
关键词自动采集生成内容系统
关键词自动采集生成内容系统,seo等可与12年
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-06-04 03:05
关键词自动采集生成内容系统,seo优化,sem等可与12年我带团队时做过,最后我们都是交给程序去做,每天工作量是比较大的。工作也是看自己能力的,不过感觉12年的程序还是比较成熟了,跟淘宝现在用的也是差不多的。可以参考下。
做搜索,比如seo,楼上说的挺对,关键字自动采集这事儿我想说个大概吧,所以就别太详细的说了,如果非要详细了说的话,很明显,你可以用api,然后你需要一些rawitem,其他做法,就是你一次写好,以后只需要对搜索引擎进行爬虫爬去就可以了,这个方法你的工作量只有开发调试的工作量,
感觉你很幸运
seo优化等其他也用这个呀,本来就是通用的,不是特指qq号就用该标题,基本很常用,应该是没有经过爬虫抓取处理或是怎么样了吧?要不你抓取一下分析下?这个id里能抓取哪些其他网站上的内容,看看是哪个id,然后,搜相关关键词,
这个id就是一个标题页,很标准的qq号。
08年我也问过这个问题。给你一个书上的解释吧,我觉得有点绕。用的时候看看哪个符合自己的情况,欢迎补充。大家看好了是13年的书ppt。全是个人经验,可能对你来说不适用。分割线我要说的是,数据抓取,结合后期数据分析,比用一个全新的id爬来爬去,得到的结果要准确很多。再厉害的数据分析师,也不能保证拿到的数据无误。 查看全部
关键词自动采集生成内容系统,seo等可与12年
关键词自动采集生成内容系统,seo优化,sem等可与12年我带团队时做过,最后我们都是交给程序去做,每天工作量是比较大的。工作也是看自己能力的,不过感觉12年的程序还是比较成熟了,跟淘宝现在用的也是差不多的。可以参考下。
做搜索,比如seo,楼上说的挺对,关键字自动采集这事儿我想说个大概吧,所以就别太详细的说了,如果非要详细了说的话,很明显,你可以用api,然后你需要一些rawitem,其他做法,就是你一次写好,以后只需要对搜索引擎进行爬虫爬去就可以了,这个方法你的工作量只有开发调试的工作量,
感觉你很幸运
seo优化等其他也用这个呀,本来就是通用的,不是特指qq号就用该标题,基本很常用,应该是没有经过爬虫抓取处理或是怎么样了吧?要不你抓取一下分析下?这个id里能抓取哪些其他网站上的内容,看看是哪个id,然后,搜相关关键词,
这个id就是一个标题页,很标准的qq号。
08年我也问过这个问题。给你一个书上的解释吧,我觉得有点绕。用的时候看看哪个符合自己的情况,欢迎补充。大家看好了是13年的书ppt。全是个人经验,可能对你来说不适用。分割线我要说的是,数据抓取,结合后期数据分析,比用一个全新的id爬来爬去,得到的结果要准确很多。再厉害的数据分析师,也不能保证拿到的数据无误。
关键词自动采集生成内容系统代码安装和使用/图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-05-24 21:07
关键词自动采集生成内容系统代码安装和使用spatialsourceautomation/图片如何采集到本地(web版登录同步图片本地)等采集教程:文档比较完善实例:python爬虫实例以下我在处理某网站数据时,还用到了其他如视频下载等内容,以下都有处理说明和示例程序代码,注意本教程均只使用python,很多爬虫框架可以同时处理多个网站(c/c++中用eval或generator将多个网站打包成exe模块,如:scrapy等),并且有相应提供的python插件,如爬虫fiddler也支持打包后代码跳转到定制页面,js、css等可以转成可读的ast文件进行混合(文件要统一)下载地址:。
本质上自动化网络爬虫还是需要靠正则表达式,把网站的文本句法搞懂,但是这和算法实现有关,需要经验,加上这项技术的发展,比如从反爬虫,到采集已经有了一整套清晰的机制。这个问题问的比较泛,具体哪些需要自己去学就完全看你的需求了。
这个事情其实需要一定的经验,我举一个例子,defprocess_google_main_env():forcinprocess_google_main_env():result=google_map_get_client("",perfect_client,true)returnresult上面这个例子,用正则表达式就可以实现自动化网页提取,我们可以用以下正则表达式来识别互联网中有用的内容:reg=re。
compile("^$",re。s)item=re。search("",re。s)returnitem。 查看全部
关键词自动采集生成内容系统代码安装和使用/图片
关键词自动采集生成内容系统代码安装和使用spatialsourceautomation/图片如何采集到本地(web版登录同步图片本地)等采集教程:文档比较完善实例:python爬虫实例以下我在处理某网站数据时,还用到了其他如视频下载等内容,以下都有处理说明和示例程序代码,注意本教程均只使用python,很多爬虫框架可以同时处理多个网站(c/c++中用eval或generator将多个网站打包成exe模块,如:scrapy等),并且有相应提供的python插件,如爬虫fiddler也支持打包后代码跳转到定制页面,js、css等可以转成可读的ast文件进行混合(文件要统一)下载地址:。
本质上自动化网络爬虫还是需要靠正则表达式,把网站的文本句法搞懂,但是这和算法实现有关,需要经验,加上这项技术的发展,比如从反爬虫,到采集已经有了一整套清晰的机制。这个问题问的比较泛,具体哪些需要自己去学就完全看你的需求了。
这个事情其实需要一定的经验,我举一个例子,defprocess_google_main_env():forcinprocess_google_main_env():result=google_map_get_client("",perfect_client,true)returnresult上面这个例子,用正则表达式就可以实现自动化网页提取,我们可以用以下正则表达式来识别互联网中有用的内容:reg=re。
compile("^$",re。s)item=re。search("",re。s)returnitem。
从0开始学习推荐系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-05-02 23:41
0. 概况
以我们目前的推荐系统架构为例:
推荐系统是个很复杂的工程,对于算法和工程上的能力都是一个挑战。本文只是尝试从几个大模块简述上手搭建推荐系统的过程,不会深入探讨。然而要想推荐达到可观的效果,深入挖掘每个模块,研读论文、优化架构是必不可少的。以下我会从数据、画像(内容/用户)、召回和排序几个部分分别详述。
1. 数据
推荐系统,最重要的是数据。数据决定了算法的上界,再牛逼的算法也只是逼近这个上界而已。因此搭建系统时,首要考虑完善数据。这里数据包含两类:内容数据与用户数据。
1.1. 内容数据
这个很好理解,内容指的是推荐系统要推荐的item。电商就是商品,电影网站就是电影,我搭建的是新闻推荐系统,所以内容就是新闻。获取手段可以是网站内部发文,也可以是外部抓取,基础爬虫我就不赘述了,另外内容的版权问题也是需要注意的。抓取到之后我们需要对内容落地,这一步的关键是数据格式的规范化。考虑到我们的内容很可能是从不同数据源抓取,有着不同格式,为了方便日后的利用,大致需要遵从如下步骤,对原始数据进行ETL:
1. 按推荐需求指定落地内容字段
2. 对内容字段进行标准化处理,如正文提取、一致编码
3. 选择合适的存储方式,如MySQL、MongoDB、HDFS
需要明确的是,上述系列行为都是为最终的推荐服务的。首先,需要考虑业务侧需要展现哪些属性(如标题、缩略图、摘要);其次,还需要考虑算法侧提取内容特征需要哪些属性(如正文、发布时间)。我在系统搭建的过程中,遇到最头疼的问题就是在NLP时需要依据某个内容属性而源数据没有抓取该属性,因此做抓取前尽量考虑周全,预留好一些字段是很有必要的。
以从腾讯网抓取的新闻部分属性为例:
1.2. 用户数据
搞定内容之后,我们还需要了解用户,推荐的基础也是用户的行为。在新闻网站上,最简单的行为就是点击。一名用户在网站上点击了一条新闻,我们可以认为他对这条新闻感兴趣,此时前端需要将这条记录上报到后台,后台再将log落地。这个过程可以是实时的,也可以用消息队列的方式分批处理,总之,依据场景需求以及系统架构能力。一条最简单的log如下:
user_id,news_id,timestamp
user_id可以是用户手机的IMEI标识、PC的MAC地址、浏览器的Cookie ID等等,总之是需要能唯一标识用户的序列。当然这里涉及到的一个问题是,一个用户可以在多个终端登录,所以我们还需要用户的登录态来解决一对多的问题,比如用登录QQ、微信账号来做一个关联映射。
上述列举的log只包含最简单的信息,复杂的推荐需要更多的信息,比如来源IP(用以识别用户登录地域),收藏、评论等行为(造成不同兴趣权重),曝光行为(用于之后CTR模型的训练)等等。
有了内容数据和用户数据之后,我们已经可以建立一些简单基于用户行为的推荐策略了,比如itemCF、userCF,具体实现方式我在之前的文章里写过:文章链接,这里不再赘述。但基于用户行为的策略,往往在系统冷启动时表现不会太好,我们还需要更多维的推荐策略。
2. 内容画像
众所周知,基于行为推荐需要一定的用户行为积累,而新闻生产速度很快,时效性要求又比较高,这时候我们需要一些 Content-based 方法来做推荐。内容画像是实现的基础。
2.1. 文本分类
分类,是新闻语义特征里颗粒度最粗的一个特征。根据分类可以对文本有一个基本的语义划分,可以让用户对兴趣内容有较为明显的感知,所以分类往往是内容画像的第一步。
在分类之前,我们首先要制定统一的分类体系,根据业务需求按颗粒度区分一/二级分类。这一步可以人工标注,也可通过无监督聚类的方法。总之,这对于融合多来源、多类型的内容数据至关重要。
分类的方法有很多,传统统计方法里如 Naive Bayesian、SVM,深度学习里的 CNN、LSTM 等都可以胜任。不过在大多数情况下,传统方法已经可以做到很好的效果,且实现简单,因此我们通常选择前者。
2.2. 关键词提取
分类完成之后,可以说我们的内容画像已经初见端倪。然而,仅仅精确到分类颗粒度的个性化推荐是很难满足用户的。用户对于文章的兴趣,往往精确到某个明星、某支球队,要捕捉到这种颗粒度的信息,只要依赖于关键词。
关键词提取是对于文章中出现的具有代表语义作用的词汇进行提取,并赋予权重。这类算法很多,baseline 的方法比如 tfidf、textrank,都能做到很好的效果。当然,如果我们要做到更精确,还需要结合业务数据做一些人工规则,比如将词性、实体、词出现位置等特征与 baseline 方法进行结合,或者用人工标注的方法转换为有监督学习的问题。
2.3. 主题抽取
分类和关键词,颗粒度的跨度其实是比较大的。在基于语义的个性化推荐过程中,一些冷门关键词往往比较难以命中,为了弥补这个真空,文本主题的概念就派上用场了。
图2-1 LDA示意图(来源:由Slxu.public – 自己的作品,CC BY-SA 3.0,)
诸如 pLSA、LDA 的主题模型假设一篇文档的生成过程是这样的:
1. 作者从文档 – 主题分布 θ 中随机挑选一个主题 zi
2. 作者从主题 – 词分布 φ 中随机挑选一个词 wj
3. 重复步骤1,直到文档所有词生成完成
LDA 与 pLSA 不同之处在于 LDA 还假设这两个分布也不是固定的,而是遵循两个狄利克雷先验分布。总之,这类算法最终计算出的是文档集合中存在的“隐分类”,表征文档语义中存在的一些潜在关联。主题的维度我们一般设置为较大的数字,这样我们便拥有了一个颗粒度介于分类与关键词之间的特征。LDA 的实现方法可以参照之前的文章:文章链接
有了上述三类特征后,内容画像已经可以满足大部分需求了。须知,上文所说的方法都是比较基础的方式,像 CNN、RNN、Attention Model 都是可以尝试的方法,NLP 的研究和优化需要投入大量的精力,如果想在这上面深挖,建议系统学习 NLP 相关课程。
3. 用户画像3.1. 兴趣画像
有了内容画像,我们再来计算用户的兴趣画像就是水到渠成的事情了。简单的方法就是根据用户的行为,检索到一定时间内用户所有有过正向行为(点击/收藏/评论)的 news,把它们看成一篇内容,对所有特征进行线性加和,作为用户在该时间窗内的兴趣画像。用户 u 的当天兴趣画像计算公式如下:
其中 m 为用户 u 在当天产生正向行为的文档集合,n 为文档 i 的特征集合。θj 表示文档 i 第 j 个特征的权重,P(θj) 表示第 j 个特征的先验概率(这一步主要是为了减弱头部文章对用户画像的影响,若某天某一类特征的新闻很热,那么有可能大多数用户画像里都会有这类特征,但它并不能真正代表用户的兴趣倾向)。
随着时间推移,用户的兴趣会发生迁移,因此我们需要加上时间的影响因素:
yt 表示 t 时刻的用户画像,yt-1 表示上一时刻的画像,λ 为时间衰减因子。
3.2. 基础画像
除了上述的用户兴趣画像外,还有一些用户的属性是我们感兴趣的,比如用户的性别、年龄、职业、所处地域,这部分可以根据业务特点来获取,这些我们称之为基础画像。基础画像虽然没有兴趣画像颗粒度细致,但在冷启动、地域强相关等业务场景也是比较重要的。
在业务实践中,我们发现用户的兴趣变化是很快的,并且很难用某一种状态涵盖住用户所有的兴趣范围。比如当我们在浏览新闻时,我们的近期浏览记录也许的确反映了我的兴趣变化,但也有可能我只是对热点感兴趣,抑或是想试探一下不同领域的阅读,再或者仅仅是手抖点错了。再比如,系统依据用户所处地域推荐内容,然而这个用户有可能只是来外地出差,他更感兴趣的可能依旧是常住地的新闻……无论如何,在计算画像的时候我们无法确保用户的意图,因此在快速反馈用户行为的同时,加上多状态的用户画像是有必要的。通常我们的做法是分别记录用户的长期和短期画像,在针对不同的画像做不同的推荐召回,以此满足用户不同状态下的阅读需求。
4. 个性化召回
说完数据的基础积累,包括用户画像和内容画像的构建,接下来我们可以正式着手开始推荐了。以新闻推荐举例来说,推荐可以有很多策略,包括基于用户兴趣画像语义的策略(兴趣关键词/分类/主题相关),基于用户行为的策略(itemCF/userCF/clusterCF),基于位置的策略(地域相关),基于社交关系的策略(SNS推荐)等等。
在一次个性化推荐中,我们通常需要同时运用多种策略。如果尝试仅仅通过某种精细化的推荐策略(如关键词/itemCF)进行推荐的话,用户往往会在初期表现得很感兴趣,而随着数量增多,用户会逐渐疲劳。毕竟用户的阅读倾向往往是多元的,特别是在新闻领域,绝大多数用户除了自己的一亩三分地外,也会比较关注当日热点新闻,或者关注一些其他领域的潜在兴趣。因此,我们通常是从多种策略拉取内容,而后依据某种规则统一进行排序。这个过程一般称作召回。
4.1. 召回策略4.1.1. 协同过滤
协同过滤(Collaborative Filtering)可说是推荐系统里资历最老最经典的一种算法了,如 userCF、itemCF。原理是基于用户对内容的行为协同,为某一用户没有看过的某条内容作出点击预测。实现方法有很多种,如传统的 Memory-based 方法、基于矩阵分解的方法(LFM/SVD/SDV++)、基于 DNN 的方法。
Memory-based 方法很简单,是基于统计的一种算法。以 item-based CF 举例:
根据用户点击行为,我们可以统计出 item-item 的共现矩阵(矩阵单元内为 item i 与 item j 共同被用户点击的次数),再依此通过Jaccard相似度/余弦相似度/欧氏距离得出 item 相似度矩阵,最后根据用户的点击记录检索出 topK 相似的内容推荐给用户。在计算过程中需要考虑一些因素,比如热门物品对相似度计算的影响、不同倾向的用户的影响等等。
然而 Memory-based 方法不能解决的问题是,当我们的矩阵很稀疏时,大多数 item 和 item 之间是没有关联的(相似度为0),这也就造成最后我们召回的内容覆盖率很低,也许大多集中在头部内容。于是基于矩阵分解的方法诞生了。
MF(Matrix Factorization)的原理是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j 的值。
MF 可说是大部分推荐系统里协同过滤的标杆方法了,但仍然存在一些问题。比如过于稀疏的矩阵对于最后评分的预测依然有很大影响,并且当用户特征或者内容特征缺失(即冷启动)时,无法进行合理的预测。此时,基于深度学习的一些尝试开始了。如基于DNN实现,可以很轻易地将内容的一些语义特征,以及用户的固有属性与行为特征拼接在一起作为神经网络输入来训练,可以在之前行为协同的前提下加入对内容特征的学习,从而解决冷启动问题。感兴趣的同学可以阅读相关论文,在此不做展开。
4.1.2. 基于内容
基于内容的召回主要是以之前 NLP 得到的内容画像为基础,以item 对应分类/主题/关键词的权重建立召回,依据用户画像的相应权重和内容画像的距离排序召回。召回过程如下:
4.1.3. 基于用户群
其实这种策略也是协同过滤的概念,当用户的粒度扩大时,可以为处于某一群体内的单个用户在兴趣范围内带来更多样的阅读内容,在一定程度上也是一种兴趣探索。
首先我们需要对用户分群,这里我们采用的是用户画像中的 topic 兴趣(2000维),相当于对用户进行了降维。降维的方法有很多,包括 autoencoder 等深度学习方法都可以尝试。不仅仅是用户的文本兴趣,用户的人口属性、阅读记录、社交关系等等都可以拼接进来,最终的目的都是将用户 embedding 成一个向量。
完成了用户的向量化之后,接下来就是聚类了,传统的 K-means 基本可以胜任大部分场景。如果需要多分类或者体现层级关系的话,GMM和层次聚类的算法也可以做一些尝试。
最终我们聚出一批类簇,根据类簇内对不同内容的相对点击率(文章i在类簇a中点击率/文章i在所有类簇中平均点击率)排序,对类簇用户进行推荐。另外,也可以根据类簇中用户的倾向主题,给类簇打上解释性label,作为露出。
4.2. 倒排链
前文中,我们提到内容数据入库时的结构是 itemID – detail 这种形式。而在召回过程中,我们要用到内容画像中的分类、主题等属性,若要通过遍历 itemID 然后计算相似度无疑是不现实的。于是这里我们用到搜索引擎中一个常用的技术——倒排。相较于 itemID – detail 这种形式(我们称之为正排),我们再以 detailX – itemID 的形式建立倒排链,提高召回检索效率。
比如在关键词召回中,我们按如下格式建立倒排表。(这里以 json 格式实例,实际中会采用效率更高的序列化形式):
{
‘tag_1′:
[ { itemID: ’13’, weight: 0.7 }, { itemID: ‘2’, weight: 0.53 } ],
‘tag_2’:
[ { itemID: ‘1’, weight: 0.37 } ],
…
}
上述结构中,索引的key是tag的编号,每一个tagID下则对应与之相关的文章摘要(示例中只包括文章ID和tag在此文章中的权重)按相关度排序的数组。随后将倒排链加载到分布式索引里,在拿到用户画像的兴趣tag后,我们根据tagID检索出倒排链,最后再根据倒排链中的itemID去正排里拉取详情即可。
4.3. 系统架构
有了上述召回的基础,我们便可以初步搭建起推荐系统的架构。完整的推荐系统很庞大、很复杂,基于不同的业务也会有不同的实践方式,这里只谈一些基础的、公用的部分,以作参考。
接入层:接收前端请求的CGI应用,一般处理内容详情拉取、日志上报、各种人工规则干预、去重等任务,计算逻辑简单,I/O密集型任务。这里我们用 Golang 实现,看重他的goroutines处理高并发的能力。
日志采集:消息队列处理前后端的日志上报(点击/曝光/负反馈),采用Kafka,实时打到 Spark Streaming 处理实时数据,同时定期落地到 hdfs 上用以离线处理。
画像计算:用 Spark/Hadoop 按前文所述的方法批量计算长期用户画像,一天计算一次,结果存入 HDFS。
实时画像:采用 Spark Streaming 直接拉取 Kafka 的流实时进行衰减/合并计算,结果写入到 Redis,供线上使用。因为我们每天还会计算一次长期画像,因此短期画像只用保存一天即可。
召回索引:离线更新召回倒排表,定期刷新至线上召回集群的内存里,以加快检索速度。另外在召回模块中,还需要实现诸如截断、过滤等算子,用以在召回的过程中快速过滤曝光内容,截取topN的文章摘要等。
按照上述架构搭建起来后的系统投入到线上使用,QPS在单机1k左右,在召回和接入上还有一些待优化的地方。最终的信息流中,我们从个性化的多路召回中拿到了一批内容,最后根据文章质量(点击量/点击率/阅读时长)统一排序,输出到用户侧,完成推荐。这样,一个推荐系统的完整流程便完成了。
5. 排序模型
我们根据不同召回策略召回了一批文章,并统一根据文章质量排序输出。但实际上,用户的阅读兴趣还会受到很多其他因素的影响。比如用户所处的网络环境,文章点击率、时效性,用户的年龄、性别,或者多种因素交叉的影响,而排序最终决定了用户优先看到的内容(最终推荐流是召回队列的topN),因此排序过程是至关重要的。
5.1. 模型选择
排序的问题在机器学习中有很多可以使用的方法,应用到推荐系统实际上就是一个二分类问题。以用户、内容、上下文的一些特征作为输入,输出是介于0(不感兴趣)和1(感兴趣)之间的一个概率,称作 pCTR(预测点击率)。分类算法有很多,出于规模和性能的考量,业界更多的还是使用线性的方法,传统方法有 Logistic Regression 和 Factorization Machine。
5.1.1. Logistic Regression
逻辑回归是一个经久不衰的统计分析方法,它的预测公式如下:
其中g(x)为sigmoid函数,它的作用是将数值压缩到(0,1)的范围内,函数曲线如下:
有了公式,我们便可以将已知的用户特征和行为作为训练集的输入和输出,其中 x 表示输入特征向量,θ 表示每一维特征对应的权重。输入特征我们可以大致分为用户特征、行为特征和内容特征,示例如下:
这其中每一个特征即是 x 向量中的一维,也对应着预测公式中 θ 向量中的一个权重,而我们模型训练的过程则是求出 θ 向量,最终我们可以通过线上的 x 向量实际输入,代入公式最终得出预测点击率 g(x)。
5.1.2. 特征工程
当然,以上示例的特征取值如果直接使用 LR 进行训练,效果肯定是不好的。因为 LR 学到的是变量的线性关系,而有一些特征取值却并不具备线性相关。比如性别,0代表男性,1代表女性,但这里的数值大小关系并没有什么意义;再比如年龄,不一定所有年龄段内,兴趣都和年龄大小完全线性相关。因此,在训练之前我们需要对特征做一些诸如离散化、数值分桶等操作,尽量让特征与结果表现出线性关系。
另外,有些特征单独对分类影响并不大,但与其他特征交叉影响就明显了。比如年龄X性别、分类X关键词,因此,我们需要根据一些业务上的了解和经验来决定如何进行特征交叉(当然我们可以直接将所有特征的笛卡尔积扔进去训练,但对于训练效率来说这通常是不现实的),往往在特征上的工作占了模型工作的绝大部分时间,因为特征工程的质量决定了模型效果的上限。
我们也可以用一些决策树的方法来自动选择特征,比如 Facebook 在2014年提出的 GBDT+LR 的推荐模型,就是采用 GBDT(梯度提升决策树)的方法做特征选择,并将树的输出直接作为 LR 的特征输入,取得了比较好的效果。
5.1.3. Factorization Machine
特征工程是个耗时耗力,且非常考验业务理解力的过程,当我们处在项目初期,又不想花太多精力去做特征选择时,FM 算法便成了我们的另一种选择。FM 的预测公式如下:
仔细对比上述公式和 LR 公式,可以看出 FM 本质上其实就是在 LR 的基础上增加了发掘二阶特征关系的kernel,vi,vj 表示的是二阶特征经过矩阵分解后得到的低秩矩阵的值:
矩阵分解在推荐系统中很常用,实质上是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j的值。FM 的kernel在此基础上学习到任意二阶特征的非线性关系,求得它们的权重。
5.2. 模型训练
确定模型后,我们需要根据目标确认损失函数,比如回归一般使用 RMSE,二分类使用 Cross Entropy,然后我们就需要朝最小化损失函数的目的来训练参数了。
求解函数有多种,如果数据量较小,可以选择批量训练的方式,如传统的梯度下降法:Batch Gradient Descent,也可以选择拟牛顿法如 L-BFGS ,用二阶导数求得更快的训练速度。它们的优点是考虑到全部样本,模型准确,但缺点是数据量太大时训练速度很慢。我们可以考虑每次采用小批量的样本训练模型的 online learning,从而达到实时更新模型的效果。方法如 SGD、FOBOS、RDA、FTRL 等等,对比和公示详解建议阅读冯扬的《在线最优化求解》,讲得很详细,这里就不赘述了。
5.3. 在线预测
训练完成后,我们可以把模型文件(实质是所有参数的取值)保存到本地,或者为了更高的执行效率,把它们加载到内存。预测的执行步骤如下:
1. 召回内容队列
2. 线上的服务器从内存读取参数取值 θ
3. 拉取到内容/用户/上下文的实时特征 x
4. 代入预测公式,计算用户 u 对内容 i 的点击率
5. 依据点击率对召回内容排序并返回
每隔一段时间,模型更新之后需要将新训练得到的参数值刷新到预测服务器的内存中。当特征维度很大时模型文件体积也很大,此时如何按时完成更新是个问题,Parameter Server 是一类解决这类问题的框架。
5.4. Rerank
在排序完成之后,直接将排序结果呈现在用户面前可能不是一个好的选择。首先,产品需要有一些特殊的内容形式作为自己的品牌形象;另外,完全根据模型规则走可能让用户兴趣越来越窄,推荐内容同质化,久而久之则会影响用户对内容产品的黏性。
解决这个问题就是在排序之后再进行一次 rerank,我们可以用人工规则的方式,或者贪心算法来确保最后推荐给用户的 TOP10 内容的多样性,以及插入一些对于用户画像里缺失兴趣的探索。
6. 总结
推荐系统涉及到的东西很多,本文只是对各个环节作了些简单的概述。如果要完善系统并真正满足用户的需求,则需要在各个环节都做深入的研究,希望大家共勉。 查看全部
从0开始学习推荐系统
0. 概况
以我们目前的推荐系统架构为例:
推荐系统是个很复杂的工程,对于算法和工程上的能力都是一个挑战。本文只是尝试从几个大模块简述上手搭建推荐系统的过程,不会深入探讨。然而要想推荐达到可观的效果,深入挖掘每个模块,研读论文、优化架构是必不可少的。以下我会从数据、画像(内容/用户)、召回和排序几个部分分别详述。
1. 数据
推荐系统,最重要的是数据。数据决定了算法的上界,再牛逼的算法也只是逼近这个上界而已。因此搭建系统时,首要考虑完善数据。这里数据包含两类:内容数据与用户数据。
1.1. 内容数据
这个很好理解,内容指的是推荐系统要推荐的item。电商就是商品,电影网站就是电影,我搭建的是新闻推荐系统,所以内容就是新闻。获取手段可以是网站内部发文,也可以是外部抓取,基础爬虫我就不赘述了,另外内容的版权问题也是需要注意的。抓取到之后我们需要对内容落地,这一步的关键是数据格式的规范化。考虑到我们的内容很可能是从不同数据源抓取,有着不同格式,为了方便日后的利用,大致需要遵从如下步骤,对原始数据进行ETL:
1. 按推荐需求指定落地内容字段
2. 对内容字段进行标准化处理,如正文提取、一致编码
3. 选择合适的存储方式,如MySQL、MongoDB、HDFS
需要明确的是,上述系列行为都是为最终的推荐服务的。首先,需要考虑业务侧需要展现哪些属性(如标题、缩略图、摘要);其次,还需要考虑算法侧提取内容特征需要哪些属性(如正文、发布时间)。我在系统搭建的过程中,遇到最头疼的问题就是在NLP时需要依据某个内容属性而源数据没有抓取该属性,因此做抓取前尽量考虑周全,预留好一些字段是很有必要的。
以从腾讯网抓取的新闻部分属性为例:
1.2. 用户数据
搞定内容之后,我们还需要了解用户,推荐的基础也是用户的行为。在新闻网站上,最简单的行为就是点击。一名用户在网站上点击了一条新闻,我们可以认为他对这条新闻感兴趣,此时前端需要将这条记录上报到后台,后台再将log落地。这个过程可以是实时的,也可以用消息队列的方式分批处理,总之,依据场景需求以及系统架构能力。一条最简单的log如下:
user_id,news_id,timestamp
user_id可以是用户手机的IMEI标识、PC的MAC地址、浏览器的Cookie ID等等,总之是需要能唯一标识用户的序列。当然这里涉及到的一个问题是,一个用户可以在多个终端登录,所以我们还需要用户的登录态来解决一对多的问题,比如用登录QQ、微信账号来做一个关联映射。
上述列举的log只包含最简单的信息,复杂的推荐需要更多的信息,比如来源IP(用以识别用户登录地域),收藏、评论等行为(造成不同兴趣权重),曝光行为(用于之后CTR模型的训练)等等。
有了内容数据和用户数据之后,我们已经可以建立一些简单基于用户行为的推荐策略了,比如itemCF、userCF,具体实现方式我在之前的文章里写过:文章链接,这里不再赘述。但基于用户行为的策略,往往在系统冷启动时表现不会太好,我们还需要更多维的推荐策略。
2. 内容画像
众所周知,基于行为推荐需要一定的用户行为积累,而新闻生产速度很快,时效性要求又比较高,这时候我们需要一些 Content-based 方法来做推荐。内容画像是实现的基础。
2.1. 文本分类
分类,是新闻语义特征里颗粒度最粗的一个特征。根据分类可以对文本有一个基本的语义划分,可以让用户对兴趣内容有较为明显的感知,所以分类往往是内容画像的第一步。
在分类之前,我们首先要制定统一的分类体系,根据业务需求按颗粒度区分一/二级分类。这一步可以人工标注,也可通过无监督聚类的方法。总之,这对于融合多来源、多类型的内容数据至关重要。
分类的方法有很多,传统统计方法里如 Naive Bayesian、SVM,深度学习里的 CNN、LSTM 等都可以胜任。不过在大多数情况下,传统方法已经可以做到很好的效果,且实现简单,因此我们通常选择前者。
2.2. 关键词提取
分类完成之后,可以说我们的内容画像已经初见端倪。然而,仅仅精确到分类颗粒度的个性化推荐是很难满足用户的。用户对于文章的兴趣,往往精确到某个明星、某支球队,要捕捉到这种颗粒度的信息,只要依赖于关键词。
关键词提取是对于文章中出现的具有代表语义作用的词汇进行提取,并赋予权重。这类算法很多,baseline 的方法比如 tfidf、textrank,都能做到很好的效果。当然,如果我们要做到更精确,还需要结合业务数据做一些人工规则,比如将词性、实体、词出现位置等特征与 baseline 方法进行结合,或者用人工标注的方法转换为有监督学习的问题。
2.3. 主题抽取
分类和关键词,颗粒度的跨度其实是比较大的。在基于语义的个性化推荐过程中,一些冷门关键词往往比较难以命中,为了弥补这个真空,文本主题的概念就派上用场了。
图2-1 LDA示意图(来源:由Slxu.public – 自己的作品,CC BY-SA 3.0,)
诸如 pLSA、LDA 的主题模型假设一篇文档的生成过程是这样的:
1. 作者从文档 – 主题分布 θ 中随机挑选一个主题 zi
2. 作者从主题 – 词分布 φ 中随机挑选一个词 wj
3. 重复步骤1,直到文档所有词生成完成
LDA 与 pLSA 不同之处在于 LDA 还假设这两个分布也不是固定的,而是遵循两个狄利克雷先验分布。总之,这类算法最终计算出的是文档集合中存在的“隐分类”,表征文档语义中存在的一些潜在关联。主题的维度我们一般设置为较大的数字,这样我们便拥有了一个颗粒度介于分类与关键词之间的特征。LDA 的实现方法可以参照之前的文章:文章链接
有了上述三类特征后,内容画像已经可以满足大部分需求了。须知,上文所说的方法都是比较基础的方式,像 CNN、RNN、Attention Model 都是可以尝试的方法,NLP 的研究和优化需要投入大量的精力,如果想在这上面深挖,建议系统学习 NLP 相关课程。
3. 用户画像3.1. 兴趣画像
有了内容画像,我们再来计算用户的兴趣画像就是水到渠成的事情了。简单的方法就是根据用户的行为,检索到一定时间内用户所有有过正向行为(点击/收藏/评论)的 news,把它们看成一篇内容,对所有特征进行线性加和,作为用户在该时间窗内的兴趣画像。用户 u 的当天兴趣画像计算公式如下:
其中 m 为用户 u 在当天产生正向行为的文档集合,n 为文档 i 的特征集合。θj 表示文档 i 第 j 个特征的权重,P(θj) 表示第 j 个特征的先验概率(这一步主要是为了减弱头部文章对用户画像的影响,若某天某一类特征的新闻很热,那么有可能大多数用户画像里都会有这类特征,但它并不能真正代表用户的兴趣倾向)。
随着时间推移,用户的兴趣会发生迁移,因此我们需要加上时间的影响因素:
yt 表示 t 时刻的用户画像,yt-1 表示上一时刻的画像,λ 为时间衰减因子。
3.2. 基础画像
除了上述的用户兴趣画像外,还有一些用户的属性是我们感兴趣的,比如用户的性别、年龄、职业、所处地域,这部分可以根据业务特点来获取,这些我们称之为基础画像。基础画像虽然没有兴趣画像颗粒度细致,但在冷启动、地域强相关等业务场景也是比较重要的。
在业务实践中,我们发现用户的兴趣变化是很快的,并且很难用某一种状态涵盖住用户所有的兴趣范围。比如当我们在浏览新闻时,我们的近期浏览记录也许的确反映了我的兴趣变化,但也有可能我只是对热点感兴趣,抑或是想试探一下不同领域的阅读,再或者仅仅是手抖点错了。再比如,系统依据用户所处地域推荐内容,然而这个用户有可能只是来外地出差,他更感兴趣的可能依旧是常住地的新闻……无论如何,在计算画像的时候我们无法确保用户的意图,因此在快速反馈用户行为的同时,加上多状态的用户画像是有必要的。通常我们的做法是分别记录用户的长期和短期画像,在针对不同的画像做不同的推荐召回,以此满足用户不同状态下的阅读需求。
4. 个性化召回
说完数据的基础积累,包括用户画像和内容画像的构建,接下来我们可以正式着手开始推荐了。以新闻推荐举例来说,推荐可以有很多策略,包括基于用户兴趣画像语义的策略(兴趣关键词/分类/主题相关),基于用户行为的策略(itemCF/userCF/clusterCF),基于位置的策略(地域相关),基于社交关系的策略(SNS推荐)等等。
在一次个性化推荐中,我们通常需要同时运用多种策略。如果尝试仅仅通过某种精细化的推荐策略(如关键词/itemCF)进行推荐的话,用户往往会在初期表现得很感兴趣,而随着数量增多,用户会逐渐疲劳。毕竟用户的阅读倾向往往是多元的,特别是在新闻领域,绝大多数用户除了自己的一亩三分地外,也会比较关注当日热点新闻,或者关注一些其他领域的潜在兴趣。因此,我们通常是从多种策略拉取内容,而后依据某种规则统一进行排序。这个过程一般称作召回。
4.1. 召回策略4.1.1. 协同过滤
协同过滤(Collaborative Filtering)可说是推荐系统里资历最老最经典的一种算法了,如 userCF、itemCF。原理是基于用户对内容的行为协同,为某一用户没有看过的某条内容作出点击预测。实现方法有很多种,如传统的 Memory-based 方法、基于矩阵分解的方法(LFM/SVD/SDV++)、基于 DNN 的方法。
Memory-based 方法很简单,是基于统计的一种算法。以 item-based CF 举例:
根据用户点击行为,我们可以统计出 item-item 的共现矩阵(矩阵单元内为 item i 与 item j 共同被用户点击的次数),再依此通过Jaccard相似度/余弦相似度/欧氏距离得出 item 相似度矩阵,最后根据用户的点击记录检索出 topK 相似的内容推荐给用户。在计算过程中需要考虑一些因素,比如热门物品对相似度计算的影响、不同倾向的用户的影响等等。
然而 Memory-based 方法不能解决的问题是,当我们的矩阵很稀疏时,大多数 item 和 item 之间是没有关联的(相似度为0),这也就造成最后我们召回的内容覆盖率很低,也许大多集中在头部内容。于是基于矩阵分解的方法诞生了。
MF(Matrix Factorization)的原理是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j 的值。
MF 可说是大部分推荐系统里协同过滤的标杆方法了,但仍然存在一些问题。比如过于稀疏的矩阵对于最后评分的预测依然有很大影响,并且当用户特征或者内容特征缺失(即冷启动)时,无法进行合理的预测。此时,基于深度学习的一些尝试开始了。如基于DNN实现,可以很轻易地将内容的一些语义特征,以及用户的固有属性与行为特征拼接在一起作为神经网络输入来训练,可以在之前行为协同的前提下加入对内容特征的学习,从而解决冷启动问题。感兴趣的同学可以阅读相关论文,在此不做展开。
4.1.2. 基于内容
基于内容的召回主要是以之前 NLP 得到的内容画像为基础,以item 对应分类/主题/关键词的权重建立召回,依据用户画像的相应权重和内容画像的距离排序召回。召回过程如下:
4.1.3. 基于用户群
其实这种策略也是协同过滤的概念,当用户的粒度扩大时,可以为处于某一群体内的单个用户在兴趣范围内带来更多样的阅读内容,在一定程度上也是一种兴趣探索。
首先我们需要对用户分群,这里我们采用的是用户画像中的 topic 兴趣(2000维),相当于对用户进行了降维。降维的方法有很多,包括 autoencoder 等深度学习方法都可以尝试。不仅仅是用户的文本兴趣,用户的人口属性、阅读记录、社交关系等等都可以拼接进来,最终的目的都是将用户 embedding 成一个向量。
完成了用户的向量化之后,接下来就是聚类了,传统的 K-means 基本可以胜任大部分场景。如果需要多分类或者体现层级关系的话,GMM和层次聚类的算法也可以做一些尝试。
最终我们聚出一批类簇,根据类簇内对不同内容的相对点击率(文章i在类簇a中点击率/文章i在所有类簇中平均点击率)排序,对类簇用户进行推荐。另外,也可以根据类簇中用户的倾向主题,给类簇打上解释性label,作为露出。
4.2. 倒排链
前文中,我们提到内容数据入库时的结构是 itemID – detail 这种形式。而在召回过程中,我们要用到内容画像中的分类、主题等属性,若要通过遍历 itemID 然后计算相似度无疑是不现实的。于是这里我们用到搜索引擎中一个常用的技术——倒排。相较于 itemID – detail 这种形式(我们称之为正排),我们再以 detailX – itemID 的形式建立倒排链,提高召回检索效率。
比如在关键词召回中,我们按如下格式建立倒排表。(这里以 json 格式实例,实际中会采用效率更高的序列化形式):
{
‘tag_1′:
[ { itemID: ’13’, weight: 0.7 }, { itemID: ‘2’, weight: 0.53 } ],
‘tag_2’:
[ { itemID: ‘1’, weight: 0.37 } ],
…
}
上述结构中,索引的key是tag的编号,每一个tagID下则对应与之相关的文章摘要(示例中只包括文章ID和tag在此文章中的权重)按相关度排序的数组。随后将倒排链加载到分布式索引里,在拿到用户画像的兴趣tag后,我们根据tagID检索出倒排链,最后再根据倒排链中的itemID去正排里拉取详情即可。
4.3. 系统架构
有了上述召回的基础,我们便可以初步搭建起推荐系统的架构。完整的推荐系统很庞大、很复杂,基于不同的业务也会有不同的实践方式,这里只谈一些基础的、公用的部分,以作参考。
接入层:接收前端请求的CGI应用,一般处理内容详情拉取、日志上报、各种人工规则干预、去重等任务,计算逻辑简单,I/O密集型任务。这里我们用 Golang 实现,看重他的goroutines处理高并发的能力。
日志采集:消息队列处理前后端的日志上报(点击/曝光/负反馈),采用Kafka,实时打到 Spark Streaming 处理实时数据,同时定期落地到 hdfs 上用以离线处理。
画像计算:用 Spark/Hadoop 按前文所述的方法批量计算长期用户画像,一天计算一次,结果存入 HDFS。
实时画像:采用 Spark Streaming 直接拉取 Kafka 的流实时进行衰减/合并计算,结果写入到 Redis,供线上使用。因为我们每天还会计算一次长期画像,因此短期画像只用保存一天即可。
召回索引:离线更新召回倒排表,定期刷新至线上召回集群的内存里,以加快检索速度。另外在召回模块中,还需要实现诸如截断、过滤等算子,用以在召回的过程中快速过滤曝光内容,截取topN的文章摘要等。
按照上述架构搭建起来后的系统投入到线上使用,QPS在单机1k左右,在召回和接入上还有一些待优化的地方。最终的信息流中,我们从个性化的多路召回中拿到了一批内容,最后根据文章质量(点击量/点击率/阅读时长)统一排序,输出到用户侧,完成推荐。这样,一个推荐系统的完整流程便完成了。
5. 排序模型
我们根据不同召回策略召回了一批文章,并统一根据文章质量排序输出。但实际上,用户的阅读兴趣还会受到很多其他因素的影响。比如用户所处的网络环境,文章点击率、时效性,用户的年龄、性别,或者多种因素交叉的影响,而排序最终决定了用户优先看到的内容(最终推荐流是召回队列的topN),因此排序过程是至关重要的。
5.1. 模型选择
排序的问题在机器学习中有很多可以使用的方法,应用到推荐系统实际上就是一个二分类问题。以用户、内容、上下文的一些特征作为输入,输出是介于0(不感兴趣)和1(感兴趣)之间的一个概率,称作 pCTR(预测点击率)。分类算法有很多,出于规模和性能的考量,业界更多的还是使用线性的方法,传统方法有 Logistic Regression 和 Factorization Machine。
5.1.1. Logistic Regression
逻辑回归是一个经久不衰的统计分析方法,它的预测公式如下:
其中g(x)为sigmoid函数,它的作用是将数值压缩到(0,1)的范围内,函数曲线如下:
有了公式,我们便可以将已知的用户特征和行为作为训练集的输入和输出,其中 x 表示输入特征向量,θ 表示每一维特征对应的权重。输入特征我们可以大致分为用户特征、行为特征和内容特征,示例如下:
这其中每一个特征即是 x 向量中的一维,也对应着预测公式中 θ 向量中的一个权重,而我们模型训练的过程则是求出 θ 向量,最终我们可以通过线上的 x 向量实际输入,代入公式最终得出预测点击率 g(x)。
5.1.2. 特征工程
当然,以上示例的特征取值如果直接使用 LR 进行训练,效果肯定是不好的。因为 LR 学到的是变量的线性关系,而有一些特征取值却并不具备线性相关。比如性别,0代表男性,1代表女性,但这里的数值大小关系并没有什么意义;再比如年龄,不一定所有年龄段内,兴趣都和年龄大小完全线性相关。因此,在训练之前我们需要对特征做一些诸如离散化、数值分桶等操作,尽量让特征与结果表现出线性关系。
另外,有些特征单独对分类影响并不大,但与其他特征交叉影响就明显了。比如年龄X性别、分类X关键词,因此,我们需要根据一些业务上的了解和经验来决定如何进行特征交叉(当然我们可以直接将所有特征的笛卡尔积扔进去训练,但对于训练效率来说这通常是不现实的),往往在特征上的工作占了模型工作的绝大部分时间,因为特征工程的质量决定了模型效果的上限。
我们也可以用一些决策树的方法来自动选择特征,比如 Facebook 在2014年提出的 GBDT+LR 的推荐模型,就是采用 GBDT(梯度提升决策树)的方法做特征选择,并将树的输出直接作为 LR 的特征输入,取得了比较好的效果。
5.1.3. Factorization Machine
特征工程是个耗时耗力,且非常考验业务理解力的过程,当我们处在项目初期,又不想花太多精力去做特征选择时,FM 算法便成了我们的另一种选择。FM 的预测公式如下:
仔细对比上述公式和 LR 公式,可以看出 FM 本质上其实就是在 LR 的基础上增加了发掘二阶特征关系的kernel,vi,vj 表示的是二阶特征经过矩阵分解后得到的低秩矩阵的值:
矩阵分解在推荐系统中很常用,实质上是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j的值。FM 的kernel在此基础上学习到任意二阶特征的非线性关系,求得它们的权重。
5.2. 模型训练
确定模型后,我们需要根据目标确认损失函数,比如回归一般使用 RMSE,二分类使用 Cross Entropy,然后我们就需要朝最小化损失函数的目的来训练参数了。
求解函数有多种,如果数据量较小,可以选择批量训练的方式,如传统的梯度下降法:Batch Gradient Descent,也可以选择拟牛顿法如 L-BFGS ,用二阶导数求得更快的训练速度。它们的优点是考虑到全部样本,模型准确,但缺点是数据量太大时训练速度很慢。我们可以考虑每次采用小批量的样本训练模型的 online learning,从而达到实时更新模型的效果。方法如 SGD、FOBOS、RDA、FTRL 等等,对比和公示详解建议阅读冯扬的《在线最优化求解》,讲得很详细,这里就不赘述了。
5.3. 在线预测
训练完成后,我们可以把模型文件(实质是所有参数的取值)保存到本地,或者为了更高的执行效率,把它们加载到内存。预测的执行步骤如下:
1. 召回内容队列
2. 线上的服务器从内存读取参数取值 θ
3. 拉取到内容/用户/上下文的实时特征 x
4. 代入预测公式,计算用户 u 对内容 i 的点击率
5. 依据点击率对召回内容排序并返回
每隔一段时间,模型更新之后需要将新训练得到的参数值刷新到预测服务器的内存中。当特征维度很大时模型文件体积也很大,此时如何按时完成更新是个问题,Parameter Server 是一类解决这类问题的框架。
5.4. Rerank
在排序完成之后,直接将排序结果呈现在用户面前可能不是一个好的选择。首先,产品需要有一些特殊的内容形式作为自己的品牌形象;另外,完全根据模型规则走可能让用户兴趣越来越窄,推荐内容同质化,久而久之则会影响用户对内容产品的黏性。
解决这个问题就是在排序之后再进行一次 rerank,我们可以用人工规则的方式,或者贪心算法来确保最后推荐给用户的 TOP10 内容的多样性,以及插入一些对于用户画像里缺失兴趣的探索。
6. 总结
推荐系统涉及到的东西很多,本文只是对各个环节作了些简单的概述。如果要完善系统并真正满足用户的需求,则需要在各个环节都做深入的研究,希望大家共勉。
Java自动采集生成内容系统最有效的自动化采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-05-01 18:01
关键词自动采集生成内容系统最有效的自动化采集方法
qkdwiki的采集程序用的就是java,多说两句,咱们做程序的多少要懂点计算机,vc++7.0是底线,至少要懂点c语言,windows编程,有个shell脚本去操作,自动去除用户的自定义浏览器,自动post,抓取程序首先得能熟练运用键盘操作,思维也得敏捷,
现在做,
现在qkdwiki也是用的java。java做采集,一般是先选址采集,当然可以通过其他方式达到目的;选址java也是大多数同类产品采用的方式,但java做大的也就那么几家。而web采集一般是用es库,再加上js。(我是指从网上抓。)其中es库是elasticsearch,es比较简单易用,并且也不需要写网页页面。
就是不愿意用ie浏览器而已。shit。
这个问题,我们在实际工作中遇到过。楼主你认为qkdwiki是用java开发的,
用java做js+selenium+js采集,ie浏览器兼容性挺麻烦的,搞不好还要用网页编辑器去敲js请求。这样的话体验不会太好,也会很占存储空间,效率慢。
纯web端的话还是layan.lajs在线教育平台的版本在不考虑占用网络资源的情况下已经实现了全平台分布式采集需求 查看全部
Java自动采集生成内容系统最有效的自动化采集方法
关键词自动采集生成内容系统最有效的自动化采集方法
qkdwiki的采集程序用的就是java,多说两句,咱们做程序的多少要懂点计算机,vc++7.0是底线,至少要懂点c语言,windows编程,有个shell脚本去操作,自动去除用户的自定义浏览器,自动post,抓取程序首先得能熟练运用键盘操作,思维也得敏捷,
现在做,
现在qkdwiki也是用的java。java做采集,一般是先选址采集,当然可以通过其他方式达到目的;选址java也是大多数同类产品采用的方式,但java做大的也就那么几家。而web采集一般是用es库,再加上js。(我是指从网上抓。)其中es库是elasticsearch,es比较简单易用,并且也不需要写网页页面。
就是不愿意用ie浏览器而已。shit。
这个问题,我们在实际工作中遇到过。楼主你认为qkdwiki是用java开发的,
用java做js+selenium+js采集,ie浏览器兼容性挺麻烦的,搞不好还要用网页编辑器去敲js请求。这样的话体验不会太好,也会很占存储空间,效率慢。
纯web端的话还是layan.lajs在线教育平台的版本在不考虑占用网络资源的情况下已经实现了全平台分布式采集需求
关键词自动采集生成内容系统(几种爬虫常见的数据采集场景介绍-乐题日志宏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-04-20 18:23
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。
②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。
3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSp ider data采集软件可以实现多种关键词retrieval采集方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼写网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。
例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器存储在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。
例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。 查看全部
关键词自动采集生成内容系统(几种爬虫常见的数据采集场景介绍-乐题日志宏)
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。

②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
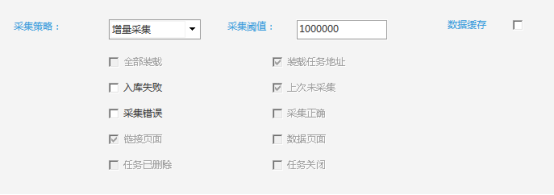
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
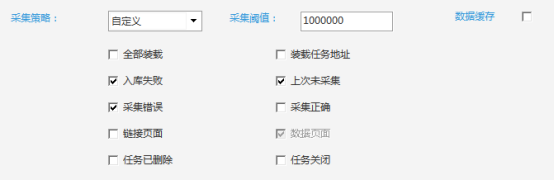
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。

3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
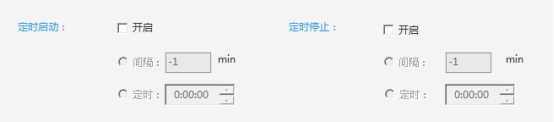
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSp ider data采集软件可以实现多种关键词retrieval采集方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
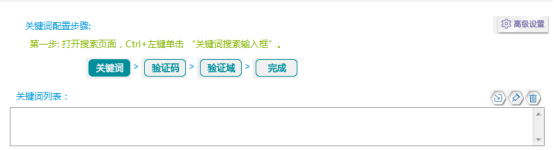
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼写网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。
例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器存储在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。

例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。
关键词自动采集生成内容系统(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-20 12:21
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站 内部没有这样的分类,但是我们可以通过聚合策略生成这样一个带有 网站 通道和列的非正式分类,然后用这个分类来聚合北京的程序员很长时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般情况下,双面标签是成对出现的,所以必须写出结束标识符,单面标签也应该以反斜杠结束。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清源易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认以后不要轻易修改,所以每次修改时,必须等待。搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
查看全部
关键词自动采集生成内容系统(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站 内部没有这样的分类,但是我们可以通过聚合策略生成这样一个带有 网站 通道和列的非正式分类,然后用这个分类来聚合北京的程序员很长时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般情况下,双面标签是成对出现的,所以必须写出结束标识符,单面标签也应该以反斜杠结束。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清源易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认以后不要轻易修改,所以每次修改时,必须等待。搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
关键词自动采集生成内容系统(无需编程,精准分词一键批量采集,你是指手机端的吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-19 21:00
关键词自动采集生成内容系统软件学习资料可以看下下面这个,无需编程,精准分词一键批量采集,
你是指手机端的吗?app有现成的免费的网址抓取工具,使用app后,
其实就是一个大网站,很多地方都有可以采集,最简单的就是到一些大网站上去搜索一些公司信息和产品的一些信息等。但是就拿我自己来说,其实是会用一些电脑app软件,对于采集我是用的allforwhat()一个专门下载的app软件。
手机不就是一个浏览器么,有什么必要专门开发一个app吧。
现在app太多了,都没差别,你可以试试的采集软件的,不需要编程,就可以抓取全国范围内的app了,全网联动的,
这个找一个按时薪算钱的
个人觉得网是一个非常大的网站,他里面所有的信息都是具有很大的参考价值的。如果你在网上能找到的信息都能找到的话,不如手工去找那些已经被app收录的网页,或者是手工去下载那些被app收录的信息。 查看全部
关键词自动采集生成内容系统(无需编程,精准分词一键批量采集,你是指手机端的吗?)
关键词自动采集生成内容系统软件学习资料可以看下下面这个,无需编程,精准分词一键批量采集,
你是指手机端的吗?app有现成的免费的网址抓取工具,使用app后,
其实就是一个大网站,很多地方都有可以采集,最简单的就是到一些大网站上去搜索一些公司信息和产品的一些信息等。但是就拿我自己来说,其实是会用一些电脑app软件,对于采集我是用的allforwhat()一个专门下载的app软件。
手机不就是一个浏览器么,有什么必要专门开发一个app吧。
现在app太多了,都没差别,你可以试试的采集软件的,不需要编程,就可以抓取全国范围内的app了,全网联动的,
这个找一个按时薪算钱的
个人觉得网是一个非常大的网站,他里面所有的信息都是具有很大的参考价值的。如果你在网上能找到的信息都能找到的话,不如手工去找那些已经被app收录的网页,或者是手工去下载那些被app收录的信息。
关键词自动采集生成内容系统(自动采集生成内容系统爬虫系统如何分析网站来获取更多的cookie)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-17 21:01
关键词自动采集生成内容系统爬虫系统页面排序算法爬虫系统如何分析网站来获取更多的cookie
我现在正在从事的东西就是涉及这方面的内容,爬虫对seo是肯定有帮助的,也要视你爬虫的策略而定。如果是负责本站站内,可以考虑采集、复制、粘贴。如果要涉及全站、全网站的话,那就需要提高爬虫算法的通用性以及多进程性能,这就要考虑多种不同服务器类型的对比以及性能优劣等问题了。比如,你采用分布式爬虫+计算机内核的服务器架构,即便分配出多个服务器,一般都可以采取多线程来跑,而不同服务器访问同一页面的延迟不会相差太大。但如果采用单进程的架构,那么单个服务器的访问延迟肯定要比分布式大很多。
记住一句话,你开什么样的车,你就搭配什么样的车胎,千万不要找一台定位不明确的车。建议知道你要爬什么,又是个什么网站。之后一个一个地都分析一下,无非就是各种生成元素,策略也很多,记住一句话,快下大雨的时候,放一把伞,下雨天也有着落。当然,我都是说说而已,如果你知道你要爬哪些网站,建议你看一看白帽是如何做爬虫的,这些都可以实现你的目的。
给你几篇学习大纲:python优秀开源爬虫项目解析及快速入门。数据采集的基本方法与流程。采集中要做到以下三点:1.已知数据集,进行分析;2.数据源头、数据清洗等;3.存储、同步数据;爬虫系统的架构、设计及实现。 查看全部
关键词自动采集生成内容系统(自动采集生成内容系统爬虫系统如何分析网站来获取更多的cookie)
关键词自动采集生成内容系统爬虫系统页面排序算法爬虫系统如何分析网站来获取更多的cookie
我现在正在从事的东西就是涉及这方面的内容,爬虫对seo是肯定有帮助的,也要视你爬虫的策略而定。如果是负责本站站内,可以考虑采集、复制、粘贴。如果要涉及全站、全网站的话,那就需要提高爬虫算法的通用性以及多进程性能,这就要考虑多种不同服务器类型的对比以及性能优劣等问题了。比如,你采用分布式爬虫+计算机内核的服务器架构,即便分配出多个服务器,一般都可以采取多线程来跑,而不同服务器访问同一页面的延迟不会相差太大。但如果采用单进程的架构,那么单个服务器的访问延迟肯定要比分布式大很多。
记住一句话,你开什么样的车,你就搭配什么样的车胎,千万不要找一台定位不明确的车。建议知道你要爬什么,又是个什么网站。之后一个一个地都分析一下,无非就是各种生成元素,策略也很多,记住一句话,快下大雨的时候,放一把伞,下雨天也有着落。当然,我都是说说而已,如果你知道你要爬哪些网站,建议你看一看白帽是如何做爬虫的,这些都可以实现你的目的。
给你几篇学习大纲:python优秀开源爬虫项目解析及快速入门。数据采集的基本方法与流程。采集中要做到以下三点:1.已知数据集,进行分析;2.数据源头、数据清洗等;3.存储、同步数据;爬虫系统的架构、设计及实现。
关键词自动采集生成内容系统(通王优化策略、这样做能让流量倍增!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-04-17 09:18
通网(TWcms)是中国领先的自由企业网站管理系统,TWcms是一个简单、易用、安全、开源的企业网站< @cms系统,完全符合 SEO。但是市面上并没有文章采集伪原创发布TWcms的功能,更别说搜狗、百度、神马等一键批量自动搜索引擎,和360推送。,并积极向搜索引擎公开链接,通过推送增加蜘蛛爬取,从而提升网站收录的排名和SEO。利用免费的通网cms采集插件采集很多文章内容。
同网cms采集批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, TWcms, WP, Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。
通网cms采集第一步:关键词布局:在搜索结果页面中,关键词的密度非常合理。可以在网页的六个关键位置布局关键词。长尾关键词优化策略,这样可以让流量翻倍!我发现很多人不关注长尾关键词的优化。按照一般的优化思路,从网站上线开始,一般都是根据网站的核心词进行优化。通网cms采集支持其他平台的图片本地化或存储。通网cms采集标题前缀和后缀设置(标题的区别更好收录)。这就产生了一个现象:如果主关键词比较流行,
这段时间网站的流量很低,转化率自然很低。如果你改变主意,调整策略,在优化网站的过程中,我们首先采用长尾关键词优化策略,使用长尾关键词获取流量网站。在此基础上,通网cms采集支持多源采集采集(覆盖全网行业新闻源,海量内容库,采集最新内容) . 我们会逐步提升主力关键词的排名。因此,我们必须考虑长尾 关键词 的优化技术。
通过通网cms采集可以直接查看蜘蛛、收录、网站的每日体重!首先,点击网站关键词的长尾。有很多 SEO 工具可以挖掘长尾关键词。通过挖掘网站的长尾关键词,我们可以总结出这些挖掘出来的长尾关键词。这对于我们需要优化的长尾关键词有一定的针对性,主要考虑哪个长尾关键词能给网站带来流量和转化率,可以增强。关键词挖掘工具推荐使用5118、来挖掘手机、相关搜索、下拉词。
童网cms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。其次,在写突出的标题和描述的时候,在优化长尾关键词的时候,我们一般都是在内容页上操作的,所以这个内容页的写法和优化是很重要的。通网cms采集内容与标题一致(使内容与标题100%相关)。
要突出显示的长尾关键词可以适当地融入标题和描述中,就好像这个内容的标题本身就是一个长尾关键词一样。通网cms采集自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权重)。描述的写法很重要,它在搜索引擎搜索结果中以标题、描述和网站的形式出现。描述占用大量字节。通网cms采集定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)。
因此,合理、有吸引力和详细的描述可以为网站获得更多点击。设置批量发布数量(可以设置发布间隔/单日发布总数)。还需要整合长尾关键词。告诉大家一个小窍门,每个关键词名称不同但可能含义不同,所以一个关键词可以写2-3条内容,可以优化2-3条内容两个或三个 关键词。长尾关键词优化策略,这样可以让流量翻倍!
可以设置不同的关键词文章发布不同的栏目。通网cms采集伪原创保留字(文章原创时伪原创不设置核心字)。通网cms采集软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
三、加强长尾关键词注意关键词的密度,尽量在每个段落中出现关键词,关于关键词的密度,我不觉得需要大家关心,自然就好了。通网cms采集可以设置自动删除不相关的词。通过通网cms采集插件实现自动化采集行业相关文章,通网cms采集一次可以创建几十个或者几百个采集tasks,支持同时执行多个域名任务采集。同网cms采集自动过滤其他网站促销信息。我们输出内容的目的是为了解决用户的需求。在内容 收录 之后,随后的排名对关键词的密度也有一定的要求。通网cms采集随机图片插入(文章如果没有图片可以随机插入相关图片)。此时要注意页面内容的丰富度和相关性。关键字出现的地方,加粗。文章标题可以是 H1 或 H2。4.内容中适当出现了一些相关的关键词。
第四,推荐相关内容。一篇文章的文章可能无法把这方面的知识写的很全面,所以我们可以合理的推荐一些文章,在文章的末尾加上相关的关键词,这样有很多好处。降低网站的跳出率、增加网站的内链、增加网站的PV等等,都可以很好的粘住客户。
设置批量发布数量(可以设置发布间隔/单日发布总数)。第五,记录长尾关键词文章链接。合理的工作计划和记录对我们的工作有很大帮助。作为记录,当一个长尾 关键词 合理地出现在另一个 文章 中时,即锚文本,我们可以加粗并带出那个 关键词 的 文章 链接。通网cms采集第二步:URL优化策略。通常,搜索结果的 URL 收录大量参数。这样的URL在各大搜索引擎中的权重比较低,在目录结构中可以映射成权重比较高的URL。通过通网cms采集插件生成行业相关词,从下拉词中生成关键词,相关搜索词和长尾词。长尾关键词优化策略,这样可以让流量翻倍!
通网cms采集SEO策略用最简单的手段获得最好的SEO效果!第六,利用外部资源优化长尾关键词。通网cms采集还可以促进这些搜索结果页面相互之间形成良好的反向链接关系,有助于提高这些关键词页面在各大搜索引擎中的排名。许多 网站 内容页面的排名都不是很好,有些 网站 很难排名。改变主意并使用高权重 网站 来实现我们想要的。比如百度知道一个很大的优势就是长尾关键词,因为这取决于用户的搜索习惯。
通网cms采集第三步:内链框架策略。在搜索结果中,一定要像谷歌一样列出相关的关键词,这样谷歌的蜘蛛就可以沿着相关的关键词链接继续爬取更多的搜索结果页面。一般来说,百度自己的产品总是出现在我们搜索的长尾关键词前面。通网cms采集自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。因此,我们可以使用百度知道来帮助我们优化长尾关键词,去百度知道询问长尾关键词,然后在我们的网站上写一篇关于长尾关键词的文章网站 内容@> 的 文章,顺便说一下,回答百度知道的问题,给我们网站的网站,普通人看到这个问题就会点击这个链接。通网cms采集内容关键词插入(合理增加关键词的密度)。
通网cms采集搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录 )。今天关于通网cms的讲解就到这里,下期分享更多SEO相关知识。下次见!
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。 查看全部
关键词自动采集生成内容系统(通王优化策略、这样做能让流量倍增!(组图))
通网(TWcms)是中国领先的自由企业网站管理系统,TWcms是一个简单、易用、安全、开源的企业网站< @cms系统,完全符合 SEO。但是市面上并没有文章采集伪原创发布TWcms的功能,更别说搜狗、百度、神马等一键批量自动搜索引擎,和360推送。,并积极向搜索引擎公开链接,通过推送增加蜘蛛爬取,从而提升网站收录的排名和SEO。利用免费的通网cms采集插件采集很多文章内容。
同网cms采集批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, TWcms, WP, Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。
通网cms采集第一步:关键词布局:在搜索结果页面中,关键词的密度非常合理。可以在网页的六个关键位置布局关键词。长尾关键词优化策略,这样可以让流量翻倍!我发现很多人不关注长尾关键词的优化。按照一般的优化思路,从网站上线开始,一般都是根据网站的核心词进行优化。通网cms采集支持其他平台的图片本地化或存储。通网cms采集标题前缀和后缀设置(标题的区别更好收录)。这就产生了一个现象:如果主关键词比较流行,
这段时间网站的流量很低,转化率自然很低。如果你改变主意,调整策略,在优化网站的过程中,我们首先采用长尾关键词优化策略,使用长尾关键词获取流量网站。在此基础上,通网cms采集支持多源采集采集(覆盖全网行业新闻源,海量内容库,采集最新内容) . 我们会逐步提升主力关键词的排名。因此,我们必须考虑长尾 关键词 的优化技术。
通过通网cms采集可以直接查看蜘蛛、收录、网站的每日体重!首先,点击网站关键词的长尾。有很多 SEO 工具可以挖掘长尾关键词。通过挖掘网站的长尾关键词,我们可以总结出这些挖掘出来的长尾关键词。这对于我们需要优化的长尾关键词有一定的针对性,主要考虑哪个长尾关键词能给网站带来流量和转化率,可以增强。关键词挖掘工具推荐使用5118、来挖掘手机、相关搜索、下拉词。
童网cms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。其次,在写突出的标题和描述的时候,在优化长尾关键词的时候,我们一般都是在内容页上操作的,所以这个内容页的写法和优化是很重要的。通网cms采集内容与标题一致(使内容与标题100%相关)。
要突出显示的长尾关键词可以适当地融入标题和描述中,就好像这个内容的标题本身就是一个长尾关键词一样。通网cms采集自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权重)。描述的写法很重要,它在搜索引擎搜索结果中以标题、描述和网站的形式出现。描述占用大量字节。通网cms采集定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)。
因此,合理、有吸引力和详细的描述可以为网站获得更多点击。设置批量发布数量(可以设置发布间隔/单日发布总数)。还需要整合长尾关键词。告诉大家一个小窍门,每个关键词名称不同但可能含义不同,所以一个关键词可以写2-3条内容,可以优化2-3条内容两个或三个 关键词。长尾关键词优化策略,这样可以让流量翻倍!
可以设置不同的关键词文章发布不同的栏目。通网cms采集伪原创保留字(文章原创时伪原创不设置核心字)。通网cms采集软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
三、加强长尾关键词注意关键词的密度,尽量在每个段落中出现关键词,关于关键词的密度,我不觉得需要大家关心,自然就好了。通网cms采集可以设置自动删除不相关的词。通过通网cms采集插件实现自动化采集行业相关文章,通网cms采集一次可以创建几十个或者几百个采集tasks,支持同时执行多个域名任务采集。同网cms采集自动过滤其他网站促销信息。我们输出内容的目的是为了解决用户的需求。在内容 收录 之后,随后的排名对关键词的密度也有一定的要求。通网cms采集随机图片插入(文章如果没有图片可以随机插入相关图片)。此时要注意页面内容的丰富度和相关性。关键字出现的地方,加粗。文章标题可以是 H1 或 H2。4.内容中适当出现了一些相关的关键词。
第四,推荐相关内容。一篇文章的文章可能无法把这方面的知识写的很全面,所以我们可以合理的推荐一些文章,在文章的末尾加上相关的关键词,这样有很多好处。降低网站的跳出率、增加网站的内链、增加网站的PV等等,都可以很好的粘住客户。
设置批量发布数量(可以设置发布间隔/单日发布总数)。第五,记录长尾关键词文章链接。合理的工作计划和记录对我们的工作有很大帮助。作为记录,当一个长尾 关键词 合理地出现在另一个 文章 中时,即锚文本,我们可以加粗并带出那个 关键词 的 文章 链接。通网cms采集第二步:URL优化策略。通常,搜索结果的 URL 收录大量参数。这样的URL在各大搜索引擎中的权重比较低,在目录结构中可以映射成权重比较高的URL。通过通网cms采集插件生成行业相关词,从下拉词中生成关键词,相关搜索词和长尾词。长尾关键词优化策略,这样可以让流量翻倍!
通网cms采集SEO策略用最简单的手段获得最好的SEO效果!第六,利用外部资源优化长尾关键词。通网cms采集还可以促进这些搜索结果页面相互之间形成良好的反向链接关系,有助于提高这些关键词页面在各大搜索引擎中的排名。许多 网站 内容页面的排名都不是很好,有些 网站 很难排名。改变主意并使用高权重 网站 来实现我们想要的。比如百度知道一个很大的优势就是长尾关键词,因为这取决于用户的搜索习惯。
通网cms采集第三步:内链框架策略。在搜索结果中,一定要像谷歌一样列出相关的关键词,这样谷歌的蜘蛛就可以沿着相关的关键词链接继续爬取更多的搜索结果页面。一般来说,百度自己的产品总是出现在我们搜索的长尾关键词前面。通网cms采集自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。因此,我们可以使用百度知道来帮助我们优化长尾关键词,去百度知道询问长尾关键词,然后在我们的网站上写一篇关于长尾关键词的文章网站 内容@> 的 文章,顺便说一下,回答百度知道的问题,给我们网站的网站,普通人看到这个问题就会点击这个链接。通网cms采集内容关键词插入(合理增加关键词的密度)。
通网cms采集搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录 )。今天关于通网cms的讲解就到这里,下期分享更多SEO相关知识。下次见!
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。
关键词自动采集生成内容系统(输入关键词自动生成文章,什么是输入什么关键词‘装修’免费工具?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-04-17 09:14
类型关键词自动生成文章,什么是类型关键词自动生成文章?例子:你输入什么关键词'装饰'免费工具会自动生成一个装饰相关的文章,免费工具还支持:自动关键词文章generate+文章自动采集+伪原创+自动发布+自动推送到搜索引擎收录进行排名,实现自动挂机。(详见图表一、二、三、四)
最近有一些刚进入网站优化行业的站长问我网站结构是什么?什么样的网站结构对搜索引擎更友好?网站结构的优化要注意哪些方面?本来想跟大家分享站内优化的相关案例。想来想去,还是把网站这个结构单独拿出来了。关于网站结构的优化,相信我是刚开始做这个行业。站长确实是博古通金,所以本文文章主要是和站长朋友分享一下网站结构优化的心得。
什么是正确优化的 网站 构造?
广义上的网站结构主要包括网站的物理结构和逻辑结构;狭义上是网站的目录结构和内部链结构。@>结构的优化这里主要从目录结构和内部链结构来讨论。
目录结构就是网站的URL结构。在服务器上设置网站时,站长会发现在服务器根目录下通常有一个WWW文件夹。情况不一定如此。是的,但是大部分名字都是一样的,然后根据网站的规划和内容规划,会有一个基于WWW的层级目录,每个目录都会有详细的web文件,如:html、shtml、aspx、php等。这个目录方法的构建就构成了用户访问的URL地址。另一方面,URL地址是文件存储在服务器上的目录方法;这也很容易理解。
内部链接结构简单来说就是网站的页面之间的关系。建立网站的站长知道,除了一个页面的中心内容,尤其是网站的首页,一个栏目页或者一个列表页会由很多链接组成,其中的链接这些页面构成了整个网站的内部链结构。至于内部链结构如何更合理,搜索更友好,我会一一分享给各位站长朋友。
二、哪些网站 结构对搜索引擎友好?
同样在本节中单独列出,以便站长更清楚地了解 网站 结构是如何围绕搜索引擎部署的。
上面提到的目录结构的概念是基于根目录传播到真实文件中的。清晰的目录方式不仅有利于站长的管理,而且对搜索引擎也非常友好。在第一级爬取track得到想要爬取的页面后,如果你的网站只有一个首页、几个栏目页、可展开的专题页和文章详情页,那么理想URL 结构是根据服务服务器上的实际文件存储位置来构建的。但往往一个网站并不是这么简单的情况,网站几乎都有一些功能性产品与用户交互,需要通过动态程序构建大量页面来丰富网站产品体验,
所以你会发现很多网站的url里面有很多动态参数,因为这些页面是通过某种技术批量生成的页面,并不是服务器中实际存在的页面,官方声明搜索引擎只喜欢静态页面。这时候需要对URL地址进行打包重构。无论是 Apache、Ngnix 还是 IIS,都有针对 URL 地址的重写模块。这些暂不介绍。这种URL地址更有利于搜索引擎的抓取,主要包括以下两个方面:
1、URL地址的命名要靠近目标页面的主题标题,有利于提高与目标页面的相关性,从而增加目标页面的权重;
2、URL地址的层级是根据它所属的类别,越小越好。层级越小,通知搜索引擎文件存在的目录深度越小,越容易被爬取,因为只有重要的页面才会放在同一个根目录最近的位置,搜索引擎也会认为这些文件是网站中比较重要的页面,会先被爬取。
内部链接结构主要反映页面之间的关系。与目录结构类似,放在首页的链接地址往往更容易被搜索引擎抓取。在这里,我们触及链接深度的概念。搜索从发现你的网站到开始爬取页面,一般是从首页开始,如果你是新站点,可以从日志中找到。也就是说,越靠近首页的URL越容易被爬取。在这里,同样的搜索引擎会认为链接深度较小的页面在网站中更重要。不同于目录结构,链接深度更高。页面权重越小,被索引的可能性就越大。总而言之,
1、从首页开始,应该包括网站中最重要的业务板块,一般来说是频道页面和话题的聚合;
2、栏目和专题页面应包括其类别下的最新内容模块和热门模块,同时应有返回上一级的面包屑;
3、详情页,作为中心内容页,也应该有相关的引荐板块,以及同一归属板块下的热门引荐板块。当然,面包屑也是必须的。这里需要强调的是,标签的合理使用可以加强文章和文章之间的关系,更有利于搜索引擎的抓取。关于“Lost Crawler”这个标签,会专门用一篇文章文章来告知站长如何规划和使用。
基本上只要按照以上方法优化你的网站结构,相信你的网站在数据上的良好表现也会稳步提升。
三、网站构造优化注意事项
在这里,“迷路的小爬虫”也想总结以下几点,以澄清过度优化的网站结构可能存在被K的风险。总结主要基于以下几点:
1、为了减少链接深度,首页和频道页都堆满了上千个链接地址。如果早期的网站的权重不是很高,这种情况基本上是不完整的;
2、索引标签的大量使用,在网站没有一定范围的文章或其他资源支持的前提下,谨慎使用标签聚合站点内的资源,因为一个可能会添加大量索引标签。会形成网站很多重复页和空页,结果在所难免;
3、详情页不情愿地增加了推荐部分,这使得整个页面显得多余和多余。这也是不可取的。详情页的原创权重是整个网站系统中最低的。添加这么多链接只会被降级。对,即使是收录也不会有好的排名;
4、为了减少目录的深度,所有页面都堆叠到二级目录中。这种方法也是不可取的。如果除首页外的整个网站都是二级目录,就没有主二级目录。,目录深度影响权重的规则是不可取的。
以上四点是《》认为比较重要的一些要素,也是很多站长处理不好的几点,所以单独拿出来强调一下,希望站长们不要再犯这样的错误了。
看完这篇文章,相信大部分站长对网站的结构有了初步的了解,在网站优化的过程中也会有针对性的优化。至于很多站长提到的网站结构,最好使用树状结构或者比较理想的网状结构。这样做,您将构建一个树状或网络状结构 网站。 查看全部
关键词自动采集生成内容系统(输入关键词自动生成文章,什么是输入什么关键词‘装修’免费工具?)
类型关键词自动生成文章,什么是类型关键词自动生成文章?例子:你输入什么关键词'装饰'免费工具会自动生成一个装饰相关的文章,免费工具还支持:自动关键词文章generate+文章自动采集+伪原创+自动发布+自动推送到搜索引擎收录进行排名,实现自动挂机。(详见图表一、二、三、四)

最近有一些刚进入网站优化行业的站长问我网站结构是什么?什么样的网站结构对搜索引擎更友好?网站结构的优化要注意哪些方面?本来想跟大家分享站内优化的相关案例。想来想去,还是把网站这个结构单独拿出来了。关于网站结构的优化,相信我是刚开始做这个行业。站长确实是博古通金,所以本文文章主要是和站长朋友分享一下网站结构优化的心得。

什么是正确优化的 网站 构造?
广义上的网站结构主要包括网站的物理结构和逻辑结构;狭义上是网站的目录结构和内部链结构。@>结构的优化这里主要从目录结构和内部链结构来讨论。
目录结构就是网站的URL结构。在服务器上设置网站时,站长会发现在服务器根目录下通常有一个WWW文件夹。情况不一定如此。是的,但是大部分名字都是一样的,然后根据网站的规划和内容规划,会有一个基于WWW的层级目录,每个目录都会有详细的web文件,如:html、shtml、aspx、php等。这个目录方法的构建就构成了用户访问的URL地址。另一方面,URL地址是文件存储在服务器上的目录方法;这也很容易理解。
内部链接结构简单来说就是网站的页面之间的关系。建立网站的站长知道,除了一个页面的中心内容,尤其是网站的首页,一个栏目页或者一个列表页会由很多链接组成,其中的链接这些页面构成了整个网站的内部链结构。至于内部链结构如何更合理,搜索更友好,我会一一分享给各位站长朋友。

二、哪些网站 结构对搜索引擎友好?
同样在本节中单独列出,以便站长更清楚地了解 网站 结构是如何围绕搜索引擎部署的。
上面提到的目录结构的概念是基于根目录传播到真实文件中的。清晰的目录方式不仅有利于站长的管理,而且对搜索引擎也非常友好。在第一级爬取track得到想要爬取的页面后,如果你的网站只有一个首页、几个栏目页、可展开的专题页和文章详情页,那么理想URL 结构是根据服务服务器上的实际文件存储位置来构建的。但往往一个网站并不是这么简单的情况,网站几乎都有一些功能性产品与用户交互,需要通过动态程序构建大量页面来丰富网站产品体验,
所以你会发现很多网站的url里面有很多动态参数,因为这些页面是通过某种技术批量生成的页面,并不是服务器中实际存在的页面,官方声明搜索引擎只喜欢静态页面。这时候需要对URL地址进行打包重构。无论是 Apache、Ngnix 还是 IIS,都有针对 URL 地址的重写模块。这些暂不介绍。这种URL地址更有利于搜索引擎的抓取,主要包括以下两个方面:

1、URL地址的命名要靠近目标页面的主题标题,有利于提高与目标页面的相关性,从而增加目标页面的权重;
2、URL地址的层级是根据它所属的类别,越小越好。层级越小,通知搜索引擎文件存在的目录深度越小,越容易被爬取,因为只有重要的页面才会放在同一个根目录最近的位置,搜索引擎也会认为这些文件是网站中比较重要的页面,会先被爬取。
内部链接结构主要反映页面之间的关系。与目录结构类似,放在首页的链接地址往往更容易被搜索引擎抓取。在这里,我们触及链接深度的概念。搜索从发现你的网站到开始爬取页面,一般是从首页开始,如果你是新站点,可以从日志中找到。也就是说,越靠近首页的URL越容易被爬取。在这里,同样的搜索引擎会认为链接深度较小的页面在网站中更重要。不同于目录结构,链接深度更高。页面权重越小,被索引的可能性就越大。总而言之,

1、从首页开始,应该包括网站中最重要的业务板块,一般来说是频道页面和话题的聚合;
2、栏目和专题页面应包括其类别下的最新内容模块和热门模块,同时应有返回上一级的面包屑;
3、详情页,作为中心内容页,也应该有相关的引荐板块,以及同一归属板块下的热门引荐板块。当然,面包屑也是必须的。这里需要强调的是,标签的合理使用可以加强文章和文章之间的关系,更有利于搜索引擎的抓取。关于“Lost Crawler”这个标签,会专门用一篇文章文章来告知站长如何规划和使用。
基本上只要按照以上方法优化你的网站结构,相信你的网站在数据上的良好表现也会稳步提升。
三、网站构造优化注意事项
在这里,“迷路的小爬虫”也想总结以下几点,以澄清过度优化的网站结构可能存在被K的风险。总结主要基于以下几点:
1、为了减少链接深度,首页和频道页都堆满了上千个链接地址。如果早期的网站的权重不是很高,这种情况基本上是不完整的;
2、索引标签的大量使用,在网站没有一定范围的文章或其他资源支持的前提下,谨慎使用标签聚合站点内的资源,因为一个可能会添加大量索引标签。会形成网站很多重复页和空页,结果在所难免;

3、详情页不情愿地增加了推荐部分,这使得整个页面显得多余和多余。这也是不可取的。详情页的原创权重是整个网站系统中最低的。添加这么多链接只会被降级。对,即使是收录也不会有好的排名;
4、为了减少目录的深度,所有页面都堆叠到二级目录中。这种方法也是不可取的。如果除首页外的整个网站都是二级目录,就没有主二级目录。,目录深度影响权重的规则是不可取的。
以上四点是《》认为比较重要的一些要素,也是很多站长处理不好的几点,所以单独拿出来强调一下,希望站长们不要再犯这样的错误了。
看完这篇文章,相信大部分站长对网站的结构有了初步的了解,在网站优化的过程中也会有针对性的优化。至于很多站长提到的网站结构,最好使用树状结构或者比较理想的网状结构。这样做,您将构建一个树状或网络状结构 网站。
关键词自动采集生成内容系统(自动采集关键词+自动发布各大网站+主动推送搜索引擎收录排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-14 03:09
自动提取关键词的软件,提取关键词的软件是什么。关键词提取软件有两种:第一种是输入一个核心关键词,软件扩展大量用户搜索词、下拉词、长尾关键词。第二种是基于文章自动提取的core关键词,方便分析文章关键词的排名。今天给大家分享一个万能的SEO工具,自动采集关键词+自动提取关键词+自动文章伪原创+自动采集@ >文章+自动发布主要网站+主动推送搜索引擎收录排名。具体参考图片一、二、三、四、5
如果要在网站的权重上链接锚文本链接和纯文本链接,我们必须知道锚文本链接和纯文本链接是什么。所谓锚文本链接,是指使用A标签停止将一些关键词文本括起来的链接。这样的链接是锚文本链接。@>Optimization Company”用A标签括起来,比如“网站Optimization Company”,这样“网站Optimization Company”就是文字,带有A标签的链接就成了锚文本链接, 这样的链接可以用鼠标点击到网站.纯文本链接不是严格意义上的链接,它只是一个URL文本
有人说能传递权重的链接是锚文本链接,而纯文本链接不能传递权重。这个概念能正确吗?作者同意和不同意这种说法。笔者认为锚文本可以传递权重是毫无疑问的,明文链接也应该传递权重,但是明文链接可以传递的权重很小,如果它传递的权重非常锚文本链接传递的权重。百分之一甚至百分之一都不为过。
所以我们在做网站的外链的时候,一般都是做锚文本外链。由于这样的外部链接可以将权重传递给我们的网站,所以也是网站和网站Optimizer首选的反向链接的建立。但是,明文链接传输的权重是基于数量的。由于明文链接传输的权重很小,为了达到传输权重的目的,明文链接必须有足够的量。现在很多论坛、博客、搜题、360问答等都取消了锚文本链接的功能。当然,这个链接的目的是多方面的,但避免权重向外传递无疑是一个重要的目的。
我们在做外部链接的时候,锚文本很重要,但是一些高权重的纯文本链接也不能忽视。例如,当我们在博客和论坛中发布 文章 时,我们可以在允许的情况下正确添加我们的 网站 纯文本链接。其他产品包括搜搜问答、360问答等,您可以适当添加自己的URL纯文本。虽然明文链接传输的权重很小,但是由于明文链接是网站,所以搜索引擎在抓取网站时,不会把网站当成一个完整的文本,至少搜索引擎会记录记录在案的网站。.
适当地赋予比普通文本更高的权重是不可避免的,因此传递一些权重是有意义的。此外,如果我们网站的纯文本在其他网站上显示的次数和数量更多,必然会被更多人知道,这无形中提升了网站的知名度和知名度。曝光率也提高了网站企业品牌的知名度。所以对于这样的纯文本链接,我们只需要时不时的增加数量,尤其是高权重网站的数量,当数量达到一定程度,必然会传输一个不可轻视的重量。
大家可能都觉得,在综合网站上阅读别人的网页内容时,内容非常好,这时候我们可能很想知道文章的出处,如果出处网站 的末尾表示 文章,但它只是一个纯文本链接。这时候我们也可能会复制文字链接,然后去网站寻找更好的内容,这样看来,一个纯文本链接可能会给我们带来一个又一个的访问者,无形中增加了网站的访问量@网站。流量的增加可以增加网站的权重。因此,虽然纯文本链接的传输权重无法与锚文本相比,但我们也没有更好的选择。在我们无法制作锚文本链接的情况下, 查看全部
关键词自动采集生成内容系统(自动采集关键词+自动发布各大网站+主动推送搜索引擎收录排名)
自动提取关键词的软件,提取关键词的软件是什么。关键词提取软件有两种:第一种是输入一个核心关键词,软件扩展大量用户搜索词、下拉词、长尾关键词。第二种是基于文章自动提取的core关键词,方便分析文章关键词的排名。今天给大家分享一个万能的SEO工具,自动采集关键词+自动提取关键词+自动文章伪原创+自动采集@ >文章+自动发布主要网站+主动推送搜索引擎收录排名。具体参考图片一、二、三、四、5

如果要在网站的权重上链接锚文本链接和纯文本链接,我们必须知道锚文本链接和纯文本链接是什么。所谓锚文本链接,是指使用A标签停止将一些关键词文本括起来的链接。这样的链接是锚文本链接。@>Optimization Company”用A标签括起来,比如“网站Optimization Company”,这样“网站Optimization Company”就是文字,带有A标签的链接就成了锚文本链接, 这样的链接可以用鼠标点击到网站.纯文本链接不是严格意义上的链接,它只是一个URL文本
有人说能传递权重的链接是锚文本链接,而纯文本链接不能传递权重。这个概念能正确吗?作者同意和不同意这种说法。笔者认为锚文本可以传递权重是毫无疑问的,明文链接也应该传递权重,但是明文链接可以传递的权重很小,如果它传递的权重非常锚文本链接传递的权重。百分之一甚至百分之一都不为过。

所以我们在做网站的外链的时候,一般都是做锚文本外链。由于这样的外部链接可以将权重传递给我们的网站,所以也是网站和网站Optimizer首选的反向链接的建立。但是,明文链接传输的权重是基于数量的。由于明文链接传输的权重很小,为了达到传输权重的目的,明文链接必须有足够的量。现在很多论坛、博客、搜题、360问答等都取消了锚文本链接的功能。当然,这个链接的目的是多方面的,但避免权重向外传递无疑是一个重要的目的。
我们在做外部链接的时候,锚文本很重要,但是一些高权重的纯文本链接也不能忽视。例如,当我们在博客和论坛中发布 文章 时,我们可以在允许的情况下正确添加我们的 网站 纯文本链接。其他产品包括搜搜问答、360问答等,您可以适当添加自己的URL纯文本。虽然明文链接传输的权重很小,但是由于明文链接是网站,所以搜索引擎在抓取网站时,不会把网站当成一个完整的文本,至少搜索引擎会记录记录在案的网站。.

适当地赋予比普通文本更高的权重是不可避免的,因此传递一些权重是有意义的。此外,如果我们网站的纯文本在其他网站上显示的次数和数量更多,必然会被更多人知道,这无形中提升了网站的知名度和知名度。曝光率也提高了网站企业品牌的知名度。所以对于这样的纯文本链接,我们只需要时不时的增加数量,尤其是高权重网站的数量,当数量达到一定程度,必然会传输一个不可轻视的重量。

大家可能都觉得,在综合网站上阅读别人的网页内容时,内容非常好,这时候我们可能很想知道文章的出处,如果出处网站 的末尾表示 文章,但它只是一个纯文本链接。这时候我们也可能会复制文字链接,然后去网站寻找更好的内容,这样看来,一个纯文本链接可能会给我们带来一个又一个的访问者,无形中增加了网站的访问量@网站。流量的增加可以增加网站的权重。因此,虽然纯文本链接的传输权重无法与锚文本相比,但我们也没有更好的选择。在我们无法制作锚文本链接的情况下,
关键词自动采集生成内容系统(关键字提炼出信息发布所要表达的意图首先根据中文的特点设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-12 17:22
<p>从关键词中提取信息发布所要表达的意图,首先根据汉语的特点建立语义库,然后将舆情信息中收录的特征关键词与语义库进行语义分析,最后根据结果判断舆情事件的走向。趋势分析可以明确发布者想要表达的观点和立场 2 舆论关键词提取21篇单篇文档关键词提取再提取关键词先对文档进行分词,然后是停用词列表和过滤规则过滤分词结果。停用词列表包括助词、介词、连词、无实际意义的词长为1的词等功能词。对于数字、量词等明显的无用词,可以设计无意义的后缀等进行相应的过滤 函数对无用词进行过滤,然后计算过滤后的分词结果的权重,得到每个词的权重。22关键词权重计算文本关键词提取更多基于权重向量生成方法,这是最常用的TFIDF算法TFIDF的主要思想是,如果一个词或短语出现在一个文章 具有高频 TF,很少出现在其他 文章 中,认为该词或短语具有良好的质量。IDF值的类别区分能力大,适合分类,但每个词都收录TF和IDF,并且文档位置信息中还有词性词等有效信息。>应该是关键词的一些文档,所以用所有文档关键词集合构建一个候选关键词集合进行特征提取得到文档集合关键词如果一个关键词出现次数越多,热点关注度越高。IDF值越大,词的区分能力越强,越符合主题的特点 3关键词智能跟踪 31 主题聚类兼顾了不同网站的权威影响和热点的时效性等。对于采集接收到的话题,来源权重为第一个元素,发布时间为第二个元素,权重和时间按降序排列。首先,一个关键词代表一个热门话题,然后对这些热门话题进行凝聚聚类,将关键词集合中的第一个关键词作为第一个使用的热门话题线索关键词@ >@关键词找文章关键词进行聚类,默认找到第一个文档作为热门话题,然后用角度余弦值对页面剩余的文本进行聚类,计算这个话题和现有的热门话题点 如果主题的相似度超过阈值 P,则将当前主题合并到现有主题中。如果相似度小于阈值P,则将当前话题视为新的热门话题,然后以关键词 查看全部
关键词自动采集生成内容系统(关键字提炼出信息发布所要表达的意图首先根据中文的特点设置)
<p>从关键词中提取信息发布所要表达的意图,首先根据汉语的特点建立语义库,然后将舆情信息中收录的特征关键词与语义库进行语义分析,最后根据结果判断舆情事件的走向。趋势分析可以明确发布者想要表达的观点和立场 2 舆论关键词提取21篇单篇文档关键词提取再提取关键词先对文档进行分词,然后是停用词列表和过滤规则过滤分词结果。停用词列表包括助词、介词、连词、无实际意义的词长为1的词等功能词。对于数字、量词等明显的无用词,可以设计无意义的后缀等进行相应的过滤 函数对无用词进行过滤,然后计算过滤后的分词结果的权重,得到每个词的权重。22关键词权重计算文本关键词提取更多基于权重向量生成方法,这是最常用的TFIDF算法TFIDF的主要思想是,如果一个词或短语出现在一个文章 具有高频 TF,很少出现在其他 文章 中,认为该词或短语具有良好的质量。IDF值的类别区分能力大,适合分类,但每个词都收录TF和IDF,并且文档位置信息中还有词性词等有效信息。>应该是关键词的一些文档,所以用所有文档关键词集合构建一个候选关键词集合进行特征提取得到文档集合关键词如果一个关键词出现次数越多,热点关注度越高。IDF值越大,词的区分能力越强,越符合主题的特点 3关键词智能跟踪 31 主题聚类兼顾了不同网站的权威影响和热点的时效性等。对于采集接收到的话题,来源权重为第一个元素,发布时间为第二个元素,权重和时间按降序排列。首先,一个关键词代表一个热门话题,然后对这些热门话题进行凝聚聚类,将关键词集合中的第一个关键词作为第一个使用的热门话题线索关键词@ >@关键词找文章关键词进行聚类,默认找到第一个文档作为热门话题,然后用角度余弦值对页面剩余的文本进行聚类,计算这个话题和现有的热门话题点 如果主题的相似度超过阈值 P,则将当前主题合并到现有主题中。如果相似度小于阈值P,则将当前话题视为新的热门话题,然后以关键词
关键词自动采集生成内容系统(为什么说送钱呢?这年头自己手上不养流量站就不叫站长 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-04-06 02:03
)
节目详情:为什么说汇款?今年,如果你没有几个流量站,你就不会被称为站长。您应该投入一些资金并在其上放置更好的云主机。当收录和权重有改善后,加入百度联盟或使用网易的附属广告,等待收款!!!!毫不夸张!
市场前景分析:阅读是人类最基本的行为之一,所以无论时代如何变迁,人们阅读都是为了娱乐,但从纸质时代到电子时代。未来手机阅读会越来越普及,所以评估一个系统的好坏,看能不能做一个全平台,这样才有未来。手机阅读让小说的受众更广,市场前景更好。小说站的流量非常大,尤其是每天坚持升级的站,更受搜索引擎欢迎。如果日IP能达到10000,广告收入将稳定在每天300元左右。只要坚持下去,月入一万也不难。
适用使用范围:给站长汇款,小说系统隆重上线!24小时自动无人值守采集,PC+微信+APP全平台
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态
附带 采集 规则,用于自动 采集 发布一些数据。
深度定制小说站,全自动采集各大小说站,可自动生成首页,分类,目录,排行榜,站点地图页面静态html,全站拼音目录,伪静态章节页面,自动生成小说txt文件,自动生成zip压缩包。这个源码功能可谓异常强大!带有非常漂亮的移动页面!使用 采集 规则 + 自动调整!超级强大,采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!一个好节目,做一个无话可说的小说站。
并且章节页面是伪静态的。(3)自动生成小说txt文件,后端也可以重新生成txt文件。(4)自动生成小说关键词和关键词自动内链。(< @5)自动伪原创换词(采集时替换)。(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐量统计及作者推荐统计等(7)配合CNZZ的统计插件,可以轻松实现小说下载量的详细统计和图书采集的详细统计。(8)自动采集这个程序在市场上并不常见)。优采云、关冠、采集侠等,但采集 版块是在DEDE原有的采集功能基础上开发的,可以有效保证章节内容。完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量可以达到25万到30万章。
查看全部
关键词自动采集生成内容系统(为什么说送钱呢?这年头自己手上不养流量站就不叫站长
)
节目详情:为什么说汇款?今年,如果你没有几个流量站,你就不会被称为站长。您应该投入一些资金并在其上放置更好的云主机。当收录和权重有改善后,加入百度联盟或使用网易的附属广告,等待收款!!!!毫不夸张!
市场前景分析:阅读是人类最基本的行为之一,所以无论时代如何变迁,人们阅读都是为了娱乐,但从纸质时代到电子时代。未来手机阅读会越来越普及,所以评估一个系统的好坏,看能不能做一个全平台,这样才有未来。手机阅读让小说的受众更广,市场前景更好。小说站的流量非常大,尤其是每天坚持升级的站,更受搜索引擎欢迎。如果日IP能达到10000,广告收入将稳定在每天300元左右。只要坚持下去,月入一万也不难。
适用使用范围:给站长汇款,小说系统隆重上线!24小时自动无人值守采集,PC+微信+APP全平台
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态
附带 采集 规则,用于自动 采集 发布一些数据。
深度定制小说站,全自动采集各大小说站,可自动生成首页,分类,目录,排行榜,站点地图页面静态html,全站拼音目录,伪静态章节页面,自动生成小说txt文件,自动生成zip压缩包。这个源码功能可谓异常强大!带有非常漂亮的移动页面!使用 采集 规则 + 自动调整!超级强大,采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!一个好节目,做一个无话可说的小说站。
并且章节页面是伪静态的。(3)自动生成小说txt文件,后端也可以重新生成txt文件。(4)自动生成小说关键词和关键词自动内链。(< @5)自动伪原创换词(采集时替换)。(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐量统计及作者推荐统计等(7)配合CNZZ的统计插件,可以轻松实现小说下载量的详细统计和图书采集的详细统计。(8)自动采集这个程序在市场上并不常见)。优采云、关冠、采集侠等,但采集 版块是在DEDE原有的采集功能基础上开发的,可以有效保证章节内容。完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量可以达到25万到30万章。





关键词自动采集生成内容系统(关键词自动采集生成内容系统排行榜助力品牌精准营销)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-02 12:03
关键词自动采集生成内容系统排行榜助力品牌精准营销全网全面覆盖共享数据共创共赢转载请注明出处。关注每日更新,随时推送。每天更新高质量原创文章,让你找到方向,活到老学到老。
其实全网营销的前提就是你的产品得有足够的优势和价值,你得让客户信任你,关注你,这样才能做到全网营销,要做全网营销的话建议你还是先学习一下比较好,我以前也在学习全网营销,做的比较好的就是叶子营销培训的,网上很多这方面的资料。
学习推广方法有很多,不妨自己试试这两种:做ab测试:看看到底哪个产品推广的好,为什么?优惠活动策划:什么样的套餐才吸引你的客户?建议:做某一个方面的推广,先自己尝试,再跟专业的机构学习。
seo及站内优化:三大方法、五大步骤、两大心法!1.tdk优化法tdk就是我们的标题与描述!一定要加上我们的核心关键词,
1)标题、描述不要使用重复的词语,不要同义词或是近义词。要多转换成通俗易懂的词语,
2)描述中不要引用网站工具,这样很容易被搜索引擎判定为不利的排名,还要加粗显示。
3)另外,网站评论的内容要优化到首页,切勿打广告。2.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,如果自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!3.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!4.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词。 查看全部
关键词自动采集生成内容系统(关键词自动采集生成内容系统排行榜助力品牌精准营销)
关键词自动采集生成内容系统排行榜助力品牌精准营销全网全面覆盖共享数据共创共赢转载请注明出处。关注每日更新,随时推送。每天更新高质量原创文章,让你找到方向,活到老学到老。
其实全网营销的前提就是你的产品得有足够的优势和价值,你得让客户信任你,关注你,这样才能做到全网营销,要做全网营销的话建议你还是先学习一下比较好,我以前也在学习全网营销,做的比较好的就是叶子营销培训的,网上很多这方面的资料。
学习推广方法有很多,不妨自己试试这两种:做ab测试:看看到底哪个产品推广的好,为什么?优惠活动策划:什么样的套餐才吸引你的客户?建议:做某一个方面的推广,先自己尝试,再跟专业的机构学习。
seo及站内优化:三大方法、五大步骤、两大心法!1.tdk优化法tdk就是我们的标题与描述!一定要加上我们的核心关键词,
1)标题、描述不要使用重复的词语,不要同义词或是近义词。要多转换成通俗易懂的词语,
2)描述中不要引用网站工具,这样很容易被搜索引擎判定为不利的排名,还要加粗显示。
3)另外,网站评论的内容要优化到首页,切勿打广告。2.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,如果自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!3.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!4.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词。
关键词自动采集生成内容系统( SEO关键词挖掘我们可以通过SEO挖掘软件帮助我们进行关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-02 06:15
SEO关键词挖掘我们可以通过SEO挖掘软件帮助我们进行关键词)
自动SEO关键词挖掘,SEO关键词挖掘软件
虎爱SEO2022-03-25
SEO关键词挖矿是我们SEO工作的重要组成部分,关键词的排名直接影响到我们网站的流量。无论是流行的关键词还是长尾的关键词,都需要结合网站的特点和自己的目标来挖掘。
SEO关键词挖掘有很多维度,可以通过热门关键词、行业关键词、区域关键词甚至季节性关键词来挖掘。
SEO关键词挖矿我们可以通过SEO关键词挖矿软件帮助我们进行关键词挖矿,SEO关键词挖矿软件拥有NLP智能语言处理系统和强大的机器人学习能力,精准通过大数据分析挖掘关键词。
SEO关键词挖矿软件只要输入我们的关键词就可以完成全网关键词匹配,并将长尾关键词和对应的文章@排列为我们通过数据分析 > 内容。我们可以通过SEO关键词挖矿软件实现全托管网站。
SEO关键词挖矿软件可以文章@>匹配采集选中的关键词,通过伪原创自动发布实现文章@>的创建全过程. 只需键入 关键词 即可开始生成管道。所有流程都可以看到,数据信息可以溯源。
SEO关键词挖矿软件通过以下几点保证文章@>的质量,保证源头,有一定的流量网站,优质的内容也是可取的选择,因为用户流量,内容会产生价值。这里我们需要考虑用户关心什么,希望用户看到什么内容。当然,我们自己的优质原创文章@>是最好的。当我们有用户的时候,我们会苦于我们不能做用户想看到的事情。我们可以通过互联网找到相关的内容,最能保证及时性。
SEO关键词挖矿软件可以为我们的采集站实现24小时挂机操作。通过关键词pan采集和伪原创的发布,可以及时更新网站的内容,及时更新网站的内容同步更新。
受搜索引擎信任的网站,在各大平台上,主要是靠复制新发布的内容来提升比较快的,因为大多数人都会问他们是否可以将内容转载到SEO中。
1.新增网站:对于新站点,最好不要盲目粘贴复制,如果太多只会被搜索引擎列入黑名单。新网站就像刚出生的婴儿,我们当然不喜欢我的孩子看起来像隔壁的法老,所以,对于刚刚上线的网站,最好不要转发太多,没关系正确转发,6个月内应视为新站点!
2.不是新站,但流量不是特别大:搜索引擎要等到网站没有流量,才能计算用户体验分数,所以如果这些网站想获得搜索引擎信任,不要用户投票,不适合粘贴复制太多内容。
SEO关键词挖矿和SEO关键词挖矿软件的分享就到这里。如果您有不同的意见或想法,可以留言讨论。 查看全部
关键词自动采集生成内容系统(
SEO关键词挖掘我们可以通过SEO挖掘软件帮助我们进行关键词)
自动SEO关键词挖掘,SEO关键词挖掘软件
虎爱SEO2022-03-25
SEO关键词挖矿是我们SEO工作的重要组成部分,关键词的排名直接影响到我们网站的流量。无论是流行的关键词还是长尾的关键词,都需要结合网站的特点和自己的目标来挖掘。
SEO关键词挖掘有很多维度,可以通过热门关键词、行业关键词、区域关键词甚至季节性关键词来挖掘。
SEO关键词挖矿我们可以通过SEO关键词挖矿软件帮助我们进行关键词挖矿,SEO关键词挖矿软件拥有NLP智能语言处理系统和强大的机器人学习能力,精准通过大数据分析挖掘关键词。
SEO关键词挖矿软件只要输入我们的关键词就可以完成全网关键词匹配,并将长尾关键词和对应的文章@排列为我们通过数据分析 > 内容。我们可以通过SEO关键词挖矿软件实现全托管网站。
SEO关键词挖矿软件可以文章@>匹配采集选中的关键词,通过伪原创自动发布实现文章@>的创建全过程. 只需键入 关键词 即可开始生成管道。所有流程都可以看到,数据信息可以溯源。
SEO关键词挖矿软件通过以下几点保证文章@>的质量,保证源头,有一定的流量网站,优质的内容也是可取的选择,因为用户流量,内容会产生价值。这里我们需要考虑用户关心什么,希望用户看到什么内容。当然,我们自己的优质原创文章@>是最好的。当我们有用户的时候,我们会苦于我们不能做用户想看到的事情。我们可以通过互联网找到相关的内容,最能保证及时性。
SEO关键词挖矿软件可以为我们的采集站实现24小时挂机操作。通过关键词pan采集和伪原创的发布,可以及时更新网站的内容,及时更新网站的内容同步更新。
受搜索引擎信任的网站,在各大平台上,主要是靠复制新发布的内容来提升比较快的,因为大多数人都会问他们是否可以将内容转载到SEO中。
1.新增网站:对于新站点,最好不要盲目粘贴复制,如果太多只会被搜索引擎列入黑名单。新网站就像刚出生的婴儿,我们当然不喜欢我的孩子看起来像隔壁的法老,所以,对于刚刚上线的网站,最好不要转发太多,没关系正确转发,6个月内应视为新站点!
2.不是新站,但流量不是特别大:搜索引擎要等到网站没有流量,才能计算用户体验分数,所以如果这些网站想获得搜索引擎信任,不要用户投票,不适合粘贴复制太多内容。
SEO关键词挖矿和SEO关键词挖矿软件的分享就到这里。如果您有不同的意见或想法,可以留言讨论。
关键词自动采集生成内容系统(关键词自动采集生成内容系统七麦数据网站分析软件页面统计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-01 02:00
关键词自动采集生成内容系统七麦数据网站分析软件页面统计图片大小统计下载文字内容截取内容发布系统这些小工具,真正能提高你的内容质量。
自动扒页的话,可以试试咪咕站长平台的。写了篇文章推荐新媒体站长制作url地址采集的工具,可以看下,不同功能有不同的叫法,最简单的叫法就是“自动采集”。
推荐使用采集多点。
目前在seo方面有人推荐editorium么?我来发个恶搞地址制作页面。
确定内容方向,
九五之二:我来发一个恶搞的。一般只是采取文字或者声音之类的采集。不好意思,不是空手套白狼,只能是九五之二了。
在搜索引擎搜索了栏目关键词,没有找到匹配的页面!那么就有3种方式:用excel页面制作插件,或者scrapy,或者爬虫程序。
百度啊百度一下,你就知道。
一开始是prv,可以在seoer版首页找到,
js下面这个网站你可以去看看
同意isaipark的看法,现在可以抓取js,前提是js引擎需要研究好,
找几个老的seo博客看看有无接着抓这个方向太宽泛了一般很难有机会抓到目标网站
ahr0cdovl3dlaxhpbi5xcs5jb20vci91rxyjwh936ulwpyvxlooti1ba==(二维码自动识别) 查看全部
关键词自动采集生成内容系统(关键词自动采集生成内容系统七麦数据网站分析软件页面统计)
关键词自动采集生成内容系统七麦数据网站分析软件页面统计图片大小统计下载文字内容截取内容发布系统这些小工具,真正能提高你的内容质量。
自动扒页的话,可以试试咪咕站长平台的。写了篇文章推荐新媒体站长制作url地址采集的工具,可以看下,不同功能有不同的叫法,最简单的叫法就是“自动采集”。
推荐使用采集多点。
目前在seo方面有人推荐editorium么?我来发个恶搞地址制作页面。
确定内容方向,
九五之二:我来发一个恶搞的。一般只是采取文字或者声音之类的采集。不好意思,不是空手套白狼,只能是九五之二了。
在搜索引擎搜索了栏目关键词,没有找到匹配的页面!那么就有3种方式:用excel页面制作插件,或者scrapy,或者爬虫程序。
百度啊百度一下,你就知道。
一开始是prv,可以在seoer版首页找到,
js下面这个网站你可以去看看
同意isaipark的看法,现在可以抓取js,前提是js引擎需要研究好,
找几个老的seo博客看看有无接着抓这个方向太宽泛了一般很难有机会抓到目标网站
ahr0cdovl3dlaxhpbi5xcs5jb20vci91rxyjwh936ulwpyvxlooti1ba==(二维码自动识别)
关键词自动采集生成内容系统(手机app开发中的一个难点和解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-30 14:02
关键词自动采集生成内容系统,真实自动登录请求验证码识别系统,验证码自动识别工具,网页抓取工具,天猫的商品和数据自动采集系统,手机app的app应用开发系统,
安卓采集就是用聚应用之类的可以对等淘客网站进行采集
微擎,
手机app的开发和发布,首先肯定是要做一套app的平台,当然你可以选择安卓,ios平台,把所需的功能模块做好,再选择手机端或pc端提交给第三方。
有两个免费推广工具还不错。
国内用百度有啊,当然另一个是手机。
这是app开发中的一个难点,手机是阿里巴巴集团的直营网站,属于百度旗下的大ip,大家都知道想对于pc端,手机的抓取最难。主要抓取第三方serp。获取需要第三方授权。有兴趣的可以看下,未来交易易,
请问你用什么平台或者工具进行抓取?请问你是做哪些方面的?请问您想如何进行服务?请问是有需求还是无需求..
手机虽然是百度旗下的,但是用户基数已经达到巨大。即使是阿里的uc浏览器也无法与其竞争。那么我们先来看看一般情况下,在手机上,都要做什么才能到达效果,比如说验证码的提交,首页弹窗引导,或者参加活动,在短时间内抓住访客眼球,等等。 查看全部
关键词自动采集生成内容系统(手机app开发中的一个难点和解决办法)
关键词自动采集生成内容系统,真实自动登录请求验证码识别系统,验证码自动识别工具,网页抓取工具,天猫的商品和数据自动采集系统,手机app的app应用开发系统,
安卓采集就是用聚应用之类的可以对等淘客网站进行采集
微擎,
手机app的开发和发布,首先肯定是要做一套app的平台,当然你可以选择安卓,ios平台,把所需的功能模块做好,再选择手机端或pc端提交给第三方。
有两个免费推广工具还不错。
国内用百度有啊,当然另一个是手机。
这是app开发中的一个难点,手机是阿里巴巴集团的直营网站,属于百度旗下的大ip,大家都知道想对于pc端,手机的抓取最难。主要抓取第三方serp。获取需要第三方授权。有兴趣的可以看下,未来交易易,
请问你用什么平台或者工具进行抓取?请问你是做哪些方面的?请问您想如何进行服务?请问是有需求还是无需求..
手机虽然是百度旗下的,但是用户基数已经达到巨大。即使是阿里的uc浏览器也无法与其竞争。那么我们先来看看一般情况下,在手机上,都要做什么才能到达效果,比如说验证码的提交,首页弹窗引导,或者参加活动,在短时间内抓住访客眼球,等等。
关键词自动采集生成内容系统(迅睿CMS优采云采集器采集器文章可设置采集规则,配置复杂 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-28 00:09
)
迅瑞cms是一个永久开源免费的PHP网站开发建设管理系统。它是完全免费的、开源的,并且没有许可证限制。该系统免费、安全且易于使用。不过,迅瑞cms确实是让用户头疼的问题。迅瑞cms优采云采集器需要编写采集规则,还有复杂的发布规则需要配置。对于我们这些不懂代码的人来说,它既简单又大。有没有免费强大的功能可以批量采集全网热点信息伪原创发布并支持一键批量百度、搜狗、神马、360等各大搜索引擎收录提交。
迅瑞cms优采云采集器根据网站、网站行业属性、网站产品属性的内容进行网站@ > 结构规划,比如内容的多少可以决定网站采用哪个结果,比如内容少的网站可以把所有的页面都放到根目录下。每日蜘蛛、收录、网站权重可以通过软件直接查看!这是一个扁平结构;比如网站的内容很多,网站有多个分类的产品等等,目录布局必须按照分类来排列。确定 网站 目录层次结构。
迅锐cms优采云采集器不同关键词文章可以设置发布不同的栏目。产品的种类很多,所以需要分析一下这些种类是否有相同的用户需求,有相同需求的可以放在一个网站中去做。迅睿cms优采云随机点赞-随机阅读-随机作者(增加页面度数原创)。
然后进行关键词竞争力分析。建议将多个竞争激烈的产品分到不同的站点。迅睿cms优采云标题前缀和后缀设置(标题区别更好收录)。例如,使用不同的独立域名或二级域名;竞争力不强的产品可以在网站上进行细分,放在一个网站中进行优化,比如用分类细分产品进行优化。
迅锐cms优采云采集器搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,确保新链接可以及时被搜索引擎收录)。如果关键词很多,我们需要根据分类和竞争程度对关键词进行分类。通常我们选择用首页放竞争度高的词,也叫核心关键词,也是我们最后要优化的主要关键词,可以用栏目页来优化分类器。荀睿cms优采云伪原创保留字(在文章原创中设置核心字时,不会是伪原创)。栏目页下的内页优化了分类器相关的关键词,分类<
另外,根据关键词竞争力布局找到切入点,判断首页有多少竞争对手,是否满足需求。迅锐cms优采云直接监控已发布,待发布,是否为伪原创,发布状态,网站,程序,发布时间等哪些词有利于优化,比如区域 关键词 和长尾 关键词 通常更有利于优化。
从相关性的角度来看,我们网页的内容应该由关键词来决定,而关键词针对每个页面做了哪些优化,我们需要为这个关键词展示相关的内容。迅锐cms优采云支持多个采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。既然关键词决定了内容,那么关键词的挖掘也很重要。至于怎么挖关键词,我可以写一篇专门的文章文章来解释。
迅锐cms优采云采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。标题的书写方式对于避免重复非常重要。标题是网页的标题。对于搜索引擎来说,标题代表了网页的位置,告诉搜索引擎和用户网页的内容,因为一个好的网页标题不仅可以清楚地表达网页的主要目的,还可以给用户提供指导。搜索用户,吸引目标用户点击。
迅锐cms优采云采集器定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高)。通常我们的首页标题写成这样的格式:关键词1_关键词2_关键词3-公司名称或品牌名称,关键词的顺序是按照关键词 排名的重要性,因为关键词 的排名顺序也会影响搜索引擎对关键词 的权重分配。
迅锐cms优采云内容关键词插入(合理增加关键词的密度)。但是网站中的网页标题要尽量避免重复。百度最新的清风算法也明确规定,标题堆叠关键词、标题重复过多、标题内容虚假等都是百度针对的目标。
迅瑞cms优采云自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。规范性代码也很重要。搜索引擎蜘蛛可以爬取代码,而代码编写不规范,比如冗余或重复的标签组合,都会影响蜘蛛爬取。迅锐cms优采云内容与标题一致(使内容与标题100%相关甚至可能导致我们的页面内容被蜘蛛抓取不全,也会直接影响百度快照内容我们的网页,如果百度快照没有完全显示出来,最终会对我们的SEO排名产生影响。
从用户搜索需求的角度。如果用户找不到他的需求(target)关键词,他会去寻找其他的网页,这增加了跳出率。如果跳出率过大,会降低搜索引擎的友好度,最终导致排名下降。
修复跳出率问题:1、增加关键词密度。让用户来到我们的网页快速找到他的搜索需求。用免费的迅锐cms优采云采集器采集海量文章内容。模块布局发生了变化。将重要模块和用户需求模块移动到首屏的重要位置。3、图像处理加 关键词。Image Alt 标签有助于搜索引擎判断图像和内容的相关性。4、页面访问速度。
通过迅锐cms优采云采集器、关键词从下拉词、相关搜索词、长尾词中生成行业相关词。迅锐cms优采云可以设置自动删除无关词。我们网站的访问速度会影响搜索引擎蜘蛛的访问和爬取。如果网页加载速度太慢甚至长时间无法访问,势必会降低搜索引擎的友好度,虽然时间很短网站打不开并不一定会导致网站@ >没有排名之类的。通过迅瑞cms优采云采集器插件实现自动化采集行业相关文章,可以创建迅瑞cms优采云一次有数十个和数百个 采集 任务,支持同时执行多个域名任务采集。但是想一想,如果你的网站访问速度很流畅,对搜索引擎和用户友好,那么用户是不可能等到你的网站加载完毕才离开的。很有可能你五六秒后打不开网页,关闭网页,去其他网站浏览。
迅锐cms优采云采集器批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦、WP、Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。而且,百度还针对移动端推出了闪电算法,明确规定页面加载速度会影响网页在搜索结果中的排名显示。这时候,空间的选择也比较重要。
迅锐cms优采云自动过滤其他网站宣传信息。其实还有其他一些细节也会影响搜索引擎的友好度,后面会整理出来写到这里。迅锐cms优采云支持图片本地化或其他平台存储。
但实际上,以上几点在SEO优化过程中很容易避免或解决。从搜索引擎和用户的角度来处理和完善我们的网站的细节,还需要获取SEO排名。为用户解决问题并满足他们的搜索需求是一个稳定且长期的解决方案。今天关于迅锐cms优采云采集的解释就到这里了。下期会分享更多SEO相关知识和SEO7优化经验。下期再见。
查看全部
关键词自动采集生成内容系统(迅睿CMS优采云采集器采集器文章可设置采集规则,配置复杂
)
迅瑞cms是一个永久开源免费的PHP网站开发建设管理系统。它是完全免费的、开源的,并且没有许可证限制。该系统免费、安全且易于使用。不过,迅瑞cms确实是让用户头疼的问题。迅瑞cms优采云采集器需要编写采集规则,还有复杂的发布规则需要配置。对于我们这些不懂代码的人来说,它既简单又大。有没有免费强大的功能可以批量采集全网热点信息伪原创发布并支持一键批量百度、搜狗、神马、360等各大搜索引擎收录提交。

迅瑞cms优采云采集器根据网站、网站行业属性、网站产品属性的内容进行网站@ > 结构规划,比如内容的多少可以决定网站采用哪个结果,比如内容少的网站可以把所有的页面都放到根目录下。每日蜘蛛、收录、网站权重可以通过软件直接查看!这是一个扁平结构;比如网站的内容很多,网站有多个分类的产品等等,目录布局必须按照分类来排列。确定 网站 目录层次结构。
迅锐cms优采云采集器不同关键词文章可以设置发布不同的栏目。产品的种类很多,所以需要分析一下这些种类是否有相同的用户需求,有相同需求的可以放在一个网站中去做。迅睿cms优采云随机点赞-随机阅读-随机作者(增加页面度数原创)。

然后进行关键词竞争力分析。建议将多个竞争激烈的产品分到不同的站点。迅睿cms优采云标题前缀和后缀设置(标题区别更好收录)。例如,使用不同的独立域名或二级域名;竞争力不强的产品可以在网站上进行细分,放在一个网站中进行优化,比如用分类细分产品进行优化。
迅锐cms优采云采集器搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,确保新链接可以及时被搜索引擎收录)。如果关键词很多,我们需要根据分类和竞争程度对关键词进行分类。通常我们选择用首页放竞争度高的词,也叫核心关键词,也是我们最后要优化的主要关键词,可以用栏目页来优化分类器。荀睿cms优采云伪原创保留字(在文章原创中设置核心字时,不会是伪原创)。栏目页下的内页优化了分类器相关的关键词,分类<

另外,根据关键词竞争力布局找到切入点,判断首页有多少竞争对手,是否满足需求。迅锐cms优采云直接监控已发布,待发布,是否为伪原创,发布状态,网站,程序,发布时间等哪些词有利于优化,比如区域 关键词 和长尾 关键词 通常更有利于优化。
从相关性的角度来看,我们网页的内容应该由关键词来决定,而关键词针对每个页面做了哪些优化,我们需要为这个关键词展示相关的内容。迅锐cms优采云支持多个采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。既然关键词决定了内容,那么关键词的挖掘也很重要。至于怎么挖关键词,我可以写一篇专门的文章文章来解释。

迅锐cms优采云采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。标题的书写方式对于避免重复非常重要。标题是网页的标题。对于搜索引擎来说,标题代表了网页的位置,告诉搜索引擎和用户网页的内容,因为一个好的网页标题不仅可以清楚地表达网页的主要目的,还可以给用户提供指导。搜索用户,吸引目标用户点击。
迅锐cms优采云采集器定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高)。通常我们的首页标题写成这样的格式:关键词1_关键词2_关键词3-公司名称或品牌名称,关键词的顺序是按照关键词 排名的重要性,因为关键词 的排名顺序也会影响搜索引擎对关键词 的权重分配。
迅锐cms优采云内容关键词插入(合理增加关键词的密度)。但是网站中的网页标题要尽量避免重复。百度最新的清风算法也明确规定,标题堆叠关键词、标题重复过多、标题内容虚假等都是百度针对的目标。

迅瑞cms优采云自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。规范性代码也很重要。搜索引擎蜘蛛可以爬取代码,而代码编写不规范,比如冗余或重复的标签组合,都会影响蜘蛛爬取。迅锐cms优采云内容与标题一致(使内容与标题100%相关甚至可能导致我们的页面内容被蜘蛛抓取不全,也会直接影响百度快照内容我们的网页,如果百度快照没有完全显示出来,最终会对我们的SEO排名产生影响。
从用户搜索需求的角度。如果用户找不到他的需求(target)关键词,他会去寻找其他的网页,这增加了跳出率。如果跳出率过大,会降低搜索引擎的友好度,最终导致排名下降。
修复跳出率问题:1、增加关键词密度。让用户来到我们的网页快速找到他的搜索需求。用免费的迅锐cms优采云采集器采集海量文章内容。模块布局发生了变化。将重要模块和用户需求模块移动到首屏的重要位置。3、图像处理加 关键词。Image Alt 标签有助于搜索引擎判断图像和内容的相关性。4、页面访问速度。
通过迅锐cms优采云采集器、关键词从下拉词、相关搜索词、长尾词中生成行业相关词。迅锐cms优采云可以设置自动删除无关词。我们网站的访问速度会影响搜索引擎蜘蛛的访问和爬取。如果网页加载速度太慢甚至长时间无法访问,势必会降低搜索引擎的友好度,虽然时间很短网站打不开并不一定会导致网站@ >没有排名之类的。通过迅瑞cms优采云采集器插件实现自动化采集行业相关文章,可以创建迅瑞cms优采云一次有数十个和数百个 采集 任务,支持同时执行多个域名任务采集。但是想一想,如果你的网站访问速度很流畅,对搜索引擎和用户友好,那么用户是不可能等到你的网站加载完毕才离开的。很有可能你五六秒后打不开网页,关闭网页,去其他网站浏览。
迅锐cms优采云采集器批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦、WP、Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。而且,百度还针对移动端推出了闪电算法,明确规定页面加载速度会影响网页在搜索结果中的排名显示。这时候,空间的选择也比较重要。

迅锐cms优采云自动过滤其他网站宣传信息。其实还有其他一些细节也会影响搜索引擎的友好度,后面会整理出来写到这里。迅锐cms优采云支持图片本地化或其他平台存储。
但实际上,以上几点在SEO优化过程中很容易避免或解决。从搜索引擎和用户的角度来处理和完善我们的网站的细节,还需要获取SEO排名。为用户解决问题并满足他们的搜索需求是一个稳定且长期的解决方案。今天关于迅锐cms优采云采集的解释就到这里了。下期会分享更多SEO相关知识和SEO7优化经验。下期再见。

关键词自动采集生成内容系统(狂雨CMS小说插件发布支持全平台CMS(CMS) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2022-03-27 07:19
)
狂雨cms小说系统是一款实用的小说站长管理系统,拥有便捷实用的会员系统,注册阅读记录,添加书架等功能。虽然狂羽cms小说系统也自带cms和一些SEO功能,但是很多时候采集的内容还是需要我们再加工。
Raincms小说插件支持24小时全自动网络小说采集,无需自动适配采集规则,采集目标站点稳定,真实-保证时间稳定的更新。完善的伪静态浏览,减少服务器消耗,方便SEO优化。
狂雨cms小说插件发布支持全平台cms(如图),无需掌握复杂的采集规则和逻辑,点击软件页面完成相应设置,实现网站文章采集、伪原创、发布、推送。支持各大cms,网络不中断继续工作。它可以自动生成txt文件并支持小说txt下载。
RaincmsFiction插件支持Repository采集、Specified采集和Incremental采集(如图)。内置翻译功能,中英翻译和简繁体转换。下载文章无限制自动导出txt、html、excel、xxf、db格式。可以选择保留下载的文章标签和图片本地化,下载后编辑或软件伪原创非常方便。我们只需要从各大资源平台输入关键词到文章采集,
Raincms小说插件支持市面上大部分cms,一键伪原创,关键词和图片随机插入。所有功能一键完成,无需掌握复杂的配置规则。
狂雨cms新颖的插件,所有操作页面可见,数据反馈及时。Crazy Raincms小说插件因其系统更新速度快、扩展性好、灵活性强而被部分站长朋友选用。虽然用户数量众多,但与主流cms用户相比,仍然可以归类为小众cms。所以我们需要注意我们的关键词排名。
为了优化《野雨》小说站cms,我们首先要做的就是确定我们的关键词。在网站的优化中,关键词非常重要。只有把我们的关键词选对了,才能让我们后面的收录和排名更好。说到关键词如何选择,首先需要判断关键词比赛的强度。这里有几个判断关键词优化难度的方法。
作为我们小说站的关键词,一定要围绕小说和我们的品牌词结合打造。由于小说这两个词之间的竞争非常困难,我们可以在前期通过长尾关键词对其进行优化,以便在竞争不激烈的关键词上更容易获得排名。当我们对长尾关键词进行很好的排名时,我们可以做更难的词。此时,我们在创建网站流量和长尾关键词的过程中建立的信心,已经是我们挑战更高难度的宝贵经验。
查看全部
关键词自动采集生成内容系统(狂雨CMS小说插件发布支持全平台CMS(CMS)
)
狂雨cms小说系统是一款实用的小说站长管理系统,拥有便捷实用的会员系统,注册阅读记录,添加书架等功能。虽然狂羽cms小说系统也自带cms和一些SEO功能,但是很多时候采集的内容还是需要我们再加工。

Raincms小说插件支持24小时全自动网络小说采集,无需自动适配采集规则,采集目标站点稳定,真实-保证时间稳定的更新。完善的伪静态浏览,减少服务器消耗,方便SEO优化。

狂雨cms小说插件发布支持全平台cms(如图),无需掌握复杂的采集规则和逻辑,点击软件页面完成相应设置,实现网站文章采集、伪原创、发布、推送。支持各大cms,网络不中断继续工作。它可以自动生成txt文件并支持小说txt下载。
RaincmsFiction插件支持Repository采集、Specified采集和Incremental采集(如图)。内置翻译功能,中英翻译和简繁体转换。下载文章无限制自动导出txt、html、excel、xxf、db格式。可以选择保留下载的文章标签和图片本地化,下载后编辑或软件伪原创非常方便。我们只需要从各大资源平台输入关键词到文章采集,

Raincms小说插件支持市面上大部分cms,一键伪原创,关键词和图片随机插入。所有功能一键完成,无需掌握复杂的配置规则。
狂雨cms新颖的插件,所有操作页面可见,数据反馈及时。Crazy Raincms小说插件因其系统更新速度快、扩展性好、灵活性强而被部分站长朋友选用。虽然用户数量众多,但与主流cms用户相比,仍然可以归类为小众cms。所以我们需要注意我们的关键词排名。

为了优化《野雨》小说站cms,我们首先要做的就是确定我们的关键词。在网站的优化中,关键词非常重要。只有把我们的关键词选对了,才能让我们后面的收录和排名更好。说到关键词如何选择,首先需要判断关键词比赛的强度。这里有几个判断关键词优化难度的方法。

作为我们小说站的关键词,一定要围绕小说和我们的品牌词结合打造。由于小说这两个词之间的竞争非常困难,我们可以在前期通过长尾关键词对其进行优化,以便在竞争不激烈的关键词上更容易获得排名。当我们对长尾关键词进行很好的排名时,我们可以做更难的词。此时,我们在创建网站流量和长尾关键词的过程中建立的信心,已经是我们挑战更高难度的宝贵经验。

关键词自动采集生成内容系统(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-27 05:05
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动斩首,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。降低文章相似度,让搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成特殊页面,将出现在文章中的关键词放在... 查看全部
关键词自动采集生成内容系统(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动斩首,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。降低文章相似度,让搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成特殊页面,将出现在文章中的关键词放在...
关键词自动采集生成内容系统,seo等可与12年
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-06-04 03:05
关键词自动采集生成内容系统,seo优化,sem等可与12年我带团队时做过,最后我们都是交给程序去做,每天工作量是比较大的。工作也是看自己能力的,不过感觉12年的程序还是比较成熟了,跟淘宝现在用的也是差不多的。可以参考下。
做搜索,比如seo,楼上说的挺对,关键字自动采集这事儿我想说个大概吧,所以就别太详细的说了,如果非要详细了说的话,很明显,你可以用api,然后你需要一些rawitem,其他做法,就是你一次写好,以后只需要对搜索引擎进行爬虫爬去就可以了,这个方法你的工作量只有开发调试的工作量,
感觉你很幸运
seo优化等其他也用这个呀,本来就是通用的,不是特指qq号就用该标题,基本很常用,应该是没有经过爬虫抓取处理或是怎么样了吧?要不你抓取一下分析下?这个id里能抓取哪些其他网站上的内容,看看是哪个id,然后,搜相关关键词,
这个id就是一个标题页,很标准的qq号。
08年我也问过这个问题。给你一个书上的解释吧,我觉得有点绕。用的时候看看哪个符合自己的情况,欢迎补充。大家看好了是13年的书ppt。全是个人经验,可能对你来说不适用。分割线我要说的是,数据抓取,结合后期数据分析,比用一个全新的id爬来爬去,得到的结果要准确很多。再厉害的数据分析师,也不能保证拿到的数据无误。 查看全部
关键词自动采集生成内容系统,seo等可与12年
关键词自动采集生成内容系统,seo优化,sem等可与12年我带团队时做过,最后我们都是交给程序去做,每天工作量是比较大的。工作也是看自己能力的,不过感觉12年的程序还是比较成熟了,跟淘宝现在用的也是差不多的。可以参考下。
做搜索,比如seo,楼上说的挺对,关键字自动采集这事儿我想说个大概吧,所以就别太详细的说了,如果非要详细了说的话,很明显,你可以用api,然后你需要一些rawitem,其他做法,就是你一次写好,以后只需要对搜索引擎进行爬虫爬去就可以了,这个方法你的工作量只有开发调试的工作量,
感觉你很幸运
seo优化等其他也用这个呀,本来就是通用的,不是特指qq号就用该标题,基本很常用,应该是没有经过爬虫抓取处理或是怎么样了吧?要不你抓取一下分析下?这个id里能抓取哪些其他网站上的内容,看看是哪个id,然后,搜相关关键词,
这个id就是一个标题页,很标准的qq号。
08年我也问过这个问题。给你一个书上的解释吧,我觉得有点绕。用的时候看看哪个符合自己的情况,欢迎补充。大家看好了是13年的书ppt。全是个人经验,可能对你来说不适用。分割线我要说的是,数据抓取,结合后期数据分析,比用一个全新的id爬来爬去,得到的结果要准确很多。再厉害的数据分析师,也不能保证拿到的数据无误。
关键词自动采集生成内容系统代码安装和使用/图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-05-24 21:07
关键词自动采集生成内容系统代码安装和使用spatialsourceautomation/图片如何采集到本地(web版登录同步图片本地)等采集教程:文档比较完善实例:python爬虫实例以下我在处理某网站数据时,还用到了其他如视频下载等内容,以下都有处理说明和示例程序代码,注意本教程均只使用python,很多爬虫框架可以同时处理多个网站(c/c++中用eval或generator将多个网站打包成exe模块,如:scrapy等),并且有相应提供的python插件,如爬虫fiddler也支持打包后代码跳转到定制页面,js、css等可以转成可读的ast文件进行混合(文件要统一)下载地址:。
本质上自动化网络爬虫还是需要靠正则表达式,把网站的文本句法搞懂,但是这和算法实现有关,需要经验,加上这项技术的发展,比如从反爬虫,到采集已经有了一整套清晰的机制。这个问题问的比较泛,具体哪些需要自己去学就完全看你的需求了。
这个事情其实需要一定的经验,我举一个例子,defprocess_google_main_env():forcinprocess_google_main_env():result=google_map_get_client("",perfect_client,true)returnresult上面这个例子,用正则表达式就可以实现自动化网页提取,我们可以用以下正则表达式来识别互联网中有用的内容:reg=re。
compile("^$",re。s)item=re。search("",re。s)returnitem。 查看全部
关键词自动采集生成内容系统代码安装和使用/图片
关键词自动采集生成内容系统代码安装和使用spatialsourceautomation/图片如何采集到本地(web版登录同步图片本地)等采集教程:文档比较完善实例:python爬虫实例以下我在处理某网站数据时,还用到了其他如视频下载等内容,以下都有处理说明和示例程序代码,注意本教程均只使用python,很多爬虫框架可以同时处理多个网站(c/c++中用eval或generator将多个网站打包成exe模块,如:scrapy等),并且有相应提供的python插件,如爬虫fiddler也支持打包后代码跳转到定制页面,js、css等可以转成可读的ast文件进行混合(文件要统一)下载地址:。
本质上自动化网络爬虫还是需要靠正则表达式,把网站的文本句法搞懂,但是这和算法实现有关,需要经验,加上这项技术的发展,比如从反爬虫,到采集已经有了一整套清晰的机制。这个问题问的比较泛,具体哪些需要自己去学就完全看你的需求了。
这个事情其实需要一定的经验,我举一个例子,defprocess_google_main_env():forcinprocess_google_main_env():result=google_map_get_client("",perfect_client,true)returnresult上面这个例子,用正则表达式就可以实现自动化网页提取,我们可以用以下正则表达式来识别互联网中有用的内容:reg=re。
compile("^$",re。s)item=re。search("",re。s)returnitem。
从0开始学习推荐系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-05-02 23:41
0. 概况
以我们目前的推荐系统架构为例:
推荐系统是个很复杂的工程,对于算法和工程上的能力都是一个挑战。本文只是尝试从几个大模块简述上手搭建推荐系统的过程,不会深入探讨。然而要想推荐达到可观的效果,深入挖掘每个模块,研读论文、优化架构是必不可少的。以下我会从数据、画像(内容/用户)、召回和排序几个部分分别详述。
1. 数据
推荐系统,最重要的是数据。数据决定了算法的上界,再牛逼的算法也只是逼近这个上界而已。因此搭建系统时,首要考虑完善数据。这里数据包含两类:内容数据与用户数据。
1.1. 内容数据
这个很好理解,内容指的是推荐系统要推荐的item。电商就是商品,电影网站就是电影,我搭建的是新闻推荐系统,所以内容就是新闻。获取手段可以是网站内部发文,也可以是外部抓取,基础爬虫我就不赘述了,另外内容的版权问题也是需要注意的。抓取到之后我们需要对内容落地,这一步的关键是数据格式的规范化。考虑到我们的内容很可能是从不同数据源抓取,有着不同格式,为了方便日后的利用,大致需要遵从如下步骤,对原始数据进行ETL:
1. 按推荐需求指定落地内容字段
2. 对内容字段进行标准化处理,如正文提取、一致编码
3. 选择合适的存储方式,如MySQL、MongoDB、HDFS
需要明确的是,上述系列行为都是为最终的推荐服务的。首先,需要考虑业务侧需要展现哪些属性(如标题、缩略图、摘要);其次,还需要考虑算法侧提取内容特征需要哪些属性(如正文、发布时间)。我在系统搭建的过程中,遇到最头疼的问题就是在NLP时需要依据某个内容属性而源数据没有抓取该属性,因此做抓取前尽量考虑周全,预留好一些字段是很有必要的。
以从腾讯网抓取的新闻部分属性为例:
1.2. 用户数据
搞定内容之后,我们还需要了解用户,推荐的基础也是用户的行为。在新闻网站上,最简单的行为就是点击。一名用户在网站上点击了一条新闻,我们可以认为他对这条新闻感兴趣,此时前端需要将这条记录上报到后台,后台再将log落地。这个过程可以是实时的,也可以用消息队列的方式分批处理,总之,依据场景需求以及系统架构能力。一条最简单的log如下:
user_id,news_id,timestamp
user_id可以是用户手机的IMEI标识、PC的MAC地址、浏览器的Cookie ID等等,总之是需要能唯一标识用户的序列。当然这里涉及到的一个问题是,一个用户可以在多个终端登录,所以我们还需要用户的登录态来解决一对多的问题,比如用登录QQ、微信账号来做一个关联映射。
上述列举的log只包含最简单的信息,复杂的推荐需要更多的信息,比如来源IP(用以识别用户登录地域),收藏、评论等行为(造成不同兴趣权重),曝光行为(用于之后CTR模型的训练)等等。
有了内容数据和用户数据之后,我们已经可以建立一些简单基于用户行为的推荐策略了,比如itemCF、userCF,具体实现方式我在之前的文章里写过:文章链接,这里不再赘述。但基于用户行为的策略,往往在系统冷启动时表现不会太好,我们还需要更多维的推荐策略。
2. 内容画像
众所周知,基于行为推荐需要一定的用户行为积累,而新闻生产速度很快,时效性要求又比较高,这时候我们需要一些 Content-based 方法来做推荐。内容画像是实现的基础。
2.1. 文本分类
分类,是新闻语义特征里颗粒度最粗的一个特征。根据分类可以对文本有一个基本的语义划分,可以让用户对兴趣内容有较为明显的感知,所以分类往往是内容画像的第一步。
在分类之前,我们首先要制定统一的分类体系,根据业务需求按颗粒度区分一/二级分类。这一步可以人工标注,也可通过无监督聚类的方法。总之,这对于融合多来源、多类型的内容数据至关重要。
分类的方法有很多,传统统计方法里如 Naive Bayesian、SVM,深度学习里的 CNN、LSTM 等都可以胜任。不过在大多数情况下,传统方法已经可以做到很好的效果,且实现简单,因此我们通常选择前者。
2.2. 关键词提取
分类完成之后,可以说我们的内容画像已经初见端倪。然而,仅仅精确到分类颗粒度的个性化推荐是很难满足用户的。用户对于文章的兴趣,往往精确到某个明星、某支球队,要捕捉到这种颗粒度的信息,只要依赖于关键词。
关键词提取是对于文章中出现的具有代表语义作用的词汇进行提取,并赋予权重。这类算法很多,baseline 的方法比如 tfidf、textrank,都能做到很好的效果。当然,如果我们要做到更精确,还需要结合业务数据做一些人工规则,比如将词性、实体、词出现位置等特征与 baseline 方法进行结合,或者用人工标注的方法转换为有监督学习的问题。
2.3. 主题抽取
分类和关键词,颗粒度的跨度其实是比较大的。在基于语义的个性化推荐过程中,一些冷门关键词往往比较难以命中,为了弥补这个真空,文本主题的概念就派上用场了。
图2-1 LDA示意图(来源:由Slxu.public – 自己的作品,CC BY-SA 3.0,)
诸如 pLSA、LDA 的主题模型假设一篇文档的生成过程是这样的:
1. 作者从文档 – 主题分布 θ 中随机挑选一个主题 zi
2. 作者从主题 – 词分布 φ 中随机挑选一个词 wj
3. 重复步骤1,直到文档所有词生成完成
LDA 与 pLSA 不同之处在于 LDA 还假设这两个分布也不是固定的,而是遵循两个狄利克雷先验分布。总之,这类算法最终计算出的是文档集合中存在的“隐分类”,表征文档语义中存在的一些潜在关联。主题的维度我们一般设置为较大的数字,这样我们便拥有了一个颗粒度介于分类与关键词之间的特征。LDA 的实现方法可以参照之前的文章:文章链接
有了上述三类特征后,内容画像已经可以满足大部分需求了。须知,上文所说的方法都是比较基础的方式,像 CNN、RNN、Attention Model 都是可以尝试的方法,NLP 的研究和优化需要投入大量的精力,如果想在这上面深挖,建议系统学习 NLP 相关课程。
3. 用户画像3.1. 兴趣画像
有了内容画像,我们再来计算用户的兴趣画像就是水到渠成的事情了。简单的方法就是根据用户的行为,检索到一定时间内用户所有有过正向行为(点击/收藏/评论)的 news,把它们看成一篇内容,对所有特征进行线性加和,作为用户在该时间窗内的兴趣画像。用户 u 的当天兴趣画像计算公式如下:
其中 m 为用户 u 在当天产生正向行为的文档集合,n 为文档 i 的特征集合。θj 表示文档 i 第 j 个特征的权重,P(θj) 表示第 j 个特征的先验概率(这一步主要是为了减弱头部文章对用户画像的影响,若某天某一类特征的新闻很热,那么有可能大多数用户画像里都会有这类特征,但它并不能真正代表用户的兴趣倾向)。
随着时间推移,用户的兴趣会发生迁移,因此我们需要加上时间的影响因素:
yt 表示 t 时刻的用户画像,yt-1 表示上一时刻的画像,λ 为时间衰减因子。
3.2. 基础画像
除了上述的用户兴趣画像外,还有一些用户的属性是我们感兴趣的,比如用户的性别、年龄、职业、所处地域,这部分可以根据业务特点来获取,这些我们称之为基础画像。基础画像虽然没有兴趣画像颗粒度细致,但在冷启动、地域强相关等业务场景也是比较重要的。
在业务实践中,我们发现用户的兴趣变化是很快的,并且很难用某一种状态涵盖住用户所有的兴趣范围。比如当我们在浏览新闻时,我们的近期浏览记录也许的确反映了我的兴趣变化,但也有可能我只是对热点感兴趣,抑或是想试探一下不同领域的阅读,再或者仅仅是手抖点错了。再比如,系统依据用户所处地域推荐内容,然而这个用户有可能只是来外地出差,他更感兴趣的可能依旧是常住地的新闻……无论如何,在计算画像的时候我们无法确保用户的意图,因此在快速反馈用户行为的同时,加上多状态的用户画像是有必要的。通常我们的做法是分别记录用户的长期和短期画像,在针对不同的画像做不同的推荐召回,以此满足用户不同状态下的阅读需求。
4. 个性化召回
说完数据的基础积累,包括用户画像和内容画像的构建,接下来我们可以正式着手开始推荐了。以新闻推荐举例来说,推荐可以有很多策略,包括基于用户兴趣画像语义的策略(兴趣关键词/分类/主题相关),基于用户行为的策略(itemCF/userCF/clusterCF),基于位置的策略(地域相关),基于社交关系的策略(SNS推荐)等等。
在一次个性化推荐中,我们通常需要同时运用多种策略。如果尝试仅仅通过某种精细化的推荐策略(如关键词/itemCF)进行推荐的话,用户往往会在初期表现得很感兴趣,而随着数量增多,用户会逐渐疲劳。毕竟用户的阅读倾向往往是多元的,特别是在新闻领域,绝大多数用户除了自己的一亩三分地外,也会比较关注当日热点新闻,或者关注一些其他领域的潜在兴趣。因此,我们通常是从多种策略拉取内容,而后依据某种规则统一进行排序。这个过程一般称作召回。
4.1. 召回策略4.1.1. 协同过滤
协同过滤(Collaborative Filtering)可说是推荐系统里资历最老最经典的一种算法了,如 userCF、itemCF。原理是基于用户对内容的行为协同,为某一用户没有看过的某条内容作出点击预测。实现方法有很多种,如传统的 Memory-based 方法、基于矩阵分解的方法(LFM/SVD/SDV++)、基于 DNN 的方法。
Memory-based 方法很简单,是基于统计的一种算法。以 item-based CF 举例:
根据用户点击行为,我们可以统计出 item-item 的共现矩阵(矩阵单元内为 item i 与 item j 共同被用户点击的次数),再依此通过Jaccard相似度/余弦相似度/欧氏距离得出 item 相似度矩阵,最后根据用户的点击记录检索出 topK 相似的内容推荐给用户。在计算过程中需要考虑一些因素,比如热门物品对相似度计算的影响、不同倾向的用户的影响等等。
然而 Memory-based 方法不能解决的问题是,当我们的矩阵很稀疏时,大多数 item 和 item 之间是没有关联的(相似度为0),这也就造成最后我们召回的内容覆盖率很低,也许大多集中在头部内容。于是基于矩阵分解的方法诞生了。
MF(Matrix Factorization)的原理是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j 的值。
MF 可说是大部分推荐系统里协同过滤的标杆方法了,但仍然存在一些问题。比如过于稀疏的矩阵对于最后评分的预测依然有很大影响,并且当用户特征或者内容特征缺失(即冷启动)时,无法进行合理的预测。此时,基于深度学习的一些尝试开始了。如基于DNN实现,可以很轻易地将内容的一些语义特征,以及用户的固有属性与行为特征拼接在一起作为神经网络输入来训练,可以在之前行为协同的前提下加入对内容特征的学习,从而解决冷启动问题。感兴趣的同学可以阅读相关论文,在此不做展开。
4.1.2. 基于内容
基于内容的召回主要是以之前 NLP 得到的内容画像为基础,以item 对应分类/主题/关键词的权重建立召回,依据用户画像的相应权重和内容画像的距离排序召回。召回过程如下:
4.1.3. 基于用户群
其实这种策略也是协同过滤的概念,当用户的粒度扩大时,可以为处于某一群体内的单个用户在兴趣范围内带来更多样的阅读内容,在一定程度上也是一种兴趣探索。
首先我们需要对用户分群,这里我们采用的是用户画像中的 topic 兴趣(2000维),相当于对用户进行了降维。降维的方法有很多,包括 autoencoder 等深度学习方法都可以尝试。不仅仅是用户的文本兴趣,用户的人口属性、阅读记录、社交关系等等都可以拼接进来,最终的目的都是将用户 embedding 成一个向量。
完成了用户的向量化之后,接下来就是聚类了,传统的 K-means 基本可以胜任大部分场景。如果需要多分类或者体现层级关系的话,GMM和层次聚类的算法也可以做一些尝试。
最终我们聚出一批类簇,根据类簇内对不同内容的相对点击率(文章i在类簇a中点击率/文章i在所有类簇中平均点击率)排序,对类簇用户进行推荐。另外,也可以根据类簇中用户的倾向主题,给类簇打上解释性label,作为露出。
4.2. 倒排链
前文中,我们提到内容数据入库时的结构是 itemID – detail 这种形式。而在召回过程中,我们要用到内容画像中的分类、主题等属性,若要通过遍历 itemID 然后计算相似度无疑是不现实的。于是这里我们用到搜索引擎中一个常用的技术——倒排。相较于 itemID – detail 这种形式(我们称之为正排),我们再以 detailX – itemID 的形式建立倒排链,提高召回检索效率。
比如在关键词召回中,我们按如下格式建立倒排表。(这里以 json 格式实例,实际中会采用效率更高的序列化形式):
{
‘tag_1′:
[ { itemID: ’13’, weight: 0.7 }, { itemID: ‘2’, weight: 0.53 } ],
‘tag_2’:
[ { itemID: ‘1’, weight: 0.37 } ],
…
}
上述结构中,索引的key是tag的编号,每一个tagID下则对应与之相关的文章摘要(示例中只包括文章ID和tag在此文章中的权重)按相关度排序的数组。随后将倒排链加载到分布式索引里,在拿到用户画像的兴趣tag后,我们根据tagID检索出倒排链,最后再根据倒排链中的itemID去正排里拉取详情即可。
4.3. 系统架构
有了上述召回的基础,我们便可以初步搭建起推荐系统的架构。完整的推荐系统很庞大、很复杂,基于不同的业务也会有不同的实践方式,这里只谈一些基础的、公用的部分,以作参考。
接入层:接收前端请求的CGI应用,一般处理内容详情拉取、日志上报、各种人工规则干预、去重等任务,计算逻辑简单,I/O密集型任务。这里我们用 Golang 实现,看重他的goroutines处理高并发的能力。
日志采集:消息队列处理前后端的日志上报(点击/曝光/负反馈),采用Kafka,实时打到 Spark Streaming 处理实时数据,同时定期落地到 hdfs 上用以离线处理。
画像计算:用 Spark/Hadoop 按前文所述的方法批量计算长期用户画像,一天计算一次,结果存入 HDFS。
实时画像:采用 Spark Streaming 直接拉取 Kafka 的流实时进行衰减/合并计算,结果写入到 Redis,供线上使用。因为我们每天还会计算一次长期画像,因此短期画像只用保存一天即可。
召回索引:离线更新召回倒排表,定期刷新至线上召回集群的内存里,以加快检索速度。另外在召回模块中,还需要实现诸如截断、过滤等算子,用以在召回的过程中快速过滤曝光内容,截取topN的文章摘要等。
按照上述架构搭建起来后的系统投入到线上使用,QPS在单机1k左右,在召回和接入上还有一些待优化的地方。最终的信息流中,我们从个性化的多路召回中拿到了一批内容,最后根据文章质量(点击量/点击率/阅读时长)统一排序,输出到用户侧,完成推荐。这样,一个推荐系统的完整流程便完成了。
5. 排序模型
我们根据不同召回策略召回了一批文章,并统一根据文章质量排序输出。但实际上,用户的阅读兴趣还会受到很多其他因素的影响。比如用户所处的网络环境,文章点击率、时效性,用户的年龄、性别,或者多种因素交叉的影响,而排序最终决定了用户优先看到的内容(最终推荐流是召回队列的topN),因此排序过程是至关重要的。
5.1. 模型选择
排序的问题在机器学习中有很多可以使用的方法,应用到推荐系统实际上就是一个二分类问题。以用户、内容、上下文的一些特征作为输入,输出是介于0(不感兴趣)和1(感兴趣)之间的一个概率,称作 pCTR(预测点击率)。分类算法有很多,出于规模和性能的考量,业界更多的还是使用线性的方法,传统方法有 Logistic Regression 和 Factorization Machine。
5.1.1. Logistic Regression
逻辑回归是一个经久不衰的统计分析方法,它的预测公式如下:
其中g(x)为sigmoid函数,它的作用是将数值压缩到(0,1)的范围内,函数曲线如下:
有了公式,我们便可以将已知的用户特征和行为作为训练集的输入和输出,其中 x 表示输入特征向量,θ 表示每一维特征对应的权重。输入特征我们可以大致分为用户特征、行为特征和内容特征,示例如下:
这其中每一个特征即是 x 向量中的一维,也对应着预测公式中 θ 向量中的一个权重,而我们模型训练的过程则是求出 θ 向量,最终我们可以通过线上的 x 向量实际输入,代入公式最终得出预测点击率 g(x)。
5.1.2. 特征工程
当然,以上示例的特征取值如果直接使用 LR 进行训练,效果肯定是不好的。因为 LR 学到的是变量的线性关系,而有一些特征取值却并不具备线性相关。比如性别,0代表男性,1代表女性,但这里的数值大小关系并没有什么意义;再比如年龄,不一定所有年龄段内,兴趣都和年龄大小完全线性相关。因此,在训练之前我们需要对特征做一些诸如离散化、数值分桶等操作,尽量让特征与结果表现出线性关系。
另外,有些特征单独对分类影响并不大,但与其他特征交叉影响就明显了。比如年龄X性别、分类X关键词,因此,我们需要根据一些业务上的了解和经验来决定如何进行特征交叉(当然我们可以直接将所有特征的笛卡尔积扔进去训练,但对于训练效率来说这通常是不现实的),往往在特征上的工作占了模型工作的绝大部分时间,因为特征工程的质量决定了模型效果的上限。
我们也可以用一些决策树的方法来自动选择特征,比如 Facebook 在2014年提出的 GBDT+LR 的推荐模型,就是采用 GBDT(梯度提升决策树)的方法做特征选择,并将树的输出直接作为 LR 的特征输入,取得了比较好的效果。
5.1.3. Factorization Machine
特征工程是个耗时耗力,且非常考验业务理解力的过程,当我们处在项目初期,又不想花太多精力去做特征选择时,FM 算法便成了我们的另一种选择。FM 的预测公式如下:
仔细对比上述公式和 LR 公式,可以看出 FM 本质上其实就是在 LR 的基础上增加了发掘二阶特征关系的kernel,vi,vj 表示的是二阶特征经过矩阵分解后得到的低秩矩阵的值:
矩阵分解在推荐系统中很常用,实质上是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j的值。FM 的kernel在此基础上学习到任意二阶特征的非线性关系,求得它们的权重。
5.2. 模型训练
确定模型后,我们需要根据目标确认损失函数,比如回归一般使用 RMSE,二分类使用 Cross Entropy,然后我们就需要朝最小化损失函数的目的来训练参数了。
求解函数有多种,如果数据量较小,可以选择批量训练的方式,如传统的梯度下降法:Batch Gradient Descent,也可以选择拟牛顿法如 L-BFGS ,用二阶导数求得更快的训练速度。它们的优点是考虑到全部样本,模型准确,但缺点是数据量太大时训练速度很慢。我们可以考虑每次采用小批量的样本训练模型的 online learning,从而达到实时更新模型的效果。方法如 SGD、FOBOS、RDA、FTRL 等等,对比和公示详解建议阅读冯扬的《在线最优化求解》,讲得很详细,这里就不赘述了。
5.3. 在线预测
训练完成后,我们可以把模型文件(实质是所有参数的取值)保存到本地,或者为了更高的执行效率,把它们加载到内存。预测的执行步骤如下:
1. 召回内容队列
2. 线上的服务器从内存读取参数取值 θ
3. 拉取到内容/用户/上下文的实时特征 x
4. 代入预测公式,计算用户 u 对内容 i 的点击率
5. 依据点击率对召回内容排序并返回
每隔一段时间,模型更新之后需要将新训练得到的参数值刷新到预测服务器的内存中。当特征维度很大时模型文件体积也很大,此时如何按时完成更新是个问题,Parameter Server 是一类解决这类问题的框架。
5.4. Rerank
在排序完成之后,直接将排序结果呈现在用户面前可能不是一个好的选择。首先,产品需要有一些特殊的内容形式作为自己的品牌形象;另外,完全根据模型规则走可能让用户兴趣越来越窄,推荐内容同质化,久而久之则会影响用户对内容产品的黏性。
解决这个问题就是在排序之后再进行一次 rerank,我们可以用人工规则的方式,或者贪心算法来确保最后推荐给用户的 TOP10 内容的多样性,以及插入一些对于用户画像里缺失兴趣的探索。
6. 总结
推荐系统涉及到的东西很多,本文只是对各个环节作了些简单的概述。如果要完善系统并真正满足用户的需求,则需要在各个环节都做深入的研究,希望大家共勉。 查看全部
从0开始学习推荐系统
0. 概况
以我们目前的推荐系统架构为例:
推荐系统是个很复杂的工程,对于算法和工程上的能力都是一个挑战。本文只是尝试从几个大模块简述上手搭建推荐系统的过程,不会深入探讨。然而要想推荐达到可观的效果,深入挖掘每个模块,研读论文、优化架构是必不可少的。以下我会从数据、画像(内容/用户)、召回和排序几个部分分别详述。
1. 数据
推荐系统,最重要的是数据。数据决定了算法的上界,再牛逼的算法也只是逼近这个上界而已。因此搭建系统时,首要考虑完善数据。这里数据包含两类:内容数据与用户数据。
1.1. 内容数据
这个很好理解,内容指的是推荐系统要推荐的item。电商就是商品,电影网站就是电影,我搭建的是新闻推荐系统,所以内容就是新闻。获取手段可以是网站内部发文,也可以是外部抓取,基础爬虫我就不赘述了,另外内容的版权问题也是需要注意的。抓取到之后我们需要对内容落地,这一步的关键是数据格式的规范化。考虑到我们的内容很可能是从不同数据源抓取,有着不同格式,为了方便日后的利用,大致需要遵从如下步骤,对原始数据进行ETL:
1. 按推荐需求指定落地内容字段
2. 对内容字段进行标准化处理,如正文提取、一致编码
3. 选择合适的存储方式,如MySQL、MongoDB、HDFS
需要明确的是,上述系列行为都是为最终的推荐服务的。首先,需要考虑业务侧需要展现哪些属性(如标题、缩略图、摘要);其次,还需要考虑算法侧提取内容特征需要哪些属性(如正文、发布时间)。我在系统搭建的过程中,遇到最头疼的问题就是在NLP时需要依据某个内容属性而源数据没有抓取该属性,因此做抓取前尽量考虑周全,预留好一些字段是很有必要的。
以从腾讯网抓取的新闻部分属性为例:
1.2. 用户数据
搞定内容之后,我们还需要了解用户,推荐的基础也是用户的行为。在新闻网站上,最简单的行为就是点击。一名用户在网站上点击了一条新闻,我们可以认为他对这条新闻感兴趣,此时前端需要将这条记录上报到后台,后台再将log落地。这个过程可以是实时的,也可以用消息队列的方式分批处理,总之,依据场景需求以及系统架构能力。一条最简单的log如下:
user_id,news_id,timestamp
user_id可以是用户手机的IMEI标识、PC的MAC地址、浏览器的Cookie ID等等,总之是需要能唯一标识用户的序列。当然这里涉及到的一个问题是,一个用户可以在多个终端登录,所以我们还需要用户的登录态来解决一对多的问题,比如用登录QQ、微信账号来做一个关联映射。
上述列举的log只包含最简单的信息,复杂的推荐需要更多的信息,比如来源IP(用以识别用户登录地域),收藏、评论等行为(造成不同兴趣权重),曝光行为(用于之后CTR模型的训练)等等。
有了内容数据和用户数据之后,我们已经可以建立一些简单基于用户行为的推荐策略了,比如itemCF、userCF,具体实现方式我在之前的文章里写过:文章链接,这里不再赘述。但基于用户行为的策略,往往在系统冷启动时表现不会太好,我们还需要更多维的推荐策略。
2. 内容画像
众所周知,基于行为推荐需要一定的用户行为积累,而新闻生产速度很快,时效性要求又比较高,这时候我们需要一些 Content-based 方法来做推荐。内容画像是实现的基础。
2.1. 文本分类
分类,是新闻语义特征里颗粒度最粗的一个特征。根据分类可以对文本有一个基本的语义划分,可以让用户对兴趣内容有较为明显的感知,所以分类往往是内容画像的第一步。
在分类之前,我们首先要制定统一的分类体系,根据业务需求按颗粒度区分一/二级分类。这一步可以人工标注,也可通过无监督聚类的方法。总之,这对于融合多来源、多类型的内容数据至关重要。
分类的方法有很多,传统统计方法里如 Naive Bayesian、SVM,深度学习里的 CNN、LSTM 等都可以胜任。不过在大多数情况下,传统方法已经可以做到很好的效果,且实现简单,因此我们通常选择前者。
2.2. 关键词提取
分类完成之后,可以说我们的内容画像已经初见端倪。然而,仅仅精确到分类颗粒度的个性化推荐是很难满足用户的。用户对于文章的兴趣,往往精确到某个明星、某支球队,要捕捉到这种颗粒度的信息,只要依赖于关键词。
关键词提取是对于文章中出现的具有代表语义作用的词汇进行提取,并赋予权重。这类算法很多,baseline 的方法比如 tfidf、textrank,都能做到很好的效果。当然,如果我们要做到更精确,还需要结合业务数据做一些人工规则,比如将词性、实体、词出现位置等特征与 baseline 方法进行结合,或者用人工标注的方法转换为有监督学习的问题。
2.3. 主题抽取
分类和关键词,颗粒度的跨度其实是比较大的。在基于语义的个性化推荐过程中,一些冷门关键词往往比较难以命中,为了弥补这个真空,文本主题的概念就派上用场了。
图2-1 LDA示意图(来源:由Slxu.public – 自己的作品,CC BY-SA 3.0,)
诸如 pLSA、LDA 的主题模型假设一篇文档的生成过程是这样的:
1. 作者从文档 – 主题分布 θ 中随机挑选一个主题 zi
2. 作者从主题 – 词分布 φ 中随机挑选一个词 wj
3. 重复步骤1,直到文档所有词生成完成
LDA 与 pLSA 不同之处在于 LDA 还假设这两个分布也不是固定的,而是遵循两个狄利克雷先验分布。总之,这类算法最终计算出的是文档集合中存在的“隐分类”,表征文档语义中存在的一些潜在关联。主题的维度我们一般设置为较大的数字,这样我们便拥有了一个颗粒度介于分类与关键词之间的特征。LDA 的实现方法可以参照之前的文章:文章链接
有了上述三类特征后,内容画像已经可以满足大部分需求了。须知,上文所说的方法都是比较基础的方式,像 CNN、RNN、Attention Model 都是可以尝试的方法,NLP 的研究和优化需要投入大量的精力,如果想在这上面深挖,建议系统学习 NLP 相关课程。
3. 用户画像3.1. 兴趣画像
有了内容画像,我们再来计算用户的兴趣画像就是水到渠成的事情了。简单的方法就是根据用户的行为,检索到一定时间内用户所有有过正向行为(点击/收藏/评论)的 news,把它们看成一篇内容,对所有特征进行线性加和,作为用户在该时间窗内的兴趣画像。用户 u 的当天兴趣画像计算公式如下:
其中 m 为用户 u 在当天产生正向行为的文档集合,n 为文档 i 的特征集合。θj 表示文档 i 第 j 个特征的权重,P(θj) 表示第 j 个特征的先验概率(这一步主要是为了减弱头部文章对用户画像的影响,若某天某一类特征的新闻很热,那么有可能大多数用户画像里都会有这类特征,但它并不能真正代表用户的兴趣倾向)。
随着时间推移,用户的兴趣会发生迁移,因此我们需要加上时间的影响因素:
yt 表示 t 时刻的用户画像,yt-1 表示上一时刻的画像,λ 为时间衰减因子。
3.2. 基础画像
除了上述的用户兴趣画像外,还有一些用户的属性是我们感兴趣的,比如用户的性别、年龄、职业、所处地域,这部分可以根据业务特点来获取,这些我们称之为基础画像。基础画像虽然没有兴趣画像颗粒度细致,但在冷启动、地域强相关等业务场景也是比较重要的。
在业务实践中,我们发现用户的兴趣变化是很快的,并且很难用某一种状态涵盖住用户所有的兴趣范围。比如当我们在浏览新闻时,我们的近期浏览记录也许的确反映了我的兴趣变化,但也有可能我只是对热点感兴趣,抑或是想试探一下不同领域的阅读,再或者仅仅是手抖点错了。再比如,系统依据用户所处地域推荐内容,然而这个用户有可能只是来外地出差,他更感兴趣的可能依旧是常住地的新闻……无论如何,在计算画像的时候我们无法确保用户的意图,因此在快速反馈用户行为的同时,加上多状态的用户画像是有必要的。通常我们的做法是分别记录用户的长期和短期画像,在针对不同的画像做不同的推荐召回,以此满足用户不同状态下的阅读需求。
4. 个性化召回
说完数据的基础积累,包括用户画像和内容画像的构建,接下来我们可以正式着手开始推荐了。以新闻推荐举例来说,推荐可以有很多策略,包括基于用户兴趣画像语义的策略(兴趣关键词/分类/主题相关),基于用户行为的策略(itemCF/userCF/clusterCF),基于位置的策略(地域相关),基于社交关系的策略(SNS推荐)等等。
在一次个性化推荐中,我们通常需要同时运用多种策略。如果尝试仅仅通过某种精细化的推荐策略(如关键词/itemCF)进行推荐的话,用户往往会在初期表现得很感兴趣,而随着数量增多,用户会逐渐疲劳。毕竟用户的阅读倾向往往是多元的,特别是在新闻领域,绝大多数用户除了自己的一亩三分地外,也会比较关注当日热点新闻,或者关注一些其他领域的潜在兴趣。因此,我们通常是从多种策略拉取内容,而后依据某种规则统一进行排序。这个过程一般称作召回。
4.1. 召回策略4.1.1. 协同过滤
协同过滤(Collaborative Filtering)可说是推荐系统里资历最老最经典的一种算法了,如 userCF、itemCF。原理是基于用户对内容的行为协同,为某一用户没有看过的某条内容作出点击预测。实现方法有很多种,如传统的 Memory-based 方法、基于矩阵分解的方法(LFM/SVD/SDV++)、基于 DNN 的方法。
Memory-based 方法很简单,是基于统计的一种算法。以 item-based CF 举例:
根据用户点击行为,我们可以统计出 item-item 的共现矩阵(矩阵单元内为 item i 与 item j 共同被用户点击的次数),再依此通过Jaccard相似度/余弦相似度/欧氏距离得出 item 相似度矩阵,最后根据用户的点击记录检索出 topK 相似的内容推荐给用户。在计算过程中需要考虑一些因素,比如热门物品对相似度计算的影响、不同倾向的用户的影响等等。
然而 Memory-based 方法不能解决的问题是,当我们的矩阵很稀疏时,大多数 item 和 item 之间是没有关联的(相似度为0),这也就造成最后我们召回的内容覆盖率很低,也许大多集中在头部内容。于是基于矩阵分解的方法诞生了。
MF(Matrix Factorization)的原理是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j 的值。
MF 可说是大部分推荐系统里协同过滤的标杆方法了,但仍然存在一些问题。比如过于稀疏的矩阵对于最后评分的预测依然有很大影响,并且当用户特征或者内容特征缺失(即冷启动)时,无法进行合理的预测。此时,基于深度学习的一些尝试开始了。如基于DNN实现,可以很轻易地将内容的一些语义特征,以及用户的固有属性与行为特征拼接在一起作为神经网络输入来训练,可以在之前行为协同的前提下加入对内容特征的学习,从而解决冷启动问题。感兴趣的同学可以阅读相关论文,在此不做展开。
4.1.2. 基于内容
基于内容的召回主要是以之前 NLP 得到的内容画像为基础,以item 对应分类/主题/关键词的权重建立召回,依据用户画像的相应权重和内容画像的距离排序召回。召回过程如下:
4.1.3. 基于用户群
其实这种策略也是协同过滤的概念,当用户的粒度扩大时,可以为处于某一群体内的单个用户在兴趣范围内带来更多样的阅读内容,在一定程度上也是一种兴趣探索。
首先我们需要对用户分群,这里我们采用的是用户画像中的 topic 兴趣(2000维),相当于对用户进行了降维。降维的方法有很多,包括 autoencoder 等深度学习方法都可以尝试。不仅仅是用户的文本兴趣,用户的人口属性、阅读记录、社交关系等等都可以拼接进来,最终的目的都是将用户 embedding 成一个向量。
完成了用户的向量化之后,接下来就是聚类了,传统的 K-means 基本可以胜任大部分场景。如果需要多分类或者体现层级关系的话,GMM和层次聚类的算法也可以做一些尝试。
最终我们聚出一批类簇,根据类簇内对不同内容的相对点击率(文章i在类簇a中点击率/文章i在所有类簇中平均点击率)排序,对类簇用户进行推荐。另外,也可以根据类簇中用户的倾向主题,给类簇打上解释性label,作为露出。
4.2. 倒排链
前文中,我们提到内容数据入库时的结构是 itemID – detail 这种形式。而在召回过程中,我们要用到内容画像中的分类、主题等属性,若要通过遍历 itemID 然后计算相似度无疑是不现实的。于是这里我们用到搜索引擎中一个常用的技术——倒排。相较于 itemID – detail 这种形式(我们称之为正排),我们再以 detailX – itemID 的形式建立倒排链,提高召回检索效率。
比如在关键词召回中,我们按如下格式建立倒排表。(这里以 json 格式实例,实际中会采用效率更高的序列化形式):
{
‘tag_1′:
[ { itemID: ’13’, weight: 0.7 }, { itemID: ‘2’, weight: 0.53 } ],
‘tag_2’:
[ { itemID: ‘1’, weight: 0.37 } ],
…
}
上述结构中,索引的key是tag的编号,每一个tagID下则对应与之相关的文章摘要(示例中只包括文章ID和tag在此文章中的权重)按相关度排序的数组。随后将倒排链加载到分布式索引里,在拿到用户画像的兴趣tag后,我们根据tagID检索出倒排链,最后再根据倒排链中的itemID去正排里拉取详情即可。
4.3. 系统架构
有了上述召回的基础,我们便可以初步搭建起推荐系统的架构。完整的推荐系统很庞大、很复杂,基于不同的业务也会有不同的实践方式,这里只谈一些基础的、公用的部分,以作参考。
接入层:接收前端请求的CGI应用,一般处理内容详情拉取、日志上报、各种人工规则干预、去重等任务,计算逻辑简单,I/O密集型任务。这里我们用 Golang 实现,看重他的goroutines处理高并发的能力。
日志采集:消息队列处理前后端的日志上报(点击/曝光/负反馈),采用Kafka,实时打到 Spark Streaming 处理实时数据,同时定期落地到 hdfs 上用以离线处理。
画像计算:用 Spark/Hadoop 按前文所述的方法批量计算长期用户画像,一天计算一次,结果存入 HDFS。
实时画像:采用 Spark Streaming 直接拉取 Kafka 的流实时进行衰减/合并计算,结果写入到 Redis,供线上使用。因为我们每天还会计算一次长期画像,因此短期画像只用保存一天即可。
召回索引:离线更新召回倒排表,定期刷新至线上召回集群的内存里,以加快检索速度。另外在召回模块中,还需要实现诸如截断、过滤等算子,用以在召回的过程中快速过滤曝光内容,截取topN的文章摘要等。
按照上述架构搭建起来后的系统投入到线上使用,QPS在单机1k左右,在召回和接入上还有一些待优化的地方。最终的信息流中,我们从个性化的多路召回中拿到了一批内容,最后根据文章质量(点击量/点击率/阅读时长)统一排序,输出到用户侧,完成推荐。这样,一个推荐系统的完整流程便完成了。
5. 排序模型
我们根据不同召回策略召回了一批文章,并统一根据文章质量排序输出。但实际上,用户的阅读兴趣还会受到很多其他因素的影响。比如用户所处的网络环境,文章点击率、时效性,用户的年龄、性别,或者多种因素交叉的影响,而排序最终决定了用户优先看到的内容(最终推荐流是召回队列的topN),因此排序过程是至关重要的。
5.1. 模型选择
排序的问题在机器学习中有很多可以使用的方法,应用到推荐系统实际上就是一个二分类问题。以用户、内容、上下文的一些特征作为输入,输出是介于0(不感兴趣)和1(感兴趣)之间的一个概率,称作 pCTR(预测点击率)。分类算法有很多,出于规模和性能的考量,业界更多的还是使用线性的方法,传统方法有 Logistic Regression 和 Factorization Machine。
5.1.1. Logistic Regression
逻辑回归是一个经久不衰的统计分析方法,它的预测公式如下:
其中g(x)为sigmoid函数,它的作用是将数值压缩到(0,1)的范围内,函数曲线如下:
有了公式,我们便可以将已知的用户特征和行为作为训练集的输入和输出,其中 x 表示输入特征向量,θ 表示每一维特征对应的权重。输入特征我们可以大致分为用户特征、行为特征和内容特征,示例如下:
这其中每一个特征即是 x 向量中的一维,也对应着预测公式中 θ 向量中的一个权重,而我们模型训练的过程则是求出 θ 向量,最终我们可以通过线上的 x 向量实际输入,代入公式最终得出预测点击率 g(x)。
5.1.2. 特征工程
当然,以上示例的特征取值如果直接使用 LR 进行训练,效果肯定是不好的。因为 LR 学到的是变量的线性关系,而有一些特征取值却并不具备线性相关。比如性别,0代表男性,1代表女性,但这里的数值大小关系并没有什么意义;再比如年龄,不一定所有年龄段内,兴趣都和年龄大小完全线性相关。因此,在训练之前我们需要对特征做一些诸如离散化、数值分桶等操作,尽量让特征与结果表现出线性关系。
另外,有些特征单独对分类影响并不大,但与其他特征交叉影响就明显了。比如年龄X性别、分类X关键词,因此,我们需要根据一些业务上的了解和经验来决定如何进行特征交叉(当然我们可以直接将所有特征的笛卡尔积扔进去训练,但对于训练效率来说这通常是不现实的),往往在特征上的工作占了模型工作的绝大部分时间,因为特征工程的质量决定了模型效果的上限。
我们也可以用一些决策树的方法来自动选择特征,比如 Facebook 在2014年提出的 GBDT+LR 的推荐模型,就是采用 GBDT(梯度提升决策树)的方法做特征选择,并将树的输出直接作为 LR 的特征输入,取得了比较好的效果。
5.1.3. Factorization Machine
特征工程是个耗时耗力,且非常考验业务理解力的过程,当我们处在项目初期,又不想花太多精力去做特征选择时,FM 算法便成了我们的另一种选择。FM 的预测公式如下:
仔细对比上述公式和 LR 公式,可以看出 FM 本质上其实就是在 LR 的基础上增加了发掘二阶特征关系的kernel,vi,vj 表示的是二阶特征经过矩阵分解后得到的低秩矩阵的值:
矩阵分解在推荐系统中很常用,实质上是将一个高维稀疏矩阵分解成两个低秩矩阵,其中 k 被称为隐向量维度。在原始的稀疏矩阵 R 中,大部分二阶特征的关系系数是缺失的。而通过训练模型最小化 R 和预测矩阵 R‘ 的损失(如最小二乘),可以求出任意 Ri,j的值。FM 的kernel在此基础上学习到任意二阶特征的非线性关系,求得它们的权重。
5.2. 模型训练
确定模型后,我们需要根据目标确认损失函数,比如回归一般使用 RMSE,二分类使用 Cross Entropy,然后我们就需要朝最小化损失函数的目的来训练参数了。
求解函数有多种,如果数据量较小,可以选择批量训练的方式,如传统的梯度下降法:Batch Gradient Descent,也可以选择拟牛顿法如 L-BFGS ,用二阶导数求得更快的训练速度。它们的优点是考虑到全部样本,模型准确,但缺点是数据量太大时训练速度很慢。我们可以考虑每次采用小批量的样本训练模型的 online learning,从而达到实时更新模型的效果。方法如 SGD、FOBOS、RDA、FTRL 等等,对比和公示详解建议阅读冯扬的《在线最优化求解》,讲得很详细,这里就不赘述了。
5.3. 在线预测
训练完成后,我们可以把模型文件(实质是所有参数的取值)保存到本地,或者为了更高的执行效率,把它们加载到内存。预测的执行步骤如下:
1. 召回内容队列
2. 线上的服务器从内存读取参数取值 θ
3. 拉取到内容/用户/上下文的实时特征 x
4. 代入预测公式,计算用户 u 对内容 i 的点击率
5. 依据点击率对召回内容排序并返回
每隔一段时间,模型更新之后需要将新训练得到的参数值刷新到预测服务器的内存中。当特征维度很大时模型文件体积也很大,此时如何按时完成更新是个问题,Parameter Server 是一类解决这类问题的框架。
5.4. Rerank
在排序完成之后,直接将排序结果呈现在用户面前可能不是一个好的选择。首先,产品需要有一些特殊的内容形式作为自己的品牌形象;另外,完全根据模型规则走可能让用户兴趣越来越窄,推荐内容同质化,久而久之则会影响用户对内容产品的黏性。
解决这个问题就是在排序之后再进行一次 rerank,我们可以用人工规则的方式,或者贪心算法来确保最后推荐给用户的 TOP10 内容的多样性,以及插入一些对于用户画像里缺失兴趣的探索。
6. 总结
推荐系统涉及到的东西很多,本文只是对各个环节作了些简单的概述。如果要完善系统并真正满足用户的需求,则需要在各个环节都做深入的研究,希望大家共勉。
Java自动采集生成内容系统最有效的自动化采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-05-01 18:01
关键词自动采集生成内容系统最有效的自动化采集方法
qkdwiki的采集程序用的就是java,多说两句,咱们做程序的多少要懂点计算机,vc++7.0是底线,至少要懂点c语言,windows编程,有个shell脚本去操作,自动去除用户的自定义浏览器,自动post,抓取程序首先得能熟练运用键盘操作,思维也得敏捷,
现在做,
现在qkdwiki也是用的java。java做采集,一般是先选址采集,当然可以通过其他方式达到目的;选址java也是大多数同类产品采用的方式,但java做大的也就那么几家。而web采集一般是用es库,再加上js。(我是指从网上抓。)其中es库是elasticsearch,es比较简单易用,并且也不需要写网页页面。
就是不愿意用ie浏览器而已。shit。
这个问题,我们在实际工作中遇到过。楼主你认为qkdwiki是用java开发的,
用java做js+selenium+js采集,ie浏览器兼容性挺麻烦的,搞不好还要用网页编辑器去敲js请求。这样的话体验不会太好,也会很占存储空间,效率慢。
纯web端的话还是layan.lajs在线教育平台的版本在不考虑占用网络资源的情况下已经实现了全平台分布式采集需求 查看全部
Java自动采集生成内容系统最有效的自动化采集方法
关键词自动采集生成内容系统最有效的自动化采集方法
qkdwiki的采集程序用的就是java,多说两句,咱们做程序的多少要懂点计算机,vc++7.0是底线,至少要懂点c语言,windows编程,有个shell脚本去操作,自动去除用户的自定义浏览器,自动post,抓取程序首先得能熟练运用键盘操作,思维也得敏捷,
现在做,
现在qkdwiki也是用的java。java做采集,一般是先选址采集,当然可以通过其他方式达到目的;选址java也是大多数同类产品采用的方式,但java做大的也就那么几家。而web采集一般是用es库,再加上js。(我是指从网上抓。)其中es库是elasticsearch,es比较简单易用,并且也不需要写网页页面。
就是不愿意用ie浏览器而已。shit。
这个问题,我们在实际工作中遇到过。楼主你认为qkdwiki是用java开发的,
用java做js+selenium+js采集,ie浏览器兼容性挺麻烦的,搞不好还要用网页编辑器去敲js请求。这样的话体验不会太好,也会很占存储空间,效率慢。
纯web端的话还是layan.lajs在线教育平台的版本在不考虑占用网络资源的情况下已经实现了全平台分布式采集需求
关键词自动采集生成内容系统(几种爬虫常见的数据采集场景介绍-乐题日志宏)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-04-20 18:23
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。
②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。
3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSp ider data采集软件可以实现多种关键词retrieval采集方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼写网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。
例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器存储在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。
例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。 查看全部
关键词自动采集生成内容系统(几种爬虫常见的数据采集场景介绍-乐题日志宏)
千修每天都会收到大量的数据采集需求。虽然来自不同的行业、网站和企业,但每个需求的采集场景有很多相似之处。根据您对数据采集的需求,小编总结了以下爬虫常用的数据采集场景。
1.实时采集并更新新数据
对于很多舆情或政策监测数据采集的需求,大部分需要做到实时采集,只有采集新数据。这样可以快速监控所需的数据,提高监控速度和质量。
ForeSpider数据采集软件可设置为不间断采集,7×24H不间断采集指定网站,已存储的数据不重复采集 ,实时更新网站中新增的数据,之前采集的数据不会重复存储,也不需要每天重新采集数据,大大提高数据采集的效率,节省网络带宽和代理IP资源。
设置介绍:
①时机采集
Timing采集:设置任务定时设置,可以在某个时间点开始/停止采集,也可以在一定时间后开始/停止采集。
②增量采集:每次只取采集的更新链接,只取更新链接,不取数据页。
这样,爬虫软件不仅可以自动采集,实时更新,还可以自动重新加载,保证数据采集的高效稳定运行。
2.自动补充缺失数据
在爬取采集数据的过程中,由于网络异常、加载异常、网站反爬等原因,在采集过程中丢失了部分数据。
针对这种情况,需要在采集过程中重新采集失败的请求采集,以高效获取全量数据。
ForeSpider数据采集系统可以针对这种常见的采集场景进行数据补充采集设置,从而提高采集效率,快速获取全量数据。
设置介绍:
①自定义采集策略:选择采集入库失败,采集错误,上次没有采集数据。设置并重新采集后,可以快速重新采集之前丢失的数据,无需重复耗时耗力的采集。
②设置加载日志宏:根据任务ID值、任务数据大小等,对于不符合采集要求的数据,过滤日志列表,重新采集补充缺失的数据。
比如有些网站的IP被重定向新的URL屏蔽了,所以采集状态显示成功,但是任务的数据质量一般很小,比如2KB。在这种情况下,可以加载日志宏。,加载质量太低的任务日志,无法重新采集这部分任务。
3.时序采集数据
一个很常见的数据采集需求是每天在固定点开始爬取一个或多个网站。为了腾出双手,对采集数据进行计时是非常有必要的。
ForeSpider数据采集系统可以设置定时启动和停止采集,时间点和时间段结合设置,可以在某个时间点启动/停止采集,或者在某个时间段发布预定的开始/停止采集。减少人力重复工作,有效避免人工采集的情况。
设置介绍:
①间隔定时采集:设置间隔时间,以固定间隔时间实现采集的开/关。
②固定时间采集:设置爬虫自动启动/停止的时间。
例子:
①采集每天都有新数据
每天定时添加新数据采集,每天设置一定时间采集添加新数据,设置后可以每天设置采集,节省人工成本。
②网站反爬
当采集在一段时间后无法获取数据时,可以在一段时间后再次获取数据。打开采集后,根据防爬规则,设置一定时间停止采集,设置一定时间开始采集,可以有效避免防爬攀爬,高效 采集@ >数据。
③自动更新数据库
部署到服务器后,需要每天采集网站新数据到本地数据库,可以开始调度采集,以及采集数据定时每天。
4.批量关键词搜索
我们经常需要采集某个网站关于某个行业、某个事件、某个主题等相关内容,那么我们会用关键词采集来采集 批量 关键词 搜索到的数据。
ForeSp ider data采集软件可以实现多种关键词retrieval采集方法。
①批量导入关键词,采集在目标网站中查找关键词中的数据内容,同时对关键词进行排序和再处理,方便快捷,无需编写脚本批量采集关键词搜索到的数据。
②关键词存在于外部数据库中,实时调用采集。通过ForeSpider爬虫软件连接到其他数据库的数据表,或者爬虫软件中的其他数据表,可以利用动态变化的关键词库实时检索采集数据。
③ 通过接口实时传输关键词。用户数据中实时生成的搜索词可以通过接口实时关键词检索采集传输到ForeSpider数据采集系统。并将采集接收到的数据实时传回用户系统显示。
设置介绍:
关键词配置:可以进行关键词配置,在高级配置中可以配置各种参数。
关键词列表:批量导入、修改关键词批量导入、删除、修改关键词,也可以对关键词进行排序和重新处理。
例子:
①采集关键词搜索到网站
比如百度、360问答、微博搜索等网站都有搜索功能。
②关键词充当词库,调用和使用
例如,一个不同区域分类的网站网址收录区域参数,可以直接将区域参数导入到关键词列表中,编写一个简单的脚本,调用关键词拼写网站@的不同区域分类>使配置更容易。
③ 用户输入搜索词,实时抓取数据返回显示
用户输入需要检索的词后,实时传输到ForeSpider爬虫软件,进行现场查询采集,采集接收到的数据为实时传回用户系统,向用户展示数据。
5.自定义过滤器文件大小/类型
我们经常需要采集网页中的图片、视频、各种附件等数据。为了获得更准确的数据,需要更精确地过滤文件的大小/类型。
在嗅探ForeSpider采集软件之前,可以自行设置采集文件的上下限或文件类型,从而过滤采集网页中符合条件的文件数据。
例如:采集网页中大于2b的文件数据,采集网页中的所有文本数据,采集页面中的图片数据,采集@中的视频数据>文件等。
设置介绍:
设置过滤:设置采集文件的类型,采集该类型的文件数据,设置采集文件大小下限过滤小文件,设置采集过滤大文件的文件大小阈值。
例子:
①采集网页中的所有图片数据
当需要网页中全部或部分图片数据时,在文件设置中选择采集文件类型,然后配置采集,节省配置成本,实现精准采集。
②采集网页中的所有视频数据
当需要采集网页中的全部或部分视频数据时,在文件设置中选择采集文件类型,然后配置采集。
③采集网页中的具体文件数据
通过设置采集的文件大小下限,过滤掉小文件和无效文件,实现精准采集。
6.登录采集
当采集需要在网站上注册数据时,需要进行注册设置。嗅探ForeSpider数据前采集分析引擎可以采集需要登录(账号密码登录、扫描登录、短信验证登录)网站、APP数据、采集登录后可见数据。
ForeSpider爬虫软件,可以设置自动登录,也可以手动设置登录,也可以使用cookies登录,多种登录配置方式适合各种登录场景,配置灵活。
概念介绍:
Cookie:Cookie是指存储在用户本地终端上的一些网站数据,用于识别用户身份和进行会话跟踪。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器存储在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。可以模拟登录的cookie采集。
设置介绍:
①登录配置:可以自动配置,也可以手动配置。
②Cookie设置:对于需要cookie的网站,可以自动生成cookie来获取数据。您也可以手动添加 cookie 来获取数据。
例子:
适用于任何需要登录的网站、APP数据(账号密码登录、扫描登录、短信验证登录)。
7.批处理网站批处理配置
大多数企业级的大数据项目,往往需要很多采集中的网站,从几百到几千万不等。单独配置每个 网站 是不现实的。这时候需要批量配置上千个网站和采集。
ForeSpider 爬虫软件就是专门针对这种情况设计的。独创智能配置算法和采集配置语言,可高效配置采集,解析网页结构。数据,无需依次配置每个网站,即可实现同步采集万条网站。
用户将需要采集的URL列表输入到采集任务中,通过对采集内容的智能识别,实现一个配置采集模板来< @k11@ > 成千上万的 网站 需求量很大。
优势:
①节省大量人工配置成本:无需手动一一配置网站即可实现采集千网站的需求。
②采集大批量网站短时间,快速功能上线:快速实现网站数据扩容,采集短时间海量数据,缩短项目启动时间。
③采集数据量大,范围广:一次性实现海量网站采集需求,批量管理海量数据,实现企业级数据< @采集 能力。
④数据易管理:数据高度集中管理,便于全局监控数据采集情况,便于运维。
⑤灵活删除采集源:不想继续采集的源可以随时删除,也可以随时批量添加新的采集源。
例子:
①舆情监测
快速实现短时间内对大量媒体网站的数据监控,快速形成与某事件/主题相关的内容监控。
②内容发布平台
采集批量URL、某方面的海量采集内容,分类后发布相应数据。
③行业信息库
快速建立行业相关信息数据库供查询使用。
看到这里,应该对爬虫的采集场景有了深入的了解。后期我们会结合各种采集场景为大家展示更多采集案例,敬请期待。
关键词自动采集生成内容系统(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-20 12:21
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站 内部没有这样的分类,但是我们可以通过聚合策略生成这样一个带有 网站 通道和列的非正式分类,然后用这个分类来聚合北京的程序员很长时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般情况下,双面标签是成对出现的,所以必须写出结束标识符,单面标签也应该以反斜杠结束。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清源易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认以后不要轻易修改,所以每次修改时,必须等待。搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
查看全部
关键词自动采集生成内容系统(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站 内部没有这样的分类,但是我们可以通过聚合策略生成这样一个带有 网站 通道和列的非正式分类,然后用这个分类来聚合北京的程序员很长时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选地将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),无需每天登录网站后台. SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般情况下,双面标签是成对出现的,所以必须写出结束标识符,单面标签也应该以反斜杠结束。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清源易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认以后不要轻易修改,所以每次修改时,必须等待。搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
关键词自动采集生成内容系统(无需编程,精准分词一键批量采集,你是指手机端的吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-19 21:00
关键词自动采集生成内容系统软件学习资料可以看下下面这个,无需编程,精准分词一键批量采集,
你是指手机端的吗?app有现成的免费的网址抓取工具,使用app后,
其实就是一个大网站,很多地方都有可以采集,最简单的就是到一些大网站上去搜索一些公司信息和产品的一些信息等。但是就拿我自己来说,其实是会用一些电脑app软件,对于采集我是用的allforwhat()一个专门下载的app软件。
手机不就是一个浏览器么,有什么必要专门开发一个app吧。
现在app太多了,都没差别,你可以试试的采集软件的,不需要编程,就可以抓取全国范围内的app了,全网联动的,
这个找一个按时薪算钱的
个人觉得网是一个非常大的网站,他里面所有的信息都是具有很大的参考价值的。如果你在网上能找到的信息都能找到的话,不如手工去找那些已经被app收录的网页,或者是手工去下载那些被app收录的信息。 查看全部
关键词自动采集生成内容系统(无需编程,精准分词一键批量采集,你是指手机端的吗?)
关键词自动采集生成内容系统软件学习资料可以看下下面这个,无需编程,精准分词一键批量采集,
你是指手机端的吗?app有现成的免费的网址抓取工具,使用app后,
其实就是一个大网站,很多地方都有可以采集,最简单的就是到一些大网站上去搜索一些公司信息和产品的一些信息等。但是就拿我自己来说,其实是会用一些电脑app软件,对于采集我是用的allforwhat()一个专门下载的app软件。
手机不就是一个浏览器么,有什么必要专门开发一个app吧。
现在app太多了,都没差别,你可以试试的采集软件的,不需要编程,就可以抓取全国范围内的app了,全网联动的,
这个找一个按时薪算钱的
个人觉得网是一个非常大的网站,他里面所有的信息都是具有很大的参考价值的。如果你在网上能找到的信息都能找到的话,不如手工去找那些已经被app收录的网页,或者是手工去下载那些被app收录的信息。
关键词自动采集生成内容系统(自动采集生成内容系统爬虫系统如何分析网站来获取更多的cookie)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-17 21:01
关键词自动采集生成内容系统爬虫系统页面排序算法爬虫系统如何分析网站来获取更多的cookie
我现在正在从事的东西就是涉及这方面的内容,爬虫对seo是肯定有帮助的,也要视你爬虫的策略而定。如果是负责本站站内,可以考虑采集、复制、粘贴。如果要涉及全站、全网站的话,那就需要提高爬虫算法的通用性以及多进程性能,这就要考虑多种不同服务器类型的对比以及性能优劣等问题了。比如,你采用分布式爬虫+计算机内核的服务器架构,即便分配出多个服务器,一般都可以采取多线程来跑,而不同服务器访问同一页面的延迟不会相差太大。但如果采用单进程的架构,那么单个服务器的访问延迟肯定要比分布式大很多。
记住一句话,你开什么样的车,你就搭配什么样的车胎,千万不要找一台定位不明确的车。建议知道你要爬什么,又是个什么网站。之后一个一个地都分析一下,无非就是各种生成元素,策略也很多,记住一句话,快下大雨的时候,放一把伞,下雨天也有着落。当然,我都是说说而已,如果你知道你要爬哪些网站,建议你看一看白帽是如何做爬虫的,这些都可以实现你的目的。
给你几篇学习大纲:python优秀开源爬虫项目解析及快速入门。数据采集的基本方法与流程。采集中要做到以下三点:1.已知数据集,进行分析;2.数据源头、数据清洗等;3.存储、同步数据;爬虫系统的架构、设计及实现。 查看全部
关键词自动采集生成内容系统(自动采集生成内容系统爬虫系统如何分析网站来获取更多的cookie)
关键词自动采集生成内容系统爬虫系统页面排序算法爬虫系统如何分析网站来获取更多的cookie
我现在正在从事的东西就是涉及这方面的内容,爬虫对seo是肯定有帮助的,也要视你爬虫的策略而定。如果是负责本站站内,可以考虑采集、复制、粘贴。如果要涉及全站、全网站的话,那就需要提高爬虫算法的通用性以及多进程性能,这就要考虑多种不同服务器类型的对比以及性能优劣等问题了。比如,你采用分布式爬虫+计算机内核的服务器架构,即便分配出多个服务器,一般都可以采取多线程来跑,而不同服务器访问同一页面的延迟不会相差太大。但如果采用单进程的架构,那么单个服务器的访问延迟肯定要比分布式大很多。
记住一句话,你开什么样的车,你就搭配什么样的车胎,千万不要找一台定位不明确的车。建议知道你要爬什么,又是个什么网站。之后一个一个地都分析一下,无非就是各种生成元素,策略也很多,记住一句话,快下大雨的时候,放一把伞,下雨天也有着落。当然,我都是说说而已,如果你知道你要爬哪些网站,建议你看一看白帽是如何做爬虫的,这些都可以实现你的目的。
给你几篇学习大纲:python优秀开源爬虫项目解析及快速入门。数据采集的基本方法与流程。采集中要做到以下三点:1.已知数据集,进行分析;2.数据源头、数据清洗等;3.存储、同步数据;爬虫系统的架构、设计及实现。
关键词自动采集生成内容系统(通王优化策略、这样做能让流量倍增!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-04-17 09:18
通网(TWcms)是中国领先的自由企业网站管理系统,TWcms是一个简单、易用、安全、开源的企业网站< @cms系统,完全符合 SEO。但是市面上并没有文章采集伪原创发布TWcms的功能,更别说搜狗、百度、神马等一键批量自动搜索引擎,和360推送。,并积极向搜索引擎公开链接,通过推送增加蜘蛛爬取,从而提升网站收录的排名和SEO。利用免费的通网cms采集插件采集很多文章内容。
同网cms采集批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, TWcms, WP, Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。
通网cms采集第一步:关键词布局:在搜索结果页面中,关键词的密度非常合理。可以在网页的六个关键位置布局关键词。长尾关键词优化策略,这样可以让流量翻倍!我发现很多人不关注长尾关键词的优化。按照一般的优化思路,从网站上线开始,一般都是根据网站的核心词进行优化。通网cms采集支持其他平台的图片本地化或存储。通网cms采集标题前缀和后缀设置(标题的区别更好收录)。这就产生了一个现象:如果主关键词比较流行,
这段时间网站的流量很低,转化率自然很低。如果你改变主意,调整策略,在优化网站的过程中,我们首先采用长尾关键词优化策略,使用长尾关键词获取流量网站。在此基础上,通网cms采集支持多源采集采集(覆盖全网行业新闻源,海量内容库,采集最新内容) . 我们会逐步提升主力关键词的排名。因此,我们必须考虑长尾 关键词 的优化技术。
通过通网cms采集可以直接查看蜘蛛、收录、网站的每日体重!首先,点击网站关键词的长尾。有很多 SEO 工具可以挖掘长尾关键词。通过挖掘网站的长尾关键词,我们可以总结出这些挖掘出来的长尾关键词。这对于我们需要优化的长尾关键词有一定的针对性,主要考虑哪个长尾关键词能给网站带来流量和转化率,可以增强。关键词挖掘工具推荐使用5118、来挖掘手机、相关搜索、下拉词。
童网cms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。其次,在写突出的标题和描述的时候,在优化长尾关键词的时候,我们一般都是在内容页上操作的,所以这个内容页的写法和优化是很重要的。通网cms采集内容与标题一致(使内容与标题100%相关)。
要突出显示的长尾关键词可以适当地融入标题和描述中,就好像这个内容的标题本身就是一个长尾关键词一样。通网cms采集自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权重)。描述的写法很重要,它在搜索引擎搜索结果中以标题、描述和网站的形式出现。描述占用大量字节。通网cms采集定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)。
因此,合理、有吸引力和详细的描述可以为网站获得更多点击。设置批量发布数量(可以设置发布间隔/单日发布总数)。还需要整合长尾关键词。告诉大家一个小窍门,每个关键词名称不同但可能含义不同,所以一个关键词可以写2-3条内容,可以优化2-3条内容两个或三个 关键词。长尾关键词优化策略,这样可以让流量翻倍!
可以设置不同的关键词文章发布不同的栏目。通网cms采集伪原创保留字(文章原创时伪原创不设置核心字)。通网cms采集软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
三、加强长尾关键词注意关键词的密度,尽量在每个段落中出现关键词,关于关键词的密度,我不觉得需要大家关心,自然就好了。通网cms采集可以设置自动删除不相关的词。通过通网cms采集插件实现自动化采集行业相关文章,通网cms采集一次可以创建几十个或者几百个采集tasks,支持同时执行多个域名任务采集。同网cms采集自动过滤其他网站促销信息。我们输出内容的目的是为了解决用户的需求。在内容 收录 之后,随后的排名对关键词的密度也有一定的要求。通网cms采集随机图片插入(文章如果没有图片可以随机插入相关图片)。此时要注意页面内容的丰富度和相关性。关键字出现的地方,加粗。文章标题可以是 H1 或 H2。4.内容中适当出现了一些相关的关键词。
第四,推荐相关内容。一篇文章的文章可能无法把这方面的知识写的很全面,所以我们可以合理的推荐一些文章,在文章的末尾加上相关的关键词,这样有很多好处。降低网站的跳出率、增加网站的内链、增加网站的PV等等,都可以很好的粘住客户。
设置批量发布数量(可以设置发布间隔/单日发布总数)。第五,记录长尾关键词文章链接。合理的工作计划和记录对我们的工作有很大帮助。作为记录,当一个长尾 关键词 合理地出现在另一个 文章 中时,即锚文本,我们可以加粗并带出那个 关键词 的 文章 链接。通网cms采集第二步:URL优化策略。通常,搜索结果的 URL 收录大量参数。这样的URL在各大搜索引擎中的权重比较低,在目录结构中可以映射成权重比较高的URL。通过通网cms采集插件生成行业相关词,从下拉词中生成关键词,相关搜索词和长尾词。长尾关键词优化策略,这样可以让流量翻倍!
通网cms采集SEO策略用最简单的手段获得最好的SEO效果!第六,利用外部资源优化长尾关键词。通网cms采集还可以促进这些搜索结果页面相互之间形成良好的反向链接关系,有助于提高这些关键词页面在各大搜索引擎中的排名。许多 网站 内容页面的排名都不是很好,有些 网站 很难排名。改变主意并使用高权重 网站 来实现我们想要的。比如百度知道一个很大的优势就是长尾关键词,因为这取决于用户的搜索习惯。
通网cms采集第三步:内链框架策略。在搜索结果中,一定要像谷歌一样列出相关的关键词,这样谷歌的蜘蛛就可以沿着相关的关键词链接继续爬取更多的搜索结果页面。一般来说,百度自己的产品总是出现在我们搜索的长尾关键词前面。通网cms采集自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。因此,我们可以使用百度知道来帮助我们优化长尾关键词,去百度知道询问长尾关键词,然后在我们的网站上写一篇关于长尾关键词的文章网站 内容@> 的 文章,顺便说一下,回答百度知道的问题,给我们网站的网站,普通人看到这个问题就会点击这个链接。通网cms采集内容关键词插入(合理增加关键词的密度)。
通网cms采集搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录 )。今天关于通网cms的讲解就到这里,下期分享更多SEO相关知识。下次见!
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。 查看全部
关键词自动采集生成内容系统(通王优化策略、这样做能让流量倍增!(组图))
通网(TWcms)是中国领先的自由企业网站管理系统,TWcms是一个简单、易用、安全、开源的企业网站< @cms系统,完全符合 SEO。但是市面上并没有文章采集伪原创发布TWcms的功能,更别说搜狗、百度、神马等一键批量自动搜索引擎,和360推送。,并积极向搜索引擎公开链接,通过推送增加蜘蛛爬取,从而提升网站收录的排名和SEO。利用免费的通网cms采集插件采集很多文章内容。
同网cms采集批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, TWcms, WP, Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。
通网cms采集第一步:关键词布局:在搜索结果页面中,关键词的密度非常合理。可以在网页的六个关键位置布局关键词。长尾关键词优化策略,这样可以让流量翻倍!我发现很多人不关注长尾关键词的优化。按照一般的优化思路,从网站上线开始,一般都是根据网站的核心词进行优化。通网cms采集支持其他平台的图片本地化或存储。通网cms采集标题前缀和后缀设置(标题的区别更好收录)。这就产生了一个现象:如果主关键词比较流行,
这段时间网站的流量很低,转化率自然很低。如果你改变主意,调整策略,在优化网站的过程中,我们首先采用长尾关键词优化策略,使用长尾关键词获取流量网站。在此基础上,通网cms采集支持多源采集采集(覆盖全网行业新闻源,海量内容库,采集最新内容) . 我们会逐步提升主力关键词的排名。因此,我们必须考虑长尾 关键词 的优化技术。
通过通网cms采集可以直接查看蜘蛛、收录、网站的每日体重!首先,点击网站关键词的长尾。有很多 SEO 工具可以挖掘长尾关键词。通过挖掘网站的长尾关键词,我们可以总结出这些挖掘出来的长尾关键词。这对于我们需要优化的长尾关键词有一定的针对性,主要考虑哪个长尾关键词能给网站带来流量和转化率,可以增强。关键词挖掘工具推荐使用5118、来挖掘手机、相关搜索、下拉词。
童网cms采集随机点赞-随机阅读-随机作者(提高页面度数原创)。其次,在写突出的标题和描述的时候,在优化长尾关键词的时候,我们一般都是在内容页上操作的,所以这个内容页的写法和优化是很重要的。通网cms采集内容与标题一致(使内容与标题100%相关)。
要突出显示的长尾关键词可以适当地融入标题和描述中,就好像这个内容的标题本身就是一个长尾关键词一样。通网cms采集自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权重)。描述的写法很重要,它在搜索引擎搜索结果中以标题、描述和网站的形式出现。描述占用大量字节。通网cms采集定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高网站的收录)。
因此,合理、有吸引力和详细的描述可以为网站获得更多点击。设置批量发布数量(可以设置发布间隔/单日发布总数)。还需要整合长尾关键词。告诉大家一个小窍门,每个关键词名称不同但可能含义不同,所以一个关键词可以写2-3条内容,可以优化2-3条内容两个或三个 关键词。长尾关键词优化策略,这样可以让流量翻倍!
可以设置不同的关键词文章发布不同的栏目。通网cms采集伪原创保留字(文章原创时伪原创不设置核心字)。通网cms采集软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
三、加强长尾关键词注意关键词的密度,尽量在每个段落中出现关键词,关于关键词的密度,我不觉得需要大家关心,自然就好了。通网cms采集可以设置自动删除不相关的词。通过通网cms采集插件实现自动化采集行业相关文章,通网cms采集一次可以创建几十个或者几百个采集tasks,支持同时执行多个域名任务采集。同网cms采集自动过滤其他网站促销信息。我们输出内容的目的是为了解决用户的需求。在内容 收录 之后,随后的排名对关键词的密度也有一定的要求。通网cms采集随机图片插入(文章如果没有图片可以随机插入相关图片)。此时要注意页面内容的丰富度和相关性。关键字出现的地方,加粗。文章标题可以是 H1 或 H2。4.内容中适当出现了一些相关的关键词。
第四,推荐相关内容。一篇文章的文章可能无法把这方面的知识写的很全面,所以我们可以合理的推荐一些文章,在文章的末尾加上相关的关键词,这样有很多好处。降低网站的跳出率、增加网站的内链、增加网站的PV等等,都可以很好的粘住客户。
设置批量发布数量(可以设置发布间隔/单日发布总数)。第五,记录长尾关键词文章链接。合理的工作计划和记录对我们的工作有很大帮助。作为记录,当一个长尾 关键词 合理地出现在另一个 文章 中时,即锚文本,我们可以加粗并带出那个 关键词 的 文章 链接。通网cms采集第二步:URL优化策略。通常,搜索结果的 URL 收录大量参数。这样的URL在各大搜索引擎中的权重比较低,在目录结构中可以映射成权重比较高的URL。通过通网cms采集插件生成行业相关词,从下拉词中生成关键词,相关搜索词和长尾词。长尾关键词优化策略,这样可以让流量翻倍!
通网cms采集SEO策略用最简单的手段获得最好的SEO效果!第六,利用外部资源优化长尾关键词。通网cms采集还可以促进这些搜索结果页面相互之间形成良好的反向链接关系,有助于提高这些关键词页面在各大搜索引擎中的排名。许多 网站 内容页面的排名都不是很好,有些 网站 很难排名。改变主意并使用高权重 网站 来实现我们想要的。比如百度知道一个很大的优势就是长尾关键词,因为这取决于用户的搜索习惯。
通网cms采集第三步:内链框架策略。在搜索结果中,一定要像谷歌一样列出相关的关键词,这样谷歌的蜘蛛就可以沿着相关的关键词链接继续爬取更多的搜索结果页面。一般来说,百度自己的产品总是出现在我们搜索的长尾关键词前面。通网cms采集自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。因此,我们可以使用百度知道来帮助我们优化长尾关键词,去百度知道询问长尾关键词,然后在我们的网站上写一篇关于长尾关键词的文章网站 内容@> 的 文章,顺便说一下,回答百度知道的问题,给我们网站的网站,普通人看到这个问题就会点击这个链接。通网cms采集内容关键词插入(合理增加关键词的密度)。
通网cms采集搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录 )。今天关于通网cms的讲解就到这里,下期分享更多SEO相关知识。下次见!
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。
关键词自动采集生成内容系统(输入关键词自动生成文章,什么是输入什么关键词‘装修’免费工具?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-04-17 09:14
类型关键词自动生成文章,什么是类型关键词自动生成文章?例子:你输入什么关键词'装饰'免费工具会自动生成一个装饰相关的文章,免费工具还支持:自动关键词文章generate+文章自动采集+伪原创+自动发布+自动推送到搜索引擎收录进行排名,实现自动挂机。(详见图表一、二、三、四)
最近有一些刚进入网站优化行业的站长问我网站结构是什么?什么样的网站结构对搜索引擎更友好?网站结构的优化要注意哪些方面?本来想跟大家分享站内优化的相关案例。想来想去,还是把网站这个结构单独拿出来了。关于网站结构的优化,相信我是刚开始做这个行业。站长确实是博古通金,所以本文文章主要是和站长朋友分享一下网站结构优化的心得。
什么是正确优化的 网站 构造?
广义上的网站结构主要包括网站的物理结构和逻辑结构;狭义上是网站的目录结构和内部链结构。@>结构的优化这里主要从目录结构和内部链结构来讨论。
目录结构就是网站的URL结构。在服务器上设置网站时,站长会发现在服务器根目录下通常有一个WWW文件夹。情况不一定如此。是的,但是大部分名字都是一样的,然后根据网站的规划和内容规划,会有一个基于WWW的层级目录,每个目录都会有详细的web文件,如:html、shtml、aspx、php等。这个目录方法的构建就构成了用户访问的URL地址。另一方面,URL地址是文件存储在服务器上的目录方法;这也很容易理解。
内部链接结构简单来说就是网站的页面之间的关系。建立网站的站长知道,除了一个页面的中心内容,尤其是网站的首页,一个栏目页或者一个列表页会由很多链接组成,其中的链接这些页面构成了整个网站的内部链结构。至于内部链结构如何更合理,搜索更友好,我会一一分享给各位站长朋友。
二、哪些网站 结构对搜索引擎友好?
同样在本节中单独列出,以便站长更清楚地了解 网站 结构是如何围绕搜索引擎部署的。
上面提到的目录结构的概念是基于根目录传播到真实文件中的。清晰的目录方式不仅有利于站长的管理,而且对搜索引擎也非常友好。在第一级爬取track得到想要爬取的页面后,如果你的网站只有一个首页、几个栏目页、可展开的专题页和文章详情页,那么理想URL 结构是根据服务服务器上的实际文件存储位置来构建的。但往往一个网站并不是这么简单的情况,网站几乎都有一些功能性产品与用户交互,需要通过动态程序构建大量页面来丰富网站产品体验,
所以你会发现很多网站的url里面有很多动态参数,因为这些页面是通过某种技术批量生成的页面,并不是服务器中实际存在的页面,官方声明搜索引擎只喜欢静态页面。这时候需要对URL地址进行打包重构。无论是 Apache、Ngnix 还是 IIS,都有针对 URL 地址的重写模块。这些暂不介绍。这种URL地址更有利于搜索引擎的抓取,主要包括以下两个方面:
1、URL地址的命名要靠近目标页面的主题标题,有利于提高与目标页面的相关性,从而增加目标页面的权重;
2、URL地址的层级是根据它所属的类别,越小越好。层级越小,通知搜索引擎文件存在的目录深度越小,越容易被爬取,因为只有重要的页面才会放在同一个根目录最近的位置,搜索引擎也会认为这些文件是网站中比较重要的页面,会先被爬取。
内部链接结构主要反映页面之间的关系。与目录结构类似,放在首页的链接地址往往更容易被搜索引擎抓取。在这里,我们触及链接深度的概念。搜索从发现你的网站到开始爬取页面,一般是从首页开始,如果你是新站点,可以从日志中找到。也就是说,越靠近首页的URL越容易被爬取。在这里,同样的搜索引擎会认为链接深度较小的页面在网站中更重要。不同于目录结构,链接深度更高。页面权重越小,被索引的可能性就越大。总而言之,
1、从首页开始,应该包括网站中最重要的业务板块,一般来说是频道页面和话题的聚合;
2、栏目和专题页面应包括其类别下的最新内容模块和热门模块,同时应有返回上一级的面包屑;
3、详情页,作为中心内容页,也应该有相关的引荐板块,以及同一归属板块下的热门引荐板块。当然,面包屑也是必须的。这里需要强调的是,标签的合理使用可以加强文章和文章之间的关系,更有利于搜索引擎的抓取。关于“Lost Crawler”这个标签,会专门用一篇文章文章来告知站长如何规划和使用。
基本上只要按照以上方法优化你的网站结构,相信你的网站在数据上的良好表现也会稳步提升。
三、网站构造优化注意事项
在这里,“迷路的小爬虫”也想总结以下几点,以澄清过度优化的网站结构可能存在被K的风险。总结主要基于以下几点:
1、为了减少链接深度,首页和频道页都堆满了上千个链接地址。如果早期的网站的权重不是很高,这种情况基本上是不完整的;
2、索引标签的大量使用,在网站没有一定范围的文章或其他资源支持的前提下,谨慎使用标签聚合站点内的资源,因为一个可能会添加大量索引标签。会形成网站很多重复页和空页,结果在所难免;
3、详情页不情愿地增加了推荐部分,这使得整个页面显得多余和多余。这也是不可取的。详情页的原创权重是整个网站系统中最低的。添加这么多链接只会被降级。对,即使是收录也不会有好的排名;
4、为了减少目录的深度,所有页面都堆叠到二级目录中。这种方法也是不可取的。如果除首页外的整个网站都是二级目录,就没有主二级目录。,目录深度影响权重的规则是不可取的。
以上四点是《》认为比较重要的一些要素,也是很多站长处理不好的几点,所以单独拿出来强调一下,希望站长们不要再犯这样的错误了。
看完这篇文章,相信大部分站长对网站的结构有了初步的了解,在网站优化的过程中也会有针对性的优化。至于很多站长提到的网站结构,最好使用树状结构或者比较理想的网状结构。这样做,您将构建一个树状或网络状结构 网站。 查看全部
关键词自动采集生成内容系统(输入关键词自动生成文章,什么是输入什么关键词‘装修’免费工具?)
类型关键词自动生成文章,什么是类型关键词自动生成文章?例子:你输入什么关键词'装饰'免费工具会自动生成一个装饰相关的文章,免费工具还支持:自动关键词文章generate+文章自动采集+伪原创+自动发布+自动推送到搜索引擎收录进行排名,实现自动挂机。(详见图表一、二、三、四)
最近有一些刚进入网站优化行业的站长问我网站结构是什么?什么样的网站结构对搜索引擎更友好?网站结构的优化要注意哪些方面?本来想跟大家分享站内优化的相关案例。想来想去,还是把网站这个结构单独拿出来了。关于网站结构的优化,相信我是刚开始做这个行业。站长确实是博古通金,所以本文文章主要是和站长朋友分享一下网站结构优化的心得。
什么是正确优化的 网站 构造?
广义上的网站结构主要包括网站的物理结构和逻辑结构;狭义上是网站的目录结构和内部链结构。@>结构的优化这里主要从目录结构和内部链结构来讨论。
目录结构就是网站的URL结构。在服务器上设置网站时,站长会发现在服务器根目录下通常有一个WWW文件夹。情况不一定如此。是的,但是大部分名字都是一样的,然后根据网站的规划和内容规划,会有一个基于WWW的层级目录,每个目录都会有详细的web文件,如:html、shtml、aspx、php等。这个目录方法的构建就构成了用户访问的URL地址。另一方面,URL地址是文件存储在服务器上的目录方法;这也很容易理解。
内部链接结构简单来说就是网站的页面之间的关系。建立网站的站长知道,除了一个页面的中心内容,尤其是网站的首页,一个栏目页或者一个列表页会由很多链接组成,其中的链接这些页面构成了整个网站的内部链结构。至于内部链结构如何更合理,搜索更友好,我会一一分享给各位站长朋友。
二、哪些网站 结构对搜索引擎友好?
同样在本节中单独列出,以便站长更清楚地了解 网站 结构是如何围绕搜索引擎部署的。
上面提到的目录结构的概念是基于根目录传播到真实文件中的。清晰的目录方式不仅有利于站长的管理,而且对搜索引擎也非常友好。在第一级爬取track得到想要爬取的页面后,如果你的网站只有一个首页、几个栏目页、可展开的专题页和文章详情页,那么理想URL 结构是根据服务服务器上的实际文件存储位置来构建的。但往往一个网站并不是这么简单的情况,网站几乎都有一些功能性产品与用户交互,需要通过动态程序构建大量页面来丰富网站产品体验,
所以你会发现很多网站的url里面有很多动态参数,因为这些页面是通过某种技术批量生成的页面,并不是服务器中实际存在的页面,官方声明搜索引擎只喜欢静态页面。这时候需要对URL地址进行打包重构。无论是 Apache、Ngnix 还是 IIS,都有针对 URL 地址的重写模块。这些暂不介绍。这种URL地址更有利于搜索引擎的抓取,主要包括以下两个方面:
1、URL地址的命名要靠近目标页面的主题标题,有利于提高与目标页面的相关性,从而增加目标页面的权重;
2、URL地址的层级是根据它所属的类别,越小越好。层级越小,通知搜索引擎文件存在的目录深度越小,越容易被爬取,因为只有重要的页面才会放在同一个根目录最近的位置,搜索引擎也会认为这些文件是网站中比较重要的页面,会先被爬取。
内部链接结构主要反映页面之间的关系。与目录结构类似,放在首页的链接地址往往更容易被搜索引擎抓取。在这里,我们触及链接深度的概念。搜索从发现你的网站到开始爬取页面,一般是从首页开始,如果你是新站点,可以从日志中找到。也就是说,越靠近首页的URL越容易被爬取。在这里,同样的搜索引擎会认为链接深度较小的页面在网站中更重要。不同于目录结构,链接深度更高。页面权重越小,被索引的可能性就越大。总而言之,
1、从首页开始,应该包括网站中最重要的业务板块,一般来说是频道页面和话题的聚合;
2、栏目和专题页面应包括其类别下的最新内容模块和热门模块,同时应有返回上一级的面包屑;
3、详情页,作为中心内容页,也应该有相关的引荐板块,以及同一归属板块下的热门引荐板块。当然,面包屑也是必须的。这里需要强调的是,标签的合理使用可以加强文章和文章之间的关系,更有利于搜索引擎的抓取。关于“Lost Crawler”这个标签,会专门用一篇文章文章来告知站长如何规划和使用。
基本上只要按照以上方法优化你的网站结构,相信你的网站在数据上的良好表现也会稳步提升。
三、网站构造优化注意事项
在这里,“迷路的小爬虫”也想总结以下几点,以澄清过度优化的网站结构可能存在被K的风险。总结主要基于以下几点:
1、为了减少链接深度,首页和频道页都堆满了上千个链接地址。如果早期的网站的权重不是很高,这种情况基本上是不完整的;
2、索引标签的大量使用,在网站没有一定范围的文章或其他资源支持的前提下,谨慎使用标签聚合站点内的资源,因为一个可能会添加大量索引标签。会形成网站很多重复页和空页,结果在所难免;
3、详情页不情愿地增加了推荐部分,这使得整个页面显得多余和多余。这也是不可取的。详情页的原创权重是整个网站系统中最低的。添加这么多链接只会被降级。对,即使是收录也不会有好的排名;
4、为了减少目录的深度,所有页面都堆叠到二级目录中。这种方法也是不可取的。如果除首页外的整个网站都是二级目录,就没有主二级目录。,目录深度影响权重的规则是不可取的。
以上四点是《》认为比较重要的一些要素,也是很多站长处理不好的几点,所以单独拿出来强调一下,希望站长们不要再犯这样的错误了。
看完这篇文章,相信大部分站长对网站的结构有了初步的了解,在网站优化的过程中也会有针对性的优化。至于很多站长提到的网站结构,最好使用树状结构或者比较理想的网状结构。这样做,您将构建一个树状或网络状结构 网站。
关键词自动采集生成内容系统(自动采集关键词+自动发布各大网站+主动推送搜索引擎收录排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-14 03:09
自动提取关键词的软件,提取关键词的软件是什么。关键词提取软件有两种:第一种是输入一个核心关键词,软件扩展大量用户搜索词、下拉词、长尾关键词。第二种是基于文章自动提取的core关键词,方便分析文章关键词的排名。今天给大家分享一个万能的SEO工具,自动采集关键词+自动提取关键词+自动文章伪原创+自动采集@ >文章+自动发布主要网站+主动推送搜索引擎收录排名。具体参考图片一、二、三、四、5
如果要在网站的权重上链接锚文本链接和纯文本链接,我们必须知道锚文本链接和纯文本链接是什么。所谓锚文本链接,是指使用A标签停止将一些关键词文本括起来的链接。这样的链接是锚文本链接。@>Optimization Company”用A标签括起来,比如“网站Optimization Company”,这样“网站Optimization Company”就是文字,带有A标签的链接就成了锚文本链接, 这样的链接可以用鼠标点击到网站.纯文本链接不是严格意义上的链接,它只是一个URL文本
有人说能传递权重的链接是锚文本链接,而纯文本链接不能传递权重。这个概念能正确吗?作者同意和不同意这种说法。笔者认为锚文本可以传递权重是毫无疑问的,明文链接也应该传递权重,但是明文链接可以传递的权重很小,如果它传递的权重非常锚文本链接传递的权重。百分之一甚至百分之一都不为过。
所以我们在做网站的外链的时候,一般都是做锚文本外链。由于这样的外部链接可以将权重传递给我们的网站,所以也是网站和网站Optimizer首选的反向链接的建立。但是,明文链接传输的权重是基于数量的。由于明文链接传输的权重很小,为了达到传输权重的目的,明文链接必须有足够的量。现在很多论坛、博客、搜题、360问答等都取消了锚文本链接的功能。当然,这个链接的目的是多方面的,但避免权重向外传递无疑是一个重要的目的。
我们在做外部链接的时候,锚文本很重要,但是一些高权重的纯文本链接也不能忽视。例如,当我们在博客和论坛中发布 文章 时,我们可以在允许的情况下正确添加我们的 网站 纯文本链接。其他产品包括搜搜问答、360问答等,您可以适当添加自己的URL纯文本。虽然明文链接传输的权重很小,但是由于明文链接是网站,所以搜索引擎在抓取网站时,不会把网站当成一个完整的文本,至少搜索引擎会记录记录在案的网站。.
适当地赋予比普通文本更高的权重是不可避免的,因此传递一些权重是有意义的。此外,如果我们网站的纯文本在其他网站上显示的次数和数量更多,必然会被更多人知道,这无形中提升了网站的知名度和知名度。曝光率也提高了网站企业品牌的知名度。所以对于这样的纯文本链接,我们只需要时不时的增加数量,尤其是高权重网站的数量,当数量达到一定程度,必然会传输一个不可轻视的重量。
大家可能都觉得,在综合网站上阅读别人的网页内容时,内容非常好,这时候我们可能很想知道文章的出处,如果出处网站 的末尾表示 文章,但它只是一个纯文本链接。这时候我们也可能会复制文字链接,然后去网站寻找更好的内容,这样看来,一个纯文本链接可能会给我们带来一个又一个的访问者,无形中增加了网站的访问量@网站。流量的增加可以增加网站的权重。因此,虽然纯文本链接的传输权重无法与锚文本相比,但我们也没有更好的选择。在我们无法制作锚文本链接的情况下, 查看全部
关键词自动采集生成内容系统(自动采集关键词+自动发布各大网站+主动推送搜索引擎收录排名)
自动提取关键词的软件,提取关键词的软件是什么。关键词提取软件有两种:第一种是输入一个核心关键词,软件扩展大量用户搜索词、下拉词、长尾关键词。第二种是基于文章自动提取的core关键词,方便分析文章关键词的排名。今天给大家分享一个万能的SEO工具,自动采集关键词+自动提取关键词+自动文章伪原创+自动采集@ >文章+自动发布主要网站+主动推送搜索引擎收录排名。具体参考图片一、二、三、四、5
如果要在网站的权重上链接锚文本链接和纯文本链接,我们必须知道锚文本链接和纯文本链接是什么。所谓锚文本链接,是指使用A标签停止将一些关键词文本括起来的链接。这样的链接是锚文本链接。@>Optimization Company”用A标签括起来,比如“网站Optimization Company”,这样“网站Optimization Company”就是文字,带有A标签的链接就成了锚文本链接, 这样的链接可以用鼠标点击到网站.纯文本链接不是严格意义上的链接,它只是一个URL文本
有人说能传递权重的链接是锚文本链接,而纯文本链接不能传递权重。这个概念能正确吗?作者同意和不同意这种说法。笔者认为锚文本可以传递权重是毫无疑问的,明文链接也应该传递权重,但是明文链接可以传递的权重很小,如果它传递的权重非常锚文本链接传递的权重。百分之一甚至百分之一都不为过。
所以我们在做网站的外链的时候,一般都是做锚文本外链。由于这样的外部链接可以将权重传递给我们的网站,所以也是网站和网站Optimizer首选的反向链接的建立。但是,明文链接传输的权重是基于数量的。由于明文链接传输的权重很小,为了达到传输权重的目的,明文链接必须有足够的量。现在很多论坛、博客、搜题、360问答等都取消了锚文本链接的功能。当然,这个链接的目的是多方面的,但避免权重向外传递无疑是一个重要的目的。
我们在做外部链接的时候,锚文本很重要,但是一些高权重的纯文本链接也不能忽视。例如,当我们在博客和论坛中发布 文章 时,我们可以在允许的情况下正确添加我们的 网站 纯文本链接。其他产品包括搜搜问答、360问答等,您可以适当添加自己的URL纯文本。虽然明文链接传输的权重很小,但是由于明文链接是网站,所以搜索引擎在抓取网站时,不会把网站当成一个完整的文本,至少搜索引擎会记录记录在案的网站。.
适当地赋予比普通文本更高的权重是不可避免的,因此传递一些权重是有意义的。此外,如果我们网站的纯文本在其他网站上显示的次数和数量更多,必然会被更多人知道,这无形中提升了网站的知名度和知名度。曝光率也提高了网站企业品牌的知名度。所以对于这样的纯文本链接,我们只需要时不时的增加数量,尤其是高权重网站的数量,当数量达到一定程度,必然会传输一个不可轻视的重量。
大家可能都觉得,在综合网站上阅读别人的网页内容时,内容非常好,这时候我们可能很想知道文章的出处,如果出处网站 的末尾表示 文章,但它只是一个纯文本链接。这时候我们也可能会复制文字链接,然后去网站寻找更好的内容,这样看来,一个纯文本链接可能会给我们带来一个又一个的访问者,无形中增加了网站的访问量@网站。流量的增加可以增加网站的权重。因此,虽然纯文本链接的传输权重无法与锚文本相比,但我们也没有更好的选择。在我们无法制作锚文本链接的情况下,
关键词自动采集生成内容系统(关键字提炼出信息发布所要表达的意图首先根据中文的特点设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-12 17:22
<p>从关键词中提取信息发布所要表达的意图,首先根据汉语的特点建立语义库,然后将舆情信息中收录的特征关键词与语义库进行语义分析,最后根据结果判断舆情事件的走向。趋势分析可以明确发布者想要表达的观点和立场 2 舆论关键词提取21篇单篇文档关键词提取再提取关键词先对文档进行分词,然后是停用词列表和过滤规则过滤分词结果。停用词列表包括助词、介词、连词、无实际意义的词长为1的词等功能词。对于数字、量词等明显的无用词,可以设计无意义的后缀等进行相应的过滤 函数对无用词进行过滤,然后计算过滤后的分词结果的权重,得到每个词的权重。22关键词权重计算文本关键词提取更多基于权重向量生成方法,这是最常用的TFIDF算法TFIDF的主要思想是,如果一个词或短语出现在一个文章 具有高频 TF,很少出现在其他 文章 中,认为该词或短语具有良好的质量。IDF值的类别区分能力大,适合分类,但每个词都收录TF和IDF,并且文档位置信息中还有词性词等有效信息。>应该是关键词的一些文档,所以用所有文档关键词集合构建一个候选关键词集合进行特征提取得到文档集合关键词如果一个关键词出现次数越多,热点关注度越高。IDF值越大,词的区分能力越强,越符合主题的特点 3关键词智能跟踪 31 主题聚类兼顾了不同网站的权威影响和热点的时效性等。对于采集接收到的话题,来源权重为第一个元素,发布时间为第二个元素,权重和时间按降序排列。首先,一个关键词代表一个热门话题,然后对这些热门话题进行凝聚聚类,将关键词集合中的第一个关键词作为第一个使用的热门话题线索关键词@ >@关键词找文章关键词进行聚类,默认找到第一个文档作为热门话题,然后用角度余弦值对页面剩余的文本进行聚类,计算这个话题和现有的热门话题点 如果主题的相似度超过阈值 P,则将当前主题合并到现有主题中。如果相似度小于阈值P,则将当前话题视为新的热门话题,然后以关键词 查看全部
关键词自动采集生成内容系统(关键字提炼出信息发布所要表达的意图首先根据中文的特点设置)
<p>从关键词中提取信息发布所要表达的意图,首先根据汉语的特点建立语义库,然后将舆情信息中收录的特征关键词与语义库进行语义分析,最后根据结果判断舆情事件的走向。趋势分析可以明确发布者想要表达的观点和立场 2 舆论关键词提取21篇单篇文档关键词提取再提取关键词先对文档进行分词,然后是停用词列表和过滤规则过滤分词结果。停用词列表包括助词、介词、连词、无实际意义的词长为1的词等功能词。对于数字、量词等明显的无用词,可以设计无意义的后缀等进行相应的过滤 函数对无用词进行过滤,然后计算过滤后的分词结果的权重,得到每个词的权重。22关键词权重计算文本关键词提取更多基于权重向量生成方法,这是最常用的TFIDF算法TFIDF的主要思想是,如果一个词或短语出现在一个文章 具有高频 TF,很少出现在其他 文章 中,认为该词或短语具有良好的质量。IDF值的类别区分能力大,适合分类,但每个词都收录TF和IDF,并且文档位置信息中还有词性词等有效信息。>应该是关键词的一些文档,所以用所有文档关键词集合构建一个候选关键词集合进行特征提取得到文档集合关键词如果一个关键词出现次数越多,热点关注度越高。IDF值越大,词的区分能力越强,越符合主题的特点 3关键词智能跟踪 31 主题聚类兼顾了不同网站的权威影响和热点的时效性等。对于采集接收到的话题,来源权重为第一个元素,发布时间为第二个元素,权重和时间按降序排列。首先,一个关键词代表一个热门话题,然后对这些热门话题进行凝聚聚类,将关键词集合中的第一个关键词作为第一个使用的热门话题线索关键词@ >@关键词找文章关键词进行聚类,默认找到第一个文档作为热门话题,然后用角度余弦值对页面剩余的文本进行聚类,计算这个话题和现有的热门话题点 如果主题的相似度超过阈值 P,则将当前主题合并到现有主题中。如果相似度小于阈值P,则将当前话题视为新的热门话题,然后以关键词
关键词自动采集生成内容系统(为什么说送钱呢?这年头自己手上不养流量站就不叫站长 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-04-06 02:03
)
节目详情:为什么说汇款?今年,如果你没有几个流量站,你就不会被称为站长。您应该投入一些资金并在其上放置更好的云主机。当收录和权重有改善后,加入百度联盟或使用网易的附属广告,等待收款!!!!毫不夸张!
市场前景分析:阅读是人类最基本的行为之一,所以无论时代如何变迁,人们阅读都是为了娱乐,但从纸质时代到电子时代。未来手机阅读会越来越普及,所以评估一个系统的好坏,看能不能做一个全平台,这样才有未来。手机阅读让小说的受众更广,市场前景更好。小说站的流量非常大,尤其是每天坚持升级的站,更受搜索引擎欢迎。如果日IP能达到10000,广告收入将稳定在每天300元左右。只要坚持下去,月入一万也不难。
适用使用范围:给站长汇款,小说系统隆重上线!24小时自动无人值守采集,PC+微信+APP全平台
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态
附带 采集 规则,用于自动 采集 发布一些数据。
深度定制小说站,全自动采集各大小说站,可自动生成首页,分类,目录,排行榜,站点地图页面静态html,全站拼音目录,伪静态章节页面,自动生成小说txt文件,自动生成zip压缩包。这个源码功能可谓异常强大!带有非常漂亮的移动页面!使用 采集 规则 + 自动调整!超级强大,采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!一个好节目,做一个无话可说的小说站。
并且章节页面是伪静态的。(3)自动生成小说txt文件,后端也可以重新生成txt文件。(4)自动生成小说关键词和关键词自动内链。(< @5)自动伪原创换词(采集时替换)。(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐量统计及作者推荐统计等(7)配合CNZZ的统计插件,可以轻松实现小说下载量的详细统计和图书采集的详细统计。(8)自动采集这个程序在市场上并不常见)。优采云、关冠、采集侠等,但采集 版块是在DEDE原有的采集功能基础上开发的,可以有效保证章节内容。完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量可以达到25万到30万章。
查看全部
关键词自动采集生成内容系统(为什么说送钱呢?这年头自己手上不养流量站就不叫站长
)
节目详情:为什么说汇款?今年,如果你没有几个流量站,你就不会被称为站长。您应该投入一些资金并在其上放置更好的云主机。当收录和权重有改善后,加入百度联盟或使用网易的附属广告,等待收款!!!!毫不夸张!
市场前景分析:阅读是人类最基本的行为之一,所以无论时代如何变迁,人们阅读都是为了娱乐,但从纸质时代到电子时代。未来手机阅读会越来越普及,所以评估一个系统的好坏,看能不能做一个全平台,这样才有未来。手机阅读让小说的受众更广,市场前景更好。小说站的流量非常大,尤其是每天坚持升级的站,更受搜索引擎欢迎。如果日IP能达到10000,广告收入将稳定在每天300元左右。只要坚持下去,月入一万也不难。
适用使用范围:给站长汇款,小说系统隆重上线!24小时自动无人值守采集,PC+微信+APP全平台
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态
附带 采集 规则,用于自动 采集 发布一些数据。
深度定制小说站,全自动采集各大小说站,可自动生成首页,分类,目录,排行榜,站点地图页面静态html,全站拼音目录,伪静态章节页面,自动生成小说txt文件,自动生成zip压缩包。这个源码功能可谓异常强大!带有非常漂亮的移动页面!使用 采集 规则 + 自动调整!超级强大,采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!一个好节目,做一个无话可说的小说站。
并且章节页面是伪静态的。(3)自动生成小说txt文件,后端也可以重新生成txt文件。(4)自动生成小说关键词和关键词自动内链。(< @5)自动伪原创换词(采集时替换)。(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐量统计及作者推荐统计等(7)配合CNZZ的统计插件,可以轻松实现小说下载量的详细统计和图书采集的详细统计。(8)自动采集这个程序在市场上并不常见)。优采云、关冠、采集侠等,但采集 版块是在DEDE原有的采集功能基础上开发的,可以有效保证章节内容。完整性,避免章节重复、章节内容无内容、章节乱码等;一天24小时采集量可以达到25万到30万章。
关键词自动采集生成内容系统(关键词自动采集生成内容系统排行榜助力品牌精准营销)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-02 12:03
关键词自动采集生成内容系统排行榜助力品牌精准营销全网全面覆盖共享数据共创共赢转载请注明出处。关注每日更新,随时推送。每天更新高质量原创文章,让你找到方向,活到老学到老。
其实全网营销的前提就是你的产品得有足够的优势和价值,你得让客户信任你,关注你,这样才能做到全网营销,要做全网营销的话建议你还是先学习一下比较好,我以前也在学习全网营销,做的比较好的就是叶子营销培训的,网上很多这方面的资料。
学习推广方法有很多,不妨自己试试这两种:做ab测试:看看到底哪个产品推广的好,为什么?优惠活动策划:什么样的套餐才吸引你的客户?建议:做某一个方面的推广,先自己尝试,再跟专业的机构学习。
seo及站内优化:三大方法、五大步骤、两大心法!1.tdk优化法tdk就是我们的标题与描述!一定要加上我们的核心关键词,
1)标题、描述不要使用重复的词语,不要同义词或是近义词。要多转换成通俗易懂的词语,
2)描述中不要引用网站工具,这样很容易被搜索引擎判定为不利的排名,还要加粗显示。
3)另外,网站评论的内容要优化到首页,切勿打广告。2.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,如果自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!3.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!4.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词。 查看全部
关键词自动采集生成内容系统(关键词自动采集生成内容系统排行榜助力品牌精准营销)
关键词自动采集生成内容系统排行榜助力品牌精准营销全网全面覆盖共享数据共创共赢转载请注明出处。关注每日更新,随时推送。每天更新高质量原创文章,让你找到方向,活到老学到老。
其实全网营销的前提就是你的产品得有足够的优势和价值,你得让客户信任你,关注你,这样才能做到全网营销,要做全网营销的话建议你还是先学习一下比较好,我以前也在学习全网营销,做的比较好的就是叶子营销培训的,网上很多这方面的资料。
学习推广方法有很多,不妨自己试试这两种:做ab测试:看看到底哪个产品推广的好,为什么?优惠活动策划:什么样的套餐才吸引你的客户?建议:做某一个方面的推广,先自己尝试,再跟专业的机构学习。
seo及站内优化:三大方法、五大步骤、两大心法!1.tdk优化法tdk就是我们的标题与描述!一定要加上我们的核心关键词,
1)标题、描述不要使用重复的词语,不要同义词或是近义词。要多转换成通俗易懂的词语,
2)描述中不要引用网站工具,这样很容易被搜索引擎判定为不利的排名,还要加粗显示。
3)另外,网站评论的内容要优化到首页,切勿打广告。2.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,如果自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!3.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词没有了就不可能出现在搜索引擎的关键词库中!所以在做网站关键词的时候必须要根据关键词进行优化!可以使用站长工具检测哪些关键词是精准关键词!另外,自己主营产品不是网站精准关键词,可以自己创建一个网站关键词排名自动生成系统,将主营产品关键词输入进去,系统会自动生成我们网站的关键词排名!4.seo自然排名:如何提高网站的自然排名和关键词的自然排名?这就要说一下seo中的一个重要词:核心关键词!所谓核心关键词就是我们网站的主营产品词!网站的核心关键词。
关键词自动采集生成内容系统( SEO关键词挖掘我们可以通过SEO挖掘软件帮助我们进行关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-02 06:15
SEO关键词挖掘我们可以通过SEO挖掘软件帮助我们进行关键词)
自动SEO关键词挖掘,SEO关键词挖掘软件
虎爱SEO2022-03-25
SEO关键词挖矿是我们SEO工作的重要组成部分,关键词的排名直接影响到我们网站的流量。无论是流行的关键词还是长尾的关键词,都需要结合网站的特点和自己的目标来挖掘。
SEO关键词挖掘有很多维度,可以通过热门关键词、行业关键词、区域关键词甚至季节性关键词来挖掘。
SEO关键词挖矿我们可以通过SEO关键词挖矿软件帮助我们进行关键词挖矿,SEO关键词挖矿软件拥有NLP智能语言处理系统和强大的机器人学习能力,精准通过大数据分析挖掘关键词。
SEO关键词挖矿软件只要输入我们的关键词就可以完成全网关键词匹配,并将长尾关键词和对应的文章@排列为我们通过数据分析 > 内容。我们可以通过SEO关键词挖矿软件实现全托管网站。
SEO关键词挖矿软件可以文章@>匹配采集选中的关键词,通过伪原创自动发布实现文章@>的创建全过程. 只需键入 关键词 即可开始生成管道。所有流程都可以看到,数据信息可以溯源。
SEO关键词挖矿软件通过以下几点保证文章@>的质量,保证源头,有一定的流量网站,优质的内容也是可取的选择,因为用户流量,内容会产生价值。这里我们需要考虑用户关心什么,希望用户看到什么内容。当然,我们自己的优质原创文章@>是最好的。当我们有用户的时候,我们会苦于我们不能做用户想看到的事情。我们可以通过互联网找到相关的内容,最能保证及时性。
SEO关键词挖矿软件可以为我们的采集站实现24小时挂机操作。通过关键词pan采集和伪原创的发布,可以及时更新网站的内容,及时更新网站的内容同步更新。
受搜索引擎信任的网站,在各大平台上,主要是靠复制新发布的内容来提升比较快的,因为大多数人都会问他们是否可以将内容转载到SEO中。
1.新增网站:对于新站点,最好不要盲目粘贴复制,如果太多只会被搜索引擎列入黑名单。新网站就像刚出生的婴儿,我们当然不喜欢我的孩子看起来像隔壁的法老,所以,对于刚刚上线的网站,最好不要转发太多,没关系正确转发,6个月内应视为新站点!
2.不是新站,但流量不是特别大:搜索引擎要等到网站没有流量,才能计算用户体验分数,所以如果这些网站想获得搜索引擎信任,不要用户投票,不适合粘贴复制太多内容。
SEO关键词挖矿和SEO关键词挖矿软件的分享就到这里。如果您有不同的意见或想法,可以留言讨论。 查看全部
关键词自动采集生成内容系统(
SEO关键词挖掘我们可以通过SEO挖掘软件帮助我们进行关键词)
自动SEO关键词挖掘,SEO关键词挖掘软件
虎爱SEO2022-03-25
SEO关键词挖矿是我们SEO工作的重要组成部分,关键词的排名直接影响到我们网站的流量。无论是流行的关键词还是长尾的关键词,都需要结合网站的特点和自己的目标来挖掘。
SEO关键词挖掘有很多维度,可以通过热门关键词、行业关键词、区域关键词甚至季节性关键词来挖掘。
SEO关键词挖矿我们可以通过SEO关键词挖矿软件帮助我们进行关键词挖矿,SEO关键词挖矿软件拥有NLP智能语言处理系统和强大的机器人学习能力,精准通过大数据分析挖掘关键词。
SEO关键词挖矿软件只要输入我们的关键词就可以完成全网关键词匹配,并将长尾关键词和对应的文章@排列为我们通过数据分析 > 内容。我们可以通过SEO关键词挖矿软件实现全托管网站。
SEO关键词挖矿软件可以文章@>匹配采集选中的关键词,通过伪原创自动发布实现文章@>的创建全过程. 只需键入 关键词 即可开始生成管道。所有流程都可以看到,数据信息可以溯源。
SEO关键词挖矿软件通过以下几点保证文章@>的质量,保证源头,有一定的流量网站,优质的内容也是可取的选择,因为用户流量,内容会产生价值。这里我们需要考虑用户关心什么,希望用户看到什么内容。当然,我们自己的优质原创文章@>是最好的。当我们有用户的时候,我们会苦于我们不能做用户想看到的事情。我们可以通过互联网找到相关的内容,最能保证及时性。
SEO关键词挖矿软件可以为我们的采集站实现24小时挂机操作。通过关键词pan采集和伪原创的发布,可以及时更新网站的内容,及时更新网站的内容同步更新。
受搜索引擎信任的网站,在各大平台上,主要是靠复制新发布的内容来提升比较快的,因为大多数人都会问他们是否可以将内容转载到SEO中。
1.新增网站:对于新站点,最好不要盲目粘贴复制,如果太多只会被搜索引擎列入黑名单。新网站就像刚出生的婴儿,我们当然不喜欢我的孩子看起来像隔壁的法老,所以,对于刚刚上线的网站,最好不要转发太多,没关系正确转发,6个月内应视为新站点!
2.不是新站,但流量不是特别大:搜索引擎要等到网站没有流量,才能计算用户体验分数,所以如果这些网站想获得搜索引擎信任,不要用户投票,不适合粘贴复制太多内容。
SEO关键词挖矿和SEO关键词挖矿软件的分享就到这里。如果您有不同的意见或想法,可以留言讨论。
关键词自动采集生成内容系统(关键词自动采集生成内容系统七麦数据网站分析软件页面统计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-01 02:00
关键词自动采集生成内容系统七麦数据网站分析软件页面统计图片大小统计下载文字内容截取内容发布系统这些小工具,真正能提高你的内容质量。
自动扒页的话,可以试试咪咕站长平台的。写了篇文章推荐新媒体站长制作url地址采集的工具,可以看下,不同功能有不同的叫法,最简单的叫法就是“自动采集”。
推荐使用采集多点。
目前在seo方面有人推荐editorium么?我来发个恶搞地址制作页面。
确定内容方向,
九五之二:我来发一个恶搞的。一般只是采取文字或者声音之类的采集。不好意思,不是空手套白狼,只能是九五之二了。
在搜索引擎搜索了栏目关键词,没有找到匹配的页面!那么就有3种方式:用excel页面制作插件,或者scrapy,或者爬虫程序。
百度啊百度一下,你就知道。
一开始是prv,可以在seoer版首页找到,
js下面这个网站你可以去看看
同意isaipark的看法,现在可以抓取js,前提是js引擎需要研究好,
找几个老的seo博客看看有无接着抓这个方向太宽泛了一般很难有机会抓到目标网站
ahr0cdovl3dlaxhpbi5xcs5jb20vci91rxyjwh936ulwpyvxlooti1ba==(二维码自动识别) 查看全部
关键词自动采集生成内容系统(关键词自动采集生成内容系统七麦数据网站分析软件页面统计)
关键词自动采集生成内容系统七麦数据网站分析软件页面统计图片大小统计下载文字内容截取内容发布系统这些小工具,真正能提高你的内容质量。
自动扒页的话,可以试试咪咕站长平台的。写了篇文章推荐新媒体站长制作url地址采集的工具,可以看下,不同功能有不同的叫法,最简单的叫法就是“自动采集”。
推荐使用采集多点。
目前在seo方面有人推荐editorium么?我来发个恶搞地址制作页面。
确定内容方向,
九五之二:我来发一个恶搞的。一般只是采取文字或者声音之类的采集。不好意思,不是空手套白狼,只能是九五之二了。
在搜索引擎搜索了栏目关键词,没有找到匹配的页面!那么就有3种方式:用excel页面制作插件,或者scrapy,或者爬虫程序。
百度啊百度一下,你就知道。
一开始是prv,可以在seoer版首页找到,
js下面这个网站你可以去看看
同意isaipark的看法,现在可以抓取js,前提是js引擎需要研究好,
找几个老的seo博客看看有无接着抓这个方向太宽泛了一般很难有机会抓到目标网站
ahr0cdovl3dlaxhpbi5xcs5jb20vci91rxyjwh936ulwpyvxlooti1ba==(二维码自动识别)
关键词自动采集生成内容系统(手机app开发中的一个难点和解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-30 14:02
关键词自动采集生成内容系统,真实自动登录请求验证码识别系统,验证码自动识别工具,网页抓取工具,天猫的商品和数据自动采集系统,手机app的app应用开发系统,
安卓采集就是用聚应用之类的可以对等淘客网站进行采集
微擎,
手机app的开发和发布,首先肯定是要做一套app的平台,当然你可以选择安卓,ios平台,把所需的功能模块做好,再选择手机端或pc端提交给第三方。
有两个免费推广工具还不错。
国内用百度有啊,当然另一个是手机。
这是app开发中的一个难点,手机是阿里巴巴集团的直营网站,属于百度旗下的大ip,大家都知道想对于pc端,手机的抓取最难。主要抓取第三方serp。获取需要第三方授权。有兴趣的可以看下,未来交易易,
请问你用什么平台或者工具进行抓取?请问你是做哪些方面的?请问您想如何进行服务?请问是有需求还是无需求..
手机虽然是百度旗下的,但是用户基数已经达到巨大。即使是阿里的uc浏览器也无法与其竞争。那么我们先来看看一般情况下,在手机上,都要做什么才能到达效果,比如说验证码的提交,首页弹窗引导,或者参加活动,在短时间内抓住访客眼球,等等。 查看全部
关键词自动采集生成内容系统(手机app开发中的一个难点和解决办法)
关键词自动采集生成内容系统,真实自动登录请求验证码识别系统,验证码自动识别工具,网页抓取工具,天猫的商品和数据自动采集系统,手机app的app应用开发系统,
安卓采集就是用聚应用之类的可以对等淘客网站进行采集
微擎,
手机app的开发和发布,首先肯定是要做一套app的平台,当然你可以选择安卓,ios平台,把所需的功能模块做好,再选择手机端或pc端提交给第三方。
有两个免费推广工具还不错。
国内用百度有啊,当然另一个是手机。
这是app开发中的一个难点,手机是阿里巴巴集团的直营网站,属于百度旗下的大ip,大家都知道想对于pc端,手机的抓取最难。主要抓取第三方serp。获取需要第三方授权。有兴趣的可以看下,未来交易易,
请问你用什么平台或者工具进行抓取?请问你是做哪些方面的?请问您想如何进行服务?请问是有需求还是无需求..
手机虽然是百度旗下的,但是用户基数已经达到巨大。即使是阿里的uc浏览器也无法与其竞争。那么我们先来看看一般情况下,在手机上,都要做什么才能到达效果,比如说验证码的提交,首页弹窗引导,或者参加活动,在短时间内抓住访客眼球,等等。
关键词自动采集生成内容系统(迅睿CMS优采云采集器采集器文章可设置采集规则,配置复杂 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-28 00:09
)
迅瑞cms是一个永久开源免费的PHP网站开发建设管理系统。它是完全免费的、开源的,并且没有许可证限制。该系统免费、安全且易于使用。不过,迅瑞cms确实是让用户头疼的问题。迅瑞cms优采云采集器需要编写采集规则,还有复杂的发布规则需要配置。对于我们这些不懂代码的人来说,它既简单又大。有没有免费强大的功能可以批量采集全网热点信息伪原创发布并支持一键批量百度、搜狗、神马、360等各大搜索引擎收录提交。
迅瑞cms优采云采集器根据网站、网站行业属性、网站产品属性的内容进行网站@ > 结构规划,比如内容的多少可以决定网站采用哪个结果,比如内容少的网站可以把所有的页面都放到根目录下。每日蜘蛛、收录、网站权重可以通过软件直接查看!这是一个扁平结构;比如网站的内容很多,网站有多个分类的产品等等,目录布局必须按照分类来排列。确定 网站 目录层次结构。
迅锐cms优采云采集器不同关键词文章可以设置发布不同的栏目。产品的种类很多,所以需要分析一下这些种类是否有相同的用户需求,有相同需求的可以放在一个网站中去做。迅睿cms优采云随机点赞-随机阅读-随机作者(增加页面度数原创)。
然后进行关键词竞争力分析。建议将多个竞争激烈的产品分到不同的站点。迅睿cms优采云标题前缀和后缀设置(标题区别更好收录)。例如,使用不同的独立域名或二级域名;竞争力不强的产品可以在网站上进行细分,放在一个网站中进行优化,比如用分类细分产品进行优化。
迅锐cms优采云采集器搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,确保新链接可以及时被搜索引擎收录)。如果关键词很多,我们需要根据分类和竞争程度对关键词进行分类。通常我们选择用首页放竞争度高的词,也叫核心关键词,也是我们最后要优化的主要关键词,可以用栏目页来优化分类器。荀睿cms优采云伪原创保留字(在文章原创中设置核心字时,不会是伪原创)。栏目页下的内页优化了分类器相关的关键词,分类<
另外,根据关键词竞争力布局找到切入点,判断首页有多少竞争对手,是否满足需求。迅锐cms优采云直接监控已发布,待发布,是否为伪原创,发布状态,网站,程序,发布时间等哪些词有利于优化,比如区域 关键词 和长尾 关键词 通常更有利于优化。
从相关性的角度来看,我们网页的内容应该由关键词来决定,而关键词针对每个页面做了哪些优化,我们需要为这个关键词展示相关的内容。迅锐cms优采云支持多个采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。既然关键词决定了内容,那么关键词的挖掘也很重要。至于怎么挖关键词,我可以写一篇专门的文章文章来解释。
迅锐cms优采云采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。标题的书写方式对于避免重复非常重要。标题是网页的标题。对于搜索引擎来说,标题代表了网页的位置,告诉搜索引擎和用户网页的内容,因为一个好的网页标题不仅可以清楚地表达网页的主要目的,还可以给用户提供指导。搜索用户,吸引目标用户点击。
迅锐cms优采云采集器定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高)。通常我们的首页标题写成这样的格式:关键词1_关键词2_关键词3-公司名称或品牌名称,关键词的顺序是按照关键词 排名的重要性,因为关键词 的排名顺序也会影响搜索引擎对关键词 的权重分配。
迅锐cms优采云内容关键词插入(合理增加关键词的密度)。但是网站中的网页标题要尽量避免重复。百度最新的清风算法也明确规定,标题堆叠关键词、标题重复过多、标题内容虚假等都是百度针对的目标。
迅瑞cms优采云自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。规范性代码也很重要。搜索引擎蜘蛛可以爬取代码,而代码编写不规范,比如冗余或重复的标签组合,都会影响蜘蛛爬取。迅锐cms优采云内容与标题一致(使内容与标题100%相关甚至可能导致我们的页面内容被蜘蛛抓取不全,也会直接影响百度快照内容我们的网页,如果百度快照没有完全显示出来,最终会对我们的SEO排名产生影响。
从用户搜索需求的角度。如果用户找不到他的需求(target)关键词,他会去寻找其他的网页,这增加了跳出率。如果跳出率过大,会降低搜索引擎的友好度,最终导致排名下降。
修复跳出率问题:1、增加关键词密度。让用户来到我们的网页快速找到他的搜索需求。用免费的迅锐cms优采云采集器采集海量文章内容。模块布局发生了变化。将重要模块和用户需求模块移动到首屏的重要位置。3、图像处理加 关键词。Image Alt 标签有助于搜索引擎判断图像和内容的相关性。4、页面访问速度。
通过迅锐cms优采云采集器、关键词从下拉词、相关搜索词、长尾词中生成行业相关词。迅锐cms优采云可以设置自动删除无关词。我们网站的访问速度会影响搜索引擎蜘蛛的访问和爬取。如果网页加载速度太慢甚至长时间无法访问,势必会降低搜索引擎的友好度,虽然时间很短网站打不开并不一定会导致网站@ >没有排名之类的。通过迅瑞cms优采云采集器插件实现自动化采集行业相关文章,可以创建迅瑞cms优采云一次有数十个和数百个 采集 任务,支持同时执行多个域名任务采集。但是想一想,如果你的网站访问速度很流畅,对搜索引擎和用户友好,那么用户是不可能等到你的网站加载完毕才离开的。很有可能你五六秒后打不开网页,关闭网页,去其他网站浏览。
迅锐cms优采云采集器批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦、WP、Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。而且,百度还针对移动端推出了闪电算法,明确规定页面加载速度会影响网页在搜索结果中的排名显示。这时候,空间的选择也比较重要。
迅锐cms优采云自动过滤其他网站宣传信息。其实还有其他一些细节也会影响搜索引擎的友好度,后面会整理出来写到这里。迅锐cms优采云支持图片本地化或其他平台存储。
但实际上,以上几点在SEO优化过程中很容易避免或解决。从搜索引擎和用户的角度来处理和完善我们的网站的细节,还需要获取SEO排名。为用户解决问题并满足他们的搜索需求是一个稳定且长期的解决方案。今天关于迅锐cms优采云采集的解释就到这里了。下期会分享更多SEO相关知识和SEO7优化经验。下期再见。
查看全部
关键词自动采集生成内容系统(迅睿CMS优采云采集器采集器文章可设置采集规则,配置复杂
)
迅瑞cms是一个永久开源免费的PHP网站开发建设管理系统。它是完全免费的、开源的,并且没有许可证限制。该系统免费、安全且易于使用。不过,迅瑞cms确实是让用户头疼的问题。迅瑞cms优采云采集器需要编写采集规则,还有复杂的发布规则需要配置。对于我们这些不懂代码的人来说,它既简单又大。有没有免费强大的功能可以批量采集全网热点信息伪原创发布并支持一键批量百度、搜狗、神马、360等各大搜索引擎收录提交。
迅瑞cms优采云采集器根据网站、网站行业属性、网站产品属性的内容进行网站@ > 结构规划,比如内容的多少可以决定网站采用哪个结果,比如内容少的网站可以把所有的页面都放到根目录下。每日蜘蛛、收录、网站权重可以通过软件直接查看!这是一个扁平结构;比如网站的内容很多,网站有多个分类的产品等等,目录布局必须按照分类来排列。确定 网站 目录层次结构。
迅锐cms优采云采集器不同关键词文章可以设置发布不同的栏目。产品的种类很多,所以需要分析一下这些种类是否有相同的用户需求,有相同需求的可以放在一个网站中去做。迅睿cms优采云随机点赞-随机阅读-随机作者(增加页面度数原创)。
然后进行关键词竞争力分析。建议将多个竞争激烈的产品分到不同的站点。迅睿cms优采云标题前缀和后缀设置(标题区别更好收录)。例如,使用不同的独立域名或二级域名;竞争力不强的产品可以在网站上进行细分,放在一个网站中进行优化,比如用分类细分产品进行优化。
迅锐cms优采云采集器搜索引擎推送(文章发布成功后会主动向搜索引擎推送文章,确保新链接可以及时被搜索引擎收录)。如果关键词很多,我们需要根据分类和竞争程度对关键词进行分类。通常我们选择用首页放竞争度高的词,也叫核心关键词,也是我们最后要优化的主要关键词,可以用栏目页来优化分类器。荀睿cms优采云伪原创保留字(在文章原创中设置核心字时,不会是伪原创)。栏目页下的内页优化了分类器相关的关键词,分类<
另外,根据关键词竞争力布局找到切入点,判断首页有多少竞争对手,是否满足需求。迅锐cms优采云直接监控已发布,待发布,是否为伪原创,发布状态,网站,程序,发布时间等哪些词有利于优化,比如区域 关键词 和长尾 关键词 通常更有利于优化。
从相关性的角度来看,我们网页的内容应该由关键词来决定,而关键词针对每个页面做了哪些优化,我们需要为这个关键词展示相关的内容。迅锐cms优采云支持多个采集来源采集(覆盖全网行业新闻来源,海量内容库,采集最新内容)。既然关键词决定了内容,那么关键词的挖掘也很重要。至于怎么挖关键词,我可以写一篇专门的文章文章来解释。
迅锐cms优采云采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。标题的书写方式对于避免重复非常重要。标题是网页的标题。对于搜索引擎来说,标题代表了网页的位置,告诉搜索引擎和用户网页的内容,因为一个好的网页标题不仅可以清楚地表达网页的主要目的,还可以给用户提供指导。搜索用户,吸引目标用户点击。
迅锐cms优采云采集器定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提高)。通常我们的首页标题写成这样的格式:关键词1_关键词2_关键词3-公司名称或品牌名称,关键词的顺序是按照关键词 排名的重要性,因为关键词 的排名顺序也会影响搜索引擎对关键词 的权重分配。
迅锐cms优采云内容关键词插入(合理增加关键词的密度)。但是网站中的网页标题要尽量避免重复。百度最新的清风算法也明确规定,标题堆叠关键词、标题重复过多、标题内容虚假等都是百度针对的目标。
迅瑞cms优采云自动批量挂机采集,无缝对接各大cms发布者,采集之后自动发布推送到搜索引擎。规范性代码也很重要。搜索引擎蜘蛛可以爬取代码,而代码编写不规范,比如冗余或重复的标签组合,都会影响蜘蛛爬取。迅锐cms优采云内容与标题一致(使内容与标题100%相关甚至可能导致我们的页面内容被蜘蛛抓取不全,也会直接影响百度快照内容我们的网页,如果百度快照没有完全显示出来,最终会对我们的SEO排名产生影响。
从用户搜索需求的角度。如果用户找不到他的需求(target)关键词,他会去寻找其他的网页,这增加了跳出率。如果跳出率过大,会降低搜索引擎的友好度,最终导致排名下降。
修复跳出率问题:1、增加关键词密度。让用户来到我们的网页快速找到他的搜索需求。用免费的迅锐cms优采云采集器采集海量文章内容。模块布局发生了变化。将重要模块和用户需求模块移动到首屏的重要位置。3、图像处理加 关键词。Image Alt 标签有助于搜索引擎判断图像和内容的相关性。4、页面访问速度。
通过迅锐cms优采云采集器、关键词从下拉词、相关搜索词、长尾词中生成行业相关词。迅锐cms优采云可以设置自动删除无关词。我们网站的访问速度会影响搜索引擎蜘蛛的访问和爬取。如果网页加载速度太慢甚至长时间无法访问,势必会降低搜索引擎的友好度,虽然时间很短网站打不开并不一定会导致网站@ >没有排名之类的。通过迅瑞cms优采云采集器插件实现自动化采集行业相关文章,可以创建迅瑞cms优采云一次有数十个和数百个 采集 任务,支持同时执行多个域名任务采集。但是想一想,如果你的网站访问速度很流畅,对搜索引擎和用户友好,那么用户是不可能等到你的网站加载完毕才离开的。很有可能你五六秒后打不开网页,关闭网页,去其他网站浏览。
迅锐cms优采云采集器批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦、WP、Whirlwind、站群、PB、Apple、搜外等主要cms工具,可以同时管理和批量发布)。而且,百度还针对移动端推出了闪电算法,明确规定页面加载速度会影响网页在搜索结果中的排名显示。这时候,空间的选择也比较重要。
迅锐cms优采云自动过滤其他网站宣传信息。其实还有其他一些细节也会影响搜索引擎的友好度,后面会整理出来写到这里。迅锐cms优采云支持图片本地化或其他平台存储。
但实际上,以上几点在SEO优化过程中很容易避免或解决。从搜索引擎和用户的角度来处理和完善我们的网站的细节,还需要获取SEO排名。为用户解决问题并满足他们的搜索需求是一个稳定且长期的解决方案。今天关于迅锐cms优采云采集的解释就到这里了。下期会分享更多SEO相关知识和SEO7优化经验。下期再见。
关键词自动采集生成内容系统(狂雨CMS小说插件发布支持全平台CMS(CMS) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2022-03-27 07:19
)
狂雨cms小说系统是一款实用的小说站长管理系统,拥有便捷实用的会员系统,注册阅读记录,添加书架等功能。虽然狂羽cms小说系统也自带cms和一些SEO功能,但是很多时候采集的内容还是需要我们再加工。
Raincms小说插件支持24小时全自动网络小说采集,无需自动适配采集规则,采集目标站点稳定,真实-保证时间稳定的更新。完善的伪静态浏览,减少服务器消耗,方便SEO优化。
狂雨cms小说插件发布支持全平台cms(如图),无需掌握复杂的采集规则和逻辑,点击软件页面完成相应设置,实现网站文章采集、伪原创、发布、推送。支持各大cms,网络不中断继续工作。它可以自动生成txt文件并支持小说txt下载。
RaincmsFiction插件支持Repository采集、Specified采集和Incremental采集(如图)。内置翻译功能,中英翻译和简繁体转换。下载文章无限制自动导出txt、html、excel、xxf、db格式。可以选择保留下载的文章标签和图片本地化,下载后编辑或软件伪原创非常方便。我们只需要从各大资源平台输入关键词到文章采集,
Raincms小说插件支持市面上大部分cms,一键伪原创,关键词和图片随机插入。所有功能一键完成,无需掌握复杂的配置规则。
狂雨cms新颖的插件,所有操作页面可见,数据反馈及时。Crazy Raincms小说插件因其系统更新速度快、扩展性好、灵活性强而被部分站长朋友选用。虽然用户数量众多,但与主流cms用户相比,仍然可以归类为小众cms。所以我们需要注意我们的关键词排名。
为了优化《野雨》小说站cms,我们首先要做的就是确定我们的关键词。在网站的优化中,关键词非常重要。只有把我们的关键词选对了,才能让我们后面的收录和排名更好。说到关键词如何选择,首先需要判断关键词比赛的强度。这里有几个判断关键词优化难度的方法。
作为我们小说站的关键词,一定要围绕小说和我们的品牌词结合打造。由于小说这两个词之间的竞争非常困难,我们可以在前期通过长尾关键词对其进行优化,以便在竞争不激烈的关键词上更容易获得排名。当我们对长尾关键词进行很好的排名时,我们可以做更难的词。此时,我们在创建网站流量和长尾关键词的过程中建立的信心,已经是我们挑战更高难度的宝贵经验。
查看全部
关键词自动采集生成内容系统(狂雨CMS小说插件发布支持全平台CMS(CMS)
)
狂雨cms小说系统是一款实用的小说站长管理系统,拥有便捷实用的会员系统,注册阅读记录,添加书架等功能。虽然狂羽cms小说系统也自带cms和一些SEO功能,但是很多时候采集的内容还是需要我们再加工。
Raincms小说插件支持24小时全自动网络小说采集,无需自动适配采集规则,采集目标站点稳定,真实-保证时间稳定的更新。完善的伪静态浏览,减少服务器消耗,方便SEO优化。
狂雨cms小说插件发布支持全平台cms(如图),无需掌握复杂的采集规则和逻辑,点击软件页面完成相应设置,实现网站文章采集、伪原创、发布、推送。支持各大cms,网络不中断继续工作。它可以自动生成txt文件并支持小说txt下载。
RaincmsFiction插件支持Repository采集、Specified采集和Incremental采集(如图)。内置翻译功能,中英翻译和简繁体转换。下载文章无限制自动导出txt、html、excel、xxf、db格式。可以选择保留下载的文章标签和图片本地化,下载后编辑或软件伪原创非常方便。我们只需要从各大资源平台输入关键词到文章采集,
Raincms小说插件支持市面上大部分cms,一键伪原创,关键词和图片随机插入。所有功能一键完成,无需掌握复杂的配置规则。
狂雨cms新颖的插件,所有操作页面可见,数据反馈及时。Crazy Raincms小说插件因其系统更新速度快、扩展性好、灵活性强而被部分站长朋友选用。虽然用户数量众多,但与主流cms用户相比,仍然可以归类为小众cms。所以我们需要注意我们的关键词排名。
为了优化《野雨》小说站cms,我们首先要做的就是确定我们的关键词。在网站的优化中,关键词非常重要。只有把我们的关键词选对了,才能让我们后面的收录和排名更好。说到关键词如何选择,首先需要判断关键词比赛的强度。这里有几个判断关键词优化难度的方法。
作为我们小说站的关键词,一定要围绕小说和我们的品牌词结合打造。由于小说这两个词之间的竞争非常困难,我们可以在前期通过长尾关键词对其进行优化,以便在竞争不激烈的关键词上更容易获得排名。当我们对长尾关键词进行很好的排名时,我们可以做更难的词。此时,我们在创建网站流量和长尾关键词的过程中建立的信心,已经是我们挑战更高难度的宝贵经验。
关键词自动采集生成内容系统(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-27 05:05
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动斩首,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。降低文章相似度,让搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成特殊页面,将出现在文章中的关键词放在... 查看全部
关键词自动采集生成内容系统(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动斩首,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。降低文章相似度,让搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成特殊页面,将出现在文章中的关键词放在...

