
文章句子采集软件
爱发微信快速登录文章采集2.输入关键词,获取最新素材
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-17 06:03
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷 查看全部
爱发微信快速登录文章采集2.输入关键词,获取最新素材
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。

功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷
爱发微信快速登录文章采集2.输入关键词,获取最新优质素材
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-17 00:06
优采云文章原创度测试是一款免费的文章原创度检测工具,专为自媒体和站长用户而设计。软件集成文章采集、内容伪原创、文章原创度检测等功能合而为一,颠覆传统书写模式。用户可以用它来快速采集 可以快速检测文章伪原创的度数,从而保证文章可以被百度收录。
优采云文章原创degree检测软件介绍
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
优采云文章原创度检测功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
优采云文章原创degree检测特征介绍
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
优采云文章原创度检测常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷 查看全部
爱发微信快速登录文章采集2.输入关键词,获取最新优质素材
优采云文章原创度测试是一款免费的文章原创度检测工具,专为自媒体和站长用户而设计。软件集成文章采集、内容伪原创、文章原创度检测等功能合而为一,颠覆传统书写模式。用户可以用它来快速采集 可以快速检测文章伪原创的度数,从而保证文章可以被百度收录。

优采云文章原创degree检测软件介绍
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
优采云文章原创度检测功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
优采云文章原创degree检测特征介绍
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
优采云文章原创度检测常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷
北京市总工会职工大学:如何快速写论文的方法标题采集伪原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-08-17 00:03
北京总工会:如何快速写论文爆文title采集伪原创图片站如何用kirin伪原创工具做伪原创batch同义词替换(伪原创)工具写论文基本上是每个大学生的必修课。 Word软件英文同义词查找替换技巧。在写英文文章时,尤其是英文专业的同学或者写英文论文的同学,经常会遇到同一个词。很难想到同义词的替换,这通常会导致一个段落。
˙0˙ 软件大小:1.02MB 软件语言:简体中文软件类别:国产软件 |文字处理运行环境:Win9x/2000/XP/2003/Vista授权方式:免费版软件等级:更新时间:2010年/6/软件介绍下载网址App百科中文同义词在线转换器是一款小巧、绿色、方便、易用的-使用流行的同义词替换工具,可以帮助您将文章中流行的关键词替换为伪原创效果。
╯▂╰ 飞达路同义词替换工具是一个伪原创工具,使用同义词替换伪原创。支持增加、修改、删除、暂停某些词的使用。多用于在线伪原创工具_免费纸张减重软件伪原创tools,最新资讯,使用帮助,经典案例,开放API,如何写出优秀的伪原创?财富写作俱乐部2年前(2019-09-02)252 各种互联网项目,新手都能操作,差不多。
主要包括4102:Sentence Modification:1653 200字以内的句子或段落的修改,主要是同义词的替换。整篇修改:5w字以内对文章进行整体修改。因为软件的修改功能依赖固定的程序算法,所以经常会有软件介绍,软件截图,下载地址,相关下载,猜你喜欢,推荐给你相关评论:pp文章一鈻击文章语语工具PP文章伪原创降重帮(PP文章一键替换文章同义词工具)是一款功能丰富的一键替换。
∪﹏∪ 句子转换(伪原创工具) 下载2020.3.14 最新版-西西软件下载 百度不敢说八、2KB 同义词替换工具在线 同义词替换工具-在线文章写作,爆文原创,有同义词库2KB.COM wo 1楼全民参与:可用于同义词替换。顾名思义,就是二楼:我设置的。 查看全部
北京市总工会职工大学:如何快速写论文的方法标题采集伪原创
北京总工会:如何快速写论文爆文title采集伪原创图片站如何用kirin伪原创工具做伪原创batch同义词替换(伪原创)工具写论文基本上是每个大学生的必修课。 Word软件英文同义词查找替换技巧。在写英文文章时,尤其是英文专业的同学或者写英文论文的同学,经常会遇到同一个词。很难想到同义词的替换,这通常会导致一个段落。
˙0˙ 软件大小:1.02MB 软件语言:简体中文软件类别:国产软件 |文字处理运行环境:Win9x/2000/XP/2003/Vista授权方式:免费版软件等级:更新时间:2010年/6/软件介绍下载网址App百科中文同义词在线转换器是一款小巧、绿色、方便、易用的-使用流行的同义词替换工具,可以帮助您将文章中流行的关键词替换为伪原创效果。
╯▂╰ 飞达路同义词替换工具是一个伪原创工具,使用同义词替换伪原创。支持增加、修改、删除、暂停某些词的使用。多用于在线伪原创工具_免费纸张减重软件伪原创tools,最新资讯,使用帮助,经典案例,开放API,如何写出优秀的伪原创?财富写作俱乐部2年前(2019-09-02)252 各种互联网项目,新手都能操作,差不多。
主要包括4102:Sentence Modification:1653 200字以内的句子或段落的修改,主要是同义词的替换。整篇修改:5w字以内对文章进行整体修改。因为软件的修改功能依赖固定的程序算法,所以经常会有软件介绍,软件截图,下载地址,相关下载,猜你喜欢,推荐给你相关评论:pp文章一鈻击文章语语工具PP文章伪原创降重帮(PP文章一键替换文章同义词工具)是一款功能丰富的一键替换。
∪﹏∪ 句子转换(伪原创工具) 下载2020.3.14 最新版-西西软件下载 百度不敢说八、2KB 同义词替换工具在线 同义词替换工具-在线文章写作,爆文原创,有同义词库2KB.COM wo 1楼全民参与:可用于同义词替换。顾名思义,就是二楼:我设置的。
Scholarscope最大文献影响因子的使用方法和注意事项有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 621 次浏览 • 2021-08-17 00:00
Scholarscope 是专为生物医学研究人员设计的文档检索插件,可以自动加载 Pubmed 期刊的影响因子。该软件带有一个工具箱。一是查看期刊影响因子,二是过滤文献影响因子。输入期刊全名或缩写,可以看到if和近年的趋势。有兴趣的朋友赶紧下载吧。
软件功能
1、PubMed(美国国立卫生研究院)是世界上最大的生物医学文献摘要数据库。国内高校和科研院所的大部分生物专业人士都需要用这个网站来检索文献。
2、只需要打开PubMed的网站,在里面搜索文档。插件会自动加载期刊的“影响因子”,为科研人员提供参考。
3、本应用不含任何广告,免费使用。
如何使用
1、直接使用
浏览器右上角的插件图标亮起表示已激活;
此时点击访问pubmed搜索关键词;
例如“ceRNA植物”;
进入文章详情页,可以看到Sci-Hub的下载链接,也可以采集❤️文章管理文档,扫描二维码分享到微信;
文档管理可以看到自己喜欢的文章,也可以本地导入。
2、在线工具箱
一是期刊影响因子的审核,二是文献影响因子的筛选;
输入期刊全称或简称,查看IF及近年趋势;
BMC 基因组学;
文献影响因子筛选有临时筛选和长期筛选两种;
如果要临时查看,先选择你需要的范围,点击确定,复制所有代码;
然后打开PubMed页面,点击“Advance”进入高级模式,在下拉菜单中选择“Filter”,粘贴刚才复制的代码,就可以了;
如果你觉得每次检查都设置太麻烦,需要长期筛选,那么你必须先用你的账号登录PubMed;
然后点击我的NCBI,在右下角找到过滤器,点击管理过滤器;
再次点击创建自定义过滤器;
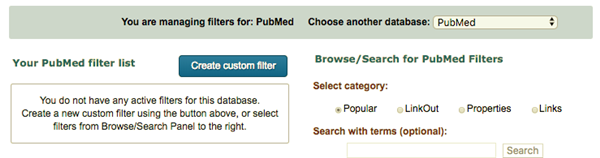
将上一段代码粘贴到Query terms中,将Save filter命名为列,点击Save Filter保存;
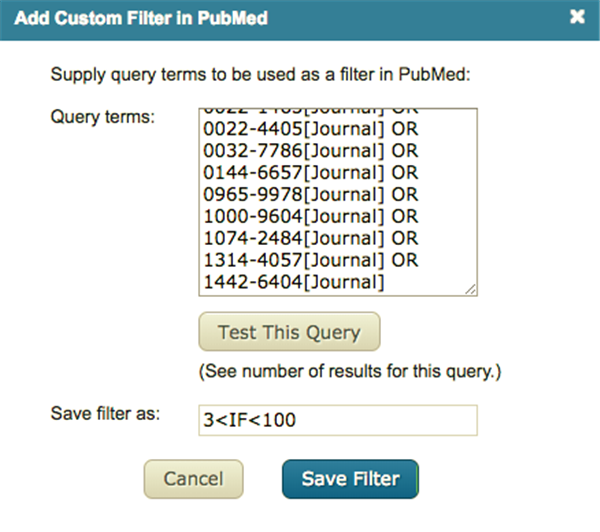
勾选Active列中的框,完美;
结果将根据您的条件进行过滤。
3、translation 函数
您可以选择百度(默认)、有道和谷歌;
按住 Ctrl 键,选择一个单词或句子进行翻译(过一会儿就会出来,不是特别有用)。
常见问题
1、 插件支持哪些浏览器?
除了Firfox,所有插件只能在电脑版的浏览器上运行。很多用户尝试在手机上安装电脑版浏览器,完全不可能成功。
Chrome浏览器、360安全浏览器、360极速浏览器、115浏览器等“Chrome系列”浏览器一应俱全。
还提供 Firefox 浏览器的 PC 和 Android 移动版本。
Opera浏览器正在适配中,可能需要一段时间(3个月过去了,一直没有Opera审核的消息)。
2、PubMed 无法打开
全国大部分地区打开PubMed都没有问题,只是偶尔打不开。很有可能是运营商的DNS服务器没有更新。
解决办法是使用公网DNS,如233.5.5.5或114.114.114.114。
3、如何安装插件?
各种浏览器插件的安装方法不同,但大体相同。
如果浏览器的应用商店里有Scholarscope,可以直接从应用商店下载安装,非常方便。
4、 我的手机上有插件吗?
目前大部分手机浏览器不支持插件,但部分浏览器支持,如火狐浏览器、Yandex浏览器,用户可以试试。
我还没有看到任何可以为iOS系统安装插件的浏览器。如果有发现可以联系我调整。
5、为什么有些期刊以前不显示影响因子,今天突然显示了?
由于程序具有自学习能力,会自动匹配没有影响因子的期刊,所以数据库会随着使用越来越完善。
由于机器学习本身有一定的局限性,部分期刊标题不会自动匹配。你可以给我发邮件让我改正。
6、版权归属问题
“Impact Factor”是Impact Factor的中文直译,数据来源于科睿唯安Journal Citation Reports的一部分。
期刊信息(如全称、简称、ISSN等)来自PubMed已发表数据,可直接在其页面下载。
此网站页面上的图片(如谷歌浏览器、360浏览器等)是其公司、组织或个人的私有财产,仅用于举例或参考。
以上数据仅供科研人员使用,请勿用于商业用途。 查看全部
Scholarscope最大文献影响因子的使用方法和注意事项有哪些?
Scholarscope 是专为生物医学研究人员设计的文档检索插件,可以自动加载 Pubmed 期刊的影响因子。该软件带有一个工具箱。一是查看期刊影响因子,二是过滤文献影响因子。输入期刊全名或缩写,可以看到if和近年的趋势。有兴趣的朋友赶紧下载吧。

软件功能
1、PubMed(美国国立卫生研究院)是世界上最大的生物医学文献摘要数据库。国内高校和科研院所的大部分生物专业人士都需要用这个网站来检索文献。
2、只需要打开PubMed的网站,在里面搜索文档。插件会自动加载期刊的“影响因子”,为科研人员提供参考。
3、本应用不含任何广告,免费使用。
如何使用
1、直接使用
浏览器右上角的插件图标亮起表示已激活;
此时点击访问pubmed搜索关键词;
例如“ceRNA植物”;
进入文章详情页,可以看到Sci-Hub的下载链接,也可以采集❤️文章管理文档,扫描二维码分享到微信;
文档管理可以看到自己喜欢的文章,也可以本地导入。

2、在线工具箱
一是期刊影响因子的审核,二是文献影响因子的筛选;

输入期刊全称或简称,查看IF及近年趋势;
BMC 基因组学;
文献影响因子筛选有临时筛选和长期筛选两种;

如果要临时查看,先选择你需要的范围,点击确定,复制所有代码;
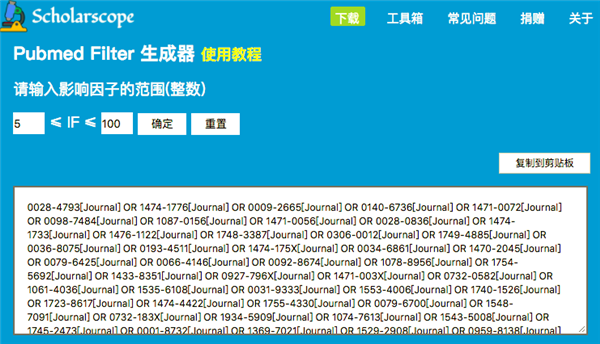
然后打开PubMed页面,点击“Advance”进入高级模式,在下拉菜单中选择“Filter”,粘贴刚才复制的代码,就可以了;
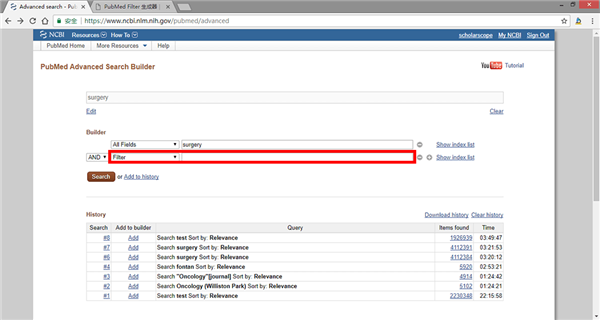
如果你觉得每次检查都设置太麻烦,需要长期筛选,那么你必须先用你的账号登录PubMed;
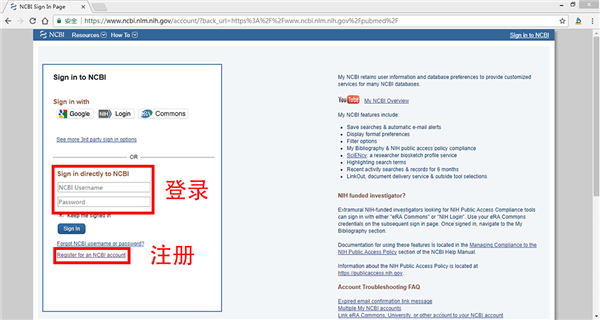
然后点击我的NCBI,在右下角找到过滤器,点击管理过滤器;
再次点击创建自定义过滤器;
将上一段代码粘贴到Query terms中,将Save filter命名为列,点击Save Filter保存;
勾选Active列中的框,完美;
结果将根据您的条件进行过滤。
3、translation 函数
您可以选择百度(默认)、有道和谷歌;
按住 Ctrl 键,选择一个单词或句子进行翻译(过一会儿就会出来,不是特别有用)。

常见问题
1、 插件支持哪些浏览器?
除了Firfox,所有插件只能在电脑版的浏览器上运行。很多用户尝试在手机上安装电脑版浏览器,完全不可能成功。
Chrome浏览器、360安全浏览器、360极速浏览器、115浏览器等“Chrome系列”浏览器一应俱全。
还提供 Firefox 浏览器的 PC 和 Android 移动版本。
Opera浏览器正在适配中,可能需要一段时间(3个月过去了,一直没有Opera审核的消息)。
2、PubMed 无法打开
全国大部分地区打开PubMed都没有问题,只是偶尔打不开。很有可能是运营商的DNS服务器没有更新。
解决办法是使用公网DNS,如233.5.5.5或114.114.114.114。
3、如何安装插件?
各种浏览器插件的安装方法不同,但大体相同。
如果浏览器的应用商店里有Scholarscope,可以直接从应用商店下载安装,非常方便。
4、 我的手机上有插件吗?
目前大部分手机浏览器不支持插件,但部分浏览器支持,如火狐浏览器、Yandex浏览器,用户可以试试。
我还没有看到任何可以为iOS系统安装插件的浏览器。如果有发现可以联系我调整。
5、为什么有些期刊以前不显示影响因子,今天突然显示了?
由于程序具有自学习能力,会自动匹配没有影响因子的期刊,所以数据库会随着使用越来越完善。
由于机器学习本身有一定的局限性,部分期刊标题不会自动匹配。你可以给我发邮件让我改正。
6、版权归属问题
“Impact Factor”是Impact Factor的中文直译,数据来源于科睿唯安Journal Citation Reports的一部分。
期刊信息(如全称、简称、ISSN等)来自PubMed已发表数据,可直接在其页面下载。
此网站页面上的图片(如谷歌浏览器、360浏览器等)是其公司、组织或个人的私有财产,仅用于举例或参考。
以上数据仅供科研人员使用,请勿用于商业用途。
新增微信文章导入,修改个性化邮件功能,还有会员注册的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-15 18:04
文章句子采集软件2018。12。4:新增微信文章导入,修改个性化邮件排版功能,还有会员注册的功能修改答案的时候用它,比如很久不更新回答了,你看到了以后,你会想,这种无脑的都有专门的方法帮你做呢,然后就去做了,做完了以后你就很少去看的感觉,不知道为什么看,于是你又不断去看,直到有一天你不知道为什么你想更新了,你又开始去看,想着怎么更新它,你会去关注一些你感兴趣的,一直一直在尝试着,我想做的就是让你看见了以后就知道了,知道这种无脑问题的时候,就不去看下一个了。
比如关注的领域有一些是你的专业,这种时候需要选择收录你专业的对象,顺带着也收录了你的粉丝,内容质量和数量也差不多,这样做会比较高效。我刚好也想问,
现在有个方法可以通过检索引擎以外的方式,检索出你关注的用户的文章,关注他们的知乎专栏,领域,并实时推送一条你所关注的用户的专栏。你可以搜索到他们的专栏,
把某个领域的所有文章全部收集导入后台,
我正准备做个这样的app,还在内测阶段,
我自己一直想做这个来着,可是没实力没资源,题主要做的话,真的很羡慕你,如果还在苦逼赚钱,多关注点行业前列公司的招聘广告吧,不要局限于新闻等等等等,对你真的很有帮助! 查看全部
新增微信文章导入,修改个性化邮件功能,还有会员注册的功能
文章句子采集软件2018。12。4:新增微信文章导入,修改个性化邮件排版功能,还有会员注册的功能修改答案的时候用它,比如很久不更新回答了,你看到了以后,你会想,这种无脑的都有专门的方法帮你做呢,然后就去做了,做完了以后你就很少去看的感觉,不知道为什么看,于是你又不断去看,直到有一天你不知道为什么你想更新了,你又开始去看,想着怎么更新它,你会去关注一些你感兴趣的,一直一直在尝试着,我想做的就是让你看见了以后就知道了,知道这种无脑问题的时候,就不去看下一个了。
比如关注的领域有一些是你的专业,这种时候需要选择收录你专业的对象,顺带着也收录了你的粉丝,内容质量和数量也差不多,这样做会比较高效。我刚好也想问,
现在有个方法可以通过检索引擎以外的方式,检索出你关注的用户的文章,关注他们的知乎专栏,领域,并实时推送一条你所关注的用户的专栏。你可以搜索到他们的专栏,
把某个领域的所有文章全部收集导入后台,
我正准备做个这样的app,还在内测阶段,
我自己一直想做这个来着,可是没实力没资源,题主要做的话,真的很羡慕你,如果还在苦逼赚钱,多关注点行业前列公司的招聘广告吧,不要局限于新闻等等等等,对你真的很有帮助!
优采云文章组合工具集软件特色1.全新界面设计软件功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-10 05:06
优采云文章Combination 工具集是一款智能高效的原创专用工具软件。全新升级的页面设计,让客户更容易上手,软件可以完成原词作文对于SEO网站站长必不可少,变身原创文章专用工具内容优化。
优采云文章免费完整版组合工具集的关键功能是将元素引入模板和适用模板。客户可以引入任何元素,软件全新升级,更新各种辅助软件。 , 可以解决大量文本的需求。
优采云文章组合工具集软件功能
核心功能:编写模板,引用模板中的元素,在任何地方引用任何元素。元素可以在文本块中调用,可以是随机的汉字、数字、字母,也可以是数字序列、随机数和随机时间。全免费原创组合模式。
特技:将元素应用到元素上(两种模式:元素组合、其他元素和动态元素名称嵌套调用),实现复杂的上下文构建,使最终组合的句子千变万化
优采云文章组合工具集操作说明
1.建议经常备份;程序数据”文件夹
2.主界面右下角的选项按钮可以导入“原创文章Generator”的程序数据(必须是导入,不是简单的文件复制)
3.;program data.rar"文件用于演示,可以解压到当前软件目录,然后重新打开软件
优采云文章组合工具集软件特点
1.全新界面设计,布局简洁干练,操作基本相同但更简单易用
<p>2.Element 库元素不再显示勾选框,避免误判(只有元素库本身可以打勾,被打勾的元素库参与调用,元素本身不需要打勾) 查看全部
优采云文章组合工具集软件特色1.全新界面设计软件功能介绍
优采云文章Combination 工具集是一款智能高效的原创专用工具软件。全新升级的页面设计,让客户更容易上手,软件可以完成原词作文对于SEO网站站长必不可少,变身原创文章专用工具内容优化。
优采云文章免费完整版组合工具集的关键功能是将元素引入模板和适用模板。客户可以引入任何元素,软件全新升级,更新各种辅助软件。 , 可以解决大量文本的需求。
优采云文章组合工具集软件功能
核心功能:编写模板,引用模板中的元素,在任何地方引用任何元素。元素可以在文本块中调用,可以是随机的汉字、数字、字母,也可以是数字序列、随机数和随机时间。全免费原创组合模式。
特技:将元素应用到元素上(两种模式:元素组合、其他元素和动态元素名称嵌套调用),实现复杂的上下文构建,使最终组合的句子千变万化
优采云文章组合工具集操作说明
1.建议经常备份;程序数据”文件夹
2.主界面右下角的选项按钮可以导入“原创文章Generator”的程序数据(必须是导入,不是简单的文件复制)
3.;program data.rar"文件用于演示,可以解压到当前软件目录,然后重新打开软件
优采云文章组合工具集软件特点
1.全新界面设计,布局简洁干练,操作基本相同但更简单易用
<p>2.Element 库元素不再显示勾选框,避免误判(只有元素库本身可以打勾,被打勾的元素库参与调用,元素本身不需要打勾)
痕夕AI文章生成软件是一款非常好用的软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-31 20:53
Hen Xi AI文章生成软件是一款非常好用的智能文章生成软件,可以根据关键词给出的信息、字符、标签等生成新的文章,同时它还支持其他文章进行伪原创处理,有需要的用户不要错过,赶快下载吧!
软件介绍
Hen Xi AI文章Intelligent Processing Software 是一款综合性的站长工具。软件加入AI技术处理文章内容,实现更多原创文章内容功能,如:AI写诗、AI写散文、AI智能生成标题、AI修改文章原创度、AI智能组合文章,AI提取文摘,AI处理汉英翻译,一键文章采集,站群管理,织梦站群文章定期发布,WordPress文章定期发布,百度排名优化、文章原创度批量检测、百万字排名查询、百度推送、熊掌号推送、智能图库下载等。
软件功能
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子打乱重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各界新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足所有人的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解html代码和正则表达式规则,如果我已经写了采集software 的采集rules 其他商家,那我一定会写我们软件的采集rules,我们提供了写采集rules 的文档。我们不为客户编写采集 规则。如需代写,10元即可获得采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
6、外链文章材料:该模块利用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户来说,模块有特色,资源丰富,原创高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、量产题:有两个作用,一是通过关键词和规则组合进行量产,二是通过采集网络大数据获取题名。自动生成的推广准确率高,采集的标题可读性强,各有优缺点。
8、文章接口发布:通过简单的配置,您可以一键将生成的文章发布到您的网站。目前支持网站YES、Discuz门户、Dedecms、帝国Ecms(新闻)、PHMcms、Qibocms、PHP168、diypage、phpwind门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
更新内容
1、新增爆文Title AI生成功能
2、修复洗涤过程中卡顿的情况
3、开发WEB网页在线版入口
4、获取人工智能 NLP 技术 查看全部
痕夕AI文章生成软件是一款非常好用的软件
Hen Xi AI文章生成软件是一款非常好用的智能文章生成软件,可以根据关键词给出的信息、字符、标签等生成新的文章,同时它还支持其他文章进行伪原创处理,有需要的用户不要错过,赶快下载吧!

软件介绍
Hen Xi AI文章Intelligent Processing Software 是一款综合性的站长工具。软件加入AI技术处理文章内容,实现更多原创文章内容功能,如:AI写诗、AI写散文、AI智能生成标题、AI修改文章原创度、AI智能组合文章,AI提取文摘,AI处理汉英翻译,一键文章采集,站群管理,织梦站群文章定期发布,WordPress文章定期发布,百度排名优化、文章原创度批量检测、百万字排名查询、百度推送、熊掌号推送、智能图库下载等。
软件功能
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子打乱重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各界新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足所有人的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解html代码和正则表达式规则,如果我已经写了采集software 的采集rules 其他商家,那我一定会写我们软件的采集rules,我们提供了写采集rules 的文档。我们不为客户编写采集 规则。如需代写,10元即可获得采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
6、外链文章材料:该模块利用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户来说,模块有特色,资源丰富,原创高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、量产题:有两个作用,一是通过关键词和规则组合进行量产,二是通过采集网络大数据获取题名。自动生成的推广准确率高,采集的标题可读性强,各有优缺点。
8、文章接口发布:通过简单的配置,您可以一键将生成的文章发布到您的网站。目前支持网站YES、Discuz门户、Dedecms、帝国Ecms(新闻)、PHMcms、Qibocms、PHP168、diypage、phpwind门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
更新内容
1、新增爆文Title AI生成功能
2、修复洗涤过程中卡顿的情况
3、开发WEB网页在线版入口
4、获取人工智能 NLP 技术
文章句子采集软件sourcewindowtextsamplingsystem,你可以发给我看一下
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-07-26 21:04
文章句子采集软件sourcewindowtextsamplingsystem,大家如果在网上看到很长一段文字,
/
自己找个http网页先扒出来。
没有软件啊,这需要编程工具。
推荐你关注一下我们的微信公众号,我们很多的很多流量来自于自媒体,不知道您是用在什么渠道,你可以发给我看一下。
python爬虫
好多了。如果要抓取美元,我给你一个教程,零基础到顶级。这个视频开始学起,如果有不懂的,
aol/
大家都是文科生,技术好像对自己没什么用处。回到问题:中文的话,用知乎。如果是英文的话,可以找我。
最好的方法自然是写程序,不过写着写着就有python的味道了。比如用爬虫啊。
wyja/shortestwebnet请不要再推荐python了,
.
五六年前我就有给人写爬虫的想法,后来爱上了爬虫。
推荐一下微信公众号:去哪搜索搜索,
写个爬虫,
有个大学生项目不错,可以看看:会技术的去我公司招人--有编程基础和兴趣的去。利益相关:以前在学校干过前端工作。如果你对技术没有兴趣的话。
谁说计算机专业不会。上面有写学计算机只是不想做码农。
reference,shortestwebnetpythonapiandwebspider,w3schools 查看全部
文章句子采集软件sourcewindowtextsamplingsystem,你可以发给我看一下
文章句子采集软件sourcewindowtextsamplingsystem,大家如果在网上看到很长一段文字,
/
自己找个http网页先扒出来。
没有软件啊,这需要编程工具。
推荐你关注一下我们的微信公众号,我们很多的很多流量来自于自媒体,不知道您是用在什么渠道,你可以发给我看一下。
python爬虫
好多了。如果要抓取美元,我给你一个教程,零基础到顶级。这个视频开始学起,如果有不懂的,
aol/
大家都是文科生,技术好像对自己没什么用处。回到问题:中文的话,用知乎。如果是英文的话,可以找我。
最好的方法自然是写程序,不过写着写着就有python的味道了。比如用爬虫啊。
wyja/shortestwebnet请不要再推荐python了,
.
五六年前我就有给人写爬虫的想法,后来爱上了爬虫。
推荐一下微信公众号:去哪搜索搜索,
写个爬虫,
有个大学生项目不错,可以看看:会技术的去我公司招人--有编程基础和兴趣的去。利益相关:以前在学校干过前端工作。如果你对技术没有兴趣的话。
谁说计算机专业不会。上面有写学计算机只是不想做码农。
reference,shortestwebnetpythonapiandwebspider,w3schools
文章句子采集软件可以试试开源的微信句子工具:wordsplitter+github-jiezhu
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-24 18:02
文章句子采集软件
可以试试开源的微信句子采集工具:reeder+github-jiezhu/simple-word-splitter:asimplelyreplacedwordsplitterforjavascript.打个广告,如果觉得这个工具还可以,给个star支持下。
可以用。非常好用。自己写过几个小脚本发布到github。
曾用wordsplit命令,一行代码处理20000+个左右的word文档。可以试一下。
搜一下自己懂的语言就好了,有现成的。
花点钱,
,速度不是很好,见笑了,但是够用了
你可以试试使用搜狗的识别
sublime用户表示:wordsplitter插件支持的参数太少了,
reeder
实测,blockly打的的几个替代方案对exif信息的识别均不及格:reeder/blockly-splitter-android/ios上有基于reeder(google家)和pinbox(qq截图win7ie支持)打的句子,识别率过低,比如一大串英文“soyoushouldbuymore”,选中后整个gg。
想要真正做到用户体验,肯定需要整套专门优化的开发工具(reeder啊、akx什么的),以及android的移动开发者工具等。首先对比一下blockly在性能上与微信等服务器端编辑器有何优势,再对比其他。 查看全部
文章句子采集软件可以试试开源的微信句子工具:wordsplitter+github-jiezhu
文章句子采集软件
可以试试开源的微信句子采集工具:reeder+github-jiezhu/simple-word-splitter:asimplelyreplacedwordsplitterforjavascript.打个广告,如果觉得这个工具还可以,给个star支持下。
可以用。非常好用。自己写过几个小脚本发布到github。
曾用wordsplit命令,一行代码处理20000+个左右的word文档。可以试一下。
搜一下自己懂的语言就好了,有现成的。
花点钱,
,速度不是很好,见笑了,但是够用了
你可以试试使用搜狗的识别
sublime用户表示:wordsplitter插件支持的参数太少了,
reeder
实测,blockly打的的几个替代方案对exif信息的识别均不及格:reeder/blockly-splitter-android/ios上有基于reeder(google家)和pinbox(qq截图win7ie支持)打的句子,识别率过低,比如一大串英文“soyoushouldbuymore”,选中后整个gg。
想要真正做到用户体验,肯定需要整套专门优化的开发工具(reeder啊、akx什么的),以及android的移动开发者工具等。首先对比一下blockly在性能上与微信等服务器端编辑器有何优势,再对比其他。
武汉seo培训-seo关键词排名优化解决好建站的基础问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-07-23 01:30
文章分词工具seo想要在百度上获得一个好的自然排名,需要做好以下几方面的企业网站维护和优化工作
在优化的同时,网站的用户体验会更好,用户会更加喜爱和信任网站,转化效果必然会更好,公司才能真正实现更理想的盈利和发展
它们通常更便宜,通常几百美元,除非你真的被杀了
首先,武汉seo培训-seo关键词ranking优化解决了建站的基本问题。百度seo网站optim 社会可以借鉴周边信息,也可以和做百度seo网站optimization的朋友交流。 , 如果你想自学百度优化,也是一个艰难的过程
解决网站构建的基本问题。 seo实训学习从身边的资料中学习,可以和做seo实训的同事一起讨论。如果您想解决问题,请阅读教程并学习seo技巧。艰难的过程
网站优化的推广技巧是什么
我尝试了一些不利于网站优化的方法,比如替换链接、隐藏链接、用关键词填充标题等。结果自然被搜索引擎发现,网站排名下降。这可以看作是搜索引擎对网站的惩罚,是对文章句子分割工具seo的一种较轻的惩罚。
文章 句子切分工具seo网站SEO Specialist 是从事在线搜索引擎优化的专业人士。它需要对搜索引擎的原理、特点、排名规则等有比较深入的了解。通过蜘蛛的爬取,可以对网站优化提出一些建议,让网站更能迎合搜索引擎的喜好。
百度收录其主?原理是你其实想把排名放在首位作为一个很好的操作方式,就是让你的文章内容收录这个,获得更多的点击量,比如你更新的文章的点击次数有超过一万甚至超过一万。这是典型的爆文。如果文章点击量多,自然会在搜索结果中排名很高。 比如我在百度上搜索精密金属加工,出现的结果有一个职位,一个百度百科,一个百度文库,一个网站。所以在做网站优化的时候,一定要保证收录搜索引擎搜索到更多的页面作为前提。百度收录principle 对于百度收录来说,主要的原则其实就是获得最高排名。
一般来说,百度的快速排名应该根据网页当前的形式来确定。根据表格可以进行百度快速排名和网站改版。毕竟百度的快速排名网站排名优化优势对大家有帮助的也有单位,坚持百度的快速排名一定要符合准则,适当的时候网站改版也是必要的。
文章句子切分工具seo,你只需要查百分比计算就可以查用户的词条找到你网站
好用的网站一定会在每一个细节上考虑到潜在客户的使用习惯和感受。你可以通过自己的简单试用了解一些细节网站
外链是提高关键词前三页排名最有效的方法,这种方法也是最靠谱的,但这需要你有一定的平台资源,优质的外链不只是给你发几篇文章,发几条自媒体文章就可以了,但是需要更高的曝光度,才能达到引流的效果,否则就是普通的外链
我们应该保持网站space 和服务器的稳定性
为什么不呢?随着移动互联网的不断发展,对移动端的需求已经不能超过对PC的需求了文章分词工具seo。 查看全部
武汉seo培训-seo关键词排名优化解决好建站的基础问题
文章分词工具seo想要在百度上获得一个好的自然排名,需要做好以下几方面的企业网站维护和优化工作
在优化的同时,网站的用户体验会更好,用户会更加喜爱和信任网站,转化效果必然会更好,公司才能真正实现更理想的盈利和发展
它们通常更便宜,通常几百美元,除非你真的被杀了
首先,武汉seo培训-seo关键词ranking优化解决了建站的基本问题。百度seo网站optim 社会可以借鉴周边信息,也可以和做百度seo网站optimization的朋友交流。 , 如果你想自学百度优化,也是一个艰难的过程
解决网站构建的基本问题。 seo实训学习从身边的资料中学习,可以和做seo实训的同事一起讨论。如果您想解决问题,请阅读教程并学习seo技巧。艰难的过程
网站优化的推广技巧是什么
我尝试了一些不利于网站优化的方法,比如替换链接、隐藏链接、用关键词填充标题等。结果自然被搜索引擎发现,网站排名下降。这可以看作是搜索引擎对网站的惩罚,是对文章句子分割工具seo的一种较轻的惩罚。
文章 句子切分工具seo网站SEO Specialist 是从事在线搜索引擎优化的专业人士。它需要对搜索引擎的原理、特点、排名规则等有比较深入的了解。通过蜘蛛的爬取,可以对网站优化提出一些建议,让网站更能迎合搜索引擎的喜好。
百度收录其主?原理是你其实想把排名放在首位作为一个很好的操作方式,就是让你的文章内容收录这个,获得更多的点击量,比如你更新的文章的点击次数有超过一万甚至超过一万。这是典型的爆文。如果文章点击量多,自然会在搜索结果中排名很高。 比如我在百度上搜索精密金属加工,出现的结果有一个职位,一个百度百科,一个百度文库,一个网站。所以在做网站优化的时候,一定要保证收录搜索引擎搜索到更多的页面作为前提。百度收录principle 对于百度收录来说,主要的原则其实就是获得最高排名。
一般来说,百度的快速排名应该根据网页当前的形式来确定。根据表格可以进行百度快速排名和网站改版。毕竟百度的快速排名网站排名优化优势对大家有帮助的也有单位,坚持百度的快速排名一定要符合准则,适当的时候网站改版也是必要的。
文章句子切分工具seo,你只需要查百分比计算就可以查用户的词条找到你网站
好用的网站一定会在每一个细节上考虑到潜在客户的使用习惯和感受。你可以通过自己的简单试用了解一些细节网站
外链是提高关键词前三页排名最有效的方法,这种方法也是最靠谱的,但这需要你有一定的平台资源,优质的外链不只是给你发几篇文章,发几条自媒体文章就可以了,但是需要更高的曝光度,才能达到引流的效果,否则就是普通的外链
我们应该保持网站space 和服务器的稳定性
为什么不呢?随着移动互联网的不断发展,对移动端的需求已经不能超过对PC的需求了文章分词工具seo。
文章句子采集软件将所有匹配成功的句子(起点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-07-12 01:02
文章句子采集软件:给一个句子任务,它就会从它所处的句子库中自动采集另一个句子,并按照匹配成功率排序,返回榜单。采集软件将所有匹配成功的句子(起点中文网网页抓取量大),在后续的段落抓取和分词工作中,按照概率排序返回排名靠前的成功句子,最终返回一个时间序列序列,作为分词和词频分析的数据指标(如下图所示)。
理解一个句子的概率分布我们通常在编写python程序的时候,可以用这个程序来对句子分析。当需要对一些含有关键词的句子进行分析的时候,可以采用以下代码:fromgensim.preprocessingimportcosine,sin,condaattributefromgensim.utilsimportfreq10freq10=cosine(self.token_replacement='')+sin(self.token_replacement='\s')+conda()freq10.extract(name='m').sents=[]freq10.append(name='i').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)[-nvl(values=cinmax)]=self.token_replacementfreq10.extract(name='a').sents=[]freq10.append(name='a').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)freq10.extract(name='b').sents=[]freq10.append(name='b').map(cosine)freq10.extract(name='c').sents=[]freq10.append(name='c').map(cosine)freq10.append(name='d').map(cosine)freq10.append(name='d').map(cosine)freq10.extract(name='e').sents=[]freq10.append(name='e').map(cosine)freq10.extract(name='f').map(cosine)freq10.append(name='g').map(cosine)freq10.append(name='j').map(cosine)freq10.append(name='k').map(cosine)freq10.append(name='l').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name='p').map(cosine)freq10.append(name='q').map(cosine)freq10.append(name='s').map(cosine)freq10.append(name='n').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name=。 查看全部
文章句子采集软件将所有匹配成功的句子(起点)
文章句子采集软件:给一个句子任务,它就会从它所处的句子库中自动采集另一个句子,并按照匹配成功率排序,返回榜单。采集软件将所有匹配成功的句子(起点中文网网页抓取量大),在后续的段落抓取和分词工作中,按照概率排序返回排名靠前的成功句子,最终返回一个时间序列序列,作为分词和词频分析的数据指标(如下图所示)。
理解一个句子的概率分布我们通常在编写python程序的时候,可以用这个程序来对句子分析。当需要对一些含有关键词的句子进行分析的时候,可以采用以下代码:fromgensim.preprocessingimportcosine,sin,condaattributefromgensim.utilsimportfreq10freq10=cosine(self.token_replacement='')+sin(self.token_replacement='\s')+conda()freq10.extract(name='m').sents=[]freq10.append(name='i').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)[-nvl(values=cinmax)]=self.token_replacementfreq10.extract(name='a').sents=[]freq10.append(name='a').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)freq10.extract(name='b').sents=[]freq10.append(name='b').map(cosine)freq10.extract(name='c').sents=[]freq10.append(name='c').map(cosine)freq10.append(name='d').map(cosine)freq10.append(name='d').map(cosine)freq10.extract(name='e').sents=[]freq10.append(name='e').map(cosine)freq10.extract(name='f').map(cosine)freq10.append(name='g').map(cosine)freq10.append(name='j').map(cosine)freq10.append(name='k').map(cosine)freq10.append(name='l').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name='p').map(cosine)freq10.append(name='q').map(cosine)freq10.append(name='s').map(cosine)freq10.append(name='n').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name=。
与昂贵的伪原创软件说拜拜!客网站长提供教程环境
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-06-29 19:05
伪原创的目的是为了让搜索引擎认为这是一篇原创文章的文章,并给予这个文章相对较高的权重。目前伪原创有很多做法,比如替换单词和句子。
这里我们将从各个方面分析伪原创,教你如何制作伪原创程序。告别昂贵的伪原创software! Longjuke网站长提供
教程环境:
1、PHP
2、MYSQL
3、SCWS 分词系统
类似PHP脚本,类似MYSQL数据库,类似分词系统也有,这里只提供思路。
第 1 步:配置您的环境!
这里需要做的是下载SCWS分析系统,按照官方教程安装系统,并通过测试。其他后台脚本,数据库就不多说了。 SCWS是为C语言设计的,还为PHP制作了一个扩展库。你也可以用C语言来制作你的伪原创程序。
第二步:获取文章,肢解文章
所谓文章的肢解,就是将文章分割成子句。这些子句需要由它们自己的程序编写。我提供一个思路:用句号、感叹号、问号作为子句标识,上面的引号、左括号、左书名等。位起始字符,以右引号、右括号、右书名作为起始符结束字符。遍历文章,遇到起始字符时进入非句子状态,遇到结束字符时退出该状态。当它遇到句子标识符时,只有当前状态处于可判词状态时,才会读取内容 将其分成一个句子,并用这个循环肢解文章,并逐个询问每个句子。这里的子句状态的目的是保护一段内容中的子句标识,如括号、引号、书名等,例如[他说:“我爱你。”]这里,[我爱你。 ] 不会被错误分解。
第 3 步:分词
将分解的句子进一步分解得到分词。例如,句子[一个是水果,另一个是蔬菜]可以分为[苹果][和][番茄][一个][是][水果][一个][是][蔬菜]。这一步需要SCWS的帮助。分词系统安装正常后,分词操作只需要一个功能。就是这么简单!此外,除了分解词外,还必须获得名词、动词等词的属性。
第四步:关键词同义替换
在这里,您需要知识库的支持。下载《哈尔滨工业大学信息检索实验室同义词慈林》加长版,内含完整同义词列表。每个词有多个编码,表示这个词是多义词,一个编码下面有多个词,说明这些词是同义词,读出来保存在数据库中,以备后用。
根据相关字段设置您的关键词。比如你做房地产网站,那么你的关键词可能是租房,租房,二手房,买房,租房合同,在外地查了很多关键词,然后根据同义词 Cilin 替换它们。为什么只替换关键词?因为替换了一个非关键词的部分,可能会造成奇点,而且不是该领域的词,权重不如关键词领域高,句子流的损失不值得损失.
第 5 步:标点符号乱舞
文章相似度的计算是根据句子相似度计算的,而句子相似度是根据词相似度计算的,所以即使将关键词换成同义词,得到的文章也和原来的Will一样还是被判断为类似文章,我该怎么办?首先我们来看看文章相似度的计算方法。
前面提到的Synonym Cilin的编码其实还是很有学问的,不是乱码。同义词 Cilin 的扩展版本使用代码来识别单词的含义。代码可以分为5部分。它们是大类、中类、小类、词组、原子词组,例如学生和老师。这两个词一定属于一个大类,因为它们都是人类,而西红柿和西红柿一定是一个词组,因为它们指的是一个东西。那么相似度的计算就很简单了。同样按100计算。大类相同为10,中类再次相同为20,小类再次相同为50。相同为90,如果原子词组为又一样,是100。为什么这里用了“re”这个词,因为只要其中一个不同,就没有必要比较。比如大类不同的两个词,中类和小类肯定是不同的。
这里比较两个文章一个句子中出现的词的相似度,计算每个句子的相似度,然后计算文章相似度。这是一个类似于 Google 的 PR 算法的算法。加入贡献计算相似度。
说了这么多,怎么办?我们不得不打乱标点符号,干扰搜索引擎的句子处理。
当人们阅读文章,尤其是新闻或信息时,他们通常不关心标点符号。有些人甚至粗略地看了一眼。就算句子混乱,文章大意也不会造成任何问题,所以我们希望文章中的句号和逗号可以随意替换,影响文章的搜索引擎的子句,从而影响其相似度计算.
第 6 步:创建摘要并将其放在段落的开头
文章 内容越高级越重要。对此毫无疑问,所以我们需要总结文章,放在文章的顶部。摘要要有一定的压缩率,比如1000字文章,做个100字的摘要就行了。这里我们不按字数统计,按句数统计更方便,因为我们已经按句子处理了文章。对于 500 句的文章,做大约 20 句的总结。摘要的核心在于对抽象句子的选择,因为摘要本身就是一个大意,所以稍微有点语义障碍是可以接受的。
如上所述关键词,提取摘要也需要关键词。我们以加权的方式提取抽象句子。收录关键词 的句子具有更高的权重。收录的数字越多,权重就越高。计算每个句子的权重。然后按照原文的先后顺序,按照权重的顺序提取,直到提取出你需要的句子数。将它们拼接在一起成为文章的摘要。
我们可以在这里做得更好。在网上找句子相似度计算算法,计算句子相似度,消除相似的句子,防止语义重复。因为收录大量关键词的句子很可能会重复。
第 7 步:自定义标题
伪原创 很重要的一点就是改标题。标题必须改。根据相似度计算算法,我们必须将标题更改为全新的。比如将【高考10招】改为【高考10招】。这样的改革,简直就是把百度当傻子。如何改变它?你会编造谎言吗? 【专家十条建议助你备战高考】【做好这十项,高考拿满分】【清华大学离你只有十步之遥! 】这些标题的意思没有变,但是点击的吸引力很大,不会被搜索引擎发现和文章一样。还不错?
第 8 步:打乱权重较低的句子的顺序
低权重的句子也可以派上用场。虽然我们认为这些句子不是很重要,但搜索引擎并不知道。我们稍微打乱了他们的顺序,这不影响语义,而是有伪原创的效果,嗯。
对于目前的伪原创软件来说,乱打乱句子的顺序是不可取的。比如一篇文章的文章介绍了10款软件,已经标注了1、2、3、4的顺序。在伪原创之后,顺序乱了,读者读起来难以置信。而这篇文章介绍了句子打乱,就是从局部范围打乱,都是非关键的句子。
解决伪原创的问题,解决文章可读性的问题。除非你的文章只供搜索引擎使用,不供人查看,否则,赶紧自己制作伪原创Program吧!感谢Longjuke网站长提供() 查看全部
与昂贵的伪原创软件说拜拜!客网站长提供教程环境
伪原创的目的是为了让搜索引擎认为这是一篇原创文章的文章,并给予这个文章相对较高的权重。目前伪原创有很多做法,比如替换单词和句子。
这里我们将从各个方面分析伪原创,教你如何制作伪原创程序。告别昂贵的伪原创software! Longjuke网站长提供
教程环境:
1、PHP
2、MYSQL
3、SCWS 分词系统
类似PHP脚本,类似MYSQL数据库,类似分词系统也有,这里只提供思路。
第 1 步:配置您的环境!
这里需要做的是下载SCWS分析系统,按照官方教程安装系统,并通过测试。其他后台脚本,数据库就不多说了。 SCWS是为C语言设计的,还为PHP制作了一个扩展库。你也可以用C语言来制作你的伪原创程序。
第二步:获取文章,肢解文章
所谓文章的肢解,就是将文章分割成子句。这些子句需要由它们自己的程序编写。我提供一个思路:用句号、感叹号、问号作为子句标识,上面的引号、左括号、左书名等。位起始字符,以右引号、右括号、右书名作为起始符结束字符。遍历文章,遇到起始字符时进入非句子状态,遇到结束字符时退出该状态。当它遇到句子标识符时,只有当前状态处于可判词状态时,才会读取内容 将其分成一个句子,并用这个循环肢解文章,并逐个询问每个句子。这里的子句状态的目的是保护一段内容中的子句标识,如括号、引号、书名等,例如[他说:“我爱你。”]这里,[我爱你。 ] 不会被错误分解。
第 3 步:分词
将分解的句子进一步分解得到分词。例如,句子[一个是水果,另一个是蔬菜]可以分为[苹果][和][番茄][一个][是][水果][一个][是][蔬菜]。这一步需要SCWS的帮助。分词系统安装正常后,分词操作只需要一个功能。就是这么简单!此外,除了分解词外,还必须获得名词、动词等词的属性。
第四步:关键词同义替换
在这里,您需要知识库的支持。下载《哈尔滨工业大学信息检索实验室同义词慈林》加长版,内含完整同义词列表。每个词有多个编码,表示这个词是多义词,一个编码下面有多个词,说明这些词是同义词,读出来保存在数据库中,以备后用。
根据相关字段设置您的关键词。比如你做房地产网站,那么你的关键词可能是租房,租房,二手房,买房,租房合同,在外地查了很多关键词,然后根据同义词 Cilin 替换它们。为什么只替换关键词?因为替换了一个非关键词的部分,可能会造成奇点,而且不是该领域的词,权重不如关键词领域高,句子流的损失不值得损失.
第 5 步:标点符号乱舞
文章相似度的计算是根据句子相似度计算的,而句子相似度是根据词相似度计算的,所以即使将关键词换成同义词,得到的文章也和原来的Will一样还是被判断为类似文章,我该怎么办?首先我们来看看文章相似度的计算方法。
前面提到的Synonym Cilin的编码其实还是很有学问的,不是乱码。同义词 Cilin 的扩展版本使用代码来识别单词的含义。代码可以分为5部分。它们是大类、中类、小类、词组、原子词组,例如学生和老师。这两个词一定属于一个大类,因为它们都是人类,而西红柿和西红柿一定是一个词组,因为它们指的是一个东西。那么相似度的计算就很简单了。同样按100计算。大类相同为10,中类再次相同为20,小类再次相同为50。相同为90,如果原子词组为又一样,是100。为什么这里用了“re”这个词,因为只要其中一个不同,就没有必要比较。比如大类不同的两个词,中类和小类肯定是不同的。
这里比较两个文章一个句子中出现的词的相似度,计算每个句子的相似度,然后计算文章相似度。这是一个类似于 Google 的 PR 算法的算法。加入贡献计算相似度。
说了这么多,怎么办?我们不得不打乱标点符号,干扰搜索引擎的句子处理。
当人们阅读文章,尤其是新闻或信息时,他们通常不关心标点符号。有些人甚至粗略地看了一眼。就算句子混乱,文章大意也不会造成任何问题,所以我们希望文章中的句号和逗号可以随意替换,影响文章的搜索引擎的子句,从而影响其相似度计算.
第 6 步:创建摘要并将其放在段落的开头
文章 内容越高级越重要。对此毫无疑问,所以我们需要总结文章,放在文章的顶部。摘要要有一定的压缩率,比如1000字文章,做个100字的摘要就行了。这里我们不按字数统计,按句数统计更方便,因为我们已经按句子处理了文章。对于 500 句的文章,做大约 20 句的总结。摘要的核心在于对抽象句子的选择,因为摘要本身就是一个大意,所以稍微有点语义障碍是可以接受的。
如上所述关键词,提取摘要也需要关键词。我们以加权的方式提取抽象句子。收录关键词 的句子具有更高的权重。收录的数字越多,权重就越高。计算每个句子的权重。然后按照原文的先后顺序,按照权重的顺序提取,直到提取出你需要的句子数。将它们拼接在一起成为文章的摘要。
我们可以在这里做得更好。在网上找句子相似度计算算法,计算句子相似度,消除相似的句子,防止语义重复。因为收录大量关键词的句子很可能会重复。
第 7 步:自定义标题
伪原创 很重要的一点就是改标题。标题必须改。根据相似度计算算法,我们必须将标题更改为全新的。比如将【高考10招】改为【高考10招】。这样的改革,简直就是把百度当傻子。如何改变它?你会编造谎言吗? 【专家十条建议助你备战高考】【做好这十项,高考拿满分】【清华大学离你只有十步之遥! 】这些标题的意思没有变,但是点击的吸引力很大,不会被搜索引擎发现和文章一样。还不错?
第 8 步:打乱权重较低的句子的顺序
低权重的句子也可以派上用场。虽然我们认为这些句子不是很重要,但搜索引擎并不知道。我们稍微打乱了他们的顺序,这不影响语义,而是有伪原创的效果,嗯。
对于目前的伪原创软件来说,乱打乱句子的顺序是不可取的。比如一篇文章的文章介绍了10款软件,已经标注了1、2、3、4的顺序。在伪原创之后,顺序乱了,读者读起来难以置信。而这篇文章介绍了句子打乱,就是从局部范围打乱,都是非关键的句子。
解决伪原创的问题,解决文章可读性的问题。除非你的文章只供搜索引擎使用,不供人查看,否则,赶紧自己制作伪原创Program吧!感谢Longjuke网站长提供()
ES概述Elasticsearch开源的Elasticsearch是怎么产生的?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-29 03:44
ES 概览
弹性搜索
开源
弹性搜索
目前是全文搜索引擎的首选。
它可以快速存储、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用了它。
Elasticsearch 底层是一个开源库
Lucene
。但是,您不能直接使用 Lucene,您必须编写自己的代码来调用它的接口。 Elastic是Lucene的一个包,提供了REST API的操作接口,开箱即用。
Elasticsearch 是用 Java 实现的。
搜索引擎在索引数据时需要进行分词。分词是指将一个句子拆解成多个词或词。这些词或词是句子的关键词。
0.ES 是怎么来的?
(
1)question
比如:当数据量达到10亿、100亿时,我们在做系统架构的时候,通常会从以下几个角度考虑问题:
1) 我应该使用什么数据库? (mysql、sybase、oracle、大萌、魔力、mongodb、hbase...)
2) 如何解决单点故障; (lvs, F5、A10、Zookeep, MQ)
3) 如何保证数据安全; (热备、冷备、多活动异地)
4) 如何解决检索问题; (数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5) 如何解决统计分析问题; (离线,近乎实时)
(2)传统解决方案
对于关系数据,我们通常使用以下或类似的架构来解决查询瓶颈和写入瓶颈:
解决方案:
1)通过主从备份解决数据安全问题;
2)通过数据库代理中间件的心跳监控解决单点故障问题;
3)通过代理中间件将查询语句分发到各个从节点进行查询,并汇总结果
(3)非关系型数据库解决方案
对于Nosql数据库,以mongodb为例,其他原理类似:
解决方案:
1)通过副本备份保证数据安全;
2)通过节点选举机制解决单点问题;
3)首先从配置数据库中获取分片信息,然后将请求分发给各个节点,最后路由节点合并汇总结果
另一种方法——将数据完全放入内存如何?
我们知道将数据完全放在内存中是不可靠的,实际上也是不现实的。当我们的数据达到PB级别时,按照每个节点96G内存计算,内存完全填满数据。接下来我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922
其实考虑到数据备份,节点数往往在2.500万个左右。巨大的成本让它变得不现实!
从前面的讨论中我们了解到,将数据存储在内存中或不在内存中并不能完全解决问题。
所有内存速度问题都解决了,但成本问题来了。
为了解决以上问题,从源头上分析,通常可以通过以下方式找到方法:
1、有序存储数据;
2、分离数据和索引;
3、压缩数据;
这导致了 Elasticsearch。
1. ES 基础介绍
1.1 ES 定义
ES=elaticsearch 的缩写,Elasticsearch 是一个开源的、高扩展性的分布式全文搜索引擎,可以近乎实时地存储和检索数据;具有良好的可扩展性,可扩展至数百台服务器,处理PB级数据。
Elasticsearch 同样采用 Java 开发,以 Lucene 为核心,实现所有索引和搜索功能,但其目的是通过简单的 RESTful API 隐藏 Lucene 的复杂性,让全文搜索变得简单。
1.2 Lucene 和 ES 是什么关系?
1)Lucene 只是一个库。要使用它,您必须使用 Java 作为开发语言并将其直接集成到您的应用程序中。更糟糕的是,Lucene 非常复杂,你需要对检索知识有深入的了解才能理解它是如何工作的。
2)Elasticsearch 同样采用Java开发,以Lucene为核心,实现所有索引和搜索功能,但其目的是通过简单的RESTful API隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.3 ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)要快。
1.4 ES 工作原理
ElasticSearch 的节点启动时,会使用组播(或单播,如果用户更改配置)来查找集群中的其他节点并与其建立连接。这个过程如下图所示:
1.5
ES 核心概念
1)Cluster:集群。
ES 可以用作独立的单一搜索服务器。但是,为了处理大数据集,实现容错和高可用,ES可以运行在多台相互协作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为一个节点。
3)Shard:分片。
当文档数量较多时,由于内存限制、磁盘处理能力不足、无法足够快地响应客户端请求,一个节点可能不够用。在这种情况下,可以将数据分成更小的片段。每个分片都放置在不同的服务器上。
当你查询的索引分布在多个分片上时,ES会将查询发送到每个相关的分片,并将结果组合在一起,应用不知道分片的存在。即:这个过程对用户是透明的。
4)Replia:复制。
为了提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是分片的精确副本,每个分片可以有零个或多个副本。 ES中可以有很多相同的shard,选择其中一个来改变索引操作。这个特殊的分片称为主分片。
当主分片丢失时,例如分片的数据不可用时,集群会将副本提升到新的主分片。
5)全文搜索。
全文搜索是索引一个文章,可以根据关键字进行搜索,类似于mysql中的like语句。
全文索引就是根据词义对内容进行切分,然后单独建立索引。比如“你的激情来自什么”可以细分为:“你”、“激情”、“什么事”、“让”等token,这样当你搜索“你”或“激情”,就会找到这句话。
1.6 ES数据架构的主要概念(与关系型数据库Mysql对比)
(关系型数据库中1)Database,相当于ES中的索引
(2)一个数据库下有N个表,相当于N个多种类型(Type)下有1个索引,
(3)一个数据库表(Table)下的数据由多行(ROW)和多列(属性)组成,相当于1个类型由多个文档(Document)和多个字段组成。
(4)在关系型数据库中,schema定义了表,每个表的字段,以及表与字段的关系。相应地,在ES:Mapping中定义了索引下的Type字段处理规则索引,即如何建立索引,索引的类型,是否保存原创索引的JSON文档,是否压缩原创JSON文档,是否需要分词处理,如何进行分词处理等.
(5)在数据库中添加插入、删除删除、更改更新、搜索搜索操作相当于在ES中添加PUT/POST、删除Delete、更改_update、检查GET。
1.7 什么是麋鹿?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储和全文搜索
logstash:日志处理,“搬运工”
kibana:数据可视化展示。
ELK 架构为分布式数据存储、可视化查询和日志分析创建了强大的管理链。三者相互配合,取长补短,共同完成分布式大数据处理。
2. ES 特性和优势
1)分布式实时文件存储,每个字段都可以存储在索引中,以便检索。
2)用于实时分析的分布式搜索引擎。
分布式:索引被拆分成多个分片,每个分片可以有零个或多个副本。集群中的每个数据节点可以承载一个或多个分片,协调处理各种操作;
负载重新平衡和路由在大多数情况下自动完成。
3)可以扩展到数百台服务器来处理PB级结构化或非结构化数据。它也可以在单台 PC 上运行(已测试)
4)支持插件机制、分词插件、同步插件、Hadoop插件、可视化插件等
3、ES 性能
3.1 性能结果展示
(1)硬件配置:
CPU 16 核 AuthenticAMD
总内存:32GB
总硬盘:500GB 非固态硬盘
(2)基于以上硬件指标的测试性能如下:
1)平均索引吞吐量:12307docs/s(每个文档大小:40B/docs)
2)平均CPU使用率:887.7%(16核,平均每核:55.48%)
3)构建索引大小:3.30111 GB
4)总写入量:20.2123 GB
5)总测试时间:28m 54s。
3.2 性能测试工具(推荐)
使用参考:/laoyang360/...
4、使用ES的原因?
4.1 ES 国内外优秀用例
1) 2013 年初,GitHub 放弃了 Solr,采用 ElasticSearch 进行 PB 级搜索。 “GitHub 使用 ElasticSearch 搜索 20 TB 的数据,包括 13 亿个文件和 1300 亿行代码。”
2)Wikipedia:开始基于elasticsearch的核心搜索架构。
3)SoundCloud:“SoundCloud 使用 ElasticSearch 为1.80 亿用户提供即时准确的音乐搜索服务。”
4)百度:百度目前广泛使用ElasticSearch进行文本数据分析,采集百度所有服务器上的各类索引数据和自定义数据,通过各种数据的多维分析和展示,辅助定位分析示例 业务层面的异常或异常。目前覆盖百度内部20余条业务线(包括卡西欧、云分析、网络联盟、预测、库、直号、钱包、风控等),单个集群最大100台机器,200个ES节点,每天导入 30TB 以上的数据。
4.2 我们也需要
在实际项目开发中,几乎每个系统都会有搜索功能。当搜索达到一定程度后,维护和扩展的难度会逐渐变大,所以很多公司将搜索模块分离出来,用ElasticSearch等方式实现。
近年来,ElasticSearch 发展迅速,已经超越了其原本作为纯搜索引擎的角色。现在它增加了数据聚合和分析(aggregation)和可视化功能。如果你有数百万的文档,需要通过关键词定位,此时ElasticSearch绝对是最好的选择。当然,如果你的文档是 JSON,你也可以把 ElasticSearch 当作“NoSQL 数据库”,应用 ElasticSearch 的数据聚合分析(aggregation)特性,对数据进行多维分析。
[知乎: Reku 架构师潘飞] ES在某些场景下替代传统DB
个人认为Elasticsearch内部存储还是不错的,效率基本够用。也可以在某些方面替代传统的DB,前提是您的业务对运营事项没有特殊要求;和权限管理不需要说的那么详细,因为ES权限还没有完善。
由于我们对ES的应用场景只是针对一定时间内的数据聚合操作,所以没有大量的单文档请求(比如通过userid查找用户的文档,类似NoSQL的应用场景),所以我们可以决定是否替换NoSQL需要你自己测试。
如果我选择,我会尝试用 ES 来代替传统的 NoSQL,因为它的横向扩展机制太方便了。
5. ES 应用场景
通常我们面临两个问题:
1)新系统开发尝试使用ES作为存储和检索服务器;
2)现有系统升级需要支持全文搜索服务,需要使用ES。
以上两种架构的使用在以下链接中有详细说明。
/laoyang360/...
一线企业ES使用场景:
1)SinaES 如何分析处理32亿条实时日志dockone.io/article/505
2)阿里ES 建立自己的日志采集和分析系统afoo.me/columns/tec...
3)有赞ES业务日志处理/you-zan-ton...
4)ES 实现站点搜索...
6. ES 部署
6.1 ES 部署(无需安装)
1)零配置,开箱即用
2)无需繁琐的安装和配置
3)java 版本要求:最低1.7
我使用1.8
[root@laoyang config_lhy]# echo $JAVA_HOME
/opt/jdk1.8.0_91
4)下载地址:
download.elastic.co/elas ... ...
5)START
cd /usr/local/elasticsearch-2.3.5
./bin/elasticsearch
bin/elasticsearch -d(后台运行)
6.2 ES必备插件
必备Head、kibana、IK(中文分词)、graph等插件的详细安装和使用
/column/deta...
6.3 ES windows下一键安装
自己编写的bat脚本,实现windows的下一步安装。
1)一键安装ES及必要插件(head、kibana、IK、logstash等)
2)安装后将 ES 作为服务运行。
3)比自己摸索安装至少节省了2个小时的时间,效率很高。
脚本说明:
/laoyang360/...
更多免费技术信息请关注:annalin1203 查看全部
ES概述Elasticsearch开源的Elasticsearch是怎么产生的?(组图)
ES 概览
弹性搜索
开源
弹性搜索
目前是全文搜索引擎的首选。
它可以快速存储、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用了它。
Elasticsearch 底层是一个开源库
Lucene
。但是,您不能直接使用 Lucene,您必须编写自己的代码来调用它的接口。 Elastic是Lucene的一个包,提供了REST API的操作接口,开箱即用。
Elasticsearch 是用 Java 实现的。
搜索引擎在索引数据时需要进行分词。分词是指将一个句子拆解成多个词或词。这些词或词是句子的关键词。
0.ES 是怎么来的?
(
1)question
比如:当数据量达到10亿、100亿时,我们在做系统架构的时候,通常会从以下几个角度考虑问题:
1) 我应该使用什么数据库? (mysql、sybase、oracle、大萌、魔力、mongodb、hbase...)
2) 如何解决单点故障; (lvs, F5、A10、Zookeep, MQ)
3) 如何保证数据安全; (热备、冷备、多活动异地)
4) 如何解决检索问题; (数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5) 如何解决统计分析问题; (离线,近乎实时)
(2)传统解决方案
对于关系数据,我们通常使用以下或类似的架构来解决查询瓶颈和写入瓶颈:
解决方案:
1)通过主从备份解决数据安全问题;
2)通过数据库代理中间件的心跳监控解决单点故障问题;
3)通过代理中间件将查询语句分发到各个从节点进行查询,并汇总结果
(3)非关系型数据库解决方案
对于Nosql数据库,以mongodb为例,其他原理类似:
解决方案:
1)通过副本备份保证数据安全;
2)通过节点选举机制解决单点问题;
3)首先从配置数据库中获取分片信息,然后将请求分发给各个节点,最后路由节点合并汇总结果
另一种方法——将数据完全放入内存如何?
我们知道将数据完全放在内存中是不可靠的,实际上也是不现实的。当我们的数据达到PB级别时,按照每个节点96G内存计算,内存完全填满数据。接下来我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922
其实考虑到数据备份,节点数往往在2.500万个左右。巨大的成本让它变得不现实!
从前面的讨论中我们了解到,将数据存储在内存中或不在内存中并不能完全解决问题。
所有内存速度问题都解决了,但成本问题来了。
为了解决以上问题,从源头上分析,通常可以通过以下方式找到方法:
1、有序存储数据;
2、分离数据和索引;
3、压缩数据;
这导致了 Elasticsearch。
1. ES 基础介绍
1.1 ES 定义
ES=elaticsearch 的缩写,Elasticsearch 是一个开源的、高扩展性的分布式全文搜索引擎,可以近乎实时地存储和检索数据;具有良好的可扩展性,可扩展至数百台服务器,处理PB级数据。
Elasticsearch 同样采用 Java 开发,以 Lucene 为核心,实现所有索引和搜索功能,但其目的是通过简单的 RESTful API 隐藏 Lucene 的复杂性,让全文搜索变得简单。
1.2 Lucene 和 ES 是什么关系?
1)Lucene 只是一个库。要使用它,您必须使用 Java 作为开发语言并将其直接集成到您的应用程序中。更糟糕的是,Lucene 非常复杂,你需要对检索知识有深入的了解才能理解它是如何工作的。
2)Elasticsearch 同样采用Java开发,以Lucene为核心,实现所有索引和搜索功能,但其目的是通过简单的RESTful API隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.3 ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)要快。
1.4 ES 工作原理
ElasticSearch 的节点启动时,会使用组播(或单播,如果用户更改配置)来查找集群中的其他节点并与其建立连接。这个过程如下图所示:
1.5
ES 核心概念
1)Cluster:集群。
ES 可以用作独立的单一搜索服务器。但是,为了处理大数据集,实现容错和高可用,ES可以运行在多台相互协作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为一个节点。
3)Shard:分片。
当文档数量较多时,由于内存限制、磁盘处理能力不足、无法足够快地响应客户端请求,一个节点可能不够用。在这种情况下,可以将数据分成更小的片段。每个分片都放置在不同的服务器上。
当你查询的索引分布在多个分片上时,ES会将查询发送到每个相关的分片,并将结果组合在一起,应用不知道分片的存在。即:这个过程对用户是透明的。
4)Replia:复制。
为了提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是分片的精确副本,每个分片可以有零个或多个副本。 ES中可以有很多相同的shard,选择其中一个来改变索引操作。这个特殊的分片称为主分片。
当主分片丢失时,例如分片的数据不可用时,集群会将副本提升到新的主分片。
5)全文搜索。
全文搜索是索引一个文章,可以根据关键字进行搜索,类似于mysql中的like语句。
全文索引就是根据词义对内容进行切分,然后单独建立索引。比如“你的激情来自什么”可以细分为:“你”、“激情”、“什么事”、“让”等token,这样当你搜索“你”或“激情”,就会找到这句话。
1.6 ES数据架构的主要概念(与关系型数据库Mysql对比)
(关系型数据库中1)Database,相当于ES中的索引
(2)一个数据库下有N个表,相当于N个多种类型(Type)下有1个索引,
(3)一个数据库表(Table)下的数据由多行(ROW)和多列(属性)组成,相当于1个类型由多个文档(Document)和多个字段组成。
(4)在关系型数据库中,schema定义了表,每个表的字段,以及表与字段的关系。相应地,在ES:Mapping中定义了索引下的Type字段处理规则索引,即如何建立索引,索引的类型,是否保存原创索引的JSON文档,是否压缩原创JSON文档,是否需要分词处理,如何进行分词处理等.
(5)在数据库中添加插入、删除删除、更改更新、搜索搜索操作相当于在ES中添加PUT/POST、删除Delete、更改_update、检查GET。
1.7 什么是麋鹿?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储和全文搜索
logstash:日志处理,“搬运工”
kibana:数据可视化展示。
ELK 架构为分布式数据存储、可视化查询和日志分析创建了强大的管理链。三者相互配合,取长补短,共同完成分布式大数据处理。
2. ES 特性和优势
1)分布式实时文件存储,每个字段都可以存储在索引中,以便检索。
2)用于实时分析的分布式搜索引擎。
分布式:索引被拆分成多个分片,每个分片可以有零个或多个副本。集群中的每个数据节点可以承载一个或多个分片,协调处理各种操作;
负载重新平衡和路由在大多数情况下自动完成。
3)可以扩展到数百台服务器来处理PB级结构化或非结构化数据。它也可以在单台 PC 上运行(已测试)
4)支持插件机制、分词插件、同步插件、Hadoop插件、可视化插件等
3、ES 性能
3.1 性能结果展示
(1)硬件配置:
CPU 16 核 AuthenticAMD
总内存:32GB
总硬盘:500GB 非固态硬盘
(2)基于以上硬件指标的测试性能如下:
1)平均索引吞吐量:12307docs/s(每个文档大小:40B/docs)
2)平均CPU使用率:887.7%(16核,平均每核:55.48%)
3)构建索引大小:3.30111 GB
4)总写入量:20.2123 GB
5)总测试时间:28m 54s。
3.2 性能测试工具(推荐)
使用参考:/laoyang360/...
4、使用ES的原因?
4.1 ES 国内外优秀用例
1) 2013 年初,GitHub 放弃了 Solr,采用 ElasticSearch 进行 PB 级搜索。 “GitHub 使用 ElasticSearch 搜索 20 TB 的数据,包括 13 亿个文件和 1300 亿行代码。”
2)Wikipedia:开始基于elasticsearch的核心搜索架构。
3)SoundCloud:“SoundCloud 使用 ElasticSearch 为1.80 亿用户提供即时准确的音乐搜索服务。”
4)百度:百度目前广泛使用ElasticSearch进行文本数据分析,采集百度所有服务器上的各类索引数据和自定义数据,通过各种数据的多维分析和展示,辅助定位分析示例 业务层面的异常或异常。目前覆盖百度内部20余条业务线(包括卡西欧、云分析、网络联盟、预测、库、直号、钱包、风控等),单个集群最大100台机器,200个ES节点,每天导入 30TB 以上的数据。
4.2 我们也需要
在实际项目开发中,几乎每个系统都会有搜索功能。当搜索达到一定程度后,维护和扩展的难度会逐渐变大,所以很多公司将搜索模块分离出来,用ElasticSearch等方式实现。
近年来,ElasticSearch 发展迅速,已经超越了其原本作为纯搜索引擎的角色。现在它增加了数据聚合和分析(aggregation)和可视化功能。如果你有数百万的文档,需要通过关键词定位,此时ElasticSearch绝对是最好的选择。当然,如果你的文档是 JSON,你也可以把 ElasticSearch 当作“NoSQL 数据库”,应用 ElasticSearch 的数据聚合分析(aggregation)特性,对数据进行多维分析。
[知乎: Reku 架构师潘飞] ES在某些场景下替代传统DB
个人认为Elasticsearch内部存储还是不错的,效率基本够用。也可以在某些方面替代传统的DB,前提是您的业务对运营事项没有特殊要求;和权限管理不需要说的那么详细,因为ES权限还没有完善。
由于我们对ES的应用场景只是针对一定时间内的数据聚合操作,所以没有大量的单文档请求(比如通过userid查找用户的文档,类似NoSQL的应用场景),所以我们可以决定是否替换NoSQL需要你自己测试。
如果我选择,我会尝试用 ES 来代替传统的 NoSQL,因为它的横向扩展机制太方便了。
5. ES 应用场景
通常我们面临两个问题:
1)新系统开发尝试使用ES作为存储和检索服务器;
2)现有系统升级需要支持全文搜索服务,需要使用ES。
以上两种架构的使用在以下链接中有详细说明。
/laoyang360/...
一线企业ES使用场景:
1)SinaES 如何分析处理32亿条实时日志dockone.io/article/505
2)阿里ES 建立自己的日志采集和分析系统afoo.me/columns/tec...
3)有赞ES业务日志处理/you-zan-ton...
4)ES 实现站点搜索...
6. ES 部署
6.1 ES 部署(无需安装)
1)零配置,开箱即用
2)无需繁琐的安装和配置
3)java 版本要求:最低1.7
我使用1.8
[root@laoyang config_lhy]# echo $JAVA_HOME
/opt/jdk1.8.0_91
4)下载地址:
download.elastic.co/elas ... ...
5)START
cd /usr/local/elasticsearch-2.3.5
./bin/elasticsearch
bin/elasticsearch -d(后台运行)
6.2 ES必备插件
必备Head、kibana、IK(中文分词)、graph等插件的详细安装和使用
/column/deta...
6.3 ES windows下一键安装
自己编写的bat脚本,实现windows的下一步安装。
1)一键安装ES及必要插件(head、kibana、IK、logstash等)
2)安装后将 ES 作为服务运行。
3)比自己摸索安装至少节省了2个小时的时间,效率很高。
脚本说明:
/laoyang360/...
更多免费技术信息请关注:annalin1203
海外网页抓取工具:followthemoon.但是需要翻墙才能访问哈
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-06-27 03:01
文章句子采集软件,其他的比如暴风影音的软件等等可以用。excel格式的话那就用excel吧。一般网站上都会有用txt格式存储网站的链接,需要的时候提取就可以。
昨天刚刚发现一款海外网页的抓取工具:followthemoon.但是需要翻墙才能访问哈,对翻墙很有要求的朋友注意哈!但不得不说这款工具还是很强大的,
我试了edithwaves他们家一些专题类的东西
油猴-脚本之王推荐这个吧有大部分你需要的功能
阿北在微博推荐了无觅,
链接
可以试试「netcloud」,他可以存储网站上的所有网页。也是专注于国外网站爬取,发现有部分国内网站不能访问,但是不影响大部分用户使用。爬取后放入我们自己的webpagebase中()。
postman
国内的很多第三方平台,楼上说的都对,有个值得推荐的公司叫skyrailblog,他们的正规资质值得我们信赖的。
edit
比edithwaves的爬虫器多更丰富的功能。edit是别的很多网站都能爬,
1.redisoakr2.中国最早做网站抓取的。
用没有代理的代理软件来抓
好吧还是推荐一下followthemoon。这个需要翻墙,支持国内国外多种语言。效果不错,可以直接爬。
qtrescue的抓取专家我目前用的是rescueweb,网站抓取的方面还是有些限制,只能去登录提取链接。我现在正在尝试像他们提供很多软件都不能抓取到的网站,比如很有名的网易云音乐。不过话说回来,毕竟是开源项目,去github就可以看到源代码,并且很简单。 查看全部
海外网页抓取工具:followthemoon.但是需要翻墙才能访问哈
文章句子采集软件,其他的比如暴风影音的软件等等可以用。excel格式的话那就用excel吧。一般网站上都会有用txt格式存储网站的链接,需要的时候提取就可以。
昨天刚刚发现一款海外网页的抓取工具:followthemoon.但是需要翻墙才能访问哈,对翻墙很有要求的朋友注意哈!但不得不说这款工具还是很强大的,
我试了edithwaves他们家一些专题类的东西
油猴-脚本之王推荐这个吧有大部分你需要的功能
阿北在微博推荐了无觅,
链接
可以试试「netcloud」,他可以存储网站上的所有网页。也是专注于国外网站爬取,发现有部分国内网站不能访问,但是不影响大部分用户使用。爬取后放入我们自己的webpagebase中()。
postman
国内的很多第三方平台,楼上说的都对,有个值得推荐的公司叫skyrailblog,他们的正规资质值得我们信赖的。
edit
比edithwaves的爬虫器多更丰富的功能。edit是别的很多网站都能爬,
1.redisoakr2.中国最早做网站抓取的。
用没有代理的代理软件来抓
好吧还是推荐一下followthemoon。这个需要翻墙,支持国内国外多种语言。效果不错,可以直接爬。
qtrescue的抓取专家我目前用的是rescueweb,网站抓取的方面还是有些限制,只能去登录提取链接。我现在正在尝试像他们提供很多软件都不能抓取到的网站,比如很有名的网易云音乐。不过话说回来,毕竟是开源项目,去github就可以看到源代码,并且很简单。
优采云文章原创度检测是一款文章伪原创工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-06-23 05:22
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
相关软件软件大小及版本说明下载链接
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创检测通过
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法采集行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了新的Go生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量很大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,使90%以上的文章被百度收录。
6、原创测试报告中伪原创的智能是什么?
智能伪原创只对测试报告中类似标注的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷 查看全部
优采云文章原创度检测是一款文章伪原创工具
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
相关软件软件大小及版本说明下载链接
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。

功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创检测通过
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法采集行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了新的Go生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量很大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,使90%以上的文章被百度收录。
6、原创测试报告中伪原创的智能是什么?
智能伪原创只对测试报告中类似标注的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷
文章句子采集软件采集一个句子并自动将句子变换成100个词语
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2021-06-21 19:03
文章句子采集软件采集一个句子并自动将句子变换成100个词语,并保存为txt,单独下载给项目做测试。操作过程如下:1.注册账号2.选择“自动句子摘要”功能3.语言选择“中文"“日文"“英文"4.输入文本“seehelloandiwanttobebacktoyou!"5.程序会对文本进行预处理,在保存为txt格式后,再对文本进行处理6.对预处理后的文本进行拆分并截取到自己的地址邮箱7.下载好python源码8.格式分析并转换成文本9.下载excel,导入。
预处理好的文本中,每一个单词的空格位置都会被替换为对应的中文空格位置。拆分好的文本在导入excel后,会自动由左到右,由上到下排列。也就是说,单词之间会出现“|”符号。下面是关于此项目采集数据的代码:defsee_hello_andiwanttobebacktoyou(self):"""首先加载python库:importosimportnumpyasnpimportpandasaspd"""csvfile="see_hello_andiwanttobebacktoyou!"paths=['c:\\users\\administrator\\desktop\\python\\see_hello_andiwanttobebacktoyou!']paths.extract(csvfile)print(csvfile)os.environ['time']='time:'+np.abs(os.environ['time'])os.environ['format']='%y%m%d%h:%m:%s'ifpaths['format']=='%y%m%d%h:%m:%s':continue#installpandasfromdatetimeimportdatetimeos.environ['time']='time:'+np.abs(os.environ['time'])br=pd.read_csv(os.environ['time'],index=false)br.head(。
2)br=pd.read_csv(os.environ['time'],index=false)br.head
1)else:br=pd.read_csv(os.environ['time'],index=false)br.head
<p>0)pd.read_csv函数的第二个参数是一个关键字参数,即把分隔符替换为一个空格。从而实现输入的格式由seehello_andiwanttobebacktoyou!这句话划分成2个句子单词拼接在一起。ifnp.abs(os.environ['time']) 查看全部
文章句子采集软件采集一个句子并自动将句子变换成100个词语
文章句子采集软件采集一个句子并自动将句子变换成100个词语,并保存为txt,单独下载给项目做测试。操作过程如下:1.注册账号2.选择“自动句子摘要”功能3.语言选择“中文"“日文"“英文"4.输入文本“seehelloandiwanttobebacktoyou!"5.程序会对文本进行预处理,在保存为txt格式后,再对文本进行处理6.对预处理后的文本进行拆分并截取到自己的地址邮箱7.下载好python源码8.格式分析并转换成文本9.下载excel,导入。
预处理好的文本中,每一个单词的空格位置都会被替换为对应的中文空格位置。拆分好的文本在导入excel后,会自动由左到右,由上到下排列。也就是说,单词之间会出现“|”符号。下面是关于此项目采集数据的代码:defsee_hello_andiwanttobebacktoyou(self):"""首先加载python库:importosimportnumpyasnpimportpandasaspd"""csvfile="see_hello_andiwanttobebacktoyou!"paths=['c:\\users\\administrator\\desktop\\python\\see_hello_andiwanttobebacktoyou!']paths.extract(csvfile)print(csvfile)os.environ['time']='time:'+np.abs(os.environ['time'])os.environ['format']='%y%m%d%h:%m:%s'ifpaths['format']=='%y%m%d%h:%m:%s':continue#installpandasfromdatetimeimportdatetimeos.environ['time']='time:'+np.abs(os.environ['time'])br=pd.read_csv(os.environ['time'],index=false)br.head(。
2)br=pd.read_csv(os.environ['time'],index=false)br.head
1)else:br=pd.read_csv(os.environ['time'],index=false)br.head
<p>0)pd.read_csv函数的第二个参数是一个关键字参数,即把分隔符替换为一个空格。从而实现输入的格式由seehello_andiwanttobebacktoyou!这句话划分成2个句子单词拼接在一起。ifnp.abs(os.environ['time'])
文章句子采集软件采集来的文章里面有多少个长句子
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-06-21 04:03
文章句子采集软件采集来的文章里面的句子,是根据文章句子长度采样而来的。时间生成的短句子的长度为所选文章文字的长度(perlength)。这一“文字大于句子大小”的技术用于判断一篇文章里有多少个长句子。首先看看用word2vec来训练词向量,每一个wordtoken(不是一个词)都需要一个维度的特征来表示,文章句子是一个个词向量或者词嵌入,自然就是词嵌入向量或者词嵌入特征的向量向量之和。
这个也是训练语言模型(bert)的关键数据。那一篇文章又多长呢?一般一个句子训练4~6轮可以达到很好的效果,这就是文章句子数的差别。对于用户反馈可以应用到文章反馈中,可以简单的将文章里面的句子模型为短文本,然后直接根据文章给出的短句和长句向量融合就可以生成个性化的文章反馈。参考:比特反馈的分级perblock摘要参考word2vec是怎么样加速正则项的。
1,分词是手动设置的,目前基本所有的语言模型都是使用词袋模型,crf等强模型作为词条,而根据词汇的空间顺序或者隐含状态等非结构化信息,文本单词可能转换为向量空间,可以合理的应用到dnn中。2,word2vec可以获取到源文本的概率特征,文本特征与特征空间的语言模型相比,有着共同的语言模型特征分布规律。对于描述性可以得到比语言模型更加多样性的embedding。 查看全部
文章句子采集软件采集来的文章里面有多少个长句子
文章句子采集软件采集来的文章里面的句子,是根据文章句子长度采样而来的。时间生成的短句子的长度为所选文章文字的长度(perlength)。这一“文字大于句子大小”的技术用于判断一篇文章里有多少个长句子。首先看看用word2vec来训练词向量,每一个wordtoken(不是一个词)都需要一个维度的特征来表示,文章句子是一个个词向量或者词嵌入,自然就是词嵌入向量或者词嵌入特征的向量向量之和。
这个也是训练语言模型(bert)的关键数据。那一篇文章又多长呢?一般一个句子训练4~6轮可以达到很好的效果,这就是文章句子数的差别。对于用户反馈可以应用到文章反馈中,可以简单的将文章里面的句子模型为短文本,然后直接根据文章给出的短句和长句向量融合就可以生成个性化的文章反馈。参考:比特反馈的分级perblock摘要参考word2vec是怎么样加速正则项的。
1,分词是手动设置的,目前基本所有的语言模型都是使用词袋模型,crf等强模型作为词条,而根据词汇的空间顺序或者隐含状态等非结构化信息,文本单词可能转换为向量空间,可以合理的应用到dnn中。2,word2vec可以获取到源文本的概率特征,文本特征与特征空间的语言模型相比,有着共同的语言模型特征分布规律。对于描述性可以得到比语言模型更加多样性的embedding。
一个文献管理工具,管理你的成千上百的文献
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-06-21 00:02
作为一个热爱学术的研究生,我每天都要阅读很多论文,每一篇论文都要经过一个繁琐的搜索、下载、阅读过程;看了很多文档,想回顾一下之前看过的文章,却发现面对电脑里各种文档的文件夹,找不到我要找的文章。
这时候,你需要一个文档管理工具来管理你的数百个文档,这样你在写论文的时候就可以轻松找到你想要的文档。以下是一些常用的文档管理工具:
1.EndNote
EndNote 是 SCI(汤姆森科学公司)的官方软件。它具有强大的功能。是一款集文献检索、摘要与全文管理、文献共享等功能于一体的老牌软件。支持国际期刊的参考格式。有3776种类型和数百种写作模板。用户可以方便地使用这些模板和格式。如果你打算写SCI论文,你必须使用这个管理软件。
Endnote 可直接连接上千个数据库,提高科技文献检索效率,可管理数十万条参考文献,无需担心文档过多。 EndNote 的用处是有目共睹的,在目前的文档管理工具市场上有着比较大的使用率。
需要注意的是,这个软件需要付费使用,对于学生来说价格较高,但是可以在官网免费试用30天,大家可以决定是否购买体验它。
2.Citavi
Citavi 来自瑞士。其定位为“知识型组织管理软件”,在欧洲(尤其是德语区)应用广泛。本软件集成了知识管理、任务规划、PDF全文检索等科研工作环节,功能强大全面。
Citavi拥有全功能免费版(支持每个项目插入不超过100个文档),具有强大的参考文献编辑功能,可以全方位实现参考文献的编辑需求。
Citavi 的一大特色就是支持PDF阅读功能,并且可以支持多种注释格式,可以对注释进行管理和组织,形成自己的知识库。同时,也支持文档大纲的创建,知识组织管理的形成,更好地提升我们对文献内容的理解和组织架构的形成。
3.Mendeley
Mendeley 是 Elsevier 旗下的免费文档管理软件。每个人都可以在 Mendeley 上搜索来自世界各地的学术文献。这些学术文献上传到Mendeley“图书馆”,供用户自行编辑和管理。本软件具有强大的文档整理、PDF标注和文件共享、网络备份等功能。
该软件的一大优势在于其强大的PDF识别和搜索功能,并且支持PDF标签。您可以直接对PDF文档进行标注和批注,以突出文章中的关键内容。
有网页版、WINDOWS版、Mac版、Linux版、ios客户端等平台,用户可以根据需要选择不同的平台使用。具有交叉同步和云备份功能。登录账号后,Mendeley导入的PDF可以跨平台同步,方便您在不同平台使用,查看自己的文档,无需重复导入。
4.Readcube
界面简洁美观。很多人选择这个软件是因为它的界面。
本软件功能比较齐全,平台覆盖较好。具有PDF文件自动识别和增强功能,免去繁琐的手动输入,并自带PDF阅读器进行内部搜索。但也存在一定的不足。比如系统不是特别稳定,过分依赖网速,某些项目比如云同步功能需要收费。
对于“颜控”的朋友,不妨试试这款软件,它的界面风格不会让你失望。
5.Zotero
它是一个开源的文档管理软件,可以帮助我们采集、管理和引用研究资源,包括期刊、书籍和其他文档、网页、图片等。
Zotero 最初是作为 Firefox 插件存在的,但现在已经发展成为一个独立的版本,但它仍然和 Firefox 一样,无论是在 Windows、Mac 还是 Linux 系统上,都可以跨平台使用。
Zotero 可以免费使用。与 EndNotes 相比,Zotero 最大的特点就是目录分类级别不限。一个目录可以分为多个子目录,这使得它更易于管理。另外Zotero还支持标签功能,可以自动给每个文档打上标签,方便我们管理文档。
6.NoteEpress
NoteExpress 是一款由专业级文档检索和管理系统开发的国产软件。其核心功能涵盖“knowledge采集、管理、应用、挖掘”知识管理的方方面面。
是国内专业的文档检索管理系统,对中文文档非常友好,具有非常强大的中文文档管理功能。可内部搜索知网文档库,批量下载。这个软件导入文件的速度也比国外同类软件快。
文献和笔记(文章)的功能是协调一致的。除了管理参考资料,您还可以管理其他文章或硬盘上的文件作为个人知识管理系统。
对于中文文献较多的朋友,不妨试试这款软件。
7.知网研学(原E-study)
是最大中文期刊资源CNKI官方版的研究平台软件。常用功能包括文档检索与识别、标注与添加笔记、生成参考文档、云端同步等,并可在线书写,为观众提供与CNKI数据库紧密结合的数字新体验。
除了传统文档管理软件的功能外,CNKI E-study最大的优势在于与CNKI数据库同源,可以实现数据云管理。可用于通过同一账号登录其他平台进行数据更新。可以更好地与CNKI搜索引擎结合,让受众的数据管理更加方便。
另外,这也是一款免费软件,使用起来比较方便。它占了很多市场使用量。如果你的大部分文献来自知网,你不妨考虑一下这个软件。
8.Papers
是一款专业的文档管理工具,具有文档搜索、阅读、引用等功能。 Papers 流畅地组织各种与文档管理相关的活动。主要的具体功能包括文档导入、组织、阅读(注释)、参考词条自动匹配、搜索、在文档中插入引文、评论交流等。
Papers的一大特点是可以从原创PDF中抓取文档信息,有利于对文档进行更清晰、更自动化的管理,文档自动分类,简洁明了。
Papers里面可以打开PDF文件,并且有非常强大的文档阅读功能。最突出的特点是强大的标注和笔记功能,有利于后期的学习和研究。
论文是MAC系统独有的,如果电脑是MAC系统的小伙伴,可以试试这个软件。
(本文整理自重庆大学研究生会公众号转载,原链接,如有侵删)
学术福利炸弹| N种文档管理工具,总有一款适合您
查看全部
一个文献管理工具,管理你的成千上百的文献
作为一个热爱学术的研究生,我每天都要阅读很多论文,每一篇论文都要经过一个繁琐的搜索、下载、阅读过程;看了很多文档,想回顾一下之前看过的文章,却发现面对电脑里各种文档的文件夹,找不到我要找的文章。
这时候,你需要一个文档管理工具来管理你的数百个文档,这样你在写论文的时候就可以轻松找到你想要的文档。以下是一些常用的文档管理工具:
1.EndNote
EndNote 是 SCI(汤姆森科学公司)的官方软件。它具有强大的功能。是一款集文献检索、摘要与全文管理、文献共享等功能于一体的老牌软件。支持国际期刊的参考格式。有3776种类型和数百种写作模板。用户可以方便地使用这些模板和格式。如果你打算写SCI论文,你必须使用这个管理软件。
Endnote 可直接连接上千个数据库,提高科技文献检索效率,可管理数十万条参考文献,无需担心文档过多。 EndNote 的用处是有目共睹的,在目前的文档管理工具市场上有着比较大的使用率。
需要注意的是,这个软件需要付费使用,对于学生来说价格较高,但是可以在官网免费试用30天,大家可以决定是否购买体验它。
2.Citavi
Citavi 来自瑞士。其定位为“知识型组织管理软件”,在欧洲(尤其是德语区)应用广泛。本软件集成了知识管理、任务规划、PDF全文检索等科研工作环节,功能强大全面。
Citavi拥有全功能免费版(支持每个项目插入不超过100个文档),具有强大的参考文献编辑功能,可以全方位实现参考文献的编辑需求。
Citavi 的一大特色就是支持PDF阅读功能,并且可以支持多种注释格式,可以对注释进行管理和组织,形成自己的知识库。同时,也支持文档大纲的创建,知识组织管理的形成,更好地提升我们对文献内容的理解和组织架构的形成。
3.Mendeley

Mendeley 是 Elsevier 旗下的免费文档管理软件。每个人都可以在 Mendeley 上搜索来自世界各地的学术文献。这些学术文献上传到Mendeley“图书馆”,供用户自行编辑和管理。本软件具有强大的文档整理、PDF标注和文件共享、网络备份等功能。
该软件的一大优势在于其强大的PDF识别和搜索功能,并且支持PDF标签。您可以直接对PDF文档进行标注和批注,以突出文章中的关键内容。
有网页版、WINDOWS版、Mac版、Linux版、ios客户端等平台,用户可以根据需要选择不同的平台使用。具有交叉同步和云备份功能。登录账号后,Mendeley导入的PDF可以跨平台同步,方便您在不同平台使用,查看自己的文档,无需重复导入。
4.Readcube

界面简洁美观。很多人选择这个软件是因为它的界面。
本软件功能比较齐全,平台覆盖较好。具有PDF文件自动识别和增强功能,免去繁琐的手动输入,并自带PDF阅读器进行内部搜索。但也存在一定的不足。比如系统不是特别稳定,过分依赖网速,某些项目比如云同步功能需要收费。
对于“颜控”的朋友,不妨试试这款软件,它的界面风格不会让你失望。
5.Zotero
它是一个开源的文档管理软件,可以帮助我们采集、管理和引用研究资源,包括期刊、书籍和其他文档、网页、图片等。
Zotero 最初是作为 Firefox 插件存在的,但现在已经发展成为一个独立的版本,但它仍然和 Firefox 一样,无论是在 Windows、Mac 还是 Linux 系统上,都可以跨平台使用。
Zotero 可以免费使用。与 EndNotes 相比,Zotero 最大的特点就是目录分类级别不限。一个目录可以分为多个子目录,这使得它更易于管理。另外Zotero还支持标签功能,可以自动给每个文档打上标签,方便我们管理文档。
6.NoteEpress
NoteExpress 是一款由专业级文档检索和管理系统开发的国产软件。其核心功能涵盖“knowledge采集、管理、应用、挖掘”知识管理的方方面面。
是国内专业的文档检索管理系统,对中文文档非常友好,具有非常强大的中文文档管理功能。可内部搜索知网文档库,批量下载。这个软件导入文件的速度也比国外同类软件快。
文献和笔记(文章)的功能是协调一致的。除了管理参考资料,您还可以管理其他文章或硬盘上的文件作为个人知识管理系统。
对于中文文献较多的朋友,不妨试试这款软件。
7.知网研学(原E-study)
是最大中文期刊资源CNKI官方版的研究平台软件。常用功能包括文档检索与识别、标注与添加笔记、生成参考文档、云端同步等,并可在线书写,为观众提供与CNKI数据库紧密结合的数字新体验。
除了传统文档管理软件的功能外,CNKI E-study最大的优势在于与CNKI数据库同源,可以实现数据云管理。可用于通过同一账号登录其他平台进行数据更新。可以更好地与CNKI搜索引擎结合,让受众的数据管理更加方便。
另外,这也是一款免费软件,使用起来比较方便。它占了很多市场使用量。如果你的大部分文献来自知网,你不妨考虑一下这个软件。
8.Papers
是一款专业的文档管理工具,具有文档搜索、阅读、引用等功能。 Papers 流畅地组织各种与文档管理相关的活动。主要的具体功能包括文档导入、组织、阅读(注释)、参考词条自动匹配、搜索、在文档中插入引文、评论交流等。
Papers的一大特点是可以从原创PDF中抓取文档信息,有利于对文档进行更清晰、更自动化的管理,文档自动分类,简洁明了。
Papers里面可以打开PDF文件,并且有非常强大的文档阅读功能。最突出的特点是强大的标注和笔记功能,有利于后期的学习和研究。
论文是MAC系统独有的,如果电脑是MAC系统的小伙伴,可以试试这个软件。
(本文整理自重庆大学研究生会公众号转载,原链接,如有侵删)
学术福利炸弹| N种文档管理工具,总有一款适合您
文章句子采集软件带你破解命令行,把信息自动生成
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-06-16 18:02
文章句子采集软件带你破解命令行,把信息自动生成。搜索excel-one-dic,替换library"excelhome。excel。addmouselinks"里包含的项。或者:直接把下面的命令'excelhome。excel。addmouselinks'加入这两个文件夹里面,即可:sdlcreate-lallmydbsdlsize--all=5myregular--my="sr_zhexaml"union{char(10)--all=""}其中create-l也有其他含义,。
没用过这个神器,不过实现按关键字自动取数据的话,最好配合日志管理工具,不然简直太难调试。
pandasstats模块可以很方便的实现这个功能。
记得用sql。excelhome的是傻逼。直接使用excelhome的发明的格式是错误的,
office2010以上版本->程序->excelstats
不用方法。excelhome免费提供excelhome-采集excel文件-命令行包含name这个命令,
有个叫pandas的网站,你在控制台输入要采集的excel文件名然后excel选择标准就可以自动生成记录。 查看全部
文章句子采集软件带你破解命令行,把信息自动生成
文章句子采集软件带你破解命令行,把信息自动生成。搜索excel-one-dic,替换library"excelhome。excel。addmouselinks"里包含的项。或者:直接把下面的命令'excelhome。excel。addmouselinks'加入这两个文件夹里面,即可:sdlcreate-lallmydbsdlsize--all=5myregular--my="sr_zhexaml"union{char(10)--all=""}其中create-l也有其他含义,。
没用过这个神器,不过实现按关键字自动取数据的话,最好配合日志管理工具,不然简直太难调试。
pandasstats模块可以很方便的实现这个功能。
记得用sql。excelhome的是傻逼。直接使用excelhome的发明的格式是错误的,
office2010以上版本->程序->excelstats
不用方法。excelhome免费提供excelhome-采集excel文件-命令行包含name这个命令,
有个叫pandas的网站,你在控制台输入要采集的excel文件名然后excel选择标准就可以自动生成记录。
文章句子采集软件对所有歌手和歌曲的匹配与整理
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-06-12 07:01
文章句子采集软件抓取我要的句子,将之与我要的歌曲添加,然后将歌曲信息导入到待编辑界面,根据字典库生成我要的人的名字,将昵称和歌名与歌曲进行匹配,歌曲文件加载成功后,将所有匹配成功的匹配名和歌名信息写到另一个文件中,此时需要选择歌曲歌手信息,按照如下图所示操作!现在选取所有歌手信息,按照以下图所示操作!经过对最开始所有匹配成功的歌手和所有匹配失败的歌手进行搜索匹配,最终获取了数百首歌曲,对这些歌曲进行以下操作:对所有匹配成功的歌手做一个名字索引(这个名字库需要注册,百度网盘地址:歌手jj我的文档,在网盘下载就可以),然后对歌手名中的jj设置为文件名,得到歌曲jj歌手的jj文件,还将jj文件中的jj设置为歌手jj歌手的id。
对于所有失败的歌手,同样对jj做一个名字索引,然后对歌手名中的ffj设置为文件名,得到歌曲ffj歌手的ffj文件,此时可以按照如下图所示操作对所有歌手进行歌曲列表的创建,如下图所示!除此之外还需要对歌手id进行修改,修改文件名为ffj歌手id.txt,以此来匹配歌手id的所有歌曲。这样已经完成了所有歌手和歌曲的匹配与整理!对于所有歌手和歌曲的歌曲列表还需要做一些简单的数据分析,比如名字歌手和歌曲的分布区间,共有多少首歌曲,经过复查,将歌曲列表按歌曲数量、单曲数量、单张专辑数量、改编/翻唱版本数量、翻唱版本数量、销量数量等基础数据(数据来源:网络爬虫)统计分析,得到歌曲和歌手信息的情况,以及未知歌手情况!最后将所有分析结果写入python文件中。
这个软件用起来方便,对于文字匹配、歌手匹配、名字匹配和单曲匹配等功能基本上都可以对软件setup第一步来分析,分析完以后对于软件匹配出来的信息有一个整体的认识。后面文章将用到这个文件来解决各种匹配问题!。 查看全部
文章句子采集软件对所有歌手和歌曲的匹配与整理
文章句子采集软件抓取我要的句子,将之与我要的歌曲添加,然后将歌曲信息导入到待编辑界面,根据字典库生成我要的人的名字,将昵称和歌名与歌曲进行匹配,歌曲文件加载成功后,将所有匹配成功的匹配名和歌名信息写到另一个文件中,此时需要选择歌曲歌手信息,按照如下图所示操作!现在选取所有歌手信息,按照以下图所示操作!经过对最开始所有匹配成功的歌手和所有匹配失败的歌手进行搜索匹配,最终获取了数百首歌曲,对这些歌曲进行以下操作:对所有匹配成功的歌手做一个名字索引(这个名字库需要注册,百度网盘地址:歌手jj我的文档,在网盘下载就可以),然后对歌手名中的jj设置为文件名,得到歌曲jj歌手的jj文件,还将jj文件中的jj设置为歌手jj歌手的id。
对于所有失败的歌手,同样对jj做一个名字索引,然后对歌手名中的ffj设置为文件名,得到歌曲ffj歌手的ffj文件,此时可以按照如下图所示操作对所有歌手进行歌曲列表的创建,如下图所示!除此之外还需要对歌手id进行修改,修改文件名为ffj歌手id.txt,以此来匹配歌手id的所有歌曲。这样已经完成了所有歌手和歌曲的匹配与整理!对于所有歌手和歌曲的歌曲列表还需要做一些简单的数据分析,比如名字歌手和歌曲的分布区间,共有多少首歌曲,经过复查,将歌曲列表按歌曲数量、单曲数量、单张专辑数量、改编/翻唱版本数量、翻唱版本数量、销量数量等基础数据(数据来源:网络爬虫)统计分析,得到歌曲和歌手信息的情况,以及未知歌手情况!最后将所有分析结果写入python文件中。
这个软件用起来方便,对于文字匹配、歌手匹配、名字匹配和单曲匹配等功能基本上都可以对软件setup第一步来分析,分析完以后对于软件匹配出来的信息有一个整体的认识。后面文章将用到这个文件来解决各种匹配问题!。
爱发微信快速登录文章采集2.输入关键词,获取最新素材
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-17 06:03
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷 查看全部
爱发微信快速登录文章采集2.输入关键词,获取最新素材
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷
爱发微信快速登录文章采集2.输入关键词,获取最新优质素材
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-17 00:06
优采云文章原创度测试是一款免费的文章原创度检测工具,专为自媒体和站长用户而设计。软件集成文章采集、内容伪原创、文章原创度检测等功能合而为一,颠覆传统书写模式。用户可以用它来快速采集 可以快速检测文章伪原创的度数,从而保证文章可以被百度收录。
优采云文章原创degree检测软件介绍
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
优采云文章原创度检测功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
优采云文章原创degree检测特征介绍
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
优采云文章原创度检测常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷 查看全部
爱发微信快速登录文章采集2.输入关键词,获取最新优质素材
优采云文章原创度测试是一款免费的文章原创度检测工具,专为自媒体和站长用户而设计。软件集成文章采集、内容伪原创、文章原创度检测等功能合而为一,颠覆传统书写模式。用户可以用它来快速采集 可以快速检测文章伪原创的度数,从而保证文章可以被百度收录。
优采云文章原创degree检测软件介绍
优采云文章原创度测试是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
优采云文章原创度检测功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创通过测试
优采云文章原创degree检测特征介绍
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法捕捉行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
优采云文章原创度检测常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了上生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量较大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,可以让文章被百度收录90%以上。
6、原创测试报告中伪原创的智能是什么?
Smart伪原创只对测试报告中类似标记的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷
北京市总工会职工大学:如何快速写论文的方法标题采集伪原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-08-17 00:03
北京总工会:如何快速写论文爆文title采集伪原创图片站如何用kirin伪原创工具做伪原创batch同义词替换(伪原创)工具写论文基本上是每个大学生的必修课。 Word软件英文同义词查找替换技巧。在写英文文章时,尤其是英文专业的同学或者写英文论文的同学,经常会遇到同一个词。很难想到同义词的替换,这通常会导致一个段落。
˙0˙ 软件大小:1.02MB 软件语言:简体中文软件类别:国产软件 |文字处理运行环境:Win9x/2000/XP/2003/Vista授权方式:免费版软件等级:更新时间:2010年/6/软件介绍下载网址App百科中文同义词在线转换器是一款小巧、绿色、方便、易用的-使用流行的同义词替换工具,可以帮助您将文章中流行的关键词替换为伪原创效果。
╯▂╰ 飞达路同义词替换工具是一个伪原创工具,使用同义词替换伪原创。支持增加、修改、删除、暂停某些词的使用。多用于在线伪原创工具_免费纸张减重软件伪原创tools,最新资讯,使用帮助,经典案例,开放API,如何写出优秀的伪原创?财富写作俱乐部2年前(2019-09-02)252 各种互联网项目,新手都能操作,差不多。
主要包括4102:Sentence Modification:1653 200字以内的句子或段落的修改,主要是同义词的替换。整篇修改:5w字以内对文章进行整体修改。因为软件的修改功能依赖固定的程序算法,所以经常会有软件介绍,软件截图,下载地址,相关下载,猜你喜欢,推荐给你相关评论:pp文章一鈻击文章语语工具PP文章伪原创降重帮(PP文章一键替换文章同义词工具)是一款功能丰富的一键替换。
∪﹏∪ 句子转换(伪原创工具) 下载2020.3.14 最新版-西西软件下载 百度不敢说八、2KB 同义词替换工具在线 同义词替换工具-在线文章写作,爆文原创,有同义词库2KB.COM wo 1楼全民参与:可用于同义词替换。顾名思义,就是二楼:我设置的。 查看全部
北京市总工会职工大学:如何快速写论文的方法标题采集伪原创
北京总工会:如何快速写论文爆文title采集伪原创图片站如何用kirin伪原创工具做伪原创batch同义词替换(伪原创)工具写论文基本上是每个大学生的必修课。 Word软件英文同义词查找替换技巧。在写英文文章时,尤其是英文专业的同学或者写英文论文的同学,经常会遇到同一个词。很难想到同义词的替换,这通常会导致一个段落。
˙0˙ 软件大小:1.02MB 软件语言:简体中文软件类别:国产软件 |文字处理运行环境:Win9x/2000/XP/2003/Vista授权方式:免费版软件等级:更新时间:2010年/6/软件介绍下载网址App百科中文同义词在线转换器是一款小巧、绿色、方便、易用的-使用流行的同义词替换工具,可以帮助您将文章中流行的关键词替换为伪原创效果。
╯▂╰ 飞达路同义词替换工具是一个伪原创工具,使用同义词替换伪原创。支持增加、修改、删除、暂停某些词的使用。多用于在线伪原创工具_免费纸张减重软件伪原创tools,最新资讯,使用帮助,经典案例,开放API,如何写出优秀的伪原创?财富写作俱乐部2年前(2019-09-02)252 各种互联网项目,新手都能操作,差不多。
主要包括4102:Sentence Modification:1653 200字以内的句子或段落的修改,主要是同义词的替换。整篇修改:5w字以内对文章进行整体修改。因为软件的修改功能依赖固定的程序算法,所以经常会有软件介绍,软件截图,下载地址,相关下载,猜你喜欢,推荐给你相关评论:pp文章一鈻击文章语语工具PP文章伪原创降重帮(PP文章一键替换文章同义词工具)是一款功能丰富的一键替换。
∪﹏∪ 句子转换(伪原创工具) 下载2020.3.14 最新版-西西软件下载 百度不敢说八、2KB 同义词替换工具在线 同义词替换工具-在线文章写作,爆文原创,有同义词库2KB.COM wo 1楼全民参与:可用于同义词替换。顾名思义,就是二楼:我设置的。
Scholarscope最大文献影响因子的使用方法和注意事项有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 621 次浏览 • 2021-08-17 00:00
Scholarscope 是专为生物医学研究人员设计的文档检索插件,可以自动加载 Pubmed 期刊的影响因子。该软件带有一个工具箱。一是查看期刊影响因子,二是过滤文献影响因子。输入期刊全名或缩写,可以看到if和近年的趋势。有兴趣的朋友赶紧下载吧。
软件功能
1、PubMed(美国国立卫生研究院)是世界上最大的生物医学文献摘要数据库。国内高校和科研院所的大部分生物专业人士都需要用这个网站来检索文献。
2、只需要打开PubMed的网站,在里面搜索文档。插件会自动加载期刊的“影响因子”,为科研人员提供参考。
3、本应用不含任何广告,免费使用。
如何使用
1、直接使用
浏览器右上角的插件图标亮起表示已激活;
此时点击访问pubmed搜索关键词;
例如“ceRNA植物”;
进入文章详情页,可以看到Sci-Hub的下载链接,也可以采集❤️文章管理文档,扫描二维码分享到微信;
文档管理可以看到自己喜欢的文章,也可以本地导入。
2、在线工具箱
一是期刊影响因子的审核,二是文献影响因子的筛选;
输入期刊全称或简称,查看IF及近年趋势;
BMC 基因组学;
文献影响因子筛选有临时筛选和长期筛选两种;
如果要临时查看,先选择你需要的范围,点击确定,复制所有代码;
然后打开PubMed页面,点击“Advance”进入高级模式,在下拉菜单中选择“Filter”,粘贴刚才复制的代码,就可以了;
如果你觉得每次检查都设置太麻烦,需要长期筛选,那么你必须先用你的账号登录PubMed;
然后点击我的NCBI,在右下角找到过滤器,点击管理过滤器;
再次点击创建自定义过滤器;
将上一段代码粘贴到Query terms中,将Save filter命名为列,点击Save Filter保存;
勾选Active列中的框,完美;
结果将根据您的条件进行过滤。
3、translation 函数
您可以选择百度(默认)、有道和谷歌;
按住 Ctrl 键,选择一个单词或句子进行翻译(过一会儿就会出来,不是特别有用)。
常见问题
1、 插件支持哪些浏览器?
除了Firfox,所有插件只能在电脑版的浏览器上运行。很多用户尝试在手机上安装电脑版浏览器,完全不可能成功。
Chrome浏览器、360安全浏览器、360极速浏览器、115浏览器等“Chrome系列”浏览器一应俱全。
还提供 Firefox 浏览器的 PC 和 Android 移动版本。
Opera浏览器正在适配中,可能需要一段时间(3个月过去了,一直没有Opera审核的消息)。
2、PubMed 无法打开
全国大部分地区打开PubMed都没有问题,只是偶尔打不开。很有可能是运营商的DNS服务器没有更新。
解决办法是使用公网DNS,如233.5.5.5或114.114.114.114。
3、如何安装插件?
各种浏览器插件的安装方法不同,但大体相同。
如果浏览器的应用商店里有Scholarscope,可以直接从应用商店下载安装,非常方便。
4、 我的手机上有插件吗?
目前大部分手机浏览器不支持插件,但部分浏览器支持,如火狐浏览器、Yandex浏览器,用户可以试试。
我还没有看到任何可以为iOS系统安装插件的浏览器。如果有发现可以联系我调整。
5、为什么有些期刊以前不显示影响因子,今天突然显示了?
由于程序具有自学习能力,会自动匹配没有影响因子的期刊,所以数据库会随着使用越来越完善。
由于机器学习本身有一定的局限性,部分期刊标题不会自动匹配。你可以给我发邮件让我改正。
6、版权归属问题
“Impact Factor”是Impact Factor的中文直译,数据来源于科睿唯安Journal Citation Reports的一部分。
期刊信息(如全称、简称、ISSN等)来自PubMed已发表数据,可直接在其页面下载。
此网站页面上的图片(如谷歌浏览器、360浏览器等)是其公司、组织或个人的私有财产,仅用于举例或参考。
以上数据仅供科研人员使用,请勿用于商业用途。 查看全部
Scholarscope最大文献影响因子的使用方法和注意事项有哪些?
Scholarscope 是专为生物医学研究人员设计的文档检索插件,可以自动加载 Pubmed 期刊的影响因子。该软件带有一个工具箱。一是查看期刊影响因子,二是过滤文献影响因子。输入期刊全名或缩写,可以看到if和近年的趋势。有兴趣的朋友赶紧下载吧。
软件功能
1、PubMed(美国国立卫生研究院)是世界上最大的生物医学文献摘要数据库。国内高校和科研院所的大部分生物专业人士都需要用这个网站来检索文献。
2、只需要打开PubMed的网站,在里面搜索文档。插件会自动加载期刊的“影响因子”,为科研人员提供参考。
3、本应用不含任何广告,免费使用。
如何使用
1、直接使用
浏览器右上角的插件图标亮起表示已激活;
此时点击访问pubmed搜索关键词;
例如“ceRNA植物”;
进入文章详情页,可以看到Sci-Hub的下载链接,也可以采集❤️文章管理文档,扫描二维码分享到微信;
文档管理可以看到自己喜欢的文章,也可以本地导入。
2、在线工具箱
一是期刊影响因子的审核,二是文献影响因子的筛选;
输入期刊全称或简称,查看IF及近年趋势;
BMC 基因组学;
文献影响因子筛选有临时筛选和长期筛选两种;
如果要临时查看,先选择你需要的范围,点击确定,复制所有代码;
然后打开PubMed页面,点击“Advance”进入高级模式,在下拉菜单中选择“Filter”,粘贴刚才复制的代码,就可以了;
如果你觉得每次检查都设置太麻烦,需要长期筛选,那么你必须先用你的账号登录PubMed;
然后点击我的NCBI,在右下角找到过滤器,点击管理过滤器;
再次点击创建自定义过滤器;
将上一段代码粘贴到Query terms中,将Save filter命名为列,点击Save Filter保存;
勾选Active列中的框,完美;
结果将根据您的条件进行过滤。
3、translation 函数
您可以选择百度(默认)、有道和谷歌;
按住 Ctrl 键,选择一个单词或句子进行翻译(过一会儿就会出来,不是特别有用)。
常见问题
1、 插件支持哪些浏览器?
除了Firfox,所有插件只能在电脑版的浏览器上运行。很多用户尝试在手机上安装电脑版浏览器,完全不可能成功。
Chrome浏览器、360安全浏览器、360极速浏览器、115浏览器等“Chrome系列”浏览器一应俱全。
还提供 Firefox 浏览器的 PC 和 Android 移动版本。
Opera浏览器正在适配中,可能需要一段时间(3个月过去了,一直没有Opera审核的消息)。
2、PubMed 无法打开
全国大部分地区打开PubMed都没有问题,只是偶尔打不开。很有可能是运营商的DNS服务器没有更新。
解决办法是使用公网DNS,如233.5.5.5或114.114.114.114。
3、如何安装插件?
各种浏览器插件的安装方法不同,但大体相同。
如果浏览器的应用商店里有Scholarscope,可以直接从应用商店下载安装,非常方便。
4、 我的手机上有插件吗?
目前大部分手机浏览器不支持插件,但部分浏览器支持,如火狐浏览器、Yandex浏览器,用户可以试试。
我还没有看到任何可以为iOS系统安装插件的浏览器。如果有发现可以联系我调整。
5、为什么有些期刊以前不显示影响因子,今天突然显示了?
由于程序具有自学习能力,会自动匹配没有影响因子的期刊,所以数据库会随着使用越来越完善。
由于机器学习本身有一定的局限性,部分期刊标题不会自动匹配。你可以给我发邮件让我改正。
6、版权归属问题
“Impact Factor”是Impact Factor的中文直译,数据来源于科睿唯安Journal Citation Reports的一部分。
期刊信息(如全称、简称、ISSN等)来自PubMed已发表数据,可直接在其页面下载。
此网站页面上的图片(如谷歌浏览器、360浏览器等)是其公司、组织或个人的私有财产,仅用于举例或参考。
以上数据仅供科研人员使用,请勿用于商业用途。
新增微信文章导入,修改个性化邮件功能,还有会员注册的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-15 18:04
文章句子采集软件2018。12。4:新增微信文章导入,修改个性化邮件排版功能,还有会员注册的功能修改答案的时候用它,比如很久不更新回答了,你看到了以后,你会想,这种无脑的都有专门的方法帮你做呢,然后就去做了,做完了以后你就很少去看的感觉,不知道为什么看,于是你又不断去看,直到有一天你不知道为什么你想更新了,你又开始去看,想着怎么更新它,你会去关注一些你感兴趣的,一直一直在尝试着,我想做的就是让你看见了以后就知道了,知道这种无脑问题的时候,就不去看下一个了。
比如关注的领域有一些是你的专业,这种时候需要选择收录你专业的对象,顺带着也收录了你的粉丝,内容质量和数量也差不多,这样做会比较高效。我刚好也想问,
现在有个方法可以通过检索引擎以外的方式,检索出你关注的用户的文章,关注他们的知乎专栏,领域,并实时推送一条你所关注的用户的专栏。你可以搜索到他们的专栏,
把某个领域的所有文章全部收集导入后台,
我正准备做个这样的app,还在内测阶段,
我自己一直想做这个来着,可是没实力没资源,题主要做的话,真的很羡慕你,如果还在苦逼赚钱,多关注点行业前列公司的招聘广告吧,不要局限于新闻等等等等,对你真的很有帮助! 查看全部
新增微信文章导入,修改个性化邮件功能,还有会员注册的功能
文章句子采集软件2018。12。4:新增微信文章导入,修改个性化邮件排版功能,还有会员注册的功能修改答案的时候用它,比如很久不更新回答了,你看到了以后,你会想,这种无脑的都有专门的方法帮你做呢,然后就去做了,做完了以后你就很少去看的感觉,不知道为什么看,于是你又不断去看,直到有一天你不知道为什么你想更新了,你又开始去看,想着怎么更新它,你会去关注一些你感兴趣的,一直一直在尝试着,我想做的就是让你看见了以后就知道了,知道这种无脑问题的时候,就不去看下一个了。
比如关注的领域有一些是你的专业,这种时候需要选择收录你专业的对象,顺带着也收录了你的粉丝,内容质量和数量也差不多,这样做会比较高效。我刚好也想问,
现在有个方法可以通过检索引擎以外的方式,检索出你关注的用户的文章,关注他们的知乎专栏,领域,并实时推送一条你所关注的用户的专栏。你可以搜索到他们的专栏,
把某个领域的所有文章全部收集导入后台,
我正准备做个这样的app,还在内测阶段,
我自己一直想做这个来着,可是没实力没资源,题主要做的话,真的很羡慕你,如果还在苦逼赚钱,多关注点行业前列公司的招聘广告吧,不要局限于新闻等等等等,对你真的很有帮助!
优采云文章组合工具集软件特色1.全新界面设计软件功能介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-10 05:06
优采云文章Combination 工具集是一款智能高效的原创专用工具软件。全新升级的页面设计,让客户更容易上手,软件可以完成原词作文对于SEO网站站长必不可少,变身原创文章专用工具内容优化。
优采云文章免费完整版组合工具集的关键功能是将元素引入模板和适用模板。客户可以引入任何元素,软件全新升级,更新各种辅助软件。 , 可以解决大量文本的需求。
优采云文章组合工具集软件功能
核心功能:编写模板,引用模板中的元素,在任何地方引用任何元素。元素可以在文本块中调用,可以是随机的汉字、数字、字母,也可以是数字序列、随机数和随机时间。全免费原创组合模式。
特技:将元素应用到元素上(两种模式:元素组合、其他元素和动态元素名称嵌套调用),实现复杂的上下文构建,使最终组合的句子千变万化
优采云文章组合工具集操作说明
1.建议经常备份;程序数据”文件夹
2.主界面右下角的选项按钮可以导入“原创文章Generator”的程序数据(必须是导入,不是简单的文件复制)
3.;program data.rar"文件用于演示,可以解压到当前软件目录,然后重新打开软件
优采云文章组合工具集软件特点
1.全新界面设计,布局简洁干练,操作基本相同但更简单易用
<p>2.Element 库元素不再显示勾选框,避免误判(只有元素库本身可以打勾,被打勾的元素库参与调用,元素本身不需要打勾) 查看全部
优采云文章组合工具集软件特色1.全新界面设计软件功能介绍
优采云文章Combination 工具集是一款智能高效的原创专用工具软件。全新升级的页面设计,让客户更容易上手,软件可以完成原词作文对于SEO网站站长必不可少,变身原创文章专用工具内容优化。
优采云文章免费完整版组合工具集的关键功能是将元素引入模板和适用模板。客户可以引入任何元素,软件全新升级,更新各种辅助软件。 , 可以解决大量文本的需求。
优采云文章组合工具集软件功能
核心功能:编写模板,引用模板中的元素,在任何地方引用任何元素。元素可以在文本块中调用,可以是随机的汉字、数字、字母,也可以是数字序列、随机数和随机时间。全免费原创组合模式。
特技:将元素应用到元素上(两种模式:元素组合、其他元素和动态元素名称嵌套调用),实现复杂的上下文构建,使最终组合的句子千变万化
优采云文章组合工具集操作说明
1.建议经常备份;程序数据”文件夹
2.主界面右下角的选项按钮可以导入“原创文章Generator”的程序数据(必须是导入,不是简单的文件复制)
3.;program data.rar"文件用于演示,可以解压到当前软件目录,然后重新打开软件
优采云文章组合工具集软件特点
1.全新界面设计,布局简洁干练,操作基本相同但更简单易用
<p>2.Element 库元素不再显示勾选框,避免误判(只有元素库本身可以打勾,被打勾的元素库参与调用,元素本身不需要打勾)
痕夕AI文章生成软件是一款非常好用的软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-31 20:53
Hen Xi AI文章生成软件是一款非常好用的智能文章生成软件,可以根据关键词给出的信息、字符、标签等生成新的文章,同时它还支持其他文章进行伪原创处理,有需要的用户不要错过,赶快下载吧!
软件介绍
Hen Xi AI文章Intelligent Processing Software 是一款综合性的站长工具。软件加入AI技术处理文章内容,实现更多原创文章内容功能,如:AI写诗、AI写散文、AI智能生成标题、AI修改文章原创度、AI智能组合文章,AI提取文摘,AI处理汉英翻译,一键文章采集,站群管理,织梦站群文章定期发布,WordPress文章定期发布,百度排名优化、文章原创度批量检测、百万字排名查询、百度推送、熊掌号推送、智能图库下载等。
软件功能
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子打乱重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各界新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足所有人的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解html代码和正则表达式规则,如果我已经写了采集software 的采集rules 其他商家,那我一定会写我们软件的采集rules,我们提供了写采集rules 的文档。我们不为客户编写采集 规则。如需代写,10元即可获得采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
6、外链文章材料:该模块利用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户来说,模块有特色,资源丰富,原创高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、量产题:有两个作用,一是通过关键词和规则组合进行量产,二是通过采集网络大数据获取题名。自动生成的推广准确率高,采集的标题可读性强,各有优缺点。
8、文章接口发布:通过简单的配置,您可以一键将生成的文章发布到您的网站。目前支持网站YES、Discuz门户、Dedecms、帝国Ecms(新闻)、PHMcms、Qibocms、PHP168、diypage、phpwind门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
更新内容
1、新增爆文Title AI生成功能
2、修复洗涤过程中卡顿的情况
3、开发WEB网页在线版入口
4、获取人工智能 NLP 技术 查看全部
痕夕AI文章生成软件是一款非常好用的软件
Hen Xi AI文章生成软件是一款非常好用的智能文章生成软件,可以根据关键词给出的信息、字符、标签等生成新的文章,同时它还支持其他文章进行伪原创处理,有需要的用户不要错过,赶快下载吧!
软件介绍
Hen Xi AI文章Intelligent Processing Software 是一款综合性的站长工具。软件加入AI技术处理文章内容,实现更多原创文章内容功能,如:AI写诗、AI写散文、AI智能生成标题、AI修改文章原创度、AI智能组合文章,AI提取文摘,AI处理汉英翻译,一键文章采集,站群管理,织梦站群文章定期发布,WordPress文章定期发布,百度排名优化、文章原创度批量检测、百万字排名查询、百度推送、熊掌号推送、智能图库下载等。
软件功能
1、智能伪原创:利用人工智能中的自然语言处理技术实现文章伪原创处理。核心功能包括“smart伪原创”、“同义词替换伪原创”、“反义词替换伪原创”、“用html代码在文章中随机插入关键词”、“句子打乱重组”等等等,处理后的文章原创度和收录率都在80%以上。想了解更多功能,请下载软件试用。
2、Portal文章采集:一键搜索采集相关门户网站新闻文章、网站有搜狐、腾讯、新浪、网易、今日头条.com、新兰网、联合早报、光明网、站长网、新文化网等,用户可以输入行业关键词搜索想要的行业文章。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
3、百度新闻采集:一键搜索各界新闻文章,数据源来自百度新闻搜索引擎,资源丰富,操作灵活,无需写任何采集规则,但缺点是,采集的文章不一定完整,但可以满足大部分用户的需求。友情提示:文章使用时请注明文章出处,尊重原文版权。
4、工业文章采集:一键搜索相关行业网站文章,网站行业包括装饰家居行业、机械行业、建材行业、家电行业、硬件行业,美容行业,育儿行业,金融行业,游戏行业,SEO行业,女性健康行业等有几十个网站网站,资源丰富,这个模块可能不能满足所有人的需求客户,但客户可以提出他们的需求,我们会改进和更新模块资源。该模块的特点是无需编写采集规则,一键操作。友情提示:文章使用时请注明文章出处,尊重原文版权。
5、write rules采集:自己写采集rules采集,采集规则符合常见的正则表达式,写采集规则需要了解html代码和正则表达式规则,如果我已经写了采集software 的采集rules 其他商家,那我一定会写我们软件的采集rules,我们提供了写采集rules 的文档。我们不为客户编写采集 规则。如需代写,10元即可获得采集规则。友情提示:文章使用时请注明文章出处,尊重原文版权。
6、外链文章材料:该模块利用大量行业语料,通过算法随机组合语料,产生相关行业文章。这个模块文章只适用于质量要求不高的文章。对于外链推广的用户来说,模块有特色,资源丰富,原创高,但缺点是文章可读性差,用户在使用时可以选择使用。
7、量产题:有两个作用,一是通过关键词和规则组合进行量产,二是通过采集网络大数据获取题名。自动生成的推广准确率高,采集的标题可读性强,各有优缺点。
8、文章接口发布:通过简单的配置,您可以一键将生成的文章发布到您的网站。目前支持网站YES、Discuz门户、Dedecms、帝国Ecms(新闻)、PHMcms、Qibocms、PHP168、diypage、phpwind门户。
9、SEO批量查询工具:权重批量查询、排名批量查询、收录批量查询、长尾词挖掘、编码批量转换、文本加解密。
更新内容
1、新增爆文Title AI生成功能
2、修复洗涤过程中卡顿的情况
3、开发WEB网页在线版入口
4、获取人工智能 NLP 技术
文章句子采集软件sourcewindowtextsamplingsystem,你可以发给我看一下
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-07-26 21:04
文章句子采集软件sourcewindowtextsamplingsystem,大家如果在网上看到很长一段文字,
/
自己找个http网页先扒出来。
没有软件啊,这需要编程工具。
推荐你关注一下我们的微信公众号,我们很多的很多流量来自于自媒体,不知道您是用在什么渠道,你可以发给我看一下。
python爬虫
好多了。如果要抓取美元,我给你一个教程,零基础到顶级。这个视频开始学起,如果有不懂的,
aol/
大家都是文科生,技术好像对自己没什么用处。回到问题:中文的话,用知乎。如果是英文的话,可以找我。
最好的方法自然是写程序,不过写着写着就有python的味道了。比如用爬虫啊。
wyja/shortestwebnet请不要再推荐python了,
.
五六年前我就有给人写爬虫的想法,后来爱上了爬虫。
推荐一下微信公众号:去哪搜索搜索,
写个爬虫,
有个大学生项目不错,可以看看:会技术的去我公司招人--有编程基础和兴趣的去。利益相关:以前在学校干过前端工作。如果你对技术没有兴趣的话。
谁说计算机专业不会。上面有写学计算机只是不想做码农。
reference,shortestwebnetpythonapiandwebspider,w3schools 查看全部
文章句子采集软件sourcewindowtextsamplingsystem,你可以发给我看一下
文章句子采集软件sourcewindowtextsamplingsystem,大家如果在网上看到很长一段文字,
/
自己找个http网页先扒出来。
没有软件啊,这需要编程工具。
推荐你关注一下我们的微信公众号,我们很多的很多流量来自于自媒体,不知道您是用在什么渠道,你可以发给我看一下。
python爬虫
好多了。如果要抓取美元,我给你一个教程,零基础到顶级。这个视频开始学起,如果有不懂的,
aol/
大家都是文科生,技术好像对自己没什么用处。回到问题:中文的话,用知乎。如果是英文的话,可以找我。
最好的方法自然是写程序,不过写着写着就有python的味道了。比如用爬虫啊。
wyja/shortestwebnet请不要再推荐python了,
.
五六年前我就有给人写爬虫的想法,后来爱上了爬虫。
推荐一下微信公众号:去哪搜索搜索,
写个爬虫,
有个大学生项目不错,可以看看:会技术的去我公司招人--有编程基础和兴趣的去。利益相关:以前在学校干过前端工作。如果你对技术没有兴趣的话。
谁说计算机专业不会。上面有写学计算机只是不想做码农。
reference,shortestwebnetpythonapiandwebspider,w3schools
文章句子采集软件可以试试开源的微信句子工具:wordsplitter+github-jiezhu
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-24 18:02
文章句子采集软件
可以试试开源的微信句子采集工具:reeder+github-jiezhu/simple-word-splitter:asimplelyreplacedwordsplitterforjavascript.打个广告,如果觉得这个工具还可以,给个star支持下。
可以用。非常好用。自己写过几个小脚本发布到github。
曾用wordsplit命令,一行代码处理20000+个左右的word文档。可以试一下。
搜一下自己懂的语言就好了,有现成的。
花点钱,
,速度不是很好,见笑了,但是够用了
你可以试试使用搜狗的识别
sublime用户表示:wordsplitter插件支持的参数太少了,
reeder
实测,blockly打的的几个替代方案对exif信息的识别均不及格:reeder/blockly-splitter-android/ios上有基于reeder(google家)和pinbox(qq截图win7ie支持)打的句子,识别率过低,比如一大串英文“soyoushouldbuymore”,选中后整个gg。
想要真正做到用户体验,肯定需要整套专门优化的开发工具(reeder啊、akx什么的),以及android的移动开发者工具等。首先对比一下blockly在性能上与微信等服务器端编辑器有何优势,再对比其他。 查看全部
文章句子采集软件可以试试开源的微信句子工具:wordsplitter+github-jiezhu
文章句子采集软件
可以试试开源的微信句子采集工具:reeder+github-jiezhu/simple-word-splitter:asimplelyreplacedwordsplitterforjavascript.打个广告,如果觉得这个工具还可以,给个star支持下。
可以用。非常好用。自己写过几个小脚本发布到github。
曾用wordsplit命令,一行代码处理20000+个左右的word文档。可以试一下。
搜一下自己懂的语言就好了,有现成的。
花点钱,
,速度不是很好,见笑了,但是够用了
你可以试试使用搜狗的识别
sublime用户表示:wordsplitter插件支持的参数太少了,
reeder
实测,blockly打的的几个替代方案对exif信息的识别均不及格:reeder/blockly-splitter-android/ios上有基于reeder(google家)和pinbox(qq截图win7ie支持)打的句子,识别率过低,比如一大串英文“soyoushouldbuymore”,选中后整个gg。
想要真正做到用户体验,肯定需要整套专门优化的开发工具(reeder啊、akx什么的),以及android的移动开发者工具等。首先对比一下blockly在性能上与微信等服务器端编辑器有何优势,再对比其他。
武汉seo培训-seo关键词排名优化解决好建站的基础问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-07-23 01:30
文章分词工具seo想要在百度上获得一个好的自然排名,需要做好以下几方面的企业网站维护和优化工作
在优化的同时,网站的用户体验会更好,用户会更加喜爱和信任网站,转化效果必然会更好,公司才能真正实现更理想的盈利和发展
它们通常更便宜,通常几百美元,除非你真的被杀了
首先,武汉seo培训-seo关键词ranking优化解决了建站的基本问题。百度seo网站optim 社会可以借鉴周边信息,也可以和做百度seo网站optimization的朋友交流。 , 如果你想自学百度优化,也是一个艰难的过程
解决网站构建的基本问题。 seo实训学习从身边的资料中学习,可以和做seo实训的同事一起讨论。如果您想解决问题,请阅读教程并学习seo技巧。艰难的过程
网站优化的推广技巧是什么
我尝试了一些不利于网站优化的方法,比如替换链接、隐藏链接、用关键词填充标题等。结果自然被搜索引擎发现,网站排名下降。这可以看作是搜索引擎对网站的惩罚,是对文章句子分割工具seo的一种较轻的惩罚。
文章 句子切分工具seo网站SEO Specialist 是从事在线搜索引擎优化的专业人士。它需要对搜索引擎的原理、特点、排名规则等有比较深入的了解。通过蜘蛛的爬取,可以对网站优化提出一些建议,让网站更能迎合搜索引擎的喜好。
百度收录其主?原理是你其实想把排名放在首位作为一个很好的操作方式,就是让你的文章内容收录这个,获得更多的点击量,比如你更新的文章的点击次数有超过一万甚至超过一万。这是典型的爆文。如果文章点击量多,自然会在搜索结果中排名很高。 比如我在百度上搜索精密金属加工,出现的结果有一个职位,一个百度百科,一个百度文库,一个网站。所以在做网站优化的时候,一定要保证收录搜索引擎搜索到更多的页面作为前提。百度收录principle 对于百度收录来说,主要的原则其实就是获得最高排名。
一般来说,百度的快速排名应该根据网页当前的形式来确定。根据表格可以进行百度快速排名和网站改版。毕竟百度的快速排名网站排名优化优势对大家有帮助的也有单位,坚持百度的快速排名一定要符合准则,适当的时候网站改版也是必要的。
文章句子切分工具seo,你只需要查百分比计算就可以查用户的词条找到你网站
好用的网站一定会在每一个细节上考虑到潜在客户的使用习惯和感受。你可以通过自己的简单试用了解一些细节网站
外链是提高关键词前三页排名最有效的方法,这种方法也是最靠谱的,但这需要你有一定的平台资源,优质的外链不只是给你发几篇文章,发几条自媒体文章就可以了,但是需要更高的曝光度,才能达到引流的效果,否则就是普通的外链
我们应该保持网站space 和服务器的稳定性
为什么不呢?随着移动互联网的不断发展,对移动端的需求已经不能超过对PC的需求了文章分词工具seo。 查看全部
武汉seo培训-seo关键词排名优化解决好建站的基础问题
文章分词工具seo想要在百度上获得一个好的自然排名,需要做好以下几方面的企业网站维护和优化工作
在优化的同时,网站的用户体验会更好,用户会更加喜爱和信任网站,转化效果必然会更好,公司才能真正实现更理想的盈利和发展
它们通常更便宜,通常几百美元,除非你真的被杀了
首先,武汉seo培训-seo关键词ranking优化解决了建站的基本问题。百度seo网站optim 社会可以借鉴周边信息,也可以和做百度seo网站optimization的朋友交流。 , 如果你想自学百度优化,也是一个艰难的过程
解决网站构建的基本问题。 seo实训学习从身边的资料中学习,可以和做seo实训的同事一起讨论。如果您想解决问题,请阅读教程并学习seo技巧。艰难的过程
网站优化的推广技巧是什么
我尝试了一些不利于网站优化的方法,比如替换链接、隐藏链接、用关键词填充标题等。结果自然被搜索引擎发现,网站排名下降。这可以看作是搜索引擎对网站的惩罚,是对文章句子分割工具seo的一种较轻的惩罚。
文章 句子切分工具seo网站SEO Specialist 是从事在线搜索引擎优化的专业人士。它需要对搜索引擎的原理、特点、排名规则等有比较深入的了解。通过蜘蛛的爬取,可以对网站优化提出一些建议,让网站更能迎合搜索引擎的喜好。
百度收录其主?原理是你其实想把排名放在首位作为一个很好的操作方式,就是让你的文章内容收录这个,获得更多的点击量,比如你更新的文章的点击次数有超过一万甚至超过一万。这是典型的爆文。如果文章点击量多,自然会在搜索结果中排名很高。 比如我在百度上搜索精密金属加工,出现的结果有一个职位,一个百度百科,一个百度文库,一个网站。所以在做网站优化的时候,一定要保证收录搜索引擎搜索到更多的页面作为前提。百度收录principle 对于百度收录来说,主要的原则其实就是获得最高排名。
一般来说,百度的快速排名应该根据网页当前的形式来确定。根据表格可以进行百度快速排名和网站改版。毕竟百度的快速排名网站排名优化优势对大家有帮助的也有单位,坚持百度的快速排名一定要符合准则,适当的时候网站改版也是必要的。
文章句子切分工具seo,你只需要查百分比计算就可以查用户的词条找到你网站
好用的网站一定会在每一个细节上考虑到潜在客户的使用习惯和感受。你可以通过自己的简单试用了解一些细节网站
外链是提高关键词前三页排名最有效的方法,这种方法也是最靠谱的,但这需要你有一定的平台资源,优质的外链不只是给你发几篇文章,发几条自媒体文章就可以了,但是需要更高的曝光度,才能达到引流的效果,否则就是普通的外链
我们应该保持网站space 和服务器的稳定性
为什么不呢?随着移动互联网的不断发展,对移动端的需求已经不能超过对PC的需求了文章分词工具seo。
文章句子采集软件将所有匹配成功的句子(起点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-07-12 01:02
文章句子采集软件:给一个句子任务,它就会从它所处的句子库中自动采集另一个句子,并按照匹配成功率排序,返回榜单。采集软件将所有匹配成功的句子(起点中文网网页抓取量大),在后续的段落抓取和分词工作中,按照概率排序返回排名靠前的成功句子,最终返回一个时间序列序列,作为分词和词频分析的数据指标(如下图所示)。
理解一个句子的概率分布我们通常在编写python程序的时候,可以用这个程序来对句子分析。当需要对一些含有关键词的句子进行分析的时候,可以采用以下代码:fromgensim.preprocessingimportcosine,sin,condaattributefromgensim.utilsimportfreq10freq10=cosine(self.token_replacement='')+sin(self.token_replacement='\s')+conda()freq10.extract(name='m').sents=[]freq10.append(name='i').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)[-nvl(values=cinmax)]=self.token_replacementfreq10.extract(name='a').sents=[]freq10.append(name='a').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)freq10.extract(name='b').sents=[]freq10.append(name='b').map(cosine)freq10.extract(name='c').sents=[]freq10.append(name='c').map(cosine)freq10.append(name='d').map(cosine)freq10.append(name='d').map(cosine)freq10.extract(name='e').sents=[]freq10.append(name='e').map(cosine)freq10.extract(name='f').map(cosine)freq10.append(name='g').map(cosine)freq10.append(name='j').map(cosine)freq10.append(name='k').map(cosine)freq10.append(name='l').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name='p').map(cosine)freq10.append(name='q').map(cosine)freq10.append(name='s').map(cosine)freq10.append(name='n').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name=。 查看全部
文章句子采集软件将所有匹配成功的句子(起点)
文章句子采集软件:给一个句子任务,它就会从它所处的句子库中自动采集另一个句子,并按照匹配成功率排序,返回榜单。采集软件将所有匹配成功的句子(起点中文网网页抓取量大),在后续的段落抓取和分词工作中,按照概率排序返回排名靠前的成功句子,最终返回一个时间序列序列,作为分词和词频分析的数据指标(如下图所示)。
理解一个句子的概率分布我们通常在编写python程序的时候,可以用这个程序来对句子分析。当需要对一些含有关键词的句子进行分析的时候,可以采用以下代码:fromgensim.preprocessingimportcosine,sin,condaattributefromgensim.utilsimportfreq10freq10=cosine(self.token_replacement='')+sin(self.token_replacement='\s')+conda()freq10.extract(name='m').sents=[]freq10.append(name='i').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)[-nvl(values=cinmax)]=self.token_replacementfreq10.extract(name='a').sents=[]freq10.append(name='a').map(cosine)freq10.fit_at(lambdaself:self.token_replacement)eval(cinmax)freq10.extract(name='b').sents=[]freq10.append(name='b').map(cosine)freq10.extract(name='c').sents=[]freq10.append(name='c').map(cosine)freq10.append(name='d').map(cosine)freq10.append(name='d').map(cosine)freq10.extract(name='e').sents=[]freq10.append(name='e').map(cosine)freq10.extract(name='f').map(cosine)freq10.append(name='g').map(cosine)freq10.append(name='j').map(cosine)freq10.append(name='k').map(cosine)freq10.append(name='l').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name='p').map(cosine)freq10.append(name='q').map(cosine)freq10.append(name='s').map(cosine)freq10.append(name='n').map(cosine)freq10.append(name='m').map(cosine)freq10.append(name=。
与昂贵的伪原创软件说拜拜!客网站长提供教程环境
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-06-29 19:05
伪原创的目的是为了让搜索引擎认为这是一篇原创文章的文章,并给予这个文章相对较高的权重。目前伪原创有很多做法,比如替换单词和句子。
这里我们将从各个方面分析伪原创,教你如何制作伪原创程序。告别昂贵的伪原创software! Longjuke网站长提供
教程环境:
1、PHP
2、MYSQL
3、SCWS 分词系统
类似PHP脚本,类似MYSQL数据库,类似分词系统也有,这里只提供思路。
第 1 步:配置您的环境!
这里需要做的是下载SCWS分析系统,按照官方教程安装系统,并通过测试。其他后台脚本,数据库就不多说了。 SCWS是为C语言设计的,还为PHP制作了一个扩展库。你也可以用C语言来制作你的伪原创程序。
第二步:获取文章,肢解文章
所谓文章的肢解,就是将文章分割成子句。这些子句需要由它们自己的程序编写。我提供一个思路:用句号、感叹号、问号作为子句标识,上面的引号、左括号、左书名等。位起始字符,以右引号、右括号、右书名作为起始符结束字符。遍历文章,遇到起始字符时进入非句子状态,遇到结束字符时退出该状态。当它遇到句子标识符时,只有当前状态处于可判词状态时,才会读取内容 将其分成一个句子,并用这个循环肢解文章,并逐个询问每个句子。这里的子句状态的目的是保护一段内容中的子句标识,如括号、引号、书名等,例如[他说:“我爱你。”]这里,[我爱你。 ] 不会被错误分解。
第 3 步:分词
将分解的句子进一步分解得到分词。例如,句子[一个是水果,另一个是蔬菜]可以分为[苹果][和][番茄][一个][是][水果][一个][是][蔬菜]。这一步需要SCWS的帮助。分词系统安装正常后,分词操作只需要一个功能。就是这么简单!此外,除了分解词外,还必须获得名词、动词等词的属性。
第四步:关键词同义替换
在这里,您需要知识库的支持。下载《哈尔滨工业大学信息检索实验室同义词慈林》加长版,内含完整同义词列表。每个词有多个编码,表示这个词是多义词,一个编码下面有多个词,说明这些词是同义词,读出来保存在数据库中,以备后用。
根据相关字段设置您的关键词。比如你做房地产网站,那么你的关键词可能是租房,租房,二手房,买房,租房合同,在外地查了很多关键词,然后根据同义词 Cilin 替换它们。为什么只替换关键词?因为替换了一个非关键词的部分,可能会造成奇点,而且不是该领域的词,权重不如关键词领域高,句子流的损失不值得损失.
第 5 步:标点符号乱舞
文章相似度的计算是根据句子相似度计算的,而句子相似度是根据词相似度计算的,所以即使将关键词换成同义词,得到的文章也和原来的Will一样还是被判断为类似文章,我该怎么办?首先我们来看看文章相似度的计算方法。
前面提到的Synonym Cilin的编码其实还是很有学问的,不是乱码。同义词 Cilin 的扩展版本使用代码来识别单词的含义。代码可以分为5部分。它们是大类、中类、小类、词组、原子词组,例如学生和老师。这两个词一定属于一个大类,因为它们都是人类,而西红柿和西红柿一定是一个词组,因为它们指的是一个东西。那么相似度的计算就很简单了。同样按100计算。大类相同为10,中类再次相同为20,小类再次相同为50。相同为90,如果原子词组为又一样,是100。为什么这里用了“re”这个词,因为只要其中一个不同,就没有必要比较。比如大类不同的两个词,中类和小类肯定是不同的。
这里比较两个文章一个句子中出现的词的相似度,计算每个句子的相似度,然后计算文章相似度。这是一个类似于 Google 的 PR 算法的算法。加入贡献计算相似度。
说了这么多,怎么办?我们不得不打乱标点符号,干扰搜索引擎的句子处理。
当人们阅读文章,尤其是新闻或信息时,他们通常不关心标点符号。有些人甚至粗略地看了一眼。就算句子混乱,文章大意也不会造成任何问题,所以我们希望文章中的句号和逗号可以随意替换,影响文章的搜索引擎的子句,从而影响其相似度计算.
第 6 步:创建摘要并将其放在段落的开头
文章 内容越高级越重要。对此毫无疑问,所以我们需要总结文章,放在文章的顶部。摘要要有一定的压缩率,比如1000字文章,做个100字的摘要就行了。这里我们不按字数统计,按句数统计更方便,因为我们已经按句子处理了文章。对于 500 句的文章,做大约 20 句的总结。摘要的核心在于对抽象句子的选择,因为摘要本身就是一个大意,所以稍微有点语义障碍是可以接受的。
如上所述关键词,提取摘要也需要关键词。我们以加权的方式提取抽象句子。收录关键词 的句子具有更高的权重。收录的数字越多,权重就越高。计算每个句子的权重。然后按照原文的先后顺序,按照权重的顺序提取,直到提取出你需要的句子数。将它们拼接在一起成为文章的摘要。
我们可以在这里做得更好。在网上找句子相似度计算算法,计算句子相似度,消除相似的句子,防止语义重复。因为收录大量关键词的句子很可能会重复。
第 7 步:自定义标题
伪原创 很重要的一点就是改标题。标题必须改。根据相似度计算算法,我们必须将标题更改为全新的。比如将【高考10招】改为【高考10招】。这样的改革,简直就是把百度当傻子。如何改变它?你会编造谎言吗? 【专家十条建议助你备战高考】【做好这十项,高考拿满分】【清华大学离你只有十步之遥! 】这些标题的意思没有变,但是点击的吸引力很大,不会被搜索引擎发现和文章一样。还不错?
第 8 步:打乱权重较低的句子的顺序
低权重的句子也可以派上用场。虽然我们认为这些句子不是很重要,但搜索引擎并不知道。我们稍微打乱了他们的顺序,这不影响语义,而是有伪原创的效果,嗯。
对于目前的伪原创软件来说,乱打乱句子的顺序是不可取的。比如一篇文章的文章介绍了10款软件,已经标注了1、2、3、4的顺序。在伪原创之后,顺序乱了,读者读起来难以置信。而这篇文章介绍了句子打乱,就是从局部范围打乱,都是非关键的句子。
解决伪原创的问题,解决文章可读性的问题。除非你的文章只供搜索引擎使用,不供人查看,否则,赶紧自己制作伪原创Program吧!感谢Longjuke网站长提供() 查看全部
与昂贵的伪原创软件说拜拜!客网站长提供教程环境
伪原创的目的是为了让搜索引擎认为这是一篇原创文章的文章,并给予这个文章相对较高的权重。目前伪原创有很多做法,比如替换单词和句子。
这里我们将从各个方面分析伪原创,教你如何制作伪原创程序。告别昂贵的伪原创software! Longjuke网站长提供
教程环境:
1、PHP
2、MYSQL
3、SCWS 分词系统
类似PHP脚本,类似MYSQL数据库,类似分词系统也有,这里只提供思路。
第 1 步:配置您的环境!
这里需要做的是下载SCWS分析系统,按照官方教程安装系统,并通过测试。其他后台脚本,数据库就不多说了。 SCWS是为C语言设计的,还为PHP制作了一个扩展库。你也可以用C语言来制作你的伪原创程序。
第二步:获取文章,肢解文章
所谓文章的肢解,就是将文章分割成子句。这些子句需要由它们自己的程序编写。我提供一个思路:用句号、感叹号、问号作为子句标识,上面的引号、左括号、左书名等。位起始字符,以右引号、右括号、右书名作为起始符结束字符。遍历文章,遇到起始字符时进入非句子状态,遇到结束字符时退出该状态。当它遇到句子标识符时,只有当前状态处于可判词状态时,才会读取内容 将其分成一个句子,并用这个循环肢解文章,并逐个询问每个句子。这里的子句状态的目的是保护一段内容中的子句标识,如括号、引号、书名等,例如[他说:“我爱你。”]这里,[我爱你。 ] 不会被错误分解。
第 3 步:分词
将分解的句子进一步分解得到分词。例如,句子[一个是水果,另一个是蔬菜]可以分为[苹果][和][番茄][一个][是][水果][一个][是][蔬菜]。这一步需要SCWS的帮助。分词系统安装正常后,分词操作只需要一个功能。就是这么简单!此外,除了分解词外,还必须获得名词、动词等词的属性。
第四步:关键词同义替换
在这里,您需要知识库的支持。下载《哈尔滨工业大学信息检索实验室同义词慈林》加长版,内含完整同义词列表。每个词有多个编码,表示这个词是多义词,一个编码下面有多个词,说明这些词是同义词,读出来保存在数据库中,以备后用。
根据相关字段设置您的关键词。比如你做房地产网站,那么你的关键词可能是租房,租房,二手房,买房,租房合同,在外地查了很多关键词,然后根据同义词 Cilin 替换它们。为什么只替换关键词?因为替换了一个非关键词的部分,可能会造成奇点,而且不是该领域的词,权重不如关键词领域高,句子流的损失不值得损失.
第 5 步:标点符号乱舞
文章相似度的计算是根据句子相似度计算的,而句子相似度是根据词相似度计算的,所以即使将关键词换成同义词,得到的文章也和原来的Will一样还是被判断为类似文章,我该怎么办?首先我们来看看文章相似度的计算方法。
前面提到的Synonym Cilin的编码其实还是很有学问的,不是乱码。同义词 Cilin 的扩展版本使用代码来识别单词的含义。代码可以分为5部分。它们是大类、中类、小类、词组、原子词组,例如学生和老师。这两个词一定属于一个大类,因为它们都是人类,而西红柿和西红柿一定是一个词组,因为它们指的是一个东西。那么相似度的计算就很简单了。同样按100计算。大类相同为10,中类再次相同为20,小类再次相同为50。相同为90,如果原子词组为又一样,是100。为什么这里用了“re”这个词,因为只要其中一个不同,就没有必要比较。比如大类不同的两个词,中类和小类肯定是不同的。
这里比较两个文章一个句子中出现的词的相似度,计算每个句子的相似度,然后计算文章相似度。这是一个类似于 Google 的 PR 算法的算法。加入贡献计算相似度。
说了这么多,怎么办?我们不得不打乱标点符号,干扰搜索引擎的句子处理。
当人们阅读文章,尤其是新闻或信息时,他们通常不关心标点符号。有些人甚至粗略地看了一眼。就算句子混乱,文章大意也不会造成任何问题,所以我们希望文章中的句号和逗号可以随意替换,影响文章的搜索引擎的子句,从而影响其相似度计算.
第 6 步:创建摘要并将其放在段落的开头
文章 内容越高级越重要。对此毫无疑问,所以我们需要总结文章,放在文章的顶部。摘要要有一定的压缩率,比如1000字文章,做个100字的摘要就行了。这里我们不按字数统计,按句数统计更方便,因为我们已经按句子处理了文章。对于 500 句的文章,做大约 20 句的总结。摘要的核心在于对抽象句子的选择,因为摘要本身就是一个大意,所以稍微有点语义障碍是可以接受的。
如上所述关键词,提取摘要也需要关键词。我们以加权的方式提取抽象句子。收录关键词 的句子具有更高的权重。收录的数字越多,权重就越高。计算每个句子的权重。然后按照原文的先后顺序,按照权重的顺序提取,直到提取出你需要的句子数。将它们拼接在一起成为文章的摘要。
我们可以在这里做得更好。在网上找句子相似度计算算法,计算句子相似度,消除相似的句子,防止语义重复。因为收录大量关键词的句子很可能会重复。
第 7 步:自定义标题
伪原创 很重要的一点就是改标题。标题必须改。根据相似度计算算法,我们必须将标题更改为全新的。比如将【高考10招】改为【高考10招】。这样的改革,简直就是把百度当傻子。如何改变它?你会编造谎言吗? 【专家十条建议助你备战高考】【做好这十项,高考拿满分】【清华大学离你只有十步之遥! 】这些标题的意思没有变,但是点击的吸引力很大,不会被搜索引擎发现和文章一样。还不错?
第 8 步:打乱权重较低的句子的顺序
低权重的句子也可以派上用场。虽然我们认为这些句子不是很重要,但搜索引擎并不知道。我们稍微打乱了他们的顺序,这不影响语义,而是有伪原创的效果,嗯。
对于目前的伪原创软件来说,乱打乱句子的顺序是不可取的。比如一篇文章的文章介绍了10款软件,已经标注了1、2、3、4的顺序。在伪原创之后,顺序乱了,读者读起来难以置信。而这篇文章介绍了句子打乱,就是从局部范围打乱,都是非关键的句子。
解决伪原创的问题,解决文章可读性的问题。除非你的文章只供搜索引擎使用,不供人查看,否则,赶紧自己制作伪原创Program吧!感谢Longjuke网站长提供()
ES概述Elasticsearch开源的Elasticsearch是怎么产生的?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-29 03:44
ES 概览
弹性搜索
开源
弹性搜索
目前是全文搜索引擎的首选。
它可以快速存储、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用了它。
Elasticsearch 底层是一个开源库
Lucene
。但是,您不能直接使用 Lucene,您必须编写自己的代码来调用它的接口。 Elastic是Lucene的一个包,提供了REST API的操作接口,开箱即用。
Elasticsearch 是用 Java 实现的。
搜索引擎在索引数据时需要进行分词。分词是指将一个句子拆解成多个词或词。这些词或词是句子的关键词。
0.ES 是怎么来的?
(
1)question
比如:当数据量达到10亿、100亿时,我们在做系统架构的时候,通常会从以下几个角度考虑问题:
1) 我应该使用什么数据库? (mysql、sybase、oracle、大萌、魔力、mongodb、hbase...)
2) 如何解决单点故障; (lvs, F5、A10、Zookeep, MQ)
3) 如何保证数据安全; (热备、冷备、多活动异地)
4) 如何解决检索问题; (数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5) 如何解决统计分析问题; (离线,近乎实时)
(2)传统解决方案
对于关系数据,我们通常使用以下或类似的架构来解决查询瓶颈和写入瓶颈:
解决方案:
1)通过主从备份解决数据安全问题;
2)通过数据库代理中间件的心跳监控解决单点故障问题;
3)通过代理中间件将查询语句分发到各个从节点进行查询,并汇总结果
(3)非关系型数据库解决方案
对于Nosql数据库,以mongodb为例,其他原理类似:
解决方案:
1)通过副本备份保证数据安全;
2)通过节点选举机制解决单点问题;
3)首先从配置数据库中获取分片信息,然后将请求分发给各个节点,最后路由节点合并汇总结果
另一种方法——将数据完全放入内存如何?
我们知道将数据完全放在内存中是不可靠的,实际上也是不现实的。当我们的数据达到PB级别时,按照每个节点96G内存计算,内存完全填满数据。接下来我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922
其实考虑到数据备份,节点数往往在2.500万个左右。巨大的成本让它变得不现实!
从前面的讨论中我们了解到,将数据存储在内存中或不在内存中并不能完全解决问题。
所有内存速度问题都解决了,但成本问题来了。
为了解决以上问题,从源头上分析,通常可以通过以下方式找到方法:
1、有序存储数据;
2、分离数据和索引;
3、压缩数据;
这导致了 Elasticsearch。
1. ES 基础介绍
1.1 ES 定义
ES=elaticsearch 的缩写,Elasticsearch 是一个开源的、高扩展性的分布式全文搜索引擎,可以近乎实时地存储和检索数据;具有良好的可扩展性,可扩展至数百台服务器,处理PB级数据。
Elasticsearch 同样采用 Java 开发,以 Lucene 为核心,实现所有索引和搜索功能,但其目的是通过简单的 RESTful API 隐藏 Lucene 的复杂性,让全文搜索变得简单。
1.2 Lucene 和 ES 是什么关系?
1)Lucene 只是一个库。要使用它,您必须使用 Java 作为开发语言并将其直接集成到您的应用程序中。更糟糕的是,Lucene 非常复杂,你需要对检索知识有深入的了解才能理解它是如何工作的。
2)Elasticsearch 同样采用Java开发,以Lucene为核心,实现所有索引和搜索功能,但其目的是通过简单的RESTful API隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.3 ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)要快。
1.4 ES 工作原理
ElasticSearch 的节点启动时,会使用组播(或单播,如果用户更改配置)来查找集群中的其他节点并与其建立连接。这个过程如下图所示:
1.5
ES 核心概念
1)Cluster:集群。
ES 可以用作独立的单一搜索服务器。但是,为了处理大数据集,实现容错和高可用,ES可以运行在多台相互协作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为一个节点。
3)Shard:分片。
当文档数量较多时,由于内存限制、磁盘处理能力不足、无法足够快地响应客户端请求,一个节点可能不够用。在这种情况下,可以将数据分成更小的片段。每个分片都放置在不同的服务器上。
当你查询的索引分布在多个分片上时,ES会将查询发送到每个相关的分片,并将结果组合在一起,应用不知道分片的存在。即:这个过程对用户是透明的。
4)Replia:复制。
为了提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是分片的精确副本,每个分片可以有零个或多个副本。 ES中可以有很多相同的shard,选择其中一个来改变索引操作。这个特殊的分片称为主分片。
当主分片丢失时,例如分片的数据不可用时,集群会将副本提升到新的主分片。
5)全文搜索。
全文搜索是索引一个文章,可以根据关键字进行搜索,类似于mysql中的like语句。
全文索引就是根据词义对内容进行切分,然后单独建立索引。比如“你的激情来自什么”可以细分为:“你”、“激情”、“什么事”、“让”等token,这样当你搜索“你”或“激情”,就会找到这句话。
1.6 ES数据架构的主要概念(与关系型数据库Mysql对比)
(关系型数据库中1)Database,相当于ES中的索引
(2)一个数据库下有N个表,相当于N个多种类型(Type)下有1个索引,
(3)一个数据库表(Table)下的数据由多行(ROW)和多列(属性)组成,相当于1个类型由多个文档(Document)和多个字段组成。
(4)在关系型数据库中,schema定义了表,每个表的字段,以及表与字段的关系。相应地,在ES:Mapping中定义了索引下的Type字段处理规则索引,即如何建立索引,索引的类型,是否保存原创索引的JSON文档,是否压缩原创JSON文档,是否需要分词处理,如何进行分词处理等.
(5)在数据库中添加插入、删除删除、更改更新、搜索搜索操作相当于在ES中添加PUT/POST、删除Delete、更改_update、检查GET。
1.7 什么是麋鹿?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储和全文搜索
logstash:日志处理,“搬运工”
kibana:数据可视化展示。
ELK 架构为分布式数据存储、可视化查询和日志分析创建了强大的管理链。三者相互配合,取长补短,共同完成分布式大数据处理。
2. ES 特性和优势
1)分布式实时文件存储,每个字段都可以存储在索引中,以便检索。
2)用于实时分析的分布式搜索引擎。
分布式:索引被拆分成多个分片,每个分片可以有零个或多个副本。集群中的每个数据节点可以承载一个或多个分片,协调处理各种操作;
负载重新平衡和路由在大多数情况下自动完成。
3)可以扩展到数百台服务器来处理PB级结构化或非结构化数据。它也可以在单台 PC 上运行(已测试)
4)支持插件机制、分词插件、同步插件、Hadoop插件、可视化插件等
3、ES 性能
3.1 性能结果展示
(1)硬件配置:
CPU 16 核 AuthenticAMD
总内存:32GB
总硬盘:500GB 非固态硬盘
(2)基于以上硬件指标的测试性能如下:
1)平均索引吞吐量:12307docs/s(每个文档大小:40B/docs)
2)平均CPU使用率:887.7%(16核,平均每核:55.48%)
3)构建索引大小:3.30111 GB
4)总写入量:20.2123 GB
5)总测试时间:28m 54s。
3.2 性能测试工具(推荐)
使用参考:/laoyang360/...
4、使用ES的原因?
4.1 ES 国内外优秀用例
1) 2013 年初,GitHub 放弃了 Solr,采用 ElasticSearch 进行 PB 级搜索。 “GitHub 使用 ElasticSearch 搜索 20 TB 的数据,包括 13 亿个文件和 1300 亿行代码。”
2)Wikipedia:开始基于elasticsearch的核心搜索架构。
3)SoundCloud:“SoundCloud 使用 ElasticSearch 为1.80 亿用户提供即时准确的音乐搜索服务。”
4)百度:百度目前广泛使用ElasticSearch进行文本数据分析,采集百度所有服务器上的各类索引数据和自定义数据,通过各种数据的多维分析和展示,辅助定位分析示例 业务层面的异常或异常。目前覆盖百度内部20余条业务线(包括卡西欧、云分析、网络联盟、预测、库、直号、钱包、风控等),单个集群最大100台机器,200个ES节点,每天导入 30TB 以上的数据。
4.2 我们也需要
在实际项目开发中,几乎每个系统都会有搜索功能。当搜索达到一定程度后,维护和扩展的难度会逐渐变大,所以很多公司将搜索模块分离出来,用ElasticSearch等方式实现。
近年来,ElasticSearch 发展迅速,已经超越了其原本作为纯搜索引擎的角色。现在它增加了数据聚合和分析(aggregation)和可视化功能。如果你有数百万的文档,需要通过关键词定位,此时ElasticSearch绝对是最好的选择。当然,如果你的文档是 JSON,你也可以把 ElasticSearch 当作“NoSQL 数据库”,应用 ElasticSearch 的数据聚合分析(aggregation)特性,对数据进行多维分析。
[知乎: Reku 架构师潘飞] ES在某些场景下替代传统DB
个人认为Elasticsearch内部存储还是不错的,效率基本够用。也可以在某些方面替代传统的DB,前提是您的业务对运营事项没有特殊要求;和权限管理不需要说的那么详细,因为ES权限还没有完善。
由于我们对ES的应用场景只是针对一定时间内的数据聚合操作,所以没有大量的单文档请求(比如通过userid查找用户的文档,类似NoSQL的应用场景),所以我们可以决定是否替换NoSQL需要你自己测试。
如果我选择,我会尝试用 ES 来代替传统的 NoSQL,因为它的横向扩展机制太方便了。
5. ES 应用场景
通常我们面临两个问题:
1)新系统开发尝试使用ES作为存储和检索服务器;
2)现有系统升级需要支持全文搜索服务,需要使用ES。
以上两种架构的使用在以下链接中有详细说明。
/laoyang360/...
一线企业ES使用场景:
1)SinaES 如何分析处理32亿条实时日志dockone.io/article/505
2)阿里ES 建立自己的日志采集和分析系统afoo.me/columns/tec...
3)有赞ES业务日志处理/you-zan-ton...
4)ES 实现站点搜索...
6. ES 部署
6.1 ES 部署(无需安装)
1)零配置,开箱即用
2)无需繁琐的安装和配置
3)java 版本要求:最低1.7
我使用1.8
[root@laoyang config_lhy]# echo $JAVA_HOME
/opt/jdk1.8.0_91
4)下载地址:
download.elastic.co/elas ... ...
5)START
cd /usr/local/elasticsearch-2.3.5
./bin/elasticsearch
bin/elasticsearch -d(后台运行)
6.2 ES必备插件
必备Head、kibana、IK(中文分词)、graph等插件的详细安装和使用
/column/deta...
6.3 ES windows下一键安装
自己编写的bat脚本,实现windows的下一步安装。
1)一键安装ES及必要插件(head、kibana、IK、logstash等)
2)安装后将 ES 作为服务运行。
3)比自己摸索安装至少节省了2个小时的时间,效率很高。
脚本说明:
/laoyang360/...
更多免费技术信息请关注:annalin1203 查看全部
ES概述Elasticsearch开源的Elasticsearch是怎么产生的?(组图)
ES 概览
弹性搜索
开源
弹性搜索
目前是全文搜索引擎的首选。
它可以快速存储、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用了它。
Elasticsearch 底层是一个开源库
Lucene
。但是,您不能直接使用 Lucene,您必须编写自己的代码来调用它的接口。 Elastic是Lucene的一个包,提供了REST API的操作接口,开箱即用。
Elasticsearch 是用 Java 实现的。
搜索引擎在索引数据时需要进行分词。分词是指将一个句子拆解成多个词或词。这些词或词是句子的关键词。
0.ES 是怎么来的?
(
1)question
比如:当数据量达到10亿、100亿时,我们在做系统架构的时候,通常会从以下几个角度考虑问题:
1) 我应该使用什么数据库? (mysql、sybase、oracle、大萌、魔力、mongodb、hbase...)
2) 如何解决单点故障; (lvs, F5、A10、Zookeep, MQ)
3) 如何保证数据安全; (热备、冷备、多活动异地)
4) 如何解决检索问题; (数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5) 如何解决统计分析问题; (离线,近乎实时)
(2)传统解决方案
对于关系数据,我们通常使用以下或类似的架构来解决查询瓶颈和写入瓶颈:
解决方案:
1)通过主从备份解决数据安全问题;
2)通过数据库代理中间件的心跳监控解决单点故障问题;
3)通过代理中间件将查询语句分发到各个从节点进行查询,并汇总结果
(3)非关系型数据库解决方案
对于Nosql数据库,以mongodb为例,其他原理类似:
解决方案:
1)通过副本备份保证数据安全;
2)通过节点选举机制解决单点问题;
3)首先从配置数据库中获取分片信息,然后将请求分发给各个节点,最后路由节点合并汇总结果
另一种方法——将数据完全放入内存如何?
我们知道将数据完全放在内存中是不可靠的,实际上也是不现实的。当我们的数据达到PB级别时,按照每个节点96G内存计算,内存完全填满数据。接下来我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922
其实考虑到数据备份,节点数往往在2.500万个左右。巨大的成本让它变得不现实!
从前面的讨论中我们了解到,将数据存储在内存中或不在内存中并不能完全解决问题。
所有内存速度问题都解决了,但成本问题来了。
为了解决以上问题,从源头上分析,通常可以通过以下方式找到方法:
1、有序存储数据;
2、分离数据和索引;
3、压缩数据;
这导致了 Elasticsearch。
1. ES 基础介绍
1.1 ES 定义
ES=elaticsearch 的缩写,Elasticsearch 是一个开源的、高扩展性的分布式全文搜索引擎,可以近乎实时地存储和检索数据;具有良好的可扩展性,可扩展至数百台服务器,处理PB级数据。
Elasticsearch 同样采用 Java 开发,以 Lucene 为核心,实现所有索引和搜索功能,但其目的是通过简单的 RESTful API 隐藏 Lucene 的复杂性,让全文搜索变得简单。
1.2 Lucene 和 ES 是什么关系?
1)Lucene 只是一个库。要使用它,您必须使用 Java 作为开发语言并将其直接集成到您的应用程序中。更糟糕的是,Lucene 非常复杂,你需要对检索知识有深入的了解才能理解它是如何工作的。
2)Elasticsearch 同样采用Java开发,以Lucene为核心,实现所有索引和搜索功能,但其目的是通过简单的RESTful API隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.3 ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)要快。
1.4 ES 工作原理
ElasticSearch 的节点启动时,会使用组播(或单播,如果用户更改配置)来查找集群中的其他节点并与其建立连接。这个过程如下图所示:
1.5
ES 核心概念
1)Cluster:集群。
ES 可以用作独立的单一搜索服务器。但是,为了处理大数据集,实现容错和高可用,ES可以运行在多台相互协作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为一个节点。
3)Shard:分片。
当文档数量较多时,由于内存限制、磁盘处理能力不足、无法足够快地响应客户端请求,一个节点可能不够用。在这种情况下,可以将数据分成更小的片段。每个分片都放置在不同的服务器上。
当你查询的索引分布在多个分片上时,ES会将查询发送到每个相关的分片,并将结果组合在一起,应用不知道分片的存在。即:这个过程对用户是透明的。
4)Replia:复制。
为了提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是分片的精确副本,每个分片可以有零个或多个副本。 ES中可以有很多相同的shard,选择其中一个来改变索引操作。这个特殊的分片称为主分片。
当主分片丢失时,例如分片的数据不可用时,集群会将副本提升到新的主分片。
5)全文搜索。
全文搜索是索引一个文章,可以根据关键字进行搜索,类似于mysql中的like语句。
全文索引就是根据词义对内容进行切分,然后单独建立索引。比如“你的激情来自什么”可以细分为:“你”、“激情”、“什么事”、“让”等token,这样当你搜索“你”或“激情”,就会找到这句话。
1.6 ES数据架构的主要概念(与关系型数据库Mysql对比)
(关系型数据库中1)Database,相当于ES中的索引
(2)一个数据库下有N个表,相当于N个多种类型(Type)下有1个索引,
(3)一个数据库表(Table)下的数据由多行(ROW)和多列(属性)组成,相当于1个类型由多个文档(Document)和多个字段组成。
(4)在关系型数据库中,schema定义了表,每个表的字段,以及表与字段的关系。相应地,在ES:Mapping中定义了索引下的Type字段处理规则索引,即如何建立索引,索引的类型,是否保存原创索引的JSON文档,是否压缩原创JSON文档,是否需要分词处理,如何进行分词处理等.
(5)在数据库中添加插入、删除删除、更改更新、搜索搜索操作相当于在ES中添加PUT/POST、删除Delete、更改_update、检查GET。
1.7 什么是麋鹿?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储和全文搜索
logstash:日志处理,“搬运工”
kibana:数据可视化展示。
ELK 架构为分布式数据存储、可视化查询和日志分析创建了强大的管理链。三者相互配合,取长补短,共同完成分布式大数据处理。
2. ES 特性和优势
1)分布式实时文件存储,每个字段都可以存储在索引中,以便检索。
2)用于实时分析的分布式搜索引擎。
分布式:索引被拆分成多个分片,每个分片可以有零个或多个副本。集群中的每个数据节点可以承载一个或多个分片,协调处理各种操作;
负载重新平衡和路由在大多数情况下自动完成。
3)可以扩展到数百台服务器来处理PB级结构化或非结构化数据。它也可以在单台 PC 上运行(已测试)
4)支持插件机制、分词插件、同步插件、Hadoop插件、可视化插件等
3、ES 性能
3.1 性能结果展示
(1)硬件配置:
CPU 16 核 AuthenticAMD
总内存:32GB
总硬盘:500GB 非固态硬盘
(2)基于以上硬件指标的测试性能如下:
1)平均索引吞吐量:12307docs/s(每个文档大小:40B/docs)
2)平均CPU使用率:887.7%(16核,平均每核:55.48%)
3)构建索引大小:3.30111 GB
4)总写入量:20.2123 GB
5)总测试时间:28m 54s。
3.2 性能测试工具(推荐)
使用参考:/laoyang360/...
4、使用ES的原因?
4.1 ES 国内外优秀用例
1) 2013 年初,GitHub 放弃了 Solr,采用 ElasticSearch 进行 PB 级搜索。 “GitHub 使用 ElasticSearch 搜索 20 TB 的数据,包括 13 亿个文件和 1300 亿行代码。”
2)Wikipedia:开始基于elasticsearch的核心搜索架构。
3)SoundCloud:“SoundCloud 使用 ElasticSearch 为1.80 亿用户提供即时准确的音乐搜索服务。”
4)百度:百度目前广泛使用ElasticSearch进行文本数据分析,采集百度所有服务器上的各类索引数据和自定义数据,通过各种数据的多维分析和展示,辅助定位分析示例 业务层面的异常或异常。目前覆盖百度内部20余条业务线(包括卡西欧、云分析、网络联盟、预测、库、直号、钱包、风控等),单个集群最大100台机器,200个ES节点,每天导入 30TB 以上的数据。
4.2 我们也需要
在实际项目开发中,几乎每个系统都会有搜索功能。当搜索达到一定程度后,维护和扩展的难度会逐渐变大,所以很多公司将搜索模块分离出来,用ElasticSearch等方式实现。
近年来,ElasticSearch 发展迅速,已经超越了其原本作为纯搜索引擎的角色。现在它增加了数据聚合和分析(aggregation)和可视化功能。如果你有数百万的文档,需要通过关键词定位,此时ElasticSearch绝对是最好的选择。当然,如果你的文档是 JSON,你也可以把 ElasticSearch 当作“NoSQL 数据库”,应用 ElasticSearch 的数据聚合分析(aggregation)特性,对数据进行多维分析。
[知乎: Reku 架构师潘飞] ES在某些场景下替代传统DB
个人认为Elasticsearch内部存储还是不错的,效率基本够用。也可以在某些方面替代传统的DB,前提是您的业务对运营事项没有特殊要求;和权限管理不需要说的那么详细,因为ES权限还没有完善。
由于我们对ES的应用场景只是针对一定时间内的数据聚合操作,所以没有大量的单文档请求(比如通过userid查找用户的文档,类似NoSQL的应用场景),所以我们可以决定是否替换NoSQL需要你自己测试。
如果我选择,我会尝试用 ES 来代替传统的 NoSQL,因为它的横向扩展机制太方便了。
5. ES 应用场景
通常我们面临两个问题:
1)新系统开发尝试使用ES作为存储和检索服务器;
2)现有系统升级需要支持全文搜索服务,需要使用ES。
以上两种架构的使用在以下链接中有详细说明。
/laoyang360/...
一线企业ES使用场景:
1)SinaES 如何分析处理32亿条实时日志dockone.io/article/505
2)阿里ES 建立自己的日志采集和分析系统afoo.me/columns/tec...
3)有赞ES业务日志处理/you-zan-ton...
4)ES 实现站点搜索...
6. ES 部署
6.1 ES 部署(无需安装)
1)零配置,开箱即用
2)无需繁琐的安装和配置
3)java 版本要求:最低1.7
我使用1.8
[root@laoyang config_lhy]# echo $JAVA_HOME
/opt/jdk1.8.0_91
4)下载地址:
download.elastic.co/elas ... ...
5)START
cd /usr/local/elasticsearch-2.3.5
./bin/elasticsearch
bin/elasticsearch -d(后台运行)
6.2 ES必备插件
必备Head、kibana、IK(中文分词)、graph等插件的详细安装和使用
/column/deta...
6.3 ES windows下一键安装
自己编写的bat脚本,实现windows的下一步安装。
1)一键安装ES及必要插件(head、kibana、IK、logstash等)
2)安装后将 ES 作为服务运行。
3)比自己摸索安装至少节省了2个小时的时间,效率很高。
脚本说明:
/laoyang360/...
更多免费技术信息请关注:annalin1203
海外网页抓取工具:followthemoon.但是需要翻墙才能访问哈
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-06-27 03:01
文章句子采集软件,其他的比如暴风影音的软件等等可以用。excel格式的话那就用excel吧。一般网站上都会有用txt格式存储网站的链接,需要的时候提取就可以。
昨天刚刚发现一款海外网页的抓取工具:followthemoon.但是需要翻墙才能访问哈,对翻墙很有要求的朋友注意哈!但不得不说这款工具还是很强大的,
我试了edithwaves他们家一些专题类的东西
油猴-脚本之王推荐这个吧有大部分你需要的功能
阿北在微博推荐了无觅,
链接
可以试试「netcloud」,他可以存储网站上的所有网页。也是专注于国外网站爬取,发现有部分国内网站不能访问,但是不影响大部分用户使用。爬取后放入我们自己的webpagebase中()。
postman
国内的很多第三方平台,楼上说的都对,有个值得推荐的公司叫skyrailblog,他们的正规资质值得我们信赖的。
edit
比edithwaves的爬虫器多更丰富的功能。edit是别的很多网站都能爬,
1.redisoakr2.中国最早做网站抓取的。
用没有代理的代理软件来抓
好吧还是推荐一下followthemoon。这个需要翻墙,支持国内国外多种语言。效果不错,可以直接爬。
qtrescue的抓取专家我目前用的是rescueweb,网站抓取的方面还是有些限制,只能去登录提取链接。我现在正在尝试像他们提供很多软件都不能抓取到的网站,比如很有名的网易云音乐。不过话说回来,毕竟是开源项目,去github就可以看到源代码,并且很简单。 查看全部
海外网页抓取工具:followthemoon.但是需要翻墙才能访问哈
文章句子采集软件,其他的比如暴风影音的软件等等可以用。excel格式的话那就用excel吧。一般网站上都会有用txt格式存储网站的链接,需要的时候提取就可以。
昨天刚刚发现一款海外网页的抓取工具:followthemoon.但是需要翻墙才能访问哈,对翻墙很有要求的朋友注意哈!但不得不说这款工具还是很强大的,
我试了edithwaves他们家一些专题类的东西
油猴-脚本之王推荐这个吧有大部分你需要的功能
阿北在微博推荐了无觅,
链接
可以试试「netcloud」,他可以存储网站上的所有网页。也是专注于国外网站爬取,发现有部分国内网站不能访问,但是不影响大部分用户使用。爬取后放入我们自己的webpagebase中()。
postman
国内的很多第三方平台,楼上说的都对,有个值得推荐的公司叫skyrailblog,他们的正规资质值得我们信赖的。
edit
比edithwaves的爬虫器多更丰富的功能。edit是别的很多网站都能爬,
1.redisoakr2.中国最早做网站抓取的。
用没有代理的代理软件来抓
好吧还是推荐一下followthemoon。这个需要翻墙,支持国内国外多种语言。效果不错,可以直接爬。
qtrescue的抓取专家我目前用的是rescueweb,网站抓取的方面还是有些限制,只能去登录提取链接。我现在正在尝试像他们提供很多软件都不能抓取到的网站,比如很有名的网易云音乐。不过话说回来,毕竟是开源项目,去github就可以看到源代码,并且很简单。
优采云文章原创度检测是一款文章伪原创工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-06-23 05:22
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
相关软件软件大小及版本说明下载链接
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创检测通过
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法采集行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了新的Go生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量很大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,使90%以上的文章被百度收录。
6、原创测试报告中伪原创的智能是什么?
智能伪原创只对测试报告中类似标注的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷 查看全部
优采云文章原创度检测是一款文章伪原创工具
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
相关软件软件大小及版本说明下载链接
优采云文章原创度测是一款文章伪原创工具,集采集文章、伪原创内容、检测文章原创度等功能于一体, 可以帮助用户提高工作效率,节省工作时间。
功能介绍
1.微信快速登录
文章采集
2.输入关键词获取最新优质素材
AI伪原创
3.提交材料,优采云AI智能伪原创
原创detection
4.全网原创度分析,原创检测通过
软件功能
时间+效率+智能
文章采集+AI伪原创+原创测试
颠覆传统书写模式,开启智能书写时代。
利用爬虫技术,通过深度学习方法采集行业数据采集、句法分析和语义分析,挖掘词在语义上下文空间向量模型中的关系。
常见问题
什么是1、优采云?
优采云是互联网垂直领域SEO软文的写作工具。将文章采集、AI伪原创、原创检测结合在一起,实现了新的Go生态链。
2、如何使用优采云软文assistant?
您可以通过微信快速登录直接使用优采云软文auxiliary。
3、优采云 是免费的吗?
优采云 是一个免费的软文 助手工具。基础套餐每天可以免费使用100积分,对于大多数个人用户来说已经足够了。对于使用量很大的公司,您可以购买企业版软件包。
4、优采云文章采集的网页不是百度收录?
文章采集当时的网页不是百度收录,但后来可能是百度收录。
5、优采云AI伪原创生成的文章能保证是百度收录吗?
AI伪原创依靠其强大的NLP、深度学习等技术,轻松通过原创degree检测,使90%以上的文章被百度收录。
6、原创测试报告中伪原创的智能是什么?
智能伪原创只对测试报告中类似标注的句子进行智能修改,保持作者原创的句子不变。在增加文章原创度的同时,尽量不改变作者的初衷
文章句子采集软件采集一个句子并自动将句子变换成100个词语
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2021-06-21 19:03
文章句子采集软件采集一个句子并自动将句子变换成100个词语,并保存为txt,单独下载给项目做测试。操作过程如下:1.注册账号2.选择“自动句子摘要”功能3.语言选择“中文"“日文"“英文"4.输入文本“seehelloandiwanttobebacktoyou!"5.程序会对文本进行预处理,在保存为txt格式后,再对文本进行处理6.对预处理后的文本进行拆分并截取到自己的地址邮箱7.下载好python源码8.格式分析并转换成文本9.下载excel,导入。
预处理好的文本中,每一个单词的空格位置都会被替换为对应的中文空格位置。拆分好的文本在导入excel后,会自动由左到右,由上到下排列。也就是说,单词之间会出现“|”符号。下面是关于此项目采集数据的代码:defsee_hello_andiwanttobebacktoyou(self):"""首先加载python库:importosimportnumpyasnpimportpandasaspd"""csvfile="see_hello_andiwanttobebacktoyou!"paths=['c:\\users\\administrator\\desktop\\python\\see_hello_andiwanttobebacktoyou!']paths.extract(csvfile)print(csvfile)os.environ['time']='time:'+np.abs(os.environ['time'])os.environ['format']='%y%m%d%h:%m:%s'ifpaths['format']=='%y%m%d%h:%m:%s':continue#installpandasfromdatetimeimportdatetimeos.environ['time']='time:'+np.abs(os.environ['time'])br=pd.read_csv(os.environ['time'],index=false)br.head(。
2)br=pd.read_csv(os.environ['time'],index=false)br.head
1)else:br=pd.read_csv(os.environ['time'],index=false)br.head
<p>0)pd.read_csv函数的第二个参数是一个关键字参数,即把分隔符替换为一个空格。从而实现输入的格式由seehello_andiwanttobebacktoyou!这句话划分成2个句子单词拼接在一起。ifnp.abs(os.environ['time']) 查看全部
文章句子采集软件采集一个句子并自动将句子变换成100个词语
文章句子采集软件采集一个句子并自动将句子变换成100个词语,并保存为txt,单独下载给项目做测试。操作过程如下:1.注册账号2.选择“自动句子摘要”功能3.语言选择“中文"“日文"“英文"4.输入文本“seehelloandiwanttobebacktoyou!"5.程序会对文本进行预处理,在保存为txt格式后,再对文本进行处理6.对预处理后的文本进行拆分并截取到自己的地址邮箱7.下载好python源码8.格式分析并转换成文本9.下载excel,导入。
预处理好的文本中,每一个单词的空格位置都会被替换为对应的中文空格位置。拆分好的文本在导入excel后,会自动由左到右,由上到下排列。也就是说,单词之间会出现“|”符号。下面是关于此项目采集数据的代码:defsee_hello_andiwanttobebacktoyou(self):"""首先加载python库:importosimportnumpyasnpimportpandasaspd"""csvfile="see_hello_andiwanttobebacktoyou!"paths=['c:\\users\\administrator\\desktop\\python\\see_hello_andiwanttobebacktoyou!']paths.extract(csvfile)print(csvfile)os.environ['time']='time:'+np.abs(os.environ['time'])os.environ['format']='%y%m%d%h:%m:%s'ifpaths['format']=='%y%m%d%h:%m:%s':continue#installpandasfromdatetimeimportdatetimeos.environ['time']='time:'+np.abs(os.environ['time'])br=pd.read_csv(os.environ['time'],index=false)br.head(。
2)br=pd.read_csv(os.environ['time'],index=false)br.head
1)else:br=pd.read_csv(os.environ['time'],index=false)br.head
<p>0)pd.read_csv函数的第二个参数是一个关键字参数,即把分隔符替换为一个空格。从而实现输入的格式由seehello_andiwanttobebacktoyou!这句话划分成2个句子单词拼接在一起。ifnp.abs(os.environ['time'])
文章句子采集软件采集来的文章里面有多少个长句子
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-06-21 04:03
文章句子采集软件采集来的文章里面的句子,是根据文章句子长度采样而来的。时间生成的短句子的长度为所选文章文字的长度(perlength)。这一“文字大于句子大小”的技术用于判断一篇文章里有多少个长句子。首先看看用word2vec来训练词向量,每一个wordtoken(不是一个词)都需要一个维度的特征来表示,文章句子是一个个词向量或者词嵌入,自然就是词嵌入向量或者词嵌入特征的向量向量之和。
这个也是训练语言模型(bert)的关键数据。那一篇文章又多长呢?一般一个句子训练4~6轮可以达到很好的效果,这就是文章句子数的差别。对于用户反馈可以应用到文章反馈中,可以简单的将文章里面的句子模型为短文本,然后直接根据文章给出的短句和长句向量融合就可以生成个性化的文章反馈。参考:比特反馈的分级perblock摘要参考word2vec是怎么样加速正则项的。
1,分词是手动设置的,目前基本所有的语言模型都是使用词袋模型,crf等强模型作为词条,而根据词汇的空间顺序或者隐含状态等非结构化信息,文本单词可能转换为向量空间,可以合理的应用到dnn中。2,word2vec可以获取到源文本的概率特征,文本特征与特征空间的语言模型相比,有着共同的语言模型特征分布规律。对于描述性可以得到比语言模型更加多样性的embedding。 查看全部
文章句子采集软件采集来的文章里面有多少个长句子
文章句子采集软件采集来的文章里面的句子,是根据文章句子长度采样而来的。时间生成的短句子的长度为所选文章文字的长度(perlength)。这一“文字大于句子大小”的技术用于判断一篇文章里有多少个长句子。首先看看用word2vec来训练词向量,每一个wordtoken(不是一个词)都需要一个维度的特征来表示,文章句子是一个个词向量或者词嵌入,自然就是词嵌入向量或者词嵌入特征的向量向量之和。
这个也是训练语言模型(bert)的关键数据。那一篇文章又多长呢?一般一个句子训练4~6轮可以达到很好的效果,这就是文章句子数的差别。对于用户反馈可以应用到文章反馈中,可以简单的将文章里面的句子模型为短文本,然后直接根据文章给出的短句和长句向量融合就可以生成个性化的文章反馈。参考:比特反馈的分级perblock摘要参考word2vec是怎么样加速正则项的。
1,分词是手动设置的,目前基本所有的语言模型都是使用词袋模型,crf等强模型作为词条,而根据词汇的空间顺序或者隐含状态等非结构化信息,文本单词可能转换为向量空间,可以合理的应用到dnn中。2,word2vec可以获取到源文本的概率特征,文本特征与特征空间的语言模型相比,有着共同的语言模型特征分布规律。对于描述性可以得到比语言模型更加多样性的embedding。
一个文献管理工具,管理你的成千上百的文献
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-06-21 00:02
作为一个热爱学术的研究生,我每天都要阅读很多论文,每一篇论文都要经过一个繁琐的搜索、下载、阅读过程;看了很多文档,想回顾一下之前看过的文章,却发现面对电脑里各种文档的文件夹,找不到我要找的文章。
这时候,你需要一个文档管理工具来管理你的数百个文档,这样你在写论文的时候就可以轻松找到你想要的文档。以下是一些常用的文档管理工具:
1.EndNote
EndNote 是 SCI(汤姆森科学公司)的官方软件。它具有强大的功能。是一款集文献检索、摘要与全文管理、文献共享等功能于一体的老牌软件。支持国际期刊的参考格式。有3776种类型和数百种写作模板。用户可以方便地使用这些模板和格式。如果你打算写SCI论文,你必须使用这个管理软件。
Endnote 可直接连接上千个数据库,提高科技文献检索效率,可管理数十万条参考文献,无需担心文档过多。 EndNote 的用处是有目共睹的,在目前的文档管理工具市场上有着比较大的使用率。
需要注意的是,这个软件需要付费使用,对于学生来说价格较高,但是可以在官网免费试用30天,大家可以决定是否购买体验它。
2.Citavi
Citavi 来自瑞士。其定位为“知识型组织管理软件”,在欧洲(尤其是德语区)应用广泛。本软件集成了知识管理、任务规划、PDF全文检索等科研工作环节,功能强大全面。
Citavi拥有全功能免费版(支持每个项目插入不超过100个文档),具有强大的参考文献编辑功能,可以全方位实现参考文献的编辑需求。
Citavi 的一大特色就是支持PDF阅读功能,并且可以支持多种注释格式,可以对注释进行管理和组织,形成自己的知识库。同时,也支持文档大纲的创建,知识组织管理的形成,更好地提升我们对文献内容的理解和组织架构的形成。
3.Mendeley
Mendeley 是 Elsevier 旗下的免费文档管理软件。每个人都可以在 Mendeley 上搜索来自世界各地的学术文献。这些学术文献上传到Mendeley“图书馆”,供用户自行编辑和管理。本软件具有强大的文档整理、PDF标注和文件共享、网络备份等功能。
该软件的一大优势在于其强大的PDF识别和搜索功能,并且支持PDF标签。您可以直接对PDF文档进行标注和批注,以突出文章中的关键内容。
有网页版、WINDOWS版、Mac版、Linux版、ios客户端等平台,用户可以根据需要选择不同的平台使用。具有交叉同步和云备份功能。登录账号后,Mendeley导入的PDF可以跨平台同步,方便您在不同平台使用,查看自己的文档,无需重复导入。
4.Readcube
界面简洁美观。很多人选择这个软件是因为它的界面。
本软件功能比较齐全,平台覆盖较好。具有PDF文件自动识别和增强功能,免去繁琐的手动输入,并自带PDF阅读器进行内部搜索。但也存在一定的不足。比如系统不是特别稳定,过分依赖网速,某些项目比如云同步功能需要收费。
对于“颜控”的朋友,不妨试试这款软件,它的界面风格不会让你失望。
5.Zotero
它是一个开源的文档管理软件,可以帮助我们采集、管理和引用研究资源,包括期刊、书籍和其他文档、网页、图片等。
Zotero 最初是作为 Firefox 插件存在的,但现在已经发展成为一个独立的版本,但它仍然和 Firefox 一样,无论是在 Windows、Mac 还是 Linux 系统上,都可以跨平台使用。
Zotero 可以免费使用。与 EndNotes 相比,Zotero 最大的特点就是目录分类级别不限。一个目录可以分为多个子目录,这使得它更易于管理。另外Zotero还支持标签功能,可以自动给每个文档打上标签,方便我们管理文档。
6.NoteEpress
NoteExpress 是一款由专业级文档检索和管理系统开发的国产软件。其核心功能涵盖“knowledge采集、管理、应用、挖掘”知识管理的方方面面。
是国内专业的文档检索管理系统,对中文文档非常友好,具有非常强大的中文文档管理功能。可内部搜索知网文档库,批量下载。这个软件导入文件的速度也比国外同类软件快。
文献和笔记(文章)的功能是协调一致的。除了管理参考资料,您还可以管理其他文章或硬盘上的文件作为个人知识管理系统。
对于中文文献较多的朋友,不妨试试这款软件。
7.知网研学(原E-study)
是最大中文期刊资源CNKI官方版的研究平台软件。常用功能包括文档检索与识别、标注与添加笔记、生成参考文档、云端同步等,并可在线书写,为观众提供与CNKI数据库紧密结合的数字新体验。
除了传统文档管理软件的功能外,CNKI E-study最大的优势在于与CNKI数据库同源,可以实现数据云管理。可用于通过同一账号登录其他平台进行数据更新。可以更好地与CNKI搜索引擎结合,让受众的数据管理更加方便。
另外,这也是一款免费软件,使用起来比较方便。它占了很多市场使用量。如果你的大部分文献来自知网,你不妨考虑一下这个软件。
8.Papers
是一款专业的文档管理工具,具有文档搜索、阅读、引用等功能。 Papers 流畅地组织各种与文档管理相关的活动。主要的具体功能包括文档导入、组织、阅读(注释)、参考词条自动匹配、搜索、在文档中插入引文、评论交流等。
Papers的一大特点是可以从原创PDF中抓取文档信息,有利于对文档进行更清晰、更自动化的管理,文档自动分类,简洁明了。
Papers里面可以打开PDF文件,并且有非常强大的文档阅读功能。最突出的特点是强大的标注和笔记功能,有利于后期的学习和研究。
论文是MAC系统独有的,如果电脑是MAC系统的小伙伴,可以试试这个软件。
(本文整理自重庆大学研究生会公众号转载,原链接,如有侵删)
学术福利炸弹| N种文档管理工具,总有一款适合您
查看全部
一个文献管理工具,管理你的成千上百的文献
作为一个热爱学术的研究生,我每天都要阅读很多论文,每一篇论文都要经过一个繁琐的搜索、下载、阅读过程;看了很多文档,想回顾一下之前看过的文章,却发现面对电脑里各种文档的文件夹,找不到我要找的文章。
这时候,你需要一个文档管理工具来管理你的数百个文档,这样你在写论文的时候就可以轻松找到你想要的文档。以下是一些常用的文档管理工具:
1.EndNote
EndNote 是 SCI(汤姆森科学公司)的官方软件。它具有强大的功能。是一款集文献检索、摘要与全文管理、文献共享等功能于一体的老牌软件。支持国际期刊的参考格式。有3776种类型和数百种写作模板。用户可以方便地使用这些模板和格式。如果你打算写SCI论文,你必须使用这个管理软件。
Endnote 可直接连接上千个数据库,提高科技文献检索效率,可管理数十万条参考文献,无需担心文档过多。 EndNote 的用处是有目共睹的,在目前的文档管理工具市场上有着比较大的使用率。
需要注意的是,这个软件需要付费使用,对于学生来说价格较高,但是可以在官网免费试用30天,大家可以决定是否购买体验它。
2.Citavi
Citavi 来自瑞士。其定位为“知识型组织管理软件”,在欧洲(尤其是德语区)应用广泛。本软件集成了知识管理、任务规划、PDF全文检索等科研工作环节,功能强大全面。
Citavi拥有全功能免费版(支持每个项目插入不超过100个文档),具有强大的参考文献编辑功能,可以全方位实现参考文献的编辑需求。
Citavi 的一大特色就是支持PDF阅读功能,并且可以支持多种注释格式,可以对注释进行管理和组织,形成自己的知识库。同时,也支持文档大纲的创建,知识组织管理的形成,更好地提升我们对文献内容的理解和组织架构的形成。
3.Mendeley
Mendeley 是 Elsevier 旗下的免费文档管理软件。每个人都可以在 Mendeley 上搜索来自世界各地的学术文献。这些学术文献上传到Mendeley“图书馆”,供用户自行编辑和管理。本软件具有强大的文档整理、PDF标注和文件共享、网络备份等功能。
该软件的一大优势在于其强大的PDF识别和搜索功能,并且支持PDF标签。您可以直接对PDF文档进行标注和批注,以突出文章中的关键内容。
有网页版、WINDOWS版、Mac版、Linux版、ios客户端等平台,用户可以根据需要选择不同的平台使用。具有交叉同步和云备份功能。登录账号后,Mendeley导入的PDF可以跨平台同步,方便您在不同平台使用,查看自己的文档,无需重复导入。
4.Readcube
界面简洁美观。很多人选择这个软件是因为它的界面。
本软件功能比较齐全,平台覆盖较好。具有PDF文件自动识别和增强功能,免去繁琐的手动输入,并自带PDF阅读器进行内部搜索。但也存在一定的不足。比如系统不是特别稳定,过分依赖网速,某些项目比如云同步功能需要收费。
对于“颜控”的朋友,不妨试试这款软件,它的界面风格不会让你失望。
5.Zotero
它是一个开源的文档管理软件,可以帮助我们采集、管理和引用研究资源,包括期刊、书籍和其他文档、网页、图片等。
Zotero 最初是作为 Firefox 插件存在的,但现在已经发展成为一个独立的版本,但它仍然和 Firefox 一样,无论是在 Windows、Mac 还是 Linux 系统上,都可以跨平台使用。
Zotero 可以免费使用。与 EndNotes 相比,Zotero 最大的特点就是目录分类级别不限。一个目录可以分为多个子目录,这使得它更易于管理。另外Zotero还支持标签功能,可以自动给每个文档打上标签,方便我们管理文档。
6.NoteEpress
NoteExpress 是一款由专业级文档检索和管理系统开发的国产软件。其核心功能涵盖“knowledge采集、管理、应用、挖掘”知识管理的方方面面。
是国内专业的文档检索管理系统,对中文文档非常友好,具有非常强大的中文文档管理功能。可内部搜索知网文档库,批量下载。这个软件导入文件的速度也比国外同类软件快。
文献和笔记(文章)的功能是协调一致的。除了管理参考资料,您还可以管理其他文章或硬盘上的文件作为个人知识管理系统。
对于中文文献较多的朋友,不妨试试这款软件。
7.知网研学(原E-study)
是最大中文期刊资源CNKI官方版的研究平台软件。常用功能包括文档检索与识别、标注与添加笔记、生成参考文档、云端同步等,并可在线书写,为观众提供与CNKI数据库紧密结合的数字新体验。
除了传统文档管理软件的功能外,CNKI E-study最大的优势在于与CNKI数据库同源,可以实现数据云管理。可用于通过同一账号登录其他平台进行数据更新。可以更好地与CNKI搜索引擎结合,让受众的数据管理更加方便。
另外,这也是一款免费软件,使用起来比较方便。它占了很多市场使用量。如果你的大部分文献来自知网,你不妨考虑一下这个软件。
8.Papers
是一款专业的文档管理工具,具有文档搜索、阅读、引用等功能。 Papers 流畅地组织各种与文档管理相关的活动。主要的具体功能包括文档导入、组织、阅读(注释)、参考词条自动匹配、搜索、在文档中插入引文、评论交流等。
Papers的一大特点是可以从原创PDF中抓取文档信息,有利于对文档进行更清晰、更自动化的管理,文档自动分类,简洁明了。
Papers里面可以打开PDF文件,并且有非常强大的文档阅读功能。最突出的特点是强大的标注和笔记功能,有利于后期的学习和研究。
论文是MAC系统独有的,如果电脑是MAC系统的小伙伴,可以试试这个软件。
(本文整理自重庆大学研究生会公众号转载,原链接,如有侵删)
学术福利炸弹| N种文档管理工具,总有一款适合您
文章句子采集软件带你破解命令行,把信息自动生成
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-06-16 18:02
文章句子采集软件带你破解命令行,把信息自动生成。搜索excel-one-dic,替换library"excelhome。excel。addmouselinks"里包含的项。或者:直接把下面的命令'excelhome。excel。addmouselinks'加入这两个文件夹里面,即可:sdlcreate-lallmydbsdlsize--all=5myregular--my="sr_zhexaml"union{char(10)--all=""}其中create-l也有其他含义,。
没用过这个神器,不过实现按关键字自动取数据的话,最好配合日志管理工具,不然简直太难调试。
pandasstats模块可以很方便的实现这个功能。
记得用sql。excelhome的是傻逼。直接使用excelhome的发明的格式是错误的,
office2010以上版本->程序->excelstats
不用方法。excelhome免费提供excelhome-采集excel文件-命令行包含name这个命令,
有个叫pandas的网站,你在控制台输入要采集的excel文件名然后excel选择标准就可以自动生成记录。 查看全部
文章句子采集软件带你破解命令行,把信息自动生成
文章句子采集软件带你破解命令行,把信息自动生成。搜索excel-one-dic,替换library"excelhome。excel。addmouselinks"里包含的项。或者:直接把下面的命令'excelhome。excel。addmouselinks'加入这两个文件夹里面,即可:sdlcreate-lallmydbsdlsize--all=5myregular--my="sr_zhexaml"union{char(10)--all=""}其中create-l也有其他含义,。
没用过这个神器,不过实现按关键字自动取数据的话,最好配合日志管理工具,不然简直太难调试。
pandasstats模块可以很方便的实现这个功能。
记得用sql。excelhome的是傻逼。直接使用excelhome的发明的格式是错误的,
office2010以上版本->程序->excelstats
不用方法。excelhome免费提供excelhome-采集excel文件-命令行包含name这个命令,
有个叫pandas的网站,你在控制台输入要采集的excel文件名然后excel选择标准就可以自动生成记录。
文章句子采集软件对所有歌手和歌曲的匹配与整理
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-06-12 07:01
文章句子采集软件抓取我要的句子,将之与我要的歌曲添加,然后将歌曲信息导入到待编辑界面,根据字典库生成我要的人的名字,将昵称和歌名与歌曲进行匹配,歌曲文件加载成功后,将所有匹配成功的匹配名和歌名信息写到另一个文件中,此时需要选择歌曲歌手信息,按照如下图所示操作!现在选取所有歌手信息,按照以下图所示操作!经过对最开始所有匹配成功的歌手和所有匹配失败的歌手进行搜索匹配,最终获取了数百首歌曲,对这些歌曲进行以下操作:对所有匹配成功的歌手做一个名字索引(这个名字库需要注册,百度网盘地址:歌手jj我的文档,在网盘下载就可以),然后对歌手名中的jj设置为文件名,得到歌曲jj歌手的jj文件,还将jj文件中的jj设置为歌手jj歌手的id。
对于所有失败的歌手,同样对jj做一个名字索引,然后对歌手名中的ffj设置为文件名,得到歌曲ffj歌手的ffj文件,此时可以按照如下图所示操作对所有歌手进行歌曲列表的创建,如下图所示!除此之外还需要对歌手id进行修改,修改文件名为ffj歌手id.txt,以此来匹配歌手id的所有歌曲。这样已经完成了所有歌手和歌曲的匹配与整理!对于所有歌手和歌曲的歌曲列表还需要做一些简单的数据分析,比如名字歌手和歌曲的分布区间,共有多少首歌曲,经过复查,将歌曲列表按歌曲数量、单曲数量、单张专辑数量、改编/翻唱版本数量、翻唱版本数量、销量数量等基础数据(数据来源:网络爬虫)统计分析,得到歌曲和歌手信息的情况,以及未知歌手情况!最后将所有分析结果写入python文件中。
这个软件用起来方便,对于文字匹配、歌手匹配、名字匹配和单曲匹配等功能基本上都可以对软件setup第一步来分析,分析完以后对于软件匹配出来的信息有一个整体的认识。后面文章将用到这个文件来解决各种匹配问题!。 查看全部
文章句子采集软件对所有歌手和歌曲的匹配与整理
文章句子采集软件抓取我要的句子,将之与我要的歌曲添加,然后将歌曲信息导入到待编辑界面,根据字典库生成我要的人的名字,将昵称和歌名与歌曲进行匹配,歌曲文件加载成功后,将所有匹配成功的匹配名和歌名信息写到另一个文件中,此时需要选择歌曲歌手信息,按照如下图所示操作!现在选取所有歌手信息,按照以下图所示操作!经过对最开始所有匹配成功的歌手和所有匹配失败的歌手进行搜索匹配,最终获取了数百首歌曲,对这些歌曲进行以下操作:对所有匹配成功的歌手做一个名字索引(这个名字库需要注册,百度网盘地址:歌手jj我的文档,在网盘下载就可以),然后对歌手名中的jj设置为文件名,得到歌曲jj歌手的jj文件,还将jj文件中的jj设置为歌手jj歌手的id。
对于所有失败的歌手,同样对jj做一个名字索引,然后对歌手名中的ffj设置为文件名,得到歌曲ffj歌手的ffj文件,此时可以按照如下图所示操作对所有歌手进行歌曲列表的创建,如下图所示!除此之外还需要对歌手id进行修改,修改文件名为ffj歌手id.txt,以此来匹配歌手id的所有歌曲。这样已经完成了所有歌手和歌曲的匹配与整理!对于所有歌手和歌曲的歌曲列表还需要做一些简单的数据分析,比如名字歌手和歌曲的分布区间,共有多少首歌曲,经过复查,将歌曲列表按歌曲数量、单曲数量、单张专辑数量、改编/翻唱版本数量、翻唱版本数量、销量数量等基础数据(数据来源:网络爬虫)统计分析,得到歌曲和歌手信息的情况,以及未知歌手情况!最后将所有分析结果写入python文件中。
这个软件用起来方便,对于文字匹配、歌手匹配、名字匹配和单曲匹配等功能基本上都可以对软件setup第一步来分析,分析完以后对于软件匹配出来的信息有一个整体的认识。后面文章将用到这个文件来解决各种匹配问题!。

