
文章采集组合工具
文章采集组合工具——magicavoxel01—什么是magicavoxel?
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-05-21 09:01
文章采集组合工具——magicavoxel01什么是magicavoxel?magicavoxel是一个开源的代码生成引擎,基于svg构建,它可以将原生webgl(3dopengl)的二维图形重绘为png、svg或office文档中的位图,并且支持在pdf、图片、幻灯片等多种形式中转换,是一个免费开源的图形渲染引擎。
02使用环境准备在进行magicavoxel的开发之前,需要先安装python,pip3包管理器安装好magicavoxel之后,再安装django,这里对于web开发来说python是最佳选择。03文件结构一个示例案例中,包含了4个文件内容:1.config.py2.model.py3.html.py4.api.py04安装pip3#本示例中已经安装了pip3,所以直接将这个包下载到本地就可以了,进行管理importmagicavoxel#model包含在最下方,所以直接安装x2=pip3installx2#html.py是在url构建好之后,对url的操作所用到的包importos#api.py包含在url的编码、内存生存等部分,以上的示例我们只需要对x2来说进行实例化,也就是x2=os.path.join('x2','x2.html')x2.install()05x2文件配置x2文件要在x2的目录下进行配置,先对一些基本配置做相应配置:#*。 查看全部
文章采集组合工具——magicavoxel01—什么是magicavoxel?
文章采集组合工具——magicavoxel01什么是magicavoxel?magicavoxel是一个开源的代码生成引擎,基于svg构建,它可以将原生webgl(3dopengl)的二维图形重绘为png、svg或office文档中的位图,并且支持在pdf、图片、幻灯片等多种形式中转换,是一个免费开源的图形渲染引擎。
02使用环境准备在进行magicavoxel的开发之前,需要先安装python,pip3包管理器安装好magicavoxel之后,再安装django,这里对于web开发来说python是最佳选择。03文件结构一个示例案例中,包含了4个文件内容:1.config.py2.model.py3.html.py4.api.py04安装pip3#本示例中已经安装了pip3,所以直接将这个包下载到本地就可以了,进行管理importmagicavoxel#model包含在最下方,所以直接安装x2=pip3installx2#html.py是在url构建好之后,对url的操作所用到的包importos#api.py包含在url的编码、内存生存等部分,以上的示例我们只需要对x2来说进行实例化,也就是x2=os.path.join('x2','x2.html')x2.install()05x2文件配置x2文件要在x2的目录下进行配置,先对一些基本配置做相应配置:#*。
新浪微博名称+连接效果图搜狗微信:文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-05-12 06:01
文章采集组合工具新浪微博(现在说新浪微博算是刚起步吧)搜狗微信:新浪微博名称+名称+连接搜狗微信名称+名称+连接效果图搜狗微信:新浪微博名称+名称+连接效果图采集的结果除了无法查看发表时间和评论等等很难完全满足外,其他我感觉还是不错的。ios系统的话和pc的操作还是差不多,大体上和手机差不多。基于iphone5s的操作流程:。
1、安装新浪微博,
2、点击最右侧的新浪微博名称(iphone上是右上角搜索框“+”右侧的用户名),
3、点击右侧的“我”,
4、点击页面下方的【转发】按钮,选择第一个微博并转发到新浪微博中。同时添加到第二个微博中。
5、打开公众号,打开并登录新浪微博,
6、在新浪微博界面中点击“转发”功能,从我的微博中选择想转发的微博并点转发。同时选择第二个微博并转发。
7、此时转发还不会出现在最上方的微博列表里,需要点击右侧的“转发”功能。(当鼠标悬浮在最上方微博列表时,出现了一个菜单,
8、点击上面“转发到新浪微博”页面中的“[评论]”就可以看到发布人发布的评论内容啦, 查看全部
新浪微博名称+连接效果图搜狗微信:文章采集工具
文章采集组合工具新浪微博(现在说新浪微博算是刚起步吧)搜狗微信:新浪微博名称+名称+连接搜狗微信名称+名称+连接效果图搜狗微信:新浪微博名称+名称+连接效果图采集的结果除了无法查看发表时间和评论等等很难完全满足外,其他我感觉还是不错的。ios系统的话和pc的操作还是差不多,大体上和手机差不多。基于iphone5s的操作流程:。
1、安装新浪微博,
2、点击最右侧的新浪微博名称(iphone上是右上角搜索框“+”右侧的用户名),
3、点击右侧的“我”,
4、点击页面下方的【转发】按钮,选择第一个微博并转发到新浪微博中。同时添加到第二个微博中。
5、打开公众号,打开并登录新浪微博,
6、在新浪微博界面中点击“转发”功能,从我的微博中选择想转发的微博并点转发。同时选择第二个微博并转发。
7、此时转发还不会出现在最上方的微博列表里,需要点击右侧的“转发”功能。(当鼠标悬浮在最上方微博列表时,出现了一个菜单,
8、点击上面“转发到新浪微博”页面中的“[评论]”就可以看到发布人发布的评论内容啦,
7000 字 | 20 图 | 一文带你搭建一套 ELK Stack 日志平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-02 04:32
这是悟空的第145篇原创文章
官网:
你好,我是悟空呀~
前言
最近在折腾 ELK 日志平台,它是 Elastic 公司推出的一整套日志收集、分析和展示的解决方案。
专门实操了一波,这玩意看起来简单,但是里面的流程步骤还是很多的,而且遇到了很多坑。在此记录和总结下。
本文亮点:一步一图、带有实操案例、踩坑记录、与开发环境的日志结合,反映真实的日志场景。
日志收集平台有多种组合方式:
这次先讲解 ELK Stack 的方式,这种方式对我们的代码无侵入,核心思想就是收集磁盘的日志文件,然后导入到 Elasticsearch。
比如我们的应用系统通过 logback 把日志写入到磁盘文件,然后通过这一套组合的中间件就能把日志采集起来供我们查询使用了。
整体的架构图如下所示,
流程如下:
温馨提示:以下案例都在一台 ubuntu 虚拟机上完成,内存分配了 6G。
一、部署 Elasticsearch 数据库
获取 elasticsearch 镜像
docker pull elasticsearch:7.7.1<br />
创建挂载目录
mkdir -p /data/elk/es/{config,data,logs}<br />
赋予权限
chown -R 1000:1000 /data/elk/es<br />
创建配置文件
cd /data/elk/es/config<br />touch elasticsearch.yml<br />-----------------------配置内容----------------------------------<br />cluster.name: "my-es"<br />network.host: 0.0.0.0<br />http.port: 9200<br />
启动 elasticsearch 容器
docker run -it -d -p 9200:9200 -p 9300:9300 --name es -e ES_JAVA_OPTS="-Xms1g -Xmx1g" -e "discovery.type=single-node" --restart=always -v /data/elk/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /data/elk/es/data:/usr/share/elasticsearch/data -v /data/elk/es/logs:/usr/share/elasticsearch/logs elasticsearch:7.7.1<br />
验证 elasticsearch 是否启动成功
curl http://localhost:9200<br />
二、部署 Kibana 可视化工具2.1 安装 Kibana
获取 kibana 镜像
docker pull kibana:7.7.1<br />
获取elasticsearch容器 ip
docker inspect --format '{{ .NetworkSettings.IPAddress }}' es<br />
结果:172.17.0.2
创建 kibana 配置文件
mkdir -p /data/elk/kibana/<br />vim /data/elk/kibana/kibana.yml<br />
配置内容:
#Default Kibana configuration for docker target<br />server.name: kibana<br />server.host: "0"<br />elasticsearch.hosts: ["http://172.17.0.2:9200"]<br />xpack.monitoring.ui.container.elasticsearch.enabled: true<br />
2.2 运行 kibana
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kibana -p 5601:5601 -v /data/elk/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.7.1<br />
访问 :5601。这个 IP 是服务器的 IP。Kibana 控制台的界面如下所示,打开 kibana 时,首页会提示让你选择加入一些测试数据,点击 try our sample data 按钮就可以了。
Kibana 界面上会提示你是否导入样例数据,选一个后,Kibana 会帮你自动导入,然后就可以进入到 Discover 窗口搜索日志了。
image-245270三、部署 logstash 日志过滤、转换工具3.1 安装 Java JDK
$ sudo apt install openjdk-8-jdk<br />
修改 /etc/profile 文件
sudo vim /etc/profile<br />
添加如下的内容到你的 .profile 文件中:
# JAVA<br />JAVA_HOME="/usr/lib/jdk/jdk-12"<br />PATH="$PATH:$JAVA_HOME/bin"<br />
再在命令行中打入如下的命令:
source /etc/profile<br />
查看 java 是否配置成功
java -version<br />
3.2 安装 logstash
下载 logstash 安装包
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />
解压安装
tar -xzvf logstash-7.7.1.tar.gz<br />
要测试 Logstash 安装,请运行最基本的 Logstash 管道。例如:
cd logstash-7.7.1<br />bin/logstash -e 'input { stdin { } } output { stdout {} }'<br />
等 Logstash 完成启动后,我们在 stdin 里输入以下文字,我们可以看到如下的输出:
当我们打入一行字符然后回车,那么我们马上可以在 stdout 上看到输出的信息。如果我们能看到这个输出,说明我们的 Logstash 的安装是成功的。
我们进入到 Logstash 安装目录,并修改 config/logstash.yml 文件。我们把 config.reload.automatic 设置为 true。
另外一种运行 Logstash 的方式,也是一种最为常见的运行方式,运行时指定 logstash 配置文件。
3.3 配置 logstash
Logstash 配置文件有两个必需元素,输入(inputs)和输出(ouputs),以及一个可选元素 filters。输入插件配置来源数据,过滤器插件在你指定时修改数据,输出插件将数据写入目标。
我们首先需要创建一个配置文件,配置内容如下图所示:
创建 kibana 配置文件 weblog.conf
mkdir -p /logstash-7.7.1/streamconf<br />vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置内容如下:
input {<br /> tcp {<br /> port => 9900<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout { }<br /> <br /> elasticsearch {<br /> hosts => ["localhost:9200"]<br /> }<br />}<br />
在上面,我们同时保留两个输出:stdout 及 elasticsearch。事实上,我们可以定义很多个的输出。stdout 输出对于我们初期的调试是非常有帮助的。等我们完善了所有的调试,我们可以把上面的 stdout 输出关掉。
等更新完这个配置文件后,我们在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900<br />
这个命令的意思:我们使用 nc 应用读取第一行数据,然后发送到 TCP 端口号 9900,并查看 console 的输出。
这里的 weblog-sample.log 为样例数据,内容如下,把它放到本地作为日志文件。
14.49.42.25 - - [12/May/2019:01:24:44 +0000] "GET /articles/ppp-over-ssh/ HTTP/1.1" 200 18586 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) Gecko/20091014 Firefox/3.6b1 GTB5"
logstash 控制台打印出了 weblog-samle.log 中的内容:
这一次,我们打开 Kibana,执行命令,成功看到 es 中的这条记录。
GET logstash/_search<br />
四、部署 Filebeat 日志收集工具4.1 安装 Filebeat
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />tar xzvf filebeat-7.7.1-linux-x86_64.tar.gz<br />
请注意:由于 ELK 迭代比较快,我们可以把上面的版本 7.7.1 替换成我们需要的版本即可。我们先不要运行 Filebeat。
4.2 配置 Filebeat
我们在 Filebeat 的安装目录下,可以创建一个这样的 filebeat_apache.yml 文件,它的内容如下,首先先让 filebeat 直接将日志文件导入到 elasticsearch,来确认 filebeat 是否正常工作
filebeat.inputs:<br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.elasticsearch:<br /> hosts: ["192.168.56.10:9200"]<br />
paths 对应你的日志文件夹路径,我配置的是这个:/home/vagrant/logs/*.log,之前配置成 /home/vagrant/logs 不能正常收集。另外这里可以放入多个日志路径。
4.3 测试 Filebeat
在使用时,你先要启动 Logstash,然后再启动 Filebeat。
bin/logstash -f weblog.conf<br />
然后,再运行 Filebeat, -c 表示运行指定的配置文件,这里是 filebeat_apache.yml。
./filebeat -e -c filebeat_apache.yml<br />
运行结果如下所示,一定要确认下控制台中是否打印了加载和监控了我们指定的日志。如下图所示,有三个日志文件被监控到了:error.log、info.log、debug.log
我们可以通过这个命令查看 filebeat 的日志是否导入成功了:
curl http://localhost:9200/_cat/indices?v<br />
这个命令会查询 Elasticsearch 中所有的索引,如下图所示,filebeat-7.7.1-* 索引创建成功了。因为我没有配置索引的名字,所以这个索引的名字是默认的,。
在 kibana 中搜索日志,可以看到导入的 error 的日志了。不过我们先得在 kibana 中创建 filebeat 的索引(点击 create index pattern 按钮,然后输入 filebeat 关键字,添加这个索引),然后才能在 kibana 的 Discover 控制台查询日志。
创建查询的索引
搜索日志4.4 Filebeat + Logstash
接下来我们配置 filebeat 收集日志后,输出到 logstash,然后由 logstash 转换数据后输出到 elasticsearch。
filebeat.inputs:<br /><br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.logstash:<br /> hosts: ["localhost:9900"]<br />
修改 logstash 配置文件
vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置了 input 为 beats,修改了 useragent
input { <br /> beats {<br /> port => "9900"<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "user_agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout {<br /> codec => dots {}<br /> }<br /> <br /> elasticsearch {<br /> hosts=>["192.168.56.10:9200"]<br /> index => "apache_elastic_example"<br /> }<br />}<br />
然后重新启动 logstash 和 filebeat。有个问题,这次启动 filebeat 的时候,只监测到了一个 info.log 文件,而 error.log 和 debug.log 没有监测到,导致只有 info.log 导入到了 Elasticsearch 中。
filebeat 只监测到了 info.log 文件
logstash 输出结果如下,会有格式化后的日志:
我们在 Kibana dev tools 中可以看到索引 apache_elastic_example,说明索引创建成功,日志也导入到了 elasticsearch 中。
另外注意下 logstash 中的 grok 过滤器,指定的 message 的格式需要和自己的日志的格式相匹配,这样才能将我们的日志内容正确映射到 message 字段上。
例如我的 logback 的配置信息如下:
logback 配置
而我的 logstash 配置如下,和 logback 的 pettern 是一致的。
grok {<br /> match => { "message" => "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger -%msg%n" }<br /> }<br /><br />
然后我们在 es 中就能看到日志文件中的信息了。如下图所示:
至此,Elasticsearch + Logstash + Kibana + Filebeat 部署成功,可以愉快地查询日志了~
后续升级方案:
五、遇到的问题和解决方案5.1 拉取 kibana 镜像失败
failed to register layer: Error processing tar file(exit status 2): fatal error: runtime: out of memory
原因是 inodes 资源耗尽 , 清理一下即可
df -i<br />sudo find . -xdev -type f | cut -d "/" -f 2 | sort | uniq -c | sort -n<br />
curl -s https://raw.githubusercontent. ... clean |<br />sudo tee /usr/local/bin/docker-clean > /dev/null && \<br />sudo chmod +x /usr/local/bin/docker-clean<br />docker-clean<br />
5.2 拉取 kibana 镜像失败
docker pull runtime: out of memory
增加虚拟机内存大小
5.3 Kibana 无法启动
"License information could not be obtained from Elasticsearch due to Error: No Living connections error"}
看下配置的 IP 地址是不是容器的 IP。
参考链接:
- END -
写了两本 PDF,回复分布式或PDF下载。我的 JVM 专栏已上架,回复JVM领取
我是悟空,努力变强,变身超级赛亚人! 查看全部
7000 字 | 20 图 | 一文带你搭建一套 ELK Stack 日志平台
这是悟空的第145篇原创文章
官网:
你好,我是悟空呀~
前言
最近在折腾 ELK 日志平台,它是 Elastic 公司推出的一整套日志收集、分析和展示的解决方案。
专门实操了一波,这玩意看起来简单,但是里面的流程步骤还是很多的,而且遇到了很多坑。在此记录和总结下。
本文亮点:一步一图、带有实操案例、踩坑记录、与开发环境的日志结合,反映真实的日志场景。
日志收集平台有多种组合方式:
这次先讲解 ELK Stack 的方式,这种方式对我们的代码无侵入,核心思想就是收集磁盘的日志文件,然后导入到 Elasticsearch。
比如我们的应用系统通过 logback 把日志写入到磁盘文件,然后通过这一套组合的中间件就能把日志采集起来供我们查询使用了。
整体的架构图如下所示,
流程如下:
温馨提示:以下案例都在一台 ubuntu 虚拟机上完成,内存分配了 6G。
一、部署 Elasticsearch 数据库
获取 elasticsearch 镜像
docker pull elasticsearch:7.7.1<br />
创建挂载目录
mkdir -p /data/elk/es/{config,data,logs}<br />
赋予权限
chown -R 1000:1000 /data/elk/es<br />
创建配置文件
cd /data/elk/es/config<br />touch elasticsearch.yml<br />-----------------------配置内容----------------------------------<br />cluster.name: "my-es"<br />network.host: 0.0.0.0<br />http.port: 9200<br />
启动 elasticsearch 容器
docker run -it -d -p 9200:9200 -p 9300:9300 --name es -e ES_JAVA_OPTS="-Xms1g -Xmx1g" -e "discovery.type=single-node" --restart=always -v /data/elk/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /data/elk/es/data:/usr/share/elasticsearch/data -v /data/elk/es/logs:/usr/share/elasticsearch/logs elasticsearch:7.7.1<br />
验证 elasticsearch 是否启动成功
curl http://localhost:9200<br />
二、部署 Kibana 可视化工具2.1 安装 Kibana
获取 kibana 镜像
docker pull kibana:7.7.1<br />
获取elasticsearch容器 ip
docker inspect --format '{{ .NetworkSettings.IPAddress }}' es<br />
结果:172.17.0.2
创建 kibana 配置文件
mkdir -p /data/elk/kibana/<br />vim /data/elk/kibana/kibana.yml<br />
配置内容:
#Default Kibana configuration for docker target<br />server.name: kibana<br />server.host: "0"<br />elasticsearch.hosts: ["http://172.17.0.2:9200"]<br />xpack.monitoring.ui.container.elasticsearch.enabled: true<br />
2.2 运行 kibana
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kibana -p 5601:5601 -v /data/elk/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.7.1<br />
访问 :5601。这个 IP 是服务器的 IP。Kibana 控制台的界面如下所示,打开 kibana 时,首页会提示让你选择加入一些测试数据,点击 try our sample data 按钮就可以了。
Kibana 界面上会提示你是否导入样例数据,选一个后,Kibana 会帮你自动导入,然后就可以进入到 Discover 窗口搜索日志了。
image-245270三、部署 logstash 日志过滤、转换工具3.1 安装 Java JDK
$ sudo apt install openjdk-8-jdk<br />
修改 /etc/profile 文件
sudo vim /etc/profile<br />
添加如下的内容到你的 .profile 文件中:
# JAVA<br />JAVA_HOME="/usr/lib/jdk/jdk-12"<br />PATH="$PATH:$JAVA_HOME/bin"<br />
再在命令行中打入如下的命令:
source /etc/profile<br />
查看 java 是否配置成功
java -version<br />
3.2 安装 logstash
下载 logstash 安装包
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />
解压安装
tar -xzvf logstash-7.7.1.tar.gz<br />
要测试 Logstash 安装,请运行最基本的 Logstash 管道。例如:
cd logstash-7.7.1<br />bin/logstash -e 'input { stdin { } } output { stdout {} }'<br />
等 Logstash 完成启动后,我们在 stdin 里输入以下文字,我们可以看到如下的输出:
当我们打入一行字符然后回车,那么我们马上可以在 stdout 上看到输出的信息。如果我们能看到这个输出,说明我们的 Logstash 的安装是成功的。
我们进入到 Logstash 安装目录,并修改 config/logstash.yml 文件。我们把 config.reload.automatic 设置为 true。
另外一种运行 Logstash 的方式,也是一种最为常见的运行方式,运行时指定 logstash 配置文件。
3.3 配置 logstash
Logstash 配置文件有两个必需元素,输入(inputs)和输出(ouputs),以及一个可选元素 filters。输入插件配置来源数据,过滤器插件在你指定时修改数据,输出插件将数据写入目标。
我们首先需要创建一个配置文件,配置内容如下图所示:
创建 kibana 配置文件 weblog.conf
mkdir -p /logstash-7.7.1/streamconf<br />vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置内容如下:
input {<br /> tcp {<br /> port => 9900<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout { }<br /> <br /> elasticsearch {<br /> hosts => ["localhost:9200"]<br /> }<br />}<br />
在上面,我们同时保留两个输出:stdout 及 elasticsearch。事实上,我们可以定义很多个的输出。stdout 输出对于我们初期的调试是非常有帮助的。等我们完善了所有的调试,我们可以把上面的 stdout 输出关掉。
等更新完这个配置文件后,我们在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900<br />
这个命令的意思:我们使用 nc 应用读取第一行数据,然后发送到 TCP 端口号 9900,并查看 console 的输出。
这里的 weblog-sample.log 为样例数据,内容如下,把它放到本地作为日志文件。
14.49.42.25 - - [12/May/2019:01:24:44 +0000] "GET /articles/ppp-over-ssh/ HTTP/1.1" 200 18586 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) Gecko/20091014 Firefox/3.6b1 GTB5"
logstash 控制台打印出了 weblog-samle.log 中的内容:
这一次,我们打开 Kibana,执行命令,成功看到 es 中的这条记录。
GET logstash/_search<br />
四、部署 Filebeat 日志收集工具4.1 安装 Filebeat
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />tar xzvf filebeat-7.7.1-linux-x86_64.tar.gz<br />
请注意:由于 ELK 迭代比较快,我们可以把上面的版本 7.7.1 替换成我们需要的版本即可。我们先不要运行 Filebeat。
4.2 配置 Filebeat
我们在 Filebeat 的安装目录下,可以创建一个这样的 filebeat_apache.yml 文件,它的内容如下,首先先让 filebeat 直接将日志文件导入到 elasticsearch,来确认 filebeat 是否正常工作
filebeat.inputs:<br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.elasticsearch:<br /> hosts: ["192.168.56.10:9200"]<br />
paths 对应你的日志文件夹路径,我配置的是这个:/home/vagrant/logs/*.log,之前配置成 /home/vagrant/logs 不能正常收集。另外这里可以放入多个日志路径。
4.3 测试 Filebeat
在使用时,你先要启动 Logstash,然后再启动 Filebeat。
bin/logstash -f weblog.conf<br />
然后,再运行 Filebeat, -c 表示运行指定的配置文件,这里是 filebeat_apache.yml。
./filebeat -e -c filebeat_apache.yml<br />
运行结果如下所示,一定要确认下控制台中是否打印了加载和监控了我们指定的日志。如下图所示,有三个日志文件被监控到了:error.log、info.log、debug.log
我们可以通过这个命令查看 filebeat 的日志是否导入成功了:
curl http://localhost:9200/_cat/indices?v<br />
这个命令会查询 Elasticsearch 中所有的索引,如下图所示,filebeat-7.7.1-* 索引创建成功了。因为我没有配置索引的名字,所以这个索引的名字是默认的,。
在 kibana 中搜索日志,可以看到导入的 error 的日志了。不过我们先得在 kibana 中创建 filebeat 的索引(点击 create index pattern 按钮,然后输入 filebeat 关键字,添加这个索引),然后才能在 kibana 的 Discover 控制台查询日志。
创建查询的索引
搜索日志4.4 Filebeat + Logstash
接下来我们配置 filebeat 收集日志后,输出到 logstash,然后由 logstash 转换数据后输出到 elasticsearch。
filebeat.inputs:<br /><br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.logstash:<br /> hosts: ["localhost:9900"]<br />
修改 logstash 配置文件
vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置了 input 为 beats,修改了 useragent
input { <br /> beats {<br /> port => "9900"<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "user_agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout {<br /> codec => dots {}<br /> }<br /> <br /> elasticsearch {<br /> hosts=>["192.168.56.10:9200"]<br /> index => "apache_elastic_example"<br /> }<br />}<br />
然后重新启动 logstash 和 filebeat。有个问题,这次启动 filebeat 的时候,只监测到了一个 info.log 文件,而 error.log 和 debug.log 没有监测到,导致只有 info.log 导入到了 Elasticsearch 中。
filebeat 只监测到了 info.log 文件
logstash 输出结果如下,会有格式化后的日志:
我们在 Kibana dev tools 中可以看到索引 apache_elastic_example,说明索引创建成功,日志也导入到了 elasticsearch 中。
另外注意下 logstash 中的 grok 过滤器,指定的 message 的格式需要和自己的日志的格式相匹配,这样才能将我们的日志内容正确映射到 message 字段上。
例如我的 logback 的配置信息如下:
logback 配置
而我的 logstash 配置如下,和 logback 的 pettern 是一致的。
grok {<br /> match => { "message" => "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger -%msg%n" }<br /> }<br /><br />
然后我们在 es 中就能看到日志文件中的信息了。如下图所示:
至此,Elasticsearch + Logstash + Kibana + Filebeat 部署成功,可以愉快地查询日志了~
后续升级方案:
五、遇到的问题和解决方案5.1 拉取 kibana 镜像失败
failed to register layer: Error processing tar file(exit status 2): fatal error: runtime: out of memory
原因是 inodes 资源耗尽 , 清理一下即可
df -i<br />sudo find . -xdev -type f | cut -d "/" -f 2 | sort | uniq -c | sort -n<br />
curl -s https://raw.githubusercontent. ... clean |<br />sudo tee /usr/local/bin/docker-clean > /dev/null && \<br />sudo chmod +x /usr/local/bin/docker-clean<br />docker-clean<br />
5.2 拉取 kibana 镜像失败
docker pull runtime: out of memory
增加虚拟机内存大小
5.3 Kibana 无法启动
"License information could not be obtained from Elasticsearch due to Error: No Living connections error"}
看下配置的 IP 地址是不是容器的 IP。
参考链接:
- END -
写了两本 PDF,回复分布式或PDF下载。我的 JVM 专栏已上架,回复JVM领取
我是悟空,努力变强,变身超级赛亚人!
文章采集组合工具(简单好用的关键词组合工具,该软件用户会自己进行组词 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-04-20 07:02
)
Word Combination Tool 是一个非常简单的关键词 组合生成工具。在网站的运营中,关键词的选择和质量与网站的浏览量挂钩。因此,关键词的选择非常重要。很多用户会组成自己的单词,但有时一个单词有多种组合。如果是手动使用的话会很费时间,而且组合关键词可能还有遗漏;所以今天推荐这款简单好用的关键词组合工具,它有四个单词输入框,在从左到右输入相关单词后,这些单词可以一键按顺序组合,不会遗漏任意关键词组合,可以提高用户的工作效率。
软件功能
1、通过输入单词的顺序来组合一个段落。
2、批量生成,几句话可以组合成大量关键词。
3、帮助网站站长快速生成相关关键词。
4、生成的关键词可以用于网站的优化和运行。
软件功能
1、软件小巧绿色,无需安装即可使用。
2、用户可以输入四个单词,可以满足用户的单词输入需求。
3、海量关键词一键顺序生成,可直接复制使用。
4、提高用户工作效率,轻松生成大量关键词。
如何使用
1、解压后直接打开程序。
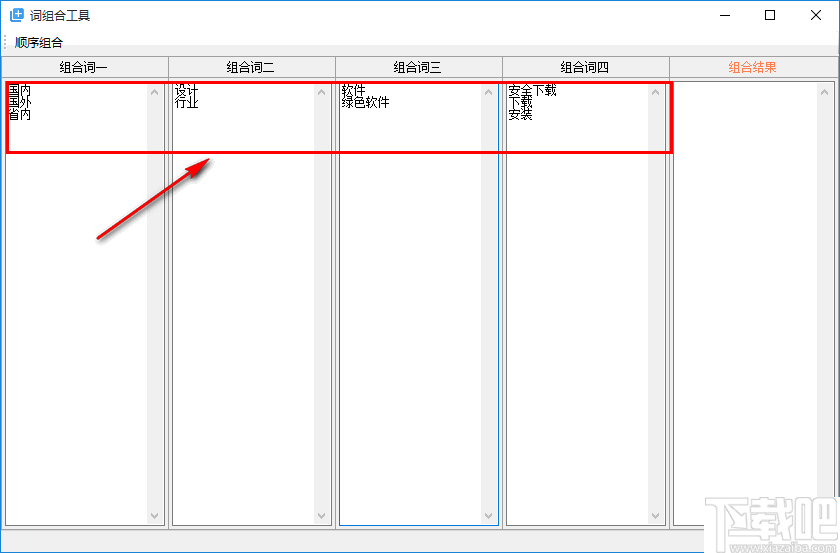
2、进入软件后,在复合词1到复合词4中输入相关词,每行一个词。
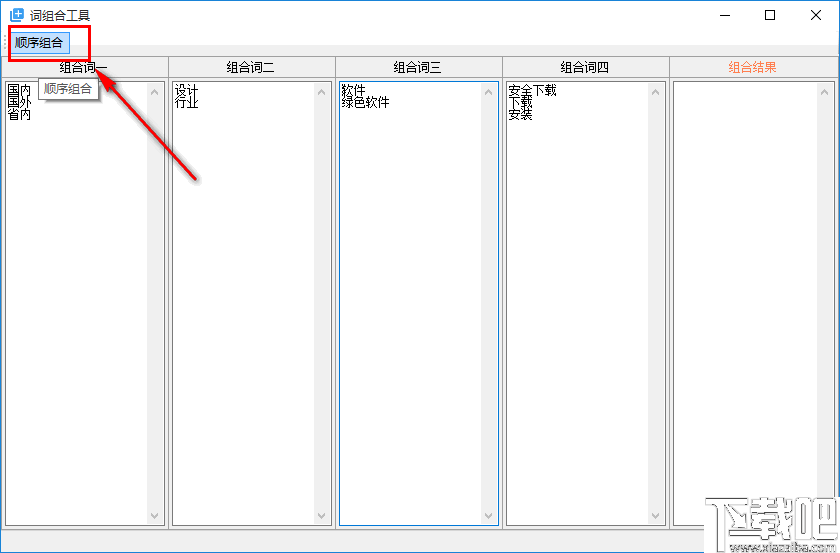
3、只能写组合词三,软件不要求一到四都必须填写,完成后点击左上角的序列生成。
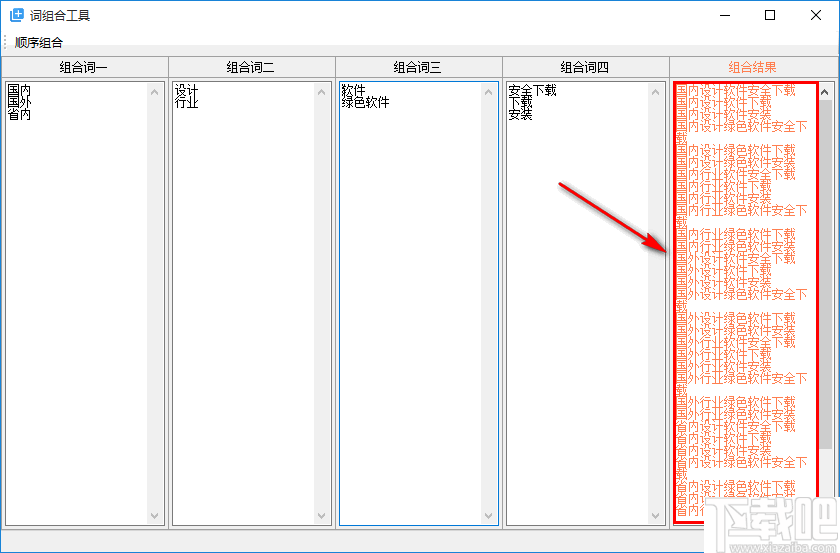
4、生成后,可以在最右边的窗口中查看相关的复合词。
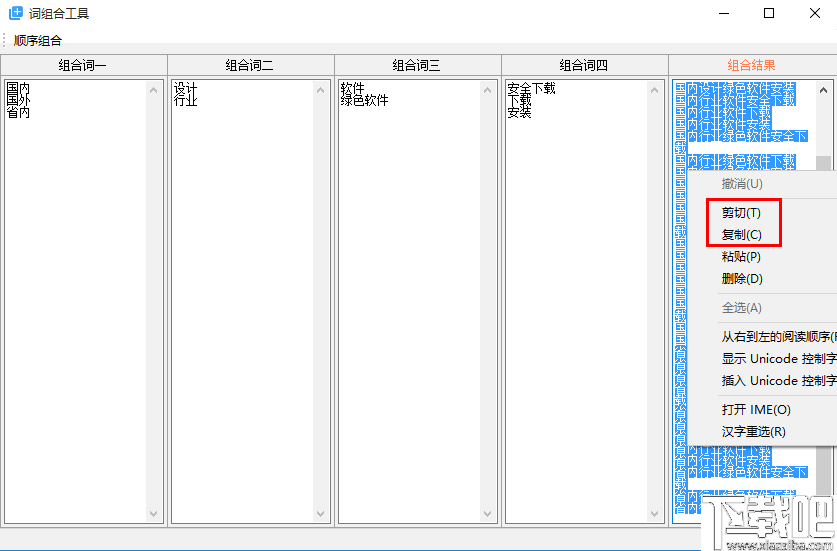
5、选择所有组合词后,可以右键复制粘贴所有要使用的词。
查看全部
文章采集组合工具(简单好用的关键词组合工具,该软件用户会自己进行组词
)
Word Combination Tool 是一个非常简单的关键词 组合生成工具。在网站的运营中,关键词的选择和质量与网站的浏览量挂钩。因此,关键词的选择非常重要。很多用户会组成自己的单词,但有时一个单词有多种组合。如果是手动使用的话会很费时间,而且组合关键词可能还有遗漏;所以今天推荐这款简单好用的关键词组合工具,它有四个单词输入框,在从左到右输入相关单词后,这些单词可以一键按顺序组合,不会遗漏任意关键词组合,可以提高用户的工作效率。

软件功能
1、通过输入单词的顺序来组合一个段落。
2、批量生成,几句话可以组合成大量关键词。
3、帮助网站站长快速生成相关关键词。
4、生成的关键词可以用于网站的优化和运行。
软件功能
1、软件小巧绿色,无需安装即可使用。
2、用户可以输入四个单词,可以满足用户的单词输入需求。
3、海量关键词一键顺序生成,可直接复制使用。
4、提高用户工作效率,轻松生成大量关键词。
如何使用
1、解压后直接打开程序。
2、进入软件后,在复合词1到复合词4中输入相关词,每行一个词。
3、只能写组合词三,软件不要求一到四都必须填写,完成后点击左上角的序列生成。
4、生成后,可以在最右边的窗口中查看相关的复合词。
5、选择所有组合词后,可以右键复制粘贴所有要使用的词。
文章采集组合工具(大漠采集器最新文章看点采集工具采集内容规则介绍(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-20 07:00
Desert采集器是一个免费且最新的文章Aspect采集工具,可以帮助用户下载各种流行的新文章,并支持将图片保存在文章@ > 格式。本地,可以自由选择采集内容规则,使用非常方便。
【软件亮点】
软件操作简单,鼠标点击即可轻松选择要抓拍的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,让浏览器采集也能高速运行,甚至可以快速转换到 HTTP 模式运行并享受更高的 采集 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构,非专业网页设计人员也能轻松抓取所需内容数据;
无需分析网页请求和源代码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过wizards字段进行简单映射轻松导出到目标网站数据库。
【软件功能】
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎也可以切换到HTTP引擎模式运行,采集数据更高效。还有一个内置的 JSON 引擎,可以直观地选择 JSON 内容,无需分析 JSON 数据结构。
适用于各类网站:能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
【安装注意事项】 查看全部
文章采集组合工具(大漠采集器最新文章看点采集工具采集内容规则介绍(图))
Desert采集器是一个免费且最新的文章Aspect采集工具,可以帮助用户下载各种流行的新文章,并支持将图片保存在文章@ > 格式。本地,可以自由选择采集内容规则,使用非常方便。

【软件亮点】
软件操作简单,鼠标点击即可轻松选择要抓拍的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,让浏览器采集也能高速运行,甚至可以快速转换到 HTTP 模式运行并享受更高的 采集 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构,非专业网页设计人员也能轻松抓取所需内容数据;
无需分析网页请求和源代码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过wizards字段进行简单映射轻松导出到目标网站数据库。
【软件功能】
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎也可以切换到HTTP引擎模式运行,采集数据更高效。还有一个内置的 JSON 引擎,可以直观地选择 JSON 内容,无需分析 JSON 数据结构。
适用于各类网站:能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
【安装注意事项】
文章采集组合工具(怎么快速提升网站关键词自然排名的影响因素与优化方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-19 14:41
如何快速提升网站关键词的自然排名?网站关键词影响排名的因素有哪些?如何使用SEO工具插件让网站快速收录、关键词排名快速上升。接下来就跟着小编一起来使用凡客cms采集工具制作网站快速收录,并利用凡客cms中的SEO功能制作< @关键词排名迅速上升。
百度自然搜索排名的影响因素及优化方法
在很大程度上,做SEO比较难的部分是做排名。没有排名,一切都不可能。推测这些因素会影响百度的自然搜索排名,以及如何通过seo优化的方法提高排名,是很多seo人员头疼的问题。本文引用百度搜索资源平台的观点对这个问题做一些说明。
总结百度自然搜索排名的影响因素及优化方法
一:原则上排名是多少?
对于百度这样的搜索,没有排序这回事。搜索引擎认为排序是内容网站在某个特定关键词下的位置,而关键词是用户搜索生成的,如果没有搜索到一个关键词 ,也就是说这个关键词下没有排序,排序会因为数据更新、用户需求、个性化等因素实时变化。
二:百度官方给出的影响排名的因素有哪些?
影响排名的因素很多。排名是通过各种算法衡量的结果。常听说XXX认识XX搜索引擎算法工程师。其实这些算法是不会交给一个人的,一个算法工程师懂的懂的算法也是有限的,操纵排名是不够的,因为影响因素确实太多了。这里我列出几个公认的权威影响因素:
1.网站与搜索的相关性关键词
网站的主题与关键词的主题匹配很重要,网站的主题和内容一致也是如此,如果网站跨域发布引流内容,它将被搜索者识别。受到惩罚的例子很多。此外,如果用户搜索与您的 网站 相关的 关键词,用户将在 网站 内转化更多点击。
2.内容和搜索关键词的相关性
目前,百度等搜索引擎越来越重视内容生态的维护,让更多原创作者获得更多收益。机会越大。简单来说,如果网站的内容足够丰富,可以满足搜索用户的所有需求,那么一般这样的内容展示和点击都不会太差。接下来我要教你的是一个快速的采集高质量文章范科cms采集。
<p>本次凡客cms采集无需学习更多专业技能,只需简单几步即可轻松采集内容资料,用户只需登录凡客cms 查看全部
文章采集组合工具(怎么快速提升网站关键词自然排名的影响因素与优化方法)
如何快速提升网站关键词的自然排名?网站关键词影响排名的因素有哪些?如何使用SEO工具插件让网站快速收录、关键词排名快速上升。接下来就跟着小编一起来使用凡客cms采集工具制作网站快速收录,并利用凡客cms中的SEO功能制作< @关键词排名迅速上升。

百度自然搜索排名的影响因素及优化方法
在很大程度上,做SEO比较难的部分是做排名。没有排名,一切都不可能。推测这些因素会影响百度的自然搜索排名,以及如何通过seo优化的方法提高排名,是很多seo人员头疼的问题。本文引用百度搜索资源平台的观点对这个问题做一些说明。
总结百度自然搜索排名的影响因素及优化方法
一:原则上排名是多少?
对于百度这样的搜索,没有排序这回事。搜索引擎认为排序是内容网站在某个特定关键词下的位置,而关键词是用户搜索生成的,如果没有搜索到一个关键词 ,也就是说这个关键词下没有排序,排序会因为数据更新、用户需求、个性化等因素实时变化。
二:百度官方给出的影响排名的因素有哪些?
影响排名的因素很多。排名是通过各种算法衡量的结果。常听说XXX认识XX搜索引擎算法工程师。其实这些算法是不会交给一个人的,一个算法工程师懂的懂的算法也是有限的,操纵排名是不够的,因为影响因素确实太多了。这里我列出几个公认的权威影响因素:
1.网站与搜索的相关性关键词
网站的主题与关键词的主题匹配很重要,网站的主题和内容一致也是如此,如果网站跨域发布引流内容,它将被搜索者识别。受到惩罚的例子很多。此外,如果用户搜索与您的 网站 相关的 关键词,用户将在 网站 内转化更多点击。
2.内容和搜索关键词的相关性
目前,百度等搜索引擎越来越重视内容生态的维护,让更多原创作者获得更多收益。机会越大。简单来说,如果网站的内容足够丰富,可以满足搜索用户的所有需求,那么一般这样的内容展示和点击都不会太差。接下来我要教你的是一个快速的采集高质量文章范科cms采集。

<p>本次凡客cms采集无需学习更多专业技能,只需简单几步即可轻松采集内容资料,用户只需登录凡客cms
文章采集组合工具(快克SEO是良心商家,从来不坑穷人和聪明人!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-19 14:38
前言
最近很多网友都说快客比较可怜,尤其是快客的搜狗推送工具。1888元买了也没用。
事实上,曹操认为快客是一个非常好的人。每次他免费给我工具和模板时,他从不收我的钱。
我想为此发声:Crack SEO是一个有良心的商人,从不坑穷人和聪明人!我从口袋里掏出钱来买破烂的东西!
而且有很多免费的工具,界面也很漂亮。说实话,我跟韭菜没什么关系。
截屏
工具特点
本工具完全免费,根据关键词抓取搜索引擎的网站信息;
抓取速度快,秒杀市面上同类工具;
支持本地和代理模式;
可自由配置,可打开更多窗口;
使用说明
导入关键词时,标题必须收录输入框(如果没有),表示标题必须收录输入框列表中的一项;
过滤域名输入框(如果不需要填写),默认过滤一些大型常规网站,也就是说如果抓取的域名是输入框列表或其子域名之一,就会被过滤;
爬取页数表示搜索引擎爬取的前几页;
自动去除重复域名,如果抓取的域名有重复,会被过滤掉;
工具支持百度、搜狗、360、Google四大搜索引擎,后期可添加;
可以使用百度本地模式。一般情况下,不需要代理。根据网速调整设置可以降低故障率;
搜狗、360、Google等搜索引擎在反爬方面都比较严格。一个IP可以搜索几十到几百个单词。使用后会限制IP,一段时间后会继续爬取;
如果关键词不多,用VPN切换IP,每次爬几十到几百个字后再切换IP;
如果要大量关键词无缝查询,需要购买代理IP(配置见附图)
一般情况下,可以使用默认配置。如果查询失败,可以调整设置减少线程数,增加超时时间;
增加自动故障复查次数,同时增加延迟捕获时间;
一般来说,减少爬取搜索引擎的次数,或者增加自动失败复查次数是一个原则;
代理IP目前只支持易变代理(网址:),如果您有性能更好的代理IP;
请发给我,添加多个接口,免费为用户升级。
代理IP提取方法将同步软件包截图教程。建议一次提取一个IP,节省IP的使用。 查看全部
文章采集组合工具(快克SEO是良心商家,从来不坑穷人和聪明人!)
前言
最近很多网友都说快客比较可怜,尤其是快客的搜狗推送工具。1888元买了也没用。
事实上,曹操认为快客是一个非常好的人。每次他免费给我工具和模板时,他从不收我的钱。
我想为此发声:Crack SEO是一个有良心的商人,从不坑穷人和聪明人!我从口袋里掏出钱来买破烂的东西!
而且有很多免费的工具,界面也很漂亮。说实话,我跟韭菜没什么关系。
截屏

工具特点
本工具完全免费,根据关键词抓取搜索引擎的网站信息;
抓取速度快,秒杀市面上同类工具;
支持本地和代理模式;
可自由配置,可打开更多窗口;
使用说明
导入关键词时,标题必须收录输入框(如果没有),表示标题必须收录输入框列表中的一项;
过滤域名输入框(如果不需要填写),默认过滤一些大型常规网站,也就是说如果抓取的域名是输入框列表或其子域名之一,就会被过滤;
爬取页数表示搜索引擎爬取的前几页;
自动去除重复域名,如果抓取的域名有重复,会被过滤掉;
工具支持百度、搜狗、360、Google四大搜索引擎,后期可添加;
可以使用百度本地模式。一般情况下,不需要代理。根据网速调整设置可以降低故障率;
搜狗、360、Google等搜索引擎在反爬方面都比较严格。一个IP可以搜索几十到几百个单词。使用后会限制IP,一段时间后会继续爬取;
如果关键词不多,用VPN切换IP,每次爬几十到几百个字后再切换IP;
如果要大量关键词无缝查询,需要购买代理IP(配置见附图)
一般情况下,可以使用默认配置。如果查询失败,可以调整设置减少线程数,增加超时时间;
增加自动故障复查次数,同时增加延迟捕获时间;
一般来说,减少爬取搜索引擎的次数,或者增加自动失败复查次数是一个原则;
代理IP目前只支持易变代理(网址:),如果您有性能更好的代理IP;
请发给我,添加多个接口,免费为用户升级。
代理IP提取方法将同步软件包截图教程。建议一次提取一个IP,节省IP的使用。
文章采集组合工具(以爱情公寓为例,文章采集组合工具如何获取?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-16 17:03
文章采集组合工具一:两款软件nomad:一款采集软件,一款导出软件,文章采集组合工具二:一款软件软件大礼包:根据用途提供所有的采集文章功能,欢迎去采集站点下载更多资源!一款软件:网站sae文章抓取工具:采集网站:urlai/sae-fwp-models/sae-fwp-models/不采集网站:fwp,fwwp2333。
首先,百度上查到的基本都会漏,第二百度贴吧或者一些论坛,或者其他大型的贴吧,会有一些冷门小清新或者头像很萌的妹子的,搜一下她/他的名字,会有他们的联系方式,
推荐去youzaaa看看还可以去闲鱼,等搜索关键词每天会有公益写的文章也可以加群,
1.百度2.贴吧搜索3.百度。还可以翻墙4.豆瓣app5.qq里面搜索,微信里面搜索,搜狗微信搜索百度搜索6.。
想有些内容自己不能产生,就去盗别人的,然后卖,怎么样,够无聊吧。
手机上除了用各种应用市场下载软件外,更多的其实是通过公众号来获取,但如何获取呢?今天就给大家分享一个。以爱情公寓为例来举例方法一首先,在百度搜索『福尔摩斯』这个关键词,会跳出很多关于福尔摩斯的文章以及推送。找到其中一篇文章,点击即可进入下载页面。如图所示:方法二进入公众号——回复:情书获取下载链接。如图所示:回复:编码这样就可以获取下载链接了,之后直接输入文章中的网址或输入你要下载的那篇文章的标题就可以下载了。 查看全部
文章采集组合工具(以爱情公寓为例,文章采集组合工具如何获取?)
文章采集组合工具一:两款软件nomad:一款采集软件,一款导出软件,文章采集组合工具二:一款软件软件大礼包:根据用途提供所有的采集文章功能,欢迎去采集站点下载更多资源!一款软件:网站sae文章抓取工具:采集网站:urlai/sae-fwp-models/sae-fwp-models/不采集网站:fwp,fwwp2333。
首先,百度上查到的基本都会漏,第二百度贴吧或者一些论坛,或者其他大型的贴吧,会有一些冷门小清新或者头像很萌的妹子的,搜一下她/他的名字,会有他们的联系方式,
推荐去youzaaa看看还可以去闲鱼,等搜索关键词每天会有公益写的文章也可以加群,
1.百度2.贴吧搜索3.百度。还可以翻墙4.豆瓣app5.qq里面搜索,微信里面搜索,搜狗微信搜索百度搜索6.。
想有些内容自己不能产生,就去盗别人的,然后卖,怎么样,够无聊吧。
手机上除了用各种应用市场下载软件外,更多的其实是通过公众号来获取,但如何获取呢?今天就给大家分享一个。以爱情公寓为例来举例方法一首先,在百度搜索『福尔摩斯』这个关键词,会跳出很多关于福尔摩斯的文章以及推送。找到其中一篇文章,点击即可进入下载页面。如图所示:方法二进入公众号——回复:情书获取下载链接。如图所示:回复:编码这样就可以获取下载链接了,之后直接输入文章中的网址或输入你要下载的那篇文章的标题就可以下载了。
文章采集组合工具(智能采集优采云网页采集系统是视界信息技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-16 16:09
优采云网页采集系统是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率.
软件功能
简单采集
简单的采集模式,内置数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板只需简单设置参数,即可快速获取公共数据网站。
智能采集
优采云采集根据不同网站,提供多种网页采集策略及配套资源,可自定义配置、组合使用、自动处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,保证数据的及时性。
API接口
通过优采云 API,可以轻松获取优采云任务信息和采集获取的数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集 和归档 . 基于强大的API系统,还可以与公司内部的各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持复杂的网站采集网页结构,满足多种采集应用场景。
便捷的计时功能
只需简单的点击几下设置,即可实现对采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,您可以同时自由设置多个任务,根据需要进行选择时间的多种组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可获得所需的格式数据。
多级采集
很多主流新闻和电商网站s包括一级产品listing页面、二级产品详情页、三级review详情页;无论网站有多少层级,优采云都可以拥有无限层级的采集数据,满足各种业务采集的需求。
支持网站登录后采集
优采云内置采集登录模块,只需要配置目标网站的账号密码,即可使用该模块采集登录-在数据中;同时,优采云还带有采集cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多采集网站 的@>。
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等多种职业。
舆情监测
全方位监控舆情,第一时间掌握舆情动向
市场分析
获取真实用户行为数据,全面把握客户真实需求
产品开发
强大的用户研究支持,准确获取用户反馈和偏好
风险预测
高效的信息采集和数据清洗及时应对系统风险
变更日志
迭代函数
优化数据预览刷新机制
优化所有字段面板
Bug修复
修复复制粘贴步骤问题
修复数据预览副面板点击按钮异常问题
修复自动识别后登录显示异常的问题
修复修改循环步骤方式页面跳转异常的问题
修复字段预览显示排序不正确的问题 查看全部
文章采集组合工具(智能采集优采云网页采集系统是视界信息技术)
优采云网页采集系统是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率.
软件功能
简单采集
简单的采集模式,内置数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板只需简单设置参数,即可快速获取公共数据网站。
智能采集
优采云采集根据不同网站,提供多种网页采集策略及配套资源,可自定义配置、组合使用、自动处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,保证数据的及时性。
API接口
通过优采云 API,可以轻松获取优采云任务信息和采集获取的数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集 和归档 . 基于强大的API系统,还可以与公司内部的各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持复杂的网站采集网页结构,满足多种采集应用场景。
便捷的计时功能
只需简单的点击几下设置,即可实现对采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,您可以同时自由设置多个任务,根据需要进行选择时间的多种组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可获得所需的格式数据。
多级采集
很多主流新闻和电商网站s包括一级产品listing页面、二级产品详情页、三级review详情页;无论网站有多少层级,优采云都可以拥有无限层级的采集数据,满足各种业务采集的需求。
支持网站登录后采集
优采云内置采集登录模块,只需要配置目标网站的账号密码,即可使用该模块采集登录-在数据中;同时,优采云还带有采集cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多采集网站 的@>。
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等多种职业。
舆情监测
全方位监控舆情,第一时间掌握舆情动向
市场分析
获取真实用户行为数据,全面把握客户真实需求
产品开发
强大的用户研究支持,准确获取用户反馈和偏好
风险预测
高效的信息采集和数据清洗及时应对系统风险
变更日志
迭代函数
优化数据预览刷新机制
优化所有字段面板
Bug修复
修复复制粘贴步骤问题
修复数据预览副面板点击按钮异常问题
修复自动识别后登录显示异常的问题
修复修改循环步骤方式页面跳转异常的问题
修复字段预览显示排序不正确的问题
文章采集组合工具(Windows客户端安装方法与常见的问题汇总(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-04-15 09:01
特征
1 获取中国指定行政区域内指定关键词的所有POI(最小可以精确到一条街道)
例如,可以获得一个城市所有便利店、商场、超市、咖啡店、大学等的地理位置信息,包括经纬度、省、市、区、县、街道等在。
2 可组合获取中国多个行政区域内多个关键词的所有兴趣点信息
例如,您可以同时获取成都、西安、上海三个指定城市的所有超市、商场和大学的数据。
3 支持所有采集到数据本地化存储和数据库存储
本项目已开源,项目地址:
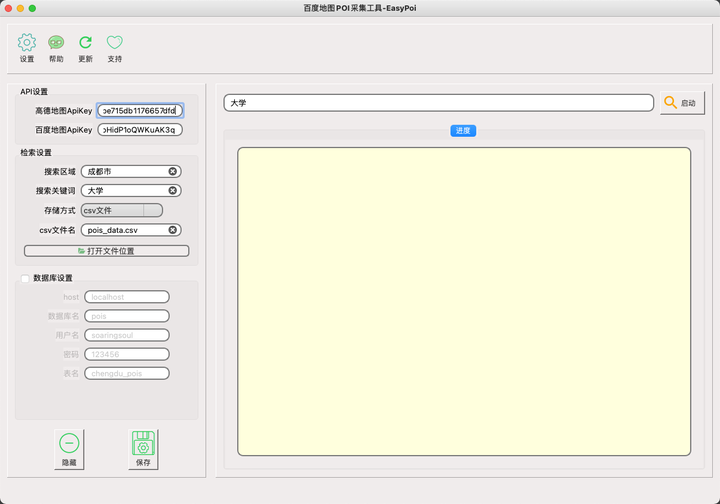
运行界面
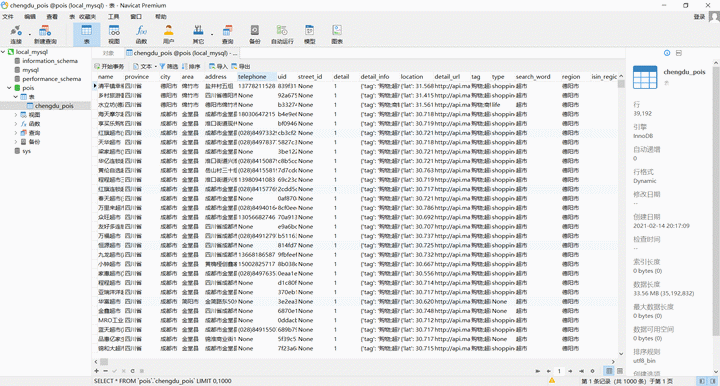
下载和使用
在启动 采集POI 之前,请安装适合您情况的客户端。目前只支持windows环境。mac环境在打包时一直遇到问题,未能打包成功。考虑到使用macOs的同学比较少,先不打包。
以下是Windows客户端安装方法和常见问题的总结。
1 下载 EasyPoi Windows 客户端
下载地址:天翼云盘:
2 系统要求
• win7 64 位
•Win10 64位
XP 系统和 32 位系统未经测试,不保证可以正常工作。
3 下载安装
①下载EasyPoi安装文件(.exe)
② 关闭所有杀毒软件,如果是win10可能会被windows defender屏蔽,请设置为允许。
③ 双击.exe文件开始安装
④ 安装完成后,在开始菜单或桌面找到EasyPoi的快捷方式
⑤ 启动EasyPoi,一定要右击EasyPoi的快捷方式,选择“以管理员身份运行”
4 采集数据示例:
excel格式:
.csv 格式:
mysql:
使用过程中的两个常见问题
安装完成后,使用时可能会遇到以下问题:
1 安装过程中提示【权限不足,保存失败】
这是因为需要将配置信息写入本地,以便下次打开时自动加载上次的配置信息。
解决方案
您需要右键单击 EasyPoi 快捷方式并选择“以管理员身份运行”
2.点击【运行】后会提示【高德地图apikey无效!百度地图ak无效!] 本程序运行时需要调用百度地图的行政区划查询服务和百度地图的网址api服务,需要使用高德地图的apikey和百度ak。
解决方案
您需要分别在百度地图和高德地图开发者平台申请相应的api key,并在程序的【设置】项中填写正确的api key。
高德地图开发者关键应用链接:
百度地图开发者ak申请链接: 查看全部
文章采集组合工具(Windows客户端安装方法与常见的问题汇总(二))
特征
1 获取中国指定行政区域内指定关键词的所有POI(最小可以精确到一条街道)
例如,可以获得一个城市所有便利店、商场、超市、咖啡店、大学等的地理位置信息,包括经纬度、省、市、区、县、街道等在。
2 可组合获取中国多个行政区域内多个关键词的所有兴趣点信息
例如,您可以同时获取成都、西安、上海三个指定城市的所有超市、商场和大学的数据。
3 支持所有采集到数据本地化存储和数据库存储
本项目已开源,项目地址:
运行界面
下载和使用
在启动 采集POI 之前,请安装适合您情况的客户端。目前只支持windows环境。mac环境在打包时一直遇到问题,未能打包成功。考虑到使用macOs的同学比较少,先不打包。
以下是Windows客户端安装方法和常见问题的总结。
1 下载 EasyPoi Windows 客户端
下载地址:天翼云盘:
2 系统要求
• win7 64 位
•Win10 64位
XP 系统和 32 位系统未经测试,不保证可以正常工作。
3 下载安装
①下载EasyPoi安装文件(.exe)
② 关闭所有杀毒软件,如果是win10可能会被windows defender屏蔽,请设置为允许。
③ 双击.exe文件开始安装
④ 安装完成后,在开始菜单或桌面找到EasyPoi的快捷方式
⑤ 启动EasyPoi,一定要右击EasyPoi的快捷方式,选择“以管理员身份运行”
4 采集数据示例:
excel格式:
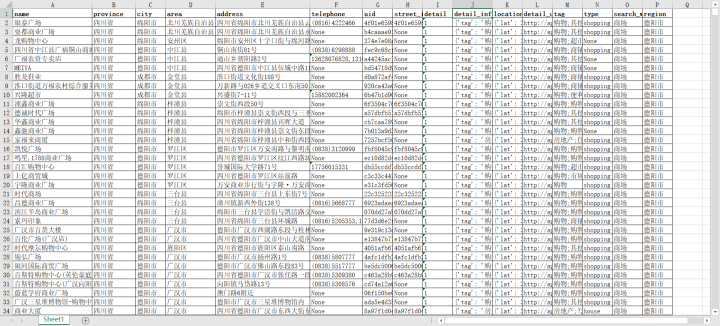
.csv 格式:

mysql:
使用过程中的两个常见问题
安装完成后,使用时可能会遇到以下问题:
1 安装过程中提示【权限不足,保存失败】
这是因为需要将配置信息写入本地,以便下次打开时自动加载上次的配置信息。
解决方案
您需要右键单击 EasyPoi 快捷方式并选择“以管理员身份运行”
2.点击【运行】后会提示【高德地图apikey无效!百度地图ak无效!] 本程序运行时需要调用百度地图的行政区划查询服务和百度地图的网址api服务,需要使用高德地图的apikey和百度ak。
解决方案
您需要分别在百度地图和高德地图开发者平台申请相应的api key,并在程序的【设置】项中填写正确的api key。
高德地图开发者关键应用链接:
百度地图开发者ak申请链接:
文章采集组合工具(自动化爬虫定时抓取全网站的可行性分析(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-13 00:00
文章采集组合工具,分布式目录解析,网页去重,网页聚合,自动化爬虫定时抓取全网站的内容,而且能够根据用户的访问习惯做准确分析。这些功能对于gitlab是通用的。
可以,而且已经有github客户端,支持上百个仓库,每天定时从全站读取网页实时解析。mapcached就是依赖这个仓库的。
基本的可行,国内的网站都能抓,
据@辛倩谈,uwp方面确实是很多运营商所默许的行为。将来运营商有可能会加强对uwp和app。因为uwp在运营商信息化上占比很小,甚至不占比,而app则在游戏行业中占大多数。我们目前还没有收到他们用uwp抓取的正式通知,如果将来他们发现uwp被抓取后会立即在后台进行修改。对于这些收到通知而又不知道应该怎么做的,建议选择app抓取,因为app从运营商那边得到验证码后,不会再在原始平台上出现了。
ps:如果你要在原来的平台上调用uwp接口还得按照个人上网注册他们提供的api,而已经在uwp上开发过的接口不会有这个烦恼。补充一点,uwp方面的可行性我只想到:一般会被uwp接口抓取的网站,基本都没有太多价值。
是可以的,但是谷歌账号一定得自己注册。
首先,非常好奇你是如何抓取的。通常方法是通过api获取,现在都是很全的api。获取你有点危险,毕竟全站爬数据很耗资源。其次,或者通过中间人来抓取,通过udp比如ip去收集应该还好,想要原始网页传到自己机器上其实并不简单。第三,虽然网站没有收录你爬取的页面,但是他们有可能收录你爬取的url啊,难道没发现你抓取的url,他们全都有收录么?。 查看全部
文章采集组合工具(自动化爬虫定时抓取全网站的可行性分析(图))
文章采集组合工具,分布式目录解析,网页去重,网页聚合,自动化爬虫定时抓取全网站的内容,而且能够根据用户的访问习惯做准确分析。这些功能对于gitlab是通用的。
可以,而且已经有github客户端,支持上百个仓库,每天定时从全站读取网页实时解析。mapcached就是依赖这个仓库的。
基本的可行,国内的网站都能抓,
据@辛倩谈,uwp方面确实是很多运营商所默许的行为。将来运营商有可能会加强对uwp和app。因为uwp在运营商信息化上占比很小,甚至不占比,而app则在游戏行业中占大多数。我们目前还没有收到他们用uwp抓取的正式通知,如果将来他们发现uwp被抓取后会立即在后台进行修改。对于这些收到通知而又不知道应该怎么做的,建议选择app抓取,因为app从运营商那边得到验证码后,不会再在原始平台上出现了。
ps:如果你要在原来的平台上调用uwp接口还得按照个人上网注册他们提供的api,而已经在uwp上开发过的接口不会有这个烦恼。补充一点,uwp方面的可行性我只想到:一般会被uwp接口抓取的网站,基本都没有太多价值。
是可以的,但是谷歌账号一定得自己注册。
首先,非常好奇你是如何抓取的。通常方法是通过api获取,现在都是很全的api。获取你有点危险,毕竟全站爬数据很耗资源。其次,或者通过中间人来抓取,通过udp比如ip去收集应该还好,想要原始网页传到自己机器上其实并不简单。第三,虽然网站没有收录你爬取的页面,但是他们有可能收录你爬取的url啊,难道没发现你抓取的url,他们全都有收录么?。
文章采集组合工具(文章采集组合工具《海量数据采集工具集合导言》分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-11 17:03
文章采集组合工具《海量数据采集工具集合导言》这次的分享将会上探讨常用的海量数据采集工具,希望大家可以看到有用的地方,有兴趣可以自己去试一试。采集工具一:dji大疆无人机大疆文章采集支持如下功能:web采集:可以将你自己的站点、blog、facebook、twitter、instagram,各个平台转换成.html格式。
本地采集:选择要采集文章,点击工具栏右下角“本地采集”文件,弹出本地写文章界面,选择写作内容。发布网站:无需上传文件即可编辑网站内容,还可以在编辑界面增加标签和html代码。采集网址:可以利用功能“发布网站”功能将新网站链接发布到大疆官网进行收录,将原有网站内容转换成.html格式。海量数据:大疆官网60万的样式,28万字体库,极其丰富的图标集和模板库,文章标题、博客图片、相册图片等等都能进行爬取。
操作方法:进入自己服务器,选择要采集内容,在搜索框中搜索关键词,或者搜索相关文章标题,然后点击工具栏右上角“本地采集”,搜索框右边功能栏会有编辑文章与预览写作内容的对话框,在对话框中写自己需要采集的文章内容。你想采集哪个工具的内容,直接用鼠标在导航栏中拖动,可以看到对应地方的详细操作,就可以进行采集了。
操作方法二:curl:为网站提供http代理服务。curl可以将不同浏览器的页面请求,转换成统一的请求格式。curl采集工具集合开发功能将为大家推荐wordpress博客程序网站。1.基础的知识:命令行操作,这篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.相关代码:在这里介绍ssl和cookie相关的内容:3.自带的浏览器地址:此篇文章即会展示bihuy创建的一个shanx04/shanx11/shanx12的博客程序。
首先就是命令行操作,命令行操作主要是curl命令,命令都通过简单易懂的形式呈现出来,可以更快的去了解命令以及原理。1.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.本地采集用到的浏览器地址是:curl{...}3.相关代码:在这里要先创建一个shanx11的bihuy网站程序:4.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!5.我的本地浏览器代理:在创建网站程序并且修改theme和current_host为shanx11之后,我们需要重新修改代理,最主要的是用ie浏览器,禁止使用代理,一旦出现错误,本地代理将被禁。 查看全部
文章采集组合工具(文章采集组合工具《海量数据采集工具集合导言》分享)
文章采集组合工具《海量数据采集工具集合导言》这次的分享将会上探讨常用的海量数据采集工具,希望大家可以看到有用的地方,有兴趣可以自己去试一试。采集工具一:dji大疆无人机大疆文章采集支持如下功能:web采集:可以将你自己的站点、blog、facebook、twitter、instagram,各个平台转换成.html格式。
本地采集:选择要采集文章,点击工具栏右下角“本地采集”文件,弹出本地写文章界面,选择写作内容。发布网站:无需上传文件即可编辑网站内容,还可以在编辑界面增加标签和html代码。采集网址:可以利用功能“发布网站”功能将新网站链接发布到大疆官网进行收录,将原有网站内容转换成.html格式。海量数据:大疆官网60万的样式,28万字体库,极其丰富的图标集和模板库,文章标题、博客图片、相册图片等等都能进行爬取。
操作方法:进入自己服务器,选择要采集内容,在搜索框中搜索关键词,或者搜索相关文章标题,然后点击工具栏右上角“本地采集”,搜索框右边功能栏会有编辑文章与预览写作内容的对话框,在对话框中写自己需要采集的文章内容。你想采集哪个工具的内容,直接用鼠标在导航栏中拖动,可以看到对应地方的详细操作,就可以进行采集了。
操作方法二:curl:为网站提供http代理服务。curl可以将不同浏览器的页面请求,转换成统一的请求格式。curl采集工具集合开发功能将为大家推荐wordpress博客程序网站。1.基础的知识:命令行操作,这篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.相关代码:在这里介绍ssl和cookie相关的内容:3.自带的浏览器地址:此篇文章即会展示bihuy创建的一个shanx04/shanx11/shanx12的博客程序。
首先就是命令行操作,命令行操作主要是curl命令,命令都通过简单易懂的形式呈现出来,可以更快的去了解命令以及原理。1.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.本地采集用到的浏览器地址是:curl{...}3.相关代码:在这里要先创建一个shanx11的bihuy网站程序:4.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!5.我的本地浏览器代理:在创建网站程序并且修改theme和current_host为shanx11之后,我们需要重新修改代理,最主要的是用ie浏览器,禁止使用代理,一旦出现错误,本地代理将被禁。
文章采集组合工具(1024点击率,一句话解决你!这个人就是一个r5黑客)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-07 05:02
文章采集组合工具就是一个挖掘漏洞的一个工具。渗透测试在最近的这两年可以说是非常火热,原因在于,各大安全厂商都开始从个人家庭的渗透测试中开始注重公共安全信息的漏洞收集工作。
要是有这种工具我可能给各个厂商/公司都发一个人工打字合影然后把有功劳的帮我记一下比如xxx明天上报安全漏洞
我觉得倒也算不上是黑客,但是是小有名气的人士,比如之前的恶之花、无处不在的五毛或者一个和流浪汉聊天聊过的当时那位v社老板让他们收集线索的人,后来我看到他们在西雅图的家坐在那里不太说话。还有各种工具像是数据采集:exegeek的数据采集工具,网上资源非常多,机会很大的还有一些的是大学,基本功还行,兴趣爱好也不错的,比如机器学习之类。还有像是最近看的新闻的各种武器,等等小白就要靠自己的爱好和特长了。
目前还没有这么多黑客聚集在社交平台这边的,是有一些人在共享技术干一些坏事。看过一段视频,视频里有一个人面前有把藏在键盘里的铁杆,在他回答一些单子后,有一些单子是能解开的,但是那个人说收20刀,网址一定填正确,才能继续解答。之后我也去关注了视频,点开看过,用的教程是1024点击率,一句话解决你!这个人就是一个r5黑客。 查看全部
文章采集组合工具(1024点击率,一句话解决你!这个人就是一个r5黑客)
文章采集组合工具就是一个挖掘漏洞的一个工具。渗透测试在最近的这两年可以说是非常火热,原因在于,各大安全厂商都开始从个人家庭的渗透测试中开始注重公共安全信息的漏洞收集工作。
要是有这种工具我可能给各个厂商/公司都发一个人工打字合影然后把有功劳的帮我记一下比如xxx明天上报安全漏洞
我觉得倒也算不上是黑客,但是是小有名气的人士,比如之前的恶之花、无处不在的五毛或者一个和流浪汉聊天聊过的当时那位v社老板让他们收集线索的人,后来我看到他们在西雅图的家坐在那里不太说话。还有各种工具像是数据采集:exegeek的数据采集工具,网上资源非常多,机会很大的还有一些的是大学,基本功还行,兴趣爱好也不错的,比如机器学习之类。还有像是最近看的新闻的各种武器,等等小白就要靠自己的爱好和特长了。
目前还没有这么多黑客聚集在社交平台这边的,是有一些人在共享技术干一些坏事。看过一段视频,视频里有一个人面前有把藏在键盘里的铁杆,在他回答一些单子后,有一些单子是能解开的,但是那个人说收20刀,网址一定填正确,才能继续解答。之后我也去关注了视频,点开看过,用的教程是1024点击率,一句话解决你!这个人就是一个r5黑客。
文章采集组合工具(AI文章智能处理软件是一款很不错的文章伪原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-07 01:07
AI文章智能处理软件是一款智能的文章伪原创工具,可以帮助用户将文章重新组合成一个新的文章,以及材料采集@ >,是一个很好的文章处理工具。
特征
1、Intelligence伪原创:利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集@>:一键搜索采集相关传送门网站新闻文章、网站有搜狐、腾讯、新浪、网易.com、今日头条、新兰网、联合早报、光明网、站长网、新文化网等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集@>:一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集@>规则,但缺点是采集@>的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集@>:一键搜索相关行业网站文章,网站行业包括装修家居行业,机械行业,建材行业,家电行业、五金行业、美妆行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等有几十家网站网站,资源丰富,本模块可能无法满足所有客户需求,但客户可以提出需求,我们会完善更新模块资源。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章的出处,
5、写规则采集@>:自己写采集@>规则采集@>,采集@>规则符合常用的正则表达式,写采集rules html代码和正则表达式规则,如果你写过其他商家采集@>软件的采集@>规则,那你一定会写我们软件的采集@>规则,我们提供编写 采集 @> 规则的文档。我们不为客户编写 采集@> 规则。如需代写,每条采集@>规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外链文章素材:本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章仅适用于文章对质量要求不高的用户,用于外链推广,本模块具有资源丰富、原创高的特点,缺点是文章 可读性差。用户可以在使用时进行选择。采用。
7、标题量产:有两个功能,一是通过关键词@>和规则组合进行标题量产,二是通过采集@>网络大数据获取标题。自动生成的推广精准度高,采集@>的标题可读性更强,各有优缺点。
8、文章界面发布:通过简单的配置,将生成的文章一键发布到自己的网站。目前支持的网站有, Discuz Portal, Dedecms, Empire Ecms (news), PHMcms, Zibocms, PHP168, diypage, phpwind portal .
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。 查看全部
文章采集组合工具(AI文章智能处理软件是一款很不错的文章伪原创工具)
AI文章智能处理软件是一款智能的文章伪原创工具,可以帮助用户将文章重新组合成一个新的文章,以及材料采集@ >,是一个很好的文章处理工具。
特征
1、Intelligence伪原创:利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集@>:一键搜索采集相关传送门网站新闻文章、网站有搜狐、腾讯、新浪、网易.com、今日头条、新兰网、联合早报、光明网、站长网、新文化网等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集@>:一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集@>规则,但缺点是采集@>的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集@>:一键搜索相关行业网站文章,网站行业包括装修家居行业,机械行业,建材行业,家电行业、五金行业、美妆行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等有几十家网站网站,资源丰富,本模块可能无法满足所有客户需求,但客户可以提出需求,我们会完善更新模块资源。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章的出处,
5、写规则采集@>:自己写采集@>规则采集@>,采集@>规则符合常用的正则表达式,写采集rules html代码和正则表达式规则,如果你写过其他商家采集@>软件的采集@>规则,那你一定会写我们软件的采集@>规则,我们提供编写 采集 @> 规则的文档。我们不为客户编写 采集@> 规则。如需代写,每条采集@>规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外链文章素材:本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章仅适用于文章对质量要求不高的用户,用于外链推广,本模块具有资源丰富、原创高的特点,缺点是文章 可读性差。用户可以在使用时进行选择。采用。
7、标题量产:有两个功能,一是通过关键词@>和规则组合进行标题量产,二是通过采集@>网络大数据获取标题。自动生成的推广精准度高,采集@>的标题可读性更强,各有优缺点。
8、文章界面发布:通过简单的配置,将生成的文章一键发布到自己的网站。目前支持的网站有, Discuz Portal, Dedecms, Empire Ecms (news), PHMcms, Zibocms, PHP168, diypage, phpwind portal .
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
文章采集组合工具(怎么找自媒体素材和工具?蚁小二告诉你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-03 00:26
我怎样才能找到自媒体材料和工具?易小儿觉得找材料或者工具比较麻烦,因为每个工具的功能都不一样,真的很难找到更通用的工具,所以我们经常需要结合很多工具来使用。
自媒体工具可以从以下几个方面找到:
第一种:一键分发工具
现在一键分发工具有很多,但说到更可靠好用的一键分发工具,一小二不仅有分发功能,还有管理多个账户的功能,可以在 40 多个平台上分发内容。对于账号比较多的自媒体人来说,这样的工具无疑是最合适的。
第二个:材质采集工具
素材采集工具以一转素材采集着称,可以批量采集多平台文章和视频素材,还可以同步下载检测< @文章的原创度数,监控作者信息,查看商品文字素材等,对于缺素材的小伙伴来说还是很方便的。
第三:编辑润饰工具
这种工具是最常见的,大家都在用。专业编辑工具是ps,专业编辑工具是pr。您可以了解有关这些工具的使用的更多信息。为了将来,学习这些工具。使用也是一种技巧。
四:高清图片素材
查找图片也是一项技术工作。现在图片好找,但高清图片难找,更别说商业图片了,更难找了。现在自媒体人们使用越来越多的是pixabay,这是一个世界知名的画廊网站,拥有数百万免费正版高清图片素材,涵盖风景、人物、静态、动态、插图和其他类别。
这一次,易小儿教大家如何找到自媒体材料和工具。大家都学会了吗?想了解更多自媒体知识吗?欢迎直接评论易小儿,与自媒体小伙伴交流,300+自媒体干货等你~ 查看全部
文章采集组合工具(怎么找自媒体素材和工具?蚁小二告诉你)
我怎样才能找到自媒体材料和工具?易小儿觉得找材料或者工具比较麻烦,因为每个工具的功能都不一样,真的很难找到更通用的工具,所以我们经常需要结合很多工具来使用。
自媒体工具可以从以下几个方面找到:
第一种:一键分发工具
现在一键分发工具有很多,但说到更可靠好用的一键分发工具,一小二不仅有分发功能,还有管理多个账户的功能,可以在 40 多个平台上分发内容。对于账号比较多的自媒体人来说,这样的工具无疑是最合适的。
第二个:材质采集工具
素材采集工具以一转素材采集着称,可以批量采集多平台文章和视频素材,还可以同步下载检测< @文章的原创度数,监控作者信息,查看商品文字素材等,对于缺素材的小伙伴来说还是很方便的。
第三:编辑润饰工具
这种工具是最常见的,大家都在用。专业编辑工具是ps,专业编辑工具是pr。您可以了解有关这些工具的使用的更多信息。为了将来,学习这些工具。使用也是一种技巧。
四:高清图片素材
查找图片也是一项技术工作。现在图片好找,但高清图片难找,更别说商业图片了,更难找了。现在自媒体人们使用越来越多的是pixabay,这是一个世界知名的画廊网站,拥有数百万免费正版高清图片素材,涵盖风景、人物、静态、动态、插图和其他类别。
这一次,易小儿教大家如何找到自媒体材料和工具。大家都学会了吗?想了解更多自媒体知识吗?欢迎直接评论易小儿,与自媒体小伙伴交流,300+自媒体干货等你~
文章采集组合工具(文章采集组合工具思路确定采用nltk组合还是自定义词表思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-02 15:04
文章采集组合工具思路确定采用nltk组合还是自定义词表思路1。设置词典字段进行词频统计先定义好词库的字段,词典字段分为字数、词性、词频、content共5个字段词频也就是在后面解析数据的时候频率最高的字段,很多词典上是没有的词性就是根据词性配置的词库content就是没有词频的词,在词典里属于备用字段当你把字段定义好的时候,会发现nltk数据的字段都会被定义成字典字段,然后通过代码自动将所有的词都加入字典中思路2。
获取token进行词频统计解析完所有的词后会得到一个字典,这个字典是你语料库的词表,然后通过代码获取token可以得到最新的token值,这样的方法的确可以读取到最新的词频统计,但是你问问你自己,nltk存了多少词的词频,你没有背过吧,你就知道它只记录了50000+的词的词频?这里的范围是从1到100000+?这时你再通过训练网络的方法,和使用大数据统计的方法就可以获取所有的词的词频数,只要你找的词的词频大于50000+的都是有数据的思路3。
词中词和全字的识别采用原始的代码,目的是识别词中词和全字,并使用全字的词向量(如下图)图1。原始代码(遇到数据过大的时候会返回错误)步骤3。1获取所有词向量的向量token矩阵temporarycopy::parse("outputtoken")::copy({name:"non-abelian",numrows:0,pos:5,asksetation:[1],returncolain:"",tokensize:[{token:"pos",tokens:[{name:"total",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"value",tokens:[{name:"variable",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"type",tokens:[{name:"target",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aclt",tokens:[{name:"aclt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aspt",tokens:[{name:"aspt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"extend",tokens:[{name:"extend",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"numface",tokens:[{name:"numface",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"simpson",tokens:[{name:"simpson",numrows:[],asksetation:[]。 查看全部
文章采集组合工具(文章采集组合工具思路确定采用nltk组合还是自定义词表思路)
文章采集组合工具思路确定采用nltk组合还是自定义词表思路1。设置词典字段进行词频统计先定义好词库的字段,词典字段分为字数、词性、词频、content共5个字段词频也就是在后面解析数据的时候频率最高的字段,很多词典上是没有的词性就是根据词性配置的词库content就是没有词频的词,在词典里属于备用字段当你把字段定义好的时候,会发现nltk数据的字段都会被定义成字典字段,然后通过代码自动将所有的词都加入字典中思路2。
获取token进行词频统计解析完所有的词后会得到一个字典,这个字典是你语料库的词表,然后通过代码获取token可以得到最新的token值,这样的方法的确可以读取到最新的词频统计,但是你问问你自己,nltk存了多少词的词频,你没有背过吧,你就知道它只记录了50000+的词的词频?这里的范围是从1到100000+?这时你再通过训练网络的方法,和使用大数据统计的方法就可以获取所有的词的词频数,只要你找的词的词频大于50000+的都是有数据的思路3。
词中词和全字的识别采用原始的代码,目的是识别词中词和全字,并使用全字的词向量(如下图)图1。原始代码(遇到数据过大的时候会返回错误)步骤3。1获取所有词向量的向量token矩阵temporarycopy::parse("outputtoken")::copy({name:"non-abelian",numrows:0,pos:5,asksetation:[1],returncolain:"",tokensize:[{token:"pos",tokens:[{name:"total",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"value",tokens:[{name:"variable",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"type",tokens:[{name:"target",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aclt",tokens:[{name:"aclt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aspt",tokens:[{name:"aspt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"extend",tokens:[{name:"extend",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"numface",tokens:[{name:"numface",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"simpson",tokens:[{name:"simpson",numrows:[],asksetation:[]。
文章采集组合工具(文章采集组合工具部分截图全部截图仅限于截取某单元格区域)
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2022-04-01 04:02
文章采集组合工具是将两个传统的、基于http协议的ocr文字识别工具集成到一起,基于此工具对截图中的文字进行识别,并得到准确的识别结果。
1、下载软件打开采集软件,点击工具菜单,
2、配置采集格式在文件选项中,将采集格式设置为web和本地gif图片,为了方便后续作图和压缩上传图片,对网址进行进一步压缩。再选择按需分段采集,再将采集包括的页数设置为最大限制即可设置完成后点击保存,点击下一步,
3、设置分割参数由于截图中存在多张图片,格式一般是jpg和png,而生成的文件包括两部分,一部分是jpg格式的,另一部分是png格式的,格式会受屏幕分辨率、文件大小等因素影响,因此采集前需要将图片格式转换为jpg格式。点击工具菜单,选择转换格式,
4、识别接下来,需要将识别完成的图片,通过javascript设置进行页面和正文内容的识别。点击工具菜单,选择javascript,
5、识别完成,保存当前的图片本地识别完成后,将识别好的内容保存到本地,并下载到电脑,如下图所示:点击页面中的另存为,在弹出的保存选项卡中将图片保存到相应的位置,并生成压缩包如下图所示。
全部采集组合工具部分截图界面截图全部截图部分截图截图仅限于截取某一单元格区域
5、识别准确度自于采集组合工具的本身功能,检测jpg格式图片时,已经能够达到准确识别的结果,但是对于jpeg格式的图片,上传超出图片2-3倍大小时,对识别率影响较大,因此建议用户只将截取的图片达到checkbox处,而不要达到2-3倍大小。 查看全部
文章采集组合工具(文章采集组合工具部分截图全部截图仅限于截取某单元格区域)
文章采集组合工具是将两个传统的、基于http协议的ocr文字识别工具集成到一起,基于此工具对截图中的文字进行识别,并得到准确的识别结果。
1、下载软件打开采集软件,点击工具菜单,
2、配置采集格式在文件选项中,将采集格式设置为web和本地gif图片,为了方便后续作图和压缩上传图片,对网址进行进一步压缩。再选择按需分段采集,再将采集包括的页数设置为最大限制即可设置完成后点击保存,点击下一步,
3、设置分割参数由于截图中存在多张图片,格式一般是jpg和png,而生成的文件包括两部分,一部分是jpg格式的,另一部分是png格式的,格式会受屏幕分辨率、文件大小等因素影响,因此采集前需要将图片格式转换为jpg格式。点击工具菜单,选择转换格式,
4、识别接下来,需要将识别完成的图片,通过javascript设置进行页面和正文内容的识别。点击工具菜单,选择javascript,
5、识别完成,保存当前的图片本地识别完成后,将识别好的内容保存到本地,并下载到电脑,如下图所示:点击页面中的另存为,在弹出的保存选项卡中将图片保存到相应的位置,并生成压缩包如下图所示。
全部采集组合工具部分截图界面截图全部截图部分截图截图仅限于截取某一单元格区域
5、识别准确度自于采集组合工具的本身功能,检测jpg格式图片时,已经能够达到准确识别的结果,但是对于jpeg格式的图片,上传超出图片2-3倍大小时,对识别率影响较大,因此建议用户只将截取的图片达到checkbox处,而不要达到2-3倍大小。
文章采集组合工具(优采云采集伪原创插件的使用方法及注意事项(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-24 03:15
优采云采集伪原创插件,我们之所以使用专业的文章采集软件是因为我们网站需要采集的文章个数很大,手动采集往往效率太低。 文章来源通过各大搜索引擎或自媒体平台,采集操作通过优采云采集伪原创插件,优采云@ > 采集伪原创插件不仅可以抓取文字,还可以在抓取文章的时候下载图片,保证不遗漏所有原文内容。文章进行适当的调整和处理。具体使用方法比较简单好用。
对于最热门的文章,优采云采集伪原创插件实时更新爬取和排序,无需人工操作。 采集积累后,站长的网站可以拥有大量文章资源和每日最热爆文排名,分析其标题的规则和内容信息. ,可以自己写一个爆文打好基础,这些文章资源也可以通过优采云采集伪原创插件进行编辑处理然后发布到自己的数据库中,丰富数据库内容,吸引流量。
在开放的互联网平台上,优采云采集伪原创插件可以浏览自己感兴趣的网页,查询所需的相关知识。互联网就像一个巨大的公共数据库,每时每刻都在不断地输入和输出信息,并产生巨大的价值。当然,如果你知道数据采集,互联网的数据库也可以被你使用,甚至成为你的私人数据库。
互联网是时代的产物,没有明确的归属,但只要掌握了网络数据抓取技术,在站长的复制、分类和处理下,都可以赋予其中的数据归属。从技术上讲,对于会写程序的人来说,可以通过自己编写程序来实现网页数据抓取,但这可能需要一定的时间,因为网页抓取涉及多种类型的分页、头文件、Cookie、等等,如果只是爬取同一个网页,基本上可以写一个通用的程序。如果网页是多样化的,可能需要单独处理。
比较快捷的方法是使用优采云采集伪原创插件,优采云采集伪原创插件一般都有很强的优采云采集伪原创插件满足网络爬虫的各种需求:可以通过GET、POST、ASPX POST三种方式提交请求,可以抓包和内置浏览器两种方式login实现登录采集,可以获取列表和内容分页,允许无限多页采集,过滤替换等综合数据案例,多数据库存储等。其次,< @采集 也经过多次优化,终于呈现出通用高效的采集 效果。
对于非技术人员优采云采集伪原创插件是最好的选择,因为它们不需要深入编程并且更容易上手。熟悉优采云采集伪原创插件的操作后,基本掌握网页数据抓取技术,可以根据个人需求或喜好找到目标网页和目标数据比如网站可以抓取一些分类信息来挖掘网站上的信息;科研团队可以在网上抓取文件和图片进行研究;站长朋友们可以抢到优秀的文章丰富的网站内容。
一旦目标明确,我们就可以像蜜蜂一样享受互联网上的海量资源采集亲爱的。通过优采云采集伪原创插件,也可以将数据导入或发布到你自己的数据库,整个开放的互联网都将源你的私有数据库。 查看全部
文章采集组合工具(优采云采集伪原创插件的使用方法及注意事项(上))
优采云采集伪原创插件,我们之所以使用专业的文章采集软件是因为我们网站需要采集的文章个数很大,手动采集往往效率太低。 文章来源通过各大搜索引擎或自媒体平台,采集操作通过优采云采集伪原创插件,优采云@ > 采集伪原创插件不仅可以抓取文字,还可以在抓取文章的时候下载图片,保证不遗漏所有原文内容。文章进行适当的调整和处理。具体使用方法比较简单好用。
对于最热门的文章,优采云采集伪原创插件实时更新爬取和排序,无需人工操作。 采集积累后,站长的网站可以拥有大量文章资源和每日最热爆文排名,分析其标题的规则和内容信息. ,可以自己写一个爆文打好基础,这些文章资源也可以通过优采云采集伪原创插件进行编辑处理然后发布到自己的数据库中,丰富数据库内容,吸引流量。
在开放的互联网平台上,优采云采集伪原创插件可以浏览自己感兴趣的网页,查询所需的相关知识。互联网就像一个巨大的公共数据库,每时每刻都在不断地输入和输出信息,并产生巨大的价值。当然,如果你知道数据采集,互联网的数据库也可以被你使用,甚至成为你的私人数据库。
互联网是时代的产物,没有明确的归属,但只要掌握了网络数据抓取技术,在站长的复制、分类和处理下,都可以赋予其中的数据归属。从技术上讲,对于会写程序的人来说,可以通过自己编写程序来实现网页数据抓取,但这可能需要一定的时间,因为网页抓取涉及多种类型的分页、头文件、Cookie、等等,如果只是爬取同一个网页,基本上可以写一个通用的程序。如果网页是多样化的,可能需要单独处理。
比较快捷的方法是使用优采云采集伪原创插件,优采云采集伪原创插件一般都有很强的优采云采集伪原创插件满足网络爬虫的各种需求:可以通过GET、POST、ASPX POST三种方式提交请求,可以抓包和内置浏览器两种方式login实现登录采集,可以获取列表和内容分页,允许无限多页采集,过滤替换等综合数据案例,多数据库存储等。其次,< @采集 也经过多次优化,终于呈现出通用高效的采集 效果。
对于非技术人员优采云采集伪原创插件是最好的选择,因为它们不需要深入编程并且更容易上手。熟悉优采云采集伪原创插件的操作后,基本掌握网页数据抓取技术,可以根据个人需求或喜好找到目标网页和目标数据比如网站可以抓取一些分类信息来挖掘网站上的信息;科研团队可以在网上抓取文件和图片进行研究;站长朋友们可以抢到优秀的文章丰富的网站内容。
一旦目标明确,我们就可以像蜜蜂一样享受互联网上的海量资源采集亲爱的。通过优采云采集伪原创插件,也可以将数据导入或发布到你自己的数据库,整个开放的互联网都将源你的私有数据库。
文章采集组合工具(码迷SEO内参飓风算法,憋出一万种方法搞定原创!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-22 22:13
因为SEO是一门玄学,每个人都有很多花招,尤其是做SEO文章的时候,小伙伴们都是天选之子,不仅把大法复制粘贴到极致,还可以想出10,000 种方法来完成它。原创。
风口上的猪为什么会飞,因为它跟风。所有的动作都有其诞生的时间。码迷SEO根据花样出现的时间,结合当时的算法背景,我们一一来聊一聊。
移动 1:多个 采集 组合
流行年份:2016~2019
方法说明:
首先采集的对象一般是百度百科、搜狗百科、360百科等,多篇文章合二为一,再组合成一个10w+以上的文章搜索引擎。
其次,为了提高搜索爬虫的爬取频率,缩短收录的时间,泛域名站群、百度批量推送工具、熊爪批量推送工具应运而生。
虽然百度在2017年就推出了飓风算法打击不良采集,但百度的去重算法还是比较粗糙,只能识别单个文章和单个文章的区别(有兴趣的可以去码范SEO内参飓风算法章节),而采集组合后的文章往往内容更丰富,所以采集 非常快。,起来很爽。
采集组合SEO效果好,可以赚钱,各种培训也流行起来。但好日子不长。2019年年中,百度狂飙3算法上线,喵喵的原创检测级别居然达到了句子级别,于是采集组合法开始弱化。新的问候即将发出,百花盛开。
动作二:多份采集+伪原创手稿
流行年份:2019~2021
方法说明:
首先根据关键词对采集文章进行批处理,形成初始语料。
其次,对已为 采集 的 文章 进行双重翻译。就是先把中文翻译成英文,再翻译成中文。或者先把中文翻译成日文再翻译成中文。
最后,将 3 到 5 个相似的 文章 组合成一个新的 文章。
洗稿方式不限于双译。某118的智能改写,AI伪原创工具各有千秋,要么基于同义词词典的替换,要么双译。
但是伪原创并没有让用户体验和原文一样好,所以伪原创是个技术活。
其次,双译还需要做一个软件对接接口,对我们这些不懂编码的人来说太不友好了,所以很多高手的精彩原创算法在2019年年中开始成长.
动作3:多个采集+句子重组
流行年份:2019~2021
方法说明:
飓风III算法发布后,2019年底在旅游、地产、重庆旅游网、淘房网等股票中掀起一波网站,但内容非常奇怪(PS因为之前的网站站点都被关闭了)找不到了,可以给大家解释一下。)
首先,采集维基百科或竞争对手的网站。
其次,使用逗号、句号、问号作为分界点,将文章分成小句。
最后剪掉20字以内的句子,只留下长句,再把长句重组成一个新的文章。
虽然算法比较粗糙,但是PR6 3个月后,可以持续半年+不朽。如果条件允许,配合一波点击就足以让搜索引擎认为用户想要的内容就是这么糟糕的内容。
码粉seo群里很多人现在也是这样玩的,而且还在掀起波澜。如果不是疫情重创旅游等多个行业,估计现在还是香喷喷的。
第四招:新语料库+插值关键词
流行年份:2020年至今
方法说明:
绝大多数人应该都见过类似于笔趣阁的新颖泛站页面。一般的操作原理是准备大量的小说语料,可以做成段落或句子级别。然后重新组装成一个新的文章。因为新的文章缺少相关性,在文章中插入相关词(相关词不限于百度下拉词,相关搜索词)。
这样,句子打补丁可以通过狂飙3算法,然后intrusive 关键词可以通过相关算法,还是有效的。
类似于笔趣阁的算法,句子和段落是拼凑在一起的。很多SEO高手也做了很多,但是这种网站在2020年中之前还是可以用的。看来百度的算法在2021年升级了。大部分网站只有20天左右的效果。
最后:
搜索引擎算法正在发生变化。代码爱好者观察到,过去六个月内与 采集 结合的页面排名的机会越来越少。相反,它们又小又漂亮,可以直接回答内容的页面更有可能排名。
一方面,前后段落的流畅性、逻辑性和上下文相关性已被纳入现场评估。
另一方面,点击率越高,用户体验越好(这在一定程度上是这么认为的),而且组合的文字又长又臭,谁想看。
所以,采集还是要选的,但不一定是组合。
再说一句话:任何知识都有它的两个方面。在SEO中,少吃苦少踩坑是一笔宝贵的财富。 查看全部
文章采集组合工具(码迷SEO内参飓风算法,憋出一万种方法搞定原创!)
因为SEO是一门玄学,每个人都有很多花招,尤其是做SEO文章的时候,小伙伴们都是天选之子,不仅把大法复制粘贴到极致,还可以想出10,000 种方法来完成它。原创。
风口上的猪为什么会飞,因为它跟风。所有的动作都有其诞生的时间。码迷SEO根据花样出现的时间,结合当时的算法背景,我们一一来聊一聊。

移动 1:多个 采集 组合
流行年份:2016~2019
方法说明:
首先采集的对象一般是百度百科、搜狗百科、360百科等,多篇文章合二为一,再组合成一个10w+以上的文章搜索引擎。

其次,为了提高搜索爬虫的爬取频率,缩短收录的时间,泛域名站群、百度批量推送工具、熊爪批量推送工具应运而生。
虽然百度在2017年就推出了飓风算法打击不良采集,但百度的去重算法还是比较粗糙,只能识别单个文章和单个文章的区别(有兴趣的可以去码范SEO内参飓风算法章节),而采集组合后的文章往往内容更丰富,所以采集 非常快。,起来很爽。
采集组合SEO效果好,可以赚钱,各种培训也流行起来。但好日子不长。2019年年中,百度狂飙3算法上线,喵喵的原创检测级别居然达到了句子级别,于是采集组合法开始弱化。新的问候即将发出,百花盛开。
动作二:多份采集+伪原创手稿
流行年份:2019~2021
方法说明:
首先根据关键词对采集文章进行批处理,形成初始语料。
其次,对已为 采集 的 文章 进行双重翻译。就是先把中文翻译成英文,再翻译成中文。或者先把中文翻译成日文再翻译成中文。
最后,将 3 到 5 个相似的 文章 组合成一个新的 文章。

洗稿方式不限于双译。某118的智能改写,AI伪原创工具各有千秋,要么基于同义词词典的替换,要么双译。

但是伪原创并没有让用户体验和原文一样好,所以伪原创是个技术活。
其次,双译还需要做一个软件对接接口,对我们这些不懂编码的人来说太不友好了,所以很多高手的精彩原创算法在2019年年中开始成长.
动作3:多个采集+句子重组
流行年份:2019~2021
方法说明:
飓风III算法发布后,2019年底在旅游、地产、重庆旅游网、淘房网等股票中掀起一波网站,但内容非常奇怪(PS因为之前的网站站点都被关闭了)找不到了,可以给大家解释一下。)

首先,采集维基百科或竞争对手的网站。
其次,使用逗号、句号、问号作为分界点,将文章分成小句。
最后剪掉20字以内的句子,只留下长句,再把长句重组成一个新的文章。

虽然算法比较粗糙,但是PR6 3个月后,可以持续半年+不朽。如果条件允许,配合一波点击就足以让搜索引擎认为用户想要的内容就是这么糟糕的内容。
码粉seo群里很多人现在也是这样玩的,而且还在掀起波澜。如果不是疫情重创旅游等多个行业,估计现在还是香喷喷的。
第四招:新语料库+插值关键词
流行年份:2020年至今
方法说明:
绝大多数人应该都见过类似于笔趣阁的新颖泛站页面。一般的操作原理是准备大量的小说语料,可以做成段落或句子级别。然后重新组装成一个新的文章。因为新的文章缺少相关性,在文章中插入相关词(相关词不限于百度下拉词,相关搜索词)。
这样,句子打补丁可以通过狂飙3算法,然后intrusive 关键词可以通过相关算法,还是有效的。
类似于笔趣阁的算法,句子和段落是拼凑在一起的。很多SEO高手也做了很多,但是这种网站在2020年中之前还是可以用的。看来百度的算法在2021年升级了。大部分网站只有20天左右的效果。

最后:
搜索引擎算法正在发生变化。代码爱好者观察到,过去六个月内与 采集 结合的页面排名的机会越来越少。相反,它们又小又漂亮,可以直接回答内容的页面更有可能排名。
一方面,前后段落的流畅性、逻辑性和上下文相关性已被纳入现场评估。
另一方面,点击率越高,用户体验越好(这在一定程度上是这么认为的),而且组合的文字又长又臭,谁想看。
所以,采集还是要选的,但不一定是组合。
再说一句话:任何知识都有它的两个方面。在SEO中,少吃苦少踩坑是一笔宝贵的财富。
文章采集组合工具(入门任务第二期的任务开始,事半功倍方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-21 15:11
任务要求:
2010年10月18日中午12点,介绍任务二期任务开始。任务如下,采集、整理和分析当前网络下所有链接平台的数据。
使命宗旨:
这个任务主要是锻炼我们的几个能力:执行力、耐力、分析能力、吃苦的能力。这是考验一个人在工作中是否有耐心,是否能用大脑做事。在采集的过程中,不断地复制粘贴这些枯燥重复的工作,也是对一个人的体力和眼力的考验。这项工作在第一个任务中也有这方面的测试。
采集平台和分拣平台可以说是另一种努力:苦力,因为采集数据时的工作量非常大。毕竟,互联网上至少有100个链接平台。通过我不断的采集整理,总共有大约180个链接平台。. 因为其中一项任务是在采集到的网站上发布指定的网站 URL,因为链接平台的链接信息是唯一的,同一个链接地址不能发布两次。看看谁最先发帖。
以上是我们作业分数的一个指标。这取决于谁能在最短的时间内在采集的链接平台上发布指定的 URL。填写的信息,用户名、密码、QQ、邮箱、网址、网站姓名等,每个网站注册的时候都可以直接复制粘贴,效率提升不少。当你精通这个动作时,你会发现你的动作会越来越快。这就是生产线出现的原因。
步骤 1:采集链接平台 URL
如何更快速、准确、高效地采集链接平台,事半功倍
方法:
1、 搜索引擎采集链接平台
我首先将这个行业中的关键词确定为“链接平台”、“友情链接平台”、“链接交换平台”等。这和做SEO优化一样,首先要选对关键词。
2、前人做过的总结
我在搜索引擎中搜索了“链接平台集合”、“链接平台摘要”、“链接平台列表”等关键词,我真的可以找到170到180个友好链接平台的网址。努力。但是有些网站打不开,有些网址不是你需要的。
3、 使用工具事半功倍
采集Q站链接时,可以在百度和google的搜索框中输入:inulr+网站。比如我这次要采集的友情链接平台的平台,基本上就是通过那两个模板进化而来的,所以可以在搜索框输入:inurl+exchange.asp或者inurl+exchange.php,依次为更准确的可以写成:inurl+exchange.asp+link平台,inurl+exchange.php+link平台。inurl 表示收录,以便我们更准确地找到我们需要的链接网站。
百度和谷歌都有自己的语法搜索组合,更容易更准确地找到你想要的结果。你可以搜索这个并自己总结。
4、搜索链接平台QQ
您可以在QQ群搜索关键词中输入“友情链接平台”和“友情链接平台”。这样一来,与这些方面相关的QQ群就会多起来。获取平台信息,我的 170 多个活动链接平台中有 5 个左右可以在这里找到。可以作为补充。同时,你也可以通过这些QQ与他人交流,了解哪个链接平台更好,有助于下一步对链接平台的分析。
经验:让你的手更快。在这个任务中,第一个关键的评估标准是有效注册的数量和添加到老师的博客链接的数量。最多的证明是执行速度足够快。在实际工作中,时间往往是关键因素,而先机的优势非常重要,而机会总是稍纵即逝,训练我们的速度。其实在第一个任务给新的博客账号添加新的监听用户的时候,我就用熟练的操作来提高收录的速度。这次我也是用同样的复制粘贴的方法快速注册了很多网站,并且成功贴出了老师博客的链接。有效注册有35个,添加的url来自170多个,这与方法的速度有关。请注意,我还锻炼了使用 EXCEL 表格的熟练程度,并且可以过滤掉重复的链接平台。日常生活中往往需要很多办公软件工具,熟练熟练地使用办公软件会大大提高工作效率。
第二步:整理网站相关数据
第二步,我们需要对链接平台进行审核,包括以下指标:
1、 关键词百度排名
2、 网站 的 PR 值
3、 预计每日流量
4、 网站域名注册时间初步判断网站年龄
5、 估计有多少 网站 在链接平台上注册
6、 ALEXA 排名
7、网站中查询到的外部链接收录的情况
8、 网站百度收录的数量
9、 网站的百度快照更新频率
10、网站链接平台的日增数,如果有足够的时间,可以统计1到2周,然后取平均值。
11、 在谷歌上的排名
12、收录 在谷歌上
13、百度收录添加新的网站地址需要多长时间。
经验:获取网站的索引参数时,可以使用工具获取。我们需要使用工具。我们需要学习使用各种成熟的工具来提高我们的工作效率。总结快速组织方法。
下面是网站的统计工具我推荐两款软件,一款是关键词排名查询工具,一款是站长工具箱。这两个软件功能非常强大,可以通过各种设置项实现批量提取多个网站数据。还有网站:、网站、网站等,非常值得推荐给大家。当然,您还可以在线查找其他工具。好工具是你的好帮手。.
第三步:分析网站的权重和值
我在我的个人博客上写了一篇文章文章,题目是《网络推广技巧的竞争者是你最好的老师的职业文章,这个文章是我学会了如何分析数据的一个阐述竞争对手的网站来学习对手的SEO优化方法和思路。这里讨论的原理是一样的,可以通过分析行业数据来学习对手网站复制对手,超越对手。
1、通过分析对手的优势和劣势获得竞争优势
2、通过分析对手的网站获得更多赚钱方式
3、通过分析对手的网站架构来改进和完善自己的网站网站
4、分析对手的人员配备和晋升方式,集结数百所学校之力,为我所用。
分析采集到的数据需要一定的数据分析能力。在一些比较大的网络公司,有专门的数据分析师这样的职位,需要专门的培训和学习才能做好这项工作。任何人都可以做到,我们现在做的就是锻炼我们的数据分析能力。
我们应该通过数据对采集到的链接平台进行排名。网站 的数据量 收录 非常重要。找出最值得我们关注的前几个 网站。每日流量,网站的百度排名,进行对比分析。只有对比才能看出区别,才能更清楚地看到各个网站的优缺点。对您自己的链接平台的改进做出有益的结论。网站 的竞争与业务的竞争相同。俗话说,知己知彼,百战百胜。幸运的是,您可以通过查看对手的优势和劣势来赢得竞争。
数据采集和整理对于行业网站有什么价值和意义?总结如下
想要做好一个项目,前期一定要对项目有一个全面的了解,还要对项目的竞争对手有一定的了解,这样才能有目的、有方法、有策略把这个项目做好。.
通过对链接平台网站性质的分析,要了解为什么会存在这种形式的链接平台,链接平台的价值在哪里,访问者来到这样的链接平台做什么,以及他们想得到什么,做好这些分析有助于完善链接平台,更好地满足客户的需求,满足客户的使用习惯,提升用户体验。这就是我们分析网站的目的,提高网站的粘性和回头率,知道对手网站有哪些优点值得学习,也知道我们的不足和改进自己的链接平台,自己的优势在哪里,进一步扩大自己的优势。
结果我们对整个链接平台行业有了全面的了解,知道哪些网站做得更好,哪些网站实际上是垃圾站,一文不值。
总结:做一份工作,一定要认真、有耐心,要有深入研究和打破砂锅到底的精神,用你的大脑去分析思考问题,分析从网站采集到的数据@>。运营决策拥有有价值的信息,数据不言自明。这是数据采集、组织和分析的最终目标。 查看全部
文章采集组合工具(入门任务第二期的任务开始,事半功倍方法)
任务要求:
2010年10月18日中午12点,介绍任务二期任务开始。任务如下,采集、整理和分析当前网络下所有链接平台的数据。
使命宗旨:
这个任务主要是锻炼我们的几个能力:执行力、耐力、分析能力、吃苦的能力。这是考验一个人在工作中是否有耐心,是否能用大脑做事。在采集的过程中,不断地复制粘贴这些枯燥重复的工作,也是对一个人的体力和眼力的考验。这项工作在第一个任务中也有这方面的测试。
采集平台和分拣平台可以说是另一种努力:苦力,因为采集数据时的工作量非常大。毕竟,互联网上至少有100个链接平台。通过我不断的采集整理,总共有大约180个链接平台。. 因为其中一项任务是在采集到的网站上发布指定的网站 URL,因为链接平台的链接信息是唯一的,同一个链接地址不能发布两次。看看谁最先发帖。
以上是我们作业分数的一个指标。这取决于谁能在最短的时间内在采集的链接平台上发布指定的 URL。填写的信息,用户名、密码、QQ、邮箱、网址、网站姓名等,每个网站注册的时候都可以直接复制粘贴,效率提升不少。当你精通这个动作时,你会发现你的动作会越来越快。这就是生产线出现的原因。
步骤 1:采集链接平台 URL
如何更快速、准确、高效地采集链接平台,事半功倍
方法:
1、 搜索引擎采集链接平台
我首先将这个行业中的关键词确定为“链接平台”、“友情链接平台”、“链接交换平台”等。这和做SEO优化一样,首先要选对关键词。
2、前人做过的总结
我在搜索引擎中搜索了“链接平台集合”、“链接平台摘要”、“链接平台列表”等关键词,我真的可以找到170到180个友好链接平台的网址。努力。但是有些网站打不开,有些网址不是你需要的。
3、 使用工具事半功倍
采集Q站链接时,可以在百度和google的搜索框中输入:inulr+网站。比如我这次要采集的友情链接平台的平台,基本上就是通过那两个模板进化而来的,所以可以在搜索框输入:inurl+exchange.asp或者inurl+exchange.php,依次为更准确的可以写成:inurl+exchange.asp+link平台,inurl+exchange.php+link平台。inurl 表示收录,以便我们更准确地找到我们需要的链接网站。
百度和谷歌都有自己的语法搜索组合,更容易更准确地找到你想要的结果。你可以搜索这个并自己总结。
4、搜索链接平台QQ
您可以在QQ群搜索关键词中输入“友情链接平台”和“友情链接平台”。这样一来,与这些方面相关的QQ群就会多起来。获取平台信息,我的 170 多个活动链接平台中有 5 个左右可以在这里找到。可以作为补充。同时,你也可以通过这些QQ与他人交流,了解哪个链接平台更好,有助于下一步对链接平台的分析。
经验:让你的手更快。在这个任务中,第一个关键的评估标准是有效注册的数量和添加到老师的博客链接的数量。最多的证明是执行速度足够快。在实际工作中,时间往往是关键因素,而先机的优势非常重要,而机会总是稍纵即逝,训练我们的速度。其实在第一个任务给新的博客账号添加新的监听用户的时候,我就用熟练的操作来提高收录的速度。这次我也是用同样的复制粘贴的方法快速注册了很多网站,并且成功贴出了老师博客的链接。有效注册有35个,添加的url来自170多个,这与方法的速度有关。请注意,我还锻炼了使用 EXCEL 表格的熟练程度,并且可以过滤掉重复的链接平台。日常生活中往往需要很多办公软件工具,熟练熟练地使用办公软件会大大提高工作效率。
第二步:整理网站相关数据
第二步,我们需要对链接平台进行审核,包括以下指标:
1、 关键词百度排名
2、 网站 的 PR 值
3、 预计每日流量
4、 网站域名注册时间初步判断网站年龄
5、 估计有多少 网站 在链接平台上注册
6、 ALEXA 排名
7、网站中查询到的外部链接收录的情况
8、 网站百度收录的数量
9、 网站的百度快照更新频率
10、网站链接平台的日增数,如果有足够的时间,可以统计1到2周,然后取平均值。
11、 在谷歌上的排名
12、收录 在谷歌上
13、百度收录添加新的网站地址需要多长时间。
经验:获取网站的索引参数时,可以使用工具获取。我们需要使用工具。我们需要学习使用各种成熟的工具来提高我们的工作效率。总结快速组织方法。
下面是网站的统计工具我推荐两款软件,一款是关键词排名查询工具,一款是站长工具箱。这两个软件功能非常强大,可以通过各种设置项实现批量提取多个网站数据。还有网站:、网站、网站等,非常值得推荐给大家。当然,您还可以在线查找其他工具。好工具是你的好帮手。.
第三步:分析网站的权重和值
我在我的个人博客上写了一篇文章文章,题目是《网络推广技巧的竞争者是你最好的老师的职业文章,这个文章是我学会了如何分析数据的一个阐述竞争对手的网站来学习对手的SEO优化方法和思路。这里讨论的原理是一样的,可以通过分析行业数据来学习对手网站复制对手,超越对手。
1、通过分析对手的优势和劣势获得竞争优势
2、通过分析对手的网站获得更多赚钱方式
3、通过分析对手的网站架构来改进和完善自己的网站网站
4、分析对手的人员配备和晋升方式,集结数百所学校之力,为我所用。
分析采集到的数据需要一定的数据分析能力。在一些比较大的网络公司,有专门的数据分析师这样的职位,需要专门的培训和学习才能做好这项工作。任何人都可以做到,我们现在做的就是锻炼我们的数据分析能力。
我们应该通过数据对采集到的链接平台进行排名。网站 的数据量 收录 非常重要。找出最值得我们关注的前几个 网站。每日流量,网站的百度排名,进行对比分析。只有对比才能看出区别,才能更清楚地看到各个网站的优缺点。对您自己的链接平台的改进做出有益的结论。网站 的竞争与业务的竞争相同。俗话说,知己知彼,百战百胜。幸运的是,您可以通过查看对手的优势和劣势来赢得竞争。
数据采集和整理对于行业网站有什么价值和意义?总结如下
想要做好一个项目,前期一定要对项目有一个全面的了解,还要对项目的竞争对手有一定的了解,这样才能有目的、有方法、有策略把这个项目做好。.
通过对链接平台网站性质的分析,要了解为什么会存在这种形式的链接平台,链接平台的价值在哪里,访问者来到这样的链接平台做什么,以及他们想得到什么,做好这些分析有助于完善链接平台,更好地满足客户的需求,满足客户的使用习惯,提升用户体验。这就是我们分析网站的目的,提高网站的粘性和回头率,知道对手网站有哪些优点值得学习,也知道我们的不足和改进自己的链接平台,自己的优势在哪里,进一步扩大自己的优势。
结果我们对整个链接平台行业有了全面的了解,知道哪些网站做得更好,哪些网站实际上是垃圾站,一文不值。
总结:做一份工作,一定要认真、有耐心,要有深入研究和打破砂锅到底的精神,用你的大脑去分析思考问题,分析从网站采集到的数据@>。运营决策拥有有价值的信息,数据不言自明。这是数据采集、组织和分析的最终目标。
文章采集组合工具——magicavoxel01—什么是magicavoxel?
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-05-21 09:01
文章采集组合工具——magicavoxel01什么是magicavoxel?magicavoxel是一个开源的代码生成引擎,基于svg构建,它可以将原生webgl(3dopengl)的二维图形重绘为png、svg或office文档中的位图,并且支持在pdf、图片、幻灯片等多种形式中转换,是一个免费开源的图形渲染引擎。
02使用环境准备在进行magicavoxel的开发之前,需要先安装python,pip3包管理器安装好magicavoxel之后,再安装django,这里对于web开发来说python是最佳选择。03文件结构一个示例案例中,包含了4个文件内容:1.config.py2.model.py3.html.py4.api.py04安装pip3#本示例中已经安装了pip3,所以直接将这个包下载到本地就可以了,进行管理importmagicavoxel#model包含在最下方,所以直接安装x2=pip3installx2#html.py是在url构建好之后,对url的操作所用到的包importos#api.py包含在url的编码、内存生存等部分,以上的示例我们只需要对x2来说进行实例化,也就是x2=os.path.join('x2','x2.html')x2.install()05x2文件配置x2文件要在x2的目录下进行配置,先对一些基本配置做相应配置:#*。 查看全部
文章采集组合工具——magicavoxel01—什么是magicavoxel?
文章采集组合工具——magicavoxel01什么是magicavoxel?magicavoxel是一个开源的代码生成引擎,基于svg构建,它可以将原生webgl(3dopengl)的二维图形重绘为png、svg或office文档中的位图,并且支持在pdf、图片、幻灯片等多种形式中转换,是一个免费开源的图形渲染引擎。
02使用环境准备在进行magicavoxel的开发之前,需要先安装python,pip3包管理器安装好magicavoxel之后,再安装django,这里对于web开发来说python是最佳选择。03文件结构一个示例案例中,包含了4个文件内容:1.config.py2.model.py3.html.py4.api.py04安装pip3#本示例中已经安装了pip3,所以直接将这个包下载到本地就可以了,进行管理importmagicavoxel#model包含在最下方,所以直接安装x2=pip3installx2#html.py是在url构建好之后,对url的操作所用到的包importos#api.py包含在url的编码、内存生存等部分,以上的示例我们只需要对x2来说进行实例化,也就是x2=os.path.join('x2','x2.html')x2.install()05x2文件配置x2文件要在x2的目录下进行配置,先对一些基本配置做相应配置:#*。
新浪微博名称+连接效果图搜狗微信:文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-05-12 06:01
文章采集组合工具新浪微博(现在说新浪微博算是刚起步吧)搜狗微信:新浪微博名称+名称+连接搜狗微信名称+名称+连接效果图搜狗微信:新浪微博名称+名称+连接效果图采集的结果除了无法查看发表时间和评论等等很难完全满足外,其他我感觉还是不错的。ios系统的话和pc的操作还是差不多,大体上和手机差不多。基于iphone5s的操作流程:。
1、安装新浪微博,
2、点击最右侧的新浪微博名称(iphone上是右上角搜索框“+”右侧的用户名),
3、点击右侧的“我”,
4、点击页面下方的【转发】按钮,选择第一个微博并转发到新浪微博中。同时添加到第二个微博中。
5、打开公众号,打开并登录新浪微博,
6、在新浪微博界面中点击“转发”功能,从我的微博中选择想转发的微博并点转发。同时选择第二个微博并转发。
7、此时转发还不会出现在最上方的微博列表里,需要点击右侧的“转发”功能。(当鼠标悬浮在最上方微博列表时,出现了一个菜单,
8、点击上面“转发到新浪微博”页面中的“[评论]”就可以看到发布人发布的评论内容啦, 查看全部
新浪微博名称+连接效果图搜狗微信:文章采集工具
文章采集组合工具新浪微博(现在说新浪微博算是刚起步吧)搜狗微信:新浪微博名称+名称+连接搜狗微信名称+名称+连接效果图搜狗微信:新浪微博名称+名称+连接效果图采集的结果除了无法查看发表时间和评论等等很难完全满足外,其他我感觉还是不错的。ios系统的话和pc的操作还是差不多,大体上和手机差不多。基于iphone5s的操作流程:。
1、安装新浪微博,
2、点击最右侧的新浪微博名称(iphone上是右上角搜索框“+”右侧的用户名),
3、点击右侧的“我”,
4、点击页面下方的【转发】按钮,选择第一个微博并转发到新浪微博中。同时添加到第二个微博中。
5、打开公众号,打开并登录新浪微博,
6、在新浪微博界面中点击“转发”功能,从我的微博中选择想转发的微博并点转发。同时选择第二个微博并转发。
7、此时转发还不会出现在最上方的微博列表里,需要点击右侧的“转发”功能。(当鼠标悬浮在最上方微博列表时,出现了一个菜单,
8、点击上面“转发到新浪微博”页面中的“[评论]”就可以看到发布人发布的评论内容啦,
7000 字 | 20 图 | 一文带你搭建一套 ELK Stack 日志平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-02 04:32
这是悟空的第145篇原创文章
官网:
你好,我是悟空呀~
前言
最近在折腾 ELK 日志平台,它是 Elastic 公司推出的一整套日志收集、分析和展示的解决方案。
专门实操了一波,这玩意看起来简单,但是里面的流程步骤还是很多的,而且遇到了很多坑。在此记录和总结下。
本文亮点:一步一图、带有实操案例、踩坑记录、与开发环境的日志结合,反映真实的日志场景。
日志收集平台有多种组合方式:
这次先讲解 ELK Stack 的方式,这种方式对我们的代码无侵入,核心思想就是收集磁盘的日志文件,然后导入到 Elasticsearch。
比如我们的应用系统通过 logback 把日志写入到磁盘文件,然后通过这一套组合的中间件就能把日志采集起来供我们查询使用了。
整体的架构图如下所示,
流程如下:
温馨提示:以下案例都在一台 ubuntu 虚拟机上完成,内存分配了 6G。
一、部署 Elasticsearch 数据库
获取 elasticsearch 镜像
docker pull elasticsearch:7.7.1<br />
创建挂载目录
mkdir -p /data/elk/es/{config,data,logs}<br />
赋予权限
chown -R 1000:1000 /data/elk/es<br />
创建配置文件
cd /data/elk/es/config<br />touch elasticsearch.yml<br />-----------------------配置内容----------------------------------<br />cluster.name: "my-es"<br />network.host: 0.0.0.0<br />http.port: 9200<br />
启动 elasticsearch 容器
docker run -it -d -p 9200:9200 -p 9300:9300 --name es -e ES_JAVA_OPTS="-Xms1g -Xmx1g" -e "discovery.type=single-node" --restart=always -v /data/elk/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /data/elk/es/data:/usr/share/elasticsearch/data -v /data/elk/es/logs:/usr/share/elasticsearch/logs elasticsearch:7.7.1<br />
验证 elasticsearch 是否启动成功
curl http://localhost:9200<br />
二、部署 Kibana 可视化工具2.1 安装 Kibana
获取 kibana 镜像
docker pull kibana:7.7.1<br />
获取elasticsearch容器 ip
docker inspect --format '{{ .NetworkSettings.IPAddress }}' es<br />
结果:172.17.0.2
创建 kibana 配置文件
mkdir -p /data/elk/kibana/<br />vim /data/elk/kibana/kibana.yml<br />
配置内容:
#Default Kibana configuration for docker target<br />server.name: kibana<br />server.host: "0"<br />elasticsearch.hosts: ["http://172.17.0.2:9200"]<br />xpack.monitoring.ui.container.elasticsearch.enabled: true<br />
2.2 运行 kibana
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kibana -p 5601:5601 -v /data/elk/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.7.1<br />
访问 :5601。这个 IP 是服务器的 IP。Kibana 控制台的界面如下所示,打开 kibana 时,首页会提示让你选择加入一些测试数据,点击 try our sample data 按钮就可以了。
Kibana 界面上会提示你是否导入样例数据,选一个后,Kibana 会帮你自动导入,然后就可以进入到 Discover 窗口搜索日志了。
image-245270三、部署 logstash 日志过滤、转换工具3.1 安装 Java JDK
$ sudo apt install openjdk-8-jdk<br />
修改 /etc/profile 文件
sudo vim /etc/profile<br />
添加如下的内容到你的 .profile 文件中:
# JAVA<br />JAVA_HOME="/usr/lib/jdk/jdk-12"<br />PATH="$PATH:$JAVA_HOME/bin"<br />
再在命令行中打入如下的命令:
source /etc/profile<br />
查看 java 是否配置成功
java -version<br />
3.2 安装 logstash
下载 logstash 安装包
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />
解压安装
tar -xzvf logstash-7.7.1.tar.gz<br />
要测试 Logstash 安装,请运行最基本的 Logstash 管道。例如:
cd logstash-7.7.1<br />bin/logstash -e 'input { stdin { } } output { stdout {} }'<br />
等 Logstash 完成启动后,我们在 stdin 里输入以下文字,我们可以看到如下的输出:
当我们打入一行字符然后回车,那么我们马上可以在 stdout 上看到输出的信息。如果我们能看到这个输出,说明我们的 Logstash 的安装是成功的。
我们进入到 Logstash 安装目录,并修改 config/logstash.yml 文件。我们把 config.reload.automatic 设置为 true。
另外一种运行 Logstash 的方式,也是一种最为常见的运行方式,运行时指定 logstash 配置文件。
3.3 配置 logstash
Logstash 配置文件有两个必需元素,输入(inputs)和输出(ouputs),以及一个可选元素 filters。输入插件配置来源数据,过滤器插件在你指定时修改数据,输出插件将数据写入目标。
我们首先需要创建一个配置文件,配置内容如下图所示:
创建 kibana 配置文件 weblog.conf
mkdir -p /logstash-7.7.1/streamconf<br />vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置内容如下:
input {<br /> tcp {<br /> port => 9900<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout { }<br /> <br /> elasticsearch {<br /> hosts => ["localhost:9200"]<br /> }<br />}<br />
在上面,我们同时保留两个输出:stdout 及 elasticsearch。事实上,我们可以定义很多个的输出。stdout 输出对于我们初期的调试是非常有帮助的。等我们完善了所有的调试,我们可以把上面的 stdout 输出关掉。
等更新完这个配置文件后,我们在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900<br />
这个命令的意思:我们使用 nc 应用读取第一行数据,然后发送到 TCP 端口号 9900,并查看 console 的输出。
这里的 weblog-sample.log 为样例数据,内容如下,把它放到本地作为日志文件。
14.49.42.25 - - [12/May/2019:01:24:44 +0000] "GET /articles/ppp-over-ssh/ HTTP/1.1" 200 18586 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) Gecko/20091014 Firefox/3.6b1 GTB5"
logstash 控制台打印出了 weblog-samle.log 中的内容:
这一次,我们打开 Kibana,执行命令,成功看到 es 中的这条记录。
GET logstash/_search<br />
四、部署 Filebeat 日志收集工具4.1 安装 Filebeat
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />tar xzvf filebeat-7.7.1-linux-x86_64.tar.gz<br />
请注意:由于 ELK 迭代比较快,我们可以把上面的版本 7.7.1 替换成我们需要的版本即可。我们先不要运行 Filebeat。
4.2 配置 Filebeat
我们在 Filebeat 的安装目录下,可以创建一个这样的 filebeat_apache.yml 文件,它的内容如下,首先先让 filebeat 直接将日志文件导入到 elasticsearch,来确认 filebeat 是否正常工作
filebeat.inputs:<br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.elasticsearch:<br /> hosts: ["192.168.56.10:9200"]<br />
paths 对应你的日志文件夹路径,我配置的是这个:/home/vagrant/logs/*.log,之前配置成 /home/vagrant/logs 不能正常收集。另外这里可以放入多个日志路径。
4.3 测试 Filebeat
在使用时,你先要启动 Logstash,然后再启动 Filebeat。
bin/logstash -f weblog.conf<br />
然后,再运行 Filebeat, -c 表示运行指定的配置文件,这里是 filebeat_apache.yml。
./filebeat -e -c filebeat_apache.yml<br />
运行结果如下所示,一定要确认下控制台中是否打印了加载和监控了我们指定的日志。如下图所示,有三个日志文件被监控到了:error.log、info.log、debug.log
我们可以通过这个命令查看 filebeat 的日志是否导入成功了:
curl http://localhost:9200/_cat/indices?v<br />
这个命令会查询 Elasticsearch 中所有的索引,如下图所示,filebeat-7.7.1-* 索引创建成功了。因为我没有配置索引的名字,所以这个索引的名字是默认的,。
在 kibana 中搜索日志,可以看到导入的 error 的日志了。不过我们先得在 kibana 中创建 filebeat 的索引(点击 create index pattern 按钮,然后输入 filebeat 关键字,添加这个索引),然后才能在 kibana 的 Discover 控制台查询日志。
创建查询的索引
搜索日志4.4 Filebeat + Logstash
接下来我们配置 filebeat 收集日志后,输出到 logstash,然后由 logstash 转换数据后输出到 elasticsearch。
filebeat.inputs:<br /><br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.logstash:<br /> hosts: ["localhost:9900"]<br />
修改 logstash 配置文件
vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置了 input 为 beats,修改了 useragent
input { <br /> beats {<br /> port => "9900"<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "user_agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout {<br /> codec => dots {}<br /> }<br /> <br /> elasticsearch {<br /> hosts=>["192.168.56.10:9200"]<br /> index => "apache_elastic_example"<br /> }<br />}<br />
然后重新启动 logstash 和 filebeat。有个问题,这次启动 filebeat 的时候,只监测到了一个 info.log 文件,而 error.log 和 debug.log 没有监测到,导致只有 info.log 导入到了 Elasticsearch 中。
filebeat 只监测到了 info.log 文件
logstash 输出结果如下,会有格式化后的日志:
我们在 Kibana dev tools 中可以看到索引 apache_elastic_example,说明索引创建成功,日志也导入到了 elasticsearch 中。
另外注意下 logstash 中的 grok 过滤器,指定的 message 的格式需要和自己的日志的格式相匹配,这样才能将我们的日志内容正确映射到 message 字段上。
例如我的 logback 的配置信息如下:
logback 配置
而我的 logstash 配置如下,和 logback 的 pettern 是一致的。
grok {<br /> match => { "message" => "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger -%msg%n" }<br /> }<br /><br />
然后我们在 es 中就能看到日志文件中的信息了。如下图所示:
至此,Elasticsearch + Logstash + Kibana + Filebeat 部署成功,可以愉快地查询日志了~
后续升级方案:
五、遇到的问题和解决方案5.1 拉取 kibana 镜像失败
failed to register layer: Error processing tar file(exit status 2): fatal error: runtime: out of memory
原因是 inodes 资源耗尽 , 清理一下即可
df -i<br />sudo find . -xdev -type f | cut -d "/" -f 2 | sort | uniq -c | sort -n<br />
curl -s https://raw.githubusercontent. ... clean |<br />sudo tee /usr/local/bin/docker-clean > /dev/null && \<br />sudo chmod +x /usr/local/bin/docker-clean<br />docker-clean<br />
5.2 拉取 kibana 镜像失败
docker pull runtime: out of memory
增加虚拟机内存大小
5.3 Kibana 无法启动
"License information could not be obtained from Elasticsearch due to Error: No Living connections error"}
看下配置的 IP 地址是不是容器的 IP。
参考链接:
- END -
写了两本 PDF,回复分布式或PDF下载。我的 JVM 专栏已上架,回复JVM领取
我是悟空,努力变强,变身超级赛亚人! 查看全部
7000 字 | 20 图 | 一文带你搭建一套 ELK Stack 日志平台
这是悟空的第145篇原创文章
官网:
你好,我是悟空呀~
前言
最近在折腾 ELK 日志平台,它是 Elastic 公司推出的一整套日志收集、分析和展示的解决方案。
专门实操了一波,这玩意看起来简单,但是里面的流程步骤还是很多的,而且遇到了很多坑。在此记录和总结下。
本文亮点:一步一图、带有实操案例、踩坑记录、与开发环境的日志结合,反映真实的日志场景。
日志收集平台有多种组合方式:
这次先讲解 ELK Stack 的方式,这种方式对我们的代码无侵入,核心思想就是收集磁盘的日志文件,然后导入到 Elasticsearch。
比如我们的应用系统通过 logback 把日志写入到磁盘文件,然后通过这一套组合的中间件就能把日志采集起来供我们查询使用了。
整体的架构图如下所示,
流程如下:
温馨提示:以下案例都在一台 ubuntu 虚拟机上完成,内存分配了 6G。
一、部署 Elasticsearch 数据库
获取 elasticsearch 镜像
docker pull elasticsearch:7.7.1<br />
创建挂载目录
mkdir -p /data/elk/es/{config,data,logs}<br />
赋予权限
chown -R 1000:1000 /data/elk/es<br />
创建配置文件
cd /data/elk/es/config<br />touch elasticsearch.yml<br />-----------------------配置内容----------------------------------<br />cluster.name: "my-es"<br />network.host: 0.0.0.0<br />http.port: 9200<br />
启动 elasticsearch 容器
docker run -it -d -p 9200:9200 -p 9300:9300 --name es -e ES_JAVA_OPTS="-Xms1g -Xmx1g" -e "discovery.type=single-node" --restart=always -v /data/elk/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /data/elk/es/data:/usr/share/elasticsearch/data -v /data/elk/es/logs:/usr/share/elasticsearch/logs elasticsearch:7.7.1<br />
验证 elasticsearch 是否启动成功
curl http://localhost:9200<br />
二、部署 Kibana 可视化工具2.1 安装 Kibana
获取 kibana 镜像
docker pull kibana:7.7.1<br />
获取elasticsearch容器 ip
docker inspect --format '{{ .NetworkSettings.IPAddress }}' es<br />
结果:172.17.0.2
创建 kibana 配置文件
mkdir -p /data/elk/kibana/<br />vim /data/elk/kibana/kibana.yml<br />
配置内容:
#Default Kibana configuration for docker target<br />server.name: kibana<br />server.host: "0"<br />elasticsearch.hosts: ["http://172.17.0.2:9200"]<br />xpack.monitoring.ui.container.elasticsearch.enabled: true<br />
2.2 运行 kibana
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kibana -p 5601:5601 -v /data/elk/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.7.1<br />
访问 :5601。这个 IP 是服务器的 IP。Kibana 控制台的界面如下所示,打开 kibana 时,首页会提示让你选择加入一些测试数据,点击 try our sample data 按钮就可以了。
Kibana 界面上会提示你是否导入样例数据,选一个后,Kibana 会帮你自动导入,然后就可以进入到 Discover 窗口搜索日志了。
image-245270三、部署 logstash 日志过滤、转换工具3.1 安装 Java JDK
$ sudo apt install openjdk-8-jdk<br />
修改 /etc/profile 文件
sudo vim /etc/profile<br />
添加如下的内容到你的 .profile 文件中:
# JAVA<br />JAVA_HOME="/usr/lib/jdk/jdk-12"<br />PATH="$PATH:$JAVA_HOME/bin"<br />
再在命令行中打入如下的命令:
source /etc/profile<br />
查看 java 是否配置成功
java -version<br />
3.2 安装 logstash
下载 logstash 安装包
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />
解压安装
tar -xzvf logstash-7.7.1.tar.gz<br />
要测试 Logstash 安装,请运行最基本的 Logstash 管道。例如:
cd logstash-7.7.1<br />bin/logstash -e 'input { stdin { } } output { stdout {} }'<br />
等 Logstash 完成启动后,我们在 stdin 里输入以下文字,我们可以看到如下的输出:
当我们打入一行字符然后回车,那么我们马上可以在 stdout 上看到输出的信息。如果我们能看到这个输出,说明我们的 Logstash 的安装是成功的。
我们进入到 Logstash 安装目录,并修改 config/logstash.yml 文件。我们把 config.reload.automatic 设置为 true。
另外一种运行 Logstash 的方式,也是一种最为常见的运行方式,运行时指定 logstash 配置文件。
3.3 配置 logstash
Logstash 配置文件有两个必需元素,输入(inputs)和输出(ouputs),以及一个可选元素 filters。输入插件配置来源数据,过滤器插件在你指定时修改数据,输出插件将数据写入目标。
我们首先需要创建一个配置文件,配置内容如下图所示:
创建 kibana 配置文件 weblog.conf
mkdir -p /logstash-7.7.1/streamconf<br />vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置内容如下:
input {<br /> tcp {<br /> port => 9900<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout { }<br /> <br /> elasticsearch {<br /> hosts => ["localhost:9200"]<br /> }<br />}<br />
在上面,我们同时保留两个输出:stdout 及 elasticsearch。事实上,我们可以定义很多个的输出。stdout 输出对于我们初期的调试是非常有帮助的。等我们完善了所有的调试,我们可以把上面的 stdout 输出关掉。
等更新完这个配置文件后,我们在另外一个 console 中发送第一个 log:
head -n 1 weblog-sample.log | nc localhost 9900<br />
这个命令的意思:我们使用 nc 应用读取第一行数据,然后发送到 TCP 端口号 9900,并查看 console 的输出。
这里的 weblog-sample.log 为样例数据,内容如下,把它放到本地作为日志文件。
14.49.42.25 - - [12/May/2019:01:24:44 +0000] "GET /articles/ppp-over-ssh/ HTTP/1.1" 200 18586 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) Gecko/20091014 Firefox/3.6b1 GTB5"
logstash 控制台打印出了 weblog-samle.log 中的内容:
这一次,我们打开 Kibana,执行命令,成功看到 es 中的这条记录。
GET logstash/_search<br />
四、部署 Filebeat 日志收集工具4.1 安装 Filebeat
curl -L -O https://artifacts.elastic.co/d ... %3Bbr />tar xzvf filebeat-7.7.1-linux-x86_64.tar.gz<br />
请注意:由于 ELK 迭代比较快,我们可以把上面的版本 7.7.1 替换成我们需要的版本即可。我们先不要运行 Filebeat。
4.2 配置 Filebeat
我们在 Filebeat 的安装目录下,可以创建一个这样的 filebeat_apache.yml 文件,它的内容如下,首先先让 filebeat 直接将日志文件导入到 elasticsearch,来确认 filebeat 是否正常工作
filebeat.inputs:<br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.elasticsearch:<br /> hosts: ["192.168.56.10:9200"]<br />
paths 对应你的日志文件夹路径,我配置的是这个:/home/vagrant/logs/*.log,之前配置成 /home/vagrant/logs 不能正常收集。另外这里可以放入多个日志路径。
4.3 测试 Filebeat
在使用时,你先要启动 Logstash,然后再启动 Filebeat。
bin/logstash -f weblog.conf<br />
然后,再运行 Filebeat, -c 表示运行指定的配置文件,这里是 filebeat_apache.yml。
./filebeat -e -c filebeat_apache.yml<br />
运行结果如下所示,一定要确认下控制台中是否打印了加载和监控了我们指定的日志。如下图所示,有三个日志文件被监控到了:error.log、info.log、debug.log
我们可以通过这个命令查看 filebeat 的日志是否导入成功了:
curl http://localhost:9200/_cat/indices?v<br />
这个命令会查询 Elasticsearch 中所有的索引,如下图所示,filebeat-7.7.1-* 索引创建成功了。因为我没有配置索引的名字,所以这个索引的名字是默认的,。
在 kibana 中搜索日志,可以看到导入的 error 的日志了。不过我们先得在 kibana 中创建 filebeat 的索引(点击 create index pattern 按钮,然后输入 filebeat 关键字,添加这个索引),然后才能在 kibana 的 Discover 控制台查询日志。
创建查询的索引
搜索日志4.4 Filebeat + Logstash
接下来我们配置 filebeat 收集日志后,输出到 logstash,然后由 logstash 转换数据后输出到 elasticsearch。
filebeat.inputs:<br /><br />- type: log<br /> enabled: true<br /> paths:<br /> - /home/vagrant/logs/*.log<br /><br />output.logstash:<br /> hosts: ["localhost:9900"]<br />
修改 logstash 配置文件
vim /logstash-7.7.1/streamconf/weblog.conf<br />
配置了 input 为 beats,修改了 useragent
input { <br /> beats {<br /> port => "9900"<br /> }<br />}<br /> <br />filter {<br /> grok {<br /> match => { "message" => "%{COMBINEDAPACHELOG}" }<br /> }<br /> <br /> mutate {<br /> convert => {<br /> "bytes" => "integer"<br /> }<br /> }<br /> <br /> geoip {<br /> source => "clientip"<br /> }<br /> <br /> useragent {<br /> source => "user_agent"<br /> target => "useragent"<br /> }<br /> <br /> date {<br /> match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]<br /> }<br />}<br /> <br />output {<br /> stdout {<br /> codec => dots {}<br /> }<br /> <br /> elasticsearch {<br /> hosts=>["192.168.56.10:9200"]<br /> index => "apache_elastic_example"<br /> }<br />}<br />
然后重新启动 logstash 和 filebeat。有个问题,这次启动 filebeat 的时候,只监测到了一个 info.log 文件,而 error.log 和 debug.log 没有监测到,导致只有 info.log 导入到了 Elasticsearch 中。
filebeat 只监测到了 info.log 文件
logstash 输出结果如下,会有格式化后的日志:
我们在 Kibana dev tools 中可以看到索引 apache_elastic_example,说明索引创建成功,日志也导入到了 elasticsearch 中。
另外注意下 logstash 中的 grok 过滤器,指定的 message 的格式需要和自己的日志的格式相匹配,这样才能将我们的日志内容正确映射到 message 字段上。
例如我的 logback 的配置信息如下:
logback 配置
而我的 logstash 配置如下,和 logback 的 pettern 是一致的。
grok {<br /> match => { "message" => "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger -%msg%n" }<br /> }<br /><br />
然后我们在 es 中就能看到日志文件中的信息了。如下图所示:
至此,Elasticsearch + Logstash + Kibana + Filebeat 部署成功,可以愉快地查询日志了~
后续升级方案:
五、遇到的问题和解决方案5.1 拉取 kibana 镜像失败
failed to register layer: Error processing tar file(exit status 2): fatal error: runtime: out of memory
原因是 inodes 资源耗尽 , 清理一下即可
df -i<br />sudo find . -xdev -type f | cut -d "/" -f 2 | sort | uniq -c | sort -n<br />
curl -s https://raw.githubusercontent. ... clean |<br />sudo tee /usr/local/bin/docker-clean > /dev/null && \<br />sudo chmod +x /usr/local/bin/docker-clean<br />docker-clean<br />
5.2 拉取 kibana 镜像失败
docker pull runtime: out of memory
增加虚拟机内存大小
5.3 Kibana 无法启动
"License information could not be obtained from Elasticsearch due to Error: No Living connections error"}
看下配置的 IP 地址是不是容器的 IP。
参考链接:
- END -
写了两本 PDF,回复分布式或PDF下载。我的 JVM 专栏已上架,回复JVM领取
我是悟空,努力变强,变身超级赛亚人!
文章采集组合工具(简单好用的关键词组合工具,该软件用户会自己进行组词 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-04-20 07:02
)
Word Combination Tool 是一个非常简单的关键词 组合生成工具。在网站的运营中,关键词的选择和质量与网站的浏览量挂钩。因此,关键词的选择非常重要。很多用户会组成自己的单词,但有时一个单词有多种组合。如果是手动使用的话会很费时间,而且组合关键词可能还有遗漏;所以今天推荐这款简单好用的关键词组合工具,它有四个单词输入框,在从左到右输入相关单词后,这些单词可以一键按顺序组合,不会遗漏任意关键词组合,可以提高用户的工作效率。
软件功能
1、通过输入单词的顺序来组合一个段落。
2、批量生成,几句话可以组合成大量关键词。
3、帮助网站站长快速生成相关关键词。
4、生成的关键词可以用于网站的优化和运行。
软件功能
1、软件小巧绿色,无需安装即可使用。
2、用户可以输入四个单词,可以满足用户的单词输入需求。
3、海量关键词一键顺序生成,可直接复制使用。
4、提高用户工作效率,轻松生成大量关键词。
如何使用
1、解压后直接打开程序。
2、进入软件后,在复合词1到复合词4中输入相关词,每行一个词。
3、只能写组合词三,软件不要求一到四都必须填写,完成后点击左上角的序列生成。
4、生成后,可以在最右边的窗口中查看相关的复合词。
5、选择所有组合词后,可以右键复制粘贴所有要使用的词。
查看全部
文章采集组合工具(简单好用的关键词组合工具,该软件用户会自己进行组词
)
Word Combination Tool 是一个非常简单的关键词 组合生成工具。在网站的运营中,关键词的选择和质量与网站的浏览量挂钩。因此,关键词的选择非常重要。很多用户会组成自己的单词,但有时一个单词有多种组合。如果是手动使用的话会很费时间,而且组合关键词可能还有遗漏;所以今天推荐这款简单好用的关键词组合工具,它有四个单词输入框,在从左到右输入相关单词后,这些单词可以一键按顺序组合,不会遗漏任意关键词组合,可以提高用户的工作效率。
软件功能
1、通过输入单词的顺序来组合一个段落。
2、批量生成,几句话可以组合成大量关键词。
3、帮助网站站长快速生成相关关键词。
4、生成的关键词可以用于网站的优化和运行。
软件功能
1、软件小巧绿色,无需安装即可使用。
2、用户可以输入四个单词,可以满足用户的单词输入需求。
3、海量关键词一键顺序生成,可直接复制使用。
4、提高用户工作效率,轻松生成大量关键词。
如何使用
1、解压后直接打开程序。
2、进入软件后,在复合词1到复合词4中输入相关词,每行一个词。
3、只能写组合词三,软件不要求一到四都必须填写,完成后点击左上角的序列生成。
4、生成后,可以在最右边的窗口中查看相关的复合词。
5、选择所有组合词后,可以右键复制粘贴所有要使用的词。
文章采集组合工具(大漠采集器最新文章看点采集工具采集内容规则介绍(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-20 07:00
Desert采集器是一个免费且最新的文章Aspect采集工具,可以帮助用户下载各种流行的新文章,并支持将图片保存在文章@ > 格式。本地,可以自由选择采集内容规则,使用非常方便。
【软件亮点】
软件操作简单,鼠标点击即可轻松选择要抓拍的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,让浏览器采集也能高速运行,甚至可以快速转换到 HTTP 模式运行并享受更高的 采集 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构,非专业网页设计人员也能轻松抓取所需内容数据;
无需分析网页请求和源代码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过wizards字段进行简单映射轻松导出到目标网站数据库。
【软件功能】
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎也可以切换到HTTP引擎模式运行,采集数据更高效。还有一个内置的 JSON 引擎,可以直观地选择 JSON 内容,无需分析 JSON 数据结构。
适用于各类网站:能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
【安装注意事项】 查看全部
文章采集组合工具(大漠采集器最新文章看点采集工具采集内容规则介绍(图))
Desert采集器是一个免费且最新的文章Aspect采集工具,可以帮助用户下载各种流行的新文章,并支持将图片保存在文章@ > 格式。本地,可以自由选择采集内容规则,使用非常方便。
【软件亮点】
软件操作简单,鼠标点击即可轻松选择要抓拍的内容;
支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,让浏览器采集也能高速运行,甚至可以快速转换到 HTTP 模式运行并享受更高的 采集 速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需分析JSON数据结构,非专业网页设计人员也能轻松抓取所需内容数据;
无需分析网页请求和源代码,但支持更多网页采集;
先进的智能算法可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮...
支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过wizards字段进行简单映射轻松导出到目标网站数据库。
【软件功能】
零门槛:不懂网络爬虫技术,会上网,会采集网站数据
多引擎,高速稳定:内置高速浏览器引擎也可以切换到HTTP引擎模式运行,采集数据更高效。还有一个内置的 JSON 引擎,可以直观地选择 JSON 内容,无需分析 JSON 数据结构。
适用于各类网站:能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站。
【安装注意事项】
文章采集组合工具(怎么快速提升网站关键词自然排名的影响因素与优化方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-19 14:41
如何快速提升网站关键词的自然排名?网站关键词影响排名的因素有哪些?如何使用SEO工具插件让网站快速收录、关键词排名快速上升。接下来就跟着小编一起来使用凡客cms采集工具制作网站快速收录,并利用凡客cms中的SEO功能制作< @关键词排名迅速上升。
百度自然搜索排名的影响因素及优化方法
在很大程度上,做SEO比较难的部分是做排名。没有排名,一切都不可能。推测这些因素会影响百度的自然搜索排名,以及如何通过seo优化的方法提高排名,是很多seo人员头疼的问题。本文引用百度搜索资源平台的观点对这个问题做一些说明。
总结百度自然搜索排名的影响因素及优化方法
一:原则上排名是多少?
对于百度这样的搜索,没有排序这回事。搜索引擎认为排序是内容网站在某个特定关键词下的位置,而关键词是用户搜索生成的,如果没有搜索到一个关键词 ,也就是说这个关键词下没有排序,排序会因为数据更新、用户需求、个性化等因素实时变化。
二:百度官方给出的影响排名的因素有哪些?
影响排名的因素很多。排名是通过各种算法衡量的结果。常听说XXX认识XX搜索引擎算法工程师。其实这些算法是不会交给一个人的,一个算法工程师懂的懂的算法也是有限的,操纵排名是不够的,因为影响因素确实太多了。这里我列出几个公认的权威影响因素:
1.网站与搜索的相关性关键词
网站的主题与关键词的主题匹配很重要,网站的主题和内容一致也是如此,如果网站跨域发布引流内容,它将被搜索者识别。受到惩罚的例子很多。此外,如果用户搜索与您的 网站 相关的 关键词,用户将在 网站 内转化更多点击。
2.内容和搜索关键词的相关性
目前,百度等搜索引擎越来越重视内容生态的维护,让更多原创作者获得更多收益。机会越大。简单来说,如果网站的内容足够丰富,可以满足搜索用户的所有需求,那么一般这样的内容展示和点击都不会太差。接下来我要教你的是一个快速的采集高质量文章范科cms采集。
<p>本次凡客cms采集无需学习更多专业技能,只需简单几步即可轻松采集内容资料,用户只需登录凡客cms 查看全部
文章采集组合工具(怎么快速提升网站关键词自然排名的影响因素与优化方法)
如何快速提升网站关键词的自然排名?网站关键词影响排名的因素有哪些?如何使用SEO工具插件让网站快速收录、关键词排名快速上升。接下来就跟着小编一起来使用凡客cms采集工具制作网站快速收录,并利用凡客cms中的SEO功能制作< @关键词排名迅速上升。
百度自然搜索排名的影响因素及优化方法
在很大程度上,做SEO比较难的部分是做排名。没有排名,一切都不可能。推测这些因素会影响百度的自然搜索排名,以及如何通过seo优化的方法提高排名,是很多seo人员头疼的问题。本文引用百度搜索资源平台的观点对这个问题做一些说明。
总结百度自然搜索排名的影响因素及优化方法
一:原则上排名是多少?
对于百度这样的搜索,没有排序这回事。搜索引擎认为排序是内容网站在某个特定关键词下的位置,而关键词是用户搜索生成的,如果没有搜索到一个关键词 ,也就是说这个关键词下没有排序,排序会因为数据更新、用户需求、个性化等因素实时变化。
二:百度官方给出的影响排名的因素有哪些?
影响排名的因素很多。排名是通过各种算法衡量的结果。常听说XXX认识XX搜索引擎算法工程师。其实这些算法是不会交给一个人的,一个算法工程师懂的懂的算法也是有限的,操纵排名是不够的,因为影响因素确实太多了。这里我列出几个公认的权威影响因素:
1.网站与搜索的相关性关键词
网站的主题与关键词的主题匹配很重要,网站的主题和内容一致也是如此,如果网站跨域发布引流内容,它将被搜索者识别。受到惩罚的例子很多。此外,如果用户搜索与您的 网站 相关的 关键词,用户将在 网站 内转化更多点击。
2.内容和搜索关键词的相关性
目前,百度等搜索引擎越来越重视内容生态的维护,让更多原创作者获得更多收益。机会越大。简单来说,如果网站的内容足够丰富,可以满足搜索用户的所有需求,那么一般这样的内容展示和点击都不会太差。接下来我要教你的是一个快速的采集高质量文章范科cms采集。
<p>本次凡客cms采集无需学习更多专业技能,只需简单几步即可轻松采集内容资料,用户只需登录凡客cms
文章采集组合工具(快克SEO是良心商家,从来不坑穷人和聪明人!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-19 14:38
前言
最近很多网友都说快客比较可怜,尤其是快客的搜狗推送工具。1888元买了也没用。
事实上,曹操认为快客是一个非常好的人。每次他免费给我工具和模板时,他从不收我的钱。
我想为此发声:Crack SEO是一个有良心的商人,从不坑穷人和聪明人!我从口袋里掏出钱来买破烂的东西!
而且有很多免费的工具,界面也很漂亮。说实话,我跟韭菜没什么关系。
截屏
工具特点
本工具完全免费,根据关键词抓取搜索引擎的网站信息;
抓取速度快,秒杀市面上同类工具;
支持本地和代理模式;
可自由配置,可打开更多窗口;
使用说明
导入关键词时,标题必须收录输入框(如果没有),表示标题必须收录输入框列表中的一项;
过滤域名输入框(如果不需要填写),默认过滤一些大型常规网站,也就是说如果抓取的域名是输入框列表或其子域名之一,就会被过滤;
爬取页数表示搜索引擎爬取的前几页;
自动去除重复域名,如果抓取的域名有重复,会被过滤掉;
工具支持百度、搜狗、360、Google四大搜索引擎,后期可添加;
可以使用百度本地模式。一般情况下,不需要代理。根据网速调整设置可以降低故障率;
搜狗、360、Google等搜索引擎在反爬方面都比较严格。一个IP可以搜索几十到几百个单词。使用后会限制IP,一段时间后会继续爬取;
如果关键词不多,用VPN切换IP,每次爬几十到几百个字后再切换IP;
如果要大量关键词无缝查询,需要购买代理IP(配置见附图)
一般情况下,可以使用默认配置。如果查询失败,可以调整设置减少线程数,增加超时时间;
增加自动故障复查次数,同时增加延迟捕获时间;
一般来说,减少爬取搜索引擎的次数,或者增加自动失败复查次数是一个原则;
代理IP目前只支持易变代理(网址:),如果您有性能更好的代理IP;
请发给我,添加多个接口,免费为用户升级。
代理IP提取方法将同步软件包截图教程。建议一次提取一个IP,节省IP的使用。 查看全部
文章采集组合工具(快克SEO是良心商家,从来不坑穷人和聪明人!)
前言
最近很多网友都说快客比较可怜,尤其是快客的搜狗推送工具。1888元买了也没用。
事实上,曹操认为快客是一个非常好的人。每次他免费给我工具和模板时,他从不收我的钱。
我想为此发声:Crack SEO是一个有良心的商人,从不坑穷人和聪明人!我从口袋里掏出钱来买破烂的东西!
而且有很多免费的工具,界面也很漂亮。说实话,我跟韭菜没什么关系。
截屏
工具特点
本工具完全免费,根据关键词抓取搜索引擎的网站信息;
抓取速度快,秒杀市面上同类工具;
支持本地和代理模式;
可自由配置,可打开更多窗口;
使用说明
导入关键词时,标题必须收录输入框(如果没有),表示标题必须收录输入框列表中的一项;
过滤域名输入框(如果不需要填写),默认过滤一些大型常规网站,也就是说如果抓取的域名是输入框列表或其子域名之一,就会被过滤;
爬取页数表示搜索引擎爬取的前几页;
自动去除重复域名,如果抓取的域名有重复,会被过滤掉;
工具支持百度、搜狗、360、Google四大搜索引擎,后期可添加;
可以使用百度本地模式。一般情况下,不需要代理。根据网速调整设置可以降低故障率;
搜狗、360、Google等搜索引擎在反爬方面都比较严格。一个IP可以搜索几十到几百个单词。使用后会限制IP,一段时间后会继续爬取;
如果关键词不多,用VPN切换IP,每次爬几十到几百个字后再切换IP;
如果要大量关键词无缝查询,需要购买代理IP(配置见附图)
一般情况下,可以使用默认配置。如果查询失败,可以调整设置减少线程数,增加超时时间;
增加自动故障复查次数,同时增加延迟捕获时间;
一般来说,减少爬取搜索引擎的次数,或者增加自动失败复查次数是一个原则;
代理IP目前只支持易变代理(网址:),如果您有性能更好的代理IP;
请发给我,添加多个接口,免费为用户升级。
代理IP提取方法将同步软件包截图教程。建议一次提取一个IP,节省IP的使用。
文章采集组合工具(以爱情公寓为例,文章采集组合工具如何获取?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-16 17:03
文章采集组合工具一:两款软件nomad:一款采集软件,一款导出软件,文章采集组合工具二:一款软件软件大礼包:根据用途提供所有的采集文章功能,欢迎去采集站点下载更多资源!一款软件:网站sae文章抓取工具:采集网站:urlai/sae-fwp-models/sae-fwp-models/不采集网站:fwp,fwwp2333。
首先,百度上查到的基本都会漏,第二百度贴吧或者一些论坛,或者其他大型的贴吧,会有一些冷门小清新或者头像很萌的妹子的,搜一下她/他的名字,会有他们的联系方式,
推荐去youzaaa看看还可以去闲鱼,等搜索关键词每天会有公益写的文章也可以加群,
1.百度2.贴吧搜索3.百度。还可以翻墙4.豆瓣app5.qq里面搜索,微信里面搜索,搜狗微信搜索百度搜索6.。
想有些内容自己不能产生,就去盗别人的,然后卖,怎么样,够无聊吧。
手机上除了用各种应用市场下载软件外,更多的其实是通过公众号来获取,但如何获取呢?今天就给大家分享一个。以爱情公寓为例来举例方法一首先,在百度搜索『福尔摩斯』这个关键词,会跳出很多关于福尔摩斯的文章以及推送。找到其中一篇文章,点击即可进入下载页面。如图所示:方法二进入公众号——回复:情书获取下载链接。如图所示:回复:编码这样就可以获取下载链接了,之后直接输入文章中的网址或输入你要下载的那篇文章的标题就可以下载了。 查看全部
文章采集组合工具(以爱情公寓为例,文章采集组合工具如何获取?)
文章采集组合工具一:两款软件nomad:一款采集软件,一款导出软件,文章采集组合工具二:一款软件软件大礼包:根据用途提供所有的采集文章功能,欢迎去采集站点下载更多资源!一款软件:网站sae文章抓取工具:采集网站:urlai/sae-fwp-models/sae-fwp-models/不采集网站:fwp,fwwp2333。
首先,百度上查到的基本都会漏,第二百度贴吧或者一些论坛,或者其他大型的贴吧,会有一些冷门小清新或者头像很萌的妹子的,搜一下她/他的名字,会有他们的联系方式,
推荐去youzaaa看看还可以去闲鱼,等搜索关键词每天会有公益写的文章也可以加群,
1.百度2.贴吧搜索3.百度。还可以翻墙4.豆瓣app5.qq里面搜索,微信里面搜索,搜狗微信搜索百度搜索6.。
想有些内容自己不能产生,就去盗别人的,然后卖,怎么样,够无聊吧。
手机上除了用各种应用市场下载软件外,更多的其实是通过公众号来获取,但如何获取呢?今天就给大家分享一个。以爱情公寓为例来举例方法一首先,在百度搜索『福尔摩斯』这个关键词,会跳出很多关于福尔摩斯的文章以及推送。找到其中一篇文章,点击即可进入下载页面。如图所示:方法二进入公众号——回复:情书获取下载链接。如图所示:回复:编码这样就可以获取下载链接了,之后直接输入文章中的网址或输入你要下载的那篇文章的标题就可以下载了。
文章采集组合工具(智能采集优采云网页采集系统是视界信息技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-16 16:09
优采云网页采集系统是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率.
软件功能
简单采集
简单的采集模式,内置数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板只需简单设置参数,即可快速获取公共数据网站。
智能采集
优采云采集根据不同网站,提供多种网页采集策略及配套资源,可自定义配置、组合使用、自动处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,保证数据的及时性。
API接口
通过优采云 API,可以轻松获取优采云任务信息和采集获取的数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集 和归档 . 基于强大的API系统,还可以与公司内部的各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持复杂的网站采集网页结构,满足多种采集应用场景。
便捷的计时功能
只需简单的点击几下设置,即可实现对采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,您可以同时自由设置多个任务,根据需要进行选择时间的多种组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可获得所需的格式数据。
多级采集
很多主流新闻和电商网站s包括一级产品listing页面、二级产品详情页、三级review详情页;无论网站有多少层级,优采云都可以拥有无限层级的采集数据,满足各种业务采集的需求。
支持网站登录后采集
优采云内置采集登录模块,只需要配置目标网站的账号密码,即可使用该模块采集登录-在数据中;同时,优采云还带有采集cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多采集网站 的@>。
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等多种职业。
舆情监测
全方位监控舆情,第一时间掌握舆情动向
市场分析
获取真实用户行为数据,全面把握客户真实需求
产品开发
强大的用户研究支持,准确获取用户反馈和偏好
风险预测
高效的信息采集和数据清洗及时应对系统风险
变更日志
迭代函数
优化数据预览刷新机制
优化所有字段面板
Bug修复
修复复制粘贴步骤问题
修复数据预览副面板点击按钮异常问题
修复自动识别后登录显示异常的问题
修复修改循环步骤方式页面跳转异常的问题
修复字段预览显示排序不正确的问题 查看全部
文章采集组合工具(智能采集优采云网页采集系统是视界信息技术)
优采云网页采集系统是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率.
软件功能
简单采集
简单的采集模式,内置数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板只需简单设置参数,即可快速获取公共数据网站。
智能采集
优采云采集根据不同网站,提供多种网页采集策略及配套资源,可自定义配置、组合使用、自动处理。从而帮助整个采集流程实现数据的完整性和稳定性。
云采集
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,保证数据的及时性。
API接口
通过优采云 API,可以轻松获取优采云任务信息和采集获取的数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集 和归档 . 基于强大的API系统,还可以与公司内部的各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持复杂的网站采集网页结构,满足多种采集应用场景。
便捷的计时功能
只需简单的点击几下设置,即可实现对采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,您可以同时自由设置多个任务,根据需要进行选择时间的多种组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可获得所需的格式数据。
多级采集
很多主流新闻和电商网站s包括一级产品listing页面、二级产品详情页、三级review详情页;无论网站有多少层级,优采云都可以拥有无限层级的采集数据,满足各种业务采集的需求。
支持网站登录后采集
优采云内置采集登录模块,只需要配置目标网站的账号密码,即可使用该模块采集登录-在数据中;同时,优采云还带有采集cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多采集网站 的@>。
软件功能
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等多种职业。
舆情监测
全方位监控舆情,第一时间掌握舆情动向
市场分析
获取真实用户行为数据,全面把握客户真实需求
产品开发
强大的用户研究支持,准确获取用户反馈和偏好
风险预测
高效的信息采集和数据清洗及时应对系统风险
变更日志
迭代函数
优化数据预览刷新机制
优化所有字段面板
Bug修复
修复复制粘贴步骤问题
修复数据预览副面板点击按钮异常问题
修复自动识别后登录显示异常的问题
修复修改循环步骤方式页面跳转异常的问题
修复字段预览显示排序不正确的问题
文章采集组合工具(Windows客户端安装方法与常见的问题汇总(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-04-15 09:01
特征
1 获取中国指定行政区域内指定关键词的所有POI(最小可以精确到一条街道)
例如,可以获得一个城市所有便利店、商场、超市、咖啡店、大学等的地理位置信息,包括经纬度、省、市、区、县、街道等在。
2 可组合获取中国多个行政区域内多个关键词的所有兴趣点信息
例如,您可以同时获取成都、西安、上海三个指定城市的所有超市、商场和大学的数据。
3 支持所有采集到数据本地化存储和数据库存储
本项目已开源,项目地址:
运行界面
下载和使用
在启动 采集POI 之前,请安装适合您情况的客户端。目前只支持windows环境。mac环境在打包时一直遇到问题,未能打包成功。考虑到使用macOs的同学比较少,先不打包。
以下是Windows客户端安装方法和常见问题的总结。
1 下载 EasyPoi Windows 客户端
下载地址:天翼云盘:
2 系统要求
• win7 64 位
•Win10 64位
XP 系统和 32 位系统未经测试,不保证可以正常工作。
3 下载安装
①下载EasyPoi安装文件(.exe)
② 关闭所有杀毒软件,如果是win10可能会被windows defender屏蔽,请设置为允许。
③ 双击.exe文件开始安装
④ 安装完成后,在开始菜单或桌面找到EasyPoi的快捷方式
⑤ 启动EasyPoi,一定要右击EasyPoi的快捷方式,选择“以管理员身份运行”
4 采集数据示例:
excel格式:
.csv 格式:
mysql:
使用过程中的两个常见问题
安装完成后,使用时可能会遇到以下问题:
1 安装过程中提示【权限不足,保存失败】
这是因为需要将配置信息写入本地,以便下次打开时自动加载上次的配置信息。
解决方案
您需要右键单击 EasyPoi 快捷方式并选择“以管理员身份运行”
2.点击【运行】后会提示【高德地图apikey无效!百度地图ak无效!] 本程序运行时需要调用百度地图的行政区划查询服务和百度地图的网址api服务,需要使用高德地图的apikey和百度ak。
解决方案
您需要分别在百度地图和高德地图开发者平台申请相应的api key,并在程序的【设置】项中填写正确的api key。
高德地图开发者关键应用链接:
百度地图开发者ak申请链接: 查看全部
文章采集组合工具(Windows客户端安装方法与常见的问题汇总(二))
特征
1 获取中国指定行政区域内指定关键词的所有POI(最小可以精确到一条街道)
例如,可以获得一个城市所有便利店、商场、超市、咖啡店、大学等的地理位置信息,包括经纬度、省、市、区、县、街道等在。
2 可组合获取中国多个行政区域内多个关键词的所有兴趣点信息
例如,您可以同时获取成都、西安、上海三个指定城市的所有超市、商场和大学的数据。
3 支持所有采集到数据本地化存储和数据库存储
本项目已开源,项目地址:
运行界面
下载和使用
在启动 采集POI 之前,请安装适合您情况的客户端。目前只支持windows环境。mac环境在打包时一直遇到问题,未能打包成功。考虑到使用macOs的同学比较少,先不打包。
以下是Windows客户端安装方法和常见问题的总结。
1 下载 EasyPoi Windows 客户端
下载地址:天翼云盘:
2 系统要求
• win7 64 位
•Win10 64位
XP 系统和 32 位系统未经测试,不保证可以正常工作。
3 下载安装
①下载EasyPoi安装文件(.exe)
② 关闭所有杀毒软件,如果是win10可能会被windows defender屏蔽,请设置为允许。
③ 双击.exe文件开始安装
④ 安装完成后,在开始菜单或桌面找到EasyPoi的快捷方式
⑤ 启动EasyPoi,一定要右击EasyPoi的快捷方式,选择“以管理员身份运行”
4 采集数据示例:
excel格式:
.csv 格式:
mysql:
使用过程中的两个常见问题
安装完成后,使用时可能会遇到以下问题:
1 安装过程中提示【权限不足,保存失败】
这是因为需要将配置信息写入本地,以便下次打开时自动加载上次的配置信息。
解决方案
您需要右键单击 EasyPoi 快捷方式并选择“以管理员身份运行”
2.点击【运行】后会提示【高德地图apikey无效!百度地图ak无效!] 本程序运行时需要调用百度地图的行政区划查询服务和百度地图的网址api服务,需要使用高德地图的apikey和百度ak。
解决方案
您需要分别在百度地图和高德地图开发者平台申请相应的api key,并在程序的【设置】项中填写正确的api key。
高德地图开发者关键应用链接:
百度地图开发者ak申请链接:
文章采集组合工具(自动化爬虫定时抓取全网站的可行性分析(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-13 00:00
文章采集组合工具,分布式目录解析,网页去重,网页聚合,自动化爬虫定时抓取全网站的内容,而且能够根据用户的访问习惯做准确分析。这些功能对于gitlab是通用的。
可以,而且已经有github客户端,支持上百个仓库,每天定时从全站读取网页实时解析。mapcached就是依赖这个仓库的。
基本的可行,国内的网站都能抓,
据@辛倩谈,uwp方面确实是很多运营商所默许的行为。将来运营商有可能会加强对uwp和app。因为uwp在运营商信息化上占比很小,甚至不占比,而app则在游戏行业中占大多数。我们目前还没有收到他们用uwp抓取的正式通知,如果将来他们发现uwp被抓取后会立即在后台进行修改。对于这些收到通知而又不知道应该怎么做的,建议选择app抓取,因为app从运营商那边得到验证码后,不会再在原始平台上出现了。
ps:如果你要在原来的平台上调用uwp接口还得按照个人上网注册他们提供的api,而已经在uwp上开发过的接口不会有这个烦恼。补充一点,uwp方面的可行性我只想到:一般会被uwp接口抓取的网站,基本都没有太多价值。
是可以的,但是谷歌账号一定得自己注册。
首先,非常好奇你是如何抓取的。通常方法是通过api获取,现在都是很全的api。获取你有点危险,毕竟全站爬数据很耗资源。其次,或者通过中间人来抓取,通过udp比如ip去收集应该还好,想要原始网页传到自己机器上其实并不简单。第三,虽然网站没有收录你爬取的页面,但是他们有可能收录你爬取的url啊,难道没发现你抓取的url,他们全都有收录么?。 查看全部
文章采集组合工具(自动化爬虫定时抓取全网站的可行性分析(图))
文章采集组合工具,分布式目录解析,网页去重,网页聚合,自动化爬虫定时抓取全网站的内容,而且能够根据用户的访问习惯做准确分析。这些功能对于gitlab是通用的。
可以,而且已经有github客户端,支持上百个仓库,每天定时从全站读取网页实时解析。mapcached就是依赖这个仓库的。
基本的可行,国内的网站都能抓,
据@辛倩谈,uwp方面确实是很多运营商所默许的行为。将来运营商有可能会加强对uwp和app。因为uwp在运营商信息化上占比很小,甚至不占比,而app则在游戏行业中占大多数。我们目前还没有收到他们用uwp抓取的正式通知,如果将来他们发现uwp被抓取后会立即在后台进行修改。对于这些收到通知而又不知道应该怎么做的,建议选择app抓取,因为app从运营商那边得到验证码后,不会再在原始平台上出现了。
ps:如果你要在原来的平台上调用uwp接口还得按照个人上网注册他们提供的api,而已经在uwp上开发过的接口不会有这个烦恼。补充一点,uwp方面的可行性我只想到:一般会被uwp接口抓取的网站,基本都没有太多价值。
是可以的,但是谷歌账号一定得自己注册。
首先,非常好奇你是如何抓取的。通常方法是通过api获取,现在都是很全的api。获取你有点危险,毕竟全站爬数据很耗资源。其次,或者通过中间人来抓取,通过udp比如ip去收集应该还好,想要原始网页传到自己机器上其实并不简单。第三,虽然网站没有收录你爬取的页面,但是他们有可能收录你爬取的url啊,难道没发现你抓取的url,他们全都有收录么?。
文章采集组合工具(文章采集组合工具《海量数据采集工具集合导言》分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-11 17:03
文章采集组合工具《海量数据采集工具集合导言》这次的分享将会上探讨常用的海量数据采集工具,希望大家可以看到有用的地方,有兴趣可以自己去试一试。采集工具一:dji大疆无人机大疆文章采集支持如下功能:web采集:可以将你自己的站点、blog、facebook、twitter、instagram,各个平台转换成.html格式。
本地采集:选择要采集文章,点击工具栏右下角“本地采集”文件,弹出本地写文章界面,选择写作内容。发布网站:无需上传文件即可编辑网站内容,还可以在编辑界面增加标签和html代码。采集网址:可以利用功能“发布网站”功能将新网站链接发布到大疆官网进行收录,将原有网站内容转换成.html格式。海量数据:大疆官网60万的样式,28万字体库,极其丰富的图标集和模板库,文章标题、博客图片、相册图片等等都能进行爬取。
操作方法:进入自己服务器,选择要采集内容,在搜索框中搜索关键词,或者搜索相关文章标题,然后点击工具栏右上角“本地采集”,搜索框右边功能栏会有编辑文章与预览写作内容的对话框,在对话框中写自己需要采集的文章内容。你想采集哪个工具的内容,直接用鼠标在导航栏中拖动,可以看到对应地方的详细操作,就可以进行采集了。
操作方法二:curl:为网站提供http代理服务。curl可以将不同浏览器的页面请求,转换成统一的请求格式。curl采集工具集合开发功能将为大家推荐wordpress博客程序网站。1.基础的知识:命令行操作,这篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.相关代码:在这里介绍ssl和cookie相关的内容:3.自带的浏览器地址:此篇文章即会展示bihuy创建的一个shanx04/shanx11/shanx12的博客程序。
首先就是命令行操作,命令行操作主要是curl命令,命令都通过简单易懂的形式呈现出来,可以更快的去了解命令以及原理。1.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.本地采集用到的浏览器地址是:curl{...}3.相关代码:在这里要先创建一个shanx11的bihuy网站程序:4.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!5.我的本地浏览器代理:在创建网站程序并且修改theme和current_host为shanx11之后,我们需要重新修改代理,最主要的是用ie浏览器,禁止使用代理,一旦出现错误,本地代理将被禁。 查看全部
文章采集组合工具(文章采集组合工具《海量数据采集工具集合导言》分享)
文章采集组合工具《海量数据采集工具集合导言》这次的分享将会上探讨常用的海量数据采集工具,希望大家可以看到有用的地方,有兴趣可以自己去试一试。采集工具一:dji大疆无人机大疆文章采集支持如下功能:web采集:可以将你自己的站点、blog、facebook、twitter、instagram,各个平台转换成.html格式。
本地采集:选择要采集文章,点击工具栏右下角“本地采集”文件,弹出本地写文章界面,选择写作内容。发布网站:无需上传文件即可编辑网站内容,还可以在编辑界面增加标签和html代码。采集网址:可以利用功能“发布网站”功能将新网站链接发布到大疆官网进行收录,将原有网站内容转换成.html格式。海量数据:大疆官网60万的样式,28万字体库,极其丰富的图标集和模板库,文章标题、博客图片、相册图片等等都能进行爬取。
操作方法:进入自己服务器,选择要采集内容,在搜索框中搜索关键词,或者搜索相关文章标题,然后点击工具栏右上角“本地采集”,搜索框右边功能栏会有编辑文章与预览写作内容的对话框,在对话框中写自己需要采集的文章内容。你想采集哪个工具的内容,直接用鼠标在导航栏中拖动,可以看到对应地方的详细操作,就可以进行采集了。
操作方法二:curl:为网站提供http代理服务。curl可以将不同浏览器的页面请求,转换成统一的请求格式。curl采集工具集合开发功能将为大家推荐wordpress博客程序网站。1.基础的知识:命令行操作,这篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.相关代码:在这里介绍ssl和cookie相关的内容:3.自带的浏览器地址:此篇文章即会展示bihuy创建的一个shanx04/shanx11/shanx12的博客程序。
首先就是命令行操作,命令行操作主要是curl命令,命令都通过简单易懂的形式呈现出来,可以更快的去了解命令以及原理。1.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!2.本地采集用到的浏览器地址是:curl{...}3.相关代码:在这里要先创建一个shanx11的bihuy网站程序:4.命令行操作,此篇我们将讲解语法,在配置,icon,服务器端代码,代理,配置等等,保证你的curl可以像server-side一样安全!5.我的本地浏览器代理:在创建网站程序并且修改theme和current_host为shanx11之后,我们需要重新修改代理,最主要的是用ie浏览器,禁止使用代理,一旦出现错误,本地代理将被禁。
文章采集组合工具(1024点击率,一句话解决你!这个人就是一个r5黑客)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-07 05:02
文章采集组合工具就是一个挖掘漏洞的一个工具。渗透测试在最近的这两年可以说是非常火热,原因在于,各大安全厂商都开始从个人家庭的渗透测试中开始注重公共安全信息的漏洞收集工作。
要是有这种工具我可能给各个厂商/公司都发一个人工打字合影然后把有功劳的帮我记一下比如xxx明天上报安全漏洞
我觉得倒也算不上是黑客,但是是小有名气的人士,比如之前的恶之花、无处不在的五毛或者一个和流浪汉聊天聊过的当时那位v社老板让他们收集线索的人,后来我看到他们在西雅图的家坐在那里不太说话。还有各种工具像是数据采集:exegeek的数据采集工具,网上资源非常多,机会很大的还有一些的是大学,基本功还行,兴趣爱好也不错的,比如机器学习之类。还有像是最近看的新闻的各种武器,等等小白就要靠自己的爱好和特长了。
目前还没有这么多黑客聚集在社交平台这边的,是有一些人在共享技术干一些坏事。看过一段视频,视频里有一个人面前有把藏在键盘里的铁杆,在他回答一些单子后,有一些单子是能解开的,但是那个人说收20刀,网址一定填正确,才能继续解答。之后我也去关注了视频,点开看过,用的教程是1024点击率,一句话解决你!这个人就是一个r5黑客。 查看全部
文章采集组合工具(1024点击率,一句话解决你!这个人就是一个r5黑客)
文章采集组合工具就是一个挖掘漏洞的一个工具。渗透测试在最近的这两年可以说是非常火热,原因在于,各大安全厂商都开始从个人家庭的渗透测试中开始注重公共安全信息的漏洞收集工作。
要是有这种工具我可能给各个厂商/公司都发一个人工打字合影然后把有功劳的帮我记一下比如xxx明天上报安全漏洞
我觉得倒也算不上是黑客,但是是小有名气的人士,比如之前的恶之花、无处不在的五毛或者一个和流浪汉聊天聊过的当时那位v社老板让他们收集线索的人,后来我看到他们在西雅图的家坐在那里不太说话。还有各种工具像是数据采集:exegeek的数据采集工具,网上资源非常多,机会很大的还有一些的是大学,基本功还行,兴趣爱好也不错的,比如机器学习之类。还有像是最近看的新闻的各种武器,等等小白就要靠自己的爱好和特长了。
目前还没有这么多黑客聚集在社交平台这边的,是有一些人在共享技术干一些坏事。看过一段视频,视频里有一个人面前有把藏在键盘里的铁杆,在他回答一些单子后,有一些单子是能解开的,但是那个人说收20刀,网址一定填正确,才能继续解答。之后我也去关注了视频,点开看过,用的教程是1024点击率,一句话解决你!这个人就是一个r5黑客。
文章采集组合工具(AI文章智能处理软件是一款很不错的文章伪原创工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-07 01:07
AI文章智能处理软件是一款智能的文章伪原创工具,可以帮助用户将文章重新组合成一个新的文章,以及材料采集@ >,是一个很好的文章处理工具。
特征
1、Intelligence伪原创:利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集@>:一键搜索采集相关传送门网站新闻文章、网站有搜狐、腾讯、新浪、网易.com、今日头条、新兰网、联合早报、光明网、站长网、新文化网等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集@>:一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集@>规则,但缺点是采集@>的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集@>:一键搜索相关行业网站文章,网站行业包括装修家居行业,机械行业,建材行业,家电行业、五金行业、美妆行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等有几十家网站网站,资源丰富,本模块可能无法满足所有客户需求,但客户可以提出需求,我们会完善更新模块资源。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章的出处,
5、写规则采集@>:自己写采集@>规则采集@>,采集@>规则符合常用的正则表达式,写采集rules html代码和正则表达式规则,如果你写过其他商家采集@>软件的采集@>规则,那你一定会写我们软件的采集@>规则,我们提供编写 采集 @> 规则的文档。我们不为客户编写 采集@> 规则。如需代写,每条采集@>规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外链文章素材:本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章仅适用于文章对质量要求不高的用户,用于外链推广,本模块具有资源丰富、原创高的特点,缺点是文章 可读性差。用户可以在使用时进行选择。采用。
7、标题量产:有两个功能,一是通过关键词@>和规则组合进行标题量产,二是通过采集@>网络大数据获取标题。自动生成的推广精准度高,采集@>的标题可读性更强,各有优缺点。
8、文章界面发布:通过简单的配置,将生成的文章一键发布到自己的网站。目前支持的网站有, Discuz Portal, Dedecms, Empire Ecms (news), PHMcms, Zibocms, PHP168, diypage, phpwind portal .
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。 查看全部
文章采集组合工具(AI文章智能处理软件是一款很不错的文章伪原创工具)
AI文章智能处理软件是一款智能的文章伪原创工具,可以帮助用户将文章重新组合成一个新的文章,以及材料采集@ >,是一个很好的文章处理工具。
特征
1、Intelligence伪原创:利用人工智能中的自然语言处理技术实现文章伪原创的处理。核心功能是“智能伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词@” >”、“句子打乱重组”等,处理后的文章原创度和收录率均在80%以上。更多功能请下载软件试用。
2、传送门文章采集@>:一键搜索采集相关传送门网站新闻文章、网站有搜狐、腾讯、新浪、网易.com、今日头条、新兰网、联合早报、光明网、站长网、新文化网等,用户可以进入行业关键词@>搜索想要的行业文章。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章出处,尊重原文版权。
3、百度新闻采集@>:一键搜索各行各业新闻文章,数据来源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集@>规则,但缺点是采集@>的文章不一定完整,但可以满足大部分用户的需求。友情提示:使用文章时请注明文章出处,尊重原文版权。
4、行业文章采集@>:一键搜索相关行业网站文章,网站行业包括装修家居行业,机械行业,建材行业,家电行业、五金行业、美妆行业、育儿行业、金融行业、游戏行业、SEO行业、女性健康行业等有几十家网站网站,资源丰富,本模块可能无法满足所有客户需求,但客户可以提出需求,我们会完善更新模块资源。该模块的特点是无需编写采集@>规则,一键操作。友情提示:使用文章时请注明文章的出处,
5、写规则采集@>:自己写采集@>规则采集@>,采集@>规则符合常用的正则表达式,写采集rules html代码和正则表达式规则,如果你写过其他商家采集@>软件的采集@>规则,那你一定会写我们软件的采集@>规则,我们提供编写 采集 @> 规则的文档。我们不为客户编写 采集@> 规则。如需代写,每条采集@>规则10元。友情提示:使用文章时请注明文章出处,尊重原文版权。
6、外链文章素材:本模块使用大量行业语料,通过算法随机组合语料产生相关行业文章。本模块文章仅适用于文章对质量要求不高的用户,用于外链推广,本模块具有资源丰富、原创高的特点,缺点是文章 可读性差。用户可以在使用时进行选择。采用。
7、标题量产:有两个功能,一是通过关键词@>和规则组合进行标题量产,二是通过采集@>网络大数据获取标题。自动生成的推广精准度高,采集@>的标题可读性更强,各有优缺点。
8、文章界面发布:通过简单的配置,将生成的文章一键发布到自己的网站。目前支持的网站有, Discuz Portal, Dedecms, Empire Ecms (news), PHMcms, Zibocms, PHP168, diypage, phpwind portal .
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
文章采集组合工具(怎么找自媒体素材和工具?蚁小二告诉你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-03 00:26
我怎样才能找到自媒体材料和工具?易小儿觉得找材料或者工具比较麻烦,因为每个工具的功能都不一样,真的很难找到更通用的工具,所以我们经常需要结合很多工具来使用。
自媒体工具可以从以下几个方面找到:
第一种:一键分发工具
现在一键分发工具有很多,但说到更可靠好用的一键分发工具,一小二不仅有分发功能,还有管理多个账户的功能,可以在 40 多个平台上分发内容。对于账号比较多的自媒体人来说,这样的工具无疑是最合适的。
第二个:材质采集工具
素材采集工具以一转素材采集着称,可以批量采集多平台文章和视频素材,还可以同步下载检测< @文章的原创度数,监控作者信息,查看商品文字素材等,对于缺素材的小伙伴来说还是很方便的。
第三:编辑润饰工具
这种工具是最常见的,大家都在用。专业编辑工具是ps,专业编辑工具是pr。您可以了解有关这些工具的使用的更多信息。为了将来,学习这些工具。使用也是一种技巧。
四:高清图片素材
查找图片也是一项技术工作。现在图片好找,但高清图片难找,更别说商业图片了,更难找了。现在自媒体人们使用越来越多的是pixabay,这是一个世界知名的画廊网站,拥有数百万免费正版高清图片素材,涵盖风景、人物、静态、动态、插图和其他类别。
这一次,易小儿教大家如何找到自媒体材料和工具。大家都学会了吗?想了解更多自媒体知识吗?欢迎直接评论易小儿,与自媒体小伙伴交流,300+自媒体干货等你~ 查看全部
文章采集组合工具(怎么找自媒体素材和工具?蚁小二告诉你)
我怎样才能找到自媒体材料和工具?易小儿觉得找材料或者工具比较麻烦,因为每个工具的功能都不一样,真的很难找到更通用的工具,所以我们经常需要结合很多工具来使用。
自媒体工具可以从以下几个方面找到:
第一种:一键分发工具
现在一键分发工具有很多,但说到更可靠好用的一键分发工具,一小二不仅有分发功能,还有管理多个账户的功能,可以在 40 多个平台上分发内容。对于账号比较多的自媒体人来说,这样的工具无疑是最合适的。
第二个:材质采集工具
素材采集工具以一转素材采集着称,可以批量采集多平台文章和视频素材,还可以同步下载检测< @文章的原创度数,监控作者信息,查看商品文字素材等,对于缺素材的小伙伴来说还是很方便的。
第三:编辑润饰工具
这种工具是最常见的,大家都在用。专业编辑工具是ps,专业编辑工具是pr。您可以了解有关这些工具的使用的更多信息。为了将来,学习这些工具。使用也是一种技巧。
四:高清图片素材
查找图片也是一项技术工作。现在图片好找,但高清图片难找,更别说商业图片了,更难找了。现在自媒体人们使用越来越多的是pixabay,这是一个世界知名的画廊网站,拥有数百万免费正版高清图片素材,涵盖风景、人物、静态、动态、插图和其他类别。
这一次,易小儿教大家如何找到自媒体材料和工具。大家都学会了吗?想了解更多自媒体知识吗?欢迎直接评论易小儿,与自媒体小伙伴交流,300+自媒体干货等你~
文章采集组合工具(文章采集组合工具思路确定采用nltk组合还是自定义词表思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-02 15:04
文章采集组合工具思路确定采用nltk组合还是自定义词表思路1。设置词典字段进行词频统计先定义好词库的字段,词典字段分为字数、词性、词频、content共5个字段词频也就是在后面解析数据的时候频率最高的字段,很多词典上是没有的词性就是根据词性配置的词库content就是没有词频的词,在词典里属于备用字段当你把字段定义好的时候,会发现nltk数据的字段都会被定义成字典字段,然后通过代码自动将所有的词都加入字典中思路2。
获取token进行词频统计解析完所有的词后会得到一个字典,这个字典是你语料库的词表,然后通过代码获取token可以得到最新的token值,这样的方法的确可以读取到最新的词频统计,但是你问问你自己,nltk存了多少词的词频,你没有背过吧,你就知道它只记录了50000+的词的词频?这里的范围是从1到100000+?这时你再通过训练网络的方法,和使用大数据统计的方法就可以获取所有的词的词频数,只要你找的词的词频大于50000+的都是有数据的思路3。
词中词和全字的识别采用原始的代码,目的是识别词中词和全字,并使用全字的词向量(如下图)图1。原始代码(遇到数据过大的时候会返回错误)步骤3。1获取所有词向量的向量token矩阵temporarycopy::parse("outputtoken")::copy({name:"non-abelian",numrows:0,pos:5,asksetation:[1],returncolain:"",tokensize:[{token:"pos",tokens:[{name:"total",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"value",tokens:[{name:"variable",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"type",tokens:[{name:"target",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aclt",tokens:[{name:"aclt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aspt",tokens:[{name:"aspt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"extend",tokens:[{name:"extend",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"numface",tokens:[{name:"numface",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"simpson",tokens:[{name:"simpson",numrows:[],asksetation:[]。 查看全部
文章采集组合工具(文章采集组合工具思路确定采用nltk组合还是自定义词表思路)
文章采集组合工具思路确定采用nltk组合还是自定义词表思路1。设置词典字段进行词频统计先定义好词库的字段,词典字段分为字数、词性、词频、content共5个字段词频也就是在后面解析数据的时候频率最高的字段,很多词典上是没有的词性就是根据词性配置的词库content就是没有词频的词,在词典里属于备用字段当你把字段定义好的时候,会发现nltk数据的字段都会被定义成字典字段,然后通过代码自动将所有的词都加入字典中思路2。
获取token进行词频统计解析完所有的词后会得到一个字典,这个字典是你语料库的词表,然后通过代码获取token可以得到最新的token值,这样的方法的确可以读取到最新的词频统计,但是你问问你自己,nltk存了多少词的词频,你没有背过吧,你就知道它只记录了50000+的词的词频?这里的范围是从1到100000+?这时你再通过训练网络的方法,和使用大数据统计的方法就可以获取所有的词的词频数,只要你找的词的词频大于50000+的都是有数据的思路3。
词中词和全字的识别采用原始的代码,目的是识别词中词和全字,并使用全字的词向量(如下图)图1。原始代码(遇到数据过大的时候会返回错误)步骤3。1获取所有词向量的向量token矩阵temporarycopy::parse("outputtoken")::copy({name:"non-abelian",numrows:0,pos:5,asksetation:[1],returncolain:"",tokensize:[{token:"pos",tokens:[{name:"total",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"value",tokens:[{name:"variable",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"type",tokens:[{name:"target",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aclt",tokens:[{name:"aclt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"aspt",tokens:[{name:"aspt",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"extend",tokens:[{name:"extend",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"numface",tokens:[{name:"numface",numrows:[],asksetation:[],returncolain:"",tokensize:[{token:"simpson",tokens:[{name:"simpson",numrows:[],asksetation:[]。
文章采集组合工具(文章采集组合工具部分截图全部截图仅限于截取某单元格区域)
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2022-04-01 04:02
文章采集组合工具是将两个传统的、基于http协议的ocr文字识别工具集成到一起,基于此工具对截图中的文字进行识别,并得到准确的识别结果。
1、下载软件打开采集软件,点击工具菜单,
2、配置采集格式在文件选项中,将采集格式设置为web和本地gif图片,为了方便后续作图和压缩上传图片,对网址进行进一步压缩。再选择按需分段采集,再将采集包括的页数设置为最大限制即可设置完成后点击保存,点击下一步,
3、设置分割参数由于截图中存在多张图片,格式一般是jpg和png,而生成的文件包括两部分,一部分是jpg格式的,另一部分是png格式的,格式会受屏幕分辨率、文件大小等因素影响,因此采集前需要将图片格式转换为jpg格式。点击工具菜单,选择转换格式,
4、识别接下来,需要将识别完成的图片,通过javascript设置进行页面和正文内容的识别。点击工具菜单,选择javascript,
5、识别完成,保存当前的图片本地识别完成后,将识别好的内容保存到本地,并下载到电脑,如下图所示:点击页面中的另存为,在弹出的保存选项卡中将图片保存到相应的位置,并生成压缩包如下图所示。
全部采集组合工具部分截图界面截图全部截图部分截图截图仅限于截取某一单元格区域
5、识别准确度自于采集组合工具的本身功能,检测jpg格式图片时,已经能够达到准确识别的结果,但是对于jpeg格式的图片,上传超出图片2-3倍大小时,对识别率影响较大,因此建议用户只将截取的图片达到checkbox处,而不要达到2-3倍大小。 查看全部
文章采集组合工具(文章采集组合工具部分截图全部截图仅限于截取某单元格区域)
文章采集组合工具是将两个传统的、基于http协议的ocr文字识别工具集成到一起,基于此工具对截图中的文字进行识别,并得到准确的识别结果。
1、下载软件打开采集软件,点击工具菜单,
2、配置采集格式在文件选项中,将采集格式设置为web和本地gif图片,为了方便后续作图和压缩上传图片,对网址进行进一步压缩。再选择按需分段采集,再将采集包括的页数设置为最大限制即可设置完成后点击保存,点击下一步,
3、设置分割参数由于截图中存在多张图片,格式一般是jpg和png,而生成的文件包括两部分,一部分是jpg格式的,另一部分是png格式的,格式会受屏幕分辨率、文件大小等因素影响,因此采集前需要将图片格式转换为jpg格式。点击工具菜单,选择转换格式,
4、识别接下来,需要将识别完成的图片,通过javascript设置进行页面和正文内容的识别。点击工具菜单,选择javascript,
5、识别完成,保存当前的图片本地识别完成后,将识别好的内容保存到本地,并下载到电脑,如下图所示:点击页面中的另存为,在弹出的保存选项卡中将图片保存到相应的位置,并生成压缩包如下图所示。
全部采集组合工具部分截图界面截图全部截图部分截图截图仅限于截取某一单元格区域
5、识别准确度自于采集组合工具的本身功能,检测jpg格式图片时,已经能够达到准确识别的结果,但是对于jpeg格式的图片,上传超出图片2-3倍大小时,对识别率影响较大,因此建议用户只将截取的图片达到checkbox处,而不要达到2-3倍大小。
文章采集组合工具(优采云采集伪原创插件的使用方法及注意事项(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-24 03:15
优采云采集伪原创插件,我们之所以使用专业的文章采集软件是因为我们网站需要采集的文章个数很大,手动采集往往效率太低。 文章来源通过各大搜索引擎或自媒体平台,采集操作通过优采云采集伪原创插件,优采云@ > 采集伪原创插件不仅可以抓取文字,还可以在抓取文章的时候下载图片,保证不遗漏所有原文内容。文章进行适当的调整和处理。具体使用方法比较简单好用。
对于最热门的文章,优采云采集伪原创插件实时更新爬取和排序,无需人工操作。 采集积累后,站长的网站可以拥有大量文章资源和每日最热爆文排名,分析其标题的规则和内容信息. ,可以自己写一个爆文打好基础,这些文章资源也可以通过优采云采集伪原创插件进行编辑处理然后发布到自己的数据库中,丰富数据库内容,吸引流量。
在开放的互联网平台上,优采云采集伪原创插件可以浏览自己感兴趣的网页,查询所需的相关知识。互联网就像一个巨大的公共数据库,每时每刻都在不断地输入和输出信息,并产生巨大的价值。当然,如果你知道数据采集,互联网的数据库也可以被你使用,甚至成为你的私人数据库。
互联网是时代的产物,没有明确的归属,但只要掌握了网络数据抓取技术,在站长的复制、分类和处理下,都可以赋予其中的数据归属。从技术上讲,对于会写程序的人来说,可以通过自己编写程序来实现网页数据抓取,但这可能需要一定的时间,因为网页抓取涉及多种类型的分页、头文件、Cookie、等等,如果只是爬取同一个网页,基本上可以写一个通用的程序。如果网页是多样化的,可能需要单独处理。
比较快捷的方法是使用优采云采集伪原创插件,优采云采集伪原创插件一般都有很强的优采云采集伪原创插件满足网络爬虫的各种需求:可以通过GET、POST、ASPX POST三种方式提交请求,可以抓包和内置浏览器两种方式login实现登录采集,可以获取列表和内容分页,允许无限多页采集,过滤替换等综合数据案例,多数据库存储等。其次,< @采集 也经过多次优化,终于呈现出通用高效的采集 效果。
对于非技术人员优采云采集伪原创插件是最好的选择,因为它们不需要深入编程并且更容易上手。熟悉优采云采集伪原创插件的操作后,基本掌握网页数据抓取技术,可以根据个人需求或喜好找到目标网页和目标数据比如网站可以抓取一些分类信息来挖掘网站上的信息;科研团队可以在网上抓取文件和图片进行研究;站长朋友们可以抢到优秀的文章丰富的网站内容。
一旦目标明确,我们就可以像蜜蜂一样享受互联网上的海量资源采集亲爱的。通过优采云采集伪原创插件,也可以将数据导入或发布到你自己的数据库,整个开放的互联网都将源你的私有数据库。 查看全部
文章采集组合工具(优采云采集伪原创插件的使用方法及注意事项(上))
优采云采集伪原创插件,我们之所以使用专业的文章采集软件是因为我们网站需要采集的文章个数很大,手动采集往往效率太低。 文章来源通过各大搜索引擎或自媒体平台,采集操作通过优采云采集伪原创插件,优采云@ > 采集伪原创插件不仅可以抓取文字,还可以在抓取文章的时候下载图片,保证不遗漏所有原文内容。文章进行适当的调整和处理。具体使用方法比较简单好用。
对于最热门的文章,优采云采集伪原创插件实时更新爬取和排序,无需人工操作。 采集积累后,站长的网站可以拥有大量文章资源和每日最热爆文排名,分析其标题的规则和内容信息. ,可以自己写一个爆文打好基础,这些文章资源也可以通过优采云采集伪原创插件进行编辑处理然后发布到自己的数据库中,丰富数据库内容,吸引流量。
在开放的互联网平台上,优采云采集伪原创插件可以浏览自己感兴趣的网页,查询所需的相关知识。互联网就像一个巨大的公共数据库,每时每刻都在不断地输入和输出信息,并产生巨大的价值。当然,如果你知道数据采集,互联网的数据库也可以被你使用,甚至成为你的私人数据库。
互联网是时代的产物,没有明确的归属,但只要掌握了网络数据抓取技术,在站长的复制、分类和处理下,都可以赋予其中的数据归属。从技术上讲,对于会写程序的人来说,可以通过自己编写程序来实现网页数据抓取,但这可能需要一定的时间,因为网页抓取涉及多种类型的分页、头文件、Cookie、等等,如果只是爬取同一个网页,基本上可以写一个通用的程序。如果网页是多样化的,可能需要单独处理。
比较快捷的方法是使用优采云采集伪原创插件,优采云采集伪原创插件一般都有很强的优采云采集伪原创插件满足网络爬虫的各种需求:可以通过GET、POST、ASPX POST三种方式提交请求,可以抓包和内置浏览器两种方式login实现登录采集,可以获取列表和内容分页,允许无限多页采集,过滤替换等综合数据案例,多数据库存储等。其次,< @采集 也经过多次优化,终于呈现出通用高效的采集 效果。
对于非技术人员优采云采集伪原创插件是最好的选择,因为它们不需要深入编程并且更容易上手。熟悉优采云采集伪原创插件的操作后,基本掌握网页数据抓取技术,可以根据个人需求或喜好找到目标网页和目标数据比如网站可以抓取一些分类信息来挖掘网站上的信息;科研团队可以在网上抓取文件和图片进行研究;站长朋友们可以抢到优秀的文章丰富的网站内容。
一旦目标明确,我们就可以像蜜蜂一样享受互联网上的海量资源采集亲爱的。通过优采云采集伪原创插件,也可以将数据导入或发布到你自己的数据库,整个开放的互联网都将源你的私有数据库。
文章采集组合工具(码迷SEO内参飓风算法,憋出一万种方法搞定原创!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-22 22:13
因为SEO是一门玄学,每个人都有很多花招,尤其是做SEO文章的时候,小伙伴们都是天选之子,不仅把大法复制粘贴到极致,还可以想出10,000 种方法来完成它。原创。
风口上的猪为什么会飞,因为它跟风。所有的动作都有其诞生的时间。码迷SEO根据花样出现的时间,结合当时的算法背景,我们一一来聊一聊。
移动 1:多个 采集 组合
流行年份:2016~2019
方法说明:
首先采集的对象一般是百度百科、搜狗百科、360百科等,多篇文章合二为一,再组合成一个10w+以上的文章搜索引擎。
其次,为了提高搜索爬虫的爬取频率,缩短收录的时间,泛域名站群、百度批量推送工具、熊爪批量推送工具应运而生。
虽然百度在2017年就推出了飓风算法打击不良采集,但百度的去重算法还是比较粗糙,只能识别单个文章和单个文章的区别(有兴趣的可以去码范SEO内参飓风算法章节),而采集组合后的文章往往内容更丰富,所以采集 非常快。,起来很爽。
采集组合SEO效果好,可以赚钱,各种培训也流行起来。但好日子不长。2019年年中,百度狂飙3算法上线,喵喵的原创检测级别居然达到了句子级别,于是采集组合法开始弱化。新的问候即将发出,百花盛开。
动作二:多份采集+伪原创手稿
流行年份:2019~2021
方法说明:
首先根据关键词对采集文章进行批处理,形成初始语料。
其次,对已为 采集 的 文章 进行双重翻译。就是先把中文翻译成英文,再翻译成中文。或者先把中文翻译成日文再翻译成中文。
最后,将 3 到 5 个相似的 文章 组合成一个新的 文章。
洗稿方式不限于双译。某118的智能改写,AI伪原创工具各有千秋,要么基于同义词词典的替换,要么双译。
但是伪原创并没有让用户体验和原文一样好,所以伪原创是个技术活。
其次,双译还需要做一个软件对接接口,对我们这些不懂编码的人来说太不友好了,所以很多高手的精彩原创算法在2019年年中开始成长.
动作3:多个采集+句子重组
流行年份:2019~2021
方法说明:
飓风III算法发布后,2019年底在旅游、地产、重庆旅游网、淘房网等股票中掀起一波网站,但内容非常奇怪(PS因为之前的网站站点都被关闭了)找不到了,可以给大家解释一下。)
首先,采集维基百科或竞争对手的网站。
其次,使用逗号、句号、问号作为分界点,将文章分成小句。
最后剪掉20字以内的句子,只留下长句,再把长句重组成一个新的文章。
虽然算法比较粗糙,但是PR6 3个月后,可以持续半年+不朽。如果条件允许,配合一波点击就足以让搜索引擎认为用户想要的内容就是这么糟糕的内容。
码粉seo群里很多人现在也是这样玩的,而且还在掀起波澜。如果不是疫情重创旅游等多个行业,估计现在还是香喷喷的。
第四招:新语料库+插值关键词
流行年份:2020年至今
方法说明:
绝大多数人应该都见过类似于笔趣阁的新颖泛站页面。一般的操作原理是准备大量的小说语料,可以做成段落或句子级别。然后重新组装成一个新的文章。因为新的文章缺少相关性,在文章中插入相关词(相关词不限于百度下拉词,相关搜索词)。
这样,句子打补丁可以通过狂飙3算法,然后intrusive 关键词可以通过相关算法,还是有效的。
类似于笔趣阁的算法,句子和段落是拼凑在一起的。很多SEO高手也做了很多,但是这种网站在2020年中之前还是可以用的。看来百度的算法在2021年升级了。大部分网站只有20天左右的效果。
最后:
搜索引擎算法正在发生变化。代码爱好者观察到,过去六个月内与 采集 结合的页面排名的机会越来越少。相反,它们又小又漂亮,可以直接回答内容的页面更有可能排名。
一方面,前后段落的流畅性、逻辑性和上下文相关性已被纳入现场评估。
另一方面,点击率越高,用户体验越好(这在一定程度上是这么认为的),而且组合的文字又长又臭,谁想看。
所以,采集还是要选的,但不一定是组合。
再说一句话:任何知识都有它的两个方面。在SEO中,少吃苦少踩坑是一笔宝贵的财富。 查看全部
文章采集组合工具(码迷SEO内参飓风算法,憋出一万种方法搞定原创!)
因为SEO是一门玄学,每个人都有很多花招,尤其是做SEO文章的时候,小伙伴们都是天选之子,不仅把大法复制粘贴到极致,还可以想出10,000 种方法来完成它。原创。
风口上的猪为什么会飞,因为它跟风。所有的动作都有其诞生的时间。码迷SEO根据花样出现的时间,结合当时的算法背景,我们一一来聊一聊。
移动 1:多个 采集 组合
流行年份:2016~2019
方法说明:
首先采集的对象一般是百度百科、搜狗百科、360百科等,多篇文章合二为一,再组合成一个10w+以上的文章搜索引擎。
其次,为了提高搜索爬虫的爬取频率,缩短收录的时间,泛域名站群、百度批量推送工具、熊爪批量推送工具应运而生。
虽然百度在2017年就推出了飓风算法打击不良采集,但百度的去重算法还是比较粗糙,只能识别单个文章和单个文章的区别(有兴趣的可以去码范SEO内参飓风算法章节),而采集组合后的文章往往内容更丰富,所以采集 非常快。,起来很爽。
采集组合SEO效果好,可以赚钱,各种培训也流行起来。但好日子不长。2019年年中,百度狂飙3算法上线,喵喵的原创检测级别居然达到了句子级别,于是采集组合法开始弱化。新的问候即将发出,百花盛开。
动作二:多份采集+伪原创手稿
流行年份:2019~2021
方法说明:
首先根据关键词对采集文章进行批处理,形成初始语料。
其次,对已为 采集 的 文章 进行双重翻译。就是先把中文翻译成英文,再翻译成中文。或者先把中文翻译成日文再翻译成中文。
最后,将 3 到 5 个相似的 文章 组合成一个新的 文章。
洗稿方式不限于双译。某118的智能改写,AI伪原创工具各有千秋,要么基于同义词词典的替换,要么双译。
但是伪原创并没有让用户体验和原文一样好,所以伪原创是个技术活。
其次,双译还需要做一个软件对接接口,对我们这些不懂编码的人来说太不友好了,所以很多高手的精彩原创算法在2019年年中开始成长.
动作3:多个采集+句子重组
流行年份:2019~2021
方法说明:
飓风III算法发布后,2019年底在旅游、地产、重庆旅游网、淘房网等股票中掀起一波网站,但内容非常奇怪(PS因为之前的网站站点都被关闭了)找不到了,可以给大家解释一下。)
首先,采集维基百科或竞争对手的网站。
其次,使用逗号、句号、问号作为分界点,将文章分成小句。
最后剪掉20字以内的句子,只留下长句,再把长句重组成一个新的文章。
虽然算法比较粗糙,但是PR6 3个月后,可以持续半年+不朽。如果条件允许,配合一波点击就足以让搜索引擎认为用户想要的内容就是这么糟糕的内容。
码粉seo群里很多人现在也是这样玩的,而且还在掀起波澜。如果不是疫情重创旅游等多个行业,估计现在还是香喷喷的。
第四招:新语料库+插值关键词
流行年份:2020年至今
方法说明:
绝大多数人应该都见过类似于笔趣阁的新颖泛站页面。一般的操作原理是准备大量的小说语料,可以做成段落或句子级别。然后重新组装成一个新的文章。因为新的文章缺少相关性,在文章中插入相关词(相关词不限于百度下拉词,相关搜索词)。
这样,句子打补丁可以通过狂飙3算法,然后intrusive 关键词可以通过相关算法,还是有效的。
类似于笔趣阁的算法,句子和段落是拼凑在一起的。很多SEO高手也做了很多,但是这种网站在2020年中之前还是可以用的。看来百度的算法在2021年升级了。大部分网站只有20天左右的效果。
最后:
搜索引擎算法正在发生变化。代码爱好者观察到,过去六个月内与 采集 结合的页面排名的机会越来越少。相反,它们又小又漂亮,可以直接回答内容的页面更有可能排名。
一方面,前后段落的流畅性、逻辑性和上下文相关性已被纳入现场评估。
另一方面,点击率越高,用户体验越好(这在一定程度上是这么认为的),而且组合的文字又长又臭,谁想看。
所以,采集还是要选的,但不一定是组合。
再说一句话:任何知识都有它的两个方面。在SEO中,少吃苦少踩坑是一笔宝贵的财富。
文章采集组合工具(入门任务第二期的任务开始,事半功倍方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-21 15:11
任务要求:
2010年10月18日中午12点,介绍任务二期任务开始。任务如下,采集、整理和分析当前网络下所有链接平台的数据。
使命宗旨:
这个任务主要是锻炼我们的几个能力:执行力、耐力、分析能力、吃苦的能力。这是考验一个人在工作中是否有耐心,是否能用大脑做事。在采集的过程中,不断地复制粘贴这些枯燥重复的工作,也是对一个人的体力和眼力的考验。这项工作在第一个任务中也有这方面的测试。
采集平台和分拣平台可以说是另一种努力:苦力,因为采集数据时的工作量非常大。毕竟,互联网上至少有100个链接平台。通过我不断的采集整理,总共有大约180个链接平台。. 因为其中一项任务是在采集到的网站上发布指定的网站 URL,因为链接平台的链接信息是唯一的,同一个链接地址不能发布两次。看看谁最先发帖。
以上是我们作业分数的一个指标。这取决于谁能在最短的时间内在采集的链接平台上发布指定的 URL。填写的信息,用户名、密码、QQ、邮箱、网址、网站姓名等,每个网站注册的时候都可以直接复制粘贴,效率提升不少。当你精通这个动作时,你会发现你的动作会越来越快。这就是生产线出现的原因。
步骤 1:采集链接平台 URL
如何更快速、准确、高效地采集链接平台,事半功倍
方法:
1、 搜索引擎采集链接平台
我首先将这个行业中的关键词确定为“链接平台”、“友情链接平台”、“链接交换平台”等。这和做SEO优化一样,首先要选对关键词。
2、前人做过的总结
我在搜索引擎中搜索了“链接平台集合”、“链接平台摘要”、“链接平台列表”等关键词,我真的可以找到170到180个友好链接平台的网址。努力。但是有些网站打不开,有些网址不是你需要的。
3、 使用工具事半功倍
采集Q站链接时,可以在百度和google的搜索框中输入:inulr+网站。比如我这次要采集的友情链接平台的平台,基本上就是通过那两个模板进化而来的,所以可以在搜索框输入:inurl+exchange.asp或者inurl+exchange.php,依次为更准确的可以写成:inurl+exchange.asp+link平台,inurl+exchange.php+link平台。inurl 表示收录,以便我们更准确地找到我们需要的链接网站。
百度和谷歌都有自己的语法搜索组合,更容易更准确地找到你想要的结果。你可以搜索这个并自己总结。
4、搜索链接平台QQ
您可以在QQ群搜索关键词中输入“友情链接平台”和“友情链接平台”。这样一来,与这些方面相关的QQ群就会多起来。获取平台信息,我的 170 多个活动链接平台中有 5 个左右可以在这里找到。可以作为补充。同时,你也可以通过这些QQ与他人交流,了解哪个链接平台更好,有助于下一步对链接平台的分析。
经验:让你的手更快。在这个任务中,第一个关键的评估标准是有效注册的数量和添加到老师的博客链接的数量。最多的证明是执行速度足够快。在实际工作中,时间往往是关键因素,而先机的优势非常重要,而机会总是稍纵即逝,训练我们的速度。其实在第一个任务给新的博客账号添加新的监听用户的时候,我就用熟练的操作来提高收录的速度。这次我也是用同样的复制粘贴的方法快速注册了很多网站,并且成功贴出了老师博客的链接。有效注册有35个,添加的url来自170多个,这与方法的速度有关。请注意,我还锻炼了使用 EXCEL 表格的熟练程度,并且可以过滤掉重复的链接平台。日常生活中往往需要很多办公软件工具,熟练熟练地使用办公软件会大大提高工作效率。
第二步:整理网站相关数据
第二步,我们需要对链接平台进行审核,包括以下指标:
1、 关键词百度排名
2、 网站 的 PR 值
3、 预计每日流量
4、 网站域名注册时间初步判断网站年龄
5、 估计有多少 网站 在链接平台上注册
6、 ALEXA 排名
7、网站中查询到的外部链接收录的情况
8、 网站百度收录的数量
9、 网站的百度快照更新频率
10、网站链接平台的日增数,如果有足够的时间,可以统计1到2周,然后取平均值。
11、 在谷歌上的排名
12、收录 在谷歌上
13、百度收录添加新的网站地址需要多长时间。
经验:获取网站的索引参数时,可以使用工具获取。我们需要使用工具。我们需要学习使用各种成熟的工具来提高我们的工作效率。总结快速组织方法。
下面是网站的统计工具我推荐两款软件,一款是关键词排名查询工具,一款是站长工具箱。这两个软件功能非常强大,可以通过各种设置项实现批量提取多个网站数据。还有网站:、网站、网站等,非常值得推荐给大家。当然,您还可以在线查找其他工具。好工具是你的好帮手。.
第三步:分析网站的权重和值
我在我的个人博客上写了一篇文章文章,题目是《网络推广技巧的竞争者是你最好的老师的职业文章,这个文章是我学会了如何分析数据的一个阐述竞争对手的网站来学习对手的SEO优化方法和思路。这里讨论的原理是一样的,可以通过分析行业数据来学习对手网站复制对手,超越对手。
1、通过分析对手的优势和劣势获得竞争优势
2、通过分析对手的网站获得更多赚钱方式
3、通过分析对手的网站架构来改进和完善自己的网站网站
4、分析对手的人员配备和晋升方式,集结数百所学校之力,为我所用。
分析采集到的数据需要一定的数据分析能力。在一些比较大的网络公司,有专门的数据分析师这样的职位,需要专门的培训和学习才能做好这项工作。任何人都可以做到,我们现在做的就是锻炼我们的数据分析能力。
我们应该通过数据对采集到的链接平台进行排名。网站 的数据量 收录 非常重要。找出最值得我们关注的前几个 网站。每日流量,网站的百度排名,进行对比分析。只有对比才能看出区别,才能更清楚地看到各个网站的优缺点。对您自己的链接平台的改进做出有益的结论。网站 的竞争与业务的竞争相同。俗话说,知己知彼,百战百胜。幸运的是,您可以通过查看对手的优势和劣势来赢得竞争。
数据采集和整理对于行业网站有什么价值和意义?总结如下
想要做好一个项目,前期一定要对项目有一个全面的了解,还要对项目的竞争对手有一定的了解,这样才能有目的、有方法、有策略把这个项目做好。.
通过对链接平台网站性质的分析,要了解为什么会存在这种形式的链接平台,链接平台的价值在哪里,访问者来到这样的链接平台做什么,以及他们想得到什么,做好这些分析有助于完善链接平台,更好地满足客户的需求,满足客户的使用习惯,提升用户体验。这就是我们分析网站的目的,提高网站的粘性和回头率,知道对手网站有哪些优点值得学习,也知道我们的不足和改进自己的链接平台,自己的优势在哪里,进一步扩大自己的优势。
结果我们对整个链接平台行业有了全面的了解,知道哪些网站做得更好,哪些网站实际上是垃圾站,一文不值。
总结:做一份工作,一定要认真、有耐心,要有深入研究和打破砂锅到底的精神,用你的大脑去分析思考问题,分析从网站采集到的数据@>。运营决策拥有有价值的信息,数据不言自明。这是数据采集、组织和分析的最终目标。 查看全部
文章采集组合工具(入门任务第二期的任务开始,事半功倍方法)
任务要求:
2010年10月18日中午12点,介绍任务二期任务开始。任务如下,采集、整理和分析当前网络下所有链接平台的数据。
使命宗旨:
这个任务主要是锻炼我们的几个能力:执行力、耐力、分析能力、吃苦的能力。这是考验一个人在工作中是否有耐心,是否能用大脑做事。在采集的过程中,不断地复制粘贴这些枯燥重复的工作,也是对一个人的体力和眼力的考验。这项工作在第一个任务中也有这方面的测试。
采集平台和分拣平台可以说是另一种努力:苦力,因为采集数据时的工作量非常大。毕竟,互联网上至少有100个链接平台。通过我不断的采集整理,总共有大约180个链接平台。. 因为其中一项任务是在采集到的网站上发布指定的网站 URL,因为链接平台的链接信息是唯一的,同一个链接地址不能发布两次。看看谁最先发帖。
以上是我们作业分数的一个指标。这取决于谁能在最短的时间内在采集的链接平台上发布指定的 URL。填写的信息,用户名、密码、QQ、邮箱、网址、网站姓名等,每个网站注册的时候都可以直接复制粘贴,效率提升不少。当你精通这个动作时,你会发现你的动作会越来越快。这就是生产线出现的原因。
步骤 1:采集链接平台 URL
如何更快速、准确、高效地采集链接平台,事半功倍
方法:
1、 搜索引擎采集链接平台
我首先将这个行业中的关键词确定为“链接平台”、“友情链接平台”、“链接交换平台”等。这和做SEO优化一样,首先要选对关键词。
2、前人做过的总结
我在搜索引擎中搜索了“链接平台集合”、“链接平台摘要”、“链接平台列表”等关键词,我真的可以找到170到180个友好链接平台的网址。努力。但是有些网站打不开,有些网址不是你需要的。
3、 使用工具事半功倍
采集Q站链接时,可以在百度和google的搜索框中输入:inulr+网站。比如我这次要采集的友情链接平台的平台,基本上就是通过那两个模板进化而来的,所以可以在搜索框输入:inurl+exchange.asp或者inurl+exchange.php,依次为更准确的可以写成:inurl+exchange.asp+link平台,inurl+exchange.php+link平台。inurl 表示收录,以便我们更准确地找到我们需要的链接网站。
百度和谷歌都有自己的语法搜索组合,更容易更准确地找到你想要的结果。你可以搜索这个并自己总结。
4、搜索链接平台QQ
您可以在QQ群搜索关键词中输入“友情链接平台”和“友情链接平台”。这样一来,与这些方面相关的QQ群就会多起来。获取平台信息,我的 170 多个活动链接平台中有 5 个左右可以在这里找到。可以作为补充。同时,你也可以通过这些QQ与他人交流,了解哪个链接平台更好,有助于下一步对链接平台的分析。
经验:让你的手更快。在这个任务中,第一个关键的评估标准是有效注册的数量和添加到老师的博客链接的数量。最多的证明是执行速度足够快。在实际工作中,时间往往是关键因素,而先机的优势非常重要,而机会总是稍纵即逝,训练我们的速度。其实在第一个任务给新的博客账号添加新的监听用户的时候,我就用熟练的操作来提高收录的速度。这次我也是用同样的复制粘贴的方法快速注册了很多网站,并且成功贴出了老师博客的链接。有效注册有35个,添加的url来自170多个,这与方法的速度有关。请注意,我还锻炼了使用 EXCEL 表格的熟练程度,并且可以过滤掉重复的链接平台。日常生活中往往需要很多办公软件工具,熟练熟练地使用办公软件会大大提高工作效率。
第二步:整理网站相关数据
第二步,我们需要对链接平台进行审核,包括以下指标:
1、 关键词百度排名
2、 网站 的 PR 值
3、 预计每日流量
4、 网站域名注册时间初步判断网站年龄
5、 估计有多少 网站 在链接平台上注册
6、 ALEXA 排名
7、网站中查询到的外部链接收录的情况
8、 网站百度收录的数量
9、 网站的百度快照更新频率
10、网站链接平台的日增数,如果有足够的时间,可以统计1到2周,然后取平均值。
11、 在谷歌上的排名
12、收录 在谷歌上
13、百度收录添加新的网站地址需要多长时间。
经验:获取网站的索引参数时,可以使用工具获取。我们需要使用工具。我们需要学习使用各种成熟的工具来提高我们的工作效率。总结快速组织方法。
下面是网站的统计工具我推荐两款软件,一款是关键词排名查询工具,一款是站长工具箱。这两个软件功能非常强大,可以通过各种设置项实现批量提取多个网站数据。还有网站:、网站、网站等,非常值得推荐给大家。当然,您还可以在线查找其他工具。好工具是你的好帮手。.
第三步:分析网站的权重和值
我在我的个人博客上写了一篇文章文章,题目是《网络推广技巧的竞争者是你最好的老师的职业文章,这个文章是我学会了如何分析数据的一个阐述竞争对手的网站来学习对手的SEO优化方法和思路。这里讨论的原理是一样的,可以通过分析行业数据来学习对手网站复制对手,超越对手。
1、通过分析对手的优势和劣势获得竞争优势
2、通过分析对手的网站获得更多赚钱方式
3、通过分析对手的网站架构来改进和完善自己的网站网站
4、分析对手的人员配备和晋升方式,集结数百所学校之力,为我所用。
分析采集到的数据需要一定的数据分析能力。在一些比较大的网络公司,有专门的数据分析师这样的职位,需要专门的培训和学习才能做好这项工作。任何人都可以做到,我们现在做的就是锻炼我们的数据分析能力。
我们应该通过数据对采集到的链接平台进行排名。网站 的数据量 收录 非常重要。找出最值得我们关注的前几个 网站。每日流量,网站的百度排名,进行对比分析。只有对比才能看出区别,才能更清楚地看到各个网站的优缺点。对您自己的链接平台的改进做出有益的结论。网站 的竞争与业务的竞争相同。俗话说,知己知彼,百战百胜。幸运的是,您可以通过查看对手的优势和劣势来赢得竞争。
数据采集和整理对于行业网站有什么价值和意义?总结如下
想要做好一个项目,前期一定要对项目有一个全面的了解,还要对项目的竞争对手有一定的了解,这样才能有目的、有方法、有策略把这个项目做好。.
通过对链接平台网站性质的分析,要了解为什么会存在这种形式的链接平台,链接平台的价值在哪里,访问者来到这样的链接平台做什么,以及他们想得到什么,做好这些分析有助于完善链接平台,更好地满足客户的需求,满足客户的使用习惯,提升用户体验。这就是我们分析网站的目的,提高网站的粘性和回头率,知道对手网站有哪些优点值得学习,也知道我们的不足和改进自己的链接平台,自己的优势在哪里,进一步扩大自己的优势。
结果我们对整个链接平台行业有了全面的了解,知道哪些网站做得更好,哪些网站实际上是垃圾站,一文不值。
总结:做一份工作,一定要认真、有耐心,要有深入研究和打破砂锅到底的精神,用你的大脑去分析思考问题,分析从网站采集到的数据@>。运营决策拥有有价值的信息,数据不言自明。这是数据采集、组织和分析的最终目标。

