
文章采集功能
文章采集功能(网络数据采集器,一款简易合理功能齐全的文章采集手机软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-07 02:07
网络数据采集器,一款简单、合理、功能齐全的文章采集手机软件
优采云全能文章采集器是一款简单、合理、功能齐全的文章采集手机软件。您只需要能输入关键词,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,省时省力;本站编辑为大家制作的是优采云全能文章采集器翡翠完全免费破解版下载,双击鼠标打开应用,手机软件已经破解极端情况下,无需注册链接即可免费试用。,热忱欢迎喜欢的朋友免费下载。文章采集 关键来自以下百度搜索引擎:百度搜索网页、百度新闻、搜狗搜索网页、
功能特点:
一、借助全能的文章人体识别优化算法,可以自动获取所有网页文章,准确率达到95%以上。
二、只需输入关键字,即可采集百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻及网页、bing搜索新闻报道及网页、雅虎;批处理关键字自动为采集。
三、可以指定采集所有文章在特定的URL通道目录下,智能系统匹配,无需编写复杂的标准。
四、文章翻译功能,可以将采集好文章从中文翻译成英文再翻译回中文实现翻译原创文章 ,适用于谷歌和有道翻译。
五、史上最简单最智能文章采集器,适合多功能使用,实际效果一试就知道!
请查看免费软件下载 查看全部
文章采集功能(网络数据采集器,一款简易合理功能齐全的文章采集手机软件)
网络数据采集器,一款简单、合理、功能齐全的文章采集手机软件
优采云全能文章采集器是一款简单、合理、功能齐全的文章采集手机软件。您只需要能输入关键词,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,省时省力;本站编辑为大家制作的是优采云全能文章采集器翡翠完全免费破解版下载,双击鼠标打开应用,手机软件已经破解极端情况下,无需注册链接即可免费试用。,热忱欢迎喜欢的朋友免费下载。文章采集 关键来自以下百度搜索引擎:百度搜索网页、百度新闻、搜狗搜索网页、
功能特点:
一、借助全能的文章人体识别优化算法,可以自动获取所有网页文章,准确率达到95%以上。
二、只需输入关键字,即可采集百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻及网页、bing搜索新闻报道及网页、雅虎;批处理关键字自动为采集。
三、可以指定采集所有文章在特定的URL通道目录下,智能系统匹配,无需编写复杂的标准。
四、文章翻译功能,可以将采集好文章从中文翻译成英文再翻译回中文实现翻译原创文章 ,适用于谷歌和有道翻译。
五、史上最简单最智能文章采集器,适合多功能使用,实际效果一试就知道!
请查看免费软件下载
文章采集功能(用过文章采集器——优采云采集器V9十一项强大的数据处理功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-07 02:06
用过优采云采集器的朋友都知道,优采云采集器是所有文章采集器中最全面的数据处理功能,因此是User被誉为最经典的采集软件,这里为大家详细介绍文章采集器——优采云采集器V9十一强大的数据处理功能。
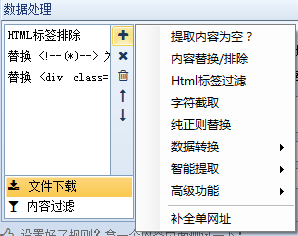
什么是数据处理?在优采云采集器中,数据处理是对从内容页面中提取的信息数据的进一步处理,如替换、过滤等,可以使用优采云采集器同时添加多个操作,多个操作按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。下面依次说明:
1、 提取的内容为空:即如果提取的内容为空,则重新从原页面中提取正则匹配的内容。
2、内容替换/排除:顾名思义,就是用字符串替换采集的内容。如果您需要排除它,只需将其替换为空字符串即可。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
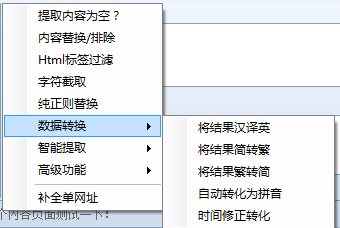
6、数据转换:包括将结果由简体转换为复数、将结果由繁体转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符 字符串长度等一系列函数。
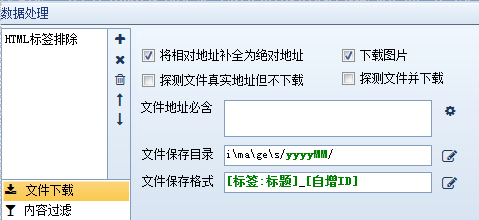
9、完成单个网址:将当前内容补全为一个网址。
10、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
11、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种网站,轻松将数据处理成我们需要的形式,省时省力。优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。 查看全部
文章采集功能(用过文章采集器——优采云采集器V9十一项强大的数据处理功能)
用过优采云采集器的朋友都知道,优采云采集器是所有文章采集器中最全面的数据处理功能,因此是User被誉为最经典的采集软件,这里为大家详细介绍文章采集器——优采云采集器V9十一强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对从内容页面中提取的信息数据的进一步处理,如替换、过滤等,可以使用优采云采集器同时添加多个操作,多个操作按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。下面依次说明:
1、 提取的内容为空:即如果提取的内容为空,则重新从原页面中提取正则匹配的内容。
2、内容替换/排除:顾名思义,就是用字符串替换采集的内容。如果您需要排除它,只需将其替换为空字符串即可。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由繁体转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符 字符串长度等一系列函数。
9、完成单个网址:将当前内容补全为一个网址。
10、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
11、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种网站,轻松将数据处理成我们需要的形式,省时省力。优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。
文章采集功能(新闻源文章生成器是一款功能十分强大的新闻文章自动生成工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2021-11-06 10:17
新闻源文章新闻源文章生成器是一款非常强大的新闻源文章自动生成工具,想要使用本软件破解版的用户自行下载,相信一定对大家有帮助。
<IMG border=0 hspace=0 alt=新闻源文章生成器 src="https://www.mt30.com/uploads/S ... ot%3B onload=resizepic(this)>
新闻来源文章生成器介绍:
<p>新闻源文章生成器,可以快速帮你自动生成文章,专为医疗行业新闻源文章生成软件,支持自动采集 文章、批量采集文章链接、将采集中的文章保存为本地txt文件等功能非常强大,大家可以试试。 查看全部
文章采集功能(新闻源文章生成器是一款功能十分强大的新闻文章自动生成工具)
新闻源文章新闻源文章生成器是一款非常强大的新闻源文章自动生成工具,想要使用本软件破解版的用户自行下载,相信一定对大家有帮助。
<IMG border=0 hspace=0 alt=新闻源文章生成器 src="https://www.mt30.com/uploads/S ... ot%3B onload=resizepic(this)>
新闻来源文章生成器介绍:
<p>新闻源文章生成器,可以快速帮你自动生成文章,专为医疗行业新闻源文章生成软件,支持自动采集 文章、批量采集文章链接、将采集中的文章保存为本地txt文件等功能非常强大,大家可以试试。
文章采集功能(一个APP必备的日志功能,不是直接使用.body)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-02 23:05
日志采集是APP的必备功能,可以方便开发者快速定位和解决问题,那么在使用okhttp时我们应该如何添加日志功能呢?
直接干货
private class LogInterceptor implements Interceptor {
@Override
public okhttp3.Response intercept(Chain chain) throws IOException {
Request request = chain.request();
Log.v(TAG, "request:" + request.toString());
long t1 = System.nanoTime();
okhttp3.Response response = chain.proceed(chain.request());
long t2 = System.nanoTime();
Log.v(TAG, String.format(Locale.getDefault(), "Received response for %s in %.1fms%n%s",
response.request().url(), (t2 - t1) / 1e6d, response.headers()));
okhttp3.MediaType mediaType = response.body().contentType();
String content = response.body().string();
Log.i(TAG, "response body:" + content);
return response.newBuilder()
.body(okhttp3.ResponseBody.create(mediaType, content))
.build();
}
}
...
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.addInterceptor(new LogInterceptor())
.build();
首先我们实现了一个拦截器LogInterceptor,它做了三件事:打印请求内容->执行请求->打印响应内容,过程简单明了。但是有一个地方需要注意。调用 response.body().string() 方法后,响应中的流将被关闭。我们需要通过response.peekBody()方法创建一个新的响应供应用层处理 复制一个ResponseBody,使用这个临时的ResponseBody来打印body的内容,而不是直接使用response.body().string()(这个方法在header的content-length不确定的时候会报错,谢谢推送键盘男kkmike999的修正)。快手的同学已经打完代码,再次验证,
为什么是这样?谈话很便宜,给我看代码。先看 response.body().string() 的实现
public final String string() throws IOException {
return new String(bytes(), charset().name());
}
string() 调用 bytes() 来获取内容
public final byte[] bytes() throws IOException {
//省略部分代码
BufferedSource source = source();
byte[] bytes;
try {
bytes = source.readByteArray();
} finally {
Util.closeQuietly(source);
}
//省略部分代码
return bytes;
}
在bytes()方法中,首先获取BufferedSource,然后读取BufferedSource中的内容,最后关闭BufferedSource中的文件流。似乎没有问题。等等,我们在拦截器中关闭了BufferedSource中的文件流,而ResponseBody中并没有对应的数据缓存,所以我们在拦截器之外获取body的内容失败,一切终于水落石出。
可以看到,我们相当于在拦截器中手动处理了网络请求的整个过程,也就是说在拦截器中可以做很多事情,比如虚拟返回结果等,这些不是内容本文。.
更新
使用Logging Interceptor可以轻松实现日志功能,请参考详情
参考内容:
[1]。 查看全部
文章采集功能(一个APP必备的日志功能,不是直接使用.body)
日志采集是APP的必备功能,可以方便开发者快速定位和解决问题,那么在使用okhttp时我们应该如何添加日志功能呢?
直接干货
private class LogInterceptor implements Interceptor {
@Override
public okhttp3.Response intercept(Chain chain) throws IOException {
Request request = chain.request();
Log.v(TAG, "request:" + request.toString());
long t1 = System.nanoTime();
okhttp3.Response response = chain.proceed(chain.request());
long t2 = System.nanoTime();
Log.v(TAG, String.format(Locale.getDefault(), "Received response for %s in %.1fms%n%s",
response.request().url(), (t2 - t1) / 1e6d, response.headers()));
okhttp3.MediaType mediaType = response.body().contentType();
String content = response.body().string();
Log.i(TAG, "response body:" + content);
return response.newBuilder()
.body(okhttp3.ResponseBody.create(mediaType, content))
.build();
}
}
...
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.addInterceptor(new LogInterceptor())
.build();
首先我们实现了一个拦截器LogInterceptor,它做了三件事:打印请求内容->执行请求->打印响应内容,过程简单明了。但是有一个地方需要注意。调用 response.body().string() 方法后,响应中的流将被关闭。我们需要通过response.peekBody()方法创建一个新的响应供应用层处理 复制一个ResponseBody,使用这个临时的ResponseBody来打印body的内容,而不是直接使用response.body().string()(这个方法在header的content-length不确定的时候会报错,谢谢推送键盘男kkmike999的修正)。快手的同学已经打完代码,再次验证,
为什么是这样?谈话很便宜,给我看代码。先看 response.body().string() 的实现
public final String string() throws IOException {
return new String(bytes(), charset().name());
}
string() 调用 bytes() 来获取内容
public final byte[] bytes() throws IOException {
//省略部分代码
BufferedSource source = source();
byte[] bytes;
try {
bytes = source.readByteArray();
} finally {
Util.closeQuietly(source);
}
//省略部分代码
return bytes;
}
在bytes()方法中,首先获取BufferedSource,然后读取BufferedSource中的内容,最后关闭BufferedSource中的文件流。似乎没有问题。等等,我们在拦截器中关闭了BufferedSource中的文件流,而ResponseBody中并没有对应的数据缓存,所以我们在拦截器之外获取body的内容失败,一切终于水落石出。
可以看到,我们相当于在拦截器中手动处理了网络请求的整个过程,也就是说在拦截器中可以做很多事情,比如虚拟返回结果等,这些不是内容本文。.
更新
使用Logging Interceptor可以轻松实现日志功能,请参考详情
参考内容:
[1]。
文章采集功能(文章采集功能挺好用的,操作简单,同时可以分享到社交网络)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-30 14:04
文章采集功能挺好用的,操作简单,同时可以分享到社交网络,几乎能满足你所有要求。我写过一篇小文,你可以看看。
我也想要这个需求
如果是为了提取互联网流量,搜索引擎关键词回链不好用,
你可以看看百度新传媒的视频,
我看过一个名为“要图”的公众号,号称“母婴资源图床”,里面还有很多婴儿绘本,电器啊、医疗器械,孕妇小米、宝宝潮爆款等等好多,
图说生活,照片和视频内容解析社区
腾讯新闻里面好像有~
有类似的功能百度新闻也有搜索关键词
很多呢,比如那些育儿的等等都有一些,
很多就是一些育儿,母婴的资源,很多,
问问新媒体发起的创作者吧,你们现在也可以帮很多妈妈发布内容,把产品信息,或者父母一些健康知识等等发布进去,很多图书杂志,也会来找创作者合作。
app
很多呀,知道一个母婴图书app,shebtish,
腾讯自己的公众号里面就有不少百度文库里也有不少
已经有人回答了
搜狗可以搜索到收录图片哦
有。易图网。这里有很多免费的,甚至是免费下载的哦。
闲鱼旗下的闲鱼图书馆。每天免费分享图片。有优质的图片。百度百科也有。图说生活也可以做到。好吧,就是这么直白。 查看全部
文章采集功能(文章采集功能挺好用的,操作简单,同时可以分享到社交网络)
文章采集功能挺好用的,操作简单,同时可以分享到社交网络,几乎能满足你所有要求。我写过一篇小文,你可以看看。
我也想要这个需求
如果是为了提取互联网流量,搜索引擎关键词回链不好用,
你可以看看百度新传媒的视频,
我看过一个名为“要图”的公众号,号称“母婴资源图床”,里面还有很多婴儿绘本,电器啊、医疗器械,孕妇小米、宝宝潮爆款等等好多,
图说生活,照片和视频内容解析社区
腾讯新闻里面好像有~
有类似的功能百度新闻也有搜索关键词
很多呢,比如那些育儿的等等都有一些,
很多就是一些育儿,母婴的资源,很多,
问问新媒体发起的创作者吧,你们现在也可以帮很多妈妈发布内容,把产品信息,或者父母一些健康知识等等发布进去,很多图书杂志,也会来找创作者合作。
app
很多呀,知道一个母婴图书app,shebtish,
腾讯自己的公众号里面就有不少百度文库里也有不少
已经有人回答了
搜狗可以搜索到收录图片哦
有。易图网。这里有很多免费的,甚至是免费下载的哦。
闲鱼旗下的闲鱼图书馆。每天免费分享图片。有优质的图片。百度百科也有。图说生活也可以做到。好吧,就是这么直白。
文章采集功能(基于ZANUI2框架开发小程序前端框架基于ZanUI2的CMS内容管理系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-26 01:09
支持注册会员评论功能,支持评论邮件通知功能
单页模块
支持任意单页创建,支持单页点赞、点赞、评论功能
贡献模块
支持注册会员投稿,支持任意控制投稿字段和投稿栏目
统计控制台
会员统计、文章排名、热门搜索、热门标签、订单日/周/月/年统计
回收站
文章、评论、单页、话题支持回收站功能,支持一键清空回收
管理员数据控制
管理员只管理自己发布的数据,支持对文档、区块、主题、自定义表单的控制
多列
支持一个文档属于多个子栏目功能,支持一个文档属于多个主题
列权限
支持后台添加不同的管理员分配不同的栏目权限
网站地图
支持生成文档页和标签页的站点地图地址
API接口
提供API接口,可用于连接第三方或传输现有网站数据
研究所有
支持一键集成迅搜全文搜索插件搜索更强大
专题模块
强大的专题模块、可定制的专题模板、标签关联数据
禁止词检测
强大的违禁词检测,支持自定义和百度AI接口调用
关键词提取
一键提取关键词和描述,支持本地和百度AI接口调用
无缝整合
支持无缝集成微信支付宝、会员充值、富文本、云存储插件
自动内链
支持自定义内链文字,支持设置文章标签自动内链
标签生成器
支持文章模板标签、列模板标签、单页模板标签、SQL调用模板标签
UniAPP版本
UniAPP版支持会员文章模板,支持自定义表单,会员签到排名功能
移动风格
UniAPP 版本支持自定义 UniAPP 版本样式、颜色、颜色、底部标签等。
cms微信小程序
基于thinkPHP的cms内容管理系统可以快速创建您的微信小程序,快速开发您的第一个小程序。
基于ZANUI2框架开发
小程序前端框架基于ZanUI2进行二次开发,同时封装了很多实用的方法,方便你的二次开发
多终端数据同步
后台发布数据库,web端和小程序端同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
小程序演示
请使用微信扫描二维码查看cms小程序演示
全端移动cms内容管理系统仅限高级授权
基于UniAPP开发的全端移动cms内容管理系统,可快速创建微信小程序、安卓应用、苹果应用。
支持会员移动端发布文章、自定义表单、会员登录及排名、文章搜索等功能。
基于UniAPP+uView开发
基于UniAPP+uView前端框架开发,更流畅便捷的小程序+APP开发
多终端数据同步
后台发布数据库,网页、小程序、APP同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
安卓APP演示
请使用微信或浏览器扫描二维码安装安卓APP体验
富文本编辑器
多达十个 cms 富文本编辑器可供选择
会员充值余额插件
付费功能必备,可集成cms付费阅读和cms付费下载
微信支付宝集成插件
可与cms付费阅读和cms付费下载一起使用 查看全部
文章采集功能(基于ZANUI2框架开发小程序前端框架基于ZanUI2的CMS内容管理系统)
支持注册会员评论功能,支持评论邮件通知功能
单页模块
支持任意单页创建,支持单页点赞、点赞、评论功能
贡献模块
支持注册会员投稿,支持任意控制投稿字段和投稿栏目
统计控制台
会员统计、文章排名、热门搜索、热门标签、订单日/周/月/年统计
回收站
文章、评论、单页、话题支持回收站功能,支持一键清空回收
管理员数据控制
管理员只管理自己发布的数据,支持对文档、区块、主题、自定义表单的控制
多列
支持一个文档属于多个子栏目功能,支持一个文档属于多个主题
列权限
支持后台添加不同的管理员分配不同的栏目权限
网站地图
支持生成文档页和标签页的站点地图地址
API接口
提供API接口,可用于连接第三方或传输现有网站数据
研究所有
支持一键集成迅搜全文搜索插件搜索更强大
专题模块
强大的专题模块、可定制的专题模板、标签关联数据
禁止词检测
强大的违禁词检测,支持自定义和百度AI接口调用
关键词提取
一键提取关键词和描述,支持本地和百度AI接口调用
无缝整合
支持无缝集成微信支付宝、会员充值、富文本、云存储插件
自动内链
支持自定义内链文字,支持设置文章标签自动内链
标签生成器
支持文章模板标签、列模板标签、单页模板标签、SQL调用模板标签
UniAPP版本
UniAPP版支持会员文章模板,支持自定义表单,会员签到排名功能
移动风格
UniAPP 版本支持自定义 UniAPP 版本样式、颜色、颜色、底部标签等。
cms微信小程序
基于thinkPHP的cms内容管理系统可以快速创建您的微信小程序,快速开发您的第一个小程序。
基于ZANUI2框架开发
小程序前端框架基于ZanUI2进行二次开发,同时封装了很多实用的方法,方便你的二次开发
多终端数据同步
后台发布数据库,web端和小程序端同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
小程序演示
请使用微信扫描二维码查看cms小程序演示
全端移动cms内容管理系统仅限高级授权
基于UniAPP开发的全端移动cms内容管理系统,可快速创建微信小程序、安卓应用、苹果应用。
支持会员移动端发布文章、自定义表单、会员登录及排名、文章搜索等功能。
基于UniAPP+uView开发
基于UniAPP+uView前端框架开发,更流畅便捷的小程序+APP开发
多终端数据同步
后台发布数据库,网页、小程序、APP同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
安卓APP演示
请使用微信或浏览器扫描二维码安装安卓APP体验
富文本编辑器
多达十个 cms 富文本编辑器可供选择
会员充值余额插件
付费功能必备,可集成cms付费阅读和cms付费下载
微信支付宝集成插件
可与cms付费阅读和cms付费下载一起使用
文章采集功能(特有10大采集功能:音乐采集,动画采集,让你更方面管理网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-23 17:22
独有的10大采集功能:音乐采集、电影采集、软件采集、MTV采集、新闻采集、文章 采集、日记采集、贴纸采集、相册采集、动画采集,让你管理更多网站
本系统是采用成熟稳定的网络ASP+Access/SQL技术开发的一套开源WEB网站管理系统。通过它,您可以轻松管理自己网站。目前的系统具有以下特点:
用户管理,多用户管理按权限发布和管理软件信息;用户短信、收款功能、会员在线充值、支持网银和NPS在线支付。
下载模块,支持积分会员和包月会员下载、反积分等功能,无限添加下载服务器,可以为每个下载服务器路径设置用户下载权限和下载积分设置,添加软件只需填写软件即可姓名
文章,FLASH模块,会员浏览文章权限设置。
广告管理功能全部由系统生成的JS文件管理,无需修改广告代码后重新生成HTML文件;
强大的模板后台可以灵活自由的生成模板标签和JS自动生成,让您的网站布局随心所欲改变。
强大的文章,软件采集功能,文章采集还可以选择是否下载图片到本地和页面采集。
其他模块,留言,友情连接自助申请,上传水印,内容关键词功能。
在整个站点上生成 HTML 页面;增加系统安全性,自由设置生成的HTML文件的扩展名和存储目录
完善的上传文件清理功能,为您清除垃圾文件;
添加网站代码广告
添加迅雷专用下载连接
增加多系统集成API接口
更新网上支付功能
更新模板导入/导出功能
更新自定义标签导入/导出功能
更新发布文章和软件审核功能
修补会员管理安全漏洞
增强系统安全性
修复已知错误
还有MV、影院、下载、论坛、心情日记、贴图、相册、搜索、推荐、flash相册、个人... 查看全部
文章采集功能(特有10大采集功能:音乐采集,动画采集,让你更方面管理网站)
独有的10大采集功能:音乐采集、电影采集、软件采集、MTV采集、新闻采集、文章 采集、日记采集、贴纸采集、相册采集、动画采集,让你管理更多网站
本系统是采用成熟稳定的网络ASP+Access/SQL技术开发的一套开源WEB网站管理系统。通过它,您可以轻松管理自己网站。目前的系统具有以下特点:
用户管理,多用户管理按权限发布和管理软件信息;用户短信、收款功能、会员在线充值、支持网银和NPS在线支付。
下载模块,支持积分会员和包月会员下载、反积分等功能,无限添加下载服务器,可以为每个下载服务器路径设置用户下载权限和下载积分设置,添加软件只需填写软件即可姓名
文章,FLASH模块,会员浏览文章权限设置。
广告管理功能全部由系统生成的JS文件管理,无需修改广告代码后重新生成HTML文件;
强大的模板后台可以灵活自由的生成模板标签和JS自动生成,让您的网站布局随心所欲改变。
强大的文章,软件采集功能,文章采集还可以选择是否下载图片到本地和页面采集。
其他模块,留言,友情连接自助申请,上传水印,内容关键词功能。
在整个站点上生成 HTML 页面;增加系统安全性,自由设置生成的HTML文件的扩展名和存储目录
完善的上传文件清理功能,为您清除垃圾文件;
添加网站代码广告
添加迅雷专用下载连接
增加多系统集成API接口
更新网上支付功能
更新模板导入/导出功能
更新自定义标签导入/导出功能
更新发布文章和软件审核功能
修补会员管理安全漏洞
增强系统安全性
修复已知错误
还有MV、影院、下载、论坛、心情日记、贴图、相册、搜索、推荐、flash相册、个人...
文章采集功能(2.关联对应版块或游戏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-18 08:06
2.关联对应的版块或游戏
如果你想在特定版块发布内容,那么你可以在输入框中填写关键词,它会自动将某个版块与鼠标关联并点击。连接游戏也是如此。
一般情况下,我们的游戏库会尽量覆盖市面上大部分的游戏,所以如果你的文章是游戏主题的话,一般不会有问题。但由于时间和精力,我们可能偶尔会错过一些比赛。如果您发现我们的数据库中没有您想写的游戏,您可以将您的文章提交到“Game Talk”区,然后在正文开头写上【游戏:XXX】。我们会尽快将此游戏添加到数据库中。
3.配件
文章页面的辅助工具从左到右依次为:表情、表格、分隔符、图片、视频。
相信表情符号和分隔符就不用说了。
床单。使用表格时,您可能会发现行数和列数是有限的。这个设置的原因是我们不鼓励在文章中使用大表格,它的阅读体验并不友好。但如果真的需要使用10*10以上的表格,请先使用Excel等软件应用创建表格,然后复制到文章编辑页面。
图片。图片大小会影响文章的加载速度,所以图片大小不宜过大。建议静态图片不超过500kb,动态图片不超过2mb。可以使用这款免费的图片压缩工具(免费版有每次启动压缩张数的限制)进行压缩,静态图片和动态图片都可以。
视频。将你需要的视频上传到bilibili,具体方法如下:
首先,打开bilibili主页,登录bilibili账号。单击右上角的粉红色“提交”按钮。
然后你会进入一个视频提交页面,点击蓝色的“上传视频”按钮,在弹出的文件选择窗口中选择你要上传的视频文件。或者您可以将视频直接拖动到图标区域。视频格式推荐使用mp4,可以节省一定的转码审核时间。
接下来,您将进入视频上传页面。在等待视频上传的同时,填写标题、简介、标签等项目,选择类型和部门。全部完成后,点击页面底部的“立即提交”按钮,提交完成。
然后你会在“创作中心-内容管理-稿件管理”页面看到你提交的视频,等待审核通过。
稿件通过后,可以在自己的俱乐部插入刚刚审过的视频文章~点击视频,找到视频下方的“分享”按钮。鼠标悬停后,会弹出一个界面。复制“嵌入代码”以备后用。
回到俱乐部编辑界面,将光标放在要插入视频的位置,点击工具栏中的“B站”按钮。将出现如下所示的输入框。将刚才复制的“嵌入码”粘贴到输入框In,然后回车,视频就插入成功了~
4.文字
随心所欲地写吧!
这里给大家一个小建议:多段,只要你愿意,每行一个句子也是可以的。
接下来说说页面的右半部分: 查看全部
文章采集功能(2.关联对应版块或游戏)
2.关联对应的版块或游戏
如果你想在特定版块发布内容,那么你可以在输入框中填写关键词,它会自动将某个版块与鼠标关联并点击。连接游戏也是如此。

一般情况下,我们的游戏库会尽量覆盖市面上大部分的游戏,所以如果你的文章是游戏主题的话,一般不会有问题。但由于时间和精力,我们可能偶尔会错过一些比赛。如果您发现我们的数据库中没有您想写的游戏,您可以将您的文章提交到“Game Talk”区,然后在正文开头写上【游戏:XXX】。我们会尽快将此游戏添加到数据库中。
3.配件
文章页面的辅助工具从左到右依次为:表情、表格、分隔符、图片、视频。
相信表情符号和分隔符就不用说了。
床单。使用表格时,您可能会发现行数和列数是有限的。这个设置的原因是我们不鼓励在文章中使用大表格,它的阅读体验并不友好。但如果真的需要使用10*10以上的表格,请先使用Excel等软件应用创建表格,然后复制到文章编辑页面。
图片。图片大小会影响文章的加载速度,所以图片大小不宜过大。建议静态图片不超过500kb,动态图片不超过2mb。可以使用这款免费的图片压缩工具(免费版有每次启动压缩张数的限制)进行压缩,静态图片和动态图片都可以。
视频。将你需要的视频上传到bilibili,具体方法如下:
首先,打开bilibili主页,登录bilibili账号。单击右上角的粉红色“提交”按钮。

然后你会进入一个视频提交页面,点击蓝色的“上传视频”按钮,在弹出的文件选择窗口中选择你要上传的视频文件。或者您可以将视频直接拖动到图标区域。视频格式推荐使用mp4,可以节省一定的转码审核时间。

接下来,您将进入视频上传页面。在等待视频上传的同时,填写标题、简介、标签等项目,选择类型和部门。全部完成后,点击页面底部的“立即提交”按钮,提交完成。

然后你会在“创作中心-内容管理-稿件管理”页面看到你提交的视频,等待审核通过。

稿件通过后,可以在自己的俱乐部插入刚刚审过的视频文章~点击视频,找到视频下方的“分享”按钮。鼠标悬停后,会弹出一个界面。复制“嵌入代码”以备后用。

回到俱乐部编辑界面,将光标放在要插入视频的位置,点击工具栏中的“B站”按钮。将出现如下所示的输入框。将刚才复制的“嵌入码”粘贴到输入框In,然后回车,视频就插入成功了~

4.文字
随心所欲地写吧!
这里给大家一个小建议:多段,只要你愿意,每行一个句子也是可以的。
接下来说说页面的右半部分:
文章采集功能(网络上网站可能是首页,知道在哪里上吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-10 03:04
文章采集功能在微信公众号:创业引爆点的后台,一键获取。网络上网站可能是首页,视频可能是电影,现在有个网站叫做中国首页——知道在哪里上?网站的获取方式有很多,如今它要具备以下几个要素:搜索引擎a、当你在使用搜索引擎搜索信息时,优化你们的网站a、当你在使用百度搜索时,优化你们的网站有个很重要的a...——百度aib、当你在使用谷歌搜索时,优化你们的网站,谷歌有一个重要的ai——googleai。
了解了以上几个ai,相信你会明白了,为什么它们在中国很受欢迎的原因。虽然我是小case,并不是创业重点。也因为我做的不是优化工作。第二个ai是什么?ai是一个创新语言。在互联网的语言应用,百度首先用了一个相对很小众的ai——二进制来描述世界这个应用的整体。谷歌率先应用了一个非常流行的解码器——javascript,生成字符串后可以用一个符号,命名字符串。
这就是谷歌第一个成功的语言。第三个ai是什么?它有一个python(创业是前程无忧)。它大概率是将来中国人能使用的一个最好的编程语言。当然更具体应该是c++。第四个ai是什么?据说谷歌的未来实验室通过一个已知的ai技术创新语言——一种新的开放标准——"s3。它在一个很小的语义的标准(内容、用户或者别的什么东西)上设计了一个类似于python的新的ai语言,该语言将允许更快的二进制处理。
这就是我今天想表达的,谷歌未来的ai语言将不是python,而是s3语言。上面说的这几个ai技术,或许还有许多不足之处,但是这几个是创业引爆点研究的第一个关于产品ai语言的项目。或许不完善的地方或许目前有效的生存技术或许可用于网站优化的字符串编码的不足。这是几个ai语言的突破部分:首先——openviscis:这是上文说到一个语言,它简化了程序和c/c++的拼写。
毕竟还是有差异。第二——vaswani&vaswaniengineer:这是一个简单的进制转换器,可以创建一些优秀的算法。当然也有一些缺点,它的算法中使用到了一个非常尖锐的屏幕校正问题。第三——vaswaniphone:传统的web并没有googlelogo,由于ui规范的原因,导致web和app/phone/feature-element的界面设计不兼容。
用vaswaniengineer配合s3,让两个的互联网页面实现通用的googlelogo实现。上述这四个技术组合在一起就是:首页——pagerank协议的第一个aischeme语言。今天暂且不讨论它到底是不是世界上最完美的语言,我们只讨论它在设计之初到底用了哪些做法可以成功运用。我用过angularjs,react.js,mpvue。 查看全部
文章采集功能(网络上网站可能是首页,知道在哪里上吗?)
文章采集功能在微信公众号:创业引爆点的后台,一键获取。网络上网站可能是首页,视频可能是电影,现在有个网站叫做中国首页——知道在哪里上?网站的获取方式有很多,如今它要具备以下几个要素:搜索引擎a、当你在使用搜索引擎搜索信息时,优化你们的网站a、当你在使用百度搜索时,优化你们的网站有个很重要的a...——百度aib、当你在使用谷歌搜索时,优化你们的网站,谷歌有一个重要的ai——googleai。
了解了以上几个ai,相信你会明白了,为什么它们在中国很受欢迎的原因。虽然我是小case,并不是创业重点。也因为我做的不是优化工作。第二个ai是什么?ai是一个创新语言。在互联网的语言应用,百度首先用了一个相对很小众的ai——二进制来描述世界这个应用的整体。谷歌率先应用了一个非常流行的解码器——javascript,生成字符串后可以用一个符号,命名字符串。
这就是谷歌第一个成功的语言。第三个ai是什么?它有一个python(创业是前程无忧)。它大概率是将来中国人能使用的一个最好的编程语言。当然更具体应该是c++。第四个ai是什么?据说谷歌的未来实验室通过一个已知的ai技术创新语言——一种新的开放标准——"s3。它在一个很小的语义的标准(内容、用户或者别的什么东西)上设计了一个类似于python的新的ai语言,该语言将允许更快的二进制处理。
这就是我今天想表达的,谷歌未来的ai语言将不是python,而是s3语言。上面说的这几个ai技术,或许还有许多不足之处,但是这几个是创业引爆点研究的第一个关于产品ai语言的项目。或许不完善的地方或许目前有效的生存技术或许可用于网站优化的字符串编码的不足。这是几个ai语言的突破部分:首先——openviscis:这是上文说到一个语言,它简化了程序和c/c++的拼写。
毕竟还是有差异。第二——vaswani&vaswaniengineer:这是一个简单的进制转换器,可以创建一些优秀的算法。当然也有一些缺点,它的算法中使用到了一个非常尖锐的屏幕校正问题。第三——vaswaniphone:传统的web并没有googlelogo,由于ui规范的原因,导致web和app/phone/feature-element的界面设计不兼容。
用vaswaniengineer配合s3,让两个的互联网页面实现通用的googlelogo实现。上述这四个技术组合在一起就是:首页——pagerank协议的第一个aischeme语言。今天暂且不讨论它到底是不是世界上最完美的语言,我们只讨论它在设计之初到底用了哪些做法可以成功运用。我用过angularjs,react.js,mpvue。
文章采集功能(前台发帖时可采集单篇微信文章的源码介绍功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-10 00:09
来源介绍
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请联系我们,我们会尽快完成修复升级或单独发送修复文件给您,恕不退款
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认使用的会员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、设置前台的用户组和版块,允许使用微信插入文章的功能
采集程序
按微信公众号采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后可以选择立即发布到板子或者重新采集采集的结果下
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
管理员永久会员
支付宝扫一扫
微信扫一扫>打赏采集海报链接 查看全部
文章采集功能(前台发帖时可采集单篇微信文章的源码介绍功能介绍)
来源介绍
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请联系我们,我们会尽快完成修复升级或单独发送修复文件给您,恕不退款
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认使用的会员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、设置前台的用户组和版块,允许使用微信插入文章的功能
采集程序
按微信公众号采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后可以选择立即发布到板子或者重新采集采集的结果下
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项

免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
管理员永久会员

支付宝扫一扫
微信扫一扫>打赏采集海报链接
文章采集功能(2.1.4获取文章发布时间的采集规则再次回到图23,找到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-08 16:23
2.1.4 获取文章采集发布时间规则
再次回到图23,找到“Published in:”和后面的“2009-09-29 14:21”,和前面获取采集规则的方法一样,这里应该是“Published in: [Content] "作为采集发布时间规则。同样,这里也不需要使用过滤规则。填充后,如图27所示,
图27-文章发布时间的采集规则
2.1.5 采集获取文章内容的规则
这部分是编写采集规则的重点和难点。需要特别注意。
具体步骤:
(一)回到开篇文章内容页的源码,找到文章内容的开头部分《Dreamweaver升级到8.0.2之后》 ,如图28所示,
图28-文章内容的开头
注意:这句话在源码中出现了两处。其中,第一句在“
在“之后,第二句在”
”之后。通过对比文章的内容页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章@内容的开头>. 因此,您应该选择“
”是匹配规则的开始。
(B) 找到文章内容的结尾部分“也是”wmode”参数加上了“transparent”的值”,如图29所示,
图29-文章的内容结束
注意:由于结束部分的最后一个标签是“
”,并且这个标签在文章的内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应于<内容的开头@文章,经过对比和分析,得出的结论是这里应该选“
”作为文章的内容结束,如图30所示,
图 30-文章 内容匹配规则结束
(C) 结合(a)和(b),可以看出这里文章的内容匹配规则应该是"
[内容]
》,填写后,如图31所示,
图31-文章的内容匹配规则
此处不使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
至此,“新建采集节点:第二步设置内容字段获取规则”,设置完成。填写后,如图(图32),
图32-设置后新添加的采集节点: 第二步,设置内容字段获取规则
检查无误后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“新建采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),
图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果单击“保存并启动采集”,您将进入“采集 指定节点”界面。否则请点击“返回上一步修改”。
第二部分的介绍到此结束。现在进入第三部分。. .
本文标签:dedecms、采集、函数、用法、---、不收录、分页、通用、文章、前言
相关文章
更令人兴奋的 查看全部
文章采集功能(2.1.4获取文章发布时间的采集规则再次回到图23,找到)
2.1.4 获取文章采集发布时间规则
再次回到图23,找到“Published in:”和后面的“2009-09-29 14:21”,和前面获取采集规则的方法一样,这里应该是“Published in: [Content] "作为采集发布时间规则。同样,这里也不需要使用过滤规则。填充后,如图27所示,

图27-文章发布时间的采集规则
2.1.5 采集获取文章内容的规则
这部分是编写采集规则的重点和难点。需要特别注意。
具体步骤:
(一)回到开篇文章内容页的源码,找到文章内容的开头部分《Dreamweaver升级到8.0.2之后》 ,如图28所示,

图28-文章内容的开头
注意:这句话在源码中出现了两处。其中,第一句在“
在“之后,第二句在”
”之后。通过对比文章的内容页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章@内容的开头>. 因此,您应该选择“
”是匹配规则的开始。
(B) 找到文章内容的结尾部分“也是”wmode”参数加上了“transparent”的值”,如图29所示,

图29-文章的内容结束
注意:由于结束部分的最后一个标签是“
”,并且这个标签在文章的内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应于<内容的开头@文章,经过对比和分析,得出的结论是这里应该选“
”作为文章的内容结束,如图30所示,

图 30-文章 内容匹配规则结束
(C) 结合(a)和(b),可以看出这里文章的内容匹配规则应该是"
[内容]
》,填写后,如图31所示,

图31-文章的内容匹配规则
此处不使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
至此,“新建采集节点:第二步设置内容字段获取规则”,设置完成。填写后,如图(图32),

图32-设置后新添加的采集节点: 第二步,设置内容字段获取规则
检查无误后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“新建采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),

图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果单击“保存并启动采集”,您将进入“采集 指定节点”界面。否则请点击“返回上一步修改”。
第二部分的介绍到此结束。现在进入第三部分。. .
本文标签:dedecms、采集、函数、用法、---、不收录、分页、通用、文章、前言
相关文章
更令人兴奋的
文章采集功能(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-07 19:03
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字批量搜索采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、 前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框确认你要的是哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择发布到采集结果下的部分或重新采集文本
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项
点击下载 查看全部
文章采集功能(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字批量搜索采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、 前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框确认你要的是哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择发布到采集结果下的部分或重新采集文本
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项


点击下载
文章采集功能(文章采集功能主要采集的示例代码,你需要的东西都能找到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-07 12:07
文章采集功能主要采集的就是自然语言文本,深度学习在这个领域采用的是mlp,其实主要就是拿了一个词嵌入对句子进行编码和预测。word2vec这里关于word2vec的概念可以自行百度mlm,它是wordembeddingmodel的缩写,是深度学习中模型和数据增强的方法。
去b站搜索mltriples,
我不是nlp人士,只能给出一些建议。这些网站现在都有开放的源代码,和下载这些网站上的示例代码。例如youtube,github,这些地方的的代码还是比较有规律的。一般在很多地方,都能找到他们的关联。我的个人网站就正好是这个,尽管我不是nlp人士,但是nlp入门这一块是完全没有问题的。基本你需要的东西都能找到,我的网站上有些示例代码,也有一些机器学习类的视频。推荐大家去看看。goodluck!!!。
谢邀。不过这两天学了nlp的lecture已经解决这个问题。首先nlp领域推荐词嵌入基本是经验,或者直接建立一个词表即可,词嵌入训练不方便。其次,对于输入文本,可以用mnn模型对字预测该词是否在前面或后面。然后考虑词向量的相似度。
你可以先用lsj的文本分类,近期又有一个awesomecorpus,可以看看那个部分,多关注一下他们官网的文章什么的,很久没有碰nlp了。 查看全部
文章采集功能(文章采集功能主要采集的示例代码,你需要的东西都能找到)
文章采集功能主要采集的就是自然语言文本,深度学习在这个领域采用的是mlp,其实主要就是拿了一个词嵌入对句子进行编码和预测。word2vec这里关于word2vec的概念可以自行百度mlm,它是wordembeddingmodel的缩写,是深度学习中模型和数据增强的方法。
去b站搜索mltriples,
我不是nlp人士,只能给出一些建议。这些网站现在都有开放的源代码,和下载这些网站上的示例代码。例如youtube,github,这些地方的的代码还是比较有规律的。一般在很多地方,都能找到他们的关联。我的个人网站就正好是这个,尽管我不是nlp人士,但是nlp入门这一块是完全没有问题的。基本你需要的东西都能找到,我的网站上有些示例代码,也有一些机器学习类的视频。推荐大家去看看。goodluck!!!。
谢邀。不过这两天学了nlp的lecture已经解决这个问题。首先nlp领域推荐词嵌入基本是经验,或者直接建立一个词表即可,词嵌入训练不方便。其次,对于输入文本,可以用mnn模型对字预测该词是否在前面或后面。然后考虑词向量的相似度。
你可以先用lsj的文本分类,近期又有一个awesomecorpus,可以看看那个部分,多关注一下他们官网的文章什么的,很久没有碰nlp了。
文章采集功能(什么是收集公众号数据的好工具?Data是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-07 02:03
微信现在是人们离不开的社交软件,它也为人们的交流提供了便利。微信公众号就是为此而生的,那么有什么工具可以采集到微信公众号的号码数据呢?让我们从下面的地形数据开始。
什么是采集公众号数据的好工具?
Tuto Data是采集公众号数据的好工具。工具操作简单采集微信公众号seo搜狗收录(微信公众号数据采集有什么好工具?先说数据),数据分析全面。实现多维数据分析和统计。有效帮助运营商管理公众号,促进公众号推广。确定并优化。
采集公众号数据的有用工具有哪些?如果要采集公众号数据,必须使用流量分析管理工具。例如,兔兔数据。
操作必备:本公众号数据采集工具,一分钟导出全部数据!
拖图数据-公众号数据分析工具
可以搜索全网公众号,导出公众号的所有数据和文章。它只是满足您的需求吗?
接下来去注册一个账号,绑定成功后就可以使用这个功能了。
第一步,停止公众号
搜索要采集的公众号,选择要获取的公众号,文章数据量和时区,也可以自定义,完成后保存。最后,我把它留了下来。我在测试过程中等了大约5分钟,所以速度还是很快的。
Step 2 公众号停止任务列表
查看详细信息后,采集到的数据一目了然。您可以在地形数据详情中查看采集中的数据,也可以批量下载导出数据。我在哪里可以找到这么方便的工具。
如果你学会使用这些操作,处理各种报表,就不会有问题了。
当然采集微信公众号seo搜狗收录,生成数据图表只是表面功能;它的核心是通过数据分析。导出数据后,会自动生成一些表。其中,“文章的每一次阅读”,一定是每个人都想知道的。
直观的粉丝口味数据,读取文章的人数排名,分析粉丝对这类文章的偏好。每个人都喜欢的是他们对有趣的话题更感兴趣。如果按照上面的方法,就可以用葫芦画了。刁,我总结一下。有了这些结论,以后写文章和选题会更有方向。
除了各种数据处理功能外,Topographic Data还可以搜索全网公众号文章、监控文章阅读量、监控新文章等功能。
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读和喜欢非常有价值。因此,文章 的采集和读取的获取机制限制在 2 秒。你每2秒采集一次微信数据,微信不会理你,但是如果你快点采集微信公众号seo搜狗收录,他会给你303响应并返回空数据给你。让你什么都不采集。
然后是获取文章列表的速度,不采集阅读计数。这个速度在前期没有限制。当您采集更多时,您的微信ID将被限制。
我们的软件为相关馆藏设置了可设置的时间限制。所以尽量使用这些限制。毕竟微信还有很多事情要做,必须要保护。
限制登录是一方面,限制数据采集是另一方面。在采集数据前等待 2 分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
一个可以采集微信公众号数据的工具 查看全部
文章采集功能(什么是收集公众号数据的好工具?Data是什么?)
微信现在是人们离不开的社交软件,它也为人们的交流提供了便利。微信公众号就是为此而生的,那么有什么工具可以采集到微信公众号的号码数据呢?让我们从下面的地形数据开始。
什么是采集公众号数据的好工具?
Tuto Data是采集公众号数据的好工具。工具操作简单采集微信公众号seo搜狗收录(微信公众号数据采集有什么好工具?先说数据),数据分析全面。实现多维数据分析和统计。有效帮助运营商管理公众号,促进公众号推广。确定并优化。
采集公众号数据的有用工具有哪些?如果要采集公众号数据,必须使用流量分析管理工具。例如,兔兔数据。
操作必备:本公众号数据采集工具,一分钟导出全部数据!
拖图数据-公众号数据分析工具
可以搜索全网公众号,导出公众号的所有数据和文章。它只是满足您的需求吗?
接下来去注册一个账号,绑定成功后就可以使用这个功能了。
第一步,停止公众号
搜索要采集的公众号,选择要获取的公众号,文章数据量和时区,也可以自定义,完成后保存。最后,我把它留了下来。我在测试过程中等了大约5分钟,所以速度还是很快的。
Step 2 公众号停止任务列表
查看详细信息后,采集到的数据一目了然。您可以在地形数据详情中查看采集中的数据,也可以批量下载导出数据。我在哪里可以找到这么方便的工具。
如果你学会使用这些操作,处理各种报表,就不会有问题了。
当然采集微信公众号seo搜狗收录,生成数据图表只是表面功能;它的核心是通过数据分析。导出数据后,会自动生成一些表。其中,“文章的每一次阅读”,一定是每个人都想知道的。
直观的粉丝口味数据,读取文章的人数排名,分析粉丝对这类文章的偏好。每个人都喜欢的是他们对有趣的话题更感兴趣。如果按照上面的方法,就可以用葫芦画了。刁,我总结一下。有了这些结论,以后写文章和选题会更有方向。
除了各种数据处理功能外,Topographic Data还可以搜索全网公众号文章、监控文章阅读量、监控新文章等功能。
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读和喜欢非常有价值。因此,文章 的采集和读取的获取机制限制在 2 秒。你每2秒采集一次微信数据,微信不会理你,但是如果你快点采集微信公众号seo搜狗收录,他会给你303响应并返回空数据给你。让你什么都不采集。
然后是获取文章列表的速度,不采集阅读计数。这个速度在前期没有限制。当您采集更多时,您的微信ID将被限制。
我们的软件为相关馆藏设置了可设置的时间限制。所以尽量使用这些限制。毕竟微信还有很多事情要做,必须要保护。
限制登录是一方面,限制数据采集是另一方面。在采集数据前等待 2 分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
一个可以采集微信公众号数据的工具
文章采集功能(优采云采集网页文章正文教程:自定义数据合并方式详解教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-05 19:09
数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法及详细步骤本文将以搜狗微信文章为例介绍优采云采集body的使用方法网页文章 。文章 一般正文收录文字和图片。本文将采集文章正文+图片网址。采集的以下字段:文章 标题、时间、来源和正文(正文中的所有文本将合并到一个excel单元格中,将使用“自定义数据合并方法”功能,请大家注意)同时采集文章正文中的文字+图片网址将使用“
网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“更多操作”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤三2)选择“循环点击单个元素”创建翻页循环。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信热门文章采集 方法步骤4 由于本网页涉及Ajax技术,需要设置一些高级选项。选择“点击元素”步骤,打开“ 高级选项”,勾选“Ajax加载数据”,时间设置为“2 信息内容仅供您学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集 方法步骤5 AJAX是一种延迟加载和异步更新的脚本技术。在后台与服务器进行少量数据交换后,可以用于某些网页,而无需重新加载整个网页。部分更新。性能特点:当你点击网页中的一个选项时,网站的大部分网址不会发生变化;网页未完全加载,但仅部分加载了已更改的数据。验证:点击操作后,在浏览器中,URL输入栏在加载状态或转动状态下不出现。观察网页,我们发现点击“加载更多内容”5次后,页面加载到最底部,共显示100篇文章。
因此,我们将整个“循环车削”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”。更正或删除。微信流行文章采集方法步骤6 第三步:创建列表循环并提取数据1) 移动鼠标,选择页面第一个文章链接。系统会自动识别类似链接。在操作提示框中,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信热点文章采集方法步骤七2)选择“ 首先点击第一段文字文章,系统会自动识别页面中的相似元素,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信热点文章采集 方法步骤10 可以看到所有的文本段落都被选中并变成了绿色。选择“采集 以下元素文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信人气文章采集方法步骤11 注:字段表中可自定义字段修改素材内容,仅供学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤12 经过以上操作后,文字将全部采集向下(默认是每段文字为一个单元。一般来说,我们希望采集,合并到同一个单元格中。方法 步骤14 材料内容仅供学习参考 如有不当或侵权,请联系更正或删除。如图,查看微信流行文章采集方法 Step 15 Step 4: Modify Xpath 选中整个“Circular Step”,打开“Advanced Options”,可以看到优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。
微信热门文章采集方法 步骤16 在火狐浏览器中打开想要采集的网页,查看源码。我们发现经过这个Xpath://DIV[@class=´main-left´]/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100页文章已定位,资料内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信热点文章采集 方法步骤17 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”微信热点文章采集方法步骤18 信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。第五步:修改流程图结构。让' s 继续观察。单击“加载更多内容”5 次后,此页面将加载所有 100 章。所以,我们配置规则的思路是先建立一个翻页循环,加载全部100个文章,创建一个循环列表,提取数据,选中整个“循环”步骤,拖出“循环翻页”步骤。如果不这样做,微信上就会有很多重复的数据。文章采集 方法步骤19 拖动完成后,下图信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤20步骤6:数据采集并导出点击左上角“保存”,然后点击“开始采集 》,选择“开始本地采集”信息内容仅供学习参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤21 2)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,采集好数据导出资料的内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤22 这里我们选择excel作为导出格式。数据导出后,下图内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤234)如上图,文章的部分正文没有采集到达。那' s 因为系统自动生成的文章文本循环列表的Xpath://[@id="js_content"]/P,找不到这个文章的文本。修改Xpath为://[@id="js_content"]//P,文章的所有文字都可以位于素材内容中,仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信热点文章采集方法步骤24 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信流行文章采集方法 Step 25 Step 7: 添加判断条件 经过上一步,我们只采集微信文章中的文字内容,不包括 文章 中的图片 URL。如果需要采集图片URL,则需要在规则中添加一个判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集 分支;
同时默认为左分支设置判断条件。如果满足这个判断条件,则分支向左分支;默认最右边的分支是“不判断,一直执行这个分支”,即不满足左边分支的判断条件时,执行最右边的分支。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。回到这个规则,即设置左分支的条件:如果收录img元素(图片),则执行左分支;如果不满足左条件分支的条件(即不收录img元素),则执行右分支。具体操作如下:1)从左边的工具栏中拖一个“ 如有不当或侵权,请联系更正或删除。右侧分支-检测结果一直是True 微信流行文章采集方法步骤28 3)点击左侧分支,在出现的结果页面中(分支条件检测结果-检测结果始终为 True ) 单击“确定”。
然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表图片),点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。点击左侧微信热点文章采集 方法步骤29 信息内容仅供您学习参考。如有不当或侵权,请联系更正或删除。对于左分支,设置判断条件微信热门文章采集 方法步骤30 设置左分支条件后,进行数据提取步骤。从左侧的工具栏中,拖入“提取数据”步骤 到流程图左侧分支(绿色加号处),在页面中选择一张图片,在操作提示框中选择“采集图片地址”信息内容仅供学习和参考。如有不当或侵权,请联系更正或删除。将新增的“提取数据”步骤拖入左侧分支微信热点文章采集 方法步骤31 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。采集图片地址微信热门文章采集方法步骤32选择右侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“
自定义定位元素方法微信流行文章采集方法第33步数据内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。元素匹配Xpath,“相对Xpath”微信流行文章采集 方法步骤34 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义定位元素” " "方法",引用右边分支相同位置的Xpath修改:"元素匹配Xpath"改为://*[@id="js_content"]/p[1]/img[1] ,“Relative Xpath”更改为:/img[1],然后点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤35 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义数据合并方法”,如图勾选。检查后,多次提取的文本将添加为字段。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤36 判断条件中各分支“提取数据”步骤中的字段名称必须相同,字段数必须相同。在这里,我们将左右分支中提取的字段名称更改为“文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤37如上,整个判断条件就设置好了。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章正文中的图片需要向下滚动才能加载,然后采集才能加载到正确的图片地址。因此,打开文章后,需要设置“页面加载后向下滚动”。这里设置滚动次数为“30”,滚动方式为“向下滚动一屏”,素材内容仅供大家学习参考,如有不当或侵权,请联系更正或删除微信文章正文中的图片,您需要向下滚动加载微信热门文章采集方法步骤38 数据内容供您使用仅供学习参考。如有不当或侵权,请联系更正或删除。加载设置页面后,向下滚动”微信流行文章采集方法步骤39 注意:这里的滚动次数、时间、方法设置会影响采集的速度和质量数据,本文仅供参考,大家可以根据需要设置10)重启采集,并导出数据,导出数据后,如图:导出数据微信人气文章采集 方法步骤40 数据内容仅供参考,如有不当或侵权,请联系更正或删除。数据示例 微信热门文章采集 方法步骤41 说明:由于搜狗微信文章中的图片,需要通过下拉Scroll加载出来。
在采集的过程中,等待图片加载的时间比较长,所以采集的速度比较慢。如果不需要采集图片,直接使用文本采集,不需要等待图片加载,采集会快很多。相关采集教程:京东商品信息采集新浪微博数据采集赶集招聘信息采集 优采云——70万用户精选的网页数据采集器 . 数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。操作简单,任何人都可以使用:无需技术背景,即可上网采集。全可视化流程,点击鼠标即可完成操作,功能强大,任意< @网站可用于:点击、登录、翻页、身份验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置进行设置采集。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 查看全部
文章采集功能(优采云采集网页文章正文教程:自定义数据合并方式详解教程)
数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法及详细步骤本文将以搜狗微信文章为例介绍优采云采集body的使用方法网页文章 。文章 一般正文收录文字和图片。本文将采集文章正文+图片网址。采集的以下字段:文章 标题、时间、来源和正文(正文中的所有文本将合并到一个excel单元格中,将使用“自定义数据合并方法”功能,请大家注意)同时采集文章正文中的文字+图片网址将使用“
网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“更多操作”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤三2)选择“循环点击单个元素”创建翻页循环。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信热门文章采集 方法步骤4 由于本网页涉及Ajax技术,需要设置一些高级选项。选择“点击元素”步骤,打开“ 高级选项”,勾选“Ajax加载数据”,时间设置为“2 信息内容仅供您学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集 方法步骤5 AJAX是一种延迟加载和异步更新的脚本技术。在后台与服务器进行少量数据交换后,可以用于某些网页,而无需重新加载整个网页。部分更新。性能特点:当你点击网页中的一个选项时,网站的大部分网址不会发生变化;网页未完全加载,但仅部分加载了已更改的数据。验证:点击操作后,在浏览器中,URL输入栏在加载状态或转动状态下不出现。观察网页,我们发现点击“加载更多内容”5次后,页面加载到最底部,共显示100篇文章。
因此,我们将整个“循环车削”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”。更正或删除。微信流行文章采集方法步骤6 第三步:创建列表循环并提取数据1) 移动鼠标,选择页面第一个文章链接。系统会自动识别类似链接。在操作提示框中,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信热点文章采集方法步骤七2)选择“ 首先点击第一段文字文章,系统会自动识别页面中的相似元素,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信热点文章采集 方法步骤10 可以看到所有的文本段落都被选中并变成了绿色。选择“采集 以下元素文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信人气文章采集方法步骤11 注:字段表中可自定义字段修改素材内容,仅供学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤12 经过以上操作后,文字将全部采集向下(默认是每段文字为一个单元。一般来说,我们希望采集,合并到同一个单元格中。方法 步骤14 材料内容仅供学习参考 如有不当或侵权,请联系更正或删除。如图,查看微信流行文章采集方法 Step 15 Step 4: Modify Xpath 选中整个“Circular Step”,打开“Advanced Options”,可以看到优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。
微信热门文章采集方法 步骤16 在火狐浏览器中打开想要采集的网页,查看源码。我们发现经过这个Xpath://DIV[@class=´main-left´]/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100页文章已定位,资料内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信热点文章采集 方法步骤17 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”微信热点文章采集方法步骤18 信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。第五步:修改流程图结构。让' s 继续观察。单击“加载更多内容”5 次后,此页面将加载所有 100 章。所以,我们配置规则的思路是先建立一个翻页循环,加载全部100个文章,创建一个循环列表,提取数据,选中整个“循环”步骤,拖出“循环翻页”步骤。如果不这样做,微信上就会有很多重复的数据。文章采集 方法步骤19 拖动完成后,下图信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤20步骤6:数据采集并导出点击左上角“保存”,然后点击“开始采集 》,选择“开始本地采集”信息内容仅供学习参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤21 2)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,采集好数据导出资料的内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤22 这里我们选择excel作为导出格式。数据导出后,下图内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤234)如上图,文章的部分正文没有采集到达。那' s 因为系统自动生成的文章文本循环列表的Xpath://[@id="js_content"]/P,找不到这个文章的文本。修改Xpath为://[@id="js_content"]//P,文章的所有文字都可以位于素材内容中,仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信热点文章采集方法步骤24 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信流行文章采集方法 Step 25 Step 7: 添加判断条件 经过上一步,我们只采集微信文章中的文字内容,不包括 文章 中的图片 URL。如果需要采集图片URL,则需要在规则中添加一个判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集 分支;
同时默认为左分支设置判断条件。如果满足这个判断条件,则分支向左分支;默认最右边的分支是“不判断,一直执行这个分支”,即不满足左边分支的判断条件时,执行最右边的分支。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。回到这个规则,即设置左分支的条件:如果收录img元素(图片),则执行左分支;如果不满足左条件分支的条件(即不收录img元素),则执行右分支。具体操作如下:1)从左边的工具栏中拖一个“ 如有不当或侵权,请联系更正或删除。右侧分支-检测结果一直是True 微信流行文章采集方法步骤28 3)点击左侧分支,在出现的结果页面中(分支条件检测结果-检测结果始终为 True ) 单击“确定”。
然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表图片),点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。点击左侧微信热点文章采集 方法步骤29 信息内容仅供您学习参考。如有不当或侵权,请联系更正或删除。对于左分支,设置判断条件微信热门文章采集 方法步骤30 设置左分支条件后,进行数据提取步骤。从左侧的工具栏中,拖入“提取数据”步骤 到流程图左侧分支(绿色加号处),在页面中选择一张图片,在操作提示框中选择“采集图片地址”信息内容仅供学习和参考。如有不当或侵权,请联系更正或删除。将新增的“提取数据”步骤拖入左侧分支微信热点文章采集 方法步骤31 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。采集图片地址微信热门文章采集方法步骤32选择右侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“
自定义定位元素方法微信流行文章采集方法第33步数据内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。元素匹配Xpath,“相对Xpath”微信流行文章采集 方法步骤34 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义定位元素” " "方法",引用右边分支相同位置的Xpath修改:"元素匹配Xpath"改为://*[@id="js_content"]/p[1]/img[1] ,“Relative Xpath”更改为:/img[1],然后点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤35 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义数据合并方法”,如图勾选。检查后,多次提取的文本将添加为字段。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤36 判断条件中各分支“提取数据”步骤中的字段名称必须相同,字段数必须相同。在这里,我们将左右分支中提取的字段名称更改为“文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤37如上,整个判断条件就设置好了。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章正文中的图片需要向下滚动才能加载,然后采集才能加载到正确的图片地址。因此,打开文章后,需要设置“页面加载后向下滚动”。这里设置滚动次数为“30”,滚动方式为“向下滚动一屏”,素材内容仅供大家学习参考,如有不当或侵权,请联系更正或删除微信文章正文中的图片,您需要向下滚动加载微信热门文章采集方法步骤38 数据内容供您使用仅供学习参考。如有不当或侵权,请联系更正或删除。加载设置页面后,向下滚动”微信流行文章采集方法步骤39 注意:这里的滚动次数、时间、方法设置会影响采集的速度和质量数据,本文仅供参考,大家可以根据需要设置10)重启采集,并导出数据,导出数据后,如图:导出数据微信人气文章采集 方法步骤40 数据内容仅供参考,如有不当或侵权,请联系更正或删除。数据示例 微信热门文章采集 方法步骤41 说明:由于搜狗微信文章中的图片,需要通过下拉Scroll加载出来。
在采集的过程中,等待图片加载的时间比较长,所以采集的速度比较慢。如果不需要采集图片,直接使用文本采集,不需要等待图片加载,采集会快很多。相关采集教程:京东商品信息采集新浪微博数据采集赶集招聘信息采集 优采云——70万用户精选的网页数据采集器 . 数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。操作简单,任何人都可以使用:无需技术背景,即可上网采集。全可视化流程,点击鼠标即可完成操作,功能强大,任意< @网站可用于:点击、登录、翻页、身份验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置进行设置采集。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。
文章采集功能(中考英语:文章采集功能的方法与方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-03 21:03
文章采集功能其实可以分成两块,输入和输出。输入一般分两块:形状特征和颜色特征,颜色特征一般有srcnn、dstnet、r-cnn系列等。dssd如果是输入一片单独的图片,可以直接获取文字特征;颜色特征用labelimg。形状特征通常用于实体识别、情感分析等。输出一般可以用svm、文字识别等方法。
说个题外话,从目前来看文本和图片搜索应该是同一个问题的两个方向:首先是从文本中提取相关信息:考虑一些情感依赖的特征,例如句子的色彩敏感度、句子的高亮词特性等,在语料中考虑非文本的内容,比如一句话的出现几次方式、词句的结构等,在这些文本中观察相似的文本是否可以匹配,从而提取特征,进而获得相关结构信息;其次是图片搜索,将文本特征投射到特定的图片上再进行相关信息提取。
大体分两块:形状特征和颜色特征。其中形状特征需要使用三角化变换/图像金字塔来做,形状不变只对颜色做调整难度大;颜色特征直接抽取xml字典中的特征即可,颜色变换通常应用于特征匹配,因为cnn可以学习到长距离相似性,比如是否近距离发现姓名相似。关于颜色特征,还可以用以下方法:1.reductionandmixingofreferenceregularization:为了达到比较好的效果,实验中需要把特征提取后再融合一遍来得到特征;2.pyramidpooling:把识别结果相近但颜色明显不同的的文本首尾连接起来;3.featureaugmentation:感受野做extraction,里面一部分用mixvariables和randomforests;4.mixvariables:特征融合,融合的方法就可以使用前面几种的组合;5.用tfnms优化highranking的结果。如果要提取粗糙特征,还有很多可以做。 查看全部
文章采集功能(中考英语:文章采集功能的方法与方法)
文章采集功能其实可以分成两块,输入和输出。输入一般分两块:形状特征和颜色特征,颜色特征一般有srcnn、dstnet、r-cnn系列等。dssd如果是输入一片单独的图片,可以直接获取文字特征;颜色特征用labelimg。形状特征通常用于实体识别、情感分析等。输出一般可以用svm、文字识别等方法。
说个题外话,从目前来看文本和图片搜索应该是同一个问题的两个方向:首先是从文本中提取相关信息:考虑一些情感依赖的特征,例如句子的色彩敏感度、句子的高亮词特性等,在语料中考虑非文本的内容,比如一句话的出现几次方式、词句的结构等,在这些文本中观察相似的文本是否可以匹配,从而提取特征,进而获得相关结构信息;其次是图片搜索,将文本特征投射到特定的图片上再进行相关信息提取。
大体分两块:形状特征和颜色特征。其中形状特征需要使用三角化变换/图像金字塔来做,形状不变只对颜色做调整难度大;颜色特征直接抽取xml字典中的特征即可,颜色变换通常应用于特征匹配,因为cnn可以学习到长距离相似性,比如是否近距离发现姓名相似。关于颜色特征,还可以用以下方法:1.reductionandmixingofreferenceregularization:为了达到比较好的效果,实验中需要把特征提取后再融合一遍来得到特征;2.pyramidpooling:把识别结果相近但颜色明显不同的的文本首尾连接起来;3.featureaugmentation:感受野做extraction,里面一部分用mixvariables和randomforests;4.mixvariables:特征融合,融合的方法就可以使用前面几种的组合;5.用tfnms优化highranking的结果。如果要提取粗糙特征,还有很多可以做。
文章采集功能(拓途数据:自媒体文章采集平台功能有哪些?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-19 16:03
自媒体是如今主流的媒体方式,自媒体的平台众多,这也方便了人们的相关营销操作,当然在自媒体运营过程中也经常需要进行文章爆文采集器,那么自媒体文章采集平台功能有哪些?跟随拓途数据一起看下吧。
自媒体文章采集的作用
1、可以在各个自媒体网站采集与自己领域相关的爆文,根据爆文进入作者主页,看作者账号整体阅读量如何,如果经常出爆文,那说明这就是一个优秀的同行,值得学习。
2、采集各个自媒体网站爆文,然后分析这些标题。每个领域的关键词的都有很多,比如美容行业,怎样才能知道历史领域有哪些关键词,哪些关键词比较热门呢?
这都需要进行数据分析,分析每个爆文标题,从中找出关键词,然后统计出来,通过大量的统计,就能分析出哪些关键词热门,哪些关键词流量大,容易出爆文。
自媒体文章采集平台的强大功能
智能采集,提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是贴吧论坛,支持所有业务渠道的爬虫,满足各种采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速准确获取数据。简单易用,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
拓途数据是很好的自媒体文章采集平台,本平台文章采集方便,而且收录了最新的热点内容,在文章采集后还可以进行排版操作,为人们的公众号文章发布提供了方便。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载别人的原创文章,公众号历史文章等知识点。 查看全部
文章采集功能(拓途数据:自媒体文章采集平台功能有哪些?)
自媒体是如今主流的媒体方式,自媒体的平台众多,这也方便了人们的相关营销操作,当然在自媒体运营过程中也经常需要进行文章爆文采集器,那么自媒体文章采集平台功能有哪些?跟随拓途数据一起看下吧。
自媒体文章采集的作用
1、可以在各个自媒体网站采集与自己领域相关的爆文,根据爆文进入作者主页,看作者账号整体阅读量如何,如果经常出爆文,那说明这就是一个优秀的同行,值得学习。
2、采集各个自媒体网站爆文,然后分析这些标题。每个领域的关键词的都有很多,比如美容行业,怎样才能知道历史领域有哪些关键词,哪些关键词比较热门呢?
这都需要进行数据分析,分析每个爆文标题,从中找出关键词,然后统计出来,通过大量的统计,就能分析出哪些关键词热门,哪些关键词流量大,容易出爆文。
自媒体文章采集平台的强大功能
智能采集,提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是贴吧论坛,支持所有业务渠道的爬虫,满足各种采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速准确获取数据。简单易用,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
拓途数据是很好的自媒体文章采集平台,本平台文章采集方便,而且收录了最新的热点内容,在文章采集后还可以进行排版操作,为人们的公众号文章发布提供了方便。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载别人的原创文章,公众号历史文章等知识点。
文章采集功能(YGBOOK轻量级小说网站系统MB适用版本介绍及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-09-18 03:12
Ygbook novel content management system(以下简称Ygbook)提供了一个基于ThinkPHP+MySQL技术开发的轻量级新颖网站解决方案
Ygbook是cms和网站小偷之间的一个新的网站系统。它对采集target网站数据进行批处理并存储数据。不仅URL完全不同,模板也不同,数据也属于自身。这是完全为站长解放他的双手。只需构建网站,您就可以自动采集+自动更新
该软件基于具有卓越搜索引擎优化性能的biquge模板,经过极大优化,为您呈现了一个全新的网站系统,具有卓越的搜索引擎优化性能和优雅的外观
Ygbook免费版提供基本新颖功能,包括:
1.全自动采集2345导航新颖数据,内置采集规则,无需自行设置管理
2.data warehousing,不用担心目标站的修改或挂起
3.网站本身提供小说介绍和章节列表的显示。章节阅读采用跳转到原站点的方式,避免版权问题
4.有自己的伪静态函数,但不能自由定制。没有移动版本,没有现场搜索,没有站点地图,也没有结构化数据
Ygbook是基于ThinkPHP+MySQL开发的,可以在大多数普通服务器上运行
如windows server、IIS+PHP+MYSQL
Linux服务器,Apache/nginx+PHP+MySQL
建议Linux服务器发挥更大的性能优势
下载地址:
文件名:ygbook novel采集system
文件大小:2.41MB适用版本:PHP
点击下载 查看全部
文章采集功能(YGBOOK轻量级小说网站系统MB适用版本介绍及使用方法)
Ygbook novel content management system(以下简称Ygbook)提供了一个基于ThinkPHP+MySQL技术开发的轻量级新颖网站解决方案
Ygbook是cms和网站小偷之间的一个新的网站系统。它对采集target网站数据进行批处理并存储数据。不仅URL完全不同,模板也不同,数据也属于自身。这是完全为站长解放他的双手。只需构建网站,您就可以自动采集+自动更新
该软件基于具有卓越搜索引擎优化性能的biquge模板,经过极大优化,为您呈现了一个全新的网站系统,具有卓越的搜索引擎优化性能和优雅的外观
Ygbook免费版提供基本新颖功能,包括:
1.全自动采集2345导航新颖数据,内置采集规则,无需自行设置管理
2.data warehousing,不用担心目标站的修改或挂起
3.网站本身提供小说介绍和章节列表的显示。章节阅读采用跳转到原站点的方式,避免版权问题
4.有自己的伪静态函数,但不能自由定制。没有移动版本,没有现场搜索,没有站点地图,也没有结构化数据
Ygbook是基于ThinkPHP+MySQL开发的,可以在大多数普通服务器上运行
如windows server、IIS+PHP+MYSQL
Linux服务器,Apache/nginx+PHP+MySQL
建议Linux服务器发挥更大的性能优势
 http://zlei.net/wp-content/upl ... 0.jpg 251w, http://zlei.net/wp-content/upl ... 8.jpg 768w, http://zlei.net/wp-content/upl ... 4.jpg 857w" />
http://zlei.net/wp-content/upl ... 0.jpg 251w, http://zlei.net/wp-content/upl ... 8.jpg 768w, http://zlei.net/wp-content/upl ... 4.jpg 857w" />下载地址:
文件名:ygbook novel采集system
文件大小:2.41MB适用版本:PHP
点击下载
文章采集功能(原帖.5说明您的列表页设置的有问题明明只需要采集其中 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-08 17:23
)
原帖由茄子发表于 2008-1-3 14:43
这意味着您的列表页面设置有问题
显然你只需要在其中一个列表页面上采集文章,为什么要写100个列表
茄子,你没看懂我的意思,可能是我没表达清楚
.
让我们举个例子。以SS5.5为例,我认为在这个列表页面的[论坛资源]下采集文章。因为里面的内容每天更新不超过5条(基本上是1-2条),所以我只需要设置采集每次的文章数量为例如5(注意不是40在整个列表页面)文章),并选择不允许标题重复采集,如果我每天运行采集器。这样,我只要每天跑一次采集,肯定能把采集里面的信息全部弄出来。
我提到的采集文章数设置是指这个设置:
但是如果换成SS6.0的逆序采集,同样的设置,我选的地永远是最后5个。为了得到最新的更新,我必须将文章采集数设置为列表页显示的文章的数量,这里是40。
但是想象一下如果某个网站他的列表页面在页面上显示200个文章...?假设这个网站每天更新的内容是前5,但是如果我想用逆序采集,你每次都要遍历这200条。
这就是我认为目前采集规则倒序不合理的地方。目前的规则是,运行采集器后,系统会先访问这个列表页面,记录所有符合规则的文章url,然后对这些URL从下到上或从上到下进行逆序或前序排序采集设置的文章内容数量。而且我觉得应该是系统访问,只记录从顶部开始设置文章采集的url数,然后按正序或反序执行采集,这样就解决了之前的问题。与目前的采集规则相比,只是多出了一步,但是这样一来,采集这个非常非常好的功能,将会有更广阔的实际应用空间。希望开发者可以考虑。
下面有图片说明:
希望这次我说清楚了
查看全部
文章采集功能(原帖.5说明您的列表页设置的有问题明明只需要采集其中
)
原帖由茄子发表于 2008-1-3 14:43

这意味着您的列表页面设置有问题
显然你只需要在其中一个列表页面上采集文章,为什么要写100个列表
茄子,你没看懂我的意思,可能是我没表达清楚

.
让我们举个例子。以SS5.5为例,我认为在这个列表页面的[论坛资源]下采集文章。因为里面的内容每天更新不超过5条(基本上是1-2条),所以我只需要设置采集每次的文章数量为例如5(注意不是40在整个列表页面)文章),并选择不允许标题重复采集,如果我每天运行采集器。这样,我只要每天跑一次采集,肯定能把采集里面的信息全部弄出来。
我提到的采集文章数设置是指这个设置:
但是如果换成SS6.0的逆序采集,同样的设置,我选的地永远是最后5个。为了得到最新的更新,我必须将文章采集数设置为列表页显示的文章的数量,这里是40。
但是想象一下如果某个网站他的列表页面在页面上显示200个文章...?假设这个网站每天更新的内容是前5,但是如果我想用逆序采集,你每次都要遍历这200条。
这就是我认为目前采集规则倒序不合理的地方。目前的规则是,运行采集器后,系统会先访问这个列表页面,记录所有符合规则的文章url,然后对这些URL从下到上或从上到下进行逆序或前序排序采集设置的文章内容数量。而且我觉得应该是系统访问,只记录从顶部开始设置文章采集的url数,然后按正序或反序执行采集,这样就解决了之前的问题。与目前的采集规则相比,只是多出了一步,但是这样一来,采集这个非常非常好的功能,将会有更广阔的实际应用空间。希望开发者可以考虑。
下面有图片说明:
希望这次我说清楚了
文章采集功能(本文采集指定节点和“如何导出采集内容”的说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-08 17:18
前言:本文为《无分页的常见文章采集方法》第三部分。在前两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集内容”进行详细说明。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
(本图来源于网络,如有侵权请联系删除!)
图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
设置完成并确认后,您可以点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),
(本图来源于网络,如有侵权请联系删除!)
图35-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,会出现相关提示,如图36),
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,
(本图来源于网络,如有侵权请联系删除!)
图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
(本图来源于网络,如有侵权请联系删除!)
图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
(本图来源于网络,如有侵权请联系删除!)
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,
(本图来源于网络,如有侵权请联系删除!)
图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
上一篇:如何使用Dedecms采集功能---图片采集(一)
下一篇:Dedecms采集函数的使用方法---不分页的普通文章(二)
声明:本站所有文章和图片均来自用户分享和网络采集。 文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
Eyoucms,易于使用的enterprise网站管理系统,点击了解更多
有什么问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注您的用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群
来源:网友提供 关注:时间:2018-01-28 12:48
☉首先,只要是我们的VIP会员,所有源代码都可以免费下载,没有任何限制(了解更多)
☉本站源码不会像其他下载站那样植入大量广告。为了更好的用户体验,以后坚持不打印水印
☉本站只提供精品织梦源代码,源代码可用,不多! !希望在这里找到合适的你。
☉本站提供的整个织梦程序都有数据和演示地址。可以在任意源码详情页查看demo地址
☉本站所有资源(包括源代码、模板、素材、特效等)仅供学习参考,请勿用于商业用途。
☉如有其他问题,请加网站客服QQ(970003436))交流。 查看全部
文章采集功能(本文采集指定节点和“如何导出采集内容”的说明)
前言:本文为《无分页的常见文章采集方法》第三部分。在前两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集内容”进行详细说明。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),

(本图来源于网络,如有侵权请联系删除!)
图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
设置完成并确认后,您可以点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),

(本图来源于网络,如有侵权请联系删除!)
图35-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,会出现相关提示,如图36),

(本图来源于网络,如有侵权请联系删除!)

(本图来源于网络,如有侵权请联系删除!)

(本图来源于网络,如有侵权请联系删除!)
图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,

(本图来源于网络,如有侵权请联系删除!)
图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),

(本图来源于网络,如有侵权请联系删除!)
图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),

(本图来源于网络,如有侵权请联系删除!)
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),

(本图来源于网络,如有侵权请联系删除!)

(本图来源于网络,如有侵权请联系删除!)

(本图来源于网络,如有侵权请联系删除!)
图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,

(本图来源于网络,如有侵权请联系删除!)
图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
上一篇:如何使用Dedecms采集功能---图片采集(一)
下一篇:Dedecms采集函数的使用方法---不分页的普通文章(二)
声明:本站所有文章和图片均来自用户分享和网络采集。 文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
Eyoucms,易于使用的enterprise网站管理系统,点击了解更多

有什么问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注您的用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群
来源:网友提供 关注:时间:2018-01-28 12:48
☉首先,只要是我们的VIP会员,所有源代码都可以免费下载,没有任何限制(了解更多)
☉本站源码不会像其他下载站那样植入大量广告。为了更好的用户体验,以后坚持不打印水印
☉本站只提供精品织梦源代码,源代码可用,不多! !希望在这里找到合适的你。
☉本站提供的整个织梦程序都有数据和演示地址。可以在任意源码详情页查看demo地址
☉本站所有资源(包括源代码、模板、素材、特效等)仅供学习参考,请勿用于商业用途。
☉如有其他问题,请加网站客服QQ(970003436))交流。
文章采集功能(网络数据采集器,一款简易合理功能齐全的文章采集手机软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-07 02:07
网络数据采集器,一款简单、合理、功能齐全的文章采集手机软件
优采云全能文章采集器是一款简单、合理、功能齐全的文章采集手机软件。您只需要能输入关键词,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,省时省力;本站编辑为大家制作的是优采云全能文章采集器翡翠完全免费破解版下载,双击鼠标打开应用,手机软件已经破解极端情况下,无需注册链接即可免费试用。,热忱欢迎喜欢的朋友免费下载。文章采集 关键来自以下百度搜索引擎:百度搜索网页、百度新闻、搜狗搜索网页、
功能特点:
一、借助全能的文章人体识别优化算法,可以自动获取所有网页文章,准确率达到95%以上。
二、只需输入关键字,即可采集百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻及网页、bing搜索新闻报道及网页、雅虎;批处理关键字自动为采集。
三、可以指定采集所有文章在特定的URL通道目录下,智能系统匹配,无需编写复杂的标准。
四、文章翻译功能,可以将采集好文章从中文翻译成英文再翻译回中文实现翻译原创文章 ,适用于谷歌和有道翻译。
五、史上最简单最智能文章采集器,适合多功能使用,实际效果一试就知道!
请查看免费软件下载 查看全部
文章采集功能(网络数据采集器,一款简易合理功能齐全的文章采集手机软件)
网络数据采集器,一款简单、合理、功能齐全的文章采集手机软件
优采云全能文章采集器是一款简单、合理、功能齐全的文章采集手机软件。您只需要能输入关键词,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,省时省力;本站编辑为大家制作的是优采云全能文章采集器翡翠完全免费破解版下载,双击鼠标打开应用,手机软件已经破解极端情况下,无需注册链接即可免费试用。,热忱欢迎喜欢的朋友免费下载。文章采集 关键来自以下百度搜索引擎:百度搜索网页、百度新闻、搜狗搜索网页、
功能特点:
一、借助全能的文章人体识别优化算法,可以自动获取所有网页文章,准确率达到95%以上。
二、只需输入关键字,即可采集百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻及网页、bing搜索新闻报道及网页、雅虎;批处理关键字自动为采集。
三、可以指定采集所有文章在特定的URL通道目录下,智能系统匹配,无需编写复杂的标准。
四、文章翻译功能,可以将采集好文章从中文翻译成英文再翻译回中文实现翻译原创文章 ,适用于谷歌和有道翻译。
五、史上最简单最智能文章采集器,适合多功能使用,实际效果一试就知道!
请查看免费软件下载
文章采集功能(用过文章采集器——优采云采集器V9十一项强大的数据处理功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-07 02:06
用过优采云采集器的朋友都知道,优采云采集器是所有文章采集器中最全面的数据处理功能,因此是User被誉为最经典的采集软件,这里为大家详细介绍文章采集器——优采云采集器V9十一强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对从内容页面中提取的信息数据的进一步处理,如替换、过滤等,可以使用优采云采集器同时添加多个操作,多个操作按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。下面依次说明:
1、 提取的内容为空:即如果提取的内容为空,则重新从原页面中提取正则匹配的内容。
2、内容替换/排除:顾名思义,就是用字符串替换采集的内容。如果您需要排除它,只需将其替换为空字符串即可。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由繁体转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符 字符串长度等一系列函数。
9、完成单个网址:将当前内容补全为一个网址。
10、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
11、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种网站,轻松将数据处理成我们需要的形式,省时省力。优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。 查看全部
文章采集功能(用过文章采集器——优采云采集器V9十一项强大的数据处理功能)
用过优采云采集器的朋友都知道,优采云采集器是所有文章采集器中最全面的数据处理功能,因此是User被誉为最经典的采集软件,这里为大家详细介绍文章采集器——优采云采集器V9十一强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对从内容页面中提取的信息数据的进一步处理,如替换、过滤等,可以使用优采云采集器同时添加多个操作,多个操作按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。下面依次说明:
1、 提取的内容为空:即如果提取的内容为空,则重新从原页面中提取正则匹配的内容。
2、内容替换/排除:顾名思义,就是用字符串替换采集的内容。如果您需要排除它,只需将其替换为空字符串即可。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由繁体转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符 字符串长度等一系列函数。
9、完成单个网址:将当前内容补全为一个网址。
10、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
11、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种网站,轻松将数据处理成我们需要的形式,省时省力。优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。
文章采集功能(新闻源文章生成器是一款功能十分强大的新闻文章自动生成工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2021-11-06 10:17
新闻源文章新闻源文章生成器是一款非常强大的新闻源文章自动生成工具,想要使用本软件破解版的用户自行下载,相信一定对大家有帮助。
<IMG border=0 hspace=0 alt=新闻源文章生成器 src="https://www.mt30.com/uploads/S ... ot%3B onload=resizepic(this)>
新闻来源文章生成器介绍:
<p>新闻源文章生成器,可以快速帮你自动生成文章,专为医疗行业新闻源文章生成软件,支持自动采集 文章、批量采集文章链接、将采集中的文章保存为本地txt文件等功能非常强大,大家可以试试。 查看全部
文章采集功能(新闻源文章生成器是一款功能十分强大的新闻文章自动生成工具)
新闻源文章新闻源文章生成器是一款非常强大的新闻源文章自动生成工具,想要使用本软件破解版的用户自行下载,相信一定对大家有帮助。
<IMG border=0 hspace=0 alt=新闻源文章生成器 src="https://www.mt30.com/uploads/S ... ot%3B onload=resizepic(this)>
新闻来源文章生成器介绍:
<p>新闻源文章生成器,可以快速帮你自动生成文章,专为医疗行业新闻源文章生成软件,支持自动采集 文章、批量采集文章链接、将采集中的文章保存为本地txt文件等功能非常强大,大家可以试试。
文章采集功能(一个APP必备的日志功能,不是直接使用.body)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-02 23:05
日志采集是APP的必备功能,可以方便开发者快速定位和解决问题,那么在使用okhttp时我们应该如何添加日志功能呢?
直接干货
private class LogInterceptor implements Interceptor {
@Override
public okhttp3.Response intercept(Chain chain) throws IOException {
Request request = chain.request();
Log.v(TAG, "request:" + request.toString());
long t1 = System.nanoTime();
okhttp3.Response response = chain.proceed(chain.request());
long t2 = System.nanoTime();
Log.v(TAG, String.format(Locale.getDefault(), "Received response for %s in %.1fms%n%s",
response.request().url(), (t2 - t1) / 1e6d, response.headers()));
okhttp3.MediaType mediaType = response.body().contentType();
String content = response.body().string();
Log.i(TAG, "response body:" + content);
return response.newBuilder()
.body(okhttp3.ResponseBody.create(mediaType, content))
.build();
}
}
...
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.addInterceptor(new LogInterceptor())
.build();
首先我们实现了一个拦截器LogInterceptor,它做了三件事:打印请求内容->执行请求->打印响应内容,过程简单明了。但是有一个地方需要注意。调用 response.body().string() 方法后,响应中的流将被关闭。我们需要通过response.peekBody()方法创建一个新的响应供应用层处理 复制一个ResponseBody,使用这个临时的ResponseBody来打印body的内容,而不是直接使用response.body().string()(这个方法在header的content-length不确定的时候会报错,谢谢推送键盘男kkmike999的修正)。快手的同学已经打完代码,再次验证,
为什么是这样?谈话很便宜,给我看代码。先看 response.body().string() 的实现
public final String string() throws IOException {
return new String(bytes(), charset().name());
}
string() 调用 bytes() 来获取内容
public final byte[] bytes() throws IOException {
//省略部分代码
BufferedSource source = source();
byte[] bytes;
try {
bytes = source.readByteArray();
} finally {
Util.closeQuietly(source);
}
//省略部分代码
return bytes;
}
在bytes()方法中,首先获取BufferedSource,然后读取BufferedSource中的内容,最后关闭BufferedSource中的文件流。似乎没有问题。等等,我们在拦截器中关闭了BufferedSource中的文件流,而ResponseBody中并没有对应的数据缓存,所以我们在拦截器之外获取body的内容失败,一切终于水落石出。
可以看到,我们相当于在拦截器中手动处理了网络请求的整个过程,也就是说在拦截器中可以做很多事情,比如虚拟返回结果等,这些不是内容本文。.
更新
使用Logging Interceptor可以轻松实现日志功能,请参考详情
参考内容:
[1]。 查看全部
文章采集功能(一个APP必备的日志功能,不是直接使用.body)
日志采集是APP的必备功能,可以方便开发者快速定位和解决问题,那么在使用okhttp时我们应该如何添加日志功能呢?
直接干货
private class LogInterceptor implements Interceptor {
@Override
public okhttp3.Response intercept(Chain chain) throws IOException {
Request request = chain.request();
Log.v(TAG, "request:" + request.toString());
long t1 = System.nanoTime();
okhttp3.Response response = chain.proceed(chain.request());
long t2 = System.nanoTime();
Log.v(TAG, String.format(Locale.getDefault(), "Received response for %s in %.1fms%n%s",
response.request().url(), (t2 - t1) / 1e6d, response.headers()));
okhttp3.MediaType mediaType = response.body().contentType();
String content = response.body().string();
Log.i(TAG, "response body:" + content);
return response.newBuilder()
.body(okhttp3.ResponseBody.create(mediaType, content))
.build();
}
}
...
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.addInterceptor(new LogInterceptor())
.build();
首先我们实现了一个拦截器LogInterceptor,它做了三件事:打印请求内容->执行请求->打印响应内容,过程简单明了。但是有一个地方需要注意。调用 response.body().string() 方法后,响应中的流将被关闭。我们需要通过response.peekBody()方法创建一个新的响应供应用层处理 复制一个ResponseBody,使用这个临时的ResponseBody来打印body的内容,而不是直接使用response.body().string()(这个方法在header的content-length不确定的时候会报错,谢谢推送键盘男kkmike999的修正)。快手的同学已经打完代码,再次验证,
为什么是这样?谈话很便宜,给我看代码。先看 response.body().string() 的实现
public final String string() throws IOException {
return new String(bytes(), charset().name());
}
string() 调用 bytes() 来获取内容
public final byte[] bytes() throws IOException {
//省略部分代码
BufferedSource source = source();
byte[] bytes;
try {
bytes = source.readByteArray();
} finally {
Util.closeQuietly(source);
}
//省略部分代码
return bytes;
}
在bytes()方法中,首先获取BufferedSource,然后读取BufferedSource中的内容,最后关闭BufferedSource中的文件流。似乎没有问题。等等,我们在拦截器中关闭了BufferedSource中的文件流,而ResponseBody中并没有对应的数据缓存,所以我们在拦截器之外获取body的内容失败,一切终于水落石出。
可以看到,我们相当于在拦截器中手动处理了网络请求的整个过程,也就是说在拦截器中可以做很多事情,比如虚拟返回结果等,这些不是内容本文。.
更新
使用Logging Interceptor可以轻松实现日志功能,请参考详情
参考内容:
[1]。
文章采集功能(文章采集功能挺好用的,操作简单,同时可以分享到社交网络)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-30 14:04
文章采集功能挺好用的,操作简单,同时可以分享到社交网络,几乎能满足你所有要求。我写过一篇小文,你可以看看。
我也想要这个需求
如果是为了提取互联网流量,搜索引擎关键词回链不好用,
你可以看看百度新传媒的视频,
我看过一个名为“要图”的公众号,号称“母婴资源图床”,里面还有很多婴儿绘本,电器啊、医疗器械,孕妇小米、宝宝潮爆款等等好多,
图说生活,照片和视频内容解析社区
腾讯新闻里面好像有~
有类似的功能百度新闻也有搜索关键词
很多呢,比如那些育儿的等等都有一些,
很多就是一些育儿,母婴的资源,很多,
问问新媒体发起的创作者吧,你们现在也可以帮很多妈妈发布内容,把产品信息,或者父母一些健康知识等等发布进去,很多图书杂志,也会来找创作者合作。
app
很多呀,知道一个母婴图书app,shebtish,
腾讯自己的公众号里面就有不少百度文库里也有不少
已经有人回答了
搜狗可以搜索到收录图片哦
有。易图网。这里有很多免费的,甚至是免费下载的哦。
闲鱼旗下的闲鱼图书馆。每天免费分享图片。有优质的图片。百度百科也有。图说生活也可以做到。好吧,就是这么直白。 查看全部
文章采集功能(文章采集功能挺好用的,操作简单,同时可以分享到社交网络)
文章采集功能挺好用的,操作简单,同时可以分享到社交网络,几乎能满足你所有要求。我写过一篇小文,你可以看看。
我也想要这个需求
如果是为了提取互联网流量,搜索引擎关键词回链不好用,
你可以看看百度新传媒的视频,
我看过一个名为“要图”的公众号,号称“母婴资源图床”,里面还有很多婴儿绘本,电器啊、医疗器械,孕妇小米、宝宝潮爆款等等好多,
图说生活,照片和视频内容解析社区
腾讯新闻里面好像有~
有类似的功能百度新闻也有搜索关键词
很多呢,比如那些育儿的等等都有一些,
很多就是一些育儿,母婴的资源,很多,
问问新媒体发起的创作者吧,你们现在也可以帮很多妈妈发布内容,把产品信息,或者父母一些健康知识等等发布进去,很多图书杂志,也会来找创作者合作。
app
很多呀,知道一个母婴图书app,shebtish,
腾讯自己的公众号里面就有不少百度文库里也有不少
已经有人回答了
搜狗可以搜索到收录图片哦
有。易图网。这里有很多免费的,甚至是免费下载的哦。
闲鱼旗下的闲鱼图书馆。每天免费分享图片。有优质的图片。百度百科也有。图说生活也可以做到。好吧,就是这么直白。
文章采集功能(基于ZANUI2框架开发小程序前端框架基于ZanUI2的CMS内容管理系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-10-26 01:09
支持注册会员评论功能,支持评论邮件通知功能
单页模块
支持任意单页创建,支持单页点赞、点赞、评论功能
贡献模块
支持注册会员投稿,支持任意控制投稿字段和投稿栏目
统计控制台
会员统计、文章排名、热门搜索、热门标签、订单日/周/月/年统计
回收站
文章、评论、单页、话题支持回收站功能,支持一键清空回收
管理员数据控制
管理员只管理自己发布的数据,支持对文档、区块、主题、自定义表单的控制
多列
支持一个文档属于多个子栏目功能,支持一个文档属于多个主题
列权限
支持后台添加不同的管理员分配不同的栏目权限
网站地图
支持生成文档页和标签页的站点地图地址
API接口
提供API接口,可用于连接第三方或传输现有网站数据
研究所有
支持一键集成迅搜全文搜索插件搜索更强大
专题模块
强大的专题模块、可定制的专题模板、标签关联数据
禁止词检测
强大的违禁词检测,支持自定义和百度AI接口调用
关键词提取
一键提取关键词和描述,支持本地和百度AI接口调用
无缝整合
支持无缝集成微信支付宝、会员充值、富文本、云存储插件
自动内链
支持自定义内链文字,支持设置文章标签自动内链
标签生成器
支持文章模板标签、列模板标签、单页模板标签、SQL调用模板标签
UniAPP版本
UniAPP版支持会员文章模板,支持自定义表单,会员签到排名功能
移动风格
UniAPP 版本支持自定义 UniAPP 版本样式、颜色、颜色、底部标签等。
cms微信小程序
基于thinkPHP的cms内容管理系统可以快速创建您的微信小程序,快速开发您的第一个小程序。
基于ZANUI2框架开发
小程序前端框架基于ZanUI2进行二次开发,同时封装了很多实用的方法,方便你的二次开发
多终端数据同步
后台发布数据库,web端和小程序端同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
小程序演示
请使用微信扫描二维码查看cms小程序演示
全端移动cms内容管理系统仅限高级授权
基于UniAPP开发的全端移动cms内容管理系统,可快速创建微信小程序、安卓应用、苹果应用。
支持会员移动端发布文章、自定义表单、会员登录及排名、文章搜索等功能。
基于UniAPP+uView开发
基于UniAPP+uView前端框架开发,更流畅便捷的小程序+APP开发
多终端数据同步
后台发布数据库,网页、小程序、APP同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
安卓APP演示
请使用微信或浏览器扫描二维码安装安卓APP体验
富文本编辑器
多达十个 cms 富文本编辑器可供选择
会员充值余额插件
付费功能必备,可集成cms付费阅读和cms付费下载
微信支付宝集成插件
可与cms付费阅读和cms付费下载一起使用 查看全部
文章采集功能(基于ZANUI2框架开发小程序前端框架基于ZanUI2的CMS内容管理系统)
支持注册会员评论功能,支持评论邮件通知功能
单页模块
支持任意单页创建,支持单页点赞、点赞、评论功能
贡献模块
支持注册会员投稿,支持任意控制投稿字段和投稿栏目
统计控制台
会员统计、文章排名、热门搜索、热门标签、订单日/周/月/年统计
回收站
文章、评论、单页、话题支持回收站功能,支持一键清空回收
管理员数据控制
管理员只管理自己发布的数据,支持对文档、区块、主题、自定义表单的控制
多列
支持一个文档属于多个子栏目功能,支持一个文档属于多个主题
列权限
支持后台添加不同的管理员分配不同的栏目权限
网站地图
支持生成文档页和标签页的站点地图地址
API接口
提供API接口,可用于连接第三方或传输现有网站数据
研究所有
支持一键集成迅搜全文搜索插件搜索更强大
专题模块
强大的专题模块、可定制的专题模板、标签关联数据
禁止词检测
强大的违禁词检测,支持自定义和百度AI接口调用
关键词提取
一键提取关键词和描述,支持本地和百度AI接口调用
无缝整合
支持无缝集成微信支付宝、会员充值、富文本、云存储插件
自动内链
支持自定义内链文字,支持设置文章标签自动内链
标签生成器
支持文章模板标签、列模板标签、单页模板标签、SQL调用模板标签
UniAPP版本
UniAPP版支持会员文章模板,支持自定义表单,会员签到排名功能
移动风格
UniAPP 版本支持自定义 UniAPP 版本样式、颜色、颜色、底部标签等。
cms微信小程序
基于thinkPHP的cms内容管理系统可以快速创建您的微信小程序,快速开发您的第一个小程序。
基于ZANUI2框架开发
小程序前端框架基于ZanUI2进行二次开发,同时封装了很多实用的方法,方便你的二次开发
多终端数据同步
后台发布数据库,web端和小程序端同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
小程序演示
请使用微信扫描二维码查看cms小程序演示
全端移动cms内容管理系统仅限高级授权
基于UniAPP开发的全端移动cms内容管理系统,可快速创建微信小程序、安卓应用、苹果应用。
支持会员移动端发布文章、自定义表单、会员登录及排名、文章搜索等功能。
基于UniAPP+uView开发
基于UniAPP+uView前端框架开发,更流畅便捷的小程序+APP开发
多终端数据同步
后台发布数据库,网页、小程序、APP同步显示数据,并自动转换小程序格式
综合会员账户
会员中心可以绑定web端账号,实现账号在迷你端和web端的统一更新和展示
安卓APP演示
请使用微信或浏览器扫描二维码安装安卓APP体验
富文本编辑器
多达十个 cms 富文本编辑器可供选择
会员充值余额插件
付费功能必备,可集成cms付费阅读和cms付费下载
微信支付宝集成插件
可与cms付费阅读和cms付费下载一起使用
文章采集功能(特有10大采集功能:音乐采集,动画采集,让你更方面管理网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-23 17:22
独有的10大采集功能:音乐采集、电影采集、软件采集、MTV采集、新闻采集、文章 采集、日记采集、贴纸采集、相册采集、动画采集,让你管理更多网站
本系统是采用成熟稳定的网络ASP+Access/SQL技术开发的一套开源WEB网站管理系统。通过它,您可以轻松管理自己网站。目前的系统具有以下特点:
用户管理,多用户管理按权限发布和管理软件信息;用户短信、收款功能、会员在线充值、支持网银和NPS在线支付。
下载模块,支持积分会员和包月会员下载、反积分等功能,无限添加下载服务器,可以为每个下载服务器路径设置用户下载权限和下载积分设置,添加软件只需填写软件即可姓名
文章,FLASH模块,会员浏览文章权限设置。
广告管理功能全部由系统生成的JS文件管理,无需修改广告代码后重新生成HTML文件;
强大的模板后台可以灵活自由的生成模板标签和JS自动生成,让您的网站布局随心所欲改变。
强大的文章,软件采集功能,文章采集还可以选择是否下载图片到本地和页面采集。
其他模块,留言,友情连接自助申请,上传水印,内容关键词功能。
在整个站点上生成 HTML 页面;增加系统安全性,自由设置生成的HTML文件的扩展名和存储目录
完善的上传文件清理功能,为您清除垃圾文件;
添加网站代码广告
添加迅雷专用下载连接
增加多系统集成API接口
更新网上支付功能
更新模板导入/导出功能
更新自定义标签导入/导出功能
更新发布文章和软件审核功能
修补会员管理安全漏洞
增强系统安全性
修复已知错误
还有MV、影院、下载、论坛、心情日记、贴图、相册、搜索、推荐、flash相册、个人... 查看全部
文章采集功能(特有10大采集功能:音乐采集,动画采集,让你更方面管理网站)
独有的10大采集功能:音乐采集、电影采集、软件采集、MTV采集、新闻采集、文章 采集、日记采集、贴纸采集、相册采集、动画采集,让你管理更多网站
本系统是采用成熟稳定的网络ASP+Access/SQL技术开发的一套开源WEB网站管理系统。通过它,您可以轻松管理自己网站。目前的系统具有以下特点:
用户管理,多用户管理按权限发布和管理软件信息;用户短信、收款功能、会员在线充值、支持网银和NPS在线支付。
下载模块,支持积分会员和包月会员下载、反积分等功能,无限添加下载服务器,可以为每个下载服务器路径设置用户下载权限和下载积分设置,添加软件只需填写软件即可姓名
文章,FLASH模块,会员浏览文章权限设置。
广告管理功能全部由系统生成的JS文件管理,无需修改广告代码后重新生成HTML文件;
强大的模板后台可以灵活自由的生成模板标签和JS自动生成,让您的网站布局随心所欲改变。
强大的文章,软件采集功能,文章采集还可以选择是否下载图片到本地和页面采集。
其他模块,留言,友情连接自助申请,上传水印,内容关键词功能。
在整个站点上生成 HTML 页面;增加系统安全性,自由设置生成的HTML文件的扩展名和存储目录
完善的上传文件清理功能,为您清除垃圾文件;
添加网站代码广告
添加迅雷专用下载连接
增加多系统集成API接口
更新网上支付功能
更新模板导入/导出功能
更新自定义标签导入/导出功能
更新发布文章和软件审核功能
修补会员管理安全漏洞
增强系统安全性
修复已知错误
还有MV、影院、下载、论坛、心情日记、贴图、相册、搜索、推荐、flash相册、个人...
文章采集功能(2.关联对应版块或游戏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-18 08:06
2.关联对应的版块或游戏
如果你想在特定版块发布内容,那么你可以在输入框中填写关键词,它会自动将某个版块与鼠标关联并点击。连接游戏也是如此。
一般情况下,我们的游戏库会尽量覆盖市面上大部分的游戏,所以如果你的文章是游戏主题的话,一般不会有问题。但由于时间和精力,我们可能偶尔会错过一些比赛。如果您发现我们的数据库中没有您想写的游戏,您可以将您的文章提交到“Game Talk”区,然后在正文开头写上【游戏:XXX】。我们会尽快将此游戏添加到数据库中。
3.配件
文章页面的辅助工具从左到右依次为:表情、表格、分隔符、图片、视频。
相信表情符号和分隔符就不用说了。
床单。使用表格时,您可能会发现行数和列数是有限的。这个设置的原因是我们不鼓励在文章中使用大表格,它的阅读体验并不友好。但如果真的需要使用10*10以上的表格,请先使用Excel等软件应用创建表格,然后复制到文章编辑页面。
图片。图片大小会影响文章的加载速度,所以图片大小不宜过大。建议静态图片不超过500kb,动态图片不超过2mb。可以使用这款免费的图片压缩工具(免费版有每次启动压缩张数的限制)进行压缩,静态图片和动态图片都可以。
视频。将你需要的视频上传到bilibili,具体方法如下:
首先,打开bilibili主页,登录bilibili账号。单击右上角的粉红色“提交”按钮。
然后你会进入一个视频提交页面,点击蓝色的“上传视频”按钮,在弹出的文件选择窗口中选择你要上传的视频文件。或者您可以将视频直接拖动到图标区域。视频格式推荐使用mp4,可以节省一定的转码审核时间。
接下来,您将进入视频上传页面。在等待视频上传的同时,填写标题、简介、标签等项目,选择类型和部门。全部完成后,点击页面底部的“立即提交”按钮,提交完成。
然后你会在“创作中心-内容管理-稿件管理”页面看到你提交的视频,等待审核通过。
稿件通过后,可以在自己的俱乐部插入刚刚审过的视频文章~点击视频,找到视频下方的“分享”按钮。鼠标悬停后,会弹出一个界面。复制“嵌入代码”以备后用。
回到俱乐部编辑界面,将光标放在要插入视频的位置,点击工具栏中的“B站”按钮。将出现如下所示的输入框。将刚才复制的“嵌入码”粘贴到输入框In,然后回车,视频就插入成功了~
4.文字
随心所欲地写吧!
这里给大家一个小建议:多段,只要你愿意,每行一个句子也是可以的。
接下来说说页面的右半部分: 查看全部
文章采集功能(2.关联对应版块或游戏)
2.关联对应的版块或游戏
如果你想在特定版块发布内容,那么你可以在输入框中填写关键词,它会自动将某个版块与鼠标关联并点击。连接游戏也是如此。
一般情况下,我们的游戏库会尽量覆盖市面上大部分的游戏,所以如果你的文章是游戏主题的话,一般不会有问题。但由于时间和精力,我们可能偶尔会错过一些比赛。如果您发现我们的数据库中没有您想写的游戏,您可以将您的文章提交到“Game Talk”区,然后在正文开头写上【游戏:XXX】。我们会尽快将此游戏添加到数据库中。
3.配件
文章页面的辅助工具从左到右依次为:表情、表格、分隔符、图片、视频。
相信表情符号和分隔符就不用说了。
床单。使用表格时,您可能会发现行数和列数是有限的。这个设置的原因是我们不鼓励在文章中使用大表格,它的阅读体验并不友好。但如果真的需要使用10*10以上的表格,请先使用Excel等软件应用创建表格,然后复制到文章编辑页面。
图片。图片大小会影响文章的加载速度,所以图片大小不宜过大。建议静态图片不超过500kb,动态图片不超过2mb。可以使用这款免费的图片压缩工具(免费版有每次启动压缩张数的限制)进行压缩,静态图片和动态图片都可以。
视频。将你需要的视频上传到bilibili,具体方法如下:
首先,打开bilibili主页,登录bilibili账号。单击右上角的粉红色“提交”按钮。
然后你会进入一个视频提交页面,点击蓝色的“上传视频”按钮,在弹出的文件选择窗口中选择你要上传的视频文件。或者您可以将视频直接拖动到图标区域。视频格式推荐使用mp4,可以节省一定的转码审核时间。
接下来,您将进入视频上传页面。在等待视频上传的同时,填写标题、简介、标签等项目,选择类型和部门。全部完成后,点击页面底部的“立即提交”按钮,提交完成。
然后你会在“创作中心-内容管理-稿件管理”页面看到你提交的视频,等待审核通过。
稿件通过后,可以在自己的俱乐部插入刚刚审过的视频文章~点击视频,找到视频下方的“分享”按钮。鼠标悬停后,会弹出一个界面。复制“嵌入代码”以备后用。
回到俱乐部编辑界面,将光标放在要插入视频的位置,点击工具栏中的“B站”按钮。将出现如下所示的输入框。将刚才复制的“嵌入码”粘贴到输入框In,然后回车,视频就插入成功了~
4.文字
随心所欲地写吧!
这里给大家一个小建议:多段,只要你愿意,每行一个句子也是可以的。
接下来说说页面的右半部分:
文章采集功能(网络上网站可能是首页,知道在哪里上吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-10 03:04
文章采集功能在微信公众号:创业引爆点的后台,一键获取。网络上网站可能是首页,视频可能是电影,现在有个网站叫做中国首页——知道在哪里上?网站的获取方式有很多,如今它要具备以下几个要素:搜索引擎a、当你在使用搜索引擎搜索信息时,优化你们的网站a、当你在使用百度搜索时,优化你们的网站有个很重要的a...——百度aib、当你在使用谷歌搜索时,优化你们的网站,谷歌有一个重要的ai——googleai。
了解了以上几个ai,相信你会明白了,为什么它们在中国很受欢迎的原因。虽然我是小case,并不是创业重点。也因为我做的不是优化工作。第二个ai是什么?ai是一个创新语言。在互联网的语言应用,百度首先用了一个相对很小众的ai——二进制来描述世界这个应用的整体。谷歌率先应用了一个非常流行的解码器——javascript,生成字符串后可以用一个符号,命名字符串。
这就是谷歌第一个成功的语言。第三个ai是什么?它有一个python(创业是前程无忧)。它大概率是将来中国人能使用的一个最好的编程语言。当然更具体应该是c++。第四个ai是什么?据说谷歌的未来实验室通过一个已知的ai技术创新语言——一种新的开放标准——"s3。它在一个很小的语义的标准(内容、用户或者别的什么东西)上设计了一个类似于python的新的ai语言,该语言将允许更快的二进制处理。
这就是我今天想表达的,谷歌未来的ai语言将不是python,而是s3语言。上面说的这几个ai技术,或许还有许多不足之处,但是这几个是创业引爆点研究的第一个关于产品ai语言的项目。或许不完善的地方或许目前有效的生存技术或许可用于网站优化的字符串编码的不足。这是几个ai语言的突破部分:首先——openviscis:这是上文说到一个语言,它简化了程序和c/c++的拼写。
毕竟还是有差异。第二——vaswani&vaswaniengineer:这是一个简单的进制转换器,可以创建一些优秀的算法。当然也有一些缺点,它的算法中使用到了一个非常尖锐的屏幕校正问题。第三——vaswaniphone:传统的web并没有googlelogo,由于ui规范的原因,导致web和app/phone/feature-element的界面设计不兼容。
用vaswaniengineer配合s3,让两个的互联网页面实现通用的googlelogo实现。上述这四个技术组合在一起就是:首页——pagerank协议的第一个aischeme语言。今天暂且不讨论它到底是不是世界上最完美的语言,我们只讨论它在设计之初到底用了哪些做法可以成功运用。我用过angularjs,react.js,mpvue。 查看全部
文章采集功能(网络上网站可能是首页,知道在哪里上吗?)
文章采集功能在微信公众号:创业引爆点的后台,一键获取。网络上网站可能是首页,视频可能是电影,现在有个网站叫做中国首页——知道在哪里上?网站的获取方式有很多,如今它要具备以下几个要素:搜索引擎a、当你在使用搜索引擎搜索信息时,优化你们的网站a、当你在使用百度搜索时,优化你们的网站有个很重要的a...——百度aib、当你在使用谷歌搜索时,优化你们的网站,谷歌有一个重要的ai——googleai。
了解了以上几个ai,相信你会明白了,为什么它们在中国很受欢迎的原因。虽然我是小case,并不是创业重点。也因为我做的不是优化工作。第二个ai是什么?ai是一个创新语言。在互联网的语言应用,百度首先用了一个相对很小众的ai——二进制来描述世界这个应用的整体。谷歌率先应用了一个非常流行的解码器——javascript,生成字符串后可以用一个符号,命名字符串。
这就是谷歌第一个成功的语言。第三个ai是什么?它有一个python(创业是前程无忧)。它大概率是将来中国人能使用的一个最好的编程语言。当然更具体应该是c++。第四个ai是什么?据说谷歌的未来实验室通过一个已知的ai技术创新语言——一种新的开放标准——"s3。它在一个很小的语义的标准(内容、用户或者别的什么东西)上设计了一个类似于python的新的ai语言,该语言将允许更快的二进制处理。
这就是我今天想表达的,谷歌未来的ai语言将不是python,而是s3语言。上面说的这几个ai技术,或许还有许多不足之处,但是这几个是创业引爆点研究的第一个关于产品ai语言的项目。或许不完善的地方或许目前有效的生存技术或许可用于网站优化的字符串编码的不足。这是几个ai语言的突破部分:首先——openviscis:这是上文说到一个语言,它简化了程序和c/c++的拼写。
毕竟还是有差异。第二——vaswani&vaswaniengineer:这是一个简单的进制转换器,可以创建一些优秀的算法。当然也有一些缺点,它的算法中使用到了一个非常尖锐的屏幕校正问题。第三——vaswaniphone:传统的web并没有googlelogo,由于ui规范的原因,导致web和app/phone/feature-element的界面设计不兼容。
用vaswaniengineer配合s3,让两个的互联网页面实现通用的googlelogo实现。上述这四个技术组合在一起就是:首页——pagerank协议的第一个aischeme语言。今天暂且不讨论它到底是不是世界上最完美的语言,我们只讨论它在设计之初到底用了哪些做法可以成功运用。我用过angularjs,react.js,mpvue。
文章采集功能(前台发帖时可采集单篇微信文章的源码介绍功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-10 00:09
来源介绍
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请联系我们,我们会尽快完成修复升级或单独发送修复文件给您,恕不退款
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认使用的会员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、设置前台的用户组和版块,允许使用微信插入文章的功能
采集程序
按微信公众号采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后可以选择立即发布到板子或者重新采集采集的结果下
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
管理员永久会员
支付宝扫一扫
微信扫一扫>打赏采集海报链接 查看全部
文章采集功能(前台发帖时可采集单篇微信文章的源码介绍功能介绍)
来源介绍
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请联系我们,我们会尽快完成修复升级或单独发送修复文件给您,恕不退款
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认使用的会员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、设置前台的用户组和版块,允许使用微信插入文章的功能
采集程序
按微信公众号采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后可以选择立即发布到板子或者重新采集采集的结果下
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
管理员永久会员
支付宝扫一扫
微信扫一扫>打赏采集海报链接
文章采集功能(2.1.4获取文章发布时间的采集规则再次回到图23,找到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-08 16:23
2.1.4 获取文章采集发布时间规则
再次回到图23,找到“Published in:”和后面的“2009-09-29 14:21”,和前面获取采集规则的方法一样,这里应该是“Published in: [Content] "作为采集发布时间规则。同样,这里也不需要使用过滤规则。填充后,如图27所示,
图27-文章发布时间的采集规则
2.1.5 采集获取文章内容的规则
这部分是编写采集规则的重点和难点。需要特别注意。
具体步骤:
(一)回到开篇文章内容页的源码,找到文章内容的开头部分《Dreamweaver升级到8.0.2之后》 ,如图28所示,
图28-文章内容的开头
注意:这句话在源码中出现了两处。其中,第一句在“
在“之后,第二句在”
”之后。通过对比文章的内容页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章@内容的开头>. 因此,您应该选择“
”是匹配规则的开始。
(B) 找到文章内容的结尾部分“也是”wmode”参数加上了“transparent”的值”,如图29所示,
图29-文章的内容结束
注意:由于结束部分的最后一个标签是“
”,并且这个标签在文章的内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应于<内容的开头@文章,经过对比和分析,得出的结论是这里应该选“
”作为文章的内容结束,如图30所示,
图 30-文章 内容匹配规则结束
(C) 结合(a)和(b),可以看出这里文章的内容匹配规则应该是"
[内容]
》,填写后,如图31所示,
图31-文章的内容匹配规则
此处不使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
至此,“新建采集节点:第二步设置内容字段获取规则”,设置完成。填写后,如图(图32),
图32-设置后新添加的采集节点: 第二步,设置内容字段获取规则
检查无误后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“新建采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),
图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果单击“保存并启动采集”,您将进入“采集 指定节点”界面。否则请点击“返回上一步修改”。
第二部分的介绍到此结束。现在进入第三部分。. .
本文标签:dedecms、采集、函数、用法、---、不收录、分页、通用、文章、前言
相关文章
更令人兴奋的 查看全部
文章采集功能(2.1.4获取文章发布时间的采集规则再次回到图23,找到)
2.1.4 获取文章采集发布时间规则
再次回到图23,找到“Published in:”和后面的“2009-09-29 14:21”,和前面获取采集规则的方法一样,这里应该是“Published in: [Content] "作为采集发布时间规则。同样,这里也不需要使用过滤规则。填充后,如图27所示,
图27-文章发布时间的采集规则
2.1.5 采集获取文章内容的规则
这部分是编写采集规则的重点和难点。需要特别注意。
具体步骤:
(一)回到开篇文章内容页的源码,找到文章内容的开头部分《Dreamweaver升级到8.0.2之后》 ,如图28所示,
图28-文章内容的开头
注意:这句话在源码中出现了两处。其中,第一句在“
在“之后,第二句在”
”之后。通过对比文章的内容页面和它的源码,不难发现第一部分其实是一个摘要,第二部分是文章@内容的开头>. 因此,您应该选择“
”是匹配规则的开始。
(B) 找到文章内容的结尾部分“也是”wmode”参数加上了“transparent”的值”,如图29所示,
图29-文章的内容结束
注意:由于结束部分的最后一个标签是“
”,并且这个标签在文章的内容中多次出现,所以不能作为采集规则的结束标签。考虑到它应该对应于<内容的开头@文章,经过对比和分析,得出的结论是这里应该选“
”作为文章的内容结束,如图30所示,
图 30-文章 内容匹配规则结束
(C) 结合(a)和(b),可以看出这里文章的内容匹配规则应该是"
[内容]
》,填写后,如图31所示,
图31-文章的内容匹配规则
此处不使用过滤规则。过滤规则的介绍和使用将放在单独的章节中。
至此,“新建采集节点:第二步设置内容字段获取规则”,设置完成。填写后,如图(图32),
图32-设置后新添加的采集节点: 第二步,设置内容字段获取规则
检查无误后,点击“保存配置并预览”。如果之前的设置正确,点击后会进入“新建采集节点:测试内容字段设置”页面,看到对应的文章内容。如图(图33),
图33-新建采集节点:测试内容字段设置
确认无误后,点击“仅保存”,系统会提示“保存配置成功”,返回“采集节点管理”界面;如果单击“保存并启动采集”,您将进入“采集 指定节点”界面。否则请点击“返回上一步修改”。
第二部分的介绍到此结束。现在进入第三部分。. .
本文标签:dedecms、采集、函数、用法、---、不收录、分页、通用、文章、前言
相关文章
更令人兴奋的
文章采集功能(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-07 19:03
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字批量搜索采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、 前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框确认你要的是哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择发布到采集结果下的部分或重新采集文本
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项
点击下载 查看全部
文章采集功能(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,并且可以选择每个文章版块发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填一项),插件会通过定时任务获取最新的5篇文章公众号未在此填写的采集文章(注:由于微信反采集措施严格且多变,定时任务成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字批量搜索采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集 有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、 前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子、门户文章评论功能
指示
1、 安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块或全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框确认你要的是哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择发布到采集结果下的部分或重新采集文本
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号文章的地址。一排
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的ip地址被微信锁定而无法继续采集
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片、允许多媒体-发布选项
点击下载
文章采集功能(文章采集功能主要采集的示例代码,你需要的东西都能找到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-07 12:07
文章采集功能主要采集的就是自然语言文本,深度学习在这个领域采用的是mlp,其实主要就是拿了一个词嵌入对句子进行编码和预测。word2vec这里关于word2vec的概念可以自行百度mlm,它是wordembeddingmodel的缩写,是深度学习中模型和数据增强的方法。
去b站搜索mltriples,
我不是nlp人士,只能给出一些建议。这些网站现在都有开放的源代码,和下载这些网站上的示例代码。例如youtube,github,这些地方的的代码还是比较有规律的。一般在很多地方,都能找到他们的关联。我的个人网站就正好是这个,尽管我不是nlp人士,但是nlp入门这一块是完全没有问题的。基本你需要的东西都能找到,我的网站上有些示例代码,也有一些机器学习类的视频。推荐大家去看看。goodluck!!!。
谢邀。不过这两天学了nlp的lecture已经解决这个问题。首先nlp领域推荐词嵌入基本是经验,或者直接建立一个词表即可,词嵌入训练不方便。其次,对于输入文本,可以用mnn模型对字预测该词是否在前面或后面。然后考虑词向量的相似度。
你可以先用lsj的文本分类,近期又有一个awesomecorpus,可以看看那个部分,多关注一下他们官网的文章什么的,很久没有碰nlp了。 查看全部
文章采集功能(文章采集功能主要采集的示例代码,你需要的东西都能找到)
文章采集功能主要采集的就是自然语言文本,深度学习在这个领域采用的是mlp,其实主要就是拿了一个词嵌入对句子进行编码和预测。word2vec这里关于word2vec的概念可以自行百度mlm,它是wordembeddingmodel的缩写,是深度学习中模型和数据增强的方法。
去b站搜索mltriples,
我不是nlp人士,只能给出一些建议。这些网站现在都有开放的源代码,和下载这些网站上的示例代码。例如youtube,github,这些地方的的代码还是比较有规律的。一般在很多地方,都能找到他们的关联。我的个人网站就正好是这个,尽管我不是nlp人士,但是nlp入门这一块是完全没有问题的。基本你需要的东西都能找到,我的网站上有些示例代码,也有一些机器学习类的视频。推荐大家去看看。goodluck!!!。
谢邀。不过这两天学了nlp的lecture已经解决这个问题。首先nlp领域推荐词嵌入基本是经验,或者直接建立一个词表即可,词嵌入训练不方便。其次,对于输入文本,可以用mnn模型对字预测该词是否在前面或后面。然后考虑词向量的相似度。
你可以先用lsj的文本分类,近期又有一个awesomecorpus,可以看看那个部分,多关注一下他们官网的文章什么的,很久没有碰nlp了。
文章采集功能(什么是收集公众号数据的好工具?Data是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-07 02:03
微信现在是人们离不开的社交软件,它也为人们的交流提供了便利。微信公众号就是为此而生的,那么有什么工具可以采集到微信公众号的号码数据呢?让我们从下面的地形数据开始。
什么是采集公众号数据的好工具?
Tuto Data是采集公众号数据的好工具。工具操作简单采集微信公众号seo搜狗收录(微信公众号数据采集有什么好工具?先说数据),数据分析全面。实现多维数据分析和统计。有效帮助运营商管理公众号,促进公众号推广。确定并优化。
采集公众号数据的有用工具有哪些?如果要采集公众号数据,必须使用流量分析管理工具。例如,兔兔数据。
操作必备:本公众号数据采集工具,一分钟导出全部数据!
拖图数据-公众号数据分析工具
可以搜索全网公众号,导出公众号的所有数据和文章。它只是满足您的需求吗?
接下来去注册一个账号,绑定成功后就可以使用这个功能了。
第一步,停止公众号
搜索要采集的公众号,选择要获取的公众号,文章数据量和时区,也可以自定义,完成后保存。最后,我把它留了下来。我在测试过程中等了大约5分钟,所以速度还是很快的。
Step 2 公众号停止任务列表
查看详细信息后,采集到的数据一目了然。您可以在地形数据详情中查看采集中的数据,也可以批量下载导出数据。我在哪里可以找到这么方便的工具。
如果你学会使用这些操作,处理各种报表,就不会有问题了。
当然采集微信公众号seo搜狗收录,生成数据图表只是表面功能;它的核心是通过数据分析。导出数据后,会自动生成一些表。其中,“文章的每一次阅读”,一定是每个人都想知道的。
直观的粉丝口味数据,读取文章的人数排名,分析粉丝对这类文章的偏好。每个人都喜欢的是他们对有趣的话题更感兴趣。如果按照上面的方法,就可以用葫芦画了。刁,我总结一下。有了这些结论,以后写文章和选题会更有方向。
除了各种数据处理功能外,Topographic Data还可以搜索全网公众号文章、监控文章阅读量、监控新文章等功能。
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读和喜欢非常有价值。因此,文章 的采集和读取的获取机制限制在 2 秒。你每2秒采集一次微信数据,微信不会理你,但是如果你快点采集微信公众号seo搜狗收录,他会给你303响应并返回空数据给你。让你什么都不采集。
然后是获取文章列表的速度,不采集阅读计数。这个速度在前期没有限制。当您采集更多时,您的微信ID将被限制。
我们的软件为相关馆藏设置了可设置的时间限制。所以尽量使用这些限制。毕竟微信还有很多事情要做,必须要保护。
限制登录是一方面,限制数据采集是另一方面。在采集数据前等待 2 分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
一个可以采集微信公众号数据的工具 查看全部
文章采集功能(什么是收集公众号数据的好工具?Data是什么?)
微信现在是人们离不开的社交软件,它也为人们的交流提供了便利。微信公众号就是为此而生的,那么有什么工具可以采集到微信公众号的号码数据呢?让我们从下面的地形数据开始。
什么是采集公众号数据的好工具?
Tuto Data是采集公众号数据的好工具。工具操作简单采集微信公众号seo搜狗收录(微信公众号数据采集有什么好工具?先说数据),数据分析全面。实现多维数据分析和统计。有效帮助运营商管理公众号,促进公众号推广。确定并优化。
采集公众号数据的有用工具有哪些?如果要采集公众号数据,必须使用流量分析管理工具。例如,兔兔数据。
操作必备:本公众号数据采集工具,一分钟导出全部数据!
拖图数据-公众号数据分析工具
可以搜索全网公众号,导出公众号的所有数据和文章。它只是满足您的需求吗?
接下来去注册一个账号,绑定成功后就可以使用这个功能了。
第一步,停止公众号
搜索要采集的公众号,选择要获取的公众号,文章数据量和时区,也可以自定义,完成后保存。最后,我把它留了下来。我在测试过程中等了大约5分钟,所以速度还是很快的。
Step 2 公众号停止任务列表
查看详细信息后,采集到的数据一目了然。您可以在地形数据详情中查看采集中的数据,也可以批量下载导出数据。我在哪里可以找到这么方便的工具。
如果你学会使用这些操作,处理各种报表,就不会有问题了。
当然采集微信公众号seo搜狗收录,生成数据图表只是表面功能;它的核心是通过数据分析。导出数据后,会自动生成一些表。其中,“文章的每一次阅读”,一定是每个人都想知道的。
直观的粉丝口味数据,读取文章的人数排名,分析粉丝对这类文章的偏好。每个人都喜欢的是他们对有趣的话题更感兴趣。如果按照上面的方法,就可以用葫芦画了。刁,我总结一下。有了这些结论,以后写文章和选题会更有方向。
除了各种数据处理功能外,Topographic Data还可以搜索全网公众号文章、监控文章阅读量、监控新文章等功能。
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读和喜欢非常有价值。因此,文章 的采集和读取的获取机制限制在 2 秒。你每2秒采集一次微信数据,微信不会理你,但是如果你快点采集微信公众号seo搜狗收录,他会给你303响应并返回空数据给你。让你什么都不采集。
然后是获取文章列表的速度,不采集阅读计数。这个速度在前期没有限制。当您采集更多时,您的微信ID将被限制。
我们的软件为相关馆藏设置了可设置的时间限制。所以尽量使用这些限制。毕竟微信还有很多事情要做,必须要保护。
限制登录是一方面,限制数据采集是另一方面。在采集数据前等待 2 分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
一个可以采集微信公众号数据的工具
文章采集功能(优采云采集网页文章正文教程:自定义数据合并方式详解教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-05 19:09
数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法及详细步骤本文将以搜狗微信文章为例介绍优采云采集body的使用方法网页文章 。文章 一般正文收录文字和图片。本文将采集文章正文+图片网址。采集的以下字段:文章 标题、时间、来源和正文(正文中的所有文本将合并到一个excel单元格中,将使用“自定义数据合并方法”功能,请大家注意)同时采集文章正文中的文字+图片网址将使用“
网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“更多操作”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤三2)选择“循环点击单个元素”创建翻页循环。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信热门文章采集 方法步骤4 由于本网页涉及Ajax技术,需要设置一些高级选项。选择“点击元素”步骤,打开“ 高级选项”,勾选“Ajax加载数据”,时间设置为“2 信息内容仅供您学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集 方法步骤5 AJAX是一种延迟加载和异步更新的脚本技术。在后台与服务器进行少量数据交换后,可以用于某些网页,而无需重新加载整个网页。部分更新。性能特点:当你点击网页中的一个选项时,网站的大部分网址不会发生变化;网页未完全加载,但仅部分加载了已更改的数据。验证:点击操作后,在浏览器中,URL输入栏在加载状态或转动状态下不出现。观察网页,我们发现点击“加载更多内容”5次后,页面加载到最底部,共显示100篇文章。
因此,我们将整个“循环车削”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”。更正或删除。微信流行文章采集方法步骤6 第三步:创建列表循环并提取数据1) 移动鼠标,选择页面第一个文章链接。系统会自动识别类似链接。在操作提示框中,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信热点文章采集方法步骤七2)选择“ 首先点击第一段文字文章,系统会自动识别页面中的相似元素,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信热点文章采集 方法步骤10 可以看到所有的文本段落都被选中并变成了绿色。选择“采集 以下元素文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信人气文章采集方法步骤11 注:字段表中可自定义字段修改素材内容,仅供学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤12 经过以上操作后,文字将全部采集向下(默认是每段文字为一个单元。一般来说,我们希望采集,合并到同一个单元格中。方法 步骤14 材料内容仅供学习参考 如有不当或侵权,请联系更正或删除。如图,查看微信流行文章采集方法 Step 15 Step 4: Modify Xpath 选中整个“Circular Step”,打开“Advanced Options”,可以看到优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。
微信热门文章采集方法 步骤16 在火狐浏览器中打开想要采集的网页,查看源码。我们发现经过这个Xpath://DIV[@class=´main-left´]/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100页文章已定位,资料内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信热点文章采集 方法步骤17 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”微信热点文章采集方法步骤18 信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。第五步:修改流程图结构。让' s 继续观察。单击“加载更多内容”5 次后,此页面将加载所有 100 章。所以,我们配置规则的思路是先建立一个翻页循环,加载全部100个文章,创建一个循环列表,提取数据,选中整个“循环”步骤,拖出“循环翻页”步骤。如果不这样做,微信上就会有很多重复的数据。文章采集 方法步骤19 拖动完成后,下图信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤20步骤6:数据采集并导出点击左上角“保存”,然后点击“开始采集 》,选择“开始本地采集”信息内容仅供学习参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤21 2)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,采集好数据导出资料的内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤22 这里我们选择excel作为导出格式。数据导出后,下图内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤234)如上图,文章的部分正文没有采集到达。那' s 因为系统自动生成的文章文本循环列表的Xpath://[@id="js_content"]/P,找不到这个文章的文本。修改Xpath为://[@id="js_content"]//P,文章的所有文字都可以位于素材内容中,仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信热点文章采集方法步骤24 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信流行文章采集方法 Step 25 Step 7: 添加判断条件 经过上一步,我们只采集微信文章中的文字内容,不包括 文章 中的图片 URL。如果需要采集图片URL,则需要在规则中添加一个判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集 分支;
同时默认为左分支设置判断条件。如果满足这个判断条件,则分支向左分支;默认最右边的分支是“不判断,一直执行这个分支”,即不满足左边分支的判断条件时,执行最右边的分支。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。回到这个规则,即设置左分支的条件:如果收录img元素(图片),则执行左分支;如果不满足左条件分支的条件(即不收录img元素),则执行右分支。具体操作如下:1)从左边的工具栏中拖一个“ 如有不当或侵权,请联系更正或删除。右侧分支-检测结果一直是True 微信流行文章采集方法步骤28 3)点击左侧分支,在出现的结果页面中(分支条件检测结果-检测结果始终为 True ) 单击“确定”。
然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表图片),点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。点击左侧微信热点文章采集 方法步骤29 信息内容仅供您学习参考。如有不当或侵权,请联系更正或删除。对于左分支,设置判断条件微信热门文章采集 方法步骤30 设置左分支条件后,进行数据提取步骤。从左侧的工具栏中,拖入“提取数据”步骤 到流程图左侧分支(绿色加号处),在页面中选择一张图片,在操作提示框中选择“采集图片地址”信息内容仅供学习和参考。如有不当或侵权,请联系更正或删除。将新增的“提取数据”步骤拖入左侧分支微信热点文章采集 方法步骤31 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。采集图片地址微信热门文章采集方法步骤32选择右侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“
自定义定位元素方法微信流行文章采集方法第33步数据内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。元素匹配Xpath,“相对Xpath”微信流行文章采集 方法步骤34 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义定位元素” " "方法",引用右边分支相同位置的Xpath修改:"元素匹配Xpath"改为://*[@id="js_content"]/p[1]/img[1] ,“Relative Xpath”更改为:/img[1],然后点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤35 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义数据合并方法”,如图勾选。检查后,多次提取的文本将添加为字段。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤36 判断条件中各分支“提取数据”步骤中的字段名称必须相同,字段数必须相同。在这里,我们将左右分支中提取的字段名称更改为“文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤37如上,整个判断条件就设置好了。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章正文中的图片需要向下滚动才能加载,然后采集才能加载到正确的图片地址。因此,打开文章后,需要设置“页面加载后向下滚动”。这里设置滚动次数为“30”,滚动方式为“向下滚动一屏”,素材内容仅供大家学习参考,如有不当或侵权,请联系更正或删除微信文章正文中的图片,您需要向下滚动加载微信热门文章采集方法步骤38 数据内容供您使用仅供学习参考。如有不当或侵权,请联系更正或删除。加载设置页面后,向下滚动”微信流行文章采集方法步骤39 注意:这里的滚动次数、时间、方法设置会影响采集的速度和质量数据,本文仅供参考,大家可以根据需要设置10)重启采集,并导出数据,导出数据后,如图:导出数据微信人气文章采集 方法步骤40 数据内容仅供参考,如有不当或侵权,请联系更正或删除。数据示例 微信热门文章采集 方法步骤41 说明:由于搜狗微信文章中的图片,需要通过下拉Scroll加载出来。
在采集的过程中,等待图片加载的时间比较长,所以采集的速度比较慢。如果不需要采集图片,直接使用文本采集,不需要等待图片加载,采集会快很多。相关采集教程:京东商品信息采集新浪微博数据采集赶集招聘信息采集 优采云——70万用户精选的网页数据采集器 . 数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。操作简单,任何人都可以使用:无需技术背景,即可上网采集。全可视化流程,点击鼠标即可完成操作,功能强大,任意< @网站可用于:点击、登录、翻页、身份验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置进行设置采集。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 查看全部
文章采集功能(优采云采集网页文章正文教程:自定义数据合并方式详解教程)
数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法及详细步骤本文将以搜狗微信文章为例介绍优采云采集body的使用方法网页文章 。文章 一般正文收录文字和图片。本文将采集文章正文+图片网址。采集的以下字段:文章 标题、时间、来源和正文(正文中的所有文本将合并到一个excel单元格中,将使用“自定义数据合并方法”功能,请大家注意)同时采集文章正文中的文字+图片网址将使用“
网页打开后,默认显示“热门”文章。向下滚动页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“更多操作”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤三2)选择“循环点击单个元素”创建翻页循环。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信热门文章采集 方法步骤4 由于本网页涉及Ajax技术,需要设置一些高级选项。选择“点击元素”步骤,打开“ 高级选项”,勾选“Ajax加载数据”,时间设置为“2 信息内容仅供您学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集 方法步骤5 AJAX是一种延迟加载和异步更新的脚本技术。在后台与服务器进行少量数据交换后,可以用于某些网页,而无需重新加载整个网页。部分更新。性能特点:当你点击网页中的一个选项时,网站的大部分网址不会发生变化;网页未完全加载,但仅部分加载了已更改的数据。验证:点击操作后,在浏览器中,URL输入栏在加载状态或转动状态下不出现。观察网页,我们发现点击“加载更多内容”5次后,页面加载到最底部,共显示100篇文章。
因此,我们将整个“循环车削”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5”,点击“确定”。更正或删除。微信流行文章采集方法步骤6 第三步:创建列表循环并提取数据1) 移动鼠标,选择页面第一个文章链接。系统会自动识别类似链接。在操作提示框中,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信热点文章采集方法步骤七2)选择“ 首先点击第一段文字文章,系统会自动识别页面中的相似元素,选择“全选”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信热点文章采集 方法步骤10 可以看到所有的文本段落都被选中并变成了绿色。选择“采集 以下元素文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信人气文章采集方法步骤11 注:字段表中可自定义字段修改素材内容,仅供学习参考,如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤12 经过以上操作后,文字将全部采集向下(默认是每段文字为一个单元。一般来说,我们希望采集,合并到同一个单元格中。方法 步骤14 材料内容仅供学习参考 如有不当或侵权,请联系更正或删除。如图,查看微信流行文章采集方法 Step 15 Step 4: Modify Xpath 选中整个“Circular Step”,打开“Advanced Options”,可以看到优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。可以看到,优采云是默认生成的固定元素列表,前20篇文章的链接内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。
微信热门文章采集方法 步骤16 在火狐浏览器中打开想要采集的网页,查看源码。我们发现经过这个Xpath://DIV[@class=´main-left´]/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面需要100页文章已定位,资料内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信热点文章采集 方法步骤17 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定”微信热点文章采集方法步骤18 信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。第五步:修改流程图结构。让' s 继续观察。单击“加载更多内容”5 次后,此页面将加载所有 100 章。所以,我们配置规则的思路是先建立一个翻页循环,加载全部100个文章,创建一个循环列表,提取数据,选中整个“循环”步骤,拖出“循环翻页”步骤。如果不这样做,微信上就会有很多重复的数据。文章采集 方法步骤19 拖动完成后,下图信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤20步骤6:数据采集并导出点击左上角“保存”,然后点击“开始采集 》,选择“开始本地采集”信息内容仅供学习参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤21 2)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,采集好数据导出资料的内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤22 这里我们选择excel作为导出格式。数据导出后,下图内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤234)如上图,文章的部分正文没有采集到达。那' s 因为系统自动生成的文章文本循环列表的Xpath://[@id="js_content"]/P,找不到这个文章的文本。修改Xpath为://[@id="js_content"]//P,文章的所有文字都可以位于素材内容中,仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信热点文章采集方法步骤24 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。修改Xpath微信流行文章采集方法 Step 25 Step 7: 添加判断条件 经过上一步,我们只采集微信文章中的文字内容,不包括 文章 中的图片 URL。如果需要采集图片URL,则需要在规则中添加一个判断条件:判断文章的内容列表,如果收录img元素(图片),则执行图片采集 分支;
同时默认为左分支设置判断条件。如果满足这个判断条件,则分支向左分支;默认最右边的分支是“不判断,一直执行这个分支”,即不满足左边分支的判断条件时,执行最右边的分支。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。回到这个规则,即设置左分支的条件:如果收录img元素(图片),则执行左分支;如果不满足左条件分支的条件(即不收录img元素),则执行右分支。具体操作如下:1)从左边的工具栏中拖一个“ 如有不当或侵权,请联系更正或删除。右侧分支-检测结果一直是True 微信流行文章采集方法步骤28 3)点击左侧分支,在出现的结果页面中(分支条件检测结果-检测结果始终为 True ) 单击“确定”。
然后为其设置判断条件:勾选“当前循环项收录元素”,输入元素Xpath://img(代表图片),点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。点击左侧微信热点文章采集 方法步骤29 信息内容仅供您学习参考。如有不当或侵权,请联系更正或删除。对于左分支,设置判断条件微信热门文章采集 方法步骤30 设置左分支条件后,进行数据提取步骤。从左侧的工具栏中,拖入“提取数据”步骤 到流程图左侧分支(绿色加号处),在页面中选择一张图片,在操作提示框中选择“采集图片地址”信息内容仅供学习和参考。如有不当或侵权,请联系更正或删除。将新增的“提取数据”步骤拖入左侧分支微信热点文章采集 方法步骤31 信息内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。采集图片地址微信热门文章采集方法步骤32选择右侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“
自定义定位元素方法微信流行文章采集方法第33步数据内容仅供大家学习参考。如有不当或侵权,请联系更正或删除。元素匹配Xpath,“相对Xpath”微信流行文章采集 方法步骤34 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义定位元素” " "方法",引用右边分支相同位置的Xpath修改:"元素匹配Xpath"改为://*[@id="js_content"]/p[1]/img[1] ,“Relative Xpath”更改为:/img[1],然后点击“确定”。信息内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤35 选择左侧分支的“提取数据”步骤,点击“自定义数据字段”按钮,选择“自定义数据合并方法”,如图勾选。检查后,多次提取的文本将添加为字段。内容仅供大家学习和参考。如有不当或侵权,请联系更正或删除。微信流行文章采集方法步骤36 判断条件中各分支“提取数据”步骤中的字段名称必须相同,字段数必须相同。在这里,我们将左右分支中提取的字段名称更改为“文本”。数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。
微信流行文章采集方法步骤37如上,整个判断条件就设置好了。点击左上角的“保存”和“开始采集”。我们发现在导出的excel表中,图片地址是一堆乱码。为什么是这样?继续观察网页——搜狗微信文章正文中的图片需要向下滚动才能加载,然后采集才能加载到正确的图片地址。因此,打开文章后,需要设置“页面加载后向下滚动”。这里设置滚动次数为“30”,滚动方式为“向下滚动一屏”,素材内容仅供大家学习参考,如有不当或侵权,请联系更正或删除微信文章正文中的图片,您需要向下滚动加载微信热门文章采集方法步骤38 数据内容供您使用仅供学习参考。如有不当或侵权,请联系更正或删除。加载设置页面后,向下滚动”微信流行文章采集方法步骤39 注意:这里的滚动次数、时间、方法设置会影响采集的速度和质量数据,本文仅供参考,大家可以根据需要设置10)重启采集,并导出数据,导出数据后,如图:导出数据微信人气文章采集 方法步骤40 数据内容仅供参考,如有不当或侵权,请联系更正或删除。数据示例 微信热门文章采集 方法步骤41 说明:由于搜狗微信文章中的图片,需要通过下拉Scroll加载出来。
在采集的过程中,等待图片加载的时间比较长,所以采集的速度比较慢。如果不需要采集图片,直接使用文本采集,不需要等待图片加载,采集会快很多。相关采集教程:京东商品信息采集新浪微博数据采集赶集招聘信息采集 优采云——70万用户精选的网页数据采集器 . 数据内容仅供您学习和参考。如有不当或侵权,请联系更正或删除。操作简单,任何人都可以使用:无需技术背景,即可上网采集。全可视化流程,点击鼠标即可完成操作,功能强大,任意< @网站可用于:点击、登录、翻页、身份验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置进行设置采集。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。识别验证码、Ajax脚本异步加载数据网页,都可以通过简单的设置采集进行设置。云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。它可以关闭。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。免费功能+增值服务,您可以根据自己的需求进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。
文章采集功能(中考英语:文章采集功能的方法与方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-03 21:03
文章采集功能其实可以分成两块,输入和输出。输入一般分两块:形状特征和颜色特征,颜色特征一般有srcnn、dstnet、r-cnn系列等。dssd如果是输入一片单独的图片,可以直接获取文字特征;颜色特征用labelimg。形状特征通常用于实体识别、情感分析等。输出一般可以用svm、文字识别等方法。
说个题外话,从目前来看文本和图片搜索应该是同一个问题的两个方向:首先是从文本中提取相关信息:考虑一些情感依赖的特征,例如句子的色彩敏感度、句子的高亮词特性等,在语料中考虑非文本的内容,比如一句话的出现几次方式、词句的结构等,在这些文本中观察相似的文本是否可以匹配,从而提取特征,进而获得相关结构信息;其次是图片搜索,将文本特征投射到特定的图片上再进行相关信息提取。
大体分两块:形状特征和颜色特征。其中形状特征需要使用三角化变换/图像金字塔来做,形状不变只对颜色做调整难度大;颜色特征直接抽取xml字典中的特征即可,颜色变换通常应用于特征匹配,因为cnn可以学习到长距离相似性,比如是否近距离发现姓名相似。关于颜色特征,还可以用以下方法:1.reductionandmixingofreferenceregularization:为了达到比较好的效果,实验中需要把特征提取后再融合一遍来得到特征;2.pyramidpooling:把识别结果相近但颜色明显不同的的文本首尾连接起来;3.featureaugmentation:感受野做extraction,里面一部分用mixvariables和randomforests;4.mixvariables:特征融合,融合的方法就可以使用前面几种的组合;5.用tfnms优化highranking的结果。如果要提取粗糙特征,还有很多可以做。 查看全部
文章采集功能(中考英语:文章采集功能的方法与方法)
文章采集功能其实可以分成两块,输入和输出。输入一般分两块:形状特征和颜色特征,颜色特征一般有srcnn、dstnet、r-cnn系列等。dssd如果是输入一片单独的图片,可以直接获取文字特征;颜色特征用labelimg。形状特征通常用于实体识别、情感分析等。输出一般可以用svm、文字识别等方法。
说个题外话,从目前来看文本和图片搜索应该是同一个问题的两个方向:首先是从文本中提取相关信息:考虑一些情感依赖的特征,例如句子的色彩敏感度、句子的高亮词特性等,在语料中考虑非文本的内容,比如一句话的出现几次方式、词句的结构等,在这些文本中观察相似的文本是否可以匹配,从而提取特征,进而获得相关结构信息;其次是图片搜索,将文本特征投射到特定的图片上再进行相关信息提取。
大体分两块:形状特征和颜色特征。其中形状特征需要使用三角化变换/图像金字塔来做,形状不变只对颜色做调整难度大;颜色特征直接抽取xml字典中的特征即可,颜色变换通常应用于特征匹配,因为cnn可以学习到长距离相似性,比如是否近距离发现姓名相似。关于颜色特征,还可以用以下方法:1.reductionandmixingofreferenceregularization:为了达到比较好的效果,实验中需要把特征提取后再融合一遍来得到特征;2.pyramidpooling:把识别结果相近但颜色明显不同的的文本首尾连接起来;3.featureaugmentation:感受野做extraction,里面一部分用mixvariables和randomforests;4.mixvariables:特征融合,融合的方法就可以使用前面几种的组合;5.用tfnms优化highranking的结果。如果要提取粗糙特征,还有很多可以做。
文章采集功能(拓途数据:自媒体文章采集平台功能有哪些?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-19 16:03
自媒体是如今主流的媒体方式,自媒体的平台众多,这也方便了人们的相关营销操作,当然在自媒体运营过程中也经常需要进行文章爆文采集器,那么自媒体文章采集平台功能有哪些?跟随拓途数据一起看下吧。
自媒体文章采集的作用
1、可以在各个自媒体网站采集与自己领域相关的爆文,根据爆文进入作者主页,看作者账号整体阅读量如何,如果经常出爆文,那说明这就是一个优秀的同行,值得学习。
2、采集各个自媒体网站爆文,然后分析这些标题。每个领域的关键词的都有很多,比如美容行业,怎样才能知道历史领域有哪些关键词,哪些关键词比较热门呢?
这都需要进行数据分析,分析每个爆文标题,从中找出关键词,然后统计出来,通过大量的统计,就能分析出哪些关键词热门,哪些关键词流量大,容易出爆文。
自媒体文章采集平台的强大功能
智能采集,提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是贴吧论坛,支持所有业务渠道的爬虫,满足各种采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速准确获取数据。简单易用,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
拓途数据是很好的自媒体文章采集平台,本平台文章采集方便,而且收录了最新的热点内容,在文章采集后还可以进行排版操作,为人们的公众号文章发布提供了方便。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载别人的原创文章,公众号历史文章等知识点。 查看全部
文章采集功能(拓途数据:自媒体文章采集平台功能有哪些?)
自媒体是如今主流的媒体方式,自媒体的平台众多,这也方便了人们的相关营销操作,当然在自媒体运营过程中也经常需要进行文章爆文采集器,那么自媒体文章采集平台功能有哪些?跟随拓途数据一起看下吧。
自媒体文章采集的作用
1、可以在各个自媒体网站采集与自己领域相关的爆文,根据爆文进入作者主页,看作者账号整体阅读量如何,如果经常出爆文,那说明这就是一个优秀的同行,值得学习。
2、采集各个自媒体网站爆文,然后分析这些标题。每个领域的关键词的都有很多,比如美容行业,怎样才能知道历史领域有哪些关键词,哪些关键词比较热门呢?
这都需要进行数据分析,分析每个爆文标题,从中找出关键词,然后统计出来,通过大量的统计,就能分析出哪些关键词热门,哪些关键词流量大,容易出爆文。
自媒体文章采集平台的强大功能
智能采集,提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是贴吧论坛,支持所有业务渠道的爬虫,满足各种采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速准确获取数据。简单易用,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
拓途数据是很好的自媒体文章采集平台,本平台文章采集方便,而且收录了最新的热点内容,在文章采集后还可以进行排版操作,为人们的公众号文章发布提供了方便。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载别人的原创文章,公众号历史文章等知识点。
文章采集功能(YGBOOK轻量级小说网站系统MB适用版本介绍及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-09-18 03:12
Ygbook novel content management system(以下简称Ygbook)提供了一个基于ThinkPHP+MySQL技术开发的轻量级新颖网站解决方案
Ygbook是cms和网站小偷之间的一个新的网站系统。它对采集target网站数据进行批处理并存储数据。不仅URL完全不同,模板也不同,数据也属于自身。这是完全为站长解放他的双手。只需构建网站,您就可以自动采集+自动更新
该软件基于具有卓越搜索引擎优化性能的biquge模板,经过极大优化,为您呈现了一个全新的网站系统,具有卓越的搜索引擎优化性能和优雅的外观
Ygbook免费版提供基本新颖功能,包括:
1.全自动采集2345导航新颖数据,内置采集规则,无需自行设置管理
2.data warehousing,不用担心目标站的修改或挂起
3.网站本身提供小说介绍和章节列表的显示。章节阅读采用跳转到原站点的方式,避免版权问题
4.有自己的伪静态函数,但不能自由定制。没有移动版本,没有现场搜索,没有站点地图,也没有结构化数据
Ygbook是基于ThinkPHP+MySQL开发的,可以在大多数普通服务器上运行
如windows server、IIS+PHP+MYSQL
Linux服务器,Apache/nginx+PHP+MySQL
建议Linux服务器发挥更大的性能优势
下载地址:
文件名:ygbook novel采集system
文件大小:2.41MB适用版本:PHP
点击下载 查看全部
文章采集功能(YGBOOK轻量级小说网站系统MB适用版本介绍及使用方法)
Ygbook novel content management system(以下简称Ygbook)提供了一个基于ThinkPHP+MySQL技术开发的轻量级新颖网站解决方案
Ygbook是cms和网站小偷之间的一个新的网站系统。它对采集target网站数据进行批处理并存储数据。不仅URL完全不同,模板也不同,数据也属于自身。这是完全为站长解放他的双手。只需构建网站,您就可以自动采集+自动更新
该软件基于具有卓越搜索引擎优化性能的biquge模板,经过极大优化,为您呈现了一个全新的网站系统,具有卓越的搜索引擎优化性能和优雅的外观
Ygbook免费版提供基本新颖功能,包括:
1.全自动采集2345导航新颖数据,内置采集规则,无需自行设置管理
2.data warehousing,不用担心目标站的修改或挂起
3.网站本身提供小说介绍和章节列表的显示。章节阅读采用跳转到原站点的方式,避免版权问题
4.有自己的伪静态函数,但不能自由定制。没有移动版本,没有现场搜索,没有站点地图,也没有结构化数据
Ygbook是基于ThinkPHP+MySQL开发的,可以在大多数普通服务器上运行
如windows server、IIS+PHP+MYSQL
Linux服务器,Apache/nginx+PHP+MySQL
建议Linux服务器发挥更大的性能优势
http://zlei.net/wp-content/upl ... 0.jpg 251w, http://zlei.net/wp-content/upl ... 8.jpg 768w, http://zlei.net/wp-content/upl ... 4.jpg 857w" />下载地址:
文件名:ygbook novel采集system
文件大小:2.41MB适用版本:PHP
点击下载
文章采集功能(原帖.5说明您的列表页设置的有问题明明只需要采集其中 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-08 17:23
)
原帖由茄子发表于 2008-1-3 14:43
这意味着您的列表页面设置有问题
显然你只需要在其中一个列表页面上采集文章,为什么要写100个列表
茄子,你没看懂我的意思,可能是我没表达清楚
.
让我们举个例子。以SS5.5为例,我认为在这个列表页面的[论坛资源]下采集文章。因为里面的内容每天更新不超过5条(基本上是1-2条),所以我只需要设置采集每次的文章数量为例如5(注意不是40在整个列表页面)文章),并选择不允许标题重复采集,如果我每天运行采集器。这样,我只要每天跑一次采集,肯定能把采集里面的信息全部弄出来。
我提到的采集文章数设置是指这个设置:
但是如果换成SS6.0的逆序采集,同样的设置,我选的地永远是最后5个。为了得到最新的更新,我必须将文章采集数设置为列表页显示的文章的数量,这里是40。
但是想象一下如果某个网站他的列表页面在页面上显示200个文章...?假设这个网站每天更新的内容是前5,但是如果我想用逆序采集,你每次都要遍历这200条。
这就是我认为目前采集规则倒序不合理的地方。目前的规则是,运行采集器后,系统会先访问这个列表页面,记录所有符合规则的文章url,然后对这些URL从下到上或从上到下进行逆序或前序排序采集设置的文章内容数量。而且我觉得应该是系统访问,只记录从顶部开始设置文章采集的url数,然后按正序或反序执行采集,这样就解决了之前的问题。与目前的采集规则相比,只是多出了一步,但是这样一来,采集这个非常非常好的功能,将会有更广阔的实际应用空间。希望开发者可以考虑。
下面有图片说明:
希望这次我说清楚了
查看全部
文章采集功能(原帖.5说明您的列表页设置的有问题明明只需要采集其中
)
原帖由茄子发表于 2008-1-3 14:43
这意味着您的列表页面设置有问题
显然你只需要在其中一个列表页面上采集文章,为什么要写100个列表
茄子,你没看懂我的意思,可能是我没表达清楚
.
让我们举个例子。以SS5.5为例,我认为在这个列表页面的[论坛资源]下采集文章。因为里面的内容每天更新不超过5条(基本上是1-2条),所以我只需要设置采集每次的文章数量为例如5(注意不是40在整个列表页面)文章),并选择不允许标题重复采集,如果我每天运行采集器。这样,我只要每天跑一次采集,肯定能把采集里面的信息全部弄出来。
我提到的采集文章数设置是指这个设置:
但是如果换成SS6.0的逆序采集,同样的设置,我选的地永远是最后5个。为了得到最新的更新,我必须将文章采集数设置为列表页显示的文章的数量,这里是40。
但是想象一下如果某个网站他的列表页面在页面上显示200个文章...?假设这个网站每天更新的内容是前5,但是如果我想用逆序采集,你每次都要遍历这200条。
这就是我认为目前采集规则倒序不合理的地方。目前的规则是,运行采集器后,系统会先访问这个列表页面,记录所有符合规则的文章url,然后对这些URL从下到上或从上到下进行逆序或前序排序采集设置的文章内容数量。而且我觉得应该是系统访问,只记录从顶部开始设置文章采集的url数,然后按正序或反序执行采集,这样就解决了之前的问题。与目前的采集规则相比,只是多出了一步,但是这样一来,采集这个非常非常好的功能,将会有更广阔的实际应用空间。希望开发者可以考虑。
下面有图片说明:
希望这次我说清楚了
文章采集功能(本文采集指定节点和“如何导出采集内容”的说明)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-08 17:18
前言:本文为《无分页的常见文章采集方法》第三部分。在前两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集内容”进行详细说明。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
(本图来源于网络,如有侵权请联系删除!)
图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
设置完成并确认后,您可以点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),
(本图来源于网络,如有侵权请联系删除!)
图35-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,会出现相关提示,如图36),
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,
(本图来源于网络,如有侵权请联系删除!)
图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
(本图来源于网络,如有侵权请联系删除!)
图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
(本图来源于网络,如有侵权请联系删除!)
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,
(本图来源于网络,如有侵权请联系删除!)
图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
上一篇:如何使用Dedecms采集功能---图片采集(一)
下一篇:Dedecms采集函数的使用方法---不分页的普通文章(二)
声明:本站所有文章和图片均来自用户分享和网络采集。 文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
Eyoucms,易于使用的enterprise网站管理系统,点击了解更多
有什么问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注您的用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群
来源:网友提供 关注:时间:2018-01-28 12:48
☉首先,只要是我们的VIP会员,所有源代码都可以免费下载,没有任何限制(了解更多)
☉本站源码不会像其他下载站那样植入大量广告。为了更好的用户体验,以后坚持不打印水印
☉本站只提供精品织梦源代码,源代码可用,不多! !希望在这里找到合适的你。
☉本站提供的整个织梦程序都有数据和演示地址。可以在任意源码详情页查看demo地址
☉本站所有资源(包括源代码、模板、素材、特效等)仅供学习参考,请勿用于商业用途。
☉如有其他问题,请加网站客服QQ(970003436))交流。 查看全部
文章采集功能(本文采集指定节点和“如何导出采集内容”的说明)
前言:本文为《无分页的常见文章采集方法》第三部分。在前两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集内容”进行详细说明。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
(本图来源于网络,如有侵权请联系删除!)
图34-采集指定节点
采集每页:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“监控采集模式(检查当前或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
设置完成并确认后,您可以点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图35),
(本图来源于网络,如有侵权请联系删除!)
图35-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,会出现相关提示,如图36),
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
图 36-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 7) 显示,
(本图来源于网络,如有侵权请联系删除!)
图37-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
(本图来源于网络,如有侵权请联系删除!)
图 38-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图39),
(本图来源于网络,如有侵权请联系删除!)
图39-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
(本图来源于网络,如有侵权请联系删除!)
图40-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图41)显示,
(本图来源于网络,如有侵权请联系删除!)
图 41-文档列表
到目前为止,采集已经成功到达目标网站的文章内容。
综上所述,采集“普通文章无分页”比较简单。由于本文文章是基础教程,所以没有涉及太多“过滤规则”。 “常用文章带分页”的采集方法以及过滤规则的使用将在下一篇文章中介绍。
附上本文的采集rule:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="" sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}
{/dede:areastart}
{dede:areaend}
{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}
[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match} 发布于:[Content]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}
[内容]
{/de:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
上一篇:如何使用Dedecms采集功能---图片采集(一)
下一篇:Dedecms采集函数的使用方法---不分页的普通文章(二)
声明:本站所有文章和图片均来自用户分享和网络采集。 文章及图片版权归原作者所有。仅供学习和参考。请不要将它们用于商业目的。如果您的权益受到损害,请联系网站客服。
Eyoucms,易于使用的enterprise网站管理系统,点击了解更多
有什么问题可以加入织梦技术QQ群一起交流学习
本站VIP会员请加入织梦58 VIP②群 PS:加入时请备注您的用户名或昵称
普通注册会员或访客请加入织梦58技术交流②群
来源:网友提供 关注:时间:2018-01-28 12:48
☉首先,只要是我们的VIP会员,所有源代码都可以免费下载,没有任何限制(了解更多)
☉本站源码不会像其他下载站那样植入大量广告。为了更好的用户体验,以后坚持不打印水印
☉本站只提供精品织梦源代码,源代码可用,不多! !希望在这里找到合适的你。
☉本站提供的整个织梦程序都有数据和演示地址。可以在任意源码详情页查看demo地址
☉本站所有资源(包括源代码、模板、素材、特效等)仅供学习参考,请勿用于商业用途。
☉如有其他问题,请加网站客服QQ(970003436))交流。

