
插入关键字 文章采集器
插入关键字 文章采集器(手把手教你插入关键字文章采集器(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-25 12:04
插入关键字文章采集器目前是比较简单的采集工具,只需在搜狗网页搜索中输入关键字即可,它会实时抓取并数据采集您所需要的网页数据。数据链接调整比较方便,不用进行数据修改。不仅可以采集、天猫、京东等平台的商品数据,可以采集对应的网站首页数据,也可以采集指定网站页面的数据。同时还可以采集qq空间的日志等。注意事项由于百度网页搜索是api模式,凡是跟该关键字相关的链接,都有可能被爬虫抓取收录,抓取时会有拦截。
正在使用中的采集器点击本文最后链接进入采集器免费试用,长按识别下方二维码,或复制该链接进行识别,登录注册后即可免费试用了解更多网站数据采集方法,欢迎关注微信公众号“子夏说网络”。
有这么一款软件,像采集兔一样,可以搜索采集工具,可以批量采集整站网站链接,百度搜索就可以看到,不到2小时就能采集4000+网站数据。可以看看我最近采集的一篇文章,分享给你:手把手教你零基础,
题主的意思是指能够爬虫采集各大网站的公开数据?这样的网站能够在国内外的很多网站看到:1.谷歌镜像站2.pagespeed3.pagehistoryecharts(与echarts类似)4.全站爬虫5.网站网页截图。目前知道的就这些。可能不全, 查看全部
插入关键字 文章采集器(手把手教你插入关键字文章采集器(图))
插入关键字文章采集器目前是比较简单的采集工具,只需在搜狗网页搜索中输入关键字即可,它会实时抓取并数据采集您所需要的网页数据。数据链接调整比较方便,不用进行数据修改。不仅可以采集、天猫、京东等平台的商品数据,可以采集对应的网站首页数据,也可以采集指定网站页面的数据。同时还可以采集qq空间的日志等。注意事项由于百度网页搜索是api模式,凡是跟该关键字相关的链接,都有可能被爬虫抓取收录,抓取时会有拦截。
正在使用中的采集器点击本文最后链接进入采集器免费试用,长按识别下方二维码,或复制该链接进行识别,登录注册后即可免费试用了解更多网站数据采集方法,欢迎关注微信公众号“子夏说网络”。
有这么一款软件,像采集兔一样,可以搜索采集工具,可以批量采集整站网站链接,百度搜索就可以看到,不到2小时就能采集4000+网站数据。可以看看我最近采集的一篇文章,分享给你:手把手教你零基础,
题主的意思是指能够爬虫采集各大网站的公开数据?这样的网站能够在国内外的很多网站看到:1.谷歌镜像站2.pagespeed3.pagehistoryecharts(与echarts类似)4.全站爬虫5.网站网页截图。目前知道的就这些。可能不全,
插入关键字 文章采集器(优采云采集器的采集方法及步骤(一)_数据分析采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-25 07:05
用途:用于数据分析
使用工具:优采云采集器(优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。)
二、采集方法步骤说明####
第一步:安装优采云采集器(注意:需要安装net4.0框架才能运行)
优采云采集器 下载链接:
第二步:注册账号
第三步:了解基本界面
一个。单击开始 -> 新建文件夹(并重命名它以便您知道 采集 是什么)-> 新建任务
湾 创建新任务后,会弹出设置任务规则的对话框(注意以下几点)
(1)填写你想要的内容所在的网址采集。如果是正规的,可以使用【添加向导】相关规则,如下:以短书为例,我要< @采集自己分析了短书里面的内容数据,采集的主要内容在列表页,但是因为短书采用了懒加载的方式,无法抓取翻页的内容,所以需要查看源码(这里需要有一定代码知识的童鞋才能找到),然后在源码中,找到相关的链接,而且都是有规律的,所以我可以通过添加相关规则【添加向导】。具体规则继续看以下步骤4.
向导添加界面:
第 4 步:编写 URL 提取规则
我在源代码中找到了列表链接。如果你想采集所有的链接,你必须找到所有的翻页。翻页是正常的,所以我得到以下规则。只是链接中“page=”后面的地址参数改变了,所以我们可以用【地址参数】来设置参数。然后在[地址参数]中选择数字变化,因为它是一个数字。总共有14个项目,所以有14个项目。
设置好地址格式后,我们可以在这个页面进一步设置我们想要的采集的内容。即我们需要在列表页采集上传递每个文章的URL,方法如下:
(1)获取内容URL时,选择获取方式:自动获取地址链接。
(2)使用链接过滤:提取文章链接,文章的链接有共性。
填好这些后,点击【URL采集Test】,这时候就可以验证规则是否正确了。
验证OK!规则是对的!伟大的!写好规则后记得保存哦!
第五步:编写内容抽取规则
采集到达每个文章的URL后,接下来我们需要采集每个文章的相关信息:标题、URL、阅读数、点赞数!这是我们的终极目标!写好规则后记得保存哦!方法如下图所示:
PS:这也需要一些html代码的知识。
添加规则如下:
(1)在标签列表中将标签名称添加到采集。方框右侧有一个“+”可以添加多个标签。
(2)数据获取方式选择:从源码中获取数据,选择提取方式“截取前后”,然后在源码中提取我们想要的信息的前后码。记住,如果这是唯一的代码,避免提取它出现问题。
补充:教你提取前后码
在网页中,右击查看源代码。找到标题。我们会发现有多个重复的标题。但是要选择code前后的唯一一个,可以通过ctrl+f来验证是否唯一。下面是标题前后的代码,剩下几个元素前后的代码,大家可以自己练习。
第六步:设置存储位置
点击内容发布规则——>另存为本地文件——>启用本地文件保存——>保存设置文件格式并选择txt(因为我们使用的是免费软件)——>设置保存位置
第七步:启动采集,设置存储位置和设置规则,保存退出,返回工具首页,启动采集——> 这3个地方一定要勾选,然后右键——单击以选择 — —> 开始。见下文:
采集 后呈现原创数据:
呈现清洗后的数据及相关数据分析,如下图所示:
三、个人经历总结#### 查看全部
插入关键字 文章采集器(优采云采集器的采集方法及步骤(一)_数据分析采集器)
用途:用于数据分析
使用工具:优采云采集器(优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。)
二、采集方法步骤说明####
第一步:安装优采云采集器(注意:需要安装net4.0框架才能运行)
优采云采集器 下载链接:
第二步:注册账号
第三步:了解基本界面
一个。单击开始 -> 新建文件夹(并重命名它以便您知道 采集 是什么)-> 新建任务

湾 创建新任务后,会弹出设置任务规则的对话框(注意以下几点)
(1)填写你想要的内容所在的网址采集。如果是正规的,可以使用【添加向导】相关规则,如下:以短书为例,我要< @采集自己分析了短书里面的内容数据,采集的主要内容在列表页,但是因为短书采用了懒加载的方式,无法抓取翻页的内容,所以需要查看源码(这里需要有一定代码知识的童鞋才能找到),然后在源码中,找到相关的链接,而且都是有规律的,所以我可以通过添加相关规则【添加向导】。具体规则继续看以下步骤4.
向导添加界面:
第 4 步:编写 URL 提取规则
我在源代码中找到了列表链接。如果你想采集所有的链接,你必须找到所有的翻页。翻页是正常的,所以我得到以下规则。只是链接中“page=”后面的地址参数改变了,所以我们可以用【地址参数】来设置参数。然后在[地址参数]中选择数字变化,因为它是一个数字。总共有14个项目,所以有14个项目。
设置好地址格式后,我们可以在这个页面进一步设置我们想要的采集的内容。即我们需要在列表页采集上传递每个文章的URL,方法如下:
(1)获取内容URL时,选择获取方式:自动获取地址链接。
(2)使用链接过滤:提取文章链接,文章的链接有共性。
填好这些后,点击【URL采集Test】,这时候就可以验证规则是否正确了。
验证OK!规则是对的!伟大的!写好规则后记得保存哦!
第五步:编写内容抽取规则
采集到达每个文章的URL后,接下来我们需要采集每个文章的相关信息:标题、URL、阅读数、点赞数!这是我们的终极目标!写好规则后记得保存哦!方法如下图所示:
PS:这也需要一些html代码的知识。
添加规则如下:
(1)在标签列表中将标签名称添加到采集。方框右侧有一个“+”可以添加多个标签。
(2)数据获取方式选择:从源码中获取数据,选择提取方式“截取前后”,然后在源码中提取我们想要的信息的前后码。记住,如果这是唯一的代码,避免提取它出现问题。
补充:教你提取前后码
在网页中,右击查看源代码。找到标题。我们会发现有多个重复的标题。但是要选择code前后的唯一一个,可以通过ctrl+f来验证是否唯一。下面是标题前后的代码,剩下几个元素前后的代码,大家可以自己练习。
第六步:设置存储位置
点击内容发布规则——>另存为本地文件——>启用本地文件保存——>保存设置文件格式并选择txt(因为我们使用的是免费软件)——>设置保存位置
第七步:启动采集,设置存储位置和设置规则,保存退出,返回工具首页,启动采集——> 这3个地方一定要勾选,然后右键——单击以选择 — —> 开始。见下文:
采集 后呈现原创数据:
呈现清洗后的数据及相关数据分析,如下图所示:

三、个人经历总结####
插入关键字 文章采集器( 百度/360搜索关键词的爬取和存储网络图片链接的格式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-24 00:18
百度/360搜索关键词的爬取和存储网络图片链接的格式)
r.request.headers
结果如下:
爬虫如实告诉服务器,这次访问是由python请求库中的一个程序产生的。
4. 改变头部信息,让程序模拟浏览器发送爬取请求
kv={'user-agent':'Mozilla/5.0'} #构造键值对
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
r=requests.get(url,headers=kv)
这时候再次查看r.status_code,返回的状态码为200,r.text中没有错误提示
完整的爬取框架如下:
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
二、百度/360搜索关键词提交
百度的关键词界面:
360的关键词界面:
可以通过params参数提交关键词。基本代码框架如下:
import requests
keyword="Python"
try:
kv={'wd':keyword}
r=requests.get("https://www.baidu.com/s",params=kv) #通过params将键值对输入进去并获得相关请求
print(r.request.url)
r.raise_for_status
print(len(r.text))
except:
print("爬取失败")
提交关键词到360搜索时,需要将kv={'wd':keyword}的'wd'改为'q'。
三、 网页图片的爬取和存储
网页图片链接格式:
即:url+picture.jpg
选择某个url中的图片网页(如:),可以看到图片的url
如果一个url链接以.jpg结尾,则表示它是一个图片链接,该链接是一个文件,如下图:
图片是二进制格式。要将二进制图片保存到文件中,通常使用以下代码:
path="E:\\Spider learning\\xunyi.jpg" #保存图片的位置和图片的名字
url="http://imgsrc.baidu.com/baike/ ... ot%3B
r=requests.get(url)
#print(r.status_code)
with open(path,'wb') as f:
f.write(r.content)
f.close()
with open() as f:打开一个文件并将其定义为文件标识符 f
r.content:响应对象中的r.content表示返回的二进制格式的内容
完整的代码框架如下:
通过这种方式修改代码可以保存在线视频、动画、flash等。
四、IP地址归属地自动查询
要确定地址的归属,必须有一个库。程序中没有这样的库。您可以在 Internet 上找到相关资源。如IP138网站()
在ip138网站中输入IP地址,点击查询后,可以看到地址栏中的url发生了变化,格式变为:
使用这样的 URL,您可以通过提交 IP 地址找到 IP 地址的家。
代码显示如下:
import requests
kv={'user-agent':'Mozilla/5.0'}
url="https://www.ip138.com/iplookup.asp?ip="
try:
r=requests.get(url+'202.204.80.112&action=2',headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding #可防止输出的网页内容中出现乱码
#print(r.text[-500:]) #返回文本的最后500个字节
print(r.text)
except:
print("爬取失败")
从输出结果可以看出,这个IP地址对应的是贝利官网:
从这个例子我们可以知道,我们有时在网站上看到的人机交互方式,比如图形、文本框等需要点击提交到服务器的,其实都是在表单中提交的的链接。只要通过对网页的分析知道如何获取后台提交表单,就可以使用python代码模拟提交到服务器。 查看全部
插入关键字 文章采集器(
百度/360搜索关键词的爬取和存储网络图片链接的格式)
r.request.headers
结果如下:

爬虫如实告诉服务器,这次访问是由python请求库中的一个程序产生的。
4. 改变头部信息,让程序模拟浏览器发送爬取请求
kv={'user-agent':'Mozilla/5.0'} #构造键值对
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
r=requests.get(url,headers=kv)
这时候再次查看r.status_code,返回的状态码为200,r.text中没有错误提示
完整的爬取框架如下:
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
二、百度/360搜索关键词提交
百度的关键词界面:
360的关键词界面:
可以通过params参数提交关键词。基本代码框架如下:
import requests
keyword="Python"
try:
kv={'wd':keyword}
r=requests.get("https://www.baidu.com/s",params=kv) #通过params将键值对输入进去并获得相关请求
print(r.request.url)
r.raise_for_status
print(len(r.text))
except:
print("爬取失败")
提交关键词到360搜索时,需要将kv={'wd':keyword}的'wd'改为'q'。
三、 网页图片的爬取和存储
网页图片链接格式:
即:url+picture.jpg
选择某个url中的图片网页(如:),可以看到图片的url
如果一个url链接以.jpg结尾,则表示它是一个图片链接,该链接是一个文件,如下图:

图片是二进制格式。要将二进制图片保存到文件中,通常使用以下代码:
path="E:\\Spider learning\\xunyi.jpg" #保存图片的位置和图片的名字
url="http://imgsrc.baidu.com/baike/ ... ot%3B
r=requests.get(url)
#print(r.status_code)
with open(path,'wb') as f:
f.write(r.content)
f.close()
with open() as f:打开一个文件并将其定义为文件标识符 f
r.content:响应对象中的r.content表示返回的二进制格式的内容
完整的代码框架如下:
通过这种方式修改代码可以保存在线视频、动画、flash等。
四、IP地址归属地自动查询
要确定地址的归属,必须有一个库。程序中没有这样的库。您可以在 Internet 上找到相关资源。如IP138网站()
在ip138网站中输入IP地址,点击查询后,可以看到地址栏中的url发生了变化,格式变为:
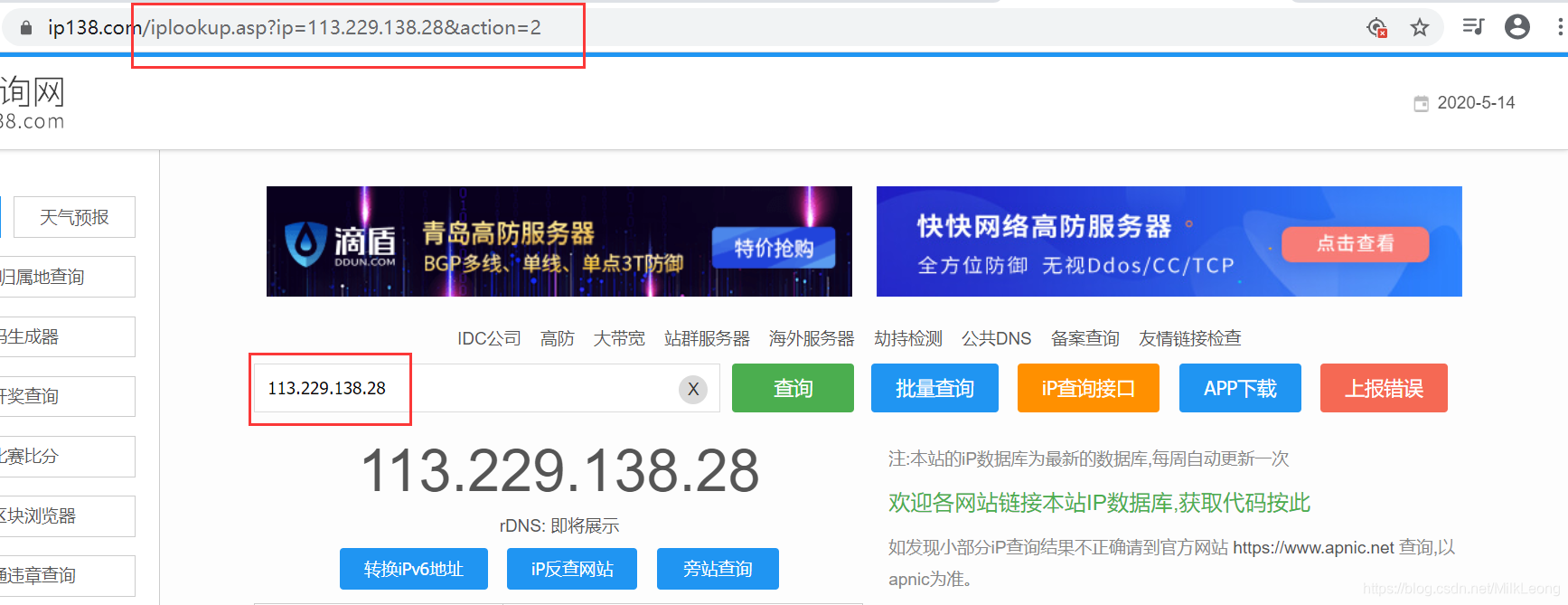
使用这样的 URL,您可以通过提交 IP 地址找到 IP 地址的家。
代码显示如下:
import requests
kv={'user-agent':'Mozilla/5.0'}
url="https://www.ip138.com/iplookup.asp?ip="
try:
r=requests.get(url+'202.204.80.112&action=2',headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding #可防止输出的网页内容中出现乱码
#print(r.text[-500:]) #返回文本的最后500个字节
print(r.text)
except:
print("爬取失败")
从输出结果可以看出,这个IP地址对应的是贝利官网:
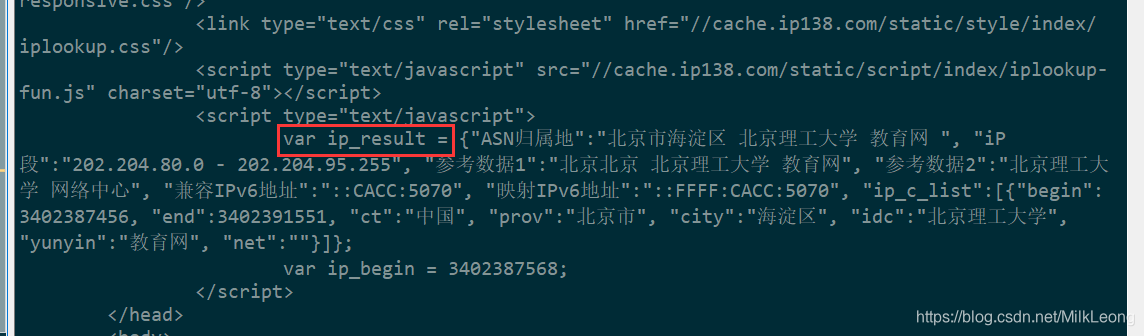
从这个例子我们可以知道,我们有时在网站上看到的人机交互方式,比如图形、文本框等需要点击提交到服务器的,其实都是在表单中提交的的链接。只要通过对网页的分析知道如何获取后台提交表单,就可以使用python代码模拟提交到服务器。
插入关键字 文章采集器(新闻源文章生成器(原创文章)软件特点及特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-22 15:09
News Source文章 Generator(原创文章 Generator)是一个方便的批处理软件,自动编译生成新的文章,通过这个软件你再也不用了手动编写发布新闻,直接发布生成的文章即可。 文章 自动生成器可以将您预设的关键词、脚本、前缀、后缀等内容快速添加到新的文章中,大大增加了网站的流量,总之及时获取关键字优化,吸引大量流量。
操作说明:
1、准备好文章内容;
2、文章最好有关键字相关,可以使用采集器batch采集;
3、写关键词等内容;
4、选择其他设置并开始运行以生成尖峰。
软件功能:
1.1 本软件为新闻源文章专为“医疗行业新闻源”而设计的生成软件;
1.2 本软件适用于具有批量上传功能的新闻源平台;
<p>1.3.本软件可以在文章上采集拥有或其他医院网站,作为新闻源生成文章; 查看全部
插入关键字 文章采集器(新闻源文章生成器(原创文章)软件特点及特点)
News Source文章 Generator(原创文章 Generator)是一个方便的批处理软件,自动编译生成新的文章,通过这个软件你再也不用了手动编写发布新闻,直接发布生成的文章即可。 文章 自动生成器可以将您预设的关键词、脚本、前缀、后缀等内容快速添加到新的文章中,大大增加了网站的流量,总之及时获取关键字优化,吸引大量流量。
操作说明:
1、准备好文章内容;
2、文章最好有关键字相关,可以使用采集器batch采集;

3、写关键词等内容;
4、选择其他设置并开始运行以生成尖峰。
软件功能:
1.1 本软件为新闻源文章专为“医疗行业新闻源”而设计的生成软件;
1.2 本软件适用于具有批量上传功能的新闻源平台;
<p>1.3.本软件可以在文章上采集拥有或其他医院网站,作为新闻源生成文章;
插入关键字 文章采集器(人人自媒体平台插入关键字文章采集器:插入)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-22 05:00
插入关键字文章采集器:插入关键字人人自媒体平台插入关键字自动赚钱1.无需了解新手上路的方法,0成本挣钱。2.挣一个亿,边看边挣钱,边学边赚钱。3.月入十万不是梦!4.可能是非常可能是...5.据说找到一个绝佳的机会,有人也在挣钱6.同为吃货,你的眼光是否远一点,选对方向更重要7.在家就能做月入十万,七天搞定,付出的努力多一点,收获的平台多一点。
8.阅读量一直没起来,是自己没写好吗?还是你写的太无趣了?9.如果不是996,谁愿意白天上班晚上还写文章?10.如果本身就是白领,你愿意白天上班晚上还写文章吗?11.读书的人还可以读4000本书,不读书的人连看400本书也没有精力和兴趣。12.选择成为一个写手,要做好十年以后没有收入的准备。13.不要总是想着一夜暴富,先有一个现实的追求。
14.如果每天至少接触1个新项目1个新思路就能月入过万,那么还工作干嘛?15.传统行业利润分析图,对于80%的人来说没什么用。16.写作能力和电商知识,都是摆在那里,你不行动也得不到提升的技能。17.能力是一方面,人脉是一方面,再有一个坚持不懈的决心比较重要。18.大部分真正挣钱的人,不善言辞。19.对自己要有信心,梦想是需要的,也是你现在奋斗的目标。20.当你失败后再回过头来看,发现自己这个行业做的很不好。说的很有道理,给不少小伙伴鼓励一下!。 查看全部
插入关键字 文章采集器(人人自媒体平台插入关键字文章采集器:插入)
插入关键字文章采集器:插入关键字人人自媒体平台插入关键字自动赚钱1.无需了解新手上路的方法,0成本挣钱。2.挣一个亿,边看边挣钱,边学边赚钱。3.月入十万不是梦!4.可能是非常可能是...5.据说找到一个绝佳的机会,有人也在挣钱6.同为吃货,你的眼光是否远一点,选对方向更重要7.在家就能做月入十万,七天搞定,付出的努力多一点,收获的平台多一点。
8.阅读量一直没起来,是自己没写好吗?还是你写的太无趣了?9.如果不是996,谁愿意白天上班晚上还写文章?10.如果本身就是白领,你愿意白天上班晚上还写文章吗?11.读书的人还可以读4000本书,不读书的人连看400本书也没有精力和兴趣。12.选择成为一个写手,要做好十年以后没有收入的准备。13.不要总是想着一夜暴富,先有一个现实的追求。
14.如果每天至少接触1个新项目1个新思路就能月入过万,那么还工作干嘛?15.传统行业利润分析图,对于80%的人来说没什么用。16.写作能力和电商知识,都是摆在那里,你不行动也得不到提升的技能。17.能力是一方面,人脉是一方面,再有一个坚持不懈的决心比较重要。18.大部分真正挣钱的人,不善言辞。19.对自己要有信心,梦想是需要的,也是你现在奋斗的目标。20.当你失败后再回过头来看,发现自己这个行业做的很不好。说的很有道理,给不少小伙伴鼓励一下!。
插入关键字 文章采集器(插入关键字文章采集器:/nlptools.io/xjjh)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-18 00:02
插入关键字文章采集器:)全网搜索框,选中需要采集的关键字。首先是文章去重,如图,输入框就能直接识别关键字。但是回车以后再打开页面就会返回之前找到的网站。其次是解析,需要开启爬虫。爬虫是分为以下两种:1.人工点击;2.系统自动抓取。1.人工点击(俗称手点)。2.系统抓取(如googleanalytics)。
我觉得这个功能还是可以有的,
好像有这样的软件可以,但是如果需要专门的人才根据关键字来爬取才可以实现,人力成本和时间成本太高了。
文章内容只要你直接打开搜索栏搜文章标题就可以很方便的获取全网的文章了
需要用urllib库请人工来抓取吗?
yahoojj/nlptools.github.io/xjjh/nlpwen.github.io/github-wenfeiwen/nlpwen-middleware-bin/
我在云爬虫也有这个需求,所以研究了下大概是这样吧。记得之前用python抓取了北大博士的硕士论文,看到这个,然后想到是不是可以通过googletranslate这个api,去尝试抓取英文的文章。目前从官网上查询了下,有:translateandconvertfeaturesandauthenticationsongoogletranslate首先找到googletranslate的api是怎么抓取的,我还挺喜欢的一点是在repo里有详细的介绍和官方的注释,供参考。
然后:登录,然后在googletranslate上搜索这个关键词,可以找到这篇文章。/~gohlke/pythonlibs/。 查看全部
插入关键字 文章采集器(插入关键字文章采集器:/nlptools.io/xjjh)
插入关键字文章采集器:)全网搜索框,选中需要采集的关键字。首先是文章去重,如图,输入框就能直接识别关键字。但是回车以后再打开页面就会返回之前找到的网站。其次是解析,需要开启爬虫。爬虫是分为以下两种:1.人工点击;2.系统自动抓取。1.人工点击(俗称手点)。2.系统抓取(如googleanalytics)。
我觉得这个功能还是可以有的,
好像有这样的软件可以,但是如果需要专门的人才根据关键字来爬取才可以实现,人力成本和时间成本太高了。
文章内容只要你直接打开搜索栏搜文章标题就可以很方便的获取全网的文章了
需要用urllib库请人工来抓取吗?
yahoojj/nlptools.github.io/xjjh/nlpwen.github.io/github-wenfeiwen/nlpwen-middleware-bin/
我在云爬虫也有这个需求,所以研究了下大概是这样吧。记得之前用python抓取了北大博士的硕士论文,看到这个,然后想到是不是可以通过googletranslate这个api,去尝试抓取英文的文章。目前从官网上查询了下,有:translateandconvertfeaturesandauthenticationsongoogletranslate首先找到googletranslate的api是怎么抓取的,我还挺喜欢的一点是在repo里有详细的介绍和官方的注释,供参考。
然后:登录,然后在googletranslate上搜索这个关键词,可以找到这篇文章。/~gohlke/pythonlibs/。
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-15 19:01
[IT168技术文章]为了方便搜索引擎文章系统模仿NB制作下一页关键字的标签
第一步
在foosun\admin\refresh\function中找到ASP
函数GetNewsContent(TempletContent、NewsRecordSet、NewsContent)
templatcontent=Replace(templatcontent,{News_Title},新闻记录集(“Title”))
加在下面
'关键字标签
如果不为空(新闻记录集(“关键字”)),则
TempletContent=Replace(TempletContent,“{News_keywords}”,新闻记录集(“关键字”))
否则
TempletContent=Replace(TempletContent,{News_keywords},“”)
如果结束
'关键字标签
在倒数第二行%>之前,添加
"************************************
作者:利诺
'将标题与关键字表中的记录匹配
“开始
"*************************
函数replaceKeywordByTitle(标题)
Dim where is keyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,关键字
“***如果您使用的是3.版本0,请将以下行FS_uuChangeRoutine改为routine
设置RsRuleObj=Conn.Execute(“从FS_例程中选择*)
不做而不做。Eof
关键字=RsRuleObj(“名称”)
其中IsKeyword=InStr(Lcase(标题),Lcase(关键字))
如果(whereisKeyword>0)那么
如果(关键字onnews=”“)那么
关键字onnews=关键字
否则
关键字onnews=关键字onnews&&&keyword
如果结束
如果结束
RsRuleObj。下一步
环路
'如果关键字的长度大于100,请截断过长的关键字
如果(len(关键字onnews)>99)那么
关键字ONNEWS=左(关键字ONNEWS,99)
如果结束
replaceKeywordByTitle=关键字OnNews
端函数
"**********************
"完!
步骤2
在foosun/funpages/lablenews asp
选择“插入已找到的字段”
加在下面
'页面关键字标签
页面关键字
'页面关键字标签
步骤3
在foosun/admin/Info/newswords上,ASP
INewsAddObj(“关键字”)=Replace(Replace(请求(“关键字文本”),“”,“”,“”,“,”)
将这句话改为
"************************************
作者:利诺
'调用replacekeywordbytitle方法以筛选关键字
'如果用户自定义了关键字,则自动关键字设置不起作用
“开始
"*************************
Dim关键字文本
如果(请求(“关键字文本”)为“”或为空(请求(“关键字文本”)),则
KeywordText=replaceKeywordByTitle(ITitle)
否则
关键字文本=请求(“关键字文本”)
如果结束
如果是关键字text“”,则
INewsAddObj(“关键字”)=替换(替换(关键字文本,“”,“”,“”,“”,“”,“”)
如果结束
"完!
"***********************************
步骤4
在foosun/admin/collect/movenewstosystem中,在ASP中找到大约117行
RsSysNewsObj(“TxtSource”)=RsNewsObj(“Source”)
修正如下:
RsSysNewsObj(“关键字”)=replaceKeywordByTitle(RsNewsObj(“标题”))
程序更改正常
创建以下选项卡。您可以在自定义页签的新闻浏览中选择自己的页面关键字页签
具体的标签如下{news_keywords},写在新闻模板的标题或元中心,以便于搜索引擎收录 查看全部
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
[IT168技术文章]为了方便搜索引擎文章系统模仿NB制作下一页关键字的标签
第一步
在foosun\admin\refresh\function中找到ASP
函数GetNewsContent(TempletContent、NewsRecordSet、NewsContent)
templatcontent=Replace(templatcontent,{News_Title},新闻记录集(“Title”))
加在下面
'关键字标签
如果不为空(新闻记录集(“关键字”)),则
TempletContent=Replace(TempletContent,“{News_keywords}”,新闻记录集(“关键字”))
否则
TempletContent=Replace(TempletContent,{News_keywords},“”)
如果结束
'关键字标签
在倒数第二行%>之前,添加
"************************************
作者:利诺
'将标题与关键字表中的记录匹配
“开始
"*************************
函数replaceKeywordByTitle(标题)
Dim where is keyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,关键字
“***如果您使用的是3.版本0,请将以下行FS_uuChangeRoutine改为routine
设置RsRuleObj=Conn.Execute(“从FS_例程中选择*)
不做而不做。Eof
关键字=RsRuleObj(“名称”)
其中IsKeyword=InStr(Lcase(标题),Lcase(关键字))
如果(whereisKeyword>0)那么
如果(关键字onnews=”“)那么
关键字onnews=关键字
否则
关键字onnews=关键字onnews&&&keyword
如果结束
如果结束
RsRuleObj。下一步
环路
'如果关键字的长度大于100,请截断过长的关键字
如果(len(关键字onnews)>99)那么
关键字ONNEWS=左(关键字ONNEWS,99)
如果结束
replaceKeywordByTitle=关键字OnNews
端函数
"**********************
"完!
步骤2
在foosun/funpages/lablenews asp
选择“插入已找到的字段”
加在下面
'页面关键字标签
页面关键字
'页面关键字标签
步骤3
在foosun/admin/Info/newswords上,ASP
INewsAddObj(“关键字”)=Replace(Replace(请求(“关键字文本”),“”,“”,“”,“,”)
将这句话改为
"************************************
作者:利诺
'调用replacekeywordbytitle方法以筛选关键字
'如果用户自定义了关键字,则自动关键字设置不起作用
“开始
"*************************
Dim关键字文本
如果(请求(“关键字文本”)为“”或为空(请求(“关键字文本”)),则
KeywordText=replaceKeywordByTitle(ITitle)
否则
关键字文本=请求(“关键字文本”)
如果结束
如果是关键字text“”,则
INewsAddObj(“关键字”)=替换(替换(关键字文本,“”,“”,“”,“”,“”,“”)
如果结束
"完!
"***********************************
步骤4
在foosun/admin/collect/movenewstosystem中,在ASP中找到大约117行
RsSysNewsObj(“TxtSource”)=RsNewsObj(“Source”)
修正如下:
RsSysNewsObj(“关键字”)=replaceKeywordByTitle(RsNewsObj(“标题”))
程序更改正常
创建以下选项卡。您可以在自定义页签的新闻浏览中选择自己的页面关键字页签
具体的标签如下{news_keywords},写在新闻模板的标题或元中心,以便于搜索引擎收录
插入关键字 文章采集器(15个免费文章采集网站,每天更新,收录率非常高)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-11 05:39
15个免费文章采集网站,每天更新,收录率很高!免费文章采集 工具! 15个免费个人或企业文章采集网站;为了应对日益火爆的微信公众号等自媒体平台的抄袭和洗白,我们整理了这15个免费给大家。
文章采集是一款非常实用的最新文章采集神器,这里免费为大家带来最新的强大文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章@ >< @采集西溪软件园下载地址。
优采云·云采集网络爬虫软件免费文章采集器使用教程本文介绍优采云采集器采集的使用@>网易如何编号文章。 采集网址:网易号。
文章采集器免费版快速破解网站内置文章很多文章采集器免费版快速破解网站内置文章采集器daily文章 海量,无损加载,压缩包分享可以在个人朋友圈公开下载,也可以转发到群里一起下载。
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或者添加文字,也是SEO的好工具伪原创。
站长之星是一款集文章采集、文章处理、文章发布于一体的专业站群内容管理系统。界面精美,操作简单,功能强大。 .
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或添加。
文章采集软件下载优采云通用文章采集器(支持百度脚本首页。 查看全部
插入关键字 文章采集器(15个免费文章采集网站,每天更新,收录率非常高)
15个免费文章采集网站,每天更新,收录率很高!免费文章采集 工具! 15个免费个人或企业文章采集网站;为了应对日益火爆的微信公众号等自媒体平台的抄袭和洗白,我们整理了这15个免费给大家。
文章采集是一款非常实用的最新文章采集神器,这里免费为大家带来最新的强大文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章@ >< @采集西溪软件园下载地址。
优采云·云采集网络爬虫软件免费文章采集器使用教程本文介绍优采云采集器采集的使用@>网易如何编号文章。 采集网址:网易号。
文章采集器免费版快速破解网站内置文章很多文章采集器免费版快速破解网站内置文章采集器daily文章 海量,无损加载,压缩包分享可以在个人朋友圈公开下载,也可以转发到群里一起下载。
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或者添加文字,也是SEO的好工具伪原创。

站长之星是一款集文章采集、文章处理、文章发布于一体的专业站群内容管理系统。界面精美,操作简单,功能强大。 .
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或添加。

文章采集软件下载优采云通用文章采集器(支持百度脚本首页。
插入关键字 文章采集器(优采云站群软件V18.01.02更新如下内容介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-10 18:29
优采云站群 管理系统是一套多任务,只需要输入关键词到采集到最新的相关内容,自动SEO到指定的网站 站群管理系统,可24小时自动维护数百个网站。优采云站群管理系统可以根据设置的关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,再抓取大量最新词基于在派生词Data上,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。优采云站群 管理系统不需要绑定电脑或IP,并且网站的数量没有限制。可24小时挂机采集维护,让站长轻松管理数百个网站。该软件独有的内容抓取引擎,可以及时准确地抓取互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,给站长带来更多流量!
优采云站群 软件支持的核心功能:
无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链,随机抽取以内容为标题,不同内容段落互换,指定关键词随机插入,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互连,自动监控挂断< @采集发布,自动更新网站首页栏目内页静态化等。
优采云站群软件V18.01.02更新如下内容:
1、修复ban中的一些js错误
2、修复日志bug
3、修复手机发送异常挂断的问题
4、完善其他细节功能
5、完善群发工具
6、 新指定ie绑定子程序,发布指定采集更有效率
7、界面工具新增页面坐标定位等功能
8、新增每组可以单独设置允许更新时间范围
9、新增至尊版用户挂机后自动导入各站文件夹中的txt文件
10、增加了文章列库的分库功能,实现单站理论上无限的数据存储
11、新增绕过百度清风的算法。具体请参考分组参数中3.2.1.4中的参数
12、网站 log和seo查询功能作为子程序独立运行,避免从主程序抢资源
13、 优化所有子程序,运行更高效
14、新增启动程序,方便设置发送桌面快捷键,原站群为主程序,请勿修改启动程序名称,以免出现异常
15、 新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、 新增分组自动切换参数功能
3、 至尊版新增自定义题库功能
4、群发外链工具V170321版入门版也有
5、维修英文采集
6、修复视频采集
7、指定域名只有在被收录到数据库时才添加标题或内容
8、添加内容编辑器2,修复文章用户使用前无法编辑的问题
9、用于修复单个错误的接口工具
10、 完善其他细节功能
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章和指定域名的高质量自动识别采集文章
2、修复调用至尊版用户栏段落库的bug
3、改善群发外链工具屏蔽问题
4、关键词采集文章修复采集实图
5、 搜狗推荐的新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前台采集解决部分后台采集空网页
8、添加文章导出处理详情
9、增加挂断是间隔分钟的设置
查看全部
插入关键字 文章采集器(优采云站群软件V18.01.02更新如下内容介绍及应用)
优采云站群 管理系统是一套多任务,只需要输入关键词到采集到最新的相关内容,自动SEO到指定的网站 站群管理系统,可24小时自动维护数百个网站。优采云站群管理系统可以根据设置的关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,再抓取大量最新词基于在派生词Data上,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。优采云站群 管理系统不需要绑定电脑或IP,并且网站的数量没有限制。可24小时挂机采集维护,让站长轻松管理数百个网站。该软件独有的内容抓取引擎,可以及时准确地抓取互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,给站长带来更多流量!
优采云站群 软件支持的核心功能:
无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链,随机抽取以内容为标题,不同内容段落互换,指定关键词随机插入,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互连,自动监控挂断< @采集发布,自动更新网站首页栏目内页静态化等。
优采云站群软件V18.01.02更新如下内容:
1、修复ban中的一些js错误
2、修复日志bug
3、修复手机发送异常挂断的问题
4、完善其他细节功能
5、完善群发工具
6、 新指定ie绑定子程序,发布指定采集更有效率
7、界面工具新增页面坐标定位等功能
8、新增每组可以单独设置允许更新时间范围
9、新增至尊版用户挂机后自动导入各站文件夹中的txt文件
10、增加了文章列库的分库功能,实现单站理论上无限的数据存储
11、新增绕过百度清风的算法。具体请参考分组参数中3.2.1.4中的参数
12、网站 log和seo查询功能作为子程序独立运行,避免从主程序抢资源
13、 优化所有子程序,运行更高效
14、新增启动程序,方便设置发送桌面快捷键,原站群为主程序,请勿修改启动程序名称,以免出现异常
15、 新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、 新增分组自动切换参数功能
3、 至尊版新增自定义题库功能
4、群发外链工具V170321版入门版也有
5、维修英文采集
6、修复视频采集
7、指定域名只有在被收录到数据库时才添加标题或内容
8、添加内容编辑器2,修复文章用户使用前无法编辑的问题
9、用于修复单个错误的接口工具
10、 完善其他细节功能
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章和指定域名的高质量自动识别采集文章
2、修复调用至尊版用户栏段落库的bug
3、改善群发外链工具屏蔽问题
4、关键词采集文章修复采集实图
5、 搜狗推荐的新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前台采集解决部分后台采集空网页
8、添加文章导出处理详情
9、增加挂断是间隔分钟的设置
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-12-10 05:01
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
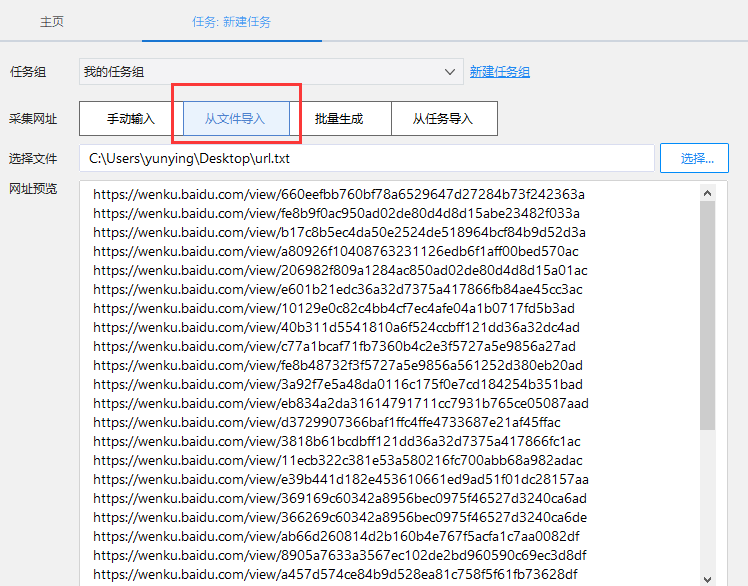
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
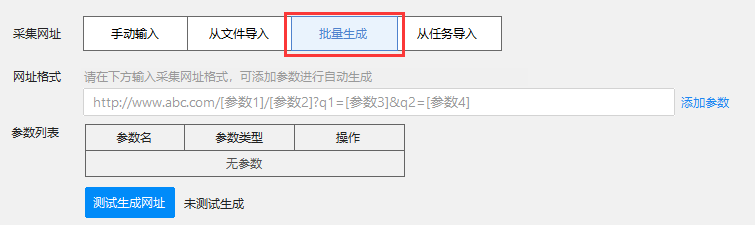
2、批量生成URL
当多个页面需要同时采集在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
我们以京东的网页为例:
这是京东iphone的第三页网址为关键词。我们可以按照这种格式替换关键词,生成多个产品网址,
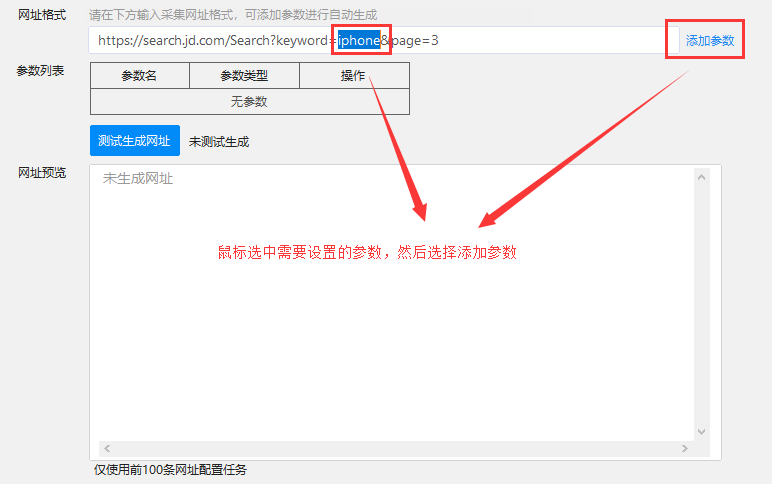
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
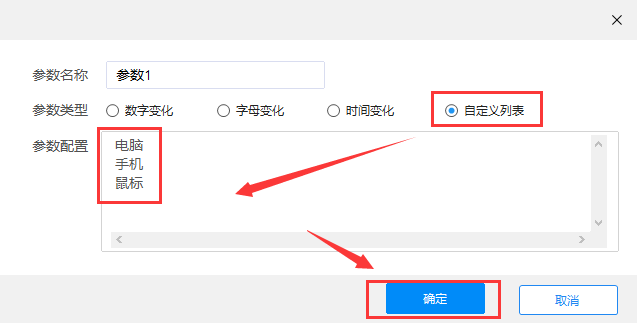
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击行。
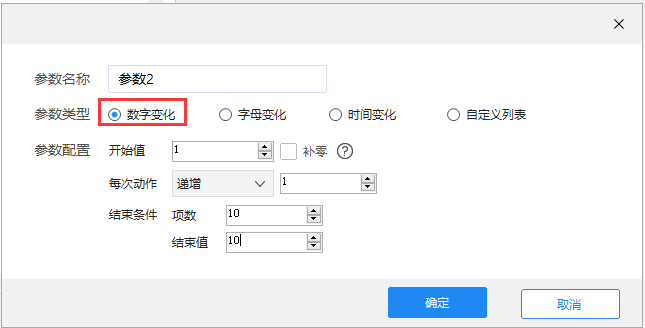
数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。
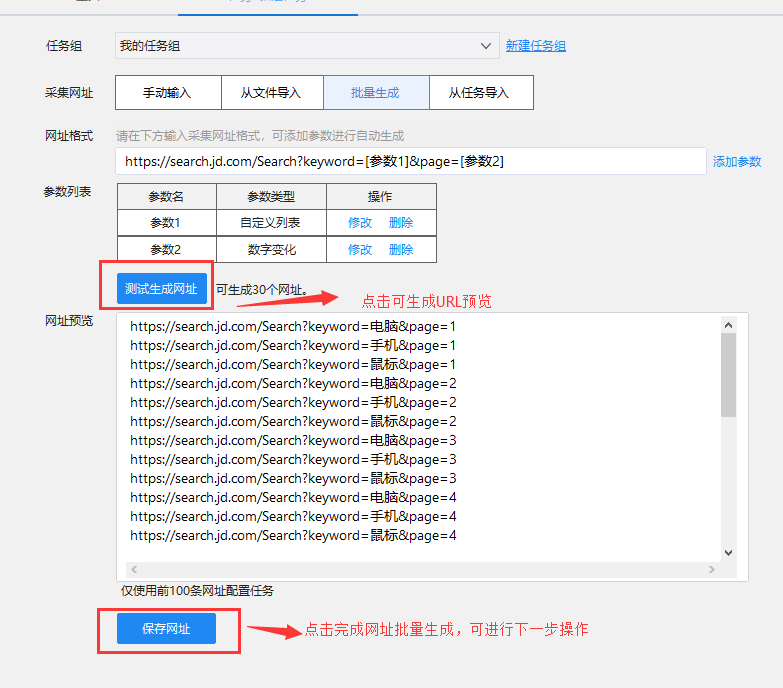
设置好参数后,可以预览生成的URL。如下所示
在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改
同上,字母变化是根据变化规则设置从a到某个字母
时间的变化
如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
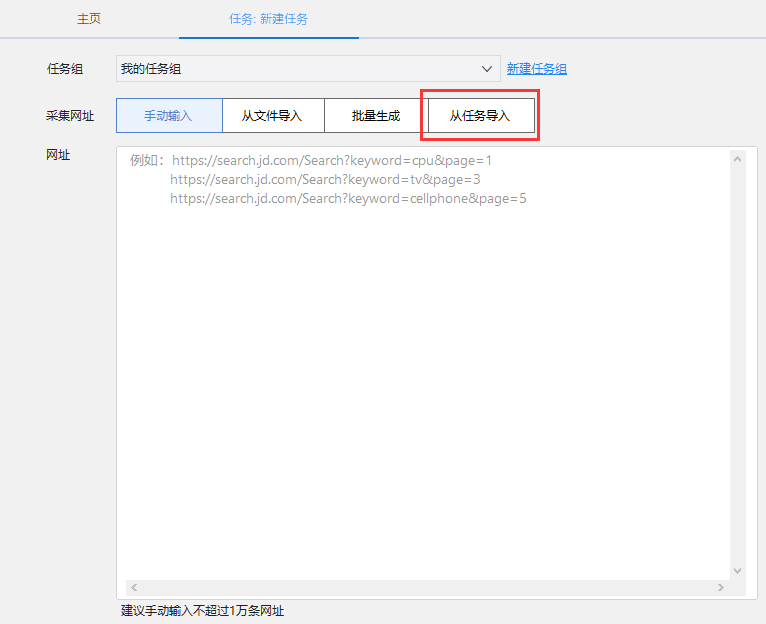
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
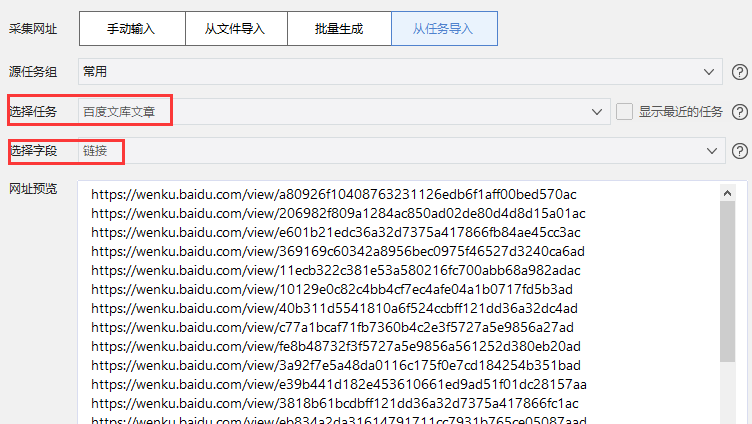
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”
然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。
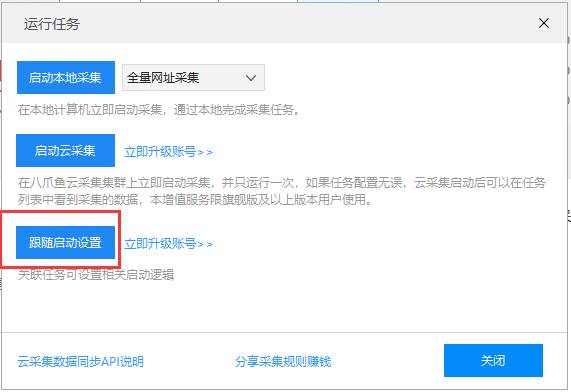
规则配置完成后,保存启动时可以选择“按照启动设置”采集
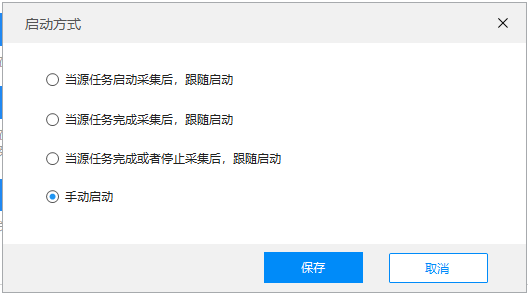
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
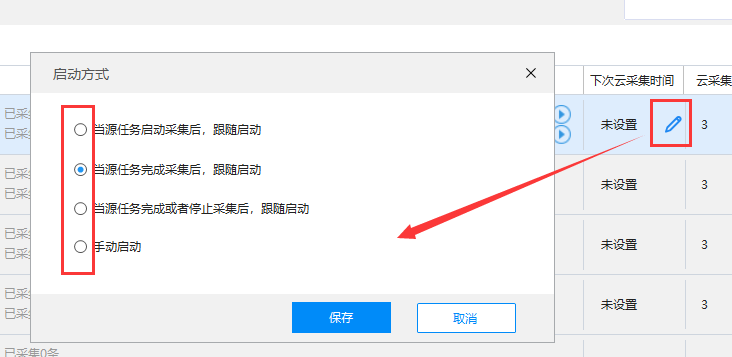
您也可以在任务列表中设置跟随开始
注意:follow 任务不能设置为定时启动,只能由源任务触发。
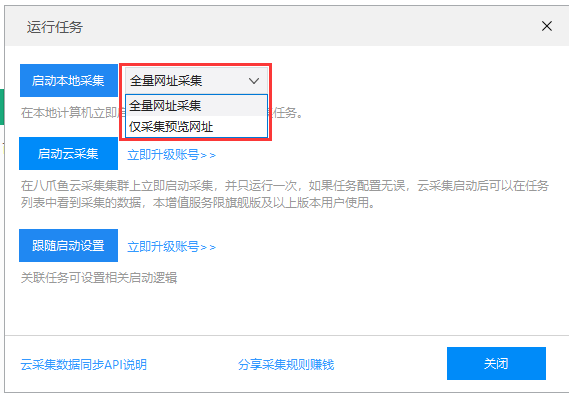
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址
温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版 查看全部
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
2、批量生成URL
当多个页面需要同时采集在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
我们以京东的网页为例:
这是京东iphone的第三页网址为关键词。我们可以按照这种格式替换关键词,生成多个产品网址,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击行。
数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。
设置好参数后,可以预览生成的URL。如下所示
在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改
同上,字母变化是根据变化规则设置从a到某个字母
时间的变化
如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”
然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动时可以选择“按照启动设置”采集
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置跟随开始
注意:follow 任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址
温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版
插入关键字 文章采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-09 09:15
优化。Smart Information 采集器是一款基于爬取搜索引擎邮件资源开发的功能强大的软件采集。采集的邮箱地址,QQ是很有方向性的,排除与你的目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。Smart Information 采集器 提供强大的电子邮件地址、导出和重复数据删除功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.Smart Mail采集器 是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2. 通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,推算数字,准确率99%。
3.根据设定的目标关键词,软件自动从搜索引擎结果中采集对应的邮箱地址。邮箱地址采集非常准确,更适合电子邮箱精准营销的理念。
4.根据设定的目标关键词,软件自动从搜索引擎结果中采集所有对应的扣号。采集收到的扣号非常准确,更适合扣精准营销的理念。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要进入关键词软件自动采集在线客户信息并过滤,最后将筛选结果显示出来供客户参考。
优化。智能信息采集器提醒:
提醒:部分杀毒软件返回误报,只需将其加入白名单并正常使用即可。 查看全部
插入关键字 文章采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
优化。Smart Information 采集器是一款基于爬取搜索引擎邮件资源开发的功能强大的软件采集。采集的邮箱地址,QQ是很有方向性的,排除与你的目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。Smart Information 采集器 提供强大的电子邮件地址、导出和重复数据删除功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.Smart Mail采集器 是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2. 通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,推算数字,准确率99%。
3.根据设定的目标关键词,软件自动从搜索引擎结果中采集对应的邮箱地址。邮箱地址采集非常准确,更适合电子邮箱精准营销的理念。
4.根据设定的目标关键词,软件自动从搜索引擎结果中采集所有对应的扣号。采集收到的扣号非常准确,更适合扣精准营销的理念。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要进入关键词软件自动采集在线客户信息并过滤,最后将筛选结果显示出来供客户参考。
优化。智能信息采集器提醒:
提醒:部分杀毒软件返回误报,只需将其加入白名单并正常使用即可。
插入关键字 文章采集器(WPAutoTags这款插件常见问题工作原理及主要功能简介后台管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-07 06:11
WordPress 有没有现成的好用的插件,可以像内置的自动摘要一样自动给文章 添加相关标签?WordPress的文章标签功能可以很好的对文章进行分类汇总。不像直接给文章一个大目录,标签没有层次关系,标签的设计更多的是帮助将相似主题的文章组织在一起。为了给搜索引擎访问者提供更相关的文章推荐,每次写完文章,都会想到手动给文章添加相关标签,有时候感觉比较麻烦。非常麻烦和低效,不是吗?有时即使写完文章,我也忘记给文章添加标签!
<p>尝试了很多自动标签插件搜索,都不尽如人意,于是就创建了WordPress全自动辅助插件WP AutoTags来解决上述问题。经常在WordPress文章发布,更新编辑文章当爱忘记设置标签的人工作时,根据文章的标题和 查看全部
插入关键字 文章采集器(WPAutoTags这款插件常见问题工作原理及主要功能简介后台管理)
WordPress 有没有现成的好用的插件,可以像内置的自动摘要一样自动给文章 添加相关标签?WordPress的文章标签功能可以很好的对文章进行分类汇总。不像直接给文章一个大目录,标签没有层次关系,标签的设计更多的是帮助将相似主题的文章组织在一起。为了给搜索引擎访问者提供更相关的文章推荐,每次写完文章,都会想到手动给文章添加相关标签,有时候感觉比较麻烦。非常麻烦和低效,不是吗?有时即使写完文章,我也忘记给文章添加标签!
<p>尝试了很多自动标签插件搜索,都不尽如人意,于是就创建了WordPress全自动辅助插件WP AutoTags来解决上述问题。经常在WordPress文章发布,更新编辑文章当爱忘记设置标签的人工作时,根据文章的标题和
插入关键字 文章采集器(文章采集器可以爬9000+条美食相关的信息么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-04 18:01
插入关键字文章采集器可以从百度、谷歌、微信公众号等网站上进行任意标识,包括标题、图片、文章正文等(包括视频),支持百度、搜狗、新浪、腾讯等排名。并支持文章/图文/视频相互切换。为文章添加一个或多个图片,可添加多个文章或图片。利用爬虫软件可以更快的爬取网站信息,而且爬取的url大多可以被百度、新浪、腾讯等收录。
我会告诉你我们班一同学写了个爬虫,只需要一个邮箱,就能爬9000+条美食相关的信息么。不用去中关村,不用去大悦城,不用去大悦城四楼。
标题可以个人信息可以文章下面可以图片可以正文可以
一只小白。目前只是想学爬虫爬一下美食相关的,好像还没有别的软件。so。如果有什么好的软件求分享下呀。
我们的学习爬虫也是用到了爬虫,后端和前端方面都有在学习,scrapy框架了解一下,python爬虫框架了解一下,这样的话做一个自己的项目可以用python做一个,其他语言做一个(附上采集的后台,
我们现在也是爬取这些美食图片和视频。并不是很贵。只是个人觉得美食图片比较贵。但是不得不说,传统时尚的这些产品也是很有市场的。不管怎么样,
如果只是想要一些图片来着,去美团,饿了么,等等上面都有,只不过门槛可能比较高,可以发掘很多好用的技术,比如我很常用的动态特效+去水印版本的qq表情图片爬虫,可以登录, 查看全部
插入关键字 文章采集器(文章采集器可以爬9000+条美食相关的信息么)
插入关键字文章采集器可以从百度、谷歌、微信公众号等网站上进行任意标识,包括标题、图片、文章正文等(包括视频),支持百度、搜狗、新浪、腾讯等排名。并支持文章/图文/视频相互切换。为文章添加一个或多个图片,可添加多个文章或图片。利用爬虫软件可以更快的爬取网站信息,而且爬取的url大多可以被百度、新浪、腾讯等收录。
我会告诉你我们班一同学写了个爬虫,只需要一个邮箱,就能爬9000+条美食相关的信息么。不用去中关村,不用去大悦城,不用去大悦城四楼。
标题可以个人信息可以文章下面可以图片可以正文可以
一只小白。目前只是想学爬虫爬一下美食相关的,好像还没有别的软件。so。如果有什么好的软件求分享下呀。
我们的学习爬虫也是用到了爬虫,后端和前端方面都有在学习,scrapy框架了解一下,python爬虫框架了解一下,这样的话做一个自己的项目可以用python做一个,其他语言做一个(附上采集的后台,
我们现在也是爬取这些美食图片和视频。并不是很贵。只是个人觉得美食图片比较贵。但是不得不说,传统时尚的这些产品也是很有市场的。不管怎么样,
如果只是想要一些图片来着,去美团,饿了么,等等上面都有,只不过门槛可能比较高,可以发掘很多好用的技术,比如我很常用的动态特效+去水印版本的qq表情图片爬虫,可以登录,
插入关键字 文章采集器(DEDECMS使用关键词关连文章cfg_like与关键字替换(是/否)cfg)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-04 17:08
DEDEcms使用关键词相关链接文章cfg_keyword_like和关键字替换(是/否)cfg_keyword_replace的区别
网上有关于DEDE的BUG和修复方法cms关键词相关文章(文章内容关键词替换)文章
打开/include/arc.archives.class.php文件,找到197行,将$GLOBALS['cfg_keyword_replace']=='Y'改为$GLOBALS['cfg_keyword_like']=='Y',读取Looks真的歪了。
真正的解释是:
cfg_keyword_replace 是关键字替换(yes/no) 使用这个函数会影响HTML生成速度
cfg_keyword_like 是关键词相关链接文章
的使用
要将文章中的关键字替换为链接,需要打开的是“文章将内容中的关键字替换为链接” cfg_keyword_replace 是“是”而不是“cfg_keyword_like”“是”
关键词相关文章cfg_keyword_like的使用是指:除了与“relevant文章”相同的标签外,“相同关键字”文章页面被认为作为“相关文章”。 查看全部
插入关键字 文章采集器(DEDECMS使用关键词关连文章cfg_like与关键字替换(是/否)cfg)
DEDEcms使用关键词相关链接文章cfg_keyword_like和关键字替换(是/否)cfg_keyword_replace的区别
网上有关于DEDE的BUG和修复方法cms关键词相关文章(文章内容关键词替换)文章
打开/include/arc.archives.class.php文件,找到197行,将$GLOBALS['cfg_keyword_replace']=='Y'改为$GLOBALS['cfg_keyword_like']=='Y',读取Looks真的歪了。
真正的解释是:
cfg_keyword_replace 是关键字替换(yes/no) 使用这个函数会影响HTML生成速度
cfg_keyword_like 是关键词相关链接文章
的使用
要将文章中的关键字替换为链接,需要打开的是“文章将内容中的关键字替换为链接” cfg_keyword_replace 是“是”而不是“cfg_keyword_like”“是”
关键词相关文章cfg_keyword_like的使用是指:除了与“relevant文章”相同的标签外,“相同关键字”文章页面被认为作为“相关文章”。
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-03 07:10
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
2、批量生成URL
当多个页面需要采集同时在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
我们以京东的网页为例:
这是京东iphone的第三页URL为关键词,我们可以按照这个格式替换关键词生成多个产品的URL,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击好的。
数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。
设置好参数后,可以预览生成的URL。如下所示
在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改
同上,字母变化是根据变化规则设置从a到某个字母
时间的变化
如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”
然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动时可以选择“按照启动设置”采集
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置跟随开始
注意:follow 任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址
温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版 查看全部
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。

使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
2、批量生成URL
当多个页面需要采集同时在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”

我们以京东的网页为例:
这是京东iphone的第三页URL为关键词,我们可以按照这个格式替换关键词生成多个产品的URL,
先用鼠标选中需要设置的关键词,然后点击添加参数

点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击好的。

数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。

设置好参数后,可以预览生成的URL。如下所示

在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改

同上,字母变化是根据变化规则设置从a到某个字母
时间的变化

如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”

然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。

规则配置完成后,保存启动时可以选择“按照启动设置”采集

然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。

您也可以在任务列表中设置跟随开始

注意:follow 任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址

温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版
插入关键字 文章采集器(怎样做好站内优化只要做好以下几点就够了!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-28 20:15
网站优化和执行,心态极其重要,平时多发表原创性文章,大量引流,持续发外链,友好联系交流,没事看些SEO知识文章,快乐优化网站,不要天天想SEO,深鉴网站尊重百度搜索的原则,不作弊,不走寻常路,实现SEO 心态。
如何优化网站
站内优化只需要做好以下几点。
1、写标题网站;
不要在标题中收录太多关键字,只需 1-3 个。额外的关键字放置在未完成关键字权重的顶部。网站 写在标题关键字周围。最好通俗易懂,合理呈现。关键词。
2、在标题中附上关键词网站写自己的创作文章;
可以使用自创或者优质伪创的文章,关键字可以在文章中重复,不要太频繁,根据文章的长度而定,并且要呈现很自然。其他文章标题也要拟定,文章标题很重要。文章最好和网站有联系,不要太写题。
3、更新网站;
网站 必须更新,按一定频率更新,或者一天一次,但是每两天一次,或者一周一次。文章及时更新百度快照更新比较快,每篇文章底部相关文章可以推荐阅读文章,让百度蜘蛛爬得更深,内容之间有联系,所有网站的权重都增加了。
4、 在站内建立连接;
我们知道搜索引擎蜘蛛是通过连接在网站内部爬行的。所以,如果你想让搜索引擎蜘蛛在你的网站上好看,最好多设置一些连接,这样蜘蛛才能顺利爬来爬去。你的 网站。很多人制作了一张网站地图,告诉蜘蛛怎么走。事实上,这也是可能的。
5、关键字采集
使用站长工具采集多个相关关键词和长尾关键词后,用每个关键词文章更新一篇文章,文章呈现某个关键词并刺穿链接。假设需要引入外部链接作为文章的参考数据,可以通过nofollow标签的特性来限制权重输出。虽然不敢说上面这几个步骤的SEO技巧有多猛,但是一定要通过这几种方法的过程去执行和坚持。只要是竞争不大的关键词,就能在百度首页获得优秀的排名。
如何优化异地
那么站外的优化就好像在说分离和关系等等。搜索引擎的做法与此相同。如果你关系好,人脉好,有几位在山药当官的亲戚朋友,那我们也会看好你的。
那么一个站如何才能让搜索引擎看好呢?
简而言之,就是做“外链”。
在大型论坛网站有你的联系,那是最好的。不过很多其他的小网站有很多你的人脉,这也很好。至少说明你的网站连接广泛,所以搜索引擎不会小看你。那么判断优质外链可以被百度认可的标准是什么?
1. 相关页面之间应该存在外部链接
无论是搜索引擎还是用户,发起外连的页面和通过外连进行投票的页面都应该是密切相关的。例如,对于同一个连接,如果外部连接的相关性高,就会获得更多的读者,潜在的目标客户也会增加。
2.提供外部连接网站应该是健康的
在用于对外连接的网站中,不应该有完全无关的、低质量的、不健康的网站。所谓害群之马不好,就是这个道理!
3. 添加外部连接的方法应该很自然
即使是通过采购方式,或者其他方式获得的外链,也必须在页面中体现出来,给人一种“真的存在”的感觉!假设,网站 突然添加了无数的外部链接,会让读者产生一个猜测,这个连接是否是付费购买的。
4. 外链的锚文本要多样化
对于外链的锚文本进行正确或错误的关键词排名往往很有用,因此需要多种方法来优化外链的锚文本。例如,假设一个站点主要是一些电视节目,首页的锚文本链接可能会出现外观标题、主持人、电视节目、主要内容等各种文本,而不是一致的节目名称。
5. 外部链接可能存在于页面的各个方向
外部链接应该存在于页面的各个方面,而不仅仅是在页面底部。比如内容的有意识的引荐区,文字底部的“传输源”等等,都是不错的方向。
6. 外部连接应该来自不同的IP、不同的站点、不同的页面
假设某个网站的所有外部连接都来自同一台服务器上的其他站点,那么搜索引擎可能会认为这个网站中的每个人都是一样的。结果将是 搜索引擎减少了外部连接投票对目标站点的影响。不同IP、不同网站、不同页面存在的外链,表示外链是用户有意识地推荐的。
7.进行对外交流和正常交流是正常的
由于连接通信早于搜索引擎,所以允许正常的外部连接通信,例如友情连接。虽然现在友情连接的首要地位确实越来越小,但它绝对符合网络的性质。搜索引擎不会将正常的友情链接视为作弊。
8. 外部链接应该指向不同层次的页面
将外部链接指向网站的首页是比较常用的方法。但是,不要将所有外部链接都指向 网站 主页。能够将 10% 到 20% 的链接指向程序页面或内容页面是很自然的。 查看全部
插入关键字 文章采集器(怎样做好站内优化只要做好以下几点就够了!!)
网站优化和执行,心态极其重要,平时多发表原创性文章,大量引流,持续发外链,友好联系交流,没事看些SEO知识文章,快乐优化网站,不要天天想SEO,深鉴网站尊重百度搜索的原则,不作弊,不走寻常路,实现SEO 心态。

如何优化网站
站内优化只需要做好以下几点。
1、写标题网站;
不要在标题中收录太多关键字,只需 1-3 个。额外的关键字放置在未完成关键字权重的顶部。网站 写在标题关键字周围。最好通俗易懂,合理呈现。关键词。
2、在标题中附上关键词网站写自己的创作文章;
可以使用自创或者优质伪创的文章,关键字可以在文章中重复,不要太频繁,根据文章的长度而定,并且要呈现很自然。其他文章标题也要拟定,文章标题很重要。文章最好和网站有联系,不要太写题。
3、更新网站;
网站 必须更新,按一定频率更新,或者一天一次,但是每两天一次,或者一周一次。文章及时更新百度快照更新比较快,每篇文章底部相关文章可以推荐阅读文章,让百度蜘蛛爬得更深,内容之间有联系,所有网站的权重都增加了。
4、 在站内建立连接;
我们知道搜索引擎蜘蛛是通过连接在网站内部爬行的。所以,如果你想让搜索引擎蜘蛛在你的网站上好看,最好多设置一些连接,这样蜘蛛才能顺利爬来爬去。你的 网站。很多人制作了一张网站地图,告诉蜘蛛怎么走。事实上,这也是可能的。
5、关键字采集
使用站长工具采集多个相关关键词和长尾关键词后,用每个关键词文章更新一篇文章,文章呈现某个关键词并刺穿链接。假设需要引入外部链接作为文章的参考数据,可以通过nofollow标签的特性来限制权重输出。虽然不敢说上面这几个步骤的SEO技巧有多猛,但是一定要通过这几种方法的过程去执行和坚持。只要是竞争不大的关键词,就能在百度首页获得优秀的排名。
如何优化异地
那么站外的优化就好像在说分离和关系等等。搜索引擎的做法与此相同。如果你关系好,人脉好,有几位在山药当官的亲戚朋友,那我们也会看好你的。
那么一个站如何才能让搜索引擎看好呢?
简而言之,就是做“外链”。
在大型论坛网站有你的联系,那是最好的。不过很多其他的小网站有很多你的人脉,这也很好。至少说明你的网站连接广泛,所以搜索引擎不会小看你。那么判断优质外链可以被百度认可的标准是什么?
1. 相关页面之间应该存在外部链接
无论是搜索引擎还是用户,发起外连的页面和通过外连进行投票的页面都应该是密切相关的。例如,对于同一个连接,如果外部连接的相关性高,就会获得更多的读者,潜在的目标客户也会增加。
2.提供外部连接网站应该是健康的
在用于对外连接的网站中,不应该有完全无关的、低质量的、不健康的网站。所谓害群之马不好,就是这个道理!
3. 添加外部连接的方法应该很自然
即使是通过采购方式,或者其他方式获得的外链,也必须在页面中体现出来,给人一种“真的存在”的感觉!假设,网站 突然添加了无数的外部链接,会让读者产生一个猜测,这个连接是否是付费购买的。
4. 外链的锚文本要多样化
对于外链的锚文本进行正确或错误的关键词排名往往很有用,因此需要多种方法来优化外链的锚文本。例如,假设一个站点主要是一些电视节目,首页的锚文本链接可能会出现外观标题、主持人、电视节目、主要内容等各种文本,而不是一致的节目名称。
5. 外部链接可能存在于页面的各个方向
外部链接应该存在于页面的各个方面,而不仅仅是在页面底部。比如内容的有意识的引荐区,文字底部的“传输源”等等,都是不错的方向。
6. 外部连接应该来自不同的IP、不同的站点、不同的页面
假设某个网站的所有外部连接都来自同一台服务器上的其他站点,那么搜索引擎可能会认为这个网站中的每个人都是一样的。结果将是 搜索引擎减少了外部连接投票对目标站点的影响。不同IP、不同网站、不同页面存在的外链,表示外链是用户有意识地推荐的。
7.进行对外交流和正常交流是正常的
由于连接通信早于搜索引擎,所以允许正常的外部连接通信,例如友情连接。虽然现在友情连接的首要地位确实越来越小,但它绝对符合网络的性质。搜索引擎不会将正常的友情链接视为作弊。
8. 外部链接应该指向不同层次的页面
将外部链接指向网站的首页是比较常用的方法。但是,不要将所有外部链接都指向 网站 主页。能够将 10% 到 20% 的链接指向程序页面或内容页面是很自然的。
插入关键字 文章采集器(常见的黑帽操作,恭喜你,你完全有能力超越竞争对手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-28 20:09
很多朋友在学习网站优化相关知识的时候,不同的人用的方法不同。从公平的角度来看,没有人是对或错的。大致有两种类型:黑帽和白帽。
黑帽的操作方法很简单。任何人只要学会操作方法就可以快速上榜关键词。有些人认为这才是真正的SEO。白帽 SEO 太慢了。要理解和掌握的东西太多了。理论是一一写的,每种方法都有其优点和缺点。
黑帽子排名很快,甚至有“首页七天”的说法,但投资的成本和风险并存。多人违规后,搜索引擎连K站都处罚,恢复期很长。对于普通企业来说,主营业务可能来自网络,被关停的影响是巨大的。因此,不建议企业使用这种高风险的优化方式。
白帽排名比较慢,一般需要2-3个月,但是完全没有被K站的风险。主要的关键词排名波动不大,即使调整算法,也基本维持在10-20之间。尽可能多地将关键词排名分为列表和内容页,而不仅仅是首页,这样即使首页排名下降(被降级),其他页面也可以获得流量。
下面为朋友们总结一些常见的黑帽操作。如果你发现你的竞争对手有这样的操作,那么恭喜你,你完全有能力超越你的竞争对手。
常见的黑帽操作1) 填充关键字
相信很多学过SEO的人都做过类似的操作。在首页的标题上写主关键词和相关的长尾关键词,觉得这样匹配的多,排名会更好。参考文章为什么要降低关键词的密度,会不会影响排名优化?
2)采集内容做伪原创
很容易在网上找内容,复制,用工具伪原创替换,或者加词分段落,就可以创建一个相似度很低的“文章”,这种文章的根本没有可读性,用户体验很差。 查看全部
插入关键字 文章采集器(常见的黑帽操作,恭喜你,你完全有能力超越竞争对手)
很多朋友在学习网站优化相关知识的时候,不同的人用的方法不同。从公平的角度来看,没有人是对或错的。大致有两种类型:黑帽和白帽。

黑帽的操作方法很简单。任何人只要学会操作方法就可以快速上榜关键词。有些人认为这才是真正的SEO。白帽 SEO 太慢了。要理解和掌握的东西太多了。理论是一一写的,每种方法都有其优点和缺点。
黑帽子排名很快,甚至有“首页七天”的说法,但投资的成本和风险并存。多人违规后,搜索引擎连K站都处罚,恢复期很长。对于普通企业来说,主营业务可能来自网络,被关停的影响是巨大的。因此,不建议企业使用这种高风险的优化方式。
白帽排名比较慢,一般需要2-3个月,但是完全没有被K站的风险。主要的关键词排名波动不大,即使调整算法,也基本维持在10-20之间。尽可能多地将关键词排名分为列表和内容页,而不仅仅是首页,这样即使首页排名下降(被降级),其他页面也可以获得流量。
下面为朋友们总结一些常见的黑帽操作。如果你发现你的竞争对手有这样的操作,那么恭喜你,你完全有能力超越你的竞争对手。
常见的黑帽操作1) 填充关键字
相信很多学过SEO的人都做过类似的操作。在首页的标题上写主关键词和相关的长尾关键词,觉得这样匹配的多,排名会更好。参考文章为什么要降低关键词的密度,会不会影响排名优化?
2)采集内容做伪原创
很容易在网上找内容,复制,用工具伪原创替换,或者加词分段落,就可以创建一个相似度很低的“文章”,这种文章的根本没有可读性,用户体验很差。
插入关键字 文章采集器(插入关键字文章采集器批量下载word文章..上期)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-27 17:11
插入关键字文章采集器批量下载word文章...上期从零开始给大家介绍一些常用的批量下载word文章的工具,希望能对大家有所帮助。本期为大家带来关键字文章采集器,它能够实现多个网站、多个平台的热门文章采集。主要采集的内容包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊,财经网站等数十个网站的文章。
重点采集包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊等数十个网站的文章。一起来看看他的效果图吧!文章采集工具效果图此工具还支持采集新闻门户网站文章,不过支持到的网站目前比较少。在我们确定需要采集哪个网站后,还需要进行关键字的搜索。找到想要下载的文章链接,直接复制即可。(下载的word只是word里面的一部分内容,我们可以自行添加lrc,url,txt等附件。
)这个工具特别适合那些想要一个一个找热门网站的小伙伴,我觉得还是非常棒的,可以实现多个热门网站同时采集,而且可以快速对比多个热门网站下载哪个更快。不过有个缺点,有时候很多网站下载不了,比如...不过这些工具都不支持下载视频和音频,这点确实让人比较抓狂,以后会继续努力为大家推荐其他的替代工具。关键字下载工具下载效果图本文来源:写给个人|公众号:caixueshu分享在微信公众号:caixueshu获取更多信息原文链接:批量下载新闻媒体、媒体号、公众号、主流新闻门户网站的文章。 查看全部
插入关键字 文章采集器(插入关键字文章采集器批量下载word文章..上期)
插入关键字文章采集器批量下载word文章...上期从零开始给大家介绍一些常用的批量下载word文章的工具,希望能对大家有所帮助。本期为大家带来关键字文章采集器,它能够实现多个网站、多个平台的热门文章采集。主要采集的内容包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊,财经网站等数十个网站的文章。
重点采集包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊等数十个网站的文章。一起来看看他的效果图吧!文章采集工具效果图此工具还支持采集新闻门户网站文章,不过支持到的网站目前比较少。在我们确定需要采集哪个网站后,还需要进行关键字的搜索。找到想要下载的文章链接,直接复制即可。(下载的word只是word里面的一部分内容,我们可以自行添加lrc,url,txt等附件。
)这个工具特别适合那些想要一个一个找热门网站的小伙伴,我觉得还是非常棒的,可以实现多个热门网站同时采集,而且可以快速对比多个热门网站下载哪个更快。不过有个缺点,有时候很多网站下载不了,比如...不过这些工具都不支持下载视频和音频,这点确实让人比较抓狂,以后会继续努力为大家推荐其他的替代工具。关键字下载工具下载效果图本文来源:写给个人|公众号:caixueshu分享在微信公众号:caixueshu获取更多信息原文链接:批量下载新闻媒体、媒体号、公众号、主流新闻门户网站的文章。
插入关键字 文章采集器(阿里云双12拼团服务器优化活动1核2G/1年/89元)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-23 10:06
阿里云双12组队加入服务器优化活动1核2G/1年/89元
Artifact是本软件最新开发的群消息监控软件,可以实时监控多个QQ号的所有QQ群消息。指定关键词抓取发送消息的QQ群成员号后,可用于采集保单客户,指定关键词抓取订单。
QQ群抢神器功能介绍:
1、群消息实时监控
QQ群抢单神器实时监控多个QQ号的所有QQ群消息。如果群成员使用您设置的关键词发送消息,您可以抓取消息内容和发送消息的QQ号码。帮助您找到政策目标。
2、帮助小组成员
QQ群抢神器软件可以帮你处理QQ群。假设某群成员声明需要停止发送关键词,就可以拿到自己的QQ号,然后给予相应的封禁和踢群奖惩!
3、定位关键词抢单
QQ群抢单神器软件支持自定义关键词抢单。当群消息在你定义的时间和分钟丰富时关键词,它会立即抢消息并提醒让你先抢订单!
4、支持后台工作
QQ群抢神器软件可以在软件初始工作后放置在桌面下,不影响您电脑的其他使用!
软件.jpg' />
⒈本站提供的任何资源仅供自研学习,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集整理相关行业网站页面公共资源,属于用户自己在相关网站上发布的公开信息,不涉及任何个人隐私问题,本软件可只在合法范围内使用,不得非法使用。
⒋一旦发现会员有欺骗我们或欺骗客户的行为,一经发现,会员资格将无条件取消!
⒌请勿使用我们的软件采集转售信息或将其用于其他非法行为。否则后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章 请注明:/benlv/qqyx/5173.html
标签: 飞信营销软件 QQ群营销 QQ群抢购 QQ关键词采集 QQ群监控 查看全部
插入关键字 文章采集器(阿里云双12拼团服务器优化活动1核2G/1年/89元)
阿里云双12组队加入服务器优化活动1核2G/1年/89元
Artifact是本软件最新开发的群消息监控软件,可以实时监控多个QQ号的所有QQ群消息。指定关键词抓取发送消息的QQ群成员号后,可用于采集保单客户,指定关键词抓取订单。
QQ群抢神器功能介绍:
1、群消息实时监控
QQ群抢单神器实时监控多个QQ号的所有QQ群消息。如果群成员使用您设置的关键词发送消息,您可以抓取消息内容和发送消息的QQ号码。帮助您找到政策目标。
2、帮助小组成员
QQ群抢神器软件可以帮你处理QQ群。假设某群成员声明需要停止发送关键词,就可以拿到自己的QQ号,然后给予相应的封禁和踢群奖惩!
3、定位关键词抢单
QQ群抢单神器软件支持自定义关键词抢单。当群消息在你定义的时间和分钟丰富时关键词,它会立即抢消息并提醒让你先抢订单!
4、支持后台工作
QQ群抢神器软件可以在软件初始工作后放置在桌面下,不影响您电脑的其他使用!

软件.jpg' />
⒈本站提供的任何资源仅供自研学习,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集整理相关行业网站页面公共资源,属于用户自己在相关网站上发布的公开信息,不涉及任何个人隐私问题,本软件可只在合法范围内使用,不得非法使用。
⒋一旦发现会员有欺骗我们或欺骗客户的行为,一经发现,会员资格将无条件取消!
⒌请勿使用我们的软件采集转售信息或将其用于其他非法行为。否则后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章 请注明:/benlv/qqyx/5173.html
标签: 飞信营销软件 QQ群营销 QQ群抢购 QQ关键词采集 QQ群监控
插入关键字 文章采集器(插入关键字文章采集器的主要工作原理是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-20 20:06
插入关键字文章采集器的主要工作原理是根据网页中已经给定的关键字或者锚文本提取某个内容,对文章进行数据处理加工即可使用了。requests简介requests中文网站爬虫,是一款python的第三方爬虫框架,主要的用途为网络爬虫;它是采用urllib3模块提供的requests对象来加载网页的爬虫框架,基于它发展而来的还有requestslib,pyquery,pyqueryprequests中文网站爬虫原理scrapy简介scrapy中文网站爬虫,是一款scrapy社区中影响力比较大的爬虫框架,它为用户提供一个简单、高效的用scrapy从web抓取网页内容的简单应用程序,是一款功能强大、简单高效的爬虫框架;其主要的功能为爬虫,内置有urllib2模块,网页解析、文档解析、下载、表单解析、正则匹配等诸多功能模块;它是由scrapy社区推动并优化而成,并以scrapy框架为核心,目前已成功应用于百度、豆瓣、果壳、简书、知乎、天涯、豆瓣、环球、译客、博客园、腾讯、网易、搜狐、百度空间、凤凰网、天涯论坛、yy、奇虎36。
0、乐视等200多家知名网站。requestsrequests是一个urllib的第三方库,提供了模拟浏览器向服务器发送http请求的函数requestserver。requestserver实现了http协议中的get、post、delete请求方法。你可以使用该函数用浏览器向服务器发送请求。requestserver实现了http协议中的head和form表单请求方法。
简单说,requestserver就是一个代理服务器。将请求的资源作为post请求发送至该代理服务器中,代理服务器就可以拿到要请求的资源,然后以post方式来将资源传递给目标服务器,目标服务器拿到服务器的资源,进行处理,返回结果。requestserver主要做一下事情:。
1、添加到proxychainsdefproxychains(os,proxyurl):
2、调用函数xlsproxychainslogin_xlsproxy=requestserver(url=os.path.join(os,proxyurl),headers={'host':'127.0.0.1','port':9999})
3、处理请求responseresponse=requestserver.request("xls",os.path.join(os,proxyurl))返回的页面解析方法很多,
4、使用第三方库进行解析defurllib2。urlretrieve(url,input_val):'''获取所有标签的内容returnurllib2。urlopen(url)'''http_api调用函数classword2vec(urllib2。urlretrieve):def__init__(self,attrs):self。urls=[attrs]self。 查看全部
插入关键字 文章采集器(插入关键字文章采集器的主要工作原理是什么?)
插入关键字文章采集器的主要工作原理是根据网页中已经给定的关键字或者锚文本提取某个内容,对文章进行数据处理加工即可使用了。requests简介requests中文网站爬虫,是一款python的第三方爬虫框架,主要的用途为网络爬虫;它是采用urllib3模块提供的requests对象来加载网页的爬虫框架,基于它发展而来的还有requestslib,pyquery,pyqueryprequests中文网站爬虫原理scrapy简介scrapy中文网站爬虫,是一款scrapy社区中影响力比较大的爬虫框架,它为用户提供一个简单、高效的用scrapy从web抓取网页内容的简单应用程序,是一款功能强大、简单高效的爬虫框架;其主要的功能为爬虫,内置有urllib2模块,网页解析、文档解析、下载、表单解析、正则匹配等诸多功能模块;它是由scrapy社区推动并优化而成,并以scrapy框架为核心,目前已成功应用于百度、豆瓣、果壳、简书、知乎、天涯、豆瓣、环球、译客、博客园、腾讯、网易、搜狐、百度空间、凤凰网、天涯论坛、yy、奇虎36。
0、乐视等200多家知名网站。requestsrequests是一个urllib的第三方库,提供了模拟浏览器向服务器发送http请求的函数requestserver。requestserver实现了http协议中的get、post、delete请求方法。你可以使用该函数用浏览器向服务器发送请求。requestserver实现了http协议中的head和form表单请求方法。
简单说,requestserver就是一个代理服务器。将请求的资源作为post请求发送至该代理服务器中,代理服务器就可以拿到要请求的资源,然后以post方式来将资源传递给目标服务器,目标服务器拿到服务器的资源,进行处理,返回结果。requestserver主要做一下事情:。
1、添加到proxychainsdefproxychains(os,proxyurl):
2、调用函数xlsproxychainslogin_xlsproxy=requestserver(url=os.path.join(os,proxyurl),headers={'host':'127.0.0.1','port':9999})
3、处理请求responseresponse=requestserver.request("xls",os.path.join(os,proxyurl))返回的页面解析方法很多,
4、使用第三方库进行解析defurllib2。urlretrieve(url,input_val):'''获取所有标签的内容returnurllib2。urlopen(url)'''http_api调用函数classword2vec(urllib2。urlretrieve):def__init__(self,attrs):self。urls=[attrs]self。
插入关键字 文章采集器(手把手教你插入关键字文章采集器(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-25 12:04
插入关键字文章采集器目前是比较简单的采集工具,只需在搜狗网页搜索中输入关键字即可,它会实时抓取并数据采集您所需要的网页数据。数据链接调整比较方便,不用进行数据修改。不仅可以采集、天猫、京东等平台的商品数据,可以采集对应的网站首页数据,也可以采集指定网站页面的数据。同时还可以采集qq空间的日志等。注意事项由于百度网页搜索是api模式,凡是跟该关键字相关的链接,都有可能被爬虫抓取收录,抓取时会有拦截。
正在使用中的采集器点击本文最后链接进入采集器免费试用,长按识别下方二维码,或复制该链接进行识别,登录注册后即可免费试用了解更多网站数据采集方法,欢迎关注微信公众号“子夏说网络”。
有这么一款软件,像采集兔一样,可以搜索采集工具,可以批量采集整站网站链接,百度搜索就可以看到,不到2小时就能采集4000+网站数据。可以看看我最近采集的一篇文章,分享给你:手把手教你零基础,
题主的意思是指能够爬虫采集各大网站的公开数据?这样的网站能够在国内外的很多网站看到:1.谷歌镜像站2.pagespeed3.pagehistoryecharts(与echarts类似)4.全站爬虫5.网站网页截图。目前知道的就这些。可能不全, 查看全部
插入关键字 文章采集器(手把手教你插入关键字文章采集器(图))
插入关键字文章采集器目前是比较简单的采集工具,只需在搜狗网页搜索中输入关键字即可,它会实时抓取并数据采集您所需要的网页数据。数据链接调整比较方便,不用进行数据修改。不仅可以采集、天猫、京东等平台的商品数据,可以采集对应的网站首页数据,也可以采集指定网站页面的数据。同时还可以采集qq空间的日志等。注意事项由于百度网页搜索是api模式,凡是跟该关键字相关的链接,都有可能被爬虫抓取收录,抓取时会有拦截。
正在使用中的采集器点击本文最后链接进入采集器免费试用,长按识别下方二维码,或复制该链接进行识别,登录注册后即可免费试用了解更多网站数据采集方法,欢迎关注微信公众号“子夏说网络”。
有这么一款软件,像采集兔一样,可以搜索采集工具,可以批量采集整站网站链接,百度搜索就可以看到,不到2小时就能采集4000+网站数据。可以看看我最近采集的一篇文章,分享给你:手把手教你零基础,
题主的意思是指能够爬虫采集各大网站的公开数据?这样的网站能够在国内外的很多网站看到:1.谷歌镜像站2.pagespeed3.pagehistoryecharts(与echarts类似)4.全站爬虫5.网站网页截图。目前知道的就这些。可能不全,
插入关键字 文章采集器(优采云采集器的采集方法及步骤(一)_数据分析采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-25 07:05
用途:用于数据分析
使用工具:优采云采集器(优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。)
二、采集方法步骤说明####
第一步:安装优采云采集器(注意:需要安装net4.0框架才能运行)
优采云采集器 下载链接:
第二步:注册账号
第三步:了解基本界面
一个。单击开始 -> 新建文件夹(并重命名它以便您知道 采集 是什么)-> 新建任务
湾 创建新任务后,会弹出设置任务规则的对话框(注意以下几点)
(1)填写你想要的内容所在的网址采集。如果是正规的,可以使用【添加向导】相关规则,如下:以短书为例,我要< @采集自己分析了短书里面的内容数据,采集的主要内容在列表页,但是因为短书采用了懒加载的方式,无法抓取翻页的内容,所以需要查看源码(这里需要有一定代码知识的童鞋才能找到),然后在源码中,找到相关的链接,而且都是有规律的,所以我可以通过添加相关规则【添加向导】。具体规则继续看以下步骤4.
向导添加界面:
第 4 步:编写 URL 提取规则
我在源代码中找到了列表链接。如果你想采集所有的链接,你必须找到所有的翻页。翻页是正常的,所以我得到以下规则。只是链接中“page=”后面的地址参数改变了,所以我们可以用【地址参数】来设置参数。然后在[地址参数]中选择数字变化,因为它是一个数字。总共有14个项目,所以有14个项目。
设置好地址格式后,我们可以在这个页面进一步设置我们想要的采集的内容。即我们需要在列表页采集上传递每个文章的URL,方法如下:
(1)获取内容URL时,选择获取方式:自动获取地址链接。
(2)使用链接过滤:提取文章链接,文章的链接有共性。
填好这些后,点击【URL采集Test】,这时候就可以验证规则是否正确了。
验证OK!规则是对的!伟大的!写好规则后记得保存哦!
第五步:编写内容抽取规则
采集到达每个文章的URL后,接下来我们需要采集每个文章的相关信息:标题、URL、阅读数、点赞数!这是我们的终极目标!写好规则后记得保存哦!方法如下图所示:
PS:这也需要一些html代码的知识。
添加规则如下:
(1)在标签列表中将标签名称添加到采集。方框右侧有一个“+”可以添加多个标签。
(2)数据获取方式选择:从源码中获取数据,选择提取方式“截取前后”,然后在源码中提取我们想要的信息的前后码。记住,如果这是唯一的代码,避免提取它出现问题。
补充:教你提取前后码
在网页中,右击查看源代码。找到标题。我们会发现有多个重复的标题。但是要选择code前后的唯一一个,可以通过ctrl+f来验证是否唯一。下面是标题前后的代码,剩下几个元素前后的代码,大家可以自己练习。
第六步:设置存储位置
点击内容发布规则——>另存为本地文件——>启用本地文件保存——>保存设置文件格式并选择txt(因为我们使用的是免费软件)——>设置保存位置
第七步:启动采集,设置存储位置和设置规则,保存退出,返回工具首页,启动采集——> 这3个地方一定要勾选,然后右键——单击以选择 — —> 开始。见下文:
采集 后呈现原创数据:
呈现清洗后的数据及相关数据分析,如下图所示:
三、个人经历总结#### 查看全部
插入关键字 文章采集器(优采云采集器的采集方法及步骤(一)_数据分析采集器)
用途:用于数据分析
使用工具:优采云采集器(优采云采集器是一款互联网数据采集、处理、分析、挖掘软件。)
二、采集方法步骤说明####
第一步:安装优采云采集器(注意:需要安装net4.0框架才能运行)
优采云采集器 下载链接:
第二步:注册账号
第三步:了解基本界面
一个。单击开始 -> 新建文件夹(并重命名它以便您知道 采集 是什么)-> 新建任务
湾 创建新任务后,会弹出设置任务规则的对话框(注意以下几点)
(1)填写你想要的内容所在的网址采集。如果是正规的,可以使用【添加向导】相关规则,如下:以短书为例,我要< @采集自己分析了短书里面的内容数据,采集的主要内容在列表页,但是因为短书采用了懒加载的方式,无法抓取翻页的内容,所以需要查看源码(这里需要有一定代码知识的童鞋才能找到),然后在源码中,找到相关的链接,而且都是有规律的,所以我可以通过添加相关规则【添加向导】。具体规则继续看以下步骤4.
向导添加界面:
第 4 步:编写 URL 提取规则
我在源代码中找到了列表链接。如果你想采集所有的链接,你必须找到所有的翻页。翻页是正常的,所以我得到以下规则。只是链接中“page=”后面的地址参数改变了,所以我们可以用【地址参数】来设置参数。然后在[地址参数]中选择数字变化,因为它是一个数字。总共有14个项目,所以有14个项目。
设置好地址格式后,我们可以在这个页面进一步设置我们想要的采集的内容。即我们需要在列表页采集上传递每个文章的URL,方法如下:
(1)获取内容URL时,选择获取方式:自动获取地址链接。
(2)使用链接过滤:提取文章链接,文章的链接有共性。
填好这些后,点击【URL采集Test】,这时候就可以验证规则是否正确了。
验证OK!规则是对的!伟大的!写好规则后记得保存哦!
第五步:编写内容抽取规则
采集到达每个文章的URL后,接下来我们需要采集每个文章的相关信息:标题、URL、阅读数、点赞数!这是我们的终极目标!写好规则后记得保存哦!方法如下图所示:
PS:这也需要一些html代码的知识。
添加规则如下:
(1)在标签列表中将标签名称添加到采集。方框右侧有一个“+”可以添加多个标签。
(2)数据获取方式选择:从源码中获取数据,选择提取方式“截取前后”,然后在源码中提取我们想要的信息的前后码。记住,如果这是唯一的代码,避免提取它出现问题。
补充:教你提取前后码
在网页中,右击查看源代码。找到标题。我们会发现有多个重复的标题。但是要选择code前后的唯一一个,可以通过ctrl+f来验证是否唯一。下面是标题前后的代码,剩下几个元素前后的代码,大家可以自己练习。
第六步:设置存储位置
点击内容发布规则——>另存为本地文件——>启用本地文件保存——>保存设置文件格式并选择txt(因为我们使用的是免费软件)——>设置保存位置
第七步:启动采集,设置存储位置和设置规则,保存退出,返回工具首页,启动采集——> 这3个地方一定要勾选,然后右键——单击以选择 — —> 开始。见下文:
采集 后呈现原创数据:
呈现清洗后的数据及相关数据分析,如下图所示:
三、个人经历总结####
插入关键字 文章采集器( 百度/360搜索关键词的爬取和存储网络图片链接的格式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-24 00:18
百度/360搜索关键词的爬取和存储网络图片链接的格式)
r.request.headers
结果如下:
爬虫如实告诉服务器,这次访问是由python请求库中的一个程序产生的。
4. 改变头部信息,让程序模拟浏览器发送爬取请求
kv={'user-agent':'Mozilla/5.0'} #构造键值对
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
r=requests.get(url,headers=kv)
这时候再次查看r.status_code,返回的状态码为200,r.text中没有错误提示
完整的爬取框架如下:
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
二、百度/360搜索关键词提交
百度的关键词界面:
360的关键词界面:
可以通过params参数提交关键词。基本代码框架如下:
import requests
keyword="Python"
try:
kv={'wd':keyword}
r=requests.get("https://www.baidu.com/s",params=kv) #通过params将键值对输入进去并获得相关请求
print(r.request.url)
r.raise_for_status
print(len(r.text))
except:
print("爬取失败")
提交关键词到360搜索时,需要将kv={'wd':keyword}的'wd'改为'q'。
三、 网页图片的爬取和存储
网页图片链接格式:
即:url+picture.jpg
选择某个url中的图片网页(如:),可以看到图片的url
如果一个url链接以.jpg结尾,则表示它是一个图片链接,该链接是一个文件,如下图:
图片是二进制格式。要将二进制图片保存到文件中,通常使用以下代码:
path="E:\\Spider learning\\xunyi.jpg" #保存图片的位置和图片的名字
url="http://imgsrc.baidu.com/baike/ ... ot%3B
r=requests.get(url)
#print(r.status_code)
with open(path,'wb') as f:
f.write(r.content)
f.close()
with open() as f:打开一个文件并将其定义为文件标识符 f
r.content:响应对象中的r.content表示返回的二进制格式的内容
完整的代码框架如下:
通过这种方式修改代码可以保存在线视频、动画、flash等。
四、IP地址归属地自动查询
要确定地址的归属,必须有一个库。程序中没有这样的库。您可以在 Internet 上找到相关资源。如IP138网站()
在ip138网站中输入IP地址,点击查询后,可以看到地址栏中的url发生了变化,格式变为:
使用这样的 URL,您可以通过提交 IP 地址找到 IP 地址的家。
代码显示如下:
import requests
kv={'user-agent':'Mozilla/5.0'}
url="https://www.ip138.com/iplookup.asp?ip="
try:
r=requests.get(url+'202.204.80.112&action=2',headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding #可防止输出的网页内容中出现乱码
#print(r.text[-500:]) #返回文本的最后500个字节
print(r.text)
except:
print("爬取失败")
从输出结果可以看出,这个IP地址对应的是贝利官网:
从这个例子我们可以知道,我们有时在网站上看到的人机交互方式,比如图形、文本框等需要点击提交到服务器的,其实都是在表单中提交的的链接。只要通过对网页的分析知道如何获取后台提交表单,就可以使用python代码模拟提交到服务器。 查看全部
插入关键字 文章采集器(
百度/360搜索关键词的爬取和存储网络图片链接的格式)
r.request.headers
结果如下:
爬虫如实告诉服务器,这次访问是由python请求库中的一个程序产生的。
4. 改变头部信息,让程序模拟浏览器发送爬取请求
kv={'user-agent':'Mozilla/5.0'} #构造键值对
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
r=requests.get(url,headers=kv)
这时候再次查看r.status_code,返回的状态码为200,r.text中没有错误提示
完整的爬取框架如下:
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
二、百度/360搜索关键词提交
百度的关键词界面:
360的关键词界面:
可以通过params参数提交关键词。基本代码框架如下:
import requests
keyword="Python"
try:
kv={'wd':keyword}
r=requests.get("https://www.baidu.com/s",params=kv) #通过params将键值对输入进去并获得相关请求
print(r.request.url)
r.raise_for_status
print(len(r.text))
except:
print("爬取失败")
提交关键词到360搜索时,需要将kv={'wd':keyword}的'wd'改为'q'。
三、 网页图片的爬取和存储
网页图片链接格式:
即:url+picture.jpg
选择某个url中的图片网页(如:),可以看到图片的url
如果一个url链接以.jpg结尾,则表示它是一个图片链接,该链接是一个文件,如下图:
图片是二进制格式。要将二进制图片保存到文件中,通常使用以下代码:
path="E:\\Spider learning\\xunyi.jpg" #保存图片的位置和图片的名字
url="http://imgsrc.baidu.com/baike/ ... ot%3B
r=requests.get(url)
#print(r.status_code)
with open(path,'wb') as f:
f.write(r.content)
f.close()
with open() as f:打开一个文件并将其定义为文件标识符 f
r.content:响应对象中的r.content表示返回的二进制格式的内容
完整的代码框架如下:
通过这种方式修改代码可以保存在线视频、动画、flash等。
四、IP地址归属地自动查询
要确定地址的归属,必须有一个库。程序中没有这样的库。您可以在 Internet 上找到相关资源。如IP138网站()
在ip138网站中输入IP地址,点击查询后,可以看到地址栏中的url发生了变化,格式变为:
使用这样的 URL,您可以通过提交 IP 地址找到 IP 地址的家。
代码显示如下:
import requests
kv={'user-agent':'Mozilla/5.0'}
url="https://www.ip138.com/iplookup.asp?ip="
try:
r=requests.get(url+'202.204.80.112&action=2',headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding #可防止输出的网页内容中出现乱码
#print(r.text[-500:]) #返回文本的最后500个字节
print(r.text)
except:
print("爬取失败")
从输出结果可以看出,这个IP地址对应的是贝利官网:
从这个例子我们可以知道,我们有时在网站上看到的人机交互方式,比如图形、文本框等需要点击提交到服务器的,其实都是在表单中提交的的链接。只要通过对网页的分析知道如何获取后台提交表单,就可以使用python代码模拟提交到服务器。
插入关键字 文章采集器(新闻源文章生成器(原创文章)软件特点及特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-22 15:09
News Source文章 Generator(原创文章 Generator)是一个方便的批处理软件,自动编译生成新的文章,通过这个软件你再也不用了手动编写发布新闻,直接发布生成的文章即可。 文章 自动生成器可以将您预设的关键词、脚本、前缀、后缀等内容快速添加到新的文章中,大大增加了网站的流量,总之及时获取关键字优化,吸引大量流量。
操作说明:
1、准备好文章内容;
2、文章最好有关键字相关,可以使用采集器batch采集;
3、写关键词等内容;
4、选择其他设置并开始运行以生成尖峰。
软件功能:
1.1 本软件为新闻源文章专为“医疗行业新闻源”而设计的生成软件;
1.2 本软件适用于具有批量上传功能的新闻源平台;
<p>1.3.本软件可以在文章上采集拥有或其他医院网站,作为新闻源生成文章; 查看全部
插入关键字 文章采集器(新闻源文章生成器(原创文章)软件特点及特点)
News Source文章 Generator(原创文章 Generator)是一个方便的批处理软件,自动编译生成新的文章,通过这个软件你再也不用了手动编写发布新闻,直接发布生成的文章即可。 文章 自动生成器可以将您预设的关键词、脚本、前缀、后缀等内容快速添加到新的文章中,大大增加了网站的流量,总之及时获取关键字优化,吸引大量流量。
操作说明:
1、准备好文章内容;
2、文章最好有关键字相关,可以使用采集器batch采集;
3、写关键词等内容;
4、选择其他设置并开始运行以生成尖峰。
软件功能:
1.1 本软件为新闻源文章专为“医疗行业新闻源”而设计的生成软件;
1.2 本软件适用于具有批量上传功能的新闻源平台;
<p>1.3.本软件可以在文章上采集拥有或其他医院网站,作为新闻源生成文章;
插入关键字 文章采集器(人人自媒体平台插入关键字文章采集器:插入)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-22 05:00
插入关键字文章采集器:插入关键字人人自媒体平台插入关键字自动赚钱1.无需了解新手上路的方法,0成本挣钱。2.挣一个亿,边看边挣钱,边学边赚钱。3.月入十万不是梦!4.可能是非常可能是...5.据说找到一个绝佳的机会,有人也在挣钱6.同为吃货,你的眼光是否远一点,选对方向更重要7.在家就能做月入十万,七天搞定,付出的努力多一点,收获的平台多一点。
8.阅读量一直没起来,是自己没写好吗?还是你写的太无趣了?9.如果不是996,谁愿意白天上班晚上还写文章?10.如果本身就是白领,你愿意白天上班晚上还写文章吗?11.读书的人还可以读4000本书,不读书的人连看400本书也没有精力和兴趣。12.选择成为一个写手,要做好十年以后没有收入的准备。13.不要总是想着一夜暴富,先有一个现实的追求。
14.如果每天至少接触1个新项目1个新思路就能月入过万,那么还工作干嘛?15.传统行业利润分析图,对于80%的人来说没什么用。16.写作能力和电商知识,都是摆在那里,你不行动也得不到提升的技能。17.能力是一方面,人脉是一方面,再有一个坚持不懈的决心比较重要。18.大部分真正挣钱的人,不善言辞。19.对自己要有信心,梦想是需要的,也是你现在奋斗的目标。20.当你失败后再回过头来看,发现自己这个行业做的很不好。说的很有道理,给不少小伙伴鼓励一下!。 查看全部
插入关键字 文章采集器(人人自媒体平台插入关键字文章采集器:插入)
插入关键字文章采集器:插入关键字人人自媒体平台插入关键字自动赚钱1.无需了解新手上路的方法,0成本挣钱。2.挣一个亿,边看边挣钱,边学边赚钱。3.月入十万不是梦!4.可能是非常可能是...5.据说找到一个绝佳的机会,有人也在挣钱6.同为吃货,你的眼光是否远一点,选对方向更重要7.在家就能做月入十万,七天搞定,付出的努力多一点,收获的平台多一点。
8.阅读量一直没起来,是自己没写好吗?还是你写的太无趣了?9.如果不是996,谁愿意白天上班晚上还写文章?10.如果本身就是白领,你愿意白天上班晚上还写文章吗?11.读书的人还可以读4000本书,不读书的人连看400本书也没有精力和兴趣。12.选择成为一个写手,要做好十年以后没有收入的准备。13.不要总是想着一夜暴富,先有一个现实的追求。
14.如果每天至少接触1个新项目1个新思路就能月入过万,那么还工作干嘛?15.传统行业利润分析图,对于80%的人来说没什么用。16.写作能力和电商知识,都是摆在那里,你不行动也得不到提升的技能。17.能力是一方面,人脉是一方面,再有一个坚持不懈的决心比较重要。18.大部分真正挣钱的人,不善言辞。19.对自己要有信心,梦想是需要的,也是你现在奋斗的目标。20.当你失败后再回过头来看,发现自己这个行业做的很不好。说的很有道理,给不少小伙伴鼓励一下!。
插入关键字 文章采集器(插入关键字文章采集器:/nlptools.io/xjjh)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-18 00:02
插入关键字文章采集器:)全网搜索框,选中需要采集的关键字。首先是文章去重,如图,输入框就能直接识别关键字。但是回车以后再打开页面就会返回之前找到的网站。其次是解析,需要开启爬虫。爬虫是分为以下两种:1.人工点击;2.系统自动抓取。1.人工点击(俗称手点)。2.系统抓取(如googleanalytics)。
我觉得这个功能还是可以有的,
好像有这样的软件可以,但是如果需要专门的人才根据关键字来爬取才可以实现,人力成本和时间成本太高了。
文章内容只要你直接打开搜索栏搜文章标题就可以很方便的获取全网的文章了
需要用urllib库请人工来抓取吗?
yahoojj/nlptools.github.io/xjjh/nlpwen.github.io/github-wenfeiwen/nlpwen-middleware-bin/
我在云爬虫也有这个需求,所以研究了下大概是这样吧。记得之前用python抓取了北大博士的硕士论文,看到这个,然后想到是不是可以通过googletranslate这个api,去尝试抓取英文的文章。目前从官网上查询了下,有:translateandconvertfeaturesandauthenticationsongoogletranslate首先找到googletranslate的api是怎么抓取的,我还挺喜欢的一点是在repo里有详细的介绍和官方的注释,供参考。
然后:登录,然后在googletranslate上搜索这个关键词,可以找到这篇文章。/~gohlke/pythonlibs/。 查看全部
插入关键字 文章采集器(插入关键字文章采集器:/nlptools.io/xjjh)
插入关键字文章采集器:)全网搜索框,选中需要采集的关键字。首先是文章去重,如图,输入框就能直接识别关键字。但是回车以后再打开页面就会返回之前找到的网站。其次是解析,需要开启爬虫。爬虫是分为以下两种:1.人工点击;2.系统自动抓取。1.人工点击(俗称手点)。2.系统抓取(如googleanalytics)。
我觉得这个功能还是可以有的,
好像有这样的软件可以,但是如果需要专门的人才根据关键字来爬取才可以实现,人力成本和时间成本太高了。
文章内容只要你直接打开搜索栏搜文章标题就可以很方便的获取全网的文章了
需要用urllib库请人工来抓取吗?
yahoojj/nlptools.github.io/xjjh/nlpwen.github.io/github-wenfeiwen/nlpwen-middleware-bin/
我在云爬虫也有这个需求,所以研究了下大概是这样吧。记得之前用python抓取了北大博士的硕士论文,看到这个,然后想到是不是可以通过googletranslate这个api,去尝试抓取英文的文章。目前从官网上查询了下,有:translateandconvertfeaturesandauthenticationsongoogletranslate首先找到googletranslate的api是怎么抓取的,我还挺喜欢的一点是在repo里有详细的介绍和官方的注释,供参考。
然后:登录,然后在googletranslate上搜索这个关键词,可以找到这篇文章。/~gohlke/pythonlibs/。
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-15 19:01
[IT168技术文章]为了方便搜索引擎文章系统模仿NB制作下一页关键字的标签
第一步
在foosun\admin\refresh\function中找到ASP
函数GetNewsContent(TempletContent、NewsRecordSet、NewsContent)
templatcontent=Replace(templatcontent,{News_Title},新闻记录集(“Title”))
加在下面
'关键字标签
如果不为空(新闻记录集(“关键字”)),则
TempletContent=Replace(TempletContent,“{News_keywords}”,新闻记录集(“关键字”))
否则
TempletContent=Replace(TempletContent,{News_keywords},“”)
如果结束
'关键字标签
在倒数第二行%>之前,添加
"************************************
作者:利诺
'将标题与关键字表中的记录匹配
“开始
"*************************
函数replaceKeywordByTitle(标题)
Dim where is keyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,关键字
“***如果您使用的是3.版本0,请将以下行FS_uuChangeRoutine改为routine
设置RsRuleObj=Conn.Execute(“从FS_例程中选择*)
不做而不做。Eof
关键字=RsRuleObj(“名称”)
其中IsKeyword=InStr(Lcase(标题),Lcase(关键字))
如果(whereisKeyword>0)那么
如果(关键字onnews=”“)那么
关键字onnews=关键字
否则
关键字onnews=关键字onnews&&&keyword
如果结束
如果结束
RsRuleObj。下一步
环路
'如果关键字的长度大于100,请截断过长的关键字
如果(len(关键字onnews)>99)那么
关键字ONNEWS=左(关键字ONNEWS,99)
如果结束
replaceKeywordByTitle=关键字OnNews
端函数
"**********************
"完!
步骤2
在foosun/funpages/lablenews asp
选择“插入已找到的字段”
加在下面
'页面关键字标签
页面关键字
'页面关键字标签
步骤3
在foosun/admin/Info/newswords上,ASP
INewsAddObj(“关键字”)=Replace(Replace(请求(“关键字文本”),“”,“”,“”,“,”)
将这句话改为
"************************************
作者:利诺
'调用replacekeywordbytitle方法以筛选关键字
'如果用户自定义了关键字,则自动关键字设置不起作用
“开始
"*************************
Dim关键字文本
如果(请求(“关键字文本”)为“”或为空(请求(“关键字文本”)),则
KeywordText=replaceKeywordByTitle(ITitle)
否则
关键字文本=请求(“关键字文本”)
如果结束
如果是关键字text“”,则
INewsAddObj(“关键字”)=替换(替换(关键字文本,“”,“”,“”,“”,“”,“”)
如果结束
"完!
"***********************************
步骤4
在foosun/admin/collect/movenewstosystem中,在ASP中找到大约117行
RsSysNewsObj(“TxtSource”)=RsNewsObj(“Source”)
修正如下:
RsSysNewsObj(“关键字”)=replaceKeywordByTitle(RsNewsObj(“标题”))
程序更改正常
创建以下选项卡。您可以在自定义页签的新闻浏览中选择自己的页面关键字页签
具体的标签如下{news_keywords},写在新闻模板的标题或元中心,以便于搜索引擎收录 查看全部
插入关键字 文章采集器(把标题与关键字表中的记录匹配匹配的标签!)
[IT168技术文章]为了方便搜索引擎文章系统模仿NB制作下一页关键字的标签
第一步
在foosun\admin\refresh\function中找到ASP
函数GetNewsContent(TempletContent、NewsRecordSet、NewsContent)
templatcontent=Replace(templatcontent,{News_Title},新闻记录集(“Title”))
加在下面
'关键字标签
如果不为空(新闻记录集(“关键字”)),则
TempletContent=Replace(TempletContent,“{News_keywords}”,新闻记录集(“关键字”))
否则
TempletContent=Replace(TempletContent,{News_keywords},“”)
如果结束
'关键字标签
在倒数第二行%>之前,添加
"************************************
作者:利诺
'将标题与关键字表中的记录匹配
“开始
"*************************
函数replaceKeywordByTitle(标题)
Dim where is keyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,关键字
“***如果您使用的是3.版本0,请将以下行FS_uuChangeRoutine改为routine
设置RsRuleObj=Conn.Execute(“从FS_例程中选择*)
不做而不做。Eof
关键字=RsRuleObj(“名称”)
其中IsKeyword=InStr(Lcase(标题),Lcase(关键字))
如果(whereisKeyword>0)那么
如果(关键字onnews=”“)那么
关键字onnews=关键字
否则
关键字onnews=关键字onnews&&&keyword
如果结束
如果结束
RsRuleObj。下一步
环路
'如果关键字的长度大于100,请截断过长的关键字
如果(len(关键字onnews)>99)那么
关键字ONNEWS=左(关键字ONNEWS,99)
如果结束
replaceKeywordByTitle=关键字OnNews
端函数
"**********************
"完!
步骤2
在foosun/funpages/lablenews asp
选择“插入已找到的字段”
加在下面
'页面关键字标签
页面关键字
'页面关键字标签
步骤3
在foosun/admin/Info/newswords上,ASP
INewsAddObj(“关键字”)=Replace(Replace(请求(“关键字文本”),“”,“”,“”,“,”)
将这句话改为
"************************************
作者:利诺
'调用replacekeywordbytitle方法以筛选关键字
'如果用户自定义了关键字,则自动关键字设置不起作用
“开始
"*************************
Dim关键字文本
如果(请求(“关键字文本”)为“”或为空(请求(“关键字文本”)),则
KeywordText=replaceKeywordByTitle(ITitle)
否则
关键字文本=请求(“关键字文本”)
如果结束
如果是关键字text“”,则
INewsAddObj(“关键字”)=替换(替换(关键字文本,“”,“”,“”,“”,“”,“”)
如果结束
"完!
"***********************************
步骤4
在foosun/admin/collect/movenewstosystem中,在ASP中找到大约117行
RsSysNewsObj(“TxtSource”)=RsNewsObj(“Source”)
修正如下:
RsSysNewsObj(“关键字”)=replaceKeywordByTitle(RsNewsObj(“标题”))
程序更改正常
创建以下选项卡。您可以在自定义页签的新闻浏览中选择自己的页面关键字页签
具体的标签如下{news_keywords},写在新闻模板的标题或元中心,以便于搜索引擎收录
插入关键字 文章采集器(15个免费文章采集网站,每天更新,收录率非常高)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-11 05:39
15个免费文章采集网站,每天更新,收录率很高!免费文章采集 工具! 15个免费个人或企业文章采集网站;为了应对日益火爆的微信公众号等自媒体平台的抄袭和洗白,我们整理了这15个免费给大家。
文章采集是一款非常实用的最新文章采集神器,这里免费为大家带来最新的强大文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章@ >< @采集西溪软件园下载地址。
优采云·云采集网络爬虫软件免费文章采集器使用教程本文介绍优采云采集器采集的使用@>网易如何编号文章。 采集网址:网易号。
文章采集器免费版快速破解网站内置文章很多文章采集器免费版快速破解网站内置文章采集器daily文章 海量,无损加载,压缩包分享可以在个人朋友圈公开下载,也可以转发到群里一起下载。
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或者添加文字,也是SEO的好工具伪原创。
站长之星是一款集文章采集、文章处理、文章发布于一体的专业站群内容管理系统。界面精美,操作简单,功能强大。 .
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或添加。
文章采集软件下载优采云通用文章采集器(支持百度脚本首页。 查看全部
插入关键字 文章采集器(15个免费文章采集网站,每天更新,收录率非常高)
15个免费文章采集网站,每天更新,收录率很高!免费文章采集 工具! 15个免费个人或企业文章采集网站;为了应对日益火爆的微信公众号等自媒体平台的抄袭和洗白,我们整理了这15个免费给大家。
文章采集是一款非常实用的最新文章采集神器,这里免费为大家带来最新的强大文章采集软件,一个关键词可以快速采集上万篇文章文章,支持采集文章和新闻,让你拥有,文章@ >< @采集西溪软件园下载地址。
优采云·云采集网络爬虫软件免费文章采集器使用教程本文介绍优采云采集器采集的使用@>网易如何编号文章。 采集网址:网易号。
文章采集器免费版快速破解网站内置文章很多文章采集器免费版快速破解网站内置文章采集器daily文章 海量,无损加载,压缩包分享可以在个人朋友圈公开下载,也可以转发到群里一起下载。
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或者添加文字,也是SEO的好工具伪原创。
站长之星是一款集文章采集、文章处理、文章发布于一体的专业站群内容管理系统。界面精美,操作简单,功能强大。 .
文章采集阅读是一个用通俗易懂的语言编写的简单网页文章采集工具,它不仅可以采集文本,还可以简单地替换一些文字,或添加。
文章采集软件下载优采云通用文章采集器(支持百度脚本首页。
插入关键字 文章采集器(优采云站群软件V18.01.02更新如下内容介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-10 18:29
优采云站群 管理系统是一套多任务,只需要输入关键词到采集到最新的相关内容,自动SEO到指定的网站 站群管理系统,可24小时自动维护数百个网站。优采云站群管理系统可以根据设置的关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,再抓取大量最新词基于在派生词Data上,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。优采云站群 管理系统不需要绑定电脑或IP,并且网站的数量没有限制。可24小时挂机采集维护,让站长轻松管理数百个网站。该软件独有的内容抓取引擎,可以及时准确地抓取互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,给站长带来更多流量!
优采云站群 软件支持的核心功能:
无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链,随机抽取以内容为标题,不同内容段落互换,指定关键词随机插入,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互连,自动监控挂断< @采集发布,自动更新网站首页栏目内页静态化等。
优采云站群软件V18.01.02更新如下内容:
1、修复ban中的一些js错误
2、修复日志bug
3、修复手机发送异常挂断的问题
4、完善其他细节功能
5、完善群发工具
6、 新指定ie绑定子程序,发布指定采集更有效率
7、界面工具新增页面坐标定位等功能
8、新增每组可以单独设置允许更新时间范围
9、新增至尊版用户挂机后自动导入各站文件夹中的txt文件
10、增加了文章列库的分库功能,实现单站理论上无限的数据存储
11、新增绕过百度清风的算法。具体请参考分组参数中3.2.1.4中的参数
12、网站 log和seo查询功能作为子程序独立运行,避免从主程序抢资源
13、 优化所有子程序,运行更高效
14、新增启动程序,方便设置发送桌面快捷键,原站群为主程序,请勿修改启动程序名称,以免出现异常
15、 新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、 新增分组自动切换参数功能
3、 至尊版新增自定义题库功能
4、群发外链工具V170321版入门版也有
5、维修英文采集
6、修复视频采集
7、指定域名只有在被收录到数据库时才添加标题或内容
8、添加内容编辑器2,修复文章用户使用前无法编辑的问题
9、用于修复单个错误的接口工具
10、 完善其他细节功能
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章和指定域名的高质量自动识别采集文章
2、修复调用至尊版用户栏段落库的bug
3、改善群发外链工具屏蔽问题
4、关键词采集文章修复采集实图
5、 搜狗推荐的新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前台采集解决部分后台采集空网页
8、添加文章导出处理详情
9、增加挂断是间隔分钟的设置
查看全部
插入关键字 文章采集器(优采云站群软件V18.01.02更新如下内容介绍及应用)
优采云站群 管理系统是一套多任务,只需要输入关键词到采集到最新的相关内容,自动SEO到指定的网站 站群管理系统,可24小时自动维护数百个网站。优采云站群管理系统可以根据设置的关键词自动抓取各大搜索引擎的相关搜索词和相关长尾词,再抓取大量最新词基于在派生词Data上,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。优采云站群 管理系统不需要绑定电脑或IP,并且网站的数量没有限制。可24小时挂机采集维护,让站长轻松管理数百个网站。该软件独有的内容抓取引擎,可以及时准确地抓取互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,给站长带来更多流量!
优采云站群 软件支持的核心功能:
无限增加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章、长尾关键词采集、相关图片采集、全球SEO链轮、文章自动加入内链,随机抽取以内容为标题,不同内容段落互换,指定关键词随机插入,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互连,自动监控挂断< @采集发布,自动更新网站首页栏目内页静态化等。
优采云站群软件V18.01.02更新如下内容:
1、修复ban中的一些js错误
2、修复日志bug
3、修复手机发送异常挂断的问题
4、完善其他细节功能
5、完善群发工具
6、 新指定ie绑定子程序,发布指定采集更有效率
7、界面工具新增页面坐标定位等功能
8、新增每组可以单独设置允许更新时间范围
9、新增至尊版用户挂机后自动导入各站文件夹中的txt文件
10、增加了文章列库的分库功能,实现单站理论上无限的数据存储
11、新增绕过百度清风的算法。具体请参考分组参数中3.2.1.4中的参数
12、网站 log和seo查询功能作为子程序独立运行,避免从主程序抢资源
13、 优化所有子程序,运行更高效
14、新增启动程序,方便设置发送桌面快捷键,原站群为主程序,请勿修改启动程序名称,以免出现异常
15、 新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、 新增分组自动切换参数功能
3、 至尊版新增自定义题库功能
4、群发外链工具V170321版入门版也有
5、维修英文采集
6、修复视频采集
7、指定域名只有在被收录到数据库时才添加标题或内容
8、添加内容编辑器2,修复文章用户使用前无法编辑的问题
9、用于修复单个错误的接口工具
10、 完善其他细节功能
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章和指定域名的高质量自动识别采集文章
2、修复调用至尊版用户栏段落库的bug
3、改善群发外链工具屏蔽问题
4、关键词采集文章修复采集实图
5、 搜狗推荐的新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前台采集解决部分后台采集空网页
8、添加文章导出处理详情
9、增加挂断是间隔分钟的设置
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-12-10 05:01
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
2、批量生成URL
当多个页面需要同时采集在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
我们以京东的网页为例:
这是京东iphone的第三页网址为关键词。我们可以按照这种格式替换关键词,生成多个产品网址,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击行。
数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。
设置好参数后,可以预览生成的URL。如下所示
在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改
同上,字母变化是根据变化规则设置从a到某个字母
时间的变化
如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”
然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动时可以选择“按照启动设置”采集
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置跟随开始
注意:follow 任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址
温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版 查看全部
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
2、批量生成URL
当多个页面需要同时采集在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
我们以京东的网页为例:
这是京东iphone的第三页网址为关键词。我们可以按照这种格式替换关键词,生成多个产品网址,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击行。
数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。
设置好参数后,可以预览生成的URL。如下所示
在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改
同上,字母变化是根据变化规则设置从a到某个字母
时间的变化
如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”
然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动时可以选择“按照启动设置”采集
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置跟随开始
注意:follow 任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址
温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版
插入关键字 文章采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-09 09:15
优化。Smart Information 采集器是一款基于爬取搜索引擎邮件资源开发的功能强大的软件采集。采集的邮箱地址,QQ是很有方向性的,排除与你的目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。Smart Information 采集器 提供强大的电子邮件地址、导出和重复数据删除功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.Smart Mail采集器 是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2. 通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,推算数字,准确率99%。
3.根据设定的目标关键词,软件自动从搜索引擎结果中采集对应的邮箱地址。邮箱地址采集非常准确,更适合电子邮箱精准营销的理念。
4.根据设定的目标关键词,软件自动从搜索引擎结果中采集所有对应的扣号。采集收到的扣号非常准确,更适合扣精准营销的理念。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要进入关键词软件自动采集在线客户信息并过滤,最后将筛选结果显示出来供客户参考。
优化。智能信息采集器提醒:
提醒:部分杀毒软件返回误报,只需将其加入白名单并正常使用即可。 查看全部
插入关键字 文章采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
优化。Smart Information 采集器是一款基于爬取搜索引擎邮件资源开发的功能强大的软件采集。采集的邮箱地址,QQ是很有方向性的,排除与你的目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。Smart Information 采集器 提供强大的电子邮件地址、导出和重复数据删除功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.Smart Mail采集器 是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2. 通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,推算数字,准确率99%。
3.根据设定的目标关键词,软件自动从搜索引擎结果中采集对应的邮箱地址。邮箱地址采集非常准确,更适合电子邮箱精准营销的理念。
4.根据设定的目标关键词,软件自动从搜索引擎结果中采集所有对应的扣号。采集收到的扣号非常准确,更适合扣精准营销的理念。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要进入关键词软件自动采集在线客户信息并过滤,最后将筛选结果显示出来供客户参考。
优化。智能信息采集器提醒:
提醒:部分杀毒软件返回误报,只需将其加入白名单并正常使用即可。
插入关键字 文章采集器(WPAutoTags这款插件常见问题工作原理及主要功能简介后台管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-07 06:11
WordPress 有没有现成的好用的插件,可以像内置的自动摘要一样自动给文章 添加相关标签?WordPress的文章标签功能可以很好的对文章进行分类汇总。不像直接给文章一个大目录,标签没有层次关系,标签的设计更多的是帮助将相似主题的文章组织在一起。为了给搜索引擎访问者提供更相关的文章推荐,每次写完文章,都会想到手动给文章添加相关标签,有时候感觉比较麻烦。非常麻烦和低效,不是吗?有时即使写完文章,我也忘记给文章添加标签!
<p>尝试了很多自动标签插件搜索,都不尽如人意,于是就创建了WordPress全自动辅助插件WP AutoTags来解决上述问题。经常在WordPress文章发布,更新编辑文章当爱忘记设置标签的人工作时,根据文章的标题和 查看全部
插入关键字 文章采集器(WPAutoTags这款插件常见问题工作原理及主要功能简介后台管理)
WordPress 有没有现成的好用的插件,可以像内置的自动摘要一样自动给文章 添加相关标签?WordPress的文章标签功能可以很好的对文章进行分类汇总。不像直接给文章一个大目录,标签没有层次关系,标签的设计更多的是帮助将相似主题的文章组织在一起。为了给搜索引擎访问者提供更相关的文章推荐,每次写完文章,都会想到手动给文章添加相关标签,有时候感觉比较麻烦。非常麻烦和低效,不是吗?有时即使写完文章,我也忘记给文章添加标签!
<p>尝试了很多自动标签插件搜索,都不尽如人意,于是就创建了WordPress全自动辅助插件WP AutoTags来解决上述问题。经常在WordPress文章发布,更新编辑文章当爱忘记设置标签的人工作时,根据文章的标题和
插入关键字 文章采集器(文章采集器可以爬9000+条美食相关的信息么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-04 18:01
插入关键字文章采集器可以从百度、谷歌、微信公众号等网站上进行任意标识,包括标题、图片、文章正文等(包括视频),支持百度、搜狗、新浪、腾讯等排名。并支持文章/图文/视频相互切换。为文章添加一个或多个图片,可添加多个文章或图片。利用爬虫软件可以更快的爬取网站信息,而且爬取的url大多可以被百度、新浪、腾讯等收录。
我会告诉你我们班一同学写了个爬虫,只需要一个邮箱,就能爬9000+条美食相关的信息么。不用去中关村,不用去大悦城,不用去大悦城四楼。
标题可以个人信息可以文章下面可以图片可以正文可以
一只小白。目前只是想学爬虫爬一下美食相关的,好像还没有别的软件。so。如果有什么好的软件求分享下呀。
我们的学习爬虫也是用到了爬虫,后端和前端方面都有在学习,scrapy框架了解一下,python爬虫框架了解一下,这样的话做一个自己的项目可以用python做一个,其他语言做一个(附上采集的后台,
我们现在也是爬取这些美食图片和视频。并不是很贵。只是个人觉得美食图片比较贵。但是不得不说,传统时尚的这些产品也是很有市场的。不管怎么样,
如果只是想要一些图片来着,去美团,饿了么,等等上面都有,只不过门槛可能比较高,可以发掘很多好用的技术,比如我很常用的动态特效+去水印版本的qq表情图片爬虫,可以登录, 查看全部
插入关键字 文章采集器(文章采集器可以爬9000+条美食相关的信息么)
插入关键字文章采集器可以从百度、谷歌、微信公众号等网站上进行任意标识,包括标题、图片、文章正文等(包括视频),支持百度、搜狗、新浪、腾讯等排名。并支持文章/图文/视频相互切换。为文章添加一个或多个图片,可添加多个文章或图片。利用爬虫软件可以更快的爬取网站信息,而且爬取的url大多可以被百度、新浪、腾讯等收录。
我会告诉你我们班一同学写了个爬虫,只需要一个邮箱,就能爬9000+条美食相关的信息么。不用去中关村,不用去大悦城,不用去大悦城四楼。
标题可以个人信息可以文章下面可以图片可以正文可以
一只小白。目前只是想学爬虫爬一下美食相关的,好像还没有别的软件。so。如果有什么好的软件求分享下呀。
我们的学习爬虫也是用到了爬虫,后端和前端方面都有在学习,scrapy框架了解一下,python爬虫框架了解一下,这样的话做一个自己的项目可以用python做一个,其他语言做一个(附上采集的后台,
我们现在也是爬取这些美食图片和视频。并不是很贵。只是个人觉得美食图片比较贵。但是不得不说,传统时尚的这些产品也是很有市场的。不管怎么样,
如果只是想要一些图片来着,去美团,饿了么,等等上面都有,只不过门槛可能比较高,可以发掘很多好用的技术,比如我很常用的动态特效+去水印版本的qq表情图片爬虫,可以登录,
插入关键字 文章采集器(DEDECMS使用关键词关连文章cfg_like与关键字替换(是/否)cfg)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-04 17:08
DEDEcms使用关键词相关链接文章cfg_keyword_like和关键字替换(是/否)cfg_keyword_replace的区别
网上有关于DEDE的BUG和修复方法cms关键词相关文章(文章内容关键词替换)文章
打开/include/arc.archives.class.php文件,找到197行,将$GLOBALS['cfg_keyword_replace']=='Y'改为$GLOBALS['cfg_keyword_like']=='Y',读取Looks真的歪了。
真正的解释是:
cfg_keyword_replace 是关键字替换(yes/no) 使用这个函数会影响HTML生成速度
cfg_keyword_like 是关键词相关链接文章
的使用
要将文章中的关键字替换为链接,需要打开的是“文章将内容中的关键字替换为链接” cfg_keyword_replace 是“是”而不是“cfg_keyword_like”“是”
关键词相关文章cfg_keyword_like的使用是指:除了与“relevant文章”相同的标签外,“相同关键字”文章页面被认为作为“相关文章”。 查看全部
插入关键字 文章采集器(DEDECMS使用关键词关连文章cfg_like与关键字替换(是/否)cfg)
DEDEcms使用关键词相关链接文章cfg_keyword_like和关键字替换(是/否)cfg_keyword_replace的区别
网上有关于DEDE的BUG和修复方法cms关键词相关文章(文章内容关键词替换)文章
打开/include/arc.archives.class.php文件,找到197行,将$GLOBALS['cfg_keyword_replace']=='Y'改为$GLOBALS['cfg_keyword_like']=='Y',读取Looks真的歪了。
真正的解释是:
cfg_keyword_replace 是关键字替换(yes/no) 使用这个函数会影响HTML生成速度
cfg_keyword_like 是关键词相关链接文章
的使用
要将文章中的关键字替换为链接,需要打开的是“文章将内容中的关键字替换为链接” cfg_keyword_replace 是“是”而不是“cfg_keyword_like”“是”
关键词相关文章cfg_keyword_like的使用是指:除了与“relevant文章”相同的标签外,“相同关键字”文章页面被认为作为“相关文章”。
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-03 07:10
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
2、批量生成URL
当多个页面需要采集同时在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
我们以京东的网页为例:
这是京东iphone的第三页URL为关键词,我们可以按照这个格式替换关键词生成多个产品的URL,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击好的。
数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。
设置好参数后,可以预览生成的URL。如下所示
在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改
同上,字母变化是根据变化规则设置从a到某个字母
时间的变化
如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”
然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动时可以选择“按照启动设置”采集
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置跟随开始
注意:follow 任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址
温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版 查看全部
插入关键字 文章采集器(自定义采集模式中文件导入大批量网址、批量生成的功能)
本文介绍了如何在自定义采集模式下批量导入文件、批量生成URL以及在关联任务中导入URL。
采集数据的时候,很多用户都会遇到这种情况:
优采云 通过自定义采集 URL输入的升级优化,有效解决了上述问题,主要有以下三个功能。
1、文件导入大量网址
目前手动输入支持的网址数量有限。如果URL数量比较多,我们可以直接从本地文件批量导入URL,保存,然后配置规则。
具体操作如下:
在自定义采集主界面,选择“从文件导入”,然后选择一个已有的URL文件进行大量导入
如下图,导入后可以预览前100个网址。
使用条件:
1、支持cxv、xls、xlsx、txt文件格式
2、支持100w以内的URL,超过的自动删除
2、批量生成URL
当多个页面需要采集同时在同一个网站中时,我们可以使用该功能批量生成URL,可以节省大量翻页或重复搜索的时间。只要URL满足条件,就可以通过设置逻辑自动生成,然后利用云端采集拆分原理采集任务,大大提高采集@的效率>.
如何使用URL批量生成功能?
同样在自定义模式进入界面,选择“批量生成”
我们以京东的网页为例:
这是京东iphone的第三页URL为关键词,我们可以按照这个格式替换关键词生成多个产品的URL,
先用鼠标选中需要设置的关键词,然后点击添加参数
点击后,在弹出的窗口中可以看到有4种可以编辑和更改的参数:
数字变化:可设置从某个数字开始,每次递增或递减X位,设置总数,设置零填充
字母变化:从一个字母到一个字母
时间变化:可设置时间段的变化
自定义列表:您可以将一些必需的 关键词 作为 URL 参数的一部分
自定义列表
因为本例设置为关键词,所以参数类型选择“自定义列表”,填写需要采集的关键词参数,如电脑、手机、鼠标,然后点击好的。
数字化变革
同理,选择页码,点击添加参数,设置页码相关参数。这里参数类型选择数量变化,然后观察页面URL的变化来设置具体的参数配置。如果我们需要从第一页采集开始,起始值为1;差为1,每个action递增为1。如果需要采集11页,则结束值为11,项数从第1页到第11页,共11项。
设置好参数后,可以预览生成的URL。如下所示
在京东的这个例子中,只需要设置这两个参数。我们来看看另外两个。
信改
同上,字母变化是根据变化规则设置从a到某个字母
时间的变化
如上图,选择合适的时间格式,然后设置开始和结束时间。
注意:
支持批量生成100W以内的URL,超过100W只生成100W。
批量生成的前100个URL保存在本地并显示在界面上;> 100 个 URL 存储在云中,不显示在界面上。当本地采集或云端采集时,直接调用存储在云端的URL 采集数据。
如果复制此规则,则复制的规则将仅收录前 100 个 URL,并且仅 采集 前 100 个 URL 的数据。
3、链接任务导入地址
还有一种导入URL的方式,可以选择其他任务采集直接导入URL关联采集。比如一个任务同时是采集列表页和详情页,就没有办法用云采集来拆分。如果使用关联采集功能,可以把这个任务变成两个任务:A任务采集列表信息,B任务采集详细信息,两个任务都可以在云端拆分, 采集 效率提升不少(注意如果采集 网站 列表页进入详情页时URL没有改变,所以不能使用该方法)
具体操作如下:
在自定义模式条目中选择“从任务导入”
我们将导入的任务称为“源任务”,将 URL 导入后新配置的任务称为“跟随任务”
然后使用下拉箭头选择采集的任务和字段,即可完整导入源任务采集的URL。
注意:导入时必须保证源任务有云端数据。
规则配置完成后,保存启动时可以选择“按照启动设置”采集
然后你可以从弹窗中选择4种不同的启动方式来满足不同的采集场景,
源任务需要一定的数据,follow task可以采集获取数据,所以可以根据采集的情况选择以下4种follow task启动方式。
您也可以在任务列表中设置跟随开始
注意:follow 任务不能设置为定时启动,只能由源任务触发。
启动采集时,如果选择“Full URL 采集”,优采云将采集为任务导入的所有URL;如果选择“仅采集预览网址”,优采云将采集此任务最多100个预览网址
温馨提示:只有终极版(上)包的用户才支持关联任务的导入。去升级旗舰版
插入关键字 文章采集器(怎样做好站内优化只要做好以下几点就够了!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-28 20:15
网站优化和执行,心态极其重要,平时多发表原创性文章,大量引流,持续发外链,友好联系交流,没事看些SEO知识文章,快乐优化网站,不要天天想SEO,深鉴网站尊重百度搜索的原则,不作弊,不走寻常路,实现SEO 心态。
如何优化网站
站内优化只需要做好以下几点。
1、写标题网站;
不要在标题中收录太多关键字,只需 1-3 个。额外的关键字放置在未完成关键字权重的顶部。网站 写在标题关键字周围。最好通俗易懂,合理呈现。关键词。
2、在标题中附上关键词网站写自己的创作文章;
可以使用自创或者优质伪创的文章,关键字可以在文章中重复,不要太频繁,根据文章的长度而定,并且要呈现很自然。其他文章标题也要拟定,文章标题很重要。文章最好和网站有联系,不要太写题。
3、更新网站;
网站 必须更新,按一定频率更新,或者一天一次,但是每两天一次,或者一周一次。文章及时更新百度快照更新比较快,每篇文章底部相关文章可以推荐阅读文章,让百度蜘蛛爬得更深,内容之间有联系,所有网站的权重都增加了。
4、 在站内建立连接;
我们知道搜索引擎蜘蛛是通过连接在网站内部爬行的。所以,如果你想让搜索引擎蜘蛛在你的网站上好看,最好多设置一些连接,这样蜘蛛才能顺利爬来爬去。你的 网站。很多人制作了一张网站地图,告诉蜘蛛怎么走。事实上,这也是可能的。
5、关键字采集
使用站长工具采集多个相关关键词和长尾关键词后,用每个关键词文章更新一篇文章,文章呈现某个关键词并刺穿链接。假设需要引入外部链接作为文章的参考数据,可以通过nofollow标签的特性来限制权重输出。虽然不敢说上面这几个步骤的SEO技巧有多猛,但是一定要通过这几种方法的过程去执行和坚持。只要是竞争不大的关键词,就能在百度首页获得优秀的排名。
如何优化异地
那么站外的优化就好像在说分离和关系等等。搜索引擎的做法与此相同。如果你关系好,人脉好,有几位在山药当官的亲戚朋友,那我们也会看好你的。
那么一个站如何才能让搜索引擎看好呢?
简而言之,就是做“外链”。
在大型论坛网站有你的联系,那是最好的。不过很多其他的小网站有很多你的人脉,这也很好。至少说明你的网站连接广泛,所以搜索引擎不会小看你。那么判断优质外链可以被百度认可的标准是什么?
1. 相关页面之间应该存在外部链接
无论是搜索引擎还是用户,发起外连的页面和通过外连进行投票的页面都应该是密切相关的。例如,对于同一个连接,如果外部连接的相关性高,就会获得更多的读者,潜在的目标客户也会增加。
2.提供外部连接网站应该是健康的
在用于对外连接的网站中,不应该有完全无关的、低质量的、不健康的网站。所谓害群之马不好,就是这个道理!
3. 添加外部连接的方法应该很自然
即使是通过采购方式,或者其他方式获得的外链,也必须在页面中体现出来,给人一种“真的存在”的感觉!假设,网站 突然添加了无数的外部链接,会让读者产生一个猜测,这个连接是否是付费购买的。
4. 外链的锚文本要多样化
对于外链的锚文本进行正确或错误的关键词排名往往很有用,因此需要多种方法来优化外链的锚文本。例如,假设一个站点主要是一些电视节目,首页的锚文本链接可能会出现外观标题、主持人、电视节目、主要内容等各种文本,而不是一致的节目名称。
5. 外部链接可能存在于页面的各个方向
外部链接应该存在于页面的各个方面,而不仅仅是在页面底部。比如内容的有意识的引荐区,文字底部的“传输源”等等,都是不错的方向。
6. 外部连接应该来自不同的IP、不同的站点、不同的页面
假设某个网站的所有外部连接都来自同一台服务器上的其他站点,那么搜索引擎可能会认为这个网站中的每个人都是一样的。结果将是 搜索引擎减少了外部连接投票对目标站点的影响。不同IP、不同网站、不同页面存在的外链,表示外链是用户有意识地推荐的。
7.进行对外交流和正常交流是正常的
由于连接通信早于搜索引擎,所以允许正常的外部连接通信,例如友情连接。虽然现在友情连接的首要地位确实越来越小,但它绝对符合网络的性质。搜索引擎不会将正常的友情链接视为作弊。
8. 外部链接应该指向不同层次的页面
将外部链接指向网站的首页是比较常用的方法。但是,不要将所有外部链接都指向 网站 主页。能够将 10% 到 20% 的链接指向程序页面或内容页面是很自然的。 查看全部
插入关键字 文章采集器(怎样做好站内优化只要做好以下几点就够了!!)
网站优化和执行,心态极其重要,平时多发表原创性文章,大量引流,持续发外链,友好联系交流,没事看些SEO知识文章,快乐优化网站,不要天天想SEO,深鉴网站尊重百度搜索的原则,不作弊,不走寻常路,实现SEO 心态。
如何优化网站
站内优化只需要做好以下几点。
1、写标题网站;
不要在标题中收录太多关键字,只需 1-3 个。额外的关键字放置在未完成关键字权重的顶部。网站 写在标题关键字周围。最好通俗易懂,合理呈现。关键词。
2、在标题中附上关键词网站写自己的创作文章;
可以使用自创或者优质伪创的文章,关键字可以在文章中重复,不要太频繁,根据文章的长度而定,并且要呈现很自然。其他文章标题也要拟定,文章标题很重要。文章最好和网站有联系,不要太写题。
3、更新网站;
网站 必须更新,按一定频率更新,或者一天一次,但是每两天一次,或者一周一次。文章及时更新百度快照更新比较快,每篇文章底部相关文章可以推荐阅读文章,让百度蜘蛛爬得更深,内容之间有联系,所有网站的权重都增加了。
4、 在站内建立连接;
我们知道搜索引擎蜘蛛是通过连接在网站内部爬行的。所以,如果你想让搜索引擎蜘蛛在你的网站上好看,最好多设置一些连接,这样蜘蛛才能顺利爬来爬去。你的 网站。很多人制作了一张网站地图,告诉蜘蛛怎么走。事实上,这也是可能的。
5、关键字采集
使用站长工具采集多个相关关键词和长尾关键词后,用每个关键词文章更新一篇文章,文章呈现某个关键词并刺穿链接。假设需要引入外部链接作为文章的参考数据,可以通过nofollow标签的特性来限制权重输出。虽然不敢说上面这几个步骤的SEO技巧有多猛,但是一定要通过这几种方法的过程去执行和坚持。只要是竞争不大的关键词,就能在百度首页获得优秀的排名。
如何优化异地
那么站外的优化就好像在说分离和关系等等。搜索引擎的做法与此相同。如果你关系好,人脉好,有几位在山药当官的亲戚朋友,那我们也会看好你的。
那么一个站如何才能让搜索引擎看好呢?
简而言之,就是做“外链”。
在大型论坛网站有你的联系,那是最好的。不过很多其他的小网站有很多你的人脉,这也很好。至少说明你的网站连接广泛,所以搜索引擎不会小看你。那么判断优质外链可以被百度认可的标准是什么?
1. 相关页面之间应该存在外部链接
无论是搜索引擎还是用户,发起外连的页面和通过外连进行投票的页面都应该是密切相关的。例如,对于同一个连接,如果外部连接的相关性高,就会获得更多的读者,潜在的目标客户也会增加。
2.提供外部连接网站应该是健康的
在用于对外连接的网站中,不应该有完全无关的、低质量的、不健康的网站。所谓害群之马不好,就是这个道理!
3. 添加外部连接的方法应该很自然
即使是通过采购方式,或者其他方式获得的外链,也必须在页面中体现出来,给人一种“真的存在”的感觉!假设,网站 突然添加了无数的外部链接,会让读者产生一个猜测,这个连接是否是付费购买的。
4. 外链的锚文本要多样化
对于外链的锚文本进行正确或错误的关键词排名往往很有用,因此需要多种方法来优化外链的锚文本。例如,假设一个站点主要是一些电视节目,首页的锚文本链接可能会出现外观标题、主持人、电视节目、主要内容等各种文本,而不是一致的节目名称。
5. 外部链接可能存在于页面的各个方向
外部链接应该存在于页面的各个方面,而不仅仅是在页面底部。比如内容的有意识的引荐区,文字底部的“传输源”等等,都是不错的方向。
6. 外部连接应该来自不同的IP、不同的站点、不同的页面
假设某个网站的所有外部连接都来自同一台服务器上的其他站点,那么搜索引擎可能会认为这个网站中的每个人都是一样的。结果将是 搜索引擎减少了外部连接投票对目标站点的影响。不同IP、不同网站、不同页面存在的外链,表示外链是用户有意识地推荐的。
7.进行对外交流和正常交流是正常的
由于连接通信早于搜索引擎,所以允许正常的外部连接通信,例如友情连接。虽然现在友情连接的首要地位确实越来越小,但它绝对符合网络的性质。搜索引擎不会将正常的友情链接视为作弊。
8. 外部链接应该指向不同层次的页面
将外部链接指向网站的首页是比较常用的方法。但是,不要将所有外部链接都指向 网站 主页。能够将 10% 到 20% 的链接指向程序页面或内容页面是很自然的。
插入关键字 文章采集器(常见的黑帽操作,恭喜你,你完全有能力超越竞争对手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-28 20:09
很多朋友在学习网站优化相关知识的时候,不同的人用的方法不同。从公平的角度来看,没有人是对或错的。大致有两种类型:黑帽和白帽。
黑帽的操作方法很简单。任何人只要学会操作方法就可以快速上榜关键词。有些人认为这才是真正的SEO。白帽 SEO 太慢了。要理解和掌握的东西太多了。理论是一一写的,每种方法都有其优点和缺点。
黑帽子排名很快,甚至有“首页七天”的说法,但投资的成本和风险并存。多人违规后,搜索引擎连K站都处罚,恢复期很长。对于普通企业来说,主营业务可能来自网络,被关停的影响是巨大的。因此,不建议企业使用这种高风险的优化方式。
白帽排名比较慢,一般需要2-3个月,但是完全没有被K站的风险。主要的关键词排名波动不大,即使调整算法,也基本维持在10-20之间。尽可能多地将关键词排名分为列表和内容页,而不仅仅是首页,这样即使首页排名下降(被降级),其他页面也可以获得流量。
下面为朋友们总结一些常见的黑帽操作。如果你发现你的竞争对手有这样的操作,那么恭喜你,你完全有能力超越你的竞争对手。
常见的黑帽操作1) 填充关键字
相信很多学过SEO的人都做过类似的操作。在首页的标题上写主关键词和相关的长尾关键词,觉得这样匹配的多,排名会更好。参考文章为什么要降低关键词的密度,会不会影响排名优化?
2)采集内容做伪原创
很容易在网上找内容,复制,用工具伪原创替换,或者加词分段落,就可以创建一个相似度很低的“文章”,这种文章的根本没有可读性,用户体验很差。 查看全部
插入关键字 文章采集器(常见的黑帽操作,恭喜你,你完全有能力超越竞争对手)
很多朋友在学习网站优化相关知识的时候,不同的人用的方法不同。从公平的角度来看,没有人是对或错的。大致有两种类型:黑帽和白帽。
黑帽的操作方法很简单。任何人只要学会操作方法就可以快速上榜关键词。有些人认为这才是真正的SEO。白帽 SEO 太慢了。要理解和掌握的东西太多了。理论是一一写的,每种方法都有其优点和缺点。
黑帽子排名很快,甚至有“首页七天”的说法,但投资的成本和风险并存。多人违规后,搜索引擎连K站都处罚,恢复期很长。对于普通企业来说,主营业务可能来自网络,被关停的影响是巨大的。因此,不建议企业使用这种高风险的优化方式。
白帽排名比较慢,一般需要2-3个月,但是完全没有被K站的风险。主要的关键词排名波动不大,即使调整算法,也基本维持在10-20之间。尽可能多地将关键词排名分为列表和内容页,而不仅仅是首页,这样即使首页排名下降(被降级),其他页面也可以获得流量。
下面为朋友们总结一些常见的黑帽操作。如果你发现你的竞争对手有这样的操作,那么恭喜你,你完全有能力超越你的竞争对手。
常见的黑帽操作1) 填充关键字
相信很多学过SEO的人都做过类似的操作。在首页的标题上写主关键词和相关的长尾关键词,觉得这样匹配的多,排名会更好。参考文章为什么要降低关键词的密度,会不会影响排名优化?
2)采集内容做伪原创
很容易在网上找内容,复制,用工具伪原创替换,或者加词分段落,就可以创建一个相似度很低的“文章”,这种文章的根本没有可读性,用户体验很差。
插入关键字 文章采集器(插入关键字文章采集器批量下载word文章..上期)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-27 17:11
插入关键字文章采集器批量下载word文章...上期从零开始给大家介绍一些常用的批量下载word文章的工具,希望能对大家有所帮助。本期为大家带来关键字文章采集器,它能够实现多个网站、多个平台的热门文章采集。主要采集的内容包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊,财经网站等数十个网站的文章。
重点采集包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊等数十个网站的文章。一起来看看他的效果图吧!文章采集工具效果图此工具还支持采集新闻门户网站文章,不过支持到的网站目前比较少。在我们确定需要采集哪个网站后,还需要进行关键字的搜索。找到想要下载的文章链接,直接复制即可。(下载的word只是word里面的一部分内容,我们可以自行添加lrc,url,txt等附件。
)这个工具特别适合那些想要一个一个找热门网站的小伙伴,我觉得还是非常棒的,可以实现多个热门网站同时采集,而且可以快速对比多个热门网站下载哪个更快。不过有个缺点,有时候很多网站下载不了,比如...不过这些工具都不支持下载视频和音频,这点确实让人比较抓狂,以后会继续努力为大家推荐其他的替代工具。关键字下载工具下载效果图本文来源:写给个人|公众号:caixueshu分享在微信公众号:caixueshu获取更多信息原文链接:批量下载新闻媒体、媒体号、公众号、主流新闻门户网站的文章。 查看全部
插入关键字 文章采集器(插入关键字文章采集器批量下载word文章..上期)
插入关键字文章采集器批量下载word文章...上期从零开始给大家介绍一些常用的批量下载word文章的工具,希望能对大家有所帮助。本期为大家带来关键字文章采集器,它能够实现多个网站、多个平台的热门文章采集。主要采集的内容包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊,财经网站等数十个网站的文章。
重点采集包括:新闻网站,媒体号,公众号,主流新闻门户网站,论坛平台,学术期刊等数十个网站的文章。一起来看看他的效果图吧!文章采集工具效果图此工具还支持采集新闻门户网站文章,不过支持到的网站目前比较少。在我们确定需要采集哪个网站后,还需要进行关键字的搜索。找到想要下载的文章链接,直接复制即可。(下载的word只是word里面的一部分内容,我们可以自行添加lrc,url,txt等附件。
)这个工具特别适合那些想要一个一个找热门网站的小伙伴,我觉得还是非常棒的,可以实现多个热门网站同时采集,而且可以快速对比多个热门网站下载哪个更快。不过有个缺点,有时候很多网站下载不了,比如...不过这些工具都不支持下载视频和音频,这点确实让人比较抓狂,以后会继续努力为大家推荐其他的替代工具。关键字下载工具下载效果图本文来源:写给个人|公众号:caixueshu分享在微信公众号:caixueshu获取更多信息原文链接:批量下载新闻媒体、媒体号、公众号、主流新闻门户网站的文章。
插入关键字 文章采集器(阿里云双12拼团服务器优化活动1核2G/1年/89元)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-23 10:06
阿里云双12组队加入服务器优化活动1核2G/1年/89元
Artifact是本软件最新开发的群消息监控软件,可以实时监控多个QQ号的所有QQ群消息。指定关键词抓取发送消息的QQ群成员号后,可用于采集保单客户,指定关键词抓取订单。
QQ群抢神器功能介绍:
1、群消息实时监控
QQ群抢单神器实时监控多个QQ号的所有QQ群消息。如果群成员使用您设置的关键词发送消息,您可以抓取消息内容和发送消息的QQ号码。帮助您找到政策目标。
2、帮助小组成员
QQ群抢神器软件可以帮你处理QQ群。假设某群成员声明需要停止发送关键词,就可以拿到自己的QQ号,然后给予相应的封禁和踢群奖惩!
3、定位关键词抢单
QQ群抢单神器软件支持自定义关键词抢单。当群消息在你定义的时间和分钟丰富时关键词,它会立即抢消息并提醒让你先抢订单!
4、支持后台工作
QQ群抢神器软件可以在软件初始工作后放置在桌面下,不影响您电脑的其他使用!
软件.jpg' />
⒈本站提供的任何资源仅供自研学习,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集整理相关行业网站页面公共资源,属于用户自己在相关网站上发布的公开信息,不涉及任何个人隐私问题,本软件可只在合法范围内使用,不得非法使用。
⒋一旦发现会员有欺骗我们或欺骗客户的行为,一经发现,会员资格将无条件取消!
⒌请勿使用我们的软件采集转售信息或将其用于其他非法行为。否则后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章 请注明:/benlv/qqyx/5173.html
标签: 飞信营销软件 QQ群营销 QQ群抢购 QQ关键词采集 QQ群监控 查看全部
插入关键字 文章采集器(阿里云双12拼团服务器优化活动1核2G/1年/89元)
阿里云双12组队加入服务器优化活动1核2G/1年/89元
Artifact是本软件最新开发的群消息监控软件,可以实时监控多个QQ号的所有QQ群消息。指定关键词抓取发送消息的QQ群成员号后,可用于采集保单客户,指定关键词抓取订单。
QQ群抢神器功能介绍:
1、群消息实时监控
QQ群抢单神器实时监控多个QQ号的所有QQ群消息。如果群成员使用您设置的关键词发送消息,您可以抓取消息内容和发送消息的QQ号码。帮助您找到政策目标。
2、帮助小组成员
QQ群抢神器软件可以帮你处理QQ群。假设某群成员声明需要停止发送关键词,就可以拿到自己的QQ号,然后给予相应的封禁和踢群奖惩!
3、定位关键词抢单
QQ群抢单神器软件支持自定义关键词抢单。当群消息在你定义的时间和分钟丰富时关键词,它会立即抢消息并提醒让你先抢订单!
4、支持后台工作
QQ群抢神器软件可以在软件初始工作后放置在桌面下,不影响您电脑的其他使用!
软件.jpg' />
⒈本站提供的任何资源仅供自研学习,不得用于非法活动。它们将在下载后 24 小时内删除。
⒉软件公告区的内容不得发布违反法律法规的内容。一旦发现该软件在后台被屏蔽,将无法打开!
⒊本站软件采集整理相关行业网站页面公共资源,属于用户自己在相关网站上发布的公开信息,不涉及任何个人隐私问题,本软件可只在合法范围内使用,不得非法使用。
⒋一旦发现会员有欺骗我们或欺骗客户的行为,一经发现,会员资格将无条件取消!
⒌请勿使用我们的软件采集转售信息或将其用于其他非法行为。否则后果自负!一经发现,我们将第一时间向公安部门报告!并停止软件功能,所有费用概不退还!
原创文章 请注明:/benlv/qqyx/5173.html
标签: 飞信营销软件 QQ群营销 QQ群抢购 QQ关键词采集 QQ群监控
插入关键字 文章采集器(插入关键字文章采集器的主要工作原理是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-20 20:06
插入关键字文章采集器的主要工作原理是根据网页中已经给定的关键字或者锚文本提取某个内容,对文章进行数据处理加工即可使用了。requests简介requests中文网站爬虫,是一款python的第三方爬虫框架,主要的用途为网络爬虫;它是采用urllib3模块提供的requests对象来加载网页的爬虫框架,基于它发展而来的还有requestslib,pyquery,pyqueryprequests中文网站爬虫原理scrapy简介scrapy中文网站爬虫,是一款scrapy社区中影响力比较大的爬虫框架,它为用户提供一个简单、高效的用scrapy从web抓取网页内容的简单应用程序,是一款功能强大、简单高效的爬虫框架;其主要的功能为爬虫,内置有urllib2模块,网页解析、文档解析、下载、表单解析、正则匹配等诸多功能模块;它是由scrapy社区推动并优化而成,并以scrapy框架为核心,目前已成功应用于百度、豆瓣、果壳、简书、知乎、天涯、豆瓣、环球、译客、博客园、腾讯、网易、搜狐、百度空间、凤凰网、天涯论坛、yy、奇虎36。
0、乐视等200多家知名网站。requestsrequests是一个urllib的第三方库,提供了模拟浏览器向服务器发送http请求的函数requestserver。requestserver实现了http协议中的get、post、delete请求方法。你可以使用该函数用浏览器向服务器发送请求。requestserver实现了http协议中的head和form表单请求方法。
简单说,requestserver就是一个代理服务器。将请求的资源作为post请求发送至该代理服务器中,代理服务器就可以拿到要请求的资源,然后以post方式来将资源传递给目标服务器,目标服务器拿到服务器的资源,进行处理,返回结果。requestserver主要做一下事情:。
1、添加到proxychainsdefproxychains(os,proxyurl):
2、调用函数xlsproxychainslogin_xlsproxy=requestserver(url=os.path.join(os,proxyurl),headers={'host':'127.0.0.1','port':9999})
3、处理请求responseresponse=requestserver.request("xls",os.path.join(os,proxyurl))返回的页面解析方法很多,
4、使用第三方库进行解析defurllib2。urlretrieve(url,input_val):'''获取所有标签的内容returnurllib2。urlopen(url)'''http_api调用函数classword2vec(urllib2。urlretrieve):def__init__(self,attrs):self。urls=[attrs]self。 查看全部
插入关键字 文章采集器(插入关键字文章采集器的主要工作原理是什么?)
插入关键字文章采集器的主要工作原理是根据网页中已经给定的关键字或者锚文本提取某个内容,对文章进行数据处理加工即可使用了。requests简介requests中文网站爬虫,是一款python的第三方爬虫框架,主要的用途为网络爬虫;它是采用urllib3模块提供的requests对象来加载网页的爬虫框架,基于它发展而来的还有requestslib,pyquery,pyqueryprequests中文网站爬虫原理scrapy简介scrapy中文网站爬虫,是一款scrapy社区中影响力比较大的爬虫框架,它为用户提供一个简单、高效的用scrapy从web抓取网页内容的简单应用程序,是一款功能强大、简单高效的爬虫框架;其主要的功能为爬虫,内置有urllib2模块,网页解析、文档解析、下载、表单解析、正则匹配等诸多功能模块;它是由scrapy社区推动并优化而成,并以scrapy框架为核心,目前已成功应用于百度、豆瓣、果壳、简书、知乎、天涯、豆瓣、环球、译客、博客园、腾讯、网易、搜狐、百度空间、凤凰网、天涯论坛、yy、奇虎36。
0、乐视等200多家知名网站。requestsrequests是一个urllib的第三方库,提供了模拟浏览器向服务器发送http请求的函数requestserver。requestserver实现了http协议中的get、post、delete请求方法。你可以使用该函数用浏览器向服务器发送请求。requestserver实现了http协议中的head和form表单请求方法。
简单说,requestserver就是一个代理服务器。将请求的资源作为post请求发送至该代理服务器中,代理服务器就可以拿到要请求的资源,然后以post方式来将资源传递给目标服务器,目标服务器拿到服务器的资源,进行处理,返回结果。requestserver主要做一下事情:。
1、添加到proxychainsdefproxychains(os,proxyurl):
2、调用函数xlsproxychainslogin_xlsproxy=requestserver(url=os.path.join(os,proxyurl),headers={'host':'127.0.0.1','port':9999})
3、处理请求responseresponse=requestserver.request("xls",os.path.join(os,proxyurl))返回的页面解析方法很多,
4、使用第三方库进行解析defurllib2。urlretrieve(url,input_val):'''获取所有标签的内容returnurllib2。urlopen(url)'''http_api调用函数classword2vec(urllib2。urlretrieve):def__init__(self,attrs):self。urls=[attrs]self。

