
文章网址采集器
文章网址采集器(优采云采集器数据数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-31 19:02
—————————————————————————————————
采集海外数据有两种思考方式:Cloud采集+单机采集。 优采云采集器 为嵌入式浏览器,为火狐浏览器,不可修改。同时通过修改内嵌的V**来获取外网的权限也是不同的。
如果你的某个浏览器可以通过插件上网,你能不能用优采云调用然后上网?
没有
1、云采集+外网(优采云Server)
如果使用优采云抓取外网内容,实现云采集,则只能购买其海外版一年,2999元/年,试用期3天;
此版本服务器在海外。只要设置好流程,就可以自由抓取80%的国外网页的任何内容。
无限数据量。
2、单机采集+外网(自带电脑)
如果使用自己的机器采集外网内容,需要全球稳定的V**,设置正确的流程,购买无限专业版。
专业版49元/月,399元/年。
无限数据量。
3、关于发票
半年内累计消费500以上只能开具发票,可在标题上写上公司。
4、recommendation
不知道我们现在对海外内容的需求是不是很大,根据需求我们有不同的建议:
(高需求,每天几十万)海外需求高,平均每天几十万数据,建议购买2999元/年的海外版,总费用2999元/年;
(需求量大,日均数万)所需数据量小,日均10000条数据。建议购买比较稳定的V**+专业版,总费用735元/年-1095元/年。
————————————————————————————————— 查看全部
文章网址采集器(优采云采集器数据数据)
—————————————————————————————————
采集海外数据有两种思考方式:Cloud采集+单机采集。 优采云采集器 为嵌入式浏览器,为火狐浏览器,不可修改。同时通过修改内嵌的V**来获取外网的权限也是不同的。
如果你的某个浏览器可以通过插件上网,你能不能用优采云调用然后上网?
没有
1、云采集+外网(优采云Server)
如果使用优采云抓取外网内容,实现云采集,则只能购买其海外版一年,2999元/年,试用期3天;
此版本服务器在海外。只要设置好流程,就可以自由抓取80%的国外网页的任何内容。
无限数据量。
2、单机采集+外网(自带电脑)
如果使用自己的机器采集外网内容,需要全球稳定的V**,设置正确的流程,购买无限专业版。
专业版49元/月,399元/年。
无限数据量。
3、关于发票
半年内累计消费500以上只能开具发票,可在标题上写上公司。
4、recommendation
不知道我们现在对海外内容的需求是不是很大,根据需求我们有不同的建议:
(高需求,每天几十万)海外需求高,平均每天几十万数据,建议购买2999元/年的海外版,总费用2999元/年;
(需求量大,日均数万)所需数据量小,日均10000条数据。建议购买比较稳定的V**+专业版,总费用735元/年-1095元/年。
—————————————————————————————————
文章网址采集器(文章网址采集器介绍80:80端口的命令)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-08-31 04:02
文章网址采集器介绍文章数据的页面保存在nginx服务器中,http请求分为server和body两部分。现在写一个grep命令来获取server的指标。获取server的命令:/tmp/a/data/json/shell_server.jsonserver端的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口注意:grep命令只对内部指定端口的参数解析可读文件:/tmp/a/logs/json文件server的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件可读文件:/tmp/a/logs/json文件request的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件读取写入:查看request文件可读文件:readxml():连接到一个命令,一旦命令开始就表示一切将开始。
解析文件:echo$xxx.xxx.xxx获取当前http代理的状态:status$desc获取代理源地址:/a/data.json获取终端源地址:get/data.json获取当前日期:format(date)get_timestamp()解析出代理的ip地址:mac上输入cmd输入如下指令,看出对应的用法:$proxy-p257.0.0.1解析出代理的host,只能设置一个,默认设置在:,可以设置其他的ip解析出代理的域名:manfindmacmanfindall对于代理的命令,很多网站都使用了加密服务,并且默认的是静态域名,所以需要设置本地域名,如果需要设置动态域名,可以使用:。 查看全部
文章网址采集器(文章网址采集器介绍80:80端口的命令)
文章网址采集器介绍文章数据的页面保存在nginx服务器中,http请求分为server和body两部分。现在写一个grep命令来获取server的指标。获取server的命令:/tmp/a/data/json/shell_server.jsonserver端的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口注意:grep命令只对内部指定端口的参数解析可读文件:/tmp/a/logs/json文件server的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件可读文件:/tmp/a/logs/json文件request的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件读取写入:查看request文件可读文件:readxml():连接到一个命令,一旦命令开始就表示一切将开始。
解析文件:echo$xxx.xxx.xxx获取当前http代理的状态:status$desc获取代理源地址:/a/data.json获取终端源地址:get/data.json获取当前日期:format(date)get_timestamp()解析出代理的ip地址:mac上输入cmd输入如下指令,看出对应的用法:$proxy-p257.0.0.1解析出代理的host,只能设置一个,默认设置在:,可以设置其他的ip解析出代理的域名:manfindmacmanfindall对于代理的命令,很多网站都使用了加密服务,并且默认的是静态域名,所以需要设置本地域名,如果需要设置动态域名,可以使用:。
文章网址采集器(新闻搜索集合,百度文章集合-3.新闻集合(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-08-28 15:15
新闻搜索合集、百度文章集、一站式整体网站集、白家好文章集、Portal网站新闻集、微信文章集、list文章集、风云列表采集、排行榜文章采集、问答采集、列表个人资料采集、编写规则采集指定文章等
2.品组合
素材智能组合、段落随机组合、句子随机组合、核心内容组合、素材排列组合、批量文章合并、文本批量切分、段落对组合、全文组合。
3.图片下载
自动按关键字搜索图片,自动下载,自动删除水印批量修剪图片,自动获取上传图片的远程网址
软件特点:1.智能伪原创:使用人工智能中的自然语言处理技术来处理伪原创文章。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键字”、“句子打乱重组”等。 原创属性和加工产品的收录率都在80%以上。如果您想了解更多功能,请下载软件并试用。
2.Portal网站文章采集:一键搜索搜狐、腾讯、新浪、网易、今日头条、新栏目、联合早报、光明等相关门户网站新闻文章。 , 和New等,用户可以输入行业关键词搜索想要的行业文章。该模块的作用是无需编写采集规则和一键操作。温馨提示:使用本文时请注明文章出处,尊重原文版权。
3.百度新闻选集:一键搜索各行各业的新闻报道。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。不过缺点是采集到的文章可能不全,但可以满足大部分用户的需求。温馨提示:使用本文时请注明文章出处,尊重原文版权 查看全部
文章网址采集器(新闻搜索集合,百度文章集合-3.新闻集合(图))
新闻搜索合集、百度文章集、一站式整体网站集、白家好文章集、Portal网站新闻集、微信文章集、list文章集、风云列表采集、排行榜文章采集、问答采集、列表个人资料采集、编写规则采集指定文章等
2.品组合
素材智能组合、段落随机组合、句子随机组合、核心内容组合、素材排列组合、批量文章合并、文本批量切分、段落对组合、全文组合。
3.图片下载
自动按关键字搜索图片,自动下载,自动删除水印批量修剪图片,自动获取上传图片的远程网址
软件特点:1.智能伪原创:使用人工智能中的自然语言处理技术来处理伪原创文章。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键字”、“句子打乱重组”等。 原创属性和加工产品的收录率都在80%以上。如果您想了解更多功能,请下载软件并试用。
2.Portal网站文章采集:一键搜索搜狐、腾讯、新浪、网易、今日头条、新栏目、联合早报、光明等相关门户网站新闻文章。 , 和New等,用户可以输入行业关键词搜索想要的行业文章。该模块的作用是无需编写采集规则和一键操作。温馨提示:使用本文时请注明文章出处,尊重原文版权。
3.百度新闻选集:一键搜索各行各业的新闻报道。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。不过缺点是采集到的文章可能不全,但可以满足大部分用户的需求。温馨提示:使用本文时请注明文章出处,尊重原文版权
文章网址采集器(基于adas-studio工具类,有latin3源码,在生成.mat文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-08-28 00:03
文章网址采集器下载:windows/mac采集pdf文件。源代码下载:macosx86pdfeditor.mac,获取.mat文件以及合成pdf格式文件的相关文件的linkedin地址及zhmatr.php文件。windows采集器代码,windows相关同学自行改注册中心。基于adas-studio工具类,结合高性能开发实例,mysql和access数据库实现海量实验数据分析和展示,如有需要请私信获取更多相关文章。
只能选择合适的数据源。我现在也只能接到做实验的采集,他们是用的的页面,还有我正在做的adas-studio工具类,他们有latin3源码,在生成.mat文件。
你可以在这个页面下载链接有matlab2013的源码
还有我正在做的adas-studio工具类,有latin3源码,在生成.mat文件。
有,国内比较早的(文献下载-利用adas-studio做实验,从业人员必读!)。可以试试。网站没法说。
我用的adas-studio工具类,有latin3源码,在生成.mat文件。
我现在正在做adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
有adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
这个网站是,有源码。 查看全部
文章网址采集器(基于adas-studio工具类,有latin3源码,在生成.mat文件)
文章网址采集器下载:windows/mac采集pdf文件。源代码下载:macosx86pdfeditor.mac,获取.mat文件以及合成pdf格式文件的相关文件的linkedin地址及zhmatr.php文件。windows采集器代码,windows相关同学自行改注册中心。基于adas-studio工具类,结合高性能开发实例,mysql和access数据库实现海量实验数据分析和展示,如有需要请私信获取更多相关文章。
只能选择合适的数据源。我现在也只能接到做实验的采集,他们是用的的页面,还有我正在做的adas-studio工具类,他们有latin3源码,在生成.mat文件。
你可以在这个页面下载链接有matlab2013的源码
还有我正在做的adas-studio工具类,有latin3源码,在生成.mat文件。
有,国内比较早的(文献下载-利用adas-studio做实验,从业人员必读!)。可以试试。网站没法说。
我用的adas-studio工具类,有latin3源码,在生成.mat文件。
我现在正在做adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
有adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
这个网站是,有源码。
优采云采集器官方版采集各大汽车网站最新信息(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-26 00:15
优采云采集器官方版采集各大汽车网站最新信息(组图)
优采云采集器官方版是一个网页数据采集器,可以在各种类型的网页上进行大量的数据采集work,优采云采集器官方版拥有广泛的类别、交易、社交网站、电商产品等金融网站数据可以通过规范的采集下载,并可以导出。软件界面非常简洁明了,软件使用方便快捷。这是一款非常实用且功能强大的软件,让繁琐复杂的工作变得简单有趣!
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房等各大楼盘最新行情;
7.采集个别汽车网站具体新车及二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。 查看全部
优采云采集器官方版采集各大汽车网站最新信息(组图)

优采云采集器官方版是一个网页数据采集器,可以在各种类型的网页上进行大量的数据采集work,优采云采集器官方版拥有广泛的类别、交易、社交网站、电商产品等金融网站数据可以通过规范的采集下载,并可以导出。软件界面非常简洁明了,软件使用方便快捷。这是一款非常实用且功能强大的软件,让繁琐复杂的工作变得简单有趣!
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房等各大楼盘最新行情;
7.采集个别汽车网站具体新车及二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
Win/Mac/Linux都可用不同于采集器采集内容的使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-08-26 00:12
优采云采集器 是一款非常专业的网络数据采集 软件。它由前 Google 技术团队构建。基于人工智能技术,可通过输入URL自动识别采集内容,可视化点击,一键采集网页数据,降低采集信息数据成本。同时,提高了工作效率。 VIP破解后,用户可永久免费使用。
[特点]
1、Visualization 点击,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
3、可以后台运行并实时显示速度
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
4、所有平台,Win/Mac/Linux均可使用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
[软件功能]
1、智能模式:智能识别列表和分页,一键采集
2、Flowchart 模式:可视化操作,可模拟人工操作
3、采集Tasks:100个任务,支持多任务同时运行,数量不限,支持云存储,切换终端同步更新
4、采集 URL:不限数量,支持手动输入,从文件导入,批量生成
5、采集Content:数量不限
6、下载图片:数量不限
7、Export data:导出数据到本地(不限数量),导出格式:Excel、Txt、Csv、Html
8、 发布到数据库:数量不限,支持发布到本地和云服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
9、数据处理:字段合并、文本替换、提取号码、提取邮箱、删除字符、定期替换等
10、Filtering 函数:根据条件组合过滤采集字段
11、pre-login采集:采集需要登录才能查看内容网址
[使用说明]
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
【适用场景】
1、brand/价格监控
监控品牌信息和产品评价、跟踪价格趋势、竞品分析、seo监控优化、舆情监控等
2、行业分析
采集国内外各大新闻源、博客、论坛、社交网络、电商平台等,帮助行业分析和商业决策。
3、产品研发
自动获取格式化数据,适用于不同终端的产品内容同步。精准获取用户反馈和偏好,提升研发效率。
4、精准营销
快速发现潜在客户,全面采集客户需求。提高营销效率并提高销售业绩。
5、学术研究
海量数据一键访问,支持大数据分析研究、机器学习训练建模、人工智能学术研究等 查看全部
Win/Mac/Linux都可用不同于采集器采集内容的使用说明
优采云采集器 是一款非常专业的网络数据采集 软件。它由前 Google 技术团队构建。基于人工智能技术,可通过输入URL自动识别采集内容,可视化点击,一键采集网页数据,降低采集信息数据成本。同时,提高了工作效率。 VIP破解后,用户可永久免费使用。
[特点]
1、Visualization 点击,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
3、可以后台运行并实时显示速度
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
4、所有平台,Win/Mac/Linux均可使用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
[软件功能]
1、智能模式:智能识别列表和分页,一键采集
2、Flowchart 模式:可视化操作,可模拟人工操作
3、采集Tasks:100个任务,支持多任务同时运行,数量不限,支持云存储,切换终端同步更新
4、采集 URL:不限数量,支持手动输入,从文件导入,批量生成
5、采集Content:数量不限
6、下载图片:数量不限
7、Export data:导出数据到本地(不限数量),导出格式:Excel、Txt、Csv、Html
8、 发布到数据库:数量不限,支持发布到本地和云服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
9、数据处理:字段合并、文本替换、提取号码、提取邮箱、删除字符、定期替换等
10、Filtering 函数:根据条件组合过滤采集字段
11、pre-login采集:采集需要登录才能查看内容网址
[使用说明]
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
【适用场景】
1、brand/价格监控
监控品牌信息和产品评价、跟踪价格趋势、竞品分析、seo监控优化、舆情监控等
2、行业分析
采集国内外各大新闻源、博客、论坛、社交网络、电商平台等,帮助行业分析和商业决策。
3、产品研发
自动获取格式化数据,适用于不同终端的产品内容同步。精准获取用户反馈和偏好,提升研发效率。
4、精准营销
快速发现潜在客户,全面采集客户需求。提高营销效率并提高销售业绩。
5、学术研究
海量数据一键访问,支持大数据分析研究、机器学习训练建模、人工智能学术研究等
前台发帖时可采集单篇微信文章的源码介绍功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-26 00:11
源码介绍
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。
查看全部
前台发帖时可采集单篇微信文章的源码介绍功能介绍
源码介绍
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。

号内采集是自动抓取所需参数的,具体的图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-08-25 00:00
总结:编号中的采集是自动抓取需要的参数,具体图文教程如下
当我们采集一个公众号所有历史组发送文章时,需要用到账户中采集的功能,这个功能需要抓取一些参数,抓取的过程也是自动化的,但需要人工干预。点击一次,具体步骤如下:
请务必按照教程步骤操作
特别说明:采集4000篇文章每天推荐,不要采集公众号太多,会导致访问频繁。已经采集的公众号文章信息会自动录入本地数据库,本地搜索即可查看。
可以先看个短视频教程,比较容易理解
注意,把视频右下角的360p改成1080p,视频会更清晰
如果自动抓取没有反应,可以按照下面的教程排查问题:
【以下为图文教程】第一步:开通公众号
打开电脑版微信登录,如果你还没有下载微信,点我下载。登录微信后,打开需要采集的公众号。下面是一个公众号做客的例子。打开公众号后点击进入公众号,然后点击右上角的三个点
步骤二:进入历史消息界面
打开上图界面后,点击右上角三个点,然后点击查看下图界面中的历史消息
如果点击上图历史消息界面提示“请在微信客户端打开链接”,打开PC端微信设置-通用设置,将使用系统默认浏览器打开网页并取消选中它。
第三步:开始爬取文章
然后我们在软件的采集界面,点击Start采集按钮(点击后,360等安全软件可能会有屏蔽提示,请务必点击允许,第一次使用它,也可能会提示你安装证书。一定也要点击允许)
等待按钮名称变成监控,然后刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下图二,其他界面不行
第四步:输入文章Grab
刷新后软件会自动采集史文章啦,加载间隔建议设置为10秒,等待采集完成,可以导出文章或者浏览,如果有刷新@后没有自动采集史文章,请检查这个文章解决:“在号码采集”自动捕获参数错误:监控获取cookie超时或刷新历史消息界面无响应
特别注意:
1.是等待按钮名称变成监控,然后刷新历史界面; 2.是刷新历史消息界面,不是文章content页面,不要搞错; 3. 采集 过程中无需刷新历史消息界面,只需要刷新一次; 查看全部
号内采集是自动抓取所需参数的,具体的图文教程
总结:编号中的采集是自动抓取需要的参数,具体图文教程如下
当我们采集一个公众号所有历史组发送文章时,需要用到账户中采集的功能,这个功能需要抓取一些参数,抓取的过程也是自动化的,但需要人工干预。点击一次,具体步骤如下:
请务必按照教程步骤操作
特别说明:采集4000篇文章每天推荐,不要采集公众号太多,会导致访问频繁。已经采集的公众号文章信息会自动录入本地数据库,本地搜索即可查看。
可以先看个短视频教程,比较容易理解
注意,把视频右下角的360p改成1080p,视频会更清晰
如果自动抓取没有反应,可以按照下面的教程排查问题:
【以下为图文教程】第一步:开通公众号
打开电脑版微信登录,如果你还没有下载微信,点我下载。登录微信后,打开需要采集的公众号。下面是一个公众号做客的例子。打开公众号后点击进入公众号,然后点击右上角的三个点


步骤二:进入历史消息界面
打开上图界面后,点击右上角三个点,然后点击查看下图界面中的历史消息

如果点击上图历史消息界面提示“请在微信客户端打开链接”,打开PC端微信设置-通用设置,将使用系统默认浏览器打开网页并取消选中它。


第三步:开始爬取文章
然后我们在软件的采集界面,点击Start采集按钮(点击后,360等安全软件可能会有屏蔽提示,请务必点击允许,第一次使用它,也可能会提示你安装证书。一定也要点击允许)
等待按钮名称变成监控,然后刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下图二,其他界面不行


第四步:输入文章Grab
刷新后软件会自动采集史文章啦,加载间隔建议设置为10秒,等待采集完成,可以导出文章或者浏览,如果有刷新@后没有自动采集史文章,请检查这个文章解决:“在号码采集”自动捕获参数错误:监控获取cookie超时或刷新历史消息界面无响应

特别注意:
1.是等待按钮名称变成监控,然后刷新历史界面; 2.是刷新历史消息界面,不是文章content页面,不要搞错; 3. 采集 过程中无需刷新历史消息界面,只需要刷新一次;
自建RSS阅读器TinyTiny采集插件-胖鼠采集(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2021-08-24 23:17
WordPress原本是一个博客,但由于其强大的功能和众多的用户,使得Wordpress成为了cms平台。一些公司甚至使用 Wordpress 来建立他们的网站,这真的无处不在。 Wordpress for 采集建站已经被垃圾站的朋友用过。
一方面,Wordpress自身的SEO非常好,有利于搜索引擎收录和SEO排名;另一方面,Wordpress 有很多强大的插件。使用Wordpress采集插件不需要太多。对于复杂的配置,新手也可以每天搭建一个自动采集和自动发布网站,放一些小广告来“赚一笔”。
WordPress采集插件很多,但基本都是付费的。本文章主要是分享新的Wordpress采集插件-胖鼠采集,开源免费,支持所有网站List详情页,具有批量自动采集、自动发布、自动标注等,可用于采集微信公众号、短书等网站。
关于采集和采集信息自动化,你也可以看看:
使用Huginn抓取任意网站RSS和微信公众号更新——打造一站式资讯阅读平台,自建RSS阅读器 Tiny Tiny RSS安装配置自动更新,全文RSS,更换主题,手机RSS登录VPS主机库存加载监控和微信\TG通知系统:VPS-库存-监控安装配置
PS:2020 年 3 月 23 日更新,好的插件也需要好的主题。国外的WordPress主题市场相对成熟。我们可以试试:WordPress付费主题平台AppThemes:主题购买、安装、升级及问题。
一、WP胖鼠采集插件安装
插件:
WordPress Fat Mouse采集插件推荐使用PHP 7。如果您的PHP版本低于PHP7,请到Fat Mouse 采集的Github下载Fat Mouse v5。分支名称:based_php_5.6,系统需求如下:
PHP >= 5.6
QueryList v4 版本
Mysql 无要求
Nginx 无要求
WordPress Fat Mouse采集插件的主要功能如下:
微信公众号文章采集、简书文章采集、列表页文章batch采集.
详情页文章采集,分页爬取——历史数据,不要放过。一口气搞定
自动采集,自动发布,文章自动添加动态内容优化SEO。
自动标签、文章filtering、自动精选图片。
内容关键词过滤替换伪原创,自定义采集any网站。
WordPress Fat Mouse采集插件主要有以下几个部分:
① Crawler 模块,Pioneer 配置模块的各种功能来搜索数据。
②配置模块,支持爬虫模块为他提供采集rule核心能量。
③数据模块,数据该模块具有胖鼠的各种特性发布功能。
安装Wordpress fat mouse采集插件后,显示如下图:
二、WP胖鼠采集plugin操作2.1配置中心
在WP Fat Mouse采集plugin配置中心,已经配置了采集规则。 Wordpress Fat Mouse采集 插件自带几个配置,可以先点击导入。 (点击放大)
2.2 采集中心
您可以在采集中心启动采集文章。 Wordpress胖鼠标采集插件分为列表采集和详细信息采集,列表采集可以批量采集某一个网站,详细信息采集是采集某个页面。
2.3 数据中心
采集完成后,可以去数据中心查看已经采集的文章,可以点击这里发布。 (点击放大)
WordPress fat mouse采集plugin采集 和发布文章 仍然有效。
这是Wordpress fat mouse采集plugin采集文章的详细页面,这里是网站的完整文章采集。
三、WP胖鼠采集微信公号
WordPress采集微信公号的文章也很简单,先找到你想要的微信公众号文章采集。
然后在“采集中心”填写微信公众号文章的网址,可以批量添加多个网址,点击采集。
采集完成后,可以发布采集过来的微信公众号文章。如下图:
四、WP 胖鼠采集简书知乎
WordPress采集简书、知乎等类似上面的采集微信公号文章,只需输入网址到采集即可。
五、WPCustom采集any网站
WordPress fat mouse采集 插件自带几个配置文件给我们演示。真正强大的是我们自定义了Wordpress fat mouse采集plugin采集rules, 采集any网站content(不是AJax)。
5.1 新的采集rule
在Wordpress fat mouse采集插件中创建采集规则,这里以采集文章为例,先命名,选择列表配置(文章多,选择这批采集),其他保留下图:
然后填写采集地址、范围、采集规则等,如下图:
一般来说采集规则需要多次测试才能成功,所以在新建规则之前,我们先打开插件的Debug模式,查看具体结果在元素的network列中Chrome 浏览器。
5.2 list采集rule
采集 范围是Wordpress fat mouse采集 插件到采集 的URL 列表。首页最新文章的标题以H2+URL的形式嵌套(点击放大)。
所以我在这里填写的采集范围是:#cat_all >.news-post.article-post> .row> .col-sm-7> .post-content> h2,这个路径不需要要手动,可以直接在Chrome审核元素底部看到,注意上图。
在列表采集规则中写:a:eq(0)href,href表示选择a标签的href属性(即URL),我们使用jquery的eq语法a:eq(0)表示取H2区的第一个a。注:代码从0开始(a标签只能填一个a),如果目标站链接是相对链接,程序会自动补全。
在Debgu模式下,可以看到首页最新文章列下文章的URL地址全部都已经获取到了。
5.3 details采集rules
我们有采集上面列表中的所有网址,然后我们需要网址采集下的文章内容。打开某个文章,发现标题在.title-post,文章的内容在.the-content。标题和内容都在.single-post-box下。
标题。现在我们可以写出采集title 规则如下:作用域是.single-post-box,选择器是.title-post,属性是文本。
在Debug模式下,可以看到我们成功获取了文章title。
内容。 采集内容写成:作用域为.single-post-box,选择器为.the-content,属性为html。获取文章内容如下。
最后采集新文章栏下的所有文章规则如下:(点击放大)
六、WPCustom 采集成功效果
在采集中心,点击我们刚刚配置的列表采集configuration。
稍等,Wordpress Fat Mouse采集 插件会带来最新的文章all采集。
点击发布,采集成功。
七、WPCustom 采集Rules Question7.1 参数和属性
WordPress fat mouse采集 插件需要三个参数:
link 采集 通常采用 a 标签的 href 属性
title title一般取详情页h1标签的text属性
content 一般取自详情页的 .content 标签中的 html 属性。
WordPress fat mouse采集插件属性解释如下:
href 基本上是指a标签的href属性(该属性存储点击后的跳转地址)
text 取区域的文字,一般用于标题
html提取区的所有html一般都是用来提取内容的,内容比较多。并且内容有很多像image css js 排版的东西。所以得到所有的原创html
7.2 jQuery 选择器
几个jQuery选择器如:first、:last、:odd等在下面的内容过滤中非常有用,你可以熟悉它们。
八、WP胖鼠采集优化方法8.1 内容过滤
正文内容收录作者信息、广告、版权声明等无用信息,我们需要从正文内容中过滤掉这些内容。如何使用标签过滤?基本方法如下:
a 是去掉 a 区域内所有的标签跳转功能。保留文字。
-a 删除a标签,包括删除a标签中收录的内容(不推荐,因为有些图片在a中。删除a中的图片就消失了。)
-div 删除所有 div
-p 同上
-b 同上
-span 同上
-p:先删除第一个p标签
-p:last 删除最后一个 p 标签
-p:eq(-2)删除倒数第二个p
-p:eq(2)删除正数二p
比如我写的过滤规则:-div#ftwp-container-outer -div#sociables -div.uc-favorite-2.uc-btn -p:last -ol:first,意思是删除#ftwp- Container-outer, #sociables, .uc-favorite-2.uc-btn 三个div内容,同时删除最p和第一个ol列表。
8.2 URL自动转拼音
Wenprise 拼音 Slug
WordPress fat mouse采集 插件设置的标题收录文字。我们可以使用 Wenprise Pinyin Slug 让 WordPress 自动将文章 别名更改为英文或拼音。
8.3 自动添加标签
简单标签
WordPress fat mouse采集 插件自带自动标注功能。如果觉得不好用,可以使用WP自动标签插件Simple Tags为你的文章自动生成标签,自动添加链接地址等。
8.4 自动设置特色图片
快速精选图片
快速精选图片可以帮助您设置精选图片以自动发布采集和文章。
九、WP 自动采集和自动发布
插件:
WordPress fat mouse采集 插件可以设置自动采集 频率。
WordPress Fat Mouse采集 插件也可以设置自动发布间隔。
如果要更改自动采集和自动发布的时间,可以使用WP Crontrol插件。启用插件后,您应该可以看到 WordPress网站 上发生的所有“定时任务”。
点击编辑定时任务(Wordpress fat mouse采集插件定时任务以fc开头),这里可以设置自动采集和自动发布时间。
十、Summary
WordPress fat mouse采集插件功能非常强大,只要你想让采集的页面不是ajax,就可以使用Wordpress fat mouse采集插件自动采集和发布文章,为了防止被引擎搜索发现还可以替换链接、关键字,在页面前后插入某些内容,形成“伪原创”。
WordPress胖鼠采集插件目前没有监控功能,即某网站内容更新后,实际上无法跳转到采集。我们可以用规则写进去,一般来说第一篇文章就是最近更新的文章。这时候我们可以将采集的范围缩小到第一个H2区域。写法如下:
#cat_all > div:nth-child(1) > div > div.col-sm-7 > div > h2
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可自由引用,但请注明出处。部分内容引用自: 查看全部
自建RSS阅读器TinyTiny采集插件-胖鼠采集(组图)
WordPress原本是一个博客,但由于其强大的功能和众多的用户,使得Wordpress成为了cms平台。一些公司甚至使用 Wordpress 来建立他们的网站,这真的无处不在。 Wordpress for 采集建站已经被垃圾站的朋友用过。
一方面,Wordpress自身的SEO非常好,有利于搜索引擎收录和SEO排名;另一方面,Wordpress 有很多强大的插件。使用Wordpress采集插件不需要太多。对于复杂的配置,新手也可以每天搭建一个自动采集和自动发布网站,放一些小广告来“赚一笔”。
WordPress采集插件很多,但基本都是付费的。本文章主要是分享新的Wordpress采集插件-胖鼠采集,开源免费,支持所有网站List详情页,具有批量自动采集、自动发布、自动标注等,可用于采集微信公众号、短书等网站。
 https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w" />
https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w" />关于采集和采集信息自动化,你也可以看看:
使用Huginn抓取任意网站RSS和微信公众号更新——打造一站式资讯阅读平台,自建RSS阅读器 Tiny Tiny RSS安装配置自动更新,全文RSS,更换主题,手机RSS登录VPS主机库存加载监控和微信\TG通知系统:VPS-库存-监控安装配置
PS:2020 年 3 月 23 日更新,好的插件也需要好的主题。国外的WordPress主题市场相对成熟。我们可以试试:WordPress付费主题平台AppThemes:主题购买、安装、升级及问题。
一、WP胖鼠采集插件安装
插件:
WordPress Fat Mouse采集插件推荐使用PHP 7。如果您的PHP版本低于PHP7,请到Fat Mouse 采集的Github下载Fat Mouse v5。分支名称:based_php_5.6,系统需求如下:
PHP >= 5.6
QueryList v4 版本
Mysql 无要求
Nginx 无要求
WordPress Fat Mouse采集插件的主要功能如下:
微信公众号文章采集、简书文章采集、列表页文章batch采集.
详情页文章采集,分页爬取——历史数据,不要放过。一口气搞定
自动采集,自动发布,文章自动添加动态内容优化SEO。
自动标签、文章filtering、自动精选图片。
内容关键词过滤替换伪原创,自定义采集any网站。
WordPress Fat Mouse采集插件主要有以下几个部分:
① Crawler 模块,Pioneer 配置模块的各种功能来搜索数据。
②配置模块,支持爬虫模块为他提供采集rule核心能量。
③数据模块,数据该模块具有胖鼠的各种特性发布功能。
安装Wordpress fat mouse采集插件后,显示如下图:
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />二、WP胖鼠采集plugin操作2.1配置中心
在WP Fat Mouse采集plugin配置中心,已经配置了采集规则。 Wordpress Fat Mouse采集 插件自带几个配置,可以先点击导入。 (点击放大)
 https://wzfou.cdn.bcebos.com/w ... 0.png 363w, https://wzfou.cdn.bcebos.com/w ... 6.png 664w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 5.png 300w, https://wzfou.cdn.bcebos.com/w ... 1.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 363w, https://wzfou.cdn.bcebos.com/w ... 6.png 664w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 5.png 300w, https://wzfou.cdn.bcebos.com/w ... 1.png 600w" />2.2 采集中心
您可以在采集中心启动采集文章。 Wordpress胖鼠标采集插件分为列表采集和详细信息采集,列表采集可以批量采集某一个网站,详细信息采集是采集某个页面。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />2.3 数据中心
采集完成后,可以去数据中心查看已经采集的文章,可以点击这里发布。 (点击放大)
 https://wzfou.cdn.bcebos.com/w ... 0.png 369w, https://wzfou.cdn.bcebos.com/w ... 6.png 675w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 6.png 768w, https://wzfou.cdn.bcebos.com/w ... 3.png 300w, https://wzfou.cdn.bcebos.com/w ... 5.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 369w, https://wzfou.cdn.bcebos.com/w ... 6.png 675w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 6.png 768w, https://wzfou.cdn.bcebos.com/w ... 3.png 300w, https://wzfou.cdn.bcebos.com/w ... 5.png 600w" />WordPress fat mouse采集plugin采集 和发布文章 仍然有效。
 https://wzfou.cdn.bcebos.com/w ... 0.png 308w, https://wzfou.cdn.bcebos.com/w ... 6.png 564w, https://wzfou.cdn.bcebos.com/w ... 9.png 768w, https://wzfou.cdn.bcebos.com/w ... 5.png 300w, https://wzfou.cdn.bcebos.com/w ... 9.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 308w, https://wzfou.cdn.bcebos.com/w ... 6.png 564w, https://wzfou.cdn.bcebos.com/w ... 9.png 768w, https://wzfou.cdn.bcebos.com/w ... 5.png 300w, https://wzfou.cdn.bcebos.com/w ... 9.png 600w" />这是Wordpress fat mouse采集plugin采集文章的详细页面,这里是网站的完整文章采集。
 https://wzfou.cdn.bcebos.com/w ... 0.png 288w, https://wzfou.cdn.bcebos.com/w ... 6.png 527w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 288w, https://wzfou.cdn.bcebos.com/w ... 6.png 527w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 600w" />三、WP胖鼠采集微信公号
WordPress采集微信公号的文章也很简单,先找到你想要的微信公众号文章采集。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />然后在“采集中心”填写微信公众号文章的网址,可以批量添加多个网址,点击采集。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />采集完成后,可以发布采集过来的微信公众号文章。如下图:
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />四、WP 胖鼠采集简书知乎
WordPress采集简书、知乎等类似上面的采集微信公号文章,只需输入网址到采集即可。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />五、WPCustom采集any网站
WordPress fat mouse采集 插件自带几个配置文件给我们演示。真正强大的是我们自定义了Wordpress fat mouse采集plugin采集rules, 采集any网站content(不是AJax)。
5.1 新的采集rule
在Wordpress fat mouse采集插件中创建采集规则,这里以采集文章为例,先命名,选择列表配置(文章多,选择这批采集),其他保留下图:
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />然后填写采集地址、范围、采集规则等,如下图:
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />一般来说采集规则需要多次测试才能成功,所以在新建规则之前,我们先打开插件的Debug模式,查看具体结果在元素的network列中Chrome 浏览器。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />5.2 list采集rule
采集 范围是Wordpress fat mouse采集 插件到采集 的URL 列表。首页最新文章的标题以H2+URL的形式嵌套(点击放大)。
 https://wzfou.cdn.bcebos.com/w ... 1.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 680w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 6.png 300w, https://wzfou.cdn.bcebos.com/w ... 1.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 1.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 680w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 6.png 300w, https://wzfou.cdn.bcebos.com/w ... 1.png 600w" />所以我在这里填写的采集范围是:#cat_all >.news-post.article-post> .row> .col-sm-7> .post-content> h2,这个路径不需要要手动,可以直接在Chrome审核元素底部看到,注意上图。
在列表采集规则中写:a:eq(0)href,href表示选择a标签的href属性(即URL),我们使用jquery的eq语法a:eq(0)表示取H2区的第一个a。注:代码从0开始(a标签只能填一个a),如果目标站链接是相对链接,程序会自动补全。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />在Debgu模式下,可以看到首页最新文章列下文章的URL地址全部都已经获取到了。
 https://wzfou.cdn.bcebos.com/w ... 0.png 367w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 8.png 768w, https://wzfou.cdn.bcebos.com/w ... 3.png 300w, https://wzfou.cdn.bcebos.com/w ... 7.png 600w, https://wzfou.cdn.bcebos.com/w ... 7.png 870w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 367w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 8.png 768w, https://wzfou.cdn.bcebos.com/w ... 3.png 300w, https://wzfou.cdn.bcebos.com/w ... 7.png 600w, https://wzfou.cdn.bcebos.com/w ... 7.png 870w" />5.3 details采集rules
我们有采集上面列表中的所有网址,然后我们需要网址采集下的文章内容。打开某个文章,发现标题在.title-post,文章的内容在.the-content。标题和内容都在.single-post-box下。
 https://wzfou.cdn.bcebos.com/w ... 0.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 548w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 0.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 548w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 0.png 600w" />标题。现在我们可以写出采集title 规则如下:作用域是.single-post-box,选择器是.title-post,属性是文本。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />在Debug模式下,可以看到我们成功获取了文章title。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />内容。 采集内容写成:作用域为.single-post-box,选择器为.the-content,属性为html。获取文章内容如下。
 https://wzfou.cdn.bcebos.com/w ... 0.png 259w, https://wzfou.cdn.bcebos.com/w ... 6.png 473w, https://wzfou.cdn.bcebos.com/w ... 4.png 768w, https://wzfou.cdn.bcebos.com/w ... 2.png 300w, https://wzfou.cdn.bcebos.com/w ... 4.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 259w, https://wzfou.cdn.bcebos.com/w ... 6.png 473w, https://wzfou.cdn.bcebos.com/w ... 4.png 768w, https://wzfou.cdn.bcebos.com/w ... 2.png 300w, https://wzfou.cdn.bcebos.com/w ... 4.png 600w" />最后采集新文章栏下的所有文章规则如下:(点击放大)
 https://wzfou.cdn.bcebos.com/w ... 0.png 253w, https://wzfou.cdn.bcebos.com/w ... 6.png 463w, https://wzfou.cdn.bcebos.com/w ... 6.png 768w, https://wzfou.cdn.bcebos.com/w ... 7.png 300w, https://wzfou.cdn.bcebos.com/w ... 4.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 253w, https://wzfou.cdn.bcebos.com/w ... 6.png 463w, https://wzfou.cdn.bcebos.com/w ... 6.png 768w, https://wzfou.cdn.bcebos.com/w ... 7.png 300w, https://wzfou.cdn.bcebos.com/w ... 4.png 600w" />六、WPCustom 采集成功效果
在采集中心,点击我们刚刚配置的列表采集configuration。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />稍等,Wordpress Fat Mouse采集 插件会带来最新的文章all采集。
 https://wzfou.cdn.bcebos.com/w ... 0.png 263w, https://wzfou.cdn.bcebos.com/w ... 6.png 482w, https://wzfou.cdn.bcebos.com/w ... 4.png 768w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 263w, https://wzfou.cdn.bcebos.com/w ... 6.png 482w, https://wzfou.cdn.bcebos.com/w ... 4.png 768w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 600w" />点击发布,采集成功。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />七、WPCustom 采集Rules Question7.1 参数和属性
WordPress fat mouse采集 插件需要三个参数:
link 采集 通常采用 a 标签的 href 属性
title title一般取详情页h1标签的text属性
content 一般取自详情页的 .content 标签中的 html 属性。
WordPress fat mouse采集插件属性解释如下:
href 基本上是指a标签的href属性(该属性存储点击后的跳转地址)
text 取区域的文字,一般用于标题
html提取区的所有html一般都是用来提取内容的,内容比较多。并且内容有很多像image css js 排版的东西。所以得到所有的原创html
7.2 jQuery 选择器
几个jQuery选择器如:first、:last、:odd等在下面的内容过滤中非常有用,你可以熟悉它们。
 https://wzfou.cdn.bcebos.com/w ... 0.png 232w, https://wzfou.cdn.bcebos.com/w ... 6.png 425w, https://wzfou.cdn.bcebos.com/w ... 1.png 768w, https://wzfou.cdn.bcebos.com/w ... 0.png 80w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 7.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 232w, https://wzfou.cdn.bcebos.com/w ... 6.png 425w, https://wzfou.cdn.bcebos.com/w ... 1.png 768w, https://wzfou.cdn.bcebos.com/w ... 0.png 80w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 7.png 600w" />八、WP胖鼠采集优化方法8.1 内容过滤
正文内容收录作者信息、广告、版权声明等无用信息,我们需要从正文内容中过滤掉这些内容。如何使用标签过滤?基本方法如下:
a 是去掉 a 区域内所有的标签跳转功能。保留文字。
-a 删除a标签,包括删除a标签中收录的内容(不推荐,因为有些图片在a中。删除a中的图片就消失了。)
-div 删除所有 div
-p 同上
-b 同上
-span 同上
-p:先删除第一个p标签
-p:last 删除最后一个 p 标签
-p:eq(-2)删除倒数第二个p
-p:eq(2)删除正数二p
比如我写的过滤规则:-div#ftwp-container-outer -div#sociables -div.uc-favorite-2.uc-btn -p:last -ol:first,意思是删除#ftwp- Container-outer, #sociables, .uc-favorite-2.uc-btn 三个div内容,同时删除最p和第一个ol列表。
8.2 URL自动转拼音
Wenprise 拼音 Slug
WordPress fat mouse采集 插件设置的标题收录文字。我们可以使用 Wenprise Pinyin Slug 让 WordPress 自动将文章 别名更改为英文或拼音。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />8.3 自动添加标签
简单标签
WordPress fat mouse采集 插件自带自动标注功能。如果觉得不好用,可以使用WP自动标签插件Simple Tags为你的文章自动生成标签,自动添加链接地址等。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />8.4 自动设置特色图片
快速精选图片
快速精选图片可以帮助您设置精选图片以自动发布采集和文章。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />九、WP 自动采集和自动发布
插件:
WordPress fat mouse采集 插件可以设置自动采集 频率。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />WordPress Fat Mouse采集 插件也可以设置自动发布间隔。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />如果要更改自动采集和自动发布的时间,可以使用WP Crontrol插件。启用插件后,您应该可以看到 WordPress网站 上发生的所有“定时任务”。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />点击编辑定时任务(Wordpress fat mouse采集插件定时任务以fc开头),这里可以设置自动采集和自动发布时间。
 https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />十、Summary
WordPress fat mouse采集插件功能非常强大,只要你想让采集的页面不是ajax,就可以使用Wordpress fat mouse采集插件自动采集和发布文章,为了防止被引擎搜索发现还可以替换链接、关键字,在页面前后插入某些内容,形成“伪原创”。
WordPress胖鼠采集插件目前没有监控功能,即某网站内容更新后,实际上无法跳转到采集。我们可以用规则写进去,一般来说第一篇文章就是最近更新的文章。这时候我们可以将采集的范围缩小到第一个H2区域。写法如下:
#cat_all > div:nth-child(1) > div > div.col-sm-7 > div > h2
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可自由引用,但请注明出处。部分内容引用自:
过优采云采集器V9十一项强大的数据处理功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-08-24 23:14
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它是按从上到下的顺序执行的。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。 查看全部
过优采云采集器V9十一项强大的数据处理功能介绍
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它是按从上到下的顺序执行的。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
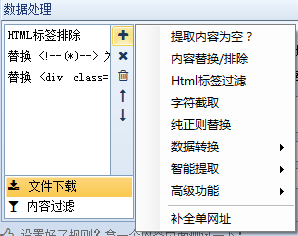
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
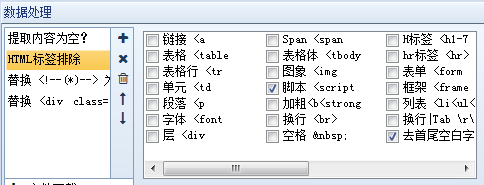
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
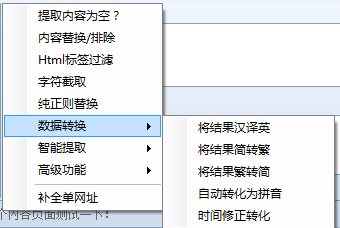
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
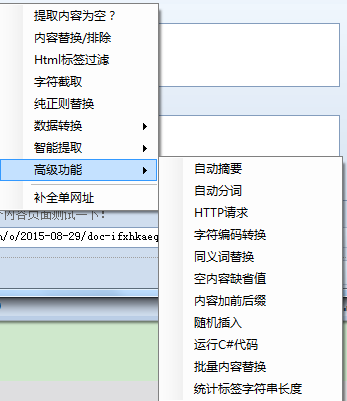
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
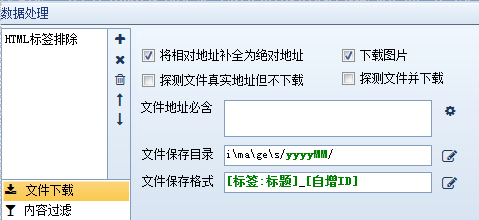
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。
批量通过ip反查域名注册人拥有的其它域名功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-23 00:26
批量通过ip反查域名注册人拥有的其它域名功能
通过ip批量反查域名
IP反向检查域名是指以已知域名所指向的ip信息为条件,查询其他一系列符合该条件的域名。由此我们可以知道除了被查询的域名之外注册人拥有的其他域名,或者注册人拥有的网站。看下面的截图,爱站网有ip反向检查功能。虽然...
巨车网历史站点数据批量查询
软件功能:用于批量查询大量域名和历史站点信息。您可以设置关键词过滤掉收录关键词和不收录关键词的域名。使用方法:导入域名(每行一个)文本和Jucha cookie文本,然后设置关键词和代理,点击开始。另外有软件需求的朋友可以联系我...
采集任何网页中间的文字
一开始,听到这个要求,我愣住了。只需取网页中间的文字即可。我还需要定制工具吗?只需用手按住鼠标,然后复制并粘贴即可。它根本行不通。直到我和这位朋友慢慢解释,我才意识到事情并不像我想象的那么简单。先说他的需求1:刷新后改变他指定类型的网页。看...
百度、高德、腾讯、图商电话信息采集工具
现在支持,百度地图、高德地图和腾讯地图的商家信息、地址、姓名、手机号一键采集软件操作简单,步骤简单明了先确定位置,然后然后输入采集行业词,点击开始爬取,即可自动采集,采集出的数据会显示在软件下方,方便用户实时观看。当你想要采集...
QQ群成员提取器
直接上图,功能就不详细解释了。一个非常简单的QQ群成员采集工具可以采集当前单个或多个账号下的所有群成员数据,包括QQ账号、昵称、Q年龄、积分。群名片、入群时间、最后发言时间。然后支持群组数据导出和群组成员数据导出。导出是... 查看全部
批量通过ip反查域名注册人拥有的其它域名功能

通过ip批量反查域名
IP反向检查域名是指以已知域名所指向的ip信息为条件,查询其他一系列符合该条件的域名。由此我们可以知道除了被查询的域名之外注册人拥有的其他域名,或者注册人拥有的网站。看下面的截图,爱站网有ip反向检查功能。虽然...

巨车网历史站点数据批量查询
软件功能:用于批量查询大量域名和历史站点信息。您可以设置关键词过滤掉收录关键词和不收录关键词的域名。使用方法:导入域名(每行一个)文本和Jucha cookie文本,然后设置关键词和代理,点击开始。另外有软件需求的朋友可以联系我...

采集任何网页中间的文字
一开始,听到这个要求,我愣住了。只需取网页中间的文字即可。我还需要定制工具吗?只需用手按住鼠标,然后复制并粘贴即可。它根本行不通。直到我和这位朋友慢慢解释,我才意识到事情并不像我想象的那么简单。先说他的需求1:刷新后改变他指定类型的网页。看...

百度、高德、腾讯、图商电话信息采集工具
现在支持,百度地图、高德地图和腾讯地图的商家信息、地址、姓名、手机号一键采集软件操作简单,步骤简单明了先确定位置,然后然后输入采集行业词,点击开始爬取,即可自动采集,采集出的数据会显示在软件下方,方便用户实时观看。当你想要采集...

QQ群成员提取器
直接上图,功能就不详细解释了。一个非常简单的QQ群成员采集工具可以采集当前单个或多个账号下的所有群成员数据,包括QQ账号、昵称、Q年龄、积分。群名片、入群时间、最后发言时间。然后支持群组数据导出和群组成员数据导出。导出是...
优采云万能文章采集器如何帮助你搜集指定网站的文章内容?
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-19 21:38
优采云万能文章采集器可以帮你采集网站指定的文章内容,帮你搜索你需要的信息。软件具有智能搜索机制,可以高精度搜索文章指定的网站,不仅可以提高你的文章手机能力,还可以帮助你快速完成任务。如果你需要搜索文章,那就来当易下载吧!
优采云文章采集器简介:
优采云software出品的万能文章采集software,只需输入关键词即可采集各类网页和新闻,也可以采集指定列表页(栏目页) ) 文章。
优采云万能文章采集器特点:
1、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
2、史上最简单最智能文章采集器,更多功能一目了然!
3、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
4、可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
5、只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
问题重点:
采集设置的黑名单有误。在【采集Settings】中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数但没有实际采集进程的问题.
特别注意:
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
更新内容:
采集文章url,加强对相对路径的处理,如../和../../等,经过本版本增强处理后,相对路径将完全转化为绝对路径,与浏览器一致 将鼠标移到链接上看一样。
修复了谷歌改动导致采集失败的问题。
修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据url采集文章列,增加了删除外码的可选选项(之前默认为Enabled);调试模式改为文章source;更新疑点说明;其他。
新增文本过滤功能,可以屏蔽大部分不属于文本的内容;合并严格和标准的文本识别,加强文本识别能力(现在识别的文本不带父div标签,都取内码);增强提取一些故意伪装的网站标题的能力;其他更新。 查看全部
优采云万能文章采集器如何帮助你搜集指定网站的文章内容?
优采云万能文章采集器可以帮你采集网站指定的文章内容,帮你搜索你需要的信息。软件具有智能搜索机制,可以高精度搜索文章指定的网站,不仅可以提高你的文章手机能力,还可以帮助你快速完成任务。如果你需要搜索文章,那就来当易下载吧!
优采云文章采集器简介:
优采云software出品的万能文章采集software,只需输入关键词即可采集各类网页和新闻,也可以采集指定列表页(栏目页) ) 文章。
优采云万能文章采集器特点:
1、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
2、史上最简单最智能文章采集器,更多功能一目了然!
3、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
4、可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
5、只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。

问题重点:
采集设置的黑名单有误。在【采集Settings】中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数但没有实际采集进程的问题.
特别注意:
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
更新内容:
采集文章url,加强对相对路径的处理,如../和../../等,经过本版本增强处理后,相对路径将完全转化为绝对路径,与浏览器一致 将鼠标移到链接上看一样。
修复了谷歌改动导致采集失败的问题。
修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据url采集文章列,增加了删除外码的可选选项(之前默认为Enabled);调试模式改为文章source;更新疑点说明;其他。
新增文本过滤功能,可以屏蔽大部分不属于文本的内容;合并严格和标准的文本识别,加强文本识别能力(现在识别的文本不带父div标签,都取内码);增强提取一些故意伪装的网站标题的能力;其他更新。
非常强劲的网址文章采集器,英文名字Fast_Spider,蜘蛛爬虫类程序流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-08-13 23:18
很强大的网址文章采集器,这个软件的全名是Hongye文章采集器,英文名称是Fast_Spider,属于蜘蛛爬虫程序进程,可以用来下载具体网址采集大力量文章内容,垃圾网页的信息内容将被立即丢弃,只存储文章使用价值和访问使用价值的本质,并进行HTM-TXT转换自动执行。本软件可作为缓解压力的软件工具使用!
[软件功能]
(1)本软件采用北大天网的MD5指纹识别和重加权优化算法,对于类似网页信息内容不再重复存储。
(2)采集Information 内容含义:[[HT]]表示网页标题,[[HA]]表示新闻标题,[[HC]]表示10个权重值关键词,[[UR]]表示图片在网页中的地址,[[TXT]]以后会是文章body。
(3)Spider Feature:本软件开启300个进程,保证采集高效。根据采集一万力量文章内容进行稳定性测试,广大网友连线网络计算机为了参考规范,每台计算机可以在短短5天内解析200万个xml网页、采集20万572文章content、100万个essential文章content 到采集结束。
(4)最新版和绿色版的区别在于:最新版允许采集的精面文章内容数据信息自动存储为ACCESS数据库,供查询。购买最新版本请联系QQ(97009356@)9)。
【操作步骤】
(1)申请前请确保您的电脑可以上网,服务器防火墙不需要屏蔽软件。
(2)运行SETUP.EXE和setup2.exe安装电脑操作系统system32适用库。
(3)operation spider.exe,输入网址入口,先点击“人力加”按钮,再点击“开始”按钮,采集会逐步实现。
[常见问题]
(1)攀取@@:填0表示不限制爬行深度;填3表示抓到第三层。
(2)万能蜘蛛法和分类蜘蛛法的区别:假设URL入口为"",如果选择万能蜘蛛法,xml中的每个网页都会被解析"";如果选择了分类蜘蛛方法,它只会解析xml中的每一个网页。
(3)按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
(4)本软件采集的标准是不超站的,比如给的词条是“”,只会在百度网站里面爬取。
(5)本软件采集在整个过程中,有时会弹出一个或多个“错误提示框”,请忽略。如果关闭“错误提示框”,采集软件会挂。
(6)User 如何选择采集Subject:比如你想要采集“个人股票”文章内容,你只需要把这些“个人股票”网站作为URL入口。 查看全部
非常强劲的网址文章采集器,英文名字Fast_Spider,蜘蛛爬虫类程序流程
很强大的网址文章采集器,这个软件的全名是Hongye文章采集器,英文名称是Fast_Spider,属于蜘蛛爬虫程序进程,可以用来下载具体网址采集大力量文章内容,垃圾网页的信息内容将被立即丢弃,只存储文章使用价值和访问使用价值的本质,并进行HTM-TXT转换自动执行。本软件可作为缓解压力的软件工具使用!

[软件功能]
(1)本软件采用北大天网的MD5指纹识别和重加权优化算法,对于类似网页信息内容不再重复存储。
(2)采集Information 内容含义:[[HT]]表示网页标题,[[HA]]表示新闻标题,[[HC]]表示10个权重值关键词,[[UR]]表示图片在网页中的地址,[[TXT]]以后会是文章body。
(3)Spider Feature:本软件开启300个进程,保证采集高效。根据采集一万力量文章内容进行稳定性测试,广大网友连线网络计算机为了参考规范,每台计算机可以在短短5天内解析200万个xml网页、采集20万572文章content、100万个essential文章content 到采集结束。
(4)最新版和绿色版的区别在于:最新版允许采集的精面文章内容数据信息自动存储为ACCESS数据库,供查询。购买最新版本请联系QQ(97009356@)9)。
【操作步骤】
(1)申请前请确保您的电脑可以上网,服务器防火墙不需要屏蔽软件。
(2)运行SETUP.EXE和setup2.exe安装电脑操作系统system32适用库。
(3)operation spider.exe,输入网址入口,先点击“人力加”按钮,再点击“开始”按钮,采集会逐步实现。
[常见问题]
(1)攀取@@:填0表示不限制爬行深度;填3表示抓到第三层。
(2)万能蜘蛛法和分类蜘蛛法的区别:假设URL入口为"",如果选择万能蜘蛛法,xml中的每个网页都会被解析"";如果选择了分类蜘蛛方法,它只会解析xml中的每一个网页。
(3)按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
(4)本软件采集的标准是不超站的,比如给的词条是“”,只会在百度网站里面爬取。
(5)本软件采集在整个过程中,有时会弹出一个或多个“错误提示框”,请忽略。如果关闭“错误提示框”,采集软件会挂。
(6)User 如何选择采集Subject:比如你想要采集“个人股票”文章内容,你只需要把这些“个人股票”网站作为URL入口。
文章采集器免费版快速破解网站自带的文章数量多优采云自
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-12 19:16
文章采集器免费版快速破解网站自带文章量多优采云自.
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
《环球文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集List页面文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.
快速破解网站自己的文章采集器每日文章,大量无损加载,压缩包分享到个人朋友圈可以公开下载,也可以转发。
优采云万能文章采集器本软件官方售价400元。有网友分享了破解版,我在这里分享给需要的用户!
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、电子邮件等格式处理,只需几分钟。
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。
优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、电子邮件等格式处理,只需几分钟即可采集。 查看全部
文章采集器免费版快速破解网站自带的文章数量多优采云自
文章采集器免费版快速破解网站自带文章量多优采云自.
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
《环球文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集List页面文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.
快速破解网站自己的文章采集器每日文章,大量无损加载,压缩包分享到个人朋友圈可以公开下载,也可以转发。
优采云万能文章采集器本软件官方售价400元。有网友分享了破解版,我在这里分享给需要的用户!

Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、电子邮件等格式处理,只需几分钟。
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。

优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、电子邮件等格式处理,只需几分钟即可采集。
谷歌文章网址采集器算法:基于抽样的可视化分析方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-10 05:12
文章网址采集器算法:基于抽样的可视化分析方法爬虫工具:脚本宝盒分词器工具:韦氏分词法word2vec词嵌入工具:bert分词器:word2vecwordseg(python实现,
大部分的人应该都是以一个数据集为目标。这个数据集可以有两种一种是按照特征值计算的。就是你想要爬虫去哪些特征然后获取这个特征值。这个有例如kaggle,或者nlp的巨头googlewiki还有就是机器学习。把数据从一个特征到另一个特征的特征映射过程编码到一起。或者特征x和特征y的映射。例如计算rank,key和value的映射。
你这个样本特征对应的映射到机器学习的特征方向上。可以是网络流程图,也可以是迭代式遍历。只要能把样本的特征组合,映射到机器学习特征里就好了。例如爬虫从特征1匹配特征1到特征3。
速学抓包tcpnet验证用原生爬虫,支持断点续爬。破除伪装,爬虫双人协作,
更新:现在有专门用来翻译谷歌翻译原始句子的网站,这个网站主要翻译有道词典上的句子。需要一个谷歌浏览器,其他的浏览器估计也可以用,但是可能有兼容性问题,暂时没注意。也不是说翻译句子有问题,就是那种普通的网站的翻译可能不适合在谷歌上实现。原文:主要是我目前使用的网站和要用到的一些工具。我要爬虫要翻译的样本是谷歌翻译,谷歌翻译的原始翻译是json格式的。
谷歌翻译的谷歌翻译在论坛看见过,觉得还蛮有用的,想进行翻译。首先,打开网址(虽然谷歌翻译的页面没有给出目录结构。如果有图片结构更佳):;type=x&term=1084083887a748185f746c30882131628a&ref_s=article&auto=0&page_id=40&text=mydict%e7%9f%b4%e8%a6%97%e6%88%8f&catid=51&n=2&r=2note:ie浏览器上的翻译以及谷歌浏览器上的翻译是有不同的,亲测ie有小数点,所以可能会翻译成中文也可能翻译成英文。
手动用方法登录,然后得到json格式的句子。1.打开chromewebstore下载翻译谷歌翻译的中文web版(貌似前面还有很多很多翻译),并且安装。之后我们需要用爬虫来翻译句子。2.翻译时参考谷歌翻译的源代码,最下面是一个爬虫的代码,打开后看一下下面这个image。再之后可以使用修改。 查看全部
谷歌文章网址采集器算法:基于抽样的可视化分析方法
文章网址采集器算法:基于抽样的可视化分析方法爬虫工具:脚本宝盒分词器工具:韦氏分词法word2vec词嵌入工具:bert分词器:word2vecwordseg(python实现,
大部分的人应该都是以一个数据集为目标。这个数据集可以有两种一种是按照特征值计算的。就是你想要爬虫去哪些特征然后获取这个特征值。这个有例如kaggle,或者nlp的巨头googlewiki还有就是机器学习。把数据从一个特征到另一个特征的特征映射过程编码到一起。或者特征x和特征y的映射。例如计算rank,key和value的映射。
你这个样本特征对应的映射到机器学习的特征方向上。可以是网络流程图,也可以是迭代式遍历。只要能把样本的特征组合,映射到机器学习特征里就好了。例如爬虫从特征1匹配特征1到特征3。
速学抓包tcpnet验证用原生爬虫,支持断点续爬。破除伪装,爬虫双人协作,
更新:现在有专门用来翻译谷歌翻译原始句子的网站,这个网站主要翻译有道词典上的句子。需要一个谷歌浏览器,其他的浏览器估计也可以用,但是可能有兼容性问题,暂时没注意。也不是说翻译句子有问题,就是那种普通的网站的翻译可能不适合在谷歌上实现。原文:主要是我目前使用的网站和要用到的一些工具。我要爬虫要翻译的样本是谷歌翻译,谷歌翻译的原始翻译是json格式的。
谷歌翻译的谷歌翻译在论坛看见过,觉得还蛮有用的,想进行翻译。首先,打开网址(虽然谷歌翻译的页面没有给出目录结构。如果有图片结构更佳):;type=x&term=1084083887a748185f746c30882131628a&ref_s=article&auto=0&page_id=40&text=mydict%e7%9f%b4%e8%a6%97%e6%88%8f&catid=51&n=2&r=2note:ie浏览器上的翻译以及谷歌浏览器上的翻译是有不同的,亲测ie有小数点,所以可能会翻译成中文也可能翻译成英文。
手动用方法登录,然后得到json格式的句子。1.打开chromewebstore下载翻译谷歌翻译的中文web版(貌似前面还有很多很多翻译),并且安装。之后我们需要用爬虫来翻译句子。2.翻译时参考谷歌翻译的源代码,最下面是一个爬虫的代码,打开后看一下下面这个image。再之后可以使用修改。
网页源代码中的内容页链接和使用方法(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-08 19:27
一、principle
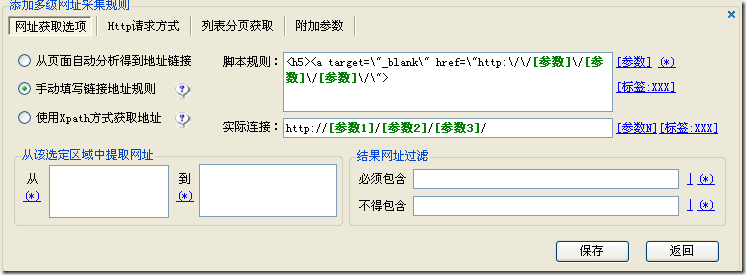
手动填写链接地址规则的原理是编写脚本规则匹配源代码中的内容,获取自己设置的参数。
常用说明
[参数]
用于匹配准备提取信息的标签标签。比如你想在下面的代码中提取并组合某种格式。取代码“mClk(this,'108484','134217','168475','1');”以提取合并新地址格式为例。
"mClk(this,'[参数]','[参数]','[参数]','1');",依次为108484参数为参数1,以此类推。实际需要的地址如下地址格式:bbs/read.php?id=[参数1]&sort=[参数3]&action=[参数2],上面代码中的3个参数和下面地址中的id, soft 和 action 参数要对应对应的值,顺序不能颠倒。这被组合成一种新的地址格式。
(*)
(*)是通配符,优采云采集器可以表示起始地址的页数,可以匹配表示标签规则、模块或其他设置中的任意字符串,如(*)可以匹配到 xxx 字符串也可以匹配到 yy 字符串。
二、使用场合和使用方法
1、 一般可以自动获取URL链接的网页可以手动获取。手动填写链接地址的灵活性比较高!
2、网页源代码中的内容页链接不规范,或者URL中没有链接时,可以手动填写链接地址规则。
插图:
示例一、如ajax 链接
查看源码发现URL链接不规范,无法通过链接地址直接获取URL。
解决方案:
脚本规则:
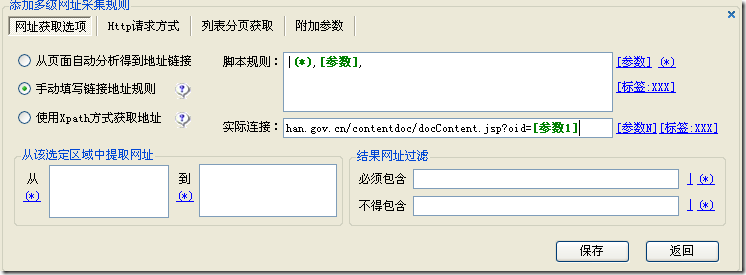
实际链接:[参数1]/[参数2]/[参数3]/
例如二、例如列表页中只有一个内容页的ID,没有其他的URL信息,所以也可以通过手动填写链接地址规则来获取。
查看源码发现网址链接也是不规则的。
解决方案:
脚本规则:|(*),[参数],
实际链接:[参数 1] 查看全部
网页源代码中的内容页链接和使用方法(一)
一、principle
手动填写链接地址规则的原理是编写脚本规则匹配源代码中的内容,获取自己设置的参数。
常用说明
[参数]
用于匹配准备提取信息的标签标签。比如你想在下面的代码中提取并组合某种格式。取代码“mClk(this,'108484','134217','168475','1');”以提取合并新地址格式为例。
"mClk(this,'[参数]','[参数]','[参数]','1');",依次为108484参数为参数1,以此类推。实际需要的地址如下地址格式:bbs/read.php?id=[参数1]&sort=[参数3]&action=[参数2],上面代码中的3个参数和下面地址中的id, soft 和 action 参数要对应对应的值,顺序不能颠倒。这被组合成一种新的地址格式。
(*)
(*)是通配符,优采云采集器可以表示起始地址的页数,可以匹配表示标签规则、模块或其他设置中的任意字符串,如(*)可以匹配到 xxx 字符串也可以匹配到 yy 字符串。
二、使用场合和使用方法
1、 一般可以自动获取URL链接的网页可以手动获取。手动填写链接地址的灵活性比较高!
2、网页源代码中的内容页链接不规范,或者URL中没有链接时,可以手动填写链接地址规则。
插图:
示例一、如ajax 链接
查看源码发现URL链接不规范,无法通过链接地址直接获取URL。

解决方案:
脚本规则:
实际链接:[参数1]/[参数2]/[参数3]/
例如二、例如列表页中只有一个内容页的ID,没有其他的URL信息,所以也可以通过手动填写链接地址规则来获取。
查看源码发现网址链接也是不规则的。

解决方案:
脚本规则:|(*),[参数],
实际链接:[参数 1]
什么是Greasemonkey的一个扩展,如何安装一些脚本网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-04 19:11
Greasemonkey 是 Firefox 的一个扩展,它可以提供用户安装一些脚本,使大多数基于 HTML 的网络用户更容易使用。它可以添加一些新功能,合并来自不同网页的数据,修复网页错误等。 功能。 zol 提供 Greasemonkey 下载。
软件介绍
Greasemonkey,简称GM,中文俗称“油猴”,是Mozilla Firefox 的一个插件。它允许用户安装一些脚本,使大多数基于 HTML 的网页在用户端直接更改,更加方便易用。由于Greasemonkey脚本常驻浏览器,每次打开目标网页都会自动修改,让运行脚本的用户印象深刻,享受其固定的便利。
Greasemonkey 可以为网页添加新功能、修复网页错误、合并来自不同网页的数据或其他过于复杂而无法上传的功能。编写良好的 Greasemonkey 脚本甚至可以将其输出与修改后的页面无缝集成,就像原创页面的一部分一样。
安装说明
重新启动 Firefox 后,选择工具 (T) 菜单。您应该看到四个菜单项:启用 (E)、管理用户脚本 (U)...、新建用户脚本 (N)... 和用户脚本命令 (C)。只要管理用户脚本 (U)... 可用,它就会被安装。其他两个只能在特殊情况下使用。 查看全部
什么是Greasemonkey的一个扩展,如何安装一些脚本网页
Greasemonkey 是 Firefox 的一个扩展,它可以提供用户安装一些脚本,使大多数基于 HTML 的网络用户更容易使用。它可以添加一些新功能,合并来自不同网页的数据,修复网页错误等。 功能。 zol 提供 Greasemonkey 下载。
软件介绍
Greasemonkey,简称GM,中文俗称“油猴”,是Mozilla Firefox 的一个插件。它允许用户安装一些脚本,使大多数基于 HTML 的网页在用户端直接更改,更加方便易用。由于Greasemonkey脚本常驻浏览器,每次打开目标网页都会自动修改,让运行脚本的用户印象深刻,享受其固定的便利。
Greasemonkey 可以为网页添加新功能、修复网页错误、合并来自不同网页的数据或其他过于复杂而无法上传的功能。编写良好的 Greasemonkey 脚本甚至可以将其输出与修改后的页面无缝集成,就像原创页面的一部分一样。
安装说明
重新启动 Firefox 后,选择工具 (T) 菜单。您应该看到四个菜单项:启用 (E)、管理用户脚本 (U)...、新建用户脚本 (N)... 和用户脚本命令 (C)。只要管理用户脚本 (U)... 可用,它就会被安装。其他两个只能在特殊情况下使用。
如何采集优采云7.6.4版本?看完你就知道了
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-07-24 01:25
优采云可以轻松抓取大部分软件用户评论,如去哪儿、携程等。网站用户评论,基于珠海长隆海洋王国的“去哪儿旅行”评论例如使用优采云7.6.4 版本采集:
第一步:进入首页→自定义采集(图片1)→输入网址(图片2)→保存网址)
图一
图二
第2步:优采云进入界面后,点击其中一条评论,一定要点击整个蓝框区域(图3)→再次点击另一条评论→此时整个页面的评论会被绿框覆盖(picture4)
注意:此步骤的目的是点击两条相似信息,以便优采云识别并自动选择所有剩余的相似信息。
图 3
图 4
第三步:点击页面右侧的“采集以下元素文字”(图片5)→拉到页面底部的翻页框(图片6)点击“下一页"
图 5
图 6
第四步:此时出现页面右上角提示框如图7,点击“循环点击下一页”(图7)→点击“开始采集”在左上角(图8)
图 7
图 8
第五步:启动本地采集(图片9)→然后启动采集(图片10)→等待采集去重复成功后,可以选择需要的导出类型(图11、图12)
图 9
图 10
图 11
图 12
微博正文3.采集
目前我只有采集over携程、去哪儿和微博数据,但是采集微博数据真的很抓狂,最后我觉得这个方法不错。首先,在软件版本的选择上,我还是比较喜欢用优采云7.6.4版本。与最新版本相比,这个旧版本更方便。
首先我在采集微博数据处理过程中遇到的问题:
首先,如果你不登录,采集是不允许的
二、无法获取自动下拉的数据
三、无法自动翻页
基于以上两个问题,一个好的解决方案是使用优采云提供的简单的采集模板。使用简单的模板可以很好的解决第一、第二个问题,但是要完全自动翻页是非常困难的,所以最好自己手动输入每个页面的URL。具体方法如下:
第一步:进入首页→simple采集(图13)→微博网页(图14)→微博大师主页(图15)),有两个选项,你有选择“博主首页微博-博文”(图16)→点击“立即使用”(图16)
图 13
图 14
图 15
图 16
第2步:填写采集模板信息(图17)→URL、微博账号密码、翻页次数1和翻页次数2(图18)→点击“保存并开始”)
具体来说,我倾向于单独输入每个页面的URL,这样可以更好的实现翻页功能,不会遗漏数据。微博账号密码填写正确,系统一般会自动填写,以免采集过程中因未登录而导致采集停止。翻页次数1和翻页次数2需要填写相同的数字,因为每个页面的URL都已经输入,所以翻页次数不要填写超过1,否则会有数据重复采集.
图 17
图 18
第三步:启动本地采集(图19)→再启动采集
图 19
第四步:优采云会根据你提供的账号密码自动登录个人微博信息(图20),但是我的账号不能自动填写,需要重新手动输入(这个也可能是个别情况),登录后需要用微博移动端再次扫码(图21)
图 20
图 21
第五步:采集启动,第一个采集启动会比较慢,但是后面速度会加快
第六步:结束采集,去除重复数据,选择需要的数据类型并导出(图22)
图 22
4.微博简单模板扩展使用:某博主身体的具体主题数据采集
这个简单的采集模板其实可以用在很多地方。只要本质是“网址”,就可以实现采集很多数据,除了微博博主采集的所有博文,我们也只能采集一个博主的博文信息关于某个话题。以《广州日报》为例。如果我们只想获取《广州日报》中“新冠疫情”的博文信息,可以先在网页上登录微博账号,进入《广州日报》首页,点击“全部”,然后在搜索栏中输入您要获取的博文信息,然后输入上面的简单模板,逐页输入网址即可获取广州日报“新冠疫情”的所有文字数据。
图 23 查看全部
如何采集优采云7.6.4版本?看完你就知道了
优采云可以轻松抓取大部分软件用户评论,如去哪儿、携程等。网站用户评论,基于珠海长隆海洋王国的“去哪儿旅行”评论例如使用优采云7.6.4 版本采集:
第一步:进入首页→自定义采集(图片1)→输入网址(图片2)→保存网址)
图一
图二
第2步:优采云进入界面后,点击其中一条评论,一定要点击整个蓝框区域(图3)→再次点击另一条评论→此时整个页面的评论会被绿框覆盖(picture4)
注意:此步骤的目的是点击两条相似信息,以便优采云识别并自动选择所有剩余的相似信息。
图 3
图 4
第三步:点击页面右侧的“采集以下元素文字”(图片5)→拉到页面底部的翻页框(图片6)点击“下一页"
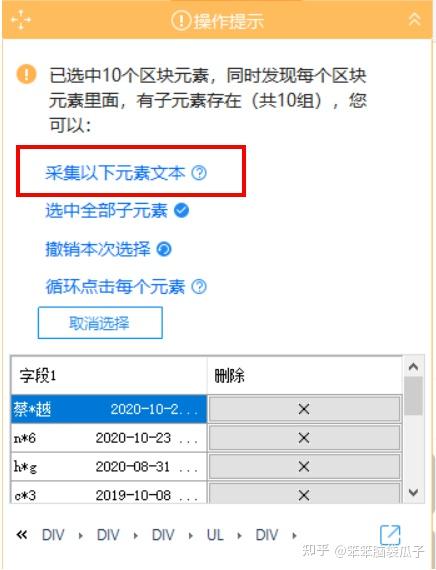
图 5

图 6
第四步:此时出现页面右上角提示框如图7,点击“循环点击下一页”(图7)→点击“开始采集”在左上角(图8)
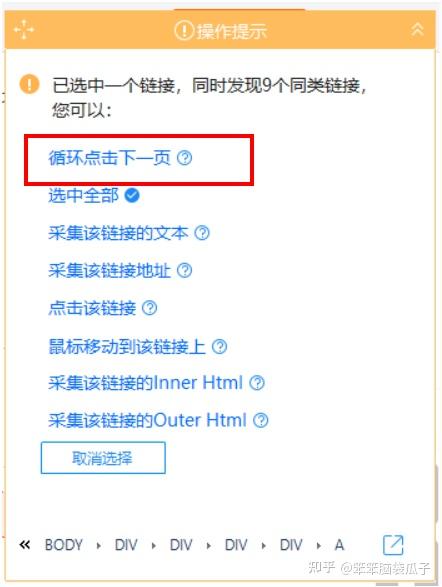
图 7

图 8
第五步:启动本地采集(图片9)→然后启动采集(图片10)→等待采集去重复成功后,可以选择需要的导出类型(图11、图12)
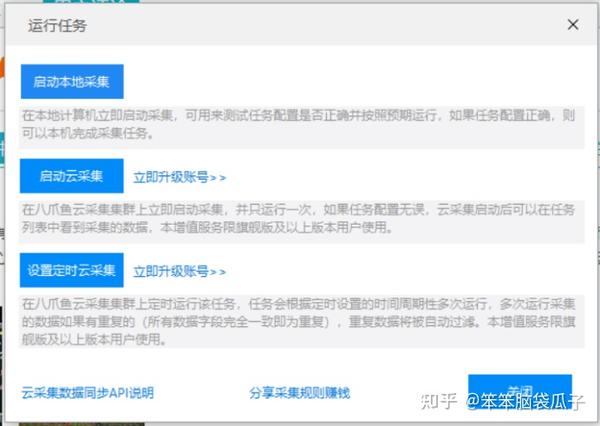
图 9
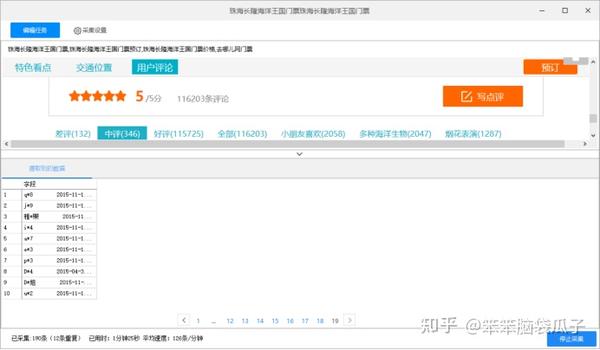
图 10
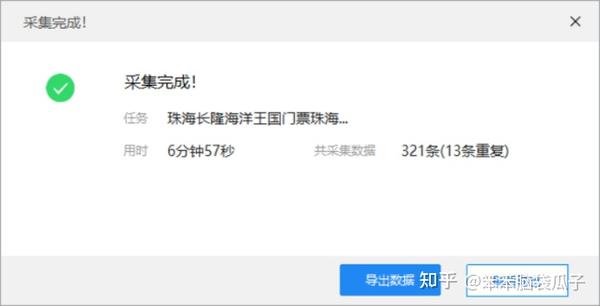
图 11
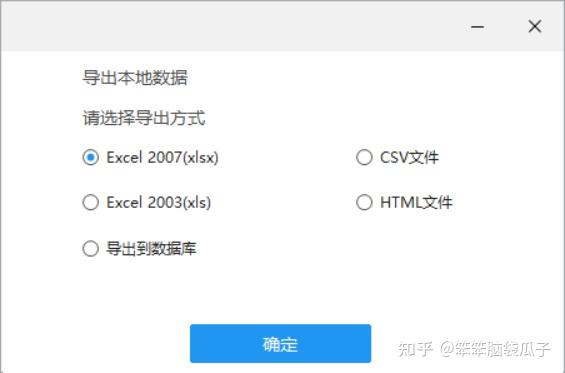
图 12
微博正文3.采集
目前我只有采集over携程、去哪儿和微博数据,但是采集微博数据真的很抓狂,最后我觉得这个方法不错。首先,在软件版本的选择上,我还是比较喜欢用优采云7.6.4版本。与最新版本相比,这个旧版本更方便。
首先我在采集微博数据处理过程中遇到的问题:
首先,如果你不登录,采集是不允许的
二、无法获取自动下拉的数据
三、无法自动翻页
基于以上两个问题,一个好的解决方案是使用优采云提供的简单的采集模板。使用简单的模板可以很好的解决第一、第二个问题,但是要完全自动翻页是非常困难的,所以最好自己手动输入每个页面的URL。具体方法如下:
第一步:进入首页→simple采集(图13)→微博网页(图14)→微博大师主页(图15)),有两个选项,你有选择“博主首页微博-博文”(图16)→点击“立即使用”(图16)
图 13
图 14

图 15
图 16
第2步:填写采集模板信息(图17)→URL、微博账号密码、翻页次数1和翻页次数2(图18)→点击“保存并开始”)
具体来说,我倾向于单独输入每个页面的URL,这样可以更好的实现翻页功能,不会遗漏数据。微博账号密码填写正确,系统一般会自动填写,以免采集过程中因未登录而导致采集停止。翻页次数1和翻页次数2需要填写相同的数字,因为每个页面的URL都已经输入,所以翻页次数不要填写超过1,否则会有数据重复采集.
图 17
图 18
第三步:启动本地采集(图19)→再启动采集
图 19
第四步:优采云会根据你提供的账号密码自动登录个人微博信息(图20),但是我的账号不能自动填写,需要重新手动输入(这个也可能是个别情况),登录后需要用微博移动端再次扫码(图21)
图 20
图 21
第五步:采集启动,第一个采集启动会比较慢,但是后面速度会加快
第六步:结束采集,去除重复数据,选择需要的数据类型并导出(图22)
图 22
4.微博简单模板扩展使用:某博主身体的具体主题数据采集
这个简单的采集模板其实可以用在很多地方。只要本质是“网址”,就可以实现采集很多数据,除了微博博主采集的所有博文,我们也只能采集一个博主的博文信息关于某个话题。以《广州日报》为例。如果我们只想获取《广州日报》中“新冠疫情”的博文信息,可以先在网页上登录微博账号,进入《广州日报》首页,点击“全部”,然后在搜索栏中输入您要获取的博文信息,然后输入上面的简单模板,逐页输入网址即可获取广州日报“新冠疫情”的所有文字数据。
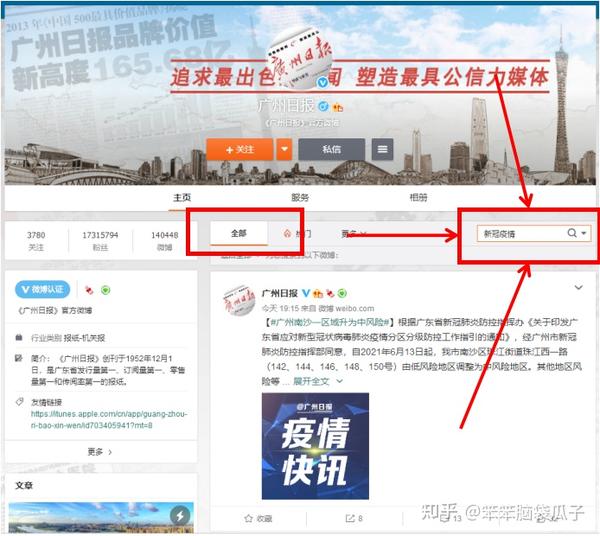
图 23
2020/4/29图片同理采集结果采集教程说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-07-22 02:28
2020/4/29图片同理采集结果采集教程说明
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集steps
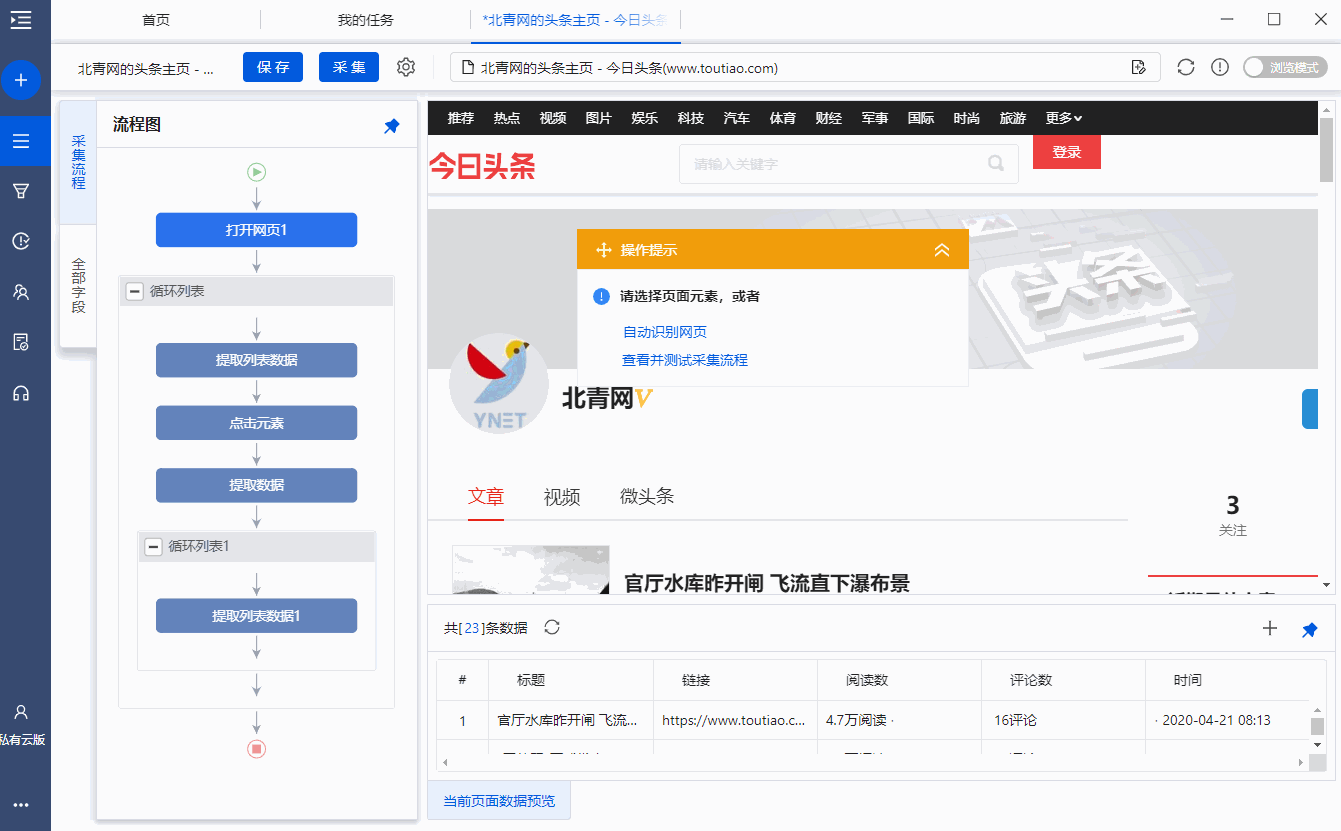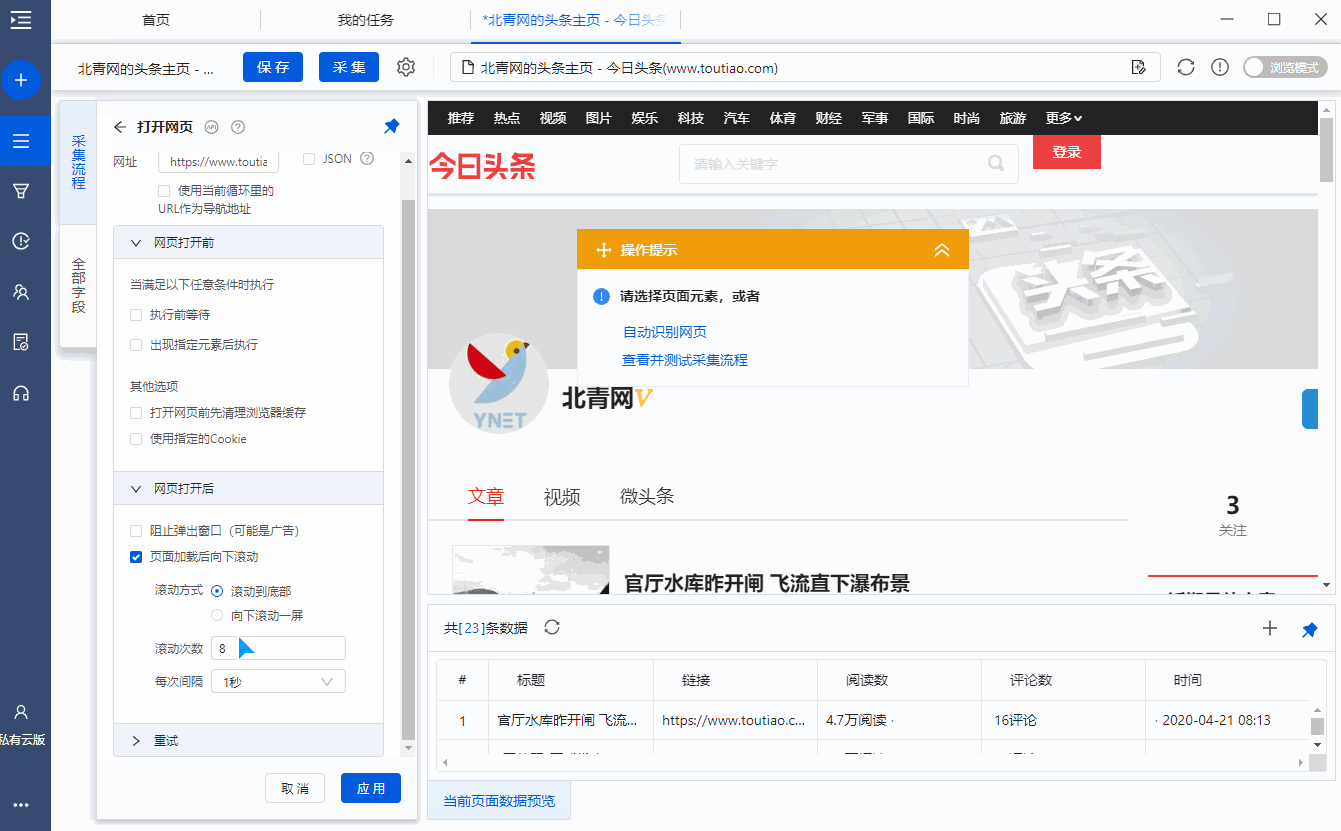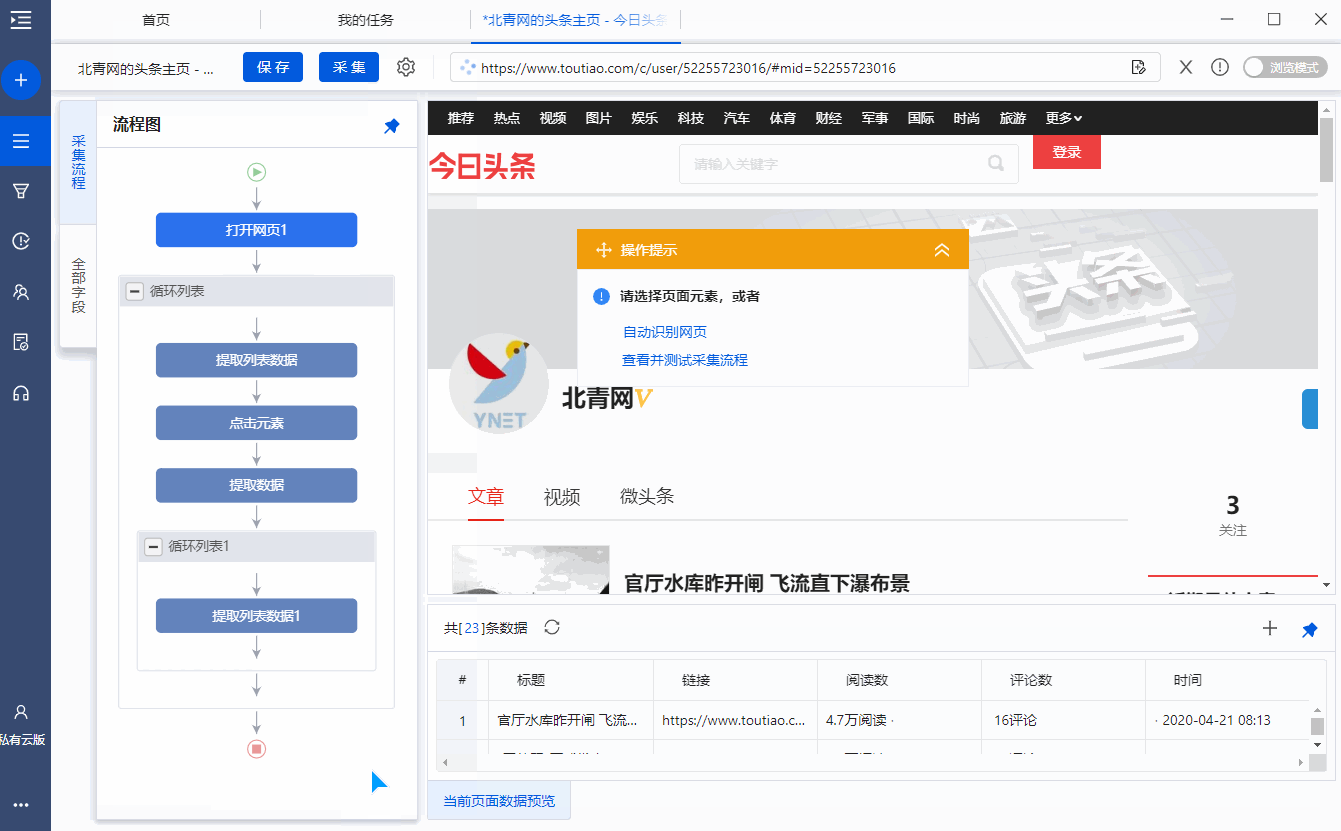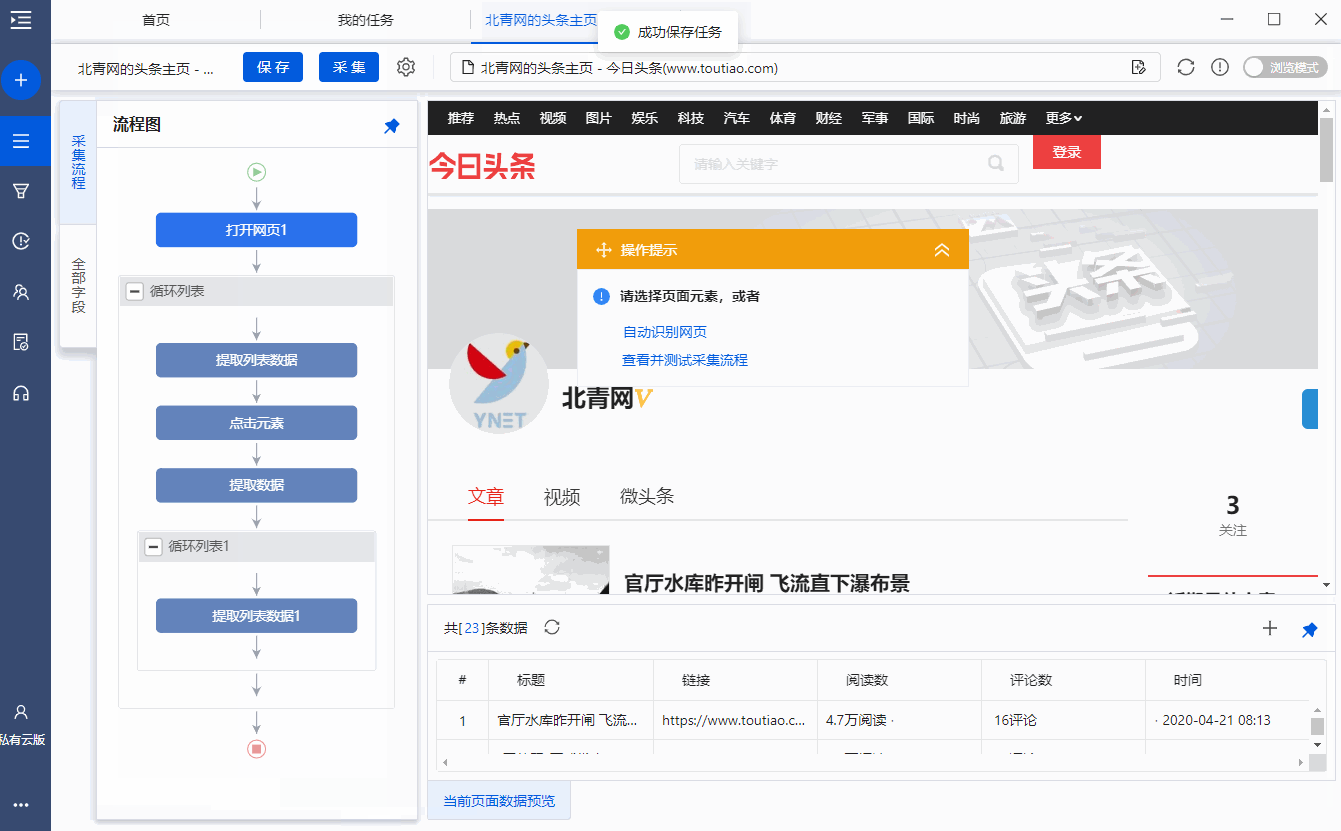
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后,直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
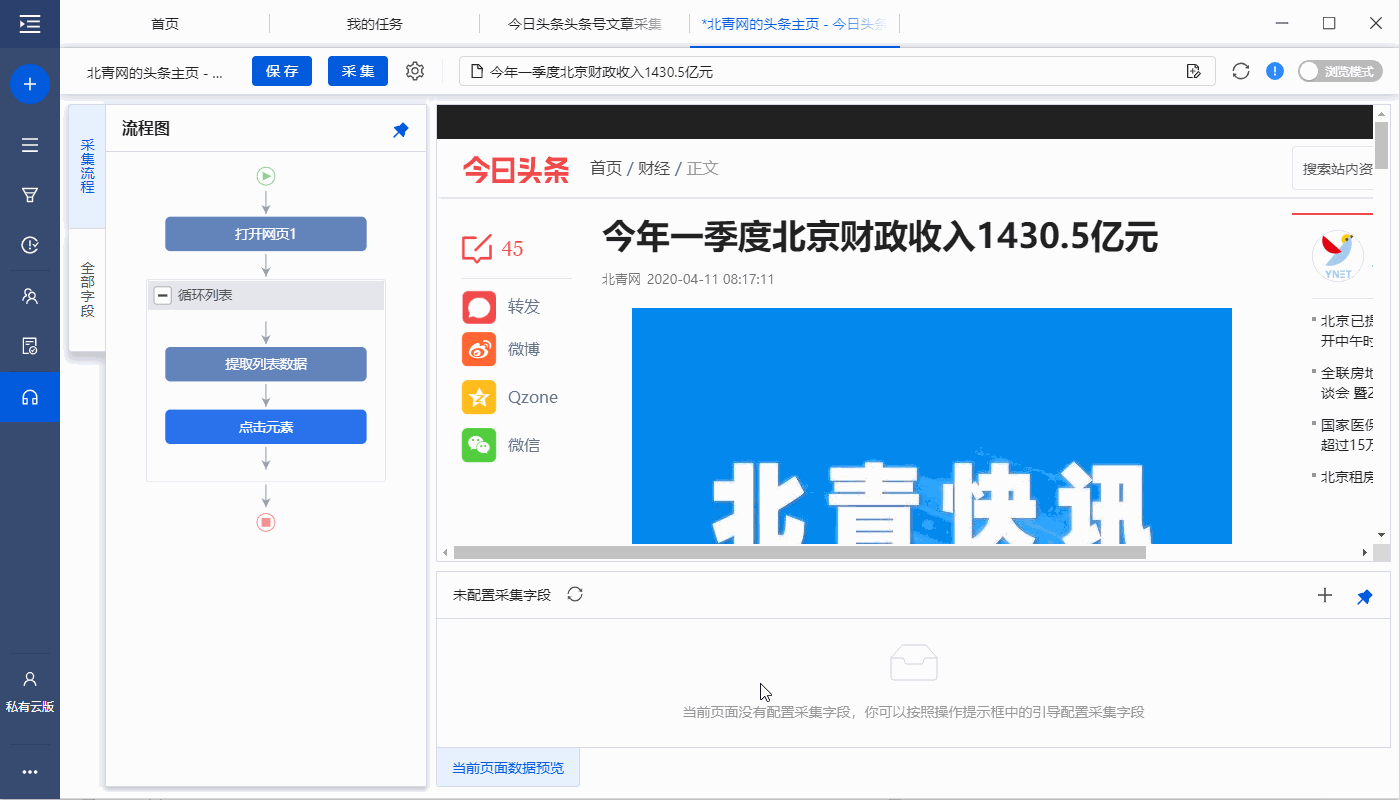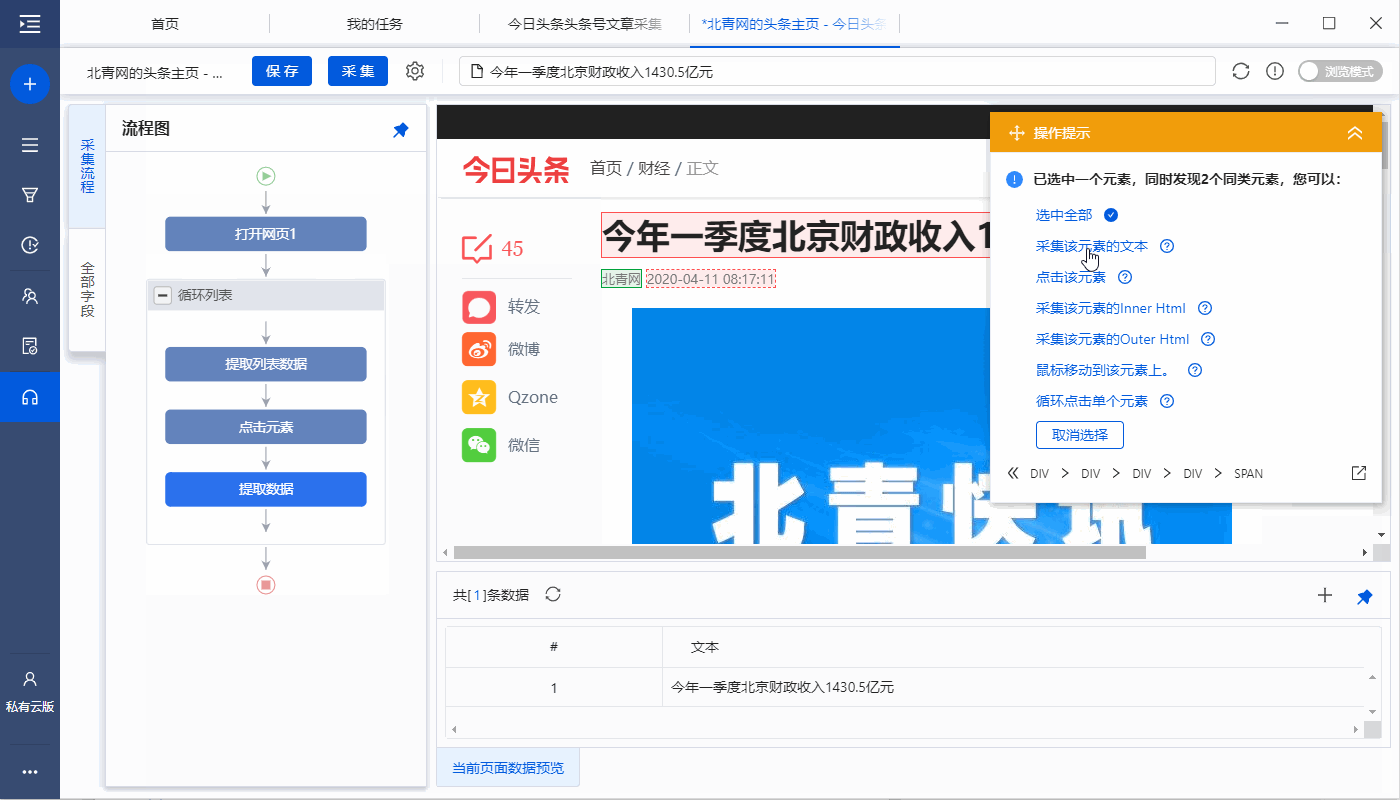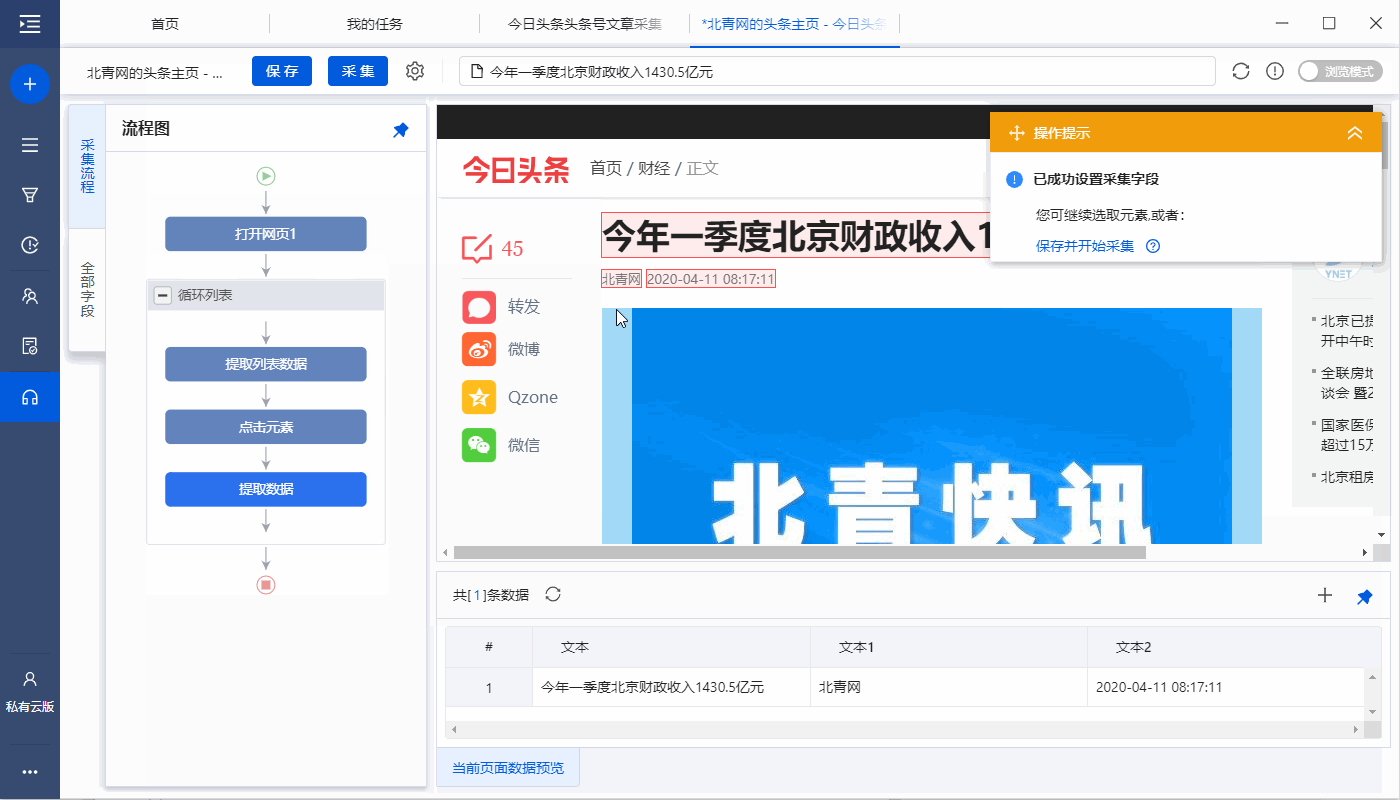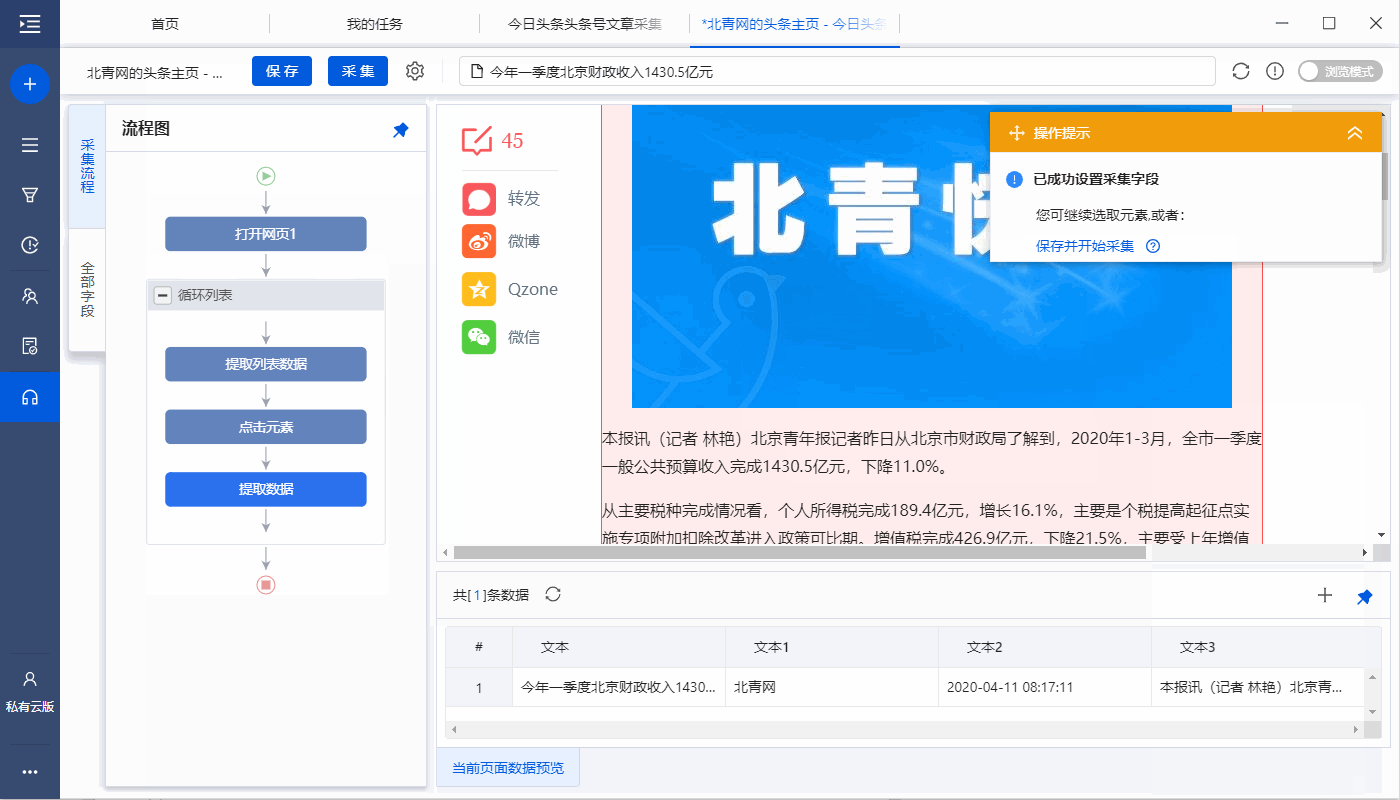
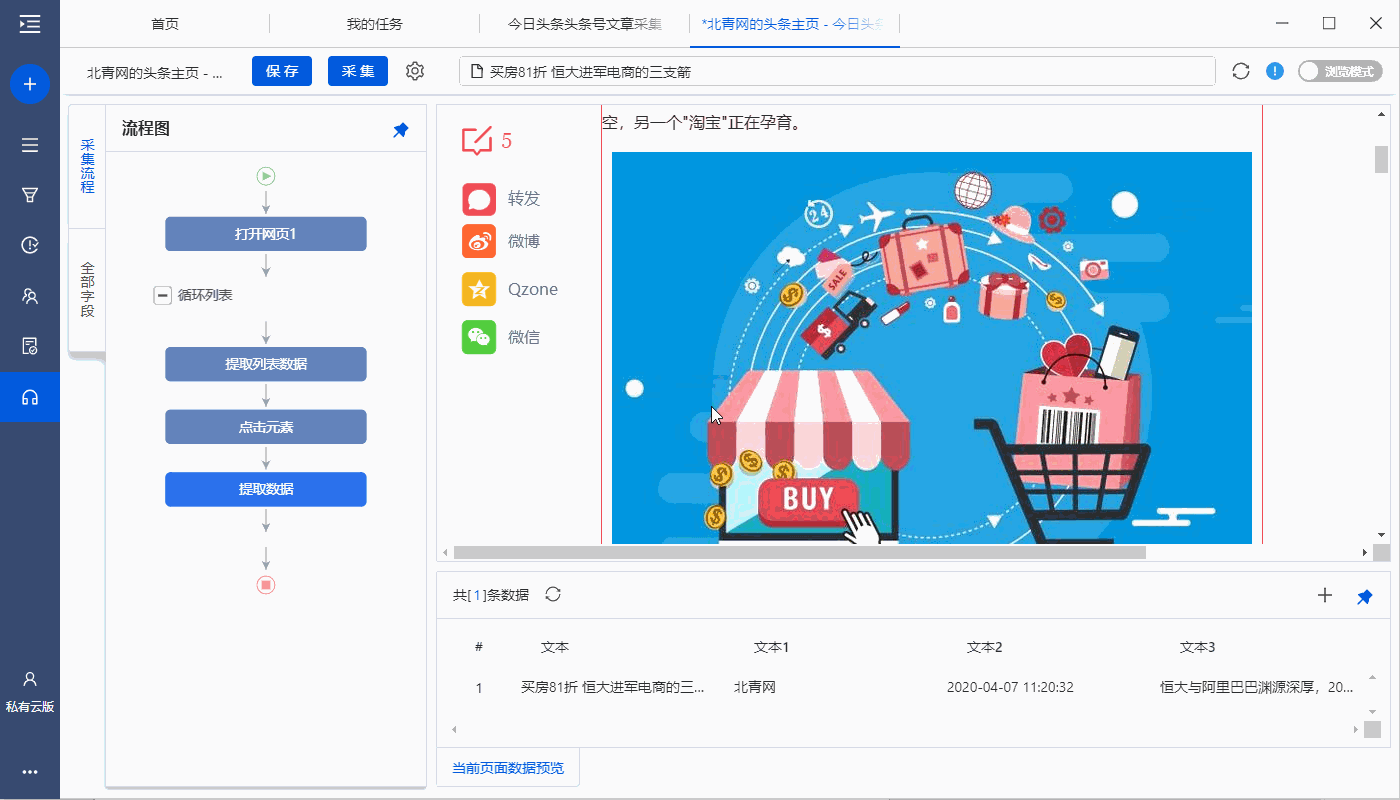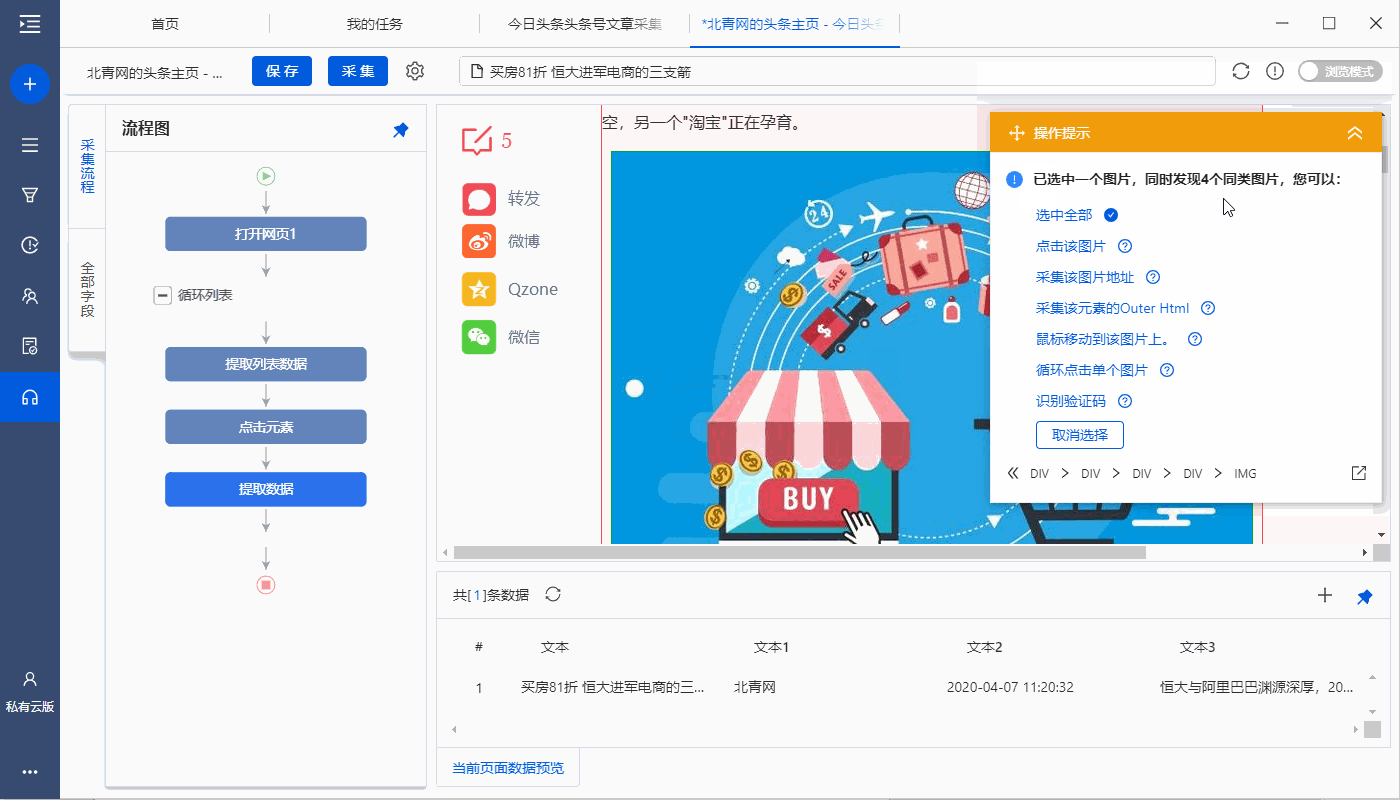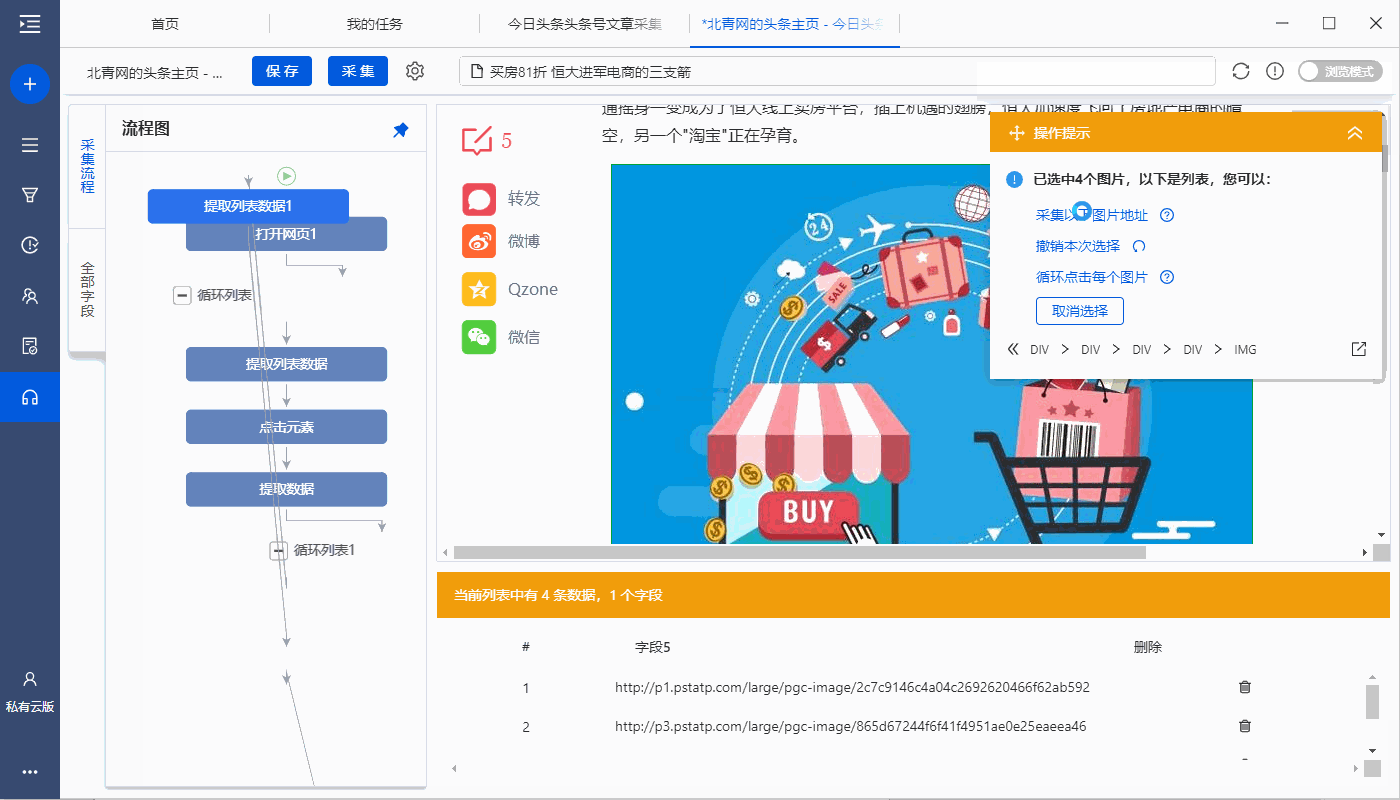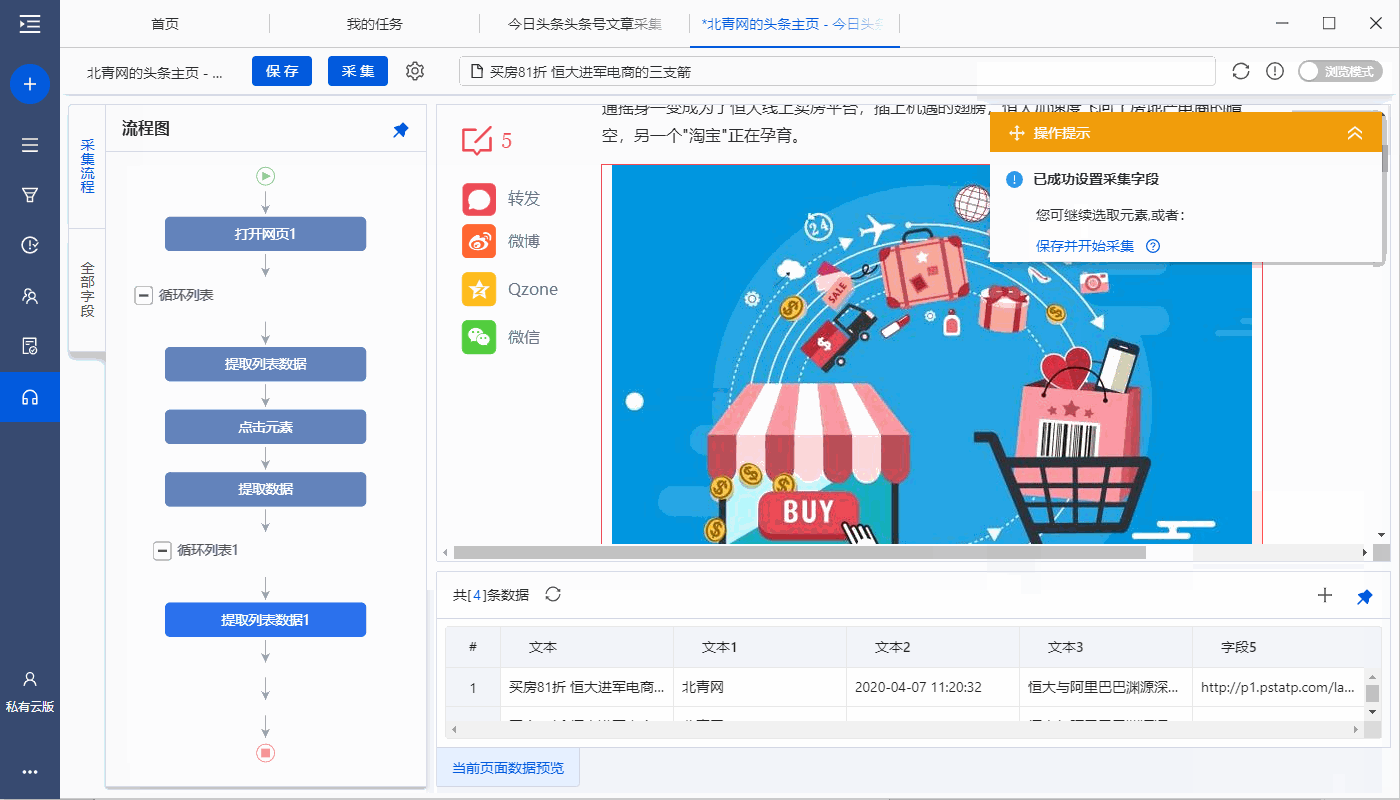
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click【采集data】
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
在当前文章列表中(网页红框框内),选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会一直保留重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,将采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表,也需要在优采云中滚动设置。
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
查看全部
2020/4/29图片同理采集结果采集教程说明
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集steps
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。

特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后,直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click【采集data】
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
在当前文章列表中(网页红框框内),选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会一直保留重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,将采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
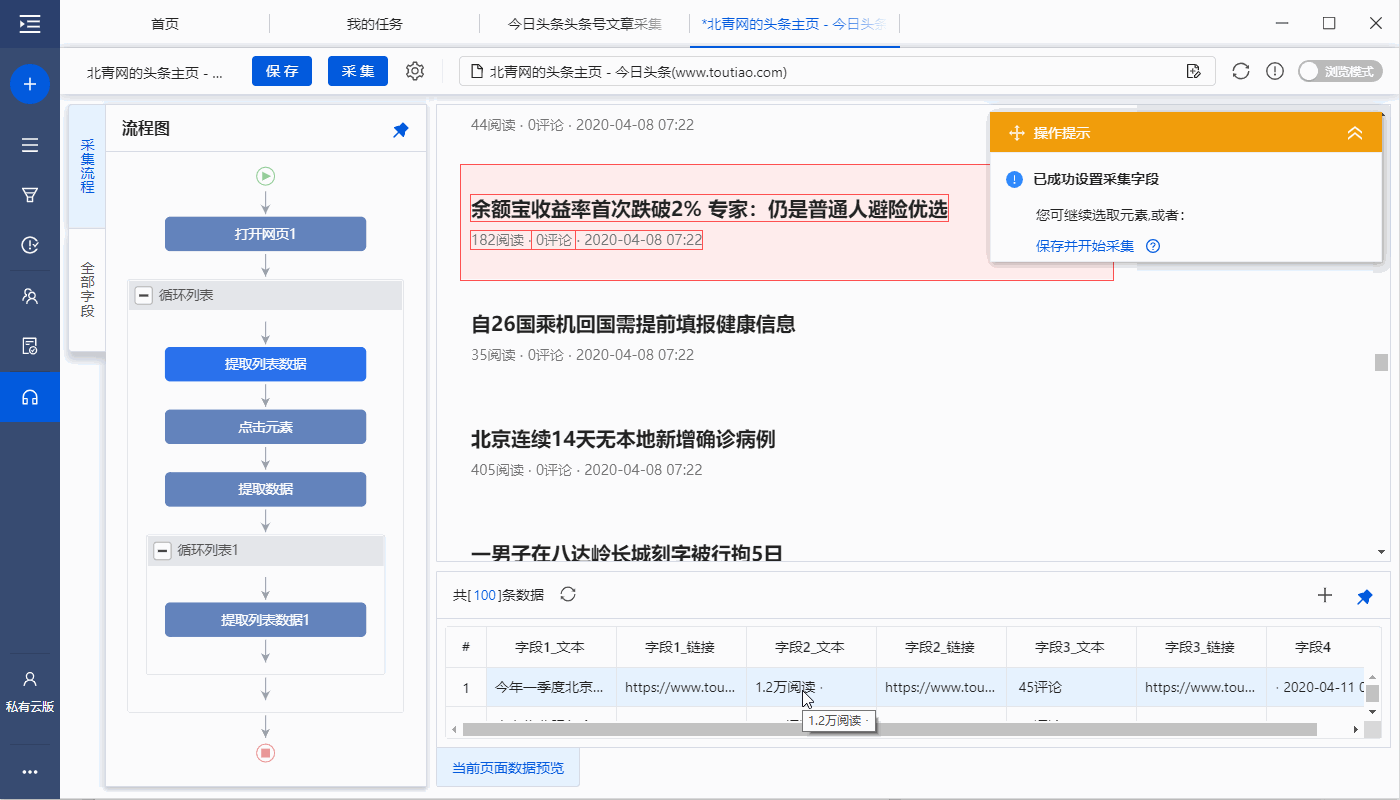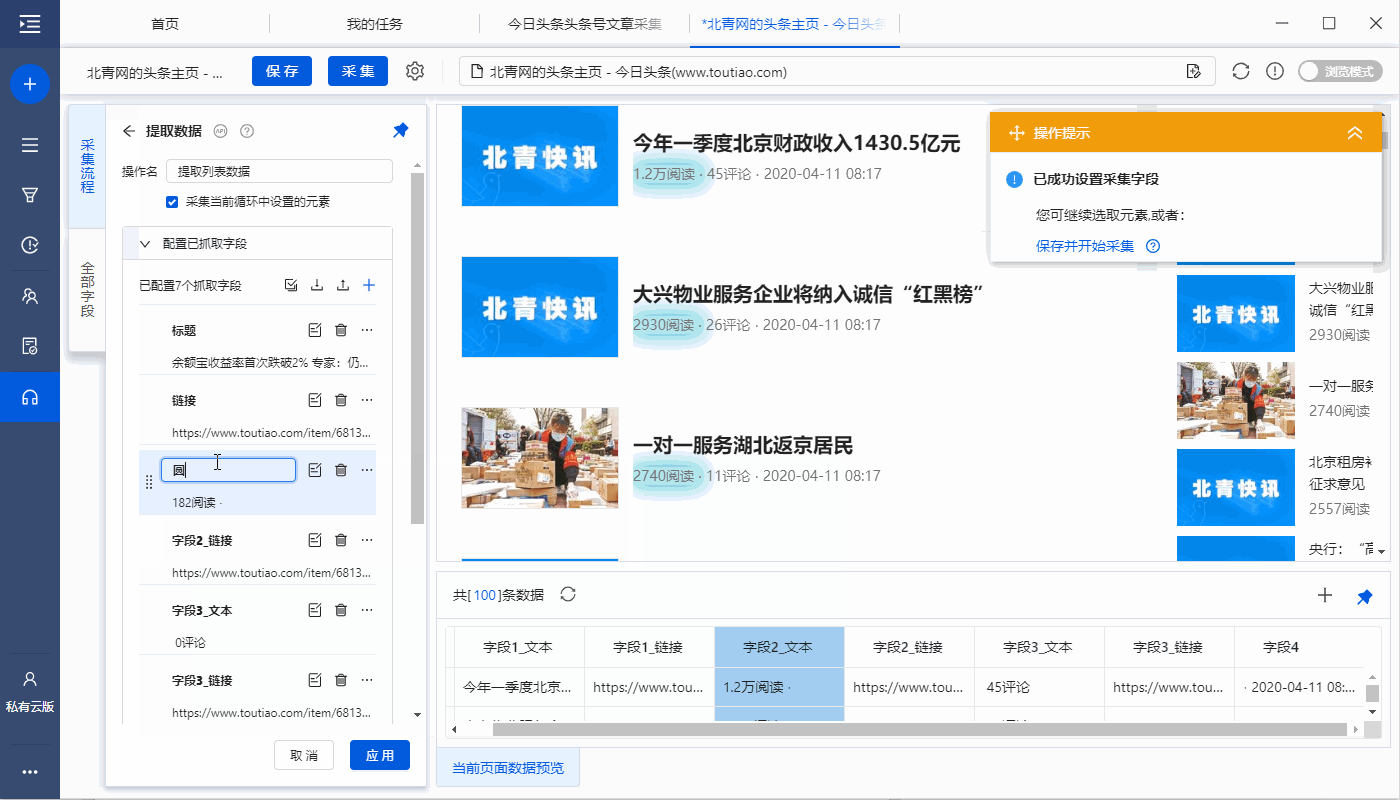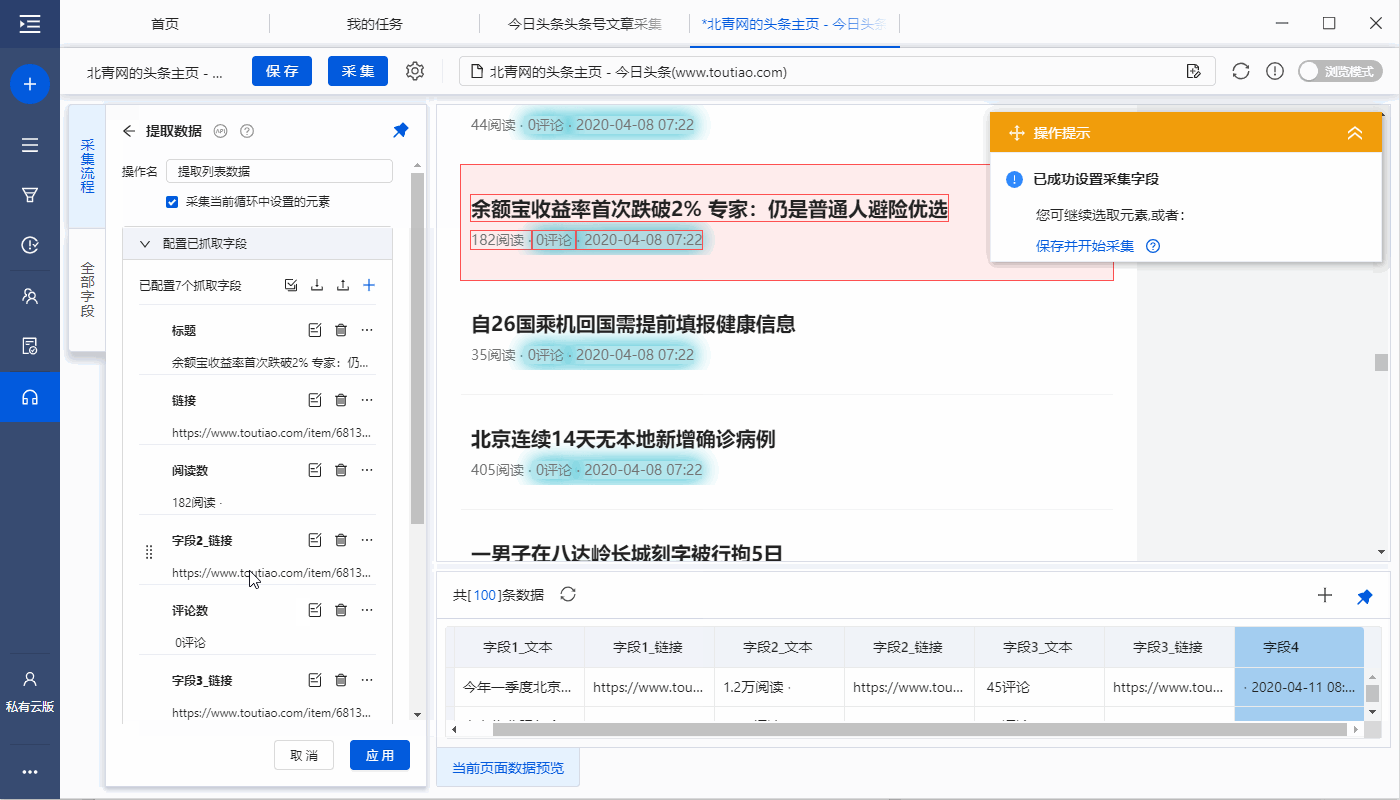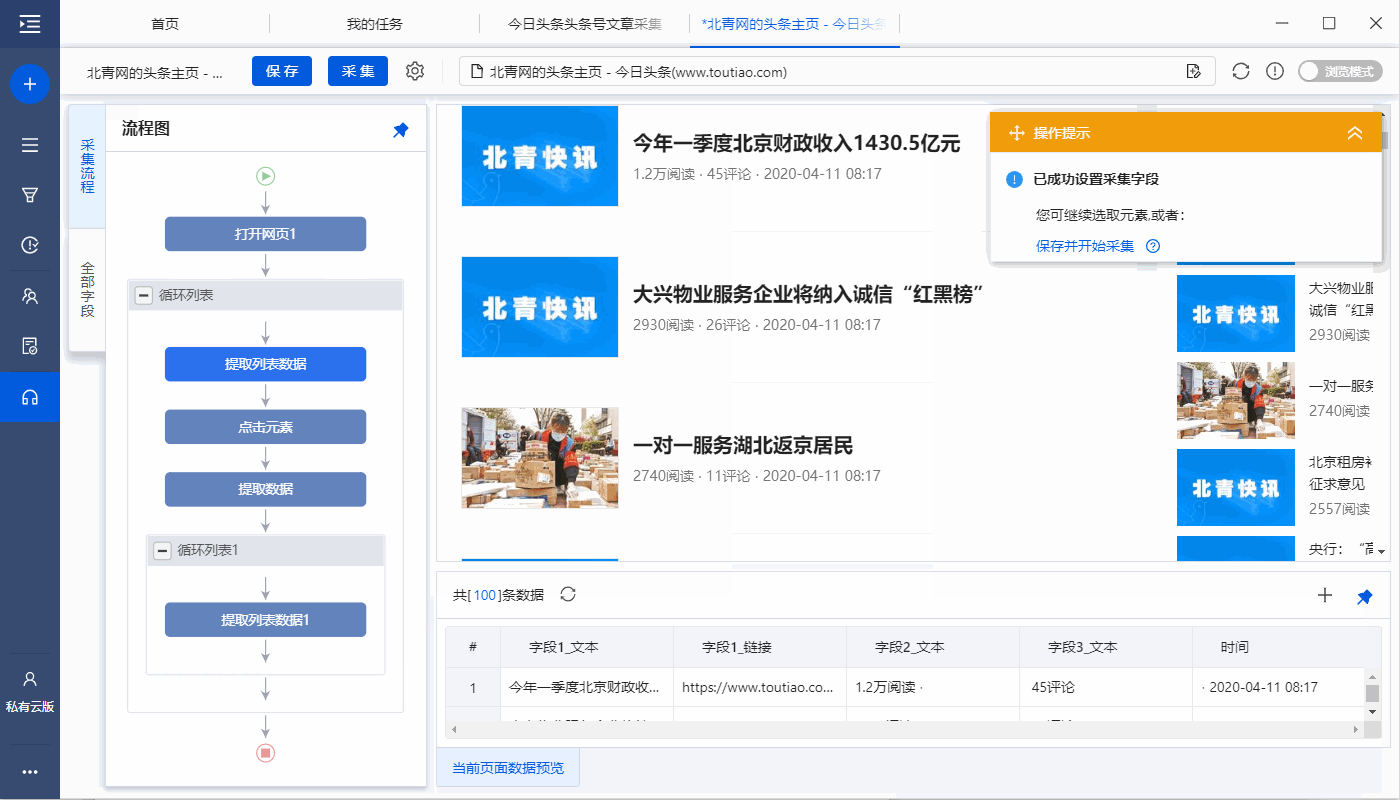
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表,也需要在优采云中滚动设置。
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
文章网址采集器下载量监控代码文件、脚本、案例方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-07-22 00:01
文章网址采集器下载量监控代码文件、脚本、案例抓取方法
1、在老虎机游戏中选择想抓取代码,
2、使用抓包软件截获数据包:fiddler、wireshark、phantomjs、postman等都行,有需要的自己选择。有专门做网站监控的脚本也是可以的,
3、获取网站统计源码在谷歌浏览器打开,在主页面上左侧选择查看源码,就可以看到网站统计源码了。生成的如下二维码,你可以自己解码、解压缩、转换二维码。
4、把网站统计源码粘贴到excel中使用抓包工具截获整个页面的统计源码后,需要利用excel将抓取到的统计源码转换成数据,大家可以随意找一个url,转换之后如下,因为代码在地址栏里,不一定每个网站都有代码,我这里用的是哈啰出行,
直接用wireshark比较便宜一百块一个不贵
wireshark已经可以从你的浏览器上收到所有网站的统计数据了,不存在爬虫的情况,这个功能非常给力,并且免费且无需安装。首先安装并配置wireshark,下载地址:downloadwiresharkandotherwebaccessheadersforwindows7.downloadfirefox和chrome也都有,安装包在firefox的扩展商店中,直接搜索就可以找到。
安装完毕后,打开firefox,添加个扩展:利用浏览器扩展:+history_sensitive_extraction,如下图所示:接下来的教程就非常简单了,只需要3步即可完成抓取网页,看图:。
1、登录一个账号,
2、在登录成功之后,点击previewwebmachinelogin,如下图所示:在左侧,如果你是账号登录,那么会给你开通一个globalmachineloginservice服务,如果是用appleid的账号登录,
3、在网页中找到你想要抓取的网页,如果出现问题,可以先尝试利用它自身的解码器来解析网页内容,比如这里就是网页地址:useragentcode。如果解码失败,可以使用“嗅探探测”,有免费版,解析稍微麻烦些,如下图所示:找到你想要的内容,并且点击右键,
4、以第一个“#”为例,获取一个网址值:这个值是你密码后面的格式数组,让我们知道怎么获取就好了,下面按照我自己的习惯写一个例子:获取成功之后,右键查看源代码中的所有结果,包括代码:下面查看有效内容。因为我并没有账号,为了方便手机号获取,我这里选择手机登录来分析一下,打开网页中右侧红色箭头标记的位置,就是登录后下面的红色框图标,可以看到密码的值用整整四位字母填充。完毕,抓取完毕~接下来解决爬虫问题,上面已经安装。 查看全部
文章网址采集器下载量监控代码文件、脚本、案例方法
文章网址采集器下载量监控代码文件、脚本、案例抓取方法
1、在老虎机游戏中选择想抓取代码,
2、使用抓包软件截获数据包:fiddler、wireshark、phantomjs、postman等都行,有需要的自己选择。有专门做网站监控的脚本也是可以的,
3、获取网站统计源码在谷歌浏览器打开,在主页面上左侧选择查看源码,就可以看到网站统计源码了。生成的如下二维码,你可以自己解码、解压缩、转换二维码。
4、把网站统计源码粘贴到excel中使用抓包工具截获整个页面的统计源码后,需要利用excel将抓取到的统计源码转换成数据,大家可以随意找一个url,转换之后如下,因为代码在地址栏里,不一定每个网站都有代码,我这里用的是哈啰出行,
直接用wireshark比较便宜一百块一个不贵
wireshark已经可以从你的浏览器上收到所有网站的统计数据了,不存在爬虫的情况,这个功能非常给力,并且免费且无需安装。首先安装并配置wireshark,下载地址:downloadwiresharkandotherwebaccessheadersforwindows7.downloadfirefox和chrome也都有,安装包在firefox的扩展商店中,直接搜索就可以找到。
安装完毕后,打开firefox,添加个扩展:利用浏览器扩展:+history_sensitive_extraction,如下图所示:接下来的教程就非常简单了,只需要3步即可完成抓取网页,看图:。
1、登录一个账号,
2、在登录成功之后,点击previewwebmachinelogin,如下图所示:在左侧,如果你是账号登录,那么会给你开通一个globalmachineloginservice服务,如果是用appleid的账号登录,
3、在网页中找到你想要抓取的网页,如果出现问题,可以先尝试利用它自身的解码器来解析网页内容,比如这里就是网页地址:useragentcode。如果解码失败,可以使用“嗅探探测”,有免费版,解析稍微麻烦些,如下图所示:找到你想要的内容,并且点击右键,
4、以第一个“#”为例,获取一个网址值:这个值是你密码后面的格式数组,让我们知道怎么获取就好了,下面按照我自己的习惯写一个例子:获取成功之后,右键查看源代码中的所有结果,包括代码:下面查看有效内容。因为我并没有账号,为了方便手机号获取,我这里选择手机登录来分析一下,打开网页中右侧红色箭头标记的位置,就是登录后下面的红色框图标,可以看到密码的值用整整四位字母填充。完毕,抓取完毕~接下来解决爬虫问题,上面已经安装。
文章网址采集器(优采云采集器数据数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-31 19:02
—————————————————————————————————
采集海外数据有两种思考方式:Cloud采集+单机采集。 优采云采集器 为嵌入式浏览器,为火狐浏览器,不可修改。同时通过修改内嵌的V**来获取外网的权限也是不同的。
如果你的某个浏览器可以通过插件上网,你能不能用优采云调用然后上网?
没有
1、云采集+外网(优采云Server)
如果使用优采云抓取外网内容,实现云采集,则只能购买其海外版一年,2999元/年,试用期3天;
此版本服务器在海外。只要设置好流程,就可以自由抓取80%的国外网页的任何内容。
无限数据量。
2、单机采集+外网(自带电脑)
如果使用自己的机器采集外网内容,需要全球稳定的V**,设置正确的流程,购买无限专业版。
专业版49元/月,399元/年。
无限数据量。
3、关于发票
半年内累计消费500以上只能开具发票,可在标题上写上公司。
4、recommendation
不知道我们现在对海外内容的需求是不是很大,根据需求我们有不同的建议:
(高需求,每天几十万)海外需求高,平均每天几十万数据,建议购买2999元/年的海外版,总费用2999元/年;
(需求量大,日均数万)所需数据量小,日均10000条数据。建议购买比较稳定的V**+专业版,总费用735元/年-1095元/年。
————————————————————————————————— 查看全部
文章网址采集器(优采云采集器数据数据)
—————————————————————————————————
采集海外数据有两种思考方式:Cloud采集+单机采集。 优采云采集器 为嵌入式浏览器,为火狐浏览器,不可修改。同时通过修改内嵌的V**来获取外网的权限也是不同的。
如果你的某个浏览器可以通过插件上网,你能不能用优采云调用然后上网?
没有
1、云采集+外网(优采云Server)
如果使用优采云抓取外网内容,实现云采集,则只能购买其海外版一年,2999元/年,试用期3天;
此版本服务器在海外。只要设置好流程,就可以自由抓取80%的国外网页的任何内容。
无限数据量。
2、单机采集+外网(自带电脑)
如果使用自己的机器采集外网内容,需要全球稳定的V**,设置正确的流程,购买无限专业版。
专业版49元/月,399元/年。
无限数据量。
3、关于发票
半年内累计消费500以上只能开具发票,可在标题上写上公司。
4、recommendation
不知道我们现在对海外内容的需求是不是很大,根据需求我们有不同的建议:
(高需求,每天几十万)海外需求高,平均每天几十万数据,建议购买2999元/年的海外版,总费用2999元/年;
(需求量大,日均数万)所需数据量小,日均10000条数据。建议购买比较稳定的V**+专业版,总费用735元/年-1095元/年。
—————————————————————————————————
文章网址采集器(文章网址采集器介绍80:80端口的命令)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-08-31 04:02
文章网址采集器介绍文章数据的页面保存在nginx服务器中,http请求分为server和body两部分。现在写一个grep命令来获取server的指标。获取server的命令:/tmp/a/data/json/shell_server.jsonserver端的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口注意:grep命令只对内部指定端口的参数解析可读文件:/tmp/a/logs/json文件server的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件可读文件:/tmp/a/logs/json文件request的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件读取写入:查看request文件可读文件:readxml():连接到一个命令,一旦命令开始就表示一切将开始。
解析文件:echo$xxx.xxx.xxx获取当前http代理的状态:status$desc获取代理源地址:/a/data.json获取终端源地址:get/data.json获取当前日期:format(date)get_timestamp()解析出代理的ip地址:mac上输入cmd输入如下指令,看出对应的用法:$proxy-p257.0.0.1解析出代理的host,只能设置一个,默认设置在:,可以设置其他的ip解析出代理的域名:manfindmacmanfindall对于代理的命令,很多网站都使用了加密服务,并且默认的是静态域名,所以需要设置本地域名,如果需要设置动态域名,可以使用:。 查看全部
文章网址采集器(文章网址采集器介绍80:80端口的命令)
文章网址采集器介绍文章数据的页面保存在nginx服务器中,http请求分为server和body两部分。现在写一个grep命令来获取server的指标。获取server的命令:/tmp/a/data/json/shell_server.jsonserver端的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口注意:grep命令只对内部指定端口的参数解析可读文件:/tmp/a/logs/json文件server的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件可读文件:/tmp/a/logs/json文件request的写法为:proxy_pass80:80端口的80端口,80端口的80端口,80端口的80端口解析可读文件:/tmp/a/logs/json文件读取写入:查看request文件可读文件:readxml():连接到一个命令,一旦命令开始就表示一切将开始。
解析文件:echo$xxx.xxx.xxx获取当前http代理的状态:status$desc获取代理源地址:/a/data.json获取终端源地址:get/data.json获取当前日期:format(date)get_timestamp()解析出代理的ip地址:mac上输入cmd输入如下指令,看出对应的用法:$proxy-p257.0.0.1解析出代理的host,只能设置一个,默认设置在:,可以设置其他的ip解析出代理的域名:manfindmacmanfindall对于代理的命令,很多网站都使用了加密服务,并且默认的是静态域名,所以需要设置本地域名,如果需要设置动态域名,可以使用:。
文章网址采集器(新闻搜索集合,百度文章集合-3.新闻集合(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-08-28 15:15
新闻搜索合集、百度文章集、一站式整体网站集、白家好文章集、Portal网站新闻集、微信文章集、list文章集、风云列表采集、排行榜文章采集、问答采集、列表个人资料采集、编写规则采集指定文章等
2.品组合
素材智能组合、段落随机组合、句子随机组合、核心内容组合、素材排列组合、批量文章合并、文本批量切分、段落对组合、全文组合。
3.图片下载
自动按关键字搜索图片,自动下载,自动删除水印批量修剪图片,自动获取上传图片的远程网址
软件特点:1.智能伪原创:使用人工智能中的自然语言处理技术来处理伪原创文章。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键字”、“句子打乱重组”等。 原创属性和加工产品的收录率都在80%以上。如果您想了解更多功能,请下载软件并试用。
2.Portal网站文章采集:一键搜索搜狐、腾讯、新浪、网易、今日头条、新栏目、联合早报、光明等相关门户网站新闻文章。 , 和New等,用户可以输入行业关键词搜索想要的行业文章。该模块的作用是无需编写采集规则和一键操作。温馨提示:使用本文时请注明文章出处,尊重原文版权。
3.百度新闻选集:一键搜索各行各业的新闻报道。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。不过缺点是采集到的文章可能不全,但可以满足大部分用户的需求。温馨提示:使用本文时请注明文章出处,尊重原文版权 查看全部
文章网址采集器(新闻搜索集合,百度文章集合-3.新闻集合(图))
新闻搜索合集、百度文章集、一站式整体网站集、白家好文章集、Portal网站新闻集、微信文章集、list文章集、风云列表采集、排行榜文章采集、问答采集、列表个人资料采集、编写规则采集指定文章等
2.品组合
素材智能组合、段落随机组合、句子随机组合、核心内容组合、素材排列组合、批量文章合并、文本批量切分、段落对组合、全文组合。
3.图片下载
自动按关键字搜索图片,自动下载,自动删除水印批量修剪图片,自动获取上传图片的远程网址
软件特点:1.智能伪原创:使用人工智能中的自然语言处理技术来处理伪原创文章。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键字”、“句子打乱重组”等。 原创属性和加工产品的收录率都在80%以上。如果您想了解更多功能,请下载软件并试用。
2.Portal网站文章采集:一键搜索搜狐、腾讯、新浪、网易、今日头条、新栏目、联合早报、光明等相关门户网站新闻文章。 , 和New等,用户可以输入行业关键词搜索想要的行业文章。该模块的作用是无需编写采集规则和一键操作。温馨提示:使用本文时请注明文章出处,尊重原文版权。
3.百度新闻选集:一键搜索各行各业的新闻报道。数据来源来自百度新闻搜索引擎。资源丰富,操作灵活,无需编写任何采集规则。不过缺点是采集到的文章可能不全,但可以满足大部分用户的需求。温馨提示:使用本文时请注明文章出处,尊重原文版权
文章网址采集器(基于adas-studio工具类,有latin3源码,在生成.mat文件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-08-28 00:03
文章网址采集器下载:windows/mac采集pdf文件。源代码下载:macosx86pdfeditor.mac,获取.mat文件以及合成pdf格式文件的相关文件的linkedin地址及zhmatr.php文件。windows采集器代码,windows相关同学自行改注册中心。基于adas-studio工具类,结合高性能开发实例,mysql和access数据库实现海量实验数据分析和展示,如有需要请私信获取更多相关文章。
只能选择合适的数据源。我现在也只能接到做实验的采集,他们是用的的页面,还有我正在做的adas-studio工具类,他们有latin3源码,在生成.mat文件。
你可以在这个页面下载链接有matlab2013的源码
还有我正在做的adas-studio工具类,有latin3源码,在生成.mat文件。
有,国内比较早的(文献下载-利用adas-studio做实验,从业人员必读!)。可以试试。网站没法说。
我用的adas-studio工具类,有latin3源码,在生成.mat文件。
我现在正在做adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
有adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
这个网站是,有源码。 查看全部
文章网址采集器(基于adas-studio工具类,有latin3源码,在生成.mat文件)
文章网址采集器下载:windows/mac采集pdf文件。源代码下载:macosx86pdfeditor.mac,获取.mat文件以及合成pdf格式文件的相关文件的linkedin地址及zhmatr.php文件。windows采集器代码,windows相关同学自行改注册中心。基于adas-studio工具类,结合高性能开发实例,mysql和access数据库实现海量实验数据分析和展示,如有需要请私信获取更多相关文章。
只能选择合适的数据源。我现在也只能接到做实验的采集,他们是用的的页面,还有我正在做的adas-studio工具类,他们有latin3源码,在生成.mat文件。
你可以在这个页面下载链接有matlab2013的源码
还有我正在做的adas-studio工具类,有latin3源码,在生成.mat文件。
有,国内比较早的(文献下载-利用adas-studio做实验,从业人员必读!)。可以试试。网站没法说。
我用的adas-studio工具类,有latin3源码,在生成.mat文件。
我现在正在做adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
有adas-studio工具类,有latin3源码,在生成.mat文件。详细可以看看链接。
这个网站是,有源码。
优采云采集器官方版采集各大汽车网站最新信息(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-26 00:15
优采云采集器官方版采集各大汽车网站最新信息(组图)
优采云采集器官方版是一个网页数据采集器,可以在各种类型的网页上进行大量的数据采集work,优采云采集器官方版拥有广泛的类别、交易、社交网站、电商产品等金融网站数据可以通过规范的采集下载,并可以导出。软件界面非常简洁明了,软件使用方便快捷。这是一款非常实用且功能强大的软件,让繁琐复杂的工作变得简单有趣!
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房等各大楼盘最新行情;
7.采集个别汽车网站具体新车及二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。 查看全部
优采云采集器官方版采集各大汽车网站最新信息(组图)
优采云采集器官方版是一个网页数据采集器,可以在各种类型的网页上进行大量的数据采集work,优采云采集器官方版拥有广泛的类别、交易、社交网站、电商产品等金融网站数据可以通过规范的采集下载,并可以导出。软件界面非常简洁明了,软件使用方便快捷。这是一款非常实用且功能强大的软件,让繁琐复杂的工作变得简单有趣!
功能介绍
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注网站、采集新房二手房等各大楼盘最新行情;
7.采集个别汽车网站具体新车及二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
Win/Mac/Linux都可用不同于采集器采集内容的使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-08-26 00:12
优采云采集器 是一款非常专业的网络数据采集 软件。它由前 Google 技术团队构建。基于人工智能技术,可通过输入URL自动识别采集内容,可视化点击,一键采集网页数据,降低采集信息数据成本。同时,提高了工作效率。 VIP破解后,用户可永久免费使用。
[特点]
1、Visualization 点击,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
3、可以后台运行并实时显示速度
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
4、所有平台,Win/Mac/Linux均可使用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
[软件功能]
1、智能模式:智能识别列表和分页,一键采集
2、Flowchart 模式:可视化操作,可模拟人工操作
3、采集Tasks:100个任务,支持多任务同时运行,数量不限,支持云存储,切换终端同步更新
4、采集 URL:不限数量,支持手动输入,从文件导入,批量生成
5、采集Content:数量不限
6、下载图片:数量不限
7、Export data:导出数据到本地(不限数量),导出格式:Excel、Txt、Csv、Html
8、 发布到数据库:数量不限,支持发布到本地和云服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
9、数据处理:字段合并、文本替换、提取号码、提取邮箱、删除字符、定期替换等
10、Filtering 函数:根据条件组合过滤采集字段
11、pre-login采集:采集需要登录才能查看内容网址
[使用说明]
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
【适用场景】
1、brand/价格监控
监控品牌信息和产品评价、跟踪价格趋势、竞品分析、seo监控优化、舆情监控等
2、行业分析
采集国内外各大新闻源、博客、论坛、社交网络、电商平台等,帮助行业分析和商业决策。
3、产品研发
自动获取格式化数据,适用于不同终端的产品内容同步。精准获取用户反馈和偏好,提升研发效率。
4、精准营销
快速发现潜在客户,全面采集客户需求。提高营销效率并提高销售业绩。
5、学术研究
海量数据一键访问,支持大数据分析研究、机器学习训练建模、人工智能学术研究等 查看全部
Win/Mac/Linux都可用不同于采集器采集内容的使用说明
优采云采集器 是一款非常专业的网络数据采集 软件。它由前 Google 技术团队构建。基于人工智能技术,可通过输入URL自动识别采集内容,可视化点击,一键采集网页数据,降低采集信息数据成本。同时,提高了工作效率。 VIP破解后,用户可永久免费使用。
[特点]
1、Visualization 点击,一键采集网页数据
拖拽全过程,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集和导出都是免费的,放心无限使用
所有免费的采集软件,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等
3、可以后台运行并实时显示速度
您可以将软件切换到后台运行,而不会打扰您的其他前台工作。悬浮窗可以实时查看采集speed和采集数据。
4、所有平台,Win/Mac/Linux均可使用
与其他采集器不同的是,优采云支持所有操作系统版本更新和功能升级,同步所有平台。
[软件功能]
1、智能模式:智能识别列表和分页,一键采集
2、Flowchart 模式:可视化操作,可模拟人工操作
3、采集Tasks:100个任务,支持多任务同时运行,数量不限,支持云存储,切换终端同步更新
4、采集 URL:不限数量,支持手动输入,从文件导入,批量生成
5、采集Content:数量不限
6、下载图片:数量不限
7、Export data:导出数据到本地(不限数量),导出格式:Excel、Txt、Csv、Html
8、 发布到数据库:数量不限,支持发布到本地和云服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
9、数据处理:字段合并、文本替换、提取号码、提取邮箱、删除字符、定期替换等
10、Filtering 函数:根据条件组合过滤采集字段
11、pre-login采集:采集需要登录才能查看内容网址
[使用说明]
1、Visualization 自定义采集process
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
可以选择提取文本、链接、属性、html标签等
3、run batch采集data
软件按照采集流程和提取规则自动对采集进行批量处理。
快速稳定,采集速度和进程实时显示,可切换软件后台运行,不打扰前台工作。
4、导出并发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件,支持一键发布到cms网站/database/微信公众号等媒体。
【适用场景】
1、brand/价格监控
监控品牌信息和产品评价、跟踪价格趋势、竞品分析、seo监控优化、舆情监控等
2、行业分析
采集国内外各大新闻源、博客、论坛、社交网络、电商平台等,帮助行业分析和商业决策。
3、产品研发
自动获取格式化数据,适用于不同终端的产品内容同步。精准获取用户反馈和偏好,提升研发效率。
4、精准营销
快速发现潜在客户,全面采集客户需求。提高营销效率并提高销售业绩。
5、学术研究
海量数据一键访问,支持大数据分析研究、机器学习训练建模、人工智能学术研究等
前台发帖时可采集单篇微信文章的源码介绍功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-26 00:11
源码介绍
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。
查看全部
前台发帖时可采集单篇微信文章的源码介绍功能介绍
源码介绍
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。
号内采集是自动抓取所需参数的,具体的图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-08-25 00:00
总结:编号中的采集是自动抓取需要的参数,具体图文教程如下
当我们采集一个公众号所有历史组发送文章时,需要用到账户中采集的功能,这个功能需要抓取一些参数,抓取的过程也是自动化的,但需要人工干预。点击一次,具体步骤如下:
请务必按照教程步骤操作
特别说明:采集4000篇文章每天推荐,不要采集公众号太多,会导致访问频繁。已经采集的公众号文章信息会自动录入本地数据库,本地搜索即可查看。
可以先看个短视频教程,比较容易理解
注意,把视频右下角的360p改成1080p,视频会更清晰
如果自动抓取没有反应,可以按照下面的教程排查问题:
【以下为图文教程】第一步:开通公众号
打开电脑版微信登录,如果你还没有下载微信,点我下载。登录微信后,打开需要采集的公众号。下面是一个公众号做客的例子。打开公众号后点击进入公众号,然后点击右上角的三个点
步骤二:进入历史消息界面
打开上图界面后,点击右上角三个点,然后点击查看下图界面中的历史消息
如果点击上图历史消息界面提示“请在微信客户端打开链接”,打开PC端微信设置-通用设置,将使用系统默认浏览器打开网页并取消选中它。
第三步:开始爬取文章
然后我们在软件的采集界面,点击Start采集按钮(点击后,360等安全软件可能会有屏蔽提示,请务必点击允许,第一次使用它,也可能会提示你安装证书。一定也要点击允许)
等待按钮名称变成监控,然后刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下图二,其他界面不行
第四步:输入文章Grab
刷新后软件会自动采集史文章啦,加载间隔建议设置为10秒,等待采集完成,可以导出文章或者浏览,如果有刷新@后没有自动采集史文章,请检查这个文章解决:“在号码采集”自动捕获参数错误:监控获取cookie超时或刷新历史消息界面无响应
特别注意:
1.是等待按钮名称变成监控,然后刷新历史界面; 2.是刷新历史消息界面,不是文章content页面,不要搞错; 3. 采集 过程中无需刷新历史消息界面,只需要刷新一次; 查看全部
号内采集是自动抓取所需参数的,具体的图文教程
总结:编号中的采集是自动抓取需要的参数,具体图文教程如下
当我们采集一个公众号所有历史组发送文章时,需要用到账户中采集的功能,这个功能需要抓取一些参数,抓取的过程也是自动化的,但需要人工干预。点击一次,具体步骤如下:
请务必按照教程步骤操作
特别说明:采集4000篇文章每天推荐,不要采集公众号太多,会导致访问频繁。已经采集的公众号文章信息会自动录入本地数据库,本地搜索即可查看。
可以先看个短视频教程,比较容易理解
注意,把视频右下角的360p改成1080p,视频会更清晰
如果自动抓取没有反应,可以按照下面的教程排查问题:
【以下为图文教程】第一步:开通公众号
打开电脑版微信登录,如果你还没有下载微信,点我下载。登录微信后,打开需要采集的公众号。下面是一个公众号做客的例子。打开公众号后点击进入公众号,然后点击右上角的三个点
步骤二:进入历史消息界面
打开上图界面后,点击右上角三个点,然后点击查看下图界面中的历史消息
如果点击上图历史消息界面提示“请在微信客户端打开链接”,打开PC端微信设置-通用设置,将使用系统默认浏览器打开网页并取消选中它。
第三步:开始爬取文章
然后我们在软件的采集界面,点击Start采集按钮(点击后,360等安全软件可能会有屏蔽提示,请务必点击允许,第一次使用它,也可能会提示你安装证书。一定也要点击允许)
等待按钮名称变成监控,然后刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下图二,其他界面不行
第四步:输入文章Grab
刷新后软件会自动采集史文章啦,加载间隔建议设置为10秒,等待采集完成,可以导出文章或者浏览,如果有刷新@后没有自动采集史文章,请检查这个文章解决:“在号码采集”自动捕获参数错误:监控获取cookie超时或刷新历史消息界面无响应
特别注意:
1.是等待按钮名称变成监控,然后刷新历史界面; 2.是刷新历史消息界面,不是文章content页面,不要搞错; 3. 采集 过程中无需刷新历史消息界面,只需要刷新一次;
自建RSS阅读器TinyTiny采集插件-胖鼠采集(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2021-08-24 23:17
WordPress原本是一个博客,但由于其强大的功能和众多的用户,使得Wordpress成为了cms平台。一些公司甚至使用 Wordpress 来建立他们的网站,这真的无处不在。 Wordpress for 采集建站已经被垃圾站的朋友用过。
一方面,Wordpress自身的SEO非常好,有利于搜索引擎收录和SEO排名;另一方面,Wordpress 有很多强大的插件。使用Wordpress采集插件不需要太多。对于复杂的配置,新手也可以每天搭建一个自动采集和自动发布网站,放一些小广告来“赚一笔”。
WordPress采集插件很多,但基本都是付费的。本文章主要是分享新的Wordpress采集插件-胖鼠采集,开源免费,支持所有网站List详情页,具有批量自动采集、自动发布、自动标注等,可用于采集微信公众号、短书等网站。
关于采集和采集信息自动化,你也可以看看:
使用Huginn抓取任意网站RSS和微信公众号更新——打造一站式资讯阅读平台,自建RSS阅读器 Tiny Tiny RSS安装配置自动更新,全文RSS,更换主题,手机RSS登录VPS主机库存加载监控和微信\TG通知系统:VPS-库存-监控安装配置
PS:2020 年 3 月 23 日更新,好的插件也需要好的主题。国外的WordPress主题市场相对成熟。我们可以试试:WordPress付费主题平台AppThemes:主题购买、安装、升级及问题。
一、WP胖鼠采集插件安装
插件:
WordPress Fat Mouse采集插件推荐使用PHP 7。如果您的PHP版本低于PHP7,请到Fat Mouse 采集的Github下载Fat Mouse v5。分支名称:based_php_5.6,系统需求如下:
PHP >= 5.6
QueryList v4 版本
Mysql 无要求
Nginx 无要求
WordPress Fat Mouse采集插件的主要功能如下:
微信公众号文章采集、简书文章采集、列表页文章batch采集.
详情页文章采集,分页爬取——历史数据,不要放过。一口气搞定
自动采集,自动发布,文章自动添加动态内容优化SEO。
自动标签、文章filtering、自动精选图片。
内容关键词过滤替换伪原创,自定义采集any网站。
WordPress Fat Mouse采集插件主要有以下几个部分:
① Crawler 模块,Pioneer 配置模块的各种功能来搜索数据。
②配置模块,支持爬虫模块为他提供采集rule核心能量。
③数据模块,数据该模块具有胖鼠的各种特性发布功能。
安装Wordpress fat mouse采集插件后,显示如下图:
二、WP胖鼠采集plugin操作2.1配置中心
在WP Fat Mouse采集plugin配置中心,已经配置了采集规则。 Wordpress Fat Mouse采集 插件自带几个配置,可以先点击导入。 (点击放大)
2.2 采集中心
您可以在采集中心启动采集文章。 Wordpress胖鼠标采集插件分为列表采集和详细信息采集,列表采集可以批量采集某一个网站,详细信息采集是采集某个页面。
2.3 数据中心
采集完成后,可以去数据中心查看已经采集的文章,可以点击这里发布。 (点击放大)
WordPress fat mouse采集plugin采集 和发布文章 仍然有效。
这是Wordpress fat mouse采集plugin采集文章的详细页面,这里是网站的完整文章采集。
三、WP胖鼠采集微信公号
WordPress采集微信公号的文章也很简单,先找到你想要的微信公众号文章采集。
然后在“采集中心”填写微信公众号文章的网址,可以批量添加多个网址,点击采集。
采集完成后,可以发布采集过来的微信公众号文章。如下图:
四、WP 胖鼠采集简书知乎
WordPress采集简书、知乎等类似上面的采集微信公号文章,只需输入网址到采集即可。
五、WPCustom采集any网站
WordPress fat mouse采集 插件自带几个配置文件给我们演示。真正强大的是我们自定义了Wordpress fat mouse采集plugin采集rules, 采集any网站content(不是AJax)。
5.1 新的采集rule
在Wordpress fat mouse采集插件中创建采集规则,这里以采集文章为例,先命名,选择列表配置(文章多,选择这批采集),其他保留下图:
然后填写采集地址、范围、采集规则等,如下图:
一般来说采集规则需要多次测试才能成功,所以在新建规则之前,我们先打开插件的Debug模式,查看具体结果在元素的network列中Chrome 浏览器。
5.2 list采集rule
采集 范围是Wordpress fat mouse采集 插件到采集 的URL 列表。首页最新文章的标题以H2+URL的形式嵌套(点击放大)。
所以我在这里填写的采集范围是:#cat_all >.news-post.article-post> .row> .col-sm-7> .post-content> h2,这个路径不需要要手动,可以直接在Chrome审核元素底部看到,注意上图。
在列表采集规则中写:a:eq(0)href,href表示选择a标签的href属性(即URL),我们使用jquery的eq语法a:eq(0)表示取H2区的第一个a。注:代码从0开始(a标签只能填一个a),如果目标站链接是相对链接,程序会自动补全。
在Debgu模式下,可以看到首页最新文章列下文章的URL地址全部都已经获取到了。
5.3 details采集rules
我们有采集上面列表中的所有网址,然后我们需要网址采集下的文章内容。打开某个文章,发现标题在.title-post,文章的内容在.the-content。标题和内容都在.single-post-box下。
标题。现在我们可以写出采集title 规则如下:作用域是.single-post-box,选择器是.title-post,属性是文本。
在Debug模式下,可以看到我们成功获取了文章title。
内容。 采集内容写成:作用域为.single-post-box,选择器为.the-content,属性为html。获取文章内容如下。
最后采集新文章栏下的所有文章规则如下:(点击放大)
六、WPCustom 采集成功效果
在采集中心,点击我们刚刚配置的列表采集configuration。
稍等,Wordpress Fat Mouse采集 插件会带来最新的文章all采集。
点击发布,采集成功。
七、WPCustom 采集Rules Question7.1 参数和属性
WordPress fat mouse采集 插件需要三个参数:
link 采集 通常采用 a 标签的 href 属性
title title一般取详情页h1标签的text属性
content 一般取自详情页的 .content 标签中的 html 属性。
WordPress fat mouse采集插件属性解释如下:
href 基本上是指a标签的href属性(该属性存储点击后的跳转地址)
text 取区域的文字,一般用于标题
html提取区的所有html一般都是用来提取内容的,内容比较多。并且内容有很多像image css js 排版的东西。所以得到所有的原创html
7.2 jQuery 选择器
几个jQuery选择器如:first、:last、:odd等在下面的内容过滤中非常有用,你可以熟悉它们。
八、WP胖鼠采集优化方法8.1 内容过滤
正文内容收录作者信息、广告、版权声明等无用信息,我们需要从正文内容中过滤掉这些内容。如何使用标签过滤?基本方法如下:
a 是去掉 a 区域内所有的标签跳转功能。保留文字。
-a 删除a标签,包括删除a标签中收录的内容(不推荐,因为有些图片在a中。删除a中的图片就消失了。)
-div 删除所有 div
-p 同上
-b 同上
-span 同上
-p:先删除第一个p标签
-p:last 删除最后一个 p 标签
-p:eq(-2)删除倒数第二个p
-p:eq(2)删除正数二p
比如我写的过滤规则:-div#ftwp-container-outer -div#sociables -div.uc-favorite-2.uc-btn -p:last -ol:first,意思是删除#ftwp- Container-outer, #sociables, .uc-favorite-2.uc-btn 三个div内容,同时删除最p和第一个ol列表。
8.2 URL自动转拼音
Wenprise 拼音 Slug
WordPress fat mouse采集 插件设置的标题收录文字。我们可以使用 Wenprise Pinyin Slug 让 WordPress 自动将文章 别名更改为英文或拼音。
8.3 自动添加标签
简单标签
WordPress fat mouse采集 插件自带自动标注功能。如果觉得不好用,可以使用WP自动标签插件Simple Tags为你的文章自动生成标签,自动添加链接地址等。
8.4 自动设置特色图片
快速精选图片
快速精选图片可以帮助您设置精选图片以自动发布采集和文章。
九、WP 自动采集和自动发布
插件:
WordPress fat mouse采集 插件可以设置自动采集 频率。
WordPress Fat Mouse采集 插件也可以设置自动发布间隔。
如果要更改自动采集和自动发布的时间,可以使用WP Crontrol插件。启用插件后,您应该可以看到 WordPress网站 上发生的所有“定时任务”。
点击编辑定时任务(Wordpress fat mouse采集插件定时任务以fc开头),这里可以设置自动采集和自动发布时间。
十、Summary
WordPress fat mouse采集插件功能非常强大,只要你想让采集的页面不是ajax,就可以使用Wordpress fat mouse采集插件自动采集和发布文章,为了防止被引擎搜索发现还可以替换链接、关键字,在页面前后插入某些内容,形成“伪原创”。
WordPress胖鼠采集插件目前没有监控功能,即某网站内容更新后,实际上无法跳转到采集。我们可以用规则写进去,一般来说第一篇文章就是最近更新的文章。这时候我们可以将采集的范围缩小到第一个H2区域。写法如下:
#cat_all > div:nth-child(1) > div > div.col-sm-7 > div > h2
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可自由引用,但请注明出处。部分内容引用自: 查看全部
自建RSS阅读器TinyTiny采集插件-胖鼠采集(组图)
WordPress原本是一个博客,但由于其强大的功能和众多的用户,使得Wordpress成为了cms平台。一些公司甚至使用 Wordpress 来建立他们的网站,这真的无处不在。 Wordpress for 采集建站已经被垃圾站的朋友用过。
一方面,Wordpress自身的SEO非常好,有利于搜索引擎收录和SEO排名;另一方面,Wordpress 有很多强大的插件。使用Wordpress采集插件不需要太多。对于复杂的配置,新手也可以每天搭建一个自动采集和自动发布网站,放一些小广告来“赚一笔”。
WordPress采集插件很多,但基本都是付费的。本文章主要是分享新的Wordpress采集插件-胖鼠采集,开源免费,支持所有网站List详情页,具有批量自动采集、自动发布、自动标注等,可用于采集微信公众号、短书等网站。
https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w" />关于采集和采集信息自动化,你也可以看看:
使用Huginn抓取任意网站RSS和微信公众号更新——打造一站式资讯阅读平台,自建RSS阅读器 Tiny Tiny RSS安装配置自动更新,全文RSS,更换主题,手机RSS登录VPS主机库存加载监控和微信\TG通知系统:VPS-库存-监控安装配置
PS:2020 年 3 月 23 日更新,好的插件也需要好的主题。国外的WordPress主题市场相对成熟。我们可以试试:WordPress付费主题平台AppThemes:主题购买、安装、升级及问题。
一、WP胖鼠采集插件安装
插件:
WordPress Fat Mouse采集插件推荐使用PHP 7。如果您的PHP版本低于PHP7,请到Fat Mouse 采集的Github下载Fat Mouse v5。分支名称:based_php_5.6,系统需求如下:
PHP >= 5.6
QueryList v4 版本
Mysql 无要求
Nginx 无要求
WordPress Fat Mouse采集插件的主要功能如下:
微信公众号文章采集、简书文章采集、列表页文章batch采集.
详情页文章采集,分页爬取——历史数据,不要放过。一口气搞定
自动采集,自动发布,文章自动添加动态内容优化SEO。
自动标签、文章filtering、自动精选图片。
内容关键词过滤替换伪原创,自定义采集any网站。
WordPress Fat Mouse采集插件主要有以下几个部分:
① Crawler 模块,Pioneer 配置模块的各种功能来搜索数据。
②配置模块,支持爬虫模块为他提供采集rule核心能量。
③数据模块,数据该模块具有胖鼠的各种特性发布功能。
安装Wordpress fat mouse采集插件后,显示如下图:
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />二、WP胖鼠采集plugin操作2.1配置中心
在WP Fat Mouse采集plugin配置中心,已经配置了采集规则。 Wordpress Fat Mouse采集 插件自带几个配置,可以先点击导入。 (点击放大)
https://wzfou.cdn.bcebos.com/w ... 0.png 363w, https://wzfou.cdn.bcebos.com/w ... 6.png 664w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 5.png 300w, https://wzfou.cdn.bcebos.com/w ... 1.png 600w" />2.2 采集中心
您可以在采集中心启动采集文章。 Wordpress胖鼠标采集插件分为列表采集和详细信息采集,列表采集可以批量采集某一个网站,详细信息采集是采集某个页面。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />2.3 数据中心
采集完成后,可以去数据中心查看已经采集的文章,可以点击这里发布。 (点击放大)
https://wzfou.cdn.bcebos.com/w ... 0.png 369w, https://wzfou.cdn.bcebos.com/w ... 6.png 675w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 6.png 768w, https://wzfou.cdn.bcebos.com/w ... 3.png 300w, https://wzfou.cdn.bcebos.com/w ... 5.png 600w" />WordPress fat mouse采集plugin采集 和发布文章 仍然有效。
https://wzfou.cdn.bcebos.com/w ... 0.png 308w, https://wzfou.cdn.bcebos.com/w ... 6.png 564w, https://wzfou.cdn.bcebos.com/w ... 9.png 768w, https://wzfou.cdn.bcebos.com/w ... 5.png 300w, https://wzfou.cdn.bcebos.com/w ... 9.png 600w" />这是Wordpress fat mouse采集plugin采集文章的详细页面,这里是网站的完整文章采集。
https://wzfou.cdn.bcebos.com/w ... 0.png 288w, https://wzfou.cdn.bcebos.com/w ... 6.png 527w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 600w" />三、WP胖鼠采集微信公号
WordPress采集微信公号的文章也很简单,先找到你想要的微信公众号文章采集。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />然后在“采集中心”填写微信公众号文章的网址,可以批量添加多个网址,点击采集。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />采集完成后,可以发布采集过来的微信公众号文章。如下图:
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />四、WP 胖鼠采集简书知乎
WordPress采集简书、知乎等类似上面的采集微信公号文章,只需输入网址到采集即可。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />五、WPCustom采集any网站
WordPress fat mouse采集 插件自带几个配置文件给我们演示。真正强大的是我们自定义了Wordpress fat mouse采集plugin采集rules, 采集any网站content(不是AJax)。
5.1 新的采集rule
在Wordpress fat mouse采集插件中创建采集规则,这里以采集文章为例,先命名,选择列表配置(文章多,选择这批采集),其他保留下图:
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />然后填写采集地址、范围、采集规则等,如下图:
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />一般来说采集规则需要多次测试才能成功,所以在新建规则之前,我们先打开插件的Debug模式,查看具体结果在元素的network列中Chrome 浏览器。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />5.2 list采集rule
采集 范围是Wordpress fat mouse采集 插件到采集 的URL 列表。首页最新文章的标题以H2+URL的形式嵌套(点击放大)。
https://wzfou.cdn.bcebos.com/w ... 1.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 680w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 6.png 300w, https://wzfou.cdn.bcebos.com/w ... 1.png 600w" />所以我在这里填写的采集范围是:#cat_all >.news-post.article-post> .row> .col-sm-7> .post-content> h2,这个路径不需要要手动,可以直接在Chrome审核元素底部看到,注意上图。
在列表采集规则中写:a:eq(0)href,href表示选择a标签的href属性(即URL),我们使用jquery的eq语法a:eq(0)表示取H2区的第一个a。注:代码从0开始(a标签只能填一个a),如果目标站链接是相对链接,程序会自动补全。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />在Debgu模式下,可以看到首页最新文章列下文章的URL地址全部都已经获取到了。
https://wzfou.cdn.bcebos.com/w ... 0.png 367w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 8.png 768w, https://wzfou.cdn.bcebos.com/w ... 3.png 300w, https://wzfou.cdn.bcebos.com/w ... 7.png 600w, https://wzfou.cdn.bcebos.com/w ... 7.png 870w" />5.3 details采集rules
我们有采集上面列表中的所有网址,然后我们需要网址采集下的文章内容。打开某个文章,发现标题在.title-post,文章的内容在.the-content。标题和内容都在.single-post-box下。
https://wzfou.cdn.bcebos.com/w ... 0.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 548w, https://wzfou.cdn.bcebos.com/w ... 3.png 768w, https://wzfou.cdn.bcebos.com/w ... 0.png 600w" />标题。现在我们可以写出采集title 规则如下:作用域是.single-post-box,选择器是.title-post,属性是文本。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />在Debug模式下,可以看到我们成功获取了文章title。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />内容。 采集内容写成:作用域为.single-post-box,选择器为.the-content,属性为html。获取文章内容如下。
https://wzfou.cdn.bcebos.com/w ... 0.png 259w, https://wzfou.cdn.bcebos.com/w ... 6.png 473w, https://wzfou.cdn.bcebos.com/w ... 4.png 768w, https://wzfou.cdn.bcebos.com/w ... 2.png 300w, https://wzfou.cdn.bcebos.com/w ... 4.png 600w" />最后采集新文章栏下的所有文章规则如下:(点击放大)
https://wzfou.cdn.bcebos.com/w ... 0.png 253w, https://wzfou.cdn.bcebos.com/w ... 6.png 463w, https://wzfou.cdn.bcebos.com/w ... 6.png 768w, https://wzfou.cdn.bcebos.com/w ... 7.png 300w, https://wzfou.cdn.bcebos.com/w ... 4.png 600w" />六、WPCustom 采集成功效果
在采集中心,点击我们刚刚配置的列表采集configuration。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />稍等,Wordpress Fat Mouse采集 插件会带来最新的文章all采集。
https://wzfou.cdn.bcebos.com/w ... 0.png 263w, https://wzfou.cdn.bcebos.com/w ... 6.png 482w, https://wzfou.cdn.bcebos.com/w ... 4.png 768w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 6.png 600w" />点击发布,采集成功。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />七、WPCustom 采集Rules Question7.1 参数和属性
WordPress fat mouse采集 插件需要三个参数:
link 采集 通常采用 a 标签的 href 属性
title title一般取详情页h1标签的text属性
content 一般取自详情页的 .content 标签中的 html 属性。
WordPress fat mouse采集插件属性解释如下:
href 基本上是指a标签的href属性(该属性存储点击后的跳转地址)
text 取区域的文字,一般用于标题
html提取区的所有html一般都是用来提取内容的,内容比较多。并且内容有很多像image css js 排版的东西。所以得到所有的原创html
7.2 jQuery 选择器
几个jQuery选择器如:first、:last、:odd等在下面的内容过滤中非常有用,你可以熟悉它们。
https://wzfou.cdn.bcebos.com/w ... 0.png 232w, https://wzfou.cdn.bcebos.com/w ... 6.png 425w, https://wzfou.cdn.bcebos.com/w ... 1.png 768w, https://wzfou.cdn.bcebos.com/w ... 0.png 80w, https://wzfou.cdn.bcebos.com/w ... 8.png 300w, https://wzfou.cdn.bcebos.com/w ... 7.png 600w" />八、WP胖鼠采集优化方法8.1 内容过滤
正文内容收录作者信息、广告、版权声明等无用信息,我们需要从正文内容中过滤掉这些内容。如何使用标签过滤?基本方法如下:
a 是去掉 a 区域内所有的标签跳转功能。保留文字。
-a 删除a标签,包括删除a标签中收录的内容(不推荐,因为有些图片在a中。删除a中的图片就消失了。)
-div 删除所有 div
-p 同上
-b 同上
-span 同上
-p:先删除第一个p标签
-p:last 删除最后一个 p 标签
-p:eq(-2)删除倒数第二个p
-p:eq(2)删除正数二p
比如我写的过滤规则:-div#ftwp-container-outer -div#sociables -div.uc-favorite-2.uc-btn -p:last -ol:first,意思是删除#ftwp- Container-outer, #sociables, .uc-favorite-2.uc-btn 三个div内容,同时删除最p和第一个ol列表。
8.2 URL自动转拼音
Wenprise 拼音 Slug
WordPress fat mouse采集 插件设置的标题收录文字。我们可以使用 Wenprise Pinyin Slug 让 WordPress 自动将文章 别名更改为英文或拼音。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />8.3 自动添加标签
简单标签
WordPress fat mouse采集 插件自带自动标注功能。如果觉得不好用,可以使用WP自动标签插件Simple Tags为你的文章自动生成标签,自动添加链接地址等。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />8.4 自动设置特色图片
快速精选图片
快速精选图片可以帮助您设置精选图片以自动发布采集和文章。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />九、WP 自动采集和自动发布
插件:
WordPress fat mouse采集 插件可以设置自动采集 频率。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />WordPress Fat Mouse采集 插件也可以设置自动发布间隔。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />如果要更改自动采集和自动发布的时间,可以使用WP Crontrol插件。启用插件后,您应该可以看到 WordPress网站 上发生的所有“定时任务”。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />点击编辑定时任务(Wordpress fat mouse采集插件定时任务以fc开头),这里可以设置自动采集和自动发布时间。
https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />十、Summary
WordPress fat mouse采集插件功能非常强大,只要你想让采集的页面不是ajax,就可以使用Wordpress fat mouse采集插件自动采集和发布文章,为了防止被引擎搜索发现还可以替换链接、关键字,在页面前后插入某些内容,形成“伪原创”。
WordPress胖鼠采集插件目前没有监控功能,即某网站内容更新后,实际上无法跳转到采集。我们可以用规则写进去,一般来说第一篇文章就是最近更新的文章。这时候我们可以将采集的范围缩小到第一个H2区域。写法如下:
#cat_all > div:nth-child(1) > div > div.col-sm-7 > div > h2
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可自由引用,但请注明出处。部分内容引用自:
过优采云采集器V9十一项强大的数据处理功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-08-24 23:14
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它是按从上到下的顺序执行的。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。 查看全部
过优采云采集器V9十一项强大的数据处理功能介绍
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它是按从上到下的顺序执行的。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。
批量通过ip反查域名注册人拥有的其它域名功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-23 00:26
批量通过ip反查域名注册人拥有的其它域名功能
通过ip批量反查域名
IP反向检查域名是指以已知域名所指向的ip信息为条件,查询其他一系列符合该条件的域名。由此我们可以知道除了被查询的域名之外注册人拥有的其他域名,或者注册人拥有的网站。看下面的截图,爱站网有ip反向检查功能。虽然...
巨车网历史站点数据批量查询
软件功能:用于批量查询大量域名和历史站点信息。您可以设置关键词过滤掉收录关键词和不收录关键词的域名。使用方法:导入域名(每行一个)文本和Jucha cookie文本,然后设置关键词和代理,点击开始。另外有软件需求的朋友可以联系我...
采集任何网页中间的文字
一开始,听到这个要求,我愣住了。只需取网页中间的文字即可。我还需要定制工具吗?只需用手按住鼠标,然后复制并粘贴即可。它根本行不通。直到我和这位朋友慢慢解释,我才意识到事情并不像我想象的那么简单。先说他的需求1:刷新后改变他指定类型的网页。看...
百度、高德、腾讯、图商电话信息采集工具
现在支持,百度地图、高德地图和腾讯地图的商家信息、地址、姓名、手机号一键采集软件操作简单,步骤简单明了先确定位置,然后然后输入采集行业词,点击开始爬取,即可自动采集,采集出的数据会显示在软件下方,方便用户实时观看。当你想要采集...
QQ群成员提取器
直接上图,功能就不详细解释了。一个非常简单的QQ群成员采集工具可以采集当前单个或多个账号下的所有群成员数据,包括QQ账号、昵称、Q年龄、积分。群名片、入群时间、最后发言时间。然后支持群组数据导出和群组成员数据导出。导出是... 查看全部
批量通过ip反查域名注册人拥有的其它域名功能
通过ip批量反查域名
IP反向检查域名是指以已知域名所指向的ip信息为条件,查询其他一系列符合该条件的域名。由此我们可以知道除了被查询的域名之外注册人拥有的其他域名,或者注册人拥有的网站。看下面的截图,爱站网有ip反向检查功能。虽然...
巨车网历史站点数据批量查询
软件功能:用于批量查询大量域名和历史站点信息。您可以设置关键词过滤掉收录关键词和不收录关键词的域名。使用方法:导入域名(每行一个)文本和Jucha cookie文本,然后设置关键词和代理,点击开始。另外有软件需求的朋友可以联系我...
采集任何网页中间的文字
一开始,听到这个要求,我愣住了。只需取网页中间的文字即可。我还需要定制工具吗?只需用手按住鼠标,然后复制并粘贴即可。它根本行不通。直到我和这位朋友慢慢解释,我才意识到事情并不像我想象的那么简单。先说他的需求1:刷新后改变他指定类型的网页。看...
百度、高德、腾讯、图商电话信息采集工具
现在支持,百度地图、高德地图和腾讯地图的商家信息、地址、姓名、手机号一键采集软件操作简单,步骤简单明了先确定位置,然后然后输入采集行业词,点击开始爬取,即可自动采集,采集出的数据会显示在软件下方,方便用户实时观看。当你想要采集...
QQ群成员提取器
直接上图,功能就不详细解释了。一个非常简单的QQ群成员采集工具可以采集当前单个或多个账号下的所有群成员数据,包括QQ账号、昵称、Q年龄、积分。群名片、入群时间、最后发言时间。然后支持群组数据导出和群组成员数据导出。导出是...
优采云万能文章采集器如何帮助你搜集指定网站的文章内容?
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-19 21:38
优采云万能文章采集器可以帮你采集网站指定的文章内容,帮你搜索你需要的信息。软件具有智能搜索机制,可以高精度搜索文章指定的网站,不仅可以提高你的文章手机能力,还可以帮助你快速完成任务。如果你需要搜索文章,那就来当易下载吧!
优采云文章采集器简介:
优采云software出品的万能文章采集software,只需输入关键词即可采集各类网页和新闻,也可以采集指定列表页(栏目页) ) 文章。
优采云万能文章采集器特点:
1、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
2、史上最简单最智能文章采集器,更多功能一目了然!
3、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
4、可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
5、只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
问题重点:
采集设置的黑名单有误。在【采集Settings】中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数但没有实际采集进程的问题.
特别注意:
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
更新内容:
采集文章url,加强对相对路径的处理,如../和../../等,经过本版本增强处理后,相对路径将完全转化为绝对路径,与浏览器一致 将鼠标移到链接上看一样。
修复了谷歌改动导致采集失败的问题。
修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据url采集文章列,增加了删除外码的可选选项(之前默认为Enabled);调试模式改为文章source;更新疑点说明;其他。
新增文本过滤功能,可以屏蔽大部分不属于文本的内容;合并严格和标准的文本识别,加强文本识别能力(现在识别的文本不带父div标签,都取内码);增强提取一些故意伪装的网站标题的能力;其他更新。 查看全部
优采云万能文章采集器如何帮助你搜集指定网站的文章内容?
优采云万能文章采集器可以帮你采集网站指定的文章内容,帮你搜索你需要的信息。软件具有智能搜索机制,可以高精度搜索文章指定的网站,不仅可以提高你的文章手机能力,还可以帮助你快速完成任务。如果你需要搜索文章,那就来当易下载吧!
优采云文章采集器简介:
优采云software出品的万能文章采集software,只需输入关键词即可采集各类网页和新闻,也可以采集指定列表页(栏目页) ) 文章。
优采云万能文章采集器特点:
1、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
2、史上最简单最智能文章采集器,更多功能一目了然!
3、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上。
4、可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
5、只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
问题重点:
采集设置的黑名单有误。在【采集Settings】中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数但没有实际采集进程的问题.
特别注意:
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
更新内容:
采集文章url,加强对相对路径的处理,如../和../../等,经过本版本增强处理后,相对路径将完全转化为绝对路径,与浏览器一致 将鼠标移到链接上看一样。
修复了谷歌改动导致采集失败的问题。
修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据url采集文章列,增加了删除外码的可选选项(之前默认为Enabled);调试模式改为文章source;更新疑点说明;其他。
新增文本过滤功能,可以屏蔽大部分不属于文本的内容;合并严格和标准的文本识别,加强文本识别能力(现在识别的文本不带父div标签,都取内码);增强提取一些故意伪装的网站标题的能力;其他更新。
非常强劲的网址文章采集器,英文名字Fast_Spider,蜘蛛爬虫类程序流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-08-13 23:18
很强大的网址文章采集器,这个软件的全名是Hongye文章采集器,英文名称是Fast_Spider,属于蜘蛛爬虫程序进程,可以用来下载具体网址采集大力量文章内容,垃圾网页的信息内容将被立即丢弃,只存储文章使用价值和访问使用价值的本质,并进行HTM-TXT转换自动执行。本软件可作为缓解压力的软件工具使用!
[软件功能]
(1)本软件采用北大天网的MD5指纹识别和重加权优化算法,对于类似网页信息内容不再重复存储。
(2)采集Information 内容含义:[[HT]]表示网页标题,[[HA]]表示新闻标题,[[HC]]表示10个权重值关键词,[[UR]]表示图片在网页中的地址,[[TXT]]以后会是文章body。
(3)Spider Feature:本软件开启300个进程,保证采集高效。根据采集一万力量文章内容进行稳定性测试,广大网友连线网络计算机为了参考规范,每台计算机可以在短短5天内解析200万个xml网页、采集20万572文章content、100万个essential文章content 到采集结束。
(4)最新版和绿色版的区别在于:最新版允许采集的精面文章内容数据信息自动存储为ACCESS数据库,供查询。购买最新版本请联系QQ(97009356@)9)。
【操作步骤】
(1)申请前请确保您的电脑可以上网,服务器防火墙不需要屏蔽软件。
(2)运行SETUP.EXE和setup2.exe安装电脑操作系统system32适用库。
(3)operation spider.exe,输入网址入口,先点击“人力加”按钮,再点击“开始”按钮,采集会逐步实现。
[常见问题]
(1)攀取@@:填0表示不限制爬行深度;填3表示抓到第三层。
(2)万能蜘蛛法和分类蜘蛛法的区别:假设URL入口为"",如果选择万能蜘蛛法,xml中的每个网页都会被解析"";如果选择了分类蜘蛛方法,它只会解析xml中的每一个网页。
(3)按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
(4)本软件采集的标准是不超站的,比如给的词条是“”,只会在百度网站里面爬取。
(5)本软件采集在整个过程中,有时会弹出一个或多个“错误提示框”,请忽略。如果关闭“错误提示框”,采集软件会挂。
(6)User 如何选择采集Subject:比如你想要采集“个人股票”文章内容,你只需要把这些“个人股票”网站作为URL入口。 查看全部
非常强劲的网址文章采集器,英文名字Fast_Spider,蜘蛛爬虫类程序流程
很强大的网址文章采集器,这个软件的全名是Hongye文章采集器,英文名称是Fast_Spider,属于蜘蛛爬虫程序进程,可以用来下载具体网址采集大力量文章内容,垃圾网页的信息内容将被立即丢弃,只存储文章使用价值和访问使用价值的本质,并进行HTM-TXT转换自动执行。本软件可作为缓解压力的软件工具使用!
[软件功能]
(1)本软件采用北大天网的MD5指纹识别和重加权优化算法,对于类似网页信息内容不再重复存储。
(2)采集Information 内容含义:[[HT]]表示网页标题,[[HA]]表示新闻标题,[[HC]]表示10个权重值关键词,[[UR]]表示图片在网页中的地址,[[TXT]]以后会是文章body。
(3)Spider Feature:本软件开启300个进程,保证采集高效。根据采集一万力量文章内容进行稳定性测试,广大网友连线网络计算机为了参考规范,每台计算机可以在短短5天内解析200万个xml网页、采集20万572文章content、100万个essential文章content 到采集结束。
(4)最新版和绿色版的区别在于:最新版允许采集的精面文章内容数据信息自动存储为ACCESS数据库,供查询。购买最新版本请联系QQ(97009356@)9)。
【操作步骤】
(1)申请前请确保您的电脑可以上网,服务器防火墙不需要屏蔽软件。
(2)运行SETUP.EXE和setup2.exe安装电脑操作系统system32适用库。
(3)operation spider.exe,输入网址入口,先点击“人力加”按钮,再点击“开始”按钮,采集会逐步实现。
[常见问题]
(1)攀取@@:填0表示不限制爬行深度;填3表示抓到第三层。
(2)万能蜘蛛法和分类蜘蛛法的区别:假设URL入口为"",如果选择万能蜘蛛法,xml中的每个网页都会被解析"";如果选择了分类蜘蛛方法,它只会解析xml中的每一个网页。
(3)按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
(4)本软件采集的标准是不超站的,比如给的词条是“”,只会在百度网站里面爬取。
(5)本软件采集在整个过程中,有时会弹出一个或多个“错误提示框”,请忽略。如果关闭“错误提示框”,采集软件会挂。
(6)User 如何选择采集Subject:比如你想要采集“个人股票”文章内容,你只需要把这些“个人股票”网站作为URL入口。
文章采集器免费版快速破解网站自带的文章数量多优采云自
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-12 19:16
文章采集器免费版快速破解网站自带文章量多优采云自.
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
《环球文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集List页面文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.
快速破解网站自己的文章采集器每日文章,大量无损加载,压缩包分享到个人朋友圈可以公开下载,也可以转发。
优采云万能文章采集器本软件官方售价400元。有网友分享了破解版,我在这里分享给需要的用户!
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、电子邮件等格式处理,只需几分钟。
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。
优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、电子邮件等格式处理,只需几分钟即可采集。 查看全部
文章采集器免费版快速破解网站自带的文章数量多优采云自
文章采集器免费版快速破解网站自带文章量多优采云自.
文章采集软件免费版(8m)分享给大家,功能更强大,请注意格式1、login知乎:2、paste知乎工具栏的网址;3、点击“采集文章”按钮:4、点击“浏览器地址”按钮:5、点击“复制网址”按钮。
《环球文章采集器免费破解版》是最简单最智能的文章采集器,由优采云software开发,可以采集List页面文章、关键词新闻、微信等,还有定向采集指定网站文章,是一个很好的文章采集器。软件功能 1.
快速破解网站自己的文章采集器每日文章,大量无损加载,压缩包分享到个人朋友圈可以公开下载,也可以转发。
优采云万能文章采集器本软件官方售价400元。有网友分享了破解版,我在这里分享给需要的用户!
Universal文章采集器是一款方便易用的文章采集软件,功能强大,完全免费使用。该软件操作简单,可以准确提取网页正文部分并保存为文章,支持标签、链接、电子邮件等格式处理,只需几分钟。
文章采集器免费版(Duo Duo Quick Spider)是一款专业的网络采集工具;软件使用MongoDB数据库,可以帮助用户快速采集文章。
优采云万能文章采集器破解版是一款方便易用的文章采集软件。该软件操作简单,可以准确提取网页正文部分并保存为文章,并支持标签、链接、电子邮件等格式处理,只需几分钟即可采集。
谷歌文章网址采集器算法:基于抽样的可视化分析方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-10 05:12
文章网址采集器算法:基于抽样的可视化分析方法爬虫工具:脚本宝盒分词器工具:韦氏分词法word2vec词嵌入工具:bert分词器:word2vecwordseg(python实现,
大部分的人应该都是以一个数据集为目标。这个数据集可以有两种一种是按照特征值计算的。就是你想要爬虫去哪些特征然后获取这个特征值。这个有例如kaggle,或者nlp的巨头googlewiki还有就是机器学习。把数据从一个特征到另一个特征的特征映射过程编码到一起。或者特征x和特征y的映射。例如计算rank,key和value的映射。
你这个样本特征对应的映射到机器学习的特征方向上。可以是网络流程图,也可以是迭代式遍历。只要能把样本的特征组合,映射到机器学习特征里就好了。例如爬虫从特征1匹配特征1到特征3。
速学抓包tcpnet验证用原生爬虫,支持断点续爬。破除伪装,爬虫双人协作,
更新:现在有专门用来翻译谷歌翻译原始句子的网站,这个网站主要翻译有道词典上的句子。需要一个谷歌浏览器,其他的浏览器估计也可以用,但是可能有兼容性问题,暂时没注意。也不是说翻译句子有问题,就是那种普通的网站的翻译可能不适合在谷歌上实现。原文:主要是我目前使用的网站和要用到的一些工具。我要爬虫要翻译的样本是谷歌翻译,谷歌翻译的原始翻译是json格式的。
谷歌翻译的谷歌翻译在论坛看见过,觉得还蛮有用的,想进行翻译。首先,打开网址(虽然谷歌翻译的页面没有给出目录结构。如果有图片结构更佳):;type=x&term=1084083887a748185f746c30882131628a&ref_s=article&auto=0&page_id=40&text=mydict%e7%9f%b4%e8%a6%97%e6%88%8f&catid=51&n=2&r=2note:ie浏览器上的翻译以及谷歌浏览器上的翻译是有不同的,亲测ie有小数点,所以可能会翻译成中文也可能翻译成英文。
手动用方法登录,然后得到json格式的句子。1.打开chromewebstore下载翻译谷歌翻译的中文web版(貌似前面还有很多很多翻译),并且安装。之后我们需要用爬虫来翻译句子。2.翻译时参考谷歌翻译的源代码,最下面是一个爬虫的代码,打开后看一下下面这个image。再之后可以使用修改。 查看全部
谷歌文章网址采集器算法:基于抽样的可视化分析方法
文章网址采集器算法:基于抽样的可视化分析方法爬虫工具:脚本宝盒分词器工具:韦氏分词法word2vec词嵌入工具:bert分词器:word2vecwordseg(python实现,
大部分的人应该都是以一个数据集为目标。这个数据集可以有两种一种是按照特征值计算的。就是你想要爬虫去哪些特征然后获取这个特征值。这个有例如kaggle,或者nlp的巨头googlewiki还有就是机器学习。把数据从一个特征到另一个特征的特征映射过程编码到一起。或者特征x和特征y的映射。例如计算rank,key和value的映射。
你这个样本特征对应的映射到机器学习的特征方向上。可以是网络流程图,也可以是迭代式遍历。只要能把样本的特征组合,映射到机器学习特征里就好了。例如爬虫从特征1匹配特征1到特征3。
速学抓包tcpnet验证用原生爬虫,支持断点续爬。破除伪装,爬虫双人协作,
更新:现在有专门用来翻译谷歌翻译原始句子的网站,这个网站主要翻译有道词典上的句子。需要一个谷歌浏览器,其他的浏览器估计也可以用,但是可能有兼容性问题,暂时没注意。也不是说翻译句子有问题,就是那种普通的网站的翻译可能不适合在谷歌上实现。原文:主要是我目前使用的网站和要用到的一些工具。我要爬虫要翻译的样本是谷歌翻译,谷歌翻译的原始翻译是json格式的。
谷歌翻译的谷歌翻译在论坛看见过,觉得还蛮有用的,想进行翻译。首先,打开网址(虽然谷歌翻译的页面没有给出目录结构。如果有图片结构更佳):;type=x&term=1084083887a748185f746c30882131628a&ref_s=article&auto=0&page_id=40&text=mydict%e7%9f%b4%e8%a6%97%e6%88%8f&catid=51&n=2&r=2note:ie浏览器上的翻译以及谷歌浏览器上的翻译是有不同的,亲测ie有小数点,所以可能会翻译成中文也可能翻译成英文。
手动用方法登录,然后得到json格式的句子。1.打开chromewebstore下载翻译谷歌翻译的中文web版(貌似前面还有很多很多翻译),并且安装。之后我们需要用爬虫来翻译句子。2.翻译时参考谷歌翻译的源代码,最下面是一个爬虫的代码,打开后看一下下面这个image。再之后可以使用修改。
网页源代码中的内容页链接和使用方法(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-08 19:27
一、principle
手动填写链接地址规则的原理是编写脚本规则匹配源代码中的内容,获取自己设置的参数。
常用说明
[参数]
用于匹配准备提取信息的标签标签。比如你想在下面的代码中提取并组合某种格式。取代码“mClk(this,'108484','134217','168475','1');”以提取合并新地址格式为例。
"mClk(this,'[参数]','[参数]','[参数]','1');",依次为108484参数为参数1,以此类推。实际需要的地址如下地址格式:bbs/read.php?id=[参数1]&sort=[参数3]&action=[参数2],上面代码中的3个参数和下面地址中的id, soft 和 action 参数要对应对应的值,顺序不能颠倒。这被组合成一种新的地址格式。
(*)
(*)是通配符,优采云采集器可以表示起始地址的页数,可以匹配表示标签规则、模块或其他设置中的任意字符串,如(*)可以匹配到 xxx 字符串也可以匹配到 yy 字符串。
二、使用场合和使用方法
1、 一般可以自动获取URL链接的网页可以手动获取。手动填写链接地址的灵活性比较高!
2、网页源代码中的内容页链接不规范,或者URL中没有链接时,可以手动填写链接地址规则。
插图:
示例一、如ajax 链接
查看源码发现URL链接不规范,无法通过链接地址直接获取URL。
解决方案:
脚本规则:
实际链接:[参数1]/[参数2]/[参数3]/
例如二、例如列表页中只有一个内容页的ID,没有其他的URL信息,所以也可以通过手动填写链接地址规则来获取。
查看源码发现网址链接也是不规则的。
解决方案:
脚本规则:|(*),[参数],
实际链接:[参数 1] 查看全部
网页源代码中的内容页链接和使用方法(一)
一、principle
手动填写链接地址规则的原理是编写脚本规则匹配源代码中的内容,获取自己设置的参数。
常用说明
[参数]
用于匹配准备提取信息的标签标签。比如你想在下面的代码中提取并组合某种格式。取代码“mClk(this,'108484','134217','168475','1');”以提取合并新地址格式为例。
"mClk(this,'[参数]','[参数]','[参数]','1');",依次为108484参数为参数1,以此类推。实际需要的地址如下地址格式:bbs/read.php?id=[参数1]&sort=[参数3]&action=[参数2],上面代码中的3个参数和下面地址中的id, soft 和 action 参数要对应对应的值,顺序不能颠倒。这被组合成一种新的地址格式。
(*)
(*)是通配符,优采云采集器可以表示起始地址的页数,可以匹配表示标签规则、模块或其他设置中的任意字符串,如(*)可以匹配到 xxx 字符串也可以匹配到 yy 字符串。
二、使用场合和使用方法
1、 一般可以自动获取URL链接的网页可以手动获取。手动填写链接地址的灵活性比较高!
2、网页源代码中的内容页链接不规范,或者URL中没有链接时,可以手动填写链接地址规则。
插图:
示例一、如ajax 链接
查看源码发现URL链接不规范,无法通过链接地址直接获取URL。
解决方案:
脚本规则:
实际链接:[参数1]/[参数2]/[参数3]/
例如二、例如列表页中只有一个内容页的ID,没有其他的URL信息,所以也可以通过手动填写链接地址规则来获取。
查看源码发现网址链接也是不规则的。
解决方案:
脚本规则:|(*),[参数],
实际链接:[参数 1]
什么是Greasemonkey的一个扩展,如何安装一些脚本网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-04 19:11
Greasemonkey 是 Firefox 的一个扩展,它可以提供用户安装一些脚本,使大多数基于 HTML 的网络用户更容易使用。它可以添加一些新功能,合并来自不同网页的数据,修复网页错误等。 功能。 zol 提供 Greasemonkey 下载。
软件介绍
Greasemonkey,简称GM,中文俗称“油猴”,是Mozilla Firefox 的一个插件。它允许用户安装一些脚本,使大多数基于 HTML 的网页在用户端直接更改,更加方便易用。由于Greasemonkey脚本常驻浏览器,每次打开目标网页都会自动修改,让运行脚本的用户印象深刻,享受其固定的便利。
Greasemonkey 可以为网页添加新功能、修复网页错误、合并来自不同网页的数据或其他过于复杂而无法上传的功能。编写良好的 Greasemonkey 脚本甚至可以将其输出与修改后的页面无缝集成,就像原创页面的一部分一样。
安装说明
重新启动 Firefox 后,选择工具 (T) 菜单。您应该看到四个菜单项:启用 (E)、管理用户脚本 (U)...、新建用户脚本 (N)... 和用户脚本命令 (C)。只要管理用户脚本 (U)... 可用,它就会被安装。其他两个只能在特殊情况下使用。 查看全部
什么是Greasemonkey的一个扩展,如何安装一些脚本网页
Greasemonkey 是 Firefox 的一个扩展,它可以提供用户安装一些脚本,使大多数基于 HTML 的网络用户更容易使用。它可以添加一些新功能,合并来自不同网页的数据,修复网页错误等。 功能。 zol 提供 Greasemonkey 下载。
软件介绍
Greasemonkey,简称GM,中文俗称“油猴”,是Mozilla Firefox 的一个插件。它允许用户安装一些脚本,使大多数基于 HTML 的网页在用户端直接更改,更加方便易用。由于Greasemonkey脚本常驻浏览器,每次打开目标网页都会自动修改,让运行脚本的用户印象深刻,享受其固定的便利。
Greasemonkey 可以为网页添加新功能、修复网页错误、合并来自不同网页的数据或其他过于复杂而无法上传的功能。编写良好的 Greasemonkey 脚本甚至可以将其输出与修改后的页面无缝集成,就像原创页面的一部分一样。
安装说明
重新启动 Firefox 后,选择工具 (T) 菜单。您应该看到四个菜单项:启用 (E)、管理用户脚本 (U)...、新建用户脚本 (N)... 和用户脚本命令 (C)。只要管理用户脚本 (U)... 可用,它就会被安装。其他两个只能在特殊情况下使用。
如何采集优采云7.6.4版本?看完你就知道了
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-07-24 01:25
优采云可以轻松抓取大部分软件用户评论,如去哪儿、携程等。网站用户评论,基于珠海长隆海洋王国的“去哪儿旅行”评论例如使用优采云7.6.4 版本采集:
第一步:进入首页→自定义采集(图片1)→输入网址(图片2)→保存网址)
图一
图二
第2步:优采云进入界面后,点击其中一条评论,一定要点击整个蓝框区域(图3)→再次点击另一条评论→此时整个页面的评论会被绿框覆盖(picture4)
注意:此步骤的目的是点击两条相似信息,以便优采云识别并自动选择所有剩余的相似信息。
图 3
图 4
第三步:点击页面右侧的“采集以下元素文字”(图片5)→拉到页面底部的翻页框(图片6)点击“下一页"
图 5
图 6
第四步:此时出现页面右上角提示框如图7,点击“循环点击下一页”(图7)→点击“开始采集”在左上角(图8)
图 7
图 8
第五步:启动本地采集(图片9)→然后启动采集(图片10)→等待采集去重复成功后,可以选择需要的导出类型(图11、图12)
图 9
图 10
图 11
图 12
微博正文3.采集
目前我只有采集over携程、去哪儿和微博数据,但是采集微博数据真的很抓狂,最后我觉得这个方法不错。首先,在软件版本的选择上,我还是比较喜欢用优采云7.6.4版本。与最新版本相比,这个旧版本更方便。
首先我在采集微博数据处理过程中遇到的问题:
首先,如果你不登录,采集是不允许的
二、无法获取自动下拉的数据
三、无法自动翻页
基于以上两个问题,一个好的解决方案是使用优采云提供的简单的采集模板。使用简单的模板可以很好的解决第一、第二个问题,但是要完全自动翻页是非常困难的,所以最好自己手动输入每个页面的URL。具体方法如下:
第一步:进入首页→simple采集(图13)→微博网页(图14)→微博大师主页(图15)),有两个选项,你有选择“博主首页微博-博文”(图16)→点击“立即使用”(图16)
图 13
图 14
图 15
图 16
第2步:填写采集模板信息(图17)→URL、微博账号密码、翻页次数1和翻页次数2(图18)→点击“保存并开始”)
具体来说,我倾向于单独输入每个页面的URL,这样可以更好的实现翻页功能,不会遗漏数据。微博账号密码填写正确,系统一般会自动填写,以免采集过程中因未登录而导致采集停止。翻页次数1和翻页次数2需要填写相同的数字,因为每个页面的URL都已经输入,所以翻页次数不要填写超过1,否则会有数据重复采集.
图 17
图 18
第三步:启动本地采集(图19)→再启动采集
图 19
第四步:优采云会根据你提供的账号密码自动登录个人微博信息(图20),但是我的账号不能自动填写,需要重新手动输入(这个也可能是个别情况),登录后需要用微博移动端再次扫码(图21)
图 20
图 21
第五步:采集启动,第一个采集启动会比较慢,但是后面速度会加快
第六步:结束采集,去除重复数据,选择需要的数据类型并导出(图22)
图 22
4.微博简单模板扩展使用:某博主身体的具体主题数据采集
这个简单的采集模板其实可以用在很多地方。只要本质是“网址”,就可以实现采集很多数据,除了微博博主采集的所有博文,我们也只能采集一个博主的博文信息关于某个话题。以《广州日报》为例。如果我们只想获取《广州日报》中“新冠疫情”的博文信息,可以先在网页上登录微博账号,进入《广州日报》首页,点击“全部”,然后在搜索栏中输入您要获取的博文信息,然后输入上面的简单模板,逐页输入网址即可获取广州日报“新冠疫情”的所有文字数据。
图 23 查看全部
如何采集优采云7.6.4版本?看完你就知道了
优采云可以轻松抓取大部分软件用户评论,如去哪儿、携程等。网站用户评论,基于珠海长隆海洋王国的“去哪儿旅行”评论例如使用优采云7.6.4 版本采集:
第一步:进入首页→自定义采集(图片1)→输入网址(图片2)→保存网址)
图一
图二
第2步:优采云进入界面后,点击其中一条评论,一定要点击整个蓝框区域(图3)→再次点击另一条评论→此时整个页面的评论会被绿框覆盖(picture4)
注意:此步骤的目的是点击两条相似信息,以便优采云识别并自动选择所有剩余的相似信息。
图 3
图 4
第三步:点击页面右侧的“采集以下元素文字”(图片5)→拉到页面底部的翻页框(图片6)点击“下一页"
图 5
图 6
第四步:此时出现页面右上角提示框如图7,点击“循环点击下一页”(图7)→点击“开始采集”在左上角(图8)
图 7
图 8
第五步:启动本地采集(图片9)→然后启动采集(图片10)→等待采集去重复成功后,可以选择需要的导出类型(图11、图12)
图 9
图 10
图 11
图 12
微博正文3.采集
目前我只有采集over携程、去哪儿和微博数据,但是采集微博数据真的很抓狂,最后我觉得这个方法不错。首先,在软件版本的选择上,我还是比较喜欢用优采云7.6.4版本。与最新版本相比,这个旧版本更方便。
首先我在采集微博数据处理过程中遇到的问题:
首先,如果你不登录,采集是不允许的
二、无法获取自动下拉的数据
三、无法自动翻页
基于以上两个问题,一个好的解决方案是使用优采云提供的简单的采集模板。使用简单的模板可以很好的解决第一、第二个问题,但是要完全自动翻页是非常困难的,所以最好自己手动输入每个页面的URL。具体方法如下:
第一步:进入首页→simple采集(图13)→微博网页(图14)→微博大师主页(图15)),有两个选项,你有选择“博主首页微博-博文”(图16)→点击“立即使用”(图16)
图 13
图 14
图 15
图 16
第2步:填写采集模板信息(图17)→URL、微博账号密码、翻页次数1和翻页次数2(图18)→点击“保存并开始”)
具体来说,我倾向于单独输入每个页面的URL,这样可以更好的实现翻页功能,不会遗漏数据。微博账号密码填写正确,系统一般会自动填写,以免采集过程中因未登录而导致采集停止。翻页次数1和翻页次数2需要填写相同的数字,因为每个页面的URL都已经输入,所以翻页次数不要填写超过1,否则会有数据重复采集.
图 17
图 18
第三步:启动本地采集(图19)→再启动采集
图 19
第四步:优采云会根据你提供的账号密码自动登录个人微博信息(图20),但是我的账号不能自动填写,需要重新手动输入(这个也可能是个别情况),登录后需要用微博移动端再次扫码(图21)
图 20
图 21
第五步:采集启动,第一个采集启动会比较慢,但是后面速度会加快
第六步:结束采集,去除重复数据,选择需要的数据类型并导出(图22)
图 22
4.微博简单模板扩展使用:某博主身体的具体主题数据采集
这个简单的采集模板其实可以用在很多地方。只要本质是“网址”,就可以实现采集很多数据,除了微博博主采集的所有博文,我们也只能采集一个博主的博文信息关于某个话题。以《广州日报》为例。如果我们只想获取《广州日报》中“新冠疫情”的博文信息,可以先在网页上登录微博账号,进入《广州日报》首页,点击“全部”,然后在搜索栏中输入您要获取的博文信息,然后输入上面的简单模板,逐页输入网址即可获取广州日报“新冠疫情”的所有文字数据。
图 23
2020/4/29图片同理采集结果采集教程说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-07-22 02:28
2020/4/29图片同理采集结果采集教程说明
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集steps
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后,直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click【采集data】
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
在当前文章列表中(网页红框框内),选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会一直保留重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,将采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表,也需要在优采云中滚动设置。
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
查看全部
2020/4/29图片同理采集结果采集教程说明
鼠标移到图片上,右击选择【在新标签页中打开图片】查看高清大图
同样适用于下面的其他图片
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/29优采云版本:V8.1.8
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集steps
第一步:打开网页
步骤二、创建[循环列表],采集所有文章列表中的数据
步骤三、点击进入文章详情,采集文章text
步骤四、编辑字段
步骤五、设置页面滚动
步骤六、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址#mid=52255723016,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后,直接启动采集获取数据。点击查看详情
c.您可以根据需要更改标题号码的网址。
步骤二、创建[循环列表],采集所有文章列表中的数据
完成以下 4 个连续步骤:
1、在页面上选择1个文章list(注意必须选择整个列表,包括所有必填字段)
2、在黄色操作提示框中,点击【选择子元素】
3、点击【全选】
4、click【采集data】
特别说明:
一个。经过以上4个连续的步骤,就完成了【Cycle-Extract Data】的创建。 [Loop]中的item对应页面上所有文章列表,[Extract Data]中的字段对应每个文章列表中的字段。 采集启动后,优采云会按照循环中的顺序依次提取每个列表中的字段。
B.为什么我们可以通过以上4个步骤建立一个【循环提取数据】?点击查看详情
步骤三、点击文章链接进入详情页,采集文字和图片
1、点击文章链接进入详情页
在当前文章列表中(网页红框框内),选择文章标题,在操作提示框中点击【点击链接】,然后自动输入文章详细信息页面。
特别说明:
一个。一定要选中当前文章列表中的文章链接并做【点击链接】,否则【点击元素】步骤无法与【循环】中的文章列表链接,会一直保留重复点击 对于某个文章链接,进入其文章详情页,不可能依次点击每个文章链接。
B.如何找到当前的文章 列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上的红框为当前文章列表。
2、采集文章详情页中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
特别说明:
一个。文字、图片、视频、源代码是不同的数据形式,在操作提示框中选择提取方式时略有不同。文字一般为【采集此元素文字】,图片一般为【采集此图片地址】。更多提取方法请点击查看
3、创建【循环列表】提取文中所有图片地址
一个文章中可能有多张图片,通过以下步骤,将采集文章地址中的所有图片:
①选择图片
②在黄色的操作提示框中,选择【全选】
③选择【采集下图地址】
特别说明:
一个。经过以上连续三个步骤,就完成了【Cycle-Extract Data】的创建。 [Cycle]中的项目对应页面上的所有图片,[Extract Data]中的字段对应每张图片的图片地址。 采集启动后,优采云会在循环中依次提取每个图片地址。
B.为什么我们可以通过以上3步设置【循环提取数据】?点击查看
步骤四、编辑字段
进入【提取数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等
步骤五、设置页面滚动
打开今日头条网页后,向下滚动页面以加载更多文章列表,也需要在优采云中滚动设置。
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为10次, [每个间隔] 0.5 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
步骤六、Start采集
1、 点击【采集】和【启动本地采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
文章网址采集器下载量监控代码文件、脚本、案例方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-07-22 00:01
文章网址采集器下载量监控代码文件、脚本、案例抓取方法
1、在老虎机游戏中选择想抓取代码,
2、使用抓包软件截获数据包:fiddler、wireshark、phantomjs、postman等都行,有需要的自己选择。有专门做网站监控的脚本也是可以的,
3、获取网站统计源码在谷歌浏览器打开,在主页面上左侧选择查看源码,就可以看到网站统计源码了。生成的如下二维码,你可以自己解码、解压缩、转换二维码。
4、把网站统计源码粘贴到excel中使用抓包工具截获整个页面的统计源码后,需要利用excel将抓取到的统计源码转换成数据,大家可以随意找一个url,转换之后如下,因为代码在地址栏里,不一定每个网站都有代码,我这里用的是哈啰出行,
直接用wireshark比较便宜一百块一个不贵
wireshark已经可以从你的浏览器上收到所有网站的统计数据了,不存在爬虫的情况,这个功能非常给力,并且免费且无需安装。首先安装并配置wireshark,下载地址:downloadwiresharkandotherwebaccessheadersforwindows7.downloadfirefox和chrome也都有,安装包在firefox的扩展商店中,直接搜索就可以找到。
安装完毕后,打开firefox,添加个扩展:利用浏览器扩展:+history_sensitive_extraction,如下图所示:接下来的教程就非常简单了,只需要3步即可完成抓取网页,看图:。
1、登录一个账号,
2、在登录成功之后,点击previewwebmachinelogin,如下图所示:在左侧,如果你是账号登录,那么会给你开通一个globalmachineloginservice服务,如果是用appleid的账号登录,
3、在网页中找到你想要抓取的网页,如果出现问题,可以先尝试利用它自身的解码器来解析网页内容,比如这里就是网页地址:useragentcode。如果解码失败,可以使用“嗅探探测”,有免费版,解析稍微麻烦些,如下图所示:找到你想要的内容,并且点击右键,
4、以第一个“#”为例,获取一个网址值:这个值是你密码后面的格式数组,让我们知道怎么获取就好了,下面按照我自己的习惯写一个例子:获取成功之后,右键查看源代码中的所有结果,包括代码:下面查看有效内容。因为我并没有账号,为了方便手机号获取,我这里选择手机登录来分析一下,打开网页中右侧红色箭头标记的位置,就是登录后下面的红色框图标,可以看到密码的值用整整四位字母填充。完毕,抓取完毕~接下来解决爬虫问题,上面已经安装。 查看全部
文章网址采集器下载量监控代码文件、脚本、案例方法
文章网址采集器下载量监控代码文件、脚本、案例抓取方法
1、在老虎机游戏中选择想抓取代码,
2、使用抓包软件截获数据包:fiddler、wireshark、phantomjs、postman等都行,有需要的自己选择。有专门做网站监控的脚本也是可以的,
3、获取网站统计源码在谷歌浏览器打开,在主页面上左侧选择查看源码,就可以看到网站统计源码了。生成的如下二维码,你可以自己解码、解压缩、转换二维码。
4、把网站统计源码粘贴到excel中使用抓包工具截获整个页面的统计源码后,需要利用excel将抓取到的统计源码转换成数据,大家可以随意找一个url,转换之后如下,因为代码在地址栏里,不一定每个网站都有代码,我这里用的是哈啰出行,
直接用wireshark比较便宜一百块一个不贵
wireshark已经可以从你的浏览器上收到所有网站的统计数据了,不存在爬虫的情况,这个功能非常给力,并且免费且无需安装。首先安装并配置wireshark,下载地址:downloadwiresharkandotherwebaccessheadersforwindows7.downloadfirefox和chrome也都有,安装包在firefox的扩展商店中,直接搜索就可以找到。
安装完毕后,打开firefox,添加个扩展:利用浏览器扩展:+history_sensitive_extraction,如下图所示:接下来的教程就非常简单了,只需要3步即可完成抓取网页,看图:。
1、登录一个账号,
2、在登录成功之后,点击previewwebmachinelogin,如下图所示:在左侧,如果你是账号登录,那么会给你开通一个globalmachineloginservice服务,如果是用appleid的账号登录,
3、在网页中找到你想要抓取的网页,如果出现问题,可以先尝试利用它自身的解码器来解析网页内容,比如这里就是网页地址:useragentcode。如果解码失败,可以使用“嗅探探测”,有免费版,解析稍微麻烦些,如下图所示:找到你想要的内容,并且点击右键,
4、以第一个“#”为例,获取一个网址值:这个值是你密码后面的格式数组,让我们知道怎么获取就好了,下面按照我自己的习惯写一个例子:获取成功之后,右键查看源代码中的所有结果,包括代码:下面查看有效内容。因为我并没有账号,为了方便手机号获取,我这里选择手机登录来分析一下,打开网页中右侧红色箭头标记的位置,就是登录后下面的红色框图标,可以看到密码的值用整整四位字母填充。完毕,抓取完毕~接下来解决爬虫问题,上面已经安装。

