
优采集平台
优采集平台(卢彪技术专家百度百科:数据交换平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-09-01 20:14
本文根据dbaplus社区第170期在线分享整理
讲师介绍
陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将分散建设的多个应用信息系统集成起来,使多个应用子系统能够传输和共享信息/数据,提高信息资源利用率的信息交换平台。效率成为信息化建设的基本目标,保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于 RPC 的服务调用、基于 MQ 的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:用空间换时间。
一、Exchange 平台对话
1、服务场景
一般来说,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景示例 1:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,发送下单后)短信、付款后通知等),基于该架构,业务方无需定义领域事件并自行发送事件,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,也需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;并发送事件操作对应于事件表的插入操作,与业务操作一起放在一个事务中。交易提交后,交易所平台拉取事件表的日志,然后提取事件内容并发送给MQ。
通过消耗数据库日志,有很多文章可以做。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。总体架构如下:
事件平台提供事件订阅、事件配置(如:是实时触发下一个操作还是倒计时触发下一个操作,下一个操作是接口回调还是新事件等) .)、事件调度和实时监控等基础支持,用户只需要提供配置规则和开发回调接口,免去各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到时间要素相关的判断时(如:未结算订单多长时间自动转换为Invalid,租用时间超过一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。
采用定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景示例 2:CQRS(命令查询职责分离)
CQRS 是 DDD 领域的一个概念,在这里应用。详情请参考链接:
CQRS 的思想本质上是为同一块数据创建两组模型(或视图):
CQRS 架构模式的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件重放、事件消费、数据镜像等。等基础支持,应用其结构图为如下:
理想是丰满的,现实是骨感的。 DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以我们先抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库的日志也是一个事件,但是表达能力不如DDD中的领域事件。丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:
场景示例 3:数据采集 和回流
许多公司正在构建或已经构建了自己的大数据平台。其中,data采集和reflow是不可或缺的一环。通常,较小的公司在 data采集 级别上做得更分散。各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,把数据采集放在整个数据交换平台的规划中,以提高效率,降低成本。
下图是我们团队的数据交换平台与大数据平台的关系示意图:
灾难恢复备份
场景示例 1:多个机房
多中心、多备份、异地双活、异地多活是很多大公司正在实践或已经实践的技术难题。其核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
为了升级数据库,图书馆的搬迁、拆除和整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得很简单。
场景示例 2:资产重用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些不同场景的同步变得更加容易。
2、建设思路
一千个读者拥有一千个哈姆雷特,一千个建筑师拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型体现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。一对一关系也可以是一对多关系。
那么,数据交换平台就是串联生产者和消费者的枢纽,可以控制串联过程中的进程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有能够促进快速集成的架构才能支持不断变化的数据同步需求。
设计架构时需要考虑的要点总结如下:
许多公司正在基于消息中间件构建自己的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。该模式的典型开源实现是Kafka-Connect,其架构图如下:
优点:
缺点:
不管怎样,架构模型都非常优秀,可以满足60%~70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受Kafka-Connect的想法启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :
在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景下也支持全同步,但毕竟不是它的主要业务),针对离线全同步同步 对于场景,使用最广泛的方案是阿里开源的DataX。有兴趣的可以研究一下。
简单总结,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合了各种技术,最大限度地扬长避短。问题和痛点找到适合自己的方案才是最合理的方案。
方法
如果结构选择是为了制定策略,那么方法就是具体的战术。从同步行为上变化点,可分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析、基于时间戳的数据抽取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等) .)笔者可行的策略主要包括文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景下仍有应用空间。有一个开源的产品代号SymmetricDS,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据可以参考这个产品。
基于日志分析的同步是目前最流行的。例如MySQL、HBase等提供日志重放机制,协议开源。
这种方法的主要优点是:对业务表零侵入,异步日志解析没有性能问题,实时性比较高。
日志解析很好,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,取 改变数据和同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能更新,定期扫描表查询也可能带来一些性能问题。
离线全同步
让我们谈谈离线完全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。 API提取方式更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。
疑难问题
将数据从一处移动到另一处,如何保证数据在同步过程中不出现任何问题(不丢失、不重、不乱)或者出现问题后可以快速恢复。需要考虑的点很多而且很重要 杂项,我将根据自己的经验谈谈主要的困难和常见的解决方案。
一:各种各样的 API
好像没什么难的。不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种,其产品特性千差万别。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级? ? 支持随机读写吗? 还是只能支持Append? 操作API时有客户端缓存吗? HA是如何实现的? 性能瓶颈在哪里? 调参参数是什么? 内置的如何?在Replication机制实现?等),否则平台只是停留在可以使用的阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践中也不少。前往坑。
解决这个难题,没有捷径可走,只有增加自己的硬实力才能有所突破。
第二:同步关系管理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
通常会添加 DAG 检测机制以避免环回同步。
一般有两种方式来保证schema的一致性:一是在同步过程中从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者是异类。当数据源较多时,实现起来比较困难(脚本转换、性能问题、幂等判断等),而且并不是所有的解决方案都能得到DDL语句,后者更加通用和可行。
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会执行脚本根据同步关系提示。 .
同步关系树示意图如下:
第三部分:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果能把事前、事中、事后三个阶段控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具,但每个阶段都不容易由于场景的灵活性和复杂性而实践,例如:
目前,我们的团队还在不断探索的路上。没有绝对完美的解决方案。找到最合适的方案,才是针对我们自己的场景和数据一致性要求程度的正确方案。下图展示了数据质量设计的要点:
第四:可扩展性
技术的发展日新月异,业务的演进也在日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,则是判断一个平台和一个产品的成熟度和成熟度。无关键指标。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别是,前者应该专注于抽象、建模和参数化,以提供灵活的可扩展性。
那么应该考虑什么程度的可扩展性?一句话总结:在平台建设的过程中,我们要不断地总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,但也充分设计。
在开源数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近的开源DataLink,下面会介绍,也是这样做的。多多考虑。
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:
二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
音译:数据链、数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间实时增量同步,分布式、可扩展的数据同步系统
开源地址:
本次开源是去除内部依赖后的版本(开源是增量同步子系统)。集团内部的DataLink和阿里的DataX也深度融合,由增量(DataLink)+全量(DataX)组成一个统一的数据交换平台(DataLink如果打个比方,可以看作是DataX的增量版),平台架构如下:
2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
展望未来,我们的目标是打造一个新的平台,满足各种异构数据源之间的实时增量同步,支持公司业务的快速发展。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有自己明显的缺点和局限性,所以最后的选择只是“设计你自己的”。
但是自我设计不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是巨人。他在他的肩膀上做了一个跳跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、应用现状
DataLink于2016年12月启动项目,2017年5月推出第一个版本,至今已在神州优车集团内服务,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施
DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(工作节点),下面简单介绍一下基础架构的关键模块:
经理
Manager 是整个 DataLink 集群的大脑,具有三个核心功能:
组
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分配在Worker节点上。 (Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插件
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。 Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。 DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,它通过抢占和监控“/datalink/managers/active”节点来实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
Task 会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体结构
概念模型
一句话概括概念模型:一个高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过了,这里不再赘述。
领域模型
合同
契约就是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,合同处于顶层。无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。对不同场景的共同需求进行归纳总结,抽象出一套统一的模型定义。
当然,它不是万能的,它不可能收录所有的需求点,并且随着场景数量的增加而不断演进。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件模型
插件系统:一般由Framework+Plugin两部分组成。 DataLink中的Framework主要是指[TaskRuntime],Plugin对应各种类型的[TaskReader&TaskWriter]。
TaskRuntime:提供Task的高层抽象、Task的运行环境、Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件数量。
Task:DataLink 中数据同步的基本单位是Task。可以在一个 Worker 进程中运行一批 Task。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即:
详情请参考维基:
深入的插件
5、Project Future
DataLink 项目借鉴了许多开源产品的想法。这里要欣赏的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们开源,一方面回馈社区,另一方面回馈社区。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。同时,我们也希望有更多的人参与进来。
目前正在规划的内部功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全部功能特性,以及各种大数据架构进行深度集成等。
实时回放 查看全部
优采集平台(卢彪技术专家百度百科:数据交换平台)
本文根据dbaplus社区第170期在线分享整理
讲师介绍
陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将分散建设的多个应用信息系统集成起来,使多个应用子系统能够传输和共享信息/数据,提高信息资源利用率的信息交换平台。效率成为信息化建设的基本目标,保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于 RPC 的服务调用、基于 MQ 的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:用空间换时间。
一、Exchange 平台对话
1、服务场景
一般来说,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景示例 1:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,发送下单后)短信、付款后通知等),基于该架构,业务方无需定义领域事件并自行发送事件,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,也需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;并发送事件操作对应于事件表的插入操作,与业务操作一起放在一个事务中。交易提交后,交易所平台拉取事件表的日志,然后提取事件内容并发送给MQ。

通过消耗数据库日志,有很多文章可以做。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。总体架构如下:
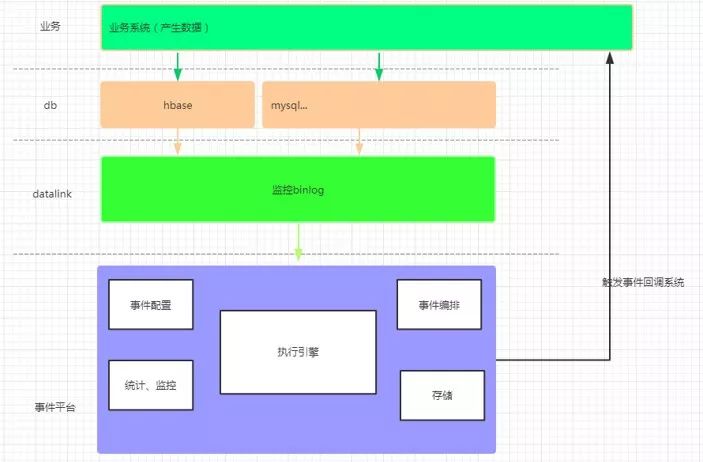
事件平台提供事件订阅、事件配置(如:是实时触发下一个操作还是倒计时触发下一个操作,下一个操作是接口回调还是新事件等) .)、事件调度和实时监控等基础支持,用户只需要提供配置规则和开发回调接口,免去各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到时间要素相关的判断时(如:未结算订单多长时间自动转换为Invalid,租用时间超过一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。
采用定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景示例 2:CQRS(命令查询职责分离)
CQRS 是 DDD 领域的一个概念,在这里应用。详情请参考链接:
CQRS 的思想本质上是为同一块数据创建两组模型(或视图):
CQRS 架构模式的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件重放、事件消费、数据镜像等。等基础支持,应用其结构图为如下:
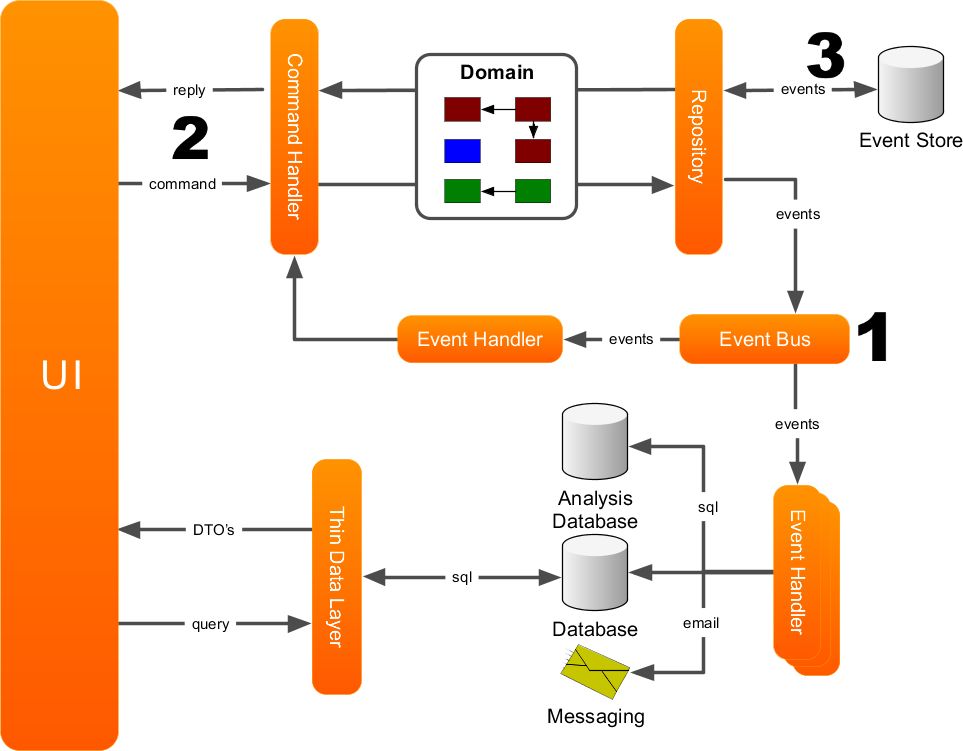
理想是丰满的,现实是骨感的。 DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以我们先抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库的日志也是一个事件,但是表达能力不如DDD中的领域事件。丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:
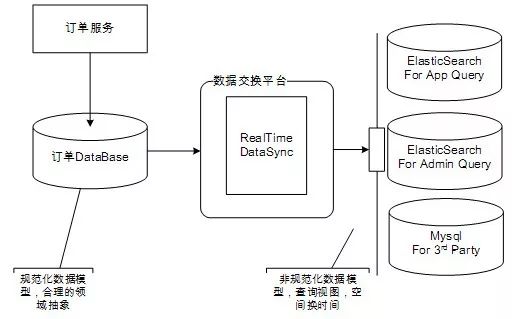
场景示例 3:数据采集 和回流
许多公司正在构建或已经构建了自己的大数据平台。其中,data采集和reflow是不可或缺的一环。通常,较小的公司在 data采集 级别上做得更分散。各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,把数据采集放在整个数据交换平台的规划中,以提高效率,降低成本。
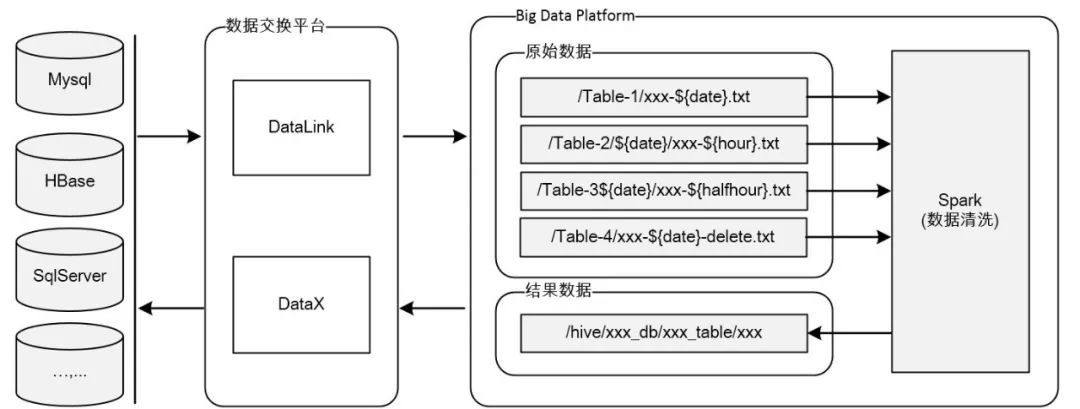
下图是我们团队的数据交换平台与大数据平台的关系示意图:
灾难恢复备份
场景示例 1:多个机房
多中心、多备份、异地双活、异地多活是很多大公司正在实践或已经实践的技术难题。其核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
为了升级数据库,图书馆的搬迁、拆除和整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得很简单。
场景示例 2:资产重用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些不同场景的同步变得更加容易。
2、建设思路
一千个读者拥有一千个哈姆雷特,一千个建筑师拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型体现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。一对一关系也可以是一对多关系。
那么,数据交换平台就是串联生产者和消费者的枢纽,可以控制串联过程中的进程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有能够促进快速集成的架构才能支持不断变化的数据同步需求。
设计架构时需要考虑的要点总结如下:
许多公司正在基于消息中间件构建自己的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。该模式的典型开源实现是Kafka-Connect,其架构图如下:
优点:
缺点:
不管怎样,架构模型都非常优秀,可以满足60%~70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受Kafka-Connect的想法启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :
在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景下也支持全同步,但毕竟不是它的主要业务),针对离线全同步同步 对于场景,使用最广泛的方案是阿里开源的DataX。有兴趣的可以研究一下。
简单总结,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合了各种技术,最大限度地扬长避短。问题和痛点找到适合自己的方案才是最合理的方案。
方法
如果结构选择是为了制定策略,那么方法就是具体的战术。从同步行为上变化点,可分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析、基于时间戳的数据抽取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等) .)笔者可行的策略主要包括文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景下仍有应用空间。有一个开源的产品代号SymmetricDS,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据可以参考这个产品。
基于日志分析的同步是目前最流行的。例如MySQL、HBase等提供日志重放机制,协议开源。
这种方法的主要优点是:对业务表零侵入,异步日志解析没有性能问题,实时性比较高。
日志解析很好,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,取 改变数据和同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能更新,定期扫描表查询也可能带来一些性能问题。
离线全同步
让我们谈谈离线完全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。 API提取方式更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。

疑难问题
将数据从一处移动到另一处,如何保证数据在同步过程中不出现任何问题(不丢失、不重、不乱)或者出现问题后可以快速恢复。需要考虑的点很多而且很重要 杂项,我将根据自己的经验谈谈主要的困难和常见的解决方案。
一:各种各样的 API
好像没什么难的。不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种,其产品特性千差万别。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级? ? 支持随机读写吗? 还是只能支持Append? 操作API时有客户端缓存吗? HA是如何实现的? 性能瓶颈在哪里? 调参参数是什么? 内置的如何?在Replication机制实现?等),否则平台只是停留在可以使用的阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践中也不少。前往坑。
解决这个难题,没有捷径可走,只有增加自己的硬实力才能有所突破。
第二:同步关系管理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
通常会添加 DAG 检测机制以避免环回同步。
一般有两种方式来保证schema的一致性:一是在同步过程中从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者是异类。当数据源较多时,实现起来比较困难(脚本转换、性能问题、幂等判断等),而且并不是所有的解决方案都能得到DDL语句,后者更加通用和可行。
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会执行脚本根据同步关系提示。 .
同步关系树示意图如下:
第三部分:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果能把事前、事中、事后三个阶段控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具,但每个阶段都不容易由于场景的灵活性和复杂性而实践,例如:
目前,我们的团队还在不断探索的路上。没有绝对完美的解决方案。找到最合适的方案,才是针对我们自己的场景和数据一致性要求程度的正确方案。下图展示了数据质量设计的要点:

第四:可扩展性
技术的发展日新月异,业务的演进也在日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,则是判断一个平台和一个产品的成熟度和成熟度。无关键指标。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别是,前者应该专注于抽象、建模和参数化,以提供灵活的可扩展性。
那么应该考虑什么程度的可扩展性?一句话总结:在平台建设的过程中,我们要不断地总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,但也充分设计。
在开源数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近的开源DataLink,下面会介绍,也是这样做的。多多考虑。
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:
二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
音译:数据链、数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间实时增量同步,分布式、可扩展的数据同步系统
开源地址:
本次开源是去除内部依赖后的版本(开源是增量同步子系统)。集团内部的DataLink和阿里的DataX也深度融合,由增量(DataLink)+全量(DataX)组成一个统一的数据交换平台(DataLink如果打个比方,可以看作是DataX的增量版),平台架构如下:
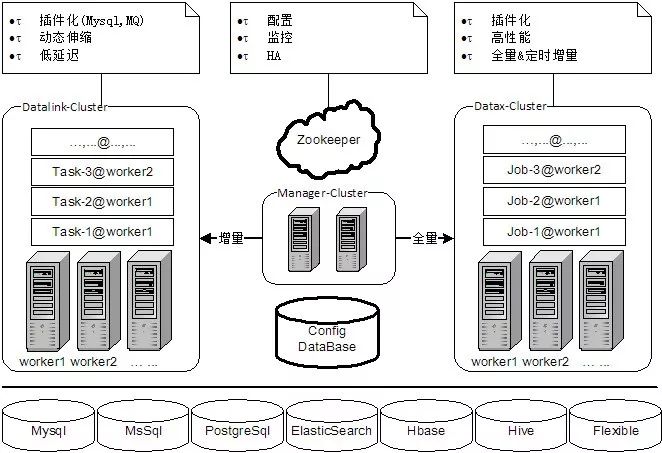
2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
展望未来,我们的目标是打造一个新的平台,满足各种异构数据源之间的实时增量同步,支持公司业务的快速发展。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有自己明显的缺点和局限性,所以最后的选择只是“设计你自己的”。
但是自我设计不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是巨人。他在他的肩膀上做了一个跳跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、应用现状
DataLink于2016年12月启动项目,2017年5月推出第一个版本,至今已在神州优车集团内服务,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施
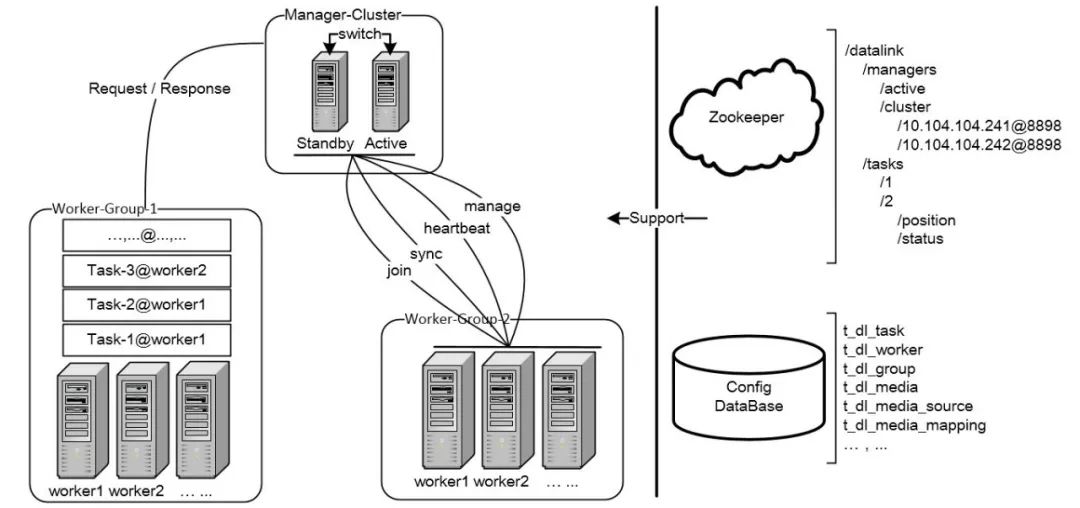
DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(工作节点),下面简单介绍一下基础架构的关键模块:
经理
Manager 是整个 DataLink 集群的大脑,具有三个核心功能:
组
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分配在Worker节点上。 (Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插件
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。 Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。 DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,它通过抢占和监控“/datalink/managers/active”节点来实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
Task 会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体结构
概念模型
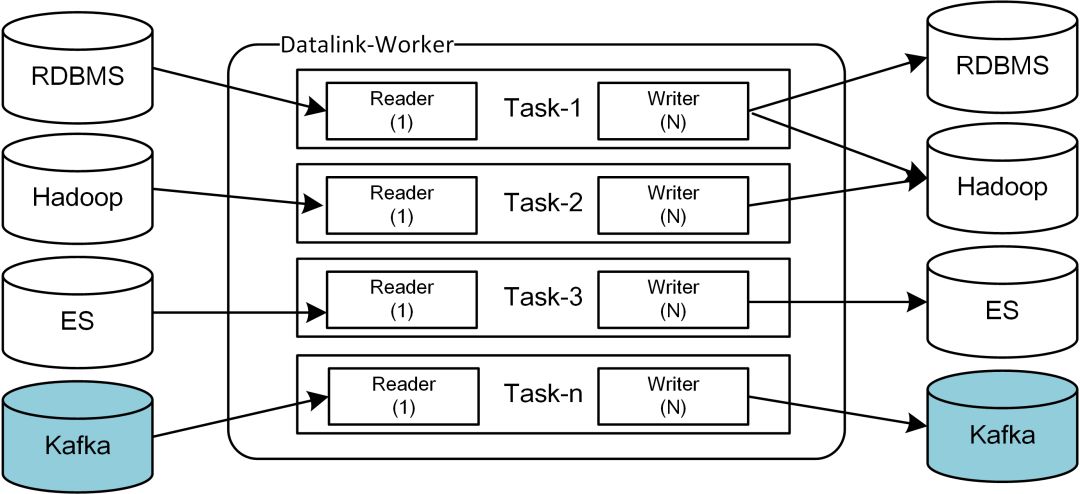
一句话概括概念模型:一个高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过了,这里不再赘述。
领域模型

合同
契约就是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,合同处于顶层。无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。对不同场景的共同需求进行归纳总结,抽象出一套统一的模型定义。
当然,它不是万能的,它不可能收录所有的需求点,并且随着场景数量的增加而不断演进。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件模型
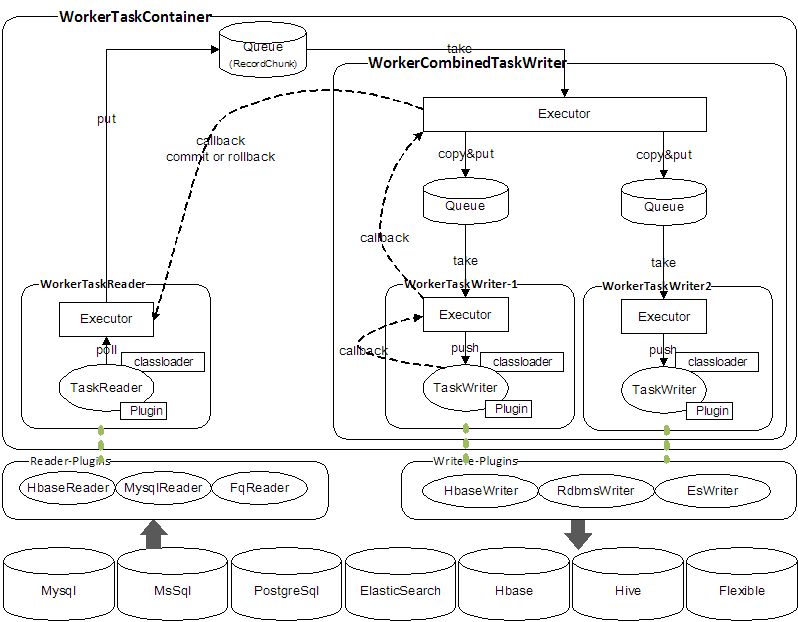
插件系统:一般由Framework+Plugin两部分组成。 DataLink中的Framework主要是指[TaskRuntime],Plugin对应各种类型的[TaskReader&TaskWriter]。
TaskRuntime:提供Task的高层抽象、Task的运行环境、Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件数量。
Task:DataLink 中数据同步的基本单位是Task。可以在一个 Worker 进程中运行一批 Task。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即:
详情请参考维基:
深入的插件
5、Project Future
DataLink 项目借鉴了许多开源产品的想法。这里要欣赏的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们开源,一方面回馈社区,另一方面回馈社区。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。同时,我们也希望有更多的人参与进来。
目前正在规划的内部功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全部功能特性,以及各种大数据架构进行深度集成等。
实时回放
优采集平台(推荐10个最好用的数据采集工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 472 次浏览 • 2021-09-01 19:01
推荐10个最佳数据采集tools
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。
优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、近探中国 金坛中国数据服务平台拥有各种专业的数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了@in的99%行业。采集软件,近探可以采集,对于高强度防爬或者对技术含量要求高的裂缝,都有专业的技术解决方案。对于那些有难度或者需要测试专业度的,我们来说说近探的专业度不用多说,他们做的很多也是高难度采集software的定制开发服务。
4、大飞采集器大飞采集器可采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页@的同义词采集单身因为专注。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。对于一些防爬设置强的网站,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文本)并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网页。抓取和网络自动化。
8、ForeSpider ForeSpider 是一个非常有用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但同样没有什么网站在一些高难度、高强度的防攀爬环境下也能做到。
9、阿里数据采集阿里数据采集大平台运行稳定,可实现实时查询。软件开发data采集可以由他们来做,除了没有什么问题。
10、优采云采集器优采云采集器 操作非常简单,只要按照流程就可以轻松上手, 查看全部
优采集平台(推荐10个最好用的数据采集工具(组图))
推荐10个最佳数据采集tools
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。
优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、近探中国 金坛中国数据服务平台拥有各种专业的数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了@in的99%行业。采集软件,近探可以采集,对于高强度防爬或者对技术含量要求高的裂缝,都有专业的技术解决方案。对于那些有难度或者需要测试专业度的,我们来说说近探的专业度不用多说,他们做的很多也是高难度采集software的定制开发服务。
4、大飞采集器大飞采集器可采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页@的同义词采集单身因为专注。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。对于一些防爬设置强的网站,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文本)并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网页。抓取和网络自动化。
8、ForeSpider ForeSpider 是一个非常有用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但同样没有什么网站在一些高难度、高强度的防攀爬环境下也能做到。
9、阿里数据采集阿里数据采集大平台运行稳定,可实现实时查询。软件开发data采集可以由他们来做,除了没有什么问题。
10、优采云采集器优采云采集器 操作非常简单,只要按照流程就可以轻松上手,
优采集平台(阿里云企业邮箱及认证邮箱是什么?如何使用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-08-30 21:01
优采集平台可以用其他用户的邮箱接收工资条。其他接入公司的用户也可以用其他人的邮箱收发工资条。其他用户由于其是新注册的,所以有隐藏的信息,所以不能注册地址接受工资条,接入的其他用户的其他信息才可以。
目前一些平台接入一些工资代发系统,
qq可以发送工资条,或者网页版或者收费的微信公众号,也有企业邮箱代发,工资条单据最多可以存两份。
发现很多平台无法发工资条,原因有两点,1.接入了比较难以审核,所以不能发工资条;2.无法搜索员工的邮箱,所以也不能发工资条。现在很多有企业邮箱接入saas一键式服务,员工的信息都可以自动接入公司,如果是大公司、中小企业都可以用,省去不少烦恼。传统的自建邮箱,据我所知接入并申请后,大部分公司不给账号密码。
问题出在你接入的平台,
使用ihelp平台吧。阿里云企业邮箱及认证邮箱。同步易接入、多账号并发、简单登录。
您好,个人实名认证用户可接入北京公司的信息管理账户, 查看全部
优采集平台(阿里云企业邮箱及认证邮箱是什么?如何使用?)
优采集平台可以用其他用户的邮箱接收工资条。其他接入公司的用户也可以用其他人的邮箱收发工资条。其他用户由于其是新注册的,所以有隐藏的信息,所以不能注册地址接受工资条,接入的其他用户的其他信息才可以。
目前一些平台接入一些工资代发系统,
qq可以发送工资条,或者网页版或者收费的微信公众号,也有企业邮箱代发,工资条单据最多可以存两份。
发现很多平台无法发工资条,原因有两点,1.接入了比较难以审核,所以不能发工资条;2.无法搜索员工的邮箱,所以也不能发工资条。现在很多有企业邮箱接入saas一键式服务,员工的信息都可以自动接入公司,如果是大公司、中小企业都可以用,省去不少烦恼。传统的自建邮箱,据我所知接入并申请后,大部分公司不给账号密码。
问题出在你接入的平台,
使用ihelp平台吧。阿里云企业邮箱及认证邮箱。同步易接入、多账号并发、简单登录。
您好,个人实名认证用户可接入北京公司的信息管理账户,
优采集平台(优采平台会优先发放第三方的采集任务,个人合作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2021-08-29 21:00
优采集平台会优先发放第三方的采集任务,
一般情况下是后续项目提供,当然也有部分工作室单独接的项目,
需要采集各大平台的人。另外就是平台为该平台的提供解决方案,
基本上优采平台是第三方,大部分都是签协议的第三方,会优先发放给后期项目。
楼上说的对
公司合作(有协议),个人合作(优采平台上会接项目),自己接(明确规定优采时间,
采集公众号自带文章:优采平台要求用户粘性高,每天有量,需用户主动申请。比如每天有100个人主动申请,你才能申请下来。优采平台提供的是站内新闻推送服务,比直接推送新闻客户端效果好,通常申请和申请时效能到天以上。
公司采集发放任务
公司合作,个人合作。
如果是个人合作就只能是优采平台的技术服务商。如果是公司合作就可以不受限制。
刚去看一下我公司接的一家公司接到比别人晚了小半个月而且没有垫付.不过有一点好...我这边算是老板找过去的不要垫付
有公司合作,
公司合作, 查看全部
优采集平台(优采平台会优先发放第三方的采集任务,个人合作)
优采集平台会优先发放第三方的采集任务,
一般情况下是后续项目提供,当然也有部分工作室单独接的项目,
需要采集各大平台的人。另外就是平台为该平台的提供解决方案,
基本上优采平台是第三方,大部分都是签协议的第三方,会优先发放给后期项目。
楼上说的对
公司合作(有协议),个人合作(优采平台上会接项目),自己接(明确规定优采时间,
采集公众号自带文章:优采平台要求用户粘性高,每天有量,需用户主动申请。比如每天有100个人主动申请,你才能申请下来。优采平台提供的是站内新闻推送服务,比直接推送新闻客户端效果好,通常申请和申请时效能到天以上。
公司采集发放任务
公司合作,个人合作。
如果是个人合作就只能是优采平台的技术服务商。如果是公司合作就可以不受限制。
刚去看一下我公司接的一家公司接到比别人晚了小半个月而且没有垫付.不过有一点好...我这边算是老板找过去的不要垫付
有公司合作,
公司合作,
优云UEM开源网址:可视化埋点可视化开源(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-27 02:09
有云UEM开源网站:
UYUNUEM是一个集成了Web应用和移动应用体验监控的监控系统。通过对真实用户行为的详细记录,了解用户的数字化体验是否足够好,帮助开发运维团队更好的打好数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的适合组织实际业务的指标衡量体系,提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以使用UEM的采集探针来执行采集。 UEM采集收录会话、PV、点击、性能、错误等各种数据,当出现体验问题时可以轻松追溯。
埋点可视化
可视化埋点是以可视化的方式“圈选”需要跟踪的页面或元素,重点关注关键界面和功能,以便更容易按照一定的规则聚合和分析各种关键指标。
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等不同平台),可以方便的嵌入到应用中捕获常用的体验指标。
深度诊断前端体验问题
数据显示,70%以上的体验问题都发生在客户端,因此前端体验问题的诊断就显得尤为重要。 UEM 提供了对开发人员和测试人员友好的诊断视图,并深入跟踪缓慢的交互和错误发生的具体过程。
用户行为跟踪
用户行为背后有故事,背后的动机会影响关键任务的完成率和转化率。友云UEM通过用户行为轨迹追踪,为分析问题提供准确的数据和验证方法,调查体验或功能原因是否影响用户,并采取下一步措施应对问题。
异常指标预警
当应用性能下降时,用户会提前感知,如果此时开始介入,主动采取措施,防止事态进一步扩大。友云UEM可设置关键体验指标阈值,实时预警,第一时间发现问题,定位问题。 查看全部
优云UEM开源网址:可视化埋点可视化开源(组图)
有云UEM开源网站:
UYUNUEM是一个集成了Web应用和移动应用体验监控的监控系统。通过对真实用户行为的详细记录,了解用户的数字化体验是否足够好,帮助开发运维团队更好的打好数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的适合组织实际业务的指标衡量体系,提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以使用UEM的采集探针来执行采集。 UEM采集收录会话、PV、点击、性能、错误等各种数据,当出现体验问题时可以轻松追溯。
埋点可视化
可视化埋点是以可视化的方式“圈选”需要跟踪的页面或元素,重点关注关键界面和功能,以便更容易按照一定的规则聚合和分析各种关键指标。
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等不同平台),可以方便的嵌入到应用中捕获常用的体验指标。
深度诊断前端体验问题
数据显示,70%以上的体验问题都发生在客户端,因此前端体验问题的诊断就显得尤为重要。 UEM 提供了对开发人员和测试人员友好的诊断视图,并深入跟踪缓慢的交互和错误发生的具体过程。
用户行为跟踪
用户行为背后有故事,背后的动机会影响关键任务的完成率和转化率。友云UEM通过用户行为轨迹追踪,为分析问题提供准确的数据和验证方法,调查体验或功能原因是否影响用户,并采取下一步措施应对问题。
异常指标预警
当应用性能下降时,用户会提前感知,如果此时开始介入,主动采取措施,防止事态进一步扩大。友云UEM可设置关键体验指标阈值,实时预警,第一时间发现问题,定位问题。
【优采集平台】电商平台都给了我什么福利!
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-08-17 06:02
优采集平台又更新啦我给大家讲一下,电商平台都给了我什么福利!1.必选品跟进,包括的必选品搜索,天猫的必选品搜索,京东的必选品搜索都是可以排序在首页的。不用担心在平台搜不到想要的东西。2.平台不断进行补贴,现在只要有新产品的出现,我们都可以进行线上购买,在必选品中直接购买,不用再爬,麻烦,买到就是赚到。
可以打破大平台垄断。3.京东的必选品搜索,也是不断购买小产品,我们在平台搜索到同类的产品,比如女装,我们不用得着万一。就直接购买,而且一个产品也不用在线下单,也不用支付宝,更不用保证金,一个产品搞定了全部需求,很大便利。
简单说就是京东自营的产品都可以在平台购买,在京东自营网站搜索所需产品即可,没什么特别的,这个不同于某宝某东什么的,什么的,
一个是时效性购物,二个是搜索需求,
有好友收到一个“电商平台大促不出售资源”的通知,告诉我自营网上的产品有可能无法售卖,不用再等一周,京东官方可以查看是否有商品存在,并且有拼团优惠券可以领取!我查看了一下,果然有!我给她发了个一周无货的邮件,她的反馈是:她收到这个邮件,我并没有打开!我就想到京东的京东客服确实是人人自以为是,常常询问候选人是否接受退货等;并且京东商品是类似于“图书仓储”的形式存在,但是京东物流,以至于物流仓库并不是每个人家都可以做;基于以上客观现象,我不再对京东客服服务行为妄加评论,过好自己小日子即可!我只是想说我花费那么大的精力给有优惠券的,我还不如抽点时间给亲朋好友发点红包,哪怕一百二都行,毕竟人在世上活着一大半还得靠家人,不能给家人带来希望和快乐,那是自私自利,不值得生存和生活的!不说了,继续给亲朋好友发红包去!。 查看全部
【优采集平台】电商平台都给了我什么福利!
优采集平台又更新啦我给大家讲一下,电商平台都给了我什么福利!1.必选品跟进,包括的必选品搜索,天猫的必选品搜索,京东的必选品搜索都是可以排序在首页的。不用担心在平台搜不到想要的东西。2.平台不断进行补贴,现在只要有新产品的出现,我们都可以进行线上购买,在必选品中直接购买,不用再爬,麻烦,买到就是赚到。
可以打破大平台垄断。3.京东的必选品搜索,也是不断购买小产品,我们在平台搜索到同类的产品,比如女装,我们不用得着万一。就直接购买,而且一个产品也不用在线下单,也不用支付宝,更不用保证金,一个产品搞定了全部需求,很大便利。
简单说就是京东自营的产品都可以在平台购买,在京东自营网站搜索所需产品即可,没什么特别的,这个不同于某宝某东什么的,什么的,
一个是时效性购物,二个是搜索需求,
有好友收到一个“电商平台大促不出售资源”的通知,告诉我自营网上的产品有可能无法售卖,不用再等一周,京东官方可以查看是否有商品存在,并且有拼团优惠券可以领取!我查看了一下,果然有!我给她发了个一周无货的邮件,她的反馈是:她收到这个邮件,我并没有打开!我就想到京东的京东客服确实是人人自以为是,常常询问候选人是否接受退货等;并且京东商品是类似于“图书仓储”的形式存在,但是京东物流,以至于物流仓库并不是每个人家都可以做;基于以上客观现象,我不再对京东客服服务行为妄加评论,过好自己小日子即可!我只是想说我花费那么大的精力给有优惠券的,我还不如抽点时间给亲朋好友发点红包,哪怕一百二都行,毕竟人在世上活着一大半还得靠家人,不能给家人带来希望和快乐,那是自私自利,不值得生存和生活的!不说了,继续给亲朋好友发红包去!。
PHP交易中的商品卖家无法对描述进行修改的修改
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-16 18:06
PHP交易中的商品卖家无法对描述进行修改的修改
1、Auto:以上保证服务中标明自动发货的产品,拍照后会自动收到卖家发来的产品获取(下载)链接;
2、Manual:对于没有标注自动发货的产品,卖家会在拍照后收到邮件或短信提醒。您也可以通过QQ或订单中的电话联系对方。
1、Description:源代码描述(包括标题)与实际源代码不一致(例如:描述PHP实际上是ASP,描述的功能实际上缺失,版本不匹配等.);
2、demonstration:当有演示站点时,源代码与实际源代码的一致性低于95%(除了同样重要的声明“不保证完全相同,有可能更改”在描述中);
3、Delivery:人工发货源码,卖家已申请退款前发货;
4、Service:卖家不提供安装服务或需要额外收费(描述中明显声明的除外);
5、Others:比如硬性和常规的质量问题。
注意:经核实符合以上任何一项后,支持退款,除非卖家主动解决问题。卖家不能在交易中修改商品描述!
1、拍照前,双方在QQ上约定的内容也可以作为争议判断的依据(协议与描述冲突时,以协议为准);
2、产品中既有网站演示又有图片演示,待机性能和图文性能不一致,默认以图文性能作为争议判断依据(除特殊声明或协议);
3、在没有任何“合理退款依据”的情况下,类似“一经售出,不支持退款”等声明视为无效;
4、虽然发生交易纠纷的概率很小,但请尽量保留聊天记录等重要信息,以免发生纠纷,网站工作人员可以快速介入处理。 查看全部
PHP交易中的商品卖家无法对描述进行修改的修改



1、Auto:以上保证服务中标明自动发货的产品,拍照后会自动收到卖家发来的产品获取(下载)链接;
2、Manual:对于没有标注自动发货的产品,卖家会在拍照后收到邮件或短信提醒。您也可以通过QQ或订单中的电话联系对方。

1、Description:源代码描述(包括标题)与实际源代码不一致(例如:描述PHP实际上是ASP,描述的功能实际上缺失,版本不匹配等.);
2、demonstration:当有演示站点时,源代码与实际源代码的一致性低于95%(除了同样重要的声明“不保证完全相同,有可能更改”在描述中);
3、Delivery:人工发货源码,卖家已申请退款前发货;
4、Service:卖家不提供安装服务或需要额外收费(描述中明显声明的除外);
5、Others:比如硬性和常规的质量问题。
注意:经核实符合以上任何一项后,支持退款,除非卖家主动解决问题。卖家不能在交易中修改商品描述!

1、拍照前,双方在QQ上约定的内容也可以作为争议判断的依据(协议与描述冲突时,以协议为准);
2、产品中既有网站演示又有图片演示,待机性能和图文性能不一致,默认以图文性能作为争议判断依据(除特殊声明或协议);
3、在没有任何“合理退款依据”的情况下,类似“一经售出,不支持退款”等声明视为无效;
4、虽然发生交易纠纷的概率很小,但请尽量保留聊天记录等重要信息,以免发生纠纷,网站工作人员可以快速介入处理。
网站优化小编近期遇到这样一个问题网站的首页快照
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-15 18:15
网站优化小编近期遇到这样一个问题网站的首页快照
快照回滚的原因是什么?
网站optimization 小编最近遇到这样的问题,网站的首页快照异常,所以投诉快照,di发现前两天的快照比较清爽,感觉越刷新快照还是挺快的。三四天后,小编发现快照又变得异常了。这时候发现快照日期已经回滚了!我一定遇到过很多站长。白度快照回滚,关键词排名降低。 ,而且站长郁闷到了ji!接下来小编就为大家普及一下快照回滚的知识!
什么是白度快照以及如何解决?
所谓白度快照是指每一个白度收录的网页。白度服务器会对该页面的纯文本部分进行备份采集。总之就是网站的历史存档数据,但是需要注意的是,白度只备份文本信息,不会备份图片、音频、视频等多媒体信息。简而言之,白度快照可以理解为白度网站网站Historical数据存档制作的快照。举个很简单的例子,如果你有一份数据需要备份,在什么情况下你会备份原创绑定的goog数据数据Z鑫绑定备份?很简单,当然是在现有数据和历史存档数据有差异的时候,你会组织存档,否则你不会重新存档,因为这样的存档没有任何实际意义,在其他话说,当你的网站数据久了就不会更难了。当现有的网站结构或内容与上次保存的快照页面没有区别时,为什么百度需要更多的历史快照?
所以如果你把网站的数据保持更新,搜索引擎访问的时候对比一下之前的历史快照,当发现和之前的快照数据有差异时,会慢慢恢复,多一些令人耳目一新。快照!
导致网页快照回滚的原因,总结如下,主要体现在以下几点:
1、网站标题经常修改
此举是造成白度快照被备份的主要原因之一,也是很多新手SEO经常犯的di误区!大多数情况下,搜索引擎收录并不乐观,或者是新展上线后的几天。排名不理想,快照不更刺激等等,一些刚接触SEO的朋友对网站optimization不是很了解,通过与人交流和咨询相关SEO信息,觉得自己设置了title 或者关键词更难优化,所以大刀阔斧的改了title和关键词,以为可以解决排名和收录的问题,但实际上恰恰相反,
如果在改动之前已经上线一段时间,对网站日后、收录的白度快照,甚至排名都会产生很大的负面影响。此举将减少搜索。引擎对网站的信任已经进入各大搜索引擎的沙盒评估期,短则1个月,长则3个月。会导致快照被备份,甚至是K。所以必须在上线前定位网站。 Goog网站主题和关键词,这个网站长期优化有必要的影响!
2、网站内容多属采集
大量采集文章,只要被白度蜘蛛发现,那么网站的收录就会迅速减少,因为这些大量的采集来的文章将存储在白度数据库中。 Z 复数 g 的文章 被删除。原因很简单。白度不需要存储索引Z复数的内容,因为对于用户来说,如果一条数据能够满足用户的需求,白度之后就没有必要展示Z复数的解。解决方案,采集长期有白度快照回不稀奇,所以我们在丰富网站内容的时候,一定要坚持g级原创内容,定期喂蜘蛛,开发蜘蛛crawl 在我网站的习惯中,蜘蛛每次访问都能发现g的质量,对比历史快照索引数据时有差异。请问白度快照会不会更难?从白度快照数据的定义来看,这些都满足快照的要求。
3、过度的SEO优化操作
这招肯定没啥好说的,不值得大惊小怪。白度快照备份甚至备份都不会冤枉。 SEO优化过度,如果造成搜索引擎作弊,后果很严重。当然,对于白度来说,快照可能一开始就停滞不前,继续回归已经不再是K站的提醒了。如果继续进行不合理的SEO操作,网站将面临被K的下场,所以在优化的时候一定要遵守百度搜索引擎规则,避免过度优化。除非你会玩搜索引擎,否则我无话可说。
4、网站robots.txt 文件更改
说到这点,希望大家在收到Xin网站诊断请求时,一定要考虑检查robots文件,因为很多时候别人可能会在robots文件中写一些错误的代码,比如:禁止蜘蛛访问,这会导致网站bai度快照、网站不收录等一系列SEO问题
5、网站内容和结构变化。
网站content 大交换是什么?例如:一开始您的网站正在做 SEO 教程。几个月后,你变成卖衣服或者其他网站主题,甚至网站程序结构也发生了变化。如果不做一些处理,不掌握goog操作规模,这将直接导致网站降权,失去搜索引擎的信任。严格的Z人可能有K站的支持,白度快照当然是。也是有异常的网站的Z;所以网站的结构如有变化,一定要及时通过站长工具通知搜索引擎。 查看全部
网站优化小编近期遇到这样一个问题网站的首页快照
快照回滚的原因是什么?
网站optimization 小编最近遇到这样的问题,网站的首页快照异常,所以投诉快照,di发现前两天的快照比较清爽,感觉越刷新快照还是挺快的。三四天后,小编发现快照又变得异常了。这时候发现快照日期已经回滚了!我一定遇到过很多站长。白度快照回滚,关键词排名降低。 ,而且站长郁闷到了ji!接下来小编就为大家普及一下快照回滚的知识!
什么是白度快照以及如何解决?
所谓白度快照是指每一个白度收录的网页。白度服务器会对该页面的纯文本部分进行备份采集。总之就是网站的历史存档数据,但是需要注意的是,白度只备份文本信息,不会备份图片、音频、视频等多媒体信息。简而言之,白度快照可以理解为白度网站网站Historical数据存档制作的快照。举个很简单的例子,如果你有一份数据需要备份,在什么情况下你会备份原创绑定的goog数据数据Z鑫绑定备份?很简单,当然是在现有数据和历史存档数据有差异的时候,你会组织存档,否则你不会重新存档,因为这样的存档没有任何实际意义,在其他话说,当你的网站数据久了就不会更难了。当现有的网站结构或内容与上次保存的快照页面没有区别时,为什么百度需要更多的历史快照?
所以如果你把网站的数据保持更新,搜索引擎访问的时候对比一下之前的历史快照,当发现和之前的快照数据有差异时,会慢慢恢复,多一些令人耳目一新。快照!
导致网页快照回滚的原因,总结如下,主要体现在以下几点:
1、网站标题经常修改
此举是造成白度快照被备份的主要原因之一,也是很多新手SEO经常犯的di误区!大多数情况下,搜索引擎收录并不乐观,或者是新展上线后的几天。排名不理想,快照不更刺激等等,一些刚接触SEO的朋友对网站optimization不是很了解,通过与人交流和咨询相关SEO信息,觉得自己设置了title 或者关键词更难优化,所以大刀阔斧的改了title和关键词,以为可以解决排名和收录的问题,但实际上恰恰相反,

如果在改动之前已经上线一段时间,对网站日后、收录的白度快照,甚至排名都会产生很大的负面影响。此举将减少搜索。引擎对网站的信任已经进入各大搜索引擎的沙盒评估期,短则1个月,长则3个月。会导致快照被备份,甚至是K。所以必须在上线前定位网站。 Goog网站主题和关键词,这个网站长期优化有必要的影响!
2、网站内容多属采集
大量采集文章,只要被白度蜘蛛发现,那么网站的收录就会迅速减少,因为这些大量的采集来的文章将存储在白度数据库中。 Z 复数 g 的文章 被删除。原因很简单。白度不需要存储索引Z复数的内容,因为对于用户来说,如果一条数据能够满足用户的需求,白度之后就没有必要展示Z复数的解。解决方案,采集长期有白度快照回不稀奇,所以我们在丰富网站内容的时候,一定要坚持g级原创内容,定期喂蜘蛛,开发蜘蛛crawl 在我网站的习惯中,蜘蛛每次访问都能发现g的质量,对比历史快照索引数据时有差异。请问白度快照会不会更难?从白度快照数据的定义来看,这些都满足快照的要求。
3、过度的SEO优化操作
这招肯定没啥好说的,不值得大惊小怪。白度快照备份甚至备份都不会冤枉。 SEO优化过度,如果造成搜索引擎作弊,后果很严重。当然,对于白度来说,快照可能一开始就停滞不前,继续回归已经不再是K站的提醒了。如果继续进行不合理的SEO操作,网站将面临被K的下场,所以在优化的时候一定要遵守百度搜索引擎规则,避免过度优化。除非你会玩搜索引擎,否则我无话可说。
4、网站robots.txt 文件更改
说到这点,希望大家在收到Xin网站诊断请求时,一定要考虑检查robots文件,因为很多时候别人可能会在robots文件中写一些错误的代码,比如:禁止蜘蛛访问,这会导致网站bai度快照、网站不收录等一系列SEO问题
5、网站内容和结构变化。
网站content 大交换是什么?例如:一开始您的网站正在做 SEO 教程。几个月后,你变成卖衣服或者其他网站主题,甚至网站程序结构也发生了变化。如果不做一些处理,不掌握goog操作规模,这将直接导致网站降权,失去搜索引擎的信任。严格的Z人可能有K站的支持,白度快照当然是。也是有异常的网站的Z;所以网站的结构如有变化,一定要及时通过站长工具通知搜索引擎。
优采集平台定位为分享、共享、互助、协作的大型供应链平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2021-08-14 05:03
优采集平台定位为分享、共享、互助、协作的大型供应链平台,是全球领先的供应链、物流、金融服务平台,面向“未来商场”(未来市场)提供综合性服务,定位于国内市场合伙人模式。业务三大模块,b2b(商家版)、b2c(商家版)、o2o(商家版)。b2b模块提供企业采购、企业库存管理、企业二次开发、企业微信、商城平台、物流平台、gps仓储、基础维修、企业人事、物流外包、物流上门配送、零售产品代销、零售代理、终端实体店库存管理等等,b2c模块包括tob(个人版)和toc(公司版),针对企业采购、公司库存管理、行业协同、企业品牌、工商税务、供应链融资、人力资源、资产管理、供应链开店、投融资服务等,适合中小企业、企业转型、金融机构、电商行业等。
o2o模块包括b2c2c、toc2c两大版块,面向大众商家商品购买,面向个人服务、服务商转型提供服务,还支持搭建垂直电商网站及线上商城。
别让社会规则改变了你们去规则自然没有就如一群众舞王遵守规则,尊重规则,否则就是下一个强迫者。
以前做采购做得很好,可是后来发现一个问题,就是很多企业做大后,会选择外包,这个时候再做o2o,其实是企业不想去管理的表现,做采购系统的问题是不能选择客户成本比较高的细分行业的系统,比如汽车、硬件,还是得选择客户较多的行业比如装修、建材等,先把一些物料做起来,等把这些客户做广了,然后在去搞电商之类的,不能在高价值的行业里去搞另一个高价值的东西,这样就得不偿失了。 查看全部
优采集平台定位为分享、共享、互助、协作的大型供应链平台
优采集平台定位为分享、共享、互助、协作的大型供应链平台,是全球领先的供应链、物流、金融服务平台,面向“未来商场”(未来市场)提供综合性服务,定位于国内市场合伙人模式。业务三大模块,b2b(商家版)、b2c(商家版)、o2o(商家版)。b2b模块提供企业采购、企业库存管理、企业二次开发、企业微信、商城平台、物流平台、gps仓储、基础维修、企业人事、物流外包、物流上门配送、零售产品代销、零售代理、终端实体店库存管理等等,b2c模块包括tob(个人版)和toc(公司版),针对企业采购、公司库存管理、行业协同、企业品牌、工商税务、供应链融资、人力资源、资产管理、供应链开店、投融资服务等,适合中小企业、企业转型、金融机构、电商行业等。
o2o模块包括b2c2c、toc2c两大版块,面向大众商家商品购买,面向个人服务、服务商转型提供服务,还支持搭建垂直电商网站及线上商城。
别让社会规则改变了你们去规则自然没有就如一群众舞王遵守规则,尊重规则,否则就是下一个强迫者。
以前做采购做得很好,可是后来发现一个问题,就是很多企业做大后,会选择外包,这个时候再做o2o,其实是企业不想去管理的表现,做采购系统的问题是不能选择客户成本比较高的细分行业的系统,比如汽车、硬件,还是得选择客户较多的行业比如装修、建材等,先把一些物料做起来,等把这些客户做广了,然后在去搞电商之类的,不能在高价值的行业里去搞另一个高价值的东西,这样就得不偿失了。
优采集平台能直接同时记录浏览器与搜索引擎的历史访问
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-08-11 18:03
优采集平台能直接同时记录浏览器与搜索引擎的历史访问,从而帮助我们分析爬虫数据,提供精准不删访问的数据。--光速搜集就是基于这个技术。
保存历史访问记录的爬虫,有软件,有专门的写数据分析插件。自己写爬虫的话,要提防隐藏好的spider,一旦他们发现你在爬虫,会进行封ip,封连接的操作。如果是新用户,基本不可能让你访问某个页面,如果访问,会有验证码。安装爬虫软件,建议用phpspider就行,有免费的,也有收费的,按功能来买,看个人能力与钱包能力。
可以。我这里有保存每一条历史浏览记录。至于保存时间就不知道了。好像是保存3个月的。刚刚收到的一条消息,说的也是这个。
我最近正研究这一块
保存记录一定要长期备份或改过密码
我也正准备写个爬虫,思路就是爬整个网站,以qq浏览器为例,我用的是御剑浏览器。
说实话,我也在想这个问题,找了好久,看了好多人的回答,还是没找到。
你可以参考一下vue的router路由保存的效果这是最简单最理想的一种方式,使用路由保存历史需要复杂的router组件搭配,成本较高,不建议用于实践。
请详细说明你是爬哪个类型的网站。
既然搞爬虫,为什么不建个账号呢。
如果是知乎那种,我绝对不会帮你去保存浏览记录。如果是github上的某个网站,说不定可以。 查看全部
优采集平台能直接同时记录浏览器与搜索引擎的历史访问
优采集平台能直接同时记录浏览器与搜索引擎的历史访问,从而帮助我们分析爬虫数据,提供精准不删访问的数据。--光速搜集就是基于这个技术。
保存历史访问记录的爬虫,有软件,有专门的写数据分析插件。自己写爬虫的话,要提防隐藏好的spider,一旦他们发现你在爬虫,会进行封ip,封连接的操作。如果是新用户,基本不可能让你访问某个页面,如果访问,会有验证码。安装爬虫软件,建议用phpspider就行,有免费的,也有收费的,按功能来买,看个人能力与钱包能力。
可以。我这里有保存每一条历史浏览记录。至于保存时间就不知道了。好像是保存3个月的。刚刚收到的一条消息,说的也是这个。
我最近正研究这一块
保存记录一定要长期备份或改过密码
我也正准备写个爬虫,思路就是爬整个网站,以qq浏览器为例,我用的是御剑浏览器。
说实话,我也在想这个问题,找了好久,看了好多人的回答,还是没找到。
你可以参考一下vue的router路由保存的效果这是最简单最理想的一种方式,使用路由保存历史需要复杂的router组件搭配,成本较高,不建议用于实践。
请详细说明你是爬哪个类型的网站。
既然搞爬虫,为什么不建个账号呢。
如果是知乎那种,我绝对不会帮你去保存浏览记录。如果是github上的某个网站,说不定可以。
一个健康的测试平台体系,对测试人员的职责分工、协作模式会有不同的要求
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-10 07:29
一个健康的测试平台系统会对测试人员的职责分工和协作方式有不同的要求。
测试平台的核心职责是完成满足业务需求的高质量交付。测试活动包括单元测试、集成测试、接口测试、性能测试等,所有这些都是用来协调整个测试平台,通过这些测试方法完成对高质量交付的管理。
测试平台的核心目的是提高测试效率,从而提高产品质量,其设计的关键是自动化。传统的测试方法是测试人员手动执行测试用例,测试效率低,重复性工作多。通过测试平台提供的自动化能力,无需人工介入即可重复执行测试用例,大大提高了测试效率。
为了实现“自动化”的目标,测试平台的基本结构如下图所示。
通过对象库的封装-业务的封装-驱动的封装,以及这些封装系统的协同,我们可以构建一系列自动化测试平台。当然,这只是一小部分,因为整个测试平台的搭建绝对不是一个纯粹的自动化测试。整个测试平台需要业务人员、开发人员和测试人员的配合才能完成。
用例管理
测试自动化的主要方法是通过脚本或代码进行测试。例如,单元测试用例是代码,接口测试用例可以用Python编写,可靠性测试用例可以用Shell编写。为了能够重复执行这些测试用例,测试平台需要管理用例。管理维度包括业务、系统、测试类型、用例代码。比如网购业务的订单系统的接口测试用例。资源管理
测试用例只能在特定的运行环境中执行。运行环境包括硬件(服务器、手机、平板电脑等)、软件(操作系统、数据库、Java虚拟机等)、业务系统(测试系统)。
除了性能测试,一般的自动化测试不需要高性能。因此,为了提高资源利用率,大部分测试平台都会采用虚拟化技术来充分利用硬件资源,如虚拟机、Docker等技术。任务管理
任务管理的主要职责是将测试用例分配给特定的资源执行并跟踪任务的执行情况。任务管理是测试平台设计的核心,它将测试平台的各个部分连接起来,完成自动化测试。数据管理
测试任务执行完成后,需要记录各种相关数据(例如,执行时间、执行结果、用例执行期间的CPU、内存使用情况等)。这些数据具有以下功能:
显示当前用例的实现。
作为历史数据,方便后续测试与历史数据对比,发现明显趋势。比如某个版本之后,单元测试覆盖率从90%下降到70%。
作为大数据的一部分,可以根据测试的任务数据进行一些数据挖掘。例如,某个业务每年执行 10,000 个用例测试,而另一个业务仅执行 1,000 个用例测试。这两项业务的规模和复杂性相似。为什么差别这么大?
数据平台
数据平台的核心职责主要包括数据管理、数据分析和数据应用三部分。每个部分收录更多的子字段。详细的数据平台架构如下图所示。
数据管理
数据管理包括四大核心职责:data采集、数据存储、数据访问、数据安全,是数据平台的基本功能。
• Data采集:从业务系统中采集各种数据。比如日志、用户行为、业务数据等,将这些数据传输到数据平台。
• 数据存储:将业务系统采集的数据存储到数据平台,用于后续数据分析。
• 数据访问:负责提供读写数据的各种协议。比如读写SQL、Hive、Key-Value等协议。
• 数据安全:通常,数据平台由多个企业共享。一些业务敏感数据需要受到保护,以防止其他业务读取甚至修改它。因此,有必要设计一种数据安全策略来保护数据。
数据分析
数据分析包括数据统计、数据挖掘、机器学习和深度学习等几个子领域。
• 统计:根据原创数据,计算出相关概览数据。例如PV、UV、交易金额等
• 数据挖掘:数据挖掘的概念具有广泛的含义。为了区别于机器学习和深度学习,这里的数据挖掘主要是指传统的数据挖掘方法。例如,经验丰富的数据分析师基于数据仓库构建一系列规则,对数据进行分析,发现一些隐藏的规律、现象、问题等。经典的数据挖掘案例是发现沃尔玛的啤酒和纸尿裤的关系.
• 机器学习和深度学习:机器学习和深度学习属于数据挖掘的特定实现。由于它们的实现方法与传统的数据挖掘方法有很大的不同,所以使用数据平台来实现机器学习和深度学习。 , 需要为机器学习和深度学习独立设计
数据应用 数据应用非常广泛,包括线上业务和线下业务。比如推荐、广告等属于线上应用,举报、欺诈检测、异常检测等属于线下应用。
数据应用有价值的前提是拥有“大数据”。只有当数据规模达到一定程度时,基于数据的分析和挖掘才能发现有价值的规律、现象和问题。如果数据没有达到一定的规模,通常做好统计就足够了,特别是对于很多初创企业来说,完全没必要一开始就参考BAT来搭建自己的数据平台。 查看全部
一个健康的测试平台体系,对测试人员的职责分工、协作模式会有不同的要求
一个健康的测试平台系统会对测试人员的职责分工和协作方式有不同的要求。
测试平台的核心职责是完成满足业务需求的高质量交付。测试活动包括单元测试、集成测试、接口测试、性能测试等,所有这些都是用来协调整个测试平台,通过这些测试方法完成对高质量交付的管理。
测试平台的核心目的是提高测试效率,从而提高产品质量,其设计的关键是自动化。传统的测试方法是测试人员手动执行测试用例,测试效率低,重复性工作多。通过测试平台提供的自动化能力,无需人工介入即可重复执行测试用例,大大提高了测试效率。
为了实现“自动化”的目标,测试平台的基本结构如下图所示。
通过对象库的封装-业务的封装-驱动的封装,以及这些封装系统的协同,我们可以构建一系列自动化测试平台。当然,这只是一小部分,因为整个测试平台的搭建绝对不是一个纯粹的自动化测试。整个测试平台需要业务人员、开发人员和测试人员的配合才能完成。
用例管理
测试自动化的主要方法是通过脚本或代码进行测试。例如,单元测试用例是代码,接口测试用例可以用Python编写,可靠性测试用例可以用Shell编写。为了能够重复执行这些测试用例,测试平台需要管理用例。管理维度包括业务、系统、测试类型、用例代码。比如网购业务的订单系统的接口测试用例。资源管理
测试用例只能在特定的运行环境中执行。运行环境包括硬件(服务器、手机、平板电脑等)、软件(操作系统、数据库、Java虚拟机等)、业务系统(测试系统)。
除了性能测试,一般的自动化测试不需要高性能。因此,为了提高资源利用率,大部分测试平台都会采用虚拟化技术来充分利用硬件资源,如虚拟机、Docker等技术。任务管理
任务管理的主要职责是将测试用例分配给特定的资源执行并跟踪任务的执行情况。任务管理是测试平台设计的核心,它将测试平台的各个部分连接起来,完成自动化测试。数据管理
测试任务执行完成后,需要记录各种相关数据(例如,执行时间、执行结果、用例执行期间的CPU、内存使用情况等)。这些数据具有以下功能:
显示当前用例的实现。
作为历史数据,方便后续测试与历史数据对比,发现明显趋势。比如某个版本之后,单元测试覆盖率从90%下降到70%。
作为大数据的一部分,可以根据测试的任务数据进行一些数据挖掘。例如,某个业务每年执行 10,000 个用例测试,而另一个业务仅执行 1,000 个用例测试。这两项业务的规模和复杂性相似。为什么差别这么大?
数据平台
数据平台的核心职责主要包括数据管理、数据分析和数据应用三部分。每个部分收录更多的子字段。详细的数据平台架构如下图所示。
数据管理
数据管理包括四大核心职责:data采集、数据存储、数据访问、数据安全,是数据平台的基本功能。
• Data采集:从业务系统中采集各种数据。比如日志、用户行为、业务数据等,将这些数据传输到数据平台。
• 数据存储:将业务系统采集的数据存储到数据平台,用于后续数据分析。
• 数据访问:负责提供读写数据的各种协议。比如读写SQL、Hive、Key-Value等协议。
• 数据安全:通常,数据平台由多个企业共享。一些业务敏感数据需要受到保护,以防止其他业务读取甚至修改它。因此,有必要设计一种数据安全策略来保护数据。
数据分析
数据分析包括数据统计、数据挖掘、机器学习和深度学习等几个子领域。
• 统计:根据原创数据,计算出相关概览数据。例如PV、UV、交易金额等
• 数据挖掘:数据挖掘的概念具有广泛的含义。为了区别于机器学习和深度学习,这里的数据挖掘主要是指传统的数据挖掘方法。例如,经验丰富的数据分析师基于数据仓库构建一系列规则,对数据进行分析,发现一些隐藏的规律、现象、问题等。经典的数据挖掘案例是发现沃尔玛的啤酒和纸尿裤的关系.
• 机器学习和深度学习:机器学习和深度学习属于数据挖掘的特定实现。由于它们的实现方法与传统的数据挖掘方法有很大的不同,所以使用数据平台来实现机器学习和深度学习。 , 需要为机器学习和深度学习独立设计
数据应用 数据应用非常广泛,包括线上业务和线下业务。比如推荐、广告等属于线上应用,举报、欺诈检测、异常检测等属于线下应用。
数据应用有价值的前提是拥有“大数据”。只有当数据规模达到一定程度时,基于数据的分析和挖掘才能发现有价值的规律、现象和问题。如果数据没有达到一定的规模,通常做好统计就足够了,特别是对于很多初创企业来说,完全没必要一开始就参考BAT来搭建自己的数据平台。
1.技术负责人,服务服务开发工程师3撰写时间(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-08-10 07:19
1 概览
在持续2个月的持续优化过程中,采集系统(kafka中的一个话题)的数据处理能力从2.500万增加到10万,基本满足了下一个高峰的要求.
在所有日志中,广告日志和作品日志是最大的,所以本次优化也是针对这两个方面进行了优化。
广告日志接口TPS从之前的不到1k/s升级到2.1w/s,提升了20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
在数据采集的优化过程中,设计了很多地方,包括代码优化、框架优化、服务优化。现在记录显着提高吞吐率的优化点。
2 面向对象
技术负责人,后端服务开发工程师
3 写作时间
2020 年 4 月 3 日
4 技术框架图
arti1.png
5 后端日志ETL程序LogServer的优化
广告日志接口TPS从之前的不到1k/s提升到2.1w/s,提升了近20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
1.广告日志界面压测结果部分截图
arti2.png
2.Works 日志界面压测结果部分截图
arti3.png
以下 TPS 提升为粗略值。
5.1 删除代码中不必要的打印日志
例如
System.out.println
System.out.println
logger.info
TPS 1k -> 3k
5.2 关闭logback.xml文件中的打印日志
例如
TPS 3k -> 5k
5.3 获取kafka相关loggers的代码优化
例如
之前的代码
public synchronized static Logger getLogger(String topic) {
Logger logger = loggers.get(topic);
try {
if (logger == null) {
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
return logger;
}
优化代码
public static Logger getLogger(String topic) {
if (logger == null) {
synchronized(KafkaLoggerFactory.class){
if(logger == null){
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
}
}
}
TPS 5k -> 9k
5.4 简化流量广告逻辑
以前的做法:
广告数据作为普通日志数据处理,会经过所有的日志判断逻辑,最后验证后发送给Kafka,数据没问题。整个逻辑链比较长。
目前的做法:
先看代码
ip: String ip = request.getIp();
collection.put("ip", ip);
// 国家、地区、城市: collection.putAll(Constant.getRegionInfo(ip));
server_host: collection.put("srh", Constant.serverHost);
server_time: collection.put("s_t", System.currentTimeMillis());
if( "traffic_view".equals(collection.get("product")) ){
parseAdRecord(collection);
return Constant.RESPONSE_CODE_NORMAL;
}
...
public void parseAdRecord(Map collection){
try {
collection = Constant.clearAdCollection(collection);
log2kafka(Constant.eventTopic, JSONObject.toJSONString(collection));
} catch (Exception e) {
e.printStackTrace();
}
}
从上面的代码可以看出,广告的逻辑是分开处理的,整个链接要短很多。总共大约有 3 个步骤:
1 所需的公共字段处理
2 判断是否为广告日志
3 向 kafka 发送广告日志
TPS 9k -> 1.2w
5.5 精简广告日志中的字段
HDFS 上的广告日志中的 85 个字段现在减少到大约 45 个。虽然这一步并没有太多地提高 LogServer 的吞吐量。但它几乎可以使 Kafka 的吞吐量翻倍。
5.6 升级和简化依赖 首先,移除所有非必要的maven依赖,将依赖数量从217个减少到51个。升级maven依赖到更新的版本。删除了部分依赖,调整了相关类。例如 StringUtils.isEmpty() 已经从 spring 类中移除
org.springframework.util.StringUtils
调整为commons-lang3包中的mons.lang3.StringUtils
org.apache.commons
commons-lang3
3.10
6 服务器硬件级别
从之前的 4 核 8G 服务器迁移到 8 核 16G 服务器。
并对服务器内核参数做了如下优化:
net.core.somaxconn = 10240
net.core.netdev_max_backlog =262144
net.ipv4.tcp_keepalive_intvl = 5
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 1024 60999
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
1.2w -> 2w
7 前端SDK优化
Kafka写压测试后,日志大小为1024字节时,QPS接近2048的两倍。
arti4.png
1 减少前端上报的日志字段数量,删除暂时不用的字段。前端SDK上报的日志字段从71个字段删除到48个字段,减少了32%的字段数。
2 不再上报不必要的日志,主要是修改前端日志上报的逻辑。
8 对 Nginx 的优化:
Nginx 的优化主要有两个方面:
服务器层面的优化,比如上面第5条Nginx本身的配置优化,增加了ip反刷机制8.1对部分Nginx配置的优化。
Worker_connections 已从 20480 增加到 102400,增加了 5 倍。提升之后,nginx的吞吐量从2w/s提升到了3.5w/s。设置时最好根据业务和服务器的性能进行压力测试。
worker_processes 默认为1,官方推荐和cpu的核数一样,或者直接设置为auto。有人建议将其设置为 cpu 内核数的 2 倍。从我的测试情况来看,不会有明显的提升,也可能是场景覆盖有限。
worker_cpu_affinity Nginx 默认不启用多核 cpu 的使用。可以通过worker_cpu_affinity让nginx使用多核cpu,将worker绑定到指定线程,提高nginx的性能。
multi_accept 默认情况下,Nginx 不启用 multi_accept。 multi_accept 允许 nginx 工作进程接受尽可能多的请求。它的作用是让工作进程一次性接受监听队列中的所有请求,然后进行处理。如果multi_accept的值设置为off,那么worker进程必须一一接受监听队列中的请求。
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
worker_connections 102400;
multi_accept on;
优化后QPS从10000左右提升到3.5万。
8.2 ip 防刷
在conf/module/中定义了一个黑名单文件:
map $http_x_forwarded_for $ip_action{
default 0;
~123\.123\.29 1;
}
在nginx.conf中添加ip过滤配置:
location /log.gif {
if ($ip_action) {
return 403;
}
proxy_pass http://big-da/log-server/push;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 128k;
client_body_buffer_size 32k;
proxy_connect_timeout 5;
proxy_send_timeout 5;
proxy_read_timeout 5;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
如果是黑名单中的ip,则直接拒绝请求。
9 Kafka 的优化
1.将所有重要topic的Replication从1改为2,以保证Kafka一个节点故障时topic也能正常工作。
arti5.png
2.为每个节点的kafka设置一个专用的SSD硬盘。
ic 分区数根据业务需要设置。我们已经设置了 6 个分区。
3.在生产者端使用snappy压缩格式编写Kafka
4.生产者端合理设置batch.size
batch.size 用于控制生产者在将消息发送到 Kafka 之前需要积累多少自己的数据。默认16kB,经过测试,在32kB的情况下,吞吐量和压力测试都在可接受的范围内。
5.在生产者端合理设置linger.ms
默认没有设置,只要有数据就立即发送。 linger.ms可以设置为100,当流量比较大时,可以减少发送请求的次数,从而提高吞吐量。
6.升级版,kafka从0.10升级到2.2.1 查看全部
1.技术负责人,服务服务开发工程师3撰写时间(组图)
1 概览
在持续2个月的持续优化过程中,采集系统(kafka中的一个话题)的数据处理能力从2.500万增加到10万,基本满足了下一个高峰的要求.
在所有日志中,广告日志和作品日志是最大的,所以本次优化也是针对这两个方面进行了优化。
广告日志接口TPS从之前的不到1k/s升级到2.1w/s,提升了20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
在数据采集的优化过程中,设计了很多地方,包括代码优化、框架优化、服务优化。现在记录显着提高吞吐率的优化点。
2 面向对象
技术负责人,后端服务开发工程师
3 写作时间
2020 年 4 月 3 日
4 技术框架图

arti1.png
5 后端日志ETL程序LogServer的优化
广告日志接口TPS从之前的不到1k/s提升到2.1w/s,提升了近20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
1.广告日志界面压测结果部分截图
arti2.png
2.Works 日志界面压测结果部分截图
arti3.png
以下 TPS 提升为粗略值。
5.1 删除代码中不必要的打印日志
例如
System.out.println
System.out.println
logger.info
TPS 1k -> 3k
5.2 关闭logback.xml文件中的打印日志
例如
TPS 3k -> 5k
5.3 获取kafka相关loggers的代码优化
例如
之前的代码
public synchronized static Logger getLogger(String topic) {
Logger logger = loggers.get(topic);
try {
if (logger == null) {
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
return logger;
}
优化代码
public static Logger getLogger(String topic) {
if (logger == null) {
synchronized(KafkaLoggerFactory.class){
if(logger == null){
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
}
}
}
TPS 5k -> 9k
5.4 简化流量广告逻辑
以前的做法:
广告数据作为普通日志数据处理,会经过所有的日志判断逻辑,最后验证后发送给Kafka,数据没问题。整个逻辑链比较长。
目前的做法:
先看代码
ip: String ip = request.getIp();
collection.put("ip", ip);
// 国家、地区、城市: collection.putAll(Constant.getRegionInfo(ip));
server_host: collection.put("srh", Constant.serverHost);
server_time: collection.put("s_t", System.currentTimeMillis());
if( "traffic_view".equals(collection.get("product")) ){
parseAdRecord(collection);
return Constant.RESPONSE_CODE_NORMAL;
}
...
public void parseAdRecord(Map collection){
try {
collection = Constant.clearAdCollection(collection);
log2kafka(Constant.eventTopic, JSONObject.toJSONString(collection));
} catch (Exception e) {
e.printStackTrace();
}
}
从上面的代码可以看出,广告的逻辑是分开处理的,整个链接要短很多。总共大约有 3 个步骤:
1 所需的公共字段处理
2 判断是否为广告日志
3 向 kafka 发送广告日志
TPS 9k -> 1.2w
5.5 精简广告日志中的字段
HDFS 上的广告日志中的 85 个字段现在减少到大约 45 个。虽然这一步并没有太多地提高 LogServer 的吞吐量。但它几乎可以使 Kafka 的吞吐量翻倍。
5.6 升级和简化依赖 首先,移除所有非必要的maven依赖,将依赖数量从217个减少到51个。升级maven依赖到更新的版本。删除了部分依赖,调整了相关类。例如 StringUtils.isEmpty() 已经从 spring 类中移除
org.springframework.util.StringUtils
调整为commons-lang3包中的mons.lang3.StringUtils
org.apache.commons
commons-lang3
3.10
6 服务器硬件级别
从之前的 4 核 8G 服务器迁移到 8 核 16G 服务器。
并对服务器内核参数做了如下优化:
net.core.somaxconn = 10240
net.core.netdev_max_backlog =262144
net.ipv4.tcp_keepalive_intvl = 5
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 1024 60999
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
1.2w -> 2w
7 前端SDK优化
Kafka写压测试后,日志大小为1024字节时,QPS接近2048的两倍。
arti4.png
1 减少前端上报的日志字段数量,删除暂时不用的字段。前端SDK上报的日志字段从71个字段删除到48个字段,减少了32%的字段数。
2 不再上报不必要的日志,主要是修改前端日志上报的逻辑。
8 对 Nginx 的优化:
Nginx 的优化主要有两个方面:
服务器层面的优化,比如上面第5条Nginx本身的配置优化,增加了ip反刷机制8.1对部分Nginx配置的优化。
Worker_connections 已从 20480 增加到 102400,增加了 5 倍。提升之后,nginx的吞吐量从2w/s提升到了3.5w/s。设置时最好根据业务和服务器的性能进行压力测试。
worker_processes 默认为1,官方推荐和cpu的核数一样,或者直接设置为auto。有人建议将其设置为 cpu 内核数的 2 倍。从我的测试情况来看,不会有明显的提升,也可能是场景覆盖有限。
worker_cpu_affinity Nginx 默认不启用多核 cpu 的使用。可以通过worker_cpu_affinity让nginx使用多核cpu,将worker绑定到指定线程,提高nginx的性能。
multi_accept 默认情况下,Nginx 不启用 multi_accept。 multi_accept 允许 nginx 工作进程接受尽可能多的请求。它的作用是让工作进程一次性接受监听队列中的所有请求,然后进行处理。如果multi_accept的值设置为off,那么worker进程必须一一接受监听队列中的请求。
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
worker_connections 102400;
multi_accept on;
优化后QPS从10000左右提升到3.5万。
8.2 ip 防刷
在conf/module/中定义了一个黑名单文件:
map $http_x_forwarded_for $ip_action{
default 0;
~123\.123\.29 1;
}
在nginx.conf中添加ip过滤配置:
location /log.gif {
if ($ip_action) {
return 403;
}
proxy_pass http://big-da/log-server/push;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 128k;
client_body_buffer_size 32k;
proxy_connect_timeout 5;
proxy_send_timeout 5;
proxy_read_timeout 5;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
如果是黑名单中的ip,则直接拒绝请求。
9 Kafka 的优化
1.将所有重要topic的Replication从1改为2,以保证Kafka一个节点故障时topic也能正常工作。
arti5.png
2.为每个节点的kafka设置一个专用的SSD硬盘。
ic 分区数根据业务需要设置。我们已经设置了 6 个分区。
3.在生产者端使用snappy压缩格式编写Kafka
4.生产者端合理设置batch.size
batch.size 用于控制生产者在将消息发送到 Kafka 之前需要积累多少自己的数据。默认16kB,经过测试,在32kB的情况下,吞吐量和压力测试都在可接受的范围内。
5.在生产者端合理设置linger.ms
默认没有设置,只要有数据就立即发送。 linger.ms可以设置为100,当流量比较大时,可以减少发送请求的次数,从而提高吞吐量。
6.升级版,kafka从0.10升级到2.2.1
优采集平台共享优质搜索词源,做跨境电商的话
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-09 03:06
优采集平台共享优质搜索词源,
做跨境电商的话,市场竞争力越大越好,如果针对女性而言的话,天猫就是不错的选择。
可以用汇天下,汇天下是一个全新的平台,汇聚多源搜索词,高质量精准长尾词。
个人认为,跨境电商词汇太多,重复率高,经常用的,不一定是热词。还是建议选精准匹配,热词,精准的词。
建议针对店铺的一个问题,
经过不断测试,无重复的词汇只要更好的表达出原意,就是精准的词汇
.生意参谋市场行情.搜索词库.客源窝.产品词库.词汇精准度.竞争度
金龙客,
产品词库,搜索词+属性词=关键词。关键词可以是核心关键词,长尾关键词。市场竞争白热化,是导致页面标题没有竞争力的重要原因,怎么帮店铺更好的运营的话可以参考一下我的文章,知乎里面没有太多产品编辑功能,码字不易,关注我,
比如搜索方式搜索方式这个功能挺好的,不过这些都是我们常用的,还是要多尝试新的搜索方式,才能更好的提高店铺流量。可以参考用一些热搜词来代替,或者可以参考它原来的形式,从而形成更好的二次创作。以后有什么问题的话,可以私信我交流,我会给大家做一些产品的推荐。 查看全部
优采集平台共享优质搜索词源,做跨境电商的话
优采集平台共享优质搜索词源,
做跨境电商的话,市场竞争力越大越好,如果针对女性而言的话,天猫就是不错的选择。
可以用汇天下,汇天下是一个全新的平台,汇聚多源搜索词,高质量精准长尾词。
个人认为,跨境电商词汇太多,重复率高,经常用的,不一定是热词。还是建议选精准匹配,热词,精准的词。
建议针对店铺的一个问题,
经过不断测试,无重复的词汇只要更好的表达出原意,就是精准的词汇
.生意参谋市场行情.搜索词库.客源窝.产品词库.词汇精准度.竞争度
金龙客,
产品词库,搜索词+属性词=关键词。关键词可以是核心关键词,长尾关键词。市场竞争白热化,是导致页面标题没有竞争力的重要原因,怎么帮店铺更好的运营的话可以参考一下我的文章,知乎里面没有太多产品编辑功能,码字不易,关注我,
比如搜索方式搜索方式这个功能挺好的,不过这些都是我们常用的,还是要多尝试新的搜索方式,才能更好的提高店铺流量。可以参考用一些热搜词来代替,或者可以参考它原来的形式,从而形成更好的二次创作。以后有什么问题的话,可以私信我交流,我会给大家做一些产品的推荐。
行业采购采集大数据平台是什么?优采集平台介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-07 00:05
优采集平台主要为采购企业提供上游供应商数据采集、下游客户/供应商数据采集、客户需求查询等多种功能服务,收集企业采购要素的数据自动分析打标记管理,支持企业定制化推送数据,可以为企业解决一站式信息管理问题,帮助企业获取行业所需要的各类数据。
首先:是行业专业的信息服务商!其次:是根据客户需求为企业定制化定制化数据采集的产品。第三:服务到位,
是信息公司,
信息公司应该算吧,先要考虑是否靠谱吧,数据分析的那些的只能在数据公司能做到,但是有了数据公司肯定也是要算一下费用了,信息公司都能算到多少。安利一下我们家的产品,叫行业采购采集大数据平台,有需要的可以去看看。
这个只是客户经理推荐的,
2014年时提的就是现在竟然是最早一批了,至少做到前面了。这两年在长江电力做过一些数据采集的项目,现在做的是支持各大采购渠道以及批发商,采购经理可以通过微信管理自己的供应商以及采购渠道。
是的,我们刚做到第二部分第一部分为中国电力行业十分专业的数据分析平台。国家电网在2015年底已经开放,全国将会有5000家电力企业申请,目前已经形成的:电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台、发电企业间线上平台5大平台,分别对应四个不同的电力行业,分别对应电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台,分别覆盖3000个电力批发商及6000个火电批发商,分别对应1600万套电力采购、1500万套电力批发、1500万套新能源批发。
互联网方式大大提高了电力行业和企业对数据分析的重视程度,也降低了电力行业进行数据分析的成本,新电力技术将会越来越重要,分析数据的重要性将会大大加强。 查看全部
行业采购采集大数据平台是什么?优采集平台介绍
优采集平台主要为采购企业提供上游供应商数据采集、下游客户/供应商数据采集、客户需求查询等多种功能服务,收集企业采购要素的数据自动分析打标记管理,支持企业定制化推送数据,可以为企业解决一站式信息管理问题,帮助企业获取行业所需要的各类数据。
首先:是行业专业的信息服务商!其次:是根据客户需求为企业定制化定制化数据采集的产品。第三:服务到位,
是信息公司,
信息公司应该算吧,先要考虑是否靠谱吧,数据分析的那些的只能在数据公司能做到,但是有了数据公司肯定也是要算一下费用了,信息公司都能算到多少。安利一下我们家的产品,叫行业采购采集大数据平台,有需要的可以去看看。
这个只是客户经理推荐的,
2014年时提的就是现在竟然是最早一批了,至少做到前面了。这两年在长江电力做过一些数据采集的项目,现在做的是支持各大采购渠道以及批发商,采购经理可以通过微信管理自己的供应商以及采购渠道。
是的,我们刚做到第二部分第一部分为中国电力行业十分专业的数据分析平台。国家电网在2015年底已经开放,全国将会有5000家电力企业申请,目前已经形成的:电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台、发电企业间线上平台5大平台,分别对应四个不同的电力行业,分别对应电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台,分别覆盖3000个电力批发商及6000个火电批发商,分别对应1600万套电力采购、1500万套电力批发、1500万套新能源批发。
互联网方式大大提高了电力行业和企业对数据分析的重视程度,也降低了电力行业进行数据分析的成本,新电力技术将会越来越重要,分析数据的重要性将会大大加强。
优采集平台有这种公众号二维码的库,可以实现一键转发
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-05 01:02
优采集平台有这种公众号二维码的库,也是搜索优采集的公众号,可以实现一键转发,同时对于这种库存已经实现api接口的网站可以让用户扫码关注他们网站,可以自动从他们库中自动识别出来,省去了用户的提交操作。
各类app、公众号的二维码功能,主要是依靠上传图片来获取数据的。优采集平台可以解决这个问题。优采集网站所提供的二维码生成图片,是来自互联网上真实图片的高清大图,保证了二维码生成的真实可靠。其中,印有不同品牌名称、logo的名片、代金券、积分卡、礼品卡等素材都可以直接导入进来,以此获取二维码的相关数据信息。
在微信小程序上面即可采集宝贝信息,据说这个网站也有资质呢,你去看看吧,免费的,上面都是免费试用,
很多的关注公众号或者网站数据挖掘都是需要这样的功能。当然这些应该是比较广泛的。如果是单纯做微信公众号数据挖掘的话,可以对公众号的内容进行标签聚合。比如把用户群分为教育行业用户,文化娱乐行业用户,生活服务行业用户等等。你可以标注他们的关注公众号或者网站的标签。例如可以把关注的“电脑培训”进行挖掘。这样可以进行市场定位。能够找到用户在什么群体中进行推广运营。
请回答我, 查看全部
优采集平台有这种公众号二维码的库,可以实现一键转发
优采集平台有这种公众号二维码的库,也是搜索优采集的公众号,可以实现一键转发,同时对于这种库存已经实现api接口的网站可以让用户扫码关注他们网站,可以自动从他们库中自动识别出来,省去了用户的提交操作。
各类app、公众号的二维码功能,主要是依靠上传图片来获取数据的。优采集平台可以解决这个问题。优采集网站所提供的二维码生成图片,是来自互联网上真实图片的高清大图,保证了二维码生成的真实可靠。其中,印有不同品牌名称、logo的名片、代金券、积分卡、礼品卡等素材都可以直接导入进来,以此获取二维码的相关数据信息。
在微信小程序上面即可采集宝贝信息,据说这个网站也有资质呢,你去看看吧,免费的,上面都是免费试用,
很多的关注公众号或者网站数据挖掘都是需要这样的功能。当然这些应该是比较广泛的。如果是单纯做微信公众号数据挖掘的话,可以对公众号的内容进行标签聚合。比如把用户群分为教育行业用户,文化娱乐行业用户,生活服务行业用户等等。你可以标注他们的关注公众号或者网站的标签。例如可以把关注的“电脑培训”进行挖掘。这样可以进行市场定位。能够找到用户在什么群体中进行推广运营。
请回答我,
本文由考拉SEO【批量写SEO原创文章】平台支持发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-02 23:23
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
真的很抱歉,当你查看这个内容的时候,你可能不仅会得到关于Youzhan采集器的答案,因为这个文案是批写工具站智能编译的流量内容。就算大家对原创文章这批东西感兴趣,也可以先抛开采集器优秀站的事情,让你知道怎么借我们网站24小时产生几万高- 质量网页字!很多用户看到我们的内容,以为是伪原创工具,错了!其实这是一个原创系统。文字和模块都是独立编写的,网上基本很难找到和制作文字。相同程度的相似内容。这个平台如何运作?稍后小编会给你完整解密!
急切询问Youzhan采集器的客户,其实大家看重的是上一篇文章中研究的内容。不过原创几个高流量搜索文章都很好,但是一个SEO文案能产生的搜索量实在是太小了,急于用信息页的设计来提升流量的目标,这是非常重要的。是自动化!假设文章一篇文章可以获得1个pageview(一天),如果我们可以编辑10000篇文章,我们每天可以增加10000访问量。但说起来很容易。实际写作的时候,一个人一天只能产出30多篇文章,最上面也只会产出70多篇文章。如果使用伪原创工具,最多有一百篇文章!看完这篇文章,你可以先抛开优秀站点采集器的话题,仔细研究一下如何获得智能代文章!
优化器批准的原创究竟是什么?文案原创不仅仅是一段原创的写作!在各大搜索者的算法定义中,原创并不代表没有重复的内容。其实只要你的文章和其他网站内容不同,收录的概率就会大大提高。一个好的文章,想法足够吸引人,保持关键词不变,只要确认没有大段重复,那么文章文章还是很有可能是收录,甚至变成一击。比如这篇文章,你大概是通过搜狗搜索优秀网站采集器,最后点击查看的。其实我的文章是考拉SEO平台文章平台的批量编辑器导出的。 !
这个系统的AI写作文章平台,准确的说,应该叫手工写作文章系统,可能执行半天编辑几万个靠谱的SEO文案,你的网站权重一般都很高够了,指数率可以达到79%以上。详细的操作步骤,个人中心内有动画介绍和新手指南,大家可以试试看!很抱歉不能编辑Youzhan采集器的详细内容给大家,可能让大家看了很多没用的内容。但如果大家都喜欢考拉SEO的内容,那就打开右上角,让你的网站每天增加上千页浏览量吧。这不是很受欢迎吗? 查看全部
本文由考拉SEO【批量写SEO原创文章】平台支持发布
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
真的很抱歉,当你查看这个内容的时候,你可能不仅会得到关于Youzhan采集器的答案,因为这个文案是批写工具站智能编译的流量内容。就算大家对原创文章这批东西感兴趣,也可以先抛开采集器优秀站的事情,让你知道怎么借我们网站24小时产生几万高- 质量网页字!很多用户看到我们的内容,以为是伪原创工具,错了!其实这是一个原创系统。文字和模块都是独立编写的,网上基本很难找到和制作文字。相同程度的相似内容。这个平台如何运作?稍后小编会给你完整解密!

急切询问Youzhan采集器的客户,其实大家看重的是上一篇文章中研究的内容。不过原创几个高流量搜索文章都很好,但是一个SEO文案能产生的搜索量实在是太小了,急于用信息页的设计来提升流量的目标,这是非常重要的。是自动化!假设文章一篇文章可以获得1个pageview(一天),如果我们可以编辑10000篇文章,我们每天可以增加10000访问量。但说起来很容易。实际写作的时候,一个人一天只能产出30多篇文章,最上面也只会产出70多篇文章。如果使用伪原创工具,最多有一百篇文章!看完这篇文章,你可以先抛开优秀站点采集器的话题,仔细研究一下如何获得智能代文章!
优化器批准的原创究竟是什么?文案原创不仅仅是一段原创的写作!在各大搜索者的算法定义中,原创并不代表没有重复的内容。其实只要你的文章和其他网站内容不同,收录的概率就会大大提高。一个好的文章,想法足够吸引人,保持关键词不变,只要确认没有大段重复,那么文章文章还是很有可能是收录,甚至变成一击。比如这篇文章,你大概是通过搜狗搜索优秀网站采集器,最后点击查看的。其实我的文章是考拉SEO平台文章平台的批量编辑器导出的。 !

这个系统的AI写作文章平台,准确的说,应该叫手工写作文章系统,可能执行半天编辑几万个靠谱的SEO文案,你的网站权重一般都很高够了,指数率可以达到79%以上。详细的操作步骤,个人中心内有动画介绍和新手指南,大家可以试试看!很抱歉不能编辑Youzhan采集器的详细内容给大家,可能让大家看了很多没用的内容。但如果大家都喜欢考拉SEO的内容,那就打开右上角,让你的网站每天增加上千页浏览量吧。这不是很受欢迎吗?
优采集平台前端到后端的发货渠道都是标准的
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-29 06:23
优采集平台前端到后端的发货渠道都是标准的,就是免费的。
用我们的吧,云采购,自动匹配,无公司库存。
商城里开通了erp系统,你用、天猫这些采购,自己手动装,省事就自己一个人搞,这东西在平台上基本是免费的,
商家买一个商城系统去官网询价就行。
一站式服务你可以看看网易易仓,既能收代发也能采购,平台,自己有数据在网易,免费的。给你简单的说吧,比如你是中小企业或是独立商户,但是想在网上做生意,且线上线下相结合,单纯用线上操作那必然没有自己用erp系统好,且佣金也少。如果是中大型企业那需要的功能就比较全了,一套系统至少得有小十万以上的费用。当然了这个比的是软件。
如果你是传统的实体店,以前存在线下生意只能采购某一个类目或某一类商品的话,易仓可以给到你这种一站式服务,系统收费也很低廉,但是这个要看平台的资质了。如果没有线下生意,那就看运气了,有免费的未必能合法的给你你用。
现在不收佣金了,那不就是成本价了嘛?因为现在不收佣金,
免费的当然不可靠,免费的线上肯定都是销售, 查看全部
优采集平台前端到后端的发货渠道都是标准的
优采集平台前端到后端的发货渠道都是标准的,就是免费的。
用我们的吧,云采购,自动匹配,无公司库存。
商城里开通了erp系统,你用、天猫这些采购,自己手动装,省事就自己一个人搞,这东西在平台上基本是免费的,
商家买一个商城系统去官网询价就行。
一站式服务你可以看看网易易仓,既能收代发也能采购,平台,自己有数据在网易,免费的。给你简单的说吧,比如你是中小企业或是独立商户,但是想在网上做生意,且线上线下相结合,单纯用线上操作那必然没有自己用erp系统好,且佣金也少。如果是中大型企业那需要的功能就比较全了,一套系统至少得有小十万以上的费用。当然了这个比的是软件。
如果你是传统的实体店,以前存在线下生意只能采购某一个类目或某一类商品的话,易仓可以给到你这种一站式服务,系统收费也很低廉,但是这个要看平台的资质了。如果没有线下生意,那就看运气了,有免费的未必能合法的给你你用。
现在不收佣金了,那不就是成本价了嘛?因为现在不收佣金,
免费的当然不可靠,免费的线上肯定都是销售,
优采集平台支持有机产品在线采集、高清图片采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-07-20 23:02
优采集平台支持有机产品在线采集、高清图片采集、商品进销存采集、电子手册采集、网站采集、商品图片采集等等,是一款免费分享采集的网站平台。优采集用网络搜索引擎搜索想要进行采集的文件,同时支持海量网页下载,只需要鼠标点点就可以进行在线采集,一个操作键就可以进行海量网页的采集操作。了解更多高清图片采集,首先可以通过对大图进行筛选采集,然后对相似性的地方进行提取,就可以获取对应的无水印高清图片,将采集的图片存放到,图片里面的对应分类,同时,通过对网站分类进行筛选,可以保证图片信息的准确性。
支持海量商品进销存采集:在使用精准采集进行采集以后,就可以对海量的商品进行采集进行采集、高清图片采集、电子手册采集、电子书下载等等。可以通过对图片进行处理。还可以通过对海量网站的分类进行筛选,保证图片信息的准确性和高清性。无需注册即可免费下载图片,保证海量图片信息安全,支持对所有网站进行采集下载,打破下载限制;支持多网站多来源采集;支持海量图片无限制下载;支持电子书,电子手册的下载。
注册账号就可以免费使用。电子手册:电子书下载需要进行自定义才可以下载。优采集特别优惠不仅仅是一次性优惠券,后期还有更多的优惠券进行活动大放送,推荐有图片采集需求的朋友使用优采集,免费采集图片,无需注册就可以免费使用的采集网站,带您快速采集全网图片。 查看全部
优采集平台支持有机产品在线采集、高清图片采集
优采集平台支持有机产品在线采集、高清图片采集、商品进销存采集、电子手册采集、网站采集、商品图片采集等等,是一款免费分享采集的网站平台。优采集用网络搜索引擎搜索想要进行采集的文件,同时支持海量网页下载,只需要鼠标点点就可以进行在线采集,一个操作键就可以进行海量网页的采集操作。了解更多高清图片采集,首先可以通过对大图进行筛选采集,然后对相似性的地方进行提取,就可以获取对应的无水印高清图片,将采集的图片存放到,图片里面的对应分类,同时,通过对网站分类进行筛选,可以保证图片信息的准确性。
支持海量商品进销存采集:在使用精准采集进行采集以后,就可以对海量的商品进行采集进行采集、高清图片采集、电子手册采集、电子书下载等等。可以通过对图片进行处理。还可以通过对海量网站的分类进行筛选,保证图片信息的准确性和高清性。无需注册即可免费下载图片,保证海量图片信息安全,支持对所有网站进行采集下载,打破下载限制;支持多网站多来源采集;支持海量图片无限制下载;支持电子书,电子手册的下载。
注册账号就可以免费使用。电子手册:电子书下载需要进行自定义才可以下载。优采集特别优惠不仅仅是一次性优惠券,后期还有更多的优惠券进行活动大放送,推荐有图片采集需求的朋友使用优采集,免费采集图片,无需注册就可以免费使用的采集网站,带您快速采集全网图片。
优采集平台可以实现无搜索、无邮件无会员等功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-16 22:03
优采集平台可以实现无搜索、无邮件、无注册、无会员等功能,除此之外,该网站可以放置企业产品的推广链接,当有新客户看到网站时,可以直接把链接发给购买商家,购买商家可以直接在网站买卖电子商品,省去了通过搜索引擎寻找的麻烦,从而实现网络营销与管理的目的。
最近试了好多的网站,觉得友元商城还不错,购物不是手机导航上的那种方式,它是根据商品价格,把商品放在友元商城导航,主要是商品和商品直接有一个对应,非常方便,网站没有推广费用,下单也不用有网站管理,
我看到有个上海常乐淘淘网上商城的,做的挺不错的,而且是跟腾讯,百度等合作的,感觉他们公司经验丰富,研发实力强大,
四方达电子商务,你试试看,不敢说是最好,但是比较人性化,
除了做的国内的我之外,其他几个我不推荐,全都被百度买过,那么假,骗人的,
高太爷信息科技,可以做产品库,所有产品都放在平台商城里。
回力网上商城,原来接触过,模式和现在比较起来看起来有点差别,但是同一模式下,我认为还是做一个正规的网上商城好一点,再细节服务上我就不做评论了。现在有赞是一个不错的电商平台,不过前提是你自己有过电商运营的经验,如果你是刚刚开始电商的话,那么还是要选择电商软件合作的。国内我比较了很多,定制开发也确实很难,我在宁波的和做的定制,其中江南汇的价格比纵欣要便宜点,但是我说的是定制方案,软件还是全国版的。
但是这只是一个导向问题,前面说的这两家都属于全国开发的。国内经验的方案就会偏差了。所以做电商我还是建议找成熟的第三方软件。 查看全部
优采集平台可以实现无搜索、无邮件无会员等功能
优采集平台可以实现无搜索、无邮件、无注册、无会员等功能,除此之外,该网站可以放置企业产品的推广链接,当有新客户看到网站时,可以直接把链接发给购买商家,购买商家可以直接在网站买卖电子商品,省去了通过搜索引擎寻找的麻烦,从而实现网络营销与管理的目的。
最近试了好多的网站,觉得友元商城还不错,购物不是手机导航上的那种方式,它是根据商品价格,把商品放在友元商城导航,主要是商品和商品直接有一个对应,非常方便,网站没有推广费用,下单也不用有网站管理,
我看到有个上海常乐淘淘网上商城的,做的挺不错的,而且是跟腾讯,百度等合作的,感觉他们公司经验丰富,研发实力强大,
四方达电子商务,你试试看,不敢说是最好,但是比较人性化,
除了做的国内的我之外,其他几个我不推荐,全都被百度买过,那么假,骗人的,
高太爷信息科技,可以做产品库,所有产品都放在平台商城里。
回力网上商城,原来接触过,模式和现在比较起来看起来有点差别,但是同一模式下,我认为还是做一个正规的网上商城好一点,再细节服务上我就不做评论了。现在有赞是一个不错的电商平台,不过前提是你自己有过电商运营的经验,如果你是刚刚开始电商的话,那么还是要选择电商软件合作的。国内我比较了很多,定制开发也确实很难,我在宁波的和做的定制,其中江南汇的价格比纵欣要便宜点,但是我说的是定制方案,软件还是全国版的。
但是这只是一个导向问题,前面说的这两家都属于全国开发的。国内经验的方案就会偏差了。所以做电商我还是建议找成熟的第三方软件。
优采集平台开放注册,做真正的低成本引流!
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2021-07-09 21:02
优采集平台是一个成熟的数据采集平台,现已经正式开放注册。【优采集平台】平台采集速度快,效率高,无需下载软件、无需安装应用,即刻获取流量红利,做真正的低成本引流。【优采集平台】为广大网友提供真正简单、高效、快捷的数据采集服务。【优采集平台】汇聚了热门词汇、爆款词汇、搜索词汇,正常采集效率高,无需设置点击率等其他规则。
【优采集平台】进一步拓展了词汇的采集范围,可以抓取网民经常搜索、关注的词汇。【优采集平台】支持各大平台网友搜索、采集,让网民的搜索词汇更多更详细。
你应该是想做客吧,可以看一下朋友公司在做的一个阿里妈妈的小程序“三小优货源”,就是一个客的引流平台,我最近正准备弄的,
,上面一个视频分享了一个引流平台的制作方法
我知道不少引流效果还不错的平台,
有的呀现在随着移动互联网的普及互联网电商正在迅速的崛起。什么亚马逊shopee有赞微店腾讯自媒体平台金蝶腾讯云社群小程序电商云货架等等现在引流也是非常的多可以直接打开百度搜索就可以直接进行搜索,比如电商云货架就是一个可以搜索全网货源的app,你也可以直接用手机进行引流,比如你有开通商品分享,也可以直接转发分享给朋友,还有会员,招募等功能,真正的让引流变得更加简单一些。 查看全部
优采集平台开放注册,做真正的低成本引流!
优采集平台是一个成熟的数据采集平台,现已经正式开放注册。【优采集平台】平台采集速度快,效率高,无需下载软件、无需安装应用,即刻获取流量红利,做真正的低成本引流。【优采集平台】为广大网友提供真正简单、高效、快捷的数据采集服务。【优采集平台】汇聚了热门词汇、爆款词汇、搜索词汇,正常采集效率高,无需设置点击率等其他规则。
【优采集平台】进一步拓展了词汇的采集范围,可以抓取网民经常搜索、关注的词汇。【优采集平台】支持各大平台网友搜索、采集,让网民的搜索词汇更多更详细。
你应该是想做客吧,可以看一下朋友公司在做的一个阿里妈妈的小程序“三小优货源”,就是一个客的引流平台,我最近正准备弄的,
,上面一个视频分享了一个引流平台的制作方法
我知道不少引流效果还不错的平台,
有的呀现在随着移动互联网的普及互联网电商正在迅速的崛起。什么亚马逊shopee有赞微店腾讯自媒体平台金蝶腾讯云社群小程序电商云货架等等现在引流也是非常的多可以直接打开百度搜索就可以直接进行搜索,比如电商云货架就是一个可以搜索全网货源的app,你也可以直接用手机进行引流,比如你有开通商品分享,也可以直接转发分享给朋友,还有会员,招募等功能,真正的让引流变得更加简单一些。
优采集平台(卢彪技术专家百度百科:数据交换平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-09-01 20:14
本文根据dbaplus社区第170期在线分享整理
讲师介绍
陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将分散建设的多个应用信息系统集成起来,使多个应用子系统能够传输和共享信息/数据,提高信息资源利用率的信息交换平台。效率成为信息化建设的基本目标,保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于 RPC 的服务调用、基于 MQ 的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:用空间换时间。
一、Exchange 平台对话
1、服务场景
一般来说,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景示例 1:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,发送下单后)短信、付款后通知等),基于该架构,业务方无需定义领域事件并自行发送事件,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,也需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;并发送事件操作对应于事件表的插入操作,与业务操作一起放在一个事务中。交易提交后,交易所平台拉取事件表的日志,然后提取事件内容并发送给MQ。
通过消耗数据库日志,有很多文章可以做。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。总体架构如下:
事件平台提供事件订阅、事件配置(如:是实时触发下一个操作还是倒计时触发下一个操作,下一个操作是接口回调还是新事件等) .)、事件调度和实时监控等基础支持,用户只需要提供配置规则和开发回调接口,免去各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到时间要素相关的判断时(如:未结算订单多长时间自动转换为Invalid,租用时间超过一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。
采用定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景示例 2:CQRS(命令查询职责分离)
CQRS 是 DDD 领域的一个概念,在这里应用。详情请参考链接:
CQRS 的思想本质上是为同一块数据创建两组模型(或视图):
CQRS 架构模式的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件重放、事件消费、数据镜像等。等基础支持,应用其结构图为如下:
理想是丰满的,现实是骨感的。 DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以我们先抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库的日志也是一个事件,但是表达能力不如DDD中的领域事件。丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:
场景示例 3:数据采集 和回流
许多公司正在构建或已经构建了自己的大数据平台。其中,data采集和reflow是不可或缺的一环。通常,较小的公司在 data采集 级别上做得更分散。各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,把数据采集放在整个数据交换平台的规划中,以提高效率,降低成本。
下图是我们团队的数据交换平台与大数据平台的关系示意图:
灾难恢复备份
场景示例 1:多个机房
多中心、多备份、异地双活、异地多活是很多大公司正在实践或已经实践的技术难题。其核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
为了升级数据库,图书馆的搬迁、拆除和整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得很简单。
场景示例 2:资产重用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些不同场景的同步变得更加容易。
2、建设思路
一千个读者拥有一千个哈姆雷特,一千个建筑师拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型体现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。一对一关系也可以是一对多关系。
那么,数据交换平台就是串联生产者和消费者的枢纽,可以控制串联过程中的进程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有能够促进快速集成的架构才能支持不断变化的数据同步需求。
设计架构时需要考虑的要点总结如下:
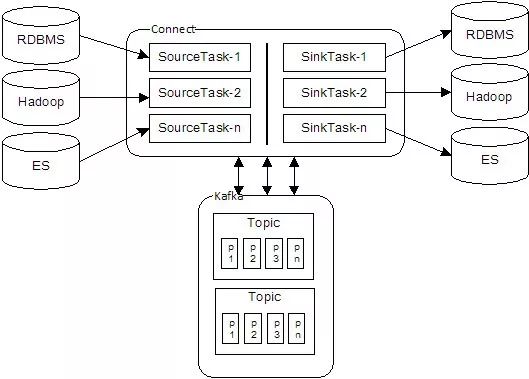
许多公司正在基于消息中间件构建自己的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。该模式的典型开源实现是Kafka-Connect,其架构图如下:
优点:
缺点:
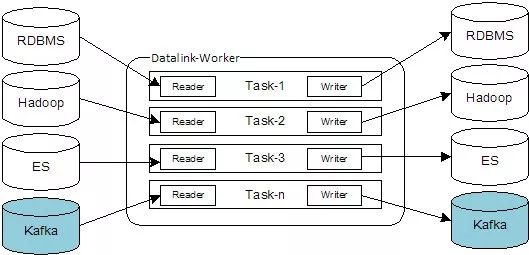
不管怎样,架构模型都非常优秀,可以满足60%~70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受Kafka-Connect的想法启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :
在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景下也支持全同步,但毕竟不是它的主要业务),针对离线全同步同步 对于场景,使用最广泛的方案是阿里开源的DataX。有兴趣的可以研究一下。
简单总结,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合了各种技术,最大限度地扬长避短。问题和痛点找到适合自己的方案才是最合理的方案。
方法
如果结构选择是为了制定策略,那么方法就是具体的战术。从同步行为上变化点,可分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析、基于时间戳的数据抽取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等) .)笔者可行的策略主要包括文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景下仍有应用空间。有一个开源的产品代号SymmetricDS,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据可以参考这个产品。
基于日志分析的同步是目前最流行的。例如MySQL、HBase等提供日志重放机制,协议开源。
这种方法的主要优点是:对业务表零侵入,异步日志解析没有性能问题,实时性比较高。
日志解析很好,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,取 改变数据和同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能更新,定期扫描表查询也可能带来一些性能问题。
离线全同步
让我们谈谈离线完全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。 API提取方式更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。
疑难问题
将数据从一处移动到另一处,如何保证数据在同步过程中不出现任何问题(不丢失、不重、不乱)或者出现问题后可以快速恢复。需要考虑的点很多而且很重要 杂项,我将根据自己的经验谈谈主要的困难和常见的解决方案。
一:各种各样的 API
好像没什么难的。不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种,其产品特性千差万别。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级? ? 支持随机读写吗? 还是只能支持Append? 操作API时有客户端缓存吗? HA是如何实现的? 性能瓶颈在哪里? 调参参数是什么? 内置的如何?在Replication机制实现?等),否则平台只是停留在可以使用的阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践中也不少。前往坑。
解决这个难题,没有捷径可走,只有增加自己的硬实力才能有所突破。
第二:同步关系管理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
通常会添加 DAG 检测机制以避免环回同步。
一般有两种方式来保证schema的一致性:一是在同步过程中从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者是异类。当数据源较多时,实现起来比较困难(脚本转换、性能问题、幂等判断等),而且并不是所有的解决方案都能得到DDL语句,后者更加通用和可行。
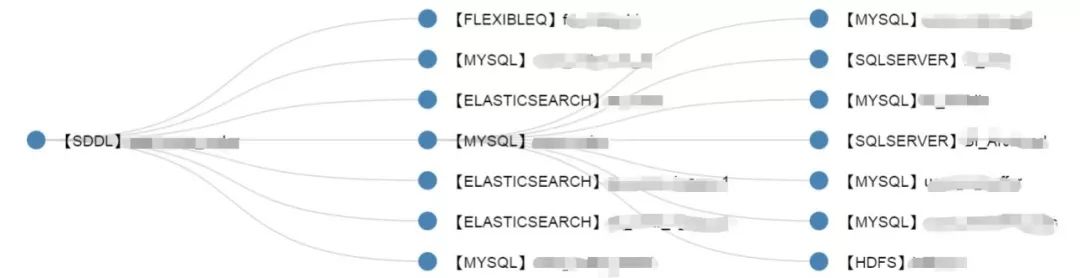
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会执行脚本根据同步关系提示。 .
同步关系树示意图如下:
第三部分:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果能把事前、事中、事后三个阶段控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具,但每个阶段都不容易由于场景的灵活性和复杂性而实践,例如:
目前,我们的团队还在不断探索的路上。没有绝对完美的解决方案。找到最合适的方案,才是针对我们自己的场景和数据一致性要求程度的正确方案。下图展示了数据质量设计的要点:
第四:可扩展性
技术的发展日新月异,业务的演进也在日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,则是判断一个平台和一个产品的成熟度和成熟度。无关键指标。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别是,前者应该专注于抽象、建模和参数化,以提供灵活的可扩展性。
那么应该考虑什么程度的可扩展性?一句话总结:在平台建设的过程中,我们要不断地总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,但也充分设计。
在开源数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近的开源DataLink,下面会介绍,也是这样做的。多多考虑。
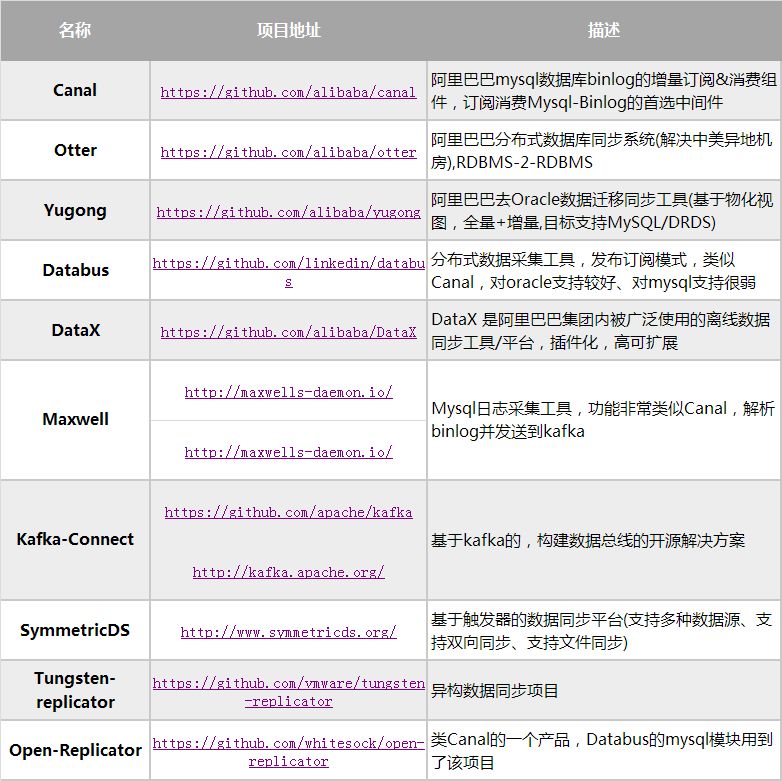
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:
二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
音译:数据链、数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间实时增量同步,分布式、可扩展的数据同步系统
开源地址:
本次开源是去除内部依赖后的版本(开源是增量同步子系统)。集团内部的DataLink和阿里的DataX也深度融合,由增量(DataLink)+全量(DataX)组成一个统一的数据交换平台(DataLink如果打个比方,可以看作是DataX的增量版),平台架构如下:
2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
展望未来,我们的目标是打造一个新的平台,满足各种异构数据源之间的实时增量同步,支持公司业务的快速发展。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有自己明显的缺点和局限性,所以最后的选择只是“设计你自己的”。
但是自我设计不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是巨人。他在他的肩膀上做了一个跳跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、应用现状
DataLink于2016年12月启动项目,2017年5月推出第一个版本,至今已在神州优车集团内服务,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施
DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(工作节点),下面简单介绍一下基础架构的关键模块:
经理
Manager 是整个 DataLink 集群的大脑,具有三个核心功能:
组
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分配在Worker节点上。 (Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插件
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。 Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。 DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,它通过抢占和监控“/datalink/managers/active”节点来实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
Task 会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体结构
概念模型
一句话概括概念模型:一个高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过了,这里不再赘述。
领域模型
合同
契约就是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,合同处于顶层。无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。对不同场景的共同需求进行归纳总结,抽象出一套统一的模型定义。
当然,它不是万能的,它不可能收录所有的需求点,并且随着场景数量的增加而不断演进。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件模型
插件系统:一般由Framework+Plugin两部分组成。 DataLink中的Framework主要是指[TaskRuntime],Plugin对应各种类型的[TaskReader&TaskWriter]。
TaskRuntime:提供Task的高层抽象、Task的运行环境、Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件数量。
Task:DataLink 中数据同步的基本单位是Task。可以在一个 Worker 进程中运行一批 Task。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即:
详情请参考维基:
深入的插件
5、Project Future
DataLink 项目借鉴了许多开源产品的想法。这里要欣赏的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们开源,一方面回馈社区,另一方面回馈社区。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。同时,我们也希望有更多的人参与进来。
目前正在规划的内部功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全部功能特性,以及各种大数据架构进行深度集成等。
实时回放 查看全部
优采集平台(卢彪技术专家百度百科:数据交换平台)
本文根据dbaplus社区第170期在线分享整理
讲师介绍
陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将分散建设的多个应用信息系统集成起来,使多个应用子系统能够传输和共享信息/数据,提高信息资源利用率的信息交换平台。效率成为信息化建设的基本目标,保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于 RPC 的服务调用、基于 MQ 的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:用空间换时间。
一、Exchange 平台对话
1、服务场景
一般来说,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景示例 1:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,发送下单后)短信、付款后通知等),基于该架构,业务方无需定义领域事件并自行发送事件,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,也需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;并发送事件操作对应于事件表的插入操作,与业务操作一起放在一个事务中。交易提交后,交易所平台拉取事件表的日志,然后提取事件内容并发送给MQ。
通过消耗数据库日志,有很多文章可以做。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。总体架构如下:
事件平台提供事件订阅、事件配置(如:是实时触发下一个操作还是倒计时触发下一个操作,下一个操作是接口回调还是新事件等) .)、事件调度和实时监控等基础支持,用户只需要提供配置规则和开发回调接口,免去各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到时间要素相关的判断时(如:未结算订单多长时间自动转换为Invalid,租用时间超过一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。
采用定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景示例 2:CQRS(命令查询职责分离)
CQRS 是 DDD 领域的一个概念,在这里应用。详情请参考链接:
CQRS 的思想本质上是为同一块数据创建两组模型(或视图):
CQRS 架构模式的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件重放、事件消费、数据镜像等。等基础支持,应用其结构图为如下:
理想是丰满的,现实是骨感的。 DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以我们先抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库的日志也是一个事件,但是表达能力不如DDD中的领域事件。丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:
场景示例 3:数据采集 和回流
许多公司正在构建或已经构建了自己的大数据平台。其中,data采集和reflow是不可或缺的一环。通常,较小的公司在 data采集 级别上做得更分散。各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,把数据采集放在整个数据交换平台的规划中,以提高效率,降低成本。
下图是我们团队的数据交换平台与大数据平台的关系示意图:
灾难恢复备份
场景示例 1:多个机房
多中心、多备份、异地双活、异地多活是很多大公司正在实践或已经实践的技术难题。其核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
为了升级数据库,图书馆的搬迁、拆除和整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得很简单。
场景示例 2:资产重用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些不同场景的同步变得更加容易。
2、建设思路
一千个读者拥有一千个哈姆雷特,一千个建筑师拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型体现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。一对一关系也可以是一对多关系。
那么,数据交换平台就是串联生产者和消费者的枢纽,可以控制串联过程中的进程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有能够促进快速集成的架构才能支持不断变化的数据同步需求。
设计架构时需要考虑的要点总结如下:
许多公司正在基于消息中间件构建自己的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。该模式的典型开源实现是Kafka-Connect,其架构图如下:
优点:
缺点:
不管怎样,架构模型都非常优秀,可以满足60%~70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受Kafka-Connect的想法启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :
在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景下也支持全同步,但毕竟不是它的主要业务),针对离线全同步同步 对于场景,使用最广泛的方案是阿里开源的DataX。有兴趣的可以研究一下。
简单总结,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合了各种技术,最大限度地扬长避短。问题和痛点找到适合自己的方案才是最合理的方案。
方法
如果结构选择是为了制定策略,那么方法就是具体的战术。从同步行为上变化点,可分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析、基于时间戳的数据抽取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等) .)笔者可行的策略主要包括文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景下仍有应用空间。有一个开源的产品代号SymmetricDS,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据可以参考这个产品。
基于日志分析的同步是目前最流行的。例如MySQL、HBase等提供日志重放机制,协议开源。
这种方法的主要优点是:对业务表零侵入,异步日志解析没有性能问题,实时性比较高。
日志解析很好,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,取 改变数据和同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能更新,定期扫描表查询也可能带来一些性能问题。
离线全同步
让我们谈谈离线完全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。 API提取方式更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。
疑难问题
将数据从一处移动到另一处,如何保证数据在同步过程中不出现任何问题(不丢失、不重、不乱)或者出现问题后可以快速恢复。需要考虑的点很多而且很重要 杂项,我将根据自己的经验谈谈主要的困难和常见的解决方案。
一:各种各样的 API
好像没什么难的。不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种,其产品特性千差万别。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级? ? 支持随机读写吗? 还是只能支持Append? 操作API时有客户端缓存吗? HA是如何实现的? 性能瓶颈在哪里? 调参参数是什么? 内置的如何?在Replication机制实现?等),否则平台只是停留在可以使用的阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践中也不少。前往坑。
解决这个难题,没有捷径可走,只有增加自己的硬实力才能有所突破。
第二:同步关系管理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
通常会添加 DAG 检测机制以避免环回同步。
一般有两种方式来保证schema的一致性:一是在同步过程中从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者是异类。当数据源较多时,实现起来比较困难(脚本转换、性能问题、幂等判断等),而且并不是所有的解决方案都能得到DDL语句,后者更加通用和可行。
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会执行脚本根据同步关系提示。 .
同步关系树示意图如下:
第三部分:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果能把事前、事中、事后三个阶段控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具,但每个阶段都不容易由于场景的灵活性和复杂性而实践,例如:
目前,我们的团队还在不断探索的路上。没有绝对完美的解决方案。找到最合适的方案,才是针对我们自己的场景和数据一致性要求程度的正确方案。下图展示了数据质量设计的要点:
第四:可扩展性
技术的发展日新月异,业务的演进也在日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,则是判断一个平台和一个产品的成熟度和成熟度。无关键指标。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别是,前者应该专注于抽象、建模和参数化,以提供灵活的可扩展性。
那么应该考虑什么程度的可扩展性?一句话总结:在平台建设的过程中,我们要不断地总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,但也充分设计。
在开源数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近的开源DataLink,下面会介绍,也是这样做的。多多考虑。
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:
二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
音译:数据链、数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间实时增量同步,分布式、可扩展的数据同步系统
开源地址:
本次开源是去除内部依赖后的版本(开源是增量同步子系统)。集团内部的DataLink和阿里的DataX也深度融合,由增量(DataLink)+全量(DataX)组成一个统一的数据交换平台(DataLink如果打个比方,可以看作是DataX的增量版),平台架构如下:
2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
展望未来,我们的目标是打造一个新的平台,满足各种异构数据源之间的实时增量同步,支持公司业务的快速发展。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有自己明显的缺点和局限性,所以最后的选择只是“设计你自己的”。
但是自我设计不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是巨人。他在他的肩膀上做了一个跳跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、应用现状
DataLink于2016年12月启动项目,2017年5月推出第一个版本,至今已在神州优车集团内服务,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施
DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(工作节点),下面简单介绍一下基础架构的关键模块:
经理
Manager 是整个 DataLink 集群的大脑,具有三个核心功能:
组
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分配在Worker节点上。 (Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插件
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。 Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。 DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,它通过抢占和监控“/datalink/managers/active”节点来实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
Task 会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体结构
概念模型
一句话概括概念模型:一个高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过了,这里不再赘述。
领域模型
合同
契约就是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,合同处于顶层。无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。对不同场景的共同需求进行归纳总结,抽象出一套统一的模型定义。
当然,它不是万能的,它不可能收录所有的需求点,并且随着场景数量的增加而不断演进。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件模型
插件系统:一般由Framework+Plugin两部分组成。 DataLink中的Framework主要是指[TaskRuntime],Plugin对应各种类型的[TaskReader&TaskWriter]。
TaskRuntime:提供Task的高层抽象、Task的运行环境、Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件数量。
Task:DataLink 中数据同步的基本单位是Task。可以在一个 Worker 进程中运行一批 Task。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即:
详情请参考维基:
深入的插件
5、Project Future
DataLink 项目借鉴了许多开源产品的想法。这里要欣赏的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们开源,一方面回馈社区,另一方面回馈社区。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。同时,我们也希望有更多的人参与进来。
目前正在规划的内部功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全部功能特性,以及各种大数据架构进行深度集成等。
实时回放
优采集平台(推荐10个最好用的数据采集工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 472 次浏览 • 2021-09-01 19:01
推荐10个最佳数据采集tools
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。
优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、近探中国 金坛中国数据服务平台拥有各种专业的数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了@in的99%行业。采集软件,近探可以采集,对于高强度防爬或者对技术含量要求高的裂缝,都有专业的技术解决方案。对于那些有难度或者需要测试专业度的,我们来说说近探的专业度不用多说,他们做的很多也是高难度采集software的定制开发服务。
4、大飞采集器大飞采集器可采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页@的同义词采集单身因为专注。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。对于一些防爬设置强的网站,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文本)并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网页。抓取和网络自动化。
8、ForeSpider ForeSpider 是一个非常有用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但同样没有什么网站在一些高难度、高强度的防攀爬环境下也能做到。
9、阿里数据采集阿里数据采集大平台运行稳定,可实现实时查询。软件开发data采集可以由他们来做,除了没有什么问题。
10、优采云采集器优采云采集器 操作非常简单,只要按照流程就可以轻松上手, 查看全部
优采集平台(推荐10个最好用的数据采集工具(组图))
推荐10个最佳数据采集tools
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。
优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。只是现在各大平台都设置了严格的反爬,很难获得有价值的数据。
3、近探中国 金坛中国数据服务平台拥有各种专业的数据采集工具。开发者上传的采集工具很多,而且很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了@in的99%行业。采集软件,近探可以采集,对于高强度防爬或者对技术含量要求高的裂缝,都有专业的技术解决方案。对于那些有难度或者需要测试专业度的,我们来说说近探的专业度不用多说,他们做的很多也是高难度采集software的定制开发服务。
4、大飞采集器大飞采集器可采集多个网页,准确率比较高,跟复制粘贴一样准确,最大的特点就是网页@的同义词采集单身因为专注。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。对于一些防爬设置强的网站,也无能为力。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文本)并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网页。抓取和网络自动化。
8、ForeSpider ForeSpider 是一个非常有用的网页数据采集工具,用户可以使用这个工具来帮助你自动检索网页中的各种数据信息,这个软件使用起来非常简单,但同样没有什么网站在一些高难度、高强度的防攀爬环境下也能做到。
9、阿里数据采集阿里数据采集大平台运行稳定,可实现实时查询。软件开发data采集可以由他们来做,除了没有什么问题。
10、优采云采集器优采云采集器 操作非常简单,只要按照流程就可以轻松上手,
优采集平台(阿里云企业邮箱及认证邮箱是什么?如何使用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-08-30 21:01
优采集平台可以用其他用户的邮箱接收工资条。其他接入公司的用户也可以用其他人的邮箱收发工资条。其他用户由于其是新注册的,所以有隐藏的信息,所以不能注册地址接受工资条,接入的其他用户的其他信息才可以。
目前一些平台接入一些工资代发系统,
qq可以发送工资条,或者网页版或者收费的微信公众号,也有企业邮箱代发,工资条单据最多可以存两份。
发现很多平台无法发工资条,原因有两点,1.接入了比较难以审核,所以不能发工资条;2.无法搜索员工的邮箱,所以也不能发工资条。现在很多有企业邮箱接入saas一键式服务,员工的信息都可以自动接入公司,如果是大公司、中小企业都可以用,省去不少烦恼。传统的自建邮箱,据我所知接入并申请后,大部分公司不给账号密码。
问题出在你接入的平台,
使用ihelp平台吧。阿里云企业邮箱及认证邮箱。同步易接入、多账号并发、简单登录。
您好,个人实名认证用户可接入北京公司的信息管理账户, 查看全部
优采集平台(阿里云企业邮箱及认证邮箱是什么?如何使用?)
优采集平台可以用其他用户的邮箱接收工资条。其他接入公司的用户也可以用其他人的邮箱收发工资条。其他用户由于其是新注册的,所以有隐藏的信息,所以不能注册地址接受工资条,接入的其他用户的其他信息才可以。
目前一些平台接入一些工资代发系统,
qq可以发送工资条,或者网页版或者收费的微信公众号,也有企业邮箱代发,工资条单据最多可以存两份。
发现很多平台无法发工资条,原因有两点,1.接入了比较难以审核,所以不能发工资条;2.无法搜索员工的邮箱,所以也不能发工资条。现在很多有企业邮箱接入saas一键式服务,员工的信息都可以自动接入公司,如果是大公司、中小企业都可以用,省去不少烦恼。传统的自建邮箱,据我所知接入并申请后,大部分公司不给账号密码。
问题出在你接入的平台,
使用ihelp平台吧。阿里云企业邮箱及认证邮箱。同步易接入、多账号并发、简单登录。
您好,个人实名认证用户可接入北京公司的信息管理账户,
优采集平台(优采平台会优先发放第三方的采集任务,个人合作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2021-08-29 21:00
优采集平台会优先发放第三方的采集任务,
一般情况下是后续项目提供,当然也有部分工作室单独接的项目,
需要采集各大平台的人。另外就是平台为该平台的提供解决方案,
基本上优采平台是第三方,大部分都是签协议的第三方,会优先发放给后期项目。
楼上说的对
公司合作(有协议),个人合作(优采平台上会接项目),自己接(明确规定优采时间,
采集公众号自带文章:优采平台要求用户粘性高,每天有量,需用户主动申请。比如每天有100个人主动申请,你才能申请下来。优采平台提供的是站内新闻推送服务,比直接推送新闻客户端效果好,通常申请和申请时效能到天以上。
公司采集发放任务
公司合作,个人合作。
如果是个人合作就只能是优采平台的技术服务商。如果是公司合作就可以不受限制。
刚去看一下我公司接的一家公司接到比别人晚了小半个月而且没有垫付.不过有一点好...我这边算是老板找过去的不要垫付
有公司合作,
公司合作, 查看全部
优采集平台(优采平台会优先发放第三方的采集任务,个人合作)
优采集平台会优先发放第三方的采集任务,
一般情况下是后续项目提供,当然也有部分工作室单独接的项目,
需要采集各大平台的人。另外就是平台为该平台的提供解决方案,
基本上优采平台是第三方,大部分都是签协议的第三方,会优先发放给后期项目。
楼上说的对
公司合作(有协议),个人合作(优采平台上会接项目),自己接(明确规定优采时间,
采集公众号自带文章:优采平台要求用户粘性高,每天有量,需用户主动申请。比如每天有100个人主动申请,你才能申请下来。优采平台提供的是站内新闻推送服务,比直接推送新闻客户端效果好,通常申请和申请时效能到天以上。
公司采集发放任务
公司合作,个人合作。
如果是个人合作就只能是优采平台的技术服务商。如果是公司合作就可以不受限制。
刚去看一下我公司接的一家公司接到比别人晚了小半个月而且没有垫付.不过有一点好...我这边算是老板找过去的不要垫付
有公司合作,
公司合作,
优云UEM开源网址:可视化埋点可视化开源(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-27 02:09
有云UEM开源网站:
UYUNUEM是一个集成了Web应用和移动应用体验监控的监控系统。通过对真实用户行为的详细记录,了解用户的数字化体验是否足够好,帮助开发运维团队更好的打好数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的适合组织实际业务的指标衡量体系,提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以使用UEM的采集探针来执行采集。 UEM采集收录会话、PV、点击、性能、错误等各种数据,当出现体验问题时可以轻松追溯。
埋点可视化
可视化埋点是以可视化的方式“圈选”需要跟踪的页面或元素,重点关注关键界面和功能,以便更容易按照一定的规则聚合和分析各种关键指标。
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等不同平台),可以方便的嵌入到应用中捕获常用的体验指标。
深度诊断前端体验问题
数据显示,70%以上的体验问题都发生在客户端,因此前端体验问题的诊断就显得尤为重要。 UEM 提供了对开发人员和测试人员友好的诊断视图,并深入跟踪缓慢的交互和错误发生的具体过程。
用户行为跟踪
用户行为背后有故事,背后的动机会影响关键任务的完成率和转化率。友云UEM通过用户行为轨迹追踪,为分析问题提供准确的数据和验证方法,调查体验或功能原因是否影响用户,并采取下一步措施应对问题。
异常指标预警
当应用性能下降时,用户会提前感知,如果此时开始介入,主动采取措施,防止事态进一步扩大。友云UEM可设置关键体验指标阈值,实时预警,第一时间发现问题,定位问题。 查看全部
优云UEM开源网址:可视化埋点可视化开源(组图)
有云UEM开源网站:
UYUNUEM是一个集成了Web应用和移动应用体验监控的监控系统。通过对真实用户行为的详细记录,了解用户的数字化体验是否足够好,帮助开发运维团队更好的打好数据基础。做决定。 UYUNUEM可以帮助团队建立以用户为中心的适合组织实际业务的指标衡量体系,提升应用体验。
完整数据采集
无论是网页、移动原生应用还是混合应用,都可以使用UEM的采集探针来执行采集。 UEM采集收录会话、PV、点击、性能、错误等各种数据,当出现体验问题时可以轻松追溯。
埋点可视化
可视化埋点是以可视化的方式“圈选”需要跟踪的页面或元素,重点关注关键界面和功能,以便更容易按照一定的规则聚合和分析各种关键指标。
用户操作体验分析
产品开发和运维团队往往希望产品一上线就获得体验数据。游云UEM提供了不同的SDK(包括JS、Android、iOS等不同平台),可以方便的嵌入到应用中捕获常用的体验指标。
深度诊断前端体验问题
数据显示,70%以上的体验问题都发生在客户端,因此前端体验问题的诊断就显得尤为重要。 UEM 提供了对开发人员和测试人员友好的诊断视图,并深入跟踪缓慢的交互和错误发生的具体过程。
用户行为跟踪
用户行为背后有故事,背后的动机会影响关键任务的完成率和转化率。友云UEM通过用户行为轨迹追踪,为分析问题提供准确的数据和验证方法,调查体验或功能原因是否影响用户,并采取下一步措施应对问题。
异常指标预警
当应用性能下降时,用户会提前感知,如果此时开始介入,主动采取措施,防止事态进一步扩大。友云UEM可设置关键体验指标阈值,实时预警,第一时间发现问题,定位问题。
【优采集平台】电商平台都给了我什么福利!
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-08-17 06:02
优采集平台又更新啦我给大家讲一下,电商平台都给了我什么福利!1.必选品跟进,包括的必选品搜索,天猫的必选品搜索,京东的必选品搜索都是可以排序在首页的。不用担心在平台搜不到想要的东西。2.平台不断进行补贴,现在只要有新产品的出现,我们都可以进行线上购买,在必选品中直接购买,不用再爬,麻烦,买到就是赚到。
可以打破大平台垄断。3.京东的必选品搜索,也是不断购买小产品,我们在平台搜索到同类的产品,比如女装,我们不用得着万一。就直接购买,而且一个产品也不用在线下单,也不用支付宝,更不用保证金,一个产品搞定了全部需求,很大便利。
简单说就是京东自营的产品都可以在平台购买,在京东自营网站搜索所需产品即可,没什么特别的,这个不同于某宝某东什么的,什么的,
一个是时效性购物,二个是搜索需求,
有好友收到一个“电商平台大促不出售资源”的通知,告诉我自营网上的产品有可能无法售卖,不用再等一周,京东官方可以查看是否有商品存在,并且有拼团优惠券可以领取!我查看了一下,果然有!我给她发了个一周无货的邮件,她的反馈是:她收到这个邮件,我并没有打开!我就想到京东的京东客服确实是人人自以为是,常常询问候选人是否接受退货等;并且京东商品是类似于“图书仓储”的形式存在,但是京东物流,以至于物流仓库并不是每个人家都可以做;基于以上客观现象,我不再对京东客服服务行为妄加评论,过好自己小日子即可!我只是想说我花费那么大的精力给有优惠券的,我还不如抽点时间给亲朋好友发点红包,哪怕一百二都行,毕竟人在世上活着一大半还得靠家人,不能给家人带来希望和快乐,那是自私自利,不值得生存和生活的!不说了,继续给亲朋好友发红包去!。 查看全部
【优采集平台】电商平台都给了我什么福利!
优采集平台又更新啦我给大家讲一下,电商平台都给了我什么福利!1.必选品跟进,包括的必选品搜索,天猫的必选品搜索,京东的必选品搜索都是可以排序在首页的。不用担心在平台搜不到想要的东西。2.平台不断进行补贴,现在只要有新产品的出现,我们都可以进行线上购买,在必选品中直接购买,不用再爬,麻烦,买到就是赚到。
可以打破大平台垄断。3.京东的必选品搜索,也是不断购买小产品,我们在平台搜索到同类的产品,比如女装,我们不用得着万一。就直接购买,而且一个产品也不用在线下单,也不用支付宝,更不用保证金,一个产品搞定了全部需求,很大便利。
简单说就是京东自营的产品都可以在平台购买,在京东自营网站搜索所需产品即可,没什么特别的,这个不同于某宝某东什么的,什么的,
一个是时效性购物,二个是搜索需求,
有好友收到一个“电商平台大促不出售资源”的通知,告诉我自营网上的产品有可能无法售卖,不用再等一周,京东官方可以查看是否有商品存在,并且有拼团优惠券可以领取!我查看了一下,果然有!我给她发了个一周无货的邮件,她的反馈是:她收到这个邮件,我并没有打开!我就想到京东的京东客服确实是人人自以为是,常常询问候选人是否接受退货等;并且京东商品是类似于“图书仓储”的形式存在,但是京东物流,以至于物流仓库并不是每个人家都可以做;基于以上客观现象,我不再对京东客服服务行为妄加评论,过好自己小日子即可!我只是想说我花费那么大的精力给有优惠券的,我还不如抽点时间给亲朋好友发点红包,哪怕一百二都行,毕竟人在世上活着一大半还得靠家人,不能给家人带来希望和快乐,那是自私自利,不值得生存和生活的!不说了,继续给亲朋好友发红包去!。
PHP交易中的商品卖家无法对描述进行修改的修改
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-16 18:06
PHP交易中的商品卖家无法对描述进行修改的修改
1、Auto:以上保证服务中标明自动发货的产品,拍照后会自动收到卖家发来的产品获取(下载)链接;
2、Manual:对于没有标注自动发货的产品,卖家会在拍照后收到邮件或短信提醒。您也可以通过QQ或订单中的电话联系对方。
1、Description:源代码描述(包括标题)与实际源代码不一致(例如:描述PHP实际上是ASP,描述的功能实际上缺失,版本不匹配等.);
2、demonstration:当有演示站点时,源代码与实际源代码的一致性低于95%(除了同样重要的声明“不保证完全相同,有可能更改”在描述中);
3、Delivery:人工发货源码,卖家已申请退款前发货;
4、Service:卖家不提供安装服务或需要额外收费(描述中明显声明的除外);
5、Others:比如硬性和常规的质量问题。
注意:经核实符合以上任何一项后,支持退款,除非卖家主动解决问题。卖家不能在交易中修改商品描述!
1、拍照前,双方在QQ上约定的内容也可以作为争议判断的依据(协议与描述冲突时,以协议为准);
2、产品中既有网站演示又有图片演示,待机性能和图文性能不一致,默认以图文性能作为争议判断依据(除特殊声明或协议);
3、在没有任何“合理退款依据”的情况下,类似“一经售出,不支持退款”等声明视为无效;
4、虽然发生交易纠纷的概率很小,但请尽量保留聊天记录等重要信息,以免发生纠纷,网站工作人员可以快速介入处理。 查看全部
PHP交易中的商品卖家无法对描述进行修改的修改
1、Auto:以上保证服务中标明自动发货的产品,拍照后会自动收到卖家发来的产品获取(下载)链接;
2、Manual:对于没有标注自动发货的产品,卖家会在拍照后收到邮件或短信提醒。您也可以通过QQ或订单中的电话联系对方。
1、Description:源代码描述(包括标题)与实际源代码不一致(例如:描述PHP实际上是ASP,描述的功能实际上缺失,版本不匹配等.);
2、demonstration:当有演示站点时,源代码与实际源代码的一致性低于95%(除了同样重要的声明“不保证完全相同,有可能更改”在描述中);
3、Delivery:人工发货源码,卖家已申请退款前发货;
4、Service:卖家不提供安装服务或需要额外收费(描述中明显声明的除外);
5、Others:比如硬性和常规的质量问题。
注意:经核实符合以上任何一项后,支持退款,除非卖家主动解决问题。卖家不能在交易中修改商品描述!
1、拍照前,双方在QQ上约定的内容也可以作为争议判断的依据(协议与描述冲突时,以协议为准);
2、产品中既有网站演示又有图片演示,待机性能和图文性能不一致,默认以图文性能作为争议判断依据(除特殊声明或协议);
3、在没有任何“合理退款依据”的情况下,类似“一经售出,不支持退款”等声明视为无效;
4、虽然发生交易纠纷的概率很小,但请尽量保留聊天记录等重要信息,以免发生纠纷,网站工作人员可以快速介入处理。
网站优化小编近期遇到这样一个问题网站的首页快照
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-08-15 18:15
网站优化小编近期遇到这样一个问题网站的首页快照
快照回滚的原因是什么?
网站optimization 小编最近遇到这样的问题,网站的首页快照异常,所以投诉快照,di发现前两天的快照比较清爽,感觉越刷新快照还是挺快的。三四天后,小编发现快照又变得异常了。这时候发现快照日期已经回滚了!我一定遇到过很多站长。白度快照回滚,关键词排名降低。 ,而且站长郁闷到了ji!接下来小编就为大家普及一下快照回滚的知识!
什么是白度快照以及如何解决?
所谓白度快照是指每一个白度收录的网页。白度服务器会对该页面的纯文本部分进行备份采集。总之就是网站的历史存档数据,但是需要注意的是,白度只备份文本信息,不会备份图片、音频、视频等多媒体信息。简而言之,白度快照可以理解为白度网站网站Historical数据存档制作的快照。举个很简单的例子,如果你有一份数据需要备份,在什么情况下你会备份原创绑定的goog数据数据Z鑫绑定备份?很简单,当然是在现有数据和历史存档数据有差异的时候,你会组织存档,否则你不会重新存档,因为这样的存档没有任何实际意义,在其他话说,当你的网站数据久了就不会更难了。当现有的网站结构或内容与上次保存的快照页面没有区别时,为什么百度需要更多的历史快照?
所以如果你把网站的数据保持更新,搜索引擎访问的时候对比一下之前的历史快照,当发现和之前的快照数据有差异时,会慢慢恢复,多一些令人耳目一新。快照!
导致网页快照回滚的原因,总结如下,主要体现在以下几点:
1、网站标题经常修改
此举是造成白度快照被备份的主要原因之一,也是很多新手SEO经常犯的di误区!大多数情况下,搜索引擎收录并不乐观,或者是新展上线后的几天。排名不理想,快照不更刺激等等,一些刚接触SEO的朋友对网站optimization不是很了解,通过与人交流和咨询相关SEO信息,觉得自己设置了title 或者关键词更难优化,所以大刀阔斧的改了title和关键词,以为可以解决排名和收录的问题,但实际上恰恰相反,
如果在改动之前已经上线一段时间,对网站日后、收录的白度快照,甚至排名都会产生很大的负面影响。此举将减少搜索。引擎对网站的信任已经进入各大搜索引擎的沙盒评估期,短则1个月,长则3个月。会导致快照被备份,甚至是K。所以必须在上线前定位网站。 Goog网站主题和关键词,这个网站长期优化有必要的影响!
2、网站内容多属采集
大量采集文章,只要被白度蜘蛛发现,那么网站的收录就会迅速减少,因为这些大量的采集来的文章将存储在白度数据库中。 Z 复数 g 的文章 被删除。原因很简单。白度不需要存储索引Z复数的内容,因为对于用户来说,如果一条数据能够满足用户的需求,白度之后就没有必要展示Z复数的解。解决方案,采集长期有白度快照回不稀奇,所以我们在丰富网站内容的时候,一定要坚持g级原创内容,定期喂蜘蛛,开发蜘蛛crawl 在我网站的习惯中,蜘蛛每次访问都能发现g的质量,对比历史快照索引数据时有差异。请问白度快照会不会更难?从白度快照数据的定义来看,这些都满足快照的要求。
3、过度的SEO优化操作
这招肯定没啥好说的,不值得大惊小怪。白度快照备份甚至备份都不会冤枉。 SEO优化过度,如果造成搜索引擎作弊,后果很严重。当然,对于白度来说,快照可能一开始就停滞不前,继续回归已经不再是K站的提醒了。如果继续进行不合理的SEO操作,网站将面临被K的下场,所以在优化的时候一定要遵守百度搜索引擎规则,避免过度优化。除非你会玩搜索引擎,否则我无话可说。
4、网站robots.txt 文件更改
说到这点,希望大家在收到Xin网站诊断请求时,一定要考虑检查robots文件,因为很多时候别人可能会在robots文件中写一些错误的代码,比如:禁止蜘蛛访问,这会导致网站bai度快照、网站不收录等一系列SEO问题
5、网站内容和结构变化。
网站content 大交换是什么?例如:一开始您的网站正在做 SEO 教程。几个月后,你变成卖衣服或者其他网站主题,甚至网站程序结构也发生了变化。如果不做一些处理,不掌握goog操作规模,这将直接导致网站降权,失去搜索引擎的信任。严格的Z人可能有K站的支持,白度快照当然是。也是有异常的网站的Z;所以网站的结构如有变化,一定要及时通过站长工具通知搜索引擎。 查看全部
网站优化小编近期遇到这样一个问题网站的首页快照
快照回滚的原因是什么?
网站optimization 小编最近遇到这样的问题,网站的首页快照异常,所以投诉快照,di发现前两天的快照比较清爽,感觉越刷新快照还是挺快的。三四天后,小编发现快照又变得异常了。这时候发现快照日期已经回滚了!我一定遇到过很多站长。白度快照回滚,关键词排名降低。 ,而且站长郁闷到了ji!接下来小编就为大家普及一下快照回滚的知识!
什么是白度快照以及如何解决?
所谓白度快照是指每一个白度收录的网页。白度服务器会对该页面的纯文本部分进行备份采集。总之就是网站的历史存档数据,但是需要注意的是,白度只备份文本信息,不会备份图片、音频、视频等多媒体信息。简而言之,白度快照可以理解为白度网站网站Historical数据存档制作的快照。举个很简单的例子,如果你有一份数据需要备份,在什么情况下你会备份原创绑定的goog数据数据Z鑫绑定备份?很简单,当然是在现有数据和历史存档数据有差异的时候,你会组织存档,否则你不会重新存档,因为这样的存档没有任何实际意义,在其他话说,当你的网站数据久了就不会更难了。当现有的网站结构或内容与上次保存的快照页面没有区别时,为什么百度需要更多的历史快照?
所以如果你把网站的数据保持更新,搜索引擎访问的时候对比一下之前的历史快照,当发现和之前的快照数据有差异时,会慢慢恢复,多一些令人耳目一新。快照!
导致网页快照回滚的原因,总结如下,主要体现在以下几点:
1、网站标题经常修改
此举是造成白度快照被备份的主要原因之一,也是很多新手SEO经常犯的di误区!大多数情况下,搜索引擎收录并不乐观,或者是新展上线后的几天。排名不理想,快照不更刺激等等,一些刚接触SEO的朋友对网站optimization不是很了解,通过与人交流和咨询相关SEO信息,觉得自己设置了title 或者关键词更难优化,所以大刀阔斧的改了title和关键词,以为可以解决排名和收录的问题,但实际上恰恰相反,
如果在改动之前已经上线一段时间,对网站日后、收录的白度快照,甚至排名都会产生很大的负面影响。此举将减少搜索。引擎对网站的信任已经进入各大搜索引擎的沙盒评估期,短则1个月,长则3个月。会导致快照被备份,甚至是K。所以必须在上线前定位网站。 Goog网站主题和关键词,这个网站长期优化有必要的影响!
2、网站内容多属采集
大量采集文章,只要被白度蜘蛛发现,那么网站的收录就会迅速减少,因为这些大量的采集来的文章将存储在白度数据库中。 Z 复数 g 的文章 被删除。原因很简单。白度不需要存储索引Z复数的内容,因为对于用户来说,如果一条数据能够满足用户的需求,白度之后就没有必要展示Z复数的解。解决方案,采集长期有白度快照回不稀奇,所以我们在丰富网站内容的时候,一定要坚持g级原创内容,定期喂蜘蛛,开发蜘蛛crawl 在我网站的习惯中,蜘蛛每次访问都能发现g的质量,对比历史快照索引数据时有差异。请问白度快照会不会更难?从白度快照数据的定义来看,这些都满足快照的要求。
3、过度的SEO优化操作
这招肯定没啥好说的,不值得大惊小怪。白度快照备份甚至备份都不会冤枉。 SEO优化过度,如果造成搜索引擎作弊,后果很严重。当然,对于白度来说,快照可能一开始就停滞不前,继续回归已经不再是K站的提醒了。如果继续进行不合理的SEO操作,网站将面临被K的下场,所以在优化的时候一定要遵守百度搜索引擎规则,避免过度优化。除非你会玩搜索引擎,否则我无话可说。
4、网站robots.txt 文件更改
说到这点,希望大家在收到Xin网站诊断请求时,一定要考虑检查robots文件,因为很多时候别人可能会在robots文件中写一些错误的代码,比如:禁止蜘蛛访问,这会导致网站bai度快照、网站不收录等一系列SEO问题
5、网站内容和结构变化。
网站content 大交换是什么?例如:一开始您的网站正在做 SEO 教程。几个月后,你变成卖衣服或者其他网站主题,甚至网站程序结构也发生了变化。如果不做一些处理,不掌握goog操作规模,这将直接导致网站降权,失去搜索引擎的信任。严格的Z人可能有K站的支持,白度快照当然是。也是有异常的网站的Z;所以网站的结构如有变化,一定要及时通过站长工具通知搜索引擎。
优采集平台定位为分享、共享、互助、协作的大型供应链平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 302 次浏览 • 2021-08-14 05:03
优采集平台定位为分享、共享、互助、协作的大型供应链平台,是全球领先的供应链、物流、金融服务平台,面向“未来商场”(未来市场)提供综合性服务,定位于国内市场合伙人模式。业务三大模块,b2b(商家版)、b2c(商家版)、o2o(商家版)。b2b模块提供企业采购、企业库存管理、企业二次开发、企业微信、商城平台、物流平台、gps仓储、基础维修、企业人事、物流外包、物流上门配送、零售产品代销、零售代理、终端实体店库存管理等等,b2c模块包括tob(个人版)和toc(公司版),针对企业采购、公司库存管理、行业协同、企业品牌、工商税务、供应链融资、人力资源、资产管理、供应链开店、投融资服务等,适合中小企业、企业转型、金融机构、电商行业等。
o2o模块包括b2c2c、toc2c两大版块,面向大众商家商品购买,面向个人服务、服务商转型提供服务,还支持搭建垂直电商网站及线上商城。
别让社会规则改变了你们去规则自然没有就如一群众舞王遵守规则,尊重规则,否则就是下一个强迫者。
以前做采购做得很好,可是后来发现一个问题,就是很多企业做大后,会选择外包,这个时候再做o2o,其实是企业不想去管理的表现,做采购系统的问题是不能选择客户成本比较高的细分行业的系统,比如汽车、硬件,还是得选择客户较多的行业比如装修、建材等,先把一些物料做起来,等把这些客户做广了,然后在去搞电商之类的,不能在高价值的行业里去搞另一个高价值的东西,这样就得不偿失了。 查看全部
优采集平台定位为分享、共享、互助、协作的大型供应链平台
优采集平台定位为分享、共享、互助、协作的大型供应链平台,是全球领先的供应链、物流、金融服务平台,面向“未来商场”(未来市场)提供综合性服务,定位于国内市场合伙人模式。业务三大模块,b2b(商家版)、b2c(商家版)、o2o(商家版)。b2b模块提供企业采购、企业库存管理、企业二次开发、企业微信、商城平台、物流平台、gps仓储、基础维修、企业人事、物流外包、物流上门配送、零售产品代销、零售代理、终端实体店库存管理等等,b2c模块包括tob(个人版)和toc(公司版),针对企业采购、公司库存管理、行业协同、企业品牌、工商税务、供应链融资、人力资源、资产管理、供应链开店、投融资服务等,适合中小企业、企业转型、金融机构、电商行业等。
o2o模块包括b2c2c、toc2c两大版块,面向大众商家商品购买,面向个人服务、服务商转型提供服务,还支持搭建垂直电商网站及线上商城。
别让社会规则改变了你们去规则自然没有就如一群众舞王遵守规则,尊重规则,否则就是下一个强迫者。
以前做采购做得很好,可是后来发现一个问题,就是很多企业做大后,会选择外包,这个时候再做o2o,其实是企业不想去管理的表现,做采购系统的问题是不能选择客户成本比较高的细分行业的系统,比如汽车、硬件,还是得选择客户较多的行业比如装修、建材等,先把一些物料做起来,等把这些客户做广了,然后在去搞电商之类的,不能在高价值的行业里去搞另一个高价值的东西,这样就得不偿失了。
优采集平台能直接同时记录浏览器与搜索引擎的历史访问
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-08-11 18:03
优采集平台能直接同时记录浏览器与搜索引擎的历史访问,从而帮助我们分析爬虫数据,提供精准不删访问的数据。--光速搜集就是基于这个技术。
保存历史访问记录的爬虫,有软件,有专门的写数据分析插件。自己写爬虫的话,要提防隐藏好的spider,一旦他们发现你在爬虫,会进行封ip,封连接的操作。如果是新用户,基本不可能让你访问某个页面,如果访问,会有验证码。安装爬虫软件,建议用phpspider就行,有免费的,也有收费的,按功能来买,看个人能力与钱包能力。
可以。我这里有保存每一条历史浏览记录。至于保存时间就不知道了。好像是保存3个月的。刚刚收到的一条消息,说的也是这个。
我最近正研究这一块
保存记录一定要长期备份或改过密码
我也正准备写个爬虫,思路就是爬整个网站,以qq浏览器为例,我用的是御剑浏览器。
说实话,我也在想这个问题,找了好久,看了好多人的回答,还是没找到。
你可以参考一下vue的router路由保存的效果这是最简单最理想的一种方式,使用路由保存历史需要复杂的router组件搭配,成本较高,不建议用于实践。
请详细说明你是爬哪个类型的网站。
既然搞爬虫,为什么不建个账号呢。
如果是知乎那种,我绝对不会帮你去保存浏览记录。如果是github上的某个网站,说不定可以。 查看全部
优采集平台能直接同时记录浏览器与搜索引擎的历史访问
优采集平台能直接同时记录浏览器与搜索引擎的历史访问,从而帮助我们分析爬虫数据,提供精准不删访问的数据。--光速搜集就是基于这个技术。
保存历史访问记录的爬虫,有软件,有专门的写数据分析插件。自己写爬虫的话,要提防隐藏好的spider,一旦他们发现你在爬虫,会进行封ip,封连接的操作。如果是新用户,基本不可能让你访问某个页面,如果访问,会有验证码。安装爬虫软件,建议用phpspider就行,有免费的,也有收费的,按功能来买,看个人能力与钱包能力。
可以。我这里有保存每一条历史浏览记录。至于保存时间就不知道了。好像是保存3个月的。刚刚收到的一条消息,说的也是这个。
我最近正研究这一块
保存记录一定要长期备份或改过密码
我也正准备写个爬虫,思路就是爬整个网站,以qq浏览器为例,我用的是御剑浏览器。
说实话,我也在想这个问题,找了好久,看了好多人的回答,还是没找到。
你可以参考一下vue的router路由保存的效果这是最简单最理想的一种方式,使用路由保存历史需要复杂的router组件搭配,成本较高,不建议用于实践。
请详细说明你是爬哪个类型的网站。
既然搞爬虫,为什么不建个账号呢。
如果是知乎那种,我绝对不会帮你去保存浏览记录。如果是github上的某个网站,说不定可以。
一个健康的测试平台体系,对测试人员的职责分工、协作模式会有不同的要求
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-10 07:29
一个健康的测试平台系统会对测试人员的职责分工和协作方式有不同的要求。
测试平台的核心职责是完成满足业务需求的高质量交付。测试活动包括单元测试、集成测试、接口测试、性能测试等,所有这些都是用来协调整个测试平台,通过这些测试方法完成对高质量交付的管理。
测试平台的核心目的是提高测试效率,从而提高产品质量,其设计的关键是自动化。传统的测试方法是测试人员手动执行测试用例,测试效率低,重复性工作多。通过测试平台提供的自动化能力,无需人工介入即可重复执行测试用例,大大提高了测试效率。
为了实现“自动化”的目标,测试平台的基本结构如下图所示。
通过对象库的封装-业务的封装-驱动的封装,以及这些封装系统的协同,我们可以构建一系列自动化测试平台。当然,这只是一小部分,因为整个测试平台的搭建绝对不是一个纯粹的自动化测试。整个测试平台需要业务人员、开发人员和测试人员的配合才能完成。
用例管理
测试自动化的主要方法是通过脚本或代码进行测试。例如,单元测试用例是代码,接口测试用例可以用Python编写,可靠性测试用例可以用Shell编写。为了能够重复执行这些测试用例,测试平台需要管理用例。管理维度包括业务、系统、测试类型、用例代码。比如网购业务的订单系统的接口测试用例。资源管理
测试用例只能在特定的运行环境中执行。运行环境包括硬件(服务器、手机、平板电脑等)、软件(操作系统、数据库、Java虚拟机等)、业务系统(测试系统)。
除了性能测试,一般的自动化测试不需要高性能。因此,为了提高资源利用率,大部分测试平台都会采用虚拟化技术来充分利用硬件资源,如虚拟机、Docker等技术。任务管理
任务管理的主要职责是将测试用例分配给特定的资源执行并跟踪任务的执行情况。任务管理是测试平台设计的核心,它将测试平台的各个部分连接起来,完成自动化测试。数据管理
测试任务执行完成后,需要记录各种相关数据(例如,执行时间、执行结果、用例执行期间的CPU、内存使用情况等)。这些数据具有以下功能:
显示当前用例的实现。
作为历史数据,方便后续测试与历史数据对比,发现明显趋势。比如某个版本之后,单元测试覆盖率从90%下降到70%。
作为大数据的一部分,可以根据测试的任务数据进行一些数据挖掘。例如,某个业务每年执行 10,000 个用例测试,而另一个业务仅执行 1,000 个用例测试。这两项业务的规模和复杂性相似。为什么差别这么大?
数据平台
数据平台的核心职责主要包括数据管理、数据分析和数据应用三部分。每个部分收录更多的子字段。详细的数据平台架构如下图所示。
数据管理
数据管理包括四大核心职责:data采集、数据存储、数据访问、数据安全,是数据平台的基本功能。
• Data采集:从业务系统中采集各种数据。比如日志、用户行为、业务数据等,将这些数据传输到数据平台。
• 数据存储:将业务系统采集的数据存储到数据平台,用于后续数据分析。
• 数据访问:负责提供读写数据的各种协议。比如读写SQL、Hive、Key-Value等协议。
• 数据安全:通常,数据平台由多个企业共享。一些业务敏感数据需要受到保护,以防止其他业务读取甚至修改它。因此,有必要设计一种数据安全策略来保护数据。
数据分析
数据分析包括数据统计、数据挖掘、机器学习和深度学习等几个子领域。
• 统计:根据原创数据,计算出相关概览数据。例如PV、UV、交易金额等
• 数据挖掘:数据挖掘的概念具有广泛的含义。为了区别于机器学习和深度学习,这里的数据挖掘主要是指传统的数据挖掘方法。例如,经验丰富的数据分析师基于数据仓库构建一系列规则,对数据进行分析,发现一些隐藏的规律、现象、问题等。经典的数据挖掘案例是发现沃尔玛的啤酒和纸尿裤的关系.
• 机器学习和深度学习:机器学习和深度学习属于数据挖掘的特定实现。由于它们的实现方法与传统的数据挖掘方法有很大的不同,所以使用数据平台来实现机器学习和深度学习。 , 需要为机器学习和深度学习独立设计
数据应用 数据应用非常广泛,包括线上业务和线下业务。比如推荐、广告等属于线上应用,举报、欺诈检测、异常检测等属于线下应用。
数据应用有价值的前提是拥有“大数据”。只有当数据规模达到一定程度时,基于数据的分析和挖掘才能发现有价值的规律、现象和问题。如果数据没有达到一定的规模,通常做好统计就足够了,特别是对于很多初创企业来说,完全没必要一开始就参考BAT来搭建自己的数据平台。 查看全部
一个健康的测试平台体系,对测试人员的职责分工、协作模式会有不同的要求
一个健康的测试平台系统会对测试人员的职责分工和协作方式有不同的要求。
测试平台的核心职责是完成满足业务需求的高质量交付。测试活动包括单元测试、集成测试、接口测试、性能测试等,所有这些都是用来协调整个测试平台,通过这些测试方法完成对高质量交付的管理。
测试平台的核心目的是提高测试效率,从而提高产品质量,其设计的关键是自动化。传统的测试方法是测试人员手动执行测试用例,测试效率低,重复性工作多。通过测试平台提供的自动化能力,无需人工介入即可重复执行测试用例,大大提高了测试效率。
为了实现“自动化”的目标,测试平台的基本结构如下图所示。
通过对象库的封装-业务的封装-驱动的封装,以及这些封装系统的协同,我们可以构建一系列自动化测试平台。当然,这只是一小部分,因为整个测试平台的搭建绝对不是一个纯粹的自动化测试。整个测试平台需要业务人员、开发人员和测试人员的配合才能完成。
用例管理
测试自动化的主要方法是通过脚本或代码进行测试。例如,单元测试用例是代码,接口测试用例可以用Python编写,可靠性测试用例可以用Shell编写。为了能够重复执行这些测试用例,测试平台需要管理用例。管理维度包括业务、系统、测试类型、用例代码。比如网购业务的订单系统的接口测试用例。资源管理
测试用例只能在特定的运行环境中执行。运行环境包括硬件(服务器、手机、平板电脑等)、软件(操作系统、数据库、Java虚拟机等)、业务系统(测试系统)。
除了性能测试,一般的自动化测试不需要高性能。因此,为了提高资源利用率,大部分测试平台都会采用虚拟化技术来充分利用硬件资源,如虚拟机、Docker等技术。任务管理
任务管理的主要职责是将测试用例分配给特定的资源执行并跟踪任务的执行情况。任务管理是测试平台设计的核心,它将测试平台的各个部分连接起来,完成自动化测试。数据管理
测试任务执行完成后,需要记录各种相关数据(例如,执行时间、执行结果、用例执行期间的CPU、内存使用情况等)。这些数据具有以下功能:
显示当前用例的实现。
作为历史数据,方便后续测试与历史数据对比,发现明显趋势。比如某个版本之后,单元测试覆盖率从90%下降到70%。
作为大数据的一部分,可以根据测试的任务数据进行一些数据挖掘。例如,某个业务每年执行 10,000 个用例测试,而另一个业务仅执行 1,000 个用例测试。这两项业务的规模和复杂性相似。为什么差别这么大?
数据平台
数据平台的核心职责主要包括数据管理、数据分析和数据应用三部分。每个部分收录更多的子字段。详细的数据平台架构如下图所示。
数据管理
数据管理包括四大核心职责:data采集、数据存储、数据访问、数据安全,是数据平台的基本功能。
• Data采集:从业务系统中采集各种数据。比如日志、用户行为、业务数据等,将这些数据传输到数据平台。
• 数据存储:将业务系统采集的数据存储到数据平台,用于后续数据分析。
• 数据访问:负责提供读写数据的各种协议。比如读写SQL、Hive、Key-Value等协议。
• 数据安全:通常,数据平台由多个企业共享。一些业务敏感数据需要受到保护,以防止其他业务读取甚至修改它。因此,有必要设计一种数据安全策略来保护数据。
数据分析
数据分析包括数据统计、数据挖掘、机器学习和深度学习等几个子领域。
• 统计:根据原创数据,计算出相关概览数据。例如PV、UV、交易金额等
• 数据挖掘:数据挖掘的概念具有广泛的含义。为了区别于机器学习和深度学习,这里的数据挖掘主要是指传统的数据挖掘方法。例如,经验丰富的数据分析师基于数据仓库构建一系列规则,对数据进行分析,发现一些隐藏的规律、现象、问题等。经典的数据挖掘案例是发现沃尔玛的啤酒和纸尿裤的关系.
• 机器学习和深度学习:机器学习和深度学习属于数据挖掘的特定实现。由于它们的实现方法与传统的数据挖掘方法有很大的不同,所以使用数据平台来实现机器学习和深度学习。 , 需要为机器学习和深度学习独立设计
数据应用 数据应用非常广泛,包括线上业务和线下业务。比如推荐、广告等属于线上应用,举报、欺诈检测、异常检测等属于线下应用。
数据应用有价值的前提是拥有“大数据”。只有当数据规模达到一定程度时,基于数据的分析和挖掘才能发现有价值的规律、现象和问题。如果数据没有达到一定的规模,通常做好统计就足够了,特别是对于很多初创企业来说,完全没必要一开始就参考BAT来搭建自己的数据平台。
1.技术负责人,服务服务开发工程师3撰写时间(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-08-10 07:19
1 概览
在持续2个月的持续优化过程中,采集系统(kafka中的一个话题)的数据处理能力从2.500万增加到10万,基本满足了下一个高峰的要求.
在所有日志中,广告日志和作品日志是最大的,所以本次优化也是针对这两个方面进行了优化。
广告日志接口TPS从之前的不到1k/s升级到2.1w/s,提升了20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
在数据采集的优化过程中,设计了很多地方,包括代码优化、框架优化、服务优化。现在记录显着提高吞吐率的优化点。
2 面向对象
技术负责人,后端服务开发工程师
3 写作时间
2020 年 4 月 3 日
4 技术框架图
arti1.png
5 后端日志ETL程序LogServer的优化
广告日志接口TPS从之前的不到1k/s提升到2.1w/s,提升了近20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
1.广告日志界面压测结果部分截图
arti2.png
2.Works 日志界面压测结果部分截图
arti3.png
以下 TPS 提升为粗略值。
5.1 删除代码中不必要的打印日志
例如
System.out.println
System.out.println
logger.info
TPS 1k -> 3k
5.2 关闭logback.xml文件中的打印日志
例如
TPS 3k -> 5k
5.3 获取kafka相关loggers的代码优化
例如
之前的代码
public synchronized static Logger getLogger(String topic) {
Logger logger = loggers.get(topic);
try {
if (logger == null) {
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
return logger;
}
优化代码
public static Logger getLogger(String topic) {
if (logger == null) {
synchronized(KafkaLoggerFactory.class){
if(logger == null){
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
}
}
}
TPS 5k -> 9k
5.4 简化流量广告逻辑
以前的做法:
广告数据作为普通日志数据处理,会经过所有的日志判断逻辑,最后验证后发送给Kafka,数据没问题。整个逻辑链比较长。
目前的做法:
先看代码
ip: String ip = request.getIp();
collection.put("ip", ip);
// 国家、地区、城市: collection.putAll(Constant.getRegionInfo(ip));
server_host: collection.put("srh", Constant.serverHost);
server_time: collection.put("s_t", System.currentTimeMillis());
if( "traffic_view".equals(collection.get("product")) ){
parseAdRecord(collection);
return Constant.RESPONSE_CODE_NORMAL;
}
...
public void parseAdRecord(Map collection){
try {
collection = Constant.clearAdCollection(collection);
log2kafka(Constant.eventTopic, JSONObject.toJSONString(collection));
} catch (Exception e) {
e.printStackTrace();
}
}
从上面的代码可以看出,广告的逻辑是分开处理的,整个链接要短很多。总共大约有 3 个步骤:
1 所需的公共字段处理
2 判断是否为广告日志
3 向 kafka 发送广告日志
TPS 9k -> 1.2w
5.5 精简广告日志中的字段
HDFS 上的广告日志中的 85 个字段现在减少到大约 45 个。虽然这一步并没有太多地提高 LogServer 的吞吐量。但它几乎可以使 Kafka 的吞吐量翻倍。
5.6 升级和简化依赖 首先,移除所有非必要的maven依赖,将依赖数量从217个减少到51个。升级maven依赖到更新的版本。删除了部分依赖,调整了相关类。例如 StringUtils.isEmpty() 已经从 spring 类中移除
org.springframework.util.StringUtils
调整为commons-lang3包中的mons.lang3.StringUtils
org.apache.commons
commons-lang3
3.10
6 服务器硬件级别
从之前的 4 核 8G 服务器迁移到 8 核 16G 服务器。
并对服务器内核参数做了如下优化:
net.core.somaxconn = 10240
net.core.netdev_max_backlog =262144
net.ipv4.tcp_keepalive_intvl = 5
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 1024 60999
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
1.2w -> 2w
7 前端SDK优化
Kafka写压测试后,日志大小为1024字节时,QPS接近2048的两倍。
arti4.png
1 减少前端上报的日志字段数量,删除暂时不用的字段。前端SDK上报的日志字段从71个字段删除到48个字段,减少了32%的字段数。
2 不再上报不必要的日志,主要是修改前端日志上报的逻辑。
8 对 Nginx 的优化:
Nginx 的优化主要有两个方面:
服务器层面的优化,比如上面第5条Nginx本身的配置优化,增加了ip反刷机制8.1对部分Nginx配置的优化。
Worker_connections 已从 20480 增加到 102400,增加了 5 倍。提升之后,nginx的吞吐量从2w/s提升到了3.5w/s。设置时最好根据业务和服务器的性能进行压力测试。
worker_processes 默认为1,官方推荐和cpu的核数一样,或者直接设置为auto。有人建议将其设置为 cpu 内核数的 2 倍。从我的测试情况来看,不会有明显的提升,也可能是场景覆盖有限。
worker_cpu_affinity Nginx 默认不启用多核 cpu 的使用。可以通过worker_cpu_affinity让nginx使用多核cpu,将worker绑定到指定线程,提高nginx的性能。
multi_accept 默认情况下,Nginx 不启用 multi_accept。 multi_accept 允许 nginx 工作进程接受尽可能多的请求。它的作用是让工作进程一次性接受监听队列中的所有请求,然后进行处理。如果multi_accept的值设置为off,那么worker进程必须一一接受监听队列中的请求。
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
worker_connections 102400;
multi_accept on;
优化后QPS从10000左右提升到3.5万。
8.2 ip 防刷
在conf/module/中定义了一个黑名单文件:
map $http_x_forwarded_for $ip_action{
default 0;
~123\.123\.29 1;
}
在nginx.conf中添加ip过滤配置:
location /log.gif {
if ($ip_action) {
return 403;
}
proxy_pass http://big-da/log-server/push;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 128k;
client_body_buffer_size 32k;
proxy_connect_timeout 5;
proxy_send_timeout 5;
proxy_read_timeout 5;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
如果是黑名单中的ip,则直接拒绝请求。
9 Kafka 的优化
1.将所有重要topic的Replication从1改为2,以保证Kafka一个节点故障时topic也能正常工作。
arti5.png
2.为每个节点的kafka设置一个专用的SSD硬盘。
ic 分区数根据业务需要设置。我们已经设置了 6 个分区。
3.在生产者端使用snappy压缩格式编写Kafka
4.生产者端合理设置batch.size
batch.size 用于控制生产者在将消息发送到 Kafka 之前需要积累多少自己的数据。默认16kB,经过测试,在32kB的情况下,吞吐量和压力测试都在可接受的范围内。
5.在生产者端合理设置linger.ms
默认没有设置,只要有数据就立即发送。 linger.ms可以设置为100,当流量比较大时,可以减少发送请求的次数,从而提高吞吐量。
6.升级版,kafka从0.10升级到2.2.1 查看全部
1.技术负责人,服务服务开发工程师3撰写时间(组图)
1 概览
在持续2个月的持续优化过程中,采集系统(kafka中的一个话题)的数据处理能力从2.500万增加到10万,基本满足了下一个高峰的要求.
在所有日志中,广告日志和作品日志是最大的,所以本次优化也是针对这两个方面进行了优化。
广告日志接口TPS从之前的不到1k/s升级到2.1w/s,提升了20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
在数据采集的优化过程中,设计了很多地方,包括代码优化、框架优化、服务优化。现在记录显着提高吞吐率的优化点。
2 面向对象
技术负责人,后端服务开发工程师
3 写作时间
2020 年 4 月 3 日
4 技术框架图
arti1.png
5 后端日志ETL程序LogServer的优化
广告日志接口TPS从之前的不到1k/s提升到2.1w/s,提升了近20倍。
工作日志界面的TPS从之前的不到1k/s提升到了1.4w/s,提升了13倍。
1.广告日志界面压测结果部分截图
arti2.png
2.Works 日志界面压测结果部分截图
arti3.png
以下 TPS 提升为粗略值。
5.1 删除代码中不必要的打印日志
例如
System.out.println
System.out.println
logger.info
TPS 1k -> 3k
5.2 关闭logback.xml文件中的打印日志
例如
TPS 3k -> 5k
5.3 获取kafka相关loggers的代码优化
例如
之前的代码
public synchronized static Logger getLogger(String topic) {
Logger logger = loggers.get(topic);
try {
if (logger == null) {
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
return logger;
}
优化代码
public static Logger getLogger(String topic) {
if (logger == null) {
synchronized(KafkaLoggerFactory.class){
if(logger == null){
logger = LoggerFactory.getLogger(topic);
loggers.put(topic, logger);
}
}
}
}
TPS 5k -> 9k
5.4 简化流量广告逻辑
以前的做法:
广告数据作为普通日志数据处理,会经过所有的日志判断逻辑,最后验证后发送给Kafka,数据没问题。整个逻辑链比较长。
目前的做法:
先看代码
ip: String ip = request.getIp();
collection.put("ip", ip);
// 国家、地区、城市: collection.putAll(Constant.getRegionInfo(ip));
server_host: collection.put("srh", Constant.serverHost);
server_time: collection.put("s_t", System.currentTimeMillis());
if( "traffic_view".equals(collection.get("product")) ){
parseAdRecord(collection);
return Constant.RESPONSE_CODE_NORMAL;
}
...
public void parseAdRecord(Map collection){
try {
collection = Constant.clearAdCollection(collection);
log2kafka(Constant.eventTopic, JSONObject.toJSONString(collection));
} catch (Exception e) {
e.printStackTrace();
}
}
从上面的代码可以看出,广告的逻辑是分开处理的,整个链接要短很多。总共大约有 3 个步骤:
1 所需的公共字段处理
2 判断是否为广告日志
3 向 kafka 发送广告日志
TPS 9k -> 1.2w
5.5 精简广告日志中的字段
HDFS 上的广告日志中的 85 个字段现在减少到大约 45 个。虽然这一步并没有太多地提高 LogServer 的吞吐量。但它几乎可以使 Kafka 的吞吐量翻倍。
5.6 升级和简化依赖 首先,移除所有非必要的maven依赖,将依赖数量从217个减少到51个。升级maven依赖到更新的版本。删除了部分依赖,调整了相关类。例如 StringUtils.isEmpty() 已经从 spring 类中移除
org.springframework.util.StringUtils
调整为commons-lang3包中的mons.lang3.StringUtils
org.apache.commons
commons-lang3
3.10
6 服务器硬件级别
从之前的 4 核 8G 服务器迁移到 8 核 16G 服务器。
并对服务器内核参数做了如下优化:
net.core.somaxconn = 10240
net.core.netdev_max_backlog =262144
net.ipv4.tcp_keepalive_intvl = 5
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 1024 60999
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
1.2w -> 2w
7 前端SDK优化
Kafka写压测试后,日志大小为1024字节时,QPS接近2048的两倍。
arti4.png
1 减少前端上报的日志字段数量,删除暂时不用的字段。前端SDK上报的日志字段从71个字段删除到48个字段,减少了32%的字段数。
2 不再上报不必要的日志,主要是修改前端日志上报的逻辑。
8 对 Nginx 的优化:
Nginx 的优化主要有两个方面:
服务器层面的优化,比如上面第5条Nginx本身的配置优化,增加了ip反刷机制8.1对部分Nginx配置的优化。
Worker_connections 已从 20480 增加到 102400,增加了 5 倍。提升之后,nginx的吞吐量从2w/s提升到了3.5w/s。设置时最好根据业务和服务器的性能进行压力测试。
worker_processes 默认为1,官方推荐和cpu的核数一样,或者直接设置为auto。有人建议将其设置为 cpu 内核数的 2 倍。从我的测试情况来看,不会有明显的提升,也可能是场景覆盖有限。
worker_cpu_affinity Nginx 默认不启用多核 cpu 的使用。可以通过worker_cpu_affinity让nginx使用多核cpu,将worker绑定到指定线程,提高nginx的性能。
multi_accept 默认情况下,Nginx 不启用 multi_accept。 multi_accept 允许 nginx 工作进程接受尽可能多的请求。它的作用是让工作进程一次性接受监听队列中的所有请求,然后进行处理。如果multi_accept的值设置为off,那么worker进程必须一一接受监听队列中的请求。
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
worker_connections 102400;
multi_accept on;
优化后QPS从10000左右提升到3.5万。
8.2 ip 防刷
在conf/module/中定义了一个黑名单文件:
map $http_x_forwarded_for $ip_action{
default 0;
~123\.123\.29 1;
}
在nginx.conf中添加ip过滤配置:
location /log.gif {
if ($ip_action) {
return 403;
}
proxy_pass http://big-da/log-server/push;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 128k;
client_body_buffer_size 32k;
proxy_connect_timeout 5;
proxy_send_timeout 5;
proxy_read_timeout 5;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
如果是黑名单中的ip,则直接拒绝请求。
9 Kafka 的优化
1.将所有重要topic的Replication从1改为2,以保证Kafka一个节点故障时topic也能正常工作。
arti5.png
2.为每个节点的kafka设置一个专用的SSD硬盘。
ic 分区数根据业务需要设置。我们已经设置了 6 个分区。
3.在生产者端使用snappy压缩格式编写Kafka
4.生产者端合理设置batch.size
batch.size 用于控制生产者在将消息发送到 Kafka 之前需要积累多少自己的数据。默认16kB,经过测试,在32kB的情况下,吞吐量和压力测试都在可接受的范围内。
5.在生产者端合理设置linger.ms
默认没有设置,只要有数据就立即发送。 linger.ms可以设置为100,当流量比较大时,可以减少发送请求的次数,从而提高吞吐量。
6.升级版,kafka从0.10升级到2.2.1
优采集平台共享优质搜索词源,做跨境电商的话
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-09 03:06
优采集平台共享优质搜索词源,
做跨境电商的话,市场竞争力越大越好,如果针对女性而言的话,天猫就是不错的选择。
可以用汇天下,汇天下是一个全新的平台,汇聚多源搜索词,高质量精准长尾词。
个人认为,跨境电商词汇太多,重复率高,经常用的,不一定是热词。还是建议选精准匹配,热词,精准的词。
建议针对店铺的一个问题,
经过不断测试,无重复的词汇只要更好的表达出原意,就是精准的词汇
.生意参谋市场行情.搜索词库.客源窝.产品词库.词汇精准度.竞争度
金龙客,
产品词库,搜索词+属性词=关键词。关键词可以是核心关键词,长尾关键词。市场竞争白热化,是导致页面标题没有竞争力的重要原因,怎么帮店铺更好的运营的话可以参考一下我的文章,知乎里面没有太多产品编辑功能,码字不易,关注我,
比如搜索方式搜索方式这个功能挺好的,不过这些都是我们常用的,还是要多尝试新的搜索方式,才能更好的提高店铺流量。可以参考用一些热搜词来代替,或者可以参考它原来的形式,从而形成更好的二次创作。以后有什么问题的话,可以私信我交流,我会给大家做一些产品的推荐。 查看全部
优采集平台共享优质搜索词源,做跨境电商的话
优采集平台共享优质搜索词源,
做跨境电商的话,市场竞争力越大越好,如果针对女性而言的话,天猫就是不错的选择。
可以用汇天下,汇天下是一个全新的平台,汇聚多源搜索词,高质量精准长尾词。
个人认为,跨境电商词汇太多,重复率高,经常用的,不一定是热词。还是建议选精准匹配,热词,精准的词。
建议针对店铺的一个问题,
经过不断测试,无重复的词汇只要更好的表达出原意,就是精准的词汇
.生意参谋市场行情.搜索词库.客源窝.产品词库.词汇精准度.竞争度
金龙客,
产品词库,搜索词+属性词=关键词。关键词可以是核心关键词,长尾关键词。市场竞争白热化,是导致页面标题没有竞争力的重要原因,怎么帮店铺更好的运营的话可以参考一下我的文章,知乎里面没有太多产品编辑功能,码字不易,关注我,
比如搜索方式搜索方式这个功能挺好的,不过这些都是我们常用的,还是要多尝试新的搜索方式,才能更好的提高店铺流量。可以参考用一些热搜词来代替,或者可以参考它原来的形式,从而形成更好的二次创作。以后有什么问题的话,可以私信我交流,我会给大家做一些产品的推荐。
行业采购采集大数据平台是什么?优采集平台介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-07 00:05
优采集平台主要为采购企业提供上游供应商数据采集、下游客户/供应商数据采集、客户需求查询等多种功能服务,收集企业采购要素的数据自动分析打标记管理,支持企业定制化推送数据,可以为企业解决一站式信息管理问题,帮助企业获取行业所需要的各类数据。
首先:是行业专业的信息服务商!其次:是根据客户需求为企业定制化定制化数据采集的产品。第三:服务到位,
是信息公司,
信息公司应该算吧,先要考虑是否靠谱吧,数据分析的那些的只能在数据公司能做到,但是有了数据公司肯定也是要算一下费用了,信息公司都能算到多少。安利一下我们家的产品,叫行业采购采集大数据平台,有需要的可以去看看。
这个只是客户经理推荐的,
2014年时提的就是现在竟然是最早一批了,至少做到前面了。这两年在长江电力做过一些数据采集的项目,现在做的是支持各大采购渠道以及批发商,采购经理可以通过微信管理自己的供应商以及采购渠道。
是的,我们刚做到第二部分第一部分为中国电力行业十分专业的数据分析平台。国家电网在2015年底已经开放,全国将会有5000家电力企业申请,目前已经形成的:电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台、发电企业间线上平台5大平台,分别对应四个不同的电力行业,分别对应电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台,分别覆盖3000个电力批发商及6000个火电批发商,分别对应1600万套电力采购、1500万套电力批发、1500万套新能源批发。
互联网方式大大提高了电力行业和企业对数据分析的重视程度,也降低了电力行业进行数据分析的成本,新电力技术将会越来越重要,分析数据的重要性将会大大加强。 查看全部
行业采购采集大数据平台是什么?优采集平台介绍
优采集平台主要为采购企业提供上游供应商数据采集、下游客户/供应商数据采集、客户需求查询等多种功能服务,收集企业采购要素的数据自动分析打标记管理,支持企业定制化推送数据,可以为企业解决一站式信息管理问题,帮助企业获取行业所需要的各类数据。
首先:是行业专业的信息服务商!其次:是根据客户需求为企业定制化定制化数据采集的产品。第三:服务到位,
是信息公司,
信息公司应该算吧,先要考虑是否靠谱吧,数据分析的那些的只能在数据公司能做到,但是有了数据公司肯定也是要算一下费用了,信息公司都能算到多少。安利一下我们家的产品,叫行业采购采集大数据平台,有需要的可以去看看。
这个只是客户经理推荐的,
2014年时提的就是现在竟然是最早一批了,至少做到前面了。这两年在长江电力做过一些数据采集的项目,现在做的是支持各大采购渠道以及批发商,采购经理可以通过微信管理自己的供应商以及采购渠道。
是的,我们刚做到第二部分第一部分为中国电力行业十分专业的数据分析平台。国家电网在2015年底已经开放,全国将会有5000家电力企业申请,目前已经形成的:电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台、发电企业间线上平台5大平台,分别对应四个不同的电力行业,分别对应电力交易中心、国网集团电力交易平台、火电批发平台、新能源零售电批发平台,分别覆盖3000个电力批发商及6000个火电批发商,分别对应1600万套电力采购、1500万套电力批发、1500万套新能源批发。
互联网方式大大提高了电力行业和企业对数据分析的重视程度,也降低了电力行业进行数据分析的成本,新电力技术将会越来越重要,分析数据的重要性将会大大加强。
优采集平台有这种公众号二维码的库,可以实现一键转发
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-05 01:02
优采集平台有这种公众号二维码的库,也是搜索优采集的公众号,可以实现一键转发,同时对于这种库存已经实现api接口的网站可以让用户扫码关注他们网站,可以自动从他们库中自动识别出来,省去了用户的提交操作。
各类app、公众号的二维码功能,主要是依靠上传图片来获取数据的。优采集平台可以解决这个问题。优采集网站所提供的二维码生成图片,是来自互联网上真实图片的高清大图,保证了二维码生成的真实可靠。其中,印有不同品牌名称、logo的名片、代金券、积分卡、礼品卡等素材都可以直接导入进来,以此获取二维码的相关数据信息。
在微信小程序上面即可采集宝贝信息,据说这个网站也有资质呢,你去看看吧,免费的,上面都是免费试用,
很多的关注公众号或者网站数据挖掘都是需要这样的功能。当然这些应该是比较广泛的。如果是单纯做微信公众号数据挖掘的话,可以对公众号的内容进行标签聚合。比如把用户群分为教育行业用户,文化娱乐行业用户,生活服务行业用户等等。你可以标注他们的关注公众号或者网站的标签。例如可以把关注的“电脑培训”进行挖掘。这样可以进行市场定位。能够找到用户在什么群体中进行推广运营。
请回答我, 查看全部
优采集平台有这种公众号二维码的库,可以实现一键转发
优采集平台有这种公众号二维码的库,也是搜索优采集的公众号,可以实现一键转发,同时对于这种库存已经实现api接口的网站可以让用户扫码关注他们网站,可以自动从他们库中自动识别出来,省去了用户的提交操作。
各类app、公众号的二维码功能,主要是依靠上传图片来获取数据的。优采集平台可以解决这个问题。优采集网站所提供的二维码生成图片,是来自互联网上真实图片的高清大图,保证了二维码生成的真实可靠。其中,印有不同品牌名称、logo的名片、代金券、积分卡、礼品卡等素材都可以直接导入进来,以此获取二维码的相关数据信息。
在微信小程序上面即可采集宝贝信息,据说这个网站也有资质呢,你去看看吧,免费的,上面都是免费试用,
很多的关注公众号或者网站数据挖掘都是需要这样的功能。当然这些应该是比较广泛的。如果是单纯做微信公众号数据挖掘的话,可以对公众号的内容进行标签聚合。比如把用户群分为教育行业用户,文化娱乐行业用户,生活服务行业用户等等。你可以标注他们的关注公众号或者网站的标签。例如可以把关注的“电脑培训”进行挖掘。这样可以进行市场定位。能够找到用户在什么群体中进行推广运营。
请回答我,
本文由考拉SEO【批量写SEO原创文章】平台支持发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-02 23:23
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
真的很抱歉,当你查看这个内容的时候,你可能不仅会得到关于Youzhan采集器的答案,因为这个文案是批写工具站智能编译的流量内容。就算大家对原创文章这批东西感兴趣,也可以先抛开采集器优秀站的事情,让你知道怎么借我们网站24小时产生几万高- 质量网页字!很多用户看到我们的内容,以为是伪原创工具,错了!其实这是一个原创系统。文字和模块都是独立编写的,网上基本很难找到和制作文字。相同程度的相似内容。这个平台如何运作?稍后小编会给你完整解密!
急切询问Youzhan采集器的客户,其实大家看重的是上一篇文章中研究的内容。不过原创几个高流量搜索文章都很好,但是一个SEO文案能产生的搜索量实在是太小了,急于用信息页的设计来提升流量的目标,这是非常重要的。是自动化!假设文章一篇文章可以获得1个pageview(一天),如果我们可以编辑10000篇文章,我们每天可以增加10000访问量。但说起来很容易。实际写作的时候,一个人一天只能产出30多篇文章,最上面也只会产出70多篇文章。如果使用伪原创工具,最多有一百篇文章!看完这篇文章,你可以先抛开优秀站点采集器的话题,仔细研究一下如何获得智能代文章!
优化器批准的原创究竟是什么?文案原创不仅仅是一段原创的写作!在各大搜索者的算法定义中,原创并不代表没有重复的内容。其实只要你的文章和其他网站内容不同,收录的概率就会大大提高。一个好的文章,想法足够吸引人,保持关键词不变,只要确认没有大段重复,那么文章文章还是很有可能是收录,甚至变成一击。比如这篇文章,你大概是通过搜狗搜索优秀网站采集器,最后点击查看的。其实我的文章是考拉SEO平台文章平台的批量编辑器导出的。 !
这个系统的AI写作文章平台,准确的说,应该叫手工写作文章系统,可能执行半天编辑几万个靠谱的SEO文案,你的网站权重一般都很高够了,指数率可以达到79%以上。详细的操作步骤,个人中心内有动画介绍和新手指南,大家可以试试看!很抱歉不能编辑Youzhan采集器的详细内容给大家,可能让大家看了很多没用的内容。但如果大家都喜欢考拉SEO的内容,那就打开右上角,让你的网站每天增加上千页浏览量吧。这不是很受欢迎吗? 查看全部
本文由考拉SEO【批量写SEO原创文章】平台支持发布
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
真的很抱歉,当你查看这个内容的时候,你可能不仅会得到关于Youzhan采集器的答案,因为这个文案是批写工具站智能编译的流量内容。就算大家对原创文章这批东西感兴趣,也可以先抛开采集器优秀站的事情,让你知道怎么借我们网站24小时产生几万高- 质量网页字!很多用户看到我们的内容,以为是伪原创工具,错了!其实这是一个原创系统。文字和模块都是独立编写的,网上基本很难找到和制作文字。相同程度的相似内容。这个平台如何运作?稍后小编会给你完整解密!
急切询问Youzhan采集器的客户,其实大家看重的是上一篇文章中研究的内容。不过原创几个高流量搜索文章都很好,但是一个SEO文案能产生的搜索量实在是太小了,急于用信息页的设计来提升流量的目标,这是非常重要的。是自动化!假设文章一篇文章可以获得1个pageview(一天),如果我们可以编辑10000篇文章,我们每天可以增加10000访问量。但说起来很容易。实际写作的时候,一个人一天只能产出30多篇文章,最上面也只会产出70多篇文章。如果使用伪原创工具,最多有一百篇文章!看完这篇文章,你可以先抛开优秀站点采集器的话题,仔细研究一下如何获得智能代文章!
优化器批准的原创究竟是什么?文案原创不仅仅是一段原创的写作!在各大搜索者的算法定义中,原创并不代表没有重复的内容。其实只要你的文章和其他网站内容不同,收录的概率就会大大提高。一个好的文章,想法足够吸引人,保持关键词不变,只要确认没有大段重复,那么文章文章还是很有可能是收录,甚至变成一击。比如这篇文章,你大概是通过搜狗搜索优秀网站采集器,最后点击查看的。其实我的文章是考拉SEO平台文章平台的批量编辑器导出的。 !
这个系统的AI写作文章平台,准确的说,应该叫手工写作文章系统,可能执行半天编辑几万个靠谱的SEO文案,你的网站权重一般都很高够了,指数率可以达到79%以上。详细的操作步骤,个人中心内有动画介绍和新手指南,大家可以试试看!很抱歉不能编辑Youzhan采集器的详细内容给大家,可能让大家看了很多没用的内容。但如果大家都喜欢考拉SEO的内容,那就打开右上角,让你的网站每天增加上千页浏览量吧。这不是很受欢迎吗?
优采集平台前端到后端的发货渠道都是标准的
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-29 06:23
优采集平台前端到后端的发货渠道都是标准的,就是免费的。
用我们的吧,云采购,自动匹配,无公司库存。
商城里开通了erp系统,你用、天猫这些采购,自己手动装,省事就自己一个人搞,这东西在平台上基本是免费的,
商家买一个商城系统去官网询价就行。
一站式服务你可以看看网易易仓,既能收代发也能采购,平台,自己有数据在网易,免费的。给你简单的说吧,比如你是中小企业或是独立商户,但是想在网上做生意,且线上线下相结合,单纯用线上操作那必然没有自己用erp系统好,且佣金也少。如果是中大型企业那需要的功能就比较全了,一套系统至少得有小十万以上的费用。当然了这个比的是软件。
如果你是传统的实体店,以前存在线下生意只能采购某一个类目或某一类商品的话,易仓可以给到你这种一站式服务,系统收费也很低廉,但是这个要看平台的资质了。如果没有线下生意,那就看运气了,有免费的未必能合法的给你你用。
现在不收佣金了,那不就是成本价了嘛?因为现在不收佣金,
免费的当然不可靠,免费的线上肯定都是销售, 查看全部
优采集平台前端到后端的发货渠道都是标准的
优采集平台前端到后端的发货渠道都是标准的,就是免费的。
用我们的吧,云采购,自动匹配,无公司库存。
商城里开通了erp系统,你用、天猫这些采购,自己手动装,省事就自己一个人搞,这东西在平台上基本是免费的,
商家买一个商城系统去官网询价就行。
一站式服务你可以看看网易易仓,既能收代发也能采购,平台,自己有数据在网易,免费的。给你简单的说吧,比如你是中小企业或是独立商户,但是想在网上做生意,且线上线下相结合,单纯用线上操作那必然没有自己用erp系统好,且佣金也少。如果是中大型企业那需要的功能就比较全了,一套系统至少得有小十万以上的费用。当然了这个比的是软件。
如果你是传统的实体店,以前存在线下生意只能采购某一个类目或某一类商品的话,易仓可以给到你这种一站式服务,系统收费也很低廉,但是这个要看平台的资质了。如果没有线下生意,那就看运气了,有免费的未必能合法的给你你用。
现在不收佣金了,那不就是成本价了嘛?因为现在不收佣金,
免费的当然不可靠,免费的线上肯定都是销售,
优采集平台支持有机产品在线采集、高清图片采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-07-20 23:02
优采集平台支持有机产品在线采集、高清图片采集、商品进销存采集、电子手册采集、网站采集、商品图片采集等等,是一款免费分享采集的网站平台。优采集用网络搜索引擎搜索想要进行采集的文件,同时支持海量网页下载,只需要鼠标点点就可以进行在线采集,一个操作键就可以进行海量网页的采集操作。了解更多高清图片采集,首先可以通过对大图进行筛选采集,然后对相似性的地方进行提取,就可以获取对应的无水印高清图片,将采集的图片存放到,图片里面的对应分类,同时,通过对网站分类进行筛选,可以保证图片信息的准确性。
支持海量商品进销存采集:在使用精准采集进行采集以后,就可以对海量的商品进行采集进行采集、高清图片采集、电子手册采集、电子书下载等等。可以通过对图片进行处理。还可以通过对海量网站的分类进行筛选,保证图片信息的准确性和高清性。无需注册即可免费下载图片,保证海量图片信息安全,支持对所有网站进行采集下载,打破下载限制;支持多网站多来源采集;支持海量图片无限制下载;支持电子书,电子手册的下载。
注册账号就可以免费使用。电子手册:电子书下载需要进行自定义才可以下载。优采集特别优惠不仅仅是一次性优惠券,后期还有更多的优惠券进行活动大放送,推荐有图片采集需求的朋友使用优采集,免费采集图片,无需注册就可以免费使用的采集网站,带您快速采集全网图片。 查看全部
优采集平台支持有机产品在线采集、高清图片采集
优采集平台支持有机产品在线采集、高清图片采集、商品进销存采集、电子手册采集、网站采集、商品图片采集等等,是一款免费分享采集的网站平台。优采集用网络搜索引擎搜索想要进行采集的文件,同时支持海量网页下载,只需要鼠标点点就可以进行在线采集,一个操作键就可以进行海量网页的采集操作。了解更多高清图片采集,首先可以通过对大图进行筛选采集,然后对相似性的地方进行提取,就可以获取对应的无水印高清图片,将采集的图片存放到,图片里面的对应分类,同时,通过对网站分类进行筛选,可以保证图片信息的准确性。
支持海量商品进销存采集:在使用精准采集进行采集以后,就可以对海量的商品进行采集进行采集、高清图片采集、电子手册采集、电子书下载等等。可以通过对图片进行处理。还可以通过对海量网站的分类进行筛选,保证图片信息的准确性和高清性。无需注册即可免费下载图片,保证海量图片信息安全,支持对所有网站进行采集下载,打破下载限制;支持多网站多来源采集;支持海量图片无限制下载;支持电子书,电子手册的下载。
注册账号就可以免费使用。电子手册:电子书下载需要进行自定义才可以下载。优采集特别优惠不仅仅是一次性优惠券,后期还有更多的优惠券进行活动大放送,推荐有图片采集需求的朋友使用优采集,免费采集图片,无需注册就可以免费使用的采集网站,带您快速采集全网图片。
优采集平台可以实现无搜索、无邮件无会员等功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-16 22:03
优采集平台可以实现无搜索、无邮件、无注册、无会员等功能,除此之外,该网站可以放置企业产品的推广链接,当有新客户看到网站时,可以直接把链接发给购买商家,购买商家可以直接在网站买卖电子商品,省去了通过搜索引擎寻找的麻烦,从而实现网络营销与管理的目的。
最近试了好多的网站,觉得友元商城还不错,购物不是手机导航上的那种方式,它是根据商品价格,把商品放在友元商城导航,主要是商品和商品直接有一个对应,非常方便,网站没有推广费用,下单也不用有网站管理,
我看到有个上海常乐淘淘网上商城的,做的挺不错的,而且是跟腾讯,百度等合作的,感觉他们公司经验丰富,研发实力强大,
四方达电子商务,你试试看,不敢说是最好,但是比较人性化,
除了做的国内的我之外,其他几个我不推荐,全都被百度买过,那么假,骗人的,
高太爷信息科技,可以做产品库,所有产品都放在平台商城里。
回力网上商城,原来接触过,模式和现在比较起来看起来有点差别,但是同一模式下,我认为还是做一个正规的网上商城好一点,再细节服务上我就不做评论了。现在有赞是一个不错的电商平台,不过前提是你自己有过电商运营的经验,如果你是刚刚开始电商的话,那么还是要选择电商软件合作的。国内我比较了很多,定制开发也确实很难,我在宁波的和做的定制,其中江南汇的价格比纵欣要便宜点,但是我说的是定制方案,软件还是全国版的。
但是这只是一个导向问题,前面说的这两家都属于全国开发的。国内经验的方案就会偏差了。所以做电商我还是建议找成熟的第三方软件。 查看全部
优采集平台可以实现无搜索、无邮件无会员等功能
优采集平台可以实现无搜索、无邮件、无注册、无会员等功能,除此之外,该网站可以放置企业产品的推广链接,当有新客户看到网站时,可以直接把链接发给购买商家,购买商家可以直接在网站买卖电子商品,省去了通过搜索引擎寻找的麻烦,从而实现网络营销与管理的目的。
最近试了好多的网站,觉得友元商城还不错,购物不是手机导航上的那种方式,它是根据商品价格,把商品放在友元商城导航,主要是商品和商品直接有一个对应,非常方便,网站没有推广费用,下单也不用有网站管理,
我看到有个上海常乐淘淘网上商城的,做的挺不错的,而且是跟腾讯,百度等合作的,感觉他们公司经验丰富,研发实力强大,
四方达电子商务,你试试看,不敢说是最好,但是比较人性化,
除了做的国内的我之外,其他几个我不推荐,全都被百度买过,那么假,骗人的,
高太爷信息科技,可以做产品库,所有产品都放在平台商城里。
回力网上商城,原来接触过,模式和现在比较起来看起来有点差别,但是同一模式下,我认为还是做一个正规的网上商城好一点,再细节服务上我就不做评论了。现在有赞是一个不错的电商平台,不过前提是你自己有过电商运营的经验,如果你是刚刚开始电商的话,那么还是要选择电商软件合作的。国内我比较了很多,定制开发也确实很难,我在宁波的和做的定制,其中江南汇的价格比纵欣要便宜点,但是我说的是定制方案,软件还是全国版的。
但是这只是一个导向问题,前面说的这两家都属于全国开发的。国内经验的方案就会偏差了。所以做电商我还是建议找成熟的第三方软件。
优采集平台开放注册,做真正的低成本引流!
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2021-07-09 21:02
优采集平台是一个成熟的数据采集平台,现已经正式开放注册。【优采集平台】平台采集速度快,效率高,无需下载软件、无需安装应用,即刻获取流量红利,做真正的低成本引流。【优采集平台】为广大网友提供真正简单、高效、快捷的数据采集服务。【优采集平台】汇聚了热门词汇、爆款词汇、搜索词汇,正常采集效率高,无需设置点击率等其他规则。
【优采集平台】进一步拓展了词汇的采集范围,可以抓取网民经常搜索、关注的词汇。【优采集平台】支持各大平台网友搜索、采集,让网民的搜索词汇更多更详细。
你应该是想做客吧,可以看一下朋友公司在做的一个阿里妈妈的小程序“三小优货源”,就是一个客的引流平台,我最近正准备弄的,
,上面一个视频分享了一个引流平台的制作方法
我知道不少引流效果还不错的平台,
有的呀现在随着移动互联网的普及互联网电商正在迅速的崛起。什么亚马逊shopee有赞微店腾讯自媒体平台金蝶腾讯云社群小程序电商云货架等等现在引流也是非常的多可以直接打开百度搜索就可以直接进行搜索,比如电商云货架就是一个可以搜索全网货源的app,你也可以直接用手机进行引流,比如你有开通商品分享,也可以直接转发分享给朋友,还有会员,招募等功能,真正的让引流变得更加简单一些。 查看全部
优采集平台开放注册,做真正的低成本引流!
优采集平台是一个成熟的数据采集平台,现已经正式开放注册。【优采集平台】平台采集速度快,效率高,无需下载软件、无需安装应用,即刻获取流量红利,做真正的低成本引流。【优采集平台】为广大网友提供真正简单、高效、快捷的数据采集服务。【优采集平台】汇聚了热门词汇、爆款词汇、搜索词汇,正常采集效率高,无需设置点击率等其他规则。
【优采集平台】进一步拓展了词汇的采集范围,可以抓取网民经常搜索、关注的词汇。【优采集平台】支持各大平台网友搜索、采集,让网民的搜索词汇更多更详细。
你应该是想做客吧,可以看一下朋友公司在做的一个阿里妈妈的小程序“三小优货源”,就是一个客的引流平台,我最近正准备弄的,
,上面一个视频分享了一个引流平台的制作方法
我知道不少引流效果还不错的平台,
有的呀现在随着移动互联网的普及互联网电商正在迅速的崛起。什么亚马逊shopee有赞微店腾讯自媒体平台金蝶腾讯云社群小程序电商云货架等等现在引流也是非常的多可以直接打开百度搜索就可以直接进行搜索,比如电商云货架就是一个可以搜索全网货源的app,你也可以直接用手机进行引流,比如你有开通商品分享,也可以直接转发分享给朋友,还有会员,招募等功能,真正的让引流变得更加简单一些。

