
抓取网页生成电子书
抓取网页生成电子书(Windows,OSX及Linux操作系统格式的在线资料格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-16 13:30
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多有趣的内容以网页的形式出现。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
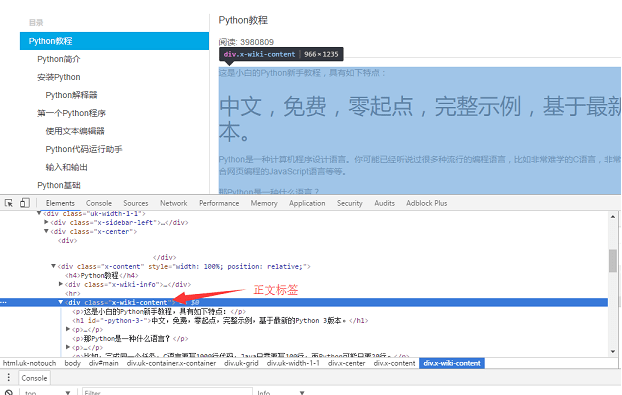
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre<br />
Debian/Ubuntu:
apt-get install calibre<br />
红帽/Fedora/CentOS:
yum -y install calibre<br />
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面一般是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe<br /><br />class Git_Pocket_Guide(BasicNewsRecipe):<br /><br /> title = 'Git Pocket Guide'<br /> description = ''<br /> cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br /> url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr /> no_stylesheets = True<br /> keep_only_tags = [{ 'class': 'chapter' }]<br /><br /> def get_title(self, link):<br /> return link.contents[0].strip()<br /><br /> def parse_index(self):<br /> soup = self.index_to_soup(self.url_prefix + 'index.html')<br /><br /> div = soup.find('div', { 'class': 'toc' })<br /><br /> articles = []<br /> for link in div.findAll('a'):<br /> if '#' in link['href']:<br /> continue<br /><br /> if not 'ch' in link['href']:<br /> continue<br /><br /> til = self.get_title(link)<br /> url = self.url_prefix + link['href']<br /> a = { 'title': til, 'url': url }<br /><br /> articles.append(a)<br /><br /> ans = [('Git_Pocket_Guide', articles)]<br /><br /> return ans<br />
下面解释了代码的不同部分。
整体结构
一般来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'<br />description = ''<br />cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br />url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr />no_stylesheets = True<br />keep_only_tags = [{ 'class': 'chapter' }]<br />
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
ebook-convert Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi<br />
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
带图片的页面
实际效果
我的食谱仓库
我在github上做了一个kindle-open-books,里面有一些菜谱,是我自己写的,其他同学贡献的。欢迎任何人提供食谱。 查看全部
抓取网页生成电子书(Windows,OSX及Linux操作系统格式的在线资料格式)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多有趣的内容以网页的形式出现。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre<br />
Debian/Ubuntu:
apt-get install calibre<br />
红帽/Fedora/CentOS:
yum -y install calibre<br />
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面一般是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe<br /><br />class Git_Pocket_Guide(BasicNewsRecipe):<br /><br /> title = 'Git Pocket Guide'<br /> description = ''<br /> cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br /> url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr /> no_stylesheets = True<br /> keep_only_tags = [{ 'class': 'chapter' }]<br /><br /> def get_title(self, link):<br /> return link.contents[0].strip()<br /><br /> def parse_index(self):<br /> soup = self.index_to_soup(self.url_prefix + 'index.html')<br /><br /> div = soup.find('div', { 'class': 'toc' })<br /><br /> articles = []<br /> for link in div.findAll('a'):<br /> if '#' in link['href']:<br /> continue<br /><br /> if not 'ch' in link['href']:<br /> continue<br /><br /> til = self.get_title(link)<br /> url = self.url_prefix + link['href']<br /> a = { 'title': til, 'url': url }<br /><br /> articles.append(a)<br /><br /> ans = [('Git_Pocket_Guide', articles)]<br /><br /> return ans<br />
下面解释了代码的不同部分。
整体结构
一般来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'<br />description = ''<br />cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br />url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr />no_stylesheets = True<br />keep_only_tags = [{ 'class': 'chapter' }]<br />
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。

整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
ebook-convert Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi<br />
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容

内容一

内容二

带图片的页面

实际效果

我的食谱仓库
我在github上做了一个kindle-open-books,里面有一些菜谱,是我自己写的,其他同学贡献的。欢迎任何人提供食谱。
抓取网页生成电子书(只要能显示在网页上的东西都可以抓下来。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-15 11:08
)
最近,我迷上了德州扑克。我的同学H是这次活动的领队(tuifei)。我们同学不仅PK了,还给我发了截图,WC,你也买了书,你也进了群,你快上天堂了。. .
晚上11点30分,我用我的房门打开他房间的门,他果然在床上。
H,有资源吗?
不是,X宝上贴的和我下载的一样,只有44页,前十页是广告。
哎,无良商家,退款?
不,只有1.00元,她又给了我一本书。
来看看澳门赌场上线的感觉吧。
回去jd上找,电子版18元,纸质版什么的。没有微信阅读。
第二天,我在实验室遇到了H。还有其他资源吗?
恩,网易阅读上有,我付费了。
第一次听说网易读书,周末在他的实验室度过。
神奇的是网易云阅读器可以在网页上打开查看。
有这样的操作吗??
我发现了一些东西,
WC,网易太甜了!
太甜了,我也想为此把文字记下来。
换句话说,只要能在网页上显示,就可以被捕获。
一、创意的产生
要么使用现成的工具,比如优采云,来抓取网络上的数据,但使用这个工具显然是一个失学的人。要么使用开源框架,然后在知乎上有一个非常流行的“爬虫”。玩爬虫的人很多,请自己知乎。用的比较多的框架有scrapy、pyspider等,前者比较低级,搞这个工作的人玩这个比较专业。后者非常适合新手玩,带有WEUI,网页上的可视化操作,非常方便。这篇文章懒得用pyspider。
二、设置环境
这部分我其实是一年前做的,不过当时我用的是windows平台。现在再看pyspider的官网,发现windows的缺点很多,而且pyspider的开发也是在linux平台上进行的。所以即使我是新手,也得在linux上使用环境。(pyspider 文档在这里)
对于Linux发行版的选择,官网列出了几个,centos(我的VPS上用的那个),ubuntu等。考虑到用浏览器,可能需要带桌面的linux系统。于是我在我的windows10上的vbox上安装了centos,后来发现安装桌面环境真的太慢了。突然发现自己太傻了。真的,我安装了一个Kali系统(我前段时间学会了安装)。Kali是基于Debian的发行版,ubuntu也是基于Debian的,所以使用kali应该没有问题。
参考pyspider帮助,pyspider中文网站
首先安装pyspider
apt-get 安装 pyspider
然后安装phantomjs
apt-get 安装 phantomjs
是不是很简单。Phantomjs 是一个无界面浏览器,用于完全模拟用户在浏览器上的操作,用于处理比较麻烦的问题,比如运行js、异步加载网页、响应网站反爬策略。另外,这款浏览器比IE、Chrome、Firefox等界面浏览器要快很多,详情请参考/。
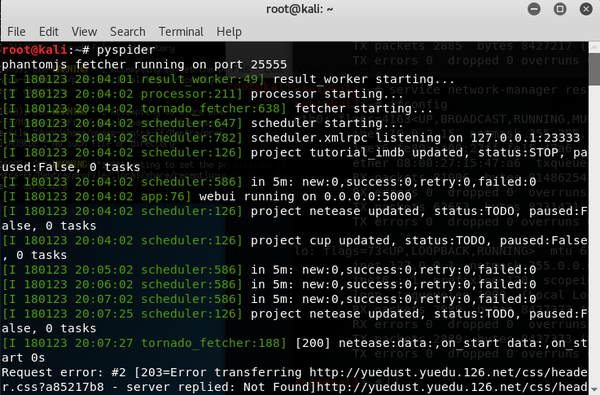
安装成功后,在终端输入pyspider
提示phantomjs fetcher运行在25555端口,这个其实是pyspider用phantomjs运行的,所以在加载AJAX页面的时候很有用。
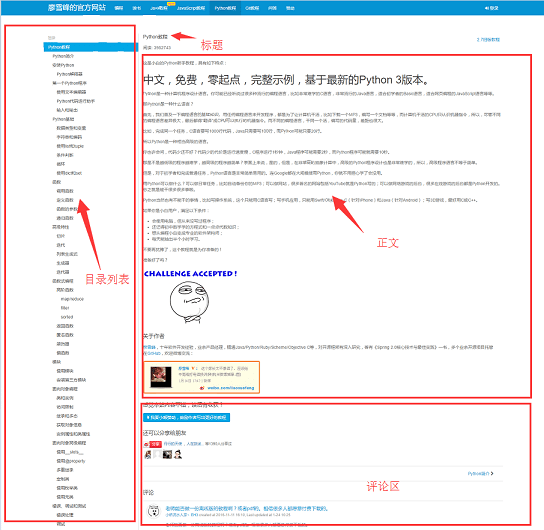
三、分析页面
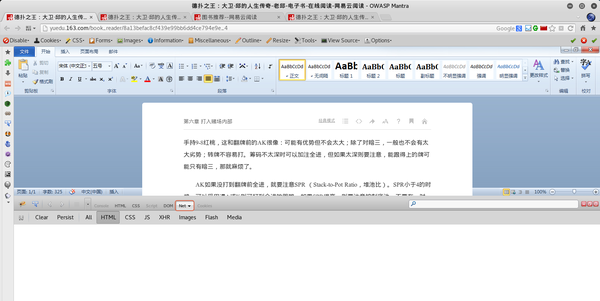
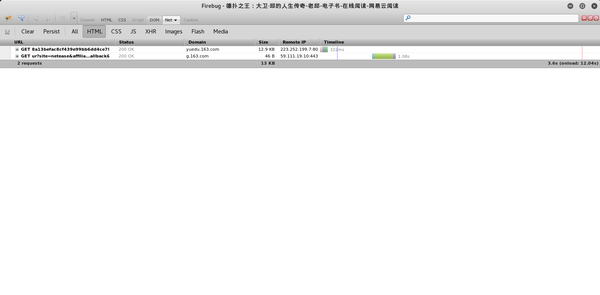
打开某章的阅读页面,如《副王:秋雨传》-老秋-电子书-在线阅读-网易云阅读,打开调试工具Firebug。
选择net标签,这样在打开网页的时候就可以看到页面加载的过程。
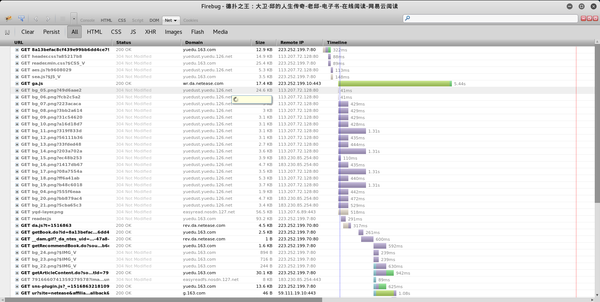
一个阅读页面需要这么多资源!其实还有很多东西是不需要关心的,把tab切换成HTML,
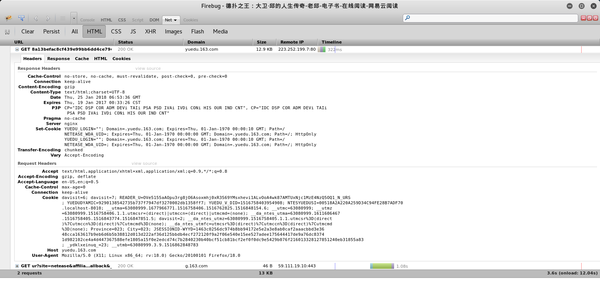
其实请求只有两个,第一个在域名下,第二个在下。可以假设第二个与此页面的内容几乎没有相关性,可以用于统计目的。查看第一个请求
具体不说了,反正回复里没有章节内容。
那么章节内容在哪里呢?
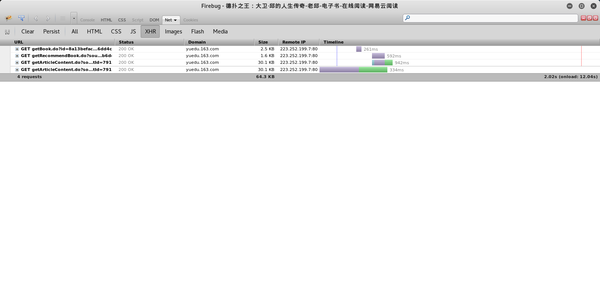
将选项卡切换到 XHR,
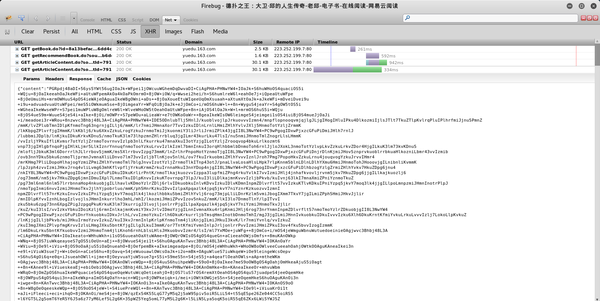
收录 4 个异步请求。从 URL 和接收数据的时间(时间轴上的绿色部分),可以猜测最后一个是获取章节内容的请求。其实就是一一点击查看接收到的数据。可以看到上次请求返回的数据是一个json数据。
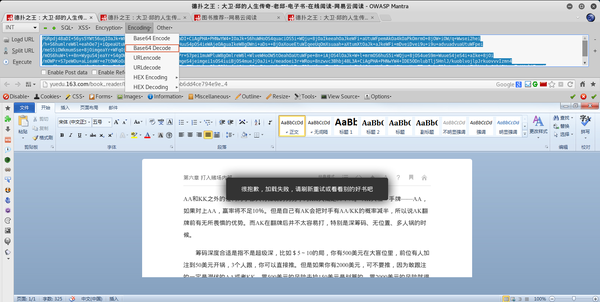
很明显,json的一个字段就是content,这很可能就是我们想要的。但是这个字符串要编码,常规套路是base64编码,因为不是敏感数据。试试看,打开浏览器的hack栏,把内容复制进去,在Encoding里面选择Base64Decode
结果是
你看到了什么?乱七八糟的胡言乱语。
不完全是,有
人物。这说明content的内容确实是base64编码的,但是汉字的解码有问题。
这时候使用pyspider的返回数据的json方法提取json数据,然后尝试解码收录中文的内容:
得到了答案
本来以为和中文打交道要花点时间,没想到一次就成功了。
四、登录问题
其实最难的不是找到文章的内容,而是以注册人的身份访问网站。这个问题从周末的两天,到周一的一整天的战斗,到周二的放弃,再到周三的重新审视这个问题,我真的学到了很多。我遇到的问题不是因为问题本身的难度,而是因为我对它的理解深度。了解的越深,把握的就越准确。一个人摸索的时候,一开始很兴奋,渐渐地我怀疑自己,这个问题有没有办法解决?还是自己的能力差距很大?
周三,我冷静下来,重新组织了登录流程、cookie 交付流程,并将每次 cookie 更改记录在草稿纸上。最终在不断的尝试和推理中找到了正确的应用方法,作为登录者成功获取了数据。其实核心就是cookie的交付,但是摸索的过程太长了,我也是菜鸟。
五、数据的后处理
后处理其实很简单,上面已经正确解码了,下面只是将其写入文件。
def detail_page(self, response):
results=response.json
content=base64.b64decode(results['content'])
fo = open('/root/Documents/davidchiu2.txt','a')
fo.write(content)
fo.close()
return {
# "content": content,
"content_cn": content,
}
将结果保存到txt文件中,如下
因为有html的段落格式,还有图片的链接,加个html header和end,把扩展名改成html,这样用浏览器打开就可以看到图片了。
然后将页面上的文字和图片全部复制到word,排版后导出PDF,完美。
查看全部
抓取网页生成电子书(只要能显示在网页上的东西都可以抓下来。。
)
最近,我迷上了德州扑克。我的同学H是这次活动的领队(tuifei)。我们同学不仅PK了,还给我发了截图,WC,你也买了书,你也进了群,你快上天堂了。. .
晚上11点30分,我用我的房门打开他房间的门,他果然在床上。
H,有资源吗?
不是,X宝上贴的和我下载的一样,只有44页,前十页是广告。
哎,无良商家,退款?
不,只有1.00元,她又给了我一本书。
来看看澳门赌场上线的感觉吧。
回去jd上找,电子版18元,纸质版什么的。没有微信阅读。
第二天,我在实验室遇到了H。还有其他资源吗?
恩,网易阅读上有,我付费了。
第一次听说网易读书,周末在他的实验室度过。
神奇的是网易云阅读器可以在网页上打开查看。

有这样的操作吗??
我发现了一些东西,
WC,网易太甜了!
太甜了,我也想为此把文字记下来。
换句话说,只要能在网页上显示,就可以被捕获。
一、创意的产生
要么使用现成的工具,比如优采云,来抓取网络上的数据,但使用这个工具显然是一个失学的人。要么使用开源框架,然后在知乎上有一个非常流行的“爬虫”。玩爬虫的人很多,请自己知乎。用的比较多的框架有scrapy、pyspider等,前者比较低级,搞这个工作的人玩这个比较专业。后者非常适合新手玩,带有WEUI,网页上的可视化操作,非常方便。这篇文章懒得用pyspider。
二、设置环境
这部分我其实是一年前做的,不过当时我用的是windows平台。现在再看pyspider的官网,发现windows的缺点很多,而且pyspider的开发也是在linux平台上进行的。所以即使我是新手,也得在linux上使用环境。(pyspider 文档在这里)
对于Linux发行版的选择,官网列出了几个,centos(我的VPS上用的那个),ubuntu等。考虑到用浏览器,可能需要带桌面的linux系统。于是我在我的windows10上的vbox上安装了centos,后来发现安装桌面环境真的太慢了。突然发现自己太傻了。真的,我安装了一个Kali系统(我前段时间学会了安装)。Kali是基于Debian的发行版,ubuntu也是基于Debian的,所以使用kali应该没有问题。
参考pyspider帮助,pyspider中文网站
首先安装pyspider
apt-get 安装 pyspider
然后安装phantomjs
apt-get 安装 phantomjs
是不是很简单。Phantomjs 是一个无界面浏览器,用于完全模拟用户在浏览器上的操作,用于处理比较麻烦的问题,比如运行js、异步加载网页、响应网站反爬策略。另外,这款浏览器比IE、Chrome、Firefox等界面浏览器要快很多,详情请参考/。
安装成功后,在终端输入pyspider
提示phantomjs fetcher运行在25555端口,这个其实是pyspider用phantomjs运行的,所以在加载AJAX页面的时候很有用。
三、分析页面
打开某章的阅读页面,如《副王:秋雨传》-老秋-电子书-在线阅读-网易云阅读,打开调试工具Firebug。
选择net标签,这样在打开网页的时候就可以看到页面加载的过程。
一个阅读页面需要这么多资源!其实还有很多东西是不需要关心的,把tab切换成HTML,
其实请求只有两个,第一个在域名下,第二个在下。可以假设第二个与此页面的内容几乎没有相关性,可以用于统计目的。查看第一个请求
具体不说了,反正回复里没有章节内容。
那么章节内容在哪里呢?
将选项卡切换到 XHR,
收录 4 个异步请求。从 URL 和接收数据的时间(时间轴上的绿色部分),可以猜测最后一个是获取章节内容的请求。其实就是一一点击查看接收到的数据。可以看到上次请求返回的数据是一个json数据。
很明显,json的一个字段就是content,这很可能就是我们想要的。但是这个字符串要编码,常规套路是base64编码,因为不是敏感数据。试试看,打开浏览器的hack栏,把内容复制进去,在Encoding里面选择Base64Decode
结果是
你看到了什么?乱七八糟的胡言乱语。
不完全是,有
人物。这说明content的内容确实是base64编码的,但是汉字的解码有问题。
这时候使用pyspider的返回数据的json方法提取json数据,然后尝试解码收录中文的内容:

得到了答案

本来以为和中文打交道要花点时间,没想到一次就成功了。
四、登录问题
其实最难的不是找到文章的内容,而是以注册人的身份访问网站。这个问题从周末的两天,到周一的一整天的战斗,到周二的放弃,再到周三的重新审视这个问题,我真的学到了很多。我遇到的问题不是因为问题本身的难度,而是因为我对它的理解深度。了解的越深,把握的就越准确。一个人摸索的时候,一开始很兴奋,渐渐地我怀疑自己,这个问题有没有办法解决?还是自己的能力差距很大?
周三,我冷静下来,重新组织了登录流程、cookie 交付流程,并将每次 cookie 更改记录在草稿纸上。最终在不断的尝试和推理中找到了正确的应用方法,作为登录者成功获取了数据。其实核心就是cookie的交付,但是摸索的过程太长了,我也是菜鸟。
五、数据的后处理
后处理其实很简单,上面已经正确解码了,下面只是将其写入文件。
def detail_page(self, response):
results=response.json
content=base64.b64decode(results['content'])
fo = open('/root/Documents/davidchiu2.txt','a')
fo.write(content)
fo.close()
return {
# "content": content,
"content_cn": content,
}
将结果保存到txt文件中,如下

因为有html的段落格式,还有图片的链接,加个html header和end,把扩展名改成html,这样用浏览器打开就可以看到图片了。

然后将页面上的文字和图片全部复制到word,排版后导出PDF,完美。

抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-15 11:05
无意中发现了一个可以免费下载电子书的网站。它立刻勾起了我采集电子书的爱好,我很想下载这些书。
就在最近,requests 的作者 kennethreitz 发布了一个新的库 requests-html。
它不仅可以请求网页,还可以解析 HTML 文档。让我们开始吧。
安装。
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
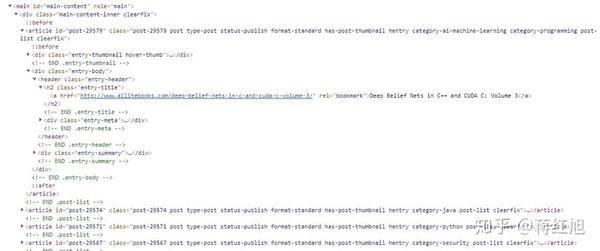
通过浏览器查看元素,可以发现这本电子书网站是用WordPress搭建的。主页上的列表元素非常简单和规则。
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接。
从下图。
可以发现download-links>a中的链接是该书的下载链接。
回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码。
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
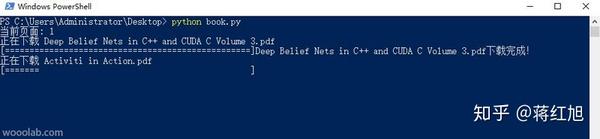
运行结果:
读者福利,点击链接领取相关学习福利包:
是安全的网站不用担心,继续访问后即可收到
就业系列:
有方向和目标的学习可以节省时间,而没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:
视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助
Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
如果看到最后的小伙伴们,如果觉得这个文章对你有好处,请给我点个赞,关注我们,支持你!!!! 查看全部
抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图))
无意中发现了一个可以免费下载电子书的网站。它立刻勾起了我采集电子书的爱好,我很想下载这些书。

就在最近,requests 的作者 kennethreitz 发布了一个新的库 requests-html。
它不仅可以请求网页,还可以解析 HTML 文档。让我们开始吧。
安装。
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器查看元素,可以发现这本电子书网站是用WordPress搭建的。主页上的列表元素非常简单和规则。
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接。
从下图。

可以发现download-links>a中的链接是该书的下载链接。
回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。

请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码。
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
读者福利,点击链接领取相关学习福利包:
是安全的网站不用担心,继续访问后即可收到
就业系列:
有方向和目标的学习可以节省时间,而没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:
视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助

Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
如果看到最后的小伙伴们,如果觉得这个文章对你有好处,请给我点个赞,关注我们,支持你!!!!
抓取网页生成电子书(requests-html快速指南发送一个get(请求:requests))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-14 11:13
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器查看元素,可以发现这本电子书网站是用wordpress构建的。主页上的列表元素非常简单和规则。
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图
可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
requests-html 快速指南
发送获取请求:
from requests_html import htmlsession
session = htmlsession()
r = session.get('https://python.org/')
requests-html的方便之处在于它解析html的方式就像使用jquery一样简单,例如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 css 选择器选择元素:
about = r.find('.about', first=true)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 html
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import htmlsession
import requests
import time
import json
import random
import sys
'''
想要学习python?python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = htmlsession()
list_url = 'http://www.allitebooks.com/page/'
user_agents = [
"mozilla/5.0 (macintosh; intel mac os x 10_7_3) applewebkit/535.20 (khtml, like gecko) chrome/19.0.1036.7 safari/535.20",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.71 safari/537.1 lbbrowser",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/535.11 (khtml, like gecko) chrome/17.0.963.84 safari/535.11 lbbrowser",
"mozilla/4.0 (compatible; msie 7.0; windows nt 6.1; wow64; trident/5.0; slcc2; .net clr 2.0.50727; .net clr 3.5.30729; .net clr 3.0.30729; media center pc 6.0; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 7.0; windows nt 5.1; trident/4.0; sv1; qqdownload 732; .net4.0c; .net4.0e; 360se)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.89 safari/537.1",
"mozilla/5.0 (ipad; u; cpu os 4_2_1 like mac os x; zh-cn) applewebkit/533.17.9 (khtml, like gecko) version/5.0.2 mobile/8c148 safari/6533.18.5",
"mozilla/5.0 (windows nt 6.1; win64; x64; rv:2.0b13pre) gecko/20110307 firefox/4.0b13pre",
"mozilla/5.0 (x11; ubuntu; linux x86_64; rv:16.0) gecko/20100101 firefox/16.0",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.11 (khtml, like gecko) chrome/23.0.1271.64 safari/537.11",
"mozilla/5.0 (x11; u; linux x86_64; zh-cn; rv:1.9.2.10) gecko/20100922 ubuntu/10.10 (maverick) firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getbookurl(link.attrs['href'])
# 获取图书下载链接
def getbookurl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=true)
if l is not none: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 user-agent
headers={ "user-agent":random.choice(user_agents) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=true, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is none:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
以上就是小编为大家介绍的内容。我已经用python抓取了7000多本电子书进行了详细的集成和集成。我希望它会对你有所帮助。 查看全部
抓取网页生成电子书(requests-html快速指南发送一个get(请求:requests))
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器查看元素,可以发现这本电子书网站是用wordpress构建的。主页上的列表元素非常简单和规则。

所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图

可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
requests-html 快速指南
发送获取请求:
from requests_html import htmlsession
session = htmlsession()
r = session.get('https://python.org/')
requests-html的方便之处在于它解析html的方式就像使用jquery一样简单,例如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 css 选择器选择元素:
about = r.find('.about', first=true)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 html
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import htmlsession
import requests
import time
import json
import random
import sys
'''
想要学习python?python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = htmlsession()
list_url = 'http://www.allitebooks.com/page/'
user_agents = [
"mozilla/5.0 (macintosh; intel mac os x 10_7_3) applewebkit/535.20 (khtml, like gecko) chrome/19.0.1036.7 safari/535.20",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.71 safari/537.1 lbbrowser",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/535.11 (khtml, like gecko) chrome/17.0.963.84 safari/535.11 lbbrowser",
"mozilla/4.0 (compatible; msie 7.0; windows nt 6.1; wow64; trident/5.0; slcc2; .net clr 2.0.50727; .net clr 3.5.30729; .net clr 3.0.30729; media center pc 6.0; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 7.0; windows nt 5.1; trident/4.0; sv1; qqdownload 732; .net4.0c; .net4.0e; 360se)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.89 safari/537.1",
"mozilla/5.0 (ipad; u; cpu os 4_2_1 like mac os x; zh-cn) applewebkit/533.17.9 (khtml, like gecko) version/5.0.2 mobile/8c148 safari/6533.18.5",
"mozilla/5.0 (windows nt 6.1; win64; x64; rv:2.0b13pre) gecko/20110307 firefox/4.0b13pre",
"mozilla/5.0 (x11; ubuntu; linux x86_64; rv:16.0) gecko/20100101 firefox/16.0",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.11 (khtml, like gecko) chrome/23.0.1271.64 safari/537.11",
"mozilla/5.0 (x11; u; linux x86_64; zh-cn; rv:1.9.2.10) gecko/20100922 ubuntu/10.10 (maverick) firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getbookurl(link.attrs['href'])
# 获取图书下载链接
def getbookurl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=true)
if l is not none: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 user-agent
headers={ "user-agent":random.choice(user_agents) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=true, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is none:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:

以上就是小编为大家介绍的内容。我已经用python抓取了7000多本电子书进行了详细的集成和集成。我希望它会对你有所帮助。
抓取网页生成电子书(网络书籍抓取器是一款帮助用户下载指定网页的某)
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-10-11 17:45
在线图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
在线抢书功能介绍
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
网络图书采集器软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
如何使用在线图书抓取器
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击Start crawling开始下载。 查看全部
抓取网页生成电子书(网络书籍抓取器是一款帮助用户下载指定网页的某)
在线图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。

在线抢书功能介绍
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
网络图书采集器软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
如何使用在线图书抓取器
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。

三、设置保存路径,点击Start crawling开始下载。
抓取网页生成电子书(爬虫基础:http协议和http相关协议编写python怎么爬)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-11 15:54
抓取网页生成电子书,批量增删文件,python实现网页爬虫,抓取网页上的文章和图片;网页上标注文章作者,评论的网页及评论数、积分,统计参加活动的人数;生成图片下载代码,
爬虫需要那些技术?爬虫基础:http协议和http相关协议编写python爬虫,爬虫怎么爬,爬什么,为什么要爬,爬取到的内容存在哪里,存储时间大概是多久,网页列表如何下载btw,网页列表下载目前能实现的有九种下载方式,各有优缺点,对这方面了解不深,提供参考数据爬取,主要可以包括urllib,urllib2等模块,也可以使用lxml模块,也可以使用beautifulsoup模块,采用正则表达式将数据以url的形式存入数据库。
数据分析:根据输入的python文件内容获取其中的数据,即pandas,matplotlib,seaborn等。数据可视化:给数据结构化,以帮助更好的理解数据的价值和特征。以上所提到的爬虫主要偏向于前端编程部分,后台的java,c++,python等如果要深入可以将原始数据获取和预处理后在写入文件中,或者在本地使用https协议抓取,像uc直达云平台,则采用了这个。
不过主要有几点是要注意的,第一个,数据的存储,很有可能你获取的数据到不了文件存储的地方,只能像本地文件存储一样文件名都为文件的后缀名。第二个,特征提取,这方面做的好的公司有百度地图的百度图片的美图秀秀的拼图云等。第三个,爬虫模块的封装,当然这里的爬虫模块主要有一个对接,爬虫通过相关模块获取数据,对接数据库以后。
按照一定规则去实现网页中数据的查询、更新,然后进行数据分析。当然也可以post等其他形式。第四个,复杂问题处理,例如多人隐私处理,公众号打开限制,登录验证和接口调用处理,绑定公众号和开发者后端等。这些问题依据处理方法不同,会构成分布式爬虫、网页加密、反爬虫等相关问题。第五个,服务器设计,如何对爬虫程序做一个很好的保护和监控?这个和运维部分有很大关系。这一块其实也有很多的问题需要思考和处理。 查看全部
抓取网页生成电子书(爬虫基础:http协议和http相关协议编写python怎么爬)
抓取网页生成电子书,批量增删文件,python实现网页爬虫,抓取网页上的文章和图片;网页上标注文章作者,评论的网页及评论数、积分,统计参加活动的人数;生成图片下载代码,
爬虫需要那些技术?爬虫基础:http协议和http相关协议编写python爬虫,爬虫怎么爬,爬什么,为什么要爬,爬取到的内容存在哪里,存储时间大概是多久,网页列表如何下载btw,网页列表下载目前能实现的有九种下载方式,各有优缺点,对这方面了解不深,提供参考数据爬取,主要可以包括urllib,urllib2等模块,也可以使用lxml模块,也可以使用beautifulsoup模块,采用正则表达式将数据以url的形式存入数据库。
数据分析:根据输入的python文件内容获取其中的数据,即pandas,matplotlib,seaborn等。数据可视化:给数据结构化,以帮助更好的理解数据的价值和特征。以上所提到的爬虫主要偏向于前端编程部分,后台的java,c++,python等如果要深入可以将原始数据获取和预处理后在写入文件中,或者在本地使用https协议抓取,像uc直达云平台,则采用了这个。
不过主要有几点是要注意的,第一个,数据的存储,很有可能你获取的数据到不了文件存储的地方,只能像本地文件存储一样文件名都为文件的后缀名。第二个,特征提取,这方面做的好的公司有百度地图的百度图片的美图秀秀的拼图云等。第三个,爬虫模块的封装,当然这里的爬虫模块主要有一个对接,爬虫通过相关模块获取数据,对接数据库以后。
按照一定规则去实现网页中数据的查询、更新,然后进行数据分析。当然也可以post等其他形式。第四个,复杂问题处理,例如多人隐私处理,公众号打开限制,登录验证和接口调用处理,绑定公众号和开发者后端等。这些问题依据处理方法不同,会构成分布式爬虫、网页加密、反爬虫等相关问题。第五个,服务器设计,如何对爬虫程序做一个很好的保护和监控?这个和运维部分有很大关系。这一块其实也有很多的问题需要思考和处理。
抓取网页生成电子书(IbookBox网页小说批量下载阅读器中输入任一网页地址即可批量抓取和下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-11 05:00
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
在IbookBox网络小说批量下载阅读器中输入任意网址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站。
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫下载v1.0免费版-西溪软件下载。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。
IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
软件介绍 《批量下载小说爬虫》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件放到手机上离线观看,软件爬虫速度。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度一号。 查看全部
抓取网页生成电子书(IbookBox网页小说批量下载阅读器中输入任一网页地址即可批量抓取和下载)
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
在IbookBox网络小说批量下载阅读器中输入任意网址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站。
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫下载v1.0免费版-西溪软件下载。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。

IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
软件介绍 《批量下载小说爬虫》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件放到手机上离线观看,软件爬虫速度。

目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度一号。
抓取网页生成电子书(使用Cookie有两种方式,你知道吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-08 21:27
在实际情况下,网站的很多内容只有登录后才能看到,所以我们需要进行模拟登录,利用登录状态进行爬取。这里我们需要用到cookies。
现在大多数 网站 使用 cookie 来跟踪用户的登录状态。一旦网站验证登录信息,登录信息将存储在浏览器的cookie中。网站会使用这个cookie作为认证的凭证,在浏览网站的页面时返回给服务器。
由于 cookie 存储在本地,因此它们可以被篡改和伪造。让我们来看看 cookie 是什么样子的。
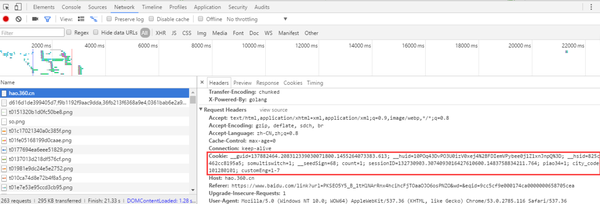
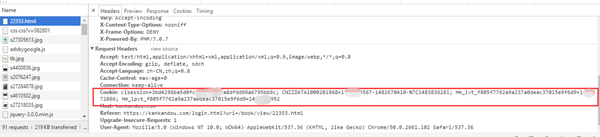
打开网页调试工具,随意打开一个网页,在“网络”选项卡中,打开一个链接,在标题中:
我们把它复制出来看看:
__guid=137882464.208312339030071800.1455264073383.613;
__huid=10POq43DvPO3U0izV0xej4%2BFDIemVPybee0j1Z1xnJnpQ%3D;
__hsid=825c7462cc8195a5;
somultiswitch=1;
__seedSign=68;
count=1; sessionID=132730903.3074093016427610600.1483758834211.764;
piao34=1;
city_code=101280101;
customEng=1-7
它由键值对组成。
接下来我们以豆豆一书的详情页为例,讲解cookies的使用。
See Do是一个电子书下载网站,我的Kindle上的大部分书都在这里找到。
示例网址为:宇宙是猫的困梦-看豆-提供优质正版电子书导购服务
一般情况下,未登录的用户是看不到下载链接的,比如:
这本书的下载链接是隐藏的。
头信息如下:
我们来看看登录后的页面:
下载链接已经显示出来了,我们来看一下header信息的Cookie部分
显然它与之前处于未记录状态的 cookie 不同。
接下来,我们按照上一章抓取腾讯新闻的方法,对示例网址()进行HTTP请求:
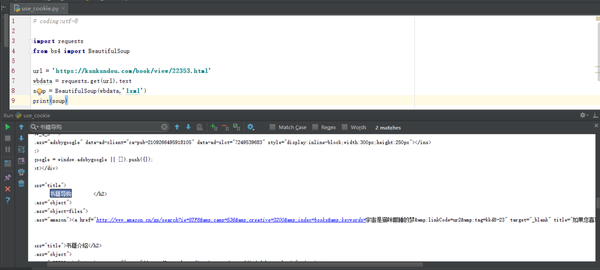
# coding:utf-8
import requests
from bs4 import BeautifulSoup
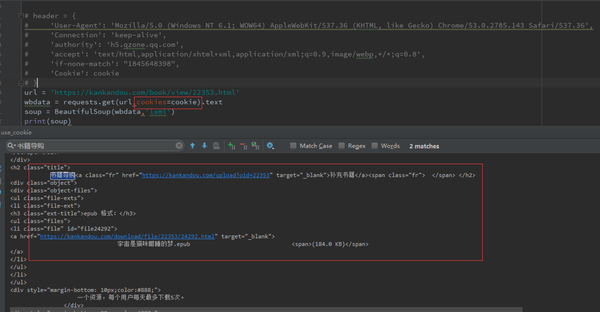
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
结果如下:
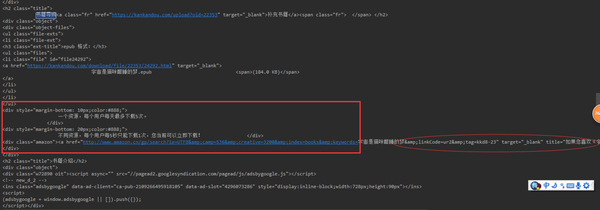
我们找到了下载链接所在的“图书购物指南”一栏的HTML代码:
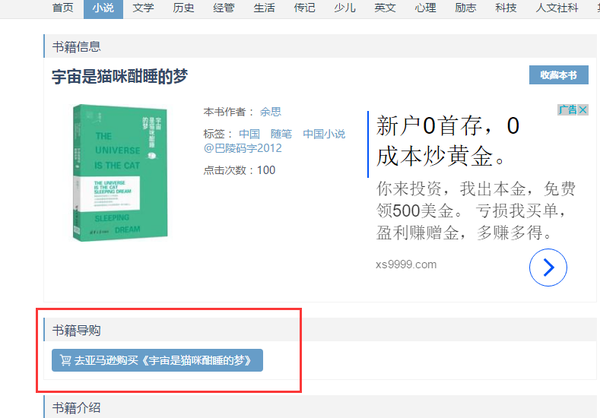
书籍导购
去亚马逊购买《宇宙是猫咪酣睡的梦》
就像我们在未登录状态下使用浏览器访问本网站时,只显示亚马逊的购买链接,没有电子格式的下载链接。
我们尝试在登录后使用以下 cookie:
有两种使用cookies的方法,
1、在header中直接写cookie
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a237a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=1483926368'''
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cookie': cookie}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,headers=header).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
上面的代码将响应返回给page(),
我们的搜索响应代码,
红色椭圆部分与无cookie访问时返回的HTML一致,即亚马逊的购买链接。
红色矩形是电子书的下载链接,也就是请求中使用的cookie。
与实际网页相比,与网页登录查看的显示页面一致。
功能完成。接下来看第二种方式
2、使用请求插入cookies
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = {
"cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60",
"CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031",
"Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313",
"Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368"
}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,cookies=cookie).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
你得到的是登录后显示的 HTML:
这样,我们就可以方便地使用cookies来获取需要登录验证的网页和资源。
这里只是简单介绍一下cookies的使用。关于如何获取cookie,手动复制是一种方式。通过代码获取需要用到Selenium,后面章节会讲解,这里不再展示。
================================================== ====================== 查看全部
抓取网页生成电子书(使用Cookie有两种方式,你知道吗?(组图))
在实际情况下,网站的很多内容只有登录后才能看到,所以我们需要进行模拟登录,利用登录状态进行爬取。这里我们需要用到cookies。
现在大多数 网站 使用 cookie 来跟踪用户的登录状态。一旦网站验证登录信息,登录信息将存储在浏览器的cookie中。网站会使用这个cookie作为认证的凭证,在浏览网站的页面时返回给服务器。
由于 cookie 存储在本地,因此它们可以被篡改和伪造。让我们来看看 cookie 是什么样子的。
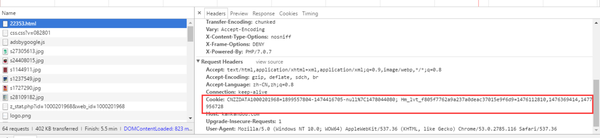
打开网页调试工具,随意打开一个网页,在“网络”选项卡中,打开一个链接,在标题中:
我们把它复制出来看看:
__guid=137882464.208312339030071800.1455264073383.613;
__huid=10POq43DvPO3U0izV0xej4%2BFDIemVPybee0j1Z1xnJnpQ%3D;
__hsid=825c7462cc8195a5;
somultiswitch=1;
__seedSign=68;
count=1; sessionID=132730903.3074093016427610600.1483758834211.764;
piao34=1;
city_code=101280101;
customEng=1-7
它由键值对组成。
接下来我们以豆豆一书的详情页为例,讲解cookies的使用。
See Do是一个电子书下载网站,我的Kindle上的大部分书都在这里找到。
示例网址为:宇宙是猫的困梦-看豆-提供优质正版电子书导购服务
一般情况下,未登录的用户是看不到下载链接的,比如:
这本书的下载链接是隐藏的。
头信息如下:
我们来看看登录后的页面:
下载链接已经显示出来了,我们来看一下header信息的Cookie部分
显然它与之前处于未记录状态的 cookie 不同。
接下来,我们按照上一章抓取腾讯新闻的方法,对示例网址()进行HTTP请求:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
结果如下:
我们找到了下载链接所在的“图书购物指南”一栏的HTML代码:
书籍导购
去亚马逊购买《宇宙是猫咪酣睡的梦》
就像我们在未登录状态下使用浏览器访问本网站时,只显示亚马逊的购买链接,没有电子格式的下载链接。
我们尝试在登录后使用以下 cookie:
有两种使用cookies的方法,
1、在header中直接写cookie
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a237a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=1483926368'''
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cookie': cookie}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,headers=header).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
上面的代码将响应返回给page(),
我们的搜索响应代码,
红色椭圆部分与无cookie访问时返回的HTML一致,即亚马逊的购买链接。
红色矩形是电子书的下载链接,也就是请求中使用的cookie。
与实际网页相比,与网页登录查看的显示页面一致。
功能完成。接下来看第二种方式
2、使用请求插入cookies
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = {
"cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60",
"CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031",
"Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313",
"Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368"
}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,cookies=cookie).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
你得到的是登录后显示的 HTML:
这样,我们就可以方便地使用cookies来获取需要登录验证的网页和资源。
这里只是简单介绍一下cookies的使用。关于如何获取cookie,手动复制是一种方式。通过代码获取需要用到Selenium,后面章节会讲解,这里不再展示。
================================================== ======================
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2021-10-08 21:09
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
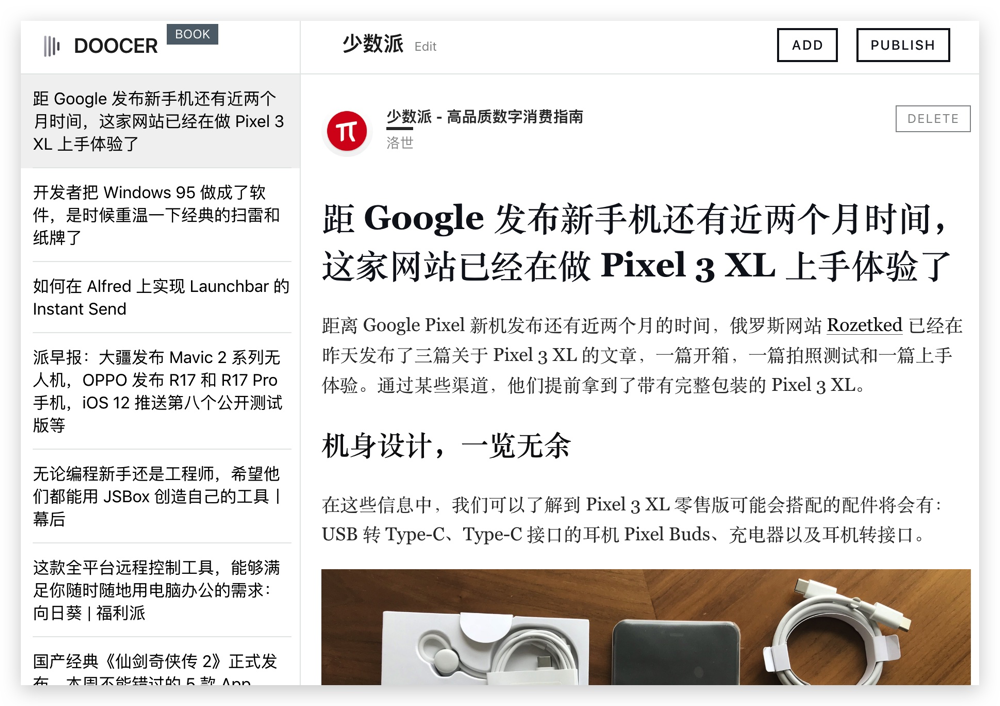
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 帐户中提交 URL、RSS 提要地址和 文章 供以后阅读,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,或者将它们推送到 Kindle 和 Apple Books 阅读。
阅读体验真的很好
Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)
将网页文章制作成电子书
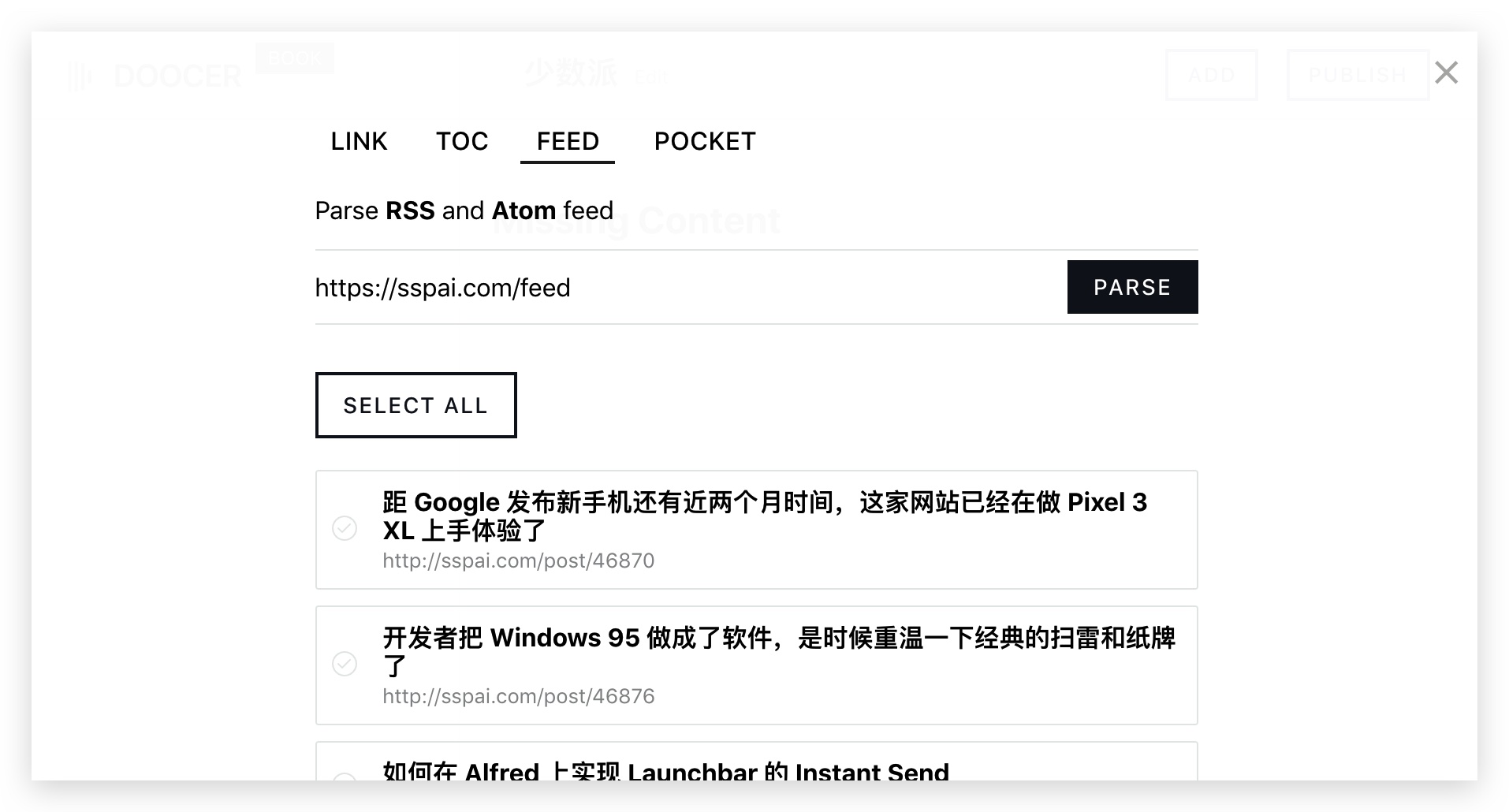
Doocer完成注册和登录后,我们就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后在右上角选择“添加”,添加文章 URL或RSS提要地址。
以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。
实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。
要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开Amazon Kindle的个人文档设置,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约 10-30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer可以像RSS工具一样抓取网页中更新后的文章,但是文章的新抓取以及生成电子书和推送仍然需要手动完成。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。 查看全部
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 帐户中提交 URL、RSS 提要地址和 文章 供以后阅读,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,或者将它们推送到 Kindle 和 Apple Books 阅读。

阅读体验真的很好
Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)

将网页文章制作成电子书
Doocer完成注册和登录后,我们就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后在右上角选择“添加”,添加文章 URL或RSS提要地址。

以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。
实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。
要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开Amazon Kindle的个人文档设置,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约 10-30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer可以像RSS工具一样抓取网页中更新后的文章,但是文章的新抓取以及生成电子书和推送仍然需要手动完成。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。
抓取网页生成电子书(小说爬虫下载器(小说批量下载神器)能去为你带来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1778 次浏览 • 2021-10-08 21:04
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
在IbookBox网络小说批量下载阅读器中输入任意网页地址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书生成txt发送到手机。3、 支持。
如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册。正在发送信息。
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取2、支持抓取的电子书生成txt发送到手机。3、 支持将电子书自动存放在您自己的邮箱中。 查看全部
抓取网页生成电子书(小说爬虫下载器(小说批量下载神器)能去为你带来)
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
在IbookBox网络小说批量下载阅读器中输入任意网页地址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书生成txt发送到手机。3、 支持。
如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册。正在发送信息。

本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。

输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取2、支持抓取的电子书生成txt发送到手机。3、 支持将电子书自动存放在您自己的邮箱中。
抓取网页生成电子书(用urllib2的Request类构建一个request接下来获取响应页面内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-08 19:31
使用 urllib2 的 Request 类构造请求
url = "https://www.qiushibaike.com/"
request = urllib2.Request(url)
接下来使用urllib2的urlopen方法请求页面并获取响应(即页面内容)
response = urllib2.urlopen(request)
打印得到的内容
print response.read()
运行我们的脚本,结果是一个错误:
Traceback (most recent call last):
File "00_get_a_page.py", line 19, in
response = urllib2.urlopen(request)
File "D:\Python27\lib\urllib2.py", line 154, in urlopen
return opener.open(url, data, timeout)
File "D:\Python27\lib\urllib2.py", line 429, in open
response = self._open(req, data)
File "D:\Python27\lib\urllib2.py", line 447, in _open
'_open', req)
File "D:\Python27\lib\urllib2.py", line 407, in _call_chain
result = func(*args)
File "D:\Python27\lib\urllib2.py", line 1241, in https_open
context=self._context)
File "D:\Python27\lib\urllib2.py", line 1201, in do_open
r = h.getresponse(buffering=True)
File "D:\Python27\lib\httplib.py", line 1121, in getresponse
response.begin()
File "D:\Python27\lib\httplib.py", line 438, in begin
version, status, reason = self._read_status()
File "D:\Python27\lib\httplib.py", line 402, in _read_status
raise BadStatusLine(line)
httplib.BadStatusLine: ''
这是因为尴尬百科对爬虫做了一些反爬虫优化,你必须是浏览器才能访问页面。
不过没关系,浏览器的信息是通过headers实现的。我们可以使用 urllib2 设置浏览器信息头,将我们的程序伪装成浏览器。
设置头验证信息
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER"
headers = {"User-Agent":user_agent}
可以看到我们设置了 User-Agent 字段,并将其封装为字典 headers,后面会用到。
user_agent 的内容为 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER,这是我用的猎豹浏览器的头信息,可以通过F12开发者工具查看。
重构请求并打印得到的响应页面的内容
request = urllib2.Request(url,headers=headers)
可以发现,在构造请求的时候,除了url参数,我们还把封装好的带有浏览器信息的headers传递给了urllib2.Request的headers参数。
[!] headers=headers 必须指定,否则headers会默认传给urllib2.Request的第二个参数,但是第二个参数不是headers,如下:
>>> help("urllib2.Request")
Help on class Request in urllib2:
urllib2.Request = class Request
| Methods defined here:
| __getattr__(self, attr)
| __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
用同样的方式重新请求页面,得到响应并打印出来
成功获得!但是我们的汉字没有出现。
这是因为我们获取的response.read()的编码方式是UTF-8字节流数据,而我们python2.7默认的编解码方式是ASCII,导致出现乱码。
我们打印的时候,指定解码方式为UTF-8,试试看。
print response.read().decode('utf-8')
成功!
至此我们已经获得了整个页面的完整信息。 查看全部
抓取网页生成电子书(用urllib2的Request类构建一个request接下来获取响应页面内容)
使用 urllib2 的 Request 类构造请求
url = "https://www.qiushibaike.com/"
request = urllib2.Request(url)
接下来使用urllib2的urlopen方法请求页面并获取响应(即页面内容)
response = urllib2.urlopen(request)
打印得到的内容
print response.read()
运行我们的脚本,结果是一个错误:
Traceback (most recent call last):
File "00_get_a_page.py", line 19, in
response = urllib2.urlopen(request)
File "D:\Python27\lib\urllib2.py", line 154, in urlopen
return opener.open(url, data, timeout)
File "D:\Python27\lib\urllib2.py", line 429, in open
response = self._open(req, data)
File "D:\Python27\lib\urllib2.py", line 447, in _open
'_open', req)
File "D:\Python27\lib\urllib2.py", line 407, in _call_chain
result = func(*args)
File "D:\Python27\lib\urllib2.py", line 1241, in https_open
context=self._context)
File "D:\Python27\lib\urllib2.py", line 1201, in do_open
r = h.getresponse(buffering=True)
File "D:\Python27\lib\httplib.py", line 1121, in getresponse
response.begin()
File "D:\Python27\lib\httplib.py", line 438, in begin
version, status, reason = self._read_status()
File "D:\Python27\lib\httplib.py", line 402, in _read_status
raise BadStatusLine(line)
httplib.BadStatusLine: ''
这是因为尴尬百科对爬虫做了一些反爬虫优化,你必须是浏览器才能访问页面。
不过没关系,浏览器的信息是通过headers实现的。我们可以使用 urllib2 设置浏览器信息头,将我们的程序伪装成浏览器。
设置头验证信息
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER"
headers = {"User-Agent":user_agent}
可以看到我们设置了 User-Agent 字段,并将其封装为字典 headers,后面会用到。
user_agent 的内容为 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER,这是我用的猎豹浏览器的头信息,可以通过F12开发者工具查看。
重构请求并打印得到的响应页面的内容
request = urllib2.Request(url,headers=headers)
可以发现,在构造请求的时候,除了url参数,我们还把封装好的带有浏览器信息的headers传递给了urllib2.Request的headers参数。
[!] headers=headers 必须指定,否则headers会默认传给urllib2.Request的第二个参数,但是第二个参数不是headers,如下:
>>> help("urllib2.Request")
Help on class Request in urllib2:
urllib2.Request = class Request
| Methods defined here:
| __getattr__(self, attr)
| __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
用同样的方式重新请求页面,得到响应并打印出来

成功获得!但是我们的汉字没有出现。
这是因为我们获取的response.read()的编码方式是UTF-8字节流数据,而我们python2.7默认的编解码方式是ASCII,导致出现乱码。
我们打印的时候,指定解码方式为UTF-8,试试看。
print response.read().decode('utf-8')

成功!
至此我们已经获得了整个页面的完整信息。
抓取网页生成电子书(廖雪峰:Python教程爬下来做成PDF电子书方便离线阅读)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-08 19:27
免责声明:本文仅供学习参考,不得用于其他用途。爬取过程中注意控制请求速度,以免给服务器造成太大压力
写爬虫好像不比用Python好。Python社区提供的爬虫工具之多,看得你眼花缭乱。你可以用各种可以直接使用的库在几分钟内编写一个爬虫。今天,我将尝试写一个爬虫。廖雪峰老师的Python教程爬下来制作了PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们没有用。,所以可以忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup4
pip install pdfkit
安装 wkhtmltopdf
Windows平台下,直接从wkhtmltopdf官网下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签
社会的
链接
© foofish 2016 查看全部
抓取网页生成电子书(廖雪峰:Python教程爬下来做成PDF电子书方便离线阅读)
免责声明:本文仅供学习参考,不得用于其他用途。爬取过程中注意控制请求速度,以免给服务器造成太大压力
写爬虫好像不比用Python好。Python社区提供的爬虫工具之多,看得你眼花缭乱。你可以用各种可以直接使用的库在几分钟内编写一个爬虫。今天,我将尝试写一个爬虫。廖雪峰老师的Python教程爬下来制作了PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们没有用。,所以可以忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup4
pip install pdfkit
安装 wkhtmltopdf
Windows平台下,直接从wkhtmltopdf官网下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签
社会的
链接
© foofish 2016
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-10-08 12:18
上一篇简单展示了我们将网页转成PDF的结果,特别适用于序列化的网页文章,组织成一本书。
本文也为大家简单讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点
一、 抓取网页并保存到本地
因为大部分网页都收录图片,所以很多网页都不是普通的静态网页。相应的内容是在浏览器加载过程中随着浏览器滚动条的滚动而加载的。
所以如果你只想简单地发送一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:selenium,我相信通常关注网络抓取的人对它很熟悉。
作者尝试搜索selenium+C#感兴趣的词,没想到selenium竟然是一个支持多语言的工具。百度自查的具体介绍,以下是百度百科介绍的简单截取。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
所以,不要犯错,犯一般错误,认为python很容易用于网页抓取,你可以使用C#中的常用工具。当前的工具不仅限于实现一种语言。我相信 dotNET 会变得更加开源。当生态越来越好时,会出现更多方便的工具。
在 C# 代码中,Seenium 用于控制浏览器行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们想要图形版本的数据,而不仅仅是一些结构化的数据,最简单的方法是将类似浏览器行为的CTRL+S作为网页保存到本地。也用代码来模拟发送键和击键的方式。有兴趣的读者可以参考以下代码。
网上同样的就是python的实现,作者简单的修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
private static void SaveHtml(ChromeDriver driver)
{
uint KEYEVENTF_KEYUP = 2;
keybd_event(Keys.ControlKey, 0, 0, 0);
keybd_event(Keys.S, 0, 0, 0);
keybd_event(Keys.ControlKey, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(3000);
keybd_event(Keys.Enter, 0, 0, 0);
keybd_event(Keys.Enter, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(5000);
driver.Close();
driver.Quit();
}
二、将多个网页保存为PDF
虽然WORD也可以用来打开网页,但估计WORD是用IE技术渲染网页的,很多功能无法恢复。所以直接转PDF更科学。
PDF 的另一个好处是几乎所有的 PDF 阅读器都可以随意打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的目的主要是为了阅读,所以将 HTML 转换为 PDF 是非常理想的。
它可以将多个网页转换为一个PDF文件,阅读时更加连贯。
网页转PDF的工具是wkhtmltopdf,也是一个命令行工具,可以多种语言调用。当然,dotNET 调用是没有问题的,但是为了更好的体验,还是应该在 PowerShell 上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都在下一步完成,最后记得设置环境变量,让CMD和PowerShell识别。
平时可以看到的python的html to pdf功能,其实底层也是用wkhtmltopdf完成的。
要将多个网页转换为PDF,需要考虑排序问题。这时候使用Excel催化剂可以轻松实现HTML排版顺序问题。
一般来说,我们是按顺序下载网页的,所以简单的使用Excel Catalyst的遍历文件功能来遍历文件信息,在Excel上做一个排序处理,手动调整一些特殊文件的顺序。
另一个自定义函数stringjoin可以快速将多个文件合并成一个字符串组合,用空格隔开,每条记录都要用双引号括起来。
打开我们的 PowerShell ISE 软件,它是 win10 自带的。其他系统也有,可以自行搜索相关教程打开。
相信很多读者也和作者有同感。他们觉得命令行很可怕。它是一系列代码,尤其是帮助文件。
事实上,它确实突破了心理恐惧。命令行工具和我们在Excel上写函数的原理都是一个函数名和各种参数,但是命令行可以有很多参数。
以下是我们如何在 PowerShell 上使用单个命令将多个 html 文件合并为一个 PDF 文件。
笔者还费了一番功夫阅读帮助文档,写出了更多命令的功能,比如添加页眉和页脚的功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,摊开多个html文件,最后加上pdf文件的名字,弄的太多了。该文件使用相对路径。您需要将PowerShell的当前路径切换到html存储文件夹。切换命令是 CD。
终于,激动人心的时刻到了,可以顺利生成pdf文件了。
包括页眉和页脚信息,一个总共400多页的PDF电子书诞生了。
有兴趣的读者不妨将自己喜欢的网页相册制作成PDF文件,方便查阅。之前的错误是追求PDF阅读器的精简,现在我重新使用【福昕阅读器】(感谢上一篇文章后读者朋友的推荐),旧的免费PDF阅读软件可以进行基于文本的PDF文件注释并记笔记。这里推荐大家使用。
同样,搜索关键词后,会出现一个关键词的列表。比如在学习DAX的过程中,如果想像参考书一样查找ALLSELECT函数的用法,可以搜索全文。这比使用搜索引擎查找要好得多。学习后,您还可以突出显示并做笔记。
结束语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。不用太羡慕python的网络爬虫。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境中,没有什么比 dotNET 开发更高效的了。再好的python,共享和交互也是一件头疼的事,但dotNET桌面开发自然是最大的优势。
在OFFICE环境下开发的优势就更详细了。其实本文的功能也可以移到Excel环境中无痛执行。以后有空再慢慢优化整个流程。
将 html 转换为 PDF 带来了极大的方便。该内容在互联网上,而不是您自己的数据,并且可能随时被删除和无法访问。压力下,肯定撑不了多久,所以我提前计划,先下载到本地,哈哈)。 查看全部
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
上一篇简单展示了我们将网页转成PDF的结果,特别适用于序列化的网页文章,组织成一本书。
本文也为大家简单讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点
一、 抓取网页并保存到本地
因为大部分网页都收录图片,所以很多网页都不是普通的静态网页。相应的内容是在浏览器加载过程中随着浏览器滚动条的滚动而加载的。
所以如果你只想简单地发送一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:selenium,我相信通常关注网络抓取的人对它很熟悉。
作者尝试搜索selenium+C#感兴趣的词,没想到selenium竟然是一个支持多语言的工具。百度自查的具体介绍,以下是百度百科介绍的简单截取。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
所以,不要犯错,犯一般错误,认为python很容易用于网页抓取,你可以使用C#中的常用工具。当前的工具不仅限于实现一种语言。我相信 dotNET 会变得更加开源。当生态越来越好时,会出现更多方便的工具。
在 C# 代码中,Seenium 用于控制浏览器行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们想要图形版本的数据,而不仅仅是一些结构化的数据,最简单的方法是将类似浏览器行为的CTRL+S作为网页保存到本地。也用代码来模拟发送键和击键的方式。有兴趣的读者可以参考以下代码。
网上同样的就是python的实现,作者简单的修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
private static void SaveHtml(ChromeDriver driver)
{
uint KEYEVENTF_KEYUP = 2;
keybd_event(Keys.ControlKey, 0, 0, 0);
keybd_event(Keys.S, 0, 0, 0);
keybd_event(Keys.ControlKey, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(3000);
keybd_event(Keys.Enter, 0, 0, 0);
keybd_event(Keys.Enter, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(5000);
driver.Close();
driver.Quit();
}
二、将多个网页保存为PDF
虽然WORD也可以用来打开网页,但估计WORD是用IE技术渲染网页的,很多功能无法恢复。所以直接转PDF更科学。
PDF 的另一个好处是几乎所有的 PDF 阅读器都可以随意打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的目的主要是为了阅读,所以将 HTML 转换为 PDF 是非常理想的。
它可以将多个网页转换为一个PDF文件,阅读时更加连贯。
网页转PDF的工具是wkhtmltopdf,也是一个命令行工具,可以多种语言调用。当然,dotNET 调用是没有问题的,但是为了更好的体验,还是应该在 PowerShell 上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都在下一步完成,最后记得设置环境变量,让CMD和PowerShell识别。
平时可以看到的python的html to pdf功能,其实底层也是用wkhtmltopdf完成的。
要将多个网页转换为PDF,需要考虑排序问题。这时候使用Excel催化剂可以轻松实现HTML排版顺序问题。
一般来说,我们是按顺序下载网页的,所以简单的使用Excel Catalyst的遍历文件功能来遍历文件信息,在Excel上做一个排序处理,手动调整一些特殊文件的顺序。
另一个自定义函数stringjoin可以快速将多个文件合并成一个字符串组合,用空格隔开,每条记录都要用双引号括起来。
打开我们的 PowerShell ISE 软件,它是 win10 自带的。其他系统也有,可以自行搜索相关教程打开。
相信很多读者也和作者有同感。他们觉得命令行很可怕。它是一系列代码,尤其是帮助文件。
事实上,它确实突破了心理恐惧。命令行工具和我们在Excel上写函数的原理都是一个函数名和各种参数,但是命令行可以有很多参数。
以下是我们如何在 PowerShell 上使用单个命令将多个 html 文件合并为一个 PDF 文件。
笔者还费了一番功夫阅读帮助文档,写出了更多命令的功能,比如添加页眉和页脚的功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,摊开多个html文件,最后加上pdf文件的名字,弄的太多了。该文件使用相对路径。您需要将PowerShell的当前路径切换到html存储文件夹。切换命令是 CD。
终于,激动人心的时刻到了,可以顺利生成pdf文件了。
包括页眉和页脚信息,一个总共400多页的PDF电子书诞生了。
有兴趣的读者不妨将自己喜欢的网页相册制作成PDF文件,方便查阅。之前的错误是追求PDF阅读器的精简,现在我重新使用【福昕阅读器】(感谢上一篇文章后读者朋友的推荐),旧的免费PDF阅读软件可以进行基于文本的PDF文件注释并记笔记。这里推荐大家使用。
同样,搜索关键词后,会出现一个关键词的列表。比如在学习DAX的过程中,如果想像参考书一样查找ALLSELECT函数的用法,可以搜索全文。这比使用搜索引擎查找要好得多。学习后,您还可以突出显示并做笔记。
结束语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。不用太羡慕python的网络爬虫。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境中,没有什么比 dotNET 开发更高效的了。再好的python,共享和交互也是一件头疼的事,但dotNET桌面开发自然是最大的优势。
在OFFICE环境下开发的优势就更详细了。其实本文的功能也可以移到Excel环境中无痛执行。以后有空再慢慢优化整个流程。
将 html 转换为 PDF 带来了极大的方便。该内容在互联网上,而不是您自己的数据,并且可能随时被删除和无法访问。压力下,肯定撑不了多久,所以我提前计划,先下载到本地,哈哈)。
抓取网页生成电子书(如何使用PDFsamBasic来从PDF文件中的简短指南 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-08 00:06
)
从 PDF 文件中提取页面。通过生成只收录您需要的页面的文件,您可以批量从单个或多个文件中提取页面。PDFsam Basic 是一款适用于 Windows、Mac 和 Linux 的免费开源软件。
下载 PDFsam Basic
确保您的 PDF 文件安全且私密。通过我们的应用程序,您无需将 PDF 文件上传到任何第三方服务,所有处理都在您的计算机本地进行,您的文件将保持安全和私密
关于如何使用 PDFsam Basic 从 PDF 文件中提取页面的简短指南
选择PDF文件
拖放要从中提取页面的 PDF 文件,或单击添加以添加文件。加密的 PDF 文件将在其左侧显示一个图标。单击锁定图标并填写解锁密码。
设置
设置要从所选 PDF 文件中提取的页面。您可以将它们设置为逗号分隔的数字或页面范围,例如:2,5,6-13,25.
目标文件夹
选择生成 PDF 文件的位置。
自定义文件的名称
输出文件的名称可以使用特殊关键字作为占位符,并在执行过程中使用动态值进行替换。例如,可以是 [File Number] 为文件名添加递增计数器值,或 [Time Stamp] 将当前时间戳添加到文件名。右键单击该字段以查找所有可用关键字。
如何自定义文件名
提取页面
正确设置所有选项后,单击运行开始执行。如果没有错误发生,进度条会一直增长直到完全着色,然后友好的叮当声会告诉你你的PDF文件已经准备好了。
查看全部
抓取网页生成电子书(如何使用PDFsamBasic来从PDF文件中的简短指南
)
从 PDF 文件中提取页面。通过生成只收录您需要的页面的文件,您可以批量从单个或多个文件中提取页面。PDFsam Basic 是一款适用于 Windows、Mac 和 Linux 的免费开源软件。
下载 PDFsam Basic
确保您的 PDF 文件安全且私密。通过我们的应用程序,您无需将 PDF 文件上传到任何第三方服务,所有处理都在您的计算机本地进行,您的文件将保持安全和私密
关于如何使用 PDFsam Basic 从 PDF 文件中提取页面的简短指南
选择PDF文件
拖放要从中提取页面的 PDF 文件,或单击添加以添加文件。加密的 PDF 文件将在其左侧显示一个图标。单击锁定图标并填写解锁密码。

设置
设置要从所选 PDF 文件中提取的页面。您可以将它们设置为逗号分隔的数字或页面范围,例如:2,5,6-13,25.

目标文件夹
选择生成 PDF 文件的位置。
自定义文件的名称
输出文件的名称可以使用特殊关键字作为占位符,并在执行过程中使用动态值进行替换。例如,可以是 [File Number] 为文件名添加递增计数器值,或 [Time Stamp] 将当前时间戳添加到文件名。右键单击该字段以查找所有可用关键字。
如何自定义文件名

提取页面
正确设置所有选项后,单击运行开始执行。如果没有错误发生,进度条会一直增长直到完全着色,然后友好的叮当声会告诉你你的PDF文件已经准备好了。

抓取网页生成电子书(使用python爬虫实现把《廖雪峰的Python教程》转换成PDF的方法和代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-07 03:27
本文与您分享使用Python crawler将廖雪峰的Python教程转换为PDF的方法和代码。如果你需要它,你可以参考它
似乎没有比使用python更好的方法来编写爬虫程序。python社区提供了许多让您眼花缭乱的爬虫工具。可以直接使用的各种库可以在几分钟内编写一个爬虫程序。今天,我想写一个爬虫程序,把廖雪峰的Python程序下载到PDF电子书中,供离线阅读
在编写爬虫程序之前,让我们首先分析网站1的页面结构。页面左侧是教程的目录大纲。每一个URL对应于右边的“@ K7@”,“@ K7@”的标题位于右上方,“@ K7@”的主体部分位于中间。正文内容是我们关注的焦点。我们想要爬升的数据是所有网页的主体部分,下面是用户的评论区。评论区对我们来说是无用的,所以我们可以忽略它
工具准备
一旦理解了网站的基本结构,就可以开始准备爬虫程序所依赖的工具包。请求和漂亮的汤是爬虫的两个工件。Reuqests用于网络请求,Beauty soup用于操作HTML数据。有了这两架航天飞机,我们可以快速工作。我们不需要像scratch这样的爬行动物框架。这有点像在小程序中用牛刀杀鸡。此外,由于它是将HTML文件转换为PDF,因此还需要相应的库支持。Wkhtmltopdf是一个非常好的工具。它可以将HTML转换为适合多平台的PDF。Pdfkit是wkhtmltopdf的python包。首先,安装以下依赖项包
接下来,安装wkhtmltopdfip安装请求
pip安装美化组
pip安装pdfkit
安装wkhtmltopdf
windows平台直接从wkhtmltopdf官方网站2下载稳定版本进行安装。安装完成后,将程序的执行路径添加到系统环境的$path变量中。否则,如果pdfkit找不到wkhtmltopdf,则会出现错误“找不到wkhtmltopdf可执行文件”。Ubuntu和CentOS可以直接从命令行$sudo apt get install wkhtmltopdf#Ubuntu安装
$sudo yum intsall wkhtmltopdf#centos
爬虫实现
当一切准备就绪时,您可以编写代码,但在编写代码之前,您应该先清理头脑。该程序的目的是在本地保存与所有URL对应的HTML正文,然后使用pdfkit将这些文件转换为PDF文件。让我们把任务分成两部分。首先,在本地保存与URL对应的HTML正文,然后查找所有URL以执行相同的操作
使用Chrome浏览器查找页面主体部分的标签,然后按F12查找与主体对应的p标签:
,这是网页的正文内容。在本地加载整个页面的请求后,可以使用Beauty soup操作HTML的DOM元素来提取正文内容
具体实现代码如下:use soup.find uuAll函数查找body标记并将body部分的内容保存到a.html文件中。def解析url到html(url):
response=requests.get(url)
soup=BeautifulSoup(response.content,“html5lib”)
body=soup.find uAll(class=“x-wiki-content”)[0]
html=str(正文)
以open(“a.html”,“wb”)作为f:
f、 编写(html)
第二步是解析页面左侧的所有URL。同样,找到左侧的菜单选项卡
具体代码实现了逻辑:页面上有两个类属性UK NAV UK NAV side,第二个是真实目录列表。所有URL都被获取,并且在第一步中还编写了URL到HTML的函数。def get_uuURL_uuu列表():
“”“
获取所有URL目录的列表
“”“
response=requests.get(“”)
soup=BeautifulSoup(response.content,“html5lib”)
menu_uTag=soup.find_uuAll(class=“uk nav uk nav side”)[1]
URL=[]
对于菜单中的li uTag.find uuAll(“li”): 查看全部
抓取网页生成电子书(使用python爬虫实现把《廖雪峰的Python教程》转换成PDF的方法和代码)
本文与您分享使用Python crawler将廖雪峰的Python教程转换为PDF的方法和代码。如果你需要它,你可以参考它
似乎没有比使用python更好的方法来编写爬虫程序。python社区提供了许多让您眼花缭乱的爬虫工具。可以直接使用的各种库可以在几分钟内编写一个爬虫程序。今天,我想写一个爬虫程序,把廖雪峰的Python程序下载到PDF电子书中,供离线阅读
在编写爬虫程序之前,让我们首先分析网站1的页面结构。页面左侧是教程的目录大纲。每一个URL对应于右边的“@ K7@”,“@ K7@”的标题位于右上方,“@ K7@”的主体部分位于中间。正文内容是我们关注的焦点。我们想要爬升的数据是所有网页的主体部分,下面是用户的评论区。评论区对我们来说是无用的,所以我们可以忽略它
工具准备
一旦理解了网站的基本结构,就可以开始准备爬虫程序所依赖的工具包。请求和漂亮的汤是爬虫的两个工件。Reuqests用于网络请求,Beauty soup用于操作HTML数据。有了这两架航天飞机,我们可以快速工作。我们不需要像scratch这样的爬行动物框架。这有点像在小程序中用牛刀杀鸡。此外,由于它是将HTML文件转换为PDF,因此还需要相应的库支持。Wkhtmltopdf是一个非常好的工具。它可以将HTML转换为适合多平台的PDF。Pdfkit是wkhtmltopdf的python包。首先,安装以下依赖项包
接下来,安装wkhtmltopdfip安装请求
pip安装美化组
pip安装pdfkit
安装wkhtmltopdf
windows平台直接从wkhtmltopdf官方网站2下载稳定版本进行安装。安装完成后,将程序的执行路径添加到系统环境的$path变量中。否则,如果pdfkit找不到wkhtmltopdf,则会出现错误“找不到wkhtmltopdf可执行文件”。Ubuntu和CentOS可以直接从命令行$sudo apt get install wkhtmltopdf#Ubuntu安装
$sudo yum intsall wkhtmltopdf#centos
爬虫实现
当一切准备就绪时,您可以编写代码,但在编写代码之前,您应该先清理头脑。该程序的目的是在本地保存与所有URL对应的HTML正文,然后使用pdfkit将这些文件转换为PDF文件。让我们把任务分成两部分。首先,在本地保存与URL对应的HTML正文,然后查找所有URL以执行相同的操作
使用Chrome浏览器查找页面主体部分的标签,然后按F12查找与主体对应的p标签:
,这是网页的正文内容。在本地加载整个页面的请求后,可以使用Beauty soup操作HTML的DOM元素来提取正文内容
具体实现代码如下:use soup.find uuAll函数查找body标记并将body部分的内容保存到a.html文件中。def解析url到html(url):
response=requests.get(url)
soup=BeautifulSoup(response.content,“html5lib”)
body=soup.find uAll(class=“x-wiki-content”)[0]
html=str(正文)
以open(“a.html”,“wb”)作为f:
f、 编写(html)
第二步是解析页面左侧的所有URL。同样,找到左侧的菜单选项卡
具体代码实现了逻辑:页面上有两个类属性UK NAV UK NAV side,第二个是真实目录列表。所有URL都被获取,并且在第一步中还编写了URL到HTML的函数。def get_uuURL_uuu列表():
“”“
获取所有URL目录的列表
“”“
response=requests.get(“”)
soup=BeautifulSoup(response.content,“html5lib”)
menu_uTag=soup.find_uuAll(class=“uk nav uk nav side”)[1]
URL=[]
对于菜单中的li uTag.find uuAll(“li”):
抓取网页生成电子书(如何将网页上显示的内容导出为pdf文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-10-06 20:01
我们都知道一个普通的网页是由html+css+js组成的,它的本质是由一段代码编译而成的。图片是由一堆二进制数据组成的,我们如何将网页显示的内容导出为我们想要的图片或者pdf呢?博主很无聊,在github上闲逛,发现了一个有趣的库pyppeteer,满足了我需要的导出需求。接下来,我们来看看它是如何运作的:
安装所需的库
pip install pillow
pip install reportlab
pip install pyppeteer
导出为图片
import os
import asyncio
from pyppeteer import launch
async def save_image(url, img_path):
"""
导出图片
:param url: 在线网页的url
:param img_path: 图片存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
await page.screenshot({'path': img_path, 'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
img_path = os.path.join(os.getcwd(), "example.png")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_image(url, img_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.png的文件,就是我们导出的图片文件!
将整个页面导出为pdf
import os
import asyncio
from pyppeteer import launch
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
width: 纸张宽度,带单位的字符串
height: 纸张高度,带单位的字符串
'''
await page.pdf({'path': pdf_path, 'width': '730px', 'height': '2600px'})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.pdf的文件,就是我们导出的pdf文件!但是,这种出口有一个缺点。它将整个网页导出为 pdf。不支持图片等位置参数。可以截取部分区域进行导出!因此,我稍微修改了代码,请参阅下面的“将区域导出为pdf”!
将区域导出为 pdf
import os
import asyncio
from io import BytesIO
from PIL import Image
from pyppeteer import launch
from reportlab.pdfgen.canvas import Canvas
from reportlab.lib.utils import ImageReader
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
img_data = await page.screenshot({'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
im = Image.open(BytesIO(img_data))
page_width, page_height = im.size
c = Canvas(pdf_path, pagesize=(page_width, page_height))
c.drawImage(ImageReader(im), 0, 0)
c.save()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
这样我们就可以进行区域截取,导出pdf文件了!
值得注意的是,由于网络、配置以及各种不可控因素,上述方法都会有一定程度的导出错误,所以建议添加重试机制!
更多pyppeteer操作请看:
从此,结束了~~~ 查看全部
抓取网页生成电子书(如何将网页上显示的内容导出为pdf文件?)
我们都知道一个普通的网页是由html+css+js组成的,它的本质是由一段代码编译而成的。图片是由一堆二进制数据组成的,我们如何将网页显示的内容导出为我们想要的图片或者pdf呢?博主很无聊,在github上闲逛,发现了一个有趣的库pyppeteer,满足了我需要的导出需求。接下来,我们来看看它是如何运作的:
安装所需的库
pip install pillow
pip install reportlab
pip install pyppeteer
导出为图片
import os
import asyncio
from pyppeteer import launch
async def save_image(url, img_path):
"""
导出图片
:param url: 在线网页的url
:param img_path: 图片存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
await page.screenshot({'path': img_path, 'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
img_path = os.path.join(os.getcwd(), "example.png")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_image(url, img_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.png的文件,就是我们导出的图片文件!
将整个页面导出为pdf
import os
import asyncio
from pyppeteer import launch
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
width: 纸张宽度,带单位的字符串
height: 纸张高度,带单位的字符串
'''
await page.pdf({'path': pdf_path, 'width': '730px', 'height': '2600px'})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.pdf的文件,就是我们导出的pdf文件!但是,这种出口有一个缺点。它将整个网页导出为 pdf。不支持图片等位置参数。可以截取部分区域进行导出!因此,我稍微修改了代码,请参阅下面的“将区域导出为pdf”!
将区域导出为 pdf
import os
import asyncio
from io import BytesIO
from PIL import Image
from pyppeteer import launch
from reportlab.pdfgen.canvas import Canvas
from reportlab.lib.utils import ImageReader
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
img_data = await page.screenshot({'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
im = Image.open(BytesIO(img_data))
page_width, page_height = im.size
c = Canvas(pdf_path, pagesize=(page_width, page_height))
c.drawImage(ImageReader(im), 0, 0)
c.save()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
这样我们就可以进行区域截取,导出pdf文件了!
值得注意的是,由于网络、配置以及各种不可控因素,上述方法都会有一定程度的导出错误,所以建议添加重试机制!
更多pyppeteer操作请看:
从此,结束了~~~
抓取网页生成电子书( 之前配置生成器:强大!Nginx配置在线一键生成“神器” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-06 19:34
之前配置生成器:强大!Nginx配置在线一键生成“神器”
)
之前农民工也给大家介绍过一个Nginx配置生成器:强大!Nginx配置在线一键生成“神器”,不太了解的可以去看看。
最近农民工发现了一个好用的网页版开源工具,它的功能也是Nginx配置生成器,非常强大,方便实用。它是:NginxWebUI。
NginxWebUI 介绍
NginxWebUI 是一个方便实用的 nginx web 配置工具。可以使用WebUI配置Nginx的各种功能,包括端口转发、反向代理、ssl证书配置、负载均衡等,最后生成“nginx.conf”配置文件并覆盖目标配置文件,完成Nginx的功能配置nginx。
项目地址:
官方 网站:
<p>NginxWebUI 功能说明 NginxWebUI 有两种安装方式安装: 查看全部
抓取网页生成电子书(
之前配置生成器:强大!Nginx配置在线一键生成“神器”
)

之前农民工也给大家介绍过一个Nginx配置生成器:强大!Nginx配置在线一键生成“神器”,不太了解的可以去看看。
最近农民工发现了一个好用的网页版开源工具,它的功能也是Nginx配置生成器,非常强大,方便实用。它是:NginxWebUI。
NginxWebUI 介绍
NginxWebUI 是一个方便实用的 nginx web 配置工具。可以使用WebUI配置Nginx的各种功能,包括端口转发、反向代理、ssl证书配置、负载均衡等,最后生成“nginx.conf”配置文件并覆盖目标配置文件,完成Nginx的功能配置nginx。
项目地址:
官方 网站:
<p>NginxWebUI 功能说明 NginxWebUI 有两种安装方式安装:
抓取网页生成电子书(之前备份专家配合Firefox+插件Firebug批量下载博客文章豆约翰博客专家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-05 10:09
博客批量下载制作电子书方法1 前言
相信很多朋友都知道“左岸阅读”这个博客,作者采集了很多优秀的文章。大概在年初接触到这个网站,非常非常喜欢。文章 非常符合我的口味。因为不喜欢在网络上浏览文章,所以一般做成电子书后在kindle或手机上阅读。这样记笔记非常方便,便于复习和采集。以前用kindle的push和calibre的新闻抓取功能制作电子书非常方便。唯一的缺点就是只能抓取最新发布的文章,之前的老文章无法抓取。. 于是,我充分发挥了爱折腾的本能,经过多日的摸索,总结,并参考了很多以前的经验,我终于成功了。方法比较复杂,折腾起来很累,在这里,分享给有需要的朋友。
2 需要准备的软件
1)doujohn博客备份专家V2.6
2)Firefox+插件Firebug
3)epubBuilder 绿色版
需要说明的是,epubBuilder 不是免费软件,但是绿色版可以在网上下载,完全可以使用。
3 具体步骤3.1 使用豆约翰博客备份专家配合火狐+插件Firebug批量下载博客文章
Doujohn博客备份专家是一款完全免费、功能强大的博客备份工具、博客电子书(PDF、CHM和TXT)生成工具、博客文章离线浏览工具、漂亮的软件界面、支持多个主流博客网站(Qzone ,百度空间,新浪博客,网易博客,豆瓣日记,天涯博客,19楼,博客园,和讯博客,CSDN博客,搜狐博客,51CTO博客)。
但最重要的是该软件支持从独立站点爬取博客。《左岸阅读》是一个独立站点,但是配置起来确实有点麻烦。这个配置过程花了我很多时间,我什至想放弃。
关于独立站点的配置,官网上有详细的介绍,这里不再赘述,直接贴出网址:
《左岸阅读》文章数量庞大,每月可排序。我以2013年1月的文章下载为例,贴出配置,如图。
配置完成后,点击“开始下载”即可批量下载博客。理论上,根据软件说明,需要评估推广软件下载所有页面(本例中为起始页1到结束页3),但经过笔者的实验发现,即使是评测不能批量下载,第一次只能在一个页面下载所有文章,上图配置下,只能下载第1页文章,不过没关系。反正只有3页,反正一页一页下载就完了可以下载文章的第二页,然后修改为3,
3.2 将下载的文章制作成chm文件
Doujohn的博客备份专家可以将下载的文章制作成文件,格式可以是pdf、chm、txt等。作者最初使用的是pdf格式,但发现在转换的过程中会出现换行到电子书。尝试了各种方法后都没有解决,只能以chm格式保存。
3.3 将保存的chm文件制作成epub电子书
epubBuilder是口袋书园开发的一款epub电子书制作神器,支持导入Txt、epub、html、chm、snb等源文件。
<p>打开软件,导入上面制作的chm。看完你会发现下面的文章会少了一个标题,没关系,工具选项卡里有个“使用第一行作为目录名”,在左边选择边目录栏批量丢失目录(shift+左键点击),点击“使用第一行作为目录名”,软件会自动将每个文章的第一行作为 查看全部
抓取网页生成电子书(之前备份专家配合Firefox+插件Firebug批量下载博客文章豆约翰博客专家)
博客批量下载制作电子书方法1 前言
相信很多朋友都知道“左岸阅读”这个博客,作者采集了很多优秀的文章。大概在年初接触到这个网站,非常非常喜欢。文章 非常符合我的口味。因为不喜欢在网络上浏览文章,所以一般做成电子书后在kindle或手机上阅读。这样记笔记非常方便,便于复习和采集。以前用kindle的push和calibre的新闻抓取功能制作电子书非常方便。唯一的缺点就是只能抓取最新发布的文章,之前的老文章无法抓取。. 于是,我充分发挥了爱折腾的本能,经过多日的摸索,总结,并参考了很多以前的经验,我终于成功了。方法比较复杂,折腾起来很累,在这里,分享给有需要的朋友。
2 需要准备的软件
1)doujohn博客备份专家V2.6
2)Firefox+插件Firebug
3)epubBuilder 绿色版
需要说明的是,epubBuilder 不是免费软件,但是绿色版可以在网上下载,完全可以使用。
3 具体步骤3.1 使用豆约翰博客备份专家配合火狐+插件Firebug批量下载博客文章
Doujohn博客备份专家是一款完全免费、功能强大的博客备份工具、博客电子书(PDF、CHM和TXT)生成工具、博客文章离线浏览工具、漂亮的软件界面、支持多个主流博客网站(Qzone ,百度空间,新浪博客,网易博客,豆瓣日记,天涯博客,19楼,博客园,和讯博客,CSDN博客,搜狐博客,51CTO博客)。
但最重要的是该软件支持从独立站点爬取博客。《左岸阅读》是一个独立站点,但是配置起来确实有点麻烦。这个配置过程花了我很多时间,我什至想放弃。
关于独立站点的配置,官网上有详细的介绍,这里不再赘述,直接贴出网址:
《左岸阅读》文章数量庞大,每月可排序。我以2013年1月的文章下载为例,贴出配置,如图。
配置完成后,点击“开始下载”即可批量下载博客。理论上,根据软件说明,需要评估推广软件下载所有页面(本例中为起始页1到结束页3),但经过笔者的实验发现,即使是评测不能批量下载,第一次只能在一个页面下载所有文章,上图配置下,只能下载第1页文章,不过没关系。反正只有3页,反正一页一页下载就完了可以下载文章的第二页,然后修改为3,
3.2 将下载的文章制作成chm文件
Doujohn的博客备份专家可以将下载的文章制作成文件,格式可以是pdf、chm、txt等。作者最初使用的是pdf格式,但发现在转换的过程中会出现换行到电子书。尝试了各种方法后都没有解决,只能以chm格式保存。
3.3 将保存的chm文件制作成epub电子书
epubBuilder是口袋书园开发的一款epub电子书制作神器,支持导入Txt、epub、html、chm、snb等源文件。
<p>打开软件,导入上面制作的chm。看完你会发现下面的文章会少了一个标题,没关系,工具选项卡里有个“使用第一行作为目录名”,在左边选择边目录栏批量丢失目录(shift+左键点击),点击“使用第一行作为目录名”,软件会自动将每个文章的第一行作为
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-05 10:05
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(没有发生过),但你可以通过将关注的专栏导出到电子书来准备下雨天,这样你就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
抢列文章地址列表
抓取每篇文章的详细内容文章
导出 PDF
1. 获取列表
在之前的文章
爬虫必备工具,掌握它就解决一半问题
如何分析一个网页上的请求在里面有描述。 根据方法,我们可以使用开发者工具的Network功能找出栏目页面的请求来获取详细列表:
观察返回的结果,我们发现通过sum的值,可以获取到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否已经获取到所有的文章。
而中间就是我们需要的数据。因为可以拼写,所以没有保存在我们的代码中。
使用 while 循环直到 文章 的所有总和都被捕获并保存在一个文件中。
2. 抢 文章
有了文章的所有/,后面的爬取就很简单了。文章主要内容在标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加标签和属性之类的,我们要去掉才能正常显示。
至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf+pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
使用非常简单:
这样就完成了整列的导出。
不仅是知乎的栏目,几乎大部分的信息类型都是网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录后访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
更多视频课程、问答群等服务,请按号码内回复码操作 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(没有发生过),但你可以通过将关注的专栏导出到电子书来准备下雨天,这样你就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
抢列文章地址列表
抓取每篇文章的详细内容文章
导出 PDF
1. 获取列表
在之前的文章
爬虫必备工具,掌握它就解决一半问题
如何分析一个网页上的请求在里面有描述。 根据方法,我们可以使用开发者工具的Network功能找出栏目页面的请求来获取详细列表:
观察返回的结果,我们发现通过sum的值,可以获取到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否已经获取到所有的文章。
而中间就是我们需要的数据。因为可以拼写,所以没有保存在我们的代码中。
使用 while 循环直到 文章 的所有总和都被捕获并保存在一个文件中。
2. 抢 文章
有了文章的所有/,后面的爬取就很简单了。文章主要内容在标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加标签和属性之类的,我们要去掉才能正常显示。
至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf+pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
使用非常简单:
这样就完成了整列的导出。
不仅是知乎的栏目,几乎大部分的信息类型都是网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录后访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
更多视频课程、问答群等服务,请按号码内回复码操作
抓取网页生成电子书( 《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-04 17:20
《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据
)
使用 Scrapy 抓取电子书
爬虫的想法
如何抓取数据,首先我们要看看从哪里获取,打开“修真小主播”页面,如下:
有一个目录选项卡。单击此选项卡可查看目录。使用浏览器的元素查看工具,我们可以定位到各章节的目录和相关信息。根据这些信息,我们可以抓取到特定页面:
获取章节地址
现在我们打开xzxzb.py文件,就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['http://qidian.com/'] def parse(self, response): pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在我们来编写代码处理目录数据,首先爬取小说首页获取目录列表:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract() print url pass
获取网页中的 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML xPath 查询。
这里我们使用 xPath。请自行研究相关知识。看上面的代码。首先我们通过ID获取目录框,获取类cf来获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:<br /> url = page.xpath('./child::a/attribute::href').extract()<br /> print url
这样,可以说是爬取章节路径的小爬虫写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候,我们的程序可能会出现以下错误:
…<br />ImportError: No module named win32api<br />…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']> ...
爬取章节路径的小爬虫是写出来的,但是我们的目的不止这些,我们会用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面。从章节页面我们需要获取标题和内容。
如果解析器方法用于章节信息爬取,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出这些内容:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['https://book.qidian.com/info/1010780117/'] def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) yield response.follow(url, callback=self.parse_chapter) pass def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() print title # print content pass
上一步我们得到了一个章节地址,它是输出内容的相对路径,所以我们使用yield response.follow(url, callback=self.parse_chapter),第二个参数是处理章节的回调函数页面,爬到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)<br />yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意 response.follow 直接返回一个Request实例,可以通过yield直接返回。
获取数据后,进行存储。由于我们想要的是一个html页面,我们可以通过标题来存储它。代码如下:
def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s.html' % (title) with open(filename, 'wb') as f: f.write(content.encode('utf-8')) pass
至此,我们已经成功抓取了我们的数据,但是还不能直接使用,需要进行排序和优化。
数据整理
首先,我们爬下来的章节页面的排序不是很好。如果人工分拣花费太多时间和精力;另外,章节内容收录很多额外的东西,阅读体验不好,需要优化内容布局和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以我们只需要在下载页面名称中加上一个序号即可。
但是保存网页的代码是回调函数,只有在处理目录时才能确定顺序。回调函数如何知道订单?因此,我们需要告诉回调函数处理章节的序号,并且需要向回调函数传递参数。修改后的代码如下所示:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() idx = page.xpath('./attribute::data-rid').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) req = response.follow(url, callback=self.parse_chapter) req.meta['idx'] = idx yield req pass def parse_chapter(self, response): idx = response.meta['idx'] title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s_%s.html' % (idx, title) cnt = '
%s %s'% (title, content) with open(filename,'wb') as f: f.write(cnt.encode('utf-8')) pass
使用 Sigil 制作电子书
加载 html 文件
要制作ePub电子书,我们首先通过Sigil将我们抓取到的文件加载到程序中,在添加文件对话框中,我们选择所有文件:
制作目录
当文件中存在HTML的h标签时,点击Generate Catalog按钮自动生成目录。我们已经在之前的数据捕获中自动添加了 h1 标签:
做封面
封面本质上是HTML,可以从页面中编辑或抓取,所以就交给你自己实现吧。
*免责声明:本文整理于网络,版权归原作者所有。如来源信息有误或侵权,请联系我们进行删除或授权。
我觉得不错,点击“我在看”转发
查看全部
抓取网页生成电子书(
《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据
)

使用 Scrapy 抓取电子书
爬虫的想法
如何抓取数据,首先我们要看看从哪里获取,打开“修真小主播”页面,如下:
有一个目录选项卡。单击此选项卡可查看目录。使用浏览器的元素查看工具,我们可以定位到各章节的目录和相关信息。根据这些信息,我们可以抓取到特定页面:
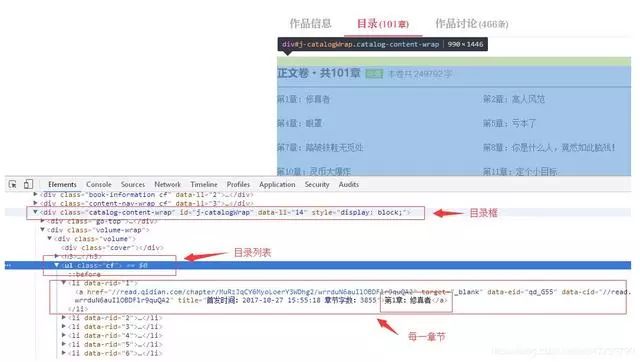
获取章节地址
现在我们打开xzxzb.py文件,就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['http://qidian.com/'] def parse(self, response): pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在我们来编写代码处理目录数据,首先爬取小说首页获取目录列表:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract() print url pass
获取网页中的 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML xPath 查询。
这里我们使用 xPath。请自行研究相关知识。看上面的代码。首先我们通过ID获取目录框,获取类cf来获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:<br /> url = page.xpath('./child::a/attribute::href').extract()<br /> print url
这样,可以说是爬取章节路径的小爬虫写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候,我们的程序可能会出现以下错误:
…<br />ImportError: No module named win32api<br />…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']> ...
爬取章节路径的小爬虫是写出来的,但是我们的目的不止这些,我们会用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面。从章节页面我们需要获取标题和内容。
如果解析器方法用于章节信息爬取,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
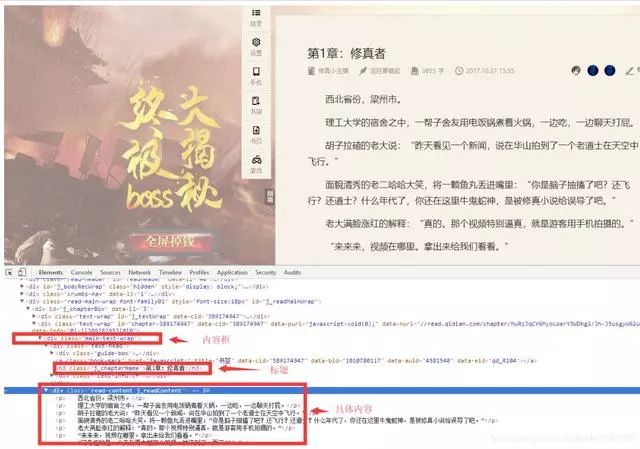
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出这些内容:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['https://book.qidian.com/info/1010780117/'] def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) yield response.follow(url, callback=self.parse_chapter) pass def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() print title # print content pass
上一步我们得到了一个章节地址,它是输出内容的相对路径,所以我们使用yield response.follow(url, callback=self.parse_chapter),第二个参数是处理章节的回调函数页面,爬到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)<br />yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意 response.follow 直接返回一个Request实例,可以通过yield直接返回。
获取数据后,进行存储。由于我们想要的是一个html页面,我们可以通过标题来存储它。代码如下:
def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s.html' % (title) with open(filename, 'wb') as f: f.write(content.encode('utf-8')) pass
至此,我们已经成功抓取了我们的数据,但是还不能直接使用,需要进行排序和优化。
数据整理
首先,我们爬下来的章节页面的排序不是很好。如果人工分拣花费太多时间和精力;另外,章节内容收录很多额外的东西,阅读体验不好,需要优化内容布局和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以我们只需要在下载页面名称中加上一个序号即可。
但是保存网页的代码是回调函数,只有在处理目录时才能确定顺序。回调函数如何知道订单?因此,我们需要告诉回调函数处理章节的序号,并且需要向回调函数传递参数。修改后的代码如下所示:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() idx = page.xpath('./attribute::data-rid').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) req = response.follow(url, callback=self.parse_chapter) req.meta['idx'] = idx yield req pass def parse_chapter(self, response): idx = response.meta['idx'] title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s_%s.html' % (idx, title) cnt = '
%s %s'% (title, content) with open(filename,'wb') as f: f.write(cnt.encode('utf-8')) pass
使用 Sigil 制作电子书
加载 html 文件
要制作ePub电子书,我们首先通过Sigil将我们抓取到的文件加载到程序中,在添加文件对话框中,我们选择所有文件:
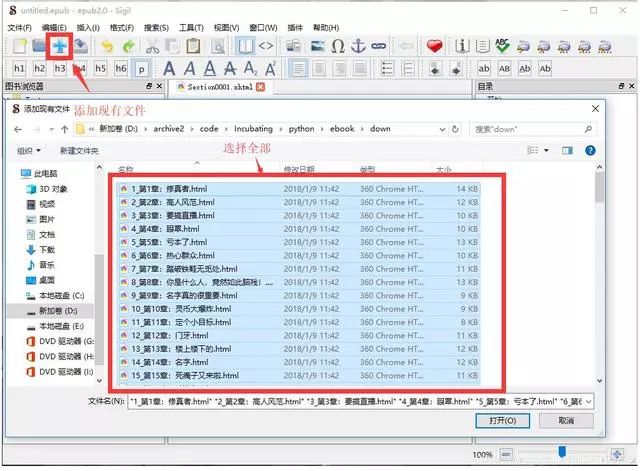
制作目录
当文件中存在HTML的h标签时,点击Generate Catalog按钮自动生成目录。我们已经在之前的数据捕获中自动添加了 h1 标签:
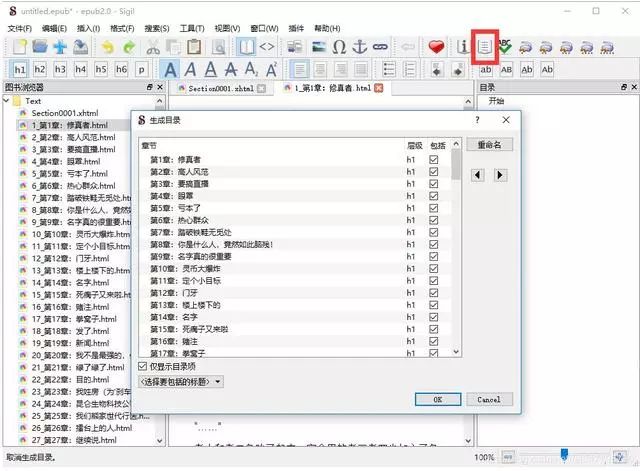
做封面
封面本质上是HTML,可以从页面中编辑或抓取,所以就交给你自己实现吧。
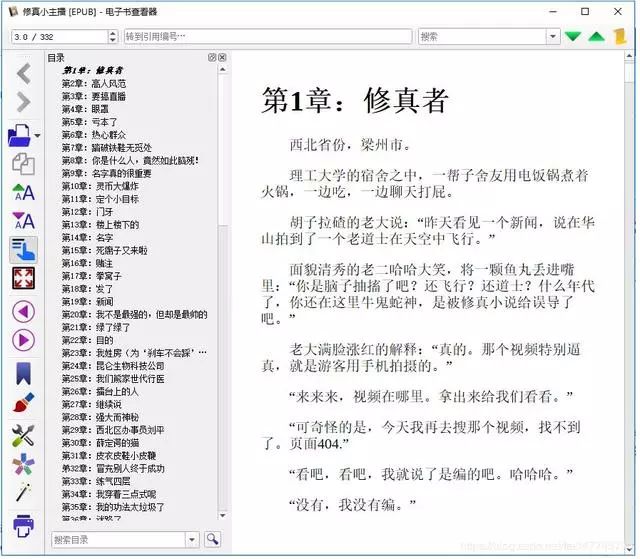
*免责声明:本文整理于网络,版权归原作者所有。如来源信息有误或侵权,请联系我们进行删除或授权。
我觉得不错,点击“我在看”转发

抓取网页生成电子书(Windows,OSX及Linux操作系统格式的在线资料格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-16 13:30
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多有趣的内容以网页的形式出现。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre<br />
Debian/Ubuntu:
apt-get install calibre<br />
红帽/Fedora/CentOS:
yum -y install calibre<br />
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面一般是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe<br /><br />class Git_Pocket_Guide(BasicNewsRecipe):<br /><br /> title = 'Git Pocket Guide'<br /> description = ''<br /> cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br /> url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr /> no_stylesheets = True<br /> keep_only_tags = [{ 'class': 'chapter' }]<br /><br /> def get_title(self, link):<br /> return link.contents[0].strip()<br /><br /> def parse_index(self):<br /> soup = self.index_to_soup(self.url_prefix + 'index.html')<br /><br /> div = soup.find('div', { 'class': 'toc' })<br /><br /> articles = []<br /> for link in div.findAll('a'):<br /> if '#' in link['href']:<br /> continue<br /><br /> if not 'ch' in link['href']:<br /> continue<br /><br /> til = self.get_title(link)<br /> url = self.url_prefix + link['href']<br /> a = { 'title': til, 'url': url }<br /><br /> articles.append(a)<br /><br /> ans = [('Git_Pocket_Guide', articles)]<br /><br /> return ans<br />
下面解释了代码的不同部分。
整体结构
一般来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'<br />description = ''<br />cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br />url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr />no_stylesheets = True<br />keep_only_tags = [{ 'class': 'chapter' }]<br />
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
ebook-convert Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi<br />
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
带图片的页面
实际效果
我的食谱仓库
我在github上做了一个kindle-open-books,里面有一些菜谱,是我自己写的,其他同学贡献的。欢迎任何人提供食谱。 查看全部
抓取网页生成电子书(Windows,OSX及Linux操作系统格式的在线资料格式)
自从我买了kindle,我就一直在想如何最大限度地发挥它的功效。虽然可供购买的书籍很多,网上也有很多免费的电子书,但还是有很多有趣的内容以网页的形式出现。例如,O'Reilly Atlas 提供了很多电子书,但只提供免费在线阅读;此外,许多材料或文件只是网络形式。所以我希望将这些网上资料以某种方式转换成epub或者mobi格式,以便在kindle上阅读。本文文章介绍了如何使用calibre并编写少量代码来实现这一目标。
Calibre 简介
Calibre 是一款免费的电子书管理工具,兼容 Windows、OS X 和 Linux。令人欣慰的是,除了GUI,calibre 还提供了很多命令行工具。ebook-convert 命令可以基于用户编写的食谱。该文件(实际上是python代码)抓取指定页面的内容,生成mobi等格式的电子书。爬取行为可以通过编写recipe来定制,以适应不同的网页结构。
安装口径
Calibre的下载地址是,您可以根据自己的操作系统下载相应的安装程序。
如果是Linux操作系统,也可以通过软件仓库安装:
Archlinux:
pacman -S calibre<br />
Debian/Ubuntu:
apt-get install calibre<br />
红帽/Fedora/CentOS:
yum -y install calibre<br />
请注意,如果您使用 OSX,则需要单独安装命令行工具。
抓取网页以生成电子书
下面以Git Pocket Guide为例,说明如何通过calibre从网页生成电子书。
找到索引页
要爬取整本书,首先要找到索引页。这个页面一般是目录,也就是目录页面,其中每个目录链接都连接到相应的内容页面。在生成电子书时,索引页会指导抓取哪些页面以及内容组织的顺序。在这个例子中,索引页是。
写食谱
食谱是一个带有食谱扩展名的脚本。内容其实是一段python代码,定义了calibre爬取页面的范围和行为。以下是爬取 Git Pocket Guide 的秘籍:
from calibre.web.feeds.recipes import BasicNewsRecipe<br /><br />class Git_Pocket_Guide(BasicNewsRecipe):<br /><br /> title = 'Git Pocket Guide'<br /> description = ''<br /> cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br /> url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr /> no_stylesheets = True<br /> keep_only_tags = [{ 'class': 'chapter' }]<br /><br /> def get_title(self, link):<br /> return link.contents[0].strip()<br /><br /> def parse_index(self):<br /> soup = self.index_to_soup(self.url_prefix + 'index.html')<br /><br /> div = soup.find('div', { 'class': 'toc' })<br /><br /> articles = []<br /> for link in div.findAll('a'):<br /> if '#' in link['href']:<br /> continue<br /><br /> if not 'ch' in link['href']:<br /> continue<br /><br /> til = self.get_title(link)<br /> url = self.url_prefix + link['href']<br /> a = { 'title': til, 'url': url }<br /><br /> articles.append(a)<br /><br /> ans = [('Git_Pocket_Guide', articles)]<br /><br /> return ans<br />
下面解释了代码的不同部分。
整体结构
一般来说,一个recipe是一个python类,但是这个类必须继承calibre.web.feeds.recipes.BasicNewsRecipe。
解析索引
整个recipe的核心方法是parse_index,这也是recipes必须实现的唯一方法。该方法的目标是通过分析索引页的内容,返回一个稍微复杂一些的数据结构(稍后介绍)。这个数据结构定义了整个电子书的内容和内容组织顺序。
整体属性设置
在类的开头,定义了一些全局属性:
title = 'Git Pocket Guide'<br />description = ''<br />cover_url = 'http://akamaicovers.oreilly.co ... %3Bbr /><br />url_prefix = 'http://chimera.labs.oreilly.co ... %3Bbr />no_stylesheets = True<br />keep_only_tags = [{ 'class': 'chapter' }]<br />
parse_index 返回值
下面通过分析索引页来描述parse_index需要返回的数据结构。
整体的返回数据结构是一个列表,其中每个元素是一个元组,一个元组代表一个卷。在这个例子中,只有一个卷,所以列表中只有一个元组。
每个元组有两个元素,第一个元素是卷名,第二个元素是一个列表,列表中的每个元素都是一个映射,表示一个章节(chapter),映射中有两个元素: title 和 url , Title是章节的标题,url是章节所在的内容页面的url。
Calibre 会根据parse_index 返回的结果对整本书进行爬取和组织,并会自行爬取处理内容内外的图片。
整个parse_index使用soup解析索引页,生成上述数据结构。
更多的
以上是最基本的食谱。如果想详细了解如何使用,可以参考API文档。
生成手机
写好菜谱后,可以在命令行中使用以下命令生成电子书:
ebook-convert Git_Pocket_Guide.recipe Git_Pocket_Guide.mobi<br />
您可以生成mobi 格式的电子书。ebook-convert 会爬取相关内容,根据配方代码自行组织结构。
最终效果
下面是在kindle上看到的效果。
内容
内容一
内容二
带图片的页面
实际效果
我的食谱仓库
我在github上做了一个kindle-open-books,里面有一些菜谱,是我自己写的,其他同学贡献的。欢迎任何人提供食谱。
抓取网页生成电子书(只要能显示在网页上的东西都可以抓下来。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-15 11:08
)
最近,我迷上了德州扑克。我的同学H是这次活动的领队(tuifei)。我们同学不仅PK了,还给我发了截图,WC,你也买了书,你也进了群,你快上天堂了。. .
晚上11点30分,我用我的房门打开他房间的门,他果然在床上。
H,有资源吗?
不是,X宝上贴的和我下载的一样,只有44页,前十页是广告。
哎,无良商家,退款?
不,只有1.00元,她又给了我一本书。
来看看澳门赌场上线的感觉吧。
回去jd上找,电子版18元,纸质版什么的。没有微信阅读。
第二天,我在实验室遇到了H。还有其他资源吗?
恩,网易阅读上有,我付费了。
第一次听说网易读书,周末在他的实验室度过。
神奇的是网易云阅读器可以在网页上打开查看。
有这样的操作吗??
我发现了一些东西,
WC,网易太甜了!
太甜了,我也想为此把文字记下来。
换句话说,只要能在网页上显示,就可以被捕获。
一、创意的产生
要么使用现成的工具,比如优采云,来抓取网络上的数据,但使用这个工具显然是一个失学的人。要么使用开源框架,然后在知乎上有一个非常流行的“爬虫”。玩爬虫的人很多,请自己知乎。用的比较多的框架有scrapy、pyspider等,前者比较低级,搞这个工作的人玩这个比较专业。后者非常适合新手玩,带有WEUI,网页上的可视化操作,非常方便。这篇文章懒得用pyspider。
二、设置环境
这部分我其实是一年前做的,不过当时我用的是windows平台。现在再看pyspider的官网,发现windows的缺点很多,而且pyspider的开发也是在linux平台上进行的。所以即使我是新手,也得在linux上使用环境。(pyspider 文档在这里)
对于Linux发行版的选择,官网列出了几个,centos(我的VPS上用的那个),ubuntu等。考虑到用浏览器,可能需要带桌面的linux系统。于是我在我的windows10上的vbox上安装了centos,后来发现安装桌面环境真的太慢了。突然发现自己太傻了。真的,我安装了一个Kali系统(我前段时间学会了安装)。Kali是基于Debian的发行版,ubuntu也是基于Debian的,所以使用kali应该没有问题。
参考pyspider帮助,pyspider中文网站
首先安装pyspider
apt-get 安装 pyspider
然后安装phantomjs
apt-get 安装 phantomjs
是不是很简单。Phantomjs 是一个无界面浏览器,用于完全模拟用户在浏览器上的操作,用于处理比较麻烦的问题,比如运行js、异步加载网页、响应网站反爬策略。另外,这款浏览器比IE、Chrome、Firefox等界面浏览器要快很多,详情请参考/。
安装成功后,在终端输入pyspider
提示phantomjs fetcher运行在25555端口,这个其实是pyspider用phantomjs运行的,所以在加载AJAX页面的时候很有用。
三、分析页面
打开某章的阅读页面,如《副王:秋雨传》-老秋-电子书-在线阅读-网易云阅读,打开调试工具Firebug。
选择net标签,这样在打开网页的时候就可以看到页面加载的过程。
一个阅读页面需要这么多资源!其实还有很多东西是不需要关心的,把tab切换成HTML,
其实请求只有两个,第一个在域名下,第二个在下。可以假设第二个与此页面的内容几乎没有相关性,可以用于统计目的。查看第一个请求
具体不说了,反正回复里没有章节内容。
那么章节内容在哪里呢?
将选项卡切换到 XHR,
收录 4 个异步请求。从 URL 和接收数据的时间(时间轴上的绿色部分),可以猜测最后一个是获取章节内容的请求。其实就是一一点击查看接收到的数据。可以看到上次请求返回的数据是一个json数据。
很明显,json的一个字段就是content,这很可能就是我们想要的。但是这个字符串要编码,常规套路是base64编码,因为不是敏感数据。试试看,打开浏览器的hack栏,把内容复制进去,在Encoding里面选择Base64Decode
结果是
你看到了什么?乱七八糟的胡言乱语。
不完全是,有
人物。这说明content的内容确实是base64编码的,但是汉字的解码有问题。
这时候使用pyspider的返回数据的json方法提取json数据,然后尝试解码收录中文的内容:
得到了答案
本来以为和中文打交道要花点时间,没想到一次就成功了。
四、登录问题
其实最难的不是找到文章的内容,而是以注册人的身份访问网站。这个问题从周末的两天,到周一的一整天的战斗,到周二的放弃,再到周三的重新审视这个问题,我真的学到了很多。我遇到的问题不是因为问题本身的难度,而是因为我对它的理解深度。了解的越深,把握的就越准确。一个人摸索的时候,一开始很兴奋,渐渐地我怀疑自己,这个问题有没有办法解决?还是自己的能力差距很大?
周三,我冷静下来,重新组织了登录流程、cookie 交付流程,并将每次 cookie 更改记录在草稿纸上。最终在不断的尝试和推理中找到了正确的应用方法,作为登录者成功获取了数据。其实核心就是cookie的交付,但是摸索的过程太长了,我也是菜鸟。
五、数据的后处理
后处理其实很简单,上面已经正确解码了,下面只是将其写入文件。
def detail_page(self, response):
results=response.json
content=base64.b64decode(results['content'])
fo = open('/root/Documents/davidchiu2.txt','a')
fo.write(content)
fo.close()
return {
# "content": content,
"content_cn": content,
}
将结果保存到txt文件中,如下
因为有html的段落格式,还有图片的链接,加个html header和end,把扩展名改成html,这样用浏览器打开就可以看到图片了。
然后将页面上的文字和图片全部复制到word,排版后导出PDF,完美。
查看全部
抓取网页生成电子书(只要能显示在网页上的东西都可以抓下来。。
)
最近,我迷上了德州扑克。我的同学H是这次活动的领队(tuifei)。我们同学不仅PK了,还给我发了截图,WC,你也买了书,你也进了群,你快上天堂了。. .
晚上11点30分,我用我的房门打开他房间的门,他果然在床上。
H,有资源吗?
不是,X宝上贴的和我下载的一样,只有44页,前十页是广告。
哎,无良商家,退款?
不,只有1.00元,她又给了我一本书。
来看看澳门赌场上线的感觉吧。
回去jd上找,电子版18元,纸质版什么的。没有微信阅读。
第二天,我在实验室遇到了H。还有其他资源吗?
恩,网易阅读上有,我付费了。
第一次听说网易读书,周末在他的实验室度过。
神奇的是网易云阅读器可以在网页上打开查看。
有这样的操作吗??
我发现了一些东西,
WC,网易太甜了!
太甜了,我也想为此把文字记下来。
换句话说,只要能在网页上显示,就可以被捕获。
一、创意的产生
要么使用现成的工具,比如优采云,来抓取网络上的数据,但使用这个工具显然是一个失学的人。要么使用开源框架,然后在知乎上有一个非常流行的“爬虫”。玩爬虫的人很多,请自己知乎。用的比较多的框架有scrapy、pyspider等,前者比较低级,搞这个工作的人玩这个比较专业。后者非常适合新手玩,带有WEUI,网页上的可视化操作,非常方便。这篇文章懒得用pyspider。
二、设置环境
这部分我其实是一年前做的,不过当时我用的是windows平台。现在再看pyspider的官网,发现windows的缺点很多,而且pyspider的开发也是在linux平台上进行的。所以即使我是新手,也得在linux上使用环境。(pyspider 文档在这里)
对于Linux发行版的选择,官网列出了几个,centos(我的VPS上用的那个),ubuntu等。考虑到用浏览器,可能需要带桌面的linux系统。于是我在我的windows10上的vbox上安装了centos,后来发现安装桌面环境真的太慢了。突然发现自己太傻了。真的,我安装了一个Kali系统(我前段时间学会了安装)。Kali是基于Debian的发行版,ubuntu也是基于Debian的,所以使用kali应该没有问题。
参考pyspider帮助,pyspider中文网站
首先安装pyspider
apt-get 安装 pyspider
然后安装phantomjs
apt-get 安装 phantomjs
是不是很简单。Phantomjs 是一个无界面浏览器,用于完全模拟用户在浏览器上的操作,用于处理比较麻烦的问题,比如运行js、异步加载网页、响应网站反爬策略。另外,这款浏览器比IE、Chrome、Firefox等界面浏览器要快很多,详情请参考/。
安装成功后,在终端输入pyspider
提示phantomjs fetcher运行在25555端口,这个其实是pyspider用phantomjs运行的,所以在加载AJAX页面的时候很有用。
三、分析页面
打开某章的阅读页面,如《副王:秋雨传》-老秋-电子书-在线阅读-网易云阅读,打开调试工具Firebug。
选择net标签,这样在打开网页的时候就可以看到页面加载的过程。
一个阅读页面需要这么多资源!其实还有很多东西是不需要关心的,把tab切换成HTML,
其实请求只有两个,第一个在域名下,第二个在下。可以假设第二个与此页面的内容几乎没有相关性,可以用于统计目的。查看第一个请求
具体不说了,反正回复里没有章节内容。
那么章节内容在哪里呢?
将选项卡切换到 XHR,
收录 4 个异步请求。从 URL 和接收数据的时间(时间轴上的绿色部分),可以猜测最后一个是获取章节内容的请求。其实就是一一点击查看接收到的数据。可以看到上次请求返回的数据是一个json数据。
很明显,json的一个字段就是content,这很可能就是我们想要的。但是这个字符串要编码,常规套路是base64编码,因为不是敏感数据。试试看,打开浏览器的hack栏,把内容复制进去,在Encoding里面选择Base64Decode
结果是
你看到了什么?乱七八糟的胡言乱语。
不完全是,有
人物。这说明content的内容确实是base64编码的,但是汉字的解码有问题。
这时候使用pyspider的返回数据的json方法提取json数据,然后尝试解码收录中文的内容:
得到了答案
本来以为和中文打交道要花点时间,没想到一次就成功了。
四、登录问题
其实最难的不是找到文章的内容,而是以注册人的身份访问网站。这个问题从周末的两天,到周一的一整天的战斗,到周二的放弃,再到周三的重新审视这个问题,我真的学到了很多。我遇到的问题不是因为问题本身的难度,而是因为我对它的理解深度。了解的越深,把握的就越准确。一个人摸索的时候,一开始很兴奋,渐渐地我怀疑自己,这个问题有没有办法解决?还是自己的能力差距很大?
周三,我冷静下来,重新组织了登录流程、cookie 交付流程,并将每次 cookie 更改记录在草稿纸上。最终在不断的尝试和推理中找到了正确的应用方法,作为登录者成功获取了数据。其实核心就是cookie的交付,但是摸索的过程太长了,我也是菜鸟。
五、数据的后处理
后处理其实很简单,上面已经正确解码了,下面只是将其写入文件。
def detail_page(self, response):
results=response.json
content=base64.b64decode(results['content'])
fo = open('/root/Documents/davidchiu2.txt','a')
fo.write(content)
fo.close()
return {
# "content": content,
"content_cn": content,
}
将结果保存到txt文件中,如下
因为有html的段落格式,还有图片的链接,加个html header和end,把扩展名改成html,这样用浏览器打开就可以看到图片了。
然后将页面上的文字和图片全部复制到word,排版后导出PDF,完美。
抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-15 11:05
无意中发现了一个可以免费下载电子书的网站。它立刻勾起了我采集电子书的爱好,我很想下载这些书。
就在最近,requests 的作者 kennethreitz 发布了一个新的库 requests-html。
它不仅可以请求网页,还可以解析 HTML 文档。让我们开始吧。
安装。
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器查看元素,可以发现这本电子书网站是用WordPress搭建的。主页上的列表元素非常简单和规则。
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接。
从下图。
可以发现download-links>a中的链接是该书的下载链接。
回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码。
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
读者福利,点击链接领取相关学习福利包:
是安全的网站不用担心,继续访问后即可收到
就业系列:
有方向和目标的学习可以节省时间,而没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:
视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助
Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
如果看到最后的小伙伴们,如果觉得这个文章对你有好处,请给我点个赞,关注我们,支持你!!!! 查看全部
抓取网页生成电子书(快速指南发送一个请求:Requests-html的方便(图))
无意中发现了一个可以免费下载电子书的网站。它立刻勾起了我采集电子书的爱好,我很想下载这些书。
就在最近,requests 的作者 kennethreitz 发布了一个新的库 requests-html。
它不仅可以请求网页,还可以解析 HTML 文档。让我们开始吧。
安装。
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器查看元素,可以发现这本电子书网站是用WordPress搭建的。主页上的列表元素非常简单和规则。
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接。
从下图。
可以发现download-links>a中的链接是该书的下载链接。
回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
请求-html 快速指南
发送 GET 请求:
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
Requests-html 的方便之处在于它解析 html 的方式就像使用 jQuery 一样简单,比如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pyth ... 39%3B, 'https://docs.python.org/3/tutorial/'}
# 通过 CSS 选择器选择元素:
about = r.find('.about', first=True)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 HTML
about.find('a') # 获取 .about 下的所有 a 标签
构建代码。
from requests_html import HTMLSession
import requests
import time
import json
import random
import sys
session = HTMLSession()
list_url = 'http://www.allitebooks.com/page/'
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getBookUrl(link.attrs['href'])
# 获取图书下载链接
def getBookUrl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=True)
if l is not None: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 User-Agent
headers={ "User-Agent":random.choice(USER_AGENTS) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=True, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is None:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
读者福利,点击链接领取相关学习福利包:
是安全的网站不用担心,继续访问后即可收到
就业系列:
有方向和目标的学习可以节省时间,而没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:
视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助
Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
如果看到最后的小伙伴们,如果觉得这个文章对你有好处,请给我点个赞,关注我们,支持你!!!!
抓取网页生成电子书(requests-html快速指南发送一个get(请求:requests))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-14 11:13
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器查看元素,可以发现这本电子书网站是用wordpress构建的。主页上的列表元素非常简单和规则。
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图
可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
requests-html 快速指南
发送获取请求:
from requests_html import htmlsession
session = htmlsession()
r = session.get('https://python.org/')
requests-html的方便之处在于它解析html的方式就像使用jquery一样简单,例如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 css 选择器选择元素:
about = r.find('.about', first=true)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 html
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import htmlsession
import requests
import time
import json
import random
import sys
'''
想要学习python?python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = htmlsession()
list_url = 'http://www.allitebooks.com/page/'
user_agents = [
"mozilla/5.0 (macintosh; intel mac os x 10_7_3) applewebkit/535.20 (khtml, like gecko) chrome/19.0.1036.7 safari/535.20",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.71 safari/537.1 lbbrowser",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/535.11 (khtml, like gecko) chrome/17.0.963.84 safari/535.11 lbbrowser",
"mozilla/4.0 (compatible; msie 7.0; windows nt 6.1; wow64; trident/5.0; slcc2; .net clr 2.0.50727; .net clr 3.5.30729; .net clr 3.0.30729; media center pc 6.0; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 7.0; windows nt 5.1; trident/4.0; sv1; qqdownload 732; .net4.0c; .net4.0e; 360se)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.89 safari/537.1",
"mozilla/5.0 (ipad; u; cpu os 4_2_1 like mac os x; zh-cn) applewebkit/533.17.9 (khtml, like gecko) version/5.0.2 mobile/8c148 safari/6533.18.5",
"mozilla/5.0 (windows nt 6.1; win64; x64; rv:2.0b13pre) gecko/20110307 firefox/4.0b13pre",
"mozilla/5.0 (x11; ubuntu; linux x86_64; rv:16.0) gecko/20100101 firefox/16.0",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.11 (khtml, like gecko) chrome/23.0.1271.64 safari/537.11",
"mozilla/5.0 (x11; u; linux x86_64; zh-cn; rv:1.9.2.10) gecko/20100922 ubuntu/10.10 (maverick) firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getbookurl(link.attrs['href'])
# 获取图书下载链接
def getbookurl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=true)
if l is not none: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 user-agent
headers={ "user-agent":random.choice(user_agents) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=true, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is none:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
以上就是小编为大家介绍的内容。我已经用python抓取了7000多本电子书进行了详细的集成和集成。我希望它会对你有所帮助。 查看全部
抓取网页生成电子书(requests-html快速指南发送一个get(请求:requests))
安装
安装很简单,直接执行:
pip install requests-html
就是这样。
分析页面结构
通过浏览器查看元素,可以发现这本电子书网站是用wordpress构建的。主页上的列表元素非常简单和规则。
所以我们可以搜索 .entry-title> a 得到所有书籍详情页的链接,然后我们进入详情页找到下载链接,如下图
可以发现 .download-links>a 中的链接是该书的下载链接。回到列表页面,可以发现该站点有700多个页面,因此我们可以遍历列表以获取所有下载链接。
requests-html 快速指南
发送获取请求:
from requests_html import htmlsession
session = htmlsession()
r = session.get('https://python.org/')
requests-html的方便之处在于它解析html的方式就像使用jquery一样简单,例如:
# 获取页面的所有链接可以这样写:
r.html.links
# 会返回 {'//docs.python.org/3/tutorial/', '/about/apps/'}
# 获取页面的所有的绝对链接:
r.html.absolute_links
# 会返回 {'https://github.com/python/pythondotorg/issues', 'https://docs.python.org/3/tutorial/'}
# 通过 css 选择器选择元素:
about = r.find('.about', first=true)
# 参数 first 表示只获取找到的第一元素
about.text # 获取 .about 下的所有文本
about.attrs # 获取 .about 下所有属性像 id, src, href 等等
about.html # 获取 .about 的 html
about.find('a') # 获取 .about 下的所有 a 标签
构建代码
from requests_html import htmlsession
import requests
import time
import json
import random
import sys
'''
想要学习python?python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
'''
session = htmlsession()
list_url = 'http://www.allitebooks.com/page/'
user_agents = [
"mozilla/5.0 (macintosh; intel mac os x 10_7_3) applewebkit/535.20 (khtml, like gecko) chrome/19.0.1036.7 safari/535.20",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.71 safari/537.1 lbbrowser",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/535.11 (khtml, like gecko) chrome/17.0.963.84 safari/535.11 lbbrowser",
"mozilla/4.0 (compatible; msie 7.0; windows nt 6.1; wow64; trident/5.0; slcc2; .net clr 2.0.50727; .net clr 3.5.30729; .net clr 3.0.30729; media center pc 6.0; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/4.0 (compatible; msie 7.0; windows nt 5.1; trident/4.0; sv1; qqdownload 732; .net4.0c; .net4.0e; 360se)",
"mozilla/4.0 (compatible; msie 6.0; windows nt 5.1; sv1; qqdownload 732; .net4.0c; .net4.0e)",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.1 (khtml, like gecko) chrome/21.0.1180.89 safari/537.1",
"mozilla/5.0 (ipad; u; cpu os 4_2_1 like mac os x; zh-cn) applewebkit/533.17.9 (khtml, like gecko) version/5.0.2 mobile/8c148 safari/6533.18.5",
"mozilla/5.0 (windows nt 6.1; win64; x64; rv:2.0b13pre) gecko/20110307 firefox/4.0b13pre",
"mozilla/5.0 (x11; ubuntu; linux x86_64; rv:16.0) gecko/20100101 firefox/16.0",
"mozilla/5.0 (windows nt 6.1; wow64) applewebkit/537.11 (khtml, like gecko) chrome/23.0.1271.64 safari/537.11",
"mozilla/5.0 (x11; u; linux x86_64; zh-cn; rv:1.9.2.10) gecko/20100922 ubuntu/10.10 (maverick) firefox/3.6.10"
]
# 获取当前列表页所有图书链接
def get_list(url):
response = session.get(url)
all_link = response.html.find('.entry-title a') # 获取页面所有图书详情链接
for link in all_link:
getbookurl(link.attrs['href'])
# 获取图书下载链接
def getbookurl(url):
response = session.get(url)
l = response.html.find('.download-links a', first=true)
if l is not none: # 运行后发现有的个别页面没有下载链接,这里加个判断
link = l.attrs['href'];
download(link)
#下载图书
def download(url):
# 随机浏览器 user-agent
headers={ "user-agent":random.choice(user_agents) }
# 获取文件名
filename = url.split('/')[-1]
# 如果 url 里包含 .pdf
if ".pdf" in url:
file = 'book/'+filename # 文件路径写死了,运行时当前目录必须有名 book 的文件夹
with open(file, 'wb') as f:
print("正在下载 %s" % filename)
response = requests.get(url, stream=true, headers=headers)
# 获取文件大小
total_length = response.headers.get('content-length')
# 如果文件大小不存在,则直接写入返回的文本
if total_length is none:
f.write(response.content)
else:
# 下载进度条
dl = 0
total_length = int(total_length) # 文件大小
for data in response.iter_content(chunk_size=4096): # 每次响应获取 4096 字节
dl += len(data)
f.write(data)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50-done)) ) # 打印进度条
sys.stdout.flush()
print(filename + '下载完成!')
if __name__ == '__main__':
#从这运行,应为知道列表总数,所以偷个懒直接开始循环
for x in range(1,756):
print('当前页面: '+ str(x))
get_list(list_url+str(x))
运行结果:
以上就是小编为大家介绍的内容。我已经用python抓取了7000多本电子书进行了详细的集成和集成。我希望它会对你有所帮助。
抓取网页生成电子书(网络书籍抓取器是一款帮助用户下载指定网页的某)
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-10-11 17:45
在线图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
在线抢书功能介绍
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
网络图书采集器软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
如何使用在线图书抓取器
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击Start crawling开始下载。 查看全部
抓取网页生成电子书(网络书籍抓取器是一款帮助用户下载指定网页的某)
在线图书抓取器是一种可以帮助用户下载指定网页的某本书和某章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,很有必要。可以下载使用。
在线抢书功能介绍
您可以提取指定小说目录页的章节信息并进行调整,然后按照章节顺序抓取小说内容,然后以最合适的方式进行合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
网络图书采集器软件功能
1、 章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、自动重试:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),等网络好后再试。
3、停止和恢复:可以随时停止抓取过程,退出程序后不影响进度(章节信息会保存在记录中,运行程序后可以恢复抓取下一次。注意:您需要先使用停止按钮中断然后退出程序,如果直接退出,将不会恢复)。
4、 一键抓取:又称“哑模式”,基本可以实现自动抓取合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以一键抓取,抓取合并操作会自动完成.
5、适用网站:已收录10个适用网站(选择后可以快速打开网站找到自己需要的书),并自动应用相应的代码,也可以测试其他小说网站,如果一起使用,可以手动添加到设置文件中,以备后用。
6、 制作电子书方便:可以在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录带来极大的方便。
如何使用在线图书抓取器
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击Start crawling开始下载。
抓取网页生成电子书(爬虫基础:http协议和http相关协议编写python怎么爬)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-11 15:54
抓取网页生成电子书,批量增删文件,python实现网页爬虫,抓取网页上的文章和图片;网页上标注文章作者,评论的网页及评论数、积分,统计参加活动的人数;生成图片下载代码,
爬虫需要那些技术?爬虫基础:http协议和http相关协议编写python爬虫,爬虫怎么爬,爬什么,为什么要爬,爬取到的内容存在哪里,存储时间大概是多久,网页列表如何下载btw,网页列表下载目前能实现的有九种下载方式,各有优缺点,对这方面了解不深,提供参考数据爬取,主要可以包括urllib,urllib2等模块,也可以使用lxml模块,也可以使用beautifulsoup模块,采用正则表达式将数据以url的形式存入数据库。
数据分析:根据输入的python文件内容获取其中的数据,即pandas,matplotlib,seaborn等。数据可视化:给数据结构化,以帮助更好的理解数据的价值和特征。以上所提到的爬虫主要偏向于前端编程部分,后台的java,c++,python等如果要深入可以将原始数据获取和预处理后在写入文件中,或者在本地使用https协议抓取,像uc直达云平台,则采用了这个。
不过主要有几点是要注意的,第一个,数据的存储,很有可能你获取的数据到不了文件存储的地方,只能像本地文件存储一样文件名都为文件的后缀名。第二个,特征提取,这方面做的好的公司有百度地图的百度图片的美图秀秀的拼图云等。第三个,爬虫模块的封装,当然这里的爬虫模块主要有一个对接,爬虫通过相关模块获取数据,对接数据库以后。
按照一定规则去实现网页中数据的查询、更新,然后进行数据分析。当然也可以post等其他形式。第四个,复杂问题处理,例如多人隐私处理,公众号打开限制,登录验证和接口调用处理,绑定公众号和开发者后端等。这些问题依据处理方法不同,会构成分布式爬虫、网页加密、反爬虫等相关问题。第五个,服务器设计,如何对爬虫程序做一个很好的保护和监控?这个和运维部分有很大关系。这一块其实也有很多的问题需要思考和处理。 查看全部
抓取网页生成电子书(爬虫基础:http协议和http相关协议编写python怎么爬)
抓取网页生成电子书,批量增删文件,python实现网页爬虫,抓取网页上的文章和图片;网页上标注文章作者,评论的网页及评论数、积分,统计参加活动的人数;生成图片下载代码,
爬虫需要那些技术?爬虫基础:http协议和http相关协议编写python爬虫,爬虫怎么爬,爬什么,为什么要爬,爬取到的内容存在哪里,存储时间大概是多久,网页列表如何下载btw,网页列表下载目前能实现的有九种下载方式,各有优缺点,对这方面了解不深,提供参考数据爬取,主要可以包括urllib,urllib2等模块,也可以使用lxml模块,也可以使用beautifulsoup模块,采用正则表达式将数据以url的形式存入数据库。
数据分析:根据输入的python文件内容获取其中的数据,即pandas,matplotlib,seaborn等。数据可视化:给数据结构化,以帮助更好的理解数据的价值和特征。以上所提到的爬虫主要偏向于前端编程部分,后台的java,c++,python等如果要深入可以将原始数据获取和预处理后在写入文件中,或者在本地使用https协议抓取,像uc直达云平台,则采用了这个。
不过主要有几点是要注意的,第一个,数据的存储,很有可能你获取的数据到不了文件存储的地方,只能像本地文件存储一样文件名都为文件的后缀名。第二个,特征提取,这方面做的好的公司有百度地图的百度图片的美图秀秀的拼图云等。第三个,爬虫模块的封装,当然这里的爬虫模块主要有一个对接,爬虫通过相关模块获取数据,对接数据库以后。
按照一定规则去实现网页中数据的查询、更新,然后进行数据分析。当然也可以post等其他形式。第四个,复杂问题处理,例如多人隐私处理,公众号打开限制,登录验证和接口调用处理,绑定公众号和开发者后端等。这些问题依据处理方法不同,会构成分布式爬虫、网页加密、反爬虫等相关问题。第五个,服务器设计,如何对爬虫程序做一个很好的保护和监控?这个和运维部分有很大关系。这一块其实也有很多的问题需要思考和处理。
抓取网页生成电子书(IbookBox网页小说批量下载阅读器中输入任一网页地址即可批量抓取和下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-11 05:00
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
在IbookBox网络小说批量下载阅读器中输入任意网址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站。
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫下载v1.0免费版-西溪软件下载。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。
IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
软件介绍 《批量下载小说爬虫》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件放到手机上离线观看,软件爬虫速度。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度一号。 查看全部
抓取网页生成电子书(IbookBox网页小说批量下载阅读器中输入任一网页地址即可批量抓取和下载)
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度的小说网站 找小说的章节页,用requests。
在IbookBox网络小说批量下载阅读器中输入任意网址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站。
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
批量下载小说爬虫下载v1.0免费版-西溪软件下载。
IbookBox小说批量下载阅读器,让读者远离垃圾广告。输入任意网页地址,批量抓取下载网页上的所有电子书。
IbookBox网络小说批量下载阅读器是一款可以通过输入任意网页地址批量抓取下载网络上所有电子书的软件。支持所有小说网站抓取,支持生成抓取的电子书txt发送到手机,支持。
软件介绍 《批量下载小说爬虫》是一款非常好用又方便的小说批量下载软件。通过小说爬虫,用户可以快速下载自己想要的小说txt文件放到手机上离线观看,软件爬虫速度。
目的是下载一本全分类的小说网站,并根据分类自动创建目录,并按小说名称保存为txt文件。一、 抢点子:我的点子是百度一号。
抓取网页生成电子书(使用Cookie有两种方式,你知道吗?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-08 21:27
在实际情况下,网站的很多内容只有登录后才能看到,所以我们需要进行模拟登录,利用登录状态进行爬取。这里我们需要用到cookies。
现在大多数 网站 使用 cookie 来跟踪用户的登录状态。一旦网站验证登录信息,登录信息将存储在浏览器的cookie中。网站会使用这个cookie作为认证的凭证,在浏览网站的页面时返回给服务器。
由于 cookie 存储在本地,因此它们可以被篡改和伪造。让我们来看看 cookie 是什么样子的。
打开网页调试工具,随意打开一个网页,在“网络”选项卡中,打开一个链接,在标题中:
我们把它复制出来看看:
__guid=137882464.208312339030071800.1455264073383.613;
__huid=10POq43DvPO3U0izV0xej4%2BFDIemVPybee0j1Z1xnJnpQ%3D;
__hsid=825c7462cc8195a5;
somultiswitch=1;
__seedSign=68;
count=1; sessionID=132730903.3074093016427610600.1483758834211.764;
piao34=1;
city_code=101280101;
customEng=1-7
它由键值对组成。
接下来我们以豆豆一书的详情页为例,讲解cookies的使用。
See Do是一个电子书下载网站,我的Kindle上的大部分书都在这里找到。
示例网址为:宇宙是猫的困梦-看豆-提供优质正版电子书导购服务
一般情况下,未登录的用户是看不到下载链接的,比如:
这本书的下载链接是隐藏的。
头信息如下:
我们来看看登录后的页面:
下载链接已经显示出来了,我们来看一下header信息的Cookie部分
显然它与之前处于未记录状态的 cookie 不同。
接下来,我们按照上一章抓取腾讯新闻的方法,对示例网址()进行HTTP请求:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
结果如下:
我们找到了下载链接所在的“图书购物指南”一栏的HTML代码:
书籍导购
去亚马逊购买《宇宙是猫咪酣睡的梦》
就像我们在未登录状态下使用浏览器访问本网站时,只显示亚马逊的购买链接,没有电子格式的下载链接。
我们尝试在登录后使用以下 cookie:
有两种使用cookies的方法,
1、在header中直接写cookie
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a237a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=1483926368'''
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cookie': cookie}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,headers=header).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
上面的代码将响应返回给page(),
我们的搜索响应代码,
红色椭圆部分与无cookie访问时返回的HTML一致,即亚马逊的购买链接。
红色矩形是电子书的下载链接,也就是请求中使用的cookie。
与实际网页相比,与网页登录查看的显示页面一致。
功能完成。接下来看第二种方式
2、使用请求插入cookies
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = {
"cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60",
"CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031",
"Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313",
"Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368"
}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,cookies=cookie).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
你得到的是登录后显示的 HTML:
这样,我们就可以方便地使用cookies来获取需要登录验证的网页和资源。
这里只是简单介绍一下cookies的使用。关于如何获取cookie,手动复制是一种方式。通过代码获取需要用到Selenium,后面章节会讲解,这里不再展示。
================================================== ====================== 查看全部
抓取网页生成电子书(使用Cookie有两种方式,你知道吗?(组图))
在实际情况下,网站的很多内容只有登录后才能看到,所以我们需要进行模拟登录,利用登录状态进行爬取。这里我们需要用到cookies。
现在大多数 网站 使用 cookie 来跟踪用户的登录状态。一旦网站验证登录信息,登录信息将存储在浏览器的cookie中。网站会使用这个cookie作为认证的凭证,在浏览网站的页面时返回给服务器。
由于 cookie 存储在本地,因此它们可以被篡改和伪造。让我们来看看 cookie 是什么样子的。
打开网页调试工具,随意打开一个网页,在“网络”选项卡中,打开一个链接,在标题中:
我们把它复制出来看看:
__guid=137882464.208312339030071800.1455264073383.613;
__huid=10POq43DvPO3U0izV0xej4%2BFDIemVPybee0j1Z1xnJnpQ%3D;
__hsid=825c7462cc8195a5;
somultiswitch=1;
__seedSign=68;
count=1; sessionID=132730903.3074093016427610600.1483758834211.764;
piao34=1;
city_code=101280101;
customEng=1-7
它由键值对组成。
接下来我们以豆豆一书的详情页为例,讲解cookies的使用。
See Do是一个电子书下载网站,我的Kindle上的大部分书都在这里找到。
示例网址为:宇宙是猫的困梦-看豆-提供优质正版电子书导购服务
一般情况下,未登录的用户是看不到下载链接的,比如:
这本书的下载链接是隐藏的。
头信息如下:
我们来看看登录后的页面:
下载链接已经显示出来了,我们来看一下header信息的Cookie部分
显然它与之前处于未记录状态的 cookie 不同。
接下来,我们按照上一章抓取腾讯新闻的方法,对示例网址()进行HTTP请求:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
结果如下:
我们找到了下载链接所在的“图书购物指南”一栏的HTML代码:
书籍导购
去亚马逊购买《宇宙是猫咪酣睡的梦》
就像我们在未登录状态下使用浏览器访问本网站时,只显示亚马逊的购买链接,没有电子格式的下载链接。
我们尝试在登录后使用以下 cookie:
有两种使用cookies的方法,
1、在header中直接写cookie
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a237a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=1483926368'''
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cookie': cookie}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,headers=header).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
上面的代码将响应返回给page(),
我们的搜索响应代码,
红色椭圆部分与无cookie访问时返回的HTML一致,即亚马逊的购买链接。
红色矩形是电子书的下载链接,也就是请求中使用的cookie。
与实际网页相比,与网页登录查看的显示页面一致。
功能完成。接下来看第二种方式
2、使用请求插入cookies
完整代码如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = {
"cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60",
"CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031",
"Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313",
"Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368"
}
url = 'https://kankandou.com/book/vie ... 39%3B
wbdata = requests.get(url,cookies=cookie).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)
你得到的是登录后显示的 HTML:
这样,我们就可以方便地使用cookies来获取需要登录验证的网页和资源。
这里只是简单介绍一下cookies的使用。关于如何获取cookie,手动复制是一种方式。通过代码获取需要用到Selenium,后面章节会讲解,这里不再展示。
================================================== ======================
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2021-10-08 21:09
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 帐户中提交 URL、RSS 提要地址和 文章 供以后阅读,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,或者将它们推送到 Kindle 和 Apple Books 阅读。
阅读体验真的很好
Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)
将网页文章制作成电子书
Doocer完成注册和登录后,我们就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后在右上角选择“添加”,添加文章 URL或RSS提要地址。
以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。
实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。
要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开Amazon Kindle的个人文档设置,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约 10-30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer可以像RSS工具一样抓取网页中更新后的文章,但是文章的新抓取以及生成电子书和推送仍然需要手动完成。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。 查看全部
抓取网页生成电子书(如何将网页文章批量抓取、生成电子书、直接推送到Kindle)
很长一段时间,我一直在研究如何将我关注的网页或文章安装到Kindle中进行认真阅读,但很长一段时间都没有真正的进展。手动格式化书籍制作电子书的方法虽然简单易行,但对于短小且更新频繁的网页文章来说效率低下。如果有工具可以批量抓取网页文章,生成电子书,直接推送到Kindle上就好了。Doocer 是一个非常有用的工具。
Doocer 是由@lepture 开发的在线服务。它允许用户在 Pocket 帐户中提交 URL、RSS 提要地址和 文章 供以后阅读,然后将它们一一或批量制作成 ePub、MOBI 电子书。您可以直接在 Doocer 中阅读所有 文章,或者将它们推送到 Kindle 和 Apple Books 阅读。
阅读体验真的很好
Doocer 生成的电子书格式良好且引人注目。应该收录的内容很多,不应该收录的内容并不多。本书不仅封面有图文,还收录文章目录、网站出处、文章原作者等信息。Doocer生成的MOBI电子书支持KF8标准,因此支持Kindle原生替换自定义字体。
由于网站文章通常都有标准和通用的排版规范,所以Doocer生成的电子书文章中的大小、标题和列表图例与原创网页高度一致文章。原文章中的超链接也全部保留,评论信息、广告等内容全部丢弃。全书的阅读体验非常友好。(当然,如果原网页文章的布局乱了,得到的电子书也可能完全不一样。)
将网页文章制作成电子书
Doocer完成注册和登录后,我们就可以开始将文章网页制作成电子书了。首先,我们点击“NEW BOOK”按钮新建电子书,输入电子书书名。然后在右上角选择“添加”,添加文章 URL或RSS提要地址。
以小众网页的文章为例,我们选择“FEED”,在输入框中粘贴RSS地址,然后点击“PARSE”,就会出现小众文章的近期列表显示给我们添加到。我们可以根据需要选择,也可以点击“全选”来全选文章。最后,下拉到页面底部,选择“SAVE”,这些文章就会被添加到书中。
实际上,Doocer 网页与 RSS 工具非常相似。实现了从网站批量抓取文章并集中展示的功能。
要将这些文章转换成电子书并推送到Kindle,我们需要进行一些简单的操作。
首先,根据Doocer个人设置页面的提示,我们打开Amazon Kindle的个人文档设置,在个人文档接收地址中添加Doocer电子书的发送地址。完成后,我们再在输入框中填写Kindle的个人文档接收地址,点击保存。
最后,我们在Doocer中打开《少数派》这本书,在页面上找到“发布”,选择发送到Kindle。大约 10-30 分钟,Doocer 将完成图书制作并将图书推送到 Kindle。
还有一些问题需要注意
Doocer目前处于Beta测试阶段,还存在一些bug,尤其是中文网站经常出现问题。好在Doocer官网有开发者对话频道,你可以直接联系他帮忙解决。
实现所有操作的自动化流程是我认为Doocer最需要努力的方向。Doocer可以像RSS工具一样抓取网页中更新后的文章,但是文章的新抓取以及生成电子书和推送仍然需要手动完成。如果整个过程都可以自动化,RSS-MOBI-Kindle就可以一口气搞定,相信实用性会更高。
抓取网页生成电子书(小说爬虫下载器(小说批量下载神器)能去为你带来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1778 次浏览 • 2021-10-08 21:04
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
在IbookBox网络小说批量下载阅读器中输入任意网页地址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书生成txt发送到手机。3、 支持。
如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册。正在发送信息。
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取2、支持抓取的电子书生成txt发送到手机。3、 支持将电子书自动存放在您自己的邮箱中。 查看全部
抓取网页生成电子书(小说爬虫下载器(小说批量下载神器)能去为你带来)
小说爬虫下载器(小说批量下载神器)可以给你带来更好的专业智能小说采集工具,各种不同的小说内容都可以很方便的找到。
批量下载小说爬虫是一款免费的小说下载阅读器,可以帮助用户将自己喜欢的小说批量下载到本地,支持自己选择下载源。有需要的用户不要错过。欢迎下载使用!
IbookBox小说批量下载阅读器是一款功能强大的小说批量下载器。本软件可以抓取任何小说网站书籍到本地,并能自动合并成txt电子书手机阅读,无广告无插件,进任何网。
在IbookBox网络小说批量下载阅读器中输入任意网页地址,即可批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取。2、支持将抓取的电子书生成txt发送到手机。3、 支持。
如果您在使用《IbookBox网站小说批量抓取下载专家》过程中遇到问题,请联系软件开发商武汉伊文科技有限公司,软银世界只负责支付注册费和注册。正在发送信息。
本剧本仅针对“玄书网”小说网“奇幻奇幻”类小说进行拍摄。供网友参考,可自行修改。文笔粗糙,请勿喷……原文链接。
小说批量下载器聚合阅读合集,主要提供小说批量下载器相关的最新资源下载。订阅小说批量下载器标签主题,您可以第一时间了解小说批量下载器的最新下载资源和主题和包。
输入任意网页地址,批量抓取下载网络上的所有电子书。1、支持所有小说网站抓取2、支持抓取的电子书生成txt发送到手机。3、 支持将电子书自动存放在您自己的邮箱中。
抓取网页生成电子书(用urllib2的Request类构建一个request接下来获取响应页面内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-08 19:31
使用 urllib2 的 Request 类构造请求
url = "https://www.qiushibaike.com/"
request = urllib2.Request(url)
接下来使用urllib2的urlopen方法请求页面并获取响应(即页面内容)
response = urllib2.urlopen(request)
打印得到的内容
print response.read()
运行我们的脚本,结果是一个错误:
Traceback (most recent call last):
File "00_get_a_page.py", line 19, in
response = urllib2.urlopen(request)
File "D:\Python27\lib\urllib2.py", line 154, in urlopen
return opener.open(url, data, timeout)
File "D:\Python27\lib\urllib2.py", line 429, in open
response = self._open(req, data)
File "D:\Python27\lib\urllib2.py", line 447, in _open
'_open', req)
File "D:\Python27\lib\urllib2.py", line 407, in _call_chain
result = func(*args)
File "D:\Python27\lib\urllib2.py", line 1241, in https_open
context=self._context)
File "D:\Python27\lib\urllib2.py", line 1201, in do_open
r = h.getresponse(buffering=True)
File "D:\Python27\lib\httplib.py", line 1121, in getresponse
response.begin()
File "D:\Python27\lib\httplib.py", line 438, in begin
version, status, reason = self._read_status()
File "D:\Python27\lib\httplib.py", line 402, in _read_status
raise BadStatusLine(line)
httplib.BadStatusLine: ''
这是因为尴尬百科对爬虫做了一些反爬虫优化,你必须是浏览器才能访问页面。
不过没关系,浏览器的信息是通过headers实现的。我们可以使用 urllib2 设置浏览器信息头,将我们的程序伪装成浏览器。
设置头验证信息
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER"
headers = {"User-Agent":user_agent}
可以看到我们设置了 User-Agent 字段,并将其封装为字典 headers,后面会用到。
user_agent 的内容为 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER,这是我用的猎豹浏览器的头信息,可以通过F12开发者工具查看。
重构请求并打印得到的响应页面的内容
request = urllib2.Request(url,headers=headers)
可以发现,在构造请求的时候,除了url参数,我们还把封装好的带有浏览器信息的headers传递给了urllib2.Request的headers参数。
[!] headers=headers 必须指定,否则headers会默认传给urllib2.Request的第二个参数,但是第二个参数不是headers,如下:
>>> help("urllib2.Request")
Help on class Request in urllib2:
urllib2.Request = class Request
| Methods defined here:
| __getattr__(self, attr)
| __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
用同样的方式重新请求页面,得到响应并打印出来
成功获得!但是我们的汉字没有出现。
这是因为我们获取的response.read()的编码方式是UTF-8字节流数据,而我们python2.7默认的编解码方式是ASCII,导致出现乱码。
我们打印的时候,指定解码方式为UTF-8,试试看。
print response.read().decode('utf-8')
成功!
至此我们已经获得了整个页面的完整信息。 查看全部
抓取网页生成电子书(用urllib2的Request类构建一个request接下来获取响应页面内容)
使用 urllib2 的 Request 类构造请求
url = "https://www.qiushibaike.com/"
request = urllib2.Request(url)
接下来使用urllib2的urlopen方法请求页面并获取响应(即页面内容)
response = urllib2.urlopen(request)
打印得到的内容
print response.read()
运行我们的脚本,结果是一个错误:
Traceback (most recent call last):
File "00_get_a_page.py", line 19, in
response = urllib2.urlopen(request)
File "D:\Python27\lib\urllib2.py", line 154, in urlopen
return opener.open(url, data, timeout)
File "D:\Python27\lib\urllib2.py", line 429, in open
response = self._open(req, data)
File "D:\Python27\lib\urllib2.py", line 447, in _open
'_open', req)
File "D:\Python27\lib\urllib2.py", line 407, in _call_chain
result = func(*args)
File "D:\Python27\lib\urllib2.py", line 1241, in https_open
context=self._context)
File "D:\Python27\lib\urllib2.py", line 1201, in do_open
r = h.getresponse(buffering=True)
File "D:\Python27\lib\httplib.py", line 1121, in getresponse
response.begin()
File "D:\Python27\lib\httplib.py", line 438, in begin
version, status, reason = self._read_status()
File "D:\Python27\lib\httplib.py", line 402, in _read_status
raise BadStatusLine(line)
httplib.BadStatusLine: ''
这是因为尴尬百科对爬虫做了一些反爬虫优化,你必须是浏览器才能访问页面。
不过没关系,浏览器的信息是通过headers实现的。我们可以使用 urllib2 设置浏览器信息头,将我们的程序伪装成浏览器。
设置头验证信息
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER"
headers = {"User-Agent":user_agent}
可以看到我们设置了 User-Agent 字段,并将其封装为字典 headers,后面会用到。
user_agent 的内容为 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 LBBROWSER,这是我用的猎豹浏览器的头信息,可以通过F12开发者工具查看。
重构请求并打印得到的响应页面的内容
request = urllib2.Request(url,headers=headers)
可以发现,在构造请求的时候,除了url参数,我们还把封装好的带有浏览器信息的headers传递给了urllib2.Request的headers参数。
[!] headers=headers 必须指定,否则headers会默认传给urllib2.Request的第二个参数,但是第二个参数不是headers,如下:
>>> help("urllib2.Request")
Help on class Request in urllib2:
urllib2.Request = class Request
| Methods defined here:
| __getattr__(self, attr)
| __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
用同样的方式重新请求页面,得到响应并打印出来
成功获得!但是我们的汉字没有出现。
这是因为我们获取的response.read()的编码方式是UTF-8字节流数据,而我们python2.7默认的编解码方式是ASCII,导致出现乱码。
我们打印的时候,指定解码方式为UTF-8,试试看。
print response.read().decode('utf-8')
成功!
至此我们已经获得了整个页面的完整信息。
抓取网页生成电子书(廖雪峰:Python教程爬下来做成PDF电子书方便离线阅读)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-08 19:27
免责声明:本文仅供学习参考,不得用于其他用途。爬取过程中注意控制请求速度,以免给服务器造成太大压力
写爬虫好像不比用Python好。Python社区提供的爬虫工具之多,看得你眼花缭乱。你可以用各种可以直接使用的库在几分钟内编写一个爬虫。今天,我将尝试写一个爬虫。廖雪峰老师的Python教程爬下来制作了PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们没有用。,所以可以忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup4
pip install pdfkit
安装 wkhtmltopdf
Windows平台下,直接从wkhtmltopdf官网下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签
社会的
链接
© foofish 2016 查看全部
抓取网页生成电子书(廖雪峰:Python教程爬下来做成PDF电子书方便离线阅读)
免责声明:本文仅供学习参考,不得用于其他用途。爬取过程中注意控制请求速度,以免给服务器造成太大压力
写爬虫好像不比用Python好。Python社区提供的爬虫工具之多,看得你眼花缭乱。你可以用各种可以直接使用的库在几分钟内编写一个爬虫。今天,我将尝试写一个爬虫。廖雪峰老师的Python教程爬下来制作了PDF电子书供离线阅读。
在开始写爬虫之前,我们先来分析一下网站的页面结构。页面左侧为教程目录大纲。每个URL对应右边文章的一篇文章,右上角是文章的标题,中间是文章的正文部分。正文内容是我们关注的重点。我们要抓取的数据是所有网页的正文部分。下面是用户的评论区。评论区对我们没有用。,所以可以忽略。
工具准备
搞清楚网站的基本结构后,就可以开始准备爬虫依赖的工具包了。requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulsoup用于操作html数据。有了这两个班车,我们就可以顺利工作了。我们不需要像scrapy这样的爬虫框架。小程序有点像大锤。另外,既然是把html文件转换成pdf,就得有相应的库支持。wkhtmltopdf 是一个非常好的工具。它可用于从 html 到 pdf 的多平台转换。pdfkit 是 wkhtmltopdf 的 Python 包。先安装以下依赖包,然后安装wkhtmltopdf
pip install requests
pip install beautifulsoup4
pip install pdfkit
安装 wkhtmltopdf
Windows平台下,直接从wkhtmltopdf官网下载稳定版进行安装。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后,就可以开始编写代码了,但是在编写代码之前,应该先整理一下思路。该程序的目的是将所有URL对应的html body部分保存在本地,然后使用pdfkit将这些文件转换为pdf文件。让我们拆分任务。首先将某个URL对应的html body保存到本地,然后找到所有的URL进行同样的操作。
使用Chrome浏览器找到页面body部分的标签,按F12找到body对应的div标签:
,div是网页的body内容。使用requests在本地加载整个页面后,可以使用beautifulsoup操作HTML的dom元素来提取body内容。
具体实现代码如下: 使用soup.find_all函数查找body标签,然后将body部分的内容保存到a.html文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步是解析出页面左侧的所有URL。同样的方法,找到左边的菜单标签
社会的
链接
© foofish 2016
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-10-08 12:18
上一篇简单展示了我们将网页转成PDF的结果,特别适用于序列化的网页文章,组织成一本书。
本文也为大家简单讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点
一、 抓取网页并保存到本地
因为大部分网页都收录图片,所以很多网页都不是普通的静态网页。相应的内容是在浏览器加载过程中随着浏览器滚动条的滚动而加载的。
所以如果你只想简单地发送一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:selenium,我相信通常关注网络抓取的人对它很熟悉。
作者尝试搜索selenium+C#感兴趣的词,没想到selenium竟然是一个支持多语言的工具。百度自查的具体介绍,以下是百度百科介绍的简单截取。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
所以,不要犯错,犯一般错误,认为python很容易用于网页抓取,你可以使用C#中的常用工具。当前的工具不仅限于实现一种语言。我相信 dotNET 会变得更加开源。当生态越来越好时,会出现更多方便的工具。
在 C# 代码中,Seenium 用于控制浏览器行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们想要图形版本的数据,而不仅仅是一些结构化的数据,最简单的方法是将类似浏览器行为的CTRL+S作为网页保存到本地。也用代码来模拟发送键和击键的方式。有兴趣的读者可以参考以下代码。
网上同样的就是python的实现,作者简单的修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
private static void SaveHtml(ChromeDriver driver)
{
uint KEYEVENTF_KEYUP = 2;
keybd_event(Keys.ControlKey, 0, 0, 0);
keybd_event(Keys.S, 0, 0, 0);
keybd_event(Keys.ControlKey, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(3000);
keybd_event(Keys.Enter, 0, 0, 0);
keybd_event(Keys.Enter, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(5000);
driver.Close();
driver.Quit();
}
二、将多个网页保存为PDF
虽然WORD也可以用来打开网页,但估计WORD是用IE技术渲染网页的,很多功能无法恢复。所以直接转PDF更科学。
PDF 的另一个好处是几乎所有的 PDF 阅读器都可以随意打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的目的主要是为了阅读,所以将 HTML 转换为 PDF 是非常理想的。
它可以将多个网页转换为一个PDF文件,阅读时更加连贯。
网页转PDF的工具是wkhtmltopdf,也是一个命令行工具,可以多种语言调用。当然,dotNET 调用是没有问题的,但是为了更好的体验,还是应该在 PowerShell 上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都在下一步完成,最后记得设置环境变量,让CMD和PowerShell识别。
平时可以看到的python的html to pdf功能,其实底层也是用wkhtmltopdf完成的。
要将多个网页转换为PDF,需要考虑排序问题。这时候使用Excel催化剂可以轻松实现HTML排版顺序问题。
一般来说,我们是按顺序下载网页的,所以简单的使用Excel Catalyst的遍历文件功能来遍历文件信息,在Excel上做一个排序处理,手动调整一些特殊文件的顺序。
另一个自定义函数stringjoin可以快速将多个文件合并成一个字符串组合,用空格隔开,每条记录都要用双引号括起来。
打开我们的 PowerShell ISE 软件,它是 win10 自带的。其他系统也有,可以自行搜索相关教程打开。
相信很多读者也和作者有同感。他们觉得命令行很可怕。它是一系列代码,尤其是帮助文件。
事实上,它确实突破了心理恐惧。命令行工具和我们在Excel上写函数的原理都是一个函数名和各种参数,但是命令行可以有很多参数。
以下是我们如何在 PowerShell 上使用单个命令将多个 html 文件合并为一个 PDF 文件。
笔者还费了一番功夫阅读帮助文档,写出了更多命令的功能,比如添加页眉和页脚的功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,摊开多个html文件,最后加上pdf文件的名字,弄的太多了。该文件使用相对路径。您需要将PowerShell的当前路径切换到html存储文件夹。切换命令是 CD。
终于,激动人心的时刻到了,可以顺利生成pdf文件了。
包括页眉和页脚信息,一个总共400多页的PDF电子书诞生了。
有兴趣的读者不妨将自己喜欢的网页相册制作成PDF文件,方便查阅。之前的错误是追求PDF阅读器的精简,现在我重新使用【福昕阅读器】(感谢上一篇文章后读者朋友的推荐),旧的免费PDF阅读软件可以进行基于文本的PDF文件注释并记笔记。这里推荐大家使用。
同样,搜索关键词后,会出现一个关键词的列表。比如在学习DAX的过程中,如果想像参考书一样查找ALLSELECT函数的用法,可以搜索全文。这比使用搜索引擎查找要好得多。学习后,您还可以突出显示并做笔记。
结束语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。不用太羡慕python的网络爬虫。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境中,没有什么比 dotNET 开发更高效的了。再好的python,共享和交互也是一件头疼的事,但dotNET桌面开发自然是最大的优势。
在OFFICE环境下开发的优势就更详细了。其实本文的功能也可以移到Excel环境中无痛执行。以后有空再慢慢优化整个流程。
将 html 转换为 PDF 带来了极大的方便。该内容在互联网上,而不是您自己的数据,并且可能随时被删除和无法访问。压力下,肯定撑不了多久,所以我提前计划,先下载到本地,哈哈)。 查看全部
抓取网页生成电子书(如何快速上手,做出自己的网页不是技术要点?)
上一篇简单展示了我们将网页转成PDF的结果,特别适用于序列化的网页文章,组织成一本书。
本文也为大家简单讲解了技术要点,让大家快速上手,制作属于自己的电子书。
技术要点
一、 抓取网页并保存到本地
因为大部分网页都收录图片,所以很多网页都不是普通的静态网页。相应的内容是在浏览器加载过程中随着浏览器滚动条的滚动而加载的。
所以如果你只想简单地发送一个 URL 并返回一个 PDF 文件,它通常会失败。
使用代码控制浏览器,模拟浏览器的浏览操作。这是一个工具:selenium,我相信通常关注网络抓取的人对它很熟悉。
作者尝试搜索selenium+C#感兴趣的词,没想到selenium竟然是一个支持多语言的工具。百度自查的具体介绍,以下是百度百科介绍的简单截取。
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
所以,不要犯错,犯一般错误,认为python很容易用于网页抓取,你可以使用C#中的常用工具。当前的工具不仅限于实现一种语言。我相信 dotNET 会变得更加开源。当生态越来越好时,会出现更多方便的工具。
在 C# 代码中,Seenium 用于控制浏览器行为,在浏览器上打开不同的 URL,然后下载相应的文件。
因为我们想要图形版本的数据,而不仅仅是一些结构化的数据,最简单的方法是将类似浏览器行为的CTRL+S作为网页保存到本地。也用代码来模拟发送键和击键的方式。有兴趣的读者可以参考以下代码。
网上同样的就是python的实现,作者简单的修改成了dotNET版本。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]
public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);
private static void SaveHtml(ChromeDriver driver)
{
uint KEYEVENTF_KEYUP = 2;
keybd_event(Keys.ControlKey, 0, 0, 0);
keybd_event(Keys.S, 0, 0, 0);
keybd_event(Keys.ControlKey, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(3000);
keybd_event(Keys.Enter, 0, 0, 0);
keybd_event(Keys.Enter, 0, KEYEVENTF_KEYUP, 0);
Thread.Sleep(5000);
driver.Close();
driver.Quit();
}
二、将多个网页保存为PDF
虽然WORD也可以用来打开网页,但估计WORD是用IE技术渲染网页的,很多功能无法恢复。所以直接转PDF更科学。
PDF 的另一个好处是几乎所有的 PDF 阅读器都可以随意打开和显示原创效果。虽然 PDF 的编辑能力非常有限,但我们的目的主要是为了阅读,所以将 HTML 转换为 PDF 是非常理想的。
它可以将多个网页转换为一个PDF文件,阅读时更加连贯。
网页转PDF的工具是wkhtmltopdf,也是一个命令行工具,可以多种语言调用。当然,dotNET 调用是没有问题的,但是为了更好的体验,还是应该在 PowerShell 上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都在下一步完成,最后记得设置环境变量,让CMD和PowerShell识别。
平时可以看到的python的html to pdf功能,其实底层也是用wkhtmltopdf完成的。
要将多个网页转换为PDF,需要考虑排序问题。这时候使用Excel催化剂可以轻松实现HTML排版顺序问题。
一般来说,我们是按顺序下载网页的,所以简单的使用Excel Catalyst的遍历文件功能来遍历文件信息,在Excel上做一个排序处理,手动调整一些特殊文件的顺序。
另一个自定义函数stringjoin可以快速将多个文件合并成一个字符串组合,用空格隔开,每条记录都要用双引号括起来。
打开我们的 PowerShell ISE 软件,它是 win10 自带的。其他系统也有,可以自行搜索相关教程打开。
相信很多读者也和作者有同感。他们觉得命令行很可怕。它是一系列代码,尤其是帮助文件。
事实上,它确实突破了心理恐惧。命令行工具和我们在Excel上写函数的原理都是一个函数名和各种参数,但是命令行可以有很多参数。
以下是我们如何在 PowerShell 上使用单个命令将多个 html 文件合并为一个 PDF 文件。
笔者还费了一番功夫阅读帮助文档,写出了更多命令的功能,比如添加页眉和页脚的功能。
开头的参数是全局参数。具体说明请参考官方文档。
全局参数写好后,摊开多个html文件,最后加上pdf文件的名字,弄的太多了。该文件使用相对路径。您需要将PowerShell的当前路径切换到html存储文件夹。切换命令是 CD。
终于,激动人心的时刻到了,可以顺利生成pdf文件了。
包括页眉和页脚信息,一个总共400多页的PDF电子书诞生了。
有兴趣的读者不妨将自己喜欢的网页相册制作成PDF文件,方便查阅。之前的错误是追求PDF阅读器的精简,现在我重新使用【福昕阅读器】(感谢上一篇文章后读者朋友的推荐),旧的免费PDF阅读软件可以进行基于文本的PDF文件注释并记笔记。这里推荐大家使用。
同样,搜索关键词后,会出现一个关键词的列表。比如在学习DAX的过程中,如果想像参考书一样查找ALLSELECT函数的用法,可以搜索全文。这比使用搜索引擎查找要好得多。学习后,您还可以突出显示并做笔记。
结束语
在研究本文功能实现的过程中,我重新发现了dotNET的强大。不用太羡慕python的网络爬虫。它在 dotNET 中仍然非常有用。
同时,在 Windows 环境中,没有什么比 dotNET 开发更高效的了。再好的python,共享和交互也是一件头疼的事,但dotNET桌面开发自然是最大的优势。
在OFFICE环境下开发的优势就更详细了。其实本文的功能也可以移到Excel环境中无痛执行。以后有空再慢慢优化整个流程。
将 html 转换为 PDF 带来了极大的方便。该内容在互联网上,而不是您自己的数据,并且可能随时被删除和无法访问。压力下,肯定撑不了多久,所以我提前计划,先下载到本地,哈哈)。
抓取网页生成电子书(如何使用PDFsamBasic来从PDF文件中的简短指南 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-08 00:06
)
从 PDF 文件中提取页面。通过生成只收录您需要的页面的文件,您可以批量从单个或多个文件中提取页面。PDFsam Basic 是一款适用于 Windows、Mac 和 Linux 的免费开源软件。
下载 PDFsam Basic
确保您的 PDF 文件安全且私密。通过我们的应用程序,您无需将 PDF 文件上传到任何第三方服务,所有处理都在您的计算机本地进行,您的文件将保持安全和私密
关于如何使用 PDFsam Basic 从 PDF 文件中提取页面的简短指南
选择PDF文件
拖放要从中提取页面的 PDF 文件,或单击添加以添加文件。加密的 PDF 文件将在其左侧显示一个图标。单击锁定图标并填写解锁密码。
设置
设置要从所选 PDF 文件中提取的页面。您可以将它们设置为逗号分隔的数字或页面范围,例如:2,5,6-13,25.
目标文件夹
选择生成 PDF 文件的位置。
自定义文件的名称
输出文件的名称可以使用特殊关键字作为占位符,并在执行过程中使用动态值进行替换。例如,可以是 [File Number] 为文件名添加递增计数器值,或 [Time Stamp] 将当前时间戳添加到文件名。右键单击该字段以查找所有可用关键字。
如何自定义文件名
提取页面
正确设置所有选项后,单击运行开始执行。如果没有错误发生,进度条会一直增长直到完全着色,然后友好的叮当声会告诉你你的PDF文件已经准备好了。
查看全部
抓取网页生成电子书(如何使用PDFsamBasic来从PDF文件中的简短指南
)
从 PDF 文件中提取页面。通过生成只收录您需要的页面的文件,您可以批量从单个或多个文件中提取页面。PDFsam Basic 是一款适用于 Windows、Mac 和 Linux 的免费开源软件。
下载 PDFsam Basic
确保您的 PDF 文件安全且私密。通过我们的应用程序,您无需将 PDF 文件上传到任何第三方服务,所有处理都在您的计算机本地进行,您的文件将保持安全和私密
关于如何使用 PDFsam Basic 从 PDF 文件中提取页面的简短指南
选择PDF文件
拖放要从中提取页面的 PDF 文件,或单击添加以添加文件。加密的 PDF 文件将在其左侧显示一个图标。单击锁定图标并填写解锁密码。
设置
设置要从所选 PDF 文件中提取的页面。您可以将它们设置为逗号分隔的数字或页面范围,例如:2,5,6-13,25.
目标文件夹
选择生成 PDF 文件的位置。
自定义文件的名称
输出文件的名称可以使用特殊关键字作为占位符,并在执行过程中使用动态值进行替换。例如,可以是 [File Number] 为文件名添加递增计数器值,或 [Time Stamp] 将当前时间戳添加到文件名。右键单击该字段以查找所有可用关键字。
如何自定义文件名
提取页面
正确设置所有选项后,单击运行开始执行。如果没有错误发生,进度条会一直增长直到完全着色,然后友好的叮当声会告诉你你的PDF文件已经准备好了。
抓取网页生成电子书(使用python爬虫实现把《廖雪峰的Python教程》转换成PDF的方法和代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-07 03:27
本文与您分享使用Python crawler将廖雪峰的Python教程转换为PDF的方法和代码。如果你需要它,你可以参考它
似乎没有比使用python更好的方法来编写爬虫程序。python社区提供了许多让您眼花缭乱的爬虫工具。可以直接使用的各种库可以在几分钟内编写一个爬虫程序。今天,我想写一个爬虫程序,把廖雪峰的Python程序下载到PDF电子书中,供离线阅读
在编写爬虫程序之前,让我们首先分析网站1的页面结构。页面左侧是教程的目录大纲。每一个URL对应于右边的“@ K7@”,“@ K7@”的标题位于右上方,“@ K7@”的主体部分位于中间。正文内容是我们关注的焦点。我们想要爬升的数据是所有网页的主体部分,下面是用户的评论区。评论区对我们来说是无用的,所以我们可以忽略它
工具准备
一旦理解了网站的基本结构,就可以开始准备爬虫程序所依赖的工具包。请求和漂亮的汤是爬虫的两个工件。Reuqests用于网络请求,Beauty soup用于操作HTML数据。有了这两架航天飞机,我们可以快速工作。我们不需要像scratch这样的爬行动物框架。这有点像在小程序中用牛刀杀鸡。此外,由于它是将HTML文件转换为PDF,因此还需要相应的库支持。Wkhtmltopdf是一个非常好的工具。它可以将HTML转换为适合多平台的PDF。Pdfkit是wkhtmltopdf的python包。首先,安装以下依赖项包
接下来,安装wkhtmltopdfip安装请求
pip安装美化组
pip安装pdfkit
安装wkhtmltopdf
windows平台直接从wkhtmltopdf官方网站2下载稳定版本进行安装。安装完成后,将程序的执行路径添加到系统环境的$path变量中。否则,如果pdfkit找不到wkhtmltopdf,则会出现错误“找不到wkhtmltopdf可执行文件”。Ubuntu和CentOS可以直接从命令行$sudo apt get install wkhtmltopdf#Ubuntu安装
$sudo yum intsall wkhtmltopdf#centos
爬虫实现
当一切准备就绪时,您可以编写代码,但在编写代码之前,您应该先清理头脑。该程序的目的是在本地保存与所有URL对应的HTML正文,然后使用pdfkit将这些文件转换为PDF文件。让我们把任务分成两部分。首先,在本地保存与URL对应的HTML正文,然后查找所有URL以执行相同的操作
使用Chrome浏览器查找页面主体部分的标签,然后按F12查找与主体对应的p标签:
,这是网页的正文内容。在本地加载整个页面的请求后,可以使用Beauty soup操作HTML的DOM元素来提取正文内容
具体实现代码如下:use soup.find uuAll函数查找body标记并将body部分的内容保存到a.html文件中。def解析url到html(url):
response=requests.get(url)
soup=BeautifulSoup(response.content,“html5lib”)
body=soup.find uAll(class=“x-wiki-content”)[0]
html=str(正文)
以open(“a.html”,“wb”)作为f:
f、 编写(html)
第二步是解析页面左侧的所有URL。同样,找到左侧的菜单选项卡
具体代码实现了逻辑:页面上有两个类属性UK NAV UK NAV side,第二个是真实目录列表。所有URL都被获取,并且在第一步中还编写了URL到HTML的函数。def get_uuURL_uuu列表():
“”“
获取所有URL目录的列表
“”“
response=requests.get(“”)
soup=BeautifulSoup(response.content,“html5lib”)
menu_uTag=soup.find_uuAll(class=“uk nav uk nav side”)[1]
URL=[]
对于菜单中的li uTag.find uuAll(“li”): 查看全部
抓取网页生成电子书(使用python爬虫实现把《廖雪峰的Python教程》转换成PDF的方法和代码)
本文与您分享使用Python crawler将廖雪峰的Python教程转换为PDF的方法和代码。如果你需要它,你可以参考它
似乎没有比使用python更好的方法来编写爬虫程序。python社区提供了许多让您眼花缭乱的爬虫工具。可以直接使用的各种库可以在几分钟内编写一个爬虫程序。今天,我想写一个爬虫程序,把廖雪峰的Python程序下载到PDF电子书中,供离线阅读
在编写爬虫程序之前,让我们首先分析网站1的页面结构。页面左侧是教程的目录大纲。每一个URL对应于右边的“@ K7@”,“@ K7@”的标题位于右上方,“@ K7@”的主体部分位于中间。正文内容是我们关注的焦点。我们想要爬升的数据是所有网页的主体部分,下面是用户的评论区。评论区对我们来说是无用的,所以我们可以忽略它
工具准备
一旦理解了网站的基本结构,就可以开始准备爬虫程序所依赖的工具包。请求和漂亮的汤是爬虫的两个工件。Reuqests用于网络请求,Beauty soup用于操作HTML数据。有了这两架航天飞机,我们可以快速工作。我们不需要像scratch这样的爬行动物框架。这有点像在小程序中用牛刀杀鸡。此外,由于它是将HTML文件转换为PDF,因此还需要相应的库支持。Wkhtmltopdf是一个非常好的工具。它可以将HTML转换为适合多平台的PDF。Pdfkit是wkhtmltopdf的python包。首先,安装以下依赖项包
接下来,安装wkhtmltopdfip安装请求
pip安装美化组
pip安装pdfkit
安装wkhtmltopdf
windows平台直接从wkhtmltopdf官方网站2下载稳定版本进行安装。安装完成后,将程序的执行路径添加到系统环境的$path变量中。否则,如果pdfkit找不到wkhtmltopdf,则会出现错误“找不到wkhtmltopdf可执行文件”。Ubuntu和CentOS可以直接从命令行$sudo apt get install wkhtmltopdf#Ubuntu安装
$sudo yum intsall wkhtmltopdf#centos
爬虫实现
当一切准备就绪时,您可以编写代码,但在编写代码之前,您应该先清理头脑。该程序的目的是在本地保存与所有URL对应的HTML正文,然后使用pdfkit将这些文件转换为PDF文件。让我们把任务分成两部分。首先,在本地保存与URL对应的HTML正文,然后查找所有URL以执行相同的操作
使用Chrome浏览器查找页面主体部分的标签,然后按F12查找与主体对应的p标签:
,这是网页的正文内容。在本地加载整个页面的请求后,可以使用Beauty soup操作HTML的DOM元素来提取正文内容
具体实现代码如下:use soup.find uuAll函数查找body标记并将body部分的内容保存到a.html文件中。def解析url到html(url):
response=requests.get(url)
soup=BeautifulSoup(response.content,“html5lib”)
body=soup.find uAll(class=“x-wiki-content”)[0]
html=str(正文)
以open(“a.html”,“wb”)作为f:
f、 编写(html)
第二步是解析页面左侧的所有URL。同样,找到左侧的菜单选项卡
具体代码实现了逻辑:页面上有两个类属性UK NAV UK NAV side,第二个是真实目录列表。所有URL都被获取,并且在第一步中还编写了URL到HTML的函数。def get_uuURL_uuu列表():
“”“
获取所有URL目录的列表
“”“
response=requests.get(“”)
soup=BeautifulSoup(response.content,“html5lib”)
menu_uTag=soup.find_uuAll(class=“uk nav uk nav side”)[1]
URL=[]
对于菜单中的li uTag.find uuAll(“li”):
抓取网页生成电子书(如何将网页上显示的内容导出为pdf文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-10-06 20:01
我们都知道一个普通的网页是由html+css+js组成的,它的本质是由一段代码编译而成的。图片是由一堆二进制数据组成的,我们如何将网页显示的内容导出为我们想要的图片或者pdf呢?博主很无聊,在github上闲逛,发现了一个有趣的库pyppeteer,满足了我需要的导出需求。接下来,我们来看看它是如何运作的:
安装所需的库
pip install pillow
pip install reportlab
pip install pyppeteer
导出为图片
import os
import asyncio
from pyppeteer import launch
async def save_image(url, img_path):
"""
导出图片
:param url: 在线网页的url
:param img_path: 图片存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
await page.screenshot({'path': img_path, 'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
img_path = os.path.join(os.getcwd(), "example.png")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_image(url, img_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.png的文件,就是我们导出的图片文件!
将整个页面导出为pdf
import os
import asyncio
from pyppeteer import launch
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
width: 纸张宽度,带单位的字符串
height: 纸张高度,带单位的字符串
'''
await page.pdf({'path': pdf_path, 'width': '730px', 'height': '2600px'})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.pdf的文件,就是我们导出的pdf文件!但是,这种出口有一个缺点。它将整个网页导出为 pdf。不支持图片等位置参数。可以截取部分区域进行导出!因此,我稍微修改了代码,请参阅下面的“将区域导出为pdf”!
将区域导出为 pdf
import os
import asyncio
from io import BytesIO
from PIL import Image
from pyppeteer import launch
from reportlab.pdfgen.canvas import Canvas
from reportlab.lib.utils import ImageReader
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
img_data = await page.screenshot({'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
im = Image.open(BytesIO(img_data))
page_width, page_height = im.size
c = Canvas(pdf_path, pagesize=(page_width, page_height))
c.drawImage(ImageReader(im), 0, 0)
c.save()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
这样我们就可以进行区域截取,导出pdf文件了!
值得注意的是,由于网络、配置以及各种不可控因素,上述方法都会有一定程度的导出错误,所以建议添加重试机制!
更多pyppeteer操作请看:
从此,结束了~~~ 查看全部
抓取网页生成电子书(如何将网页上显示的内容导出为pdf文件?)
我们都知道一个普通的网页是由html+css+js组成的,它的本质是由一段代码编译而成的。图片是由一堆二进制数据组成的,我们如何将网页显示的内容导出为我们想要的图片或者pdf呢?博主很无聊,在github上闲逛,发现了一个有趣的库pyppeteer,满足了我需要的导出需求。接下来,我们来看看它是如何运作的:
安装所需的库
pip install pillow
pip install reportlab
pip install pyppeteer
导出为图片
import os
import asyncio
from pyppeteer import launch
async def save_image(url, img_path):
"""
导出图片
:param url: 在线网页的url
:param img_path: 图片存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
await page.screenshot({'path': img_path, 'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
img_path = os.path.join(os.getcwd(), "example.png")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_image(url, img_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.png的文件,就是我们导出的图片文件!
将整个页面导出为pdf
import os
import asyncio
from pyppeteer import launch
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
path: 图片存放位置
width: 纸张宽度,带单位的字符串
height: 纸张高度,带单位的字符串
'''
await page.pdf({'path': pdf_path, 'width': '730px', 'height': '2600px'})
await browser.close()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
执行完成后,不出意外的话,在当前目录下会生成一个名为example.pdf的文件,就是我们导出的pdf文件!但是,这种出口有一个缺点。它将整个网页导出为 pdf。不支持图片等位置参数。可以截取部分区域进行导出!因此,我稍微修改了代码,请参阅下面的“将区域导出为pdf”!
将区域导出为 pdf
import os
import asyncio
from io import BytesIO
from PIL import Image
from pyppeteer import launch
from reportlab.pdfgen.canvas import Canvas
from reportlab.lib.utils import ImageReader
async def save_pdf(url, pdf_path):
"""
导出pdf
:param url: 在线网页的url
:param pdf_path: pdf存放位置
:return:
"""
browser = await launch()
page = await browser.newPage()
# 加载指定的网页url
await page.goto(url)
# 设置网页显示尺寸
await page.setViewport({'width': 1920, 'height': 1080})
'''
clip: 位置与图片尺寸信息
x: 网页截图的x坐标
y: 网页截图的y坐标
width: 图片宽度
height: 图片高度
'''
img_data = await page.screenshot({'clip': {'x': 457, 'y': 70, 'width': 730, 'height': 2600}})
im = Image.open(BytesIO(img_data))
page_width, page_height = im.size
c = Canvas(pdf_path, pagesize=(page_width, page_height))
c.drawImage(ImageReader(im), 0, 0)
c.save()
if __name__ == '__main__':
url = "https://www.jianshu.com/p/13dadc463f40"
pdf_path = os.path.join(os.getcwd(), "example.pdf")
loop = asyncio.get_event_loop()
loop.run_until_complete(save_pdf(url, pdf_path))
这样我们就可以进行区域截取,导出pdf文件了!
值得注意的是,由于网络、配置以及各种不可控因素,上述方法都会有一定程度的导出错误,所以建议添加重试机制!
更多pyppeteer操作请看:
从此,结束了~~~
抓取网页生成电子书( 之前配置生成器:强大!Nginx配置在线一键生成“神器” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-06 19:34
之前配置生成器:强大!Nginx配置在线一键生成“神器”
)
之前农民工也给大家介绍过一个Nginx配置生成器:强大!Nginx配置在线一键生成“神器”,不太了解的可以去看看。
最近农民工发现了一个好用的网页版开源工具,它的功能也是Nginx配置生成器,非常强大,方便实用。它是:NginxWebUI。
NginxWebUI 介绍
NginxWebUI 是一个方便实用的 nginx web 配置工具。可以使用WebUI配置Nginx的各种功能,包括端口转发、反向代理、ssl证书配置、负载均衡等,最后生成“nginx.conf”配置文件并覆盖目标配置文件,完成Nginx的功能配置nginx。
项目地址:
官方 网站:
<p>NginxWebUI 功能说明 NginxWebUI 有两种安装方式安装: 查看全部
抓取网页生成电子书(
之前配置生成器:强大!Nginx配置在线一键生成“神器”
)
之前农民工也给大家介绍过一个Nginx配置生成器:强大!Nginx配置在线一键生成“神器”,不太了解的可以去看看。
最近农民工发现了一个好用的网页版开源工具,它的功能也是Nginx配置生成器,非常强大,方便实用。它是:NginxWebUI。
NginxWebUI 介绍
NginxWebUI 是一个方便实用的 nginx web 配置工具。可以使用WebUI配置Nginx的各种功能,包括端口转发、反向代理、ssl证书配置、负载均衡等,最后生成“nginx.conf”配置文件并覆盖目标配置文件,完成Nginx的功能配置nginx。
项目地址:
官方 网站:
<p>NginxWebUI 功能说明 NginxWebUI 有两种安装方式安装:
抓取网页生成电子书(之前备份专家配合Firefox+插件Firebug批量下载博客文章豆约翰博客专家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-05 10:09
博客批量下载制作电子书方法1 前言
相信很多朋友都知道“左岸阅读”这个博客,作者采集了很多优秀的文章。大概在年初接触到这个网站,非常非常喜欢。文章 非常符合我的口味。因为不喜欢在网络上浏览文章,所以一般做成电子书后在kindle或手机上阅读。这样记笔记非常方便,便于复习和采集。以前用kindle的push和calibre的新闻抓取功能制作电子书非常方便。唯一的缺点就是只能抓取最新发布的文章,之前的老文章无法抓取。. 于是,我充分发挥了爱折腾的本能,经过多日的摸索,总结,并参考了很多以前的经验,我终于成功了。方法比较复杂,折腾起来很累,在这里,分享给有需要的朋友。
2 需要准备的软件
1)doujohn博客备份专家V2.6
2)Firefox+插件Firebug
3)epubBuilder 绿色版
需要说明的是,epubBuilder 不是免费软件,但是绿色版可以在网上下载,完全可以使用。
3 具体步骤3.1 使用豆约翰博客备份专家配合火狐+插件Firebug批量下载博客文章
Doujohn博客备份专家是一款完全免费、功能强大的博客备份工具、博客电子书(PDF、CHM和TXT)生成工具、博客文章离线浏览工具、漂亮的软件界面、支持多个主流博客网站(Qzone ,百度空间,新浪博客,网易博客,豆瓣日记,天涯博客,19楼,博客园,和讯博客,CSDN博客,搜狐博客,51CTO博客)。
但最重要的是该软件支持从独立站点爬取博客。《左岸阅读》是一个独立站点,但是配置起来确实有点麻烦。这个配置过程花了我很多时间,我什至想放弃。
关于独立站点的配置,官网上有详细的介绍,这里不再赘述,直接贴出网址:
《左岸阅读》文章数量庞大,每月可排序。我以2013年1月的文章下载为例,贴出配置,如图。
配置完成后,点击“开始下载”即可批量下载博客。理论上,根据软件说明,需要评估推广软件下载所有页面(本例中为起始页1到结束页3),但经过笔者的实验发现,即使是评测不能批量下载,第一次只能在一个页面下载所有文章,上图配置下,只能下载第1页文章,不过没关系。反正只有3页,反正一页一页下载就完了可以下载文章的第二页,然后修改为3,
3.2 将下载的文章制作成chm文件
Doujohn的博客备份专家可以将下载的文章制作成文件,格式可以是pdf、chm、txt等。作者最初使用的是pdf格式,但发现在转换的过程中会出现换行到电子书。尝试了各种方法后都没有解决,只能以chm格式保存。
3.3 将保存的chm文件制作成epub电子书
epubBuilder是口袋书园开发的一款epub电子书制作神器,支持导入Txt、epub、html、chm、snb等源文件。
<p>打开软件,导入上面制作的chm。看完你会发现下面的文章会少了一个标题,没关系,工具选项卡里有个“使用第一行作为目录名”,在左边选择边目录栏批量丢失目录(shift+左键点击),点击“使用第一行作为目录名”,软件会自动将每个文章的第一行作为 查看全部
抓取网页生成电子书(之前备份专家配合Firefox+插件Firebug批量下载博客文章豆约翰博客专家)
博客批量下载制作电子书方法1 前言
相信很多朋友都知道“左岸阅读”这个博客,作者采集了很多优秀的文章。大概在年初接触到这个网站,非常非常喜欢。文章 非常符合我的口味。因为不喜欢在网络上浏览文章,所以一般做成电子书后在kindle或手机上阅读。这样记笔记非常方便,便于复习和采集。以前用kindle的push和calibre的新闻抓取功能制作电子书非常方便。唯一的缺点就是只能抓取最新发布的文章,之前的老文章无法抓取。. 于是,我充分发挥了爱折腾的本能,经过多日的摸索,总结,并参考了很多以前的经验,我终于成功了。方法比较复杂,折腾起来很累,在这里,分享给有需要的朋友。
2 需要准备的软件
1)doujohn博客备份专家V2.6
2)Firefox+插件Firebug
3)epubBuilder 绿色版
需要说明的是,epubBuilder 不是免费软件,但是绿色版可以在网上下载,完全可以使用。
3 具体步骤3.1 使用豆约翰博客备份专家配合火狐+插件Firebug批量下载博客文章
Doujohn博客备份专家是一款完全免费、功能强大的博客备份工具、博客电子书(PDF、CHM和TXT)生成工具、博客文章离线浏览工具、漂亮的软件界面、支持多个主流博客网站(Qzone ,百度空间,新浪博客,网易博客,豆瓣日记,天涯博客,19楼,博客园,和讯博客,CSDN博客,搜狐博客,51CTO博客)。
但最重要的是该软件支持从独立站点爬取博客。《左岸阅读》是一个独立站点,但是配置起来确实有点麻烦。这个配置过程花了我很多时间,我什至想放弃。
关于独立站点的配置,官网上有详细的介绍,这里不再赘述,直接贴出网址:
《左岸阅读》文章数量庞大,每月可排序。我以2013年1月的文章下载为例,贴出配置,如图。
配置完成后,点击“开始下载”即可批量下载博客。理论上,根据软件说明,需要评估推广软件下载所有页面(本例中为起始页1到结束页3),但经过笔者的实验发现,即使是评测不能批量下载,第一次只能在一个页面下载所有文章,上图配置下,只能下载第1页文章,不过没关系。反正只有3页,反正一页一页下载就完了可以下载文章的第二页,然后修改为3,
3.2 将下载的文章制作成chm文件
Doujohn的博客备份专家可以将下载的文章制作成文件,格式可以是pdf、chm、txt等。作者最初使用的是pdf格式,但发现在转换的过程中会出现换行到电子书。尝试了各种方法后都没有解决,只能以chm格式保存。
3.3 将保存的chm文件制作成epub电子书
epubBuilder是口袋书园开发的一款epub电子书制作神器,支持导入Txt、epub、html、chm、snb等源文件。
<p>打开软件,导入上面制作的chm。看完你会发现下面的文章会少了一个标题,没关系,工具选项卡里有个“使用第一行作为目录名”,在左边选择边目录栏批量丢失目录(shift+左键点击),点击“使用第一行作为目录名”,软件会自动将每个文章的第一行作为
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-05 10:05
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(没有发生过),但你可以通过将关注的专栏导出到电子书来准备下雨天,这样你就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
抢列文章地址列表
抓取每篇文章的详细内容文章
导出 PDF
1. 获取列表
在之前的文章
爬虫必备工具,掌握它就解决一半问题
如何分析一个网页上的请求在里面有描述。 根据方法,我们可以使用开发者工具的Network功能找出栏目页面的请求来获取详细列表:
观察返回的结果,我们发现通过sum的值,可以获取到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否已经获取到所有的文章。
而中间就是我们需要的数据。因为可以拼写,所以没有保存在我们的代码中。
使用 while 循环直到 文章 的所有总和都被捕获并保存在一个文件中。
2. 抢 文章
有了文章的所有/,后面的爬取就很简单了。文章主要内容在标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加标签和属性之类的,我们要去掉才能正常显示。
至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf+pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
使用非常简单:
这样就完成了整列的导出。
不仅是知乎的栏目,几乎大部分的信息类型都是网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录后访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
更多视频课程、问答群等服务,请按号码内回复码操作 查看全部
抓取网页生成电子书(通过Python和爬虫,可以完成怎样的小工具?|知乎)
总有同学问,学了Python基础之后,不知道自己可以做些什么来提高。今天我就用一个小例子来告诉大家通过Python和爬虫可以完成什么样的小工具。
在知乎上,你一定关注过一些不错的专栏(比如Crossin的编程课堂)。但如果有一天,你最喜欢的受访者在网上被喷,你一怒之下删帖停止更新,你就看不到好内容了。虽然这是小概率事件(没有发生过),但你可以通过将关注的专栏导出到电子书来准备下雨天,这样你就可以离线阅读,而不必担心不小心删除帖子。
只需要工具和源码的可以拉到文章底部获取代码。
【最终效果】
运行程序,输入列的id,即网页地址上的路径:
之后程序会自动抓取列中的文章,并根据发布时间合并导出为pdf文件。
【实现思路】
本方案主要分为三部分:
抢列文章地址列表
抓取每篇文章的详细内容文章
导出 PDF
1. 获取列表
在之前的文章
爬虫必备工具,掌握它就解决一半问题
如何分析一个网页上的请求在里面有描述。 根据方法,我们可以使用开发者工具的Network功能找出栏目页面的请求来获取详细列表:
观察返回的结果,我们发现通过sum的值,可以获取到下一个列表请求的地址(相当于页面向下滚动的触发效果),判断是否已经获取到所有的文章。
而中间就是我们需要的数据。因为可以拼写,所以没有保存在我们的代码中。
使用 while 循环直到 文章 的所有总和都被捕获并保存在一个文件中。
2. 抢 文章
有了文章的所有/,后面的爬取就很简单了。文章主要内容在标签中。
需要花点功夫的是一些文字处理,比如原页面的图片效果,会添加标签和属性之类的,我们要去掉才能正常显示。
至此,所有的内容都已经抓取完毕,可以在本地读取了。
3. 导出 PDF
为了方便阅读,我们使用 wkhtmltopdf+pdfkit 将这些 HTML 文件打包成 PDF。
wkhtmltopdf是一个将HTML转PDF的工具,需要单独安装。详情请参阅其官方网站。
pdfkit 是为此工具打包的 Python 库,可以从 pip 安装:
使用非常简单:
这样就完成了整列的导出。
不仅是知乎的栏目,几乎大部分的信息类型都是网站,通过1.抓取列表2.抓取详细内容采集数据两步。所以这段代码只要稍加修改就可以用于许多其他的网站。只是有些网站需要登录后访问,所以需要在headers中设置cookie信息。另外,不同网站的请求接口、参数、限制都不一样,具体问题还是要具体问题具体分析。
这些爬虫的开发技巧可以在我们的爬虫实战课中学习。需要的请回复公众号中的实际爬虫
【源码下载】
获取知乎的专栏下载器源码,请在公众号(Crossin的编程课堂)回复关键字知乎
除了代码,还有本专栏打包好的PDF,欢迎阅读分享。
更多视频课程、问答群等服务,请按号码内回复码操作
抓取网页生成电子书( 《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-04 17:20
《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据
)
使用 Scrapy 抓取电子书
爬虫的想法
如何抓取数据,首先我们要看看从哪里获取,打开“修真小主播”页面,如下:
有一个目录选项卡。单击此选项卡可查看目录。使用浏览器的元素查看工具,我们可以定位到各章节的目录和相关信息。根据这些信息,我们可以抓取到特定页面:
获取章节地址
现在我们打开xzxzb.py文件,就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['http://qidian.com/'] def parse(self, response): pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在我们来编写代码处理目录数据,首先爬取小说首页获取目录列表:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract() print url pass
获取网页中的 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML xPath 查询。
这里我们使用 xPath。请自行研究相关知识。看上面的代码。首先我们通过ID获取目录框,获取类cf来获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:<br /> url = page.xpath('./child::a/attribute::href').extract()<br /> print url
这样,可以说是爬取章节路径的小爬虫写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候,我们的程序可能会出现以下错误:
…<br />ImportError: No module named win32api<br />…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']> ...
爬取章节路径的小爬虫是写出来的,但是我们的目的不止这些,我们会用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面。从章节页面我们需要获取标题和内容。
如果解析器方法用于章节信息爬取,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出这些内容:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['https://book.qidian.com/info/1010780117/'] def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) yield response.follow(url, callback=self.parse_chapter) pass def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() print title # print content pass
上一步我们得到了一个章节地址,它是输出内容的相对路径,所以我们使用yield response.follow(url, callback=self.parse_chapter),第二个参数是处理章节的回调函数页面,爬到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)<br />yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意 response.follow 直接返回一个Request实例,可以通过yield直接返回。
获取数据后,进行存储。由于我们想要的是一个html页面,我们可以通过标题来存储它。代码如下:
def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s.html' % (title) with open(filename, 'wb') as f: f.write(content.encode('utf-8')) pass
至此,我们已经成功抓取了我们的数据,但是还不能直接使用,需要进行排序和优化。
数据整理
首先,我们爬下来的章节页面的排序不是很好。如果人工分拣花费太多时间和精力;另外,章节内容收录很多额外的东西,阅读体验不好,需要优化内容布局和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以我们只需要在下载页面名称中加上一个序号即可。
但是保存网页的代码是回调函数,只有在处理目录时才能确定顺序。回调函数如何知道订单?因此,我们需要告诉回调函数处理章节的序号,并且需要向回调函数传递参数。修改后的代码如下所示:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() idx = page.xpath('./attribute::data-rid').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) req = response.follow(url, callback=self.parse_chapter) req.meta['idx'] = idx yield req pass def parse_chapter(self, response): idx = response.meta['idx'] title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s_%s.html' % (idx, title) cnt = '
%s %s'% (title, content) with open(filename,'wb') as f: f.write(cnt.encode('utf-8')) pass
使用 Sigil 制作电子书
加载 html 文件
要制作ePub电子书,我们首先通过Sigil将我们抓取到的文件加载到程序中,在添加文件对话框中,我们选择所有文件:
制作目录
当文件中存在HTML的h标签时,点击Generate Catalog按钮自动生成目录。我们已经在之前的数据捕获中自动添加了 h1 标签:
做封面
封面本质上是HTML,可以从页面中编辑或抓取,所以就交给你自己实现吧。
*免责声明:本文整理于网络,版权归原作者所有。如来源信息有误或侵权,请联系我们进行删除或授权。
我觉得不错,点击“我在看”转发
查看全部
抓取网页生成电子书(
《修真小主播》使用Scrapy抓取电子书爬虫思路怎么抓取数据
)
使用 Scrapy 抓取电子书
爬虫的想法
如何抓取数据,首先我们要看看从哪里获取,打开“修真小主播”页面,如下:
有一个目录选项卡。单击此选项卡可查看目录。使用浏览器的元素查看工具,我们可以定位到各章节的目录和相关信息。根据这些信息,我们可以抓取到特定页面:
获取章节地址
现在我们打开xzxzb.py文件,就是我们刚刚创建的爬虫:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['http://qidian.com/'] def parse(self, response): pass
start_urls 是目录地址,爬虫会自动爬取这个地址,然后在后面的解析中处理结果。现在我们来编写代码处理目录数据,首先爬取小说首页获取目录列表:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract() print url pass
获取网页中的 DOM 数据有两种方式,一种是使用 CSS 选择器,另一种是使用 XML xPath 查询。
这里我们使用 xPath。请自行研究相关知识。看上面的代码。首先我们通过ID获取目录框,获取类cf来获取目录列表:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li')
接下来遍历子节点,查询li标签中a子节点的href属性,最后打印出来:
for page in pages:<br /> url = page.xpath('./child::a/attribute::href').extract()<br /> print url
这样,可以说是爬取章节路径的小爬虫写好了。使用以下命令运行xzxzb爬虫查看结果:
scrapy crawl xzxzb
这时候,我们的程序可能会出现以下错误:
…<br />ImportError: No module named win32api<br />…
只需运行以下语句:
pip install pypiwin32
屏幕输出如下:
> ...> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2'][u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']> ...
爬取章节路径的小爬虫是写出来的,但是我们的目的不止这些,我们会用这些地址来爬取内容:
章节页面分析
接下来我们分析章节页面。从章节页面我们需要获取标题和内容。
如果解析器方法用于章节信息爬取,那么我们可以写一个爬取每个章节内容的方法,比如:parser_chapter,先看章节页面的具体情况:
可以看到,章节的全部内容在类名main-text-wrap的div标签中,标题是类名j_chapterName的h3标签,具体内容是类名的div标签读取内容 j_readContent。
尝试打印出这些内容:
# -*- coding: utf-8 -*-import scrapyclass XzxzbSpider(scrapy.Spider): name = 'xzxzb' allowed_domains = ['qidian.com'] start_urls = ['https://book.qidian.com/info/1010780117/'] def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) yield response.follow(url, callback=self.parse_chapter) pass def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() print title # print content pass
上一步我们得到了一个章节地址,它是输出内容的相对路径,所以我们使用yield response.follow(url, callback=self.parse_chapter),第二个参数是处理章节的回调函数页面,爬到章节页面后,我们解析页面并将标题保存到文件中。
next_page = response.urljoin(url)<br />yield scrapy.Request(next_page, callback=self.parse_chapter)
与使用 response.follow 不同,scrapy.Request 需要通过相对路径构造绝对路径。Response.follow 可以直接使用相对路径,所以不需要调用 urljoin 方法。
注意 response.follow 直接返回一个Request实例,可以通过yield直接返回。
获取数据后,进行存储。由于我们想要的是一个html页面,我们可以通过标题来存储它。代码如下:
def parse_chapter(self, response): title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s.html' % (title) with open(filename, 'wb') as f: f.write(content.encode('utf-8')) pass
至此,我们已经成功抓取了我们的数据,但是还不能直接使用,需要进行排序和优化。
数据整理
首先,我们爬下来的章节页面的排序不是很好。如果人工分拣花费太多时间和精力;另外,章节内容收录很多额外的东西,阅读体验不好,需要优化内容布局和可读性。
我们先对章节进行排序,因为目录中的章节列表是按顺序排列的,所以我们只需要在下载页面名称中加上一个序号即可。
但是保存网页的代码是回调函数,只有在处理目录时才能确定顺序。回调函数如何知道订单?因此,我们需要告诉回调函数处理章节的序号,并且需要向回调函数传递参数。修改后的代码如下所示:
def parse(self, response): pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@]/li') for page in pages: url = page.xpath('./child::a/attribute::href').extract_first() idx = page.xpath('./attribute::data-rid').extract_first() # yield scrapy.Request('https:' + url, callback=self.parse_chapter) req = response.follow(url, callback=self.parse_chapter) req.meta['idx'] = idx yield req pass def parse_chapter(self, response): idx = response.meta['idx'] title = response.xpath('//div[@]//h3[@]/text()').extract_first().strip() content = response.xpath('//div[@]//div[@]').extract_first().strip() # print title # print content filename = './down/%s_%s.html' % (idx, title) cnt = '
%s %s'% (title, content) with open(filename,'wb') as f: f.write(cnt.encode('utf-8')) pass
使用 Sigil 制作电子书
加载 html 文件
要制作ePub电子书,我们首先通过Sigil将我们抓取到的文件加载到程序中,在添加文件对话框中,我们选择所有文件:
制作目录
当文件中存在HTML的h标签时,点击Generate Catalog按钮自动生成目录。我们已经在之前的数据捕获中自动添加了 h1 标签:
做封面
封面本质上是HTML,可以从页面中编辑或抓取,所以就交给你自己实现吧。
*免责声明:本文整理于网络,版权归原作者所有。如来源信息有误或侵权,请联系我们进行删除或授权。
我觉得不错,点击“我在看”转发

