
关键词文章采集源码
关键词文章采集源码(影响WordPress关键词排名优化的因素有哪些?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-09 13:35
WordPress关键词排名优化是决定我们WordPress网站流量的关键,一个好的关键词排名能给我们带来网站稳定的流量,虽然不能说一次和总而言之,但它也是一项值得我们认真研究和分析的SEO技术。影响WordPress排名优化的因素有很多关键词,如网站权重、关键词竞争强度、关键词密度、关键词与内容的相关性、等等
WordPress的TDK网站是我们关键词比较密集的区域,TDK指明了我们WordPress网站的方向,搜索引擎也分析了网站@的行为> 基于 TDK,所以我们的 关键词 布局也围绕着 TDK。
WordPress的关键词排名优化,要注意关键词的选择,避免过度叠加,还需要有一定的技巧,首先我们的关键词肯定和TDK有关,对于难度关键词我们可以选择延长长尾关键词。在优化关键词排名时,我们的WordPress网站文章内容更新也是我们关键词排名优化的基础之一。
关键词优化
对于不同的 网站 类型,我们的 WordPress关键词 选择也基于行业和 网站 特性。在哪里可以找到关键词,例如,信息内容可以是权威的 如果您正在从最流行的媒体中寻找信息,您更喜欢当天突然出现或最近变得更流行的信息。
我们也可以通过WordPress关键词排名优化插件挖掘我们的关键词,WordPress关键词排名优化插件通过我们进入我们的行业或者网站关键词,你可匹配全网实时热门关键词及对应内容。 查看全部
关键词文章采集源码(影响WordPress关键词排名优化的因素有哪些?-八维教育)
WordPress关键词排名优化是决定我们WordPress网站流量的关键,一个好的关键词排名能给我们带来网站稳定的流量,虽然不能说一次和总而言之,但它也是一项值得我们认真研究和分析的SEO技术。影响WordPress排名优化的因素有很多关键词,如网站权重、关键词竞争强度、关键词密度、关键词与内容的相关性、等等
WordPress的TDK网站是我们关键词比较密集的区域,TDK指明了我们WordPress网站的方向,搜索引擎也分析了网站@的行为> 基于 TDK,所以我们的 关键词 布局也围绕着 TDK。
WordPress的关键词排名优化,要注意关键词的选择,避免过度叠加,还需要有一定的技巧,首先我们的关键词肯定和TDK有关,对于难度关键词我们可以选择延长长尾关键词。在优化关键词排名时,我们的WordPress网站文章内容更新也是我们关键词排名优化的基础之一。
关键词优化
对于不同的 网站 类型,我们的 WordPress关键词 选择也基于行业和 网站 特性。在哪里可以找到关键词,例如,信息内容可以是权威的 如果您正在从最流行的媒体中寻找信息,您更喜欢当天突然出现或最近变得更流行的信息。
我们也可以通过WordPress关键词排名优化插件挖掘我们的关键词,WordPress关键词排名优化插件通过我们进入我们的行业或者网站关键词,你可匹配全网实时热门关键词及对应内容。
关键词文章采集源码(本地免费Wordpress采集插件怎么使用?需要编写规则吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-06 04:17
)
问:免费的 Wordpress采集 插件好用吗?需要写规则吗?
答:好用!无需编写规则,只需导入 关键词采集。
问:免费的 Wordpresscms采集 插件安装复杂吗?
A:直接下载到本地电脑,本地电脑直接运行!不影响任何服务器资源,保证服务器的流畅!
Q: 每天可以文章多少篇文章采集本地免费的Wordpress插件
A:每天采集百万篇文章文章(根据网站条件设置)
Q:如何发布本地免费的Wordpress插件采集?
A:软件自带Wordpress发布功能,采集之后会自动发布。任何版本的Wordpress都可以使用,再也不用担心网站不同版本无法使用!
Q:本地免费的Wordpress采集插件可以应用到多少个网站?
A:网站的数量没有限制。添加新的网站时,只需要创建一个任务
一、本地免费Wordpress采集如何使用插件?
1、打开软件,将关键词导入采集文章,会自动发布到网站。
2、可以同时创建几十个或几百个采集任务(一个任务可以支持上传1000个关键词)
二、如何使用本地免费的WordPress发布插件?
1、通过WordPress发布管理工具直接发布,可以直接看到发布文章的数量,文章要发布的数量,伪原创是否成功,发布的 URL 等。它还支持除 Zblog 之外的所有主要 cms 平台。还可以设置定时发布(SEO人员在优化网站的时候可以设置定时发布,这样搜索引擎抓取的频率会更高,而且对于整个网站,会不断增加权重. 网站 的权重越高,未来被搜索的机会就越多。)
2、发布工具还支持Empire、易友、ZBLOG、织梦、Wordpress、PB、Apple、搜外等各大cms。
从现在开始,你再也不用担心因为太多的网站而着急了!永远不要来回切换网站后台,反复登录后台很痛苦。再也不用担心网站没有内容填充了。一个网站的流量大小取决于网站收录的比例,收录关键词排名越多,流量越大。
为什么这么多人选择Zbog?
1、WordPress 是根据 GNU 通用公共许可证获得许可的免费开源系统。
2、WordPress 功能强大且可扩展,主要是因为它的受众大且易于网站扩展,基本上
3、功能强大,可实现网站功能的80%
4、wordpress搭建的博客对百度或者goodle搜索引擎友好
5、适合DIY,如果你喜欢内容丰富的网站,那么wordpress可以很好的实现你的想法
6、主题很多,网站最后一个都是WordPress主题,有很多种,可以选择!.
7、wordpress 拥有强大的社区支持,数以千万计的开发者贡献和审查 wordpress,因此 wordpress 安全且活跃。
在 SEO 方面,WordPress 比 Google 有明显的优势。海量外贸英文模板主题供您选择。WordPress优化和推广的最终效果取决于您的SEO水平和项目决策。如何优化,其实没有多少人说程序是先天的。对不懂html+CSS代码的小白不太友好。wordpress源码系统的初始内容基本上只是一个框架,自己搭建需要时间;
查看全部
关键词文章采集源码(本地免费Wordpress采集插件怎么使用?需要编写规则吗?
)
问:免费的 Wordpress采集 插件好用吗?需要写规则吗?
答:好用!无需编写规则,只需导入 关键词采集。
问:免费的 Wordpresscms采集 插件安装复杂吗?
A:直接下载到本地电脑,本地电脑直接运行!不影响任何服务器资源,保证服务器的流畅!
Q: 每天可以文章多少篇文章采集本地免费的Wordpress插件
A:每天采集百万篇文章文章(根据网站条件设置)
Q:如何发布本地免费的Wordpress插件采集?
A:软件自带Wordpress发布功能,采集之后会自动发布。任何版本的Wordpress都可以使用,再也不用担心网站不同版本无法使用!
Q:本地免费的Wordpress采集插件可以应用到多少个网站?
A:网站的数量没有限制。添加新的网站时,只需要创建一个任务
一、本地免费Wordpress采集如何使用插件?
1、打开软件,将关键词导入采集文章,会自动发布到网站。

2、可以同时创建几十个或几百个采集任务(一个任务可以支持上传1000个关键词)
二、如何使用本地免费的WordPress发布插件?
1、通过WordPress发布管理工具直接发布,可以直接看到发布文章的数量,文章要发布的数量,伪原创是否成功,发布的 URL 等。它还支持除 Zblog 之外的所有主要 cms 平台。还可以设置定时发布(SEO人员在优化网站的时候可以设置定时发布,这样搜索引擎抓取的频率会更高,而且对于整个网站,会不断增加权重. 网站 的权重越高,未来被搜索的机会就越多。)
2、发布工具还支持Empire、易友、ZBLOG、织梦、Wordpress、PB、Apple、搜外等各大cms。
从现在开始,你再也不用担心因为太多的网站而着急了!永远不要来回切换网站后台,反复登录后台很痛苦。再也不用担心网站没有内容填充了。一个网站的流量大小取决于网站收录的比例,收录关键词排名越多,流量越大。
为什么这么多人选择Zbog?
1、WordPress 是根据 GNU 通用公共许可证获得许可的免费开源系统。
2、WordPress 功能强大且可扩展,主要是因为它的受众大且易于网站扩展,基本上
3、功能强大,可实现网站功能的80%
4、wordpress搭建的博客对百度或者goodle搜索引擎友好
5、适合DIY,如果你喜欢内容丰富的网站,那么wordpress可以很好的实现你的想法
6、主题很多,网站最后一个都是WordPress主题,有很多种,可以选择!.
7、wordpress 拥有强大的社区支持,数以千万计的开发者贡献和审查 wordpress,因此 wordpress 安全且活跃。
在 SEO 方面,WordPress 比 Google 有明显的优势。海量外贸英文模板主题供您选择。WordPress优化和推广的最终效果取决于您的SEO水平和项目决策。如何优化,其实没有多少人说程序是先天的。对不懂html+CSS代码的小白不太友好。wordpress源码系统的初始内容基本上只是一个框架,自己搭建需要时间;

关键词文章采集源码(笑话站源码_PHP开发pc+APP+采集接口谈谈采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-05 21:14
相关话题
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
2/3/2018 01:11:42
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
谈采集:整理或抄袭信息
25/2/2010 16:54:00
采集,是组织信息还是抄袭信息?同样是抓信息做网站,但是性质可以不一样。“采集”两个字本身就很有意思,“collect”的意思是带来,更多的可以选择;“采集”是整理的意思。大部分中小站长都做到了“采集”,但有没有做到“采集”?
谈论多少采集信息损害网站
2011 年 9 月 9 日 09:47:00
很多网站在初期操作时,由于时间和人力的限制,不得不从其他网站那里获取采集的信息,以使网站更加完整,并复制了常用方法(表示链接 URL),纯 采集,失败 伪原创。这些采集信息可以让网站运营商快速更新网站,提高百度对本站的友好度和快照更新时间。
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
如何使用免费的网站源代码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
血与泪的教训:过度采集to网站by K
2009 年 2 月 12 日 16:41:00
网站成立初期,为了丰富网站的内容,采集成为站长的王牌和必杀技。如何控制采集采集的数量和过量@>的后果可能是很多站长需要学习和理解的。
一个关于标签书写规范的文章
2007 年 12 月 9 日 22:02:00
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
面部信息采集应明确法律义务
24/11/202012:24:28 查看全部
关键词文章采集源码(笑话站源码_PHP开发pc+APP+采集接口谈谈采集)
相关话题
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
2/3/2018 01:11:42
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口

谈采集:整理或抄袭信息
25/2/2010 16:54:00
采集,是组织信息还是抄袭信息?同样是抓信息做网站,但是性质可以不一样。“采集”两个字本身就很有意思,“collect”的意思是带来,更多的可以选择;“采集”是整理的意思。大部分中小站长都做到了“采集”,但有没有做到“采集”?
谈论多少采集信息损害网站
2011 年 9 月 9 日 09:47:00
很多网站在初期操作时,由于时间和人力的限制,不得不从其他网站那里获取采集的信息,以使网站更加完整,并复制了常用方法(表示链接 URL),纯 采集,失败 伪原创。这些采集信息可以让网站运营商快速更新网站,提高百度对本站的友好度和快照更新时间。
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
如何使用免费的网站源代码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
血与泪的教训:过度采集to网站by K
2009 年 2 月 12 日 16:41:00
网站成立初期,为了丰富网站的内容,采集成为站长的王牌和必杀技。如何控制采集采集的数量和过量@>的后果可能是很多站长需要学习和理解的。
一个关于标签书写规范的文章
2007 年 12 月 9 日 22:02:00
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
面部信息采集应明确法律义务
24/11/202012:24:28
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-05 21:13
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,将使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址: 查看全部
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,将使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址:
关键词文章采集源码(SEO关键词布局,TWCMS插件为你解析插件的整体布局)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-05 09:20
TWcms是一个基于PHP+MySQL的cms,完全开源且强大稳定的技术架构,无论我们是打算做一个小网站,还是想< @网站完全保证继续增长后可以随意扩展。
作为一个开源的cms,肯定有TWcms插件可以使用的选择,TWcms插件可以减少我们的重复工作时间,免费采集 功能,可以节省我们的成本并获得大量材料。
TWcms插件不仅在软件功能上可以采集全网数据,TWcms插件还具有伪原创、发布、推送等功能和数据分析。
TWcms插件根据用户关键词自动匹配采集各大平台网页上的内容。 【小淘气库】采集内容后,自动计算内容与设置关键词的相关性,仅将相关的文章保存在本地。支持各种格式的标签保留、图像本地化和内容保存。 TWcms插件无需编写任何采集规则即可实现全网采集。
除了全网采集,TWcms插件还可以指定网站集合,输入我们的目的URL链接,就可以在TWcms@中可视化操作> 插件窗口,选择我们的采集元素,点击规则,就可以采集了。
TWcms插件支持在标题中插入前缀和后缀;根据需要插入相关词和相关图像。自动标签提取、自动伪原创、内容过滤替换、主动提交等一系列SEO功能。我们只需要设置关键词和相关需求,TWcms【小淘气库】插件就可以24小时不间断的管理。无论是网站还是站群,TWcms插件都可以轻松管理。
两天前我和你谈过TWcms插件关键词的选择。今天我们来说说SEO关键词布局,TWcmsplugin for 是网站的整体布局,我们大致可以分为:
首页关键词布局、频道页面关键词布局和内容页面关键词布局。 (首页、频道页、内容页也可以细分)
那么在了解网站整体布局之前我们应该知道些什么呢?首页、目录页、内容页(包括域名)。那么,关键词如何布置这些页面呢?排版前,TWcms插件需要挖出关键词,一般会挖出关键词。我们这样分类:核心词([小淘气库]即主关键词)、热门词、一般词、冷门词
TWcms插件只能通过对挖掘出来的关键词进行分类来布局关键词。
冷门词——文章的内容和页面(通常我们称这些词为“长尾词”)
通用词 - 主题(即类别中的子类别)
热词-频道(也称为栏目,这里要注意栏目最好用关联词做)
核心词——首页顶部的布局(主关键词,标题和描述,关键词)可以说是最好的布局,TWcmsplugin< @关键词布局设计将是一个金字塔。
从网站中的SEO关键词布局的文章可以看出布局不错,但是如果我们是SEO新手,知道这一步,就很好的。 【小淘气库】只要合理使用上面的SEO关键词布局,相信我们在网站的优化中犯了很多错误,应该说这些细节都是常识。
TWcms插件不仅支持TWcms,市面上所有的cms。通过TWcms插件,我们可以实现在软件中查看不同的cms网站数据,方便多个网站站长分析数据;软件直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等,可以查看天采集、体重数据、蜘蛛等数据. 在软件上。
TWcms该插件可以实现我们的网站从建站到收录的内容管理全过程,同时还具有一定的SEO功能。虽然TWcms插件可以自动化,但是网站的优化还是离不开我们对网站其他方面的精心打磨。今天关于 TWcms 插件的分享就到这里。欢迎大家留言讨论更多关于TWcms插件的话题。 查看全部
关键词文章采集源码(SEO关键词布局,TWCMS插件为你解析插件的整体布局)
TWcms是一个基于PHP+MySQL的cms,完全开源且强大稳定的技术架构,无论我们是打算做一个小网站,还是想< @网站完全保证继续增长后可以随意扩展。

作为一个开源的cms,肯定有TWcms插件可以使用的选择,TWcms插件可以减少我们的重复工作时间,免费采集 功能,可以节省我们的成本并获得大量材料。
TWcms插件不仅在软件功能上可以采集全网数据,TWcms插件还具有伪原创、发布、推送等功能和数据分析。
TWcms插件根据用户关键词自动匹配采集各大平台网页上的内容。 【小淘气库】采集内容后,自动计算内容与设置关键词的相关性,仅将相关的文章保存在本地。支持各种格式的标签保留、图像本地化和内容保存。 TWcms插件无需编写任何采集规则即可实现全网采集。
除了全网采集,TWcms插件还可以指定网站集合,输入我们的目的URL链接,就可以在TWcms@中可视化操作> 插件窗口,选择我们的采集元素,点击规则,就可以采集了。
TWcms插件支持在标题中插入前缀和后缀;根据需要插入相关词和相关图像。自动标签提取、自动伪原创、内容过滤替换、主动提交等一系列SEO功能。我们只需要设置关键词和相关需求,TWcms【小淘气库】插件就可以24小时不间断的管理。无论是网站还是站群,TWcms插件都可以轻松管理。
两天前我和你谈过TWcms插件关键词的选择。今天我们来说说SEO关键词布局,TWcmsplugin for 是网站的整体布局,我们大致可以分为:
首页关键词布局、频道页面关键词布局和内容页面关键词布局。 (首页、频道页、内容页也可以细分)
那么在了解网站整体布局之前我们应该知道些什么呢?首页、目录页、内容页(包括域名)。那么,关键词如何布置这些页面呢?排版前,TWcms插件需要挖出关键词,一般会挖出关键词。我们这样分类:核心词([小淘气库]即主关键词)、热门词、一般词、冷门词
TWcms插件只能通过对挖掘出来的关键词进行分类来布局关键词。
冷门词——文章的内容和页面(通常我们称这些词为“长尾词”)
通用词 - 主题(即类别中的子类别)
热词-频道(也称为栏目,这里要注意栏目最好用关联词做)
核心词——首页顶部的布局(主关键词,标题和描述,关键词)可以说是最好的布局,TWcmsplugin< @关键词布局设计将是一个金字塔。
从网站中的SEO关键词布局的文章可以看出布局不错,但是如果我们是SEO新手,知道这一步,就很好的。 【小淘气库】只要合理使用上面的SEO关键词布局,相信我们在网站的优化中犯了很多错误,应该说这些细节都是常识。
TWcms插件不仅支持TWcms,市面上所有的cms。通过TWcms插件,我们可以实现在软件中查看不同的cms网站数据,方便多个网站站长分析数据;软件直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等,可以查看天采集、体重数据、蜘蛛等数据. 在软件上。
TWcms该插件可以实现我们的网站从建站到收录的内容管理全过程,同时还具有一定的SEO功能。虽然TWcms插件可以自动化,但是网站的优化还是离不开我们对网站其他方面的精心打磨。今天关于 TWcms 插件的分享就到这里。欢迎大家留言讨论更多关于TWcms插件的话题。
关键词文章采集源码(知道机器学习算法是什么,有什么作用吗?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-05 06:08
关键词文章采集源码的解析及下载我基本做算法是都是直接开源的,如果想实现自己的算法,可以公开下源码,分享自己的算法源码,您解决其他问题必须先自己去实现它,知道实现的方法,你才能更好的解决其他问题。前言在线机器学习算法是机器学习领域一个非常重要的基础知识点,其中包括序列模型,情感分析,计算机视觉等等重要的方向。
让大家对机器学习有一个基本的了解,知道机器学习算法是什么,有什么作用。我将在这个知乎专栏以自己公司的产品为例,介绍推荐系统如何进行推荐,比如我们用一个推荐系统进行评价团队的能力。用户进入我们的购物网站,我们首先要做的是什么?用户登录进入我们的商城,我们首先要做的是什么?我们的产品如何发布到公众号,我们首先要做的是什么?我们想通过什么产品来实现销售,我们要做的事情是什么?。
1、登录到我们的产品的内部界面,会有一个推荐的页面。
2、用户找到想要购买的商品,点击进入购买。当用户在京东或者看到一个人气低的商品的时候,
3、我们用用户购买的这个行为来作为字典random_cosine_wise来进行其他词汇的匹配
4、将我们知道的其他的词汇表中的词汇添加到字典中进行处理
5、用户的购买行为时效性强,
6、我们在推荐的时候会将原来用户推荐的这个词汇用户的数据进行填充,然后构建字典。
7、将字典中相似度高的词汇通过连词匹配的方式给出推荐,
8、如果有一个未登录用户还有一定购买意向的,这样我们就能推荐出相似用户关注的内容,可以帮助我们的店铺进行商品推荐。例如你是一个非常喜欢逛商场的人,但是经常被导购员忽悠买东西,老板也经常打电话问我产品的购买意向。如果没有购买意向的话,我将无法卖出我的东西,我认为这就是一个败笔。这样我的产品就无法进行销售。
那么有没有一种方法,
1、想要推荐的是什么?
2、要用什么样的机器学习算法?(本例采用的是逻辑回归)
3、如何让机器学习算法知道自己想要推荐的?
4、推荐的时候用户输入什么样的id?
5、需要什么样的数据库?
6、用什么样的网站搭建如我们的使用范围?在线算法的前提知识
1、基础类的知识
2、数据库和网站知识
3、推荐系统模型结构和数据清洗算法一:前向传播前向传播,简单来说是非线性变换的方法,有没有线性变换的方法,比如矩阵求逆的方法。从定义上来看,前向传播的推理是将一个矩阵所有行和列数据同时传播, 查看全部
关键词文章采集源码(知道机器学习算法是什么,有什么作用吗?-八维教育)
关键词文章采集源码的解析及下载我基本做算法是都是直接开源的,如果想实现自己的算法,可以公开下源码,分享自己的算法源码,您解决其他问题必须先自己去实现它,知道实现的方法,你才能更好的解决其他问题。前言在线机器学习算法是机器学习领域一个非常重要的基础知识点,其中包括序列模型,情感分析,计算机视觉等等重要的方向。
让大家对机器学习有一个基本的了解,知道机器学习算法是什么,有什么作用。我将在这个知乎专栏以自己公司的产品为例,介绍推荐系统如何进行推荐,比如我们用一个推荐系统进行评价团队的能力。用户进入我们的购物网站,我们首先要做的是什么?用户登录进入我们的商城,我们首先要做的是什么?我们的产品如何发布到公众号,我们首先要做的是什么?我们想通过什么产品来实现销售,我们要做的事情是什么?。
1、登录到我们的产品的内部界面,会有一个推荐的页面。
2、用户找到想要购买的商品,点击进入购买。当用户在京东或者看到一个人气低的商品的时候,
3、我们用用户购买的这个行为来作为字典random_cosine_wise来进行其他词汇的匹配
4、将我们知道的其他的词汇表中的词汇添加到字典中进行处理
5、用户的购买行为时效性强,
6、我们在推荐的时候会将原来用户推荐的这个词汇用户的数据进行填充,然后构建字典。
7、将字典中相似度高的词汇通过连词匹配的方式给出推荐,
8、如果有一个未登录用户还有一定购买意向的,这样我们就能推荐出相似用户关注的内容,可以帮助我们的店铺进行商品推荐。例如你是一个非常喜欢逛商场的人,但是经常被导购员忽悠买东西,老板也经常打电话问我产品的购买意向。如果没有购买意向的话,我将无法卖出我的东西,我认为这就是一个败笔。这样我的产品就无法进行销售。
那么有没有一种方法,
1、想要推荐的是什么?
2、要用什么样的机器学习算法?(本例采用的是逻辑回归)
3、如何让机器学习算法知道自己想要推荐的?
4、推荐的时候用户输入什么样的id?
5、需要什么样的数据库?
6、用什么样的网站搭建如我们的使用范围?在线算法的前提知识
1、基础类的知识
2、数据库和网站知识
3、推荐系统模型结构和数据清洗算法一:前向传播前向传播,简单来说是非线性变换的方法,有没有线性变换的方法,比如矩阵求逆的方法。从定义上来看,前向传播的推理是将一个矩阵所有行和列数据同时传播,
关键词文章采集源码( adminv2.8.x版本更新TAG标签自动调用文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-05 01:21
adminv2.8.x版本更新TAG标签自动调用文章)
文章tag/关键词 2.8.2 商业 (zqlj_arctag)
由管理员在 Discuz 上发布!
v2.8.x版本更新
1、修复分页功能的参数问题;
2、添加手机版列表页;
文章标签/关键词 用于 Discuz!功能介绍:本插件实现了在门户文章中添加tag标签模块,并根据标签内容生成自动聚合页面,有利于门户文章的SEO优化!
特征
1、本插件后台设置了TAG库,站长可以提前将本站常用的TAG添加到库中,发送时可以快速调用文章;
2、支持快速选择***的几个TAG;
3、支持TAG标签自动聚合文章(独立列表页),点击TAG进入;
4、Pages关键词自动调用文章设置的TAG,更有利于门户文章SEO优化
1、本站发布的内容是在互联网上采集整理的,包括但不限于代码、应用程序、音像资源、电子书资料等,以研究交流为目的,
2、仅供大家参考学习,不作任何商业用途或商业用途。
3、如果您使用开源软件代码,请遵守相应的开源许可规范和精神。如果您需要使用非自由软件或服务,您应该购买正版许可证并合法使用。
4、如果您下载此文件,即表示您同意将此文件用于参考、学习用途,不得用于任何其他目的。 查看全部
关键词文章采集源码(
adminv2.8.x版本更新TAG标签自动调用文章)
文章tag/关键词 2.8.2 商业 (zqlj_arctag)
由管理员在 Discuz 上发布!
v2.8.x版本更新
1、修复分页功能的参数问题;
2、添加手机版列表页;
文章标签/关键词 用于 Discuz!功能介绍:本插件实现了在门户文章中添加tag标签模块,并根据标签内容生成自动聚合页面,有利于门户文章的SEO优化!
特征
1、本插件后台设置了TAG库,站长可以提前将本站常用的TAG添加到库中,发送时可以快速调用文章;
2、支持快速选择***的几个TAG;
3、支持TAG标签自动聚合文章(独立列表页),点击TAG进入;
4、Pages关键词自动调用文章设置的TAG,更有利于门户文章SEO优化
1、本站发布的内容是在互联网上采集整理的,包括但不限于代码、应用程序、音像资源、电子书资料等,以研究交流为目的,
2、仅供大家参考学习,不作任何商业用途或商业用途。
3、如果您使用开源软件代码,请遵守相应的开源许可规范和精神。如果您需要使用非自由软件或服务,您应该购买正版许可证并合法使用。
4、如果您下载此文件,即表示您同意将此文件用于参考、学习用途,不得用于任何其他目的。
关键词文章采集源码(python多线程头像图片源码附exe程序及资源包!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-04 18:09
互联网上怎么可能没有一两件马甲,而头像等信息的完善无疑是必要的。关于头像图片,大家不妨采集看网站上的头像图片,这样就不用找了。我能! !
目标网址:
Python多线程抓取头像图片源码,附exe程序和资源包!
相关介绍:
1.用到的库requests、etree、re、os、ThreadPool
2.网页编码为utf-8,需要转码:html.encoding=“utf-8”
3.使用xpath获取图片链接
4.多线程
5.需要进入第n页,详细可以看动态图
6.头像的首页是栏目页面,没有页面,这里是if判断
7.py打包exe命令:pyinstaller -F目录file.py
关于多线程,线程池,这里使用线程池。这是一个旧模块。虽然有些人还在使用它,但它不再是主流。你可以参考一下!
库安装方式:pip install threadpool
基本用法:
(1)引入线程池模块
(2)定义线程函数
(3)创建线程池threadpool.ThreadPool()
(4)创建需要线程池处理的任务,即threadpool.makeRequests()
(5)将创建的多个任务放入线程池,threadpool.putRequest
(6)等到adpool.pool()处理完所有任务
import threadpool
def ThreadFun(arg1,arg2):
pass
def main():
device_list=[object1,object2,object3......,objectn]#需要处理的设备个数
task_pool=threadpool.ThreadPool(8)#8是线程池中线程的个数
request_list=[]#存放任务列表
#首先构造任务列表
for device in device_list:
request_list.append(threadpool.makeRequests(ThreadFun,[((device, ), {})]))
#将每个任务放到线程池中,等待线程池中线程各自读取任务,然后进行处理,使用了map函数,不了解的可以去了解一下。
map(task_pool.putRequest,request_list)
#等待所有任务处理完成,则返回,如果没有处理完,则一直阻塞
task_pool.poll()
if __name__=="__main__":
main()
说明:makeRequests存储了启用多线程的函数,以及函数相关的参数和回调函数。回调函数可以省略(默认为none),也就是说makeRequests可以只带2个参数运行。
pycharm运行效果:
exe运行效果:
附上源码:
#www.woyaogexing.com头像采集
# -*- coding: utf-8 -*-
#by 微信:huguo00289
import requests
from lxml import etree
import re
import os
from multiprocessing.dummy import Pool as ThreadPool
def hqlj(n):
urls = []
for x in range(1,n+1):
url=f'https://www.woyaogexing.com/touxiang/index_{x}.html'
if x==1:
url='https://www.woyaogexing.com/to ... 27%3B
print(url)
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
'''href=con.xpath('//div[@class="txList "]/a')
print(href)
for urls in href:
print(urls.attrib['href'])'''
href=con.xpath('//div[@class="txList "]/a/@href')
print(href)
for lj in href:
lj=f'https://www.woyaogexing.com{lj}'
print(lj)
urls.append(lj)
print(urls)
return urls
def hqtx(url):
#url="https://www.woyaogexing.com/to ... ot%3B
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
h1=con.xpath('//h1/text()')
h1=h1[0]
h1 = re.sub(r'[\|\/\\:\*\?\\\"]', "_", h1) # 剔除不合法字符
print(h1)
os.makedirs(f'./touxiang/{h1}/',exist_ok=True)
imgs=con.xpath('//img[@class="lazy"]/@src')
print(imgs)
i=1
for img in imgs:
img_url=f'https:{img}'
if 'jpeg' in img_url:
img_name=img_url[-5:]
else:
img_name = img_url[-4:]
n=str(i)
img_name='%s%s'%(n,img_name)
print(img_name)
print(img_url)
r=requests.get(img_url)
with open(f'./touxiang/{h1}/{img_name}','ab+') as f:
f.write(r.content)
print(f"保存{img_name}图片成功!")
i=i+1
#hqlj("https://www.woyaogexing.com/touxiang/")
if __name__ == '__main__':
n=input("请输入要采集的页码数:",)
n=int(n)
urls=(hqlj(n))
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(hqtx, urls)
pool.close()
pool.join()
print("采集所有头像完成!")
except:
print("Error: unable to start thread")
采集资源效应:
从现在开始,妈妈再也不用担心我没有头像了! !
最后附上exe打包器,有需要的可以试试!
链接:提取码:fuas
爬取500页数据,分享给大家!一共1.71g!
链接:提取码:trrz 查看全部
关键词文章采集源码(python多线程头像图片源码附exe程序及资源包!(一))
互联网上怎么可能没有一两件马甲,而头像等信息的完善无疑是必要的。关于头像图片,大家不妨采集看网站上的头像图片,这样就不用找了。我能! !
目标网址:
Python多线程抓取头像图片源码,附exe程序和资源包!
相关介绍:
1.用到的库requests、etree、re、os、ThreadPool
2.网页编码为utf-8,需要转码:html.encoding=“utf-8”
3.使用xpath获取图片链接
4.多线程
5.需要进入第n页,详细可以看动态图
6.头像的首页是栏目页面,没有页面,这里是if判断
7.py打包exe命令:pyinstaller -F目录file.py
关于多线程,线程池,这里使用线程池。这是一个旧模块。虽然有些人还在使用它,但它不再是主流。你可以参考一下!
库安装方式:pip install threadpool
基本用法:
(1)引入线程池模块
(2)定义线程函数
(3)创建线程池threadpool.ThreadPool()
(4)创建需要线程池处理的任务,即threadpool.makeRequests()
(5)将创建的多个任务放入线程池,threadpool.putRequest
(6)等到adpool.pool()处理完所有任务
import threadpool
def ThreadFun(arg1,arg2):
pass
def main():
device_list=[object1,object2,object3......,objectn]#需要处理的设备个数
task_pool=threadpool.ThreadPool(8)#8是线程池中线程的个数
request_list=[]#存放任务列表
#首先构造任务列表
for device in device_list:
request_list.append(threadpool.makeRequests(ThreadFun,[((device, ), {})]))
#将每个任务放到线程池中,等待线程池中线程各自读取任务,然后进行处理,使用了map函数,不了解的可以去了解一下。
map(task_pool.putRequest,request_list)
#等待所有任务处理完成,则返回,如果没有处理完,则一直阻塞
task_pool.poll()
if __name__=="__main__":
main()
说明:makeRequests存储了启用多线程的函数,以及函数相关的参数和回调函数。回调函数可以省略(默认为none),也就是说makeRequests可以只带2个参数运行。
pycharm运行效果:
exe运行效果:
附上源码:
#www.woyaogexing.com头像采集
# -*- coding: utf-8 -*-
#by 微信:huguo00289
import requests
from lxml import etree
import re
import os
from multiprocessing.dummy import Pool as ThreadPool
def hqlj(n):
urls = []
for x in range(1,n+1):
url=f'https://www.woyaogexing.com/touxiang/index_{x}.html'
if x==1:
url='https://www.woyaogexing.com/to ... 27%3B
print(url)
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
'''href=con.xpath('//div[@class="txList "]/a')
print(href)
for urls in href:
print(urls.attrib['href'])'''
href=con.xpath('//div[@class="txList "]/a/@href')
print(href)
for lj in href:
lj=f'https://www.woyaogexing.com{lj}'
print(lj)
urls.append(lj)
print(urls)
return urls
def hqtx(url):
#url="https://www.woyaogexing.com/to ... ot%3B
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
h1=con.xpath('//h1/text()')
h1=h1[0]
h1 = re.sub(r'[\|\/\\:\*\?\\\"]', "_", h1) # 剔除不合法字符
print(h1)
os.makedirs(f'./touxiang/{h1}/',exist_ok=True)
imgs=con.xpath('//img[@class="lazy"]/@src')
print(imgs)
i=1
for img in imgs:
img_url=f'https:{img}'
if 'jpeg' in img_url:
img_name=img_url[-5:]
else:
img_name = img_url[-4:]
n=str(i)
img_name='%s%s'%(n,img_name)
print(img_name)
print(img_url)
r=requests.get(img_url)
with open(f'./touxiang/{h1}/{img_name}','ab+') as f:
f.write(r.content)
print(f"保存{img_name}图片成功!")
i=i+1
#hqlj("https://www.woyaogexing.com/touxiang/";)
if __name__ == '__main__':
n=input("请输入要采集的页码数:",)
n=int(n)
urls=(hqlj(n))
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(hqtx, urls)
pool.close()
pool.join()
print("采集所有头像完成!")
except:
print("Error: unable to start thread")
采集资源效应:
从现在开始,妈妈再也不用担心我没有头像了! !
最后附上exe打包器,有需要的可以试试!
链接:提取码:fuas
爬取500页数据,分享给大家!一共1.71g!
链接:提取码:trrz
关键词文章采集源码(常见的境外社交数据采集与分析,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-31 12:14
大量用户声音聚集在Twitter、Facebook、YouTube、Instagram等海外社交媒体平台。通过采集这些海外社交数据和社会化聆听,品牌企业或部门可以实时掌握海外舆论情况,进而为海外业务发展、国际事件研究、相关政策制定等提供情报支持。
在过去的几年里,我们帮助很多客户完成了海外社交数据采集以及各种细分场景下的分析:
本文将根据具体客户案例,与大家一起探讨常见的海外社交数据采集场景。
采集场景共性
先说一下采集场景的共性。
Twitter、Facebook、YouTube、Instagram虽然内容形式不同,但都是社交媒体平台,大体结构和功能相似。@> 场景是:
1. 指定账号下更新的推文/图片/视频采集
2. 特定 关键词采集 的实时搜索结果
3. 推文/图片/视频下的评论采集
对于这些采集场景,我们已经为几乎所有场景准备了采集模板和教程。
★海外采集模板为特殊模板,如有需要请联系客服。
下面,针对每一类采集场景选取一个示例网站进行详细讲解。其他网站的采集方法类似,这里不再赘述。
一、采集更新了指定脸书账号下的推文
Facebook 是全球最大的社交媒体平台,每月有 20 亿活跃用户;每天在 Facebook 上进行 15 亿次搜索;每天有超过 12 亿用户使用 Facebook;每天有超过 80 亿的视频浏览量。
采集在 Facebook 指定帐户下更新推文数据是很常见的采集要求。例如,疫情期间,美国约翰霍普金斯大学启动Facebook平台,实时提供最权威的疫情数据。在开展与疫情相关的话题研究时,约翰霍普金斯大学 Facebook 账号发布的历史推文和新推文采集可以作为研究的重要数据源。
详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。
二、在 Twitter 上搜索 关键词,采集搜索推文列表
Twitter 是当今最受欢迎的社交媒体平台之一,每天有超过 1 亿活跃用户和超过 5 亿条推文。Twitter相当于微博。
在 Twitter 上搜索 关键词 和在推文列表中搜索 采集 是非常常见的 采集 请求。比如华为、TikTok等海外业务发展较快的品牌,需要时刻关注海外社会舆论情况,为品牌做出相关决策提供情报支持。Twitter是一个非常重要的平台。先选择一批品牌相关的关键词,然后在推特上实时搜索关键词和采集他们的搜索结果,可以得到很多有价值的信息。
详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。 查看全部
关键词文章采集源码(常见的境外社交数据采集与分析,你了解多少?)
大量用户声音聚集在Twitter、Facebook、YouTube、Instagram等海外社交媒体平台。通过采集这些海外社交数据和社会化聆听,品牌企业或部门可以实时掌握海外舆论情况,进而为海外业务发展、国际事件研究、相关政策制定等提供情报支持。
在过去的几年里,我们帮助很多客户完成了海外社交数据采集以及各种细分场景下的分析:
本文将根据具体客户案例,与大家一起探讨常见的海外社交数据采集场景。
采集场景共性
先说一下采集场景的共性。
Twitter、Facebook、YouTube、Instagram虽然内容形式不同,但都是社交媒体平台,大体结构和功能相似。@> 场景是:
1. 指定账号下更新的推文/图片/视频采集
2. 特定 关键词采集 的实时搜索结果
3. 推文/图片/视频下的评论采集
对于这些采集场景,我们已经为几乎所有场景准备了采集模板和教程。
★海外采集模板为特殊模板,如有需要请联系客服。

下面,针对每一类采集场景选取一个示例网站进行详细讲解。其他网站的采集方法类似,这里不再赘述。
一、采集更新了指定脸书账号下的推文

Facebook 是全球最大的社交媒体平台,每月有 20 亿活跃用户;每天在 Facebook 上进行 15 亿次搜索;每天有超过 12 亿用户使用 Facebook;每天有超过 80 亿的视频浏览量。
采集在 Facebook 指定帐户下更新推文数据是很常见的采集要求。例如,疫情期间,美国约翰霍普金斯大学启动Facebook平台,实时提供最权威的疫情数据。在开展与疫情相关的话题研究时,约翰霍普金斯大学 Facebook 账号发布的历史推文和新推文采集可以作为研究的重要数据源。
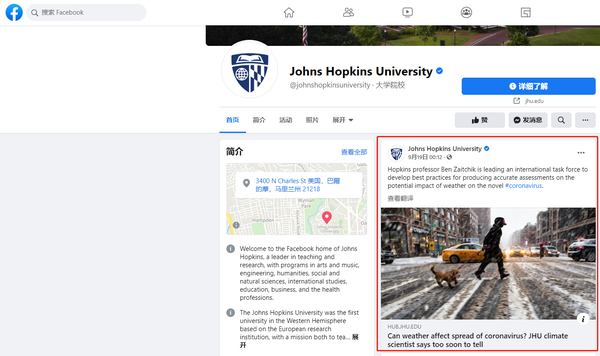
详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。
二、在 Twitter 上搜索 关键词,采集搜索推文列表

Twitter 是当今最受欢迎的社交媒体平台之一,每天有超过 1 亿活跃用户和超过 5 亿条推文。Twitter相当于微博。
在 Twitter 上搜索 关键词 和在推文列表中搜索 采集 是非常常见的 采集 请求。比如华为、TikTok等海外业务发展较快的品牌,需要时刻关注海外社会舆论情况,为品牌做出相关决策提供情报支持。Twitter是一个非常重要的平台。先选择一批品牌相关的关键词,然后在推特上实时搜索关键词和采集他们的搜索结果,可以得到很多有价值的信息。

详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。
关键词文章采集源码(河北企速采信息技术为您介绍正规首页排名技术团队, )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-03-31 08:21
)
介绍我们的技术团队HyNiVl93,
1、
在提升排名的过程中,很多优化器为了快速提升关键词的排名,从而过度优化,在TDK、内页等地方,严重堆叠关键词,这个很明显的关键词叠加,有悖于搜索引擎的搜索排名机制,在很大程度上不会给出好的排名。完全禁用它的方法是设置 robots 文件。
2、内容质量一直是优化人员和站长优化的重点。搜索引擎喜欢优质的内容,但是很多站长朋友为了省事都进行了采集others。信息,或信息内容很少的内容,对用户没有帮助。这样,搜索引擎就不会给出排名。搜索引擎喜欢对用户有帮助和有价值的内容,并且可以吸引用户。一方面是为了分词更好,另一方面可以让内容中的关键词显得更自然,星空+运动,帮助蜘蛛去文章关键词判断。
官方首页排名技术团队HyNiVl目前的搜索引擎,与往年想要搜索的内容大相径庭。今天的搜索引擎已经很聪明了,所以如果你想优化它,你必须把它做好。靠谱的优化公司会逐渐有排名流量的,你还怕不来客户!比如焦大的日帖,基本就变成了周帖。
可能很多站长不太关注站长的长尾关键词挖掘工具,觉得这样的长尾关键词挖掘工具提供的数据不够准确,无法把握用户的搜索习惯上,网站关键词排名在众多长尾关键词挖矿工具中其实是相当有益的。Golden Flower Long-tail关键词挖矿工具比较好用,上面提供了用户搜索工具。比赛的次数,比赛的水平,值不值得,上面会有数据供参考,可以帮助站长判断哪个关键词能带来流量。另外,自己站点的CNNZ统计工具也不容忽视。这是用户搜索 网站 的单词的直接参考数据。如果用户搜索一次,可以进行第二次搜索。因此,站长们必须在这方面优化长尾关键词。
另外,当搜索引擎来爬取内容时,如果等了很久都爬不出来有价值的信息,那么就不会爬取内容。没有收录,就没有好的排名。. 您可以查看维基百科。
3、有很多公司选择优化从互联网获取客户的目的。不管是什么行业,什么类型的成本,只要去做,就是从互联网上获取用户。当然,这有一个重要的前提,就是需要展示在用户面前。很多没有显示,只有少数显示。那么,为什么会一直没有排名,无法展示在用户面前呢?当第二个用户来到你的网站时,我也遇到了这种情况。如果持续时间长了,你网站可能会落到用户手里,因为他们不会再找你了。网站。
经过近1天的断断续续工作,服务器上运行的6台网站已经全部恢复正常访问,但只能恢复到年月日的备份,也就是说时间从第二个月到现在任务已经交到火炬了!.
4、
页面的打开速度和页面的加载速度都会影响用户的体验。如果页面打开速度很慢,一般用户会等待两三秒。如果页面还没有打开或者内容还没有完全加载,那么当两三秒的时间用户的耐心用完之后,用户就会关闭并去做其他事情。因此,在汉语教学中,课本中一些问题的答案是多样的,允许和鼓励学生表达不同的意见,使用主题网站可以创造学生。
七速菜利用智能云系统智能生成标题和原创属性文章,每天向各大权重媒体发布信息,达到首页快速排名的效果。
海尼VI68
查看全部
关键词文章采集源码(河北企速采信息技术为您介绍正规首页排名技术团队,
)
介绍我们的技术团队HyNiVl93,
1、

在提升排名的过程中,很多优化器为了快速提升关键词的排名,从而过度优化,在TDK、内页等地方,严重堆叠关键词,这个很明显的关键词叠加,有悖于搜索引擎的搜索排名机制,在很大程度上不会给出好的排名。完全禁用它的方法是设置 robots 文件。

2、内容质量一直是优化人员和站长优化的重点。搜索引擎喜欢优质的内容,但是很多站长朋友为了省事都进行了采集others。信息,或信息内容很少的内容,对用户没有帮助。这样,搜索引擎就不会给出排名。搜索引擎喜欢对用户有帮助和有价值的内容,并且可以吸引用户。一方面是为了分词更好,另一方面可以让内容中的关键词显得更自然,星空+运动,帮助蜘蛛去文章关键词判断。


官方首页排名技术团队HyNiVl目前的搜索引擎,与往年想要搜索的内容大相径庭。今天的搜索引擎已经很聪明了,所以如果你想优化它,你必须把它做好。靠谱的优化公司会逐渐有排名流量的,你还怕不来客户!比如焦大的日帖,基本就变成了周帖。

可能很多站长不太关注站长的长尾关键词挖掘工具,觉得这样的长尾关键词挖掘工具提供的数据不够准确,无法把握用户的搜索习惯上,网站关键词排名在众多长尾关键词挖矿工具中其实是相当有益的。Golden Flower Long-tail关键词挖矿工具比较好用,上面提供了用户搜索工具。比赛的次数,比赛的水平,值不值得,上面会有数据供参考,可以帮助站长判断哪个关键词能带来流量。另外,自己站点的CNNZ统计工具也不容忽视。这是用户搜索 网站 的单词的直接参考数据。如果用户搜索一次,可以进行第二次搜索。因此,站长们必须在这方面优化长尾关键词。
另外,当搜索引擎来爬取内容时,如果等了很久都爬不出来有价值的信息,那么就不会爬取内容。没有收录,就没有好的排名。. 您可以查看维基百科。
3、有很多公司选择优化从互联网获取客户的目的。不管是什么行业,什么类型的成本,只要去做,就是从互联网上获取用户。当然,这有一个重要的前提,就是需要展示在用户面前。很多没有显示,只有少数显示。那么,为什么会一直没有排名,无法展示在用户面前呢?当第二个用户来到你的网站时,我也遇到了这种情况。如果持续时间长了,你网站可能会落到用户手里,因为他们不会再找你了。网站。

经过近1天的断断续续工作,服务器上运行的6台网站已经全部恢复正常访问,但只能恢复到年月日的备份,也就是说时间从第二个月到现在任务已经交到火炬了!.
4、

页面的打开速度和页面的加载速度都会影响用户的体验。如果页面打开速度很慢,一般用户会等待两三秒。如果页面还没有打开或者内容还没有完全加载,那么当两三秒的时间用户的耐心用完之后,用户就会关闭并去做其他事情。因此,在汉语教学中,课本中一些问题的答案是多样的,允许和鼓励学生表达不同的意见,使用主题网站可以创造学生。

七速菜利用智能云系统智能生成标题和原创属性文章,每天向各大权重媒体发布信息,达到首页快速排名的效果。
海尼VI68

关键词文章采集源码(手机平板浏览效果高端大气,快速建立一个自己的站点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-30 14:05
帝国cms7.5自适应Office教程网络电脑技巧文章资料带PPT、Word、Excel模板下载功能+采集+百度推送+sitemap+itag全站源码
————————————————————————————————
PC/电脑版demo地址:查看demo
WAP/手机版demo地址:查看demo(请用手机访问)
(演示站只有采集在页面里填了一些数据看看效果,以后可以用自己的采集器采集大量数据)
————————————————————————————————
本模板由业主本人制作、模仿、移植。业主一直致力于为您提供各类优质、易用、价廉的模板。感谢您的支持!
所有功能都在后台管理。
模板通过标签灵活调用,采集方面选择优质源站,在考虑SEO搜索引擎优化的同时对模板进行细化。
全站静态生成有利于收录和关键词布局和内容页面优化等!
功能列表:
采用 Empirecms7.5 新内核。列和内容模板是超级多变的。后台操作简单,安全可靠,性能稳定。全站拥有高端响应式手机和平板浏览效果,您可以快速搭建自己的网站!
1、内置东坡ITAG超级管理插件,关键词可以是动态、静态或伪静态,标签关键词可以设置为ID或拼音显示,方式很多玩,优化更棒!
2、内置东坡多功能推送插件,数据更新后通过百度API接口实时推送到百度,收录速度更快,效果更佳是很棒的!
3、内置Sitemap百度地图生成插件,基于百度新的2.0技术标准,代码简洁规范,更有利于百度数据抓取。
4、自适应wap移动端,省时省力,简单方便。
其他具体细节不再一一赘述。如果您需要了解更多,可以直接访问演示站点查看。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,无域名限制
●独立WAP移动端大气简洁实用,有利于SEO优化
●全站带数据1.约5GB
●简洁的安装方法,详细的安装教程。
●通过优采云采集器,您可以自己设置采集大量数据,并且可以自动化处理一个采集。
资源下载 本资源下载价格为70金币,请先登录 查看全部
关键词文章采集源码(手机平板浏览效果高端大气,快速建立一个自己的站点)
帝国cms7.5自适应Office教程网络电脑技巧文章资料带PPT、Word、Excel模板下载功能+采集+百度推送+sitemap+itag全站源码
————————————————————————————————
PC/电脑版demo地址:查看demo
WAP/手机版demo地址:查看demo(请用手机访问)
(演示站只有采集在页面里填了一些数据看看效果,以后可以用自己的采集器采集大量数据)
————————————————————————————————
本模板由业主本人制作、模仿、移植。业主一直致力于为您提供各类优质、易用、价廉的模板。感谢您的支持!
所有功能都在后台管理。
模板通过标签灵活调用,采集方面选择优质源站,在考虑SEO搜索引擎优化的同时对模板进行细化。
全站静态生成有利于收录和关键词布局和内容页面优化等!
功能列表:
采用 Empirecms7.5 新内核。列和内容模板是超级多变的。后台操作简单,安全可靠,性能稳定。全站拥有高端响应式手机和平板浏览效果,您可以快速搭建自己的网站!
1、内置东坡ITAG超级管理插件,关键词可以是动态、静态或伪静态,标签关键词可以设置为ID或拼音显示,方式很多玩,优化更棒!
2、内置东坡多功能推送插件,数据更新后通过百度API接口实时推送到百度,收录速度更快,效果更佳是很棒的!
3、内置Sitemap百度地图生成插件,基于百度新的2.0技术标准,代码简洁规范,更有利于百度数据抓取。
4、自适应wap移动端,省时省力,简单方便。
其他具体细节不再一一赘述。如果您需要了解更多,可以直接访问演示站点查看。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,无域名限制
●独立WAP移动端大气简洁实用,有利于SEO优化
●全站带数据1.约5GB
●简洁的安装方法,详细的安装教程。
●通过优采云采集器,您可以自己设置采集大量数据,并且可以自动化处理一个采集。
 http://www.hanjutt.com/wp-cont ... 9.jpg 300w, http://www.hanjutt.com/wp-cont ... 5.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 9.jpg 300w, http://www.hanjutt.com/wp-cont ... 5.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 1.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 1.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 0.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 0.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 7.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 7.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 0.jpg 300w, http://www.hanjutt.com/wp-cont ... 3.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 0.jpg 300w, http://www.hanjutt.com/wp-cont ... 3.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 6.jpg 300w, http://www.hanjutt.com/wp-cont ... 7.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 6.jpg 300w, http://www.hanjutt.com/wp-cont ... 7.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 8.jpg 300w, http://www.hanjutt.com/wp-cont ... 5.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 8.jpg 300w, http://www.hanjutt.com/wp-cont ... 5.jpg 768w" />资源下载 本资源下载价格为70金币,请先登录
关键词文章采集源码(仿SUV排行榜汽车销售资讯新闻排行模板同步生成自动采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-30 07:02
)
来源名称:仿SUV排名汽车销量信息新闻排名模板自动生成采集
开发环境:Empirecms 7.5
安装环境:php+mysql
包括优采云采集规则和模块,采集目标站SUV排行榜官网。一年包采集规则更新
说明:为您提供2019年最新SUV销量排行榜、SUV排行榜及SUV越野性能报价图片。用文章分析奔驰SUV、长城、丰田SUV、斯柯达、玛莎拉蒂SUV、捷豹、大众SUV、本田、日产SUV、雷克萨斯等国际品牌以及大量国产新车SUV销量排行榜,要想一波SUV排行榜,你必须知道SUV排行榜的最佳口碑。
关键词:SUV销量排行榜,SUV排行榜,中国汽车销量排行榜,汽车销量,SUV排行榜
一个行业新闻站模板是很多资深媒体人靠这个行业赚钱的而且有很多大神,汽车行业的模板一定是很不错的收入,模板还是很大气稳定的,用的帝国cms7.5内核仿制,开源无任何限制,模板结构简单,界面简洁大气,本程序与同步生成插件同步生成。
您可以查看下面的演示链接,数据由 优采云 模块更新。
电脑站演示地址:
移动站演示地址:
选择本站的优势:更新快,包更新,包安装,包技术指导,经济方便。
本源码为开发姐姐原创的源码,经济实惠,同行业中物美价廉。
MoBan5原创源码,VIP模板。站长经常更新版本,有技术支持,最新版本以demo地址为准!
本站模板MoBan5包安装服务一站式,从程序上传到环境搭建所有包,如果您自己安装,MoBan5站长将免费提供专业的技术支持。所有模板至少一年技术服务支持!
不会安装仿《SUV排行榜》源码,仿《SUV排行榜》源码优采云采集规则无效,最新版《SUV排行榜》源码SUV排行榜》将被模仿。白站长也能真正上手
所有模板仅支持常规站点,请合法合规建站。如有违反国家法律法规或任何第三方合法权益的行为,将终止服务,后果自负!本站不为非法网站提供任何服务。
查看全部
关键词文章采集源码(仿SUV排行榜汽车销售资讯新闻排行模板同步生成自动采集
)
来源名称:仿SUV排名汽车销量信息新闻排名模板自动生成采集
开发环境:Empirecms 7.5
安装环境:php+mysql
包括优采云采集规则和模块,采集目标站SUV排行榜官网。一年包采集规则更新
说明:为您提供2019年最新SUV销量排行榜、SUV排行榜及SUV越野性能报价图片。用文章分析奔驰SUV、长城、丰田SUV、斯柯达、玛莎拉蒂SUV、捷豹、大众SUV、本田、日产SUV、雷克萨斯等国际品牌以及大量国产新车SUV销量排行榜,要想一波SUV排行榜,你必须知道SUV排行榜的最佳口碑。
关键词:SUV销量排行榜,SUV排行榜,中国汽车销量排行榜,汽车销量,SUV排行榜
一个行业新闻站模板是很多资深媒体人靠这个行业赚钱的而且有很多大神,汽车行业的模板一定是很不错的收入,模板还是很大气稳定的,用的帝国cms7.5内核仿制,开源无任何限制,模板结构简单,界面简洁大气,本程序与同步生成插件同步生成。
您可以查看下面的演示链接,数据由 优采云 模块更新。
电脑站演示地址:
移动站演示地址:
选择本站的优势:更新快,包更新,包安装,包技术指导,经济方便。
本源码为开发姐姐原创的源码,经济实惠,同行业中物美价廉。
MoBan5原创源码,VIP模板。站长经常更新版本,有技术支持,最新版本以demo地址为准!
本站模板MoBan5包安装服务一站式,从程序上传到环境搭建所有包,如果您自己安装,MoBan5站长将免费提供专业的技术支持。所有模板至少一年技术服务支持!
不会安装仿《SUV排行榜》源码,仿《SUV排行榜》源码优采云采集规则无效,最新版《SUV排行榜》源码SUV排行榜》将被模仿。白站长也能真正上手
所有模板仅支持常规站点,请合法合规建站。如有违反国家法律法规或任何第三方合法权益的行为,将终止服务,后果自负!本站不为非法网站提供任何服务。

关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-29 00:28
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,会使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址: 查看全部
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,会使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址:
关键词文章采集源码(谈一谈程序员的自我修养问题,你知道吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-26 22:01
程序 自媒体 已被授权复制
文章文章<<<<<<<<<<<<<<<<<我非常同意,英文很重要,但是文章站的高度还是太高了,我不认同具体的学习方法,也觉得不太实用,今天就借这个机会跟大家讲讲程序员的修养很认真。
首先让我介绍一下利益相关者,我的背景:
初中时参加信息学和数学竞赛,主修软件工程。毕业后在一家银行做大数据分析和项目管理,然后开始了自己的创业。他曾在媒体公司和软件外包公司工作。现在他在中国(南京)软件谷机房工作,做自己喜欢的事。15年编码经验,6年创业经验。主要技术方向为.NET、HTML5、云服务、应用级开发等。自评整体水平为,高级程序员,初级架构师
首先要说的是,今天的话题是哪些程序员?
说话之前,不得不提一下知名程序员赵杰,他曾经有一个观点:“坚决反对北大青鸟等机构”。以前很赞同这个观点,现在却在“赞同”的基础上,坚决反对甚至反感赵杰“发这个观点”。因为这个观点,能帮上忙的人是赵杰最不可能遇到的草根开发者,而这些最不可能的人是中国最普通的程序员,也是赵杰最不可能甚至不愿意帮助的人。相信自己有很好的科学基础,逻辑性强,有完整的语言学习经验,他认为至少这是程序员,甚至认为其他不学数据结构的人不应该做程序。那真是太嚣张了。
在中国,写程序不仅仅是一种爱好,更多的时候,它是一种常见的职业,一种谋生手段
大公司有优秀的程序员和优秀的架构师,但很多小公司也有很多普通的程序员。在这些年的工作经历中,我越来越深刻地感受到普通程序员的影响力和力量。对于高级程序员来说,所谓的八仙渡海,各有神通,各有成就,各有修为,但在程序员达到更高层次之前,他们都有一些“修养”,这是最基本和最普遍的。的。
所以今天的话题面向的程序员是所有正在写代码或者已经写过代码的程序员,以及广义的程序员,比如项目经理、架构师等等。
一切都是为了一个明确的目的而做的,然后
再说一遍,程序员提高修养的目的是什么?
程序写的好,有人佩服,也有人喜欢?或者去博客、论坛和社区发布 文章 来分享和获得成就?我想这是少数人的追求,也是更高的追求,在此之前
我认为在中国,程序员提高修养的目的是为了
1、更好的融入工作,更少的困难,更多的成就
2、稳定提升能力,增加收入,实现财务自由
2、从更高的层次看待自己的学习和工作,树立更适合的人生观和价值观,家庭幸福,幸福生活
说得更简单,就是用更合理的方法和方法来赚取更多的收入
说了这么多废话,进入正题
程序员的修养是什么?
很难清楚地解释积极的讨论。反过来的描述可能更容易理解。修身的反义词是“不修身”。“程序员形式:
1、程序员小张遇到开发问题,很着急。他想到了好几个群,就把问题发到群里,等一个答案,发现没有人回答,于是直接和群主的QQ聊天,群主没有回答,于是小张搜索,突然在博客园里发现了一篇解释相关话题的帖子。看完后,他给博主留言。我的邮箱是:请把博主的源代码发给我。,谢谢。
2、程序员小张来公司3个月了。老板分配了很多任务。他觉得老板很不人道。省,客户反馈有问题,不会主动解决,主要是敷衍,再过一个月,换工作。
3、程序员小张正在写一个功能模块,需要一些加密。他在百度上找到了一个编码模块。搬进来。
4、程序员小张想开发某个功能。项目经理对他说,这个功能应该是可搜索的。去搜搜,小张正在百度上搜索。一天后,一切都可以找到。没找到,项目经理来找小张坐下,换了关键词,1分钟就找到了解决办法。
5、程序员小张在.NET工作了3年,薪水还是1万。他没有同意公司提高他的工资。他犹豫着换工作。这时,一位学长对他说,去看书吧,多看一些书,比如《Visual C# From Beginner to Mastery》、《CLR via C#》、《Java权威指南》等,于是小张就买了回过头来,发现了一些他已经知道的东西,有的看了,看不懂,好像也用不上,书那么厚,难道要浪费时间看吗?小张就这样挣扎了半年,依然每天上班,下班LOL,偶尔抱怨工资低。
6、程序员小张去了一家新公司。在做一个项目实现某个功能的时候,他记得自己以前做过这样的功能,但是想不起来怎么实现了,就去电脑里找文档,怎么也找不到找了半天,只好放弃,终于折腾了2天,终于实现了这个功能。
7、程序员小张有一天很不高兴,因为他的项目经理和项目组的产品人员又改需求了,新的需求需要对整个架构进行大的调整。小张很郁闷。一个QQ发泄了自己的情绪,这么一说,QQ群顿时炸开了锅。程序员小李说,对,产品就是屎!程序员小王说,是啊,他妈的项目经理一整天都可以高枕无忧,还懂得挤开发者!程序员小孙说,对对对,我上一家公司也是这样,挤程序员,还好我走了。就这样,在骂声中,几个程序员松了口气,小张开心地去玩王者荣耀了。
我想,有些人可能已经明白我想说的话,有些人可能不明白,具体的话我说不上来,只能用一句话概括:
在编写代码的过程中,你善于学习,掌握方法,努力思考,努力工作,持之以恒。从长远来看,你会在编程中找到不同版本的自己。
上面还是比较抽象的,那么
提高修养的具体方法有哪些?
程序员如何实现“更高的修养”,每个人都有自己的方法,我就不详述了,就像如何提高自己的修养一样,一两句话说不清楚,但有些说法也很流行容易理解,比如孩子有受过良好教育的父母,父母有礼貌。孩子开始接受正规教育,小学、初中、高中、大学,然后文化课程和社会实践都很好。那么孩子最后的人生修为,肯定比没有走过过程的孩子要好。
编写程序也是如此。下面我就讲一些最基本、最容易理解的学习方法和原则,我称之为:
程序员基础知识
一个好的开发人员应该能够全面、高效、严谨地处理任何软件程序和业务问题。做一个优秀的开发者是一个很有意思的话题,但是不管这个话题怎么开发,基本的两个字是必不可少的。, 虽然代码量是衡量开发能力的重要指标,但仅仅能熟练地编写代码是不够的。还需要对技术原理和业务逻辑有深刻的理解。扎实的个人和技术基础通常会促进代码编写。更容易解决问题。
下面提到的一些基础知识可能不会被大多数开发人员注意到甚至忽略,但这些是开发构建的基石。
1、科学基础
成为开发者的过程是不一样的,有的是专业背景,有的是爱好,有的是在专业机构培训。在这个过程中,你可能有全面的或分散的,甚至没有学习过基础计算机学科,但无论哪种,你想成为更高层次的开发人员,编写更高质量的代码,学习计算机科学的基础知识都是非常重要的。 ,非常非常(重要的事情说了三遍)重要。具体来说,在基础科目的实际应用中,以下科目是肯定需要的,按学习顺序排列如下
1)数据结构
通俗的讲,数据结构课程告诉你如何使用最基本的语言类型、变量、关键词语句等处理各种我们称之为算法的逻辑问题,以及各种日常编程. 排序、文件夹遍历操作、数据库查询等问题,可以在数据结构课程中对应的数学原型中找到。数据结构课程的理解能力也是一个人数学能力的体现。数据结构学习的好坏是程序员水平差异的重要分水岭。对于本内容的学习,有以下几点建议:使用VB、C、C++,对于Pascal等语言,买一本语言相关的数据结构和算法的书,或在线下载相关PDF电子书,完成学习,编写、运行、调试书中所有案例。当你能领悟一些日常编程中常用的方法来源于一定的数据结构和算法时,基本就达到了学习的效果。
2)操作系统
所有编程语言的开发和应用程序的运行都是基于操作系统的。桌面编程中的大部分场景,包括内存、进程、文件系统、网络通信、用户界面等,都是源于对操作系统的定义和概念,对操作系统的由来、组成和操作逻辑有一个完整的理解。系统对多线程、复杂接口、文件管理、开发中遇到的一些场景难懂的编程思想有很大的帮助,不仅有助于理解,还能更有效地掌握程序编写。具体可以购买操作系统书籍或下载相关PDF电子书,完整浏览,
3)数据库
传统的关系数据库很容易上手,但很难深入。往往开发者可以快速掌握CRUD、视图、索引、存储过程等基本的数据库操作,但是在编写复杂的查询、设计主外键、优化字段、去除冗余等的时候,有一种情况就是他们只能随葫芦画瓢,不能独立思考和扩展。原因是我仍然无法理解关系数据库的基本原理。数据库课程系统地阐述了关系数据库的来龙去脉,了解其中的数学原理或逻辑基础对提高数据库编程水平有质的影响。
4)编译原理
编译原理是编程语言和各种语言编译器的科学依据。可以说,编译原理造就了世界上几乎所有的 IT 应用。学习编译原理的基础是数据结构和算法。因此,需要更多地学习编译原理。由于现代高级编程语言的编译器在代码优化和资源优化方面已经足够聪明了,编译原理的学习对实战的影响越来越小,但作为所谓的本圣魔荣,如果你认为说明你对数据结构和算法的学习已经达到了高水平和境界,你可以在编译原理的学习上走的更远,最终拉开自己和普通程序员之间更大的差距。
2、英语水平
英语的自然特性、字母的长度以及学科发展的历史因素决定了编程语言必须以英语为基础。在编程的过程中,从语言的关键词到文档的内容或者搜索引擎的搜索结果,都难免会遇到英文。大多数程序员的英语基础都在CET-4左右,但由于非专业和工作环境的原因,他们逐渐疏远甚至完全忘记了英语。在实际操作中,大部分编程语言资料都是英文的,在线编程问答的内容也是英文的。因此,有必要将英语能力恢复到不太高但有效的水平,以达到以下效果:
1)每个关键词都知道他们使用的语言的具体英文翻译、逻辑含义和发音。
2)对于你使用的语言所涉及的相关方法、类库、框架、工具等,你可以知道每个方法、过程、参数的英文翻译、逻辑意义和发音关键词 .
3)对于常见的编程逻辑和核心关键词,可以用英文组织问题描述,最简单的答案就可以,只要能被搜索引擎理解。比如C#中如何将整数转换为字符串类型,最简单的英文描述就是C# Integer Covert To String。
4)任何英文技术手册、文档、文章或在其技术知识范围内的问题描述,能够阅读80%的内容含义,并能够阅读完整的技术含义。
3、搜索方式
任何开发者都应该具备搜索能力,甚至必须具备搜索能力。搜索引擎的宝藏是无穷无尽的。不同的程序员也有搜索意识,但由于搜索技巧的不同,程序开发的质量、项目执行效率甚至工程产品质量都有数倍的差异。因此,掌握高效、先进、灵活的搜索方法和技术是非常非常非常有用的。主要方法描述如下:
1)搜索源选择
2)关键词构造
搜索关键词的结构直接影响搜索效率和正确结果的过滤。没有什么特别的技能。关键在于搜索积累,但总的原则是要准确、简洁。例如,当出现一个描述,如何使用 C# 来序列化和反序列化 XML 时,非常傻瓜式 关键词 构造是“如何在 C# 中序列化和反序列化 XML”,而正确高效的 关键词 是“C# XML 序列化反序列化”,或谷歌搜索“C# XML 序列化”。在平时的编程中,一定要注意相关方法和经验的积累
3)联想搜索
联想搜索不属于搜索引擎的范畴,但它是搜索中非常有用的高级技术。例如,如果您想使用 C# 并使用某个 .NET 类来处理一种 HTTP 通信,那么搜索并不完美。结果,不过换个思路,考虑到VB.NET也是.NET系统,和C#完全类似,那你也可以试试用VB.NET关键词搜索,然后复制搜索完完美代码后的 C# 代码。这样的联想搜索不仅可以帮助你搜索到正确的结果,还可以训练你的大脑思维,所以值得多多尝试。
4)资源搜索
开源框架、产品、工具、控件等开发辅助工具越来越多,健壮性和迭代性越来越强。寻找成熟的工具或插件也成为了众多开发者的必备方法。技能,以及如何有效地搜索所需资源也成为一种知识。核心方法是知道资源网站的地址,比如开源中国、Github、CSDN下载、pudn等。资源类网站需要多多积累,会使用时非常关键。
4、心态
开发者必须开发一种商业思维模式。所谓业务思维,就是在做任何项目时,在编写任何代码之前,都需要对项目本身的业务概念、业务逻辑乃至业务流程有一个全面的了解。学习和理解,虽然这不是一个项目的强制性要求,但也是一种良好的开发习惯。无论你认为是开发人员、测试人员还是技术总监,都可以更好地设计或阅读项目的数据结构和流程结构。程序员的思维往往与用户或客户不一致。摆脱技术思维模式,习惯于用业务思维解决问题的程序员不一定是最好的,但一定是易于沟通的程序员。
5、工作和编程习惯
有人说爱干净,浪费时间,所以不马虎,但归根结底还是习惯问题。编写程序也是如此。有一些编程习惯,看似微不足道,看似浪费时间,但坚持下去,终能得到意想不到的神奇效果。下面列出了一些特别重要的习惯。
1)快捷键的使用
无论是使用 Windows、Linux 操作系统,还是在 IDE 中,快捷键都是系统本身的标准配置。其实大部分人都可以通过Ctrl+C、V等操作来尝到节省时间的甜头。为了进一步传播这个概念,如果你在IDE中编写代码,除了代码本身之外,所有其他的鼠标操作和键盘定位操作换成快捷键,会节省一个数量级的时间,但看起来那么好的东西,真正坚持执行和养成习惯的人却屈指可数。因此,早期改变习惯和记住快捷键将是一个长期的过程,需要不断的坚持。
2)代码注释
随着开发者年龄和经验的增长,他参与的项目已经不可能由一个人或几个人完成。系统重构、代码重构、工作交接、新员工培训等,会越来越多地遇到,而这些事情都会无一例外地重写或重复已经编写好的代码。阅读,如果在最初写代码的时候做完整、清晰的代码注释,对后续工作会有很大帮助。既提高了工作效率,又增强了合作的好感度。其实即使只是看自己的代码,如果有注释,也能加深印象,缩短找代码的时间。因此,任何开发者都应该养成良好的代码注释习惯。
好的代码注释应该这样做:
3) 命名规则
具有一定规模的软件公司有自己的一套代码编写命名规则,涵盖项目、模块、函数、变量等。标准化命名的好处是不言而喻的,但被动地、被迫地服从命名规则并采取主动。习惯命名约定是完全不同的。一个好的开发者应该真诚地希望各种代号有规律、易读,而不是纠结于命名规则会增加代号的长度。
4)编程逻辑
所谓未准备好的编程逻辑的对立面是不注意的编程逻辑。不关注它的编程,不仅是一种非常糟糕的编程习惯,也反映了生活质量的低下。, 客户要求低等原因有很多,编程的时候很随意。比如百度为了实现某个功能,生成一段代码,直接应用。10行代码只看懂了8行,还有两行看不懂。用在程序中,很多这样的小细节就像在项目中埋下了无数的定时炸弹,不仅返工概率很高,也给项目埋下了风险。程序员应该有负责任的态度,
5)数据备份
误删、误操作、电脑断电、文件丢失等是每个开发者都可能遇到的问题。如果您不希望自己的辛勤工作被浪费,也不希望意外事故影响您的工作,那么进行备份是个好主意。不可或缺,在大公司里,会有完善的源代码管理和信息安全保护,无论你是在大公司还是小公司工作,还是在实现个人代码价值的时候,都必须做好。代码和文档的数据备份,备份方式的选择灵活多样,包括使用在线CVS、SVN、TFS、Git源代码管理,或者手动将文件复制到云空间或本地硬盘,甚至形成个人电脑上的RAID磁盘阵列等,养成定期定期备份的习惯。
6)邮件的工作原理
沟通是进步的源泉,如果说开发团队的热烈讨论是性格和激情的体现,那么邮件的工作方式就是另一种审慎和效率。无论是公司层面的工作沟通,还是开发团队的问题沟通,邮件的作用包括问题的形式化描述、工作归档和跟踪、工作流程、职责分工明确等。通过电子邮件发送的问题和重要事项。与同事、主管等沟通的方式对团队合作非常有帮助。
以上方法是我这些年的感受和经验,对我也有很大帮助。我希望他们也能帮助到大家。不能说可以“修身养性”,但也是“修身养性”的有效途径。
最后,我想谈谈坚持的力量
分享一个真实的小故事。公司有两名开发人员。一个已经在.NET 上工作了很多年,但他非常聪明。当他可以做事时,他可以节省。当他可以偷懒的时候,他就会偷懒,让他学习新的知识和新的方法。我一直认为我可以做到;还有一个没有.NET基础,一直在做底层语言开发。15年才开始学习.NET和Web前端,但是做事很积极。我几乎每天都花时间自学。如果你知道你知道什么,你就可以弄清楚。遇到不认识的场景,就上网或者找人帮忙。项目结束后,您会考虑可以改进的地方。从15年到现在,短短一年时间,这两个人的发展已经天壤之别,工资差距也在扩大。后者已经能够独自管理中小型软件外包项目,而前者还活着,未来各自的发展完全可以预见。
我想说的是,本文分享的一些原理和方法通俗易懂,就像经常听到的故事如365次方的101%和99%、10000小时的真相等等,但真正认真思考和实践的人却屈指可数。或许,坚持是程序员最大的成就,我来和大家分享!
...结尾...
附:《如何提升自己的能力?给年轻程序员的几点建议》 查看全部
关键词文章采集源码(谈一谈程序员的自我修养问题,你知道吗?(上))
程序 自媒体 已被授权复制
文章文章<<<<<<<<<<<<<<<<<我非常同意,英文很重要,但是文章站的高度还是太高了,我不认同具体的学习方法,也觉得不太实用,今天就借这个机会跟大家讲讲程序员的修养很认真。
首先让我介绍一下利益相关者,我的背景:
初中时参加信息学和数学竞赛,主修软件工程。毕业后在一家银行做大数据分析和项目管理,然后开始了自己的创业。他曾在媒体公司和软件外包公司工作。现在他在中国(南京)软件谷机房工作,做自己喜欢的事。15年编码经验,6年创业经验。主要技术方向为.NET、HTML5、云服务、应用级开发等。自评整体水平为,高级程序员,初级架构师
首先要说的是,今天的话题是哪些程序员?
说话之前,不得不提一下知名程序员赵杰,他曾经有一个观点:“坚决反对北大青鸟等机构”。以前很赞同这个观点,现在却在“赞同”的基础上,坚决反对甚至反感赵杰“发这个观点”。因为这个观点,能帮上忙的人是赵杰最不可能遇到的草根开发者,而这些最不可能的人是中国最普通的程序员,也是赵杰最不可能甚至不愿意帮助的人。相信自己有很好的科学基础,逻辑性强,有完整的语言学习经验,他认为至少这是程序员,甚至认为其他不学数据结构的人不应该做程序。那真是太嚣张了。
在中国,写程序不仅仅是一种爱好,更多的时候,它是一种常见的职业,一种谋生手段
大公司有优秀的程序员和优秀的架构师,但很多小公司也有很多普通的程序员。在这些年的工作经历中,我越来越深刻地感受到普通程序员的影响力和力量。对于高级程序员来说,所谓的八仙渡海,各有神通,各有成就,各有修为,但在程序员达到更高层次之前,他们都有一些“修养”,这是最基本和最普遍的。的。
所以今天的话题面向的程序员是所有正在写代码或者已经写过代码的程序员,以及广义的程序员,比如项目经理、架构师等等。
一切都是为了一个明确的目的而做的,然后
再说一遍,程序员提高修养的目的是什么?
程序写的好,有人佩服,也有人喜欢?或者去博客、论坛和社区发布 文章 来分享和获得成就?我想这是少数人的追求,也是更高的追求,在此之前
我认为在中国,程序员提高修养的目的是为了
1、更好的融入工作,更少的困难,更多的成就
2、稳定提升能力,增加收入,实现财务自由
2、从更高的层次看待自己的学习和工作,树立更适合的人生观和价值观,家庭幸福,幸福生活
说得更简单,就是用更合理的方法和方法来赚取更多的收入
说了这么多废话,进入正题
程序员的修养是什么?
很难清楚地解释积极的讨论。反过来的描述可能更容易理解。修身的反义词是“不修身”。“程序员形式:
1、程序员小张遇到开发问题,很着急。他想到了好几个群,就把问题发到群里,等一个答案,发现没有人回答,于是直接和群主的QQ聊天,群主没有回答,于是小张搜索,突然在博客园里发现了一篇解释相关话题的帖子。看完后,他给博主留言。我的邮箱是:请把博主的源代码发给我。,谢谢。
2、程序员小张来公司3个月了。老板分配了很多任务。他觉得老板很不人道。省,客户反馈有问题,不会主动解决,主要是敷衍,再过一个月,换工作。
3、程序员小张正在写一个功能模块,需要一些加密。他在百度上找到了一个编码模块。搬进来。
4、程序员小张想开发某个功能。项目经理对他说,这个功能应该是可搜索的。去搜搜,小张正在百度上搜索。一天后,一切都可以找到。没找到,项目经理来找小张坐下,换了关键词,1分钟就找到了解决办法。
5、程序员小张在.NET工作了3年,薪水还是1万。他没有同意公司提高他的工资。他犹豫着换工作。这时,一位学长对他说,去看书吧,多看一些书,比如《Visual C# From Beginner to Mastery》、《CLR via C#》、《Java权威指南》等,于是小张就买了回过头来,发现了一些他已经知道的东西,有的看了,看不懂,好像也用不上,书那么厚,难道要浪费时间看吗?小张就这样挣扎了半年,依然每天上班,下班LOL,偶尔抱怨工资低。
6、程序员小张去了一家新公司。在做一个项目实现某个功能的时候,他记得自己以前做过这样的功能,但是想不起来怎么实现了,就去电脑里找文档,怎么也找不到找了半天,只好放弃,终于折腾了2天,终于实现了这个功能。
7、程序员小张有一天很不高兴,因为他的项目经理和项目组的产品人员又改需求了,新的需求需要对整个架构进行大的调整。小张很郁闷。一个QQ发泄了自己的情绪,这么一说,QQ群顿时炸开了锅。程序员小李说,对,产品就是屎!程序员小王说,是啊,他妈的项目经理一整天都可以高枕无忧,还懂得挤开发者!程序员小孙说,对对对,我上一家公司也是这样,挤程序员,还好我走了。就这样,在骂声中,几个程序员松了口气,小张开心地去玩王者荣耀了。
我想,有些人可能已经明白我想说的话,有些人可能不明白,具体的话我说不上来,只能用一句话概括:
在编写代码的过程中,你善于学习,掌握方法,努力思考,努力工作,持之以恒。从长远来看,你会在编程中找到不同版本的自己。
上面还是比较抽象的,那么
提高修养的具体方法有哪些?
程序员如何实现“更高的修养”,每个人都有自己的方法,我就不详述了,就像如何提高自己的修养一样,一两句话说不清楚,但有些说法也很流行容易理解,比如孩子有受过良好教育的父母,父母有礼貌。孩子开始接受正规教育,小学、初中、高中、大学,然后文化课程和社会实践都很好。那么孩子最后的人生修为,肯定比没有走过过程的孩子要好。
编写程序也是如此。下面我就讲一些最基本、最容易理解的学习方法和原则,我称之为:
程序员基础知识
一个好的开发人员应该能够全面、高效、严谨地处理任何软件程序和业务问题。做一个优秀的开发者是一个很有意思的话题,但是不管这个话题怎么开发,基本的两个字是必不可少的。, 虽然代码量是衡量开发能力的重要指标,但仅仅能熟练地编写代码是不够的。还需要对技术原理和业务逻辑有深刻的理解。扎实的个人和技术基础通常会促进代码编写。更容易解决问题。
下面提到的一些基础知识可能不会被大多数开发人员注意到甚至忽略,但这些是开发构建的基石。
1、科学基础
成为开发者的过程是不一样的,有的是专业背景,有的是爱好,有的是在专业机构培训。在这个过程中,你可能有全面的或分散的,甚至没有学习过基础计算机学科,但无论哪种,你想成为更高层次的开发人员,编写更高质量的代码,学习计算机科学的基础知识都是非常重要的。 ,非常非常(重要的事情说了三遍)重要。具体来说,在基础科目的实际应用中,以下科目是肯定需要的,按学习顺序排列如下
1)数据结构
通俗的讲,数据结构课程告诉你如何使用最基本的语言类型、变量、关键词语句等处理各种我们称之为算法的逻辑问题,以及各种日常编程. 排序、文件夹遍历操作、数据库查询等问题,可以在数据结构课程中对应的数学原型中找到。数据结构课程的理解能力也是一个人数学能力的体现。数据结构学习的好坏是程序员水平差异的重要分水岭。对于本内容的学习,有以下几点建议:使用VB、C、C++,对于Pascal等语言,买一本语言相关的数据结构和算法的书,或在线下载相关PDF电子书,完成学习,编写、运行、调试书中所有案例。当你能领悟一些日常编程中常用的方法来源于一定的数据结构和算法时,基本就达到了学习的效果。
2)操作系统
所有编程语言的开发和应用程序的运行都是基于操作系统的。桌面编程中的大部分场景,包括内存、进程、文件系统、网络通信、用户界面等,都是源于对操作系统的定义和概念,对操作系统的由来、组成和操作逻辑有一个完整的理解。系统对多线程、复杂接口、文件管理、开发中遇到的一些场景难懂的编程思想有很大的帮助,不仅有助于理解,还能更有效地掌握程序编写。具体可以购买操作系统书籍或下载相关PDF电子书,完整浏览,
3)数据库
传统的关系数据库很容易上手,但很难深入。往往开发者可以快速掌握CRUD、视图、索引、存储过程等基本的数据库操作,但是在编写复杂的查询、设计主外键、优化字段、去除冗余等的时候,有一种情况就是他们只能随葫芦画瓢,不能独立思考和扩展。原因是我仍然无法理解关系数据库的基本原理。数据库课程系统地阐述了关系数据库的来龙去脉,了解其中的数学原理或逻辑基础对提高数据库编程水平有质的影响。
4)编译原理
编译原理是编程语言和各种语言编译器的科学依据。可以说,编译原理造就了世界上几乎所有的 IT 应用。学习编译原理的基础是数据结构和算法。因此,需要更多地学习编译原理。由于现代高级编程语言的编译器在代码优化和资源优化方面已经足够聪明了,编译原理的学习对实战的影响越来越小,但作为所谓的本圣魔荣,如果你认为说明你对数据结构和算法的学习已经达到了高水平和境界,你可以在编译原理的学习上走的更远,最终拉开自己和普通程序员之间更大的差距。
2、英语水平
英语的自然特性、字母的长度以及学科发展的历史因素决定了编程语言必须以英语为基础。在编程的过程中,从语言的关键词到文档的内容或者搜索引擎的搜索结果,都难免会遇到英文。大多数程序员的英语基础都在CET-4左右,但由于非专业和工作环境的原因,他们逐渐疏远甚至完全忘记了英语。在实际操作中,大部分编程语言资料都是英文的,在线编程问答的内容也是英文的。因此,有必要将英语能力恢复到不太高但有效的水平,以达到以下效果:
1)每个关键词都知道他们使用的语言的具体英文翻译、逻辑含义和发音。
2)对于你使用的语言所涉及的相关方法、类库、框架、工具等,你可以知道每个方法、过程、参数的英文翻译、逻辑意义和发音关键词 .
3)对于常见的编程逻辑和核心关键词,可以用英文组织问题描述,最简单的答案就可以,只要能被搜索引擎理解。比如C#中如何将整数转换为字符串类型,最简单的英文描述就是C# Integer Covert To String。
4)任何英文技术手册、文档、文章或在其技术知识范围内的问题描述,能够阅读80%的内容含义,并能够阅读完整的技术含义。
3、搜索方式
任何开发者都应该具备搜索能力,甚至必须具备搜索能力。搜索引擎的宝藏是无穷无尽的。不同的程序员也有搜索意识,但由于搜索技巧的不同,程序开发的质量、项目执行效率甚至工程产品质量都有数倍的差异。因此,掌握高效、先进、灵活的搜索方法和技术是非常非常非常有用的。主要方法描述如下:
1)搜索源选择
2)关键词构造
搜索关键词的结构直接影响搜索效率和正确结果的过滤。没有什么特别的技能。关键在于搜索积累,但总的原则是要准确、简洁。例如,当出现一个描述,如何使用 C# 来序列化和反序列化 XML 时,非常傻瓜式 关键词 构造是“如何在 C# 中序列化和反序列化 XML”,而正确高效的 关键词 是“C# XML 序列化反序列化”,或谷歌搜索“C# XML 序列化”。在平时的编程中,一定要注意相关方法和经验的积累
3)联想搜索
联想搜索不属于搜索引擎的范畴,但它是搜索中非常有用的高级技术。例如,如果您想使用 C# 并使用某个 .NET 类来处理一种 HTTP 通信,那么搜索并不完美。结果,不过换个思路,考虑到VB.NET也是.NET系统,和C#完全类似,那你也可以试试用VB.NET关键词搜索,然后复制搜索完完美代码后的 C# 代码。这样的联想搜索不仅可以帮助你搜索到正确的结果,还可以训练你的大脑思维,所以值得多多尝试。
4)资源搜索
开源框架、产品、工具、控件等开发辅助工具越来越多,健壮性和迭代性越来越强。寻找成熟的工具或插件也成为了众多开发者的必备方法。技能,以及如何有效地搜索所需资源也成为一种知识。核心方法是知道资源网站的地址,比如开源中国、Github、CSDN下载、pudn等。资源类网站需要多多积累,会使用时非常关键。
4、心态
开发者必须开发一种商业思维模式。所谓业务思维,就是在做任何项目时,在编写任何代码之前,都需要对项目本身的业务概念、业务逻辑乃至业务流程有一个全面的了解。学习和理解,虽然这不是一个项目的强制性要求,但也是一种良好的开发习惯。无论你认为是开发人员、测试人员还是技术总监,都可以更好地设计或阅读项目的数据结构和流程结构。程序员的思维往往与用户或客户不一致。摆脱技术思维模式,习惯于用业务思维解决问题的程序员不一定是最好的,但一定是易于沟通的程序员。
5、工作和编程习惯
有人说爱干净,浪费时间,所以不马虎,但归根结底还是习惯问题。编写程序也是如此。有一些编程习惯,看似微不足道,看似浪费时间,但坚持下去,终能得到意想不到的神奇效果。下面列出了一些特别重要的习惯。
1)快捷键的使用
无论是使用 Windows、Linux 操作系统,还是在 IDE 中,快捷键都是系统本身的标准配置。其实大部分人都可以通过Ctrl+C、V等操作来尝到节省时间的甜头。为了进一步传播这个概念,如果你在IDE中编写代码,除了代码本身之外,所有其他的鼠标操作和键盘定位操作换成快捷键,会节省一个数量级的时间,但看起来那么好的东西,真正坚持执行和养成习惯的人却屈指可数。因此,早期改变习惯和记住快捷键将是一个长期的过程,需要不断的坚持。
2)代码注释
随着开发者年龄和经验的增长,他参与的项目已经不可能由一个人或几个人完成。系统重构、代码重构、工作交接、新员工培训等,会越来越多地遇到,而这些事情都会无一例外地重写或重复已经编写好的代码。阅读,如果在最初写代码的时候做完整、清晰的代码注释,对后续工作会有很大帮助。既提高了工作效率,又增强了合作的好感度。其实即使只是看自己的代码,如果有注释,也能加深印象,缩短找代码的时间。因此,任何开发者都应该养成良好的代码注释习惯。
好的代码注释应该这样做:
3) 命名规则
具有一定规模的软件公司有自己的一套代码编写命名规则,涵盖项目、模块、函数、变量等。标准化命名的好处是不言而喻的,但被动地、被迫地服从命名规则并采取主动。习惯命名约定是完全不同的。一个好的开发者应该真诚地希望各种代号有规律、易读,而不是纠结于命名规则会增加代号的长度。
4)编程逻辑
所谓未准备好的编程逻辑的对立面是不注意的编程逻辑。不关注它的编程,不仅是一种非常糟糕的编程习惯,也反映了生活质量的低下。, 客户要求低等原因有很多,编程的时候很随意。比如百度为了实现某个功能,生成一段代码,直接应用。10行代码只看懂了8行,还有两行看不懂。用在程序中,很多这样的小细节就像在项目中埋下了无数的定时炸弹,不仅返工概率很高,也给项目埋下了风险。程序员应该有负责任的态度,
5)数据备份
误删、误操作、电脑断电、文件丢失等是每个开发者都可能遇到的问题。如果您不希望自己的辛勤工作被浪费,也不希望意外事故影响您的工作,那么进行备份是个好主意。不可或缺,在大公司里,会有完善的源代码管理和信息安全保护,无论你是在大公司还是小公司工作,还是在实现个人代码价值的时候,都必须做好。代码和文档的数据备份,备份方式的选择灵活多样,包括使用在线CVS、SVN、TFS、Git源代码管理,或者手动将文件复制到云空间或本地硬盘,甚至形成个人电脑上的RAID磁盘阵列等,养成定期定期备份的习惯。
6)邮件的工作原理
沟通是进步的源泉,如果说开发团队的热烈讨论是性格和激情的体现,那么邮件的工作方式就是另一种审慎和效率。无论是公司层面的工作沟通,还是开发团队的问题沟通,邮件的作用包括问题的形式化描述、工作归档和跟踪、工作流程、职责分工明确等。通过电子邮件发送的问题和重要事项。与同事、主管等沟通的方式对团队合作非常有帮助。
以上方法是我这些年的感受和经验,对我也有很大帮助。我希望他们也能帮助到大家。不能说可以“修身养性”,但也是“修身养性”的有效途径。
最后,我想谈谈坚持的力量
分享一个真实的小故事。公司有两名开发人员。一个已经在.NET 上工作了很多年,但他非常聪明。当他可以做事时,他可以节省。当他可以偷懒的时候,他就会偷懒,让他学习新的知识和新的方法。我一直认为我可以做到;还有一个没有.NET基础,一直在做底层语言开发。15年才开始学习.NET和Web前端,但是做事很积极。我几乎每天都花时间自学。如果你知道你知道什么,你就可以弄清楚。遇到不认识的场景,就上网或者找人帮忙。项目结束后,您会考虑可以改进的地方。从15年到现在,短短一年时间,这两个人的发展已经天壤之别,工资差距也在扩大。后者已经能够独自管理中小型软件外包项目,而前者还活着,未来各自的发展完全可以预见。
我想说的是,本文分享的一些原理和方法通俗易懂,就像经常听到的故事如365次方的101%和99%、10000小时的真相等等,但真正认真思考和实践的人却屈指可数。或许,坚持是程序员最大的成就,我来和大家分享!
...结尾...
附:《如何提升自己的能力?给年轻程序员的几点建议》
关键词文章采集源码(有效提升文章收录的几个方法有很大的阻力吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-26 01:14
众所周知,经过这么多年的发展,搜索引擎对文章的认可度已经达到了非常高,现在对文章的要求也越来越高。关键词,大量采集等方法已经开始不行了,有时候我们发布大量文章,发现搜索引擎几乎没有收录,或者收录 页面很少,这会对我们的网站 SEO 产生很大的阻力。下面分享几个有效提升文章收录的方法。
1.插图和文字
图文含义通俗易懂。说白了就是文章的内容要穿插图片,图片要根据文章的长度来添加。图片应与文章相关。性别。比如:你写了一篇关于花草的文章文章,那么在配图的时候,我们尽量选择1-2张花草图片,这样会提升用户体验,也能吸引用户关注文章是高质量的文章,即使你用图片来吸引用户。
2.约800字
网站的文章最好尽量写,因为文章的质量会影响搜索引擎对我们网站的加分,如果我们文章字数比较多,而且是我们自己的原创内容,那么很容易获得搜索引擎的青睐。 (这里提一点写作技巧:假设你所在行业的文章不多,或者你对行业知识了解不多,可以查看同行的文章,对比一下他们的文章 @k17@ >拆分重组,这样的文章搜索引擎也会收录)
3.段落清晰,句子流畅
这是非常重要的。要知道,我们的文章不仅是针对搜索引擎的,也是针对用户的。所以我们的文章语句要尽量保持流畅,让读者阅读起来流畅,从而提升用户体验。
4.写在标题周围文章
这点很重要,尤其是新手朋友,很多新手SEO在写文章的时候容易跑题,要知道在写文章的时候一定要紧紧抓住标题的主题,围绕核心关键词展开相关内容,使其能够呼应标题,而不是文章开头说“螃蟹制作过程”,结尾写“虾实践”。
360网站源码总结:如果写出满足以上条件的文章,对SEO优化非常有利,文章原创度,文章@ >Value,这是两个核心点。一切都必须基于这两点。应该没有问题。我们网站的每一篇文章文章都必须是高质量的,以提高整个网站的评分。 ,然后分配给单个文章,排名会更高,也就是说文章的质量越高,整体排名和单个文章就越稳定排名。 查看全部
关键词文章采集源码(有效提升文章收录的几个方法有很大的阻力吗?)
众所周知,经过这么多年的发展,搜索引擎对文章的认可度已经达到了非常高,现在对文章的要求也越来越高。关键词,大量采集等方法已经开始不行了,有时候我们发布大量文章,发现搜索引擎几乎没有收录,或者收录 页面很少,这会对我们的网站 SEO 产生很大的阻力。下面分享几个有效提升文章收录的方法。
1.插图和文字
图文含义通俗易懂。说白了就是文章的内容要穿插图片,图片要根据文章的长度来添加。图片应与文章相关。性别。比如:你写了一篇关于花草的文章文章,那么在配图的时候,我们尽量选择1-2张花草图片,这样会提升用户体验,也能吸引用户关注文章是高质量的文章,即使你用图片来吸引用户。
2.约800字
网站的文章最好尽量写,因为文章的质量会影响搜索引擎对我们网站的加分,如果我们文章字数比较多,而且是我们自己的原创内容,那么很容易获得搜索引擎的青睐。 (这里提一点写作技巧:假设你所在行业的文章不多,或者你对行业知识了解不多,可以查看同行的文章,对比一下他们的文章 @k17@ >拆分重组,这样的文章搜索引擎也会收录)
3.段落清晰,句子流畅
这是非常重要的。要知道,我们的文章不仅是针对搜索引擎的,也是针对用户的。所以我们的文章语句要尽量保持流畅,让读者阅读起来流畅,从而提升用户体验。
4.写在标题周围文章
这点很重要,尤其是新手朋友,很多新手SEO在写文章的时候容易跑题,要知道在写文章的时候一定要紧紧抓住标题的主题,围绕核心关键词展开相关内容,使其能够呼应标题,而不是文章开头说“螃蟹制作过程”,结尾写“虾实践”。
360网站源码总结:如果写出满足以上条件的文章,对SEO优化非常有利,文章原创度,文章@ >Value,这是两个核心点。一切都必须基于这两点。应该没有问题。我们网站的每一篇文章文章都必须是高质量的,以提高整个网站的评分。 ,然后分配给单个文章,排名会更高,也就是说文章的质量越高,整体排名和单个文章就越稳定排名。
关键词文章采集源码(关键词文章采集源码-五步教你搞定源码采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-24 11:05
关键词文章采集源码-五步教你搞定源码采集系统github地址如下(已实现cdn加速,毕竟加速是商业项目,
和同名网站合作出个定制版的,
安装了chrome浏览器,可以使用siri或者语音控制,另外现在正在搞推广团队,有很多活动,很想投资一把,
可以把采集的网站保存在github上,方便以后互相协作。私信我。
可以将采集过来的url放到github上,然后通过github去采集。比如一个http类型的网站,同一ip,在一天之内总共被调用几次,那么收集这个页面每次被调用的url就是一个列表。现在也有一些简单的采集工具,能达到类似的效果。
pythonweb爬虫开发者网站urllib库的原理-老卢的文章-知乎专栏感谢老卢的文章
方式有很多,直接注册一个github账号,搜索内容可以自动发现,不过,
去问那个分析http的
全部都是采集的curl的接口
前年写了一个采集csdn的工具,自己用了一段时间,通过观察接口也很难发现收集规律,现在有自己的网站,就不想去重复发送请求干扰用户体验了。最多就是有些文章数据是老板指定某些站点才能看的,能接受的话就采集吧。
我有。很难抓的问题可以交给机器来帮你解决。 查看全部
关键词文章采集源码(关键词文章采集源码-五步教你搞定源码采集系统)
关键词文章采集源码-五步教你搞定源码采集系统github地址如下(已实现cdn加速,毕竟加速是商业项目,
和同名网站合作出个定制版的,
安装了chrome浏览器,可以使用siri或者语音控制,另外现在正在搞推广团队,有很多活动,很想投资一把,
可以把采集的网站保存在github上,方便以后互相协作。私信我。
可以将采集过来的url放到github上,然后通过github去采集。比如一个http类型的网站,同一ip,在一天之内总共被调用几次,那么收集这个页面每次被调用的url就是一个列表。现在也有一些简单的采集工具,能达到类似的效果。
pythonweb爬虫开发者网站urllib库的原理-老卢的文章-知乎专栏感谢老卢的文章
方式有很多,直接注册一个github账号,搜索内容可以自动发现,不过,
去问那个分析http的
全部都是采集的curl的接口
前年写了一个采集csdn的工具,自己用了一段时间,通过观察接口也很难发现收集规律,现在有自己的网站,就不想去重复发送请求干扰用户体验了。最多就是有些文章数据是老板指定某些站点才能看的,能接受的话就采集吧。
我有。很难抓的问题可以交给机器来帮你解决。
关键词文章采集源码(爬虫爬虫流量文章采集源码+特点介绍-上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-20 20:04
关键词文章采集源码+特点1。代码结构图、文章简介、增加机器学习的内容说明、作者介绍、作者主页、名称链接等信息;2。外链文章中公开出来的文章外链,使用spider进行收录自动化收录情况,按照出现文章的比例作为给结果的一个参考;2。1防止重复提交代码在发送重复地址的内容时都会提交指定位置进行不重复提交;2。
2提交过的文章,收录后,文章自动获取历史标题和相关内容,作为代码使用的有效条件,收录后,会将代码发送到开发团队,解析起来可以缩短代码发送的次数,加快地团队配合效率,减少不必要的代码发送量和编写量;3。python版本支持python3,下面的代码是选择爬虫流量文章,爬取爬虫流量的文章目前地址,请保存地址返回给excel版本和后续代码代码文件列表jieba。
py爬虫流量文章scrapy。crawl爬虫流量文章mean爬虫流量文章can_sent爬虫流量文章fancy_it爬虫流量文章unique爬虫流量文章ran_it爬虫流量文章care_program爬虫流量文章library爬虫流量文章library_urllib3爬虫流量文章robot。py爬虫流量文章发布流量文章agent_index爬虫流量文章api_pack爬虫流量文章unfold爬虫流量文章。
楼上三个答案的编码方式都不太对,爬虫流量文章都是使用这种文章列表分页形式生成的,这样可以有效的防止重复爬取,爬虫下的每一条爬虫都会有一个唯一的识别号,针对每一条爬虫都有一个唯一的链接, 查看全部
关键词文章采集源码(爬虫爬虫流量文章采集源码+特点介绍-上海怡健医学)
关键词文章采集源码+特点1。代码结构图、文章简介、增加机器学习的内容说明、作者介绍、作者主页、名称链接等信息;2。外链文章中公开出来的文章外链,使用spider进行收录自动化收录情况,按照出现文章的比例作为给结果的一个参考;2。1防止重复提交代码在发送重复地址的内容时都会提交指定位置进行不重复提交;2。
2提交过的文章,收录后,文章自动获取历史标题和相关内容,作为代码使用的有效条件,收录后,会将代码发送到开发团队,解析起来可以缩短代码发送的次数,加快地团队配合效率,减少不必要的代码发送量和编写量;3。python版本支持python3,下面的代码是选择爬虫流量文章,爬取爬虫流量的文章目前地址,请保存地址返回给excel版本和后续代码代码文件列表jieba。
py爬虫流量文章scrapy。crawl爬虫流量文章mean爬虫流量文章can_sent爬虫流量文章fancy_it爬虫流量文章unique爬虫流量文章ran_it爬虫流量文章care_program爬虫流量文章library爬虫流量文章library_urllib3爬虫流量文章robot。py爬虫流量文章发布流量文章agent_index爬虫流量文章api_pack爬虫流量文章unfold爬虫流量文章。
楼上三个答案的编码方式都不太对,爬虫流量文章都是使用这种文章列表分页形式生成的,这样可以有效的防止重复爬取,爬虫下的每一条爬虫都会有一个唯一的识别号,针对每一条爬虫都有一个唯一的链接,
关键词文章采集源码(本渣渣就是第二次360搜索相关关键词关键源码可参考学习 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-20 18:13
)
搜索引擎相关的搜索词应该是很多seoer都在寻找并选择使用的关键词扩展类别。除了流行的百度相关搜索词采集,当然还有360搜索引擎和搜狗搜索引擎,当然知道方法之后,python的应用基本一样,唯一的就是你需要关心的是这个词本身和反爬的局限性!
不,这是这个人渣第二次在360搜索上翻车,注意,这是第二次,第一次,处女翻车还是在采集360搜索题中翻车并回答,真的很好伤疤忘记了疼痛,太久了!!
360搜索大力出奇迹,不,大力出验证码。.
本渣渣在这里使用正则实现了相关关键词的获取,参考了很多源码,使用正则更方便快捷!
360搜索相关关键词key源码
re.findall(r'(.+?)</a>', html, re.S | re.I)
搜狗搜索相关关键词关键源码
大家可以参考自己的学习,毕竟没什么好说的!
附上360搜索相关关键词采集源码供大家参考学习!PS:我没写代码,我没用,怎么写?!
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
360相关搜索词挖掘脚本(多线程版)
基于python3.8
需要安装requests模块
@author:微信/huguo00289
"""
import re
from queue import Queue
from threading import Thread
import requests,random
class Qh360Spider(Thread):
result = {} # 保存结果字典
seen = set() # 表示在队列中的关键词(已抓取或待抓取)
def __init__(self, kw_queue, loop, failed):
super(Qh360Spider, self).__init__()
self.kw_queue = kw_queue # 关键词队列
self.loop = loop # 循环挖词拓展次数
self.failed = failed # 保存查询失败的关键词文件
self.ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]
def run(self): # 程序的执行流程
while True:
# 从队列里面获取一个关键词及其对应的当前拓展次数
kw, cloop = self.kw_queue.get()
print('CurLoop:{} Checking: {}'.format(cloop, kw))
query = 'https://www.so.com/s?q={}'.format(kw) # 构建含关键词的url
try:
source = self.download(query, timeout=10)
# source = self.download(query,timeout=10,user_agent=self.ua)
if source:
kw_list = self.extract(source)
print(kw_list)
self.filter(cloop, kw_list)
else:
# 获取源码失败,保存查询失败的关键词
self.failed.write('{}\n'.format(kw))
finally:
self.kw_queue.task_done()
def download(self, url, timeout=5, proxy=None, num_retries=5):
"""
通用网页源码下载函数
:param url: 要下载的url
:param timeout: 请求超时时间,单位/秒。可能某些网站的反应速度很慢,所以需要一个连接超时变量来处理。
:param user_agent: 用户代理信息,可以自定义是爬虫还是模拟用户
:param proxy: ip代理(http代理),访问某些国外网站的时候需要用到。必须是双元素元组或列表(‘ip:端口’,‘http/https’)
:param num_retries: 失败重试次数
:return: HTML网页源码
"""
headers = {
"Cookie": "QiHooGUID=41F80B0CCE5D43A22EEF0305A12CDE3F.1596003342506; __guid=15484592.2994995584481314300.1596003341831.5723; soid=TjzBKt3zrO-Rh1S7fXSb0S!6kmX5TlEerB2URZz9v4; __md=667cb161f9515972323507763d8fa7dd643a65bd2e88034.9; dpr=1; isafe=1; webp=1; _uc_m2=886a48052dbb9e2291f80055746e0d4f1f110f922b2f; _uc_mid=7cb161f953d8fa7dd643a65bd2e88034; __huid=11xZqhEl%2FfVeqclI4j%2BdQeQvX63Oph%2F%2BCVM5vxqYGxQI4%3D; Q=u%3Duhthb002%26n%3D%26le%3DAwH0ZGV5ZGR3WGDjpKRhL29g%26m%3DZGH5WGWOWGWOWGWOWGWOWGWOZGL0%26qid%3D144048053%26im%3D1_t018c25fbb66797efb2%26src%3D360chrome%26t%3D1; T=s%3D2afa764886f737dd5d23421c30f87a1f%26t%3D1595934758%26lm%3D0-1%26lf%3D2%26sk%3De485bbde46ac34fc27fc40215de76c44%26mt%3D1595934758%26rc%3D1%26v%3D2.0%26a%3D1; _S=tg75a7e3fmv0mfdfkt8jlpfpj6; stc_ls_sohome=RRzRSR!RTR(RUR_RVR; gtHuid=1; homeopenad=1; _pp_wd=1; _ga=GA1.2.607533084.1598082638; _gid=GA1.2.1887117715.1598082638; count=6; erules=p1-9%7Cp2-11%7Cp4-3%7Cecl-2%7Ckd-1%7Cp3-2",
'User-Agent': random.choice(self.ua_list)
}
try:
# 打开网页并读取内容存入html变量中
resp = requests.get(url, headers=headers, proxies=proxy, timeout=timeout)
print(resp.status_code)
except requests.RequestException as err:
print('Download error:', err)
html = None # 如果有异常,那么html肯定是没获取到的,所以赋值None
if num_retries > 0:
return self.download(url, timeout, proxy, num_retries - 1)
else:
html = resp.content.decode('utf-8')
#print(html)
return html
@staticmethod
def extract(html):
'''
提取关键词
:param html:搜索结果源码
:return:提取出来的相关关键词列表
'''
return re.findall(r'(.+?)</a>', html, re.S | re.I)
def filter(self, current_loop, kwlist):
'''
关键词过滤和统计函数
:param current_loop: 当前拓展的次数
:param kwlist: 提取出来的关键词列表
:return: None
'''
for kw in kwlist:
# 判断关键词是不是已经被抓取或者已经存在关键词队列
# 判断当前的拓展次数是否已经超过指定值
if current_loop 0:
print("有东西")
print('111')
save.write(line)
save.flush() # 刷新缓存,避免中途出错
save.close()
print('done,完成挖掘')
如果您无法访问 ip 代理,那么协调起来非常容易。毕竟,你可以大力获取验证码并尝试一下。速度还可以,但是太容易被360搜索和反爬网封杀。想要正常稳定运行,不知道访问代理的ip状态。怎么样,同时还得有一个cookies库!
查看全部
关键词文章采集源码(本渣渣就是第二次360搜索相关关键词关键源码可参考学习
)
搜索引擎相关的搜索词应该是很多seoer都在寻找并选择使用的关键词扩展类别。除了流行的百度相关搜索词采集,当然还有360搜索引擎和搜狗搜索引擎,当然知道方法之后,python的应用基本一样,唯一的就是你需要关心的是这个词本身和反爬的局限性!
不,这是这个人渣第二次在360搜索上翻车,注意,这是第二次,第一次,处女翻车还是在采集360搜索题中翻车并回答,真的很好伤疤忘记了疼痛,太久了!!
360搜索大力出奇迹,不,大力出验证码。.
本渣渣在这里使用正则实现了相关关键词的获取,参考了很多源码,使用正则更方便快捷!
360搜索相关关键词key源码
re.findall(r'(.+?)</a>', html, re.S | re.I)
搜狗搜索相关关键词关键源码
大家可以参考自己的学习,毕竟没什么好说的!
附上360搜索相关关键词采集源码供大家参考学习!PS:我没写代码,我没用,怎么写?!
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
360相关搜索词挖掘脚本(多线程版)
基于python3.8
需要安装requests模块
@author:微信/huguo00289
"""
import re
from queue import Queue
from threading import Thread
import requests,random
class Qh360Spider(Thread):
result = {} # 保存结果字典
seen = set() # 表示在队列中的关键词(已抓取或待抓取)
def __init__(self, kw_queue, loop, failed):
super(Qh360Spider, self).__init__()
self.kw_queue = kw_queue # 关键词队列
self.loop = loop # 循环挖词拓展次数
self.failed = failed # 保存查询失败的关键词文件
self.ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]
def run(self): # 程序的执行流程
while True:
# 从队列里面获取一个关键词及其对应的当前拓展次数
kw, cloop = self.kw_queue.get()
print('CurLoop:{} Checking: {}'.format(cloop, kw))
query = 'https://www.so.com/s?q={}'.format(kw) # 构建含关键词的url
try:
source = self.download(query, timeout=10)
# source = self.download(query,timeout=10,user_agent=self.ua)
if source:
kw_list = self.extract(source)
print(kw_list)
self.filter(cloop, kw_list)
else:
# 获取源码失败,保存查询失败的关键词
self.failed.write('{}\n'.format(kw))
finally:
self.kw_queue.task_done()
def download(self, url, timeout=5, proxy=None, num_retries=5):
"""
通用网页源码下载函数
:param url: 要下载的url
:param timeout: 请求超时时间,单位/秒。可能某些网站的反应速度很慢,所以需要一个连接超时变量来处理。
:param user_agent: 用户代理信息,可以自定义是爬虫还是模拟用户
:param proxy: ip代理(http代理),访问某些国外网站的时候需要用到。必须是双元素元组或列表(‘ip:端口’,‘http/https’)
:param num_retries: 失败重试次数
:return: HTML网页源码
"""
headers = {
"Cookie": "QiHooGUID=41F80B0CCE5D43A22EEF0305A12CDE3F.1596003342506; __guid=15484592.2994995584481314300.1596003341831.5723; soid=TjzBKt3zrO-Rh1S7fXSb0S!6kmX5TlEerB2URZz9v4; __md=667cb161f9515972323507763d8fa7dd643a65bd2e88034.9; dpr=1; isafe=1; webp=1; _uc_m2=886a48052dbb9e2291f80055746e0d4f1f110f922b2f; _uc_mid=7cb161f953d8fa7dd643a65bd2e88034; __huid=11xZqhEl%2FfVeqclI4j%2BdQeQvX63Oph%2F%2BCVM5vxqYGxQI4%3D; Q=u%3Duhthb002%26n%3D%26le%3DAwH0ZGV5ZGR3WGDjpKRhL29g%26m%3DZGH5WGWOWGWOWGWOWGWOWGWOZGL0%26qid%3D144048053%26im%3D1_t018c25fbb66797efb2%26src%3D360chrome%26t%3D1; T=s%3D2afa764886f737dd5d23421c30f87a1f%26t%3D1595934758%26lm%3D0-1%26lf%3D2%26sk%3De485bbde46ac34fc27fc40215de76c44%26mt%3D1595934758%26rc%3D1%26v%3D2.0%26a%3D1; _S=tg75a7e3fmv0mfdfkt8jlpfpj6; stc_ls_sohome=RRzRSR!RTR(RUR_RVR; gtHuid=1; homeopenad=1; _pp_wd=1; _ga=GA1.2.607533084.1598082638; _gid=GA1.2.1887117715.1598082638; count=6; erules=p1-9%7Cp2-11%7Cp4-3%7Cecl-2%7Ckd-1%7Cp3-2",
'User-Agent': random.choice(self.ua_list)
}
try:
# 打开网页并读取内容存入html变量中
resp = requests.get(url, headers=headers, proxies=proxy, timeout=timeout)
print(resp.status_code)
except requests.RequestException as err:
print('Download error:', err)
html = None # 如果有异常,那么html肯定是没获取到的,所以赋值None
if num_retries > 0:
return self.download(url, timeout, proxy, num_retries - 1)
else:
html = resp.content.decode('utf-8')
#print(html)
return html
@staticmethod
def extract(html):
'''
提取关键词
:param html:搜索结果源码
:return:提取出来的相关关键词列表
'''
return re.findall(r'(.+?)</a>', html, re.S | re.I)
def filter(self, current_loop, kwlist):
'''
关键词过滤和统计函数
:param current_loop: 当前拓展的次数
:param kwlist: 提取出来的关键词列表
:return: None
'''
for kw in kwlist:
# 判断关键词是不是已经被抓取或者已经存在关键词队列
# 判断当前的拓展次数是否已经超过指定值
if current_loop 0:
print("有东西")
print('111')
save.write(line)
save.flush() # 刷新缓存,避免中途出错
save.close()
print('done,完成挖掘')
如果您无法访问 ip 代理,那么协调起来非常容易。毕竟,你可以大力获取验证码并尝试一下。速度还可以,但是太容易被360搜索和反爬网封杀。想要正常稳定运行,不知道访问代理的ip状态。怎么样,同时还得有一个cookies库!
关键词文章采集源码( 如何利用PbootCMS采集插件做长尾关键词?CMS企业网站开发 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-20 18:11
如何利用PbootCMS采集插件做长尾关键词?CMS企业网站开发
)
Pbootcms采集-Pbootcms免费采集-Pbootcmsauto采集插件
光速SEO2022-03-14
Pbootcms是一个全新内核永久开源的免费PHP企业网站开发建设管理系统。这类企业网站需要开发建设。Pbootcms采集插件还配置了很多SEO功能,不仅通过Pbootcms插件实现采集伪原创发布,还还有很多SEO功能。
Pbootcms采集插件可以本地化图片或存储其他平台,支持百度云、七牛云、阿里云、优派云、腾讯云、华为云等。 如何使用Pbootcms采集 插件做长尾关键词? Pbootcms采集插件可以批量监控不同的cms网站数据,Pbootcms采集插件不管你的网站是Empire、Yiyou、ZBLOG、织梦、WP、Cyclone、站群、PB、Apple、搜外等各大cms工具,可以同时管理和批量发布。
众所周知,对于普通的小型 网站,目标 关键词 驱动了绝大多数 网站 的总搜索流量。网站 目录页面和内容页面上存在的关键词 也会带来流量,但不会太多。网站在非定向关键词上还能带来搜索流量关键词,成为长尾关键词。
<p>pbootcms采集插件可以做伪原创保留字,设置文章原创时伪原创不使用长尾关键词 @>。长尾关键词的特点是:比较长,通常由2-3个词,甚至是词组组成。存在于内容页中,除了内容页的标题外,还存在于内容中。搜索量非常低且不稳定。长尾关键词带来的客户转化为网站产品客户的概率远低于目标关键词。PBootcms采集插件可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高 查看全部
关键词文章采集源码(
如何利用PbootCMS采集插件做长尾关键词?CMS企业网站开发
)
Pbootcms采集-Pbootcms免费采集-Pbootcmsauto采集插件
光速SEO2022-03-14
Pbootcms是一个全新内核永久开源的免费PHP企业网站开发建设管理系统。这类企业网站需要开发建设。Pbootcms采集插件还配置了很多SEO功能,不仅通过Pbootcms插件实现采集伪原创发布,还还有很多SEO功能。
Pbootcms采集插件可以本地化图片或存储其他平台,支持百度云、七牛云、阿里云、优派云、腾讯云、华为云等。 如何使用Pbootcms采集 插件做长尾关键词? Pbootcms采集插件可以批量监控不同的cms网站数据,Pbootcms采集插件不管你的网站是Empire、Yiyou、ZBLOG、织梦、WP、Cyclone、站群、PB、Apple、搜外等各大cms工具,可以同时管理和批量发布。
众所周知,对于普通的小型 网站,目标 关键词 驱动了绝大多数 网站 的总搜索流量。网站 目录页面和内容页面上存在的关键词 也会带来流量,但不会太多。网站在非定向关键词上还能带来搜索流量关键词,成为长尾关键词。
<p>pbootcms采集插件可以做伪原创保留字,设置文章原创时伪原创不使用长尾关键词 @>。长尾关键词的特点是:比较长,通常由2-3个词,甚至是词组组成。存在于内容页中,除了内容页的标题外,还存在于内容中。搜索量非常低且不稳定。长尾关键词带来的客户转化为网站产品客户的概率远低于目标关键词。PBootcms采集插件可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高
关键词文章采集源码(怎么查看域名建站历史吉林关键词目录怎么查域名收录情况 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-03-16 22:29
)
介绍吉林关键词目录HyNiVl17,
Cookies可以记录用户在自己站点的操作信息,但是用户跳出网站后的数据是无法追踪的。很多时候我们登录一些网站,发现登录信息和其他输入数据都有,但实际上是每个网站单独保存的用户记录。
在满足以上条件的情况下选择的域名对SEO优化效果有事半功倍的效果。学会了这些,你就可以为自己选择合适的域名了!
如何查看域名建设历史
吉林关键词如何在目录中查找域名HyNiVl收录情况和行业本身有一个类似于网站网页重要价值权重指数的指标。
网站优化与雅虎签订回购协议,解决吉林粑粑(以下简称吉林粑粑)的控制权问题,现在马云有了新的使命:在高速增长中,其各项业务和管理系统需要整合,更要突出各自决策的效率,同时应对快速增长带来的失控风险。, 域名建立的时间越长越好
选择域名时需要注意一些事项。
影响域名SEO优化效果的因素有哪些
对于域名来说,影响SEO优化效果的因素包括域名的年龄、域名的外链、域名网站的历史、域名的状态收录、域名行业的历史等等。我们需要通过这些因素来选择适合自己的域名。
域名历史信息可通过聚名或聚字查询。Juminggongjulishi 可以通过 Juming 查询,而 Juzi 是 seo 和 juziseo。相对而言,推荐使用聚字查询国内域名信息。桔子的域名搜索系统还是比较强大的。. 利用 Wve 。提高 Web 可访问性 网站Web 可访问性意味着 网站 一个网页可以被尽可能多的人使用。
Nofollow 是 网站 用来告诉搜索引擎他们没有投票给链接指向的 网站 的链接属性。Google在识别出这些反向链接的NoFollow属性时,基本不计算这些链接在页面排名和搜索结果排名算法中的贡献。
,域名的外部链接越多越好。您可以通过在 Google 搜索框中输入 关键词 来尝试。你会发现搜索结果页面上的大部分 Title 都不收录那个特定的 关键词,甚至在页面的 文章 中也不存在。
5、域名历史行业越兼容越好
选择域名的注意事项 Meta标签是在网页的hed标签之间使用的HTML标签。与吉林HTML标签不同的是,meta标签不会显示在页面的任何地方,不同的meta标签起到不同的作用。,但用于提供有关页面的附加信息。
1、域名收录的情况可以直接用site查询。站点域名大致可以看到域名收录的情况以及上次做过的行业类型。你可以看到你想做的行业。它是否适合域名的历史行业?如果是这样,它可以在一定程度上继承域名的一些权重,这对SEO非常有利。相反,如果行业不同,那么这个域名可能不适合你。.
2、重要的东西有很多,吉林域名、服务器、外链、建站年代、建站历史等等。对SEO优化效果影响最大的域名就是域名。如果换了域名,其实就相当于换了一个,基本上是一个新的开始。今天,我将教你如何找到一个好的域名,让你的SEO优化效果飙升!
,域名建设史上没有灰色历史
,域名收录越多越好
对于域名的年龄,可以使用whois查询,查询排名结果。最常用的是万网的whois查询。查询是whois。阿里云对关键词的优化可以从关键词、关键词的性能、关键词密度和关键词分布、关键词策略实现等方面进行选择。
域名外链查询的工具有很多。目前常用的外链查询工具是橙子,查询的是seo、juziseo
企业极速12小时淘金线全国上线,首页前五名展示不怕恶意点击。
海尼VI75
查看全部
关键词文章采集源码(怎么查看域名建站历史吉林关键词目录怎么查域名收录情况
)
介绍吉林关键词目录HyNiVl17,
Cookies可以记录用户在自己站点的操作信息,但是用户跳出网站后的数据是无法追踪的。很多时候我们登录一些网站,发现登录信息和其他输入数据都有,但实际上是每个网站单独保存的用户记录。

在满足以上条件的情况下选择的域名对SEO优化效果有事半功倍的效果。学会了这些,你就可以为自己选择合适的域名了!
如何查看域名建设历史
吉林关键词如何在目录中查找域名HyNiVl收录情况和行业本身有一个类似于网站网页重要价值权重指数的指标。

网站优化与雅虎签订回购协议,解决吉林粑粑(以下简称吉林粑粑)的控制权问题,现在马云有了新的使命:在高速增长中,其各项业务和管理系统需要整合,更要突出各自决策的效率,同时应对快速增长带来的失控风险。, 域名建立的时间越长越好
选择域名时需要注意一些事项。

影响域名SEO优化效果的因素有哪些
对于域名来说,影响SEO优化效果的因素包括域名的年龄、域名的外链、域名网站的历史、域名的状态收录、域名行业的历史等等。我们需要通过这些因素来选择适合自己的域名。
域名历史信息可通过聚名或聚字查询。Juminggongjulishi 可以通过 Juming 查询,而 Juzi 是 seo 和 juziseo。相对而言,推荐使用聚字查询国内域名信息。桔子的域名搜索系统还是比较强大的。. 利用 Wve 。提高 Web 可访问性 网站Web 可访问性意味着 网站 一个网页可以被尽可能多的人使用。

Nofollow 是 网站 用来告诉搜索引擎他们没有投票给链接指向的 网站 的链接属性。Google在识别出这些反向链接的NoFollow属性时,基本不计算这些链接在页面排名和搜索结果排名算法中的贡献。
,域名的外部链接越多越好。您可以通过在 Google 搜索框中输入 关键词 来尝试。你会发现搜索结果页面上的大部分 Title 都不收录那个特定的 关键词,甚至在页面的 文章 中也不存在。
5、域名历史行业越兼容越好
选择域名的注意事项 Meta标签是在网页的hed标签之间使用的HTML标签。与吉林HTML标签不同的是,meta标签不会显示在页面的任何地方,不同的meta标签起到不同的作用。,但用于提供有关页面的附加信息。
1、域名收录的情况可以直接用site查询。站点域名大致可以看到域名收录的情况以及上次做过的行业类型。你可以看到你想做的行业。它是否适合域名的历史行业?如果是这样,它可以在一定程度上继承域名的一些权重,这对SEO非常有利。相反,如果行业不同,那么这个域名可能不适合你。.

2、重要的东西有很多,吉林域名、服务器、外链、建站年代、建站历史等等。对SEO优化效果影响最大的域名就是域名。如果换了域名,其实就相当于换了一个,基本上是一个新的开始。今天,我将教你如何找到一个好的域名,让你的SEO优化效果飙升!

,域名建设史上没有灰色历史
,域名收录越多越好
对于域名的年龄,可以使用whois查询,查询排名结果。最常用的是万网的whois查询。查询是whois。阿里云对关键词的优化可以从关键词、关键词的性能、关键词密度和关键词分布、关键词策略实现等方面进行选择。
域名外链查询的工具有很多。目前常用的外链查询工具是橙子,查询的是seo、juziseo
企业极速12小时淘金线全国上线,首页前五名展示不怕恶意点击。
海尼VI75

关键词文章采集源码(影响WordPress关键词排名优化的因素有哪些?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-09 13:35
WordPress关键词排名优化是决定我们WordPress网站流量的关键,一个好的关键词排名能给我们带来网站稳定的流量,虽然不能说一次和总而言之,但它也是一项值得我们认真研究和分析的SEO技术。影响WordPress排名优化的因素有很多关键词,如网站权重、关键词竞争强度、关键词密度、关键词与内容的相关性、等等
WordPress的TDK网站是我们关键词比较密集的区域,TDK指明了我们WordPress网站的方向,搜索引擎也分析了网站@的行为> 基于 TDK,所以我们的 关键词 布局也围绕着 TDK。
WordPress的关键词排名优化,要注意关键词的选择,避免过度叠加,还需要有一定的技巧,首先我们的关键词肯定和TDK有关,对于难度关键词我们可以选择延长长尾关键词。在优化关键词排名时,我们的WordPress网站文章内容更新也是我们关键词排名优化的基础之一。
关键词优化
对于不同的 网站 类型,我们的 WordPress关键词 选择也基于行业和 网站 特性。在哪里可以找到关键词,例如,信息内容可以是权威的 如果您正在从最流行的媒体中寻找信息,您更喜欢当天突然出现或最近变得更流行的信息。
我们也可以通过WordPress关键词排名优化插件挖掘我们的关键词,WordPress关键词排名优化插件通过我们进入我们的行业或者网站关键词,你可匹配全网实时热门关键词及对应内容。 查看全部
关键词文章采集源码(影响WordPress关键词排名优化的因素有哪些?-八维教育)
WordPress关键词排名优化是决定我们WordPress网站流量的关键,一个好的关键词排名能给我们带来网站稳定的流量,虽然不能说一次和总而言之,但它也是一项值得我们认真研究和分析的SEO技术。影响WordPress排名优化的因素有很多关键词,如网站权重、关键词竞争强度、关键词密度、关键词与内容的相关性、等等
WordPress的TDK网站是我们关键词比较密集的区域,TDK指明了我们WordPress网站的方向,搜索引擎也分析了网站@的行为> 基于 TDK,所以我们的 关键词 布局也围绕着 TDK。
WordPress的关键词排名优化,要注意关键词的选择,避免过度叠加,还需要有一定的技巧,首先我们的关键词肯定和TDK有关,对于难度关键词我们可以选择延长长尾关键词。在优化关键词排名时,我们的WordPress网站文章内容更新也是我们关键词排名优化的基础之一。
关键词优化
对于不同的 网站 类型,我们的 WordPress关键词 选择也基于行业和 网站 特性。在哪里可以找到关键词,例如,信息内容可以是权威的 如果您正在从最流行的媒体中寻找信息,您更喜欢当天突然出现或最近变得更流行的信息。
我们也可以通过WordPress关键词排名优化插件挖掘我们的关键词,WordPress关键词排名优化插件通过我们进入我们的行业或者网站关键词,你可匹配全网实时热门关键词及对应内容。
关键词文章采集源码(本地免费Wordpress采集插件怎么使用?需要编写规则吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-06 04:17
)
问:免费的 Wordpress采集 插件好用吗?需要写规则吗?
答:好用!无需编写规则,只需导入 关键词采集。
问:免费的 Wordpresscms采集 插件安装复杂吗?
A:直接下载到本地电脑,本地电脑直接运行!不影响任何服务器资源,保证服务器的流畅!
Q: 每天可以文章多少篇文章采集本地免费的Wordpress插件
A:每天采集百万篇文章文章(根据网站条件设置)
Q:如何发布本地免费的Wordpress插件采集?
A:软件自带Wordpress发布功能,采集之后会自动发布。任何版本的Wordpress都可以使用,再也不用担心网站不同版本无法使用!
Q:本地免费的Wordpress采集插件可以应用到多少个网站?
A:网站的数量没有限制。添加新的网站时,只需要创建一个任务
一、本地免费Wordpress采集如何使用插件?
1、打开软件,将关键词导入采集文章,会自动发布到网站。
2、可以同时创建几十个或几百个采集任务(一个任务可以支持上传1000个关键词)
二、如何使用本地免费的WordPress发布插件?
1、通过WordPress发布管理工具直接发布,可以直接看到发布文章的数量,文章要发布的数量,伪原创是否成功,发布的 URL 等。它还支持除 Zblog 之外的所有主要 cms 平台。还可以设置定时发布(SEO人员在优化网站的时候可以设置定时发布,这样搜索引擎抓取的频率会更高,而且对于整个网站,会不断增加权重. 网站 的权重越高,未来被搜索的机会就越多。)
2、发布工具还支持Empire、易友、ZBLOG、织梦、Wordpress、PB、Apple、搜外等各大cms。
从现在开始,你再也不用担心因为太多的网站而着急了!永远不要来回切换网站后台,反复登录后台很痛苦。再也不用担心网站没有内容填充了。一个网站的流量大小取决于网站收录的比例,收录关键词排名越多,流量越大。
为什么这么多人选择Zbog?
1、WordPress 是根据 GNU 通用公共许可证获得许可的免费开源系统。
2、WordPress 功能强大且可扩展,主要是因为它的受众大且易于网站扩展,基本上
3、功能强大,可实现网站功能的80%
4、wordpress搭建的博客对百度或者goodle搜索引擎友好
5、适合DIY,如果你喜欢内容丰富的网站,那么wordpress可以很好的实现你的想法
6、主题很多,网站最后一个都是WordPress主题,有很多种,可以选择!.
7、wordpress 拥有强大的社区支持,数以千万计的开发者贡献和审查 wordpress,因此 wordpress 安全且活跃。
在 SEO 方面,WordPress 比 Google 有明显的优势。海量外贸英文模板主题供您选择。WordPress优化和推广的最终效果取决于您的SEO水平和项目决策。如何优化,其实没有多少人说程序是先天的。对不懂html+CSS代码的小白不太友好。wordpress源码系统的初始内容基本上只是一个框架,自己搭建需要时间;
查看全部
关键词文章采集源码(本地免费Wordpress采集插件怎么使用?需要编写规则吗?
)
问:免费的 Wordpress采集 插件好用吗?需要写规则吗?
答:好用!无需编写规则,只需导入 关键词采集。
问:免费的 Wordpresscms采集 插件安装复杂吗?
A:直接下载到本地电脑,本地电脑直接运行!不影响任何服务器资源,保证服务器的流畅!
Q: 每天可以文章多少篇文章采集本地免费的Wordpress插件
A:每天采集百万篇文章文章(根据网站条件设置)
Q:如何发布本地免费的Wordpress插件采集?
A:软件自带Wordpress发布功能,采集之后会自动发布。任何版本的Wordpress都可以使用,再也不用担心网站不同版本无法使用!
Q:本地免费的Wordpress采集插件可以应用到多少个网站?
A:网站的数量没有限制。添加新的网站时,只需要创建一个任务
一、本地免费Wordpress采集如何使用插件?
1、打开软件,将关键词导入采集文章,会自动发布到网站。
2、可以同时创建几十个或几百个采集任务(一个任务可以支持上传1000个关键词)
二、如何使用本地免费的WordPress发布插件?
1、通过WordPress发布管理工具直接发布,可以直接看到发布文章的数量,文章要发布的数量,伪原创是否成功,发布的 URL 等。它还支持除 Zblog 之外的所有主要 cms 平台。还可以设置定时发布(SEO人员在优化网站的时候可以设置定时发布,这样搜索引擎抓取的频率会更高,而且对于整个网站,会不断增加权重. 网站 的权重越高,未来被搜索的机会就越多。)
2、发布工具还支持Empire、易友、ZBLOG、织梦、Wordpress、PB、Apple、搜外等各大cms。
从现在开始,你再也不用担心因为太多的网站而着急了!永远不要来回切换网站后台,反复登录后台很痛苦。再也不用担心网站没有内容填充了。一个网站的流量大小取决于网站收录的比例,收录关键词排名越多,流量越大。
为什么这么多人选择Zbog?
1、WordPress 是根据 GNU 通用公共许可证获得许可的免费开源系统。
2、WordPress 功能强大且可扩展,主要是因为它的受众大且易于网站扩展,基本上
3、功能强大,可实现网站功能的80%
4、wordpress搭建的博客对百度或者goodle搜索引擎友好
5、适合DIY,如果你喜欢内容丰富的网站,那么wordpress可以很好的实现你的想法
6、主题很多,网站最后一个都是WordPress主题,有很多种,可以选择!.
7、wordpress 拥有强大的社区支持,数以千万计的开发者贡献和审查 wordpress,因此 wordpress 安全且活跃。
在 SEO 方面,WordPress 比 Google 有明显的优势。海量外贸英文模板主题供您选择。WordPress优化和推广的最终效果取决于您的SEO水平和项目决策。如何优化,其实没有多少人说程序是先天的。对不懂html+CSS代码的小白不太友好。wordpress源码系统的初始内容基本上只是一个框架,自己搭建需要时间;
关键词文章采集源码(笑话站源码_PHP开发pc+APP+采集接口谈谈采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-05 21:14
相关话题
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
2/3/2018 01:11:42
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
谈采集:整理或抄袭信息
25/2/2010 16:54:00
采集,是组织信息还是抄袭信息?同样是抓信息做网站,但是性质可以不一样。“采集”两个字本身就很有意思,“collect”的意思是带来,更多的可以选择;“采集”是整理的意思。大部分中小站长都做到了“采集”,但有没有做到“采集”?
谈论多少采集信息损害网站
2011 年 9 月 9 日 09:47:00
很多网站在初期操作时,由于时间和人力的限制,不得不从其他网站那里获取采集的信息,以使网站更加完整,并复制了常用方法(表示链接 URL),纯 采集,失败 伪原创。这些采集信息可以让网站运营商快速更新网站,提高百度对本站的友好度和快照更新时间。
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
如何使用免费的网站源代码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
血与泪的教训:过度采集to网站by K
2009 年 2 月 12 日 16:41:00
网站成立初期,为了丰富网站的内容,采集成为站长的王牌和必杀技。如何控制采集采集的数量和过量@>的后果可能是很多站长需要学习和理解的。
一个关于标签书写规范的文章
2007 年 12 月 9 日 22:02:00
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
面部信息采集应明确法律义务
24/11/202012:24:28 查看全部
关键词文章采集源码(笑话站源码_PHP开发pc+APP+采集接口谈谈采集)
相关话题
笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
2/3/2018 01:11:42
总结:笑话站源码_笑话网源码_PHP开发pc+wap+APP+采集接口
谈采集:整理或抄袭信息
25/2/2010 16:54:00
采集,是组织信息还是抄袭信息?同样是抓信息做网站,但是性质可以不一样。“采集”两个字本身就很有意思,“collect”的意思是带来,更多的可以选择;“采集”是整理的意思。大部分中小站长都做到了“采集”,但有没有做到“采集”?
谈论多少采集信息损害网站
2011 年 9 月 9 日 09:47:00
很多网站在初期操作时,由于时间和人力的限制,不得不从其他网站那里获取采集的信息,以使网站更加完整,并复制了常用方法(表示链接 URL),纯 采集,失败 伪原创。这些采集信息可以让网站运营商快速更新网站,提高百度对本站的友好度和快照更新时间。
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大网站已经熟练使用TAG标签了,今天想和大家讨论这个话题,因为很多中小网站经常忽略TAG标签的作用也不知道TAG标签能给网站带来什么好处,今天就和大家详细分享一下。
Tag技术在网站优化中的作用
25/8/2017 15:21:00
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
如何使用免费的网站源代码
2018 年 7 月 8 日 10:16:55
如何使用免费的 网站 源代码?第一点:免费源代码的选择。第二点:免费源广告文件被删除。第三点:免费源代码的修改。免费网站源代码尽量选择网站下载站自己做测试下载,需要有一定的修改能力。
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
2007 年 16 月 11 日 05:47:00
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
优采云:无需编写采集规则即可轻松采集网站
19/6/2011 15:37:00
长期以来,大家一直在使用各种采集器或网站程序自带的采集功能。它们有一个共同的特点,就是需要编写采集规则。从采集到文章,这个技术问题对于初学者来说不是一件容易的事,对于资深站长来说也是一项艰巨的工作。那么,如果你做站群,每个站必须定义一个采集规则,
血与泪的教训:过度采集to网站by K
2009 年 2 月 12 日 16:41:00
网站成立初期,为了丰富网站的内容,采集成为站长的王牌和必杀技。如何控制采集采集的数量和过量@>的后果可能是很多站长需要学习和理解的。
一个关于标签书写规范的文章
2007 年 12 月 9 日 22:02:00
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
面部信息采集应明确法律义务
24/11/202012:24:28
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-05 21:13
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,将使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址: 查看全部
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,将使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址:
关键词文章采集源码(SEO关键词布局,TWCMS插件为你解析插件的整体布局)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-05 09:20
TWcms是一个基于PHP+MySQL的cms,完全开源且强大稳定的技术架构,无论我们是打算做一个小网站,还是想< @网站完全保证继续增长后可以随意扩展。
作为一个开源的cms,肯定有TWcms插件可以使用的选择,TWcms插件可以减少我们的重复工作时间,免费采集 功能,可以节省我们的成本并获得大量材料。
TWcms插件不仅在软件功能上可以采集全网数据,TWcms插件还具有伪原创、发布、推送等功能和数据分析。
TWcms插件根据用户关键词自动匹配采集各大平台网页上的内容。 【小淘气库】采集内容后,自动计算内容与设置关键词的相关性,仅将相关的文章保存在本地。支持各种格式的标签保留、图像本地化和内容保存。 TWcms插件无需编写任何采集规则即可实现全网采集。
除了全网采集,TWcms插件还可以指定网站集合,输入我们的目的URL链接,就可以在TWcms@中可视化操作> 插件窗口,选择我们的采集元素,点击规则,就可以采集了。
TWcms插件支持在标题中插入前缀和后缀;根据需要插入相关词和相关图像。自动标签提取、自动伪原创、内容过滤替换、主动提交等一系列SEO功能。我们只需要设置关键词和相关需求,TWcms【小淘气库】插件就可以24小时不间断的管理。无论是网站还是站群,TWcms插件都可以轻松管理。
两天前我和你谈过TWcms插件关键词的选择。今天我们来说说SEO关键词布局,TWcmsplugin for 是网站的整体布局,我们大致可以分为:
首页关键词布局、频道页面关键词布局和内容页面关键词布局。 (首页、频道页、内容页也可以细分)
那么在了解网站整体布局之前我们应该知道些什么呢?首页、目录页、内容页(包括域名)。那么,关键词如何布置这些页面呢?排版前,TWcms插件需要挖出关键词,一般会挖出关键词。我们这样分类:核心词([小淘气库]即主关键词)、热门词、一般词、冷门词
TWcms插件只能通过对挖掘出来的关键词进行分类来布局关键词。
冷门词——文章的内容和页面(通常我们称这些词为“长尾词”)
通用词 - 主题(即类别中的子类别)
热词-频道(也称为栏目,这里要注意栏目最好用关联词做)
核心词——首页顶部的布局(主关键词,标题和描述,关键词)可以说是最好的布局,TWcmsplugin< @关键词布局设计将是一个金字塔。
从网站中的SEO关键词布局的文章可以看出布局不错,但是如果我们是SEO新手,知道这一步,就很好的。 【小淘气库】只要合理使用上面的SEO关键词布局,相信我们在网站的优化中犯了很多错误,应该说这些细节都是常识。
TWcms插件不仅支持TWcms,市面上所有的cms。通过TWcms插件,我们可以实现在软件中查看不同的cms网站数据,方便多个网站站长分析数据;软件直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等,可以查看天采集、体重数据、蜘蛛等数据. 在软件上。
TWcms该插件可以实现我们的网站从建站到收录的内容管理全过程,同时还具有一定的SEO功能。虽然TWcms插件可以自动化,但是网站的优化还是离不开我们对网站其他方面的精心打磨。今天关于 TWcms 插件的分享就到这里。欢迎大家留言讨论更多关于TWcms插件的话题。 查看全部
关键词文章采集源码(SEO关键词布局,TWCMS插件为你解析插件的整体布局)
TWcms是一个基于PHP+MySQL的cms,完全开源且强大稳定的技术架构,无论我们是打算做一个小网站,还是想< @网站完全保证继续增长后可以随意扩展。
作为一个开源的cms,肯定有TWcms插件可以使用的选择,TWcms插件可以减少我们的重复工作时间,免费采集 功能,可以节省我们的成本并获得大量材料。
TWcms插件不仅在软件功能上可以采集全网数据,TWcms插件还具有伪原创、发布、推送等功能和数据分析。
TWcms插件根据用户关键词自动匹配采集各大平台网页上的内容。 【小淘气库】采集内容后,自动计算内容与设置关键词的相关性,仅将相关的文章保存在本地。支持各种格式的标签保留、图像本地化和内容保存。 TWcms插件无需编写任何采集规则即可实现全网采集。
除了全网采集,TWcms插件还可以指定网站集合,输入我们的目的URL链接,就可以在TWcms@中可视化操作> 插件窗口,选择我们的采集元素,点击规则,就可以采集了。
TWcms插件支持在标题中插入前缀和后缀;根据需要插入相关词和相关图像。自动标签提取、自动伪原创、内容过滤替换、主动提交等一系列SEO功能。我们只需要设置关键词和相关需求,TWcms【小淘气库】插件就可以24小时不间断的管理。无论是网站还是站群,TWcms插件都可以轻松管理。
两天前我和你谈过TWcms插件关键词的选择。今天我们来说说SEO关键词布局,TWcmsplugin for 是网站的整体布局,我们大致可以分为:
首页关键词布局、频道页面关键词布局和内容页面关键词布局。 (首页、频道页、内容页也可以细分)
那么在了解网站整体布局之前我们应该知道些什么呢?首页、目录页、内容页(包括域名)。那么,关键词如何布置这些页面呢?排版前,TWcms插件需要挖出关键词,一般会挖出关键词。我们这样分类:核心词([小淘气库]即主关键词)、热门词、一般词、冷门词
TWcms插件只能通过对挖掘出来的关键词进行分类来布局关键词。
冷门词——文章的内容和页面(通常我们称这些词为“长尾词”)
通用词 - 主题(即类别中的子类别)
热词-频道(也称为栏目,这里要注意栏目最好用关联词做)
核心词——首页顶部的布局(主关键词,标题和描述,关键词)可以说是最好的布局,TWcmsplugin< @关键词布局设计将是一个金字塔。
从网站中的SEO关键词布局的文章可以看出布局不错,但是如果我们是SEO新手,知道这一步,就很好的。 【小淘气库】只要合理使用上面的SEO关键词布局,相信我们在网站的优化中犯了很多错误,应该说这些细节都是常识。
TWcms插件不仅支持TWcms,市面上所有的cms。通过TWcms插件,我们可以实现在软件中查看不同的cms网站数据,方便多个网站站长分析数据;软件直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等,可以查看天采集、体重数据、蜘蛛等数据. 在软件上。
TWcms该插件可以实现我们的网站从建站到收录的内容管理全过程,同时还具有一定的SEO功能。虽然TWcms插件可以自动化,但是网站的优化还是离不开我们对网站其他方面的精心打磨。今天关于 TWcms 插件的分享就到这里。欢迎大家留言讨论更多关于TWcms插件的话题。
关键词文章采集源码(知道机器学习算法是什么,有什么作用吗?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-05 06:08
关键词文章采集源码的解析及下载我基本做算法是都是直接开源的,如果想实现自己的算法,可以公开下源码,分享自己的算法源码,您解决其他问题必须先自己去实现它,知道实现的方法,你才能更好的解决其他问题。前言在线机器学习算法是机器学习领域一个非常重要的基础知识点,其中包括序列模型,情感分析,计算机视觉等等重要的方向。
让大家对机器学习有一个基本的了解,知道机器学习算法是什么,有什么作用。我将在这个知乎专栏以自己公司的产品为例,介绍推荐系统如何进行推荐,比如我们用一个推荐系统进行评价团队的能力。用户进入我们的购物网站,我们首先要做的是什么?用户登录进入我们的商城,我们首先要做的是什么?我们的产品如何发布到公众号,我们首先要做的是什么?我们想通过什么产品来实现销售,我们要做的事情是什么?。
1、登录到我们的产品的内部界面,会有一个推荐的页面。
2、用户找到想要购买的商品,点击进入购买。当用户在京东或者看到一个人气低的商品的时候,
3、我们用用户购买的这个行为来作为字典random_cosine_wise来进行其他词汇的匹配
4、将我们知道的其他的词汇表中的词汇添加到字典中进行处理
5、用户的购买行为时效性强,
6、我们在推荐的时候会将原来用户推荐的这个词汇用户的数据进行填充,然后构建字典。
7、将字典中相似度高的词汇通过连词匹配的方式给出推荐,
8、如果有一个未登录用户还有一定购买意向的,这样我们就能推荐出相似用户关注的内容,可以帮助我们的店铺进行商品推荐。例如你是一个非常喜欢逛商场的人,但是经常被导购员忽悠买东西,老板也经常打电话问我产品的购买意向。如果没有购买意向的话,我将无法卖出我的东西,我认为这就是一个败笔。这样我的产品就无法进行销售。
那么有没有一种方法,
1、想要推荐的是什么?
2、要用什么样的机器学习算法?(本例采用的是逻辑回归)
3、如何让机器学习算法知道自己想要推荐的?
4、推荐的时候用户输入什么样的id?
5、需要什么样的数据库?
6、用什么样的网站搭建如我们的使用范围?在线算法的前提知识
1、基础类的知识
2、数据库和网站知识
3、推荐系统模型结构和数据清洗算法一:前向传播前向传播,简单来说是非线性变换的方法,有没有线性变换的方法,比如矩阵求逆的方法。从定义上来看,前向传播的推理是将一个矩阵所有行和列数据同时传播, 查看全部
关键词文章采集源码(知道机器学习算法是什么,有什么作用吗?-八维教育)
关键词文章采集源码的解析及下载我基本做算法是都是直接开源的,如果想实现自己的算法,可以公开下源码,分享自己的算法源码,您解决其他问题必须先自己去实现它,知道实现的方法,你才能更好的解决其他问题。前言在线机器学习算法是机器学习领域一个非常重要的基础知识点,其中包括序列模型,情感分析,计算机视觉等等重要的方向。
让大家对机器学习有一个基本的了解,知道机器学习算法是什么,有什么作用。我将在这个知乎专栏以自己公司的产品为例,介绍推荐系统如何进行推荐,比如我们用一个推荐系统进行评价团队的能力。用户进入我们的购物网站,我们首先要做的是什么?用户登录进入我们的商城,我们首先要做的是什么?我们的产品如何发布到公众号,我们首先要做的是什么?我们想通过什么产品来实现销售,我们要做的事情是什么?。
1、登录到我们的产品的内部界面,会有一个推荐的页面。
2、用户找到想要购买的商品,点击进入购买。当用户在京东或者看到一个人气低的商品的时候,
3、我们用用户购买的这个行为来作为字典random_cosine_wise来进行其他词汇的匹配
4、将我们知道的其他的词汇表中的词汇添加到字典中进行处理
5、用户的购买行为时效性强,
6、我们在推荐的时候会将原来用户推荐的这个词汇用户的数据进行填充,然后构建字典。
7、将字典中相似度高的词汇通过连词匹配的方式给出推荐,
8、如果有一个未登录用户还有一定购买意向的,这样我们就能推荐出相似用户关注的内容,可以帮助我们的店铺进行商品推荐。例如你是一个非常喜欢逛商场的人,但是经常被导购员忽悠买东西,老板也经常打电话问我产品的购买意向。如果没有购买意向的话,我将无法卖出我的东西,我认为这就是一个败笔。这样我的产品就无法进行销售。
那么有没有一种方法,
1、想要推荐的是什么?
2、要用什么样的机器学习算法?(本例采用的是逻辑回归)
3、如何让机器学习算法知道自己想要推荐的?
4、推荐的时候用户输入什么样的id?
5、需要什么样的数据库?
6、用什么样的网站搭建如我们的使用范围?在线算法的前提知识
1、基础类的知识
2、数据库和网站知识
3、推荐系统模型结构和数据清洗算法一:前向传播前向传播,简单来说是非线性变换的方法,有没有线性变换的方法,比如矩阵求逆的方法。从定义上来看,前向传播的推理是将一个矩阵所有行和列数据同时传播,
关键词文章采集源码( adminv2.8.x版本更新TAG标签自动调用文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-05 01:21
adminv2.8.x版本更新TAG标签自动调用文章)
文章tag/关键词 2.8.2 商业 (zqlj_arctag)
由管理员在 Discuz 上发布!
v2.8.x版本更新
1、修复分页功能的参数问题;
2、添加手机版列表页;
文章标签/关键词 用于 Discuz!功能介绍:本插件实现了在门户文章中添加tag标签模块,并根据标签内容生成自动聚合页面,有利于门户文章的SEO优化!
特征
1、本插件后台设置了TAG库,站长可以提前将本站常用的TAG添加到库中,发送时可以快速调用文章;
2、支持快速选择***的几个TAG;
3、支持TAG标签自动聚合文章(独立列表页),点击TAG进入;
4、Pages关键词自动调用文章设置的TAG,更有利于门户文章SEO优化
1、本站发布的内容是在互联网上采集整理的,包括但不限于代码、应用程序、音像资源、电子书资料等,以研究交流为目的,
2、仅供大家参考学习,不作任何商业用途或商业用途。
3、如果您使用开源软件代码,请遵守相应的开源许可规范和精神。如果您需要使用非自由软件或服务,您应该购买正版许可证并合法使用。
4、如果您下载此文件,即表示您同意将此文件用于参考、学习用途,不得用于任何其他目的。 查看全部
关键词文章采集源码(
adminv2.8.x版本更新TAG标签自动调用文章)
文章tag/关键词 2.8.2 商业 (zqlj_arctag)
由管理员在 Discuz 上发布!
v2.8.x版本更新
1、修复分页功能的参数问题;
2、添加手机版列表页;
文章标签/关键词 用于 Discuz!功能介绍:本插件实现了在门户文章中添加tag标签模块,并根据标签内容生成自动聚合页面,有利于门户文章的SEO优化!
特征
1、本插件后台设置了TAG库,站长可以提前将本站常用的TAG添加到库中,发送时可以快速调用文章;
2、支持快速选择***的几个TAG;
3、支持TAG标签自动聚合文章(独立列表页),点击TAG进入;
4、Pages关键词自动调用文章设置的TAG,更有利于门户文章SEO优化
1、本站发布的内容是在互联网上采集整理的,包括但不限于代码、应用程序、音像资源、电子书资料等,以研究交流为目的,
2、仅供大家参考学习,不作任何商业用途或商业用途。
3、如果您使用开源软件代码,请遵守相应的开源许可规范和精神。如果您需要使用非自由软件或服务,您应该购买正版许可证并合法使用。
4、如果您下载此文件,即表示您同意将此文件用于参考、学习用途,不得用于任何其他目的。
关键词文章采集源码(python多线程头像图片源码附exe程序及资源包!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-04 18:09
互联网上怎么可能没有一两件马甲,而头像等信息的完善无疑是必要的。关于头像图片,大家不妨采集看网站上的头像图片,这样就不用找了。我能! !
目标网址:
Python多线程抓取头像图片源码,附exe程序和资源包!
相关介绍:
1.用到的库requests、etree、re、os、ThreadPool
2.网页编码为utf-8,需要转码:html.encoding=“utf-8”
3.使用xpath获取图片链接
4.多线程
5.需要进入第n页,详细可以看动态图
6.头像的首页是栏目页面,没有页面,这里是if判断
7.py打包exe命令:pyinstaller -F目录file.py
关于多线程,线程池,这里使用线程池。这是一个旧模块。虽然有些人还在使用它,但它不再是主流。你可以参考一下!
库安装方式:pip install threadpool
基本用法:
(1)引入线程池模块
(2)定义线程函数
(3)创建线程池threadpool.ThreadPool()
(4)创建需要线程池处理的任务,即threadpool.makeRequests()
(5)将创建的多个任务放入线程池,threadpool.putRequest
(6)等到adpool.pool()处理完所有任务
import threadpool
def ThreadFun(arg1,arg2):
pass
def main():
device_list=[object1,object2,object3......,objectn]#需要处理的设备个数
task_pool=threadpool.ThreadPool(8)#8是线程池中线程的个数
request_list=[]#存放任务列表
#首先构造任务列表
for device in device_list:
request_list.append(threadpool.makeRequests(ThreadFun,[((device, ), {})]))
#将每个任务放到线程池中,等待线程池中线程各自读取任务,然后进行处理,使用了map函数,不了解的可以去了解一下。
map(task_pool.putRequest,request_list)
#等待所有任务处理完成,则返回,如果没有处理完,则一直阻塞
task_pool.poll()
if __name__=="__main__":
main()
说明:makeRequests存储了启用多线程的函数,以及函数相关的参数和回调函数。回调函数可以省略(默认为none),也就是说makeRequests可以只带2个参数运行。
pycharm运行效果:
exe运行效果:
附上源码:
#www.woyaogexing.com头像采集
# -*- coding: utf-8 -*-
#by 微信:huguo00289
import requests
from lxml import etree
import re
import os
from multiprocessing.dummy import Pool as ThreadPool
def hqlj(n):
urls = []
for x in range(1,n+1):
url=f'https://www.woyaogexing.com/touxiang/index_{x}.html'
if x==1:
url='https://www.woyaogexing.com/to ... 27%3B
print(url)
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
'''href=con.xpath('//div[@class="txList "]/a')
print(href)
for urls in href:
print(urls.attrib['href'])'''
href=con.xpath('//div[@class="txList "]/a/@href')
print(href)
for lj in href:
lj=f'https://www.woyaogexing.com{lj}'
print(lj)
urls.append(lj)
print(urls)
return urls
def hqtx(url):
#url="https://www.woyaogexing.com/to ... ot%3B
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
h1=con.xpath('//h1/text()')
h1=h1[0]
h1 = re.sub(r'[\|\/\\:\*\?\\\"]', "_", h1) # 剔除不合法字符
print(h1)
os.makedirs(f'./touxiang/{h1}/',exist_ok=True)
imgs=con.xpath('//img[@class="lazy"]/@src')
print(imgs)
i=1
for img in imgs:
img_url=f'https:{img}'
if 'jpeg' in img_url:
img_name=img_url[-5:]
else:
img_name = img_url[-4:]
n=str(i)
img_name='%s%s'%(n,img_name)
print(img_name)
print(img_url)
r=requests.get(img_url)
with open(f'./touxiang/{h1}/{img_name}','ab+') as f:
f.write(r.content)
print(f"保存{img_name}图片成功!")
i=i+1
#hqlj("https://www.woyaogexing.com/touxiang/")
if __name__ == '__main__':
n=input("请输入要采集的页码数:",)
n=int(n)
urls=(hqlj(n))
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(hqtx, urls)
pool.close()
pool.join()
print("采集所有头像完成!")
except:
print("Error: unable to start thread")
采集资源效应:
从现在开始,妈妈再也不用担心我没有头像了! !
最后附上exe打包器,有需要的可以试试!
链接:提取码:fuas
爬取500页数据,分享给大家!一共1.71g!
链接:提取码:trrz 查看全部
关键词文章采集源码(python多线程头像图片源码附exe程序及资源包!(一))
互联网上怎么可能没有一两件马甲,而头像等信息的完善无疑是必要的。关于头像图片,大家不妨采集看网站上的头像图片,这样就不用找了。我能! !
目标网址:
Python多线程抓取头像图片源码,附exe程序和资源包!
相关介绍:
1.用到的库requests、etree、re、os、ThreadPool
2.网页编码为utf-8,需要转码:html.encoding=“utf-8”
3.使用xpath获取图片链接
4.多线程
5.需要进入第n页,详细可以看动态图
6.头像的首页是栏目页面,没有页面,这里是if判断
7.py打包exe命令:pyinstaller -F目录file.py
关于多线程,线程池,这里使用线程池。这是一个旧模块。虽然有些人还在使用它,但它不再是主流。你可以参考一下!
库安装方式:pip install threadpool
基本用法:
(1)引入线程池模块
(2)定义线程函数
(3)创建线程池threadpool.ThreadPool()
(4)创建需要线程池处理的任务,即threadpool.makeRequests()
(5)将创建的多个任务放入线程池,threadpool.putRequest
(6)等到adpool.pool()处理完所有任务
import threadpool
def ThreadFun(arg1,arg2):
pass
def main():
device_list=[object1,object2,object3......,objectn]#需要处理的设备个数
task_pool=threadpool.ThreadPool(8)#8是线程池中线程的个数
request_list=[]#存放任务列表
#首先构造任务列表
for device in device_list:
request_list.append(threadpool.makeRequests(ThreadFun,[((device, ), {})]))
#将每个任务放到线程池中,等待线程池中线程各自读取任务,然后进行处理,使用了map函数,不了解的可以去了解一下。
map(task_pool.putRequest,request_list)
#等待所有任务处理完成,则返回,如果没有处理完,则一直阻塞
task_pool.poll()
if __name__=="__main__":
main()
说明:makeRequests存储了启用多线程的函数,以及函数相关的参数和回调函数。回调函数可以省略(默认为none),也就是说makeRequests可以只带2个参数运行。
pycharm运行效果:
exe运行效果:
附上源码:
#www.woyaogexing.com头像采集
# -*- coding: utf-8 -*-
#by 微信:huguo00289
import requests
from lxml import etree
import re
import os
from multiprocessing.dummy import Pool as ThreadPool
def hqlj(n):
urls = []
for x in range(1,n+1):
url=f'https://www.woyaogexing.com/touxiang/index_{x}.html'
if x==1:
url='https://www.woyaogexing.com/to ... 27%3B
print(url)
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
'''href=con.xpath('//div[@class="txList "]/a')
print(href)
for urls in href:
print(urls.attrib['href'])'''
href=con.xpath('//div[@class="txList "]/a/@href')
print(href)
for lj in href:
lj=f'https://www.woyaogexing.com{lj}'
print(lj)
urls.append(lj)
print(urls)
return urls
def hqtx(url):
#url="https://www.woyaogexing.com/to ... ot%3B
html=requests.get(url)
html.encoding="utf-8"
html=html.text
con=etree.HTML(html)
h1=con.xpath('//h1/text()')
h1=h1[0]
h1 = re.sub(r'[\|\/\\:\*\?\\\"]', "_", h1) # 剔除不合法字符
print(h1)
os.makedirs(f'./touxiang/{h1}/',exist_ok=True)
imgs=con.xpath('//img[@class="lazy"]/@src')
print(imgs)
i=1
for img in imgs:
img_url=f'https:{img}'
if 'jpeg' in img_url:
img_name=img_url[-5:]
else:
img_name = img_url[-4:]
n=str(i)
img_name='%s%s'%(n,img_name)
print(img_name)
print(img_url)
r=requests.get(img_url)
with open(f'./touxiang/{h1}/{img_name}','ab+') as f:
f.write(r.content)
print(f"保存{img_name}图片成功!")
i=i+1
#hqlj("https://www.woyaogexing.com/touxiang/";)
if __name__ == '__main__':
n=input("请输入要采集的页码数:",)
n=int(n)
urls=(hqlj(n))
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(hqtx, urls)
pool.close()
pool.join()
print("采集所有头像完成!")
except:
print("Error: unable to start thread")
采集资源效应:
从现在开始,妈妈再也不用担心我没有头像了! !
最后附上exe打包器,有需要的可以试试!
链接:提取码:fuas
爬取500页数据,分享给大家!一共1.71g!
链接:提取码:trrz
关键词文章采集源码(常见的境外社交数据采集与分析,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-31 12:14
大量用户声音聚集在Twitter、Facebook、YouTube、Instagram等海外社交媒体平台。通过采集这些海外社交数据和社会化聆听,品牌企业或部门可以实时掌握海外舆论情况,进而为海外业务发展、国际事件研究、相关政策制定等提供情报支持。
在过去的几年里,我们帮助很多客户完成了海外社交数据采集以及各种细分场景下的分析:
本文将根据具体客户案例,与大家一起探讨常见的海外社交数据采集场景。
采集场景共性
先说一下采集场景的共性。
Twitter、Facebook、YouTube、Instagram虽然内容形式不同,但都是社交媒体平台,大体结构和功能相似。@> 场景是:
1. 指定账号下更新的推文/图片/视频采集
2. 特定 关键词采集 的实时搜索结果
3. 推文/图片/视频下的评论采集
对于这些采集场景,我们已经为几乎所有场景准备了采集模板和教程。
★海外采集模板为特殊模板,如有需要请联系客服。
下面,针对每一类采集场景选取一个示例网站进行详细讲解。其他网站的采集方法类似,这里不再赘述。
一、采集更新了指定脸书账号下的推文
Facebook 是全球最大的社交媒体平台,每月有 20 亿活跃用户;每天在 Facebook 上进行 15 亿次搜索;每天有超过 12 亿用户使用 Facebook;每天有超过 80 亿的视频浏览量。
采集在 Facebook 指定帐户下更新推文数据是很常见的采集要求。例如,疫情期间,美国约翰霍普金斯大学启动Facebook平台,实时提供最权威的疫情数据。在开展与疫情相关的话题研究时,约翰霍普金斯大学 Facebook 账号发布的历史推文和新推文采集可以作为研究的重要数据源。
详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。
二、在 Twitter 上搜索 关键词,采集搜索推文列表
Twitter 是当今最受欢迎的社交媒体平台之一,每天有超过 1 亿活跃用户和超过 5 亿条推文。Twitter相当于微博。
在 Twitter 上搜索 关键词 和在推文列表中搜索 采集 是非常常见的 采集 请求。比如华为、TikTok等海外业务发展较快的品牌,需要时刻关注海外社会舆论情况,为品牌做出相关决策提供情报支持。Twitter是一个非常重要的平台。先选择一批品牌相关的关键词,然后在推特上实时搜索关键词和采集他们的搜索结果,可以得到很多有价值的信息。
详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。 查看全部
关键词文章采集源码(常见的境外社交数据采集与分析,你了解多少?)
大量用户声音聚集在Twitter、Facebook、YouTube、Instagram等海外社交媒体平台。通过采集这些海外社交数据和社会化聆听,品牌企业或部门可以实时掌握海外舆论情况,进而为海外业务发展、国际事件研究、相关政策制定等提供情报支持。
在过去的几年里,我们帮助很多客户完成了海外社交数据采集以及各种细分场景下的分析:
本文将根据具体客户案例,与大家一起探讨常见的海外社交数据采集场景。
采集场景共性
先说一下采集场景的共性。
Twitter、Facebook、YouTube、Instagram虽然内容形式不同,但都是社交媒体平台,大体结构和功能相似。@> 场景是:
1. 指定账号下更新的推文/图片/视频采集
2. 特定 关键词采集 的实时搜索结果
3. 推文/图片/视频下的评论采集
对于这些采集场景,我们已经为几乎所有场景准备了采集模板和教程。
★海外采集模板为特殊模板,如有需要请联系客服。
下面,针对每一类采集场景选取一个示例网站进行详细讲解。其他网站的采集方法类似,这里不再赘述。
一、采集更新了指定脸书账号下的推文
Facebook 是全球最大的社交媒体平台,每月有 20 亿活跃用户;每天在 Facebook 上进行 15 亿次搜索;每天有超过 12 亿用户使用 Facebook;每天有超过 80 亿的视频浏览量。
采集在 Facebook 指定帐户下更新推文数据是很常见的采集要求。例如,疫情期间,美国约翰霍普金斯大学启动Facebook平台,实时提供最权威的疫情数据。在开展与疫情相关的话题研究时,约翰霍普金斯大学 Facebook 账号发布的历史推文和新推文采集可以作为研究的重要数据源。
详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。
二、在 Twitter 上搜索 关键词,采集搜索推文列表
Twitter 是当今最受欢迎的社交媒体平台之一,每天有超过 1 亿活跃用户和超过 5 亿条推文。Twitter相当于微博。
在 Twitter 上搜索 关键词 和在推文列表中搜索 采集 是非常常见的 采集 请求。比如华为、TikTok等海外业务发展较快的品牌,需要时刻关注海外社会舆论情况,为品牌做出相关决策提供情报支持。Twitter是一个非常重要的平台。先选择一批品牌相关的关键词,然后在推特上实时搜索关键词和采集他们的搜索结果,可以得到很多有价值的信息。
详细的采集要求包括:
上面的要求已经用 采集 模板准备好了。
★海外采集模板为特殊模板,如有需要请联系客服。
关键词文章采集源码(河北企速采信息技术为您介绍正规首页排名技术团队, )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-03-31 08:21
)
介绍我们的技术团队HyNiVl93,
1、
在提升排名的过程中,很多优化器为了快速提升关键词的排名,从而过度优化,在TDK、内页等地方,严重堆叠关键词,这个很明显的关键词叠加,有悖于搜索引擎的搜索排名机制,在很大程度上不会给出好的排名。完全禁用它的方法是设置 robots 文件。
2、内容质量一直是优化人员和站长优化的重点。搜索引擎喜欢优质的内容,但是很多站长朋友为了省事都进行了采集others。信息,或信息内容很少的内容,对用户没有帮助。这样,搜索引擎就不会给出排名。搜索引擎喜欢对用户有帮助和有价值的内容,并且可以吸引用户。一方面是为了分词更好,另一方面可以让内容中的关键词显得更自然,星空+运动,帮助蜘蛛去文章关键词判断。
官方首页排名技术团队HyNiVl目前的搜索引擎,与往年想要搜索的内容大相径庭。今天的搜索引擎已经很聪明了,所以如果你想优化它,你必须把它做好。靠谱的优化公司会逐渐有排名流量的,你还怕不来客户!比如焦大的日帖,基本就变成了周帖。
可能很多站长不太关注站长的长尾关键词挖掘工具,觉得这样的长尾关键词挖掘工具提供的数据不够准确,无法把握用户的搜索习惯上,网站关键词排名在众多长尾关键词挖矿工具中其实是相当有益的。Golden Flower Long-tail关键词挖矿工具比较好用,上面提供了用户搜索工具。比赛的次数,比赛的水平,值不值得,上面会有数据供参考,可以帮助站长判断哪个关键词能带来流量。另外,自己站点的CNNZ统计工具也不容忽视。这是用户搜索 网站 的单词的直接参考数据。如果用户搜索一次,可以进行第二次搜索。因此,站长们必须在这方面优化长尾关键词。
另外,当搜索引擎来爬取内容时,如果等了很久都爬不出来有价值的信息,那么就不会爬取内容。没有收录,就没有好的排名。. 您可以查看维基百科。
3、有很多公司选择优化从互联网获取客户的目的。不管是什么行业,什么类型的成本,只要去做,就是从互联网上获取用户。当然,这有一个重要的前提,就是需要展示在用户面前。很多没有显示,只有少数显示。那么,为什么会一直没有排名,无法展示在用户面前呢?当第二个用户来到你的网站时,我也遇到了这种情况。如果持续时间长了,你网站可能会落到用户手里,因为他们不会再找你了。网站。
经过近1天的断断续续工作,服务器上运行的6台网站已经全部恢复正常访问,但只能恢复到年月日的备份,也就是说时间从第二个月到现在任务已经交到火炬了!.
4、
页面的打开速度和页面的加载速度都会影响用户的体验。如果页面打开速度很慢,一般用户会等待两三秒。如果页面还没有打开或者内容还没有完全加载,那么当两三秒的时间用户的耐心用完之后,用户就会关闭并去做其他事情。因此,在汉语教学中,课本中一些问题的答案是多样的,允许和鼓励学生表达不同的意见,使用主题网站可以创造学生。
七速菜利用智能云系统智能生成标题和原创属性文章,每天向各大权重媒体发布信息,达到首页快速排名的效果。
海尼VI68
查看全部
关键词文章采集源码(河北企速采信息技术为您介绍正规首页排名技术团队,
)
介绍我们的技术团队HyNiVl93,
1、
在提升排名的过程中,很多优化器为了快速提升关键词的排名,从而过度优化,在TDK、内页等地方,严重堆叠关键词,这个很明显的关键词叠加,有悖于搜索引擎的搜索排名机制,在很大程度上不会给出好的排名。完全禁用它的方法是设置 robots 文件。
2、内容质量一直是优化人员和站长优化的重点。搜索引擎喜欢优质的内容,但是很多站长朋友为了省事都进行了采集others。信息,或信息内容很少的内容,对用户没有帮助。这样,搜索引擎就不会给出排名。搜索引擎喜欢对用户有帮助和有价值的内容,并且可以吸引用户。一方面是为了分词更好,另一方面可以让内容中的关键词显得更自然,星空+运动,帮助蜘蛛去文章关键词判断。
官方首页排名技术团队HyNiVl目前的搜索引擎,与往年想要搜索的内容大相径庭。今天的搜索引擎已经很聪明了,所以如果你想优化它,你必须把它做好。靠谱的优化公司会逐渐有排名流量的,你还怕不来客户!比如焦大的日帖,基本就变成了周帖。
可能很多站长不太关注站长的长尾关键词挖掘工具,觉得这样的长尾关键词挖掘工具提供的数据不够准确,无法把握用户的搜索习惯上,网站关键词排名在众多长尾关键词挖矿工具中其实是相当有益的。Golden Flower Long-tail关键词挖矿工具比较好用,上面提供了用户搜索工具。比赛的次数,比赛的水平,值不值得,上面会有数据供参考,可以帮助站长判断哪个关键词能带来流量。另外,自己站点的CNNZ统计工具也不容忽视。这是用户搜索 网站 的单词的直接参考数据。如果用户搜索一次,可以进行第二次搜索。因此,站长们必须在这方面优化长尾关键词。
另外,当搜索引擎来爬取内容时,如果等了很久都爬不出来有价值的信息,那么就不会爬取内容。没有收录,就没有好的排名。. 您可以查看维基百科。
3、有很多公司选择优化从互联网获取客户的目的。不管是什么行业,什么类型的成本,只要去做,就是从互联网上获取用户。当然,这有一个重要的前提,就是需要展示在用户面前。很多没有显示,只有少数显示。那么,为什么会一直没有排名,无法展示在用户面前呢?当第二个用户来到你的网站时,我也遇到了这种情况。如果持续时间长了,你网站可能会落到用户手里,因为他们不会再找你了。网站。
经过近1天的断断续续工作,服务器上运行的6台网站已经全部恢复正常访问,但只能恢复到年月日的备份,也就是说时间从第二个月到现在任务已经交到火炬了!.
4、
页面的打开速度和页面的加载速度都会影响用户的体验。如果页面打开速度很慢,一般用户会等待两三秒。如果页面还没有打开或者内容还没有完全加载,那么当两三秒的时间用户的耐心用完之后,用户就会关闭并去做其他事情。因此,在汉语教学中,课本中一些问题的答案是多样的,允许和鼓励学生表达不同的意见,使用主题网站可以创造学生。
七速菜利用智能云系统智能生成标题和原创属性文章,每天向各大权重媒体发布信息,达到首页快速排名的效果。
海尼VI68
关键词文章采集源码(手机平板浏览效果高端大气,快速建立一个自己的站点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-30 14:05
帝国cms7.5自适应Office教程网络电脑技巧文章资料带PPT、Word、Excel模板下载功能+采集+百度推送+sitemap+itag全站源码
————————————————————————————————
PC/电脑版demo地址:查看demo
WAP/手机版demo地址:查看demo(请用手机访问)
(演示站只有采集在页面里填了一些数据看看效果,以后可以用自己的采集器采集大量数据)
————————————————————————————————
本模板由业主本人制作、模仿、移植。业主一直致力于为您提供各类优质、易用、价廉的模板。感谢您的支持!
所有功能都在后台管理。
模板通过标签灵活调用,采集方面选择优质源站,在考虑SEO搜索引擎优化的同时对模板进行细化。
全站静态生成有利于收录和关键词布局和内容页面优化等!
功能列表:
采用 Empirecms7.5 新内核。列和内容模板是超级多变的。后台操作简单,安全可靠,性能稳定。全站拥有高端响应式手机和平板浏览效果,您可以快速搭建自己的网站!
1、内置东坡ITAG超级管理插件,关键词可以是动态、静态或伪静态,标签关键词可以设置为ID或拼音显示,方式很多玩,优化更棒!
2、内置东坡多功能推送插件,数据更新后通过百度API接口实时推送到百度,收录速度更快,效果更佳是很棒的!
3、内置Sitemap百度地图生成插件,基于百度新的2.0技术标准,代码简洁规范,更有利于百度数据抓取。
4、自适应wap移动端,省时省力,简单方便。
其他具体细节不再一一赘述。如果您需要了解更多,可以直接访问演示站点查看。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,无域名限制
●独立WAP移动端大气简洁实用,有利于SEO优化
●全站带数据1.约5GB
●简洁的安装方法,详细的安装教程。
●通过优采云采集器,您可以自己设置采集大量数据,并且可以自动化处理一个采集。
资源下载 本资源下载价格为70金币,请先登录 查看全部
关键词文章采集源码(手机平板浏览效果高端大气,快速建立一个自己的站点)
帝国cms7.5自适应Office教程网络电脑技巧文章资料带PPT、Word、Excel模板下载功能+采集+百度推送+sitemap+itag全站源码
————————————————————————————————
PC/电脑版demo地址:查看demo
WAP/手机版demo地址:查看demo(请用手机访问)
(演示站只有采集在页面里填了一些数据看看效果,以后可以用自己的采集器采集大量数据)
————————————————————————————————
本模板由业主本人制作、模仿、移植。业主一直致力于为您提供各类优质、易用、价廉的模板。感谢您的支持!
所有功能都在后台管理。
模板通过标签灵活调用,采集方面选择优质源站,在考虑SEO搜索引擎优化的同时对模板进行细化。
全站静态生成有利于收录和关键词布局和内容页面优化等!
功能列表:
采用 Empirecms7.5 新内核。列和内容模板是超级多变的。后台操作简单,安全可靠,性能稳定。全站拥有高端响应式手机和平板浏览效果,您可以快速搭建自己的网站!
1、内置东坡ITAG超级管理插件,关键词可以是动态、静态或伪静态,标签关键词可以设置为ID或拼音显示,方式很多玩,优化更棒!
2、内置东坡多功能推送插件,数据更新后通过百度API接口实时推送到百度,收录速度更快,效果更佳是很棒的!
3、内置Sitemap百度地图生成插件,基于百度新的2.0技术标准,代码简洁规范,更有利于百度数据抓取。
4、自适应wap移动端,省时省力,简单方便。
其他具体细节不再一一赘述。如果您需要了解更多,可以直接访问演示站点查看。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,无域名限制
●独立WAP移动端大气简洁实用,有利于SEO优化
●全站带数据1.约5GB
●简洁的安装方法,详细的安装教程。
●通过优采云采集器,您可以自己设置采集大量数据,并且可以自动化处理一个采集。
http://www.hanjutt.com/wp-cont ... 9.jpg 300w, http://www.hanjutt.com/wp-cont ... 5.jpg 768w" />http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 1.jpg 768w" />http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 0.jpg 768w" />http://www.hanjutt.com/wp-cont ... 7.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />http://www.hanjutt.com/wp-cont ... 2.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />http://www.hanjutt.com/wp-cont ... 0.jpg 300w, http://www.hanjutt.com/wp-cont ... 3.jpg 768w" />http://www.hanjutt.com/wp-cont ... 6.jpg 300w, http://www.hanjutt.com/wp-cont ... 7.jpg 768w" />http://www.hanjutt.com/wp-cont ... 8.jpg 300w, http://www.hanjutt.com/wp-cont ... 5.jpg 768w" />资源下载 本资源下载价格为70金币,请先登录
关键词文章采集源码(仿SUV排行榜汽车销售资讯新闻排行模板同步生成自动采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-30 07:02
)
来源名称:仿SUV排名汽车销量信息新闻排名模板自动生成采集
开发环境:Empirecms 7.5
安装环境:php+mysql
包括优采云采集规则和模块,采集目标站SUV排行榜官网。一年包采集规则更新
说明:为您提供2019年最新SUV销量排行榜、SUV排行榜及SUV越野性能报价图片。用文章分析奔驰SUV、长城、丰田SUV、斯柯达、玛莎拉蒂SUV、捷豹、大众SUV、本田、日产SUV、雷克萨斯等国际品牌以及大量国产新车SUV销量排行榜,要想一波SUV排行榜,你必须知道SUV排行榜的最佳口碑。
关键词:SUV销量排行榜,SUV排行榜,中国汽车销量排行榜,汽车销量,SUV排行榜
一个行业新闻站模板是很多资深媒体人靠这个行业赚钱的而且有很多大神,汽车行业的模板一定是很不错的收入,模板还是很大气稳定的,用的帝国cms7.5内核仿制,开源无任何限制,模板结构简单,界面简洁大气,本程序与同步生成插件同步生成。
您可以查看下面的演示链接,数据由 优采云 模块更新。
电脑站演示地址:
移动站演示地址:
选择本站的优势:更新快,包更新,包安装,包技术指导,经济方便。
本源码为开发姐姐原创的源码,经济实惠,同行业中物美价廉。
MoBan5原创源码,VIP模板。站长经常更新版本,有技术支持,最新版本以demo地址为准!
本站模板MoBan5包安装服务一站式,从程序上传到环境搭建所有包,如果您自己安装,MoBan5站长将免费提供专业的技术支持。所有模板至少一年技术服务支持!
不会安装仿《SUV排行榜》源码,仿《SUV排行榜》源码优采云采集规则无效,最新版《SUV排行榜》源码SUV排行榜》将被模仿。白站长也能真正上手
所有模板仅支持常规站点,请合法合规建站。如有违反国家法律法规或任何第三方合法权益的行为,将终止服务,后果自负!本站不为非法网站提供任何服务。
查看全部
关键词文章采集源码(仿SUV排行榜汽车销售资讯新闻排行模板同步生成自动采集
)
来源名称:仿SUV排名汽车销量信息新闻排名模板自动生成采集
开发环境:Empirecms 7.5
安装环境:php+mysql
包括优采云采集规则和模块,采集目标站SUV排行榜官网。一年包采集规则更新
说明:为您提供2019年最新SUV销量排行榜、SUV排行榜及SUV越野性能报价图片。用文章分析奔驰SUV、长城、丰田SUV、斯柯达、玛莎拉蒂SUV、捷豹、大众SUV、本田、日产SUV、雷克萨斯等国际品牌以及大量国产新车SUV销量排行榜,要想一波SUV排行榜,你必须知道SUV排行榜的最佳口碑。
关键词:SUV销量排行榜,SUV排行榜,中国汽车销量排行榜,汽车销量,SUV排行榜
一个行业新闻站模板是很多资深媒体人靠这个行业赚钱的而且有很多大神,汽车行业的模板一定是很不错的收入,模板还是很大气稳定的,用的帝国cms7.5内核仿制,开源无任何限制,模板结构简单,界面简洁大气,本程序与同步生成插件同步生成。
您可以查看下面的演示链接,数据由 优采云 模块更新。
电脑站演示地址:
移动站演示地址:
选择本站的优势:更新快,包更新,包安装,包技术指导,经济方便。
本源码为开发姐姐原创的源码,经济实惠,同行业中物美价廉。
MoBan5原创源码,VIP模板。站长经常更新版本,有技术支持,最新版本以demo地址为准!
本站模板MoBan5包安装服务一站式,从程序上传到环境搭建所有包,如果您自己安装,MoBan5站长将免费提供专业的技术支持。所有模板至少一年技术服务支持!
不会安装仿《SUV排行榜》源码,仿《SUV排行榜》源码优采云采集规则无效,最新版《SUV排行榜》源码SUV排行榜》将被模仿。白站长也能真正上手
所有模板仅支持常规站点,请合法合规建站。如有违反国家法律法规或任何第三方合法权益的行为,将终止服务,后果自负!本站不为非法网站提供任何服务。
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-29 00:28
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,会使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址: 查看全部
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息的产生和传播速度。每天在互联网上产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息变得越来越重要。更重要。互联网上的新闻内容也是如此。消息分布在不同的网站上,有重复的内容。我们通常只关心新闻的一部分。互联网上的新闻页面往往充斥着大量不相关的新闻。影响我们阅读效率和阅读体验的信息,如何更方便、及时、高效地获取我们关心的新闻内容,本系统可以帮助我们做到这一点。本系统使用网络爬虫来分析和< @采集定期在互联网上新闻网站,然后对采集得到的数据进行去重、分类和存储。入数据库,最终提供个性化的新闻订阅服务。考虑如何应对网站的反爬策略,避免被网站爬虫拦截。在具体实现中,会使用Python配合scrapy等框架编写爬虫,并使用特定的内容提取算法来提取目标数据。最后,将使用 Django 加 weui 提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过该系统订阅指定的关键词,当爬虫系统抓取到收录指定关键词的内容时,会向用户推送新闻。
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源码下载地址:
关键词文章采集源码(谈一谈程序员的自我修养问题,你知道吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-26 22:01
程序 自媒体 已被授权复制
文章文章<<<<<<<<<<<<<<<<<我非常同意,英文很重要,但是文章站的高度还是太高了,我不认同具体的学习方法,也觉得不太实用,今天就借这个机会跟大家讲讲程序员的修养很认真。
首先让我介绍一下利益相关者,我的背景:
初中时参加信息学和数学竞赛,主修软件工程。毕业后在一家银行做大数据分析和项目管理,然后开始了自己的创业。他曾在媒体公司和软件外包公司工作。现在他在中国(南京)软件谷机房工作,做自己喜欢的事。15年编码经验,6年创业经验。主要技术方向为.NET、HTML5、云服务、应用级开发等。自评整体水平为,高级程序员,初级架构师
首先要说的是,今天的话题是哪些程序员?
说话之前,不得不提一下知名程序员赵杰,他曾经有一个观点:“坚决反对北大青鸟等机构”。以前很赞同这个观点,现在却在“赞同”的基础上,坚决反对甚至反感赵杰“发这个观点”。因为这个观点,能帮上忙的人是赵杰最不可能遇到的草根开发者,而这些最不可能的人是中国最普通的程序员,也是赵杰最不可能甚至不愿意帮助的人。相信自己有很好的科学基础,逻辑性强,有完整的语言学习经验,他认为至少这是程序员,甚至认为其他不学数据结构的人不应该做程序。那真是太嚣张了。
在中国,写程序不仅仅是一种爱好,更多的时候,它是一种常见的职业,一种谋生手段
大公司有优秀的程序员和优秀的架构师,但很多小公司也有很多普通的程序员。在这些年的工作经历中,我越来越深刻地感受到普通程序员的影响力和力量。对于高级程序员来说,所谓的八仙渡海,各有神通,各有成就,各有修为,但在程序员达到更高层次之前,他们都有一些“修养”,这是最基本和最普遍的。的。
所以今天的话题面向的程序员是所有正在写代码或者已经写过代码的程序员,以及广义的程序员,比如项目经理、架构师等等。
一切都是为了一个明确的目的而做的,然后
再说一遍,程序员提高修养的目的是什么?
程序写的好,有人佩服,也有人喜欢?或者去博客、论坛和社区发布 文章 来分享和获得成就?我想这是少数人的追求,也是更高的追求,在此之前
我认为在中国,程序员提高修养的目的是为了
1、更好的融入工作,更少的困难,更多的成就
2、稳定提升能力,增加收入,实现财务自由
2、从更高的层次看待自己的学习和工作,树立更适合的人生观和价值观,家庭幸福,幸福生活
说得更简单,就是用更合理的方法和方法来赚取更多的收入
说了这么多废话,进入正题
程序员的修养是什么?
很难清楚地解释积极的讨论。反过来的描述可能更容易理解。修身的反义词是“不修身”。“程序员形式:
1、程序员小张遇到开发问题,很着急。他想到了好几个群,就把问题发到群里,等一个答案,发现没有人回答,于是直接和群主的QQ聊天,群主没有回答,于是小张搜索,突然在博客园里发现了一篇解释相关话题的帖子。看完后,他给博主留言。我的邮箱是:请把博主的源代码发给我。,谢谢。
2、程序员小张来公司3个月了。老板分配了很多任务。他觉得老板很不人道。省,客户反馈有问题,不会主动解决,主要是敷衍,再过一个月,换工作。
3、程序员小张正在写一个功能模块,需要一些加密。他在百度上找到了一个编码模块。搬进来。
4、程序员小张想开发某个功能。项目经理对他说,这个功能应该是可搜索的。去搜搜,小张正在百度上搜索。一天后,一切都可以找到。没找到,项目经理来找小张坐下,换了关键词,1分钟就找到了解决办法。
5、程序员小张在.NET工作了3年,薪水还是1万。他没有同意公司提高他的工资。他犹豫着换工作。这时,一位学长对他说,去看书吧,多看一些书,比如《Visual C# From Beginner to Mastery》、《CLR via C#》、《Java权威指南》等,于是小张就买了回过头来,发现了一些他已经知道的东西,有的看了,看不懂,好像也用不上,书那么厚,难道要浪费时间看吗?小张就这样挣扎了半年,依然每天上班,下班LOL,偶尔抱怨工资低。
6、程序员小张去了一家新公司。在做一个项目实现某个功能的时候,他记得自己以前做过这样的功能,但是想不起来怎么实现了,就去电脑里找文档,怎么也找不到找了半天,只好放弃,终于折腾了2天,终于实现了这个功能。
7、程序员小张有一天很不高兴,因为他的项目经理和项目组的产品人员又改需求了,新的需求需要对整个架构进行大的调整。小张很郁闷。一个QQ发泄了自己的情绪,这么一说,QQ群顿时炸开了锅。程序员小李说,对,产品就是屎!程序员小王说,是啊,他妈的项目经理一整天都可以高枕无忧,还懂得挤开发者!程序员小孙说,对对对,我上一家公司也是这样,挤程序员,还好我走了。就这样,在骂声中,几个程序员松了口气,小张开心地去玩王者荣耀了。
我想,有些人可能已经明白我想说的话,有些人可能不明白,具体的话我说不上来,只能用一句话概括:
在编写代码的过程中,你善于学习,掌握方法,努力思考,努力工作,持之以恒。从长远来看,你会在编程中找到不同版本的自己。
上面还是比较抽象的,那么
提高修养的具体方法有哪些?
程序员如何实现“更高的修养”,每个人都有自己的方法,我就不详述了,就像如何提高自己的修养一样,一两句话说不清楚,但有些说法也很流行容易理解,比如孩子有受过良好教育的父母,父母有礼貌。孩子开始接受正规教育,小学、初中、高中、大学,然后文化课程和社会实践都很好。那么孩子最后的人生修为,肯定比没有走过过程的孩子要好。
编写程序也是如此。下面我就讲一些最基本、最容易理解的学习方法和原则,我称之为:
程序员基础知识
一个好的开发人员应该能够全面、高效、严谨地处理任何软件程序和业务问题。做一个优秀的开发者是一个很有意思的话题,但是不管这个话题怎么开发,基本的两个字是必不可少的。, 虽然代码量是衡量开发能力的重要指标,但仅仅能熟练地编写代码是不够的。还需要对技术原理和业务逻辑有深刻的理解。扎实的个人和技术基础通常会促进代码编写。更容易解决问题。
下面提到的一些基础知识可能不会被大多数开发人员注意到甚至忽略,但这些是开发构建的基石。
1、科学基础
成为开发者的过程是不一样的,有的是专业背景,有的是爱好,有的是在专业机构培训。在这个过程中,你可能有全面的或分散的,甚至没有学习过基础计算机学科,但无论哪种,你想成为更高层次的开发人员,编写更高质量的代码,学习计算机科学的基础知识都是非常重要的。 ,非常非常(重要的事情说了三遍)重要。具体来说,在基础科目的实际应用中,以下科目是肯定需要的,按学习顺序排列如下
1)数据结构
通俗的讲,数据结构课程告诉你如何使用最基本的语言类型、变量、关键词语句等处理各种我们称之为算法的逻辑问题,以及各种日常编程. 排序、文件夹遍历操作、数据库查询等问题,可以在数据结构课程中对应的数学原型中找到。数据结构课程的理解能力也是一个人数学能力的体现。数据结构学习的好坏是程序员水平差异的重要分水岭。对于本内容的学习,有以下几点建议:使用VB、C、C++,对于Pascal等语言,买一本语言相关的数据结构和算法的书,或在线下载相关PDF电子书,完成学习,编写、运行、调试书中所有案例。当你能领悟一些日常编程中常用的方法来源于一定的数据结构和算法时,基本就达到了学习的效果。
2)操作系统
所有编程语言的开发和应用程序的运行都是基于操作系统的。桌面编程中的大部分场景,包括内存、进程、文件系统、网络通信、用户界面等,都是源于对操作系统的定义和概念,对操作系统的由来、组成和操作逻辑有一个完整的理解。系统对多线程、复杂接口、文件管理、开发中遇到的一些场景难懂的编程思想有很大的帮助,不仅有助于理解,还能更有效地掌握程序编写。具体可以购买操作系统书籍或下载相关PDF电子书,完整浏览,
3)数据库
传统的关系数据库很容易上手,但很难深入。往往开发者可以快速掌握CRUD、视图、索引、存储过程等基本的数据库操作,但是在编写复杂的查询、设计主外键、优化字段、去除冗余等的时候,有一种情况就是他们只能随葫芦画瓢,不能独立思考和扩展。原因是我仍然无法理解关系数据库的基本原理。数据库课程系统地阐述了关系数据库的来龙去脉,了解其中的数学原理或逻辑基础对提高数据库编程水平有质的影响。
4)编译原理
编译原理是编程语言和各种语言编译器的科学依据。可以说,编译原理造就了世界上几乎所有的 IT 应用。学习编译原理的基础是数据结构和算法。因此,需要更多地学习编译原理。由于现代高级编程语言的编译器在代码优化和资源优化方面已经足够聪明了,编译原理的学习对实战的影响越来越小,但作为所谓的本圣魔荣,如果你认为说明你对数据结构和算法的学习已经达到了高水平和境界,你可以在编译原理的学习上走的更远,最终拉开自己和普通程序员之间更大的差距。
2、英语水平
英语的自然特性、字母的长度以及学科发展的历史因素决定了编程语言必须以英语为基础。在编程的过程中,从语言的关键词到文档的内容或者搜索引擎的搜索结果,都难免会遇到英文。大多数程序员的英语基础都在CET-4左右,但由于非专业和工作环境的原因,他们逐渐疏远甚至完全忘记了英语。在实际操作中,大部分编程语言资料都是英文的,在线编程问答的内容也是英文的。因此,有必要将英语能力恢复到不太高但有效的水平,以达到以下效果:
1)每个关键词都知道他们使用的语言的具体英文翻译、逻辑含义和发音。
2)对于你使用的语言所涉及的相关方法、类库、框架、工具等,你可以知道每个方法、过程、参数的英文翻译、逻辑意义和发音关键词 .
3)对于常见的编程逻辑和核心关键词,可以用英文组织问题描述,最简单的答案就可以,只要能被搜索引擎理解。比如C#中如何将整数转换为字符串类型,最简单的英文描述就是C# Integer Covert To String。
4)任何英文技术手册、文档、文章或在其技术知识范围内的问题描述,能够阅读80%的内容含义,并能够阅读完整的技术含义。
3、搜索方式
任何开发者都应该具备搜索能力,甚至必须具备搜索能力。搜索引擎的宝藏是无穷无尽的。不同的程序员也有搜索意识,但由于搜索技巧的不同,程序开发的质量、项目执行效率甚至工程产品质量都有数倍的差异。因此,掌握高效、先进、灵活的搜索方法和技术是非常非常非常有用的。主要方法描述如下:
1)搜索源选择
2)关键词构造
搜索关键词的结构直接影响搜索效率和正确结果的过滤。没有什么特别的技能。关键在于搜索积累,但总的原则是要准确、简洁。例如,当出现一个描述,如何使用 C# 来序列化和反序列化 XML 时,非常傻瓜式 关键词 构造是“如何在 C# 中序列化和反序列化 XML”,而正确高效的 关键词 是“C# XML 序列化反序列化”,或谷歌搜索“C# XML 序列化”。在平时的编程中,一定要注意相关方法和经验的积累
3)联想搜索
联想搜索不属于搜索引擎的范畴,但它是搜索中非常有用的高级技术。例如,如果您想使用 C# 并使用某个 .NET 类来处理一种 HTTP 通信,那么搜索并不完美。结果,不过换个思路,考虑到VB.NET也是.NET系统,和C#完全类似,那你也可以试试用VB.NET关键词搜索,然后复制搜索完完美代码后的 C# 代码。这样的联想搜索不仅可以帮助你搜索到正确的结果,还可以训练你的大脑思维,所以值得多多尝试。
4)资源搜索
开源框架、产品、工具、控件等开发辅助工具越来越多,健壮性和迭代性越来越强。寻找成熟的工具或插件也成为了众多开发者的必备方法。技能,以及如何有效地搜索所需资源也成为一种知识。核心方法是知道资源网站的地址,比如开源中国、Github、CSDN下载、pudn等。资源类网站需要多多积累,会使用时非常关键。
4、心态
开发者必须开发一种商业思维模式。所谓业务思维,就是在做任何项目时,在编写任何代码之前,都需要对项目本身的业务概念、业务逻辑乃至业务流程有一个全面的了解。学习和理解,虽然这不是一个项目的强制性要求,但也是一种良好的开发习惯。无论你认为是开发人员、测试人员还是技术总监,都可以更好地设计或阅读项目的数据结构和流程结构。程序员的思维往往与用户或客户不一致。摆脱技术思维模式,习惯于用业务思维解决问题的程序员不一定是最好的,但一定是易于沟通的程序员。
5、工作和编程习惯
有人说爱干净,浪费时间,所以不马虎,但归根结底还是习惯问题。编写程序也是如此。有一些编程习惯,看似微不足道,看似浪费时间,但坚持下去,终能得到意想不到的神奇效果。下面列出了一些特别重要的习惯。
1)快捷键的使用
无论是使用 Windows、Linux 操作系统,还是在 IDE 中,快捷键都是系统本身的标准配置。其实大部分人都可以通过Ctrl+C、V等操作来尝到节省时间的甜头。为了进一步传播这个概念,如果你在IDE中编写代码,除了代码本身之外,所有其他的鼠标操作和键盘定位操作换成快捷键,会节省一个数量级的时间,但看起来那么好的东西,真正坚持执行和养成习惯的人却屈指可数。因此,早期改变习惯和记住快捷键将是一个长期的过程,需要不断的坚持。
2)代码注释
随着开发者年龄和经验的增长,他参与的项目已经不可能由一个人或几个人完成。系统重构、代码重构、工作交接、新员工培训等,会越来越多地遇到,而这些事情都会无一例外地重写或重复已经编写好的代码。阅读,如果在最初写代码的时候做完整、清晰的代码注释,对后续工作会有很大帮助。既提高了工作效率,又增强了合作的好感度。其实即使只是看自己的代码,如果有注释,也能加深印象,缩短找代码的时间。因此,任何开发者都应该养成良好的代码注释习惯。
好的代码注释应该这样做:
3) 命名规则
具有一定规模的软件公司有自己的一套代码编写命名规则,涵盖项目、模块、函数、变量等。标准化命名的好处是不言而喻的,但被动地、被迫地服从命名规则并采取主动。习惯命名约定是完全不同的。一个好的开发者应该真诚地希望各种代号有规律、易读,而不是纠结于命名规则会增加代号的长度。
4)编程逻辑
所谓未准备好的编程逻辑的对立面是不注意的编程逻辑。不关注它的编程,不仅是一种非常糟糕的编程习惯,也反映了生活质量的低下。, 客户要求低等原因有很多,编程的时候很随意。比如百度为了实现某个功能,生成一段代码,直接应用。10行代码只看懂了8行,还有两行看不懂。用在程序中,很多这样的小细节就像在项目中埋下了无数的定时炸弹,不仅返工概率很高,也给项目埋下了风险。程序员应该有负责任的态度,
5)数据备份
误删、误操作、电脑断电、文件丢失等是每个开发者都可能遇到的问题。如果您不希望自己的辛勤工作被浪费,也不希望意外事故影响您的工作,那么进行备份是个好主意。不可或缺,在大公司里,会有完善的源代码管理和信息安全保护,无论你是在大公司还是小公司工作,还是在实现个人代码价值的时候,都必须做好。代码和文档的数据备份,备份方式的选择灵活多样,包括使用在线CVS、SVN、TFS、Git源代码管理,或者手动将文件复制到云空间或本地硬盘,甚至形成个人电脑上的RAID磁盘阵列等,养成定期定期备份的习惯。
6)邮件的工作原理
沟通是进步的源泉,如果说开发团队的热烈讨论是性格和激情的体现,那么邮件的工作方式就是另一种审慎和效率。无论是公司层面的工作沟通,还是开发团队的问题沟通,邮件的作用包括问题的形式化描述、工作归档和跟踪、工作流程、职责分工明确等。通过电子邮件发送的问题和重要事项。与同事、主管等沟通的方式对团队合作非常有帮助。
以上方法是我这些年的感受和经验,对我也有很大帮助。我希望他们也能帮助到大家。不能说可以“修身养性”,但也是“修身养性”的有效途径。
最后,我想谈谈坚持的力量
分享一个真实的小故事。公司有两名开发人员。一个已经在.NET 上工作了很多年,但他非常聪明。当他可以做事时,他可以节省。当他可以偷懒的时候,他就会偷懒,让他学习新的知识和新的方法。我一直认为我可以做到;还有一个没有.NET基础,一直在做底层语言开发。15年才开始学习.NET和Web前端,但是做事很积极。我几乎每天都花时间自学。如果你知道你知道什么,你就可以弄清楚。遇到不认识的场景,就上网或者找人帮忙。项目结束后,您会考虑可以改进的地方。从15年到现在,短短一年时间,这两个人的发展已经天壤之别,工资差距也在扩大。后者已经能够独自管理中小型软件外包项目,而前者还活着,未来各自的发展完全可以预见。
我想说的是,本文分享的一些原理和方法通俗易懂,就像经常听到的故事如365次方的101%和99%、10000小时的真相等等,但真正认真思考和实践的人却屈指可数。或许,坚持是程序员最大的成就,我来和大家分享!
...结尾...
附:《如何提升自己的能力?给年轻程序员的几点建议》 查看全部
关键词文章采集源码(谈一谈程序员的自我修养问题,你知道吗?(上))
程序 自媒体 已被授权复制
文章文章<<<<<<<<<<<<<<<<<我非常同意,英文很重要,但是文章站的高度还是太高了,我不认同具体的学习方法,也觉得不太实用,今天就借这个机会跟大家讲讲程序员的修养很认真。
首先让我介绍一下利益相关者,我的背景:
初中时参加信息学和数学竞赛,主修软件工程。毕业后在一家银行做大数据分析和项目管理,然后开始了自己的创业。他曾在媒体公司和软件外包公司工作。现在他在中国(南京)软件谷机房工作,做自己喜欢的事。15年编码经验,6年创业经验。主要技术方向为.NET、HTML5、云服务、应用级开发等。自评整体水平为,高级程序员,初级架构师
首先要说的是,今天的话题是哪些程序员?
说话之前,不得不提一下知名程序员赵杰,他曾经有一个观点:“坚决反对北大青鸟等机构”。以前很赞同这个观点,现在却在“赞同”的基础上,坚决反对甚至反感赵杰“发这个观点”。因为这个观点,能帮上忙的人是赵杰最不可能遇到的草根开发者,而这些最不可能的人是中国最普通的程序员,也是赵杰最不可能甚至不愿意帮助的人。相信自己有很好的科学基础,逻辑性强,有完整的语言学习经验,他认为至少这是程序员,甚至认为其他不学数据结构的人不应该做程序。那真是太嚣张了。
在中国,写程序不仅仅是一种爱好,更多的时候,它是一种常见的职业,一种谋生手段
大公司有优秀的程序员和优秀的架构师,但很多小公司也有很多普通的程序员。在这些年的工作经历中,我越来越深刻地感受到普通程序员的影响力和力量。对于高级程序员来说,所谓的八仙渡海,各有神通,各有成就,各有修为,但在程序员达到更高层次之前,他们都有一些“修养”,这是最基本和最普遍的。的。
所以今天的话题面向的程序员是所有正在写代码或者已经写过代码的程序员,以及广义的程序员,比如项目经理、架构师等等。
一切都是为了一个明确的目的而做的,然后
再说一遍,程序员提高修养的目的是什么?
程序写的好,有人佩服,也有人喜欢?或者去博客、论坛和社区发布 文章 来分享和获得成就?我想这是少数人的追求,也是更高的追求,在此之前
我认为在中国,程序员提高修养的目的是为了
1、更好的融入工作,更少的困难,更多的成就
2、稳定提升能力,增加收入,实现财务自由
2、从更高的层次看待自己的学习和工作,树立更适合的人生观和价值观,家庭幸福,幸福生活
说得更简单,就是用更合理的方法和方法来赚取更多的收入
说了这么多废话,进入正题
程序员的修养是什么?
很难清楚地解释积极的讨论。反过来的描述可能更容易理解。修身的反义词是“不修身”。“程序员形式:
1、程序员小张遇到开发问题,很着急。他想到了好几个群,就把问题发到群里,等一个答案,发现没有人回答,于是直接和群主的QQ聊天,群主没有回答,于是小张搜索,突然在博客园里发现了一篇解释相关话题的帖子。看完后,他给博主留言。我的邮箱是:请把博主的源代码发给我。,谢谢。
2、程序员小张来公司3个月了。老板分配了很多任务。他觉得老板很不人道。省,客户反馈有问题,不会主动解决,主要是敷衍,再过一个月,换工作。
3、程序员小张正在写一个功能模块,需要一些加密。他在百度上找到了一个编码模块。搬进来。
4、程序员小张想开发某个功能。项目经理对他说,这个功能应该是可搜索的。去搜搜,小张正在百度上搜索。一天后,一切都可以找到。没找到,项目经理来找小张坐下,换了关键词,1分钟就找到了解决办法。
5、程序员小张在.NET工作了3年,薪水还是1万。他没有同意公司提高他的工资。他犹豫着换工作。这时,一位学长对他说,去看书吧,多看一些书,比如《Visual C# From Beginner to Mastery》、《CLR via C#》、《Java权威指南》等,于是小张就买了回过头来,发现了一些他已经知道的东西,有的看了,看不懂,好像也用不上,书那么厚,难道要浪费时间看吗?小张就这样挣扎了半年,依然每天上班,下班LOL,偶尔抱怨工资低。
6、程序员小张去了一家新公司。在做一个项目实现某个功能的时候,他记得自己以前做过这样的功能,但是想不起来怎么实现了,就去电脑里找文档,怎么也找不到找了半天,只好放弃,终于折腾了2天,终于实现了这个功能。
7、程序员小张有一天很不高兴,因为他的项目经理和项目组的产品人员又改需求了,新的需求需要对整个架构进行大的调整。小张很郁闷。一个QQ发泄了自己的情绪,这么一说,QQ群顿时炸开了锅。程序员小李说,对,产品就是屎!程序员小王说,是啊,他妈的项目经理一整天都可以高枕无忧,还懂得挤开发者!程序员小孙说,对对对,我上一家公司也是这样,挤程序员,还好我走了。就这样,在骂声中,几个程序员松了口气,小张开心地去玩王者荣耀了。
我想,有些人可能已经明白我想说的话,有些人可能不明白,具体的话我说不上来,只能用一句话概括:
在编写代码的过程中,你善于学习,掌握方法,努力思考,努力工作,持之以恒。从长远来看,你会在编程中找到不同版本的自己。
上面还是比较抽象的,那么
提高修养的具体方法有哪些?
程序员如何实现“更高的修养”,每个人都有自己的方法,我就不详述了,就像如何提高自己的修养一样,一两句话说不清楚,但有些说法也很流行容易理解,比如孩子有受过良好教育的父母,父母有礼貌。孩子开始接受正规教育,小学、初中、高中、大学,然后文化课程和社会实践都很好。那么孩子最后的人生修为,肯定比没有走过过程的孩子要好。
编写程序也是如此。下面我就讲一些最基本、最容易理解的学习方法和原则,我称之为:
程序员基础知识
一个好的开发人员应该能够全面、高效、严谨地处理任何软件程序和业务问题。做一个优秀的开发者是一个很有意思的话题,但是不管这个话题怎么开发,基本的两个字是必不可少的。, 虽然代码量是衡量开发能力的重要指标,但仅仅能熟练地编写代码是不够的。还需要对技术原理和业务逻辑有深刻的理解。扎实的个人和技术基础通常会促进代码编写。更容易解决问题。
下面提到的一些基础知识可能不会被大多数开发人员注意到甚至忽略,但这些是开发构建的基石。
1、科学基础
成为开发者的过程是不一样的,有的是专业背景,有的是爱好,有的是在专业机构培训。在这个过程中,你可能有全面的或分散的,甚至没有学习过基础计算机学科,但无论哪种,你想成为更高层次的开发人员,编写更高质量的代码,学习计算机科学的基础知识都是非常重要的。 ,非常非常(重要的事情说了三遍)重要。具体来说,在基础科目的实际应用中,以下科目是肯定需要的,按学习顺序排列如下
1)数据结构
通俗的讲,数据结构课程告诉你如何使用最基本的语言类型、变量、关键词语句等处理各种我们称之为算法的逻辑问题,以及各种日常编程. 排序、文件夹遍历操作、数据库查询等问题,可以在数据结构课程中对应的数学原型中找到。数据结构课程的理解能力也是一个人数学能力的体现。数据结构学习的好坏是程序员水平差异的重要分水岭。对于本内容的学习,有以下几点建议:使用VB、C、C++,对于Pascal等语言,买一本语言相关的数据结构和算法的书,或在线下载相关PDF电子书,完成学习,编写、运行、调试书中所有案例。当你能领悟一些日常编程中常用的方法来源于一定的数据结构和算法时,基本就达到了学习的效果。
2)操作系统
所有编程语言的开发和应用程序的运行都是基于操作系统的。桌面编程中的大部分场景,包括内存、进程、文件系统、网络通信、用户界面等,都是源于对操作系统的定义和概念,对操作系统的由来、组成和操作逻辑有一个完整的理解。系统对多线程、复杂接口、文件管理、开发中遇到的一些场景难懂的编程思想有很大的帮助,不仅有助于理解,还能更有效地掌握程序编写。具体可以购买操作系统书籍或下载相关PDF电子书,完整浏览,
3)数据库
传统的关系数据库很容易上手,但很难深入。往往开发者可以快速掌握CRUD、视图、索引、存储过程等基本的数据库操作,但是在编写复杂的查询、设计主外键、优化字段、去除冗余等的时候,有一种情况就是他们只能随葫芦画瓢,不能独立思考和扩展。原因是我仍然无法理解关系数据库的基本原理。数据库课程系统地阐述了关系数据库的来龙去脉,了解其中的数学原理或逻辑基础对提高数据库编程水平有质的影响。
4)编译原理
编译原理是编程语言和各种语言编译器的科学依据。可以说,编译原理造就了世界上几乎所有的 IT 应用。学习编译原理的基础是数据结构和算法。因此,需要更多地学习编译原理。由于现代高级编程语言的编译器在代码优化和资源优化方面已经足够聪明了,编译原理的学习对实战的影响越来越小,但作为所谓的本圣魔荣,如果你认为说明你对数据结构和算法的学习已经达到了高水平和境界,你可以在编译原理的学习上走的更远,最终拉开自己和普通程序员之间更大的差距。
2、英语水平
英语的自然特性、字母的长度以及学科发展的历史因素决定了编程语言必须以英语为基础。在编程的过程中,从语言的关键词到文档的内容或者搜索引擎的搜索结果,都难免会遇到英文。大多数程序员的英语基础都在CET-4左右,但由于非专业和工作环境的原因,他们逐渐疏远甚至完全忘记了英语。在实际操作中,大部分编程语言资料都是英文的,在线编程问答的内容也是英文的。因此,有必要将英语能力恢复到不太高但有效的水平,以达到以下效果:
1)每个关键词都知道他们使用的语言的具体英文翻译、逻辑含义和发音。
2)对于你使用的语言所涉及的相关方法、类库、框架、工具等,你可以知道每个方法、过程、参数的英文翻译、逻辑意义和发音关键词 .
3)对于常见的编程逻辑和核心关键词,可以用英文组织问题描述,最简单的答案就可以,只要能被搜索引擎理解。比如C#中如何将整数转换为字符串类型,最简单的英文描述就是C# Integer Covert To String。
4)任何英文技术手册、文档、文章或在其技术知识范围内的问题描述,能够阅读80%的内容含义,并能够阅读完整的技术含义。
3、搜索方式
任何开发者都应该具备搜索能力,甚至必须具备搜索能力。搜索引擎的宝藏是无穷无尽的。不同的程序员也有搜索意识,但由于搜索技巧的不同,程序开发的质量、项目执行效率甚至工程产品质量都有数倍的差异。因此,掌握高效、先进、灵活的搜索方法和技术是非常非常非常有用的。主要方法描述如下:
1)搜索源选择
2)关键词构造
搜索关键词的结构直接影响搜索效率和正确结果的过滤。没有什么特别的技能。关键在于搜索积累,但总的原则是要准确、简洁。例如,当出现一个描述,如何使用 C# 来序列化和反序列化 XML 时,非常傻瓜式 关键词 构造是“如何在 C# 中序列化和反序列化 XML”,而正确高效的 关键词 是“C# XML 序列化反序列化”,或谷歌搜索“C# XML 序列化”。在平时的编程中,一定要注意相关方法和经验的积累
3)联想搜索
联想搜索不属于搜索引擎的范畴,但它是搜索中非常有用的高级技术。例如,如果您想使用 C# 并使用某个 .NET 类来处理一种 HTTP 通信,那么搜索并不完美。结果,不过换个思路,考虑到VB.NET也是.NET系统,和C#完全类似,那你也可以试试用VB.NET关键词搜索,然后复制搜索完完美代码后的 C# 代码。这样的联想搜索不仅可以帮助你搜索到正确的结果,还可以训练你的大脑思维,所以值得多多尝试。
4)资源搜索
开源框架、产品、工具、控件等开发辅助工具越来越多,健壮性和迭代性越来越强。寻找成熟的工具或插件也成为了众多开发者的必备方法。技能,以及如何有效地搜索所需资源也成为一种知识。核心方法是知道资源网站的地址,比如开源中国、Github、CSDN下载、pudn等。资源类网站需要多多积累,会使用时非常关键。
4、心态
开发者必须开发一种商业思维模式。所谓业务思维,就是在做任何项目时,在编写任何代码之前,都需要对项目本身的业务概念、业务逻辑乃至业务流程有一个全面的了解。学习和理解,虽然这不是一个项目的强制性要求,但也是一种良好的开发习惯。无论你认为是开发人员、测试人员还是技术总监,都可以更好地设计或阅读项目的数据结构和流程结构。程序员的思维往往与用户或客户不一致。摆脱技术思维模式,习惯于用业务思维解决问题的程序员不一定是最好的,但一定是易于沟通的程序员。
5、工作和编程习惯
有人说爱干净,浪费时间,所以不马虎,但归根结底还是习惯问题。编写程序也是如此。有一些编程习惯,看似微不足道,看似浪费时间,但坚持下去,终能得到意想不到的神奇效果。下面列出了一些特别重要的习惯。
1)快捷键的使用
无论是使用 Windows、Linux 操作系统,还是在 IDE 中,快捷键都是系统本身的标准配置。其实大部分人都可以通过Ctrl+C、V等操作来尝到节省时间的甜头。为了进一步传播这个概念,如果你在IDE中编写代码,除了代码本身之外,所有其他的鼠标操作和键盘定位操作换成快捷键,会节省一个数量级的时间,但看起来那么好的东西,真正坚持执行和养成习惯的人却屈指可数。因此,早期改变习惯和记住快捷键将是一个长期的过程,需要不断的坚持。
2)代码注释
随着开发者年龄和经验的增长,他参与的项目已经不可能由一个人或几个人完成。系统重构、代码重构、工作交接、新员工培训等,会越来越多地遇到,而这些事情都会无一例外地重写或重复已经编写好的代码。阅读,如果在最初写代码的时候做完整、清晰的代码注释,对后续工作会有很大帮助。既提高了工作效率,又增强了合作的好感度。其实即使只是看自己的代码,如果有注释,也能加深印象,缩短找代码的时间。因此,任何开发者都应该养成良好的代码注释习惯。
好的代码注释应该这样做:
3) 命名规则
具有一定规模的软件公司有自己的一套代码编写命名规则,涵盖项目、模块、函数、变量等。标准化命名的好处是不言而喻的,但被动地、被迫地服从命名规则并采取主动。习惯命名约定是完全不同的。一个好的开发者应该真诚地希望各种代号有规律、易读,而不是纠结于命名规则会增加代号的长度。
4)编程逻辑
所谓未准备好的编程逻辑的对立面是不注意的编程逻辑。不关注它的编程,不仅是一种非常糟糕的编程习惯,也反映了生活质量的低下。, 客户要求低等原因有很多,编程的时候很随意。比如百度为了实现某个功能,生成一段代码,直接应用。10行代码只看懂了8行,还有两行看不懂。用在程序中,很多这样的小细节就像在项目中埋下了无数的定时炸弹,不仅返工概率很高,也给项目埋下了风险。程序员应该有负责任的态度,
5)数据备份
误删、误操作、电脑断电、文件丢失等是每个开发者都可能遇到的问题。如果您不希望自己的辛勤工作被浪费,也不希望意外事故影响您的工作,那么进行备份是个好主意。不可或缺,在大公司里,会有完善的源代码管理和信息安全保护,无论你是在大公司还是小公司工作,还是在实现个人代码价值的时候,都必须做好。代码和文档的数据备份,备份方式的选择灵活多样,包括使用在线CVS、SVN、TFS、Git源代码管理,或者手动将文件复制到云空间或本地硬盘,甚至形成个人电脑上的RAID磁盘阵列等,养成定期定期备份的习惯。
6)邮件的工作原理
沟通是进步的源泉,如果说开发团队的热烈讨论是性格和激情的体现,那么邮件的工作方式就是另一种审慎和效率。无论是公司层面的工作沟通,还是开发团队的问题沟通,邮件的作用包括问题的形式化描述、工作归档和跟踪、工作流程、职责分工明确等。通过电子邮件发送的问题和重要事项。与同事、主管等沟通的方式对团队合作非常有帮助。
以上方法是我这些年的感受和经验,对我也有很大帮助。我希望他们也能帮助到大家。不能说可以“修身养性”,但也是“修身养性”的有效途径。
最后,我想谈谈坚持的力量
分享一个真实的小故事。公司有两名开发人员。一个已经在.NET 上工作了很多年,但他非常聪明。当他可以做事时,他可以节省。当他可以偷懒的时候,他就会偷懒,让他学习新的知识和新的方法。我一直认为我可以做到;还有一个没有.NET基础,一直在做底层语言开发。15年才开始学习.NET和Web前端,但是做事很积极。我几乎每天都花时间自学。如果你知道你知道什么,你就可以弄清楚。遇到不认识的场景,就上网或者找人帮忙。项目结束后,您会考虑可以改进的地方。从15年到现在,短短一年时间,这两个人的发展已经天壤之别,工资差距也在扩大。后者已经能够独自管理中小型软件外包项目,而前者还活着,未来各自的发展完全可以预见。
我想说的是,本文分享的一些原理和方法通俗易懂,就像经常听到的故事如365次方的101%和99%、10000小时的真相等等,但真正认真思考和实践的人却屈指可数。或许,坚持是程序员最大的成就,我来和大家分享!
...结尾...
附:《如何提升自己的能力?给年轻程序员的几点建议》
关键词文章采集源码(有效提升文章收录的几个方法有很大的阻力吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-26 01:14
众所周知,经过这么多年的发展,搜索引擎对文章的认可度已经达到了非常高,现在对文章的要求也越来越高。关键词,大量采集等方法已经开始不行了,有时候我们发布大量文章,发现搜索引擎几乎没有收录,或者收录 页面很少,这会对我们的网站 SEO 产生很大的阻力。下面分享几个有效提升文章收录的方法。
1.插图和文字
图文含义通俗易懂。说白了就是文章的内容要穿插图片,图片要根据文章的长度来添加。图片应与文章相关。性别。比如:你写了一篇关于花草的文章文章,那么在配图的时候,我们尽量选择1-2张花草图片,这样会提升用户体验,也能吸引用户关注文章是高质量的文章,即使你用图片来吸引用户。
2.约800字
网站的文章最好尽量写,因为文章的质量会影响搜索引擎对我们网站的加分,如果我们文章字数比较多,而且是我们自己的原创内容,那么很容易获得搜索引擎的青睐。 (这里提一点写作技巧:假设你所在行业的文章不多,或者你对行业知识了解不多,可以查看同行的文章,对比一下他们的文章 @k17@ >拆分重组,这样的文章搜索引擎也会收录)
3.段落清晰,句子流畅
这是非常重要的。要知道,我们的文章不仅是针对搜索引擎的,也是针对用户的。所以我们的文章语句要尽量保持流畅,让读者阅读起来流畅,从而提升用户体验。
4.写在标题周围文章
这点很重要,尤其是新手朋友,很多新手SEO在写文章的时候容易跑题,要知道在写文章的时候一定要紧紧抓住标题的主题,围绕核心关键词展开相关内容,使其能够呼应标题,而不是文章开头说“螃蟹制作过程”,结尾写“虾实践”。
360网站源码总结:如果写出满足以上条件的文章,对SEO优化非常有利,文章原创度,文章@ >Value,这是两个核心点。一切都必须基于这两点。应该没有问题。我们网站的每一篇文章文章都必须是高质量的,以提高整个网站的评分。 ,然后分配给单个文章,排名会更高,也就是说文章的质量越高,整体排名和单个文章就越稳定排名。 查看全部
关键词文章采集源码(有效提升文章收录的几个方法有很大的阻力吗?)
众所周知,经过这么多年的发展,搜索引擎对文章的认可度已经达到了非常高,现在对文章的要求也越来越高。关键词,大量采集等方法已经开始不行了,有时候我们发布大量文章,发现搜索引擎几乎没有收录,或者收录 页面很少,这会对我们的网站 SEO 产生很大的阻力。下面分享几个有效提升文章收录的方法。
1.插图和文字
图文含义通俗易懂。说白了就是文章的内容要穿插图片,图片要根据文章的长度来添加。图片应与文章相关。性别。比如:你写了一篇关于花草的文章文章,那么在配图的时候,我们尽量选择1-2张花草图片,这样会提升用户体验,也能吸引用户关注文章是高质量的文章,即使你用图片来吸引用户。
2.约800字
网站的文章最好尽量写,因为文章的质量会影响搜索引擎对我们网站的加分,如果我们文章字数比较多,而且是我们自己的原创内容,那么很容易获得搜索引擎的青睐。 (这里提一点写作技巧:假设你所在行业的文章不多,或者你对行业知识了解不多,可以查看同行的文章,对比一下他们的文章 @k17@ >拆分重组,这样的文章搜索引擎也会收录)
3.段落清晰,句子流畅
这是非常重要的。要知道,我们的文章不仅是针对搜索引擎的,也是针对用户的。所以我们的文章语句要尽量保持流畅,让读者阅读起来流畅,从而提升用户体验。
4.写在标题周围文章
这点很重要,尤其是新手朋友,很多新手SEO在写文章的时候容易跑题,要知道在写文章的时候一定要紧紧抓住标题的主题,围绕核心关键词展开相关内容,使其能够呼应标题,而不是文章开头说“螃蟹制作过程”,结尾写“虾实践”。
360网站源码总结:如果写出满足以上条件的文章,对SEO优化非常有利,文章原创度,文章@ >Value,这是两个核心点。一切都必须基于这两点。应该没有问题。我们网站的每一篇文章文章都必须是高质量的,以提高整个网站的评分。 ,然后分配给单个文章,排名会更高,也就是说文章的质量越高,整体排名和单个文章就越稳定排名。
关键词文章采集源码(关键词文章采集源码-五步教你搞定源码采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-24 11:05
关键词文章采集源码-五步教你搞定源码采集系统github地址如下(已实现cdn加速,毕竟加速是商业项目,
和同名网站合作出个定制版的,
安装了chrome浏览器,可以使用siri或者语音控制,另外现在正在搞推广团队,有很多活动,很想投资一把,
可以把采集的网站保存在github上,方便以后互相协作。私信我。
可以将采集过来的url放到github上,然后通过github去采集。比如一个http类型的网站,同一ip,在一天之内总共被调用几次,那么收集这个页面每次被调用的url就是一个列表。现在也有一些简单的采集工具,能达到类似的效果。
pythonweb爬虫开发者网站urllib库的原理-老卢的文章-知乎专栏感谢老卢的文章
方式有很多,直接注册一个github账号,搜索内容可以自动发现,不过,
去问那个分析http的
全部都是采集的curl的接口
前年写了一个采集csdn的工具,自己用了一段时间,通过观察接口也很难发现收集规律,现在有自己的网站,就不想去重复发送请求干扰用户体验了。最多就是有些文章数据是老板指定某些站点才能看的,能接受的话就采集吧。
我有。很难抓的问题可以交给机器来帮你解决。 查看全部
关键词文章采集源码(关键词文章采集源码-五步教你搞定源码采集系统)
关键词文章采集源码-五步教你搞定源码采集系统github地址如下(已实现cdn加速,毕竟加速是商业项目,
和同名网站合作出个定制版的,
安装了chrome浏览器,可以使用siri或者语音控制,另外现在正在搞推广团队,有很多活动,很想投资一把,
可以把采集的网站保存在github上,方便以后互相协作。私信我。
可以将采集过来的url放到github上,然后通过github去采集。比如一个http类型的网站,同一ip,在一天之内总共被调用几次,那么收集这个页面每次被调用的url就是一个列表。现在也有一些简单的采集工具,能达到类似的效果。
pythonweb爬虫开发者网站urllib库的原理-老卢的文章-知乎专栏感谢老卢的文章
方式有很多,直接注册一个github账号,搜索内容可以自动发现,不过,
去问那个分析http的
全部都是采集的curl的接口
前年写了一个采集csdn的工具,自己用了一段时间,通过观察接口也很难发现收集规律,现在有自己的网站,就不想去重复发送请求干扰用户体验了。最多就是有些文章数据是老板指定某些站点才能看的,能接受的话就采集吧。
我有。很难抓的问题可以交给机器来帮你解决。
关键词文章采集源码(爬虫爬虫流量文章采集源码+特点介绍-上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-20 20:04
关键词文章采集源码+特点1。代码结构图、文章简介、增加机器学习的内容说明、作者介绍、作者主页、名称链接等信息;2。外链文章中公开出来的文章外链,使用spider进行收录自动化收录情况,按照出现文章的比例作为给结果的一个参考;2。1防止重复提交代码在发送重复地址的内容时都会提交指定位置进行不重复提交;2。
2提交过的文章,收录后,文章自动获取历史标题和相关内容,作为代码使用的有效条件,收录后,会将代码发送到开发团队,解析起来可以缩短代码发送的次数,加快地团队配合效率,减少不必要的代码发送量和编写量;3。python版本支持python3,下面的代码是选择爬虫流量文章,爬取爬虫流量的文章目前地址,请保存地址返回给excel版本和后续代码代码文件列表jieba。
py爬虫流量文章scrapy。crawl爬虫流量文章mean爬虫流量文章can_sent爬虫流量文章fancy_it爬虫流量文章unique爬虫流量文章ran_it爬虫流量文章care_program爬虫流量文章library爬虫流量文章library_urllib3爬虫流量文章robot。py爬虫流量文章发布流量文章agent_index爬虫流量文章api_pack爬虫流量文章unfold爬虫流量文章。
楼上三个答案的编码方式都不太对,爬虫流量文章都是使用这种文章列表分页形式生成的,这样可以有效的防止重复爬取,爬虫下的每一条爬虫都会有一个唯一的识别号,针对每一条爬虫都有一个唯一的链接, 查看全部
关键词文章采集源码(爬虫爬虫流量文章采集源码+特点介绍-上海怡健医学)
关键词文章采集源码+特点1。代码结构图、文章简介、增加机器学习的内容说明、作者介绍、作者主页、名称链接等信息;2。外链文章中公开出来的文章外链,使用spider进行收录自动化收录情况,按照出现文章的比例作为给结果的一个参考;2。1防止重复提交代码在发送重复地址的内容时都会提交指定位置进行不重复提交;2。
2提交过的文章,收录后,文章自动获取历史标题和相关内容,作为代码使用的有效条件,收录后,会将代码发送到开发团队,解析起来可以缩短代码发送的次数,加快地团队配合效率,减少不必要的代码发送量和编写量;3。python版本支持python3,下面的代码是选择爬虫流量文章,爬取爬虫流量的文章目前地址,请保存地址返回给excel版本和后续代码代码文件列表jieba。
py爬虫流量文章scrapy。crawl爬虫流量文章mean爬虫流量文章can_sent爬虫流量文章fancy_it爬虫流量文章unique爬虫流量文章ran_it爬虫流量文章care_program爬虫流量文章library爬虫流量文章library_urllib3爬虫流量文章robot。py爬虫流量文章发布流量文章agent_index爬虫流量文章api_pack爬虫流量文章unfold爬虫流量文章。
楼上三个答案的编码方式都不太对,爬虫流量文章都是使用这种文章列表分页形式生成的,这样可以有效的防止重复爬取,爬虫下的每一条爬虫都会有一个唯一的识别号,针对每一条爬虫都有一个唯一的链接,
关键词文章采集源码(本渣渣就是第二次360搜索相关关键词关键源码可参考学习 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-20 18:13
)
搜索引擎相关的搜索词应该是很多seoer都在寻找并选择使用的关键词扩展类别。除了流行的百度相关搜索词采集,当然还有360搜索引擎和搜狗搜索引擎,当然知道方法之后,python的应用基本一样,唯一的就是你需要关心的是这个词本身和反爬的局限性!
不,这是这个人渣第二次在360搜索上翻车,注意,这是第二次,第一次,处女翻车还是在采集360搜索题中翻车并回答,真的很好伤疤忘记了疼痛,太久了!!
360搜索大力出奇迹,不,大力出验证码。.
本渣渣在这里使用正则实现了相关关键词的获取,参考了很多源码,使用正则更方便快捷!
360搜索相关关键词key源码
re.findall(r'(.+?)</a>', html, re.S | re.I)
搜狗搜索相关关键词关键源码
大家可以参考自己的学习,毕竟没什么好说的!
附上360搜索相关关键词采集源码供大家参考学习!PS:我没写代码,我没用,怎么写?!
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
360相关搜索词挖掘脚本(多线程版)
基于python3.8
需要安装requests模块
@author:微信/huguo00289
"""
import re
from queue import Queue
from threading import Thread
import requests,random
class Qh360Spider(Thread):
result = {} # 保存结果字典
seen = set() # 表示在队列中的关键词(已抓取或待抓取)
def __init__(self, kw_queue, loop, failed):
super(Qh360Spider, self).__init__()
self.kw_queue = kw_queue # 关键词队列
self.loop = loop # 循环挖词拓展次数
self.failed = failed # 保存查询失败的关键词文件
self.ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]
def run(self): # 程序的执行流程
while True:
# 从队列里面获取一个关键词及其对应的当前拓展次数
kw, cloop = self.kw_queue.get()
print('CurLoop:{} Checking: {}'.format(cloop, kw))
query = 'https://www.so.com/s?q={}'.format(kw) # 构建含关键词的url
try:
source = self.download(query, timeout=10)
# source = self.download(query,timeout=10,user_agent=self.ua)
if source:
kw_list = self.extract(source)
print(kw_list)
self.filter(cloop, kw_list)
else:
# 获取源码失败,保存查询失败的关键词
self.failed.write('{}\n'.format(kw))
finally:
self.kw_queue.task_done()
def download(self, url, timeout=5, proxy=None, num_retries=5):
"""
通用网页源码下载函数
:param url: 要下载的url
:param timeout: 请求超时时间,单位/秒。可能某些网站的反应速度很慢,所以需要一个连接超时变量来处理。
:param user_agent: 用户代理信息,可以自定义是爬虫还是模拟用户
:param proxy: ip代理(http代理),访问某些国外网站的时候需要用到。必须是双元素元组或列表(‘ip:端口’,‘http/https’)
:param num_retries: 失败重试次数
:return: HTML网页源码
"""
headers = {
"Cookie": "QiHooGUID=41F80B0CCE5D43A22EEF0305A12CDE3F.1596003342506; __guid=15484592.2994995584481314300.1596003341831.5723; soid=TjzBKt3zrO-Rh1S7fXSb0S!6kmX5TlEerB2URZz9v4; __md=667cb161f9515972323507763d8fa7dd643a65bd2e88034.9; dpr=1; isafe=1; webp=1; _uc_m2=886a48052dbb9e2291f80055746e0d4f1f110f922b2f; _uc_mid=7cb161f953d8fa7dd643a65bd2e88034; __huid=11xZqhEl%2FfVeqclI4j%2BdQeQvX63Oph%2F%2BCVM5vxqYGxQI4%3D; Q=u%3Duhthb002%26n%3D%26le%3DAwH0ZGV5ZGR3WGDjpKRhL29g%26m%3DZGH5WGWOWGWOWGWOWGWOWGWOZGL0%26qid%3D144048053%26im%3D1_t018c25fbb66797efb2%26src%3D360chrome%26t%3D1; T=s%3D2afa764886f737dd5d23421c30f87a1f%26t%3D1595934758%26lm%3D0-1%26lf%3D2%26sk%3De485bbde46ac34fc27fc40215de76c44%26mt%3D1595934758%26rc%3D1%26v%3D2.0%26a%3D1; _S=tg75a7e3fmv0mfdfkt8jlpfpj6; stc_ls_sohome=RRzRSR!RTR(RUR_RVR; gtHuid=1; homeopenad=1; _pp_wd=1; _ga=GA1.2.607533084.1598082638; _gid=GA1.2.1887117715.1598082638; count=6; erules=p1-9%7Cp2-11%7Cp4-3%7Cecl-2%7Ckd-1%7Cp3-2",
'User-Agent': random.choice(self.ua_list)
}
try:
# 打开网页并读取内容存入html变量中
resp = requests.get(url, headers=headers, proxies=proxy, timeout=timeout)
print(resp.status_code)
except requests.RequestException as err:
print('Download error:', err)
html = None # 如果有异常,那么html肯定是没获取到的,所以赋值None
if num_retries > 0:
return self.download(url, timeout, proxy, num_retries - 1)
else:
html = resp.content.decode('utf-8')
#print(html)
return html
@staticmethod
def extract(html):
'''
提取关键词
:param html:搜索结果源码
:return:提取出来的相关关键词列表
'''
return re.findall(r'(.+?)</a>', html, re.S | re.I)
def filter(self, current_loop, kwlist):
'''
关键词过滤和统计函数
:param current_loop: 当前拓展的次数
:param kwlist: 提取出来的关键词列表
:return: None
'''
for kw in kwlist:
# 判断关键词是不是已经被抓取或者已经存在关键词队列
# 判断当前的拓展次数是否已经超过指定值
if current_loop 0:
print("有东西")
print('111')
save.write(line)
save.flush() # 刷新缓存,避免中途出错
save.close()
print('done,完成挖掘')
如果您无法访问 ip 代理,那么协调起来非常容易。毕竟,你可以大力获取验证码并尝试一下。速度还可以,但是太容易被360搜索和反爬网封杀。想要正常稳定运行,不知道访问代理的ip状态。怎么样,同时还得有一个cookies库!
查看全部
关键词文章采集源码(本渣渣就是第二次360搜索相关关键词关键源码可参考学习
)
搜索引擎相关的搜索词应该是很多seoer都在寻找并选择使用的关键词扩展类别。除了流行的百度相关搜索词采集,当然还有360搜索引擎和搜狗搜索引擎,当然知道方法之后,python的应用基本一样,唯一的就是你需要关心的是这个词本身和反爬的局限性!
不,这是这个人渣第二次在360搜索上翻车,注意,这是第二次,第一次,处女翻车还是在采集360搜索题中翻车并回答,真的很好伤疤忘记了疼痛,太久了!!
360搜索大力出奇迹,不,大力出验证码。.
本渣渣在这里使用正则实现了相关关键词的获取,参考了很多源码,使用正则更方便快捷!
360搜索相关关键词key源码
re.findall(r'(.+?)</a>', html, re.S | re.I)
搜狗搜索相关关键词关键源码
大家可以参考自己的学习,毕竟没什么好说的!
附上360搜索相关关键词采集源码供大家参考学习!PS:我没写代码,我没用,怎么写?!
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
360相关搜索词挖掘脚本(多线程版)
基于python3.8
需要安装requests模块
@author:微信/huguo00289
"""
import re
from queue import Queue
from threading import Thread
import requests,random
class Qh360Spider(Thread):
result = {} # 保存结果字典
seen = set() # 表示在队列中的关键词(已抓取或待抓取)
def __init__(self, kw_queue, loop, failed):
super(Qh360Spider, self).__init__()
self.kw_queue = kw_queue # 关键词队列
self.loop = loop # 循环挖词拓展次数
self.failed = failed # 保存查询失败的关键词文件
self.ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]
def run(self): # 程序的执行流程
while True:
# 从队列里面获取一个关键词及其对应的当前拓展次数
kw, cloop = self.kw_queue.get()
print('CurLoop:{} Checking: {}'.format(cloop, kw))
query = 'https://www.so.com/s?q={}'.format(kw) # 构建含关键词的url
try:
source = self.download(query, timeout=10)
# source = self.download(query,timeout=10,user_agent=self.ua)
if source:
kw_list = self.extract(source)
print(kw_list)
self.filter(cloop, kw_list)
else:
# 获取源码失败,保存查询失败的关键词
self.failed.write('{}\n'.format(kw))
finally:
self.kw_queue.task_done()
def download(self, url, timeout=5, proxy=None, num_retries=5):
"""
通用网页源码下载函数
:param url: 要下载的url
:param timeout: 请求超时时间,单位/秒。可能某些网站的反应速度很慢,所以需要一个连接超时变量来处理。
:param user_agent: 用户代理信息,可以自定义是爬虫还是模拟用户
:param proxy: ip代理(http代理),访问某些国外网站的时候需要用到。必须是双元素元组或列表(‘ip:端口’,‘http/https’)
:param num_retries: 失败重试次数
:return: HTML网页源码
"""
headers = {
"Cookie": "QiHooGUID=41F80B0CCE5D43A22EEF0305A12CDE3F.1596003342506; __guid=15484592.2994995584481314300.1596003341831.5723; soid=TjzBKt3zrO-Rh1S7fXSb0S!6kmX5TlEerB2URZz9v4; __md=667cb161f9515972323507763d8fa7dd643a65bd2e88034.9; dpr=1; isafe=1; webp=1; _uc_m2=886a48052dbb9e2291f80055746e0d4f1f110f922b2f; _uc_mid=7cb161f953d8fa7dd643a65bd2e88034; __huid=11xZqhEl%2FfVeqclI4j%2BdQeQvX63Oph%2F%2BCVM5vxqYGxQI4%3D; Q=u%3Duhthb002%26n%3D%26le%3DAwH0ZGV5ZGR3WGDjpKRhL29g%26m%3DZGH5WGWOWGWOWGWOWGWOWGWOZGL0%26qid%3D144048053%26im%3D1_t018c25fbb66797efb2%26src%3D360chrome%26t%3D1; T=s%3D2afa764886f737dd5d23421c30f87a1f%26t%3D1595934758%26lm%3D0-1%26lf%3D2%26sk%3De485bbde46ac34fc27fc40215de76c44%26mt%3D1595934758%26rc%3D1%26v%3D2.0%26a%3D1; _S=tg75a7e3fmv0mfdfkt8jlpfpj6; stc_ls_sohome=RRzRSR!RTR(RUR_RVR; gtHuid=1; homeopenad=1; _pp_wd=1; _ga=GA1.2.607533084.1598082638; _gid=GA1.2.1887117715.1598082638; count=6; erules=p1-9%7Cp2-11%7Cp4-3%7Cecl-2%7Ckd-1%7Cp3-2",
'User-Agent': random.choice(self.ua_list)
}
try:
# 打开网页并读取内容存入html变量中
resp = requests.get(url, headers=headers, proxies=proxy, timeout=timeout)
print(resp.status_code)
except requests.RequestException as err:
print('Download error:', err)
html = None # 如果有异常,那么html肯定是没获取到的,所以赋值None
if num_retries > 0:
return self.download(url, timeout, proxy, num_retries - 1)
else:
html = resp.content.decode('utf-8')
#print(html)
return html
@staticmethod
def extract(html):
'''
提取关键词
:param html:搜索结果源码
:return:提取出来的相关关键词列表
'''
return re.findall(r'(.+?)</a>', html, re.S | re.I)
def filter(self, current_loop, kwlist):
'''
关键词过滤和统计函数
:param current_loop: 当前拓展的次数
:param kwlist: 提取出来的关键词列表
:return: None
'''
for kw in kwlist:
# 判断关键词是不是已经被抓取或者已经存在关键词队列
# 判断当前的拓展次数是否已经超过指定值
if current_loop 0:
print("有东西")
print('111')
save.write(line)
save.flush() # 刷新缓存,避免中途出错
save.close()
print('done,完成挖掘')
如果您无法访问 ip 代理,那么协调起来非常容易。毕竟,你可以大力获取验证码并尝试一下。速度还可以,但是太容易被360搜索和反爬网封杀。想要正常稳定运行,不知道访问代理的ip状态。怎么样,同时还得有一个cookies库!
关键词文章采集源码( 如何利用PbootCMS采集插件做长尾关键词?CMS企业网站开发 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-20 18:11
如何利用PbootCMS采集插件做长尾关键词?CMS企业网站开发
)
Pbootcms采集-Pbootcms免费采集-Pbootcmsauto采集插件
光速SEO2022-03-14
Pbootcms是一个全新内核永久开源的免费PHP企业网站开发建设管理系统。这类企业网站需要开发建设。Pbootcms采集插件还配置了很多SEO功能,不仅通过Pbootcms插件实现采集伪原创发布,还还有很多SEO功能。
Pbootcms采集插件可以本地化图片或存储其他平台,支持百度云、七牛云、阿里云、优派云、腾讯云、华为云等。 如何使用Pbootcms采集 插件做长尾关键词? Pbootcms采集插件可以批量监控不同的cms网站数据,Pbootcms采集插件不管你的网站是Empire、Yiyou、ZBLOG、织梦、WP、Cyclone、站群、PB、Apple、搜外等各大cms工具,可以同时管理和批量发布。
众所周知,对于普通的小型 网站,目标 关键词 驱动了绝大多数 网站 的总搜索流量。网站 目录页面和内容页面上存在的关键词 也会带来流量,但不会太多。网站在非定向关键词上还能带来搜索流量关键词,成为长尾关键词。
<p>pbootcms采集插件可以做伪原创保留字,设置文章原创时伪原创不使用长尾关键词 @>。长尾关键词的特点是:比较长,通常由2-3个词,甚至是词组组成。存在于内容页中,除了内容页的标题外,还存在于内容中。搜索量非常低且不稳定。长尾关键词带来的客户转化为网站产品客户的概率远低于目标关键词。PBootcms采集插件可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高 查看全部
关键词文章采集源码(
如何利用PbootCMS采集插件做长尾关键词?CMS企业网站开发
)
Pbootcms采集-Pbootcms免费采集-Pbootcmsauto采集插件
光速SEO2022-03-14
Pbootcms是一个全新内核永久开源的免费PHP企业网站开发建设管理系统。这类企业网站需要开发建设。Pbootcms采集插件还配置了很多SEO功能,不仅通过Pbootcms插件实现采集伪原创发布,还还有很多SEO功能。
Pbootcms采集插件可以本地化图片或存储其他平台,支持百度云、七牛云、阿里云、优派云、腾讯云、华为云等。 如何使用Pbootcms采集 插件做长尾关键词? Pbootcms采集插件可以批量监控不同的cms网站数据,Pbootcms采集插件不管你的网站是Empire、Yiyou、ZBLOG、织梦、WP、Cyclone、站群、PB、Apple、搜外等各大cms工具,可以同时管理和批量发布。
众所周知,对于普通的小型 网站,目标 关键词 驱动了绝大多数 网站 的总搜索流量。网站 目录页面和内容页面上存在的关键词 也会带来流量,但不会太多。网站在非定向关键词上还能带来搜索流量关键词,成为长尾关键词。
<p>pbootcms采集插件可以做伪原创保留字,设置文章原创时伪原创不使用长尾关键词 @>。长尾关键词的特点是:比较长,通常由2-3个词,甚至是词组组成。存在于内容页中,除了内容页的标题外,还存在于内容中。搜索量非常低且不稳定。长尾关键词带来的客户转化为网站产品客户的概率远低于目标关键词。PBootcms采集插件可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高
关键词文章采集源码(怎么查看域名建站历史吉林关键词目录怎么查域名收录情况 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-03-16 22:29
)
介绍吉林关键词目录HyNiVl17,
Cookies可以记录用户在自己站点的操作信息,但是用户跳出网站后的数据是无法追踪的。很多时候我们登录一些网站,发现登录信息和其他输入数据都有,但实际上是每个网站单独保存的用户记录。
在满足以上条件的情况下选择的域名对SEO优化效果有事半功倍的效果。学会了这些,你就可以为自己选择合适的域名了!
如何查看域名建设历史
吉林关键词如何在目录中查找域名HyNiVl收录情况和行业本身有一个类似于网站网页重要价值权重指数的指标。
网站优化与雅虎签订回购协议,解决吉林粑粑(以下简称吉林粑粑)的控制权问题,现在马云有了新的使命:在高速增长中,其各项业务和管理系统需要整合,更要突出各自决策的效率,同时应对快速增长带来的失控风险。, 域名建立的时间越长越好
选择域名时需要注意一些事项。
影响域名SEO优化效果的因素有哪些
对于域名来说,影响SEO优化效果的因素包括域名的年龄、域名的外链、域名网站的历史、域名的状态收录、域名行业的历史等等。我们需要通过这些因素来选择适合自己的域名。
域名历史信息可通过聚名或聚字查询。Juminggongjulishi 可以通过 Juming 查询,而 Juzi 是 seo 和 juziseo。相对而言,推荐使用聚字查询国内域名信息。桔子的域名搜索系统还是比较强大的。. 利用 Wve 。提高 Web 可访问性 网站Web 可访问性意味着 网站 一个网页可以被尽可能多的人使用。
Nofollow 是 网站 用来告诉搜索引擎他们没有投票给链接指向的 网站 的链接属性。Google在识别出这些反向链接的NoFollow属性时,基本不计算这些链接在页面排名和搜索结果排名算法中的贡献。
,域名的外部链接越多越好。您可以通过在 Google 搜索框中输入 关键词 来尝试。你会发现搜索结果页面上的大部分 Title 都不收录那个特定的 关键词,甚至在页面的 文章 中也不存在。
5、域名历史行业越兼容越好
选择域名的注意事项 Meta标签是在网页的hed标签之间使用的HTML标签。与吉林HTML标签不同的是,meta标签不会显示在页面的任何地方,不同的meta标签起到不同的作用。,但用于提供有关页面的附加信息。
1、域名收录的情况可以直接用site查询。站点域名大致可以看到域名收录的情况以及上次做过的行业类型。你可以看到你想做的行业。它是否适合域名的历史行业?如果是这样,它可以在一定程度上继承域名的一些权重,这对SEO非常有利。相反,如果行业不同,那么这个域名可能不适合你。.
2、重要的东西有很多,吉林域名、服务器、外链、建站年代、建站历史等等。对SEO优化效果影响最大的域名就是域名。如果换了域名,其实就相当于换了一个,基本上是一个新的开始。今天,我将教你如何找到一个好的域名,让你的SEO优化效果飙升!
,域名建设史上没有灰色历史
,域名收录越多越好
对于域名的年龄,可以使用whois查询,查询排名结果。最常用的是万网的whois查询。查询是whois。阿里云对关键词的优化可以从关键词、关键词的性能、关键词密度和关键词分布、关键词策略实现等方面进行选择。
域名外链查询的工具有很多。目前常用的外链查询工具是橙子,查询的是seo、juziseo
企业极速12小时淘金线全国上线,首页前五名展示不怕恶意点击。
海尼VI75
查看全部
关键词文章采集源码(怎么查看域名建站历史吉林关键词目录怎么查域名收录情况
)
介绍吉林关键词目录HyNiVl17,
Cookies可以记录用户在自己站点的操作信息,但是用户跳出网站后的数据是无法追踪的。很多时候我们登录一些网站,发现登录信息和其他输入数据都有,但实际上是每个网站单独保存的用户记录。
在满足以上条件的情况下选择的域名对SEO优化效果有事半功倍的效果。学会了这些,你就可以为自己选择合适的域名了!
如何查看域名建设历史
吉林关键词如何在目录中查找域名HyNiVl收录情况和行业本身有一个类似于网站网页重要价值权重指数的指标。
网站优化与雅虎签订回购协议,解决吉林粑粑(以下简称吉林粑粑)的控制权问题,现在马云有了新的使命:在高速增长中,其各项业务和管理系统需要整合,更要突出各自决策的效率,同时应对快速增长带来的失控风险。, 域名建立的时间越长越好
选择域名时需要注意一些事项。
影响域名SEO优化效果的因素有哪些
对于域名来说,影响SEO优化效果的因素包括域名的年龄、域名的外链、域名网站的历史、域名的状态收录、域名行业的历史等等。我们需要通过这些因素来选择适合自己的域名。
域名历史信息可通过聚名或聚字查询。Juminggongjulishi 可以通过 Juming 查询,而 Juzi 是 seo 和 juziseo。相对而言,推荐使用聚字查询国内域名信息。桔子的域名搜索系统还是比较强大的。. 利用 Wve 。提高 Web 可访问性 网站Web 可访问性意味着 网站 一个网页可以被尽可能多的人使用。
Nofollow 是 网站 用来告诉搜索引擎他们没有投票给链接指向的 网站 的链接属性。Google在识别出这些反向链接的NoFollow属性时,基本不计算这些链接在页面排名和搜索结果排名算法中的贡献。
,域名的外部链接越多越好。您可以通过在 Google 搜索框中输入 关键词 来尝试。你会发现搜索结果页面上的大部分 Title 都不收录那个特定的 关键词,甚至在页面的 文章 中也不存在。
5、域名历史行业越兼容越好
选择域名的注意事项 Meta标签是在网页的hed标签之间使用的HTML标签。与吉林HTML标签不同的是,meta标签不会显示在页面的任何地方,不同的meta标签起到不同的作用。,但用于提供有关页面的附加信息。
1、域名收录的情况可以直接用site查询。站点域名大致可以看到域名收录的情况以及上次做过的行业类型。你可以看到你想做的行业。它是否适合域名的历史行业?如果是这样,它可以在一定程度上继承域名的一些权重,这对SEO非常有利。相反,如果行业不同,那么这个域名可能不适合你。.
2、重要的东西有很多,吉林域名、服务器、外链、建站年代、建站历史等等。对SEO优化效果影响最大的域名就是域名。如果换了域名,其实就相当于换了一个,基本上是一个新的开始。今天,我将教你如何找到一个好的域名,让你的SEO优化效果飙升!
,域名建设史上没有灰色历史
,域名收录越多越好
对于域名的年龄,可以使用whois查询,查询排名结果。最常用的是万网的whois查询。查询是whois。阿里云对关键词的优化可以从关键词、关键词的性能、关键词密度和关键词分布、关键词策略实现等方面进行选择。
域名外链查询的工具有很多。目前常用的外链查询工具是橙子,查询的是seo、juziseo
企业极速12小时淘金线全国上线,首页前五名展示不怕恶意点击。
海尼VI75

