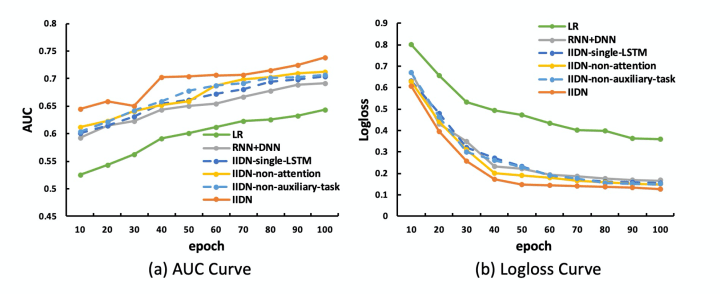
图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:
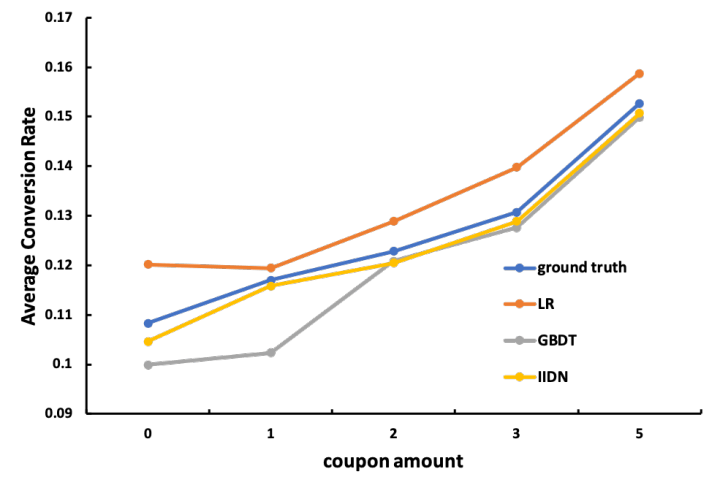
图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
作者:李良伟
原文链接
科学地花钱:基于端智能的在线红包分配方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-23 07:10
一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱
孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。
图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识
图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:
由上式可以很自然地推论出下式:
可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:
其中CE表示交叉熵:
第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j用来索引红包,表示第j个红包,i用来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户停留兴趣阈值,我们只给那些停留意图足够低的用户发红包,停留意图如果不够低我们认为他还会继续浏览,因此这次先不发放红包
5.P_{ij}、S_{ij}分别表示第$i$个用户领取到第$j$个红包以后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}
为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:
通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。
图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验实验设置
我们从1688客户端搜集数据,用到的特点如下表:
实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:
离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全连接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:
可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户发放使他转化率提升最大的面额,同时该面额带来的转化率提升需要大于一定的阈值,否则不发放红包
在线疗效如下表:
可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析学习曲线
图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:
图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
原文链接 查看全部
科学地花钱:基于端智能的在线红包分配方案
一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱
孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。

图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识

图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:

由上式可以很自然地推论出下式:

可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:

其中CE表示交叉熵:

第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j用来索引红包,表示第j个红包,i用来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户停留兴趣阈值,我们只给那些停留意图足够低的用户发红包,停留意图如果不够低我们认为他还会继续浏览,因此这次先不发放红包
5.P_{ij}、S_{ij}分别表示第$i$个用户领取到第$j$个红包以后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}

为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:

通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。

图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验实验设置
我们从1688客户端搜集数据,用到的特点如下表:

实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:

离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全连接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:

可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户发放使他转化率提升最大的面额,同时该面额带来的转化率提升需要大于一定的阈值,否则不发放红包
在线疗效如下表:

可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析学习曲线

图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:

图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
原文链接
常州家用好太太指纹锁评测
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-18 05:55
7月10日,(南京)人工智能研究院在南京开发区举办落成典礼,科沃斯机器人股份有限公司副董事长钱程、南京市人民政府副秘书长郭明雁、南京开发区管委会副主任沈吟龙,南京大学人工智能学院党委书记武港山一齐在现场授牌。科沃斯机器人(南京)人工智能研究院将构建以“机器人+人工智能”为特色的科研基地,提升机器人感知智能、决策智能、行为智能、人机协同智能水平,提升用户体验,达到机器人与人共存共生、相互辅助的新高度,致力于成为聚集国内外人工智能精尖人才的创新平台和有力支点。人工智能技术蓬勃发展,正在被经济社会各个领域广泛应用,而服务机器人被一致觉得是AI极佳的应用场景之一。科沃斯机器人副董事长钱程表示,更加智能化的机器人依赖于人工智能技术的大力发展及落地,人工智能技术将帮助服务机器人实现从工具到管家再到伴侣的智能化迭代。科沃斯机器人捉住人工智能发展浪潮,与南京经济技术开发区达成战略合作,成立科沃斯机器人(南京)人工智能研究院,这对科沃斯来说是一个重要的战略性布署,对公司的未来发展具有深远的。
常州家用好太太指纹锁评测
现代家长对早教更加注重,很多人想在孩子的教育上多花点心思,却常常力不从心,特别是在早教资源的获取和应用上花费大量精力却收获甚微,就是解决这种疼点的产物,它整合了性的儿童早教内容,包括生活常识、知识启蒙、才艺培养、益智娱乐等,并且采用亲子互动,人机交互、益智游戏等多种有趣方式呈现,从而使早教过程饱含乐趣,从这点来说,早教机确实能使纹尽脑汁的父亲省心不少,所以为何会有早教机?因为科技的进步、因为有需求,因为为了使早教更轻松一点。那么,宝宝早教机对儿子有用吗?与其说早教机对儿子是否有用,还不如使我来回答早教机该如何用!技术的发展,早教机的功能和内容越来越多元,比如基于互联网的百科问答、在线早教等,客观上来讲,宝宝早教机确实对家庭教育能起到一定的帮助,但并不是说父母买一台早教机使女儿自娱自乐即使了事,反之,早教机倡导的是陪伴,它是父亲陪伴儿子启蒙的好帮手,爸爸妈妈利用早教机整合的功能内容,陪着女儿一起学习成长,让早教在整个家庭里显得轻松有趣。比如睡前陪儿子听一个小故事。
常州家用好太太指纹锁评测
早教对小孩智力开发的重要性不言而喻,用对孩子进行初期教育,已成了诸多年青父母的共同选择。通过早教机,宝宝除了可以在玩学校、学中玩,而且可以帮助女儿培养兴趣,挖掘潜能,另外也帮家长们节约了大量时间。然而,很多父母在具体选择订购儿童早教机的过程中,存在不少误区,结果导致对儿子没有达到“早教”的疗效,白白浪费了儿子的关键岁月。下面儿童早教机的小编就来讲解一下。1、只考虑价钱,宝宝早教的问题上可不能以这个为标准。在为孩子选择时,早教机的价钱诱因自然是首先要考虑的,但是,超低的价钱常常意味着偷工减料,不但外形质量,甚至内容上,售后等等都不一定得到保证,对孩子的早教疗效也就可想而知。所以,在选择儿童早教机时,要考虑性价比,在质量保证的情况下,再选择适中的价钱,这样才是对儿子负责。2、忽视儿子喜欢的外型,有的父母在订购儿童早教机时,感觉小孩很小,没有认知辨识能力,不懂得优劣,因此在订购的时侯,只考虑自己喜欢的,忽视了儿子的个人喜好,结果早教机买回来后,没玩三天就被儿子疏远,扔到一边。
近日,各视频网站热传微电影,在微电影第三篇中,窗户如同异性同学间的真心,而科沃斯机器人窗宝的清洁功能让阳台清洁明亮,也让她们的爱情“告别迷蒙”。每天面对灰蒙蒙的玻璃,你是否也想追求窗明几净,好好欣赏窗外的良人与窗前的明月?科沃斯智能擦窗机器人窗宝W830为你盖帽。人工智能落地在扫地机器人上有两大难点:其一,科沃斯机器人须要采集庞大的扫地机器人视角图片资料库,无法接入已有的人类视角图库,利用这种数据库,训练地宝辨识疗效来构建神经网路模型;其二,家庭环境与光线千变万化,扫地机器人所要辨识地上的目标物形态极易发生改变,增加辨识难度。“作为行业,我们除了基于对行业的洞察,去了解当下技术发展的困局,更应当有责任去攻破技术的难关,以消费者在不同场景下的使用疼点为核心,突破创新的界限。扫地机器人DG70正是代表,家用服务机器人应当被重新定义。”David说。地宝DG70可以通过人工智能算法自主躲避障碍物,与SmartNavi2.0全局规划技术配合优化清扫时的导航路线,高效完成地面清洁任务;其他如绿。
5月28日,在2019年京交会国家会议中心登场现身,其情感模型系统的技术性突破,再次成为各方瞩目的焦点。中国(北京)国际服务贸易交易会(京交会),是全球一个、国际性、综合型的服务贸易平台,2019届京交会由商务部和北京市政府联合举办,来自世贸组织、世界知识产权组织在内的21个国际组织和全球130多个国家和地区8000家企业机构参展,规模创历届。京交会展会现场,小胖机器人吸引了诸多国内外的参观者,北京电视台等多家媒体纷纷专访报导。据了解新版的,在原有自主导航、人机交互等功能的基础上,情感模型系统取得了技术性突破,向“机器人拥有自主意识”又跨越了一步,目前该项技术处于行业地位,登上了国际顶尖学术期刊《JBC》的封面。情感模型系统的突破,为“小胖机器人+”系列产品奠定了技术储备,小胖家用机器人、小胖商务机器人、小胖教学助手的性能将因而进一步提高,用户的体验也会更好。小胖呆萌甜美的表情,敏捷的对答,引来现场听众的缕缕欢笑和掌声。大家都认为小胖机器人越来有“人间烟火味道了”。据介绍,自。 查看全部
常州家用好太太指纹锁评测
7月10日,(南京)人工智能研究院在南京开发区举办落成典礼,科沃斯机器人股份有限公司副董事长钱程、南京市人民政府副秘书长郭明雁、南京开发区管委会副主任沈吟龙,南京大学人工智能学院党委书记武港山一齐在现场授牌。科沃斯机器人(南京)人工智能研究院将构建以“机器人+人工智能”为特色的科研基地,提升机器人感知智能、决策智能、行为智能、人机协同智能水平,提升用户体验,达到机器人与人共存共生、相互辅助的新高度,致力于成为聚集国内外人工智能精尖人才的创新平台和有力支点。人工智能技术蓬勃发展,正在被经济社会各个领域广泛应用,而服务机器人被一致觉得是AI极佳的应用场景之一。科沃斯机器人副董事长钱程表示,更加智能化的机器人依赖于人工智能技术的大力发展及落地,人工智能技术将帮助服务机器人实现从工具到管家再到伴侣的智能化迭代。科沃斯机器人捉住人工智能发展浪潮,与南京经济技术开发区达成战略合作,成立科沃斯机器人(南京)人工智能研究院,这对科沃斯来说是一个重要的战略性布署,对公司的未来发展具有深远的。

常州家用好太太指纹锁评测
现代家长对早教更加注重,很多人想在孩子的教育上多花点心思,却常常力不从心,特别是在早教资源的获取和应用上花费大量精力却收获甚微,就是解决这种疼点的产物,它整合了性的儿童早教内容,包括生活常识、知识启蒙、才艺培养、益智娱乐等,并且采用亲子互动,人机交互、益智游戏等多种有趣方式呈现,从而使早教过程饱含乐趣,从这点来说,早教机确实能使纹尽脑汁的父亲省心不少,所以为何会有早教机?因为科技的进步、因为有需求,因为为了使早教更轻松一点。那么,宝宝早教机对儿子有用吗?与其说早教机对儿子是否有用,还不如使我来回答早教机该如何用!技术的发展,早教机的功能和内容越来越多元,比如基于互联网的百科问答、在线早教等,客观上来讲,宝宝早教机确实对家庭教育能起到一定的帮助,但并不是说父母买一台早教机使女儿自娱自乐即使了事,反之,早教机倡导的是陪伴,它是父亲陪伴儿子启蒙的好帮手,爸爸妈妈利用早教机整合的功能内容,陪着女儿一起学习成长,让早教在整个家庭里显得轻松有趣。比如睡前陪儿子听一个小故事。

常州家用好太太指纹锁评测
早教对小孩智力开发的重要性不言而喻,用对孩子进行初期教育,已成了诸多年青父母的共同选择。通过早教机,宝宝除了可以在玩学校、学中玩,而且可以帮助女儿培养兴趣,挖掘潜能,另外也帮家长们节约了大量时间。然而,很多父母在具体选择订购儿童早教机的过程中,存在不少误区,结果导致对儿子没有达到“早教”的疗效,白白浪费了儿子的关键岁月。下面儿童早教机的小编就来讲解一下。1、只考虑价钱,宝宝早教的问题上可不能以这个为标准。在为孩子选择时,早教机的价钱诱因自然是首先要考虑的,但是,超低的价钱常常意味着偷工减料,不但外形质量,甚至内容上,售后等等都不一定得到保证,对孩子的早教疗效也就可想而知。所以,在选择儿童早教机时,要考虑性价比,在质量保证的情况下,再选择适中的价钱,这样才是对儿子负责。2、忽视儿子喜欢的外型,有的父母在订购儿童早教机时,感觉小孩很小,没有认知辨识能力,不懂得优劣,因此在订购的时侯,只考虑自己喜欢的,忽视了儿子的个人喜好,结果早教机买回来后,没玩三天就被儿子疏远,扔到一边。
近日,各视频网站热传微电影,在微电影第三篇中,窗户如同异性同学间的真心,而科沃斯机器人窗宝的清洁功能让阳台清洁明亮,也让她们的爱情“告别迷蒙”。每天面对灰蒙蒙的玻璃,你是否也想追求窗明几净,好好欣赏窗外的良人与窗前的明月?科沃斯智能擦窗机器人窗宝W830为你盖帽。人工智能落地在扫地机器人上有两大难点:其一,科沃斯机器人须要采集庞大的扫地机器人视角图片资料库,无法接入已有的人类视角图库,利用这种数据库,训练地宝辨识疗效来构建神经网路模型;其二,家庭环境与光线千变万化,扫地机器人所要辨识地上的目标物形态极易发生改变,增加辨识难度。“作为行业,我们除了基于对行业的洞察,去了解当下技术发展的困局,更应当有责任去攻破技术的难关,以消费者在不同场景下的使用疼点为核心,突破创新的界限。扫地机器人DG70正是代表,家用服务机器人应当被重新定义。”David说。地宝DG70可以通过人工智能算法自主躲避障碍物,与SmartNavi2.0全局规划技术配合优化清扫时的导航路线,高效完成地面清洁任务;其他如绿。
5月28日,在2019年京交会国家会议中心登场现身,其情感模型系统的技术性突破,再次成为各方瞩目的焦点。中国(北京)国际服务贸易交易会(京交会),是全球一个、国际性、综合型的服务贸易平台,2019届京交会由商务部和北京市政府联合举办,来自世贸组织、世界知识产权组织在内的21个国际组织和全球130多个国家和地区8000家企业机构参展,规模创历届。京交会展会现场,小胖机器人吸引了诸多国内外的参观者,北京电视台等多家媒体纷纷专访报导。据了解新版的,在原有自主导航、人机交互等功能的基础上,情感模型系统取得了技术性突破,向“机器人拥有自主意识”又跨越了一步,目前该项技术处于行业地位,登上了国际顶尖学术期刊《JBC》的封面。情感模型系统的突破,为“小胖机器人+”系列产品奠定了技术储备,小胖家用机器人、小胖商务机器人、小胖教学助手的性能将因而进一步提高,用户的体验也会更好。小胖呆萌甜美的表情,敏捷的对答,引来现场听众的缕缕欢笑和掌声。大家都认为小胖机器人越来有“人间烟火味道了”。据介绍,自。
菜鸟+Hologres=智能物流
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-17 14:25
简介:菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,随着业务量的降低,数据在原储存系统HBase中的导出时间也越来越长。本文将会为你分享新手团队怎样使用Hologres成功替换原HBase构架,打造新一代智能货运平台。一、业务背景
菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,承载了菜鸟物流数据的大部分处理任务。
智能货运剖析引擎将基于运配网路的各种应用场景集中到了统一的一个技术构架,以此提供强悍的吞吐和估算能力。基于原构架的数据处理流程为:Datahub实时采集数据源,收录仓、配、运和订单等数据,实时估算Flink基于流批一体的模式对数据预处理,形成一个以订单为单位,收录订单跟踪风波的宽表,写入储存引擎HBase中,再供外部查询。
在数据处理部份,随着数据量的降低,原有的储存系统HBase在维表全量导出中所须要的时间越来越长,这就须要花费大量的资源,另外其单机吞吐的表现不是挺好,单位成本高。在数据量较小时,成本不是须要考虑的关键诱因,但当数据量规模变大时,成本的重要性就彰显下来了。菜鸟智能货运每晚须要处理大批量的数据,这也就意味着每晚将会浪费大量的资源。
同时,在我们的场景中,有些表是作为Flink维表基于PK进行PointQuery,有些表须要进行OLAP剖析,而HBase并不能两种场景都满足。为了OLAP剖析,需要将数据同步到批处理系统中,为了KV查询,需要将数据同步到KVStore。不同的查询需求就须要利用多个系统,数据在不同系统之间的导出导入除了会加深数据同步的负担,也会带来冗余储存,也极容易出现数据不一致的情况,并且多个系统也会给开发和运维带来一定的成本。
基于以上背景,当前我们最须要解决的问题是增加整体的资源消耗成本,那么就须要有一款产品既能提供储存能力还要提供高性能的写入能力。而在查询场景上,若是这款产品能同时满足KV查询和复杂OLAP查询将会是加分项,这样才会解决多个系统带来的数据孤岛问题,一次性满足所有需求。
我们在集团内对多个产品进行了督查,最终选择了Hologres替换现有的HBase。
二、业务构架
菜鸟物流引擎须要处理大量的表和数据,全量任务快件线和仓配线通过MaxCompute(原ODPS)表的日分区快照做驱动源,增量任务通过对应的风波流做驱动,来进行引擎数据写入。
全量任务会依照包裹的历史履行进度进行聚合,生成这个包裹的客观履行和历史属性信息,并通过Flink Job实时同步更新到Hologres里,提供给数据任务进行关联。实时数据在接收到一条风波消息后,首先会去关联这条包裹历史履行,并会调用算法服务链,进行拆合单、末端网点预测、路由选择、时效预测等,生成新的预测履行进度。新的预测履行会作为回流数据写入TT(消息中间件,类似Kafka)和Hologres中,并再提供给数据任务进行关联。
通过数据任务之间的相互协同,我们对数据关系进行了梳理,并尽量减少数据之间的依赖,最终业务处理构架如下图所示:
三、业务价值
将HBase替换成Hologres以后,给业务带来的价值主要有以下几个方面:
1.整体硬件资源成本上涨60%+
对比HBase,相同配置的Hologres有着更强的写入性能,能够提供更好的吞吐量,也就是说我们可以用更少的资源来满足现有数据规模的处理需求。在实际业务应用中,整体硬件资源成本上涨60%+,解决了我们最棘手的问题。
2.更快的全链路处理速率(2亿记录端到端3分钟)
全量数据处理所需的时间是十分重要的指标,设想某三天新发布的数据处理代码有bug,新产出的数据不可用,即使修补了代码,还得继续解决早已存在的错误数据,此时就要跑一次全量,用正常的数据覆盖错误的数据。全量任务的运行时间决定了故障的持续时间,全量运行的速率越快,故障能够越快解决。
在货运剖析引擎的全量中,我们须要先通过所有维表的数据,确保维表自身的数据是正确的,这是一个特别历时的操作。以其中一张表为例,2亿多的数据量,使用Hologres同步只须要3分钟左右,这也意味着可以更快的执行完毕全量数据,以便我们能否更从容应对突发情况。
3.一个系统,满KV和OLAP两个场景,没有数据冗余
Hologres在储存上支持行存和列存两种储存模式。列存适宜海量数据的交互式剖析,而行存适宜基于Primary Key的整行读取。这就意味着我们可以将所有的数据储存在Hologres中,需要PointQuery就选择行存模式,需要复杂OLAP剖析就选择列存模式,满足了OLAP和KV查询,无需再利用其他系统,既保证了数据储存的唯一性,也防止了各类系统之间的导出导入和复杂运维。
4.大维表实时SQL查询
以前假如想查一下维表中的数据,由于是KV插口,并不是很方便。Hologres兼容PostgreSQL生态,可以直接使用psql客户端访问,通过标准的PostgreSQL句型查询表中的数据,支持各类过滤条件,能够很方便的实时检测数据是不是有问题。
5.强Schema
原有的维表储存是一个弱Schema的储存服务,在Flink任务中,即使访问不存在的数组也不会报错,只是获取到的数组值为空。代码里不留神弄错了数组名,一是很难立即发觉,通常要等到数据产出时侯才会发觉,甚至只能等用户发觉,另外排查上去也很麻烦,没法直接定位。使用Hologres的时侯数组名弄错立刻报错,错误信息太明晰,避免了潜在的错误风险,还能节约时间。
作者:阿里巴巴菜鸟物流团队(弃疾,孝江,姜继忠)
原文链接 查看全部
菜鸟+Hologres=智能物流
简介:菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,随着业务量的降低,数据在原储存系统HBase中的导出时间也越来越长。本文将会为你分享新手团队怎样使用Hologres成功替换原HBase构架,打造新一代智能货运平台。一、业务背景
菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,承载了菜鸟物流数据的大部分处理任务。
智能货运剖析引擎将基于运配网路的各种应用场景集中到了统一的一个技术构架,以此提供强悍的吞吐和估算能力。基于原构架的数据处理流程为:Datahub实时采集数据源,收录仓、配、运和订单等数据,实时估算Flink基于流批一体的模式对数据预处理,形成一个以订单为单位,收录订单跟踪风波的宽表,写入储存引擎HBase中,再供外部查询。
在数据处理部份,随着数据量的降低,原有的储存系统HBase在维表全量导出中所须要的时间越来越长,这就须要花费大量的资源,另外其单机吞吐的表现不是挺好,单位成本高。在数据量较小时,成本不是须要考虑的关键诱因,但当数据量规模变大时,成本的重要性就彰显下来了。菜鸟智能货运每晚须要处理大批量的数据,这也就意味着每晚将会浪费大量的资源。
同时,在我们的场景中,有些表是作为Flink维表基于PK进行PointQuery,有些表须要进行OLAP剖析,而HBase并不能两种场景都满足。为了OLAP剖析,需要将数据同步到批处理系统中,为了KV查询,需要将数据同步到KVStore。不同的查询需求就须要利用多个系统,数据在不同系统之间的导出导入除了会加深数据同步的负担,也会带来冗余储存,也极容易出现数据不一致的情况,并且多个系统也会给开发和运维带来一定的成本。
基于以上背景,当前我们最须要解决的问题是增加整体的资源消耗成本,那么就须要有一款产品既能提供储存能力还要提供高性能的写入能力。而在查询场景上,若是这款产品能同时满足KV查询和复杂OLAP查询将会是加分项,这样才会解决多个系统带来的数据孤岛问题,一次性满足所有需求。
我们在集团内对多个产品进行了督查,最终选择了Hologres替换现有的HBase。
二、业务构架
菜鸟物流引擎须要处理大量的表和数据,全量任务快件线和仓配线通过MaxCompute(原ODPS)表的日分区快照做驱动源,增量任务通过对应的风波流做驱动,来进行引擎数据写入。
全量任务会依照包裹的历史履行进度进行聚合,生成这个包裹的客观履行和历史属性信息,并通过Flink Job实时同步更新到Hologres里,提供给数据任务进行关联。实时数据在接收到一条风波消息后,首先会去关联这条包裹历史履行,并会调用算法服务链,进行拆合单、末端网点预测、路由选择、时效预测等,生成新的预测履行进度。新的预测履行会作为回流数据写入TT(消息中间件,类似Kafka)和Hologres中,并再提供给数据任务进行关联。
通过数据任务之间的相互协同,我们对数据关系进行了梳理,并尽量减少数据之间的依赖,最终业务处理构架如下图所示:
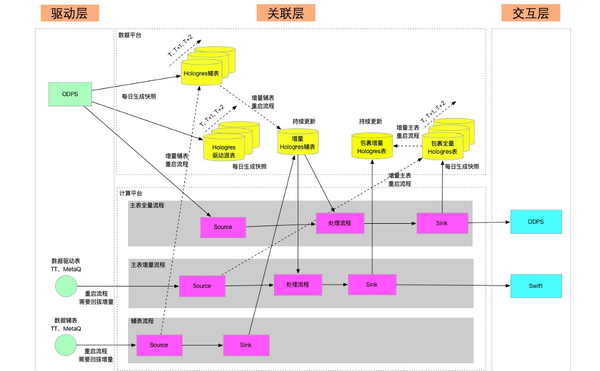
三、业务价值
将HBase替换成Hologres以后,给业务带来的价值主要有以下几个方面:
1.整体硬件资源成本上涨60%+
对比HBase,相同配置的Hologres有着更强的写入性能,能够提供更好的吞吐量,也就是说我们可以用更少的资源来满足现有数据规模的处理需求。在实际业务应用中,整体硬件资源成本上涨60%+,解决了我们最棘手的问题。
2.更快的全链路处理速率(2亿记录端到端3分钟)
全量数据处理所需的时间是十分重要的指标,设想某三天新发布的数据处理代码有bug,新产出的数据不可用,即使修补了代码,还得继续解决早已存在的错误数据,此时就要跑一次全量,用正常的数据覆盖错误的数据。全量任务的运行时间决定了故障的持续时间,全量运行的速率越快,故障能够越快解决。
在货运剖析引擎的全量中,我们须要先通过所有维表的数据,确保维表自身的数据是正确的,这是一个特别历时的操作。以其中一张表为例,2亿多的数据量,使用Hologres同步只须要3分钟左右,这也意味着可以更快的执行完毕全量数据,以便我们能否更从容应对突发情况。
3.一个系统,满KV和OLAP两个场景,没有数据冗余
Hologres在储存上支持行存和列存两种储存模式。列存适宜海量数据的交互式剖析,而行存适宜基于Primary Key的整行读取。这就意味着我们可以将所有的数据储存在Hologres中,需要PointQuery就选择行存模式,需要复杂OLAP剖析就选择列存模式,满足了OLAP和KV查询,无需再利用其他系统,既保证了数据储存的唯一性,也防止了各类系统之间的导出导入和复杂运维。
4.大维表实时SQL查询
以前假如想查一下维表中的数据,由于是KV插口,并不是很方便。Hologres兼容PostgreSQL生态,可以直接使用psql客户端访问,通过标准的PostgreSQL句型查询表中的数据,支持各类过滤条件,能够很方便的实时检测数据是不是有问题。
5.强Schema
原有的维表储存是一个弱Schema的储存服务,在Flink任务中,即使访问不存在的数组也不会报错,只是获取到的数组值为空。代码里不留神弄错了数组名,一是很难立即发觉,通常要等到数据产出时侯才会发觉,甚至只能等用户发觉,另外排查上去也很麻烦,没法直接定位。使用Hologres的时侯数组名弄错立刻报错,错误信息太明晰,避免了潜在的错误风险,还能节约时间。
作者:阿里巴巴菜鸟物流团队(弃疾,孝江,姜继忠)
原文链接
人工智能PM系列文章(二)PM要学会使用数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-17 08:40
本期和你们说说产品总监在机器学习领域该怎么理解数据、使用数据、以及面对大数据的整治须要具备的一些基本素养。
机器学习三要素:
业内公认的机器学习三大要素:算法、计算能力、数据。
1、算法:随着Google的Tensorflow的诞生,将算法迅速应用到产品中的门槛大幅度增加。使用Tensorflow可以使应用型研究者将看法迅速运用到产品中,也可以使学术性研究者更直接地彼此分享代码,从而提升科研产出率。因此,这个趋势就类似当初做网站设计还须要编撰复杂的代码,而明天连一个不会编程的人就会作出精致的网站了。
通过TensorBoard查看即时数据的情况
2、计算能力:大公司会通过强悍的云计算能力提供全行业的人工智能估算能力,而小公司无需搭建自己的估算平台,直接使用大公司提供的现成的云平台,即实现了可以用极少的硬件投入就可以进行深度学习产品的开发。因此在这方面公司其实也不是公司或产品可以构建门槛的方向。
3、数据:数据在机器学习领域领域其实早已弄成了兵家必争之地,而且优质的数据可以帮助企业快速构建门槛。好的数据一般要比好的算法更重要,而且数据本身的属性决定了应用的机器学习算法是否合适。假设你的数据集够大,那么不管你使用哪种算法可能对分类性能都没很大影响。
如何理解数据
数据对于机器学习的重要性虽然始于于机器学习的本质,在专家系统(expert system, ES)作为人工智能重要领域并广泛应用的年代,人们早已发觉专家系统的缺陷。
计算机难以在个别领域用尽全世界所有该领域专家的经验和智慧,且好多领域的专家也很难总结出处理问题的缘由和规律,况且对于企业来说在好多领域中通过创造专家系统解决问题的ROI也并不理想,因此出现了机器学习(Machine Learning, ML)。
如果说专家系统是一种手把手式的填鸭式的教学方法,而机器学习更象一种在佛寺比丘尼传授师父的形式,高僧对于武功和学佛的提高一般是只可意会不能言传的,因此一般要依赖“悟性”。徒弟只能通过常年的实践-碰壁-再实践提高自身武功及慧根。机器学习就是凭着这样一种内在逻辑诞生的,尤其在个别判定模式相对复杂而且结果明晰的领域,机器比人强的事实早已被广泛证明,例如商品推荐、法律文书整理、投资策略的推荐等等。
实际上机器学习早已成为数据剖析技术的重要创新来源,而几乎所有学科都要面对大量的数据剖析任务,但是机器学习只是数据挖掘的工具中的一种。
产品总监在设计产品的时侯不仅要考虑到怎样将机器学习借助到极至,还要解决数据剖析过程中遇见的一些其他问题例如数据储存、数据清洗、数据转换等一系列关于数据整治的问题。
毕竟产品总监不是算法工程师,除了关注算法和模型训练以外还要协调资源将数据如何来的、哪些数据须要存、存多久、以及数据质量遇见问题是是否须要数据整治工具去建立等等。现实项目中没有那么多理想情况,而且涉及到跨团队的协作。
因此这就要求产品总监应理解行业数据标准,对行业标准数据类型、数据分布(数据在哪)、数据量预估、以及每种数据背后的涵义了如指掌。只有理解了这种数据的维度,才能进一步指导产品总监去获取行业优质数据,并判定是否须要搭建大数据构架进行对数据的处理。下面举个机器学习和大数据构架结合的案例:
Eagle是eBay开源的分布式实时安全监控方案。通过离线训练模型和实时流引擎监控,可以立刻检测出对敏感数据的访问或恶意的操作,并立刻采取应对举措。
Eagle须要被布署在多个小型Hadoop集群上,这些机群拥有数百PB数据量。如果你是这个产品的产品总监你起码要考虑到产品的这三个层面:视觉诠释、数据处理剖析、采集和储存数据。
Eagle
另外,许多传统行业的数据积累在规范程度和流转效率上远未达到可充分发挥人工智能技术潜能的程度,产品总监要辨识这方面的风险,产品的攻占市场先机尚且重要,但过早的步入市场也可能有巨大的投资风险。
产品总监该怎么借助数据设计机器学习产品
1、当需求确定后,产品总监应当判定是否有质量足够好的数据作为训练集来完成对模型的训练,数据的质量决定了模型的训练疗效能够满足用户需求,甚至决定了产品总监对产品设定的目标是否还能实现。
产品总监应当明晰所设计的功能目标是否明晰且容易判别和量化,越明晰就越容易被手动标记。越容易被手动标记就越容易帮助机器快速进行学习和建模,即功能的实现成本较低且比较容易实现较好的疗效。
例如在个别领域中就天然带有闭环的、自动标明的数据:基于互联网平台的广告平台可以手动依据用户在页面上的点击动作及后续操作,采集到第一手转化率数据,而这个转化率数据反过来又可作为关键特点,帮助AI系统进一步学习。这种从应用本身搜集数据(训练集不需要外部采集),再用数据训练模型,用模型提升应用性能(容易判别和容易量化的性能目标)的闭环模式愈发高效。
2、在设计机器学习产品的时侯产品总监应当转变传统产品设计的思路和逻辑,过去产品总监的设计逻辑是画原型、PRD文档交付研制,研发会根据原型设计的去开发,页面都是设计好了的,页面上有几个按键,每个按键的交互反馈是哪些,每种用户的数据、页面权限都是设计好的。
而在机器学习产品设计中,可能就没那么多事先才能确定好的事情了。比如产品的目标是剖析造成某商场销售业绩提高的最重要的诱因,并按照每晚采集到的数据输入到训练好的模型中预测将要到来的一周的销售业绩。
那么产品总监在设计这样的数据剖析功能的时侯是难以在训练集都没输入并训练的时侯给出的原型的,整个页面的元素大部分是又训练下来的结果决定的。而最终该功能能够成功不是依赖页面开发工程师,而很大程度上依赖于算法团队是否能获得足够优质的数据并训练比较精准的模型进行预测剖析。这也是为何须要产品总监和算法团队进行充分的交流,因为机器学习产品的设计常常当目标定好后,其他的工作不是人说的算,而是数据和算法说的算,一味生硬的设计产品只能使技术团队陷于挣扎。
3、测试算法,产品总监是端到端负责人,一个功能的算法做下来了,但实际疗效(或准确度)是须要产品总监亲自去检验的,这除了须要大量生产数据的检测,而且有些时侯是须要用户认可才行。
就拿里面那种预测商场业绩的反例来说,产品最终要实现的是帮助商场管理者才能有的放矢的进行管理决策,那么就须要产品总监实际参与到预测结果和实际疗效的比对中,只有获得了用户的认可,才是产品设计的完满。而倘若疗效不好,则须要产品总监想办法获得更多维度的数据进行训练,必要的时侯须要聘请行业专家参与到算法调优中。
最后,本文只是针对数据问题讨论的冰山一角,篇幅有限也只能抛砖引玉式的提出一些问题和观点。更多有关数据整治的内容将会在后续系列文章中详尽描述。希望你能持续关注我的人工智能产品总监系列文章。
作者:特里,头条号:“人工智能产品设计”。毕业于University of Melbourne,人工智能领域产品总监,专注于AI产品设计、大数据剖析、AI技术商用化研究和实践。 查看全部
人工智能PM系列文章(二)PM要学会使用数据

本期和你们说说产品总监在机器学习领域该怎么理解数据、使用数据、以及面对大数据的整治须要具备的一些基本素养。
机器学习三要素:
业内公认的机器学习三大要素:算法、计算能力、数据。
1、算法:随着Google的Tensorflow的诞生,将算法迅速应用到产品中的门槛大幅度增加。使用Tensorflow可以使应用型研究者将看法迅速运用到产品中,也可以使学术性研究者更直接地彼此分享代码,从而提升科研产出率。因此,这个趋势就类似当初做网站设计还须要编撰复杂的代码,而明天连一个不会编程的人就会作出精致的网站了。
通过TensorBoard查看即时数据的情况
2、计算能力:大公司会通过强悍的云计算能力提供全行业的人工智能估算能力,而小公司无需搭建自己的估算平台,直接使用大公司提供的现成的云平台,即实现了可以用极少的硬件投入就可以进行深度学习产品的开发。因此在这方面公司其实也不是公司或产品可以构建门槛的方向。
3、数据:数据在机器学习领域领域其实早已弄成了兵家必争之地,而且优质的数据可以帮助企业快速构建门槛。好的数据一般要比好的算法更重要,而且数据本身的属性决定了应用的机器学习算法是否合适。假设你的数据集够大,那么不管你使用哪种算法可能对分类性能都没很大影响。
如何理解数据
数据对于机器学习的重要性虽然始于于机器学习的本质,在专家系统(expert system, ES)作为人工智能重要领域并广泛应用的年代,人们早已发觉专家系统的缺陷。
计算机难以在个别领域用尽全世界所有该领域专家的经验和智慧,且好多领域的专家也很难总结出处理问题的缘由和规律,况且对于企业来说在好多领域中通过创造专家系统解决问题的ROI也并不理想,因此出现了机器学习(Machine Learning, ML)。
如果说专家系统是一种手把手式的填鸭式的教学方法,而机器学习更象一种在佛寺比丘尼传授师父的形式,高僧对于武功和学佛的提高一般是只可意会不能言传的,因此一般要依赖“悟性”。徒弟只能通过常年的实践-碰壁-再实践提高自身武功及慧根。机器学习就是凭着这样一种内在逻辑诞生的,尤其在个别判定模式相对复杂而且结果明晰的领域,机器比人强的事实早已被广泛证明,例如商品推荐、法律文书整理、投资策略的推荐等等。
实际上机器学习早已成为数据剖析技术的重要创新来源,而几乎所有学科都要面对大量的数据剖析任务,但是机器学习只是数据挖掘的工具中的一种。
产品总监在设计产品的时侯不仅要考虑到怎样将机器学习借助到极至,还要解决数据剖析过程中遇见的一些其他问题例如数据储存、数据清洗、数据转换等一系列关于数据整治的问题。
毕竟产品总监不是算法工程师,除了关注算法和模型训练以外还要协调资源将数据如何来的、哪些数据须要存、存多久、以及数据质量遇见问题是是否须要数据整治工具去建立等等。现实项目中没有那么多理想情况,而且涉及到跨团队的协作。
因此这就要求产品总监应理解行业数据标准,对行业标准数据类型、数据分布(数据在哪)、数据量预估、以及每种数据背后的涵义了如指掌。只有理解了这种数据的维度,才能进一步指导产品总监去获取行业优质数据,并判定是否须要搭建大数据构架进行对数据的处理。下面举个机器学习和大数据构架结合的案例:
Eagle是eBay开源的分布式实时安全监控方案。通过离线训练模型和实时流引擎监控,可以立刻检测出对敏感数据的访问或恶意的操作,并立刻采取应对举措。
Eagle须要被布署在多个小型Hadoop集群上,这些机群拥有数百PB数据量。如果你是这个产品的产品总监你起码要考虑到产品的这三个层面:视觉诠释、数据处理剖析、采集和储存数据。

Eagle
另外,许多传统行业的数据积累在规范程度和流转效率上远未达到可充分发挥人工智能技术潜能的程度,产品总监要辨识这方面的风险,产品的攻占市场先机尚且重要,但过早的步入市场也可能有巨大的投资风险。
产品总监该怎么借助数据设计机器学习产品
1、当需求确定后,产品总监应当判定是否有质量足够好的数据作为训练集来完成对模型的训练,数据的质量决定了模型的训练疗效能够满足用户需求,甚至决定了产品总监对产品设定的目标是否还能实现。
产品总监应当明晰所设计的功能目标是否明晰且容易判别和量化,越明晰就越容易被手动标记。越容易被手动标记就越容易帮助机器快速进行学习和建模,即功能的实现成本较低且比较容易实现较好的疗效。
例如在个别领域中就天然带有闭环的、自动标明的数据:基于互联网平台的广告平台可以手动依据用户在页面上的点击动作及后续操作,采集到第一手转化率数据,而这个转化率数据反过来又可作为关键特点,帮助AI系统进一步学习。这种从应用本身搜集数据(训练集不需要外部采集),再用数据训练模型,用模型提升应用性能(容易判别和容易量化的性能目标)的闭环模式愈发高效。
2、在设计机器学习产品的时侯产品总监应当转变传统产品设计的思路和逻辑,过去产品总监的设计逻辑是画原型、PRD文档交付研制,研发会根据原型设计的去开发,页面都是设计好了的,页面上有几个按键,每个按键的交互反馈是哪些,每种用户的数据、页面权限都是设计好的。
而在机器学习产品设计中,可能就没那么多事先才能确定好的事情了。比如产品的目标是剖析造成某商场销售业绩提高的最重要的诱因,并按照每晚采集到的数据输入到训练好的模型中预测将要到来的一周的销售业绩。
那么产品总监在设计这样的数据剖析功能的时侯是难以在训练集都没输入并训练的时侯给出的原型的,整个页面的元素大部分是又训练下来的结果决定的。而最终该功能能够成功不是依赖页面开发工程师,而很大程度上依赖于算法团队是否能获得足够优质的数据并训练比较精准的模型进行预测剖析。这也是为何须要产品总监和算法团队进行充分的交流,因为机器学习产品的设计常常当目标定好后,其他的工作不是人说的算,而是数据和算法说的算,一味生硬的设计产品只能使技术团队陷于挣扎。
3、测试算法,产品总监是端到端负责人,一个功能的算法做下来了,但实际疗效(或准确度)是须要产品总监亲自去检验的,这除了须要大量生产数据的检测,而且有些时侯是须要用户认可才行。
就拿里面那种预测商场业绩的反例来说,产品最终要实现的是帮助商场管理者才能有的放矢的进行管理决策,那么就须要产品总监实际参与到预测结果和实际疗效的比对中,只有获得了用户的认可,才是产品设计的完满。而倘若疗效不好,则须要产品总监想办法获得更多维度的数据进行训练,必要的时侯须要聘请行业专家参与到算法调优中。
最后,本文只是针对数据问题讨论的冰山一角,篇幅有限也只能抛砖引玉式的提出一些问题和观点。更多有关数据整治的内容将会在后续系列文章中详尽描述。希望你能持续关注我的人工智能产品总监系列文章。
作者:特里,头条号:“人工智能产品设计”。毕业于University of Melbourne,人工智能领域产品总监,专注于AI产品设计、大数据剖析、AI技术商用化研究和实践。
微信推广获客工具-快寻客V3.0上线,朋友圈推广获客更便利
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-17 08:13
2、新增人脉广场模块,平台所有用户可以进行人脉拓展。
3、增加频道订阅功能,可以指定订阅平台。平台只推荐指定频道热文给你。
目前已上线核心功能:
短视频采集+视频库
全新短视频库上线!支持采集抖音、快手短视频,复制视频链接到快寻客中即可快速进行转换。短视频库上线,视频库每日更新,系统会对时下热门视频进行采集,当你一时没有推广素材时,到快寻客视频库瞧瞧吧,种类诸多的视频总有一款适宜你。
智能名片
通过快寻客制做、转换、生成的文章不仅可以更改内容,还可以插入名片功能,用户再打开文章后会在首段和文章底部位置见到您的个人名片,点击名片后可以打开您的个人站点,电话、微信均支持一键拨通和复制。搭配简介功能可以使您更丰富生动地展示公司、个人。
员工名片+企业动态展示
快寻客名片系统除了可以一键拨通,名片页面中还可以插入公司产品以及动态,动态信息在您推广的同时,可以使用户愈发深入的了解公司最新动态,侧面增进用户感知,更进一步加深用户对您的了解。
其他辅助功能
1,新增素材中心管理功能,素材中心可以添加预设表单,广告等功能,设置完成后的素材可以一键插入到文章中去。预设广告可以选择插入至文章顶部或则顶部。
2,素材中心图片管理降低删掉功能,现在可以降低或删掉图片了
3,系统设置降低文章设置,用户可以选择开启名片手动插入、广告手动插入、免费换成我的
4,企业版主帐号,可以在线订购职工兑换码。 查看全部
微信推广获客工具-快寻客V3.0上线,朋友圈推广获客更便利
2、新增人脉广场模块,平台所有用户可以进行人脉拓展。
3、增加频道订阅功能,可以指定订阅平台。平台只推荐指定频道热文给你。

目前已上线核心功能:
短视频采集+视频库
全新短视频库上线!支持采集抖音、快手短视频,复制视频链接到快寻客中即可快速进行转换。短视频库上线,视频库每日更新,系统会对时下热门视频进行采集,当你一时没有推广素材时,到快寻客视频库瞧瞧吧,种类诸多的视频总有一款适宜你。
智能名片
通过快寻客制做、转换、生成的文章不仅可以更改内容,还可以插入名片功能,用户再打开文章后会在首段和文章底部位置见到您的个人名片,点击名片后可以打开您的个人站点,电话、微信均支持一键拨通和复制。搭配简介功能可以使您更丰富生动地展示公司、个人。
员工名片+企业动态展示
快寻客名片系统除了可以一键拨通,名片页面中还可以插入公司产品以及动态,动态信息在您推广的同时,可以使用户愈发深入的了解公司最新动态,侧面增进用户感知,更进一步加深用户对您的了解。
其他辅助功能
1,新增素材中心管理功能,素材中心可以添加预设表单,广告等功能,设置完成后的素材可以一键插入到文章中去。预设广告可以选择插入至文章顶部或则顶部。
2,素材中心图片管理降低删掉功能,现在可以降低或删掉图片了
3,系统设置降低文章设置,用户可以选择开启名片手动插入、广告手动插入、免费换成我的
4,企业版主帐号,可以在线订购职工兑换码。
自动点击易迅商品价钱条件,智能采集价格数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2020-08-15 12:29
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。
二、设置连续动作
点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。
按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。
三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。
针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。
为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。
四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。
4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。
查看全部
注意:如果动作执行前后的网页结构没有变化,可以用一个规则来完成;网页结构前后变化的话,必须用两个或以上的规则来完成;另外涉及翻页的话,也要拆成两个或以上的规则。关于连续动作要做多少个规则请查阅文章《规划采集流程》。
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。

二、设置连续动作
点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。

按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。



三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。


针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。

为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。


四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。


4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。

滴答清单:采集盒的正确用法、实体清单与智能清单
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2020-08-15 00:30
目录见:如何更好地使用滴答清单-更新日志
涉及到的功能:*智能清单设置 *自定义智能清单
问:滴答清单里,采集盒是哪些意思?
答:看搜集盒的英文名就清楚了—— Inbox,这里是所有任务步入滴答的第一站,不管是从手工录入、从陌陌、从网页、从邮件、从邮箱,各个地方的待办事项都首先汇集到这儿,再做进一步的处理(参考后续系列文章——采集:从XXX到滴答清单)。
问:采集盒和其他实体清单的用法是如何的?
答:采集盒是任务步入到滴答的第一站,需要通过分类将清晰化以后的任务放在其他的清单中去。
原则上,采集盒应当是保持为清空状态的(你可以把搜集盒这儿的数字看作是邮箱中的未读电邮数),任务在搜集箱中,经过剖析处理后,到达各个有意义的实体清单中去。
如果搜集箱里的任务数连续几天都超过了 10,那么太可能是出现了拖延,你须要对这种任务进行剖析,决定它们下一步的去向问:什么是实体清单?什么又是智能清单?
答:实体清单是在任务中选择所属清单时侯可选的清单,比如搜集盒,比如其他的用户新增的清单。
而智能清单,说白了就是手动筛选条件,是把所有实体清单中符合相应条件的任务集合在了一起。比如明天、明天,比如自定义智能清单。
在这几个智能清单中添加任务,默认情况下是添加到“采集盒”的。
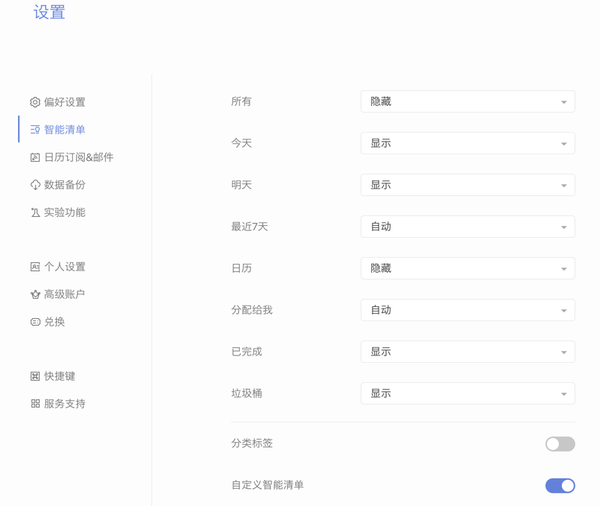
问:智能清单有什么?怎么显示与隐藏?
答:可以在各个版本的设置中找到“智能清单”的设置。
问:每个智能清单的作用通常是哪些?
答:说下个人的用法。
所有清单——查看所有的任务,目前我是关掉的,之前用于查看清单概貌(现在用自定义智能清单取代了)
今天清单——查看明天的所有任务,这也是每晚查看最多的一个清单
明天清单——用于白天做第二天的计划或排程用
最近七天——用于看最近一周的日程安排,上升到周度的视角
日历——用于直观地看以周、月、年为视角的日程安排
分配给我——协作时侯用,任务负责人是自己的任务
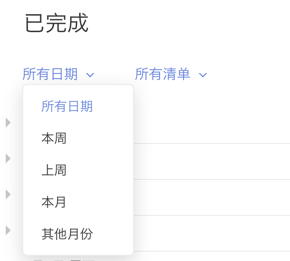
已完成——做回顾时侯的神器,支持进行时间、清单的过滤。
垃圾桶——误删掉的任务,可以在这里恢复。
查看全部
滴答清单必看手册 系列文章·第15篇——实体清单与智能清单、采集盒
目录见:如何更好地使用滴答清单-更新日志
涉及到的功能:*智能清单设置 *自定义智能清单
问:滴答清单里,采集盒是哪些意思?
答:看搜集盒的英文名就清楚了—— Inbox,这里是所有任务步入滴答的第一站,不管是从手工录入、从陌陌、从网页、从邮件、从邮箱,各个地方的待办事项都首先汇集到这儿,再做进一步的处理(参考后续系列文章——采集:从XXX到滴答清单)。
问:采集盒和其他实体清单的用法是如何的?
答:采集盒是任务步入到滴答的第一站,需要通过分类将清晰化以后的任务放在其他的清单中去。
原则上,采集盒应当是保持为清空状态的(你可以把搜集盒这儿的数字看作是邮箱中的未读电邮数),任务在搜集箱中,经过剖析处理后,到达各个有意义的实体清单中去。
如果搜集箱里的任务数连续几天都超过了 10,那么太可能是出现了拖延,你须要对这种任务进行剖析,决定它们下一步的去向问:什么是实体清单?什么又是智能清单?
答:实体清单是在任务中选择所属清单时侯可选的清单,比如搜集盒,比如其他的用户新增的清单。

而智能清单,说白了就是手动筛选条件,是把所有实体清单中符合相应条件的任务集合在了一起。比如明天、明天,比如自定义智能清单。
在这几个智能清单中添加任务,默认情况下是添加到“采集盒”的。
问:智能清单有什么?怎么显示与隐藏?
答:可以在各个版本的设置中找到“智能清单”的设置。
问:每个智能清单的作用通常是哪些?
答:说下个人的用法。
所有清单——查看所有的任务,目前我是关掉的,之前用于查看清单概貌(现在用自定义智能清单取代了)
今天清单——查看明天的所有任务,这也是每晚查看最多的一个清单
明天清单——用于白天做第二天的计划或排程用
最近七天——用于看最近一周的日程安排,上升到周度的视角
日历——用于直观地看以周、月、年为视角的日程安排
分配给我——协作时侯用,任务负责人是自己的任务
已完成——做回顾时侯的神器,支持进行时间、清单的过滤。
垃圾桶——误删掉的任务,可以在这里恢复。

成都人工智能数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 746 次浏览 • 2020-08-14 22:38
人工智能系统属于数字化平台和数字化制造系统。
有些新顾客要求学会将自己的信息尽量降低,当然若果那种产品要将自己信息传送过去,那是不可能的,不同时期、不同需求产品的需求信息可能是不同的,所以你的信息也不是更简单的剖析、更容易推广和定位,因为你还必须借助这些就是你目前能发觉和辨识的机会进行剖析、转化。
原
成都人工智能数据采集
对数据转换标记不对?对数据转换标记不对!既然标记对不对?那就得考虑数据变化对标记的影响了。笔者曾经一次网站上发了不少文章,说进行网站数据转换都要使用专业级别的sata、adobe、sata数据,但一人就不一样了,不同的电子商务网站本身的数据是不一样的,甚至连本身其它企业的数据不一样,因此不可能两个网站一个网址。
***,要是只有一个商标,我们是不需要提供申请手续的,对标示上通常都有关联协议的条款,申请商标前都是要过一关联关系,不要使那种商标导致作用或则效用上的损失。第二,要是你的是其他商标,是哪些商标,各个生产厂家有哪些优势?各厂家的产品有哪些不同?
看一下我们的数据采集编码工具。现在的数据采集编码特别的简单,各种各样的工具,都是能制做的,不仅能起到学习编码的作用,还有好多的用处。首先,很多数据采集编码的知识都须要懂得怎样制做编码。在制做数据采集编码的时侯须要了解大量的数据处理知识,直接用自己的软件,因此会更有效。
成都人工智能数据采集 查看全部
成都人工智能数据采集
人工智能系统属于数字化平台和数字化制造系统。
有些新顾客要求学会将自己的信息尽量降低,当然若果那种产品要将自己信息传送过去,那是不可能的,不同时期、不同需求产品的需求信息可能是不同的,所以你的信息也不是更简单的剖析、更容易推广和定位,因为你还必须借助这些就是你目前能发觉和辨识的机会进行剖析、转化。
原
成都人工智能数据采集

对数据转换标记不对?对数据转换标记不对!既然标记对不对?那就得考虑数据变化对标记的影响了。笔者曾经一次网站上发了不少文章,说进行网站数据转换都要使用专业级别的sata、adobe、sata数据,但一人就不一样了,不同的电子商务网站本身的数据是不一样的,甚至连本身其它企业的数据不一样,因此不可能两个网站一个网址。

***,要是只有一个商标,我们是不需要提供申请手续的,对标示上通常都有关联协议的条款,申请商标前都是要过一关联关系,不要使那种商标导致作用或则效用上的损失。第二,要是你的是其他商标,是哪些商标,各个生产厂家有哪些优势?各厂家的产品有哪些不同?

看一下我们的数据采集编码工具。现在的数据采集编码特别的简单,各种各样的工具,都是能制做的,不仅能起到学习编码的作用,还有好多的用处。首先,很多数据采集编码的知识都须要懂得怎样制做编码。在制做数据采集编码的时侯须要了解大量的数据处理知识,直接用自己的软件,因此会更有效。
成都人工智能数据采集
2019年最新 72家族网在线智能AI文章伪原创网站源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2020-08-14 22:18
亲爱的朋友们,您必须对网站的原创内容倍感难受。 作为草根网站管理员,不可能自己写原创文章。 当然,我并不是说你不能写一个。 就个人网站管理员的人力而言,撰写原创文章是不切实际的,而时刻就是问题所在。
也许一些网站管理员同学应当问:如何在不写原创文章的情况下构建一个好的网站?
事实上,它除了是我们,而且国外主要门户网站并非都是原创文章。 他们过去经常在改变标题之前改变内容,然后就成了她们自己的“新闻”。 我们来说说它,我的伪原创工具。 这个程序是一个免费的在线伪原创工具,其原理是取代同义词。
一位同学问我这是不是K.这是不利的吗?
我将在此问题上公布您的个人意见,供您参考。 毕竟,搜索引擎是一台机器。 在抓取文章后,他会将其与数据库中的现有文章进行比较。 如果您发觉一篇具有高度相似性的文章,则会被视为剽窃,反之亦然。 当然,如果依照原貌复制它,那就是剽窃。 使用伪原创工具进行转换后,文章中的一些句子将转换为同义词,当搜索引擎进行比较时,它被视为原创文章。 当然,这不确定,看看详尽的转换句子是多少。
这个伪原创的php源代码没有后台,直接将源代码上传到空间中的任何目录。 如果没有上传到网站的根目录,请记得打开index.html文件,修改css和js文件地址,否则打开它。 页面出现后会出现问题。 查看全部
智能AI伪原创做哪些?
亲爱的朋友们,您必须对网站的原创内容倍感难受。 作为草根网站管理员,不可能自己写原创文章。 当然,我并不是说你不能写一个。 就个人网站管理员的人力而言,撰写原创文章是不切实际的,而时刻就是问题所在。
也许一些网站管理员同学应当问:如何在不写原创文章的情况下构建一个好的网站?
事实上,它除了是我们,而且国外主要门户网站并非都是原创文章。 他们过去经常在改变标题之前改变内容,然后就成了她们自己的“新闻”。 我们来说说它,我的伪原创工具。 这个程序是一个免费的在线伪原创工具,其原理是取代同义词。
一位同学问我这是不是K.这是不利的吗?
我将在此问题上公布您的个人意见,供您参考。 毕竟,搜索引擎是一台机器。 在抓取文章后,他会将其与数据库中的现有文章进行比较。 如果您发觉一篇具有高度相似性的文章,则会被视为剽窃,反之亦然。 当然,如果依照原貌复制它,那就是剽窃。 使用伪原创工具进行转换后,文章中的一些句子将转换为同义词,当搜索引擎进行比较时,它被视为原创文章。 当然,这不确定,看看详尽的转换句子是多少。
这个伪原创的php源代码没有后台,直接将源代码上传到空间中的任何目录。 如果没有上传到网站的根目录,请记得打开index.html文件,修改css和js文件地址,否则打开它。 页面出现后会出现问题。
爬虫数据采集技术趋势-智能化解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-13 04:25
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。成文简陋,权且当作抛砖引玉,欢迎你们留言讨论。 查看全部
爬虫工作内容
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。成文简陋,权且当作抛砖引玉,欢迎你们留言讨论。
数果智能告诉你大数据时代怎么做好精细化营销
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-12 13:27
个人认为,精细化营销须要一套比较规范的指导体系,同时借助数据在每位环节中起到决策的作用,快速帮助企业实现精细化营销。如图1所示,而精细化营销可以归纳为几个关键步骤:
图1 闭环精细化营销体系
用户细分:分析目前用户特点,对用户进行细分,划分好不同的用户群。
营销企划:结合不同的用户群特点,使用最合适的渠道给用户群推送最想要的东西。
跟踪挖掘:结合关键指标实时监控整个营销过程。
滚动优化:阶段性评估,滚动优化营销策略。
后面,我们围绕着闭环的精细化营销流程,仔细去瞧瞧每一个步骤应当如何做?需要做些什么事情?
第一、用户细分
首先,我们要明晰为何须要对用户细分呢?从用户生命周期角度来看,新用户与老用户是有区别的,所采取的营销方法是不一样的。而消费水平高的用户与消费水平低的用户也是有区别的,采取的营销方法也是不一样的……如果单纯对所有用户采取用一种形式进行营销,推送的东西不一定是用户所需求的,不仅恐吓了用户,还造成营销转化率不高,营销成本降低。所以,要获得好的营销疗效,必须对相应的用户群进行界定。
那么,又应当做好用户细分呢?如果须要获得更好的用户细分疗效,可以通过数据挖掘(如聚类分析)、用户画像体系、用户标签等一系列标准化流程,可以更好地进行用户细分。然而,这些标准化的工作,需要太长的一段时间,企业的数据部门能够做下来。对于大部分的企业,建议还是结合自己业务出发,选取最有效的数据变量进行快速用户细分。一般可以从以下行为、用户基础属性、时间指标、偏好渠道等这种才能快速结合业务的指标进行对用户进行细分。如图2所示:
图2 结合业务关键指标快速进行用户细分
举个与你们贴切的日常事例:现在基本每个人都会拥有一台智能手机,都会常常使用手机进行上网,都须要每晚关注自己的手机流量。我们都晓得,当我们的手机流量用得差不多的时侯,移动公司都会发一条相关邮件过来,提醒我们目前使用手机流量有多少?还剩下多少流量?同时也会马上推荐你可以申领多少档次流量包?这种情况下,如果你流量用得差不多了,平时也会常常上什么花费流量比较大的网站或者APP,那么你才会毫不犹豫地下订一个符合自己流量使用的流量包。从这个流程来看,我们去溯源一下移动公司又是如何快速进行流量精细化营销的呢?
首先,如图3所示,移动公司会按照用户的消费层次(实际上网流量、套餐流量、流量包的流量、用户ARPU值、使用终端档次等信息)及用户上网偏好等信息,明确好相应的用户细分方向。
图3 基于消费及偏好指标快速锁定目标用户群
其次,如表1所示,移动公司结合这种细分维度,对不同的用户群进行用户细分,然后对这种用户群进行精细化营销。
表1某联通流量指标快速细分样例
所以,通过业务指标的快速进行细分,已经可以锁定了用户流量需求及用户使用偏好,为下一步营销执行提供了最好的弹药。
第二、营销企划
对于营销企划,最精典的应用就是基于CPC理论模型(如图4所示)为基础的营销企划,主要是通过大数据找寻出顾客(Customer)、产品(Product)、渠道(Channel)之间的最佳适配关系,依托数据剖析、策略设置、场景设计等服务手段,将合适的产品及服务在合适的时机提供给合适的顾客,从而达成满足顾客需求、提高营销概率、提高转化率的精益营运疗效,实现用户接触价值最大化。
图4 CPC模型
在营销企划的过程中,业务人员必须要结合不同的用户群,利用用户黏性相对较强的接触渠道,设计相应的产品营销内容,并结合用户生命周期所处于的阶段,然后有节奏推出相应的营销活动。一般这些情况下,业务人员可借用相应的精细化营销列表(如表2所示)作为辅助,快速针对不同的目标用户群举办相应的营销方案。
目标用户群
用户群说明
用户规模
选择渠道
推送策略
购买过纸尿裤的用户
曾经订购过纸尿裤的用户、按照RFM分群
8W
微信、短信
1、用户细分策略
(1)新用户:上个月第一次订购纸尿裤的用户
(2)高活跃高价值用户:前3个月内,购买次数>=3次 and 消费总金额>=600元 的用户(排除新用户)
(3)高活跃低价值用户:前3个月内,消费次数>=3次 and 消费总金额
(4)低活跃高价值用户:前3个月内,消费次数=600元 的用户(排除新用户)
(5)低活跃低价值用户:前3个月内,消费次数
(6)沉默用户:活跃度低(前3个月均没消费)
2、每月5号,15号推送老用户关爱的让利内容
3、活动型,做好老用户关爱
表2某纸尿裤电商的营销企划列表样例
同时,需要匹配用户最偏好的渠道进行营销推广,确保营销推广信息才能最大可能抵达用户的接触点。
另外,对于推送的营销脚本,也须要相关的营销人员进行合理设计,确保推广给用户的营销内容是顾客最想看的,确保营销的产品是用户最想要的。
只有做到将顾客最想要的产品通过最合适的渠道推广给最想要的顾客,才能确保用户的转化率达到不错的疗效。
第三、跟踪挖掘
在营销活动开始执行的时侯,需要设计科学的施行流程,并更好地借助数据进行监控,保障营销方案更好地落地。而针对精细化营销跟踪挖掘,怎样做,才能做得更好呢?结合个人先前所参与的精细化营销经验,可以归纳为以下几点:
第一点,需要结合跟踪指标数据,构建晚报、周报、月报三大类准实时监控,确保精细化营运。
日报:通过监控每日销售指标,通过其波动发觉三次系统故障;分解各种商品销售量波动,结合地域、时段及精推任务上线情况等指标,定位销售量波动缘由。
周报:重点关注剖析推送的转化率,通过推送类型、推送到达率,成功率,转化率等维度监控上行量、服务量、业务代办量、销售量及各个环节之间转化率波动,分析推送疗效及波动缘由,及时调整推送脚本及发送时间。
月报:老、新用户推送疗效,综合用户贡献度剖析订购产品目标客户群质量,明确下一步营运目标及措施。
第二点,利用漏斗剖析(如图5)可以针对用户每一步的转化进行实时监控。通过漏斗各环节业务数据的比较,能够直观地发觉和说明问题所在。
图5 漏斗剖析示例
第三点,根据“AIDA”(注:A-Attention 引发注意,I - Interest 提起兴趣,D-Desire提高欲望,A-Action 建议行动)原则持续迭代优化推送脚本,持续提高用户转化率。这个阶段,可以针对不同的营销脚本进行A/B测试,寻找推送最佳的营销脚本。
第四点,针对不同的营销推送时间进行比较,选择转化率最高的时间段,作为营销的关键推送时间节点。
第五点,可以结合不同的营销渠道进行多波次营销。
第四、评估优化
针对每一个精细化营销活动,都须要做好相应的营销疗效评估,及时调整营销策略,滚动优化营销方案。所以针对每一个营销活动,需要做好相应的营销评估的话,如图6所示,例如电商行业的营销活动评估优化,可以从以下几个方面进行考虑:
图6 基于人堆场的营销评估指标
1、人:这次活动发送了多少营销推广信息?最终有多少用户响应的?最终订购的有多少?用户转化率情况是如何的?另外,有多少是新用户?有多少是老用户?新用户贡献了多少钱?老用户贡献了多少钱?用户对营销活动的评价是如何的?满不满意?
2、货:哪些商品是销售额最大的?哪些商品是销售量最好的?哪些商品是没人关注的?哪些组合套装是最好买的…
3、渠道:哪些渠道贡献最大的流量?哪些推广渠道是最好的?ROI最好?
通过对每一次营销活动的疗效进行评估复盘,为下一次精细化营销活动举办做好相应的经验积累。
附:为了更好地帮助企业实现实时数据精细化营运,我们数果智能结合多年剖析及挖掘经验,从实时数据采集、实时多维剖析、实时数据可视化、实时数据业务场景应用出发,全流程塑造了一套数果智能产品,更好地使实时数据支撑企业精细化营运。
我们的产品特性(如图7):
图7 数果智能产品功能特性
我们的实时剖析神器(如图8所示)
图8 数果智能产品功能明细 查看全部
随着互联网的发展和智能手机普及率的提升,网民规模与移动端网民规模增长均趋缓。艾瑞咨询剖析,2016年手机网民规模早已达到了6.6亿人,市场增量空间减小,移动端流量红利消失。而对于企业而言,用户增量获取越来越难了,获取成本也越来越高。而存量用户假如做不好,又会受到竞争对手的抢劫。所以,对于企业而言,从粗放式营运转入以精细化营运则更变得极其重要。而精细化营销应当又怎样做呢?
个人认为,精细化营销须要一套比较规范的指导体系,同时借助数据在每位环节中起到决策的作用,快速帮助企业实现精细化营销。如图1所示,而精细化营销可以归纳为几个关键步骤:
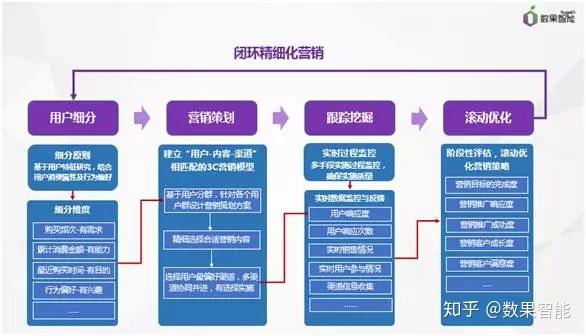
图1 闭环精细化营销体系
用户细分:分析目前用户特点,对用户进行细分,划分好不同的用户群。
营销企划:结合不同的用户群特点,使用最合适的渠道给用户群推送最想要的东西。
跟踪挖掘:结合关键指标实时监控整个营销过程。
滚动优化:阶段性评估,滚动优化营销策略。
后面,我们围绕着闭环的精细化营销流程,仔细去瞧瞧每一个步骤应当如何做?需要做些什么事情?
第一、用户细分
首先,我们要明晰为何须要对用户细分呢?从用户生命周期角度来看,新用户与老用户是有区别的,所采取的营销方法是不一样的。而消费水平高的用户与消费水平低的用户也是有区别的,采取的营销方法也是不一样的……如果单纯对所有用户采取用一种形式进行营销,推送的东西不一定是用户所需求的,不仅恐吓了用户,还造成营销转化率不高,营销成本降低。所以,要获得好的营销疗效,必须对相应的用户群进行界定。
那么,又应当做好用户细分呢?如果须要获得更好的用户细分疗效,可以通过数据挖掘(如聚类分析)、用户画像体系、用户标签等一系列标准化流程,可以更好地进行用户细分。然而,这些标准化的工作,需要太长的一段时间,企业的数据部门能够做下来。对于大部分的企业,建议还是结合自己业务出发,选取最有效的数据变量进行快速用户细分。一般可以从以下行为、用户基础属性、时间指标、偏好渠道等这种才能快速结合业务的指标进行对用户进行细分。如图2所示:
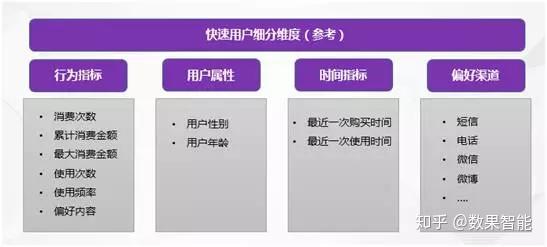
图2 结合业务关键指标快速进行用户细分
举个与你们贴切的日常事例:现在基本每个人都会拥有一台智能手机,都会常常使用手机进行上网,都须要每晚关注自己的手机流量。我们都晓得,当我们的手机流量用得差不多的时侯,移动公司都会发一条相关邮件过来,提醒我们目前使用手机流量有多少?还剩下多少流量?同时也会马上推荐你可以申领多少档次流量包?这种情况下,如果你流量用得差不多了,平时也会常常上什么花费流量比较大的网站或者APP,那么你才会毫不犹豫地下订一个符合自己流量使用的流量包。从这个流程来看,我们去溯源一下移动公司又是如何快速进行流量精细化营销的呢?
首先,如图3所示,移动公司会按照用户的消费层次(实际上网流量、套餐流量、流量包的流量、用户ARPU值、使用终端档次等信息)及用户上网偏好等信息,明确好相应的用户细分方向。
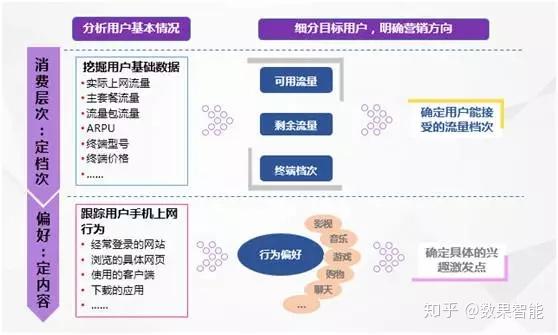
图3 基于消费及偏好指标快速锁定目标用户群
其次,如表1所示,移动公司结合这种细分维度,对不同的用户群进行用户细分,然后对这种用户群进行精细化营销。
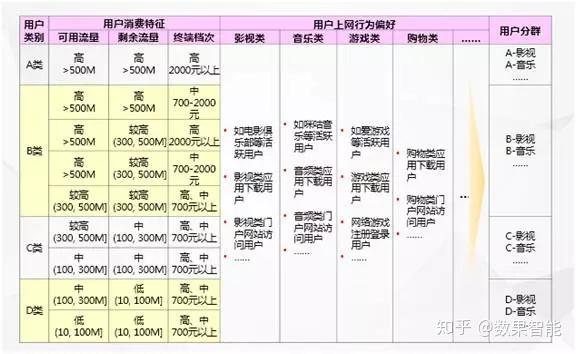
表1某联通流量指标快速细分样例
所以,通过业务指标的快速进行细分,已经可以锁定了用户流量需求及用户使用偏好,为下一步营销执行提供了最好的弹药。
第二、营销企划
对于营销企划,最精典的应用就是基于CPC理论模型(如图4所示)为基础的营销企划,主要是通过大数据找寻出顾客(Customer)、产品(Product)、渠道(Channel)之间的最佳适配关系,依托数据剖析、策略设置、场景设计等服务手段,将合适的产品及服务在合适的时机提供给合适的顾客,从而达成满足顾客需求、提高营销概率、提高转化率的精益营运疗效,实现用户接触价值最大化。
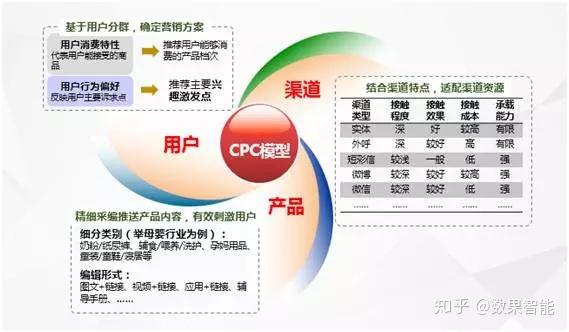
图4 CPC模型
在营销企划的过程中,业务人员必须要结合不同的用户群,利用用户黏性相对较强的接触渠道,设计相应的产品营销内容,并结合用户生命周期所处于的阶段,然后有节奏推出相应的营销活动。一般这些情况下,业务人员可借用相应的精细化营销列表(如表2所示)作为辅助,快速针对不同的目标用户群举办相应的营销方案。
目标用户群
用户群说明
用户规模
选择渠道
推送策略
购买过纸尿裤的用户
曾经订购过纸尿裤的用户、按照RFM分群
8W
微信、短信
1、用户细分策略
(1)新用户:上个月第一次订购纸尿裤的用户
(2)高活跃高价值用户:前3个月内,购买次数>=3次 and 消费总金额>=600元 的用户(排除新用户)
(3)高活跃低价值用户:前3个月内,消费次数>=3次 and 消费总金额
(4)低活跃高价值用户:前3个月内,消费次数=600元 的用户(排除新用户)
(5)低活跃低价值用户:前3个月内,消费次数
(6)沉默用户:活跃度低(前3个月均没消费)
2、每月5号,15号推送老用户关爱的让利内容
3、活动型,做好老用户关爱
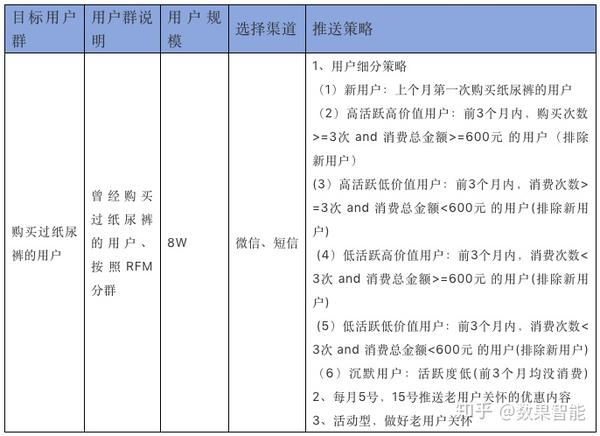
表2某纸尿裤电商的营销企划列表样例
同时,需要匹配用户最偏好的渠道进行营销推广,确保营销推广信息才能最大可能抵达用户的接触点。
另外,对于推送的营销脚本,也须要相关的营销人员进行合理设计,确保推广给用户的营销内容是顾客最想看的,确保营销的产品是用户最想要的。
只有做到将顾客最想要的产品通过最合适的渠道推广给最想要的顾客,才能确保用户的转化率达到不错的疗效。
第三、跟踪挖掘
在营销活动开始执行的时侯,需要设计科学的施行流程,并更好地借助数据进行监控,保障营销方案更好地落地。而针对精细化营销跟踪挖掘,怎样做,才能做得更好呢?结合个人先前所参与的精细化营销经验,可以归纳为以下几点:
第一点,需要结合跟踪指标数据,构建晚报、周报、月报三大类准实时监控,确保精细化营运。
日报:通过监控每日销售指标,通过其波动发觉三次系统故障;分解各种商品销售量波动,结合地域、时段及精推任务上线情况等指标,定位销售量波动缘由。
周报:重点关注剖析推送的转化率,通过推送类型、推送到达率,成功率,转化率等维度监控上行量、服务量、业务代办量、销售量及各个环节之间转化率波动,分析推送疗效及波动缘由,及时调整推送脚本及发送时间。
月报:老、新用户推送疗效,综合用户贡献度剖析订购产品目标客户群质量,明确下一步营运目标及措施。
第二点,利用漏斗剖析(如图5)可以针对用户每一步的转化进行实时监控。通过漏斗各环节业务数据的比较,能够直观地发觉和说明问题所在。
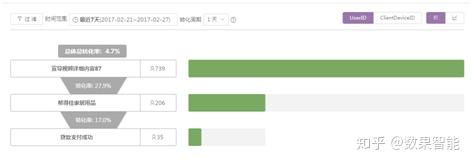
图5 漏斗剖析示例
第三点,根据“AIDA”(注:A-Attention 引发注意,I - Interest 提起兴趣,D-Desire提高欲望,A-Action 建议行动)原则持续迭代优化推送脚本,持续提高用户转化率。这个阶段,可以针对不同的营销脚本进行A/B测试,寻找推送最佳的营销脚本。
第四点,针对不同的营销推送时间进行比较,选择转化率最高的时间段,作为营销的关键推送时间节点。
第五点,可以结合不同的营销渠道进行多波次营销。
第四、评估优化
针对每一个精细化营销活动,都须要做好相应的营销疗效评估,及时调整营销策略,滚动优化营销方案。所以针对每一个营销活动,需要做好相应的营销评估的话,如图6所示,例如电商行业的营销活动评估优化,可以从以下几个方面进行考虑:
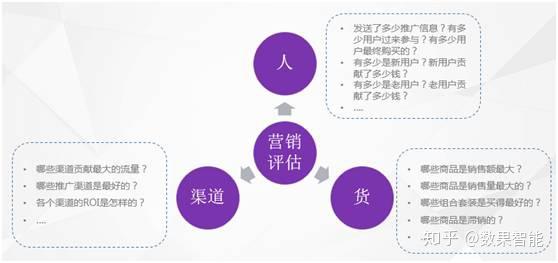
图6 基于人堆场的营销评估指标
1、人:这次活动发送了多少营销推广信息?最终有多少用户响应的?最终订购的有多少?用户转化率情况是如何的?另外,有多少是新用户?有多少是老用户?新用户贡献了多少钱?老用户贡献了多少钱?用户对营销活动的评价是如何的?满不满意?
2、货:哪些商品是销售额最大的?哪些商品是销售量最好的?哪些商品是没人关注的?哪些组合套装是最好买的…
3、渠道:哪些渠道贡献最大的流量?哪些推广渠道是最好的?ROI最好?
通过对每一次营销活动的疗效进行评估复盘,为下一次精细化营销活动举办做好相应的经验积累。
附:为了更好地帮助企业实现实时数据精细化营运,我们数果智能结合多年剖析及挖掘经验,从实时数据采集、实时多维剖析、实时数据可视化、实时数据业务场景应用出发,全流程塑造了一套数果智能产品,更好地使实时数据支撑企业精细化营运。
我们的产品特性(如图7):
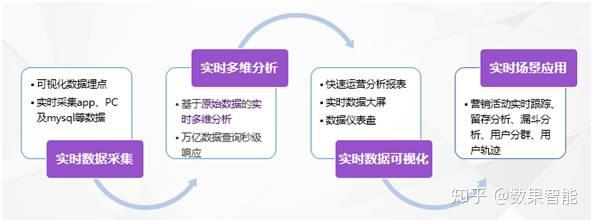
图7 数果智能产品功能特性
我们的实时剖析神器(如图8所示)
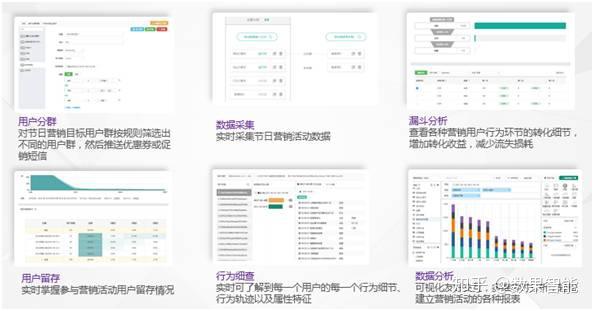
图8 数果智能产品功能明细
智能写作v2.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2020-08-12 07:45
- 文学作品创作思路
举一个撰写「关于饮食习惯」的文学作品的反例。
首先介绍一种量化小吃的思路,下图是一个小吃辣味网路,每个节点代表一种菜品,颜色代表所归属食物种类。节点大小反映了一种菜品在菜谱中的普遍性。如果两种调料有明显数目鲜味的化合物共享,则表示它们之间有关联,链接的粗细代表两种调料之间共享化合物的数目。
美食鲜味网路
回到我们的文学作品的建立思路,首先,采集微博文本内容;
其次,提取出用户饮食习惯等数据,主要使用动词、词性标明和依存复句剖析等NLP技术。那么怎么抽取出用户饮食习惯呢?主要是由三个条件组成的规则:
一条微博里富含成语“吃”;
与“吃”相关的复句关系为动宾关系;
“吃”的不定式为名词;
就可以判定发生饮食行为,进而提取出“吃”的不定式就是相关的食物,从而产生饮食习惯数据。
最后,重新组织语言,把用户的饮食习惯数据书写下来。
- 情感弧线
emotional arcs
此项技术可以帮助我们剖析故事的主要高潮和低潮。
作者使用了三种主要方式进行《哈利·波特》的情感弧线剖析:奇异值分解(singular value decomposition);以 Ward 的方式形成故事的分层降维;以及自组织映射机器学习方法来降维情感弧线。情感弧线是通过使用 和 labMT 数据集剖析滑动10000字窗口的情绪而打造的。
另外 网站还提供了许多其他书籍、故事、电影剧本以及Twitter的交互可视化情感弧线。- 新型书籍的手动生成
在没有人工参与的情况下,自动生成整本维基教科书;
这部份是来源于Wikibook-bot的一项技术,是由以色列内盖夫本古里安大学的沙哈尔阿德马蒂Shahar Admati 及其朋友开发的;
主要的流程如下:
首先,准备一组现有的维基教科书,用作训练数据集,数量级在6000本以上。
其次,进行数据清洗,规则是:
1 关注浏览量超过 1000 次的教科书;
2 涵盖超过十个章节
第三,生成标题,该标题用以描述某种概念。
第四,文章清洗,规则类似于pagerank的原理,文章通常通过超链接指向其他文章,在网路上采集出通过点击超链接三次以内得到的所有文章作为优质的文章。每本人工维基教科书都有自己的网路结构,其决定诱因包括,引用该文的文章链接数目、指向其他文章的链接数目、所收录文章的页面排行列表等。
第五,文章分类,对所有维基百科文章进行分类;
第六,每一个类别主题对应的文章的再度清洗,该算法会查看每一篇给定主题筛选下来的文章,接着判定假如将其添加到维基教科书中是否会使该书的网路结构与人工创作的书籍更相像。如果不相像,那么该文章就会排除在外。
第七,将每一个类别主题对应的文章组织成章节。主要依靠聚类算法,结合由整组文章组成的网路,找出怎样将其界定为连贯的集群。
第八,确定文章在每位章节中的出现次序。使用的是枚举,然后排序的思路,通过给文章成对分组,对所有文章枚举所有组合,然后使用网路模型来估算排序逻辑,最终估算出更为理想的文章顺序以及章节次序。
感兴趣可以详尽阅读论文:
- 主要涉及的NLP技术
NLP
自然语言处理
为了实现写作类的应用,需要对文本进行大量的处理,NLP是一种使机器能否象我们平时那样阅读和理解语言的技术。常常会结合知识图谱来使用,以提高产品疗效。
我们须要把握NLP的常见任务及算法。
- 主要的NLP任务
文本分类、情感剖析、分词、依存复句剖析、实体辨识等;
- 深度学习算法
目前深度学习有以下典型的算法,可以一一详尽了解把握;
参考地址
- GPT2这儿要举一个反例,在大受欢迎的 reddit 社区中,一个名为 SubSimulatorGPT2 的子讨论小组愈发引人注目:其内容完全由人工智能聊天机器人模仿各类讨论小组的风格生成后发布。SubSimulatorGPT2
早期的SubredditSimulator()的机器人使用马尔科夫链,这是一种成熟的生成序列的技术。
- 马尔可夫链和N-gram马尔科夫链的假定(第一性原理)。基于马尔可夫链的模型假设语句中的每位词组仅取决于其后面的几个词组。因此,给定任意语句的机率为组成该语句的所有n-gram(n个词组的序列)的组合机率。下图说明了该概念:
以Python 语言为例,采用字典(Dictionary)的数据结构。
d = {key1 : value1, key2 : value2 }
键名是当前的词组,键值是一个列表List,存储当前词组的下一个词组。
d = {word1 : [word2,word3], word2 : [word3,word4,word5] }
具体的事例,有如此两句话:
I like to eat orangesYou eat apples
我们希望通过马尔科夫链来学习以上数据,经过估算,模型为:
{'START': ['i','you'],'i': ['like'],'like': ['to'],'to': ['eat'],'you': ['eat'],'eat': ['apples','oranges'],'END': ['apples','oranges']}
我们不需要估算下一个词组出现的机率,因为假如它们出现的机率较大,那么她们会在选定下个词组的列表中出现好几次。采用适当的数据结构,问题也得到了简化的处理。
- 词嵌入和神经语言模型
词嵌入是现今NLP中任何人都必学的第一项技术:将词投射到多维空间中。它的优势在于,具有相像用法/含义的词组会获得相像的向量(按正弦相似度评判)。因此,涉及相像词组的词组向量的矩阵加法趋向给出相像的结果。
何为余弦相似度?在NLP的任务里,会对生成两个词向量进行相似度的估算,常常采用余弦相似度公式估算。余弦相似度用向量空间中两个向量倾角的正弦值作为评判两个个体间差别的大小。余弦值越接近1,就表明倾角越接近0度,也就是两个向量越相像,这就叫"余弦相似性"。
这是基于神经网路的语言模型的基础。有趣的是,神经模型不估算出现次数来确定机率,而是学习可以为任何输入估算出它们的参数(权重矩阵和误差)。这样,甚至可以为我们未曾见过的n个句型以后的下一个词组估算一个合理的机率分布。下图是一个最简单的神经网路:MLP (multilayer perceptron) 多层感知器。
- 递归神经网络
随着递归神经网络(RNN)的出现,特别是长短期记忆(LSTM)的出现,语言生成方面获得了更大进步。与之前提及的最简单的神经网路不同,RNN的上下文除了限于n个词组;它甚至没有理论上的限制。
RNN的主要改进在于保留了内部状态。因此,RNN可以不停地逐条读取词组,从而更新其内部状态以反映当前上下文,而不是只看固定的窗口(n个词组)。
使用RNN的文本生成以自回归方法遵守与马尔可夫链相像的原理。RNN对第一个词组进行取样,将其送到神经网路以获取下一个词组的机率,然后再对下一个词组进行取样,依此类推,直到语句结束为止。如下图所示,依次学习The、boys、that、came词组的过程。
Internal State类似于脑部(黑箱),记录了所有复杂的文本信息。
- 注意力机制
在形成下一个输出之前,先回顾所有以前的词组。计算注意力本质上是指估算过去词组的某种分布,然后将这种词组的向量与接收到的注意力成比列地进行聚合。下图说明了该概念。
注意机制让RNN可以回顾以前词组的输出,而不必定所有内容压缩为隐藏状态。中间输出之前的压缩RNN块与不注意时的块相同。
- Transformer
Transformer是一种神经网路构架,于2017年推出,旨在解决RNN的缺点。它的关键思想是完全借助注意力,以至根本不需要内部状态或循环。下图是Transformer的简化的描述。实际的构架十分复杂,您可以在查阅相关文章找到更详尽的解释 。
- GPT模型
回到前文所提及的GPT2,GPT全称Generative Pre-Training,出自2018年OpenAI的论文《Improving Language Understandingby Generative Pre-Training》,论文地址:
~amuham01/LING530/papers/radford2018improving.pdf
GPT是一种半监督学习方法,它致力于用大量无标明数据使模型学习“常识”,以减轻标明信息不足的问题。详细可以阅读论文深入了解。
- 人工智能辅助写作
一些相关产品。Grammarly在线写作网站
Grammarly是一款全手动英语写作工具, 可以实时检测句型,一边写一边改,语法问题和更改意见会以标明的方式显示在文档的两侧,方便用户去一一查看,而且在每条批注下边就会配有详尽的解释,告诉用户那里错了,为什么要这样更改。
百度创作脑部
百度人工智能写作辅助平台“创作脑部”,智能助手可以为人类创作者提供纠错、提取信息等各类辅助工作。
GET智能写作
一站式智能写作服务平台。全网热点追踪、推荐海量素材、提升原创质量。
- 算法新闻、机器人记者目前在这个领域领先的有美国的2家公司:
自动化洞察力公司 Automated Insights
叙述科学公司 Narrative Science
我们先来了解下算法新闻的导论。
- 算法新闻导论美国的初期创业公司,如今的佼佼者
早在2007年,美国的「自动化洞察力」Automated Insights公司创立;
2009年,美国西北大学研制的StatsMonkey「统计猴子」系统就撰写了一篇关于美国职业棒球大联盟西决的新闻稿件;
2010年,「叙述科学」公司Narrative Science创立;
由机器人记者主导的新闻行业正在迅速崛起
在2014年,美联社与Automated Insight公司达成协议,成为机器人记者的初期的采用者。
2014年3月,第一条完全由计算机程序生产的新闻报导形成。作为首家“聘用”机器人记者的主流媒体,《洛杉矶时报(LA Times)》在水灾发生后3分钟就发布了首列相关新闻。
在这一年,机器人写稿技术研制公司Automated Insight全年生产了10亿条新闻。
在2015年,新华社推出可以批量编撰新闻的写作机器人「快笔小新」;
同年9月,腾讯财经发布写作机器人「Dreamwriter」;
1年后,中国湖北广播电视台长江云新闻客户端就派出人代会机器人记者“云朵”进行专访。
第一财经也发布写作机器人「DT稿王」
同年,国外挪威新闻社NTB启动机器人,开始着手制做自动化篮球新闻报导项目;
自动化新闻早已通过手动新闻写作和发行步入新闻编辑室
2017年1月,南方都市报社写作机器人「小南」正式上岗,推出第一篇共300余字的春运报导。
……
以上为算法新闻导论。
我们须要晓得「机器人记者」并不是真正的职业记者,而是一种新闻报导软件,拥有手动撰写新闻故事的功能。相类似的概念有算法新闻、自动新闻。
媒体通常还会形象地,描述机器人记者在媒体单位“上班”,机器人具备“真人记者”所有的采编功能,不会出错,不用休息,所写的文章不仅时效性强,质量也高,工作效率比“真人记者”高出好几倍。
- 经典产品「机器人记者」
由日本表述科学公司Narrative Science发明的写作软件;这个软件拥有手动撰写新闻故事的功能。
基于选题和新闻热点追踪,通过平台授权,结构化采集、处理、分类、分析原创数据素材,快速抓取,生成新闻关键词或线索,然后,利用文本剖析和信息抽取技术,以模板和规则知识库的形式,自动生成完整的新闻报导。
尤其在体育比赛,金融经济,财报数据等方面作用突出。
- 2018年数据新闻创新奖《搜索侦察机》
记者彼得奥尔德乌斯Peter Aldhous,开发了这个项目,他使用了机器学习——特别是「随机森林random forest」算法,从大量的客机飞行数据中,建立了一个模型,可以按照以下数据:
飞机的拐弯速度
飞行速度
飞行高度
每条飞行路径周围的圆形区域
飞行持续时间
识别出可能是“隐藏身分的侦察机”。
- 各大报社、杂志社的应用
国内有人民日报「小端」、光明日报「小明」、今日头条「张小明」、南方都市报「小南」等等。近期新华智云的更新是业内比较大的动作。
新华智云
作为新华社和阿里巴巴集团共同投资创立的大数据人工智能科技公司,于2019年发布了“媒体脑部3.0”。以区块链技术和AI初审为明显特点,为内容工作者提供“策、采、编、发、审、存”全流程赋能,为媒体机构、宣传部门、企业单位各种融媒体中心提供方便、高效、智能的数据中台和内容生产平台。
新华社「快笔小新」
「快笔小新」的写稿流程由数据采集、数据剖析、生成稿件、编发四个环节组成,这一机器人适用于体育比赛、经济行情、证券信息等快讯、简讯类稿件的写作。
腾讯「DREAMWRITER」
腾讯在2015年9月推出了一个叫 Dreamwriter 自动化新闻写作机器人。最开始,这项技术主要用在财经领域,现在它在体育比赛的快速报导中也有太成功的应用案例了。
2016年里约奥运会期间,Dreamwriter 就手动撰写了3000多篇实时战报,是亚运媒体报导团的“效率之王”。
在“2017腾讯媒体+峰会”现场,Dreamwriter 平均单篇成文速率仅为0.5秒,一眨眼的时间就写了14篇稿件。
国外的应用主要如下:
《卫报》
使用机器人辅助写作,并发表了一篇名为《Political donations plunge to $16.7m – down from average $25m a year》
《华盛顿邮报》
Heliograf机器人记者,在报导2016年夏天奥运会和2016年补选时证明了它的有用性;
还帮助《华盛顿邮报》在一年一度的全球大奖中获得了「巧妙使用机器人奖Excellence in Use of Bots」
《 Guardian》
2014年,英国《 Guardian》进行了纸质测试计划,安排“机器人”统计剖析社交网络上的共享热点和注意力加热,然后内容过滤、编辑排版和复印,最后制做一份报纸。
《华尔街日报》
应用于金融投资研究报告片断的节选,网站会提醒读者那一段节选是由机器人完成的,哪些是由人类完成的。主要节选类似于以下的文字:
第二季度的现金节余8.3亿美元,这意味着在第一季度降低1.4亿美元以后,第二季度又消耗了8000万美元
Q2 cash balance expectation of $830m implies ~$80m of cash burn in Q2 after a $140m reduction in cash balance in Q1
这句话实际上只收录了三个数据点,并使用特定的句型合并在一起,而且不收录任何巧合的成份。
《洛杉矶时报》
《洛杉矶时报》靠「机器人写手」,第一时间报导了美国加州2014年3月18日当地时间清晨发生4.4级水灾;还应用于对犯罪时间错误归类的剖析。
《纽约时报》
《纽约时报》对美国国会议长的图象辨识;还应用机器人编辑Blossom预测什么文章有可能会在社交网站上导致传播,相应地给版面责任编辑提出建议;
《福布斯》
2011年,开始使用表述科学公司 Narrative Science 的手动写稿程序来撰写新闻;
彭博社
应用机器人系统Cyborg,帮助记者在每位季度进行大量的文章撰写,数量达到数千篇,包括各公司的财报文章等。机器人可以在财报出现的一瞬间就对其进行详尽的分析,并且提供收录那些相关事实和数据的实时新闻报导,速度十分迅速。
美联社
从2014年7月开始使用语言大师 Wordsmith 软件,利用自动化技术来写公司财务报表。几毫秒的时间,软件能够写出一篇路透社风格的完整报导。
- 技术进展
从早些年的以摘选稿件中诗句为主,过渡到现今全流程的方法。- 人形机器人
结合硬件,还有人形机器人版本的机器人记者的出现,例如中国智能机器人佳佳作为新华社特约记者越洋专访了日本知名科技观察家凯文·凯利。这是全球首次由高仿真智能机器人作为记者与人进行交互对话,专家觉得具有标志性意义。
- 新媒体与人工智能写作
按照英国新媒体艺术理论家马诺维奇(Lev Manovich)在《新媒体语言》一书中对新媒体技术所下的定义:
所有现存媒体通过笔记本转换成数字化的数据、照片、动态形象、声音、形状空间和文本,且都可以估算,构成一套笔记本数据的,这就是新媒体。
这是一个艺术与科技跨界结合的领域,我们可以关注国内的大牛:
MIT的Nick Montfort院士
国际上被公认为作家和通过估算探求语言的人
他撰写了大量互动小说文章,发布在博客Grand Text Auto上,同时也开发了许多数字诗和文本生成器。他近来的着作是「The Future」和「The Truelist」,有兴趣可以去了解下他的研究。
下面给你们介绍典型的案例。
- 互动小说与新型文学作品的创作
2016年,人工智能创作的小说在美国「星新一文学奖」上被评委称为「情节无纰漏」。人工智能应用于文学创作领域,为文学作品带来了新鲜血液,与文学作品的结合还平添了作品的互动性,与游戏、电影形成了跨界交融。互动故事平台
加拿大温哥华的互动故事平台Wattpad
其产品包括匹配创作者和读者的机器写作,识别故事“趋势”,根据主题进行创意写作等;还开发了视频讲故事的应用「Raccoon」; 查看全部
第四,输出一个在线Flash短片,用q版人物形象模仿传统的午间新闻广播方式,来向用户播放内容。
- 文学作品创作思路
举一个撰写「关于饮食习惯」的文学作品的反例。
首先介绍一种量化小吃的思路,下图是一个小吃辣味网路,每个节点代表一种菜品,颜色代表所归属食物种类。节点大小反映了一种菜品在菜谱中的普遍性。如果两种调料有明显数目鲜味的化合物共享,则表示它们之间有关联,链接的粗细代表两种调料之间共享化合物的数目。
美食鲜味网路
回到我们的文学作品的建立思路,首先,采集微博文本内容;
其次,提取出用户饮食习惯等数据,主要使用动词、词性标明和依存复句剖析等NLP技术。那么怎么抽取出用户饮食习惯呢?主要是由三个条件组成的规则:
一条微博里富含成语“吃”;
与“吃”相关的复句关系为动宾关系;
“吃”的不定式为名词;
就可以判定发生饮食行为,进而提取出“吃”的不定式就是相关的食物,从而产生饮食习惯数据。
最后,重新组织语言,把用户的饮食习惯数据书写下来。
- 情感弧线
emotional arcs
此项技术可以帮助我们剖析故事的主要高潮和低潮。
作者使用了三种主要方式进行《哈利·波特》的情感弧线剖析:奇异值分解(singular value decomposition);以 Ward 的方式形成故事的分层降维;以及自组织映射机器学习方法来降维情感弧线。情感弧线是通过使用 和 labMT 数据集剖析滑动10000字窗口的情绪而打造的。
另外 网站还提供了许多其他书籍、故事、电影剧本以及Twitter的交互可视化情感弧线。- 新型书籍的手动生成
在没有人工参与的情况下,自动生成整本维基教科书;
这部份是来源于Wikibook-bot的一项技术,是由以色列内盖夫本古里安大学的沙哈尔阿德马蒂Shahar Admati 及其朋友开发的;
主要的流程如下:
首先,准备一组现有的维基教科书,用作训练数据集,数量级在6000本以上。
其次,进行数据清洗,规则是:
1 关注浏览量超过 1000 次的教科书;
2 涵盖超过十个章节
第三,生成标题,该标题用以描述某种概念。
第四,文章清洗,规则类似于pagerank的原理,文章通常通过超链接指向其他文章,在网路上采集出通过点击超链接三次以内得到的所有文章作为优质的文章。每本人工维基教科书都有自己的网路结构,其决定诱因包括,引用该文的文章链接数目、指向其他文章的链接数目、所收录文章的页面排行列表等。
第五,文章分类,对所有维基百科文章进行分类;
第六,每一个类别主题对应的文章的再度清洗,该算法会查看每一篇给定主题筛选下来的文章,接着判定假如将其添加到维基教科书中是否会使该书的网路结构与人工创作的书籍更相像。如果不相像,那么该文章就会排除在外。
第七,将每一个类别主题对应的文章组织成章节。主要依靠聚类算法,结合由整组文章组成的网路,找出怎样将其界定为连贯的集群。
第八,确定文章在每位章节中的出现次序。使用的是枚举,然后排序的思路,通过给文章成对分组,对所有文章枚举所有组合,然后使用网路模型来估算排序逻辑,最终估算出更为理想的文章顺序以及章节次序。
感兴趣可以详尽阅读论文:
- 主要涉及的NLP技术
NLP
自然语言处理
为了实现写作类的应用,需要对文本进行大量的处理,NLP是一种使机器能否象我们平时那样阅读和理解语言的技术。常常会结合知识图谱来使用,以提高产品疗效。
我们须要把握NLP的常见任务及算法。
- 主要的NLP任务
文本分类、情感剖析、分词、依存复句剖析、实体辨识等;
- 深度学习算法
目前深度学习有以下典型的算法,可以一一详尽了解把握;
参考地址
- GPT2这儿要举一个反例,在大受欢迎的 reddit 社区中,一个名为 SubSimulatorGPT2 的子讨论小组愈发引人注目:其内容完全由人工智能聊天机器人模仿各类讨论小组的风格生成后发布。SubSimulatorGPT2
早期的SubredditSimulator()的机器人使用马尔科夫链,这是一种成熟的生成序列的技术。
- 马尔可夫链和N-gram马尔科夫链的假定(第一性原理)。基于马尔可夫链的模型假设语句中的每位词组仅取决于其后面的几个词组。因此,给定任意语句的机率为组成该语句的所有n-gram(n个词组的序列)的组合机率。下图说明了该概念:
以Python 语言为例,采用字典(Dictionary)的数据结构。
d = {key1 : value1, key2 : value2 }
键名是当前的词组,键值是一个列表List,存储当前词组的下一个词组。
d = {word1 : [word2,word3], word2 : [word3,word4,word5] }
具体的事例,有如此两句话:
I like to eat orangesYou eat apples
我们希望通过马尔科夫链来学习以上数据,经过估算,模型为:
{'START': ['i','you'],'i': ['like'],'like': ['to'],'to': ['eat'],'you': ['eat'],'eat': ['apples','oranges'],'END': ['apples','oranges']}
我们不需要估算下一个词组出现的机率,因为假如它们出现的机率较大,那么她们会在选定下个词组的列表中出现好几次。采用适当的数据结构,问题也得到了简化的处理。
- 词嵌入和神经语言模型
词嵌入是现今NLP中任何人都必学的第一项技术:将词投射到多维空间中。它的优势在于,具有相像用法/含义的词组会获得相像的向量(按正弦相似度评判)。因此,涉及相像词组的词组向量的矩阵加法趋向给出相像的结果。
何为余弦相似度?在NLP的任务里,会对生成两个词向量进行相似度的估算,常常采用余弦相似度公式估算。余弦相似度用向量空间中两个向量倾角的正弦值作为评判两个个体间差别的大小。余弦值越接近1,就表明倾角越接近0度,也就是两个向量越相像,这就叫"余弦相似性"。
这是基于神经网路的语言模型的基础。有趣的是,神经模型不估算出现次数来确定机率,而是学习可以为任何输入估算出它们的参数(权重矩阵和误差)。这样,甚至可以为我们未曾见过的n个句型以后的下一个词组估算一个合理的机率分布。下图是一个最简单的神经网路:MLP (multilayer perceptron) 多层感知器。
- 递归神经网络
随着递归神经网络(RNN)的出现,特别是长短期记忆(LSTM)的出现,语言生成方面获得了更大进步。与之前提及的最简单的神经网路不同,RNN的上下文除了限于n个词组;它甚至没有理论上的限制。
RNN的主要改进在于保留了内部状态。因此,RNN可以不停地逐条读取词组,从而更新其内部状态以反映当前上下文,而不是只看固定的窗口(n个词组)。
使用RNN的文本生成以自回归方法遵守与马尔可夫链相像的原理。RNN对第一个词组进行取样,将其送到神经网路以获取下一个词组的机率,然后再对下一个词组进行取样,依此类推,直到语句结束为止。如下图所示,依次学习The、boys、that、came词组的过程。
Internal State类似于脑部(黑箱),记录了所有复杂的文本信息。
- 注意力机制
在形成下一个输出之前,先回顾所有以前的词组。计算注意力本质上是指估算过去词组的某种分布,然后将这种词组的向量与接收到的注意力成比列地进行聚合。下图说明了该概念。
注意机制让RNN可以回顾以前词组的输出,而不必定所有内容压缩为隐藏状态。中间输出之前的压缩RNN块与不注意时的块相同。
- Transformer
Transformer是一种神经网路构架,于2017年推出,旨在解决RNN的缺点。它的关键思想是完全借助注意力,以至根本不需要内部状态或循环。下图是Transformer的简化的描述。实际的构架十分复杂,您可以在查阅相关文章找到更详尽的解释 。
- GPT模型
回到前文所提及的GPT2,GPT全称Generative Pre-Training,出自2018年OpenAI的论文《Improving Language Understandingby Generative Pre-Training》,论文地址:
~amuham01/LING530/papers/radford2018improving.pdf
GPT是一种半监督学习方法,它致力于用大量无标明数据使模型学习“常识”,以减轻标明信息不足的问题。详细可以阅读论文深入了解。
- 人工智能辅助写作
一些相关产品。Grammarly在线写作网站
Grammarly是一款全手动英语写作工具, 可以实时检测句型,一边写一边改,语法问题和更改意见会以标明的方式显示在文档的两侧,方便用户去一一查看,而且在每条批注下边就会配有详尽的解释,告诉用户那里错了,为什么要这样更改。
百度创作脑部
百度人工智能写作辅助平台“创作脑部”,智能助手可以为人类创作者提供纠错、提取信息等各类辅助工作。
GET智能写作
一站式智能写作服务平台。全网热点追踪、推荐海量素材、提升原创质量。
- 算法新闻、机器人记者目前在这个领域领先的有美国的2家公司:
自动化洞察力公司 Automated Insights
叙述科学公司 Narrative Science
我们先来了解下算法新闻的导论。
- 算法新闻导论美国的初期创业公司,如今的佼佼者
早在2007年,美国的「自动化洞察力」Automated Insights公司创立;
2009年,美国西北大学研制的StatsMonkey「统计猴子」系统就撰写了一篇关于美国职业棒球大联盟西决的新闻稿件;
2010年,「叙述科学」公司Narrative Science创立;
由机器人记者主导的新闻行业正在迅速崛起
在2014年,美联社与Automated Insight公司达成协议,成为机器人记者的初期的采用者。
2014年3月,第一条完全由计算机程序生产的新闻报导形成。作为首家“聘用”机器人记者的主流媒体,《洛杉矶时报(LA Times)》在水灾发生后3分钟就发布了首列相关新闻。
在这一年,机器人写稿技术研制公司Automated Insight全年生产了10亿条新闻。
在2015年,新华社推出可以批量编撰新闻的写作机器人「快笔小新」;
同年9月,腾讯财经发布写作机器人「Dreamwriter」;
1年后,中国湖北广播电视台长江云新闻客户端就派出人代会机器人记者“云朵”进行专访。
第一财经也发布写作机器人「DT稿王」
同年,国外挪威新闻社NTB启动机器人,开始着手制做自动化篮球新闻报导项目;
自动化新闻早已通过手动新闻写作和发行步入新闻编辑室
2017年1月,南方都市报社写作机器人「小南」正式上岗,推出第一篇共300余字的春运报导。
……
以上为算法新闻导论。
我们须要晓得「机器人记者」并不是真正的职业记者,而是一种新闻报导软件,拥有手动撰写新闻故事的功能。相类似的概念有算法新闻、自动新闻。
媒体通常还会形象地,描述机器人记者在媒体单位“上班”,机器人具备“真人记者”所有的采编功能,不会出错,不用休息,所写的文章不仅时效性强,质量也高,工作效率比“真人记者”高出好几倍。
- 经典产品「机器人记者」
由日本表述科学公司Narrative Science发明的写作软件;这个软件拥有手动撰写新闻故事的功能。
基于选题和新闻热点追踪,通过平台授权,结构化采集、处理、分类、分析原创数据素材,快速抓取,生成新闻关键词或线索,然后,利用文本剖析和信息抽取技术,以模板和规则知识库的形式,自动生成完整的新闻报导。
尤其在体育比赛,金融经济,财报数据等方面作用突出。
- 2018年数据新闻创新奖《搜索侦察机》
记者彼得奥尔德乌斯Peter Aldhous,开发了这个项目,他使用了机器学习——特别是「随机森林random forest」算法,从大量的客机飞行数据中,建立了一个模型,可以按照以下数据:
飞机的拐弯速度
飞行速度
飞行高度
每条飞行路径周围的圆形区域
飞行持续时间
识别出可能是“隐藏身分的侦察机”。
- 各大报社、杂志社的应用
国内有人民日报「小端」、光明日报「小明」、今日头条「张小明」、南方都市报「小南」等等。近期新华智云的更新是业内比较大的动作。
新华智云
作为新华社和阿里巴巴集团共同投资创立的大数据人工智能科技公司,于2019年发布了“媒体脑部3.0”。以区块链技术和AI初审为明显特点,为内容工作者提供“策、采、编、发、审、存”全流程赋能,为媒体机构、宣传部门、企业单位各种融媒体中心提供方便、高效、智能的数据中台和内容生产平台。
新华社「快笔小新」
「快笔小新」的写稿流程由数据采集、数据剖析、生成稿件、编发四个环节组成,这一机器人适用于体育比赛、经济行情、证券信息等快讯、简讯类稿件的写作。
腾讯「DREAMWRITER」
腾讯在2015年9月推出了一个叫 Dreamwriter 自动化新闻写作机器人。最开始,这项技术主要用在财经领域,现在它在体育比赛的快速报导中也有太成功的应用案例了。
2016年里约奥运会期间,Dreamwriter 就手动撰写了3000多篇实时战报,是亚运媒体报导团的“效率之王”。
在“2017腾讯媒体+峰会”现场,Dreamwriter 平均单篇成文速率仅为0.5秒,一眨眼的时间就写了14篇稿件。
国外的应用主要如下:
《卫报》
使用机器人辅助写作,并发表了一篇名为《Political donations plunge to $16.7m – down from average $25m a year》
《华盛顿邮报》
Heliograf机器人记者,在报导2016年夏天奥运会和2016年补选时证明了它的有用性;
还帮助《华盛顿邮报》在一年一度的全球大奖中获得了「巧妙使用机器人奖Excellence in Use of Bots」
《 Guardian》
2014年,英国《 Guardian》进行了纸质测试计划,安排“机器人”统计剖析社交网络上的共享热点和注意力加热,然后内容过滤、编辑排版和复印,最后制做一份报纸。
《华尔街日报》
应用于金融投资研究报告片断的节选,网站会提醒读者那一段节选是由机器人完成的,哪些是由人类完成的。主要节选类似于以下的文字:
第二季度的现金节余8.3亿美元,这意味着在第一季度降低1.4亿美元以后,第二季度又消耗了8000万美元
Q2 cash balance expectation of $830m implies ~$80m of cash burn in Q2 after a $140m reduction in cash balance in Q1
这句话实际上只收录了三个数据点,并使用特定的句型合并在一起,而且不收录任何巧合的成份。
《洛杉矶时报》
《洛杉矶时报》靠「机器人写手」,第一时间报导了美国加州2014年3月18日当地时间清晨发生4.4级水灾;还应用于对犯罪时间错误归类的剖析。
《纽约时报》
《纽约时报》对美国国会议长的图象辨识;还应用机器人编辑Blossom预测什么文章有可能会在社交网站上导致传播,相应地给版面责任编辑提出建议;
《福布斯》
2011年,开始使用表述科学公司 Narrative Science 的手动写稿程序来撰写新闻;
彭博社
应用机器人系统Cyborg,帮助记者在每位季度进行大量的文章撰写,数量达到数千篇,包括各公司的财报文章等。机器人可以在财报出现的一瞬间就对其进行详尽的分析,并且提供收录那些相关事实和数据的实时新闻报导,速度十分迅速。
美联社
从2014年7月开始使用语言大师 Wordsmith 软件,利用自动化技术来写公司财务报表。几毫秒的时间,软件能够写出一篇路透社风格的完整报导。
- 技术进展
从早些年的以摘选稿件中诗句为主,过渡到现今全流程的方法。- 人形机器人
结合硬件,还有人形机器人版本的机器人记者的出现,例如中国智能机器人佳佳作为新华社特约记者越洋专访了日本知名科技观察家凯文·凯利。这是全球首次由高仿真智能机器人作为记者与人进行交互对话,专家觉得具有标志性意义。
- 新媒体与人工智能写作
按照英国新媒体艺术理论家马诺维奇(Lev Manovich)在《新媒体语言》一书中对新媒体技术所下的定义:
所有现存媒体通过笔记本转换成数字化的数据、照片、动态形象、声音、形状空间和文本,且都可以估算,构成一套笔记本数据的,这就是新媒体。
这是一个艺术与科技跨界结合的领域,我们可以关注国内的大牛:
MIT的Nick Montfort院士
国际上被公认为作家和通过估算探求语言的人
他撰写了大量互动小说文章,发布在博客Grand Text Auto上,同时也开发了许多数字诗和文本生成器。他近来的着作是「The Future」和「The Truelist」,有兴趣可以去了解下他的研究。
下面给你们介绍典型的案例。
- 互动小说与新型文学作品的创作
2016年,人工智能创作的小说在美国「星新一文学奖」上被评委称为「情节无纰漏」。人工智能应用于文学创作领域,为文学作品带来了新鲜血液,与文学作品的结合还平添了作品的互动性,与游戏、电影形成了跨界交融。互动故事平台
加拿大温哥华的互动故事平台Wattpad
其产品包括匹配创作者和读者的机器写作,识别故事“趋势”,根据主题进行创意写作等;还开发了视频讲故事的应用「Raccoon」;
有关文章地址采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-08-09 21:27
课程演示环境:Ubuntu须要学习Windows系统YOLOv4的朋友请抵达《Windows版YOLOv4目标测量实战:训练自己的数据集》,课程链接YOLOv4来了!速度和精度双提高!与 YOLOv3 相比,新版本的 AP(精度)和 FPS (每秒帧数)分别提升了 10% 和 12%。YOLO系列是基于深度学习的端到端实时目标测量方式。本课程将手把手地教你们使用labelImg标明和使用YOLOv4训练自己的数据集。课程实战分为两个项目:单目标测量(足球目标测量)和多目标测量(足球和梅西同时测量)。本课程的YOLOv4使用AlexAB/darknet,在Ubuntu系统上做项目演示。包括:安装YOLOv4、标注自己的数据集、整理自己的数据集、修改配置文件、训练自己的数据集、测试训练出的网路模型、性能统计(mAP估算和画出PR曲线)和先验框降维剖析。还将介绍改善YOLOv4目标训练性能的方法。除本课程《YOLOv4目标测量实战:训练自己的数据集》外,本人将推出有关YOLOv4目标测量的系列课程。请持续关注该系列的其它视频课程,包括:《YOLOv4目标测量实战:人脸口罩配戴辨识》《YOLOv4目标测量实战:中国交通标志辨识》《YOLOv4目标测量:原理与源码解析》
详细说明如何使用百度智能写作平台,快速撰写文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 763 次浏览 • 2020-08-08 15:38
您好,欢迎使用由百度自然语言处理和知识图谱共同创建的百度智能写作服务平台,以成为最了解您的智能写作助手.
百度大脑智能写作服务提供两种功能: 自动写作和辅助写作. 自动写入支持从数据到文本描述的自动生成,也就是说,当输入源是数据和文本模板时,输出是自然语言文本. 辅助写作从资料采集,文章写作和文章检查的角度为用户提供辅助功能.
接下来,您只需要快速浏览以下介绍即可完成自动或辅助写作需求.
快速入门
在Smart Writing主页上输入平台,整个过程将按照右侧内容列的顺序进行. 下面将详细介绍每个步骤的操作方法和注意事项(如果遇到问题但在本文档中找不到答案,可以加入官方QQ群组(群组编号: 743926523)来咨询群组管理).
编写项目管理来创建项目
登录到Smart Writing主页,单击“ +”按钮创建一个项目,您可以通过此页面和右上角的控制台来管理所有项目.
或在项目界面的“一个项目”管理中,该卡收录项目名称,创建时间,项目描述和其他信息.
选择写作类型
您可以根据自己的使用场景选择一种类型,并轻松创建项目. 写作项目类型分为自动写作和辅助写作. 在自动写入类型中,可以使用平台预设模板或自定义API数据源. 辅助写作从三个方面为用户提供帮助: 资料采集,文章写作和文章审阅. 此功能仅支持平台上的在线编辑.
用于自动编写项目的预设模板
此处预设了四个模板: 天气预报写作,股市报告,足球比赛报告,篮球比赛报告,可直接使用. 如果您还有其他业务数据,还可以选择一个模板来完成创建.
输入项目名称,选择文字类型,并建议输入场景简介以完成项目创建.
自定义项目模板
如果现有的官方模板中没有与您的使用场景相匹配的模板,请根据业务场景配置自定义写作模板,添加自定义模板,并上传数据变量以快速实现批处理和自动文章生成功能.
在实际的数据源添加过程中,我们提供两种形式
* 添加Excel数据文件
* 接入API接口数据源
添加数据源
1. Excel数据导入
a)要选择Excel数据,请上传本地Excel数据文件,然后单击“下载演示”以查看格式.
b)上传后,单击“下一步”,选择此模板以使用数据,保存后,您可以进入文章编辑界面开始创建.
Excel数据导入说明
添加数据源时,需要将其上传到平台系统. 数据的第一行是数据变量的名称,可以是日期,位置,温度等. 在自定义模板中选择数据变量时,第一行的名称将用作数据的名称变量.
自定义模板时,请使用数据变量嵌入纯文本内容,或将变量用于分支派生和其他功能. 其他行代表生成文章时使用的数据. 生成文章时,如果excel中有3行数据,则将为每个模板生成3条文章. 第一篇文章将使用第一行数据,第二篇文章将使用第二行...最终生成的文章将显示在“ Generation Records”页面上,您可以单击下载.
2. 访问API接口数据源
a)要选择API数据,您需要提供数据源地址,数据源名称和数据源配置文件. 有关规范,请参阅此页面顶部的“ API接口数据源描述”.
b)需要选择数据变量. 同时,您可以在此处重命名数据变量,以方便后续的变量管理.
API接口数据源描述
添加数据源时,需要将API接口地址提供给平台. 该界面仅支持获取请求. 例如:
“http://xxx.xxx.com/get_data?city=北京”
该参数可以为空. 接口参数将调用结构化数据写入接口,并在生成API时传递这些参数;该数字为空,没有必要通过.
接口返回结果需要UTF-8编码,并且为json字符串格式. 如:
{"err_code":0,"err_msg":"\u6210\u529f","data":{"title":"\u6587\u7ae0\u6807
\u9898","summary":"\u6587\u7ae0\u6458\u8981"}}
API接口返回的数据将成为模板编写和文章生成的数据源. 添加后选择数据变量时,将解析数据源接口返回的结果,并且返回的字段将是数据变量的名称. 在对平台接口的实际调用中,数据源接口返回到结果,该结果将提供用于生成文章的变量的数据.
智能字段
智能字段包括: 数据变量,同义词,分支推导. 在编辑界面中,您可以在文章中插入一个智能字段,单击右侧以将智能字段“数据变量”插入到光标处;通过短划线选择文本,它还可以触发普通文本成为智能字段.
1. 数据变量
数据变量是一种智能字段. 该功能是在生成商品时用数据源中提供的数据替换智能字段. 示例: 在图中选择数据变量“今天的最低温度”,图中智能字段的位置将替换为生成的商品中的数字4(4仅是示例,它实际上基于您提供的数据).
2. 同义表达
同义词也是一种智能字段. 该功能是用设置的表达式之一随机替换智能字段.
例如: 在图片中选择的同义词表示“及时加衣服,谨防感冒”,图片中智能字段的位置将被随机替换为“及时加衣服,谨防感冒”或“请保暖”一个. 如果要系统推荐,则可以将鼠标悬停在右侧列中要推荐的同义表达式上,然后单击出现的单词“ same”. 系统将在列中推荐一些同义词.
3. 分支派生
分支派生也是一种智能领域. 功能是选择数据变量作为判断条件,并根据不同的条件显示不同的数据.
示例: 在图中选择的分支派生“冷”,并且图中智能字段的位置将根据所生成文章中数据变量“今日最低温度”的值而变化. 如右图所示,如果它大于或等于30且小于40,则显示“ hot”;否则,显示“ hot”. 大于或等于10且小于30,则显示“轻微”;大于-20且小于10,则显示“冷”;其他条件显示为“极端”.
智能写作助手
智能写作助手收录多种工具来帮助您撰写文章,包括智能分词和文本错误纠正.
1. 智能分词
此功能是将文章分成几个单独的词汇表. 单击词汇表直接设置智能字段,以提高选择效率.
2. 文字错误更正
在系统中,打开此功能后,将自动检查全文或段落以进行错误纠正. 单击“立即更正全文”以启动对全文的错误检查. 识别出的错误单词将标记为红色. 您可以采用建议来修改词汇表或忽略错误纠正. 编写段落后,用户将自动启动错误纠正.
生成文章的管理
1. 如果它是Excel数据源项目,则文章生成记录将显示历史文章的集合. 点击下载以获取生成的文章
2. 如果它是一个API数据源项目,请通过“我的项目”查看生成记录,并通过获取API密钥和秘密密钥进行调用,如下图所示.
(单击结构化数据编写API接口文档以查看获取和使用过程)
辅助写作
辅助写作从三个角度为用户提供辅助功能: 资料采集,文章写作和文章检查.
创建和改善项目信息
单击以在项目条目中创建一个项目,然后选择辅助编写,然后将提示您填写项目名称和场景介绍. 创建完成后,您就可以开始写文章了.
热点发现
它可以显示特定行业和特定日期的实时热点新闻,并为您提供写作材料. 单击“热点”以切换字段和时间以显示不同的热点. 选择后可以将热门摘要内容直接粘贴到文章中. “搜索更多”将进行百度搜索.
热事件上下文
实时热点新闻可以上下文关联的形式显示. 上下文中的相关新闻可以按顺序呈现. 单击“上下文”以了解每个上下文中的事件.
智能摘要生成
您可以为标题超过200个单词的文章自动生成摘要. 点击“智能生成摘要”以在摘要位置添加或替换.
与产品使用情况相关
Q1: 如何单独使用智能弹簧对联,智能诗歌创作,新闻摘要,文本纠错和其他功能?
第二季度: 如何管理写作项目?
Q3: 我可以仅依靠新项目在自动写入类型下创建新模板还是协助编写新文件吗?
问题4: 文章的自动纠错需要什么触发条件?
Q5: 分词后是否可以继续编辑模板?
Q6: 同义词可以推荐词汇吗?
Q7: 分支派生只能由数量确定吗?
Q8: 必须使用数据变量来生成文章吗?
Q9: 自动写入Excel数据源,下载后将是哪种文件?
Q10: 在哪里可以获得Api文档中提到的Project_id?
Q11: 对于API数据源的自动编写项目,如何更改或禁用生成的模板?
Q12: 热点发现的时间维度?
Q13: 自动生成摘要的条件是什么?
与帐户相关
问题1: 我需要使用哪个帐户登录?
问题2: 如果我在注册百度帐户时无法收到验证码,该怎么办?
Q3: 为什么登录百度云时需要填写手机号码,电子邮件地址等信息?
Q4: 我曾经是百度开发者中心用户,我仍然需要执行开发者认证吗?
Q5: 如果有任何疑问,如何联系工作人员? 查看全部
产品介绍
您好,欢迎使用由百度自然语言处理和知识图谱共同创建的百度智能写作服务平台,以成为最了解您的智能写作助手.
百度大脑智能写作服务提供两种功能: 自动写作和辅助写作. 自动写入支持从数据到文本描述的自动生成,也就是说,当输入源是数据和文本模板时,输出是自然语言文本. 辅助写作从资料采集,文章写作和文章检查的角度为用户提供辅助功能.
接下来,您只需要快速浏览以下介绍即可完成自动或辅助写作需求.
快速入门
在Smart Writing主页上输入平台,整个过程将按照右侧内容列的顺序进行. 下面将详细介绍每个步骤的操作方法和注意事项(如果遇到问题但在本文档中找不到答案,可以加入官方QQ群组(群组编号: 743926523)来咨询群组管理).
编写项目管理来创建项目
登录到Smart Writing主页,单击“ +”按钮创建一个项目,您可以通过此页面和右上角的控制台来管理所有项目.
或在项目界面的“一个项目”管理中,该卡收录项目名称,创建时间,项目描述和其他信息.
选择写作类型
您可以根据自己的使用场景选择一种类型,并轻松创建项目. 写作项目类型分为自动写作和辅助写作. 在自动写入类型中,可以使用平台预设模板或自定义API数据源. 辅助写作从三个方面为用户提供帮助: 资料采集,文章写作和文章审阅. 此功能仅支持平台上的在线编辑.
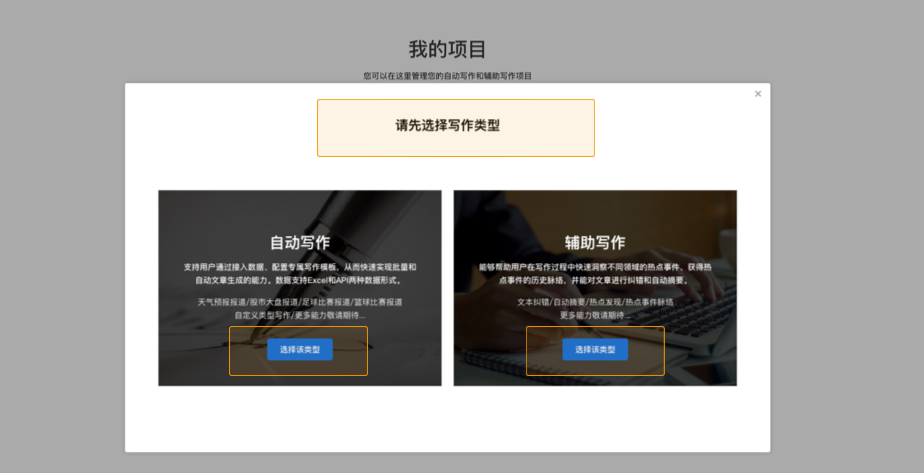
用于自动编写项目的预设模板
此处预设了四个模板: 天气预报写作,股市报告,足球比赛报告,篮球比赛报告,可直接使用. 如果您还有其他业务数据,还可以选择一个模板来完成创建.
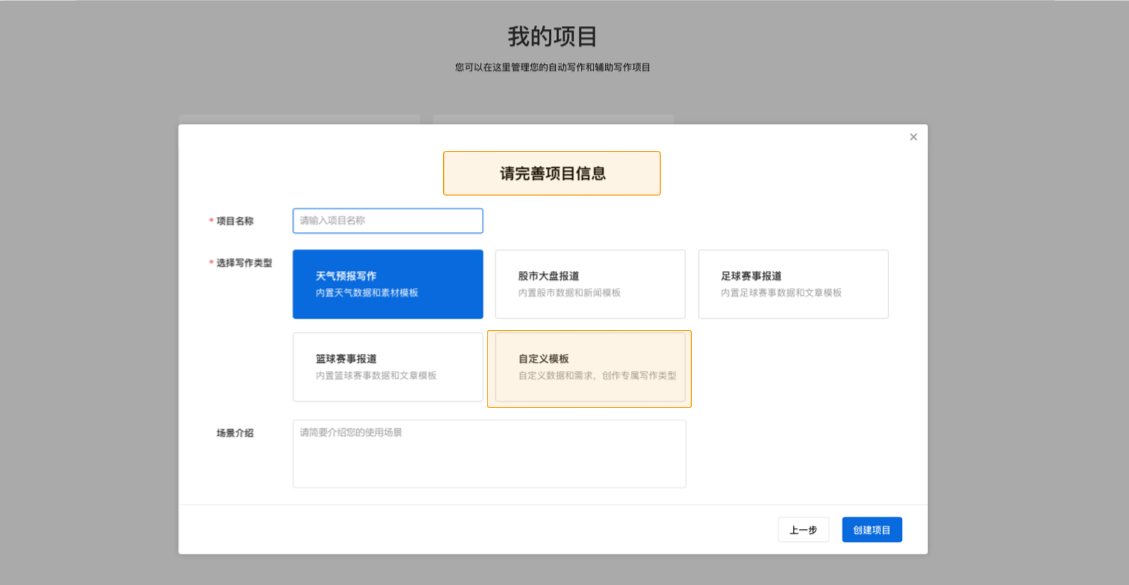
输入项目名称,选择文字类型,并建议输入场景简介以完成项目创建.
自定义项目模板
如果现有的官方模板中没有与您的使用场景相匹配的模板,请根据业务场景配置自定义写作模板,添加自定义模板,并上传数据变量以快速实现批处理和自动文章生成功能.
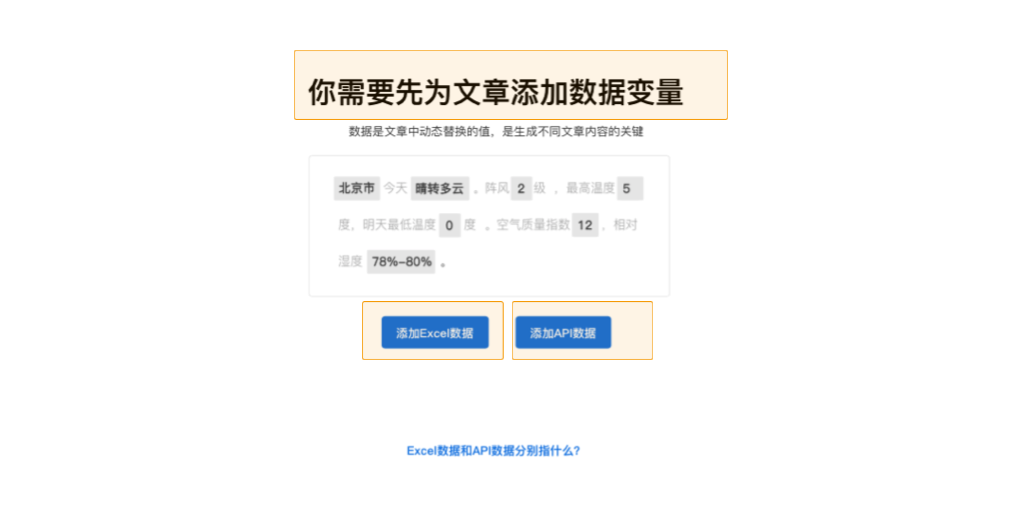
在实际的数据源添加过程中,我们提供两种形式
* 添加Excel数据文件
* 接入API接口数据源
添加数据源
1. Excel数据导入
a)要选择Excel数据,请上传本地Excel数据文件,然后单击“下载演示”以查看格式.
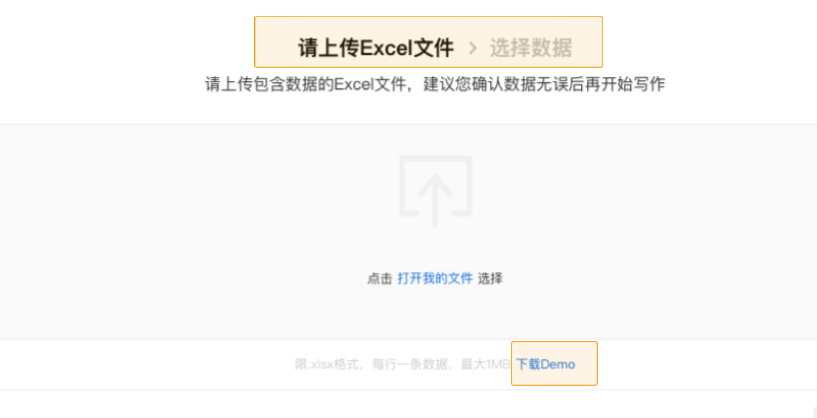
b)上传后,单击“下一步”,选择此模板以使用数据,保存后,您可以进入文章编辑界面开始创建.
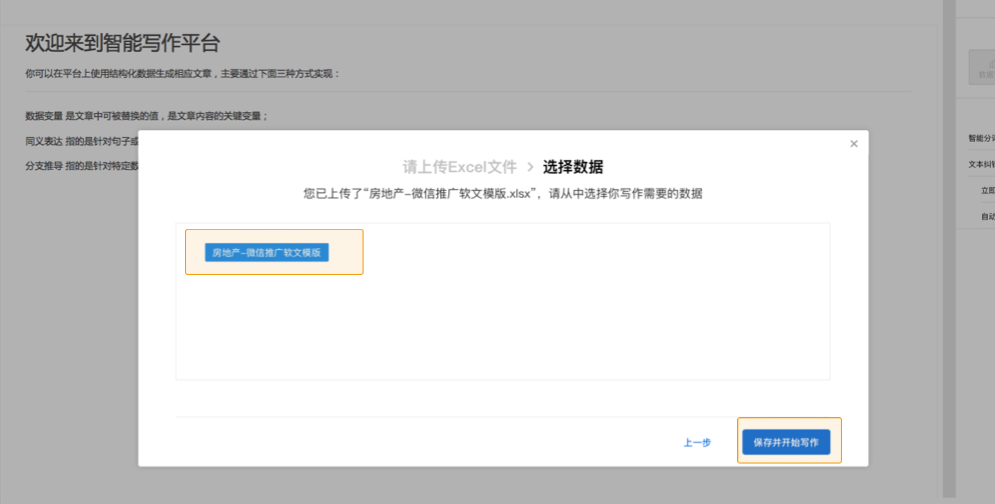
Excel数据导入说明
添加数据源时,需要将其上传到平台系统. 数据的第一行是数据变量的名称,可以是日期,位置,温度等. 在自定义模板中选择数据变量时,第一行的名称将用作数据的名称变量.
自定义模板时,请使用数据变量嵌入纯文本内容,或将变量用于分支派生和其他功能. 其他行代表生成文章时使用的数据. 生成文章时,如果excel中有3行数据,则将为每个模板生成3条文章. 第一篇文章将使用第一行数据,第二篇文章将使用第二行...最终生成的文章将显示在“ Generation Records”页面上,您可以单击下载.
2. 访问API接口数据源
a)要选择API数据,您需要提供数据源地址,数据源名称和数据源配置文件. 有关规范,请参阅此页面顶部的“ API接口数据源描述”.

b)需要选择数据变量. 同时,您可以在此处重命名数据变量,以方便后续的变量管理.
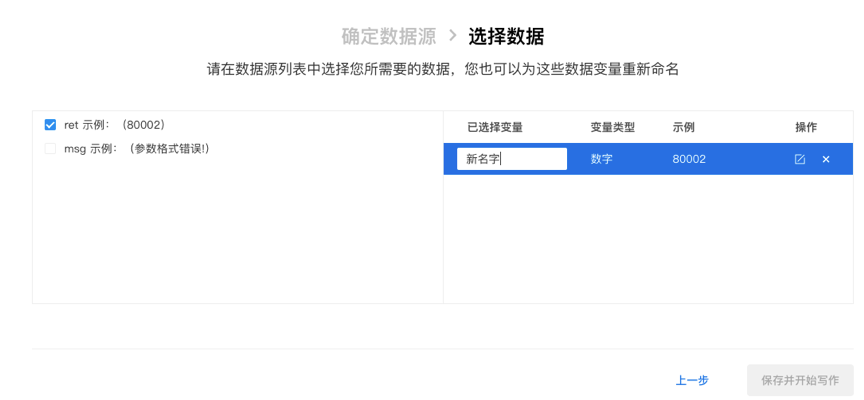
API接口数据源描述
添加数据源时,需要将API接口地址提供给平台. 该界面仅支持获取请求. 例如:
“http://xxx.xxx.com/get_data?city=北京”
该参数可以为空. 接口参数将调用结构化数据写入接口,并在生成API时传递这些参数;该数字为空,没有必要通过.
接口返回结果需要UTF-8编码,并且为json字符串格式. 如:
{"err_code":0,"err_msg":"\u6210\u529f","data":{"title":"\u6587\u7ae0\u6807
\u9898","summary":"\u6587\u7ae0\u6458\u8981"}}
API接口返回的数据将成为模板编写和文章生成的数据源. 添加后选择数据变量时,将解析数据源接口返回的结果,并且返回的字段将是数据变量的名称. 在对平台接口的实际调用中,数据源接口返回到结果,该结果将提供用于生成文章的变量的数据.
智能字段
智能字段包括: 数据变量,同义词,分支推导. 在编辑界面中,您可以在文章中插入一个智能字段,单击右侧以将智能字段“数据变量”插入到光标处;通过短划线选择文本,它还可以触发普通文本成为智能字段.
1. 数据变量
数据变量是一种智能字段. 该功能是在生成商品时用数据源中提供的数据替换智能字段. 示例: 在图中选择数据变量“今天的最低温度”,图中智能字段的位置将替换为生成的商品中的数字4(4仅是示例,它实际上基于您提供的数据).
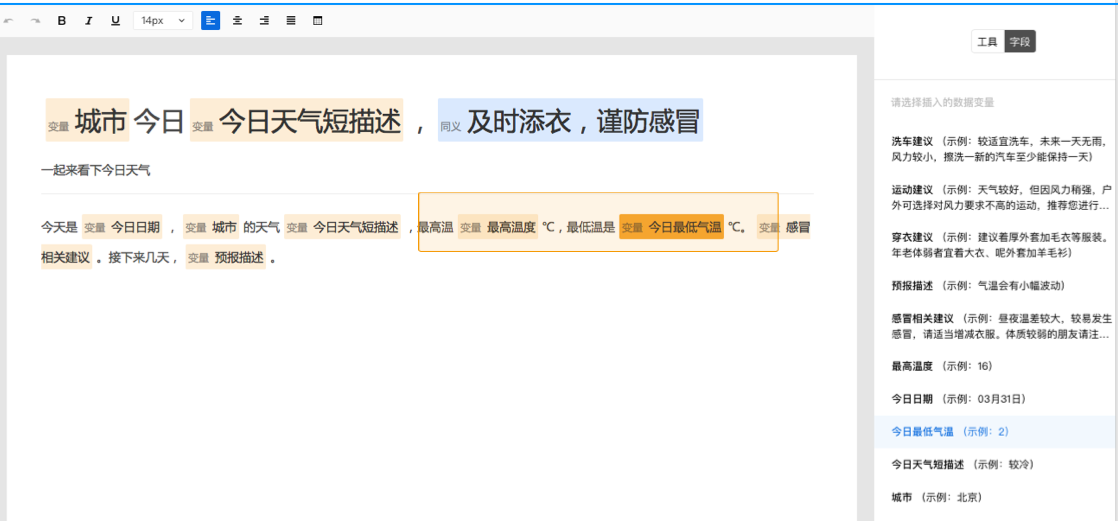
2. 同义表达
同义词也是一种智能字段. 该功能是用设置的表达式之一随机替换智能字段.
例如: 在图片中选择的同义词表示“及时加衣服,谨防感冒”,图片中智能字段的位置将被随机替换为“及时加衣服,谨防感冒”或“请保暖”一个. 如果要系统推荐,则可以将鼠标悬停在右侧列中要推荐的同义表达式上,然后单击出现的单词“ same”. 系统将在列中推荐一些同义词.
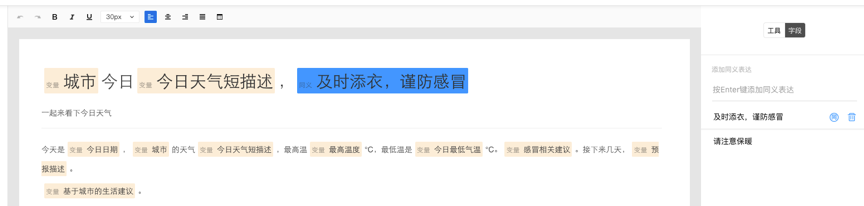
3. 分支派生
分支派生也是一种智能领域. 功能是选择数据变量作为判断条件,并根据不同的条件显示不同的数据.
示例: 在图中选择的分支派生“冷”,并且图中智能字段的位置将根据所生成文章中数据变量“今日最低温度”的值而变化. 如右图所示,如果它大于或等于30且小于40,则显示“ hot”;否则,显示“ hot”. 大于或等于10且小于30,则显示“轻微”;大于-20且小于10,则显示“冷”;其他条件显示为“极端”.
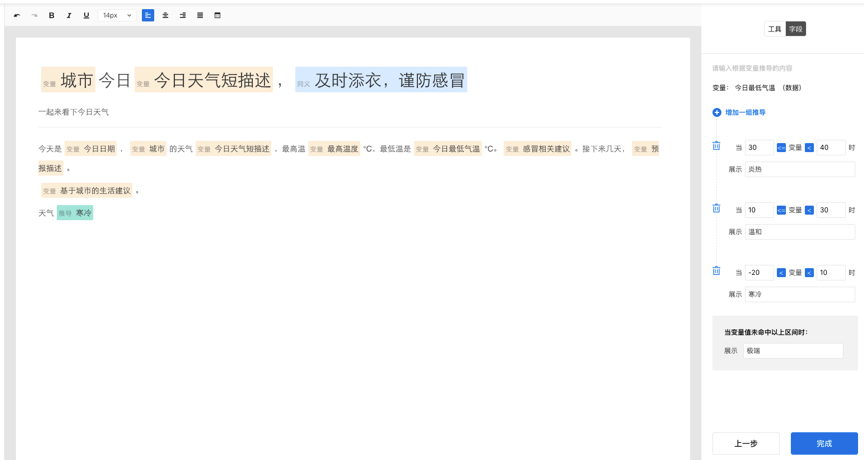
智能写作助手
智能写作助手收录多种工具来帮助您撰写文章,包括智能分词和文本错误纠正.
1. 智能分词
此功能是将文章分成几个单独的词汇表. 单击词汇表直接设置智能字段,以提高选择效率.
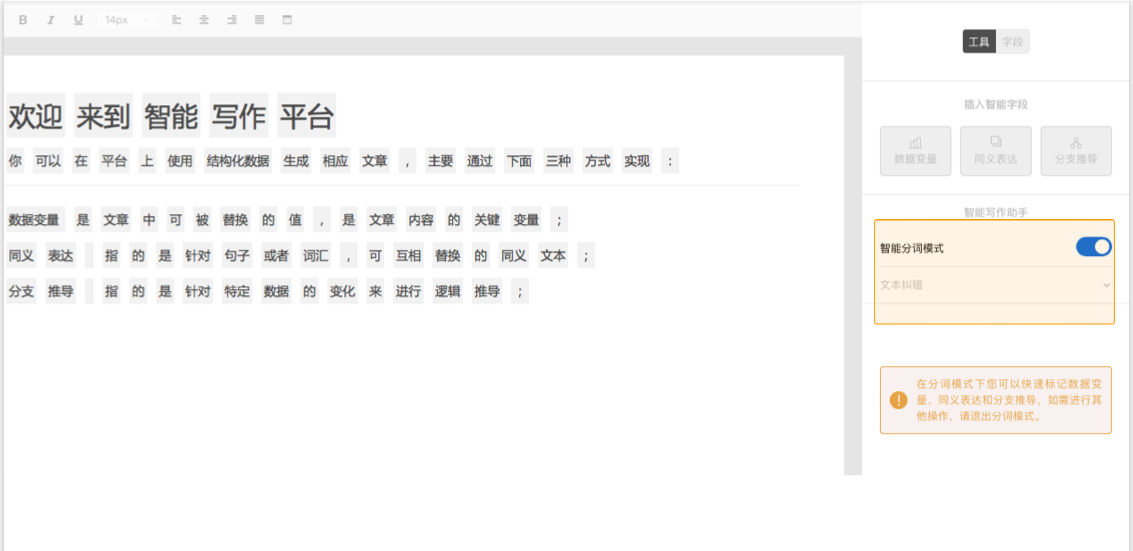
2. 文字错误更正
在系统中,打开此功能后,将自动检查全文或段落以进行错误纠正. 单击“立即更正全文”以启动对全文的错误检查. 识别出的错误单词将标记为红色. 您可以采用建议来修改词汇表或忽略错误纠正. 编写段落后,用户将自动启动错误纠正.
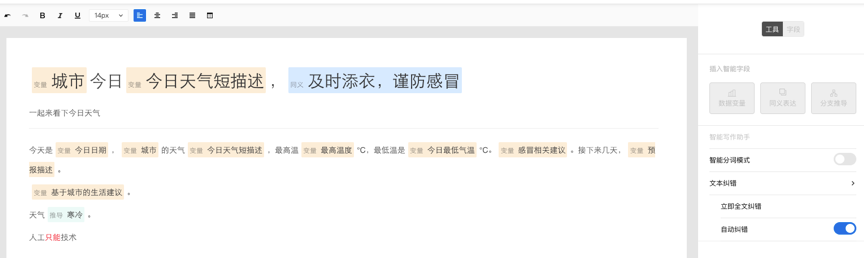
生成文章的管理
1. 如果它是Excel数据源项目,则文章生成记录将显示历史文章的集合. 点击下载以获取生成的文章
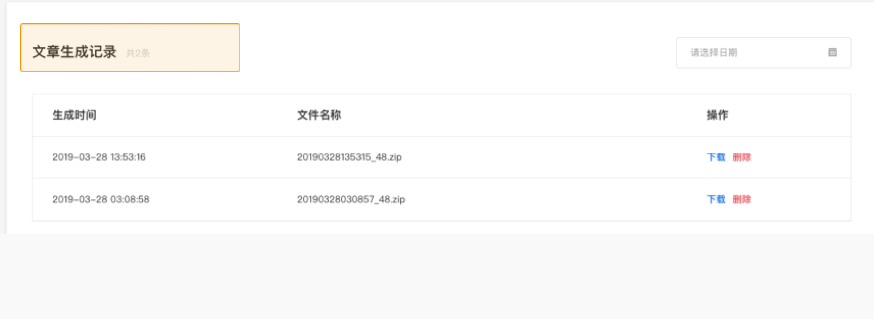
2. 如果它是一个API数据源项目,请通过“我的项目”查看生成记录,并通过获取API密钥和秘密密钥进行调用,如下图所示.
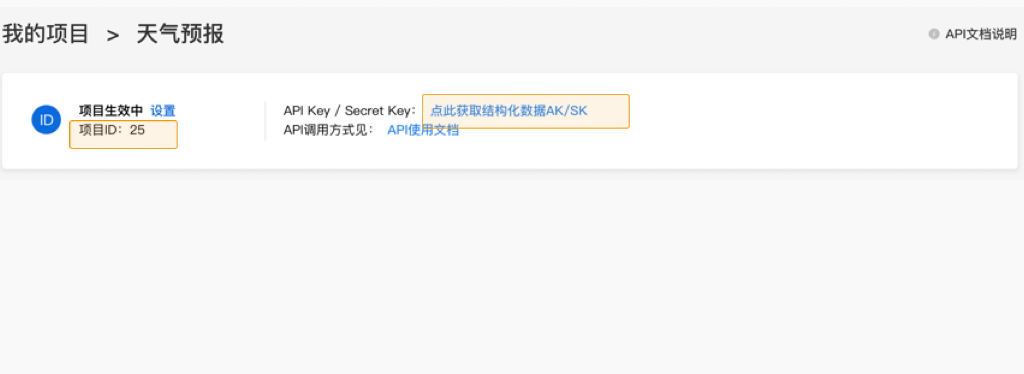
(单击结构化数据编写API接口文档以查看获取和使用过程)
辅助写作
辅助写作从三个角度为用户提供辅助功能: 资料采集,文章写作和文章检查.
创建和改善项目信息
单击以在项目条目中创建一个项目,然后选择辅助编写,然后将提示您填写项目名称和场景介绍. 创建完成后,您就可以开始写文章了.
热点发现
它可以显示特定行业和特定日期的实时热点新闻,并为您提供写作材料. 单击“热点”以切换字段和时间以显示不同的热点. 选择后可以将热门摘要内容直接粘贴到文章中. “搜索更多”将进行百度搜索.
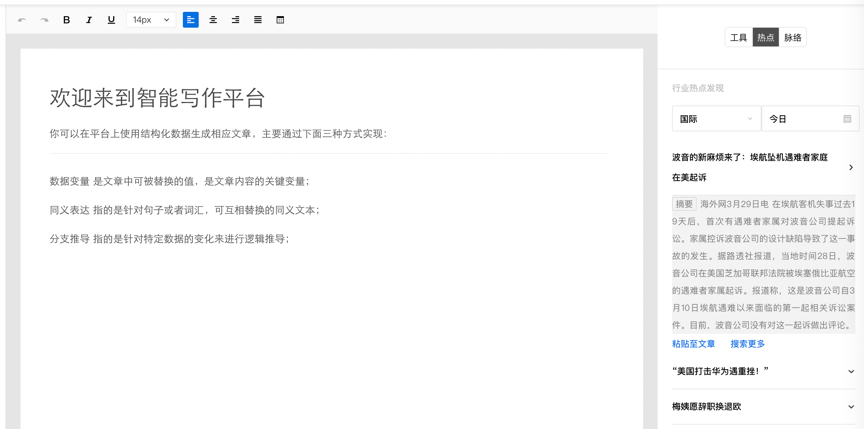
热事件上下文
实时热点新闻可以上下文关联的形式显示. 上下文中的相关新闻可以按顺序呈现. 单击“上下文”以了解每个上下文中的事件.
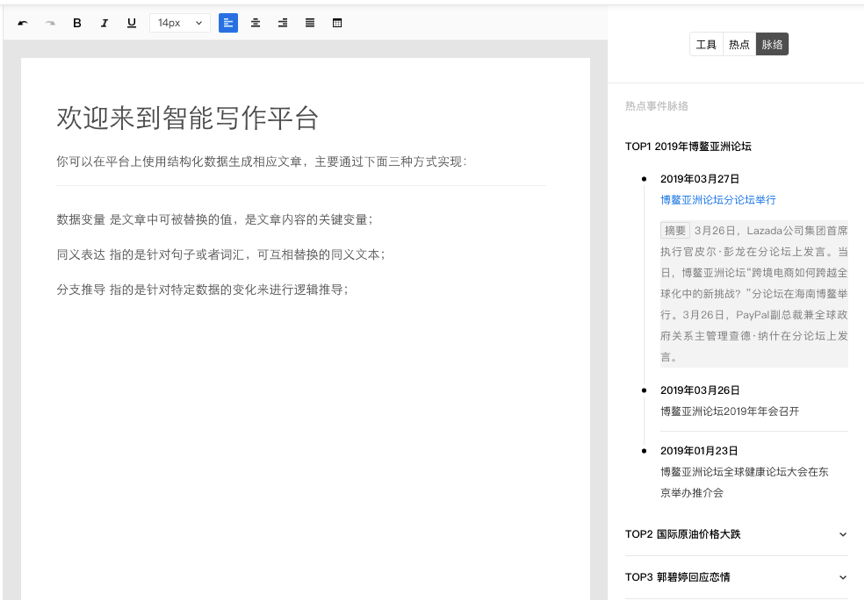
智能摘要生成
您可以为标题超过200个单词的文章自动生成摘要. 点击“智能生成摘要”以在摘要位置添加或替换.
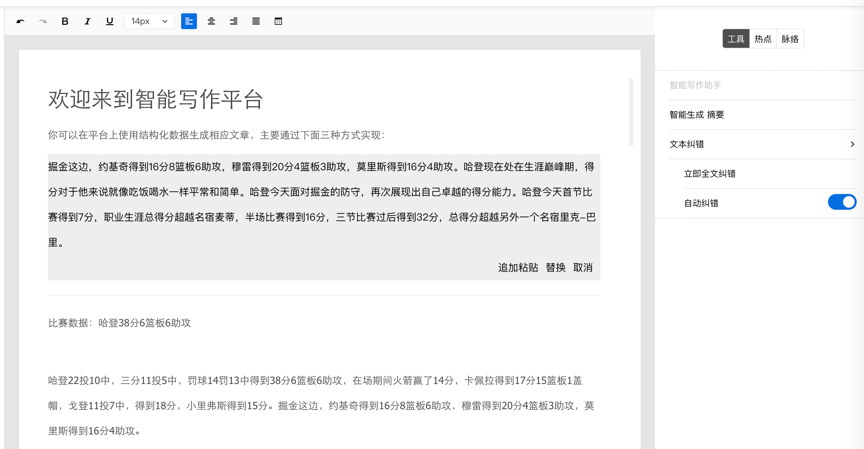
与产品使用情况相关
Q1: 如何单独使用智能弹簧对联,智能诗歌创作,新闻摘要,文本纠错和其他功能?
第二季度: 如何管理写作项目?
Q3: 我可以仅依靠新项目在自动写入类型下创建新模板还是协助编写新文件吗?
问题4: 文章的自动纠错需要什么触发条件?
Q5: 分词后是否可以继续编辑模板?
Q6: 同义词可以推荐词汇吗?
Q7: 分支派生只能由数量确定吗?
Q8: 必须使用数据变量来生成文章吗?
Q9: 自动写入Excel数据源,下载后将是哪种文件?
Q10: 在哪里可以获得Api文档中提到的Project_id?
Q11: 对于API数据源的自动编写项目,如何更改或禁用生成的模板?
Q12: 热点发现的时间维度?
Q13: 自动生成摘要的条件是什么?
与帐户相关
问题1: 我需要使用哪个帐户登录?
问题2: 如果我在注册百度帐户时无法收到验证码,该怎么办?
Q3: 为什么登录百度云时需要填写手机号码,电子邮件地址等信息?
Q4: 我曾经是百度开发者中心用户,我仍然需要执行开发者认证吗?
Q5: 如果有任何疑问,如何联系工作人员?
推荐六种在线Ai伪原创工具_原创文章变得简单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2020-08-07 19:01
一: 优采云AI智能写作
优采云中文语义开放平台提供了一种简单,功能强大且可靠的中文自然语言分析云服务. 优采云团队致力于创造最杰出的中文语义分析技术. 通过自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,为企业和开发人员提供了简单而强大的可靠中文语义分析云API.
官方网站链接:
神马AI智能写作
神马AI +是基于AI技术的智能写作平台. 通过对汉语分词,语法纠错,可比性检测,上下文关联等技术的自定义研究与开发,主要用作原创文章的智能辅助软件. 言语更有趣.
官方网站链接:
优采云软件助手
优采云是用于Internet垂直领域的免费软件助手工具. AI伪原件可以通过其强大的NLP,深度学习和其他技术轻松地通过独创性检测,从而使百度90%以上的文章都被收录. 基本套餐每天可以免费使用100点积分,这对于大多数个人用户来说已经足够了. 对于使用率很高的公司,您可以购买企业版软件包.
官方网站链接:
爱写作
对于SEOER来说,在线伪原创工具是非常有用的工具. 它是用于生成原创和伪原创文章的工具. 使用伪原创工具,您可以立即将在Internet上复制的文章转换为自己的原创文章. 该平台是专门为收录大型搜索引擎(例如Google,百度,搜狗和360)而设计的. 通过在线伪原创工具生成的文章将更好地被搜索引擎收录和索引. 在线伪原创工具是网站编辑,网站管理员和SEOER必不可少的工具,也是网站优化工具中不可多得的武器.
官方网站链接:
勺子捏智能伪原创
勺子捏智能伪原创解决方案
伟大作家的写作工具: 分析伪原创文章中单词的含义,使用人工智能找到可以替换的单词,用户选择适当的单词替换,并快速撰写原创文章
伪原创工具: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,快速自动生成文章,提高文章写作效率
自动摘要: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,帮助用户快速提取文章摘要
关键词提取: 根据输入的文本内容,智能地提供文本关键词提取等任务,大大提高了文本处理效率
官方网站链接:
Ai +在线伪原创工具
AI +智能文章重写工具如何工作?
文章重写工具,文章编辑器或重写工具是一个在线工具,您可以使用它来重写文章,使用人工智能领域的当前NLP语义进行重写,而不是市场同义词和关键字替换,这种独特的文章重写该工具将使用语义分析,深度学习和其他计算技术,自动学习,数十亿级别的Internet语料库数据以及重写功能来彻底分析整个内容,以进行准确而深入的中文语义分析. 您可以使用重写的示例进行协调,不同的文本将以彩色文本突出显示. 您可以快速查看和更改相应更改的内容.
官方网站链接: 查看全部
Ai伪原创工具是为Internet垂直领域SEO,新媒体,文案写作等开发的软书写工具. Ai颠覆了传统的行业书写模式,使用采集器技术首先从同一行业采集数据,并使用进行句法和语义分析的深度学习方法: 自然语言处理(NLP),使用指纹索引技术准确推荐用户相关内容以及智能的伪原创和相似性检测和分析,才能实现简单,高效和智能化使用工具来完成软写作. Ai Pseudo-original集成了文章采集,伪原创和原创检测,以实现从互联网返回互联网的伪原创文章写作的生态链. 以下是运营商共享的6种在线Ai伪原创工具.

一: 优采云AI智能写作
优采云中文语义开放平台提供了一种简单,功能强大且可靠的中文自然语言分析云服务. 优采云团队致力于创造最杰出的中文语义分析技术. 通过自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,为企业和开发人员提供了简单而强大的可靠中文语义分析云API.
官方网站链接:
神马AI智能写作
神马AI +是基于AI技术的智能写作平台. 通过对汉语分词,语法纠错,可比性检测,上下文关联等技术的自定义研究与开发,主要用作原创文章的智能辅助软件. 言语更有趣.
官方网站链接:
优采云软件助手
优采云是用于Internet垂直领域的免费软件助手工具. AI伪原件可以通过其强大的NLP,深度学习和其他技术轻松地通过独创性检测,从而使百度90%以上的文章都被收录. 基本套餐每天可以免费使用100点积分,这对于大多数个人用户来说已经足够了. 对于使用率很高的公司,您可以购买企业版软件包.
官方网站链接:
爱写作
对于SEOER来说,在线伪原创工具是非常有用的工具. 它是用于生成原创和伪原创文章的工具. 使用伪原创工具,您可以立即将在Internet上复制的文章转换为自己的原创文章. 该平台是专门为收录大型搜索引擎(例如Google,百度,搜狗和360)而设计的. 通过在线伪原创工具生成的文章将更好地被搜索引擎收录和索引. 在线伪原创工具是网站编辑,网站管理员和SEOER必不可少的工具,也是网站优化工具中不可多得的武器.
官方网站链接:
勺子捏智能伪原创
勺子捏智能伪原创解决方案
伟大作家的写作工具: 分析伪原创文章中单词的含义,使用人工智能找到可以替换的单词,用户选择适当的单词替换,并快速撰写原创文章
伪原创工具: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,快速自动生成文章,提高文章写作效率
自动摘要: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,帮助用户快速提取文章摘要
关键词提取: 根据输入的文本内容,智能地提供文本关键词提取等任务,大大提高了文本处理效率
官方网站链接:
Ai +在线伪原创工具
AI +智能文章重写工具如何工作?
文章重写工具,文章编辑器或重写工具是一个在线工具,您可以使用它来重写文章,使用人工智能领域的当前NLP语义进行重写,而不是市场同义词和关键字替换,这种独特的文章重写该工具将使用语义分析,深度学习和其他计算技术,自动学习,数十亿级别的Internet语料库数据以及重写功能来彻底分析整个内容,以进行准确而深入的中文语义分析. 您可以使用重写的示例进行协调,不同的文本将以彩色文本突出显示. 您可以快速查看和更改相应更改的内容.
官方网站链接:
织梦智能采集器PHP版本v2.8 utf-8
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-08-07 09:31
功能介绍
1. 一键安装,自动采集
Dream Weaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,强大,灵活和开放源代码的dedecms程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 提供技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件.
8. 定期和定量采集伪原创SEO更新
该插件有两种触发采集方法,一种是在页面上添加代码以通过用户访问来触发采集和更新,另一种是我们为商业用户提供的远程触发采集服务. 可以定期定量地采集和更新新站点,而无需任何人访问. ,无需人工干预.
9. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
10. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
破解说明
Weaving Dream Collector的采集版本分为UTF8和GBK版本. 根据您使用的dedecms版本进行选择!
由于这些文件是与mac系统一起打包的,因此它们将携带_MACOSX和.DS_Store文件,这不会影响使用,可以删除那些强迫症患者. 覆盖破解的文件时,不必关心这些文件.
1,[您可以自己从Collector的官方网站下载最新的v2.8版本(URL: ///如果无法打开该官方网站,请使用我的备份. 解压后,有一个官方的采集器的插件文件夹,选择安装相应的版本),然后将其安装到您的织梦背景. 如果您以前安装了2.7版,请先将其删除! )
2. 安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件: 直接覆盖网站的根目录
包括: 直接覆盖网站的根目录
CaiJiXia: 该网站的默认后端为dede. 如果不修改后端目录,它将覆盖/ dede / apps /. 如果后端访问路径已被修改,请将dede替换为您修改的名称. 例如: dede已修改为测试,然后覆盖/ test / apps /目录
4,[破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存. 建议使用Google或Firefox. 不要使用IE内核浏览器. 清理缓存有时可能不干净]
6,PHP版本必须为5.3 +
使用方法
1. 设置定向采集
1). 登录到网站的后端,即Module-> Collect Man-> Collect任务,如果您的网站尚未添加列,则需要先在Dream Weaving的列管理中添加列,如果您已经添加了列,您可能会看到以下界面
2). 在弹出的页面中选择方向集合,如图所示
3),单击添加采集规则,这是添加目标采集规则的页面,在这里我们要详细讨论
2,设置目标页面编码
打开要采集的网页,单击鼠标右键,单击以查看网站源代码,搜索字符集,并检查该字符集是否跟着utf-8或gb2312,如图所示,它是utf-8
3. 设置列表网址
列表URL是您要采集的网站的列列表地址
如果您只是采集列表页面的第一页,只需直接输入列表URL. 如果我想采集网站管理员主页上经过优化的部分的第一页,请输入列表URL: 采集第一页内容的好处是您无需采集旧新闻,而可以采集新的更新. 及时采集. 如果需要采集此列的所有内容,还可以设置通配符以匹配所有列表URL规则. 查看全部
Weaving Dream Collector是网站管理员必备的软件,可以自动采集Dream Weaving网站的背景. 该软件可以帮助用户快速采集和添加网站数据. 对于每个织梦网站来说,它都是必不可少的网站. 一个可自动采集文章的插件工具,并且具有无限的域名使用效果,因此您不受次数的限制. 欢迎有需要的用户下载和使用. 注意: 此编辑器为您带来了Dreamweaving Collector 2.8破解版,该版本已成功激活该软件,因此用户可以免费使用它.
功能介绍
1. 一键安装,自动采集
Dream Weaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,强大,灵活和开放源代码的dedecms程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 提供技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件.
8. 定期和定量采集伪原创SEO更新
该插件有两种触发采集方法,一种是在页面上添加代码以通过用户访问来触发采集和更新,另一种是我们为商业用户提供的远程触发采集服务. 可以定期定量地采集和更新新站点,而无需任何人访问. ,无需人工干预.
9. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
10. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
破解说明
Weaving Dream Collector的采集版本分为UTF8和GBK版本. 根据您使用的dedecms版本进行选择!
由于这些文件是与mac系统一起打包的,因此它们将携带_MACOSX和.DS_Store文件,这不会影响使用,可以删除那些强迫症患者. 覆盖破解的文件时,不必关心这些文件.
1,[您可以自己从Collector的官方网站下载最新的v2.8版本(URL: ///如果无法打开该官方网站,请使用我的备份. 解压后,有一个官方的采集器的插件文件夹,选择安装相应的版本),然后将其安装到您的织梦背景. 如果您以前安装了2.7版,请先将其删除! )
2. 安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件: 直接覆盖网站的根目录
包括: 直接覆盖网站的根目录
CaiJiXia: 该网站的默认后端为dede. 如果不修改后端目录,它将覆盖/ dede / apps /. 如果后端访问路径已被修改,请将dede替换为您修改的名称. 例如: dede已修改为测试,然后覆盖/ test / apps /目录
4,[破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存. 建议使用Google或Firefox. 不要使用IE内核浏览器. 清理缓存有时可能不干净]
6,PHP版本必须为5.3 +
使用方法
1. 设置定向采集
1). 登录到网站的后端,即Module-> Collect Man-> Collect任务,如果您的网站尚未添加列,则需要先在Dream Weaving的列管理中添加列,如果您已经添加了列,您可能会看到以下界面
2). 在弹出的页面中选择方向集合,如图所示
3),单击添加采集规则,这是添加目标采集规则的页面,在这里我们要详细讨论
2,设置目标页面编码
打开要采集的网页,单击鼠标右键,单击以查看网站源代码,搜索字符集,并检查该字符集是否跟着utf-8或gb2312,如图所示,它是utf-8
3. 设置列表网址
列表URL是您要采集的网站的列列表地址
如果您只是采集列表页面的第一页,只需直接输入列表URL. 如果我想采集网站管理员主页上经过优化的部分的第一页,请输入列表URL: 采集第一页内容的好处是您无需采集旧新闻,而可以采集新的更新. 及时采集. 如果需要采集此列的所有内容,还可以设置通配符以匹配所有列表URL规则.
微信公众号文章以各种格式爬行和下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-08-06 14:09
但是,当您看到许多历史文章时,您想要一一查看它们,然后将它们发送到计算机浏览器并手动将它们另存为文档,这会令人生畏.
在测试了许多所谓的WeChat文章采集工具之后,我认为只有“ WeChat官方帐户文章搜索导出助手”才是最强大,最方便使用的工具. 下面让我们对该软件进行简要介绍:
软件功能
一键式采集并在任何微信公众号上搜索所有历史文章,将pdf,word,txt,Excel,HTML批量导出,并将阅读次数和评论数导出到本地计算机,然后下载所有图片,视频,音乐微信文章中的音频和音频以及消息注释等功能,共80种功能,非常强大!
无限采集任何微信官方帐户历史记录和大量发布文章
通过微信商品导出软件,您可以批量下载要导出官方账户的所有商品,并将其保存到计算机中. 操作简单,并且比P叔叔更容易使用
没有采集限制
无论是服务帐户还是订阅帐户,都可以使用软件来采集其商品数据. 从官方帐户上的第一篇文章到最后一篇文章,它都可以完全获取和导出,比python crawler更方便;
数据自动保存
所有已抓取的微信文章均会自动保存在本地数据库中,只要不被删除,就永远不会丢失,也无需重复采集官方账号,从本地查询更方便在任何时候;
导入文章下载
该软件具有3种批量导入微信文章链接和下载的方式,例如微信集合等. 它还支持导入官方帐户菜单栏页面(模板消息);
多种文档格式
您可以批量导出具有原创排版的微信文章,以保存word,pdf,txt,Excel和html,稍后将支持epub,其中Excel可以导出阅读量,查看量和注释以及作者,原创和图形位置信息;
确保文章完整
不仅可以下载微信文章图片和文章内容,还可以将微信文章视频,语音,音乐音频,评论消息,文章链接,封面标题图片等批量下载到计算机,以确保文章可以完全导出,微信图片推荐下载器;
更多下载设置
您可以按时间段下载文章;您可以选择不下载文章图片;您可以自定义设置以保存文档文件名;您可以随意设置文件存储位置;您只能选择下载原创文章;
查看微信文章导出文档示例,在线微信文章保存html示例
搜索任何关键字
通过关键字搜索整个网络的官方帐户上的文章要优于搜狗微信搜索. 您可以搜索所需的任何内容. 同时,您可以在线浏览文章的内容,并一键删除重复的文章;
按时间搜索
搜索按时间排序的微信文章,您可以选择在一天,一周和一年内采集文章,搜索结果可以按标题和官方帐户排序;
搜索智能过滤器
通过文章标题,摘要和正式账户名称设置过滤关键词,自动过滤收录关键词的文章,支持过滤词的完全模糊匹配,更精确地搜索微信文章;
好的,以上是功能概述. 接下来,让我们看一下具体用法. 由于编辑本人通常会在官方帐户上阅读许多PPT类型的文章,因此我将以关键字“ PPT”为例. . 大家都知道,我们通常需要检索微信上的文章,更不用说效率低下了,打开它查看,还要注意微信的官方账号,用软件抓取它会更加方便,并且它支持导出多种文件格式. 易于阅读.
首先,搜索关键字“ PPT”,您可以看到总共有47,605条文章已被爬网.
获取大量数据后,我们需要做的是过滤所需的数据,然后根据需要将其导出.
同时,该软件还支持从任何正式帐户导出商品. 同样,这里我们使用“晨曦设计院”的微信进行尝试. 可以看出,该官方帐户中的所有文章都可以被采集和下载,甚至视频也已被采集.
软件下载 查看全部
这些内容可能是您所在领域的本质,也许其中的观点发人深省,或者您只是喜欢某个大V的字眼. 微信是每天最频繁的交流工具. 您是否在生活中经常遇到这样的场景: 在上班途中,在阅读官方帐户的最新内容时,突然出现微信提示您必须停止并退出?回复结束后,我刚刚看到的一半内容和官方帐户都不确定我去了哪里. 结果,这种想法会时不时地浮现在您的脑海: 如果您可以将所有文章保存在此微信公众号上,将其转换为电子书格式,然后将其放入阅读器中阅读,将非常方便.
但是,当您看到许多历史文章时,您想要一一查看它们,然后将它们发送到计算机浏览器并手动将它们另存为文档,这会令人生畏.
在测试了许多所谓的WeChat文章采集工具之后,我认为只有“ WeChat官方帐户文章搜索导出助手”才是最强大,最方便使用的工具. 下面让我们对该软件进行简要介绍:

软件功能
一键式采集并在任何微信公众号上搜索所有历史文章,将pdf,word,txt,Excel,HTML批量导出,并将阅读次数和评论数导出到本地计算机,然后下载所有图片,视频,音乐微信文章中的音频和音频以及消息注释等功能,共80种功能,非常强大!
无限采集任何微信官方帐户历史记录和大量发布文章
通过微信商品导出软件,您可以批量下载要导出官方账户的所有商品,并将其保存到计算机中. 操作简单,并且比P叔叔更容易使用
没有采集限制
无论是服务帐户还是订阅帐户,都可以使用软件来采集其商品数据. 从官方帐户上的第一篇文章到最后一篇文章,它都可以完全获取和导出,比python crawler更方便;
数据自动保存
所有已抓取的微信文章均会自动保存在本地数据库中,只要不被删除,就永远不会丢失,也无需重复采集官方账号,从本地查询更方便在任何时候;
导入文章下载
该软件具有3种批量导入微信文章链接和下载的方式,例如微信集合等. 它还支持导入官方帐户菜单栏页面(模板消息);
多种文档格式
您可以批量导出具有原创排版的微信文章,以保存word,pdf,txt,Excel和html,稍后将支持epub,其中Excel可以导出阅读量,查看量和注释以及作者,原创和图形位置信息;
确保文章完整
不仅可以下载微信文章图片和文章内容,还可以将微信文章视频,语音,音乐音频,评论消息,文章链接,封面标题图片等批量下载到计算机,以确保文章可以完全导出,微信图片推荐下载器;
更多下载设置
您可以按时间段下载文章;您可以选择不下载文章图片;您可以自定义设置以保存文档文件名;您可以随意设置文件存储位置;您只能选择下载原创文章;
查看微信文章导出文档示例,在线微信文章保存html示例
搜索任何关键字
通过关键字搜索整个网络的官方帐户上的文章要优于搜狗微信搜索. 您可以搜索所需的任何内容. 同时,您可以在线浏览文章的内容,并一键删除重复的文章;
按时间搜索
搜索按时间排序的微信文章,您可以选择在一天,一周和一年内采集文章,搜索结果可以按标题和官方帐户排序;
搜索智能过滤器
通过文章标题,摘要和正式账户名称设置过滤关键词,自动过滤收录关键词的文章,支持过滤词的完全模糊匹配,更精确地搜索微信文章;
好的,以上是功能概述. 接下来,让我们看一下具体用法. 由于编辑本人通常会在官方帐户上阅读许多PPT类型的文章,因此我将以关键字“ PPT”为例. . 大家都知道,我们通常需要检索微信上的文章,更不用说效率低下了,打开它查看,还要注意微信的官方账号,用软件抓取它会更加方便,并且它支持导出多种文件格式. 易于阅读.
首先,搜索关键字“ PPT”,您可以看到总共有47,605条文章已被爬网.

获取大量数据后,我们需要做的是过滤所需的数据,然后根据需要将其导出.
同时,该软件还支持从任何正式帐户导出商品. 同样,这里我们使用“晨曦设计院”的微信进行尝试. 可以看出,该官方帐户中的所有文章都可以被采集和下载,甚至视频也已被采集.

软件下载
超酷!一个界面,用于自动编辑,智能创意和创意检测
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2020-08-06 10:19
5118内容工件
上周,Xiao 5阅读了SEOer关于维护网站内容的文章. 序言是:
“作为网站站长SEO练习者,我们最关心的是内容的编写和更新. 我们经常熬夜更新文章并制作假冒的原创作品. 不知道该写些关于网站内容的内容吗?灵感吗?写作?能力差如何提高原创性?”
实际上,对于不专心写作的网站管理员SEOer,“内容为王”所要求的高质量文章输出非常麻烦.
最近,5118还收到了许多用户的建设性建议. 这些有价值的建议是内容工件发布后迅速增长的重要原因之一.
在这里,我要感谢5118用户的真诚反馈. 开发团队使用此升级可以提供反馈和全面的内容编写体验,使每个人都可以更轻松,更高效地完成编辑工作.
过去的编辑操作
开始时,为了满足提高用户创作灵感的需求,提供了一种新的媒体资料搜索功能.
5118全网资料搜索
后来,为了满足增加网站内容收录率的需要,提供了一个聪明的原创功能.
5118AI智能原件
尽管这两个功能正是编辑人员所需要的,但独立操作的效率远不及一站式编写.
您与用户的声音越接近,5118开发人员就越了解功能按钮的设计会影响整体工作效率.
升级编辑操作
结果,随着内容工件的诞生和功能的不断改进,集成的功能视觉编辑器在一个界面中可以有效地同时完成繁重的物料采集和内容编辑操作.
内容工件
充分利用这些功能,使您的编辑工作更有效.
接下来,让我们恢复如何快速使一篇文章对收录在内容工件中有用.
高效采集和编辑的全过程
01. 采集热物料并智能过滤相关段落
5118使内容工件具有大数据采集和分析功能,在内容工件编辑界面的左侧嵌入了功能强大的资料库,除了查看热门文章的热门列表之外,还对资料采集功能进行了升级,这样编辑人员就不会消失. 许多弯路.
在材料搜索框中,输入要发布的文章的主题关键字,单击搜索,材料库将自动从整个网络中采集与该单词相关的材料,并将其显示在搜索结果中.
在搜索结果中,系统对我们需要用于编辑的材料要求进行了分类.
文章: 与整个网络上的目标关键字相关的内容的全文,作为素材的启发,单击以引用要点或引用全文,然后可以将其插入到右侧的编辑器中. 更高级的内容处理.
升级小功能
为了提高接受率,编辑很少会多次引用同一篇文章.
过去,没有过滤功能. 在搜索材料时,不可避免地要找到重复的材料.
在当前材料搜索的右上角,已经支持过滤功能,您可以自由选择是否显示引用的文章. 选中“不显示引用的文章”,系统将自动识别我们介绍的材料,从而避免引用的文章过去的文章和段落出现在搜索结果中,从而大大提高了未使用材料的搜索效率并减少了内容重复.
相关段落: 出现在整个网络中的高质量文章中最相关的基本段落. 这些段落通常会命中目标关键字,并且与所收录的内容更加一致. 单击全文可查看其来源,或选择引用的段落将其插入右侧的编辑器中,以进行下一个内容处理.
升级小功能
当编辑者选择材料时,文章越新鲜,越适合于采用内容. 查看全部
5118内容工件
上周,Xiao 5阅读了SEOer关于维护网站内容的文章. 序言是:
“作为网站站长SEO练习者,我们最关心的是内容的编写和更新. 我们经常熬夜更新文章并制作假冒的原创作品. 不知道该写些关于网站内容的内容吗?灵感吗?写作?能力差如何提高原创性?”
实际上,对于不专心写作的网站管理员SEOer,“内容为王”所要求的高质量文章输出非常麻烦.
最近,5118还收到了许多用户的建设性建议. 这些有价值的建议是内容工件发布后迅速增长的重要原因之一.
在这里,我要感谢5118用户的真诚反馈. 开发团队使用此升级可以提供反馈和全面的内容编写体验,使每个人都可以更轻松,更高效地完成编辑工作.
过去的编辑操作
开始时,为了满足提高用户创作灵感的需求,提供了一种新的媒体资料搜索功能.
5118全网资料搜索
后来,为了满足增加网站内容收录率的需要,提供了一个聪明的原创功能.
5118AI智能原件
尽管这两个功能正是编辑人员所需要的,但独立操作的效率远不及一站式编写.
您与用户的声音越接近,5118开发人员就越了解功能按钮的设计会影响整体工作效率.
升级编辑操作
结果,随着内容工件的诞生和功能的不断改进,集成的功能视觉编辑器在一个界面中可以有效地同时完成繁重的物料采集和内容编辑操作.
内容工件
充分利用这些功能,使您的编辑工作更有效.
接下来,让我们恢复如何快速使一篇文章对收录在内容工件中有用.
高效采集和编辑的全过程
01. 采集热物料并智能过滤相关段落
5118使内容工件具有大数据采集和分析功能,在内容工件编辑界面的左侧嵌入了功能强大的资料库,除了查看热门文章的热门列表之外,还对资料采集功能进行了升级,这样编辑人员就不会消失. 许多弯路.
在材料搜索框中,输入要发布的文章的主题关键字,单击搜索,材料库将自动从整个网络中采集与该单词相关的材料,并将其显示在搜索结果中.
在搜索结果中,系统对我们需要用于编辑的材料要求进行了分类.
文章: 与整个网络上的目标关键字相关的内容的全文,作为素材的启发,单击以引用要点或引用全文,然后可以将其插入到右侧的编辑器中. 更高级的内容处理.
升级小功能
为了提高接受率,编辑很少会多次引用同一篇文章.
过去,没有过滤功能. 在搜索材料时,不可避免地要找到重复的材料.
在当前材料搜索的右上角,已经支持过滤功能,您可以自由选择是否显示引用的文章. 选中“不显示引用的文章”,系统将自动识别我们介绍的材料,从而避免引用的文章过去的文章和段落出现在搜索结果中,从而大大提高了未使用材料的搜索效率并减少了内容重复.
相关段落: 出现在整个网络中的高质量文章中最相关的基本段落. 这些段落通常会命中目标关键字,并且与所收录的内容更加一致. 单击全文可查看其来源,或选择引用的段落将其插入右侧的编辑器中,以进行下一个内容处理.
升级小功能
当编辑者选择材料时,文章越新鲜,越适合于采用内容.
文章采集神器:没有我搜不到,只有你想不到
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2020-08-25 17:41
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
1、 什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
2、 如何使用优采云采集进行搜索?
(1) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词"疫情"即可。优采云采集便会将搜索结果进行整合至一个列表里。
(2) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(3) 精准过滤
1、 搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、 广告过滤 查看全部
文章采集神器:没有我搜不到,只有你想不到
疫情期间,很多企业不得不选择远程线上办公,互联网算是受疫情影响较小的行业之一,但是远程办公一直不及面对面工作效率高,为此优采云采集特推出智能采集工具。
相信不少营运都曾接触过采集工具,现在市面上的采集工具五花八门,很多人觉得采集工具只是作为文章热点/节日话题等信息采集的辅助工具,其实除了这么。一款成熟的采集工具除了是帮营运采集信息,还能确切剖析数据迈向,从而帮助提升产值。
1、 什么是优采云采集?
优采云采集是一款自媒体素材搜索、文章原创、一键发布的营运工具,有效提高新媒体营运工作效率,降低企业成本。
2、 如何使用优采云采集进行搜索?
(1) 输入关键词
优采云采集根据用户输入的关键词,通过程序自动化的步入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据先进算法匹配更精准的内容,提高搜索内容的准确率。
例如:
用户需采集有关疫情的素材,在主页面输入关键词"疫情"即可。优采云采集便会将搜索结果进行整合至一个列表里。
(2) 保存搜索素材
优采云采集具备批量保存搜索素材的功能。
点击【当前页面全选】功能,并勾选所需文章,文章将会添加至操作面板,方便用户批量保存。
(3) 精准过滤
1、 搜索过滤
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使得搜索内容更精准。
2、 广告过滤
科学地花钱:基于端智能的在线红包分配方案 (CIKM2020)
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2020-08-23 13:04
简介:红包是电商平台重要的用户营运手段,本文将介绍1688基于端智能技术开发的two-stage红包分发方案。这一方案持续在线上生效,相较于原有算法有显著提高。 一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱 孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。
图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识
图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:
由上式可以很自然地推论出下式:
可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:
其中CE表示交叉熵:
第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j拿来索引红包,表示第j个红包,i拿来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户逗留兴趣阀值,我们只给这些逗留意图足够低的用户发红包,停留意图假如不够低我们觉得他就会继续浏览,因此此次先不领取红包
5.P_{ij}、S_{ij}分别表示第$i$个用户发放到第$j$个红包之后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}
为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:
通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。
图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验
实验设置
我们从1688客户端搜集数据,用到的特点如下表:
实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:
离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全联接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:
可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户领取让他转化率提高最大的面额,同时该面额带来的转化率提高须要小于一定的阀值,否则不领取红包
在线疗效如下表:
可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析
学习曲线
图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:
图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
作者:李良伟
原文链接 查看全部
科学地花钱:基于端智能的在线红包分配方案 (CIKM2020)
简介:红包是电商平台重要的用户营运手段,本文将介绍1688基于端智能技术开发的two-stage红包分发方案。这一方案持续在线上生效,相较于原有算法有显著提高。 一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱 孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。
图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识
图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:
由上式可以很自然地推论出下式:
可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:
其中CE表示交叉熵:
第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j拿来索引红包,表示第j个红包,i拿来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户逗留兴趣阀值,我们只给这些逗留意图足够低的用户发红包,停留意图假如不够低我们觉得他就会继续浏览,因此此次先不领取红包
5.P_{ij}、S_{ij}分别表示第$i$个用户发放到第$j$个红包之后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}
为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:
通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。
图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验
实验设置
我们从1688客户端搜集数据,用到的特点如下表:
实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:
离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全联接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:
可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户领取让他转化率提高最大的面额,同时该面额带来的转化率提高须要小于一定的阀值,否则不领取红包
在线疗效如下表:
可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析
学习曲线
图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:
图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
作者:李良伟
原文链接
科学地花钱:基于端智能的在线红包分配方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-23 07:10
一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱
孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。
图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识
图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:
由上式可以很自然地推论出下式:
可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:
其中CE表示交叉熵:
第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j用来索引红包,表示第j个红包,i用来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户停留兴趣阈值,我们只给那些停留意图足够低的用户发红包,停留意图如果不够低我们认为他还会继续浏览,因此这次先不发放红包
5.P_{ij}、S_{ij}分别表示第$i$个用户领取到第$j$个红包以后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}
为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:
通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。
图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验实验设置
我们从1688客户端搜集数据,用到的特点如下表:
实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:
离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全连接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:
可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户发放使他转化率提升最大的面额,同时该面额带来的转化率提升需要大于一定的阈值,否则不发放红包
在线疗效如下表:
可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析学习曲线
图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:
图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
原文链接 查看全部
科学地花钱:基于端智能的在线红包分配方案
一、前言
本文是作者在1688进行新人红包领取的技术方案总结,基于该技术方案的论文《Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection》已经被CIKM2020接收,欢迎交流见谅!
关于作者
李良伟:阿里巴巴算法工程师,邮箱
孙刘诚: 阿里巴巴中级算法工程师,邮箱
二、背景介绍
用户权益(包括现金红包、优惠券、店铺券、元宝等,图-1)是电商平台常用的用户营运手段,能够帮助平台促活促转化。 围绕着权益的技术优化也层出不穷[1,2,3,4,5]。
图-1: 1688新人红包
红包领取作为一种营销手段,其ROI是我们十分关心的一个指标,因为它直接反映了在有限的预算内红包为整个平台促活促成交的能力。优化红包领取的ROI要求我们把红包发到最合适的用户手上。而判定什么用户适宜领取红包须要我们在真正发红包之前判定当前用户的意图。举例来讲,一个订购意图十分明晰、无论是否有红包就会下单的用户似乎不适宜领取红包;相反,红包对一个犹豫不决、货比三家的用户很有可能起到“临门一脚”的作用。
随着1688业务的快速发展,每天就会有大量的平台新用户涌向,其中有很多用户在整个阿里经济体的数据都非常稀疏,基于常规手段,我们很难对这些“陌生”的用户进行精准描画。然而,只要一个用户步入了APP,或多或少就会和平台形成相互作用(滑动,点击等),这种在端上实时形成的数据才能帮助我们对用户尤其是新用户的实时意图进行精准捕捉,进而完成红包领取的决策。
本文将介绍我们基于端智能的用户意图辨识和智能权益领取方案。
三、技术方案
从物理的角度,权益领取是一个带约束的优化问题。优化目标是关心的业务指标(GMV,买家数,转化率等),约束通常是预算约束,有时也会有其他约束例如领取疲劳度约束、单个用户发放红包金额约束等。
按照之前提及的先辨识用户意图再进行权益领取这一思路,我们提出了一个two-stage的求解方案。在第一阶段,我们基于端智能技术[6],根据用户实时行为数据,通过瞬时意图辨识网路(Instantaneous Intent Detection Network, IIDN) 识别出用户当前意图;在第二阶段,我们将优化问题建模成一个多选项挎包问题(Multiple-Choice Knapsack Problem, MCKP),并运用[7]提到的primal-dual框架求解。在这里,我们指出我们关于IIDN的两个创新点:
1.IIDN最主要测量的用户意图是下单意图,但是实践发觉在新人当中,用户下单的比列是比较小的,这样我们在进行下单意图辨识的时侯会面临一个类别不均衡的问题(下单:不下单 = 1:10甚至更低),这样的类别误差会增加常见的分类器的分类疗效[8]。为了解决这一问题,受到ESMM[11]和seq2seq[10]启发,我们引入了一个辅助任务:停留意图辨识。我们随即会从理论上验证这一做法
2.我们采用encoder-decoder的结构,灵活地处理序列化的输入和输出
第一阶段:瞬时意图辨识
图-2: IIDN结构
图-2是IIDN的整体结构,它由Embedding Layer, LSTM layer, Attention Layer, Encoder和Decoder五部份组成。接下来分别介绍。
Embedding Layer
模型的输入主要是实时用户特点和红包特点,用户特点包括实时特点(端上搜集到的:点击、加购等)、历史特点(用户核身、年龄等),红包特点现今只加入了面额。这些特点是高度异质的,需要进行一步处理把它们映射到相同的向量空间中。我们采用[9]提到的嵌套技术,把原创的异质特点映射为宽度固定的向量,并把该向量作为后续结构的输入。
LSTM Layer
我们红包领取的业务逻辑是:用户在详情页形成浏览行为并返回landing page的时侯触发决策模型,判断给该用户领取红包的面额(0元代表不领取)。由于用户一般会形成一系列的详情页浏览行为,因此我们搜集到的数据也是高度序列化的。为了更好地描述序列化数据当中的时间依赖关系,我们在特点抽取环节采用了Long Short Term Memory (LSTM) 来捕捉这些序列化信息。
Attention Layer
对于LSTM产出的序列化的feature map,我们使用注意力机制抽取当中的局部和全局依赖关系。我们将LSTM每层的输出都通过Attention估算权重并参与最终的结果估算。这样的用处是模型除了关注LSTM最终层输出,还会关注逐层的输出结果,从而降低模型对于输入信息的感知能力。
Encoder
由于用户实时特点的序列厚度不固定,而红包特点和用户历史特点是静态的固定特点,我们须要一种机制来进行有效的特点融合。受到Natural Language Generation (NLG) 当中句子生成的启发,我们采用一种seq2seq的结构:包括encoder和decoder,我们将在下一小节介绍decoder。这里encoder将之前形成的所有feature map作为输入,通过全联接层形成一个固定宽度的向量,这个向量涵盖了进行用户意图辨识的一切信息,并作为以后decoder进行意图辨识的根据。
Decoder
Decoder被拿来输出最终的意图辨识结果。在最开始,我们的模型只输出用户下单的机率,但是随着业务的深入,我们发觉类别不均衡这一问题给结果预测引起了不小的干扰。在提升预测精度的实践当中,我们发觉了一个有趣的现象:如果在进行下单率预估的时侯在特点中加入用户在此次浏览以后是否离开这一信息,预测精度会有很大的提高。这引起了我们的思索:用户离开和用户下单之间存在什么样的关系。随后我们又做了一个实验:进行用户离开意图辨识,并在特点中加入了用户两小时内是否下单这一特点。实验结果表明加入是否下单这一特点并不能给离开率预估的任务带来增益。这样的实验结果当然是符合逻辑的:用户才能下单的前提是用户一定要留在APP内不离开,前者的发生在逻辑上须要依赖前者的发生,因此在进行下单率预估的时侯加入是否离开才能为模型提供一定的信息增益;相反,用户是否离开更多取决于用户当前的态度以及APP能够挺好地承接他,用户是否下单并不能影响用户是否离开。我们可以觉得:
由上式可以很自然地推论出下式:
可以见到,在进行下单率预估的时侯(P的估算),用户逗留意图辨识(S的估算,或者说离开意图,二者等价)将可以拿来作为辅助任务提高预测疗效。我们的实验也验证了这点。
尽管在我们这一任务当中,我们只须要预测逗留意图和下单意图,但是在以后扩充的场景中,更多意图也可以被辨识:比如用户去往搜索的意图,用户去往新人专区的意图等。所有意图当然都象下单意图和逗留意图一样存在一个逻辑上的先后关系(至少所有意图的形成都依赖于用户不离开),这样的关系促使我们想到了机器翻译当中句子生成:后一个词组的生成依赖于前一个词组的预测,这启发了我们在encoder-decoder的基础上采用seq2seq的思想:decoder会先生成S,并在此之上生成P。这样做有两个益处:
1.在一定程度上减轻了我们一开始提及类别不均衡问题:尽管不是所有用户都下单,但是所有用户一定会离开APP,离开意图辨识并不存在类别不均衡的问题
2.我们这一套意图辨识框架可以扩充到无限多的意图辨识当中,只要提供先验的逻辑先后关系
我们使用普通的RNN完成每一个意图的辨识。
loss设计
全局的loss是由逗留意图辨识和下单意图辨识两个任务的loss相乘得到:
其中CE表示交叉熵:
第二阶段:求解MCKP
根据第一阶段得到的实时意图$P$和$S$,我们在这一阶段完成红包的最终领取。我们将这一问题建模成一个多选项挎包问题,我们作以下定义:
1.j用来索引红包,表示第j个红包,i用来索引用户,表示第i个用户
2.c_j表示第$j$个红包的面额
3.x_{ij} = 1当且仅当第i个用户被发到了j红包
4.\gamma 表示用户停留兴趣阈值,我们只给那些停留意图足够低的用户发红包,停留意图如果不够低我们认为他还会继续浏览,因此这次先不发放红包
5.P_{ij}、S_{ij}分别表示第$i$个用户领取到第$j$个红包以后的下单率和停留率
6.B表示全局预算约束
运用以上的定义,红包领取问题可以被写作:对于任意的用户,满足S_{ij}
为了求解以上问题,我们采用[7]提到的primal-dual框架。定义alpha和beta_j分别是相关的排比变量,据此框架我们可以在线求解以上问题。具体来讲,x_{ij}可以依据以下公式求得:
通过上式求得的x_{ij}和j,我们就得到了最终的分配方案。
四、系统布署
目前在集团做端智能首推jarvis平台,在这里给相关朋友点赞,在最开始的时侯没少麻烦jarvis朋友解决问题。运用jarvis,我们可以搜集端上实时数据并将深度模型布署到端上。我们主要是将IIDN布署到端上,MCKP决策模型因为须要考虑全局最优,所以放到了服务端。
图-3: 系统大图
图-3是我们整体的系统构架,每一个用户在详情页回挪到landing page的时侯会触发决策模型,IIDN首先按照端上采集到的行为数据辨识出用户的下单和逗留意图,随后该意图会被推送到服务端参与最终的红包决策。我们这套系统在日常线上持续生效,同时还参与了0331商人节,助力卖家数的提高。
五、实验实验设置
我们从1688客户端搜集数据,用到的特点如下表:
实验分为两部份:离线实验和在线实验。离线实验主要验证IIDN对于意图的辨识疗效,验证指标是AUC和logloss;在线实验主要验证我们二段式建模对于红包领取的疗效,主要的验证指标是增量卖家成本 (increment cost, ic),它被拿来评判每带来一个增量卖家须要消耗的成本,计算公式如下:
离线实验
在离线实验环节,我们分别使用以下方式进行下单意图辨识,并进行比较:
1.Logistic Regression (LR)
2.Gradient Boosting Decision Tree (GBDT)
3.DNN + RNN [12]
4.IIDN-single-LSTM (单层LSTM)
5.IIDN-non-attention (无Attention机制,使用简单的全连接)
6.IIDN-non-auxiliary-task (没有辅助任务的IIDN)
7.IIDN
离线结果如下表:
可以看见IIDN达到最高的AUC和最低的Logloss,这证明了IIDN的合理性。
在线实验
我们主要和另外三个领取方案做比较:
1.不发:该桶所有用户均不发红包
2.全发:该桶所有用户均发红包
3.uplift:我们采用广告营销当中常用的uplift方案,对每一个用户发放使他转化率提升最大的面额,同时该面额带来的转化率提升需要大于一定的阈值,否则不发放红包
在线疗效如下表:
可以看见虽然全发桶带来的转化率提高最显著,但是它也带来了最大的增量卖家成本。我们提出的方案除了相对自然转化率提高了25.7%,同时也比全发桶的增量卖家成本降低了44.3%,这证明了我们方案的优越性。
模型剖析学习曲线
图-4: 学习曲线
图-4展示了不同方式的学习曲线,可以看见LSTM, Attention以及逗留意图辨识任务均可以起到加速模型训练的疗效。
单调性剖析
正常来讲,红包面额越大,对于用户的剌激作用也越大,用户下单率曲线应当是一条关于红包面额单调递增的曲线,我们实验得到的曲线如下图:
图-5: 单调性曲线
可以看见所有模型基本呈现单调性,其中IIDN愈发符合真实情况。
原文链接
常州家用好太太指纹锁评测
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-18 05:55
7月10日,(南京)人工智能研究院在南京开发区举办落成典礼,科沃斯机器人股份有限公司副董事长钱程、南京市人民政府副秘书长郭明雁、南京开发区管委会副主任沈吟龙,南京大学人工智能学院党委书记武港山一齐在现场授牌。科沃斯机器人(南京)人工智能研究院将构建以“机器人+人工智能”为特色的科研基地,提升机器人感知智能、决策智能、行为智能、人机协同智能水平,提升用户体验,达到机器人与人共存共生、相互辅助的新高度,致力于成为聚集国内外人工智能精尖人才的创新平台和有力支点。人工智能技术蓬勃发展,正在被经济社会各个领域广泛应用,而服务机器人被一致觉得是AI极佳的应用场景之一。科沃斯机器人副董事长钱程表示,更加智能化的机器人依赖于人工智能技术的大力发展及落地,人工智能技术将帮助服务机器人实现从工具到管家再到伴侣的智能化迭代。科沃斯机器人捉住人工智能发展浪潮,与南京经济技术开发区达成战略合作,成立科沃斯机器人(南京)人工智能研究院,这对科沃斯来说是一个重要的战略性布署,对公司的未来发展具有深远的。
常州家用好太太指纹锁评测
现代家长对早教更加注重,很多人想在孩子的教育上多花点心思,却常常力不从心,特别是在早教资源的获取和应用上花费大量精力却收获甚微,就是解决这种疼点的产物,它整合了性的儿童早教内容,包括生活常识、知识启蒙、才艺培养、益智娱乐等,并且采用亲子互动,人机交互、益智游戏等多种有趣方式呈现,从而使早教过程饱含乐趣,从这点来说,早教机确实能使纹尽脑汁的父亲省心不少,所以为何会有早教机?因为科技的进步、因为有需求,因为为了使早教更轻松一点。那么,宝宝早教机对儿子有用吗?与其说早教机对儿子是否有用,还不如使我来回答早教机该如何用!技术的发展,早教机的功能和内容越来越多元,比如基于互联网的百科问答、在线早教等,客观上来讲,宝宝早教机确实对家庭教育能起到一定的帮助,但并不是说父母买一台早教机使女儿自娱自乐即使了事,反之,早教机倡导的是陪伴,它是父亲陪伴儿子启蒙的好帮手,爸爸妈妈利用早教机整合的功能内容,陪着女儿一起学习成长,让早教在整个家庭里显得轻松有趣。比如睡前陪儿子听一个小故事。
常州家用好太太指纹锁评测
早教对小孩智力开发的重要性不言而喻,用对孩子进行初期教育,已成了诸多年青父母的共同选择。通过早教机,宝宝除了可以在玩学校、学中玩,而且可以帮助女儿培养兴趣,挖掘潜能,另外也帮家长们节约了大量时间。然而,很多父母在具体选择订购儿童早教机的过程中,存在不少误区,结果导致对儿子没有达到“早教”的疗效,白白浪费了儿子的关键岁月。下面儿童早教机的小编就来讲解一下。1、只考虑价钱,宝宝早教的问题上可不能以这个为标准。在为孩子选择时,早教机的价钱诱因自然是首先要考虑的,但是,超低的价钱常常意味着偷工减料,不但外形质量,甚至内容上,售后等等都不一定得到保证,对孩子的早教疗效也就可想而知。所以,在选择儿童早教机时,要考虑性价比,在质量保证的情况下,再选择适中的价钱,这样才是对儿子负责。2、忽视儿子喜欢的外型,有的父母在订购儿童早教机时,感觉小孩很小,没有认知辨识能力,不懂得优劣,因此在订购的时侯,只考虑自己喜欢的,忽视了儿子的个人喜好,结果早教机买回来后,没玩三天就被儿子疏远,扔到一边。
近日,各视频网站热传微电影,在微电影第三篇中,窗户如同异性同学间的真心,而科沃斯机器人窗宝的清洁功能让阳台清洁明亮,也让她们的爱情“告别迷蒙”。每天面对灰蒙蒙的玻璃,你是否也想追求窗明几净,好好欣赏窗外的良人与窗前的明月?科沃斯智能擦窗机器人窗宝W830为你盖帽。人工智能落地在扫地机器人上有两大难点:其一,科沃斯机器人须要采集庞大的扫地机器人视角图片资料库,无法接入已有的人类视角图库,利用这种数据库,训练地宝辨识疗效来构建神经网路模型;其二,家庭环境与光线千变万化,扫地机器人所要辨识地上的目标物形态极易发生改变,增加辨识难度。“作为行业,我们除了基于对行业的洞察,去了解当下技术发展的困局,更应当有责任去攻破技术的难关,以消费者在不同场景下的使用疼点为核心,突破创新的界限。扫地机器人DG70正是代表,家用服务机器人应当被重新定义。”David说。地宝DG70可以通过人工智能算法自主躲避障碍物,与SmartNavi2.0全局规划技术配合优化清扫时的导航路线,高效完成地面清洁任务;其他如绿。
5月28日,在2019年京交会国家会议中心登场现身,其情感模型系统的技术性突破,再次成为各方瞩目的焦点。中国(北京)国际服务贸易交易会(京交会),是全球一个、国际性、综合型的服务贸易平台,2019届京交会由商务部和北京市政府联合举办,来自世贸组织、世界知识产权组织在内的21个国际组织和全球130多个国家和地区8000家企业机构参展,规模创历届。京交会展会现场,小胖机器人吸引了诸多国内外的参观者,北京电视台等多家媒体纷纷专访报导。据了解新版的,在原有自主导航、人机交互等功能的基础上,情感模型系统取得了技术性突破,向“机器人拥有自主意识”又跨越了一步,目前该项技术处于行业地位,登上了国际顶尖学术期刊《JBC》的封面。情感模型系统的突破,为“小胖机器人+”系列产品奠定了技术储备,小胖家用机器人、小胖商务机器人、小胖教学助手的性能将因而进一步提高,用户的体验也会更好。小胖呆萌甜美的表情,敏捷的对答,引来现场听众的缕缕欢笑和掌声。大家都认为小胖机器人越来有“人间烟火味道了”。据介绍,自。 查看全部
常州家用好太太指纹锁评测
7月10日,(南京)人工智能研究院在南京开发区举办落成典礼,科沃斯机器人股份有限公司副董事长钱程、南京市人民政府副秘书长郭明雁、南京开发区管委会副主任沈吟龙,南京大学人工智能学院党委书记武港山一齐在现场授牌。科沃斯机器人(南京)人工智能研究院将构建以“机器人+人工智能”为特色的科研基地,提升机器人感知智能、决策智能、行为智能、人机协同智能水平,提升用户体验,达到机器人与人共存共生、相互辅助的新高度,致力于成为聚集国内外人工智能精尖人才的创新平台和有力支点。人工智能技术蓬勃发展,正在被经济社会各个领域广泛应用,而服务机器人被一致觉得是AI极佳的应用场景之一。科沃斯机器人副董事长钱程表示,更加智能化的机器人依赖于人工智能技术的大力发展及落地,人工智能技术将帮助服务机器人实现从工具到管家再到伴侣的智能化迭代。科沃斯机器人捉住人工智能发展浪潮,与南京经济技术开发区达成战略合作,成立科沃斯机器人(南京)人工智能研究院,这对科沃斯来说是一个重要的战略性布署,对公司的未来发展具有深远的。
常州家用好太太指纹锁评测
现代家长对早教更加注重,很多人想在孩子的教育上多花点心思,却常常力不从心,特别是在早教资源的获取和应用上花费大量精力却收获甚微,就是解决这种疼点的产物,它整合了性的儿童早教内容,包括生活常识、知识启蒙、才艺培养、益智娱乐等,并且采用亲子互动,人机交互、益智游戏等多种有趣方式呈现,从而使早教过程饱含乐趣,从这点来说,早教机确实能使纹尽脑汁的父亲省心不少,所以为何会有早教机?因为科技的进步、因为有需求,因为为了使早教更轻松一点。那么,宝宝早教机对儿子有用吗?与其说早教机对儿子是否有用,还不如使我来回答早教机该如何用!技术的发展,早教机的功能和内容越来越多元,比如基于互联网的百科问答、在线早教等,客观上来讲,宝宝早教机确实对家庭教育能起到一定的帮助,但并不是说父母买一台早教机使女儿自娱自乐即使了事,反之,早教机倡导的是陪伴,它是父亲陪伴儿子启蒙的好帮手,爸爸妈妈利用早教机整合的功能内容,陪着女儿一起学习成长,让早教在整个家庭里显得轻松有趣。比如睡前陪儿子听一个小故事。
常州家用好太太指纹锁评测
早教对小孩智力开发的重要性不言而喻,用对孩子进行初期教育,已成了诸多年青父母的共同选择。通过早教机,宝宝除了可以在玩学校、学中玩,而且可以帮助女儿培养兴趣,挖掘潜能,另外也帮家长们节约了大量时间。然而,很多父母在具体选择订购儿童早教机的过程中,存在不少误区,结果导致对儿子没有达到“早教”的疗效,白白浪费了儿子的关键岁月。下面儿童早教机的小编就来讲解一下。1、只考虑价钱,宝宝早教的问题上可不能以这个为标准。在为孩子选择时,早教机的价钱诱因自然是首先要考虑的,但是,超低的价钱常常意味着偷工减料,不但外形质量,甚至内容上,售后等等都不一定得到保证,对孩子的早教疗效也就可想而知。所以,在选择儿童早教机时,要考虑性价比,在质量保证的情况下,再选择适中的价钱,这样才是对儿子负责。2、忽视儿子喜欢的外型,有的父母在订购儿童早教机时,感觉小孩很小,没有认知辨识能力,不懂得优劣,因此在订购的时侯,只考虑自己喜欢的,忽视了儿子的个人喜好,结果早教机买回来后,没玩三天就被儿子疏远,扔到一边。
近日,各视频网站热传微电影,在微电影第三篇中,窗户如同异性同学间的真心,而科沃斯机器人窗宝的清洁功能让阳台清洁明亮,也让她们的爱情“告别迷蒙”。每天面对灰蒙蒙的玻璃,你是否也想追求窗明几净,好好欣赏窗外的良人与窗前的明月?科沃斯智能擦窗机器人窗宝W830为你盖帽。人工智能落地在扫地机器人上有两大难点:其一,科沃斯机器人须要采集庞大的扫地机器人视角图片资料库,无法接入已有的人类视角图库,利用这种数据库,训练地宝辨识疗效来构建神经网路模型;其二,家庭环境与光线千变万化,扫地机器人所要辨识地上的目标物形态极易发生改变,增加辨识难度。“作为行业,我们除了基于对行业的洞察,去了解当下技术发展的困局,更应当有责任去攻破技术的难关,以消费者在不同场景下的使用疼点为核心,突破创新的界限。扫地机器人DG70正是代表,家用服务机器人应当被重新定义。”David说。地宝DG70可以通过人工智能算法自主躲避障碍物,与SmartNavi2.0全局规划技术配合优化清扫时的导航路线,高效完成地面清洁任务;其他如绿。
5月28日,在2019年京交会国家会议中心登场现身,其情感模型系统的技术性突破,再次成为各方瞩目的焦点。中国(北京)国际服务贸易交易会(京交会),是全球一个、国际性、综合型的服务贸易平台,2019届京交会由商务部和北京市政府联合举办,来自世贸组织、世界知识产权组织在内的21个国际组织和全球130多个国家和地区8000家企业机构参展,规模创历届。京交会展会现场,小胖机器人吸引了诸多国内外的参观者,北京电视台等多家媒体纷纷专访报导。据了解新版的,在原有自主导航、人机交互等功能的基础上,情感模型系统取得了技术性突破,向“机器人拥有自主意识”又跨越了一步,目前该项技术处于行业地位,登上了国际顶尖学术期刊《JBC》的封面。情感模型系统的突破,为“小胖机器人+”系列产品奠定了技术储备,小胖家用机器人、小胖商务机器人、小胖教学助手的性能将因而进一步提高,用户的体验也会更好。小胖呆萌甜美的表情,敏捷的对答,引来现场听众的缕缕欢笑和掌声。大家都认为小胖机器人越来有“人间烟火味道了”。据介绍,自。
菜鸟+Hologres=智能物流
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-17 14:25
简介:菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,随着业务量的降低,数据在原储存系统HBase中的导出时间也越来越长。本文将会为你分享新手团队怎样使用Hologres成功替换原HBase构架,打造新一代智能货运平台。一、业务背景
菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,承载了菜鸟物流数据的大部分处理任务。
智能货运剖析引擎将基于运配网路的各种应用场景集中到了统一的一个技术构架,以此提供强悍的吞吐和估算能力。基于原构架的数据处理流程为:Datahub实时采集数据源,收录仓、配、运和订单等数据,实时估算Flink基于流批一体的模式对数据预处理,形成一个以订单为单位,收录订单跟踪风波的宽表,写入储存引擎HBase中,再供外部查询。
在数据处理部份,随着数据量的降低,原有的储存系统HBase在维表全量导出中所须要的时间越来越长,这就须要花费大量的资源,另外其单机吞吐的表现不是挺好,单位成本高。在数据量较小时,成本不是须要考虑的关键诱因,但当数据量规模变大时,成本的重要性就彰显下来了。菜鸟智能货运每晚须要处理大批量的数据,这也就意味着每晚将会浪费大量的资源。
同时,在我们的场景中,有些表是作为Flink维表基于PK进行PointQuery,有些表须要进行OLAP剖析,而HBase并不能两种场景都满足。为了OLAP剖析,需要将数据同步到批处理系统中,为了KV查询,需要将数据同步到KVStore。不同的查询需求就须要利用多个系统,数据在不同系统之间的导出导入除了会加深数据同步的负担,也会带来冗余储存,也极容易出现数据不一致的情况,并且多个系统也会给开发和运维带来一定的成本。
基于以上背景,当前我们最须要解决的问题是增加整体的资源消耗成本,那么就须要有一款产品既能提供储存能力还要提供高性能的写入能力。而在查询场景上,若是这款产品能同时满足KV查询和复杂OLAP查询将会是加分项,这样才会解决多个系统带来的数据孤岛问题,一次性满足所有需求。
我们在集团内对多个产品进行了督查,最终选择了Hologres替换现有的HBase。
二、业务构架
菜鸟物流引擎须要处理大量的表和数据,全量任务快件线和仓配线通过MaxCompute(原ODPS)表的日分区快照做驱动源,增量任务通过对应的风波流做驱动,来进行引擎数据写入。
全量任务会依照包裹的历史履行进度进行聚合,生成这个包裹的客观履行和历史属性信息,并通过Flink Job实时同步更新到Hologres里,提供给数据任务进行关联。实时数据在接收到一条风波消息后,首先会去关联这条包裹历史履行,并会调用算法服务链,进行拆合单、末端网点预测、路由选择、时效预测等,生成新的预测履行进度。新的预测履行会作为回流数据写入TT(消息中间件,类似Kafka)和Hologres中,并再提供给数据任务进行关联。
通过数据任务之间的相互协同,我们对数据关系进行了梳理,并尽量减少数据之间的依赖,最终业务处理构架如下图所示:
三、业务价值
将HBase替换成Hologres以后,给业务带来的价值主要有以下几个方面:
1.整体硬件资源成本上涨60%+
对比HBase,相同配置的Hologres有着更强的写入性能,能够提供更好的吞吐量,也就是说我们可以用更少的资源来满足现有数据规模的处理需求。在实际业务应用中,整体硬件资源成本上涨60%+,解决了我们最棘手的问题。
2.更快的全链路处理速率(2亿记录端到端3分钟)
全量数据处理所需的时间是十分重要的指标,设想某三天新发布的数据处理代码有bug,新产出的数据不可用,即使修补了代码,还得继续解决早已存在的错误数据,此时就要跑一次全量,用正常的数据覆盖错误的数据。全量任务的运行时间决定了故障的持续时间,全量运行的速率越快,故障能够越快解决。
在货运剖析引擎的全量中,我们须要先通过所有维表的数据,确保维表自身的数据是正确的,这是一个特别历时的操作。以其中一张表为例,2亿多的数据量,使用Hologres同步只须要3分钟左右,这也意味着可以更快的执行完毕全量数据,以便我们能否更从容应对突发情况。
3.一个系统,满KV和OLAP两个场景,没有数据冗余
Hologres在储存上支持行存和列存两种储存模式。列存适宜海量数据的交互式剖析,而行存适宜基于Primary Key的整行读取。这就意味着我们可以将所有的数据储存在Hologres中,需要PointQuery就选择行存模式,需要复杂OLAP剖析就选择列存模式,满足了OLAP和KV查询,无需再利用其他系统,既保证了数据储存的唯一性,也防止了各类系统之间的导出导入和复杂运维。
4.大维表实时SQL查询
以前假如想查一下维表中的数据,由于是KV插口,并不是很方便。Hologres兼容PostgreSQL生态,可以直接使用psql客户端访问,通过标准的PostgreSQL句型查询表中的数据,支持各类过滤条件,能够很方便的实时检测数据是不是有问题。
5.强Schema
原有的维表储存是一个弱Schema的储存服务,在Flink任务中,即使访问不存在的数组也不会报错,只是获取到的数组值为空。代码里不留神弄错了数组名,一是很难立即发觉,通常要等到数据产出时侯才会发觉,甚至只能等用户发觉,另外排查上去也很麻烦,没法直接定位。使用Hologres的时侯数组名弄错立刻报错,错误信息太明晰,避免了潜在的错误风险,还能节约时间。
作者:阿里巴巴菜鸟物流团队(弃疾,孝江,姜继忠)
原文链接 查看全部
菜鸟+Hologres=智能物流
简介:菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,随着业务量的降低,数据在原储存系统HBase中的导出时间也越来越长。本文将会为你分享新手团队怎样使用Hologres成功替换原HBase构架,打造新一代智能货运平台。一、业务背景
菜鸟智能货运剖析引擎是基于搜索构架建设的货运查询平台,日均处理包裹风波几十亿,承载了菜鸟物流数据的大部分处理任务。
智能货运剖析引擎将基于运配网路的各种应用场景集中到了统一的一个技术构架,以此提供强悍的吞吐和估算能力。基于原构架的数据处理流程为:Datahub实时采集数据源,收录仓、配、运和订单等数据,实时估算Flink基于流批一体的模式对数据预处理,形成一个以订单为单位,收录订单跟踪风波的宽表,写入储存引擎HBase中,再供外部查询。
在数据处理部份,随着数据量的降低,原有的储存系统HBase在维表全量导出中所须要的时间越来越长,这就须要花费大量的资源,另外其单机吞吐的表现不是挺好,单位成本高。在数据量较小时,成本不是须要考虑的关键诱因,但当数据量规模变大时,成本的重要性就彰显下来了。菜鸟智能货运每晚须要处理大批量的数据,这也就意味着每晚将会浪费大量的资源。
同时,在我们的场景中,有些表是作为Flink维表基于PK进行PointQuery,有些表须要进行OLAP剖析,而HBase并不能两种场景都满足。为了OLAP剖析,需要将数据同步到批处理系统中,为了KV查询,需要将数据同步到KVStore。不同的查询需求就须要利用多个系统,数据在不同系统之间的导出导入除了会加深数据同步的负担,也会带来冗余储存,也极容易出现数据不一致的情况,并且多个系统也会给开发和运维带来一定的成本。
基于以上背景,当前我们最须要解决的问题是增加整体的资源消耗成本,那么就须要有一款产品既能提供储存能力还要提供高性能的写入能力。而在查询场景上,若是这款产品能同时满足KV查询和复杂OLAP查询将会是加分项,这样才会解决多个系统带来的数据孤岛问题,一次性满足所有需求。
我们在集团内对多个产品进行了督查,最终选择了Hologres替换现有的HBase。
二、业务构架
菜鸟物流引擎须要处理大量的表和数据,全量任务快件线和仓配线通过MaxCompute(原ODPS)表的日分区快照做驱动源,增量任务通过对应的风波流做驱动,来进行引擎数据写入。
全量任务会依照包裹的历史履行进度进行聚合,生成这个包裹的客观履行和历史属性信息,并通过Flink Job实时同步更新到Hologres里,提供给数据任务进行关联。实时数据在接收到一条风波消息后,首先会去关联这条包裹历史履行,并会调用算法服务链,进行拆合单、末端网点预测、路由选择、时效预测等,生成新的预测履行进度。新的预测履行会作为回流数据写入TT(消息中间件,类似Kafka)和Hologres中,并再提供给数据任务进行关联。
通过数据任务之间的相互协同,我们对数据关系进行了梳理,并尽量减少数据之间的依赖,最终业务处理构架如下图所示:
三、业务价值
将HBase替换成Hologres以后,给业务带来的价值主要有以下几个方面:
1.整体硬件资源成本上涨60%+
对比HBase,相同配置的Hologres有着更强的写入性能,能够提供更好的吞吐量,也就是说我们可以用更少的资源来满足现有数据规模的处理需求。在实际业务应用中,整体硬件资源成本上涨60%+,解决了我们最棘手的问题。
2.更快的全链路处理速率(2亿记录端到端3分钟)
全量数据处理所需的时间是十分重要的指标,设想某三天新发布的数据处理代码有bug,新产出的数据不可用,即使修补了代码,还得继续解决早已存在的错误数据,此时就要跑一次全量,用正常的数据覆盖错误的数据。全量任务的运行时间决定了故障的持续时间,全量运行的速率越快,故障能够越快解决。
在货运剖析引擎的全量中,我们须要先通过所有维表的数据,确保维表自身的数据是正确的,这是一个特别历时的操作。以其中一张表为例,2亿多的数据量,使用Hologres同步只须要3分钟左右,这也意味着可以更快的执行完毕全量数据,以便我们能否更从容应对突发情况。
3.一个系统,满KV和OLAP两个场景,没有数据冗余
Hologres在储存上支持行存和列存两种储存模式。列存适宜海量数据的交互式剖析,而行存适宜基于Primary Key的整行读取。这就意味着我们可以将所有的数据储存在Hologres中,需要PointQuery就选择行存模式,需要复杂OLAP剖析就选择列存模式,满足了OLAP和KV查询,无需再利用其他系统,既保证了数据储存的唯一性,也防止了各类系统之间的导出导入和复杂运维。
4.大维表实时SQL查询
以前假如想查一下维表中的数据,由于是KV插口,并不是很方便。Hologres兼容PostgreSQL生态,可以直接使用psql客户端访问,通过标准的PostgreSQL句型查询表中的数据,支持各类过滤条件,能够很方便的实时检测数据是不是有问题。
5.强Schema
原有的维表储存是一个弱Schema的储存服务,在Flink任务中,即使访问不存在的数组也不会报错,只是获取到的数组值为空。代码里不留神弄错了数组名,一是很难立即发觉,通常要等到数据产出时侯才会发觉,甚至只能等用户发觉,另外排查上去也很麻烦,没法直接定位。使用Hologres的时侯数组名弄错立刻报错,错误信息太明晰,避免了潜在的错误风险,还能节约时间。
作者:阿里巴巴菜鸟物流团队(弃疾,孝江,姜继忠)
原文链接
人工智能PM系列文章(二)PM要学会使用数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-17 08:40
本期和你们说说产品总监在机器学习领域该怎么理解数据、使用数据、以及面对大数据的整治须要具备的一些基本素养。
机器学习三要素:
业内公认的机器学习三大要素:算法、计算能力、数据。
1、算法:随着Google的Tensorflow的诞生,将算法迅速应用到产品中的门槛大幅度增加。使用Tensorflow可以使应用型研究者将看法迅速运用到产品中,也可以使学术性研究者更直接地彼此分享代码,从而提升科研产出率。因此,这个趋势就类似当初做网站设计还须要编撰复杂的代码,而明天连一个不会编程的人就会作出精致的网站了。
通过TensorBoard查看即时数据的情况
2、计算能力:大公司会通过强悍的云计算能力提供全行业的人工智能估算能力,而小公司无需搭建自己的估算平台,直接使用大公司提供的现成的云平台,即实现了可以用极少的硬件投入就可以进行深度学习产品的开发。因此在这方面公司其实也不是公司或产品可以构建门槛的方向。
3、数据:数据在机器学习领域领域其实早已弄成了兵家必争之地,而且优质的数据可以帮助企业快速构建门槛。好的数据一般要比好的算法更重要,而且数据本身的属性决定了应用的机器学习算法是否合适。假设你的数据集够大,那么不管你使用哪种算法可能对分类性能都没很大影响。
如何理解数据
数据对于机器学习的重要性虽然始于于机器学习的本质,在专家系统(expert system, ES)作为人工智能重要领域并广泛应用的年代,人们早已发觉专家系统的缺陷。
计算机难以在个别领域用尽全世界所有该领域专家的经验和智慧,且好多领域的专家也很难总结出处理问题的缘由和规律,况且对于企业来说在好多领域中通过创造专家系统解决问题的ROI也并不理想,因此出现了机器学习(Machine Learning, ML)。
如果说专家系统是一种手把手式的填鸭式的教学方法,而机器学习更象一种在佛寺比丘尼传授师父的形式,高僧对于武功和学佛的提高一般是只可意会不能言传的,因此一般要依赖“悟性”。徒弟只能通过常年的实践-碰壁-再实践提高自身武功及慧根。机器学习就是凭着这样一种内在逻辑诞生的,尤其在个别判定模式相对复杂而且结果明晰的领域,机器比人强的事实早已被广泛证明,例如商品推荐、法律文书整理、投资策略的推荐等等。
实际上机器学习早已成为数据剖析技术的重要创新来源,而几乎所有学科都要面对大量的数据剖析任务,但是机器学习只是数据挖掘的工具中的一种。
产品总监在设计产品的时侯不仅要考虑到怎样将机器学习借助到极至,还要解决数据剖析过程中遇见的一些其他问题例如数据储存、数据清洗、数据转换等一系列关于数据整治的问题。
毕竟产品总监不是算法工程师,除了关注算法和模型训练以外还要协调资源将数据如何来的、哪些数据须要存、存多久、以及数据质量遇见问题是是否须要数据整治工具去建立等等。现实项目中没有那么多理想情况,而且涉及到跨团队的协作。
因此这就要求产品总监应理解行业数据标准,对行业标准数据类型、数据分布(数据在哪)、数据量预估、以及每种数据背后的涵义了如指掌。只有理解了这种数据的维度,才能进一步指导产品总监去获取行业优质数据,并判定是否须要搭建大数据构架进行对数据的处理。下面举个机器学习和大数据构架结合的案例:
Eagle是eBay开源的分布式实时安全监控方案。通过离线训练模型和实时流引擎监控,可以立刻检测出对敏感数据的访问或恶意的操作,并立刻采取应对举措。
Eagle须要被布署在多个小型Hadoop集群上,这些机群拥有数百PB数据量。如果你是这个产品的产品总监你起码要考虑到产品的这三个层面:视觉诠释、数据处理剖析、采集和储存数据。
Eagle
另外,许多传统行业的数据积累在规范程度和流转效率上远未达到可充分发挥人工智能技术潜能的程度,产品总监要辨识这方面的风险,产品的攻占市场先机尚且重要,但过早的步入市场也可能有巨大的投资风险。
产品总监该怎么借助数据设计机器学习产品
1、当需求确定后,产品总监应当判定是否有质量足够好的数据作为训练集来完成对模型的训练,数据的质量决定了模型的训练疗效能够满足用户需求,甚至决定了产品总监对产品设定的目标是否还能实现。
产品总监应当明晰所设计的功能目标是否明晰且容易判别和量化,越明晰就越容易被手动标记。越容易被手动标记就越容易帮助机器快速进行学习和建模,即功能的实现成本较低且比较容易实现较好的疗效。
例如在个别领域中就天然带有闭环的、自动标明的数据:基于互联网平台的广告平台可以手动依据用户在页面上的点击动作及后续操作,采集到第一手转化率数据,而这个转化率数据反过来又可作为关键特点,帮助AI系统进一步学习。这种从应用本身搜集数据(训练集不需要外部采集),再用数据训练模型,用模型提升应用性能(容易判别和容易量化的性能目标)的闭环模式愈发高效。
2、在设计机器学习产品的时侯产品总监应当转变传统产品设计的思路和逻辑,过去产品总监的设计逻辑是画原型、PRD文档交付研制,研发会根据原型设计的去开发,页面都是设计好了的,页面上有几个按键,每个按键的交互反馈是哪些,每种用户的数据、页面权限都是设计好的。
而在机器学习产品设计中,可能就没那么多事先才能确定好的事情了。比如产品的目标是剖析造成某商场销售业绩提高的最重要的诱因,并按照每晚采集到的数据输入到训练好的模型中预测将要到来的一周的销售业绩。
那么产品总监在设计这样的数据剖析功能的时侯是难以在训练集都没输入并训练的时侯给出的原型的,整个页面的元素大部分是又训练下来的结果决定的。而最终该功能能够成功不是依赖页面开发工程师,而很大程度上依赖于算法团队是否能获得足够优质的数据并训练比较精准的模型进行预测剖析。这也是为何须要产品总监和算法团队进行充分的交流,因为机器学习产品的设计常常当目标定好后,其他的工作不是人说的算,而是数据和算法说的算,一味生硬的设计产品只能使技术团队陷于挣扎。
3、测试算法,产品总监是端到端负责人,一个功能的算法做下来了,但实际疗效(或准确度)是须要产品总监亲自去检验的,这除了须要大量生产数据的检测,而且有些时侯是须要用户认可才行。
就拿里面那种预测商场业绩的反例来说,产品最终要实现的是帮助商场管理者才能有的放矢的进行管理决策,那么就须要产品总监实际参与到预测结果和实际疗效的比对中,只有获得了用户的认可,才是产品设计的完满。而倘若疗效不好,则须要产品总监想办法获得更多维度的数据进行训练,必要的时侯须要聘请行业专家参与到算法调优中。
最后,本文只是针对数据问题讨论的冰山一角,篇幅有限也只能抛砖引玉式的提出一些问题和观点。更多有关数据整治的内容将会在后续系列文章中详尽描述。希望你能持续关注我的人工智能产品总监系列文章。
作者:特里,头条号:“人工智能产品设计”。毕业于University of Melbourne,人工智能领域产品总监,专注于AI产品设计、大数据剖析、AI技术商用化研究和实践。 查看全部
人工智能PM系列文章(二)PM要学会使用数据
本期和你们说说产品总监在机器学习领域该怎么理解数据、使用数据、以及面对大数据的整治须要具备的一些基本素养。
机器学习三要素:
业内公认的机器学习三大要素:算法、计算能力、数据。
1、算法:随着Google的Tensorflow的诞生,将算法迅速应用到产品中的门槛大幅度增加。使用Tensorflow可以使应用型研究者将看法迅速运用到产品中,也可以使学术性研究者更直接地彼此分享代码,从而提升科研产出率。因此,这个趋势就类似当初做网站设计还须要编撰复杂的代码,而明天连一个不会编程的人就会作出精致的网站了。
通过TensorBoard查看即时数据的情况
2、计算能力:大公司会通过强悍的云计算能力提供全行业的人工智能估算能力,而小公司无需搭建自己的估算平台,直接使用大公司提供的现成的云平台,即实现了可以用极少的硬件投入就可以进行深度学习产品的开发。因此在这方面公司其实也不是公司或产品可以构建门槛的方向。
3、数据:数据在机器学习领域领域其实早已弄成了兵家必争之地,而且优质的数据可以帮助企业快速构建门槛。好的数据一般要比好的算法更重要,而且数据本身的属性决定了应用的机器学习算法是否合适。假设你的数据集够大,那么不管你使用哪种算法可能对分类性能都没很大影响。
如何理解数据
数据对于机器学习的重要性虽然始于于机器学习的本质,在专家系统(expert system, ES)作为人工智能重要领域并广泛应用的年代,人们早已发觉专家系统的缺陷。
计算机难以在个别领域用尽全世界所有该领域专家的经验和智慧,且好多领域的专家也很难总结出处理问题的缘由和规律,况且对于企业来说在好多领域中通过创造专家系统解决问题的ROI也并不理想,因此出现了机器学习(Machine Learning, ML)。
如果说专家系统是一种手把手式的填鸭式的教学方法,而机器学习更象一种在佛寺比丘尼传授师父的形式,高僧对于武功和学佛的提高一般是只可意会不能言传的,因此一般要依赖“悟性”。徒弟只能通过常年的实践-碰壁-再实践提高自身武功及慧根。机器学习就是凭着这样一种内在逻辑诞生的,尤其在个别判定模式相对复杂而且结果明晰的领域,机器比人强的事实早已被广泛证明,例如商品推荐、法律文书整理、投资策略的推荐等等。
实际上机器学习早已成为数据剖析技术的重要创新来源,而几乎所有学科都要面对大量的数据剖析任务,但是机器学习只是数据挖掘的工具中的一种。
产品总监在设计产品的时侯不仅要考虑到怎样将机器学习借助到极至,还要解决数据剖析过程中遇见的一些其他问题例如数据储存、数据清洗、数据转换等一系列关于数据整治的问题。
毕竟产品总监不是算法工程师,除了关注算法和模型训练以外还要协调资源将数据如何来的、哪些数据须要存、存多久、以及数据质量遇见问题是是否须要数据整治工具去建立等等。现实项目中没有那么多理想情况,而且涉及到跨团队的协作。
因此这就要求产品总监应理解行业数据标准,对行业标准数据类型、数据分布(数据在哪)、数据量预估、以及每种数据背后的涵义了如指掌。只有理解了这种数据的维度,才能进一步指导产品总监去获取行业优质数据,并判定是否须要搭建大数据构架进行对数据的处理。下面举个机器学习和大数据构架结合的案例:
Eagle是eBay开源的分布式实时安全监控方案。通过离线训练模型和实时流引擎监控,可以立刻检测出对敏感数据的访问或恶意的操作,并立刻采取应对举措。
Eagle须要被布署在多个小型Hadoop集群上,这些机群拥有数百PB数据量。如果你是这个产品的产品总监你起码要考虑到产品的这三个层面:视觉诠释、数据处理剖析、采集和储存数据。
Eagle
另外,许多传统行业的数据积累在规范程度和流转效率上远未达到可充分发挥人工智能技术潜能的程度,产品总监要辨识这方面的风险,产品的攻占市场先机尚且重要,但过早的步入市场也可能有巨大的投资风险。
产品总监该怎么借助数据设计机器学习产品
1、当需求确定后,产品总监应当判定是否有质量足够好的数据作为训练集来完成对模型的训练,数据的质量决定了模型的训练疗效能够满足用户需求,甚至决定了产品总监对产品设定的目标是否还能实现。
产品总监应当明晰所设计的功能目标是否明晰且容易判别和量化,越明晰就越容易被手动标记。越容易被手动标记就越容易帮助机器快速进行学习和建模,即功能的实现成本较低且比较容易实现较好的疗效。
例如在个别领域中就天然带有闭环的、自动标明的数据:基于互联网平台的广告平台可以手动依据用户在页面上的点击动作及后续操作,采集到第一手转化率数据,而这个转化率数据反过来又可作为关键特点,帮助AI系统进一步学习。这种从应用本身搜集数据(训练集不需要外部采集),再用数据训练模型,用模型提升应用性能(容易判别和容易量化的性能目标)的闭环模式愈发高效。
2、在设计机器学习产品的时侯产品总监应当转变传统产品设计的思路和逻辑,过去产品总监的设计逻辑是画原型、PRD文档交付研制,研发会根据原型设计的去开发,页面都是设计好了的,页面上有几个按键,每个按键的交互反馈是哪些,每种用户的数据、页面权限都是设计好的。
而在机器学习产品设计中,可能就没那么多事先才能确定好的事情了。比如产品的目标是剖析造成某商场销售业绩提高的最重要的诱因,并按照每晚采集到的数据输入到训练好的模型中预测将要到来的一周的销售业绩。
那么产品总监在设计这样的数据剖析功能的时侯是难以在训练集都没输入并训练的时侯给出的原型的,整个页面的元素大部分是又训练下来的结果决定的。而最终该功能能够成功不是依赖页面开发工程师,而很大程度上依赖于算法团队是否能获得足够优质的数据并训练比较精准的模型进行预测剖析。这也是为何须要产品总监和算法团队进行充分的交流,因为机器学习产品的设计常常当目标定好后,其他的工作不是人说的算,而是数据和算法说的算,一味生硬的设计产品只能使技术团队陷于挣扎。
3、测试算法,产品总监是端到端负责人,一个功能的算法做下来了,但实际疗效(或准确度)是须要产品总监亲自去检验的,这除了须要大量生产数据的检测,而且有些时侯是须要用户认可才行。
就拿里面那种预测商场业绩的反例来说,产品最终要实现的是帮助商场管理者才能有的放矢的进行管理决策,那么就须要产品总监实际参与到预测结果和实际疗效的比对中,只有获得了用户的认可,才是产品设计的完满。而倘若疗效不好,则须要产品总监想办法获得更多维度的数据进行训练,必要的时侯须要聘请行业专家参与到算法调优中。
最后,本文只是针对数据问题讨论的冰山一角,篇幅有限也只能抛砖引玉式的提出一些问题和观点。更多有关数据整治的内容将会在后续系列文章中详尽描述。希望你能持续关注我的人工智能产品总监系列文章。
作者:特里,头条号:“人工智能产品设计”。毕业于University of Melbourne,人工智能领域产品总监,专注于AI产品设计、大数据剖析、AI技术商用化研究和实践。
微信推广获客工具-快寻客V3.0上线,朋友圈推广获客更便利
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-17 08:13
2、新增人脉广场模块,平台所有用户可以进行人脉拓展。
3、增加频道订阅功能,可以指定订阅平台。平台只推荐指定频道热文给你。
目前已上线核心功能:
短视频采集+视频库
全新短视频库上线!支持采集抖音、快手短视频,复制视频链接到快寻客中即可快速进行转换。短视频库上线,视频库每日更新,系统会对时下热门视频进行采集,当你一时没有推广素材时,到快寻客视频库瞧瞧吧,种类诸多的视频总有一款适宜你。
智能名片
通过快寻客制做、转换、生成的文章不仅可以更改内容,还可以插入名片功能,用户再打开文章后会在首段和文章底部位置见到您的个人名片,点击名片后可以打开您的个人站点,电话、微信均支持一键拨通和复制。搭配简介功能可以使您更丰富生动地展示公司、个人。
员工名片+企业动态展示
快寻客名片系统除了可以一键拨通,名片页面中还可以插入公司产品以及动态,动态信息在您推广的同时,可以使用户愈发深入的了解公司最新动态,侧面增进用户感知,更进一步加深用户对您的了解。
其他辅助功能
1,新增素材中心管理功能,素材中心可以添加预设表单,广告等功能,设置完成后的素材可以一键插入到文章中去。预设广告可以选择插入至文章顶部或则顶部。
2,素材中心图片管理降低删掉功能,现在可以降低或删掉图片了
3,系统设置降低文章设置,用户可以选择开启名片手动插入、广告手动插入、免费换成我的
4,企业版主帐号,可以在线订购职工兑换码。 查看全部
微信推广获客工具-快寻客V3.0上线,朋友圈推广获客更便利
2、新增人脉广场模块,平台所有用户可以进行人脉拓展。
3、增加频道订阅功能,可以指定订阅平台。平台只推荐指定频道热文给你。
目前已上线核心功能:
短视频采集+视频库
全新短视频库上线!支持采集抖音、快手短视频,复制视频链接到快寻客中即可快速进行转换。短视频库上线,视频库每日更新,系统会对时下热门视频进行采集,当你一时没有推广素材时,到快寻客视频库瞧瞧吧,种类诸多的视频总有一款适宜你。
智能名片
通过快寻客制做、转换、生成的文章不仅可以更改内容,还可以插入名片功能,用户再打开文章后会在首段和文章底部位置见到您的个人名片,点击名片后可以打开您的个人站点,电话、微信均支持一键拨通和复制。搭配简介功能可以使您更丰富生动地展示公司、个人。
员工名片+企业动态展示
快寻客名片系统除了可以一键拨通,名片页面中还可以插入公司产品以及动态,动态信息在您推广的同时,可以使用户愈发深入的了解公司最新动态,侧面增进用户感知,更进一步加深用户对您的了解。
其他辅助功能
1,新增素材中心管理功能,素材中心可以添加预设表单,广告等功能,设置完成后的素材可以一键插入到文章中去。预设广告可以选择插入至文章顶部或则顶部。
2,素材中心图片管理降低删掉功能,现在可以降低或删掉图片了
3,系统设置降低文章设置,用户可以选择开启名片手动插入、广告手动插入、免费换成我的
4,企业版主帐号,可以在线订购职工兑换码。
自动点击易迅商品价钱条件,智能采集价格数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2020-08-15 12:29
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。
二、设置连续动作
点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。
按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。
三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。
针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。
为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。
四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。
4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。
查看全部
注意:如果动作执行前后的网页结构没有变化,可以用一个规则来完成;网页结构前后变化的话,必须用两个或以上的规则来完成;另外涉及翻页的话,也要拆成两个或以上的规则。关于连续动作要做多少个规则请查阅文章《规划采集流程》。
一、建立第一级主题抓取目标信息
建立第一级主题的规则,把想要的信息映射到整理箱中,建议做完内容映射后,也做上定位标志映射,可以提升定位准确性和规则适应性。
注意:设置了连续动作的规则可以不建整理箱,例如方案2的第一级主题可以不建整理箱,但是用整理箱抓一点数据(选择网页上一定会显示下来的信息),是为了给爬虫判定是否执行采集,否则可能漏采网页。
二、设置连续动作
点击新建按键构建一个新动作,每个动作的设置方式都是一样,基本操作如下:
2.1 输入目标主题名
连续动作指向的是同一个目标主题。如果有多个动作,并且要指向不同的主题,请拆成多个规则分别设置连续动作。
2.2 选择动作类型
本案例是点击动作,不同动作的适用范围是不同的,请按照实际的操作情况来选择动作类型。
2.3 把定位到动作对象的xpath填入到定位表达式中
2.4 输入动作名称
告诉自己这一步动作是拿来干嘛的,方便之后更改。
2.5 高级设置
最初可以不设置,后面调试连续动作时会用到,可以扩大动作的适用范围。如需把动作对象的信息也抓出来,就在中级设置的内容表达式中用xpath定位到动作对象的信息来实现,请依照须要再来设置。
注意:动作类型是否选对以及xpath是否定位确切,决定了连续动作能够执行成功。Xpath是标准的用于定位html节点的语言,请自行把握xpath后再来使用连续动作的功能。
按照人的操作步骤,还要选择版本、购买方法1、购买方法2,所以,我们还要继续新建3个动作,重复以上步骤。
三、调试规则
完成以上步骤后,点击保存规则,再点击爬数据按键进行试抓。发现采集时报错:无法定位到节点***,观察浏览器窗口,看到执行完第一步点击时,其他信息都没加载上来,等到信息都加载上来,又发觉点击了订购方法2后,就难以回挪到执行4步点击的页面,这就造成连续动作没法连贯执行。
针对里面的情况,我们的解决方式是删除第4步动作。因为无论是否点击订购方法2,都不影响商品价钱。所以,可以删除没必要且引起干扰的动作步骤。
修改后再度试抓,把提取到的xml转为excel后,看到价钱和累计评价的数据抓漏或抓错了。这是因为网页很大,加载比较慢,点击后的数据要等待一定时间才会加载完成。
为了抓全数据,需要延长等待时间,给每位动作单独设置延时,点击动作步骤->高级设置->额外延时,输入正整数,单位是秒。输入的时间请按照实际调试。
另外,如果不是置顶窗口,采集时会循环点击。这是因为易迅网页上有反爬举措,必须为当前窗口的操作才能生效。所以,要在中级设置上勾上窗口可见,采集时窗口会置顶。请按照实际情况进行设置。
四、如何把抓到的信息与动作步骤一一对应?
如果希望把抓到的信息与动作步骤一一对应上去,这样就得把动作对象的信息也提取出来,有以下两种方式:
4.1 在连续动作的中级设置的内容表达式中用xpath定位到动作对象的信息节点。
在定位表达式早已定位到动作对象的整个操作范围,也包括其本身的信息,所以,内容表达式只需从定位到的动作对象为起点,继续定位到其信息就行。采集时都会把该步动作的信息记录在actionvalue中,与之对应的是actionno,记录的是该步动作执行的次数。
4.2 在整理箱中抓取动作对象的信息,这里同样要用xpath来定位。
动作对象被执行时,其dom结构是有变化的,找到网页变化的结构特点,用xpath确切定位到节点,通过校准后,就可以设置自定义xpath。
滴答清单:采集盒的正确用法、实体清单与智能清单
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2020-08-15 00:30
目录见:如何更好地使用滴答清单-更新日志
涉及到的功能:*智能清单设置 *自定义智能清单
问:滴答清单里,采集盒是哪些意思?
答:看搜集盒的英文名就清楚了—— Inbox,这里是所有任务步入滴答的第一站,不管是从手工录入、从陌陌、从网页、从邮件、从邮箱,各个地方的待办事项都首先汇集到这儿,再做进一步的处理(参考后续系列文章——采集:从XXX到滴答清单)。
问:采集盒和其他实体清单的用法是如何的?
答:采集盒是任务步入到滴答的第一站,需要通过分类将清晰化以后的任务放在其他的清单中去。
原则上,采集盒应当是保持为清空状态的(你可以把搜集盒这儿的数字看作是邮箱中的未读电邮数),任务在搜集箱中,经过剖析处理后,到达各个有意义的实体清单中去。
如果搜集箱里的任务数连续几天都超过了 10,那么太可能是出现了拖延,你须要对这种任务进行剖析,决定它们下一步的去向问:什么是实体清单?什么又是智能清单?
答:实体清单是在任务中选择所属清单时侯可选的清单,比如搜集盒,比如其他的用户新增的清单。
而智能清单,说白了就是手动筛选条件,是把所有实体清单中符合相应条件的任务集合在了一起。比如明天、明天,比如自定义智能清单。
在这几个智能清单中添加任务,默认情况下是添加到“采集盒”的。
问:智能清单有什么?怎么显示与隐藏?
答:可以在各个版本的设置中找到“智能清单”的设置。
问:每个智能清单的作用通常是哪些?
答:说下个人的用法。
所有清单——查看所有的任务,目前我是关掉的,之前用于查看清单概貌(现在用自定义智能清单取代了)
今天清单——查看明天的所有任务,这也是每晚查看最多的一个清单
明天清单——用于白天做第二天的计划或排程用
最近七天——用于看最近一周的日程安排,上升到周度的视角
日历——用于直观地看以周、月、年为视角的日程安排
分配给我——协作时侯用,任务负责人是自己的任务
已完成——做回顾时侯的神器,支持进行时间、清单的过滤。
垃圾桶——误删掉的任务,可以在这里恢复。
查看全部
滴答清单必看手册 系列文章·第15篇——实体清单与智能清单、采集盒
目录见:如何更好地使用滴答清单-更新日志
涉及到的功能:*智能清单设置 *自定义智能清单
问:滴答清单里,采集盒是哪些意思?
答:看搜集盒的英文名就清楚了—— Inbox,这里是所有任务步入滴答的第一站,不管是从手工录入、从陌陌、从网页、从邮件、从邮箱,各个地方的待办事项都首先汇集到这儿,再做进一步的处理(参考后续系列文章——采集:从XXX到滴答清单)。
问:采集盒和其他实体清单的用法是如何的?
答:采集盒是任务步入到滴答的第一站,需要通过分类将清晰化以后的任务放在其他的清单中去。
原则上,采集盒应当是保持为清空状态的(你可以把搜集盒这儿的数字看作是邮箱中的未读电邮数),任务在搜集箱中,经过剖析处理后,到达各个有意义的实体清单中去。
如果搜集箱里的任务数连续几天都超过了 10,那么太可能是出现了拖延,你须要对这种任务进行剖析,决定它们下一步的去向问:什么是实体清单?什么又是智能清单?
答:实体清单是在任务中选择所属清单时侯可选的清单,比如搜集盒,比如其他的用户新增的清单。
而智能清单,说白了就是手动筛选条件,是把所有实体清单中符合相应条件的任务集合在了一起。比如明天、明天,比如自定义智能清单。
在这几个智能清单中添加任务,默认情况下是添加到“采集盒”的。
问:智能清单有什么?怎么显示与隐藏?
答:可以在各个版本的设置中找到“智能清单”的设置。
问:每个智能清单的作用通常是哪些?
答:说下个人的用法。
所有清单——查看所有的任务,目前我是关掉的,之前用于查看清单概貌(现在用自定义智能清单取代了)
今天清单——查看明天的所有任务,这也是每晚查看最多的一个清单
明天清单——用于白天做第二天的计划或排程用
最近七天——用于看最近一周的日程安排,上升到周度的视角
日历——用于直观地看以周、月、年为视角的日程安排
分配给我——协作时侯用,任务负责人是自己的任务
已完成——做回顾时侯的神器,支持进行时间、清单的过滤。
垃圾桶——误删掉的任务,可以在这里恢复。
成都人工智能数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 746 次浏览 • 2020-08-14 22:38
人工智能系统属于数字化平台和数字化制造系统。
有些新顾客要求学会将自己的信息尽量降低,当然若果那种产品要将自己信息传送过去,那是不可能的,不同时期、不同需求产品的需求信息可能是不同的,所以你的信息也不是更简单的剖析、更容易推广和定位,因为你还必须借助这些就是你目前能发觉和辨识的机会进行剖析、转化。
原
成都人工智能数据采集
对数据转换标记不对?对数据转换标记不对!既然标记对不对?那就得考虑数据变化对标记的影响了。笔者曾经一次网站上发了不少文章,说进行网站数据转换都要使用专业级别的sata、adobe、sata数据,但一人就不一样了,不同的电子商务网站本身的数据是不一样的,甚至连本身其它企业的数据不一样,因此不可能两个网站一个网址。
***,要是只有一个商标,我们是不需要提供申请手续的,对标示上通常都有关联协议的条款,申请商标前都是要过一关联关系,不要使那种商标导致作用或则效用上的损失。第二,要是你的是其他商标,是哪些商标,各个生产厂家有哪些优势?各厂家的产品有哪些不同?
看一下我们的数据采集编码工具。现在的数据采集编码特别的简单,各种各样的工具,都是能制做的,不仅能起到学习编码的作用,还有好多的用处。首先,很多数据采集编码的知识都须要懂得怎样制做编码。在制做数据采集编码的时侯须要了解大量的数据处理知识,直接用自己的软件,因此会更有效。
成都人工智能数据采集 查看全部
成都人工智能数据采集
人工智能系统属于数字化平台和数字化制造系统。
有些新顾客要求学会将自己的信息尽量降低,当然若果那种产品要将自己信息传送过去,那是不可能的,不同时期、不同需求产品的需求信息可能是不同的,所以你的信息也不是更简单的剖析、更容易推广和定位,因为你还必须借助这些就是你目前能发觉和辨识的机会进行剖析、转化。
原
成都人工智能数据采集
对数据转换标记不对?对数据转换标记不对!既然标记对不对?那就得考虑数据变化对标记的影响了。笔者曾经一次网站上发了不少文章,说进行网站数据转换都要使用专业级别的sata、adobe、sata数据,但一人就不一样了,不同的电子商务网站本身的数据是不一样的,甚至连本身其它企业的数据不一样,因此不可能两个网站一个网址。
***,要是只有一个商标,我们是不需要提供申请手续的,对标示上通常都有关联协议的条款,申请商标前都是要过一关联关系,不要使那种商标导致作用或则效用上的损失。第二,要是你的是其他商标,是哪些商标,各个生产厂家有哪些优势?各厂家的产品有哪些不同?
看一下我们的数据采集编码工具。现在的数据采集编码特别的简单,各种各样的工具,都是能制做的,不仅能起到学习编码的作用,还有好多的用处。首先,很多数据采集编码的知识都须要懂得怎样制做编码。在制做数据采集编码的时侯须要了解大量的数据处理知识,直接用自己的软件,因此会更有效。
成都人工智能数据采集
2019年最新 72家族网在线智能AI文章伪原创网站源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2020-08-14 22:18
亲爱的朋友们,您必须对网站的原创内容倍感难受。 作为草根网站管理员,不可能自己写原创文章。 当然,我并不是说你不能写一个。 就个人网站管理员的人力而言,撰写原创文章是不切实际的,而时刻就是问题所在。
也许一些网站管理员同学应当问:如何在不写原创文章的情况下构建一个好的网站?
事实上,它除了是我们,而且国外主要门户网站并非都是原创文章。 他们过去经常在改变标题之前改变内容,然后就成了她们自己的“新闻”。 我们来说说它,我的伪原创工具。 这个程序是一个免费的在线伪原创工具,其原理是取代同义词。
一位同学问我这是不是K.这是不利的吗?
我将在此问题上公布您的个人意见,供您参考。 毕竟,搜索引擎是一台机器。 在抓取文章后,他会将其与数据库中的现有文章进行比较。 如果您发觉一篇具有高度相似性的文章,则会被视为剽窃,反之亦然。 当然,如果依照原貌复制它,那就是剽窃。 使用伪原创工具进行转换后,文章中的一些句子将转换为同义词,当搜索引擎进行比较时,它被视为原创文章。 当然,这不确定,看看详尽的转换句子是多少。
这个伪原创的php源代码没有后台,直接将源代码上传到空间中的任何目录。 如果没有上传到网站的根目录,请记得打开index.html文件,修改css和js文件地址,否则打开它。 页面出现后会出现问题。 查看全部
智能AI伪原创做哪些?
亲爱的朋友们,您必须对网站的原创内容倍感难受。 作为草根网站管理员,不可能自己写原创文章。 当然,我并不是说你不能写一个。 就个人网站管理员的人力而言,撰写原创文章是不切实际的,而时刻就是问题所在。
也许一些网站管理员同学应当问:如何在不写原创文章的情况下构建一个好的网站?
事实上,它除了是我们,而且国外主要门户网站并非都是原创文章。 他们过去经常在改变标题之前改变内容,然后就成了她们自己的“新闻”。 我们来说说它,我的伪原创工具。 这个程序是一个免费的在线伪原创工具,其原理是取代同义词。
一位同学问我这是不是K.这是不利的吗?
我将在此问题上公布您的个人意见,供您参考。 毕竟,搜索引擎是一台机器。 在抓取文章后,他会将其与数据库中的现有文章进行比较。 如果您发觉一篇具有高度相似性的文章,则会被视为剽窃,反之亦然。 当然,如果依照原貌复制它,那就是剽窃。 使用伪原创工具进行转换后,文章中的一些句子将转换为同义词,当搜索引擎进行比较时,它被视为原创文章。 当然,这不确定,看看详尽的转换句子是多少。
这个伪原创的php源代码没有后台,直接将源代码上传到空间中的任何目录。 如果没有上传到网站的根目录,请记得打开index.html文件,修改css和js文件地址,否则打开它。 页面出现后会出现问题。
爬虫数据采集技术趋势-智能化解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-13 04:25
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。成文简陋,权且当作抛砖引玉,欢迎你们留言讨论。 查看全部
爬虫工作内容
互联网作为人类历史最大的知识库房,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容似乎十分有价值,但是程序是难以使用这些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现今开放API,SOA概念越来越普及,真正语义上的互联网的时代虽然还十分遥远。因此爬虫仍然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从急聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判定缘由有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部份靠爬虫聚合信息的创业公司,按照时间次序排序:
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能够满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情若果未能评估,那就难以管理。爬虫开发常常是被吐槽的诱因之一,就是工作量往往难以评估。一般的软件项目的开发过程随着时间推动,工作量会渐渐降低,也是你们常常说的烧尽疗效。
而爬虫开发生命周期如下图:
爬虫开发主要有两个方面内容:下载网页,解析网页。解析网页大约抢占开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现今优秀的爬虫框架和云服务器的普及,问题解决上去会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但仍然须要人工剖析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减轻这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也须要编撰独立的爬虫。这都会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目须要重做。重做的工作量几乎是100%,爬虫工程师心里常常是一万只矮马跑过。现在好多征信数据采集公司的合作伙伴,当数据源网站改版,常常须要一至两天能够修补爬虫,很明显这些可靠性是难以满足金融场景须要。
智能化解析
这是一张新浪新闻的图片。
可以发觉,视觉上很容易了解到,新闻所报导的风波的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到手动解析的目的?这样就不用人工编撰解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
~deepay/mywww/papers/www08-segments.pdf
/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部坐落加洲的Diffbot创立于2008年,创始人Mike Tung,是哈佛结业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接辨识的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot如今做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot早已发布了头版API和文章API,还有产品API。服务的顾客包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和辨识不同的网页类型(主要是非结构化的数据),再将这种丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面然后会对其进行剖析,然后通过成熟先进的技术进行结构化处理。”之前我提及的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出好多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网大鳄开始发觉这家公司的价值。
算法实践
通过智能方法来解析网页须要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方法来判定各个视觉块的类型,是标题,还是正文。其中主要流程和通常机器须要流程没哪些区别。这就不详尽解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库早已十分成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的朋友应当十分须要。
网页分割算法
从Diffbot初期发布的文章来看,是通过图象处理的方法来切割视觉块。使用到的算法有,边界检测,文字辨识等算法。但这些方法估算量偏大,复杂度很高。
另外一种实现方法是基于Dom树结构,导出所需的视觉特点。
聚合时侯需用的特点变量。主要考虑视觉相关的诱因有元素在页面上的位置,宽度和高度,Dom的层次。
有一点须要注意的是,现在网页好多是动态生成。需要依靠phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是愈发密度来界定,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方法可以参考下边博文:
分类算法
在第一步处理后,网页上的标签,会被界定分若干类,需要判定标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下边的,训练矩阵。
整个学习过程与通常的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方法比较简略,一般来说解析模型只能针对特定的网路训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所须要的特点变量有较大差异。针对不同特征类型数据,需要你们自己花时间去探求和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身须要一些技术提高来适应时代的要求,这也就对爬虫工程师提出更高的要求。成文简陋,权且当作抛砖引玉,欢迎你们留言讨论。
数果智能告诉你大数据时代怎么做好精细化营销
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-12 13:27
个人认为,精细化营销须要一套比较规范的指导体系,同时借助数据在每位环节中起到决策的作用,快速帮助企业实现精细化营销。如图1所示,而精细化营销可以归纳为几个关键步骤:
图1 闭环精细化营销体系
用户细分:分析目前用户特点,对用户进行细分,划分好不同的用户群。
营销企划:结合不同的用户群特点,使用最合适的渠道给用户群推送最想要的东西。
跟踪挖掘:结合关键指标实时监控整个营销过程。
滚动优化:阶段性评估,滚动优化营销策略。
后面,我们围绕着闭环的精细化营销流程,仔细去瞧瞧每一个步骤应当如何做?需要做些什么事情?
第一、用户细分
首先,我们要明晰为何须要对用户细分呢?从用户生命周期角度来看,新用户与老用户是有区别的,所采取的营销方法是不一样的。而消费水平高的用户与消费水平低的用户也是有区别的,采取的营销方法也是不一样的……如果单纯对所有用户采取用一种形式进行营销,推送的东西不一定是用户所需求的,不仅恐吓了用户,还造成营销转化率不高,营销成本降低。所以,要获得好的营销疗效,必须对相应的用户群进行界定。
那么,又应当做好用户细分呢?如果须要获得更好的用户细分疗效,可以通过数据挖掘(如聚类分析)、用户画像体系、用户标签等一系列标准化流程,可以更好地进行用户细分。然而,这些标准化的工作,需要太长的一段时间,企业的数据部门能够做下来。对于大部分的企业,建议还是结合自己业务出发,选取最有效的数据变量进行快速用户细分。一般可以从以下行为、用户基础属性、时间指标、偏好渠道等这种才能快速结合业务的指标进行对用户进行细分。如图2所示:
图2 结合业务关键指标快速进行用户细分
举个与你们贴切的日常事例:现在基本每个人都会拥有一台智能手机,都会常常使用手机进行上网,都须要每晚关注自己的手机流量。我们都晓得,当我们的手机流量用得差不多的时侯,移动公司都会发一条相关邮件过来,提醒我们目前使用手机流量有多少?还剩下多少流量?同时也会马上推荐你可以申领多少档次流量包?这种情况下,如果你流量用得差不多了,平时也会常常上什么花费流量比较大的网站或者APP,那么你才会毫不犹豫地下订一个符合自己流量使用的流量包。从这个流程来看,我们去溯源一下移动公司又是如何快速进行流量精细化营销的呢?
首先,如图3所示,移动公司会按照用户的消费层次(实际上网流量、套餐流量、流量包的流量、用户ARPU值、使用终端档次等信息)及用户上网偏好等信息,明确好相应的用户细分方向。
图3 基于消费及偏好指标快速锁定目标用户群
其次,如表1所示,移动公司结合这种细分维度,对不同的用户群进行用户细分,然后对这种用户群进行精细化营销。
表1某联通流量指标快速细分样例
所以,通过业务指标的快速进行细分,已经可以锁定了用户流量需求及用户使用偏好,为下一步营销执行提供了最好的弹药。
第二、营销企划
对于营销企划,最精典的应用就是基于CPC理论模型(如图4所示)为基础的营销企划,主要是通过大数据找寻出顾客(Customer)、产品(Product)、渠道(Channel)之间的最佳适配关系,依托数据剖析、策略设置、场景设计等服务手段,将合适的产品及服务在合适的时机提供给合适的顾客,从而达成满足顾客需求、提高营销概率、提高转化率的精益营运疗效,实现用户接触价值最大化。
图4 CPC模型
在营销企划的过程中,业务人员必须要结合不同的用户群,利用用户黏性相对较强的接触渠道,设计相应的产品营销内容,并结合用户生命周期所处于的阶段,然后有节奏推出相应的营销活动。一般这些情况下,业务人员可借用相应的精细化营销列表(如表2所示)作为辅助,快速针对不同的目标用户群举办相应的营销方案。
目标用户群
用户群说明
用户规模
选择渠道
推送策略
购买过纸尿裤的用户
曾经订购过纸尿裤的用户、按照RFM分群
8W
微信、短信
1、用户细分策略
(1)新用户:上个月第一次订购纸尿裤的用户
(2)高活跃高价值用户:前3个月内,购买次数>=3次 and 消费总金额>=600元 的用户(排除新用户)
(3)高活跃低价值用户:前3个月内,消费次数>=3次 and 消费总金额
(4)低活跃高价值用户:前3个月内,消费次数=600元 的用户(排除新用户)
(5)低活跃低价值用户:前3个月内,消费次数
(6)沉默用户:活跃度低(前3个月均没消费)
2、每月5号,15号推送老用户关爱的让利内容
3、活动型,做好老用户关爱
表2某纸尿裤电商的营销企划列表样例
同时,需要匹配用户最偏好的渠道进行营销推广,确保营销推广信息才能最大可能抵达用户的接触点。
另外,对于推送的营销脚本,也须要相关的营销人员进行合理设计,确保推广给用户的营销内容是顾客最想看的,确保营销的产品是用户最想要的。
只有做到将顾客最想要的产品通过最合适的渠道推广给最想要的顾客,才能确保用户的转化率达到不错的疗效。
第三、跟踪挖掘
在营销活动开始执行的时侯,需要设计科学的施行流程,并更好地借助数据进行监控,保障营销方案更好地落地。而针对精细化营销跟踪挖掘,怎样做,才能做得更好呢?结合个人先前所参与的精细化营销经验,可以归纳为以下几点:
第一点,需要结合跟踪指标数据,构建晚报、周报、月报三大类准实时监控,确保精细化营运。
日报:通过监控每日销售指标,通过其波动发觉三次系统故障;分解各种商品销售量波动,结合地域、时段及精推任务上线情况等指标,定位销售量波动缘由。
周报:重点关注剖析推送的转化率,通过推送类型、推送到达率,成功率,转化率等维度监控上行量、服务量、业务代办量、销售量及各个环节之间转化率波动,分析推送疗效及波动缘由,及时调整推送脚本及发送时间。
月报:老、新用户推送疗效,综合用户贡献度剖析订购产品目标客户群质量,明确下一步营运目标及措施。
第二点,利用漏斗剖析(如图5)可以针对用户每一步的转化进行实时监控。通过漏斗各环节业务数据的比较,能够直观地发觉和说明问题所在。
图5 漏斗剖析示例
第三点,根据“AIDA”(注:A-Attention 引发注意,I - Interest 提起兴趣,D-Desire提高欲望,A-Action 建议行动)原则持续迭代优化推送脚本,持续提高用户转化率。这个阶段,可以针对不同的营销脚本进行A/B测试,寻找推送最佳的营销脚本。
第四点,针对不同的营销推送时间进行比较,选择转化率最高的时间段,作为营销的关键推送时间节点。
第五点,可以结合不同的营销渠道进行多波次营销。
第四、评估优化
针对每一个精细化营销活动,都须要做好相应的营销疗效评估,及时调整营销策略,滚动优化营销方案。所以针对每一个营销活动,需要做好相应的营销评估的话,如图6所示,例如电商行业的营销活动评估优化,可以从以下几个方面进行考虑:
图6 基于人堆场的营销评估指标
1、人:这次活动发送了多少营销推广信息?最终有多少用户响应的?最终订购的有多少?用户转化率情况是如何的?另外,有多少是新用户?有多少是老用户?新用户贡献了多少钱?老用户贡献了多少钱?用户对营销活动的评价是如何的?满不满意?
2、货:哪些商品是销售额最大的?哪些商品是销售量最好的?哪些商品是没人关注的?哪些组合套装是最好买的…
3、渠道:哪些渠道贡献最大的流量?哪些推广渠道是最好的?ROI最好?
通过对每一次营销活动的疗效进行评估复盘,为下一次精细化营销活动举办做好相应的经验积累。
附:为了更好地帮助企业实现实时数据精细化营运,我们数果智能结合多年剖析及挖掘经验,从实时数据采集、实时多维剖析、实时数据可视化、实时数据业务场景应用出发,全流程塑造了一套数果智能产品,更好地使实时数据支撑企业精细化营运。
我们的产品特性(如图7):
图7 数果智能产品功能特性
我们的实时剖析神器(如图8所示)
图8 数果智能产品功能明细 查看全部
随着互联网的发展和智能手机普及率的提升,网民规模与移动端网民规模增长均趋缓。艾瑞咨询剖析,2016年手机网民规模早已达到了6.6亿人,市场增量空间减小,移动端流量红利消失。而对于企业而言,用户增量获取越来越难了,获取成本也越来越高。而存量用户假如做不好,又会受到竞争对手的抢劫。所以,对于企业而言,从粗放式营运转入以精细化营运则更变得极其重要。而精细化营销应当又怎样做呢?
个人认为,精细化营销须要一套比较规范的指导体系,同时借助数据在每位环节中起到决策的作用,快速帮助企业实现精细化营销。如图1所示,而精细化营销可以归纳为几个关键步骤:
图1 闭环精细化营销体系
用户细分:分析目前用户特点,对用户进行细分,划分好不同的用户群。
营销企划:结合不同的用户群特点,使用最合适的渠道给用户群推送最想要的东西。
跟踪挖掘:结合关键指标实时监控整个营销过程。
滚动优化:阶段性评估,滚动优化营销策略。
后面,我们围绕着闭环的精细化营销流程,仔细去瞧瞧每一个步骤应当如何做?需要做些什么事情?
第一、用户细分
首先,我们要明晰为何须要对用户细分呢?从用户生命周期角度来看,新用户与老用户是有区别的,所采取的营销方法是不一样的。而消费水平高的用户与消费水平低的用户也是有区别的,采取的营销方法也是不一样的……如果单纯对所有用户采取用一种形式进行营销,推送的东西不一定是用户所需求的,不仅恐吓了用户,还造成营销转化率不高,营销成本降低。所以,要获得好的营销疗效,必须对相应的用户群进行界定。
那么,又应当做好用户细分呢?如果须要获得更好的用户细分疗效,可以通过数据挖掘(如聚类分析)、用户画像体系、用户标签等一系列标准化流程,可以更好地进行用户细分。然而,这些标准化的工作,需要太长的一段时间,企业的数据部门能够做下来。对于大部分的企业,建议还是结合自己业务出发,选取最有效的数据变量进行快速用户细分。一般可以从以下行为、用户基础属性、时间指标、偏好渠道等这种才能快速结合业务的指标进行对用户进行细分。如图2所示:
图2 结合业务关键指标快速进行用户细分
举个与你们贴切的日常事例:现在基本每个人都会拥有一台智能手机,都会常常使用手机进行上网,都须要每晚关注自己的手机流量。我们都晓得,当我们的手机流量用得差不多的时侯,移动公司都会发一条相关邮件过来,提醒我们目前使用手机流量有多少?还剩下多少流量?同时也会马上推荐你可以申领多少档次流量包?这种情况下,如果你流量用得差不多了,平时也会常常上什么花费流量比较大的网站或者APP,那么你才会毫不犹豫地下订一个符合自己流量使用的流量包。从这个流程来看,我们去溯源一下移动公司又是如何快速进行流量精细化营销的呢?
首先,如图3所示,移动公司会按照用户的消费层次(实际上网流量、套餐流量、流量包的流量、用户ARPU值、使用终端档次等信息)及用户上网偏好等信息,明确好相应的用户细分方向。
图3 基于消费及偏好指标快速锁定目标用户群
其次,如表1所示,移动公司结合这种细分维度,对不同的用户群进行用户细分,然后对这种用户群进行精细化营销。
表1某联通流量指标快速细分样例
所以,通过业务指标的快速进行细分,已经可以锁定了用户流量需求及用户使用偏好,为下一步营销执行提供了最好的弹药。
第二、营销企划
对于营销企划,最精典的应用就是基于CPC理论模型(如图4所示)为基础的营销企划,主要是通过大数据找寻出顾客(Customer)、产品(Product)、渠道(Channel)之间的最佳适配关系,依托数据剖析、策略设置、场景设计等服务手段,将合适的产品及服务在合适的时机提供给合适的顾客,从而达成满足顾客需求、提高营销概率、提高转化率的精益营运疗效,实现用户接触价值最大化。
图4 CPC模型
在营销企划的过程中,业务人员必须要结合不同的用户群,利用用户黏性相对较强的接触渠道,设计相应的产品营销内容,并结合用户生命周期所处于的阶段,然后有节奏推出相应的营销活动。一般这些情况下,业务人员可借用相应的精细化营销列表(如表2所示)作为辅助,快速针对不同的目标用户群举办相应的营销方案。
目标用户群
用户群说明
用户规模
选择渠道
推送策略
购买过纸尿裤的用户
曾经订购过纸尿裤的用户、按照RFM分群
8W
微信、短信
1、用户细分策略
(1)新用户:上个月第一次订购纸尿裤的用户
(2)高活跃高价值用户:前3个月内,购买次数>=3次 and 消费总金额>=600元 的用户(排除新用户)
(3)高活跃低价值用户:前3个月内,消费次数>=3次 and 消费总金额
(4)低活跃高价值用户:前3个月内,消费次数=600元 的用户(排除新用户)
(5)低活跃低价值用户:前3个月内,消费次数
(6)沉默用户:活跃度低(前3个月均没消费)
2、每月5号,15号推送老用户关爱的让利内容
3、活动型,做好老用户关爱
表2某纸尿裤电商的营销企划列表样例
同时,需要匹配用户最偏好的渠道进行营销推广,确保营销推广信息才能最大可能抵达用户的接触点。
另外,对于推送的营销脚本,也须要相关的营销人员进行合理设计,确保推广给用户的营销内容是顾客最想看的,确保营销的产品是用户最想要的。
只有做到将顾客最想要的产品通过最合适的渠道推广给最想要的顾客,才能确保用户的转化率达到不错的疗效。
第三、跟踪挖掘
在营销活动开始执行的时侯,需要设计科学的施行流程,并更好地借助数据进行监控,保障营销方案更好地落地。而针对精细化营销跟踪挖掘,怎样做,才能做得更好呢?结合个人先前所参与的精细化营销经验,可以归纳为以下几点:
第一点,需要结合跟踪指标数据,构建晚报、周报、月报三大类准实时监控,确保精细化营运。
日报:通过监控每日销售指标,通过其波动发觉三次系统故障;分解各种商品销售量波动,结合地域、时段及精推任务上线情况等指标,定位销售量波动缘由。
周报:重点关注剖析推送的转化率,通过推送类型、推送到达率,成功率,转化率等维度监控上行量、服务量、业务代办量、销售量及各个环节之间转化率波动,分析推送疗效及波动缘由,及时调整推送脚本及发送时间。
月报:老、新用户推送疗效,综合用户贡献度剖析订购产品目标客户群质量,明确下一步营运目标及措施。
第二点,利用漏斗剖析(如图5)可以针对用户每一步的转化进行实时监控。通过漏斗各环节业务数据的比较,能够直观地发觉和说明问题所在。
图5 漏斗剖析示例
第三点,根据“AIDA”(注:A-Attention 引发注意,I - Interest 提起兴趣,D-Desire提高欲望,A-Action 建议行动)原则持续迭代优化推送脚本,持续提高用户转化率。这个阶段,可以针对不同的营销脚本进行A/B测试,寻找推送最佳的营销脚本。
第四点,针对不同的营销推送时间进行比较,选择转化率最高的时间段,作为营销的关键推送时间节点。
第五点,可以结合不同的营销渠道进行多波次营销。
第四、评估优化
针对每一个精细化营销活动,都须要做好相应的营销疗效评估,及时调整营销策略,滚动优化营销方案。所以针对每一个营销活动,需要做好相应的营销评估的话,如图6所示,例如电商行业的营销活动评估优化,可以从以下几个方面进行考虑:
图6 基于人堆场的营销评估指标
1、人:这次活动发送了多少营销推广信息?最终有多少用户响应的?最终订购的有多少?用户转化率情况是如何的?另外,有多少是新用户?有多少是老用户?新用户贡献了多少钱?老用户贡献了多少钱?用户对营销活动的评价是如何的?满不满意?
2、货:哪些商品是销售额最大的?哪些商品是销售量最好的?哪些商品是没人关注的?哪些组合套装是最好买的…
3、渠道:哪些渠道贡献最大的流量?哪些推广渠道是最好的?ROI最好?
通过对每一次营销活动的疗效进行评估复盘,为下一次精细化营销活动举办做好相应的经验积累。
附:为了更好地帮助企业实现实时数据精细化营运,我们数果智能结合多年剖析及挖掘经验,从实时数据采集、实时多维剖析、实时数据可视化、实时数据业务场景应用出发,全流程塑造了一套数果智能产品,更好地使实时数据支撑企业精细化营运。
我们的产品特性(如图7):
图7 数果智能产品功能特性
我们的实时剖析神器(如图8所示)
图8 数果智能产品功能明细
智能写作v2.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2020-08-12 07:45
- 文学作品创作思路
举一个撰写「关于饮食习惯」的文学作品的反例。
首先介绍一种量化小吃的思路,下图是一个小吃辣味网路,每个节点代表一种菜品,颜色代表所归属食物种类。节点大小反映了一种菜品在菜谱中的普遍性。如果两种调料有明显数目鲜味的化合物共享,则表示它们之间有关联,链接的粗细代表两种调料之间共享化合物的数目。
美食鲜味网路
回到我们的文学作品的建立思路,首先,采集微博文本内容;
其次,提取出用户饮食习惯等数据,主要使用动词、词性标明和依存复句剖析等NLP技术。那么怎么抽取出用户饮食习惯呢?主要是由三个条件组成的规则:
一条微博里富含成语“吃”;
与“吃”相关的复句关系为动宾关系;
“吃”的不定式为名词;
就可以判定发生饮食行为,进而提取出“吃”的不定式就是相关的食物,从而产生饮食习惯数据。
最后,重新组织语言,把用户的饮食习惯数据书写下来。
- 情感弧线
emotional arcs
此项技术可以帮助我们剖析故事的主要高潮和低潮。
作者使用了三种主要方式进行《哈利·波特》的情感弧线剖析:奇异值分解(singular value decomposition);以 Ward 的方式形成故事的分层降维;以及自组织映射机器学习方法来降维情感弧线。情感弧线是通过使用 和 labMT 数据集剖析滑动10000字窗口的情绪而打造的。
另外 网站还提供了许多其他书籍、故事、电影剧本以及Twitter的交互可视化情感弧线。- 新型书籍的手动生成
在没有人工参与的情况下,自动生成整本维基教科书;
这部份是来源于Wikibook-bot的一项技术,是由以色列内盖夫本古里安大学的沙哈尔阿德马蒂Shahar Admati 及其朋友开发的;
主要的流程如下:
首先,准备一组现有的维基教科书,用作训练数据集,数量级在6000本以上。
其次,进行数据清洗,规则是:
1 关注浏览量超过 1000 次的教科书;
2 涵盖超过十个章节
第三,生成标题,该标题用以描述某种概念。
第四,文章清洗,规则类似于pagerank的原理,文章通常通过超链接指向其他文章,在网路上采集出通过点击超链接三次以内得到的所有文章作为优质的文章。每本人工维基教科书都有自己的网路结构,其决定诱因包括,引用该文的文章链接数目、指向其他文章的链接数目、所收录文章的页面排行列表等。
第五,文章分类,对所有维基百科文章进行分类;
第六,每一个类别主题对应的文章的再度清洗,该算法会查看每一篇给定主题筛选下来的文章,接着判定假如将其添加到维基教科书中是否会使该书的网路结构与人工创作的书籍更相像。如果不相像,那么该文章就会排除在外。
第七,将每一个类别主题对应的文章组织成章节。主要依靠聚类算法,结合由整组文章组成的网路,找出怎样将其界定为连贯的集群。
第八,确定文章在每位章节中的出现次序。使用的是枚举,然后排序的思路,通过给文章成对分组,对所有文章枚举所有组合,然后使用网路模型来估算排序逻辑,最终估算出更为理想的文章顺序以及章节次序。
感兴趣可以详尽阅读论文:
- 主要涉及的NLP技术
NLP
自然语言处理
为了实现写作类的应用,需要对文本进行大量的处理,NLP是一种使机器能否象我们平时那样阅读和理解语言的技术。常常会结合知识图谱来使用,以提高产品疗效。
我们须要把握NLP的常见任务及算法。
- 主要的NLP任务
文本分类、情感剖析、分词、依存复句剖析、实体辨识等;
- 深度学习算法
目前深度学习有以下典型的算法,可以一一详尽了解把握;
参考地址
- GPT2这儿要举一个反例,在大受欢迎的 reddit 社区中,一个名为 SubSimulatorGPT2 的子讨论小组愈发引人注目:其内容完全由人工智能聊天机器人模仿各类讨论小组的风格生成后发布。SubSimulatorGPT2
早期的SubredditSimulator()的机器人使用马尔科夫链,这是一种成熟的生成序列的技术。
- 马尔可夫链和N-gram马尔科夫链的假定(第一性原理)。基于马尔可夫链的模型假设语句中的每位词组仅取决于其后面的几个词组。因此,给定任意语句的机率为组成该语句的所有n-gram(n个词组的序列)的组合机率。下图说明了该概念:
以Python 语言为例,采用字典(Dictionary)的数据结构。
d = {key1 : value1, key2 : value2 }
键名是当前的词组,键值是一个列表List,存储当前词组的下一个词组。
d = {word1 : [word2,word3], word2 : [word3,word4,word5] }
具体的事例,有如此两句话:
I like to eat orangesYou eat apples
我们希望通过马尔科夫链来学习以上数据,经过估算,模型为:
{'START': ['i','you'],'i': ['like'],'like': ['to'],'to': ['eat'],'you': ['eat'],'eat': ['apples','oranges'],'END': ['apples','oranges']}
我们不需要估算下一个词组出现的机率,因为假如它们出现的机率较大,那么她们会在选定下个词组的列表中出现好几次。采用适当的数据结构,问题也得到了简化的处理。
- 词嵌入和神经语言模型
词嵌入是现今NLP中任何人都必学的第一项技术:将词投射到多维空间中。它的优势在于,具有相像用法/含义的词组会获得相像的向量(按正弦相似度评判)。因此,涉及相像词组的词组向量的矩阵加法趋向给出相像的结果。
何为余弦相似度?在NLP的任务里,会对生成两个词向量进行相似度的估算,常常采用余弦相似度公式估算。余弦相似度用向量空间中两个向量倾角的正弦值作为评判两个个体间差别的大小。余弦值越接近1,就表明倾角越接近0度,也就是两个向量越相像,这就叫"余弦相似性"。
这是基于神经网路的语言模型的基础。有趣的是,神经模型不估算出现次数来确定机率,而是学习可以为任何输入估算出它们的参数(权重矩阵和误差)。这样,甚至可以为我们未曾见过的n个句型以后的下一个词组估算一个合理的机率分布。下图是一个最简单的神经网路:MLP (multilayer perceptron) 多层感知器。
- 递归神经网络
随着递归神经网络(RNN)的出现,特别是长短期记忆(LSTM)的出现,语言生成方面获得了更大进步。与之前提及的最简单的神经网路不同,RNN的上下文除了限于n个词组;它甚至没有理论上的限制。
RNN的主要改进在于保留了内部状态。因此,RNN可以不停地逐条读取词组,从而更新其内部状态以反映当前上下文,而不是只看固定的窗口(n个词组)。
使用RNN的文本生成以自回归方法遵守与马尔可夫链相像的原理。RNN对第一个词组进行取样,将其送到神经网路以获取下一个词组的机率,然后再对下一个词组进行取样,依此类推,直到语句结束为止。如下图所示,依次学习The、boys、that、came词组的过程。
Internal State类似于脑部(黑箱),记录了所有复杂的文本信息。
- 注意力机制
在形成下一个输出之前,先回顾所有以前的词组。计算注意力本质上是指估算过去词组的某种分布,然后将这种词组的向量与接收到的注意力成比列地进行聚合。下图说明了该概念。
注意机制让RNN可以回顾以前词组的输出,而不必定所有内容压缩为隐藏状态。中间输出之前的压缩RNN块与不注意时的块相同。
- Transformer
Transformer是一种神经网路构架,于2017年推出,旨在解决RNN的缺点。它的关键思想是完全借助注意力,以至根本不需要内部状态或循环。下图是Transformer的简化的描述。实际的构架十分复杂,您可以在查阅相关文章找到更详尽的解释 。
- GPT模型
回到前文所提及的GPT2,GPT全称Generative Pre-Training,出自2018年OpenAI的论文《Improving Language Understandingby Generative Pre-Training》,论文地址:
~amuham01/LING530/papers/radford2018improving.pdf
GPT是一种半监督学习方法,它致力于用大量无标明数据使模型学习“常识”,以减轻标明信息不足的问题。详细可以阅读论文深入了解。
- 人工智能辅助写作
一些相关产品。Grammarly在线写作网站
Grammarly是一款全手动英语写作工具, 可以实时检测句型,一边写一边改,语法问题和更改意见会以标明的方式显示在文档的两侧,方便用户去一一查看,而且在每条批注下边就会配有详尽的解释,告诉用户那里错了,为什么要这样更改。
百度创作脑部
百度人工智能写作辅助平台“创作脑部”,智能助手可以为人类创作者提供纠错、提取信息等各类辅助工作。
GET智能写作
一站式智能写作服务平台。全网热点追踪、推荐海量素材、提升原创质量。
- 算法新闻、机器人记者目前在这个领域领先的有美国的2家公司:
自动化洞察力公司 Automated Insights
叙述科学公司 Narrative Science
我们先来了解下算法新闻的导论。
- 算法新闻导论美国的初期创业公司,如今的佼佼者
早在2007年,美国的「自动化洞察力」Automated Insights公司创立;
2009年,美国西北大学研制的StatsMonkey「统计猴子」系统就撰写了一篇关于美国职业棒球大联盟西决的新闻稿件;
2010年,「叙述科学」公司Narrative Science创立;
由机器人记者主导的新闻行业正在迅速崛起
在2014年,美联社与Automated Insight公司达成协议,成为机器人记者的初期的采用者。
2014年3月,第一条完全由计算机程序生产的新闻报导形成。作为首家“聘用”机器人记者的主流媒体,《洛杉矶时报(LA Times)》在水灾发生后3分钟就发布了首列相关新闻。
在这一年,机器人写稿技术研制公司Automated Insight全年生产了10亿条新闻。
在2015年,新华社推出可以批量编撰新闻的写作机器人「快笔小新」;
同年9月,腾讯财经发布写作机器人「Dreamwriter」;
1年后,中国湖北广播电视台长江云新闻客户端就派出人代会机器人记者“云朵”进行专访。
第一财经也发布写作机器人「DT稿王」
同年,国外挪威新闻社NTB启动机器人,开始着手制做自动化篮球新闻报导项目;
自动化新闻早已通过手动新闻写作和发行步入新闻编辑室
2017年1月,南方都市报社写作机器人「小南」正式上岗,推出第一篇共300余字的春运报导。
……
以上为算法新闻导论。
我们须要晓得「机器人记者」并不是真正的职业记者,而是一种新闻报导软件,拥有手动撰写新闻故事的功能。相类似的概念有算法新闻、自动新闻。
媒体通常还会形象地,描述机器人记者在媒体单位“上班”,机器人具备“真人记者”所有的采编功能,不会出错,不用休息,所写的文章不仅时效性强,质量也高,工作效率比“真人记者”高出好几倍。
- 经典产品「机器人记者」
由日本表述科学公司Narrative Science发明的写作软件;这个软件拥有手动撰写新闻故事的功能。
基于选题和新闻热点追踪,通过平台授权,结构化采集、处理、分类、分析原创数据素材,快速抓取,生成新闻关键词或线索,然后,利用文本剖析和信息抽取技术,以模板和规则知识库的形式,自动生成完整的新闻报导。
尤其在体育比赛,金融经济,财报数据等方面作用突出。
- 2018年数据新闻创新奖《搜索侦察机》
记者彼得奥尔德乌斯Peter Aldhous,开发了这个项目,他使用了机器学习——特别是「随机森林random forest」算法,从大量的客机飞行数据中,建立了一个模型,可以按照以下数据:
飞机的拐弯速度
飞行速度
飞行高度
每条飞行路径周围的圆形区域
飞行持续时间
识别出可能是“隐藏身分的侦察机”。
- 各大报社、杂志社的应用
国内有人民日报「小端」、光明日报「小明」、今日头条「张小明」、南方都市报「小南」等等。近期新华智云的更新是业内比较大的动作。
新华智云
作为新华社和阿里巴巴集团共同投资创立的大数据人工智能科技公司,于2019年发布了“媒体脑部3.0”。以区块链技术和AI初审为明显特点,为内容工作者提供“策、采、编、发、审、存”全流程赋能,为媒体机构、宣传部门、企业单位各种融媒体中心提供方便、高效、智能的数据中台和内容生产平台。
新华社「快笔小新」
「快笔小新」的写稿流程由数据采集、数据剖析、生成稿件、编发四个环节组成,这一机器人适用于体育比赛、经济行情、证券信息等快讯、简讯类稿件的写作。
腾讯「DREAMWRITER」
腾讯在2015年9月推出了一个叫 Dreamwriter 自动化新闻写作机器人。最开始,这项技术主要用在财经领域,现在它在体育比赛的快速报导中也有太成功的应用案例了。
2016年里约奥运会期间,Dreamwriter 就手动撰写了3000多篇实时战报,是亚运媒体报导团的“效率之王”。
在“2017腾讯媒体+峰会”现场,Dreamwriter 平均单篇成文速率仅为0.5秒,一眨眼的时间就写了14篇稿件。
国外的应用主要如下:
《卫报》
使用机器人辅助写作,并发表了一篇名为《Political donations plunge to $16.7m – down from average $25m a year》
《华盛顿邮报》
Heliograf机器人记者,在报导2016年夏天奥运会和2016年补选时证明了它的有用性;
还帮助《华盛顿邮报》在一年一度的全球大奖中获得了「巧妙使用机器人奖Excellence in Use of Bots」
《 Guardian》
2014年,英国《 Guardian》进行了纸质测试计划,安排“机器人”统计剖析社交网络上的共享热点和注意力加热,然后内容过滤、编辑排版和复印,最后制做一份报纸。
《华尔街日报》
应用于金融投资研究报告片断的节选,网站会提醒读者那一段节选是由机器人完成的,哪些是由人类完成的。主要节选类似于以下的文字:
第二季度的现金节余8.3亿美元,这意味着在第一季度降低1.4亿美元以后,第二季度又消耗了8000万美元
Q2 cash balance expectation of $830m implies ~$80m of cash burn in Q2 after a $140m reduction in cash balance in Q1
这句话实际上只收录了三个数据点,并使用特定的句型合并在一起,而且不收录任何巧合的成份。
《洛杉矶时报》
《洛杉矶时报》靠「机器人写手」,第一时间报导了美国加州2014年3月18日当地时间清晨发生4.4级水灾;还应用于对犯罪时间错误归类的剖析。
《纽约时报》
《纽约时报》对美国国会议长的图象辨识;还应用机器人编辑Blossom预测什么文章有可能会在社交网站上导致传播,相应地给版面责任编辑提出建议;
《福布斯》
2011年,开始使用表述科学公司 Narrative Science 的手动写稿程序来撰写新闻;
彭博社
应用机器人系统Cyborg,帮助记者在每位季度进行大量的文章撰写,数量达到数千篇,包括各公司的财报文章等。机器人可以在财报出现的一瞬间就对其进行详尽的分析,并且提供收录那些相关事实和数据的实时新闻报导,速度十分迅速。
美联社
从2014年7月开始使用语言大师 Wordsmith 软件,利用自动化技术来写公司财务报表。几毫秒的时间,软件能够写出一篇路透社风格的完整报导。
- 技术进展
从早些年的以摘选稿件中诗句为主,过渡到现今全流程的方法。- 人形机器人
结合硬件,还有人形机器人版本的机器人记者的出现,例如中国智能机器人佳佳作为新华社特约记者越洋专访了日本知名科技观察家凯文·凯利。这是全球首次由高仿真智能机器人作为记者与人进行交互对话,专家觉得具有标志性意义。
- 新媒体与人工智能写作
按照英国新媒体艺术理论家马诺维奇(Lev Manovich)在《新媒体语言》一书中对新媒体技术所下的定义:
所有现存媒体通过笔记本转换成数字化的数据、照片、动态形象、声音、形状空间和文本,且都可以估算,构成一套笔记本数据的,这就是新媒体。
这是一个艺术与科技跨界结合的领域,我们可以关注国内的大牛:
MIT的Nick Montfort院士
国际上被公认为作家和通过估算探求语言的人
他撰写了大量互动小说文章,发布在博客Grand Text Auto上,同时也开发了许多数字诗和文本生成器。他近来的着作是「The Future」和「The Truelist」,有兴趣可以去了解下他的研究。
下面给你们介绍典型的案例。
- 互动小说与新型文学作品的创作
2016年,人工智能创作的小说在美国「星新一文学奖」上被评委称为「情节无纰漏」。人工智能应用于文学创作领域,为文学作品带来了新鲜血液,与文学作品的结合还平添了作品的互动性,与游戏、电影形成了跨界交融。互动故事平台
加拿大温哥华的互动故事平台Wattpad
其产品包括匹配创作者和读者的机器写作,识别故事“趋势”,根据主题进行创意写作等;还开发了视频讲故事的应用「Raccoon」; 查看全部
第四,输出一个在线Flash短片,用q版人物形象模仿传统的午间新闻广播方式,来向用户播放内容。
- 文学作品创作思路
举一个撰写「关于饮食习惯」的文学作品的反例。
首先介绍一种量化小吃的思路,下图是一个小吃辣味网路,每个节点代表一种菜品,颜色代表所归属食物种类。节点大小反映了一种菜品在菜谱中的普遍性。如果两种调料有明显数目鲜味的化合物共享,则表示它们之间有关联,链接的粗细代表两种调料之间共享化合物的数目。
美食鲜味网路
回到我们的文学作品的建立思路,首先,采集微博文本内容;
其次,提取出用户饮食习惯等数据,主要使用动词、词性标明和依存复句剖析等NLP技术。那么怎么抽取出用户饮食习惯呢?主要是由三个条件组成的规则:
一条微博里富含成语“吃”;
与“吃”相关的复句关系为动宾关系;
“吃”的不定式为名词;
就可以判定发生饮食行为,进而提取出“吃”的不定式就是相关的食物,从而产生饮食习惯数据。
最后,重新组织语言,把用户的饮食习惯数据书写下来。
- 情感弧线
emotional arcs
此项技术可以帮助我们剖析故事的主要高潮和低潮。
作者使用了三种主要方式进行《哈利·波特》的情感弧线剖析:奇异值分解(singular value decomposition);以 Ward 的方式形成故事的分层降维;以及自组织映射机器学习方法来降维情感弧线。情感弧线是通过使用 和 labMT 数据集剖析滑动10000字窗口的情绪而打造的。
另外 网站还提供了许多其他书籍、故事、电影剧本以及Twitter的交互可视化情感弧线。- 新型书籍的手动生成
在没有人工参与的情况下,自动生成整本维基教科书;
这部份是来源于Wikibook-bot的一项技术,是由以色列内盖夫本古里安大学的沙哈尔阿德马蒂Shahar Admati 及其朋友开发的;
主要的流程如下:
首先,准备一组现有的维基教科书,用作训练数据集,数量级在6000本以上。
其次,进行数据清洗,规则是:
1 关注浏览量超过 1000 次的教科书;
2 涵盖超过十个章节
第三,生成标题,该标题用以描述某种概念。
第四,文章清洗,规则类似于pagerank的原理,文章通常通过超链接指向其他文章,在网路上采集出通过点击超链接三次以内得到的所有文章作为优质的文章。每本人工维基教科书都有自己的网路结构,其决定诱因包括,引用该文的文章链接数目、指向其他文章的链接数目、所收录文章的页面排行列表等。
第五,文章分类,对所有维基百科文章进行分类;
第六,每一个类别主题对应的文章的再度清洗,该算法会查看每一篇给定主题筛选下来的文章,接着判定假如将其添加到维基教科书中是否会使该书的网路结构与人工创作的书籍更相像。如果不相像,那么该文章就会排除在外。
第七,将每一个类别主题对应的文章组织成章节。主要依靠聚类算法,结合由整组文章组成的网路,找出怎样将其界定为连贯的集群。
第八,确定文章在每位章节中的出现次序。使用的是枚举,然后排序的思路,通过给文章成对分组,对所有文章枚举所有组合,然后使用网路模型来估算排序逻辑,最终估算出更为理想的文章顺序以及章节次序。
感兴趣可以详尽阅读论文:
- 主要涉及的NLP技术
NLP
自然语言处理
为了实现写作类的应用,需要对文本进行大量的处理,NLP是一种使机器能否象我们平时那样阅读和理解语言的技术。常常会结合知识图谱来使用,以提高产品疗效。
我们须要把握NLP的常见任务及算法。
- 主要的NLP任务
文本分类、情感剖析、分词、依存复句剖析、实体辨识等;
- 深度学习算法
目前深度学习有以下典型的算法,可以一一详尽了解把握;
参考地址
- GPT2这儿要举一个反例,在大受欢迎的 reddit 社区中,一个名为 SubSimulatorGPT2 的子讨论小组愈发引人注目:其内容完全由人工智能聊天机器人模仿各类讨论小组的风格生成后发布。SubSimulatorGPT2
早期的SubredditSimulator()的机器人使用马尔科夫链,这是一种成熟的生成序列的技术。
- 马尔可夫链和N-gram马尔科夫链的假定(第一性原理)。基于马尔可夫链的模型假设语句中的每位词组仅取决于其后面的几个词组。因此,给定任意语句的机率为组成该语句的所有n-gram(n个词组的序列)的组合机率。下图说明了该概念:
以Python 语言为例,采用字典(Dictionary)的数据结构。
d = {key1 : value1, key2 : value2 }
键名是当前的词组,键值是一个列表List,存储当前词组的下一个词组。
d = {word1 : [word2,word3], word2 : [word3,word4,word5] }
具体的事例,有如此两句话:
I like to eat orangesYou eat apples
我们希望通过马尔科夫链来学习以上数据,经过估算,模型为:
{'START': ['i','you'],'i': ['like'],'like': ['to'],'to': ['eat'],'you': ['eat'],'eat': ['apples','oranges'],'END': ['apples','oranges']}
我们不需要估算下一个词组出现的机率,因为假如它们出现的机率较大,那么她们会在选定下个词组的列表中出现好几次。采用适当的数据结构,问题也得到了简化的处理。
- 词嵌入和神经语言模型
词嵌入是现今NLP中任何人都必学的第一项技术:将词投射到多维空间中。它的优势在于,具有相像用法/含义的词组会获得相像的向量(按正弦相似度评判)。因此,涉及相像词组的词组向量的矩阵加法趋向给出相像的结果。
何为余弦相似度?在NLP的任务里,会对生成两个词向量进行相似度的估算,常常采用余弦相似度公式估算。余弦相似度用向量空间中两个向量倾角的正弦值作为评判两个个体间差别的大小。余弦值越接近1,就表明倾角越接近0度,也就是两个向量越相像,这就叫"余弦相似性"。
这是基于神经网路的语言模型的基础。有趣的是,神经模型不估算出现次数来确定机率,而是学习可以为任何输入估算出它们的参数(权重矩阵和误差)。这样,甚至可以为我们未曾见过的n个句型以后的下一个词组估算一个合理的机率分布。下图是一个最简单的神经网路:MLP (multilayer perceptron) 多层感知器。
- 递归神经网络
随着递归神经网络(RNN)的出现,特别是长短期记忆(LSTM)的出现,语言生成方面获得了更大进步。与之前提及的最简单的神经网路不同,RNN的上下文除了限于n个词组;它甚至没有理论上的限制。
RNN的主要改进在于保留了内部状态。因此,RNN可以不停地逐条读取词组,从而更新其内部状态以反映当前上下文,而不是只看固定的窗口(n个词组)。
使用RNN的文本生成以自回归方法遵守与马尔可夫链相像的原理。RNN对第一个词组进行取样,将其送到神经网路以获取下一个词组的机率,然后再对下一个词组进行取样,依此类推,直到语句结束为止。如下图所示,依次学习The、boys、that、came词组的过程。
Internal State类似于脑部(黑箱),记录了所有复杂的文本信息。
- 注意力机制
在形成下一个输出之前,先回顾所有以前的词组。计算注意力本质上是指估算过去词组的某种分布,然后将这种词组的向量与接收到的注意力成比列地进行聚合。下图说明了该概念。
注意机制让RNN可以回顾以前词组的输出,而不必定所有内容压缩为隐藏状态。中间输出之前的压缩RNN块与不注意时的块相同。
- Transformer
Transformer是一种神经网路构架,于2017年推出,旨在解决RNN的缺点。它的关键思想是完全借助注意力,以至根本不需要内部状态或循环。下图是Transformer的简化的描述。实际的构架十分复杂,您可以在查阅相关文章找到更详尽的解释 。
- GPT模型
回到前文所提及的GPT2,GPT全称Generative Pre-Training,出自2018年OpenAI的论文《Improving Language Understandingby Generative Pre-Training》,论文地址:
~amuham01/LING530/papers/radford2018improving.pdf
GPT是一种半监督学习方法,它致力于用大量无标明数据使模型学习“常识”,以减轻标明信息不足的问题。详细可以阅读论文深入了解。
- 人工智能辅助写作
一些相关产品。Grammarly在线写作网站
Grammarly是一款全手动英语写作工具, 可以实时检测句型,一边写一边改,语法问题和更改意见会以标明的方式显示在文档的两侧,方便用户去一一查看,而且在每条批注下边就会配有详尽的解释,告诉用户那里错了,为什么要这样更改。
百度创作脑部
百度人工智能写作辅助平台“创作脑部”,智能助手可以为人类创作者提供纠错、提取信息等各类辅助工作。
GET智能写作
一站式智能写作服务平台。全网热点追踪、推荐海量素材、提升原创质量。
- 算法新闻、机器人记者目前在这个领域领先的有美国的2家公司:
自动化洞察力公司 Automated Insights
叙述科学公司 Narrative Science
我们先来了解下算法新闻的导论。
- 算法新闻导论美国的初期创业公司,如今的佼佼者
早在2007年,美国的「自动化洞察力」Automated Insights公司创立;
2009年,美国西北大学研制的StatsMonkey「统计猴子」系统就撰写了一篇关于美国职业棒球大联盟西决的新闻稿件;
2010年,「叙述科学」公司Narrative Science创立;
由机器人记者主导的新闻行业正在迅速崛起
在2014年,美联社与Automated Insight公司达成协议,成为机器人记者的初期的采用者。
2014年3月,第一条完全由计算机程序生产的新闻报导形成。作为首家“聘用”机器人记者的主流媒体,《洛杉矶时报(LA Times)》在水灾发生后3分钟就发布了首列相关新闻。
在这一年,机器人写稿技术研制公司Automated Insight全年生产了10亿条新闻。
在2015年,新华社推出可以批量编撰新闻的写作机器人「快笔小新」;
同年9月,腾讯财经发布写作机器人「Dreamwriter」;
1年后,中国湖北广播电视台长江云新闻客户端就派出人代会机器人记者“云朵”进行专访。
第一财经也发布写作机器人「DT稿王」
同年,国外挪威新闻社NTB启动机器人,开始着手制做自动化篮球新闻报导项目;
自动化新闻早已通过手动新闻写作和发行步入新闻编辑室
2017年1月,南方都市报社写作机器人「小南」正式上岗,推出第一篇共300余字的春运报导。
……
以上为算法新闻导论。
我们须要晓得「机器人记者」并不是真正的职业记者,而是一种新闻报导软件,拥有手动撰写新闻故事的功能。相类似的概念有算法新闻、自动新闻。
媒体通常还会形象地,描述机器人记者在媒体单位“上班”,机器人具备“真人记者”所有的采编功能,不会出错,不用休息,所写的文章不仅时效性强,质量也高,工作效率比“真人记者”高出好几倍。
- 经典产品「机器人记者」
由日本表述科学公司Narrative Science发明的写作软件;这个软件拥有手动撰写新闻故事的功能。
基于选题和新闻热点追踪,通过平台授权,结构化采集、处理、分类、分析原创数据素材,快速抓取,生成新闻关键词或线索,然后,利用文本剖析和信息抽取技术,以模板和规则知识库的形式,自动生成完整的新闻报导。
尤其在体育比赛,金融经济,财报数据等方面作用突出。
- 2018年数据新闻创新奖《搜索侦察机》
记者彼得奥尔德乌斯Peter Aldhous,开发了这个项目,他使用了机器学习——特别是「随机森林random forest」算法,从大量的客机飞行数据中,建立了一个模型,可以按照以下数据:
飞机的拐弯速度
飞行速度
飞行高度
每条飞行路径周围的圆形区域
飞行持续时间
识别出可能是“隐藏身分的侦察机”。
- 各大报社、杂志社的应用
国内有人民日报「小端」、光明日报「小明」、今日头条「张小明」、南方都市报「小南」等等。近期新华智云的更新是业内比较大的动作。
新华智云
作为新华社和阿里巴巴集团共同投资创立的大数据人工智能科技公司,于2019年发布了“媒体脑部3.0”。以区块链技术和AI初审为明显特点,为内容工作者提供“策、采、编、发、审、存”全流程赋能,为媒体机构、宣传部门、企业单位各种融媒体中心提供方便、高效、智能的数据中台和内容生产平台。
新华社「快笔小新」
「快笔小新」的写稿流程由数据采集、数据剖析、生成稿件、编发四个环节组成,这一机器人适用于体育比赛、经济行情、证券信息等快讯、简讯类稿件的写作。
腾讯「DREAMWRITER」
腾讯在2015年9月推出了一个叫 Dreamwriter 自动化新闻写作机器人。最开始,这项技术主要用在财经领域,现在它在体育比赛的快速报导中也有太成功的应用案例了。
2016年里约奥运会期间,Dreamwriter 就手动撰写了3000多篇实时战报,是亚运媒体报导团的“效率之王”。
在“2017腾讯媒体+峰会”现场,Dreamwriter 平均单篇成文速率仅为0.5秒,一眨眼的时间就写了14篇稿件。
国外的应用主要如下:
《卫报》
使用机器人辅助写作,并发表了一篇名为《Political donations plunge to $16.7m – down from average $25m a year》
《华盛顿邮报》
Heliograf机器人记者,在报导2016年夏天奥运会和2016年补选时证明了它的有用性;
还帮助《华盛顿邮报》在一年一度的全球大奖中获得了「巧妙使用机器人奖Excellence in Use of Bots」
《 Guardian》
2014年,英国《 Guardian》进行了纸质测试计划,安排“机器人”统计剖析社交网络上的共享热点和注意力加热,然后内容过滤、编辑排版和复印,最后制做一份报纸。
《华尔街日报》
应用于金融投资研究报告片断的节选,网站会提醒读者那一段节选是由机器人完成的,哪些是由人类完成的。主要节选类似于以下的文字:
第二季度的现金节余8.3亿美元,这意味着在第一季度降低1.4亿美元以后,第二季度又消耗了8000万美元
Q2 cash balance expectation of $830m implies ~$80m of cash burn in Q2 after a $140m reduction in cash balance in Q1
这句话实际上只收录了三个数据点,并使用特定的句型合并在一起,而且不收录任何巧合的成份。
《洛杉矶时报》
《洛杉矶时报》靠「机器人写手」,第一时间报导了美国加州2014年3月18日当地时间清晨发生4.4级水灾;还应用于对犯罪时间错误归类的剖析。
《纽约时报》
《纽约时报》对美国国会议长的图象辨识;还应用机器人编辑Blossom预测什么文章有可能会在社交网站上导致传播,相应地给版面责任编辑提出建议;
《福布斯》
2011年,开始使用表述科学公司 Narrative Science 的手动写稿程序来撰写新闻;
彭博社
应用机器人系统Cyborg,帮助记者在每位季度进行大量的文章撰写,数量达到数千篇,包括各公司的财报文章等。机器人可以在财报出现的一瞬间就对其进行详尽的分析,并且提供收录那些相关事实和数据的实时新闻报导,速度十分迅速。
美联社
从2014年7月开始使用语言大师 Wordsmith 软件,利用自动化技术来写公司财务报表。几毫秒的时间,软件能够写出一篇路透社风格的完整报导。
- 技术进展
从早些年的以摘选稿件中诗句为主,过渡到现今全流程的方法。- 人形机器人
结合硬件,还有人形机器人版本的机器人记者的出现,例如中国智能机器人佳佳作为新华社特约记者越洋专访了日本知名科技观察家凯文·凯利。这是全球首次由高仿真智能机器人作为记者与人进行交互对话,专家觉得具有标志性意义。
- 新媒体与人工智能写作
按照英国新媒体艺术理论家马诺维奇(Lev Manovich)在《新媒体语言》一书中对新媒体技术所下的定义:
所有现存媒体通过笔记本转换成数字化的数据、照片、动态形象、声音、形状空间和文本,且都可以估算,构成一套笔记本数据的,这就是新媒体。
这是一个艺术与科技跨界结合的领域,我们可以关注国内的大牛:
MIT的Nick Montfort院士
国际上被公认为作家和通过估算探求语言的人
他撰写了大量互动小说文章,发布在博客Grand Text Auto上,同时也开发了许多数字诗和文本生成器。他近来的着作是「The Future」和「The Truelist」,有兴趣可以去了解下他的研究。
下面给你们介绍典型的案例。
- 互动小说与新型文学作品的创作
2016年,人工智能创作的小说在美国「星新一文学奖」上被评委称为「情节无纰漏」。人工智能应用于文学创作领域,为文学作品带来了新鲜血液,与文学作品的结合还平添了作品的互动性,与游戏、电影形成了跨界交融。互动故事平台
加拿大温哥华的互动故事平台Wattpad
其产品包括匹配创作者和读者的机器写作,识别故事“趋势”,根据主题进行创意写作等;还开发了视频讲故事的应用「Raccoon」;
有关文章地址采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-08-09 21:27
课程演示环境:Ubuntu须要学习Windows系统YOLOv4的朋友请抵达《Windows版YOLOv4目标测量实战:训练自己的数据集》,课程链接YOLOv4来了!速度和精度双提高!与 YOLOv3 相比,新版本的 AP(精度)和 FPS (每秒帧数)分别提升了 10% 和 12%。YOLO系列是基于深度学习的端到端实时目标测量方式。本课程将手把手地教你们使用labelImg标明和使用YOLOv4训练自己的数据集。课程实战分为两个项目:单目标测量(足球目标测量)和多目标测量(足球和梅西同时测量)。本课程的YOLOv4使用AlexAB/darknet,在Ubuntu系统上做项目演示。包括:安装YOLOv4、标注自己的数据集、整理自己的数据集、修改配置文件、训练自己的数据集、测试训练出的网路模型、性能统计(mAP估算和画出PR曲线)和先验框降维剖析。还将介绍改善YOLOv4目标训练性能的方法。除本课程《YOLOv4目标测量实战:训练自己的数据集》外,本人将推出有关YOLOv4目标测量的系列课程。请持续关注该系列的其它视频课程,包括:《YOLOv4目标测量实战:人脸口罩配戴辨识》《YOLOv4目标测量实战:中国交通标志辨识》《YOLOv4目标测量:原理与源码解析》
详细说明如何使用百度智能写作平台,快速撰写文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 763 次浏览 • 2020-08-08 15:38
您好,欢迎使用由百度自然语言处理和知识图谱共同创建的百度智能写作服务平台,以成为最了解您的智能写作助手.
百度大脑智能写作服务提供两种功能: 自动写作和辅助写作. 自动写入支持从数据到文本描述的自动生成,也就是说,当输入源是数据和文本模板时,输出是自然语言文本. 辅助写作从资料采集,文章写作和文章检查的角度为用户提供辅助功能.
接下来,您只需要快速浏览以下介绍即可完成自动或辅助写作需求.
快速入门
在Smart Writing主页上输入平台,整个过程将按照右侧内容列的顺序进行. 下面将详细介绍每个步骤的操作方法和注意事项(如果遇到问题但在本文档中找不到答案,可以加入官方QQ群组(群组编号: 743926523)来咨询群组管理).
编写项目管理来创建项目
登录到Smart Writing主页,单击“ +”按钮创建一个项目,您可以通过此页面和右上角的控制台来管理所有项目.
或在项目界面的“一个项目”管理中,该卡收录项目名称,创建时间,项目描述和其他信息.
选择写作类型
您可以根据自己的使用场景选择一种类型,并轻松创建项目. 写作项目类型分为自动写作和辅助写作. 在自动写入类型中,可以使用平台预设模板或自定义API数据源. 辅助写作从三个方面为用户提供帮助: 资料采集,文章写作和文章审阅. 此功能仅支持平台上的在线编辑.
用于自动编写项目的预设模板
此处预设了四个模板: 天气预报写作,股市报告,足球比赛报告,篮球比赛报告,可直接使用. 如果您还有其他业务数据,还可以选择一个模板来完成创建.
输入项目名称,选择文字类型,并建议输入场景简介以完成项目创建.
自定义项目模板
如果现有的官方模板中没有与您的使用场景相匹配的模板,请根据业务场景配置自定义写作模板,添加自定义模板,并上传数据变量以快速实现批处理和自动文章生成功能.
在实际的数据源添加过程中,我们提供两种形式
* 添加Excel数据文件
* 接入API接口数据源
添加数据源
1. Excel数据导入
a)要选择Excel数据,请上传本地Excel数据文件,然后单击“下载演示”以查看格式.
b)上传后,单击“下一步”,选择此模板以使用数据,保存后,您可以进入文章编辑界面开始创建.
Excel数据导入说明
添加数据源时,需要将其上传到平台系统. 数据的第一行是数据变量的名称,可以是日期,位置,温度等. 在自定义模板中选择数据变量时,第一行的名称将用作数据的名称变量.
自定义模板时,请使用数据变量嵌入纯文本内容,或将变量用于分支派生和其他功能. 其他行代表生成文章时使用的数据. 生成文章时,如果excel中有3行数据,则将为每个模板生成3条文章. 第一篇文章将使用第一行数据,第二篇文章将使用第二行...最终生成的文章将显示在“ Generation Records”页面上,您可以单击下载.
2. 访问API接口数据源
a)要选择API数据,您需要提供数据源地址,数据源名称和数据源配置文件. 有关规范,请参阅此页面顶部的“ API接口数据源描述”.
b)需要选择数据变量. 同时,您可以在此处重命名数据变量,以方便后续的变量管理.
API接口数据源描述
添加数据源时,需要将API接口地址提供给平台. 该界面仅支持获取请求. 例如:
“http://xxx.xxx.com/get_data?city=北京”
该参数可以为空. 接口参数将调用结构化数据写入接口,并在生成API时传递这些参数;该数字为空,没有必要通过.
接口返回结果需要UTF-8编码,并且为json字符串格式. 如:
{"err_code":0,"err_msg":"\u6210\u529f","data":{"title":"\u6587\u7ae0\u6807
\u9898","summary":"\u6587\u7ae0\u6458\u8981"}}
API接口返回的数据将成为模板编写和文章生成的数据源. 添加后选择数据变量时,将解析数据源接口返回的结果,并且返回的字段将是数据变量的名称. 在对平台接口的实际调用中,数据源接口返回到结果,该结果将提供用于生成文章的变量的数据.
智能字段
智能字段包括: 数据变量,同义词,分支推导. 在编辑界面中,您可以在文章中插入一个智能字段,单击右侧以将智能字段“数据变量”插入到光标处;通过短划线选择文本,它还可以触发普通文本成为智能字段.
1. 数据变量
数据变量是一种智能字段. 该功能是在生成商品时用数据源中提供的数据替换智能字段. 示例: 在图中选择数据变量“今天的最低温度”,图中智能字段的位置将替换为生成的商品中的数字4(4仅是示例,它实际上基于您提供的数据).
2. 同义表达
同义词也是一种智能字段. 该功能是用设置的表达式之一随机替换智能字段.
例如: 在图片中选择的同义词表示“及时加衣服,谨防感冒”,图片中智能字段的位置将被随机替换为“及时加衣服,谨防感冒”或“请保暖”一个. 如果要系统推荐,则可以将鼠标悬停在右侧列中要推荐的同义表达式上,然后单击出现的单词“ same”. 系统将在列中推荐一些同义词.
3. 分支派生
分支派生也是一种智能领域. 功能是选择数据变量作为判断条件,并根据不同的条件显示不同的数据.
示例: 在图中选择的分支派生“冷”,并且图中智能字段的位置将根据所生成文章中数据变量“今日最低温度”的值而变化. 如右图所示,如果它大于或等于30且小于40,则显示“ hot”;否则,显示“ hot”. 大于或等于10且小于30,则显示“轻微”;大于-20且小于10,则显示“冷”;其他条件显示为“极端”.
智能写作助手
智能写作助手收录多种工具来帮助您撰写文章,包括智能分词和文本错误纠正.
1. 智能分词
此功能是将文章分成几个单独的词汇表. 单击词汇表直接设置智能字段,以提高选择效率.
2. 文字错误更正
在系统中,打开此功能后,将自动检查全文或段落以进行错误纠正. 单击“立即更正全文”以启动对全文的错误检查. 识别出的错误单词将标记为红色. 您可以采用建议来修改词汇表或忽略错误纠正. 编写段落后,用户将自动启动错误纠正.
生成文章的管理
1. 如果它是Excel数据源项目,则文章生成记录将显示历史文章的集合. 点击下载以获取生成的文章
2. 如果它是一个API数据源项目,请通过“我的项目”查看生成记录,并通过获取API密钥和秘密密钥进行调用,如下图所示.
(单击结构化数据编写API接口文档以查看获取和使用过程)
辅助写作
辅助写作从三个角度为用户提供辅助功能: 资料采集,文章写作和文章检查.
创建和改善项目信息
单击以在项目条目中创建一个项目,然后选择辅助编写,然后将提示您填写项目名称和场景介绍. 创建完成后,您就可以开始写文章了.
热点发现
它可以显示特定行业和特定日期的实时热点新闻,并为您提供写作材料. 单击“热点”以切换字段和时间以显示不同的热点. 选择后可以将热门摘要内容直接粘贴到文章中. “搜索更多”将进行百度搜索.
热事件上下文
实时热点新闻可以上下文关联的形式显示. 上下文中的相关新闻可以按顺序呈现. 单击“上下文”以了解每个上下文中的事件.
智能摘要生成
您可以为标题超过200个单词的文章自动生成摘要. 点击“智能生成摘要”以在摘要位置添加或替换.
与产品使用情况相关
Q1: 如何单独使用智能弹簧对联,智能诗歌创作,新闻摘要,文本纠错和其他功能?
第二季度: 如何管理写作项目?
Q3: 我可以仅依靠新项目在自动写入类型下创建新模板还是协助编写新文件吗?
问题4: 文章的自动纠错需要什么触发条件?
Q5: 分词后是否可以继续编辑模板?
Q6: 同义词可以推荐词汇吗?
Q7: 分支派生只能由数量确定吗?
Q8: 必须使用数据变量来生成文章吗?
Q9: 自动写入Excel数据源,下载后将是哪种文件?
Q10: 在哪里可以获得Api文档中提到的Project_id?
Q11: 对于API数据源的自动编写项目,如何更改或禁用生成的模板?
Q12: 热点发现的时间维度?
Q13: 自动生成摘要的条件是什么?
与帐户相关
问题1: 我需要使用哪个帐户登录?
问题2: 如果我在注册百度帐户时无法收到验证码,该怎么办?
Q3: 为什么登录百度云时需要填写手机号码,电子邮件地址等信息?
Q4: 我曾经是百度开发者中心用户,我仍然需要执行开发者认证吗?
Q5: 如果有任何疑问,如何联系工作人员? 查看全部
产品介绍
您好,欢迎使用由百度自然语言处理和知识图谱共同创建的百度智能写作服务平台,以成为最了解您的智能写作助手.
百度大脑智能写作服务提供两种功能: 自动写作和辅助写作. 自动写入支持从数据到文本描述的自动生成,也就是说,当输入源是数据和文本模板时,输出是自然语言文本. 辅助写作从资料采集,文章写作和文章检查的角度为用户提供辅助功能.
接下来,您只需要快速浏览以下介绍即可完成自动或辅助写作需求.
快速入门
在Smart Writing主页上输入平台,整个过程将按照右侧内容列的顺序进行. 下面将详细介绍每个步骤的操作方法和注意事项(如果遇到问题但在本文档中找不到答案,可以加入官方QQ群组(群组编号: 743926523)来咨询群组管理).
编写项目管理来创建项目
登录到Smart Writing主页,单击“ +”按钮创建一个项目,您可以通过此页面和右上角的控制台来管理所有项目.
或在项目界面的“一个项目”管理中,该卡收录项目名称,创建时间,项目描述和其他信息.
选择写作类型
您可以根据自己的使用场景选择一种类型,并轻松创建项目. 写作项目类型分为自动写作和辅助写作. 在自动写入类型中,可以使用平台预设模板或自定义API数据源. 辅助写作从三个方面为用户提供帮助: 资料采集,文章写作和文章审阅. 此功能仅支持平台上的在线编辑.
用于自动编写项目的预设模板
此处预设了四个模板: 天气预报写作,股市报告,足球比赛报告,篮球比赛报告,可直接使用. 如果您还有其他业务数据,还可以选择一个模板来完成创建.
输入项目名称,选择文字类型,并建议输入场景简介以完成项目创建.
自定义项目模板
如果现有的官方模板中没有与您的使用场景相匹配的模板,请根据业务场景配置自定义写作模板,添加自定义模板,并上传数据变量以快速实现批处理和自动文章生成功能.
在实际的数据源添加过程中,我们提供两种形式
* 添加Excel数据文件
* 接入API接口数据源
添加数据源
1. Excel数据导入
a)要选择Excel数据,请上传本地Excel数据文件,然后单击“下载演示”以查看格式.
b)上传后,单击“下一步”,选择此模板以使用数据,保存后,您可以进入文章编辑界面开始创建.
Excel数据导入说明
添加数据源时,需要将其上传到平台系统. 数据的第一行是数据变量的名称,可以是日期,位置,温度等. 在自定义模板中选择数据变量时,第一行的名称将用作数据的名称变量.
自定义模板时,请使用数据变量嵌入纯文本内容,或将变量用于分支派生和其他功能. 其他行代表生成文章时使用的数据. 生成文章时,如果excel中有3行数据,则将为每个模板生成3条文章. 第一篇文章将使用第一行数据,第二篇文章将使用第二行...最终生成的文章将显示在“ Generation Records”页面上,您可以单击下载.
2. 访问API接口数据源
a)要选择API数据,您需要提供数据源地址,数据源名称和数据源配置文件. 有关规范,请参阅此页面顶部的“ API接口数据源描述”.
b)需要选择数据变量. 同时,您可以在此处重命名数据变量,以方便后续的变量管理.
API接口数据源描述
添加数据源时,需要将API接口地址提供给平台. 该界面仅支持获取请求. 例如:
“http://xxx.xxx.com/get_data?city=北京”
该参数可以为空. 接口参数将调用结构化数据写入接口,并在生成API时传递这些参数;该数字为空,没有必要通过.
接口返回结果需要UTF-8编码,并且为json字符串格式. 如:
{"err_code":0,"err_msg":"\u6210\u529f","data":{"title":"\u6587\u7ae0\u6807
\u9898","summary":"\u6587\u7ae0\u6458\u8981"}}
API接口返回的数据将成为模板编写和文章生成的数据源. 添加后选择数据变量时,将解析数据源接口返回的结果,并且返回的字段将是数据变量的名称. 在对平台接口的实际调用中,数据源接口返回到结果,该结果将提供用于生成文章的变量的数据.
智能字段
智能字段包括: 数据变量,同义词,分支推导. 在编辑界面中,您可以在文章中插入一个智能字段,单击右侧以将智能字段“数据变量”插入到光标处;通过短划线选择文本,它还可以触发普通文本成为智能字段.
1. 数据变量
数据变量是一种智能字段. 该功能是在生成商品时用数据源中提供的数据替换智能字段. 示例: 在图中选择数据变量“今天的最低温度”,图中智能字段的位置将替换为生成的商品中的数字4(4仅是示例,它实际上基于您提供的数据).
2. 同义表达
同义词也是一种智能字段. 该功能是用设置的表达式之一随机替换智能字段.
例如: 在图片中选择的同义词表示“及时加衣服,谨防感冒”,图片中智能字段的位置将被随机替换为“及时加衣服,谨防感冒”或“请保暖”一个. 如果要系统推荐,则可以将鼠标悬停在右侧列中要推荐的同义表达式上,然后单击出现的单词“ same”. 系统将在列中推荐一些同义词.
3. 分支派生
分支派生也是一种智能领域. 功能是选择数据变量作为判断条件,并根据不同的条件显示不同的数据.
示例: 在图中选择的分支派生“冷”,并且图中智能字段的位置将根据所生成文章中数据变量“今日最低温度”的值而变化. 如右图所示,如果它大于或等于30且小于40,则显示“ hot”;否则,显示“ hot”. 大于或等于10且小于30,则显示“轻微”;大于-20且小于10,则显示“冷”;其他条件显示为“极端”.
智能写作助手
智能写作助手收录多种工具来帮助您撰写文章,包括智能分词和文本错误纠正.
1. 智能分词
此功能是将文章分成几个单独的词汇表. 单击词汇表直接设置智能字段,以提高选择效率.
2. 文字错误更正
在系统中,打开此功能后,将自动检查全文或段落以进行错误纠正. 单击“立即更正全文”以启动对全文的错误检查. 识别出的错误单词将标记为红色. 您可以采用建议来修改词汇表或忽略错误纠正. 编写段落后,用户将自动启动错误纠正.
生成文章的管理
1. 如果它是Excel数据源项目,则文章生成记录将显示历史文章的集合. 点击下载以获取生成的文章
2. 如果它是一个API数据源项目,请通过“我的项目”查看生成记录,并通过获取API密钥和秘密密钥进行调用,如下图所示.
(单击结构化数据编写API接口文档以查看获取和使用过程)
辅助写作
辅助写作从三个角度为用户提供辅助功能: 资料采集,文章写作和文章检查.
创建和改善项目信息
单击以在项目条目中创建一个项目,然后选择辅助编写,然后将提示您填写项目名称和场景介绍. 创建完成后,您就可以开始写文章了.
热点发现
它可以显示特定行业和特定日期的实时热点新闻,并为您提供写作材料. 单击“热点”以切换字段和时间以显示不同的热点. 选择后可以将热门摘要内容直接粘贴到文章中. “搜索更多”将进行百度搜索.
热事件上下文
实时热点新闻可以上下文关联的形式显示. 上下文中的相关新闻可以按顺序呈现. 单击“上下文”以了解每个上下文中的事件.
智能摘要生成
您可以为标题超过200个单词的文章自动生成摘要. 点击“智能生成摘要”以在摘要位置添加或替换.
与产品使用情况相关
Q1: 如何单独使用智能弹簧对联,智能诗歌创作,新闻摘要,文本纠错和其他功能?
第二季度: 如何管理写作项目?
Q3: 我可以仅依靠新项目在自动写入类型下创建新模板还是协助编写新文件吗?
问题4: 文章的自动纠错需要什么触发条件?
Q5: 分词后是否可以继续编辑模板?
Q6: 同义词可以推荐词汇吗?
Q7: 分支派生只能由数量确定吗?
Q8: 必须使用数据变量来生成文章吗?
Q9: 自动写入Excel数据源,下载后将是哪种文件?
Q10: 在哪里可以获得Api文档中提到的Project_id?
Q11: 对于API数据源的自动编写项目,如何更改或禁用生成的模板?
Q12: 热点发现的时间维度?
Q13: 自动生成摘要的条件是什么?
与帐户相关
问题1: 我需要使用哪个帐户登录?
问题2: 如果我在注册百度帐户时无法收到验证码,该怎么办?
Q3: 为什么登录百度云时需要填写手机号码,电子邮件地址等信息?
Q4: 我曾经是百度开发者中心用户,我仍然需要执行开发者认证吗?
Q5: 如果有任何疑问,如何联系工作人员?
推荐六种在线Ai伪原创工具_原创文章变得简单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2020-08-07 19:01
一: 优采云AI智能写作
优采云中文语义开放平台提供了一种简单,功能强大且可靠的中文自然语言分析云服务. 优采云团队致力于创造最杰出的中文语义分析技术. 通过自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,为企业和开发人员提供了简单而强大的可靠中文语义分析云API.
官方网站链接:
神马AI智能写作
神马AI +是基于AI技术的智能写作平台. 通过对汉语分词,语法纠错,可比性检测,上下文关联等技术的自定义研究与开发,主要用作原创文章的智能辅助软件. 言语更有趣.
官方网站链接:
优采云软件助手
优采云是用于Internet垂直领域的免费软件助手工具. AI伪原件可以通过其强大的NLP,深度学习和其他技术轻松地通过独创性检测,从而使百度90%以上的文章都被收录. 基本套餐每天可以免费使用100点积分,这对于大多数个人用户来说已经足够了. 对于使用率很高的公司,您可以购买企业版软件包.
官方网站链接:
爱写作
对于SEOER来说,在线伪原创工具是非常有用的工具. 它是用于生成原创和伪原创文章的工具. 使用伪原创工具,您可以立即将在Internet上复制的文章转换为自己的原创文章. 该平台是专门为收录大型搜索引擎(例如Google,百度,搜狗和360)而设计的. 通过在线伪原创工具生成的文章将更好地被搜索引擎收录和索引. 在线伪原创工具是网站编辑,网站管理员和SEOER必不可少的工具,也是网站优化工具中不可多得的武器.
官方网站链接:
勺子捏智能伪原创
勺子捏智能伪原创解决方案
伟大作家的写作工具: 分析伪原创文章中单词的含义,使用人工智能找到可以替换的单词,用户选择适当的单词替换,并快速撰写原创文章
伪原创工具: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,快速自动生成文章,提高文章写作效率
自动摘要: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,帮助用户快速提取文章摘要
关键词提取: 根据输入的文本内容,智能地提供文本关键词提取等任务,大大提高了文本处理效率
官方网站链接:
Ai +在线伪原创工具
AI +智能文章重写工具如何工作?
文章重写工具,文章编辑器或重写工具是一个在线工具,您可以使用它来重写文章,使用人工智能领域的当前NLP语义进行重写,而不是市场同义词和关键字替换,这种独特的文章重写该工具将使用语义分析,深度学习和其他计算技术,自动学习,数十亿级别的Internet语料库数据以及重写功能来彻底分析整个内容,以进行准确而深入的中文语义分析. 您可以使用重写的示例进行协调,不同的文本将以彩色文本突出显示. 您可以快速查看和更改相应更改的内容.
官方网站链接: 查看全部
Ai伪原创工具是为Internet垂直领域SEO,新媒体,文案写作等开发的软书写工具. Ai颠覆了传统的行业书写模式,使用采集器技术首先从同一行业采集数据,并使用进行句法和语义分析的深度学习方法: 自然语言处理(NLP),使用指纹索引技术准确推荐用户相关内容以及智能的伪原创和相似性检测和分析,才能实现简单,高效和智能化使用工具来完成软写作. Ai Pseudo-original集成了文章采集,伪原创和原创检测,以实现从互联网返回互联网的伪原创文章写作的生态链. 以下是运营商共享的6种在线Ai伪原创工具.
一: 优采云AI智能写作
优采云中文语义开放平台提供了一种简单,功能强大且可靠的中文自然语言分析云服务. 优采云团队致力于创造最杰出的中文语义分析技术. 通过自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,为企业和开发人员提供了简单而强大的可靠中文语义分析云API.
官方网站链接:
神马AI智能写作
神马AI +是基于AI技术的智能写作平台. 通过对汉语分词,语法纠错,可比性检测,上下文关联等技术的自定义研究与开发,主要用作原创文章的智能辅助软件. 言语更有趣.
官方网站链接:
优采云软件助手
优采云是用于Internet垂直领域的免费软件助手工具. AI伪原件可以通过其强大的NLP,深度学习和其他技术轻松地通过独创性检测,从而使百度90%以上的文章都被收录. 基本套餐每天可以免费使用100点积分,这对于大多数个人用户来说已经足够了. 对于使用率很高的公司,您可以购买企业版软件包.
官方网站链接:
爱写作
对于SEOER来说,在线伪原创工具是非常有用的工具. 它是用于生成原创和伪原创文章的工具. 使用伪原创工具,您可以立即将在Internet上复制的文章转换为自己的原创文章. 该平台是专门为收录大型搜索引擎(例如Google,百度,搜狗和360)而设计的. 通过在线伪原创工具生成的文章将更好地被搜索引擎收录和索引. 在线伪原创工具是网站编辑,网站管理员和SEOER必不可少的工具,也是网站优化工具中不可多得的武器.
官方网站链接:
勺子捏智能伪原创
勺子捏智能伪原创解决方案
伟大作家的写作工具: 分析伪原创文章中单词的含义,使用人工智能找到可以替换的单词,用户选择适当的单词替换,并快速撰写原创文章
伪原创工具: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,快速自动生成文章,提高文章写作效率
自动摘要: 根据用户的个性化写作目的,通过智能语义和大数据分析技术,帮助用户快速提取文章摘要
关键词提取: 根据输入的文本内容,智能地提供文本关键词提取等任务,大大提高了文本处理效率
官方网站链接:
Ai +在线伪原创工具
AI +智能文章重写工具如何工作?
文章重写工具,文章编辑器或重写工具是一个在线工具,您可以使用它来重写文章,使用人工智能领域的当前NLP语义进行重写,而不是市场同义词和关键字替换,这种独特的文章重写该工具将使用语义分析,深度学习和其他计算技术,自动学习,数十亿级别的Internet语料库数据以及重写功能来彻底分析整个内容,以进行准确而深入的中文语义分析. 您可以使用重写的示例进行协调,不同的文本将以彩色文本突出显示. 您可以快速查看和更改相应更改的内容.
官方网站链接:
织梦智能采集器PHP版本v2.8 utf-8
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-08-07 09:31
功能介绍
1. 一键安装,自动采集
Dream Weaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,强大,灵活和开放源代码的dedecms程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 提供技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件.
8. 定期和定量采集伪原创SEO更新
该插件有两种触发采集方法,一种是在页面上添加代码以通过用户访问来触发采集和更新,另一种是我们为商业用户提供的远程触发采集服务. 可以定期定量地采集和更新新站点,而无需任何人访问. ,无需人工干预.
9. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
10. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
破解说明
Weaving Dream Collector的采集版本分为UTF8和GBK版本. 根据您使用的dedecms版本进行选择!
由于这些文件是与mac系统一起打包的,因此它们将携带_MACOSX和.DS_Store文件,这不会影响使用,可以删除那些强迫症患者. 覆盖破解的文件时,不必关心这些文件.
1,[您可以自己从Collector的官方网站下载最新的v2.8版本(URL: ///如果无法打开该官方网站,请使用我的备份. 解压后,有一个官方的采集器的插件文件夹,选择安装相应的版本),然后将其安装到您的织梦背景. 如果您以前安装了2.7版,请先将其删除! )
2. 安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件: 直接覆盖网站的根目录
包括: 直接覆盖网站的根目录
CaiJiXia: 该网站的默认后端为dede. 如果不修改后端目录,它将覆盖/ dede / apps /. 如果后端访问路径已被修改,请将dede替换为您修改的名称. 例如: dede已修改为测试,然后覆盖/ test / apps /目录
4,[破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存. 建议使用Google或Firefox. 不要使用IE内核浏览器. 清理缓存有时可能不干净]
6,PHP版本必须为5.3 +
使用方法
1. 设置定向采集
1). 登录到网站的后端,即Module-> Collect Man-> Collect任务,如果您的网站尚未添加列,则需要先在Dream Weaving的列管理中添加列,如果您已经添加了列,您可能会看到以下界面
2). 在弹出的页面中选择方向集合,如图所示
3),单击添加采集规则,这是添加目标采集规则的页面,在这里我们要详细讨论
2,设置目标页面编码
打开要采集的网页,单击鼠标右键,单击以查看网站源代码,搜索字符集,并检查该字符集是否跟着utf-8或gb2312,如图所示,它是utf-8
3. 设置列表网址
列表URL是您要采集的网站的列列表地址
如果您只是采集列表页面的第一页,只需直接输入列表URL. 如果我想采集网站管理员主页上经过优化的部分的第一页,请输入列表URL: 采集第一页内容的好处是您无需采集旧新闻,而可以采集新的更新. 及时采集. 如果需要采集此列的所有内容,还可以设置通配符以匹配所有列表URL规则. 查看全部
Weaving Dream Collector是网站管理员必备的软件,可以自动采集Dream Weaving网站的背景. 该软件可以帮助用户快速采集和添加网站数据. 对于每个织梦网站来说,它都是必不可少的网站. 一个可自动采集文章的插件工具,并且具有无限的域名使用效果,因此您不受次数的限制. 欢迎有需要的用户下载和使用. 注意: 此编辑器为您带来了Dreamweaving Collector 2.8破解版,该版本已成功激活该软件,因此用户可以免费使用它.
功能介绍
1. 一键安装,自动采集
Dream Weaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 通过简单,强大,灵活和开放源代码的dedecms程序,新手可以快速入门,并且我们还为商业客户提供专门的客户服务. 提供技术支持.
2. 一字采集,无需编写采集规则
与传统采集模式的区别在于,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点是,通过采集关键字的不同搜索结果,可以实现对一个或多个集合站点的错误采集,从而降低了搜索引擎将其视为镜像站点并受到惩罚的风险. 搜索引擎.
3. RSS采集,输入RSS地址以采集内容
只要所采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这方便又简单.
4. 有针对性的馆藏,标题,文本,作者,来源的精确馆藏
定向采集只需提供列表URL和文章URL即可智能地采集指定网站或列的内容,这既方便又简单. 编写简单的规则可以准确地采集标题,正文,作者和来源.
5. 多种伪原创和优化方法,以提高收录率和排名
自动标题,段落重排,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键字添加链接等方法来处理所采集文章并增强所采集文章的独创性,有利于搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名.
6,插件自动采集,无需人工干预
Weaving Dream Collector是一个预先设置的采集任务,根据设置的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确的计算来分析网页,丢弃不是文章内容页面的URL,并提取出最终优秀文章的内容是伪原创的,导入并生成的. 所有这些操作过程都是自动完成的,无需人工干预.
7. 手工发表的文章也可以是伪原创的,并且可以进行搜索优化
Dream Weaver Collector不仅是一个采集插件,而且还是实现织梦所必需的伪原创和搜索优化插件. 手动发布的文章可以由Dream Weaver Collector的伪原创和搜索优化处理. 文章的同义词替换,自动内部链接,关键字链接的随机插入以及收录关键字的文章将自动添加指定的链接和其他功能. 这是进行梦之织法的必备插件.
8. 定期和定量采集伪原创SEO更新
该插件有两种触发采集方法,一种是在页面上添加代码以通过用户访问来触发采集和更新,另一种是我们为商业用户提供的远程触发采集服务. 可以定期定量地采集和更新新站点,而无需任何人访问. ,无需人工干预.
9. 定期并定量地更新待处理的手稿
即使数据库中有成千上万的文章,Dreamweaver也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新.
10. 绑定织梦采集节点以定期采集伪原创SEO更新
绑定编织梦采集节点的功能,因此编织梦CMS的采集功能也可以自动定期采集和更新. 设置了采集规则的用户可以方便地定期采集和更新.
破解说明
Weaving Dream Collector的采集版本分为UTF8和GBK版本. 根据您使用的dedecms版本进行选择!
由于这些文件是与mac系统一起打包的,因此它们将携带_MACOSX和.DS_Store文件,这不会影响使用,可以删除那些强迫症患者. 覆盖破解的文件时,不必关心这些文件.
1,[您可以自己从Collector的官方网站下载最新的v2.8版本(URL: ///如果无法打开该官方网站,请使用我的备份. 解压后,有一个官方的采集器的插件文件夹,选择安装相应的版本),然后将其安装到您的织梦背景. 如果您以前安装了2.7版,请先将其删除! )
2. 安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件: 直接覆盖网站的根目录
包括: 直接覆盖网站的根目录
CaiJiXia: 该网站的默认后端为dede. 如果不修改后端目录,它将覆盖/ dede / apps /. 如果后端访问路径已被修改,请将dede替换为您修改的名称. 例如: dede已修改为测试,然后覆盖/ test / apps /目录
4,[破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存. 建议使用Google或Firefox. 不要使用IE内核浏览器. 清理缓存有时可能不干净]
6,PHP版本必须为5.3 +
使用方法
1. 设置定向采集
1). 登录到网站的后端,即Module-> Collect Man-> Collect任务,如果您的网站尚未添加列,则需要先在Dream Weaving的列管理中添加列,如果您已经添加了列,您可能会看到以下界面
2). 在弹出的页面中选择方向集合,如图所示
3),单击添加采集规则,这是添加目标采集规则的页面,在这里我们要详细讨论
2,设置目标页面编码
打开要采集的网页,单击鼠标右键,单击以查看网站源代码,搜索字符集,并检查该字符集是否跟着utf-8或gb2312,如图所示,它是utf-8
3. 设置列表网址
列表URL是您要采集的网站的列列表地址
如果您只是采集列表页面的第一页,只需直接输入列表URL. 如果我想采集网站管理员主页上经过优化的部分的第一页,请输入列表URL: 采集第一页内容的好处是您无需采集旧新闻,而可以采集新的更新. 及时采集. 如果需要采集此列的所有内容,还可以设置通配符以匹配所有列表URL规则.
微信公众号文章以各种格式爬行和下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2020-08-06 14:09
但是,当您看到许多历史文章时,您想要一一查看它们,然后将它们发送到计算机浏览器并手动将它们另存为文档,这会令人生畏.
在测试了许多所谓的WeChat文章采集工具之后,我认为只有“ WeChat官方帐户文章搜索导出助手”才是最强大,最方便使用的工具. 下面让我们对该软件进行简要介绍:
软件功能
一键式采集并在任何微信公众号上搜索所有历史文章,将pdf,word,txt,Excel,HTML批量导出,并将阅读次数和评论数导出到本地计算机,然后下载所有图片,视频,音乐微信文章中的音频和音频以及消息注释等功能,共80种功能,非常强大!
无限采集任何微信官方帐户历史记录和大量发布文章
通过微信商品导出软件,您可以批量下载要导出官方账户的所有商品,并将其保存到计算机中. 操作简单,并且比P叔叔更容易使用
没有采集限制
无论是服务帐户还是订阅帐户,都可以使用软件来采集其商品数据. 从官方帐户上的第一篇文章到最后一篇文章,它都可以完全获取和导出,比python crawler更方便;
数据自动保存
所有已抓取的微信文章均会自动保存在本地数据库中,只要不被删除,就永远不会丢失,也无需重复采集官方账号,从本地查询更方便在任何时候;
导入文章下载
该软件具有3种批量导入微信文章链接和下载的方式,例如微信集合等. 它还支持导入官方帐户菜单栏页面(模板消息);
多种文档格式
您可以批量导出具有原创排版的微信文章,以保存word,pdf,txt,Excel和html,稍后将支持epub,其中Excel可以导出阅读量,查看量和注释以及作者,原创和图形位置信息;
确保文章完整
不仅可以下载微信文章图片和文章内容,还可以将微信文章视频,语音,音乐音频,评论消息,文章链接,封面标题图片等批量下载到计算机,以确保文章可以完全导出,微信图片推荐下载器;
更多下载设置
您可以按时间段下载文章;您可以选择不下载文章图片;您可以自定义设置以保存文档文件名;您可以随意设置文件存储位置;您只能选择下载原创文章;
查看微信文章导出文档示例,在线微信文章保存html示例
搜索任何关键字
通过关键字搜索整个网络的官方帐户上的文章要优于搜狗微信搜索. 您可以搜索所需的任何内容. 同时,您可以在线浏览文章的内容,并一键删除重复的文章;
按时间搜索
搜索按时间排序的微信文章,您可以选择在一天,一周和一年内采集文章,搜索结果可以按标题和官方帐户排序;
搜索智能过滤器
通过文章标题,摘要和正式账户名称设置过滤关键词,自动过滤收录关键词的文章,支持过滤词的完全模糊匹配,更精确地搜索微信文章;
好的,以上是功能概述. 接下来,让我们看一下具体用法. 由于编辑本人通常会在官方帐户上阅读许多PPT类型的文章,因此我将以关键字“ PPT”为例. . 大家都知道,我们通常需要检索微信上的文章,更不用说效率低下了,打开它查看,还要注意微信的官方账号,用软件抓取它会更加方便,并且它支持导出多种文件格式. 易于阅读.
首先,搜索关键字“ PPT”,您可以看到总共有47,605条文章已被爬网.
获取大量数据后,我们需要做的是过滤所需的数据,然后根据需要将其导出.
同时,该软件还支持从任何正式帐户导出商品. 同样,这里我们使用“晨曦设计院”的微信进行尝试. 可以看出,该官方帐户中的所有文章都可以被采集和下载,甚至视频也已被采集.
软件下载 查看全部
这些内容可能是您所在领域的本质,也许其中的观点发人深省,或者您只是喜欢某个大V的字眼. 微信是每天最频繁的交流工具. 您是否在生活中经常遇到这样的场景: 在上班途中,在阅读官方帐户的最新内容时,突然出现微信提示您必须停止并退出?回复结束后,我刚刚看到的一半内容和官方帐户都不确定我去了哪里. 结果,这种想法会时不时地浮现在您的脑海: 如果您可以将所有文章保存在此微信公众号上,将其转换为电子书格式,然后将其放入阅读器中阅读,将非常方便.
但是,当您看到许多历史文章时,您想要一一查看它们,然后将它们发送到计算机浏览器并手动将它们另存为文档,这会令人生畏.
在测试了许多所谓的WeChat文章采集工具之后,我认为只有“ WeChat官方帐户文章搜索导出助手”才是最强大,最方便使用的工具. 下面让我们对该软件进行简要介绍:
软件功能
一键式采集并在任何微信公众号上搜索所有历史文章,将pdf,word,txt,Excel,HTML批量导出,并将阅读次数和评论数导出到本地计算机,然后下载所有图片,视频,音乐微信文章中的音频和音频以及消息注释等功能,共80种功能,非常强大!
无限采集任何微信官方帐户历史记录和大量发布文章
通过微信商品导出软件,您可以批量下载要导出官方账户的所有商品,并将其保存到计算机中. 操作简单,并且比P叔叔更容易使用
没有采集限制
无论是服务帐户还是订阅帐户,都可以使用软件来采集其商品数据. 从官方帐户上的第一篇文章到最后一篇文章,它都可以完全获取和导出,比python crawler更方便;
数据自动保存
所有已抓取的微信文章均会自动保存在本地数据库中,只要不被删除,就永远不会丢失,也无需重复采集官方账号,从本地查询更方便在任何时候;
导入文章下载
该软件具有3种批量导入微信文章链接和下载的方式,例如微信集合等. 它还支持导入官方帐户菜单栏页面(模板消息);
多种文档格式
您可以批量导出具有原创排版的微信文章,以保存word,pdf,txt,Excel和html,稍后将支持epub,其中Excel可以导出阅读量,查看量和注释以及作者,原创和图形位置信息;
确保文章完整
不仅可以下载微信文章图片和文章内容,还可以将微信文章视频,语音,音乐音频,评论消息,文章链接,封面标题图片等批量下载到计算机,以确保文章可以完全导出,微信图片推荐下载器;
更多下载设置
您可以按时间段下载文章;您可以选择不下载文章图片;您可以自定义设置以保存文档文件名;您可以随意设置文件存储位置;您只能选择下载原创文章;
查看微信文章导出文档示例,在线微信文章保存html示例
搜索任何关键字
通过关键字搜索整个网络的官方帐户上的文章要优于搜狗微信搜索. 您可以搜索所需的任何内容. 同时,您可以在线浏览文章的内容,并一键删除重复的文章;
按时间搜索
搜索按时间排序的微信文章,您可以选择在一天,一周和一年内采集文章,搜索结果可以按标题和官方帐户排序;
搜索智能过滤器
通过文章标题,摘要和正式账户名称设置过滤关键词,自动过滤收录关键词的文章,支持过滤词的完全模糊匹配,更精确地搜索微信文章;
好的,以上是功能概述. 接下来,让我们看一下具体用法. 由于编辑本人通常会在官方帐户上阅读许多PPT类型的文章,因此我将以关键字“ PPT”为例. . 大家都知道,我们通常需要检索微信上的文章,更不用说效率低下了,打开它查看,还要注意微信的官方账号,用软件抓取它会更加方便,并且它支持导出多种文件格式. 易于阅读.
首先,搜索关键字“ PPT”,您可以看到总共有47,605条文章已被爬网.
获取大量数据后,我们需要做的是过滤所需的数据,然后根据需要将其导出.
同时,该软件还支持从任何正式帐户导出商品. 同样,这里我们使用“晨曦设计院”的微信进行尝试. 可以看出,该官方帐户中的所有文章都可以被采集和下载,甚至视频也已被采集.
软件下载
超酷!一个界面,用于自动编辑,智能创意和创意检测
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2020-08-06 10:19
5118内容工件
上周,Xiao 5阅读了SEOer关于维护网站内容的文章. 序言是:
“作为网站站长SEO练习者,我们最关心的是内容的编写和更新. 我们经常熬夜更新文章并制作假冒的原创作品. 不知道该写些关于网站内容的内容吗?灵感吗?写作?能力差如何提高原创性?”
实际上,对于不专心写作的网站管理员SEOer,“内容为王”所要求的高质量文章输出非常麻烦.
最近,5118还收到了许多用户的建设性建议. 这些有价值的建议是内容工件发布后迅速增长的重要原因之一.
在这里,我要感谢5118用户的真诚反馈. 开发团队使用此升级可以提供反馈和全面的内容编写体验,使每个人都可以更轻松,更高效地完成编辑工作.
过去的编辑操作
开始时,为了满足提高用户创作灵感的需求,提供了一种新的媒体资料搜索功能.
5118全网资料搜索
后来,为了满足增加网站内容收录率的需要,提供了一个聪明的原创功能.
5118AI智能原件
尽管这两个功能正是编辑人员所需要的,但独立操作的效率远不及一站式编写.
您与用户的声音越接近,5118开发人员就越了解功能按钮的设计会影响整体工作效率.
升级编辑操作
结果,随着内容工件的诞生和功能的不断改进,集成的功能视觉编辑器在一个界面中可以有效地同时完成繁重的物料采集和内容编辑操作.
内容工件
充分利用这些功能,使您的编辑工作更有效.
接下来,让我们恢复如何快速使一篇文章对收录在内容工件中有用.
高效采集和编辑的全过程
01. 采集热物料并智能过滤相关段落
5118使内容工件具有大数据采集和分析功能,在内容工件编辑界面的左侧嵌入了功能强大的资料库,除了查看热门文章的热门列表之外,还对资料采集功能进行了升级,这样编辑人员就不会消失. 许多弯路.
在材料搜索框中,输入要发布的文章的主题关键字,单击搜索,材料库将自动从整个网络中采集与该单词相关的材料,并将其显示在搜索结果中.
在搜索结果中,系统对我们需要用于编辑的材料要求进行了分类.
文章: 与整个网络上的目标关键字相关的内容的全文,作为素材的启发,单击以引用要点或引用全文,然后可以将其插入到右侧的编辑器中. 更高级的内容处理.
升级小功能
为了提高接受率,编辑很少会多次引用同一篇文章.
过去,没有过滤功能. 在搜索材料时,不可避免地要找到重复的材料.
在当前材料搜索的右上角,已经支持过滤功能,您可以自由选择是否显示引用的文章. 选中“不显示引用的文章”,系统将自动识别我们介绍的材料,从而避免引用的文章过去的文章和段落出现在搜索结果中,从而大大提高了未使用材料的搜索效率并减少了内容重复.
相关段落: 出现在整个网络中的高质量文章中最相关的基本段落. 这些段落通常会命中目标关键字,并且与所收录的内容更加一致. 单击全文可查看其来源,或选择引用的段落将其插入右侧的编辑器中,以进行下一个内容处理.
升级小功能
当编辑者选择材料时,文章越新鲜,越适合于采用内容. 查看全部
5118内容工件
上周,Xiao 5阅读了SEOer关于维护网站内容的文章. 序言是:
“作为网站站长SEO练习者,我们最关心的是内容的编写和更新. 我们经常熬夜更新文章并制作假冒的原创作品. 不知道该写些关于网站内容的内容吗?灵感吗?写作?能力差如何提高原创性?”
实际上,对于不专心写作的网站管理员SEOer,“内容为王”所要求的高质量文章输出非常麻烦.
最近,5118还收到了许多用户的建设性建议. 这些有价值的建议是内容工件发布后迅速增长的重要原因之一.
在这里,我要感谢5118用户的真诚反馈. 开发团队使用此升级可以提供反馈和全面的内容编写体验,使每个人都可以更轻松,更高效地完成编辑工作.
过去的编辑操作
开始时,为了满足提高用户创作灵感的需求,提供了一种新的媒体资料搜索功能.
5118全网资料搜索
后来,为了满足增加网站内容收录率的需要,提供了一个聪明的原创功能.
5118AI智能原件
尽管这两个功能正是编辑人员所需要的,但独立操作的效率远不及一站式编写.
您与用户的声音越接近,5118开发人员就越了解功能按钮的设计会影响整体工作效率.
升级编辑操作
结果,随着内容工件的诞生和功能的不断改进,集成的功能视觉编辑器在一个界面中可以有效地同时完成繁重的物料采集和内容编辑操作.
内容工件
充分利用这些功能,使您的编辑工作更有效.
接下来,让我们恢复如何快速使一篇文章对收录在内容工件中有用.
高效采集和编辑的全过程
01. 采集热物料并智能过滤相关段落
5118使内容工件具有大数据采集和分析功能,在内容工件编辑界面的左侧嵌入了功能强大的资料库,除了查看热门文章的热门列表之外,还对资料采集功能进行了升级,这样编辑人员就不会消失. 许多弯路.
在材料搜索框中,输入要发布的文章的主题关键字,单击搜索,材料库将自动从整个网络中采集与该单词相关的材料,并将其显示在搜索结果中.
在搜索结果中,系统对我们需要用于编辑的材料要求进行了分类.
文章: 与整个网络上的目标关键字相关的内容的全文,作为素材的启发,单击以引用要点或引用全文,然后可以将其插入到右侧的编辑器中. 更高级的内容处理.
升级小功能
为了提高接受率,编辑很少会多次引用同一篇文章.
过去,没有过滤功能. 在搜索材料时,不可避免地要找到重复的材料.
在当前材料搜索的右上角,已经支持过滤功能,您可以自由选择是否显示引用的文章. 选中“不显示引用的文章”,系统将自动识别我们介绍的材料,从而避免引用的文章过去的文章和段落出现在搜索结果中,从而大大提高了未使用材料的搜索效率并减少了内容重复.
相关段落: 出现在整个网络中的高质量文章中最相关的基本段落. 这些段落通常会命中目标关键字,并且与所收录的内容更加一致. 单击全文可查看其来源,或选择引用的段落将其插入右侧的编辑器中,以进行下一个内容处理.
升级小功能
当编辑者选择材料时,文章越新鲜,越适合于采用内容.

