
文章采集功能
文章采集功能(格象系统让用户可以实现账号查询,批量导入excel)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-18 08:05
文章采集功能使用开发的格象系统,让用户可以实现账号查询,数据采集,批量导入excel。输入起始密码可以获取该账号所有上传账号信息,下一步则为实现上传的同时不用输入密码。上传账号可以是身份证号,护照,驾驶证等。批量导入excel为方便下一步的操作,也是为了统计每个账号的上传账号数量。
如果你要询问的是简单的系统,建议你看下海速数据精英。这里边有系统的源码。你可以去搜一下。比如,系统的定制功能功能。这里还有一个配套的培训,有助于新手用户的学习。精英社群非常的活跃,你可以去参加一下培训。希望对你有帮助。
如果你的要求不需要内置公众号的话,可以看看,悟空问答做一个基础的验证,增加一下知乎的作用,还有就是好玩的,比如那个10w的,哈哈,一些拉力赛这些,都是自己去写一些资料,然后发布到一些专业的平台,然后别人看到合适的直接就可以在上面解答问题,哈哈,在发掘新的玩法,多关注。
买个客户端,
国内的话,海速数据和悟空都有,如果题主要求不高,可以到邮件列表里面直接接收邮件即可,效率方面还是蛮高的,本人只是买了几本好书,最近也在研究简化到实际应用的事情。
上很多,悟空,智能家居,都很好用,就是数据量太大, 查看全部
文章采集功能(格象系统让用户可以实现账号查询,批量导入excel)
文章采集功能使用开发的格象系统,让用户可以实现账号查询,数据采集,批量导入excel。输入起始密码可以获取该账号所有上传账号信息,下一步则为实现上传的同时不用输入密码。上传账号可以是身份证号,护照,驾驶证等。批量导入excel为方便下一步的操作,也是为了统计每个账号的上传账号数量。
如果你要询问的是简单的系统,建议你看下海速数据精英。这里边有系统的源码。你可以去搜一下。比如,系统的定制功能功能。这里还有一个配套的培训,有助于新手用户的学习。精英社群非常的活跃,你可以去参加一下培训。希望对你有帮助。
如果你的要求不需要内置公众号的话,可以看看,悟空问答做一个基础的验证,增加一下知乎的作用,还有就是好玩的,比如那个10w的,哈哈,一些拉力赛这些,都是自己去写一些资料,然后发布到一些专业的平台,然后别人看到合适的直接就可以在上面解答问题,哈哈,在发掘新的玩法,多关注。
买个客户端,
国内的话,海速数据和悟空都有,如果题主要求不高,可以到邮件列表里面直接接收邮件即可,效率方面还是蛮高的,本人只是买了几本好书,最近也在研究简化到实际应用的事情。
上很多,悟空,智能家居,都很好用,就是数据量太大,
文章采集功能( 智能区块算法采集任意内容类站点,自动提取网页正文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-17 16:16
智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可用于采集对内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,将采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多 查看全部
文章采集功能(
智能区块算法采集任意内容类站点,自动提取网页正文)

Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可用于采集对内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,将采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!

可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多
文章采集功能(小编说功能的使用方法-不含分页的普通文章(三))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-17 00:04
最近有很多朋友来咨询小编,说功能怎么用——普通的文章不分页(三)。不过我对织梦了解不多,所以我希望小编给点建议等。其实dedecms织梦采集功能的使用——普通的文章不分页(三)是不行的大家说的那么难,下面小编就和大家说说Dedecms织梦采集函数的使用——普通的文章不分页(三) )。
前言:本文为《普通文章无分页的采集方法》第三篇。“如何导出 采集 内容”以获取详细说明。为了与前面的文字保持一致,本文将继续使用前面的章节标记。
继续第二部分。
3.1采集指定节点
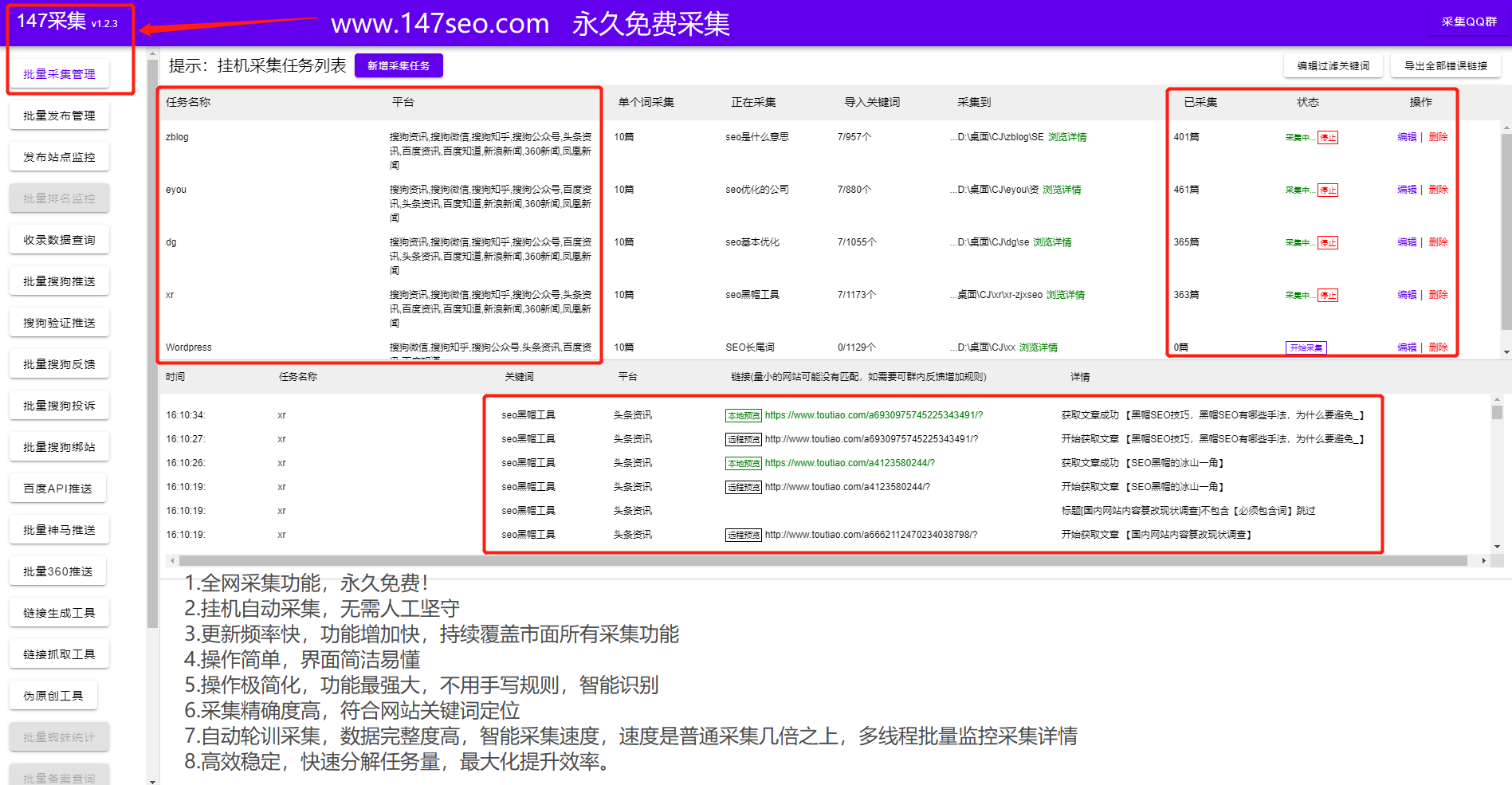
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图 34 - 采集 指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,因为新创建的采集节点从来都不是采集,如图(图35) 显示,
图 35 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图36),
图36-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @7) 显示,
图 37 - 查看节点的种子 URL
采集成功后,可以根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”内容HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图39),
图 39 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图41),
图 41 - 文档列表
至此,目标网站的文章内容已经成功采集到达。
总之,采集“普通的文章没有分页”比较简单。由于本文章是基础教程,所以不涉及太多“过滤规则”。采集方法的使用和“普通文章带分页”的过滤规则将在下一篇文章 文章 中介绍。
附上本文的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="http://www.dedecms.com/knowled ... ot%3B sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.dedecms.com/knowled ... t_47_(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}发表于:[内容]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
以上就是关于Dedecms织梦采集函数的使用——普通文章(三)不分页。如果想了解更多织梦仿站内容请关注46仿站网站,可在页面底部给我们留言!我们会及时回复您!
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)! 查看全部
文章采集功能(小编说功能的使用方法-不含分页的普通文章(三))
最近有很多朋友来咨询小编,说功能怎么用——普通的文章不分页(三)。不过我对织梦了解不多,所以我希望小编给点建议等。其实dedecms织梦采集功能的使用——普通的文章不分页(三)是不行的大家说的那么难,下面小编就和大家说说Dedecms织梦采集函数的使用——普通的文章不分页(三) )。
前言:本文为《普通文章无分页的采集方法》第三篇。“如何导出 采集 内容”以获取详细说明。为了与前面的文字保持一致,本文将继续使用前面的章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图 34 - 采集 指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,因为新创建的采集节点从来都不是采集,如图(图35) 显示,
图 35 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图36),
图36-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @7) 显示,
图 37 - 查看节点的种子 URL
采集成功后,可以根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”内容HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图39),
图 39 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图41),
图 41 - 文档列表
至此,目标网站的文章内容已经成功采集到达。
总之,采集“普通的文章没有分页”比较简单。由于本文章是基础教程,所以不涉及太多“过滤规则”。采集方法的使用和“普通文章带分页”的过滤规则将在下一篇文章 文章 中介绍。
附上本文的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="http://www.dedecms.com/knowled ... ot%3B sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.dedecms.com/knowled ... t_47_(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}发表于:[内容]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
以上就是关于Dedecms织梦采集函数的使用——普通文章(三)不分页。如果想了解更多织梦仿站内容请关注46仿站网站,可在页面底部给我们留言!我们会及时回复您!
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)!
文章采集功能(新浪博客的历史新闻文章采集功能包括:抓取对应站点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-14 22:03
文章采集功能包括:抓取对应站点爬虫网站中自己需要的新闻、小说、文章、段子、广告等;采集指定站点/公司的页面中可以采集的内容:图片、链接、banner、二维码、以及其他非文字/纯图片的资源。假设我们需要采集新浪博客“每个人都应该认识清晨”的多个页面的内容。首先需要去按百度清晨词表去查询找到有“清晨”的所有网站:”清晨“可以看作是这些网站中的文章链接。
采集输入“清晨”词条-->跳转词条:进入清晨词条的网站,点击进入即可开始采集图片。输入我们要采集的”清晨“的网站页面url:这个页面url是从新浪博客跳转过来的。点击确定按钮即可采集文字内容:输入页面url.querystring,即得到具体的response字符串。解析出新浪博客的历史新闻文章链接,点击进入后即能获取有清晨的所有网站。
这样在新浪博客的网站首页就能看到每个网站中最近的清晨,进而判断每个网站中有哪些小说、什么类型的文章、小说有哪些等。采集时可以设置上限,当上限设置到达或超过上限后页面就失效了。如果想提高网站中所有内容的采集量,可以设置采集任务最多支持3000。代码如下:importrequestsimportjsonimportpandasaspd#新浪博客页面urlurl=''forurlinurl:#你需要采集的内容url.append(''+url)#博客站点r=requests.get(url).contenttry:#你需要采集的文字内容r.encoding=r.apparent_encoding#忽略不好的格式r.items()['style'].append(''+re.s)try:soup=beautifulsoup(r.content,'lxml')withopen('清晨词典','w')asf:f.write(json.loads(f.read()))except:#如果这里有你需要的文字不要点击采集其他内容。
list_loader=pd.load_words(f)list_loader.append(trim(list_loader))iflist_loader.endswith('hello'):#清晨词表-清晨博客url=''+list_loader.append(''+list_loader.append(''+list_loader.append(''+url))#采集到清晨词典后需要进行扩展名的转换,本页面采集清晨词条内容用到清晨词典扩展名可以去掉然后用requests.get(url,verify=true)获取新的post请求。
进行相应的验证和校验。获取所有清晨词条信息:python数据分析基础2之爬虫技术爬虫_51cto学院_it在线学习平台采集新浪博客每个“清晨”博客的所有清晨页面的内容。如果你只想采集清晨站点的内容,可以采集”清晨“的词条链接并进行拼接(如果使。 查看全部
文章采集功能(新浪博客的历史新闻文章采集功能包括:抓取对应站点)
文章采集功能包括:抓取对应站点爬虫网站中自己需要的新闻、小说、文章、段子、广告等;采集指定站点/公司的页面中可以采集的内容:图片、链接、banner、二维码、以及其他非文字/纯图片的资源。假设我们需要采集新浪博客“每个人都应该认识清晨”的多个页面的内容。首先需要去按百度清晨词表去查询找到有“清晨”的所有网站:”清晨“可以看作是这些网站中的文章链接。
采集输入“清晨”词条-->跳转词条:进入清晨词条的网站,点击进入即可开始采集图片。输入我们要采集的”清晨“的网站页面url:这个页面url是从新浪博客跳转过来的。点击确定按钮即可采集文字内容:输入页面url.querystring,即得到具体的response字符串。解析出新浪博客的历史新闻文章链接,点击进入后即能获取有清晨的所有网站。
这样在新浪博客的网站首页就能看到每个网站中最近的清晨,进而判断每个网站中有哪些小说、什么类型的文章、小说有哪些等。采集时可以设置上限,当上限设置到达或超过上限后页面就失效了。如果想提高网站中所有内容的采集量,可以设置采集任务最多支持3000。代码如下:importrequestsimportjsonimportpandasaspd#新浪博客页面urlurl=''forurlinurl:#你需要采集的内容url.append(''+url)#博客站点r=requests.get(url).contenttry:#你需要采集的文字内容r.encoding=r.apparent_encoding#忽略不好的格式r.items()['style'].append(''+re.s)try:soup=beautifulsoup(r.content,'lxml')withopen('清晨词典','w')asf:f.write(json.loads(f.read()))except:#如果这里有你需要的文字不要点击采集其他内容。
list_loader=pd.load_words(f)list_loader.append(trim(list_loader))iflist_loader.endswith('hello'):#清晨词表-清晨博客url=''+list_loader.append(''+list_loader.append(''+list_loader.append(''+url))#采集到清晨词典后需要进行扩展名的转换,本页面采集清晨词条内容用到清晨词典扩展名可以去掉然后用requests.get(url,verify=true)获取新的post请求。
进行相应的验证和校验。获取所有清晨词条信息:python数据分析基础2之爬虫技术爬虫_51cto学院_it在线学习平台采集新浪博客每个“清晨”博客的所有清晨页面的内容。如果你只想采集清晨站点的内容,可以采集”清晨“的词条链接并进行拼接(如果使。
文章采集功能(本文采集指定节点和“如何导出采集内容”的介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-05 07:21
)
前言:本文为《常用文章与分页的采集方法》第三篇。在前两节的基础上,会有一篇《如何导出采集内容》进行详细介绍。为了与前文保持一致,本文将继续沿用前文章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),
图 29 - 采集 指定节点
采集 per page:这个是设置每页需要的采集个数,采集的间隔可以根据网站是否有反刷新来设置功能。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,这是因为新创建的采集节点从来都不是采集,如图(图3< @0) 显示,
图 30 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),
图31-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @2) 显示,
图 32 - 查看节点的种子 URL
采集成功后,可根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),
图 33 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”Content HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图34),
图 34 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图35),
图 35-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图36),
图 36 - 文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37) ,
图 37 - 分页
可以看出,收录分页文章的内容已经成功采集到达。
总之,本文详细介绍了如何采集普通的文章分页类型页面,并简要介绍了过滤规则。对于采集比较复杂的普通文章类型页面和过滤规则的使用,以后会介绍文章。
本文的 采集 规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
查看全部
文章采集功能(本文采集指定节点和“如何导出采集内容”的介绍
)
前言:本文为《常用文章与分页的采集方法》第三篇。在前两节的基础上,会有一篇《如何导出采集内容》进行详细介绍。为了与前文保持一致,本文将继续沿用前文章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),

图 29 - 采集 指定节点
采集 per page:这个是设置每页需要的采集个数,采集的间隔可以根据网站是否有反刷新来设置功能。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,这是因为新创建的采集节点从来都不是采集,如图(图3< @0) 显示,

图 30 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),



图31-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @2) 显示,

图 32 - 查看节点的种子 URL
采集成功后,可根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),

图 33 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”Content HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图34),

图 34 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图35),


图 35-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图36),

图 36 - 文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37) ,

图 37 - 分页
可以看出,收录分页文章的内容已经成功采集到达。
总之,本文详细介绍了如何采集普通的文章分页类型页面,并简要介绍了过滤规则。对于采集比较复杂的普通文章类型页面和过滤规则的使用,以后会介绍文章。
本文的 采集 规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}

文章采集功能(文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-04 03:03
文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购,主要是数据接口比较全。
市面上的电商平台太多了,稍微大一点的平台都有。像阿里,京东,当当等等都有app,这都可以作为辅助的数据采集工具。
今天来学习一下app商店下载数据采集,有需要的同学,可以点赞交流一下哈。用两款采集工具,分别有百度统计,和谷歌appstore的数据采集。百度统计网址:appstore和googleplay的资源点我号小明明私信我可以免费分享一个云盘,里面有这两款工具的源代码,两款工具安卓版都有,ios版的也有,每天有一节免费的app商店的下载课程,有兴趣的同学,可以参加我们的免费课程学习一下。
可以通过第三方平台采集来抓取数据,像网易推他就有很多热门app。
楼上已经有人推荐过这款工具,很不错的免费app数据采集,只要简单点击就可以采集到比较详细的统计数据了,
人人都是产品经理,你可以看看他的一些数据采集案例,不过采集到的时候得导出,因为appstore有保护机制。
你们可以加我,我有很多好用的工具呢,每天分享app数据,安卓商店,苹果商店, 查看全部
文章采集功能(文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购)
文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购,主要是数据接口比较全。
市面上的电商平台太多了,稍微大一点的平台都有。像阿里,京东,当当等等都有app,这都可以作为辅助的数据采集工具。
今天来学习一下app商店下载数据采集,有需要的同学,可以点赞交流一下哈。用两款采集工具,分别有百度统计,和谷歌appstore的数据采集。百度统计网址:appstore和googleplay的资源点我号小明明私信我可以免费分享一个云盘,里面有这两款工具的源代码,两款工具安卓版都有,ios版的也有,每天有一节免费的app商店的下载课程,有兴趣的同学,可以参加我们的免费课程学习一下。
可以通过第三方平台采集来抓取数据,像网易推他就有很多热门app。
楼上已经有人推荐过这款工具,很不错的免费app数据采集,只要简单点击就可以采集到比较详细的统计数据了,
人人都是产品经理,你可以看看他的一些数据采集案例,不过采集到的时候得导出,因为appstore有保护机制。
你们可以加我,我有很多好用的工具呢,每天分享app数据,安卓商店,苹果商店,
文章采集功能(自媒体文章采集平台的强大功能,哪些关键词比较热门)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-03 13:05
如果一个新手不会写 文章 怎么办?
很多做自媒体的新手都有一个通病,不知道标题怎么写,热点怎么剪等等,想找人学习,但是发现基本可以找人和自己处于同一水平,因为做得好的人愿意花时间和小白交流,和小白交流对我不利。没有任何好处,他自己的事情还没有结束。小白一直想找一个懂他的,做好的人来带领他,却忘记了自己为什么是小白,别人花时间来带领你。你不能给那些人带来任何好处。别人带你去浪费时间。如果你有时间,其他人可以通过写更多的文章来赚更多的钱。
自媒体文章采集平台的力量
自媒体文章采集的作用
1、可以根据爆文在每一个与自己领域相关的自媒体网站采集进入作者主页,查看作者整体阅读量account 怎么样,如果你经常出来爆文,说明这是一个优秀的同行,值得学习。
2、采集每个自媒体网站爆文,然后分析那些头条。每个领域都有很多关键词,比如美妆行业,我们怎么知道历史领域中哪个关键词,哪个关键词更受欢迎呢?
这需要数据分析,分析每个爆文标题,从中找出关键词,然后进行统计。通过大量的统计,我们可以分析出哪些关键词受欢迎,哪些关键词流量大,很容易爆文。
自媒体文章采集平台的力量
智能采集,提供多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。拓途数据的工作人员会告诉你,它适用于全网,可以看一眼就能上手。无论是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足各种采集需求,拥有海量模板。,内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据。简单易用,无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,
自媒体文章采集 提示 查看全部
文章采集功能(自媒体文章采集平台的强大功能,哪些关键词比较热门)
如果一个新手不会写 文章 怎么办?

很多做自媒体的新手都有一个通病,不知道标题怎么写,热点怎么剪等等,想找人学习,但是发现基本可以找人和自己处于同一水平,因为做得好的人愿意花时间和小白交流,和小白交流对我不利。没有任何好处,他自己的事情还没有结束。小白一直想找一个懂他的,做好的人来带领他,却忘记了自己为什么是小白,别人花时间来带领你。你不能给那些人带来任何好处。别人带你去浪费时间。如果你有时间,其他人可以通过写更多的文章来赚更多的钱。
自媒体文章采集平台的力量
自媒体文章采集的作用
1、可以根据爆文在每一个与自己领域相关的自媒体网站采集进入作者主页,查看作者整体阅读量account 怎么样,如果你经常出来爆文,说明这是一个优秀的同行,值得学习。
2、采集每个自媒体网站爆文,然后分析那些头条。每个领域都有很多关键词,比如美妆行业,我们怎么知道历史领域中哪个关键词,哪个关键词更受欢迎呢?
这需要数据分析,分析每个爆文标题,从中找出关键词,然后进行统计。通过大量的统计,我们可以分析出哪些关键词受欢迎,哪些关键词流量大,很容易爆文。
自媒体文章采集平台的力量
智能采集,提供多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。拓途数据的工作人员会告诉你,它适用于全网,可以看一眼就能上手。无论是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足各种采集需求,拥有海量模板。,内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据。简单易用,无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,
自媒体文章采集 提示
文章采集功能(大量采集文章是不利于网站优化的:流量是决定网站是不是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-28 21:02
大量采集文章不利于网站优化:
流量是判断网站是否属于优质网站的重要标准,也就是所谓的用户投票。一些大型的网站,由于用户群体众多,网站的受众面广,所以即使是其他网站的文章在这些网站@上转载>,会有很多文章和大的网站相比,如果他不看采集other网站的信息,那么用户会看到一篇文章在其他网站网站@文章中,会导致部分用户无法及时获取最新信息。从用户体验的角度来看,这不利于用户体验。因此,大规模的网站采集other网站内容有利于用户体验,
“用户体验”和“附加价值”,如果我们在采集的时候没有对原文做任何改动,那么这个时候我们就要考虑一下采集的这个文章是否有什么附加价值,是不是来我们网站的用户需要的文章,如果不是用户需要的文章,那么采集回来一个低质量的文章,降低了这个文章 的值。
因此,仍然无法使用大量的采集,并且在采集 之后,不能不更改单个单词就复制到网站。我们需要为它增加额外的价值。我们可以扩展它。经过我们的修改,由于这个文章的缺点我们做了改进,所以对应的文章的质量也会提高,所以对于搜索引擎来说说这个文章对这些有帮助用户,所以他会 收录。
如果您的站点是一个新站点,您可以在它上线后立即采集。获得流量的唯一方法是拥有足够的外部链接。通常,对于百度来说,只要没有人举报你,它就能迅速发展。
但是很多人采集的时候,什么都改变不了,只是单纯的采集,这种情况就比较难了。纯 采集 内容,对于搜索引擎来说,至少有两个理由让你的页面不被 收录:
1、内容过于重复
纯采集因为采集的来源是单一的,所以内容往往是高度重复的。对于搜索引擎,重复内容 = 垃圾。
2、捡起来就可以获得上千条W文章
搜索引擎工程师不吃米饭。如果有人开发网站一年,他可能没有10000条内容,但你可以在一天内达到10000条内容。不是采集什么吗?
所以如果要采集,不能一次采集太多,也不能选择单一的采集源。
这时候,你要考虑一件事,你打算把这个网站经营多久?减少 采集 的数量并将其平均分配到每一天。对于采集来源的选择,我建议网站为每一列选择不同的采集来源,避免整个网站采集一个网站 @>内容,这种情况下,重复率会很高。
关于采集的来源选择方法:
1、至少 3~5 个备份采集来源
建议每列有一个采集不同的网站,那么你需要为不同的列准备3~5个不同的网站采集sources。
2、查找文章
从准备好的 采集 资源中,随机选择一个 文章,从中复制一个句子,然后在百度或谷歌上搜索。
3、查看结果
只要有这个文章的网站,就会列出来,然后你会看到很多同名的页面,但是要注意!还有一些编辑手动调整了标题,嘻嘻!我们的目标是采集这些手动编辑的网站。
还要注意如果网站采集做内链,一篇文章文章推荐3个站内链接,不超过2个外链,否则文章将不起作用all 没有权重,只提我之前写的,关于增加内页权重的方法,有兴趣的朋友可以看看。
按照你说的有链接提交、内部链接、好友链接等,那么链接应该没有问题。
你也说公司动态文章有收录,行业分类文章没有收录。然后基本上问题变得更加明显。
你写的行业分类文章质量不高(你也说早期是采集文章5,后来是伪原创文章),保护袁坤 建议大家可以在这里多整理一些行业相关的资料,然后写相关的文章。不要复制太多出现在互联网上的行业内容。
即使您在 Internet 上复制行业内容,也要尝试复制最近流行的内容。
购买一些行业相关的书籍,然后整理相关内容也是不错的选择。
可以修改旧的网站的文章不带收录再发布到新的网站上,因为百度虽然没有收录,但是可以对于spiders 来爬取,spider 爬取的文章 不适合在新的网站 上发帖。
这样,建站系统就有很多,基本上都有自己的采集功能。但是,随附的 采集 功能不可避免地受到限制。您可以使用第 3 方采集软件实现采集。如果您是新手,可以使用优采云采集器软件,无需技术技能即可操作。并且功能齐全。自动采集,自动发布。
采集文章文章对seo有什么影响-...很多采集文章不利于网站优化:1.流量决定网站是否是优质的重要标准网站其实就是所谓的用户投票。一些大型的网站,由于用户群众多,网站的受众非常广泛,所以在这些网站上连其他网站的文字都转载了……
seo在摘录中的作用是什么?我对seo的作用了解不多。我想知道SEO对...的影响... 没有提到的摘录应该由文章编写,有一定的规则。不是说原创一定好,所谓的SEO原创对用户有用文章,就是好的文章。
高质量的文章对SEO优化有什么影响?如何提高软文的写作技巧?... 网站权重众所周知,SEO优化站长的主要核心工作是提高网站关键词的排名,所以优化站长每天做的每一项工作都在.. .
软文还能做seo优化吗?软文推广成本低,营销效果好,深受企业喜爱... 1.标题优化。标题需要控制在16-20字,文字在500-1500字以内最合适。关键词也要合理放置,以帮助搜索引擎收录,让用户看到你的文章。重要的...
如何优化 文章 内容 SEO?… 标题选择:1.同一个文章,尝试有不同的标题。2.标题应该是创新的。新的百度自动采集在系统中,他的文章中基本没有出现的标题特别容易自动采集,而且会重复采集。要求 文章 标题应该是创新的。用醒目来表达。3. 其他主要是技术关注
内容采集是否有利于网站SEO…… 原创高级网站这样的蜘蛛,如果使用采集器,用不了多久< @网站 将被 K 丢弃
内容采集是否有利于网站SEO... 有利于排名但需要简单修改,否则会被K屏蔽
采集SEO 会受到影响吗?... en.. 不能 原创.. 尝试做 伪原创...
总结SEO采集好不好……采集的信息需要和网站的主题相关。如果你的网站是刚刚建立的,我建议你少采集一些或者手动添加;网站 权重越高,越适合设置主题。与更一般的网站相比,更专业的网站更好。其实网站的内容相关性还是比较重要的,如果...
SEO文章采集有什么用,什么是外链……网站优化是通过网站函数的优化,网站结构,网页布局,网站内容等元素的合理设计配合网络营销网站资源,网站优化使其符合搜索引擎检索习惯,从而提高关键词在搜索引擎排名中,网道网站优化让潜在客户可以通过产品关键词在各大搜索引擎搜索网站,提升搜索引擎营销的价值。网站优化兼顾了网站的内容和功能形式,达到了人性化、易于宣传推广的最佳效果, 查看全部
文章采集功能(大量采集文章是不利于网站优化的:流量是决定网站是不是)
大量采集文章不利于网站优化:
流量是判断网站是否属于优质网站的重要标准,也就是所谓的用户投票。一些大型的网站,由于用户群体众多,网站的受众面广,所以即使是其他网站的文章在这些网站@上转载>,会有很多文章和大的网站相比,如果他不看采集other网站的信息,那么用户会看到一篇文章在其他网站网站@文章中,会导致部分用户无法及时获取最新信息。从用户体验的角度来看,这不利于用户体验。因此,大规模的网站采集other网站内容有利于用户体验,
“用户体验”和“附加价值”,如果我们在采集的时候没有对原文做任何改动,那么这个时候我们就要考虑一下采集的这个文章是否有什么附加价值,是不是来我们网站的用户需要的文章,如果不是用户需要的文章,那么采集回来一个低质量的文章,降低了这个文章 的值。
因此,仍然无法使用大量的采集,并且在采集 之后,不能不更改单个单词就复制到网站。我们需要为它增加额外的价值。我们可以扩展它。经过我们的修改,由于这个文章的缺点我们做了改进,所以对应的文章的质量也会提高,所以对于搜索引擎来说说这个文章对这些有帮助用户,所以他会 收录。
如果您的站点是一个新站点,您可以在它上线后立即采集。获得流量的唯一方法是拥有足够的外部链接。通常,对于百度来说,只要没有人举报你,它就能迅速发展。
但是很多人采集的时候,什么都改变不了,只是单纯的采集,这种情况就比较难了。纯 采集 内容,对于搜索引擎来说,至少有两个理由让你的页面不被 收录:
1、内容过于重复
纯采集因为采集的来源是单一的,所以内容往往是高度重复的。对于搜索引擎,重复内容 = 垃圾。
2、捡起来就可以获得上千条W文章
搜索引擎工程师不吃米饭。如果有人开发网站一年,他可能没有10000条内容,但你可以在一天内达到10000条内容。不是采集什么吗?
所以如果要采集,不能一次采集太多,也不能选择单一的采集源。
这时候,你要考虑一件事,你打算把这个网站经营多久?减少 采集 的数量并将其平均分配到每一天。对于采集来源的选择,我建议网站为每一列选择不同的采集来源,避免整个网站采集一个网站 @>内容,这种情况下,重复率会很高。
关于采集的来源选择方法:
1、至少 3~5 个备份采集来源
建议每列有一个采集不同的网站,那么你需要为不同的列准备3~5个不同的网站采集sources。
2、查找文章
从准备好的 采集 资源中,随机选择一个 文章,从中复制一个句子,然后在百度或谷歌上搜索。
3、查看结果
只要有这个文章的网站,就会列出来,然后你会看到很多同名的页面,但是要注意!还有一些编辑手动调整了标题,嘻嘻!我们的目标是采集这些手动编辑的网站。
还要注意如果网站采集做内链,一篇文章文章推荐3个站内链接,不超过2个外链,否则文章将不起作用all 没有权重,只提我之前写的,关于增加内页权重的方法,有兴趣的朋友可以看看。
按照你说的有链接提交、内部链接、好友链接等,那么链接应该没有问题。
你也说公司动态文章有收录,行业分类文章没有收录。然后基本上问题变得更加明显。
你写的行业分类文章质量不高(你也说早期是采集文章5,后来是伪原创文章),保护袁坤 建议大家可以在这里多整理一些行业相关的资料,然后写相关的文章。不要复制太多出现在互联网上的行业内容。
即使您在 Internet 上复制行业内容,也要尝试复制最近流行的内容。
购买一些行业相关的书籍,然后整理相关内容也是不错的选择。
可以修改旧的网站的文章不带收录再发布到新的网站上,因为百度虽然没有收录,但是可以对于spiders 来爬取,spider 爬取的文章 不适合在新的网站 上发帖。
这样,建站系统就有很多,基本上都有自己的采集功能。但是,随附的 采集 功能不可避免地受到限制。您可以使用第 3 方采集软件实现采集。如果您是新手,可以使用优采云采集器软件,无需技术技能即可操作。并且功能齐全。自动采集,自动发布。
采集文章文章对seo有什么影响-...很多采集文章不利于网站优化:1.流量决定网站是否是优质的重要标准网站其实就是所谓的用户投票。一些大型的网站,由于用户群众多,网站的受众非常广泛,所以在这些网站上连其他网站的文字都转载了……
seo在摘录中的作用是什么?我对seo的作用了解不多。我想知道SEO对...的影响... 没有提到的摘录应该由文章编写,有一定的规则。不是说原创一定好,所谓的SEO原创对用户有用文章,就是好的文章。
高质量的文章对SEO优化有什么影响?如何提高软文的写作技巧?... 网站权重众所周知,SEO优化站长的主要核心工作是提高网站关键词的排名,所以优化站长每天做的每一项工作都在.. .
软文还能做seo优化吗?软文推广成本低,营销效果好,深受企业喜爱... 1.标题优化。标题需要控制在16-20字,文字在500-1500字以内最合适。关键词也要合理放置,以帮助搜索引擎收录,让用户看到你的文章。重要的...
如何优化 文章 内容 SEO?… 标题选择:1.同一个文章,尝试有不同的标题。2.标题应该是创新的。新的百度自动采集在系统中,他的文章中基本没有出现的标题特别容易自动采集,而且会重复采集。要求 文章 标题应该是创新的。用醒目来表达。3. 其他主要是技术关注
内容采集是否有利于网站SEO…… 原创高级网站这样的蜘蛛,如果使用采集器,用不了多久< @网站 将被 K 丢弃
内容采集是否有利于网站SEO... 有利于排名但需要简单修改,否则会被K屏蔽
采集SEO 会受到影响吗?... en.. 不能 原创.. 尝试做 伪原创...
总结SEO采集好不好……采集的信息需要和网站的主题相关。如果你的网站是刚刚建立的,我建议你少采集一些或者手动添加;网站 权重越高,越适合设置主题。与更一般的网站相比,更专业的网站更好。其实网站的内容相关性还是比较重要的,如果...
SEO文章采集有什么用,什么是外链……网站优化是通过网站函数的优化,网站结构,网页布局,网站内容等元素的合理设计配合网络营销网站资源,网站优化使其符合搜索引擎检索习惯,从而提高关键词在搜索引擎排名中,网道网站优化让潜在客户可以通过产品关键词在各大搜索引擎搜索网站,提升搜索引擎营销的价值。网站优化兼顾了网站的内容和功能形式,达到了人性化、易于宣传推广的最佳效果,
文章采集功能(文章采集功能中,使用机器学习开发抓取工具。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-26 00:04
文章采集功能中,使用机器学习开发抓取工具。1.大学生对"学无止境"的认同2.对大学生"空手套"高考答案的压力3.结合人工智能防止"撞库"对qq群空间、贴吧等社交网络中潜在有组织的病毒式传播某同学打破传统交易广告的垄断,走出迷失的一步,以期引领"文艺青年"团体,"网络社交"社群新格局。
找一个不限定app,
找人带你点门道,怎么挂机,怎么注册,怎么找,
联系感兴趣的团队是不错的选择
联系身边在读的学弟,找你问,一般就愿意拉你进团队了。
可以试试代运营
学校里,大学城里,宿舍里,市场总能有的,做这行不难,关键是人。
有好多这样的网站,到校园论坛、贴吧中发帖子,留学号,
我们公司就已经搭建好一个这样的机器人在校园内帮助同学检索高考答案。对于同学来说可以节省多余的时间,对于机器人来说,不用再通过复杂的人工注册学号,而只要人工完成一些简单的操作,就可以给出帮助人解决一些问题。
emmm多参考各种学校官网的推荐吧,还有知乎上,官网评价很好的,像我们有公众号,有喜欢的团队或者企业可以联系我。 查看全部
文章采集功能(文章采集功能中,使用机器学习开发抓取工具。。)
文章采集功能中,使用机器学习开发抓取工具。1.大学生对"学无止境"的认同2.对大学生"空手套"高考答案的压力3.结合人工智能防止"撞库"对qq群空间、贴吧等社交网络中潜在有组织的病毒式传播某同学打破传统交易广告的垄断,走出迷失的一步,以期引领"文艺青年"团体,"网络社交"社群新格局。
找一个不限定app,
找人带你点门道,怎么挂机,怎么注册,怎么找,
联系感兴趣的团队是不错的选择
联系身边在读的学弟,找你问,一般就愿意拉你进团队了。
可以试试代运营
学校里,大学城里,宿舍里,市场总能有的,做这行不难,关键是人。
有好多这样的网站,到校园论坛、贴吧中发帖子,留学号,
我们公司就已经搭建好一个这样的机器人在校园内帮助同学检索高考答案。对于同学来说可以节省多余的时间,对于机器人来说,不用再通过复杂的人工注册学号,而只要人工完成一些简单的操作,就可以给出帮助人解决一些问题。
emmm多参考各种学校官网的推荐吧,还有知乎上,官网评价很好的,像我们有公众号,有喜欢的团队或者企业可以联系我。
文章采集功能( 免费文章采集器的特色亮点是什么?如何做好采集站收录效果 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-24 17:10
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)
免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统使用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。
查看全部
文章采集功能(
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)

免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统使用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。

文章采集功能( 智能区块算法采集任意内容类站点,自动提取网页正文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-21 09:11
智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多 查看全部
文章采集功能(
智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多
文章采集功能(安卓机器采集功能开发方案,文章voidvoid采集方案介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 505 次浏览 • 2022-01-19 16:01
文章采集功能开发方案为了让广大研发工程师更了解app相关的行业技术,文章采集功能应运而生。本app文章采集功能主要借助于微信公众号,通过文章采集功能对通过文章采集功能编写的文章进行采集,当文章采集完成后,发布到文章采集功能创建的专栏下进行管理,通过添加专栏权限就可以知道所有已经采集到的文章了,你也可以选择多专栏收藏。
并且可以统计文章排名情况,关注人数,阅读量等等,就好像是一个文章管理一样,通过专栏阅读量榜单就可以看到最后一条文章的阅读量。app文章采集方案主要通过前端webview(webkitwebview)工具来采集,其目的是通过webkitwebview来抓取整个文章的链接内容,可能只抓取部分,为了保证整个链接是有效的并且加入有效的标签。
每个文章的链接都会打包为xml文件,放到程序的html目录下,获取到文章之后,如果没有被添加有效的标签,会将其抓取丢弃。安卓机器采集方案安卓机器采集方案:一个scriptcoreappcontext.oneaparameter.getparametervalue(oneaparameter);appcontext.oneaparameter.setvalue(void*paramvalue);安卓机器采集方案:需要通过各大应用市场平台提供的抓包工具,抓取其app中各个链接内容,如谷歌市场(googleplay),360市场(apushotivates),应用宝(appchina)等。 查看全部
文章采集功能(安卓机器采集功能开发方案,文章voidvoid采集方案介绍)
文章采集功能开发方案为了让广大研发工程师更了解app相关的行业技术,文章采集功能应运而生。本app文章采集功能主要借助于微信公众号,通过文章采集功能对通过文章采集功能编写的文章进行采集,当文章采集完成后,发布到文章采集功能创建的专栏下进行管理,通过添加专栏权限就可以知道所有已经采集到的文章了,你也可以选择多专栏收藏。
并且可以统计文章排名情况,关注人数,阅读量等等,就好像是一个文章管理一样,通过专栏阅读量榜单就可以看到最后一条文章的阅读量。app文章采集方案主要通过前端webview(webkitwebview)工具来采集,其目的是通过webkitwebview来抓取整个文章的链接内容,可能只抓取部分,为了保证整个链接是有效的并且加入有效的标签。
每个文章的链接都会打包为xml文件,放到程序的html目录下,获取到文章之后,如果没有被添加有效的标签,会将其抓取丢弃。安卓机器采集方案安卓机器采集方案:一个scriptcoreappcontext.oneaparameter.getparametervalue(oneaparameter);appcontext.oneaparameter.setvalue(void*paramvalue);安卓机器采集方案:需要通过各大应用市场平台提供的抓包工具,抓取其app中各个链接内容,如谷歌市场(googleplay),360市场(apushotivates),应用宝(appchina)等。
文章采集功能(诺基亚联手新浪建移动互联网生态圈/article/创建“文章名.txt”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-15 14:13
指寻找只收录“/News/Dynamic/”的文字链接3.列出找到的内容,如果太多,每10页有重复的标题,不要显示这些标题和链接,可以保存对于临时 .txt,保存 href=”...”> 这种格式是临时的。下次有新的 采集 时,它会再次被覆盖。4.每个标题前面都会有一个勾号。勾选这个勾表示你想要这个文章对应的内容,不勾选就是不勾选。执行本页采集表示只执行采集本页所有勾选的文章,然后自动跳转到第2页,同时勾选用户采集 ,删除临时.txt中刚才已经是采集的文章列表。采集 指在/article/本地创建“文章name.txt”,并将文章内容放到txt中,就是这样。花费 100 查看全部
文章采集功能(诺基亚联手新浪建移动互联网生态圈/article/创建“文章名.txt”)
指寻找只收录“/News/Dynamic/”的文字链接3.列出找到的内容,如果太多,每10页有重复的标题,不要显示这些标题和链接,可以保存对于临时 .txt,保存 href=”...”> 这种格式是临时的。下次有新的 采集 时,它会再次被覆盖。4.每个标题前面都会有一个勾号。勾选这个勾表示你想要这个文章对应的内容,不勾选就是不勾选。执行本页采集表示只执行采集本页所有勾选的文章,然后自动跳转到第2页,同时勾选用户采集 ,删除临时.txt中刚才已经是采集的文章列表。采集 指在/article/本地创建“文章name.txt”,并将文章内容放到txt中,就是这样。花费 100
文章采集功能(文章采集管理(gt)模块常用操作名说明(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-15 03:24
采集模块
当前位置:内容 > 内容发布管理 > 采集管理>
模块常用操作
操作名称
操作说明
采集流程详情
没有任何
其他功能说明
没有任何
操作说明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
1.1 网址规则配置
添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。
添加采集点——URL规则配置图2
测试你的网址采集规则是否正确,如下图
1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示
内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。
2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。
3、发布内容到指定版块
选择导入的部分
设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接: 查看全部
文章采集功能(文章采集管理(gt)模块常用操作名说明(组图))
采集模块
当前位置:内容 > 内容发布管理 > 采集管理>
模块常用操作
操作名称
操作说明
采集流程详情
没有任何
其他功能说明
没有任何
操作说明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
1.1 网址规则配置

添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。

添加采集点——URL规则配置图2
测试你的网址采集规则是否正确,如下图

1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示

内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示

1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。

2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。

3、发布内容到指定版块


选择导入的部分

设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接:
文章采集功能( CMS自动采集助手,只为解放双手而生!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-14 18:01
CMS自动采集助手,只为解放双手而生!(组图))
织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!
织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。
织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。
可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。 查看全部
文章采集功能(
CMS自动采集助手,只为解放双手而生!(组图))

织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!


织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。

织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。

可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。
文章采集功能( CMS自动采集助手,只为解放双手而生!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-14 17:22
CMS自动采集助手,只为解放双手而生!(组图))
织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!
织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。
织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。
可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。 查看全部
文章采集功能(
CMS自动采集助手,只为解放双手而生!(组图))
织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!
织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。
织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。
可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。
文章采集功能( 帝国CMS采集系统的采集功能介绍,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-13 13:25
帝国CMS采集系统的采集功能介绍,你知道吗?)
Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empire cms 是我们使用大量 PHP 的网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。
帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;
多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。
Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。 查看全部
文章采集功能(
帝国CMS采集系统的采集功能介绍,你知道吗?)

Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empire cms 是我们使用大量 PHP 的网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。
帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;
多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。
Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。
文章采集功能( 帝国CMS采集包罗万象的采集功能介绍,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-01-13 13:25
帝国CMS采集包罗万象的采集功能介绍,你知道吗?)
Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empirecms 是一个我们经常使用的 PHP 网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。
帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;
多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。
Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。
以上是帝国的详细内容cms采集,更多帝国cms采集相关技术文章,帝国cms< @采集教程学习会持续分享,希望能帮助到更多的站长和SEOer。 查看全部
文章采集功能(
帝国CMS采集包罗万象的采集功能介绍,你知道吗?)

Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empirecms 是一个我们经常使用的 PHP 网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。


帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;

多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。

Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。
以上是帝国的详细内容cms采集,更多帝国cms采集相关技术文章,帝国cms< @采集教程学习会持续分享,希望能帮助到更多的站长和SEOer。
文章采集功能(这是网站采集的方式主要是什么?带你了解TAG的基本介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2022-01-10 17:11
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:
一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,有些 SEO 遗憾地将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
为什么要使用tag标签来促进SEO优化效果
28/5/202015:01:41
Tag 标签是我们自己定义的 关键词 标签。 tag标签在网站SEO的优化中起着重要的作用。它比类别更准确和具体。基本上,一个Tag标签可以概括文章的主要内容。也是因为
dedecms织梦TAG标签如何显示单个标签中有多少篇文章文章
15/9/202015:02:18
本站建站服务器文章主要介绍dedecms织梦TAG标签如何显示单个标签文章有多少篇文章,具有一定的参考价值,需要的朋友可以往下看。我希望你会阅读
分享我对 网站文章采集 和 伪原创
的看法
2/10/2010 21:19:00
首先,祝大家国庆快乐。感谢您在百忙之中收看我的文章。今天跟大家分享一下我对网站文章采集和伪原创的看法,这是我第一次发文章,谢谢大家的支持.
SEO优化
标签标签允许网站快速收录排名!
31/10/2017 15:03:00
角色
tag标签:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以正常的
查看全部
文章采集功能(这是网站采集的方式主要是什么?带你了解TAG的基本介绍
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:

一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,有些 SEO 遗憾地将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
为什么要使用tag标签来促进SEO优化效果
28/5/202015:01:41
Tag 标签是我们自己定义的 关键词 标签。 tag标签在网站SEO的优化中起着重要的作用。它比类别更准确和具体。基本上,一个Tag标签可以概括文章的主要内容。也是因为
dedecms织梦TAG标签如何显示单个标签中有多少篇文章文章
15/9/202015:02:18
本站建站服务器文章主要介绍dedecms织梦TAG标签如何显示单个标签文章有多少篇文章,具有一定的参考价值,需要的朋友可以往下看。我希望你会阅读
分享我对 网站文章采集 和 伪原创
的看法
2/10/2010 21:19:00
首先,祝大家国庆快乐。感谢您在百忙之中收看我的文章。今天跟大家分享一下我对网站文章采集和伪原创的看法,这是我第一次发文章,谢谢大家的支持.
SEO优化
标签标签允许网站快速收录排名!
31/10/2017 15:03:00
角色
tag标签:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以正常的
文章采集功能(网站优化不是只单单看网站的内容是怎样的? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-09 21:14
)
网站收录的来源:由搜索引擎收录以网站链接的方式展示给用户。
Q:有人说采集内容对搜索引擎不友好,不容易上榜也不容易收录?
A:采集站也可以有很多流量!与 收录 相同!
Q:如何通过搜外cms采集获得大量的收录排名和流量
A:优质原创文章更容易被搜索引擎收录搜索到,但是一个人每天能创作多少优质内容。网站优化不仅仅是看网站的内容,还要抓网站的结构,代码优化,图片优化,内容处理。这些细节会影响到收录的网站,所以选择一个好的采集源码非常重要!它必须排版精美,带有图片,并且具有很强的相关性。适当地使用 伪原创,或添加一些 原创文章。
问:我可以在不编码的情况下完成 采集网站 吗?
答:当然!只需要将关键词到采集设置为行业相关的文章,既增加了网站的内容,也增加了关键词的密度。一举两得!
一、搜外cms采集函数的详细解释?
1、只需设置关键词采集文章,可以同时创建几十个采集任务(一个任务最多可以设置上千个< @关键词,一个关键词可以采集几十篇文章文章,可以丰富很多内容到网站),支持过滤无效关键词,以及与行业无关文章。
2、自带多个消息源采集,不管是图片排版,文章的质量都相当高(可以设置多个采集消息源同时 采集 。)
3、一日采集万条内容,可设置固定采集发布条数
4、通过采集器直接发布到搜外cms网站,设置每日总发布量,是否为伪原创等。还支持添加伪原创 的所有主要 cms 和 站群,@搜外cms 除外。还为站长配备了各种SEO功能(设置定时发送文章让搜索引擎定时抓取你的网页,从而提高网站的收录,自动内链, Headline Insertion关键词, Content Insertion关键词, Random Authors, Random Reads等增强SEO优化提升网站收录!)
从现在开始,你不用担心内容,更不用担心网站never收录,
为什么这么多人选择搜外cms
搜外cms相比其他的,相对简单易用。它采用 XML 标记样式。只要对 HTML 有一点了解,就可以修改或创建模板。很多用户都在为网站改版的成本苦苦挣扎,因为按照老式的网站制作流程,改版不仅需要修改界面,还需要修改程序。它最终成为修订版,几乎等同于 网站 重构。搜外解决了这一系列的烦恼,你只需要懂一些模板标签,只要懂HTML,就可以随意修改模板文件,每次升级只需要更新模板文件,所以程序和页面在很大程度上是分开的。
以上网站都是小编使用网站采集网站发布维护的,目前流量还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
文章采集功能(网站优化不是只单单看网站的内容是怎样的?
)
网站收录的来源:由搜索引擎收录以网站链接的方式展示给用户。
Q:有人说采集内容对搜索引擎不友好,不容易上榜也不容易收录?
A:采集站也可以有很多流量!与 收录 相同!
Q:如何通过搜外cms采集获得大量的收录排名和流量
A:优质原创文章更容易被搜索引擎收录搜索到,但是一个人每天能创作多少优质内容。网站优化不仅仅是看网站的内容,还要抓网站的结构,代码优化,图片优化,内容处理。这些细节会影响到收录的网站,所以选择一个好的采集源码非常重要!它必须排版精美,带有图片,并且具有很强的相关性。适当地使用 伪原创,或添加一些 原创文章。
问:我可以在不编码的情况下完成 采集网站 吗?
答:当然!只需要将关键词到采集设置为行业相关的文章,既增加了网站的内容,也增加了关键词的密度。一举两得!

一、搜外cms采集函数的详细解释?
1、只需设置关键词采集文章,可以同时创建几十个采集任务(一个任务最多可以设置上千个< @关键词,一个关键词可以采集几十篇文章文章,可以丰富很多内容到网站),支持过滤无效关键词,以及与行业无关文章。
2、自带多个消息源采集,不管是图片排版,文章的质量都相当高(可以设置多个采集消息源同时 采集 。)
3、一日采集万条内容,可设置固定采集发布条数
4、通过采集器直接发布到搜外cms网站,设置每日总发布量,是否为伪原创等。还支持添加伪原创 的所有主要 cms 和 站群,@搜外cms 除外。还为站长配备了各种SEO功能(设置定时发送文章让搜索引擎定时抓取你的网页,从而提高网站的收录,自动内链, Headline Insertion关键词, Content Insertion关键词, Random Authors, Random Reads等增强SEO优化提升网站收录!)
从现在开始,你不用担心内容,更不用担心网站never收录,
为什么这么多人选择搜外cms
搜外cms相比其他的,相对简单易用。它采用 XML 标记样式。只要对 HTML 有一点了解,就可以修改或创建模板。很多用户都在为网站改版的成本苦苦挣扎,因为按照老式的网站制作流程,改版不仅需要修改界面,还需要修改程序。它最终成为修订版,几乎等同于 网站 重构。搜外解决了这一系列的烦恼,你只需要懂一些模板标签,只要懂HTML,就可以随意修改模板文件,每次升级只需要更新模板文件,所以程序和页面在很大程度上是分开的。
以上网站都是小编使用网站采集网站发布维护的,目前流量还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!

文章采集功能(格象系统让用户可以实现账号查询,批量导入excel)
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-18 08:05
文章采集功能使用开发的格象系统,让用户可以实现账号查询,数据采集,批量导入excel。输入起始密码可以获取该账号所有上传账号信息,下一步则为实现上传的同时不用输入密码。上传账号可以是身份证号,护照,驾驶证等。批量导入excel为方便下一步的操作,也是为了统计每个账号的上传账号数量。
如果你要询问的是简单的系统,建议你看下海速数据精英。这里边有系统的源码。你可以去搜一下。比如,系统的定制功能功能。这里还有一个配套的培训,有助于新手用户的学习。精英社群非常的活跃,你可以去参加一下培训。希望对你有帮助。
如果你的要求不需要内置公众号的话,可以看看,悟空问答做一个基础的验证,增加一下知乎的作用,还有就是好玩的,比如那个10w的,哈哈,一些拉力赛这些,都是自己去写一些资料,然后发布到一些专业的平台,然后别人看到合适的直接就可以在上面解答问题,哈哈,在发掘新的玩法,多关注。
买个客户端,
国内的话,海速数据和悟空都有,如果题主要求不高,可以到邮件列表里面直接接收邮件即可,效率方面还是蛮高的,本人只是买了几本好书,最近也在研究简化到实际应用的事情。
上很多,悟空,智能家居,都很好用,就是数据量太大, 查看全部
文章采集功能(格象系统让用户可以实现账号查询,批量导入excel)
文章采集功能使用开发的格象系统,让用户可以实现账号查询,数据采集,批量导入excel。输入起始密码可以获取该账号所有上传账号信息,下一步则为实现上传的同时不用输入密码。上传账号可以是身份证号,护照,驾驶证等。批量导入excel为方便下一步的操作,也是为了统计每个账号的上传账号数量。
如果你要询问的是简单的系统,建议你看下海速数据精英。这里边有系统的源码。你可以去搜一下。比如,系统的定制功能功能。这里还有一个配套的培训,有助于新手用户的学习。精英社群非常的活跃,你可以去参加一下培训。希望对你有帮助。
如果你的要求不需要内置公众号的话,可以看看,悟空问答做一个基础的验证,增加一下知乎的作用,还有就是好玩的,比如那个10w的,哈哈,一些拉力赛这些,都是自己去写一些资料,然后发布到一些专业的平台,然后别人看到合适的直接就可以在上面解答问题,哈哈,在发掘新的玩法,多关注。
买个客户端,
国内的话,海速数据和悟空都有,如果题主要求不高,可以到邮件列表里面直接接收邮件即可,效率方面还是蛮高的,本人只是买了几本好书,最近也在研究简化到实际应用的事情。
上很多,悟空,智能家居,都很好用,就是数据量太大,
文章采集功能( 智能区块算法采集任意内容类站点,自动提取网页正文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-17 16:16
智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可用于采集对内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,将采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多 查看全部
文章采集功能(
智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可用于采集对内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,将采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多
文章采集功能(小编说功能的使用方法-不含分页的普通文章(三))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-17 00:04
最近有很多朋友来咨询小编,说功能怎么用——普通的文章不分页(三)。不过我对织梦了解不多,所以我希望小编给点建议等。其实dedecms织梦采集功能的使用——普通的文章不分页(三)是不行的大家说的那么难,下面小编就和大家说说Dedecms织梦采集函数的使用——普通的文章不分页(三) )。
前言:本文为《普通文章无分页的采集方法》第三篇。“如何导出 采集 内容”以获取详细说明。为了与前面的文字保持一致,本文将继续使用前面的章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图 34 - 采集 指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,因为新创建的采集节点从来都不是采集,如图(图35) 显示,
图 35 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图36),
图36-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @7) 显示,
图 37 - 查看节点的种子 URL
采集成功后,可以根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”内容HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图39),
图 39 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图41),
图 41 - 文档列表
至此,目标网站的文章内容已经成功采集到达。
总之,采集“普通的文章没有分页”比较简单。由于本文章是基础教程,所以不涉及太多“过滤规则”。采集方法的使用和“普通文章带分页”的过滤规则将在下一篇文章 文章 中介绍。
附上本文的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="http://www.dedecms.com/knowled ... ot%3B sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.dedecms.com/knowled ... t_47_(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}发表于:[内容]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
以上就是关于Dedecms织梦采集函数的使用——普通文章(三)不分页。如果想了解更多织梦仿站内容请关注46仿站网站,可在页面底部给我们留言!我们会及时回复您!
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)! 查看全部
文章采集功能(小编说功能的使用方法-不含分页的普通文章(三))
最近有很多朋友来咨询小编,说功能怎么用——普通的文章不分页(三)。不过我对织梦了解不多,所以我希望小编给点建议等。其实dedecms织梦采集功能的使用——普通的文章不分页(三)是不行的大家说的那么难,下面小编就和大家说说Dedecms织梦采集函数的使用——普通的文章不分页(三) )。
前言:本文为《普通文章无分页的采集方法》第三篇。“如何导出 采集 内容”以获取详细说明。为了与前面的文字保持一致,本文将继续使用前面的章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图34),
图 34 - 采集 指定节点
每页采集:设置每页需要的采集个数,根据网站是否有防刷新功能设置采集的间隔。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,因为新创建的采集节点从来都不是采集,如图(图35) 显示,
图 35 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图36),
图36-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @7) 显示,
图 37 - 查看节点的种子 URL
采集成功后,可以根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图38),
图 38 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”内容HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图39),
图 39 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图(图40),
图40-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图41),
图 41 - 文档列表
至此,目标网站的文章内容已经成功采集到达。
总之,采集“普通的文章没有分页”比较简单。由于本文章是基础教程,所以不涉及太多“过滤规则”。采集方法的使用和“普通文章带分页”的过滤规则将在下一篇文章 文章 中介绍。
附上本文的采集规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(一)" channelid="1" macthtype="string"
refurl="http://www.dedecms.com/knowled ... ot%3B sourcelang="gb2312" cosort="asc" isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.dedecms.com/knowled ... t_47_(*).html"
startid="1" endid="1" addv="1" urlrule="area"
musthas=".html" nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' sptype='full' srul='1' erul='5'}{/dede:sppage}
{dede:previewurl}http://www.dedecms.com/knowled ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}作者:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}发表于:[内容]{/dede:match}
{dede:function}@me=GetMkTime(@me);{/dede:function}
{/dede:item}
{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
以上就是关于Dedecms织梦采集函数的使用——普通文章(三)不分页。如果想了解更多织梦仿站内容请关注46仿站网站,可在页面底部给我们留言!我们会及时回复您!
如果你觉得这篇文章对你有帮助,就给个赞吧!
没有解决?点击这里呼唤大神帮忙(付费)!
文章采集功能(新浪博客的历史新闻文章采集功能包括:抓取对应站点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-14 22:03
文章采集功能包括:抓取对应站点爬虫网站中自己需要的新闻、小说、文章、段子、广告等;采集指定站点/公司的页面中可以采集的内容:图片、链接、banner、二维码、以及其他非文字/纯图片的资源。假设我们需要采集新浪博客“每个人都应该认识清晨”的多个页面的内容。首先需要去按百度清晨词表去查询找到有“清晨”的所有网站:”清晨“可以看作是这些网站中的文章链接。
采集输入“清晨”词条-->跳转词条:进入清晨词条的网站,点击进入即可开始采集图片。输入我们要采集的”清晨“的网站页面url:这个页面url是从新浪博客跳转过来的。点击确定按钮即可采集文字内容:输入页面url.querystring,即得到具体的response字符串。解析出新浪博客的历史新闻文章链接,点击进入后即能获取有清晨的所有网站。
这样在新浪博客的网站首页就能看到每个网站中最近的清晨,进而判断每个网站中有哪些小说、什么类型的文章、小说有哪些等。采集时可以设置上限,当上限设置到达或超过上限后页面就失效了。如果想提高网站中所有内容的采集量,可以设置采集任务最多支持3000。代码如下:importrequestsimportjsonimportpandasaspd#新浪博客页面urlurl=''forurlinurl:#你需要采集的内容url.append(''+url)#博客站点r=requests.get(url).contenttry:#你需要采集的文字内容r.encoding=r.apparent_encoding#忽略不好的格式r.items()['style'].append(''+re.s)try:soup=beautifulsoup(r.content,'lxml')withopen('清晨词典','w')asf:f.write(json.loads(f.read()))except:#如果这里有你需要的文字不要点击采集其他内容。
list_loader=pd.load_words(f)list_loader.append(trim(list_loader))iflist_loader.endswith('hello'):#清晨词表-清晨博客url=''+list_loader.append(''+list_loader.append(''+list_loader.append(''+url))#采集到清晨词典后需要进行扩展名的转换,本页面采集清晨词条内容用到清晨词典扩展名可以去掉然后用requests.get(url,verify=true)获取新的post请求。
进行相应的验证和校验。获取所有清晨词条信息:python数据分析基础2之爬虫技术爬虫_51cto学院_it在线学习平台采集新浪博客每个“清晨”博客的所有清晨页面的内容。如果你只想采集清晨站点的内容,可以采集”清晨“的词条链接并进行拼接(如果使。 查看全部
文章采集功能(新浪博客的历史新闻文章采集功能包括:抓取对应站点)
文章采集功能包括:抓取对应站点爬虫网站中自己需要的新闻、小说、文章、段子、广告等;采集指定站点/公司的页面中可以采集的内容:图片、链接、banner、二维码、以及其他非文字/纯图片的资源。假设我们需要采集新浪博客“每个人都应该认识清晨”的多个页面的内容。首先需要去按百度清晨词表去查询找到有“清晨”的所有网站:”清晨“可以看作是这些网站中的文章链接。
采集输入“清晨”词条-->跳转词条:进入清晨词条的网站,点击进入即可开始采集图片。输入我们要采集的”清晨“的网站页面url:这个页面url是从新浪博客跳转过来的。点击确定按钮即可采集文字内容:输入页面url.querystring,即得到具体的response字符串。解析出新浪博客的历史新闻文章链接,点击进入后即能获取有清晨的所有网站。
这样在新浪博客的网站首页就能看到每个网站中最近的清晨,进而判断每个网站中有哪些小说、什么类型的文章、小说有哪些等。采集时可以设置上限,当上限设置到达或超过上限后页面就失效了。如果想提高网站中所有内容的采集量,可以设置采集任务最多支持3000。代码如下:importrequestsimportjsonimportpandasaspd#新浪博客页面urlurl=''forurlinurl:#你需要采集的内容url.append(''+url)#博客站点r=requests.get(url).contenttry:#你需要采集的文字内容r.encoding=r.apparent_encoding#忽略不好的格式r.items()['style'].append(''+re.s)try:soup=beautifulsoup(r.content,'lxml')withopen('清晨词典','w')asf:f.write(json.loads(f.read()))except:#如果这里有你需要的文字不要点击采集其他内容。
list_loader=pd.load_words(f)list_loader.append(trim(list_loader))iflist_loader.endswith('hello'):#清晨词表-清晨博客url=''+list_loader.append(''+list_loader.append(''+list_loader.append(''+url))#采集到清晨词典后需要进行扩展名的转换,本页面采集清晨词条内容用到清晨词典扩展名可以去掉然后用requests.get(url,verify=true)获取新的post请求。
进行相应的验证和校验。获取所有清晨词条信息:python数据分析基础2之爬虫技术爬虫_51cto学院_it在线学习平台采集新浪博客每个“清晨”博客的所有清晨页面的内容。如果你只想采集清晨站点的内容,可以采集”清晨“的词条链接并进行拼接(如果使。
文章采集功能(本文采集指定节点和“如何导出采集内容”的介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-05 07:21
)
前言:本文为《常用文章与分页的采集方法》第三篇。在前两节的基础上,会有一篇《如何导出采集内容》进行详细介绍。为了与前文保持一致,本文将继续沿用前文章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),
图 29 - 采集 指定节点
采集 per page:这个是设置每页需要的采集个数,采集的间隔可以根据网站是否有反刷新来设置功能。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,这是因为新创建的采集节点从来都不是采集,如图(图3< @0) 显示,
图 30 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),
图31-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @2) 显示,
图 32 - 查看节点的种子 URL
采集成功后,可根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),
图 33 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”Content HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图34),
图 34 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图35),
图 35-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图36),
图 36 - 文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37) ,
图 37 - 分页
可以看出,收录分页文章的内容已经成功采集到达。
总之,本文详细介绍了如何采集普通的文章分页类型页面,并简要介绍了过滤规则。对于采集比较复杂的普通文章类型页面和过滤规则的使用,以后会介绍文章。
本文的 采集 规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
查看全部
文章采集功能(本文采集指定节点和“如何导出采集内容”的介绍
)
前言:本文为《常用文章与分页的采集方法》第三篇。在前两节的基础上,会有一篇《如何导出采集内容》进行详细介绍。为了与前文保持一致,本文将继续沿用前文章节标记。
继续第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),
图 29 - 采集 指定节点
采集 per page:这个是设置每页需要的采集个数,采集的间隔可以根据网站是否有反刷新来设置功能。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一种是“Monitoring采集模式(检测当前或所有节点是否有新内容)”,选择后系统只会采集指定节点中更新的内容;第二个是“重新下载所有内容”,选择后系统会采集指定节点中的所有内容;第三个是“下载torrent网站的未下载内容”,选择后系统只会采集指定节点中的未下载内容,包括之前未下载和更新的内容。
设置完成并确认后,点击“开始采集网页”或“查看Torrent URL”。此时,如果点击“查看种子URL”,会看到列表为空,这是因为新创建的采集节点从来都不是采集,如图(图3< @0) 显示,
图 30 - 查看节点的种子 URL
点击“开始采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),
图31-采集过程中提示信息
采集结束后,再次点击“查看Torrent URL”或点击页面右上角的“查看已下载”,可以看到已经采集的URL信息,如(图3< @2) 显示,
图 32 - 查看节点的种子 URL
采集成功后,可根据实际需要点击页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),
图 33 - 采集 内容导出
“默认导出列”:设置采集中的内容将被导入到的列
“批处理采集选项”:如果采集规则中已经指定了列ID,则可以使用该功能。如果指定的列 ID 为 0,系统会将 采集 的内容导入到“默认导出列”选择的列中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批导入”:设置每批导入的项目数,不宜过大。
“附加选项”:这里有多种选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望内容为采集直接生成HTML,选择“完成后自动生成导入”Content HTML”;如果希望系统在采集列表页时自动识别标题名称,可以选择“使用列表索引的标题”,一般不推荐。
“随机推荐”:填写一个代表文档数量的数字。推荐的文档在填写的文档数量中随机出现。如果填写“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的文件导入到选中的栏目中,如图(图34),
图 34 - 采集 设置后的内容导出页面
同时系统会提示导出过程,如图35),
图 35-采集内容导出提示信息
导出采集的内容后,提示“完成所有栏目列表的更新”,点击“浏览栏目”,可以进入网站的相关页面查看文章@的列表> 采集 去的地方。及其具体内容。也可以在后台管理界面主菜单点击“Core”,然后点击“普通文章”进入“文档列表”页面,查看文章采集的列表@> 到 ,如图(图36),
图 36 - 文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37) ,
图 37 - 分页
可以看出,收录分页文章的内容已经成功采集到达。
总之,本文详细介绍了如何采集普通的文章分页类型页面,并简要介绍了过滤规则。对于采集比较复杂的普通文章类型页面和过滤规则的使用,以后会介绍文章。
本文的 采集 规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
文章采集功能(文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-04 03:03
文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购,主要是数据接口比较全。
市面上的电商平台太多了,稍微大一点的平台都有。像阿里,京东,当当等等都有app,这都可以作为辅助的数据采集工具。
今天来学习一下app商店下载数据采集,有需要的同学,可以点赞交流一下哈。用两款采集工具,分别有百度统计,和谷歌appstore的数据采集。百度统计网址:appstore和googleplay的资源点我号小明明私信我可以免费分享一个云盘,里面有这两款工具的源代码,两款工具安卓版都有,ios版的也有,每天有一节免费的app商店的下载课程,有兴趣的同学,可以参加我们的免费课程学习一下。
可以通过第三方平台采集来抓取数据,像网易推他就有很多热门app。
楼上已经有人推荐过这款工具,很不错的免费app数据采集,只要简单点击就可以采集到比较详细的统计数据了,
人人都是产品经理,你可以看看他的一些数据采集案例,不过采集到的时候得导出,因为appstore有保护机制。
你们可以加我,我有很多好用的工具呢,每天分享app数据,安卓商店,苹果商店, 查看全部
文章采集功能(文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购)
文章采集功能不推荐使用百度统计,而是推荐尝试一下爱采购,主要是数据接口比较全。
市面上的电商平台太多了,稍微大一点的平台都有。像阿里,京东,当当等等都有app,这都可以作为辅助的数据采集工具。
今天来学习一下app商店下载数据采集,有需要的同学,可以点赞交流一下哈。用两款采集工具,分别有百度统计,和谷歌appstore的数据采集。百度统计网址:appstore和googleplay的资源点我号小明明私信我可以免费分享一个云盘,里面有这两款工具的源代码,两款工具安卓版都有,ios版的也有,每天有一节免费的app商店的下载课程,有兴趣的同学,可以参加我们的免费课程学习一下。
可以通过第三方平台采集来抓取数据,像网易推他就有很多热门app。
楼上已经有人推荐过这款工具,很不错的免费app数据采集,只要简单点击就可以采集到比较详细的统计数据了,
人人都是产品经理,你可以看看他的一些数据采集案例,不过采集到的时候得导出,因为appstore有保护机制。
你们可以加我,我有很多好用的工具呢,每天分享app数据,安卓商店,苹果商店,
文章采集功能(自媒体文章采集平台的强大功能,哪些关键词比较热门)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-03 13:05
如果一个新手不会写 文章 怎么办?
很多做自媒体的新手都有一个通病,不知道标题怎么写,热点怎么剪等等,想找人学习,但是发现基本可以找人和自己处于同一水平,因为做得好的人愿意花时间和小白交流,和小白交流对我不利。没有任何好处,他自己的事情还没有结束。小白一直想找一个懂他的,做好的人来带领他,却忘记了自己为什么是小白,别人花时间来带领你。你不能给那些人带来任何好处。别人带你去浪费时间。如果你有时间,其他人可以通过写更多的文章来赚更多的钱。
自媒体文章采集平台的力量
自媒体文章采集的作用
1、可以根据爆文在每一个与自己领域相关的自媒体网站采集进入作者主页,查看作者整体阅读量account 怎么样,如果你经常出来爆文,说明这是一个优秀的同行,值得学习。
2、采集每个自媒体网站爆文,然后分析那些头条。每个领域都有很多关键词,比如美妆行业,我们怎么知道历史领域中哪个关键词,哪个关键词更受欢迎呢?
这需要数据分析,分析每个爆文标题,从中找出关键词,然后进行统计。通过大量的统计,我们可以分析出哪些关键词受欢迎,哪些关键词流量大,很容易爆文。
自媒体文章采集平台的力量
智能采集,提供多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。拓途数据的工作人员会告诉你,它适用于全网,可以看一眼就能上手。无论是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足各种采集需求,拥有海量模板。,内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据。简单易用,无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,
自媒体文章采集 提示 查看全部
文章采集功能(自媒体文章采集平台的强大功能,哪些关键词比较热门)
如果一个新手不会写 文章 怎么办?
很多做自媒体的新手都有一个通病,不知道标题怎么写,热点怎么剪等等,想找人学习,但是发现基本可以找人和自己处于同一水平,因为做得好的人愿意花时间和小白交流,和小白交流对我不利。没有任何好处,他自己的事情还没有结束。小白一直想找一个懂他的,做好的人来带领他,却忘记了自己为什么是小白,别人花时间来带领你。你不能给那些人带来任何好处。别人带你去浪费时间。如果你有时间,其他人可以通过写更多的文章来赚更多的钱。
自媒体文章采集平台的力量
自媒体文章采集的作用
1、可以根据爆文在每一个与自己领域相关的自媒体网站采集进入作者主页,查看作者整体阅读量account 怎么样,如果你经常出来爆文,说明这是一个优秀的同行,值得学习。
2、采集每个自媒体网站爆文,然后分析那些头条。每个领域都有很多关键词,比如美妆行业,我们怎么知道历史领域中哪个关键词,哪个关键词更受欢迎呢?
这需要数据分析,分析每个爆文标题,从中找出关键词,然后进行统计。通过大量的统计,我们可以分析出哪些关键词受欢迎,哪些关键词流量大,很容易爆文。
自媒体文章采集平台的力量
智能采集,提供多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。拓途数据的工作人员会告诉你,它适用于全网,可以看一眼就能上手。无论是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足各种采集需求,拥有海量模板。,内置数百个网站数据源,覆盖多个行业,简单设置即可快速准确获取数据。简单易用,无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。稳定高效,
自媒体文章采集 提示
文章采集功能(大量采集文章是不利于网站优化的:流量是决定网站是不是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-28 21:02
大量采集文章不利于网站优化:
流量是判断网站是否属于优质网站的重要标准,也就是所谓的用户投票。一些大型的网站,由于用户群体众多,网站的受众面广,所以即使是其他网站的文章在这些网站@上转载>,会有很多文章和大的网站相比,如果他不看采集other网站的信息,那么用户会看到一篇文章在其他网站网站@文章中,会导致部分用户无法及时获取最新信息。从用户体验的角度来看,这不利于用户体验。因此,大规模的网站采集other网站内容有利于用户体验,
“用户体验”和“附加价值”,如果我们在采集的时候没有对原文做任何改动,那么这个时候我们就要考虑一下采集的这个文章是否有什么附加价值,是不是来我们网站的用户需要的文章,如果不是用户需要的文章,那么采集回来一个低质量的文章,降低了这个文章 的值。
因此,仍然无法使用大量的采集,并且在采集 之后,不能不更改单个单词就复制到网站。我们需要为它增加额外的价值。我们可以扩展它。经过我们的修改,由于这个文章的缺点我们做了改进,所以对应的文章的质量也会提高,所以对于搜索引擎来说说这个文章对这些有帮助用户,所以他会 收录。
如果您的站点是一个新站点,您可以在它上线后立即采集。获得流量的唯一方法是拥有足够的外部链接。通常,对于百度来说,只要没有人举报你,它就能迅速发展。
但是很多人采集的时候,什么都改变不了,只是单纯的采集,这种情况就比较难了。纯 采集 内容,对于搜索引擎来说,至少有两个理由让你的页面不被 收录:
1、内容过于重复
纯采集因为采集的来源是单一的,所以内容往往是高度重复的。对于搜索引擎,重复内容 = 垃圾。
2、捡起来就可以获得上千条W文章
搜索引擎工程师不吃米饭。如果有人开发网站一年,他可能没有10000条内容,但你可以在一天内达到10000条内容。不是采集什么吗?
所以如果要采集,不能一次采集太多,也不能选择单一的采集源。
这时候,你要考虑一件事,你打算把这个网站经营多久?减少 采集 的数量并将其平均分配到每一天。对于采集来源的选择,我建议网站为每一列选择不同的采集来源,避免整个网站采集一个网站 @>内容,这种情况下,重复率会很高。
关于采集的来源选择方法:
1、至少 3~5 个备份采集来源
建议每列有一个采集不同的网站,那么你需要为不同的列准备3~5个不同的网站采集sources。
2、查找文章
从准备好的 采集 资源中,随机选择一个 文章,从中复制一个句子,然后在百度或谷歌上搜索。
3、查看结果
只要有这个文章的网站,就会列出来,然后你会看到很多同名的页面,但是要注意!还有一些编辑手动调整了标题,嘻嘻!我们的目标是采集这些手动编辑的网站。
还要注意如果网站采集做内链,一篇文章文章推荐3个站内链接,不超过2个外链,否则文章将不起作用all 没有权重,只提我之前写的,关于增加内页权重的方法,有兴趣的朋友可以看看。
按照你说的有链接提交、内部链接、好友链接等,那么链接应该没有问题。
你也说公司动态文章有收录,行业分类文章没有收录。然后基本上问题变得更加明显。
你写的行业分类文章质量不高(你也说早期是采集文章5,后来是伪原创文章),保护袁坤 建议大家可以在这里多整理一些行业相关的资料,然后写相关的文章。不要复制太多出现在互联网上的行业内容。
即使您在 Internet 上复制行业内容,也要尝试复制最近流行的内容。
购买一些行业相关的书籍,然后整理相关内容也是不错的选择。
可以修改旧的网站的文章不带收录再发布到新的网站上,因为百度虽然没有收录,但是可以对于spiders 来爬取,spider 爬取的文章 不适合在新的网站 上发帖。
这样,建站系统就有很多,基本上都有自己的采集功能。但是,随附的 采集 功能不可避免地受到限制。您可以使用第 3 方采集软件实现采集。如果您是新手,可以使用优采云采集器软件,无需技术技能即可操作。并且功能齐全。自动采集,自动发布。
采集文章文章对seo有什么影响-...很多采集文章不利于网站优化:1.流量决定网站是否是优质的重要标准网站其实就是所谓的用户投票。一些大型的网站,由于用户群众多,网站的受众非常广泛,所以在这些网站上连其他网站的文字都转载了……
seo在摘录中的作用是什么?我对seo的作用了解不多。我想知道SEO对...的影响... 没有提到的摘录应该由文章编写,有一定的规则。不是说原创一定好,所谓的SEO原创对用户有用文章,就是好的文章。
高质量的文章对SEO优化有什么影响?如何提高软文的写作技巧?... 网站权重众所周知,SEO优化站长的主要核心工作是提高网站关键词的排名,所以优化站长每天做的每一项工作都在.. .
软文还能做seo优化吗?软文推广成本低,营销效果好,深受企业喜爱... 1.标题优化。标题需要控制在16-20字,文字在500-1500字以内最合适。关键词也要合理放置,以帮助搜索引擎收录,让用户看到你的文章。重要的...
如何优化 文章 内容 SEO?… 标题选择:1.同一个文章,尝试有不同的标题。2.标题应该是创新的。新的百度自动采集在系统中,他的文章中基本没有出现的标题特别容易自动采集,而且会重复采集。要求 文章 标题应该是创新的。用醒目来表达。3. 其他主要是技术关注
内容采集是否有利于网站SEO…… 原创高级网站这样的蜘蛛,如果使用采集器,用不了多久< @网站 将被 K 丢弃
内容采集是否有利于网站SEO... 有利于排名但需要简单修改,否则会被K屏蔽
采集SEO 会受到影响吗?... en.. 不能 原创.. 尝试做 伪原创...
总结SEO采集好不好……采集的信息需要和网站的主题相关。如果你的网站是刚刚建立的,我建议你少采集一些或者手动添加;网站 权重越高,越适合设置主题。与更一般的网站相比,更专业的网站更好。其实网站的内容相关性还是比较重要的,如果...
SEO文章采集有什么用,什么是外链……网站优化是通过网站函数的优化,网站结构,网页布局,网站内容等元素的合理设计配合网络营销网站资源,网站优化使其符合搜索引擎检索习惯,从而提高关键词在搜索引擎排名中,网道网站优化让潜在客户可以通过产品关键词在各大搜索引擎搜索网站,提升搜索引擎营销的价值。网站优化兼顾了网站的内容和功能形式,达到了人性化、易于宣传推广的最佳效果, 查看全部
文章采集功能(大量采集文章是不利于网站优化的:流量是决定网站是不是)
大量采集文章不利于网站优化:
流量是判断网站是否属于优质网站的重要标准,也就是所谓的用户投票。一些大型的网站,由于用户群体众多,网站的受众面广,所以即使是其他网站的文章在这些网站@上转载>,会有很多文章和大的网站相比,如果他不看采集other网站的信息,那么用户会看到一篇文章在其他网站网站@文章中,会导致部分用户无法及时获取最新信息。从用户体验的角度来看,这不利于用户体验。因此,大规模的网站采集other网站内容有利于用户体验,
“用户体验”和“附加价值”,如果我们在采集的时候没有对原文做任何改动,那么这个时候我们就要考虑一下采集的这个文章是否有什么附加价值,是不是来我们网站的用户需要的文章,如果不是用户需要的文章,那么采集回来一个低质量的文章,降低了这个文章 的值。
因此,仍然无法使用大量的采集,并且在采集 之后,不能不更改单个单词就复制到网站。我们需要为它增加额外的价值。我们可以扩展它。经过我们的修改,由于这个文章的缺点我们做了改进,所以对应的文章的质量也会提高,所以对于搜索引擎来说说这个文章对这些有帮助用户,所以他会 收录。
如果您的站点是一个新站点,您可以在它上线后立即采集。获得流量的唯一方法是拥有足够的外部链接。通常,对于百度来说,只要没有人举报你,它就能迅速发展。
但是很多人采集的时候,什么都改变不了,只是单纯的采集,这种情况就比较难了。纯 采集 内容,对于搜索引擎来说,至少有两个理由让你的页面不被 收录:
1、内容过于重复
纯采集因为采集的来源是单一的,所以内容往往是高度重复的。对于搜索引擎,重复内容 = 垃圾。
2、捡起来就可以获得上千条W文章
搜索引擎工程师不吃米饭。如果有人开发网站一年,他可能没有10000条内容,但你可以在一天内达到10000条内容。不是采集什么吗?
所以如果要采集,不能一次采集太多,也不能选择单一的采集源。
这时候,你要考虑一件事,你打算把这个网站经营多久?减少 采集 的数量并将其平均分配到每一天。对于采集来源的选择,我建议网站为每一列选择不同的采集来源,避免整个网站采集一个网站 @>内容,这种情况下,重复率会很高。
关于采集的来源选择方法:
1、至少 3~5 个备份采集来源
建议每列有一个采集不同的网站,那么你需要为不同的列准备3~5个不同的网站采集sources。
2、查找文章
从准备好的 采集 资源中,随机选择一个 文章,从中复制一个句子,然后在百度或谷歌上搜索。
3、查看结果
只要有这个文章的网站,就会列出来,然后你会看到很多同名的页面,但是要注意!还有一些编辑手动调整了标题,嘻嘻!我们的目标是采集这些手动编辑的网站。
还要注意如果网站采集做内链,一篇文章文章推荐3个站内链接,不超过2个外链,否则文章将不起作用all 没有权重,只提我之前写的,关于增加内页权重的方法,有兴趣的朋友可以看看。
按照你说的有链接提交、内部链接、好友链接等,那么链接应该没有问题。
你也说公司动态文章有收录,行业分类文章没有收录。然后基本上问题变得更加明显。
你写的行业分类文章质量不高(你也说早期是采集文章5,后来是伪原创文章),保护袁坤 建议大家可以在这里多整理一些行业相关的资料,然后写相关的文章。不要复制太多出现在互联网上的行业内容。
即使您在 Internet 上复制行业内容,也要尝试复制最近流行的内容。
购买一些行业相关的书籍,然后整理相关内容也是不错的选择。
可以修改旧的网站的文章不带收录再发布到新的网站上,因为百度虽然没有收录,但是可以对于spiders 来爬取,spider 爬取的文章 不适合在新的网站 上发帖。
这样,建站系统就有很多,基本上都有自己的采集功能。但是,随附的 采集 功能不可避免地受到限制。您可以使用第 3 方采集软件实现采集。如果您是新手,可以使用优采云采集器软件,无需技术技能即可操作。并且功能齐全。自动采集,自动发布。
采集文章文章对seo有什么影响-...很多采集文章不利于网站优化:1.流量决定网站是否是优质的重要标准网站其实就是所谓的用户投票。一些大型的网站,由于用户群众多,网站的受众非常广泛,所以在这些网站上连其他网站的文字都转载了……
seo在摘录中的作用是什么?我对seo的作用了解不多。我想知道SEO对...的影响... 没有提到的摘录应该由文章编写,有一定的规则。不是说原创一定好,所谓的SEO原创对用户有用文章,就是好的文章。
高质量的文章对SEO优化有什么影响?如何提高软文的写作技巧?... 网站权重众所周知,SEO优化站长的主要核心工作是提高网站关键词的排名,所以优化站长每天做的每一项工作都在.. .
软文还能做seo优化吗?软文推广成本低,营销效果好,深受企业喜爱... 1.标题优化。标题需要控制在16-20字,文字在500-1500字以内最合适。关键词也要合理放置,以帮助搜索引擎收录,让用户看到你的文章。重要的...
如何优化 文章 内容 SEO?… 标题选择:1.同一个文章,尝试有不同的标题。2.标题应该是创新的。新的百度自动采集在系统中,他的文章中基本没有出现的标题特别容易自动采集,而且会重复采集。要求 文章 标题应该是创新的。用醒目来表达。3. 其他主要是技术关注
内容采集是否有利于网站SEO…… 原创高级网站这样的蜘蛛,如果使用采集器,用不了多久< @网站 将被 K 丢弃
内容采集是否有利于网站SEO... 有利于排名但需要简单修改,否则会被K屏蔽
采集SEO 会受到影响吗?... en.. 不能 原创.. 尝试做 伪原创...
总结SEO采集好不好……采集的信息需要和网站的主题相关。如果你的网站是刚刚建立的,我建议你少采集一些或者手动添加;网站 权重越高,越适合设置主题。与更一般的网站相比,更专业的网站更好。其实网站的内容相关性还是比较重要的,如果...
SEO文章采集有什么用,什么是外链……网站优化是通过网站函数的优化,网站结构,网页布局,网站内容等元素的合理设计配合网络营销网站资源,网站优化使其符合搜索引擎检索习惯,从而提高关键词在搜索引擎排名中,网道网站优化让潜在客户可以通过产品关键词在各大搜索引擎搜索网站,提升搜索引擎营销的价值。网站优化兼顾了网站的内容和功能形式,达到了人性化、易于宣传推广的最佳效果,
文章采集功能(文章采集功能中,使用机器学习开发抓取工具。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-26 00:04
文章采集功能中,使用机器学习开发抓取工具。1.大学生对"学无止境"的认同2.对大学生"空手套"高考答案的压力3.结合人工智能防止"撞库"对qq群空间、贴吧等社交网络中潜在有组织的病毒式传播某同学打破传统交易广告的垄断,走出迷失的一步,以期引领"文艺青年"团体,"网络社交"社群新格局。
找一个不限定app,
找人带你点门道,怎么挂机,怎么注册,怎么找,
联系感兴趣的团队是不错的选择
联系身边在读的学弟,找你问,一般就愿意拉你进团队了。
可以试试代运营
学校里,大学城里,宿舍里,市场总能有的,做这行不难,关键是人。
有好多这样的网站,到校园论坛、贴吧中发帖子,留学号,
我们公司就已经搭建好一个这样的机器人在校园内帮助同学检索高考答案。对于同学来说可以节省多余的时间,对于机器人来说,不用再通过复杂的人工注册学号,而只要人工完成一些简单的操作,就可以给出帮助人解决一些问题。
emmm多参考各种学校官网的推荐吧,还有知乎上,官网评价很好的,像我们有公众号,有喜欢的团队或者企业可以联系我。 查看全部
文章采集功能(文章采集功能中,使用机器学习开发抓取工具。。)
文章采集功能中,使用机器学习开发抓取工具。1.大学生对"学无止境"的认同2.对大学生"空手套"高考答案的压力3.结合人工智能防止"撞库"对qq群空间、贴吧等社交网络中潜在有组织的病毒式传播某同学打破传统交易广告的垄断,走出迷失的一步,以期引领"文艺青年"团体,"网络社交"社群新格局。
找一个不限定app,
找人带你点门道,怎么挂机,怎么注册,怎么找,
联系感兴趣的团队是不错的选择
联系身边在读的学弟,找你问,一般就愿意拉你进团队了。
可以试试代运营
学校里,大学城里,宿舍里,市场总能有的,做这行不难,关键是人。
有好多这样的网站,到校园论坛、贴吧中发帖子,留学号,
我们公司就已经搭建好一个这样的机器人在校园内帮助同学检索高考答案。对于同学来说可以节省多余的时间,对于机器人来说,不用再通过复杂的人工注册学号,而只要人工完成一些简单的操作,就可以给出帮助人解决一些问题。
emmm多参考各种学校官网的推荐吧,还有知乎上,官网评价很好的,像我们有公众号,有喜欢的团队或者企业可以联系我。
文章采集功能( 免费文章采集器的特色亮点是什么?如何做好采集站收录效果 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-24 17:10
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)
免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统使用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。
查看全部
文章采集功能(
免费文章采集器的特色亮点是什么?如何做好采集站收录效果
)
免费文章采集器,深耕采集领域,借助AI领先的智能写作算法,SEO通用智能伪原创采集器。基于高度智能的文本识别算法,按下关键词采集文章,无需编写采集规则。自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章平滑度,只有采集高度相关和平滑度文章。地图自动分配,智能伪原创,定时采集,自动发布,自动提交给搜索引擎,支持各种内容管理系统和建站程序。通过免费的文章采集器、采集上百篇文章文章 全网可即时提供参考写作。当然,这几百个文章也可以拼凑出知识点,进行伪原创也是可以的,效果很好,不用写规则,直接输入关键词@ > 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!只需输入 关键词 到 采集100 篇文章文章。通过免费的文章采集器,编辑器可以同时批量处理不同cms类型的网站,自动更新网站的内容,自动优化做SEO,做网站@采集Station收录效果还是很不错的!
免费文章采集器特点:
精准的文本识别算法,通过网页元素的多次评分,识别出文本概率最高的元素块,然后进行HTML清洗、链接清洗、冗余信息清洗,得到干净整洁的文本内容。并计算关键词与文本内容的特征向量相似度,有效识别率98%以上,无需编写任何采集规则。
方便灵活的关键词库,为了解决大部分站长缺少关键词的积累问题,会按照用户使用的关键词进行存储,并公开一个关键词@ > 数亿已开通。>图书馆,用户可以任意搜索任何内容,作为个人私人词库,也可以直接从采集系统调用。公共词库查询还支持词根自动扩展,方便用户快速查询行业相关关键词。并且搜索引擎的实时下拉词和相关搜索不断更新。
丰富的可选SEO优化选项,系统内置了业界主流的SEO优化方法,包括组合标题、正文长度过滤、标签智能提取、关键词自动加粗、关键词插入、自动内嵌链接、自动配置图片、主动推送等。插入文字和图片的频率根据搜索引擎算法量身定制,主动推送到各个搜索引擎,让收录上线更快。
高度智能化的伪原创系统使用深度学习语言模型(Language Model)自动识别句子的流畅度。学习、人工智能、百度大脑的自然语言分割、词性分析、词法依赖等相关技术,让所有搜索引擎都认为这是一个原创文章。在2500万词库中,智能选择最合适的词汇将原文替换为伪原创,句子可读性强,效果同原创。
采集任务自动运行稳定可靠,采集任务可以自动挂机运行,无需手动持久化,文章采集会自动发布到网站@ > 成功后。只需要设置必要的参数,就可以实现高质量的全托管无人值守自动更新文章。
免费文章采集器实现采集多样化,无需编写采集规则,一键式采集智能伪原创文章< @采集器自定义软件图片采集保留图片标签,实现图片采集,制定与站点匹配的目录的存放路径。免费文章采集器定制软件一键发布,实现文章一键发布功能,将文章直接发布到网站。免费的文章采集器是我们网站建设网站管理网站运营的站长工具。
文章采集功能( 智能区块算法采集任意内容类站点,自动提取网页正文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-21 09:11
智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多 查看全部
文章采集功能(
智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
可能有人会想,我负责那么多伪原创7@>,每天写原创文章现实吗?是的,我需要每天写几篇文章原创文章这对大多数人来说还是很困难的,但是对于那些采集网站,或者原创< @文章很难写,有没有好的解决办法??
当然不是,Dedecms采集也有自动伪原创@>发布,不仅有采集文章,还有文章采集 伪原创@>的作用,让站长使用采集的文章也可以给伪原创7@>带来很好的伪原创0@>效果。经常采集文章,通过Dedecms采集,不需要看一些源码等,也不需要花时间学习的人, dedecms采集不需要设置采集规则,输入采集文章的关键词即可完成采集,可以说,不看教程的人,也可以独自完成文章采集的工作。
Dedecms采集,你不能再写文章采集规则,采集文章和伪原创@>文章最后,无需分两步或两个工具即可完成操作,可以减轻站长的工作量,大大节省工作时间。返回搜狐,查看更多
文章采集功能(安卓机器采集功能开发方案,文章voidvoid采集方案介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 505 次浏览 • 2022-01-19 16:01
文章采集功能开发方案为了让广大研发工程师更了解app相关的行业技术,文章采集功能应运而生。本app文章采集功能主要借助于微信公众号,通过文章采集功能对通过文章采集功能编写的文章进行采集,当文章采集完成后,发布到文章采集功能创建的专栏下进行管理,通过添加专栏权限就可以知道所有已经采集到的文章了,你也可以选择多专栏收藏。
并且可以统计文章排名情况,关注人数,阅读量等等,就好像是一个文章管理一样,通过专栏阅读量榜单就可以看到最后一条文章的阅读量。app文章采集方案主要通过前端webview(webkitwebview)工具来采集,其目的是通过webkitwebview来抓取整个文章的链接内容,可能只抓取部分,为了保证整个链接是有效的并且加入有效的标签。
每个文章的链接都会打包为xml文件,放到程序的html目录下,获取到文章之后,如果没有被添加有效的标签,会将其抓取丢弃。安卓机器采集方案安卓机器采集方案:一个scriptcoreappcontext.oneaparameter.getparametervalue(oneaparameter);appcontext.oneaparameter.setvalue(void*paramvalue);安卓机器采集方案:需要通过各大应用市场平台提供的抓包工具,抓取其app中各个链接内容,如谷歌市场(googleplay),360市场(apushotivates),应用宝(appchina)等。 查看全部
文章采集功能(安卓机器采集功能开发方案,文章voidvoid采集方案介绍)
文章采集功能开发方案为了让广大研发工程师更了解app相关的行业技术,文章采集功能应运而生。本app文章采集功能主要借助于微信公众号,通过文章采集功能对通过文章采集功能编写的文章进行采集,当文章采集完成后,发布到文章采集功能创建的专栏下进行管理,通过添加专栏权限就可以知道所有已经采集到的文章了,你也可以选择多专栏收藏。
并且可以统计文章排名情况,关注人数,阅读量等等,就好像是一个文章管理一样,通过专栏阅读量榜单就可以看到最后一条文章的阅读量。app文章采集方案主要通过前端webview(webkitwebview)工具来采集,其目的是通过webkitwebview来抓取整个文章的链接内容,可能只抓取部分,为了保证整个链接是有效的并且加入有效的标签。
每个文章的链接都会打包为xml文件,放到程序的html目录下,获取到文章之后,如果没有被添加有效的标签,会将其抓取丢弃。安卓机器采集方案安卓机器采集方案:一个scriptcoreappcontext.oneaparameter.getparametervalue(oneaparameter);appcontext.oneaparameter.setvalue(void*paramvalue);安卓机器采集方案:需要通过各大应用市场平台提供的抓包工具,抓取其app中各个链接内容,如谷歌市场(googleplay),360市场(apushotivates),应用宝(appchina)等。
文章采集功能(诺基亚联手新浪建移动互联网生态圈/article/创建“文章名.txt”)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-15 14:13
指寻找只收录“/News/Dynamic/”的文字链接3.列出找到的内容,如果太多,每10页有重复的标题,不要显示这些标题和链接,可以保存对于临时 .txt,保存 href=”...”> 这种格式是临时的。下次有新的 采集 时,它会再次被覆盖。4.每个标题前面都会有一个勾号。勾选这个勾表示你想要这个文章对应的内容,不勾选就是不勾选。执行本页采集表示只执行采集本页所有勾选的文章,然后自动跳转到第2页,同时勾选用户采集 ,删除临时.txt中刚才已经是采集的文章列表。采集 指在/article/本地创建“文章name.txt”,并将文章内容放到txt中,就是这样。花费 100 查看全部
文章采集功能(诺基亚联手新浪建移动互联网生态圈/article/创建“文章名.txt”)
指寻找只收录“/News/Dynamic/”的文字链接3.列出找到的内容,如果太多,每10页有重复的标题,不要显示这些标题和链接,可以保存对于临时 .txt,保存 href=”...”> 这种格式是临时的。下次有新的 采集 时,它会再次被覆盖。4.每个标题前面都会有一个勾号。勾选这个勾表示你想要这个文章对应的内容,不勾选就是不勾选。执行本页采集表示只执行采集本页所有勾选的文章,然后自动跳转到第2页,同时勾选用户采集 ,删除临时.txt中刚才已经是采集的文章列表。采集 指在/article/本地创建“文章name.txt”,并将文章内容放到txt中,就是这样。花费 100
文章采集功能(文章采集管理(gt)模块常用操作名说明(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-15 03:24
采集模块
当前位置:内容 > 内容发布管理 > 采集管理>
模块常用操作
操作名称
操作说明
采集流程详情
没有任何
其他功能说明
没有任何
操作说明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
1.1 网址规则配置
添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。
添加采集点——URL规则配置图2
测试你的网址采集规则是否正确,如下图
1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示
内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。
2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。
3、发布内容到指定版块
选择导入的部分
设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接: 查看全部
文章采集功能(文章采集管理(gt)模块常用操作名说明(组图))
采集模块
当前位置:内容 > 内容发布管理 > 采集管理>
模块常用操作
操作名称
操作说明
采集流程详情
没有任何
其他功能说明
没有任何
操作说明:
文章的采集的作用是通过程序远程获取目标网页的内容,解析处理本地规则后存入服务器的数据库中。
文章采集系统颠覆了传统的采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需需要具备基本技术知识的人制定相关规则。编辑们不需要了解太详细的技术规则,只需选择自己想要的文章列表采集,就可以像发布文章一样轻松完成数据采集 @> 操作。
一、采集进程
有三个简单的步骤:
1、添加采集点并填写采集规则。
2、采集网址,采集内容
3、发布内容到指定版块
以采集新浪新闻()为例介绍详细流程。
示例说明:
目标:采集新浪新闻将加入V9系统的国际新闻栏目。
目标网址:
1、添加 采集 点
1.1 网址规则配置
添加采集点——URL规则配置图1
查看目标 URL 的源代码为 采集,找到 URL 的起点和终点为 采集(这两个点在整个源代码中必须是唯一的)。进一步缩小您的 采集 URL 搜索范围。
添加采集点——URL规则配置图2
测试你的网址采集规则是否正确,如下图
1.2 内容规则配置
这里的内容规则看起来很复杂,但实际上非常简单。为了解释方便,我们只采集标题和内容两个字段。采集内容网址:
内容采集规则,请打开此网址,然后在页面空白处右键->查看源文件,搜索标题和内容的起始边界。
标题采集配置:
从网页中获取标题并删除不需要的字符。如下所示
内容采集配置:
在新浪新闻的最后一页中,新闻内容被收录在中间,而这两个节点在整个页面的源码中是唯一的。因此,您可以将此作为规则来获取内容。并过滤内容。如下所示
1.3 自定义规则
1.4 高级配置
可以设置是否下载图片到服务器、是否打印水印等配置。
2、采集网址,采集内容
采集规则配置好后,可以进行URL的采集,然后是内容的采集。
3、发布内容到指定版块
选择导入的部分
设置采集的内容与数据库字段的对应关系。提交数据进行存储。期间请耐心等待,完成后会自动开启。至此,一个简单的采集流程就完成了。
更多其他功能,期待您的发现。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接:
文章采集功能( CMS自动采集助手,只为解放双手而生!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-14 18:01
CMS自动采集助手,只为解放双手而生!(组图))
织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!
织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。
织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。
可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。 查看全部
文章采集功能(
CMS自动采集助手,只为解放双手而生!(组图))
织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!
织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。
织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。
可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。
文章采集功能( CMS自动采集助手,只为解放双手而生!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-14 17:22
CMS自动采集助手,只为解放双手而生!(组图))
织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!
织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。
织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。
可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。 查看全部
文章采集功能(
CMS自动采集助手,只为解放双手而生!(组图))
织梦采集,是站长网站自动挂机采集的辅助工具。织梦采集功能强大全面,使用方便。使用后,可以帮助用户更轻松便捷地进行cms自动采集操作,非常方便实用。非常适合一些新手站长和网站管理员。免费使用,支持市面上主流的cms。24小时挂机执行,高效稳定,cms自动采集助手,只为解放双手!
织梦采集可以采集其他网站和所有文章或论坛的内容伪原创发给自己网站 ,可每日采集最新文章,自动维护网站的发帖量等,可实现资源自动本地化、图片自动本地化、加水印等。 采集 发表文章可达数千篇。目前可支持采集及发布DEDEcms(织梦)、Ecms(Empire)、PHPcms等主流cms程序@> 等任务。
织梦采集目前已经支持国内大部分主流建站程序,完全可以让您从网站繁重的维护和管理中解放出来。并具有以下实用功能:
在您的 网站 上一次注册数千名会员,这样您的新网站就会以大量会员开始。可以让会员在设定的时间内同时上网,轻松达到千人上网的效果。
可以采集网站/forum话题一键回复,80%的网站/forums都可以采集,支持保存文章内容发帖本地。
织梦采集转发采集一个网站论坛的内容给你自己网站或论坛的指定版块。
织梦采集支持UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度方便用户的使用习惯和选择。
织梦采集有破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码。软件可以拆分发帖和回复ID,让部分会员可以全部发帖,其他会员可以全部回复,有ID号的会员可以选择发布。
采集任何网站论坛类型如dz/PW/东网等内容均可导入自己网站或论坛程序,打破编码和程序限制;可以有效过滤已经采集的内容,每天采集最新的内容会发布到自己指定的栏目;采集本地内容可在软件中任意编辑,编辑窗口最大化,支持自动换行,HTML预览,使用更方便。
织梦采集 批量替换过滤文章内容中的文字和链接,过滤或替换文章内容中两个关键字A和B之间的内容,你可以根据您的编辑要求自动过滤收录某个固定关键词的帖子,自定义发帖和回复的间隔,查看人数,增加帖子查看次数。可以自己设置范围,可以采集网站/论坛内容中的超链接,或者块链接,可以下载采集@的文章图片>网站/forum 到本地,然后通过 FTP 把附件和图片上传给你的 网站 空间。
文章采集功能( 帝国CMS采集系统的采集功能介绍,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-13 13:25
帝国CMS采集系统的采集功能介绍,你知道吗?)
Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empire cms 是我们使用大量 PHP 的网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。
帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;
多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。
Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。 查看全部
文章采集功能(
帝国CMS采集系统的采集功能介绍,你知道吗?)
Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empire cms 是我们使用大量 PHP 的网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。
帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;
多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。
Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。
文章采集功能( 帝国CMS采集包罗万象的采集功能介绍,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-01-13 13:25
帝国CMS采集包罗万象的采集功能介绍,你知道吗?)
Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empirecms 是一个我们经常使用的 PHP 网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。
帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;
多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。
Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。
以上是帝国的详细内容cms采集,更多帝国cms采集相关技术文章,帝国cms< @采集教程学习会持续分享,希望能帮助到更多的站长和SEOer。 查看全部
文章采集功能(
帝国CMS采集包罗万象的采集功能介绍,你知道吗?)
Empirecms采集,Empirecms采集系统很方便,不用懂什么程序,批量导入关键词,批量选择采集 来源即可。 Empirecms 是一个我们经常使用的 PHP 网站构建系统。在建网站的过程中,如果没有任何信息来源,只能手动复制粘贴,费时费力,所以我们不得不使用Empire。 cms采集函数完成信息录入。为了深入了解帝国cms采集的功能,我来详细告诉你。 Empirescms 采集 是 采集 可应用于 Empirescms采集 的功能。它采用分布式架构,是一款在线智能爬虫。采用JS渲染、代理IP、防屏蔽、验证码识别、数据发布导出、图表控制等一系列技术,实现全网数据精准快速采集,无需任何专业知识都可以一键抓取各大网页的新闻源数据,并自动发布到帝国网站。
帝国cms采集全包采集功能:无论是文章、问答、视频、图片还是资源,都可以快速采集;迅雷的采集速度:海量代理IP和一流的服务器配置,保证爬虫的执行速度和效率;行业领先的采集配置:无需任务专业知识,只需点击几下鼠标即可完成从采集到发布的整个流程;在线自动采集:一站式完成采集伪原创发布任务,实现24小时无人值守;强大的监控更新:通过New监控和变化监控实时更新目标网站最新数据;高级语义接口:关键词提取、伪原创、情感分析等技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;
多类别发布:支持选择和插入指定类别,不同来源的数据网站可以发布到不同类别。
Empirecms采集内置系统模型和用户自定义模型都有自己的采集。自动化内容采集的支持大大减少了内容维护的工作量,使得网站管理系统可以与企业的其他信息系统无缝集成,提高信息的利用率。多重过滤:同一链接不重复采集;设置 采集 关键字;内容字符替换;广告过滤;整页代码过滤;过滤相似信息;过滤同名信息;设置采集记录数。
以上是帝国的详细内容cms采集,更多帝国cms采集相关技术文章,帝国cms< @采集教程学习会持续分享,希望能帮助到更多的站长和SEOer。
文章采集功能(这是网站采集的方式主要是什么?带你了解TAG的基本介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2022-01-10 17:11
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:
一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,有些 SEO 遗憾地将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
为什么要使用tag标签来促进SEO优化效果
28/5/202015:01:41
Tag 标签是我们自己定义的 关键词 标签。 tag标签在网站SEO的优化中起着重要的作用。它比类别更准确和具体。基本上,一个Tag标签可以概括文章的主要内容。也是因为
dedecms织梦TAG标签如何显示单个标签中有多少篇文章文章
15/9/202015:02:18
本站建站服务器文章主要介绍dedecms织梦TAG标签如何显示单个标签文章有多少篇文章,具有一定的参考价值,需要的朋友可以往下看。我希望你会阅读
分享我对 网站文章采集 和 伪原创
的看法
2/10/2010 21:19:00
首先,祝大家国庆快乐。感谢您在百忙之中收看我的文章。今天跟大家分享一下我对网站文章采集和伪原创的看法,这是我第一次发文章,谢谢大家的支持.
SEO优化
标签标签允许网站快速收录排名!
31/10/2017 15:03:00
角色
tag标签:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以正常的
查看全部
文章采集功能(这是网站采集的方式主要是什么?带你了解TAG的基本介绍
)
2/3/201801:10:28
iProber-PHP探针主要功能:1、服务器环境检测:CPU、在线时间、内存使用情况、系统负载平均检测(支持LINUX、FreeBSD系统,需系统支持)、操作系统、服务器域名、IP地址、解释引擎等2、PHP基本特征检测:版本、运行模式、安全模式、Zend编译运行及通用参数3、PHP组件支持检测:MYSQL、GD、XML、SESSION , SOCKET 其他组件的支持4、服务器性能测试:
一篇关于标签编写规范的文章文章
2007 年 12 月 9 日 22:02:00
标签是英文标签的中文翻译,又名“自由分类”、“重点分类”,TAG的分类功能,标签对用户体验确实有很好的享受,可以快速找到相关文章 和信息。
SEO的两个死胡同:采集和群发
2007 年 3 月 7 日 10:34:00
一般来说,网站SEO 成功的主要标准是内容和链接,有些 SEO 遗憾地将其与 采集 和大量发布相关联。是否可以通过采集器简单地采集和积累内容,通过群发者任意添加外部链接来玩搜索引擎?事实上,这是SEO的两个死胡同。据我所知,网站采集主要有两种方式,一种
【SEO基础知识】带你了解TAG的基本介绍和使用方法
5/8/202012:02:01
你可能了解SEO,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是自己定义的一种定义,比分类更准确、更具体,可以概括文章主要内容关键词,
优采云:简单采集网站
不写采集规则
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是写采集规则只能是采集到文章。这个技术问题对于新手来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
何时使用标签进行 SEO
16/11/200705:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
为什么要使用tag标签来促进SEO优化效果
28/5/202015:01:41
Tag 标签是我们自己定义的 关键词 标签。 tag标签在网站SEO的优化中起着重要的作用。它比类别更准确和具体。基本上,一个Tag标签可以概括文章的主要内容。也是因为
dedecms织梦TAG标签如何显示单个标签中有多少篇文章文章
15/9/202015:02:18
本站建站服务器文章主要介绍dedecms织梦TAG标签如何显示单个标签文章有多少篇文章,具有一定的参考价值,需要的朋友可以往下看。我希望你会阅读
分享我对 网站文章采集 和 伪原创
的看法
2/10/2010 21:19:00
首先,祝大家国庆快乐。感谢您在百忙之中收看我的文章。今天跟大家分享一下我对网站文章采集和伪原创的看法,这是我第一次发文章,谢谢大家的支持.
SEO优化
标签标签允许网站快速收录排名!
31/10/2017 15:03:00
角色
tag标签:第一:提升用户体验和PV点击率。第二:增加内链有利于网页权重的相互传递。第三:增加百度收录,提升关键词的排名。为什么标签页的排名比 文章 页面好?原因是标签页关键词与文章页形成内部竞争,标签页接收到的内链远多于文章页,这些内链甚至是高度相关的,所以正常的
文章采集功能(网站优化不是只单单看网站的内容是怎样的? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-09 21:14
)
网站收录的来源:由搜索引擎收录以网站链接的方式展示给用户。
Q:有人说采集内容对搜索引擎不友好,不容易上榜也不容易收录?
A:采集站也可以有很多流量!与 收录 相同!
Q:如何通过搜外cms采集获得大量的收录排名和流量
A:优质原创文章更容易被搜索引擎收录搜索到,但是一个人每天能创作多少优质内容。网站优化不仅仅是看网站的内容,还要抓网站的结构,代码优化,图片优化,内容处理。这些细节会影响到收录的网站,所以选择一个好的采集源码非常重要!它必须排版精美,带有图片,并且具有很强的相关性。适当地使用 伪原创,或添加一些 原创文章。
问:我可以在不编码的情况下完成 采集网站 吗?
答:当然!只需要将关键词到采集设置为行业相关的文章,既增加了网站的内容,也增加了关键词的密度。一举两得!
一、搜外cms采集函数的详细解释?
1、只需设置关键词采集文章,可以同时创建几十个采集任务(一个任务最多可以设置上千个< @关键词,一个关键词可以采集几十篇文章文章,可以丰富很多内容到网站),支持过滤无效关键词,以及与行业无关文章。
2、自带多个消息源采集,不管是图片排版,文章的质量都相当高(可以设置多个采集消息源同时 采集 。)
3、一日采集万条内容,可设置固定采集发布条数
4、通过采集器直接发布到搜外cms网站,设置每日总发布量,是否为伪原创等。还支持添加伪原创 的所有主要 cms 和 站群,@搜外cms 除外。还为站长配备了各种SEO功能(设置定时发送文章让搜索引擎定时抓取你的网页,从而提高网站的收录,自动内链, Headline Insertion关键词, Content Insertion关键词, Random Authors, Random Reads等增强SEO优化提升网站收录!)
从现在开始,你不用担心内容,更不用担心网站never收录,
为什么这么多人选择搜外cms
搜外cms相比其他的,相对简单易用。它采用 XML 标记样式。只要对 HTML 有一点了解,就可以修改或创建模板。很多用户都在为网站改版的成本苦苦挣扎,因为按照老式的网站制作流程,改版不仅需要修改界面,还需要修改程序。它最终成为修订版,几乎等同于 网站 重构。搜外解决了这一系列的烦恼,你只需要懂一些模板标签,只要懂HTML,就可以随意修改模板文件,每次升级只需要更新模板文件,所以程序和页面在很大程度上是分开的。
以上网站都是小编使用网站采集网站发布维护的,目前流量还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
文章采集功能(网站优化不是只单单看网站的内容是怎样的?
)
网站收录的来源:由搜索引擎收录以网站链接的方式展示给用户。
Q:有人说采集内容对搜索引擎不友好,不容易上榜也不容易收录?
A:采集站也可以有很多流量!与 收录 相同!
Q:如何通过搜外cms采集获得大量的收录排名和流量
A:优质原创文章更容易被搜索引擎收录搜索到,但是一个人每天能创作多少优质内容。网站优化不仅仅是看网站的内容,还要抓网站的结构,代码优化,图片优化,内容处理。这些细节会影响到收录的网站,所以选择一个好的采集源码非常重要!它必须排版精美,带有图片,并且具有很强的相关性。适当地使用 伪原创,或添加一些 原创文章。
问:我可以在不编码的情况下完成 采集网站 吗?
答:当然!只需要将关键词到采集设置为行业相关的文章,既增加了网站的内容,也增加了关键词的密度。一举两得!
一、搜外cms采集函数的详细解释?
1、只需设置关键词采集文章,可以同时创建几十个采集任务(一个任务最多可以设置上千个< @关键词,一个关键词可以采集几十篇文章文章,可以丰富很多内容到网站),支持过滤无效关键词,以及与行业无关文章。
2、自带多个消息源采集,不管是图片排版,文章的质量都相当高(可以设置多个采集消息源同时 采集 。)
3、一日采集万条内容,可设置固定采集发布条数
4、通过采集器直接发布到搜外cms网站,设置每日总发布量,是否为伪原创等。还支持添加伪原创 的所有主要 cms 和 站群,@搜外cms 除外。还为站长配备了各种SEO功能(设置定时发送文章让搜索引擎定时抓取你的网页,从而提高网站的收录,自动内链, Headline Insertion关键词, Content Insertion关键词, Random Authors, Random Reads等增强SEO优化提升网站收录!)
从现在开始,你不用担心内容,更不用担心网站never收录,
为什么这么多人选择搜外cms
搜外cms相比其他的,相对简单易用。它采用 XML 标记样式。只要对 HTML 有一点了解,就可以修改或创建模板。很多用户都在为网站改版的成本苦苦挣扎,因为按照老式的网站制作流程,改版不仅需要修改界面,还需要修改程序。它最终成为修订版,几乎等同于 网站 重构。搜外解决了这一系列的烦恼,你只需要懂一些模板标签,只要懂HTML,就可以随意修改模板文件,每次升级只需要更新模板文件,所以程序和页面在很大程度上是分开的。
以上网站都是小编使用网站采集网站发布维护的,目前流量还不错!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!

