
开放源代码
推荐10款流行的java开源的网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-06-29 08:03
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫 查看全部
1:JAVA爬虫WebCollector(Star:1345)
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫
网络爬虫_基于各类语言的开源网络爬虫总汇
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-06-13 08:02
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可
开源JAVA单机爬虫框架简介,优缺点剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-06 08:01
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。 查看全部
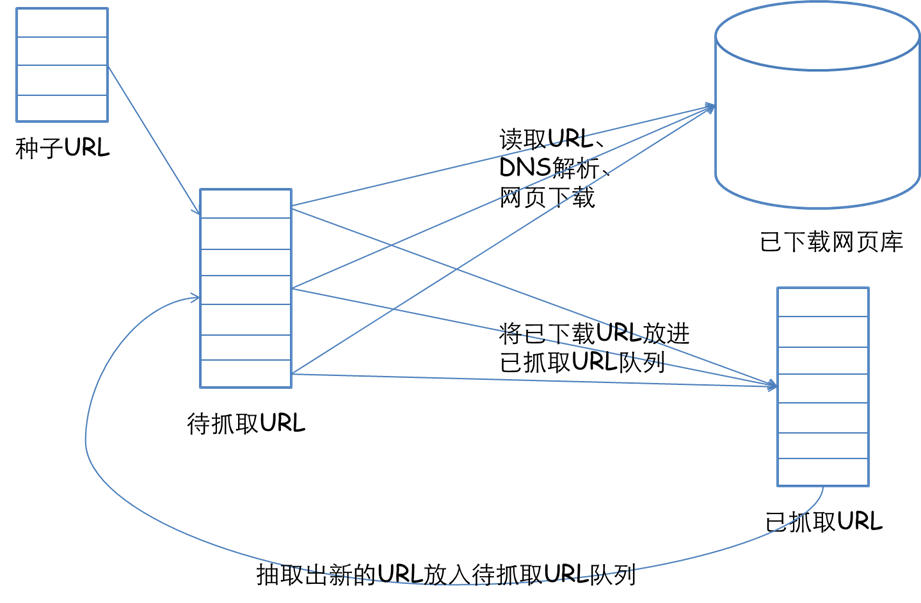
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。
一个简单的开源PHP爬虫框架『Phpfetcher』
采集交流 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2020-05-27 08:02
fanfank 文章作者
完整的代码贴下来我看一下,或者在微博私信我,我帮你看一下
aa
//下面两行促使这个项目被下载出来后本文件能直接运行
$demo_include_path = dirname(__FILE__) . ‘/../’;
set_include_path(get_include_path() . PATH_SEPARATOR . $demo_include_path);
require_once(‘phpfetcher.php’);
class mycrawler extends Phpfetcher_Crawler_Default {
public function handlePage($page) {
var_dump($page);
//打印处当前页面的第1个h1标题内荣(下标从0开始)
$strFirstH1 = trim($page->sel(‘//title’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo $page->sel(‘//title’, 0)->plaintext;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
//任务的名子随意起,这里把名子叫qqnews
//the key is the name of a job, here names it qqnews
‘qqnews’ => array(
‘start_page’ => ‘#8217;, //起始网页
‘link_rules’ => array(
/*
* 所有在这里列举的正则规则,只要能匹配到超链接,那么那条爬虫才会爬到那条超链接
* Regex rules are listed here, the crawler will follow any hyperlinks once the regex matches
*/
//’#news\.qq\.com/a/\d+/\d+\.htm$#’,
),
//爬虫从开始页面算起,最多爬取的深度,设置为2表示爬取深度为1
//Crawler’s max following depth, 1 stands for only crawl the start page
‘max_depth’ => 1,
) ,
);
$crawler->setFetchJobs($arrJobs)->run(); //这一行的疗效和下边两行的疗效一样
其他的没变
aa
public function read() {
$this->_strContent = curl_exec($this->_curlHandle);
是_strContent取到了false造成的 这个是啥缘由呢Page default.php
fanfank 文章作者
我这儿返回的是403 forbidden,查了一下晓得缘由了,因为user_agent的问题csdn把爬虫给禁了。你可以这样更改:找到文件Phpfetcher/Page/Default.php,然后搜『user_agent』,把上面改掉,我改成『firefox』就可以了,当然你可以可以改得更真实一点,例如哪些『Mozilla/5.0 AppleWebKit』之类的
有些网站会依照UA来屏蔽恳求,可能是因为个别UA有恶意功击的特点,或者一些爬虫之类的开源爬虫框架,之前百度有一段时间屏蔽360浏览器就是通过360浏览器里一些特定的UA来做到的,当然后来360浏览器把UA给更改嗯,就须要依照其它特点屏蔽了。
所以你这儿先改一下user_agent吧。
aa
多谢哈
试着改成Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0 也不行呢
试了这儿的也不行 恐怕还是curl的问题
fanfank 文章作者
我这儿执行都是正常的,结果也能下来。还是通过微博私信说吧,这里说得刷屏了
aa
围脖id是?
fanfank 文章作者
另外是,你贴的代码上面,标点符号不对啊,你的start_page对应那一行的标点,怎么是英文的单冒号?后面的单冒号似乎也不是个单冒号吧?要全部用英语的单冒号才行。
aa
符号是对的哈 都是英语的 没句型错误
joke
为什么匹配的内容都一样?
代码:
sel(‘//span[@id=”text110″]’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo “”;
echo $page->sel(‘//span[@id=”text110″]’, 0)->plaintext;
echo “”;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
‘joke’ => array(
‘start_page’ => ‘#8217;,
‘link_rules’ => array(
‘#/\woke\wtml/\w+/20151021\d+\.htm$#’,
),
‘max_depth’ => 2,
) ,
);
$crawler->setFetchJobs($arrJobs)->run();
fanfank 文章作者
你的代码没贴全,而且匹配的内容都一样我没很理解是哪些意思,这个问题有点长,你直接在微博私信我,我帮你看一下
fanfank 文章作者
已经修补了。之前的问题是爬虫不认识站内链接,例如有的超链接是『/entry』这样的,而不是『』。现在最新的Phpfetcher早已就能辨识站内链接,可以试一下
joke
谢谢 ,搞定了
modejun
楼主您好,问问假如我晓得了一个网站开源爬虫框架,但是要递交post参数,这个要如何弄呢,朋友提供一下思路
fanfank 文章作者
提交post参数,那觉得场景很特殊的,因为这个就不是单纯地按照链接爬取网页内容了,而且假如真的提供这个功能,针对什么样的链接什么样的参数,怎么递交,然后返回的内容是如何处理这种,目前我觉得似乎不太适宜爬虫做。或者你在微博私信我,告诉我你的使用场景是哪些,我瞧瞧是不是考虑找时间加进去
modejun
场景就是有一翻页时用ajax post递交的page参数,如果是get就太easy。还有顺便问问,如果翻页我明天试了要解决的话就是调节深度,但是似乎最大是20,还有就是更改正则循环调用setFetchJobs这个方式,总是觉得不是这么完美,有哪些好的思路解决翻页这个问题吗,现在公司在定方案我想多了解把这个框架的优势发挥下来,感谢了。
fanfank 文章作者
如果像你说的是个post恳求,那么它返回的应当不是一个HTML格式的文档,通常都是json格式的,然后由当前页面将异步返回的内容加载显示下来。
你们的post恳求应当是有类似pn,rn等参数,如果大家仅仅是想领到post恳求的所有内容,可以直接写一个for循环,然后使用php的curl来直接发送post恳求获取每一个页面内容,可以不使用爬虫,因为这个爬虫基本原理是针对GET恳求返回的HTML页面的,然后手动抽取HTML的标签
最大深度可以更改类『Phpfetcher_Crawler_Default』中的『MAX_DEPTH』变量,把20改成-1就没有限制了,不过建议还是设一个上限比较好
可以不需要循环更改正则呀,设置正则规则的可以是一个链表,把上面的所有你认为合适的正则都列上就可以,除非说你的正则表达式还得依据页面的某个参数或则内容不同而更改,那这个情况还是相对特殊了一点···
翻页的解决,如果是GET就用爬虫,如果是POST,那么直接for循环之后调用curl会更好。
;;;
好像不错
;;;
能不能写个DOM选择器和技巧的文档,最好支持css选择DOM标签,有子节点,父节点,兄弟节点选择才好
fanfank 文章作者
在这个项目的github页面:,中文说明的第2节上面,有介绍dom选择器的文档
jeremy
博主。。为什么https的页面没办法恳求呢? 查看全部
报dom为空

fanfank 文章作者
完整的代码贴下来我看一下,或者在微博私信我,我帮你看一下
aa
//下面两行促使这个项目被下载出来后本文件能直接运行
$demo_include_path = dirname(__FILE__) . ‘/../’;
set_include_path(get_include_path() . PATH_SEPARATOR . $demo_include_path);
require_once(‘phpfetcher.php’);
class mycrawler extends Phpfetcher_Crawler_Default {
public function handlePage($page) {
var_dump($page);
//打印处当前页面的第1个h1标题内荣(下标从0开始)
$strFirstH1 = trim($page->sel(‘//title’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo $page->sel(‘//title’, 0)->plaintext;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
//任务的名子随意起,这里把名子叫qqnews
//the key is the name of a job, here names it qqnews
‘qqnews’ => array(
‘start_page’ => ‘#8217;, //起始网页
‘link_rules’ => array(
/*
* 所有在这里列举的正则规则,只要能匹配到超链接,那么那条爬虫才会爬到那条超链接
* Regex rules are listed here, the crawler will follow any hyperlinks once the regex matches
*/
//’#news\.qq\.com/a/\d+/\d+\.htm$#’,
),
//爬虫从开始页面算起,最多爬取的深度,设置为2表示爬取深度为1
//Crawler’s max following depth, 1 stands for only crawl the start page
‘max_depth’ => 1,
) ,
);
$crawler->setFetchJobs($arrJobs)->run(); //这一行的疗效和下边两行的疗效一样
其他的没变
aa
public function read() {
$this->_strContent = curl_exec($this->_curlHandle);
是_strContent取到了false造成的 这个是啥缘由呢Page default.php
fanfank 文章作者
我这儿返回的是403 forbidden,查了一下晓得缘由了,因为user_agent的问题csdn把爬虫给禁了。你可以这样更改:找到文件Phpfetcher/Page/Default.php,然后搜『user_agent』,把上面改掉,我改成『firefox』就可以了,当然你可以可以改得更真实一点,例如哪些『Mozilla/5.0 AppleWebKit』之类的
有些网站会依照UA来屏蔽恳求,可能是因为个别UA有恶意功击的特点,或者一些爬虫之类的开源爬虫框架,之前百度有一段时间屏蔽360浏览器就是通过360浏览器里一些特定的UA来做到的,当然后来360浏览器把UA给更改嗯,就须要依照其它特点屏蔽了。
所以你这儿先改一下user_agent吧。
aa
多谢哈
试着改成Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0 也不行呢
试了这儿的也不行 恐怕还是curl的问题
fanfank 文章作者
我这儿执行都是正常的,结果也能下来。还是通过微博私信说吧,这里说得刷屏了
aa
围脖id是?
fanfank 文章作者
另外是,你贴的代码上面,标点符号不对啊,你的start_page对应那一行的标点,怎么是英文的单冒号?后面的单冒号似乎也不是个单冒号吧?要全部用英语的单冒号才行。
aa
符号是对的哈 都是英语的 没句型错误
joke
为什么匹配的内容都一样?
代码:
sel(‘//span[@id=”text110″]’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo “”;
echo $page->sel(‘//span[@id=”text110″]’, 0)->plaintext;
echo “”;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
‘joke’ => array(
‘start_page’ => ‘#8217;,
‘link_rules’ => array(
‘#/\woke\wtml/\w+/20151021\d+\.htm$#’,
),
‘max_depth’ => 2,
) ,
);
$crawler->setFetchJobs($arrJobs)->run();
fanfank 文章作者
你的代码没贴全,而且匹配的内容都一样我没很理解是哪些意思,这个问题有点长,你直接在微博私信我,我帮你看一下
fanfank 文章作者
已经修补了。之前的问题是爬虫不认识站内链接,例如有的超链接是『/entry』这样的,而不是『』。现在最新的Phpfetcher早已就能辨识站内链接,可以试一下
joke
谢谢 ,搞定了
modejun
楼主您好,问问假如我晓得了一个网站开源爬虫框架,但是要递交post参数,这个要如何弄呢,朋友提供一下思路
fanfank 文章作者
提交post参数,那觉得场景很特殊的,因为这个就不是单纯地按照链接爬取网页内容了,而且假如真的提供这个功能,针对什么样的链接什么样的参数,怎么递交,然后返回的内容是如何处理这种,目前我觉得似乎不太适宜爬虫做。或者你在微博私信我,告诉我你的使用场景是哪些,我瞧瞧是不是考虑找时间加进去
modejun
场景就是有一翻页时用ajax post递交的page参数,如果是get就太easy。还有顺便问问,如果翻页我明天试了要解决的话就是调节深度,但是似乎最大是20,还有就是更改正则循环调用setFetchJobs这个方式,总是觉得不是这么完美,有哪些好的思路解决翻页这个问题吗,现在公司在定方案我想多了解把这个框架的优势发挥下来,感谢了。
fanfank 文章作者
如果像你说的是个post恳求,那么它返回的应当不是一个HTML格式的文档,通常都是json格式的,然后由当前页面将异步返回的内容加载显示下来。
你们的post恳求应当是有类似pn,rn等参数,如果大家仅仅是想领到post恳求的所有内容,可以直接写一个for循环,然后使用php的curl来直接发送post恳求获取每一个页面内容,可以不使用爬虫,因为这个爬虫基本原理是针对GET恳求返回的HTML页面的,然后手动抽取HTML的标签
最大深度可以更改类『Phpfetcher_Crawler_Default』中的『MAX_DEPTH』变量,把20改成-1就没有限制了,不过建议还是设一个上限比较好
可以不需要循环更改正则呀,设置正则规则的可以是一个链表,把上面的所有你认为合适的正则都列上就可以,除非说你的正则表达式还得依据页面的某个参数或则内容不同而更改,那这个情况还是相对特殊了一点···
翻页的解决,如果是GET就用爬虫,如果是POST,那么直接for循环之后调用curl会更好。
;;;
好像不错
;;;
能不能写个DOM选择器和技巧的文档,最好支持css选择DOM标签,有子节点,父节点,兄弟节点选择才好
fanfank 文章作者
在这个项目的github页面:,中文说明的第2节上面,有介绍dom选择器的文档
jeremy
博主。。为什么https的页面没办法恳求呢?
基于 Java 的开源网路爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-05-15 08:00
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。 查看全部
WebCollector 是一个无须配置、便于二次开发的Java爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:

最新Maven地址请参考文档:
文档地址:
内核架构图:
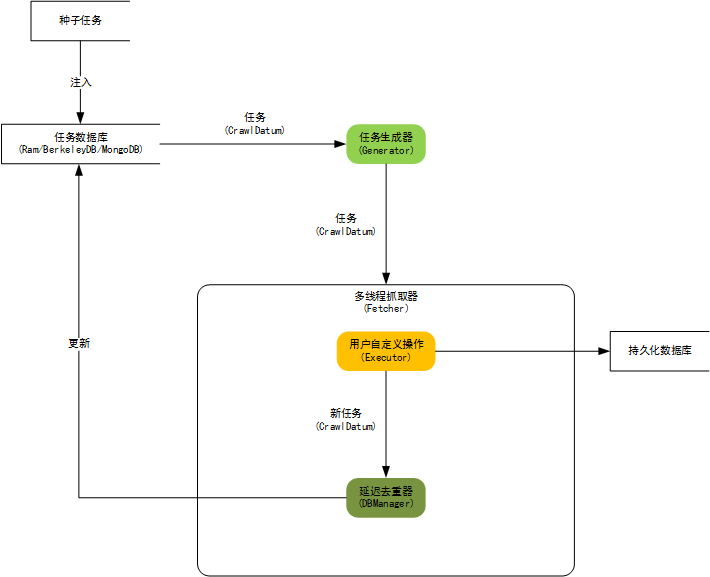
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。
分享15个最受欢迎的Python开源框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-05-12 08:02
1. Django: Python Web应用开发框架
Django 应该是最出名的Python框架,GAE甚至Erlang都有框架受它影响。Django是走大而全的方向,它最出名的是其全自动化的管理后台:只须要使用起ORM,做简单的对象定义,它能够手动生成数据库结构、以及全功能的管理后台。
2. Diesel:基于Greenlet的风波I/O框架
Diesel提供一个整洁的API来编撰网路客户端和服务器。支持TCP和UDP。
3. Flask:一个用Python编撰的轻量级Web应用框架
Flask是一个使用Python编撰的轻量级Web应用框架。基于Werkzeug WSGI工具箱和Jinja2 模板引擎。Flask也被称为“microframework”,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。
4. Cubes:轻量级Python OLAP框架
Cubes是一个轻量级Python框架,包含OLAP、多维数据剖析和浏览聚合数据(aggregated data)等工具。
5. Kartograph.py:创造矢量地图的轻量级Python框架
Kartograph是一个Python库,用来为ESRI生成SVG地图。Kartograph.py目前仍处于beta阶段,你可以在virtualenv环境出来测试。
6. Pulsar:Python的风波驱动并发框架
Pulsar是一个风波驱动的并发框架,有了pulsar,你可以写出在不同进程或线程中运行一个或多个活动的异步服务器。
7. Web2py:全栈式Web框架
Web2py是一个为Python语言提供的全功能Web应用框架,旨在敏捷快速的开发Web应用,具有快速、安全以及可移植的数据库驱动的应用,兼容Google App Engine。
8. Falcon:构建云API和网路应用前端的高性能Python框架
Falcon是一个建立云API的高性能Python框架,它鼓励使用REST构架风格,尽可能以最少的力气做最多的事情。
9. Dpark:Python版的Spark
DPark是Spark的Python克隆,是一个Python实现的分布式估算框架,可以十分便捷地实现大规模数据处理和迭代估算。DPark由豆瓣实现,目前豆瓣内部的绝大多数数据剖析都使用DPark完成,正日趋构建。
10. Buildbot:基于Python的持续集成测试框架
Buildbot是一个开源框架,可以自动化软件建立、测试和发布等过程。每当代码有改变,服务器要求不同平台上的客户端立刻进行代码重构和测试,收集并报告不同平台的建立和测试结果。
11. Zerorpc:基于ZeroMQ的高性能分布式RPC框架
Zerorpc是一个基于ZeroMQ和MessagePack开发的远程过程调用协议(RPC)实现。和 Zerorpc 一起使用的 Service API 被称为 zeroservice。Zerorpc 可以通过编程或命令行方法调用。
12. Bottle:微型Python Web框架
Bottle是一个简单高效的遵守WSGI的微型python Web框架。说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。
13. Tornado:异步非阻塞IO的Python Web框架
Tornado的全称是Torado Web Server,从名子上看就可晓得它可以用作Web服务器,但同时它也是一个Python Web的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook竞购了以后便开源了下来。
14. webpy:轻量级的Python Web框架
webpy的设计理念力求精简(Keep it simple and powerful)开源爬虫框架 python,源码太简略,只提供一个框架所必须的东西开源爬虫框架 python,不依赖大量的第三方模块,它没有URL路由、没有模板也没有数据库的访问。
15. Scrapy:Python的爬虫框架
Scrapy是一个使用Python编撰的,轻量级的,简单轻巧,并且使用上去十分的便捷。 查看全部

1. Django: Python Web应用开发框架
Django 应该是最出名的Python框架,GAE甚至Erlang都有框架受它影响。Django是走大而全的方向,它最出名的是其全自动化的管理后台:只须要使用起ORM,做简单的对象定义,它能够手动生成数据库结构、以及全功能的管理后台。
2. Diesel:基于Greenlet的风波I/O框架
Diesel提供一个整洁的API来编撰网路客户端和服务器。支持TCP和UDP。
3. Flask:一个用Python编撰的轻量级Web应用框架
Flask是一个使用Python编撰的轻量级Web应用框架。基于Werkzeug WSGI工具箱和Jinja2 模板引擎。Flask也被称为“microframework”,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。
4. Cubes:轻量级Python OLAP框架
Cubes是一个轻量级Python框架,包含OLAP、多维数据剖析和浏览聚合数据(aggregated data)等工具。
5. Kartograph.py:创造矢量地图的轻量级Python框架
Kartograph是一个Python库,用来为ESRI生成SVG地图。Kartograph.py目前仍处于beta阶段,你可以在virtualenv环境出来测试。
6. Pulsar:Python的风波驱动并发框架
Pulsar是一个风波驱动的并发框架,有了pulsar,你可以写出在不同进程或线程中运行一个或多个活动的异步服务器。
7. Web2py:全栈式Web框架
Web2py是一个为Python语言提供的全功能Web应用框架,旨在敏捷快速的开发Web应用,具有快速、安全以及可移植的数据库驱动的应用,兼容Google App Engine。
8. Falcon:构建云API和网路应用前端的高性能Python框架
Falcon是一个建立云API的高性能Python框架,它鼓励使用REST构架风格,尽可能以最少的力气做最多的事情。
9. Dpark:Python版的Spark
DPark是Spark的Python克隆,是一个Python实现的分布式估算框架,可以十分便捷地实现大规模数据处理和迭代估算。DPark由豆瓣实现,目前豆瓣内部的绝大多数数据剖析都使用DPark完成,正日趋构建。
10. Buildbot:基于Python的持续集成测试框架
Buildbot是一个开源框架,可以自动化软件建立、测试和发布等过程。每当代码有改变,服务器要求不同平台上的客户端立刻进行代码重构和测试,收集并报告不同平台的建立和测试结果。
11. Zerorpc:基于ZeroMQ的高性能分布式RPC框架
Zerorpc是一个基于ZeroMQ和MessagePack开发的远程过程调用协议(RPC)实现。和 Zerorpc 一起使用的 Service API 被称为 zeroservice。Zerorpc 可以通过编程或命令行方法调用。
12. Bottle:微型Python Web框架
Bottle是一个简单高效的遵守WSGI的微型python Web框架。说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。
13. Tornado:异步非阻塞IO的Python Web框架
Tornado的全称是Torado Web Server,从名子上看就可晓得它可以用作Web服务器,但同时它也是一个Python Web的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook竞购了以后便开源了下来。
14. webpy:轻量级的Python Web框架
webpy的设计理念力求精简(Keep it simple and powerful)开源爬虫框架 python,源码太简略,只提供一个框架所必须的东西开源爬虫框架 python,不依赖大量的第三方模块,它没有URL路由、没有模板也没有数据库的访问。
15. Scrapy:Python的爬虫框架
Scrapy是一个使用Python编撰的,轻量级的,简单轻巧,并且使用上去十分的便捷。
Web爬虫 | 开源项目 | 第1页 | 深度开源
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-05-11 08:03
码头工人 1年前
Web爬虫
Encog是一个中级神经网路和机器人/爬虫开发泛型。Encog提供的这两种功能可以单独分开使用来创建神经网路或HTTP机器人程序,同时Encog还支持将这两种中级功能联合上去使用。Encog支持...
码头工人 1年前
Web爬虫
Crawler是一个简单的Web爬虫。它使你不用编撰沉闷爬虫,容易出错的代码,而只专注于所须要抓取网站的结构。此外它还特别适于使用。 CrawlerConfiguration cfg = new C...
码头工人 1年前
Web爬虫
Ex-Crawler分成三部份(Crawler Daemon,Gui Client和Web搜索引擎),这三部份组合上去将成为一个灵活和强悍的爬虫和搜索引擎。其中Web搜索引擎部份采用PHP开发,...
码头工人 1年前
Web爬虫
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。
码头工人 1年前
Web爬虫
Smart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接链表开始,提供两种遍历模式:最大迭代和最大深度。可以设置过滤器限...
码头工人 1年前
Web爬虫
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
码头工人 1年前
Web爬虫
Web-Harvest是一个Java开源Web数据抽取工具。它还能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技...
码头工人 1年前
Web爬虫
snoics-reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方法获取到的资源全部抓取到本地,包括网页和...
码头工人 1年前
Web爬虫
JoBo是一个用于下载整个Web站点的简单工具。它本质是一个Web Spider。与其它下载工具相比较它的主要优势是能否手动填充form(如:自动登入)和使用cookies来处理session。...
码头工人 1年前
Web爬虫
spindle是一个建立在Lucene工具包之上的Web索引/搜索工具.它包括一个用于创建索引的HTTP spider和一个用于搜索这种索引的搜索类。spindle项目提供了一组JSP标签库促使...
码头工人 1年前
Web爬虫
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
码头工人 1年前
Web爬虫
JSpider:是一个完全可配置和订制的Web Spider引擎.你可以借助它来检测网站的错误(内在的服务器错误等),网站内外部链接检测,分析网站的结构(可创建一个网站地图),下载整个Web站点...
码头工人 1年前
Web爬虫
Arachnid:是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spid...
码头工人 1年前
Web爬虫
WebLech是一个功能强悍的Web站点下载与镜像工具。它支持按功能需求来下载web站点并才能尽可能模仿标准Web浏览器的行为。WebLech有一个功能控制台并采用多线程操作。
码头工人 1年前
Web爬虫
Arale主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。Arale才能下载整个web站点或来自web站点的个别资源。Arale就能够把动态页面映射成静态页面。
码头工人 1年前
Web爬虫
Heritrix是一个开源爬虫,可扩充的web爬虫项目。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。
码头工人 1年前
Web爬虫
LARM才能为Jakarta Lucene搜索引擎框架的用户提供一个纯Java的搜索解决方案。它包含才能为文件,数据库表格构建索引的方式和为Web站点建索引的爬虫。
码头工人 1年前
Web爬虫 查看全部
Crawljax是一个开源Java工具用于Ajax Web应用程序的自动化抓取和测试。Crawljax才能抓取/爬行任何基于Ajax的Web应用程序通过触发风波和在表单中填充数据。 收录时间:2...

码头工人 1年前
Web爬虫
Encog是一个中级神经网路和机器人/爬虫开发泛型。Encog提供的这两种功能可以单独分开使用来创建神经网路或HTTP机器人程序,同时Encog还支持将这两种中级功能联合上去使用。Encog支持...
码头工人 1年前
Web爬虫
Crawler是一个简单的Web爬虫。它使你不用编撰沉闷爬虫,容易出错的代码,而只专注于所须要抓取网站的结构。此外它还特别适于使用。 CrawlerConfiguration cfg = new C...
码头工人 1年前
Web爬虫
Ex-Crawler分成三部份(Crawler Daemon,Gui Client和Web搜索引擎),这三部份组合上去将成为一个灵活和强悍的爬虫和搜索引擎。其中Web搜索引擎部份采用PHP开发,...
码头工人 1年前
Web爬虫
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。
码头工人 1年前
Web爬虫
Smart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接链表开始,提供两种遍历模式:最大迭代和最大深度。可以设置过滤器限...
码头工人 1年前
Web爬虫
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
码头工人 1年前
Web爬虫
Web-Harvest是一个Java开源Web数据抽取工具。它还能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技...
码头工人 1年前
Web爬虫
snoics-reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方法获取到的资源全部抓取到本地,包括网页和...
码头工人 1年前
Web爬虫
JoBo是一个用于下载整个Web站点的简单工具。它本质是一个Web Spider。与其它下载工具相比较它的主要优势是能否手动填充form(如:自动登入)和使用cookies来处理session。...
码头工人 1年前
Web爬虫
spindle是一个建立在Lucene工具包之上的Web索引/搜索工具.它包括一个用于创建索引的HTTP spider和一个用于搜索这种索引的搜索类。spindle项目提供了一组JSP标签库促使...
码头工人 1年前
Web爬虫
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
码头工人 1年前
Web爬虫
JSpider:是一个完全可配置和订制的Web Spider引擎.你可以借助它来检测网站的错误(内在的服务器错误等),网站内外部链接检测,分析网站的结构(可创建一个网站地图),下载整个Web站点...
码头工人 1年前
Web爬虫
Arachnid:是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spid...
码头工人 1年前
Web爬虫
WebLech是一个功能强悍的Web站点下载与镜像工具。它支持按功能需求来下载web站点并才能尽可能模仿标准Web浏览器的行为。WebLech有一个功能控制台并采用多线程操作。
码头工人 1年前
Web爬虫
Arale主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。Arale才能下载整个web站点或来自web站点的个别资源。Arale就能够把动态页面映射成静态页面。
码头工人 1年前
Web爬虫
Heritrix是一个开源爬虫,可扩充的web爬虫项目。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。
码头工人 1年前
Web爬虫
LARM才能为Jakarta Lucene搜索引擎框架的用户提供一个纯Java的搜索解决方案。它包含才能为文件,数据库表格构建索引的方式和为Web站点建索引的爬虫。
码头工人 1年前
Web爬虫
开源通用爬虫框架YayCrawler.zip
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-08 08:02
压缩包爆破揭秘工具(7z、rar、zip)
压缩包内包含三个工具,分别可以拿来爆破揭秘7z压缩包、rar压缩包和zip压缩包。
立即下载
方方条纹注册机
方方条纹注册机,适用于方方条纹所有的系列,全部系列均可以完美注册
立即下载
常用破WIFI字典(很全)
常用wifi密码,弱口令字典,多一份资源,多一分人品.
立即下载
算法第四版 高清完整中文版PDF
《算法 第4版 》是Sedgewick之专著 与高德纳TAOCP一脉相承 是算法领域精典的参考书 涵盖所有程序员必须把握的50种算法 全面介绍了关于算法和数据结构的必备知识 并非常针对排序 搜索 图处理和字符串处理进行了阐述 第4版具体给出了每个程序员应知应会的50个算法 提供了实际代码 而且这种Java代码实现采用了模块化的编程风格 读者可以便捷地加以改建
立即下载
Camtasia 9安装及破解方式绝对有效
附件中注册方式亲测有效,加以整理与你们共享。由于附件小于60m传不起来,另附Camtasia 9百度云下载地址。免费自取链接: 密码:xees
立即下载
分布式服务框架原理与实践(高清完整版)
第1章应用构架演化1 1.1传统垂直应用构架2 1.1.1垂直应用构架介绍2 1.1.2垂直应用构架面临的挑战4 1.2RPC构架6 1.2.1RPC框架原理6 1.2.2最简单的RPC框架实现8 1.2.3业界主流RPC框架14 1.2.4RPC框架面临的挑战17 1.3SOA服务化构架18 1.3.1面向服务设计的原则18 1.3.2服务整治19 1.4微服务构架21 1.4.1哪些是微服务21 1.4.2微服务构架对比SOA22 1.5总结23 第2章分布式服务框架入门25 2.1分布式服务框架诞生背景26 2.1.1应用从集中式迈向分布式.26?
立即下载
DroidCamX 专业版破解版6.7最新版
DroidCamX 专业版破解版6.7最新版,已经包含PC端和Android端
立即下载
ModbusTCP/RTU网段设计
基于UIP协议栈,实现MODBUS联网,可参考本文档资料开源爬虫框架,有MODBUS协议介绍
立即下载
Java项目经验汇总(简历项目素材)
Java项目经验汇总(简历项目素材)
立即下载
电磁场与电磁波第四版谢处方 PDF
电磁场与电磁波第四版谢处方 (清晰版),做天线设计的可以作为参考。
立即下载
iCopy解码软件v1.0.1.7.exe
解ic,id,hid卡密码破解ic,id,hid卡密码破解ic,id,hid破解ic,id,hid卡破解ic,id,hid卡密码密码卡密码破解ic,id,hid卡...
立即下载
source insight 4.0.0087 注册机序列号Patched(2017/10/17)
最新的sourceinsight4.0.0087和谐license及和谐文件。真正的4087版本,使用附件中的license文件,替换sourceinsight4.exe
立即下载
html+css+js制做的一个动态的圣诞贺卡
该代码是博客上面的代码,代码上面有要用到的图片资源和音乐资源。
立即下载
win10,修改mac地址的两种方式
win10,修改mac地址的两种方式,可以更改mac地址。win10,修改mac地址的两种方式,可以更改mac地址。
立即下载
计算机编程入门图文教程
图文结合的编程入门书,简单易懂,入门必备基础书。不过是英语的,需要一点点阅读能力
立即下载
Microsoft Visual C++ 14.0(安装包)
安装python依赖包报错信息"microsoft visual c++ 14.0 is required"的解决办法。具体参考我的博客:1. 下载此文件.2.解压安装(可能比较久).3.再次执行pip install xx命令。
立即下载
Adobe Premiere Pro CC 2017精典教程(pdf版-高清文字)
《Adobe Premiere Pro CC 2017精典教程(彩色版)》共分为18课,每课都围绕着具体的事例讲解,步骤详尽,重点明晰,手把手教您进行实 际操作。本书除全面介绍了Adobe Premiere Pro CC的操作流程外,还详尽介绍了Premiere Pro CC的新功能。书中给出了大量的提示和方法,帮助您更gao效地使用 Adobe Premiere Pro。
立即下载
高等物理第七版(同济大学)下册pdf
高等物理第七版(同济大学)下册教材pdf(PS:高等物理第七版上上册均有,因上传文件容量有限,因此分为两次上传,请有须要下册的同事点开我的资源下载页进行下载)
立即下载
60分钟学会OrCAD-Capture-CIS
60分钟学会OrCAD-Capture-CIS 很不错的资料开源爬虫框架,推荐给你们
立即下载 查看全部

压缩包爆破揭秘工具(7z、rar、zip)
压缩包内包含三个工具,分别可以拿来爆破揭秘7z压缩包、rar压缩包和zip压缩包。
立即下载

方方条纹注册机
方方条纹注册机,适用于方方条纹所有的系列,全部系列均可以完美注册
立即下载

常用破WIFI字典(很全)
常用wifi密码,弱口令字典,多一份资源,多一分人品.
立即下载

算法第四版 高清完整中文版PDF
《算法 第4版 》是Sedgewick之专著 与高德纳TAOCP一脉相承 是算法领域精典的参考书 涵盖所有程序员必须把握的50种算法 全面介绍了关于算法和数据结构的必备知识 并非常针对排序 搜索 图处理和字符串处理进行了阐述 第4版具体给出了每个程序员应知应会的50个算法 提供了实际代码 而且这种Java代码实现采用了模块化的编程风格 读者可以便捷地加以改建
立即下载
Camtasia 9安装及破解方式绝对有效
附件中注册方式亲测有效,加以整理与你们共享。由于附件小于60m传不起来,另附Camtasia 9百度云下载地址。免费自取链接: 密码:xees
立即下载
分布式服务框架原理与实践(高清完整版)
第1章应用构架演化1 1.1传统垂直应用构架2 1.1.1垂直应用构架介绍2 1.1.2垂直应用构架面临的挑战4 1.2RPC构架6 1.2.1RPC框架原理6 1.2.2最简单的RPC框架实现8 1.2.3业界主流RPC框架14 1.2.4RPC框架面临的挑战17 1.3SOA服务化构架18 1.3.1面向服务设计的原则18 1.3.2服务整治19 1.4微服务构架21 1.4.1哪些是微服务21 1.4.2微服务构架对比SOA22 1.5总结23 第2章分布式服务框架入门25 2.1分布式服务框架诞生背景26 2.1.1应用从集中式迈向分布式.26?
立即下载
DroidCamX 专业版破解版6.7最新版
DroidCamX 专业版破解版6.7最新版,已经包含PC端和Android端
立即下载
ModbusTCP/RTU网段设计
基于UIP协议栈,实现MODBUS联网,可参考本文档资料开源爬虫框架,有MODBUS协议介绍
立即下载

Java项目经验汇总(简历项目素材)
Java项目经验汇总(简历项目素材)
立即下载
电磁场与电磁波第四版谢处方 PDF
电磁场与电磁波第四版谢处方 (清晰版),做天线设计的可以作为参考。
立即下载
iCopy解码软件v1.0.1.7.exe
解ic,id,hid卡密码破解ic,id,hid卡密码破解ic,id,hid破解ic,id,hid卡破解ic,id,hid卡密码密码卡密码破解ic,id,hid卡...
立即下载
source insight 4.0.0087 注册机序列号Patched(2017/10/17)
最新的sourceinsight4.0.0087和谐license及和谐文件。真正的4087版本,使用附件中的license文件,替换sourceinsight4.exe
立即下载
html+css+js制做的一个动态的圣诞贺卡
该代码是博客上面的代码,代码上面有要用到的图片资源和音乐资源。
立即下载

win10,修改mac地址的两种方式
win10,修改mac地址的两种方式,可以更改mac地址。win10,修改mac地址的两种方式,可以更改mac地址。
立即下载
计算机编程入门图文教程
图文结合的编程入门书,简单易懂,入门必备基础书。不过是英语的,需要一点点阅读能力
立即下载
Microsoft Visual C++ 14.0(安装包)
安装python依赖包报错信息"microsoft visual c++ 14.0 is required"的解决办法。具体参考我的博客:1. 下载此文件.2.解压安装(可能比较久).3.再次执行pip install xx命令。
立即下载
Adobe Premiere Pro CC 2017精典教程(pdf版-高清文字)
《Adobe Premiere Pro CC 2017精典教程(彩色版)》共分为18课,每课都围绕着具体的事例讲解,步骤详尽,重点明晰,手把手教您进行实 际操作。本书除全面介绍了Adobe Premiere Pro CC的操作流程外,还详尽介绍了Premiere Pro CC的新功能。书中给出了大量的提示和方法,帮助您更gao效地使用 Adobe Premiere Pro。
立即下载
高等物理第七版(同济大学)下册pdf
高等物理第七版(同济大学)下册教材pdf(PS:高等物理第七版上上册均有,因上传文件容量有限,因此分为两次上传,请有须要下册的同事点开我的资源下载页进行下载)
立即下载
60分钟学会OrCAD-Capture-CIS
60分钟学会OrCAD-Capture-CIS 很不错的资料开源爬虫框架,推荐给你们
立即下载
开源爬虫框架各有哪些优缺点
采集交流 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2020-05-04 08:06
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。 查看全部
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。
织梦团购系统DEDE5
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-04-07 11:11
(6)使用第一个网站账号登录网站,在网站下方有“管理织梦”,进入后台进行相关设置
织梦DEDE5凭着其专业的技术、丰富的电子商务经验在第一时刻因此最流行的购物形式推出开源程序。独立编译模板、自由更改、代码简约,安全高效、数据缓存等技术的应用,使其能在大浏览量的环境下快速稳定运行,切实节省网站成本,提升形象。
同行业比较,织梦DEDE5的优势在那里?
整体规划 摒弃开发速率慢,效率低下、冗余严重的框架。投入大量的时间和精力,打造最简约高效的程序
开源程序 我们盼望公正、公正、开放的竞争环境,也希望给用户最大的自由度,方便对程序的维护和强化
功能强悍 拥有Groupon模式的全部主流模块,功能全面、强大,辅助模块不断持续开发中
使用简单 全部采用人性化设计、智能化管理,只要会操作笔记本就可以管理网站
瞬间建站 不用做模板,不用改程序,强大的团购网站瞬间构建
投入极低 投入数千元即可拥有织梦团购管理系统商业版程序,它仅是您急聘一个程序员1个月的工资
多重保障 持续开发保障、技术服务保证、问题修正保障,让您的网站发展彻底无后顾之忧
程序只是起步,服务更为重要。持续性的技术优势和不断下降的市场经验织梦团购管理系统,更提高了已有和潜在顾客的信心。时刻关注国内外相关领域内的进展和动态,不断创新,使越来越多的人相信织梦开源团购系统开发平台辉煌的明日。
使用说明:
(1)下载最新更新的程序包解压并上传到空间服务器根目录中
(2)执行安装织梦团购管理系统,如本地安装测试则访问:
(3)进入安装界面,填写MYSQL地址,通常为本地地址localhost,输入MYSQL的帐号和密码
(4)安装完成后针对install.php文件进行删掉,确保网站安全 查看全部

(6)使用第一个网站账号登录网站,在网站下方有“管理织梦”,进入后台进行相关设置
织梦DEDE5凭着其专业的技术、丰富的电子商务经验在第一时刻因此最流行的购物形式推出开源程序。独立编译模板、自由更改、代码简约,安全高效、数据缓存等技术的应用,使其能在大浏览量的环境下快速稳定运行,切实节省网站成本,提升形象。
同行业比较,织梦DEDE5的优势在那里?
整体规划 摒弃开发速率慢,效率低下、冗余严重的框架。投入大量的时间和精力,打造最简约高效的程序
开源程序 我们盼望公正、公正、开放的竞争环境,也希望给用户最大的自由度,方便对程序的维护和强化
功能强悍 拥有Groupon模式的全部主流模块,功能全面、强大,辅助模块不断持续开发中
使用简单 全部采用人性化设计、智能化管理,只要会操作笔记本就可以管理网站
瞬间建站 不用做模板,不用改程序,强大的团购网站瞬间构建
投入极低 投入数千元即可拥有织梦团购管理系统商业版程序,它仅是您急聘一个程序员1个月的工资
多重保障 持续开发保障、技术服务保证、问题修正保障,让您的网站发展彻底无后顾之忧
程序只是起步,服务更为重要。持续性的技术优势和不断下降的市场经验织梦团购管理系统,更提高了已有和潜在顾客的信心。时刻关注国内外相关领域内的进展和动态,不断创新,使越来越多的人相信织梦开源团购系统开发平台辉煌的明日。
使用说明:
(1)下载最新更新的程序包解压并上传到空间服务器根目录中
(2)执行安装织梦团购管理系统,如本地安装测试则访问:
(3)进入安装界面,填写MYSQL地址,通常为本地地址localhost,输入MYSQL的帐号和密码
(4)安装完成后针对install.php文件进行删掉,确保网站安全
推荐10款流行的java开源的网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-06-29 08:03
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫 查看全部
1:JAVA爬虫WebCollector(Star:1345)
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫
网络爬虫_基于各类语言的开源网络爬虫总汇
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-06-13 08:02
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可
开源JAVA单机爬虫框架简介,优缺点剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-06 08:01
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。 查看全部
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。
一个简单的开源PHP爬虫框架『Phpfetcher』
采集交流 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2020-05-27 08:02
fanfank 文章作者
完整的代码贴下来我看一下,或者在微博私信我,我帮你看一下
aa
//下面两行促使这个项目被下载出来后本文件能直接运行
$demo_include_path = dirname(__FILE__) . ‘/../’;
set_include_path(get_include_path() . PATH_SEPARATOR . $demo_include_path);
require_once(‘phpfetcher.php’);
class mycrawler extends Phpfetcher_Crawler_Default {
public function handlePage($page) {
var_dump($page);
//打印处当前页面的第1个h1标题内荣(下标从0开始)
$strFirstH1 = trim($page->sel(‘//title’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo $page->sel(‘//title’, 0)->plaintext;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
//任务的名子随意起,这里把名子叫qqnews
//the key is the name of a job, here names it qqnews
‘qqnews’ => array(
‘start_page’ => ‘#8217;, //起始网页
‘link_rules’ => array(
/*
* 所有在这里列举的正则规则,只要能匹配到超链接,那么那条爬虫才会爬到那条超链接
* Regex rules are listed here, the crawler will follow any hyperlinks once the regex matches
*/
//’#news\.qq\.com/a/\d+/\d+\.htm$#’,
),
//爬虫从开始页面算起,最多爬取的深度,设置为2表示爬取深度为1
//Crawler’s max following depth, 1 stands for only crawl the start page
‘max_depth’ => 1,
) ,
);
$crawler->setFetchJobs($arrJobs)->run(); //这一行的疗效和下边两行的疗效一样
其他的没变
aa
public function read() {
$this->_strContent = curl_exec($this->_curlHandle);
是_strContent取到了false造成的 这个是啥缘由呢Page default.php
fanfank 文章作者
我这儿返回的是403 forbidden,查了一下晓得缘由了,因为user_agent的问题csdn把爬虫给禁了。你可以这样更改:找到文件Phpfetcher/Page/Default.php,然后搜『user_agent』,把上面改掉,我改成『firefox』就可以了,当然你可以可以改得更真实一点,例如哪些『Mozilla/5.0 AppleWebKit』之类的
有些网站会依照UA来屏蔽恳求,可能是因为个别UA有恶意功击的特点,或者一些爬虫之类的开源爬虫框架,之前百度有一段时间屏蔽360浏览器就是通过360浏览器里一些特定的UA来做到的,当然后来360浏览器把UA给更改嗯,就须要依照其它特点屏蔽了。
所以你这儿先改一下user_agent吧。
aa
多谢哈
试着改成Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0 也不行呢
试了这儿的也不行 恐怕还是curl的问题
fanfank 文章作者
我这儿执行都是正常的,结果也能下来。还是通过微博私信说吧,这里说得刷屏了
aa
围脖id是?
fanfank 文章作者
另外是,你贴的代码上面,标点符号不对啊,你的start_page对应那一行的标点,怎么是英文的单冒号?后面的单冒号似乎也不是个单冒号吧?要全部用英语的单冒号才行。
aa
符号是对的哈 都是英语的 没句型错误
joke
为什么匹配的内容都一样?
代码:
sel(‘//span[@id=”text110″]’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo “”;
echo $page->sel(‘//span[@id=”text110″]’, 0)->plaintext;
echo “”;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
‘joke’ => array(
‘start_page’ => ‘#8217;,
‘link_rules’ => array(
‘#/\woke\wtml/\w+/20151021\d+\.htm$#’,
),
‘max_depth’ => 2,
) ,
);
$crawler->setFetchJobs($arrJobs)->run();
fanfank 文章作者
你的代码没贴全,而且匹配的内容都一样我没很理解是哪些意思,这个问题有点长,你直接在微博私信我,我帮你看一下
fanfank 文章作者
已经修补了。之前的问题是爬虫不认识站内链接,例如有的超链接是『/entry』这样的,而不是『』。现在最新的Phpfetcher早已就能辨识站内链接,可以试一下
joke
谢谢 ,搞定了
modejun
楼主您好,问问假如我晓得了一个网站开源爬虫框架,但是要递交post参数,这个要如何弄呢,朋友提供一下思路
fanfank 文章作者
提交post参数,那觉得场景很特殊的,因为这个就不是单纯地按照链接爬取网页内容了,而且假如真的提供这个功能,针对什么样的链接什么样的参数,怎么递交,然后返回的内容是如何处理这种,目前我觉得似乎不太适宜爬虫做。或者你在微博私信我,告诉我你的使用场景是哪些,我瞧瞧是不是考虑找时间加进去
modejun
场景就是有一翻页时用ajax post递交的page参数,如果是get就太easy。还有顺便问问,如果翻页我明天试了要解决的话就是调节深度,但是似乎最大是20,还有就是更改正则循环调用setFetchJobs这个方式,总是觉得不是这么完美,有哪些好的思路解决翻页这个问题吗,现在公司在定方案我想多了解把这个框架的优势发挥下来,感谢了。
fanfank 文章作者
如果像你说的是个post恳求,那么它返回的应当不是一个HTML格式的文档,通常都是json格式的,然后由当前页面将异步返回的内容加载显示下来。
你们的post恳求应当是有类似pn,rn等参数,如果大家仅仅是想领到post恳求的所有内容,可以直接写一个for循环,然后使用php的curl来直接发送post恳求获取每一个页面内容,可以不使用爬虫,因为这个爬虫基本原理是针对GET恳求返回的HTML页面的,然后手动抽取HTML的标签
最大深度可以更改类『Phpfetcher_Crawler_Default』中的『MAX_DEPTH』变量,把20改成-1就没有限制了,不过建议还是设一个上限比较好
可以不需要循环更改正则呀,设置正则规则的可以是一个链表,把上面的所有你认为合适的正则都列上就可以,除非说你的正则表达式还得依据页面的某个参数或则内容不同而更改,那这个情况还是相对特殊了一点···
翻页的解决,如果是GET就用爬虫,如果是POST,那么直接for循环之后调用curl会更好。
;;;
好像不错
;;;
能不能写个DOM选择器和技巧的文档,最好支持css选择DOM标签,有子节点,父节点,兄弟节点选择才好
fanfank 文章作者
在这个项目的github页面:,中文说明的第2节上面,有介绍dom选择器的文档
jeremy
博主。。为什么https的页面没办法恳求呢? 查看全部
报dom为空
fanfank 文章作者
完整的代码贴下来我看一下,或者在微博私信我,我帮你看一下
aa
//下面两行促使这个项目被下载出来后本文件能直接运行
$demo_include_path = dirname(__FILE__) . ‘/../’;
set_include_path(get_include_path() . PATH_SEPARATOR . $demo_include_path);
require_once(‘phpfetcher.php’);
class mycrawler extends Phpfetcher_Crawler_Default {
public function handlePage($page) {
var_dump($page);
//打印处当前页面的第1个h1标题内荣(下标从0开始)
$strFirstH1 = trim($page->sel(‘//title’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo $page->sel(‘//title’, 0)->plaintext;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
//任务的名子随意起,这里把名子叫qqnews
//the key is the name of a job, here names it qqnews
‘qqnews’ => array(
‘start_page’ => ‘#8217;, //起始网页
‘link_rules’ => array(
/*
* 所有在这里列举的正则规则,只要能匹配到超链接,那么那条爬虫才会爬到那条超链接
* Regex rules are listed here, the crawler will follow any hyperlinks once the regex matches
*/
//’#news\.qq\.com/a/\d+/\d+\.htm$#’,
),
//爬虫从开始页面算起,最多爬取的深度,设置为2表示爬取深度为1
//Crawler’s max following depth, 1 stands for only crawl the start page
‘max_depth’ => 1,
) ,
);
$crawler->setFetchJobs($arrJobs)->run(); //这一行的疗效和下边两行的疗效一样
其他的没变
aa
public function read() {
$this->_strContent = curl_exec($this->_curlHandle);
是_strContent取到了false造成的 这个是啥缘由呢Page default.php
fanfank 文章作者
我这儿返回的是403 forbidden,查了一下晓得缘由了,因为user_agent的问题csdn把爬虫给禁了。你可以这样更改:找到文件Phpfetcher/Page/Default.php,然后搜『user_agent』,把上面改掉,我改成『firefox』就可以了,当然你可以可以改得更真实一点,例如哪些『Mozilla/5.0 AppleWebKit』之类的
有些网站会依照UA来屏蔽恳求,可能是因为个别UA有恶意功击的特点,或者一些爬虫之类的开源爬虫框架,之前百度有一段时间屏蔽360浏览器就是通过360浏览器里一些特定的UA来做到的,当然后来360浏览器把UA给更改嗯,就须要依照其它特点屏蔽了。
所以你这儿先改一下user_agent吧。
aa
多谢哈
试着改成Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0 也不行呢
试了这儿的也不行 恐怕还是curl的问题
fanfank 文章作者
我这儿执行都是正常的,结果也能下来。还是通过微博私信说吧,这里说得刷屏了
aa
围脖id是?
fanfank 文章作者
另外是,你贴的代码上面,标点符号不对啊,你的start_page对应那一行的标点,怎么是英文的单冒号?后面的单冒号似乎也不是个单冒号吧?要全部用英语的单冒号才行。
aa
符号是对的哈 都是英语的 没句型错误
joke
为什么匹配的内容都一样?
代码:
sel(‘//span[@id=”text110″]’, 0)->plaintext);
if (!empty($strFirstH1)) {
echo “”;
echo $page->sel(‘//span[@id=”text110″]’, 0)->plaintext;
echo “”;
echo “\n”;
}
}
}
$crawler = new mycrawler();
$arrJobs = array(
‘joke’ => array(
‘start_page’ => ‘#8217;,
‘link_rules’ => array(
‘#/\woke\wtml/\w+/20151021\d+\.htm$#’,
),
‘max_depth’ => 2,
) ,
);
$crawler->setFetchJobs($arrJobs)->run();
fanfank 文章作者
你的代码没贴全,而且匹配的内容都一样我没很理解是哪些意思,这个问题有点长,你直接在微博私信我,我帮你看一下
fanfank 文章作者
已经修补了。之前的问题是爬虫不认识站内链接,例如有的超链接是『/entry』这样的,而不是『』。现在最新的Phpfetcher早已就能辨识站内链接,可以试一下
joke
谢谢 ,搞定了
modejun
楼主您好,问问假如我晓得了一个网站开源爬虫框架,但是要递交post参数,这个要如何弄呢,朋友提供一下思路
fanfank 文章作者
提交post参数,那觉得场景很特殊的,因为这个就不是单纯地按照链接爬取网页内容了,而且假如真的提供这个功能,针对什么样的链接什么样的参数,怎么递交,然后返回的内容是如何处理这种,目前我觉得似乎不太适宜爬虫做。或者你在微博私信我,告诉我你的使用场景是哪些,我瞧瞧是不是考虑找时间加进去
modejun
场景就是有一翻页时用ajax post递交的page参数,如果是get就太easy。还有顺便问问,如果翻页我明天试了要解决的话就是调节深度,但是似乎最大是20,还有就是更改正则循环调用setFetchJobs这个方式,总是觉得不是这么完美,有哪些好的思路解决翻页这个问题吗,现在公司在定方案我想多了解把这个框架的优势发挥下来,感谢了。
fanfank 文章作者
如果像你说的是个post恳求,那么它返回的应当不是一个HTML格式的文档,通常都是json格式的,然后由当前页面将异步返回的内容加载显示下来。
你们的post恳求应当是有类似pn,rn等参数,如果大家仅仅是想领到post恳求的所有内容,可以直接写一个for循环,然后使用php的curl来直接发送post恳求获取每一个页面内容,可以不使用爬虫,因为这个爬虫基本原理是针对GET恳求返回的HTML页面的,然后手动抽取HTML的标签
最大深度可以更改类『Phpfetcher_Crawler_Default』中的『MAX_DEPTH』变量,把20改成-1就没有限制了,不过建议还是设一个上限比较好
可以不需要循环更改正则呀,设置正则规则的可以是一个链表,把上面的所有你认为合适的正则都列上就可以,除非说你的正则表达式还得依据页面的某个参数或则内容不同而更改,那这个情况还是相对特殊了一点···
翻页的解决,如果是GET就用爬虫,如果是POST,那么直接for循环之后调用curl会更好。
;;;
好像不错
;;;
能不能写个DOM选择器和技巧的文档,最好支持css选择DOM标签,有子节点,父节点,兄弟节点选择才好
fanfank 文章作者
在这个项目的github页面:,中文说明的第2节上面,有介绍dom选择器的文档
jeremy
博主。。为什么https的页面没办法恳求呢?
基于 Java 的开源网路爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-05-15 08:00
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。 查看全部
WebCollector 是一个无须配置、便于二次开发的Java爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎诸位前来贡献代码:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有太强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:
最新Maven地址请参考文档:
文档地址:
内核架构图:
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
可以为每位 URL 设置附加信息(MetaData),利用附加信息可以完成好多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
使用插件机制,用户可订制自己的Http请求、过滤器、执行器等插件。
内置一套基于显存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理常年和大量级的任务java单机爬虫框架,并具有断点爬取功能,不会由于宕机、关闭造成数据遗失。
集成 selenium,可以对 JavaScript 生成信息进行抽取
可轻松自定义 http 请求,并外置多代理随机切换功能。 可通过定义 http 请求实现模拟登陆。
使用 slf4j 作为日志店面,可对接多种日志
使用类似Hadoop的Configuration机制,可为每位爬虫订制配置信息。
网页正文提取项目 ContentExtractor 已划入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方式。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取疗效指标 :
标题抽取和日期抽取使用简单启发式算法java单机爬虫框架,并没有象正文抽取算法一样在标准数据集上测试,算法仍在更新中。
分享15个最受欢迎的Python开源框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-05-12 08:02
1. Django: Python Web应用开发框架
Django 应该是最出名的Python框架,GAE甚至Erlang都有框架受它影响。Django是走大而全的方向,它最出名的是其全自动化的管理后台:只须要使用起ORM,做简单的对象定义,它能够手动生成数据库结构、以及全功能的管理后台。
2. Diesel:基于Greenlet的风波I/O框架
Diesel提供一个整洁的API来编撰网路客户端和服务器。支持TCP和UDP。
3. Flask:一个用Python编撰的轻量级Web应用框架
Flask是一个使用Python编撰的轻量级Web应用框架。基于Werkzeug WSGI工具箱和Jinja2 模板引擎。Flask也被称为“microframework”,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。
4. Cubes:轻量级Python OLAP框架
Cubes是一个轻量级Python框架,包含OLAP、多维数据剖析和浏览聚合数据(aggregated data)等工具。
5. Kartograph.py:创造矢量地图的轻量级Python框架
Kartograph是一个Python库,用来为ESRI生成SVG地图。Kartograph.py目前仍处于beta阶段,你可以在virtualenv环境出来测试。
6. Pulsar:Python的风波驱动并发框架
Pulsar是一个风波驱动的并发框架,有了pulsar,你可以写出在不同进程或线程中运行一个或多个活动的异步服务器。
7. Web2py:全栈式Web框架
Web2py是一个为Python语言提供的全功能Web应用框架,旨在敏捷快速的开发Web应用,具有快速、安全以及可移植的数据库驱动的应用,兼容Google App Engine。
8. Falcon:构建云API和网路应用前端的高性能Python框架
Falcon是一个建立云API的高性能Python框架,它鼓励使用REST构架风格,尽可能以最少的力气做最多的事情。
9. Dpark:Python版的Spark
DPark是Spark的Python克隆,是一个Python实现的分布式估算框架,可以十分便捷地实现大规模数据处理和迭代估算。DPark由豆瓣实现,目前豆瓣内部的绝大多数数据剖析都使用DPark完成,正日趋构建。
10. Buildbot:基于Python的持续集成测试框架
Buildbot是一个开源框架,可以自动化软件建立、测试和发布等过程。每当代码有改变,服务器要求不同平台上的客户端立刻进行代码重构和测试,收集并报告不同平台的建立和测试结果。
11. Zerorpc:基于ZeroMQ的高性能分布式RPC框架
Zerorpc是一个基于ZeroMQ和MessagePack开发的远程过程调用协议(RPC)实现。和 Zerorpc 一起使用的 Service API 被称为 zeroservice。Zerorpc 可以通过编程或命令行方法调用。
12. Bottle:微型Python Web框架
Bottle是一个简单高效的遵守WSGI的微型python Web框架。说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。
13. Tornado:异步非阻塞IO的Python Web框架
Tornado的全称是Torado Web Server,从名子上看就可晓得它可以用作Web服务器,但同时它也是一个Python Web的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook竞购了以后便开源了下来。
14. webpy:轻量级的Python Web框架
webpy的设计理念力求精简(Keep it simple and powerful)开源爬虫框架 python,源码太简略,只提供一个框架所必须的东西开源爬虫框架 python,不依赖大量的第三方模块,它没有URL路由、没有模板也没有数据库的访问。
15. Scrapy:Python的爬虫框架
Scrapy是一个使用Python编撰的,轻量级的,简单轻巧,并且使用上去十分的便捷。 查看全部
1. Django: Python Web应用开发框架
Django 应该是最出名的Python框架,GAE甚至Erlang都有框架受它影响。Django是走大而全的方向,它最出名的是其全自动化的管理后台:只须要使用起ORM,做简单的对象定义,它能够手动生成数据库结构、以及全功能的管理后台。
2. Diesel:基于Greenlet的风波I/O框架
Diesel提供一个整洁的API来编撰网路客户端和服务器。支持TCP和UDP。
3. Flask:一个用Python编撰的轻量级Web应用框架
Flask是一个使用Python编撰的轻量级Web应用框架。基于Werkzeug WSGI工具箱和Jinja2 模板引擎。Flask也被称为“microframework”,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。
4. Cubes:轻量级Python OLAP框架
Cubes是一个轻量级Python框架,包含OLAP、多维数据剖析和浏览聚合数据(aggregated data)等工具。
5. Kartograph.py:创造矢量地图的轻量级Python框架
Kartograph是一个Python库,用来为ESRI生成SVG地图。Kartograph.py目前仍处于beta阶段,你可以在virtualenv环境出来测试。
6. Pulsar:Python的风波驱动并发框架
Pulsar是一个风波驱动的并发框架,有了pulsar,你可以写出在不同进程或线程中运行一个或多个活动的异步服务器。
7. Web2py:全栈式Web框架
Web2py是一个为Python语言提供的全功能Web应用框架,旨在敏捷快速的开发Web应用,具有快速、安全以及可移植的数据库驱动的应用,兼容Google App Engine。
8. Falcon:构建云API和网路应用前端的高性能Python框架
Falcon是一个建立云API的高性能Python框架,它鼓励使用REST构架风格,尽可能以最少的力气做最多的事情。
9. Dpark:Python版的Spark
DPark是Spark的Python克隆,是一个Python实现的分布式估算框架,可以十分便捷地实现大规模数据处理和迭代估算。DPark由豆瓣实现,目前豆瓣内部的绝大多数数据剖析都使用DPark完成,正日趋构建。
10. Buildbot:基于Python的持续集成测试框架
Buildbot是一个开源框架,可以自动化软件建立、测试和发布等过程。每当代码有改变,服务器要求不同平台上的客户端立刻进行代码重构和测试,收集并报告不同平台的建立和测试结果。
11. Zerorpc:基于ZeroMQ的高性能分布式RPC框架
Zerorpc是一个基于ZeroMQ和MessagePack开发的远程过程调用协议(RPC)实现。和 Zerorpc 一起使用的 Service API 被称为 zeroservice。Zerorpc 可以通过编程或命令行方法调用。
12. Bottle:微型Python Web框架
Bottle是一个简单高效的遵守WSGI的微型python Web框架。说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。
13. Tornado:异步非阻塞IO的Python Web框架
Tornado的全称是Torado Web Server,从名子上看就可晓得它可以用作Web服务器,但同时它也是一个Python Web的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook竞购了以后便开源了下来。
14. webpy:轻量级的Python Web框架
webpy的设计理念力求精简(Keep it simple and powerful)开源爬虫框架 python,源码太简略,只提供一个框架所必须的东西开源爬虫框架 python,不依赖大量的第三方模块,它没有URL路由、没有模板也没有数据库的访问。
15. Scrapy:Python的爬虫框架
Scrapy是一个使用Python编撰的,轻量级的,简单轻巧,并且使用上去十分的便捷。
Web爬虫 | 开源项目 | 第1页 | 深度开源
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-05-11 08:03
码头工人 1年前
Web爬虫
Encog是一个中级神经网路和机器人/爬虫开发泛型。Encog提供的这两种功能可以单独分开使用来创建神经网路或HTTP机器人程序,同时Encog还支持将这两种中级功能联合上去使用。Encog支持...
码头工人 1年前
Web爬虫
Crawler是一个简单的Web爬虫。它使你不用编撰沉闷爬虫,容易出错的代码,而只专注于所须要抓取网站的结构。此外它还特别适于使用。 CrawlerConfiguration cfg = new C...
码头工人 1年前
Web爬虫
Ex-Crawler分成三部份(Crawler Daemon,Gui Client和Web搜索引擎),这三部份组合上去将成为一个灵活和强悍的爬虫和搜索引擎。其中Web搜索引擎部份采用PHP开发,...
码头工人 1年前
Web爬虫
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。
码头工人 1年前
Web爬虫
Smart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接链表开始,提供两种遍历模式:最大迭代和最大深度。可以设置过滤器限...
码头工人 1年前
Web爬虫
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
码头工人 1年前
Web爬虫
Web-Harvest是一个Java开源Web数据抽取工具。它还能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技...
码头工人 1年前
Web爬虫
snoics-reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方法获取到的资源全部抓取到本地,包括网页和...
码头工人 1年前
Web爬虫
JoBo是一个用于下载整个Web站点的简单工具。它本质是一个Web Spider。与其它下载工具相比较它的主要优势是能否手动填充form(如:自动登入)和使用cookies来处理session。...
码头工人 1年前
Web爬虫
spindle是一个建立在Lucene工具包之上的Web索引/搜索工具.它包括一个用于创建索引的HTTP spider和一个用于搜索这种索引的搜索类。spindle项目提供了一组JSP标签库促使...
码头工人 1年前
Web爬虫
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
码头工人 1年前
Web爬虫
JSpider:是一个完全可配置和订制的Web Spider引擎.你可以借助它来检测网站的错误(内在的服务器错误等),网站内外部链接检测,分析网站的结构(可创建一个网站地图),下载整个Web站点...
码头工人 1年前
Web爬虫
Arachnid:是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spid...
码头工人 1年前
Web爬虫
WebLech是一个功能强悍的Web站点下载与镜像工具。它支持按功能需求来下载web站点并才能尽可能模仿标准Web浏览器的行为。WebLech有一个功能控制台并采用多线程操作。
码头工人 1年前
Web爬虫
Arale主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。Arale才能下载整个web站点或来自web站点的个别资源。Arale就能够把动态页面映射成静态页面。
码头工人 1年前
Web爬虫
Heritrix是一个开源爬虫,可扩充的web爬虫项目。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。
码头工人 1年前
Web爬虫
LARM才能为Jakarta Lucene搜索引擎框架的用户提供一个纯Java的搜索解决方案。它包含才能为文件,数据库表格构建索引的方式和为Web站点建索引的爬虫。
码头工人 1年前
Web爬虫 查看全部
Crawljax是一个开源Java工具用于Ajax Web应用程序的自动化抓取和测试。Crawljax才能抓取/爬行任何基于Ajax的Web应用程序通过触发风波和在表单中填充数据。 收录时间:2...
码头工人 1年前
Web爬虫
Encog是一个中级神经网路和机器人/爬虫开发泛型。Encog提供的这两种功能可以单独分开使用来创建神经网路或HTTP机器人程序,同时Encog还支持将这两种中级功能联合上去使用。Encog支持...
码头工人 1年前
Web爬虫
Crawler是一个简单的Web爬虫。它使你不用编撰沉闷爬虫,容易出错的代码,而只专注于所须要抓取网站的结构。此外它还特别适于使用。 CrawlerConfiguration cfg = new C...
码头工人 1年前
Web爬虫
Ex-Crawler分成三部份(Crawler Daemon,Gui Client和Web搜索引擎),这三部份组合上去将成为一个灵活和强悍的爬虫和搜索引擎。其中Web搜索引擎部份采用PHP开发,...
码头工人 1年前
Web爬虫
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。
码头工人 1年前
Web爬虫
Smart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接链表开始,提供两种遍历模式:最大迭代和最大深度。可以设置过滤器限...
码头工人 1年前
Web爬虫
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
码头工人 1年前
Web爬虫
Web-Harvest是一个Java开源Web数据抽取工具。它还能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技...
码头工人 1年前
Web爬虫
snoics-reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方法获取到的资源全部抓取到本地,包括网页和...
码头工人 1年前
Web爬虫
JoBo是一个用于下载整个Web站点的简单工具。它本质是一个Web Spider。与其它下载工具相比较它的主要优势是能否手动填充form(如:自动登入)和使用cookies来处理session。...
码头工人 1年前
Web爬虫
spindle是一个建立在Lucene工具包之上的Web索引/搜索工具.它包括一个用于创建索引的HTTP spider和一个用于搜索这种索引的搜索类。spindle项目提供了一组JSP标签库促使...
码头工人 1年前
Web爬虫
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
码头工人 1年前
Web爬虫
JSpider:是一个完全可配置和订制的Web Spider引擎.你可以借助它来检测网站的错误(内在的服务器错误等),网站内外部链接检测,分析网站的结构(可创建一个网站地图),下载整个Web站点...
码头工人 1年前
Web爬虫
Arachnid:是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spid...
码头工人 1年前
Web爬虫
WebLech是一个功能强悍的Web站点下载与镜像工具。它支持按功能需求来下载web站点并才能尽可能模仿标准Web浏览器的行为。WebLech有一个功能控制台并采用多线程操作。
码头工人 1年前
Web爬虫
Arale主要为个人使用而设计,而没有象其它爬虫一样是关注于页面索引。Arale才能下载整个web站点或来自web站点的个别资源。Arale就能够把动态页面映射成静态页面。
码头工人 1年前
Web爬虫
Heritrix是一个开源爬虫,可扩充的web爬虫项目。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。
码头工人 1年前
Web爬虫
LARM才能为Jakarta Lucene搜索引擎框架的用户提供一个纯Java的搜索解决方案。它包含才能为文件,数据库表格构建索引的方式和为Web站点建索引的爬虫。
码头工人 1年前
Web爬虫
开源通用爬虫框架YayCrawler.zip
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-08 08:02
压缩包爆破揭秘工具(7z、rar、zip)
压缩包内包含三个工具,分别可以拿来爆破揭秘7z压缩包、rar压缩包和zip压缩包。
立即下载
方方条纹注册机
方方条纹注册机,适用于方方条纹所有的系列,全部系列均可以完美注册
立即下载
常用破WIFI字典(很全)
常用wifi密码,弱口令字典,多一份资源,多一分人品.
立即下载
算法第四版 高清完整中文版PDF
《算法 第4版 》是Sedgewick之专著 与高德纳TAOCP一脉相承 是算法领域精典的参考书 涵盖所有程序员必须把握的50种算法 全面介绍了关于算法和数据结构的必备知识 并非常针对排序 搜索 图处理和字符串处理进行了阐述 第4版具体给出了每个程序员应知应会的50个算法 提供了实际代码 而且这种Java代码实现采用了模块化的编程风格 读者可以便捷地加以改建
立即下载
Camtasia 9安装及破解方式绝对有效
附件中注册方式亲测有效,加以整理与你们共享。由于附件小于60m传不起来,另附Camtasia 9百度云下载地址。免费自取链接: 密码:xees
立即下载
分布式服务框架原理与实践(高清完整版)
第1章应用构架演化1 1.1传统垂直应用构架2 1.1.1垂直应用构架介绍2 1.1.2垂直应用构架面临的挑战4 1.2RPC构架6 1.2.1RPC框架原理6 1.2.2最简单的RPC框架实现8 1.2.3业界主流RPC框架14 1.2.4RPC框架面临的挑战17 1.3SOA服务化构架18 1.3.1面向服务设计的原则18 1.3.2服务整治19 1.4微服务构架21 1.4.1哪些是微服务21 1.4.2微服务构架对比SOA22 1.5总结23 第2章分布式服务框架入门25 2.1分布式服务框架诞生背景26 2.1.1应用从集中式迈向分布式.26?
立即下载
DroidCamX 专业版破解版6.7最新版
DroidCamX 专业版破解版6.7最新版,已经包含PC端和Android端
立即下载
ModbusTCP/RTU网段设计
基于UIP协议栈,实现MODBUS联网,可参考本文档资料开源爬虫框架,有MODBUS协议介绍
立即下载
Java项目经验汇总(简历项目素材)
Java项目经验汇总(简历项目素材)
立即下载
电磁场与电磁波第四版谢处方 PDF
电磁场与电磁波第四版谢处方 (清晰版),做天线设计的可以作为参考。
立即下载
iCopy解码软件v1.0.1.7.exe
解ic,id,hid卡密码破解ic,id,hid卡密码破解ic,id,hid破解ic,id,hid卡破解ic,id,hid卡密码密码卡密码破解ic,id,hid卡...
立即下载
source insight 4.0.0087 注册机序列号Patched(2017/10/17)
最新的sourceinsight4.0.0087和谐license及和谐文件。真正的4087版本,使用附件中的license文件,替换sourceinsight4.exe
立即下载
html+css+js制做的一个动态的圣诞贺卡
该代码是博客上面的代码,代码上面有要用到的图片资源和音乐资源。
立即下载
win10,修改mac地址的两种方式
win10,修改mac地址的两种方式,可以更改mac地址。win10,修改mac地址的两种方式,可以更改mac地址。
立即下载
计算机编程入门图文教程
图文结合的编程入门书,简单易懂,入门必备基础书。不过是英语的,需要一点点阅读能力
立即下载
Microsoft Visual C++ 14.0(安装包)
安装python依赖包报错信息"microsoft visual c++ 14.0 is required"的解决办法。具体参考我的博客:1. 下载此文件.2.解压安装(可能比较久).3.再次执行pip install xx命令。
立即下载
Adobe Premiere Pro CC 2017精典教程(pdf版-高清文字)
《Adobe Premiere Pro CC 2017精典教程(彩色版)》共分为18课,每课都围绕着具体的事例讲解,步骤详尽,重点明晰,手把手教您进行实 际操作。本书除全面介绍了Adobe Premiere Pro CC的操作流程外,还详尽介绍了Premiere Pro CC的新功能。书中给出了大量的提示和方法,帮助您更gao效地使用 Adobe Premiere Pro。
立即下载
高等物理第七版(同济大学)下册pdf
高等物理第七版(同济大学)下册教材pdf(PS:高等物理第七版上上册均有,因上传文件容量有限,因此分为两次上传,请有须要下册的同事点开我的资源下载页进行下载)
立即下载
60分钟学会OrCAD-Capture-CIS
60分钟学会OrCAD-Capture-CIS 很不错的资料开源爬虫框架,推荐给你们
立即下载 查看全部
压缩包爆破揭秘工具(7z、rar、zip)
压缩包内包含三个工具,分别可以拿来爆破揭秘7z压缩包、rar压缩包和zip压缩包。
立即下载
方方条纹注册机
方方条纹注册机,适用于方方条纹所有的系列,全部系列均可以完美注册
立即下载
常用破WIFI字典(很全)
常用wifi密码,弱口令字典,多一份资源,多一分人品.
立即下载
算法第四版 高清完整中文版PDF
《算法 第4版 》是Sedgewick之专著 与高德纳TAOCP一脉相承 是算法领域精典的参考书 涵盖所有程序员必须把握的50种算法 全面介绍了关于算法和数据结构的必备知识 并非常针对排序 搜索 图处理和字符串处理进行了阐述 第4版具体给出了每个程序员应知应会的50个算法 提供了实际代码 而且这种Java代码实现采用了模块化的编程风格 读者可以便捷地加以改建
立即下载
Camtasia 9安装及破解方式绝对有效
附件中注册方式亲测有效,加以整理与你们共享。由于附件小于60m传不起来,另附Camtasia 9百度云下载地址。免费自取链接: 密码:xees
立即下载
分布式服务框架原理与实践(高清完整版)
第1章应用构架演化1 1.1传统垂直应用构架2 1.1.1垂直应用构架介绍2 1.1.2垂直应用构架面临的挑战4 1.2RPC构架6 1.2.1RPC框架原理6 1.2.2最简单的RPC框架实现8 1.2.3业界主流RPC框架14 1.2.4RPC框架面临的挑战17 1.3SOA服务化构架18 1.3.1面向服务设计的原则18 1.3.2服务整治19 1.4微服务构架21 1.4.1哪些是微服务21 1.4.2微服务构架对比SOA22 1.5总结23 第2章分布式服务框架入门25 2.1分布式服务框架诞生背景26 2.1.1应用从集中式迈向分布式.26?
立即下载
DroidCamX 专业版破解版6.7最新版
DroidCamX 专业版破解版6.7最新版,已经包含PC端和Android端
立即下载
ModbusTCP/RTU网段设计
基于UIP协议栈,实现MODBUS联网,可参考本文档资料开源爬虫框架,有MODBUS协议介绍
立即下载
Java项目经验汇总(简历项目素材)
Java项目经验汇总(简历项目素材)
立即下载
电磁场与电磁波第四版谢处方 PDF
电磁场与电磁波第四版谢处方 (清晰版),做天线设计的可以作为参考。
立即下载
iCopy解码软件v1.0.1.7.exe
解ic,id,hid卡密码破解ic,id,hid卡密码破解ic,id,hid破解ic,id,hid卡破解ic,id,hid卡密码密码卡密码破解ic,id,hid卡...
立即下载
source insight 4.0.0087 注册机序列号Patched(2017/10/17)
最新的sourceinsight4.0.0087和谐license及和谐文件。真正的4087版本,使用附件中的license文件,替换sourceinsight4.exe
立即下载
html+css+js制做的一个动态的圣诞贺卡
该代码是博客上面的代码,代码上面有要用到的图片资源和音乐资源。
立即下载
win10,修改mac地址的两种方式
win10,修改mac地址的两种方式,可以更改mac地址。win10,修改mac地址的两种方式,可以更改mac地址。
立即下载
计算机编程入门图文教程
图文结合的编程入门书,简单易懂,入门必备基础书。不过是英语的,需要一点点阅读能力
立即下载
Microsoft Visual C++ 14.0(安装包)
安装python依赖包报错信息"microsoft visual c++ 14.0 is required"的解决办法。具体参考我的博客:1. 下载此文件.2.解压安装(可能比较久).3.再次执行pip install xx命令。
立即下载
Adobe Premiere Pro CC 2017精典教程(pdf版-高清文字)
《Adobe Premiere Pro CC 2017精典教程(彩色版)》共分为18课,每课都围绕着具体的事例讲解,步骤详尽,重点明晰,手把手教您进行实 际操作。本书除全面介绍了Adobe Premiere Pro CC的操作流程外,还详尽介绍了Premiere Pro CC的新功能。书中给出了大量的提示和方法,帮助您更gao效地使用 Adobe Premiere Pro。
立即下载
高等物理第七版(同济大学)下册pdf
高等物理第七版(同济大学)下册教材pdf(PS:高等物理第七版上上册均有,因上传文件容量有限,因此分为两次上传,请有须要下册的同事点开我的资源下载页进行下载)
立即下载
60分钟学会OrCAD-Capture-CIS
60分钟学会OrCAD-Capture-CIS 很不错的资料开源爬虫框架,推荐给你们
立即下载
开源爬虫框架各有哪些优缺点
采集交流 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2020-05-04 08:06
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。 查看全部
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。
织梦团购系统DEDE5
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-04-07 11:11
(6)使用第一个网站账号登录网站,在网站下方有“管理织梦”,进入后台进行相关设置
织梦DEDE5凭着其专业的技术、丰富的电子商务经验在第一时刻因此最流行的购物形式推出开源程序。独立编译模板、自由更改、代码简约,安全高效、数据缓存等技术的应用,使其能在大浏览量的环境下快速稳定运行,切实节省网站成本,提升形象。
同行业比较,织梦DEDE5的优势在那里?
整体规划 摒弃开发速率慢,效率低下、冗余严重的框架。投入大量的时间和精力,打造最简约高效的程序
开源程序 我们盼望公正、公正、开放的竞争环境,也希望给用户最大的自由度,方便对程序的维护和强化
功能强悍 拥有Groupon模式的全部主流模块,功能全面、强大,辅助模块不断持续开发中
使用简单 全部采用人性化设计、智能化管理,只要会操作笔记本就可以管理网站
瞬间建站 不用做模板,不用改程序,强大的团购网站瞬间构建
投入极低 投入数千元即可拥有织梦团购管理系统商业版程序,它仅是您急聘一个程序员1个月的工资
多重保障 持续开发保障、技术服务保证、问题修正保障,让您的网站发展彻底无后顾之忧
程序只是起步,服务更为重要。持续性的技术优势和不断下降的市场经验织梦团购管理系统,更提高了已有和潜在顾客的信心。时刻关注国内外相关领域内的进展和动态,不断创新,使越来越多的人相信织梦开源团购系统开发平台辉煌的明日。
使用说明:
(1)下载最新更新的程序包解压并上传到空间服务器根目录中
(2)执行安装织梦团购管理系统,如本地安装测试则访问:
(3)进入安装界面,填写MYSQL地址,通常为本地地址localhost,输入MYSQL的帐号和密码
(4)安装完成后针对install.php文件进行删掉,确保网站安全 查看全部
(6)使用第一个网站账号登录网站,在网站下方有“管理织梦”,进入后台进行相关设置
织梦DEDE5凭着其专业的技术、丰富的电子商务经验在第一时刻因此最流行的购物形式推出开源程序。独立编译模板、自由更改、代码简约,安全高效、数据缓存等技术的应用,使其能在大浏览量的环境下快速稳定运行,切实节省网站成本,提升形象。
同行业比较,织梦DEDE5的优势在那里?
整体规划 摒弃开发速率慢,效率低下、冗余严重的框架。投入大量的时间和精力,打造最简约高效的程序
开源程序 我们盼望公正、公正、开放的竞争环境,也希望给用户最大的自由度,方便对程序的维护和强化
功能强悍 拥有Groupon模式的全部主流模块,功能全面、强大,辅助模块不断持续开发中
使用简单 全部采用人性化设计、智能化管理,只要会操作笔记本就可以管理网站
瞬间建站 不用做模板,不用改程序,强大的团购网站瞬间构建
投入极低 投入数千元即可拥有织梦团购管理系统商业版程序,它仅是您急聘一个程序员1个月的工资
多重保障 持续开发保障、技术服务保证、问题修正保障,让您的网站发展彻底无后顾之忧
程序只是起步,服务更为重要。持续性的技术优势和不断下降的市场经验织梦团购管理系统,更提高了已有和潜在顾客的信心。时刻关注国内外相关领域内的进展和动态,不断创新,使越来越多的人相信织梦开源团购系统开发平台辉煌的明日。
使用说明:
(1)下载最新更新的程序包解压并上传到空间服务器根目录中
(2)执行安装织梦团购管理系统,如本地安装测试则访问:
(3)进入安装界面,填写MYSQL地址,通常为本地地址localhost,输入MYSQL的帐号和密码
(4)安装完成后针对install.php文件进行删掉,确保网站安全

