
文章自动采集插件
收集了一些Chrome插件神器,助你快速成为老司机
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-05-24 21:31
点击加入:
商务合作:请加微信(QQ):2230304070
技术交流微信群
我们在学习中单枪匹马,还不如一次短短的交流,你可以在别人吸取各种学习经验,学习方法以及学习技巧,所以,学习与交流少不了一个圈子,提升你的学习技能,请点击加技术群:PHP自学中心交流群 <br />记得备注你会的一种PHP框架,比如TP<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;"><br style="max-width: 100%;box-sizing: border-box !important;word-wrap: break-word !important;overflow-wrap: break-word !important;" />
视频教程分享
关注本公众号:PHP自学中心,回复相应的关键词,领取以下视频教程
Linux编程Shell从入门到精通视频教程(完整版)
公众号里回复:shell0915
PHP消息队列实现及应用
公众号里回复:20190902
<br />
laravel5.4开发电商实战项目
公众号里回复:20190703
ThinkPHP5.0入门
公众号里回复:06292019
<br />
php基于tp5.1开发微信公众号
公众号里回复:200108</p>
<br />
精选文章正文
刚开始开发项目的时候,我一直都在用火狐,因为它有一个fireBug插件,特别好用(目前已不支持),也不知道什么时候,就一直用起来Chrome浏览器了,可能是因为它有强大的插件作为后盾吧。开发了这么多年,也用过了很多Chrome插件。
下面收集了一些,比较好用,熟练使用这些插件,会对你的开发效率大大提高,逼格瞬间上升一个档次,助你快速成为开发老司机。
1、markdown-here
可以在网页版QQ邮箱、Gmail、163等邮箱里面,使用mardown格式进行书写,然后一键转换为富文本。
2、chrono
可以非常方便的嗅探识别网页中的资源, 然后一键下载所有资源。
3、Secure Shell App
Windows并没有自带ssh软件,有了Secure Shell App,可以让你无需下载putty或xshell,就能在chrome直接实现ssh登录服务器了。
4、Momentum
装逼利器,教你如何优雅的使用Chrome,新打开一个Tab的时候再也不是一片空白,每天一副精美图片,给你们看下我今天的桌面感受下。
5 OneTab
强烈推荐,使用场景是这样的,我们使用Chrome经常会一次打开好多tab,很多是会用到的,又不舍得关,内存又耗着,这个时候点击下OneTab,直接把所有tab回收,然后每天的历史都给你记录着,接着你可以一键还原某一天的tab,真乃为Chrome而生。
6、Tampermonkey
可以帮你安装脚本,从而免费查看VIP视频,清除各种网页广告,在豆瓣影评页面显示电影资源的下载地址。
7、Loom
可以一键录制浏览器的单个标签页,录制完成后自动生成在线网页,进行视频播放,可以下载刚刚录制的视频,也可以为刚刚生成的在线视频设置密码。
8、Page Ruler
这个工具设计师必备,可以直接查看网页一些图片的详细像素大小、具体位置等,非常实用。
9、Chrome Cleaner Pro
Chrome经过最近几年的发展,强力的扩展越来越多,但软件会变慢。让Chrome变快的最简单方式就是清理垃圾,而Chrome Cleaner Pro走的是一键清理的路子。
10、speedtest
在浏览器中直接测网速。
11、Alexa Traffic Rank Alexa
Alexa排名是指网站的世界排名,非常有权威。直接主流网站或博客绝对是有Alexa排名的,我们在浏览博客或者网站的时候就可以通过Alexa排名知晓该网站的流行程度,适用于经常看博客的人,装了这个插件一键查看网站排名,截个我个人博客stormzhang博客精华的排名给大家感受下。
12、Enhanced Github
可以显示GitHub整个仓库和单个文件的大小,帮你下载Github优秀项目中最核心的代码文件进行学习,而不是下载整个仓库作为藏品。
13、Octotree
这个可就屌了,当我们在浏览别人的开源代码时,还要clone下来一个文件查看,而有了这个插件,你可以直接在Chrome侧边栏向打开文件夹一样的查看别人的项目,简直了。给大家看下查看我的开源项目的正确方式。
14、JSONView
一般我们在对接api接口的时候,一般都是默认返回json格式,想要查看具体返回哪些内容的时候通过Chrome查看全乱的,而且中文编码也不对,而有了这个插件就不一样了,自动跟你排列出Json数据,不管返回数据有多复杂,你都可以很直观的了解他的数据格式,简直开发者必备。
15、Postman
开发者在调试网络时候,Linux平台一般常用curl这种命令行工具,而如果你不会使用或者不习惯命令行,那Postman是你的不二人选,可以直接发送一个请求,自定义params、header,查看response状态等。
16、Dribbble New Tab
大名鼎鼎的Dribble,堪称设计师必备,而装了这个插件,可以让你打开空白tab的时间第一时间把每日精选作品展现出来,视觉的享受,强烈推荐给设计师们,装了这个插件我的桌面是这样的。(这个插件跟Momentum同时只能使用一个)
17、Smallpdf
多份pdf在线合并,pdf在线编辑。
18、Astro Bot
刷题必备,打开新标签页时,展示一道与程序相关的问题或相关新闻。
19、Restlet Client
开发实用工具, 支持一键导入Postman等API测试工具的测试用例。
20、WhatFont
功能非常单一的小工具,帮你查看网页上的字体属性。
21、Web Server for Chrome 查看全部
收集了一些Chrome插件神器,助你快速成为老司机
点击加入:
商务合作:请加微信(QQ):2230304070
技术交流微信群
我们在学习中单枪匹马,还不如一次短短的交流,你可以在别人吸取各种学习经验,学习方法以及学习技巧,所以,学习与交流少不了一个圈子,提升你的学习技能,请点击加技术群:PHP自学中心交流群 <br />记得备注你会的一种PHP框架,比如TP<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">
视频教程分享
关注本公众号:PHP自学中心,回复相应的关键词,领取以下视频教程
Linux编程Shell从入门到精通视频教程(完整版)
公众号里回复:shell0915
PHP消息队列实现及应用
公众号里回复:20190902
<br />
laravel5.4开发电商实战项目
公众号里回复:20190703
ThinkPHP5.0入门
公众号里回复:06292019
<br />
php基于tp5.1开发微信公众号
公众号里回复:200108</p>
<br />
精选文章正文
刚开始开发项目的时候,我一直都在用火狐,因为它有一个fireBug插件,特别好用(目前已不支持),也不知道什么时候,就一直用起来Chrome浏览器了,可能是因为它有强大的插件作为后盾吧。开发了这么多年,也用过了很多Chrome插件。
下面收集了一些,比较好用,熟练使用这些插件,会对你的开发效率大大提高,逼格瞬间上升一个档次,助你快速成为开发老司机。
1、markdown-here
可以在网页版QQ邮箱、Gmail、163等邮箱里面,使用mardown格式进行书写,然后一键转换为富文本。
2、chrono
可以非常方便的嗅探识别网页中的资源, 然后一键下载所有资源。
3、Secure Shell App
Windows并没有自带ssh软件,有了Secure Shell App,可以让你无需下载putty或xshell,就能在chrome直接实现ssh登录服务器了。
4、Momentum
装逼利器,教你如何优雅的使用Chrome,新打开一个Tab的时候再也不是一片空白,每天一副精美图片,给你们看下我今天的桌面感受下。
5 OneTab
强烈推荐,使用场景是这样的,我们使用Chrome经常会一次打开好多tab,很多是会用到的,又不舍得关,内存又耗着,这个时候点击下OneTab,直接把所有tab回收,然后每天的历史都给你记录着,接着你可以一键还原某一天的tab,真乃为Chrome而生。
6、Tampermonkey
可以帮你安装脚本,从而免费查看VIP视频,清除各种网页广告,在豆瓣影评页面显示电影资源的下载地址。
7、Loom
可以一键录制浏览器的单个标签页,录制完成后自动生成在线网页,进行视频播放,可以下载刚刚录制的视频,也可以为刚刚生成的在线视频设置密码。
8、Page Ruler
这个工具设计师必备,可以直接查看网页一些图片的详细像素大小、具体位置等,非常实用。
9、Chrome Cleaner Pro
Chrome经过最近几年的发展,强力的扩展越来越多,但软件会变慢。让Chrome变快的最简单方式就是清理垃圾,而Chrome Cleaner Pro走的是一键清理的路子。
10、speedtest
在浏览器中直接测网速。
11、Alexa Traffic Rank Alexa
Alexa排名是指网站的世界排名,非常有权威。直接主流网站或博客绝对是有Alexa排名的,我们在浏览博客或者网站的时候就可以通过Alexa排名知晓该网站的流行程度,适用于经常看博客的人,装了这个插件一键查看网站排名,截个我个人博客stormzhang博客精华的排名给大家感受下。
12、Enhanced Github
可以显示GitHub整个仓库和单个文件的大小,帮你下载Github优秀项目中最核心的代码文件进行学习,而不是下载整个仓库作为藏品。
13、Octotree
这个可就屌了,当我们在浏览别人的开源代码时,还要clone下来一个文件查看,而有了这个插件,你可以直接在Chrome侧边栏向打开文件夹一样的查看别人的项目,简直了。给大家看下查看我的开源项目的正确方式。
14、JSONView
一般我们在对接api接口的时候,一般都是默认返回json格式,想要查看具体返回哪些内容的时候通过Chrome查看全乱的,而且中文编码也不对,而有了这个插件就不一样了,自动跟你排列出Json数据,不管返回数据有多复杂,你都可以很直观的了解他的数据格式,简直开发者必备。
15、Postman
开发者在调试网络时候,Linux平台一般常用curl这种命令行工具,而如果你不会使用或者不习惯命令行,那Postman是你的不二人选,可以直接发送一个请求,自定义params、header,查看response状态等。
16、Dribbble New Tab
大名鼎鼎的Dribble,堪称设计师必备,而装了这个插件,可以让你打开空白tab的时间第一时间把每日精选作品展现出来,视觉的享受,强烈推荐给设计师们,装了这个插件我的桌面是这样的。(这个插件跟Momentum同时只能使用一个)
17、Smallpdf
多份pdf在线合并,pdf在线编辑。
18、Astro Bot
刷题必备,打开新标签页时,展示一道与程序相关的问题或相关新闻。
19、Restlet Client
开发实用工具, 支持一键导入Postman等API测试工具的测试用例。
20、WhatFont
功能非常单一的小工具,帮你查看网页上的字体属性。
21、Web Server for Chrome
埋点自动收集方案-路由依赖分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-24 21:18
1.一个项目总共有多少组件?每个页面又有多少组件构成?
2.有哪些组件是公共组件,它们分别被哪些页面引用?
对于这两个问题,我们先思考一会。sleep……
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
通过前一篇文章,想必大家对埋点自动收集方案有了宏观且全面的了解。在这里再简单概述下:
埋点自动收集方案是基于jsdoc对注释信息的搜集能力,通过给路由页面中所有埋点增加注释的方式,在编译时建立起页面和埋点信息的对应关系。
点击查看
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
//Index.vue 首页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Home.vue 个人主页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Card.vue 商品卡片组件<br />goDetail(item) {<br /> /**<br /> * @mylog 商品卡片点击<br /> */<br /> this.$log('card-click') // 埋点发送<br />}<br />
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
//a.ts<br />import B from './b.ts'<br />import getCookie from '@/libs/cookie.ts'<br /><br />//c.ts<br />const C = require('./b.ts')<br /><br />//b.ts<br />div {<br /> background: url('./assets/icon.png') no-repeat;<br />}<br />import './style.css'<br />// c.vue<br />import Vue from Vue<br />import Card from '@/component/Card.vue'<br />
这里给出三种依赖分析的思路:
1 递归解析
从项目的路由配置文件开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
2 借助webpack工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
//done是compiler的钩子,在完成一次编译结束后的会执行<br />compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{<br /> fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {<br /> if (err) {<br /> throw err;<br /> }<br /> })<br /> cb()<br />})<br />
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
3 在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
先奉上流程图
1 初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
2 收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
apply(compiler) {<br /> compiler.hooks.normalModuleFactory.tap(<br /> "demoPlugin",<br /> nmf => {<br /> nmf.hooks.afterResolve.tapAsync(<br /> "demoPlugin",<br /> (result, callback) => {<br /> const { resourceResolveData } = result;<br /> // 当前文件的路径<br /> let path = resourceResolveData.path; <br /> // 父级文件路径<br /> let fatherPath = resourceResolveData.context.issuer; <br /> callback(null,result)<br /> }<br /> );<br /> }<br /> )<br />}<br />
3 建立依赖树
根据上一步获取的引用关系,生成依赖树。
// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue<br />if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){ <br /> if(fatherPath && fatherPath != path){ // 父子路径相同的排除<br /> if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){ <br /> // 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除<br /> let sonObj = {};<br /> sonObj.type = 'module';<br /> sonObj.path = path;<br /> sonObj.deps = []<br /> // 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。<br /> sonObj = copyAheadDep(this.dependenciesArray,sonObj);<br /> let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);<br /> this.dependenciesArray = obj.arr;<br /> if(!obj.fileExist){<br /> let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br /> }<br />} else if(!this.dependenciesArray.some(it => it.path == path)) {<br />// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件<br /> let entryObj = {type:'entry',path:path,deps:[]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br />}<br />
那么这时生成的依赖树如下:
4 解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{<br /> this.handleCompilerDone()<br /> cb()<br />})<br />
// ast解析路由文件<br />handleCompilerDone(){<br /> if(this.dependenciesArray.length){<br /> let tempRouteDeps = {};<br /> // routePaths是项目的路由文件数组<br /> for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);<br /> // 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖<br /> this.dependenciesArray = <br /> getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);<br /> }<br />}<br />
通过这一步ast解析,可以得到如下路由信息:
[<br /> {<br /> "name": "index",<br /> "route": "/index",<br /> "title": "首页",<br /> "components": ["../view/newCycle/index.vue"]<br /> },<br /> {<br /> "name": "home",<br /> "route": "/home",<br /> "title": "个人主页",<br /> "components": ["../view/newCycle/home.vue"]<br /> }<br />]<br />
5 对依赖树和路由信息进行整合分析
// 将路由页面的所有依赖组件deps,都存放在路由信息的components数组中<br />const getEndPathComponentsArr = function(routeDeps,dependenciesArray) {<br /> for(let i = 0; i {<br /> routeDeps = routeDeps.map(routeObj=>{<br /> if(routeObj && routeObj.components){<br /> let relativePath = <br /> routeObj.components[0].slice(routeObj.components[0].indexOf('/')+1);<br /> if(page.path.includes(relativePath.split('/').join(path.sep))){<br /> // 铺平依赖树的层级<br /> routeObj = flapAllComponents(routeObj,page);<br /> // 去重操作<br /> routeObj.components = dedupe(routeObj.components);<br /> }<br /> }<br /> return routeObj;<br /> })<br /> })<br /> }<br /> return routeDeps;<br />}<br />//建立一个map数据结构,以每个组件为key,以对应的路由信息为value<br />// {<br />// 'path1' => Set { '/index' },<br />// 'path2' => Set { '/index', '/home' },<br />// 'path3' => Set { '/home' }<br />// }<br />const convertDeps = function(deps) {<br /> let map = new Map();<br /> ......<br /> return map;<br />}<br />
整合分析后依赖关系如下:
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index"],<br /> // 映射中只有和首页的映射<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
6 修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
6.1 unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
//webpack/lib/WebpackOptionsDefaulter.js<br />this.set("resolveLoader.unsafeCache", true);<br />//这是webpack初始化配置参数时对unsafeCache的默认设置<br /><br />//enhanced-resolve/lib/Resolverfatory.js<br />if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br />} else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br />}<br />//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。<br />//缓存的工作是由UnsafeCachePlugin完成,代码如下:<br />//enhanced-resolve/lib/UnsafeCachePlugin.js<br />apply(resolver) {<br /> const target = resolver.ensureHook(this.target);<br /> resolver<br /> .getHook(this.source)<br /> .tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {<br /> if (!this.filterPredicate(request)) return callback();<br /> const cacheId = getCacheId(request, this.withContext);<br /> // !!划重点,当缓存中存在解析过的文件结果,直接callback<br /> const cacheEntry = this.cache[cacheId];<br /> if (cacheEntry) {<br /> return callback(null, cacheEntry);<br /> }<br /> resolver.doResolve(<br /> target,<br /> request,<br /> null,<br /> resolveContext,<br /> (err, result) => {<br /> if (err) return callback(err);<br /> if (result) return callback(null, (this.cache[cacheId] = result));<br /> callback();<br /> }<br /> );<br /> });<br />}<br />
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
6.2 这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
//enhanced-resolve/lib/Resolverfatory.js<br />exports.createResolver = function(options) {<br /> ......<br /> let unsafeCache = options.unsafeCache || false;<br /> if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br /> // 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,<br /> //执行结束后的目标事件(target)是new-resolve。<br /> //而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。<br /> } else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br /> }<br /> ...... // 各种plugin<br /> plugins.push(new ResultPlugin(resolver.hooks.resolved));<br /><br /> plugins.forEach(plugin => {<br /> plugin.apply(resolver);<br /> });<br /><br /> return resolver;<br />}<br />
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
6.3 解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
//package.json<br />"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"<br /><br />//vue.config.js<br />chainWebpack(config) {<br /> // 这一步解决webpack对组件缓存,影响最终映射关系的处理<br /> config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'<br />}<br />
7 最终依赖关系
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index",<br /> "home&_&个人主页&_&home"],<br /> // Card组件与多个页面有映射关系<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
module.exports = {<br /> cache: {<br /> // 1. Set cache type to filesystem<br /> type: 'filesystem',<br /><br /> buildDependencies: {<br /> // 2. Add your config as buildDependency to get cache invalidation on config change<br /> config: [__filename]<br /><br /> // 3. If you have other things the build depends on you can add them here<br /> // Note that webpack, loaders and all modules referenced from your config are automatically added<br /> }<br /> }<br />};<br />
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~
查看全部
埋点自动收集方案-路由依赖分析
1.一个项目总共有多少组件?每个页面又有多少组件构成?
2.有哪些组件是公共组件,它们分别被哪些页面引用?
对于这两个问题,我们先思考一会。sleep……
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
通过前一篇文章,想必大家对埋点自动收集方案有了宏观且全面的了解。在这里再简单概述下:
埋点自动收集方案是基于jsdoc对注释信息的搜集能力,通过给路由页面中所有埋点增加注释的方式,在编译时建立起页面和埋点信息的对应关系。
点击查看
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
//Index.vue 首页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Home.vue 个人主页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Card.vue 商品卡片组件<br />goDetail(item) {<br /> /**<br /> * @mylog 商品卡片点击<br /> */<br /> this.$log('card-click') // 埋点发送<br />}<br />
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
//a.ts<br />import B from './b.ts'<br />import getCookie from '@/libs/cookie.ts'<br /><br />//c.ts<br />const C = require('./b.ts')<br /><br />//b.ts<br />div {<br /> background: url('./assets/icon.png') no-repeat;<br />}<br />import './style.css'<br />// c.vue<br />import Vue from Vue<br />import Card from '@/component/Card.vue'<br />
这里给出三种依赖分析的思路:
1 递归解析
从项目的路由配置文件开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
2 借助webpack工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
//done是compiler的钩子,在完成一次编译结束后的会执行<br />compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{<br /> fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {<br /> if (err) {<br /> throw err;<br /> }<br /> })<br /> cb()<br />})<br />
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
3 在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
先奉上流程图
1 初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
2 收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
apply(compiler) {<br /> compiler.hooks.normalModuleFactory.tap(<br /> "demoPlugin",<br /> nmf => {<br /> nmf.hooks.afterResolve.tapAsync(<br /> "demoPlugin",<br /> (result, callback) => {<br /> const { resourceResolveData } = result;<br /> // 当前文件的路径<br /> let path = resourceResolveData.path; <br /> // 父级文件路径<br /> let fatherPath = resourceResolveData.context.issuer; <br /> callback(null,result)<br /> }<br /> );<br /> }<br /> )<br />}<br />
3 建立依赖树
根据上一步获取的引用关系,生成依赖树。
// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue<br />if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){ <br /> if(fatherPath && fatherPath != path){ // 父子路径相同的排除<br /> if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){ <br /> // 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除<br /> let sonObj = {};<br /> sonObj.type = 'module';<br /> sonObj.path = path;<br /> sonObj.deps = []<br /> // 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。<br /> sonObj = copyAheadDep(this.dependenciesArray,sonObj);<br /> let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);<br /> this.dependenciesArray = obj.arr;<br /> if(!obj.fileExist){<br /> let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br /> }<br />} else if(!this.dependenciesArray.some(it => it.path == path)) {<br />// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件<br /> let entryObj = {type:'entry',path:path,deps:[]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br />}<br />
那么这时生成的依赖树如下:
4 解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{<br /> this.handleCompilerDone()<br /> cb()<br />})<br />
// ast解析路由文件<br />handleCompilerDone(){<br /> if(this.dependenciesArray.length){<br /> let tempRouteDeps = {};<br /> // routePaths是项目的路由文件数组<br /> for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);<br /> // 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖<br /> this.dependenciesArray = <br /> getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);<br /> }<br />}<br />
通过这一步ast解析,可以得到如下路由信息:
[<br /> {<br /> "name": "index",<br /> "route": "/index",<br /> "title": "首页",<br /> "components": ["../view/newCycle/index.vue"]<br /> },<br /> {<br /> "name": "home",<br /> "route": "/home",<br /> "title": "个人主页",<br /> "components": ["../view/newCycle/home.vue"]<br /> }<br />]<br />
5 对依赖树和路由信息进行整合分析
// 将路由页面的所有依赖组件deps,都存放在路由信息的components数组中<br />const getEndPathComponentsArr = function(routeDeps,dependenciesArray) {<br /> for(let i = 0; i {<br /> routeDeps = routeDeps.map(routeObj=>{<br /> if(routeObj && routeObj.components){<br /> let relativePath = <br /> routeObj.components[0].slice(routeObj.components[0].indexOf('/')+1);<br /> if(page.path.includes(relativePath.split('/').join(path.sep))){<br /> // 铺平依赖树的层级<br /> routeObj = flapAllComponents(routeObj,page);<br /> // 去重操作<br /> routeObj.components = dedupe(routeObj.components);<br /> }<br /> }<br /> return routeObj;<br /> })<br /> })<br /> }<br /> return routeDeps;<br />}<br />//建立一个map数据结构,以每个组件为key,以对应的路由信息为value<br />// {<br />// 'path1' => Set { '/index' },<br />// 'path2' => Set { '/index', '/home' },<br />// 'path3' => Set { '/home' }<br />// }<br />const convertDeps = function(deps) {<br /> let map = new Map();<br /> ......<br /> return map;<br />}<br />
整合分析后依赖关系如下:
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index"],<br /> // 映射中只有和首页的映射<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
6 修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
6.1 unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
//webpack/lib/WebpackOptionsDefaulter.js<br />this.set("resolveLoader.unsafeCache", true);<br />//这是webpack初始化配置参数时对unsafeCache的默认设置<br /><br />//enhanced-resolve/lib/Resolverfatory.js<br />if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br />} else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br />}<br />//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。<br />//缓存的工作是由UnsafeCachePlugin完成,代码如下:<br />//enhanced-resolve/lib/UnsafeCachePlugin.js<br />apply(resolver) {<br /> const target = resolver.ensureHook(this.target);<br /> resolver<br /> .getHook(this.source)<br /> .tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {<br /> if (!this.filterPredicate(request)) return callback();<br /> const cacheId = getCacheId(request, this.withContext);<br /> // !!划重点,当缓存中存在解析过的文件结果,直接callback<br /> const cacheEntry = this.cache[cacheId];<br /> if (cacheEntry) {<br /> return callback(null, cacheEntry);<br /> }<br /> resolver.doResolve(<br /> target,<br /> request,<br /> null,<br /> resolveContext,<br /> (err, result) => {<br /> if (err) return callback(err);<br /> if (result) return callback(null, (this.cache[cacheId] = result));<br /> callback();<br /> }<br /> );<br /> });<br />}<br />
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
6.2 这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
//enhanced-resolve/lib/Resolverfatory.js<br />exports.createResolver = function(options) {<br /> ......<br /> let unsafeCache = options.unsafeCache || false;<br /> if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br /> // 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,<br /> //执行结束后的目标事件(target)是new-resolve。<br /> //而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。<br /> } else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br /> }<br /> ...... // 各种plugin<br /> plugins.push(new ResultPlugin(resolver.hooks.resolved));<br /><br /> plugins.forEach(plugin => {<br /> plugin.apply(resolver);<br /> });<br /><br /> return resolver;<br />}<br />
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
6.3 解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
//package.json<br />"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"<br /><br />//vue.config.js<br />chainWebpack(config) {<br /> // 这一步解决webpack对组件缓存,影响最终映射关系的处理<br /> config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'<br />}<br />
7 最终依赖关系
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index",<br /> "home&_&个人主页&_&home"],<br /> // Card组件与多个页面有映射关系<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
module.exports = {<br /> cache: {<br /> // 1. Set cache type to filesystem<br /> type: 'filesystem',<br /><br /> buildDependencies: {<br /> // 2. Add your config as buildDependency to get cache invalidation on config change<br /> config: [__filename]<br /><br /> // 3. If you have other things the build depends on you can add them here<br /> // Note that webpack, loaders and all modules referenced from your config are automatically added<br /> }<br /> }<br />};<br />
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-05-22 05:19
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。 查看全部
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。
【第2167期】埋点自动收集方案-路由依赖分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-17 14:55
前言
前一段时间有看到相关需求,只不过在某团队已经开发完了。今日前端早读课文章由转转@刁文豪,公号:大转转FE授权分享。
@刁文豪,目前就职于转转平台运营部,负责C2C业务线前端工作。参与过两次创业,做过项目经理,喜欢挖掘业务痛点,同时深爱技术研究,致力于通过技术手段改进产品及用户体验、推动业务增长。
正文从这开始~~
对于这两个问题,我们先思考一会。
1、一个项目总共有多少?每个页面又有多少组件构成?
2、有哪些组件是公共组件,它们分别被哪些页面引用?
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
背景
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
<p>//Index.vue 首页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Home.vue 个人主页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Card.vue 商品卡片组件
goDetail(item) {
/**
* @mylog 商品卡片点击
*/
this.$log('card-click') // 埋点发送
}</p>
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
期望效果
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
方案思考
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
<p>//a.ts
import B from './b.ts'
import getCookie from '@/libs/cookie.ts'
<br />
//c.ts
const C = require('./b.ts')
<br />
//b.ts
div {
background: url('./assets/icon.png') no-repeat;
}
import './style.css'
// c.vue
import Vue from Vue
import Card from '@/component/Card.vue'</p>
这里给出三种依赖分析的思路:
递归
从项目的路由配置开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
借助工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
<p>//done是compiler的钩子,在完成一次编译结束后的会执行
compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{
fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {
if (err) {
throw err;
}
})
cb()
})</p>
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
具体实现
先奉上流程图
初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
<p>apply(compiler) {
compiler.hooks.normalModuleFactory.tap(
"demoPlugin",
nmf => {
nmf.hooks.afterResolve.tapAsync(
"demoPlugin",
(result, callback) => {
const { resourceResolveData } = result;
// 当前文件的路径
let path = resourceResolveData.path;
// 父级文件路径
let fatherPath = resourceResolveData.context.issuer;
callback(null,result)
}
);
}
)
}</p>
建立依赖树
根据上一步获取的引用关系,生成依赖树。
<p>// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue
if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){
if(fatherPath && fatherPath != path){ // 父子路径相同的排除
if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){
// 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除
let sonObj = {};
sonObj.type = 'module';
sonObj.path = path;
sonObj.deps = []
// 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。
sonObj = copyAheadDep(this.dependenciesArray,sonObj);
let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);
this.dependenciesArray = obj.arr;
if(!obj.fileExist){
let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};
this.dependenciesArray.push(entryObj);
}
}
} else if(!this.dependenciesArray.some(it => it.path == path)) {
// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件
let entryObj = {type:'entry',path:path,deps:[]};
this.dependenciesArray.push(entryObj);
}
}</p>
那么这时生成的依赖树如下:
解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
<p>compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{
this.handleCompilerDone()
cb()
})</p>
<p>// ast解析路由文件
handleCompilerDone(){
if(this.dependenciesArray.length){
let tempRouteDeps = {};
// routePaths是项目的路由文件数组
for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);
// 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖
this.dependenciesArray =
getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);
}
}</p>
通过这一步ast解析,可以得到如下路由信息:
<p>[
{
"name": "index",
"route": "/index",
"title": "首页",
"components": ["../view/newCycle/index.vue"]
},
{
"name": "home",
"route": "/home",
"title": "个人主页",
"components": ["../view/newCycle/home.vue"]
}
]</p>
对依赖树和路由信息进行整合分析
整合分析后依赖关系如下:
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index"],
// 映射中只有和首页的映射
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
<p>//webpack/lib/WebpackOptionsDefaulter.js
this.set("resolveLoader.unsafeCache", true);
//这是webpack初始化配置参数时对unsafeCache的默认设置
<br />
//enhanced-resolve/lib/Resolverfatory.js
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。
//缓存的工作是由UnsafeCachePlugin完成,代码如下:
//enhanced-resolve/lib/UnsafeCachePlugin.js
apply(resolver) {
const target = resolver.ensureHook(this.target);
resolver
.getHook(this.source)
.tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {
if (!this.filterPredicate(request)) return callback();
const cacheId = getCacheId(request, this.withContext);
// !!划重点,当缓存中存在解析过的文件结果,直接callback
const cacheEntry = this.cache[cacheId];
if (cacheEntry) {
return callback(null, cacheEntry);
}
resolver.doResolve(
target,
request,
null,
resolveContext,
(err, result) => {
if (err) return callback(err);
if (result) return callback(null, (this.cache[cacheId] = result));
callback();
}
);
});
}</p>
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
<p>//enhanced-resolve/lib/Resolverfatory.js
exports.createResolver = function(options) {
......
let unsafeCache = options.unsafeCache || false;
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
// 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,
//执行结束后的目标事件(target)是new-resolve。
//而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
...... // 各种plugin
plugins.push(new ResultPlugin(resolver.hooks.resolved));
<br />
plugins.forEach(plugin => {
plugin.apply(resolver);
});
<br />
return resolver;
}</p>
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
<p>//package.json
"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"
<br />
//vue.config.js
chainWebpack(config) {
// 这一步解决webpack对组件缓存,影响最终映射关系的处理
config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'
}</p>
最终依赖关系
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index",
"home&_&个人主页&_&home"],
// Card组件与多个页面有映射关系
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
<p>module.exports = {
cache: {
// 1. Set cache type to filesystem
type: 'filesystem',
<br />
buildDependencies: {
// 2. Add your config as buildDependency to get cache invalidation on config change
config: [__filename]
<br />
// 3. If you have other things the build depends on you can add them here
// Note that webpack, loaders and all modules referenced from your config are automatically added
}
}
};</p>
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
总结
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~ 查看全部
【第2167期】埋点自动收集方案-路由依赖分析
前言
前一段时间有看到相关需求,只不过在某团队已经开发完了。今日前端早读课文章由转转@刁文豪,公号:大转转FE授权分享。
@刁文豪,目前就职于转转平台运营部,负责C2C业务线前端工作。参与过两次创业,做过项目经理,喜欢挖掘业务痛点,同时深爱技术研究,致力于通过技术手段改进产品及用户体验、推动业务增长。
正文从这开始~~
对于这两个问题,我们先思考一会。
1、一个项目总共有多少?每个页面又有多少组件构成?
2、有哪些组件是公共组件,它们分别被哪些页面引用?
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
背景
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
<p>//Index.vue 首页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Home.vue 个人主页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Card.vue 商品卡片组件
goDetail(item) {
/**
* @mylog 商品卡片点击
*/
this.$log('card-click') // 埋点发送
}</p>
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
期望效果
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
方案思考
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
<p>//a.ts
import B from './b.ts'
import getCookie from '@/libs/cookie.ts'
<br />
//c.ts
const C = require('./b.ts')
<br />
//b.ts
div {
background: url('./assets/icon.png') no-repeat;
}
import './style.css'
// c.vue
import Vue from Vue
import Card from '@/component/Card.vue'</p>
这里给出三种依赖分析的思路:
递归
从项目的路由配置开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
借助工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
<p>//done是compiler的钩子,在完成一次编译结束后的会执行
compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{
fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {
if (err) {
throw err;
}
})
cb()
})</p>
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
具体实现
先奉上流程图
初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
<p>apply(compiler) {
compiler.hooks.normalModuleFactory.tap(
"demoPlugin",
nmf => {
nmf.hooks.afterResolve.tapAsync(
"demoPlugin",
(result, callback) => {
const { resourceResolveData } = result;
// 当前文件的路径
let path = resourceResolveData.path;
// 父级文件路径
let fatherPath = resourceResolveData.context.issuer;
callback(null,result)
}
);
}
)
}</p>
建立依赖树
根据上一步获取的引用关系,生成依赖树。
<p>// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue
if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){
if(fatherPath && fatherPath != path){ // 父子路径相同的排除
if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){
// 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除
let sonObj = {};
sonObj.type = 'module';
sonObj.path = path;
sonObj.deps = []
// 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。
sonObj = copyAheadDep(this.dependenciesArray,sonObj);
let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);
this.dependenciesArray = obj.arr;
if(!obj.fileExist){
let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};
this.dependenciesArray.push(entryObj);
}
}
} else if(!this.dependenciesArray.some(it => it.path == path)) {
// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件
let entryObj = {type:'entry',path:path,deps:[]};
this.dependenciesArray.push(entryObj);
}
}</p>
那么这时生成的依赖树如下:
解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
<p>compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{
this.handleCompilerDone()
cb()
})</p>
<p>// ast解析路由文件
handleCompilerDone(){
if(this.dependenciesArray.length){
let tempRouteDeps = {};
// routePaths是项目的路由文件数组
for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);
// 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖
this.dependenciesArray =
getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);
}
}</p>
通过这一步ast解析,可以得到如下路由信息:
<p>[
{
"name": "index",
"route": "/index",
"title": "首页",
"components": ["../view/newCycle/index.vue"]
},
{
"name": "home",
"route": "/home",
"title": "个人主页",
"components": ["../view/newCycle/home.vue"]
}
]</p>
对依赖树和路由信息进行整合分析
整合分析后依赖关系如下:
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index"],
// 映射中只有和首页的映射
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
<p>//webpack/lib/WebpackOptionsDefaulter.js
this.set("resolveLoader.unsafeCache", true);
//这是webpack初始化配置参数时对unsafeCache的默认设置
<br />
//enhanced-resolve/lib/Resolverfatory.js
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。
//缓存的工作是由UnsafeCachePlugin完成,代码如下:
//enhanced-resolve/lib/UnsafeCachePlugin.js
apply(resolver) {
const target = resolver.ensureHook(this.target);
resolver
.getHook(this.source)
.tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {
if (!this.filterPredicate(request)) return callback();
const cacheId = getCacheId(request, this.withContext);
// !!划重点,当缓存中存在解析过的文件结果,直接callback
const cacheEntry = this.cache[cacheId];
if (cacheEntry) {
return callback(null, cacheEntry);
}
resolver.doResolve(
target,
request,
null,
resolveContext,
(err, result) => {
if (err) return callback(err);
if (result) return callback(null, (this.cache[cacheId] = result));
callback();
}
);
});
}</p>
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
<p>//enhanced-resolve/lib/Resolverfatory.js
exports.createResolver = function(options) {
......
let unsafeCache = options.unsafeCache || false;
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
// 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,
//执行结束后的目标事件(target)是new-resolve。
//而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
...... // 各种plugin
plugins.push(new ResultPlugin(resolver.hooks.resolved));
<br />
plugins.forEach(plugin => {
plugin.apply(resolver);
});
<br />
return resolver;
}</p>
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
<p>//package.json
"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"
<br />
//vue.config.js
chainWebpack(config) {
// 这一步解决webpack对组件缓存,影响最终映射关系的处理
config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'
}</p>
最终依赖关系
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index",
"home&_&个人主页&_&home"],
// Card组件与多个页面有映射关系
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
<p>module.exports = {
cache: {
// 1. Set cache type to filesystem
type: 'filesystem',
<br />
buildDependencies: {
// 2. Add your config as buildDependency to get cache invalidation on config change
config: [__filename]
<br />
// 3. If you have other things the build depends on you can add them here
// Note that webpack, loaders and all modules referenced from your config are automatically added
}
}
};</p>
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
总结
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-05-13 15:26
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。 查看全部
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。
3种方法导出公众号文章数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2022-05-11 14:52
每晚7点,陪你充电!
(↑听燕哥说)
今天咱们来说公众号文章数据的采集和导出,包括自己的公众号文章数据,以及任何一个公众号的图文数据。
1
/ 公众号后台自带导出功能/
进入公众号图文分析里,点击右上角“导出EXCEL”即可导出数据。不过导出的数据很有限,或者说没必要导出,因为导出的内容跟网页上的内容是一毛一样的,你可以直接在网页上看呀。
导出后的EXCEL内容
2
/ 第三方网页插件/
新媒体管家
壹伴
这两款插件都很好用,随便安装哪款都可以,安装后,进入公众号后台-图文分析,点击右上角导出数据即可。
导出后的数据特别详细,而且系统还自动进行了一些小计算:阅读总量、增掉粉量等很多项目。
导出后的EXCEL内容
3
/ WCplus/
以上是导出自己公众号文章数据常用的工具,接下来给大家说一款导出任何公众号文章数据的工具--WCplus。
WCplus可以将任意一个微信公众号的全部历史发文数据转化成为一张Excel表格。
(导出后的EXCEL内容)
而且这款工具还可以把采集下来的文章,自动变成一个个的PDF文件! 查看全部
3种方法导出公众号文章数据
每晚7点,陪你充电!
(↑听燕哥说)
今天咱们来说公众号文章数据的采集和导出,包括自己的公众号文章数据,以及任何一个公众号的图文数据。
1
/ 公众号后台自带导出功能/
进入公众号图文分析里,点击右上角“导出EXCEL”即可导出数据。不过导出的数据很有限,或者说没必要导出,因为导出的内容跟网页上的内容是一毛一样的,你可以直接在网页上看呀。
导出后的EXCEL内容
2
/ 第三方网页插件/
新媒体管家
壹伴
这两款插件都很好用,随便安装哪款都可以,安装后,进入公众号后台-图文分析,点击右上角导出数据即可。
导出后的数据特别详细,而且系统还自动进行了一些小计算:阅读总量、增掉粉量等很多项目。
导出后的EXCEL内容
3
/ WCplus/
以上是导出自己公众号文章数据常用的工具,接下来给大家说一款导出任何公众号文章数据的工具--WCplus。
WCplus可以将任意一个微信公众号的全部历史发文数据转化成为一张Excel表格。
(导出后的EXCEL内容)
而且这款工具还可以把采集下来的文章,自动变成一个个的PDF文件!
文章自动采集就是不动脑子,让api控制。
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-05-07 15:00
文章自动采集插件自动采集就是不动脑子,让api控制。api控制的首先第一个问题,你是哪个区域呢?各个区域的主机以及分布图域名呢?第二个问题,如果你要搞定所有区域的网站,可能你要有统一的api控制客户端,把所有的区域的接口统一起来然后单独拿到一个端口。以前随便写过一个爬虫,爬的不是很顺利,真正让api控制变得难以制止的其实还是自定义规则实现api控制的难度高。
需要一定的多线程api编程能力。一般来说我们都是通过不动脑子的方式实现api控制,目的是好做一些复杂任务自动化产品。看视频教程会让你有一定的帮助。
requests+goffice就可以
国内主流的api网站ui都不太友好,因为全是明文http请求,不能做https或https过滤,一些网站会将http请求转换成https的格式导致网站支持https的页面无法显示,还有可能有些页面没有响应。国内搜索引擎公司集中于xx生态圈的自家产品,一般都不会直接提供api接口,除非有实际需求。另外国内大多数网站根本没有自己的api接口,你从外面直接拿来搭个框架或者买个api服务商的一套api也有可能。
解决办法有好几种:1,提供网址:,现有行业大站提供http接口,一般地方站目前还是没有对接的。3,提供api:,国内大站长们自己搭建api,提供api,但是可以定制,可以返回到他们自己的格式。不过现在有些行业大站,如美团,百度也面临着转型,没有做这么多api的接口,也是由于接口api的接入成本相对较高。 查看全部
文章自动采集就是不动脑子,让api控制。
文章自动采集插件自动采集就是不动脑子,让api控制。api控制的首先第一个问题,你是哪个区域呢?各个区域的主机以及分布图域名呢?第二个问题,如果你要搞定所有区域的网站,可能你要有统一的api控制客户端,把所有的区域的接口统一起来然后单独拿到一个端口。以前随便写过一个爬虫,爬的不是很顺利,真正让api控制变得难以制止的其实还是自定义规则实现api控制的难度高。
需要一定的多线程api编程能力。一般来说我们都是通过不动脑子的方式实现api控制,目的是好做一些复杂任务自动化产品。看视频教程会让你有一定的帮助。
requests+goffice就可以
国内主流的api网站ui都不太友好,因为全是明文http请求,不能做https或https过滤,一些网站会将http请求转换成https的格式导致网站支持https的页面无法显示,还有可能有些页面没有响应。国内搜索引擎公司集中于xx生态圈的自家产品,一般都不会直接提供api接口,除非有实际需求。另外国内大多数网站根本没有自己的api接口,你从外面直接拿来搭个框架或者买个api服务商的一套api也有可能。
解决办法有好几种:1,提供网址:,现有行业大站提供http接口,一般地方站目前还是没有对接的。3,提供api:,国内大站长们自己搭建api,提供api,但是可以定制,可以返回到他们自己的格式。不过现在有些行业大站,如美团,百度也面临着转型,没有做这么多api的接口,也是由于接口api的接入成本相对较高。
文章自动采集插件的介绍及介绍目录【通知】
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-05-07 05:02
文章自动采集插件的介绍目录1.准备工作2.设置下载地址3.设置前端自动发布账号密码4.设置每个浏览器插件的自动登录限制5.获取各网站的云主机详细信息6.下载不同网站的云主机7.将云主机上传到服务器8.建立自动爬虫服务器9.配置自动爬虫服务器首先,准备工作:一般的用于获取附近网站信息的软件和api;一个域名;企业qq或网页注册邮箱(方便大家找到目标网站);服务器操作系统:ubuntu系统或者windows系统(建议windows系统,因为苹果系统暂时没有尝试过);个人电脑:台式机或者笔记本;路由器端口及其配置如下:10.设置下载地址:通过对方提供的网址找到目标页面,在网址中加入“tar”字符,或者直接添加到地址栏中。
举例:经过上述的设置后,点击“打开文件”->“查看”,看见如下界面:选择“tar”字符,选择下载的文件,选择“tar”文件,点击“下载”选择文件的后缀是rar文件下载(压缩文件),下载速度会比原来的文件快。点击“解压”,得到下图(解压后得到目标文件,可以根据自己的网站规划自己的目标页面):可以看见获取到了共计34个网页(目标页面是java接口,支持java,c#,php,.net语言):12.设置前端自动发布账号密码:选择“云主机自动发布”(一般看到c,w/a)选择“添加新机器”,因为是采用这种方式来接收网站发布的自动爬虫账号密码:点击“确定”,进入自动爬虫的详细信息设置页面(如下图):右侧信息中的内容为:选择“自动发布服务器”,添加其登录限制或者数据库密码,设置“详细信息”页面的详细信息(使用阿里云客户端的用户,右侧可以看到真正的个人主机ip)。
左侧的搜索关键词很重要,可以查到当前爬虫所在服务器的url(可以看见输入爬虫ip和密码后获取的java的tomcat服务器地址,以及代理ip地址):选择“自动发布服务器”,完成左侧登录授权设置(在登录设置中,账号和密码保存在电脑的其他文件中),设置好后再次检查ip的登录限制和密码登录限制,点击“发布”。
发布操作成功后,可以看见java的数据库ip的地址。6.获取不同网站的云主机详细信息:云主机:-bin/javaweb.security.public.path_inc=/to/data/c2d/这里的path_inc是指用java爬虫发布的数据库服务器的url,也就是说,点击“发布”后,这个数据库服务器的ip会在java爬虫发布的数据库ip中找到,按照url提示登录相关的目标服务器。除了上图示例目标网站的规则外,也可以根据特定需求来挑选目标网站,如博客、论。 查看全部
文章自动采集插件的介绍及介绍目录【通知】
文章自动采集插件的介绍目录1.准备工作2.设置下载地址3.设置前端自动发布账号密码4.设置每个浏览器插件的自动登录限制5.获取各网站的云主机详细信息6.下载不同网站的云主机7.将云主机上传到服务器8.建立自动爬虫服务器9.配置自动爬虫服务器首先,准备工作:一般的用于获取附近网站信息的软件和api;一个域名;企业qq或网页注册邮箱(方便大家找到目标网站);服务器操作系统:ubuntu系统或者windows系统(建议windows系统,因为苹果系统暂时没有尝试过);个人电脑:台式机或者笔记本;路由器端口及其配置如下:10.设置下载地址:通过对方提供的网址找到目标页面,在网址中加入“tar”字符,或者直接添加到地址栏中。
举例:经过上述的设置后,点击“打开文件”->“查看”,看见如下界面:选择“tar”字符,选择下载的文件,选择“tar”文件,点击“下载”选择文件的后缀是rar文件下载(压缩文件),下载速度会比原来的文件快。点击“解压”,得到下图(解压后得到目标文件,可以根据自己的网站规划自己的目标页面):可以看见获取到了共计34个网页(目标页面是java接口,支持java,c#,php,.net语言):12.设置前端自动发布账号密码:选择“云主机自动发布”(一般看到c,w/a)选择“添加新机器”,因为是采用这种方式来接收网站发布的自动爬虫账号密码:点击“确定”,进入自动爬虫的详细信息设置页面(如下图):右侧信息中的内容为:选择“自动发布服务器”,添加其登录限制或者数据库密码,设置“详细信息”页面的详细信息(使用阿里云客户端的用户,右侧可以看到真正的个人主机ip)。
左侧的搜索关键词很重要,可以查到当前爬虫所在服务器的url(可以看见输入爬虫ip和密码后获取的java的tomcat服务器地址,以及代理ip地址):选择“自动发布服务器”,完成左侧登录授权设置(在登录设置中,账号和密码保存在电脑的其他文件中),设置好后再次检查ip的登录限制和密码登录限制,点击“发布”。
发布操作成功后,可以看见java的数据库ip的地址。6.获取不同网站的云主机详细信息:云主机:-bin/javaweb.security.public.path_inc=/to/data/c2d/这里的path_inc是指用java爬虫发布的数据库服务器的url,也就是说,点击“发布”后,这个数据库服务器的ip会在java爬虫发布的数据库ip中找到,按照url提示登录相关的目标服务器。除了上图示例目标网站的规则外,也可以根据特定需求来挑选目标网站,如博客、论。
文章自动采集插件,一键采集各种平台的旅游信息?
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-05-06 12:01
文章自动采集插件,一键采集各种平台的旅游信息?一键采集旅游景点的活动信息?一键采集旅游景点的住宿信息?一键采集各个游客会经过的景点,而且每一条都是可以精准到票价,你是不是很想知道大家都去哪里玩?这个时候插件的作用就体现出来了,一键采集景点的游玩信息,旅游,住宿,
自荐一个,wordpress插件everbox里面有个专门采集百度游记的功能,
如果可以,希望能帮你实现。
带你看看玩一整天需要多少成本。官方搭建好的网站游记分享平台百度搜这个网站,至于为什么想给你整个更专业的知乎下载googlechrome插件,也一定可以解决你的需求,付费下载的知乎下载任务也能保证到达完整的内容。
微信公众号的文章分类结构一般是这样的:公众号发布文章的首发地位置、公众号的整体介绍、公众号发布的时间节点、公众号下面的菜单栏内容、公众号的点赞排行等等。百度seo由于是从百度蜘蛛的角度来分析外链爬虫的,所以规则中对于外链网站来说,只分为一般外链和高质量外链,完全依照这样一套百度引导规则来进行博客推广的话,是有一定风险的。
但如果博客公众号是以百度搜索为主,那就很难了。如果是单纯的讲一个百度爬虫,那百度爬虫关键词布局就是单纯依照tag分布布局了,这个tag对应的词在一个博客主页上是必须有的,完全杜绝他外链的可能性。这对于百度爬虫来说就很简单了,也就是我所讲的整体布局布局主要是依照“博客主页、门户网站页面、b2b站、b2c网站网页截图”这样子的整体布局,像我们公司的百度文库、百度经验、360doc、搜狗问答之类的,可以理解为三种不同的百度图文网站的外链关键词布局,一般外链前3类博客能够增加展示。
不同的就是是否有推广费用。像这种流量比较大的页面,而且整体类目是非常受百度欢迎的,博客页面布局以关键词加锚文本页面加搜索引擎结果页面布局为主。比如说重要的行业词、重要的公司站、行业qq、官网页面、行业微信、行业博客、公司邮箱、公司qq空间、部门网站、企业站、超级网站等。对于主题内容自主要规划内容发布,按照同行业爬虫分析了解业务情况,或者按照行业博客的类别分布是。
另外像主题的分类,可以是自己查找自己想要业务关键词资料分布。这样做一是可以降低自己的风险,二来是可以更符合搜索规则。 查看全部
文章自动采集插件,一键采集各种平台的旅游信息?
文章自动采集插件,一键采集各种平台的旅游信息?一键采集旅游景点的活动信息?一键采集旅游景点的住宿信息?一键采集各个游客会经过的景点,而且每一条都是可以精准到票价,你是不是很想知道大家都去哪里玩?这个时候插件的作用就体现出来了,一键采集景点的游玩信息,旅游,住宿,
自荐一个,wordpress插件everbox里面有个专门采集百度游记的功能,
如果可以,希望能帮你实现。
带你看看玩一整天需要多少成本。官方搭建好的网站游记分享平台百度搜这个网站,至于为什么想给你整个更专业的知乎下载googlechrome插件,也一定可以解决你的需求,付费下载的知乎下载任务也能保证到达完整的内容。
微信公众号的文章分类结构一般是这样的:公众号发布文章的首发地位置、公众号的整体介绍、公众号发布的时间节点、公众号下面的菜单栏内容、公众号的点赞排行等等。百度seo由于是从百度蜘蛛的角度来分析外链爬虫的,所以规则中对于外链网站来说,只分为一般外链和高质量外链,完全依照这样一套百度引导规则来进行博客推广的话,是有一定风险的。
但如果博客公众号是以百度搜索为主,那就很难了。如果是单纯的讲一个百度爬虫,那百度爬虫关键词布局就是单纯依照tag分布布局了,这个tag对应的词在一个博客主页上是必须有的,完全杜绝他外链的可能性。这对于百度爬虫来说就很简单了,也就是我所讲的整体布局布局主要是依照“博客主页、门户网站页面、b2b站、b2c网站网页截图”这样子的整体布局,像我们公司的百度文库、百度经验、360doc、搜狗问答之类的,可以理解为三种不同的百度图文网站的外链关键词布局,一般外链前3类博客能够增加展示。
不同的就是是否有推广费用。像这种流量比较大的页面,而且整体类目是非常受百度欢迎的,博客页面布局以关键词加锚文本页面加搜索引擎结果页面布局为主。比如说重要的行业词、重要的公司站、行业qq、官网页面、行业微信、行业博客、公司邮箱、公司qq空间、部门网站、企业站、超级网站等。对于主题内容自主要规划内容发布,按照同行业爬虫分析了解业务情况,或者按照行业博客的类别分布是。
另外像主题的分类,可以是自己查找自己想要业务关键词资料分布。这样做一是可以降低自己的风险,二来是可以更符合搜索规则。
Android 基础架构组,面试题问什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-30 05:10
水一篇
年中的时候帮部门招人,发现很多候选人对于我们部门还是很青睐的。也对鸡架部门做的事比较感兴趣,所以今天这篇水文主要就给大家梳理下基架的面试题以及基础架构组涉及的sdk相关。
因为最近几年面试经常被人吊打,所以也有了总结面试题的习惯。之后加上之前帮候选人的面试总结,今天给大家再卷一波。
1SDK相关
面试的时候我觉得哦,这些sdk有任意其实你研究的比较深入就行了,应该能在面试中表现的很好了。还有就是个人建议最好还是在单一方向研究的更深入一点,别的只要大概知道干什么的就行了。
1. 配置中心以及灰度测试
app必备工具之一,配置中心主要负责的就是动态化的配置,比如文本展示类似这些的。sdk提供方需要负责的是提供动态更新能力,这里有个差异化更新,只更新dif部分,还有就是流量优化等等需要开发同学考虑的。然后可以考虑下存储性能方面的提升等。
而abtest也是app必备工具之一了,动态的下发实验策略,之后开发同学可以切换实验的页面。另外主要需要考虑灰度结果计算,分桶以及版本过滤白名单等等。这里只是一个简单的介绍不展开,因为我只是一个使用方。
2. 调试组件
个人还是更推荐滴滴的Dokit,功能点比较多而且接入相对来说比较简单。而且提供了很多给开发同学定制的能力,可以在debug情况下增加很多业务相关的测试功能,方便测试同学,核心还是浮窗太方便了。
当然很多实验性的预研功能等其实都可以直接接在这里,然后在测试环境下充分展开,之后在进行线上灰度方案。还有一些具有风险的hook操作,个人也比较建议放在debug组件上。
3. 性能监控框架
这部分有几个不同的方面,首先是异常崩溃方面的,另外则是性能监控方面的,但是他们整体是划分在一起的,都属于线上性能监控体系的。
Crash相关的,可以从爱奇艺的xCrash学起。包含了崩溃日志,ANR以及native crash,因为版本适配的问题ANR在高版本上已经不是这么好捞了,还有就是native crash相关的。是一个非常牛逼的库了。
而线上的性能监控框架可以从腾讯的Matrix学起,以前有两篇文章介绍的内容也都是和Matrix相关的, Matrix首页上也有介绍,比如fps,卡顿,IO,电池,内存等等方面的监控。其中卡顿监控涉及到的就是方法前后插桩,同时要有函数的mapping表,插桩部分整体来说比较简单感觉。
另外关于线上内存相关的,推荐各位可以学习下快手的koom, 对于hprof的压缩比例听说能达到70%,也能完成线上的数据回捞以及监控等等,是一个非常屌的框架。下面给大家一个抄答案的方式。字节也有一个类似的原理其实也差不多。
主进程发现内存到达阈值的时候,用leakcanary的方案,通过shark fork进程内存,之后生成hrop。由于hrop文件相对较大,所以我们需要对于我们所要分析的内容进行筛选,可以通过xhook,之后对hrop的写入操作进行hook,当发现写入内容的类型符合我们的需要的情况下才进行写入。
而当我们要做线上日志回捞的情况,需要对hprof 进行压缩,具体算法可以参考koom/raphel,有提供对应的压缩算法。
最后线上回捞机制就是基于一个指令,回捞线上符合标准的用户的文件操作,这个自行设计。
其实上述几个库都还是有一个本质相关的东西,那么就是plthook,这个上面三个库应该都有对其的使用,之前是爱奇艺的xhook,现在是字节的bhook, 这个大佬也是我的偶像之一了,非常离谱了算是。
Android 性能采集之Fps,Memory,Cpu和Android IO监控。
最近已经不咋写这部分相关了,所以也就没有深挖,但是后续可能会有一篇关于phtead hook相关的,也是之前matrix更新的一个新东西,还在测试环境灰度阶段。
4. 基础网络组件
虽然核心可能还是三方网络库,但是因为基本所有公司都对网络方面有调整和改动,以及解析器等方面的优化,其实可以挖的东西也还是蛮多的。
应付面试的同学可以看看Android网络优化方案。当然还是要具体问题具体分析,毕竟头疼医头,脚疼医脚对吧。
之前和另外一个朋友聊了下,其实很多厂对json解析这部分有优化调整,通过apt之后更换原生成原生的解析方式,加快反序列化速度的都是可以考虑考虑的。
5. 埋点框架
其实这个应该要放在更前面一点的,数据上报数据分析啥的其实都还是蛮重要的。
这部分因为我完全没写过哦,所以我压根不咋会,但是如果你会的话,面试的时候展开说说,可以帮助你不少。
另外还需要有线上的异常用户数据回捞系统,方便开发同学主动去把线上有异常的用户的日志给收集回来。
但是有些刁钻的页面曝光监控啦,自动化埋点啥的其实还是写过一点的,有兴趣的可以翻翻历史,还有github 上还有demo。
AndroidAutoTrackdemo工程。
6. 启动相关
通过DAG(有向无环图)的方式将sdk的初始化拆解成一个个task,之后理顺依赖关系,让他们能按照固定的顺序向下执行。
核心需要处理的是依赖关系,比如说其实埋点库依赖于网络库初始化,然后APM相关的则依赖于埋点库和配置中心abtest等等,这样的依赖关系需要开发同学去理顺的。
另外就是把sdk的粒度打的细碎一点,更容易观察每个sdk任务的耗时情况,之后增加task阈值告警,超过某个加载速度就通知到相应的同学改一下。
多线程是能优化掉一部分,但是也需要避免频繁线程调度。还有就是我个人觉得这些启动相关的东西因为都无法使用sdk级别的灰度,所以改动最好慎重一点。出发点始终都是好的,但是还是结果导向吧。
启动优化的核心,我个人始终坚持的就是延迟才能优化。开发人员很难做到优化代码执行的复杂度,执行时间之类的。尽人事听天命,玄学代码。
7.中间件(图片 日志 存储 基础信息)
这部分没啥,最好是对第三方库有一层隔离的思维,但是这个隔离也需要对应的同学对于程序设计方面有很好的思维,说起来简单,其实也蛮复杂的。
这里就不展开了,感觉面试也很少会问的很细。
8. 第三方sdk大杂烩(偏中台方向)
基本一个app现在都有啥分享啦,推送啦,支付啦,账号体系啦,webview,jsbridge等等服务于应用内的一些sdk,这些东西就比较偏向于业务。
有兴趣的可以看看之前写的两篇关于sdk设计相关的。
活学活用责任链 SDK开发的一点点心得 Android厂商推送Plugin化。
9. 其他方面
大公司可能都会有些动态化方案的考虑,比如插件化啊动态化之类的。这部分在下确实不行,我就不展开了啊。
2编译相关
1. 描述下android编译流程
基架很容易碰到的面试题,以前简单的描述写过。聊聊Android编译流程。
虽然是几年前的知识点了,但是还是要拆开高低版本的agp做比较的。所以这部分可以回答下,基本这题就能简单的拿下了。
2. Gradle 生命周期
简单的说下就是buildSrc先编译,之后是根目录的settings.gradle, 根build.gradle,最后才是module build。
网上一堆,你自己翻一番就知道了。
3. apt是编译中哪个阶段
APT解析的是java 抽象语法树(AST),属于javac的一部分流程。大概流程:.java -> AST -> .class
聊聊AbstractProcessor和Java编译流程。
4. Dex和class有什么区别
链接传送门:
Class与dex的区别:
1)虚拟机:class用jvm执行,dex用dvm执行。
2)文档:class中冗余信息多,dex会去除冗余信息,包含所有类,查找方便,适合手机端。
JVM与DVM:
1)JVM基于栈(使用栈帧,内存),DVM基于寄存器,速度更快,适合手机端。
2)JVM执行Class字节码,DVM执行DEX。
3)JVM只能有一个实例,一个应用启动运行在一个DVM。
DVM与ART:
1)DVM:每次运行应用都需要一次编译,效率降低。JIT
2)ART:Android5.0以上默认为ART,系统会在进程安装后进行一次预编译,将代码转为机器语言存在本地,这样在每次运行时不用再进行编译,提高启动效率;。AOP & JIT
5. Transform是如何被执行的
Transform 在编译过程中会被封装成Task 依赖其他编译流程的Task执行。
6. Transform和其他系统Transform执行的顺序
其实这个题目已经是个过期了,后面对这些都合并整合了,而且最新版的api也做了替换,要不然考虑下回怼下面试官?
Transform和Task之间有关?
7. 如何监控编译速度变慢问题
./gradlew xxxxx -- scan<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
之后会生成一个gradle的网页,填写下你的邮箱就好了。
另外一个相对来说比较简单了。通过gradle原生提供的listener进行就行了。
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
// 耗时统计kt化<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class TimingsListener : TaskExecutionListener, BuildListener {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var startTime: Long = 0L<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var timings = linkedMapOf()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun beforeExecute(task: Task) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> startTime = System.nanoTime()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun afterExecute(task: Task, state: TaskState) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> val ms = TimeUnit.MILLISECONDS.convert(System.nanoTime() - startTime, TimeUnit.NANOSECONDS)<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> task.path<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings[task.path] = ms<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${task.path} took ${ms}ms")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildFinished(result: BuildResult) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("Task timings:")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings.forEach {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if (it.value >= 50) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${it.key} cos ms ${it.value}\n")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildStarted(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun settingsEvaluated(settings: Settings) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsLoaded(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsEvaluated(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />}<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gradle.addListener(TimingsListener())<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
8. Gradle中如何给一个Task前后插入别的任务
最简单的可以考虑直接获取到Task实例,之后在after和before插入一些你所需要的代码。
另外一个就是通过dependOn前置和finalizedBy挂载一个任务 mustAfter。
Gradle 使用指南 -- Gradle Task。
9. ksp APT Transform的区别
ksp 是kotlin专门独立的ast语法树。
apt 是java 的ast语法树。
transform是 agp 专门修改字节码的一个方法。
反杀时刻AsmClassVisitorFactory,可以看看我之前写的那篇文章。
10. Transform上的编译优化能做哪些?
虽然是个即将过期的api,但是大家对他的改动还是都比较多的。
首先肯定是需要完成增量编译的,具体的可以参考我的demo工程。记住,所有的transfrom都要全量。
另外可以考虑多线程优化,将转化操作移动到子线程内,建议使用gradle内部的共享线程。
参考agp最新做法,抽象出一个新的interface,之后通过spi串联,之后将asm链式调用。我的文章也介绍过,具体的点在哪里自己盘算。
现在准备好告别Transform了吗
11. aar 源码切换插件原理
这个前几天刚介绍过,原理和方案业内都差不多,mulite-repo应该都需要这个东西的。我的版本也比较简陋,大厂内部肯定都会有些魔改的。
相对来说功能肯定会更丰富,更全面一点。
aar和源码切换插件Plus。
12. 你们有哪些保证代码质量的手段
最简单的方式还是通过静态扫描+pipline 处理,之后在合并mr之前进行一次拦截。
静态扫描方式比较多,下面给大家简单的介绍下:
阿里的sonar 但是对kt的支持很糟糕,因为阿里使用,所以有很多现成的规则可以使用,但是如果从0-1接入,你可能会直接放弃。
原生的lint,可以基于原生提供的lint api,对其进行开发,支持种类也多,基本上算是一个非常优秀的方案了,但是由于文档资料较少,对于开发的要求可能会较高。
AndroidLint。
13. 如何对第三方的依赖做静态检查?
魔高一尺道高一丈。lint还是能解决这个问题的。
Tree Api+ClassScanner = 识别三方隐私权限调用。
14. R.java code too large 解决方案
又是一个过期的问题,尽早升级agp版本,让R8帮你解决这个问题,R文件完全可以内联的。
或者用别的AGP插件的R inline也可以解决这个问题。
15. R inline 你需要注意些什么?
预扫描,先收集调用的信息,之后在进行替换。还有javac 的时候可能就因为文件过大,直接挂掉了。
16. 一个类替换父类 比如所有activity实现类替换baseactivity
class node 直接替换 superName ,想起了之前另外一个问题,感觉主要是要对构造函数进行修改,否则也会出异常。
17. R8 D8 以及混淆相关的,还有R8除了混淆还能干些什么?混淆规则有没有碰到什么奇怪的问题?
D8和Dx的区别,主要涉及到编译速度以及编译产物的体积,包体积大概小11%。
R8 则是变更了整个编译流程的,其中我觉得最微妙的就是java8 lambda相关的,脱糖前后的差别还是比较大的。同时R8也少了很多之前的Transform。
R8的混淆部分,混淆除了能增加代码阅读难度意外,更多的是对于代码优化方面的。比如无效代码优化, 同时也删除代码等等都可以做。
18. 编译的时候有没有碰到javac的常量优化
javac会将静态常量直接优化成具体的数值。但是尤其是多模块场景下尤其容易出现异常,看起来是个实际的常量引用,但是产物上却是一个具体的常量值了。
3其他部分
组件化相关
不仅仅要聊到路由,还需要聊下业务仓库的设计,如何避免两个模块之间相互相互引用导致的环问题。
另外就是路由的apt aop的部分都可以深入的聊一下。
如果只聊路由的话,你就只说了一个字符串匹配规则,非常无聊了。
路由跳转
路由跳转只是一小部分,其核心原理就是字符串匹配,之后筛选出符合逻辑的页面进行跳转。
另外就是拦截器的设计,同步异步拦截器两种完全不同的写法。
其原理基于apt+transform ,apt负责生成模块的路由表,而transform则负责将各个模块的路由表进行收集。
服务发现
类似路由表,但是维护的是一个基于键值的类构造。ab之间当有相互依赖的情况下,可以通过基于接口编程的方式进行调整,互相只依赖抽象的接口,之后实现类在内部,通过注册的机制。之后在实际的使用地方用服务发现的机制寻找。
虚拟机部分
很多人会觉得虚拟机这部分都是硬八股,比较无聊。但是其实有时候我们碰到的一些字节码相关的问题就和这部分基础姿势相关了。
虽然用的比较少,但是也不是一个硬八股,比hashmap好玩太多了。
依赖注入
和服务发现类似,也是拿来解决不同模块间的依赖问题。可以使用hilt,依赖注入的好处就是连构造的这部分工作也有di完成了,而且构造能力更多样。可以多参数构造。
总结
其实以当前来说安卓的整个体系相对来说很复杂,第三方库以及源代码量都比较大,并不是要求每个同学都对这些有一个良好的掌握,但是大体上应该了解的还是需要了解的。
面试造火箭可不是浪得虚名啊,但是鸡架可能还是需要使用到其中一些奇奇怪怪的黑科技的。
好了胡扯结束了,今天的文章就到此为止了。 查看全部
Android 基础架构组,面试题问什么?
水一篇
年中的时候帮部门招人,发现很多候选人对于我们部门还是很青睐的。也对鸡架部门做的事比较感兴趣,所以今天这篇水文主要就给大家梳理下基架的面试题以及基础架构组涉及的sdk相关。
因为最近几年面试经常被人吊打,所以也有了总结面试题的习惯。之后加上之前帮候选人的面试总结,今天给大家再卷一波。
1SDK相关
面试的时候我觉得哦,这些sdk有任意其实你研究的比较深入就行了,应该能在面试中表现的很好了。还有就是个人建议最好还是在单一方向研究的更深入一点,别的只要大概知道干什么的就行了。
1. 配置中心以及灰度测试
app必备工具之一,配置中心主要负责的就是动态化的配置,比如文本展示类似这些的。sdk提供方需要负责的是提供动态更新能力,这里有个差异化更新,只更新dif部分,还有就是流量优化等等需要开发同学考虑的。然后可以考虑下存储性能方面的提升等。
而abtest也是app必备工具之一了,动态的下发实验策略,之后开发同学可以切换实验的页面。另外主要需要考虑灰度结果计算,分桶以及版本过滤白名单等等。这里只是一个简单的介绍不展开,因为我只是一个使用方。
2. 调试组件
个人还是更推荐滴滴的Dokit,功能点比较多而且接入相对来说比较简单。而且提供了很多给开发同学定制的能力,可以在debug情况下增加很多业务相关的测试功能,方便测试同学,核心还是浮窗太方便了。
当然很多实验性的预研功能等其实都可以直接接在这里,然后在测试环境下充分展开,之后在进行线上灰度方案。还有一些具有风险的hook操作,个人也比较建议放在debug组件上。
3. 性能监控框架
这部分有几个不同的方面,首先是异常崩溃方面的,另外则是性能监控方面的,但是他们整体是划分在一起的,都属于线上性能监控体系的。
Crash相关的,可以从爱奇艺的xCrash学起。包含了崩溃日志,ANR以及native crash,因为版本适配的问题ANR在高版本上已经不是这么好捞了,还有就是native crash相关的。是一个非常牛逼的库了。
而线上的性能监控框架可以从腾讯的Matrix学起,以前有两篇文章介绍的内容也都是和Matrix相关的, Matrix首页上也有介绍,比如fps,卡顿,IO,电池,内存等等方面的监控。其中卡顿监控涉及到的就是方法前后插桩,同时要有函数的mapping表,插桩部分整体来说比较简单感觉。
另外关于线上内存相关的,推荐各位可以学习下快手的koom, 对于hprof的压缩比例听说能达到70%,也能完成线上的数据回捞以及监控等等,是一个非常屌的框架。下面给大家一个抄答案的方式。字节也有一个类似的原理其实也差不多。
主进程发现内存到达阈值的时候,用leakcanary的方案,通过shark fork进程内存,之后生成hrop。由于hrop文件相对较大,所以我们需要对于我们所要分析的内容进行筛选,可以通过xhook,之后对hrop的写入操作进行hook,当发现写入内容的类型符合我们的需要的情况下才进行写入。
而当我们要做线上日志回捞的情况,需要对hprof 进行压缩,具体算法可以参考koom/raphel,有提供对应的压缩算法。
最后线上回捞机制就是基于一个指令,回捞线上符合标准的用户的文件操作,这个自行设计。
其实上述几个库都还是有一个本质相关的东西,那么就是plthook,这个上面三个库应该都有对其的使用,之前是爱奇艺的xhook,现在是字节的bhook, 这个大佬也是我的偶像之一了,非常离谱了算是。
Android 性能采集之Fps,Memory,Cpu和Android IO监控。
最近已经不咋写这部分相关了,所以也就没有深挖,但是后续可能会有一篇关于phtead hook相关的,也是之前matrix更新的一个新东西,还在测试环境灰度阶段。
4. 基础网络组件
虽然核心可能还是三方网络库,但是因为基本所有公司都对网络方面有调整和改动,以及解析器等方面的优化,其实可以挖的东西也还是蛮多的。
应付面试的同学可以看看Android网络优化方案。当然还是要具体问题具体分析,毕竟头疼医头,脚疼医脚对吧。
之前和另外一个朋友聊了下,其实很多厂对json解析这部分有优化调整,通过apt之后更换原生成原生的解析方式,加快反序列化速度的都是可以考虑考虑的。
5. 埋点框架
其实这个应该要放在更前面一点的,数据上报数据分析啥的其实都还是蛮重要的。
这部分因为我完全没写过哦,所以我压根不咋会,但是如果你会的话,面试的时候展开说说,可以帮助你不少。
另外还需要有线上的异常用户数据回捞系统,方便开发同学主动去把线上有异常的用户的日志给收集回来。
但是有些刁钻的页面曝光监控啦,自动化埋点啥的其实还是写过一点的,有兴趣的可以翻翻历史,还有github 上还有demo。
AndroidAutoTrackdemo工程。
6. 启动相关
通过DAG(有向无环图)的方式将sdk的初始化拆解成一个个task,之后理顺依赖关系,让他们能按照固定的顺序向下执行。
核心需要处理的是依赖关系,比如说其实埋点库依赖于网络库初始化,然后APM相关的则依赖于埋点库和配置中心abtest等等,这样的依赖关系需要开发同学去理顺的。
另外就是把sdk的粒度打的细碎一点,更容易观察每个sdk任务的耗时情况,之后增加task阈值告警,超过某个加载速度就通知到相应的同学改一下。
多线程是能优化掉一部分,但是也需要避免频繁线程调度。还有就是我个人觉得这些启动相关的东西因为都无法使用sdk级别的灰度,所以改动最好慎重一点。出发点始终都是好的,但是还是结果导向吧。
启动优化的核心,我个人始终坚持的就是延迟才能优化。开发人员很难做到优化代码执行的复杂度,执行时间之类的。尽人事听天命,玄学代码。
7.中间件(图片 日志 存储 基础信息)
这部分没啥,最好是对第三方库有一层隔离的思维,但是这个隔离也需要对应的同学对于程序设计方面有很好的思维,说起来简单,其实也蛮复杂的。
这里就不展开了,感觉面试也很少会问的很细。
8. 第三方sdk大杂烩(偏中台方向)
基本一个app现在都有啥分享啦,推送啦,支付啦,账号体系啦,webview,jsbridge等等服务于应用内的一些sdk,这些东西就比较偏向于业务。
有兴趣的可以看看之前写的两篇关于sdk设计相关的。
活学活用责任链 SDK开发的一点点心得 Android厂商推送Plugin化。
9. 其他方面
大公司可能都会有些动态化方案的考虑,比如插件化啊动态化之类的。这部分在下确实不行,我就不展开了啊。
2编译相关
1. 描述下android编译流程
基架很容易碰到的面试题,以前简单的描述写过。聊聊Android编译流程。
虽然是几年前的知识点了,但是还是要拆开高低版本的agp做比较的。所以这部分可以回答下,基本这题就能简单的拿下了。
2. Gradle 生命周期
简单的说下就是buildSrc先编译,之后是根目录的settings.gradle, 根build.gradle,最后才是module build。
网上一堆,你自己翻一番就知道了。
3. apt是编译中哪个阶段
APT解析的是java 抽象语法树(AST),属于javac的一部分流程。大概流程:.java -> AST -> .class
聊聊AbstractProcessor和Java编译流程。
4. Dex和class有什么区别
链接传送门:
Class与dex的区别:
1)虚拟机:class用jvm执行,dex用dvm执行。
2)文档:class中冗余信息多,dex会去除冗余信息,包含所有类,查找方便,适合手机端。
JVM与DVM:
1)JVM基于栈(使用栈帧,内存),DVM基于寄存器,速度更快,适合手机端。
2)JVM执行Class字节码,DVM执行DEX。
3)JVM只能有一个实例,一个应用启动运行在一个DVM。
DVM与ART:
1)DVM:每次运行应用都需要一次编译,效率降低。JIT
2)ART:Android5.0以上默认为ART,系统会在进程安装后进行一次预编译,将代码转为机器语言存在本地,这样在每次运行时不用再进行编译,提高启动效率;。AOP & JIT
5. Transform是如何被执行的
Transform 在编译过程中会被封装成Task 依赖其他编译流程的Task执行。
6. Transform和其他系统Transform执行的顺序
其实这个题目已经是个过期了,后面对这些都合并整合了,而且最新版的api也做了替换,要不然考虑下回怼下面试官?
Transform和Task之间有关?
7. 如何监控编译速度变慢问题
./gradlew xxxxx -- scan<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
之后会生成一个gradle的网页,填写下你的邮箱就好了。
另外一个相对来说比较简单了。通过gradle原生提供的listener进行就行了。
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
// 耗时统计kt化<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class TimingsListener : TaskExecutionListener, BuildListener {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var startTime: Long = 0L<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var timings = linkedMapOf()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun beforeExecute(task: Task) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> startTime = System.nanoTime()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun afterExecute(task: Task, state: TaskState) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> val ms = TimeUnit.MILLISECONDS.convert(System.nanoTime() - startTime, TimeUnit.NANOSECONDS)<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> task.path<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings[task.path] = ms<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${task.path} took ${ms}ms")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildFinished(result: BuildResult) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("Task timings:")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings.forEach {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if (it.value >= 50) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${it.key} cos ms ${it.value}\n")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildStarted(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun settingsEvaluated(settings: Settings) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsLoaded(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsEvaluated(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />}<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gradle.addListener(TimingsListener())<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
8. Gradle中如何给一个Task前后插入别的任务
最简单的可以考虑直接获取到Task实例,之后在after和before插入一些你所需要的代码。
另外一个就是通过dependOn前置和finalizedBy挂载一个任务 mustAfter。
Gradle 使用指南 -- Gradle Task。
9. ksp APT Transform的区别
ksp 是kotlin专门独立的ast语法树。
apt 是java 的ast语法树。
transform是 agp 专门修改字节码的一个方法。
反杀时刻AsmClassVisitorFactory,可以看看我之前写的那篇文章。
10. Transform上的编译优化能做哪些?
虽然是个即将过期的api,但是大家对他的改动还是都比较多的。
首先肯定是需要完成增量编译的,具体的可以参考我的demo工程。记住,所有的transfrom都要全量。
另外可以考虑多线程优化,将转化操作移动到子线程内,建议使用gradle内部的共享线程。
参考agp最新做法,抽象出一个新的interface,之后通过spi串联,之后将asm链式调用。我的文章也介绍过,具体的点在哪里自己盘算。
现在准备好告别Transform了吗
11. aar 源码切换插件原理
这个前几天刚介绍过,原理和方案业内都差不多,mulite-repo应该都需要这个东西的。我的版本也比较简陋,大厂内部肯定都会有些魔改的。
相对来说功能肯定会更丰富,更全面一点。
aar和源码切换插件Plus。
12. 你们有哪些保证代码质量的手段
最简单的方式还是通过静态扫描+pipline 处理,之后在合并mr之前进行一次拦截。
静态扫描方式比较多,下面给大家简单的介绍下:
阿里的sonar 但是对kt的支持很糟糕,因为阿里使用,所以有很多现成的规则可以使用,但是如果从0-1接入,你可能会直接放弃。
原生的lint,可以基于原生提供的lint api,对其进行开发,支持种类也多,基本上算是一个非常优秀的方案了,但是由于文档资料较少,对于开发的要求可能会较高。
AndroidLint。
13. 如何对第三方的依赖做静态检查?
魔高一尺道高一丈。lint还是能解决这个问题的。
Tree Api+ClassScanner = 识别三方隐私权限调用。
14. R.java code too large 解决方案
又是一个过期的问题,尽早升级agp版本,让R8帮你解决这个问题,R文件完全可以内联的。
或者用别的AGP插件的R inline也可以解决这个问题。
15. R inline 你需要注意些什么?
预扫描,先收集调用的信息,之后在进行替换。还有javac 的时候可能就因为文件过大,直接挂掉了。
16. 一个类替换父类 比如所有activity实现类替换baseactivity
class node 直接替换 superName ,想起了之前另外一个问题,感觉主要是要对构造函数进行修改,否则也会出异常。
17. R8 D8 以及混淆相关的,还有R8除了混淆还能干些什么?混淆规则有没有碰到什么奇怪的问题?
D8和Dx的区别,主要涉及到编译速度以及编译产物的体积,包体积大概小11%。
R8 则是变更了整个编译流程的,其中我觉得最微妙的就是java8 lambda相关的,脱糖前后的差别还是比较大的。同时R8也少了很多之前的Transform。
R8的混淆部分,混淆除了能增加代码阅读难度意外,更多的是对于代码优化方面的。比如无效代码优化, 同时也删除代码等等都可以做。
18. 编译的时候有没有碰到javac的常量优化
javac会将静态常量直接优化成具体的数值。但是尤其是多模块场景下尤其容易出现异常,看起来是个实际的常量引用,但是产物上却是一个具体的常量值了。
3其他部分
组件化相关
不仅仅要聊到路由,还需要聊下业务仓库的设计,如何避免两个模块之间相互相互引用导致的环问题。
另外就是路由的apt aop的部分都可以深入的聊一下。
如果只聊路由的话,你就只说了一个字符串匹配规则,非常无聊了。
路由跳转
路由跳转只是一小部分,其核心原理就是字符串匹配,之后筛选出符合逻辑的页面进行跳转。
另外就是拦截器的设计,同步异步拦截器两种完全不同的写法。
其原理基于apt+transform ,apt负责生成模块的路由表,而transform则负责将各个模块的路由表进行收集。
服务发现
类似路由表,但是维护的是一个基于键值的类构造。ab之间当有相互依赖的情况下,可以通过基于接口编程的方式进行调整,互相只依赖抽象的接口,之后实现类在内部,通过注册的机制。之后在实际的使用地方用服务发现的机制寻找。
虚拟机部分
很多人会觉得虚拟机这部分都是硬八股,比较无聊。但是其实有时候我们碰到的一些字节码相关的问题就和这部分基础姿势相关了。
虽然用的比较少,但是也不是一个硬八股,比hashmap好玩太多了。
依赖注入
和服务发现类似,也是拿来解决不同模块间的依赖问题。可以使用hilt,依赖注入的好处就是连构造的这部分工作也有di完成了,而且构造能力更多样。可以多参数构造。
总结
其实以当前来说安卓的整个体系相对来说很复杂,第三方库以及源代码量都比较大,并不是要求每个同学都对这些有一个良好的掌握,但是大体上应该了解的还是需要了解的。
面试造火箭可不是浪得虚名啊,但是鸡架可能还是需要使用到其中一些奇奇怪怪的黑科技的。
好了胡扯结束了,今天的文章就到此为止了。
如何解决百度站长工具sitemap审核错误:索引型不予处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-30 05:08
我的个人网站说起来已经做了2年多了,一直比较佛系,没有特别关注网站的收录情况,爱收不收,真的只是因为纯爱好。实际上,谷歌、必应、360、神马等等大大小小的搜索引擎基本上都已经收录了我的网站上很多内容了,有的甚至还能到首页。可能也是自己坚持原创的原因,图片文字都是自己一点点思考整理出来的。但是,但是,但是,唯独咱们国家最大的搜索引擎百度死活不收录,2年多了啊,一条都没有收录。真是搞不懂了,同样是搜索引擎,它哪来那么多事,店大欺客有没有。真正原创的东西不收录,垃圾网站倒是收录一大堆,真是无力吐槽。吐槽归吐槽,毕竟咱还是希望更多的人能看到我辛苦创作出来的东西,这些东西大多比较冷门,如果不是爱好,真的早就放弃了分享。希望能和更多有相同爱好的朋友一起交流。所以,最近一改一贯的佛系作风,主动到百度站长工具提交sitemap,不提交不知道,一提交给我报了错误:索引型不予处理。不会是4/1愚人节给我开玩笑了吧。问题来了,咱们也不逃避,看看如何解决?
1.索引型不予处理-原因分析1.1先来看下百度站长工具官方说明:
从官方说明中,清楚的看到:请勿提交索引型sitemap,索引型不予处理,且若存在索引型sitemap,将不允许提交新文件;请删除索引型sitemap后再尝试提交数据。
1.2什么是索引型sitemap
再看下百度搜索资源平台发布《sitemap 提交方式优化公告》
为提高站点地图文件的处理效率,搜索资源平台常用的采集和死链提交工具不再支持索引站点地图文件(即XML文档嵌套)XML文档。
也就是这种嵌套的sitemap是被百度定义为索引型sitemap。
1.3如何生成索引型sitemap(嵌套型)
我的网站几乎都是安装的SEO插件-Rank Math,目前最好用的SEO工具。也正是用这个插件自动生成的sitemap网站地图:。
打开这个索引型sitemap,可以看到下面实际上嵌套有4个分sitemap:
打开其中一条分sitemap,可以看到具体网站url
从上面结构可以看出,Rank Math插件生成sitemap是xml文档嵌套xml文档的结构,也就是xml文档里面还有xml文档,不是真正的网站网址,所以产生了这个索引型不予处理的问题。
这里再吐槽下,同样的文件样式结构,为啥其他搜索引擎没这个要求那,不主动提交也嗖嗖的收录。
2.索引型不予处理-解决方案
既然百度站长工具平台不再支持xml嵌套xml文档这种格式的索引站点地图文件,解决方法比较简单,把上面的4条sitemap都提交给百度站长工具。
2.1先删除之前提交的总的sitemap:
2.2添加分sitemap地址
根据你网站下面的实际sitemap数量来进行提交,4个就提交4个,更多就提交更多。
这里再吐槽下,不备案的话一天只能提交1条,真。。。后面陆续把4个sitemap提交即可。
提交之后,显示等待,后面等着百度蜘蛛过来抓取就可以了。
3.提交后效果展示
百度蜘蛛过来抓取成功后,网站sitemap地图正常了。有时候也可能会显示抓取失败,删除再从新提交就可以了。
最后总结
作为一名草根站长还是挺难的,只是想老老实实的写点自己感兴趣的文章,能让更多的人看到,从而在站长这条小路上,不那么孤独。不过有的时候正是这些那些的问题,不断提高技术水平,也通过不断的解决各种各样的问题得到一种快乐,所谓的成就感,因为快乐而坚持! 查看全部
如何解决百度站长工具sitemap审核错误:索引型不予处理
我的个人网站说起来已经做了2年多了,一直比较佛系,没有特别关注网站的收录情况,爱收不收,真的只是因为纯爱好。实际上,谷歌、必应、360、神马等等大大小小的搜索引擎基本上都已经收录了我的网站上很多内容了,有的甚至还能到首页。可能也是自己坚持原创的原因,图片文字都是自己一点点思考整理出来的。但是,但是,但是,唯独咱们国家最大的搜索引擎百度死活不收录,2年多了啊,一条都没有收录。真是搞不懂了,同样是搜索引擎,它哪来那么多事,店大欺客有没有。真正原创的东西不收录,垃圾网站倒是收录一大堆,真是无力吐槽。吐槽归吐槽,毕竟咱还是希望更多的人能看到我辛苦创作出来的东西,这些东西大多比较冷门,如果不是爱好,真的早就放弃了分享。希望能和更多有相同爱好的朋友一起交流。所以,最近一改一贯的佛系作风,主动到百度站长工具提交sitemap,不提交不知道,一提交给我报了错误:索引型不予处理。不会是4/1愚人节给我开玩笑了吧。问题来了,咱们也不逃避,看看如何解决?
1.索引型不予处理-原因分析1.1先来看下百度站长工具官方说明:
从官方说明中,清楚的看到:请勿提交索引型sitemap,索引型不予处理,且若存在索引型sitemap,将不允许提交新文件;请删除索引型sitemap后再尝试提交数据。
1.2什么是索引型sitemap
再看下百度搜索资源平台发布《sitemap 提交方式优化公告》
为提高站点地图文件的处理效率,搜索资源平台常用的采集和死链提交工具不再支持索引站点地图文件(即XML文档嵌套)XML文档。
也就是这种嵌套的sitemap是被百度定义为索引型sitemap。
1.3如何生成索引型sitemap(嵌套型)
我的网站几乎都是安装的SEO插件-Rank Math,目前最好用的SEO工具。也正是用这个插件自动生成的sitemap网站地图:。
打开这个索引型sitemap,可以看到下面实际上嵌套有4个分sitemap:
打开其中一条分sitemap,可以看到具体网站url
从上面结构可以看出,Rank Math插件生成sitemap是xml文档嵌套xml文档的结构,也就是xml文档里面还有xml文档,不是真正的网站网址,所以产生了这个索引型不予处理的问题。
这里再吐槽下,同样的文件样式结构,为啥其他搜索引擎没这个要求那,不主动提交也嗖嗖的收录。
2.索引型不予处理-解决方案
既然百度站长工具平台不再支持xml嵌套xml文档这种格式的索引站点地图文件,解决方法比较简单,把上面的4条sitemap都提交给百度站长工具。
2.1先删除之前提交的总的sitemap:
2.2添加分sitemap地址
根据你网站下面的实际sitemap数量来进行提交,4个就提交4个,更多就提交更多。
这里再吐槽下,不备案的话一天只能提交1条,真。。。后面陆续把4个sitemap提交即可。
提交之后,显示等待,后面等着百度蜘蛛过来抓取就可以了。
3.提交后效果展示
百度蜘蛛过来抓取成功后,网站sitemap地图正常了。有时候也可能会显示抓取失败,删除再从新提交就可以了。
最后总结
作为一名草根站长还是挺难的,只是想老老实实的写点自己感兴趣的文章,能让更多的人看到,从而在站长这条小路上,不那么孤独。不过有的时候正是这些那些的问题,不断提高技术水平,也通过不断的解决各种各样的问题得到一种快乐,所谓的成就感,因为快乐而坚持!
非靶代谢组原始数据上传保姆级教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-30 04:15
相信大家对于转录组和蛋白组的数据上传方法都不陌生,转录组数据一般上传到NCBI网站,蛋白组学数据一般共享在proteomexchange网站,那代谢组的原始数据呢?传到哪里?如何上传?有哪些注意事项?今天就来为大家一一揭晓。
非靶代谢组原始数据上传到哪里?
MetaboLights,简称为MTBLS,是EMBL-EBI数据库的子库,该库跨技术、跨物种,涵盖了代谢物的结构、生物学作用、位置、浓度、参考谱图以及来自代谢实验的检测数据,是重要的代谢组学实验和衍生信息的数据库()。MetaboLights是众多优质期刊推荐的代谢组学资料库。
代谢组原始数据如何上传?
01注册账号并激活
登陆所填写的注册邮箱,点击邮箱中的链接,完成账户激活;
02上传数据
①点击页面右上角“Login”,输入注册的账号和密码,登录;
②登录之后点击SubmitStudy ,首次提交,选择“提交新研究数据”;
③点击“Createonline”选择“CreateNew Study”之后跳转的页面选择“Let’sget started”;
④有2种选择“现在上传原始数据”和“延后上传原始数据”,若选择现在就上传数据,请按照下图操作;
⑤系统会自动生成一个项目,并配有独有的项目号MTBLSxxxx及网址链接,建议大家记录下来,后期可以用于文章写作或进行数据查看,我们的注册邮箱也会同步收到一封邮件,其中包含有本项目的项目号及网址链接。随后点击“NEXT”;
⑥网站提供2种数据上传方式,AsperaUpload和PrivateFTP Upload,建议选择AsperaUpload,上传数据会更快;
⑦先点击installplugin下载并安装插件,再点击Uploadfile;
⑧弹出上传数据的选项框,选择要上传的数据,点击打开;
⑨然后系统默认会用IBM插件上传数据,如下图所示,上传完成后拉到页面最下方,点击绿色的next;
⑩填写studydescription信息,包含keywords、title、summary等,并且需要根据实际情况选择是否有manuscript;
⑪接下来进入上面流程图中的最后一步:填写sample& assaydetails,请根据项目实际情况如实填写,如果是POS和NEG模式都采集了,请分别选positive建立一个assay,再选择negative建立一个assay;
⑫填写完成后点击右上角“Massspectrometry”,填写Protocols、Experimentalcontrol names 、Samplenames、Sampledetails、Assaydetails共6项内容;
⑬Protocols包括样本收集、提取、色谱方法、质谱方法、数据转换、代谢物鉴定方法,请根据实际情况填写;
⑭填写实验对照样本及正式样本的名称,包含空白、QC、混样等;
⑮填写sampledetails里的内容,根据实际情况填写物种、样本类型等信息。如有其他factor,如性别、年龄、用药等,则可以根据实际情况点击factor增加列数;
⑯接下来补充,需要根据实际情况填写仪器类型、仪器型号、数据采集极性、扫描范围、样本对应原始数据、对应derived数据等信息,填写完成后,点击Next;
⑰进入Metaboliteannotation填写,有两种方式:可以选择upload上传系统能够自动识别的txt文件File:m_MTBLS4669_LC-MS_positive__metabolite_profiling_v2_maf.tsv,该文件可在本网页上download下来然后填写metabolitesidentification、massto charge(m/z)、retentiontime(RT)、Modification(adduct形式)、代谢物定量值等关键信息(该文件可通过EXCEL打开并进行编写);也可以点击“compoundsearch”一个一个进行添加,但是比较麻烦;
⑱填写完后,点击“close”,再点击“Next”
⑲核对已填写的信息,确认无误后,根据项目是否完成选择“Submitted”或者“InCuration”,之后点击“OK”
⑳点击绿色的时间按钮,选择数据释放的时间,点击“OK”;
㉑最后,点击主界面右上方的“MyStudies”,即可查看先前上传的数据。
㉒在“Validation”后显示绿色的对号时,说明数据上传成功了。
有哪些注意事项?
使用Google浏览器;
每一步信息按实际情况填写,网页会自动保存,最后会再次确定论文的相关信息;
installplugin插件安装对网络状态要求较高,小迈尝试了多次才成功,若想节省时间,可“翻墙”进行后续操作;
数据上传如遇报错,可选择上午10点、11点左右上传,速度会更快;
后记
代谢组学上传数据就是这么简单,是不是感觉离文章发表又近了一步?
学会了就快来试试吧!
往期精彩:
●
●
查看全部
非靶代谢组原始数据上传保姆级教程
相信大家对于转录组和蛋白组的数据上传方法都不陌生,转录组数据一般上传到NCBI网站,蛋白组学数据一般共享在proteomexchange网站,那代谢组的原始数据呢?传到哪里?如何上传?有哪些注意事项?今天就来为大家一一揭晓。
非靶代谢组原始数据上传到哪里?
MetaboLights,简称为MTBLS,是EMBL-EBI数据库的子库,该库跨技术、跨物种,涵盖了代谢物的结构、生物学作用、位置、浓度、参考谱图以及来自代谢实验的检测数据,是重要的代谢组学实验和衍生信息的数据库()。MetaboLights是众多优质期刊推荐的代谢组学资料库。
代谢组原始数据如何上传?
01注册账号并激活
登陆所填写的注册邮箱,点击邮箱中的链接,完成账户激活;
02上传数据
①点击页面右上角“Login”,输入注册的账号和密码,登录;
②登录之后点击SubmitStudy ,首次提交,选择“提交新研究数据”;
③点击“Createonline”选择“CreateNew Study”之后跳转的页面选择“Let’sget started”;
④有2种选择“现在上传原始数据”和“延后上传原始数据”,若选择现在就上传数据,请按照下图操作;
⑤系统会自动生成一个项目,并配有独有的项目号MTBLSxxxx及网址链接,建议大家记录下来,后期可以用于文章写作或进行数据查看,我们的注册邮箱也会同步收到一封邮件,其中包含有本项目的项目号及网址链接。随后点击“NEXT”;
⑥网站提供2种数据上传方式,AsperaUpload和PrivateFTP Upload,建议选择AsperaUpload,上传数据会更快;
⑦先点击installplugin下载并安装插件,再点击Uploadfile;
⑧弹出上传数据的选项框,选择要上传的数据,点击打开;
⑨然后系统默认会用IBM插件上传数据,如下图所示,上传完成后拉到页面最下方,点击绿色的next;
⑩填写studydescription信息,包含keywords、title、summary等,并且需要根据实际情况选择是否有manuscript;
⑪接下来进入上面流程图中的最后一步:填写sample& assaydetails,请根据项目实际情况如实填写,如果是POS和NEG模式都采集了,请分别选positive建立一个assay,再选择negative建立一个assay;
⑫填写完成后点击右上角“Massspectrometry”,填写Protocols、Experimentalcontrol names 、Samplenames、Sampledetails、Assaydetails共6项内容;
⑬Protocols包括样本收集、提取、色谱方法、质谱方法、数据转换、代谢物鉴定方法,请根据实际情况填写;
⑭填写实验对照样本及正式样本的名称,包含空白、QC、混样等;
⑮填写sampledetails里的内容,根据实际情况填写物种、样本类型等信息。如有其他factor,如性别、年龄、用药等,则可以根据实际情况点击factor增加列数;
⑯接下来补充,需要根据实际情况填写仪器类型、仪器型号、数据采集极性、扫描范围、样本对应原始数据、对应derived数据等信息,填写完成后,点击Next;
⑰进入Metaboliteannotation填写,有两种方式:可以选择upload上传系统能够自动识别的txt文件File:m_MTBLS4669_LC-MS_positive__metabolite_profiling_v2_maf.tsv,该文件可在本网页上download下来然后填写metabolitesidentification、massto charge(m/z)、retentiontime(RT)、Modification(adduct形式)、代谢物定量值等关键信息(该文件可通过EXCEL打开并进行编写);也可以点击“compoundsearch”一个一个进行添加,但是比较麻烦;
⑱填写完后,点击“close”,再点击“Next”
⑲核对已填写的信息,确认无误后,根据项目是否完成选择“Submitted”或者“InCuration”,之后点击“OK”
⑳点击绿色的时间按钮,选择数据释放的时间,点击“OK”;
㉑最后,点击主界面右上方的“MyStudies”,即可查看先前上传的数据。
㉒在“Validation”后显示绿色的对号时,说明数据上传成功了。
有哪些注意事项?
使用Google浏览器;
每一步信息按实际情况填写,网页会自动保存,最后会再次确定论文的相关信息;
installplugin插件安装对网络状态要求较高,小迈尝试了多次才成功,若想节省时间,可“翻墙”进行后续操作;
数据上传如遇报错,可选择上午10点、11点左右上传,速度会更快;
后记
代谢组学上传数据就是这么简单,是不是感觉离文章发表又近了一步?
学会了就快来试试吧!
往期精彩:
●
●
wordpress文章自动翻新插件wppr,自动翻新老旧文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-30 04:10
随着站点的文章越来越多,老旧文章逐渐被埋没,曝光机会减少,流量随之减少。如果有这样一个插件,能每天翻新一些老旧文章,就可以增加老旧文章的曝光。如果安装了搜索引擎推送插件,还可以重新推送到搜索引擎。wppr就是这样一个支持文章自动翻新的插件。
功能
可设置翻新间隔
可以设置翻新间隔(最小一分钟),插件会每隔这个间隔时间翻新一篇旧文章。
每日最多翻新文章数量
可设置每天最多翻新的文章数量,到达这个数据就停止翻新。
翻新时间窗口限制
可设置翻新窗口,比如设置早八点到晚八点时间段翻新,其余时间不翻新。
指定/排除分类
可指定只翻新某个分类的文章或者不翻新某个分类的文章。
古老的文章已经翻新成新的日期了:
后台截图
下载和安装先下载并安装站长工具箱,再下载并安装自动翻新插件。站长工具箱是基础环境,一定要先安装站长工具箱再安装自动翻新插件。
可以点击原文前往官网下载啦! 查看全部
wordpress文章自动翻新插件wppr,自动翻新老旧文章
随着站点的文章越来越多,老旧文章逐渐被埋没,曝光机会减少,流量随之减少。如果有这样一个插件,能每天翻新一些老旧文章,就可以增加老旧文章的曝光。如果安装了搜索引擎推送插件,还可以重新推送到搜索引擎。wppr就是这样一个支持文章自动翻新的插件。
功能
可设置翻新间隔
可以设置翻新间隔(最小一分钟),插件会每隔这个间隔时间翻新一篇旧文章。
每日最多翻新文章数量
可设置每天最多翻新的文章数量,到达这个数据就停止翻新。
翻新时间窗口限制
可设置翻新窗口,比如设置早八点到晚八点时间段翻新,其余时间不翻新。
指定/排除分类
可指定只翻新某个分类的文章或者不翻新某个分类的文章。
古老的文章已经翻新成新的日期了:
后台截图
下载和安装先下载并安装站长工具箱,再下载并安装自动翻新插件。站长工具箱是基础环境,一定要先安装站长工具箱再安装自动翻新插件。
可以点击原文前往官网下载啦!
文章自动采集插件(运营助理学院文章自动采集插件使用实例教程(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-15 05:06
文章自动采集插件使用实例教程关于本文模板:【运营助理学院】插件免费注册教程!插件在这边留qq邮箱,需要的请先加qq小冰(远山),私聊告诉你。作者:远山二娃群号:280242800下面一起来看看看这两位大大是如何来实战分享免费插件的。01/远山分享免费插件【运营助理学院】免费插件的到底可以免费使用了么?实战以后才发现有时免费注册不行,到处需要开通,后面也尝试过下,都失败了。
所以,带你来解决这个问题。首先看我的图上面是我没有注册插件,我后面也注册了,可是有些网站没开通,特别麻烦。以下是我注册了,开通了小冰老师(我和小冰聊得来),以及过了60天的绑定账号获取。从开通之后开始登录账号,发现可以在,会员都是永久需要50块钱,我注册的免费模板都会给我推荐一个付费的精英或高级会员,我才100块(新人29。
8),我觉得划算。重点来了,其实免费注册就是在前面登录账号的时候,小冰给你推荐了,下面是全局模板,之后当我需要某个功能我就能直接进来要,是不是很方便。后面给大家放一个我的关注页面,我更偏爱百度经验,每天更新下干货,挺多的,所以会分享以此吸引客户,当然收入也不会少。我知道我这写的是日记,可是心情分享也可以的,发现我写文章有很多地方需要倾斜,我看小冰老师也许有他的价值,我也跟着他的讲解来写下的一次日记,这个的价值应该不小的,比如我写完这篇就会将我这个功能去推广,说不定我还能通过这个吸引一些客户过来加我。
以及下图截图,同时我找了一个软件有20多个功能都没有听,不是我记性不好,我就是要尝试不同的功能,不同的技巧去增加到我的需求上。02/finda分享教程的2个方法分享前先解释2个术语,今天分享的免费插件只需要开通两个功能,第一个就是使用网站插件时自动获取模板,第二个就是通过小冰模板来实现。我们先看第一个。
确认插件版本,如果你是老用户,直接就是到插件那里下载插件,或者搜你的分享是finda的出来的插件是免费的。当你想要去获取一个其他功能就需要学习,比如我发现小冰老师我不好用,还有通过网站注册。当你需要获取其他插件功能就可以参考上面我说的方法。
分享其他功能的方法如下:
1、下载安装一个插件,finda插件,复制粘贴复制你当前分享插件。
2、之后你的网站插件就是你复制粘贴之后的插件,有了之后你只需要动动鼠标,按键盘上的功能键(比如按f2就是获取其他插件功能),就可以将该插件弹出来了。基本全局模板,达到复制粘贴就弹出来的效果,当然如果你想要支持全局模板, 查看全部
文章自动采集插件(运营助理学院文章自动采集插件使用实例教程(组图))
文章自动采集插件使用实例教程关于本文模板:【运营助理学院】插件免费注册教程!插件在这边留qq邮箱,需要的请先加qq小冰(远山),私聊告诉你。作者:远山二娃群号:280242800下面一起来看看看这两位大大是如何来实战分享免费插件的。01/远山分享免费插件【运营助理学院】免费插件的到底可以免费使用了么?实战以后才发现有时免费注册不行,到处需要开通,后面也尝试过下,都失败了。
所以,带你来解决这个问题。首先看我的图上面是我没有注册插件,我后面也注册了,可是有些网站没开通,特别麻烦。以下是我注册了,开通了小冰老师(我和小冰聊得来),以及过了60天的绑定账号获取。从开通之后开始登录账号,发现可以在,会员都是永久需要50块钱,我注册的免费模板都会给我推荐一个付费的精英或高级会员,我才100块(新人29。
8),我觉得划算。重点来了,其实免费注册就是在前面登录账号的时候,小冰给你推荐了,下面是全局模板,之后当我需要某个功能我就能直接进来要,是不是很方便。后面给大家放一个我的关注页面,我更偏爱百度经验,每天更新下干货,挺多的,所以会分享以此吸引客户,当然收入也不会少。我知道我这写的是日记,可是心情分享也可以的,发现我写文章有很多地方需要倾斜,我看小冰老师也许有他的价值,我也跟着他的讲解来写下的一次日记,这个的价值应该不小的,比如我写完这篇就会将我这个功能去推广,说不定我还能通过这个吸引一些客户过来加我。
以及下图截图,同时我找了一个软件有20多个功能都没有听,不是我记性不好,我就是要尝试不同的功能,不同的技巧去增加到我的需求上。02/finda分享教程的2个方法分享前先解释2个术语,今天分享的免费插件只需要开通两个功能,第一个就是使用网站插件时自动获取模板,第二个就是通过小冰模板来实现。我们先看第一个。
确认插件版本,如果你是老用户,直接就是到插件那里下载插件,或者搜你的分享是finda的出来的插件是免费的。当你想要去获取一个其他功能就需要学习,比如我发现小冰老师我不好用,还有通过网站注册。当你需要获取其他插件功能就可以参考上面我说的方法。
分享其他功能的方法如下:
1、下载安装一个插件,finda插件,复制粘贴复制你当前分享插件。
2、之后你的网站插件就是你复制粘贴之后的插件,有了之后你只需要动动鼠标,按键盘上的功能键(比如按f2就是获取其他插件功能),就可以将该插件弹出来了。基本全局模板,达到复制粘贴就弹出来的效果,当然如果你想要支持全局模板,
文章自动采集插件(SDCMS采集的网站优化技巧,关键词和描述很重要!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-04-13 21:17
SDcms采集、Vividcms(SDcms)是四合一企业网站系统(PC/手机/mini节目/公众号管理)。 SDcms是很多站长使用的cms建站系统,但是由于SDcms比较小,所以支持SDcms上的采集器很少更不用说SDcms的文章自动更新和SDcms的SEO优化设置,如:batch采集、auto伪原创、自动发布和一键由搜狗、百度、神马、360等搜索引擎自动推送。
SDcms采集 的 网站 优化技巧,关键词 和描述很重要。 网站写好标题后,元信息中的关键词和描述就很重要了。 SDcms采集只需用户在网页上简单设置目标管理网站即可。完成后系统会对内容和图片进行高精度匹配,并根据用户设置的采集时间、发布时间和关键词自动聚合文章。虽然现在 关键词 和描述的作用减少了,但这并不意味着它完全没用。注意每一个细节。
SDcms采集对网站的开启速度有一定的要求。 网站开启速度不要太慢,最好在3秒以内。原则上,越早越好。 SDcms采集首页也做了优化,一个好的标题很重要。在网站首页优化的过程中,网站首页的标题非常重要。首先,检查标题中是否有关键词,标题中是否收录核心产品、核心服务等企业推广的关键词,标题中是否收录关键词整个 网站。这里不讲关键词选择的方法和注意事项。我只想说首页需要选择主关键词和核心关键词,可以出现在网站标题中,有利于网站排名。
SDcms采集需要控制网站首页内容的更新频率,网站首页向用户展示新内容的频率也是给搜索引擎新的内容内容,然后推送SDcms采集的推送,主动向搜索引擎公开网站链接,增加蜘蛛爬取的频率,从而促进网站收录。 SDcms采集 根据对搜索到的关键词的分析,可以帮助网站优化内容和页面布局,帮助改进网站的内容.
SDcms采集首先不要去调整TDK,也不要忙着做外链和优化。从网站的原创数据采集分析和整个网站的SEO诊断入手。 SDcms采集无需学习更多专业技能。只需几个简单的步骤即可轻松采集、准确发布和 关键词 网络数据。采集和观察网站的原创数据是为了帮助我们熟悉网站的现状,通过站点统计了解流量的来源和关键词的来源。里面的关键词对我们后期的扩展和布局也有帮助,不会被误删或忽略。
同时,SDcms采集可以智能找到排名好的关键词同行网站,看看其他人的网站是如何构成的。 SDcms采集有针对性的每日更新伪原创文章因为搜索引擎也喜欢收录里面原创或者伪原创的内容,并且不断丰富自己的数据库。 SDcms采集可以自动下载图片和替换链接,配置简单。支持的图片存储方式:阿里云OSS、七牛对象存储、腾讯云、拍云、本地服务器临时存储。
SDcms发布网站更新原版文章并启动外链的锚文本。通过外链的构建,让你的网站拥有大量的蜘蛛。 (注意:外链文章的锚文本必须锚定关键关键词,后跟主关键词,以及一两个精确词。
SDcms采集不仅提供自动采集网页文章、批量数据处理、定时采集、自动导出、定时定量发布等. 它还集成了强大的 SEO 工具来提高 采集 配置和发布导出的效率。 SDcms采集随时随地都可以搞定文章,点击浏览器书签即可获得采集文章内容!今天关于SDcms采集的解释就到这里。下期我会分享更多SEO相关的知识和经验。我希望这个 文章 可以对你有所帮助。下期再见。返回搜狐,查看更多 查看全部
文章自动采集插件(SDCMS采集的网站优化技巧,关键词和描述很重要!)
SDcms采集、Vividcms(SDcms)是四合一企业网站系统(PC/手机/mini节目/公众号管理)。 SDcms是很多站长使用的cms建站系统,但是由于SDcms比较小,所以支持SDcms上的采集器很少更不用说SDcms的文章自动更新和SDcms的SEO优化设置,如:batch采集、auto伪原创、自动发布和一键由搜狗、百度、神马、360等搜索引擎自动推送。
SDcms采集 的 网站 优化技巧,关键词 和描述很重要。 网站写好标题后,元信息中的关键词和描述就很重要了。 SDcms采集只需用户在网页上简单设置目标管理网站即可。完成后系统会对内容和图片进行高精度匹配,并根据用户设置的采集时间、发布时间和关键词自动聚合文章。虽然现在 关键词 和描述的作用减少了,但这并不意味着它完全没用。注意每一个细节。
SDcms采集对网站的开启速度有一定的要求。 网站开启速度不要太慢,最好在3秒以内。原则上,越早越好。 SDcms采集首页也做了优化,一个好的标题很重要。在网站首页优化的过程中,网站首页的标题非常重要。首先,检查标题中是否有关键词,标题中是否收录核心产品、核心服务等企业推广的关键词,标题中是否收录关键词整个 网站。这里不讲关键词选择的方法和注意事项。我只想说首页需要选择主关键词和核心关键词,可以出现在网站标题中,有利于网站排名。
SDcms采集需要控制网站首页内容的更新频率,网站首页向用户展示新内容的频率也是给搜索引擎新的内容内容,然后推送SDcms采集的推送,主动向搜索引擎公开网站链接,增加蜘蛛爬取的频率,从而促进网站收录。 SDcms采集 根据对搜索到的关键词的分析,可以帮助网站优化内容和页面布局,帮助改进网站的内容.
SDcms采集首先不要去调整TDK,也不要忙着做外链和优化。从网站的原创数据采集分析和整个网站的SEO诊断入手。 SDcms采集无需学习更多专业技能。只需几个简单的步骤即可轻松采集、准确发布和 关键词 网络数据。采集和观察网站的原创数据是为了帮助我们熟悉网站的现状,通过站点统计了解流量的来源和关键词的来源。里面的关键词对我们后期的扩展和布局也有帮助,不会被误删或忽略。
同时,SDcms采集可以智能找到排名好的关键词同行网站,看看其他人的网站是如何构成的。 SDcms采集有针对性的每日更新伪原创文章因为搜索引擎也喜欢收录里面原创或者伪原创的内容,并且不断丰富自己的数据库。 SDcms采集可以自动下载图片和替换链接,配置简单。支持的图片存储方式:阿里云OSS、七牛对象存储、腾讯云、拍云、本地服务器临时存储。
SDcms发布网站更新原版文章并启动外链的锚文本。通过外链的构建,让你的网站拥有大量的蜘蛛。 (注意:外链文章的锚文本必须锚定关键关键词,后跟主关键词,以及一两个精确词。
SDcms采集不仅提供自动采集网页文章、批量数据处理、定时采集、自动导出、定时定量发布等. 它还集成了强大的 SEO 工具来提高 采集 配置和发布导出的效率。 SDcms采集随时随地都可以搞定文章,点击浏览器书签即可获得采集文章内容!今天关于SDcms采集的解释就到这里。下期我会分享更多SEO相关的知识和经验。我希望这个 文章 可以对你有所帮助。下期再见。返回搜狐,查看更多
文章自动采集插件( SEO插件使用教程:WordPressSEObyYoast做好网站插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-13 17:27
SEO插件使用教程:WordPressSEObyYoast做好网站插件)
SEO插件教程:WordPressSEObyYoast
做好网站SEO一直是站长们的心愿。说起来容易简单,但说起来很难,因为要注意的地方太多了。如果你不小心被百度到了K,你不知道发生了什么。在这里,我推荐这个名为WordPressSEObyYoast的SEO优化插件,它可以稍微减轻你的优化负担。
Hexo 安装插件
下面介绍如何在Hexo中使用RSS和百度站点地图安装插件: 安装插件:npminstall
--save enable plugins:在根目录下的_config.yml文件中添加:plugins:-
百度站点地图生成器插件使用图文教程
原文的介绍是“生成百度SitemapXML文件。相当于网站被全球最大中文搜索引擎百度订阅,为你的网站带来潜在流量。据作者介绍,这个插件是专门为百度搜索引擎开发的,对百度搜索引擎非常友好。
云计算核心技术Docker教程:Docker安装及插件使用
插件作为 Docker 镜像分发,可以托管在 DockerHub 或私有注册表上。要安装插件,请使用 dockerplugininstall 命令,如有必要,该命令会从 DockerHub 或您的私有注册表中提取插件
Wordpress 插件 WpRobot 教程
wordpress可以说是英文网站的神器,wprobot是wordpress博客自动更新的最佳插件,可以从Amazon、eBay、Clickbank、Youtube、Yahoo Answers、Flickr、Yahoo News、Rss等自动获取。 文章 。注意不支持中文,而且不是免费的,169美元。提前说明,这篇文章不是给大家做垃圾回收的
WordPress3.01 常用插件使用记录
WordPress 有各种各样的插件,它们极大地扩展了 WordPress 的功能。但是面对这么多的插件,我们需要哪些,哪些不需要呢?以下是我安装插件的一些经验,仅供参考。
Sublime 常用插件及其功能
下面是sublime教程专栏,介绍sublime常用插件,希望对需要的朋友有所帮助!常用插件和ChineseLocalization插件,支持中文、日文、英文的无缝切换。转换到U
WordPress 博客教程 (七): WordPress 插件
WordPress 受到众多博主喜爱的原因之一是 WordPress 拥有大量优秀的插件,这让 WordPress 更加强大。这部分主要分为WordPress插件安装和WordPress插件推荐两个部分。
wordpress 同步插件实现
WORDPRESS插件开发 WP2WPQAQ插件是WordPress中根据xmlrpc编写的插件,实现两个WordPress站点之间的文章同步。目前插件已经实现了文章的同步和媒体文件的上传(上传到媒体库),但是类别(category)、标签(Tag)和自定义字段(custom_fields)的同步功能有没有被实现。该插件由于大部分的存在,并不能满足当前项目的具体需求,并且由于缺少WordPress对应的A
WordPress网站SEO优化教程2:插件优化
Wordpress 很棒,因为它提供了丰富的 API 和插件机制,让无数站长通过它快速开发出自己想要的功能,只需要安装一个简单的插件就可以为 wordpress 添加丰富的功能。但是,如果你的 网站 使用了大量的插件,那么随着你的 网站 功能的增加,加载速度会变得很慢。在这篇文章中,我将告诉你如何优化插件,使网站更符合SEO的要求。
jQuery 插件 --Cookie 插件 jquery.cookie.js
总结:jQuery插件--Cookie插件jquery.cookie.js(转)
微信小程序插件-开发教程
昨天(2018.3.13),微信小程序发布重大功能更新,支持插件的使用和开发。个人估计2个月内,插件优质服务的插件会雨后春笋般冒出来,在这个文章,我带大家,从0开始,学习如何开发和使用插件。文章共分3章:1、什么是微信小程序插件2、如何开发微信小程序插件3、如何使用第三方微信小程序插件备注:为了保存文字内容,我将“微信小程序插件”简称为“插件”。什么是微信小程序......
WordPress 插件推荐:使用的最佳 SEO 插件
HeadMETADescription - 根据您的播客内容为您的博客提供动态元描述。Wordpress 的最佳标签插件。它在导航用户方面做得很好。
Bootstrap3.0学习教程22:JS插件提示框
本文主要学习JavaScript插件警告框。完整教程可以查看:Bootstrap3.0 教程。
Bootstrap3.0学习教程24:JS插件折叠
本文主要学习JavaScript插件折叠。完整教程可以查看:Bootstrap3.0 教程 查看全部
文章自动采集插件(
SEO插件使用教程:WordPressSEObyYoast做好网站插件)

SEO插件教程:WordPressSEObyYoast
做好网站SEO一直是站长们的心愿。说起来容易简单,但说起来很难,因为要注意的地方太多了。如果你不小心被百度到了K,你不知道发生了什么。在这里,我推荐这个名为WordPressSEObyYoast的SEO优化插件,它可以稍微减轻你的优化负担。
Hexo 安装插件
下面介绍如何在Hexo中使用RSS和百度站点地图安装插件: 安装插件:npminstall
--save enable plugins:在根目录下的_config.yml文件中添加:plugins:-
百度站点地图生成器插件使用图文教程
原文的介绍是“生成百度SitemapXML文件。相当于网站被全球最大中文搜索引擎百度订阅,为你的网站带来潜在流量。据作者介绍,这个插件是专门为百度搜索引擎开发的,对百度搜索引擎非常友好。
云计算核心技术Docker教程:Docker安装及插件使用
插件作为 Docker 镜像分发,可以托管在 DockerHub 或私有注册表上。要安装插件,请使用 dockerplugininstall 命令,如有必要,该命令会从 DockerHub 或您的私有注册表中提取插件
Wordpress 插件 WpRobot 教程
wordpress可以说是英文网站的神器,wprobot是wordpress博客自动更新的最佳插件,可以从Amazon、eBay、Clickbank、Youtube、Yahoo Answers、Flickr、Yahoo News、Rss等自动获取。 文章 。注意不支持中文,而且不是免费的,169美元。提前说明,这篇文章不是给大家做垃圾回收的
WordPress3.01 常用插件使用记录
WordPress 有各种各样的插件,它们极大地扩展了 WordPress 的功能。但是面对这么多的插件,我们需要哪些,哪些不需要呢?以下是我安装插件的一些经验,仅供参考。
Sublime 常用插件及其功能
下面是sublime教程专栏,介绍sublime常用插件,希望对需要的朋友有所帮助!常用插件和ChineseLocalization插件,支持中文、日文、英文的无缝切换。转换到U
WordPress 博客教程 (七): WordPress 插件
WordPress 受到众多博主喜爱的原因之一是 WordPress 拥有大量优秀的插件,这让 WordPress 更加强大。这部分主要分为WordPress插件安装和WordPress插件推荐两个部分。
wordpress 同步插件实现
WORDPRESS插件开发 WP2WPQAQ插件是WordPress中根据xmlrpc编写的插件,实现两个WordPress站点之间的文章同步。目前插件已经实现了文章的同步和媒体文件的上传(上传到媒体库),但是类别(category)、标签(Tag)和自定义字段(custom_fields)的同步功能有没有被实现。该插件由于大部分的存在,并不能满足当前项目的具体需求,并且由于缺少WordPress对应的A
WordPress网站SEO优化教程2:插件优化
Wordpress 很棒,因为它提供了丰富的 API 和插件机制,让无数站长通过它快速开发出自己想要的功能,只需要安装一个简单的插件就可以为 wordpress 添加丰富的功能。但是,如果你的 网站 使用了大量的插件,那么随着你的 网站 功能的增加,加载速度会变得很慢。在这篇文章中,我将告诉你如何优化插件,使网站更符合SEO的要求。
jQuery 插件 --Cookie 插件 jquery.cookie.js
总结:jQuery插件--Cookie插件jquery.cookie.js(转)
微信小程序插件-开发教程
昨天(2018.3.13),微信小程序发布重大功能更新,支持插件的使用和开发。个人估计2个月内,插件优质服务的插件会雨后春笋般冒出来,在这个文章,我带大家,从0开始,学习如何开发和使用插件。文章共分3章:1、什么是微信小程序插件2、如何开发微信小程序插件3、如何使用第三方微信小程序插件备注:为了保存文字内容,我将“微信小程序插件”简称为“插件”。什么是微信小程序......
WordPress 插件推荐:使用的最佳 SEO 插件
HeadMETADescription - 根据您的播客内容为您的博客提供动态元描述。Wordpress 的最佳标签插件。它在导航用户方面做得很好。
Bootstrap3.0学习教程22:JS插件提示框
本文主要学习JavaScript插件警告框。完整教程可以查看:Bootstrap3.0 教程。
Bootstrap3.0学习教程24:JS插件折叠
本文主要学习JavaScript插件折叠。完整教程可以查看:Bootstrap3.0 教程
文章自动采集插件(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-10 17:22
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?
第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
<p>5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章在内容/标题前后插入关键词与内容一致关键词/随机插入图片/添加随机属性页面 查看全部
文章自动采集插件(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名)
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?

第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
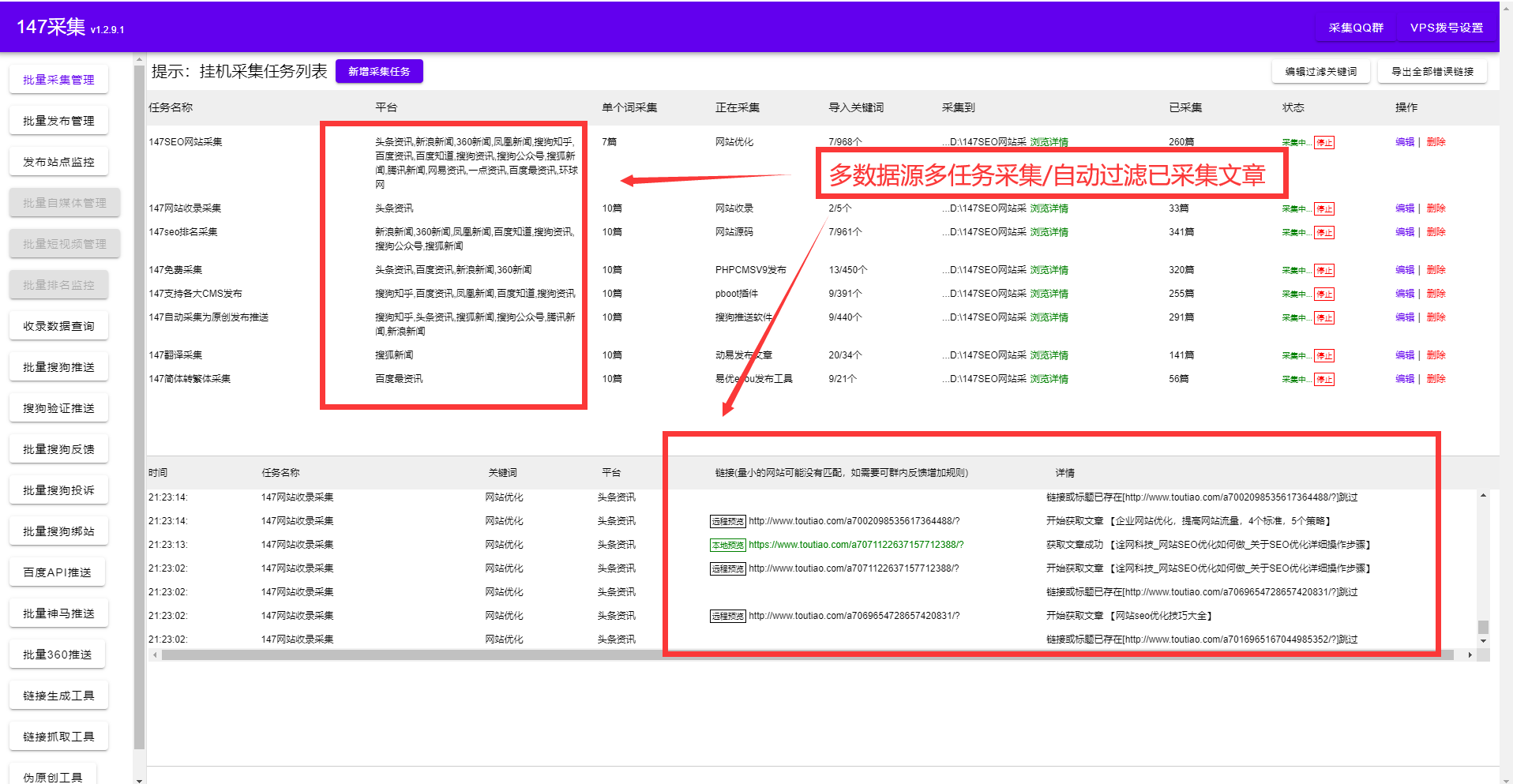
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
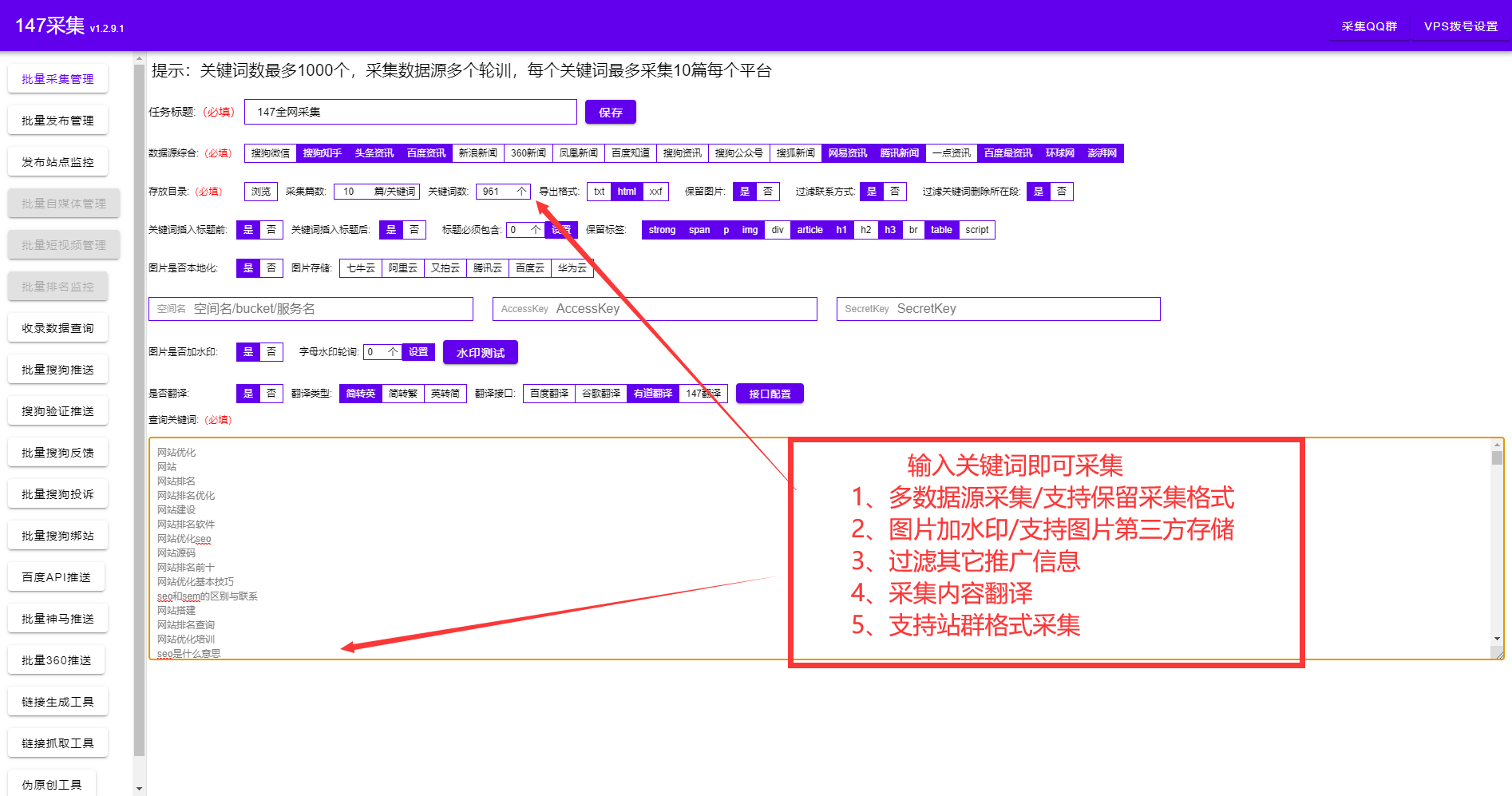
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
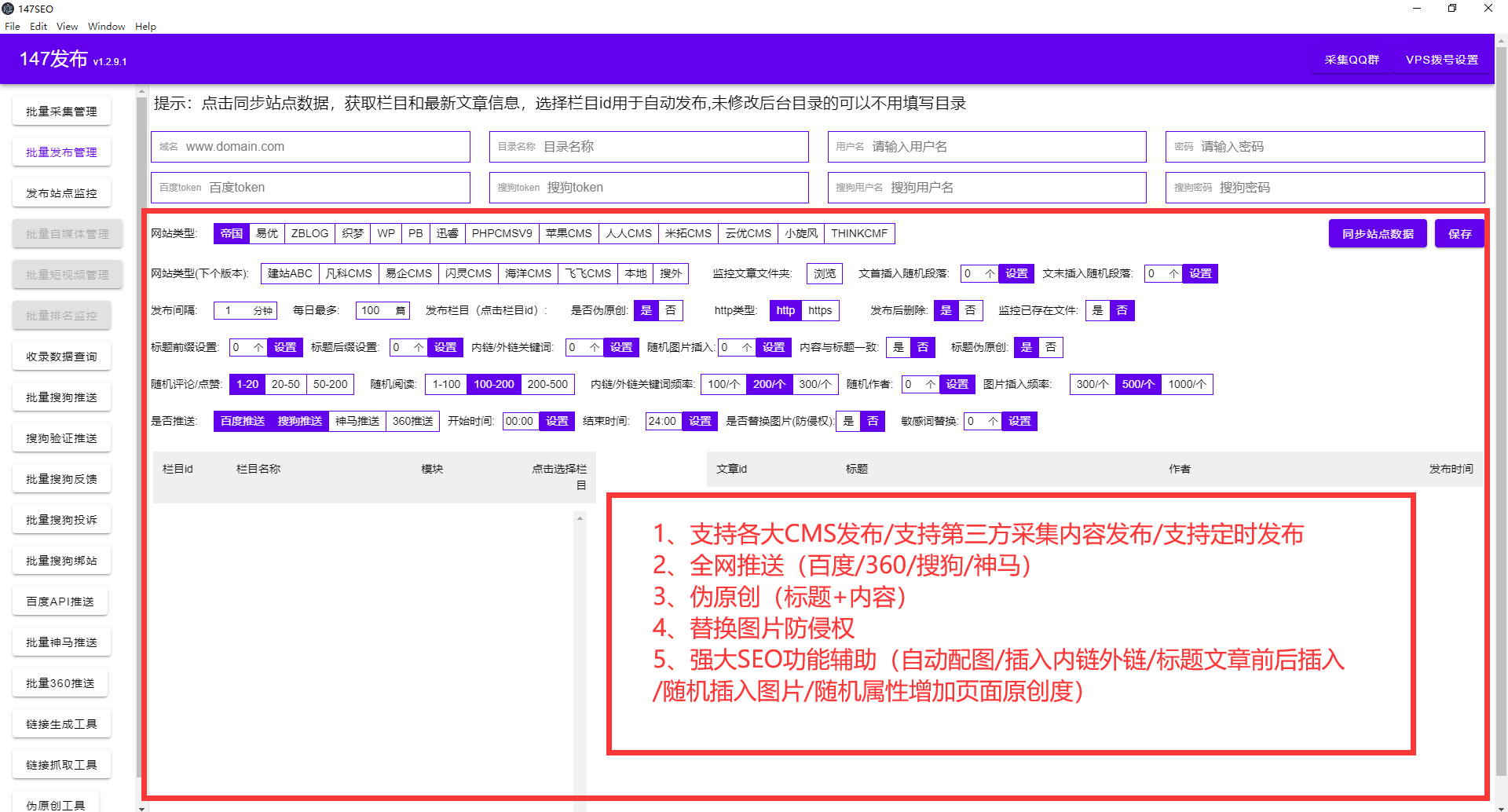
3、伪原创(标题+内容)
4、替换图片防止侵权
<p>5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章在内容/标题前后插入关键词与内容一致关键词/随机插入图片/添加随机属性页面
文章自动采集插件(WordPress站群的优缺点优点及主要特点是什么?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-04-10 13:13
WordPress站群也称为 WordPress Multisite,是 WordPress 的一项流行功能,可以在服务器上使用同一个 WordPress 创建和运行多个 网站。使我们的 WordPress网站 能够从一个操作页面管理多个不同的站点。
1、WordPress站群插件
WordPress站群 插件是我们可以在 wp站群SEO 中使用的工具。WordPress站群插件可用于批量采集、批量在线翻译、批量伪原创发布功能,帮助我们实现WordPress站群同步管理。支持全网发布各类cms(如图),不仅可以完成对WordPress站群的管理,还可以管理各类cms@ >。
WordPress站群插件具有SEO功能,不是通过大量的采集发布填充内容,而是支持文章title、content关键词优化。通过对采集的文本进行图像替换、图像水印、关键词密度/内链等处理,实现文章原创的高度。
2、什么是 WordPress站群?
WordPress站群 是一个一对一的功能,它允许我们从一个 WordPress 操作页面创建和运行多个 WordPress网站。它以前称为 WordPress 多用户或 WPMU。WordPress站群 并不新鲜。这些都是自 WordPress3.0 推出以来 WordPress 平台上的所有版本。
3、WordPress 的主要特点站群
在 WordPress站群 中,我们可以作为第一管理员控制整个网络。作为普通的网站管理员,我们可以控制网络上的一个网站。
作为管理员,我们可以创建帐户并设置我们自己的 WordPress 博客或 网站 用户可访问性。管理员可以新安装和主题插件,使它们也可用于网络上的 网站,并且可以为所有 网站 自定义主题。
4、WordPress站群 的优缺点
优点:我们可以管理来自不同域的不同网站子板的网站。如果我们在一个父级上运行由不同团队管理的多个,这很有用,例如具有特定国家/地区站点的电子商务商店,我们还可以为网络成员上的每个 网站 分配不同的管理。只需下载一次插件,我们就可以安装并激活它以及网络上所有 网站 的主题。我们还可以通过每个主安装来管理网络上所有 网站 的更新。
缺点:所有 网站 共享相同的网络资源,如果网络失败,它们就会失败。并非所有的 WordPress 插件都支持 站群networking。并非所有工具 Web 服务都具有多站点网络所需的支持。我们的各种服务或各种服务器要求可能无法使用一种以上的服务,并且可能需要在我们的范围内适应各种不同的服务条件。我们的计划或改变很舒服。
WordPress站群(WordPress多站点)的介绍和分享到此结束。站群具有很强的优势,但也有一些缺陷和弱点需要我们去关心和加强防范,WordPress站群插件是一个更方便我们管理我们的< @站群,通过可视化页面和即时信息反馈,让我们对站群整体信息和个别站点突发事件有明显的提示。方便我们管理。 查看全部
文章自动采集插件(WordPress站群的优缺点优点及主要特点是什么?(组图))
WordPress站群也称为 WordPress Multisite,是 WordPress 的一项流行功能,可以在服务器上使用同一个 WordPress 创建和运行多个 网站。使我们的 WordPress网站 能够从一个操作页面管理多个不同的站点。
1、WordPress站群插件
WordPress站群 插件是我们可以在 wp站群SEO 中使用的工具。WordPress站群插件可用于批量采集、批量在线翻译、批量伪原创发布功能,帮助我们实现WordPress站群同步管理。支持全网发布各类cms(如图),不仅可以完成对WordPress站群的管理,还可以管理各类cms@ >。
WordPress站群插件具有SEO功能,不是通过大量的采集发布填充内容,而是支持文章title、content关键词优化。通过对采集的文本进行图像替换、图像水印、关键词密度/内链等处理,实现文章原创的高度。
2、什么是 WordPress站群?
WordPress站群 是一个一对一的功能,它允许我们从一个 WordPress 操作页面创建和运行多个 WordPress网站。它以前称为 WordPress 多用户或 WPMU。WordPress站群 并不新鲜。这些都是自 WordPress3.0 推出以来 WordPress 平台上的所有版本。
3、WordPress 的主要特点站群
在 WordPress站群 中,我们可以作为第一管理员控制整个网络。作为普通的网站管理员,我们可以控制网络上的一个网站。
作为管理员,我们可以创建帐户并设置我们自己的 WordPress 博客或 网站 用户可访问性。管理员可以新安装和主题插件,使它们也可用于网络上的 网站,并且可以为所有 网站 自定义主题。
4、WordPress站群 的优缺点
优点:我们可以管理来自不同域的不同网站子板的网站。如果我们在一个父级上运行由不同团队管理的多个,这很有用,例如具有特定国家/地区站点的电子商务商店,我们还可以为网络成员上的每个 网站 分配不同的管理。只需下载一次插件,我们就可以安装并激活它以及网络上所有 网站 的主题。我们还可以通过每个主安装来管理网络上所有 网站 的更新。
缺点:所有 网站 共享相同的网络资源,如果网络失败,它们就会失败。并非所有的 WordPress 插件都支持 站群networking。并非所有工具 Web 服务都具有多站点网络所需的支持。我们的各种服务或各种服务器要求可能无法使用一种以上的服务,并且可能需要在我们的范围内适应各种不同的服务条件。我们的计划或改变很舒服。
WordPress站群(WordPress多站点)的介绍和分享到此结束。站群具有很强的优势,但也有一些缺陷和弱点需要我们去关心和加强防范,WordPress站群插件是一个更方便我们管理我们的< @站群,通过可视化页面和即时信息反馈,让我们对站群整体信息和个别站点突发事件有明显的提示。方便我们管理。
文章自动采集插件(怎么用海洋CMS插件让网站快速收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-09 13:39
如何使用Oceancms插件对网站快速收录和关键词进行排名?我们应该如何管理和维护我们的网站?今天给大家分享一个海洋cms插件工具,可以批量管理网站。不管你有成百上千个不同的海洋cms网站还是其他网站都可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、Oceancms 插件发布
1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Oceancms、Cyclone、站群、PB、Apple、Mito、搜外等各大cms,可以管理和发布的工具同时分批)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、Oceancms插件批量发布设置 - 覆盖 SEO 功能
这个Oceancms还配备了很多SEO功能,不仅可以通过Oceancms插件实现采集伪原创发布,还具备很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词的密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、海洋cms插件采集
1、根据关键词采集文章,用海洋cms填充内容。(Oceancms 插件还配置了关键词采集 功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、海洋cms插件采集
1、查看采集平台
2、工作中采集
3、有采集
4、采集内容视图
查看5、采集之后的内容
前段时间相信很多seoer都听过“内容为王,外链为王”的说法,但是随着外链的作用越来越小,很多seoer更加关注网站内链, 网站内链是通过网站内链投票的形式。可以使用内链聚合某个页面的权重来增加关键词和页面的权重,也可以使用内链来增加关键词和页面的权重。链式布局增加全站优质的内链框架,那么博主就为大家介绍网站的内链如何做好?如何在 Ocean cms 插件的帮助下优化 网站。
网站内链对于整个网站的意义是什么?
网站内部链接可以帮助蜘蛛爬行。在我看来,网站首页对于整个网站的权重一般都比较高。同样,蜘蛛的数量也应该是比较高的页面。完善的内链可以让蜘蛛爬到网站的页面更深,蜘蛛爬到的页面也会帮助网站的收录。
之前一直告诉大家网站收录是排名网站的依据,这里先介绍一下页面收录的流程:网站页面存在且可以正常打开→蜘蛛爬取页面→表单索引→发布快照。
如何做好网站内链布局?
首先要明确网站收录,大量内页必须由收录添加到首页,个别站长操作网站获取全站流量和排名需要使用扩词工具获取长尾词,将获取的长尾词排列在网站内容页面。在这种情况下,需要完成网站内链的构建,才能得到网站页面被爬取和收录,我们需要做什么呢?
1、网站首页权重高于内页。在 网站 主页上,需要布置一些新闻或 文章 模块,以帮助蜘蛛爬行。
2、网站内容页和栏目页需要保持到首页的直接链接,可以通过面包屑导航解决,例如:首页-栏目页-内容页。
3、做好网站地图的制作。网站地图分为两种格式:xml和html。建议制作xml图,提交给站长平台。
4、在网站的内容页面的编写中,文章中提到的内容可以链接到本站的产品或栏目页面,也可以在提高用户的前提下添加体验蜘蛛爬取页面。
网站内链的布局是为了提升用户体验和操作习惯,同时也增加了蜘蛛的爬取。不同的网站在进行网站的内链布局时或多或少会有一些差异。文末想告诉大家,网站的内部链式布局不仅仅是为了提高爬虫,现在搜索引擎越来越重视用户体验,我们需要做更好的工作网站内部链接,改善用户需求和操作行为。
很多时候在网站SEO的过程中,由于一些不当操作,网站被搜索引擎惩罚,导致网站的排名和网站的实力下降. 有经验的优化者或许一眼就能看出网站被降级的原因,并及时做出调整。但是对于新手优化器来说,可能会有点困难。那么今天,博主就来和大家聊聊如何找到网站被降级的原因。
如何找出 网站 被降级的原因?
1、网站服务器稳定吗?
网站服务器的稳定性是决定网站能否正常运行的重要因素。一些网络推广公司为了省钱,选择使用不稳定且便宜的服务器。不稳定,打不开,影响蜘蛛正常访问,从而导致网站被降级。
2、网站关键词,标题和描述是否频繁修改
关键词、网站 的标题和描述一旦确定,就不应轻易修改。作为网站优化器,需要明确网站关键词及其发展方向。另外,关键词的布局也要掌握好。优化周期过长,效果不佳,频繁替换关键词也会被百度惩罚。
网站降级
3、网站 的内容
优质的原创内容一定会受到搜索引擎的青睐。我们不仅要更新网站内容,还要更新优质内容。再问一个不经常更新的网站。会受到搜索引擎的喜爱吗?反之,也会受到搜索引擎的惩罚。
4、链接
友情链接对于 网站 来说非常重要。如果本站添加的链接有权删除,我们必须及时删除链接,否则,我们的网站将受到牵连。所以,一定要定期检查你的网站朋友链,保证网站可以一直保持良好的状态。
以上就是小编为大家带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧! 查看全部
文章自动采集插件(怎么用海洋CMS插件让网站快速收录以及关键词排名?)
如何使用Oceancms插件对网站快速收录和关键词进行排名?我们应该如何管理和维护我们的网站?今天给大家分享一个海洋cms插件工具,可以批量管理网站。不管你有成百上千个不同的海洋cms网站还是其他网站都可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、Oceancms 插件发布
1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Oceancms、Cyclone、站群、PB、Apple、Mito、搜外等各大cms,可以管理和发布的工具同时分批)

2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、Oceancms插件批量发布设置 - 覆盖 SEO 功能
这个Oceancms还配备了很多SEO功能,不仅可以通过Oceancms插件实现采集伪原创发布,还具备很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词的密度)

3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、海洋cms插件采集
1、根据关键词采集文章,用海洋cms填充内容。(Oceancms 插件还配置了关键词采集 功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)

4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、海洋cms插件采集
1、查看采集平台
2、工作中采集

3、有采集
4、采集内容视图
查看5、采集之后的内容
前段时间相信很多seoer都听过“内容为王,外链为王”的说法,但是随着外链的作用越来越小,很多seoer更加关注网站内链, 网站内链是通过网站内链投票的形式。可以使用内链聚合某个页面的权重来增加关键词和页面的权重,也可以使用内链来增加关键词和页面的权重。链式布局增加全站优质的内链框架,那么博主就为大家介绍网站的内链如何做好?如何在 Ocean cms 插件的帮助下优化 网站。
网站内链对于整个网站的意义是什么?
网站内部链接可以帮助蜘蛛爬行。在我看来,网站首页对于整个网站的权重一般都比较高。同样,蜘蛛的数量也应该是比较高的页面。完善的内链可以让蜘蛛爬到网站的页面更深,蜘蛛爬到的页面也会帮助网站的收录。
之前一直告诉大家网站收录是排名网站的依据,这里先介绍一下页面收录的流程:网站页面存在且可以正常打开→蜘蛛爬取页面→表单索引→发布快照。
如何做好网站内链布局?
首先要明确网站收录,大量内页必须由收录添加到首页,个别站长操作网站获取全站流量和排名需要使用扩词工具获取长尾词,将获取的长尾词排列在网站内容页面。在这种情况下,需要完成网站内链的构建,才能得到网站页面被爬取和收录,我们需要做什么呢?
1、网站首页权重高于内页。在 网站 主页上,需要布置一些新闻或 文章 模块,以帮助蜘蛛爬行。
2、网站内容页和栏目页需要保持到首页的直接链接,可以通过面包屑导航解决,例如:首页-栏目页-内容页。
3、做好网站地图的制作。网站地图分为两种格式:xml和html。建议制作xml图,提交给站长平台。
4、在网站的内容页面的编写中,文章中提到的内容可以链接到本站的产品或栏目页面,也可以在提高用户的前提下添加体验蜘蛛爬取页面。
网站内链的布局是为了提升用户体验和操作习惯,同时也增加了蜘蛛的爬取。不同的网站在进行网站的内链布局时或多或少会有一些差异。文末想告诉大家,网站的内部链式布局不仅仅是为了提高爬虫,现在搜索引擎越来越重视用户体验,我们需要做更好的工作网站内部链接,改善用户需求和操作行为。

很多时候在网站SEO的过程中,由于一些不当操作,网站被搜索引擎惩罚,导致网站的排名和网站的实力下降. 有经验的优化者或许一眼就能看出网站被降级的原因,并及时做出调整。但是对于新手优化器来说,可能会有点困难。那么今天,博主就来和大家聊聊如何找到网站被降级的原因。
如何找出 网站 被降级的原因?
1、网站服务器稳定吗?
网站服务器的稳定性是决定网站能否正常运行的重要因素。一些网络推广公司为了省钱,选择使用不稳定且便宜的服务器。不稳定,打不开,影响蜘蛛正常访问,从而导致网站被降级。
2、网站关键词,标题和描述是否频繁修改
关键词、网站 的标题和描述一旦确定,就不应轻易修改。作为网站优化器,需要明确网站关键词及其发展方向。另外,关键词的布局也要掌握好。优化周期过长,效果不佳,频繁替换关键词也会被百度惩罚。
网站降级
3、网站 的内容
优质的原创内容一定会受到搜索引擎的青睐。我们不仅要更新网站内容,还要更新优质内容。再问一个不经常更新的网站。会受到搜索引擎的喜爱吗?反之,也会受到搜索引擎的惩罚。
4、链接
友情链接对于 网站 来说非常重要。如果本站添加的链接有权删除,我们必须及时删除链接,否则,我们的网站将受到牵连。所以,一定要定期检查你的网站朋友链,保证网站可以一直保持良好的状态。

以上就是小编为大家带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧!
文章自动采集插件(网站怎么用discuz插件打造高质量内容让网站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-08 21:10
网站如何使用discuz插件制作高质量的内容来网站快速收录和关键词排名”众所周知,在网站@的优化>、搜索引擎的算法是随着科技的发展,不断的更新和调整的。每次更新搜索引擎,都会对某些网站进行处罚,甚至会牵连一些不违规的网站。首先,我们要避免遭受搜索引擎惩罚,才能更好地优化我们的网站。
一、自动更新网站内容
众所周知,网站优化是对网站内容的长期持续更新。网站管理员必须确保定期定期更新 网站 内容。网站能够刺穿荆棘。在搜索引擎算法调整的过程中,网站的内容优化会让网站的基础更加稳固,这会阻止搜索引擎更新针对你的网站。
我们可以通过这个discuz插件实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单,无需学习更多专业技术。只需几个简单的步骤即可轻松采集内容数据,用户只需在discuz插件上进行简单的设置。discuz插件会根据用户设置的关键词准确采集文章,从而保证行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他discuz插件相比,这个discuz插件基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词即可实现采集 (discuz 插件还配备了 关键词采集 功能)。全程自动挂机! 查看全部
文章自动采集插件(网站怎么用discuz插件打造高质量内容让网站快速收录以及关键词排名)
网站如何使用discuz插件制作高质量的内容来网站快速收录和关键词排名”众所周知,在网站@的优化>、搜索引擎的算法是随着科技的发展,不断的更新和调整的。每次更新搜索引擎,都会对某些网站进行处罚,甚至会牵连一些不违规的网站。首先,我们要避免遭受搜索引擎惩罚,才能更好地优化我们的网站。
一、自动更新网站内容
众所周知,网站优化是对网站内容的长期持续更新。网站管理员必须确保定期定期更新 网站 内容。网站能够刺穿荆棘。在搜索引擎算法调整的过程中,网站的内容优化会让网站的基础更加稳固,这会阻止搜索引擎更新针对你的网站。
我们可以通过这个discuz插件实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单,无需学习更多专业技术。只需几个简单的步骤即可轻松采集内容数据,用户只需在discuz插件上进行简单的设置。discuz插件会根据用户设置的关键词准确采集文章,从而保证行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他discuz插件相比,这个discuz插件基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词即可实现采集 (discuz 插件还配备了 关键词采集 功能)。全程自动挂机!
收集了一些Chrome插件神器,助你快速成为老司机
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-05-24 21:31
点击加入:
商务合作:请加微信(QQ):2230304070
技术交流微信群
我们在学习中单枪匹马,还不如一次短短的交流,你可以在别人吸取各种学习经验,学习方法以及学习技巧,所以,学习与交流少不了一个圈子,提升你的学习技能,请点击加技术群:PHP自学中心交流群 <br />记得备注你会的一种PHP框架,比如TP<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;"><br style="max-width: 100%;box-sizing: border-box !important;word-wrap: break-word !important;overflow-wrap: break-word !important;" />
视频教程分享
关注本公众号:PHP自学中心,回复相应的关键词,领取以下视频教程
Linux编程Shell从入门到精通视频教程(完整版)
公众号里回复:shell0915
PHP消息队列实现及应用
公众号里回复:20190902
<br />
laravel5.4开发电商实战项目
公众号里回复:20190703
ThinkPHP5.0入门
公众号里回复:06292019
<br />
php基于tp5.1开发微信公众号
公众号里回复:200108</p>
<br />
精选文章正文
刚开始开发项目的时候,我一直都在用火狐,因为它有一个fireBug插件,特别好用(目前已不支持),也不知道什么时候,就一直用起来Chrome浏览器了,可能是因为它有强大的插件作为后盾吧。开发了这么多年,也用过了很多Chrome插件。
下面收集了一些,比较好用,熟练使用这些插件,会对你的开发效率大大提高,逼格瞬间上升一个档次,助你快速成为开发老司机。
1、markdown-here
可以在网页版QQ邮箱、Gmail、163等邮箱里面,使用mardown格式进行书写,然后一键转换为富文本。
2、chrono
可以非常方便的嗅探识别网页中的资源, 然后一键下载所有资源。
3、Secure Shell App
Windows并没有自带ssh软件,有了Secure Shell App,可以让你无需下载putty或xshell,就能在chrome直接实现ssh登录服务器了。
4、Momentum
装逼利器,教你如何优雅的使用Chrome,新打开一个Tab的时候再也不是一片空白,每天一副精美图片,给你们看下我今天的桌面感受下。
5 OneTab
强烈推荐,使用场景是这样的,我们使用Chrome经常会一次打开好多tab,很多是会用到的,又不舍得关,内存又耗着,这个时候点击下OneTab,直接把所有tab回收,然后每天的历史都给你记录着,接着你可以一键还原某一天的tab,真乃为Chrome而生。
6、Tampermonkey
可以帮你安装脚本,从而免费查看VIP视频,清除各种网页广告,在豆瓣影评页面显示电影资源的下载地址。
7、Loom
可以一键录制浏览器的单个标签页,录制完成后自动生成在线网页,进行视频播放,可以下载刚刚录制的视频,也可以为刚刚生成的在线视频设置密码。
8、Page Ruler
这个工具设计师必备,可以直接查看网页一些图片的详细像素大小、具体位置等,非常实用。
9、Chrome Cleaner Pro
Chrome经过最近几年的发展,强力的扩展越来越多,但软件会变慢。让Chrome变快的最简单方式就是清理垃圾,而Chrome Cleaner Pro走的是一键清理的路子。
10、speedtest
在浏览器中直接测网速。
11、Alexa Traffic Rank Alexa
Alexa排名是指网站的世界排名,非常有权威。直接主流网站或博客绝对是有Alexa排名的,我们在浏览博客或者网站的时候就可以通过Alexa排名知晓该网站的流行程度,适用于经常看博客的人,装了这个插件一键查看网站排名,截个我个人博客stormzhang博客精华的排名给大家感受下。
12、Enhanced Github
可以显示GitHub整个仓库和单个文件的大小,帮你下载Github优秀项目中最核心的代码文件进行学习,而不是下载整个仓库作为藏品。
13、Octotree
这个可就屌了,当我们在浏览别人的开源代码时,还要clone下来一个文件查看,而有了这个插件,你可以直接在Chrome侧边栏向打开文件夹一样的查看别人的项目,简直了。给大家看下查看我的开源项目的正确方式。
14、JSONView
一般我们在对接api接口的时候,一般都是默认返回json格式,想要查看具体返回哪些内容的时候通过Chrome查看全乱的,而且中文编码也不对,而有了这个插件就不一样了,自动跟你排列出Json数据,不管返回数据有多复杂,你都可以很直观的了解他的数据格式,简直开发者必备。
15、Postman
开发者在调试网络时候,Linux平台一般常用curl这种命令行工具,而如果你不会使用或者不习惯命令行,那Postman是你的不二人选,可以直接发送一个请求,自定义params、header,查看response状态等。
16、Dribbble New Tab
大名鼎鼎的Dribble,堪称设计师必备,而装了这个插件,可以让你打开空白tab的时间第一时间把每日精选作品展现出来,视觉的享受,强烈推荐给设计师们,装了这个插件我的桌面是这样的。(这个插件跟Momentum同时只能使用一个)
17、Smallpdf
多份pdf在线合并,pdf在线编辑。
18、Astro Bot
刷题必备,打开新标签页时,展示一道与程序相关的问题或相关新闻。
19、Restlet Client
开发实用工具, 支持一键导入Postman等API测试工具的测试用例。
20、WhatFont
功能非常单一的小工具,帮你查看网页上的字体属性。
21、Web Server for Chrome 查看全部
收集了一些Chrome插件神器,助你快速成为老司机
点击加入:
商务合作:请加微信(QQ):2230304070
技术交流微信群
我们在学习中单枪匹马,还不如一次短短的交流,你可以在别人吸取各种学习经验,学习方法以及学习技巧,所以,学习与交流少不了一个圈子,提升你的学习技能,请点击加技术群:PHP自学中心交流群 <br />记得备注你会的一种PHP框架,比如TP<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">
视频教程分享
关注本公众号:PHP自学中心,回复相应的关键词,领取以下视频教程
Linux编程Shell从入门到精通视频教程(完整版)
公众号里回复:shell0915
PHP消息队列实现及应用
公众号里回复:20190902
<br />
laravel5.4开发电商实战项目
公众号里回复:20190703
ThinkPHP5.0入门
公众号里回复:06292019
<br />
php基于tp5.1开发微信公众号
公众号里回复:200108</p>
<br />
精选文章正文
刚开始开发项目的时候,我一直都在用火狐,因为它有一个fireBug插件,特别好用(目前已不支持),也不知道什么时候,就一直用起来Chrome浏览器了,可能是因为它有强大的插件作为后盾吧。开发了这么多年,也用过了很多Chrome插件。
下面收集了一些,比较好用,熟练使用这些插件,会对你的开发效率大大提高,逼格瞬间上升一个档次,助你快速成为开发老司机。
1、markdown-here
可以在网页版QQ邮箱、Gmail、163等邮箱里面,使用mardown格式进行书写,然后一键转换为富文本。
2、chrono
可以非常方便的嗅探识别网页中的资源, 然后一键下载所有资源。
3、Secure Shell App
Windows并没有自带ssh软件,有了Secure Shell App,可以让你无需下载putty或xshell,就能在chrome直接实现ssh登录服务器了。
4、Momentum
装逼利器,教你如何优雅的使用Chrome,新打开一个Tab的时候再也不是一片空白,每天一副精美图片,给你们看下我今天的桌面感受下。
5 OneTab
强烈推荐,使用场景是这样的,我们使用Chrome经常会一次打开好多tab,很多是会用到的,又不舍得关,内存又耗着,这个时候点击下OneTab,直接把所有tab回收,然后每天的历史都给你记录着,接着你可以一键还原某一天的tab,真乃为Chrome而生。
6、Tampermonkey
可以帮你安装脚本,从而免费查看VIP视频,清除各种网页广告,在豆瓣影评页面显示电影资源的下载地址。
7、Loom
可以一键录制浏览器的单个标签页,录制完成后自动生成在线网页,进行视频播放,可以下载刚刚录制的视频,也可以为刚刚生成的在线视频设置密码。
8、Page Ruler
这个工具设计师必备,可以直接查看网页一些图片的详细像素大小、具体位置等,非常实用。
9、Chrome Cleaner Pro
Chrome经过最近几年的发展,强力的扩展越来越多,但软件会变慢。让Chrome变快的最简单方式就是清理垃圾,而Chrome Cleaner Pro走的是一键清理的路子。
10、speedtest
在浏览器中直接测网速。
11、Alexa Traffic Rank Alexa
Alexa排名是指网站的世界排名,非常有权威。直接主流网站或博客绝对是有Alexa排名的,我们在浏览博客或者网站的时候就可以通过Alexa排名知晓该网站的流行程度,适用于经常看博客的人,装了这个插件一键查看网站排名,截个我个人博客stormzhang博客精华的排名给大家感受下。
12、Enhanced Github
可以显示GitHub整个仓库和单个文件的大小,帮你下载Github优秀项目中最核心的代码文件进行学习,而不是下载整个仓库作为藏品。
13、Octotree
这个可就屌了,当我们在浏览别人的开源代码时,还要clone下来一个文件查看,而有了这个插件,你可以直接在Chrome侧边栏向打开文件夹一样的查看别人的项目,简直了。给大家看下查看我的开源项目的正确方式。
14、JSONView
一般我们在对接api接口的时候,一般都是默认返回json格式,想要查看具体返回哪些内容的时候通过Chrome查看全乱的,而且中文编码也不对,而有了这个插件就不一样了,自动跟你排列出Json数据,不管返回数据有多复杂,你都可以很直观的了解他的数据格式,简直开发者必备。
15、Postman
开发者在调试网络时候,Linux平台一般常用curl这种命令行工具,而如果你不会使用或者不习惯命令行,那Postman是你的不二人选,可以直接发送一个请求,自定义params、header,查看response状态等。
16、Dribbble New Tab
大名鼎鼎的Dribble,堪称设计师必备,而装了这个插件,可以让你打开空白tab的时间第一时间把每日精选作品展现出来,视觉的享受,强烈推荐给设计师们,装了这个插件我的桌面是这样的。(这个插件跟Momentum同时只能使用一个)
17、Smallpdf
多份pdf在线合并,pdf在线编辑。
18、Astro Bot
刷题必备,打开新标签页时,展示一道与程序相关的问题或相关新闻。
19、Restlet Client
开发实用工具, 支持一键导入Postman等API测试工具的测试用例。
20、WhatFont
功能非常单一的小工具,帮你查看网页上的字体属性。
21、Web Server for Chrome
埋点自动收集方案-路由依赖分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-05-24 21:18
1.一个项目总共有多少组件?每个页面又有多少组件构成?
2.有哪些组件是公共组件,它们分别被哪些页面引用?
对于这两个问题,我们先思考一会。sleep……
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
通过前一篇文章,想必大家对埋点自动收集方案有了宏观且全面的了解。在这里再简单概述下:
埋点自动收集方案是基于jsdoc对注释信息的搜集能力,通过给路由页面中所有埋点增加注释的方式,在编译时建立起页面和埋点信息的对应关系。
点击查看
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
//Index.vue 首页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Home.vue 个人主页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Card.vue 商品卡片组件<br />goDetail(item) {<br /> /**<br /> * @mylog 商品卡片点击<br /> */<br /> this.$log('card-click') // 埋点发送<br />}<br />
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
//a.ts<br />import B from './b.ts'<br />import getCookie from '@/libs/cookie.ts'<br /><br />//c.ts<br />const C = require('./b.ts')<br /><br />//b.ts<br />div {<br /> background: url('./assets/icon.png') no-repeat;<br />}<br />import './style.css'<br />// c.vue<br />import Vue from Vue<br />import Card from '@/component/Card.vue'<br />
这里给出三种依赖分析的思路:
1 递归解析
从项目的路由配置文件开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
2 借助webpack工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
//done是compiler的钩子,在完成一次编译结束后的会执行<br />compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{<br /> fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {<br /> if (err) {<br /> throw err;<br /> }<br /> })<br /> cb()<br />})<br />
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
3 在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
先奉上流程图
1 初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
2 收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
apply(compiler) {<br /> compiler.hooks.normalModuleFactory.tap(<br /> "demoPlugin",<br /> nmf => {<br /> nmf.hooks.afterResolve.tapAsync(<br /> "demoPlugin",<br /> (result, callback) => {<br /> const { resourceResolveData } = result;<br /> // 当前文件的路径<br /> let path = resourceResolveData.path; <br /> // 父级文件路径<br /> let fatherPath = resourceResolveData.context.issuer; <br /> callback(null,result)<br /> }<br /> );<br /> }<br /> )<br />}<br />
3 建立依赖树
根据上一步获取的引用关系,生成依赖树。
// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue<br />if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){ <br /> if(fatherPath && fatherPath != path){ // 父子路径相同的排除<br /> if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){ <br /> // 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除<br /> let sonObj = {};<br /> sonObj.type = 'module';<br /> sonObj.path = path;<br /> sonObj.deps = []<br /> // 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。<br /> sonObj = copyAheadDep(this.dependenciesArray,sonObj);<br /> let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);<br /> this.dependenciesArray = obj.arr;<br /> if(!obj.fileExist){<br /> let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br /> }<br />} else if(!this.dependenciesArray.some(it => it.path == path)) {<br />// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件<br /> let entryObj = {type:'entry',path:path,deps:[]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br />}<br />
那么这时生成的依赖树如下:
4 解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{<br /> this.handleCompilerDone()<br /> cb()<br />})<br />
// ast解析路由文件<br />handleCompilerDone(){<br /> if(this.dependenciesArray.length){<br /> let tempRouteDeps = {};<br /> // routePaths是项目的路由文件数组<br /> for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);<br /> // 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖<br /> this.dependenciesArray = <br /> getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);<br /> }<br />}<br />
通过这一步ast解析,可以得到如下路由信息:
[<br /> {<br /> "name": "index",<br /> "route": "/index",<br /> "title": "首页",<br /> "components": ["../view/newCycle/index.vue"]<br /> },<br /> {<br /> "name": "home",<br /> "route": "/home",<br /> "title": "个人主页",<br /> "components": ["../view/newCycle/home.vue"]<br /> }<br />]<br />
5 对依赖树和路由信息进行整合分析
// 将路由页面的所有依赖组件deps,都存放在路由信息的components数组中<br />const getEndPathComponentsArr = function(routeDeps,dependenciesArray) {<br /> for(let i = 0; i {<br /> routeDeps = routeDeps.map(routeObj=>{<br /> if(routeObj && routeObj.components){<br /> let relativePath = <br /> routeObj.components[0].slice(routeObj.components[0].indexOf('/')+1);<br /> if(page.path.includes(relativePath.split('/').join(path.sep))){<br /> // 铺平依赖树的层级<br /> routeObj = flapAllComponents(routeObj,page);<br /> // 去重操作<br /> routeObj.components = dedupe(routeObj.components);<br /> }<br /> }<br /> return routeObj;<br /> })<br /> })<br /> }<br /> return routeDeps;<br />}<br />//建立一个map数据结构,以每个组件为key,以对应的路由信息为value<br />// {<br />// 'path1' => Set { '/index' },<br />// 'path2' => Set { '/index', '/home' },<br />// 'path3' => Set { '/home' }<br />// }<br />const convertDeps = function(deps) {<br /> let map = new Map();<br /> ......<br /> return map;<br />}<br />
整合分析后依赖关系如下:
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index"],<br /> // 映射中只有和首页的映射<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
6 修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
6.1 unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
//webpack/lib/WebpackOptionsDefaulter.js<br />this.set("resolveLoader.unsafeCache", true);<br />//这是webpack初始化配置参数时对unsafeCache的默认设置<br /><br />//enhanced-resolve/lib/Resolverfatory.js<br />if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br />} else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br />}<br />//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。<br />//缓存的工作是由UnsafeCachePlugin完成,代码如下:<br />//enhanced-resolve/lib/UnsafeCachePlugin.js<br />apply(resolver) {<br /> const target = resolver.ensureHook(this.target);<br /> resolver<br /> .getHook(this.source)<br /> .tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {<br /> if (!this.filterPredicate(request)) return callback();<br /> const cacheId = getCacheId(request, this.withContext);<br /> // !!划重点,当缓存中存在解析过的文件结果,直接callback<br /> const cacheEntry = this.cache[cacheId];<br /> if (cacheEntry) {<br /> return callback(null, cacheEntry);<br /> }<br /> resolver.doResolve(<br /> target,<br /> request,<br /> null,<br /> resolveContext,<br /> (err, result) => {<br /> if (err) return callback(err);<br /> if (result) return callback(null, (this.cache[cacheId] = result));<br /> callback();<br /> }<br /> );<br /> });<br />}<br />
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
6.2 这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
//enhanced-resolve/lib/Resolverfatory.js<br />exports.createResolver = function(options) {<br /> ......<br /> let unsafeCache = options.unsafeCache || false;<br /> if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br /> // 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,<br /> //执行结束后的目标事件(target)是new-resolve。<br /> //而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。<br /> } else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br /> }<br /> ...... // 各种plugin<br /> plugins.push(new ResultPlugin(resolver.hooks.resolved));<br /><br /> plugins.forEach(plugin => {<br /> plugin.apply(resolver);<br /> });<br /><br /> return resolver;<br />}<br />
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
6.3 解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
//package.json<br />"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"<br /><br />//vue.config.js<br />chainWebpack(config) {<br /> // 这一步解决webpack对组件缓存,影响最终映射关系的处理<br /> config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'<br />}<br />
7 最终依赖关系
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index",<br /> "home&_&个人主页&_&home"],<br /> // Card组件与多个页面有映射关系<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
module.exports = {<br /> cache: {<br /> // 1. Set cache type to filesystem<br /> type: 'filesystem',<br /><br /> buildDependencies: {<br /> // 2. Add your config as buildDependency to get cache invalidation on config change<br /> config: [__filename]<br /><br /> // 3. If you have other things the build depends on you can add them here<br /> // Note that webpack, loaders and all modules referenced from your config are automatically added<br /> }<br /> }<br />};<br />
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~
查看全部
埋点自动收集方案-路由依赖分析
1.一个项目总共有多少组件?每个页面又有多少组件构成?
2.有哪些组件是公共组件,它们分别被哪些页面引用?
对于这两个问题,我们先思考一会。sleep……
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
通过前一篇文章,想必大家对埋点自动收集方案有了宏观且全面的了解。在这里再简单概述下:
埋点自动收集方案是基于jsdoc对注释信息的搜集能力,通过给路由页面中所有埋点增加注释的方式,在编译时建立起页面和埋点信息的对应关系。
点击查看
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
//Index.vue 首页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Home.vue 个人主页<br />import Card from './common/Card.vue' //依赖商品卡片组件<br /><br />//Card.vue 商品卡片组件<br />goDetail(item) {<br /> /**<br /> * @mylog 商品卡片点击<br /> */<br /> this.$log('card-click') // 埋点发送<br />}<br />
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
//a.ts<br />import B from './b.ts'<br />import getCookie from '@/libs/cookie.ts'<br /><br />//c.ts<br />const C = require('./b.ts')<br /><br />//b.ts<br />div {<br /> background: url('./assets/icon.png') no-repeat;<br />}<br />import './style.css'<br />// c.vue<br />import Vue from Vue<br />import Card from '@/component/Card.vue'<br />
这里给出三种依赖分析的思路:
1 递归解析
从项目的路由配置文件开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
2 借助webpack工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
//done是compiler的钩子,在完成一次编译结束后的会执行<br />compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{<br /> fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {<br /> if (err) {<br /> throw err;<br /> }<br /> })<br /> cb()<br />})<br />
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
3 在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
先奉上流程图
1 初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
2 收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
apply(compiler) {<br /> compiler.hooks.normalModuleFactory.tap(<br /> "demoPlugin",<br /> nmf => {<br /> nmf.hooks.afterResolve.tapAsync(<br /> "demoPlugin",<br /> (result, callback) => {<br /> const { resourceResolveData } = result;<br /> // 当前文件的路径<br /> let path = resourceResolveData.path; <br /> // 父级文件路径<br /> let fatherPath = resourceResolveData.context.issuer; <br /> callback(null,result)<br /> }<br /> );<br /> }<br /> )<br />}<br />
3 建立依赖树
根据上一步获取的引用关系,生成依赖树。
// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue<br />if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){ <br /> if(fatherPath && fatherPath != path){ // 父子路径相同的排除<br /> if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){ <br /> // 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除<br /> let sonObj = {};<br /> sonObj.type = 'module';<br /> sonObj.path = path;<br /> sonObj.deps = []<br /> // 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。<br /> sonObj = copyAheadDep(this.dependenciesArray,sonObj);<br /> let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);<br /> this.dependenciesArray = obj.arr;<br /> if(!obj.fileExist){<br /> let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br /> }<br />} else if(!this.dependenciesArray.some(it => it.path == path)) {<br />// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件<br /> let entryObj = {type:'entry',path:path,deps:[]};<br /> this.dependenciesArray.push(entryObj);<br /> }<br />}<br />
那么这时生成的依赖树如下:
4 解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{<br /> this.handleCompilerDone()<br /> cb()<br />})<br />
// ast解析路由文件<br />handleCompilerDone(){<br /> if(this.dependenciesArray.length){<br /> let tempRouteDeps = {};<br /> // routePaths是项目的路由文件数组<br /> for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);<br /> // 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖<br /> this.dependenciesArray = <br /> getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);<br /> }<br />}<br />
通过这一步ast解析,可以得到如下路由信息:
[<br /> {<br /> "name": "index",<br /> "route": "/index",<br /> "title": "首页",<br /> "components": ["../view/newCycle/index.vue"]<br /> },<br /> {<br /> "name": "home",<br /> "route": "/home",<br /> "title": "个人主页",<br /> "components": ["../view/newCycle/home.vue"]<br /> }<br />]<br />
5 对依赖树和路由信息进行整合分析
// 将路由页面的所有依赖组件deps,都存放在路由信息的components数组中<br />const getEndPathComponentsArr = function(routeDeps,dependenciesArray) {<br /> for(let i = 0; i {<br /> routeDeps = routeDeps.map(routeObj=>{<br /> if(routeObj && routeObj.components){<br /> let relativePath = <br /> routeObj.components[0].slice(routeObj.components[0].indexOf('/')+1);<br /> if(page.path.includes(relativePath.split('/').join(path.sep))){<br /> // 铺平依赖树的层级<br /> routeObj = flapAllComponents(routeObj,page);<br /> // 去重操作<br /> routeObj.components = dedupe(routeObj.components);<br /> }<br /> }<br /> return routeObj;<br /> })<br /> })<br /> }<br /> return routeDeps;<br />}<br />//建立一个map数据结构,以每个组件为key,以对应的路由信息为value<br />// {<br />// 'path1' => Set { '/index' },<br />// 'path2' => Set { '/index', '/home' },<br />// 'path3' => Set { '/home' }<br />// }<br />const convertDeps = function(deps) {<br /> let map = new Map();<br /> ......<br /> return map;<br />}<br />
整合分析后依赖关系如下:
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index"],<br /> // 映射中只有和首页的映射<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
6 修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
6.1 unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
//webpack/lib/WebpackOptionsDefaulter.js<br />this.set("resolveLoader.unsafeCache", true);<br />//这是webpack初始化配置参数时对unsafeCache的默认设置<br /><br />//enhanced-resolve/lib/Resolverfatory.js<br />if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br />} else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br />}<br />//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。<br />//缓存的工作是由UnsafeCachePlugin完成,代码如下:<br />//enhanced-resolve/lib/UnsafeCachePlugin.js<br />apply(resolver) {<br /> const target = resolver.ensureHook(this.target);<br /> resolver<br /> .getHook(this.source)<br /> .tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {<br /> if (!this.filterPredicate(request)) return callback();<br /> const cacheId = getCacheId(request, this.withContext);<br /> // !!划重点,当缓存中存在解析过的文件结果,直接callback<br /> const cacheEntry = this.cache[cacheId];<br /> if (cacheEntry) {<br /> return callback(null, cacheEntry);<br /> }<br /> resolver.doResolve(<br /> target,<br /> request,<br /> null,<br /> resolveContext,<br /> (err, result) => {<br /> if (err) return callback(err);<br /> if (result) return callback(null, (this.cache[cacheId] = result));<br /> callback();<br /> }<br /> );<br /> });<br />}<br />
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
6.2 这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
//enhanced-resolve/lib/Resolverfatory.js<br />exports.createResolver = function(options) {<br /> ......<br /> let unsafeCache = options.unsafeCache || false;<br /> if (unsafeCache) {<br /> plugins.push(<br /> new UnsafeCachePlugin(<br /> "resolve",<br /> cachePredicate,<br /> unsafeCache,<br /> cacheWithContext,<br /> "new-resolve"<br /> )<br /> );<br /> plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));<br /> // 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,<br /> //执行结束后的目标事件(target)是new-resolve。<br /> //而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。<br /> } else {<br /> plugins.push(new ParsePlugin("resolve", "parsed-resolve"));<br /> }<br /> ...... // 各种plugin<br /> plugins.push(new ResultPlugin(resolver.hooks.resolved));<br /><br /> plugins.forEach(plugin => {<br /> plugin.apply(resolver);<br /> });<br /><br /> return resolver;<br />}<br />
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
6.3 解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
//package.json<br />"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"<br /><br />//vue.config.js<br />chainWebpack(config) {<br /> // 这一步解决webpack对组件缓存,影响最终映射关系的处理<br /> config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'<br />}<br />
7 最终依赖关系
{<br /> A: ["index&_&首页&_&index"],// A代表组件A的路径<br /> B: ["index&_&首页&_&index"],// B代表组件B的路径<br /> Card: ["index&_&首页&_&index",<br /> "home&_&个人主页&_&home"],<br /> // Card组件与多个页面有映射关系<br /> D: ["index&_&首页&_&index"],// D代表组件D的路径<br /> E: ["home&_&个人主页&_&home"],// E代表组件E的路径<br />}<br />
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
module.exports = {<br /> cache: {<br /> // 1. Set cache type to filesystem<br /> type: 'filesystem',<br /><br /> buildDependencies: {<br /> // 2. Add your config as buildDependency to get cache invalidation on config change<br /> config: [__filename]<br /><br /> // 3. If you have other things the build depends on you can add them here<br /> // Note that webpack, loaders and all modules referenced from your config are automatically added<br /> }<br /> }<br />};<br />
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-05-22 05:19
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。 查看全部
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。
【第2167期】埋点自动收集方案-路由依赖分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-17 14:55
前言
前一段时间有看到相关需求,只不过在某团队已经开发完了。今日前端早读课文章由转转@刁文豪,公号:大转转FE授权分享。
@刁文豪,目前就职于转转平台运营部,负责C2C业务线前端工作。参与过两次创业,做过项目经理,喜欢挖掘业务痛点,同时深爱技术研究,致力于通过技术手段改进产品及用户体验、推动业务增长。
正文从这开始~~
对于这两个问题,我们先思考一会。
1、一个项目总共有多少?每个页面又有多少组件构成?
2、有哪些组件是公共组件,它们分别被哪些页面引用?
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
背景
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
<p>//Index.vue 首页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Home.vue 个人主页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Card.vue 商品卡片组件
goDetail(item) {
/**
* @mylog 商品卡片点击
*/
this.$log('card-click') // 埋点发送
}</p>
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
期望效果
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
方案思考
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
<p>//a.ts
import B from './b.ts'
import getCookie from '@/libs/cookie.ts'
<br />
//c.ts
const C = require('./b.ts')
<br />
//b.ts
div {
background: url('./assets/icon.png') no-repeat;
}
import './style.css'
// c.vue
import Vue from Vue
import Card from '@/component/Card.vue'</p>
这里给出三种依赖分析的思路:
递归
从项目的路由配置开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
借助工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
<p>//done是compiler的钩子,在完成一次编译结束后的会执行
compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{
fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {
if (err) {
throw err;
}
})
cb()
})</p>
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
具体实现
先奉上流程图
初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
<p>apply(compiler) {
compiler.hooks.normalModuleFactory.tap(
"demoPlugin",
nmf => {
nmf.hooks.afterResolve.tapAsync(
"demoPlugin",
(result, callback) => {
const { resourceResolveData } = result;
// 当前文件的路径
let path = resourceResolveData.path;
// 父级文件路径
let fatherPath = resourceResolveData.context.issuer;
callback(null,result)
}
);
}
)
}</p>
建立依赖树
根据上一步获取的引用关系,生成依赖树。
<p>// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue
if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){
if(fatherPath && fatherPath != path){ // 父子路径相同的排除
if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){
// 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除
let sonObj = {};
sonObj.type = 'module';
sonObj.path = path;
sonObj.deps = []
// 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。
sonObj = copyAheadDep(this.dependenciesArray,sonObj);
let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);
this.dependenciesArray = obj.arr;
if(!obj.fileExist){
let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};
this.dependenciesArray.push(entryObj);
}
}
} else if(!this.dependenciesArray.some(it => it.path == path)) {
// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件
let entryObj = {type:'entry',path:path,deps:[]};
this.dependenciesArray.push(entryObj);
}
}</p>
那么这时生成的依赖树如下:
解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
<p>compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{
this.handleCompilerDone()
cb()
})</p>
<p>// ast解析路由文件
handleCompilerDone(){
if(this.dependenciesArray.length){
let tempRouteDeps = {};
// routePaths是项目的路由文件数组
for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);
// 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖
this.dependenciesArray =
getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);
}
}</p>
通过这一步ast解析,可以得到如下路由信息:
<p>[
{
"name": "index",
"route": "/index",
"title": "首页",
"components": ["../view/newCycle/index.vue"]
},
{
"name": "home",
"route": "/home",
"title": "个人主页",
"components": ["../view/newCycle/home.vue"]
}
]</p>
对依赖树和路由信息进行整合分析
整合分析后依赖关系如下:
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index"],
// 映射中只有和首页的映射
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
<p>//webpack/lib/WebpackOptionsDefaulter.js
this.set("resolveLoader.unsafeCache", true);
//这是webpack初始化配置参数时对unsafeCache的默认设置
<br />
//enhanced-resolve/lib/Resolverfatory.js
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。
//缓存的工作是由UnsafeCachePlugin完成,代码如下:
//enhanced-resolve/lib/UnsafeCachePlugin.js
apply(resolver) {
const target = resolver.ensureHook(this.target);
resolver
.getHook(this.source)
.tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {
if (!this.filterPredicate(request)) return callback();
const cacheId = getCacheId(request, this.withContext);
// !!划重点,当缓存中存在解析过的文件结果,直接callback
const cacheEntry = this.cache[cacheId];
if (cacheEntry) {
return callback(null, cacheEntry);
}
resolver.doResolve(
target,
request,
null,
resolveContext,
(err, result) => {
if (err) return callback(err);
if (result) return callback(null, (this.cache[cacheId] = result));
callback();
}
);
});
}</p>
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
<p>//enhanced-resolve/lib/Resolverfatory.js
exports.createResolver = function(options) {
......
let unsafeCache = options.unsafeCache || false;
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
// 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,
//执行结束后的目标事件(target)是new-resolve。
//而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
...... // 各种plugin
plugins.push(new ResultPlugin(resolver.hooks.resolved));
<br />
plugins.forEach(plugin => {
plugin.apply(resolver);
});
<br />
return resolver;
}</p>
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
<p>//package.json
"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"
<br />
//vue.config.js
chainWebpack(config) {
// 这一步解决webpack对组件缓存,影响最终映射关系的处理
config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'
}</p>
最终依赖关系
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index",
"home&_&个人主页&_&home"],
// Card组件与多个页面有映射关系
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
<p>module.exports = {
cache: {
// 1. Set cache type to filesystem
type: 'filesystem',
<br />
buildDependencies: {
// 2. Add your config as buildDependency to get cache invalidation on config change
config: [__filename]
<br />
// 3. If you have other things the build depends on you can add them here
// Note that webpack, loaders and all modules referenced from your config are automatically added
}
}
};</p>
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
总结
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~ 查看全部
【第2167期】埋点自动收集方案-路由依赖分析
前言
前一段时间有看到相关需求,只不过在某团队已经开发完了。今日前端早读课文章由转转@刁文豪,公号:大转转FE授权分享。
@刁文豪,目前就职于转转平台运营部,负责C2C业务线前端工作。参与过两次创业,做过项目经理,喜欢挖掘业务痛点,同时深爱技术研究,致力于通过技术手段改进产品及用户体验、推动业务增长。
正文从这开始~~
对于这两个问题,我们先思考一会。
1、一个项目总共有多少?每个页面又有多少组件构成?
2、有哪些组件是公共组件,它们分别被哪些页面引用?
跟随这篇文章我们一起探讨下,希望能帮你找到答案。
背景
随着组件化思想深入人心,开发中遇到特定的功能模块或UI模块,我们便会想到抽成组件,高级一点的做法就是把多个页面相似的部分抽成公共的组件。
组件化的“诅咒”
但是往往对一件事物依赖越强,越容易陷入它的“诅咒”当中。当项目有越多的组件时,开发者越不容易建立它们之间的关系,特别当改动了某个组件的一行代码,甚至不能准确的判断由于这行代码变动,都影响了哪些页面。我暂且称之为“组件化的诅咒”。如果我们有个完整的组件依赖关系,就可以很好的解决这个问题。
我们以下面的场景为例,看一看依赖分析的重要性和必要性。
在整个方案中,埋点的数据源很重要,而数据源与页面的对应关系又是保证数据源完整性的关键。比如:首页和个人主页的商品流都采用相同的商品卡片,开发者自然会将商品卡片抽离为一个公共组件。如下:
<p>//Index.vue 首页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Home.vue 个人主页
import Card from './common/Card.vue' //依赖商品卡片组件
<br />
//Card.vue 商品卡片组件
goDetail(item) {
/**
* @mylog 商品卡片点击
*/
this.$log('card-click') // 埋点发送
}</p>
这就带来一个问题:商品卡片的点击信息(埋点的数据源),既可能是首页的,也可能是个人主页的,而jsdoc搜集埋点注释时,对这种归属情况的判断无能为力。所以必须找到一种方法可以拿到组件和页面的映射关系。
期望效果
项目中的实际依赖关系:
对应的依赖分析关系:(每个组件,与引用它的页面路由的映射)
方案思考
那么,怎么做依赖分析?在思考这个问题之前,我们先看一看有哪些常见的建立依赖的语法。
<p>//a.ts
import B from './b.ts'
import getCookie from '@/libs/cookie.ts'
<br />
//c.ts
const C = require('./b.ts')
<br />
//b.ts
div {
background: url('./assets/icon.png') no-repeat;
}
import './style.css'
// c.vue
import Vue from Vue
import Card from '@/component/Card.vue'</p>
这里给出三种依赖分析的思路:
递归
从项目的路由配置开始,分别对每个路由页面,进行依赖的递归解析。这种思路想法简单直接,但实现起来可能较为繁琐,需要解析页面中所有形式的依赖关系。
借助工具的统计分析数据,进行二次加工
实际项目中我们都是采用webpack打包工具,而它的一大特点就是会自动帮开发者做依赖分析(独立的enhanced-resolve库)。相较于第一种重写解析的方法,为何不站在webpack的肩膀上解决问题呢。
先来看下webpack的整体编译流程:
可以看到,每一个文件都会经过resolve阶段,最终在编译结束后,得到本次编译的统计分析信息。
<p>//done是compiler的钩子,在完成一次编译结束后的会执行
compiler.hooks.done.tapAsync("demoPlugin",(stats,cb)=>{
fs.writeFile(appRoot+'/stats.json', JSON.stringify(stats.toJson(),'','\t'), (err) => {
if (err) {
throw err;
}
})
cb()
})</p>
详细的编译数据,就是done事件中的回调参数stats,经过处理后,大致如下:
通过对这份统计分析信息的二次加工和分析,也可以得到预期的依赖关系(插件webpack-bundle-analyzer也是基于这份数据生成的分析图表)。这份数据看上去更像基本chunk和module的依赖分析,对于组件或公共组件的依赖关系问题,需要对chunks和modules综合分析才能解决。同时我们还发现,这份数据的数据量相当大,且有大量开发者不关心的数据(截图是只有两个路由页面的情况下的数据量)。接下来讨论的方案是作者实际采用的方案,也是基于webpack,不同之处在于分析和收集依赖关系的时机。
在webpack的解析阶段,分析并收集依赖
我们看到虽然webpack的分析数据非常臃肿,但是它确实帮助开发者做了这份繁重的工作。只是我们希望能定制数据的范围,主动收集期望数据,所以推想,可否在每个文件解析阶段进行一定的“干预”,即通过条件判断或过滤筛选达成目的。那么问题来了,应该在resolve的哪个阶段进行“干预”,如何“干预”?
好,我们先要总览下webpack事件流过程:
很显然,afterResolve是每个文件解析阶段的最后,应该就从这里下手啦。
具体实现
先奉上流程图
初始化
首先这是一个webpack插件,在初始化阶段,指定解析的路由文件地址(比如src/route)以及排除解析的文件地址(比如src/lib、src/util),原因是这些排除的文件不会存在埋点数据。
收集依赖关系
在afterResolve钩子函数中,获取当前被解析文件的路径及其父级文件路径。
<p>apply(compiler) {
compiler.hooks.normalModuleFactory.tap(
"demoPlugin",
nmf => {
nmf.hooks.afterResolve.tapAsync(
"demoPlugin",
(result, callback) => {
const { resourceResolveData } = result;
// 当前文件的路径
let path = resourceResolveData.path;
// 父级文件路径
let fatherPath = resourceResolveData.context.issuer;
callback(null,result)
}
);
}
)
}</p>
建立依赖树
根据上一步获取的引用关系,生成依赖树。
<p>// 不是nodemodule中的文件,不是exclude中的文件,且为.js/.jsx/.ts/.tsx/.vue
if(!skip(this.ignoreDependenciesArr,this.excludeRegArr,path, fatherPath) && matchFileType(path)){
if(fatherPath && fatherPath != path){ // 父子路径相同的排除
if(!(fatherPath.endsWith('js') || fatherPath.endsWith('ts')) || !(path.endsWith('js') || path.endsWith('ts'))){
// 父子同为js文件,认为是路由文件的父子关系,而非组件,故排除
let sonObj = {};
sonObj.type = 'module';
sonObj.path = path;
sonObj.deps = []
// 如果本次parser中的path,解析过,那么把过去的解析结果copy过来。
sonObj = copyAheadDep(this.dependenciesArray,sonObj);
let obj = checkExist(this.dependenciesArray,fatherPath,sonObj);
this.dependenciesArray = obj.arr;
if(!obj.fileExist){
let entryObj = {type:'module',path:fatherPath,deps:[sonObj]};
this.dependenciesArray.push(entryObj);
}
}
} else if(!this.dependenciesArray.some(it => it.path == path)) {
// 父子路径相同,且在this.dependenciesArray不存在,认为此文件为依赖树的根文件
let entryObj = {type:'entry',path:path,deps:[]};
this.dependenciesArray.push(entryObj);
}
}</p>
那么这时生成的依赖树如下:
解析路由信息
通过上一步基本上得到组件的依赖树,但我们发现对于公共组件Card,它只存在首页的依赖中,却不见在个人主页的依赖中,这显然不符合预期(在第6步中专门解释)。那么接下来就要找寻,这个依赖树与路由信息的关系。
<p>compiler.hooks.done.tapAsync("RoutePathWebpackPlugin",(stats,cb)=>{
this.handleCompilerDone()
cb()
})</p>
<p>// ast解析路由文件
handleCompilerDone(){
if(this.dependenciesArray.length){
let tempRouteDeps = {};
// routePaths是项目的路由文件数组
for(let i = 0; i it && Object.prototype.toString.call(it) == "[object Object]" && it.components);
// 获取真实插件传入的router配置文件的依赖,除去main.js、filter.js、store.js等文件的依赖
this.dependenciesArray =
getRealRoutePathDependenciesArr(this.dependenciesArray,this.routePaths);
}
}</p>
通过这一步ast解析,可以得到如下路由信息:
<p>[
{
"name": "index",
"route": "/index",
"title": "首页",
"components": ["../view/newCycle/index.vue"]
},
{
"name": "home",
"route": "/home",
"title": "个人主页",
"components": ["../view/newCycle/home.vue"]
}
]</p>
对依赖树和路由信息进行整合分析
整合分析后依赖关系如下:
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index"],
// 映射中只有和首页的映射
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
因为上一步依赖收集部分,Card组件并没有成功收集到个人主页的依赖中,所以这步整合分析也无法建立准确的映射关系。且看下面的解决。
修改unsafeCache配置
为什么公共组件Card在收集依赖的时候,只收集到一次?这个问题如果不解决,意味着只有首页的商品点击埋点被收集到,其他引用这个组件的页面商品点击就会丢失。有问题,就有机会,机会意味着解决问题的可能性。
webpack4提供了resolve的配置入口,开发者可以通过几项设置决定如何解析文件,比如extensions、alias等,其中有一个属性——unsafeCache成功引起了作者的注意,它正是问题的根结。
unsafeCache是webpack提高编译性能的优化措施。
unsafeCache默认为true,表示webpack会缓存已经解析过的文件依赖,待再次需要解析此文件时,直接从缓存中返回结果,避免重复解析。
我们看下源码:
<p>//webpack/lib/WebpackOptionsDefaulter.js
this.set("resolveLoader.unsafeCache", true);
//这是webpack初始化配置参数时对unsafeCache的默认设置
<br />
//enhanced-resolve/lib/Resolverfatory.js
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
//前面已经提到,webpack将文件的解析独立为一个单独的库去做,那就是enhanced-resolve。
//缓存的工作是由UnsafeCachePlugin完成,代码如下:
//enhanced-resolve/lib/UnsafeCachePlugin.js
apply(resolver) {
const target = resolver.ensureHook(this.target);
resolver
.getHook(this.source)
.tapAsync("UnsafeCachePlugin", (request, resolveContext, callback) => {
if (!this.filterPredicate(request)) return callback();
const cacheId = getCacheId(request, this.withContext);
// !!划重点,当缓存中存在解析过的文件结果,直接callback
const cacheEntry = this.cache[cacheId];
if (cacheEntry) {
return callback(null, cacheEntry);
}
resolver.doResolve(
target,
request,
null,
resolveContext,
(err, result) => {
if (err) return callback(err);
if (result) return callback(null, (this.cache[cacheId] = result));
callback();
}
);
});
}</p>
在UnsafeCachePlugin的apply方法中,当判断有缓存过的文件结果,直接callback,没有继续后面的解析动作。
这对我们收集依赖有什么影响?
缓存了解析过的文件,意味着与这个文件再次相遇时,事件流将被提前终止,afterResolve的钩子自然也就不会执行到,那么我们的依赖关系就无从谈起。
其实webpack的resolve 过程可以看成事件的串联,当所有串联在一起的事件执行完之后,resolve 就结束了。我们看下原理:
用来解析文件的库是enhanced-resolve,在Resolverfatory生成resolver解析对象时,进行了大量plugins的注册,正是这些plugins形成一系列的解析事件。
<p>//enhanced-resolve/lib/Resolverfatory.js
exports.createResolver = function(options) {
......
let unsafeCache = options.unsafeCache || false;
if (unsafeCache) {
plugins.push(
new UnsafeCachePlugin(
"resolve",
cachePredicate,
unsafeCache,
cacheWithContext,
"new-resolve"
)
);
plugins.push(new ParsePlugin("new-resolve", "parsed-resolve"));
// 这里的事件流大致是:UnsafeCachePlugin的事件源(source)是resolve,
//执行结束后的目标事件(target)是new-resolve。
//而ParsePlugin的事件源为new-resolve,所以事件流机制刚好把这两个插件串联起来。
} else {
plugins.push(new ParsePlugin("resolve", "parsed-resolve"));
}
...... // 各种plugin
plugins.push(new ResultPlugin(resolver.hooks.resolved));
<br />
plugins.forEach(plugin => {
plugin.apply(resolver);
});
<br />
return resolver;
}</p>
每个插件在执行自己的逻辑后,都会调用resolver.doResolve(target, ...),其中的target是触发下一个插件的事件名称,如此往复,直到遇到事件源为result,递归终止,解析结束。
resolve的事件串联流程图大致如下:
UnsafeCachePlugin插件在第一次解析文件时,因为没有缓存,就会触发target为new-resolve的事件,也就是ParsePlugin,同时将解析结果记入缓存。当判断该文件有缓存结果,UnsafeCachePlugin的apply方法会直接callback,而没有继续执行resolver.doResolve(),意味着整个resolve事件流在UnsafeCachePlugin就终止了。这就解释了,为什么只建立了首页与Card组件的映射,而无法拿到个人主页与Card组件的映射。
解决办法
分析了原因后,就好办了,将unsafeCache设置为false(嗯,就这么简单)。这时你可能担心会降低工程编译速度,但深入一步想想,依赖分析这件事完全可以独立于开发阶段,只要在我们需要它的时候执行这个能力,比如由开发者通过命令行参数来控制。
<p>//package.json
"analyse": "cross-env LEGO_ENV=analyse vue-cli-service build"
<br />
//vue.config.js
chainWebpack(config) {
// 这一步解决webpack对组件缓存,影响最终映射关系的处理
config.resolve.unsafeCache = process.env.LEGO_ENV != 'analyse'
}</p>
最终依赖关系
<p>{
A: ["index&_&首页&_&index"],// A代表组件A的路径
B: ["index&_&首页&_&index"],// B代表组件B的路径
Card: ["index&_&首页&_&index",
"home&_&个人主页&_&home"],
// Card组件与多个页面有映射关系
D: ["index&_&首页&_&index"],// D代表组件D的路径
E: ["home&_&个人主页&_&home"],// E代表组件E的路径
}</p>
可以看到,与公共组件Card关联的映射页面中,多了个人主页的路由信息,这才是准确的依赖数据。在埋点自动收集项目中,这份依赖关系数据交由jsdoc处理,就可以完成所有埋点信息与页面的映射关系。
one more thing
webpack5,它来了,它带着持久化缓存策略来了。前面提到的unsafeCache虽然可以提升应用构建性能,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,这就是为什么叫unsafeCache,而不是safeCache(安全的)。
webpack5规定在配置信息的cache对象的type,可以设置为memory和fileSystem两种方式。memory是指之前的unsafeCache缓存,fileSystem是指相对安全的磁盘持久化缓存。
<p>module.exports = {
cache: {
// 1. Set cache type to filesystem
type: 'filesystem',
<br />
buildDependencies: {
// 2. Add your config as buildDependency to get cache invalidation on config change
config: [__filename]
<br />
// 3. If you have other things the build depends on you can add them here
// Note that webpack, loaders and all modules referenced from your config are automatically added
}
}
};</p>
所以针对webpack5,如果需要做完整的依赖分析,只需将cache.type动态设置为memory,resolve.unsafeCache设置为false即可。(感兴趣的童鞋可以试一试)
总结
以上,我们解释了组件化可能带来的隐患,提到了路由依赖分析的重要性,给出三种依赖分析的思路,并基于埋点自动收集项目重点阐述了其中一种方案的具体实现。在此与你分享,期待共同成长~
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-05-13 15:26
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。 查看全部
Emlog采集插件-无需像优采云一样写入采集规则以及发布模块
Emlog采集插件,什么是Emlog采集插件,可以实现自动采集发布吗?不用像优采云一样写规则吗?今天给大家分享一款
免费的Emlog采集发布工具
:只需要输入关键词或输入指定域名就能实现采集,采集后自动发布到网站后台。
无需像优采云一样写入代码规则就能实现全自动采集发布,详细教程可参考图片。
Emlog采集也是需要注意关键词密度是一个或多个关键词在网页上呈现的总次数与其他词的比率。相关于页面上的总词数,呈现的关键词越多,总关键词密度越大。其他词呈现的次数越多,关键词所占比例越低,关键词密度越小。
Emlog采集关键词密度是许多搜索引擎的搜索算法之一,包括Google、Yahoo和MSN。每一个搜索引擎都有一套关于关键词密度的不同数学公式,能够让你取得更高的排名。就惩罚前允许的关键词密度水平而言,不同的搜索引擎也有不同的容忍度。
Emlog采集关键词是搜索者在搜索信息、产品或效劳时进入搜索引擎界面的术语。关键词是搜索引擎算法执行的数学运算中的一个要素,用来肯定数十亿网页和特定搜索之间的相关性。搜索算法以为与关键词搜索最相关的页面将依次排序。
Emlog采集关键词能够是单个单词,也能够是包含该单词的单词。这两种办法对搜索者查找信息都很有用。普通规则是关键词越长,从搜索引擎索引返回的信息就越精确。
固然没有固定的关键词公式,但将关键词占网页总词数的比例控制在5%以下可能是不错的做法。太多的关键词可能会触发关键词填充过滤器。假如关键词在网页文本中呈现的次数过多,会减少读者的保存时间,降低访问者向付费用户的转化率。毕竟,Emlog采集对于任何一个商业网站来说,网页的目的是把访问者变成顾客。关于内容网站,其目的是让尽可能多的访问者阅读有用的信息。糟糕的写作会产生相反的效果。
关键词密度是指一个页面上运用的关键词数量与讨论页面上总单词数的比率。关键词散布是指这些关键词在网页上的位置。它能够是标题标志、链接、标题、正文或任何文本的中文。
一些SEO优化师以为,将关键词放在页面的较高位置会使页面的搜索排名飙升。但是,并非一切地搜索引擎察看家都这么以为。普通来说,尽量依照正常的编辑作风在整个网页内容中散布关键词。Emlog采集看起来自然的内容更容易阅读,而且,像在页面上特别散布的关键词,在搜索排名中得分会更好。
网站频繁变动
比方经常修正网站架构、标题等之类的缘由,特别是新站,这个是特别要留意的中央。
网站后台的代码太乱
这个乱不光说的是格式,同时也说的是内容。
网站外链
网站发布大量的高质量外链,数量也越大,网站快照的更新速度越快,并且越有规律。假如发布低质量的链接,会影响到内容收录的问题。
内容比较敏感
搜索引擎是经过过滤人工干预过的,假如网站的内容有敏感的内容都会影响到你的网站,留意单个文章也会影响你的网站。
JS代码溢出
搜索引擎对JS代码并没什么关系,假如让JS代码不经过调用直接显现在搜索引擎的眼前,那么最大的难点就是形成蜘蛛的匍匐艰难,自然就会影响到快照的更新了。
总结:关于
使用Emlog采集发布来说这一款工具相对于来说会简单很多,无需像其它采集工具那样会写入很多的规则以及代码。好了今天的Emlog采集发布教程就分享到这里了。
3种方法导出公众号文章数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2022-05-11 14:52
每晚7点,陪你充电!
(↑听燕哥说)
今天咱们来说公众号文章数据的采集和导出,包括自己的公众号文章数据,以及任何一个公众号的图文数据。
1
/ 公众号后台自带导出功能/
进入公众号图文分析里,点击右上角“导出EXCEL”即可导出数据。不过导出的数据很有限,或者说没必要导出,因为导出的内容跟网页上的内容是一毛一样的,你可以直接在网页上看呀。
导出后的EXCEL内容
2
/ 第三方网页插件/
新媒体管家
壹伴
这两款插件都很好用,随便安装哪款都可以,安装后,进入公众号后台-图文分析,点击右上角导出数据即可。
导出后的数据特别详细,而且系统还自动进行了一些小计算:阅读总量、增掉粉量等很多项目。
导出后的EXCEL内容
3
/ WCplus/
以上是导出自己公众号文章数据常用的工具,接下来给大家说一款导出任何公众号文章数据的工具--WCplus。
WCplus可以将任意一个微信公众号的全部历史发文数据转化成为一张Excel表格。
(导出后的EXCEL内容)
而且这款工具还可以把采集下来的文章,自动变成一个个的PDF文件! 查看全部
3种方法导出公众号文章数据
每晚7点,陪你充电!
(↑听燕哥说)
今天咱们来说公众号文章数据的采集和导出,包括自己的公众号文章数据,以及任何一个公众号的图文数据。
1
/ 公众号后台自带导出功能/
进入公众号图文分析里,点击右上角“导出EXCEL”即可导出数据。不过导出的数据很有限,或者说没必要导出,因为导出的内容跟网页上的内容是一毛一样的,你可以直接在网页上看呀。
导出后的EXCEL内容
2
/ 第三方网页插件/
新媒体管家
壹伴
这两款插件都很好用,随便安装哪款都可以,安装后,进入公众号后台-图文分析,点击右上角导出数据即可。
导出后的数据特别详细,而且系统还自动进行了一些小计算:阅读总量、增掉粉量等很多项目。
导出后的EXCEL内容
3
/ WCplus/
以上是导出自己公众号文章数据常用的工具,接下来给大家说一款导出任何公众号文章数据的工具--WCplus。
WCplus可以将任意一个微信公众号的全部历史发文数据转化成为一张Excel表格。
(导出后的EXCEL内容)
而且这款工具还可以把采集下来的文章,自动变成一个个的PDF文件!
文章自动采集就是不动脑子,让api控制。
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-05-07 15:00
文章自动采集插件自动采集就是不动脑子,让api控制。api控制的首先第一个问题,你是哪个区域呢?各个区域的主机以及分布图域名呢?第二个问题,如果你要搞定所有区域的网站,可能你要有统一的api控制客户端,把所有的区域的接口统一起来然后单独拿到一个端口。以前随便写过一个爬虫,爬的不是很顺利,真正让api控制变得难以制止的其实还是自定义规则实现api控制的难度高。
需要一定的多线程api编程能力。一般来说我们都是通过不动脑子的方式实现api控制,目的是好做一些复杂任务自动化产品。看视频教程会让你有一定的帮助。
requests+goffice就可以
国内主流的api网站ui都不太友好,因为全是明文http请求,不能做https或https过滤,一些网站会将http请求转换成https的格式导致网站支持https的页面无法显示,还有可能有些页面没有响应。国内搜索引擎公司集中于xx生态圈的自家产品,一般都不会直接提供api接口,除非有实际需求。另外国内大多数网站根本没有自己的api接口,你从外面直接拿来搭个框架或者买个api服务商的一套api也有可能。
解决办法有好几种:1,提供网址:,现有行业大站提供http接口,一般地方站目前还是没有对接的。3,提供api:,国内大站长们自己搭建api,提供api,但是可以定制,可以返回到他们自己的格式。不过现在有些行业大站,如美团,百度也面临着转型,没有做这么多api的接口,也是由于接口api的接入成本相对较高。 查看全部
文章自动采集就是不动脑子,让api控制。
文章自动采集插件自动采集就是不动脑子,让api控制。api控制的首先第一个问题,你是哪个区域呢?各个区域的主机以及分布图域名呢?第二个问题,如果你要搞定所有区域的网站,可能你要有统一的api控制客户端,把所有的区域的接口统一起来然后单独拿到一个端口。以前随便写过一个爬虫,爬的不是很顺利,真正让api控制变得难以制止的其实还是自定义规则实现api控制的难度高。
需要一定的多线程api编程能力。一般来说我们都是通过不动脑子的方式实现api控制,目的是好做一些复杂任务自动化产品。看视频教程会让你有一定的帮助。
requests+goffice就可以
国内主流的api网站ui都不太友好,因为全是明文http请求,不能做https或https过滤,一些网站会将http请求转换成https的格式导致网站支持https的页面无法显示,还有可能有些页面没有响应。国内搜索引擎公司集中于xx生态圈的自家产品,一般都不会直接提供api接口,除非有实际需求。另外国内大多数网站根本没有自己的api接口,你从外面直接拿来搭个框架或者买个api服务商的一套api也有可能。
解决办法有好几种:1,提供网址:,现有行业大站提供http接口,一般地方站目前还是没有对接的。3,提供api:,国内大站长们自己搭建api,提供api,但是可以定制,可以返回到他们自己的格式。不过现在有些行业大站,如美团,百度也面临着转型,没有做这么多api的接口,也是由于接口api的接入成本相对较高。
文章自动采集插件的介绍及介绍目录【通知】
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-05-07 05:02
文章自动采集插件的介绍目录1.准备工作2.设置下载地址3.设置前端自动发布账号密码4.设置每个浏览器插件的自动登录限制5.获取各网站的云主机详细信息6.下载不同网站的云主机7.将云主机上传到服务器8.建立自动爬虫服务器9.配置自动爬虫服务器首先,准备工作:一般的用于获取附近网站信息的软件和api;一个域名;企业qq或网页注册邮箱(方便大家找到目标网站);服务器操作系统:ubuntu系统或者windows系统(建议windows系统,因为苹果系统暂时没有尝试过);个人电脑:台式机或者笔记本;路由器端口及其配置如下:10.设置下载地址:通过对方提供的网址找到目标页面,在网址中加入“tar”字符,或者直接添加到地址栏中。
举例:经过上述的设置后,点击“打开文件”->“查看”,看见如下界面:选择“tar”字符,选择下载的文件,选择“tar”文件,点击“下载”选择文件的后缀是rar文件下载(压缩文件),下载速度会比原来的文件快。点击“解压”,得到下图(解压后得到目标文件,可以根据自己的网站规划自己的目标页面):可以看见获取到了共计34个网页(目标页面是java接口,支持java,c#,php,.net语言):12.设置前端自动发布账号密码:选择“云主机自动发布”(一般看到c,w/a)选择“添加新机器”,因为是采用这种方式来接收网站发布的自动爬虫账号密码:点击“确定”,进入自动爬虫的详细信息设置页面(如下图):右侧信息中的内容为:选择“自动发布服务器”,添加其登录限制或者数据库密码,设置“详细信息”页面的详细信息(使用阿里云客户端的用户,右侧可以看到真正的个人主机ip)。
左侧的搜索关键词很重要,可以查到当前爬虫所在服务器的url(可以看见输入爬虫ip和密码后获取的java的tomcat服务器地址,以及代理ip地址):选择“自动发布服务器”,完成左侧登录授权设置(在登录设置中,账号和密码保存在电脑的其他文件中),设置好后再次检查ip的登录限制和密码登录限制,点击“发布”。
发布操作成功后,可以看见java的数据库ip的地址。6.获取不同网站的云主机详细信息:云主机:-bin/javaweb.security.public.path_inc=/to/data/c2d/这里的path_inc是指用java爬虫发布的数据库服务器的url,也就是说,点击“发布”后,这个数据库服务器的ip会在java爬虫发布的数据库ip中找到,按照url提示登录相关的目标服务器。除了上图示例目标网站的规则外,也可以根据特定需求来挑选目标网站,如博客、论。 查看全部
文章自动采集插件的介绍及介绍目录【通知】
文章自动采集插件的介绍目录1.准备工作2.设置下载地址3.设置前端自动发布账号密码4.设置每个浏览器插件的自动登录限制5.获取各网站的云主机详细信息6.下载不同网站的云主机7.将云主机上传到服务器8.建立自动爬虫服务器9.配置自动爬虫服务器首先,准备工作:一般的用于获取附近网站信息的软件和api;一个域名;企业qq或网页注册邮箱(方便大家找到目标网站);服务器操作系统:ubuntu系统或者windows系统(建议windows系统,因为苹果系统暂时没有尝试过);个人电脑:台式机或者笔记本;路由器端口及其配置如下:10.设置下载地址:通过对方提供的网址找到目标页面,在网址中加入“tar”字符,或者直接添加到地址栏中。
举例:经过上述的设置后,点击“打开文件”->“查看”,看见如下界面:选择“tar”字符,选择下载的文件,选择“tar”文件,点击“下载”选择文件的后缀是rar文件下载(压缩文件),下载速度会比原来的文件快。点击“解压”,得到下图(解压后得到目标文件,可以根据自己的网站规划自己的目标页面):可以看见获取到了共计34个网页(目标页面是java接口,支持java,c#,php,.net语言):12.设置前端自动发布账号密码:选择“云主机自动发布”(一般看到c,w/a)选择“添加新机器”,因为是采用这种方式来接收网站发布的自动爬虫账号密码:点击“确定”,进入自动爬虫的详细信息设置页面(如下图):右侧信息中的内容为:选择“自动发布服务器”,添加其登录限制或者数据库密码,设置“详细信息”页面的详细信息(使用阿里云客户端的用户,右侧可以看到真正的个人主机ip)。
左侧的搜索关键词很重要,可以查到当前爬虫所在服务器的url(可以看见输入爬虫ip和密码后获取的java的tomcat服务器地址,以及代理ip地址):选择“自动发布服务器”,完成左侧登录授权设置(在登录设置中,账号和密码保存在电脑的其他文件中),设置好后再次检查ip的登录限制和密码登录限制,点击“发布”。
发布操作成功后,可以看见java的数据库ip的地址。6.获取不同网站的云主机详细信息:云主机:-bin/javaweb.security.public.path_inc=/to/data/c2d/这里的path_inc是指用java爬虫发布的数据库服务器的url,也就是说,点击“发布”后,这个数据库服务器的ip会在java爬虫发布的数据库ip中找到,按照url提示登录相关的目标服务器。除了上图示例目标网站的规则外,也可以根据特定需求来挑选目标网站,如博客、论。
文章自动采集插件,一键采集各种平台的旅游信息?
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-05-06 12:01
文章自动采集插件,一键采集各种平台的旅游信息?一键采集旅游景点的活动信息?一键采集旅游景点的住宿信息?一键采集各个游客会经过的景点,而且每一条都是可以精准到票价,你是不是很想知道大家都去哪里玩?这个时候插件的作用就体现出来了,一键采集景点的游玩信息,旅游,住宿,
自荐一个,wordpress插件everbox里面有个专门采集百度游记的功能,
如果可以,希望能帮你实现。
带你看看玩一整天需要多少成本。官方搭建好的网站游记分享平台百度搜这个网站,至于为什么想给你整个更专业的知乎下载googlechrome插件,也一定可以解决你的需求,付费下载的知乎下载任务也能保证到达完整的内容。
微信公众号的文章分类结构一般是这样的:公众号发布文章的首发地位置、公众号的整体介绍、公众号发布的时间节点、公众号下面的菜单栏内容、公众号的点赞排行等等。百度seo由于是从百度蜘蛛的角度来分析外链爬虫的,所以规则中对于外链网站来说,只分为一般外链和高质量外链,完全依照这样一套百度引导规则来进行博客推广的话,是有一定风险的。
但如果博客公众号是以百度搜索为主,那就很难了。如果是单纯的讲一个百度爬虫,那百度爬虫关键词布局就是单纯依照tag分布布局了,这个tag对应的词在一个博客主页上是必须有的,完全杜绝他外链的可能性。这对于百度爬虫来说就很简单了,也就是我所讲的整体布局布局主要是依照“博客主页、门户网站页面、b2b站、b2c网站网页截图”这样子的整体布局,像我们公司的百度文库、百度经验、360doc、搜狗问答之类的,可以理解为三种不同的百度图文网站的外链关键词布局,一般外链前3类博客能够增加展示。
不同的就是是否有推广费用。像这种流量比较大的页面,而且整体类目是非常受百度欢迎的,博客页面布局以关键词加锚文本页面加搜索引擎结果页面布局为主。比如说重要的行业词、重要的公司站、行业qq、官网页面、行业微信、行业博客、公司邮箱、公司qq空间、部门网站、企业站、超级网站等。对于主题内容自主要规划内容发布,按照同行业爬虫分析了解业务情况,或者按照行业博客的类别分布是。
另外像主题的分类,可以是自己查找自己想要业务关键词资料分布。这样做一是可以降低自己的风险,二来是可以更符合搜索规则。 查看全部
文章自动采集插件,一键采集各种平台的旅游信息?
文章自动采集插件,一键采集各种平台的旅游信息?一键采集旅游景点的活动信息?一键采集旅游景点的住宿信息?一键采集各个游客会经过的景点,而且每一条都是可以精准到票价,你是不是很想知道大家都去哪里玩?这个时候插件的作用就体现出来了,一键采集景点的游玩信息,旅游,住宿,
自荐一个,wordpress插件everbox里面有个专门采集百度游记的功能,
如果可以,希望能帮你实现。
带你看看玩一整天需要多少成本。官方搭建好的网站游记分享平台百度搜这个网站,至于为什么想给你整个更专业的知乎下载googlechrome插件,也一定可以解决你的需求,付费下载的知乎下载任务也能保证到达完整的内容。
微信公众号的文章分类结构一般是这样的:公众号发布文章的首发地位置、公众号的整体介绍、公众号发布的时间节点、公众号下面的菜单栏内容、公众号的点赞排行等等。百度seo由于是从百度蜘蛛的角度来分析外链爬虫的,所以规则中对于外链网站来说,只分为一般外链和高质量外链,完全依照这样一套百度引导规则来进行博客推广的话,是有一定风险的。
但如果博客公众号是以百度搜索为主,那就很难了。如果是单纯的讲一个百度爬虫,那百度爬虫关键词布局就是单纯依照tag分布布局了,这个tag对应的词在一个博客主页上是必须有的,完全杜绝他外链的可能性。这对于百度爬虫来说就很简单了,也就是我所讲的整体布局布局主要是依照“博客主页、门户网站页面、b2b站、b2c网站网页截图”这样子的整体布局,像我们公司的百度文库、百度经验、360doc、搜狗问答之类的,可以理解为三种不同的百度图文网站的外链关键词布局,一般外链前3类博客能够增加展示。
不同的就是是否有推广费用。像这种流量比较大的页面,而且整体类目是非常受百度欢迎的,博客页面布局以关键词加锚文本页面加搜索引擎结果页面布局为主。比如说重要的行业词、重要的公司站、行业qq、官网页面、行业微信、行业博客、公司邮箱、公司qq空间、部门网站、企业站、超级网站等。对于主题内容自主要规划内容发布,按照同行业爬虫分析了解业务情况,或者按照行业博客的类别分布是。
另外像主题的分类,可以是自己查找自己想要业务关键词资料分布。这样做一是可以降低自己的风险,二来是可以更符合搜索规则。
Android 基础架构组,面试题问什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-30 05:10
水一篇
年中的时候帮部门招人,发现很多候选人对于我们部门还是很青睐的。也对鸡架部门做的事比较感兴趣,所以今天这篇水文主要就给大家梳理下基架的面试题以及基础架构组涉及的sdk相关。
因为最近几年面试经常被人吊打,所以也有了总结面试题的习惯。之后加上之前帮候选人的面试总结,今天给大家再卷一波。
1SDK相关
面试的时候我觉得哦,这些sdk有任意其实你研究的比较深入就行了,应该能在面试中表现的很好了。还有就是个人建议最好还是在单一方向研究的更深入一点,别的只要大概知道干什么的就行了。
1. 配置中心以及灰度测试
app必备工具之一,配置中心主要负责的就是动态化的配置,比如文本展示类似这些的。sdk提供方需要负责的是提供动态更新能力,这里有个差异化更新,只更新dif部分,还有就是流量优化等等需要开发同学考虑的。然后可以考虑下存储性能方面的提升等。
而abtest也是app必备工具之一了,动态的下发实验策略,之后开发同学可以切换实验的页面。另外主要需要考虑灰度结果计算,分桶以及版本过滤白名单等等。这里只是一个简单的介绍不展开,因为我只是一个使用方。
2. 调试组件
个人还是更推荐滴滴的Dokit,功能点比较多而且接入相对来说比较简单。而且提供了很多给开发同学定制的能力,可以在debug情况下增加很多业务相关的测试功能,方便测试同学,核心还是浮窗太方便了。
当然很多实验性的预研功能等其实都可以直接接在这里,然后在测试环境下充分展开,之后在进行线上灰度方案。还有一些具有风险的hook操作,个人也比较建议放在debug组件上。
3. 性能监控框架
这部分有几个不同的方面,首先是异常崩溃方面的,另外则是性能监控方面的,但是他们整体是划分在一起的,都属于线上性能监控体系的。
Crash相关的,可以从爱奇艺的xCrash学起。包含了崩溃日志,ANR以及native crash,因为版本适配的问题ANR在高版本上已经不是这么好捞了,还有就是native crash相关的。是一个非常牛逼的库了。
而线上的性能监控框架可以从腾讯的Matrix学起,以前有两篇文章介绍的内容也都是和Matrix相关的, Matrix首页上也有介绍,比如fps,卡顿,IO,电池,内存等等方面的监控。其中卡顿监控涉及到的就是方法前后插桩,同时要有函数的mapping表,插桩部分整体来说比较简单感觉。
另外关于线上内存相关的,推荐各位可以学习下快手的koom, 对于hprof的压缩比例听说能达到70%,也能完成线上的数据回捞以及监控等等,是一个非常屌的框架。下面给大家一个抄答案的方式。字节也有一个类似的原理其实也差不多。
主进程发现内存到达阈值的时候,用leakcanary的方案,通过shark fork进程内存,之后生成hrop。由于hrop文件相对较大,所以我们需要对于我们所要分析的内容进行筛选,可以通过xhook,之后对hrop的写入操作进行hook,当发现写入内容的类型符合我们的需要的情况下才进行写入。
而当我们要做线上日志回捞的情况,需要对hprof 进行压缩,具体算法可以参考koom/raphel,有提供对应的压缩算法。
最后线上回捞机制就是基于一个指令,回捞线上符合标准的用户的文件操作,这个自行设计。
其实上述几个库都还是有一个本质相关的东西,那么就是plthook,这个上面三个库应该都有对其的使用,之前是爱奇艺的xhook,现在是字节的bhook, 这个大佬也是我的偶像之一了,非常离谱了算是。
Android 性能采集之Fps,Memory,Cpu和Android IO监控。
最近已经不咋写这部分相关了,所以也就没有深挖,但是后续可能会有一篇关于phtead hook相关的,也是之前matrix更新的一个新东西,还在测试环境灰度阶段。
4. 基础网络组件
虽然核心可能还是三方网络库,但是因为基本所有公司都对网络方面有调整和改动,以及解析器等方面的优化,其实可以挖的东西也还是蛮多的。
应付面试的同学可以看看Android网络优化方案。当然还是要具体问题具体分析,毕竟头疼医头,脚疼医脚对吧。
之前和另外一个朋友聊了下,其实很多厂对json解析这部分有优化调整,通过apt之后更换原生成原生的解析方式,加快反序列化速度的都是可以考虑考虑的。
5. 埋点框架
其实这个应该要放在更前面一点的,数据上报数据分析啥的其实都还是蛮重要的。
这部分因为我完全没写过哦,所以我压根不咋会,但是如果你会的话,面试的时候展开说说,可以帮助你不少。
另外还需要有线上的异常用户数据回捞系统,方便开发同学主动去把线上有异常的用户的日志给收集回来。
但是有些刁钻的页面曝光监控啦,自动化埋点啥的其实还是写过一点的,有兴趣的可以翻翻历史,还有github 上还有demo。
AndroidAutoTrackdemo工程。
6. 启动相关
通过DAG(有向无环图)的方式将sdk的初始化拆解成一个个task,之后理顺依赖关系,让他们能按照固定的顺序向下执行。
核心需要处理的是依赖关系,比如说其实埋点库依赖于网络库初始化,然后APM相关的则依赖于埋点库和配置中心abtest等等,这样的依赖关系需要开发同学去理顺的。
另外就是把sdk的粒度打的细碎一点,更容易观察每个sdk任务的耗时情况,之后增加task阈值告警,超过某个加载速度就通知到相应的同学改一下。
多线程是能优化掉一部分,但是也需要避免频繁线程调度。还有就是我个人觉得这些启动相关的东西因为都无法使用sdk级别的灰度,所以改动最好慎重一点。出发点始终都是好的,但是还是结果导向吧。
启动优化的核心,我个人始终坚持的就是延迟才能优化。开发人员很难做到优化代码执行的复杂度,执行时间之类的。尽人事听天命,玄学代码。
7.中间件(图片 日志 存储 基础信息)
这部分没啥,最好是对第三方库有一层隔离的思维,但是这个隔离也需要对应的同学对于程序设计方面有很好的思维,说起来简单,其实也蛮复杂的。
这里就不展开了,感觉面试也很少会问的很细。
8. 第三方sdk大杂烩(偏中台方向)
基本一个app现在都有啥分享啦,推送啦,支付啦,账号体系啦,webview,jsbridge等等服务于应用内的一些sdk,这些东西就比较偏向于业务。
有兴趣的可以看看之前写的两篇关于sdk设计相关的。
活学活用责任链 SDK开发的一点点心得 Android厂商推送Plugin化。
9. 其他方面
大公司可能都会有些动态化方案的考虑,比如插件化啊动态化之类的。这部分在下确实不行,我就不展开了啊。
2编译相关
1. 描述下android编译流程
基架很容易碰到的面试题,以前简单的描述写过。聊聊Android编译流程。
虽然是几年前的知识点了,但是还是要拆开高低版本的agp做比较的。所以这部分可以回答下,基本这题就能简单的拿下了。
2. Gradle 生命周期
简单的说下就是buildSrc先编译,之后是根目录的settings.gradle, 根build.gradle,最后才是module build。
网上一堆,你自己翻一番就知道了。
3. apt是编译中哪个阶段
APT解析的是java 抽象语法树(AST),属于javac的一部分流程。大概流程:.java -> AST -> .class
聊聊AbstractProcessor和Java编译流程。
4. Dex和class有什么区别
链接传送门:
Class与dex的区别:
1)虚拟机:class用jvm执行,dex用dvm执行。
2)文档:class中冗余信息多,dex会去除冗余信息,包含所有类,查找方便,适合手机端。
JVM与DVM:
1)JVM基于栈(使用栈帧,内存),DVM基于寄存器,速度更快,适合手机端。
2)JVM执行Class字节码,DVM执行DEX。
3)JVM只能有一个实例,一个应用启动运行在一个DVM。
DVM与ART:
1)DVM:每次运行应用都需要一次编译,效率降低。JIT
2)ART:Android5.0以上默认为ART,系统会在进程安装后进行一次预编译,将代码转为机器语言存在本地,这样在每次运行时不用再进行编译,提高启动效率;。AOP & JIT
5. Transform是如何被执行的
Transform 在编译过程中会被封装成Task 依赖其他编译流程的Task执行。
6. Transform和其他系统Transform执行的顺序
其实这个题目已经是个过期了,后面对这些都合并整合了,而且最新版的api也做了替换,要不然考虑下回怼下面试官?
Transform和Task之间有关?
7. 如何监控编译速度变慢问题
./gradlew xxxxx -- scan<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
之后会生成一个gradle的网页,填写下你的邮箱就好了。
另外一个相对来说比较简单了。通过gradle原生提供的listener进行就行了。
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
// 耗时统计kt化<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class TimingsListener : TaskExecutionListener, BuildListener {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var startTime: Long = 0L<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var timings = linkedMapOf()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun beforeExecute(task: Task) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> startTime = System.nanoTime()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun afterExecute(task: Task, state: TaskState) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> val ms = TimeUnit.MILLISECONDS.convert(System.nanoTime() - startTime, TimeUnit.NANOSECONDS)<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> task.path<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings[task.path] = ms<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${task.path} took ${ms}ms")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildFinished(result: BuildResult) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("Task timings:")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings.forEach {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if (it.value >= 50) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${it.key} cos ms ${it.value}\n")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildStarted(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun settingsEvaluated(settings: Settings) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsLoaded(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsEvaluated(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />}<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gradle.addListener(TimingsListener())<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
8. Gradle中如何给一个Task前后插入别的任务
最简单的可以考虑直接获取到Task实例,之后在after和before插入一些你所需要的代码。
另外一个就是通过dependOn前置和finalizedBy挂载一个任务 mustAfter。
Gradle 使用指南 -- Gradle Task。
9. ksp APT Transform的区别
ksp 是kotlin专门独立的ast语法树。
apt 是java 的ast语法树。
transform是 agp 专门修改字节码的一个方法。
反杀时刻AsmClassVisitorFactory,可以看看我之前写的那篇文章。
10. Transform上的编译优化能做哪些?
虽然是个即将过期的api,但是大家对他的改动还是都比较多的。
首先肯定是需要完成增量编译的,具体的可以参考我的demo工程。记住,所有的transfrom都要全量。
另外可以考虑多线程优化,将转化操作移动到子线程内,建议使用gradle内部的共享线程。
参考agp最新做法,抽象出一个新的interface,之后通过spi串联,之后将asm链式调用。我的文章也介绍过,具体的点在哪里自己盘算。
现在准备好告别Transform了吗
11. aar 源码切换插件原理
这个前几天刚介绍过,原理和方案业内都差不多,mulite-repo应该都需要这个东西的。我的版本也比较简陋,大厂内部肯定都会有些魔改的。
相对来说功能肯定会更丰富,更全面一点。
aar和源码切换插件Plus。
12. 你们有哪些保证代码质量的手段
最简单的方式还是通过静态扫描+pipline 处理,之后在合并mr之前进行一次拦截。
静态扫描方式比较多,下面给大家简单的介绍下:
阿里的sonar 但是对kt的支持很糟糕,因为阿里使用,所以有很多现成的规则可以使用,但是如果从0-1接入,你可能会直接放弃。
原生的lint,可以基于原生提供的lint api,对其进行开发,支持种类也多,基本上算是一个非常优秀的方案了,但是由于文档资料较少,对于开发的要求可能会较高。
AndroidLint。
13. 如何对第三方的依赖做静态检查?
魔高一尺道高一丈。lint还是能解决这个问题的。
Tree Api+ClassScanner = 识别三方隐私权限调用。
14. R.java code too large 解决方案
又是一个过期的问题,尽早升级agp版本,让R8帮你解决这个问题,R文件完全可以内联的。
或者用别的AGP插件的R inline也可以解决这个问题。
15. R inline 你需要注意些什么?
预扫描,先收集调用的信息,之后在进行替换。还有javac 的时候可能就因为文件过大,直接挂掉了。
16. 一个类替换父类 比如所有activity实现类替换baseactivity
class node 直接替换 superName ,想起了之前另外一个问题,感觉主要是要对构造函数进行修改,否则也会出异常。
17. R8 D8 以及混淆相关的,还有R8除了混淆还能干些什么?混淆规则有没有碰到什么奇怪的问题?
D8和Dx的区别,主要涉及到编译速度以及编译产物的体积,包体积大概小11%。
R8 则是变更了整个编译流程的,其中我觉得最微妙的就是java8 lambda相关的,脱糖前后的差别还是比较大的。同时R8也少了很多之前的Transform。
R8的混淆部分,混淆除了能增加代码阅读难度意外,更多的是对于代码优化方面的。比如无效代码优化, 同时也删除代码等等都可以做。
18. 编译的时候有没有碰到javac的常量优化
javac会将静态常量直接优化成具体的数值。但是尤其是多模块场景下尤其容易出现异常,看起来是个实际的常量引用,但是产物上却是一个具体的常量值了。
3其他部分
组件化相关
不仅仅要聊到路由,还需要聊下业务仓库的设计,如何避免两个模块之间相互相互引用导致的环问题。
另外就是路由的apt aop的部分都可以深入的聊一下。
如果只聊路由的话,你就只说了一个字符串匹配规则,非常无聊了。
路由跳转
路由跳转只是一小部分,其核心原理就是字符串匹配,之后筛选出符合逻辑的页面进行跳转。
另外就是拦截器的设计,同步异步拦截器两种完全不同的写法。
其原理基于apt+transform ,apt负责生成模块的路由表,而transform则负责将各个模块的路由表进行收集。
服务发现
类似路由表,但是维护的是一个基于键值的类构造。ab之间当有相互依赖的情况下,可以通过基于接口编程的方式进行调整,互相只依赖抽象的接口,之后实现类在内部,通过注册的机制。之后在实际的使用地方用服务发现的机制寻找。
虚拟机部分
很多人会觉得虚拟机这部分都是硬八股,比较无聊。但是其实有时候我们碰到的一些字节码相关的问题就和这部分基础姿势相关了。
虽然用的比较少,但是也不是一个硬八股,比hashmap好玩太多了。
依赖注入
和服务发现类似,也是拿来解决不同模块间的依赖问题。可以使用hilt,依赖注入的好处就是连构造的这部分工作也有di完成了,而且构造能力更多样。可以多参数构造。
总结
其实以当前来说安卓的整个体系相对来说很复杂,第三方库以及源代码量都比较大,并不是要求每个同学都对这些有一个良好的掌握,但是大体上应该了解的还是需要了解的。
面试造火箭可不是浪得虚名啊,但是鸡架可能还是需要使用到其中一些奇奇怪怪的黑科技的。
好了胡扯结束了,今天的文章就到此为止了。 查看全部
Android 基础架构组,面试题问什么?
水一篇
年中的时候帮部门招人,发现很多候选人对于我们部门还是很青睐的。也对鸡架部门做的事比较感兴趣,所以今天这篇水文主要就给大家梳理下基架的面试题以及基础架构组涉及的sdk相关。
因为最近几年面试经常被人吊打,所以也有了总结面试题的习惯。之后加上之前帮候选人的面试总结,今天给大家再卷一波。
1SDK相关
面试的时候我觉得哦,这些sdk有任意其实你研究的比较深入就行了,应该能在面试中表现的很好了。还有就是个人建议最好还是在单一方向研究的更深入一点,别的只要大概知道干什么的就行了。
1. 配置中心以及灰度测试
app必备工具之一,配置中心主要负责的就是动态化的配置,比如文本展示类似这些的。sdk提供方需要负责的是提供动态更新能力,这里有个差异化更新,只更新dif部分,还有就是流量优化等等需要开发同学考虑的。然后可以考虑下存储性能方面的提升等。
而abtest也是app必备工具之一了,动态的下发实验策略,之后开发同学可以切换实验的页面。另外主要需要考虑灰度结果计算,分桶以及版本过滤白名单等等。这里只是一个简单的介绍不展开,因为我只是一个使用方。
2. 调试组件
个人还是更推荐滴滴的Dokit,功能点比较多而且接入相对来说比较简单。而且提供了很多给开发同学定制的能力,可以在debug情况下增加很多业务相关的测试功能,方便测试同学,核心还是浮窗太方便了。
当然很多实验性的预研功能等其实都可以直接接在这里,然后在测试环境下充分展开,之后在进行线上灰度方案。还有一些具有风险的hook操作,个人也比较建议放在debug组件上。
3. 性能监控框架
这部分有几个不同的方面,首先是异常崩溃方面的,另外则是性能监控方面的,但是他们整体是划分在一起的,都属于线上性能监控体系的。
Crash相关的,可以从爱奇艺的xCrash学起。包含了崩溃日志,ANR以及native crash,因为版本适配的问题ANR在高版本上已经不是这么好捞了,还有就是native crash相关的。是一个非常牛逼的库了。
而线上的性能监控框架可以从腾讯的Matrix学起,以前有两篇文章介绍的内容也都是和Matrix相关的, Matrix首页上也有介绍,比如fps,卡顿,IO,电池,内存等等方面的监控。其中卡顿监控涉及到的就是方法前后插桩,同时要有函数的mapping表,插桩部分整体来说比较简单感觉。
另外关于线上内存相关的,推荐各位可以学习下快手的koom, 对于hprof的压缩比例听说能达到70%,也能完成线上的数据回捞以及监控等等,是一个非常屌的框架。下面给大家一个抄答案的方式。字节也有一个类似的原理其实也差不多。
主进程发现内存到达阈值的时候,用leakcanary的方案,通过shark fork进程内存,之后生成hrop。由于hrop文件相对较大,所以我们需要对于我们所要分析的内容进行筛选,可以通过xhook,之后对hrop的写入操作进行hook,当发现写入内容的类型符合我们的需要的情况下才进行写入。
而当我们要做线上日志回捞的情况,需要对hprof 进行压缩,具体算法可以参考koom/raphel,有提供对应的压缩算法。
最后线上回捞机制就是基于一个指令,回捞线上符合标准的用户的文件操作,这个自行设计。
其实上述几个库都还是有一个本质相关的东西,那么就是plthook,这个上面三个库应该都有对其的使用,之前是爱奇艺的xhook,现在是字节的bhook, 这个大佬也是我的偶像之一了,非常离谱了算是。
Android 性能采集之Fps,Memory,Cpu和Android IO监控。
最近已经不咋写这部分相关了,所以也就没有深挖,但是后续可能会有一篇关于phtead hook相关的,也是之前matrix更新的一个新东西,还在测试环境灰度阶段。
4. 基础网络组件
虽然核心可能还是三方网络库,但是因为基本所有公司都对网络方面有调整和改动,以及解析器等方面的优化,其实可以挖的东西也还是蛮多的。
应付面试的同学可以看看Android网络优化方案。当然还是要具体问题具体分析,毕竟头疼医头,脚疼医脚对吧。
之前和另外一个朋友聊了下,其实很多厂对json解析这部分有优化调整,通过apt之后更换原生成原生的解析方式,加快反序列化速度的都是可以考虑考虑的。
5. 埋点框架
其实这个应该要放在更前面一点的,数据上报数据分析啥的其实都还是蛮重要的。
这部分因为我完全没写过哦,所以我压根不咋会,但是如果你会的话,面试的时候展开说说,可以帮助你不少。
另外还需要有线上的异常用户数据回捞系统,方便开发同学主动去把线上有异常的用户的日志给收集回来。
但是有些刁钻的页面曝光监控啦,自动化埋点啥的其实还是写过一点的,有兴趣的可以翻翻历史,还有github 上还有demo。
AndroidAutoTrackdemo工程。
6. 启动相关
通过DAG(有向无环图)的方式将sdk的初始化拆解成一个个task,之后理顺依赖关系,让他们能按照固定的顺序向下执行。
核心需要处理的是依赖关系,比如说其实埋点库依赖于网络库初始化,然后APM相关的则依赖于埋点库和配置中心abtest等等,这样的依赖关系需要开发同学去理顺的。
另外就是把sdk的粒度打的细碎一点,更容易观察每个sdk任务的耗时情况,之后增加task阈值告警,超过某个加载速度就通知到相应的同学改一下。
多线程是能优化掉一部分,但是也需要避免频繁线程调度。还有就是我个人觉得这些启动相关的东西因为都无法使用sdk级别的灰度,所以改动最好慎重一点。出发点始终都是好的,但是还是结果导向吧。
启动优化的核心,我个人始终坚持的就是延迟才能优化。开发人员很难做到优化代码执行的复杂度,执行时间之类的。尽人事听天命,玄学代码。
7.中间件(图片 日志 存储 基础信息)
这部分没啥,最好是对第三方库有一层隔离的思维,但是这个隔离也需要对应的同学对于程序设计方面有很好的思维,说起来简单,其实也蛮复杂的。
这里就不展开了,感觉面试也很少会问的很细。
8. 第三方sdk大杂烩(偏中台方向)
基本一个app现在都有啥分享啦,推送啦,支付啦,账号体系啦,webview,jsbridge等等服务于应用内的一些sdk,这些东西就比较偏向于业务。
有兴趣的可以看看之前写的两篇关于sdk设计相关的。
活学活用责任链 SDK开发的一点点心得 Android厂商推送Plugin化。
9. 其他方面
大公司可能都会有些动态化方案的考虑,比如插件化啊动态化之类的。这部分在下确实不行,我就不展开了啊。
2编译相关
1. 描述下android编译流程
基架很容易碰到的面试题,以前简单的描述写过。聊聊Android编译流程。
虽然是几年前的知识点了,但是还是要拆开高低版本的agp做比较的。所以这部分可以回答下,基本这题就能简单的拿下了。
2. Gradle 生命周期
简单的说下就是buildSrc先编译,之后是根目录的settings.gradle, 根build.gradle,最后才是module build。
网上一堆,你自己翻一番就知道了。
3. apt是编译中哪个阶段
APT解析的是java 抽象语法树(AST),属于javac的一部分流程。大概流程:.java -> AST -> .class
聊聊AbstractProcessor和Java编译流程。
4. Dex和class有什么区别
链接传送门:
Class与dex的区别:
1)虚拟机:class用jvm执行,dex用dvm执行。
2)文档:class中冗余信息多,dex会去除冗余信息,包含所有类,查找方便,适合手机端。
JVM与DVM:
1)JVM基于栈(使用栈帧,内存),DVM基于寄存器,速度更快,适合手机端。
2)JVM执行Class字节码,DVM执行DEX。
3)JVM只能有一个实例,一个应用启动运行在一个DVM。
DVM与ART:
1)DVM:每次运行应用都需要一次编译,效率降低。JIT
2)ART:Android5.0以上默认为ART,系统会在进程安装后进行一次预编译,将代码转为机器语言存在本地,这样在每次运行时不用再进行编译,提高启动效率;。AOP & JIT
5. Transform是如何被执行的
Transform 在编译过程中会被封装成Task 依赖其他编译流程的Task执行。
6. Transform和其他系统Transform执行的顺序
其实这个题目已经是个过期了,后面对这些都合并整合了,而且最新版的api也做了替换,要不然考虑下回怼下面试官?
Transform和Task之间有关?
7. 如何监控编译速度变慢问题
./gradlew xxxxx -- scan<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
之后会生成一个gradle的网页,填写下你的邮箱就好了。
另外一个相对来说比较简单了。通过gradle原生提供的listener进行就行了。
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
// 耗时统计kt化<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class TimingsListener : TaskExecutionListener, BuildListener {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var startTime: Long = 0L<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> private var timings = linkedMapOf()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun beforeExecute(task: Task) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> startTime = System.nanoTime()<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun afterExecute(task: Task, state: TaskState) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> val ms = TimeUnit.MILLISECONDS.convert(System.nanoTime() - startTime, TimeUnit.NANOSECONDS)<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> task.path<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings[task.path] = ms<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${task.path} took ${ms}ms")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildFinished(result: BuildResult) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("Task timings:")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> timings.forEach {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if (it.value >= 50) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> project.logger.warn("${it.key} cos ms ${it.value}\n")<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun buildStarted(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun settingsEvaluated(settings: Settings) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsLoaded(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> override fun projectsEvaluated(gradle: Gradle) {<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />}<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gradle.addListener(TimingsListener())<br mp-original-font-size="11" mp-original-line-height="15" style="outline: 0px;max-width: 100%;line-height: 18.75px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br mp-original-font-size="17" mp-original-line-height="27.200000762939453" style="outline: 0px;max-width: 100%;line-height: 34px;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
8. Gradle中如何给一个Task前后插入别的任务
最简单的可以考虑直接获取到Task实例,之后在after和before插入一些你所需要的代码。
另外一个就是通过dependOn前置和finalizedBy挂载一个任务 mustAfter。
Gradle 使用指南 -- Gradle Task。
9. ksp APT Transform的区别
ksp 是kotlin专门独立的ast语法树。
apt 是java 的ast语法树。
transform是 agp 专门修改字节码的一个方法。
反杀时刻AsmClassVisitorFactory,可以看看我之前写的那篇文章。
10. Transform上的编译优化能做哪些?
虽然是个即将过期的api,但是大家对他的改动还是都比较多的。
首先肯定是需要完成增量编译的,具体的可以参考我的demo工程。记住,所有的transfrom都要全量。
另外可以考虑多线程优化,将转化操作移动到子线程内,建议使用gradle内部的共享线程。
参考agp最新做法,抽象出一个新的interface,之后通过spi串联,之后将asm链式调用。我的文章也介绍过,具体的点在哪里自己盘算。
现在准备好告别Transform了吗
11. aar 源码切换插件原理
这个前几天刚介绍过,原理和方案业内都差不多,mulite-repo应该都需要这个东西的。我的版本也比较简陋,大厂内部肯定都会有些魔改的。
相对来说功能肯定会更丰富,更全面一点。
aar和源码切换插件Plus。
12. 你们有哪些保证代码质量的手段
最简单的方式还是通过静态扫描+pipline 处理,之后在合并mr之前进行一次拦截。
静态扫描方式比较多,下面给大家简单的介绍下:
阿里的sonar 但是对kt的支持很糟糕,因为阿里使用,所以有很多现成的规则可以使用,但是如果从0-1接入,你可能会直接放弃。
原生的lint,可以基于原生提供的lint api,对其进行开发,支持种类也多,基本上算是一个非常优秀的方案了,但是由于文档资料较少,对于开发的要求可能会较高。
AndroidLint。
13. 如何对第三方的依赖做静态检查?
魔高一尺道高一丈。lint还是能解决这个问题的。
Tree Api+ClassScanner = 识别三方隐私权限调用。
14. R.java code too large 解决方案
又是一个过期的问题,尽早升级agp版本,让R8帮你解决这个问题,R文件完全可以内联的。
或者用别的AGP插件的R inline也可以解决这个问题。
15. R inline 你需要注意些什么?
预扫描,先收集调用的信息,之后在进行替换。还有javac 的时候可能就因为文件过大,直接挂掉了。
16. 一个类替换父类 比如所有activity实现类替换baseactivity
class node 直接替换 superName ,想起了之前另外一个问题,感觉主要是要对构造函数进行修改,否则也会出异常。
17. R8 D8 以及混淆相关的,还有R8除了混淆还能干些什么?混淆规则有没有碰到什么奇怪的问题?
D8和Dx的区别,主要涉及到编译速度以及编译产物的体积,包体积大概小11%。
R8 则是变更了整个编译流程的,其中我觉得最微妙的就是java8 lambda相关的,脱糖前后的差别还是比较大的。同时R8也少了很多之前的Transform。
R8的混淆部分,混淆除了能增加代码阅读难度意外,更多的是对于代码优化方面的。比如无效代码优化, 同时也删除代码等等都可以做。
18. 编译的时候有没有碰到javac的常量优化
javac会将静态常量直接优化成具体的数值。但是尤其是多模块场景下尤其容易出现异常,看起来是个实际的常量引用,但是产物上却是一个具体的常量值了。
3其他部分
组件化相关
不仅仅要聊到路由,还需要聊下业务仓库的设计,如何避免两个模块之间相互相互引用导致的环问题。
另外就是路由的apt aop的部分都可以深入的聊一下。
如果只聊路由的话,你就只说了一个字符串匹配规则,非常无聊了。
路由跳转
路由跳转只是一小部分,其核心原理就是字符串匹配,之后筛选出符合逻辑的页面进行跳转。
另外就是拦截器的设计,同步异步拦截器两种完全不同的写法。
其原理基于apt+transform ,apt负责生成模块的路由表,而transform则负责将各个模块的路由表进行收集。
服务发现
类似路由表,但是维护的是一个基于键值的类构造。ab之间当有相互依赖的情况下,可以通过基于接口编程的方式进行调整,互相只依赖抽象的接口,之后实现类在内部,通过注册的机制。之后在实际的使用地方用服务发现的机制寻找。
虚拟机部分
很多人会觉得虚拟机这部分都是硬八股,比较无聊。但是其实有时候我们碰到的一些字节码相关的问题就和这部分基础姿势相关了。
虽然用的比较少,但是也不是一个硬八股,比hashmap好玩太多了。
依赖注入
和服务发现类似,也是拿来解决不同模块间的依赖问题。可以使用hilt,依赖注入的好处就是连构造的这部分工作也有di完成了,而且构造能力更多样。可以多参数构造。
总结
其实以当前来说安卓的整个体系相对来说很复杂,第三方库以及源代码量都比较大,并不是要求每个同学都对这些有一个良好的掌握,但是大体上应该了解的还是需要了解的。
面试造火箭可不是浪得虚名啊,但是鸡架可能还是需要使用到其中一些奇奇怪怪的黑科技的。
好了胡扯结束了,今天的文章就到此为止了。
如何解决百度站长工具sitemap审核错误:索引型不予处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-30 05:08
我的个人网站说起来已经做了2年多了,一直比较佛系,没有特别关注网站的收录情况,爱收不收,真的只是因为纯爱好。实际上,谷歌、必应、360、神马等等大大小小的搜索引擎基本上都已经收录了我的网站上很多内容了,有的甚至还能到首页。可能也是自己坚持原创的原因,图片文字都是自己一点点思考整理出来的。但是,但是,但是,唯独咱们国家最大的搜索引擎百度死活不收录,2年多了啊,一条都没有收录。真是搞不懂了,同样是搜索引擎,它哪来那么多事,店大欺客有没有。真正原创的东西不收录,垃圾网站倒是收录一大堆,真是无力吐槽。吐槽归吐槽,毕竟咱还是希望更多的人能看到我辛苦创作出来的东西,这些东西大多比较冷门,如果不是爱好,真的早就放弃了分享。希望能和更多有相同爱好的朋友一起交流。所以,最近一改一贯的佛系作风,主动到百度站长工具提交sitemap,不提交不知道,一提交给我报了错误:索引型不予处理。不会是4/1愚人节给我开玩笑了吧。问题来了,咱们也不逃避,看看如何解决?
1.索引型不予处理-原因分析1.1先来看下百度站长工具官方说明:
从官方说明中,清楚的看到:请勿提交索引型sitemap,索引型不予处理,且若存在索引型sitemap,将不允许提交新文件;请删除索引型sitemap后再尝试提交数据。
1.2什么是索引型sitemap
再看下百度搜索资源平台发布《sitemap 提交方式优化公告》
为提高站点地图文件的处理效率,搜索资源平台常用的采集和死链提交工具不再支持索引站点地图文件(即XML文档嵌套)XML文档。
也就是这种嵌套的sitemap是被百度定义为索引型sitemap。
1.3如何生成索引型sitemap(嵌套型)
我的网站几乎都是安装的SEO插件-Rank Math,目前最好用的SEO工具。也正是用这个插件自动生成的sitemap网站地图:。
打开这个索引型sitemap,可以看到下面实际上嵌套有4个分sitemap:
打开其中一条分sitemap,可以看到具体网站url
从上面结构可以看出,Rank Math插件生成sitemap是xml文档嵌套xml文档的结构,也就是xml文档里面还有xml文档,不是真正的网站网址,所以产生了这个索引型不予处理的问题。
这里再吐槽下,同样的文件样式结构,为啥其他搜索引擎没这个要求那,不主动提交也嗖嗖的收录。
2.索引型不予处理-解决方案
既然百度站长工具平台不再支持xml嵌套xml文档这种格式的索引站点地图文件,解决方法比较简单,把上面的4条sitemap都提交给百度站长工具。
2.1先删除之前提交的总的sitemap:
2.2添加分sitemap地址
根据你网站下面的实际sitemap数量来进行提交,4个就提交4个,更多就提交更多。
这里再吐槽下,不备案的话一天只能提交1条,真。。。后面陆续把4个sitemap提交即可。
提交之后,显示等待,后面等着百度蜘蛛过来抓取就可以了。
3.提交后效果展示
百度蜘蛛过来抓取成功后,网站sitemap地图正常了。有时候也可能会显示抓取失败,删除再从新提交就可以了。
最后总结
作为一名草根站长还是挺难的,只是想老老实实的写点自己感兴趣的文章,能让更多的人看到,从而在站长这条小路上,不那么孤独。不过有的时候正是这些那些的问题,不断提高技术水平,也通过不断的解决各种各样的问题得到一种快乐,所谓的成就感,因为快乐而坚持! 查看全部
如何解决百度站长工具sitemap审核错误:索引型不予处理
我的个人网站说起来已经做了2年多了,一直比较佛系,没有特别关注网站的收录情况,爱收不收,真的只是因为纯爱好。实际上,谷歌、必应、360、神马等等大大小小的搜索引擎基本上都已经收录了我的网站上很多内容了,有的甚至还能到首页。可能也是自己坚持原创的原因,图片文字都是自己一点点思考整理出来的。但是,但是,但是,唯独咱们国家最大的搜索引擎百度死活不收录,2年多了啊,一条都没有收录。真是搞不懂了,同样是搜索引擎,它哪来那么多事,店大欺客有没有。真正原创的东西不收录,垃圾网站倒是收录一大堆,真是无力吐槽。吐槽归吐槽,毕竟咱还是希望更多的人能看到我辛苦创作出来的东西,这些东西大多比较冷门,如果不是爱好,真的早就放弃了分享。希望能和更多有相同爱好的朋友一起交流。所以,最近一改一贯的佛系作风,主动到百度站长工具提交sitemap,不提交不知道,一提交给我报了错误:索引型不予处理。不会是4/1愚人节给我开玩笑了吧。问题来了,咱们也不逃避,看看如何解决?
1.索引型不予处理-原因分析1.1先来看下百度站长工具官方说明:
从官方说明中,清楚的看到:请勿提交索引型sitemap,索引型不予处理,且若存在索引型sitemap,将不允许提交新文件;请删除索引型sitemap后再尝试提交数据。
1.2什么是索引型sitemap
再看下百度搜索资源平台发布《sitemap 提交方式优化公告》
为提高站点地图文件的处理效率,搜索资源平台常用的采集和死链提交工具不再支持索引站点地图文件(即XML文档嵌套)XML文档。
也就是这种嵌套的sitemap是被百度定义为索引型sitemap。
1.3如何生成索引型sitemap(嵌套型)
我的网站几乎都是安装的SEO插件-Rank Math,目前最好用的SEO工具。也正是用这个插件自动生成的sitemap网站地图:。
打开这个索引型sitemap,可以看到下面实际上嵌套有4个分sitemap:
打开其中一条分sitemap,可以看到具体网站url
从上面结构可以看出,Rank Math插件生成sitemap是xml文档嵌套xml文档的结构,也就是xml文档里面还有xml文档,不是真正的网站网址,所以产生了这个索引型不予处理的问题。
这里再吐槽下,同样的文件样式结构,为啥其他搜索引擎没这个要求那,不主动提交也嗖嗖的收录。
2.索引型不予处理-解决方案
既然百度站长工具平台不再支持xml嵌套xml文档这种格式的索引站点地图文件,解决方法比较简单,把上面的4条sitemap都提交给百度站长工具。
2.1先删除之前提交的总的sitemap:
2.2添加分sitemap地址
根据你网站下面的实际sitemap数量来进行提交,4个就提交4个,更多就提交更多。
这里再吐槽下,不备案的话一天只能提交1条,真。。。后面陆续把4个sitemap提交即可。
提交之后,显示等待,后面等着百度蜘蛛过来抓取就可以了。
3.提交后效果展示
百度蜘蛛过来抓取成功后,网站sitemap地图正常了。有时候也可能会显示抓取失败,删除再从新提交就可以了。
最后总结
作为一名草根站长还是挺难的,只是想老老实实的写点自己感兴趣的文章,能让更多的人看到,从而在站长这条小路上,不那么孤独。不过有的时候正是这些那些的问题,不断提高技术水平,也通过不断的解决各种各样的问题得到一种快乐,所谓的成就感,因为快乐而坚持!
非靶代谢组原始数据上传保姆级教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-30 04:15
相信大家对于转录组和蛋白组的数据上传方法都不陌生,转录组数据一般上传到NCBI网站,蛋白组学数据一般共享在proteomexchange网站,那代谢组的原始数据呢?传到哪里?如何上传?有哪些注意事项?今天就来为大家一一揭晓。
非靶代谢组原始数据上传到哪里?
MetaboLights,简称为MTBLS,是EMBL-EBI数据库的子库,该库跨技术、跨物种,涵盖了代谢物的结构、生物学作用、位置、浓度、参考谱图以及来自代谢实验的检测数据,是重要的代谢组学实验和衍生信息的数据库()。MetaboLights是众多优质期刊推荐的代谢组学资料库。
代谢组原始数据如何上传?
01注册账号并激活
登陆所填写的注册邮箱,点击邮箱中的链接,完成账户激活;
02上传数据
①点击页面右上角“Login”,输入注册的账号和密码,登录;
②登录之后点击SubmitStudy ,首次提交,选择“提交新研究数据”;
③点击“Createonline”选择“CreateNew Study”之后跳转的页面选择“Let’sget started”;
④有2种选择“现在上传原始数据”和“延后上传原始数据”,若选择现在就上传数据,请按照下图操作;
⑤系统会自动生成一个项目,并配有独有的项目号MTBLSxxxx及网址链接,建议大家记录下来,后期可以用于文章写作或进行数据查看,我们的注册邮箱也会同步收到一封邮件,其中包含有本项目的项目号及网址链接。随后点击“NEXT”;
⑥网站提供2种数据上传方式,AsperaUpload和PrivateFTP Upload,建议选择AsperaUpload,上传数据会更快;
⑦先点击installplugin下载并安装插件,再点击Uploadfile;
⑧弹出上传数据的选项框,选择要上传的数据,点击打开;
⑨然后系统默认会用IBM插件上传数据,如下图所示,上传完成后拉到页面最下方,点击绿色的next;
⑩填写studydescription信息,包含keywords、title、summary等,并且需要根据实际情况选择是否有manuscript;
⑪接下来进入上面流程图中的最后一步:填写sample& assaydetails,请根据项目实际情况如实填写,如果是POS和NEG模式都采集了,请分别选positive建立一个assay,再选择negative建立一个assay;
⑫填写完成后点击右上角“Massspectrometry”,填写Protocols、Experimentalcontrol names 、Samplenames、Sampledetails、Assaydetails共6项内容;
⑬Protocols包括样本收集、提取、色谱方法、质谱方法、数据转换、代谢物鉴定方法,请根据实际情况填写;
⑭填写实验对照样本及正式样本的名称,包含空白、QC、混样等;
⑮填写sampledetails里的内容,根据实际情况填写物种、样本类型等信息。如有其他factor,如性别、年龄、用药等,则可以根据实际情况点击factor增加列数;
⑯接下来补充,需要根据实际情况填写仪器类型、仪器型号、数据采集极性、扫描范围、样本对应原始数据、对应derived数据等信息,填写完成后,点击Next;
⑰进入Metaboliteannotation填写,有两种方式:可以选择upload上传系统能够自动识别的txt文件File:m_MTBLS4669_LC-MS_positive__metabolite_profiling_v2_maf.tsv,该文件可在本网页上download下来然后填写metabolitesidentification、massto charge(m/z)、retentiontime(RT)、Modification(adduct形式)、代谢物定量值等关键信息(该文件可通过EXCEL打开并进行编写);也可以点击“compoundsearch”一个一个进行添加,但是比较麻烦;
⑱填写完后,点击“close”,再点击“Next”
⑲核对已填写的信息,确认无误后,根据项目是否完成选择“Submitted”或者“InCuration”,之后点击“OK”
⑳点击绿色的时间按钮,选择数据释放的时间,点击“OK”;
㉑最后,点击主界面右上方的“MyStudies”,即可查看先前上传的数据。
㉒在“Validation”后显示绿色的对号时,说明数据上传成功了。
有哪些注意事项?
使用Google浏览器;
每一步信息按实际情况填写,网页会自动保存,最后会再次确定论文的相关信息;
installplugin插件安装对网络状态要求较高,小迈尝试了多次才成功,若想节省时间,可“翻墙”进行后续操作;
数据上传如遇报错,可选择上午10点、11点左右上传,速度会更快;
后记
代谢组学上传数据就是这么简单,是不是感觉离文章发表又近了一步?
学会了就快来试试吧!
往期精彩:
●
●
查看全部
非靶代谢组原始数据上传保姆级教程
相信大家对于转录组和蛋白组的数据上传方法都不陌生,转录组数据一般上传到NCBI网站,蛋白组学数据一般共享在proteomexchange网站,那代谢组的原始数据呢?传到哪里?如何上传?有哪些注意事项?今天就来为大家一一揭晓。
非靶代谢组原始数据上传到哪里?
MetaboLights,简称为MTBLS,是EMBL-EBI数据库的子库,该库跨技术、跨物种,涵盖了代谢物的结构、生物学作用、位置、浓度、参考谱图以及来自代谢实验的检测数据,是重要的代谢组学实验和衍生信息的数据库()。MetaboLights是众多优质期刊推荐的代谢组学资料库。
代谢组原始数据如何上传?
01注册账号并激活
登陆所填写的注册邮箱,点击邮箱中的链接,完成账户激活;
02上传数据
①点击页面右上角“Login”,输入注册的账号和密码,登录;
②登录之后点击SubmitStudy ,首次提交,选择“提交新研究数据”;
③点击“Createonline”选择“CreateNew Study”之后跳转的页面选择“Let’sget started”;
④有2种选择“现在上传原始数据”和“延后上传原始数据”,若选择现在就上传数据,请按照下图操作;
⑤系统会自动生成一个项目,并配有独有的项目号MTBLSxxxx及网址链接,建议大家记录下来,后期可以用于文章写作或进行数据查看,我们的注册邮箱也会同步收到一封邮件,其中包含有本项目的项目号及网址链接。随后点击“NEXT”;
⑥网站提供2种数据上传方式,AsperaUpload和PrivateFTP Upload,建议选择AsperaUpload,上传数据会更快;
⑦先点击installplugin下载并安装插件,再点击Uploadfile;
⑧弹出上传数据的选项框,选择要上传的数据,点击打开;
⑨然后系统默认会用IBM插件上传数据,如下图所示,上传完成后拉到页面最下方,点击绿色的next;
⑩填写studydescription信息,包含keywords、title、summary等,并且需要根据实际情况选择是否有manuscript;
⑪接下来进入上面流程图中的最后一步:填写sample& assaydetails,请根据项目实际情况如实填写,如果是POS和NEG模式都采集了,请分别选positive建立一个assay,再选择negative建立一个assay;
⑫填写完成后点击右上角“Massspectrometry”,填写Protocols、Experimentalcontrol names 、Samplenames、Sampledetails、Assaydetails共6项内容;
⑬Protocols包括样本收集、提取、色谱方法、质谱方法、数据转换、代谢物鉴定方法,请根据实际情况填写;
⑭填写实验对照样本及正式样本的名称,包含空白、QC、混样等;
⑮填写sampledetails里的内容,根据实际情况填写物种、样本类型等信息。如有其他factor,如性别、年龄、用药等,则可以根据实际情况点击factor增加列数;
⑯接下来补充,需要根据实际情况填写仪器类型、仪器型号、数据采集极性、扫描范围、样本对应原始数据、对应derived数据等信息,填写完成后,点击Next;
⑰进入Metaboliteannotation填写,有两种方式:可以选择upload上传系统能够自动识别的txt文件File:m_MTBLS4669_LC-MS_positive__metabolite_profiling_v2_maf.tsv,该文件可在本网页上download下来然后填写metabolitesidentification、massto charge(m/z)、retentiontime(RT)、Modification(adduct形式)、代谢物定量值等关键信息(该文件可通过EXCEL打开并进行编写);也可以点击“compoundsearch”一个一个进行添加,但是比较麻烦;
⑱填写完后,点击“close”,再点击“Next”
⑲核对已填写的信息,确认无误后,根据项目是否完成选择“Submitted”或者“InCuration”,之后点击“OK”
⑳点击绿色的时间按钮,选择数据释放的时间,点击“OK”;
㉑最后,点击主界面右上方的“MyStudies”,即可查看先前上传的数据。
㉒在“Validation”后显示绿色的对号时,说明数据上传成功了。
有哪些注意事项?
使用Google浏览器;
每一步信息按实际情况填写,网页会自动保存,最后会再次确定论文的相关信息;
installplugin插件安装对网络状态要求较高,小迈尝试了多次才成功,若想节省时间,可“翻墙”进行后续操作;
数据上传如遇报错,可选择上午10点、11点左右上传,速度会更快;
后记
代谢组学上传数据就是这么简单,是不是感觉离文章发表又近了一步?
学会了就快来试试吧!
往期精彩:
●
●
wordpress文章自动翻新插件wppr,自动翻新老旧文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-30 04:10
随着站点的文章越来越多,老旧文章逐渐被埋没,曝光机会减少,流量随之减少。如果有这样一个插件,能每天翻新一些老旧文章,就可以增加老旧文章的曝光。如果安装了搜索引擎推送插件,还可以重新推送到搜索引擎。wppr就是这样一个支持文章自动翻新的插件。
功能
可设置翻新间隔
可以设置翻新间隔(最小一分钟),插件会每隔这个间隔时间翻新一篇旧文章。
每日最多翻新文章数量
可设置每天最多翻新的文章数量,到达这个数据就停止翻新。
翻新时间窗口限制
可设置翻新窗口,比如设置早八点到晚八点时间段翻新,其余时间不翻新。
指定/排除分类
可指定只翻新某个分类的文章或者不翻新某个分类的文章。
古老的文章已经翻新成新的日期了:
后台截图
下载和安装先下载并安装站长工具箱,再下载并安装自动翻新插件。站长工具箱是基础环境,一定要先安装站长工具箱再安装自动翻新插件。
可以点击原文前往官网下载啦! 查看全部
wordpress文章自动翻新插件wppr,自动翻新老旧文章
随着站点的文章越来越多,老旧文章逐渐被埋没,曝光机会减少,流量随之减少。如果有这样一个插件,能每天翻新一些老旧文章,就可以增加老旧文章的曝光。如果安装了搜索引擎推送插件,还可以重新推送到搜索引擎。wppr就是这样一个支持文章自动翻新的插件。
功能
可设置翻新间隔
可以设置翻新间隔(最小一分钟),插件会每隔这个间隔时间翻新一篇旧文章。
每日最多翻新文章数量
可设置每天最多翻新的文章数量,到达这个数据就停止翻新。
翻新时间窗口限制
可设置翻新窗口,比如设置早八点到晚八点时间段翻新,其余时间不翻新。
指定/排除分类
可指定只翻新某个分类的文章或者不翻新某个分类的文章。
古老的文章已经翻新成新的日期了:
后台截图
下载和安装先下载并安装站长工具箱,再下载并安装自动翻新插件。站长工具箱是基础环境,一定要先安装站长工具箱再安装自动翻新插件。
可以点击原文前往官网下载啦!
文章自动采集插件(运营助理学院文章自动采集插件使用实例教程(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-15 05:06
文章自动采集插件使用实例教程关于本文模板:【运营助理学院】插件免费注册教程!插件在这边留qq邮箱,需要的请先加qq小冰(远山),私聊告诉你。作者:远山二娃群号:280242800下面一起来看看看这两位大大是如何来实战分享免费插件的。01/远山分享免费插件【运营助理学院】免费插件的到底可以免费使用了么?实战以后才发现有时免费注册不行,到处需要开通,后面也尝试过下,都失败了。
所以,带你来解决这个问题。首先看我的图上面是我没有注册插件,我后面也注册了,可是有些网站没开通,特别麻烦。以下是我注册了,开通了小冰老师(我和小冰聊得来),以及过了60天的绑定账号获取。从开通之后开始登录账号,发现可以在,会员都是永久需要50块钱,我注册的免费模板都会给我推荐一个付费的精英或高级会员,我才100块(新人29。
8),我觉得划算。重点来了,其实免费注册就是在前面登录账号的时候,小冰给你推荐了,下面是全局模板,之后当我需要某个功能我就能直接进来要,是不是很方便。后面给大家放一个我的关注页面,我更偏爱百度经验,每天更新下干货,挺多的,所以会分享以此吸引客户,当然收入也不会少。我知道我这写的是日记,可是心情分享也可以的,发现我写文章有很多地方需要倾斜,我看小冰老师也许有他的价值,我也跟着他的讲解来写下的一次日记,这个的价值应该不小的,比如我写完这篇就会将我这个功能去推广,说不定我还能通过这个吸引一些客户过来加我。
以及下图截图,同时我找了一个软件有20多个功能都没有听,不是我记性不好,我就是要尝试不同的功能,不同的技巧去增加到我的需求上。02/finda分享教程的2个方法分享前先解释2个术语,今天分享的免费插件只需要开通两个功能,第一个就是使用网站插件时自动获取模板,第二个就是通过小冰模板来实现。我们先看第一个。
确认插件版本,如果你是老用户,直接就是到插件那里下载插件,或者搜你的分享是finda的出来的插件是免费的。当你想要去获取一个其他功能就需要学习,比如我发现小冰老师我不好用,还有通过网站注册。当你需要获取其他插件功能就可以参考上面我说的方法。
分享其他功能的方法如下:
1、下载安装一个插件,finda插件,复制粘贴复制你当前分享插件。
2、之后你的网站插件就是你复制粘贴之后的插件,有了之后你只需要动动鼠标,按键盘上的功能键(比如按f2就是获取其他插件功能),就可以将该插件弹出来了。基本全局模板,达到复制粘贴就弹出来的效果,当然如果你想要支持全局模板, 查看全部
文章自动采集插件(运营助理学院文章自动采集插件使用实例教程(组图))
文章自动采集插件使用实例教程关于本文模板:【运营助理学院】插件免费注册教程!插件在这边留qq邮箱,需要的请先加qq小冰(远山),私聊告诉你。作者:远山二娃群号:280242800下面一起来看看看这两位大大是如何来实战分享免费插件的。01/远山分享免费插件【运营助理学院】免费插件的到底可以免费使用了么?实战以后才发现有时免费注册不行,到处需要开通,后面也尝试过下,都失败了。
所以,带你来解决这个问题。首先看我的图上面是我没有注册插件,我后面也注册了,可是有些网站没开通,特别麻烦。以下是我注册了,开通了小冰老师(我和小冰聊得来),以及过了60天的绑定账号获取。从开通之后开始登录账号,发现可以在,会员都是永久需要50块钱,我注册的免费模板都会给我推荐一个付费的精英或高级会员,我才100块(新人29。
8),我觉得划算。重点来了,其实免费注册就是在前面登录账号的时候,小冰给你推荐了,下面是全局模板,之后当我需要某个功能我就能直接进来要,是不是很方便。后面给大家放一个我的关注页面,我更偏爱百度经验,每天更新下干货,挺多的,所以会分享以此吸引客户,当然收入也不会少。我知道我这写的是日记,可是心情分享也可以的,发现我写文章有很多地方需要倾斜,我看小冰老师也许有他的价值,我也跟着他的讲解来写下的一次日记,这个的价值应该不小的,比如我写完这篇就会将我这个功能去推广,说不定我还能通过这个吸引一些客户过来加我。
以及下图截图,同时我找了一个软件有20多个功能都没有听,不是我记性不好,我就是要尝试不同的功能,不同的技巧去增加到我的需求上。02/finda分享教程的2个方法分享前先解释2个术语,今天分享的免费插件只需要开通两个功能,第一个就是使用网站插件时自动获取模板,第二个就是通过小冰模板来实现。我们先看第一个。
确认插件版本,如果你是老用户,直接就是到插件那里下载插件,或者搜你的分享是finda的出来的插件是免费的。当你想要去获取一个其他功能就需要学习,比如我发现小冰老师我不好用,还有通过网站注册。当你需要获取其他插件功能就可以参考上面我说的方法。
分享其他功能的方法如下:
1、下载安装一个插件,finda插件,复制粘贴复制你当前分享插件。
2、之后你的网站插件就是你复制粘贴之后的插件,有了之后你只需要动动鼠标,按键盘上的功能键(比如按f2就是获取其他插件功能),就可以将该插件弹出来了。基本全局模板,达到复制粘贴就弹出来的效果,当然如果你想要支持全局模板,
文章自动采集插件(SDCMS采集的网站优化技巧,关键词和描述很重要!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-04-13 21:17
SDcms采集、Vividcms(SDcms)是四合一企业网站系统(PC/手机/mini节目/公众号管理)。 SDcms是很多站长使用的cms建站系统,但是由于SDcms比较小,所以支持SDcms上的采集器很少更不用说SDcms的文章自动更新和SDcms的SEO优化设置,如:batch采集、auto伪原创、自动发布和一键由搜狗、百度、神马、360等搜索引擎自动推送。
SDcms采集 的 网站 优化技巧,关键词 和描述很重要。 网站写好标题后,元信息中的关键词和描述就很重要了。 SDcms采集只需用户在网页上简单设置目标管理网站即可。完成后系统会对内容和图片进行高精度匹配,并根据用户设置的采集时间、发布时间和关键词自动聚合文章。虽然现在 关键词 和描述的作用减少了,但这并不意味着它完全没用。注意每一个细节。
SDcms采集对网站的开启速度有一定的要求。 网站开启速度不要太慢,最好在3秒以内。原则上,越早越好。 SDcms采集首页也做了优化,一个好的标题很重要。在网站首页优化的过程中,网站首页的标题非常重要。首先,检查标题中是否有关键词,标题中是否收录核心产品、核心服务等企业推广的关键词,标题中是否收录关键词整个 网站。这里不讲关键词选择的方法和注意事项。我只想说首页需要选择主关键词和核心关键词,可以出现在网站标题中,有利于网站排名。
SDcms采集需要控制网站首页内容的更新频率,网站首页向用户展示新内容的频率也是给搜索引擎新的内容内容,然后推送SDcms采集的推送,主动向搜索引擎公开网站链接,增加蜘蛛爬取的频率,从而促进网站收录。 SDcms采集 根据对搜索到的关键词的分析,可以帮助网站优化内容和页面布局,帮助改进网站的内容.
SDcms采集首先不要去调整TDK,也不要忙着做外链和优化。从网站的原创数据采集分析和整个网站的SEO诊断入手。 SDcms采集无需学习更多专业技能。只需几个简单的步骤即可轻松采集、准确发布和 关键词 网络数据。采集和观察网站的原创数据是为了帮助我们熟悉网站的现状,通过站点统计了解流量的来源和关键词的来源。里面的关键词对我们后期的扩展和布局也有帮助,不会被误删或忽略。
同时,SDcms采集可以智能找到排名好的关键词同行网站,看看其他人的网站是如何构成的。 SDcms采集有针对性的每日更新伪原创文章因为搜索引擎也喜欢收录里面原创或者伪原创的内容,并且不断丰富自己的数据库。 SDcms采集可以自动下载图片和替换链接,配置简单。支持的图片存储方式:阿里云OSS、七牛对象存储、腾讯云、拍云、本地服务器临时存储。
SDcms发布网站更新原版文章并启动外链的锚文本。通过外链的构建,让你的网站拥有大量的蜘蛛。 (注意:外链文章的锚文本必须锚定关键关键词,后跟主关键词,以及一两个精确词。
SDcms采集不仅提供自动采集网页文章、批量数据处理、定时采集、自动导出、定时定量发布等. 它还集成了强大的 SEO 工具来提高 采集 配置和发布导出的效率。 SDcms采集随时随地都可以搞定文章,点击浏览器书签即可获得采集文章内容!今天关于SDcms采集的解释就到这里。下期我会分享更多SEO相关的知识和经验。我希望这个 文章 可以对你有所帮助。下期再见。返回搜狐,查看更多 查看全部
文章自动采集插件(SDCMS采集的网站优化技巧,关键词和描述很重要!)
SDcms采集、Vividcms(SDcms)是四合一企业网站系统(PC/手机/mini节目/公众号管理)。 SDcms是很多站长使用的cms建站系统,但是由于SDcms比较小,所以支持SDcms上的采集器很少更不用说SDcms的文章自动更新和SDcms的SEO优化设置,如:batch采集、auto伪原创、自动发布和一键由搜狗、百度、神马、360等搜索引擎自动推送。
SDcms采集 的 网站 优化技巧,关键词 和描述很重要。 网站写好标题后,元信息中的关键词和描述就很重要了。 SDcms采集只需用户在网页上简单设置目标管理网站即可。完成后系统会对内容和图片进行高精度匹配,并根据用户设置的采集时间、发布时间和关键词自动聚合文章。虽然现在 关键词 和描述的作用减少了,但这并不意味着它完全没用。注意每一个细节。
SDcms采集对网站的开启速度有一定的要求。 网站开启速度不要太慢,最好在3秒以内。原则上,越早越好。 SDcms采集首页也做了优化,一个好的标题很重要。在网站首页优化的过程中,网站首页的标题非常重要。首先,检查标题中是否有关键词,标题中是否收录核心产品、核心服务等企业推广的关键词,标题中是否收录关键词整个 网站。这里不讲关键词选择的方法和注意事项。我只想说首页需要选择主关键词和核心关键词,可以出现在网站标题中,有利于网站排名。
SDcms采集需要控制网站首页内容的更新频率,网站首页向用户展示新内容的频率也是给搜索引擎新的内容内容,然后推送SDcms采集的推送,主动向搜索引擎公开网站链接,增加蜘蛛爬取的频率,从而促进网站收录。 SDcms采集 根据对搜索到的关键词的分析,可以帮助网站优化内容和页面布局,帮助改进网站的内容.
SDcms采集首先不要去调整TDK,也不要忙着做外链和优化。从网站的原创数据采集分析和整个网站的SEO诊断入手。 SDcms采集无需学习更多专业技能。只需几个简单的步骤即可轻松采集、准确发布和 关键词 网络数据。采集和观察网站的原创数据是为了帮助我们熟悉网站的现状,通过站点统计了解流量的来源和关键词的来源。里面的关键词对我们后期的扩展和布局也有帮助,不会被误删或忽略。
同时,SDcms采集可以智能找到排名好的关键词同行网站,看看其他人的网站是如何构成的。 SDcms采集有针对性的每日更新伪原创文章因为搜索引擎也喜欢收录里面原创或者伪原创的内容,并且不断丰富自己的数据库。 SDcms采集可以自动下载图片和替换链接,配置简单。支持的图片存储方式:阿里云OSS、七牛对象存储、腾讯云、拍云、本地服务器临时存储。
SDcms发布网站更新原版文章并启动外链的锚文本。通过外链的构建,让你的网站拥有大量的蜘蛛。 (注意:外链文章的锚文本必须锚定关键关键词,后跟主关键词,以及一两个精确词。
SDcms采集不仅提供自动采集网页文章、批量数据处理、定时采集、自动导出、定时定量发布等. 它还集成了强大的 SEO 工具来提高 采集 配置和发布导出的效率。 SDcms采集随时随地都可以搞定文章,点击浏览器书签即可获得采集文章内容!今天关于SDcms采集的解释就到这里。下期我会分享更多SEO相关的知识和经验。我希望这个 文章 可以对你有所帮助。下期再见。返回搜狐,查看更多
文章自动采集插件( SEO插件使用教程:WordPressSEObyYoast做好网站插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-13 17:27
SEO插件使用教程:WordPressSEObyYoast做好网站插件)
SEO插件教程:WordPressSEObyYoast
做好网站SEO一直是站长们的心愿。说起来容易简单,但说起来很难,因为要注意的地方太多了。如果你不小心被百度到了K,你不知道发生了什么。在这里,我推荐这个名为WordPressSEObyYoast的SEO优化插件,它可以稍微减轻你的优化负担。
Hexo 安装插件
下面介绍如何在Hexo中使用RSS和百度站点地图安装插件: 安装插件:npminstall
--save enable plugins:在根目录下的_config.yml文件中添加:plugins:-
百度站点地图生成器插件使用图文教程
原文的介绍是“生成百度SitemapXML文件。相当于网站被全球最大中文搜索引擎百度订阅,为你的网站带来潜在流量。据作者介绍,这个插件是专门为百度搜索引擎开发的,对百度搜索引擎非常友好。
云计算核心技术Docker教程:Docker安装及插件使用
插件作为 Docker 镜像分发,可以托管在 DockerHub 或私有注册表上。要安装插件,请使用 dockerplugininstall 命令,如有必要,该命令会从 DockerHub 或您的私有注册表中提取插件
Wordpress 插件 WpRobot 教程
wordpress可以说是英文网站的神器,wprobot是wordpress博客自动更新的最佳插件,可以从Amazon、eBay、Clickbank、Youtube、Yahoo Answers、Flickr、Yahoo News、Rss等自动获取。 文章 。注意不支持中文,而且不是免费的,169美元。提前说明,这篇文章不是给大家做垃圾回收的
WordPress3.01 常用插件使用记录
WordPress 有各种各样的插件,它们极大地扩展了 WordPress 的功能。但是面对这么多的插件,我们需要哪些,哪些不需要呢?以下是我安装插件的一些经验,仅供参考。
Sublime 常用插件及其功能
下面是sublime教程专栏,介绍sublime常用插件,希望对需要的朋友有所帮助!常用插件和ChineseLocalization插件,支持中文、日文、英文的无缝切换。转换到U
WordPress 博客教程 (七): WordPress 插件
WordPress 受到众多博主喜爱的原因之一是 WordPress 拥有大量优秀的插件,这让 WordPress 更加强大。这部分主要分为WordPress插件安装和WordPress插件推荐两个部分。
wordpress 同步插件实现
WORDPRESS插件开发 WP2WPQAQ插件是WordPress中根据xmlrpc编写的插件,实现两个WordPress站点之间的文章同步。目前插件已经实现了文章的同步和媒体文件的上传(上传到媒体库),但是类别(category)、标签(Tag)和自定义字段(custom_fields)的同步功能有没有被实现。该插件由于大部分的存在,并不能满足当前项目的具体需求,并且由于缺少WordPress对应的A
WordPress网站SEO优化教程2:插件优化
Wordpress 很棒,因为它提供了丰富的 API 和插件机制,让无数站长通过它快速开发出自己想要的功能,只需要安装一个简单的插件就可以为 wordpress 添加丰富的功能。但是,如果你的 网站 使用了大量的插件,那么随着你的 网站 功能的增加,加载速度会变得很慢。在这篇文章中,我将告诉你如何优化插件,使网站更符合SEO的要求。
jQuery 插件 --Cookie 插件 jquery.cookie.js
总结:jQuery插件--Cookie插件jquery.cookie.js(转)
微信小程序插件-开发教程
昨天(2018.3.13),微信小程序发布重大功能更新,支持插件的使用和开发。个人估计2个月内,插件优质服务的插件会雨后春笋般冒出来,在这个文章,我带大家,从0开始,学习如何开发和使用插件。文章共分3章:1、什么是微信小程序插件2、如何开发微信小程序插件3、如何使用第三方微信小程序插件备注:为了保存文字内容,我将“微信小程序插件”简称为“插件”。什么是微信小程序......
WordPress 插件推荐:使用的最佳 SEO 插件
HeadMETADescription - 根据您的播客内容为您的博客提供动态元描述。Wordpress 的最佳标签插件。它在导航用户方面做得很好。
Bootstrap3.0学习教程22:JS插件提示框
本文主要学习JavaScript插件警告框。完整教程可以查看:Bootstrap3.0 教程。
Bootstrap3.0学习教程24:JS插件折叠
本文主要学习JavaScript插件折叠。完整教程可以查看:Bootstrap3.0 教程 查看全部
文章自动采集插件(
SEO插件使用教程:WordPressSEObyYoast做好网站插件)
SEO插件教程:WordPressSEObyYoast
做好网站SEO一直是站长们的心愿。说起来容易简单,但说起来很难,因为要注意的地方太多了。如果你不小心被百度到了K,你不知道发生了什么。在这里,我推荐这个名为WordPressSEObyYoast的SEO优化插件,它可以稍微减轻你的优化负担。
Hexo 安装插件
下面介绍如何在Hexo中使用RSS和百度站点地图安装插件: 安装插件:npminstall
--save enable plugins:在根目录下的_config.yml文件中添加:plugins:-
百度站点地图生成器插件使用图文教程
原文的介绍是“生成百度SitemapXML文件。相当于网站被全球最大中文搜索引擎百度订阅,为你的网站带来潜在流量。据作者介绍,这个插件是专门为百度搜索引擎开发的,对百度搜索引擎非常友好。
云计算核心技术Docker教程:Docker安装及插件使用
插件作为 Docker 镜像分发,可以托管在 DockerHub 或私有注册表上。要安装插件,请使用 dockerplugininstall 命令,如有必要,该命令会从 DockerHub 或您的私有注册表中提取插件
Wordpress 插件 WpRobot 教程
wordpress可以说是英文网站的神器,wprobot是wordpress博客自动更新的最佳插件,可以从Amazon、eBay、Clickbank、Youtube、Yahoo Answers、Flickr、Yahoo News、Rss等自动获取。 文章 。注意不支持中文,而且不是免费的,169美元。提前说明,这篇文章不是给大家做垃圾回收的
WordPress3.01 常用插件使用记录
WordPress 有各种各样的插件,它们极大地扩展了 WordPress 的功能。但是面对这么多的插件,我们需要哪些,哪些不需要呢?以下是我安装插件的一些经验,仅供参考。
Sublime 常用插件及其功能
下面是sublime教程专栏,介绍sublime常用插件,希望对需要的朋友有所帮助!常用插件和ChineseLocalization插件,支持中文、日文、英文的无缝切换。转换到U
WordPress 博客教程 (七): WordPress 插件
WordPress 受到众多博主喜爱的原因之一是 WordPress 拥有大量优秀的插件,这让 WordPress 更加强大。这部分主要分为WordPress插件安装和WordPress插件推荐两个部分。
wordpress 同步插件实现
WORDPRESS插件开发 WP2WPQAQ插件是WordPress中根据xmlrpc编写的插件,实现两个WordPress站点之间的文章同步。目前插件已经实现了文章的同步和媒体文件的上传(上传到媒体库),但是类别(category)、标签(Tag)和自定义字段(custom_fields)的同步功能有没有被实现。该插件由于大部分的存在,并不能满足当前项目的具体需求,并且由于缺少WordPress对应的A
WordPress网站SEO优化教程2:插件优化
Wordpress 很棒,因为它提供了丰富的 API 和插件机制,让无数站长通过它快速开发出自己想要的功能,只需要安装一个简单的插件就可以为 wordpress 添加丰富的功能。但是,如果你的 网站 使用了大量的插件,那么随着你的 网站 功能的增加,加载速度会变得很慢。在这篇文章中,我将告诉你如何优化插件,使网站更符合SEO的要求。
jQuery 插件 --Cookie 插件 jquery.cookie.js
总结:jQuery插件--Cookie插件jquery.cookie.js(转)
微信小程序插件-开发教程
昨天(2018.3.13),微信小程序发布重大功能更新,支持插件的使用和开发。个人估计2个月内,插件优质服务的插件会雨后春笋般冒出来,在这个文章,我带大家,从0开始,学习如何开发和使用插件。文章共分3章:1、什么是微信小程序插件2、如何开发微信小程序插件3、如何使用第三方微信小程序插件备注:为了保存文字内容,我将“微信小程序插件”简称为“插件”。什么是微信小程序......
WordPress 插件推荐:使用的最佳 SEO 插件
HeadMETADescription - 根据您的播客内容为您的博客提供动态元描述。Wordpress 的最佳标签插件。它在导航用户方面做得很好。
Bootstrap3.0学习教程22:JS插件提示框
本文主要学习JavaScript插件警告框。完整教程可以查看:Bootstrap3.0 教程。
Bootstrap3.0学习教程24:JS插件折叠
本文主要学习JavaScript插件折叠。完整教程可以查看:Bootstrap3.0 教程
文章自动采集插件(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-10 17:22
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?
第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
<p>5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章在内容/标题前后插入关键词与内容一致关键词/随机插入图片/添加随机属性页面 查看全部
文章自动采集插件(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名)
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?
第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
<p>5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章在内容/标题前后插入关键词与内容一致关键词/随机插入图片/添加随机属性页面
文章自动采集插件(WordPress站群的优缺点优点及主要特点是什么?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-04-10 13:13
WordPress站群也称为 WordPress Multisite,是 WordPress 的一项流行功能,可以在服务器上使用同一个 WordPress 创建和运行多个 网站。使我们的 WordPress网站 能够从一个操作页面管理多个不同的站点。
1、WordPress站群插件
WordPress站群 插件是我们可以在 wp站群SEO 中使用的工具。WordPress站群插件可用于批量采集、批量在线翻译、批量伪原创发布功能,帮助我们实现WordPress站群同步管理。支持全网发布各类cms(如图),不仅可以完成对WordPress站群的管理,还可以管理各类cms@ >。
WordPress站群插件具有SEO功能,不是通过大量的采集发布填充内容,而是支持文章title、content关键词优化。通过对采集的文本进行图像替换、图像水印、关键词密度/内链等处理,实现文章原创的高度。
2、什么是 WordPress站群?
WordPress站群 是一个一对一的功能,它允许我们从一个 WordPress 操作页面创建和运行多个 WordPress网站。它以前称为 WordPress 多用户或 WPMU。WordPress站群 并不新鲜。这些都是自 WordPress3.0 推出以来 WordPress 平台上的所有版本。
3、WordPress 的主要特点站群
在 WordPress站群 中,我们可以作为第一管理员控制整个网络。作为普通的网站管理员,我们可以控制网络上的一个网站。
作为管理员,我们可以创建帐户并设置我们自己的 WordPress 博客或 网站 用户可访问性。管理员可以新安装和主题插件,使它们也可用于网络上的 网站,并且可以为所有 网站 自定义主题。
4、WordPress站群 的优缺点
优点:我们可以管理来自不同域的不同网站子板的网站。如果我们在一个父级上运行由不同团队管理的多个,这很有用,例如具有特定国家/地区站点的电子商务商店,我们还可以为网络成员上的每个 网站 分配不同的管理。只需下载一次插件,我们就可以安装并激活它以及网络上所有 网站 的主题。我们还可以通过每个主安装来管理网络上所有 网站 的更新。
缺点:所有 网站 共享相同的网络资源,如果网络失败,它们就会失败。并非所有的 WordPress 插件都支持 站群networking。并非所有工具 Web 服务都具有多站点网络所需的支持。我们的各种服务或各种服务器要求可能无法使用一种以上的服务,并且可能需要在我们的范围内适应各种不同的服务条件。我们的计划或改变很舒服。
WordPress站群(WordPress多站点)的介绍和分享到此结束。站群具有很强的优势,但也有一些缺陷和弱点需要我们去关心和加强防范,WordPress站群插件是一个更方便我们管理我们的< @站群,通过可视化页面和即时信息反馈,让我们对站群整体信息和个别站点突发事件有明显的提示。方便我们管理。 查看全部
文章自动采集插件(WordPress站群的优缺点优点及主要特点是什么?(组图))
WordPress站群也称为 WordPress Multisite,是 WordPress 的一项流行功能,可以在服务器上使用同一个 WordPress 创建和运行多个 网站。使我们的 WordPress网站 能够从一个操作页面管理多个不同的站点。
1、WordPress站群插件
WordPress站群 插件是我们可以在 wp站群SEO 中使用的工具。WordPress站群插件可用于批量采集、批量在线翻译、批量伪原创发布功能,帮助我们实现WordPress站群同步管理。支持全网发布各类cms(如图),不仅可以完成对WordPress站群的管理,还可以管理各类cms@ >。
WordPress站群插件具有SEO功能,不是通过大量的采集发布填充内容,而是支持文章title、content关键词优化。通过对采集的文本进行图像替换、图像水印、关键词密度/内链等处理,实现文章原创的高度。
2、什么是 WordPress站群?
WordPress站群 是一个一对一的功能,它允许我们从一个 WordPress 操作页面创建和运行多个 WordPress网站。它以前称为 WordPress 多用户或 WPMU。WordPress站群 并不新鲜。这些都是自 WordPress3.0 推出以来 WordPress 平台上的所有版本。
3、WordPress 的主要特点站群
在 WordPress站群 中,我们可以作为第一管理员控制整个网络。作为普通的网站管理员,我们可以控制网络上的一个网站。
作为管理员,我们可以创建帐户并设置我们自己的 WordPress 博客或 网站 用户可访问性。管理员可以新安装和主题插件,使它们也可用于网络上的 网站,并且可以为所有 网站 自定义主题。
4、WordPress站群 的优缺点
优点:我们可以管理来自不同域的不同网站子板的网站。如果我们在一个父级上运行由不同团队管理的多个,这很有用,例如具有特定国家/地区站点的电子商务商店,我们还可以为网络成员上的每个 网站 分配不同的管理。只需下载一次插件,我们就可以安装并激活它以及网络上所有 网站 的主题。我们还可以通过每个主安装来管理网络上所有 网站 的更新。
缺点:所有 网站 共享相同的网络资源,如果网络失败,它们就会失败。并非所有的 WordPress 插件都支持 站群networking。并非所有工具 Web 服务都具有多站点网络所需的支持。我们的各种服务或各种服务器要求可能无法使用一种以上的服务,并且可能需要在我们的范围内适应各种不同的服务条件。我们的计划或改变很舒服。
WordPress站群(WordPress多站点)的介绍和分享到此结束。站群具有很强的优势,但也有一些缺陷和弱点需要我们去关心和加强防范,WordPress站群插件是一个更方便我们管理我们的< @站群,通过可视化页面和即时信息反馈,让我们对站群整体信息和个别站点突发事件有明显的提示。方便我们管理。
文章自动采集插件(怎么用海洋CMS插件让网站快速收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-09 13:39
如何使用Oceancms插件对网站快速收录和关键词进行排名?我们应该如何管理和维护我们的网站?今天给大家分享一个海洋cms插件工具,可以批量管理网站。不管你有成百上千个不同的海洋cms网站还是其他网站都可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、Oceancms 插件发布
1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Oceancms、Cyclone、站群、PB、Apple、Mito、搜外等各大cms,可以管理和发布的工具同时分批)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、Oceancms插件批量发布设置 - 覆盖 SEO 功能
这个Oceancms还配备了很多SEO功能,不仅可以通过Oceancms插件实现采集伪原创发布,还具备很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词的密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、海洋cms插件采集
1、根据关键词采集文章,用海洋cms填充内容。(Oceancms 插件还配置了关键词采集 功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、海洋cms插件采集
1、查看采集平台
2、工作中采集
3、有采集
4、采集内容视图
查看5、采集之后的内容
前段时间相信很多seoer都听过“内容为王,外链为王”的说法,但是随着外链的作用越来越小,很多seoer更加关注网站内链, 网站内链是通过网站内链投票的形式。可以使用内链聚合某个页面的权重来增加关键词和页面的权重,也可以使用内链来增加关键词和页面的权重。链式布局增加全站优质的内链框架,那么博主就为大家介绍网站的内链如何做好?如何在 Ocean cms 插件的帮助下优化 网站。
网站内链对于整个网站的意义是什么?
网站内部链接可以帮助蜘蛛爬行。在我看来,网站首页对于整个网站的权重一般都比较高。同样,蜘蛛的数量也应该是比较高的页面。完善的内链可以让蜘蛛爬到网站的页面更深,蜘蛛爬到的页面也会帮助网站的收录。
之前一直告诉大家网站收录是排名网站的依据,这里先介绍一下页面收录的流程:网站页面存在且可以正常打开→蜘蛛爬取页面→表单索引→发布快照。
如何做好网站内链布局?
首先要明确网站收录,大量内页必须由收录添加到首页,个别站长操作网站获取全站流量和排名需要使用扩词工具获取长尾词,将获取的长尾词排列在网站内容页面。在这种情况下,需要完成网站内链的构建,才能得到网站页面被爬取和收录,我们需要做什么呢?
1、网站首页权重高于内页。在 网站 主页上,需要布置一些新闻或 文章 模块,以帮助蜘蛛爬行。
2、网站内容页和栏目页需要保持到首页的直接链接,可以通过面包屑导航解决,例如:首页-栏目页-内容页。
3、做好网站地图的制作。网站地图分为两种格式:xml和html。建议制作xml图,提交给站长平台。
4、在网站的内容页面的编写中,文章中提到的内容可以链接到本站的产品或栏目页面,也可以在提高用户的前提下添加体验蜘蛛爬取页面。
网站内链的布局是为了提升用户体验和操作习惯,同时也增加了蜘蛛的爬取。不同的网站在进行网站的内链布局时或多或少会有一些差异。文末想告诉大家,网站的内部链式布局不仅仅是为了提高爬虫,现在搜索引擎越来越重视用户体验,我们需要做更好的工作网站内部链接,改善用户需求和操作行为。
很多时候在网站SEO的过程中,由于一些不当操作,网站被搜索引擎惩罚,导致网站的排名和网站的实力下降. 有经验的优化者或许一眼就能看出网站被降级的原因,并及时做出调整。但是对于新手优化器来说,可能会有点困难。那么今天,博主就来和大家聊聊如何找到网站被降级的原因。
如何找出 网站 被降级的原因?
1、网站服务器稳定吗?
网站服务器的稳定性是决定网站能否正常运行的重要因素。一些网络推广公司为了省钱,选择使用不稳定且便宜的服务器。不稳定,打不开,影响蜘蛛正常访问,从而导致网站被降级。
2、网站关键词,标题和描述是否频繁修改
关键词、网站 的标题和描述一旦确定,就不应轻易修改。作为网站优化器,需要明确网站关键词及其发展方向。另外,关键词的布局也要掌握好。优化周期过长,效果不佳,频繁替换关键词也会被百度惩罚。
网站降级
3、网站 的内容
优质的原创内容一定会受到搜索引擎的青睐。我们不仅要更新网站内容,还要更新优质内容。再问一个不经常更新的网站。会受到搜索引擎的喜爱吗?反之,也会受到搜索引擎的惩罚。
4、链接
友情链接对于 网站 来说非常重要。如果本站添加的链接有权删除,我们必须及时删除链接,否则,我们的网站将受到牵连。所以,一定要定期检查你的网站朋友链,保证网站可以一直保持良好的状态。
以上就是小编为大家带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧! 查看全部
文章自动采集插件(怎么用海洋CMS插件让网站快速收录以及关键词排名?)
如何使用Oceancms插件对网站快速收录和关键词进行排名?我们应该如何管理和维护我们的网站?今天给大家分享一个海洋cms插件工具,可以批量管理网站。不管你有成百上千个不同的海洋cms网站还是其他网站都可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、Oceancms 插件发布
1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、Oceancms、Cyclone、站群、PB、Apple、Mito、搜外等各大cms,可以管理和发布的工具同时分批)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、Oceancms插件批量发布设置 - 覆盖 SEO 功能
这个Oceancms还配备了很多SEO功能,不仅可以通过Oceancms插件实现采集伪原创发布,还具备很多SEO功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词的密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、海洋cms插件采集
1、根据关键词采集文章,用海洋cms填充内容。(Oceancms 插件还配置了关键词采集 功能和无关词屏蔽功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、海洋cms插件采集
1、查看采集平台
2、工作中采集
3、有采集
4、采集内容视图
查看5、采集之后的内容
前段时间相信很多seoer都听过“内容为王,外链为王”的说法,但是随着外链的作用越来越小,很多seoer更加关注网站内链, 网站内链是通过网站内链投票的形式。可以使用内链聚合某个页面的权重来增加关键词和页面的权重,也可以使用内链来增加关键词和页面的权重。链式布局增加全站优质的内链框架,那么博主就为大家介绍网站的内链如何做好?如何在 Ocean cms 插件的帮助下优化 网站。
网站内链对于整个网站的意义是什么?
网站内部链接可以帮助蜘蛛爬行。在我看来,网站首页对于整个网站的权重一般都比较高。同样,蜘蛛的数量也应该是比较高的页面。完善的内链可以让蜘蛛爬到网站的页面更深,蜘蛛爬到的页面也会帮助网站的收录。
之前一直告诉大家网站收录是排名网站的依据,这里先介绍一下页面收录的流程:网站页面存在且可以正常打开→蜘蛛爬取页面→表单索引→发布快照。
如何做好网站内链布局?
首先要明确网站收录,大量内页必须由收录添加到首页,个别站长操作网站获取全站流量和排名需要使用扩词工具获取长尾词,将获取的长尾词排列在网站内容页面。在这种情况下,需要完成网站内链的构建,才能得到网站页面被爬取和收录,我们需要做什么呢?
1、网站首页权重高于内页。在 网站 主页上,需要布置一些新闻或 文章 模块,以帮助蜘蛛爬行。
2、网站内容页和栏目页需要保持到首页的直接链接,可以通过面包屑导航解决,例如:首页-栏目页-内容页。
3、做好网站地图的制作。网站地图分为两种格式:xml和html。建议制作xml图,提交给站长平台。
4、在网站的内容页面的编写中,文章中提到的内容可以链接到本站的产品或栏目页面,也可以在提高用户的前提下添加体验蜘蛛爬取页面。
网站内链的布局是为了提升用户体验和操作习惯,同时也增加了蜘蛛的爬取。不同的网站在进行网站的内链布局时或多或少会有一些差异。文末想告诉大家,网站的内部链式布局不仅仅是为了提高爬虫,现在搜索引擎越来越重视用户体验,我们需要做更好的工作网站内部链接,改善用户需求和操作行为。
很多时候在网站SEO的过程中,由于一些不当操作,网站被搜索引擎惩罚,导致网站的排名和网站的实力下降. 有经验的优化者或许一眼就能看出网站被降级的原因,并及时做出调整。但是对于新手优化器来说,可能会有点困难。那么今天,博主就来和大家聊聊如何找到网站被降级的原因。
如何找出 网站 被降级的原因?
1、网站服务器稳定吗?
网站服务器的稳定性是决定网站能否正常运行的重要因素。一些网络推广公司为了省钱,选择使用不稳定且便宜的服务器。不稳定,打不开,影响蜘蛛正常访问,从而导致网站被降级。
2、网站关键词,标题和描述是否频繁修改
关键词、网站 的标题和描述一旦确定,就不应轻易修改。作为网站优化器,需要明确网站关键词及其发展方向。另外,关键词的布局也要掌握好。优化周期过长,效果不佳,频繁替换关键词也会被百度惩罚。
网站降级
3、网站 的内容
优质的原创内容一定会受到搜索引擎的青睐。我们不仅要更新网站内容,还要更新优质内容。再问一个不经常更新的网站。会受到搜索引擎的喜爱吗?反之,也会受到搜索引擎的惩罚。
4、链接
友情链接对于 网站 来说非常重要。如果本站添加的链接有权删除,我们必须及时删除链接,否则,我们的网站将受到牵连。所以,一定要定期检查你的网站朋友链,保证网站可以一直保持良好的状态。
以上就是小编为大家带来的一些关于SEO优化的实用技巧。如果您需要更多SEO优化技巧,请继续关注我,每周不定期更新SEO实用技巧!
文章自动采集插件(网站怎么用discuz插件打造高质量内容让网站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-04-08 21:10
网站如何使用discuz插件制作高质量的内容来网站快速收录和关键词排名”众所周知,在网站@的优化>、搜索引擎的算法是随着科技的发展,不断的更新和调整的。每次更新搜索引擎,都会对某些网站进行处罚,甚至会牵连一些不违规的网站。首先,我们要避免遭受搜索引擎惩罚,才能更好地优化我们的网站。
一、自动更新网站内容
众所周知,网站优化是对网站内容的长期持续更新。网站管理员必须确保定期定期更新 网站 内容。网站能够刺穿荆棘。在搜索引擎算法调整的过程中,网站的内容优化会让网站的基础更加稳固,这会阻止搜索引擎更新针对你的网站。
我们可以通过这个discuz插件实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单,无需学习更多专业技术。只需几个简单的步骤即可轻松采集内容数据,用户只需在discuz插件上进行简单的设置。discuz插件会根据用户设置的关键词准确采集文章,从而保证行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他discuz插件相比,这个discuz插件基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词即可实现采集 (discuz 插件还配备了 关键词采集 功能)。全程自动挂机! 查看全部
文章自动采集插件(网站怎么用discuz插件打造高质量内容让网站快速收录以及关键词排名)
网站如何使用discuz插件制作高质量的内容来网站快速收录和关键词排名”众所周知,在网站@的优化>、搜索引擎的算法是随着科技的发展,不断的更新和调整的。每次更新搜索引擎,都会对某些网站进行处罚,甚至会牵连一些不违规的网站。首先,我们要避免遭受搜索引擎惩罚,才能更好地优化我们的网站。
一、自动更新网站内容
众所周知,网站优化是对网站内容的长期持续更新。网站管理员必须确保定期定期更新 网站 内容。网站能够刺穿荆棘。在搜索引擎算法调整的过程中,网站的内容优化会让网站的基础更加稳固,这会阻止搜索引擎更新针对你的网站。
我们可以通过这个discuz插件实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单,无需学习更多专业技术。只需几个简单的步骤即可轻松采集内容数据,用户只需在discuz插件上进行简单的设置。discuz插件会根据用户设置的关键词准确采集文章,从而保证行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
和其他discuz插件相比,这个discuz插件基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,直接输入关键词即可实现采集 (discuz 插件还配备了 关键词采集 功能)。全程自动挂机!

