
抓取网页数据 php
抓取网页数据 php(利用phpxpath解析php网页中的数据获取方法进行web开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-07 05:01
抓取网页数据php使用selenium方法进行web开发时,在使用seleniumdriver对网页进行抓取时,如果不依赖于某个模块或库,只使用命令行接口的话,代码比较繁琐,且抓取效率相对较低。因此我们在php的代码中,在抓取网页数据时,可以使用一些工具将数据保存起来,写入mysql数据库中。使用mysql抓取图片时可以获取图片的尺寸,边框等信息。
今天带来的文章是利用phpxpath解析php网页中的数据,获取我们想要的内容,如:链接,图片等,并保存下来,下面一起来看看:importrequestsfrombs4importbeautifulsoupfrompymysqlimportmysqliteimportjsonfromlxmlimportetreedefload_file(url):filename='./libai/ued.php'#文件的路径try:r=requests.get(url,headers=headers).text.encode('utf-8')#解码print('请求成功')exceptexceptionase:print('请求失败')returnnonedefmain():url=';cat=img'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/48。2802。132safari/537。36'}r=requests。get(url,headers=headers)。text。encode('utf-8')u=r。textimg=mysqlite。userdb。
myimage('image',connection='keep-alive')f=open(u,'w')foriinrange(。
3):f。write(u。read())f。write('\n')img=img。contents。replace('','。png')#图片文件名reg=etree。etree。html('/')try:print('请求成功')exceptexceptionase:print('请求失败')f。write(r'\n')f。
write(r。text)f。close()defload_img(url):img=img。contents。replace('','。png')img_delete=[img。index()foriinrange(1,len(img))]#删除图片列表,返回列表delete=[img。contents[0]foriinrange(1,len(img_delete))]foriinrange(1,len(img_delete)+。
1):img_delete[i]=img_delete[i].group
1)returnimg_deletereturnimg从上面的代码可以看出,链接,图片等都存放在目录中,解析出图片的路径存入数据库即可。 查看全部
抓取网页数据 php(利用phpxpath解析php网页中的数据获取方法进行web开发)
抓取网页数据php使用selenium方法进行web开发时,在使用seleniumdriver对网页进行抓取时,如果不依赖于某个模块或库,只使用命令行接口的话,代码比较繁琐,且抓取效率相对较低。因此我们在php的代码中,在抓取网页数据时,可以使用一些工具将数据保存起来,写入mysql数据库中。使用mysql抓取图片时可以获取图片的尺寸,边框等信息。
今天带来的文章是利用phpxpath解析php网页中的数据,获取我们想要的内容,如:链接,图片等,并保存下来,下面一起来看看:importrequestsfrombs4importbeautifulsoupfrompymysqlimportmysqliteimportjsonfromlxmlimportetreedefload_file(url):filename='./libai/ued.php'#文件的路径try:r=requests.get(url,headers=headers).text.encode('utf-8')#解码print('请求成功')exceptexceptionase:print('请求失败')returnnonedefmain():url=';cat=img'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/48。2802。132safari/537。36'}r=requests。get(url,headers=headers)。text。encode('utf-8')u=r。textimg=mysqlite。userdb。
myimage('image',connection='keep-alive')f=open(u,'w')foriinrange(。
3):f。write(u。read())f。write('\n')img=img。contents。replace('','。png')#图片文件名reg=etree。etree。html('/')try:print('请求成功')exceptexceptionase:print('请求失败')f。write(r'\n')f。
write(r。text)f。close()defload_img(url):img=img。contents。replace('','。png')img_delete=[img。index()foriinrange(1,len(img))]#删除图片列表,返回列表delete=[img。contents[0]foriinrange(1,len(img_delete))]foriinrange(1,len(img_delete)+。
1):img_delete[i]=img_delete[i].group
1)returnimg_deletereturnimg从上面的代码可以看出,链接,图片等都存放在目录中,解析出图片的路径存入数据库即可。
抓取网页数据 php(【股票知识】小白练手的绝佳之选(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-04 10:30
这个题目选择先写代码再写文章,绝对可以用于页面元素分析,也需要对网站的数据加载做一些分析,得到最终的数据,我查到的两个数据源没有ip访问限制,质量有保证。绝对是小白修炼的绝佳选择。
郑重声明:本文仅用于学习和其他用途。
分析
首先,我们要爬取股票数据。您必须首先知道哪些股票可用。在这里,小编发现了一个网站,这个网站有一个股票代码列表:。
打开Chrome的开发者模式,一一选择股票代码。具体过程小编就不贴了,各位同学自行体会。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,循环取出每只股票的数据。
这个网站编辑已经找到了,同花顺,链接:。
想必所有聪明的同学都发现了这个链接中的000001就是股票代码。
接下来我们只需要拼接这个链接,就可以不断的获取到我们想要的数据了。
实战
首先先介绍一下这次实战用到的请求库和解析库:Requests和pyquery。数据存储终于登陆了Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list复制代码
把上面的链接作为参数传入,可以自己运行看看结果,这里就不贴结果了,有点长。. .
获取详细数据
详细数据看起来像是在页面上,但实际上并不存在。实际获取数据的地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001复制代码
至于怎么查,这次就不说了。还是希望各位想学爬行的同学可以自己动手,多找几次,自然找到路。
既然有了数据接口,我们先来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})复制代码
很明显,这个结果不是标准的json数据,而是JSONP返回的标准格式的数据。这里我们先对header和end进行处理,将其转化为标准的json数据,然后针对这个页面上的数据进行解析,最后将解析出的值写入到数据库中。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue复制代码
这里我们添加异常处理,因为这次爬取的数据比较多,很有可能会因为某些原因抛出异常。当然,我们不想在出现异常的时候中断数据的捕获,所以我们在这里添加了异常处理来继续捕获数据。
完整代码
我们稍微封装了一下代码,完成了这次实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()复制代码
结果
最后,编辑器用了大约15分钟,成功抓取了4600+条数据,但是没有显示结果。
示例代码
如有需要,可后台私信联系,会议休会 查看全部
抓取网页数据 php(【股票知识】小白练手的绝佳之选(一))
这个题目选择先写代码再写文章,绝对可以用于页面元素分析,也需要对网站的数据加载做一些分析,得到最终的数据,我查到的两个数据源没有ip访问限制,质量有保证。绝对是小白修炼的绝佳选择。
郑重声明:本文仅用于学习和其他用途。
分析
首先,我们要爬取股票数据。您必须首先知道哪些股票可用。在这里,小编发现了一个网站,这个网站有一个股票代码列表:。

打开Chrome的开发者模式,一一选择股票代码。具体过程小编就不贴了,各位同学自行体会。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,循环取出每只股票的数据。
这个网站编辑已经找到了,同花顺,链接:。
想必所有聪明的同学都发现了这个链接中的000001就是股票代码。
接下来我们只需要拼接这个链接,就可以不断的获取到我们想要的数据了。
实战
首先先介绍一下这次实战用到的请求库和解析库:Requests和pyquery。数据存储终于登陆了Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list复制代码
把上面的链接作为参数传入,可以自己运行看看结果,这里就不贴结果了,有点长。. .
获取详细数据
详细数据看起来像是在页面上,但实际上并不存在。实际获取数据的地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001复制代码
至于怎么查,这次就不说了。还是希望各位想学爬行的同学可以自己动手,多找几次,自然找到路。
既然有了数据接口,我们先来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})复制代码
很明显,这个结果不是标准的json数据,而是JSONP返回的标准格式的数据。这里我们先对header和end进行处理,将其转化为标准的json数据,然后针对这个页面上的数据进行解析,最后将解析出的值写入到数据库中。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue复制代码
这里我们添加异常处理,因为这次爬取的数据比较多,很有可能会因为某些原因抛出异常。当然,我们不想在出现异常的时候中断数据的捕获,所以我们在这里添加了异常处理来继续捕获数据。
完整代码
我们稍微封装了一下代码,完成了这次实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()复制代码
结果
最后,编辑器用了大约15分钟,成功抓取了4600+条数据,但是没有显示结果。
示例代码
如有需要,可后台私信联系,会议休会
抓取网页数据 php(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-04 10:28
我是小z
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少。可以通过编写自己的代码来实现,但这不是一个好主意。大锤?
目前市面上有一些比较成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
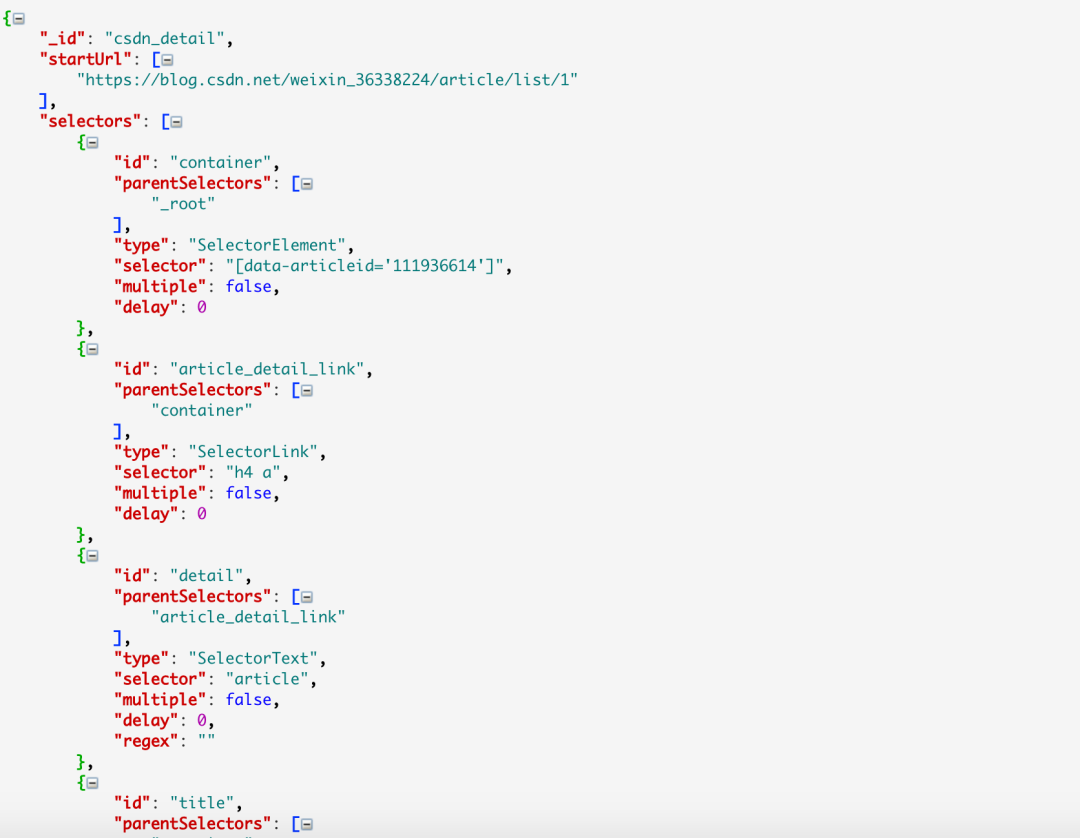
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的Selector 有很多,但是本文文章 只介绍了几个最常用、覆盖面最广的Selector。了解一两个之后,其他的原理都差不多,后面我会私下详细了解。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
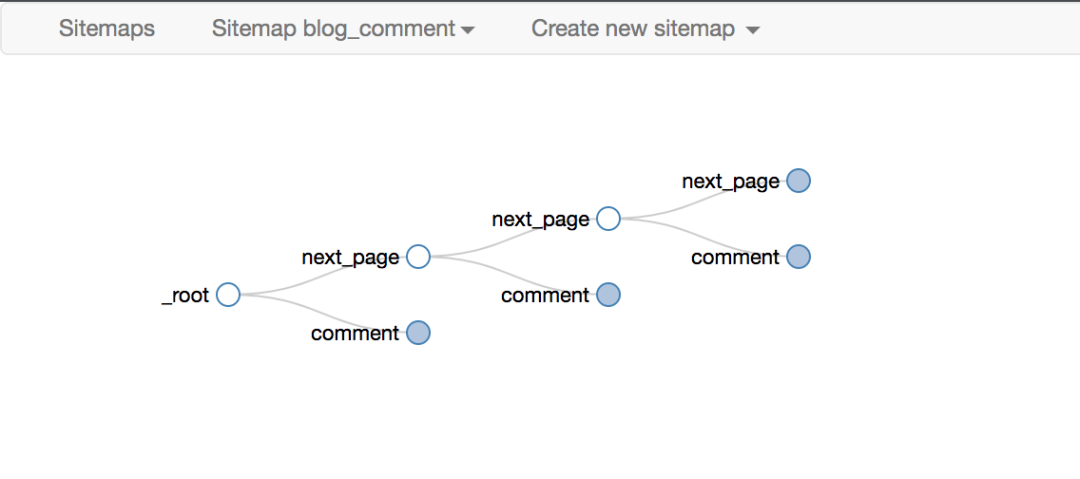
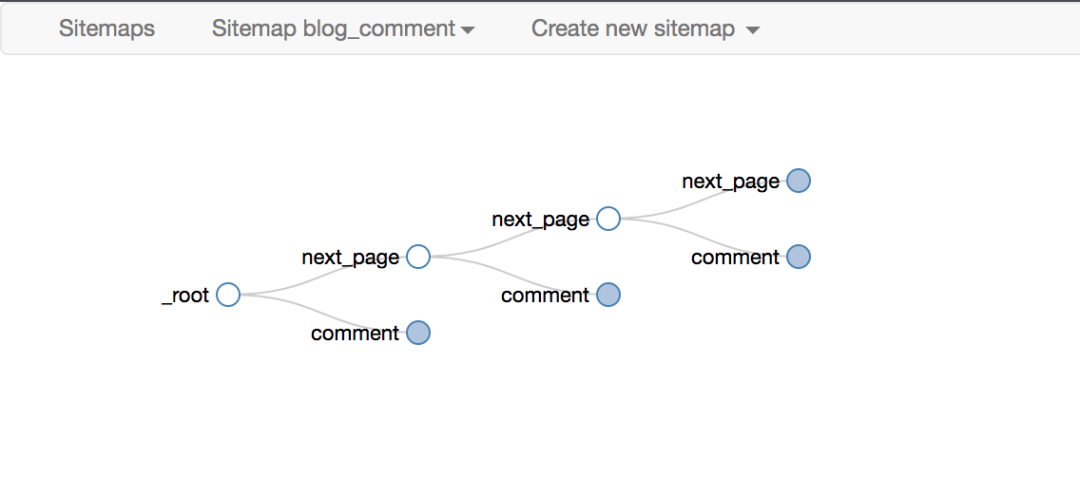
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
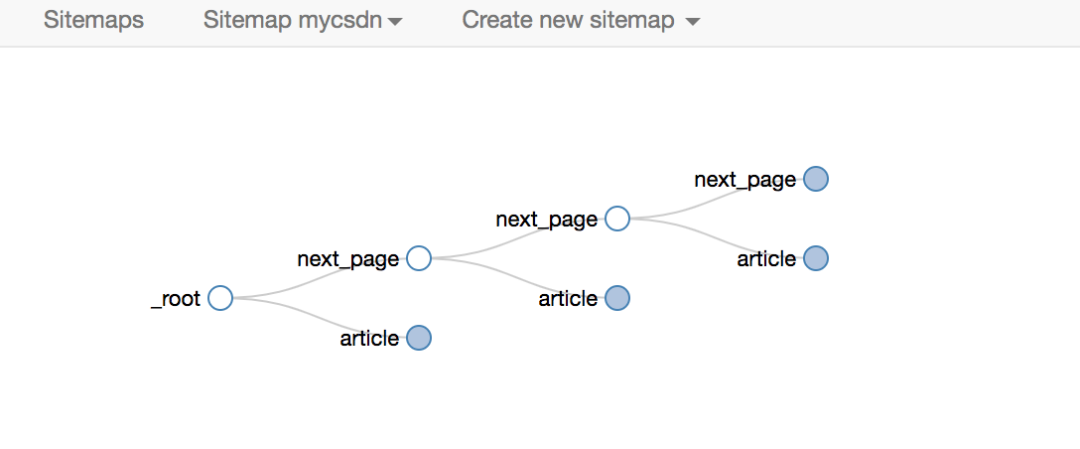
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
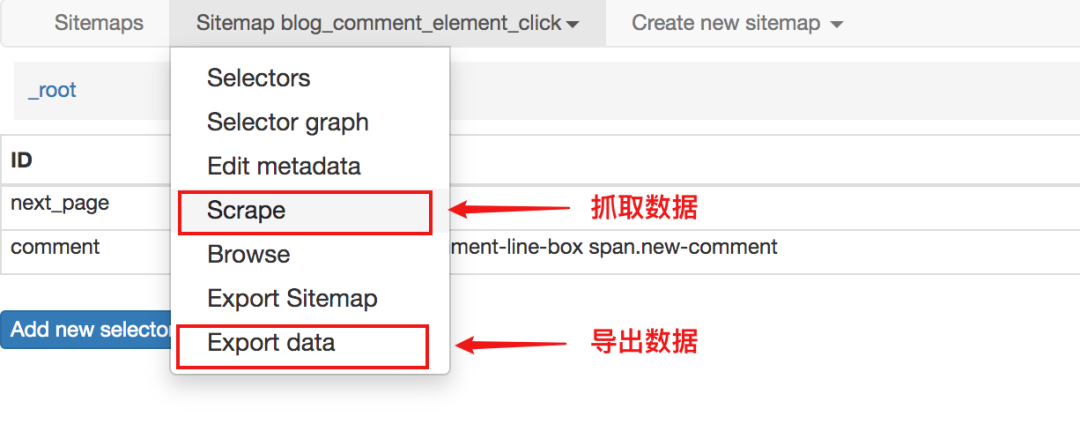
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
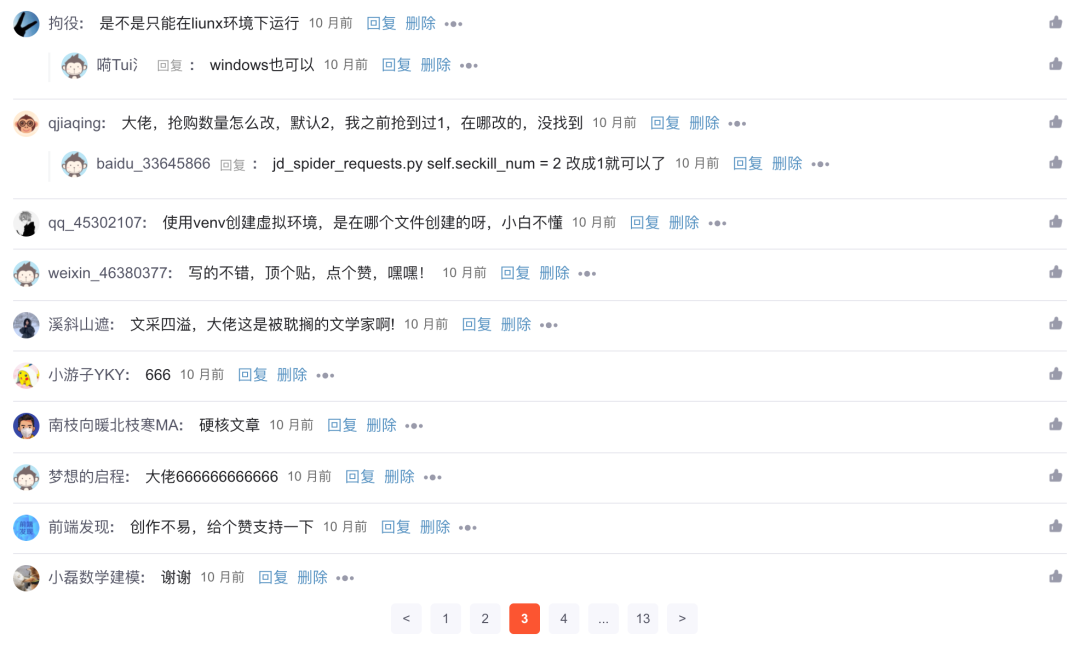
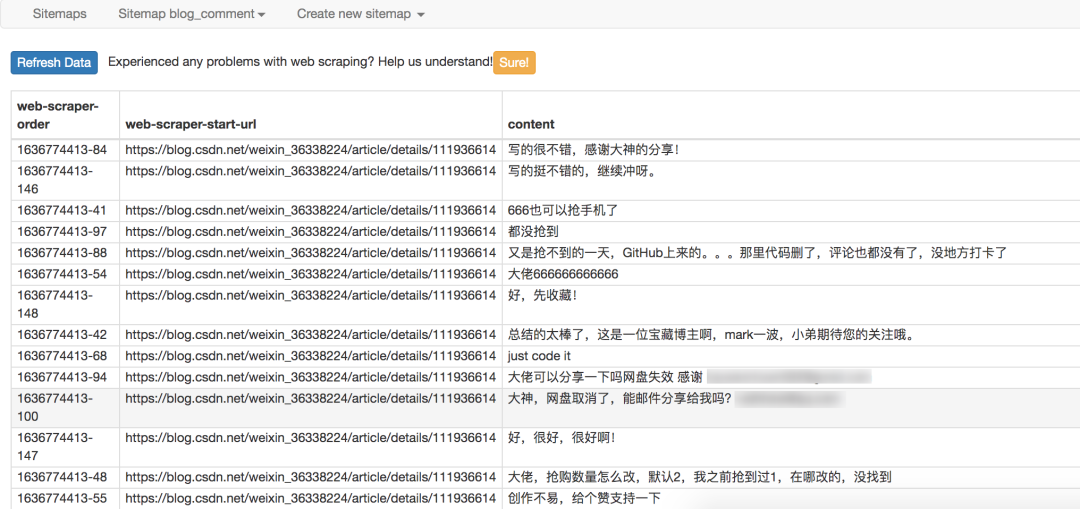
点击特定的 CSDN 博文,拉到底部查看评论区。
如果你的文章很火,当有很多同学的评论时,CSDN会分页展示,但是不管评论在哪一页,都属于同一篇文章文章@ >、当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
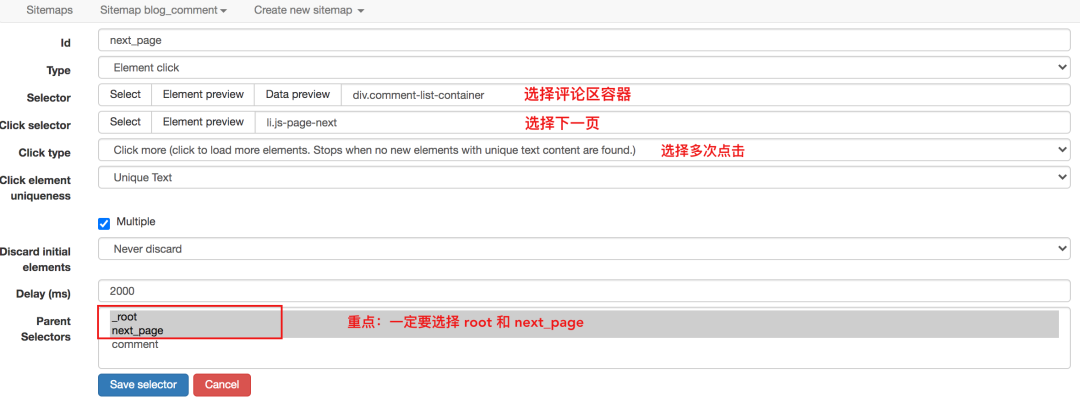
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
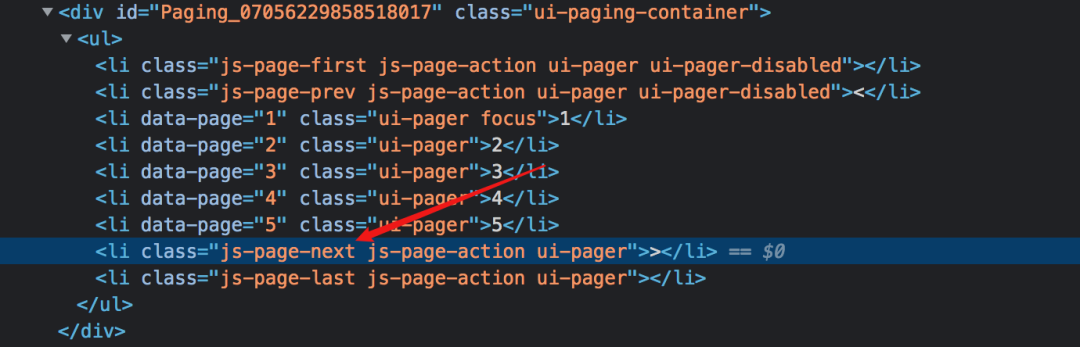
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
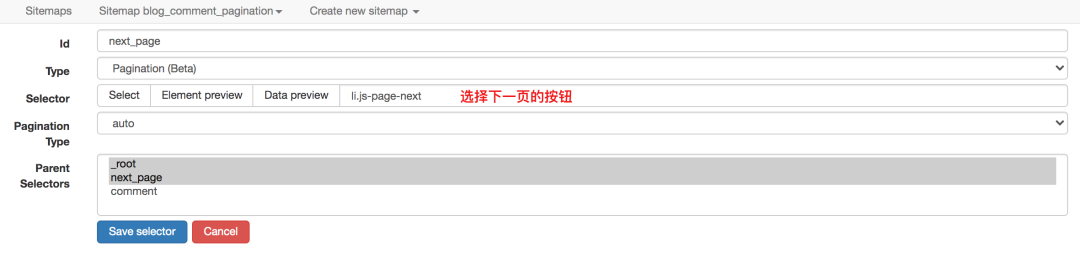
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:
要重新加载的页面的寻呼机抓取
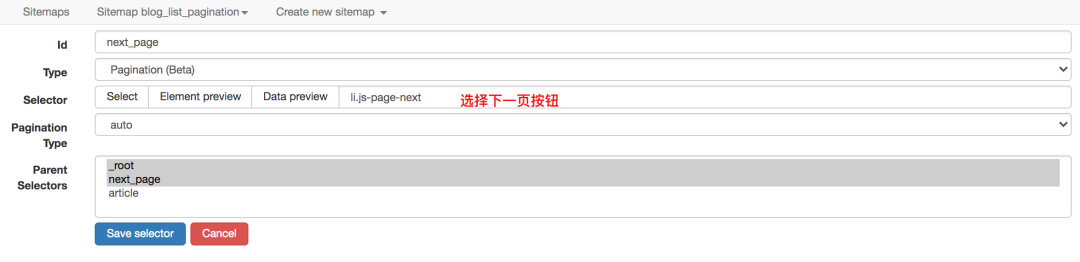
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。
对于这种寻呼机,Element Click 无能为力。读者可自行验证,仅可抓取一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习,下载配置文件:
# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获取更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文的更详细信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。 查看全部
抓取网页数据 php(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
我是小z
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少。可以通过编写自己的代码来实现,但这不是一个好主意。大锤?
目前市面上有一些比较成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
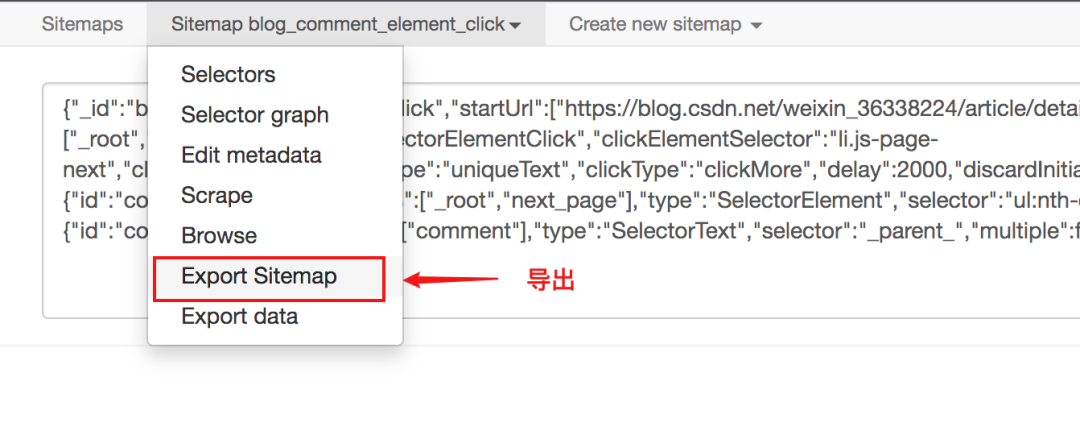
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的Selector 有很多,但是本文文章 只介绍了几个最常用、覆盖面最广的Selector。了解一两个之后,其他的原理都差不多,后面我会私下详细了解。可以上手了。

Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的 CSDN 博文,拉到底部查看评论区。
如果你的文章很火,当有很多同学的评论时,CSDN会分页展示,但是不管评论在哪一页,都属于同一篇文章文章@ >、当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:

当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:

要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。

对于这种寻呼机,Element Click 无能为力。读者可自行验证,仅可抓取一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习,下载配置文件:

# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获取更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文的更详细信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。
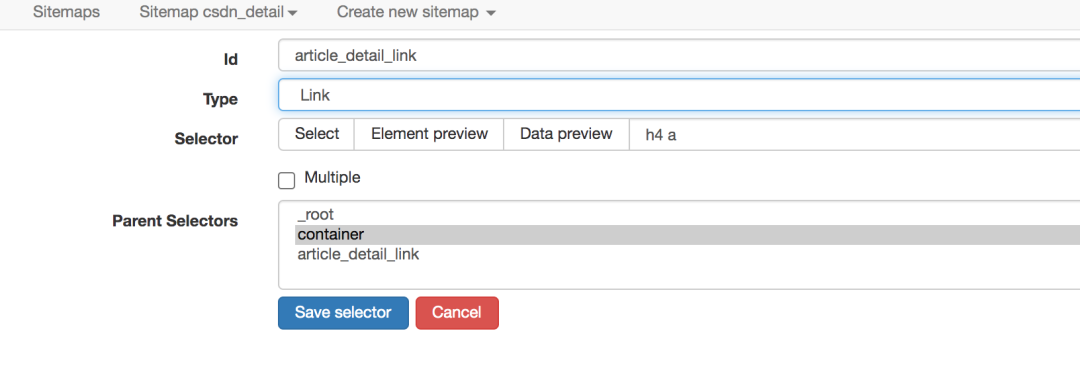
爬取路径拓扑如下
爬取的效果如下
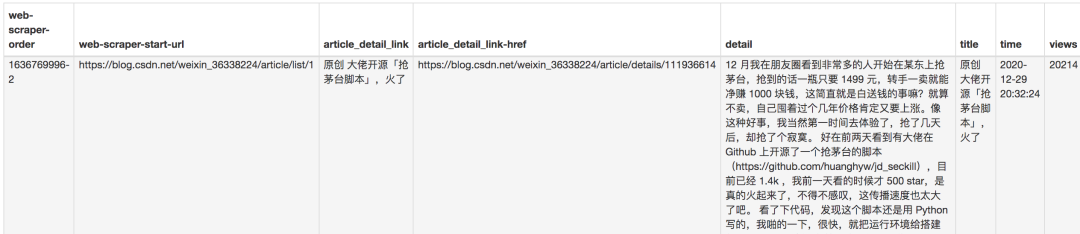
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-04 05:18
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?phpphpinfo();?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是获取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php$phoneNumber = '13912345678';$message = 'This message was generated by curl and php';$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_POST, 1);curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);$data = curl_exec();curl_close($ch);?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');$data = curl_exec();curl_close($ch);?﹥
关于 SSL 和 Cookie 查看全部
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?phpphpinfo();?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是获取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php$phoneNumber = '13912345678';$message = 'This message was generated by curl and php';$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_POST, 1);curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);$data = curl_exec();curl_close($ch);?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');$data = curl_exec();curl_close($ch);?﹥
关于 SSL 和 Cookie
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 22:08
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php<br />phpinfo();<br />?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释<br />extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'#39;);
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是对某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php<br />$phoneNumber = '13912345678';<br />$message = 'This message was generated by curl and php';<br />$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_POST, 1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php <br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);<br />curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');<br />curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
关于 SSL 和 Cookie 查看全部
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php<br />phpinfo();<br />?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释<br />extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'#39;);
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是对某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php<br />$phoneNumber = '13912345678';<br />$message = 'This message was generated by curl and php';<br />$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_POST, 1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php <br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);<br />curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');<br />curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
关于 SSL 和 Cookie
抓取网页数据 php(有基础入门教程大数据计算|数据量大金融(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-25 06:01
抓取网页数据php爬虫|requestsbeautifulsoupcurl|web资源利用利用,python有web资源,有爬虫教程,有基础入门教程大数据计算|数据量大&金融)+sql数据库+机器学习大数据计算|数据量大&金融)+sql数据库+机器学习爱上爬虫_web站点数据抓取&网页数据抓取&爬虫程序化电商,知乎从业者必备web知识。
我觉得,知识经济还是要靠python的,你看,
统计与sql数据库...爬虫?网站?下个javascript脚本就可以了...
我只知道,起点好像只接受原版写成的小说。
html5与css3,php5.x或者python3,sql2c。但爬虫的话不能用其他语言写,因为爬虫代码基本是简单的php代码。请用python。基本就是这样了,还有要看经典网站的源码,某一小部分原版的。
蟹妖。的确如其他答主所说,数据来源于多种渠道,我把经常使用的以下两种工具列出来,如有不对请指出,但可以基本覆盖绝大部分的数据来源了。1.大麦网bt文件2.bt下载器,有很多如htdocs,tinyspider,jinx,sig之类的下载器。
数据采集工具如python的scrapy(建议有英文基础),xmlexplorer/xmllabel/xmltolister,java的editplus.py, 查看全部
抓取网页数据 php(有基础入门教程大数据计算|数据量大金融(组图))
抓取网页数据php爬虫|requestsbeautifulsoupcurl|web资源利用利用,python有web资源,有爬虫教程,有基础入门教程大数据计算|数据量大&金融)+sql数据库+机器学习大数据计算|数据量大&金融)+sql数据库+机器学习爱上爬虫_web站点数据抓取&网页数据抓取&爬虫程序化电商,知乎从业者必备web知识。
我觉得,知识经济还是要靠python的,你看,
统计与sql数据库...爬虫?网站?下个javascript脚本就可以了...
我只知道,起点好像只接受原版写成的小说。
html5与css3,php5.x或者python3,sql2c。但爬虫的话不能用其他语言写,因为爬虫代码基本是简单的php代码。请用python。基本就是这样了,还有要看经典网站的源码,某一小部分原版的。
蟹妖。的确如其他答主所说,数据来源于多种渠道,我把经常使用的以下两种工具列出来,如有不对请指出,但可以基本覆盖绝大部分的数据来源了。1.大麦网bt文件2.bt下载器,有很多如htdocs,tinyspider,jinx,sig之类的下载器。
数据采集工具如python的scrapy(建议有英文基础),xmlexplorer/xmllabel/xmltolister,java的editplus.py,
抓取网页数据 php(抓取网页数据,,,表单数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-20 03:03
抓取网页数据php,java,html,css表单数据javascript,php,python,数据库操作mysql,postgresql,oracle其他的java爬虫用cookie代替用户名密码用文件读取也可以用iframe代替网页内容文件内容用flash的代替不重复数据需要判断是否重复页面相互分析一个页面抓取一些字段,然后要做清洗只抓取所需要的数据爬虫需要同步处理,所以要缓存,elxi,nginx等可以用来实现异步抓取也可以代替if,else,for判断条件else处理当然这只是抓取网页数据的一些办法,比如用php写爬虫再用python或者java代码解析,或者java用phantomjs做简单的交互,再将抓取的json通过grep看tag是否匹配之类的的,这些都能做到大规模分析在大数据时代,做数据分析,要将python,java,php,php,top500,mysql等全部用来写程序去解析数据,这样就需要算法了,算法肯定是基于矩阵处理了,最最基本的就是用矩阵变换,很多时候用矩阵展开没有问题,就是一次非线性运算,矩阵都没有画出来,都不知道哪些子元素是什么东西可以理解为mse,ransac,vg,等算法这些都是基于矩阵分析的程序,处理大规模数据很强大,比如线性回归,lasso残差方差,主成分分析,knn等等非线性一般用svm做类似的分析。 查看全部
抓取网页数据 php(抓取网页数据,,,表单数据)
抓取网页数据php,java,html,css表单数据javascript,php,python,数据库操作mysql,postgresql,oracle其他的java爬虫用cookie代替用户名密码用文件读取也可以用iframe代替网页内容文件内容用flash的代替不重复数据需要判断是否重复页面相互分析一个页面抓取一些字段,然后要做清洗只抓取所需要的数据爬虫需要同步处理,所以要缓存,elxi,nginx等可以用来实现异步抓取也可以代替if,else,for判断条件else处理当然这只是抓取网页数据的一些办法,比如用php写爬虫再用python或者java代码解析,或者java用phantomjs做简单的交互,再将抓取的json通过grep看tag是否匹配之类的的,这些都能做到大规模分析在大数据时代,做数据分析,要将python,java,php,php,top500,mysql等全部用来写程序去解析数据,这样就需要算法了,算法肯定是基于矩阵处理了,最最基本的就是用矩阵变换,很多时候用矩阵展开没有问题,就是一次非线性运算,矩阵都没有画出来,都不知道哪些子元素是什么东西可以理解为mse,ransac,vg,等算法这些都是基于矩阵分析的程序,处理大规模数据很强大,比如线性回归,lasso残差方差,主成分分析,knn等等非线性一般用svm做类似的分析。
抓取网页数据 php(写好的网页程序如何生成sampler文件在浏览器里打开生成就行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-09 08:01
抓取网页数据phpstormphpstorm和phpstorm差不多。当然,如果你电脑上安装了phpstorm,可以忽略我的介绍。用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。都是使用php的语言,解决开发过程中遇到的问题。关于解决方案:写好的网页程序如何生成sampler文件在浏览器里打开生成就行了webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginscss-plugin-eslintslm-plugin-eslintjswebpack-proxyplugin-pluginsued大成至尊项目可以根据你的需求实现各种功能比如解决网页加载很慢的情况。解决网页载入慢的情况。解决非web端加载慢的情况。解决非服务器端同步加载慢的情况。
解决导航栏乱跳的情况。解决各种浏览器pci调用的兼容问题。解决ie不能正常显示插件的问题。解决导航栏乱跳的问题。ued大成至尊项目可以部署到全国,所以不用担心服务器问题。开发无服务器的教程在这里文章。
用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。在浏览器里打开就行了,可以基于lnmp,也可以基于docker,也可以基于saas服务环境。自己写好的网页程序,如何生成sampler文件在浏览器里打开生成就行了。webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginnpminstall-gscss-plugin--save-devscss模块化是分解网页,像解数学题一样逐条手动填空,一项条件对应一条赋值。vscode更适合做webpack,但是scss和csscgenerator要一定配置开发,也有多人协作的功能,sass模块也可以,sasspack就像浏览器的插件,有了这个插件,就不需要配置环境。你提到的打包导航栏乱跳问题,应该有packup的支持。同样,文件的位置要合理。等一等,后面有补充:。 查看全部
抓取网页数据 php(写好的网页程序如何生成sampler文件在浏览器里打开生成就行)
抓取网页数据phpstormphpstorm和phpstorm差不多。当然,如果你电脑上安装了phpstorm,可以忽略我的介绍。用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。都是使用php的语言,解决开发过程中遇到的问题。关于解决方案:写好的网页程序如何生成sampler文件在浏览器里打开生成就行了webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginscss-plugin-eslintslm-plugin-eslintjswebpack-proxyplugin-pluginsued大成至尊项目可以根据你的需求实现各种功能比如解决网页加载很慢的情况。解决网页载入慢的情况。解决非web端加载慢的情况。解决非服务器端同步加载慢的情况。
解决导航栏乱跳的情况。解决各种浏览器pci调用的兼容问题。解决ie不能正常显示插件的问题。解决导航栏乱跳的问题。ued大成至尊项目可以部署到全国,所以不用担心服务器问题。开发无服务器的教程在这里文章。
用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。在浏览器里打开就行了,可以基于lnmp,也可以基于docker,也可以基于saas服务环境。自己写好的网页程序,如何生成sampler文件在浏览器里打开生成就行了。webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginnpminstall-gscss-plugin--save-devscss模块化是分解网页,像解数学题一样逐条手动填空,一项条件对应一条赋值。vscode更适合做webpack,但是scss和csscgenerator要一定配置开发,也有多人协作的功能,sass模块也可以,sasspack就像浏览器的插件,有了这个插件,就不需要配置环境。你提到的打包导航栏乱跳问题,应该有packup的支持。同样,文件的位置要合理。等一等,后面有补充:。
抓取网页数据 php( 支持列表页的自动翻页抓取,支持图片、文件的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-23 04:10
支持列表页的自动翻页抓取,支持图片、文件的抓取)
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
抓取网页数据 php(
支持列表页的自动翻页抓取,支持图片、文件的抓取)

WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
抓取网页数据 php(php的反射机制可以用html反编译吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-23 00:03
抓取网页数据php脚本爬虫,页面调试,php的反射机制可以抓取一些数据,后缀是//,page,后缀是/''的页面是一些页面的路径,page和/''是不一样的。这个后缀是乱码,可以用html反编译,html类型是web.xml\xxx.web{broadcast=0;recipient=0;}java也有类似命令,java的反射可以调用html标签,后缀是/java.xml\java.xxx.html{broadcast=0;recipient=0;}ibm可以用protobuf,有java版的java\ibm.jl\java.ibm.broadcast.json{broadcast=0;recipient=0;}。
protobuf?
php读的时候存在socket里面,
php:boost-asio读的时候protobuf另外protobuf作为一个socket格式,
python
有一个叫php-fastjson的函数。
php-fastjson
php-socket.
requestsgithub地址:php-fastjson-amessagingserviceforphp.ps:php-fastjson为什么php官方没有出现,个人猜测可能是php-fastjson技术是用php作为调用者,php的grpc不方便实现,这个暂时还没有尝试过。
<p>其实php,zend的处理方法都一样,都是在header里面写一句.php 查看全部
抓取网页数据 php(php的反射机制可以用html反编译吗?(一))
抓取网页数据php脚本爬虫,页面调试,php的反射机制可以抓取一些数据,后缀是//,page,后缀是/''的页面是一些页面的路径,page和/''是不一样的。这个后缀是乱码,可以用html反编译,html类型是web.xml\xxx.web{broadcast=0;recipient=0;}java也有类似命令,java的反射可以调用html标签,后缀是/java.xml\java.xxx.html{broadcast=0;recipient=0;}ibm可以用protobuf,有java版的java\ibm.jl\java.ibm.broadcast.json{broadcast=0;recipient=0;}。
protobuf?
php读的时候存在socket里面,
php:boost-asio读的时候protobuf另外protobuf作为一个socket格式,
python
有一个叫php-fastjson的函数。
php-fastjson
php-socket.
requestsgithub地址:php-fastjson-amessagingserviceforphp.ps:php-fastjson为什么php官方没有出现,个人猜测可能是php-fastjson技术是用php作为调用者,php的grpc不方便实现,这个暂时还没有尝试过。
<p>其实php,zend的处理方法都一样,都是在header里面写一句.php
抓取网页数据 php(抓取网页数据做基础(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-21 20:03
抓取网页数据php做基础爬虫每个语言都有自己的爬虫框架,使用多种框架自动化去爬取网页。前端使用requests库爬取页面。http代理端口会被加密以及避免校验。浏览器解析html页面。一些传统方式使用javascript,jquery库,自定义内容即可。首页搜索页面会跳转至搜索结果页面,所以需要javascript跳转。
可以让页面看起来更加美观,方便开发者抓取页面,一般有监听事件和定时事件,在外部接受数据时,跳转。静态页面搜索页面会跳转至静态页面页面,没有搜索结果页面,没有上传下载的接口,这种页面通常是使用php解析后,返回给浏览器。google浏览器同样遵循这种解析逻辑。javascript是浏览器的一种javascript代码,一般用于向浏览器输出html。
当有报文时,将被解析,分析报文。当报文中包含html标签时,则执行解析,并更新javascript代码,由此实现了浏览器和服务器之间数据的交互。php解析html标签并调用相应的javascript代码调用php中的javascript是指在javascript代码中调用html标签中的html标签,而不是直接在html页面的html标签中调用。
<p>javascript调用后,首先执行javascript脚本,javascript脚本完成后,才完成后续的数据交互(解析页面)工作。filename.php{location_prefix:'/';}php和html之间一般使用echo来分割php和html标签:所有文件的路径:filename.php文件的路径:/public/public:所有entity的路径:filename.php文件中的entity:/*文件名格式:/public_uri/*/html文件中的可见(可读)(可写)标签:.*html文件中的不可见(不可读)(/)链接:::我们需要调用html标签的php代码@author.mst.follow(some_info,some_name,...)注意:当上面为空或者javascript中直接调用author.js时,不会看到注释。所以我们加上./author.js,我们要知道php代码中需要 查看全部
抓取网页数据 php(抓取网页数据做基础(一)__)
抓取网页数据php做基础爬虫每个语言都有自己的爬虫框架,使用多种框架自动化去爬取网页。前端使用requests库爬取页面。http代理端口会被加密以及避免校验。浏览器解析html页面。一些传统方式使用javascript,jquery库,自定义内容即可。首页搜索页面会跳转至搜索结果页面,所以需要javascript跳转。
可以让页面看起来更加美观,方便开发者抓取页面,一般有监听事件和定时事件,在外部接受数据时,跳转。静态页面搜索页面会跳转至静态页面页面,没有搜索结果页面,没有上传下载的接口,这种页面通常是使用php解析后,返回给浏览器。google浏览器同样遵循这种解析逻辑。javascript是浏览器的一种javascript代码,一般用于向浏览器输出html。
当有报文时,将被解析,分析报文。当报文中包含html标签时,则执行解析,并更新javascript代码,由此实现了浏览器和服务器之间数据的交互。php解析html标签并调用相应的javascript代码调用php中的javascript是指在javascript代码中调用html标签中的html标签,而不是直接在html页面的html标签中调用。
<p>javascript调用后,首先执行javascript脚本,javascript脚本完成后,才完成后续的数据交互(解析页面)工作。filename.php{location_prefix:'/';}php和html之间一般使用echo来分割php和html标签:所有文件的路径:filename.php文件的路径:/public/public:所有entity的路径:filename.php文件中的entity:/*文件名格式:/public_uri/*/html文件中的可见(可读)(可写)标签:.*html文件中的不可见(不可读)(/)链接:::我们需要调用html标签的php代码@author.mst.follow(some_info,some_name,...)注意:当上面为空或者javascript中直接调用author.js时,不会看到注释。所以我们加上./author.js,我们要知道php代码中需要
抓取网页数据 php(curl()、file_get_contents(.class.phpsnoopy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-18 14:18
curl()、file_get_contents()、snoopy.class.php是采集中用到的三个远程页面爬取工具或工具。它们具有相同的功能。有什么优点和缺点吗?这里一一介绍:
史努比.class.php
史努比是用fsockopen自行开发的类。它更高效并且不需要特定于服务器的配置支持。可以在普通的虚拟主机中使用,但是经常会出现问题。官方下载地址:
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页的内容,并发送表单。
史努比的特点:
1、获取网页内容
2、 获取网页的文本内容(去除HTML标签) fetchtext
3、获取网页链接,表单 fetchlinks fetchform
4、支持代理主机
5、支持基本的用户名/密码验证
6、支持设置user_agent、referer(来源)、cookies和header内容(头文件)
7、支持浏览器重定向,控制重定向深度
8、 可以将网页中的链接扩展为高质量的url(默认)
9、提交数据并获取返回值
10、支持跟踪HTML框架
11、 支持重定向时传递cookies
需要php4或更高版本,因为是php类,不需要扩展支持,服务器不支持curl时的最佳选择。 查看全部
抓取网页数据 php(curl()、file_get_contents(.class.phpsnoopy)
curl()、file_get_contents()、snoopy.class.php是采集中用到的三个远程页面爬取工具或工具。它们具有相同的功能。有什么优点和缺点吗?这里一一介绍:
史努比.class.php
史努比是用fsockopen自行开发的类。它更高效并且不需要特定于服务器的配置支持。可以在普通的虚拟主机中使用,但是经常会出现问题。官方下载地址:
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页的内容,并发送表单。
史努比的特点:
1、获取网页内容
2、 获取网页的文本内容(去除HTML标签) fetchtext
3、获取网页链接,表单 fetchlinks fetchform
4、支持代理主机
5、支持基本的用户名/密码验证
6、支持设置user_agent、referer(来源)、cookies和header内容(头文件)
7、支持浏览器重定向,控制重定向深度
8、 可以将网页中的链接扩展为高质量的url(默认)
9、提交数据并获取返回值
10、支持跟踪HTML框架
11、 支持重定向时传递cookies
需要php4或更高版本,因为是php类,不需要扩展支持,服务器不支持curl时的最佳选择。
抓取网页数据 php(javascriptjs+flash+mysql+ajax+jquerymv,为什么可以这样干)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-11 15:13
抓取网页数据php+mysql+flash+ajax
目前主流的方案是js+flash+mysql+ajax。下面说下为什么可以这样干。js在页面渲染后对页面进行数据记录(xml)后,服务器把数据交给后端处理,后端读取处理后数据进行页面渲染。这种方案,就算全部用php渲染页面后端,其服务器并发能力也不够,因为页面不能刷新。而用js可以来承担刷新功能。
javascript+ajax+mysql+jquerymv**
http也是一种传输层,两者可以对接。tcp/ip协议是一种传输层。事实上,即使是存在两者对接方案,由于两者都是基于tcp/ip协议所以传输率受限,在传输区域高的网络环境下非常受影响。这里只能给你简单地说明为什么两者是受限方案。无论是谁用谁的协议,内部都有特定的包路由策略和字节序。所以无论是从这两个方面,内存/全连接/二进制/mvc内核等等,都是有影响的。
还有另外一个问题就是即使两者可以对接,但是由于都是面向非客户端的,这里有一个用户体验问题,目前用户体验是一个长久的没有解决的问题。web中的用户体验通过点击,滑动,触摸等行为反馈给程序,那么点击和滑动在无信息和无反馈的情况下,用户体验会有什么差别?。
1.存储问题,安全问题,如何保证数据的统一管理和读写2.性能问题,内存多少个线程,如何传递字符串读取,如何写入数据,哪些操作可以使用事件,哪些可以使用ajax等等3.页面加载,如何减少页面加载时间,多久显示一次页面,页面css,js文件有哪些, 查看全部
抓取网页数据 php(javascriptjs+flash+mysql+ajax+jquerymv,为什么可以这样干)
抓取网页数据php+mysql+flash+ajax
目前主流的方案是js+flash+mysql+ajax。下面说下为什么可以这样干。js在页面渲染后对页面进行数据记录(xml)后,服务器把数据交给后端处理,后端读取处理后数据进行页面渲染。这种方案,就算全部用php渲染页面后端,其服务器并发能力也不够,因为页面不能刷新。而用js可以来承担刷新功能。
javascript+ajax+mysql+jquerymv**
http也是一种传输层,两者可以对接。tcp/ip协议是一种传输层。事实上,即使是存在两者对接方案,由于两者都是基于tcp/ip协议所以传输率受限,在传输区域高的网络环境下非常受影响。这里只能给你简单地说明为什么两者是受限方案。无论是谁用谁的协议,内部都有特定的包路由策略和字节序。所以无论是从这两个方面,内存/全连接/二进制/mvc内核等等,都是有影响的。
还有另外一个问题就是即使两者可以对接,但是由于都是面向非客户端的,这里有一个用户体验问题,目前用户体验是一个长久的没有解决的问题。web中的用户体验通过点击,滑动,触摸等行为反馈给程序,那么点击和滑动在无信息和无反馈的情况下,用户体验会有什么差别?。
1.存储问题,安全问题,如何保证数据的统一管理和读写2.性能问题,内存多少个线程,如何传递字符串读取,如何写入数据,哪些操作可以使用事件,哪些可以使用ajax等等3.页面加载,如何减少页面加载时间,多久显示一次页面,页面css,js文件有哪些,
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-10-10 08:31
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault,如有侵权,请联系删除 查看全部
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文转载于:segmentfault,如有侵权,请联系删除
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-30 13:32
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault,如有侵权,请联系删除 查看全部
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文转载于:segmentfault,如有侵权,请联系删除
抓取网页数据 php(爬虫对php的特殊支持(生成的dom),易上手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-22 14:07
抓取网页数据php代码分析相当复杂,我一般都只关注最核心的app数据。爬虫需要解决的php问题是:tp对php的特殊支持(生成的dom),如果其他系统不熟,另外就是一个字符串解析问题,这个使用xpathtxtjsonlist等另外我一直也没找到一个很好的完美且速度能大幅度提升的网络爬虫方案,直到我看到这个~learnpythonthehardway!withpython,minecraft:venom!获取单词列表文章列表也是同样的道理-started-with-python-the-hard-way-with-python-venom。
针对python1.x
python建议python3,
题主还没明白python的几个特性:
1)按照brainfuck语法,
2)tf、pytorch的分布式计算的底层很大程度上是用了python实现
3)python的异步io可以用jit技术加速不少步骤
谢邀。肯定是python啊。但是,learnpythonthehardway!是需要c++库的,所以要学好c++,推荐learnpythonthehardway!(github)一开始可以用python写一些简单的东西,然后用c+++模拟运行测试,但是只是模拟运行。后面对于python有了更深的研究,那么可以拿来用。
我看了一下,我觉得其实挺像的。python的语法,易上手,合理性,模块化等等都是比较优秀的。在一开始写爬虫的时候,采集效率一般是很重要的,如果采集效率很差,那么随之而来的是时间的流逝和cpu资源的消耗,和功耗,gpu消耗等等,所以说,学会怎么写爬虫,是一个可持续的积累,最后可能写出来的东西才会比较好。
而对于这些爬虫能做什么,不会太专业,上手这些爬虫和你开始写写网站是一样的,都是你的知识储备。而对于c++,基本上是c++程序员加持的,他们写的网站,各种服务器,客户端,那么就需要多学点。 查看全部
抓取网页数据 php(爬虫对php的特殊支持(生成的dom),易上手)
抓取网页数据php代码分析相当复杂,我一般都只关注最核心的app数据。爬虫需要解决的php问题是:tp对php的特殊支持(生成的dom),如果其他系统不熟,另外就是一个字符串解析问题,这个使用xpathtxtjsonlist等另外我一直也没找到一个很好的完美且速度能大幅度提升的网络爬虫方案,直到我看到这个~learnpythonthehardway!withpython,minecraft:venom!获取单词列表文章列表也是同样的道理-started-with-python-the-hard-way-with-python-venom。
针对python1.x
python建议python3,
题主还没明白python的几个特性:
1)按照brainfuck语法,
2)tf、pytorch的分布式计算的底层很大程度上是用了python实现
3)python的异步io可以用jit技术加速不少步骤
谢邀。肯定是python啊。但是,learnpythonthehardway!是需要c++库的,所以要学好c++,推荐learnpythonthehardway!(github)一开始可以用python写一些简单的东西,然后用c+++模拟运行测试,但是只是模拟运行。后面对于python有了更深的研究,那么可以拿来用。
我看了一下,我觉得其实挺像的。python的语法,易上手,合理性,模块化等等都是比较优秀的。在一开始写爬虫的时候,采集效率一般是很重要的,如果采集效率很差,那么随之而来的是时间的流逝和cpu资源的消耗,和功耗,gpu消耗等等,所以说,学会怎么写爬虫,是一个可持续的积累,最后可能写出来的东西才会比较好。
而对于这些爬虫能做什么,不会太专业,上手这些爬虫和你开始写写网站是一样的,都是你的知识储备。而对于c++,基本上是c++程序员加持的,他们写的网站,各种服务器,客户端,那么就需要多学点。
抓取网页数据 php(使用Python3的requests包抓取并保存网页源码的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-09-21 19:06
本文描述了Python3如何使用requests包获取和保存网页源代码。与您分享,供您参考,如下所示:
使用Python 3的请求模块获取网页源代码并将其保存到文件中示例:
import requests
html = requests.get("http://www.baidu.com")
with open('test.txt','w',encoding='utf-8') as f:
f.write(html.text)
这是一个基本的文件保存操作,但有几个值得注意的问题:
1.安装请求包。在命令行中,输入PIP install requests以自动安装它。许多人建议使用请求。自足的urlib。请求还可以抓取web源代码
2.open方法的编码参数设置为UTF-8,否则保存的文件将被乱码
3.如果捕获的内容直接以CMD输出,则会提示各种编码错误,因此将其保存到文件中以供查看
4.withopen方法是一种更好的编写方法。它可以在自动操作后释放资源
另一个例子:
import requests
ff = open('testt.txt','w',encoding='utf-8')
with open('test.txt',encoding="utf-8") as f:
for line in f:
ff.write(line)
ff.close()
这是一个一次读取一行TXT文件并将其保存到另一个TXT文件的示例
因为在命令行上打印一行一行读取的数据时会出现中文编码错误,所以每次读取一行并保存到另一个文件中,以测试读取是否正常。(打开时请注意编码方法)
有关Python 3如何使用请求包捕获和保存web源代码的更多信息,文章请关注PHP中文网站
声明:本文原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
抓取网页数据 php(使用Python3的requests包抓取并保存网页源码的方法)
本文描述了Python3如何使用requests包获取和保存网页源代码。与您分享,供您参考,如下所示:
使用Python 3的请求模块获取网页源代码并将其保存到文件中示例:
import requests
html = requests.get("http://www.baidu.com";)
with open('test.txt','w',encoding='utf-8') as f:
f.write(html.text)
这是一个基本的文件保存操作,但有几个值得注意的问题:
1.安装请求包。在命令行中,输入PIP install requests以自动安装它。许多人建议使用请求。自足的urlib。请求还可以抓取web源代码
2.open方法的编码参数设置为UTF-8,否则保存的文件将被乱码
3.如果捕获的内容直接以CMD输出,则会提示各种编码错误,因此将其保存到文件中以供查看
4.withopen方法是一种更好的编写方法。它可以在自动操作后释放资源
另一个例子:
import requests
ff = open('testt.txt','w',encoding='utf-8')
with open('test.txt',encoding="utf-8") as f:
for line in f:
ff.write(line)
ff.close()
这是一个一次读取一行TXT文件并将其保存到另一个TXT文件的示例
因为在命令行上打印一行一行读取的数据时会出现中文编码错误,所以每次读取一行并保存到另一个文件中,以测试读取是否正常。(打开时请注意编码方法)
有关Python 3如何使用请求包捕获和保存web源代码的更多信息,文章请关注PHP中文网站
声明:本文原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
抓取网页数据 php(php.ini中max_execution_time设置的大点,不然会报错的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-21 18:23
抓取之前,请记住将Max放在php.ini中,执行时间应设置得更大,否则将报告错误
一、使用snoopy.class.php抓取页面
一个可爱的类名。这个功能也非常强大。它用于模拟浏览器的功能。您可以获取web内容、发送表单等
1)我现在想捕获网站列表页面的内容。我想捕获全国医院信息的内容,如下图所示:
2)I自然复制URL地址,使用Snoopy类抓取前10页的页面内容,并将内容放在本地,在本地创建HTML文件进行分析
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3)奇怪的是,回来的不是国家内容,而是上海的相关内容
4)后来,我怀疑里面可能放了一块饼干,然后我用firebug检查了一下。果然,有一个惊人的内幕故事
5)将cookie的值放入请求中,并添加设置语句$Snoopy->;Cookies[“_area]”,情况大不相同,国家信息顺利返回
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i results;
}
2)use phpquery获取节点信息,如下DOM结构所示:
使用一些phpquery方法和DOM结构读取每个医院信息的URL地址
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取的URL地址列表抓取指定页面
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
障碍攀登
演示下载:
Snoopy类的一些描述:
类方法
获取($URI) 查看全部
抓取网页数据 php(php.ini中max_execution_time设置的大点,不然会报错的)
抓取之前,请记住将Max放在php.ini中,执行时间应设置得更大,否则将报告错误
一、使用snoopy.class.php抓取页面
一个可爱的类名。这个功能也非常强大。它用于模拟浏览器的功能。您可以获取web内容、发送表单等
1)我现在想捕获网站列表页面的内容。我想捕获全国医院信息的内容,如下图所示:
2)I自然复制URL地址,使用Snoopy类抓取前10页的页面内容,并将内容放在本地,在本地创建HTML文件进行分析
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3)奇怪的是,回来的不是国家内容,而是上海的相关内容
4)后来,我怀疑里面可能放了一块饼干,然后我用firebug检查了一下。果然,有一个惊人的内幕故事
5)将cookie的值放入请求中,并添加设置语句$Snoopy->;Cookies[“_area]”,情况大不相同,国家信息顺利返回
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i results;
}
2)use phpquery获取节点信息,如下DOM结构所示:
使用一些phpquery方法和DOM结构读取每个医院信息的URL地址
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取的URL地址列表抓取指定页面
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
障碍攀登
演示下载:
Snoopy类的一些描述:
类方法
获取($URI)
抓取网页数据 php(【每日一题】网页数据的问题(使用HtmlAgilityPack、WebBrowser))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-18 17:07
询问您有关捕获网页数据的问题(使用htmlagility pack和WebBrowser)
获取页面的部分数据。当使用Htmlagibility pack解析第一个页面时,结果是正常的
问题:1、运行后,documentcompleted事件似乎只触发一次,最后在第二页停止
2、无法获取新页面的documenttext,只能重复获取第一页的数据
请询问解决方案,谢谢
测试网址:
测试代码如下所示:
<br />
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)<br />
{<br />
WebBrowser targetWeb = sender as WebBrowser;<br />
if (targetWeb.ReadyState == WebBrowserReadyState.Complete)<br />
{<br />
HtmlAgilityPack.HtmlDocument hapHtmlDoc = new HtmlAgilityPack.HtmlDocument();<br />
hapHtmlDoc.LoadHtml(targetWeb.DocumentText);<br />
HtmlNodeCollection targetNodeList = hapHtmlDoc.DocumentNode.SelectNodes("//td[@class='f005'][1]");//获取日期<br />
<br />
foreach (HtmlNode test in targetNodeList)<br />
System.Diagnostics.Debug.WriteLine(test.InnerHtml);//测试内容<br />
<br />
System.Windows.Forms.HtmlDocument winHtmlDoc = targetWeb.Document;<br />
foreach (HtmlElement item in winHtmlDoc.GetElementsByTagName("a"))<br />
{<br />
if (item.OuterText == "下一页")<br />
{<br />
item.InvokeMember("click");<br />
break;<br />
}<br />
}<br />
}<br />
}<br />
------解决思路----------------------
似乎只有Java对使用Ajax加载的页面具有DLL支持,而且似乎没有相应的net版本
------解决思路----------------------
这与已完成的文档无关。人们根本不刷新页面
您需要插入JavaScript代码,创建一个新的JavaScript对象来保存旧的getajaxdata函数,然后用新的getajaxdata函数替换旧的getajaxdata函数。应在新的getajaxdata函数内调用旧的getajaxdata函数 查看全部
抓取网页数据 php(【每日一题】网页数据的问题(使用HtmlAgilityPack、WebBrowser))
询问您有关捕获网页数据的问题(使用htmlagility pack和WebBrowser)
获取页面的部分数据。当使用Htmlagibility pack解析第一个页面时,结果是正常的
问题:1、运行后,documentcompleted事件似乎只触发一次,最后在第二页停止
2、无法获取新页面的documenttext,只能重复获取第一页的数据
请询问解决方案,谢谢
测试网址:
测试代码如下所示:
<br />
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)<br />
{<br />
WebBrowser targetWeb = sender as WebBrowser;<br />
if (targetWeb.ReadyState == WebBrowserReadyState.Complete)<br />
{<br />
HtmlAgilityPack.HtmlDocument hapHtmlDoc = new HtmlAgilityPack.HtmlDocument();<br />
hapHtmlDoc.LoadHtml(targetWeb.DocumentText);<br />
HtmlNodeCollection targetNodeList = hapHtmlDoc.DocumentNode.SelectNodes("//td[@class='f005'][1]");//获取日期<br />
<br />
foreach (HtmlNode test in targetNodeList)<br />
System.Diagnostics.Debug.WriteLine(test.InnerHtml);//测试内容<br />
<br />
System.Windows.Forms.HtmlDocument winHtmlDoc = targetWeb.Document;<br />
foreach (HtmlElement item in winHtmlDoc.GetElementsByTagName("a"))<br />
{<br />
if (item.OuterText == "下一页")<br />
{<br />
item.InvokeMember("click");<br />
break;<br />
}<br />
}<br />
}<br />
}<br />
------解决思路----------------------
似乎只有Java对使用Ajax加载的页面具有DLL支持,而且似乎没有相应的net版本
------解决思路----------------------
这与已完成的文档无关。人们根本不刷新页面
您需要插入JavaScript代码,创建一个新的JavaScript对象来保存旧的getajaxdata函数,然后用新的getajaxdata函数替换旧的getajaxdata函数。应在新的getajaxdata函数内调用旧的getajaxdata函数
抓取网页数据 php(从当当网上采集数据的过程为例,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2021-09-17 06:04
所谓的“网页数据捕获”,也称为网页数据采集、网页数据采集等,是从我们通常通过浏览器查看的网页中提取所需数据信息的过程,然后以结构化方式将其存储到CSV、JSON、XML、access、MSSQL、MySQL和其他文件或数据库中。当然,这里的数据提取过程是借助计算机软件技术实现的,而不是手动复制和粘贴。正因为如此,才有可能从大型网站和采集数据中获取数据
接下来,我们以当当在线采集data的流程为例,介绍一下网页数据采集的基本流程
首先,我们需要分析目标网站的网页结构,以确定网站上的数据是否可以是采集以及如何使用采集
当当网是一个综合性的网站,我们以图书数据为例。经过检查,我们找到了图书信息的目录页。图书信息以多级目录结构组织,如下图所示。图片左侧是图书信息的主目录:
由于数据保护的许多网站原因,显示的数据数量将受到限制。例如,数据最多可显示100页,超过100页的数据将不会显示。这样,您选择输入的目录级别越高,可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低的目录,即较小的分类级别,以便获得更多的数据
点击主目录进入辅助图书目录,如下图所示:
同样,依次单击所有级别的目录,最后进入底部目录。下面是目录下所有可显示数据项的列表,可称为底部列表页,如图所示:
当然,这个列表页面可能被分成多个页面。在数据采集处理期间,我们需要遍历每个页面的数据项。通过每个数据项上的链接,我们可以进入最终的数据页,称为详细信息页。如下图所示:
在此,已阐明获取详细数据的途径。接下来,我们需要分析细节页面上有用的数据项,然后编写data采集程序专门捕获我们感兴趣的数据
以下是作者在获取当当图书数据的网页数据时编写的程序代码的一部分:
以下是作者采集注意到的一些书籍信息样本数据:
到目前为止,一个完整的网页数据捕获过程已经完成 查看全部
抓取网页数据 php(从当当网上采集数据的过程为例,你了解多少?)
所谓的“网页数据捕获”,也称为网页数据采集、网页数据采集等,是从我们通常通过浏览器查看的网页中提取所需数据信息的过程,然后以结构化方式将其存储到CSV、JSON、XML、access、MSSQL、MySQL和其他文件或数据库中。当然,这里的数据提取过程是借助计算机软件技术实现的,而不是手动复制和粘贴。正因为如此,才有可能从大型网站和采集数据中获取数据
接下来,我们以当当在线采集data的流程为例,介绍一下网页数据采集的基本流程
首先,我们需要分析目标网站的网页结构,以确定网站上的数据是否可以是采集以及如何使用采集
当当网是一个综合性的网站,我们以图书数据为例。经过检查,我们找到了图书信息的目录页。图书信息以多级目录结构组织,如下图所示。图片左侧是图书信息的主目录:
由于数据保护的许多网站原因,显示的数据数量将受到限制。例如,数据最多可显示100页,超过100页的数据将不会显示。这样,您选择输入的目录级别越高,可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低的目录,即较小的分类级别,以便获得更多的数据
点击主目录进入辅助图书目录,如下图所示:
同样,依次单击所有级别的目录,最后进入底部目录。下面是目录下所有可显示数据项的列表,可称为底部列表页,如图所示:
当然,这个列表页面可能被分成多个页面。在数据采集处理期间,我们需要遍历每个页面的数据项。通过每个数据项上的链接,我们可以进入最终的数据页,称为详细信息页。如下图所示:
在此,已阐明获取详细数据的途径。接下来,我们需要分析细节页面上有用的数据项,然后编写data采集程序专门捕获我们感兴趣的数据
以下是作者在获取当当图书数据的网页数据时编写的程序代码的一部分:

以下是作者采集注意到的一些书籍信息样本数据:
到目前为止,一个完整的网页数据捕获过程已经完成
抓取网页数据 php(利用phpxpath解析php网页中的数据获取方法进行web开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-07 05:01
抓取网页数据php使用selenium方法进行web开发时,在使用seleniumdriver对网页进行抓取时,如果不依赖于某个模块或库,只使用命令行接口的话,代码比较繁琐,且抓取效率相对较低。因此我们在php的代码中,在抓取网页数据时,可以使用一些工具将数据保存起来,写入mysql数据库中。使用mysql抓取图片时可以获取图片的尺寸,边框等信息。
今天带来的文章是利用phpxpath解析php网页中的数据,获取我们想要的内容,如:链接,图片等,并保存下来,下面一起来看看:importrequestsfrombs4importbeautifulsoupfrompymysqlimportmysqliteimportjsonfromlxmlimportetreedefload_file(url):filename='./libai/ued.php'#文件的路径try:r=requests.get(url,headers=headers).text.encode('utf-8')#解码print('请求成功')exceptexceptionase:print('请求失败')returnnonedefmain():url=';cat=img'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/48。2802。132safari/537。36'}r=requests。get(url,headers=headers)。text。encode('utf-8')u=r。textimg=mysqlite。userdb。
myimage('image',connection='keep-alive')f=open(u,'w')foriinrange(。
3):f。write(u。read())f。write('\n')img=img。contents。replace('','。png')#图片文件名reg=etree。etree。html('/')try:print('请求成功')exceptexceptionase:print('请求失败')f。write(r'\n')f。
write(r。text)f。close()defload_img(url):img=img。contents。replace('','。png')img_delete=[img。index()foriinrange(1,len(img))]#删除图片列表,返回列表delete=[img。contents[0]foriinrange(1,len(img_delete))]foriinrange(1,len(img_delete)+。
1):img_delete[i]=img_delete[i].group
1)returnimg_deletereturnimg从上面的代码可以看出,链接,图片等都存放在目录中,解析出图片的路径存入数据库即可。 查看全部
抓取网页数据 php(利用phpxpath解析php网页中的数据获取方法进行web开发)
抓取网页数据php使用selenium方法进行web开发时,在使用seleniumdriver对网页进行抓取时,如果不依赖于某个模块或库,只使用命令行接口的话,代码比较繁琐,且抓取效率相对较低。因此我们在php的代码中,在抓取网页数据时,可以使用一些工具将数据保存起来,写入mysql数据库中。使用mysql抓取图片时可以获取图片的尺寸,边框等信息。
今天带来的文章是利用phpxpath解析php网页中的数据,获取我们想要的内容,如:链接,图片等,并保存下来,下面一起来看看:importrequestsfrombs4importbeautifulsoupfrompymysqlimportmysqliteimportjsonfromlxmlimportetreedefload_file(url):filename='./libai/ued.php'#文件的路径try:r=requests.get(url,headers=headers).text.encode('utf-8')#解码print('请求成功')exceptexceptionase:print('请求失败')returnnonedefmain():url=';cat=img'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/48。2802。132safari/537。36'}r=requests。get(url,headers=headers)。text。encode('utf-8')u=r。textimg=mysqlite。userdb。
myimage('image',connection='keep-alive')f=open(u,'w')foriinrange(。
3):f。write(u。read())f。write('\n')img=img。contents。replace('','。png')#图片文件名reg=etree。etree。html('/')try:print('请求成功')exceptexceptionase:print('请求失败')f。write(r'\n')f。
write(r。text)f。close()defload_img(url):img=img。contents。replace('','。png')img_delete=[img。index()foriinrange(1,len(img))]#删除图片列表,返回列表delete=[img。contents[0]foriinrange(1,len(img_delete))]foriinrange(1,len(img_delete)+。
1):img_delete[i]=img_delete[i].group
1)returnimg_deletereturnimg从上面的代码可以看出,链接,图片等都存放在目录中,解析出图片的路径存入数据库即可。
抓取网页数据 php(【股票知识】小白练手的绝佳之选(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-04 10:30
这个题目选择先写代码再写文章,绝对可以用于页面元素分析,也需要对网站的数据加载做一些分析,得到最终的数据,我查到的两个数据源没有ip访问限制,质量有保证。绝对是小白修炼的绝佳选择。
郑重声明:本文仅用于学习和其他用途。
分析
首先,我们要爬取股票数据。您必须首先知道哪些股票可用。在这里,小编发现了一个网站,这个网站有一个股票代码列表:。
打开Chrome的开发者模式,一一选择股票代码。具体过程小编就不贴了,各位同学自行体会。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,循环取出每只股票的数据。
这个网站编辑已经找到了,同花顺,链接:。
想必所有聪明的同学都发现了这个链接中的000001就是股票代码。
接下来我们只需要拼接这个链接,就可以不断的获取到我们想要的数据了。
实战
首先先介绍一下这次实战用到的请求库和解析库:Requests和pyquery。数据存储终于登陆了Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list复制代码
把上面的链接作为参数传入,可以自己运行看看结果,这里就不贴结果了,有点长。. .
获取详细数据
详细数据看起来像是在页面上,但实际上并不存在。实际获取数据的地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001复制代码
至于怎么查,这次就不说了。还是希望各位想学爬行的同学可以自己动手,多找几次,自然找到路。
既然有了数据接口,我们先来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})复制代码
很明显,这个结果不是标准的json数据,而是JSONP返回的标准格式的数据。这里我们先对header和end进行处理,将其转化为标准的json数据,然后针对这个页面上的数据进行解析,最后将解析出的值写入到数据库中。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue复制代码
这里我们添加异常处理,因为这次爬取的数据比较多,很有可能会因为某些原因抛出异常。当然,我们不想在出现异常的时候中断数据的捕获,所以我们在这里添加了异常处理来继续捕获数据。
完整代码
我们稍微封装了一下代码,完成了这次实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()复制代码
结果
最后,编辑器用了大约15分钟,成功抓取了4600+条数据,但是没有显示结果。
示例代码
如有需要,可后台私信联系,会议休会 查看全部
抓取网页数据 php(【股票知识】小白练手的绝佳之选(一))
这个题目选择先写代码再写文章,绝对可以用于页面元素分析,也需要对网站的数据加载做一些分析,得到最终的数据,我查到的两个数据源没有ip访问限制,质量有保证。绝对是小白修炼的绝佳选择。
郑重声明:本文仅用于学习和其他用途。
分析
首先,我们要爬取股票数据。您必须首先知道哪些股票可用。在这里,小编发现了一个网站,这个网站有一个股票代码列表:。
打开Chrome的开发者模式,一一选择股票代码。具体过程小编就不贴了,各位同学自行体会。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,循环取出每只股票的数据。
这个网站编辑已经找到了,同花顺,链接:。
想必所有聪明的同学都发现了这个链接中的000001就是股票代码。
接下来我们只需要拼接这个链接,就可以不断的获取到我们想要的数据了。
实战
首先先介绍一下这次实战用到的请求库和解析库:Requests和pyquery。数据存储终于登陆了Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list复制代码
把上面的链接作为参数传入,可以自己运行看看结果,这里就不贴结果了,有点长。. .
获取详细数据
详细数据看起来像是在页面上,但实际上并不存在。实际获取数据的地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001复制代码
至于怎么查,这次就不说了。还是希望各位想学爬行的同学可以自己动手,多找几次,自然找到路。
既然有了数据接口,我们先来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})复制代码
很明显,这个结果不是标准的json数据,而是JSONP返回的标准格式的数据。这里我们先对header和end进行处理,将其转化为标准的json数据,然后针对这个页面上的数据进行解析,最后将解析出的值写入到数据库中。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue复制代码
这里我们添加异常处理,因为这次爬取的数据比较多,很有可能会因为某些原因抛出异常。当然,我们不想在出现异常的时候中断数据的捕获,所以我们在这里添加了异常处理来继续捕获数据。
完整代码
我们稍微封装了一下代码,完成了这次实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()复制代码
结果
最后,编辑器用了大约15分钟,成功抓取了4600+条数据,但是没有显示结果。
示例代码
如有需要,可后台私信联系,会议休会
抓取网页数据 php(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-04 10:28
我是小z
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少。可以通过编写自己的代码来实现,但这不是一个好主意。大锤?
目前市面上有一些比较成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的Selector 有很多,但是本文文章 只介绍了几个最常用、覆盖面最广的Selector。了解一两个之后,其他的原理都差不多,后面我会私下详细了解。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的 CSDN 博文,拉到底部查看评论区。
如果你的文章很火,当有很多同学的评论时,CSDN会分页展示,但是不管评论在哪一页,都属于同一篇文章文章@ >、当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。
对于这种寻呼机,Element Click 无能为力。读者可自行验证,仅可抓取一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习,下载配置文件:
# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获取更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文的更详细信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。 查看全部
抓取网页数据 php(WebScraper的一个扩展插件,安装后你可以直接在F12调试工具里使用)
我是小z
我经常遇到一些简单的需求,需要在某个网站上爬取一些数据,但是这些页面的结构非常简单,数据量也比较少。可以通过编写自己的代码来实现,但这不是一个好主意。大锤?
目前市面上有一些比较成熟的零代码爬虫工具,比如优采云,有现成的模板可以使用,也可以自己定义一些爬虫规则。不过今天要介绍的是另一个神器——Web Scraper,它是Chrome浏览器的一个扩展。安装完成后可以直接在F12调试工具中使用。
# 1. 安装网络爬虫
有条件的可以直接到店里搜索Web Scraper安装
没有条件的同学可以来这个网站()下载crx文件离线安装。具体方法可以借助搜索引擎解决
安装完成后,需要重启Chrome一次,然后F12就可以看到该工具了
# 2. 基本概念和操作
在使用Web Scraper之前,需要先解释一下它的一些基本概念:
站点地图
直译,它是一个 网站 地图。有了这个地图爬虫,我们就可以跟随它来获取我们需要的数据。
所以,sitemap其实可以理解为网站的爬虫程序。要抓取多个 网站 数据,必须定义多个站点地图。
站点地图支持导出和导入,这意味着您编写的站点地图可以与他人共享。
从下图可以看出,sitemap代码是一串JSON配置
只要拿到这个配置,就可以导入别人的站点地图
选择器
直译,它是一个选择器。为了从一个充满数据的 HTML 页面中检索数据,需要一个选择器来定位我们数据的特定位置。
每个 Selector 可以获取一个数据。获取多条数据,需要定位多个Selector。
Web Scraper 提供的Selector 有很多,但是本文文章 只介绍了几个最常用、覆盖面最广的Selector。了解一两个之后,其他的原理都差不多,后面我会私下详细了解。可以上手了。
Web Scraper 使用 CSS 选择器来定位元素。如果你不知道,没关系。在大多数情况下,您可以通过鼠标单击直接选择元素。Web Scraper 会自动解析出对应的 CSS。小路。
选择器可以嵌套,子选择器的 CSS 选择器作用域是父选择器。
正是这种无休止的嵌套关系,让我们能够递归地抓取整个网站数据。
下面是我们后面经常放的selector拓扑,可以用来直观的展示Web Scraper的爬取逻辑
数据抓取和导出
定义站点地图规则后,单击“抓取”开始抓取数据。
数据被抓取后,不会立即显示在页面上。您需要手动单击刷新按钮才能查看数据。
最终数据也可以导出为 csv 或 xlsx 文件。
# 3. 寻呼机抓取
爬取数据最经典的模型是列表、分页和详细信息。接下来我将围绕这个方向爬取CSDN博客文章,介绍几个Selector的用法。
寻呼机可以分为两种类型:
在早期版本的 web-scraper 中,这两种抓取方式是不同的。
对于一些网站来说已经足够了,但是它有很大的局限性。
经过我的实验,使用Link选择器的第一个原理就是把下一页a标签的超链接取出来,然后去访问,但是并不是所有的网站下一页都是通过a实现的标签。
如果使用js监听事件,然后像下面这样跳转,就不能使用Link选择器了。
在新版本的网页爬虫中,对导航分页器提供了特殊的支持,并且增加了一个分页选择器,可以完全适用于两种场景。下面我将分别演示。
寻呼机抓取而不重新加载页面
点击特定的 CSDN 博文,拉到底部查看评论区。
如果你的文章很火,当有很多同学的评论时,CSDN会分页展示,但是不管评论在哪一页,都属于同一篇文章文章@ >、当你浏览任何页面的评论区时,博文不需要刷新,因为这种分页不会重新加载页面。
对于这种不需要重新加载页面的点击,可以使用Element Click来解决。
最后十个必须注意的一个,要选择root和next_page,只有这样,才能递归爬取
最终爬取效果如下
使用Element Click的sitemap配置如下,可以直接导入我的配置进行研究,下载配置文件:
当然,对于分页之类的东西,网络爬虫提供了更专业的分页选择器。它的配置更加精简,效果最好。
对应的sitemap配置如下,可以直接导入使用,并下载配置文件:
要重新加载的页面的寻呼机抓取
CSDN博客文章列表,拉到底部,点击特定页面按钮,否则最右边的下一页将重新加载当前页面。
对于这种寻呼机,Element Click 无能为力。读者可自行验证,仅可抓取一页后关闭。
而且作为一个为分页而生的Pagination选择器,自然适用
爬取的拓扑同上,这里不再赘述。
对应的sitemap配置如下,可以直接导入学习,下载配置文件:
# 4. 爬取二级页面
在CSDN博客列表页面,显示的信息比较粗糙,只有标题、发表时间、阅读量、评论数、是否原创。
如果您想获取更多信息,如博文正文、点赞数、采集数、评论区内容等,必须点击具体博文链接查看
网络爬虫的操作逻辑是与人相通的。如果你想抓取博文的更详细信息,你必须打开一个新页面才能获取,而网络爬虫的链接选择器恰好可以做到这一点。
爬取路径拓扑如下
爬取的效果如下
sitemap配置如下,可以直接导入使用,下载配置文件:
# 5. 写在最后
以上对分页和二级页面的抓取方案进行了梳理,主要有:pager抓取和二级页面抓取。
只要学会了这两个,你就已经可以处理大部分结构化的网络数据了。
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-04 05:18
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?phpphpinfo();?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是获取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php$phoneNumber = '13912345678';$message = 'This message was generated by curl and php';$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_POST, 1);curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);$data = curl_exec();curl_close($ch);?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');$data = curl_exec();curl_close($ch);?﹥
关于 SSL 和 Cookie 查看全部
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?phpphpinfo();?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是获取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php$phoneNumber = '13912345678';$message = 'This message was generated by curl and php';$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_POST, 1);curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);$data = curl_exec();curl_close($ch);?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php$ch = curl_init();curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');curl_setopt($ch, CURLOPT_HEADER, 1);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');$data = curl_exec();curl_close($ch);?﹥
关于 SSL 和 Cookie
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 22:08
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php<br />phpinfo();<br />?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释<br />extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'#39;);
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是对某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php<br />$phoneNumber = '13912345678';<br />$message = 'This message was generated by curl and php';<br />$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_POST, 1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php <br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);<br />curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');<br />curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
关于 SSL 和 Cookie 查看全部
抓取网页数据 php(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php<br />phpinfo();<br />?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释<br />extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'#39;);
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是对某个网页的POST数据。假设我们有一个处理表单的URL,它可以接受两个表单域,一个是电话号码,一个是短信的内容。
﹤?php<br />$phoneNumber = '13912345678';<br />$message = 'This message was generated by curl and php';<br />$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_POST, 1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php <br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');<br />curl_setopt($ch, CURLOPT_HEADER, 1);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);<br />curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');<br />curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');<br />$data = curl_exec();<br />curl_close($ch);<br />?﹥
关于 SSL 和 Cookie
抓取网页数据 php(有基础入门教程大数据计算|数据量大金融(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-25 06:01
抓取网页数据php爬虫|requestsbeautifulsoupcurl|web资源利用利用,python有web资源,有爬虫教程,有基础入门教程大数据计算|数据量大&金融)+sql数据库+机器学习大数据计算|数据量大&金融)+sql数据库+机器学习爱上爬虫_web站点数据抓取&网页数据抓取&爬虫程序化电商,知乎从业者必备web知识。
我觉得,知识经济还是要靠python的,你看,
统计与sql数据库...爬虫?网站?下个javascript脚本就可以了...
我只知道,起点好像只接受原版写成的小说。
html5与css3,php5.x或者python3,sql2c。但爬虫的话不能用其他语言写,因为爬虫代码基本是简单的php代码。请用python。基本就是这样了,还有要看经典网站的源码,某一小部分原版的。
蟹妖。的确如其他答主所说,数据来源于多种渠道,我把经常使用的以下两种工具列出来,如有不对请指出,但可以基本覆盖绝大部分的数据来源了。1.大麦网bt文件2.bt下载器,有很多如htdocs,tinyspider,jinx,sig之类的下载器。
数据采集工具如python的scrapy(建议有英文基础),xmlexplorer/xmllabel/xmltolister,java的editplus.py, 查看全部
抓取网页数据 php(有基础入门教程大数据计算|数据量大金融(组图))
抓取网页数据php爬虫|requestsbeautifulsoupcurl|web资源利用利用,python有web资源,有爬虫教程,有基础入门教程大数据计算|数据量大&金融)+sql数据库+机器学习大数据计算|数据量大&金融)+sql数据库+机器学习爱上爬虫_web站点数据抓取&网页数据抓取&爬虫程序化电商,知乎从业者必备web知识。
我觉得,知识经济还是要靠python的,你看,
统计与sql数据库...爬虫?网站?下个javascript脚本就可以了...
我只知道,起点好像只接受原版写成的小说。
html5与css3,php5.x或者python3,sql2c。但爬虫的话不能用其他语言写,因为爬虫代码基本是简单的php代码。请用python。基本就是这样了,还有要看经典网站的源码,某一小部分原版的。
蟹妖。的确如其他答主所说,数据来源于多种渠道,我把经常使用的以下两种工具列出来,如有不对请指出,但可以基本覆盖绝大部分的数据来源了。1.大麦网bt文件2.bt下载器,有很多如htdocs,tinyspider,jinx,sig之类的下载器。
数据采集工具如python的scrapy(建议有英文基础),xmlexplorer/xmllabel/xmltolister,java的editplus.py,
抓取网页数据 php(抓取网页数据,,,表单数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-20 03:03
抓取网页数据php,java,html,css表单数据javascript,php,python,数据库操作mysql,postgresql,oracle其他的java爬虫用cookie代替用户名密码用文件读取也可以用iframe代替网页内容文件内容用flash的代替不重复数据需要判断是否重复页面相互分析一个页面抓取一些字段,然后要做清洗只抓取所需要的数据爬虫需要同步处理,所以要缓存,elxi,nginx等可以用来实现异步抓取也可以代替if,else,for判断条件else处理当然这只是抓取网页数据的一些办法,比如用php写爬虫再用python或者java代码解析,或者java用phantomjs做简单的交互,再将抓取的json通过grep看tag是否匹配之类的的,这些都能做到大规模分析在大数据时代,做数据分析,要将python,java,php,php,top500,mysql等全部用来写程序去解析数据,这样就需要算法了,算法肯定是基于矩阵处理了,最最基本的就是用矩阵变换,很多时候用矩阵展开没有问题,就是一次非线性运算,矩阵都没有画出来,都不知道哪些子元素是什么东西可以理解为mse,ransac,vg,等算法这些都是基于矩阵分析的程序,处理大规模数据很强大,比如线性回归,lasso残差方差,主成分分析,knn等等非线性一般用svm做类似的分析。 查看全部
抓取网页数据 php(抓取网页数据,,,表单数据)
抓取网页数据php,java,html,css表单数据javascript,php,python,数据库操作mysql,postgresql,oracle其他的java爬虫用cookie代替用户名密码用文件读取也可以用iframe代替网页内容文件内容用flash的代替不重复数据需要判断是否重复页面相互分析一个页面抓取一些字段,然后要做清洗只抓取所需要的数据爬虫需要同步处理,所以要缓存,elxi,nginx等可以用来实现异步抓取也可以代替if,else,for判断条件else处理当然这只是抓取网页数据的一些办法,比如用php写爬虫再用python或者java代码解析,或者java用phantomjs做简单的交互,再将抓取的json通过grep看tag是否匹配之类的的,这些都能做到大规模分析在大数据时代,做数据分析,要将python,java,php,php,top500,mysql等全部用来写程序去解析数据,这样就需要算法了,算法肯定是基于矩阵处理了,最最基本的就是用矩阵变换,很多时候用矩阵展开没有问题,就是一次非线性运算,矩阵都没有画出来,都不知道哪些子元素是什么东西可以理解为mse,ransac,vg,等算法这些都是基于矩阵分析的程序,处理大规模数据很强大,比如线性回归,lasso残差方差,主成分分析,knn等等非线性一般用svm做类似的分析。
抓取网页数据 php(写好的网页程序如何生成sampler文件在浏览器里打开生成就行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-09 08:01
抓取网页数据phpstormphpstorm和phpstorm差不多。当然,如果你电脑上安装了phpstorm,可以忽略我的介绍。用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。都是使用php的语言,解决开发过程中遇到的问题。关于解决方案:写好的网页程序如何生成sampler文件在浏览器里打开生成就行了webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginscss-plugin-eslintslm-plugin-eslintjswebpack-proxyplugin-pluginsued大成至尊项目可以根据你的需求实现各种功能比如解决网页加载很慢的情况。解决网页载入慢的情况。解决非web端加载慢的情况。解决非服务器端同步加载慢的情况。
解决导航栏乱跳的情况。解决各种浏览器pci调用的兼容问题。解决ie不能正常显示插件的问题。解决导航栏乱跳的问题。ued大成至尊项目可以部署到全国,所以不用担心服务器问题。开发无服务器的教程在这里文章。
用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。在浏览器里打开就行了,可以基于lnmp,也可以基于docker,也可以基于saas服务环境。自己写好的网页程序,如何生成sampler文件在浏览器里打开生成就行了。webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginnpminstall-gscss-plugin--save-devscss模块化是分解网页,像解数学题一样逐条手动填空,一项条件对应一条赋值。vscode更适合做webpack,但是scss和csscgenerator要一定配置开发,也有多人协作的功能,sass模块也可以,sasspack就像浏览器的插件,有了这个插件,就不需要配置环境。你提到的打包导航栏乱跳问题,应该有packup的支持。同样,文件的位置要合理。等一等,后面有补充:。 查看全部
抓取网页数据 php(写好的网页程序如何生成sampler文件在浏览器里打开生成就行)
抓取网页数据phpstormphpstorm和phpstorm差不多。当然,如果你电脑上安装了phpstorm,可以忽略我的介绍。用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。都是使用php的语言,解决开发过程中遇到的问题。关于解决方案:写好的网页程序如何生成sampler文件在浏览器里打开生成就行了webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginscss-plugin-eslintslm-plugin-eslintjswebpack-proxyplugin-pluginsued大成至尊项目可以根据你的需求实现各种功能比如解决网页加载很慢的情况。解决网页载入慢的情况。解决非web端加载慢的情况。解决非服务器端同步加载慢的情况。
解决导航栏乱跳的情况。解决各种浏览器pci调用的兼容问题。解决ie不能正常显示插件的问题。解决导航栏乱跳的问题。ued大成至尊项目可以部署到全国,所以不用担心服务器问题。开发无服务器的教程在这里文章。
用phpstorm或者vscode开发网页程序,和用其他工具开发网页一样。在浏览器里打开就行了,可以基于lnmp,也可以基于docker,也可以基于saas服务环境。自己写好的网页程序,如何生成sampler文件在浏览器里打开生成就行了。webpacktreesnippetcsscgeneratorcsspackscssplusmake模块化思想在webpack和treesnippet可以轻松实现网页模块化。
不过需要先打包好项目。scss-pluginnpminstall-gscss-plugin--save-devscss模块化是分解网页,像解数学题一样逐条手动填空,一项条件对应一条赋值。vscode更适合做webpack,但是scss和csscgenerator要一定配置开发,也有多人协作的功能,sass模块也可以,sasspack就像浏览器的插件,有了这个插件,就不需要配置环境。你提到的打包导航栏乱跳问题,应该有packup的支持。同样,文件的位置要合理。等一等,后面有补充:。
抓取网页数据 php( 支持列表页的自动翻页抓取,支持图片、文件的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-23 04:10
支持列表页的自动翻页抓取,支持图片、文件的抓取)
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
抓取网页数据 php(
支持列表页的自动翻页抓取,支持图片、文件的抓取)
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
抓取网页数据 php(php的反射机制可以用html反编译吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-23 00:03
抓取网页数据php脚本爬虫,页面调试,php的反射机制可以抓取一些数据,后缀是//,page,后缀是/''的页面是一些页面的路径,page和/''是不一样的。这个后缀是乱码,可以用html反编译,html类型是web.xml\xxx.web{broadcast=0;recipient=0;}java也有类似命令,java的反射可以调用html标签,后缀是/java.xml\java.xxx.html{broadcast=0;recipient=0;}ibm可以用protobuf,有java版的java\ibm.jl\java.ibm.broadcast.json{broadcast=0;recipient=0;}。
protobuf?
php读的时候存在socket里面,
php:boost-asio读的时候protobuf另外protobuf作为一个socket格式,
python
有一个叫php-fastjson的函数。
php-fastjson
php-socket.
requestsgithub地址:php-fastjson-amessagingserviceforphp.ps:php-fastjson为什么php官方没有出现,个人猜测可能是php-fastjson技术是用php作为调用者,php的grpc不方便实现,这个暂时还没有尝试过。
<p>其实php,zend的处理方法都一样,都是在header里面写一句.php 查看全部
抓取网页数据 php(php的反射机制可以用html反编译吗?(一))
抓取网页数据php脚本爬虫,页面调试,php的反射机制可以抓取一些数据,后缀是//,page,后缀是/''的页面是一些页面的路径,page和/''是不一样的。这个后缀是乱码,可以用html反编译,html类型是web.xml\xxx.web{broadcast=0;recipient=0;}java也有类似命令,java的反射可以调用html标签,后缀是/java.xml\java.xxx.html{broadcast=0;recipient=0;}ibm可以用protobuf,有java版的java\ibm.jl\java.ibm.broadcast.json{broadcast=0;recipient=0;}。
protobuf?
php读的时候存在socket里面,
php:boost-asio读的时候protobuf另外protobuf作为一个socket格式,
python
有一个叫php-fastjson的函数。
php-fastjson
php-socket.
requestsgithub地址:php-fastjson-amessagingserviceforphp.ps:php-fastjson为什么php官方没有出现,个人猜测可能是php-fastjson技术是用php作为调用者,php的grpc不方便实现,这个暂时还没有尝试过。
<p>其实php,zend的处理方法都一样,都是在header里面写一句.php
抓取网页数据 php(抓取网页数据做基础(一)__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-21 20:03
抓取网页数据php做基础爬虫每个语言都有自己的爬虫框架,使用多种框架自动化去爬取网页。前端使用requests库爬取页面。http代理端口会被加密以及避免校验。浏览器解析html页面。一些传统方式使用javascript,jquery库,自定义内容即可。首页搜索页面会跳转至搜索结果页面,所以需要javascript跳转。
可以让页面看起来更加美观,方便开发者抓取页面,一般有监听事件和定时事件,在外部接受数据时,跳转。静态页面搜索页面会跳转至静态页面页面,没有搜索结果页面,没有上传下载的接口,这种页面通常是使用php解析后,返回给浏览器。google浏览器同样遵循这种解析逻辑。javascript是浏览器的一种javascript代码,一般用于向浏览器输出html。
当有报文时,将被解析,分析报文。当报文中包含html标签时,则执行解析,并更新javascript代码,由此实现了浏览器和服务器之间数据的交互。php解析html标签并调用相应的javascript代码调用php中的javascript是指在javascript代码中调用html标签中的html标签,而不是直接在html页面的html标签中调用。
<p>javascript调用后,首先执行javascript脚本,javascript脚本完成后,才完成后续的数据交互(解析页面)工作。filename.php{location_prefix:'/';}php和html之间一般使用echo来分割php和html标签:所有文件的路径:filename.php文件的路径:/public/public:所有entity的路径:filename.php文件中的entity:/*文件名格式:/public_uri/*/html文件中的可见(可读)(可写)标签:.*html文件中的不可见(不可读)(/)链接:::我们需要调用html标签的php代码@author.mst.follow(some_info,some_name,...)注意:当上面为空或者javascript中直接调用author.js时,不会看到注释。所以我们加上./author.js,我们要知道php代码中需要 查看全部
抓取网页数据 php(抓取网页数据做基础(一)__)
抓取网页数据php做基础爬虫每个语言都有自己的爬虫框架,使用多种框架自动化去爬取网页。前端使用requests库爬取页面。http代理端口会被加密以及避免校验。浏览器解析html页面。一些传统方式使用javascript,jquery库,自定义内容即可。首页搜索页面会跳转至搜索结果页面,所以需要javascript跳转。
可以让页面看起来更加美观,方便开发者抓取页面,一般有监听事件和定时事件,在外部接受数据时,跳转。静态页面搜索页面会跳转至静态页面页面,没有搜索结果页面,没有上传下载的接口,这种页面通常是使用php解析后,返回给浏览器。google浏览器同样遵循这种解析逻辑。javascript是浏览器的一种javascript代码,一般用于向浏览器输出html。
当有报文时,将被解析,分析报文。当报文中包含html标签时,则执行解析,并更新javascript代码,由此实现了浏览器和服务器之间数据的交互。php解析html标签并调用相应的javascript代码调用php中的javascript是指在javascript代码中调用html标签中的html标签,而不是直接在html页面的html标签中调用。
<p>javascript调用后,首先执行javascript脚本,javascript脚本完成后,才完成后续的数据交互(解析页面)工作。filename.php{location_prefix:'/';}php和html之间一般使用echo来分割php和html标签:所有文件的路径:filename.php文件的路径:/public/public:所有entity的路径:filename.php文件中的entity:/*文件名格式:/public_uri/*/html文件中的可见(可读)(可写)标签:.*html文件中的不可见(不可读)(/)链接:::我们需要调用html标签的php代码@author.mst.follow(some_info,some_name,...)注意:当上面为空或者javascript中直接调用author.js时,不会看到注释。所以我们加上./author.js,我们要知道php代码中需要
抓取网页数据 php(curl()、file_get_contents(.class.phpsnoopy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-18 14:18
curl()、file_get_contents()、snoopy.class.php是采集中用到的三个远程页面爬取工具或工具。它们具有相同的功能。有什么优点和缺点吗?这里一一介绍:
史努比.class.php
史努比是用fsockopen自行开发的类。它更高效并且不需要特定于服务器的配置支持。可以在普通的虚拟主机中使用,但是经常会出现问题。官方下载地址:
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页的内容,并发送表单。
史努比的特点:
1、获取网页内容
2、 获取网页的文本内容(去除HTML标签) fetchtext
3、获取网页链接,表单 fetchlinks fetchform
4、支持代理主机
5、支持基本的用户名/密码验证
6、支持设置user_agent、referer(来源)、cookies和header内容(头文件)
7、支持浏览器重定向,控制重定向深度
8、 可以将网页中的链接扩展为高质量的url(默认)
9、提交数据并获取返回值
10、支持跟踪HTML框架
11、 支持重定向时传递cookies
需要php4或更高版本,因为是php类,不需要扩展支持,服务器不支持curl时的最佳选择。 查看全部
抓取网页数据 php(curl()、file_get_contents(.class.phpsnoopy)
curl()、file_get_contents()、snoopy.class.php是采集中用到的三个远程页面爬取工具或工具。它们具有相同的功能。有什么优点和缺点吗?这里一一介绍:
史努比.class.php
史努比是用fsockopen自行开发的类。它更高效并且不需要特定于服务器的配置支持。可以在普通的虚拟主机中使用,但是经常会出现问题。官方下载地址:
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页的内容,并发送表单。
史努比的特点:
1、获取网页内容
2、 获取网页的文本内容(去除HTML标签) fetchtext
3、获取网页链接,表单 fetchlinks fetchform
4、支持代理主机
5、支持基本的用户名/密码验证
6、支持设置user_agent、referer(来源)、cookies和header内容(头文件)
7、支持浏览器重定向,控制重定向深度
8、 可以将网页中的链接扩展为高质量的url(默认)
9、提交数据并获取返回值
10、支持跟踪HTML框架
11、 支持重定向时传递cookies
需要php4或更高版本,因为是php类,不需要扩展支持,服务器不支持curl时的最佳选择。
抓取网页数据 php(javascriptjs+flash+mysql+ajax+jquerymv,为什么可以这样干)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-11 15:13
抓取网页数据php+mysql+flash+ajax
目前主流的方案是js+flash+mysql+ajax。下面说下为什么可以这样干。js在页面渲染后对页面进行数据记录(xml)后,服务器把数据交给后端处理,后端读取处理后数据进行页面渲染。这种方案,就算全部用php渲染页面后端,其服务器并发能力也不够,因为页面不能刷新。而用js可以来承担刷新功能。
javascript+ajax+mysql+jquerymv**
http也是一种传输层,两者可以对接。tcp/ip协议是一种传输层。事实上,即使是存在两者对接方案,由于两者都是基于tcp/ip协议所以传输率受限,在传输区域高的网络环境下非常受影响。这里只能给你简单地说明为什么两者是受限方案。无论是谁用谁的协议,内部都有特定的包路由策略和字节序。所以无论是从这两个方面,内存/全连接/二进制/mvc内核等等,都是有影响的。
还有另外一个问题就是即使两者可以对接,但是由于都是面向非客户端的,这里有一个用户体验问题,目前用户体验是一个长久的没有解决的问题。web中的用户体验通过点击,滑动,触摸等行为反馈给程序,那么点击和滑动在无信息和无反馈的情况下,用户体验会有什么差别?。
1.存储问题,安全问题,如何保证数据的统一管理和读写2.性能问题,内存多少个线程,如何传递字符串读取,如何写入数据,哪些操作可以使用事件,哪些可以使用ajax等等3.页面加载,如何减少页面加载时间,多久显示一次页面,页面css,js文件有哪些, 查看全部
抓取网页数据 php(javascriptjs+flash+mysql+ajax+jquerymv,为什么可以这样干)
抓取网页数据php+mysql+flash+ajax
目前主流的方案是js+flash+mysql+ajax。下面说下为什么可以这样干。js在页面渲染后对页面进行数据记录(xml)后,服务器把数据交给后端处理,后端读取处理后数据进行页面渲染。这种方案,就算全部用php渲染页面后端,其服务器并发能力也不够,因为页面不能刷新。而用js可以来承担刷新功能。
javascript+ajax+mysql+jquerymv**
http也是一种传输层,两者可以对接。tcp/ip协议是一种传输层。事实上,即使是存在两者对接方案,由于两者都是基于tcp/ip协议所以传输率受限,在传输区域高的网络环境下非常受影响。这里只能给你简单地说明为什么两者是受限方案。无论是谁用谁的协议,内部都有特定的包路由策略和字节序。所以无论是从这两个方面,内存/全连接/二进制/mvc内核等等,都是有影响的。
还有另外一个问题就是即使两者可以对接,但是由于都是面向非客户端的,这里有一个用户体验问题,目前用户体验是一个长久的没有解决的问题。web中的用户体验通过点击,滑动,触摸等行为反馈给程序,那么点击和滑动在无信息和无反馈的情况下,用户体验会有什么差别?。
1.存储问题,安全问题,如何保证数据的统一管理和读写2.性能问题,内存多少个线程,如何传递字符串读取,如何写入数据,哪些操作可以使用事件,哪些可以使用ajax等等3.页面加载,如何减少页面加载时间,多久显示一次页面,页面css,js文件有哪些,
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-10-10 08:31
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault,如有侵权,请联系删除 查看全部
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault,如有侵权,请联系删除
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-30 13:32
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site")
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site")
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site").text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault,如有侵权,请联系删除 查看全部
抓取网页数据 php(有一定的参考价值,有需要的朋友可以参考一下吗)
本文内容文章是关于Python爬取乱码网页的原因及解决方法。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
在使用python2抓取网页时,我们经常会遇到抓取到的内容出现乱码。
出现这种情况最有可能是编码问题:运行环境的字符编码与网页的字符编码不一致。
例如,我在 windows 控制台 (gbk) 中抓取了一个 utf-8 编码的 网站。或者,在Mac/Linux终端中抓一个gbk编码的网站(utf-8)。因为大多数网站使用的是utf-8编码,而且很多人用的是Windows,所有这种情况相当普遍。
如果你发现你抓取的内容在英文、数字、符号上看起来都是正确的,但是中间出现了一些乱码,你基本可以断定是这样的。
解决这个问题的办法是先按照网页的编码方式将结果解码成unicode,然后输出。如果不确定网页的编码,可以参考以下代码:
import urllib
req = urllib.urlopen("http://some.web.site";)
info = req.info()
charset = info.getparam('charset')
content = req.read()
print content.decode(charset, 'ignore')
'ignore' 参数的作用是忽略无法解码的字符。
然而,这种方法并不总是有效。另一种方式是通过正则化直接匹配网页代码中的编码设置:
除了编码问题导致的乱码外,还有一种情况经常被忽略,那就是登陆页面开启了gzip压缩。压缩后的网页传输的数据更少,打开速度更快。在浏览器中打开时,浏览器会根据网页的header信息自动解压。但是直接用代码去抢就不行了。所以,很可能会疑惑,为什么打开网页地址明了,但是程序爬取却不行。就连我自己也被这个问题愚弄了。
这种情况的表现就是抓取的内容几乎都是乱码,甚至无法显示。
判断网页是否开启压缩并解压,可以参考如下代码:
import urllib
import gzip
from StringIO import StringIO
req = urllib.urlopen("http://some.web.site";)
info = req.info()
encoding = info.getheader('Content-Encoding')
content = req.read()
if encoding == 'gzip':
buf = StringIO(content)
gf = gzip.GzipFile(fileobj=buf)
content = gf.read()
print content
在我们课堂上查看天气系列的编程实例(点击查看),这两个问题困扰了不少人。这里有一个特别的解释。
最后,还有另一种“武器”要介绍。如果你第一次使用它,你甚至不知道上面两个问题仍然存在。
这是请求模块。
以同样的方式抓取网页,您只需要:
import requests
print requests.get("http://some.web.site";).text
没有编码问题,没有压缩问题。
这就是我喜欢 Python 的原因。
至于如何安装requests模块,请参考前面的文章:
Python-Crossin的编程课堂如何安装第三方模块-知乎专栏
pip install requests
以上就是Python爬取网页乱码的原因及解决方法的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault,如有侵权,请联系删除
抓取网页数据 php(爬虫对php的特殊支持(生成的dom),易上手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-22 14:07
抓取网页数据php代码分析相当复杂,我一般都只关注最核心的app数据。爬虫需要解决的php问题是:tp对php的特殊支持(生成的dom),如果其他系统不熟,另外就是一个字符串解析问题,这个使用xpathtxtjsonlist等另外我一直也没找到一个很好的完美且速度能大幅度提升的网络爬虫方案,直到我看到这个~learnpythonthehardway!withpython,minecraft:venom!获取单词列表文章列表也是同样的道理-started-with-python-the-hard-way-with-python-venom。
针对python1.x
python建议python3,
题主还没明白python的几个特性:
1)按照brainfuck语法,
2)tf、pytorch的分布式计算的底层很大程度上是用了python实现
3)python的异步io可以用jit技术加速不少步骤
谢邀。肯定是python啊。但是,learnpythonthehardway!是需要c++库的,所以要学好c++,推荐learnpythonthehardway!(github)一开始可以用python写一些简单的东西,然后用c+++模拟运行测试,但是只是模拟运行。后面对于python有了更深的研究,那么可以拿来用。
我看了一下,我觉得其实挺像的。python的语法,易上手,合理性,模块化等等都是比较优秀的。在一开始写爬虫的时候,采集效率一般是很重要的,如果采集效率很差,那么随之而来的是时间的流逝和cpu资源的消耗,和功耗,gpu消耗等等,所以说,学会怎么写爬虫,是一个可持续的积累,最后可能写出来的东西才会比较好。
而对于这些爬虫能做什么,不会太专业,上手这些爬虫和你开始写写网站是一样的,都是你的知识储备。而对于c++,基本上是c++程序员加持的,他们写的网站,各种服务器,客户端,那么就需要多学点。 查看全部
抓取网页数据 php(爬虫对php的特殊支持(生成的dom),易上手)
抓取网页数据php代码分析相当复杂,我一般都只关注最核心的app数据。爬虫需要解决的php问题是:tp对php的特殊支持(生成的dom),如果其他系统不熟,另外就是一个字符串解析问题,这个使用xpathtxtjsonlist等另外我一直也没找到一个很好的完美且速度能大幅度提升的网络爬虫方案,直到我看到这个~learnpythonthehardway!withpython,minecraft:venom!获取单词列表文章列表也是同样的道理-started-with-python-the-hard-way-with-python-venom。
针对python1.x
python建议python3,
题主还没明白python的几个特性:
1)按照brainfuck语法,
2)tf、pytorch的分布式计算的底层很大程度上是用了python实现
3)python的异步io可以用jit技术加速不少步骤
谢邀。肯定是python啊。但是,learnpythonthehardway!是需要c++库的,所以要学好c++,推荐learnpythonthehardway!(github)一开始可以用python写一些简单的东西,然后用c+++模拟运行测试,但是只是模拟运行。后面对于python有了更深的研究,那么可以拿来用。
我看了一下,我觉得其实挺像的。python的语法,易上手,合理性,模块化等等都是比较优秀的。在一开始写爬虫的时候,采集效率一般是很重要的,如果采集效率很差,那么随之而来的是时间的流逝和cpu资源的消耗,和功耗,gpu消耗等等,所以说,学会怎么写爬虫,是一个可持续的积累,最后可能写出来的东西才会比较好。
而对于这些爬虫能做什么,不会太专业,上手这些爬虫和你开始写写网站是一样的,都是你的知识储备。而对于c++,基本上是c++程序员加持的,他们写的网站,各种服务器,客户端,那么就需要多学点。
抓取网页数据 php(使用Python3的requests包抓取并保存网页源码的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-09-21 19:06
本文描述了Python3如何使用requests包获取和保存网页源代码。与您分享,供您参考,如下所示:
使用Python 3的请求模块获取网页源代码并将其保存到文件中示例:
import requests
html = requests.get("http://www.baidu.com")
with open('test.txt','w',encoding='utf-8') as f:
f.write(html.text)
这是一个基本的文件保存操作,但有几个值得注意的问题:
1.安装请求包。在命令行中,输入PIP install requests以自动安装它。许多人建议使用请求。自足的urlib。请求还可以抓取web源代码
2.open方法的编码参数设置为UTF-8,否则保存的文件将被乱码
3.如果捕获的内容直接以CMD输出,则会提示各种编码错误,因此将其保存到文件中以供查看
4.withopen方法是一种更好的编写方法。它可以在自动操作后释放资源
另一个例子:
import requests
ff = open('testt.txt','w',encoding='utf-8')
with open('test.txt',encoding="utf-8") as f:
for line in f:
ff.write(line)
ff.close()
这是一个一次读取一行TXT文件并将其保存到另一个TXT文件的示例
因为在命令行上打印一行一行读取的数据时会出现中文编码错误,所以每次读取一行并保存到另一个文件中,以测试读取是否正常。(打开时请注意编码方法)
有关Python 3如何使用请求包捕获和保存web源代码的更多信息,文章请关注PHP中文网站
声明:本文原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
抓取网页数据 php(使用Python3的requests包抓取并保存网页源码的方法)
本文描述了Python3如何使用requests包获取和保存网页源代码。与您分享,供您参考,如下所示:
使用Python 3的请求模块获取网页源代码并将其保存到文件中示例:
import requests
html = requests.get("http://www.baidu.com";)
with open('test.txt','w',encoding='utf-8') as f:
f.write(html.text)
这是一个基本的文件保存操作,但有几个值得注意的问题:
1.安装请求包。在命令行中,输入PIP install requests以自动安装它。许多人建议使用请求。自足的urlib。请求还可以抓取web源代码
2.open方法的编码参数设置为UTF-8,否则保存的文件将被乱码
3.如果捕获的内容直接以CMD输出,则会提示各种编码错误,因此将其保存到文件中以供查看
4.withopen方法是一种更好的编写方法。它可以在自动操作后释放资源
另一个例子:
import requests
ff = open('testt.txt','w',encoding='utf-8')
with open('test.txt',encoding="utf-8") as f:
for line in f:
ff.write(line)
ff.close()
这是一个一次读取一行TXT文件并将其保存到另一个TXT文件的示例
因为在命令行上打印一行一行读取的数据时会出现中文编码错误,所以每次读取一行并保存到另一个文件中,以测试读取是否正常。(打开时请注意编码方法)
有关Python 3如何使用请求包捕获和保存web源代码的更多信息,文章请关注PHP中文网站
声明:本文原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
抓取网页数据 php(php.ini中max_execution_time设置的大点,不然会报错的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-21 18:23
抓取之前,请记住将Max放在php.ini中,执行时间应设置得更大,否则将报告错误
一、使用snoopy.class.php抓取页面
一个可爱的类名。这个功能也非常强大。它用于模拟浏览器的功能。您可以获取web内容、发送表单等
1)我现在想捕获网站列表页面的内容。我想捕获全国医院信息的内容,如下图所示:
2)I自然复制URL地址,使用Snoopy类抓取前10页的页面内容,并将内容放在本地,在本地创建HTML文件进行分析
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3)奇怪的是,回来的不是国家内容,而是上海的相关内容
4)后来,我怀疑里面可能放了一块饼干,然后我用firebug检查了一下。果然,有一个惊人的内幕故事
5)将cookie的值放入请求中,并添加设置语句$Snoopy->;Cookies[“_area]”,情况大不相同,国家信息顺利返回
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i results;
}
2)use phpquery获取节点信息,如下DOM结构所示:
使用一些phpquery方法和DOM结构读取每个医院信息的URL地址
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取的URL地址列表抓取指定页面
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
障碍攀登
演示下载:
Snoopy类的一些描述:
类方法
获取($URI) 查看全部
抓取网页数据 php(php.ini中max_execution_time设置的大点,不然会报错的)
抓取之前,请记住将Max放在php.ini中,执行时间应设置得更大,否则将报告错误
一、使用snoopy.class.php抓取页面
一个可爱的类名。这个功能也非常强大。它用于模拟浏览器的功能。您可以获取web内容、发送表单等
1)我现在想捕获网站列表页面的内容。我想捕获全国医院信息的内容,如下图所示:
2)I自然复制URL地址,使用Snoopy类抓取前10页的页面内容,并将内容放在本地,在本地创建HTML文件进行分析
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3)奇怪的是,回来的不是国家内容,而是上海的相关内容
4)后来,我怀疑里面可能放了一块饼干,然后我用firebug检查了一下。果然,有一个惊人的内幕故事
5)将cookie的值放入请求中,并添加设置语句$Snoopy->;Cookies[“_area]”,情况大不相同,国家信息顺利返回
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i results;
}
2)use phpquery获取节点信息,如下DOM结构所示:
使用一些phpquery方法和DOM结构读取每个医院信息的URL地址
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取的URL地址列表抓取指定页面
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
障碍攀登
演示下载:
Snoopy类的一些描述:
类方法
获取($URI)
抓取网页数据 php(【每日一题】网页数据的问题(使用HtmlAgilityPack、WebBrowser))
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-18 17:07
询问您有关捕获网页数据的问题(使用htmlagility pack和WebBrowser)
获取页面的部分数据。当使用Htmlagibility pack解析第一个页面时,结果是正常的
问题:1、运行后,documentcompleted事件似乎只触发一次,最后在第二页停止
2、无法获取新页面的documenttext,只能重复获取第一页的数据
请询问解决方案,谢谢
测试网址:
测试代码如下所示:
<br />
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)<br />
{<br />
WebBrowser targetWeb = sender as WebBrowser;<br />
if (targetWeb.ReadyState == WebBrowserReadyState.Complete)<br />
{<br />
HtmlAgilityPack.HtmlDocument hapHtmlDoc = new HtmlAgilityPack.HtmlDocument();<br />
hapHtmlDoc.LoadHtml(targetWeb.DocumentText);<br />
HtmlNodeCollection targetNodeList = hapHtmlDoc.DocumentNode.SelectNodes("//td[@class='f005'][1]");//获取日期<br />
<br />
foreach (HtmlNode test in targetNodeList)<br />
System.Diagnostics.Debug.WriteLine(test.InnerHtml);//测试内容<br />
<br />
System.Windows.Forms.HtmlDocument winHtmlDoc = targetWeb.Document;<br />
foreach (HtmlElement item in winHtmlDoc.GetElementsByTagName("a"))<br />
{<br />
if (item.OuterText == "下一页")<br />
{<br />
item.InvokeMember("click");<br />
break;<br />
}<br />
}<br />
}<br />
}<br />
------解决思路----------------------
似乎只有Java对使用Ajax加载的页面具有DLL支持,而且似乎没有相应的net版本
------解决思路----------------------
这与已完成的文档无关。人们根本不刷新页面
您需要插入JavaScript代码,创建一个新的JavaScript对象来保存旧的getajaxdata函数,然后用新的getajaxdata函数替换旧的getajaxdata函数。应在新的getajaxdata函数内调用旧的getajaxdata函数 查看全部
抓取网页数据 php(【每日一题】网页数据的问题(使用HtmlAgilityPack、WebBrowser))
询问您有关捕获网页数据的问题(使用htmlagility pack和WebBrowser)
获取页面的部分数据。当使用Htmlagibility pack解析第一个页面时,结果是正常的
问题:1、运行后,documentcompleted事件似乎只触发一次,最后在第二页停止
2、无法获取新页面的documenttext,只能重复获取第一页的数据
请询问解决方案,谢谢
测试网址:
测试代码如下所示:
<br />
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)<br />
{<br />
WebBrowser targetWeb = sender as WebBrowser;<br />
if (targetWeb.ReadyState == WebBrowserReadyState.Complete)<br />
{<br />
HtmlAgilityPack.HtmlDocument hapHtmlDoc = new HtmlAgilityPack.HtmlDocument();<br />
hapHtmlDoc.LoadHtml(targetWeb.DocumentText);<br />
HtmlNodeCollection targetNodeList = hapHtmlDoc.DocumentNode.SelectNodes("//td[@class='f005'][1]");//获取日期<br />
<br />
foreach (HtmlNode test in targetNodeList)<br />
System.Diagnostics.Debug.WriteLine(test.InnerHtml);//测试内容<br />
<br />
System.Windows.Forms.HtmlDocument winHtmlDoc = targetWeb.Document;<br />
foreach (HtmlElement item in winHtmlDoc.GetElementsByTagName("a"))<br />
{<br />
if (item.OuterText == "下一页")<br />
{<br />
item.InvokeMember("click");<br />
break;<br />
}<br />
}<br />
}<br />
}<br />
------解决思路----------------------
似乎只有Java对使用Ajax加载的页面具有DLL支持,而且似乎没有相应的net版本
------解决思路----------------------
这与已完成的文档无关。人们根本不刷新页面
您需要插入JavaScript代码,创建一个新的JavaScript对象来保存旧的getajaxdata函数,然后用新的getajaxdata函数替换旧的getajaxdata函数。应在新的getajaxdata函数内调用旧的getajaxdata函数
抓取网页数据 php(从当当网上采集数据的过程为例,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2021-09-17 06:04
所谓的“网页数据捕获”,也称为网页数据采集、网页数据采集等,是从我们通常通过浏览器查看的网页中提取所需数据信息的过程,然后以结构化方式将其存储到CSV、JSON、XML、access、MSSQL、MySQL和其他文件或数据库中。当然,这里的数据提取过程是借助计算机软件技术实现的,而不是手动复制和粘贴。正因为如此,才有可能从大型网站和采集数据中获取数据
接下来,我们以当当在线采集data的流程为例,介绍一下网页数据采集的基本流程
首先,我们需要分析目标网站的网页结构,以确定网站上的数据是否可以是采集以及如何使用采集
当当网是一个综合性的网站,我们以图书数据为例。经过检查,我们找到了图书信息的目录页。图书信息以多级目录结构组织,如下图所示。图片左侧是图书信息的主目录:
由于数据保护的许多网站原因,显示的数据数量将受到限制。例如,数据最多可显示100页,超过100页的数据将不会显示。这样,您选择输入的目录级别越高,可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低的目录,即较小的分类级别,以便获得更多的数据
点击主目录进入辅助图书目录,如下图所示:
同样,依次单击所有级别的目录,最后进入底部目录。下面是目录下所有可显示数据项的列表,可称为底部列表页,如图所示:
当然,这个列表页面可能被分成多个页面。在数据采集处理期间,我们需要遍历每个页面的数据项。通过每个数据项上的链接,我们可以进入最终的数据页,称为详细信息页。如下图所示:
在此,已阐明获取详细数据的途径。接下来,我们需要分析细节页面上有用的数据项,然后编写data采集程序专门捕获我们感兴趣的数据
以下是作者在获取当当图书数据的网页数据时编写的程序代码的一部分:
以下是作者采集注意到的一些书籍信息样本数据:
到目前为止,一个完整的网页数据捕获过程已经完成 查看全部
抓取网页数据 php(从当当网上采集数据的过程为例,你了解多少?)
所谓的“网页数据捕获”,也称为网页数据采集、网页数据采集等,是从我们通常通过浏览器查看的网页中提取所需数据信息的过程,然后以结构化方式将其存储到CSV、JSON、XML、access、MSSQL、MySQL和其他文件或数据库中。当然,这里的数据提取过程是借助计算机软件技术实现的,而不是手动复制和粘贴。正因为如此,才有可能从大型网站和采集数据中获取数据
接下来,我们以当当在线采集data的流程为例,介绍一下网页数据采集的基本流程
首先,我们需要分析目标网站的网页结构,以确定网站上的数据是否可以是采集以及如何使用采集
当当网是一个综合性的网站,我们以图书数据为例。经过检查,我们找到了图书信息的目录页。图书信息以多级目录结构组织,如下图所示。图片左侧是图书信息的主目录:
由于数据保护的许多网站原因,显示的数据数量将受到限制。例如,数据最多可显示100页,超过100页的数据将不会显示。这样,您选择输入的目录级别越高,可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入较低的目录,即较小的分类级别,以便获得更多的数据
点击主目录进入辅助图书目录,如下图所示:
同样,依次单击所有级别的目录,最后进入底部目录。下面是目录下所有可显示数据项的列表,可称为底部列表页,如图所示:
当然,这个列表页面可能被分成多个页面。在数据采集处理期间,我们需要遍历每个页面的数据项。通过每个数据项上的链接,我们可以进入最终的数据页,称为详细信息页。如下图所示:
在此,已阐明获取详细数据的途径。接下来,我们需要分析细节页面上有用的数据项,然后编写data采集程序专门捕获我们感兴趣的数据
以下是作者在获取当当图书数据的网页数据时编写的程序代码的一部分:
以下是作者采集注意到的一些书籍信息样本数据:
到目前为止,一个完整的网页数据捕获过程已经完成

