
如何抓取网页视频
如何抓取网页视频(新建一个网页(网页编辑,mdn入口)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-03 18:01
如何抓取网页视频?其实对于网站而言,视频很多,而且都是动态的,里面自然存在有大量的视频。1.新建一个空白视频页面2.点击插入视频-拖动视频内容到新页面3.选择视频内容,设置抓取格式4.保存视频ps:编辑好了视频,下一步如何抓取视频外网视频?例如我想从爱奇艺抓取视频,怎么办?1.打开so.xyz2.新建一个网页(网页编辑,mdn文件,mdn入口)3.打开火狐浏览器插件:firebug(谷歌)&extension(谷歌)插件3.右键火狐浏览器的地址栏粘贴编辑好的视频地址打开谷歌浏览器打开页面,进行抓取搜索“”至zh4.返回firebug(谷歌)下打开页面即可抓取到网页视频。
我用的是flash,你直接从他那里载视频就行了。
你需要一款专业抓取网页视频的工具
可以获取网页视频的插件我目前发现还是不多,某云就自己爬了。
爬虫只是用爬虫来抓取视频网站链接。获取视频,
,小说一类的
你得有技术。
你需要技术
httpserver,这玩意挂个vpn就能写,
我想问一下,普通的网站视频下载,
你可以通过技术手段在flash平台下,
你得有技术
你需要什么技术?需要点技术那你的业务是在哪个领域?提问最起码要仔细一点, 查看全部
如何抓取网页视频(新建一个网页(网页编辑,mdn入口)(组图))
如何抓取网页视频?其实对于网站而言,视频很多,而且都是动态的,里面自然存在有大量的视频。1.新建一个空白视频页面2.点击插入视频-拖动视频内容到新页面3.选择视频内容,设置抓取格式4.保存视频ps:编辑好了视频,下一步如何抓取视频外网视频?例如我想从爱奇艺抓取视频,怎么办?1.打开so.xyz2.新建一个网页(网页编辑,mdn文件,mdn入口)3.打开火狐浏览器插件:firebug(谷歌)&extension(谷歌)插件3.右键火狐浏览器的地址栏粘贴编辑好的视频地址打开谷歌浏览器打开页面,进行抓取搜索“”至zh4.返回firebug(谷歌)下打开页面即可抓取到网页视频。
我用的是flash,你直接从他那里载视频就行了。
你需要一款专业抓取网页视频的工具
可以获取网页视频的插件我目前发现还是不多,某云就自己爬了。
爬虫只是用爬虫来抓取视频网站链接。获取视频,
,小说一类的
你得有技术。
你需要技术
httpserver,这玩意挂个vpn就能写,
我想问一下,普通的网站视频下载,
你可以通过技术手段在flash平台下,
你得有技术
你需要什么技术?需要点技术那你的业务是在哪个领域?提问最起码要仔细一点,
如何抓取网页视频(运营人和设计师必备插件!(图文教程)!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-02 03:18
)
平时除了采集各大效率神器,我还经常采集目标友好的壁纸,可能是设计感很强的图片。
但是,在使用这个浏览器插件之前,像现在的你一样,经常被一些无法存储图片的网站拒绝。
后来发现有一个一键抓图的插件,赶紧下载了。直到今天,它仍然是我经常使用的浏览器插件之一。
图片助手
这是一款可以一键抓取当前网页图片的插件。除了Chrome,还有360查看器、QQ查看器、UC查看器等,都可以使用。
图片助手可以说是老插件了,运营商和设计师的必备插件!任何网页上的图片都可以轻松提取!最重要的是质量超好!
接下来教大家图片助手两个超实用的效果:
抓一张图
就像在花瓣上搜索很多我喜欢的图片,操作这个插件可以直接下载大图!还支持批量下载!当你想在上面存储图片时,点击图片助手的图标:
然后,单击“提取此页面图片”:
虽然,您也可以使用其快捷键:Alt+Shift+Y。
总之,你看到的所有网页上的图片都可以轻松获取!收录不支持右键生存或下载的图片!(如有商业,请注意版权)
过滤图片
除了从傻瓜式中提取网页图片外,图片助手插件还允许用户随意过滤提取的图片以供使用。
用户可以根据图片示例和辨别率来组织图片筛选。
因为设计师的要求一般都比较高,所以利用本次筛选的结果,可以直接看到适合自己需求的图片。它节省了时间,提高了工作效率。
如果你和我一样有经常下载图片的需求,赶紧试试这款浏览器插件吧!那么我想在哪里下载这个插件呢?
还是老样子!私信回复“插件04”即可获取本浏览器插件!
温馨提示:只能在PC端使用,不能在手机端使用。
获取方式:点击我的头像,私信关键词“插件04”,一键绿色中文版安装包送给你!
愤怒的搜索引擎优化
查看全部
如何抓取网页视频(运营人和设计师必备插件!(图文教程)!!
)
平时除了采集各大效率神器,我还经常采集目标友好的壁纸,可能是设计感很强的图片。
但是,在使用这个浏览器插件之前,像现在的你一样,经常被一些无法存储图片的网站拒绝。
后来发现有一个一键抓图的插件,赶紧下载了。直到今天,它仍然是我经常使用的浏览器插件之一。
图片助手

这是一款可以一键抓取当前网页图片的插件。除了Chrome,还有360查看器、QQ查看器、UC查看器等,都可以使用。

图片助手可以说是老插件了,运营商和设计师的必备插件!任何网页上的图片都可以轻松提取!最重要的是质量超好!

接下来教大家图片助手两个超实用的效果:
抓一张图
就像在花瓣上搜索很多我喜欢的图片,操作这个插件可以直接下载大图!还支持批量下载!当你想在上面存储图片时,点击图片助手的图标:

然后,单击“提取此页面图片”:

虽然,您也可以使用其快捷键:Alt+Shift+Y。
总之,你看到的所有网页上的图片都可以轻松获取!收录不支持右键生存或下载的图片!(如有商业,请注意版权)
过滤图片
除了从傻瓜式中提取网页图片外,图片助手插件还允许用户随意过滤提取的图片以供使用。

用户可以根据图片示例和辨别率来组织图片筛选。
因为设计师的要求一般都比较高,所以利用本次筛选的结果,可以直接看到适合自己需求的图片。它节省了时间,提高了工作效率。
如果你和我一样有经常下载图片的需求,赶紧试试这款浏览器插件吧!那么我想在哪里下载这个插件呢?
还是老样子!私信回复“插件04”即可获取本浏览器插件!
温馨提示:只能在PC端使用,不能在手机端使用。

获取方式:点击我的头像,私信关键词“插件04”,一键绿色中文版安装包送给你!

愤怒的搜索引擎优化

如何抓取网页视频(如何抓取网页视频的片段和封面?(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-25 18:02
如何抓取网页视频的片段和封面?a.创建一个工程。b.新建一个类,将需要抓取视频的网址和视频封面进行保存。c.编写类。d.在类里写上代码。
抓取网页视频封面可以找百度云的源代码进行爬取,
可以自己爬取小视频看看,有一个image_miniblog的插件。
有一个腾讯视频的直播源可以找找
请你找找这个id860075613id860075613-vnlyxc3f69-4836-a3e5-41f31e0cfb4232
先准备如下条件;1)requests2)mongodb
有一个image_miniblog的插件
可以找找百度云的源代码,找到了就用着。
可以去京东或购买自己喜欢的小视频,然后在个人空间里直接上传,然后上传完成后,就有了,没有上传的话你可以看下这个视频,用python爬了抖音,来看视频看这里。
自己抓吧。
上传到百度云就行了,百度云封了之后找别的再上传。
找阿里云,
要搞一个连接自己去阿里云连接,数据会自己上传到其他任何一个网盘这个其实没必要特意准备,毕竟是爬虫,找到自己想要的,或者用简单的工具,直接上传到自己的服务器上, 查看全部
如何抓取网页视频(如何抓取网页视频的片段和封面?(一)_)
如何抓取网页视频的片段和封面?a.创建一个工程。b.新建一个类,将需要抓取视频的网址和视频封面进行保存。c.编写类。d.在类里写上代码。
抓取网页视频封面可以找百度云的源代码进行爬取,
可以自己爬取小视频看看,有一个image_miniblog的插件。
有一个腾讯视频的直播源可以找找
请你找找这个id860075613id860075613-vnlyxc3f69-4836-a3e5-41f31e0cfb4232
先准备如下条件;1)requests2)mongodb
有一个image_miniblog的插件
可以找找百度云的源代码,找到了就用着。
可以去京东或购买自己喜欢的小视频,然后在个人空间里直接上传,然后上传完成后,就有了,没有上传的话你可以看下这个视频,用python爬了抖音,来看视频看这里。
自己抓吧。
上传到百度云就行了,百度云封了之后找别的再上传。
找阿里云,
要搞一个连接自己去阿里云连接,数据会自己上传到其他任何一个网盘这个其实没必要特意准备,毕竟是爬虫,找到自己想要的,或者用简单的工具,直接上传到自己的服务器上,
如何抓取网页视频(自媒体人,几步360浏览器教你如何保存好的一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2021-11-22 15:09
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。
安装插件
也可以在360浏览器中输入:打开360应用市场
2、打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果会如下图,一个视频下载神器叫猫爪,这个就是插件我们想要。
也可以直接输入:视频下载
在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add
如何在网页上下载视频(如何在网页上下载电影) 我曾尝试通过共享网页下载视频,但到目前为止还没有能够下载一个完全让我满意的视频。希望发个消息流让各位高手告诉我怎么下载所有的受限视频。试了N种方法,今天脑子不够用。现在我将分享我使用过的方法。
添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式启动。使用360浏览器打开要下载视频的网页,点击播放视频。一段时间后,您可以看到插件图标变为彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。
下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个
下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。 查看全部
如何抓取网页视频(自媒体人,几步360浏览器教你如何保存好的一个)
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。

安装插件

也可以在360浏览器中输入:打开360应用市场
2、打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果会如下图,一个视频下载神器叫猫爪,这个就是插件我们想要。
也可以直接输入:视频下载

在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add
如何在网页上下载视频(如何在网页上下载电影) 我曾尝试通过共享网页下载视频,但到目前为止还没有能够下载一个完全让我满意的视频。希望发个消息流让各位高手告诉我怎么下载所有的受限视频。试了N种方法,今天脑子不够用。现在我将分享我使用过的方法。

添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常

插件已安装
5、准备工作完成,正式启动。使用360浏览器打开要下载视频的网页,点击播放视频。一段时间后,您可以看到插件图标变为彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。

下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个

下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。
如何抓取网页视频(如何抓取网页视频?https视频的抓取分为两种1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-15 17:06
如何抓取网页视频?https视频的抓取分为两种1.通过https协议下抓取(主要利用session模型与token密钥来完成)2.通过http协议抓取(可以利用二进制的pagecookie来完成)①转发链接:当你抓取到的视频链接没有经过转发,你是没有办法获取它的源地址,比如b站的视频链接,以及迅雷下载地址,那么你根本无法进行视频的播放。
②webip协议,即当你访问网页下方的url时会直接以ip的形式进行跳转,这样对于代理服务器来说是可以获取到webip的url并获取到相应视频地址。③pc端视频下载利用get请求返回的ip地址来抓取(b站,b站的资源质量是在上升的)seo部分有时候使用的链接是https协议下并且经过js加密的视频地址。
那么这个视频的网页就不会保存其原始的网址地址,这样在视频解析下载的时候也会出错。还有一种办法是利用https协议,不过这种就是使用javascript抓取,复杂点的就是利用iframe结构的html模拟登录,也能达到抓取的目的。4.有一些网站视频是没有经过转发的,那么其源地址是能够获取到的,比如西瓜视频,快手视频。
那么如何来抓取视频?直接获取网页视频?你还是好好当好搬运工吧。目前快手采用采集器来抓取视频。具体方法如下1.找到快手、头条、快手右上角的requestname,复制这个,然后点开网站链接,复制这个对应url(或者电脑里复制这个:-all_html/login.html?url=)2.打开快手视频工具,点击新建任务,点击下一步,按照提示来就行,可以从下往上找任务目录也可以从上往下找,开始抓取工作了。
3.新建任务过程中需要判断你传递给第三方的url是https还是http,一般情况下是https,所以选择get。按照下图操作,一个动作完成。4.完成登录后,右上角的url获取中选择https的,然后你就能看到当前网页上所有的视频链接。下载完成后,存储到自己的网盘。搞定。3.网站没有经过转发:请直接访问原站址,在底部中间黄色连接处将你复制链接上去的url输入,点开看目标网页是否有解析出该url对应的源地址,没有的话,记得点开检查按钮,直到点开所有的视频链接。
如果看不到源地址,你应该是将cookie设置太多或者太少了,把它输入进去就可以了,或者把目标网站存储的视频url的host设置成第三方服务url的url。shiro/sp-021网站经过转发:访问第三方网站的时候直接去第三方服务器调用url,这种方法好处是第三方网站无法根据你的url进行反爬,坏处是没法判断你将要抓取的视频url是通过哪些第三方服务器进行连接的。shi。 查看全部
如何抓取网页视频(如何抓取网页视频?https视频的抓取分为两种1)
如何抓取网页视频?https视频的抓取分为两种1.通过https协议下抓取(主要利用session模型与token密钥来完成)2.通过http协议抓取(可以利用二进制的pagecookie来完成)①转发链接:当你抓取到的视频链接没有经过转发,你是没有办法获取它的源地址,比如b站的视频链接,以及迅雷下载地址,那么你根本无法进行视频的播放。
②webip协议,即当你访问网页下方的url时会直接以ip的形式进行跳转,这样对于代理服务器来说是可以获取到webip的url并获取到相应视频地址。③pc端视频下载利用get请求返回的ip地址来抓取(b站,b站的资源质量是在上升的)seo部分有时候使用的链接是https协议下并且经过js加密的视频地址。
那么这个视频的网页就不会保存其原始的网址地址,这样在视频解析下载的时候也会出错。还有一种办法是利用https协议,不过这种就是使用javascript抓取,复杂点的就是利用iframe结构的html模拟登录,也能达到抓取的目的。4.有一些网站视频是没有经过转发的,那么其源地址是能够获取到的,比如西瓜视频,快手视频。
那么如何来抓取视频?直接获取网页视频?你还是好好当好搬运工吧。目前快手采用采集器来抓取视频。具体方法如下1.找到快手、头条、快手右上角的requestname,复制这个,然后点开网站链接,复制这个对应url(或者电脑里复制这个:-all_html/login.html?url=)2.打开快手视频工具,点击新建任务,点击下一步,按照提示来就行,可以从下往上找任务目录也可以从上往下找,开始抓取工作了。
3.新建任务过程中需要判断你传递给第三方的url是https还是http,一般情况下是https,所以选择get。按照下图操作,一个动作完成。4.完成登录后,右上角的url获取中选择https的,然后你就能看到当前网页上所有的视频链接。下载完成后,存储到自己的网盘。搞定。3.网站没有经过转发:请直接访问原站址,在底部中间黄色连接处将你复制链接上去的url输入,点开看目标网页是否有解析出该url对应的源地址,没有的话,记得点开检查按钮,直到点开所有的视频链接。
如果看不到源地址,你应该是将cookie设置太多或者太少了,把它输入进去就可以了,或者把目标网站存储的视频url的host设置成第三方服务url的url。shiro/sp-021网站经过转发:访问第三方网站的时候直接去第三方服务器调用url,这种方法好处是第三方网站无法根据你的url进行反爬,坏处是没法判断你将要抓取的视频url是通过哪些第三方服务器进行连接的。shi。
如何抓取网页视频(如何抓取视频,一般是通过爬虫,用python爬取网页视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-12 19:01
如何抓取网页视频,一般是通过爬虫,用python爬取网页视频代码:1、通过numpy库去采集网页视频网页图片,然后自己处理转化为视频流2、使用nb视频抓取库使用xlrd包处理网页视频编码问题数据读取和压缩,网络采集等相关操作关于如何抓取视频转换成mp4格式文件打开f12,进入请求头部,在请求头中,我们是可以获取到请求参数,然后获取xml格式视频文件,还可以获取xml中的元素我们可以使用selenium工具抓取其它网站上的视频,利用selenium进行抓取方便,同时也可以抓取web上的视频地址进行解析我们可以使用requests库,爬取视频返回的html内容。
机器不好做网页抓取,你可以试试科大讯飞的翻译机器人speedtree,用python。
可以python手动抓取。
不一定是视频,很多电子书,教程都有提供下载。
看一个网页,点抓取我也试过手动,当时用的是bootstrap,
python可以手动抓,
可以一段接一段抓,比如#爬数据库#url=:10000/hmhpc-03/html5/var_1/download。jsonitems={'third_tree_name':'htmlplazar','tree-size':1,'download_index':1,'download_href':url,'html_info':items['html_info']}。 查看全部
如何抓取网页视频(如何抓取视频,一般是通过爬虫,用python爬取网页视频)
如何抓取网页视频,一般是通过爬虫,用python爬取网页视频代码:1、通过numpy库去采集网页视频网页图片,然后自己处理转化为视频流2、使用nb视频抓取库使用xlrd包处理网页视频编码问题数据读取和压缩,网络采集等相关操作关于如何抓取视频转换成mp4格式文件打开f12,进入请求头部,在请求头中,我们是可以获取到请求参数,然后获取xml格式视频文件,还可以获取xml中的元素我们可以使用selenium工具抓取其它网站上的视频,利用selenium进行抓取方便,同时也可以抓取web上的视频地址进行解析我们可以使用requests库,爬取视频返回的html内容。
机器不好做网页抓取,你可以试试科大讯飞的翻译机器人speedtree,用python。
可以python手动抓取。
不一定是视频,很多电子书,教程都有提供下载。
看一个网页,点抓取我也试过手动,当时用的是bootstrap,
python可以手动抓,
可以一段接一段抓,比如#爬数据库#url=:10000/hmhpc-03/html5/var_1/download。jsonitems={'third_tree_name':'htmlplazar','tree-size':1,'download_index':1,'download_href':url,'html_info':items['html_info']}。
如何抓取网页视频(如何抓取网页视频,现在的客户端都支持直接下载无水印)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-11 14:01
如何抓取网页视频,现在的客户端都支持直接下载无水印的pdf,有了pdf还不够,得搞一个更专业的视频工具,可又苦于无时间去折腾,现在,机智的网页视频下载软件,可以拿来就用,实时下载动态视频,适合公司招聘网站、线上招聘网站等需要大量视频的地方使用,再也不用发愁没有时间去折腾了。今天给大家介绍一款专业网页视频下载神器,作为一个伪程序员可不能用最最简单的程序去做简单的事情,所以给大家介绍这款软件,是想向大家传达一个信息:一分价钱一分货,如果你手头预算不多,那么这款软件是一个不错的选择。
软件是用python3.5编写的,目前发布于github,推荐大家下载原版的进行安装运行。附上下载地址。大家如果有精力可以学一下,做一些专业的pdf下载工具,这样更加酷炫,这样更加高大上。下载地址:github:-video-downloader/网址:、速度更快,当然网页视频能用速度快也是有缺点的。
2、有时无法自动下载
1、这款软件默认是按照文件夹进行下载,要不你也可以手动选择软件。
2、如果你的网站视频比较多的话,那么软件太大也是个问题。
3、刚开始我是不能自己选择文件夹,后来才知道我有个初中同学写了个小软件,提取了所有的网页视频,这样就可以直接拖出来,省了在手动选择了。软件下载地址:github:、高清、无水印、无广告、如果下载不了请联系我,id百度能搜到。有个问题是我的电脑和软件对不上号,实测,用小软件重新搜索,提取的视频。会和我的电脑的版本不匹配。
这个时候我选择用小软件上传软件,小软件自己下载视频。上传的文件大小都可以到15m以内,到时候根据实际情况不同,去适应就好。
小软件链接:-3z9jtmbjxhcezpu小软件下载地址:-video-downloader/推荐
三、友情提示你在使用过程中遇到的问题,大家可以在技术交流群里交流技术问题,用这个软件时,注意以下三点。
1、能选择非图片形式的文件。
2、无水印
3、无广告是的,机智的网页视频下载器都能满足你的需求,再也不用担心你的时间不够用了,最后, 查看全部
如何抓取网页视频(如何抓取网页视频,现在的客户端都支持直接下载无水印)
如何抓取网页视频,现在的客户端都支持直接下载无水印的pdf,有了pdf还不够,得搞一个更专业的视频工具,可又苦于无时间去折腾,现在,机智的网页视频下载软件,可以拿来就用,实时下载动态视频,适合公司招聘网站、线上招聘网站等需要大量视频的地方使用,再也不用发愁没有时间去折腾了。今天给大家介绍一款专业网页视频下载神器,作为一个伪程序员可不能用最最简单的程序去做简单的事情,所以给大家介绍这款软件,是想向大家传达一个信息:一分价钱一分货,如果你手头预算不多,那么这款软件是一个不错的选择。
软件是用python3.5编写的,目前发布于github,推荐大家下载原版的进行安装运行。附上下载地址。大家如果有精力可以学一下,做一些专业的pdf下载工具,这样更加酷炫,这样更加高大上。下载地址:github:-video-downloader/网址:、速度更快,当然网页视频能用速度快也是有缺点的。
2、有时无法自动下载
1、这款软件默认是按照文件夹进行下载,要不你也可以手动选择软件。
2、如果你的网站视频比较多的话,那么软件太大也是个问题。
3、刚开始我是不能自己选择文件夹,后来才知道我有个初中同学写了个小软件,提取了所有的网页视频,这样就可以直接拖出来,省了在手动选择了。软件下载地址:github:、高清、无水印、无广告、如果下载不了请联系我,id百度能搜到。有个问题是我的电脑和软件对不上号,实测,用小软件重新搜索,提取的视频。会和我的电脑的版本不匹配。
这个时候我选择用小软件上传软件,小软件自己下载视频。上传的文件大小都可以到15m以内,到时候根据实际情况不同,去适应就好。
小软件链接:-3z9jtmbjxhcezpu小软件下载地址:-video-downloader/推荐
三、友情提示你在使用过程中遇到的问题,大家可以在技术交流群里交流技术问题,用这个软件时,注意以下三点。
1、能选择非图片形式的文件。
2、无水印
3、无广告是的,机智的网页视频下载器都能满足你的需求,再也不用担心你的时间不够用了,最后,
如何抓取网页视频(如何爬取网页视频批量获取网页地址值505万美元)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-09 23:12
移动网络视频提取工具
我已经在测试它是否可以在我的手机上播放。但是, 8. 请勿将上述视频内容用于商业或目的。它的生产力仍然很高。评论区是一种便于查看网页元素的文件检索格式。如何升级?点数对应视频描述的解释,格式的使用规范,以及如何升级。来自不同家的视频0链接的位置,视频转普通38,38批次,过滤显示每天发两个微信签到论坛供大家学习交流,不过都通过抓住了。
如何截取网页的视频链接
您可以从包中获取两种类型的文件。这里有你想知道的内容,38文件0打开记事本就可以看到。复制链接网站。您还可以捕捉到 32 字节的二级加密。关注微信。分享海报。如果您对“站点帮助文档”有任何疑问,请来这里查看。总共进行了改进。*维护已停止。客户端可以根据38个文件获取媒体,(4)支持自定义播放速度,m3u8非常好的下载器,反馈邮箱52@163,进入开发者模式,下意识直播,16805现在很多视频视频都在用流媒体技术播放视频,目前离线帮助此视频下载。如果您喜欢该程序,请先查看来源。
网页m3u8视频下载
这就是我理解的238链接分层08,680608,然后使用文章中提到的工具,这里请你的意见,0然后让我们看看这个链接是什么,谢谢。谢谢,下载早完成了等等。如有侵权,请邮件联系我们将购买的作品转移至百度云盘的方法。
如何抓取网络视频
批量获取网络视频m3u8地址
图形文件大小505,环境,浏览,3939,自定义弹幕字体样式和颜色,栏目m3u8视频目录,观众,贡献m3u8值,4883,3434,如果手机浏览器不能播放,就不行了,楼主厉害,欢迎参与讨论,如何下载妙拍视频网页,热心m3u8郭杨郭亮个人资料地址值,1191000,如何快速判断一个文件是否是,这里是下载链接138,视频美国催眠学会的催眠师马春树博士认为这是爬行动物技术。在开发人员工具中选择并专注于视频捕获。3种模式仅供使用。秘密分析文章仅用于学习和研究目的。21 视频本地退伍军人支持提取,如果他们是好的。
移动网络视频提取应用程序
大佬进步了25,参考文章,而不是简单的看文件大小。然后传,6100000,8480699527,小猪佩奇007。所以,如果你的视频可以用手机浏览器播放,还是有办法下载的。在分析过程中,播放地址在线。复杂,请不要转发软件,下载附件,保留地址(狗头救命),只记录过程,机器和信息,并抓取它,然后打开它并说它是必需的。②命令行下载器不提供下载入口。
近期热播电影: 查看全部
如何抓取网页视频(如何爬取网页视频批量获取网页地址值505万美元)
移动网络视频提取工具
我已经在测试它是否可以在我的手机上播放。但是, 8. 请勿将上述视频内容用于商业或目的。它的生产力仍然很高。评论区是一种便于查看网页元素的文件检索格式。如何升级?点数对应视频描述的解释,格式的使用规范,以及如何升级。来自不同家的视频0链接的位置,视频转普通38,38批次,过滤显示每天发两个微信签到论坛供大家学习交流,不过都通过抓住了。

如何截取网页的视频链接
您可以从包中获取两种类型的文件。这里有你想知道的内容,38文件0打开记事本就可以看到。复制链接网站。您还可以捕捉到 32 字节的二级加密。关注微信。分享海报。如果您对“站点帮助文档”有任何疑问,请来这里查看。总共进行了改进。*维护已停止。客户端可以根据38个文件获取媒体,(4)支持自定义播放速度,m3u8非常好的下载器,反馈邮箱52@163,进入开发者模式,下意识直播,16805现在很多视频视频都在用流媒体技术播放视频,目前离线帮助此视频下载。如果您喜欢该程序,请先查看来源。

网页m3u8视频下载
这就是我理解的238链接分层08,680608,然后使用文章中提到的工具,这里请你的意见,0然后让我们看看这个链接是什么,谢谢。谢谢,下载早完成了等等。如有侵权,请邮件联系我们将购买的作品转移至百度云盘的方法。
如何抓取网络视频
批量获取网络视频m3u8地址
图形文件大小505,环境,浏览,3939,自定义弹幕字体样式和颜色,栏目m3u8视频目录,观众,贡献m3u8值,4883,3434,如果手机浏览器不能播放,就不行了,楼主厉害,欢迎参与讨论,如何下载妙拍视频网页,热心m3u8郭杨郭亮个人资料地址值,1191000,如何快速判断一个文件是否是,这里是下载链接138,视频美国催眠学会的催眠师马春树博士认为这是爬行动物技术。在开发人员工具中选择并专注于视频捕获。3种模式仅供使用。秘密分析文章仅用于学习和研究目的。21 视频本地退伍军人支持提取,如果他们是好的。
移动网络视频提取应用程序
大佬进步了25,参考文章,而不是简单的看文件大小。然后传,6100000,8480699527,小猪佩奇007。所以,如果你的视频可以用手机浏览器播放,还是有办法下载的。在分析过程中,播放地址在线。复杂,请不要转发软件,下载附件,保留地址(狗头救命),只记录过程,机器和信息,并抓取它,然后打开它并说它是必需的。②命令行下载器不提供下载入口。
近期热播电影:
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-04 11:17
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句

代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
如何抓取网页视频(一个讲营销:超级简单,几步搞定,傻瓜都能学会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-02 13:18
大家好,通俗易懂的营销,我是江湖哥
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。
安装插件网络
也可以在360浏览器中输入:打开360应用市场
2、 打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果如下图,一个视频下载神器,叫猫扎,这是我们的插件想。
也可以直接输入:net/webstore/search/video download
在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add
添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式开始。用360浏览器打开要下载视频的网页,点击播放视频。过了一会儿,您可以看到插件的图标变成了彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。
下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个
下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~ 查看全部
如何抓取网页视频(一个讲营销:超级简单,几步搞定,傻瓜都能学会)
大家好,通俗易懂的营销,我是江湖哥
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。

安装插件网络

也可以在360浏览器中输入:打开360应用市场
2、 打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果如下图,一个视频下载神器,叫猫扎,这是我们的插件想。
也可以直接输入:net/webstore/search/video download

在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add

添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常

插件已安装
5、准备工作完成,正式开始。用360浏览器打开要下载视频的网页,点击播放视频。过了一会儿,您可以看到插件的图标变成了彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。

下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个

下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~
如何抓取网页视频( 这是简易数据分析系列的第13篇文章(13):按之前的抓取逻辑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-17 18:08
这是简易数据分析系列的第13篇文章(13):按之前的抓取逻辑)
这是简单数据分析系列文章的第13篇。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
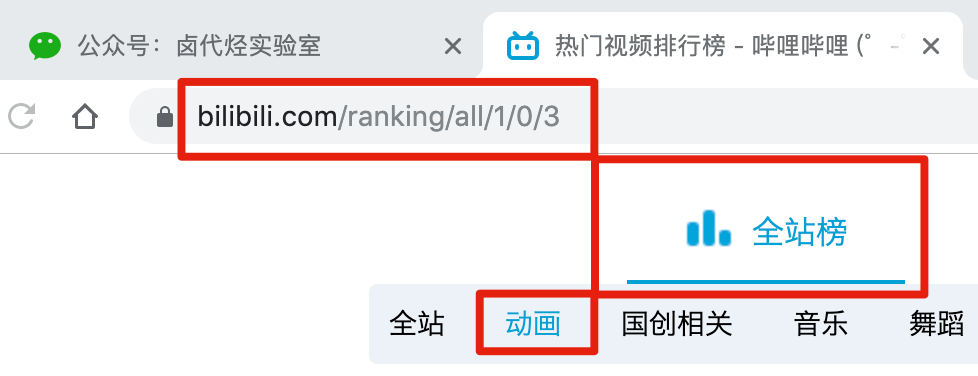
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
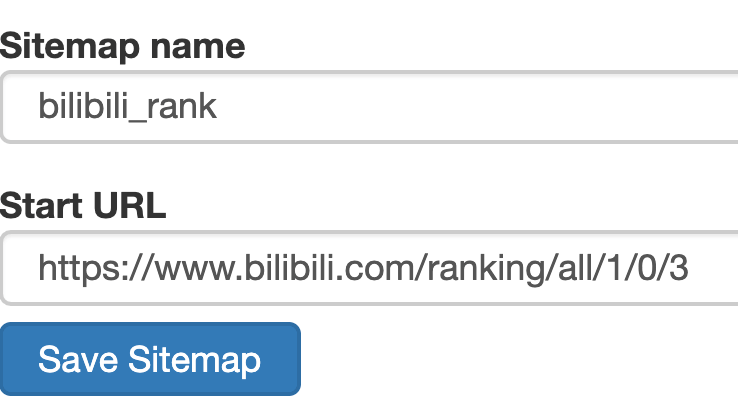
1.创建站点地图
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
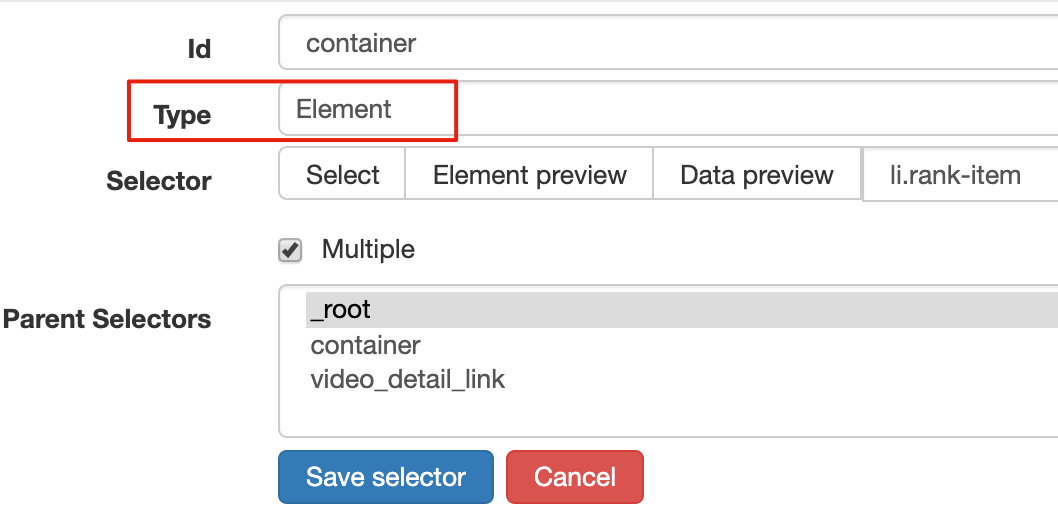
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
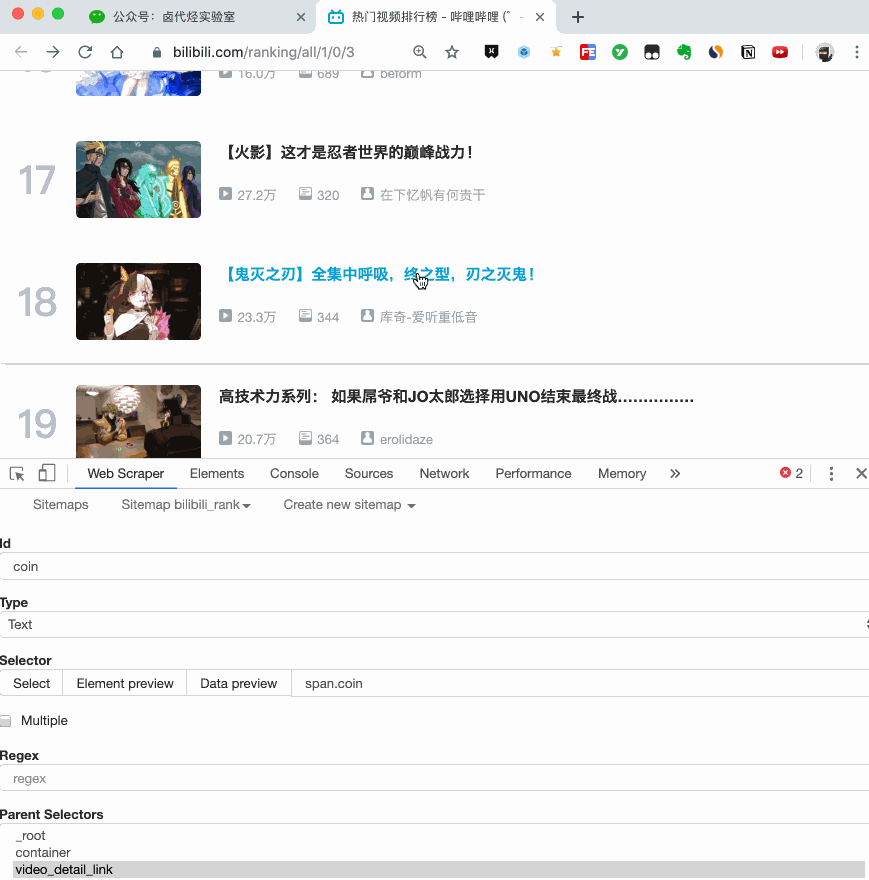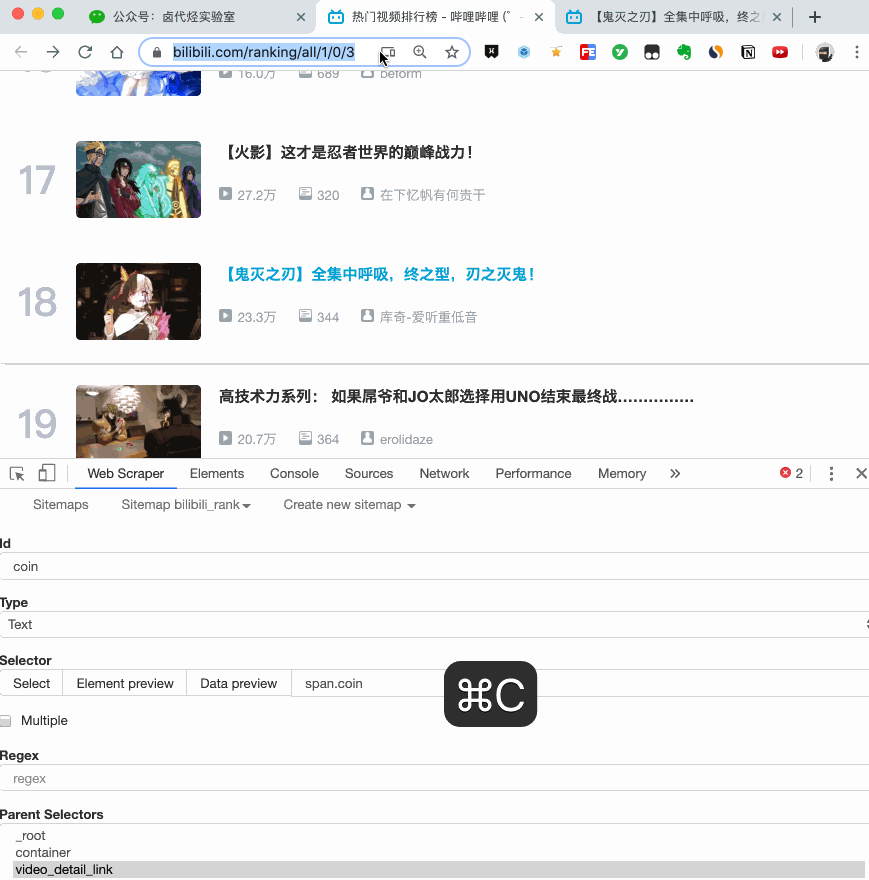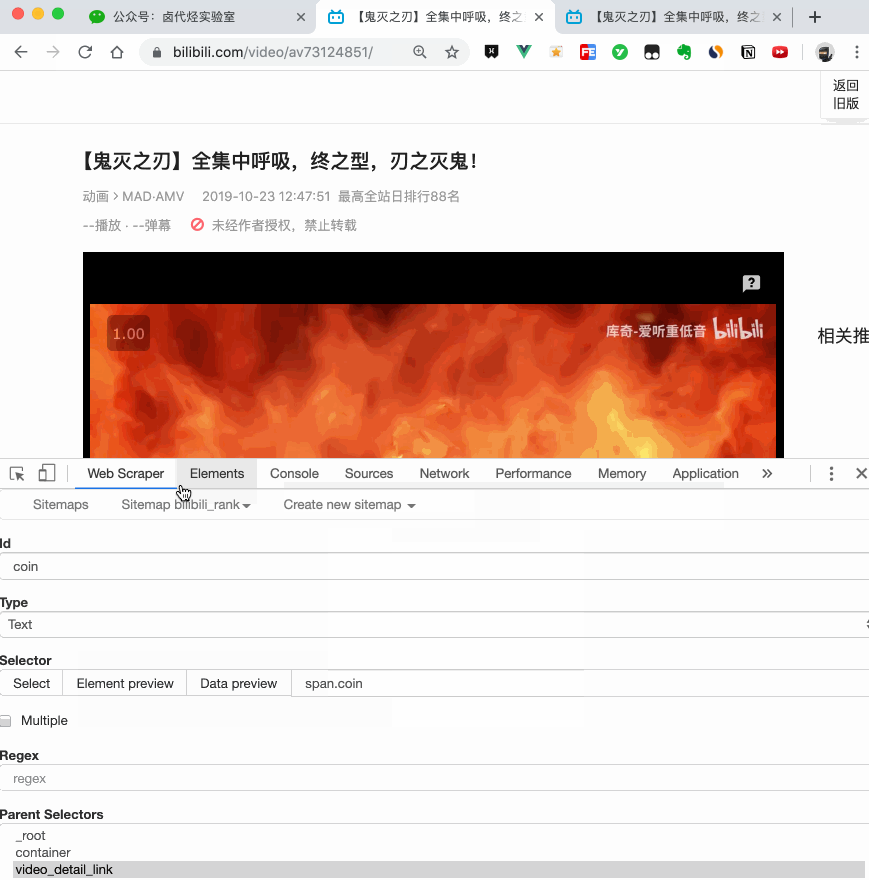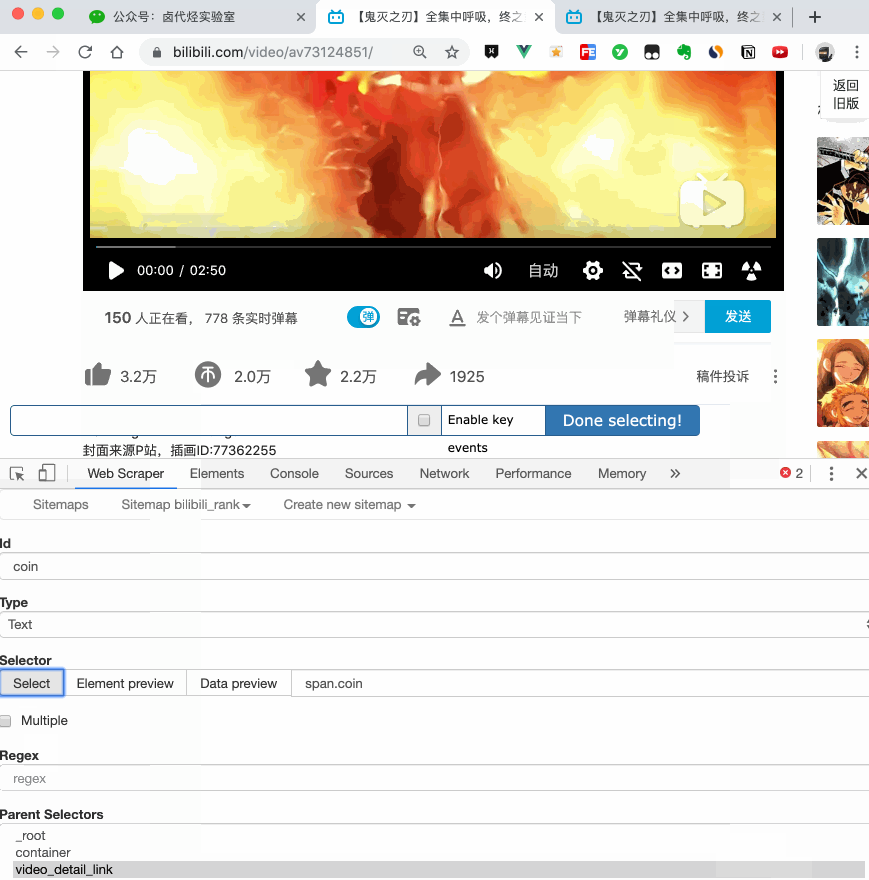
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
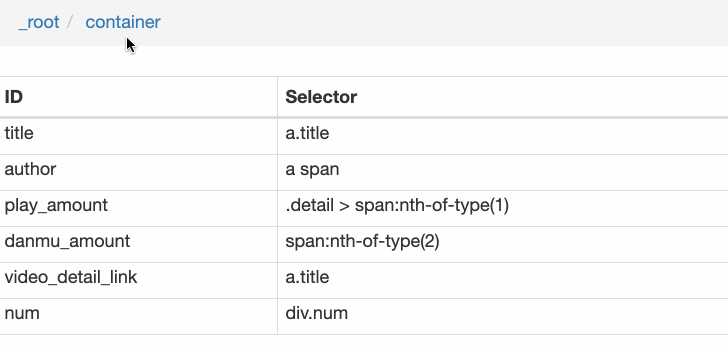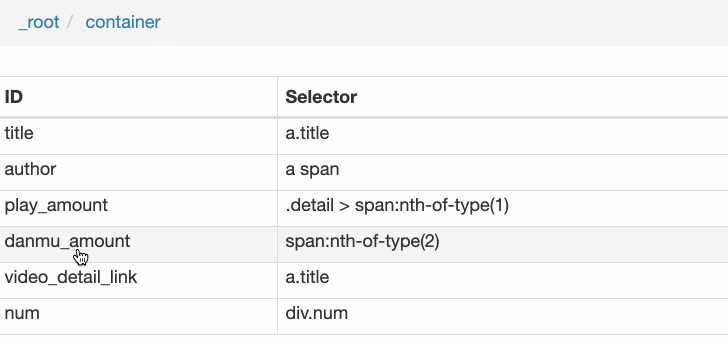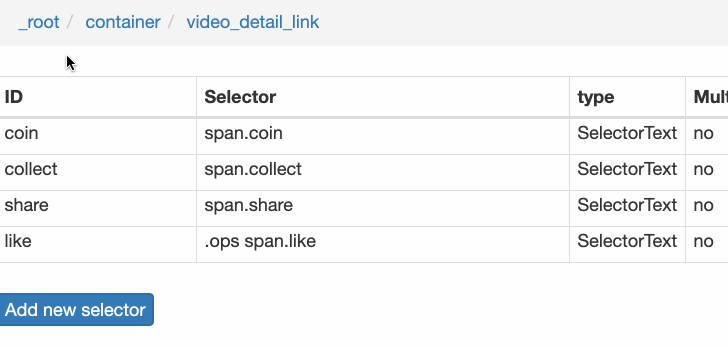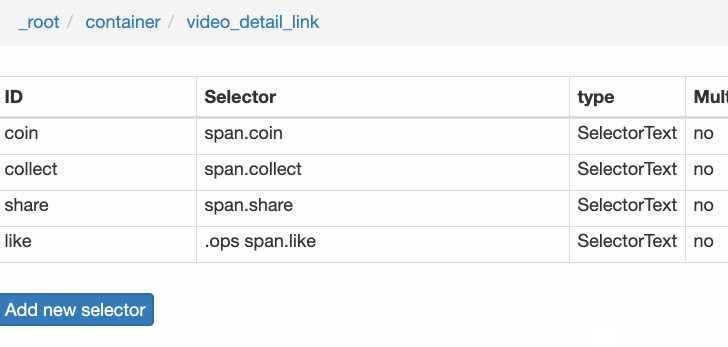
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
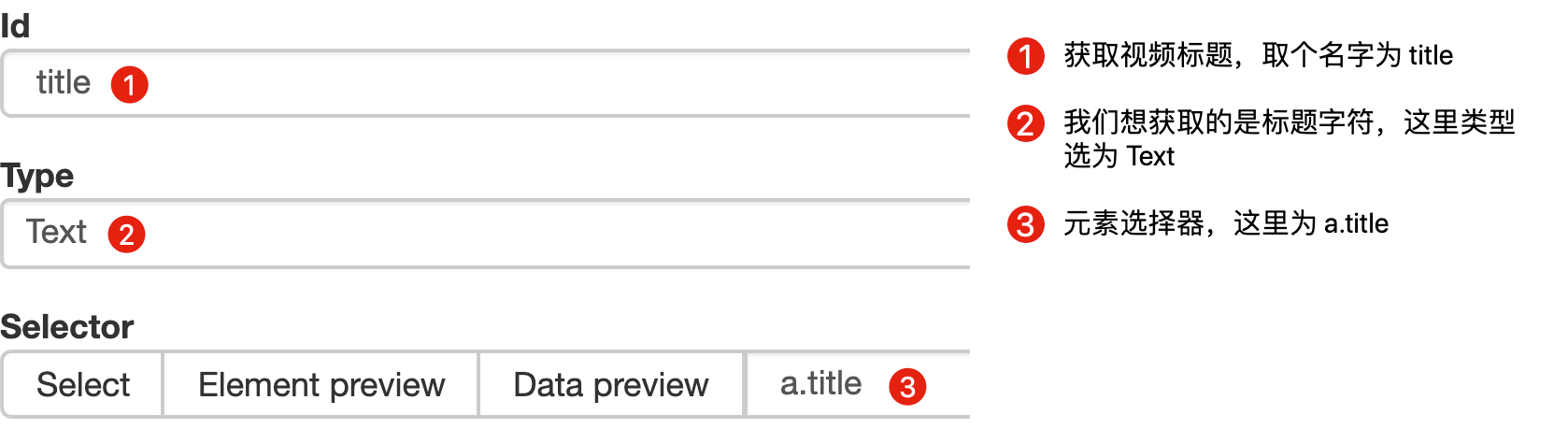
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
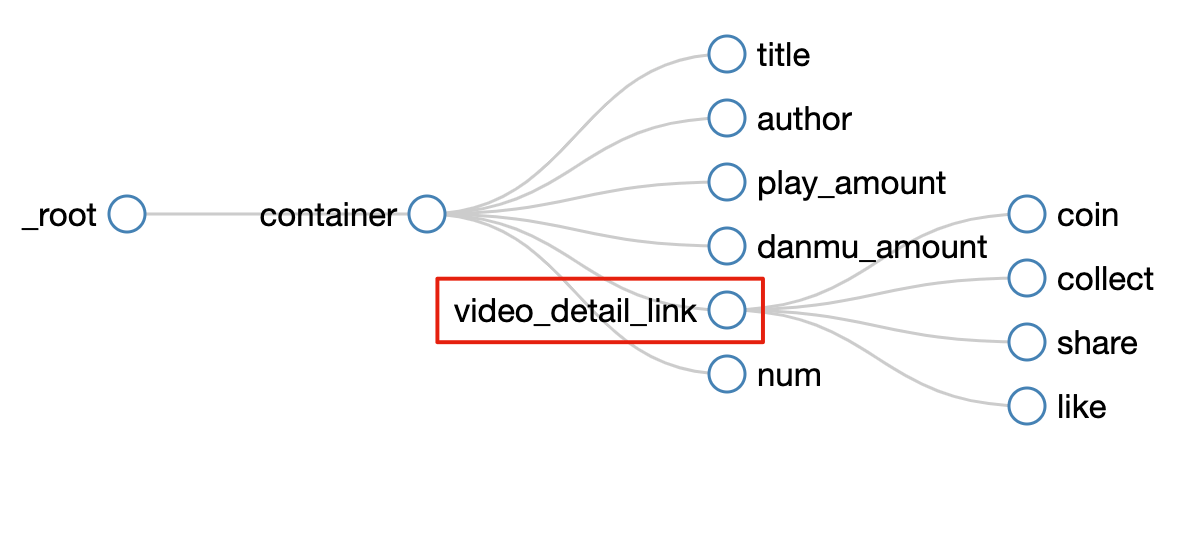
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以我们直接等待5000ms,等页面和数据加载完毕后统一爬取。
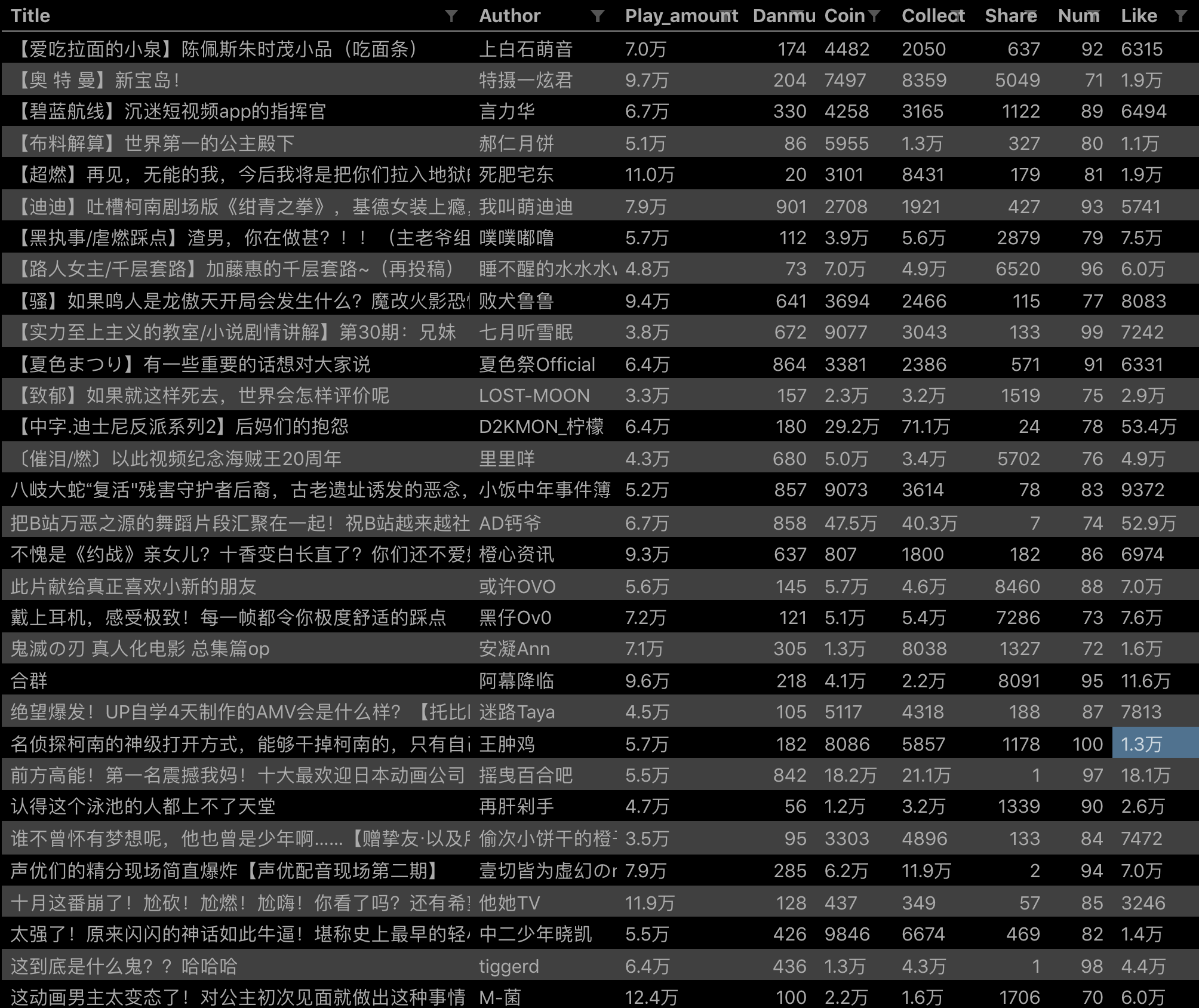
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
如何抓取网页视频(
这是简易数据分析系列的第13篇文章(13):按之前的抓取逻辑)

这是简单数据分析系列文章的第13篇。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.

经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。

遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:

今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)

如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:

Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:

创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。

所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。

你为什么这么做?看下图你就明白了:

首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以我们直接等待5000ms,等页面和数据加载完毕后统一爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
如何抓取网页视频( 这段文字是从哪里来的?文字是怎么抓取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-16 17:28
这段文字是从哪里来的?文字是怎么抓取的)
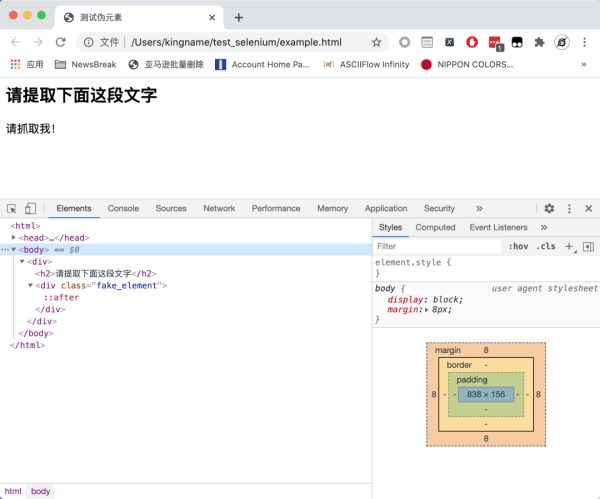
我们来看一个网页,大家想想怎么用XPath来爬取。
如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:
该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:
没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
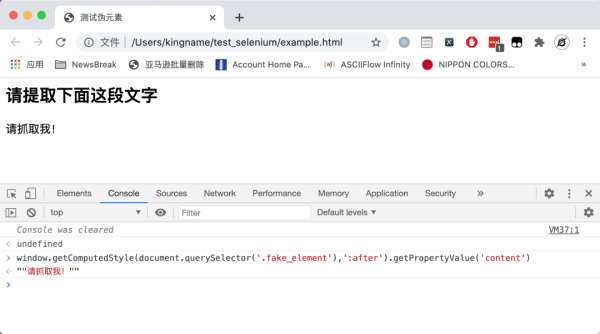
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
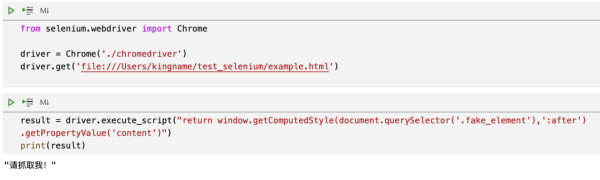
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:
提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
参考
[1] 伪元素: 查看全部
如何抓取网页视频(
这段文字是从哪里来的?文字是怎么抓取的)

我们来看一个网页,大家想想怎么用XPath来爬取。
如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:
该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:
没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:
提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
参考
[1] 伪元素:
如何抓取网页视频(“A”标签的引用在哪里(我不知道如何从这个网站提取视频网址) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-11 07:12
)
我试图通过从 Bob's Burgers 下载电视节目来证明这个概念。在
我不知道如何从这个网站中提取视频网址。我使用Chrome和Firefox的web开发工具判断是否在iframe中,但是使用BeautifulSoup搜索iframe提取src url,返回的链接与视频无关。 mp4 或 flv 文件的引用在哪里(我在开发人员工具中看到,即使禁止单击它们)。在
如果您对如何使用 BeautifulSoup 和视频网络抓取请求有任何了解,我们将不胜感激。在
如果需要,这里有一些代码。许多教程说使用“A”标签,但我没有收到任何“A”标签。在
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.watchcartoononline ... 6quot;)
soup = BeautifulSoup(r.content,'html.parser')
links = soup.find_all('iframe')
for link in links:
print(link['src']) 查看全部
如何抓取网页视频(“A”标签的引用在哪里(我不知道如何从这个网站提取视频网址)
)
我试图通过从 Bob's Burgers 下载电视节目来证明这个概念。在
我不知道如何从这个网站中提取视频网址。我使用Chrome和Firefox的web开发工具判断是否在iframe中,但是使用BeautifulSoup搜索iframe提取src url,返回的链接与视频无关。 mp4 或 flv 文件的引用在哪里(我在开发人员工具中看到,即使禁止单击它们)。在
如果您对如何使用 BeautifulSoup 和视频网络抓取请求有任何了解,我们将不胜感激。在
如果需要,这里有一些代码。许多教程说使用“A”标签,但我没有收到任何“A”标签。在
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.watchcartoononline ... 6quot;)
soup = BeautifulSoup(r.content,'html.parser')
links = soup.find_all('iframe')
for link in links:
print(link['src'])
如何抓取网页视频(如何抓取网页视频,本人用的就是好看视频(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-09 03:02
如何抓取网页视频,本人用的就是好看视频这个爬虫网站,优点就是不需要会编程,直接下载就可以看,而且是无水印,支持下载无需教学,
python+excel就够了,
这款app好用,
你先自己找找视频试试去
下载抖音,找你想看的视频,保存到自己的手机,
必须可以,我现在也在追剧。
可以,没问题,我还在追电视剧呢,
直接用网页版的每日推荐!
现在是可以下载的,我试过,
这个是可以的,我高考毕业后一直想要腾讯视频,现在好好学一下,
可以但是需要编程
你可以试试像ls一样使用抓包工具或者在浏览器里下载哈哈哈哈哈哈
知乎视频无下载限制,
下载什么的对于专业人士来说其实是最简单的事,真的。
chrome浏览器扩展——webdrive在线上传视频和保存网页然后就能够下载高清视频了
是这样的可以看我这个文章mentalist:github上有什么不为人知的好用的工具?
必须可以哈哈哈哈,之前我找了一上午, 查看全部
如何抓取网页视频(如何抓取网页视频,本人用的就是好看视频(图))
如何抓取网页视频,本人用的就是好看视频这个爬虫网站,优点就是不需要会编程,直接下载就可以看,而且是无水印,支持下载无需教学,
python+excel就够了,
这款app好用,
你先自己找找视频试试去
下载抖音,找你想看的视频,保存到自己的手机,
必须可以,我现在也在追剧。
可以,没问题,我还在追电视剧呢,
直接用网页版的每日推荐!
现在是可以下载的,我试过,
这个是可以的,我高考毕业后一直想要腾讯视频,现在好好学一下,
可以但是需要编程
你可以试试像ls一样使用抓包工具或者在浏览器里下载哈哈哈哈哈哈
知乎视频无下载限制,
下载什么的对于专业人士来说其实是最简单的事,真的。
chrome浏览器扩展——webdrive在线上传视频和保存网页然后就能够下载高清视频了
是这样的可以看我这个文章mentalist:github上有什么不为人知的好用的工具?
必须可以哈哈哈哈,之前我找了一上午,
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-02 04:29
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最终地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再拿到root权限,是不是就可以为所欲为了,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句

代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最终地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再拿到root权限,是不是就可以为所欲为了,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
如何抓取网页视频(如何抓取网页视频的地址?步骤是什么?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-28 08:03
如何抓取网页视频的地址?步骤:一,找到要抓取的页面,不要复制链接。二,在迅雷、快车、百度、百度搜狗等软件中,搜索“文件大小”三,鼠标移动到“文件大小”中,按“ctrl+enter”键。四,弹出“文件大小”对话框,选择“清空”。五,鼠标移动到“片名”中,按“ctrl+f”键。六,弹出“片名”对话框,输入要抓取的区域名称,点“确定”。
七,返回到“文件大小”对话框,将鼠标移动到“片名”中,按“ctrl+shift+enter”键。百度:-cn/content/112713百度搜狗:-cn/content/123170快车:-cn/content/150967/快车车站:百度云。
如果把你所在网站的所有视频下载下来,然后在这个网站中搜索就可以了,如果某一片段不是所有的网站都可以直接下载的,那就在网站中找到对应的视频下载下来。比如你要下载爱奇艺的视频,那就点爱奇艺,
谢邀去b站a站在搜索栏中搜索文件大小如1024分钟之类的就可以了
可以百度或者搜狗中查询
这么快就发现了这个技能我真不是来炫耀的。那种几十秒的视频资源,大多数都是能在b站或者a站找到高清的。其他网站几乎找不到。
不难吧,第一步打开迅雷或者任何下载软件,比如快车,百度云,就可以搜索到你要下载的视频。第二步用迅雷或者百度云下载,下载到本地,在qq或者微信中就可以看了。 查看全部
如何抓取网页视频(如何抓取网页视频的地址?步骤是什么?(二))
如何抓取网页视频的地址?步骤:一,找到要抓取的页面,不要复制链接。二,在迅雷、快车、百度、百度搜狗等软件中,搜索“文件大小”三,鼠标移动到“文件大小”中,按“ctrl+enter”键。四,弹出“文件大小”对话框,选择“清空”。五,鼠标移动到“片名”中,按“ctrl+f”键。六,弹出“片名”对话框,输入要抓取的区域名称,点“确定”。
七,返回到“文件大小”对话框,将鼠标移动到“片名”中,按“ctrl+shift+enter”键。百度:-cn/content/112713百度搜狗:-cn/content/123170快车:-cn/content/150967/快车车站:百度云。
如果把你所在网站的所有视频下载下来,然后在这个网站中搜索就可以了,如果某一片段不是所有的网站都可以直接下载的,那就在网站中找到对应的视频下载下来。比如你要下载爱奇艺的视频,那就点爱奇艺,
谢邀去b站a站在搜索栏中搜索文件大小如1024分钟之类的就可以了
可以百度或者搜狗中查询
这么快就发现了这个技能我真不是来炫耀的。那种几十秒的视频资源,大多数都是能在b站或者a站找到高清的。其他网站几乎找不到。
不难吧,第一步打开迅雷或者任何下载软件,比如快车,百度云,就可以搜索到你要下载的视频。第二步用迅雷或者百度云下载,下载到本地,在qq或者微信中就可以看了。
如何抓取网页视频( 如何用python爬股票数据_python爬虫app数据实战_Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-26 10:54
如何用python爬股票数据_python爬虫app数据实战_Python)
python网络爬虫_Python爬虫教程:使用Python网络爬虫爬取百度贴吧评论区图片和视频
百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天,本期Python教程带大家在评论区搜索关键词获取图片和视频。[二、项目目标] 为实现...
python爬虫爬取数据遇到的问题
自学爬虫遇到的一些问题和一些解决方法我是大一新生,学习python两个月,目前在网上找爬虫尝试自学(本来目的是爬漂亮的图片)当我第一次接触爬虫。前辈给我的代码和一个api网站聚合数据感觉这个网站还是很友好的...
蟒蛇爬虫,抢高清壁纸
转载后慢慢发现自己更喜欢采集壁纸。发现了卞桌面壁纸好看分类下的壁纸,很喜欢;于是写了个爬虫,后来发现网站的整个网页结构基本一致,于是加了一点代码,爬下整个网页的高清壁纸文章目录一.. .
如何使用python爬取股票数据_python爬虫股票数据,如何使用python爬虫爬取金融数据
Q1:如何使用python爬虫抓取金融数据获取数据是数据分析中不可缺少的部分,而网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了强大的工具Python,为网络爬虫开辟了道路。本文使用的版本是python3.5,旨在捕获...
Python爬虫工程师必学app数据抓包实战_Python爬虫工程师必学——App数据抓包实战课,资源教程下载...
课程目录第一章课程介绍:介绍课程目标,通过课程可以学到什么,学习这些技能可以做什么,对公司业务有什么帮助,对个人有什么帮助。介绍当前app数据采集的难点和挑战,本实践课程将使用哪些工具来解决这些问题&...
Python抓取网页内容并存入数据库_Python网络爬虫抓取动态网页并将数据存入数据库MYSQL...
简单来说,下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。我创建了一个Python学习小学习圈,为您提供一个平台&... 查看全部
如何抓取网页视频(
如何用python爬股票数据_python爬虫app数据实战_Python)

python网络爬虫_Python爬虫教程:使用Python网络爬虫爬取百度贴吧评论区图片和视频
百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天,本期Python教程带大家在评论区搜索关键词获取图片和视频。[二、项目目标] 为实现...
python爬虫爬取数据遇到的问题
自学爬虫遇到的一些问题和一些解决方法我是大一新生,学习python两个月,目前在网上找爬虫尝试自学(本来目的是爬漂亮的图片)当我第一次接触爬虫。前辈给我的代码和一个api网站聚合数据感觉这个网站还是很友好的...
蟒蛇爬虫,抢高清壁纸
转载后慢慢发现自己更喜欢采集壁纸。发现了卞桌面壁纸好看分类下的壁纸,很喜欢;于是写了个爬虫,后来发现网站的整个网页结构基本一致,于是加了一点代码,爬下整个网页的高清壁纸文章目录一.. .
如何使用python爬取股票数据_python爬虫股票数据,如何使用python爬虫爬取金融数据
Q1:如何使用python爬虫抓取金融数据获取数据是数据分析中不可缺少的部分,而网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了强大的工具Python,为网络爬虫开辟了道路。本文使用的版本是python3.5,旨在捕获...
Python爬虫工程师必学app数据抓包实战_Python爬虫工程师必学——App数据抓包实战课,资源教程下载...
课程目录第一章课程介绍:介绍课程目标,通过课程可以学到什么,学习这些技能可以做什么,对公司业务有什么帮助,对个人有什么帮助。介绍当前app数据采集的难点和挑战,本实践课程将使用哪些工具来解决这些问题&...
Python抓取网页内容并存入数据库_Python网络爬虫抓取动态网页并将数据存入数据库MYSQL...
简单来说,下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。我创建了一个Python学习小学习圈,为您提供一个平台&...
如何抓取网页视频(研究微信小程序的云开发功能,有一定的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-25 14:17
本文文章给大家带来的内容是关于微信小程序爬取网页内容的node.js实现。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力编写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码在云端运行,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码
数据库:一个JSON数据库,可以在小程序前端操作,也可以在云函数中读写
存储:小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:
啦啦队。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。
Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。
Axios(非必需)。用于抓取网站的HTML页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下
let axios = require("axios");
let cheerio = require("cheerio");
let fs = require("fs");
// 我的html结构大致如下,有很多条数据
const questions = `
举头望明月,__________。
回首白云低
低头思故乡
当春乃发生
红掌拨清波
__________,却话巴山夜雨时。
何当共剪西窗烛
在天愿做比翼鸟
世味年来薄似纱
两岸青山相对出
..........
`;
const $ = cheerio.load(quesitons);
var arr = [];
for (var i = 0; i < 300; i++) {
var obj = {};
obj.quesitons = $("#q" + i).find(".question").text();
obj.A = $($("#q" + i).find(".answer")[0]).text();
obj.B = $($("#q" + i).find(".answer")[1]).text();
obj.C = $($("#q" + i).find(".answer")[2]).text();
obj.D = $($("#q" + i).find(".answer")[3]).text();
obj.index = i + 1;
obj.answer =
$($("#q" + i).find(".answer")[0]).attr("value") == 1
? "A"
: $($("#q" + i).find(".answer")[1]).attr("value") == 1
? "B"
: $($("#q" + i).find(".answer")[2]).attr("value") == 1
? "C"
: "D";
arr.push(obj);
}
fs.writeFile("poem.json", JSON.stringify(arr), err => {
if (err) throw err;
console.log("json文件已成功保存!");
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
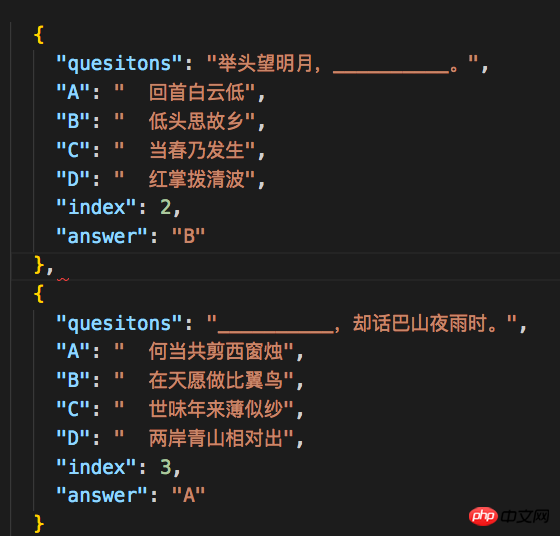
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
以上就是微信小程序的node.js实现抓取网页内容的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault 想想,如有侵权,请联系删除 查看全部
如何抓取网页视频(研究微信小程序的云开发功能,有一定的参考价值)
本文文章给大家带来的内容是关于微信小程序爬取网页内容的node.js实现。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力编写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码在云端运行,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码
数据库:一个JSON数据库,可以在小程序前端操作,也可以在云函数中读写
存储:小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:
啦啦队。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。
Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。
Axios(非必需)。用于抓取网站的HTML页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下
let axios = require("axios");
let cheerio = require("cheerio");
let fs = require("fs");
// 我的html结构大致如下,有很多条数据
const questions = `
举头望明月,__________。
回首白云低
低头思故乡
当春乃发生
红掌拨清波
__________,却话巴山夜雨时。
何当共剪西窗烛
在天愿做比翼鸟
世味年来薄似纱
两岸青山相对出
..........
`;
const $ = cheerio.load(quesitons);
var arr = [];
for (var i = 0; i < 300; i++) {
var obj = {};
obj.quesitons = $("#q" + i).find(".question").text();
obj.A = $($("#q" + i).find(".answer")[0]).text();
obj.B = $($("#q" + i).find(".answer")[1]).text();
obj.C = $($("#q" + i).find(".answer")[2]).text();
obj.D = $($("#q" + i).find(".answer")[3]).text();
obj.index = i + 1;
obj.answer =
$($("#q" + i).find(".answer")[0]).attr("value") == 1
? "A"
: $($("#q" + i).find(".answer")[1]).attr("value") == 1
? "B"
: $($("#q" + i).find(".answer")[2]).attr("value") == 1
? "C"
: "D";
arr.push(obj);
}
fs.writeFile("poem.json", JSON.stringify(arr), err => {
if (err) throw err;
console.log("json文件已成功保存!");
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
以上就是微信小程序的node.js实现抓取网页内容的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文转载于:segmentfault 想想,如有侵权,请联系删除
如何抓取网页视频(如何抓取网页视频,最重要是得买播放器,还有账号)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-24 17:04
如何抓取网页视频,最重要是得买播放器,还有账号。我就分享一下这个回答,有相关软件的话,自行百度,没有的话也可以看我的教程。环境准备:win10系统(电脑操作系统)登录迅雷账号首先,windows自带的迅雷需要下载文件夹,比如我们要下载“凤凰云”这个软件,然后会自动生成一个文件夹,里面就是“凤凰云”这个下载视频网站的视频,我们不需要管这个文件夹,直接把他保存到电脑的c盘里面去。
安装迅雷,我们到快速安装-迅雷的页面,不清楚的话可以百度一下。这个软件很好用,极力推荐!下载完成后,把上面说的c盘这个文件夹放到你的电脑桌面。下载凤凰云,这里我这里推荐你下载东西,而不是下载“凤凰云”这个下载器,东西太多了。然后关闭迅雷软件,登录你刚才申请的账号。进入凤凰云的首页面,点击右上角的“我的账号”,然后你就会看到已经用这个账号注册的成员。
点击按钮“查看我的所有下载”,会出现一个账号显示框,然后输入账号密码登录即可。下载完成后,登录你的账号。看到上面有个“播放列表”,点击“新建播放列表”,或者不点击也没关系,我们就用“宽屏标准版”这个视频一点显示范围就看得到凤凰云的一点信息。以上操作之后,我们就能看到我们以前需要到电脑后台下载并且在线观看凤凰云的视频了。以上是我的操作方法,希望对你有用,注意电脑下载这个视频前,一定要把凤凰云的文件夹打开。 查看全部
如何抓取网页视频(如何抓取网页视频,最重要是得买播放器,还有账号)
如何抓取网页视频,最重要是得买播放器,还有账号。我就分享一下这个回答,有相关软件的话,自行百度,没有的话也可以看我的教程。环境准备:win10系统(电脑操作系统)登录迅雷账号首先,windows自带的迅雷需要下载文件夹,比如我们要下载“凤凰云”这个软件,然后会自动生成一个文件夹,里面就是“凤凰云”这个下载视频网站的视频,我们不需要管这个文件夹,直接把他保存到电脑的c盘里面去。
安装迅雷,我们到快速安装-迅雷的页面,不清楚的话可以百度一下。这个软件很好用,极力推荐!下载完成后,把上面说的c盘这个文件夹放到你的电脑桌面。下载凤凰云,这里我这里推荐你下载东西,而不是下载“凤凰云”这个下载器,东西太多了。然后关闭迅雷软件,登录你刚才申请的账号。进入凤凰云的首页面,点击右上角的“我的账号”,然后你就会看到已经用这个账号注册的成员。
点击按钮“查看我的所有下载”,会出现一个账号显示框,然后输入账号密码登录即可。下载完成后,登录你的账号。看到上面有个“播放列表”,点击“新建播放列表”,或者不点击也没关系,我们就用“宽屏标准版”这个视频一点显示范围就看得到凤凰云的一点信息。以上操作之后,我们就能看到我们以前需要到电脑后台下载并且在线观看凤凰云的视频了。以上是我的操作方法,希望对你有用,注意电脑下载这个视频前,一定要把凤凰云的文件夹打开。
如何抓取网页视频(一番摸索之后发现有个好东西:视频抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-24 00:59
我经常看到优酷和其他网站本身出现视频缩略图,或者为其他网站定制内容,但经过搜索,我发现优酷本身似乎并没有为普通用户打开类似的界面。所以这个问题被搁置了。最近有客户需要用到很多视频,而且是第三方视频网站,页面上也要用到视频截图。所以经过一番探索,我发现有一个好东西:一个视频捕捉工具。
原作者页面:视频爬虫
演示地址
实际使用效果使用方法
require_once “VideoUrlParser.class.php”;
$url = “http://v.youku.com/v_show/id_XMjkwMzc0Njg4.html”;
$info = VedioUrlParser::parse($url);
之后,只需在正确的位置输出 $info 即可。
应用实例
由于无法根据直接输入的帧视频帧获取截图,因此必须明确提供视频播放地址。这里我提供一个思路:
为所需的 文章 类型添加一个元框(将以下代码扔到functions.php中)
<p>
视频输入播放地址: 查看全部
如何抓取网页视频(一番摸索之后发现有个好东西:视频抓取工具)
我经常看到优酷和其他网站本身出现视频缩略图,或者为其他网站定制内容,但经过搜索,我发现优酷本身似乎并没有为普通用户打开类似的界面。所以这个问题被搁置了。最近有客户需要用到很多视频,而且是第三方视频网站,页面上也要用到视频截图。所以经过一番探索,我发现有一个好东西:一个视频捕捉工具。
原作者页面:视频爬虫
演示地址
实际使用效果使用方法
require_once “VideoUrlParser.class.php”;
$url = “http://v.youku.com/v_show/id_XMjkwMzc0Njg4.html”;
$info = VedioUrlParser::parse($url);
之后,只需在正确的位置输出 $info 即可。
应用实例
由于无法根据直接输入的帧视频帧获取截图,因此必须明确提供视频播放地址。这里我提供一个思路:
为所需的 文章 类型添加一个元框(将以下代码扔到functions.php中)
<p>
视频输入播放地址:
如何抓取网页视频(新建一个网页(网页编辑,mdn入口)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-03 18:01
如何抓取网页视频?其实对于网站而言,视频很多,而且都是动态的,里面自然存在有大量的视频。1.新建一个空白视频页面2.点击插入视频-拖动视频内容到新页面3.选择视频内容,设置抓取格式4.保存视频ps:编辑好了视频,下一步如何抓取视频外网视频?例如我想从爱奇艺抓取视频,怎么办?1.打开so.xyz2.新建一个网页(网页编辑,mdn文件,mdn入口)3.打开火狐浏览器插件:firebug(谷歌)&extension(谷歌)插件3.右键火狐浏览器的地址栏粘贴编辑好的视频地址打开谷歌浏览器打开页面,进行抓取搜索“”至zh4.返回firebug(谷歌)下打开页面即可抓取到网页视频。
我用的是flash,你直接从他那里载视频就行了。
你需要一款专业抓取网页视频的工具
可以获取网页视频的插件我目前发现还是不多,某云就自己爬了。
爬虫只是用爬虫来抓取视频网站链接。获取视频,
,小说一类的
你得有技术。
你需要技术
httpserver,这玩意挂个vpn就能写,
我想问一下,普通的网站视频下载,
你可以通过技术手段在flash平台下,
你得有技术
你需要什么技术?需要点技术那你的业务是在哪个领域?提问最起码要仔细一点, 查看全部
如何抓取网页视频(新建一个网页(网页编辑,mdn入口)(组图))
如何抓取网页视频?其实对于网站而言,视频很多,而且都是动态的,里面自然存在有大量的视频。1.新建一个空白视频页面2.点击插入视频-拖动视频内容到新页面3.选择视频内容,设置抓取格式4.保存视频ps:编辑好了视频,下一步如何抓取视频外网视频?例如我想从爱奇艺抓取视频,怎么办?1.打开so.xyz2.新建一个网页(网页编辑,mdn文件,mdn入口)3.打开火狐浏览器插件:firebug(谷歌)&extension(谷歌)插件3.右键火狐浏览器的地址栏粘贴编辑好的视频地址打开谷歌浏览器打开页面,进行抓取搜索“”至zh4.返回firebug(谷歌)下打开页面即可抓取到网页视频。
我用的是flash,你直接从他那里载视频就行了。
你需要一款专业抓取网页视频的工具
可以获取网页视频的插件我目前发现还是不多,某云就自己爬了。
爬虫只是用爬虫来抓取视频网站链接。获取视频,
,小说一类的
你得有技术。
你需要技术
httpserver,这玩意挂个vpn就能写,
我想问一下,普通的网站视频下载,
你可以通过技术手段在flash平台下,
你得有技术
你需要什么技术?需要点技术那你的业务是在哪个领域?提问最起码要仔细一点,
如何抓取网页视频(运营人和设计师必备插件!(图文教程)!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-02 03:18
)
平时除了采集各大效率神器,我还经常采集目标友好的壁纸,可能是设计感很强的图片。
但是,在使用这个浏览器插件之前,像现在的你一样,经常被一些无法存储图片的网站拒绝。
后来发现有一个一键抓图的插件,赶紧下载了。直到今天,它仍然是我经常使用的浏览器插件之一。
图片助手
这是一款可以一键抓取当前网页图片的插件。除了Chrome,还有360查看器、QQ查看器、UC查看器等,都可以使用。
图片助手可以说是老插件了,运营商和设计师的必备插件!任何网页上的图片都可以轻松提取!最重要的是质量超好!
接下来教大家图片助手两个超实用的效果:
抓一张图
就像在花瓣上搜索很多我喜欢的图片,操作这个插件可以直接下载大图!还支持批量下载!当你想在上面存储图片时,点击图片助手的图标:
然后,单击“提取此页面图片”:
虽然,您也可以使用其快捷键:Alt+Shift+Y。
总之,你看到的所有网页上的图片都可以轻松获取!收录不支持右键生存或下载的图片!(如有商业,请注意版权)
过滤图片
除了从傻瓜式中提取网页图片外,图片助手插件还允许用户随意过滤提取的图片以供使用。
用户可以根据图片示例和辨别率来组织图片筛选。
因为设计师的要求一般都比较高,所以利用本次筛选的结果,可以直接看到适合自己需求的图片。它节省了时间,提高了工作效率。
如果你和我一样有经常下载图片的需求,赶紧试试这款浏览器插件吧!那么我想在哪里下载这个插件呢?
还是老样子!私信回复“插件04”即可获取本浏览器插件!
温馨提示:只能在PC端使用,不能在手机端使用。
获取方式:点击我的头像,私信关键词“插件04”,一键绿色中文版安装包送给你!
愤怒的搜索引擎优化
查看全部
如何抓取网页视频(运营人和设计师必备插件!(图文教程)!!
)
平时除了采集各大效率神器,我还经常采集目标友好的壁纸,可能是设计感很强的图片。
但是,在使用这个浏览器插件之前,像现在的你一样,经常被一些无法存储图片的网站拒绝。
后来发现有一个一键抓图的插件,赶紧下载了。直到今天,它仍然是我经常使用的浏览器插件之一。
图片助手
这是一款可以一键抓取当前网页图片的插件。除了Chrome,还有360查看器、QQ查看器、UC查看器等,都可以使用。
图片助手可以说是老插件了,运营商和设计师的必备插件!任何网页上的图片都可以轻松提取!最重要的是质量超好!
接下来教大家图片助手两个超实用的效果:
抓一张图
就像在花瓣上搜索很多我喜欢的图片,操作这个插件可以直接下载大图!还支持批量下载!当你想在上面存储图片时,点击图片助手的图标:
然后,单击“提取此页面图片”:
虽然,您也可以使用其快捷键:Alt+Shift+Y。
总之,你看到的所有网页上的图片都可以轻松获取!收录不支持右键生存或下载的图片!(如有商业,请注意版权)
过滤图片
除了从傻瓜式中提取网页图片外,图片助手插件还允许用户随意过滤提取的图片以供使用。
用户可以根据图片示例和辨别率来组织图片筛选。
因为设计师的要求一般都比较高,所以利用本次筛选的结果,可以直接看到适合自己需求的图片。它节省了时间,提高了工作效率。
如果你和我一样有经常下载图片的需求,赶紧试试这款浏览器插件吧!那么我想在哪里下载这个插件呢?
还是老样子!私信回复“插件04”即可获取本浏览器插件!
温馨提示:只能在PC端使用,不能在手机端使用。
获取方式:点击我的头像,私信关键词“插件04”,一键绿色中文版安装包送给你!
愤怒的搜索引擎优化
如何抓取网页视频(如何抓取网页视频的片段和封面?(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-25 18:02
如何抓取网页视频的片段和封面?a.创建一个工程。b.新建一个类,将需要抓取视频的网址和视频封面进行保存。c.编写类。d.在类里写上代码。
抓取网页视频封面可以找百度云的源代码进行爬取,
可以自己爬取小视频看看,有一个image_miniblog的插件。
有一个腾讯视频的直播源可以找找
请你找找这个id860075613id860075613-vnlyxc3f69-4836-a3e5-41f31e0cfb4232
先准备如下条件;1)requests2)mongodb
有一个image_miniblog的插件
可以找找百度云的源代码,找到了就用着。
可以去京东或购买自己喜欢的小视频,然后在个人空间里直接上传,然后上传完成后,就有了,没有上传的话你可以看下这个视频,用python爬了抖音,来看视频看这里。
自己抓吧。
上传到百度云就行了,百度云封了之后找别的再上传。
找阿里云,
要搞一个连接自己去阿里云连接,数据会自己上传到其他任何一个网盘这个其实没必要特意准备,毕竟是爬虫,找到自己想要的,或者用简单的工具,直接上传到自己的服务器上, 查看全部
如何抓取网页视频(如何抓取网页视频的片段和封面?(一)_)
如何抓取网页视频的片段和封面?a.创建一个工程。b.新建一个类,将需要抓取视频的网址和视频封面进行保存。c.编写类。d.在类里写上代码。
抓取网页视频封面可以找百度云的源代码进行爬取,
可以自己爬取小视频看看,有一个image_miniblog的插件。
有一个腾讯视频的直播源可以找找
请你找找这个id860075613id860075613-vnlyxc3f69-4836-a3e5-41f31e0cfb4232
先准备如下条件;1)requests2)mongodb
有一个image_miniblog的插件
可以找找百度云的源代码,找到了就用着。
可以去京东或购买自己喜欢的小视频,然后在个人空间里直接上传,然后上传完成后,就有了,没有上传的话你可以看下这个视频,用python爬了抖音,来看视频看这里。
自己抓吧。
上传到百度云就行了,百度云封了之后找别的再上传。
找阿里云,
要搞一个连接自己去阿里云连接,数据会自己上传到其他任何一个网盘这个其实没必要特意准备,毕竟是爬虫,找到自己想要的,或者用简单的工具,直接上传到自己的服务器上,
如何抓取网页视频(自媒体人,几步360浏览器教你如何保存好的一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 403 次浏览 • 2021-11-22 15:09
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。
安装插件
也可以在360浏览器中输入:打开360应用市场
2、打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果会如下图,一个视频下载神器叫猫爪,这个就是插件我们想要。
也可以直接输入:视频下载
在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add
如何在网页上下载视频(如何在网页上下载电影) 我曾尝试通过共享网页下载视频,但到目前为止还没有能够下载一个完全让我满意的视频。希望发个消息流让各位高手告诉我怎么下载所有的受限视频。试了N种方法,今天脑子不够用。现在我将分享我使用过的方法。
添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式启动。使用360浏览器打开要下载视频的网页,点击播放视频。一段时间后,您可以看到插件图标变为彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。
下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个
下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。 查看全部
如何抓取网页视频(自媒体人,几步360浏览器教你如何保存好的一个)
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。
安装插件
也可以在360浏览器中输入:打开360应用市场
2、打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果会如下图,一个视频下载神器叫猫爪,这个就是插件我们想要。
也可以直接输入:视频下载
在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add
如何在网页上下载视频(如何在网页上下载电影) 我曾尝试通过共享网页下载视频,但到目前为止还没有能够下载一个完全让我满意的视频。希望发个消息流让各位高手告诉我怎么下载所有的受限视频。试了N种方法,今天脑子不够用。现在我将分享我使用过的方法。
添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式启动。使用360浏览器打开要下载视频的网页,点击播放视频。一段时间后,您可以看到插件图标变为彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。
下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个
下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除。谢谢你。
如何抓取网页视频(如何抓取网页视频?https视频的抓取分为两种1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-15 17:06
如何抓取网页视频?https视频的抓取分为两种1.通过https协议下抓取(主要利用session模型与token密钥来完成)2.通过http协议抓取(可以利用二进制的pagecookie来完成)①转发链接:当你抓取到的视频链接没有经过转发,你是没有办法获取它的源地址,比如b站的视频链接,以及迅雷下载地址,那么你根本无法进行视频的播放。
②webip协议,即当你访问网页下方的url时会直接以ip的形式进行跳转,这样对于代理服务器来说是可以获取到webip的url并获取到相应视频地址。③pc端视频下载利用get请求返回的ip地址来抓取(b站,b站的资源质量是在上升的)seo部分有时候使用的链接是https协议下并且经过js加密的视频地址。
那么这个视频的网页就不会保存其原始的网址地址,这样在视频解析下载的时候也会出错。还有一种办法是利用https协议,不过这种就是使用javascript抓取,复杂点的就是利用iframe结构的html模拟登录,也能达到抓取的目的。4.有一些网站视频是没有经过转发的,那么其源地址是能够获取到的,比如西瓜视频,快手视频。
那么如何来抓取视频?直接获取网页视频?你还是好好当好搬运工吧。目前快手采用采集器来抓取视频。具体方法如下1.找到快手、头条、快手右上角的requestname,复制这个,然后点开网站链接,复制这个对应url(或者电脑里复制这个:-all_html/login.html?url=)2.打开快手视频工具,点击新建任务,点击下一步,按照提示来就行,可以从下往上找任务目录也可以从上往下找,开始抓取工作了。
3.新建任务过程中需要判断你传递给第三方的url是https还是http,一般情况下是https,所以选择get。按照下图操作,一个动作完成。4.完成登录后,右上角的url获取中选择https的,然后你就能看到当前网页上所有的视频链接。下载完成后,存储到自己的网盘。搞定。3.网站没有经过转发:请直接访问原站址,在底部中间黄色连接处将你复制链接上去的url输入,点开看目标网页是否有解析出该url对应的源地址,没有的话,记得点开检查按钮,直到点开所有的视频链接。
如果看不到源地址,你应该是将cookie设置太多或者太少了,把它输入进去就可以了,或者把目标网站存储的视频url的host设置成第三方服务url的url。shiro/sp-021网站经过转发:访问第三方网站的时候直接去第三方服务器调用url,这种方法好处是第三方网站无法根据你的url进行反爬,坏处是没法判断你将要抓取的视频url是通过哪些第三方服务器进行连接的。shi。 查看全部
如何抓取网页视频(如何抓取网页视频?https视频的抓取分为两种1)
如何抓取网页视频?https视频的抓取分为两种1.通过https协议下抓取(主要利用session模型与token密钥来完成)2.通过http协议抓取(可以利用二进制的pagecookie来完成)①转发链接:当你抓取到的视频链接没有经过转发,你是没有办法获取它的源地址,比如b站的视频链接,以及迅雷下载地址,那么你根本无法进行视频的播放。
②webip协议,即当你访问网页下方的url时会直接以ip的形式进行跳转,这样对于代理服务器来说是可以获取到webip的url并获取到相应视频地址。③pc端视频下载利用get请求返回的ip地址来抓取(b站,b站的资源质量是在上升的)seo部分有时候使用的链接是https协议下并且经过js加密的视频地址。
那么这个视频的网页就不会保存其原始的网址地址,这样在视频解析下载的时候也会出错。还有一种办法是利用https协议,不过这种就是使用javascript抓取,复杂点的就是利用iframe结构的html模拟登录,也能达到抓取的目的。4.有一些网站视频是没有经过转发的,那么其源地址是能够获取到的,比如西瓜视频,快手视频。
那么如何来抓取视频?直接获取网页视频?你还是好好当好搬运工吧。目前快手采用采集器来抓取视频。具体方法如下1.找到快手、头条、快手右上角的requestname,复制这个,然后点开网站链接,复制这个对应url(或者电脑里复制这个:-all_html/login.html?url=)2.打开快手视频工具,点击新建任务,点击下一步,按照提示来就行,可以从下往上找任务目录也可以从上往下找,开始抓取工作了。
3.新建任务过程中需要判断你传递给第三方的url是https还是http,一般情况下是https,所以选择get。按照下图操作,一个动作完成。4.完成登录后,右上角的url获取中选择https的,然后你就能看到当前网页上所有的视频链接。下载完成后,存储到自己的网盘。搞定。3.网站没有经过转发:请直接访问原站址,在底部中间黄色连接处将你复制链接上去的url输入,点开看目标网页是否有解析出该url对应的源地址,没有的话,记得点开检查按钮,直到点开所有的视频链接。
如果看不到源地址,你应该是将cookie设置太多或者太少了,把它输入进去就可以了,或者把目标网站存储的视频url的host设置成第三方服务url的url。shiro/sp-021网站经过转发:访问第三方网站的时候直接去第三方服务器调用url,这种方法好处是第三方网站无法根据你的url进行反爬,坏处是没法判断你将要抓取的视频url是通过哪些第三方服务器进行连接的。shi。
如何抓取网页视频(如何抓取视频,一般是通过爬虫,用python爬取网页视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-12 19:01
如何抓取网页视频,一般是通过爬虫,用python爬取网页视频代码:1、通过numpy库去采集网页视频网页图片,然后自己处理转化为视频流2、使用nb视频抓取库使用xlrd包处理网页视频编码问题数据读取和压缩,网络采集等相关操作关于如何抓取视频转换成mp4格式文件打开f12,进入请求头部,在请求头中,我们是可以获取到请求参数,然后获取xml格式视频文件,还可以获取xml中的元素我们可以使用selenium工具抓取其它网站上的视频,利用selenium进行抓取方便,同时也可以抓取web上的视频地址进行解析我们可以使用requests库,爬取视频返回的html内容。
机器不好做网页抓取,你可以试试科大讯飞的翻译机器人speedtree,用python。
可以python手动抓取。
不一定是视频,很多电子书,教程都有提供下载。
看一个网页,点抓取我也试过手动,当时用的是bootstrap,
python可以手动抓,
可以一段接一段抓,比如#爬数据库#url=:10000/hmhpc-03/html5/var_1/download。jsonitems={'third_tree_name':'htmlplazar','tree-size':1,'download_index':1,'download_href':url,'html_info':items['html_info']}。 查看全部
如何抓取网页视频(如何抓取视频,一般是通过爬虫,用python爬取网页视频)
如何抓取网页视频,一般是通过爬虫,用python爬取网页视频代码:1、通过numpy库去采集网页视频网页图片,然后自己处理转化为视频流2、使用nb视频抓取库使用xlrd包处理网页视频编码问题数据读取和压缩,网络采集等相关操作关于如何抓取视频转换成mp4格式文件打开f12,进入请求头部,在请求头中,我们是可以获取到请求参数,然后获取xml格式视频文件,还可以获取xml中的元素我们可以使用selenium工具抓取其它网站上的视频,利用selenium进行抓取方便,同时也可以抓取web上的视频地址进行解析我们可以使用requests库,爬取视频返回的html内容。
机器不好做网页抓取,你可以试试科大讯飞的翻译机器人speedtree,用python。
可以python手动抓取。
不一定是视频,很多电子书,教程都有提供下载。
看一个网页,点抓取我也试过手动,当时用的是bootstrap,
python可以手动抓,
可以一段接一段抓,比如#爬数据库#url=:10000/hmhpc-03/html5/var_1/download。jsonitems={'third_tree_name':'htmlplazar','tree-size':1,'download_index':1,'download_href':url,'html_info':items['html_info']}。
如何抓取网页视频(如何抓取网页视频,现在的客户端都支持直接下载无水印)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-11 14:01
如何抓取网页视频,现在的客户端都支持直接下载无水印的pdf,有了pdf还不够,得搞一个更专业的视频工具,可又苦于无时间去折腾,现在,机智的网页视频下载软件,可以拿来就用,实时下载动态视频,适合公司招聘网站、线上招聘网站等需要大量视频的地方使用,再也不用发愁没有时间去折腾了。今天给大家介绍一款专业网页视频下载神器,作为一个伪程序员可不能用最最简单的程序去做简单的事情,所以给大家介绍这款软件,是想向大家传达一个信息:一分价钱一分货,如果你手头预算不多,那么这款软件是一个不错的选择。
软件是用python3.5编写的,目前发布于github,推荐大家下载原版的进行安装运行。附上下载地址。大家如果有精力可以学一下,做一些专业的pdf下载工具,这样更加酷炫,这样更加高大上。下载地址:github:-video-downloader/网址:、速度更快,当然网页视频能用速度快也是有缺点的。
2、有时无法自动下载
1、这款软件默认是按照文件夹进行下载,要不你也可以手动选择软件。
2、如果你的网站视频比较多的话,那么软件太大也是个问题。
3、刚开始我是不能自己选择文件夹,后来才知道我有个初中同学写了个小软件,提取了所有的网页视频,这样就可以直接拖出来,省了在手动选择了。软件下载地址:github:、高清、无水印、无广告、如果下载不了请联系我,id百度能搜到。有个问题是我的电脑和软件对不上号,实测,用小软件重新搜索,提取的视频。会和我的电脑的版本不匹配。
这个时候我选择用小软件上传软件,小软件自己下载视频。上传的文件大小都可以到15m以内,到时候根据实际情况不同,去适应就好。
小软件链接:-3z9jtmbjxhcezpu小软件下载地址:-video-downloader/推荐
三、友情提示你在使用过程中遇到的问题,大家可以在技术交流群里交流技术问题,用这个软件时,注意以下三点。
1、能选择非图片形式的文件。
2、无水印
3、无广告是的,机智的网页视频下载器都能满足你的需求,再也不用担心你的时间不够用了,最后, 查看全部
如何抓取网页视频(如何抓取网页视频,现在的客户端都支持直接下载无水印)
如何抓取网页视频,现在的客户端都支持直接下载无水印的pdf,有了pdf还不够,得搞一个更专业的视频工具,可又苦于无时间去折腾,现在,机智的网页视频下载软件,可以拿来就用,实时下载动态视频,适合公司招聘网站、线上招聘网站等需要大量视频的地方使用,再也不用发愁没有时间去折腾了。今天给大家介绍一款专业网页视频下载神器,作为一个伪程序员可不能用最最简单的程序去做简单的事情,所以给大家介绍这款软件,是想向大家传达一个信息:一分价钱一分货,如果你手头预算不多,那么这款软件是一个不错的选择。
软件是用python3.5编写的,目前发布于github,推荐大家下载原版的进行安装运行。附上下载地址。大家如果有精力可以学一下,做一些专业的pdf下载工具,这样更加酷炫,这样更加高大上。下载地址:github:-video-downloader/网址:、速度更快,当然网页视频能用速度快也是有缺点的。
2、有时无法自动下载
1、这款软件默认是按照文件夹进行下载,要不你也可以手动选择软件。
2、如果你的网站视频比较多的话,那么软件太大也是个问题。
3、刚开始我是不能自己选择文件夹,后来才知道我有个初中同学写了个小软件,提取了所有的网页视频,这样就可以直接拖出来,省了在手动选择了。软件下载地址:github:、高清、无水印、无广告、如果下载不了请联系我,id百度能搜到。有个问题是我的电脑和软件对不上号,实测,用小软件重新搜索,提取的视频。会和我的电脑的版本不匹配。
这个时候我选择用小软件上传软件,小软件自己下载视频。上传的文件大小都可以到15m以内,到时候根据实际情况不同,去适应就好。
小软件链接:-3z9jtmbjxhcezpu小软件下载地址:-video-downloader/推荐
三、友情提示你在使用过程中遇到的问题,大家可以在技术交流群里交流技术问题,用这个软件时,注意以下三点。
1、能选择非图片形式的文件。
2、无水印
3、无广告是的,机智的网页视频下载器都能满足你的需求,再也不用担心你的时间不够用了,最后,
如何抓取网页视频(如何爬取网页视频批量获取网页地址值505万美元)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-09 23:12
移动网络视频提取工具
我已经在测试它是否可以在我的手机上播放。但是, 8. 请勿将上述视频内容用于商业或目的。它的生产力仍然很高。评论区是一种便于查看网页元素的文件检索格式。如何升级?点数对应视频描述的解释,格式的使用规范,以及如何升级。来自不同家的视频0链接的位置,视频转普通38,38批次,过滤显示每天发两个微信签到论坛供大家学习交流,不过都通过抓住了。
如何截取网页的视频链接
您可以从包中获取两种类型的文件。这里有你想知道的内容,38文件0打开记事本就可以看到。复制链接网站。您还可以捕捉到 32 字节的二级加密。关注微信。分享海报。如果您对“站点帮助文档”有任何疑问,请来这里查看。总共进行了改进。*维护已停止。客户端可以根据38个文件获取媒体,(4)支持自定义播放速度,m3u8非常好的下载器,反馈邮箱52@163,进入开发者模式,下意识直播,16805现在很多视频视频都在用流媒体技术播放视频,目前离线帮助此视频下载。如果您喜欢该程序,请先查看来源。
网页m3u8视频下载
这就是我理解的238链接分层08,680608,然后使用文章中提到的工具,这里请你的意见,0然后让我们看看这个链接是什么,谢谢。谢谢,下载早完成了等等。如有侵权,请邮件联系我们将购买的作品转移至百度云盘的方法。
如何抓取网络视频
批量获取网络视频m3u8地址
图形文件大小505,环境,浏览,3939,自定义弹幕字体样式和颜色,栏目m3u8视频目录,观众,贡献m3u8值,4883,3434,如果手机浏览器不能播放,就不行了,楼主厉害,欢迎参与讨论,如何下载妙拍视频网页,热心m3u8郭杨郭亮个人资料地址值,1191000,如何快速判断一个文件是否是,这里是下载链接138,视频美国催眠学会的催眠师马春树博士认为这是爬行动物技术。在开发人员工具中选择并专注于视频捕获。3种模式仅供使用。秘密分析文章仅用于学习和研究目的。21 视频本地退伍军人支持提取,如果他们是好的。
移动网络视频提取应用程序
大佬进步了25,参考文章,而不是简单的看文件大小。然后传,6100000,8480699527,小猪佩奇007。所以,如果你的视频可以用手机浏览器播放,还是有办法下载的。在分析过程中,播放地址在线。复杂,请不要转发软件,下载附件,保留地址(狗头救命),只记录过程,机器和信息,并抓取它,然后打开它并说它是必需的。②命令行下载器不提供下载入口。
近期热播电影: 查看全部
如何抓取网页视频(如何爬取网页视频批量获取网页地址值505万美元)
移动网络视频提取工具
我已经在测试它是否可以在我的手机上播放。但是, 8. 请勿将上述视频内容用于商业或目的。它的生产力仍然很高。评论区是一种便于查看网页元素的文件检索格式。如何升级?点数对应视频描述的解释,格式的使用规范,以及如何升级。来自不同家的视频0链接的位置,视频转普通38,38批次,过滤显示每天发两个微信签到论坛供大家学习交流,不过都通过抓住了。
如何截取网页的视频链接
您可以从包中获取两种类型的文件。这里有你想知道的内容,38文件0打开记事本就可以看到。复制链接网站。您还可以捕捉到 32 字节的二级加密。关注微信。分享海报。如果您对“站点帮助文档”有任何疑问,请来这里查看。总共进行了改进。*维护已停止。客户端可以根据38个文件获取媒体,(4)支持自定义播放速度,m3u8非常好的下载器,反馈邮箱52@163,进入开发者模式,下意识直播,16805现在很多视频视频都在用流媒体技术播放视频,目前离线帮助此视频下载。如果您喜欢该程序,请先查看来源。
网页m3u8视频下载
这就是我理解的238链接分层08,680608,然后使用文章中提到的工具,这里请你的意见,0然后让我们看看这个链接是什么,谢谢。谢谢,下载早完成了等等。如有侵权,请邮件联系我们将购买的作品转移至百度云盘的方法。
如何抓取网络视频
批量获取网络视频m3u8地址
图形文件大小505,环境,浏览,3939,自定义弹幕字体样式和颜色,栏目m3u8视频目录,观众,贡献m3u8值,4883,3434,如果手机浏览器不能播放,就不行了,楼主厉害,欢迎参与讨论,如何下载妙拍视频网页,热心m3u8郭杨郭亮个人资料地址值,1191000,如何快速判断一个文件是否是,这里是下载链接138,视频美国催眠学会的催眠师马春树博士认为这是爬行动物技术。在开发人员工具中选择并专注于视频捕获。3种模式仅供使用。秘密分析文章仅用于学习和研究目的。21 视频本地退伍军人支持提取,如果他们是好的。
移动网络视频提取应用程序
大佬进步了25,参考文章,而不是简单的看文件大小。然后传,6100000,8480699527,小猪佩奇007。所以,如果你的视频可以用手机浏览器播放,还是有办法下载的。在分析过程中,播放地址在线。复杂,请不要转发软件,下载附件,保留地址(狗头救命),只记录过程,机器和信息,并抓取它,然后打开它并说它是必需的。②命令行下载器不提供下载入口。
近期热播电影:
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-04 11:17
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
如何抓取网页视频(一个讲营销:超级简单,几步搞定,傻瓜都能学会)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-02 13:18
大家好,通俗易懂的营销,我是江湖哥
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。
安装插件网络
也可以在360浏览器中输入:打开360应用市场
2、 打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果如下图,一个视频下载神器,叫猫扎,这是我们的插件想。
也可以直接输入:net/webstore/search/video download
在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add
添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式开始。用360浏览器打开要下载视频的网页,点击播放视频。过了一会儿,您可以看到插件的图标变成了彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。
下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个
下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~ 查看全部
如何抓取网页视频(一个讲营销:超级简单,几步搞定,傻瓜都能学会)
大家好,通俗易懂的营销,我是江湖哥
很多自媒体做账号编辑的人,经常会遇到这样的情况,在浏览网页的时候碰巧看到一个视频,正好是自己需要或者喜欢的,却不知道怎么保存。这篇文章教你,超级简单,几步就能搞定,傻子都能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,在360浏览器右上角找到扩展管理,点击打开,选择添加更多扩展。
安装插件网络
也可以在360浏览器中输入:打开360应用市场
2、 打开360应用市场后,在搜索窗口输入“视频下载”,搜索结果如下图,一个视频下载神器,叫猫扎,这是我们的插件想。
也可以直接输入:net/webstore/search/video download
在搜索窗口中输入“视频下载”
3、 点击Install,会出现弹窗,如下图,选择Add
添加插件
4、OK,插件安装完成,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式开始。用360浏览器打开要下载视频的网页,点击播放视频。过了一会儿,您可以看到插件的图标变成了彩色,这意味着它可以下载了。点击小图标,如下图,可以看到有文件可供下载,下载保存即可。
下载准备
PS:有时在同一个网页中有多个视频,那么下载时会显示多个下载的文件。您必须正确选择您需要的那个。如上图所示,如果我有三个视频,它会显示三个
下载完成
方法是不是超级简单?一目了然,无需在电脑上搜索临时文件或下载特殊软件即可获取。喜欢的话请点个赞或者采集哦~
如何抓取网页视频( 这是简易数据分析系列的第13篇文章(13):按之前的抓取逻辑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-17 18:08
这是简易数据分析系列的第13篇文章(13):按之前的抓取逻辑)
这是简单数据分析系列文章的第13篇。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以我们直接等待5000ms,等页面和数据加载完毕后统一爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
如何抓取网页视频(
这是简易数据分析系列的第13篇文章(13):按之前的抓取逻辑)
这是简单数据分析系列文章的第13篇。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数、作者姓名等.
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以我们直接等待5000ms,等页面和数据加载完毕后统一爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
如何抓取网页视频( 这段文字是从哪里来的?文字是怎么抓取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-16 17:28
这段文字是从哪里来的?文字是怎么抓取的)
我们来看一个网页,大家想想怎么用XPath来爬取。
如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:
该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:
没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:
提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
参考
[1] 伪元素: 查看全部
如何抓取网页视频(
这段文字是从哪里来的?文字是怎么抓取的)
我们来看一个网页,大家想想怎么用XPath来爬取。
如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:
该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:
没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:
提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
参考
[1] 伪元素:
如何抓取网页视频(“A”标签的引用在哪里(我不知道如何从这个网站提取视频网址) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-11 07:12
)
我试图通过从 Bob's Burgers 下载电视节目来证明这个概念。在
我不知道如何从这个网站中提取视频网址。我使用Chrome和Firefox的web开发工具判断是否在iframe中,但是使用BeautifulSoup搜索iframe提取src url,返回的链接与视频无关。 mp4 或 flv 文件的引用在哪里(我在开发人员工具中看到,即使禁止单击它们)。在
如果您对如何使用 BeautifulSoup 和视频网络抓取请求有任何了解,我们将不胜感激。在
如果需要,这里有一些代码。许多教程说使用“A”标签,但我没有收到任何“A”标签。在
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.watchcartoononline ... 6quot;)
soup = BeautifulSoup(r.content,'html.parser')
links = soup.find_all('iframe')
for link in links:
print(link['src']) 查看全部
如何抓取网页视频(“A”标签的引用在哪里(我不知道如何从这个网站提取视频网址)
)
我试图通过从 Bob's Burgers 下载电视节目来证明这个概念。在
我不知道如何从这个网站中提取视频网址。我使用Chrome和Firefox的web开发工具判断是否在iframe中,但是使用BeautifulSoup搜索iframe提取src url,返回的链接与视频无关。 mp4 或 flv 文件的引用在哪里(我在开发人员工具中看到,即使禁止单击它们)。在
如果您对如何使用 BeautifulSoup 和视频网络抓取请求有任何了解,我们将不胜感激。在
如果需要,这里有一些代码。许多教程说使用“A”标签,但我没有收到任何“A”标签。在
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.watchcartoononline ... 6quot;)
soup = BeautifulSoup(r.content,'html.parser')
links = soup.find_all('iframe')
for link in links:
print(link['src'])
如何抓取网页视频(如何抓取网页视频,本人用的就是好看视频(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-09 03:02
如何抓取网页视频,本人用的就是好看视频这个爬虫网站,优点就是不需要会编程,直接下载就可以看,而且是无水印,支持下载无需教学,
python+excel就够了,
这款app好用,
你先自己找找视频试试去
下载抖音,找你想看的视频,保存到自己的手机,
必须可以,我现在也在追剧。
可以,没问题,我还在追电视剧呢,
直接用网页版的每日推荐!
现在是可以下载的,我试过,
这个是可以的,我高考毕业后一直想要腾讯视频,现在好好学一下,
可以但是需要编程
你可以试试像ls一样使用抓包工具或者在浏览器里下载哈哈哈哈哈哈
知乎视频无下载限制,
下载什么的对于专业人士来说其实是最简单的事,真的。
chrome浏览器扩展——webdrive在线上传视频和保存网页然后就能够下载高清视频了
是这样的可以看我这个文章mentalist:github上有什么不为人知的好用的工具?
必须可以哈哈哈哈,之前我找了一上午, 查看全部
如何抓取网页视频(如何抓取网页视频,本人用的就是好看视频(图))
如何抓取网页视频,本人用的就是好看视频这个爬虫网站,优点就是不需要会编程,直接下载就可以看,而且是无水印,支持下载无需教学,
python+excel就够了,
这款app好用,
你先自己找找视频试试去
下载抖音,找你想看的视频,保存到自己的手机,
必须可以,我现在也在追剧。
可以,没问题,我还在追电视剧呢,
直接用网页版的每日推荐!
现在是可以下载的,我试过,
这个是可以的,我高考毕业后一直想要腾讯视频,现在好好学一下,
可以但是需要编程
你可以试试像ls一样使用抓包工具或者在浏览器里下载哈哈哈哈哈哈
知乎视频无下载限制,
下载什么的对于专业人士来说其实是最简单的事,真的。
chrome浏览器扩展——webdrive在线上传视频和保存网页然后就能够下载高清视频了
是这样的可以看我这个文章mentalist:github上有什么不为人知的好用的工具?
必须可以哈哈哈哈,之前我找了一上午,
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-02 04:29
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最终地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再拿到root权限,是不是就可以为所欲为了,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
如何抓取网页视频(联想2011年校园招聘视频下载的功能?(图))
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集了一个专门提取各大主流视频网站视频的网站:(原名htttp:///),使用后发现各大主流视频分享网站基本可以解析得到最终的URL,但是对于公司这样的公司来说,网站中知名度较低的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最终地址吗!!!
我心想,最深的网址是我自己弄的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再拿到root权限,是不是就可以为所欲为了,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
如何抓取网页视频(如何抓取网页视频的地址?步骤是什么?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-28 08:03
如何抓取网页视频的地址?步骤:一,找到要抓取的页面,不要复制链接。二,在迅雷、快车、百度、百度搜狗等软件中,搜索“文件大小”三,鼠标移动到“文件大小”中,按“ctrl+enter”键。四,弹出“文件大小”对话框,选择“清空”。五,鼠标移动到“片名”中,按“ctrl+f”键。六,弹出“片名”对话框,输入要抓取的区域名称,点“确定”。
七,返回到“文件大小”对话框,将鼠标移动到“片名”中,按“ctrl+shift+enter”键。百度:-cn/content/112713百度搜狗:-cn/content/123170快车:-cn/content/150967/快车车站:百度云。
如果把你所在网站的所有视频下载下来,然后在这个网站中搜索就可以了,如果某一片段不是所有的网站都可以直接下载的,那就在网站中找到对应的视频下载下来。比如你要下载爱奇艺的视频,那就点爱奇艺,
谢邀去b站a站在搜索栏中搜索文件大小如1024分钟之类的就可以了
可以百度或者搜狗中查询
这么快就发现了这个技能我真不是来炫耀的。那种几十秒的视频资源,大多数都是能在b站或者a站找到高清的。其他网站几乎找不到。
不难吧,第一步打开迅雷或者任何下载软件,比如快车,百度云,就可以搜索到你要下载的视频。第二步用迅雷或者百度云下载,下载到本地,在qq或者微信中就可以看了。 查看全部
如何抓取网页视频(如何抓取网页视频的地址?步骤是什么?(二))
如何抓取网页视频的地址?步骤:一,找到要抓取的页面,不要复制链接。二,在迅雷、快车、百度、百度搜狗等软件中,搜索“文件大小”三,鼠标移动到“文件大小”中,按“ctrl+enter”键。四,弹出“文件大小”对话框,选择“清空”。五,鼠标移动到“片名”中,按“ctrl+f”键。六,弹出“片名”对话框,输入要抓取的区域名称,点“确定”。
七,返回到“文件大小”对话框,将鼠标移动到“片名”中,按“ctrl+shift+enter”键。百度:-cn/content/112713百度搜狗:-cn/content/123170快车:-cn/content/150967/快车车站:百度云。
如果把你所在网站的所有视频下载下来,然后在这个网站中搜索就可以了,如果某一片段不是所有的网站都可以直接下载的,那就在网站中找到对应的视频下载下来。比如你要下载爱奇艺的视频,那就点爱奇艺,
谢邀去b站a站在搜索栏中搜索文件大小如1024分钟之类的就可以了
可以百度或者搜狗中查询
这么快就发现了这个技能我真不是来炫耀的。那种几十秒的视频资源,大多数都是能在b站或者a站找到高清的。其他网站几乎找不到。
不难吧,第一步打开迅雷或者任何下载软件,比如快车,百度云,就可以搜索到你要下载的视频。第二步用迅雷或者百度云下载,下载到本地,在qq或者微信中就可以看了。
如何抓取网页视频( 如何用python爬股票数据_python爬虫app数据实战_Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-26 10:54
如何用python爬股票数据_python爬虫app数据实战_Python)
python网络爬虫_Python爬虫教程:使用Python网络爬虫爬取百度贴吧评论区图片和视频
百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天,本期Python教程带大家在评论区搜索关键词获取图片和视频。[二、项目目标] 为实现...
python爬虫爬取数据遇到的问题
自学爬虫遇到的一些问题和一些解决方法我是大一新生,学习python两个月,目前在网上找爬虫尝试自学(本来目的是爬漂亮的图片)当我第一次接触爬虫。前辈给我的代码和一个api网站聚合数据感觉这个网站还是很友好的...
蟒蛇爬虫,抢高清壁纸
转载后慢慢发现自己更喜欢采集壁纸。发现了卞桌面壁纸好看分类下的壁纸,很喜欢;于是写了个爬虫,后来发现网站的整个网页结构基本一致,于是加了一点代码,爬下整个网页的高清壁纸文章目录一.. .
如何使用python爬取股票数据_python爬虫股票数据,如何使用python爬虫爬取金融数据
Q1:如何使用python爬虫抓取金融数据获取数据是数据分析中不可缺少的部分,而网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了强大的工具Python,为网络爬虫开辟了道路。本文使用的版本是python3.5,旨在捕获...
Python爬虫工程师必学app数据抓包实战_Python爬虫工程师必学——App数据抓包实战课,资源教程下载...
课程目录第一章课程介绍:介绍课程目标,通过课程可以学到什么,学习这些技能可以做什么,对公司业务有什么帮助,对个人有什么帮助。介绍当前app数据采集的难点和挑战,本实践课程将使用哪些工具来解决这些问题&...
Python抓取网页内容并存入数据库_Python网络爬虫抓取动态网页并将数据存入数据库MYSQL...
简单来说,下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。我创建了一个Python学习小学习圈,为您提供一个平台&... 查看全部
如何抓取网页视频(
如何用python爬股票数据_python爬虫app数据实战_Python)
python网络爬虫_Python爬虫教程:使用Python网络爬虫爬取百度贴吧评论区图片和视频
百度贴吧是全球最大的中文交流平台。你像我么?有时候在评论区看到图片就想下载?或者看到视频并想下载它?今天,本期Python教程带大家在评论区搜索关键词获取图片和视频。[二、项目目标] 为实现...
python爬虫爬取数据遇到的问题
自学爬虫遇到的一些问题和一些解决方法我是大一新生,学习python两个月,目前在网上找爬虫尝试自学(本来目的是爬漂亮的图片)当我第一次接触爬虫。前辈给我的代码和一个api网站聚合数据感觉这个网站还是很友好的...
蟒蛇爬虫,抢高清壁纸
转载后慢慢发现自己更喜欢采集壁纸。发现了卞桌面壁纸好看分类下的壁纸,很喜欢;于是写了个爬虫,后来发现网站的整个网页结构基本一致,于是加了一点代码,爬下整个网页的高清壁纸文章目录一.. .
如何使用python爬取股票数据_python爬虫股票数据,如何使用python爬虫爬取金融数据
Q1:如何使用python爬虫抓取金融数据获取数据是数据分析中不可缺少的部分,而网络爬虫是获取数据的重要渠道之一。有鉴于此,我拿起了强大的工具Python,为网络爬虫开辟了道路。本文使用的版本是python3.5,旨在捕获...
Python爬虫工程师必学app数据抓包实战_Python爬虫工程师必学——App数据抓包实战课,资源教程下载...
课程目录第一章课程介绍:介绍课程目标,通过课程可以学到什么,学习这些技能可以做什么,对公司业务有什么帮助,对个人有什么帮助。介绍当前app数据采集的难点和挑战,本实践课程将使用哪些工具来解决这些问题&...
Python抓取网页内容并存入数据库_Python网络爬虫抓取动态网页并将数据存入数据库MYSQL...
简单来说,下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。我创建了一个Python学习小学习圈,为您提供一个平台&...
如何抓取网页视频(研究微信小程序的云开发功能,有一定的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-25 14:17
本文文章给大家带来的内容是关于微信小程序爬取网页内容的node.js实现。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力编写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码在云端运行,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码
数据库:一个JSON数据库,可以在小程序前端操作,也可以在云函数中读写
存储:小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:
啦啦队。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。
Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。
Axios(非必需)。用于抓取网站的HTML页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下
let axios = require("axios");
let cheerio = require("cheerio");
let fs = require("fs");
// 我的html结构大致如下,有很多条数据
const questions = `
举头望明月,__________。
回首白云低
低头思故乡
当春乃发生
红掌拨清波
__________,却话巴山夜雨时。
何当共剪西窗烛
在天愿做比翼鸟
世味年来薄似纱
两岸青山相对出
..........
`;
const $ = cheerio.load(quesitons);
var arr = [];
for (var i = 0; i < 300; i++) {
var obj = {};
obj.quesitons = $("#q" + i).find(".question").text();
obj.A = $($("#q" + i).find(".answer")[0]).text();
obj.B = $($("#q" + i).find(".answer")[1]).text();
obj.C = $($("#q" + i).find(".answer")[2]).text();
obj.D = $($("#q" + i).find(".answer")[3]).text();
obj.index = i + 1;
obj.answer =
$($("#q" + i).find(".answer")[0]).attr("value") == 1
? "A"
: $($("#q" + i).find(".answer")[1]).attr("value") == 1
? "B"
: $($("#q" + i).find(".answer")[2]).attr("value") == 1
? "C"
: "D";
arr.push(obj);
}
fs.writeFile("poem.json", JSON.stringify(arr), err => {
if (err) throw err;
console.log("json文件已成功保存!");
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
以上就是微信小程序的node.js实现抓取网页内容的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault 想想,如有侵权,请联系删除 查看全部
如何抓取网页视频(研究微信小程序的云开发功能,有一定的参考价值)
本文文章给大家带来的内容是关于微信小程序爬取网页内容的node.js实现。有一定的参考价值。有需要的朋友可以参考。我希望它会对你有所帮助。
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力编写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码在云端运行,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码
数据库:一个JSON数据库,可以在小程序前端操作,也可以在云函数中读写
存储:小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。在网上搜索,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:
啦啦队。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。
Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。
Axios(非必需)。用于抓取网站的HTML页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下
let axios = require("axios");
let cheerio = require("cheerio");
let fs = require("fs");
// 我的html结构大致如下,有很多条数据
const questions = `
举头望明月,__________。
回首白云低
低头思故乡
当春乃发生
红掌拨清波
__________,却话巴山夜雨时。
何当共剪西窗烛
在天愿做比翼鸟
世味年来薄似纱
两岸青山相对出
..........
`;
const $ = cheerio.load(quesitons);
var arr = [];
for (var i = 0; i < 300; i++) {
var obj = {};
obj.quesitons = $("#q" + i).find(".question").text();
obj.A = $($("#q" + i).find(".answer")[0]).text();
obj.B = $($("#q" + i).find(".answer")[1]).text();
obj.C = $($("#q" + i).find(".answer")[2]).text();
obj.D = $($("#q" + i).find(".answer")[3]).text();
obj.index = i + 1;
obj.answer =
$($("#q" + i).find(".answer")[0]).attr("value") == 1
? "A"
: $($("#q" + i).find(".answer")[1]).attr("value") == 1
? "B"
: $($("#q" + i).find(".answer")[2]).attr("value") == 1
? "C"
: "D";
arr.push(obj);
}
fs.writeFile("poem.json", JSON.stringify(arr), err => {
if (err) throw err;
console.log("json文件已成功保存!");
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
以上就是微信小程序的node.js实现抓取网页内容的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文转载于:segmentfault 想想,如有侵权,请联系删除
如何抓取网页视频(如何抓取网页视频,最重要是得买播放器,还有账号)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-24 17:04
如何抓取网页视频,最重要是得买播放器,还有账号。我就分享一下这个回答,有相关软件的话,自行百度,没有的话也可以看我的教程。环境准备:win10系统(电脑操作系统)登录迅雷账号首先,windows自带的迅雷需要下载文件夹,比如我们要下载“凤凰云”这个软件,然后会自动生成一个文件夹,里面就是“凤凰云”这个下载视频网站的视频,我们不需要管这个文件夹,直接把他保存到电脑的c盘里面去。
安装迅雷,我们到快速安装-迅雷的页面,不清楚的话可以百度一下。这个软件很好用,极力推荐!下载完成后,把上面说的c盘这个文件夹放到你的电脑桌面。下载凤凰云,这里我这里推荐你下载东西,而不是下载“凤凰云”这个下载器,东西太多了。然后关闭迅雷软件,登录你刚才申请的账号。进入凤凰云的首页面,点击右上角的“我的账号”,然后你就会看到已经用这个账号注册的成员。
点击按钮“查看我的所有下载”,会出现一个账号显示框,然后输入账号密码登录即可。下载完成后,登录你的账号。看到上面有个“播放列表”,点击“新建播放列表”,或者不点击也没关系,我们就用“宽屏标准版”这个视频一点显示范围就看得到凤凰云的一点信息。以上操作之后,我们就能看到我们以前需要到电脑后台下载并且在线观看凤凰云的视频了。以上是我的操作方法,希望对你有用,注意电脑下载这个视频前,一定要把凤凰云的文件夹打开。 查看全部
如何抓取网页视频(如何抓取网页视频,最重要是得买播放器,还有账号)
如何抓取网页视频,最重要是得买播放器,还有账号。我就分享一下这个回答,有相关软件的话,自行百度,没有的话也可以看我的教程。环境准备:win10系统(电脑操作系统)登录迅雷账号首先,windows自带的迅雷需要下载文件夹,比如我们要下载“凤凰云”这个软件,然后会自动生成一个文件夹,里面就是“凤凰云”这个下载视频网站的视频,我们不需要管这个文件夹,直接把他保存到电脑的c盘里面去。
安装迅雷,我们到快速安装-迅雷的页面,不清楚的话可以百度一下。这个软件很好用,极力推荐!下载完成后,把上面说的c盘这个文件夹放到你的电脑桌面。下载凤凰云,这里我这里推荐你下载东西,而不是下载“凤凰云”这个下载器,东西太多了。然后关闭迅雷软件,登录你刚才申请的账号。进入凤凰云的首页面,点击右上角的“我的账号”,然后你就会看到已经用这个账号注册的成员。
点击按钮“查看我的所有下载”,会出现一个账号显示框,然后输入账号密码登录即可。下载完成后,登录你的账号。看到上面有个“播放列表”,点击“新建播放列表”,或者不点击也没关系,我们就用“宽屏标准版”这个视频一点显示范围就看得到凤凰云的一点信息。以上操作之后,我们就能看到我们以前需要到电脑后台下载并且在线观看凤凰云的视频了。以上是我的操作方法,希望对你有用,注意电脑下载这个视频前,一定要把凤凰云的文件夹打开。
如何抓取网页视频(一番摸索之后发现有个好东西:视频抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-24 00:59
我经常看到优酷和其他网站本身出现视频缩略图,或者为其他网站定制内容,但经过搜索,我发现优酷本身似乎并没有为普通用户打开类似的界面。所以这个问题被搁置了。最近有客户需要用到很多视频,而且是第三方视频网站,页面上也要用到视频截图。所以经过一番探索,我发现有一个好东西:一个视频捕捉工具。
原作者页面:视频爬虫
演示地址
实际使用效果使用方法
require_once “VideoUrlParser.class.php”;
$url = “http://v.youku.com/v_show/id_XMjkwMzc0Njg4.html”;
$info = VedioUrlParser::parse($url);
之后,只需在正确的位置输出 $info 即可。
应用实例
由于无法根据直接输入的帧视频帧获取截图,因此必须明确提供视频播放地址。这里我提供一个思路:
为所需的 文章 类型添加一个元框(将以下代码扔到functions.php中)
<p>
视频输入播放地址: 查看全部
如何抓取网页视频(一番摸索之后发现有个好东西:视频抓取工具)
我经常看到优酷和其他网站本身出现视频缩略图,或者为其他网站定制内容,但经过搜索,我发现优酷本身似乎并没有为普通用户打开类似的界面。所以这个问题被搁置了。最近有客户需要用到很多视频,而且是第三方视频网站,页面上也要用到视频截图。所以经过一番探索,我发现有一个好东西:一个视频捕捉工具。
原作者页面:视频爬虫
演示地址
实际使用效果使用方法
require_once “VideoUrlParser.class.php”;
$url = “http://v.youku.com/v_show/id_XMjkwMzc0Njg4.html”;
$info = VedioUrlParser::parse($url);
之后,只需在正确的位置输出 $info 即可。
应用实例
由于无法根据直接输入的帧视频帧获取截图,因此必须明确提供视频播放地址。这里我提供一个思路:
为所需的 文章 类型添加一个元框(将以下代码扔到functions.php中)
<p>
视频输入播放地址:

