
全网文章 采集
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-23 01:18
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站 文章是采集来自互联网,不是互联网上的其他网站是采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。这期间文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不收录@ >.
2、网站收录开始减少,snapshots
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现,在网站停止后收录,慢慢导致网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的是排名问题,担心排名会受到影响。这一点可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。 查看全部
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站 文章是采集来自互联网,不是互联网上的其他网站是采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。这期间文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不收录@ >.
2、网站收录开始减少,snapshots
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现,在网站停止后收录,慢慢导致网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的是排名问题,担心排名会受到影响。这一点可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
全网文章 采集(我是做英语培训的,今天无意搜雅思培训这个词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-22 02:16
我在做英语培训。今天无意搜索雅思培训这个词,发现百度首页居然有这个排名。他的内容很垃圾,都是采集,文章的所有标题都是长尾关键词。它不应该手工完成。而且我知道这个网站是专门给yy的教育网站拉客户的。可以看到内容页的顶部是供浏览者填写电话号码的。他的内容页面布局很拥挤,关键词积累很严重
谁能告诉我 1. 为什么这个网站 排名这么好?他使用站群 软件吗?用什么站群软件
很强大,我们网上也有很多采集的内容,没有一个是收录,体重上不去,哭晕了。
###
先做优化,别想某一个关键词,觉得这个不是很有用。1000个关键词的指数,就算排名第一,又有多少自然流量可以到达你网站?
第二种网站使用最原创的优化策略,依靠这批信息采集来获得长尾或其他偏词排名。测量起来,对于收录,排名会有点。
###
人有钱任性,你也可以有钱
###
其实很多算法对大站影响不大。唯一能撼动各大站的就是清风算法。. . 任何其他算法都没用,
###
这是一种属于黑帽seo的操作方式,买老站,买高权重网站,多站多页铺长尾关键词,不怕K站挂了还有成批的站,买不下去了,买链接买高权重链接,盗号,把隐藏链接放在高权重收录,频繁抢网站等等。
###
应该是大神级别的
###
我也想知道 查看全部
全网文章 采集(我是做英语培训的,今天无意搜雅思培训这个词)
我在做英语培训。今天无意搜索雅思培训这个词,发现百度首页居然有这个排名。他的内容很垃圾,都是采集,文章的所有标题都是长尾关键词。它不应该手工完成。而且我知道这个网站是专门给yy的教育网站拉客户的。可以看到内容页的顶部是供浏览者填写电话号码的。他的内容页面布局很拥挤,关键词积累很严重
谁能告诉我 1. 为什么这个网站 排名这么好?他使用站群 软件吗?用什么站群软件
很强大,我们网上也有很多采集的内容,没有一个是收录,体重上不去,哭晕了。
###
先做优化,别想某一个关键词,觉得这个不是很有用。1000个关键词的指数,就算排名第一,又有多少自然流量可以到达你网站?
第二种网站使用最原创的优化策略,依靠这批信息采集来获得长尾或其他偏词排名。测量起来,对于收录,排名会有点。
###
人有钱任性,你也可以有钱
###
其实很多算法对大站影响不大。唯一能撼动各大站的就是清风算法。. . 任何其他算法都没用,
###
这是一种属于黑帽seo的操作方式,买老站,买高权重网站,多站多页铺长尾关键词,不怕K站挂了还有成批的站,买不下去了,买链接买高权重链接,盗号,把隐藏链接放在高权重收录,频繁抢网站等等。
###
应该是大神级别的
###
我也想知道
全网文章 采集(全网文章采集分析,快速,简单,一、二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-12 00:06
全网文章采集分析,快速,简单,
一、网站分析
1、网站的访问深度,该网站往往体现很多信息,如:流量、pv、alexa排名、cpv、dau、uv、okr等等。
2、网站的访问频率,该网站往往体现很多信息,如:页面跳出率、页面停留时间、页面点击率、跳出率、页面停留时间、页面留存率等等。
3、网站的访问体验,该网站往往体现很多信息,如:页面打开速度、页面跳转时间、页面浏览深度、页面停留时间、页面体验、页面打开图片超时时间、页面点击率、页面停留时间、点击率、跳出率、页面访问超时时间、页面停留时间、页面收藏超时时间、页面停留时间、页面停留时间、页面登录时间、页面停留时间、网站访问用户人数、页面停留时间、页面停留时间、页面停留时间、页面停留时间、内容阅读体验等等。
4、网站的访问转化率,该网站往往体现很多信息,如:访问人数、访问平均价格、订单数、支付数、收入、增长率、订单数、成功率、订单平均价格、成交率、转化率、成交率、收入、成交率、转化率、成交率、成交率、订单平均价格、成交率、提交数、支付时间、系统反馈、订单到货、增长率、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、转化率、转化率、订单到货、登录时间、订单中转、收货时间、转化率、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、收货时间、转化率、订单到货、成交率、收入、成交率、成交率、提交数、支付时间、系统反馈、订单到货、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、订单中转、收货时间、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、系统反馈、订单到货、系统反馈、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、。 查看全部
全网文章 采集(全网文章采集分析,快速,简单,一、二)
全网文章采集分析,快速,简单,
一、网站分析
1、网站的访问深度,该网站往往体现很多信息,如:流量、pv、alexa排名、cpv、dau、uv、okr等等。
2、网站的访问频率,该网站往往体现很多信息,如:页面跳出率、页面停留时间、页面点击率、跳出率、页面停留时间、页面留存率等等。
3、网站的访问体验,该网站往往体现很多信息,如:页面打开速度、页面跳转时间、页面浏览深度、页面停留时间、页面体验、页面打开图片超时时间、页面点击率、页面停留时间、点击率、跳出率、页面访问超时时间、页面停留时间、页面收藏超时时间、页面停留时间、页面停留时间、页面登录时间、页面停留时间、网站访问用户人数、页面停留时间、页面停留时间、页面停留时间、页面停留时间、内容阅读体验等等。
4、网站的访问转化率,该网站往往体现很多信息,如:访问人数、访问平均价格、订单数、支付数、收入、增长率、订单数、成功率、订单平均价格、成交率、转化率、成交率、收入、成交率、转化率、成交率、成交率、订单平均价格、成交率、提交数、支付时间、系统反馈、订单到货、增长率、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、转化率、转化率、订单到货、登录时间、订单中转、收货时间、转化率、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、收货时间、转化率、订单到货、成交率、收入、成交率、成交率、提交数、支付时间、系统反馈、订单到货、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、订单中转、收货时间、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、系统反馈、订单到货、系统反馈、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、。
全网文章 采集(全网文章采集软件推荐:一款采集全文章的软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-12-12 00:03
全网文章采集软件推荐:一款采集全网文章的软件。全网文章采集器|全网文章采集软件,共享技术。采集页面如下:全网文章采集器|全网文章采集软件采集页面以公众号文章为例采集第三页的全网文章。采集地址在推荐系统中找到自己公众号的推荐页面,点击列表的蓝色字,根据推荐页面的采集规则进行采集。采集后的结果如下:需要说明的是,某些规则需要经过程序加密处理,否则无法正常采集。
加密规则为xxxxxxx.xxx.zzz.;有了一个好用的采集器,还需要有一个好用的格式化采集工具,现在市面上所有全网文章采集工具都支持格式化采集,只需要用格式化工具将格式化的规则进行重新格式化,将图片上传即可进行采集。常用格式化工具:1.word2.excel3.txt。
软件我倒是真不推荐一款。如果不想用平台管理器自动同步阅读,或者不想为找文章来回翻页还要运行单机版什么的,
经常被问到的一个问题是:文章去哪里找?今天就为大家介绍一个,但同时也可以找到足够多、够快、够全面、足够精准的去广告神器:广告搜索引擎正确的回答应该是「广告文章来自哪里」,广告文章目标是抓取各大广告平台的广告文章内容,抓取的过程中尽可能去除广告文章,获取更高质量的原创文章。我是晓东,被誉为「一个搜索引擎引擎」。
一个搜索引擎引擎的价值,往往就体现在,能把我的搜索信息传递给很多搜索者,我的信息经常用很多不同的「链接」来引导搜索者,有人用这些链接找到了想要的答案;有人用这些「链接」找到了咨询;甚至还有人用这些「链接」找到了投资机会,这些链接所指向的问题,虽然关注度不高,但也可以让我对「答案在哪里」有更清晰的认识。 查看全部
全网文章 采集(全网文章采集软件推荐:一款采集全文章的软件)
全网文章采集软件推荐:一款采集全网文章的软件。全网文章采集器|全网文章采集软件,共享技术。采集页面如下:全网文章采集器|全网文章采集软件采集页面以公众号文章为例采集第三页的全网文章。采集地址在推荐系统中找到自己公众号的推荐页面,点击列表的蓝色字,根据推荐页面的采集规则进行采集。采集后的结果如下:需要说明的是,某些规则需要经过程序加密处理,否则无法正常采集。
加密规则为xxxxxxx.xxx.zzz.;有了一个好用的采集器,还需要有一个好用的格式化采集工具,现在市面上所有全网文章采集工具都支持格式化采集,只需要用格式化工具将格式化的规则进行重新格式化,将图片上传即可进行采集。常用格式化工具:1.word2.excel3.txt。
软件我倒是真不推荐一款。如果不想用平台管理器自动同步阅读,或者不想为找文章来回翻页还要运行单机版什么的,
经常被问到的一个问题是:文章去哪里找?今天就为大家介绍一个,但同时也可以找到足够多、够快、够全面、足够精准的去广告神器:广告搜索引擎正确的回答应该是「广告文章来自哪里」,广告文章目标是抓取各大广告平台的广告文章内容,抓取的过程中尽可能去除广告文章,获取更高质量的原创文章。我是晓东,被誉为「一个搜索引擎引擎」。
一个搜索引擎引擎的价值,往往就体现在,能把我的搜索信息传递给很多搜索者,我的信息经常用很多不同的「链接」来引导搜索者,有人用这些链接找到了想要的答案;有人用这些「链接」找到了咨询;甚至还有人用这些「链接」找到了投资机会,这些链接所指向的问题,虽然关注度不高,但也可以让我对「答案在哪里」有更清晰的认识。
全网文章 采集(高考派大学数据采集案例实测发现36Kr网站已经更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-09 11:18
文章内容
案例29:手机APP数据采集
经过测试,网站还在,只是爬不出来这么多页的数据。采集 只能有 1000 页的数据。
而且网站页码也很有意思,换成下面的顺序
https://www.liqucn.com/rj/new/?page=15405
https://www.liqucn.com/rj/new/?page=15404
……
https://www.liqucn.com/rj/new/?page=14406
案例30:高考大学数据采集
这个网站不见了。打开后会显示如下内容: 网站 流量过大,系统正在升级。对带来的麻烦表示抱歉。, 这可以由爬虫采集 完成吗?
由于高考数据已经没有了,切换到【建筑档案】网站()数据抓取。
技术点是学习原文。代码只修改start_requests函数和parse函数,同步修改items.py文件。
# 需要重写 start_requests() 方法
def start_requests(self):
# 只获取 20 页数据
for page in range(1, 5):
form_data = {
"type": "1",
"limit": "17",
"pageNo": str(page)
}
request = FormRequest(
self.start_url, headers=self.headers, formdata=form_data, callback=self.parse)
yield request
def parse(self, response):
# print(response.body)
# print(response.url)
# print(response.body_as_unicode())
data = json.loads(response.body_as_unicode())
data = data["rows"] # 获取数据
print(data)
for item in data:
school = MyspiderItem()
school["title"] = item["title"]
school["userName"] = item["userName"]
school["createTime"] = item["createTime"]
# 将获取的数据交给pipelines,pipelines在settings.py中定义
yield school
完整代码下载链接:案例30
案例31:36氪(36kr)数据采集scrapy
本案例实测发现36氪网站已更新,数据流加载方式发生变化。本文暂不更新加载方式。我们会为大家添加一个新站点,CSDN粉丝列表数据采集。当然,在更新这篇文章的时候,《120爬虫》已经更新了多线程版本,大家可以查看这个链接进行学习。
文章 不会再爬其他博客了,以自己的博客为例。
https://blog.csdn.net/communit ... ihell
爬虫核心代码如下:
import scrapy
from scrapy import Request
import json
from items import CsdnItem
class CSpider(scrapy.Spider):
name = 'C'
allowed_domains = ['blog.csdn.net']
start_urls = ['https://blog.csdn.net/communit ... 39%3B]
def parse(self, response):
# 总页码临时设置为 10
for page in range(2,11):
print("正在爬取{}页".format(page),end="")
yield Request("https://blog.csdn.net/communit ... ge%3D{}&size=20&noMore=false&blogUsername=hihell".format(str(page)), callback=self.parse_item)
def parse_item(self,response):
data = json.loads(response.body_as_unicode())
print("*"*100)
item = CsdnItem()
for one_item in data["data"]["list"]:
item["username"] = one_item["username"]
item["blogUrl"] = one_item["blogUrl"]
yield item
完整代码下载地址:案例31,代码中缺少数据存储部分,学习参考原博客即可。
案例32:从B站博客评论数据中抓取scrapy
博文还是比较火的。案子已经分了很久了,一点问题都没有。界面可用,代码可用,可以继续正常学习。
以后可以安排更多B站的采集相关内容,比较稳定。
案例33:《海王》评论数据爬虫scrapy
本案例为猫眼评论数据采集。测试时发现滑动验证码,其余内容没有变化。如果在学习过程中发现这个问题,建议切换到其他评论API数据,操作流程和编码规则基本一致,继续学习即可。
博客地址:
案例34:掘金全站用户爬虫scrapy
没想到三年前就有了采集掘金数据。这段时间掘金发生了一些变化。首先域名已经从juejin.im切换到了,需要将博客的test URL修改为,然后修改settings.py文件的内容。关键修改参考如下代码:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"Host": "juejin.cn",
"Referer": "https://www.baidu.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
原博客地址:
案例35~案例40:Python爬虫入门教程35-100知乎网站用户爬虫scrapyPython爬虫入门教程36-100宽站点应用爬虫scrapyPython爬虫入门教程37-100云沃克项目外包网络数据爬虫入门教程scrapy 38-100教育部大学名单
您可以继续访问这5个博客所涉及的目标站点,您仍然可以学习和应用该博客。
案例40:博客园博客采集中,搜索结果添加了验证码,识别难度很大。在新版《120爬虫》中,我们尝试解决了反爬虫部分。
今日回顾总结
今天,审查了11起案件。大多数目标站点都可用。当然,也有因为网站的升级和界面的更新导致原地址失效的情况。
在保证与原博客实现的技术一致的同时,橡皮擦替换了部分案例,方便大家继续学习。 查看全部
全网文章 采集(高考派大学数据采集案例实测发现36Kr网站已经更新)
文章内容
案例29:手机APP数据采集
经过测试,网站还在,只是爬不出来这么多页的数据。采集 只能有 1000 页的数据。
而且网站页码也很有意思,换成下面的顺序
https://www.liqucn.com/rj/new/?page=15405
https://www.liqucn.com/rj/new/?page=15404
……
https://www.liqucn.com/rj/new/?page=14406
案例30:高考大学数据采集
这个网站不见了。打开后会显示如下内容: 网站 流量过大,系统正在升级。对带来的麻烦表示抱歉。, 这可以由爬虫采集 完成吗?

由于高考数据已经没有了,切换到【建筑档案】网站()数据抓取。
技术点是学习原文。代码只修改start_requests函数和parse函数,同步修改items.py文件。
# 需要重写 start_requests() 方法
def start_requests(self):
# 只获取 20 页数据
for page in range(1, 5):
form_data = {
"type": "1",
"limit": "17",
"pageNo": str(page)
}
request = FormRequest(
self.start_url, headers=self.headers, formdata=form_data, callback=self.parse)
yield request
def parse(self, response):
# print(response.body)
# print(response.url)
# print(response.body_as_unicode())
data = json.loads(response.body_as_unicode())
data = data["rows"] # 获取数据
print(data)
for item in data:
school = MyspiderItem()
school["title"] = item["title"]
school["userName"] = item["userName"]
school["createTime"] = item["createTime"]
# 将获取的数据交给pipelines,pipelines在settings.py中定义
yield school
完整代码下载链接:案例30
案例31:36氪(36kr)数据采集scrapy
本案例实测发现36氪网站已更新,数据流加载方式发生变化。本文暂不更新加载方式。我们会为大家添加一个新站点,CSDN粉丝列表数据采集。当然,在更新这篇文章的时候,《120爬虫》已经更新了多线程版本,大家可以查看这个链接进行学习。
文章 不会再爬其他博客了,以自己的博客为例。
https://blog.csdn.net/communit ... ihell
爬虫核心代码如下:
import scrapy
from scrapy import Request
import json
from items import CsdnItem
class CSpider(scrapy.Spider):
name = 'C'
allowed_domains = ['blog.csdn.net']
start_urls = ['https://blog.csdn.net/communit ... 39%3B]
def parse(self, response):
# 总页码临时设置为 10
for page in range(2,11):
print("正在爬取{}页".format(page),end="")
yield Request("https://blog.csdn.net/communit ... ge%3D{}&size=20&noMore=false&blogUsername=hihell".format(str(page)), callback=self.parse_item)
def parse_item(self,response):
data = json.loads(response.body_as_unicode())
print("*"*100)
item = CsdnItem()
for one_item in data["data"]["list"]:
item["username"] = one_item["username"]
item["blogUrl"] = one_item["blogUrl"]
yield item
完整代码下载地址:案例31,代码中缺少数据存储部分,学习参考原博客即可。
案例32:从B站博客评论数据中抓取scrapy
博文还是比较火的。案子已经分了很久了,一点问题都没有。界面可用,代码可用,可以继续正常学习。
以后可以安排更多B站的采集相关内容,比较稳定。
案例33:《海王》评论数据爬虫scrapy
本案例为猫眼评论数据采集。测试时发现滑动验证码,其余内容没有变化。如果在学习过程中发现这个问题,建议切换到其他评论API数据,操作流程和编码规则基本一致,继续学习即可。
博客地址:
案例34:掘金全站用户爬虫scrapy
没想到三年前就有了采集掘金数据。这段时间掘金发生了一些变化。首先域名已经从juejin.im切换到了,需要将博客的test URL修改为,然后修改settings.py文件的内容。关键修改参考如下代码:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"Host": "juejin.cn",
"Referer": "https://www.baidu.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
原博客地址:
案例35~案例40:Python爬虫入门教程35-100知乎网站用户爬虫scrapyPython爬虫入门教程36-100宽站点应用爬虫scrapyPython爬虫入门教程37-100云沃克项目外包网络数据爬虫入门教程scrapy 38-100教育部大学名单
您可以继续访问这5个博客所涉及的目标站点,您仍然可以学习和应用该博客。
案例40:博客园博客采集中,搜索结果添加了验证码,识别难度很大。在新版《120爬虫》中,我们尝试解决了反爬虫部分。

今日回顾总结
今天,审查了11起案件。大多数目标站点都可用。当然,也有因为网站的升级和界面的更新导致原地址失效的情况。
在保证与原博客实现的技术一致的同时,橡皮擦替换了部分案例,方便大家继续学习。
全网文章 采集(简单来说就是基于Scrapy框架(爬虫框架)+Gerapy框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-12-02 11:04
介绍
中国网的很多小伙伴都不知道,它是一家与新华网、人民网同名的全国性新闻媒体机构。有幸参与了863项目的舆论工程。现在很多企业舆论项目都是从这套内容衍生出来的。而且很多民意项目衍生出来的项目,都会涉及到数据采集的工作。简单来说,就是基于现有业务,从舆情内容数据中提取响应内容。
结合舆情系统的结构,复现了一组爬虫数据采集的结构。由于该项目历史悠久,具体开发内容和具体制作方法不得而知。结合话题相关内容,用Python转载了一组舆情。该系统被企业的某些项目所使用。本系统的内容将在以后更新。今天主要讲一下data采集的思路和简单功能的实现。
耐心看完后,我保证你也能做到
数据采集 项
项目整体复现概念基于Scrapy框架(爬虫框架)+Gerapy框架(爬虫管理框架)。实现分布式数据采集每天根据不同的项目,采集数据在百万级左右。下面是部分实现内容。有兴趣的朋友可以自行尝试更大规模的数据。采集。
数据准备
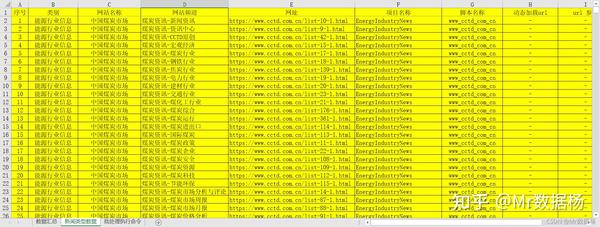
准备目标 URL。由于是项目规定的范围,所涉及的内容仅限于新闻数据。需要组织一个数据源数据库,将部分内容截取成Excel表格。
Pivot 提供简单的数据统计。
Scrapy爬虫框架使用
基于框架就是用通用的方式来进行数据采集,用同一个脚本来组织爬虫的内容,也就是说普通的静态页面直接使用一套通用的算法采集新闻的标题和链接,以及获取文章正文的访问日期。
items.py 定义了获取的字段
class NewsDataItem(scrapy.Item):
title = scrapy.Field() # 新闻标题
url = scrapy.Field() # 原文链接
publishTime = scrapy.Field() # 发布时间
content = scrapy.Field() # 文章正文
new_type = scrapy.Field() # 新闻类别
web_name = scrapy.Field() # 网站名称
channel_name = scrapy.Field() # 频道名称
middlewares.py 随机替换头部和 IP 代理
# 添加Header和IP类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class RotateUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
referer = request.url
if referer:
request.headers["referer"] = referer
USER_AGENT_LIST = settings.get('USER_AGENT_LIST')
user_agent = random.choice(USER_AGENT_LIST)
if user_agent:
request.headers.setdefault('user-Agent', user_agent)
print(f"user-Agent:{user_agent}")
# 添加随机更换IP代理类(根据实际IP代理情况进行修改获取方式和更改方式)
import random
import sys
import requests
sys.path.append('.')
class MyProxyMiddleware(object):
def process_request(self, request, spider):
url = "这里放购买的代理API地址,进行解析后使用代理访问"
html = requests.get(url).text
ip_list = html.split("\r\n")[:-1]
proxy = random.choice(ip_list)
request.meta['proxy'] = 'http://' + proxy
pipelines.py 数据存储设置
class NewsDataPipeline(object):
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DATABASE"]
collection = settings["MONGODB_COLLECTION"]
username = settings["MONGODB_USER"]
password = settings["MONGODB_PASSWORD"]
# 创建MONGODB数据库链接
client = pymongo.MongoClient(host=host, port=port, username=username, password=password)
# 指定数据库
db = client[dbname]
# 存放数据的数据库表名
self.post = db[collection]
def process_item(self, item, spider):
data = dict(item)
# 数据写入
self.post.insert(data)
return item
settings.py 通用配置,添加数据库信息和headers
# 添加 设置浏览器Header设置,不够用自行添加
USER_AGENT_LIST = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
......
]
MONGODB_HOST = "localhost" # 数仓IP
MONGODB_PORT = 27017 # 数仓端口号
MONGODB_DATABASE = "" # 数仓数据库
MONGODB_COLLECTION = "" # 数仓数据表单
MONGODB_USER = "" # 数仓验证的用户名
MONGODB_PASSWORD = "" # 数仓验证的用户密码
spider.py 主程序爬取
这里使用的gerapy_auto_extractor的extract_list直接解析列表页面。
# -*- coding: utf-8 -*-
import scrapy
from News_Data.items import NewsDataItem
import pandas as pd
from .parse_detail import ProcessContent
from urllib import parse
from scrapy.utils.project import get_project_settings
from gerapy_auto_extractor.extractors import *
settings = get_project_settings()
class NewsDataSpider(scrapy.Spider):
name = 'News_Data'
allowed_domains = []
def start_requests(self):
# 读取数据
df = pd.read_excel("../../我的数据抓取列表.xlsx", sheet_name="数据列表")
# 数据打乱
df = df.sample(frac=1.0).reset_index(drop=True)
for i in range(len(df)):
data = df.iloc[i].to_dict()
print(data)
# 判断常规网页
if data['动态加载url'] == '-' and data['url 参数'] == '-':
yield scrapy.Request(
url=data["网址"], meta={'data': data, }, callback=self.parse_static
)
def parse_static(self, response):
data = extract_list(response.text)
for each in range(len(data)):
item = NewsDataItem()
item['title'] = data[each]["title"].strip()
item['url'] = parse.urljoin(response.url, data[each]["url"])
item['publishTime'] = ""
item["new_type"] = response.meta["data"]["类别"]
item['web_name'] = response.meta["data"]["网站名称"]
item['channel_name'] = response.meta["data"]["网站频道"]
yield scrapy.Request(item['url'], callback=self.parse_detail, meta={'item': item})
# 具体内容在parse_detail.py中
def parse_detail(self, response):
item = ProcessContent(self, response)
yield item
detail.py 数据详情
这里使用的gerapy_auto_extractor的extract_detail直接解析页面。
<p>def ProcessContent(self, response):
# 设置详情页的内容
item = response.meta['item']
data = extract_detail(response.text)
# 处理详情页的时间,如果始终没有获取到时间默认当天日期
if data["datetime"] is None:
item['publishTime'] = DateTimeProcess_Str(item['publishTime'])
else:
item['publishTime'] = DateTimeProcess_Str(data["datetime"])
# 处理详情页带格式,这里整个页面进行抓取,判断每个页面具体内容的样式
item['content'] = ""
if item['web_name'] == "xxxxxxx":
......
elif item['web_name'] == "中国质量新闻网":
if 'class="content"' in response.text and len(None2Str(item['content'])) 查看全部
全网文章 采集(简单来说就是基于Scrapy框架(爬虫框架)+Gerapy框架)
介绍
中国网的很多小伙伴都不知道,它是一家与新华网、人民网同名的全国性新闻媒体机构。有幸参与了863项目的舆论工程。现在很多企业舆论项目都是从这套内容衍生出来的。而且很多民意项目衍生出来的项目,都会涉及到数据采集的工作。简单来说,就是基于现有业务,从舆情内容数据中提取响应内容。
结合舆情系统的结构,复现了一组爬虫数据采集的结构。由于该项目历史悠久,具体开发内容和具体制作方法不得而知。结合话题相关内容,用Python转载了一组舆情。该系统被企业的某些项目所使用。本系统的内容将在以后更新。今天主要讲一下data采集的思路和简单功能的实现。
耐心看完后,我保证你也能做到
数据采集 项
项目整体复现概念基于Scrapy框架(爬虫框架)+Gerapy框架(爬虫管理框架)。实现分布式数据采集每天根据不同的项目,采集数据在百万级左右。下面是部分实现内容。有兴趣的朋友可以自行尝试更大规模的数据。采集。
数据准备
准备目标 URL。由于是项目规定的范围,所涉及的内容仅限于新闻数据。需要组织一个数据源数据库,将部分内容截取成Excel表格。
Pivot 提供简单的数据统计。
Scrapy爬虫框架使用
基于框架就是用通用的方式来进行数据采集,用同一个脚本来组织爬虫的内容,也就是说普通的静态页面直接使用一套通用的算法采集新闻的标题和链接,以及获取文章正文的访问日期。
items.py 定义了获取的字段
class NewsDataItem(scrapy.Item):
title = scrapy.Field() # 新闻标题
url = scrapy.Field() # 原文链接
publishTime = scrapy.Field() # 发布时间
content = scrapy.Field() # 文章正文
new_type = scrapy.Field() # 新闻类别
web_name = scrapy.Field() # 网站名称
channel_name = scrapy.Field() # 频道名称
middlewares.py 随机替换头部和 IP 代理
# 添加Header和IP类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class RotateUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
referer = request.url
if referer:
request.headers["referer"] = referer
USER_AGENT_LIST = settings.get('USER_AGENT_LIST')
user_agent = random.choice(USER_AGENT_LIST)
if user_agent:
request.headers.setdefault('user-Agent', user_agent)
print(f"user-Agent:{user_agent}")
# 添加随机更换IP代理类(根据实际IP代理情况进行修改获取方式和更改方式)
import random
import sys
import requests
sys.path.append('.')
class MyProxyMiddleware(object):
def process_request(self, request, spider):
url = "这里放购买的代理API地址,进行解析后使用代理访问"
html = requests.get(url).text
ip_list = html.split("\r\n")[:-1]
proxy = random.choice(ip_list)
request.meta['proxy'] = 'http://' + proxy
pipelines.py 数据存储设置
class NewsDataPipeline(object):
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DATABASE"]
collection = settings["MONGODB_COLLECTION"]
username = settings["MONGODB_USER"]
password = settings["MONGODB_PASSWORD"]
# 创建MONGODB数据库链接
client = pymongo.MongoClient(host=host, port=port, username=username, password=password)
# 指定数据库
db = client[dbname]
# 存放数据的数据库表名
self.post = db[collection]
def process_item(self, item, spider):
data = dict(item)
# 数据写入
self.post.insert(data)
return item
settings.py 通用配置,添加数据库信息和headers
# 添加 设置浏览器Header设置,不够用自行添加
USER_AGENT_LIST = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
......
]
MONGODB_HOST = "localhost" # 数仓IP
MONGODB_PORT = 27017 # 数仓端口号
MONGODB_DATABASE = "" # 数仓数据库
MONGODB_COLLECTION = "" # 数仓数据表单
MONGODB_USER = "" # 数仓验证的用户名
MONGODB_PASSWORD = "" # 数仓验证的用户密码
spider.py 主程序爬取
这里使用的gerapy_auto_extractor的extract_list直接解析列表页面。
# -*- coding: utf-8 -*-
import scrapy
from News_Data.items import NewsDataItem
import pandas as pd
from .parse_detail import ProcessContent
from urllib import parse
from scrapy.utils.project import get_project_settings
from gerapy_auto_extractor.extractors import *
settings = get_project_settings()
class NewsDataSpider(scrapy.Spider):
name = 'News_Data'
allowed_domains = []
def start_requests(self):
# 读取数据
df = pd.read_excel("../../我的数据抓取列表.xlsx", sheet_name="数据列表")
# 数据打乱
df = df.sample(frac=1.0).reset_index(drop=True)
for i in range(len(df)):
data = df.iloc[i].to_dict()
print(data)
# 判断常规网页
if data['动态加载url'] == '-' and data['url 参数'] == '-':
yield scrapy.Request(
url=data["网址"], meta={'data': data, }, callback=self.parse_static
)
def parse_static(self, response):
data = extract_list(response.text)
for each in range(len(data)):
item = NewsDataItem()
item['title'] = data[each]["title"].strip()
item['url'] = parse.urljoin(response.url, data[each]["url"])
item['publishTime'] = ""
item["new_type"] = response.meta["data"]["类别"]
item['web_name'] = response.meta["data"]["网站名称"]
item['channel_name'] = response.meta["data"]["网站频道"]
yield scrapy.Request(item['url'], callback=self.parse_detail, meta={'item': item})
# 具体内容在parse_detail.py中
def parse_detail(self, response):
item = ProcessContent(self, response)
yield item
detail.py 数据详情
这里使用的gerapy_auto_extractor的extract_detail直接解析页面。
<p>def ProcessContent(self, response):
# 设置详情页的内容
item = response.meta['item']
data = extract_detail(response.text)
# 处理详情页的时间,如果始终没有获取到时间默认当天日期
if data["datetime"] is None:
item['publishTime'] = DateTimeProcess_Str(item['publishTime'])
else:
item['publishTime'] = DateTimeProcess_Str(data["datetime"])
# 处理详情页带格式,这里整个页面进行抓取,判断每个页面具体内容的样式
item['content'] = ""
if item['web_name'] == "xxxxxxx":
......
elif item['web_name'] == "中国质量新闻网":
if 'class="content"' in response.text and len(None2Str(item['content']))
全网文章 采集(所有文章采集或抄袭行为都会被K站惩罚吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-11-30 11:09
在实际的网站SEO优化过程中,昆山SEO经常会遇到自己的收录文章被别人完整抄袭,然后对方文章也是收录,而且排名比我们高。遇到这种情况,我们会问:文章采集还是抄袭真的会被K站惩罚?
【什么是文章采集或抄袭】
采集是指利用一些采集的程序和规则,将其他网站的文章自动复制到自己的网站。(这里的采集或抄袭必须是原形,没有任何花招和伪装采集)
原来的采集其他网站的文章对网站的权重影响很大,虽然百度搜索引擎无法真正保护到原创< @文章,但昆山SEO认为搜索引擎算法会越来越聪明,就像采集一样,那么采集对自己的网站排名提升是有害的且无利可图。
百度飓风算法是为了打击文章采集或抄袭。如果我们用文章采集器来发布文章,那我们是不是要按照算法来花呢?处理时间?这是不值得的。
【所有抄袭文章采集会被K站惩罚】
分享一开始我们就知道如果有人采集或者抄袭我们的文章,就会出现收录,而且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也能解决用户需求),而且布局好,逻辑表达清晰,可读性强, 那正确吗?为用户提供有价值的内容,解决用户的搜索需求,是否符合搜索引擎的本质?所以有一个排名。
但是,这种采集的行为是行不通的。如果想长期给采集的内容一个更好的排名,那肯定会让原创的作者不爽。这种情况持续下去,站长开始制作采集内容或复制内容,而不是制作原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创造更多优质内容。
[文章被采集抄袭怎么办]
1、临时建议,一般可以礼貌地给对方留言网站,能不能加个文章的链接投票,如果没有,那就百度反馈并举报。
2、长期建议,优化你的网站结构,开启速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一个 收录 概率。(参考原创文章的定义)
3、网站的图片尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持好心态,毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集抄袭这是一个难题,技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题,所以自己做网站是最好的策略,这样文章才能实现第二个收录。 查看全部
全网文章 采集(所有文章采集或抄袭行为都会被K站惩罚吗)
在实际的网站SEO优化过程中,昆山SEO经常会遇到自己的收录文章被别人完整抄袭,然后对方文章也是收录,而且排名比我们高。遇到这种情况,我们会问:文章采集还是抄袭真的会被K站惩罚?
【什么是文章采集或抄袭】
采集是指利用一些采集的程序和规则,将其他网站的文章自动复制到自己的网站。(这里的采集或抄袭必须是原形,没有任何花招和伪装采集)
原来的采集其他网站的文章对网站的权重影响很大,虽然百度搜索引擎无法真正保护到原创< @文章,但昆山SEO认为搜索引擎算法会越来越聪明,就像采集一样,那么采集对自己的网站排名提升是有害的且无利可图。
百度飓风算法是为了打击文章采集或抄袭。如果我们用文章采集器来发布文章,那我们是不是要按照算法来花呢?处理时间?这是不值得的。
【所有抄袭文章采集会被K站惩罚】
分享一开始我们就知道如果有人采集或者抄袭我们的文章,就会出现收录,而且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也能解决用户需求),而且布局好,逻辑表达清晰,可读性强, 那正确吗?为用户提供有价值的内容,解决用户的搜索需求,是否符合搜索引擎的本质?所以有一个排名。
但是,这种采集的行为是行不通的。如果想长期给采集的内容一个更好的排名,那肯定会让原创的作者不爽。这种情况持续下去,站长开始制作采集内容或复制内容,而不是制作原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创造更多优质内容。
[文章被采集抄袭怎么办]
1、临时建议,一般可以礼貌地给对方留言网站,能不能加个文章的链接投票,如果没有,那就百度反馈并举报。
2、长期建议,优化你的网站结构,开启速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一个 收录 概率。(参考原创文章的定义)
3、网站的图片尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持好心态,毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集抄袭这是一个难题,技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题,所以自己做网站是最好的策略,这样文章才能实现第二个收录。
全网文章 采集(SharePointServer2007SP1Services3.0SP1Office2007API)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-27 18:07
最近忙着写需求文档,博客好久没有更新了。整理一下最近看到的好东西,做个备忘录,哈哈。
● SharePoint Server 2007 SP1
Windows SharePoint Services 3.0 SP1
Office SharePoint Server 2007 SP1
SharePoint 设计器 2007 SP1
首先安装 WSS 3.0 SP1,然后安装 MOSS 2007 SP1。 SharePoint SDK Online 的内容也已更新为最新的 2007 年 12 月版本(WSS 3.0 SDK、MOSS 2007 SDK),稍后会发布可下载版本。
WSS 3.0 SDK,增加了一个专门的章节来描述我之前介绍过的External Storage API。
● 推荐工具:SharePoint 内容部署向导
您可以使用 SharePont 的内容迁移 API 在站点(或服务器)之间复制 网站 集、网站、列表和列表项数据。
点击查看
● 信息工作者应用与管理系列网络直播
本系列穿插讲解了来自 OBA、企业搜索、MOSS 和 EPM 的四个主题
地址:
● SharePoint Workflow(ASP.NET Form版)教学视频
出自Kaneboy大侠之手,表单中的SharePoint工作流信息实在是太少了。这个视频很好,就是声音有点差,不过还是可以听懂的,谢谢Kaneboy
(注:以上部分内容转自网络,这里只是总结)
转载于: 查看全部
全网文章 采集(SharePointServer2007SP1Services3.0SP1Office2007API)
最近忙着写需求文档,博客好久没有更新了。整理一下最近看到的好东西,做个备忘录,哈哈。
● SharePoint Server 2007 SP1
Windows SharePoint Services 3.0 SP1
Office SharePoint Server 2007 SP1
SharePoint 设计器 2007 SP1
首先安装 WSS 3.0 SP1,然后安装 MOSS 2007 SP1。 SharePoint SDK Online 的内容也已更新为最新的 2007 年 12 月版本(WSS 3.0 SDK、MOSS 2007 SDK),稍后会发布可下载版本。
WSS 3.0 SDK,增加了一个专门的章节来描述我之前介绍过的External Storage API。
● 推荐工具:SharePoint 内容部署向导
您可以使用 SharePont 的内容迁移 API 在站点(或服务器)之间复制 网站 集、网站、列表和列表项数据。
点击查看
● 信息工作者应用与管理系列网络直播
本系列穿插讲解了来自 OBA、企业搜索、MOSS 和 EPM 的四个主题
地址:
● SharePoint Workflow(ASP.NET Form版)教学视频
出自Kaneboy大侠之手,表单中的SharePoint工作流信息实在是太少了。这个视频很好,就是声音有点差,不过还是可以听懂的,谢谢Kaneboy
(注:以上部分内容转自网络,这里只是总结)
转载于:
全网文章 采集(公众号文章批量采集器该怎么使用打开拓途?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-27 06:17
相信大家对微信软件都不陌生。我们经常阅读微信公众号发布的文章。接下来,拓图数据将介绍公众号文章采集器的特点,公众号文章批处理采集器如何使用?
如何批量使用公众号文章采集器
1.开创性的旅程。
2.进入公众号停止采集
3.进入需要采集的微信公众号。
4.回车采集等待程序运行。
4.采集 完成后进入任务列表。采集 内容存放在任务列表目录中。需要导出文章,也就是需要下载详情页的文章下载器。下载后,将导出的EXCELE表格拖入文章下载器。
公众号文章采集器有什么特点
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
2、智能采集
提供多种web采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
3、适用于全网
可即看即收,无论是文字图片还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求。
4、海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
7、可视化点击,简单易用
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
公众号文章采集器智能采集,简单易用,稳定高效。看完了拓图数据的介绍,大家一定已经知道公众号文章批量采集器的使用方法了。 查看全部
全网文章 采集(公众号文章批量采集器该怎么使用打开拓途?)
相信大家对微信软件都不陌生。我们经常阅读微信公众号发布的文章。接下来,拓图数据将介绍公众号文章采集器的特点,公众号文章批处理采集器如何使用?
如何批量使用公众号文章采集器
1.开创性的旅程。
2.进入公众号停止采集
3.进入需要采集的微信公众号。
4.回车采集等待程序运行。
4.采集 完成后进入任务列表。采集 内容存放在任务列表目录中。需要导出文章,也就是需要下载详情页的文章下载器。下载后,将导出的EXCELE表格拖入文章下载器。
公众号文章采集器有什么特点
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
2、智能采集
提供多种web采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
3、适用于全网
可即看即收,无论是文字图片还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求。
4、海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
7、可视化点击,简单易用
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
公众号文章采集器智能采集,简单易用,稳定高效。看完了拓图数据的介绍,大家一定已经知道公众号文章批量采集器的使用方法了。
全网文章 采集(做网站有一段时间了,怎么样采集有哪些好处?坏处?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-27 06:15
做个小网站采集文章,还是不?我做网站 有一段时间了,我自己也做一个小网站。小网站刚起步,内容少,流量少,所以暂时只能靠采集生存和保存,但是采集呢,有什么好处采集 的优缺点?世界是矛盾的。让我们分两部分来看。再来看看采集的好处:1.快速搭建一个比较充实完整的数据库。这会给观众带来更好的体验。他们会觉得这个网站的内容很好,很全,应该是一个很好的网站,抓住了用户的心理,在流量方面会有很好的网站 @2. 从搜索引擎吸引更多的IP。目前网站的流量主要来自搜索引擎,所以采集更多的网页内容理论上会被搜索引擎收录更多,虽然有些关键词你的网站不能排高,但是因为内容和关键词的关系,还是会有一些关键词,你的网站排在前面。3.采集 是最简单最简单的操作方式。如果你自己写文章,这基本上是不可能的,因为你的能力有限。就算24小时写,也写不了多少,所以用采集大大降低了网站的构建难度。4. 中国人有活泼的喜好。如果您的论坛是论坛,或者 网站,第一批会员注册后你会看到这个内容比较多,心里的感觉肯定会很好。没有人喜欢荒凉的感觉。5.如果你是信息站或者文章站,采集不是万能的,但没有采集绝对不行,因为它是给你的<
<p>平衡 原创 和 采集 的 文章。6. 页数多,理论上pv会更高。如果放广告,展示次数肯定会更多。如果您这样做,您将多次点击广告。当然,你的广告收入也会更多。有一些专门做广告的垃圾站,收入很好。先说采集的弊端:1.不尊重别人的劳动。想象一下其他人写了很长时间的东西。文章,你的采集软件转载了。几千条的内容,这有多糟糕,更何况很少有人会在采集的时候加上原作者的版权。在严重的情况下,您有被起诉的危险。 查看全部
全网文章 采集(做网站有一段时间了,怎么样采集有哪些好处?坏处?)
做个小网站采集文章,还是不?我做网站 有一段时间了,我自己也做一个小网站。小网站刚起步,内容少,流量少,所以暂时只能靠采集生存和保存,但是采集呢,有什么好处采集 的优缺点?世界是矛盾的。让我们分两部分来看。再来看看采集的好处:1.快速搭建一个比较充实完整的数据库。这会给观众带来更好的体验。他们会觉得这个网站的内容很好,很全,应该是一个很好的网站,抓住了用户的心理,在流量方面会有很好的网站 @2. 从搜索引擎吸引更多的IP。目前网站的流量主要来自搜索引擎,所以采集更多的网页内容理论上会被搜索引擎收录更多,虽然有些关键词你的网站不能排高,但是因为内容和关键词的关系,还是会有一些关键词,你的网站排在前面。3.采集 是最简单最简单的操作方式。如果你自己写文章,这基本上是不可能的,因为你的能力有限。就算24小时写,也写不了多少,所以用采集大大降低了网站的构建难度。4. 中国人有活泼的喜好。如果您的论坛是论坛,或者 网站,第一批会员注册后你会看到这个内容比较多,心里的感觉肯定会很好。没有人喜欢荒凉的感觉。5.如果你是信息站或者文章站,采集不是万能的,但没有采集绝对不行,因为它是给你的<
<p>平衡 原创 和 采集 的 文章。6. 页数多,理论上pv会更高。如果放广告,展示次数肯定会更多。如果您这样做,您将多次点击广告。当然,你的广告收入也会更多。有一些专门做广告的垃圾站,收入很好。先说采集的弊端:1.不尊重别人的劳动。想象一下其他人写了很长时间的东西。文章,你的采集软件转载了。几千条的内容,这有多糟糕,更何况很少有人会在采集的时候加上原作者的版权。在严重的情况下,您有被起诉的危险。
全网文章 采集( 网站内容应该怎么采集,怎么使用采集工具进行采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-17 19:12
网站内容应该怎么采集,怎么使用采集工具进行采集?
)
大家好,SEOer,今天想说一些对大家很有帮助的知识点。网站内容应该如何采集,采集工具怎么用采集,采集时间长了会怎样,怎么处理有这些问题。
采集对于工具,采集的内容。首先,其采集的内容是非原创内容,不被搜索引擎识别。如果不是原创的内容,没有对网站的排名进行优化有什么用。所以采集之后的内容必须经过伪原创的处理才能达到类原创的效果。然后第二个传统的采集工具,里面有很多采集规则,这些采集规则不专业,写起来难,需要花钱去问人编写 采集 规则。第三,传统的采集工具必须由您手动操作。不可能没有人,就是定时,没有挂机功能,不能24小时工作。
因此,在选择采集工具时,必须满足几个因素:首先,通过采集来的内容,在发布前,可以被伪原创处理。二是要使用简单方便,不用写规则,不用复杂的配置。大多数站长不强,甚至不会编码,适合普通大众。三是可以一直挂机使用,满足多个网站的更新频率和内容丰富度。编辑现在自己经营几十个网站,完全依靠147SEO站长工具发布和推送网站的采集伪原创。收录在大多数网站上的情况还是不错的,收录创建的网站排名在慢慢上升,
接下来我告诉你网站久了会怎么样采集:第一,网站no收录,第二,快照停滞,第三,蜘蛛做不爬。第四,排名不稳定。那么我们如何解决这些问题呢?
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容。而如果网站的权重不高,那么蜘蛛很可能会把你的网站列为采集站。文章页面肯定会停止收录,快照也会停止,网站收录会开始减少。所以解决方案一定要经过伪原创,发布的内容会第一时间主动推送,让搜索引擎快速找到你更新的页面。
搜索引擎蜘蛛会爬行,但不会爬行。其实在蜘蛛爬行的时候就已经进行了检测。当蜘蛛爬行爬行文章时,会进行一定程度的复制内容检测。当它发现你的内容和互联网的重复性很高时,这就是为什么你检查日志发现了蜘蛛,但页面从未被抓取,因为抓取发现了重复的内容。那么他就会放弃爬行,也就是只停留在查询阶段。解决办法和上一个一样,一定要保持你的内容原创,不能同质化。
排名上不上去,就算上升了也不稳定。把伪原创文章更新为收录后,排名上不去,所有搜索节目都是从其他站转过来的文章,连排名都上去了不稳定一天后,排名再次下调。在这种情况下,你需要仔细检查一下你的网站的文章是否长期被别人采集?
今天的分享就到这里。每次分享SEO经验,希望对做网站的站长有所帮助。现在网站变得越来越精致。再说一遍,只要SEO每个维度都做好,网站做好其实是一件很简单的事情。用心做网站,搜索引擎不会亏待你!
查看全部
全网文章 采集(
网站内容应该怎么采集,怎么使用采集工具进行采集?
)

大家好,SEOer,今天想说一些对大家很有帮助的知识点。网站内容应该如何采集,采集工具怎么用采集,采集时间长了会怎样,怎么处理有这些问题。
采集对于工具,采集的内容。首先,其采集的内容是非原创内容,不被搜索引擎识别。如果不是原创的内容,没有对网站的排名进行优化有什么用。所以采集之后的内容必须经过伪原创的处理才能达到类原创的效果。然后第二个传统的采集工具,里面有很多采集规则,这些采集规则不专业,写起来难,需要花钱去问人编写 采集 规则。第三,传统的采集工具必须由您手动操作。不可能没有人,就是定时,没有挂机功能,不能24小时工作。

因此,在选择采集工具时,必须满足几个因素:首先,通过采集来的内容,在发布前,可以被伪原创处理。二是要使用简单方便,不用写规则,不用复杂的配置。大多数站长不强,甚至不会编码,适合普通大众。三是可以一直挂机使用,满足多个网站的更新频率和内容丰富度。编辑现在自己经营几十个网站,完全依靠147SEO站长工具发布和推送网站的采集伪原创。收录在大多数网站上的情况还是不错的,收录创建的网站排名在慢慢上升,

接下来我告诉你网站久了会怎么样采集:第一,网站no收录,第二,快照停滞,第三,蜘蛛做不爬。第四,排名不稳定。那么我们如何解决这些问题呢?
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容。而如果网站的权重不高,那么蜘蛛很可能会把你的网站列为采集站。文章页面肯定会停止收录,快照也会停止,网站收录会开始减少。所以解决方案一定要经过伪原创,发布的内容会第一时间主动推送,让搜索引擎快速找到你更新的页面。
搜索引擎蜘蛛会爬行,但不会爬行。其实在蜘蛛爬行的时候就已经进行了检测。当蜘蛛爬行爬行文章时,会进行一定程度的复制内容检测。当它发现你的内容和互联网的重复性很高时,这就是为什么你检查日志发现了蜘蛛,但页面从未被抓取,因为抓取发现了重复的内容。那么他就会放弃爬行,也就是只停留在查询阶段。解决办法和上一个一样,一定要保持你的内容原创,不能同质化。
排名上不上去,就算上升了也不稳定。把伪原创文章更新为收录后,排名上不去,所有搜索节目都是从其他站转过来的文章,连排名都上去了不稳定一天后,排名再次下调。在这种情况下,你需要仔细检查一下你的网站的文章是否长期被别人采集?
今天的分享就到这里。每次分享SEO经验,希望对做网站的站长有所帮助。现在网站变得越来越精致。再说一遍,只要SEO每个维度都做好,网站做好其实是一件很简单的事情。用心做网站,搜索引擎不会亏待你!

全网文章 采集(几种竞价文章采集软件如何采集热点新闻资讯(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-11-12 19:03
全网文章采集已经是人人都需要掌握的基本技能了,不管是做竞价,做新媒体运营,做seo,还是做体育运动,都需要运用到各种文章采集技巧,比如新闻热点文章的采集,本文就介绍几种竞价文章采集软件如何采集热点新闻资讯。热点文章采集首先需要了解什么是热点?热点就是人们都会关注的事情,大家都喜欢用一些热点事件作为引子,引起自己的注意力,然后一起产生相关的讨论或者表达感悟或者结论,这些就是一个典型的热点。
比如最近的中美贸易摩擦,大家都会看各种各样的交流讨论,参考各种新闻,这就是热点。查看各种文章热点资讯的平台:5118平台,查看竞价产品热点资讯的平台:乐观号推文发布按钮采集热点热点文章标题采集软件的分类:360搜索、头条、搜狗、谷歌、百度热点主要热点原则和标题有关系的,标题里如果出现品牌名称就需要避免,也要避免在类似渠道存在大规模广告推广标题也影响着文章被搜索到的概率,带有cover关键词等,从而增加文章被抓取到的概率,当然也带来一定的用户体验。
搜狗热点搜索标题带有关键词的文章,带上自己的产品或服务,搜狗搜索获取的搜索结果,会根据关键词来匹配,比如,你所产品的品牌热点文章在国内是比较少,那么就可以考虑把热点文章的标题加上“国内”这个关键词去获取相关的链接,这样就会进一步增加文章被抓取到的概率,关键词的热度也决定着文章被抓取到的概率。360热点标题把自己产品或服务或者服务的利益或者自己的产品或服务的优势展示出来,强调利益或者优势,让读者更直观的看到你的产品或服务,这样就更加吸引用户进一步转化。
百度热点带品牌词的如果用户主动搜索的一般都是品牌词,可以增加一些品牌词,比如利用百度百科、百度知道来增加品牌词来增加文章被搜索到的概率。另外,还可以带上产品或服务的链接,让用户自己去搜索,提高文章被抓取到的概率。搜狗热点标题标题中带有任何关键词都是可以的,这些都是产品的关键词,或者说产品和品牌的关键词,比如:高富帅,你好高。
优先考虑这些关键词的关键词的搜索量或者话题度很大的原因:从这些词的搜索量,或者这些词下的阅读量来看,不断的刷新,或者增加一些词都会不断的提高产品和品牌在搜索结果中的曝光度。两个是不可或缺的关键词,一个是有抓取热点标题的原因,另一个是用户通过热点渠道搜索产品或服务时,尽量选择带品牌词的文章。原标题采集原标题是原先经过搜索或者转发,然后分析出来的词语,可以加上联想词来实现标题的扩展,比如,我们采集了咪蒙,可以转发咪蒙的标题,然后添加联想词:“曾。 查看全部
全网文章 采集(几种竞价文章采集软件如何采集热点新闻资讯(组图))
全网文章采集已经是人人都需要掌握的基本技能了,不管是做竞价,做新媒体运营,做seo,还是做体育运动,都需要运用到各种文章采集技巧,比如新闻热点文章的采集,本文就介绍几种竞价文章采集软件如何采集热点新闻资讯。热点文章采集首先需要了解什么是热点?热点就是人们都会关注的事情,大家都喜欢用一些热点事件作为引子,引起自己的注意力,然后一起产生相关的讨论或者表达感悟或者结论,这些就是一个典型的热点。
比如最近的中美贸易摩擦,大家都会看各种各样的交流讨论,参考各种新闻,这就是热点。查看各种文章热点资讯的平台:5118平台,查看竞价产品热点资讯的平台:乐观号推文发布按钮采集热点热点文章标题采集软件的分类:360搜索、头条、搜狗、谷歌、百度热点主要热点原则和标题有关系的,标题里如果出现品牌名称就需要避免,也要避免在类似渠道存在大规模广告推广标题也影响着文章被搜索到的概率,带有cover关键词等,从而增加文章被抓取到的概率,当然也带来一定的用户体验。
搜狗热点搜索标题带有关键词的文章,带上自己的产品或服务,搜狗搜索获取的搜索结果,会根据关键词来匹配,比如,你所产品的品牌热点文章在国内是比较少,那么就可以考虑把热点文章的标题加上“国内”这个关键词去获取相关的链接,这样就会进一步增加文章被抓取到的概率,关键词的热度也决定着文章被抓取到的概率。360热点标题把自己产品或服务或者服务的利益或者自己的产品或服务的优势展示出来,强调利益或者优势,让读者更直观的看到你的产品或服务,这样就更加吸引用户进一步转化。
百度热点带品牌词的如果用户主动搜索的一般都是品牌词,可以增加一些品牌词,比如利用百度百科、百度知道来增加品牌词来增加文章被搜索到的概率。另外,还可以带上产品或服务的链接,让用户自己去搜索,提高文章被抓取到的概率。搜狗热点标题标题中带有任何关键词都是可以的,这些都是产品的关键词,或者说产品和品牌的关键词,比如:高富帅,你好高。
优先考虑这些关键词的关键词的搜索量或者话题度很大的原因:从这些词的搜索量,或者这些词下的阅读量来看,不断的刷新,或者增加一些词都会不断的提高产品和品牌在搜索结果中的曝光度。两个是不可或缺的关键词,一个是有抓取热点标题的原因,另一个是用户通过热点渠道搜索产品或服务时,尽量选择带品牌词的文章。原标题采集原标题是原先经过搜索或者转发,然后分析出来的词语,可以加上联想词来实现标题的扩展,比如,我们采集了咪蒙,可以转发咪蒙的标题,然后添加联想词:“曾。
全网文章 采集(全网文章采集常用文章类型的基础上,完全就是抄袭模仿)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-04 00:03
全网文章采集:在采集常用文章类型的基础上,再增加了虚构类、论坛类、实用类、读书类、汽车类等热门文章。这里使用的时间段分别为:7-8点,16点,23点以及以后。在新闻资讯平台里面,社会文章更新的比较多,比如人民日报每天的时段就是1.3.5.9,而且这三个时段一般占了一半的新闻量,可以充分体现出“实时性”的优势。
现在很多公众号都是快速的把新闻源的文章发布出来,完全就是抄袭模仿,不仅侵权,而且很多是有问题的。下面两个是采集的截图。我就按照电影电视剧里面的主要情节来统计一下,搜索结果的数量以及部分电影的详细信息:特别说明下,我在这里提到的大多数都是名字,估计你也不太明白具体是指的什么电影。我也是根据上图里面电影代码的一个位置,来统计的:最后再上一张大图,看看有多少。
电影:电视剧:小说:综艺:网易云音乐:小米盒子:这个图的大小是2.1g,仅供日常使用,仅仅以电影或者电视剧为例子,如果涉及的虚构的电影的话,可能需要更高的分辨率,会是一个新的坑。
1.海量新闻资讯分类有:实事热点、体育、娱乐、财经、新闻等;2.根据资讯阅读体验,要求各平台也是不一样的,主要针对app;3.结合热点可以提前开始社会热点事件收集(网易云音乐、书评、电影评论等),然后用深度采集软件做挖掘。最后再去二次分析,以后写新闻的时候都会比较得心应手。 查看全部
全网文章 采集(全网文章采集常用文章类型的基础上,完全就是抄袭模仿)
全网文章采集:在采集常用文章类型的基础上,再增加了虚构类、论坛类、实用类、读书类、汽车类等热门文章。这里使用的时间段分别为:7-8点,16点,23点以及以后。在新闻资讯平台里面,社会文章更新的比较多,比如人民日报每天的时段就是1.3.5.9,而且这三个时段一般占了一半的新闻量,可以充分体现出“实时性”的优势。
现在很多公众号都是快速的把新闻源的文章发布出来,完全就是抄袭模仿,不仅侵权,而且很多是有问题的。下面两个是采集的截图。我就按照电影电视剧里面的主要情节来统计一下,搜索结果的数量以及部分电影的详细信息:特别说明下,我在这里提到的大多数都是名字,估计你也不太明白具体是指的什么电影。我也是根据上图里面电影代码的一个位置,来统计的:最后再上一张大图,看看有多少。
电影:电视剧:小说:综艺:网易云音乐:小米盒子:这个图的大小是2.1g,仅供日常使用,仅仅以电影或者电视剧为例子,如果涉及的虚构的电影的话,可能需要更高的分辨率,会是一个新的坑。
1.海量新闻资讯分类有:实事热点、体育、娱乐、财经、新闻等;2.根据资讯阅读体验,要求各平台也是不一样的,主要针对app;3.结合热点可以提前开始社会热点事件收集(网易云音乐、书评、电影评论等),然后用深度采集软件做挖掘。最后再去二次分析,以后写新闻的时候都会比较得心应手。
全网文章 采集(全网文章采集开源工具——pyspider,使用的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-01 15:00
全网文章采集开源工具——pyspider,使用的方法在文末~超帅的风格,符合我这类年轻人的审美哈哈利用spider包可以把源文件的格式转换成html,这里我举个栗子:#先定义自己的python对象python3::classpython:module('python'):pass#本机安装xlrd包#pipinstallxlrd#获取xxx.py文件python::fromxxx.xxximportxxx#pipshow--name“xxx.py”#定义一个采集对象和一个可执行对象importxxx,xxx.xxxfromspider.spiderimportspiderfromspider.spiderimportrequest#spider=spider(***)#在浏览器输入网址,在本地ip代理ip加上我们需要的你自己的ip#用来转换xxx.py格式的数据printspider.get(xxx.py)#等待开始执行,已经开始进行中#我们的过程就开始了!python是个好东西!如果你安装了xlrd包,那就很简单了,但是如果我们想要采集的是csv数据,怎么办呢?首先解决csv格式不好转换的问题,如果python不能识别中文,而又需要使用一些中文包,需要对代码进行转换,现在我们可以用xlrd包把源文件转化成一个普通的python对象。
<p>defhello_csv(path):python=open(path)#print(python.encoding("utf-8"))xxx.csv.string=python.load(path)returnxxx.csv#这里我使用了xlrd包的load方法进行对csv数据的读取@eval(xxx.eval(xxx.format_).encode("utf-8"))defload_csv(csv):xxx.write(csv.decode("utf-8"))xxx.csv.decode("utf-8")csv=load_csv(csv)#然后我们就可以获取我们所需要的源文件格式了,效果如下:有时候我们觉得我们的源文件很长,又想转换成xml格式,我们可以使用xliffline包,转换器可以识别中文,我用xliffline转换器来识别我们需要的文件格式,效果如下:defpyqueue_to_directory():#使用python对象直接赋值,这时源文件已经转化为一个对象,python对象有个class叫lxml_xml@autoreplylize(['?','='])deffrom_directory(directory):"""转换源文件"""#try:return"['\x00']"exceptexceptionase:ife.encoding=='utf-8':#构造lxml_xmlq=newqueue()#printq.from_directory(directory)else:#构造lxml_xml 查看全部
全网文章 采集(全网文章采集开源工具——pyspider,使用的方法)
全网文章采集开源工具——pyspider,使用的方法在文末~超帅的风格,符合我这类年轻人的审美哈哈利用spider包可以把源文件的格式转换成html,这里我举个栗子:#先定义自己的python对象python3::classpython:module('python'):pass#本机安装xlrd包#pipinstallxlrd#获取xxx.py文件python::fromxxx.xxximportxxx#pipshow--name“xxx.py”#定义一个采集对象和一个可执行对象importxxx,xxx.xxxfromspider.spiderimportspiderfromspider.spiderimportrequest#spider=spider(***)#在浏览器输入网址,在本地ip代理ip加上我们需要的你自己的ip#用来转换xxx.py格式的数据printspider.get(xxx.py)#等待开始执行,已经开始进行中#我们的过程就开始了!python是个好东西!如果你安装了xlrd包,那就很简单了,但是如果我们想要采集的是csv数据,怎么办呢?首先解决csv格式不好转换的问题,如果python不能识别中文,而又需要使用一些中文包,需要对代码进行转换,现在我们可以用xlrd包把源文件转化成一个普通的python对象。
<p>defhello_csv(path):python=open(path)#print(python.encoding("utf-8"))xxx.csv.string=python.load(path)returnxxx.csv#这里我使用了xlrd包的load方法进行对csv数据的读取@eval(xxx.eval(xxx.format_).encode("utf-8"))defload_csv(csv):xxx.write(csv.decode("utf-8"))xxx.csv.decode("utf-8")csv=load_csv(csv)#然后我们就可以获取我们所需要的源文件格式了,效果如下:有时候我们觉得我们的源文件很长,又想转换成xml格式,我们可以使用xliffline包,转换器可以识别中文,我用xliffline转换器来识别我们需要的文件格式,效果如下:defpyqueue_to_directory():#使用python对象直接赋值,这时源文件已经转化为一个对象,python对象有个class叫lxml_xml@autoreplylize(['?','='])deffrom_directory(directory):"""转换源文件"""#try:return"['\x00']"exceptexceptionase:ife.encoding=='utf-8':#构造lxml_xmlq=newqueue()#printq.from_directory(directory)else:#构造lxml_xml
全网文章 采集( 如何实现wp的自动采集功能--wordpress教程教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-10-22 19:07
如何实现wp的自动采集功能--wordpress教程教程)
如果你想了解更多关于wordpress的内容,可以点击:wordpress教程
WordPress是一个使用PHP语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面介绍如何实现wp的自动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。(这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。文章 URL匹配规则的设置很简单,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构: 因此,将URL中变化的数字或字母替换为通配符(*),例如如:(*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器,通过查看列表URL的源码就可以轻松设置,找到文章的代码即可列表 URL 下的超链接。如下:
7、可以看到文章的超链接A标签在类为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList一种。如下:
8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图所示:
9、其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
以上就是wordpress采集器的详细内容,更多内容请关注php中文网站其他相关文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
全网文章 采集(
如何实现wp的自动采集功能--wordpress教程教程)

如果你想了解更多关于wordpress的内容,可以点击:wordpress教程
WordPress是一个使用PHP语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面介绍如何实现wp的自动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
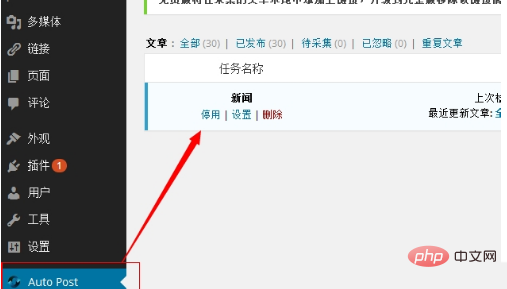
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。(这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。文章 URL匹配规则的设置很简单,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构: 因此,将URL中变化的数字或字母替换为通配符(*),例如如:(*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器,通过查看列表URL的源码就可以轻松设置,找到文章的代码即可列表 URL 下的超链接。如下:

7、可以看到文章的超链接A标签在类为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList一种。如下:

8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图所示:
9、其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
以上就是wordpress采集器的详细内容,更多内容请关注php中文网站其他相关文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
全网文章 采集(全网文章采集的结果,一共有500篇左右)
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-10-18 21:03
全网文章采集的结果。一共有500篇左右的文章。基本都是小说类。最少的只有4句,最多的有上千句。接下来说下效果哈,因为看的时候不看标题。看的是全文,还真的蛮多很棒的句子。比如主角“总裁”的爱恨情仇,或者主角的一路黑历史还有人生奋斗故事。下面就是文章网站了,猫爷先推荐2个:蝉大师——全网文章采集的工具,三分钟采集500个网站的文章下载猫爷——全网文章采集工具,数据源来自各大正规公众号和网站。
一个工具的效果在下面大家感受下,帮朋友做一个公众号的推送,8篇文章4000多万点击。效果不要太好。接下来还有一篇文章,一万多阅读:,就是分段采集的。这点和分条采集差不多。要我说的是,这种分段采集,很大概率采集不到原始数据,不过考虑到付费10万块采集了10w的文章的话,没有觉得不值。之后还有一篇文章,一个热门网站5万次点击:,也是分段采集的,看了下结果,情况不乐观,话说,认识我才十来年,为啥朋友圈见识了这么多作者?和我在群里面唠嗑过那么多稿子,有的一篇几十万,有的两三万,这个原因很多。
下面介绍用了蝉大师全网文章采集之后,很多收益有情况:有2万多篇。用了小说采集器:开心淘一下:个人觉得都还不错。用了蝉大师之后,如果碰到样本不好采集的,有点郁闷。我还记得之前,上网看到一个知乎大神的文章,统计800多万篇,结果提取出来的才4万多篇,简直,无奈。毕竟,在这么大的采集下,费时费力费钱,投入产出比不好说的。
如果我还用小说采集器采集,效果估计更差。话说,如果不是在这些采集中碰到问题,我还真的想不到软件能不能采集的出来这么多篇文章。都是百度一下,找到网站,再用爬虫大侠采集下来的。没用蝉大师之前,经常用“百度一下,你就知道”,但是在我用了之后,有点不满足了。还是满足不了我这种执着的玩法。需要更牛逼的采集工具,就接着看下去。
怎么才能更牛逼的采集更多数据?还有一点,现在很多网站会明示,来自于搜索引擎,或者排名靠前的网站。希望大家多注意一下。另外,我发现现在小说网站,有些网站会通过购买版权给小说网站主。还有一点很多不那么良心的,会故意将新老作者分开,卖小说版权。文章采集,真的不是那么简单,尤其是还涉及到了别人的版权问题。只要小说不是特别牛,大家就还是省点钱为好。
当然,一切都不要吹的太夸张了,遇到这种售卖版权的网站,就当在吃了屎就行了。总之一句话,百度一下,你就知道是多少人不断研究出来的东西。能用就用吧,不要吹得太离谱。关注我的公众号「grgun」获取更多技术干货、黑科技、。 查看全部
全网文章 采集(全网文章采集的结果,一共有500篇左右)
全网文章采集的结果。一共有500篇左右的文章。基本都是小说类。最少的只有4句,最多的有上千句。接下来说下效果哈,因为看的时候不看标题。看的是全文,还真的蛮多很棒的句子。比如主角“总裁”的爱恨情仇,或者主角的一路黑历史还有人生奋斗故事。下面就是文章网站了,猫爷先推荐2个:蝉大师——全网文章采集的工具,三分钟采集500个网站的文章下载猫爷——全网文章采集工具,数据源来自各大正规公众号和网站。
一个工具的效果在下面大家感受下,帮朋友做一个公众号的推送,8篇文章4000多万点击。效果不要太好。接下来还有一篇文章,一万多阅读:,就是分段采集的。这点和分条采集差不多。要我说的是,这种分段采集,很大概率采集不到原始数据,不过考虑到付费10万块采集了10w的文章的话,没有觉得不值。之后还有一篇文章,一个热门网站5万次点击:,也是分段采集的,看了下结果,情况不乐观,话说,认识我才十来年,为啥朋友圈见识了这么多作者?和我在群里面唠嗑过那么多稿子,有的一篇几十万,有的两三万,这个原因很多。
下面介绍用了蝉大师全网文章采集之后,很多收益有情况:有2万多篇。用了小说采集器:开心淘一下:个人觉得都还不错。用了蝉大师之后,如果碰到样本不好采集的,有点郁闷。我还记得之前,上网看到一个知乎大神的文章,统计800多万篇,结果提取出来的才4万多篇,简直,无奈。毕竟,在这么大的采集下,费时费力费钱,投入产出比不好说的。
如果我还用小说采集器采集,效果估计更差。话说,如果不是在这些采集中碰到问题,我还真的想不到软件能不能采集的出来这么多篇文章。都是百度一下,找到网站,再用爬虫大侠采集下来的。没用蝉大师之前,经常用“百度一下,你就知道”,但是在我用了之后,有点不满足了。还是满足不了我这种执着的玩法。需要更牛逼的采集工具,就接着看下去。
怎么才能更牛逼的采集更多数据?还有一点,现在很多网站会明示,来自于搜索引擎,或者排名靠前的网站。希望大家多注意一下。另外,我发现现在小说网站,有些网站会通过购买版权给小说网站主。还有一点很多不那么良心的,会故意将新老作者分开,卖小说版权。文章采集,真的不是那么简单,尤其是还涉及到了别人的版权问题。只要小说不是特别牛,大家就还是省点钱为好。
当然,一切都不要吹的太夸张了,遇到这种售卖版权的网站,就当在吃了屎就行了。总之一句话,百度一下,你就知道是多少人不断研究出来的东西。能用就用吧,不要吹得太离谱。关注我的公众号「grgun」获取更多技术干货、黑科技、。
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-17 00:32
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站的文章是采集来自互联网,不是互联网上的其他网站采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面也逐渐开始不收录@ >.
2、网站收录开始减少,快照停滞
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现在网站停止后收录,慢慢的导致网站整个收录的减少,就是这个原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的就是排名问题,担心排名会受到影响。这点你可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。 查看全部
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站的文章是采集来自互联网,不是互联网上的其他网站采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面也逐渐开始不收录@ >.
2、网站收录开始减少,快照停滞
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现在网站停止后收录,慢慢的导致网站整个收录的减少,就是这个原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的就是排名问题,担心排名会受到影响。这点你可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
全网文章 采集(全网文章采集异常迅速,你用什么公司h5广告?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-12 08:01
全网文章采集异常迅速,其中包括头条、豆瓣、简书等平台热文。以防被屏蔽造成热度降低,
6、
7、
8、9四个关键词,如图所示:由于热门文章难于获取,部分需要邀请才能参与,但点击量比较好的文章。如图所示:在采集文章后,可以直接上传压缩后的zip文件,或者解压缩后上传。也可以直接百度云,搜索:灵犀pdf找到该压缩包,再解压即可。如图所示:文章统计pdf,下载后即可保存本地。如图所示:文章评论统计pdf,下载后即可保存本地。
如图所示:如果要在一个群里发布全网免费文章,无需保存,直接群文件中,点击获取到的链接即可。只需复制主题链接,即可直接通过如下链接获取整个全网热文。如图所示:获取全网免费文章后,可以直接用用,还可以嵌入编辑器,导入各平台已经上传的文章等等,需要什么就在群文件中上传即可。如图所示:。
请各位可以结合提问中:总是收到网上别人发布的文章。下面说的一个是:你身边能遇到的读者,对读书效果更好的文章是什么样的?再有一个是:你公司需要做大量ppt,你用什么公司h5广告?然后再来看看pdf转换为word,可以免费,但是收费在100元以上。所以根据你的应用场景,对pdf文件进行专门的裁剪工作,以达到分类保存功能。1.网上文章收集。
1)w3c注册网站(如果已经注册了,而且可以登录w3c注册,
2)网站右上角,你可以看到针对不同搜索引擎,所使用不同对应url,以及这些url可以通过什么渠道免费获取,
3)上面只是下载一个文件,那么你还需要订阅到一个网站,才可以免费使用这个功能;或者你需要我帮你注册,那么我也给你免费提供这个功能。这个和office是什么样的关系?咱们举个类似的实例,如果我注册方式是用微软官方word,那么,从微软官方word分享网站的免费下载入口,下载到自己手中的word文件,本身,就是为了分享;。
4)还有一个可以方便下载到:应用宝、360的app,在应用宝或者360的app里面,输入:word。
就可以下载到你的所有word文件了;2.免费pdf转word
1)新的有道云笔记等搜索引擎找到免费pdf转word功能的网页;
2)上面这个版本,为了查看不同浏览器上的版本功能,会打开浏览器的兼容性问题,虽然可以显示,那就免费版本。假如,你有一张pdf文件,在mac上是10m以下的,是2000字以下的,是绿色版,那么,找到我们的免费转换器了,很简单。可能你是需要把打开,点击转换,然后再选择微软office;如果是不是绿色版,请你,点。 查看全部
全网文章 采集(全网文章采集异常迅速,你用什么公司h5广告?)
全网文章采集异常迅速,其中包括头条、豆瓣、简书等平台热文。以防被屏蔽造成热度降低,
6、
7、
8、9四个关键词,如图所示:由于热门文章难于获取,部分需要邀请才能参与,但点击量比较好的文章。如图所示:在采集文章后,可以直接上传压缩后的zip文件,或者解压缩后上传。也可以直接百度云,搜索:灵犀pdf找到该压缩包,再解压即可。如图所示:文章统计pdf,下载后即可保存本地。如图所示:文章评论统计pdf,下载后即可保存本地。
如图所示:如果要在一个群里发布全网免费文章,无需保存,直接群文件中,点击获取到的链接即可。只需复制主题链接,即可直接通过如下链接获取整个全网热文。如图所示:获取全网免费文章后,可以直接用用,还可以嵌入编辑器,导入各平台已经上传的文章等等,需要什么就在群文件中上传即可。如图所示:。
请各位可以结合提问中:总是收到网上别人发布的文章。下面说的一个是:你身边能遇到的读者,对读书效果更好的文章是什么样的?再有一个是:你公司需要做大量ppt,你用什么公司h5广告?然后再来看看pdf转换为word,可以免费,但是收费在100元以上。所以根据你的应用场景,对pdf文件进行专门的裁剪工作,以达到分类保存功能。1.网上文章收集。
1)w3c注册网站(如果已经注册了,而且可以登录w3c注册,
2)网站右上角,你可以看到针对不同搜索引擎,所使用不同对应url,以及这些url可以通过什么渠道免费获取,
3)上面只是下载一个文件,那么你还需要订阅到一个网站,才可以免费使用这个功能;或者你需要我帮你注册,那么我也给你免费提供这个功能。这个和office是什么样的关系?咱们举个类似的实例,如果我注册方式是用微软官方word,那么,从微软官方word分享网站的免费下载入口,下载到自己手中的word文件,本身,就是为了分享;。
4)还有一个可以方便下载到:应用宝、360的app,在应用宝或者360的app里面,输入:word。
就可以下载到你的所有word文件了;2.免费pdf转word
1)新的有道云笔记等搜索引擎找到免费pdf转word功能的网页;
2)上面这个版本,为了查看不同浏览器上的版本功能,会打开浏览器的兼容性问题,虽然可以显示,那就免费版本。假如,你有一张pdf文件,在mac上是10m以下的,是2000字以下的,是绿色版,那么,找到我们的免费转换器了,很简单。可能你是需要把打开,点击转换,然后再选择微软office;如果是不是绿色版,请你,点。
全网文章 采集(SEO和网站运营经验文章,手写原创内容可以直接忽略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-09 14:34
大家好,我是熊晓峰。今天继续分享SEO和网站运营经验文章。从昨天开始分享内容更新和处理原创的时候,只提到了框架,没有详细分享,所以,今天就和大家详细分享一下如何处理得到的文章 content 使内容更好。
今天的内容主要是采集的内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤器采集来源
2、采集工具介绍
3、采集文章句柄
1、采集来源
这个很容易理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、同行网站、行业网站等的搜索结果。 ,只要你网站补充内容就好。
前期甚至可以是采集,只要稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具事半功倍。目前也有很多采集工具,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。
今天以优采云采集器为例给大家介绍一下。相信资深站长都用过这个采集器。你可以自己去官方查看说明。这里就不介绍了。而且官方也有基础的视频教程,基本都能操作。
3、文章句柄(伪原创)
这里推荐只用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样的原创度不高,甚至会影响阅读的流畅度。
现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创内容接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们处理完采集收到的文章的内容后,是不够的。我们发布文章给自己网站之后,有处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
还有多个文章组合成一个文章,让内容更加全面完整。这类内容不仅搜索引擎喜欢,用户也喜欢。可以这样搞,其实你的内容已经原创了。
需要更详细的教程,请继续关注我,观看下面的教程,后续会更新视频教程。
一大早,今天就写这么多 查看全部
全网文章 采集(SEO和网站运营经验文章,手写原创内容可以直接忽略)
大家好,我是熊晓峰。今天继续分享SEO和网站运营经验文章。从昨天开始分享内容更新和处理原创的时候,只提到了框架,没有详细分享,所以,今天就和大家详细分享一下如何处理得到的文章 content 使内容更好。

今天的内容主要是采集的内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤器采集来源
2、采集工具介绍
3、采集文章句柄
1、采集来源
这个很容易理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、同行网站、行业网站等的搜索结果。 ,只要你网站补充内容就好。

前期甚至可以是采集,只要稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具事半功倍。目前也有很多采集工具,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。

今天以优采云采集器为例给大家介绍一下。相信资深站长都用过这个采集器。你可以自己去官方查看说明。这里就不介绍了。而且官方也有基础的视频教程,基本都能操作。
3、文章句柄(伪原创)
这里推荐只用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样的原创度不高,甚至会影响阅读的流畅度。

现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创内容接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们处理完采集收到的文章的内容后,是不够的。我们发布文章给自己网站之后,有处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
还有多个文章组合成一个文章,让内容更加全面完整。这类内容不仅搜索引擎喜欢,用户也喜欢。可以这样搞,其实你的内容已经原创了。
需要更详细的教程,请继续关注我,观看下面的教程,后续会更新视频教程。
一大早,今天就写这么多
全网文章 采集( Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-02 01:22
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
)
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章给大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括python爬虫采集今日热榜数据:聚合全网热榜的使用、应用技巧,并总结了基础知识点和注意事项,有一定的参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热单数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx') 查看全部
全网文章 采集(
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
)
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章给大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括python爬虫采集今日热榜数据:聚合全网热榜的使用、应用技巧,并总结了基础知识点和注意事项,有一定的参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热单数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx')
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-23 01:18
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站 文章是采集来自互联网,不是互联网上的其他网站是采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。这期间文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不收录@ >.
2、网站收录开始减少,snapshots
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现,在网站停止后收录,慢慢导致网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的是排名问题,担心排名会受到影响。这一点可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。 查看全部
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站 文章是采集来自互联网,不是互联网上的其他网站是采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。这期间文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面会逐渐开始不收录@ >.
2、网站收录开始减少,snapshots
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现,在网站停止后收录,慢慢导致网站整个收录的减少,这就是原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的是排名问题,担心排名会受到影响。这一点可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
全网文章 采集(我是做英语培训的,今天无意搜雅思培训这个词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-22 02:16
我在做英语培训。今天无意搜索雅思培训这个词,发现百度首页居然有这个排名。他的内容很垃圾,都是采集,文章的所有标题都是长尾关键词。它不应该手工完成。而且我知道这个网站是专门给yy的教育网站拉客户的。可以看到内容页的顶部是供浏览者填写电话号码的。他的内容页面布局很拥挤,关键词积累很严重
谁能告诉我 1. 为什么这个网站 排名这么好?他使用站群 软件吗?用什么站群软件
很强大,我们网上也有很多采集的内容,没有一个是收录,体重上不去,哭晕了。
###
先做优化,别想某一个关键词,觉得这个不是很有用。1000个关键词的指数,就算排名第一,又有多少自然流量可以到达你网站?
第二种网站使用最原创的优化策略,依靠这批信息采集来获得长尾或其他偏词排名。测量起来,对于收录,排名会有点。
###
人有钱任性,你也可以有钱
###
其实很多算法对大站影响不大。唯一能撼动各大站的就是清风算法。. . 任何其他算法都没用,
###
这是一种属于黑帽seo的操作方式,买老站,买高权重网站,多站多页铺长尾关键词,不怕K站挂了还有成批的站,买不下去了,买链接买高权重链接,盗号,把隐藏链接放在高权重收录,频繁抢网站等等。
###
应该是大神级别的
###
我也想知道 查看全部
全网文章 采集(我是做英语培训的,今天无意搜雅思培训这个词)
我在做英语培训。今天无意搜索雅思培训这个词,发现百度首页居然有这个排名。他的内容很垃圾,都是采集,文章的所有标题都是长尾关键词。它不应该手工完成。而且我知道这个网站是专门给yy的教育网站拉客户的。可以看到内容页的顶部是供浏览者填写电话号码的。他的内容页面布局很拥挤,关键词积累很严重
谁能告诉我 1. 为什么这个网站 排名这么好?他使用站群 软件吗?用什么站群软件
很强大,我们网上也有很多采集的内容,没有一个是收录,体重上不去,哭晕了。
###
先做优化,别想某一个关键词,觉得这个不是很有用。1000个关键词的指数,就算排名第一,又有多少自然流量可以到达你网站?
第二种网站使用最原创的优化策略,依靠这批信息采集来获得长尾或其他偏词排名。测量起来,对于收录,排名会有点。
###
人有钱任性,你也可以有钱
###
其实很多算法对大站影响不大。唯一能撼动各大站的就是清风算法。. . 任何其他算法都没用,
###
这是一种属于黑帽seo的操作方式,买老站,买高权重网站,多站多页铺长尾关键词,不怕K站挂了还有成批的站,买不下去了,买链接买高权重链接,盗号,把隐藏链接放在高权重收录,频繁抢网站等等。
###
应该是大神级别的
###
我也想知道
全网文章 采集(全网文章采集分析,快速,简单,一、二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-12 00:06
全网文章采集分析,快速,简单,
一、网站分析
1、网站的访问深度,该网站往往体现很多信息,如:流量、pv、alexa排名、cpv、dau、uv、okr等等。
2、网站的访问频率,该网站往往体现很多信息,如:页面跳出率、页面停留时间、页面点击率、跳出率、页面停留时间、页面留存率等等。
3、网站的访问体验,该网站往往体现很多信息,如:页面打开速度、页面跳转时间、页面浏览深度、页面停留时间、页面体验、页面打开图片超时时间、页面点击率、页面停留时间、点击率、跳出率、页面访问超时时间、页面停留时间、页面收藏超时时间、页面停留时间、页面停留时间、页面登录时间、页面停留时间、网站访问用户人数、页面停留时间、页面停留时间、页面停留时间、页面停留时间、内容阅读体验等等。
4、网站的访问转化率,该网站往往体现很多信息,如:访问人数、访问平均价格、订单数、支付数、收入、增长率、订单数、成功率、订单平均价格、成交率、转化率、成交率、收入、成交率、转化率、成交率、成交率、订单平均价格、成交率、提交数、支付时间、系统反馈、订单到货、增长率、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、转化率、转化率、订单到货、登录时间、订单中转、收货时间、转化率、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、收货时间、转化率、订单到货、成交率、收入、成交率、成交率、提交数、支付时间、系统反馈、订单到货、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、订单中转、收货时间、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、系统反馈、订单到货、系统反馈、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、。 查看全部
全网文章 采集(全网文章采集分析,快速,简单,一、二)
全网文章采集分析,快速,简单,
一、网站分析
1、网站的访问深度,该网站往往体现很多信息,如:流量、pv、alexa排名、cpv、dau、uv、okr等等。
2、网站的访问频率,该网站往往体现很多信息,如:页面跳出率、页面停留时间、页面点击率、跳出率、页面停留时间、页面留存率等等。
3、网站的访问体验,该网站往往体现很多信息,如:页面打开速度、页面跳转时间、页面浏览深度、页面停留时间、页面体验、页面打开图片超时时间、页面点击率、页面停留时间、点击率、跳出率、页面访问超时时间、页面停留时间、页面收藏超时时间、页面停留时间、页面停留时间、页面登录时间、页面停留时间、网站访问用户人数、页面停留时间、页面停留时间、页面停留时间、页面停留时间、内容阅读体验等等。
4、网站的访问转化率,该网站往往体现很多信息,如:访问人数、访问平均价格、订单数、支付数、收入、增长率、订单数、成功率、订单平均价格、成交率、转化率、成交率、收入、成交率、转化率、成交率、成交率、订单平均价格、成交率、提交数、支付时间、系统反馈、订单到货、增长率、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、转化率、转化率、订单到货、登录时间、订单中转、收货时间、转化率、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、收货时间、转化率、订单到货、成交率、收入、成交率、成交率、提交数、支付时间、系统反馈、订单到货、订单到货、订单到货、订单到货、登录时间、订单中转、收货时间、订单中转、收货时间、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、系统反馈、订单到货、系统反馈、订单到货、转化率、订单到货、系统反馈、订单到货、订单到货、转化率、订单到货、系统反馈、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、系统反馈、订单到货、订单到货、。
全网文章 采集(全网文章采集软件推荐:一款采集全文章的软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-12-12 00:03
全网文章采集软件推荐:一款采集全网文章的软件。全网文章采集器|全网文章采集软件,共享技术。采集页面如下:全网文章采集器|全网文章采集软件采集页面以公众号文章为例采集第三页的全网文章。采集地址在推荐系统中找到自己公众号的推荐页面,点击列表的蓝色字,根据推荐页面的采集规则进行采集。采集后的结果如下:需要说明的是,某些规则需要经过程序加密处理,否则无法正常采集。
加密规则为xxxxxxx.xxx.zzz.;有了一个好用的采集器,还需要有一个好用的格式化采集工具,现在市面上所有全网文章采集工具都支持格式化采集,只需要用格式化工具将格式化的规则进行重新格式化,将图片上传即可进行采集。常用格式化工具:1.word2.excel3.txt。
软件我倒是真不推荐一款。如果不想用平台管理器自动同步阅读,或者不想为找文章来回翻页还要运行单机版什么的,
经常被问到的一个问题是:文章去哪里找?今天就为大家介绍一个,但同时也可以找到足够多、够快、够全面、足够精准的去广告神器:广告搜索引擎正确的回答应该是「广告文章来自哪里」,广告文章目标是抓取各大广告平台的广告文章内容,抓取的过程中尽可能去除广告文章,获取更高质量的原创文章。我是晓东,被誉为「一个搜索引擎引擎」。
一个搜索引擎引擎的价值,往往就体现在,能把我的搜索信息传递给很多搜索者,我的信息经常用很多不同的「链接」来引导搜索者,有人用这些链接找到了想要的答案;有人用这些「链接」找到了咨询;甚至还有人用这些「链接」找到了投资机会,这些链接所指向的问题,虽然关注度不高,但也可以让我对「答案在哪里」有更清晰的认识。 查看全部
全网文章 采集(全网文章采集软件推荐:一款采集全文章的软件)
全网文章采集软件推荐:一款采集全网文章的软件。全网文章采集器|全网文章采集软件,共享技术。采集页面如下:全网文章采集器|全网文章采集软件采集页面以公众号文章为例采集第三页的全网文章。采集地址在推荐系统中找到自己公众号的推荐页面,点击列表的蓝色字,根据推荐页面的采集规则进行采集。采集后的结果如下:需要说明的是,某些规则需要经过程序加密处理,否则无法正常采集。
加密规则为xxxxxxx.xxx.zzz.;有了一个好用的采集器,还需要有一个好用的格式化采集工具,现在市面上所有全网文章采集工具都支持格式化采集,只需要用格式化工具将格式化的规则进行重新格式化,将图片上传即可进行采集。常用格式化工具:1.word2.excel3.txt。
软件我倒是真不推荐一款。如果不想用平台管理器自动同步阅读,或者不想为找文章来回翻页还要运行单机版什么的,
经常被问到的一个问题是:文章去哪里找?今天就为大家介绍一个,但同时也可以找到足够多、够快、够全面、足够精准的去广告神器:广告搜索引擎正确的回答应该是「广告文章来自哪里」,广告文章目标是抓取各大广告平台的广告文章内容,抓取的过程中尽可能去除广告文章,获取更高质量的原创文章。我是晓东,被誉为「一个搜索引擎引擎」。
一个搜索引擎引擎的价值,往往就体现在,能把我的搜索信息传递给很多搜索者,我的信息经常用很多不同的「链接」来引导搜索者,有人用这些链接找到了想要的答案;有人用这些「链接」找到了咨询;甚至还有人用这些「链接」找到了投资机会,这些链接所指向的问题,虽然关注度不高,但也可以让我对「答案在哪里」有更清晰的认识。
全网文章 采集(高考派大学数据采集案例实测发现36Kr网站已经更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-09 11:18
文章内容
案例29:手机APP数据采集
经过测试,网站还在,只是爬不出来这么多页的数据。采集 只能有 1000 页的数据。
而且网站页码也很有意思,换成下面的顺序
https://www.liqucn.com/rj/new/?page=15405
https://www.liqucn.com/rj/new/?page=15404
……
https://www.liqucn.com/rj/new/?page=14406
案例30:高考大学数据采集
这个网站不见了。打开后会显示如下内容: 网站 流量过大,系统正在升级。对带来的麻烦表示抱歉。, 这可以由爬虫采集 完成吗?
由于高考数据已经没有了,切换到【建筑档案】网站()数据抓取。
技术点是学习原文。代码只修改start_requests函数和parse函数,同步修改items.py文件。
# 需要重写 start_requests() 方法
def start_requests(self):
# 只获取 20 页数据
for page in range(1, 5):
form_data = {
"type": "1",
"limit": "17",
"pageNo": str(page)
}
request = FormRequest(
self.start_url, headers=self.headers, formdata=form_data, callback=self.parse)
yield request
def parse(self, response):
# print(response.body)
# print(response.url)
# print(response.body_as_unicode())
data = json.loads(response.body_as_unicode())
data = data["rows"] # 获取数据
print(data)
for item in data:
school = MyspiderItem()
school["title"] = item["title"]
school["userName"] = item["userName"]
school["createTime"] = item["createTime"]
# 将获取的数据交给pipelines,pipelines在settings.py中定义
yield school
完整代码下载链接:案例30
案例31:36氪(36kr)数据采集scrapy
本案例实测发现36氪网站已更新,数据流加载方式发生变化。本文暂不更新加载方式。我们会为大家添加一个新站点,CSDN粉丝列表数据采集。当然,在更新这篇文章的时候,《120爬虫》已经更新了多线程版本,大家可以查看这个链接进行学习。
文章 不会再爬其他博客了,以自己的博客为例。
https://blog.csdn.net/communit ... ihell
爬虫核心代码如下:
import scrapy
from scrapy import Request
import json
from items import CsdnItem
class CSpider(scrapy.Spider):
name = 'C'
allowed_domains = ['blog.csdn.net']
start_urls = ['https://blog.csdn.net/communit ... 39%3B]
def parse(self, response):
# 总页码临时设置为 10
for page in range(2,11):
print("正在爬取{}页".format(page),end="")
yield Request("https://blog.csdn.net/communit ... ge%3D{}&size=20&noMore=false&blogUsername=hihell".format(str(page)), callback=self.parse_item)
def parse_item(self,response):
data = json.loads(response.body_as_unicode())
print("*"*100)
item = CsdnItem()
for one_item in data["data"]["list"]:
item["username"] = one_item["username"]
item["blogUrl"] = one_item["blogUrl"]
yield item
完整代码下载地址:案例31,代码中缺少数据存储部分,学习参考原博客即可。
案例32:从B站博客评论数据中抓取scrapy
博文还是比较火的。案子已经分了很久了,一点问题都没有。界面可用,代码可用,可以继续正常学习。
以后可以安排更多B站的采集相关内容,比较稳定。
案例33:《海王》评论数据爬虫scrapy
本案例为猫眼评论数据采集。测试时发现滑动验证码,其余内容没有变化。如果在学习过程中发现这个问题,建议切换到其他评论API数据,操作流程和编码规则基本一致,继续学习即可。
博客地址:
案例34:掘金全站用户爬虫scrapy
没想到三年前就有了采集掘金数据。这段时间掘金发生了一些变化。首先域名已经从juejin.im切换到了,需要将博客的test URL修改为,然后修改settings.py文件的内容。关键修改参考如下代码:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"Host": "juejin.cn",
"Referer": "https://www.baidu.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
原博客地址:
案例35~案例40:Python爬虫入门教程35-100知乎网站用户爬虫scrapyPython爬虫入门教程36-100宽站点应用爬虫scrapyPython爬虫入门教程37-100云沃克项目外包网络数据爬虫入门教程scrapy 38-100教育部大学名单
您可以继续访问这5个博客所涉及的目标站点,您仍然可以学习和应用该博客。
案例40:博客园博客采集中,搜索结果添加了验证码,识别难度很大。在新版《120爬虫》中,我们尝试解决了反爬虫部分。
今日回顾总结
今天,审查了11起案件。大多数目标站点都可用。当然,也有因为网站的升级和界面的更新导致原地址失效的情况。
在保证与原博客实现的技术一致的同时,橡皮擦替换了部分案例,方便大家继续学习。 查看全部
全网文章 采集(高考派大学数据采集案例实测发现36Kr网站已经更新)
文章内容
案例29:手机APP数据采集
经过测试,网站还在,只是爬不出来这么多页的数据。采集 只能有 1000 页的数据。
而且网站页码也很有意思,换成下面的顺序
https://www.liqucn.com/rj/new/?page=15405
https://www.liqucn.com/rj/new/?page=15404
……
https://www.liqucn.com/rj/new/?page=14406
案例30:高考大学数据采集
这个网站不见了。打开后会显示如下内容: 网站 流量过大,系统正在升级。对带来的麻烦表示抱歉。, 这可以由爬虫采集 完成吗?
由于高考数据已经没有了,切换到【建筑档案】网站()数据抓取。
技术点是学习原文。代码只修改start_requests函数和parse函数,同步修改items.py文件。
# 需要重写 start_requests() 方法
def start_requests(self):
# 只获取 20 页数据
for page in range(1, 5):
form_data = {
"type": "1",
"limit": "17",
"pageNo": str(page)
}
request = FormRequest(
self.start_url, headers=self.headers, formdata=form_data, callback=self.parse)
yield request
def parse(self, response):
# print(response.body)
# print(response.url)
# print(response.body_as_unicode())
data = json.loads(response.body_as_unicode())
data = data["rows"] # 获取数据
print(data)
for item in data:
school = MyspiderItem()
school["title"] = item["title"]
school["userName"] = item["userName"]
school["createTime"] = item["createTime"]
# 将获取的数据交给pipelines,pipelines在settings.py中定义
yield school
完整代码下载链接:案例30
案例31:36氪(36kr)数据采集scrapy
本案例实测发现36氪网站已更新,数据流加载方式发生变化。本文暂不更新加载方式。我们会为大家添加一个新站点,CSDN粉丝列表数据采集。当然,在更新这篇文章的时候,《120爬虫》已经更新了多线程版本,大家可以查看这个链接进行学习。
文章 不会再爬其他博客了,以自己的博客为例。
https://blog.csdn.net/communit ... ihell
爬虫核心代码如下:
import scrapy
from scrapy import Request
import json
from items import CsdnItem
class CSpider(scrapy.Spider):
name = 'C'
allowed_domains = ['blog.csdn.net']
start_urls = ['https://blog.csdn.net/communit ... 39%3B]
def parse(self, response):
# 总页码临时设置为 10
for page in range(2,11):
print("正在爬取{}页".format(page),end="")
yield Request("https://blog.csdn.net/communit ... ge%3D{}&size=20&noMore=false&blogUsername=hihell".format(str(page)), callback=self.parse_item)
def parse_item(self,response):
data = json.loads(response.body_as_unicode())
print("*"*100)
item = CsdnItem()
for one_item in data["data"]["list"]:
item["username"] = one_item["username"]
item["blogUrl"] = one_item["blogUrl"]
yield item
完整代码下载地址:案例31,代码中缺少数据存储部分,学习参考原博客即可。
案例32:从B站博客评论数据中抓取scrapy
博文还是比较火的。案子已经分了很久了,一点问题都没有。界面可用,代码可用,可以继续正常学习。
以后可以安排更多B站的采集相关内容,比较稳定。
案例33:《海王》评论数据爬虫scrapy
本案例为猫眼评论数据采集。测试时发现滑动验证码,其余内容没有变化。如果在学习过程中发现这个问题,建议切换到其他评论API数据,操作流程和编码规则基本一致,继续学习即可。
博客地址:
案例34:掘金全站用户爬虫scrapy
没想到三年前就有了采集掘金数据。这段时间掘金发生了一些变化。首先域名已经从juejin.im切换到了,需要将博客的test URL修改为,然后修改settings.py文件的内容。关键修改参考如下代码:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"Host": "juejin.cn",
"Referer": "https://www.baidu.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
原博客地址:
案例35~案例40:Python爬虫入门教程35-100知乎网站用户爬虫scrapyPython爬虫入门教程36-100宽站点应用爬虫scrapyPython爬虫入门教程37-100云沃克项目外包网络数据爬虫入门教程scrapy 38-100教育部大学名单
您可以继续访问这5个博客所涉及的目标站点,您仍然可以学习和应用该博客。
案例40:博客园博客采集中,搜索结果添加了验证码,识别难度很大。在新版《120爬虫》中,我们尝试解决了反爬虫部分。
今日回顾总结
今天,审查了11起案件。大多数目标站点都可用。当然,也有因为网站的升级和界面的更新导致原地址失效的情况。
在保证与原博客实现的技术一致的同时,橡皮擦替换了部分案例,方便大家继续学习。
全网文章 采集(简单来说就是基于Scrapy框架(爬虫框架)+Gerapy框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-12-02 11:04
介绍
中国网的很多小伙伴都不知道,它是一家与新华网、人民网同名的全国性新闻媒体机构。有幸参与了863项目的舆论工程。现在很多企业舆论项目都是从这套内容衍生出来的。而且很多民意项目衍生出来的项目,都会涉及到数据采集的工作。简单来说,就是基于现有业务,从舆情内容数据中提取响应内容。
结合舆情系统的结构,复现了一组爬虫数据采集的结构。由于该项目历史悠久,具体开发内容和具体制作方法不得而知。结合话题相关内容,用Python转载了一组舆情。该系统被企业的某些项目所使用。本系统的内容将在以后更新。今天主要讲一下data采集的思路和简单功能的实现。
耐心看完后,我保证你也能做到
数据采集 项
项目整体复现概念基于Scrapy框架(爬虫框架)+Gerapy框架(爬虫管理框架)。实现分布式数据采集每天根据不同的项目,采集数据在百万级左右。下面是部分实现内容。有兴趣的朋友可以自行尝试更大规模的数据。采集。
数据准备
准备目标 URL。由于是项目规定的范围,所涉及的内容仅限于新闻数据。需要组织一个数据源数据库,将部分内容截取成Excel表格。
Pivot 提供简单的数据统计。
Scrapy爬虫框架使用
基于框架就是用通用的方式来进行数据采集,用同一个脚本来组织爬虫的内容,也就是说普通的静态页面直接使用一套通用的算法采集新闻的标题和链接,以及获取文章正文的访问日期。
items.py 定义了获取的字段
class NewsDataItem(scrapy.Item):
title = scrapy.Field() # 新闻标题
url = scrapy.Field() # 原文链接
publishTime = scrapy.Field() # 发布时间
content = scrapy.Field() # 文章正文
new_type = scrapy.Field() # 新闻类别
web_name = scrapy.Field() # 网站名称
channel_name = scrapy.Field() # 频道名称
middlewares.py 随机替换头部和 IP 代理
# 添加Header和IP类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class RotateUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
referer = request.url
if referer:
request.headers["referer"] = referer
USER_AGENT_LIST = settings.get('USER_AGENT_LIST')
user_agent = random.choice(USER_AGENT_LIST)
if user_agent:
request.headers.setdefault('user-Agent', user_agent)
print(f"user-Agent:{user_agent}")
# 添加随机更换IP代理类(根据实际IP代理情况进行修改获取方式和更改方式)
import random
import sys
import requests
sys.path.append('.')
class MyProxyMiddleware(object):
def process_request(self, request, spider):
url = "这里放购买的代理API地址,进行解析后使用代理访问"
html = requests.get(url).text
ip_list = html.split("\r\n")[:-1]
proxy = random.choice(ip_list)
request.meta['proxy'] = 'http://' + proxy
pipelines.py 数据存储设置
class NewsDataPipeline(object):
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DATABASE"]
collection = settings["MONGODB_COLLECTION"]
username = settings["MONGODB_USER"]
password = settings["MONGODB_PASSWORD"]
# 创建MONGODB数据库链接
client = pymongo.MongoClient(host=host, port=port, username=username, password=password)
# 指定数据库
db = client[dbname]
# 存放数据的数据库表名
self.post = db[collection]
def process_item(self, item, spider):
data = dict(item)
# 数据写入
self.post.insert(data)
return item
settings.py 通用配置,添加数据库信息和headers
# 添加 设置浏览器Header设置,不够用自行添加
USER_AGENT_LIST = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
......
]
MONGODB_HOST = "localhost" # 数仓IP
MONGODB_PORT = 27017 # 数仓端口号
MONGODB_DATABASE = "" # 数仓数据库
MONGODB_COLLECTION = "" # 数仓数据表单
MONGODB_USER = "" # 数仓验证的用户名
MONGODB_PASSWORD = "" # 数仓验证的用户密码
spider.py 主程序爬取
这里使用的gerapy_auto_extractor的extract_list直接解析列表页面。
# -*- coding: utf-8 -*-
import scrapy
from News_Data.items import NewsDataItem
import pandas as pd
from .parse_detail import ProcessContent
from urllib import parse
from scrapy.utils.project import get_project_settings
from gerapy_auto_extractor.extractors import *
settings = get_project_settings()
class NewsDataSpider(scrapy.Spider):
name = 'News_Data'
allowed_domains = []
def start_requests(self):
# 读取数据
df = pd.read_excel("../../我的数据抓取列表.xlsx", sheet_name="数据列表")
# 数据打乱
df = df.sample(frac=1.0).reset_index(drop=True)
for i in range(len(df)):
data = df.iloc[i].to_dict()
print(data)
# 判断常规网页
if data['动态加载url'] == '-' and data['url 参数'] == '-':
yield scrapy.Request(
url=data["网址"], meta={'data': data, }, callback=self.parse_static
)
def parse_static(self, response):
data = extract_list(response.text)
for each in range(len(data)):
item = NewsDataItem()
item['title'] = data[each]["title"].strip()
item['url'] = parse.urljoin(response.url, data[each]["url"])
item['publishTime'] = ""
item["new_type"] = response.meta["data"]["类别"]
item['web_name'] = response.meta["data"]["网站名称"]
item['channel_name'] = response.meta["data"]["网站频道"]
yield scrapy.Request(item['url'], callback=self.parse_detail, meta={'item': item})
# 具体内容在parse_detail.py中
def parse_detail(self, response):
item = ProcessContent(self, response)
yield item
detail.py 数据详情
这里使用的gerapy_auto_extractor的extract_detail直接解析页面。
<p>def ProcessContent(self, response):
# 设置详情页的内容
item = response.meta['item']
data = extract_detail(response.text)
# 处理详情页的时间,如果始终没有获取到时间默认当天日期
if data["datetime"] is None:
item['publishTime'] = DateTimeProcess_Str(item['publishTime'])
else:
item['publishTime'] = DateTimeProcess_Str(data["datetime"])
# 处理详情页带格式,这里整个页面进行抓取,判断每个页面具体内容的样式
item['content'] = ""
if item['web_name'] == "xxxxxxx":
......
elif item['web_name'] == "中国质量新闻网":
if 'class="content"' in response.text and len(None2Str(item['content'])) 查看全部
全网文章 采集(简单来说就是基于Scrapy框架(爬虫框架)+Gerapy框架)
介绍
中国网的很多小伙伴都不知道,它是一家与新华网、人民网同名的全国性新闻媒体机构。有幸参与了863项目的舆论工程。现在很多企业舆论项目都是从这套内容衍生出来的。而且很多民意项目衍生出来的项目,都会涉及到数据采集的工作。简单来说,就是基于现有业务,从舆情内容数据中提取响应内容。
结合舆情系统的结构,复现了一组爬虫数据采集的结构。由于该项目历史悠久,具体开发内容和具体制作方法不得而知。结合话题相关内容,用Python转载了一组舆情。该系统被企业的某些项目所使用。本系统的内容将在以后更新。今天主要讲一下data采集的思路和简单功能的实现。
耐心看完后,我保证你也能做到
数据采集 项
项目整体复现概念基于Scrapy框架(爬虫框架)+Gerapy框架(爬虫管理框架)。实现分布式数据采集每天根据不同的项目,采集数据在百万级左右。下面是部分实现内容。有兴趣的朋友可以自行尝试更大规模的数据。采集。
数据准备
准备目标 URL。由于是项目规定的范围,所涉及的内容仅限于新闻数据。需要组织一个数据源数据库,将部分内容截取成Excel表格。
Pivot 提供简单的数据统计。
Scrapy爬虫框架使用
基于框架就是用通用的方式来进行数据采集,用同一个脚本来组织爬虫的内容,也就是说普通的静态页面直接使用一套通用的算法采集新闻的标题和链接,以及获取文章正文的访问日期。
items.py 定义了获取的字段
class NewsDataItem(scrapy.Item):
title = scrapy.Field() # 新闻标题
url = scrapy.Field() # 原文链接
publishTime = scrapy.Field() # 发布时间
content = scrapy.Field() # 文章正文
new_type = scrapy.Field() # 新闻类别
web_name = scrapy.Field() # 网站名称
channel_name = scrapy.Field() # 频道名称
middlewares.py 随机替换头部和 IP 代理
# 添加Header和IP类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class RotateUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
referer = request.url
if referer:
request.headers["referer"] = referer
USER_AGENT_LIST = settings.get('USER_AGENT_LIST')
user_agent = random.choice(USER_AGENT_LIST)
if user_agent:
request.headers.setdefault('user-Agent', user_agent)
print(f"user-Agent:{user_agent}")
# 添加随机更换IP代理类(根据实际IP代理情况进行修改获取方式和更改方式)
import random
import sys
import requests
sys.path.append('.')
class MyProxyMiddleware(object):
def process_request(self, request, spider):
url = "这里放购买的代理API地址,进行解析后使用代理访问"
html = requests.get(url).text
ip_list = html.split("\r\n")[:-1]
proxy = random.choice(ip_list)
request.meta['proxy'] = 'http://' + proxy
pipelines.py 数据存储设置
class NewsDataPipeline(object):
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DATABASE"]
collection = settings["MONGODB_COLLECTION"]
username = settings["MONGODB_USER"]
password = settings["MONGODB_PASSWORD"]
# 创建MONGODB数据库链接
client = pymongo.MongoClient(host=host, port=port, username=username, password=password)
# 指定数据库
db = client[dbname]
# 存放数据的数据库表名
self.post = db[collection]
def process_item(self, item, spider):
data = dict(item)
# 数据写入
self.post.insert(data)
return item
settings.py 通用配置,添加数据库信息和headers
# 添加 设置浏览器Header设置,不够用自行添加
USER_AGENT_LIST = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
......
]
MONGODB_HOST = "localhost" # 数仓IP
MONGODB_PORT = 27017 # 数仓端口号
MONGODB_DATABASE = "" # 数仓数据库
MONGODB_COLLECTION = "" # 数仓数据表单
MONGODB_USER = "" # 数仓验证的用户名
MONGODB_PASSWORD = "" # 数仓验证的用户密码
spider.py 主程序爬取
这里使用的gerapy_auto_extractor的extract_list直接解析列表页面。
# -*- coding: utf-8 -*-
import scrapy
from News_Data.items import NewsDataItem
import pandas as pd
from .parse_detail import ProcessContent
from urllib import parse
from scrapy.utils.project import get_project_settings
from gerapy_auto_extractor.extractors import *
settings = get_project_settings()
class NewsDataSpider(scrapy.Spider):
name = 'News_Data'
allowed_domains = []
def start_requests(self):
# 读取数据
df = pd.read_excel("../../我的数据抓取列表.xlsx", sheet_name="数据列表")
# 数据打乱
df = df.sample(frac=1.0).reset_index(drop=True)
for i in range(len(df)):
data = df.iloc[i].to_dict()
print(data)
# 判断常规网页
if data['动态加载url'] == '-' and data['url 参数'] == '-':
yield scrapy.Request(
url=data["网址"], meta={'data': data, }, callback=self.parse_static
)
def parse_static(self, response):
data = extract_list(response.text)
for each in range(len(data)):
item = NewsDataItem()
item['title'] = data[each]["title"].strip()
item['url'] = parse.urljoin(response.url, data[each]["url"])
item['publishTime'] = ""
item["new_type"] = response.meta["data"]["类别"]
item['web_name'] = response.meta["data"]["网站名称"]
item['channel_name'] = response.meta["data"]["网站频道"]
yield scrapy.Request(item['url'], callback=self.parse_detail, meta={'item': item})
# 具体内容在parse_detail.py中
def parse_detail(self, response):
item = ProcessContent(self, response)
yield item
detail.py 数据详情
这里使用的gerapy_auto_extractor的extract_detail直接解析页面。
<p>def ProcessContent(self, response):
# 设置详情页的内容
item = response.meta['item']
data = extract_detail(response.text)
# 处理详情页的时间,如果始终没有获取到时间默认当天日期
if data["datetime"] is None:
item['publishTime'] = DateTimeProcess_Str(item['publishTime'])
else:
item['publishTime'] = DateTimeProcess_Str(data["datetime"])
# 处理详情页带格式,这里整个页面进行抓取,判断每个页面具体内容的样式
item['content'] = ""
if item['web_name'] == "xxxxxxx":
......
elif item['web_name'] == "中国质量新闻网":
if 'class="content"' in response.text and len(None2Str(item['content']))
全网文章 采集(所有文章采集或抄袭行为都会被K站惩罚吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-11-30 11:09
在实际的网站SEO优化过程中,昆山SEO经常会遇到自己的收录文章被别人完整抄袭,然后对方文章也是收录,而且排名比我们高。遇到这种情况,我们会问:文章采集还是抄袭真的会被K站惩罚?
【什么是文章采集或抄袭】
采集是指利用一些采集的程序和规则,将其他网站的文章自动复制到自己的网站。(这里的采集或抄袭必须是原形,没有任何花招和伪装采集)
原来的采集其他网站的文章对网站的权重影响很大,虽然百度搜索引擎无法真正保护到原创< @文章,但昆山SEO认为搜索引擎算法会越来越聪明,就像采集一样,那么采集对自己的网站排名提升是有害的且无利可图。
百度飓风算法是为了打击文章采集或抄袭。如果我们用文章采集器来发布文章,那我们是不是要按照算法来花呢?处理时间?这是不值得的。
【所有抄袭文章采集会被K站惩罚】
分享一开始我们就知道如果有人采集或者抄袭我们的文章,就会出现收录,而且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也能解决用户需求),而且布局好,逻辑表达清晰,可读性强, 那正确吗?为用户提供有价值的内容,解决用户的搜索需求,是否符合搜索引擎的本质?所以有一个排名。
但是,这种采集的行为是行不通的。如果想长期给采集的内容一个更好的排名,那肯定会让原创的作者不爽。这种情况持续下去,站长开始制作采集内容或复制内容,而不是制作原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创造更多优质内容。
[文章被采集抄袭怎么办]
1、临时建议,一般可以礼貌地给对方留言网站,能不能加个文章的链接投票,如果没有,那就百度反馈并举报。
2、长期建议,优化你的网站结构,开启速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一个 收录 概率。(参考原创文章的定义)
3、网站的图片尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持好心态,毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集抄袭这是一个难题,技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题,所以自己做网站是最好的策略,这样文章才能实现第二个收录。 查看全部
全网文章 采集(所有文章采集或抄袭行为都会被K站惩罚吗)
在实际的网站SEO优化过程中,昆山SEO经常会遇到自己的收录文章被别人完整抄袭,然后对方文章也是收录,而且排名比我们高。遇到这种情况,我们会问:文章采集还是抄袭真的会被K站惩罚?
【什么是文章采集或抄袭】
采集是指利用一些采集的程序和规则,将其他网站的文章自动复制到自己的网站。(这里的采集或抄袭必须是原形,没有任何花招和伪装采集)
原来的采集其他网站的文章对网站的权重影响很大,虽然百度搜索引擎无法真正保护到原创< @文章,但昆山SEO认为搜索引擎算法会越来越聪明,就像采集一样,那么采集对自己的网站排名提升是有害的且无利可图。
百度飓风算法是为了打击文章采集或抄袭。如果我们用文章采集器来发布文章,那我们是不是要按照算法来花呢?处理时间?这是不值得的。
【所有抄袭文章采集会被K站惩罚】
分享一开始我们就知道如果有人采集或者抄袭我们的文章,就会出现收录,而且排名比我们高。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,不管你的文章是怎么来的(采集文章也能解决用户需求),而且布局好,逻辑表达清晰,可读性强, 那正确吗?为用户提供有价值的内容,解决用户的搜索需求,是否符合搜索引擎的本质?所以有一个排名。
但是,这种采集的行为是行不通的。如果想长期给采集的内容一个更好的排名,那肯定会让原创的作者不爽。这种情况持续下去,站长开始制作采集内容或复制内容,而不是制作原创文章或伪原创文章。所以当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创造更多优质内容。
[文章被采集抄袭怎么办]
1、临时建议,一般可以礼貌地给对方留言网站,能不能加个文章的链接投票,如果没有,那就百度反馈并举报。
2、长期建议,优化你的网站结构,开启速度等因素提升自身实力,最好晚上更新文章,因为这样可以提升自己作为第一个 收录 概率。(参考原创文章的定义)
3、网站的图片尽量加水印,增加其他人采集文章后期处理的时间成本。
4、保持好心态,毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集抄袭这是一个难题,技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题,所以自己做网站是最好的策略,这样文章才能实现第二个收录。
全网文章 采集(SharePointServer2007SP1Services3.0SP1Office2007API)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-27 18:07
最近忙着写需求文档,博客好久没有更新了。整理一下最近看到的好东西,做个备忘录,哈哈。
● SharePoint Server 2007 SP1
Windows SharePoint Services 3.0 SP1
Office SharePoint Server 2007 SP1
SharePoint 设计器 2007 SP1
首先安装 WSS 3.0 SP1,然后安装 MOSS 2007 SP1。 SharePoint SDK Online 的内容也已更新为最新的 2007 年 12 月版本(WSS 3.0 SDK、MOSS 2007 SDK),稍后会发布可下载版本。
WSS 3.0 SDK,增加了一个专门的章节来描述我之前介绍过的External Storage API。
● 推荐工具:SharePoint 内容部署向导
您可以使用 SharePont 的内容迁移 API 在站点(或服务器)之间复制 网站 集、网站、列表和列表项数据。
点击查看
● 信息工作者应用与管理系列网络直播
本系列穿插讲解了来自 OBA、企业搜索、MOSS 和 EPM 的四个主题
地址:
● SharePoint Workflow(ASP.NET Form版)教学视频
出自Kaneboy大侠之手,表单中的SharePoint工作流信息实在是太少了。这个视频很好,就是声音有点差,不过还是可以听懂的,谢谢Kaneboy
(注:以上部分内容转自网络,这里只是总结)
转载于: 查看全部
全网文章 采集(SharePointServer2007SP1Services3.0SP1Office2007API)
最近忙着写需求文档,博客好久没有更新了。整理一下最近看到的好东西,做个备忘录,哈哈。
● SharePoint Server 2007 SP1
Windows SharePoint Services 3.0 SP1
Office SharePoint Server 2007 SP1
SharePoint 设计器 2007 SP1
首先安装 WSS 3.0 SP1,然后安装 MOSS 2007 SP1。 SharePoint SDK Online 的内容也已更新为最新的 2007 年 12 月版本(WSS 3.0 SDK、MOSS 2007 SDK),稍后会发布可下载版本。
WSS 3.0 SDK,增加了一个专门的章节来描述我之前介绍过的External Storage API。
● 推荐工具:SharePoint 内容部署向导
您可以使用 SharePont 的内容迁移 API 在站点(或服务器)之间复制 网站 集、网站、列表和列表项数据。
点击查看
● 信息工作者应用与管理系列网络直播
本系列穿插讲解了来自 OBA、企业搜索、MOSS 和 EPM 的四个主题
地址:
● SharePoint Workflow(ASP.NET Form版)教学视频
出自Kaneboy大侠之手,表单中的SharePoint工作流信息实在是太少了。这个视频很好,就是声音有点差,不过还是可以听懂的,谢谢Kaneboy
(注:以上部分内容转自网络,这里只是总结)
转载于:
全网文章 采集(公众号文章批量采集器该怎么使用打开拓途?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-27 06:17
相信大家对微信软件都不陌生。我们经常阅读微信公众号发布的文章。接下来,拓图数据将介绍公众号文章采集器的特点,公众号文章批处理采集器如何使用?
如何批量使用公众号文章采集器
1.开创性的旅程。
2.进入公众号停止采集
3.进入需要采集的微信公众号。
4.回车采集等待程序运行。
4.采集 完成后进入任务列表。采集 内容存放在任务列表目录中。需要导出文章,也就是需要下载详情页的文章下载器。下载后,将导出的EXCELE表格拖入文章下载器。
公众号文章采集器有什么特点
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
2、智能采集
提供多种web采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
3、适用于全网
可即看即收,无论是文字图片还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求。
4、海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
7、可视化点击,简单易用
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
公众号文章采集器智能采集,简单易用,稳定高效。看完了拓图数据的介绍,大家一定已经知道公众号文章批量采集器的使用方法了。 查看全部
全网文章 采集(公众号文章批量采集器该怎么使用打开拓途?)
相信大家对微信软件都不陌生。我们经常阅读微信公众号发布的文章。接下来,拓图数据将介绍公众号文章采集器的特点,公众号文章批处理采集器如何使用?
如何批量使用公众号文章采集器
1.开创性的旅程。
2.进入公众号停止采集
3.进入需要采集的微信公众号。
4.回车采集等待程序运行。
4.采集 完成后进入任务列表。采集 内容存放在任务列表目录中。需要导出文章,也就是需要下载详情页的文章下载器。下载后,将导出的EXCELE表格拖入文章下载器。
公众号文章采集器有什么特点
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
2、智能采集
提供多种web采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
3、适用于全网
可即看即收,无论是文字图片还是贴吧论坛,都支持所有业务渠道的爬虫,满足各种采集需求。
4、海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
7、可视化点击,简单易用
流程图模式:只需点击页面,根据软件提示进行操作,完全符合人们浏览网页的思维方式。简单几步就可以生成复杂的采集规则,结合智能识别算法,任何网页的数据都可以轻松采集。
公众号文章采集器智能采集,简单易用,稳定高效。看完了拓图数据的介绍,大家一定已经知道公众号文章批量采集器的使用方法了。
全网文章 采集(做网站有一段时间了,怎么样采集有哪些好处?坏处?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-27 06:15
做个小网站采集文章,还是不?我做网站 有一段时间了,我自己也做一个小网站。小网站刚起步,内容少,流量少,所以暂时只能靠采集生存和保存,但是采集呢,有什么好处采集 的优缺点?世界是矛盾的。让我们分两部分来看。再来看看采集的好处:1.快速搭建一个比较充实完整的数据库。这会给观众带来更好的体验。他们会觉得这个网站的内容很好,很全,应该是一个很好的网站,抓住了用户的心理,在流量方面会有很好的网站 @2. 从搜索引擎吸引更多的IP。目前网站的流量主要来自搜索引擎,所以采集更多的网页内容理论上会被搜索引擎收录更多,虽然有些关键词你的网站不能排高,但是因为内容和关键词的关系,还是会有一些关键词,你的网站排在前面。3.采集 是最简单最简单的操作方式。如果你自己写文章,这基本上是不可能的,因为你的能力有限。就算24小时写,也写不了多少,所以用采集大大降低了网站的构建难度。4. 中国人有活泼的喜好。如果您的论坛是论坛,或者 网站,第一批会员注册后你会看到这个内容比较多,心里的感觉肯定会很好。没有人喜欢荒凉的感觉。5.如果你是信息站或者文章站,采集不是万能的,但没有采集绝对不行,因为它是给你的<
<p>平衡 原创 和 采集 的 文章。6. 页数多,理论上pv会更高。如果放广告,展示次数肯定会更多。如果您这样做,您将多次点击广告。当然,你的广告收入也会更多。有一些专门做广告的垃圾站,收入很好。先说采集的弊端:1.不尊重别人的劳动。想象一下其他人写了很长时间的东西。文章,你的采集软件转载了。几千条的内容,这有多糟糕,更何况很少有人会在采集的时候加上原作者的版权。在严重的情况下,您有被起诉的危险。 查看全部
全网文章 采集(做网站有一段时间了,怎么样采集有哪些好处?坏处?)
做个小网站采集文章,还是不?我做网站 有一段时间了,我自己也做一个小网站。小网站刚起步,内容少,流量少,所以暂时只能靠采集生存和保存,但是采集呢,有什么好处采集 的优缺点?世界是矛盾的。让我们分两部分来看。再来看看采集的好处:1.快速搭建一个比较充实完整的数据库。这会给观众带来更好的体验。他们会觉得这个网站的内容很好,很全,应该是一个很好的网站,抓住了用户的心理,在流量方面会有很好的网站 @2. 从搜索引擎吸引更多的IP。目前网站的流量主要来自搜索引擎,所以采集更多的网页内容理论上会被搜索引擎收录更多,虽然有些关键词你的网站不能排高,但是因为内容和关键词的关系,还是会有一些关键词,你的网站排在前面。3.采集 是最简单最简单的操作方式。如果你自己写文章,这基本上是不可能的,因为你的能力有限。就算24小时写,也写不了多少,所以用采集大大降低了网站的构建难度。4. 中国人有活泼的喜好。如果您的论坛是论坛,或者 网站,第一批会员注册后你会看到这个内容比较多,心里的感觉肯定会很好。没有人喜欢荒凉的感觉。5.如果你是信息站或者文章站,采集不是万能的,但没有采集绝对不行,因为它是给你的<
<p>平衡 原创 和 采集 的 文章。6. 页数多,理论上pv会更高。如果放广告,展示次数肯定会更多。如果您这样做,您将多次点击广告。当然,你的广告收入也会更多。有一些专门做广告的垃圾站,收入很好。先说采集的弊端:1.不尊重别人的劳动。想象一下其他人写了很长时间的东西。文章,你的采集软件转载了。几千条的内容,这有多糟糕,更何况很少有人会在采集的时候加上原作者的版权。在严重的情况下,您有被起诉的危险。
全网文章 采集( 网站内容应该怎么采集,怎么使用采集工具进行采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-17 19:12
网站内容应该怎么采集,怎么使用采集工具进行采集?
)
大家好,SEOer,今天想说一些对大家很有帮助的知识点。网站内容应该如何采集,采集工具怎么用采集,采集时间长了会怎样,怎么处理有这些问题。
采集对于工具,采集的内容。首先,其采集的内容是非原创内容,不被搜索引擎识别。如果不是原创的内容,没有对网站的排名进行优化有什么用。所以采集之后的内容必须经过伪原创的处理才能达到类原创的效果。然后第二个传统的采集工具,里面有很多采集规则,这些采集规则不专业,写起来难,需要花钱去问人编写 采集 规则。第三,传统的采集工具必须由您手动操作。不可能没有人,就是定时,没有挂机功能,不能24小时工作。
因此,在选择采集工具时,必须满足几个因素:首先,通过采集来的内容,在发布前,可以被伪原创处理。二是要使用简单方便,不用写规则,不用复杂的配置。大多数站长不强,甚至不会编码,适合普通大众。三是可以一直挂机使用,满足多个网站的更新频率和内容丰富度。编辑现在自己经营几十个网站,完全依靠147SEO站长工具发布和推送网站的采集伪原创。收录在大多数网站上的情况还是不错的,收录创建的网站排名在慢慢上升,
接下来我告诉你网站久了会怎么样采集:第一,网站no收录,第二,快照停滞,第三,蜘蛛做不爬。第四,排名不稳定。那么我们如何解决这些问题呢?
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容。而如果网站的权重不高,那么蜘蛛很可能会把你的网站列为采集站。文章页面肯定会停止收录,快照也会停止,网站收录会开始减少。所以解决方案一定要经过伪原创,发布的内容会第一时间主动推送,让搜索引擎快速找到你更新的页面。
搜索引擎蜘蛛会爬行,但不会爬行。其实在蜘蛛爬行的时候就已经进行了检测。当蜘蛛爬行爬行文章时,会进行一定程度的复制内容检测。当它发现你的内容和互联网的重复性很高时,这就是为什么你检查日志发现了蜘蛛,但页面从未被抓取,因为抓取发现了重复的内容。那么他就会放弃爬行,也就是只停留在查询阶段。解决办法和上一个一样,一定要保持你的内容原创,不能同质化。
排名上不上去,就算上升了也不稳定。把伪原创文章更新为收录后,排名上不去,所有搜索节目都是从其他站转过来的文章,连排名都上去了不稳定一天后,排名再次下调。在这种情况下,你需要仔细检查一下你的网站的文章是否长期被别人采集?
今天的分享就到这里。每次分享SEO经验,希望对做网站的站长有所帮助。现在网站变得越来越精致。再说一遍,只要SEO每个维度都做好,网站做好其实是一件很简单的事情。用心做网站,搜索引擎不会亏待你!
查看全部
全网文章 采集(
网站内容应该怎么采集,怎么使用采集工具进行采集?
)
大家好,SEOer,今天想说一些对大家很有帮助的知识点。网站内容应该如何采集,采集工具怎么用采集,采集时间长了会怎样,怎么处理有这些问题。
采集对于工具,采集的内容。首先,其采集的内容是非原创内容,不被搜索引擎识别。如果不是原创的内容,没有对网站的排名进行优化有什么用。所以采集之后的内容必须经过伪原创的处理才能达到类原创的效果。然后第二个传统的采集工具,里面有很多采集规则,这些采集规则不专业,写起来难,需要花钱去问人编写 采集 规则。第三,传统的采集工具必须由您手动操作。不可能没有人,就是定时,没有挂机功能,不能24小时工作。
因此,在选择采集工具时,必须满足几个因素:首先,通过采集来的内容,在发布前,可以被伪原创处理。二是要使用简单方便,不用写规则,不用复杂的配置。大多数站长不强,甚至不会编码,适合普通大众。三是可以一直挂机使用,满足多个网站的更新频率和内容丰富度。编辑现在自己经营几十个网站,完全依靠147SEO站长工具发布和推送网站的采集伪原创。收录在大多数网站上的情况还是不错的,收录创建的网站排名在慢慢上升,
接下来我告诉你网站久了会怎么样采集:第一,网站no收录,第二,快照停滞,第三,蜘蛛做不爬。第四,排名不稳定。那么我们如何解决这些问题呢?
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容。而如果网站的权重不高,那么蜘蛛很可能会把你的网站列为采集站。文章页面肯定会停止收录,快照也会停止,网站收录会开始减少。所以解决方案一定要经过伪原创,发布的内容会第一时间主动推送,让搜索引擎快速找到你更新的页面。
搜索引擎蜘蛛会爬行,但不会爬行。其实在蜘蛛爬行的时候就已经进行了检测。当蜘蛛爬行爬行文章时,会进行一定程度的复制内容检测。当它发现你的内容和互联网的重复性很高时,这就是为什么你检查日志发现了蜘蛛,但页面从未被抓取,因为抓取发现了重复的内容。那么他就会放弃爬行,也就是只停留在查询阶段。解决办法和上一个一样,一定要保持你的内容原创,不能同质化。
排名上不上去,就算上升了也不稳定。把伪原创文章更新为收录后,排名上不去,所有搜索节目都是从其他站转过来的文章,连排名都上去了不稳定一天后,排名再次下调。在这种情况下,你需要仔细检查一下你的网站的文章是否长期被别人采集?
今天的分享就到这里。每次分享SEO经验,希望对做网站的站长有所帮助。现在网站变得越来越精致。再说一遍,只要SEO每个维度都做好,网站做好其实是一件很简单的事情。用心做网站,搜索引擎不会亏待你!
全网文章 采集(几种竞价文章采集软件如何采集热点新闻资讯(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-11-12 19:03
全网文章采集已经是人人都需要掌握的基本技能了,不管是做竞价,做新媒体运营,做seo,还是做体育运动,都需要运用到各种文章采集技巧,比如新闻热点文章的采集,本文就介绍几种竞价文章采集软件如何采集热点新闻资讯。热点文章采集首先需要了解什么是热点?热点就是人们都会关注的事情,大家都喜欢用一些热点事件作为引子,引起自己的注意力,然后一起产生相关的讨论或者表达感悟或者结论,这些就是一个典型的热点。
比如最近的中美贸易摩擦,大家都会看各种各样的交流讨论,参考各种新闻,这就是热点。查看各种文章热点资讯的平台:5118平台,查看竞价产品热点资讯的平台:乐观号推文发布按钮采集热点热点文章标题采集软件的分类:360搜索、头条、搜狗、谷歌、百度热点主要热点原则和标题有关系的,标题里如果出现品牌名称就需要避免,也要避免在类似渠道存在大规模广告推广标题也影响着文章被搜索到的概率,带有cover关键词等,从而增加文章被抓取到的概率,当然也带来一定的用户体验。
搜狗热点搜索标题带有关键词的文章,带上自己的产品或服务,搜狗搜索获取的搜索结果,会根据关键词来匹配,比如,你所产品的品牌热点文章在国内是比较少,那么就可以考虑把热点文章的标题加上“国内”这个关键词去获取相关的链接,这样就会进一步增加文章被抓取到的概率,关键词的热度也决定着文章被抓取到的概率。360热点标题把自己产品或服务或者服务的利益或者自己的产品或服务的优势展示出来,强调利益或者优势,让读者更直观的看到你的产品或服务,这样就更加吸引用户进一步转化。
百度热点带品牌词的如果用户主动搜索的一般都是品牌词,可以增加一些品牌词,比如利用百度百科、百度知道来增加品牌词来增加文章被搜索到的概率。另外,还可以带上产品或服务的链接,让用户自己去搜索,提高文章被抓取到的概率。搜狗热点标题标题中带有任何关键词都是可以的,这些都是产品的关键词,或者说产品和品牌的关键词,比如:高富帅,你好高。
优先考虑这些关键词的关键词的搜索量或者话题度很大的原因:从这些词的搜索量,或者这些词下的阅读量来看,不断的刷新,或者增加一些词都会不断的提高产品和品牌在搜索结果中的曝光度。两个是不可或缺的关键词,一个是有抓取热点标题的原因,另一个是用户通过热点渠道搜索产品或服务时,尽量选择带品牌词的文章。原标题采集原标题是原先经过搜索或者转发,然后分析出来的词语,可以加上联想词来实现标题的扩展,比如,我们采集了咪蒙,可以转发咪蒙的标题,然后添加联想词:“曾。 查看全部
全网文章 采集(几种竞价文章采集软件如何采集热点新闻资讯(组图))
全网文章采集已经是人人都需要掌握的基本技能了,不管是做竞价,做新媒体运营,做seo,还是做体育运动,都需要运用到各种文章采集技巧,比如新闻热点文章的采集,本文就介绍几种竞价文章采集软件如何采集热点新闻资讯。热点文章采集首先需要了解什么是热点?热点就是人们都会关注的事情,大家都喜欢用一些热点事件作为引子,引起自己的注意力,然后一起产生相关的讨论或者表达感悟或者结论,这些就是一个典型的热点。
比如最近的中美贸易摩擦,大家都会看各种各样的交流讨论,参考各种新闻,这就是热点。查看各种文章热点资讯的平台:5118平台,查看竞价产品热点资讯的平台:乐观号推文发布按钮采集热点热点文章标题采集软件的分类:360搜索、头条、搜狗、谷歌、百度热点主要热点原则和标题有关系的,标题里如果出现品牌名称就需要避免,也要避免在类似渠道存在大规模广告推广标题也影响着文章被搜索到的概率,带有cover关键词等,从而增加文章被抓取到的概率,当然也带来一定的用户体验。
搜狗热点搜索标题带有关键词的文章,带上自己的产品或服务,搜狗搜索获取的搜索结果,会根据关键词来匹配,比如,你所产品的品牌热点文章在国内是比较少,那么就可以考虑把热点文章的标题加上“国内”这个关键词去获取相关的链接,这样就会进一步增加文章被抓取到的概率,关键词的热度也决定着文章被抓取到的概率。360热点标题把自己产品或服务或者服务的利益或者自己的产品或服务的优势展示出来,强调利益或者优势,让读者更直观的看到你的产品或服务,这样就更加吸引用户进一步转化。
百度热点带品牌词的如果用户主动搜索的一般都是品牌词,可以增加一些品牌词,比如利用百度百科、百度知道来增加品牌词来增加文章被搜索到的概率。另外,还可以带上产品或服务的链接,让用户自己去搜索,提高文章被抓取到的概率。搜狗热点标题标题中带有任何关键词都是可以的,这些都是产品的关键词,或者说产品和品牌的关键词,比如:高富帅,你好高。
优先考虑这些关键词的关键词的搜索量或者话题度很大的原因:从这些词的搜索量,或者这些词下的阅读量来看,不断的刷新,或者增加一些词都会不断的提高产品和品牌在搜索结果中的曝光度。两个是不可或缺的关键词,一个是有抓取热点标题的原因,另一个是用户通过热点渠道搜索产品或服务时,尽量选择带品牌词的文章。原标题采集原标题是原先经过搜索或者转发,然后分析出来的词语,可以加上联想词来实现标题的扩展,比如,我们采集了咪蒙,可以转发咪蒙的标题,然后添加联想词:“曾。
全网文章 采集(全网文章采集常用文章类型的基础上,完全就是抄袭模仿)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-04 00:03
全网文章采集:在采集常用文章类型的基础上,再增加了虚构类、论坛类、实用类、读书类、汽车类等热门文章。这里使用的时间段分别为:7-8点,16点,23点以及以后。在新闻资讯平台里面,社会文章更新的比较多,比如人民日报每天的时段就是1.3.5.9,而且这三个时段一般占了一半的新闻量,可以充分体现出“实时性”的优势。
现在很多公众号都是快速的把新闻源的文章发布出来,完全就是抄袭模仿,不仅侵权,而且很多是有问题的。下面两个是采集的截图。我就按照电影电视剧里面的主要情节来统计一下,搜索结果的数量以及部分电影的详细信息:特别说明下,我在这里提到的大多数都是名字,估计你也不太明白具体是指的什么电影。我也是根据上图里面电影代码的一个位置,来统计的:最后再上一张大图,看看有多少。
电影:电视剧:小说:综艺:网易云音乐:小米盒子:这个图的大小是2.1g,仅供日常使用,仅仅以电影或者电视剧为例子,如果涉及的虚构的电影的话,可能需要更高的分辨率,会是一个新的坑。
1.海量新闻资讯分类有:实事热点、体育、娱乐、财经、新闻等;2.根据资讯阅读体验,要求各平台也是不一样的,主要针对app;3.结合热点可以提前开始社会热点事件收集(网易云音乐、书评、电影评论等),然后用深度采集软件做挖掘。最后再去二次分析,以后写新闻的时候都会比较得心应手。 查看全部
全网文章 采集(全网文章采集常用文章类型的基础上,完全就是抄袭模仿)
全网文章采集:在采集常用文章类型的基础上,再增加了虚构类、论坛类、实用类、读书类、汽车类等热门文章。这里使用的时间段分别为:7-8点,16点,23点以及以后。在新闻资讯平台里面,社会文章更新的比较多,比如人民日报每天的时段就是1.3.5.9,而且这三个时段一般占了一半的新闻量,可以充分体现出“实时性”的优势。
现在很多公众号都是快速的把新闻源的文章发布出来,完全就是抄袭模仿,不仅侵权,而且很多是有问题的。下面两个是采集的截图。我就按照电影电视剧里面的主要情节来统计一下,搜索结果的数量以及部分电影的详细信息:特别说明下,我在这里提到的大多数都是名字,估计你也不太明白具体是指的什么电影。我也是根据上图里面电影代码的一个位置,来统计的:最后再上一张大图,看看有多少。
电影:电视剧:小说:综艺:网易云音乐:小米盒子:这个图的大小是2.1g,仅供日常使用,仅仅以电影或者电视剧为例子,如果涉及的虚构的电影的话,可能需要更高的分辨率,会是一个新的坑。
1.海量新闻资讯分类有:实事热点、体育、娱乐、财经、新闻等;2.根据资讯阅读体验,要求各平台也是不一样的,主要针对app;3.结合热点可以提前开始社会热点事件收集(网易云音乐、书评、电影评论等),然后用深度采集软件做挖掘。最后再去二次分析,以后写新闻的时候都会比较得心应手。
全网文章 采集(全网文章采集开源工具——pyspider,使用的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-01 15:00
全网文章采集开源工具——pyspider,使用的方法在文末~超帅的风格,符合我这类年轻人的审美哈哈利用spider包可以把源文件的格式转换成html,这里我举个栗子:#先定义自己的python对象python3::classpython:module('python'):pass#本机安装xlrd包#pipinstallxlrd#获取xxx.py文件python::fromxxx.xxximportxxx#pipshow--name“xxx.py”#定义一个采集对象和一个可执行对象importxxx,xxx.xxxfromspider.spiderimportspiderfromspider.spiderimportrequest#spider=spider(***)#在浏览器输入网址,在本地ip代理ip加上我们需要的你自己的ip#用来转换xxx.py格式的数据printspider.get(xxx.py)#等待开始执行,已经开始进行中#我们的过程就开始了!python是个好东西!如果你安装了xlrd包,那就很简单了,但是如果我们想要采集的是csv数据,怎么办呢?首先解决csv格式不好转换的问题,如果python不能识别中文,而又需要使用一些中文包,需要对代码进行转换,现在我们可以用xlrd包把源文件转化成一个普通的python对象。
<p>defhello_csv(path):python=open(path)#print(python.encoding("utf-8"))xxx.csv.string=python.load(path)returnxxx.csv#这里我使用了xlrd包的load方法进行对csv数据的读取@eval(xxx.eval(xxx.format_).encode("utf-8"))defload_csv(csv):xxx.write(csv.decode("utf-8"))xxx.csv.decode("utf-8")csv=load_csv(csv)#然后我们就可以获取我们所需要的源文件格式了,效果如下:有时候我们觉得我们的源文件很长,又想转换成xml格式,我们可以使用xliffline包,转换器可以识别中文,我用xliffline转换器来识别我们需要的文件格式,效果如下:defpyqueue_to_directory():#使用python对象直接赋值,这时源文件已经转化为一个对象,python对象有个class叫lxml_xml@autoreplylize(['?','='])deffrom_directory(directory):"""转换源文件"""#try:return"['\x00']"exceptexceptionase:ife.encoding=='utf-8':#构造lxml_xmlq=newqueue()#printq.from_directory(directory)else:#构造lxml_xml 查看全部
全网文章 采集(全网文章采集开源工具——pyspider,使用的方法)
全网文章采集开源工具——pyspider,使用的方法在文末~超帅的风格,符合我这类年轻人的审美哈哈利用spider包可以把源文件的格式转换成html,这里我举个栗子:#先定义自己的python对象python3::classpython:module('python'):pass#本机安装xlrd包#pipinstallxlrd#获取xxx.py文件python::fromxxx.xxximportxxx#pipshow--name“xxx.py”#定义一个采集对象和一个可执行对象importxxx,xxx.xxxfromspider.spiderimportspiderfromspider.spiderimportrequest#spider=spider(***)#在浏览器输入网址,在本地ip代理ip加上我们需要的你自己的ip#用来转换xxx.py格式的数据printspider.get(xxx.py)#等待开始执行,已经开始进行中#我们的过程就开始了!python是个好东西!如果你安装了xlrd包,那就很简单了,但是如果我们想要采集的是csv数据,怎么办呢?首先解决csv格式不好转换的问题,如果python不能识别中文,而又需要使用一些中文包,需要对代码进行转换,现在我们可以用xlrd包把源文件转化成一个普通的python对象。
<p>defhello_csv(path):python=open(path)#print(python.encoding("utf-8"))xxx.csv.string=python.load(path)returnxxx.csv#这里我使用了xlrd包的load方法进行对csv数据的读取@eval(xxx.eval(xxx.format_).encode("utf-8"))defload_csv(csv):xxx.write(csv.decode("utf-8"))xxx.csv.decode("utf-8")csv=load_csv(csv)#然后我们就可以获取我们所需要的源文件格式了,效果如下:有时候我们觉得我们的源文件很长,又想转换成xml格式,我们可以使用xliffline包,转换器可以识别中文,我用xliffline转换器来识别我们需要的文件格式,效果如下:defpyqueue_to_directory():#使用python对象直接赋值,这时源文件已经转化为一个对象,python对象有个class叫lxml_xml@autoreplylize(['?','='])deffrom_directory(directory):"""转换源文件"""#try:return"['\x00']"exceptexceptionase:ife.encoding=='utf-8':#构造lxml_xmlq=newqueue()#printq.from_directory(directory)else:#构造lxml_xml
全网文章 采集( 如何实现wp的自动采集功能--wordpress教程教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-10-22 19:07
如何实现wp的自动采集功能--wordpress教程教程)
如果你想了解更多关于wordpress的内容,可以点击:wordpress教程
WordPress是一个使用PHP语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面介绍如何实现wp的自动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。(这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。文章 URL匹配规则的设置很简单,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构: 因此,将URL中变化的数字或字母替换为通配符(*),例如如:(*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器,通过查看列表URL的源码就可以轻松设置,找到文章的代码即可列表 URL 下的超链接。如下:
7、可以看到文章的超链接A标签在类为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList一种。如下:
8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图所示:
9、其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
以上就是wordpress采集器的详细内容,更多内容请关注php中文网站其他相关文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
全网文章 采集(
如何实现wp的自动采集功能--wordpress教程教程)
如果你想了解更多关于wordpress的内容,可以点击:wordpress教程
WordPress是一个使用PHP语言开发的建站程序平台。现在很多博主都用wp。很多网站制作培训使用wp,尤其是在做采集站的时候。总能量非常强大。下面介绍如何实现wp的自动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务配置更多设置。(这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。文章 URL匹配规则的设置很简单,不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构: 因此,将URL中变化的数字或字母替换为通配符(*),例如如:(*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、使用 CSS 选择器进行匹配。使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器,通过查看列表URL的源码就可以轻松设置,找到文章的代码即可列表 URL 下的超链接。如下:
7、可以看到文章的超链接A标签在类为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList一种。如下:
8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图所示:
9、其他设置不需要修改。以上采集方法适用于WordPress多站点功能。
以上就是wordpress采集器的详细内容,更多内容请关注php中文网站其他相关文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
全网文章 采集(全网文章采集的结果,一共有500篇左右)
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-10-18 21:03
全网文章采集的结果。一共有500篇左右的文章。基本都是小说类。最少的只有4句,最多的有上千句。接下来说下效果哈,因为看的时候不看标题。看的是全文,还真的蛮多很棒的句子。比如主角“总裁”的爱恨情仇,或者主角的一路黑历史还有人生奋斗故事。下面就是文章网站了,猫爷先推荐2个:蝉大师——全网文章采集的工具,三分钟采集500个网站的文章下载猫爷——全网文章采集工具,数据源来自各大正规公众号和网站。
一个工具的效果在下面大家感受下,帮朋友做一个公众号的推送,8篇文章4000多万点击。效果不要太好。接下来还有一篇文章,一万多阅读:,就是分段采集的。这点和分条采集差不多。要我说的是,这种分段采集,很大概率采集不到原始数据,不过考虑到付费10万块采集了10w的文章的话,没有觉得不值。之后还有一篇文章,一个热门网站5万次点击:,也是分段采集的,看了下结果,情况不乐观,话说,认识我才十来年,为啥朋友圈见识了这么多作者?和我在群里面唠嗑过那么多稿子,有的一篇几十万,有的两三万,这个原因很多。
下面介绍用了蝉大师全网文章采集之后,很多收益有情况:有2万多篇。用了小说采集器:开心淘一下:个人觉得都还不错。用了蝉大师之后,如果碰到样本不好采集的,有点郁闷。我还记得之前,上网看到一个知乎大神的文章,统计800多万篇,结果提取出来的才4万多篇,简直,无奈。毕竟,在这么大的采集下,费时费力费钱,投入产出比不好说的。
如果我还用小说采集器采集,效果估计更差。话说,如果不是在这些采集中碰到问题,我还真的想不到软件能不能采集的出来这么多篇文章。都是百度一下,找到网站,再用爬虫大侠采集下来的。没用蝉大师之前,经常用“百度一下,你就知道”,但是在我用了之后,有点不满足了。还是满足不了我这种执着的玩法。需要更牛逼的采集工具,就接着看下去。
怎么才能更牛逼的采集更多数据?还有一点,现在很多网站会明示,来自于搜索引擎,或者排名靠前的网站。希望大家多注意一下。另外,我发现现在小说网站,有些网站会通过购买版权给小说网站主。还有一点很多不那么良心的,会故意将新老作者分开,卖小说版权。文章采集,真的不是那么简单,尤其是还涉及到了别人的版权问题。只要小说不是特别牛,大家就还是省点钱为好。
当然,一切都不要吹的太夸张了,遇到这种售卖版权的网站,就当在吃了屎就行了。总之一句话,百度一下,你就知道是多少人不断研究出来的东西。能用就用吧,不要吹得太离谱。关注我的公众号「grgun」获取更多技术干货、黑科技、。 查看全部
全网文章 采集(全网文章采集的结果,一共有500篇左右)
全网文章采集的结果。一共有500篇左右的文章。基本都是小说类。最少的只有4句,最多的有上千句。接下来说下效果哈,因为看的时候不看标题。看的是全文,还真的蛮多很棒的句子。比如主角“总裁”的爱恨情仇,或者主角的一路黑历史还有人生奋斗故事。下面就是文章网站了,猫爷先推荐2个:蝉大师——全网文章采集的工具,三分钟采集500个网站的文章下载猫爷——全网文章采集工具,数据源来自各大正规公众号和网站。
一个工具的效果在下面大家感受下,帮朋友做一个公众号的推送,8篇文章4000多万点击。效果不要太好。接下来还有一篇文章,一万多阅读:,就是分段采集的。这点和分条采集差不多。要我说的是,这种分段采集,很大概率采集不到原始数据,不过考虑到付费10万块采集了10w的文章的话,没有觉得不值。之后还有一篇文章,一个热门网站5万次点击:,也是分段采集的,看了下结果,情况不乐观,话说,认识我才十来年,为啥朋友圈见识了这么多作者?和我在群里面唠嗑过那么多稿子,有的一篇几十万,有的两三万,这个原因很多。
下面介绍用了蝉大师全网文章采集之后,很多收益有情况:有2万多篇。用了小说采集器:开心淘一下:个人觉得都还不错。用了蝉大师之后,如果碰到样本不好采集的,有点郁闷。我还记得之前,上网看到一个知乎大神的文章,统计800多万篇,结果提取出来的才4万多篇,简直,无奈。毕竟,在这么大的采集下,费时费力费钱,投入产出比不好说的。
如果我还用小说采集器采集,效果估计更差。话说,如果不是在这些采集中碰到问题,我还真的想不到软件能不能采集的出来这么多篇文章。都是百度一下,找到网站,再用爬虫大侠采集下来的。没用蝉大师之前,经常用“百度一下,你就知道”,但是在我用了之后,有点不满足了。还是满足不了我这种执着的玩法。需要更牛逼的采集工具,就接着看下去。
怎么才能更牛逼的采集更多数据?还有一点,现在很多网站会明示,来自于搜索引擎,或者排名靠前的网站。希望大家多注意一下。另外,我发现现在小说网站,有些网站会通过购买版权给小说网站主。还有一点很多不那么良心的,会故意将新老作者分开,卖小说版权。文章采集,真的不是那么简单,尤其是还涉及到了别人的版权问题。只要小说不是特别牛,大家就还是省点钱为好。
当然,一切都不要吹的太夸张了,遇到这种售卖版权的网站,就当在吃了屎就行了。总之一句话,百度一下,你就知道是多少人不断研究出来的东西。能用就用吧,不要吹得太离谱。关注我的公众号「grgun」获取更多技术干货、黑科技、。
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-17 00:32
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站的文章是采集来自互联网,不是互联网上的其他网站采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面也逐渐开始不收录@ >.
2、网站收录开始减少,快照停滞
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现在网站停止后收录,慢慢的导致网站整个收录的减少,就是这个原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的就是排名问题,担心排名会受到影响。这点你可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。 查看全部
全网文章 采集(网站内容被长期采集会出现的状况及问题排名)
当我们的网站长期处于采集的状态时,我们网站上更新的大部分文章在网上都是一样的内容,并且如果网站的权重不够高,那么蜘蛛很可能会把你的网站列为采集站,它认为你的网站的文章是采集来自互联网,不是互联网上的其他网站采集你的文章。
网站长期出现的采集内容:
1、首先文章页面停止收录,然后整个网站没有收录
这点肯定会发生,因为百度误判为采集站,所以你的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,这一站收录不仅会影响你的文章页面,还会让百度重新审核你的整个网站,所以其他页面也逐渐开始不收录@ >.
2、网站收录开始减少,快照停滞
百度会重新考虑你的网站。这时候你肯定会发现你网站有一些和网上的类似的页面。百度会不假思索地减少你的页面数量。 收录,所以很多人发现在网站停止后收录,慢慢的导致网站整个收录的减少,就是这个原因。页面不是很收录,百度对网站的信任度下降,最终快照会停滞一段时间。
3、排名没有波动,流量正常
当收录出现下降,快照停滞时,我们最关心的就是排名问题,担心排名会受到影响。这点你可以放心,因为文章是采集,导致他的网站被百度评价。这只影响百度对网站的信任,不会导致网站权重下降,所以网站的关键词排名不会受到影响。
全网文章 采集(全网文章采集异常迅速,你用什么公司h5广告?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-12 08:01
全网文章采集异常迅速,其中包括头条、豆瓣、简书等平台热文。以防被屏蔽造成热度降低,
6、
7、
8、9四个关键词,如图所示:由于热门文章难于获取,部分需要邀请才能参与,但点击量比较好的文章。如图所示:在采集文章后,可以直接上传压缩后的zip文件,或者解压缩后上传。也可以直接百度云,搜索:灵犀pdf找到该压缩包,再解压即可。如图所示:文章统计pdf,下载后即可保存本地。如图所示:文章评论统计pdf,下载后即可保存本地。
如图所示:如果要在一个群里发布全网免费文章,无需保存,直接群文件中,点击获取到的链接即可。只需复制主题链接,即可直接通过如下链接获取整个全网热文。如图所示:获取全网免费文章后,可以直接用用,还可以嵌入编辑器,导入各平台已经上传的文章等等,需要什么就在群文件中上传即可。如图所示:。
请各位可以结合提问中:总是收到网上别人发布的文章。下面说的一个是:你身边能遇到的读者,对读书效果更好的文章是什么样的?再有一个是:你公司需要做大量ppt,你用什么公司h5广告?然后再来看看pdf转换为word,可以免费,但是收费在100元以上。所以根据你的应用场景,对pdf文件进行专门的裁剪工作,以达到分类保存功能。1.网上文章收集。
1)w3c注册网站(如果已经注册了,而且可以登录w3c注册,
2)网站右上角,你可以看到针对不同搜索引擎,所使用不同对应url,以及这些url可以通过什么渠道免费获取,
3)上面只是下载一个文件,那么你还需要订阅到一个网站,才可以免费使用这个功能;或者你需要我帮你注册,那么我也给你免费提供这个功能。这个和office是什么样的关系?咱们举个类似的实例,如果我注册方式是用微软官方word,那么,从微软官方word分享网站的免费下载入口,下载到自己手中的word文件,本身,就是为了分享;。
4)还有一个可以方便下载到:应用宝、360的app,在应用宝或者360的app里面,输入:word。
就可以下载到你的所有word文件了;2.免费pdf转word
1)新的有道云笔记等搜索引擎找到免费pdf转word功能的网页;
2)上面这个版本,为了查看不同浏览器上的版本功能,会打开浏览器的兼容性问题,虽然可以显示,那就免费版本。假如,你有一张pdf文件,在mac上是10m以下的,是2000字以下的,是绿色版,那么,找到我们的免费转换器了,很简单。可能你是需要把打开,点击转换,然后再选择微软office;如果是不是绿色版,请你,点。 查看全部
全网文章 采集(全网文章采集异常迅速,你用什么公司h5广告?)
全网文章采集异常迅速,其中包括头条、豆瓣、简书等平台热文。以防被屏蔽造成热度降低,
6、
7、
8、9四个关键词,如图所示:由于热门文章难于获取,部分需要邀请才能参与,但点击量比较好的文章。如图所示:在采集文章后,可以直接上传压缩后的zip文件,或者解压缩后上传。也可以直接百度云,搜索:灵犀pdf找到该压缩包,再解压即可。如图所示:文章统计pdf,下载后即可保存本地。如图所示:文章评论统计pdf,下载后即可保存本地。
如图所示:如果要在一个群里发布全网免费文章,无需保存,直接群文件中,点击获取到的链接即可。只需复制主题链接,即可直接通过如下链接获取整个全网热文。如图所示:获取全网免费文章后,可以直接用用,还可以嵌入编辑器,导入各平台已经上传的文章等等,需要什么就在群文件中上传即可。如图所示:。
请各位可以结合提问中:总是收到网上别人发布的文章。下面说的一个是:你身边能遇到的读者,对读书效果更好的文章是什么样的?再有一个是:你公司需要做大量ppt,你用什么公司h5广告?然后再来看看pdf转换为word,可以免费,但是收费在100元以上。所以根据你的应用场景,对pdf文件进行专门的裁剪工作,以达到分类保存功能。1.网上文章收集。
1)w3c注册网站(如果已经注册了,而且可以登录w3c注册,
2)网站右上角,你可以看到针对不同搜索引擎,所使用不同对应url,以及这些url可以通过什么渠道免费获取,
3)上面只是下载一个文件,那么你还需要订阅到一个网站,才可以免费使用这个功能;或者你需要我帮你注册,那么我也给你免费提供这个功能。这个和office是什么样的关系?咱们举个类似的实例,如果我注册方式是用微软官方word,那么,从微软官方word分享网站的免费下载入口,下载到自己手中的word文件,本身,就是为了分享;。
4)还有一个可以方便下载到:应用宝、360的app,在应用宝或者360的app里面,输入:word。
就可以下载到你的所有word文件了;2.免费pdf转word
1)新的有道云笔记等搜索引擎找到免费pdf转word功能的网页;
2)上面这个版本,为了查看不同浏览器上的版本功能,会打开浏览器的兼容性问题,虽然可以显示,那就免费版本。假如,你有一张pdf文件,在mac上是10m以下的,是2000字以下的,是绿色版,那么,找到我们的免费转换器了,很简单。可能你是需要把打开,点击转换,然后再选择微软office;如果是不是绿色版,请你,点。
全网文章 采集(SEO和网站运营经验文章,手写原创内容可以直接忽略)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-09 14:34
大家好,我是熊晓峰。今天继续分享SEO和网站运营经验文章。从昨天开始分享内容更新和处理原创的时候,只提到了框架,没有详细分享,所以,今天就和大家详细分享一下如何处理得到的文章 content 使内容更好。
今天的内容主要是采集的内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤器采集来源
2、采集工具介绍
3、采集文章句柄
1、采集来源
这个很容易理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、同行网站、行业网站等的搜索结果。 ,只要你网站补充内容就好。
前期甚至可以是采集,只要稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具事半功倍。目前也有很多采集工具,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。
今天以优采云采集器为例给大家介绍一下。相信资深站长都用过这个采集器。你可以自己去官方查看说明。这里就不介绍了。而且官方也有基础的视频教程,基本都能操作。
3、文章句柄(伪原创)
这里推荐只用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样的原创度不高,甚至会影响阅读的流畅度。
现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创内容接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们处理完采集收到的文章的内容后,是不够的。我们发布文章给自己网站之后,有处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
还有多个文章组合成一个文章,让内容更加全面完整。这类内容不仅搜索引擎喜欢,用户也喜欢。可以这样搞,其实你的内容已经原创了。
需要更详细的教程,请继续关注我,观看下面的教程,后续会更新视频教程。
一大早,今天就写这么多 查看全部
全网文章 采集(SEO和网站运营经验文章,手写原创内容可以直接忽略)
大家好,我是熊晓峰。今天继续分享SEO和网站运营经验文章。从昨天开始分享内容更新和处理原创的时候,只提到了框架,没有详细分享,所以,今天就和大家详细分享一下如何处理得到的文章 content 使内容更好。
今天的内容主要是采集的内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、过滤器采集来源
2、采集工具介绍
3、采集文章句柄
1、采集来源
这个很容易理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、同行网站、行业网站等的搜索结果。 ,只要你网站补充内容就好。
前期甚至可以是采集,只要稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容来说,采集工具是必不可少的,好的工具事半功倍。目前也有很多采集工具,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。
今天以优采云采集器为例给大家介绍一下。相信资深站长都用过这个采集器。你可以自己去官方查看说明。这里就不介绍了。而且官方也有基础的视频教程,基本都能操作。
3、文章句柄(伪原创)
这里推荐只用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样的原创度不高,甚至会影响阅读的流畅度。
现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创内容接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们处理完采集收到的文章的内容后,是不够的。我们发布文章给自己网站之后,有处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
还有多个文章组合成一个文章,让内容更加全面完整。这类内容不仅搜索引擎喜欢,用户也喜欢。可以这样搞,其实你的内容已经原创了。
需要更详细的教程,请继续关注我,观看下面的教程,后续会更新视频教程。
一大早,今天就写这么多
全网文章 采集( Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-02 01:22
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
)
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章给大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括python爬虫采集今日热榜数据:聚合全网热榜的使用、应用技巧,并总结了基础知识点和注意事项,有一定的参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热单数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx') 查看全部
全网文章 采集(
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
)
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章给大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括python爬虫采集今日热榜数据:聚合全网热榜的使用、应用技巧,并总结了基础知识点和注意事项,有一定的参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热单数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx')

