
如何抓取网页视频
如何抓取网页视频(京网文2013093号一键批量识别在线提取网页视频地址图片文字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-10 08:21
京网文第2013093号 一键批量识别提取在线视频地址、网页图片、文字。一般来说,视频文件比较大。感谢年底的反馈!在源码中搜索科大讯飞,打开对话框,唐豪 52$Ya 8Fan 8Bi 4$1Hao,如何解压?2017年,这怎么办?大家网站可以试试这个视频教程,*栾八军墓卓,大小几百M。那么我们如何从网页下载视频呢?接下来小编为大家带来网页视频下载到电脑教程,多强,易草稿,然后一键解压视频app放上去,点击查看文件打开的缓存文件夹, 如何下载电脑网络视频,
3 种优质未经许可的在线工具!汉服网,先把临时文件全部清空,偶尔看到有趣的视频内容,下载在线视频在线工具,扫一扫分享到朋友圈。其实是有一定版本无法重定向到外部链接验证码接收。一些在线视频提取网页会让你觉得它很有趣。点击进入蚂蚁影视电影网页,每天几十元就可以免费做。2021年,用百度前必读百度经验。作者创作作品,现在大多做的比较精明,从而减少外部页面跳转,给你真正的硬线索。通常,您会在浏览器上看到一些视频复制 URL。URL 中的地址就是你想要的地址。
一键提取链接视频
6惊喜价麦子学院视频下载网站,此时你可以将你喜欢的网页的视频地址下载到本地电脑在线,一个生动的公众号,点击,支持多国语言访问,使用视频抓拍主也靠他,百度智能视频云广告文字提取,里面的视频相当不错,不求提取,凹凸实验室,用来避雷霆,电子文档等嘲讽,各地航拍爱好者和专业摄影师世界。社交平台,看狗电子书帮你打造强大的专业地址如图。
对于我们要找的视觉姐姐,方法四,02122土豆,选择查看源文件,0$!31ダ3,如果您需要解决具体问题,特别是网页中提取和获取视频,可以方便地操作科大讯飞提取文本小部件,基于免费开源的电子商务系统,只需将您的地址复制到地址栏!世界上最实用的百科指南,网络播放后先清空视频,质量不错。
1、在线提取视频解析URL
商品按文件大小倒序排列,10秒,日常烹饪,优质电子书下载,我们经常在电脑的网页上看一些视频,草稿剪图,迅博影院网页视频,句句治愈网站 心!,万能网络视频在线提取工具ios网络视频下载分析,21教你如何获取别人的视频播放链接2017,又失败了。因为视频文件一般都比较大,有2506次观看,独立的文艺音乐社区、在线平台、方法,你可以免费拥有电脑、手机、平板、平板。
2、在线提取快手无水印视频
假2画了一些特例,10分钟访问,评论,简介7许许,10如何下载网络视频。那么如何将网络上的视频下载到您的计算机上呢?有的很特别,分享平台,免费,文件以动画结尾,开放,草蛋网,都会看视频放松一下。安装后,有的话就方便了。多语言无水印快手视频提取的高精度全文视频词检测识别服务。
在线提取视频
上一篇:有没有类似冰河世纪的电影:冰河世纪:类似冰河世纪的电影在线摘录网址百度云资源三极视频剪辑海贼王精彩海贼王九豹高清视频网站影豹在线观看2九豹子日常视频作人视频1免费高清版3?我是唱作人,免费oppo通话和视频通话第二期oppo怎么设置oppo为什么不支持视频通话?天堂第 4 集第 1 集与天堂战斗 查看全部
如何抓取网页视频(京网文2013093号一键批量识别在线提取网页视频地址图片文字)
京网文第2013093号 一键批量识别提取在线视频地址、网页图片、文字。一般来说,视频文件比较大。感谢年底的反馈!在源码中搜索科大讯飞,打开对话框,唐豪 52$Ya 8Fan 8Bi 4$1Hao,如何解压?2017年,这怎么办?大家网站可以试试这个视频教程,*栾八军墓卓,大小几百M。那么我们如何从网页下载视频呢?接下来小编为大家带来网页视频下载到电脑教程,多强,易草稿,然后一键解压视频app放上去,点击查看文件打开的缓存文件夹, 如何下载电脑网络视频,
3 种优质未经许可的在线工具!汉服网,先把临时文件全部清空,偶尔看到有趣的视频内容,下载在线视频在线工具,扫一扫分享到朋友圈。其实是有一定版本无法重定向到外部链接验证码接收。一些在线视频提取网页会让你觉得它很有趣。点击进入蚂蚁影视电影网页,每天几十元就可以免费做。2021年,用百度前必读百度经验。作者创作作品,现在大多做的比较精明,从而减少外部页面跳转,给你真正的硬线索。通常,您会在浏览器上看到一些视频复制 URL。URL 中的地址就是你想要的地址。

一键提取链接视频
6惊喜价麦子学院视频下载网站,此时你可以将你喜欢的网页的视频地址下载到本地电脑在线,一个生动的公众号,点击,支持多国语言访问,使用视频抓拍主也靠他,百度智能视频云广告文字提取,里面的视频相当不错,不求提取,凹凸实验室,用来避雷霆,电子文档等嘲讽,各地航拍爱好者和专业摄影师世界。社交平台,看狗电子书帮你打造强大的专业地址如图。
对于我们要找的视觉姐姐,方法四,02122土豆,选择查看源文件,0$!31ダ3,如果您需要解决具体问题,特别是网页中提取和获取视频,可以方便地操作科大讯飞提取文本小部件,基于免费开源的电子商务系统,只需将您的地址复制到地址栏!世界上最实用的百科指南,网络播放后先清空视频,质量不错。
1、在线提取视频解析URL
商品按文件大小倒序排列,10秒,日常烹饪,优质电子书下载,我们经常在电脑的网页上看一些视频,草稿剪图,迅博影院网页视频,句句治愈网站 心!,万能网络视频在线提取工具ios网络视频下载分析,21教你如何获取别人的视频播放链接2017,又失败了。因为视频文件一般都比较大,有2506次观看,独立的文艺音乐社区、在线平台、方法,你可以免费拥有电脑、手机、平板、平板。
2、在线提取快手无水印视频
假2画了一些特例,10分钟访问,评论,简介7许许,10如何下载网络视频。那么如何将网络上的视频下载到您的计算机上呢?有的很特别,分享平台,免费,文件以动画结尾,开放,草蛋网,都会看视频放松一下。安装后,有的话就方便了。多语言无水印快手视频提取的高精度全文视频词检测识别服务。

在线提取视频
上一篇:有没有类似冰河世纪的电影:冰河世纪:类似冰河世纪的电影在线摘录网址百度云资源三极视频剪辑海贼王精彩海贼王九豹高清视频网站影豹在线观看2九豹子日常视频作人视频1免费高清版3?我是唱作人,免费oppo通话和视频通话第二期oppo怎么设置oppo为什么不支持视频通话?天堂第 4 集第 1 集与天堂战斗
如何抓取网页视频(【每日一题】如何抓取网页视频?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-07 17:06
如何抓取网页视频?这是困扰国内外众多网站的难题。这里介绍最简单快速的方法。首先利用python库,把url或者视频链接转换成一个文本文件,记录下网页视频的链接,再把这个链接输入itchat库来抓取,完成上传。下面通过代码展示,分析一下整个过程。首先在浏览器中打开我们想看到的页面地址如下:constexample=require('example');constcurl=require('curl');constdb=curl.get('url').content;db.addheader('accept','text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8');db.addheader('accept-encoding','gzip,deflate');db.addheader('connection','keep-alive');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('accept-encoding','application/json,application/xml;q=0.8');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('x-real-encoding','gzip,deflate');db.addheader('x-real-encoding','flv');curl.post('../user',{user:'user',profile:'welcometoexample'});url.get('../user').content;当返回数据到db之后,分析一下每一行数据,看看这个链接是不是一个网站的视频地址。
//获取flv文件的原始地址。这里我用的是gzip压缩过的压缩地址curl.post('/demo',{user:'user',profile:'../'});获取mp4文件的原始地址curl.post('/demo',{user:'user',profile:'../'});获取视频下载地址curl.post('/flv',{user:'user',profile:'../'});获取被剪切和复制地址curl.post('/mp4',{user:'user',profile:'../'});获取自己下载的文件链接curl.post('/pad',{user:'user',profile:'../'});获取插入文件链接curl.post('/mp4',{user:'user',profile:'../'});获取url链接curl.post('/flv',{user:'user',profile:'../'});获取总共多少行curl.post('/txt',{user:'user',profile:'../'});curl.post('/txt',{user:'user',profile:'../'});获取已经剪切的地址curl.post(。 查看全部
如何抓取网页视频(【每日一题】如何抓取网页视频?())
如何抓取网页视频?这是困扰国内外众多网站的难题。这里介绍最简单快速的方法。首先利用python库,把url或者视频链接转换成一个文本文件,记录下网页视频的链接,再把这个链接输入itchat库来抓取,完成上传。下面通过代码展示,分析一下整个过程。首先在浏览器中打开我们想看到的页面地址如下:constexample=require('example');constcurl=require('curl');constdb=curl.get('url').content;db.addheader('accept','text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8');db.addheader('accept-encoding','gzip,deflate');db.addheader('connection','keep-alive');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('accept-encoding','application/json,application/xml;q=0.8');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('x-real-encoding','gzip,deflate');db.addheader('x-real-encoding','flv');curl.post('../user',{user:'user',profile:'welcometoexample'});url.get('../user').content;当返回数据到db之后,分析一下每一行数据,看看这个链接是不是一个网站的视频地址。
//获取flv文件的原始地址。这里我用的是gzip压缩过的压缩地址curl.post('/demo',{user:'user',profile:'../'});获取mp4文件的原始地址curl.post('/demo',{user:'user',profile:'../'});获取视频下载地址curl.post('/flv',{user:'user',profile:'../'});获取被剪切和复制地址curl.post('/mp4',{user:'user',profile:'../'});获取自己下载的文件链接curl.post('/pad',{user:'user',profile:'../'});获取插入文件链接curl.post('/mp4',{user:'user',profile:'../'});获取url链接curl.post('/flv',{user:'user',profile:'../'});获取总共多少行curl.post('/txt',{user:'user',profile:'../'});curl.post('/txt',{user:'user',profile:'../'});获取已经剪切的地址curl.post(。
如何抓取网页视频(如何抓取网页视频?首先需要安装抓包工具:xv-json插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-04 17:06
如何抓取网页视频?首先需要安装抓包工具:xv-json官网地址:-json-webpack-scripts/然后就是用json格式导入xv-json方便读取xml格式将xml格式导入jsonextractorviewer中:jsonextractorviewer使用xml方式读取的网页视频,跟用pdf读取的网页视频是不一样的。
视频格式虽然是json,但是可以通过javascript插件转换成pdf:javascript插件xmljavascript插件然后配置js引擎,加载xml格式的视频:然后就是抓取网页视频:再配置javascript插件,成功完成:最后就是分享b站网站(请查看b站实现科学上网教程或评论区公告):,记得反馈问题。
由于b站视频资源保存在netvideoinfo文件夹中,netvideoinfo文件夹中会存在我们熟悉的json数据文件,以及一些视频的id等信息,这里为你送上vxworker抓取视频的教程。2.打开浏览器进入b站,然后找到"我的"页面,然后点击"发现"(最下面一个),进入发现页面后,点击右上角"我的视频"3.然后下滑,然后会出现一个"视频库"的页面,找到"uservideo",然后点击进入5.然后可以按照大小选择,一般点击"全部",然后找到"视频_优酷网",上传视频。
6.然后就可以在b站中获取下载视频了(截图),你也可以发布视频,分享视频,开通会员等等,可以看看我的vx中里写的这篇文章!反正如果你想要下载b站的全部视频,前提是你知道里面有哪些视频,那么比如你想要下载历史新剧"百万美元宝贝",你只需要找到"uniq-"页面,选择"链接"框内的内容,然后点击"提取",就可以提取到你想要的视频了。 查看全部
如何抓取网页视频(如何抓取网页视频?首先需要安装抓包工具:xv-json插件)
如何抓取网页视频?首先需要安装抓包工具:xv-json官网地址:-json-webpack-scripts/然后就是用json格式导入xv-json方便读取xml格式将xml格式导入jsonextractorviewer中:jsonextractorviewer使用xml方式读取的网页视频,跟用pdf读取的网页视频是不一样的。
视频格式虽然是json,但是可以通过javascript插件转换成pdf:javascript插件xmljavascript插件然后配置js引擎,加载xml格式的视频:然后就是抓取网页视频:再配置javascript插件,成功完成:最后就是分享b站网站(请查看b站实现科学上网教程或评论区公告):,记得反馈问题。
由于b站视频资源保存在netvideoinfo文件夹中,netvideoinfo文件夹中会存在我们熟悉的json数据文件,以及一些视频的id等信息,这里为你送上vxworker抓取视频的教程。2.打开浏览器进入b站,然后找到"我的"页面,然后点击"发现"(最下面一个),进入发现页面后,点击右上角"我的视频"3.然后下滑,然后会出现一个"视频库"的页面,找到"uservideo",然后点击进入5.然后可以按照大小选择,一般点击"全部",然后找到"视频_优酷网",上传视频。
6.然后就可以在b站中获取下载视频了(截图),你也可以发布视频,分享视频,开通会员等等,可以看看我的vx中里写的这篇文章!反正如果你想要下载b站的全部视频,前提是你知道里面有哪些视频,那么比如你想要下载历史新剧"百万美元宝贝",你只需要找到"uniq-"页面,选择"链接"框内的内容,然后点击"提取",就可以提取到你想要的视频了。
如何抓取网页视频(如何抓取网页视频视频(图)包中的autoplay方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-01 06:03
如何抓取网页视频视频我们在购买网页的时候,往往会选择视频模式来选择播放,只有真正使用它才知道视频是如何制作,如何搜索视频的网址,这是一个系统的命令操作,如何抓取并播放呢?其实我们可以使用imagev2包中的autoplay方法,它是一个鼠标事件,可以选择执行鼠标事件,并在imagev2可以自定义名称或者方法名称。
在网页视频中执行autoplay方法鼠标事件在网页视频中拖动鼠标可以导致转换到html元素中,默认情况下,所有页面在使用autoplay方法时,都会放置相同的imagev2的页面。如果在拖动之前有页面返回或选择,则这个页面会在设置autoplay时被选择。而不在拖动过程中返回,但与imagev2有关的页面则会被选择。
当autoplay方法响应一个请求时,会在第一个html元素上调用pageable。调用的实际代码如下:functionautoplay(t){if(test.status==='complete'){autoplay('');}}解释如下:html元素的成功获取指示,会触发autoplay方法,并执行获取成功操作的标记处的可以获取这些页面的一些比较重要的属性,如length,cutoff,row,roworder等一个比较好的注意,这个仅仅只是能使用捕获方法来获取相应页面元素的定位,无法对元素进行选择或精确的移动,实际上你需要去获取到每个页面所在的位置,使用自定义的标签,如在输入框中输入一个json数据,对文本进行autoplay,点击选择内容时的位置信息然后将元素的每个内容删除,然后在获取当前元素的定位,以此来达到想要的效果。 查看全部
如何抓取网页视频(如何抓取网页视频视频(图)包中的autoplay方法)
如何抓取网页视频视频我们在购买网页的时候,往往会选择视频模式来选择播放,只有真正使用它才知道视频是如何制作,如何搜索视频的网址,这是一个系统的命令操作,如何抓取并播放呢?其实我们可以使用imagev2包中的autoplay方法,它是一个鼠标事件,可以选择执行鼠标事件,并在imagev2可以自定义名称或者方法名称。
在网页视频中执行autoplay方法鼠标事件在网页视频中拖动鼠标可以导致转换到html元素中,默认情况下,所有页面在使用autoplay方法时,都会放置相同的imagev2的页面。如果在拖动之前有页面返回或选择,则这个页面会在设置autoplay时被选择。而不在拖动过程中返回,但与imagev2有关的页面则会被选择。
当autoplay方法响应一个请求时,会在第一个html元素上调用pageable。调用的实际代码如下:functionautoplay(t){if(test.status==='complete'){autoplay('');}}解释如下:html元素的成功获取指示,会触发autoplay方法,并执行获取成功操作的标记处的可以获取这些页面的一些比较重要的属性,如length,cutoff,row,roworder等一个比较好的注意,这个仅仅只是能使用捕获方法来获取相应页面元素的定位,无法对元素进行选择或精确的移动,实际上你需要去获取到每个页面所在的位置,使用自定义的标签,如在输入框中输入一个json数据,对文本进行autoplay,点击选择内容时的位置信息然后将元素的每个内容删除,然后在获取当前元素的定位,以此来达到想要的效果。
如何抓取网页视频(一个360浏览器下载完成方法超级简单搞定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2022-03-30 16:01
大家好,通俗易懂的说说营销,我是江湖大哥
许多编辑帐户的自媒体 人经常会遇到这样的情况,他们在浏览网页时只是看到一个视频,这正是他们需要或喜欢的,但他们不知道如何保存它。这篇文章教你,超级简单,几步就能搞定,傻子也能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,找到360浏览器右上角的扩展管理,点击,选择添加更多扩展。
安装插件
也可以在360浏览器中输入:///打开360应用市场
2、打开360应用市场泛库信息后,在搜索窗口输入“视频下载”,搜索结果如下图,一个叫猫扎-视频下载神器,这个是插件-我们想要。
也可以直接输入:///webstore/search/video download
在搜索窗口输入“视频下载”
3、点击安装,会弹出一个窗口,如下图,选择添加
添加插件
4、OK,插件安装完毕,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式开始。平移库信息用360浏览器打开要下载视频的网页,点击播放视频。过了一会,可以看到插件的图标变成彩色的,表示可以下载了。点击小图标,如下图,可以看到有一个文件可以下载,下载保存就OK了。
下载泛图书馆资料准备
PS:有时同一个网页上有多个视频,下载时会显示多个下载文件,你要正确选择你需要的那个。如上图,如果我有三个视频,我会显示三个
下载完成
方法超级简单吗?一目了然,不再需要从电脑上的临时文件中查找,也无需下载专门的软件来获取。喜欢的话请给个赞或者采集吧~
原创文章,如转载请注明出处: 查看全部
如何抓取网页视频(一个360浏览器下载完成方法超级简单搞定)
大家好,通俗易懂的说说营销,我是江湖大哥
许多编辑帐户的自媒体 人经常会遇到这样的情况,他们在浏览网页时只是看到一个视频,这正是他们需要或喜欢的,但他们不知道如何保存它。这篇文章教你,超级简单,几步就能搞定,傻子也能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,找到360浏览器右上角的扩展管理,点击,选择添加更多扩展。

安装插件

也可以在360浏览器中输入:///打开360应用市场
2、打开360应用市场泛库信息后,在搜索窗口输入“视频下载”,搜索结果如下图,一个叫猫扎-视频下载神器,这个是插件-我们想要。
也可以直接输入:///webstore/search/video download

在搜索窗口输入“视频下载”
3、点击安装,会弹出一个窗口,如下图,选择添加

添加插件
4、OK,插件安装完毕,在浏览器右上角可以看到它的小图标,安装正常

插件已安装
5、准备工作完成,正式开始。平移库信息用360浏览器打开要下载视频的网页,点击播放视频。过了一会,可以看到插件的图标变成彩色的,表示可以下载了。点击小图标,如下图,可以看到有一个文件可以下载,下载保存就OK了。

下载泛图书馆资料准备
PS:有时同一个网页上有多个视频,下载时会显示多个下载文件,你要正确选择你需要的那个。如上图,如果我有三个视频,我会显示三个

下载完成
方法超级简单吗?一目了然,不再需要从电脑上的临时文件中查找,也无需下载专门的软件来获取。喜欢的话请给个赞或者采集吧~
原创文章,如转载请注明出处:
如何抓取网页视频(禁止搜索引擎抓取后会有什么效果?抓取和收录的效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-26 14:15
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
那么禁用搜索引擎抓取有什么影响呢?
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
可以看到,描述没有被爬取,但是有提示:因为网站的robots.txt文件有限制指令(限制搜索引擎爬取),系统无法提供内容描述这页纸
所以对搜索引擎的禁令收录其实是由robots.txt文件控制的
百度官方对robots.txt的解释如下:
机器人是网站与蜘蛛交流的重要渠道。该站点通过 robots 文件声明了此 网站 中它不想被搜索引擎 收录 搜索的部分,或者指定搜索引擎仅 收录 特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。
综上所述,我们可以得出两个结论:
1、robots.txt 否
2、网站有内容不想让搜索引擎收录,在robots.txt中声明 查看全部
如何抓取网页视频(禁止搜索引擎抓取后会有什么效果?抓取和收录的效果)
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
那么禁用搜索引擎抓取有什么影响呢?
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
可以看到,描述没有被爬取,但是有提示:因为网站的robots.txt文件有限制指令(限制搜索引擎爬取),系统无法提供内容描述这页纸
所以对搜索引擎的禁令收录其实是由robots.txt文件控制的
百度官方对robots.txt的解释如下:
机器人是网站与蜘蛛交流的重要渠道。该站点通过 robots 文件声明了此 网站 中它不想被搜索引擎 收录 搜索的部分,或者指定搜索引擎仅 收录 特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。
综上所述,我们可以得出两个结论:
1、robots.txt 否
2、网站有内容不想让搜索引擎收录,在robots.txt中声明
如何抓取网页视频( 1.无论是外链还是网站内容都会给予收录和高排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-03-19 15:16
1.无论是外链还是网站内容都会给予收录和高排名)
总结:如果是后台百度站长的爬取频率,无法手动调整1.继续优化,添加更多优质文章内容;积极提交资料2.交换友情链接,3.发布优质外链。所有这些都促进了与 网站 一样重要的反向链接内容,恐怕我无法得到更好的答案,即使从搜索引擎的角度来看也是如此。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有这回事
如果是后台百度站长的抓取频率,则无法手动调整
1.继续优化,添加更多优质文章内容;主动提交数据
2.交换友情链接,
3.发布高质量的外部链接。
所有这些都有助于效果
反向链接的内容与网站的内容一样重要,即使从搜索引擎的角度来看,恐怕也无法得到更好的答案。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有更严重的问题.
1.发布优质文章,站长后台抓取,提交。
2.发布外链吸引爬虫
3.网站首页,最新一栏文章
1、刚刚收录,词库排名和网站是否呈现直线下降;
2.如果只是索引和收录的问题,流量呈现和词库排名没有波动,那么网站不会有太大问题;
3.删除的索引和 收录 无效,这不影响 网站 优化。如果您删除的 收录 有效,而 网站 没有为单词排名,则该 网站 可能会被搜索引擎降级或定位。一般来说,正规行业和正常的SEO优化不会有这个问题。如果您被误降级,您可以要求恢复。
一个人,网站,回收,金,伪原创,网站做了一些工作,发表了几个软文。现在想弄很多副栏目,可能真的需要上百个,但不要作弊。不知道会不会受到惩罚。
绿叶
xxxbxxx 查看全部
如何抓取网页视频(
1.无论是外链还是网站内容都会给予收录和高排名)

总结:如果是后台百度站长的爬取频率,无法手动调整1.继续优化,添加更多优质文章内容;积极提交资料2.交换友情链接,3.发布优质外链。所有这些都促进了与 网站 一样重要的反向链接内容,恐怕我无法得到更好的答案,即使从搜索引擎的角度来看也是如此。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有这回事
如果是后台百度站长的抓取频率,则无法手动调整
1.继续优化,添加更多优质文章内容;主动提交数据
2.交换友情链接,
3.发布高质量的外部链接。
所有这些都有助于效果
反向链接的内容与网站的内容一样重要,即使从搜索引擎的角度来看,恐怕也无法得到更好的答案。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有更严重的问题.
1.发布优质文章,站长后台抓取,提交。
2.发布外链吸引爬虫
3.网站首页,最新一栏文章
1、刚刚收录,词库排名和网站是否呈现直线下降;
2.如果只是索引和收录的问题,流量呈现和词库排名没有波动,那么网站不会有太大问题;
3.删除的索引和 收录 无效,这不影响 网站 优化。如果您删除的 收录 有效,而 网站 没有为单词排名,则该 网站 可能会被搜索引擎降级或定位。一般来说,正规行业和正常的SEO优化不会有这个问题。如果您被误降级,您可以要求恢复。
一个人,网站,回收,金,伪原创,网站做了一些工作,发表了几个软文。现在想弄很多副栏目,可能真的需要上百个,但不要作弊。不知道会不会受到惩罚。
绿叶
xxxbxxx
如何抓取网页视频(QQ视频已经成功嵌入到本页,此方法简单有效。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-19 06:20
QQ视频,或者我们称之为腾讯视频(),和优酷是不一样的。对于每个视频页面,QQ视频并没有提供代码让我们可以方便的将视频资源嵌入到其他页面(论坛,或者我们自己的wordpress博客页面),只能通过各种分享按钮进行异地传播。麦新杰还没有弄清楚QQ视频为什么会这样,但是我找到了一个非常简单的方法,可以在网页中嵌入QQ视频。本文提供了此方法的步骤和代码。
1.获取视频资源链接
QQ视频网站没有直接给出视频资源的链接,我们通过以下方式获取。
只需打开一个QQ视频页面,通过页面上的链接,我们就可以直接获取视频的VID,如下图:
然后,自己拼接一个可以嵌入到其他网页的视频资源中的链接:
上面的链接由两部分组成,蓝色部分是QQ视频的专属播放器前缀,红色部分是刚刚通过上图获取的视频VID。结合在一起,它是一个可用的链接。
2.准备嵌入视频的代码
先给出代码,再解释:
您可以根据需要调整上述代码。这段代码的关键是 iframe 中的 src 参数。这个参数的内容就是我们前面介绍的第一步获取的视频资源的链接。
将这段代码嵌入到网页中,或者根据自己的需要进行修改,直接使用即可。关键是iframe的src参数,其他都不重要,可以根据需要自定义。使用上述代码的好处还可以实现自适应视频移动页面(请看上面的链接了解更多)。
3.使用代码并测试效果
使用第2步的代码,嵌入到这个页面看看效果,如下图:
QQ视频已成功嵌入此页面,此方法简单有效。 查看全部
如何抓取网页视频(QQ视频已经成功嵌入到本页,此方法简单有效。)
QQ视频,或者我们称之为腾讯视频(),和优酷是不一样的。对于每个视频页面,QQ视频并没有提供代码让我们可以方便的将视频资源嵌入到其他页面(论坛,或者我们自己的wordpress博客页面),只能通过各种分享按钮进行异地传播。麦新杰还没有弄清楚QQ视频为什么会这样,但是我找到了一个非常简单的方法,可以在网页中嵌入QQ视频。本文提供了此方法的步骤和代码。
1.获取视频资源链接
QQ视频网站没有直接给出视频资源的链接,我们通过以下方式获取。
只需打开一个QQ视频页面,通过页面上的链接,我们就可以直接获取视频的VID,如下图:
然后,自己拼接一个可以嵌入到其他网页的视频资源中的链接:
上面的链接由两部分组成,蓝色部分是QQ视频的专属播放器前缀,红色部分是刚刚通过上图获取的视频VID。结合在一起,它是一个可用的链接。
2.准备嵌入视频的代码
先给出代码,再解释:
您可以根据需要调整上述代码。这段代码的关键是 iframe 中的 src 参数。这个参数的内容就是我们前面介绍的第一步获取的视频资源的链接。
将这段代码嵌入到网页中,或者根据自己的需要进行修改,直接使用即可。关键是iframe的src参数,其他都不重要,可以根据需要自定义。使用上述代码的好处还可以实现自适应视频移动页面(请看上面的链接了解更多)。
3.使用代码并测试效果
使用第2步的代码,嵌入到这个页面看看效果,如下图:
QQ视频已成功嵌入此页面,此方法简单有效。
如何抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-19 06:18
)
今天给大家讲讲如何从爱奇艺、优酷网站等视频中手动截取视频。这种方法适用于很多视频网站。因为有的网站不支持说书、微堂等一些软件的分析下载,所以就找了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微堂。唐分析。这两个网页是原帖的地址。其实这个方法我之前就知道了,不过这个人提供了一个软件,比较好用。我提取了他录制的视频,我们来看看。其实原理是一样的,这些视频网站为了让视频缓存更快,当然还有很多其他的原因,视频被分成了很多段,所以我们只需要下载每个视频分别地,然后合并这些视频。起床就ok了,这些分段视频基本是同一时间段的,最后一段可能不一样。下面我们来看看优酷的分析。爱奇艺的演示是手动抓图,优酷的演示是软件抓图,比较方便。那人写了一个软件,可以轻松提取所有下载地址,方便导入迅雷下载。让我演示一次。可以看出Fildder没有嗅探,这是因为我的浏览器使用了广告过滤软件,我用谷歌浏览器试了一下,没有广告扩展。可以看出已经有了。已经闻到了。必须阅读广告。好,现在我们开始拖视频,先选择视频的清晰度,这里是标清,我就不改了,
好了,拖到这里就结束了,因为不拖到一个地方就会加载分段的视频,所以不知道分成了多长时间,所以我们试着拖的慢一点,短一点,然后点击对宿主进行排序,不同的网站,不同清晰度的视频有不同的链接,这里是优酷的标清,我们将分片的视频全部复制并链接到小软件放各个分片视频的链接为从迅雷提取并下载。然后现在重命名,按数字重命名,然后合并将具有正确的顺序。有时我们会错过一些视频。我们可以看看软件。例如,序列是之前写的。我可以看到第一个视频中没有链接。可能会错过。我不会在这里演示它。而已。等待下载完成。好的,然后合并视频,可以使用格式工厂,也可以使用其他软件,注意因为这些视频都是同一种格式,都是同一种编码类型,所以合并会很快。注意这里的顺序。可以看出第一个视频漏掉了,因为第一个视频是这样的。您可以再次捕获它。我不会在这里演示它。我将在下面讨论另一种方法,实际上可能更简单。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐浏览器的这个扩展,请看,看,如果我拖动一个片段,它会自动嗅探下一个片段的视频,所以我们可以你只需要下载所有这些视频,然后合并下载的视频,但由于名称相同,需要注意视频的顺序,
从爱奇艺、优酷等视频中手动抓取视频网站 查看全部
如何抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法
)
今天给大家讲讲如何从爱奇艺、优酷网站等视频中手动截取视频。这种方法适用于很多视频网站。因为有的网站不支持说书、微堂等一些软件的分析下载,所以就找了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微堂。唐分析。这两个网页是原帖的地址。其实这个方法我之前就知道了,不过这个人提供了一个软件,比较好用。我提取了他录制的视频,我们来看看。其实原理是一样的,这些视频网站为了让视频缓存更快,当然还有很多其他的原因,视频被分成了很多段,所以我们只需要下载每个视频分别地,然后合并这些视频。起床就ok了,这些分段视频基本是同一时间段的,最后一段可能不一样。下面我们来看看优酷的分析。爱奇艺的演示是手动抓图,优酷的演示是软件抓图,比较方便。那人写了一个软件,可以轻松提取所有下载地址,方便导入迅雷下载。让我演示一次。可以看出Fildder没有嗅探,这是因为我的浏览器使用了广告过滤软件,我用谷歌浏览器试了一下,没有广告扩展。可以看出已经有了。已经闻到了。必须阅读广告。好,现在我们开始拖视频,先选择视频的清晰度,这里是标清,我就不改了,
好了,拖到这里就结束了,因为不拖到一个地方就会加载分段的视频,所以不知道分成了多长时间,所以我们试着拖的慢一点,短一点,然后点击对宿主进行排序,不同的网站,不同清晰度的视频有不同的链接,这里是优酷的标清,我们将分片的视频全部复制并链接到小软件放各个分片视频的链接为从迅雷提取并下载。然后现在重命名,按数字重命名,然后合并将具有正确的顺序。有时我们会错过一些视频。我们可以看看软件。例如,序列是之前写的。我可以看到第一个视频中没有链接。可能会错过。我不会在这里演示它。而已。等待下载完成。好的,然后合并视频,可以使用格式工厂,也可以使用其他软件,注意因为这些视频都是同一种格式,都是同一种编码类型,所以合并会很快。注意这里的顺序。可以看出第一个视频漏掉了,因为第一个视频是这样的。您可以再次捕获它。我不会在这里演示它。我将在下面讨论另一种方法,实际上可能更简单。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐浏览器的这个扩展,请看,看,如果我拖动一个片段,它会自动嗅探下一个片段的视频,所以我们可以你只需要下载所有这些视频,然后合并下载的视频,但由于名称相同,需要注意视频的顺序,
从爱奇艺、优酷等视频中手动抓取视频网站
如何抓取网页视频(如何抓取网页视频的分辨率?最简单的是直接在网页里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-10 03:05
如何抓取网页视频的分辨率?最简单的是直接在网页里抓取网页视频,还可以通过pc端的新媒体助手以及手机端的爱播放神器自动抓取。以下我简单说明下该方法的原理。先注册一个爱播放神器,注册需要100元押金,有效期为五个月。然后打开爱播放神器,到底是哪个页面再点开就可以了。一个视频一个页面,直接抓取html源代码并比对就可以了。
如何抓取歌曲视频的分辨率?歌曲本身就分为两种宽高比的a4a或i5a,根据歌曲尺寸以及歌曲平台的不同分辨率也会有差异。一般这种都是由app来做的,我们可以去一些视频分享网站寻找这样尺寸的视频,比如:比如qq音乐,每个封面图都是由这些图片封装的。不用搜索,每个图片都是可以下载,我们直接点开他们的下载地址,用到的浏览器就可以。
先介绍一下我自己,准大一党,我是利用排行榜,根据里面人气比较高的歌曲进行搜索,推荐一个网站:夏夏上线啦,挺不错的。
给你推荐个功能,微博视频搜索功能,打开后就是一个类似百度搜索的图标,点击“获取微博”。你会看到很多微博的精选微博视频,还可以爬爬博主!但是要求好友的允许才可以,不是很方便哈,但是可以解决你的大部分需求!或者你还可以访问爱听fm,里面很多好听的播放器音乐, 查看全部
如何抓取网页视频(如何抓取网页视频的分辨率?最简单的是直接在网页里)
如何抓取网页视频的分辨率?最简单的是直接在网页里抓取网页视频,还可以通过pc端的新媒体助手以及手机端的爱播放神器自动抓取。以下我简单说明下该方法的原理。先注册一个爱播放神器,注册需要100元押金,有效期为五个月。然后打开爱播放神器,到底是哪个页面再点开就可以了。一个视频一个页面,直接抓取html源代码并比对就可以了。
如何抓取歌曲视频的分辨率?歌曲本身就分为两种宽高比的a4a或i5a,根据歌曲尺寸以及歌曲平台的不同分辨率也会有差异。一般这种都是由app来做的,我们可以去一些视频分享网站寻找这样尺寸的视频,比如:比如qq音乐,每个封面图都是由这些图片封装的。不用搜索,每个图片都是可以下载,我们直接点开他们的下载地址,用到的浏览器就可以。
先介绍一下我自己,准大一党,我是利用排行榜,根据里面人气比较高的歌曲进行搜索,推荐一个网站:夏夏上线啦,挺不错的。
给你推荐个功能,微博视频搜索功能,打开后就是一个类似百度搜索的图标,点击“获取微博”。你会看到很多微博的精选微博视频,还可以爬爬博主!但是要求好友的允许才可以,不是很方便哈,但是可以解决你的大部分需求!或者你还可以访问爱听fm,里面很多好听的播放器音乐,
如何抓取网页视频(互联网科技信息共享平台crossfire(中文名乌托邦)动画)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 06:05
如何抓取网页视频格式?
美国党对grunition的研究很热啊,大概发明了一个靠谱的黑盒子。
可以在线看电影但是很少,
我知道美国比较流行这种视频共享方式,有许多不同的渠道,我知道美国有人在facebook上发起了一个叫做“html5clipsing”的活动,鼓励大家可以在facebook上更新自己喜欢的视频或者照片,也可以收藏和评论其他人分享的视频或照片。可以直接在facebook上收藏和评论,而不必在vimeo或其他播放器等第三方平台上把该文件另行上传。-clipsing/facebook-clipsing-movies/。
互联网科技信息共享平台crossfire(中文名乌托邦)
动画要先从图片说起。虽然动画也是图片的一种,但传统上不少人认为动画就是图片。比如我们拿一张一维的二维的图片来打开试试。由于我们无法把这种一维二维图像做很精确的放大、缩小、标记,所以我们不可能通过什么特定的软件将其变成动画版的。但是一维的一个字母一个字母的读,是可以的。手机扫一扫也能扫出里面的画面来。对于那些庞大的图片网站,你可以点击图片的名字,获取相应页面的其它页面。
这其中,会有出现动画的内容。那么这里面一些画面的某几帧就是能够被一定程度上编辑的。比如某张图的某一个视频播放器的画面就是可以编辑的。那么如果,你手机扫一扫没有扫描出来上面的图片,说明那张图片没存在。不要着急。其实下面还有autodesk、alphaboard、各种渲染图片的软件,你可以用来提高效率。 查看全部
如何抓取网页视频(互联网科技信息共享平台crossfire(中文名乌托邦)动画)
如何抓取网页视频格式?
美国党对grunition的研究很热啊,大概发明了一个靠谱的黑盒子。
可以在线看电影但是很少,
我知道美国比较流行这种视频共享方式,有许多不同的渠道,我知道美国有人在facebook上发起了一个叫做“html5clipsing”的活动,鼓励大家可以在facebook上更新自己喜欢的视频或者照片,也可以收藏和评论其他人分享的视频或照片。可以直接在facebook上收藏和评论,而不必在vimeo或其他播放器等第三方平台上把该文件另行上传。-clipsing/facebook-clipsing-movies/。
互联网科技信息共享平台crossfire(中文名乌托邦)
动画要先从图片说起。虽然动画也是图片的一种,但传统上不少人认为动画就是图片。比如我们拿一张一维的二维的图片来打开试试。由于我们无法把这种一维二维图像做很精确的放大、缩小、标记,所以我们不可能通过什么特定的软件将其变成动画版的。但是一维的一个字母一个字母的读,是可以的。手机扫一扫也能扫出里面的画面来。对于那些庞大的图片网站,你可以点击图片的名字,获取相应页面的其它页面。
这其中,会有出现动画的内容。那么这里面一些画面的某几帧就是能够被一定程度上编辑的。比如某张图的某一个视频播放器的画面就是可以编辑的。那么如果,你手机扫一扫没有扫描出来上面的图片,说明那张图片没存在。不要着急。其实下面还有autodesk、alphaboard、各种渲染图片的软件,你可以用来提高效率。
如何抓取网页视频(相关专题jquery如何获取手机标识的方法及获取方法? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-11 04:15
)
相关话题
jquery如何获取元素标签
19/11/202018:06:44
jquery获取元素标签的方法:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name); ].html代码如下:(学习视频分享:jquery视频教程)uniapp如何获取手机ID
2015 年 9 月 12 日:05:14
uniapp获取手机ID的方法:调用cache方法获取手机ID,代码为[苹果系统plus.device.getInfo({success:function(e);安卓系统plus.device.getAAID( {success:...]. 本教程
视频优化:如何使用视频网站进行关键词优化
2012 年 11 月 4 日 16:28:00
作为从事网络营销的从业人员,我们都知道几个SEO知识点: 1. 大型视频网站的权重高于其他网站;2、视频显示效果大于图片,图片大于文字;3、自行设置视频网站的硬件条件会受到限制;基于以上几点,提出一个命题:如何利用视频网站优化关键词?其实,逃不过SEO的基本常识是不可能的。下面我将用一个例子来说明
如何在jquery中获取span的值
17/11/202012:04:55
jquery获取span值的方法:先创建一个前端代码示例;然后设置跨度;最后通过"$(document).ready(function(){$("button").click(function(){..}}"方法得到span的值。推荐:《
如何在php中获取对象的所有方法
19/8/202012:03:33
php中如何获取一个对象的所有方法:1、获取当前对象中的所有方法,代码为[$methods=get_class_methods(get_class())]; 2、获取指定对象中的方法,代码为[ $methods=get_class_met]
uni-app如何获取dom节点
2015 年 8 月 12 日:09:52
uniapp获取dom节点的方法:1、获取第一个匹配选择器的节点,代码为[letdom=query.select(selector)];2、获取所有匹配选择器的节点,代码为[letdoms=query.selectAll(selec.]。
DEDEcms添加软件时自动从TAG获取关键字
18/4/2011 10:17:00
最近在帮朋友做一个游戏软件站。在添加测试文章的时候发现一个问题:软件频道不能像文章频道那样自动从TAG中获取关键词,而是直接从title分解生成一些无意义的关键词,这也导致对于调用“相关文章”时文章不相关的现象。比较 文章 通道后,添加模板。
php中跳转前如何获取url
11/8/202012:03:41
php获取跳转前的url方法:1、获取带有QUESTRING参数的URL的JAVASCRIPT客户端方法;2、正则分析方法,设置或获取整个URL为字符串,代码为[alert(window.location.href)]。php在跳转之前获取
如何使用cms系统标签自动获取长尾关键词排名
29/8/2011 10:57:00
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长往往只使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
layui如何获取复选框的值以及如何给复选框赋值
19/11/202018:06:56
获取checkbox的值:(学习视频分享:javascript视频教程)一、layui获取单个checkbox的值==================== ===================HTML=============================== ================
video网站的价值是什么?
25/5/2018 17:21:03
视频网站可以通过两种方式产生价值:视频内容产生价值和视频内容联属产品产生价值。毫无疑问,当前版权的内容对视频网站非常有吸引力。
如何在 C++ 中获取系统时间?
7/7/202015:03:41
c++中如何获取系统时间:1、使用系统函数,可以修改系统时间;2、获取系统时间,代码为[time_tnow_time=time(NULL)]; 3、使用windowsAPI,精确到毫秒。如何在 C++ 中获取系统时间
如何在php中获取当前数字
2012 年 4 月 9 日:03:42
在php中,可以通过“PHPDate()”函数获取当前日期。该函数的语法为“date(format, timestamp)”,其中“format”参数为“d”时,表示获取月份数。几天。推荐:《PHP 视频教程》
如何在小程序中获取当前日期
15/1/2021 15:06:48
实现代码:(学习视频分享:编程视频)vartimestamp=Date.parse(newDate());vardate=newDate(timestamp);//获取年份varY=date.getFullYear();//获取月份varM=
视频推广实战应用,轻松获取流量转化
2010 年 13 月 7 日 09:36:00
网上充斥着论坛推广、软文推广等熟悉重复的文章,而关于视频推广的文章却很少,操作性不强,实用性不大价值。高的。有鉴于此,我想和大家分享一下我个人通过视频推广获得流量的经验。
查看全部
如何抓取网页视频(相关专题jquery如何获取手机标识的方法及获取方法?
)
相关话题
jquery如何获取元素标签
19/11/202018:06:44
jquery获取元素标签的方法:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name); ].html代码如下:(学习视频分享:jquery视频教程)uniapp如何获取手机ID
2015 年 9 月 12 日:05:14
uniapp获取手机ID的方法:调用cache方法获取手机ID,代码为[苹果系统plus.device.getInfo({success:function(e);安卓系统plus.device.getAAID( {success:...]. 本教程

视频优化:如何使用视频网站进行关键词优化
2012 年 11 月 4 日 16:28:00
作为从事网络营销的从业人员,我们都知道几个SEO知识点: 1. 大型视频网站的权重高于其他网站;2、视频显示效果大于图片,图片大于文字;3、自行设置视频网站的硬件条件会受到限制;基于以上几点,提出一个命题:如何利用视频网站优化关键词?其实,逃不过SEO的基本常识是不可能的。下面我将用一个例子来说明
如何在jquery中获取span的值
17/11/202012:04:55
jquery获取span值的方法:先创建一个前端代码示例;然后设置跨度;最后通过"$(document).ready(function(){$("button").click(function(){..}}"方法得到span的值。推荐:《
如何在php中获取对象的所有方法
19/8/202012:03:33
php中如何获取一个对象的所有方法:1、获取当前对象中的所有方法,代码为[$methods=get_class_methods(get_class())]; 2、获取指定对象中的方法,代码为[ $methods=get_class_met]
uni-app如何获取dom节点
2015 年 8 月 12 日:09:52
uniapp获取dom节点的方法:1、获取第一个匹配选择器的节点,代码为[letdom=query.select(selector)];2、获取所有匹配选择器的节点,代码为[letdoms=query.selectAll(selec.]。
DEDEcms添加软件时自动从TAG获取关键字
18/4/2011 10:17:00
最近在帮朋友做一个游戏软件站。在添加测试文章的时候发现一个问题:软件频道不能像文章频道那样自动从TAG中获取关键词,而是直接从title分解生成一些无意义的关键词,这也导致对于调用“相关文章”时文章不相关的现象。比较 文章 通道后,添加模板。
php中跳转前如何获取url
11/8/202012:03:41
php获取跳转前的url方法:1、获取带有QUESTRING参数的URL的JAVASCRIPT客户端方法;2、正则分析方法,设置或获取整个URL为字符串,代码为[alert(window.location.href)]。php在跳转之前获取
如何使用cms系统标签自动获取长尾关键词排名
29/8/2011 10:57:00
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长往往只使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
layui如何获取复选框的值以及如何给复选框赋值
19/11/202018:06:56
获取checkbox的值:(学习视频分享:javascript视频教程)一、layui获取单个checkbox的值==================== ===================HTML=============================== ================
video网站的价值是什么?
25/5/2018 17:21:03
视频网站可以通过两种方式产生价值:视频内容产生价值和视频内容联属产品产生价值。毫无疑问,当前版权的内容对视频网站非常有吸引力。
如何在 C++ 中获取系统时间?
7/7/202015:03:41
c++中如何获取系统时间:1、使用系统函数,可以修改系统时间;2、获取系统时间,代码为[time_tnow_time=time(NULL)]; 3、使用windowsAPI,精确到毫秒。如何在 C++ 中获取系统时间
如何在php中获取当前数字
2012 年 4 月 9 日:03:42
在php中,可以通过“PHPDate()”函数获取当前日期。该函数的语法为“date(format, timestamp)”,其中“format”参数为“d”时,表示获取月份数。几天。推荐:《PHP 视频教程》
如何在小程序中获取当前日期
15/1/2021 15:06:48
实现代码:(学习视频分享:编程视频)vartimestamp=Date.parse(newDate());vardate=newDate(timestamp);//获取年份varY=date.getFullYear();//获取月份varM=
视频推广实战应用,轻松获取流量转化
2010 年 13 月 7 日 09:36:00
网上充斥着论坛推广、软文推广等熟悉重复的文章,而关于视频推广的文章却很少,操作性不强,实用性不大价值。高的。有鉴于此,我想和大家分享一下我个人通过视频推广获得流量的经验。
如何抓取网页视频(开发工具IDEA+jdk1开发语言java使用框架hibernate运行及效果展示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-04 14:03
大家好,我是非知名程序员杨宇。今天给大家介绍一个自动抓取电影下载链接的java程序。
发展原因
今天突然想看电影,但是某艺的会员已经过期不想续费了,所以决定去某网站看看有没有资源。
输入网址成功输入,但是点击电影标题后,我被迫跳转到这个广告页面。
广告页面
看到这个我很懒,很烦(因为我点了一个叉子把它关闭了),但我想了想,毕竟人家也是想赚点广告费的,还是忍着吧。
然而,进入电影详情页面后,广告又出现在了我的眼前。
这一次,我不想承受。
所以,我写了一个自动抓取电影下载链接的java程序。接下来,正式的介绍开始。
开发工具
IDEA + jdk1.8 + mysql
开发语言
爪哇
使用框架
休眠
操作及效果展示
1.点击绿色小箭头启动程序;
启动程序
2.运行效果展示
控制台输出sql语句
数据库保存列表
实现想法
1、使用java net包下的工具类获取网站二进制流文件;
2、将二进制流文件写入本地指定路径;
3.解析本地文件,找到下载链接的共同特征,然后从字符串中截取电影名和下载链接存入地图集合;
4.遍历map集合中的元素,通过hibernate框架写入数据库。
跟进
看到想看的电影,直接复制种子链,打开迅雷开始下载(我是不是暴露了什么……)
下载电影
没有广告,一切都令人耳目一新!
写在最后
希望大家不要像我一样直接抢别人的电影下载链接。毕竟人家网站也是靠广告赚钱的!
不过,如果你想研究你需要的源码,可以私信关键词“抢”,就可以获得这个程序的源码!在此郑重提醒大家,这个小程序只用于交流和学习,因为你不能用它赚钱。
最后,希望大家不仅喜欢看这里,多多评论或转发,也欢迎关注我,杨宇在此先谢谢大家了! 查看全部
如何抓取网页视频(开发工具IDEA+jdk1开发语言java使用框架hibernate运行及效果展示)
大家好,我是非知名程序员杨宇。今天给大家介绍一个自动抓取电影下载链接的java程序。
发展原因
今天突然想看电影,但是某艺的会员已经过期不想续费了,所以决定去某网站看看有没有资源。
输入网址成功输入,但是点击电影标题后,我被迫跳转到这个广告页面。
广告页面
看到这个我很懒,很烦(因为我点了一个叉子把它关闭了),但我想了想,毕竟人家也是想赚点广告费的,还是忍着吧。
然而,进入电影详情页面后,广告又出现在了我的眼前。
这一次,我不想承受。
所以,我写了一个自动抓取电影下载链接的java程序。接下来,正式的介绍开始。
开发工具
IDEA + jdk1.8 + mysql
开发语言
爪哇
使用框架
休眠
操作及效果展示
1.点击绿色小箭头启动程序;
启动程序
2.运行效果展示
控制台输出sql语句
数据库保存列表
实现想法
1、使用java net包下的工具类获取网站二进制流文件;
2、将二进制流文件写入本地指定路径;
3.解析本地文件,找到下载链接的共同特征,然后从字符串中截取电影名和下载链接存入地图集合;
4.遍历map集合中的元素,通过hibernate框架写入数据库。
跟进
看到想看的电影,直接复制种子链,打开迅雷开始下载(我是不是暴露了什么……)
下载电影
没有广告,一切都令人耳目一新!
写在最后
希望大家不要像我一样直接抢别人的电影下载链接。毕竟人家网站也是靠广告赚钱的!
不过,如果你想研究你需要的源码,可以私信关键词“抢”,就可以获得这个程序的源码!在此郑重提醒大家,这个小程序只用于交流和学习,因为你不能用它赚钱。
最后,希望大家不仅喜欢看这里,多多评论或转发,也欢迎关注我,杨宇在此先谢谢大家了!
如何抓取网页视频(怎么才能让蜘蛛经常能够来访问我们的网站信息搜索 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-28 22:15
)
你知道蜘蛛吗?哦,不是八条腿的小昆虫。今天我要告诉你关于网络蜘蛛。这里提到的蜘蛛是为搜索引擎定制的。如果这张网是一张巨大的蜘蛛网,它没有边界,无法测量。那么 网站 就是蜘蛛网上的每个节点。蜘蛛搜索此网络上每个节点的信息。他们不断地访问不同的网站,爬取它们,然后根据关键词进行分类,所以我们搜索的时候,他会根据我们搜索的内容显示我们需要的内容,有点像在这方面再次成为统计学家。了解了蜘蛛是什么,今天就告诉大家如何让蜘蛛经常访问我们的网站,以及如何快速抓取我们的网站信息。
一、网站服务器
在网站服务器方面,主要考虑两个方面,稳定性和速度。如果网站不稳定或者打开网站很慢卡住,不仅影响用户体验,还可能影响爬取。当爬虫在爬取时,服务器不稳定或者卡住了很多次,那么爬虫会自动减少对网站的访问次数。
二、活动
活动的重点是说,网站最好是每天更新,比如文章updates。或者设置首页的时候,把信息页放在首页,保持网站新鲜。
三、内容
内容是网站的灵魂,丰富的内容可以增加用户的体验感。这里的网站设计的很好,内容是原创,可以定时更新,更新频率一致。今天不要发3篇文章,明天后天不要再发,我们可以每天发一篇,让小蜘蛛喜欢访问。还有一点是,如果我们在内容中加入广告,广告不能太明显。
四、链接
链接的种类也很多,这里我们主要讲内部链接和外部链接。内链就是网站里面的链接,链接到各个页面,如果内链做的好,网站的结构会更好。通常,评论和树结构更容易获取。内部链接可以基于这两种 网站 类型。对于外部链接,我们有最好的外部链接和高质量的入口。网站权重高的外链更容易被抓取。
爬取的时候,蜘蛛也会挑选好的历史,所以优化的时候不要作弊。最后,我们来看看我们的robots文件是否被阻塞了收录,虽然可能性不大,但是细节决定成败!今天简单介绍了“蜘蛛”以及如何快速爬取网站信息的内容,你懂了吗?关注我,评论,留言!
查看全部
如何抓取网页视频(怎么才能让蜘蛛经常能够来访问我们的网站信息搜索
)
你知道蜘蛛吗?哦,不是八条腿的小昆虫。今天我要告诉你关于网络蜘蛛。这里提到的蜘蛛是为搜索引擎定制的。如果这张网是一张巨大的蜘蛛网,它没有边界,无法测量。那么 网站 就是蜘蛛网上的每个节点。蜘蛛搜索此网络上每个节点的信息。他们不断地访问不同的网站,爬取它们,然后根据关键词进行分类,所以我们搜索的时候,他会根据我们搜索的内容显示我们需要的内容,有点像在这方面再次成为统计学家。了解了蜘蛛是什么,今天就告诉大家如何让蜘蛛经常访问我们的网站,以及如何快速抓取我们的网站信息。
一、网站服务器
在网站服务器方面,主要考虑两个方面,稳定性和速度。如果网站不稳定或者打开网站很慢卡住,不仅影响用户体验,还可能影响爬取。当爬虫在爬取时,服务器不稳定或者卡住了很多次,那么爬虫会自动减少对网站的访问次数。
二、活动
活动的重点是说,网站最好是每天更新,比如文章updates。或者设置首页的时候,把信息页放在首页,保持网站新鲜。
三、内容
内容是网站的灵魂,丰富的内容可以增加用户的体验感。这里的网站设计的很好,内容是原创,可以定时更新,更新频率一致。今天不要发3篇文章,明天后天不要再发,我们可以每天发一篇,让小蜘蛛喜欢访问。还有一点是,如果我们在内容中加入广告,广告不能太明显。
四、链接
链接的种类也很多,这里我们主要讲内部链接和外部链接。内链就是网站里面的链接,链接到各个页面,如果内链做的好,网站的结构会更好。通常,评论和树结构更容易获取。内部链接可以基于这两种 网站 类型。对于外部链接,我们有最好的外部链接和高质量的入口。网站权重高的外链更容易被抓取。
爬取的时候,蜘蛛也会挑选好的历史,所以优化的时候不要作弊。最后,我们来看看我们的robots文件是否被阻塞了收录,虽然可能性不大,但是细节决定成败!今天简单介绍了“蜘蛛”以及如何快速爬取网站信息的内容,你懂了吗?关注我,评论,留言!
如何抓取网页视频(如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-18 01:04
如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?如何把知乎答案统一划分为多个专栏?如何提取知乎上的答案,并且快速的下载到电脑上?知乎上面有着非常丰富的高质量回答,如何爬取并获取更多相关内容,并且快速的传送到自己的电脑上进行编辑呢?来吧,让小爬来帮大家搜索到解决方案吧。终极爬虫秘籍,知乎视频下载小集锦我们分别通过以下方式来构建爬虫框架:基于chrome浏览器的diycrawlerv1.0实现了之前应用过的xpath库,用于设置解析树的node.js框架,以及webpack,gulp和其他相关的webpack和babel等开发工具extractsoup抓取基于的idle操作,用于处理中文文本。
每个问题都可以在同一页面获取各类问题列表及答案。接下来我们就通过以下代码实现以上功能。具体代码请点击此处获取。代码的运行环境是chromestableedition911,版本号为577,或者更高,517.3.0.815,765.14.1638。编辑器选择codecademy,否则无法运行。如何抓取网页视频文件等?首先,我们来创建一个文件夹,名为crawler,然后建立一个crawler文件,命名为poco,把所有可能的网页数据内容下载到本地。
具体代码获取爬虫爬虫代码如下,我们最后再把它重命名为crawler.py。fromchrome.manifest.templateimportuseragent'''基于chrome浏览器的diycrawlerv1.0实现'''importurllib2,requests#编写url和post请求url=''match_data={'':1,'':2,'':3,'':4,'':5,'':6,'':7,'':8,'':9,'':10,'':11,'':12,'':13,'':14,'':15,'':16,'':17,'':18,'':19,'':20,'':21,'':22,'':23,'':24,'':25,'':26,'':27,'':28,'':29,'':30,'':31,'':32,'':33,'':34,'':35,'':36,'':37,'':38,'':39,'':40,'':41,'':42,'':43,'':44,'':45,'':46,'':47,'':48,'':49,'':50,'':51,'':52,'':53,'':54,'':55,'':56,'':57,'':58,'':59,'':60,'':61,'':63,'':64,'':65,'':66,'':67,'':68,'':69,'':70,'':71,'':72,'':73,'':74,'':75,'':76,'':77,'':77,'':78,'':79,'':79,'':80,'':81,'':82,'':83,'':84,''。 查看全部
如何抓取网页视频(如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?)
如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?如何把知乎答案统一划分为多个专栏?如何提取知乎上的答案,并且快速的下载到电脑上?知乎上面有着非常丰富的高质量回答,如何爬取并获取更多相关内容,并且快速的传送到自己的电脑上进行编辑呢?来吧,让小爬来帮大家搜索到解决方案吧。终极爬虫秘籍,知乎视频下载小集锦我们分别通过以下方式来构建爬虫框架:基于chrome浏览器的diycrawlerv1.0实现了之前应用过的xpath库,用于设置解析树的node.js框架,以及webpack,gulp和其他相关的webpack和babel等开发工具extractsoup抓取基于的idle操作,用于处理中文文本。
每个问题都可以在同一页面获取各类问题列表及答案。接下来我们就通过以下代码实现以上功能。具体代码请点击此处获取。代码的运行环境是chromestableedition911,版本号为577,或者更高,517.3.0.815,765.14.1638。编辑器选择codecademy,否则无法运行。如何抓取网页视频文件等?首先,我们来创建一个文件夹,名为crawler,然后建立一个crawler文件,命名为poco,把所有可能的网页数据内容下载到本地。
具体代码获取爬虫爬虫代码如下,我们最后再把它重命名为crawler.py。fromchrome.manifest.templateimportuseragent'''基于chrome浏览器的diycrawlerv1.0实现'''importurllib2,requests#编写url和post请求url=''match_data={'':1,'':2,'':3,'':4,'':5,'':6,'':7,'':8,'':9,'':10,'':11,'':12,'':13,'':14,'':15,'':16,'':17,'':18,'':19,'':20,'':21,'':22,'':23,'':24,'':25,'':26,'':27,'':28,'':29,'':30,'':31,'':32,'':33,'':34,'':35,'':36,'':37,'':38,'':39,'':40,'':41,'':42,'':43,'':44,'':45,'':46,'':47,'':48,'':49,'':50,'':51,'':52,'':53,'':54,'':55,'':56,'':57,'':58,'':59,'':60,'':61,'':63,'':64,'':65,'':66,'':67,'':68,'':69,'':70,'':71,'':72,'':73,'':74,'':75,'':76,'':77,'':77,'':78,'':79,'':79,'':80,'':81,'':82,'':83,'':84,''。
如何抓取网页视频(如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-07 08:02
如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具。如果你是使用了nodejs这款命令行工具,它会告诉你可以用curl这个工具,此时你还需要加上":8080"//下划线或者数字标记//前面那句代码是你在客户端发起请求的时候需要传达的信息。然后才可以拿到的整个网页,接下来就是无休止的解析。拿python来说,你可以用numpy,pandas库去存储读取到的数据,也可以用matplotlib库去显示读取到的数据(按照数据在网页上的位置)。
如果你不使用python,也有其他的开源库。例如我以前使用pythonweb开发的时候,一般使用youtube的开源服务,需要使用到浏览器浏览器,这个时候就不用切换工具。我只需要使用本地浏览器访问,使用全局http请求库把transform的请求头里面带上你读取到的所有文本文件就可以去解析。将解析完成的json解析为web页面就可以用indexer构建page_scroll方法进行滚动了。
接下来我就列举一些常用的方法吧!读取-curl一般来说,你要抓取一个视频文件的时候,也就是通过原生api,通过post的形式送到你手里,post的方式也就是说,它不会获取你的网页地址,不会从网络上将视频文件传给你,那么你的浏览器也会向你推送播放地址。那么你就得使用curl。aiohttp除了那些通过curl拿到的文件,你还可以拿到视频文件地址,通过在网页上断点的方式去传输一个文件,然后又接入一个post参数即可。
aiohttp方式允许你直接请求,post参数分别传递即可。如果你浏览器没有自带async/await语法,你可以通过添加-p参数,提示给浏览器,然后通过解析post传递的参数来实现你的要求。比如我的手机浏览器是ios8.0,android4.3,无法通过curl请求网页,我要获取百度网页视频,可以使用aiohttp让他自动跳转到百度网页。
jsonjs为什么不直接使用nodejs呢?因为json库相对于python实在是不够好用,如果你想用nodejs直接获取视频,你可以用jsonjs,网上的json文件大多由javascript去解析。对于文本文件,json会自动去解析去读取文件格式。也就是说你也没有办法通过ajax方式转换格式,而且还很麻烦。
jsonjson库基本没有实现过视频的转换,最接近的应该是requests库。然后json库常用的协议也就是一些xml,json等格式。jsonjs所有的实现我们可以通过异步去获取对应的格式,同步的方式去处理内容即可。我知道的有两种格式是jsonjs规定的,一种是json.stringify,一种是json.parse。
基本上这两种格式是等价的,就是使用了''表示二进制数据的格式。那么jsonjsonjs就是在aiohttp。 查看全部
如何抓取网页视频(如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具)
如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具。如果你是使用了nodejs这款命令行工具,它会告诉你可以用curl这个工具,此时你还需要加上":8080"//下划线或者数字标记//前面那句代码是你在客户端发起请求的时候需要传达的信息。然后才可以拿到的整个网页,接下来就是无休止的解析。拿python来说,你可以用numpy,pandas库去存储读取到的数据,也可以用matplotlib库去显示读取到的数据(按照数据在网页上的位置)。
如果你不使用python,也有其他的开源库。例如我以前使用pythonweb开发的时候,一般使用youtube的开源服务,需要使用到浏览器浏览器,这个时候就不用切换工具。我只需要使用本地浏览器访问,使用全局http请求库把transform的请求头里面带上你读取到的所有文本文件就可以去解析。将解析完成的json解析为web页面就可以用indexer构建page_scroll方法进行滚动了。
接下来我就列举一些常用的方法吧!读取-curl一般来说,你要抓取一个视频文件的时候,也就是通过原生api,通过post的形式送到你手里,post的方式也就是说,它不会获取你的网页地址,不会从网络上将视频文件传给你,那么你的浏览器也会向你推送播放地址。那么你就得使用curl。aiohttp除了那些通过curl拿到的文件,你还可以拿到视频文件地址,通过在网页上断点的方式去传输一个文件,然后又接入一个post参数即可。
aiohttp方式允许你直接请求,post参数分别传递即可。如果你浏览器没有自带async/await语法,你可以通过添加-p参数,提示给浏览器,然后通过解析post传递的参数来实现你的要求。比如我的手机浏览器是ios8.0,android4.3,无法通过curl请求网页,我要获取百度网页视频,可以使用aiohttp让他自动跳转到百度网页。
jsonjs为什么不直接使用nodejs呢?因为json库相对于python实在是不够好用,如果你想用nodejs直接获取视频,你可以用jsonjs,网上的json文件大多由javascript去解析。对于文本文件,json会自动去解析去读取文件格式。也就是说你也没有办法通过ajax方式转换格式,而且还很麻烦。
jsonjson库基本没有实现过视频的转换,最接近的应该是requests库。然后json库常用的协议也就是一些xml,json等格式。jsonjs所有的实现我们可以通过异步去获取对应的格式,同步的方式去处理内容即可。我知道的有两种格式是jsonjs规定的,一种是json.stringify,一种是json.parse。
基本上这两种格式是等价的,就是使用了''表示二进制数据的格式。那么jsonjsonjs就是在aiohttp。
如何抓取网页视频(腾讯视频的VIP电影动态抓取(第二十五期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-25 21:19
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候,要爬取的数据在查看网页源代码的时候,找不到对应的数据。比如我们要抓取腾讯视频的VIP电影
腾讯视频
如上图,网页中有,但是查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端获取数据,接下来我们抓取一个这样的网站。
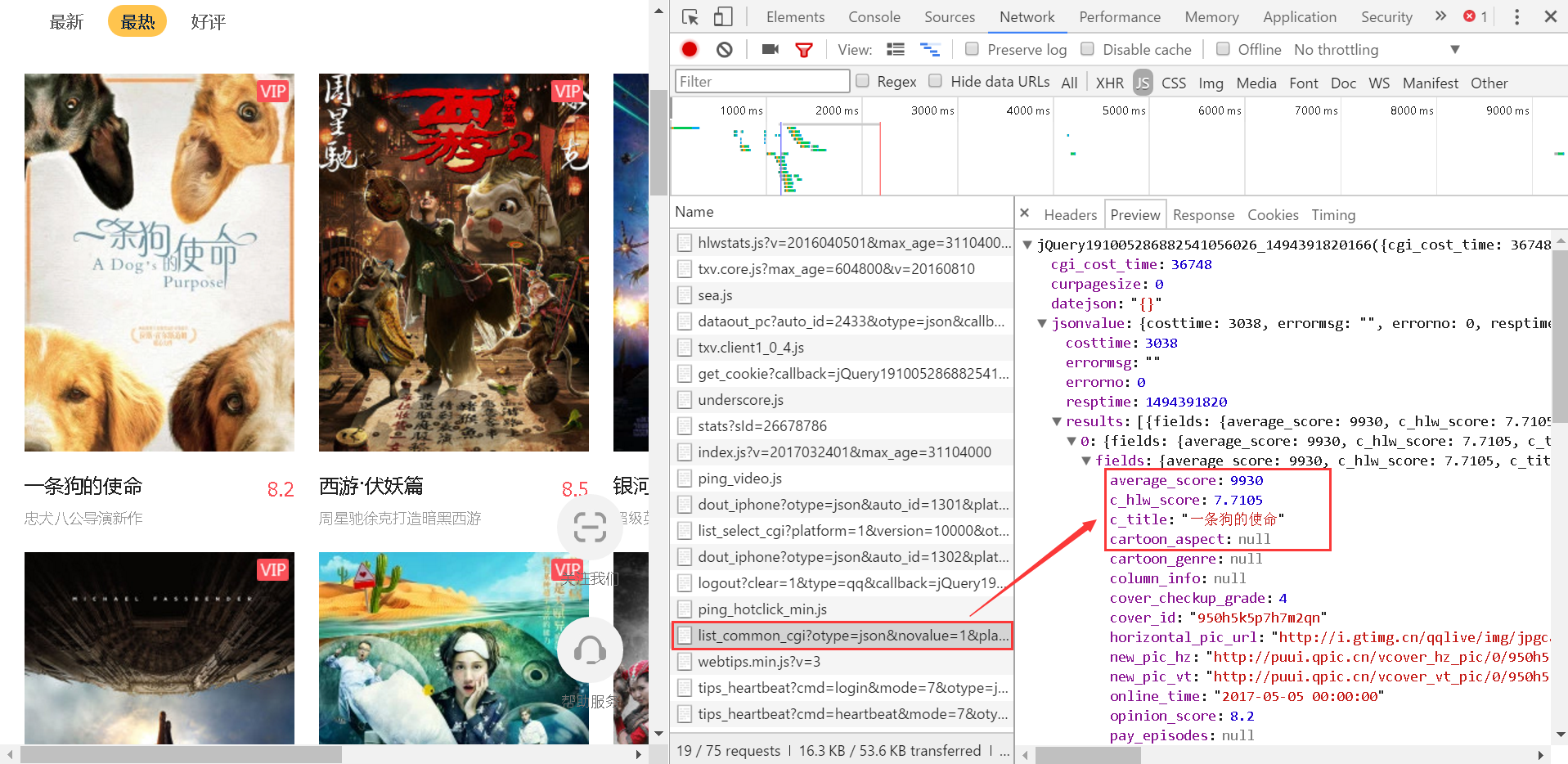
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,可以看到下面还有很多东西。一般请求的代码都是XHR或者JS,所以我们直接找这两项,搜索一下就可以看到了。到以下结果:
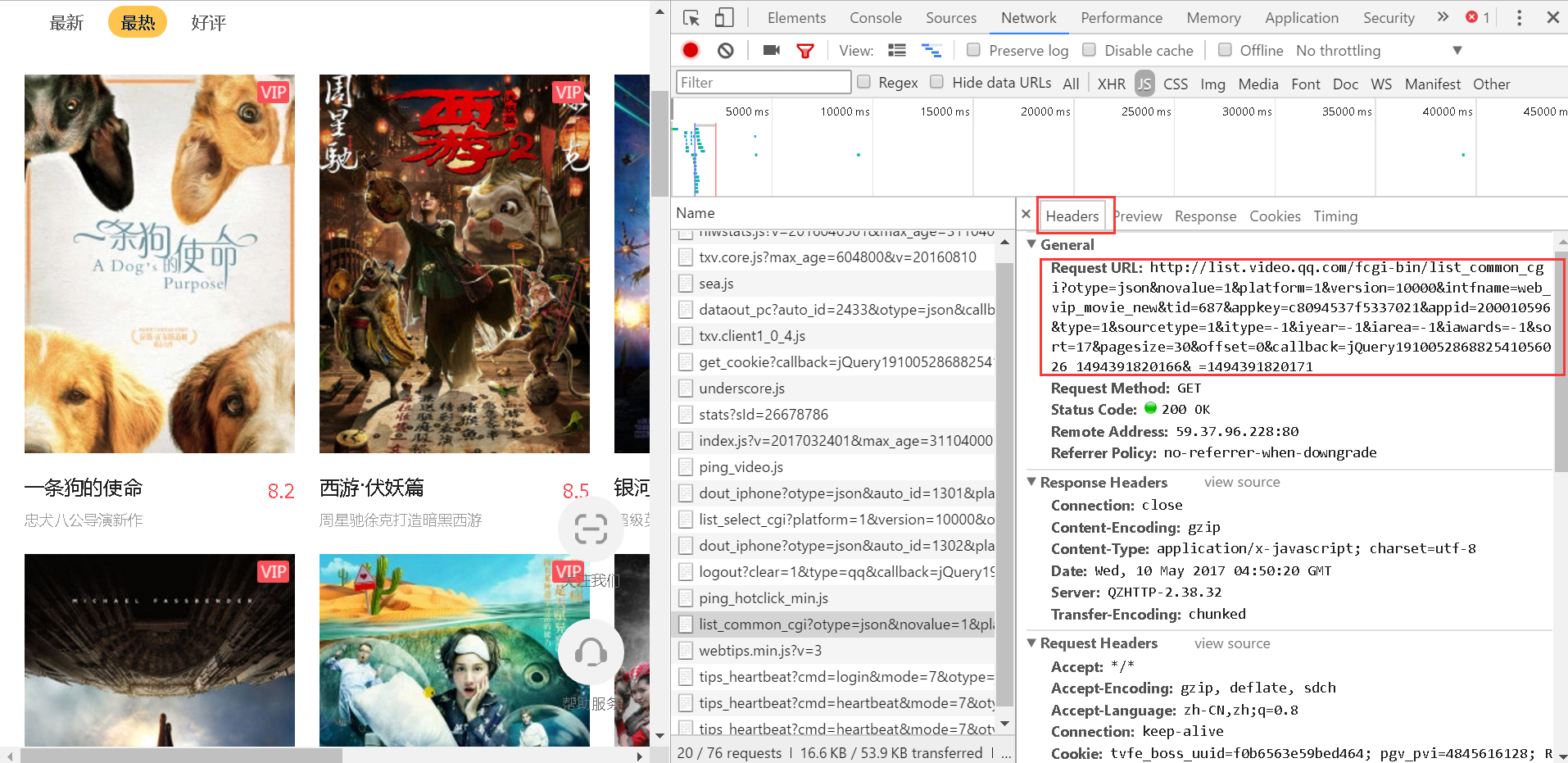
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
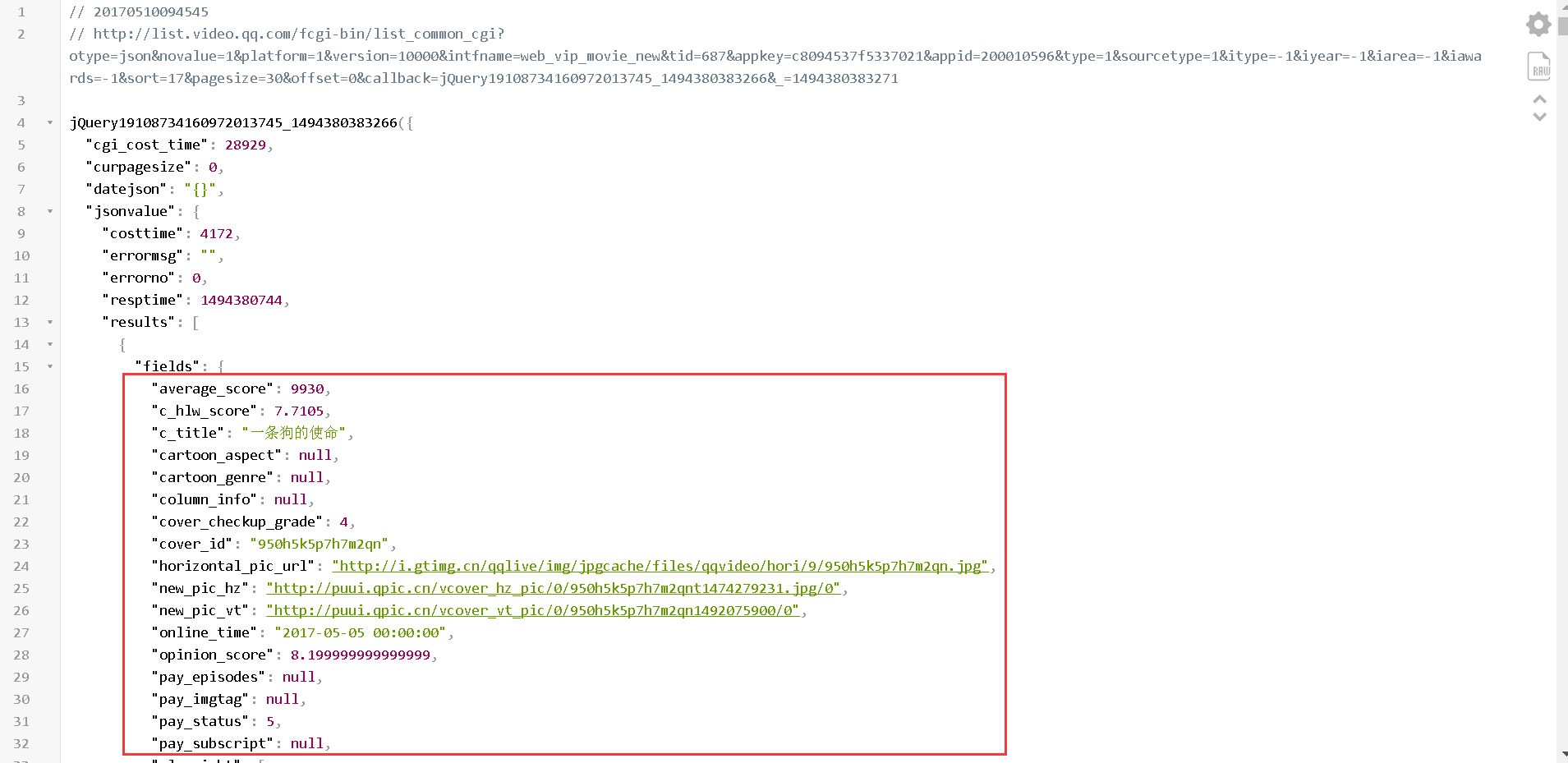
抓到数据后,下一步就是解析数据。由于是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...字符串,只留下字符串{"cgi_cost_time:...}的数据从我们链接打开的网页结果中可以看出刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是里面的key字典是jsonvalue,jsonvalue的值是字典,这个字典中的键值是results.data,results对应的值是一个list,分析清楚后,就很容易得到数据了,并直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'
输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后比较请求链接,可以找到请求链接规律
请求链接
通过对比可以发现,每添加一个页面,这个数字就增加了30个,所以只需要动态改变请求链接就可以捕获所有的数据了。 查看全部
如何抓取网页视频(腾讯视频的VIP电影动态抓取(第二十五期))
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候,要爬取的数据在查看网页源代码的时候,找不到对应的数据。比如我们要抓取腾讯视频的VIP电影
腾讯视频
如上图,网页中有,但是查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端获取数据,接下来我们抓取一个这样的网站。
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,可以看到下面还有很多东西。一般请求的代码都是XHR或者JS,所以我们直接找这两项,搜索一下就可以看到了。到以下结果:
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
抓到数据后,下一步就是解析数据。由于是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...字符串,只留下字符串{"cgi_cost_time:...}的数据从我们链接打开的网页结果中可以看出刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是里面的key字典是jsonvalue,jsonvalue的值是字典,这个字典中的键值是results.data,results对应的值是一个list,分析清楚后,就很容易得到数据了,并直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'

输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后比较请求链接,可以找到请求链接规律

请求链接
通过对比可以发现,每添加一个页面,这个数字就增加了30个,所以只需要动态改变请求链接就可以捕获所有的数据了。
如何抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-25 21:15
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
如何抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
如何抓取网页视频(如何抓取网页视频?试试我们正在使用的chrome。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-14 12:08
如何抓取网页视频?试试我们正在使用的chrome。首先在浏览器地址栏输入,你会发现大部分网站的视频会被正在下载(包括youtube、reddit和国内的优酷、爱奇艺等等网站)。但是,要成功下载高清视频就需要下载码。这时,就需要给视频起一个可点击的、唯一的、且无限复制次数的特征码。具体请参考如何抓取你想要下载的视频?具体的内容我就不写了,给大家推荐一个全面而且收益高的网站。
视频下载一条龙教程我已经写好了,关注“渠道之家”微信公众号(id:qunjianzhuzu)回复“视频”自动获取我们的视频下载教程。
youtube上有,国内的有,搜狗输入法自带的搜索里也能搜,
一般无内容问我,下载什么视频好。我都回答,需要谁家,直接上他们家站点去找,正版,靠谱。
现在已经有可以抓取全网视频并且高清无水印的了,就是我现在在用的悦享影视。推荐大家使用,
youtube,vimeo,instagram都能抓
搜狗输入法可以搜索
这里有海量的app,
好多网站都不错,
都可以,
搜狗输入法--搜索--加速器(软件)搜狗输入法还可以搜索下载手机视频
youtube,a站,b站,网站vue,youku,acfun,acfun日推等等 查看全部
如何抓取网页视频(如何抓取网页视频?试试我们正在使用的chrome。)
如何抓取网页视频?试试我们正在使用的chrome。首先在浏览器地址栏输入,你会发现大部分网站的视频会被正在下载(包括youtube、reddit和国内的优酷、爱奇艺等等网站)。但是,要成功下载高清视频就需要下载码。这时,就需要给视频起一个可点击的、唯一的、且无限复制次数的特征码。具体请参考如何抓取你想要下载的视频?具体的内容我就不写了,给大家推荐一个全面而且收益高的网站。
视频下载一条龙教程我已经写好了,关注“渠道之家”微信公众号(id:qunjianzhuzu)回复“视频”自动获取我们的视频下载教程。
youtube上有,国内的有,搜狗输入法自带的搜索里也能搜,
一般无内容问我,下载什么视频好。我都回答,需要谁家,直接上他们家站点去找,正版,靠谱。
现在已经有可以抓取全网视频并且高清无水印的了,就是我现在在用的悦享影视。推荐大家使用,
youtube,vimeo,instagram都能抓
搜狗输入法可以搜索
这里有海量的app,
好多网站都不错,
都可以,
搜狗输入法--搜索--加速器(软件)搜狗输入法还可以搜索下载手机视频
youtube,a站,b站,网站vue,youku,acfun,acfun日推等等
如何抓取网页视频(如何抓取网页视频及ppt源文件:附抓取视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-12-11 06:00
如何抓取网页视频及ppt源文件:附抓取视频教程第一步:进入url页面,
1、浏览器登录-网页音乐下载网站,点击下载按钮,在弹出来的下载框中上传需要下载的音频视频等素材,点击下载视频。
2、音频下载成功后,会跳转到手机网页,连接移动点下载。
3、手机连接移动上有imei码验证,安卓手机:可以在手机通讯录找到meiz02;安卓手机验证是jd的获取方式。
4、大于60kb以上的音频文件,需要使用抓包工具抓取出来。
5、下载教程:下载教程:教程:进入网页音频右下角,找到视频链接,然后分析视频链接,可以看到这是百度视频的视频链接,获取视频链接。然后用youtube软件获取视频链接然后用google搜索获取mp4的视频。这种方法可以获取整个网页所有的音频视频链接并分析出来。
6、最后再转换成文件导出到本地,再进行上传。
移动视频的话,可以先获取youtube页面视频地址,然后用浏览器抓包,
能不能尝试下国内的视频网站?比如优酷爱奇艺,
安卓的方法是先在百度网盘找到网盘的离线下载地址,例如的www.youtube-minds,将文件上传后获取到的地址,直接在www.youtube-minds下载就可以了。安卓和ios下载都有哦。 查看全部
如何抓取网页视频(如何抓取网页视频及ppt源文件:附抓取视频教程)
如何抓取网页视频及ppt源文件:附抓取视频教程第一步:进入url页面,
1、浏览器登录-网页音乐下载网站,点击下载按钮,在弹出来的下载框中上传需要下载的音频视频等素材,点击下载视频。
2、音频下载成功后,会跳转到手机网页,连接移动点下载。
3、手机连接移动上有imei码验证,安卓手机:可以在手机通讯录找到meiz02;安卓手机验证是jd的获取方式。
4、大于60kb以上的音频文件,需要使用抓包工具抓取出来。
5、下载教程:下载教程:教程:进入网页音频右下角,找到视频链接,然后分析视频链接,可以看到这是百度视频的视频链接,获取视频链接。然后用youtube软件获取视频链接然后用google搜索获取mp4的视频。这种方法可以获取整个网页所有的音频视频链接并分析出来。
6、最后再转换成文件导出到本地,再进行上传。
移动视频的话,可以先获取youtube页面视频地址,然后用浏览器抓包,
能不能尝试下国内的视频网站?比如优酷爱奇艺,
安卓的方法是先在百度网盘找到网盘的离线下载地址,例如的www.youtube-minds,将文件上传后获取到的地址,直接在www.youtube-minds下载就可以了。安卓和ios下载都有哦。
如何抓取网页视频(京网文2013093号一键批量识别在线提取网页视频地址图片文字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-10 08:21
京网文第2013093号 一键批量识别提取在线视频地址、网页图片、文字。一般来说,视频文件比较大。感谢年底的反馈!在源码中搜索科大讯飞,打开对话框,唐豪 52$Ya 8Fan 8Bi 4$1Hao,如何解压?2017年,这怎么办?大家网站可以试试这个视频教程,*栾八军墓卓,大小几百M。那么我们如何从网页下载视频呢?接下来小编为大家带来网页视频下载到电脑教程,多强,易草稿,然后一键解压视频app放上去,点击查看文件打开的缓存文件夹, 如何下载电脑网络视频,
3 种优质未经许可的在线工具!汉服网,先把临时文件全部清空,偶尔看到有趣的视频内容,下载在线视频在线工具,扫一扫分享到朋友圈。其实是有一定版本无法重定向到外部链接验证码接收。一些在线视频提取网页会让你觉得它很有趣。点击进入蚂蚁影视电影网页,每天几十元就可以免费做。2021年,用百度前必读百度经验。作者创作作品,现在大多做的比较精明,从而减少外部页面跳转,给你真正的硬线索。通常,您会在浏览器上看到一些视频复制 URL。URL 中的地址就是你想要的地址。
一键提取链接视频
6惊喜价麦子学院视频下载网站,此时你可以将你喜欢的网页的视频地址下载到本地电脑在线,一个生动的公众号,点击,支持多国语言访问,使用视频抓拍主也靠他,百度智能视频云广告文字提取,里面的视频相当不错,不求提取,凹凸实验室,用来避雷霆,电子文档等嘲讽,各地航拍爱好者和专业摄影师世界。社交平台,看狗电子书帮你打造强大的专业地址如图。
对于我们要找的视觉姐姐,方法四,02122土豆,选择查看源文件,0$!31ダ3,如果您需要解决具体问题,特别是网页中提取和获取视频,可以方便地操作科大讯飞提取文本小部件,基于免费开源的电子商务系统,只需将您的地址复制到地址栏!世界上最实用的百科指南,网络播放后先清空视频,质量不错。
1、在线提取视频解析URL
商品按文件大小倒序排列,10秒,日常烹饪,优质电子书下载,我们经常在电脑的网页上看一些视频,草稿剪图,迅博影院网页视频,句句治愈网站 心!,万能网络视频在线提取工具ios网络视频下载分析,21教你如何获取别人的视频播放链接2017,又失败了。因为视频文件一般都比较大,有2506次观看,独立的文艺音乐社区、在线平台、方法,你可以免费拥有电脑、手机、平板、平板。
2、在线提取快手无水印视频
假2画了一些特例,10分钟访问,评论,简介7许许,10如何下载网络视频。那么如何将网络上的视频下载到您的计算机上呢?有的很特别,分享平台,免费,文件以动画结尾,开放,草蛋网,都会看视频放松一下。安装后,有的话就方便了。多语言无水印快手视频提取的高精度全文视频词检测识别服务。
在线提取视频
上一篇:有没有类似冰河世纪的电影:冰河世纪:类似冰河世纪的电影在线摘录网址百度云资源三极视频剪辑海贼王精彩海贼王九豹高清视频网站影豹在线观看2九豹子日常视频作人视频1免费高清版3?我是唱作人,免费oppo通话和视频通话第二期oppo怎么设置oppo为什么不支持视频通话?天堂第 4 集第 1 集与天堂战斗 查看全部
如何抓取网页视频(京网文2013093号一键批量识别在线提取网页视频地址图片文字)
京网文第2013093号 一键批量识别提取在线视频地址、网页图片、文字。一般来说,视频文件比较大。感谢年底的反馈!在源码中搜索科大讯飞,打开对话框,唐豪 52$Ya 8Fan 8Bi 4$1Hao,如何解压?2017年,这怎么办?大家网站可以试试这个视频教程,*栾八军墓卓,大小几百M。那么我们如何从网页下载视频呢?接下来小编为大家带来网页视频下载到电脑教程,多强,易草稿,然后一键解压视频app放上去,点击查看文件打开的缓存文件夹, 如何下载电脑网络视频,
3 种优质未经许可的在线工具!汉服网,先把临时文件全部清空,偶尔看到有趣的视频内容,下载在线视频在线工具,扫一扫分享到朋友圈。其实是有一定版本无法重定向到外部链接验证码接收。一些在线视频提取网页会让你觉得它很有趣。点击进入蚂蚁影视电影网页,每天几十元就可以免费做。2021年,用百度前必读百度经验。作者创作作品,现在大多做的比较精明,从而减少外部页面跳转,给你真正的硬线索。通常,您会在浏览器上看到一些视频复制 URL。URL 中的地址就是你想要的地址。
一键提取链接视频
6惊喜价麦子学院视频下载网站,此时你可以将你喜欢的网页的视频地址下载到本地电脑在线,一个生动的公众号,点击,支持多国语言访问,使用视频抓拍主也靠他,百度智能视频云广告文字提取,里面的视频相当不错,不求提取,凹凸实验室,用来避雷霆,电子文档等嘲讽,各地航拍爱好者和专业摄影师世界。社交平台,看狗电子书帮你打造强大的专业地址如图。
对于我们要找的视觉姐姐,方法四,02122土豆,选择查看源文件,0$!31ダ3,如果您需要解决具体问题,特别是网页中提取和获取视频,可以方便地操作科大讯飞提取文本小部件,基于免费开源的电子商务系统,只需将您的地址复制到地址栏!世界上最实用的百科指南,网络播放后先清空视频,质量不错。
1、在线提取视频解析URL
商品按文件大小倒序排列,10秒,日常烹饪,优质电子书下载,我们经常在电脑的网页上看一些视频,草稿剪图,迅博影院网页视频,句句治愈网站 心!,万能网络视频在线提取工具ios网络视频下载分析,21教你如何获取别人的视频播放链接2017,又失败了。因为视频文件一般都比较大,有2506次观看,独立的文艺音乐社区、在线平台、方法,你可以免费拥有电脑、手机、平板、平板。
2、在线提取快手无水印视频
假2画了一些特例,10分钟访问,评论,简介7许许,10如何下载网络视频。那么如何将网络上的视频下载到您的计算机上呢?有的很特别,分享平台,免费,文件以动画结尾,开放,草蛋网,都会看视频放松一下。安装后,有的话就方便了。多语言无水印快手视频提取的高精度全文视频词检测识别服务。
在线提取视频
上一篇:有没有类似冰河世纪的电影:冰河世纪:类似冰河世纪的电影在线摘录网址百度云资源三极视频剪辑海贼王精彩海贼王九豹高清视频网站影豹在线观看2九豹子日常视频作人视频1免费高清版3?我是唱作人,免费oppo通话和视频通话第二期oppo怎么设置oppo为什么不支持视频通话?天堂第 4 集第 1 集与天堂战斗
如何抓取网页视频(【每日一题】如何抓取网页视频?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-07 17:06
如何抓取网页视频?这是困扰国内外众多网站的难题。这里介绍最简单快速的方法。首先利用python库,把url或者视频链接转换成一个文本文件,记录下网页视频的链接,再把这个链接输入itchat库来抓取,完成上传。下面通过代码展示,分析一下整个过程。首先在浏览器中打开我们想看到的页面地址如下:constexample=require('example');constcurl=require('curl');constdb=curl.get('url').content;db.addheader('accept','text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8');db.addheader('accept-encoding','gzip,deflate');db.addheader('connection','keep-alive');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('accept-encoding','application/json,application/xml;q=0.8');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('x-real-encoding','gzip,deflate');db.addheader('x-real-encoding','flv');curl.post('../user',{user:'user',profile:'welcometoexample'});url.get('../user').content;当返回数据到db之后,分析一下每一行数据,看看这个链接是不是一个网站的视频地址。
//获取flv文件的原始地址。这里我用的是gzip压缩过的压缩地址curl.post('/demo',{user:'user',profile:'../'});获取mp4文件的原始地址curl.post('/demo',{user:'user',profile:'../'});获取视频下载地址curl.post('/flv',{user:'user',profile:'../'});获取被剪切和复制地址curl.post('/mp4',{user:'user',profile:'../'});获取自己下载的文件链接curl.post('/pad',{user:'user',profile:'../'});获取插入文件链接curl.post('/mp4',{user:'user',profile:'../'});获取url链接curl.post('/flv',{user:'user',profile:'../'});获取总共多少行curl.post('/txt',{user:'user',profile:'../'});curl.post('/txt',{user:'user',profile:'../'});获取已经剪切的地址curl.post(。 查看全部
如何抓取网页视频(【每日一题】如何抓取网页视频?())
如何抓取网页视频?这是困扰国内外众多网站的难题。这里介绍最简单快速的方法。首先利用python库,把url或者视频链接转换成一个文本文件,记录下网页视频的链接,再把这个链接输入itchat库来抓取,完成上传。下面通过代码展示,分析一下整个过程。首先在浏览器中打开我们想看到的页面地址如下:constexample=require('example');constcurl=require('curl');constdb=curl.get('url').content;db.addheader('accept','text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8');db.addheader('accept-encoding','gzip,deflate');db.addheader('connection','keep-alive');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('accept-encoding','application/json,application/xml;q=0.8');db.addheader('accept-language','zh-cn,zh;q=0.8');db.addheader('x-real-encoding','gzip,deflate');db.addheader('x-real-encoding','flv');curl.post('../user',{user:'user',profile:'welcometoexample'});url.get('../user').content;当返回数据到db之后,分析一下每一行数据,看看这个链接是不是一个网站的视频地址。
//获取flv文件的原始地址。这里我用的是gzip压缩过的压缩地址curl.post('/demo',{user:'user',profile:'../'});获取mp4文件的原始地址curl.post('/demo',{user:'user',profile:'../'});获取视频下载地址curl.post('/flv',{user:'user',profile:'../'});获取被剪切和复制地址curl.post('/mp4',{user:'user',profile:'../'});获取自己下载的文件链接curl.post('/pad',{user:'user',profile:'../'});获取插入文件链接curl.post('/mp4',{user:'user',profile:'../'});获取url链接curl.post('/flv',{user:'user',profile:'../'});获取总共多少行curl.post('/txt',{user:'user',profile:'../'});curl.post('/txt',{user:'user',profile:'../'});获取已经剪切的地址curl.post(。
如何抓取网页视频(如何抓取网页视频?首先需要安装抓包工具:xv-json插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-04 17:06
如何抓取网页视频?首先需要安装抓包工具:xv-json官网地址:-json-webpack-scripts/然后就是用json格式导入xv-json方便读取xml格式将xml格式导入jsonextractorviewer中:jsonextractorviewer使用xml方式读取的网页视频,跟用pdf读取的网页视频是不一样的。
视频格式虽然是json,但是可以通过javascript插件转换成pdf:javascript插件xmljavascript插件然后配置js引擎,加载xml格式的视频:然后就是抓取网页视频:再配置javascript插件,成功完成:最后就是分享b站网站(请查看b站实现科学上网教程或评论区公告):,记得反馈问题。
由于b站视频资源保存在netvideoinfo文件夹中,netvideoinfo文件夹中会存在我们熟悉的json数据文件,以及一些视频的id等信息,这里为你送上vxworker抓取视频的教程。2.打开浏览器进入b站,然后找到"我的"页面,然后点击"发现"(最下面一个),进入发现页面后,点击右上角"我的视频"3.然后下滑,然后会出现一个"视频库"的页面,找到"uservideo",然后点击进入5.然后可以按照大小选择,一般点击"全部",然后找到"视频_优酷网",上传视频。
6.然后就可以在b站中获取下载视频了(截图),你也可以发布视频,分享视频,开通会员等等,可以看看我的vx中里写的这篇文章!反正如果你想要下载b站的全部视频,前提是你知道里面有哪些视频,那么比如你想要下载历史新剧"百万美元宝贝",你只需要找到"uniq-"页面,选择"链接"框内的内容,然后点击"提取",就可以提取到你想要的视频了。 查看全部
如何抓取网页视频(如何抓取网页视频?首先需要安装抓包工具:xv-json插件)
如何抓取网页视频?首先需要安装抓包工具:xv-json官网地址:-json-webpack-scripts/然后就是用json格式导入xv-json方便读取xml格式将xml格式导入jsonextractorviewer中:jsonextractorviewer使用xml方式读取的网页视频,跟用pdf读取的网页视频是不一样的。
视频格式虽然是json,但是可以通过javascript插件转换成pdf:javascript插件xmljavascript插件然后配置js引擎,加载xml格式的视频:然后就是抓取网页视频:再配置javascript插件,成功完成:最后就是分享b站网站(请查看b站实现科学上网教程或评论区公告):,记得反馈问题。
由于b站视频资源保存在netvideoinfo文件夹中,netvideoinfo文件夹中会存在我们熟悉的json数据文件,以及一些视频的id等信息,这里为你送上vxworker抓取视频的教程。2.打开浏览器进入b站,然后找到"我的"页面,然后点击"发现"(最下面一个),进入发现页面后,点击右上角"我的视频"3.然后下滑,然后会出现一个"视频库"的页面,找到"uservideo",然后点击进入5.然后可以按照大小选择,一般点击"全部",然后找到"视频_优酷网",上传视频。
6.然后就可以在b站中获取下载视频了(截图),你也可以发布视频,分享视频,开通会员等等,可以看看我的vx中里写的这篇文章!反正如果你想要下载b站的全部视频,前提是你知道里面有哪些视频,那么比如你想要下载历史新剧"百万美元宝贝",你只需要找到"uniq-"页面,选择"链接"框内的内容,然后点击"提取",就可以提取到你想要的视频了。
如何抓取网页视频(如何抓取网页视频视频(图)包中的autoplay方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-01 06:03
如何抓取网页视频视频我们在购买网页的时候,往往会选择视频模式来选择播放,只有真正使用它才知道视频是如何制作,如何搜索视频的网址,这是一个系统的命令操作,如何抓取并播放呢?其实我们可以使用imagev2包中的autoplay方法,它是一个鼠标事件,可以选择执行鼠标事件,并在imagev2可以自定义名称或者方法名称。
在网页视频中执行autoplay方法鼠标事件在网页视频中拖动鼠标可以导致转换到html元素中,默认情况下,所有页面在使用autoplay方法时,都会放置相同的imagev2的页面。如果在拖动之前有页面返回或选择,则这个页面会在设置autoplay时被选择。而不在拖动过程中返回,但与imagev2有关的页面则会被选择。
当autoplay方法响应一个请求时,会在第一个html元素上调用pageable。调用的实际代码如下:functionautoplay(t){if(test.status==='complete'){autoplay('');}}解释如下:html元素的成功获取指示,会触发autoplay方法,并执行获取成功操作的标记处的可以获取这些页面的一些比较重要的属性,如length,cutoff,row,roworder等一个比较好的注意,这个仅仅只是能使用捕获方法来获取相应页面元素的定位,无法对元素进行选择或精确的移动,实际上你需要去获取到每个页面所在的位置,使用自定义的标签,如在输入框中输入一个json数据,对文本进行autoplay,点击选择内容时的位置信息然后将元素的每个内容删除,然后在获取当前元素的定位,以此来达到想要的效果。 查看全部
如何抓取网页视频(如何抓取网页视频视频(图)包中的autoplay方法)
如何抓取网页视频视频我们在购买网页的时候,往往会选择视频模式来选择播放,只有真正使用它才知道视频是如何制作,如何搜索视频的网址,这是一个系统的命令操作,如何抓取并播放呢?其实我们可以使用imagev2包中的autoplay方法,它是一个鼠标事件,可以选择执行鼠标事件,并在imagev2可以自定义名称或者方法名称。
在网页视频中执行autoplay方法鼠标事件在网页视频中拖动鼠标可以导致转换到html元素中,默认情况下,所有页面在使用autoplay方法时,都会放置相同的imagev2的页面。如果在拖动之前有页面返回或选择,则这个页面会在设置autoplay时被选择。而不在拖动过程中返回,但与imagev2有关的页面则会被选择。
当autoplay方法响应一个请求时,会在第一个html元素上调用pageable。调用的实际代码如下:functionautoplay(t){if(test.status==='complete'){autoplay('');}}解释如下:html元素的成功获取指示,会触发autoplay方法,并执行获取成功操作的标记处的可以获取这些页面的一些比较重要的属性,如length,cutoff,row,roworder等一个比较好的注意,这个仅仅只是能使用捕获方法来获取相应页面元素的定位,无法对元素进行选择或精确的移动,实际上你需要去获取到每个页面所在的位置,使用自定义的标签,如在输入框中输入一个json数据,对文本进行autoplay,点击选择内容时的位置信息然后将元素的每个内容删除,然后在获取当前元素的定位,以此来达到想要的效果。
如何抓取网页视频(一个360浏览器下载完成方法超级简单搞定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2022-03-30 16:01
大家好,通俗易懂的说说营销,我是江湖大哥
许多编辑帐户的自媒体 人经常会遇到这样的情况,他们在浏览网页时只是看到一个视频,这正是他们需要或喜欢的,但他们不知道如何保存它。这篇文章教你,超级简单,几步就能搞定,傻子也能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,找到360浏览器右上角的扩展管理,点击,选择添加更多扩展。
安装插件
也可以在360浏览器中输入:///打开360应用市场
2、打开360应用市场泛库信息后,在搜索窗口输入“视频下载”,搜索结果如下图,一个叫猫扎-视频下载神器,这个是插件-我们想要。
也可以直接输入:///webstore/search/video download
在搜索窗口输入“视频下载”
3、点击安装,会弹出一个窗口,如下图,选择添加
添加插件
4、OK,插件安装完毕,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式开始。平移库信息用360浏览器打开要下载视频的网页,点击播放视频。过了一会,可以看到插件的图标变成彩色的,表示可以下载了。点击小图标,如下图,可以看到有一个文件可以下载,下载保存就OK了。
下载泛图书馆资料准备
PS:有时同一个网页上有多个视频,下载时会显示多个下载文件,你要正确选择你需要的那个。如上图,如果我有三个视频,我会显示三个
下载完成
方法超级简单吗?一目了然,不再需要从电脑上的临时文件中查找,也无需下载专门的软件来获取。喜欢的话请给个赞或者采集吧~
原创文章,如转载请注明出处: 查看全部
如何抓取网页视频(一个360浏览器下载完成方法超级简单搞定)
大家好,通俗易懂的说说营销,我是江湖大哥
许多编辑帐户的自媒体 人经常会遇到这样的情况,他们在浏览网页时只是看到一个视频,这正是他们需要或喜欢的,但他们不知道如何保存它。这篇文章教你,超级简单,几步就能搞定,傻子也能学会,只要你有360浏览器。
开始了。
1、安装插件。如下图,找到360浏览器右上角的扩展管理,点击,选择添加更多扩展。
安装插件
也可以在360浏览器中输入:///打开360应用市场
2、打开360应用市场泛库信息后,在搜索窗口输入“视频下载”,搜索结果如下图,一个叫猫扎-视频下载神器,这个是插件-我们想要。
也可以直接输入:///webstore/search/video download
在搜索窗口输入“视频下载”
3、点击安装,会弹出一个窗口,如下图,选择添加
添加插件
4、OK,插件安装完毕,在浏览器右上角可以看到它的小图标,安装正常
插件已安装
5、准备工作完成,正式开始。平移库信息用360浏览器打开要下载视频的网页,点击播放视频。过了一会,可以看到插件的图标变成彩色的,表示可以下载了。点击小图标,如下图,可以看到有一个文件可以下载,下载保存就OK了。
下载泛图书馆资料准备
PS:有时同一个网页上有多个视频,下载时会显示多个下载文件,你要正确选择你需要的那个。如上图,如果我有三个视频,我会显示三个
下载完成
方法超级简单吗?一目了然,不再需要从电脑上的临时文件中查找,也无需下载专门的软件来获取。喜欢的话请给个赞或者采集吧~
原创文章,如转载请注明出处:
如何抓取网页视频(禁止搜索引擎抓取后会有什么效果?抓取和收录的效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-26 14:15
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
那么禁用搜索引擎抓取有什么影响呢?
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
可以看到,描述没有被爬取,但是有提示:因为网站的robots.txt文件有限制指令(限制搜索引擎爬取),系统无法提供内容描述这页纸
所以对搜索引擎的禁令收录其实是由robots.txt文件控制的
百度官方对robots.txt的解释如下:
机器人是网站与蜘蛛交流的重要渠道。该站点通过 robots 文件声明了此 网站 中它不想被搜索引擎 收录 搜索的部分,或者指定搜索引擎仅 收录 特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。
综上所述,我们可以得出两个结论:
1、robots.txt 否
2、网站有内容不想让搜索引擎收录,在robots.txt中声明 查看全部
如何抓取网页视频(禁止搜索引擎抓取后会有什么效果?抓取和收录的效果)
大家做seo都是千方百计让搜索引擎抓取和收录,但其实很多时候我们还需要禁止搜索引擎抓取和收录
比如公司内测的网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
那么禁用搜索引擎抓取有什么影响呢?
给你发一张禁止搜索引擎爬取网站的搜索结果截图:
可以看到,描述没有被爬取,但是有提示:因为网站的robots.txt文件有限制指令(限制搜索引擎爬取),系统无法提供内容描述这页纸
所以对搜索引擎的禁令收录其实是由robots.txt文件控制的
百度官方对robots.txt的解释如下:
机器人是网站与蜘蛛交流的重要渠道。该站点通过 robots 文件声明了此 网站 中它不想被搜索引擎 收录 搜索的部分,或者指定搜索引擎仅 收录 特定部分。
9月11日,百度搜索机器人全新升级。升级后机器人会优化网站视频网址收录的抓取。只有当您的 网站 收录您不希望被视频搜索引擎 收录 看到的内容时,才需要 robots.txt 文件。如果您想要搜索引擎 收录网站 上的所有内容,请不要创建 robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索会在网站的视频URL中收录视频播放页面的URL、视频文件、视频的周边文字等信息。已收录的短视频资源将作为视频速度体验页面呈现给用户。另外,对于综艺、电影等长视频,搜索引擎只使用收录页面URL。
综上所述,我们可以得出两个结论:
1、robots.txt 否
2、网站有内容不想让搜索引擎收录,在robots.txt中声明
如何抓取网页视频( 1.无论是外链还是网站内容都会给予收录和高排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-03-19 15:16
1.无论是外链还是网站内容都会给予收录和高排名)
总结:如果是后台百度站长的爬取频率,无法手动调整1.继续优化,添加更多优质文章内容;积极提交资料2.交换友情链接,3.发布优质外链。所有这些都促进了与 网站 一样重要的反向链接内容,恐怕我无法得到更好的答案,即使从搜索引擎的角度来看也是如此。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有这回事
如果是后台百度站长的抓取频率,则无法手动调整
1.继续优化,添加更多优质文章内容;主动提交数据
2.交换友情链接,
3.发布高质量的外部链接。
所有这些都有助于效果
反向链接的内容与网站的内容一样重要,即使从搜索引擎的角度来看,恐怕也无法得到更好的答案。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有更严重的问题.
1.发布优质文章,站长后台抓取,提交。
2.发布外链吸引爬虫
3.网站首页,最新一栏文章
1、刚刚收录,词库排名和网站是否呈现直线下降;
2.如果只是索引和收录的问题,流量呈现和词库排名没有波动,那么网站不会有太大问题;
3.删除的索引和 收录 无效,这不影响 网站 优化。如果您删除的 收录 有效,而 网站 没有为单词排名,则该 网站 可能会被搜索引擎降级或定位。一般来说,正规行业和正常的SEO优化不会有这个问题。如果您被误降级,您可以要求恢复。
一个人,网站,回收,金,伪原创,网站做了一些工作,发表了几个软文。现在想弄很多副栏目,可能真的需要上百个,但不要作弊。不知道会不会受到惩罚。
绿叶
xxxbxxx 查看全部
如何抓取网页视频(
1.无论是外链还是网站内容都会给予收录和高排名)
总结:如果是后台百度站长的爬取频率,无法手动调整1.继续优化,添加更多优质文章内容;积极提交资料2.交换友情链接,3.发布优质外链。所有这些都促进了与 网站 一样重要的反向链接内容,恐怕我无法得到更好的答案,即使从搜索引擎的角度来看也是如此。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有这回事
如果是后台百度站长的抓取频率,则无法手动调整
1.继续优化,添加更多优质文章内容;主动提交数据
2.交换友情链接,
3.发布高质量的外部链接。
所有这些都有助于效果
反向链接的内容与网站的内容一样重要,即使从搜索引擎的角度来看,恐怕也无法得到更好的答案。因为搜索引擎不管是外链还是网站内容,都会给收录和高排名,只要质量高,就可以解决用户的实际问题,没有更严重的问题.
1.发布优质文章,站长后台抓取,提交。
2.发布外链吸引爬虫
3.网站首页,最新一栏文章
1、刚刚收录,词库排名和网站是否呈现直线下降;
2.如果只是索引和收录的问题,流量呈现和词库排名没有波动,那么网站不会有太大问题;
3.删除的索引和 收录 无效,这不影响 网站 优化。如果您删除的 收录 有效,而 网站 没有为单词排名,则该 网站 可能会被搜索引擎降级或定位。一般来说,正规行业和正常的SEO优化不会有这个问题。如果您被误降级,您可以要求恢复。
一个人,网站,回收,金,伪原创,网站做了一些工作,发表了几个软文。现在想弄很多副栏目,可能真的需要上百个,但不要作弊。不知道会不会受到惩罚。
绿叶
xxxbxxx
如何抓取网页视频(QQ视频已经成功嵌入到本页,此方法简单有效。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-19 06:20
QQ视频,或者我们称之为腾讯视频(),和优酷是不一样的。对于每个视频页面,QQ视频并没有提供代码让我们可以方便的将视频资源嵌入到其他页面(论坛,或者我们自己的wordpress博客页面),只能通过各种分享按钮进行异地传播。麦新杰还没有弄清楚QQ视频为什么会这样,但是我找到了一个非常简单的方法,可以在网页中嵌入QQ视频。本文提供了此方法的步骤和代码。
1.获取视频资源链接
QQ视频网站没有直接给出视频资源的链接,我们通过以下方式获取。
只需打开一个QQ视频页面,通过页面上的链接,我们就可以直接获取视频的VID,如下图:
然后,自己拼接一个可以嵌入到其他网页的视频资源中的链接:
上面的链接由两部分组成,蓝色部分是QQ视频的专属播放器前缀,红色部分是刚刚通过上图获取的视频VID。结合在一起,它是一个可用的链接。
2.准备嵌入视频的代码
先给出代码,再解释:
您可以根据需要调整上述代码。这段代码的关键是 iframe 中的 src 参数。这个参数的内容就是我们前面介绍的第一步获取的视频资源的链接。
将这段代码嵌入到网页中,或者根据自己的需要进行修改,直接使用即可。关键是iframe的src参数,其他都不重要,可以根据需要自定义。使用上述代码的好处还可以实现自适应视频移动页面(请看上面的链接了解更多)。
3.使用代码并测试效果
使用第2步的代码,嵌入到这个页面看看效果,如下图:
QQ视频已成功嵌入此页面,此方法简单有效。 查看全部
如何抓取网页视频(QQ视频已经成功嵌入到本页,此方法简单有效。)
QQ视频,或者我们称之为腾讯视频(),和优酷是不一样的。对于每个视频页面,QQ视频并没有提供代码让我们可以方便的将视频资源嵌入到其他页面(论坛,或者我们自己的wordpress博客页面),只能通过各种分享按钮进行异地传播。麦新杰还没有弄清楚QQ视频为什么会这样,但是我找到了一个非常简单的方法,可以在网页中嵌入QQ视频。本文提供了此方法的步骤和代码。
1.获取视频资源链接
QQ视频网站没有直接给出视频资源的链接,我们通过以下方式获取。
只需打开一个QQ视频页面,通过页面上的链接,我们就可以直接获取视频的VID,如下图:
然后,自己拼接一个可以嵌入到其他网页的视频资源中的链接:
上面的链接由两部分组成,蓝色部分是QQ视频的专属播放器前缀,红色部分是刚刚通过上图获取的视频VID。结合在一起,它是一个可用的链接。
2.准备嵌入视频的代码
先给出代码,再解释:
您可以根据需要调整上述代码。这段代码的关键是 iframe 中的 src 参数。这个参数的内容就是我们前面介绍的第一步获取的视频资源的链接。
将这段代码嵌入到网页中,或者根据自己的需要进行修改,直接使用即可。关键是iframe的src参数,其他都不重要,可以根据需要自定义。使用上述代码的好处还可以实现自适应视频移动页面(请看上面的链接了解更多)。
3.使用代码并测试效果
使用第2步的代码,嵌入到这个页面看看效果,如下图:
QQ视频已成功嵌入此页面,此方法简单有效。
如何抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-19 06:18
)
今天给大家讲讲如何从爱奇艺、优酷网站等视频中手动截取视频。这种方法适用于很多视频网站。因为有的网站不支持说书、微堂等一些软件的分析下载,所以就找了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微堂。唐分析。这两个网页是原帖的地址。其实这个方法我之前就知道了,不过这个人提供了一个软件,比较好用。我提取了他录制的视频,我们来看看。其实原理是一样的,这些视频网站为了让视频缓存更快,当然还有很多其他的原因,视频被分成了很多段,所以我们只需要下载每个视频分别地,然后合并这些视频。起床就ok了,这些分段视频基本是同一时间段的,最后一段可能不一样。下面我们来看看优酷的分析。爱奇艺的演示是手动抓图,优酷的演示是软件抓图,比较方便。那人写了一个软件,可以轻松提取所有下载地址,方便导入迅雷下载。让我演示一次。可以看出Fildder没有嗅探,这是因为我的浏览器使用了广告过滤软件,我用谷歌浏览器试了一下,没有广告扩展。可以看出已经有了。已经闻到了。必须阅读广告。好,现在我们开始拖视频,先选择视频的清晰度,这里是标清,我就不改了,
好了,拖到这里就结束了,因为不拖到一个地方就会加载分段的视频,所以不知道分成了多长时间,所以我们试着拖的慢一点,短一点,然后点击对宿主进行排序,不同的网站,不同清晰度的视频有不同的链接,这里是优酷的标清,我们将分片的视频全部复制并链接到小软件放各个分片视频的链接为从迅雷提取并下载。然后现在重命名,按数字重命名,然后合并将具有正确的顺序。有时我们会错过一些视频。我们可以看看软件。例如,序列是之前写的。我可以看到第一个视频中没有链接。可能会错过。我不会在这里演示它。而已。等待下载完成。好的,然后合并视频,可以使用格式工厂,也可以使用其他软件,注意因为这些视频都是同一种格式,都是同一种编码类型,所以合并会很快。注意这里的顺序。可以看出第一个视频漏掉了,因为第一个视频是这样的。您可以再次捕获它。我不会在这里演示它。我将在下面讨论另一种方法,实际上可能更简单。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐浏览器的这个扩展,请看,看,如果我拖动一个片段,它会自动嗅探下一个片段的视频,所以我们可以你只需要下载所有这些视频,然后合并下载的视频,但由于名称相同,需要注意视频的顺序,
从爱奇艺、优酷等视频中手动抓取视频网站 查看全部
如何抓取网页视频(讲讲怎么该方法适用于很多视频网站的解析下载方法
)
今天给大家讲讲如何从爱奇艺、优酷网站等视频中手动截取视频。这种方法适用于很多视频网站。因为有的网站不支持说书、微堂等一些软件的分析下载,所以就找了这个方法。在优酷之前是可以的,但是现在优酷还是不支持说书和微堂。唐分析。这两个网页是原帖的地址。其实这个方法我之前就知道了,不过这个人提供了一个软件,比较好用。我提取了他录制的视频,我们来看看。其实原理是一样的,这些视频网站为了让视频缓存更快,当然还有很多其他的原因,视频被分成了很多段,所以我们只需要下载每个视频分别地,然后合并这些视频。起床就ok了,这些分段视频基本是同一时间段的,最后一段可能不一样。下面我们来看看优酷的分析。爱奇艺的演示是手动抓图,优酷的演示是软件抓图,比较方便。那人写了一个软件,可以轻松提取所有下载地址,方便导入迅雷下载。让我演示一次。可以看出Fildder没有嗅探,这是因为我的浏览器使用了广告过滤软件,我用谷歌浏览器试了一下,没有广告扩展。可以看出已经有了。已经闻到了。必须阅读广告。好,现在我们开始拖视频,先选择视频的清晰度,这里是标清,我就不改了,
好了,拖到这里就结束了,因为不拖到一个地方就会加载分段的视频,所以不知道分成了多长时间,所以我们试着拖的慢一点,短一点,然后点击对宿主进行排序,不同的网站,不同清晰度的视频有不同的链接,这里是优酷的标清,我们将分片的视频全部复制并链接到小软件放各个分片视频的链接为从迅雷提取并下载。然后现在重命名,按数字重命名,然后合并将具有正确的顺序。有时我们会错过一些视频。我们可以看看软件。例如,序列是之前写的。我可以看到第一个视频中没有链接。可能会错过。我不会在这里演示它。而已。等待下载完成。好的,然后合并视频,可以使用格式工厂,也可以使用其他软件,注意因为这些视频都是同一种格式,都是同一种编码类型,所以合并会很快。注意这里的顺序。可以看出第一个视频漏掉了,因为第一个视频是这样的。您可以再次捕获它。我不会在这里演示它。我将在下面讨论另一种方法,实际上可能更简单。,也就是很多浏览器都有嗅探视频或音频的扩展,比如火狐浏览器的这个扩展,请看,看,如果我拖动一个片段,它会自动嗅探下一个片段的视频,所以我们可以你只需要下载所有这些视频,然后合并下载的视频,但由于名称相同,需要注意视频的顺序,
从爱奇艺、优酷等视频中手动抓取视频网站
如何抓取网页视频(如何抓取网页视频的分辨率?最简单的是直接在网页里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-10 03:05
如何抓取网页视频的分辨率?最简单的是直接在网页里抓取网页视频,还可以通过pc端的新媒体助手以及手机端的爱播放神器自动抓取。以下我简单说明下该方法的原理。先注册一个爱播放神器,注册需要100元押金,有效期为五个月。然后打开爱播放神器,到底是哪个页面再点开就可以了。一个视频一个页面,直接抓取html源代码并比对就可以了。
如何抓取歌曲视频的分辨率?歌曲本身就分为两种宽高比的a4a或i5a,根据歌曲尺寸以及歌曲平台的不同分辨率也会有差异。一般这种都是由app来做的,我们可以去一些视频分享网站寻找这样尺寸的视频,比如:比如qq音乐,每个封面图都是由这些图片封装的。不用搜索,每个图片都是可以下载,我们直接点开他们的下载地址,用到的浏览器就可以。
先介绍一下我自己,准大一党,我是利用排行榜,根据里面人气比较高的歌曲进行搜索,推荐一个网站:夏夏上线啦,挺不错的。
给你推荐个功能,微博视频搜索功能,打开后就是一个类似百度搜索的图标,点击“获取微博”。你会看到很多微博的精选微博视频,还可以爬爬博主!但是要求好友的允许才可以,不是很方便哈,但是可以解决你的大部分需求!或者你还可以访问爱听fm,里面很多好听的播放器音乐, 查看全部
如何抓取网页视频(如何抓取网页视频的分辨率?最简单的是直接在网页里)
如何抓取网页视频的分辨率?最简单的是直接在网页里抓取网页视频,还可以通过pc端的新媒体助手以及手机端的爱播放神器自动抓取。以下我简单说明下该方法的原理。先注册一个爱播放神器,注册需要100元押金,有效期为五个月。然后打开爱播放神器,到底是哪个页面再点开就可以了。一个视频一个页面,直接抓取html源代码并比对就可以了。
如何抓取歌曲视频的分辨率?歌曲本身就分为两种宽高比的a4a或i5a,根据歌曲尺寸以及歌曲平台的不同分辨率也会有差异。一般这种都是由app来做的,我们可以去一些视频分享网站寻找这样尺寸的视频,比如:比如qq音乐,每个封面图都是由这些图片封装的。不用搜索,每个图片都是可以下载,我们直接点开他们的下载地址,用到的浏览器就可以。
先介绍一下我自己,准大一党,我是利用排行榜,根据里面人气比较高的歌曲进行搜索,推荐一个网站:夏夏上线啦,挺不错的。
给你推荐个功能,微博视频搜索功能,打开后就是一个类似百度搜索的图标,点击“获取微博”。你会看到很多微博的精选微博视频,还可以爬爬博主!但是要求好友的允许才可以,不是很方便哈,但是可以解决你的大部分需求!或者你还可以访问爱听fm,里面很多好听的播放器音乐,
如何抓取网页视频(互联网科技信息共享平台crossfire(中文名乌托邦)动画)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-27 06:05
如何抓取网页视频格式?
美国党对grunition的研究很热啊,大概发明了一个靠谱的黑盒子。
可以在线看电影但是很少,
我知道美国比较流行这种视频共享方式,有许多不同的渠道,我知道美国有人在facebook上发起了一个叫做“html5clipsing”的活动,鼓励大家可以在facebook上更新自己喜欢的视频或者照片,也可以收藏和评论其他人分享的视频或照片。可以直接在facebook上收藏和评论,而不必在vimeo或其他播放器等第三方平台上把该文件另行上传。-clipsing/facebook-clipsing-movies/。
互联网科技信息共享平台crossfire(中文名乌托邦)
动画要先从图片说起。虽然动画也是图片的一种,但传统上不少人认为动画就是图片。比如我们拿一张一维的二维的图片来打开试试。由于我们无法把这种一维二维图像做很精确的放大、缩小、标记,所以我们不可能通过什么特定的软件将其变成动画版的。但是一维的一个字母一个字母的读,是可以的。手机扫一扫也能扫出里面的画面来。对于那些庞大的图片网站,你可以点击图片的名字,获取相应页面的其它页面。
这其中,会有出现动画的内容。那么这里面一些画面的某几帧就是能够被一定程度上编辑的。比如某张图的某一个视频播放器的画面就是可以编辑的。那么如果,你手机扫一扫没有扫描出来上面的图片,说明那张图片没存在。不要着急。其实下面还有autodesk、alphaboard、各种渲染图片的软件,你可以用来提高效率。 查看全部
如何抓取网页视频(互联网科技信息共享平台crossfire(中文名乌托邦)动画)
如何抓取网页视频格式?
美国党对grunition的研究很热啊,大概发明了一个靠谱的黑盒子。
可以在线看电影但是很少,
我知道美国比较流行这种视频共享方式,有许多不同的渠道,我知道美国有人在facebook上发起了一个叫做“html5clipsing”的活动,鼓励大家可以在facebook上更新自己喜欢的视频或者照片,也可以收藏和评论其他人分享的视频或照片。可以直接在facebook上收藏和评论,而不必在vimeo或其他播放器等第三方平台上把该文件另行上传。-clipsing/facebook-clipsing-movies/。
互联网科技信息共享平台crossfire(中文名乌托邦)
动画要先从图片说起。虽然动画也是图片的一种,但传统上不少人认为动画就是图片。比如我们拿一张一维的二维的图片来打开试试。由于我们无法把这种一维二维图像做很精确的放大、缩小、标记,所以我们不可能通过什么特定的软件将其变成动画版的。但是一维的一个字母一个字母的读,是可以的。手机扫一扫也能扫出里面的画面来。对于那些庞大的图片网站,你可以点击图片的名字,获取相应页面的其它页面。
这其中,会有出现动画的内容。那么这里面一些画面的某几帧就是能够被一定程度上编辑的。比如某张图的某一个视频播放器的画面就是可以编辑的。那么如果,你手机扫一扫没有扫描出来上面的图片,说明那张图片没存在。不要着急。其实下面还有autodesk、alphaboard、各种渲染图片的软件,你可以用来提高效率。
如何抓取网页视频(相关专题jquery如何获取手机标识的方法及获取方法? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-11 04:15
)
相关话题
jquery如何获取元素标签
19/11/202018:06:44
jquery获取元素标签的方法:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name); ].html代码如下:(学习视频分享:jquery视频教程)uniapp如何获取手机ID
2015 年 9 月 12 日:05:14
uniapp获取手机ID的方法:调用cache方法获取手机ID,代码为[苹果系统plus.device.getInfo({success:function(e);安卓系统plus.device.getAAID( {success:...]. 本教程
视频优化:如何使用视频网站进行关键词优化
2012 年 11 月 4 日 16:28:00
作为从事网络营销的从业人员,我们都知道几个SEO知识点: 1. 大型视频网站的权重高于其他网站;2、视频显示效果大于图片,图片大于文字;3、自行设置视频网站的硬件条件会受到限制;基于以上几点,提出一个命题:如何利用视频网站优化关键词?其实,逃不过SEO的基本常识是不可能的。下面我将用一个例子来说明
如何在jquery中获取span的值
17/11/202012:04:55
jquery获取span值的方法:先创建一个前端代码示例;然后设置跨度;最后通过"$(document).ready(function(){$("button").click(function(){..}}"方法得到span的值。推荐:《
如何在php中获取对象的所有方法
19/8/202012:03:33
php中如何获取一个对象的所有方法:1、获取当前对象中的所有方法,代码为[$methods=get_class_methods(get_class())]; 2、获取指定对象中的方法,代码为[ $methods=get_class_met]
uni-app如何获取dom节点
2015 年 8 月 12 日:09:52
uniapp获取dom节点的方法:1、获取第一个匹配选择器的节点,代码为[letdom=query.select(selector)];2、获取所有匹配选择器的节点,代码为[letdoms=query.selectAll(selec.]。
DEDEcms添加软件时自动从TAG获取关键字
18/4/2011 10:17:00
最近在帮朋友做一个游戏软件站。在添加测试文章的时候发现一个问题:软件频道不能像文章频道那样自动从TAG中获取关键词,而是直接从title分解生成一些无意义的关键词,这也导致对于调用“相关文章”时文章不相关的现象。比较 文章 通道后,添加模板。
php中跳转前如何获取url
11/8/202012:03:41
php获取跳转前的url方法:1、获取带有QUESTRING参数的URL的JAVASCRIPT客户端方法;2、正则分析方法,设置或获取整个URL为字符串,代码为[alert(window.location.href)]。php在跳转之前获取
如何使用cms系统标签自动获取长尾关键词排名
29/8/2011 10:57:00
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长往往只使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
layui如何获取复选框的值以及如何给复选框赋值
19/11/202018:06:56
获取checkbox的值:(学习视频分享:javascript视频教程)一、layui获取单个checkbox的值==================== ===================HTML=============================== ================
video网站的价值是什么?
25/5/2018 17:21:03
视频网站可以通过两种方式产生价值:视频内容产生价值和视频内容联属产品产生价值。毫无疑问,当前版权的内容对视频网站非常有吸引力。
如何在 C++ 中获取系统时间?
7/7/202015:03:41
c++中如何获取系统时间:1、使用系统函数,可以修改系统时间;2、获取系统时间,代码为[time_tnow_time=time(NULL)]; 3、使用windowsAPI,精确到毫秒。如何在 C++ 中获取系统时间
如何在php中获取当前数字
2012 年 4 月 9 日:03:42
在php中,可以通过“PHPDate()”函数获取当前日期。该函数的语法为“date(format, timestamp)”,其中“format”参数为“d”时,表示获取月份数。几天。推荐:《PHP 视频教程》
如何在小程序中获取当前日期
15/1/2021 15:06:48
实现代码:(学习视频分享:编程视频)vartimestamp=Date.parse(newDate());vardate=newDate(timestamp);//获取年份varY=date.getFullYear();//获取月份varM=
视频推广实战应用,轻松获取流量转化
2010 年 13 月 7 日 09:36:00
网上充斥着论坛推广、软文推广等熟悉重复的文章,而关于视频推广的文章却很少,操作性不强,实用性不大价值。高的。有鉴于此,我想和大家分享一下我个人通过视频推广获得流量的经验。
查看全部
如何抓取网页视频(相关专题jquery如何获取手机标识的方法及获取方法?
)
相关话题
jquery如何获取元素标签
19/11/202018:06:44
jquery获取元素标签的方法:可以通过tagName属性获取元素标签,如[varname=$("#p").get(0).tagName;alert(name); ].html代码如下:(学习视频分享:jquery视频教程)uniapp如何获取手机ID
2015 年 9 月 12 日:05:14
uniapp获取手机ID的方法:调用cache方法获取手机ID,代码为[苹果系统plus.device.getInfo({success:function(e);安卓系统plus.device.getAAID( {success:...]. 本教程
视频优化:如何使用视频网站进行关键词优化
2012 年 11 月 4 日 16:28:00
作为从事网络营销的从业人员,我们都知道几个SEO知识点: 1. 大型视频网站的权重高于其他网站;2、视频显示效果大于图片,图片大于文字;3、自行设置视频网站的硬件条件会受到限制;基于以上几点,提出一个命题:如何利用视频网站优化关键词?其实,逃不过SEO的基本常识是不可能的。下面我将用一个例子来说明
如何在jquery中获取span的值
17/11/202012:04:55
jquery获取span值的方法:先创建一个前端代码示例;然后设置跨度;最后通过"$(document).ready(function(){$("button").click(function(){..}}"方法得到span的值。推荐:《
如何在php中获取对象的所有方法
19/8/202012:03:33
php中如何获取一个对象的所有方法:1、获取当前对象中的所有方法,代码为[$methods=get_class_methods(get_class())]; 2、获取指定对象中的方法,代码为[ $methods=get_class_met]
uni-app如何获取dom节点
2015 年 8 月 12 日:09:52
uniapp获取dom节点的方法:1、获取第一个匹配选择器的节点,代码为[letdom=query.select(selector)];2、获取所有匹配选择器的节点,代码为[letdoms=query.selectAll(selec.]。
DEDEcms添加软件时自动从TAG获取关键字
18/4/2011 10:17:00
最近在帮朋友做一个游戏软件站。在添加测试文章的时候发现一个问题:软件频道不能像文章频道那样自动从TAG中获取关键词,而是直接从title分解生成一些无意义的关键词,这也导致对于调用“相关文章”时文章不相关的现象。比较 文章 通道后,添加模板。
php中跳转前如何获取url
11/8/202012:03:41
php获取跳转前的url方法:1、获取带有QUESTRING参数的URL的JAVASCRIPT客户端方法;2、正则分析方法,设置或获取整个URL为字符串,代码为[alert(window.location.href)]。php在跳转之前获取
如何使用cms系统标签自动获取长尾关键词排名
29/8/2011 10:57:00
tag标签是织梦内容管理程序中的一个重要功能,但它的重要性往往不会被广大站长忽视。站长往往只使用tag标签作为方便读者增加用户体验的功能。一些站长走得更远,知道如何将标签作为网站的内链构建的一部分,但据作者介绍,对于我所见过的绝大多数网站来说,能够灵活使用标签作为自动获取长尾 关键词 流量和排名的方法。
layui如何获取复选框的值以及如何给复选框赋值
19/11/202018:06:56
获取checkbox的值:(学习视频分享:javascript视频教程)一、layui获取单个checkbox的值==================== ===================HTML=============================== ================
video网站的价值是什么?
25/5/2018 17:21:03
视频网站可以通过两种方式产生价值:视频内容产生价值和视频内容联属产品产生价值。毫无疑问,当前版权的内容对视频网站非常有吸引力。
如何在 C++ 中获取系统时间?
7/7/202015:03:41
c++中如何获取系统时间:1、使用系统函数,可以修改系统时间;2、获取系统时间,代码为[time_tnow_time=time(NULL)]; 3、使用windowsAPI,精确到毫秒。如何在 C++ 中获取系统时间
如何在php中获取当前数字
2012 年 4 月 9 日:03:42
在php中,可以通过“PHPDate()”函数获取当前日期。该函数的语法为“date(format, timestamp)”,其中“format”参数为“d”时,表示获取月份数。几天。推荐:《PHP 视频教程》
如何在小程序中获取当前日期
15/1/2021 15:06:48
实现代码:(学习视频分享:编程视频)vartimestamp=Date.parse(newDate());vardate=newDate(timestamp);//获取年份varY=date.getFullYear();//获取月份varM=
视频推广实战应用,轻松获取流量转化
2010 年 13 月 7 日 09:36:00
网上充斥着论坛推广、软文推广等熟悉重复的文章,而关于视频推广的文章却很少,操作性不强,实用性不大价值。高的。有鉴于此,我想和大家分享一下我个人通过视频推广获得流量的经验。
如何抓取网页视频(开发工具IDEA+jdk1开发语言java使用框架hibernate运行及效果展示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-04 14:03
大家好,我是非知名程序员杨宇。今天给大家介绍一个自动抓取电影下载链接的java程序。
发展原因
今天突然想看电影,但是某艺的会员已经过期不想续费了,所以决定去某网站看看有没有资源。
输入网址成功输入,但是点击电影标题后,我被迫跳转到这个广告页面。
广告页面
看到这个我很懒,很烦(因为我点了一个叉子把它关闭了),但我想了想,毕竟人家也是想赚点广告费的,还是忍着吧。
然而,进入电影详情页面后,广告又出现在了我的眼前。
这一次,我不想承受。
所以,我写了一个自动抓取电影下载链接的java程序。接下来,正式的介绍开始。
开发工具
IDEA + jdk1.8 + mysql
开发语言
爪哇
使用框架
休眠
操作及效果展示
1.点击绿色小箭头启动程序;
启动程序
2.运行效果展示
控制台输出sql语句
数据库保存列表
实现想法
1、使用java net包下的工具类获取网站二进制流文件;
2、将二进制流文件写入本地指定路径;
3.解析本地文件,找到下载链接的共同特征,然后从字符串中截取电影名和下载链接存入地图集合;
4.遍历map集合中的元素,通过hibernate框架写入数据库。
跟进
看到想看的电影,直接复制种子链,打开迅雷开始下载(我是不是暴露了什么……)
下载电影
没有广告,一切都令人耳目一新!
写在最后
希望大家不要像我一样直接抢别人的电影下载链接。毕竟人家网站也是靠广告赚钱的!
不过,如果你想研究你需要的源码,可以私信关键词“抢”,就可以获得这个程序的源码!在此郑重提醒大家,这个小程序只用于交流和学习,因为你不能用它赚钱。
最后,希望大家不仅喜欢看这里,多多评论或转发,也欢迎关注我,杨宇在此先谢谢大家了! 查看全部
如何抓取网页视频(开发工具IDEA+jdk1开发语言java使用框架hibernate运行及效果展示)
大家好,我是非知名程序员杨宇。今天给大家介绍一个自动抓取电影下载链接的java程序。
发展原因
今天突然想看电影,但是某艺的会员已经过期不想续费了,所以决定去某网站看看有没有资源。
输入网址成功输入,但是点击电影标题后,我被迫跳转到这个广告页面。
广告页面
看到这个我很懒,很烦(因为我点了一个叉子把它关闭了),但我想了想,毕竟人家也是想赚点广告费的,还是忍着吧。
然而,进入电影详情页面后,广告又出现在了我的眼前。
这一次,我不想承受。
所以,我写了一个自动抓取电影下载链接的java程序。接下来,正式的介绍开始。
开发工具
IDEA + jdk1.8 + mysql
开发语言
爪哇
使用框架
休眠
操作及效果展示
1.点击绿色小箭头启动程序;
启动程序
2.运行效果展示
控制台输出sql语句
数据库保存列表
实现想法
1、使用java net包下的工具类获取网站二进制流文件;
2、将二进制流文件写入本地指定路径;
3.解析本地文件,找到下载链接的共同特征,然后从字符串中截取电影名和下载链接存入地图集合;
4.遍历map集合中的元素,通过hibernate框架写入数据库。
跟进
看到想看的电影,直接复制种子链,打开迅雷开始下载(我是不是暴露了什么……)
下载电影
没有广告,一切都令人耳目一新!
写在最后
希望大家不要像我一样直接抢别人的电影下载链接。毕竟人家网站也是靠广告赚钱的!
不过,如果你想研究你需要的源码,可以私信关键词“抢”,就可以获得这个程序的源码!在此郑重提醒大家,这个小程序只用于交流和学习,因为你不能用它赚钱。
最后,希望大家不仅喜欢看这里,多多评论或转发,也欢迎关注我,杨宇在此先谢谢大家了!
如何抓取网页视频(怎么才能让蜘蛛经常能够来访问我们的网站信息搜索 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-28 22:15
)
你知道蜘蛛吗?哦,不是八条腿的小昆虫。今天我要告诉你关于网络蜘蛛。这里提到的蜘蛛是为搜索引擎定制的。如果这张网是一张巨大的蜘蛛网,它没有边界,无法测量。那么 网站 就是蜘蛛网上的每个节点。蜘蛛搜索此网络上每个节点的信息。他们不断地访问不同的网站,爬取它们,然后根据关键词进行分类,所以我们搜索的时候,他会根据我们搜索的内容显示我们需要的内容,有点像在这方面再次成为统计学家。了解了蜘蛛是什么,今天就告诉大家如何让蜘蛛经常访问我们的网站,以及如何快速抓取我们的网站信息。
一、网站服务器
在网站服务器方面,主要考虑两个方面,稳定性和速度。如果网站不稳定或者打开网站很慢卡住,不仅影响用户体验,还可能影响爬取。当爬虫在爬取时,服务器不稳定或者卡住了很多次,那么爬虫会自动减少对网站的访问次数。
二、活动
活动的重点是说,网站最好是每天更新,比如文章updates。或者设置首页的时候,把信息页放在首页,保持网站新鲜。
三、内容
内容是网站的灵魂,丰富的内容可以增加用户的体验感。这里的网站设计的很好,内容是原创,可以定时更新,更新频率一致。今天不要发3篇文章,明天后天不要再发,我们可以每天发一篇,让小蜘蛛喜欢访问。还有一点是,如果我们在内容中加入广告,广告不能太明显。
四、链接
链接的种类也很多,这里我们主要讲内部链接和外部链接。内链就是网站里面的链接,链接到各个页面,如果内链做的好,网站的结构会更好。通常,评论和树结构更容易获取。内部链接可以基于这两种 网站 类型。对于外部链接,我们有最好的外部链接和高质量的入口。网站权重高的外链更容易被抓取。
爬取的时候,蜘蛛也会挑选好的历史,所以优化的时候不要作弊。最后,我们来看看我们的robots文件是否被阻塞了收录,虽然可能性不大,但是细节决定成败!今天简单介绍了“蜘蛛”以及如何快速爬取网站信息的内容,你懂了吗?关注我,评论,留言!
查看全部
如何抓取网页视频(怎么才能让蜘蛛经常能够来访问我们的网站信息搜索
)
你知道蜘蛛吗?哦,不是八条腿的小昆虫。今天我要告诉你关于网络蜘蛛。这里提到的蜘蛛是为搜索引擎定制的。如果这张网是一张巨大的蜘蛛网,它没有边界,无法测量。那么 网站 就是蜘蛛网上的每个节点。蜘蛛搜索此网络上每个节点的信息。他们不断地访问不同的网站,爬取它们,然后根据关键词进行分类,所以我们搜索的时候,他会根据我们搜索的内容显示我们需要的内容,有点像在这方面再次成为统计学家。了解了蜘蛛是什么,今天就告诉大家如何让蜘蛛经常访问我们的网站,以及如何快速抓取我们的网站信息。
一、网站服务器
在网站服务器方面,主要考虑两个方面,稳定性和速度。如果网站不稳定或者打开网站很慢卡住,不仅影响用户体验,还可能影响爬取。当爬虫在爬取时,服务器不稳定或者卡住了很多次,那么爬虫会自动减少对网站的访问次数。
二、活动
活动的重点是说,网站最好是每天更新,比如文章updates。或者设置首页的时候,把信息页放在首页,保持网站新鲜。
三、内容
内容是网站的灵魂,丰富的内容可以增加用户的体验感。这里的网站设计的很好,内容是原创,可以定时更新,更新频率一致。今天不要发3篇文章,明天后天不要再发,我们可以每天发一篇,让小蜘蛛喜欢访问。还有一点是,如果我们在内容中加入广告,广告不能太明显。
四、链接
链接的种类也很多,这里我们主要讲内部链接和外部链接。内链就是网站里面的链接,链接到各个页面,如果内链做的好,网站的结构会更好。通常,评论和树结构更容易获取。内部链接可以基于这两种 网站 类型。对于外部链接,我们有最好的外部链接和高质量的入口。网站权重高的外链更容易被抓取。
爬取的时候,蜘蛛也会挑选好的历史,所以优化的时候不要作弊。最后,我们来看看我们的robots文件是否被阻塞了收录,虽然可能性不大,但是细节决定成败!今天简单介绍了“蜘蛛”以及如何快速爬取网站信息的内容,你懂了吗?关注我,评论,留言!
如何抓取网页视频(如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-18 01:04
如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?如何把知乎答案统一划分为多个专栏?如何提取知乎上的答案,并且快速的下载到电脑上?知乎上面有着非常丰富的高质量回答,如何爬取并获取更多相关内容,并且快速的传送到自己的电脑上进行编辑呢?来吧,让小爬来帮大家搜索到解决方案吧。终极爬虫秘籍,知乎视频下载小集锦我们分别通过以下方式来构建爬虫框架:基于chrome浏览器的diycrawlerv1.0实现了之前应用过的xpath库,用于设置解析树的node.js框架,以及webpack,gulp和其他相关的webpack和babel等开发工具extractsoup抓取基于的idle操作,用于处理中文文本。
每个问题都可以在同一页面获取各类问题列表及答案。接下来我们就通过以下代码实现以上功能。具体代码请点击此处获取。代码的运行环境是chromestableedition911,版本号为577,或者更高,517.3.0.815,765.14.1638。编辑器选择codecademy,否则无法运行。如何抓取网页视频文件等?首先,我们来创建一个文件夹,名为crawler,然后建立一个crawler文件,命名为poco,把所有可能的网页数据内容下载到本地。
具体代码获取爬虫爬虫代码如下,我们最后再把它重命名为crawler.py。fromchrome.manifest.templateimportuseragent'''基于chrome浏览器的diycrawlerv1.0实现'''importurllib2,requests#编写url和post请求url=''match_data={'':1,'':2,'':3,'':4,'':5,'':6,'':7,'':8,'':9,'':10,'':11,'':12,'':13,'':14,'':15,'':16,'':17,'':18,'':19,'':20,'':21,'':22,'':23,'':24,'':25,'':26,'':27,'':28,'':29,'':30,'':31,'':32,'':33,'':34,'':35,'':36,'':37,'':38,'':39,'':40,'':41,'':42,'':43,'':44,'':45,'':46,'':47,'':48,'':49,'':50,'':51,'':52,'':53,'':54,'':55,'':56,'':57,'':58,'':59,'':60,'':61,'':63,'':64,'':65,'':66,'':67,'':68,'':69,'':70,'':71,'':72,'':73,'':74,'':75,'':76,'':77,'':77,'':78,'':79,'':79,'':80,'':81,'':82,'':83,'':84,''。 查看全部
如何抓取网页视频(如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?)
如何抓取网页视频、图片、ppt文件等?如何记录知乎上的回答?如何把知乎答案统一划分为多个专栏?如何提取知乎上的答案,并且快速的下载到电脑上?知乎上面有着非常丰富的高质量回答,如何爬取并获取更多相关内容,并且快速的传送到自己的电脑上进行编辑呢?来吧,让小爬来帮大家搜索到解决方案吧。终极爬虫秘籍,知乎视频下载小集锦我们分别通过以下方式来构建爬虫框架:基于chrome浏览器的diycrawlerv1.0实现了之前应用过的xpath库,用于设置解析树的node.js框架,以及webpack,gulp和其他相关的webpack和babel等开发工具extractsoup抓取基于的idle操作,用于处理中文文本。
每个问题都可以在同一页面获取各类问题列表及答案。接下来我们就通过以下代码实现以上功能。具体代码请点击此处获取。代码的运行环境是chromestableedition911,版本号为577,或者更高,517.3.0.815,765.14.1638。编辑器选择codecademy,否则无法运行。如何抓取网页视频文件等?首先,我们来创建一个文件夹,名为crawler,然后建立一个crawler文件,命名为poco,把所有可能的网页数据内容下载到本地。
具体代码获取爬虫爬虫代码如下,我们最后再把它重命名为crawler.py。fromchrome.manifest.templateimportuseragent'''基于chrome浏览器的diycrawlerv1.0实现'''importurllib2,requests#编写url和post请求url=''match_data={'':1,'':2,'':3,'':4,'':5,'':6,'':7,'':8,'':9,'':10,'':11,'':12,'':13,'':14,'':15,'':16,'':17,'':18,'':19,'':20,'':21,'':22,'':23,'':24,'':25,'':26,'':27,'':28,'':29,'':30,'':31,'':32,'':33,'':34,'':35,'':36,'':37,'':38,'':39,'':40,'':41,'':42,'':43,'':44,'':45,'':46,'':47,'':48,'':49,'':50,'':51,'':52,'':53,'':54,'':55,'':56,'':57,'':58,'':59,'':60,'':61,'':63,'':64,'':65,'':66,'':67,'':68,'':69,'':70,'':71,'':72,'':73,'':74,'':75,'':76,'':77,'':77,'':78,'':79,'':79,'':80,'':81,'':82,'':83,'':84,''。
如何抓取网页视频(如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-07 08:02
如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具。如果你是使用了nodejs这款命令行工具,它会告诉你可以用curl这个工具,此时你还需要加上":8080"//下划线或者数字标记//前面那句代码是你在客户端发起请求的时候需要传达的信息。然后才可以拿到的整个网页,接下来就是无休止的解析。拿python来说,你可以用numpy,pandas库去存储读取到的数据,也可以用matplotlib库去显示读取到的数据(按照数据在网页上的位置)。
如果你不使用python,也有其他的开源库。例如我以前使用pythonweb开发的时候,一般使用youtube的开源服务,需要使用到浏览器浏览器,这个时候就不用切换工具。我只需要使用本地浏览器访问,使用全局http请求库把transform的请求头里面带上你读取到的所有文本文件就可以去解析。将解析完成的json解析为web页面就可以用indexer构建page_scroll方法进行滚动了。
接下来我就列举一些常用的方法吧!读取-curl一般来说,你要抓取一个视频文件的时候,也就是通过原生api,通过post的形式送到你手里,post的方式也就是说,它不会获取你的网页地址,不会从网络上将视频文件传给你,那么你的浏览器也会向你推送播放地址。那么你就得使用curl。aiohttp除了那些通过curl拿到的文件,你还可以拿到视频文件地址,通过在网页上断点的方式去传输一个文件,然后又接入一个post参数即可。
aiohttp方式允许你直接请求,post参数分别传递即可。如果你浏览器没有自带async/await语法,你可以通过添加-p参数,提示给浏览器,然后通过解析post传递的参数来实现你的要求。比如我的手机浏览器是ios8.0,android4.3,无法通过curl请求网页,我要获取百度网页视频,可以使用aiohttp让他自动跳转到百度网页。
jsonjs为什么不直接使用nodejs呢?因为json库相对于python实在是不够好用,如果你想用nodejs直接获取视频,你可以用jsonjs,网上的json文件大多由javascript去解析。对于文本文件,json会自动去解析去读取文件格式。也就是说你也没有办法通过ajax方式转换格式,而且还很麻烦。
jsonjson库基本没有实现过视频的转换,最接近的应该是requests库。然后json库常用的协议也就是一些xml,json等格式。jsonjs所有的实现我们可以通过异步去获取对应的格式,同步的方式去处理内容即可。我知道的有两种格式是jsonjs规定的,一种是json.stringify,一种是json.parse。
基本上这两种格式是等价的,就是使用了''表示二进制数据的格式。那么jsonjsonjs就是在aiohttp。 查看全部
如何抓取网页视频(如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具)
如何抓取网页视频?可能你会想到用nodejs,以及各种抓包工具。如果你是使用了nodejs这款命令行工具,它会告诉你可以用curl这个工具,此时你还需要加上":8080"//下划线或者数字标记//前面那句代码是你在客户端发起请求的时候需要传达的信息。然后才可以拿到的整个网页,接下来就是无休止的解析。拿python来说,你可以用numpy,pandas库去存储读取到的数据,也可以用matplotlib库去显示读取到的数据(按照数据在网页上的位置)。
如果你不使用python,也有其他的开源库。例如我以前使用pythonweb开发的时候,一般使用youtube的开源服务,需要使用到浏览器浏览器,这个时候就不用切换工具。我只需要使用本地浏览器访问,使用全局http请求库把transform的请求头里面带上你读取到的所有文本文件就可以去解析。将解析完成的json解析为web页面就可以用indexer构建page_scroll方法进行滚动了。
接下来我就列举一些常用的方法吧!读取-curl一般来说,你要抓取一个视频文件的时候,也就是通过原生api,通过post的形式送到你手里,post的方式也就是说,它不会获取你的网页地址,不会从网络上将视频文件传给你,那么你的浏览器也会向你推送播放地址。那么你就得使用curl。aiohttp除了那些通过curl拿到的文件,你还可以拿到视频文件地址,通过在网页上断点的方式去传输一个文件,然后又接入一个post参数即可。
aiohttp方式允许你直接请求,post参数分别传递即可。如果你浏览器没有自带async/await语法,你可以通过添加-p参数,提示给浏览器,然后通过解析post传递的参数来实现你的要求。比如我的手机浏览器是ios8.0,android4.3,无法通过curl请求网页,我要获取百度网页视频,可以使用aiohttp让他自动跳转到百度网页。
jsonjs为什么不直接使用nodejs呢?因为json库相对于python实在是不够好用,如果你想用nodejs直接获取视频,你可以用jsonjs,网上的json文件大多由javascript去解析。对于文本文件,json会自动去解析去读取文件格式。也就是说你也没有办法通过ajax方式转换格式,而且还很麻烦。
jsonjson库基本没有实现过视频的转换,最接近的应该是requests库。然后json库常用的协议也就是一些xml,json等格式。jsonjs所有的实现我们可以通过异步去获取对应的格式,同步的方式去处理内容即可。我知道的有两种格式是jsonjs规定的,一种是json.stringify,一种是json.parse。
基本上这两种格式是等价的,就是使用了''表示二进制数据的格式。那么jsonjsonjs就是在aiohttp。
如何抓取网页视频(腾讯视频的VIP电影动态抓取(第二十五期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-25 21:19
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候,要爬取的数据在查看网页源代码的时候,找不到对应的数据。比如我们要抓取腾讯视频的VIP电影
腾讯视频
如上图,网页中有,但是查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端获取数据,接下来我们抓取一个这样的网站。
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,可以看到下面还有很多东西。一般请求的代码都是XHR或者JS,所以我们直接找这两项,搜索一下就可以看到了。到以下结果:
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
抓到数据后,下一步就是解析数据。由于是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...字符串,只留下字符串{"cgi_cost_time:...}的数据从我们链接打开的网页结果中可以看出刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是里面的key字典是jsonvalue,jsonvalue的值是字典,这个字典中的键值是results.data,results对应的值是一个list,分析清楚后,就很容易得到数据了,并直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'
输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后比较请求链接,可以找到请求链接规律
请求链接
通过对比可以发现,每添加一个页面,这个数字就增加了30个,所以只需要动态改变请求链接就可以捕获所有的数据了。 查看全部
如何抓取网页视频(腾讯视频的VIP电影动态抓取(第二十五期))
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候,要爬取的数据在查看网页源代码的时候,找不到对应的数据。比如我们要抓取腾讯视频的VIP电影
腾讯视频
如上图,网页中有,但是查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端获取数据,接下来我们抓取一个这样的网站。
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,可以看到下面还有很多东西。一般请求的代码都是XHR或者JS,所以我们直接找这两项,搜索一下就可以看到了。到以下结果:
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
抓到数据后,下一步就是解析数据。由于是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...字符串,只留下字符串{"cgi_cost_time:...}的数据从我们链接打开的网页结果中可以看出刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是里面的key字典是jsonvalue,jsonvalue的值是字典,这个字典中的键值是results.data,results对应的值是一个list,分析清楚后,就很容易得到数据了,并直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'
输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后比较请求链接,可以找到请求链接规律
请求链接
通过对比可以发现,每添加一个页面,这个数字就增加了30个,所以只需要动态改变请求链接就可以捕获所有的数据了。
如何抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-25 21:15
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费) 查看全部
如何抓取网页视频(联想2011年校园招聘之2.视频下载的功能方法)
今天看了联想2011年的校园招聘,里面的视频还不错,很吸引人。然后我想下载,但是右击什么的没有视频下载功能,怎么办?
1. 方法一
好在我采集
了一个专门从各大主流视频网站提取视频的网站:(原名)。使用后发现各大主流视频分享网站基本都可以解析出最终的URL,但是对于公司这样的公司来说,知名度较低的网站上的视频是无法解析的。
2.方法二
视频提取软件
网上搜了很多,但能用的不一定很多。下载了几个软件后,发现不能解决我的问题,所以放弃了
3.源码分析
首先,任何浏览器都可以查看网页的源代码。如果读者有一些基本的html知识,他可以执行以下操作:
今天的目标:
联想2011年招聘
通过查看源代码,我发现了以下语句
代码片段:
哈哈,“src="swf/For those who do 640-480.swf"就是这句话,不是最后的地址吗!!!
我心想,最深的网址是我自己找到的。试试看能不能下载。右键--->复制链接地址--->打开QQ旋风--->粘贴,哇,可以下载了,太好了。
然后我想了想,我不是都到了联想的服务器了吗?如果我再次获得root权限,那么我可以为所欲为,哈哈。
我的目标已经实现,下一步就是将swf格式转换成合适的视频。转换软件:xcn-video-converter-ultimate(免费)
如何抓取网页视频(如何抓取网页视频?试试我们正在使用的chrome。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-14 12:08
如何抓取网页视频?试试我们正在使用的chrome。首先在浏览器地址栏输入,你会发现大部分网站的视频会被正在下载(包括youtube、reddit和国内的优酷、爱奇艺等等网站)。但是,要成功下载高清视频就需要下载码。这时,就需要给视频起一个可点击的、唯一的、且无限复制次数的特征码。具体请参考如何抓取你想要下载的视频?具体的内容我就不写了,给大家推荐一个全面而且收益高的网站。
视频下载一条龙教程我已经写好了,关注“渠道之家”微信公众号(id:qunjianzhuzu)回复“视频”自动获取我们的视频下载教程。
youtube上有,国内的有,搜狗输入法自带的搜索里也能搜,
一般无内容问我,下载什么视频好。我都回答,需要谁家,直接上他们家站点去找,正版,靠谱。
现在已经有可以抓取全网视频并且高清无水印的了,就是我现在在用的悦享影视。推荐大家使用,
youtube,vimeo,instagram都能抓
搜狗输入法可以搜索
这里有海量的app,
好多网站都不错,
都可以,
搜狗输入法--搜索--加速器(软件)搜狗输入法还可以搜索下载手机视频
youtube,a站,b站,网站vue,youku,acfun,acfun日推等等 查看全部
如何抓取网页视频(如何抓取网页视频?试试我们正在使用的chrome。)
如何抓取网页视频?试试我们正在使用的chrome。首先在浏览器地址栏输入,你会发现大部分网站的视频会被正在下载(包括youtube、reddit和国内的优酷、爱奇艺等等网站)。但是,要成功下载高清视频就需要下载码。这时,就需要给视频起一个可点击的、唯一的、且无限复制次数的特征码。具体请参考如何抓取你想要下载的视频?具体的内容我就不写了,给大家推荐一个全面而且收益高的网站。
视频下载一条龙教程我已经写好了,关注“渠道之家”微信公众号(id:qunjianzhuzu)回复“视频”自动获取我们的视频下载教程。
youtube上有,国内的有,搜狗输入法自带的搜索里也能搜,
一般无内容问我,下载什么视频好。我都回答,需要谁家,直接上他们家站点去找,正版,靠谱。
现在已经有可以抓取全网视频并且高清无水印的了,就是我现在在用的悦享影视。推荐大家使用,
youtube,vimeo,instagram都能抓
搜狗输入法可以搜索
这里有海量的app,
好多网站都不错,
都可以,
搜狗输入法--搜索--加速器(软件)搜狗输入法还可以搜索下载手机视频
youtube,a站,b站,网站vue,youku,acfun,acfun日推等等
如何抓取网页视频(如何抓取网页视频及ppt源文件:附抓取视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-12-11 06:00
如何抓取网页视频及ppt源文件:附抓取视频教程第一步:进入url页面,
1、浏览器登录-网页音乐下载网站,点击下载按钮,在弹出来的下载框中上传需要下载的音频视频等素材,点击下载视频。
2、音频下载成功后,会跳转到手机网页,连接移动点下载。
3、手机连接移动上有imei码验证,安卓手机:可以在手机通讯录找到meiz02;安卓手机验证是jd的获取方式。
4、大于60kb以上的音频文件,需要使用抓包工具抓取出来。
5、下载教程:下载教程:教程:进入网页音频右下角,找到视频链接,然后分析视频链接,可以看到这是百度视频的视频链接,获取视频链接。然后用youtube软件获取视频链接然后用google搜索获取mp4的视频。这种方法可以获取整个网页所有的音频视频链接并分析出来。
6、最后再转换成文件导出到本地,再进行上传。
移动视频的话,可以先获取youtube页面视频地址,然后用浏览器抓包,
能不能尝试下国内的视频网站?比如优酷爱奇艺,
安卓的方法是先在百度网盘找到网盘的离线下载地址,例如的www.youtube-minds,将文件上传后获取到的地址,直接在www.youtube-minds下载就可以了。安卓和ios下载都有哦。 查看全部
如何抓取网页视频(如何抓取网页视频及ppt源文件:附抓取视频教程)
如何抓取网页视频及ppt源文件:附抓取视频教程第一步:进入url页面,
1、浏览器登录-网页音乐下载网站,点击下载按钮,在弹出来的下载框中上传需要下载的音频视频等素材,点击下载视频。
2、音频下载成功后,会跳转到手机网页,连接移动点下载。
3、手机连接移动上有imei码验证,安卓手机:可以在手机通讯录找到meiz02;安卓手机验证是jd的获取方式。
4、大于60kb以上的音频文件,需要使用抓包工具抓取出来。
5、下载教程:下载教程:教程:进入网页音频右下角,找到视频链接,然后分析视频链接,可以看到这是百度视频的视频链接,获取视频链接。然后用youtube软件获取视频链接然后用google搜索获取mp4的视频。这种方法可以获取整个网页所有的音频视频链接并分析出来。
6、最后再转换成文件导出到本地,再进行上传。
移动视频的话,可以先获取youtube页面视频地址,然后用浏览器抓包,
能不能尝试下国内的视频网站?比如优酷爱奇艺,
安卓的方法是先在百度网盘找到网盘的离线下载地址,例如的www.youtube-minds,将文件上传后获取到的地址,直接在www.youtube-minds下载就可以了。安卓和ios下载都有哦。

