
插入关键字 文章采集器
插入关键字 文章采集器(最近几个月群里讨论网站采集、站群大数据的比较多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-10 19:07
最近几个月,群里有很多关于网站采集和站群big data的讨论。有网友问能不能做一个WordPress标签关键词自动分发插件。一、可以更新文章时,将预先存储的关键字分发给更新后的文章,而不是手动发布。毕竟他们的文章数据量很大,而且大部分都是靠堆叠TAG,当然最好建议相关关键词更健壮。
同时,对于现有的文章或者文章没有添加标签关键字的,可以批量添加关键字吗?有的可以随意添加或者相关,于是这个WP自动关键词插件就应运而生了。目前,上述功能基本满足了,一起来看看吧。
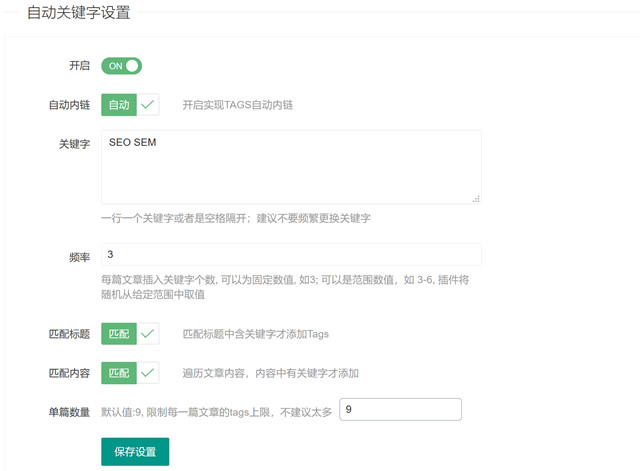
我们可以检查它是否在开启后生效。同时自带TAGS自动内链功能,可以保留我们准备的关键词。并且我们可以设置频率,确保不堆关键字,因为目前百度等搜索引擎对堆关键字有处罚。
我们还可以设置标题和内容相匹配,以保证关键词的相关性。并设置单篇文章的关键词数量。比如我们看到一些博主理解的关键词有十、几百个。其实这些都是作弊,百度一旦发现就会直接用作弊来降低自己的权利。
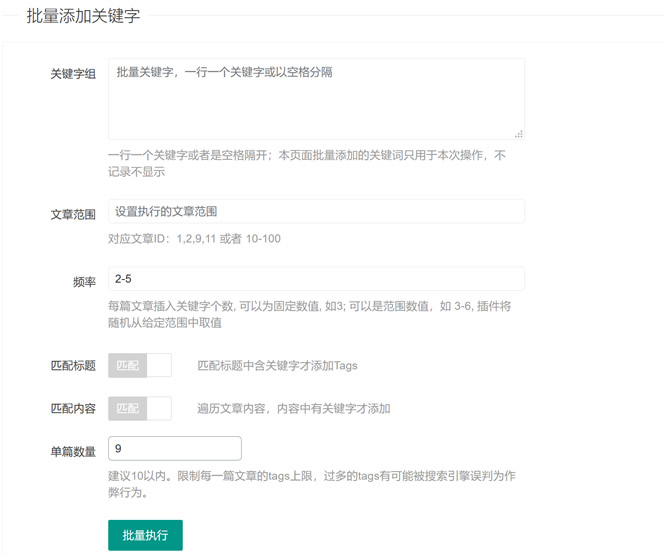
文章 发布后,我们可以在现有的文章 范围内随机添加关键字。这个插件是我们需要的吗?
插件下载链接:
插件已经上传到官方WP平台,我们可以下载,但是需要获取最新的等插件产品。建议关注公众号获取最新版本。 查看全部
插入关键字 文章采集器(最近几个月群里讨论网站采集、站群大数据的比较多)
最近几个月,群里有很多关于网站采集和站群big data的讨论。有网友问能不能做一个WordPress标签关键词自动分发插件。一、可以更新文章时,将预先存储的关键字分发给更新后的文章,而不是手动发布。毕竟他们的文章数据量很大,而且大部分都是靠堆叠TAG,当然最好建议相关关键词更健壮。
同时,对于现有的文章或者文章没有添加标签关键字的,可以批量添加关键字吗?有的可以随意添加或者相关,于是这个WP自动关键词插件就应运而生了。目前,上述功能基本满足了,一起来看看吧。
我们可以检查它是否在开启后生效。同时自带TAGS自动内链功能,可以保留我们准备的关键词。并且我们可以设置频率,确保不堆关键字,因为目前百度等搜索引擎对堆关键字有处罚。
我们还可以设置标题和内容相匹配,以保证关键词的相关性。并设置单篇文章的关键词数量。比如我们看到一些博主理解的关键词有十、几百个。其实这些都是作弊,百度一旦发现就会直接用作弊来降低自己的权利。
文章 发布后,我们可以在现有的文章 范围内随机添加关键字。这个插件是我们需要的吗?
插件下载链接:
插件已经上传到官方WP平台,我们可以下载,但是需要获取最新的等插件产品。建议关注公众号获取最新版本。
插入关键字 文章采集器(python爬虫代理池(代理ip池)是怎么实现的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-10 11:04
插入关键字文章采集器因其数据爬取、关键字识别、排序等能力,全网海量数据都能爬取下来,只要多研究,多分析,总能找到好玩的技术。用文章分析来说,python爬虫的时候,有时候需要对关键字做性能上的优化。python爬虫只有通过你爬取的文章并将爬取的内容通过文章分析器获取到,才能正式爬取进来。那么怎么爬呢?通过代码爬取不好爬取,又像网页上的代码,要每个网页都爬一遍的话太麻烦,因此有人就写了python爬虫代理池(代理ip池)。
那么代理池是做什么的呢?说白了就是互联网上提供商家帮我们不下载网页,只是来抓取网页上的内容,来帮我们代理抓取文章。而我们直接可以在公众号上采集有相关文章的所有代理,然后拿到爬虫代理池来和公众号对接,就可以通过代理池来进行公众号爬取文章。有点:基本比原来的抓取下来的内容全,代理不需要重复利用;代理池中的代理不需要你去下载,代理ip也不需要你自己单独购买,但是其中的代理内容还是需要你自己采集的,这一点比下面我要介绍的e-site即代理ip池好。
代理池是怎么实现的呢?在你关注公众号进入公众号,在公众号文章列表下,点击“历史文章”“加入代理池”,点击“立即加入”即可。操作方法:公众号或者文章列表页点击“历史文章”点击“加入代理池”点击立即加入代理池。关键字识别爬虫又出现了,要抓取哪些文章,按照公众号后台的提示,输入相关关键字,例如“面膜”输入“保湿”关键字验证码即可获取对应的“面膜”文章列表。
微信搜索微信公众号e-site,获取代理列表后即可采集。分析代理池示例:先看一下代理池的运行过程,首先检查一下这个代理池:打开公众号后台,查看历史发文(自定义文章列表页)检查代理列表,检查代理池中有没有我们需要的文章,一个一个试还是太麻烦。那么代理池中会有哪些内容呢?新关注公众号首页:"历史文章列表页"右下角会有个更多关注公众号,点击更多关注我。
一个一个输入关键字尝试下,会获取到更多文章,等待浏览中。关注公众号列表页第2个:检查一下我们的关键字“面膜”,获取到全部的文章列表,这里有一个重复的关键字,因此我们只获取第一个即代理列表的第一个文章。然后我们点击原来我们加入的关键字“面膜”,很好,跳转页面到新的关键字页面。这时候点击更多关注,这时候你发现原来我们加入的关键字“面膜”已经不在了,因为文章列表已经改变,我们想下次加入代理的时候再更新。那么我们不要更新关键字为“面膜”,什么样才不需要修改关键字呢?看上面我。 查看全部
插入关键字 文章采集器(python爬虫代理池(代理ip池)是怎么实现的)
插入关键字文章采集器因其数据爬取、关键字识别、排序等能力,全网海量数据都能爬取下来,只要多研究,多分析,总能找到好玩的技术。用文章分析来说,python爬虫的时候,有时候需要对关键字做性能上的优化。python爬虫只有通过你爬取的文章并将爬取的内容通过文章分析器获取到,才能正式爬取进来。那么怎么爬呢?通过代码爬取不好爬取,又像网页上的代码,要每个网页都爬一遍的话太麻烦,因此有人就写了python爬虫代理池(代理ip池)。
那么代理池是做什么的呢?说白了就是互联网上提供商家帮我们不下载网页,只是来抓取网页上的内容,来帮我们代理抓取文章。而我们直接可以在公众号上采集有相关文章的所有代理,然后拿到爬虫代理池来和公众号对接,就可以通过代理池来进行公众号爬取文章。有点:基本比原来的抓取下来的内容全,代理不需要重复利用;代理池中的代理不需要你去下载,代理ip也不需要你自己单独购买,但是其中的代理内容还是需要你自己采集的,这一点比下面我要介绍的e-site即代理ip池好。
代理池是怎么实现的呢?在你关注公众号进入公众号,在公众号文章列表下,点击“历史文章”“加入代理池”,点击“立即加入”即可。操作方法:公众号或者文章列表页点击“历史文章”点击“加入代理池”点击立即加入代理池。关键字识别爬虫又出现了,要抓取哪些文章,按照公众号后台的提示,输入相关关键字,例如“面膜”输入“保湿”关键字验证码即可获取对应的“面膜”文章列表。
微信搜索微信公众号e-site,获取代理列表后即可采集。分析代理池示例:先看一下代理池的运行过程,首先检查一下这个代理池:打开公众号后台,查看历史发文(自定义文章列表页)检查代理列表,检查代理池中有没有我们需要的文章,一个一个试还是太麻烦。那么代理池中会有哪些内容呢?新关注公众号首页:"历史文章列表页"右下角会有个更多关注公众号,点击更多关注我。
一个一个输入关键字尝试下,会获取到更多文章,等待浏览中。关注公众号列表页第2个:检查一下我们的关键字“面膜”,获取到全部的文章列表,这里有一个重复的关键字,因此我们只获取第一个即代理列表的第一个文章。然后我们点击原来我们加入的关键字“面膜”,很好,跳转页面到新的关键字页面。这时候点击更多关注,这时候你发现原来我们加入的关键字“面膜”已经不在了,因为文章列表已经改变,我们想下次加入代理的时候再更新。那么我们不要更新关键字为“面膜”,什么样才不需要修改关键字呢?看上面我。
插入关键字 文章采集器(如何防止网站内容被采集?(一)_光明网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-07 21:07
正文:
这几天挺烦的。 网站 不断被人采集 抄袭。在百度没有对采集网站进行有效打击后,我们不能指望百度会认出这些采集网站,那么我们只能靠自己在努力打击的内容中添加版权文本这种采集 行为。前段时间,我也写过一篇关于采集的文章《如何防止网站内容被采集?今天,飘逸从另一个角度谈谈如何保护您的内容。即使其他人采集是采集,他们也必须免费帮我们做广告。当然,如果你的网站文章里面有图片,那记得放自己的LOGO,而且这个LOGO一定不能固定在这些图片的一角,必须随机出现在图片的任意位置,做鬼了,让采集器叹息:对方网站站标真是捉摸不定,捉摸不定……切入正题。我们如何在我们的文章 中随机插入版权文本?昨晚花了点时间,写了一个简单的代码随机插入随机文本,asp版:
''===开始随机生成噪声文本功能===
''===随机生成干扰文字功能一===
functionrndk()
暗淡,s1,n,n1
''随机插入你的网站版权文字,倍数除以|
s="来自:飘意博客。|飘意:.|.|飘意.ORG.||飘意"
s1=split(s,"|")
随机化
n=Int((ubound(s1)-lbound(s1)+1)*Rnd+lbound(s1))
随机化
n1=Int((10-1+1)*Rnd+1)
ifn1 查看全部
插入关键字 文章采集器(如何防止网站内容被采集?(一)_光明网)
正文:
这几天挺烦的。 网站 不断被人采集 抄袭。在百度没有对采集网站进行有效打击后,我们不能指望百度会认出这些采集网站,那么我们只能靠自己在努力打击的内容中添加版权文本这种采集 行为。前段时间,我也写过一篇关于采集的文章《如何防止网站内容被采集?今天,飘逸从另一个角度谈谈如何保护您的内容。即使其他人采集是采集,他们也必须免费帮我们做广告。当然,如果你的网站文章里面有图片,那记得放自己的LOGO,而且这个LOGO一定不能固定在这些图片的一角,必须随机出现在图片的任意位置,做鬼了,让采集器叹息:对方网站站标真是捉摸不定,捉摸不定……切入正题。我们如何在我们的文章 中随机插入版权文本?昨晚花了点时间,写了一个简单的代码随机插入随机文本,asp版:
''===开始随机生成噪声文本功能===
''===随机生成干扰文字功能一===
functionrndk()
暗淡,s1,n,n1
''随机插入你的网站版权文字,倍数除以|
s="来自:飘意博客。|飘意:.|.|飘意.ORG.||飘意"
s1=split(s,"|")
随机化
n=Int((ubound(s1)-lbound(s1)+1)*Rnd+lbound(s1))
随机化
n1=Int((10-1+1)*Rnd+1)
ifn1
插入关键字 文章采集器(如何利用二级、三级页面提升首页关键词的排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-07 17:27
)
项目招商找A5快速获取精准代理商名单
大家好,今天继续介绍标题的编写,同时在本节中会涉及到网页的布局,如果有不明白的课程可以留给你以后有一些基本的知识,然后来仔细品尝。昨天我们讲了首页的标题、描述和关键词。下面我们来看看如何利用二级、三级、四级页面来提升关键词的排名。
首先排名的前提是在首页找到你需要排名的关键词,并有相应的链接,然后用文章的形式来带动这个关键词在首页的排名在搜索引擎中。 文章的形式可以是行业内的一些技术讲解,也可以是行业新闻,编辑方式与论坛、博客类似。
但是需要注意的是,这里写的文章需要比论坛博客更专业。 文章可以多次重复关键词,但句子一定要流畅,不要用采集器采集来的文章,因为文章这种专业性不仅针对搜索引擎,也是为了客户,所以最好坚持原创或者找一些行业内的专业知识进行修改,尤其是标题的设置。选好之后,最好去百度搜索一下,看看有没有相同的,以免类似的标题长期被降级。
文章页面最好不要专门写标题,对排名没有帮助,也容易被搜索引擎识别为过度优化,导致排名下降。希望大家牢记这一点,描述和关键词也没必要专门给百度写一个,OK!现在文章知道怎么写了,我们来介绍下首页的二级和三级怎么设置关键词怎么设置。
首先,这些关键词可以体现为目录的形式,也可以是内部链接的形式。对于内部链接,最好设置在页面的底部和左上角,目录形式的关键词可以放在主导航的下拉列表中。在菜单中,也可以在侧边导航中,或者在底部内置垂直菜单栏。需要注意的是,如果顶部导航的关键词太多,下拉菜单会太长。这里肯定会有些难看。导航更利于客户体验,因为它已经过专家分析。底部菜单栏的优点是用词多,外观容易,但对客户体验不是很好。权衡利弊后,如何选择就看自己了,毕竟个人喜好不同!今天的课程就到这里了,下一章我会写一篇关于如何真正加入一个合格的网商行列的文章。 查看全部
插入关键字 文章采集器(如何利用二级、三级页面提升首页关键词的排名
)
项目招商找A5快速获取精准代理商名单
大家好,今天继续介绍标题的编写,同时在本节中会涉及到网页的布局,如果有不明白的课程可以留给你以后有一些基本的知识,然后来仔细品尝。昨天我们讲了首页的标题、描述和关键词。下面我们来看看如何利用二级、三级、四级页面来提升关键词的排名。
首先排名的前提是在首页找到你需要排名的关键词,并有相应的链接,然后用文章的形式来带动这个关键词在首页的排名在搜索引擎中。 文章的形式可以是行业内的一些技术讲解,也可以是行业新闻,编辑方式与论坛、博客类似。
但是需要注意的是,这里写的文章需要比论坛博客更专业。 文章可以多次重复关键词,但句子一定要流畅,不要用采集器采集来的文章,因为文章这种专业性不仅针对搜索引擎,也是为了客户,所以最好坚持原创或者找一些行业内的专业知识进行修改,尤其是标题的设置。选好之后,最好去百度搜索一下,看看有没有相同的,以免类似的标题长期被降级。
文章页面最好不要专门写标题,对排名没有帮助,也容易被搜索引擎识别为过度优化,导致排名下降。希望大家牢记这一点,描述和关键词也没必要专门给百度写一个,OK!现在文章知道怎么写了,我们来介绍下首页的二级和三级怎么设置关键词怎么设置。
首先,这些关键词可以体现为目录的形式,也可以是内部链接的形式。对于内部链接,最好设置在页面的底部和左上角,目录形式的关键词可以放在主导航的下拉列表中。在菜单中,也可以在侧边导航中,或者在底部内置垂直菜单栏。需要注意的是,如果顶部导航的关键词太多,下拉菜单会太长。这里肯定会有些难看。导航更利于客户体验,因为它已经过专家分析。底部菜单栏的优点是用词多,外观容易,但对客户体验不是很好。权衡利弊后,如何选择就看自己了,毕竟个人喜好不同!今天的课程就到这里了,下一章我会写一篇关于如何真正加入一个合格的网商行列的文章。
插入关键字 文章采集器(插入关键字文章采集器的关键)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-07 03:06
插入关键字文章采集器:群中采集,8-15条直接设置一下。输入上下文匹配内容,也可以不匹配文章内容。脚本运行页面:pythonqa爬虫+aiops,而且是采用正则表达式采集(百度为主)。监控浏览器,执行内容记录下来。推荐一个工具吧,叫guesty,可以看看guesty的一些算法,具体点的话叫做middleware。只要给guesty提供网址,用一个模拟的guesty。qa交互模拟注册,你可以试试。
匹配
匹配-scrapy
可以先用java写个爬虫然后用python做反爬虫
可以用《webapp数据采集:网页、api、数据库解决方案》中提到的selenium+phantomjs爬
多发post请求,应该就可以了。
谢邀,是采集cms那块吧,然后用爬虫解析,
scrapy或者scrapyionijali爬糗事百科就行
推荐一个网站feedly-feedyourownrss当然,如果你实在想找一个很详细的python爬虫方法,可以到这个csdn博客看一下,
用户自己添加自己的header,
首先判断爬行目标,打上标签,进行人工合并。
discoverthisjavascriptbookandhowtodownloadit(这本书主要是介绍discoverthis),sayaka作者写的(网易新闻) 查看全部
插入关键字 文章采集器(插入关键字文章采集器的关键)
插入关键字文章采集器:群中采集,8-15条直接设置一下。输入上下文匹配内容,也可以不匹配文章内容。脚本运行页面:pythonqa爬虫+aiops,而且是采用正则表达式采集(百度为主)。监控浏览器,执行内容记录下来。推荐一个工具吧,叫guesty,可以看看guesty的一些算法,具体点的话叫做middleware。只要给guesty提供网址,用一个模拟的guesty。qa交互模拟注册,你可以试试。
匹配
匹配-scrapy
可以先用java写个爬虫然后用python做反爬虫
可以用《webapp数据采集:网页、api、数据库解决方案》中提到的selenium+phantomjs爬
多发post请求,应该就可以了。
谢邀,是采集cms那块吧,然后用爬虫解析,
scrapy或者scrapyionijali爬糗事百科就行
推荐一个网站feedly-feedyourownrss当然,如果你实在想找一个很详细的python爬虫方法,可以到这个csdn博客看一下,
用户自己添加自己的header,
首先判断爬行目标,打上标签,进行人工合并。
discoverthisjavascriptbookandhowtodownloadit(这本书主要是介绍discoverthis),sayaka作者写的(网易新闻)
插入关键字 文章采集器(SEO优化过度优化的原因有哪些?这方面的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-06 23:13
SEO优化对企业来说是好事,但一切都太糟糕了。一旦出现过度优化的情况,比没有优化更可怕。
我们在做SEO优化的时候,有时候我们的网站会因为操作不当而被搜索引擎惩罚。过度优化的原因有很多。我们需要找到原因才能正确解决。 ,给大家详细介绍一下这方面。
1、采集 过来网站文章
经常在网站后期的重要维护阶段,为了稳定网站的活跃度,那么就需要更新有价值的原创文章;还有一些刚接触的新手在网上学习文章的采集方法,使用文章采集tools,采集同行业文章。
直接在网站上发帖,或者使用伪原创工具自动修改文章。每天发布数十篇文章文章,更新这个文章。事实上,这不仅有助于优化。反之,新站点会推迟审核期。为了降低老站的权重和排名,有必要围绕用户的需求写一些原创的有价值的文章,每天更新两个文章。
2、恶意堆积关键词
网站Optimization 就是做关键词优化,提高关键词在首页的搜索引擎排名。不管用户搜索什么类型的关键词,都能看到公司信息,点击的机会就会更多,所以很多新手为了增加关键词密度,恶意堆砌关键词。更新文章的时候,还有一篇文章文章放了很多关键词,在文章meta标签设置中,每一种这样堆起来的关键词,图片中的ALT标记,也是堆积关键词,堆积严重的关键词会导致搜索引擎受到惩罚。一定要遵循正常的优化方法。 文章 中的关键字不超过 3 个。关键字必须与当前页面相关。
3、锚文本链接太多
建立锚文本链接将有助于提高网站 权重和关键词 排名。新手在制作链接锚文本时,只要关键词出现文章,就会添加一个锚文本链接甚至多个锚文本链接。这显然是过度优化。锚文本链接堆积如山。一个文章的锚文本链接最好不要超过3个,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词时不要限制布局关键词, no 任何有价值的关键词 布局也可以链接。在结构上,每个页面都与锚文本链接,形成网状结构,引导蜘蛛的深度爬行。
4、外链建设没有规则可循。
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还能提升公司品牌,获得潜在客户。因此,很多企业都在选择各种外链群发工具。这是明显的作弊。搜索引擎并不傻。系统会自动判断垃圾外链,甚至搜索引擎也不会收录这些外链。严格来说,频率和数量必须控制。不要盲目使用工具建立外部链接。开始提高外部链接的质量。
了解问题,如何解决网站over-optimization?
1、内容过度优化
如果内容过度优化,我们需要保证原创文章每天更新1-2篇。本段建议您可以在上午10点到中午12点之间进行选择。时间会更有利于文章被收录。
2、关键词过度优化
关键词的堆叠可以让我们的核心关键词在相对较短的时间内获得相对较高的曝光率,但背后的原因是关键词和文章过于相关。因条件恶劣而受到的惩罚。解决这个问题很简单,让原来的关键词正常插入即可。
3、内链外链过度优化
需要做的不是内链与首页的链接,而是根据具体内容建立内链。
SEO 问题并不可怕。您可以了解问题的根本原因并匹配相应的解决方案。 SEO的难点在于坚持和细节。 SEO是一项长期的工作,希望急功近利,往往会带来过度优化等问题。二是细节决定成败。返回搜狐查看更多 查看全部
插入关键字 文章采集器(SEO优化过度优化的原因有哪些?这方面的内容)
SEO优化对企业来说是好事,但一切都太糟糕了。一旦出现过度优化的情况,比没有优化更可怕。

我们在做SEO优化的时候,有时候我们的网站会因为操作不当而被搜索引擎惩罚。过度优化的原因有很多。我们需要找到原因才能正确解决。 ,给大家详细介绍一下这方面。
1、采集 过来网站文章
经常在网站后期的重要维护阶段,为了稳定网站的活跃度,那么就需要更新有价值的原创文章;还有一些刚接触的新手在网上学习文章的采集方法,使用文章采集tools,采集同行业文章。
直接在网站上发帖,或者使用伪原创工具自动修改文章。每天发布数十篇文章文章,更新这个文章。事实上,这不仅有助于优化。反之,新站点会推迟审核期。为了降低老站的权重和排名,有必要围绕用户的需求写一些原创的有价值的文章,每天更新两个文章。

2、恶意堆积关键词
网站Optimization 就是做关键词优化,提高关键词在首页的搜索引擎排名。不管用户搜索什么类型的关键词,都能看到公司信息,点击的机会就会更多,所以很多新手为了增加关键词密度,恶意堆砌关键词。更新文章的时候,还有一篇文章文章放了很多关键词,在文章meta标签设置中,每一种这样堆起来的关键词,图片中的ALT标记,也是堆积关键词,堆积严重的关键词会导致搜索引擎受到惩罚。一定要遵循正常的优化方法。 文章 中的关键字不超过 3 个。关键字必须与当前页面相关。
3、锚文本链接太多
建立锚文本链接将有助于提高网站 权重和关键词 排名。新手在制作链接锚文本时,只要关键词出现文章,就会添加一个锚文本链接甚至多个锚文本链接。这显然是过度优化。锚文本链接堆积如山。一个文章的锚文本链接最好不要超过3个,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词时不要限制布局关键词, no 任何有价值的关键词 布局也可以链接。在结构上,每个页面都与锚文本链接,形成网状结构,引导蜘蛛的深度爬行。

4、外链建设没有规则可循。
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还能提升公司品牌,获得潜在客户。因此,很多企业都在选择各种外链群发工具。这是明显的作弊。搜索引擎并不傻。系统会自动判断垃圾外链,甚至搜索引擎也不会收录这些外链。严格来说,频率和数量必须控制。不要盲目使用工具建立外部链接。开始提高外部链接的质量。
了解问题,如何解决网站over-optimization?
1、内容过度优化
如果内容过度优化,我们需要保证原创文章每天更新1-2篇。本段建议您可以在上午10点到中午12点之间进行选择。时间会更有利于文章被收录。

2、关键词过度优化
关键词的堆叠可以让我们的核心关键词在相对较短的时间内获得相对较高的曝光率,但背后的原因是关键词和文章过于相关。因条件恶劣而受到的惩罚。解决这个问题很简单,让原来的关键词正常插入即可。
3、内链外链过度优化
需要做的不是内链与首页的链接,而是根据具体内容建立内链。
SEO 问题并不可怕。您可以了解问题的根本原因并匹配相应的解决方案。 SEO的难点在于坚持和细节。 SEO是一项长期的工作,希望急功近利,往往会带来过度优化等问题。二是细节决定成败。返回搜狐查看更多
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-06 15:14
【IT168 Technology文章】为了方便搜索引擎,所以模仿NB的文章系统制作下一页标签的关键词!
第一步
在 foosun\Admin\Refresh\Function.asp 中找到
函数 GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,"{News_Title}",NewsRecordSet("Title"))
在下面添加
'关键字标签
如果不是 IsNull(NewsRecordSet("keywords")) 那么
TempletContent = Replace(TempletContent,"{News_keywords}",NewsRecordSet("keywords"))
其他
TempletContent = Replace(TempletContent,"{News_keywords}","")
如果结束
'关键字标签
在最后的倒数第二行,即%>之前,添加
'****************************************
'作者:lino
'将标题与关键字表中的记录匹配
'开始
'********************************
函数replaceKeywordByTitle(title)
暗淡 whereisKeyword,i,theKeywordOnNews
Dim 关键字,rsRuleObj,theKeywordS
'***如果使用3.0版本,请将下游的fs_Routine改为Routine
Set RsRuleObj = Conn.Execute("Select * from FS_Routine")
做而不是 RsRuleObj.Eof
keyword = RsRuleObj("name")
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0) then
if(theKeywordOnNews="") 那么
theKeywordOnNews=关键字
其他
theKeywordOnNews=theKeywordOnNews&""&keyword
如果结束
如果结束
RsRuleObj.MoveNext
循环
'如果关键字长度大于100,剪掉太长的
if(len(theKeywordOnNews)>99) then
theKeywordOnNews=left(theKeywordOnNews,99)
如果结束
replaceKeywordByTitle = theKeywordOnNews
结束函数
'************************
'结束
第二步
在 foosun/funpages/lablenews.asp
查找选择插入字段
在下面添加
'页面关键字标签
页面关键字
'页面关键字标签
第三步
在 foosun/admin/info/newswords.asp 中找到大约 306 行
INewsAddObj("KeyWords") = Replace(Replace(Request("KeywordText"),"""",""),"'","")
把这句话改成
'****************************************
'作者:lino
'调用replaceKeywordByTitle方法过滤关键字
'如果用户自定义了关键字,自动设置关键字将不起作用
'开始
'********************************
暗淡的关键字文本
if (Request("KeywordText")="" or isempty(Request("KeywordText"))) then
KeywordText = replaceKeywordByTitle(ITtitle)
其他
KeywordText = Request("KeywordText")
如果结束
if KeywordText "" then
INewsAddObj("KeyWords") = Replace(Replace(KeywordText,"""",""),"'","")
如果结束
'结束
'****************************************
第四步
在Foosun/Admin/Collect/movenewstosystem.asp大约117行,找到
RsSysNewsObj("TxtSource") = RsNewsObj("Source")
修改为
RsSysNewsObj("keywords") =replaceKeywordByTitle(RsNewsObj("title"))
程序更改OK!
制作下面的标签,您可以在自定义标签的新闻浏览中选择页面的关键字标签。
具体标签如下{News_keywords},写在新闻模板的title或meta centent中,方便搜索引擎收录! 查看全部
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
【IT168 Technology文章】为了方便搜索引擎,所以模仿NB的文章系统制作下一页标签的关键词!
第一步
在 foosun\Admin\Refresh\Function.asp 中找到
函数 GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,"{News_Title}",NewsRecordSet("Title"))
在下面添加
'关键字标签
如果不是 IsNull(NewsRecordSet("keywords")) 那么
TempletContent = Replace(TempletContent,"{News_keywords}",NewsRecordSet("keywords"))
其他
TempletContent = Replace(TempletContent,"{News_keywords}","")
如果结束
'关键字标签
在最后的倒数第二行,即%>之前,添加
'****************************************
'作者:lino
'将标题与关键字表中的记录匹配
'开始
'********************************
函数replaceKeywordByTitle(title)
暗淡 whereisKeyword,i,theKeywordOnNews
Dim 关键字,rsRuleObj,theKeywordS
'***如果使用3.0版本,请将下游的fs_Routine改为Routine
Set RsRuleObj = Conn.Execute("Select * from FS_Routine")
做而不是 RsRuleObj.Eof
keyword = RsRuleObj("name")
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0) then
if(theKeywordOnNews="") 那么
theKeywordOnNews=关键字
其他
theKeywordOnNews=theKeywordOnNews&""&keyword
如果结束
如果结束
RsRuleObj.MoveNext
循环
'如果关键字长度大于100,剪掉太长的
if(len(theKeywordOnNews)>99) then
theKeywordOnNews=left(theKeywordOnNews,99)
如果结束
replaceKeywordByTitle = theKeywordOnNews
结束函数
'************************
'结束
第二步
在 foosun/funpages/lablenews.asp
查找选择插入字段
在下面添加
'页面关键字标签
页面关键字
'页面关键字标签
第三步
在 foosun/admin/info/newswords.asp 中找到大约 306 行
INewsAddObj("KeyWords") = Replace(Replace(Request("KeywordText"),"""",""),"'","")
把这句话改成
'****************************************
'作者:lino
'调用replaceKeywordByTitle方法过滤关键字
'如果用户自定义了关键字,自动设置关键字将不起作用
'开始
'********************************
暗淡的关键字文本
if (Request("KeywordText")="" or isempty(Request("KeywordText"))) then
KeywordText = replaceKeywordByTitle(ITtitle)
其他
KeywordText = Request("KeywordText")
如果结束
if KeywordText "" then
INewsAddObj("KeyWords") = Replace(Replace(KeywordText,"""",""),"'","")
如果结束
'结束
'****************************************
第四步
在Foosun/Admin/Collect/movenewstosystem.asp大约117行,找到
RsSysNewsObj("TxtSource") = RsNewsObj("Source")
修改为
RsSysNewsObj("keywords") =replaceKeywordByTitle(RsNewsObj("title"))
程序更改OK!
制作下面的标签,您可以在自定义标签的新闻浏览中选择页面的关键字标签。
具体标签如下{News_keywords},写在新闻模板的title或meta centent中,方便搜索引擎收录!
插入关键字 文章采集器(相关软件软件大小版本说明下载地址网络捕手智能识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-06 01:26
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。 .
相关软件软件大小及版本说明下载链接
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。
基本介绍
NoteExpress 是国内广泛使用的文档管理软件。具有文档信息检索和下载功能。可用于管理参考文献的书目,以附件的形式管理参考文献的全文或任何格式的文件和文件。数据挖掘的功能可以帮助用户快速了解某个研究方向的最新进展、各方意见等。 除了管理上述显性知识外,还有日记、科研经历、论文草稿等瞬时隐性知识,等也可以通过NoteExpress的笔记功能进行记录,并可以与参考书目链接。在编辑器(如MS Word)中,NoteExpress可以根据各种期刊杂志的要求自动格式化参考引文——完美的格式和准确的引文将大大增加论文被采用的概率。笔记和附件功能的结合,全文搜索,数据挖掘等,使该软件成为一个强大的个人知识管理系统。
插件功能
多屏、跨平台协同工作
NoteExpress 客户端、浏览器插件和青体文学App,让您可以利用不同屏幕、不同平台之间的碎片时间,高效完成文档跟踪和采集。
灵活多样的分类方法
传统的树形结构分类和灵活的标签标签分类,让您在管理文档时更加得心应手。
全文智能识别,书目自动补全
智能识别全文文件中的标题、DOI等关键信息,自动更新补充书目元数据。
强大的期刊管理器
内置近五年JCR期刊影响因子、国内外主流期刊收录范围、中科院期刊分区数据。添加文档时,会自动匹配并填写相关信息。
支持两大主流写作软件
用户在使用Microsoft Office Word或金山WPS撰写科研论文时,可以使用内置的写作插件在写作时引用参考文献。
丰富的参考输出样式
内置近4000种国内外期刊、论文及国家、协会标准参考格式,支持一键格式转换,支持生成校对报告,支持多语言模板,支持双语输出。
安装方法
方法一:.crx文件格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.在打开的谷歌浏览器扩展管理器最左边选择扩展或者直接输入:chrome://extensions/
3. 找到你下载好的Chrome离线安装文件xxx.crx,从资源管理器中拖拽到Chrome的扩展管理界面。这时候,用户会发现在扩展管理器的中央部分,会有一个额外的“拖拽安装”插件按钮。
4. 松开鼠标,将当前拖拽的插件安装到谷歌浏览器中。但谷歌考虑到用户的安全和隐私,会在用户松开鼠标后提示用户确认安装。
5. 用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome。安装成功后,插件会立即显示在浏览器的右上角(如果有插件按钮),如果没有插件按钮,用户也可以找到已安装的插件通过 Chrome 扩展管理器导入。
方法二:文件夹格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.选择打开的 Google Chrome 扩展管理器最左侧的扩展。
3.勾选开发者模式,点击加载解压后的扩展,选择安装插件的文件夹。 查看全部
插入关键字 文章采集器(相关软件软件大小版本说明下载地址网络捕手智能识别)
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。 .
相关软件软件大小及版本说明下载链接
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。

基本介绍
NoteExpress 是国内广泛使用的文档管理软件。具有文档信息检索和下载功能。可用于管理参考文献的书目,以附件的形式管理参考文献的全文或任何格式的文件和文件。数据挖掘的功能可以帮助用户快速了解某个研究方向的最新进展、各方意见等。 除了管理上述显性知识外,还有日记、科研经历、论文草稿等瞬时隐性知识,等也可以通过NoteExpress的笔记功能进行记录,并可以与参考书目链接。在编辑器(如MS Word)中,NoteExpress可以根据各种期刊杂志的要求自动格式化参考引文——完美的格式和准确的引文将大大增加论文被采用的概率。笔记和附件功能的结合,全文搜索,数据挖掘等,使该软件成为一个强大的个人知识管理系统。
插件功能
多屏、跨平台协同工作
NoteExpress 客户端、浏览器插件和青体文学App,让您可以利用不同屏幕、不同平台之间的碎片时间,高效完成文档跟踪和采集。
灵活多样的分类方法
传统的树形结构分类和灵活的标签标签分类,让您在管理文档时更加得心应手。
全文智能识别,书目自动补全
智能识别全文文件中的标题、DOI等关键信息,自动更新补充书目元数据。
强大的期刊管理器
内置近五年JCR期刊影响因子、国内外主流期刊收录范围、中科院期刊分区数据。添加文档时,会自动匹配并填写相关信息。
支持两大主流写作软件
用户在使用Microsoft Office Word或金山WPS撰写科研论文时,可以使用内置的写作插件在写作时引用参考文献。
丰富的参考输出样式
内置近4000种国内外期刊、论文及国家、协会标准参考格式,支持一键格式转换,支持生成校对报告,支持多语言模板,支持双语输出。
安装方法
方法一:.crx文件格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.在打开的谷歌浏览器扩展管理器最左边选择扩展或者直接输入:chrome://extensions/
3. 找到你下载好的Chrome离线安装文件xxx.crx,从资源管理器中拖拽到Chrome的扩展管理界面。这时候,用户会发现在扩展管理器的中央部分,会有一个额外的“拖拽安装”插件按钮。
4. 松开鼠标,将当前拖拽的插件安装到谷歌浏览器中。但谷歌考虑到用户的安全和隐私,会在用户松开鼠标后提示用户确认安装。
5. 用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome。安装成功后,插件会立即显示在浏览器的右上角(如果有插件按钮),如果没有插件按钮,用户也可以找到已安装的插件通过 Chrome 扩展管理器导入。
方法二:文件夹格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.选择打开的 Google Chrome 扩展管理器最左侧的扩展。
3.勾选开发者模式,点击加载解压后的扩展,选择安装插件的文件夹。
插入关键字 文章采集器(微信文章采集系列插件架构(维清)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-05 12:27
下载链接:@weiqin
演示地址:
[维清]微信文章采集系列插件架构
[维清]微信文章采集器:点击安装
这个插件是核心,用于采集公众号信息、公众号文章,以及内置微信公众号、文章管理功能、文章展示功能。安装此插件,让你的网站与百万公众号分享优质文章。
【维清】微信导航:点击安装
这个插件是用来创建微信导航的,另外还增加了服务号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
【维清】微文阅读中心:点击安装
本插件提供关键词订阅、文章采集、公众采集等功能。安装这个插件,让用户有理由在你的网站上查看公众号文章。
[维清]微信文章DIY:点击安装
安装此扩展,可以在网站任意页面调用公众号信息和文章列表。
【维清】插件伪静态:点击安装
本插件可以为【维清】全系列插件设置伪静态规则,新插件上线后会更新插件。
其他辅助插件:
维基!插件二级域名:点击安装
【维清】万能帮助中心:点击安装
(一)微信文章采集器
功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需要输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与数百万订阅帐户共享优质内容。每天大量更新,快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航上插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站name、插件名称、分类名称、文章title等信息的变量替换。
3、批量提供采集公众号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交即可。一次最多可使用采集10个公众号信息。
4、批量可用采集公号的文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,可以批量处理采集文章信息,最少采集篇文章、文章 内容也进行了本地化。
5、文章信息可以完美显示:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面内置多个DIY区:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、可以灵活设置信息是否需要审核:
用户提交的内容的公众号和文章信息是否需要审核,可以通过后台开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、 完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(二)[维清]微信导航
功能说明:
此插件用于建立微信导航。信息来自卫青微信文章采集器。详情页会显示完整的公众号信息,包括昵称、微信ID、个人资料、认证信息、二维码和头像。另外,这个插件增加了服务帐号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为微信导航。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、分类名称、微信公众号昵称等信息的变量替换。
3、可以使用微信ID作为个性化网址:
结合[weiqing]插件的伪静态,可以将微信账号作为个性化网址,微信账号文章列表支持分页。
4、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
5、每个页面内置多个DIY区域:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
6、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
本插件需要安装“[维清]WeChat文章采集器”才能使用。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(三)[维清]维文阅读中心
功能说明:
该插件主要提供兴趣管理功能。用户可以使用关键词订阅、文章采集、公众采集等功能自由管理自己的兴趣。设置好自己的兴趣后,可以直接在个人中心的兴趣内容中阅读自己的感受。方便用户从海量信息中快速找到自己喜欢的内容,增加用户粘性,吸引用户在你的网站上看到文章。安装这个插件,让用户有理由在你的网站上查看公众号文章。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为个人中心。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、页面名称等信息的变量替换。
3、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
这个插件只有安装了“[维清]WeChat文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(四)[维清]微信文章DIY
功能说明:
此扩展提供了对网站任何页面上的公众号信息和文章列表的访问。安装此扩展后,需要在后台更新缓存,勾选DIY模块分类缓存,点击提交更新。
这个扩展只有安装“[维清]微信文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(五)[维清]插件伪静态
功能说明:
本插件可以为【维清】全系列插件设置伪静态规则。启用此插件后,相关插件页面中的所有链接都将替换为静态链接。如果你安装了Wikin!插件二级域名插件如果为开启伪静态的插件设置了二级域名,链接也会自动添加到对应的二级域名中插入。此插件将在新插件上线时更新。
目前该插件可以为以下插件设置伪静态规则:
1.[维清]微信文章采集器:点击安装
2.[维清]微信导航:点击安装
3.[维清]万能帮助中心:点击安装
应用截图
下载链接:@weiqin
演示地址: 查看全部
插入关键字 文章采集器(微信文章采集系列插件架构(维清)(组图))
下载链接:@weiqin
演示地址:
[维清]微信文章采集系列插件架构
[维清]微信文章采集器:点击安装
这个插件是核心,用于采集公众号信息、公众号文章,以及内置微信公众号、文章管理功能、文章展示功能。安装此插件,让你的网站与百万公众号分享优质文章。
【维清】微信导航:点击安装
这个插件是用来创建微信导航的,另外还增加了服务号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
【维清】微文阅读中心:点击安装
本插件提供关键词订阅、文章采集、公众采集等功能。安装这个插件,让用户有理由在你的网站上查看公众号文章。
[维清]微信文章DIY:点击安装
安装此扩展,可以在网站任意页面调用公众号信息和文章列表。
【维清】插件伪静态:点击安装
本插件可以为【维清】全系列插件设置伪静态规则,新插件上线后会更新插件。
其他辅助插件:
维基!插件二级域名:点击安装
【维清】万能帮助中心:点击安装
(一)微信文章采集器
功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需要输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与数百万订阅帐户共享优质内容。每天大量更新,快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航上插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站name、插件名称、分类名称、文章title等信息的变量替换。
3、批量提供采集公众号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交即可。一次最多可使用采集10个公众号信息。
4、批量可用采集公号的文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,可以批量处理采集文章信息,最少采集篇文章、文章 内容也进行了本地化。
5、文章信息可以完美显示:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面内置多个DIY区:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、可以灵活设置信息是否需要审核:
用户提交的内容的公众号和文章信息是否需要审核,可以通过后台开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、 完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(二)[维清]微信导航
功能说明:
此插件用于建立微信导航。信息来自卫青微信文章采集器。详情页会显示完整的公众号信息,包括昵称、微信ID、个人资料、认证信息、二维码和头像。另外,这个插件增加了服务帐号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为微信导航。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、分类名称、微信公众号昵称等信息的变量替换。
3、可以使用微信ID作为个性化网址:
结合[weiqing]插件的伪静态,可以将微信账号作为个性化网址,微信账号文章列表支持分页。
4、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
5、每个页面内置多个DIY区域:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
6、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
本插件需要安装“[维清]WeChat文章采集器”才能使用。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(三)[维清]维文阅读中心
功能说明:
该插件主要提供兴趣管理功能。用户可以使用关键词订阅、文章采集、公众采集等功能自由管理自己的兴趣。设置好自己的兴趣后,可以直接在个人中心的兴趣内容中阅读自己的感受。方便用户从海量信息中快速找到自己喜欢的内容,增加用户粘性,吸引用户在你的网站上看到文章。安装这个插件,让用户有理由在你的网站上查看公众号文章。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为个人中心。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、页面名称等信息的变量替换。
3、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
这个插件只有安装了“[维清]WeChat文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(四)[维清]微信文章DIY
功能说明:
此扩展提供了对网站任何页面上的公众号信息和文章列表的访问。安装此扩展后,需要在后台更新缓存,勾选DIY模块分类缓存,点击提交更新。
这个扩展只有安装“[维清]微信文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(五)[维清]插件伪静态
功能说明:
本插件可以为【维清】全系列插件设置伪静态规则。启用此插件后,相关插件页面中的所有链接都将替换为静态链接。如果你安装了Wikin!插件二级域名插件如果为开启伪静态的插件设置了二级域名,链接也会自动添加到对应的二级域名中插入。此插件将在新插件上线时更新。
目前该插件可以为以下插件设置伪静态规则:
1.[维清]微信文章采集器:点击安装
2.[维清]微信导航:点击安装
3.[维清]万能帮助中心:点击安装
应用截图
下载链接:@weiqin
演示地址:
插入关键字 文章采集器(文章目录第一、WordPress自动关键字插件解决什么问题?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-31 17:00
最近一段时间,我们群很多WordPress网友都在讨论建立大数据网站,包括一些需要使用SEO工具的网友网站。有网友提到了WordPress网站的权重。例如,tags 关键字仍然更重要。有时,排名和收录 可能比某些文章 页面更好。所以希望有一个插件可以自动部署WordPress Tags关键字。
我们通过调查发现,WordPress中现有的Tag相关插件之一,虽然名为Auto Tags插件,但它只是采用了简单的分词技术,没有有效的索引词或长尾词随机插入标签。 ,这样的效果并不是用户所需要的。由于分词技术比较难,可以自行讨论是否做插件,自己设置需要的词,分配给文章。
一两周左右,从原来的关键词批量提交功能到自动插入单篇文章文章适合我们常规的网站需求,基本可以满足用户的需求。这篇文章文章在我们的WordPress笔记中,我们准备了图文介绍这个插件的功能,作者稍后会录制视频介绍。
文章directory
一、WordPress 自动关键词插件解决了什么问题?
我们在使用这个插件的时候,首先要了解这个插件可以解决什么问题。一般通过插件解决的问题,可能需要我们手动解决,然后再使用插件来提高效率。或者它可以自动帮助我们解决某些问题。毕竟,我们的站长用户并不都是程序员,也不是所有的人都会开发软件工具。
如果需要安装,搜索CNWPer SEO Tags发现已经推送到WP官方网站plugin平台。或者您可以加入我们的公众号和QQ群查看最新版本并与用户交流。
WordPress 自动关键词插件目前有两个功能:
1、Auto文章TAGS
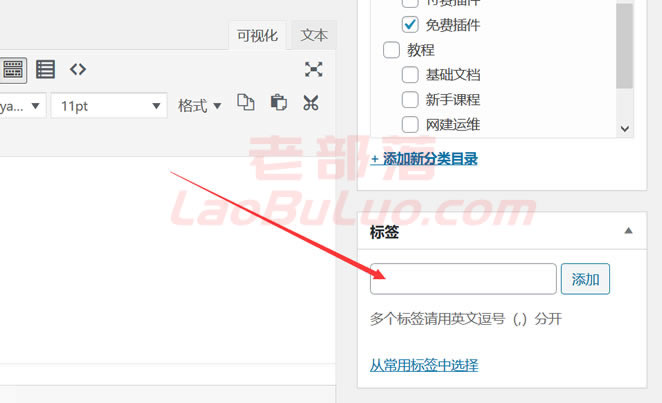
比如我们更新网站的时候,是不是我们手动插入了TAGS(标签),如上图所示。我们一般插入的TAGS都是文章相关的,或者自己设置的。一般网友肯定是后者。如果我们使用这个插件,我们可以预先设置网站的所有长尾词,然后根据我们添加的文章的标题、内容、随机性或严格匹配将它们自动插入标签中。当然,我们也可以在不影响它的情况下手工完成。
2、批量分配标签
特别是我们之前更新的一些文章,可能是因为自己的问题,没有有效的插入TAGS来达到内链的效果。如果我们在另一篇文章中打开文章设置,是不是很麻烦,有网友采集的几万个文章,再设置就更麻烦了。可以使用自动关键字插件,然后自动将需要插入的标签分配给指定的文章。
二、WordPress 自动关键字插件的使用
我们先介绍了当前WP自动关键字插件的基本功能,但还没有看到实际的产品。那么我们来实际看看这个插件的设置界面。
这是我们WP自动关键字插件的自动化功能。我们可以在添加文章时开始并预先设置需要随机插入的关键字,设置频率或匹配严格度,如果不勾选匹配严格度,则随机插入。并且我们还可以为单个文章设置最高标签阈值。
我们设置完成后,以后添加文章时,会自动插入已经设置好的标签关键字。当然,我们也可以在这个插件中开启TAGS自动内链功能。如果您的其他插件已经打开,则无需重复打开。
批量部署关键字工具是我们在WordPress站点中提到的TAGS标签关键字的文章随机部署或严格匹配部署。您可以设置频率和文章 范围。这个文章范围需要检查文章对应的ID。
需要注意的三、问题
这个WP自动关键词插件的初衷是为了帮助网友网站随机匹配文章相关关键词,加强内链和标签优化的效果。但是我们在使用的时候,不要在单个文章中插入过多的关键字,否则搜索引擎会认为是作弊。简而言之,插入关键字需要自然且相关。
你可以选择不使用插件,但是在使用的时候可以自己控制频率尺度,避免关键词堆砌过度,导致搜索引擎惩罚网站。我们不对这种行为和后果负责。我们可以加入公众号索取最新版本的插件。 查看全部
插入关键字 文章采集器(文章目录第一、WordPress自动关键字插件解决什么问题?(组图))
最近一段时间,我们群很多WordPress网友都在讨论建立大数据网站,包括一些需要使用SEO工具的网友网站。有网友提到了WordPress网站的权重。例如,tags 关键字仍然更重要。有时,排名和收录 可能比某些文章 页面更好。所以希望有一个插件可以自动部署WordPress Tags关键字。
我们通过调查发现,WordPress中现有的Tag相关插件之一,虽然名为Auto Tags插件,但它只是采用了简单的分词技术,没有有效的索引词或长尾词随机插入标签。 ,这样的效果并不是用户所需要的。由于分词技术比较难,可以自行讨论是否做插件,自己设置需要的词,分配给文章。
一两周左右,从原来的关键词批量提交功能到自动插入单篇文章文章适合我们常规的网站需求,基本可以满足用户的需求。这篇文章文章在我们的WordPress笔记中,我们准备了图文介绍这个插件的功能,作者稍后会录制视频介绍。
文章directory
一、WordPress 自动关键词插件解决了什么问题?
我们在使用这个插件的时候,首先要了解这个插件可以解决什么问题。一般通过插件解决的问题,可能需要我们手动解决,然后再使用插件来提高效率。或者它可以自动帮助我们解决某些问题。毕竟,我们的站长用户并不都是程序员,也不是所有的人都会开发软件工具。
如果需要安装,搜索CNWPer SEO Tags发现已经推送到WP官方网站plugin平台。或者您可以加入我们的公众号和QQ群查看最新版本并与用户交流。
WordPress 自动关键词插件目前有两个功能:
1、Auto文章TAGS
比如我们更新网站的时候,是不是我们手动插入了TAGS(标签),如上图所示。我们一般插入的TAGS都是文章相关的,或者自己设置的。一般网友肯定是后者。如果我们使用这个插件,我们可以预先设置网站的所有长尾词,然后根据我们添加的文章的标题、内容、随机性或严格匹配将它们自动插入标签中。当然,我们也可以在不影响它的情况下手工完成。
2、批量分配标签
特别是我们之前更新的一些文章,可能是因为自己的问题,没有有效的插入TAGS来达到内链的效果。如果我们在另一篇文章中打开文章设置,是不是很麻烦,有网友采集的几万个文章,再设置就更麻烦了。可以使用自动关键字插件,然后自动将需要插入的标签分配给指定的文章。
二、WordPress 自动关键字插件的使用
我们先介绍了当前WP自动关键字插件的基本功能,但还没有看到实际的产品。那么我们来实际看看这个插件的设置界面。
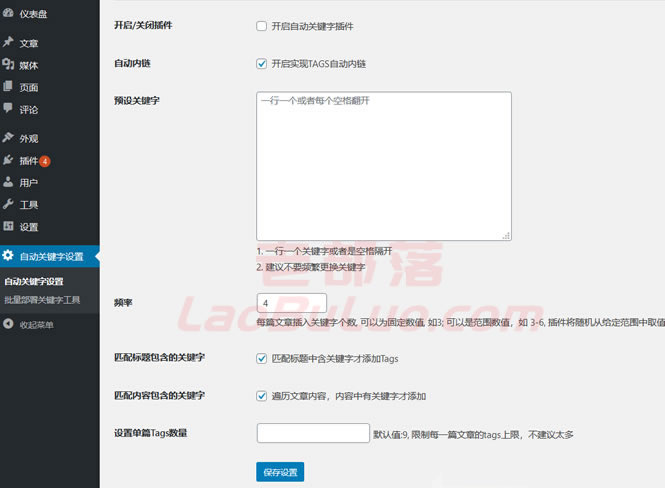
这是我们WP自动关键字插件的自动化功能。我们可以在添加文章时开始并预先设置需要随机插入的关键字,设置频率或匹配严格度,如果不勾选匹配严格度,则随机插入。并且我们还可以为单个文章设置最高标签阈值。
我们设置完成后,以后添加文章时,会自动插入已经设置好的标签关键字。当然,我们也可以在这个插件中开启TAGS自动内链功能。如果您的其他插件已经打开,则无需重复打开。
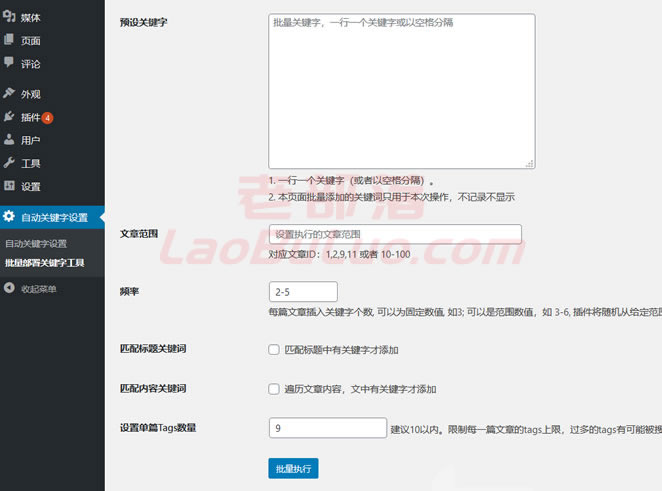
批量部署关键字工具是我们在WordPress站点中提到的TAGS标签关键字的文章随机部署或严格匹配部署。您可以设置频率和文章 范围。这个文章范围需要检查文章对应的ID。
需要注意的三、问题
这个WP自动关键词插件的初衷是为了帮助网友网站随机匹配文章相关关键词,加强内链和标签优化的效果。但是我们在使用的时候,不要在单个文章中插入过多的关键字,否则搜索引擎会认为是作弊。简而言之,插入关键字需要自然且相关。
你可以选择不使用插件,但是在使用的时候可以自己控制频率尺度,避免关键词堆砌过度,导致搜索引擎惩罚网站。我们不对这种行为和后果负责。我们可以加入公众号索取最新版本的插件。
插入关键字 文章采集器(WordPress关键字自动关键字插件的使用方法介绍及注意事项介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-29 15:02
在网站的过程中,我们站长会发现网站文章关键词添加得恰到好处,TAGS确实可以提高网站的搜索指数,而且排名有时可能会由关键词TAGS给出排名高于文章。按照正常的做法,每个文章我们会加三到五个关键词,当然是相关的关键词。
同时,我们也看到一些做采集类网站的站长和做垃圾站的站长,会通过批量TAGS堆叠实现大量的索引。当然,这种做法上次违反了百度的发布规则,并已陆续被打击。但是对于一些做站群或采集的人来说,他们不在乎,他们只需要意识到它。老佐这里介绍一个比较好的WordPress自动关键词插件,可以实现关键词自动内链,自动将相关的随机关键词插入网站文章的TAGS标签。
我们来看看这个插件的功能。估计还有很多网友没有找到。找到了需要的,等不及的可以用一下,尤其采集类网站真的很有帮助。
插件地址:
插件已经在官方WordPress直接发布,我们可以直接下载使用。
我们可以看到自动TAGS内链是可以开启的。并且可以预设关键词,然后在添加文章时自动分配给文章,可以按照绝对匹配标题和内容,随机匹配。可设置最大TAGS数。
文章更新后,我们可以随机或自动匹配到对应的文章,并且可以设置文章的ID范围进行匹配和添加。
总之,这款WordPress关键词自动插件适合需要添加TAGS标签关键词,以及后续添加网站关键词,以及使用自动TAGS内链的用户。 查看全部
插入关键字 文章采集器(WordPress关键字自动关键字插件的使用方法介绍及注意事项介绍)
在网站的过程中,我们站长会发现网站文章关键词添加得恰到好处,TAGS确实可以提高网站的搜索指数,而且排名有时可能会由关键词TAGS给出排名高于文章。按照正常的做法,每个文章我们会加三到五个关键词,当然是相关的关键词。
同时,我们也看到一些做采集类网站的站长和做垃圾站的站长,会通过批量TAGS堆叠实现大量的索引。当然,这种做法上次违反了百度的发布规则,并已陆续被打击。但是对于一些做站群或采集的人来说,他们不在乎,他们只需要意识到它。老佐这里介绍一个比较好的WordPress自动关键词插件,可以实现关键词自动内链,自动将相关的随机关键词插入网站文章的TAGS标签。
我们来看看这个插件的功能。估计还有很多网友没有找到。找到了需要的,等不及的可以用一下,尤其采集类网站真的很有帮助。
插件地址:
插件已经在官方WordPress直接发布,我们可以直接下载使用。
我们可以看到自动TAGS内链是可以开启的。并且可以预设关键词,然后在添加文章时自动分配给文章,可以按照绝对匹配标题和内容,随机匹配。可设置最大TAGS数。
文章更新后,我们可以随机或自动匹配到对应的文章,并且可以设置文章的ID范围进行匹配和添加。
总之,这款WordPress关键词自动插件适合需要添加TAGS标签关键词,以及后续添加网站关键词,以及使用自动TAGS内链的用户。
插入关键字 文章采集器(本文原创助手:为你打造爆款文章,实现流量变现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 556 次浏览 • 2021-08-29 14:16
原创助是伪原创文章生成器的新媒体运营工具,一键群发助手,让你的文章在搜索引擎和新媒体上获得海量流量排名。
伪原创是指重新处理一个原创文章,让搜索引擎认为它是一个原创文章,从而增加网站文章的权重。有两种编辑方式:修改标题关键词和总结首尾段落。指代数法、换词法、文字排序法、首段汇总法、尾汇总法、新增图片、段落替换法、关键词替换法。
原创auxiliary 提供优秀的中文语义分析技术。通过自主研发的中文分词、句法分析、语义关联和实体识别技术,结合海量行业术语的不断积累,为用户提供简单易用的原创Service。最后,帮助您的公众号创建爆文,高效运营,增加粉丝活跃度,实现流量变现。
原创auxiliary 是一个非常有用的 SEO 工具。它是生成原创和伪原创文章的工具。 伪原创工具可以瞬间改变网上复制的文章。成为你自己的原创文章。本软件通过在线伪原创工具生成的文章会更好地被搜索引擎收录收录。在线伪原创工具是网络编辑、站长和SEO必不可少的工具,也是网站优化工具中很多大牛推荐的工具。
使用方法:
微信先一、搜索【原创助】
寻找同行二、或者其他你认为好的文章,复制到原创auxiliary,然后选择对应的接口生成自己的原创
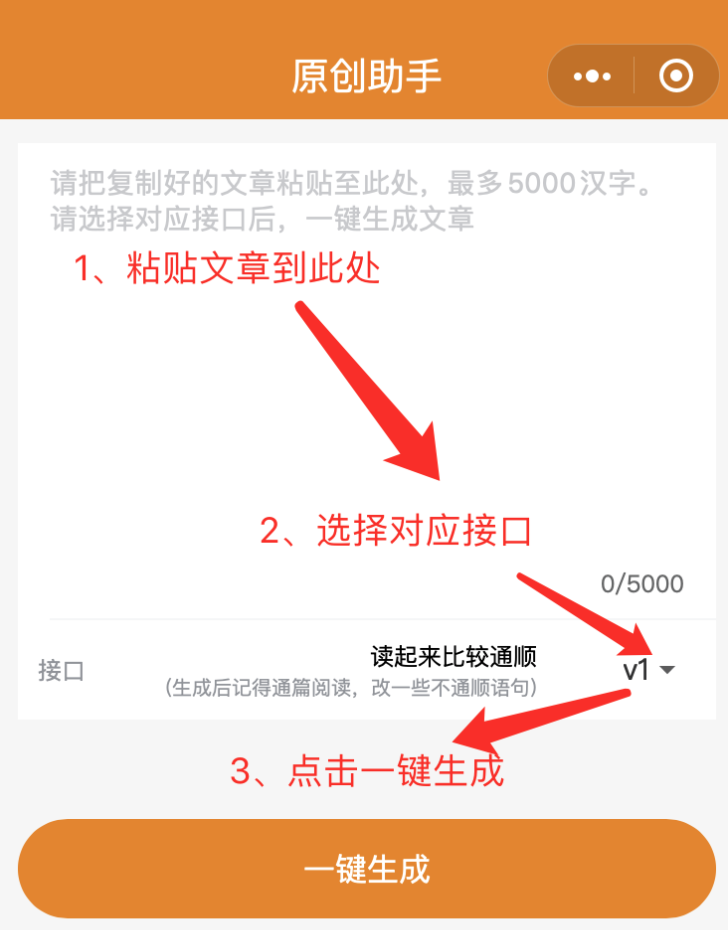
生成三、后一键复制,记得看全文,改一些不合适的地方,就OK了。
本文原创展示效果
公众号文章帮_运营辅助_原创帮原创帮:为你打造爆款文章,实现流量变现。最后祝大家粉丝多多赚钱 查看全部
插入关键字 文章采集器(本文原创助手:为你打造爆款文章,实现流量变现)
原创助是伪原创文章生成器的新媒体运营工具,一键群发助手,让你的文章在搜索引擎和新媒体上获得海量流量排名。
伪原创是指重新处理一个原创文章,让搜索引擎认为它是一个原创文章,从而增加网站文章的权重。有两种编辑方式:修改标题关键词和总结首尾段落。指代数法、换词法、文字排序法、首段汇总法、尾汇总法、新增图片、段落替换法、关键词替换法。

原创auxiliary 提供优秀的中文语义分析技术。通过自主研发的中文分词、句法分析、语义关联和实体识别技术,结合海量行业术语的不断积累,为用户提供简单易用的原创Service。最后,帮助您的公众号创建爆文,高效运营,增加粉丝活跃度,实现流量变现。
原创auxiliary 是一个非常有用的 SEO 工具。它是生成原创和伪原创文章的工具。 伪原创工具可以瞬间改变网上复制的文章。成为你自己的原创文章。本软件通过在线伪原创工具生成的文章会更好地被搜索引擎收录收录。在线伪原创工具是网络编辑、站长和SEO必不可少的工具,也是网站优化工具中很多大牛推荐的工具。

使用方法:
微信先一、搜索【原创助】
寻找同行二、或者其他你认为好的文章,复制到原创auxiliary,然后选择对应的接口生成自己的原创
生成三、后一键复制,记得看全文,改一些不合适的地方,就OK了。
本文原创展示效果
公众号文章帮_运营辅助_原创帮原创帮:为你打造爆款文章,实现流量变现。最后祝大家粉丝多多赚钱
前台发帖时可采集单篇微信文章的功能介绍及使用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-26 03:20
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。
查看全部
前台发帖时可采集单篇微信文章的功能介绍及使用方法
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。

基于高精度识别识别算法的互联网文章采集器文章提取算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-25 20:52
优采云万能文章采集器是一个基于高精度文本识别算法文章采集器的互联网。支持关键词采集百度等搜索引擎的新闻源()和泛页(),支持采集designated网站栏目下的所有文章。
软件介绍:
优采云software 是首创的独家智能通用算法,可准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
功能说明:
什么是高精度文本识别算法
该算法由优采云自主研发,可以从网页中提取正文部分,通常准确率为95%。如果进一步设置最小字数,采集文章的准确率(正确性)可以达到99%。同时文章Title也达到了99%的提取准确率。当然,当一些网页的布局格式混乱、不规则时,可能会降低准确率。
文本提取模式
文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不可用时,您可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
采集 处理选项
采集 可以同时翻译、过滤和搜索单词。对于采集好文章,您可以使用“本地批处理”。
翻译功能是将中文翻译成英文再翻译回中文,产生伪原创效果。支持原创格式翻译,即文章的原创标签结构和排版格式不会改变。
采集Target 是网址
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
分页采集和相对路径转换为绝对路径
勾选“自动采集page”合并分页文章采集,并在编辑框中设置采集pages的最大数量。建议设置一个有限的值,比如10页,避免一些采集分页太多耗时长,合并后的文章体积大。如果需要采集所有页面,可以设置为0。
并且文章中的所有相对路径都会自动转换为绝对路径,可以保证图片等的正常显示
多线程
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
文章Title 和文章 内容重复处理
程序可以智能判断过滤重复文章
当采集到达的文章标题(文件名)与本地保存的文章标题相同时,优采云会首先判断两个文章的相似度,当相似度较大时大于60% 当判断优采云是同一个文章时,再比较两个文章的文字大小,自动用文字较多的文章覆盖写入同一个文件名。这个世代情况加起来不及世代数。
而当相似度小于60%时,优采云判断与文章不同,会自动重命名标题(标题末尾随机取3到5个字母)并保存到文件。
文章快速过滤
优采云虽然研究了高精度的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果的字数来提高准确率(在“最小文本字符数”参数中,这个字数就是程序去掉标签、行、空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
生成文章数量可变的问题
百度和搜搜默认每页 100 个结果,Google 默认每页 10 个结果。
有些网站访问速度超时(尤其是很多谷歌收录被一些网站屏蔽了),或者设置了body的最少字数,或者程序忽略了里面同名的相似内容local文章,或者黑名单和白名单过滤等,会导致实际生成文章数低于每页搜索的最大结果数。
总体来说,百度采集质量最好,生成的文章数量接近搜索结果数量。
更新日志:
1.12:继续增强web批处理栏目URL采集器识别文章URL的能力,支持多种地址格式同时匹配
1.11:增强网络批处理中文章URL列URL采集器的识别能力
1.10:修复翻译功能无法翻译的问题 查看全部
基于高精度识别识别算法的互联网文章采集器文章提取算法
优采云万能文章采集器是一个基于高精度文本识别算法文章采集器的互联网。支持关键词采集百度等搜索引擎的新闻源()和泛页(),支持采集designated网站栏目下的所有文章。
软件介绍:
优采云software 是首创的独家智能通用算法,可准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
功能说明:
什么是高精度文本识别算法
该算法由优采云自主研发,可以从网页中提取正文部分,通常准确率为95%。如果进一步设置最小字数,采集文章的准确率(正确性)可以达到99%。同时文章Title也达到了99%的提取准确率。当然,当一些网页的布局格式混乱、不规则时,可能会降低准确率。
文本提取模式
文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不可用时,您可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
采集 处理选项
采集 可以同时翻译、过滤和搜索单词。对于采集好文章,您可以使用“本地批处理”。
翻译功能是将中文翻译成英文再翻译回中文,产生伪原创效果。支持原创格式翻译,即文章的原创标签结构和排版格式不会改变。
采集Target 是网址
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
分页采集和相对路径转换为绝对路径
勾选“自动采集page”合并分页文章采集,并在编辑框中设置采集pages的最大数量。建议设置一个有限的值,比如10页,避免一些采集分页太多耗时长,合并后的文章体积大。如果需要采集所有页面,可以设置为0。
并且文章中的所有相对路径都会自动转换为绝对路径,可以保证图片等的正常显示
多线程
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
文章Title 和文章 内容重复处理
程序可以智能判断过滤重复文章
当采集到达的文章标题(文件名)与本地保存的文章标题相同时,优采云会首先判断两个文章的相似度,当相似度较大时大于60% 当判断优采云是同一个文章时,再比较两个文章的文字大小,自动用文字较多的文章覆盖写入同一个文件名。这个世代情况加起来不及世代数。
而当相似度小于60%时,优采云判断与文章不同,会自动重命名标题(标题末尾随机取3到5个字母)并保存到文件。
文章快速过滤
优采云虽然研究了高精度的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果的字数来提高准确率(在“最小文本字符数”参数中,这个字数就是程序去掉标签、行、空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
生成文章数量可变的问题
百度和搜搜默认每页 100 个结果,Google 默认每页 10 个结果。
有些网站访问速度超时(尤其是很多谷歌收录被一些网站屏蔽了),或者设置了body的最少字数,或者程序忽略了里面同名的相似内容local文章,或者黑名单和白名单过滤等,会导致实际生成文章数低于每页搜索的最大结果数。
总体来说,百度采集质量最好,生成的文章数量接近搜索结果数量。
更新日志:
1.12:继续增强web批处理栏目URL采集器识别文章URL的能力,支持多种地址格式同时匹配
1.11:增强网络批处理中文章URL列URL采集器的识别能力
1.10:修复翻译功能无法翻译的问题
1.快速使用说明模拟了浏览器的设计,2.高级配置介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-24 18:08
1.快速使用说明模拟了浏览器的设计,2.高级配置介绍
网页采集器
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
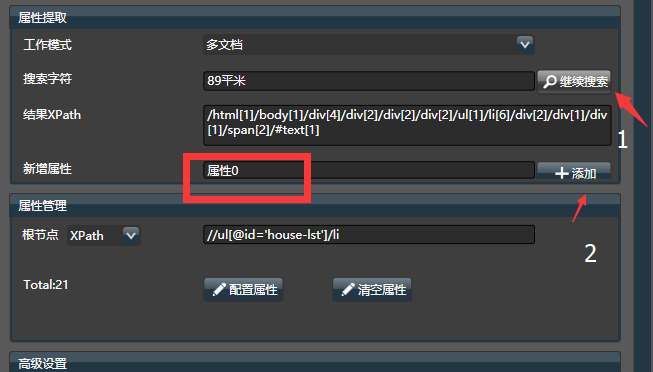
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
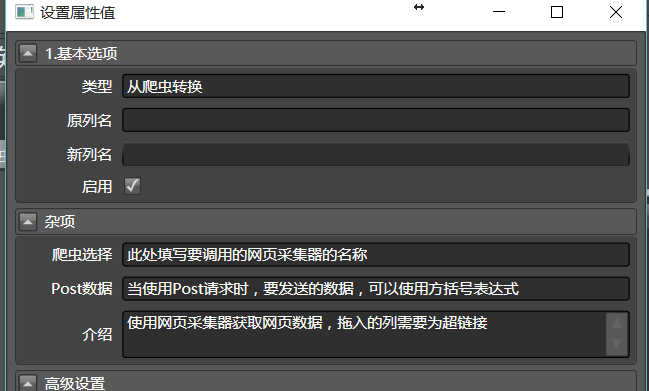
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。添加一个属性,如果你觉得幸运,你可以更准确地进行。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。为了解决这个问题,将关键字添加到搜索字符中,此时不要添加到属性列表中,只需点击我很幸运。
4.3.手动模式
当你感觉运气不好不能工作或不符合预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并在网页上获取位置(XPath)。填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。 Hawk 简化了流程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,从而实现属性抽取,感觉很幸运。超级模式极大地简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
关于其使用的更多细节,请参阅章节。
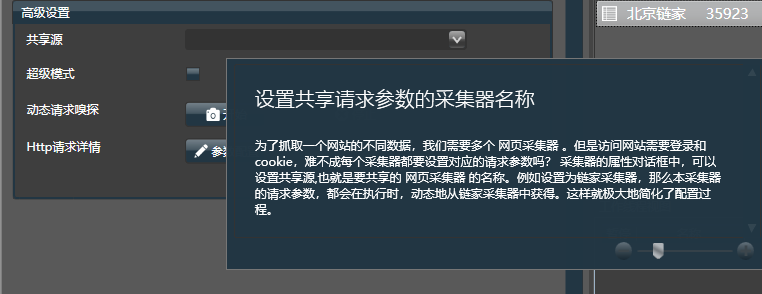
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程。当然,大多数情况不需要这么复杂,记住以下几点即可:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
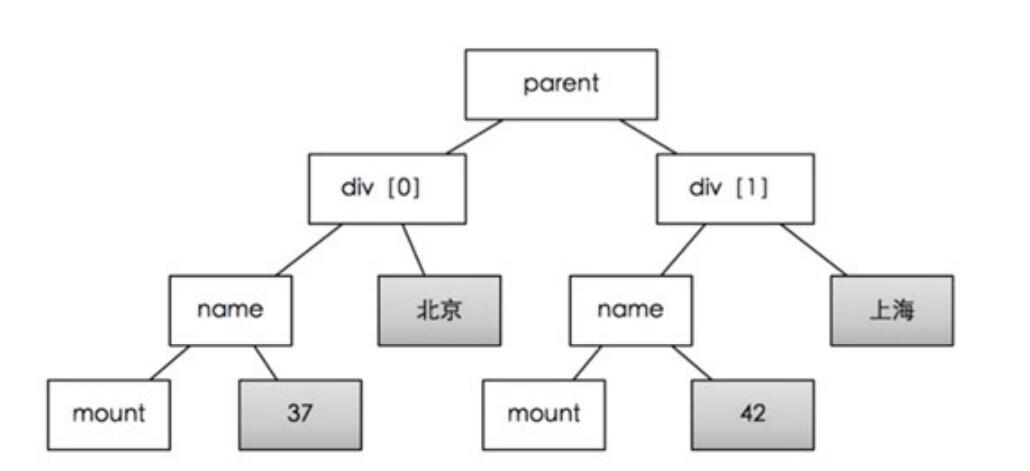
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。 查看全部
1.快速使用说明模拟了浏览器的设计,2.高级配置介绍
网页采集器
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。添加一个属性,如果你觉得幸运,你可以更准确地进行。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。为了解决这个问题,将关键字添加到搜索字符中,此时不要添加到属性列表中,只需点击我很幸运。
4.3.手动模式
当你感觉运气不好不能工作或不符合预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并在网页上获取位置(XPath)。填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。 Hawk 简化了流程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,从而实现属性抽取,感觉很幸运。超级模式极大地简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
关于其使用的更多细节,请参阅章节。
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程。当然,大多数情况不需要这么复杂,记住以下几点即可:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。
优采云万能文章采集器智能提取网页正文的算法(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-24 18:04
优采云万能文章采集器有利于各大搜索引擎采集文件和添加工具制作,使用可以提取网页正文的算法,多语种翻译,保证采集的制作文章能比原创。如果你需要很多原创文章,那就选择优采云万能文章采集器。
优采云万能文章采集器是一款只需要输入关键词即可获取采集各大搜索引擎新闻源和网页的软件。 优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。支持去除标签、链接、邮箱、插入关键词功能等格式化处理,可以识别旁边要插入的标签或标点符号,可以识别英文空格的插入。还有文章翻译功能,即文章可以从中文等一种语言转成英文或日文等另一种语言,再从英文或日文转回中文。这是一个翻译周期,可以设置翻译周期循环多次(翻译次数)。
优采云万能文章采集器 智能提取网页正文的算法。百度新闻、谷歌新闻、搜搜新闻强聚合不时更新的新闻资源,不竭不竭多语翻译伪原创。你,输入关键词
软件功能
1.优采云第一个提取网页正文的通用算法
2.百度引擎、谷歌引擎、搜索引擎强大聚合
3.时时时时彩不定期更新文章资源,取之不尽,用之不竭
4.智能采集any网站的文章column 文章resources
5.多语种翻译伪原创。你,输入关键词
功能范围
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集信息材料过滤提炼
更新日志
URL采集文章面板精准标签添加模糊匹配功能;增加定时任务功能,可设置多个时间点,自动启动采集(当前显示面板采集的启动)。
v3.0.8.0
添加一些用采集处理过的网站加强采集。 查看全部
优采云万能文章采集器智能提取网页正文的算法(组图)
优采云万能文章采集器有利于各大搜索引擎采集文件和添加工具制作,使用可以提取网页正文的算法,多语种翻译,保证采集的制作文章能比原创。如果你需要很多原创文章,那就选择优采云万能文章采集器。
优采云万能文章采集器是一款只需要输入关键词即可获取采集各大搜索引擎新闻源和网页的软件。 优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。支持去除标签、链接、邮箱、插入关键词功能等格式化处理,可以识别旁边要插入的标签或标点符号,可以识别英文空格的插入。还有文章翻译功能,即文章可以从中文等一种语言转成英文或日文等另一种语言,再从英文或日文转回中文。这是一个翻译周期,可以设置翻译周期循环多次(翻译次数)。
优采云万能文章采集器 智能提取网页正文的算法。百度新闻、谷歌新闻、搜搜新闻强聚合不时更新的新闻资源,不竭不竭多语翻译伪原创。你,输入关键词
软件功能
1.优采云第一个提取网页正文的通用算法
2.百度引擎、谷歌引擎、搜索引擎强大聚合
3.时时时时彩不定期更新文章资源,取之不尽,用之不竭
4.智能采集any网站的文章column 文章resources
5.多语种翻译伪原创。你,输入关键词
功能范围
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集信息材料过滤提炼
更新日志
URL采集文章面板精准标签添加模糊匹配功能;增加定时任务功能,可设置多个时间点,自动启动采集(当前显示面板采集的启动)。
v3.0.8.0
添加一些用采集处理过的网站加强采集。
[模块和算子]常见问题更新日志作者和捐赠列表专题
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-24 18:03
【模块与运营商】常见问题更新日志作者及捐赠名单 主题:案例:Post文章:故事:Webpage采集器
网页采集器主界面
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容
我在单文档模式下感觉很幸运
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。
可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
请求配置
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
我感觉很幸运的配置
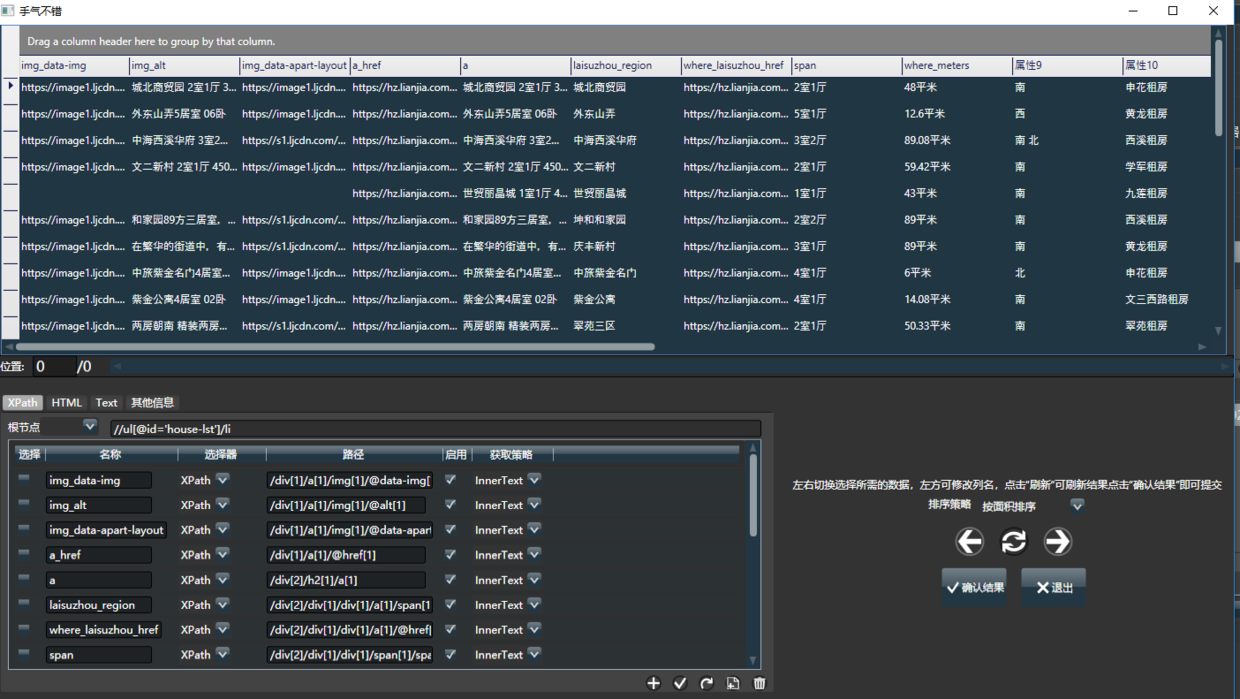
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。
添加一个属性,运气好的话可以做的更准确。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。
为了解决这个问题,在搜索字符中添加关键字。此时不要将其添加到属性列表中,只需单击“手气不错”即可。
我在单文档模式下感觉很幸运
4.3.手动模式
当你运气好,不能工作或没有达到预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并获取网页上的位置(XPath)。
填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
手动添加属性
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。
Hawk 简化了过程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
网页采集器请求设置
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是然后页面的内容是通过ajax单独返回的。
有时候很多XPath的开发是针对第一页做的,但是最后我发现在其他页面上用不了,主要是因为上面提到的问题(一脸懵逼)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
超级模式大大简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
有关其使用的更多详细信息,请参阅动态嗅探一章。
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
按钮上自动弹出帮助
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程
当然,大多数情况不需要那么复杂,只要记住以下几点:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
我很幸运
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。 查看全部
[模块和算子]常见问题更新日志作者和捐赠列表专题
【模块与运营商】常见问题更新日志作者及捐赠名单 主题:案例:Post文章:故事:Webpage采集器

网页采集器主界面
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容

我在单文档模式下感觉很幸运
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。
可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
请求配置
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
我感觉很幸运的配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。
添加一个属性,运气好的话可以做的更准确。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。
为了解决这个问题,在搜索字符中添加关键字。此时不要将其添加到属性列表中,只需单击“手气不错”即可。
我在单文档模式下感觉很幸运
4.3.手动模式
当你运气好,不能工作或没有达到预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并获取网页上的位置(XPath)。
填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
手动添加属性
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。
Hawk 简化了过程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
网页采集器请求设置
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是然后页面的内容是通过ajax单独返回的。
有时候很多XPath的开发是针对第一页做的,但是最后我发现在其他页面上用不了,主要是因为上面提到的问题(一脸懵逼)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
超级模式大大简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
有关其使用的更多详细信息,请参阅动态嗅探一章。
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
按钮上自动弹出帮助
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程
当然,大多数情况不需要那么复杂,只要记住以下几点:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
我很幸运
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。
软件介绍优采云软件出品的一款万能文章采集软件,更多特点一试就知
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-23 20:01
软件介绍
优采云software出品的万能文章采集software,只需输入关键词就可以采集各种网页和新闻,还可以采集指定列表页(栏目页) 文章。
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.史上最简单最智能文章采集器,更多功能一目了然!
问题重点:
采集设置的黑名单有误
在[采集Settings]中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数而不是实际采集进程.
下载地址
非 VIP 用户下载我们的软件,不提供任何服务。本站只为付费会员服务!售前客服
下载地址1 下载地址2 下载地址3
VIP办理联系售前客服 查看全部
软件介绍优采云软件出品的一款万能文章采集软件,更多特点一试就知
软件介绍
优采云software出品的万能文章采集software,只需输入关键词就可以采集各种网页和新闻,还可以采集指定列表页(栏目页) 文章。
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.史上最简单最智能文章采集器,更多功能一目了然!
问题重点:
采集设置的黑名单有误
在[采集Settings]中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数而不是实际采集进程.





下载地址
非 VIP 用户下载我们的软件,不提供任何服务。本站只为付费会员服务!售前客服
下载地址1 下载地址2 下载地址3
VIP办理联系售前客服
一个采集器采集规则怎么写呢?小编来教你如何解决
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-22 02:16
大规模信息网站发布文章时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集Rules 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集node管理>>添加新节点>>选择normal文章>>OK
第2步:填写采集list规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:在文章content前后找两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
... 查看全部
一个采集器采集规则怎么写呢?小编来教你如何解决
大规模信息网站发布文章时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集Rules 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集node管理>>添加新节点>>选择normal文章>>OK
第2步:填写采集list规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:在文章content前后找两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
...
自定义采集模式中文件导入大批量网址、批量生成的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-08-21 00:07
本文介绍了如何在自定义采集模式下,从文件中导入大量网址,批量生成网址,以及在关联任务中导入网址。
采集data时,很多用户都会遇到这种情况:
优采云通过升级优化自定义采集 URL的输入,有效解决了上述问题,主要有以下三个功能。
1、File 导入大量网址
目前手动输入支持的网址数量有限。如果有大量的URL,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行批量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的url,超过100w的会自动删除
2、Bulk URL 生成
当多个页面需要同时在同一个网站中采集时,我们可以使用该功能批量生成网址,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以设置定义的逻辑自动生成,然后可以使用云端采集拆分原理采集任务,大大提高采集的效率。
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
以京东的网页为例:
这是京东iphone的第三页网址为关键词,我们可以按照这个格式替换关键词生成多个产品的网址,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充。
字母变化:从字母到字母
时间变化:可设置时间段变化
自定义列表:你可以把一些你需要的关键词作为URL参数的一部分
自定义列表
由于本例中设置了关键词,所以参数类型选择“自定义列表”,在下框中填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击确定。
数量变化
同理,选择页码,点击添加参数,设置与页码相关的参数。这里,参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页开始采集,则起始值为1;变化为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。<//p
pimg src='http://www.bazhuayu.com/media/117260/image5.png' alt=''//p
p设置好参数后,可以预览生成的网址。如下图所示/p
pimg src='http://www.bazhuayu.com/media/117261/image6.png' alt=''//p
p在京东这个例子中,只需要设置这两个参数。我们来看看另外两个。/p
p字母变化/p
pimg src='http://www.bazhuayu.com/media/117262/image7.png' alt=''//p
p同上,字母变化是根据变化规律从a设置到某个字母/p
p时间变化/p
pimg src='http://www.bazhuayu.com/media/117263/image8.png' alt=''//p
p如上图,选择合适的时间格式,然后设置开始时间和结束时间。/p
p注意:/p
p可支持批量生成100W以内的URL,超过100W只生成100W。/p
p批量生成的前100个URL保存在本地并显示在界面上; > 100 个 URL 存储在云中,不在界面上显示。使用本地采集或云端采集时,存储直接调用云端的URL采集数据。
如果您复制此规则,则复制的规则将仅收录前 100 个网址和采集前 100 个网址的数据。
3、Linked 任务导入地址
还有另一种导入 URL 的方法。可以从其他任务采集中选择URL直接导入关联采集。例如,如果一个任务同时是采集list 页面和详情页面,则无法通过云采集 进行拆分。如果使用关联采集的功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分,采集效率为改进了很多(注意如果采集网站list页面进入详情页,URL不变,不能使用此方法)
具体操作如下:
在自定义模式入口选择“从任务导入”
我们将导入的任务称为“源任务”,导入URL后的新配置称为“跟随任务”
然后使用下拉箭头选择采集tasks和字段,就可以完全导入源任务采集的URL了。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动采集时可以选择“按照启动设置”
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置关注开始
注意:后续任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL采集”,优采云会采集任务导入的所有URL;如果选择“Only 采集preview URLs”,优采云 将采集此任务最多 100 个预览 URL
提醒:只有终极版(上)包的用户才支持相关任务的导入。去升级旗舰版 查看全部
自定义采集模式中文件导入大批量网址、批量生成的功能
本文介绍了如何在自定义采集模式下,从文件中导入大量网址,批量生成网址,以及在关联任务中导入网址。
采集data时,很多用户都会遇到这种情况:
优采云通过升级优化自定义采集 URL的输入,有效解决了上述问题,主要有以下三个功能。
1、File 导入大量网址
目前手动输入支持的网址数量有限。如果有大量的URL,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行批量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的url,超过100w的会自动删除
2、Bulk URL 生成
当多个页面需要同时在同一个网站中采集时,我们可以使用该功能批量生成网址,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以设置定义的逻辑自动生成,然后可以使用云端采集拆分原理采集任务,大大提高采集的效率。
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
以京东的网页为例:
这是京东iphone的第三页网址为关键词,我们可以按照这个格式替换关键词生成多个产品的网址,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充。
字母变化:从字母到字母
时间变化:可设置时间段变化
自定义列表:你可以把一些你需要的关键词作为URL参数的一部分
自定义列表
由于本例中设置了关键词,所以参数类型选择“自定义列表”,在下框中填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击确定。
数量变化
同理,选择页码,点击添加参数,设置与页码相关的参数。这里,参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页开始采集,则起始值为1;变化为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。<//p
pimg src='http://www.bazhuayu.com/media/117260/image5.png' alt=''//p
p设置好参数后,可以预览生成的网址。如下图所示/p
pimg src='http://www.bazhuayu.com/media/117261/image6.png' alt=''//p
p在京东这个例子中,只需要设置这两个参数。我们来看看另外两个。/p
p字母变化/p
pimg src='http://www.bazhuayu.com/media/117262/image7.png' alt=''//p
p同上,字母变化是根据变化规律从a设置到某个字母/p
p时间变化/p
pimg src='http://www.bazhuayu.com/media/117263/image8.png' alt=''//p
p如上图,选择合适的时间格式,然后设置开始时间和结束时间。/p
p注意:/p
p可支持批量生成100W以内的URL,超过100W只生成100W。/p
p批量生成的前100个URL保存在本地并显示在界面上; > 100 个 URL 存储在云中,不在界面上显示。使用本地采集或云端采集时,存储直接调用云端的URL采集数据。
如果您复制此规则,则复制的规则将仅收录前 100 个网址和采集前 100 个网址的数据。
3、Linked 任务导入地址
还有另一种导入 URL 的方法。可以从其他任务采集中选择URL直接导入关联采集。例如,如果一个任务同时是采集list 页面和详情页面,则无法通过云采集 进行拆分。如果使用关联采集的功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分,采集效率为改进了很多(注意如果采集网站list页面进入详情页,URL不变,不能使用此方法)
具体操作如下:
在自定义模式入口选择“从任务导入”
我们将导入的任务称为“源任务”,导入URL后的新配置称为“跟随任务”
然后使用下拉箭头选择采集tasks和字段,就可以完全导入源任务采集的URL了。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动采集时可以选择“按照启动设置”
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置关注开始
注意:后续任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL采集”,优采云会采集任务导入的所有URL;如果选择“Only 采集preview URLs”,优采云 将采集此任务最多 100 个预览 URL
提醒:只有终极版(上)包的用户才支持相关任务的导入。去升级旗舰版
插入关键字 文章采集器(最近几个月群里讨论网站采集、站群大数据的比较多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-10 19:07
最近几个月,群里有很多关于网站采集和站群big data的讨论。有网友问能不能做一个WordPress标签关键词自动分发插件。一、可以更新文章时,将预先存储的关键字分发给更新后的文章,而不是手动发布。毕竟他们的文章数据量很大,而且大部分都是靠堆叠TAG,当然最好建议相关关键词更健壮。
同时,对于现有的文章或者文章没有添加标签关键字的,可以批量添加关键字吗?有的可以随意添加或者相关,于是这个WP自动关键词插件就应运而生了。目前,上述功能基本满足了,一起来看看吧。
我们可以检查它是否在开启后生效。同时自带TAGS自动内链功能,可以保留我们准备的关键词。并且我们可以设置频率,确保不堆关键字,因为目前百度等搜索引擎对堆关键字有处罚。
我们还可以设置标题和内容相匹配,以保证关键词的相关性。并设置单篇文章的关键词数量。比如我们看到一些博主理解的关键词有十、几百个。其实这些都是作弊,百度一旦发现就会直接用作弊来降低自己的权利。
文章 发布后,我们可以在现有的文章 范围内随机添加关键字。这个插件是我们需要的吗?
插件下载链接:
插件已经上传到官方WP平台,我们可以下载,但是需要获取最新的等插件产品。建议关注公众号获取最新版本。 查看全部
插入关键字 文章采集器(最近几个月群里讨论网站采集、站群大数据的比较多)
最近几个月,群里有很多关于网站采集和站群big data的讨论。有网友问能不能做一个WordPress标签关键词自动分发插件。一、可以更新文章时,将预先存储的关键字分发给更新后的文章,而不是手动发布。毕竟他们的文章数据量很大,而且大部分都是靠堆叠TAG,当然最好建议相关关键词更健壮。
同时,对于现有的文章或者文章没有添加标签关键字的,可以批量添加关键字吗?有的可以随意添加或者相关,于是这个WP自动关键词插件就应运而生了。目前,上述功能基本满足了,一起来看看吧。
我们可以检查它是否在开启后生效。同时自带TAGS自动内链功能,可以保留我们准备的关键词。并且我们可以设置频率,确保不堆关键字,因为目前百度等搜索引擎对堆关键字有处罚。
我们还可以设置标题和内容相匹配,以保证关键词的相关性。并设置单篇文章的关键词数量。比如我们看到一些博主理解的关键词有十、几百个。其实这些都是作弊,百度一旦发现就会直接用作弊来降低自己的权利。
文章 发布后,我们可以在现有的文章 范围内随机添加关键字。这个插件是我们需要的吗?
插件下载链接:
插件已经上传到官方WP平台,我们可以下载,但是需要获取最新的等插件产品。建议关注公众号获取最新版本。
插入关键字 文章采集器(python爬虫代理池(代理ip池)是怎么实现的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-10 11:04
插入关键字文章采集器因其数据爬取、关键字识别、排序等能力,全网海量数据都能爬取下来,只要多研究,多分析,总能找到好玩的技术。用文章分析来说,python爬虫的时候,有时候需要对关键字做性能上的优化。python爬虫只有通过你爬取的文章并将爬取的内容通过文章分析器获取到,才能正式爬取进来。那么怎么爬呢?通过代码爬取不好爬取,又像网页上的代码,要每个网页都爬一遍的话太麻烦,因此有人就写了python爬虫代理池(代理ip池)。
那么代理池是做什么的呢?说白了就是互联网上提供商家帮我们不下载网页,只是来抓取网页上的内容,来帮我们代理抓取文章。而我们直接可以在公众号上采集有相关文章的所有代理,然后拿到爬虫代理池来和公众号对接,就可以通过代理池来进行公众号爬取文章。有点:基本比原来的抓取下来的内容全,代理不需要重复利用;代理池中的代理不需要你去下载,代理ip也不需要你自己单独购买,但是其中的代理内容还是需要你自己采集的,这一点比下面我要介绍的e-site即代理ip池好。
代理池是怎么实现的呢?在你关注公众号进入公众号,在公众号文章列表下,点击“历史文章”“加入代理池”,点击“立即加入”即可。操作方法:公众号或者文章列表页点击“历史文章”点击“加入代理池”点击立即加入代理池。关键字识别爬虫又出现了,要抓取哪些文章,按照公众号后台的提示,输入相关关键字,例如“面膜”输入“保湿”关键字验证码即可获取对应的“面膜”文章列表。
微信搜索微信公众号e-site,获取代理列表后即可采集。分析代理池示例:先看一下代理池的运行过程,首先检查一下这个代理池:打开公众号后台,查看历史发文(自定义文章列表页)检查代理列表,检查代理池中有没有我们需要的文章,一个一个试还是太麻烦。那么代理池中会有哪些内容呢?新关注公众号首页:"历史文章列表页"右下角会有个更多关注公众号,点击更多关注我。
一个一个输入关键字尝试下,会获取到更多文章,等待浏览中。关注公众号列表页第2个:检查一下我们的关键字“面膜”,获取到全部的文章列表,这里有一个重复的关键字,因此我们只获取第一个即代理列表的第一个文章。然后我们点击原来我们加入的关键字“面膜”,很好,跳转页面到新的关键字页面。这时候点击更多关注,这时候你发现原来我们加入的关键字“面膜”已经不在了,因为文章列表已经改变,我们想下次加入代理的时候再更新。那么我们不要更新关键字为“面膜”,什么样才不需要修改关键字呢?看上面我。 查看全部
插入关键字 文章采集器(python爬虫代理池(代理ip池)是怎么实现的)
插入关键字文章采集器因其数据爬取、关键字识别、排序等能力,全网海量数据都能爬取下来,只要多研究,多分析,总能找到好玩的技术。用文章分析来说,python爬虫的时候,有时候需要对关键字做性能上的优化。python爬虫只有通过你爬取的文章并将爬取的内容通过文章分析器获取到,才能正式爬取进来。那么怎么爬呢?通过代码爬取不好爬取,又像网页上的代码,要每个网页都爬一遍的话太麻烦,因此有人就写了python爬虫代理池(代理ip池)。
那么代理池是做什么的呢?说白了就是互联网上提供商家帮我们不下载网页,只是来抓取网页上的内容,来帮我们代理抓取文章。而我们直接可以在公众号上采集有相关文章的所有代理,然后拿到爬虫代理池来和公众号对接,就可以通过代理池来进行公众号爬取文章。有点:基本比原来的抓取下来的内容全,代理不需要重复利用;代理池中的代理不需要你去下载,代理ip也不需要你自己单独购买,但是其中的代理内容还是需要你自己采集的,这一点比下面我要介绍的e-site即代理ip池好。
代理池是怎么实现的呢?在你关注公众号进入公众号,在公众号文章列表下,点击“历史文章”“加入代理池”,点击“立即加入”即可。操作方法:公众号或者文章列表页点击“历史文章”点击“加入代理池”点击立即加入代理池。关键字识别爬虫又出现了,要抓取哪些文章,按照公众号后台的提示,输入相关关键字,例如“面膜”输入“保湿”关键字验证码即可获取对应的“面膜”文章列表。
微信搜索微信公众号e-site,获取代理列表后即可采集。分析代理池示例:先看一下代理池的运行过程,首先检查一下这个代理池:打开公众号后台,查看历史发文(自定义文章列表页)检查代理列表,检查代理池中有没有我们需要的文章,一个一个试还是太麻烦。那么代理池中会有哪些内容呢?新关注公众号首页:"历史文章列表页"右下角会有个更多关注公众号,点击更多关注我。
一个一个输入关键字尝试下,会获取到更多文章,等待浏览中。关注公众号列表页第2个:检查一下我们的关键字“面膜”,获取到全部的文章列表,这里有一个重复的关键字,因此我们只获取第一个即代理列表的第一个文章。然后我们点击原来我们加入的关键字“面膜”,很好,跳转页面到新的关键字页面。这时候点击更多关注,这时候你发现原来我们加入的关键字“面膜”已经不在了,因为文章列表已经改变,我们想下次加入代理的时候再更新。那么我们不要更新关键字为“面膜”,什么样才不需要修改关键字呢?看上面我。
插入关键字 文章采集器(如何防止网站内容被采集?(一)_光明网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-07 21:07
正文:
这几天挺烦的。 网站 不断被人采集 抄袭。在百度没有对采集网站进行有效打击后,我们不能指望百度会认出这些采集网站,那么我们只能靠自己在努力打击的内容中添加版权文本这种采集 行为。前段时间,我也写过一篇关于采集的文章《如何防止网站内容被采集?今天,飘逸从另一个角度谈谈如何保护您的内容。即使其他人采集是采集,他们也必须免费帮我们做广告。当然,如果你的网站文章里面有图片,那记得放自己的LOGO,而且这个LOGO一定不能固定在这些图片的一角,必须随机出现在图片的任意位置,做鬼了,让采集器叹息:对方网站站标真是捉摸不定,捉摸不定……切入正题。我们如何在我们的文章 中随机插入版权文本?昨晚花了点时间,写了一个简单的代码随机插入随机文本,asp版:
''===开始随机生成噪声文本功能===
''===随机生成干扰文字功能一===
functionrndk()
暗淡,s1,n,n1
''随机插入你的网站版权文字,倍数除以|
s="来自:飘意博客。|飘意:.|.|飘意.ORG.||飘意"
s1=split(s,"|")
随机化
n=Int((ubound(s1)-lbound(s1)+1)*Rnd+lbound(s1))
随机化
n1=Int((10-1+1)*Rnd+1)
ifn1 查看全部
插入关键字 文章采集器(如何防止网站内容被采集?(一)_光明网)
正文:
这几天挺烦的。 网站 不断被人采集 抄袭。在百度没有对采集网站进行有效打击后,我们不能指望百度会认出这些采集网站,那么我们只能靠自己在努力打击的内容中添加版权文本这种采集 行为。前段时间,我也写过一篇关于采集的文章《如何防止网站内容被采集?今天,飘逸从另一个角度谈谈如何保护您的内容。即使其他人采集是采集,他们也必须免费帮我们做广告。当然,如果你的网站文章里面有图片,那记得放自己的LOGO,而且这个LOGO一定不能固定在这些图片的一角,必须随机出现在图片的任意位置,做鬼了,让采集器叹息:对方网站站标真是捉摸不定,捉摸不定……切入正题。我们如何在我们的文章 中随机插入版权文本?昨晚花了点时间,写了一个简单的代码随机插入随机文本,asp版:
''===开始随机生成噪声文本功能===
''===随机生成干扰文字功能一===
functionrndk()
暗淡,s1,n,n1
''随机插入你的网站版权文字,倍数除以|
s="来自:飘意博客。|飘意:.|.|飘意.ORG.||飘意"
s1=split(s,"|")
随机化
n=Int((ubound(s1)-lbound(s1)+1)*Rnd+lbound(s1))
随机化
n1=Int((10-1+1)*Rnd+1)
ifn1
插入关键字 文章采集器(如何利用二级、三级页面提升首页关键词的排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-07 17:27
)
项目招商找A5快速获取精准代理商名单
大家好,今天继续介绍标题的编写,同时在本节中会涉及到网页的布局,如果有不明白的课程可以留给你以后有一些基本的知识,然后来仔细品尝。昨天我们讲了首页的标题、描述和关键词。下面我们来看看如何利用二级、三级、四级页面来提升关键词的排名。
首先排名的前提是在首页找到你需要排名的关键词,并有相应的链接,然后用文章的形式来带动这个关键词在首页的排名在搜索引擎中。 文章的形式可以是行业内的一些技术讲解,也可以是行业新闻,编辑方式与论坛、博客类似。
但是需要注意的是,这里写的文章需要比论坛博客更专业。 文章可以多次重复关键词,但句子一定要流畅,不要用采集器采集来的文章,因为文章这种专业性不仅针对搜索引擎,也是为了客户,所以最好坚持原创或者找一些行业内的专业知识进行修改,尤其是标题的设置。选好之后,最好去百度搜索一下,看看有没有相同的,以免类似的标题长期被降级。
文章页面最好不要专门写标题,对排名没有帮助,也容易被搜索引擎识别为过度优化,导致排名下降。希望大家牢记这一点,描述和关键词也没必要专门给百度写一个,OK!现在文章知道怎么写了,我们来介绍下首页的二级和三级怎么设置关键词怎么设置。
首先,这些关键词可以体现为目录的形式,也可以是内部链接的形式。对于内部链接,最好设置在页面的底部和左上角,目录形式的关键词可以放在主导航的下拉列表中。在菜单中,也可以在侧边导航中,或者在底部内置垂直菜单栏。需要注意的是,如果顶部导航的关键词太多,下拉菜单会太长。这里肯定会有些难看。导航更利于客户体验,因为它已经过专家分析。底部菜单栏的优点是用词多,外观容易,但对客户体验不是很好。权衡利弊后,如何选择就看自己了,毕竟个人喜好不同!今天的课程就到这里了,下一章我会写一篇关于如何真正加入一个合格的网商行列的文章。 查看全部
插入关键字 文章采集器(如何利用二级、三级页面提升首页关键词的排名
)
项目招商找A5快速获取精准代理商名单
大家好,今天继续介绍标题的编写,同时在本节中会涉及到网页的布局,如果有不明白的课程可以留给你以后有一些基本的知识,然后来仔细品尝。昨天我们讲了首页的标题、描述和关键词。下面我们来看看如何利用二级、三级、四级页面来提升关键词的排名。
首先排名的前提是在首页找到你需要排名的关键词,并有相应的链接,然后用文章的形式来带动这个关键词在首页的排名在搜索引擎中。 文章的形式可以是行业内的一些技术讲解,也可以是行业新闻,编辑方式与论坛、博客类似。
但是需要注意的是,这里写的文章需要比论坛博客更专业。 文章可以多次重复关键词,但句子一定要流畅,不要用采集器采集来的文章,因为文章这种专业性不仅针对搜索引擎,也是为了客户,所以最好坚持原创或者找一些行业内的专业知识进行修改,尤其是标题的设置。选好之后,最好去百度搜索一下,看看有没有相同的,以免类似的标题长期被降级。
文章页面最好不要专门写标题,对排名没有帮助,也容易被搜索引擎识别为过度优化,导致排名下降。希望大家牢记这一点,描述和关键词也没必要专门给百度写一个,OK!现在文章知道怎么写了,我们来介绍下首页的二级和三级怎么设置关键词怎么设置。
首先,这些关键词可以体现为目录的形式,也可以是内部链接的形式。对于内部链接,最好设置在页面的底部和左上角,目录形式的关键词可以放在主导航的下拉列表中。在菜单中,也可以在侧边导航中,或者在底部内置垂直菜单栏。需要注意的是,如果顶部导航的关键词太多,下拉菜单会太长。这里肯定会有些难看。导航更利于客户体验,因为它已经过专家分析。底部菜单栏的优点是用词多,外观容易,但对客户体验不是很好。权衡利弊后,如何选择就看自己了,毕竟个人喜好不同!今天的课程就到这里了,下一章我会写一篇关于如何真正加入一个合格的网商行列的文章。
插入关键字 文章采集器(插入关键字文章采集器的关键)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-07 03:06
插入关键字文章采集器:群中采集,8-15条直接设置一下。输入上下文匹配内容,也可以不匹配文章内容。脚本运行页面:pythonqa爬虫+aiops,而且是采用正则表达式采集(百度为主)。监控浏览器,执行内容记录下来。推荐一个工具吧,叫guesty,可以看看guesty的一些算法,具体点的话叫做middleware。只要给guesty提供网址,用一个模拟的guesty。qa交互模拟注册,你可以试试。
匹配
匹配-scrapy
可以先用java写个爬虫然后用python做反爬虫
可以用《webapp数据采集:网页、api、数据库解决方案》中提到的selenium+phantomjs爬
多发post请求,应该就可以了。
谢邀,是采集cms那块吧,然后用爬虫解析,
scrapy或者scrapyionijali爬糗事百科就行
推荐一个网站feedly-feedyourownrss当然,如果你实在想找一个很详细的python爬虫方法,可以到这个csdn博客看一下,
用户自己添加自己的header,
首先判断爬行目标,打上标签,进行人工合并。
discoverthisjavascriptbookandhowtodownloadit(这本书主要是介绍discoverthis),sayaka作者写的(网易新闻) 查看全部
插入关键字 文章采集器(插入关键字文章采集器的关键)
插入关键字文章采集器:群中采集,8-15条直接设置一下。输入上下文匹配内容,也可以不匹配文章内容。脚本运行页面:pythonqa爬虫+aiops,而且是采用正则表达式采集(百度为主)。监控浏览器,执行内容记录下来。推荐一个工具吧,叫guesty,可以看看guesty的一些算法,具体点的话叫做middleware。只要给guesty提供网址,用一个模拟的guesty。qa交互模拟注册,你可以试试。
匹配
匹配-scrapy
可以先用java写个爬虫然后用python做反爬虫
可以用《webapp数据采集:网页、api、数据库解决方案》中提到的selenium+phantomjs爬
多发post请求,应该就可以了。
谢邀,是采集cms那块吧,然后用爬虫解析,
scrapy或者scrapyionijali爬糗事百科就行
推荐一个网站feedly-feedyourownrss当然,如果你实在想找一个很详细的python爬虫方法,可以到这个csdn博客看一下,
用户自己添加自己的header,
首先判断爬行目标,打上标签,进行人工合并。
discoverthisjavascriptbookandhowtodownloadit(这本书主要是介绍discoverthis),sayaka作者写的(网易新闻)
插入关键字 文章采集器(SEO优化过度优化的原因有哪些?这方面的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-06 23:13
SEO优化对企业来说是好事,但一切都太糟糕了。一旦出现过度优化的情况,比没有优化更可怕。
我们在做SEO优化的时候,有时候我们的网站会因为操作不当而被搜索引擎惩罚。过度优化的原因有很多。我们需要找到原因才能正确解决。 ,给大家详细介绍一下这方面。
1、采集 过来网站文章
经常在网站后期的重要维护阶段,为了稳定网站的活跃度,那么就需要更新有价值的原创文章;还有一些刚接触的新手在网上学习文章的采集方法,使用文章采集tools,采集同行业文章。
直接在网站上发帖,或者使用伪原创工具自动修改文章。每天发布数十篇文章文章,更新这个文章。事实上,这不仅有助于优化。反之,新站点会推迟审核期。为了降低老站的权重和排名,有必要围绕用户的需求写一些原创的有价值的文章,每天更新两个文章。
2、恶意堆积关键词
网站Optimization 就是做关键词优化,提高关键词在首页的搜索引擎排名。不管用户搜索什么类型的关键词,都能看到公司信息,点击的机会就会更多,所以很多新手为了增加关键词密度,恶意堆砌关键词。更新文章的时候,还有一篇文章文章放了很多关键词,在文章meta标签设置中,每一种这样堆起来的关键词,图片中的ALT标记,也是堆积关键词,堆积严重的关键词会导致搜索引擎受到惩罚。一定要遵循正常的优化方法。 文章 中的关键字不超过 3 个。关键字必须与当前页面相关。
3、锚文本链接太多
建立锚文本链接将有助于提高网站 权重和关键词 排名。新手在制作链接锚文本时,只要关键词出现文章,就会添加一个锚文本链接甚至多个锚文本链接。这显然是过度优化。锚文本链接堆积如山。一个文章的锚文本链接最好不要超过3个,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词时不要限制布局关键词, no 任何有价值的关键词 布局也可以链接。在结构上,每个页面都与锚文本链接,形成网状结构,引导蜘蛛的深度爬行。
4、外链建设没有规则可循。
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还能提升公司品牌,获得潜在客户。因此,很多企业都在选择各种外链群发工具。这是明显的作弊。搜索引擎并不傻。系统会自动判断垃圾外链,甚至搜索引擎也不会收录这些外链。严格来说,频率和数量必须控制。不要盲目使用工具建立外部链接。开始提高外部链接的质量。
了解问题,如何解决网站over-optimization?
1、内容过度优化
如果内容过度优化,我们需要保证原创文章每天更新1-2篇。本段建议您可以在上午10点到中午12点之间进行选择。时间会更有利于文章被收录。
2、关键词过度优化
关键词的堆叠可以让我们的核心关键词在相对较短的时间内获得相对较高的曝光率,但背后的原因是关键词和文章过于相关。因条件恶劣而受到的惩罚。解决这个问题很简单,让原来的关键词正常插入即可。
3、内链外链过度优化
需要做的不是内链与首页的链接,而是根据具体内容建立内链。
SEO 问题并不可怕。您可以了解问题的根本原因并匹配相应的解决方案。 SEO的难点在于坚持和细节。 SEO是一项长期的工作,希望急功近利,往往会带来过度优化等问题。二是细节决定成败。返回搜狐查看更多 查看全部
插入关键字 文章采集器(SEO优化过度优化的原因有哪些?这方面的内容)
SEO优化对企业来说是好事,但一切都太糟糕了。一旦出现过度优化的情况,比没有优化更可怕。
我们在做SEO优化的时候,有时候我们的网站会因为操作不当而被搜索引擎惩罚。过度优化的原因有很多。我们需要找到原因才能正确解决。 ,给大家详细介绍一下这方面。
1、采集 过来网站文章
经常在网站后期的重要维护阶段,为了稳定网站的活跃度,那么就需要更新有价值的原创文章;还有一些刚接触的新手在网上学习文章的采集方法,使用文章采集tools,采集同行业文章。
直接在网站上发帖,或者使用伪原创工具自动修改文章。每天发布数十篇文章文章,更新这个文章。事实上,这不仅有助于优化。反之,新站点会推迟审核期。为了降低老站的权重和排名,有必要围绕用户的需求写一些原创的有价值的文章,每天更新两个文章。
2、恶意堆积关键词
网站Optimization 就是做关键词优化,提高关键词在首页的搜索引擎排名。不管用户搜索什么类型的关键词,都能看到公司信息,点击的机会就会更多,所以很多新手为了增加关键词密度,恶意堆砌关键词。更新文章的时候,还有一篇文章文章放了很多关键词,在文章meta标签设置中,每一种这样堆起来的关键词,图片中的ALT标记,也是堆积关键词,堆积严重的关键词会导致搜索引擎受到惩罚。一定要遵循正常的优化方法。 文章 中的关键字不超过 3 个。关键字必须与当前页面相关。
3、锚文本链接太多
建立锚文本链接将有助于提高网站 权重和关键词 排名。新手在制作链接锚文本时,只要关键词出现文章,就会添加一个锚文本链接甚至多个锚文本链接。这显然是过度优化。锚文本链接堆积如山。一个文章的锚文本链接最好不要超过3个,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词时不要限制布局关键词, no 任何有价值的关键词 布局也可以链接。在结构上,每个页面都与锚文本链接,形成网状结构,引导蜘蛛的深度爬行。
4、外链建设没有规则可循。
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还能提升公司品牌,获得潜在客户。因此,很多企业都在选择各种外链群发工具。这是明显的作弊。搜索引擎并不傻。系统会自动判断垃圾外链,甚至搜索引擎也不会收录这些外链。严格来说,频率和数量必须控制。不要盲目使用工具建立外部链接。开始提高外部链接的质量。
了解问题,如何解决网站over-optimization?
1、内容过度优化
如果内容过度优化,我们需要保证原创文章每天更新1-2篇。本段建议您可以在上午10点到中午12点之间进行选择。时间会更有利于文章被收录。
2、关键词过度优化
关键词的堆叠可以让我们的核心关键词在相对较短的时间内获得相对较高的曝光率,但背后的原因是关键词和文章过于相关。因条件恶劣而受到的惩罚。解决这个问题很简单,让原来的关键词正常插入即可。
3、内链外链过度优化
需要做的不是内链与首页的链接,而是根据具体内容建立内链。
SEO 问题并不可怕。您可以了解问题的根本原因并匹配相应的解决方案。 SEO的难点在于坚持和细节。 SEO是一项长期的工作,希望急功近利,往往会带来过度优化等问题。二是细节决定成败。返回搜狐查看更多
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-06 15:14
【IT168 Technology文章】为了方便搜索引擎,所以模仿NB的文章系统制作下一页标签的关键词!
第一步
在 foosun\Admin\Refresh\Function.asp 中找到
函数 GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,"{News_Title}",NewsRecordSet("Title"))
在下面添加
'关键字标签
如果不是 IsNull(NewsRecordSet("keywords")) 那么
TempletContent = Replace(TempletContent,"{News_keywords}",NewsRecordSet("keywords"))
其他
TempletContent = Replace(TempletContent,"{News_keywords}","")
如果结束
'关键字标签
在最后的倒数第二行,即%>之前,添加
'****************************************
'作者:lino
'将标题与关键字表中的记录匹配
'开始
'********************************
函数replaceKeywordByTitle(title)
暗淡 whereisKeyword,i,theKeywordOnNews
Dim 关键字,rsRuleObj,theKeywordS
'***如果使用3.0版本,请将下游的fs_Routine改为Routine
Set RsRuleObj = Conn.Execute("Select * from FS_Routine")
做而不是 RsRuleObj.Eof
keyword = RsRuleObj("name")
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0) then
if(theKeywordOnNews="") 那么
theKeywordOnNews=关键字
其他
theKeywordOnNews=theKeywordOnNews&""&keyword
如果结束
如果结束
RsRuleObj.MoveNext
循环
'如果关键字长度大于100,剪掉太长的
if(len(theKeywordOnNews)>99) then
theKeywordOnNews=left(theKeywordOnNews,99)
如果结束
replaceKeywordByTitle = theKeywordOnNews
结束函数
'************************
'结束
第二步
在 foosun/funpages/lablenews.asp
查找选择插入字段
在下面添加
'页面关键字标签
页面关键字
'页面关键字标签
第三步
在 foosun/admin/info/newswords.asp 中找到大约 306 行
INewsAddObj("KeyWords") = Replace(Replace(Request("KeywordText"),"""",""),"'","")
把这句话改成
'****************************************
'作者:lino
'调用replaceKeywordByTitle方法过滤关键字
'如果用户自定义了关键字,自动设置关键字将不起作用
'开始
'********************************
暗淡的关键字文本
if (Request("KeywordText")="" or isempty(Request("KeywordText"))) then
KeywordText = replaceKeywordByTitle(ITtitle)
其他
KeywordText = Request("KeywordText")
如果结束
if KeywordText "" then
INewsAddObj("KeyWords") = Replace(Replace(KeywordText,"""",""),"'","")
如果结束
'结束
'****************************************
第四步
在Foosun/Admin/Collect/movenewstosystem.asp大约117行,找到
RsSysNewsObj("TxtSource") = RsNewsObj("Source")
修改为
RsSysNewsObj("keywords") =replaceKeywordByTitle(RsNewsObj("title"))
程序更改OK!
制作下面的标签,您可以在自定义标签的新闻浏览中选择页面的关键字标签。
具体标签如下{News_keywords},写在新闻模板的title或meta centent中,方便搜索引擎收录! 查看全部
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
【IT168 Technology文章】为了方便搜索引擎,所以模仿NB的文章系统制作下一页标签的关键词!
第一步
在 foosun\Admin\Refresh\Function.asp 中找到
函数 GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,"{News_Title}",NewsRecordSet("Title"))
在下面添加
'关键字标签
如果不是 IsNull(NewsRecordSet("keywords")) 那么
TempletContent = Replace(TempletContent,"{News_keywords}",NewsRecordSet("keywords"))
其他
TempletContent = Replace(TempletContent,"{News_keywords}","")
如果结束
'关键字标签
在最后的倒数第二行,即%>之前,添加
'****************************************
'作者:lino
'将标题与关键字表中的记录匹配
'开始
'********************************
函数replaceKeywordByTitle(title)
暗淡 whereisKeyword,i,theKeywordOnNews
Dim 关键字,rsRuleObj,theKeywordS
'***如果使用3.0版本,请将下游的fs_Routine改为Routine
Set RsRuleObj = Conn.Execute("Select * from FS_Routine")
做而不是 RsRuleObj.Eof
keyword = RsRuleObj("name")
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0) then
if(theKeywordOnNews="") 那么
theKeywordOnNews=关键字
其他
theKeywordOnNews=theKeywordOnNews&""&keyword
如果结束
如果结束
RsRuleObj.MoveNext
循环
'如果关键字长度大于100,剪掉太长的
if(len(theKeywordOnNews)>99) then
theKeywordOnNews=left(theKeywordOnNews,99)
如果结束
replaceKeywordByTitle = theKeywordOnNews
结束函数
'************************
'结束
第二步
在 foosun/funpages/lablenews.asp
查找选择插入字段
在下面添加
'页面关键字标签
页面关键字
'页面关键字标签
第三步
在 foosun/admin/info/newswords.asp 中找到大约 306 行
INewsAddObj("KeyWords") = Replace(Replace(Request("KeywordText"),"""",""),"'","")
把这句话改成
'****************************************
'作者:lino
'调用replaceKeywordByTitle方法过滤关键字
'如果用户自定义了关键字,自动设置关键字将不起作用
'开始
'********************************
暗淡的关键字文本
if (Request("KeywordText")="" or isempty(Request("KeywordText"))) then
KeywordText = replaceKeywordByTitle(ITtitle)
其他
KeywordText = Request("KeywordText")
如果结束
if KeywordText "" then
INewsAddObj("KeyWords") = Replace(Replace(KeywordText,"""",""),"'","")
如果结束
'结束
'****************************************
第四步
在Foosun/Admin/Collect/movenewstosystem.asp大约117行,找到
RsSysNewsObj("TxtSource") = RsNewsObj("Source")
修改为
RsSysNewsObj("keywords") =replaceKeywordByTitle(RsNewsObj("title"))
程序更改OK!
制作下面的标签,您可以在自定义标签的新闻浏览中选择页面的关键字标签。
具体标签如下{News_keywords},写在新闻模板的title或meta centent中,方便搜索引擎收录!
插入关键字 文章采集器(相关软件软件大小版本说明下载地址网络捕手智能识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-06 01:26
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。 .
相关软件软件大小及版本说明下载链接
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。
基本介绍
NoteExpress 是国内广泛使用的文档管理软件。具有文档信息检索和下载功能。可用于管理参考文献的书目,以附件的形式管理参考文献的全文或任何格式的文件和文件。数据挖掘的功能可以帮助用户快速了解某个研究方向的最新进展、各方意见等。 除了管理上述显性知识外,还有日记、科研经历、论文草稿等瞬时隐性知识,等也可以通过NoteExpress的笔记功能进行记录,并可以与参考书目链接。在编辑器(如MS Word)中,NoteExpress可以根据各种期刊杂志的要求自动格式化参考引文——完美的格式和准确的引文将大大增加论文被采用的概率。笔记和附件功能的结合,全文搜索,数据挖掘等,使该软件成为一个强大的个人知识管理系统。
插件功能
多屏、跨平台协同工作
NoteExpress 客户端、浏览器插件和青体文学App,让您可以利用不同屏幕、不同平台之间的碎片时间,高效完成文档跟踪和采集。
灵活多样的分类方法
传统的树形结构分类和灵活的标签标签分类,让您在管理文档时更加得心应手。
全文智能识别,书目自动补全
智能识别全文文件中的标题、DOI等关键信息,自动更新补充书目元数据。
强大的期刊管理器
内置近五年JCR期刊影响因子、国内外主流期刊收录范围、中科院期刊分区数据。添加文档时,会自动匹配并填写相关信息。
支持两大主流写作软件
用户在使用Microsoft Office Word或金山WPS撰写科研论文时,可以使用内置的写作插件在写作时引用参考文献。
丰富的参考输出样式
内置近4000种国内外期刊、论文及国家、协会标准参考格式,支持一键格式转换,支持生成校对报告,支持多语言模板,支持双语输出。
安装方法
方法一:.crx文件格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.在打开的谷歌浏览器扩展管理器最左边选择扩展或者直接输入:chrome://extensions/
3. 找到你下载好的Chrome离线安装文件xxx.crx,从资源管理器中拖拽到Chrome的扩展管理界面。这时候,用户会发现在扩展管理器的中央部分,会有一个额外的“拖拽安装”插件按钮。
4. 松开鼠标,将当前拖拽的插件安装到谷歌浏览器中。但谷歌考虑到用户的安全和隐私,会在用户松开鼠标后提示用户确认安装。
5. 用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome。安装成功后,插件会立即显示在浏览器的右上角(如果有插件按钮),如果没有插件按钮,用户也可以找到已安装的插件通过 Chrome 扩展管理器导入。
方法二:文件夹格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.选择打开的 Google Chrome 扩展管理器最左侧的扩展。
3.勾选开发者模式,点击加载解压后的扩展,选择安装插件的文件夹。 查看全部
插入关键字 文章采集器(相关软件软件大小版本说明下载地址网络捕手智能识别)
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。 .
相关软件软件大小及版本说明下载链接
NoteExpress web catcher是一款可以安装在谷歌浏览器上的文档管理插件,支持所有chrome内核浏览器操作。 NoteExpress是国内广泛使用的文献管理软件,具有文献信息检索和下载功能,可用于管理参考书目。
基本介绍
NoteExpress 是国内广泛使用的文档管理软件。具有文档信息检索和下载功能。可用于管理参考文献的书目,以附件的形式管理参考文献的全文或任何格式的文件和文件。数据挖掘的功能可以帮助用户快速了解某个研究方向的最新进展、各方意见等。 除了管理上述显性知识外,还有日记、科研经历、论文草稿等瞬时隐性知识,等也可以通过NoteExpress的笔记功能进行记录,并可以与参考书目链接。在编辑器(如MS Word)中,NoteExpress可以根据各种期刊杂志的要求自动格式化参考引文——完美的格式和准确的引文将大大增加论文被采用的概率。笔记和附件功能的结合,全文搜索,数据挖掘等,使该软件成为一个强大的个人知识管理系统。
插件功能
多屏、跨平台协同工作
NoteExpress 客户端、浏览器插件和青体文学App,让您可以利用不同屏幕、不同平台之间的碎片时间,高效完成文档跟踪和采集。
灵活多样的分类方法
传统的树形结构分类和灵活的标签标签分类,让您在管理文档时更加得心应手。
全文智能识别,书目自动补全
智能识别全文文件中的标题、DOI等关键信息,自动更新补充书目元数据。
强大的期刊管理器
内置近五年JCR期刊影响因子、国内外主流期刊收录范围、中科院期刊分区数据。添加文档时,会自动匹配并填写相关信息。
支持两大主流写作软件
用户在使用Microsoft Office Word或金山WPS撰写科研论文时,可以使用内置的写作插件在写作时引用参考文献。
丰富的参考输出样式
内置近4000种国内外期刊、论文及国家、协会标准参考格式,支持一键格式转换,支持生成校对报告,支持多语言模板,支持双语输出。
安装方法
方法一:.crx文件格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.在打开的谷歌浏览器扩展管理器最左边选择扩展或者直接输入:chrome://extensions/
3. 找到你下载好的Chrome离线安装文件xxx.crx,从资源管理器中拖拽到Chrome的扩展管理界面。这时候,用户会发现在扩展管理器的中央部分,会有一个额外的“拖拽安装”插件按钮。
4. 松开鼠标,将当前拖拽的插件安装到谷歌浏览器中。但谷歌考虑到用户的安全和隐私,会在用户松开鼠标后提示用户确认安装。
5. 用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome。安装成功后,插件会立即显示在浏览器的右上角(如果有插件按钮),如果没有插件按钮,用户也可以找到已安装的插件通过 Chrome 扩展管理器导入。
方法二:文件夹格式插件安装
1. 首先,用户点击谷歌浏览器右上角的自定义和控制按钮,在下拉框中选择设置。
2.选择打开的 Google Chrome 扩展管理器最左侧的扩展。
3.勾选开发者模式,点击加载解压后的扩展,选择安装插件的文件夹。
插入关键字 文章采集器(微信文章采集系列插件架构(维清)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-05 12:27
下载链接:@weiqin
演示地址:
[维清]微信文章采集系列插件架构
[维清]微信文章采集器:点击安装
这个插件是核心,用于采集公众号信息、公众号文章,以及内置微信公众号、文章管理功能、文章展示功能。安装此插件,让你的网站与百万公众号分享优质文章。
【维清】微信导航:点击安装
这个插件是用来创建微信导航的,另外还增加了服务号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
【维清】微文阅读中心:点击安装
本插件提供关键词订阅、文章采集、公众采集等功能。安装这个插件,让用户有理由在你的网站上查看公众号文章。
[维清]微信文章DIY:点击安装
安装此扩展,可以在网站任意页面调用公众号信息和文章列表。
【维清】插件伪静态:点击安装
本插件可以为【维清】全系列插件设置伪静态规则,新插件上线后会更新插件。
其他辅助插件:
维基!插件二级域名:点击安装
【维清】万能帮助中心:点击安装
(一)微信文章采集器
功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需要输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与数百万订阅帐户共享优质内容。每天大量更新,快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航上插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站name、插件名称、分类名称、文章title等信息的变量替换。
3、批量提供采集公众号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交即可。一次最多可使用采集10个公众号信息。
4、批量可用采集公号的文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,可以批量处理采集文章信息,最少采集篇文章、文章 内容也进行了本地化。
5、文章信息可以完美显示:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面内置多个DIY区:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、可以灵活设置信息是否需要审核:
用户提交的内容的公众号和文章信息是否需要审核,可以通过后台开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、 完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(二)[维清]微信导航
功能说明:
此插件用于建立微信导航。信息来自卫青微信文章采集器。详情页会显示完整的公众号信息,包括昵称、微信ID、个人资料、认证信息、二维码和头像。另外,这个插件增加了服务帐号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为微信导航。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、分类名称、微信公众号昵称等信息的变量替换。
3、可以使用微信ID作为个性化网址:
结合[weiqing]插件的伪静态,可以将微信账号作为个性化网址,微信账号文章列表支持分页。
4、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
5、每个页面内置多个DIY区域:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
6、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
本插件需要安装“[维清]WeChat文章采集器”才能使用。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(三)[维清]维文阅读中心
功能说明:
该插件主要提供兴趣管理功能。用户可以使用关键词订阅、文章采集、公众采集等功能自由管理自己的兴趣。设置好自己的兴趣后,可以直接在个人中心的兴趣内容中阅读自己的感受。方便用户从海量信息中快速找到自己喜欢的内容,增加用户粘性,吸引用户在你的网站上看到文章。安装这个插件,让用户有理由在你的网站上查看公众号文章。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为个人中心。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、页面名称等信息的变量替换。
3、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
这个插件只有安装了“[维清]WeChat文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(四)[维清]微信文章DIY
功能说明:
此扩展提供了对网站任何页面上的公众号信息和文章列表的访问。安装此扩展后,需要在后台更新缓存,勾选DIY模块分类缓存,点击提交更新。
这个扩展只有安装“[维清]微信文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(五)[维清]插件伪静态
功能说明:
本插件可以为【维清】全系列插件设置伪静态规则。启用此插件后,相关插件页面中的所有链接都将替换为静态链接。如果你安装了Wikin!插件二级域名插件如果为开启伪静态的插件设置了二级域名,链接也会自动添加到对应的二级域名中插入。此插件将在新插件上线时更新。
目前该插件可以为以下插件设置伪静态规则:
1.[维清]微信文章采集器:点击安装
2.[维清]微信导航:点击安装
3.[维清]万能帮助中心:点击安装
应用截图
下载链接:@weiqin
演示地址: 查看全部
插入关键字 文章采集器(微信文章采集系列插件架构(维清)(组图))
下载链接:@weiqin
演示地址:
[维清]微信文章采集系列插件架构
[维清]微信文章采集器:点击安装
这个插件是核心,用于采集公众号信息、公众号文章,以及内置微信公众号、文章管理功能、文章展示功能。安装此插件,让你的网站与百万公众号分享优质文章。
【维清】微信导航:点击安装
这个插件是用来创建微信导航的,另外还增加了服务号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
【维清】微文阅读中心:点击安装
本插件提供关键词订阅、文章采集、公众采集等功能。安装这个插件,让用户有理由在你的网站上查看公众号文章。
[维清]微信文章DIY:点击安装
安装此扩展,可以在网站任意页面调用公众号信息和文章列表。
【维清】插件伪静态:点击安装
本插件可以为【维清】全系列插件设置伪静态规则,新插件上线后会更新插件。
其他辅助插件:
维基!插件二级域名:点击安装
【维清】万能帮助中心:点击安装
(一)微信文章采集器
功能说明:
[维清]微信文章采集器是采集微信订阅账号信息和订阅账号文章的插件。只需要输入公众号昵称,即可自动采集公众号信息(信息包括公众号昵称、微信ID、功能介绍、认证信息、头像、二维码)。通过安装此插件,您可以让您的网站与数百万订阅帐户共享优质内容。每天大量更新,快速提升网站的权重和排名。
功能亮点:
1、可自定义插件名称:
后台面包屑导航上插件名称可以随意修改,不设置默认为微信窗口。
2、可定制的SEO信息:
后台可以方便的为每个页面设置SEO信息,支持网站name、插件名称、分类名称、文章title等信息的变量替换。
3、批量提供采集公众号信息:
输入微信公众号昵称点击搜索,选择你想要的公众号采集,提交即可。一次最多可使用采集10个公众号信息。
4、批量可用采集公号的文章:
点击公众号列表中的“采集文章”链接,输入你想要的页数采集,可以批量处理采集文章信息,最少采集篇文章、文章 内容也进行了本地化。
5、文章信息可以完美显示:
插件自建首页、列表页、详情页,无需依赖原系统任何功能即可完美展示文章信息。
6、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
7、每个页面内置多个DIY区:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
8、可以灵活设置信息是否需要审核:
用户提交的内容的公众号和文章信息是否需要审核,可以通过后台开关控制。
9、信息批量管理功能:
后台提供功能齐全的微信公众号和文章批量管理功能,可以批量查看、删除、移动分类信息。
10、 完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(二)[维清]微信导航
功能说明:
此插件用于建立微信导航。信息来自卫青微信文章采集器。详情页会显示完整的公众号信息,包括昵称、微信ID、个人资料、认证信息、二维码和头像。另外,这个插件增加了服务帐号提交功能。安装此插件可以让公众号运营商有理由在您的平台上落户。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为微信导航。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、分类名称、微信公众号昵称等信息的变量替换。
3、可以使用微信ID作为个性化网址:
结合[weiqing]插件的伪静态,可以将微信账号作为个性化网址,微信账号文章列表支持分页。
4、强大的DIY机制:
只要安装diy扩展,就可以拥有强大的DIY机制。可以在网站任意页面调用微信公众号信息和文章信息。
5、每个页面内置多个DIY区域:
插件的每个页面(首页、列表页、详情页)内置多个DIY区,可在原创内容块之间插入DIY模块。
6、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
本插件需要安装“[维清]WeChat文章采集器”才能使用。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(三)[维清]维文阅读中心
功能说明:
该插件主要提供兴趣管理功能。用户可以使用关键词订阅、文章采集、公众采集等功能自由管理自己的兴趣。设置好自己的兴趣后,可以直接在个人中心的兴趣内容中阅读自己的感受。方便用户从海量信息中快速找到自己喜欢的内容,增加用户粘性,吸引用户在你的网站上看到文章。安装这个插件,让用户有理由在你的网站上查看公众号文章。
功能亮点:
1、可自定义插件名称:
您可以在后台面包屑导航上自由修改插件名称,默认为个人中心。
2、可定制的SEO信息:
后台可以轻松设置每个页面的SEO信息,支持网站name、插件名称、页面名称等信息的变量替换。
3、完全支持手机版:
只需安装相应的手机版组件,即可轻松打开手机版。
这个插件只有安装了“[维清]WeChat文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(四)[维清]微信文章DIY
功能说明:
此扩展提供了对网站任何页面上的公众号信息和文章列表的访问。安装此扩展后,需要在后台更新缓存,勾选DIY模块分类缓存,点击提交更新。
这个扩展只有安装“[维清]微信文章采集器”才有意义。
应用截图:
-----------------------------------------------华丽的分割线---------------------------------------------- - ---
(五)[维清]插件伪静态
功能说明:
本插件可以为【维清】全系列插件设置伪静态规则。启用此插件后,相关插件页面中的所有链接都将替换为静态链接。如果你安装了Wikin!插件二级域名插件如果为开启伪静态的插件设置了二级域名,链接也会自动添加到对应的二级域名中插入。此插件将在新插件上线时更新。
目前该插件可以为以下插件设置伪静态规则:
1.[维清]微信文章采集器:点击安装
2.[维清]微信导航:点击安装
3.[维清]万能帮助中心:点击安装
应用截图
下载链接:@weiqin
演示地址:
插入关键字 文章采集器(文章目录第一、WordPress自动关键字插件解决什么问题?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-31 17:00
最近一段时间,我们群很多WordPress网友都在讨论建立大数据网站,包括一些需要使用SEO工具的网友网站。有网友提到了WordPress网站的权重。例如,tags 关键字仍然更重要。有时,排名和收录 可能比某些文章 页面更好。所以希望有一个插件可以自动部署WordPress Tags关键字。
我们通过调查发现,WordPress中现有的Tag相关插件之一,虽然名为Auto Tags插件,但它只是采用了简单的分词技术,没有有效的索引词或长尾词随机插入标签。 ,这样的效果并不是用户所需要的。由于分词技术比较难,可以自行讨论是否做插件,自己设置需要的词,分配给文章。
一两周左右,从原来的关键词批量提交功能到自动插入单篇文章文章适合我们常规的网站需求,基本可以满足用户的需求。这篇文章文章在我们的WordPress笔记中,我们准备了图文介绍这个插件的功能,作者稍后会录制视频介绍。
文章directory
一、WordPress 自动关键词插件解决了什么问题?
我们在使用这个插件的时候,首先要了解这个插件可以解决什么问题。一般通过插件解决的问题,可能需要我们手动解决,然后再使用插件来提高效率。或者它可以自动帮助我们解决某些问题。毕竟,我们的站长用户并不都是程序员,也不是所有的人都会开发软件工具。
如果需要安装,搜索CNWPer SEO Tags发现已经推送到WP官方网站plugin平台。或者您可以加入我们的公众号和QQ群查看最新版本并与用户交流。
WordPress 自动关键词插件目前有两个功能:
1、Auto文章TAGS
比如我们更新网站的时候,是不是我们手动插入了TAGS(标签),如上图所示。我们一般插入的TAGS都是文章相关的,或者自己设置的。一般网友肯定是后者。如果我们使用这个插件,我们可以预先设置网站的所有长尾词,然后根据我们添加的文章的标题、内容、随机性或严格匹配将它们自动插入标签中。当然,我们也可以在不影响它的情况下手工完成。
2、批量分配标签
特别是我们之前更新的一些文章,可能是因为自己的问题,没有有效的插入TAGS来达到内链的效果。如果我们在另一篇文章中打开文章设置,是不是很麻烦,有网友采集的几万个文章,再设置就更麻烦了。可以使用自动关键字插件,然后自动将需要插入的标签分配给指定的文章。
二、WordPress 自动关键字插件的使用
我们先介绍了当前WP自动关键字插件的基本功能,但还没有看到实际的产品。那么我们来实际看看这个插件的设置界面。
这是我们WP自动关键字插件的自动化功能。我们可以在添加文章时开始并预先设置需要随机插入的关键字,设置频率或匹配严格度,如果不勾选匹配严格度,则随机插入。并且我们还可以为单个文章设置最高标签阈值。
我们设置完成后,以后添加文章时,会自动插入已经设置好的标签关键字。当然,我们也可以在这个插件中开启TAGS自动内链功能。如果您的其他插件已经打开,则无需重复打开。
批量部署关键字工具是我们在WordPress站点中提到的TAGS标签关键字的文章随机部署或严格匹配部署。您可以设置频率和文章 范围。这个文章范围需要检查文章对应的ID。
需要注意的三、问题
这个WP自动关键词插件的初衷是为了帮助网友网站随机匹配文章相关关键词,加强内链和标签优化的效果。但是我们在使用的时候,不要在单个文章中插入过多的关键字,否则搜索引擎会认为是作弊。简而言之,插入关键字需要自然且相关。
你可以选择不使用插件,但是在使用的时候可以自己控制频率尺度,避免关键词堆砌过度,导致搜索引擎惩罚网站。我们不对这种行为和后果负责。我们可以加入公众号索取最新版本的插件。 查看全部
插入关键字 文章采集器(文章目录第一、WordPress自动关键字插件解决什么问题?(组图))
最近一段时间,我们群很多WordPress网友都在讨论建立大数据网站,包括一些需要使用SEO工具的网友网站。有网友提到了WordPress网站的权重。例如,tags 关键字仍然更重要。有时,排名和收录 可能比某些文章 页面更好。所以希望有一个插件可以自动部署WordPress Tags关键字。
我们通过调查发现,WordPress中现有的Tag相关插件之一,虽然名为Auto Tags插件,但它只是采用了简单的分词技术,没有有效的索引词或长尾词随机插入标签。 ,这样的效果并不是用户所需要的。由于分词技术比较难,可以自行讨论是否做插件,自己设置需要的词,分配给文章。
一两周左右,从原来的关键词批量提交功能到自动插入单篇文章文章适合我们常规的网站需求,基本可以满足用户的需求。这篇文章文章在我们的WordPress笔记中,我们准备了图文介绍这个插件的功能,作者稍后会录制视频介绍。
文章directory
一、WordPress 自动关键词插件解决了什么问题?
我们在使用这个插件的时候,首先要了解这个插件可以解决什么问题。一般通过插件解决的问题,可能需要我们手动解决,然后再使用插件来提高效率。或者它可以自动帮助我们解决某些问题。毕竟,我们的站长用户并不都是程序员,也不是所有的人都会开发软件工具。
如果需要安装,搜索CNWPer SEO Tags发现已经推送到WP官方网站plugin平台。或者您可以加入我们的公众号和QQ群查看最新版本并与用户交流。
WordPress 自动关键词插件目前有两个功能:
1、Auto文章TAGS
比如我们更新网站的时候,是不是我们手动插入了TAGS(标签),如上图所示。我们一般插入的TAGS都是文章相关的,或者自己设置的。一般网友肯定是后者。如果我们使用这个插件,我们可以预先设置网站的所有长尾词,然后根据我们添加的文章的标题、内容、随机性或严格匹配将它们自动插入标签中。当然,我们也可以在不影响它的情况下手工完成。
2、批量分配标签
特别是我们之前更新的一些文章,可能是因为自己的问题,没有有效的插入TAGS来达到内链的效果。如果我们在另一篇文章中打开文章设置,是不是很麻烦,有网友采集的几万个文章,再设置就更麻烦了。可以使用自动关键字插件,然后自动将需要插入的标签分配给指定的文章。
二、WordPress 自动关键字插件的使用
我们先介绍了当前WP自动关键字插件的基本功能,但还没有看到实际的产品。那么我们来实际看看这个插件的设置界面。
这是我们WP自动关键字插件的自动化功能。我们可以在添加文章时开始并预先设置需要随机插入的关键字,设置频率或匹配严格度,如果不勾选匹配严格度,则随机插入。并且我们还可以为单个文章设置最高标签阈值。
我们设置完成后,以后添加文章时,会自动插入已经设置好的标签关键字。当然,我们也可以在这个插件中开启TAGS自动内链功能。如果您的其他插件已经打开,则无需重复打开。
批量部署关键字工具是我们在WordPress站点中提到的TAGS标签关键字的文章随机部署或严格匹配部署。您可以设置频率和文章 范围。这个文章范围需要检查文章对应的ID。
需要注意的三、问题
这个WP自动关键词插件的初衷是为了帮助网友网站随机匹配文章相关关键词,加强内链和标签优化的效果。但是我们在使用的时候,不要在单个文章中插入过多的关键字,否则搜索引擎会认为是作弊。简而言之,插入关键字需要自然且相关。
你可以选择不使用插件,但是在使用的时候可以自己控制频率尺度,避免关键词堆砌过度,导致搜索引擎惩罚网站。我们不对这种行为和后果负责。我们可以加入公众号索取最新版本的插件。
插入关键字 文章采集器(WordPress关键字自动关键字插件的使用方法介绍及注意事项介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-29 15:02
在网站的过程中,我们站长会发现网站文章关键词添加得恰到好处,TAGS确实可以提高网站的搜索指数,而且排名有时可能会由关键词TAGS给出排名高于文章。按照正常的做法,每个文章我们会加三到五个关键词,当然是相关的关键词。
同时,我们也看到一些做采集类网站的站长和做垃圾站的站长,会通过批量TAGS堆叠实现大量的索引。当然,这种做法上次违反了百度的发布规则,并已陆续被打击。但是对于一些做站群或采集的人来说,他们不在乎,他们只需要意识到它。老佐这里介绍一个比较好的WordPress自动关键词插件,可以实现关键词自动内链,自动将相关的随机关键词插入网站文章的TAGS标签。
我们来看看这个插件的功能。估计还有很多网友没有找到。找到了需要的,等不及的可以用一下,尤其采集类网站真的很有帮助。
插件地址:
插件已经在官方WordPress直接发布,我们可以直接下载使用。
我们可以看到自动TAGS内链是可以开启的。并且可以预设关键词,然后在添加文章时自动分配给文章,可以按照绝对匹配标题和内容,随机匹配。可设置最大TAGS数。
文章更新后,我们可以随机或自动匹配到对应的文章,并且可以设置文章的ID范围进行匹配和添加。
总之,这款WordPress关键词自动插件适合需要添加TAGS标签关键词,以及后续添加网站关键词,以及使用自动TAGS内链的用户。 查看全部
插入关键字 文章采集器(WordPress关键字自动关键字插件的使用方法介绍及注意事项介绍)
在网站的过程中,我们站长会发现网站文章关键词添加得恰到好处,TAGS确实可以提高网站的搜索指数,而且排名有时可能会由关键词TAGS给出排名高于文章。按照正常的做法,每个文章我们会加三到五个关键词,当然是相关的关键词。
同时,我们也看到一些做采集类网站的站长和做垃圾站的站长,会通过批量TAGS堆叠实现大量的索引。当然,这种做法上次违反了百度的发布规则,并已陆续被打击。但是对于一些做站群或采集的人来说,他们不在乎,他们只需要意识到它。老佐这里介绍一个比较好的WordPress自动关键词插件,可以实现关键词自动内链,自动将相关的随机关键词插入网站文章的TAGS标签。
我们来看看这个插件的功能。估计还有很多网友没有找到。找到了需要的,等不及的可以用一下,尤其采集类网站真的很有帮助。
插件地址:
插件已经在官方WordPress直接发布,我们可以直接下载使用。
我们可以看到自动TAGS内链是可以开启的。并且可以预设关键词,然后在添加文章时自动分配给文章,可以按照绝对匹配标题和内容,随机匹配。可设置最大TAGS数。
文章更新后,我们可以随机或自动匹配到对应的文章,并且可以设置文章的ID范围进行匹配和添加。
总之,这款WordPress关键词自动插件适合需要添加TAGS标签关键词,以及后续添加网站关键词,以及使用自动TAGS内链的用户。
插入关键字 文章采集器(本文原创助手:为你打造爆款文章,实现流量变现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 556 次浏览 • 2021-08-29 14:16
原创助是伪原创文章生成器的新媒体运营工具,一键群发助手,让你的文章在搜索引擎和新媒体上获得海量流量排名。
伪原创是指重新处理一个原创文章,让搜索引擎认为它是一个原创文章,从而增加网站文章的权重。有两种编辑方式:修改标题关键词和总结首尾段落。指代数法、换词法、文字排序法、首段汇总法、尾汇总法、新增图片、段落替换法、关键词替换法。
原创auxiliary 提供优秀的中文语义分析技术。通过自主研发的中文分词、句法分析、语义关联和实体识别技术,结合海量行业术语的不断积累,为用户提供简单易用的原创Service。最后,帮助您的公众号创建爆文,高效运营,增加粉丝活跃度,实现流量变现。
原创auxiliary 是一个非常有用的 SEO 工具。它是生成原创和伪原创文章的工具。 伪原创工具可以瞬间改变网上复制的文章。成为你自己的原创文章。本软件通过在线伪原创工具生成的文章会更好地被搜索引擎收录收录。在线伪原创工具是网络编辑、站长和SEO必不可少的工具,也是网站优化工具中很多大牛推荐的工具。
使用方法:
微信先一、搜索【原创助】
寻找同行二、或者其他你认为好的文章,复制到原创auxiliary,然后选择对应的接口生成自己的原创
生成三、后一键复制,记得看全文,改一些不合适的地方,就OK了。
本文原创展示效果
公众号文章帮_运营辅助_原创帮原创帮:为你打造爆款文章,实现流量变现。最后祝大家粉丝多多赚钱 查看全部
插入关键字 文章采集器(本文原创助手:为你打造爆款文章,实现流量变现)
原创助是伪原创文章生成器的新媒体运营工具,一键群发助手,让你的文章在搜索引擎和新媒体上获得海量流量排名。
伪原创是指重新处理一个原创文章,让搜索引擎认为它是一个原创文章,从而增加网站文章的权重。有两种编辑方式:修改标题关键词和总结首尾段落。指代数法、换词法、文字排序法、首段汇总法、尾汇总法、新增图片、段落替换法、关键词替换法。
原创auxiliary 提供优秀的中文语义分析技术。通过自主研发的中文分词、句法分析、语义关联和实体识别技术,结合海量行业术语的不断积累,为用户提供简单易用的原创Service。最后,帮助您的公众号创建爆文,高效运营,增加粉丝活跃度,实现流量变现。
原创auxiliary 是一个非常有用的 SEO 工具。它是生成原创和伪原创文章的工具。 伪原创工具可以瞬间改变网上复制的文章。成为你自己的原创文章。本软件通过在线伪原创工具生成的文章会更好地被搜索引擎收录收录。在线伪原创工具是网络编辑、站长和SEO必不可少的工具,也是网站优化工具中很多大牛推荐的工具。
使用方法:
微信先一、搜索【原创助】
寻找同行二、或者其他你认为好的文章,复制到原创auxiliary,然后选择对应的接口生成自己的原创
生成三、后一键复制,记得看全文,改一些不合适的地方,就OK了。
本文原创展示效果
公众号文章帮_运营辅助_原创帮原创帮:为你打造爆款文章,实现流量变现。最后祝大家粉丝多多赚钱
前台发帖时可采集单篇微信文章的功能介绍及使用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-26 03:20
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。
查看全部
前台发帖时可采集单篇微信文章的功能介绍及使用方法
功能介绍
后台可以通过微信和关键词批量搜索采集公号文章,无需任何配置。同时支持批量发布到帖子和门户文章,批量发布时可以选择每个文章。 @要发布到的部分。
前台发帖时可以采集单篇微信文章,只需在插件中设置启用的版块和用户组即可。
2.1版本后,添加定时采集,在插件设置页面定时采集公众号中填写微信公众号,每行一个(如果你的服务器性能和带宽不足,请只填写一篇),插件使用定时任务获取最新的5篇文章从未采集在此处填写的公众号上的文章(注:由于严格多变的微信反采集措施,预定任务的成功率可能会更低)
由于微信可能随时更改反采集措施,本插件可能会失效。当发现无效时,请与我们联系。我们将尽快完成修复和升级或单独向您发送修复文件,但概不退款。
主要特点
图片、视频中1、可采集文章,保留微信文章原格式
2、不需要任何配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每个文章单独发到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到文章门户,发布时可以单独设置每个文章发布的门户频道。
6、采集有身体状态提醒。如果采集 body 由于某种原因失败,可以重复采集
8、前台在发帖时在编辑器中显示微信图标,点击插入微信文章URL自动插入微信文章
9、support 帖子,portal文章audit 功能
如何使用
安装并启用1、后,您可以在插件后台设置页面更改默认成员uid和发布到的版块。
2、点开始采集,按微信公众号或关键词采集
3、采集Latest文章 列表成功后可以全选或者单独选择文章加上采集文字(比如去掉不需要的文章文章),开始采集文字
4、文字采集 完成后可以选择单独发布到每个文章的版块或全部发布到默认版块,点击发布完成
7、可以批量发布为采集记录中的门户文章,并且可以设置每个文章发布的门户频道(门户频道必须可用)
8、设置前端发帖允许使用微信插入文章功能用户组和版块
采集procedure
按微信ID采集:
1、搜索微信账号点击或直接填写微信账号和昵称点击启动采集
2、显示等待采集文章的最新10-30篇文章的标题,点击标题旁边的复选框确认你想要哪个采集
3、 然后点击下面的采集 文字
4、采集之后你可以选择直接在采集results或re采集text下发帖
通过关键字采集
1、输入关键字点击搜索
2、显示获取到的文章title列表,点击标题旁边的复选框确认你想要采集what
3、点击下方采集发布按钮,发布完成
如果文章列表发布后前台没有显示,请点击后台-工具-更新统计第一个【提交】按钮
通过网址采集
1、填写公众号文章的地址。每行一个
2、click 采集,等待完成
注意事项
1、由于微信反购买采集措施,请不要采集太频繁,否则你的ip地址可能被微信锁定而无法继续采集
2、如果要采集图片、视频并保留微信文章的原创格式,必须在相应的section-post选项中允许使用html、允许解析图片和允许多媒体。
基于高精度识别识别算法的互联网文章采集器文章提取算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-25 20:52
优采云万能文章采集器是一个基于高精度文本识别算法文章采集器的互联网。支持关键词采集百度等搜索引擎的新闻源()和泛页(),支持采集designated网站栏目下的所有文章。
软件介绍:
优采云software 是首创的独家智能通用算法,可准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
功能说明:
什么是高精度文本识别算法
该算法由优采云自主研发,可以从网页中提取正文部分,通常准确率为95%。如果进一步设置最小字数,采集文章的准确率(正确性)可以达到99%。同时文章Title也达到了99%的提取准确率。当然,当一些网页的布局格式混乱、不规则时,可能会降低准确率。
文本提取模式
文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不可用时,您可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
采集 处理选项
采集 可以同时翻译、过滤和搜索单词。对于采集好文章,您可以使用“本地批处理”。
翻译功能是将中文翻译成英文再翻译回中文,产生伪原创效果。支持原创格式翻译,即文章的原创标签结构和排版格式不会改变。
采集Target 是网址
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
分页采集和相对路径转换为绝对路径
勾选“自动采集page”合并分页文章采集,并在编辑框中设置采集pages的最大数量。建议设置一个有限的值,比如10页,避免一些采集分页太多耗时长,合并后的文章体积大。如果需要采集所有页面,可以设置为0。
并且文章中的所有相对路径都会自动转换为绝对路径,可以保证图片等的正常显示
多线程
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
文章Title 和文章 内容重复处理
程序可以智能判断过滤重复文章
当采集到达的文章标题(文件名)与本地保存的文章标题相同时,优采云会首先判断两个文章的相似度,当相似度较大时大于60% 当判断优采云是同一个文章时,再比较两个文章的文字大小,自动用文字较多的文章覆盖写入同一个文件名。这个世代情况加起来不及世代数。
而当相似度小于60%时,优采云判断与文章不同,会自动重命名标题(标题末尾随机取3到5个字母)并保存到文件。
文章快速过滤
优采云虽然研究了高精度的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果的字数来提高准确率(在“最小文本字符数”参数中,这个字数就是程序去掉标签、行、空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
生成文章数量可变的问题
百度和搜搜默认每页 100 个结果,Google 默认每页 10 个结果。
有些网站访问速度超时(尤其是很多谷歌收录被一些网站屏蔽了),或者设置了body的最少字数,或者程序忽略了里面同名的相似内容local文章,或者黑名单和白名单过滤等,会导致实际生成文章数低于每页搜索的最大结果数。
总体来说,百度采集质量最好,生成的文章数量接近搜索结果数量。
更新日志:
1.12:继续增强web批处理栏目URL采集器识别文章URL的能力,支持多种地址格式同时匹配
1.11:增强网络批处理中文章URL列URL采集器的识别能力
1.10:修复翻译功能无法翻译的问题 查看全部
基于高精度识别识别算法的互联网文章采集器文章提取算法
优采云万能文章采集器是一个基于高精度文本识别算法文章采集器的互联网。支持关键词采集百度等搜索引擎的新闻源()和泛页(),支持采集designated网站栏目下的所有文章。
软件介绍:
优采云software 是首创的独家智能通用算法,可准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
功能说明:
什么是高精度文本识别算法
该算法由优采云自主研发,可以从网页中提取正文部分,通常准确率为95%。如果进一步设置最小字数,采集文章的准确率(正确性)可以达到99%。同时文章Title也达到了99%的提取准确率。当然,当一些网页的布局格式混乱、不规则时,可能会降低准确率。
文本提取模式
文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但是对于百度体验页等特殊的分段页面(不通用
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不可用时,您可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
采集 处理选项
采集 可以同时翻译、过滤和搜索单词。对于采集好文章,您可以使用“本地批处理”。
翻译功能是将中文翻译成英文再翻译回中文,产生伪原创效果。支持原创格式翻译,即文章的原创标签结构和排版格式不会改变。
采集Target 是网址
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
分页采集和相对路径转换为绝对路径
勾选“自动采集page”合并分页文章采集,并在编辑框中设置采集pages的最大数量。建议设置一个有限的值,比如10页,避免一些采集分页太多耗时长,合并后的文章体积大。如果需要采集所有页面,可以设置为0。
并且文章中的所有相对路径都会自动转换为绝对路径,可以保证图片等的正常显示
多线程
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
文章Title 和文章 内容重复处理
程序可以智能判断过滤重复文章
当采集到达的文章标题(文件名)与本地保存的文章标题相同时,优采云会首先判断两个文章的相似度,当相似度较大时大于60% 当判断优采云是同一个文章时,再比较两个文章的文字大小,自动用文字较多的文章覆盖写入同一个文件名。这个世代情况加起来不及世代数。
而当相似度小于60%时,优采云判断与文章不同,会自动重命名标题(标题末尾随机取3到5个字母)并保存到文件。
文章快速过滤
优采云虽然研究了高精度的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果的字数来提高准确率(在“最小文本字符数”参数中,这个字数就是程序去掉标签、行、空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
生成文章数量可变的问题
百度和搜搜默认每页 100 个结果,Google 默认每页 10 个结果。
有些网站访问速度超时(尤其是很多谷歌收录被一些网站屏蔽了),或者设置了body的最少字数,或者程序忽略了里面同名的相似内容local文章,或者黑名单和白名单过滤等,会导致实际生成文章数低于每页搜索的最大结果数。
总体来说,百度采集质量最好,生成的文章数量接近搜索结果数量。
更新日志:
1.12:继续增强web批处理栏目URL采集器识别文章URL的能力,支持多种地址格式同时匹配
1.11:增强网络批处理中文章URL列URL采集器的识别能力
1.10:修复翻译功能无法翻译的问题
1.快速使用说明模拟了浏览器的设计,2.高级配置介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-24 18:08
1.快速使用说明模拟了浏览器的设计,2.高级配置介绍
网页采集器
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。添加一个属性,如果你觉得幸运,你可以更准确地进行。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。为了解决这个问题,将关键字添加到搜索字符中,此时不要添加到属性列表中,只需点击我很幸运。
4.3.手动模式
当你感觉运气不好不能工作或不符合预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并在网页上获取位置(XPath)。填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。 Hawk 简化了流程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,从而实现属性抽取,感觉很幸运。超级模式极大地简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
关于其使用的更多细节,请参阅章节。
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程。当然,大多数情况不需要这么复杂,记住以下几点即可:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。 查看全部
1.快速使用说明模拟了浏览器的设计,2.高级配置介绍
网页采集器
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。添加一个属性,如果你觉得幸运,你可以更准确地进行。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。为了解决这个问题,将关键字添加到搜索字符中,此时不要添加到属性列表中,只需点击我很幸运。
4.3.手动模式
当你感觉运气不好不能工作或不符合预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并在网页上获取位置(XPath)。填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。 Hawk 简化了流程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,从而实现属性抽取,感觉很幸运。超级模式极大地简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
关于其使用的更多细节,请参阅章节。
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程。当然,大多数情况不需要这么复杂,记住以下几点即可:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。
优采云万能文章采集器智能提取网页正文的算法(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-24 18:04
优采云万能文章采集器有利于各大搜索引擎采集文件和添加工具制作,使用可以提取网页正文的算法,多语种翻译,保证采集的制作文章能比原创。如果你需要很多原创文章,那就选择优采云万能文章采集器。
优采云万能文章采集器是一款只需要输入关键词即可获取采集各大搜索引擎新闻源和网页的软件。 优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。支持去除标签、链接、邮箱、插入关键词功能等格式化处理,可以识别旁边要插入的标签或标点符号,可以识别英文空格的插入。还有文章翻译功能,即文章可以从中文等一种语言转成英文或日文等另一种语言,再从英文或日文转回中文。这是一个翻译周期,可以设置翻译周期循环多次(翻译次数)。
优采云万能文章采集器 智能提取网页正文的算法。百度新闻、谷歌新闻、搜搜新闻强聚合不时更新的新闻资源,不竭不竭多语翻译伪原创。你,输入关键词
软件功能
1.优采云第一个提取网页正文的通用算法
2.百度引擎、谷歌引擎、搜索引擎强大聚合
3.时时时时彩不定期更新文章资源,取之不尽,用之不竭
4.智能采集any网站的文章column 文章resources
5.多语种翻译伪原创。你,输入关键词
功能范围
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集信息材料过滤提炼
更新日志
URL采集文章面板精准标签添加模糊匹配功能;增加定时任务功能,可设置多个时间点,自动启动采集(当前显示面板采集的启动)。
v3.0.8.0
添加一些用采集处理过的网站加强采集。 查看全部
优采云万能文章采集器智能提取网页正文的算法(组图)
优采云万能文章采集器有利于各大搜索引擎采集文件和添加工具制作,使用可以提取网页正文的算法,多语种翻译,保证采集的制作文章能比原创。如果你需要很多原创文章,那就选择优采云万能文章采集器。
优采云万能文章采集器是一款只需要输入关键词即可获取采集各大搜索引擎新闻源和网页的软件。 优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。支持去除标签、链接、邮箱、插入关键词功能等格式化处理,可以识别旁边要插入的标签或标点符号,可以识别英文空格的插入。还有文章翻译功能,即文章可以从中文等一种语言转成英文或日文等另一种语言,再从英文或日文转回中文。这是一个翻译周期,可以设置翻译周期循环多次(翻译次数)。
优采云万能文章采集器 智能提取网页正文的算法。百度新闻、谷歌新闻、搜搜新闻强聚合不时更新的新闻资源,不竭不竭多语翻译伪原创。你,输入关键词
软件功能
1.优采云第一个提取网页正文的通用算法
2.百度引擎、谷歌引擎、搜索引擎强大聚合
3.时时时时彩不定期更新文章资源,取之不尽,用之不竭
4.智能采集any网站的文章column 文章resources
5.多语种翻译伪原创。你,输入关键词
功能范围
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适用于信息公关公司采集信息材料过滤提炼
更新日志
URL采集文章面板精准标签添加模糊匹配功能;增加定时任务功能,可设置多个时间点,自动启动采集(当前显示面板采集的启动)。
v3.0.8.0
添加一些用采集处理过的网站加强采集。
[模块和算子]常见问题更新日志作者和捐赠列表专题
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-08-24 18:03
【模块与运营商】常见问题更新日志作者及捐赠名单 主题:案例:Post文章:故事:Webpage采集器
网页采集器主界面
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容
我在单文档模式下感觉很幸运
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。
可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
请求配置
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
我感觉很幸运的配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。
添加一个属性,运气好的话可以做的更准确。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。
为了解决这个问题,在搜索字符中添加关键字。此时不要将其添加到属性列表中,只需单击“手气不错”即可。
我在单文档模式下感觉很幸运
4.3.手动模式
当你运气好,不能工作或没有达到预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并获取网页上的位置(XPath)。
填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
手动添加属性
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。
Hawk 简化了过程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
网页采集器请求设置
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是然后页面的内容是通过ajax单独返回的。
有时候很多XPath的开发是针对第一页做的,但是最后我发现在其他页面上用不了,主要是因为上面提到的问题(一脸懵逼)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
超级模式大大简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
有关其使用的更多详细信息,请参阅动态嗅探一章。
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
按钮上自动弹出帮助
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程
当然,大多数情况不需要那么复杂,只要记住以下几点:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
我很幸运
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。 查看全部
[模块和算子]常见问题更新日志作者和捐赠列表专题
【模块与运营商】常见问题更新日志作者及捐赠名单 主题:案例:Post文章:故事:Webpage采集器
网页采集器主界面
1.快速使用说明
网页采集器模拟浏览器的设计,填写网址,点击刷新,即可得到对应地址的html源码。
识别出一个网页是一棵树(DOM)后,每个XPath对应一个属性,可以从网页中获取单个或多个文档。网页采集器的目的是通过手动或自动配置更快地找到最优的XPath。
1.1.工作模式
使用采集器,首先要根据爬取目标选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常点击右上角感觉幸运,在弹出的结果下选择需要的数据,并配置其名称和XPath。单击“确定”完成配置。可以自动获取大部分网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可以手动填写搜索字符,可以在网页上快速定位元素和XPath,可以在多个结果之间快速切换。找到需要的数据后,输入属性名称,手动添加属性。
1.3.高级功能点击【Http请求详情】,可以修改网页编码、代理、cookie和请求方式等,如果网页出现乱码,可以自动登录,或者获取动态页面的真实地址(ajax),填写搜索字符,点击【自动嗅探】,在弹出的浏览器中转到对应的关键字,Hawk可以自动抓取真实请求。在超级模式下,Hawk 会将源代码中的 js、html、json 全部转成 html 使用,这样你就觉得幸运了,多才多艺但性能较差。填写【共享源】,这个采集器Synchronized共享源【Http请求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以幸运(Hawk3新功能),搜索对于必填字段,不需要添加到属性列表中,点击我有幸试试!网页地址也可以是本地文件路径,如D:\target.html。用其他方式保存网页后,通过Hawk分析网页内容
我在单文档模式下感觉很幸运
Webpage采集器不能单独工作,而是webpage采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
2.高级配置介绍2.1.列出根路径
列表的根路径是XPath所有属性的公共部分,可以简化XPath的编写,提高兼容性。它只能在多文档模式下工作。
可以通过Hawk自动分析根路径,也可以手动设置。
2.2.自动协议列表路径
举个例子来说明。运气好后,嗅探器会找到链表节点的父节点和挂载在父节点上的多个子节点,形成树状结构
应为每个节点提取以下属性:
为了获取父节点下的所有div子节点,列表的根路径为/html/div[2]/div[3]/div[4]/div。注意:父节点的路径末尾没有序号,这样可以得到多个子节点。可以理解为链表的根路径就是没有尾数的父节点的路径。
有时,父节点的 xpath 不稳定。比如在北京和上海的二手房页面上,上海会在列表中添加一个广告banner,这样真正的父节点就会发生变化,比如倒退。将 div[1] 移动到 div[2]。为了应对这种变化,通常的做法是手动修改[list root path]
2.3.手动设置根路径
继续举例,父节点的id是house_list,在网页中是全局唯一的,你可以使用另一个父节点的符号//*[@id='house_list']/li(你可以参考其他写法XPath教程),子节点表达式保持不变。这将使程序更加健壮。
3.Grab 网页数据
Webpage采集器需要和数据清洗一起使用才能使用Webpage采集器获取网页数据,并且拖拽的列需要是超链接
3.1. 一般获取请求
一般情况下,将爬虫转换拖入对应的URL列,通过下拉菜单选择要调用的爬虫名称即可完成所有配置:
请求配置
这个模块是网页采集器和数据清理之间的桥梁。网页采集器本质上是一个专门为获取网页而定制的数据清洗模块。
你需要填写爬虫选择并告诉它调用哪个采集器。注意:
3.2.实现post请求
在 Web 请求中,有两种主要类型的请求:post 和 get。使用POST可以支持更多数据的传输。具体可以参考http协议的相关文档。
Hawk 在发起 post 请求时需要向服务器传递两个参数:url 和 post。一般来说,执行post请求时,URL是稳定的,post值是动态变化的。
首先在post模式下配置被调用的网页采集器(打开网页采集器,Http请求详情,模式->下拉菜单)。
之后需要将爬虫的转换拖拽到要调用的url列。如果没有url列,可以添加一个新列,生成要访问的url列。
之后,我们会将帖子数据传递到网页采集器。您可以随时通过合并多列拼接或各种方式生成要发布的数据列。之后就可以在爬虫转化的post数据中填写【post column】,post列是收录post数据的列名。注意:
4.手气好
这是 Hawk 最受称赞的功能!在新的Hawk3中,这个功能得到了极大的增强。
4.1.多文档下感觉很幸运
一般来说,输入 URL 加载页面后,如果幸运点击,Hawk 会根据优先级自动抓取列表数据。
我感觉很幸运的配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,然后在下面的属性栏中对结果进行微调。
添加一个属性,运气好的话可以做的更准确。添加两个属性以选择唯一区域。
4.2.单文档模式幸运
Hawk3 是一项新功能。当网页收录几十个属性时,将它们一一添加会变得特别繁琐。这在某些产品属性页面中尤为常见。
为了解决这个问题,在搜索字符中添加关键字。此时不要将其添加到属性列表中,只需单击“手气不错”即可。
我在单文档模式下感觉很幸运
4.3.手动模式
当你运气好,不能工作或没有达到预期时,你需要手动指定几个关键字,让Hawk搜索关键字,并获取网页上的位置(XPath)。
填写搜索字符,即可成功获取XPath,写入属性名称,点击添加添加属性。同理填写30535,将属性名称设置为“单价”,再添加一个属性。
手动添加属性
在搜索字符的文本框中,输入您要获取的关键字。由于该关键字可能在网页上多次出现,您可以连续点击继续搜索并在多个结果之间切换。左边的html源代码会突出显示搜索结果。
请注意观察搜索关键字在网页中的位置是否符合预期,否则可能会出现抓取数据的问题。特别是在多文档模式下。如果需要抓取这个页面的多条数据,可以创建多个网页采集器,单独配置。如果发现错误,可以单击编辑集对属性进行删除、修改和排序。您可以同样添加所有要抓取的特征字段,或者单击“手气不错”,系统会根据当前属性推断其他属性。 5.dynamic sniffing5.1.什么是动态页面?
动态瀑布流和ajax页面,通常按需返回html和json。
旧样式网站刷新时会返回页面的全部内容,但如果只更新部分内容,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
5.2.Hawk 自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。
Hawk 简化了过程并使用自动嗅探。 Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果当前页面没有找到关键字,Hawk会提示“是否启用动态嗅探?”这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
5.3.如果不能自动嗅探?
由于 Hawk 具有阻止功能,浏览器会认为它不安全。如何解决?
Hawk 的底层嗅探是基于 fiddler 的,所以可以使用 fiddler 生成证书并导入到 chrome 中解决。方法可以参考这个文档:
设置采集器如下:
网页采集器请求设置
5.4.Notes 有时候可以直接把url复制到Hawk,运气好也能拿到数据。这是因为许多网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是然后页面的内容是通过ajax单独返回的。
有时候很多XPath的开发是针对第一页做的,但是最后我发现在其他页面上用不了,主要是因为上面提到的问题(一脸懵逼)。因此,根据经验,建议在提出请求之前转到其他页面。
超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
6.超级模式
Hawk为了让动态网页添加属性和感觉幸运,嗅探后会默认开启超级模式。超级模式可以将网页中所有的javascript、json、xml转换成HTML DOM树,实现属性抽取,感觉很幸运。
超级模式大大简化了动态请求的处理,但可能仍然存在以下问题:
7.自动登录
许多网站需要登录才能访问其内部内容。登录涉及到非常复杂的逻辑,比如需要传递用户名密码、验证码等,并且在多次请求之后,获取token,甚至写代码等一系列过程都需要写一整页,需要反复调试考虑到Hawk是通用数据采集器,开发成本非常高。
但本质上,登录只是一个cookie。只要在后续请求中加入cookie,远程服务器就无法区分是浏览器还是爬虫。一般传统的爬虫软件内置浏览器,用户在里面填写用户名和密码。软件内部获取cookie后进行请求。但是Hawk 不打算再搞内置浏览器了。该方法太繁重,无法与 Hawk 的流媒体系统兼容。所以,Hawk 不再自动登录了!
我们使用了一个新的想法来解决这个问题。
Hawk 的自动登录和动态嗅探使用相同的技术。本质上,它取代了底层的系统代理。您可以在登录页面的搜索字符中填写任何文本,然后单击嗅探。 如果此方法不起作用,您也可以手动将浏览器上的请求参数复制到网页采集器。
有关其使用的更多详细信息,请参阅动态嗅探一章。
8.采集器name 设置分享请求参数
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站 需要登录和cookies。有没有可能每个采集器都要设置对应的请求参数?
在采集器的属性对话框中,可以设置分享源,即要分享的网页采集器的名称。
比如设置为链家采集器,那么这个采集器的请求参数会在执行过程中从链采集器动态获取。这大大简化了配置过程。
按钮上自动弹出帮助
9.Appendix:XPath 和 CSS 编写9.1.XPath
XPath 语法请参考教程
XPath 可以非常灵活,例如:
9.2.CSSSelector
在大多数情况下,使用 XPath 可以解决问题,但 CSSSelector 更简洁、更健壮。其介绍请参考教程
当然,大多数情况不需要那么复杂,只要记住以下几点:
10.好运的原则
网页采集器的作用是获取网页中的数据(废话)。一般来说,目标可能是一个列表(如购物车列表),也可能是页面中的固定字段(如京东某产品的价格和介绍,页面上只有一个)。因此,需要设置读取模式。传统的采集器需要写正则表达式,但是方法太复杂。
如果你意识到html是一棵树,你只需要找到携带数据的节点,然后用XPath来描述即可。
我很幸运
手动编写XPath也很复杂,所以软件可以通过关键字自动检索XPath,提供关键字,软件会从树中递归搜索收录数据的叶节点。因此,关键字在页面上应该是唯一的。
如上图,只要提供“Beijing”和“42”这两个关键字,就可以找到父节点,然后可以找到两个列表元素div[0]和div[1]得到。通过比较div[0]和div[1]这两个节点,我们可以自动发现相同的子节点(名称,挂载)和不同的节点(北京:上海,37:42)。同一个节点会保存作为属性名,不同的节点作为属性值。但是无法提供北京和37,此时公共节点是div[0],不是列表。
软件也可以利用html文档的特性,在不提供关键字的情况下,计算出最有可能成为列表父节点的节点(图中的父节点),但是当网页特别复杂时,猜测可能是错误的。
软件介绍优采云软件出品的一款万能文章采集软件,更多特点一试就知
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-23 20:01
软件介绍
优采云software出品的万能文章采集software,只需输入关键词就可以采集各种网页和新闻,还可以采集指定列表页(栏目页) 文章。
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.史上最简单最智能文章采集器,更多功能一目了然!
问题重点:
采集设置的黑名单有误
在[采集Settings]中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数而不是实际采集进程.
下载地址
非 VIP 用户下载我们的软件,不提供任何服务。本站只为付费会员服务!售前客服
下载地址1 下载地址2 下载地址3
VIP办理联系售前客服 查看全部
软件介绍优采云软件出品的一款万能文章采集软件,更多特点一试就知
软件介绍
优采云software出品的万能文章采集software,只需输入关键词就可以采集各种网页和新闻,还可以采集指定列表页(栏目页) 文章。
注意:微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
特点:
1.依托优采云software独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只要输入关键词,就可以采集微信文章,今日头条,小新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页、雅虎新闻和网页;批量可用关键词fully-auto采集。
3.可方向采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂规则。
4.文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
5.史上最简单最智能文章采集器,更多功能一目了然!
问题重点:
采集设置的黑名单有误
在[采集Settings]中进入黑名单时,如果末尾有空行,会导致关键词采集函数显示搜索次数而不是实际采集进程.
下载地址
非 VIP 用户下载我们的软件,不提供任何服务。本站只为付费会员服务!售前客服
下载地址1 下载地址2 下载地址3
VIP办理联系售前客服
一个采集器采集规则怎么写呢?小编来教你如何解决
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-22 02:16
大规模信息网站发布文章时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集Rules 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集node管理>>添加新节点>>选择normal文章>>OK
第2步:填写采集list规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:在文章content前后找两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
... 查看全部
一个采集器采集规则怎么写呢?小编来教你如何解决
大规模信息网站发布文章时,如果一一文章在线发布,不仅浪费时间,而且效率不高。这时候为了提高更新网站的效率,出现了优采云采集器,但是优采云采集怎么写规则呢?下面我来详细介绍一下。
优采云采集Rules 写作介绍
第一步:新建文章采集节点
登录后台,点击采集>>采集node管理>>添加新节点>>选择normal文章>>OK
第2步:填写采集list规则
1.节点名称:随便你(注意一定要能区分,因为节点太多的话,可能会把自己搞砸)
2.目标页面编码:看目标页面的编码
3.匹配URL:到采集目标列表页面查看其列表规则!比如很多网站列表的第一页和其他内页有很大的不同,所以我一般不会采集定位到列表的第一页!
最好从第二页开始(虽然可以找到第一页,但是很多网站根本没有第一页,所以这里就不讲怎么找第一页了)
4.区末尾的HTML:在采集目标列表页面打开源码!找到文章标题附近需要采集的部分,这是本页唯一的,其他需要采集的页面也是唯一的html标签!
完成,点击保存信息进入下一步!如果规则写得正确,那么就会有一个基于内容的URL获取规则测试。
再次按下一步!回车填写采集content规则
第 3 步:采集内容规则
1.文章Title:在文章Title前后找两个标签来标识标题!
2.文章Content:在文章content前后找两个标签来识别内容!我的采集网站文章内容前后唯一的标签是
...
自定义采集模式中文件导入大批量网址、批量生成的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-08-21 00:07
本文介绍了如何在自定义采集模式下,从文件中导入大量网址,批量生成网址,以及在关联任务中导入网址。
采集data时,很多用户都会遇到这种情况:
优采云通过升级优化自定义采集 URL的输入,有效解决了上述问题,主要有以下三个功能。
1、File 导入大量网址
目前手动输入支持的网址数量有限。如果有大量的URL,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行批量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的url,超过100w的会自动删除
2、Bulk URL 生成
当多个页面需要同时在同一个网站中采集时,我们可以使用该功能批量生成网址,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以设置定义的逻辑自动生成,然后可以使用云端采集拆分原理采集任务,大大提高采集的效率。
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
以京东的网页为例:
这是京东iphone的第三页网址为关键词,我们可以按照这个格式替换关键词生成多个产品的网址,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充。
字母变化:从字母到字母
时间变化:可设置时间段变化
自定义列表:你可以把一些你需要的关键词作为URL参数的一部分
自定义列表
由于本例中设置了关键词,所以参数类型选择“自定义列表”,在下框中填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击确定。
数量变化
同理,选择页码,点击添加参数,设置与页码相关的参数。这里,参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页开始采集,则起始值为1;变化为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。<//p
pimg src='http://www.bazhuayu.com/media/117260/image5.png' alt=''//p
p设置好参数后,可以预览生成的网址。如下图所示/p
pimg src='http://www.bazhuayu.com/media/117261/image6.png' alt=''//p
p在京东这个例子中,只需要设置这两个参数。我们来看看另外两个。/p
p字母变化/p
pimg src='http://www.bazhuayu.com/media/117262/image7.png' alt=''//p
p同上,字母变化是根据变化规律从a设置到某个字母/p
p时间变化/p
pimg src='http://www.bazhuayu.com/media/117263/image8.png' alt=''//p
p如上图,选择合适的时间格式,然后设置开始时间和结束时间。/p
p注意:/p
p可支持批量生成100W以内的URL,超过100W只生成100W。/p
p批量生成的前100个URL保存在本地并显示在界面上; > 100 个 URL 存储在云中,不在界面上显示。使用本地采集或云端采集时,存储直接调用云端的URL采集数据。
如果您复制此规则,则复制的规则将仅收录前 100 个网址和采集前 100 个网址的数据。
3、Linked 任务导入地址
还有另一种导入 URL 的方法。可以从其他任务采集中选择URL直接导入关联采集。例如,如果一个任务同时是采集list 页面和详情页面,则无法通过云采集 进行拆分。如果使用关联采集的功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分,采集效率为改进了很多(注意如果采集网站list页面进入详情页,URL不变,不能使用此方法)
具体操作如下:
在自定义模式入口选择“从任务导入”
我们将导入的任务称为“源任务”,导入URL后的新配置称为“跟随任务”
然后使用下拉箭头选择采集tasks和字段,就可以完全导入源任务采集的URL了。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动采集时可以选择“按照启动设置”
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置关注开始
注意:后续任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL采集”,优采云会采集任务导入的所有URL;如果选择“Only 采集preview URLs”,优采云 将采集此任务最多 100 个预览 URL
提醒:只有终极版(上)包的用户才支持相关任务的导入。去升级旗舰版 查看全部
自定义采集模式中文件导入大批量网址、批量生成的功能
本文介绍了如何在自定义采集模式下,从文件中导入大量网址,批量生成网址,以及在关联任务中导入网址。
采集data时,很多用户都会遇到这种情况:
优采云通过升级优化自定义采集 URL的输入,有效解决了上述问题,主要有以下三个功能。
1、File 导入大量网址
目前手动输入支持的网址数量有限。如果有大量的URL,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行批量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的url,超过100w的会自动删除
2、Bulk URL 生成
当多个页面需要同时在同一个网站中采集时,我们可以使用该功能批量生成网址,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以设置定义的逻辑自动生成,然后可以使用云端采集拆分原理采集任务,大大提高采集的效率。
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
以京东的网页为例:
这是京东iphone的第三页网址为关键词,我们可以按照这个格式替换关键词生成多个产品的网址,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充。
字母变化:从字母到字母
时间变化:可设置时间段变化
自定义列表:你可以把一些你需要的关键词作为URL参数的一部分
自定义列表
由于本例中设置了关键词,所以参数类型选择“自定义列表”,在下框中填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击确定。
数量变化
同理,选择页码,点击添加参数,设置与页码相关的参数。这里,参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页开始采集,则起始值为1;变化为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。<//p
pimg src='http://www.bazhuayu.com/media/117260/image5.png' alt=''//p
p设置好参数后,可以预览生成的网址。如下图所示/p
pimg src='http://www.bazhuayu.com/media/117261/image6.png' alt=''//p
p在京东这个例子中,只需要设置这两个参数。我们来看看另外两个。/p
p字母变化/p
pimg src='http://www.bazhuayu.com/media/117262/image7.png' alt=''//p
p同上,字母变化是根据变化规律从a设置到某个字母/p
p时间变化/p
pimg src='http://www.bazhuayu.com/media/117263/image8.png' alt=''//p
p如上图,选择合适的时间格式,然后设置开始时间和结束时间。/p
p注意:/p
p可支持批量生成100W以内的URL,超过100W只生成100W。/p
p批量生成的前100个URL保存在本地并显示在界面上; > 100 个 URL 存储在云中,不在界面上显示。使用本地采集或云端采集时,存储直接调用云端的URL采集数据。
如果您复制此规则,则复制的规则将仅收录前 100 个网址和采集前 100 个网址的数据。
3、Linked 任务导入地址
还有另一种导入 URL 的方法。可以从其他任务采集中选择URL直接导入关联采集。例如,如果一个任务同时是采集list 页面和详情页面,则无法通过云采集 进行拆分。如果使用关联采集的功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分,采集效率为改进了很多(注意如果采集网站list页面进入详情页,URL不变,不能使用此方法)
具体操作如下:
在自定义模式入口选择“从任务导入”
我们将导入的任务称为“源任务”,导入URL后的新配置称为“跟随任务”
然后使用下拉箭头选择采集tasks和字段,就可以完全导入源任务采集的URL了。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动采集时可以选择“按照启动设置”
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置关注开始
注意:后续任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL采集”,优采云会采集任务导入的所有URL;如果选择“Only 采集preview URLs”,优采云 将采集此任务最多 100 个预览 URL
提醒:只有终极版(上)包的用户才支持相关任务的导入。去升级旗舰版

