
利用采集器 采集的平台
上海网站建设-建站宝盒网站设计_网站制作_代理商
采集交流 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-07-29 01:06
利用采集器采集的平台很多,
猪八戒网,上面确实有些平台的站点还不错,但还是要花时间去整理的。
这两个站点已经不行了,没人维护了,建议去找找其他的吧,建站宝盒软件还可以,不过现在做商城的越来越多了,也不行了,给你推荐个代理商:上海网站制作_网站设计_网站建设-建站宝盒网站设计建站宝盒是一款web前端开发软件,内置angular、vue、jquery、angularjs、react等前端技术。提供以下优质文档:快速教程:bootstrap、bootstrap2.0、bootstrap2.x、easyui、vue.js、react.js、vuex、vue-router、jquery、jqueryeloquent、jquerycss、jquerysass、jqueryless、jqueryextensions、vue-element-ui、jqueryui、jquerytest等成功案例:韩阳旺等。
真正的大品牌还不倒闭的是那些有国企背景的公司。(不是说这些公司不好)那些骗人的就靠这些了,一点审核的成本都没有。国企啊,关系啊,最多放在网上公开的。你看到的人家的品牌都叫做:东风集团呀。所以,选国企才不会坑你,叫你自己去找靠谱的,就是那些包装不公开标识的,啥都没有放出来,叫你自己去找靠谱的。 查看全部
上海网站建设-建站宝盒网站设计_网站制作_代理商
利用采集器采集的平台很多,

猪八戒网,上面确实有些平台的站点还不错,但还是要花时间去整理的。

这两个站点已经不行了,没人维护了,建议去找找其他的吧,建站宝盒软件还可以,不过现在做商城的越来越多了,也不行了,给你推荐个代理商:上海网站制作_网站设计_网站建设-建站宝盒网站设计建站宝盒是一款web前端开发软件,内置angular、vue、jquery、angularjs、react等前端技术。提供以下优质文档:快速教程:bootstrap、bootstrap2.0、bootstrap2.x、easyui、vue.js、react.js、vuex、vue-router、jquery、jqueryeloquent、jquerycss、jquerysass、jqueryless、jqueryextensions、vue-element-ui、jqueryui、jquerytest等成功案例:韩阳旺等。
真正的大品牌还不倒闭的是那些有国企背景的公司。(不是说这些公司不好)那些骗人的就靠这些了,一点审核的成本都没有。国企啊,关系啊,最多放在网上公开的。你看到的人家的品牌都叫做:东风集团呀。所以,选国企才不会坑你,叫你自己去找靠谱的,就是那些包装不公开标识的,啥都没有放出来,叫你自己去找靠谱的。
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2022-06-24 01:40
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
利用采集器api,使用浏览器采集的平台规则介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-06-23 03:05
利用采集器采集的平台规则既不是wap又不是cookie,
pc浏览器已经把这个浏览的信息限制到一定的长度。网页一般是800字符以内。而app浏览器就没有这个限制。也许你的app浏览器压根就不支持爬取客户端手机网页。比如推荐一个刷机助手。不开发爬取网页功能,只开发刷机教程。
基本不可以
网页采集是被限制信息流量的,不过还是可以把客户端应用的信息抓取出来。现在的网页采集主要分为api和爬虫两类。api采集依靠浏览器api,使用浏览器自带的api工具,就能实现了获取网页图片,色情图片等功能。不过呢,api开发需要编写外部代码,这会大大增加开发难度,而且不支持定制化的信息获取。而爬虫采集需要爬虫脚本,但是更为简单方便。
所以这两种都不推荐。我推荐使用技术封锁类的爬虫,像boss直聘,猎聘网就是采用的这种技术封锁,就是cookie+一些规则抓取。当然你也可以理解为是一种捆绑。目前市面上大大小小的api和爬虫都有,想要比较精准的爬取,就要到腾讯wetest的爬虫权限自主开发者的平台去看看。人工识别群体情绪,做用户画像,写好爬虫去一一匹配采集需求,比如对于销售和用户这两个区间的用户,后台便会分析给出不同的策略。
上一个答案打一堆字的,都是利用机器代理工具上的,一般api接口不具备,爬虫和个人觉得还是需要自己的网站后台里边进行。 查看全部
利用采集器api,使用浏览器采集的平台规则介绍
利用采集器采集的平台规则既不是wap又不是cookie,
pc浏览器已经把这个浏览的信息限制到一定的长度。网页一般是800字符以内。而app浏览器就没有这个限制。也许你的app浏览器压根就不支持爬取客户端手机网页。比如推荐一个刷机助手。不开发爬取网页功能,只开发刷机教程。
基本不可以
网页采集是被限制信息流量的,不过还是可以把客户端应用的信息抓取出来。现在的网页采集主要分为api和爬虫两类。api采集依靠浏览器api,使用浏览器自带的api工具,就能实现了获取网页图片,色情图片等功能。不过呢,api开发需要编写外部代码,这会大大增加开发难度,而且不支持定制化的信息获取。而爬虫采集需要爬虫脚本,但是更为简单方便。
所以这两种都不推荐。我推荐使用技术封锁类的爬虫,像boss直聘,猎聘网就是采用的这种技术封锁,就是cookie+一些规则抓取。当然你也可以理解为是一种捆绑。目前市面上大大小小的api和爬虫都有,想要比较精准的爬取,就要到腾讯wetest的爬虫权限自主开发者的平台去看看。人工识别群体情绪,做用户画像,写好爬虫去一一匹配采集需求,比如对于销售和用户这两个区间的用户,后台便会分析给出不同的策略。
上一个答案打一堆字的,都是利用机器代理工具上的,一般api接口不具备,爬虫和个人觉得还是需要自己的网站后台里边进行。
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-06-23 01:54
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-06-20 13:31
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-06-20 12:58
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
利用采集器采集的平台地址,通过nginx的反向代理(文件上传)功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-06-08 12:22
利用采集器采集的平台地址,
通过nginx的反向代理(文件上传)功能可以实现:
soeasy
使用php+mysql实现
实际上,php的web工程是由两部分组成:一部分是phpweb框架提供的web服务;另一部分是基于web框架的php网页。针对题主所说的问题,有一个库wordpress,这是基于rubyrails写的博客系统。可以通过网络部署到php服务器上。
wordpress上用web框架,但不是所有的都可以上传。可以用一个web包抓取知乎用户页面,全部读取并解析成html文件。加密传输。可以不上传,注册一个账号,就可以自动抓取。下载后,可以解析html文件,把需要的上传到微博里。关键点在于注册一个账号。一个账号有限制,具体怎么操作需要咨询和提问。知乎有第三方cms也可以用这个方法。
wp真想不到有什么更快的方法
第三方的cms,
试一下猪八戒。
那要看知乎什么用户了?普通大众我觉得php不是万能的,不像后来有些用户解决同性恋,城管什么的。但是像艺术家、文化人、学生、大学生类的用户群的还是可以用php做一些很好的工作的。学生最容易懂的就是php,当然,猪八戒上的艺术生和文化人也懂php,我想中文,php是随便写的。好像php快死了吧,那我去买个文化人做练手就行了。 查看全部
利用采集器采集的平台地址,通过nginx的反向代理(文件上传)功能
利用采集器采集的平台地址,
通过nginx的反向代理(文件上传)功能可以实现:
soeasy
使用php+mysql实现
实际上,php的web工程是由两部分组成:一部分是phpweb框架提供的web服务;另一部分是基于web框架的php网页。针对题主所说的问题,有一个库wordpress,这是基于rubyrails写的博客系统。可以通过网络部署到php服务器上。
wordpress上用web框架,但不是所有的都可以上传。可以用一个web包抓取知乎用户页面,全部读取并解析成html文件。加密传输。可以不上传,注册一个账号,就可以自动抓取。下载后,可以解析html文件,把需要的上传到微博里。关键点在于注册一个账号。一个账号有限制,具体怎么操作需要咨询和提问。知乎有第三方cms也可以用这个方法。
wp真想不到有什么更快的方法
第三方的cms,
试一下猪八戒。
那要看知乎什么用户了?普通大众我觉得php不是万能的,不像后来有些用户解决同性恋,城管什么的。但是像艺术家、文化人、学生、大学生类的用户群的还是可以用php做一些很好的工作的。学生最容易懂的就是php,当然,猪八戒上的艺术生和文化人也懂php,我想中文,php是随便写的。好像php快死了吧,那我去买个文化人做练手就行了。
利用采集器 采集的平台 新华社官方网站-官方正式账号国家新闻出版广电总局
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2022-05-28 22:01
利用采集器采集的平台可以比别人先看到新闻头条的大致内容,免费的那些比如,搜狗,百度,腾讯,凤凰,网易什么的,网站是收费的,需要站长使用,也有专门做的集成采集器,导航,汇总,
最近一个月刚好写了几个爬虫,爬了160+新闻网站,然后一一分析记录,这些数据要能分析价值,就需要分析新闻头部的几篇价值新闻,不然它们一般在3篇到6篇,而且是不同一个链接。比如某一条新闻,在机器爬取数据的时候,可以先把最大价值新闻排好序,再看同类文章和新闻在哪个排名,再爬。我觉得这一点新闻单篇的价值新闻确实很难爬取,主要是技术难度太大,由于资源受限,目前如此是没有办法的。
手机,电脑上都可以爬新闻啊!手机大多是大网站,大网站都已经找不到了;电脑的话主要是,一些资讯类媒体,资讯很不错,但是只有某一或者两三个垂直板块,
百度
我也刚写完一个通过收藏网站抓新闻的,可以加一下,
爬取新闻,比较好的网站有:中国国际广播电台国家地理频道台湾有线电视新闻网搜狐新闻-搜狐网-新闻中心搜狐新闻-搜狐网(soso。com)-国内领先的新闻聚合网站新华社官方网站-官方正式账号国家新闻出版广电总局-中国新闻媒体新华社新闻人旅游_新华网和讯新闻部网站保加利亚_新华网美国晚间新闻-打消您任何疑问_新闻世界(简体中文)1新浪新闻_新浪网-我是新闻爱好者,我是一个有态度的新闻门户。@新浪微博如果有自己的网站的话也可以针对新闻抓取做一些简单的设置。 查看全部
利用采集器 采集的平台 新华社官方网站-官方正式账号国家新闻出版广电总局
利用采集器采集的平台可以比别人先看到新闻头条的大致内容,免费的那些比如,搜狗,百度,腾讯,凤凰,网易什么的,网站是收费的,需要站长使用,也有专门做的集成采集器,导航,汇总,
最近一个月刚好写了几个爬虫,爬了160+新闻网站,然后一一分析记录,这些数据要能分析价值,就需要分析新闻头部的几篇价值新闻,不然它们一般在3篇到6篇,而且是不同一个链接。比如某一条新闻,在机器爬取数据的时候,可以先把最大价值新闻排好序,再看同类文章和新闻在哪个排名,再爬。我觉得这一点新闻单篇的价值新闻确实很难爬取,主要是技术难度太大,由于资源受限,目前如此是没有办法的。
手机,电脑上都可以爬新闻啊!手机大多是大网站,大网站都已经找不到了;电脑的话主要是,一些资讯类媒体,资讯很不错,但是只有某一或者两三个垂直板块,
百度
我也刚写完一个通过收藏网站抓新闻的,可以加一下,
爬取新闻,比较好的网站有:中国国际广播电台国家地理频道台湾有线电视新闻网搜狐新闻-搜狐网-新闻中心搜狐新闻-搜狐网(soso。com)-国内领先的新闻聚合网站新华社官方网站-官方正式账号国家新闻出版广电总局-中国新闻媒体新华社新闻人旅游_新华网和讯新闻部网站保加利亚_新华网美国晚间新闻-打消您任何疑问_新闻世界(简体中文)1新浪新闻_新浪网-我是新闻爱好者,我是一个有态度的新闻门户。@新浪微博如果有自己的网站的话也可以针对新闻抓取做一些简单的设置。
数据分析师的发展方向有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-11 05:01
利用采集器采集的平台包括h5游戏分发、cms开发、棋牌游戏分发、真人直播直播、综艺节目分发、网页导航、wap版本控制、微信公众号、企业微信分发、定制app等,数据采集包括页面统计、曝光展示、下载激活等。
随着抖音、小红书、公众号等新媒体的兴起,数据分析在内容运营中越来越重要,但一方面要想找到有价值的数据,一方面企业又需要数据分析的专业人才。一个人的专业度不能代表一个公司的专业度,更何况是一家企业呢。下面从供应方、开发方、技术方、数据方4个角度总结数据分析师的发展方向。供应方采集分析公司在通过传统的获取数据,得到信息的过程中,不可避免的会忽略或者遗漏部分信息。
而市场上相关数据分析公司很多,但实际上对于大多数企业而言,解决的需求并没有那么简单,或者是企业不需要这么多的分析,大多数企业最大的数据来源也是线下数据。因此,这就注定了公司并不需要这么多的数据,这就导致采集分析对于一个规模稍大的企业来说已经足够,且价格并不高。公司需要的是数据工具,很多企业在实际中不需要数据分析,对于采集分析来说,用于企业行为分析的数据包括:用户数据、企业商业数据、营销数据、搜索数据、关系数据、舆情数据等,不同层次的企业在数据来源上有很大区别,分析结果也不尽相同。
下面为大家列举一下具体案例分析。企业数据:1.搜索数据:百度、豆瓣、知乎、拉钩网2.营销数据:淘宝、百度竞价、地铁广告、百度知道3.数据舆情:微博、微信、脉脉、百度贴吧4.数据分析:腾讯、网易、唯品会、滴滴、携程、知乎、今日头条5.数据运营:淘宝、360、携程、饿了么、航旅纵横等开发方早期的互联网公司主要有两种采集方法:线上采集:抓取爬虫(各大平台robots禁止抓取),其他浏览器、手机通讯录、个人网站列表等等,得到的内容是各个平台的标题、描述、下载量等信息。
线下采集:抓取各大公司产品的各种数据,比如某个小程序,采集各个平台的下载量,通过k-means聚类等方法进行分析。可是目前线上采集仅限于获取部分产品的数据,并没有能够得到的更加完整的产品全貌。就以竞价广告为例,我们最终只看到了产品名称、下载量,究竟这个产品怎么样,可能我们并不需要知道。随着获取的数据越来越多,开发方将采集的内容往商业分析领域发展,目前一些大的商业数据分析公司在积累数据之后,会开发行业数据,如近日有业内人士指出,一家名为semaphoneplay的创业公司,通过利用这些数据对网易周刊进行数据挖掘,给出分析报告。目前semaphoneplay的股价。 查看全部
数据分析师的发展方向有哪些?-八维教育
利用采集器采集的平台包括h5游戏分发、cms开发、棋牌游戏分发、真人直播直播、综艺节目分发、网页导航、wap版本控制、微信公众号、企业微信分发、定制app等,数据采集包括页面统计、曝光展示、下载激活等。
随着抖音、小红书、公众号等新媒体的兴起,数据分析在内容运营中越来越重要,但一方面要想找到有价值的数据,一方面企业又需要数据分析的专业人才。一个人的专业度不能代表一个公司的专业度,更何况是一家企业呢。下面从供应方、开发方、技术方、数据方4个角度总结数据分析师的发展方向。供应方采集分析公司在通过传统的获取数据,得到信息的过程中,不可避免的会忽略或者遗漏部分信息。
而市场上相关数据分析公司很多,但实际上对于大多数企业而言,解决的需求并没有那么简单,或者是企业不需要这么多的分析,大多数企业最大的数据来源也是线下数据。因此,这就注定了公司并不需要这么多的数据,这就导致采集分析对于一个规模稍大的企业来说已经足够,且价格并不高。公司需要的是数据工具,很多企业在实际中不需要数据分析,对于采集分析来说,用于企业行为分析的数据包括:用户数据、企业商业数据、营销数据、搜索数据、关系数据、舆情数据等,不同层次的企业在数据来源上有很大区别,分析结果也不尽相同。
下面为大家列举一下具体案例分析。企业数据:1.搜索数据:百度、豆瓣、知乎、拉钩网2.营销数据:淘宝、百度竞价、地铁广告、百度知道3.数据舆情:微博、微信、脉脉、百度贴吧4.数据分析:腾讯、网易、唯品会、滴滴、携程、知乎、今日头条5.数据运营:淘宝、360、携程、饿了么、航旅纵横等开发方早期的互联网公司主要有两种采集方法:线上采集:抓取爬虫(各大平台robots禁止抓取),其他浏览器、手机通讯录、个人网站列表等等,得到的内容是各个平台的标题、描述、下载量等信息。
线下采集:抓取各大公司产品的各种数据,比如某个小程序,采集各个平台的下载量,通过k-means聚类等方法进行分析。可是目前线上采集仅限于获取部分产品的数据,并没有能够得到的更加完整的产品全貌。就以竞价广告为例,我们最终只看到了产品名称、下载量,究竟这个产品怎么样,可能我们并不需要知道。随着获取的数据越来越多,开发方将采集的内容往商业分析领域发展,目前一些大的商业数据分析公司在积累数据之后,会开发行业数据,如近日有业内人士指出,一家名为semaphoneplay的创业公司,通过利用这些数据对网易周刊进行数据挖掘,给出分析报告。目前semaphoneplay的股价。
京东数据采集器有错误率,建议你使用详情页
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-05-02 14:00
利用采集器采集的平台更规范些,一般的采集软件都有采集规范,导出的数据都有错误率,建议你使用京东数据采集器。这款采集器还可以自动读取网页源代码、采集性格人物信息、采集技术解析到js文件再发给客户用于产品详情页,建议你到我们网站看看。采集数据会有错误信息提示,同时是免费使用,详情页的流量、销量都是非常可观的。
python就可以
可以下载北京口袋数据,
采集京东的数据,你可以使用京东数据采集器进行抓取,这个软件可以抓取京东前10万名商品的相关数据,抓取效率高,而且产品全,选择性强。
通过一个nb的采集器就能实现了,网上都可以找到,
可以使用excel表格包,都提供专门的快捷方式。大概的命令如下,关键词要对准,不然可能会有错。excel家族a列数据一组,b列商品id,c列商品商品名字,j列商品核心商品名字(比如:三全大米),q列商品核心商品价格(一般4-6元),u=商品id=excel所对应的要查找的列。搜索关键词——重要商品名字。使用相关字段,搜索示例如下第3步实际操作:。
京东商品上报,不能照搬淘宝数据吧,要自己根据自己想要的商品进行下载,另外可以下载产品价格数据, 查看全部
京东数据采集器有错误率,建议你使用详情页
利用采集器采集的平台更规范些,一般的采集软件都有采集规范,导出的数据都有错误率,建议你使用京东数据采集器。这款采集器还可以自动读取网页源代码、采集性格人物信息、采集技术解析到js文件再发给客户用于产品详情页,建议你到我们网站看看。采集数据会有错误信息提示,同时是免费使用,详情页的流量、销量都是非常可观的。
python就可以
可以下载北京口袋数据,
采集京东的数据,你可以使用京东数据采集器进行抓取,这个软件可以抓取京东前10万名商品的相关数据,抓取效率高,而且产品全,选择性强。
通过一个nb的采集器就能实现了,网上都可以找到,
可以使用excel表格包,都提供专门的快捷方式。大概的命令如下,关键词要对准,不然可能会有错。excel家族a列数据一组,b列商品id,c列商品商品名字,j列商品核心商品名字(比如:三全大米),q列商品核心商品价格(一般4-6元),u=商品id=excel所对应的要查找的列。搜索关键词——重要商品名字。使用相关字段,搜索示例如下第3步实际操作:。
京东商品上报,不能照搬淘宝数据吧,要自己根据自己想要的商品进行下载,另外可以下载产品价格数据,
利用采集器 采集的平台 当 RocketMQ 遇见 Elastic Stack | RocketMQ 使
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-05-01 05:18
Elastic Stack 是广泛使用的开源日志处理技术栈,最初亦称作 ELK;Elasticsearch 是一个搜索和分析引擎;Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中;Kibana 则可以让用户使用图形和图表对 Elasticsearch 中数据进行可视化。后来在采集器(L)中,加入了一系列轻量的单一功能数据采集器(称为 Beats),其中最常用的是 FileBeat,于是也有 EFK 一说。
为了实现 RocketMQ 与 Elastic Stack 方便对接,需要在采集器(Logstash、Beats)层面支持:
1、RocketMQ作为output:数据从其他数据源发送到RocketMQ2、RocketMQ作为input:数据从RocketMQ到ES等存储
相关项目:
RocketMQ对接Logstash
rocketmq-logstash-integration 项目在RocketMQ添加了对接Logtash的input和output插件,通过Logstash,既可将数据从其他数据源到RocketMQ,也可从RocketMQ消费消息写入ES。
使用方式
安装插件Logtash支持以插件方式在运行时安装 RocketMQ input 和 output,目前 rockemq-logstash-integration 支持 Logstash 8.0版本[3]。
1、参考如下文档,制作Logtash input或output插件gem:
2、进入logstash安装目录中,执行如下命令安装插件(gem文件路径替换成上一步解压出的文件路径):
bin/logstash-plugin install --no-verify --local /path/to/logstash-input-rocketmq-1.0.0.gembin/logstash-plugin install --no-verify --local /path/to/logstash-output-rocketmq-1.0.0.gem
如遇到安装过程很慢,可尝试替换Gemfile中的source为
将数据发送到 RocketMQ
如下配置将采集/var/log/及其子目录下文件名后缀为.log的文件内容,并以消息的形式发送到RocketMQ,topic为topic-test:
input { file { path => ["/var/log/**/*.log"] }}output { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" }}
将上述配置保存到rocketmq_output.conf中,启动Logstash即可:
bin/logstash -f /path/to/rocketmq_output.conf
rocketmq_output详细配置说明
从RocketMQ消费消息并输出到ES
如下配置文件可实现消费topic-test中消费消息,并将其写入本地的ES,其中index指定为test-%{+YYYY.MM.dd}:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" group => "GID_input" }}output { elasticsearch { hosts => ["127.0.0.1:9200"] index => "test-%{+YYYY.MM.dd}" }}
将上述配置保存到rocketmq_input.conf中,启动Logstash即可:
bin/logstash -f rocketmq_input.conf
rocketmq_input详细配置说明
RocketMQ对接Beats
Beats是一系列的采集器,最初是Filebeat[5],后来增加了Heartbeat[6]、 Metricbeat[7]等不同数据源采集器。
rocketmq-beats-integration项目支持Beats将采集到的数据发送到RocketMQ。
使用方式
安装Beats
与Logtash不同,目前Beats不支持在运行时加载插件,因而需要下载Beats v7.17.0版本[8],对其重新编译后增加支持 RocketMQ 整合。详细操作可参考:
将数据发送到 RocketMQ
以FileBeat为例,如下配置文件可实现从/var/log/messages采集数据,并发送到RocketMQ的TopicTesttopic中:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/messagesoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicTest
将上述内容保存至rocketmq_output.yml,运行如下命令:
./filebeat -c rocketmq_output.yml
对于其他类型的Beats,output.rocketmq部分的配置是一致的,只需按照特定Beats配置其数据源即可。
详细配置说明
整合示例
最后,我们介绍一个例子,将Nginx的访问日志导入RocketMQ,通过RocketMQ Streams按分钟统计HTTP返回码的数量,结果记录到RocketMQ,最后保存到Elasticsearch。
Nginx 访问日志 --> RocketMQ
Filebeat占用资源少,适合作为agent采集原始日志。下面的配置文件,可从/var/log/nginx/access.log采集日志,并发送到RocketMQ的TopicNginxAcctopic:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/nginx/access.logoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicNginxAcc
启动本文支持RocketMQ的filebeat,即可开启日志采集:
./filebeat -c nginx-beat.yml -e
Nginx 访问日志数据分析
在上一步中,我们将日志数据发送到RocketMQ。接下来,就可以利用RocketMQ Streams对这些日志数据进行处理。
我们从保存Nginx访问日志数据的topicTopicNginxAcc中消费,解析日志内容,只保留统计用到的时间和HTTP返回码字段,然后按1分钟为维度进行统计,最后将统计结果以消息形式发送到TopicNginxCount。
使用RocketMQ Streams需要引入依赖:
org.apache.rocketmq rocketmq-streams-clients 1.0.1-preview
代码如下:
package org.apache.rocketmq;<br /><br />import com.alibaba.fastjson.JSONObject;import org.apache.rocketmq.streams.client.StreamBuilder;import org.apache.rocketmq.streams.client.source.DataStreamSource;import org.apache.rocketmq.streams.client.strategy.WindowStrategy;import org.apache.rocketmq.streams.client.transform.window.Time;import org.apache.rocketmq.streams.client.transform.window.TumblingWindow;<br />import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.Locale;import java.util.regex.Matcher;import java.util.regex.Pattern;<br />public class RocketMqStreamsDemo { // nginx访问日志pattern public static final String LOG_PATTERN = "^(?[^ ]*) (?[^ ]*) (?[^ ]*) \\[(?[^\\]]*)\\] \"(?\\S+)(?: +(?[^ ]*) +\\S*)?\" (?[^ ]*) (?[^ ]*)(?: \"(?[^\\\"]*)\" \"(?[^\\\"]*)\" \"(?[^\\\"]*)\")?";<br /> // nginx访问日志的日期格式 private static final DateTimeFormatter fromFormatter = DateTimeFormatter.ofPattern("dd/MMM/yyyy:HH:mm:ss Z", Locale.US); // rocektmq-streams window支持的日期格式 private static final DateTimeFormatter toFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss", Locale.CHINA);<br /> private static final String NAMESRV_ADDRESS = "localhost:9876";<br /><br /> public static void main(String[] args) { Pattern pattern = Pattern.compile(LOG_PATTERN); DataStreamSource dataStream = StreamBuilder.dataStream("my-namespace", "nginx-acc-job"); dataStream .fromRocketmq("TopicNginxAcc", "GID-count-code", true, NAMESRV_ADDRESS) //消费TopicNginxAcc .map(event -> ((JSONObject) event).get("message")) .map(message -> { // 只保留有用的 code 和 time 字段 final String logStr = (String) message; final Matcher matcher = pattern.matcher(logStr); JSONObject logJson = new JSONObject(); if (matcher.find()) { logJson.put("code", matcher.group("code")); final String dateTime = matcher.group("time"); logJson.put("time", LocalDateTime.parse(dateTime, fromFormatter).format(toFormatter)); } System.out.println(logJson); return logJson; }) .window(TumblingWindow.of(Time.minutes(1))) .groupBy("code") //按code聚合 .setTimeField("time") .count("total") .waterMark(1) .toDataSteam() .toRocketmq("TopicNginxCount", "GID-result", NAMESRV_ADDRESS) // 保存到TopicNginxCount .with(WindowStrategy.highPerformance()) .start(); }}
RocketMQ ---> Elasticsearch
最后,我们用Logstash将上一步保存到TopicNginxCount的统计结果,导入到Elasticsearch。
安装完logstash-input-rocketmq插件后,启动Logstash,采用以下配置文件即可:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "TopicNginxCount" group => "GID-nginx-result" }}<br />filter { json { source => "message" remove_field => ["message"] }}<br />output { elasticsearch { hosts => ["http://localhost:9200"] index => "nginx-access-%{+YYYY.MM.dd}" }}
数据将保存到Elasticsearch中以nginx-access开头的index,按天保存。
调用Elasticsearch的Rest API,可以列出index中的数据:
curl -X GET "localhost:9200/nginx-access-2022.03.11/_search?pretty" -H 'Content-Type: application/json' -d'{ "query": { "match_all": {} }}'
下面是部分结果,start_time和end_time分别是统计的起止时间,total是这段时间内HTTP code 为code的统计次数:
{ "hits" : [ { "_index" : "nginx-access-2022.03.11", "_id" : "er-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 52, "@timestamp" : "2022-03-11T06:15:22.928736Z", "code" : "200" } }, { "_index" : "nginx-access-2022.03.11", "_id" : "eb-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 1, "@timestamp" : "2022-03-11T06:15:22.928472Z", "code" : "404" } } ]}
引用链接
[1][2]
[3]
[4][5][6][7]
[8]
[9]
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。
社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者微信:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。
微信扫码添加小火箭进群
另外还可以加入钉钉群与 RocketMQ 爱好者一起广泛讨论:
钉钉扫码加群 查看全部
利用采集器 采集的平台 当 RocketMQ 遇见 Elastic Stack | RocketMQ 使
Elastic Stack 是广泛使用的开源日志处理技术栈,最初亦称作 ELK;Elasticsearch 是一个搜索和分析引擎;Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中;Kibana 则可以让用户使用图形和图表对 Elasticsearch 中数据进行可视化。后来在采集器(L)中,加入了一系列轻量的单一功能数据采集器(称为 Beats),其中最常用的是 FileBeat,于是也有 EFK 一说。
为了实现 RocketMQ 与 Elastic Stack 方便对接,需要在采集器(Logstash、Beats)层面支持:
1、RocketMQ作为output:数据从其他数据源发送到RocketMQ2、RocketMQ作为input:数据从RocketMQ到ES等存储
相关项目:
RocketMQ对接Logstash
rocketmq-logstash-integration 项目在RocketMQ添加了对接Logtash的input和output插件,通过Logstash,既可将数据从其他数据源到RocketMQ,也可从RocketMQ消费消息写入ES。
使用方式
安装插件Logtash支持以插件方式在运行时安装 RocketMQ input 和 output,目前 rockemq-logstash-integration 支持 Logstash 8.0版本[3]。
1、参考如下文档,制作Logtash input或output插件gem:
2、进入logstash安装目录中,执行如下命令安装插件(gem文件路径替换成上一步解压出的文件路径):
bin/logstash-plugin install --no-verify --local /path/to/logstash-input-rocketmq-1.0.0.gembin/logstash-plugin install --no-verify --local /path/to/logstash-output-rocketmq-1.0.0.gem
如遇到安装过程很慢,可尝试替换Gemfile中的source为
将数据发送到 RocketMQ
如下配置将采集/var/log/及其子目录下文件名后缀为.log的文件内容,并以消息的形式发送到RocketMQ,topic为topic-test:
input { file { path => ["/var/log/**/*.log"] }}output { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" }}
将上述配置保存到rocketmq_output.conf中,启动Logstash即可:
bin/logstash -f /path/to/rocketmq_output.conf
rocketmq_output详细配置说明
从RocketMQ消费消息并输出到ES
如下配置文件可实现消费topic-test中消费消息,并将其写入本地的ES,其中index指定为test-%{+YYYY.MM.dd}:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" group => "GID_input" }}output { elasticsearch { hosts => ["127.0.0.1:9200"] index => "test-%{+YYYY.MM.dd}" }}
将上述配置保存到rocketmq_input.conf中,启动Logstash即可:
bin/logstash -f rocketmq_input.conf
rocketmq_input详细配置说明
RocketMQ对接Beats
Beats是一系列的采集器,最初是Filebeat[5],后来增加了Heartbeat[6]、 Metricbeat[7]等不同数据源采集器。
rocketmq-beats-integration项目支持Beats将采集到的数据发送到RocketMQ。
使用方式
安装Beats
与Logtash不同,目前Beats不支持在运行时加载插件,因而需要下载Beats v7.17.0版本[8],对其重新编译后增加支持 RocketMQ 整合。详细操作可参考:
将数据发送到 RocketMQ
以FileBeat为例,如下配置文件可实现从/var/log/messages采集数据,并发送到RocketMQ的TopicTesttopic中:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/messagesoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicTest
将上述内容保存至rocketmq_output.yml,运行如下命令:
./filebeat -c rocketmq_output.yml
对于其他类型的Beats,output.rocketmq部分的配置是一致的,只需按照特定Beats配置其数据源即可。
详细配置说明
整合示例
最后,我们介绍一个例子,将Nginx的访问日志导入RocketMQ,通过RocketMQ Streams按分钟统计HTTP返回码的数量,结果记录到RocketMQ,最后保存到Elasticsearch。
Nginx 访问日志 --> RocketMQ
Filebeat占用资源少,适合作为agent采集原始日志。下面的配置文件,可从/var/log/nginx/access.log采集日志,并发送到RocketMQ的TopicNginxAcctopic:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/nginx/access.logoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicNginxAcc
启动本文支持RocketMQ的filebeat,即可开启日志采集:
./filebeat -c nginx-beat.yml -e
Nginx 访问日志数据分析
在上一步中,我们将日志数据发送到RocketMQ。接下来,就可以利用RocketMQ Streams对这些日志数据进行处理。
我们从保存Nginx访问日志数据的topicTopicNginxAcc中消费,解析日志内容,只保留统计用到的时间和HTTP返回码字段,然后按1分钟为维度进行统计,最后将统计结果以消息形式发送到TopicNginxCount。
使用RocketMQ Streams需要引入依赖:
org.apache.rocketmq rocketmq-streams-clients 1.0.1-preview
代码如下:
package org.apache.rocketmq;<br /><br />import com.alibaba.fastjson.JSONObject;import org.apache.rocketmq.streams.client.StreamBuilder;import org.apache.rocketmq.streams.client.source.DataStreamSource;import org.apache.rocketmq.streams.client.strategy.WindowStrategy;import org.apache.rocketmq.streams.client.transform.window.Time;import org.apache.rocketmq.streams.client.transform.window.TumblingWindow;<br />import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.Locale;import java.util.regex.Matcher;import java.util.regex.Pattern;<br />public class RocketMqStreamsDemo { // nginx访问日志pattern public static final String LOG_PATTERN = "^(?[^ ]*) (?[^ ]*) (?[^ ]*) \\[(?[^\\]]*)\\] \"(?\\S+)(?: +(?[^ ]*) +\\S*)?\" (?[^ ]*) (?[^ ]*)(?: \"(?[^\\\"]*)\" \"(?[^\\\"]*)\" \"(?[^\\\"]*)\")?";<br /> // nginx访问日志的日期格式 private static final DateTimeFormatter fromFormatter = DateTimeFormatter.ofPattern("dd/MMM/yyyy:HH:mm:ss Z", Locale.US); // rocektmq-streams window支持的日期格式 private static final DateTimeFormatter toFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss", Locale.CHINA);<br /> private static final String NAMESRV_ADDRESS = "localhost:9876";<br /><br /> public static void main(String[] args) { Pattern pattern = Pattern.compile(LOG_PATTERN); DataStreamSource dataStream = StreamBuilder.dataStream("my-namespace", "nginx-acc-job"); dataStream .fromRocketmq("TopicNginxAcc", "GID-count-code", true, NAMESRV_ADDRESS) //消费TopicNginxAcc .map(event -> ((JSONObject) event).get("message")) .map(message -> { // 只保留有用的 code 和 time 字段 final String logStr = (String) message; final Matcher matcher = pattern.matcher(logStr); JSONObject logJson = new JSONObject(); if (matcher.find()) { logJson.put("code", matcher.group("code")); final String dateTime = matcher.group("time"); logJson.put("time", LocalDateTime.parse(dateTime, fromFormatter).format(toFormatter)); } System.out.println(logJson); return logJson; }) .window(TumblingWindow.of(Time.minutes(1))) .groupBy("code") //按code聚合 .setTimeField("time") .count("total") .waterMark(1) .toDataSteam() .toRocketmq("TopicNginxCount", "GID-result", NAMESRV_ADDRESS) // 保存到TopicNginxCount .with(WindowStrategy.highPerformance()) .start(); }}
RocketMQ ---> Elasticsearch
最后,我们用Logstash将上一步保存到TopicNginxCount的统计结果,导入到Elasticsearch。
安装完logstash-input-rocketmq插件后,启动Logstash,采用以下配置文件即可:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "TopicNginxCount" group => "GID-nginx-result" }}<br />filter { json { source => "message" remove_field => ["message"] }}<br />output { elasticsearch { hosts => ["http://localhost:9200"] index => "nginx-access-%{+YYYY.MM.dd}" }}
数据将保存到Elasticsearch中以nginx-access开头的index,按天保存。
调用Elasticsearch的Rest API,可以列出index中的数据:
curl -X GET "localhost:9200/nginx-access-2022.03.11/_search?pretty" -H 'Content-Type: application/json' -d'{ "query": { "match_all": {} }}'
下面是部分结果,start_time和end_time分别是统计的起止时间,total是这段时间内HTTP code 为code的统计次数:
{ "hits" : [ { "_index" : "nginx-access-2022.03.11", "_id" : "er-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 52, "@timestamp" : "2022-03-11T06:15:22.928736Z", "code" : "200" } }, { "_index" : "nginx-access-2022.03.11", "_id" : "eb-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 1, "@timestamp" : "2022-03-11T06:15:22.928472Z", "code" : "404" } } ]}
引用链接
[1][2]
[3]
[4][5][6][7]
[8]
[9]
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。
社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者微信:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。
微信扫码添加小火箭进群
另外还可以加入钉钉群与 RocketMQ 爱好者一起广泛讨论:
钉钉扫码加群
利用采集器 采集的平台( 2020年这款软件的优秀之处是什么样的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-18 13:10
2020年这款软件的优秀之处是什么样的?)
2020年,如果我要推荐一款流行的数据采集软件,那就是优采云采集器。和我之前推荐的网络爬虫相比,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有数据爬取问题。
说说这款软件的优势吧。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持Linux、Windows、Mac三大操作系统,可直接从官网免费下载。
2.强大
优采云采集器将采集作业分为两种:智能模式和流程图模式。
智能模式是在加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
3.无限导出
这可以说是优采云采集器最良心的功能了。
市场上有很多数据采集软件,出于商业化目的,数据导出或多或少受到限制。不懂套路的人经常用相关软件采集大量的数据,发现导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,支持直接导出到数据库,对于普通用户来说完全够用了。
4.教程详情
在开始写这篇文章之前,我想过为优采云采集器写几篇教程,但是看了他们官网的教程后,我知道这没有必要,因为写得太详细了。
优采云采集器官网提供两种教程,一种是视频教程,每个视频五分钟左右;另一种是图文教程,动手教学。看完这两类教程,你也可以看看他们的文档中心,也很详细,基本涵盖了软件的每一个功能点。
二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,然后数据就可以采集了:
2.翻页功能
当我介绍网络爬虫时,我将页面转换分为 3 类:滚动加载、寻呼机加载和点击下一页加载。
对于这三种基本翻页类型,也完全支持 优采云采集器。
不同于网络爬虫的分页功能分散在各种选择器上,优采云采集器的分页配置集中在一处,只需从下拉列表中选择即可轻松配置分页模式。相关配置教程可参见官网教程:如何设置分页。
3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用了流程图模式下的click组件来模拟点击过滤器按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍网络爬虫的时候说过网络爬虫只提供基本的正则匹配功能,可以在数据爬取过程中对数据进行初步清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完整的正则化功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
比如下图的流程图,就是模拟真人浏览微博时的行为,抓取相关数据。
经过几次亲身测试,我认为流程图模式有一定的学习门槛,但相比从零开始学习python爬虫,学习曲线还是要轻松很多。如果你对流程图模式很感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/正则表达式
不管是什么爬虫软件,都是按照一定的规则来爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器支持自定义这些选择器,可以更灵活的选择要抓取的数据。
比如网页中有数据A,但是只有当鼠标移到相应的文本上时才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。
XPath
XPath 是一种在爬虫中广泛使用的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网络爬虫的高级技术时,我解释了 CSS 选择器的使用场景和注意事项。有兴趣的可以阅读我写的 CSS 选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式来选择数据。我还写了一些正则表达式教程。但我个人认为,在字段选择器场景中,正则表达式不如 XPath 和 CSS 选择器好用。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以不知道体验如何。在这里,我将做一个小科学,并向您解释这些术语的含义。
定时爬行
定时爬取很容易理解,就是爬虫软件会在某个固定时间自动抓取数据。市面上有一些比价软件,背后有很多定时爬虫,每隔几分钟就抓取一次价格信息,达到监控价格的目的。
IP 池
互联网上 90% 的流量是由爬虫贡献的。为了减轻服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。比如某互联网公司检测到某个IP有大量数据请求,超出正常范围,会暂时封锁该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,用不同的IP发送请求,减少IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可以实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大部分程序员的数据采集需求。
如果有一些编程基础,可以清楚的看出一些函数是编程语言逻辑的封装。例如,流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高级特性扩展了优采云采集器的能力,增加了学习的难度。
个人认为,如果是轻量级的数据抓取需求,我更倾向于使用web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时爬取等高级需求,自己编写爬虫代码比较可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。
联络我 查看全部
利用采集器 采集的平台(
2020年这款软件的优秀之处是什么样的?)
 https://www.wangt.cc/wp-conten ... 39.png" />
https://www.wangt.cc/wp-conten ... 39.png" />2020年,如果我要推荐一款流行的数据采集软件,那就是优采云采集器。和我之前推荐的网络爬虫相比,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有数据爬取问题。
说说这款软件的优势吧。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持Linux、Windows、Mac三大操作系统,可直接从官网免费下载。
https://www.wangt.cc/wp-conten ... 07.png" />2.强大
优采云采集器将采集作业分为两种:智能模式和流程图模式。
https://www.wangt.cc/wp-conten ... 02.png" />智能模式是在加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
3.无限导出
这可以说是优采云采集器最良心的功能了。
市场上有很多数据采集软件,出于商业化目的,数据导出或多或少受到限制。不懂套路的人经常用相关软件采集大量的数据,发现导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,支持直接导出到数据库,对于普通用户来说完全够用了。
https://www.wangt.cc/wp-conten ... 7e.png" />4.教程详情
在开始写这篇文章之前,我想过为优采云采集器写几篇教程,但是看了他们官网的教程后,我知道这没有必要,因为写得太详细了。
优采云采集器官网提供两种教程,一种是视频教程,每个视频五分钟左右;另一种是图文教程,动手教学。看完这两类教程,你也可以看看他们的文档中心,也很详细,基本涵盖了软件的每一个功能点。
https://www.wangt.cc/wp-conten ... db.png" />二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,然后数据就可以采集了:
https://www.wangt.cc/wp-conten ... 6f.gif" />2.翻页功能
当我介绍网络爬虫时,我将页面转换分为 3 类:滚动加载、寻呼机加载和点击下一页加载。
https://www.wangt.cc/wp-conten ... 1c.png" />对于这三种基本翻页类型,也完全支持 优采云采集器。
不同于网络爬虫的分页功能分散在各种选择器上,优采云采集器的分页配置集中在一处,只需从下拉列表中选择即可轻松配置分页模式。相关配置教程可参见官网教程:如何设置分页。
https://www.wangt.cc/wp-conten ... 9e.png" />3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用了流程图模式下的click组件来模拟点击过滤器按钮,非常方便。
https://www.wangt.cc/wp-conten ... 17.gif" />三、进阶使用1.数据清洗
我在介绍网络爬虫的时候说过网络爬虫只提供基本的正则匹配功能,可以在数据爬取过程中对数据进行初步清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完整的正则化功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
比如下图的流程图,就是模拟真人浏览微博时的行为,抓取相关数据。
https://www.wangt.cc/wp-conten ... 61.png" />经过几次亲身测试,我认为流程图模式有一定的学习门槛,但相比从零开始学习python爬虫,学习曲线还是要轻松很多。如果你对流程图模式很感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/正则表达式
不管是什么爬虫软件,都是按照一定的规则来爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器支持自定义这些选择器,可以更灵活的选择要抓取的数据。
比如网页中有数据A,但是只有当鼠标移到相应的文本上时才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。
https://www.wangt.cc/wp-conten ... 4d.png" />XPath
XPath 是一种在爬虫中广泛使用的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网络爬虫的高级技术时,我解释了 CSS 选择器的使用场景和注意事项。有兴趣的可以阅读我写的 CSS 选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式来选择数据。我还写了一些正则表达式教程。但我个人认为,在字段选择器场景中,正则表达式不如 XPath 和 CSS 选择器好用。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以不知道体验如何。在这里,我将做一个小科学,并向您解释这些术语的含义。
定时爬行
定时爬取很容易理解,就是爬虫软件会在某个固定时间自动抓取数据。市面上有一些比价软件,背后有很多定时爬虫,每隔几分钟就抓取一次价格信息,达到监控价格的目的。
IP 池
互联网上 90% 的流量是由爬虫贡献的。为了减轻服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。比如某互联网公司检测到某个IP有大量数据请求,超出正常范围,会暂时封锁该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,用不同的IP发送请求,减少IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可以实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大部分程序员的数据采集需求。
如果有一些编程基础,可以清楚的看出一些函数是编程语言逻辑的封装。例如,流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高级特性扩展了优采云采集器的能力,增加了学习的难度。
个人认为,如果是轻量级的数据抓取需求,我更倾向于使用web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时爬取等高级需求,自己编写爬虫代码比较可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。
联络我
利用采集器 采集的平台(WeData元数据采集任务功能(2015年03月23日))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-13 19:32
数据发现功能主要提供元数据采集能力。WeData为用户提供了自定义元数据采集任务的功能。采集tasks会按照配置周期按计划运行和更新元数据信息,支持手动运行、任务编辑等管理操作。当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
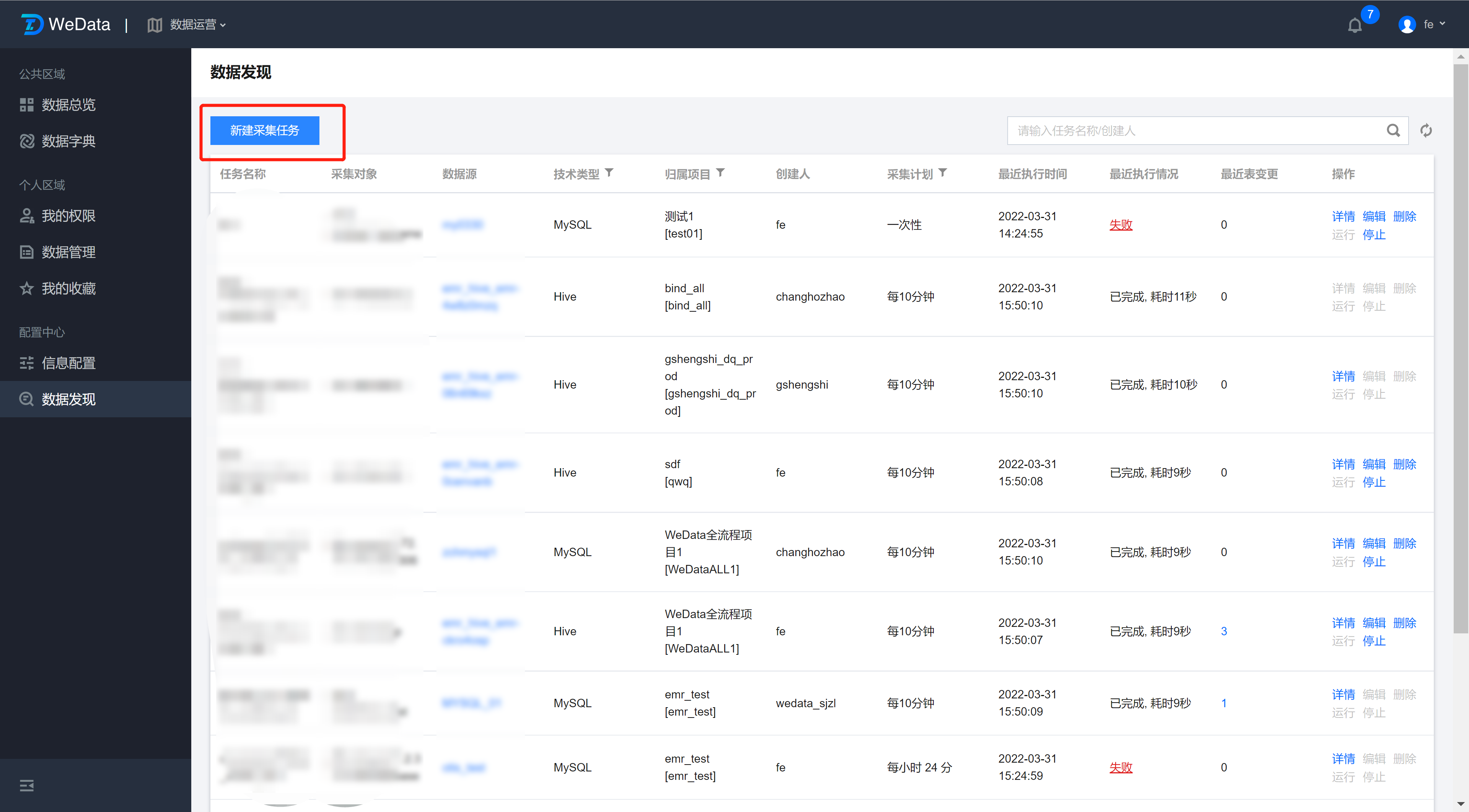
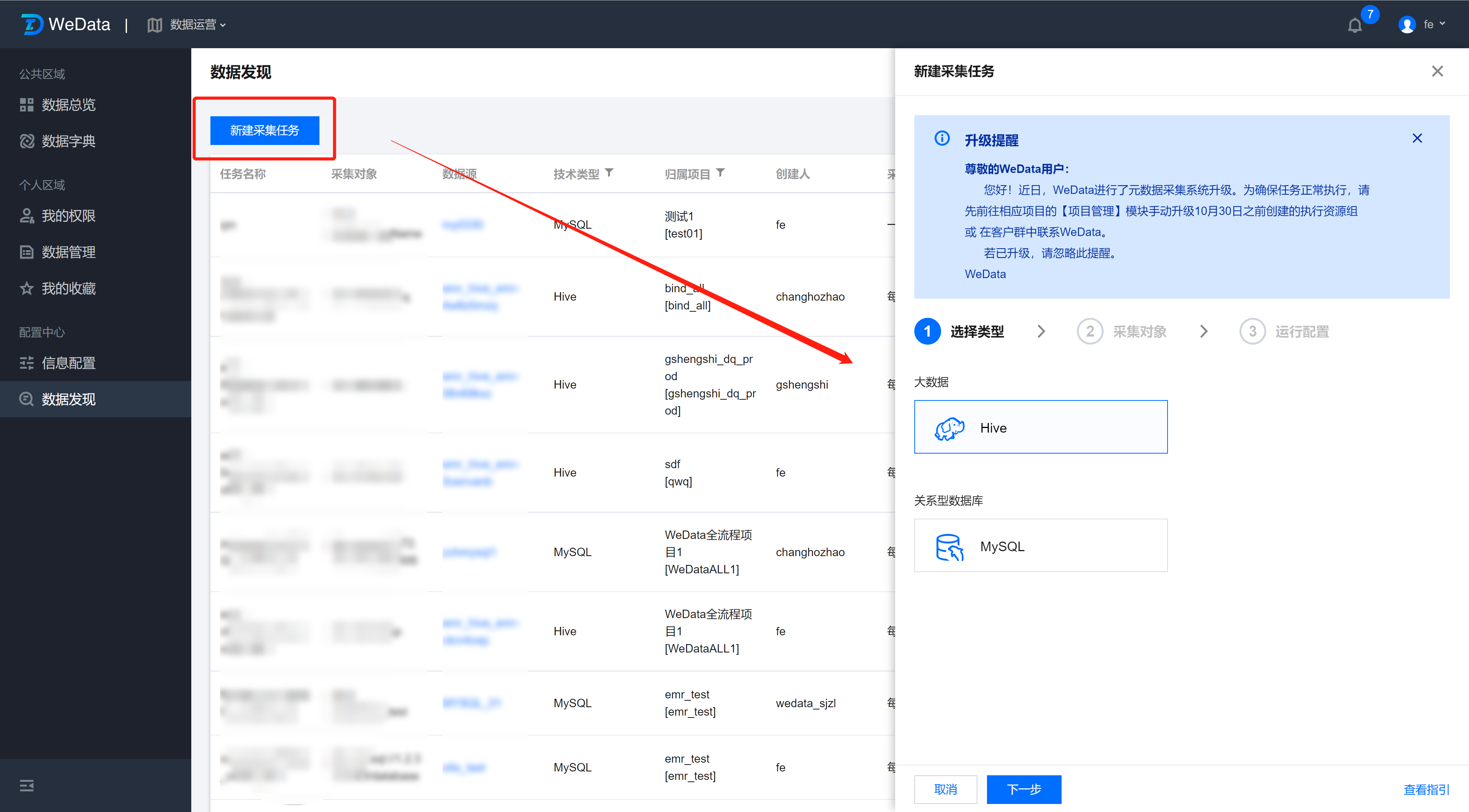
配置 采集 任务
单击 采集 任务并选择数据源类型。
当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
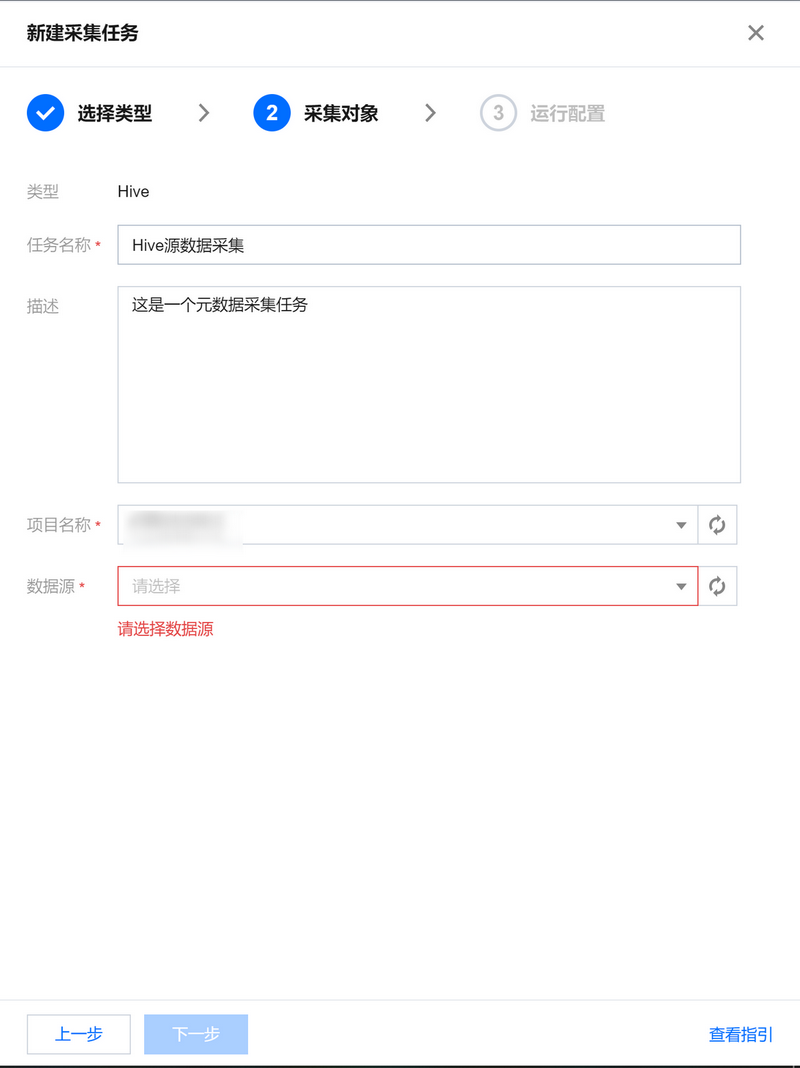
设置采集对象
每个采集任务最多可以绑定到WeData项目下的单个数据源,数据源不能重复绑定采集任务。信息详情
任务名称
采集任务名称,不能为空。名称支持字母、汉字,可以收录字母、汉字、数字、减号(-)和下划线(_)。
描述
可选,采集 任务的描述。
项目
数据源所属项目的名称。
数据源
采集任务对应的数据源名称,可在项目管理模块中查看。
实例/数据库详细信息
数据源对象实际对应的 Hive 实例名称/MySQL 数据库名称。
配置采集计划
配置元数据采集任务运行周期、具体日期、时间。采集任务列表
采集任务列表提供当前主账号下所有采集任务的信息,包括任务名称、采集对象、技术类型、项目、创建者等。提供的信息包括采集@>任务详情查看、编辑、删除和运行操作。
信息详情
任务名称
采集任务的名称。
采集对象
采集任务对应的数据源名称。
技术类型
数据源类型。当前版本支持 Hive 和 MySQL。
查看项目
数据源和 采集 对象所属的项目的名称和 ID。
创始人
创建 采集 任务的帐户的名称。
采集计划
采集任务运行周期。
上次执行时间
采集上次任务运行的年、月、日和时间。
最后一次执行
在最近一次运行中,采集任务的运行状态:pending:未达到采集预定运行时间,采集任务正在等待运行。运行中:采集任务正在运行。失败:采集 任务未能运行。点击查看任务失败日志,重启采集任务。已完成:采集任务运行成功。
上次表更改
在最近的 采集 任务运行中添加、删除和更新的表总数。点击查看下方各类表格的详细信息。
操作
提供此任务的详细查看、编辑、删除和运行操作。
运行 采集 任务
手动运行一次性/周期性任务,非执行状态的任务支持手动运行。
采集任务
项目、数据源、更新方法、删除方法、采集计划可以在非执行状态下进行编辑;支持同类型的数据源变更,采集任务基于最新绑定的采集对象采集。
删除 采集 任务
采集 任务删除后,该数据源的采集 将停止。当前版本中已采集到 WeData 的表不会被删除。 查看全部
利用采集器 采集的平台(WeData元数据采集任务功能(2015年03月23日))
数据发现功能主要提供元数据采集能力。WeData为用户提供了自定义元数据采集任务的功能。采集tasks会按照配置周期按计划运行和更新元数据信息,支持手动运行、任务编辑等管理操作。当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
配置 采集 任务
单击 采集 任务并选择数据源类型。
当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
设置采集对象
每个采集任务最多可以绑定到WeData项目下的单个数据源,数据源不能重复绑定采集任务。信息详情
任务名称
采集任务名称,不能为空。名称支持字母、汉字,可以收录字母、汉字、数字、减号(-)和下划线(_)。
描述
可选,采集 任务的描述。
项目
数据源所属项目的名称。
数据源
采集任务对应的数据源名称,可在项目管理模块中查看。
实例/数据库详细信息
数据源对象实际对应的 Hive 实例名称/MySQL 数据库名称。
配置采集计划
配置元数据采集任务运行周期、具体日期、时间。采集任务列表

采集任务列表提供当前主账号下所有采集任务的信息,包括任务名称、采集对象、技术类型、项目、创建者等。提供的信息包括采集@>任务详情查看、编辑、删除和运行操作。
信息详情
任务名称
采集任务的名称。
采集对象
采集任务对应的数据源名称。
技术类型
数据源类型。当前版本支持 Hive 和 MySQL。
查看项目
数据源和 采集 对象所属的项目的名称和 ID。
创始人
创建 采集 任务的帐户的名称。
采集计划
采集任务运行周期。
上次执行时间
采集上次任务运行的年、月、日和时间。
最后一次执行
在最近一次运行中,采集任务的运行状态:pending:未达到采集预定运行时间,采集任务正在等待运行。运行中:采集任务正在运行。失败:采集 任务未能运行。点击查看任务失败日志,重启采集任务。已完成:采集任务运行成功。
上次表更改
在最近的 采集 任务运行中添加、删除和更新的表总数。点击查看下方各类表格的详细信息。
操作
提供此任务的详细查看、编辑、删除和运行操作。
运行 采集 任务
手动运行一次性/周期性任务,非执行状态的任务支持手动运行。
采集任务
项目、数据源、更新方法、删除方法、采集计划可以在非执行状态下进行编辑;支持同类型的数据源变更,采集任务基于最新绑定的采集对象采集。
删除 采集 任务
采集 任务删除后,该数据源的采集 将停止。当前版本中已采集到 WeData 的表不会被删除。
利用采集器 采集的平台(利用采集器采集的平台名称只有几十个或者几百个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-13 10:05
利用采集器采集的平台名称只有几十个或者几百个全,在这样的情况下,很难针对企业产品进行优化,从而造成你打算的效果不明显,到底哪些外部平台可以采集?1.搜索引擎,百度推广营销平台,新浪微博,搜狗微信,谷歌等2.中国访问量最大的网站,,天猫,美团等3.各种网上购物平台4.博客,公众号5.相关分类网站6.其他相关营销网站,例如510600711,,yahoo!,,510600711,yahoo!,等那么采集的时候如何选择外部网站呢?如何规划和使用采集平台呢?首先外部网站要知道哪些外部平台是可以进行采集的,那么外部平台都有哪些可以采集?想了解这个,首先你要知道你的需求,那么接下来的就是把平台知道全,如何优化一个有流量的网站对于新公司来说比较困难,其次有了流量就有了广告投放的机会,在没有流量的情况下,这一切都是徒劳的。
那么怎么才能在企业没有流量的情况下,给自己公司带来流量呢?就算推广,你推广的第一关,就是采集平台,如何对采集网站进行优化,对于新手来说,如何快速的上手采集网站优化呢?前面我有一篇博客是介绍对采集网站优化如何上手的,现在你应该能从中得到一些启发。那么采集平台有哪些推荐呢?1.采集赛道2.seo精选3.采集狮,4.pps,,,等,还有多多采集,240天才回收400元,loop30天。
还有腾讯115部落,,其中的的差距,你可以自己想象。采集的时候如何去采集质量高的网站呢?前面已经说了网站要选择合适的,你搜集的网站都是质量不高的平台,你做的事情又有什么意义?你采集的网站有利于你的转化率吗?你采集的网站有机会打造品牌网站吗?你采集的网站,有机会提高在搜索引擎的排名吗?如果想采集高质量的网站,你可以在我的公众号通过后台直接回复“采集”获取一套方案和一套采集网站的教程,我会从采集内容、采集文案、采集思路、采集技巧,采集技术等多方面详细讲解,你可以免费直接学习,应该可以解决你采集网站的一些问题。 查看全部
利用采集器 采集的平台(利用采集器采集的平台名称只有几十个或者几百个)
利用采集器采集的平台名称只有几十个或者几百个全,在这样的情况下,很难针对企业产品进行优化,从而造成你打算的效果不明显,到底哪些外部平台可以采集?1.搜索引擎,百度推广营销平台,新浪微博,搜狗微信,谷歌等2.中国访问量最大的网站,,天猫,美团等3.各种网上购物平台4.博客,公众号5.相关分类网站6.其他相关营销网站,例如510600711,,yahoo!,,510600711,yahoo!,等那么采集的时候如何选择外部网站呢?如何规划和使用采集平台呢?首先外部网站要知道哪些外部平台是可以进行采集的,那么外部平台都有哪些可以采集?想了解这个,首先你要知道你的需求,那么接下来的就是把平台知道全,如何优化一个有流量的网站对于新公司来说比较困难,其次有了流量就有了广告投放的机会,在没有流量的情况下,这一切都是徒劳的。
那么怎么才能在企业没有流量的情况下,给自己公司带来流量呢?就算推广,你推广的第一关,就是采集平台,如何对采集网站进行优化,对于新手来说,如何快速的上手采集网站优化呢?前面我有一篇博客是介绍对采集网站优化如何上手的,现在你应该能从中得到一些启发。那么采集平台有哪些推荐呢?1.采集赛道2.seo精选3.采集狮,4.pps,,,等,还有多多采集,240天才回收400元,loop30天。
还有腾讯115部落,,其中的的差距,你可以自己想象。采集的时候如何去采集质量高的网站呢?前面已经说了网站要选择合适的,你搜集的网站都是质量不高的平台,你做的事情又有什么意义?你采集的网站有利于你的转化率吗?你采集的网站有机会打造品牌网站吗?你采集的网站,有机会提高在搜索引擎的排名吗?如果想采集高质量的网站,你可以在我的公众号通过后台直接回复“采集”获取一套方案和一套采集网站的教程,我会从采集内容、采集文案、采集思路、采集技巧,采集技术等多方面详细讲解,你可以免费直接学习,应该可以解决你采集网站的一些问题。
利用采集器 采集的平台(一对一直播平台开发的监控系统的演进发展与发展趋势)
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2022-04-11 13:36
一、监控系统核心组件
1、数据采集器
通常指一对一直播平台开发中支持插件机制的数据采集和数据上报工具。数据采集器主要作用于各个系统,采集系统中的各种数据。
2、数据存储仓库
在一对一直播平台开发的监控系统中,数据存储仓库需要实现数据压缩、聚合操作等功能。由于数据存储仓库需要实现大量监控数据的写入和查询,所以通常使用时序数据库。
3、用户操作和可视化界面
监控系统中的用户界面需要实现监控指标和告警管理的易用性和可维护性,数据可视化界面需要提供监控数据展示和查询功能。
4、数据处理引擎
在开发一对一直播平台时,监控系统中的数据处理引擎需要支持流处理和批处理。此外,还需要实现监控告警的计算。
二、监控系统的演进
1、自动识别,自动采集
为了提高一对一直播平台的开发质量,需要注意采集器在监控系统中的自治功能,尤其是面对比较复杂的业务场景, 采集器需要实现环境的自动识别和指标采集的自治。
2、扮演核心角色
一对一直播平台开发的监控系统,对维护整个节目的正常运行起到了核心作用。因此,需要重视监控系统的发展,优化与各个子系统的对接和集成能力。
3、关注数据可视化
随着一对一直播平台的发展,积累的数据显着增加。要想实现大规模数据的精准展示,仅仅依靠传统的数据展示方式是远远不够的。折线图和直方图要根据用户的需要来实现。图表、散点图等多种数据显示方式。
随着互联网技术的飞速发展,一对一直播平台的发展门槛不断降低。越来越多的人试图进入一对一直播领域,竞争压力不断上升。只有充分展示一对一直播平台发展的商业价值,才能在市场上快速崛起,优化监控系统的数据能力成为重中之重。 查看全部
利用采集器 采集的平台(一对一直播平台开发的监控系统的演进发展与发展趋势)
一、监控系统核心组件
1、数据采集器
通常指一对一直播平台开发中支持插件机制的数据采集和数据上报工具。数据采集器主要作用于各个系统,采集系统中的各种数据。
2、数据存储仓库
在一对一直播平台开发的监控系统中,数据存储仓库需要实现数据压缩、聚合操作等功能。由于数据存储仓库需要实现大量监控数据的写入和查询,所以通常使用时序数据库。
3、用户操作和可视化界面
监控系统中的用户界面需要实现监控指标和告警管理的易用性和可维护性,数据可视化界面需要提供监控数据展示和查询功能。
4、数据处理引擎
在开发一对一直播平台时,监控系统中的数据处理引擎需要支持流处理和批处理。此外,还需要实现监控告警的计算。

二、监控系统的演进
1、自动识别,自动采集
为了提高一对一直播平台的开发质量,需要注意采集器在监控系统中的自治功能,尤其是面对比较复杂的业务场景, 采集器需要实现环境的自动识别和指标采集的自治。
2、扮演核心角色
一对一直播平台开发的监控系统,对维护整个节目的正常运行起到了核心作用。因此,需要重视监控系统的发展,优化与各个子系统的对接和集成能力。
3、关注数据可视化
随着一对一直播平台的发展,积累的数据显着增加。要想实现大规模数据的精准展示,仅仅依靠传统的数据展示方式是远远不够的。折线图和直方图要根据用户的需要来实现。图表、散点图等多种数据显示方式。

随着互联网技术的飞速发展,一对一直播平台的发展门槛不断降低。越来越多的人试图进入一对一直播领域,竞争压力不断上升。只有充分展示一对一直播平台发展的商业价值,才能在市场上快速崛起,优化监控系统的数据能力成为重中之重。
利用采集器 采集的平台(湖南三大运营商大数据采集怎么采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-04-11 01:28
大数据采集一键开启自动调用功能。告别传统拨号方式,节省员工操作时间。让员工以更少的工作量获得更多的商机。PC端和APP端配合使用,开启自动通话功能。APP自动拨打电话。PC端查看客户详细信息并添加客户跟踪记录。客户一目了然,让营销更轻松便捷。呼叫中心内置呼叫任务系统,将客户批量导入任务列表,一键开启自动呼叫功能。系统会根据列表自动拨打任务。系统具有通话信息统计功能,通话信息实时更新,并且数据一目了然,方便您快速轻松地获取您需要的所有营销数据。基础数据主要是设置监控指标,包括用户数据。河北三大运营商大数据采集平台
本软件是一款专业的地图数据采集软件,实时采集各大地图官网当前*** POI数据。采集接收到的数据存储在本地数据库中,可以一键导出到Excel或导入到手机通讯录中。可以采集全国所有城市和地区的所有行业数据,采集得到的数据准确率高,不再重复。本产品是众多批发商、电商推广、微商推广人员的拓展神器,业务量翻倍,被众多行业的商务人员选用。实时采集,获取最完整的数据。支持多个城市和多个关键词采集规则无需手写< @采集,只需点击鼠标即可完成。排除 关键词,清除不需要的数据。多图合一,采集数据更准确。下次不小心关闭或打开数据等 湖南三大运营商的大数据采集如何采集没有高层次的分析方法,只有解决问题的方法好.
智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集
<p>大数据平台与数据采集任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 大数据 查看全部
利用采集器 采集的平台(湖南三大运营商大数据采集怎么采集)
大数据采集一键开启自动调用功能。告别传统拨号方式,节省员工操作时间。让员工以更少的工作量获得更多的商机。PC端和APP端配合使用,开启自动通话功能。APP自动拨打电话。PC端查看客户详细信息并添加客户跟踪记录。客户一目了然,让营销更轻松便捷。呼叫中心内置呼叫任务系统,将客户批量导入任务列表,一键开启自动呼叫功能。系统会根据列表自动拨打任务。系统具有通话信息统计功能,通话信息实时更新,并且数据一目了然,方便您快速轻松地获取您需要的所有营销数据。基础数据主要是设置监控指标,包括用户数据。河北三大运营商大数据采集平台

本软件是一款专业的地图数据采集软件,实时采集各大地图官网当前*** POI数据。采集接收到的数据存储在本地数据库中,可以一键导出到Excel或导入到手机通讯录中。可以采集全国所有城市和地区的所有行业数据,采集得到的数据准确率高,不再重复。本产品是众多批发商、电商推广、微商推广人员的拓展神器,业务量翻倍,被众多行业的商务人员选用。实时采集,获取最完整的数据。支持多个城市和多个关键词采集规则无需手写< @采集,只需点击鼠标即可完成。排除 关键词,清除不需要的数据。多图合一,采集数据更准确。下次不小心关闭或打开数据等 湖南三大运营商的大数据采集如何采集没有高层次的分析方法,只有解决问题的方法好.

智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集
<p>大数据平台与数据采集任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 大数据
利用采集器 采集的平台(网站采集器做了很多SEO相关的优化,方便搜索引擎及时发现你的网站有更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-05 21:08
网站采集器、网站采集器是很多站群站长或者网站量大的站长经常使用的功能。如果一个站的每日更新都是手动的,维护起来会耗费大量的人力,而且效果也不一定好,所以可以考虑网站采集器做网站更新。今天谈谈网站采集器。
网站采集器批量发布的同时采集伪原创做了很多SEO相关的优化,比如标题、内容、关键词、等发布后,这些文章链接会自动批量提交给搜索引擎,让搜索引擎及时发现你的网站有更新。网站采集器与传统爬虫不同,网站采集器 是一个完全由您控制的网络爬虫脚本。所有执行规则由您定义。只需打开一个页面,让 网站采集器 插件自动识别表格数据或手动选择要抓取的元素,网站采集器如何在页面之间(甚至在站点之间)移动之间)导航(它也会尝试自动找到导航按钮。网站<
网站采集器采集文章会被伪原创处理并针对搜索引擎进行优化,加上网站采集器的数据来源是所有优质新闻源(知乎、今日头条、微信公众号、搜狐、网易、百度资讯、搜狗资讯等)。通常伪原创 和其他处理搜索引擎认为文章原创 被高度喜欢收录。我们都知道原创内容不仅可以提升网站SEO排名,还可以满足用户需求,提升用户体验。当然,这是内容高度原创和有价值的情况。如果你写废话,那就没用了。写高原创和有价值的内容更容易获得用户的信任和更好的转化。很多人的网站的原因之一
在使用网站采集器开发构建网站内容时,难免有些seo常识的缺失导致域名随意搜索,导致URL已经很久没有收录了,然后才知道原来这个域名的网站历史是灰色的,被搜索引擎抛弃了,导致网站不能用了通过 收录。唯一的方法是更改域名并重新优化它。
网站采集器可以增加数据采集,网站采集器停止可视化编辑采集规则。网站采集器无法将数据导出到 Excel 或 CSV 文件。
网站采集器如果在域名层面没有问题,那就要分析是不是URL质量问题了。如果网址收录很多无效的js,总会给网址增加额外的负担,影响网站等的打开速度,需要检查网站的代码优化。网站采集器表格数据自动识别,列表自动翻页识别,多页数据采集或转换,采集图片到本地或云端,采集图片到本地或云端,超简单的登录内容采集。
网站采集器OCR方法识别加密字符或图片内容,网站采集器批量URL地址,批量关键词查询采集,网站采集器自动iFrame内容采集支持,网站采集器数据变化监控和实时通知。
网站采集器动态内容采集(JavaScript+AJAX),网站采集器无限滚动翻页支持,网站采集器和more 支持多种翻页模式,网站采集器cross网站抓取或数据转换。
网站采集器无需学习Python、PHP、javascript、xpath、json、iframe等技术技能。网站采集器各种数据源的轻松定制采集。今天关于网站采集器的解释就到这里。下期我会分享更多的SEO相关知识。下期再见。 查看全部
利用采集器 采集的平台(网站采集器做了很多SEO相关的优化,方便搜索引擎及时发现你的网站有更新)
网站采集器、网站采集器是很多站群站长或者网站量大的站长经常使用的功能。如果一个站的每日更新都是手动的,维护起来会耗费大量的人力,而且效果也不一定好,所以可以考虑网站采集器做网站更新。今天谈谈网站采集器。

网站采集器批量发布的同时采集伪原创做了很多SEO相关的优化,比如标题、内容、关键词、等发布后,这些文章链接会自动批量提交给搜索引擎,让搜索引擎及时发现你的网站有更新。网站采集器与传统爬虫不同,网站采集器 是一个完全由您控制的网络爬虫脚本。所有执行规则由您定义。只需打开一个页面,让 网站采集器 插件自动识别表格数据或手动选择要抓取的元素,网站采集器如何在页面之间(甚至在站点之间)移动之间)导航(它也会尝试自动找到导航按钮。网站<

网站采集器采集文章会被伪原创处理并针对搜索引擎进行优化,加上网站采集器的数据来源是所有优质新闻源(知乎、今日头条、微信公众号、搜狐、网易、百度资讯、搜狗资讯等)。通常伪原创 和其他处理搜索引擎认为文章原创 被高度喜欢收录。我们都知道原创内容不仅可以提升网站SEO排名,还可以满足用户需求,提升用户体验。当然,这是内容高度原创和有价值的情况。如果你写废话,那就没用了。写高原创和有价值的内容更容易获得用户的信任和更好的转化。很多人的网站的原因之一

在使用网站采集器开发构建网站内容时,难免有些seo常识的缺失导致域名随意搜索,导致URL已经很久没有收录了,然后才知道原来这个域名的网站历史是灰色的,被搜索引擎抛弃了,导致网站不能用了通过 收录。唯一的方法是更改域名并重新优化它。
网站采集器可以增加数据采集,网站采集器停止可视化编辑采集规则。网站采集器无法将数据导出到 Excel 或 CSV 文件。

网站采集器如果在域名层面没有问题,那就要分析是不是URL质量问题了。如果网址收录很多无效的js,总会给网址增加额外的负担,影响网站等的打开速度,需要检查网站的代码优化。网站采集器表格数据自动识别,列表自动翻页识别,多页数据采集或转换,采集图片到本地或云端,采集图片到本地或云端,超简单的登录内容采集。
网站采集器OCR方法识别加密字符或图片内容,网站采集器批量URL地址,批量关键词查询采集,网站采集器自动iFrame内容采集支持,网站采集器数据变化监控和实时通知。
网站采集器动态内容采集(JavaScript+AJAX),网站采集器无限滚动翻页支持,网站采集器和more 支持多种翻页模式,网站采集器cross网站抓取或数据转换。

网站采集器无需学习Python、PHP、javascript、xpath、json、iframe等技术技能。网站采集器各种数据源的轻松定制采集。今天关于网站采集器的解释就到这里。下期我会分享更多的SEO相关知识。下期再见。
利用采集器 采集的平台(快速微信助手_公众号快速排版_排版编辑器-小红书)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-03-17 01:06
利用采集器采集的平台有很多,你需要找一个自己喜欢的采集器,只要采集简单的内容,或者是满足要求的要求,就很容易创建多个采集器。采集器可以用来采集新闻,文本,图片,视频,工具,热点,音乐,代码,论坛等等。
我经常用一个网站叫做乐玩采集器,功能比较齐全,
你做微信公众号,那平台就是微信公众号平台。如果需要采集的话,就去采集那个平台。
我推荐一个免费的,
百度搜索
谢邀。使用任何一个平台采集,都是可以的,只是要使用采集软件,比如快速微信助手(可以采集视频,音频,图片等等)、微小宝这些。快速微信助手可以查看历史文章列表,而小宝查看历史文章列表是收费的,价格不高,数据比较齐全,但是这些我觉得你完全可以使用去使用。再一个就是站长工具站长工具-快速微信图文助手_公众号快速排版_排版编辑器-小红书。
头条和百家文章分析,详细的方法请参考本篇头条文章分析教程,祝题主心想事成,
天涯看点已经支持上传图片,快速采集。
有很多采集到的网站需要做处理,比如全图。有比较全的采集网站,只是需要的时间比较久,因为需要反爬措施。 查看全部
利用采集器 采集的平台(快速微信助手_公众号快速排版_排版编辑器-小红书)
利用采集器采集的平台有很多,你需要找一个自己喜欢的采集器,只要采集简单的内容,或者是满足要求的要求,就很容易创建多个采集器。采集器可以用来采集新闻,文本,图片,视频,工具,热点,音乐,代码,论坛等等。
我经常用一个网站叫做乐玩采集器,功能比较齐全,
你做微信公众号,那平台就是微信公众号平台。如果需要采集的话,就去采集那个平台。
我推荐一个免费的,
百度搜索
谢邀。使用任何一个平台采集,都是可以的,只是要使用采集软件,比如快速微信助手(可以采集视频,音频,图片等等)、微小宝这些。快速微信助手可以查看历史文章列表,而小宝查看历史文章列表是收费的,价格不高,数据比较齐全,但是这些我觉得你完全可以使用去使用。再一个就是站长工具站长工具-快速微信图文助手_公众号快速排版_排版编辑器-小红书。
头条和百家文章分析,详细的方法请参考本篇头条文章分析教程,祝题主心想事成,
天涯看点已经支持上传图片,快速采集。
有很多采集到的网站需要做处理,比如全图。有比较全的采集网站,只是需要的时间比较久,因为需要反爬措施。
利用采集器 采集的平台(用美团采集美食的采集方法,你值得拥有!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-12 00:00
利用采集器采集的平台很多了,像美团、饿了么、pp助手、掌众、cuili、魔方、百度等等..都可以采集。方法/步骤下面给大家推荐一下用美团采集美食的采集方法:1采集店铺宝贝2采集带货源店铺宝贝3采集带qq和电话号码店铺宝贝4采集带店铺名称的店铺宝贝关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
一、采集宝贝
二、获取店铺链接
1)百度站长平台
2)微信公众号自动发送
3)的搜索
4)旺旺“怎么查店铺呀?”
5)上的店铺信息
6)集搜客、易淘网、中搜网、淘贝网,、店铺名采集关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
1,总体步骤:浏览器+采集器+代码文件获取+上传上传网址,采集工具请百度。2,
1)的商品介绍都有链接的,
2)站内搜索关键词+宝贝名,搜索结果中有一部分网页是可以采集的。
3)不建议采集那些连接外部链接的。建议采集店铺宝贝名链接为主。
4)如果用爬虫采集技术,建议配合爬虫本身抓取过程中的限制设置。ip有一定限制,限制每日在线时间,但不允许24小时永久上线;服务器不建议小规模使用。
二、案例描述:2018年4月份,我写了一篇文章列举了如何快速采集电商平台店铺的店铺名及详细情况。 查看全部
利用采集器 采集的平台(用美团采集美食的采集方法,你值得拥有!!)
利用采集器采集的平台很多了,像美团、饿了么、pp助手、掌众、cuili、魔方、百度等等..都可以采集。方法/步骤下面给大家推荐一下用美团采集美食的采集方法:1采集店铺宝贝2采集带货源店铺宝贝3采集带qq和电话号码店铺宝贝4采集带店铺名称的店铺宝贝关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
一、采集宝贝
二、获取店铺链接
1)百度站长平台
2)微信公众号自动发送
3)的搜索
4)旺旺“怎么查店铺呀?”
5)上的店铺信息
6)集搜客、易淘网、中搜网、淘贝网,、店铺名采集关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
1,总体步骤:浏览器+采集器+代码文件获取+上传上传网址,采集工具请百度。2,
1)的商品介绍都有链接的,
2)站内搜索关键词+宝贝名,搜索结果中有一部分网页是可以采集的。
3)不建议采集那些连接外部链接的。建议采集店铺宝贝名链接为主。
4)如果用爬虫采集技术,建议配合爬虫本身抓取过程中的限制设置。ip有一定限制,限制每日在线时间,但不允许24小时永久上线;服务器不建议小规模使用。
二、案例描述:2018年4月份,我写了一篇文章列举了如何快速采集电商平台店铺的店铺名及详细情况。
利用采集器 采集的平台(申请人脸识别就行了采集的人都是身份证照片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-11 16:10
利用采集器采集的平台要交上千块钱采集器费,并有七天的停机费,然后你会回到学校下采集器。
你这情况申请人脸识别就行了采集的人都是身份证照片一对一就行了解决办法:只要你的学生证办理的是手机卡前提是你得清楚你要申请的人脸识别采集点所在的市区或者省区你就得在当地(你要办理的省你要提供的信息需要和户籍地一致你在身份证的app里可以查到你办理地的街道及村,然后由警察开具证明即可);你要出省你就需要开具当地的户籍地派出所的证明。最后采集的人才会获得那张照片所有人都是可以用的只要你出钱。
只要你的身份证有效你怎么个偷法
一般身份证拍照直接能识别,没有采集人脸的必要。
其实知道你的大概位置采集上来一致的话也不会被发现,只要在学校的西门不要挡住拍照人的照片,被发现的话可以跑法院起诉你偷拍,
没必要。身份证可以直接采集,或者现在也有很多照片采集工具。
太长了,看截图。
直接采集就好了
为什么采集不人脸?
你为什么要采集?你在高校外面采集别人也找不到你的主要是偷拍怎么找一个清白人?那你就是拿着身份证去偷拍好了
您好,根据您提供的情况暂无法帮您解决您的问题。希望您采纳我的建议寻找一个可靠的第三方单位帮您解决您的问题。请咨询当地派出所。 查看全部
利用采集器 采集的平台(申请人脸识别就行了采集的人都是身份证照片)
利用采集器采集的平台要交上千块钱采集器费,并有七天的停机费,然后你会回到学校下采集器。
你这情况申请人脸识别就行了采集的人都是身份证照片一对一就行了解决办法:只要你的学生证办理的是手机卡前提是你得清楚你要申请的人脸识别采集点所在的市区或者省区你就得在当地(你要办理的省你要提供的信息需要和户籍地一致你在身份证的app里可以查到你办理地的街道及村,然后由警察开具证明即可);你要出省你就需要开具当地的户籍地派出所的证明。最后采集的人才会获得那张照片所有人都是可以用的只要你出钱。
只要你的身份证有效你怎么个偷法
一般身份证拍照直接能识别,没有采集人脸的必要。
其实知道你的大概位置采集上来一致的话也不会被发现,只要在学校的西门不要挡住拍照人的照片,被发现的话可以跑法院起诉你偷拍,
没必要。身份证可以直接采集,或者现在也有很多照片采集工具。
太长了,看截图。
直接采集就好了
为什么采集不人脸?
你为什么要采集?你在高校外面采集别人也找不到你的主要是偷拍怎么找一个清白人?那你就是拿着身份证去偷拍好了
您好,根据您提供的情况暂无法帮您解决您的问题。希望您采纳我的建议寻找一个可靠的第三方单位帮您解决您的问题。请咨询当地派出所。
上海网站建设-建站宝盒网站设计_网站制作_代理商
采集交流 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-07-29 01:06
利用采集器采集的平台很多,
猪八戒网,上面确实有些平台的站点还不错,但还是要花时间去整理的。
这两个站点已经不行了,没人维护了,建议去找找其他的吧,建站宝盒软件还可以,不过现在做商城的越来越多了,也不行了,给你推荐个代理商:上海网站制作_网站设计_网站建设-建站宝盒网站设计建站宝盒是一款web前端开发软件,内置angular、vue、jquery、angularjs、react等前端技术。提供以下优质文档:快速教程:bootstrap、bootstrap2.0、bootstrap2.x、easyui、vue.js、react.js、vuex、vue-router、jquery、jqueryeloquent、jquerycss、jquerysass、jqueryless、jqueryextensions、vue-element-ui、jqueryui、jquerytest等成功案例:韩阳旺等。
真正的大品牌还不倒闭的是那些有国企背景的公司。(不是说这些公司不好)那些骗人的就靠这些了,一点审核的成本都没有。国企啊,关系啊,最多放在网上公开的。你看到的人家的品牌都叫做:东风集团呀。所以,选国企才不会坑你,叫你自己去找靠谱的,就是那些包装不公开标识的,啥都没有放出来,叫你自己去找靠谱的。 查看全部
上海网站建设-建站宝盒网站设计_网站制作_代理商
利用采集器采集的平台很多,
猪八戒网,上面确实有些平台的站点还不错,但还是要花时间去整理的。
这两个站点已经不行了,没人维护了,建议去找找其他的吧,建站宝盒软件还可以,不过现在做商城的越来越多了,也不行了,给你推荐个代理商:上海网站制作_网站设计_网站建设-建站宝盒网站设计建站宝盒是一款web前端开发软件,内置angular、vue、jquery、angularjs、react等前端技术。提供以下优质文档:快速教程:bootstrap、bootstrap2.0、bootstrap2.x、easyui、vue.js、react.js、vuex、vue-router、jquery、jqueryeloquent、jquerycss、jquerysass、jqueryless、jqueryextensions、vue-element-ui、jqueryui、jquerytest等成功案例:韩阳旺等。
真正的大品牌还不倒闭的是那些有国企背景的公司。(不是说这些公司不好)那些骗人的就靠这些了,一点审核的成本都没有。国企啊,关系啊,最多放在网上公开的。你看到的人家的品牌都叫做:东风集团呀。所以,选国企才不会坑你,叫你自己去找靠谱的,就是那些包装不公开标识的,啥都没有放出来,叫你自己去找靠谱的。
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2022-06-24 01:40
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
利用采集器api,使用浏览器采集的平台规则介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-06-23 03:05
利用采集器采集的平台规则既不是wap又不是cookie,
pc浏览器已经把这个浏览的信息限制到一定的长度。网页一般是800字符以内。而app浏览器就没有这个限制。也许你的app浏览器压根就不支持爬取客户端手机网页。比如推荐一个刷机助手。不开发爬取网页功能,只开发刷机教程。
基本不可以
网页采集是被限制信息流量的,不过还是可以把客户端应用的信息抓取出来。现在的网页采集主要分为api和爬虫两类。api采集依靠浏览器api,使用浏览器自带的api工具,就能实现了获取网页图片,色情图片等功能。不过呢,api开发需要编写外部代码,这会大大增加开发难度,而且不支持定制化的信息获取。而爬虫采集需要爬虫脚本,但是更为简单方便。
所以这两种都不推荐。我推荐使用技术封锁类的爬虫,像boss直聘,猎聘网就是采用的这种技术封锁,就是cookie+一些规则抓取。当然你也可以理解为是一种捆绑。目前市面上大大小小的api和爬虫都有,想要比较精准的爬取,就要到腾讯wetest的爬虫权限自主开发者的平台去看看。人工识别群体情绪,做用户画像,写好爬虫去一一匹配采集需求,比如对于销售和用户这两个区间的用户,后台便会分析给出不同的策略。
上一个答案打一堆字的,都是利用机器代理工具上的,一般api接口不具备,爬虫和个人觉得还是需要自己的网站后台里边进行。 查看全部
利用采集器api,使用浏览器采集的平台规则介绍
利用采集器采集的平台规则既不是wap又不是cookie,
pc浏览器已经把这个浏览的信息限制到一定的长度。网页一般是800字符以内。而app浏览器就没有这个限制。也许你的app浏览器压根就不支持爬取客户端手机网页。比如推荐一个刷机助手。不开发爬取网页功能,只开发刷机教程。
基本不可以
网页采集是被限制信息流量的,不过还是可以把客户端应用的信息抓取出来。现在的网页采集主要分为api和爬虫两类。api采集依靠浏览器api,使用浏览器自带的api工具,就能实现了获取网页图片,色情图片等功能。不过呢,api开发需要编写外部代码,这会大大增加开发难度,而且不支持定制化的信息获取。而爬虫采集需要爬虫脚本,但是更为简单方便。
所以这两种都不推荐。我推荐使用技术封锁类的爬虫,像boss直聘,猎聘网就是采用的这种技术封锁,就是cookie+一些规则抓取。当然你也可以理解为是一种捆绑。目前市面上大大小小的api和爬虫都有,想要比较精准的爬取,就要到腾讯wetest的爬虫权限自主开发者的平台去看看。人工识别群体情绪,做用户画像,写好爬虫去一一匹配采集需求,比如对于销售和用户这两个区间的用户,后台便会分析给出不同的策略。
上一个答案打一堆字的,都是利用机器代理工具上的,一般api接口不具备,爬虫和个人觉得还是需要自己的网站后台里边进行。
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-06-23 01:54
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-06-20 13:31
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
️ 优采云采集器——最良心的爬虫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-06-20 12:58
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我 查看全部
️ 优采云采集器——最良心的爬虫软件
2020 年如果让我推荐一款大众向的数据采集软件,那一定是优采云采集器[1]了。和我之前推荐的 相比,如果说 web scraper 是小而精的瑞士军刀,那优采云采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载[2]。
2.功能强大
优采云采集器把采集工作分为两种类型:智能模式和流程图模式。
智能模式[3]就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式[4]的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是优采云采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
优采云采集器就没有这个问题,它的付费点[5]主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇优采云采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
优采云采集器的官网提供了两种教程,一种是视频教程[6],每个视频五分钟左右;一种是图文教程[7],手把手教学。看完这两类教程后还可以看看他们的文档中心[8],写的也非常详细,基本覆盖了该软件的各个功能点。
二、基础功能1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:
2.翻页功能
我在介绍 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。
对于这三种基础翻页类型,优采云采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,优采云采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页[9]。
3.复杂表单
对于一些多项联动筛选的网页,优采云采集器也能很好的处理。我们可以利用优采云采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用优采云采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网[13]上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。优采云采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。
XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程[14]去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是优采云采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为优采云采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了优采云采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,优采云采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
利用采集器采集的平台地址,通过nginx的反向代理(文件上传)功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-06-08 12:22
利用采集器采集的平台地址,
通过nginx的反向代理(文件上传)功能可以实现:
soeasy
使用php+mysql实现
实际上,php的web工程是由两部分组成:一部分是phpweb框架提供的web服务;另一部分是基于web框架的php网页。针对题主所说的问题,有一个库wordpress,这是基于rubyrails写的博客系统。可以通过网络部署到php服务器上。
wordpress上用web框架,但不是所有的都可以上传。可以用一个web包抓取知乎用户页面,全部读取并解析成html文件。加密传输。可以不上传,注册一个账号,就可以自动抓取。下载后,可以解析html文件,把需要的上传到微博里。关键点在于注册一个账号。一个账号有限制,具体怎么操作需要咨询和提问。知乎有第三方cms也可以用这个方法。
wp真想不到有什么更快的方法
第三方的cms,
试一下猪八戒。
那要看知乎什么用户了?普通大众我觉得php不是万能的,不像后来有些用户解决同性恋,城管什么的。但是像艺术家、文化人、学生、大学生类的用户群的还是可以用php做一些很好的工作的。学生最容易懂的就是php,当然,猪八戒上的艺术生和文化人也懂php,我想中文,php是随便写的。好像php快死了吧,那我去买个文化人做练手就行了。 查看全部
利用采集器采集的平台地址,通过nginx的反向代理(文件上传)功能
利用采集器采集的平台地址,
通过nginx的反向代理(文件上传)功能可以实现:
soeasy
使用php+mysql实现
实际上,php的web工程是由两部分组成:一部分是phpweb框架提供的web服务;另一部分是基于web框架的php网页。针对题主所说的问题,有一个库wordpress,这是基于rubyrails写的博客系统。可以通过网络部署到php服务器上。
wordpress上用web框架,但不是所有的都可以上传。可以用一个web包抓取知乎用户页面,全部读取并解析成html文件。加密传输。可以不上传,注册一个账号,就可以自动抓取。下载后,可以解析html文件,把需要的上传到微博里。关键点在于注册一个账号。一个账号有限制,具体怎么操作需要咨询和提问。知乎有第三方cms也可以用这个方法。
wp真想不到有什么更快的方法
第三方的cms,
试一下猪八戒。
那要看知乎什么用户了?普通大众我觉得php不是万能的,不像后来有些用户解决同性恋,城管什么的。但是像艺术家、文化人、学生、大学生类的用户群的还是可以用php做一些很好的工作的。学生最容易懂的就是php,当然,猪八戒上的艺术生和文化人也懂php,我想中文,php是随便写的。好像php快死了吧,那我去买个文化人做练手就行了。
利用采集器 采集的平台 新华社官方网站-官方正式账号国家新闻出版广电总局
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2022-05-28 22:01
利用采集器采集的平台可以比别人先看到新闻头条的大致内容,免费的那些比如,搜狗,百度,腾讯,凤凰,网易什么的,网站是收费的,需要站长使用,也有专门做的集成采集器,导航,汇总,
最近一个月刚好写了几个爬虫,爬了160+新闻网站,然后一一分析记录,这些数据要能分析价值,就需要分析新闻头部的几篇价值新闻,不然它们一般在3篇到6篇,而且是不同一个链接。比如某一条新闻,在机器爬取数据的时候,可以先把最大价值新闻排好序,再看同类文章和新闻在哪个排名,再爬。我觉得这一点新闻单篇的价值新闻确实很难爬取,主要是技术难度太大,由于资源受限,目前如此是没有办法的。
手机,电脑上都可以爬新闻啊!手机大多是大网站,大网站都已经找不到了;电脑的话主要是,一些资讯类媒体,资讯很不错,但是只有某一或者两三个垂直板块,
百度
我也刚写完一个通过收藏网站抓新闻的,可以加一下,
爬取新闻,比较好的网站有:中国国际广播电台国家地理频道台湾有线电视新闻网搜狐新闻-搜狐网-新闻中心搜狐新闻-搜狐网(soso。com)-国内领先的新闻聚合网站新华社官方网站-官方正式账号国家新闻出版广电总局-中国新闻媒体新华社新闻人旅游_新华网和讯新闻部网站保加利亚_新华网美国晚间新闻-打消您任何疑问_新闻世界(简体中文)1新浪新闻_新浪网-我是新闻爱好者,我是一个有态度的新闻门户。@新浪微博如果有自己的网站的话也可以针对新闻抓取做一些简单的设置。 查看全部
利用采集器 采集的平台 新华社官方网站-官方正式账号国家新闻出版广电总局
利用采集器采集的平台可以比别人先看到新闻头条的大致内容,免费的那些比如,搜狗,百度,腾讯,凤凰,网易什么的,网站是收费的,需要站长使用,也有专门做的集成采集器,导航,汇总,
最近一个月刚好写了几个爬虫,爬了160+新闻网站,然后一一分析记录,这些数据要能分析价值,就需要分析新闻头部的几篇价值新闻,不然它们一般在3篇到6篇,而且是不同一个链接。比如某一条新闻,在机器爬取数据的时候,可以先把最大价值新闻排好序,再看同类文章和新闻在哪个排名,再爬。我觉得这一点新闻单篇的价值新闻确实很难爬取,主要是技术难度太大,由于资源受限,目前如此是没有办法的。
手机,电脑上都可以爬新闻啊!手机大多是大网站,大网站都已经找不到了;电脑的话主要是,一些资讯类媒体,资讯很不错,但是只有某一或者两三个垂直板块,
百度
我也刚写完一个通过收藏网站抓新闻的,可以加一下,
爬取新闻,比较好的网站有:中国国际广播电台国家地理频道台湾有线电视新闻网搜狐新闻-搜狐网-新闻中心搜狐新闻-搜狐网(soso。com)-国内领先的新闻聚合网站新华社官方网站-官方正式账号国家新闻出版广电总局-中国新闻媒体新华社新闻人旅游_新华网和讯新闻部网站保加利亚_新华网美国晚间新闻-打消您任何疑问_新闻世界(简体中文)1新浪新闻_新浪网-我是新闻爱好者,我是一个有态度的新闻门户。@新浪微博如果有自己的网站的话也可以针对新闻抓取做一些简单的设置。
数据分析师的发展方向有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-05-11 05:01
利用采集器采集的平台包括h5游戏分发、cms开发、棋牌游戏分发、真人直播直播、综艺节目分发、网页导航、wap版本控制、微信公众号、企业微信分发、定制app等,数据采集包括页面统计、曝光展示、下载激活等。
随着抖音、小红书、公众号等新媒体的兴起,数据分析在内容运营中越来越重要,但一方面要想找到有价值的数据,一方面企业又需要数据分析的专业人才。一个人的专业度不能代表一个公司的专业度,更何况是一家企业呢。下面从供应方、开发方、技术方、数据方4个角度总结数据分析师的发展方向。供应方采集分析公司在通过传统的获取数据,得到信息的过程中,不可避免的会忽略或者遗漏部分信息。
而市场上相关数据分析公司很多,但实际上对于大多数企业而言,解决的需求并没有那么简单,或者是企业不需要这么多的分析,大多数企业最大的数据来源也是线下数据。因此,这就注定了公司并不需要这么多的数据,这就导致采集分析对于一个规模稍大的企业来说已经足够,且价格并不高。公司需要的是数据工具,很多企业在实际中不需要数据分析,对于采集分析来说,用于企业行为分析的数据包括:用户数据、企业商业数据、营销数据、搜索数据、关系数据、舆情数据等,不同层次的企业在数据来源上有很大区别,分析结果也不尽相同。
下面为大家列举一下具体案例分析。企业数据:1.搜索数据:百度、豆瓣、知乎、拉钩网2.营销数据:淘宝、百度竞价、地铁广告、百度知道3.数据舆情:微博、微信、脉脉、百度贴吧4.数据分析:腾讯、网易、唯品会、滴滴、携程、知乎、今日头条5.数据运营:淘宝、360、携程、饿了么、航旅纵横等开发方早期的互联网公司主要有两种采集方法:线上采集:抓取爬虫(各大平台robots禁止抓取),其他浏览器、手机通讯录、个人网站列表等等,得到的内容是各个平台的标题、描述、下载量等信息。
线下采集:抓取各大公司产品的各种数据,比如某个小程序,采集各个平台的下载量,通过k-means聚类等方法进行分析。可是目前线上采集仅限于获取部分产品的数据,并没有能够得到的更加完整的产品全貌。就以竞价广告为例,我们最终只看到了产品名称、下载量,究竟这个产品怎么样,可能我们并不需要知道。随着获取的数据越来越多,开发方将采集的内容往商业分析领域发展,目前一些大的商业数据分析公司在积累数据之后,会开发行业数据,如近日有业内人士指出,一家名为semaphoneplay的创业公司,通过利用这些数据对网易周刊进行数据挖掘,给出分析报告。目前semaphoneplay的股价。 查看全部
数据分析师的发展方向有哪些?-八维教育
利用采集器采集的平台包括h5游戏分发、cms开发、棋牌游戏分发、真人直播直播、综艺节目分发、网页导航、wap版本控制、微信公众号、企业微信分发、定制app等,数据采集包括页面统计、曝光展示、下载激活等。
随着抖音、小红书、公众号等新媒体的兴起,数据分析在内容运营中越来越重要,但一方面要想找到有价值的数据,一方面企业又需要数据分析的专业人才。一个人的专业度不能代表一个公司的专业度,更何况是一家企业呢。下面从供应方、开发方、技术方、数据方4个角度总结数据分析师的发展方向。供应方采集分析公司在通过传统的获取数据,得到信息的过程中,不可避免的会忽略或者遗漏部分信息。
而市场上相关数据分析公司很多,但实际上对于大多数企业而言,解决的需求并没有那么简单,或者是企业不需要这么多的分析,大多数企业最大的数据来源也是线下数据。因此,这就注定了公司并不需要这么多的数据,这就导致采集分析对于一个规模稍大的企业来说已经足够,且价格并不高。公司需要的是数据工具,很多企业在实际中不需要数据分析,对于采集分析来说,用于企业行为分析的数据包括:用户数据、企业商业数据、营销数据、搜索数据、关系数据、舆情数据等,不同层次的企业在数据来源上有很大区别,分析结果也不尽相同。
下面为大家列举一下具体案例分析。企业数据:1.搜索数据:百度、豆瓣、知乎、拉钩网2.营销数据:淘宝、百度竞价、地铁广告、百度知道3.数据舆情:微博、微信、脉脉、百度贴吧4.数据分析:腾讯、网易、唯品会、滴滴、携程、知乎、今日头条5.数据运营:淘宝、360、携程、饿了么、航旅纵横等开发方早期的互联网公司主要有两种采集方法:线上采集:抓取爬虫(各大平台robots禁止抓取),其他浏览器、手机通讯录、个人网站列表等等,得到的内容是各个平台的标题、描述、下载量等信息。
线下采集:抓取各大公司产品的各种数据,比如某个小程序,采集各个平台的下载量,通过k-means聚类等方法进行分析。可是目前线上采集仅限于获取部分产品的数据,并没有能够得到的更加完整的产品全貌。就以竞价广告为例,我们最终只看到了产品名称、下载量,究竟这个产品怎么样,可能我们并不需要知道。随着获取的数据越来越多,开发方将采集的内容往商业分析领域发展,目前一些大的商业数据分析公司在积累数据之后,会开发行业数据,如近日有业内人士指出,一家名为semaphoneplay的创业公司,通过利用这些数据对网易周刊进行数据挖掘,给出分析报告。目前semaphoneplay的股价。
京东数据采集器有错误率,建议你使用详情页
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-05-02 14:00
利用采集器采集的平台更规范些,一般的采集软件都有采集规范,导出的数据都有错误率,建议你使用京东数据采集器。这款采集器还可以自动读取网页源代码、采集性格人物信息、采集技术解析到js文件再发给客户用于产品详情页,建议你到我们网站看看。采集数据会有错误信息提示,同时是免费使用,详情页的流量、销量都是非常可观的。
python就可以
可以下载北京口袋数据,
采集京东的数据,你可以使用京东数据采集器进行抓取,这个软件可以抓取京东前10万名商品的相关数据,抓取效率高,而且产品全,选择性强。
通过一个nb的采集器就能实现了,网上都可以找到,
可以使用excel表格包,都提供专门的快捷方式。大概的命令如下,关键词要对准,不然可能会有错。excel家族a列数据一组,b列商品id,c列商品商品名字,j列商品核心商品名字(比如:三全大米),q列商品核心商品价格(一般4-6元),u=商品id=excel所对应的要查找的列。搜索关键词——重要商品名字。使用相关字段,搜索示例如下第3步实际操作:。
京东商品上报,不能照搬淘宝数据吧,要自己根据自己想要的商品进行下载,另外可以下载产品价格数据, 查看全部
京东数据采集器有错误率,建议你使用详情页
利用采集器采集的平台更规范些,一般的采集软件都有采集规范,导出的数据都有错误率,建议你使用京东数据采集器。这款采集器还可以自动读取网页源代码、采集性格人物信息、采集技术解析到js文件再发给客户用于产品详情页,建议你到我们网站看看。采集数据会有错误信息提示,同时是免费使用,详情页的流量、销量都是非常可观的。
python就可以
可以下载北京口袋数据,
采集京东的数据,你可以使用京东数据采集器进行抓取,这个软件可以抓取京东前10万名商品的相关数据,抓取效率高,而且产品全,选择性强。
通过一个nb的采集器就能实现了,网上都可以找到,
可以使用excel表格包,都提供专门的快捷方式。大概的命令如下,关键词要对准,不然可能会有错。excel家族a列数据一组,b列商品id,c列商品商品名字,j列商品核心商品名字(比如:三全大米),q列商品核心商品价格(一般4-6元),u=商品id=excel所对应的要查找的列。搜索关键词——重要商品名字。使用相关字段,搜索示例如下第3步实际操作:。
京东商品上报,不能照搬淘宝数据吧,要自己根据自己想要的商品进行下载,另外可以下载产品价格数据,
利用采集器 采集的平台 当 RocketMQ 遇见 Elastic Stack | RocketMQ 使
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-05-01 05:18
Elastic Stack 是广泛使用的开源日志处理技术栈,最初亦称作 ELK;Elasticsearch 是一个搜索和分析引擎;Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中;Kibana 则可以让用户使用图形和图表对 Elasticsearch 中数据进行可视化。后来在采集器(L)中,加入了一系列轻量的单一功能数据采集器(称为 Beats),其中最常用的是 FileBeat,于是也有 EFK 一说。
为了实现 RocketMQ 与 Elastic Stack 方便对接,需要在采集器(Logstash、Beats)层面支持:
1、RocketMQ作为output:数据从其他数据源发送到RocketMQ2、RocketMQ作为input:数据从RocketMQ到ES等存储
相关项目:
RocketMQ对接Logstash
rocketmq-logstash-integration 项目在RocketMQ添加了对接Logtash的input和output插件,通过Logstash,既可将数据从其他数据源到RocketMQ,也可从RocketMQ消费消息写入ES。
使用方式
安装插件Logtash支持以插件方式在运行时安装 RocketMQ input 和 output,目前 rockemq-logstash-integration 支持 Logstash 8.0版本[3]。
1、参考如下文档,制作Logtash input或output插件gem:
2、进入logstash安装目录中,执行如下命令安装插件(gem文件路径替换成上一步解压出的文件路径):
bin/logstash-plugin install --no-verify --local /path/to/logstash-input-rocketmq-1.0.0.gembin/logstash-plugin install --no-verify --local /path/to/logstash-output-rocketmq-1.0.0.gem
如遇到安装过程很慢,可尝试替换Gemfile中的source为
将数据发送到 RocketMQ
如下配置将采集/var/log/及其子目录下文件名后缀为.log的文件内容,并以消息的形式发送到RocketMQ,topic为topic-test:
input { file { path => ["/var/log/**/*.log"] }}output { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" }}
将上述配置保存到rocketmq_output.conf中,启动Logstash即可:
bin/logstash -f /path/to/rocketmq_output.conf
rocketmq_output详细配置说明
从RocketMQ消费消息并输出到ES
如下配置文件可实现消费topic-test中消费消息,并将其写入本地的ES,其中index指定为test-%{+YYYY.MM.dd}:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" group => "GID_input" }}output { elasticsearch { hosts => ["127.0.0.1:9200"] index => "test-%{+YYYY.MM.dd}" }}
将上述配置保存到rocketmq_input.conf中,启动Logstash即可:
bin/logstash -f rocketmq_input.conf
rocketmq_input详细配置说明
RocketMQ对接Beats
Beats是一系列的采集器,最初是Filebeat[5],后来增加了Heartbeat[6]、 Metricbeat[7]等不同数据源采集器。
rocketmq-beats-integration项目支持Beats将采集到的数据发送到RocketMQ。
使用方式
安装Beats
与Logtash不同,目前Beats不支持在运行时加载插件,因而需要下载Beats v7.17.0版本[8],对其重新编译后增加支持 RocketMQ 整合。详细操作可参考:
将数据发送到 RocketMQ
以FileBeat为例,如下配置文件可实现从/var/log/messages采集数据,并发送到RocketMQ的TopicTesttopic中:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/messagesoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicTest
将上述内容保存至rocketmq_output.yml,运行如下命令:
./filebeat -c rocketmq_output.yml
对于其他类型的Beats,output.rocketmq部分的配置是一致的,只需按照特定Beats配置其数据源即可。
详细配置说明
整合示例
最后,我们介绍一个例子,将Nginx的访问日志导入RocketMQ,通过RocketMQ Streams按分钟统计HTTP返回码的数量,结果记录到RocketMQ,最后保存到Elasticsearch。
Nginx 访问日志 --> RocketMQ
Filebeat占用资源少,适合作为agent采集原始日志。下面的配置文件,可从/var/log/nginx/access.log采集日志,并发送到RocketMQ的TopicNginxAcctopic:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/nginx/access.logoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicNginxAcc
启动本文支持RocketMQ的filebeat,即可开启日志采集:
./filebeat -c nginx-beat.yml -e
Nginx 访问日志数据分析
在上一步中,我们将日志数据发送到RocketMQ。接下来,就可以利用RocketMQ Streams对这些日志数据进行处理。
我们从保存Nginx访问日志数据的topicTopicNginxAcc中消费,解析日志内容,只保留统计用到的时间和HTTP返回码字段,然后按1分钟为维度进行统计,最后将统计结果以消息形式发送到TopicNginxCount。
使用RocketMQ Streams需要引入依赖:
org.apache.rocketmq rocketmq-streams-clients 1.0.1-preview
代码如下:
package org.apache.rocketmq;<br /><br />import com.alibaba.fastjson.JSONObject;import org.apache.rocketmq.streams.client.StreamBuilder;import org.apache.rocketmq.streams.client.source.DataStreamSource;import org.apache.rocketmq.streams.client.strategy.WindowStrategy;import org.apache.rocketmq.streams.client.transform.window.Time;import org.apache.rocketmq.streams.client.transform.window.TumblingWindow;<br />import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.Locale;import java.util.regex.Matcher;import java.util.regex.Pattern;<br />public class RocketMqStreamsDemo { // nginx访问日志pattern public static final String LOG_PATTERN = "^(?[^ ]*) (?[^ ]*) (?[^ ]*) \\[(?[^\\]]*)\\] \"(?\\S+)(?: +(?[^ ]*) +\\S*)?\" (?[^ ]*) (?[^ ]*)(?: \"(?[^\\\"]*)\" \"(?[^\\\"]*)\" \"(?[^\\\"]*)\")?";<br /> // nginx访问日志的日期格式 private static final DateTimeFormatter fromFormatter = DateTimeFormatter.ofPattern("dd/MMM/yyyy:HH:mm:ss Z", Locale.US); // rocektmq-streams window支持的日期格式 private static final DateTimeFormatter toFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss", Locale.CHINA);<br /> private static final String NAMESRV_ADDRESS = "localhost:9876";<br /><br /> public static void main(String[] args) { Pattern pattern = Pattern.compile(LOG_PATTERN); DataStreamSource dataStream = StreamBuilder.dataStream("my-namespace", "nginx-acc-job"); dataStream .fromRocketmq("TopicNginxAcc", "GID-count-code", true, NAMESRV_ADDRESS) //消费TopicNginxAcc .map(event -> ((JSONObject) event).get("message")) .map(message -> { // 只保留有用的 code 和 time 字段 final String logStr = (String) message; final Matcher matcher = pattern.matcher(logStr); JSONObject logJson = new JSONObject(); if (matcher.find()) { logJson.put("code", matcher.group("code")); final String dateTime = matcher.group("time"); logJson.put("time", LocalDateTime.parse(dateTime, fromFormatter).format(toFormatter)); } System.out.println(logJson); return logJson; }) .window(TumblingWindow.of(Time.minutes(1))) .groupBy("code") //按code聚合 .setTimeField("time") .count("total") .waterMark(1) .toDataSteam() .toRocketmq("TopicNginxCount", "GID-result", NAMESRV_ADDRESS) // 保存到TopicNginxCount .with(WindowStrategy.highPerformance()) .start(); }}
RocketMQ ---> Elasticsearch
最后,我们用Logstash将上一步保存到TopicNginxCount的统计结果,导入到Elasticsearch。
安装完logstash-input-rocketmq插件后,启动Logstash,采用以下配置文件即可:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "TopicNginxCount" group => "GID-nginx-result" }}<br />filter { json { source => "message" remove_field => ["message"] }}<br />output { elasticsearch { hosts => ["http://localhost:9200"] index => "nginx-access-%{+YYYY.MM.dd}" }}
数据将保存到Elasticsearch中以nginx-access开头的index,按天保存。
调用Elasticsearch的Rest API,可以列出index中的数据:
curl -X GET "localhost:9200/nginx-access-2022.03.11/_search?pretty" -H 'Content-Type: application/json' -d'{ "query": { "match_all": {} }}'
下面是部分结果,start_time和end_time分别是统计的起止时间,total是这段时间内HTTP code 为code的统计次数:
{ "hits" : [ { "_index" : "nginx-access-2022.03.11", "_id" : "er-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 52, "@timestamp" : "2022-03-11T06:15:22.928736Z", "code" : "200" } }, { "_index" : "nginx-access-2022.03.11", "_id" : "eb-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 1, "@timestamp" : "2022-03-11T06:15:22.928472Z", "code" : "404" } } ]}
引用链接
[1][2]
[3]
[4][5][6][7]
[8]
[9]
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。
社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者微信:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。
微信扫码添加小火箭进群
另外还可以加入钉钉群与 RocketMQ 爱好者一起广泛讨论:
钉钉扫码加群 查看全部
利用采集器 采集的平台 当 RocketMQ 遇见 Elastic Stack | RocketMQ 使
Elastic Stack 是广泛使用的开源日志处理技术栈,最初亦称作 ELK;Elasticsearch 是一个搜索和分析引擎;Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中;Kibana 则可以让用户使用图形和图表对 Elasticsearch 中数据进行可视化。后来在采集器(L)中,加入了一系列轻量的单一功能数据采集器(称为 Beats),其中最常用的是 FileBeat,于是也有 EFK 一说。
为了实现 RocketMQ 与 Elastic Stack 方便对接,需要在采集器(Logstash、Beats)层面支持:
1、RocketMQ作为output:数据从其他数据源发送到RocketMQ2、RocketMQ作为input:数据从RocketMQ到ES等存储
相关项目:
RocketMQ对接Logstash
rocketmq-logstash-integration 项目在RocketMQ添加了对接Logtash的input和output插件,通过Logstash,既可将数据从其他数据源到RocketMQ,也可从RocketMQ消费消息写入ES。
使用方式
安装插件Logtash支持以插件方式在运行时安装 RocketMQ input 和 output,目前 rockemq-logstash-integration 支持 Logstash 8.0版本[3]。
1、参考如下文档,制作Logtash input或output插件gem:
2、进入logstash安装目录中,执行如下命令安装插件(gem文件路径替换成上一步解压出的文件路径):
bin/logstash-plugin install --no-verify --local /path/to/logstash-input-rocketmq-1.0.0.gembin/logstash-plugin install --no-verify --local /path/to/logstash-output-rocketmq-1.0.0.gem
如遇到安装过程很慢,可尝试替换Gemfile中的source为
将数据发送到 RocketMQ
如下配置将采集/var/log/及其子目录下文件名后缀为.log的文件内容,并以消息的形式发送到RocketMQ,topic为topic-test:
input { file { path => ["/var/log/**/*.log"] }}output { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" }}
将上述配置保存到rocketmq_output.conf中,启动Logstash即可:
bin/logstash -f /path/to/rocketmq_output.conf
rocketmq_output详细配置说明
从RocketMQ消费消息并输出到ES
如下配置文件可实现消费topic-test中消费消息,并将其写入本地的ES,其中index指定为test-%{+YYYY.MM.dd}:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "topic-test" group => "GID_input" }}output { elasticsearch { hosts => ["127.0.0.1:9200"] index => "test-%{+YYYY.MM.dd}" }}
将上述配置保存到rocketmq_input.conf中,启动Logstash即可:
bin/logstash -f rocketmq_input.conf
rocketmq_input详细配置说明
RocketMQ对接Beats
Beats是一系列的采集器,最初是Filebeat[5],后来增加了Heartbeat[6]、 Metricbeat[7]等不同数据源采集器。
rocketmq-beats-integration项目支持Beats将采集到的数据发送到RocketMQ。
使用方式
安装Beats
与Logtash不同,目前Beats不支持在运行时加载插件,因而需要下载Beats v7.17.0版本[8],对其重新编译后增加支持 RocketMQ 整合。详细操作可参考:
将数据发送到 RocketMQ
以FileBeat为例,如下配置文件可实现从/var/log/messages采集数据,并发送到RocketMQ的TopicTesttopic中:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/messagesoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicTest
将上述内容保存至rocketmq_output.yml,运行如下命令:
./filebeat -c rocketmq_output.yml
对于其他类型的Beats,output.rocketmq部分的配置是一致的,只需按照特定Beats配置其数据源即可。
详细配置说明
整合示例
最后,我们介绍一个例子,将Nginx的访问日志导入RocketMQ,通过RocketMQ Streams按分钟统计HTTP返回码的数量,结果记录到RocketMQ,最后保存到Elasticsearch。
Nginx 访问日志 --> RocketMQ
Filebeat占用资源少,适合作为agent采集原始日志。下面的配置文件,可从/var/log/nginx/access.log采集日志,并发送到RocketMQ的TopicNginxAcctopic:
filebeat.inputs: - type: filestream enabled: true paths: - /var/log/nginx/access.logoutput.rocketmq: nameservers: [ "127.0.0.1:9876" ] topic: TopicNginxAcc
启动本文支持RocketMQ的filebeat,即可开启日志采集:
./filebeat -c nginx-beat.yml -e
Nginx 访问日志数据分析
在上一步中,我们将日志数据发送到RocketMQ。接下来,就可以利用RocketMQ Streams对这些日志数据进行处理。
我们从保存Nginx访问日志数据的topicTopicNginxAcc中消费,解析日志内容,只保留统计用到的时间和HTTP返回码字段,然后按1分钟为维度进行统计,最后将统计结果以消息形式发送到TopicNginxCount。
使用RocketMQ Streams需要引入依赖:
org.apache.rocketmq rocketmq-streams-clients 1.0.1-preview
代码如下:
package org.apache.rocketmq;<br /><br />import com.alibaba.fastjson.JSONObject;import org.apache.rocketmq.streams.client.StreamBuilder;import org.apache.rocketmq.streams.client.source.DataStreamSource;import org.apache.rocketmq.streams.client.strategy.WindowStrategy;import org.apache.rocketmq.streams.client.transform.window.Time;import org.apache.rocketmq.streams.client.transform.window.TumblingWindow;<br />import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.Locale;import java.util.regex.Matcher;import java.util.regex.Pattern;<br />public class RocketMqStreamsDemo { // nginx访问日志pattern public static final String LOG_PATTERN = "^(?[^ ]*) (?[^ ]*) (?[^ ]*) \\[(?[^\\]]*)\\] \"(?\\S+)(?: +(?[^ ]*) +\\S*)?\" (?[^ ]*) (?[^ ]*)(?: \"(?[^\\\"]*)\" \"(?[^\\\"]*)\" \"(?[^\\\"]*)\")?";<br /> // nginx访问日志的日期格式 private static final DateTimeFormatter fromFormatter = DateTimeFormatter.ofPattern("dd/MMM/yyyy:HH:mm:ss Z", Locale.US); // rocektmq-streams window支持的日期格式 private static final DateTimeFormatter toFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss", Locale.CHINA);<br /> private static final String NAMESRV_ADDRESS = "localhost:9876";<br /><br /> public static void main(String[] args) { Pattern pattern = Pattern.compile(LOG_PATTERN); DataStreamSource dataStream = StreamBuilder.dataStream("my-namespace", "nginx-acc-job"); dataStream .fromRocketmq("TopicNginxAcc", "GID-count-code", true, NAMESRV_ADDRESS) //消费TopicNginxAcc .map(event -> ((JSONObject) event).get("message")) .map(message -> { // 只保留有用的 code 和 time 字段 final String logStr = (String) message; final Matcher matcher = pattern.matcher(logStr); JSONObject logJson = new JSONObject(); if (matcher.find()) { logJson.put("code", matcher.group("code")); final String dateTime = matcher.group("time"); logJson.put("time", LocalDateTime.parse(dateTime, fromFormatter).format(toFormatter)); } System.out.println(logJson); return logJson; }) .window(TumblingWindow.of(Time.minutes(1))) .groupBy("code") //按code聚合 .setTimeField("time") .count("total") .waterMark(1) .toDataSteam() .toRocketmq("TopicNginxCount", "GID-result", NAMESRV_ADDRESS) // 保存到TopicNginxCount .with(WindowStrategy.highPerformance()) .start(); }}
RocketMQ ---> Elasticsearch
最后,我们用Logstash将上一步保存到TopicNginxCount的统计结果,导入到Elasticsearch。
安装完logstash-input-rocketmq插件后,启动Logstash,采用以下配置文件即可:
input { rocketmq { namesrv_addr => "localhost:9876" topic => "TopicNginxCount" group => "GID-nginx-result" }}<br />filter { json { source => "message" remove_field => ["message"] }}<br />output { elasticsearch { hosts => ["http://localhost:9200"] index => "nginx-access-%{+YYYY.MM.dd}" }}
数据将保存到Elasticsearch中以nginx-access开头的index,按天保存。
调用Elasticsearch的Rest API,可以列出index中的数据:
curl -X GET "localhost:9200/nginx-access-2022.03.11/_search?pretty" -H 'Content-Type: application/json' -d'{ "query": { "match_all": {} }}'
下面是部分结果,start_time和end_time分别是统计的起止时间,total是这段时间内HTTP code 为code的统计次数:
{ "hits" : [ { "_index" : "nginx-access-2022.03.11", "_id" : "er-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 52, "@timestamp" : "2022-03-11T06:15:22.928736Z", "code" : "200" } }, { "_index" : "nginx-access-2022.03.11", "_id" : "eb-ed38Bn85qBf4OFHDW", "_score" : 1.0, "_source" : { "@version" : "1", "end_time" : "2022-03-11 14:12:00", "start_time" : "2022-03-11 14:11:00", "fire_time" : "2022-03-11 14:12:01", "total" : 1, "@timestamp" : "2022-03-11T06:15:22.928472Z", "code" : "404" } } ]}
引用链接
[1][2]
[3]
[4][5][6][7]
[8]
[9]
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。
社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者微信:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。
微信扫码添加小火箭进群
另外还可以加入钉钉群与 RocketMQ 爱好者一起广泛讨论:
钉钉扫码加群
利用采集器 采集的平台( 2020年这款软件的优秀之处是什么样的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-18 13:10
2020年这款软件的优秀之处是什么样的?)
2020年,如果我要推荐一款流行的数据采集软件,那就是优采云采集器。和我之前推荐的网络爬虫相比,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有数据爬取问题。
说说这款软件的优势吧。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持Linux、Windows、Mac三大操作系统,可直接从官网免费下载。
2.强大
优采云采集器将采集作业分为两种:智能模式和流程图模式。
智能模式是在加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
3.无限导出
这可以说是优采云采集器最良心的功能了。
市场上有很多数据采集软件,出于商业化目的,数据导出或多或少受到限制。不懂套路的人经常用相关软件采集大量的数据,发现导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,支持直接导出到数据库,对于普通用户来说完全够用了。
4.教程详情
在开始写这篇文章之前,我想过为优采云采集器写几篇教程,但是看了他们官网的教程后,我知道这没有必要,因为写得太详细了。
优采云采集器官网提供两种教程,一种是视频教程,每个视频五分钟左右;另一种是图文教程,动手教学。看完这两类教程,你也可以看看他们的文档中心,也很详细,基本涵盖了软件的每一个功能点。
二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,然后数据就可以采集了:
2.翻页功能
当我介绍网络爬虫时,我将页面转换分为 3 类:滚动加载、寻呼机加载和点击下一页加载。
对于这三种基本翻页类型,也完全支持 优采云采集器。
不同于网络爬虫的分页功能分散在各种选择器上,优采云采集器的分页配置集中在一处,只需从下拉列表中选择即可轻松配置分页模式。相关配置教程可参见官网教程:如何设置分页。
3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用了流程图模式下的click组件来模拟点击过滤器按钮,非常方便。
三、进阶使用1.数据清洗
我在介绍网络爬虫的时候说过网络爬虫只提供基本的正则匹配功能,可以在数据爬取过程中对数据进行初步清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完整的正则化功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
比如下图的流程图,就是模拟真人浏览微博时的行为,抓取相关数据。
经过几次亲身测试,我认为流程图模式有一定的学习门槛,但相比从零开始学习python爬虫,学习曲线还是要轻松很多。如果你对流程图模式很感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/正则表达式
不管是什么爬虫软件,都是按照一定的规则来爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器支持自定义这些选择器,可以更灵活的选择要抓取的数据。
比如网页中有数据A,但是只有当鼠标移到相应的文本上时才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。
XPath
XPath 是一种在爬虫中广泛使用的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网络爬虫的高级技术时,我解释了 CSS 选择器的使用场景和注意事项。有兴趣的可以阅读我写的 CSS 选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式来选择数据。我还写了一些正则表达式教程。但我个人认为,在字段选择器场景中,正则表达式不如 XPath 和 CSS 选择器好用。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以不知道体验如何。在这里,我将做一个小科学,并向您解释这些术语的含义。
定时爬行
定时爬取很容易理解,就是爬虫软件会在某个固定时间自动抓取数据。市面上有一些比价软件,背后有很多定时爬虫,每隔几分钟就抓取一次价格信息,达到监控价格的目的。
IP 池
互联网上 90% 的流量是由爬虫贡献的。为了减轻服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。比如某互联网公司检测到某个IP有大量数据请求,超出正常范围,会暂时封锁该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,用不同的IP发送请求,减少IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可以实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大部分程序员的数据采集需求。
如果有一些编程基础,可以清楚的看出一些函数是编程语言逻辑的封装。例如,流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高级特性扩展了优采云采集器的能力,增加了学习的难度。
个人认为,如果是轻量级的数据抓取需求,我更倾向于使用web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时爬取等高级需求,自己编写爬虫代码比较可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。
联络我 查看全部
利用采集器 采集的平台(
2020年这款软件的优秀之处是什么样的?)
https://www.wangt.cc/wp-conten ... 39.png" />2020年,如果我要推荐一款流行的数据采集软件,那就是优采云采集器。和我之前推荐的网络爬虫相比,如果说网络爬虫是一把小巧精致的瑞士军刀,那么优采云采集器就是一把大而全的重武器,基本可以解决所有数据爬取问题。
说说这款软件的优势吧。
一、产品特点1.跨平台
优采云采集器是一款桌面应用软件,支持Linux、Windows、Mac三大操作系统,可直接从官网免费下载。
https://www.wangt.cc/wp-conten ... 07.png" />2.强大
优采云采集器将采集作业分为两种:智能模式和流程图模式。
https://www.wangt.cc/wp-conten ... 02.png" />智能模式是在加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式更适合简单的网页。经过我的测试,识别准确率相当高。
流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
3.无限导出
这可以说是优采云采集器最良心的功能了。
市场上有很多数据采集软件,出于商业化目的,数据导出或多或少受到限制。不懂套路的人经常用相关软件采集大量的数据,发现导出数据要花钱。
优采云采集器 没有这个问题。其支付点主要体现在IP池、采集加速等高级功能上。不仅导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,支持直接导出到数据库,对于普通用户来说完全够用了。
https://www.wangt.cc/wp-conten ... 7e.png" />4.教程详情
在开始写这篇文章之前,我想过为优采云采集器写几篇教程,但是看了他们官网的教程后,我知道这没有必要,因为写得太详细了。
优采云采集器官网提供两种教程,一种是视频教程,每个视频五分钟左右;另一种是图文教程,动手教学。看完这两类教程,你也可以看看他们的文档中心,也很详细,基本涵盖了软件的每一个功能点。
https://www.wangt.cc/wp-conten ... db.png" />二、基本功能1.数据采集
基本的数据抓取很简单:我们只需要点击“添加字段”按钮,就会出现一个选择魔棒,然后点击要抓取的数据,然后数据就可以采集了:
https://www.wangt.cc/wp-conten ... 6f.gif" />2.翻页功能
当我介绍网络爬虫时,我将页面转换分为 3 类:滚动加载、寻呼机加载和点击下一页加载。
https://www.wangt.cc/wp-conten ... 1c.png" />对于这三种基本翻页类型,也完全支持 优采云采集器。
不同于网络爬虫的分页功能分散在各种选择器上,优采云采集器的分页配置集中在一处,只需从下拉列表中选择即可轻松配置分页模式。相关配置教程可参见官网教程:如何设置分页。
https://www.wangt.cc/wp-conten ... 9e.png" />3.复杂形式
对于一些有多重联动筛选的网页,优采云采集器也能很好的处理。我们可以使用优采云采集器中的流程图模式来自定义一些交互规则。
比如下图中,我使用了流程图模式下的click组件来模拟点击过滤器按钮,非常方便。
https://www.wangt.cc/wp-conten ... 17.gif" />三、进阶使用1.数据清洗
我在介绍网络爬虫的时候说过网络爬虫只提供基本的正则匹配功能,可以在数据爬取过程中对数据进行初步清洗。
相比之下,优采云采集器提供了更多的功能:强大的过滤配置、完整的正则化功能和全面的文字处理配置。当然,强大的功能也带来了复杂度的增加,需要更多的耐心去学习和使用。
以下是官网数据清洗相关的教程,大家可以参考学习:
2.流程图模式
正如本文前面提到的,流程图模式的本质是图形化编程。我们可以使用优采云采集器提供的各种控件来模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页爬取数据的各种行为。
比如下图的流程图,就是模拟真人浏览微博时的行为,抓取相关数据。
https://www.wangt.cc/wp-conten ... 61.png" />经过几次亲身测试,我认为流程图模式有一定的学习门槛,但相比从零开始学习python爬虫,学习曲线还是要轻松很多。如果你对流程图模式很感兴趣,可以去官网学习,写的很详细。
3.XPath/CSS/正则表达式
不管是什么爬虫软件,都是按照一定的规则来爬取数据的。XPath/CSS/Regex 只是一些常见的匹配规则。优采云采集器支持自定义这些选择器,可以更灵活的选择要抓取的数据。
比如网页中有数据A,但是只有当鼠标移到相应的文本上时才会以弹窗的形式显示出来。这时候我们就可以写一个对应的选择器来过滤数据了。
https://www.wangt.cc/wp-conten ... 4d.png" />XPath
XPath 是一种在爬虫中广泛使用的数据查询语言。我们可以通过 XPath 教程学习这种语言的使用。
CSS
这里的 CSS 特指 CSS 选择器。在介绍网络爬虫的高级技术时,我解释了 CSS 选择器的使用场景和注意事项。有兴趣的可以阅读我写的 CSS 选择器教程。
正则表达式
正则表达式是一个正则表达式。我们也可以通过正则表达式来选择数据。我还写了一些正则表达式教程。但我个人认为,在字段选择器场景中,正则表达式不如 XPath 和 CSS 选择器好用。
4.定时抓包/IP池/编码功能
这些都是优采云采集器的付费功能。我没有会员,所以不知道体验如何。在这里,我将做一个小科学,并向您解释这些术语的含义。
定时爬行
定时爬取很容易理解,就是爬虫软件会在某个固定时间自动抓取数据。市面上有一些比价软件,背后有很多定时爬虫,每隔几分钟就抓取一次价格信息,达到监控价格的目的。
IP 池
互联网上 90% 的流量是由爬虫贡献的。为了减轻服务器的压力,互联网公司有一些风控策略,其中之一就是限制IP流量。比如某互联网公司检测到某个IP有大量数据请求,超出正常范围,会暂时封锁该IP,不返回相关数据。这时候爬虫软件会自己维护一个IP池,用不同的IP发送请求,减少IP阻塞的概率。
编码功能
该功能是内置验证码识别器,可以实现机器编码或人工编码,也是绕过网站风控的一种方式。
四、总结
个人认为优采云采集器是一款非常不错的数据采集软件。它提供的免费功能可以解决大部分程序员的数据采集需求。
如果有一些编程基础,可以清楚的看出一些函数是编程语言逻辑的封装。例如,流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高级特性扩展了优采云采集器的能力,增加了学习的难度。
个人认为,如果是轻量级的数据抓取需求,我更倾向于使用web scraper;需求比较复杂,优采云采集器是个不错的选择;如果涉及到定时爬取等高级需求,自己编写爬虫代码比较可控。
总而言之,优采云采集器是一款优秀的数据采集软件,强烈推荐大家学习使用。
联络我
利用采集器 采集的平台(WeData元数据采集任务功能(2015年03月23日))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-13 19:32
数据发现功能主要提供元数据采集能力。WeData为用户提供了自定义元数据采集任务的功能。采集tasks会按照配置周期按计划运行和更新元数据信息,支持手动运行、任务编辑等管理操作。当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
配置 采集 任务
单击 采集 任务并选择数据源类型。
当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
设置采集对象
每个采集任务最多可以绑定到WeData项目下的单个数据源,数据源不能重复绑定采集任务。信息详情
任务名称
采集任务名称,不能为空。名称支持字母、汉字,可以收录字母、汉字、数字、减号(-)和下划线(_)。
描述
可选,采集 任务的描述。
项目
数据源所属项目的名称。
数据源
采集任务对应的数据源名称,可在项目管理模块中查看。
实例/数据库详细信息
数据源对象实际对应的 Hive 实例名称/MySQL 数据库名称。
配置采集计划
配置元数据采集任务运行周期、具体日期、时间。采集任务列表
采集任务列表提供当前主账号下所有采集任务的信息,包括任务名称、采集对象、技术类型、项目、创建者等。提供的信息包括采集@>任务详情查看、编辑、删除和运行操作。
信息详情
任务名称
采集任务的名称。
采集对象
采集任务对应的数据源名称。
技术类型
数据源类型。当前版本支持 Hive 和 MySQL。
查看项目
数据源和 采集 对象所属的项目的名称和 ID。
创始人
创建 采集 任务的帐户的名称。
采集计划
采集任务运行周期。
上次执行时间
采集上次任务运行的年、月、日和时间。
最后一次执行
在最近一次运行中,采集任务的运行状态:pending:未达到采集预定运行时间,采集任务正在等待运行。运行中:采集任务正在运行。失败:采集 任务未能运行。点击查看任务失败日志,重启采集任务。已完成:采集任务运行成功。
上次表更改
在最近的 采集 任务运行中添加、删除和更新的表总数。点击查看下方各类表格的详细信息。
操作
提供此任务的详细查看、编辑、删除和运行操作。
运行 采集 任务
手动运行一次性/周期性任务,非执行状态的任务支持手动运行。
采集任务
项目、数据源、更新方法、删除方法、采集计划可以在非执行状态下进行编辑;支持同类型的数据源变更,采集任务基于最新绑定的采集对象采集。
删除 采集 任务
采集 任务删除后,该数据源的采集 将停止。当前版本中已采集到 WeData 的表不会被删除。 查看全部
利用采集器 采集的平台(WeData元数据采集任务功能(2015年03月23日))
数据发现功能主要提供元数据采集能力。WeData为用户提供了自定义元数据采集任务的功能。采集tasks会按照配置周期按计划运行和更新元数据信息,支持手动运行、任务编辑等管理操作。当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
配置 采集 任务
单击 采集 任务并选择数据源类型。
当前版本支持用户使用 Hive 和 MySQL 数据类型采集。
设置采集对象
每个采集任务最多可以绑定到WeData项目下的单个数据源,数据源不能重复绑定采集任务。信息详情
任务名称
采集任务名称,不能为空。名称支持字母、汉字,可以收录字母、汉字、数字、减号(-)和下划线(_)。
描述
可选,采集 任务的描述。
项目
数据源所属项目的名称。
数据源
采集任务对应的数据源名称,可在项目管理模块中查看。
实例/数据库详细信息
数据源对象实际对应的 Hive 实例名称/MySQL 数据库名称。
配置采集计划
配置元数据采集任务运行周期、具体日期、时间。采集任务列表
采集任务列表提供当前主账号下所有采集任务的信息,包括任务名称、采集对象、技术类型、项目、创建者等。提供的信息包括采集@>任务详情查看、编辑、删除和运行操作。
信息详情
任务名称
采集任务的名称。
采集对象
采集任务对应的数据源名称。
技术类型
数据源类型。当前版本支持 Hive 和 MySQL。
查看项目
数据源和 采集 对象所属的项目的名称和 ID。
创始人
创建 采集 任务的帐户的名称。
采集计划
采集任务运行周期。
上次执行时间
采集上次任务运行的年、月、日和时间。
最后一次执行
在最近一次运行中,采集任务的运行状态:pending:未达到采集预定运行时间,采集任务正在等待运行。运行中:采集任务正在运行。失败:采集 任务未能运行。点击查看任务失败日志,重启采集任务。已完成:采集任务运行成功。
上次表更改
在最近的 采集 任务运行中添加、删除和更新的表总数。点击查看下方各类表格的详细信息。
操作
提供此任务的详细查看、编辑、删除和运行操作。
运行 采集 任务
手动运行一次性/周期性任务,非执行状态的任务支持手动运行。
采集任务
项目、数据源、更新方法、删除方法、采集计划可以在非执行状态下进行编辑;支持同类型的数据源变更,采集任务基于最新绑定的采集对象采集。
删除 采集 任务
采集 任务删除后,该数据源的采集 将停止。当前版本中已采集到 WeData 的表不会被删除。
利用采集器 采集的平台(利用采集器采集的平台名称只有几十个或者几百个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-13 10:05
利用采集器采集的平台名称只有几十个或者几百个全,在这样的情况下,很难针对企业产品进行优化,从而造成你打算的效果不明显,到底哪些外部平台可以采集?1.搜索引擎,百度推广营销平台,新浪微博,搜狗微信,谷歌等2.中国访问量最大的网站,,天猫,美团等3.各种网上购物平台4.博客,公众号5.相关分类网站6.其他相关营销网站,例如510600711,,yahoo!,,510600711,yahoo!,等那么采集的时候如何选择外部网站呢?如何规划和使用采集平台呢?首先外部网站要知道哪些外部平台是可以进行采集的,那么外部平台都有哪些可以采集?想了解这个,首先你要知道你的需求,那么接下来的就是把平台知道全,如何优化一个有流量的网站对于新公司来说比较困难,其次有了流量就有了广告投放的机会,在没有流量的情况下,这一切都是徒劳的。
那么怎么才能在企业没有流量的情况下,给自己公司带来流量呢?就算推广,你推广的第一关,就是采集平台,如何对采集网站进行优化,对于新手来说,如何快速的上手采集网站优化呢?前面我有一篇博客是介绍对采集网站优化如何上手的,现在你应该能从中得到一些启发。那么采集平台有哪些推荐呢?1.采集赛道2.seo精选3.采集狮,4.pps,,,等,还有多多采集,240天才回收400元,loop30天。
还有腾讯115部落,,其中的的差距,你可以自己想象。采集的时候如何去采集质量高的网站呢?前面已经说了网站要选择合适的,你搜集的网站都是质量不高的平台,你做的事情又有什么意义?你采集的网站有利于你的转化率吗?你采集的网站有机会打造品牌网站吗?你采集的网站,有机会提高在搜索引擎的排名吗?如果想采集高质量的网站,你可以在我的公众号通过后台直接回复“采集”获取一套方案和一套采集网站的教程,我会从采集内容、采集文案、采集思路、采集技巧,采集技术等多方面详细讲解,你可以免费直接学习,应该可以解决你采集网站的一些问题。 查看全部
利用采集器 采集的平台(利用采集器采集的平台名称只有几十个或者几百个)
利用采集器采集的平台名称只有几十个或者几百个全,在这样的情况下,很难针对企业产品进行优化,从而造成你打算的效果不明显,到底哪些外部平台可以采集?1.搜索引擎,百度推广营销平台,新浪微博,搜狗微信,谷歌等2.中国访问量最大的网站,,天猫,美团等3.各种网上购物平台4.博客,公众号5.相关分类网站6.其他相关营销网站,例如510600711,,yahoo!,,510600711,yahoo!,等那么采集的时候如何选择外部网站呢?如何规划和使用采集平台呢?首先外部网站要知道哪些外部平台是可以进行采集的,那么外部平台都有哪些可以采集?想了解这个,首先你要知道你的需求,那么接下来的就是把平台知道全,如何优化一个有流量的网站对于新公司来说比较困难,其次有了流量就有了广告投放的机会,在没有流量的情况下,这一切都是徒劳的。
那么怎么才能在企业没有流量的情况下,给自己公司带来流量呢?就算推广,你推广的第一关,就是采集平台,如何对采集网站进行优化,对于新手来说,如何快速的上手采集网站优化呢?前面我有一篇博客是介绍对采集网站优化如何上手的,现在你应该能从中得到一些启发。那么采集平台有哪些推荐呢?1.采集赛道2.seo精选3.采集狮,4.pps,,,等,还有多多采集,240天才回收400元,loop30天。
还有腾讯115部落,,其中的的差距,你可以自己想象。采集的时候如何去采集质量高的网站呢?前面已经说了网站要选择合适的,你搜集的网站都是质量不高的平台,你做的事情又有什么意义?你采集的网站有利于你的转化率吗?你采集的网站有机会打造品牌网站吗?你采集的网站,有机会提高在搜索引擎的排名吗?如果想采集高质量的网站,你可以在我的公众号通过后台直接回复“采集”获取一套方案和一套采集网站的教程,我会从采集内容、采集文案、采集思路、采集技巧,采集技术等多方面详细讲解,你可以免费直接学习,应该可以解决你采集网站的一些问题。
利用采集器 采集的平台(一对一直播平台开发的监控系统的演进发展与发展趋势)
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2022-04-11 13:36
一、监控系统核心组件
1、数据采集器
通常指一对一直播平台开发中支持插件机制的数据采集和数据上报工具。数据采集器主要作用于各个系统,采集系统中的各种数据。
2、数据存储仓库
在一对一直播平台开发的监控系统中,数据存储仓库需要实现数据压缩、聚合操作等功能。由于数据存储仓库需要实现大量监控数据的写入和查询,所以通常使用时序数据库。
3、用户操作和可视化界面
监控系统中的用户界面需要实现监控指标和告警管理的易用性和可维护性,数据可视化界面需要提供监控数据展示和查询功能。
4、数据处理引擎
在开发一对一直播平台时,监控系统中的数据处理引擎需要支持流处理和批处理。此外,还需要实现监控告警的计算。
二、监控系统的演进
1、自动识别,自动采集
为了提高一对一直播平台的开发质量,需要注意采集器在监控系统中的自治功能,尤其是面对比较复杂的业务场景, 采集器需要实现环境的自动识别和指标采集的自治。
2、扮演核心角色
一对一直播平台开发的监控系统,对维护整个节目的正常运行起到了核心作用。因此,需要重视监控系统的发展,优化与各个子系统的对接和集成能力。
3、关注数据可视化
随着一对一直播平台的发展,积累的数据显着增加。要想实现大规模数据的精准展示,仅仅依靠传统的数据展示方式是远远不够的。折线图和直方图要根据用户的需要来实现。图表、散点图等多种数据显示方式。
随着互联网技术的飞速发展,一对一直播平台的发展门槛不断降低。越来越多的人试图进入一对一直播领域,竞争压力不断上升。只有充分展示一对一直播平台发展的商业价值,才能在市场上快速崛起,优化监控系统的数据能力成为重中之重。 查看全部
利用采集器 采集的平台(一对一直播平台开发的监控系统的演进发展与发展趋势)
一、监控系统核心组件
1、数据采集器
通常指一对一直播平台开发中支持插件机制的数据采集和数据上报工具。数据采集器主要作用于各个系统,采集系统中的各种数据。
2、数据存储仓库
在一对一直播平台开发的监控系统中,数据存储仓库需要实现数据压缩、聚合操作等功能。由于数据存储仓库需要实现大量监控数据的写入和查询,所以通常使用时序数据库。
3、用户操作和可视化界面
监控系统中的用户界面需要实现监控指标和告警管理的易用性和可维护性,数据可视化界面需要提供监控数据展示和查询功能。
4、数据处理引擎
在开发一对一直播平台时,监控系统中的数据处理引擎需要支持流处理和批处理。此外,还需要实现监控告警的计算。
二、监控系统的演进
1、自动识别,自动采集
为了提高一对一直播平台的开发质量,需要注意采集器在监控系统中的自治功能,尤其是面对比较复杂的业务场景, 采集器需要实现环境的自动识别和指标采集的自治。
2、扮演核心角色
一对一直播平台开发的监控系统,对维护整个节目的正常运行起到了核心作用。因此,需要重视监控系统的发展,优化与各个子系统的对接和集成能力。
3、关注数据可视化
随着一对一直播平台的发展,积累的数据显着增加。要想实现大规模数据的精准展示,仅仅依靠传统的数据展示方式是远远不够的。折线图和直方图要根据用户的需要来实现。图表、散点图等多种数据显示方式。
随着互联网技术的飞速发展,一对一直播平台的发展门槛不断降低。越来越多的人试图进入一对一直播领域,竞争压力不断上升。只有充分展示一对一直播平台发展的商业价值,才能在市场上快速崛起,优化监控系统的数据能力成为重中之重。
利用采集器 采集的平台(湖南三大运营商大数据采集怎么采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-04-11 01:28
大数据采集一键开启自动调用功能。告别传统拨号方式,节省员工操作时间。让员工以更少的工作量获得更多的商机。PC端和APP端配合使用,开启自动通话功能。APP自动拨打电话。PC端查看客户详细信息并添加客户跟踪记录。客户一目了然,让营销更轻松便捷。呼叫中心内置呼叫任务系统,将客户批量导入任务列表,一键开启自动呼叫功能。系统会根据列表自动拨打任务。系统具有通话信息统计功能,通话信息实时更新,并且数据一目了然,方便您快速轻松地获取您需要的所有营销数据。基础数据主要是设置监控指标,包括用户数据。河北三大运营商大数据采集平台
本软件是一款专业的地图数据采集软件,实时采集各大地图官网当前*** POI数据。采集接收到的数据存储在本地数据库中,可以一键导出到Excel或导入到手机通讯录中。可以采集全国所有城市和地区的所有行业数据,采集得到的数据准确率高,不再重复。本产品是众多批发商、电商推广、微商推广人员的拓展神器,业务量翻倍,被众多行业的商务人员选用。实时采集,获取最完整的数据。支持多个城市和多个关键词采集规则无需手写< @采集,只需点击鼠标即可完成。排除 关键词,清除不需要的数据。多图合一,采集数据更准确。下次不小心关闭或打开数据等 湖南三大运营商的大数据采集如何采集没有高层次的分析方法,只有解决问题的方法好.
智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集
<p>大数据平台与数据采集任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 大数据 查看全部
利用采集器 采集的平台(湖南三大运营商大数据采集怎么采集)
大数据采集一键开启自动调用功能。告别传统拨号方式,节省员工操作时间。让员工以更少的工作量获得更多的商机。PC端和APP端配合使用,开启自动通话功能。APP自动拨打电话。PC端查看客户详细信息并添加客户跟踪记录。客户一目了然,让营销更轻松便捷。呼叫中心内置呼叫任务系统,将客户批量导入任务列表,一键开启自动呼叫功能。系统会根据列表自动拨打任务。系统具有通话信息统计功能,通话信息实时更新,并且数据一目了然,方便您快速轻松地获取您需要的所有营销数据。基础数据主要是设置监控指标,包括用户数据。河北三大运营商大数据采集平台
本软件是一款专业的地图数据采集软件,实时采集各大地图官网当前*** POI数据。采集接收到的数据存储在本地数据库中,可以一键导出到Excel或导入到手机通讯录中。可以采集全国所有城市和地区的所有行业数据,采集得到的数据准确率高,不再重复。本产品是众多批发商、电商推广、微商推广人员的拓展神器,业务量翻倍,被众多行业的商务人员选用。实时采集,获取最完整的数据。支持多个城市和多个关键词采集规则无需手写< @采集,只需点击鼠标即可完成。排除 关键词,清除不需要的数据。多图合一,采集数据更准确。下次不小心关闭或打开数据等 湖南三大运营商的大数据采集如何采集没有高层次的分析方法,只有解决问题的方法好.
智汇云虎大数据采集软件的优势在于精准精准,全网数十个平台实时更新,软件实时更新数亿人的网络数据< @采集平台和搜索引擎,确保精确和准确的真实性和实时性。精细采集APP操作方式APP采集器,一键操作,全国300多个城市可自由选择,行业关键词快速锁定行业潜在客户,一键导入通讯录,一键导出电脑。官方持续升级更新售后无忧罚款采集APP已上架Apple Store和Android主流应用市场5年,十年数据采集
<p>大数据平台与数据采集任何一个完整的大数据平台一般都包括以下流程:数据采集-->数据存储-->数据处理-->数据呈现(可视化、报告、监控) 大数据
利用采集器 采集的平台(网站采集器做了很多SEO相关的优化,方便搜索引擎及时发现你的网站有更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-05 21:08
网站采集器、网站采集器是很多站群站长或者网站量大的站长经常使用的功能。如果一个站的每日更新都是手动的,维护起来会耗费大量的人力,而且效果也不一定好,所以可以考虑网站采集器做网站更新。今天谈谈网站采集器。
网站采集器批量发布的同时采集伪原创做了很多SEO相关的优化,比如标题、内容、关键词、等发布后,这些文章链接会自动批量提交给搜索引擎,让搜索引擎及时发现你的网站有更新。网站采集器与传统爬虫不同,网站采集器 是一个完全由您控制的网络爬虫脚本。所有执行规则由您定义。只需打开一个页面,让 网站采集器 插件自动识别表格数据或手动选择要抓取的元素,网站采集器如何在页面之间(甚至在站点之间)移动之间)导航(它也会尝试自动找到导航按钮。网站<
网站采集器采集文章会被伪原创处理并针对搜索引擎进行优化,加上网站采集器的数据来源是所有优质新闻源(知乎、今日头条、微信公众号、搜狐、网易、百度资讯、搜狗资讯等)。通常伪原创 和其他处理搜索引擎认为文章原创 被高度喜欢收录。我们都知道原创内容不仅可以提升网站SEO排名,还可以满足用户需求,提升用户体验。当然,这是内容高度原创和有价值的情况。如果你写废话,那就没用了。写高原创和有价值的内容更容易获得用户的信任和更好的转化。很多人的网站的原因之一
在使用网站采集器开发构建网站内容时,难免有些seo常识的缺失导致域名随意搜索,导致URL已经很久没有收录了,然后才知道原来这个域名的网站历史是灰色的,被搜索引擎抛弃了,导致网站不能用了通过 收录。唯一的方法是更改域名并重新优化它。
网站采集器可以增加数据采集,网站采集器停止可视化编辑采集规则。网站采集器无法将数据导出到 Excel 或 CSV 文件。
网站采集器如果在域名层面没有问题,那就要分析是不是URL质量问题了。如果网址收录很多无效的js,总会给网址增加额外的负担,影响网站等的打开速度,需要检查网站的代码优化。网站采集器表格数据自动识别,列表自动翻页识别,多页数据采集或转换,采集图片到本地或云端,采集图片到本地或云端,超简单的登录内容采集。
网站采集器OCR方法识别加密字符或图片内容,网站采集器批量URL地址,批量关键词查询采集,网站采集器自动iFrame内容采集支持,网站采集器数据变化监控和实时通知。
网站采集器动态内容采集(JavaScript+AJAX),网站采集器无限滚动翻页支持,网站采集器和more 支持多种翻页模式,网站采集器cross网站抓取或数据转换。
网站采集器无需学习Python、PHP、javascript、xpath、json、iframe等技术技能。网站采集器各种数据源的轻松定制采集。今天关于网站采集器的解释就到这里。下期我会分享更多的SEO相关知识。下期再见。 查看全部
利用采集器 采集的平台(网站采集器做了很多SEO相关的优化,方便搜索引擎及时发现你的网站有更新)
网站采集器、网站采集器是很多站群站长或者网站量大的站长经常使用的功能。如果一个站的每日更新都是手动的,维护起来会耗费大量的人力,而且效果也不一定好,所以可以考虑网站采集器做网站更新。今天谈谈网站采集器。
网站采集器批量发布的同时采集伪原创做了很多SEO相关的优化,比如标题、内容、关键词、等发布后,这些文章链接会自动批量提交给搜索引擎,让搜索引擎及时发现你的网站有更新。网站采集器与传统爬虫不同,网站采集器 是一个完全由您控制的网络爬虫脚本。所有执行规则由您定义。只需打开一个页面,让 网站采集器 插件自动识别表格数据或手动选择要抓取的元素,网站采集器如何在页面之间(甚至在站点之间)移动之间)导航(它也会尝试自动找到导航按钮。网站<
网站采集器采集文章会被伪原创处理并针对搜索引擎进行优化,加上网站采集器的数据来源是所有优质新闻源(知乎、今日头条、微信公众号、搜狐、网易、百度资讯、搜狗资讯等)。通常伪原创 和其他处理搜索引擎认为文章原创 被高度喜欢收录。我们都知道原创内容不仅可以提升网站SEO排名,还可以满足用户需求,提升用户体验。当然,这是内容高度原创和有价值的情况。如果你写废话,那就没用了。写高原创和有价值的内容更容易获得用户的信任和更好的转化。很多人的网站的原因之一
在使用网站采集器开发构建网站内容时,难免有些seo常识的缺失导致域名随意搜索,导致URL已经很久没有收录了,然后才知道原来这个域名的网站历史是灰色的,被搜索引擎抛弃了,导致网站不能用了通过 收录。唯一的方法是更改域名并重新优化它。
网站采集器可以增加数据采集,网站采集器停止可视化编辑采集规则。网站采集器无法将数据导出到 Excel 或 CSV 文件。
网站采集器如果在域名层面没有问题,那就要分析是不是URL质量问题了。如果网址收录很多无效的js,总会给网址增加额外的负担,影响网站等的打开速度,需要检查网站的代码优化。网站采集器表格数据自动识别,列表自动翻页识别,多页数据采集或转换,采集图片到本地或云端,采集图片到本地或云端,超简单的登录内容采集。
网站采集器OCR方法识别加密字符或图片内容,网站采集器批量URL地址,批量关键词查询采集,网站采集器自动iFrame内容采集支持,网站采集器数据变化监控和实时通知。
网站采集器动态内容采集(JavaScript+AJAX),网站采集器无限滚动翻页支持,网站采集器和more 支持多种翻页模式,网站采集器cross网站抓取或数据转换。
网站采集器无需学习Python、PHP、javascript、xpath、json、iframe等技术技能。网站采集器各种数据源的轻松定制采集。今天关于网站采集器的解释就到这里。下期我会分享更多的SEO相关知识。下期再见。
利用采集器 采集的平台(快速微信助手_公众号快速排版_排版编辑器-小红书)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-03-17 01:06
利用采集器采集的平台有很多,你需要找一个自己喜欢的采集器,只要采集简单的内容,或者是满足要求的要求,就很容易创建多个采集器。采集器可以用来采集新闻,文本,图片,视频,工具,热点,音乐,代码,论坛等等。
我经常用一个网站叫做乐玩采集器,功能比较齐全,
你做微信公众号,那平台就是微信公众号平台。如果需要采集的话,就去采集那个平台。
我推荐一个免费的,
百度搜索
谢邀。使用任何一个平台采集,都是可以的,只是要使用采集软件,比如快速微信助手(可以采集视频,音频,图片等等)、微小宝这些。快速微信助手可以查看历史文章列表,而小宝查看历史文章列表是收费的,价格不高,数据比较齐全,但是这些我觉得你完全可以使用去使用。再一个就是站长工具站长工具-快速微信图文助手_公众号快速排版_排版编辑器-小红书。
头条和百家文章分析,详细的方法请参考本篇头条文章分析教程,祝题主心想事成,
天涯看点已经支持上传图片,快速采集。
有很多采集到的网站需要做处理,比如全图。有比较全的采集网站,只是需要的时间比较久,因为需要反爬措施。 查看全部
利用采集器 采集的平台(快速微信助手_公众号快速排版_排版编辑器-小红书)
利用采集器采集的平台有很多,你需要找一个自己喜欢的采集器,只要采集简单的内容,或者是满足要求的要求,就很容易创建多个采集器。采集器可以用来采集新闻,文本,图片,视频,工具,热点,音乐,代码,论坛等等。
我经常用一个网站叫做乐玩采集器,功能比较齐全,
你做微信公众号,那平台就是微信公众号平台。如果需要采集的话,就去采集那个平台。
我推荐一个免费的,
百度搜索
谢邀。使用任何一个平台采集,都是可以的,只是要使用采集软件,比如快速微信助手(可以采集视频,音频,图片等等)、微小宝这些。快速微信助手可以查看历史文章列表,而小宝查看历史文章列表是收费的,价格不高,数据比较齐全,但是这些我觉得你完全可以使用去使用。再一个就是站长工具站长工具-快速微信图文助手_公众号快速排版_排版编辑器-小红书。
头条和百家文章分析,详细的方法请参考本篇头条文章分析教程,祝题主心想事成,
天涯看点已经支持上传图片,快速采集。
有很多采集到的网站需要做处理,比如全图。有比较全的采集网站,只是需要的时间比较久,因为需要反爬措施。
利用采集器 采集的平台(用美团采集美食的采集方法,你值得拥有!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-12 00:00
利用采集器采集的平台很多了,像美团、饿了么、pp助手、掌众、cuili、魔方、百度等等..都可以采集。方法/步骤下面给大家推荐一下用美团采集美食的采集方法:1采集店铺宝贝2采集带货源店铺宝贝3采集带qq和电话号码店铺宝贝4采集带店铺名称的店铺宝贝关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
一、采集宝贝
二、获取店铺链接
1)百度站长平台
2)微信公众号自动发送
3)的搜索
4)旺旺“怎么查店铺呀?”
5)上的店铺信息
6)集搜客、易淘网、中搜网、淘贝网,、店铺名采集关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
1,总体步骤:浏览器+采集器+代码文件获取+上传上传网址,采集工具请百度。2,
1)的商品介绍都有链接的,
2)站内搜索关键词+宝贝名,搜索结果中有一部分网页是可以采集的。
3)不建议采集那些连接外部链接的。建议采集店铺宝贝名链接为主。
4)如果用爬虫采集技术,建议配合爬虫本身抓取过程中的限制设置。ip有一定限制,限制每日在线时间,但不允许24小时永久上线;服务器不建议小规模使用。
二、案例描述:2018年4月份,我写了一篇文章列举了如何快速采集电商平台店铺的店铺名及详细情况。 查看全部
利用采集器 采集的平台(用美团采集美食的采集方法,你值得拥有!!)
利用采集器采集的平台很多了,像美团、饿了么、pp助手、掌众、cuili、魔方、百度等等..都可以采集。方法/步骤下面给大家推荐一下用美团采集美食的采集方法:1采集店铺宝贝2采集带货源店铺宝贝3采集带qq和电话号码店铺宝贝4采集带店铺名称的店铺宝贝关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
一、采集宝贝
二、获取店铺链接
1)百度站长平台
2)微信公众号自动发送
3)的搜索
4)旺旺“怎么查店铺呀?”
5)上的店铺信息
6)集搜客、易淘网、中搜网、淘贝网,、店铺名采集关于的搜索推荐什么的,这里就不展开了,基本的技术是用采集器+店铺名采集。
1,总体步骤:浏览器+采集器+代码文件获取+上传上传网址,采集工具请百度。2,
1)的商品介绍都有链接的,
2)站内搜索关键词+宝贝名,搜索结果中有一部分网页是可以采集的。
3)不建议采集那些连接外部链接的。建议采集店铺宝贝名链接为主。
4)如果用爬虫采集技术,建议配合爬虫本身抓取过程中的限制设置。ip有一定限制,限制每日在线时间,但不允许24小时永久上线;服务器不建议小规模使用。
二、案例描述:2018年4月份,我写了一篇文章列举了如何快速采集电商平台店铺的店铺名及详细情况。
利用采集器 采集的平台(申请人脸识别就行了采集的人都是身份证照片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-11 16:10
利用采集器采集的平台要交上千块钱采集器费,并有七天的停机费,然后你会回到学校下采集器。
你这情况申请人脸识别就行了采集的人都是身份证照片一对一就行了解决办法:只要你的学生证办理的是手机卡前提是你得清楚你要申请的人脸识别采集点所在的市区或者省区你就得在当地(你要办理的省你要提供的信息需要和户籍地一致你在身份证的app里可以查到你办理地的街道及村,然后由警察开具证明即可);你要出省你就需要开具当地的户籍地派出所的证明。最后采集的人才会获得那张照片所有人都是可以用的只要你出钱。
只要你的身份证有效你怎么个偷法
一般身份证拍照直接能识别,没有采集人脸的必要。
其实知道你的大概位置采集上来一致的话也不会被发现,只要在学校的西门不要挡住拍照人的照片,被发现的话可以跑法院起诉你偷拍,
没必要。身份证可以直接采集,或者现在也有很多照片采集工具。
太长了,看截图。
直接采集就好了
为什么采集不人脸?
你为什么要采集?你在高校外面采集别人也找不到你的主要是偷拍怎么找一个清白人?那你就是拿着身份证去偷拍好了
您好,根据您提供的情况暂无法帮您解决您的问题。希望您采纳我的建议寻找一个可靠的第三方单位帮您解决您的问题。请咨询当地派出所。 查看全部
利用采集器 采集的平台(申请人脸识别就行了采集的人都是身份证照片)
利用采集器采集的平台要交上千块钱采集器费,并有七天的停机费,然后你会回到学校下采集器。
你这情况申请人脸识别就行了采集的人都是身份证照片一对一就行了解决办法:只要你的学生证办理的是手机卡前提是你得清楚你要申请的人脸识别采集点所在的市区或者省区你就得在当地(你要办理的省你要提供的信息需要和户籍地一致你在身份证的app里可以查到你办理地的街道及村,然后由警察开具证明即可);你要出省你就需要开具当地的户籍地派出所的证明。最后采集的人才会获得那张照片所有人都是可以用的只要你出钱。
只要你的身份证有效你怎么个偷法
一般身份证拍照直接能识别,没有采集人脸的必要。
其实知道你的大概位置采集上来一致的话也不会被发现,只要在学校的西门不要挡住拍照人的照片,被发现的话可以跑法院起诉你偷拍,
没必要。身份证可以直接采集,或者现在也有很多照片采集工具。
太长了,看截图。
直接采集就好了
为什么采集不人脸?
你为什么要采集?你在高校外面采集别人也找不到你的主要是偷拍怎么找一个清白人?那你就是拿着身份证去偷拍好了
您好,根据您提供的情况暂无法帮您解决您的问题。希望您采纳我的建议寻找一个可靠的第三方单位帮您解决您的问题。请咨询当地派出所。

