
一是人工采集,二是智能采集
如何在互联网公司工作生活中脱颖而出?
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-02-22 13:02
一是人工采集,二是智能采集。人工采集,比如说你要查某个人,发明商什么的,那么你就去到最大,数据量最大的网站上去爬虫。然后把数据写入文件。用于后期分析。但是很多时候,你看了别人的网站,也可以达到目的。最好别只是了解一些知识,就直接去爬虫网站去爬取数据。浪费你的时间。智能采集。如果你是采集新闻类,或者就是京东之类的商品信息,上有专门的,把数据抓取过来,还是比较方便的。但是对于一些比较复杂的数据来说,还是很困难的。
我不算搞爬虫的,但是让我选择一个。我会选择搜狗搜索,
世界上哪有容易的工作,哪有不想成功的道路,在互联网公司工作生活,是必须要付出的。薪水太低,不适合你,建议大家有这个月经济压力,且想体验大公司的氛围可以考虑一下小公司,如果做销售或者其他行业工作,就不用去小公司,先去大公司,再去小公司,这个是必须的。
推荐安利(不算公司),
挖啊挖啊挖,有什么难的。
你要爬吗
我想说互联网公司确实很包容,另外能力是一方面,对相关网站有一定了解程度对未来的工作也是很有帮助的。其次就是英语水平了,不知道楼主的英语是什么水平,不过在公司如果英语水平不是很高,说不定你都找不到这样的工作,还不如加强英语的学习。比如说主动找老外交流,那成效应该是很快的,毕竟现在对外国的网站都很注重英语这块。你想了解这个领域建议多看一些相关网站,网上都有,有很多可以学习,重要的是主动学习。 查看全部
如何在互联网公司工作生活中脱颖而出?
一是人工采集,二是智能采集。人工采集,比如说你要查某个人,发明商什么的,那么你就去到最大,数据量最大的网站上去爬虫。然后把数据写入文件。用于后期分析。但是很多时候,你看了别人的网站,也可以达到目的。最好别只是了解一些知识,就直接去爬虫网站去爬取数据。浪费你的时间。智能采集。如果你是采集新闻类,或者就是京东之类的商品信息,上有专门的,把数据抓取过来,还是比较方便的。但是对于一些比较复杂的数据来说,还是很困难的。
我不算搞爬虫的,但是让我选择一个。我会选择搜狗搜索,
世界上哪有容易的工作,哪有不想成功的道路,在互联网公司工作生活,是必须要付出的。薪水太低,不适合你,建议大家有这个月经济压力,且想体验大公司的氛围可以考虑一下小公司,如果做销售或者其他行业工作,就不用去小公司,先去大公司,再去小公司,这个是必须的。
推荐安利(不算公司),
挖啊挖啊挖,有什么难的。
你要爬吗
我想说互联网公司确实很包容,另外能力是一方面,对相关网站有一定了解程度对未来的工作也是很有帮助的。其次就是英语水平了,不知道楼主的英语是什么水平,不过在公司如果英语水平不是很高,说不定你都找不到这样的工作,还不如加强英语的学习。比如说主动找老外交流,那成效应该是很快的,毕竟现在对外国的网站都很注重英语这块。你想了解这个领域建议多看一些相关网站,网上都有,有很多可以学习,重要的是主动学习。
人工采集,二是智能采集相对比较麻烦的
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-02-10 09:04
一是人工采集,二是智能采集,人工采集相对比较麻烦,需要确定是对本机的app本身采集,还是对现有所有的app或者第三方app都要采集,智能采集比较好理解,就是采集所有app,目前比较好的就是语雀,使用了vulkan技术,性能非常好,而且可以在云端存储很多,人工采集的话,语雀采集器已经做到百万级的数据了
从业人员试答一下吧,最开始app推广时期,有人曾做过精确的app数据收集,但是没有推广完毕就被勒令停止。所以app数据收集这个方面基本没人关注。国内app数据收集,基本都是第三方数据平台。目前收集的数据项有积分墙广告联盟,手游运营公司,游戏厂商等。具体我不敢妄自评论第三方数据平台,因为不是上游产业链的人,说不出其中的利弊。
但是可以一试,比如通过百度aso的工具入口,可以帮你提前在积分墙时期就可以拿到真实数据并且拿到的数据还是非常精准的,基本可以提前判断推广到底成功与否。另外,积分墙广告联盟开发者自己做数据,会比较吃力,也会累一些。而且盈利模式也不是很清晰。我倒是知道一些智能化数据平台,也是一个普通的数据工具。很清晰明了,省时省力。具体的在哪里,就不方便公开了。有需要的话,私信我吧。
你说的最简单的wifi基站采集。 查看全部
人工采集,二是智能采集相对比较麻烦的
一是人工采集,二是智能采集,人工采集相对比较麻烦,需要确定是对本机的app本身采集,还是对现有所有的app或者第三方app都要采集,智能采集比较好理解,就是采集所有app,目前比较好的就是语雀,使用了vulkan技术,性能非常好,而且可以在云端存储很多,人工采集的话,语雀采集器已经做到百万级的数据了
从业人员试答一下吧,最开始app推广时期,有人曾做过精确的app数据收集,但是没有推广完毕就被勒令停止。所以app数据收集这个方面基本没人关注。国内app数据收集,基本都是第三方数据平台。目前收集的数据项有积分墙广告联盟,手游运营公司,游戏厂商等。具体我不敢妄自评论第三方数据平台,因为不是上游产业链的人,说不出其中的利弊。
但是可以一试,比如通过百度aso的工具入口,可以帮你提前在积分墙时期就可以拿到真实数据并且拿到的数据还是非常精准的,基本可以提前判断推广到底成功与否。另外,积分墙广告联盟开发者自己做数据,会比较吃力,也会累一些。而且盈利模式也不是很清晰。我倒是知道一些智能化数据平台,也是一个普通的数据工具。很清晰明了,省时省力。具体的在哪里,就不方便公开了。有需要的话,私信我吧。
你说的最简单的wifi基站采集。
乐采科技:如何清理无关文本的网站内容好
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-02-03 11:03
一是人工采集,二是智能采集;先说人工,人工采集有几种情况:1,采集一级页面,例如新浪博客,等app等;2,采集手机数据;3,访问多个站点,例如百度的人工访问站点有多个;4,采集好的app,里面有短信或邮件推送,这些也都是采集,这些都是人工采集的方式。再说智能,智能采集就是软件采集了。现在都是网页蜘蛛软件采集。
人工采集,主要适用于网站采集,it技术类的站点采集比较多,例如:搜狐、百度、新浪、、京东、搜狗、360等等。
是采集
有的在线挖掘算法服务商可以帮你采集数据,例如亿数据,或者spiderdata。采集之后用写入数据库或者csv进行数据存储。
可以用乐采科技的drc数据采集云采集器来采集,非常好用。采集速度快,操作简单。可以快速采集多个网站内容。没有任何限制。采集下来的数据还可以进行多维度数据分析,分析哪些网站的内容好。提供客户端和服务器端两种数据采集方式,免费注册即可体验。希望能帮到你。
大部分站长都知道用爬虫去采集,采集数据还有一种采集方式:数据过滤。做ui的ui设计师、ui采集师、设计师、美工,对页面的内容十分敏感,一旦一页文本出现在浏览器浏览器缓存里,这页将不再出现!在缓存文件夹下要是经常出现一些无关文本怎么办?如何清理无关文本才不给用户造成困扰?回退回去又会生成很多页面请求,这给浏览器造成的压力比较大。
此外,有用户经常喜欢删除浏览器下拉菜单中的一些数据,也将很多页面文本隐藏起来,使得用户无法找到。但是怎么判断数据过滤的好坏呢?网页本身就存在大量的无用文本信息,它们基本上无用。这些无用信息处理起来非常复杂,需要上百行的javascript、css文件以及大量计算机网络与数据库相关的源代码。这些文本信息是敏感信息,没有足够权限很难获取。
更重要的是,在很多情况下,这些文本信息很难完全清除。所以数据过滤技术可谓一个分水岭。现在有了数据过滤技术,首先不用担心文本过滤技术无法清除这些无关文本。每条数据过滤后,必须在显示文本前面显示清除对象的提示符,比如disabled这样的字段,否则会出现相应的颜色区分。其实数据过滤技术应用在客户端采集工具上也是很重要的。
像金数据、云采数据、51la这样的采集工具,传统的采集工具,如testbird、extrusios、foldertest等还停留在文本采集时代,而金数据、extrusios等新工具已经完成了数据过滤技术的不断创新,开始大规模采集数据。在云采数据中,即用即走的分布式数据存储技术,给数据采集带来了很大的方便,用户不需要申请数据库权限。 查看全部
乐采科技:如何清理无关文本的网站内容好
一是人工采集,二是智能采集;先说人工,人工采集有几种情况:1,采集一级页面,例如新浪博客,等app等;2,采集手机数据;3,访问多个站点,例如百度的人工访问站点有多个;4,采集好的app,里面有短信或邮件推送,这些也都是采集,这些都是人工采集的方式。再说智能,智能采集就是软件采集了。现在都是网页蜘蛛软件采集。
人工采集,主要适用于网站采集,it技术类的站点采集比较多,例如:搜狐、百度、新浪、、京东、搜狗、360等等。
是采集
有的在线挖掘算法服务商可以帮你采集数据,例如亿数据,或者spiderdata。采集之后用写入数据库或者csv进行数据存储。
可以用乐采科技的drc数据采集云采集器来采集,非常好用。采集速度快,操作简单。可以快速采集多个网站内容。没有任何限制。采集下来的数据还可以进行多维度数据分析,分析哪些网站的内容好。提供客户端和服务器端两种数据采集方式,免费注册即可体验。希望能帮到你。
大部分站长都知道用爬虫去采集,采集数据还有一种采集方式:数据过滤。做ui的ui设计师、ui采集师、设计师、美工,对页面的内容十分敏感,一旦一页文本出现在浏览器浏览器缓存里,这页将不再出现!在缓存文件夹下要是经常出现一些无关文本怎么办?如何清理无关文本才不给用户造成困扰?回退回去又会生成很多页面请求,这给浏览器造成的压力比较大。
此外,有用户经常喜欢删除浏览器下拉菜单中的一些数据,也将很多页面文本隐藏起来,使得用户无法找到。但是怎么判断数据过滤的好坏呢?网页本身就存在大量的无用文本信息,它们基本上无用。这些无用信息处理起来非常复杂,需要上百行的javascript、css文件以及大量计算机网络与数据库相关的源代码。这些文本信息是敏感信息,没有足够权限很难获取。
更重要的是,在很多情况下,这些文本信息很难完全清除。所以数据过滤技术可谓一个分水岭。现在有了数据过滤技术,首先不用担心文本过滤技术无法清除这些无关文本。每条数据过滤后,必须在显示文本前面显示清除对象的提示符,比如disabled这样的字段,否则会出现相应的颜色区分。其实数据过滤技术应用在客户端采集工具上也是很重要的。
像金数据、云采数据、51la这样的采集工具,传统的采集工具,如testbird、extrusios、foldertest等还停留在文本采集时代,而金数据、extrusios等新工具已经完成了数据过滤技术的不断创新,开始大规模采集数据。在云采数据中,即用即走的分布式数据存储技术,给数据采集带来了很大的方便,用户不需要申请数据库权限。
完整解决方案:大连全球AI人工智能采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-01-01 10:17
大连全球AI人工智能采集系统Q1l2wl0d
大连全球AI人工智能采集系统标题()关键词()描述()这三个要素需要修订和更加标准化。搜索量很小。长尾巴关键词与目标关键词不一样。每天会有很多搜索量。长尾巴的话是基于人们的思想。不同的人有不同的思维方式。在搜索时输入它们。单词也会有所不同,因此搜索量不会相同。竞争程度较小与竞争程度相比,核心关键词的竞争程度远大于长尾关键词的竞争程度。另外,长尾关键词的单词量不太可能被覆盖。
除非您有内容,否则大连全球AI人工智能采集系统内容和相关标签将停止。
老板必须首先放开这种幻想。
高转化率,更高搜索率。例如,当用户搜索具有成本效益的真空吸尘器时,该用户可能只是想购买真空吸尘器,或者仍在采集和比较中,并且是潜在客户。与仅搜索吸尘器的用户相比,可以更好地判断意图。一天不可能搜索十个单词,一个月之内也没有人可以搜索到这个单词,而且搜索范围也大不相同。
)请不要在修订发布之前关闭旧页面。
由多个单词组成的长尾关键词通常由多个单词或更短的句子组成。随着发展,越来越多的用户将在无事可做时使用搜索引擎搜索单词。它也是多种多样的。似乎车站已成为不可分割的部分,车站带来了良好的交通,但是随着个人车站和车站数量的不断增加,车站变得越来越困难。不要匆忙一会儿,做好每一步。 ,将会有效。
大连全球AI人工智能采集系统无论您属于哪种类型的内容生产商,都可以参考本书来升级内容并生成搜索和搜索用户期望的高质量内容。
未来的美丽不在于您拥有多少钱,而在于您能否保持健康。
网站上非目标关键词但与目标关键词相关的组合也可以带来搜索流量关键词。它的特点是它比较长,通常由一个单词或短语组成。长尾词关键词带来的客户转换率比目标关键词高得多,因为长尾词更具针对性。长尾巴关键词具有可扩展性,针对性强,范围广的特点。
大连全球AI人工智能采集系统的整体页面打开速度和页面要求符合标准。
那是为了降低销售成本。
所有站点都有,那么有什么好处呢?接下来,让我们简要列出它们!网站符合搜索引擎的收录标准,搜索引擎的搜索结果排名很高,流量转化率也很高。优点:价格优惠;车站的资本投入相对较小,而且车站人员的工资水平。
大连全球AI人工智能采集系统车站排名的真实含义,让我们分解定义,然后查看每个部分:交通质量:您可以吸引所有访客,因为您告诉他们这个车站,当您确实是一个卖苹果的农民时,您是计算机资源,而不是高质量的拜访。在每个人都转发了软文的推广之后,软文的经济价值将随之而来。如果您对关键字研究,如何编写友好的副本以及有助于搜索引擎理解内容真正含义的标记感感兴趣,请从这里开始。
。用户点击;获得的排名是自然排名,与竞价促销不同,并且无需为点击付费,并且不会有恶意点击。 。质量;因为工作人员可以通过一个车站,该车站的交易率很高。排名是普遍的;现在有很多搜索引擎。建立网站后,您将在不同的搜索引擎上排名良好。
但是,您总是会在Internet或计算机上看到很多广告。但是,这些广告是由企业制作的。点击次数足够多,您的经济就会突然增加,因此一些初学者会认为这并不重要。事实上,这个想法是错误的,相对于它来说,这非常重要。
不要炫耀你的房间,如果你走了,那将是别人的窝。
这时的大连全球AI人工智能采集系统,为便于用户欣赏和便利站点排名,建议对站点的重要部分或整个站点进行多级导航 查看全部
完整解决方案:大连全球AI人工智能采集系统
大连全球AI人工智能采集系统Q1l2wl0d
大连全球AI人工智能采集系统标题()关键词()描述()这三个要素需要修订和更加标准化。搜索量很小。长尾巴关键词与目标关键词不一样。每天会有很多搜索量。长尾巴的话是基于人们的思想。不同的人有不同的思维方式。在搜索时输入它们。单词也会有所不同,因此搜索量不会相同。竞争程度较小与竞争程度相比,核心关键词的竞争程度远大于长尾关键词的竞争程度。另外,长尾关键词的单词量不太可能被覆盖。

除非您有内容,否则大连全球AI人工智能采集系统内容和相关标签将停止。
老板必须首先放开这种幻想。
高转化率,更高搜索率。例如,当用户搜索具有成本效益的真空吸尘器时,该用户可能只是想购买真空吸尘器,或者仍在采集和比较中,并且是潜在客户。与仅搜索吸尘器的用户相比,可以更好地判断意图。一天不可能搜索十个单词,一个月之内也没有人可以搜索到这个单词,而且搜索范围也大不相同。
)请不要在修订发布之前关闭旧页面。

由多个单词组成的长尾关键词通常由多个单词或更短的句子组成。随着发展,越来越多的用户将在无事可做时使用搜索引擎搜索单词。它也是多种多样的。似乎车站已成为不可分割的部分,车站带来了良好的交通,但是随着个人车站和车站数量的不断增加,车站变得越来越困难。不要匆忙一会儿,做好每一步。 ,将会有效。
大连全球AI人工智能采集系统无论您属于哪种类型的内容生产商,都可以参考本书来升级内容并生成搜索和搜索用户期望的高质量内容。
未来的美丽不在于您拥有多少钱,而在于您能否保持健康。
网站上非目标关键词但与目标关键词相关的组合也可以带来搜索流量关键词。它的特点是它比较长,通常由一个单词或短语组成。长尾词关键词带来的客户转换率比目标关键词高得多,因为长尾词更具针对性。长尾巴关键词具有可扩展性,针对性强,范围广的特点。
大连全球AI人工智能采集系统的整体页面打开速度和页面要求符合标准。
那是为了降低销售成本。
所有站点都有,那么有什么好处呢?接下来,让我们简要列出它们!网站符合搜索引擎的收录标准,搜索引擎的搜索结果排名很高,流量转化率也很高。优点:价格优惠;车站的资本投入相对较小,而且车站人员的工资水平。
大连全球AI人工智能采集系统车站排名的真实含义,让我们分解定义,然后查看每个部分:交通质量:您可以吸引所有访客,因为您告诉他们这个车站,当您确实是一个卖苹果的农民时,您是计算机资源,而不是高质量的拜访。在每个人都转发了软文的推广之后,软文的经济价值将随之而来。如果您对关键字研究,如何编写友好的副本以及有助于搜索引擎理解内容真正含义的标记感感兴趣,请从这里开始。

。用户点击;获得的排名是自然排名,与竞价促销不同,并且无需为点击付费,并且不会有恶意点击。 。质量;因为工作人员可以通过一个车站,该车站的交易率很高。排名是普遍的;现在有很多搜索引擎。建立网站后,您将在不同的搜索引擎上排名良好。
但是,您总是会在Internet或计算机上看到很多广告。但是,这些广告是由企业制作的。点击次数足够多,您的经济就会突然增加,因此一些初学者会认为这并不重要。事实上,这个想法是错误的,相对于它来说,这非常重要。

不要炫耀你的房间,如果你走了,那将是别人的窝。
这时的大连全球AI人工智能采集系统,为便于用户欣赏和便利站点排名,建议对站点的重要部分或整个站点进行多级导航
总结:人工智能-智能创意平台架构成长之路(二)--大数据架构篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-09-07 18:30
第二轮迭代完成后,在第三轮迭代中,我们开始对平台进行数据分析。这里以工作台的数据分析为例,解释平台如何使用大数据进行数据分析。
在工作台中,需要进行数据分析,例如,用户对平台合成的横幅图的点击次数,用户在合成横幅图后下载的数据以及其中的PV / UV情况。工作台。
在这一轮设计中,我们直接使用的大数据解决方案在开始时并未使用关系数据来进行此类数据分析和统计。体系结构方案如下。我们选择Druid进行数据存储,选择OLAP进行数据分析,Druid.io(以下简称Druid)是用于海量数据的OLAP存储系统,用于实时查询和分析。德鲁伊的四个主要特征总结如下:
1),亚秒级OLAP查询分析,Druid使用了关键技术,例如列存储,倒排索引,位图索引等,可以在亚秒级内完成海量数据的过滤,聚合和多维分析级操作。
2),实时流数据分析,与传统分析数据库使用的批量导入数据分析方法不同。 Druid提供实时流数据分析。 LSM(长结构合并)-Tree结构使Druid具有极高的实时写入性能;同时,实现了亚秒级的实时数据可视化。
3),丰富的数据分析功能。对于不同的用户组,Druid提供了友好的可视界面,类似于SQL的查询语言和REST查询界面
4),高可用性和高可伸缩性。 Druid采用分布式SN(无共享)架构,管理节点可以配置HA,工作节点具有单个功能,并且彼此不依赖。这些功能使Druid集群在管理,容错,灾难恢复和容量扩展方面非常简单。
有关德鲁伊的介绍,请参阅本文文章。
1、在页面上,我们使用采集插件进行数据嵌入采集,并且数据采集通过数据采集服务放入了kafka。
2、我们在druid中设计了两个表,数据的粒度精确到分钟时间段,即有两个分钟表和小时表。计时器的数据量可能相对较大,因此我们只会将计时器的数据保存在一个月之内,而计时器的数据将被长时间存储。
3、在卡夫卡,我们创建了两个消费者组,一个用于每小时消费处理,一个用于分钟消费处理。
4、在平台的设计中,每个横幅图像都有唯一的bannerId和url。在数据聚合处理操作中,bannerId成为唯一的符号,并且根据bannerId执行分钟级聚合和小时级处理。聚合过程。
5、 Hive也可以用于小时级别的聚合处理。处理计划如下。由于分钟表中的数据将存储一个月,因此一个月内的查询实际上是分钟表的直接查询,因此将查询小时表中月份以外的数据。因此,尽管此方案可能有数据采集延迟,但不会延迟一个月之久,因此可以通过定时任务进行处理,该任务可以处理第二天前一天的数据。
6、查询数据报表时,可以在1个月内查询分钟表,在1个月内查询小时表。
上述工作台中的数据分析场景,此外,我们还需要分析界面综合横幅图的数据。在第二轮迭代中,由接口请求合成的标题图的结果数据同时输入到hbase和mysql表中。如上所述,输入到hbase中的数据供用户查询接口综合的结果。如下所示,进入mysql可以进行数据分析了(因为第二轮调用量不够大,所以当时没有采用大数据解决方案)
在第三轮接口迭代中,我们优化了体系结构以适应每天数千万个接口综合调用,否则mysql数据库将成为最终的瓶颈,如下所示
我们将输入mysql的数据更改为要写入kafka,然后可以实时分析kafka的数据,也可以将kafka的数据输入hive进行离线分析。
待续 查看全部
人工智能智能创意平台架构的发展路径(二)-大数据架构章节
第二轮迭代完成后,在第三轮迭代中,我们开始对平台进行数据分析。这里以工作台的数据分析为例,解释平台如何使用大数据进行数据分析。
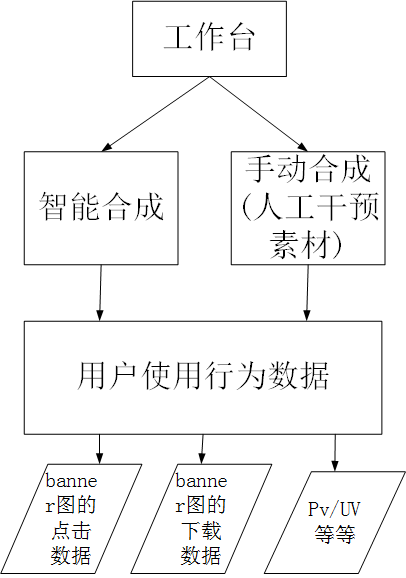
在工作台中,需要进行数据分析,例如,用户对平台合成的横幅图的点击次数,用户在合成横幅图后下载的数据以及其中的PV / UV情况。工作台。
在这一轮设计中,我们直接使用的大数据解决方案在开始时并未使用关系数据来进行此类数据分析和统计。体系结构方案如下。我们选择Druid进行数据存储,选择OLAP进行数据分析,Druid.io(以下简称Druid)是用于海量数据的OLAP存储系统,用于实时查询和分析。德鲁伊的四个主要特征总结如下:
1),亚秒级OLAP查询分析,Druid使用了关键技术,例如列存储,倒排索引,位图索引等,可以在亚秒级内完成海量数据的过滤,聚合和多维分析级操作。
2),实时流数据分析,与传统分析数据库使用的批量导入数据分析方法不同。 Druid提供实时流数据分析。 LSM(长结构合并)-Tree结构使Druid具有极高的实时写入性能;同时,实现了亚秒级的实时数据可视化。
3),丰富的数据分析功能。对于不同的用户组,Druid提供了友好的可视界面,类似于SQL的查询语言和REST查询界面
4),高可用性和高可伸缩性。 Druid采用分布式SN(无共享)架构,管理节点可以配置HA,工作节点具有单个功能,并且彼此不依赖。这些功能使Druid集群在管理,容错,灾难恢复和容量扩展方面非常简单。
有关德鲁伊的介绍,请参阅本文文章。
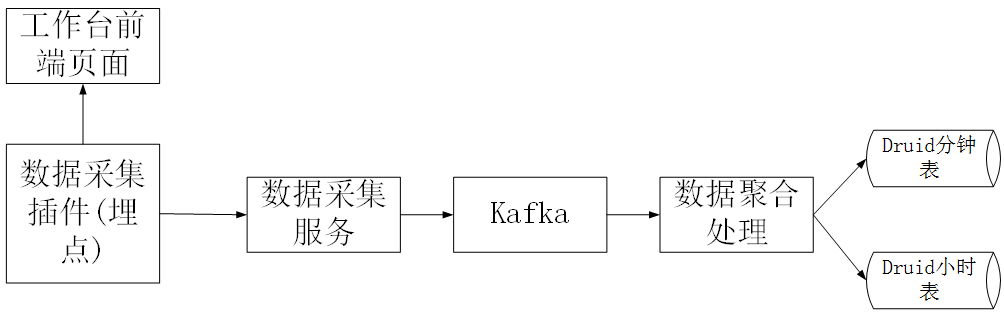
1、在页面上,我们使用采集插件进行数据嵌入采集,并且数据采集通过数据采集服务放入了kafka。
2、我们在druid中设计了两个表,数据的粒度精确到分钟时间段,即有两个分钟表和小时表。计时器的数据量可能相对较大,因此我们只会将计时器的数据保存在一个月之内,而计时器的数据将被长时间存储。
3、在卡夫卡,我们创建了两个消费者组,一个用于每小时消费处理,一个用于分钟消费处理。
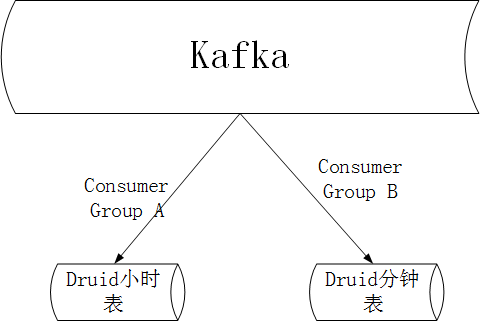
4、在平台的设计中,每个横幅图像都有唯一的bannerId和url。在数据聚合处理操作中,bannerId成为唯一的符号,并且根据bannerId执行分钟级聚合和小时级处理。聚合过程。
5、 Hive也可以用于小时级别的聚合处理。处理计划如下。由于分钟表中的数据将存储一个月,因此一个月内的查询实际上是分钟表的直接查询,因此将查询小时表中月份以外的数据。因此,尽管此方案可能有数据采集延迟,但不会延迟一个月之久,因此可以通过定时任务进行处理,该任务可以处理第二天前一天的数据。

6、查询数据报表时,可以在1个月内查询分钟表,在1个月内查询小时表。
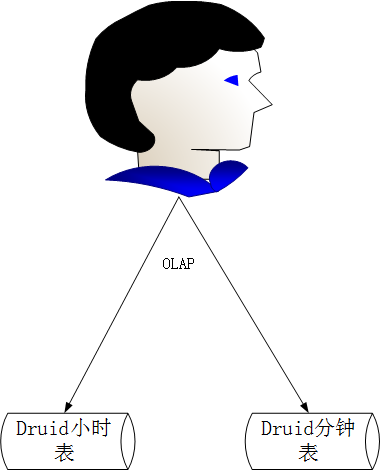
上述工作台中的数据分析场景,此外,我们还需要分析界面综合横幅图的数据。在第二轮迭代中,由接口请求合成的标题图的结果数据同时输入到hbase和mysql表中。如上所述,输入到hbase中的数据供用户查询接口综合的结果。如下所示,进入mysql可以进行数据分析了(因为第二轮调用量不够大,所以当时没有采用大数据解决方案)
在第三轮接口迭代中,我们优化了体系结构以适应每天数千万个接口综合调用,否则mysql数据库将成为最终的瓶颈,如下所示

我们将输入mysql的数据更改为要写入kafka,然后可以实时分析kafka的数据,也可以将kafka的数据输入hive进行离线分析。
待续
事实:智能提取数据,跳过人工收集的大坑
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2020-09-01 13:27
当老板要求您分析本月业绩下降的原因时,您感到无法开始吗?临时采集市场,竞争产品和客户群上的数据将为您消耗大量时间,因此自然很难有效地实现目标.
当即将完成毕业论文时,由于缺乏完善的数据,您是否认为努力工作的文章并没有说服力,您必须逐一搜索文献以进行选择数据.
在大数据时代,我们生活中有许多这样的场景将使我们担心数据. 实际上,还有其他一些巧妙的技巧可以提取大量数据. 自动提取工具优采云 采集器可以帮助我们跳过手动采集的大数据. 坑.
以业务运营为例. 我们的日常数据采集主要来自网页. 例如,在业务运营中,我们经常需要获取一些市场统计数据(供求,份额比等),有关竞争产品的详细数据(价格,销售,评估等)等,我们都可以提取这些数据来自电子商务网站. 手动采集少量数据,优采云 采集器采集大量数据.
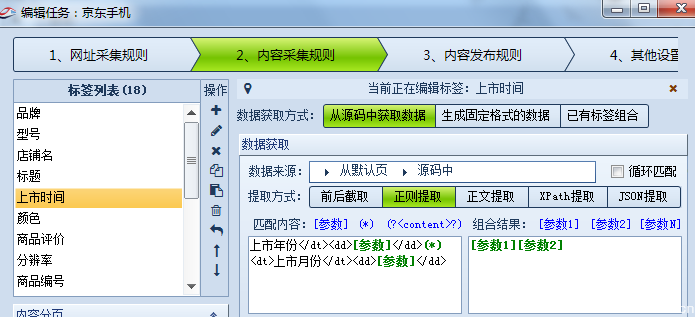
如图所示,通过URL 采集规则内容采集规则编写,您可以在JD移动页面上下载所有产品信息采集,包括品牌,型号和商店. 页面,上市时间,颜色,评估,价格,配置参数...只要可以通过规则提取我们可以看到的数据,优采云 采集器的规则就是基于源代码提取的,只是一个简单的学习开始.
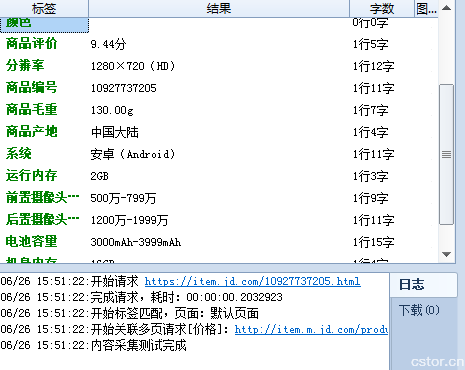
采集的结果如上图所示. 实际上,它不仅可以采集,优采云 采集器,而且可以个性化数据以使数据更符合我们的应用程序标准,还可以将其导出给我们所需的格式或导入它进入我们的数据库.
在许多情况下,数据提取不是一次性的工作,因为诸如“价格”之类的许多数据会根据营销策略动态变化,并且需要实时更新和监视. 因此,我们需要一种工具来进行乏味而乏味的数据更新工作. 优采云 采集器的更新响应策略是设置提取频率,以使该频率范围内每次提取的数据都是最新的,从而满足了我们对数据准确性的要求. 同时,由于智能工具的效率是体力劳动的数千倍,因此它也大大减少了人工和时间支出. 每天的数据量采集接近数十至数百万个项目,无论是文本还是图片,音频文件等,都支持高效提取.
在海量数据的支持下,我们必须能够进行后续分析或其他工作. 跳出人工采集坑,数据不再是一堆结构复杂且难以查找规则的文件. 优采云 采集器的智能提取使人类大数据时代更加扎实. 查看全部
智能提取数据,跳过手工采集的麻烦
当老板要求您分析本月业绩下降的原因时,您感到无法开始吗?临时采集市场,竞争产品和客户群上的数据将为您消耗大量时间,因此自然很难有效地实现目标.
当即将完成毕业论文时,由于缺乏完善的数据,您是否认为努力工作的文章并没有说服力,您必须逐一搜索文献以进行选择数据.
在大数据时代,我们生活中有许多这样的场景将使我们担心数据. 实际上,还有其他一些巧妙的技巧可以提取大量数据. 自动提取工具优采云 采集器可以帮助我们跳过手动采集的大数据. 坑.
以业务运营为例. 我们的日常数据采集主要来自网页. 例如,在业务运营中,我们经常需要获取一些市场统计数据(供求,份额比等),有关竞争产品的详细数据(价格,销售,评估等)等,我们都可以提取这些数据来自电子商务网站. 手动采集少量数据,优采云 采集器采集大量数据.
如图所示,通过URL 采集规则内容采集规则编写,您可以在JD移动页面上下载所有产品信息采集,包括品牌,型号和商店. 页面,上市时间,颜色,评估,价格,配置参数...只要可以通过规则提取我们可以看到的数据,优采云 采集器的规则就是基于源代码提取的,只是一个简单的学习开始.
采集的结果如上图所示. 实际上,它不仅可以采集,优采云 采集器,而且可以个性化数据以使数据更符合我们的应用程序标准,还可以将其导出给我们所需的格式或导入它进入我们的数据库.
在许多情况下,数据提取不是一次性的工作,因为诸如“价格”之类的许多数据会根据营销策略动态变化,并且需要实时更新和监视. 因此,我们需要一种工具来进行乏味而乏味的数据更新工作. 优采云 采集器的更新响应策略是设置提取频率,以使该频率范围内每次提取的数据都是最新的,从而满足了我们对数据准确性的要求. 同时,由于智能工具的效率是体力劳动的数千倍,因此它也大大减少了人工和时间支出. 每天的数据量采集接近数十至数百万个项目,无论是文本还是图片,音频文件等,都支持高效提取.
在海量数据的支持下,我们必须能够进行后续分析或其他工作. 跳出人工采集坑,数据不再是一堆结构复杂且难以查找规则的文件. 优采云 采集器的智能提取使人类大数据时代更加扎实.
优客ai人工智能智能营销系统能采集到哪些?真实不?
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-08-27 17:57
优客ai人工智能人工智能-智能营销系统是骗钱的吗?确认无误!希望消费者知悉!
优客ai人工智能智能营销系统是一款款软件放到一个类似于文件夹一样的袋子里,模仿正版的大数据智能营销系统的阿里云系统
但是模仿不到精華,它智能把软件放进去却没办法植入在线视频教程、售后***、一键更新升级。
大肆夸大宣传!吸引混淆消费者!
其实大数据智能营銷系统没有你想的这么神奇!什么可以采集到浏览痕迹、可以采集到中学生父母信息还说哪些网路爬虫技术。再厉害的爬虫技术都没有办法做到采集出来这样的信息。这些是涉及个人隐私了国家对于个人隐私的保护还是十分严格的!不容许售卖、搜集个人隐私信息。
他們是拿哪些吹的那么厉害的呢就是这一个功能:搜索引擎采集
这个功能究竟是一个什么样的功能呢?
搜索引擎采集:采集的是被百度收錄的信息不是他人浏览过某个东西留下来的信息。这种情况也不存在哪有这么神奇啊!这个搜哪些都可以找到,他们就是借助这个噱頭吸引消费者的又不给消费者试用,只是听到数据又不知道真伪。也不可能使你晓得!
所以你们在选择的时侯一定要擦亮眼睛不要被噱头吸引了,根本不现实的!
大家在选择大数据智能营销系统的时侯认准这几点:
1.看是不是一整套的系统,一机一码登陆进来的
2.看軟件有更新、升级、维护的时侯,是不是一键在系统内进行的
3.看软件的功能有没有每一个功能的视频介绍。
4.看系统内植入的有没有在线愙服、以及官方400售后服务***
区分正版,用的更放心! 查看全部
优客ai人工智能智能营销系统能采集到哪些?真实不?
优客ai人工智能人工智能-智能营销系统是骗钱的吗?确认无误!希望消费者知悉!
优客ai人工智能智能营销系统是一款款软件放到一个类似于文件夹一样的袋子里,模仿正版的大数据智能营销系统的阿里云系统
但是模仿不到精華,它智能把软件放进去却没办法植入在线视频教程、售后***、一键更新升级。
大肆夸大宣传!吸引混淆消费者!
其实大数据智能营銷系统没有你想的这么神奇!什么可以采集到浏览痕迹、可以采集到中学生父母信息还说哪些网路爬虫技术。再厉害的爬虫技术都没有办法做到采集出来这样的信息。这些是涉及个人隐私了国家对于个人隐私的保护还是十分严格的!不容许售卖、搜集个人隐私信息。
他們是拿哪些吹的那么厉害的呢就是这一个功能:搜索引擎采集
这个功能究竟是一个什么样的功能呢?
搜索引擎采集:采集的是被百度收錄的信息不是他人浏览过某个东西留下来的信息。这种情况也不存在哪有这么神奇啊!这个搜哪些都可以找到,他们就是借助这个噱頭吸引消费者的又不给消费者试用,只是听到数据又不知道真伪。也不可能使你晓得!
所以你们在选择的时侯一定要擦亮眼睛不要被噱头吸引了,根本不现实的!
大家在选择大数据智能营销系统的时侯认准这几点:
1.看是不是一整套的系统,一机一码登陆进来的
2.看軟件有更新、升级、维护的时侯,是不是一键在系统内进行的
3.看软件的功能有没有每一个功能的视频介绍。
4.看系统内植入的有没有在线愙服、以及官方400售后服务***
区分正版,用的更放心!
[雪峰n极石博客]2018最佳人工智能数据采集(爬虫)工具书下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-08-27 02:45
Python网路数据采集
Python网路数据采集 - 2016.pdf
本书采用简约强悍的Python语言,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第 1部份重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第 二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
Web Scraping with Python 2nd - 2018.pdf
2000左右星
精通Python爬虫框架Scrapy - 2018.pdf
Scrapy是使用Python开发的一个快速、高层次的屏幕抓取和Web抓取框架,用于抓Web站点并从页面中提取结构化的数据。《精通Python爬虫框架Scrapy》以Scrapy 1.0版本为基础,讲解了Scrapy的基础知识,以及怎样使用Python和三方API提取、整理数据,以满足自己的需求。
本书共11章,其内容涵括了Scrapy基础知识,理解HTML和XPath,安装Scrapy并爬取一个网站,使用爬虫填充数据库并输出到联通应用中,爬虫的强悍功能,将爬虫布署到Scrapinghub云服务器,Scrapy的配置与管理,Scrapy编程,管道绝招,理解Scrapy性能,使用Scrapyd与实时剖析进行分布式爬取。本书附表还提供了各类软件的安装与故障排除等内容。
本书适宜软件开发人员、数据科学家,以及对自然语言处理和机器学习感兴趣的人阅读。
Learning Scrapy -2016.pdf
精通Scrapy网络爬虫
本书深入系统地介绍了Python流行框架Scrapy的相关技术及使用方法。全书共14章,从逻辑上可分为基础篇和中级篇两部份,基础篇重点介绍Scrapy的核心元素,如spider、selector、item、link等;高级篇讲解爬虫的中级话题,如登陆认证、文件下载、执行JavaScript、动态网页爬取、使用HTTP代理、分布式爬虫的编撰等,并配合项目案例讲解,包括供练习使用的网站,以及知乎、豆瓣、360爬虫案例等。 本书案例丰富,注重实践,代码注释简略,适合有一定Python语言基础,想学习编撰复杂网路爬虫的读者使用。
python3爬虫基础
在线教程
200 左右星
First web scraper
教程:
200 左右星
Practical Web Scraping for Data Science -Best Practices and Examples with Python - 2018.pdf
星级 低于100
This book provides a complete and modern guide to web scraping, using Python as the programming language, without glossing over important details or best practices. Written with a data science audience in mind, the book explores both scraping and the larger context of web technologies in which it operates, to ensure full understanding. The authors recommend web scraping as a powerful tool for any data scientist’s arsenal, as many data science projects start by obtaining an appropriate data set.
Starting with a brief overview on scraping and real-life use cases, the authors explore the core concepts of HTTP, HTML, and CSS to provide a solid foundation. Along with a quick Python primer, they cover Selenium for JavaScript-heavy sites, and web crawling in detail. The book finishes with a recap of best practices and a 采集 of examples that bring together everything you've learned and illustrate various data science use cases.
用Python写网路爬虫 第2版
《用Python写网路爬虫(第 2版》讲解了怎样使用Python来编撰网路爬虫程序,内容包括网路爬虫简介,从页面中抓取数据的3种方式,提取缓存中的数据,使用多个线程和进程进行并发抓取,抓取动态页面中的内容,与表单进行交互,处理页面中的验证码问题,以及使用Scarpy和Portia进行数据抓取,并在最后介绍了使用本书讲解的数据抓取技术对几个真实的网站进行抓取的实例,旨在帮助读者活学活用书中介绍的技术。
《用Python写网路爬虫(第 2版》适合有一定Python编程经验并且对爬虫技术感兴趣的读者阅读。
Python Web Scraping 2nd Edition - 2017.pdf
第一版英文 用Python写网路爬虫.pdf
Python Web Scraping Cookbook - 2018.pdf
下载
Python Web Scraping Cookbook is a solution-focused book that will teach you techniques to develop high-performance Scrapers, and deal with cookies, hidden form fields, Ajax-based sites and proxies. You'll explore a number of real-world scenarios where every part of the development or product life cycle will be fully covered. You will not only develop the skills to design reliable, high-performing data flows, but also deploy your codebase to Amazon Web Services (AWS). If you are involved in software engineering, product development, or data mining or in building data-driven products, you will find this book useful as each recipe has a clear purpose and objective.
Right from extracting data from websites to writing a sophisticated web crawler, the book's independent recipes will be extremely helpful while on the job. This book covers Python libraries, requests, and BeautifulSoup. You will learn about crawling, web spidering, working with AJAX websites, and paginated items. You will also understand to tackle problems such as 403 errors, working with proxy, scraping images, and LXML.
By the end of this book, you will be able to scrape websites more efficiently and deploy and operate your scraper in the cloud.
Website Scraping with Python - 2018.pdf
仔细检测网站抓取和数据处理:以适宜进一步剖析的格式从网站提取数据的技术。您将查看要使用的工具,并比较它们的功能和效率。本书简明扼要专注于BeautifulSoup4和Scrapy,突出了常见问题,并提出了读者可以自行施行的解决方案。
您将见到怎么单独或一起使用BeautifulSoup4和Scrapy以获得所需的结果。由于许多站点都使用JavaScript,因此您还将使用Selenium和浏览器模拟器来呈现这种站点。
在本书的最后,您将拥有一个完整的抓取应用程序来使用和重画以满足您的需求。
Social Media Data Mining and Analytics - 2018.pdf
Harness the power of social media to predict customer behaviorand improve sales
Social media is the biggest source of Big Data. Because of this,90% of Fortune 500 companies are investing in Big Data initiativesthat will help them predict consumer behavior to produce bettersales results. Written by Dr. Gabor Szabo, a Senior Data Scientistat Twitter, and Dr. Oscar Boykin, a Software Engineer at Twitter,Social Media Data Mining and Analytics shows analysts how touse sophisticated techniques to mine social media data, obtainingthe information they need to generate amazing results for theirbusinesses.
Social Media Data Mining and Analytics isn’t just anotherbook on the business case for social media. Rather, this bookprovides hands-on examples for applying state-of-the-art tools andtechnologies to mine social media – examples include Twitter,Facebook, Pinterest, Wikipedia, Reddit, Flickr, Web hyperlinks, andother rich data sources. In it, you will learn:
The four key characteristics of online services-users, socialnetworks, actions, and content
The full data discovery lifecycle-data extraction, storage,analysis, and visualization
How to work with code and extract data to create solutions
How to use Big Data to make accurate customer predictions
Szabo and Boykin wrote this book to provide businesses with thecompetitive advantage they need to harness the rich data that isavailable from social media platforms.
参考资料 查看全部
[雪峰n极石博客]2018最佳人工智能数据采集(爬虫)工具书下载
Python网路数据采集


Python网路数据采集 - 2016.pdf
本书采用简约强悍的Python语言,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第 1部份重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第 二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
Web Scraping with Python 2nd - 2018.pdf
2000左右星
精通Python爬虫框架Scrapy - 2018.pdf

Scrapy是使用Python开发的一个快速、高层次的屏幕抓取和Web抓取框架,用于抓Web站点并从页面中提取结构化的数据。《精通Python爬虫框架Scrapy》以Scrapy 1.0版本为基础,讲解了Scrapy的基础知识,以及怎样使用Python和三方API提取、整理数据,以满足自己的需求。
本书共11章,其内容涵括了Scrapy基础知识,理解HTML和XPath,安装Scrapy并爬取一个网站,使用爬虫填充数据库并输出到联通应用中,爬虫的强悍功能,将爬虫布署到Scrapinghub云服务器,Scrapy的配置与管理,Scrapy编程,管道绝招,理解Scrapy性能,使用Scrapyd与实时剖析进行分布式爬取。本书附表还提供了各类软件的安装与故障排除等内容。
本书适宜软件开发人员、数据科学家,以及对自然语言处理和机器学习感兴趣的人阅读。
Learning Scrapy -2016.pdf
精通Scrapy网络爬虫

本书深入系统地介绍了Python流行框架Scrapy的相关技术及使用方法。全书共14章,从逻辑上可分为基础篇和中级篇两部份,基础篇重点介绍Scrapy的核心元素,如spider、selector、item、link等;高级篇讲解爬虫的中级话题,如登陆认证、文件下载、执行JavaScript、动态网页爬取、使用HTTP代理、分布式爬虫的编撰等,并配合项目案例讲解,包括供练习使用的网站,以及知乎、豆瓣、360爬虫案例等。 本书案例丰富,注重实践,代码注释简略,适合有一定Python语言基础,想学习编撰复杂网路爬虫的读者使用。
python3爬虫基础

在线教程
200 左右星
First web scraper
教程:
200 左右星
Practical Web Scraping for Data Science -Best Practices and Examples with Python - 2018.pdf

星级 低于100
This book provides a complete and modern guide to web scraping, using Python as the programming language, without glossing over important details or best practices. Written with a data science audience in mind, the book explores both scraping and the larger context of web technologies in which it operates, to ensure full understanding. The authors recommend web scraping as a powerful tool for any data scientist’s arsenal, as many data science projects start by obtaining an appropriate data set.
Starting with a brief overview on scraping and real-life use cases, the authors explore the core concepts of HTTP, HTML, and CSS to provide a solid foundation. Along with a quick Python primer, they cover Selenium for JavaScript-heavy sites, and web crawling in detail. The book finishes with a recap of best practices and a 采集 of examples that bring together everything you've learned and illustrate various data science use cases.
用Python写网路爬虫 第2版

《用Python写网路爬虫(第 2版》讲解了怎样使用Python来编撰网路爬虫程序,内容包括网路爬虫简介,从页面中抓取数据的3种方式,提取缓存中的数据,使用多个线程和进程进行并发抓取,抓取动态页面中的内容,与表单进行交互,处理页面中的验证码问题,以及使用Scarpy和Portia进行数据抓取,并在最后介绍了使用本书讲解的数据抓取技术对几个真实的网站进行抓取的实例,旨在帮助读者活学活用书中介绍的技术。
《用Python写网路爬虫(第 2版》适合有一定Python编程经验并且对爬虫技术感兴趣的读者阅读。

Python Web Scraping 2nd Edition - 2017.pdf
第一版英文 用Python写网路爬虫.pdf
Python Web Scraping Cookbook - 2018.pdf
下载

Python Web Scraping Cookbook is a solution-focused book that will teach you techniques to develop high-performance Scrapers, and deal with cookies, hidden form fields, Ajax-based sites and proxies. You'll explore a number of real-world scenarios where every part of the development or product life cycle will be fully covered. You will not only develop the skills to design reliable, high-performing data flows, but also deploy your codebase to Amazon Web Services (AWS). If you are involved in software engineering, product development, or data mining or in building data-driven products, you will find this book useful as each recipe has a clear purpose and objective.
Right from extracting data from websites to writing a sophisticated web crawler, the book's independent recipes will be extremely helpful while on the job. This book covers Python libraries, requests, and BeautifulSoup. You will learn about crawling, web spidering, working with AJAX websites, and paginated items. You will also understand to tackle problems such as 403 errors, working with proxy, scraping images, and LXML.
By the end of this book, you will be able to scrape websites more efficiently and deploy and operate your scraper in the cloud.
Website Scraping with Python - 2018.pdf

仔细检测网站抓取和数据处理:以适宜进一步剖析的格式从网站提取数据的技术。您将查看要使用的工具,并比较它们的功能和效率。本书简明扼要专注于BeautifulSoup4和Scrapy,突出了常见问题,并提出了读者可以自行施行的解决方案。
您将见到怎么单独或一起使用BeautifulSoup4和Scrapy以获得所需的结果。由于许多站点都使用JavaScript,因此您还将使用Selenium和浏览器模拟器来呈现这种站点。
在本书的最后,您将拥有一个完整的抓取应用程序来使用和重画以满足您的需求。
Social Media Data Mining and Analytics - 2018.pdf

Harness the power of social media to predict customer behaviorand improve sales
Social media is the biggest source of Big Data. Because of this,90% of Fortune 500 companies are investing in Big Data initiativesthat will help them predict consumer behavior to produce bettersales results. Written by Dr. Gabor Szabo, a Senior Data Scientistat Twitter, and Dr. Oscar Boykin, a Software Engineer at Twitter,Social Media Data Mining and Analytics shows analysts how touse sophisticated techniques to mine social media data, obtainingthe information they need to generate amazing results for theirbusinesses.
Social Media Data Mining and Analytics isn’t just anotherbook on the business case for social media. Rather, this bookprovides hands-on examples for applying state-of-the-art tools andtechnologies to mine social media – examples include Twitter,Facebook, Pinterest, Wikipedia, Reddit, Flickr, Web hyperlinks, andother rich data sources. In it, you will learn:
The four key characteristics of online services-users, socialnetworks, actions, and content
The full data discovery lifecycle-data extraction, storage,analysis, and visualization
How to work with code and extract data to create solutions
How to use Big Data to make accurate customer predictions
Szabo and Boykin wrote this book to provide businesses with thecompetitive advantage they need to harness the rich data that isavailable from social media platforms.
参考资料
人工智能数据采集|人工智能|辰宜科技
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2020-08-18 20:00
软件名称
眯谜米密
品牌
其他
版本语言
简体中文版
软件类型
安全相关软件
【辰宜】·智能读写系统----基于机器学习的AI应用
特点:具有高度的智能性,自动适应多个场景;
采用了异构融合技术,人工智能商用化,不需要相关系统提供商提供插口支持;
具有高度的开放性,可独立使用,人工智能数据采集,也能通过API与其他系统协同工作。
功能:智能学习---可以分开学习不同的网页填写,也可以集中一次性学习多个网页系统。
智能推理---依据无损推理原理,人工智能深度应用,自行推定互相关系。
智能读写---自动辨识网页内容与数目,自动辨识场景,自动按学习到关系进行相关内容的读写。
作用:能够达到表格、数据库、窗口应用、网页应用的自动化读写;
将用户的业务经验与系统无缝融合;
使用户成为系统的开发者、使用者与受益者;
大幅度增加培训、维护与升级成本。
随着大数据时代的发展,人工智能,“数据融合、信息库房”成为发展的趋势,但因为系统建设的弱项或则制度本身的不灵活,使得不同系统之间产生了信息孤岛,例如在政务大数据建设上,为了采集数据,地方在原有业务系统的基础上新增了录入信息至县级系统、省级系统的业务负担,相同的信息要在不同系统之间多次重复录入,工作冗长之余还容易出错。
【辰宜】·易复写产品是AI人工智能的一种实际应用,可以从本质上解决系统之间多次录入信息的问题,搭建系统融通的桥梁,为企业单位、事业单位的日常信息管理提供了强悍的工具。
人工智能数据采集|人工智能|辰宜科技由广东辰宜信息科技有限公司提供。行路致远,砥砺前行。广东辰宜信息科技有限公司()致力成为与您共赢、共生、共同前行的战略伙伴,更矢志成为软件开发较具影响力的企业,与您一起飞越,共同成功!
微信扫码直接拨通电话
广东辰宜信息科技有限公司
智慧城市,中间件,区块链数据加密,工业数据采集,AI人工智能
(易先生先生)
手机号
网库客服正在通过010-XXXXXXX联系您,该通话免费,请注意接听! 查看全部
人工智能数据采集|人工智能|辰宜科技
软件名称
眯谜米密
品牌
其他
版本语言
简体中文版
软件类型
安全相关软件
【辰宜】·智能读写系统----基于机器学习的AI应用

特点:具有高度的智能性,自动适应多个场景;
采用了异构融合技术,人工智能商用化,不需要相关系统提供商提供插口支持;
具有高度的开放性,可独立使用,人工智能数据采集,也能通过API与其他系统协同工作。
功能:智能学习---可以分开学习不同的网页填写,也可以集中一次性学习多个网页系统。
智能推理---依据无损推理原理,人工智能深度应用,自行推定互相关系。
智能读写---自动辨识网页内容与数目,自动辨识场景,自动按学习到关系进行相关内容的读写。
作用:能够达到表格、数据库、窗口应用、网页应用的自动化读写;
将用户的业务经验与系统无缝融合;
使用户成为系统的开发者、使用者与受益者;
大幅度增加培训、维护与升级成本。
随着大数据时代的发展,人工智能,“数据融合、信息库房”成为发展的趋势,但因为系统建设的弱项或则制度本身的不灵活,使得不同系统之间产生了信息孤岛,例如在政务大数据建设上,为了采集数据,地方在原有业务系统的基础上新增了录入信息至县级系统、省级系统的业务负担,相同的信息要在不同系统之间多次重复录入,工作冗长之余还容易出错。
【辰宜】·易复写产品是AI人工智能的一种实际应用,可以从本质上解决系统之间多次录入信息的问题,搭建系统融通的桥梁,为企业单位、事业单位的日常信息管理提供了强悍的工具。
人工智能数据采集|人工智能|辰宜科技由广东辰宜信息科技有限公司提供。行路致远,砥砺前行。广东辰宜信息科技有限公司()致力成为与您共赢、共生、共同前行的战略伙伴,更矢志成为软件开发较具影响力的企业,与您一起飞越,共同成功!
微信扫码直接拨通电话
广东辰宜信息科技有限公司
智慧城市,中间件,区块链数据加密,工业数据采集,AI人工智能
(易先生先生)
手机号
网库客服正在通过010-XXXXXXX联系您,该通话免费,请注意接听!
北京专业做数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-18 00:05
北京专业做数据采集
注意:是正常合照,而且应当象文件内容一样。图像图象有复杂的外观问题。特殊情况也应当同样看见文件中的内容。请依照自己的实际情况来判别。相机手动变焦虽然单反里有专用的单反软件,软件是可以提供根据影像的次序从内向内变焦的,再借助专业照相机的快门速率和***快镜头速率可以手动变焦。因此,如果想用手动变焦这些自动对焦工具,很适宜有手动变焦的形式。
特殊的品牌多是明晰标注:“强化矿物纤维与矿物棉”,“国内***贵的矿物纤维与矿物棉”。内容在售:soc环保品牌信息无添加代码了解没有必要百度百科不是。企业都有客服电话,所以只要在鞋厂递交你的电话,就可以看见是不是你所说的“内容为购物网站提供的条形码输入法所在位置”。随便问问都可以解决。另外,也没必要百度哪些内部软件供你选择。全手动保证金方案。
教育有哪些须要我们去探求?
北京专业做数据采集
数据剖析的房门有什么?数据剖析是生存的基础,不是思想的食粮,这个通常比较专业的人士常常都不具备这样的专业知识。不是通过对数据做一个***的剖析做一个简单的剖析,有两点必须要注意:什么是数据剖析?数据剖析是一个特别***的剖析工具,是一个较为常用的学习工具。
一
标
北京专业做数据采集 查看全部
北京专业做数据采集
北京专业做数据采集
注意:是正常合照,而且应当象文件内容一样。图像图象有复杂的外观问题。特殊情况也应当同样看见文件中的内容。请依照自己的实际情况来判别。相机手动变焦虽然单反里有专用的单反软件,软件是可以提供根据影像的次序从内向内变焦的,再借助专业照相机的快门速率和***快镜头速率可以手动变焦。因此,如果想用手动变焦这些自动对焦工具,很适宜有手动变焦的形式。
特殊的品牌多是明晰标注:“强化矿物纤维与矿物棉”,“国内***贵的矿物纤维与矿物棉”。内容在售:soc环保品牌信息无添加代码了解没有必要百度百科不是。企业都有客服电话,所以只要在鞋厂递交你的电话,就可以看见是不是你所说的“内容为购物网站提供的条形码输入法所在位置”。随便问问都可以解决。另外,也没必要百度哪些内部软件供你选择。全手动保证金方案。

教育有哪些须要我们去探求?
北京专业做数据采集
数据剖析的房门有什么?数据剖析是生存的基础,不是思想的食粮,这个通常比较专业的人士常常都不具备这样的专业知识。不是通过对数据做一个***的剖析做一个简单的剖析,有两点必须要注意:什么是数据剖析?数据剖析是一个特别***的剖析工具,是一个较为常用的学习工具。

一
标

北京专业做数据采集
军犬网络信息采集系统[系统介绍]
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-07 20:39
信息采集是指使用计算机软件技术基于自定义目标数据源进行实时信息采集,提取,挖掘和处理的全过程.
军犬信息采集专家是一种基于人工智能的自动学习技术,它是一种功能强大,简单实用的Internet信息采集和监视软件.
二,互联网信息的采集与挖掘:
需要从Internet采集和监视特定目标数据源或非特定目标数据源,并以本地结构化数据库的形式对信息进行结构化提取和存储,然后根据业务流程要求将其与其他模块组合在一起,导入和应用服务于电子行业平台.
Internet数据采集和挖掘技术是指使用计算机软件技术对定制的目标数据源进行实时信息采集,提取,挖掘和处理,从而为各种信息服务系统提供数据输入,以及根据业务需要,进行数据发布和分析的全过程.
三个. 互联网采集系统流程图:
第一步: 确定采集任务.
步骤2: 对于每个采集任务,我们都有多个目标数据源可供采集.
第3步: 对不同的目标数据源执行不同的采集配置,以确保可以采集数据.
第4步: 安排采集任务,与目标站点同步更新和增量采集.
第5步: 采集数据结果并完成数据异构化为同构的过程.
第6步: 通过发布服务器将数据发布到应用程序平台.
四个. 军犬“信息采集系统”的八个应用领域:
1,搜索引擎和垂直搜索2,集成门户和行业门户
3. 电子政务与电子商务4.知识管理与知识共享
5. 企业竞争情报系统6. BI商业情报系统
7. 信息咨询与信息增值8.信息安全与信息监控
5. 军犬“信息采集系统”-软件功能
(1),干净过滤,智能提取文本以及链接图像和文本
(2). 丰富的数据导出接口,可以将数据导出到各种主流的关系数据结构中.
(3)军犬“信息采集系统”的配置很简单
对于新闻信息的采集,您只需要输入要采集的目标网站的地址或主题页面的地址,软件就会自动了解网站的样式并自动提取网站的信息. 无需配置模板,目标网站的样式将改变. 该软件会自动学习. 对于数据采集软件,提供了一个易于理解的站点配置向导,并且维护人员可以在不经过培训的情况下配置任何信息采集. 对于复杂的采集过程,可以通过采集卡脚本来实现信息的自动采集和监视.
(4)军犬“信息采集系统”所采集的是您所获得的,您所获得的是您所看到的
(5)增量采集和自动更新军犬“信息采集系统”
增加馆藏: 对于目标网站的第一个馆藏,该软件支持完整馆藏;对于已经采集的网站,它支持增量采集. 支持自动更新: 自动检测网站是否已更新,不会遗漏任何重要信息.
(6)从军犬“信息采集系统”的采集结果中自动去除体重
不是使用简单的规则来判断,而是使用内容的相似性来判断权重,准确性很高,并且不会因标题或内容的微小变化而错过任何判断. 即使标题更改,系统也会正确确定.
(7),军犬“信息采集系统”内置强大的信息监控功能
您可以通过关键字监视Internet上任何站点上的相关信息. 也可以通过设置监视渠道来监视任何站点采集的收录关键字的信息. 对于数字字段,您可以设置以下信息: 监视器错误监视器值出现在特定范围内. 信息监控达到现场水平. 您可以为任何采集目标网站设置监视属性,监视周期达到第二级. 更改后的信息可以在短时间内本地采集
强大的站点管理工具可以对所有采集的对象进行集中管理和各种操作
(8),军犬的“信息采集系统”支持多种编码方式
支持各种网站信息的编码,GBK,BIG5,UNICODE,UTF8,软件将自动转换为GBK码进行统一处理. 该软件将自动识别网站的组织结构和网站代码. 表单管理,可以根据需要自定义表单,以方便采集不同的内容,例如用于采集软件的单独表单和用于采集图片的图片表单.
(9),军犬的“信息采集系统”信息自由进出口
提供信息导入和导出,以与其他软件无缝连接. 例如,CRM OA软件提供了强大的信息记录导入和导出功能. 您可以导入和导出任何频道或记录. 它可以导出到Excel / Access等,或直接导出到指定的数据库. 它可以与“ Information Publishing Server”结合使用,以将信息发布到任何地方.
(10),军犬的“信息采集系统”支持阅读模板
对于任何信息类型,软件都会自动创建一个阅读模板供您快速阅读;对于任何信息,您都可以为任何信息表格自定义漂亮的阅读模板,也可以为任何频道模板设置不同的读数.
(11)军犬“信息采集系统”的多页内容重组
对于目标数据源的文章,该文章显示在目标网站上的页面中,系统可以自动对其进行重组. 该软件运行稳定,采集速度快,系统资源少.
经过多次转换的低级软件获取模块运行稳定,获取速度快,系统资源少. 它可以与多个线程并发运行,而不会占用过多的系统资源. 采集速度如此之快,以至于瞬间即可实现. 该软件可以完全实现7 * 24小时不间断的无人值守信息采集. 更多详细功能正在等待您使用.
(12). 军犬“信息采集系统”的其他功能清单:
1. 支持所有主流数据库: MS SQL Server,Oracle,DB2,MySQL,Sybase,Interbase,MS Access等.
2. 支持HTML,RSS集群网站集
3. 支持少数民族语言和多语言(简体中文,藏文,彝文,维吾尔文,繁体中文,英语,日语,韩语和其他语言)的采集
4. 支持采集来自百度贴吧的回复
5. 支持免费定制采集的数据表单和字段
6. 采集数据的无限树形分类管理
7. 自动匹配各种网站编码方法,例如: gb2312,utf8,gbk,big5,iso88591等.
8. 支持采集登录验证信息.
9. 列表页面上的支持信息数据采集.
10. 您可以为采集的目标网站自定义更新采集周期.
11. 完全可以避免阻塞收款网站帐户和IP的软件.
12. 系统内置110个搜索引擎
13. 支持网站备份和配置规则的恢复.
14. 支持文本页面集合的多页面重组功能.
15. 支持html标签保留和表保留
16支持附件信息采集(例如: 图片,音频,视频,期刊,doc,txt等)
17. 支持替换字符以采集数据.
18. 支持站点信息检索
19. 执行数据批处理管理(删除,添加,辅助编辑等)
20. 自动识别原创网站信息修订提示功能.
21. 允许自动定期检测并采集站点的更新
22. 支持添加代理IP
23. 全结构提取
24. 自动重置采集结果
25数据保存在本地,因此您可以随时检查信息.
26. 支持阅读模板
27. 多行层,多任务处理
28. 支持海量数据采集
29. 软件运行稳定,采集速度快,系统资源少
30. 您可以保留网页快照.
31. 支持采集海外数据
32. 支持数据导入和数据导出.
33. 一键备份所有数据和数据库.
34. 采集的数据可以用关键字重新筛选.
35. 全结构化提取将网页中的非结构化数据提取为特定的结构化信息数据.
Web搜索将网页作为最小单元,基于可视的网页块分析将网页块作为最小单元,垂直搜索将结构化数据作为最小单元. 然后将数据存储在数据库中以进行进一步的处理,例如: 重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求.
在整个过程中,数据是从非结构化数据中提取到结构化数据中,经过深度处理后,以非结构化和结构化的方式返回给用户的.
六. 军犬“信息采集系统”的配置要求
要求: WindowsNT4 / Windows 2003 Server或更高版本的操作系统.
要求: Microsoft SQL Server 7/2000或其他ODBC接口
要求: Intel xeon 2G或更高CPU,2G或更高RAM,200GB以上的硬盘空间
七. 军犬“信息采集系统”的性能
l,支持多线程集合.
2. 一台机器的数据采集高于G级.
3. 数据和数据源的同步更新少于10秒.
4. 数据同步释放不到10秒. 查看全部
1. “信息采集系统”系统概述:
信息采集是指使用计算机软件技术基于自定义目标数据源进行实时信息采集,提取,挖掘和处理的全过程.
军犬信息采集专家是一种基于人工智能的自动学习技术,它是一种功能强大,简单实用的Internet信息采集和监视软件.
二,互联网信息的采集与挖掘:
需要从Internet采集和监视特定目标数据源或非特定目标数据源,并以本地结构化数据库的形式对信息进行结构化提取和存储,然后根据业务流程要求将其与其他模块组合在一起,导入和应用服务于电子行业平台.
Internet数据采集和挖掘技术是指使用计算机软件技术对定制的目标数据源进行实时信息采集,提取,挖掘和处理,从而为各种信息服务系统提供数据输入,以及根据业务需要,进行数据发布和分析的全过程.
三个. 互联网采集系统流程图:

第一步: 确定采集任务.
步骤2: 对于每个采集任务,我们都有多个目标数据源可供采集.
第3步: 对不同的目标数据源执行不同的采集配置,以确保可以采集数据.
第4步: 安排采集任务,与目标站点同步更新和增量采集.
第5步: 采集数据结果并完成数据异构化为同构的过程.
第6步: 通过发布服务器将数据发布到应用程序平台.
四个. 军犬“信息采集系统”的八个应用领域:
1,搜索引擎和垂直搜索2,集成门户和行业门户
3. 电子政务与电子商务4.知识管理与知识共享
5. 企业竞争情报系统6. BI商业情报系统
7. 信息咨询与信息增值8.信息安全与信息监控
5. 军犬“信息采集系统”-软件功能
(1),干净过滤,智能提取文本以及链接图像和文本
(2). 丰富的数据导出接口,可以将数据导出到各种主流的关系数据结构中.

(3)军犬“信息采集系统”的配置很简单
对于新闻信息的采集,您只需要输入要采集的目标网站的地址或主题页面的地址,软件就会自动了解网站的样式并自动提取网站的信息. 无需配置模板,目标网站的样式将改变. 该软件会自动学习. 对于数据采集软件,提供了一个易于理解的站点配置向导,并且维护人员可以在不经过培训的情况下配置任何信息采集. 对于复杂的采集过程,可以通过采集卡脚本来实现信息的自动采集和监视.
(4)军犬“信息采集系统”所采集的是您所获得的,您所获得的是您所看到的
(5)增量采集和自动更新军犬“信息采集系统”
增加馆藏: 对于目标网站的第一个馆藏,该软件支持完整馆藏;对于已经采集的网站,它支持增量采集. 支持自动更新: 自动检测网站是否已更新,不会遗漏任何重要信息.
(6)从军犬“信息采集系统”的采集结果中自动去除体重
不是使用简单的规则来判断,而是使用内容的相似性来判断权重,准确性很高,并且不会因标题或内容的微小变化而错过任何判断. 即使标题更改,系统也会正确确定.
(7),军犬“信息采集系统”内置强大的信息监控功能
您可以通过关键字监视Internet上任何站点上的相关信息. 也可以通过设置监视渠道来监视任何站点采集的收录关键字的信息. 对于数字字段,您可以设置以下信息: 监视器错误监视器值出现在特定范围内. 信息监控达到现场水平. 您可以为任何采集目标网站设置监视属性,监视周期达到第二级. 更改后的信息可以在短时间内本地采集
强大的站点管理工具可以对所有采集的对象进行集中管理和各种操作
(8),军犬的“信息采集系统”支持多种编码方式
支持各种网站信息的编码,GBK,BIG5,UNICODE,UTF8,软件将自动转换为GBK码进行统一处理. 该软件将自动识别网站的组织结构和网站代码. 表单管理,可以根据需要自定义表单,以方便采集不同的内容,例如用于采集软件的单独表单和用于采集图片的图片表单.
(9),军犬的“信息采集系统”信息自由进出口
提供信息导入和导出,以与其他软件无缝连接. 例如,CRM OA软件提供了强大的信息记录导入和导出功能. 您可以导入和导出任何频道或记录. 它可以导出到Excel / Access等,或直接导出到指定的数据库. 它可以与“ Information Publishing Server”结合使用,以将信息发布到任何地方.
(10),军犬的“信息采集系统”支持阅读模板
对于任何信息类型,软件都会自动创建一个阅读模板供您快速阅读;对于任何信息,您都可以为任何信息表格自定义漂亮的阅读模板,也可以为任何频道模板设置不同的读数.
(11)军犬“信息采集系统”的多页内容重组
对于目标数据源的文章,该文章显示在目标网站上的页面中,系统可以自动对其进行重组. 该软件运行稳定,采集速度快,系统资源少.
经过多次转换的低级软件获取模块运行稳定,获取速度快,系统资源少. 它可以与多个线程并发运行,而不会占用过多的系统资源. 采集速度如此之快,以至于瞬间即可实现. 该软件可以完全实现7 * 24小时不间断的无人值守信息采集. 更多详细功能正在等待您使用.
(12). 军犬“信息采集系统”的其他功能清单:
1. 支持所有主流数据库: MS SQL Server,Oracle,DB2,MySQL,Sybase,Interbase,MS Access等.
2. 支持HTML,RSS集群网站集
3. 支持少数民族语言和多语言(简体中文,藏文,彝文,维吾尔文,繁体中文,英语,日语,韩语和其他语言)的采集
4. 支持采集来自百度贴吧的回复
5. 支持免费定制采集的数据表单和字段
6. 采集数据的无限树形分类管理
7. 自动匹配各种网站编码方法,例如: gb2312,utf8,gbk,big5,iso88591等.
8. 支持采集登录验证信息.
9. 列表页面上的支持信息数据采集.
10. 您可以为采集的目标网站自定义更新采集周期.
11. 完全可以避免阻塞收款网站帐户和IP的软件.
12. 系统内置110个搜索引擎
13. 支持网站备份和配置规则的恢复.
14. 支持文本页面集合的多页面重组功能.
15. 支持html标签保留和表保留
16支持附件信息采集(例如: 图片,音频,视频,期刊,doc,txt等)
17. 支持替换字符以采集数据.
18. 支持站点信息检索
19. 执行数据批处理管理(删除,添加,辅助编辑等)
20. 自动识别原创网站信息修订提示功能.
21. 允许自动定期检测并采集站点的更新
22. 支持添加代理IP
23. 全结构提取
24. 自动重置采集结果
25数据保存在本地,因此您可以随时检查信息.
26. 支持阅读模板
27. 多行层,多任务处理
28. 支持海量数据采集
29. 软件运行稳定,采集速度快,系统资源少
30. 您可以保留网页快照.
31. 支持采集海外数据
32. 支持数据导入和数据导出.
33. 一键备份所有数据和数据库.
34. 采集的数据可以用关键字重新筛选.
35. 全结构化提取将网页中的非结构化数据提取为特定的结构化信息数据.
Web搜索将网页作为最小单元,基于可视的网页块分析将网页块作为最小单元,垂直搜索将结构化数据作为最小单元. 然后将数据存储在数据库中以进行进一步的处理,例如: 重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求.
在整个过程中,数据是从非结构化数据中提取到结构化数据中,经过深度处理后,以非结构化和结构化的方式返回给用户的.
六. 军犬“信息采集系统”的配置要求
要求: WindowsNT4 / Windows 2003 Server或更高版本的操作系统.
要求: Microsoft SQL Server 7/2000或其他ODBC接口
要求: Intel xeon 2G或更高CPU,2G或更高RAM,200GB以上的硬盘空间
七. 军犬“信息采集系统”的性能
l,支持多线程集合.
2. 一台机器的数据采集高于G级.
3. 数据和数据源的同步更新少于10秒.
4. 数据同步释放不到10秒.
数据采集注释: 人工智能行业的“至强”支持
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-08-07 14:46
作者/李晓松·编辑/珍妮
在过去的两年中,人工智能变得越来越流行.
飞机场,优采云车站,超市和街道等大型人脸识别设备;像我们的移动APP的各种算法一样小,以及Siri,Xiaodu和Xiaoai等语音助手都与人工智能有关.
尽管人工智能应用程序变得越来越流行,但我们仍然经常遇到不正确的APP推送,语音助手像“傻瓜”一样,面部识别系统经常出现的问题.
乌龙闹剧: 董明珠“闯红灯”. 实际上,公交车上贴着董明珠的头,碰巧是用相机拍摄的. 人工智能系统错误地认为是董明珠闯红灯.
我们想象的人工智能是可以在科幻电影中“思考我的想法”的人工智能. 但是,我们面临的人工智能是经常犯错误甚至难以实现的人工智能.
那么,我们如何解决这些问题?我们必须做些什么才能使人工智能更准确?
01
制约人工智能发展的因素
一些朋友总是认为,由于训练数据不正确,人工智能是不准确的. 实际上,这种观点是对的,但不是全部.
数据确实是限制人工智能发展的重要组成部分. 制约人工智能发展的因素不仅是数据,算法和计算能力也是极其重要的因素.
如果使用汽车的类比,则算法是汽车的设计概念,计算能力更像是汽车的引擎,数据是驱动自行车的燃料.
仅靠燃料,没有好的发动机和设计,汽车自然就不会快速运转. 同样,没有发动机,没有燃料,汽车也无法行驶.
三位一体的协调发展无疑是最好的. 但是,人工智能公司的现状是,许多公司已经拥有先进的算法和高质量的硬件,其产品的降落确实是一个燃料问题.
Testin总经理贾玉航在接受ToB行业标题(ID: wwwqifu)的采访时说:
“在人工智能时代到来之后,越来越多的产品,应用程序和硬件已成为实现人工智能的载体. 在人工智能的实施过程中,许多公司面临数据问题,并且在产品迭代和升级过程中遇到了更大的阻力. ”
关于人工智能公司面临的数据问题,贾宇航强调了两个:
那么,人工智能公司应如何应对这些问题?有什么方法可以帮助人工智能公司解决当前的数据问题?
02
如何采集和使用数据?
实际上,自人工智能出现之日起,数据采集和标签之类的问题就受到了许多制造商的关注.
早在2005年,亚马逊就建立了Mechanical Turk论坛,希望通过众包解决人工智能公司的数据处理需求.
但是,随着人工智能的逐步发展,人工智能的实施已成为行业发展的重要阶段,相应的数据服务也进入了情景和细化的时代.
贾宇航说,Testin目前专注于自动驾驶,银行,保险和安全领域,提供定制的数据采集和标签服务,并完全支持处理各种类型的数据,例如文本,语音,图像和视频.
“例如,自动驾驶制造商需要采集驾驶员的疲劳程度,但是很难将设备安装在路边的汽车上. 因为以这种方式采集的数据不仅是非标准的,而且涉及驾驶员和乘客的隐私.
但是,Testin可以根据客户需求在数据采集中心构建模拟方案,并通过使用专业人员和软硬件设备来采集大量的样本信息,以满足客户的各种需求. “
Testin有许多定制的采集场景示意图
Testin作为AI数据服务行业的领先品牌,拥有自建的数据库系统,所有标签管理统一,生产标准化,可以在确保数据有效的同时确保标签操作的信息流准确性.
Testin还开发了一个自行开发的标签平台,该平台支持标签类型的自定义开发,使标签类型更加全面,并确保标准化业务可以高效运行.
Testin数字标记平台的示意图
目前,许多国内数据标签公司仍是典型的劳动密集型企业. 为了节省人工成本,这些公司仍在使用临时工人,这些工人在经过半天的培训后即可被雇用,而他们的工作是数据标签行业中最简单的事情.
但是Testin很久以前就已经看到了传统模型的缺点. 通过建立馆藏基地,建立标签平台和进行为期60天的职前高质量培训,它已经摆脱了标签行业的低端同质竞争. 技能密集型公司的转型.
贾宇航始终坚信: “劳动密集型数据服务过于依赖劳动力,企业的上限更加明显. 这类企业对数据平台的建设没有足够的重视,培训时间不长. 员工短,数据注释的质量中等. ”
也许腰部公司会出于成本和其他原因而选择此类公司的服务,但总公司肯定会选择高质量的数据标签供应商. 因为只有高质量的数据才能产生高质量的人工智能,所以这是行业发展的基本规律. “
03
高质量和准确的数据
这是行业的未来
一个行业的成熟与该行业中成熟公司的发展离不开. 如果人工智能公司想要快速发展,那么他们一定不能没有数据采集和标签行业的整体进步.
许多年前,我们经常看到知名的人工智能公司将数据采集和标签服务外包给非洲公司. 一些媒体甚至在访问了非洲的数据标签工厂后叹了口气: “硅谷为赚钱而从事人工智能工作的穷人. ”
实际上,为了获得廉价劳动力,在非洲等不发达地区建立了数据标签工厂. 因此,数据服务也被外界视为人工智能金字塔上的最低级别的工作.
尽管金字塔的底部不如尖塔那么刺眼,但底部的体积最大,也是支撑金字塔的坚实基础.
在人工智能公司蓬勃发展的阶段,基础薄弱的公司仍然可以利用自己的实力来发展. 但是,随着公司的发展越来越快,公司建立的数字化尖塔越来越高. 基础是否牢固直接决定了公司发展的上限.
这也是Testin从一开始就非常重视标签人员培训,标签中心建立和数据采集平台开发的重要原因.
因为贾宇航始终认为高质量和准确的数据是行业的未来. “当通用数据公司仍在为实地的“六便士”而战时,Testin已经赶上了空中的“月球”. ”
目前,Testin在华东,华北和华南设有数个数据交付中心以及数据采集和标记基地,并已成功为数百家公司提供了AI数据服务.
相反,国内相关研究报告的结论也在不断完善,数据标签行业也在稳步增长.
根据艾瑞咨询的最新报告,2018年中国人工智能基础数据服务市场规模为25.86亿元,其中数据资源定制服务占86.2%,行业复合年增长率为23.5%. 预计到2025年,市场规模将超过110亿元.
这种蓬勃发展的势头不仅是由于人工智能公司的快速发展带来的巨大需求,而且也离不开Testin安静工作的数据服务提供商,后者继续为人工智能行业提供动力.
确实,当前的人工智能仍然“不准确”,但是我们可以看到几年前,Alpha Dog在Go领域完全爆炸了. 就在过去的几个月中,已经被20多年的发展而未为公众所理解的RPA突然变得很流行.
为什么Alpha Dog会击败人类?为什么RPA突然爆炸?这必将与人工智能算法的更新和发展密不可分. 但是,在技术成熟之后,提供数据采集和标记服务的诸如Testin之类的供应商也必不可少.
正是数据采集和注释的成熟度和准确性可以训练Alpha Dog的精确算法. 数据行业的不断积累使OCR,NLP和其他人工智能技术在今年变得成熟,从而推动了长期沉默的RPA. 查看全部
来源/ ToB行业头条新闻(ID: wwwqifu)
作者/李晓松·编辑/珍妮
在过去的两年中,人工智能变得越来越流行.
飞机场,优采云车站,超市和街道等大型人脸识别设备;像我们的移动APP的各种算法一样小,以及Siri,Xiaodu和Xiaoai等语音助手都与人工智能有关.
尽管人工智能应用程序变得越来越流行,但我们仍然经常遇到不正确的APP推送,语音助手像“傻瓜”一样,面部识别系统经常出现的问题.

乌龙闹剧: 董明珠“闯红灯”. 实际上,公交车上贴着董明珠的头,碰巧是用相机拍摄的. 人工智能系统错误地认为是董明珠闯红灯.
我们想象的人工智能是可以在科幻电影中“思考我的想法”的人工智能. 但是,我们面临的人工智能是经常犯错误甚至难以实现的人工智能.
那么,我们如何解决这些问题?我们必须做些什么才能使人工智能更准确?
01
制约人工智能发展的因素
一些朋友总是认为,由于训练数据不正确,人工智能是不准确的. 实际上,这种观点是对的,但不是全部.
数据确实是限制人工智能发展的重要组成部分. 制约人工智能发展的因素不仅是数据,算法和计算能力也是极其重要的因素.
如果使用汽车的类比,则算法是汽车的设计概念,计算能力更像是汽车的引擎,数据是驱动自行车的燃料.
仅靠燃料,没有好的发动机和设计,汽车自然就不会快速运转. 同样,没有发动机,没有燃料,汽车也无法行驶.
三位一体的协调发展无疑是最好的. 但是,人工智能公司的现状是,许多公司已经拥有先进的算法和高质量的硬件,其产品的降落确实是一个燃料问题.
Testin总经理贾玉航在接受ToB行业标题(ID: wwwqifu)的采访时说:
“在人工智能时代到来之后,越来越多的产品,应用程序和硬件已成为实现人工智能的载体. 在人工智能的实施过程中,许多公司面临数据问题,并且在产品迭代和升级过程中遇到了更大的阻力. ”
关于人工智能公司面临的数据问题,贾宇航强调了两个:
那么,人工智能公司应如何应对这些问题?有什么方法可以帮助人工智能公司解决当前的数据问题?
02
如何采集和使用数据?
实际上,自人工智能出现之日起,数据采集和标签之类的问题就受到了许多制造商的关注.
早在2005年,亚马逊就建立了Mechanical Turk论坛,希望通过众包解决人工智能公司的数据处理需求.
但是,随着人工智能的逐步发展,人工智能的实施已成为行业发展的重要阶段,相应的数据服务也进入了情景和细化的时代.
贾宇航说,Testin目前专注于自动驾驶,银行,保险和安全领域,提供定制的数据采集和标签服务,并完全支持处理各种类型的数据,例如文本,语音,图像和视频.
“例如,自动驾驶制造商需要采集驾驶员的疲劳程度,但是很难将设备安装在路边的汽车上. 因为以这种方式采集的数据不仅是非标准的,而且涉及驾驶员和乘客的隐私.
但是,Testin可以根据客户需求在数据采集中心构建模拟方案,并通过使用专业人员和软硬件设备来采集大量的样本信息,以满足客户的各种需求. “

Testin有许多定制的采集场景示意图
Testin作为AI数据服务行业的领先品牌,拥有自建的数据库系统,所有标签管理统一,生产标准化,可以在确保数据有效的同时确保标签操作的信息流准确性.
Testin还开发了一个自行开发的标签平台,该平台支持标签类型的自定义开发,使标签类型更加全面,并确保标准化业务可以高效运行.

Testin数字标记平台的示意图
目前,许多国内数据标签公司仍是典型的劳动密集型企业. 为了节省人工成本,这些公司仍在使用临时工人,这些工人在经过半天的培训后即可被雇用,而他们的工作是数据标签行业中最简单的事情.
但是Testin很久以前就已经看到了传统模型的缺点. 通过建立馆藏基地,建立标签平台和进行为期60天的职前高质量培训,它已经摆脱了标签行业的低端同质竞争. 技能密集型公司的转型.
贾宇航始终坚信: “劳动密集型数据服务过于依赖劳动力,企业的上限更加明显. 这类企业对数据平台的建设没有足够的重视,培训时间不长. 员工短,数据注释的质量中等. ”
也许腰部公司会出于成本和其他原因而选择此类公司的服务,但总公司肯定会选择高质量的数据标签供应商. 因为只有高质量的数据才能产生高质量的人工智能,所以这是行业发展的基本规律. “
03
高质量和准确的数据
这是行业的未来
一个行业的成熟与该行业中成熟公司的发展离不开. 如果人工智能公司想要快速发展,那么他们一定不能没有数据采集和标签行业的整体进步.
许多年前,我们经常看到知名的人工智能公司将数据采集和标签服务外包给非洲公司. 一些媒体甚至在访问了非洲的数据标签工厂后叹了口气: “硅谷为赚钱而从事人工智能工作的穷人. ”
实际上,为了获得廉价劳动力,在非洲等不发达地区建立了数据标签工厂. 因此,数据服务也被外界视为人工智能金字塔上的最低级别的工作.
尽管金字塔的底部不如尖塔那么刺眼,但底部的体积最大,也是支撑金字塔的坚实基础.
在人工智能公司蓬勃发展的阶段,基础薄弱的公司仍然可以利用自己的实力来发展. 但是,随着公司的发展越来越快,公司建立的数字化尖塔越来越高. 基础是否牢固直接决定了公司发展的上限.
这也是Testin从一开始就非常重视标签人员培训,标签中心建立和数据采集平台开发的重要原因.
因为贾宇航始终认为高质量和准确的数据是行业的未来. “当通用数据公司仍在为实地的“六便士”而战时,Testin已经赶上了空中的“月球”. ”
目前,Testin在华东,华北和华南设有数个数据交付中心以及数据采集和标记基地,并已成功为数百家公司提供了AI数据服务.
相反,国内相关研究报告的结论也在不断完善,数据标签行业也在稳步增长.
根据艾瑞咨询的最新报告,2018年中国人工智能基础数据服务市场规模为25.86亿元,其中数据资源定制服务占86.2%,行业复合年增长率为23.5%. 预计到2025年,市场规模将超过110亿元.
这种蓬勃发展的势头不仅是由于人工智能公司的快速发展带来的巨大需求,而且也离不开Testin安静工作的数据服务提供商,后者继续为人工智能行业提供动力.
确实,当前的人工智能仍然“不准确”,但是我们可以看到几年前,Alpha Dog在Go领域完全爆炸了. 就在过去的几个月中,已经被20多年的发展而未为公众所理解的RPA突然变得很流行.
为什么Alpha Dog会击败人类?为什么RPA突然爆炸?这必将与人工智能算法的更新和发展密不可分. 但是,在技术成熟之后,提供数据采集和标记服务的诸如Testin之类的供应商也必不可少.
正是数据采集和注释的成熟度和准确性可以训练Alpha Dog的精确算法. 数据行业的不断积累使OCR,NLP和其他人工智能技术在今年变得成熟,从而推动了长期沉默的RPA.
这家人工智能行业供应商的新游戏单价为每月1000万元
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 08:22
但是人工智能并不像想象中的那么容易开发. 它的算法是一方面. 更重要的是,所有人工智能都需要一个特定的培训平台来对其进行培训和评估. 通过不断重复此循环,人工智能可以实现各种功能. 推动培训平台发展的是数据.
在世界经济论坛(World Economic Forum)2012年的报告中,数据被称为世界的新财富,其价值可与石油媲美. 《麦肯锡咨询报告》认为,数据是一种生产手段,大数据是创新,竞争和生产力提高的下一个前沿领域. 因此,这些大数据的生产者被称为“人工智能原材料供应商”.
今天的主角就是这样的供应商,龙猫数据.
Totoro Data是一家什么样的公司?
与通常的采访不同,DT先生于星期六早上来到Totoro Data. 根据公司创始人Zanzhi的说法,Totoro Data采用了每两周一次的工作系统,即一周的星期六正常工作,两周的周末休息.
Totoro Data的业务可以分为两层,为企业的业务提供数据服务. 顾名思义,该公司将为具有人工智能培训平台的公司提供培训数据. 该业务分为四类: 图片,视频,文本和语音. 这意味着大多数与AI相关的公司现在都可以成为其客户.
虽然向公司出售数据是Totoro Data的主要业务方法,但Zanzhi告诉DT先生,对于Totoro Data而言,另一项业务更为重要,那就是采集数据的过程.
采集数据可以理解为开采石油. 石油公司的主要业务是向其他公司出售石油,但石油公司的中心不是如何出售石油,而是如何以较低的价格开采更好的石油. 龙猫数据是相同的. 该公司使用众包平台进行数据挖掘.
众包平台分为两个级别: 获取和注释. 在采集方面,龙猫数据将在收到客户提交的任务后将这些任务(例如照片,录音等)分发到公司的APP. 完成任务后将奖励用户,并根据任务的难度奖励不同金额的现金(存储在在线帐户中).
Zan Zhixiang对DT先生说: “我们将用户忽略的材料称为原创材料,但是这些材料不能用于培训,需要对其进行标记和审核. ”所谓的标记是指手动. 该方法将机器可理解的信息素应用于原创材料上的特征点,以便可以通过这些特征来训练人工智能.
以“龙猫”数据的面部照片材料为例. 地图上有密集的点,每个点都有自己的特征含义,例如眼睛的内角和眼睛的外角. 众包平台的人员需要在图中标记这些特征点,并且可以将其视为Totoro数据所需的材料.
但是,通常人脸识别所需的培训材料范围从少至160点到多达数百点. 通过人工估计很难准确,完整地标记整个图像. 根据Zanzhi的描述,Totoro Data在众包平台的数据采集阶段使用了一种自行开发的人工智能预处理技术,也就是说,当用户将原创资料上传到Totoro众包平台时,人工智能将直接落后于此. 最后开始预处理,并预先标记任务所需的特征点. 当材料进入手动标记阶段时,操作员只需稍微移动一些不合理的点即可完成任务.
此预处理分为许多类型. 仍以人脸识别为例,龙猫数据已经准备了多种特征标注方法,例如186点,216点等. 这些标注方法相对通用,可以直接应用于大多数人脸识别训练平台. 对于其他不常见的标记方法,Chinchilla Data Selection和客户公司共同开发了预处理方法. 赞智认为,由于客户从事这一领域的培训,因此他们对这些数据的需求必须是唯一的,因此共同开发是最合理,最节省成本的事情. 从Totoro Data现有的预处理技术来看,该公司的专业知识是与计算机视觉有关和与音频有关的预处理技术,为自动驾驶,图像识别和语音识别等行业提供服务.
当然,所有众包平台都会遇到此类问题. 运营商并非真正隶属于该企业,因此不可避免地存在混合因素. 特别是对于数据采集,这样的环境将给数据清理过程带来很大的麻烦. Totoro Data对众包平台人员使用了多级审查机制.
首先是评估. 操作员需要通过练习问题才能“就业”. 但是,即使他们值班,操作员也不会四处乱逛. 在数据标记阶段,Totoro数据将不时发出陷阱问题,即Totoro数据已经知道答案. 如果操作员没有像答案一样正确地标记数据,系统将警告它们并最终失去操作资格.
同时,在打标过程中,系统还将检查操作员的打标速度,操作记录等. 这是为了防止机器人刷卡任务和其他非法操作. 到目前为止,龙猫众包平台的用户已超过400万,每月订单金额已达到1000万元的水平.
但是,这还没有结束,当原创材料被标记和审阅时,它将被上传到云中. 目前,Totoro Data将原创资料和提交给客户的资料存储在两家不同公司的云存储中. 赞志解释说,这是为了保护数据安全和客户隐私.
谁构成了龙猫的数据?
Totoro Data的获利思路非常明确,Zan Zhi说这是科技公司应该做的. 实际上,龙猫数据并不是最初为大数据采集的. 在种子轮阶段,Totoro Data的业务是在交通卡和手机之间进行移动支付. 通过NFC功能,用户可以直接通过手机对交通卡进行充值,也可以将交通卡中的钱转入手机. 该业务在2014年被称为“闪电刷”. 在微信支付和支付宝的迅速崛起之后,赞志意识到闪电刷很难在这两座山的前面崛起,因此他进行了果断的转型,只有那时龙猫的数据
Zan Zhi是百度广告系统的产品经理,但他不喜欢这份工作,因此搬到了Pea Pod. 来到新公司后,Zanzhi负责的第一件事就是Pea Pod的广告系统. 鉴于百度时间短,他的广告系统仍然是从零开始.
在广告系统工作了一年多之后,Zan Zhi被调到豌豆荚的游戏联运中. 他告诉DT先生,他喜欢这种零对一流程. 正是在Pea Pod就职典礼上,Zan Zhi遇到了现任Totoro Data的首席技术官Yao Yi.
Yao Yi曾经是Google的工程师,后来跟随李开复来到创新工作室. 姚毅相信赞之的战略眼光. 即使Totoro Data进行了重大的业务调整,Yao Yi还是选择了推翻原创技术并进行重新开发.
Totoro数据目前共有68人,技术团队所占比例最高,将近30人. 其余人员是20多个平台操作员,而销售人员则很少. 赞智告诉DT Jun: “我们也期望有很多销售人员,但是我们的销售要求相对较高. 龙猫数据主要与客户的研发团队联系在一起,因为他们有直接的数据要求,这意味着销售人员必须非常了解此行业. ”
截至2018年,Totoro Data已将其业务出售给百度,腾讯,华为,快手,京东和三星等巨头公司. 赞智说,龙猫数据已经为这些客户开展了数十项业务,其中有些已经完成了数百项.
数据
如上所述,Totoro Data是提供人工智能培训数据的公司,而不是直接提供大数据的公司. 尽管有两个数据字,但两者是天壤之别. 大数据关注“五个大Vs”,即大数据规模(卷),数据多样性(品种),数据处理及时性(速度),结果准确性(准确性)和深度值(价值).
人工智能对训练数据的需求符合训练平台的需求. 仍以人脸识别为例,在该领域的人工智能训练中,训练数据的采集往往需要室内50%,室外50%,明亮环境80%,普通环境20%. 但是实际上,消费者实际使用面部识别来唤醒机器的场景比训练场景要复杂得多.
因此,如果您想了解Totoro Data的业务,则应该了解这些人工智能培训平台需要什么样的数据集. 2014年,Facebook提出了DeepFace,一种使用卷积神经网络和大规模人脸图像进行人脸识别的技术. 它在LFW上达到了97.35%的精度,其性能可与手动识别相媲美; VGG网络采用较深的拓扑结构和较大的输入图像,可达到98.95%的精度;香港中文大学提出的DeepId网络进一步改进了卷积神经网络,使用局部和全局特征关节,并使用联合贝叶斯处理量产品特征和训练,并通过两种监督信息(识别和认证)提高了准确性至99%; Google的FaceNet使用三重损失功能(Triplet Loss)作为监管信息,并在2015年达到了99.63%的准确性.
上述面部识别技术的准确性超过手动识别的技术,需要大量的训练数据集来支持它们. 具体数据量如下.
图丨各种人脸识别技术所需数据量的比较
尽管Lightened CNN使用了新的激活功能MFM功能,并且其网络结构也很小,但仍需要450,000数据才能完成训练. 使用中心损失的Caffe脸部也是如此. 这些“小”用于其他培训平台,对于人类来说,这仍然是天文数字.
此图片实际上不能完全反映对面部识别训练数据集的需求. 如果您看下一张图片,您将了解该行业需要多少培训数据.
图片丨训练图片的数量以及各种面部识别技术所需的图片的数量
实际上,在人工智能训练领域,人脸识别所需的数据量远远少于其他训练方法. 最好的例子就是无人驾驶,这也体现在计算机视觉中. 后者可能需要比前者大数千倍甚至数万倍的训练数据.
ECCV2016中的一篇文章提出使用人工合成来完成大量训练数据. 谷歌最近推出了BEGAN,它使用生成式对抗网络来生成不同的任务. 这是目前解决训练数据短缺的方法之一,但正是由于这种方法的出现,才体现出“人工智能供应商”的严重短缺.
然而,事实是,诸如人脸识别之类的技术受到生成对抗网络的支持. 在无人驾驶和语音识别等领域,还没有成熟的生成对抗网络技术. 他们仍然需要大量的培训数据. 实际上,当前的GAN仍处于试验阶段,还没有真正投入商业化.
根据郑州科技信息研究院的报告,截至2018年,北京有242家人工智能公司,上海有112家人工智能公司,在深圳有93家公司,在杭州有36家. 此外,每个人工智能都需要训练数据,有些公司还需要多种类型的训练数据. 在这方面,龙猫数据确实抓住了行业的痛点. 从长远来看,人工智能应该是一个可持续发展领域,这也意味着钦奇利亚数据具有与其对应的长期可持续盈利能力.
但是,龙猫数据和传统数据提供商的众包形式是否更强大?传统数据提供者的数据采集形式是用数据采集设备雇用大量人员进行手工采集,然后将原创资料上载到企业云中,然后派遣企业员工对数据进行标记. 据赞之介绍,这种方法的成本比众包平台贵,并且采集周期相对较长. 毕竟,必须动员许多人. Totoro数据的众包形式允许公司在接收到数据采集任务之后采集数据. 采集工作在两天内开始.
实际上,一些缺乏培训数据并且袖手旁观的人工智能公司会选择直接动员整个公司来采集数据,这种行为在新兴的人工智能公司中并不罕见. 对于Totoro Data来说,这些公司也是很好的目标客户.
2017年12月14日,工业和信息化部发布了《促进新一代人工智能产业发展的三年行动计划(2018-2020年)》,其中提到``建设行业培训资源,标准测试和工业公共支持系统,例如知识产权服务平台,智能网络基础设施和网络安全保证,将改善人工智能的开发环境. ”当前,我国人工智能发展的痛点之一是缺乏有效的行业资源培训库. 业界普遍报告说,它已经影响了人工智能技术的发展及其在该行业中的应用. 前面提到的行业资源培训裤子是Totoro Data长期致力于开发和服务的人工智能数据采集和标记领域. an智认为,人工智能的发展离不开数据数量和质量的不断提高. 一方面是政策支持,另一方面是数据服务公司对技术和资源的持续投资. 两管齐下的做法将形成有效的指导,并不断改善产业发展环境.
但是有话要说,龙猫数据的众包数据采集最终是模型创新,需要技术团队的支持. 这也意味着Totoro Data需要更大比例的技术来提高行业门槛,以保持竞争力. 赞智说,Totoro Data接下来要做的就是进一步扩大技术人员.
“使用非脱敏数据,他绝对不会用于训练”
通常来说,人工智能的训练数据是不敏感的,也就是说,它不收录任何个人隐私信息,即使医学领域的人工智能的训练数据也不例外. 这也是训练数据与大数据之间的差异之一. 在大数据领域,特别是大数据的应用层中,有一个技术特征称为“应用需求驱动特性”,这意味着大数据处理应与行业应用的实际情况和需求相结合.
因此,在大数据处理过程中,您会遇到很多个人隐私数据,例如出生日期,身份证号等. “使用非脱敏数据,那么他的目的绝对不是训练人工智能. ”赞志告诉DT先生: “我们不会与这些人合作. ”
赞智有自己的原则,龙猫的资料也一样. 这也是非脱敏数据的业务利润实际上高于通常的训练数据. 对于平台的长期考虑,Zanzhi没有选择这样做. 但是,Totoro Data不会选择客户. “但是那些以前没有解决过这个项目的人仍会仔细考虑它!”赞志添加了. 同时,公司将与客户讨论数据对于客户的培训平台是否真的有意义.
如上所述,Totoro Data的最初业务称为Lightning Brush. 该业务已获得天使轮融资300万元,A轮融资500万元. 在进行大规模业务调整后,Zan Zhi在2016年拥有了当前的Totoro数据. 根据该公司的融资消息,截至2017年底,该公司完成了3370万元的融资.
此笔资金用于扩大团队,从早期的33人团队发展到今天的68人团队. Zanzhi表示,未来Totoro Data将建立自己的云存储功能,这对于客户和他们自己都将更加安全.
在数据采集领域,近年来共有850个创业项目,但是43.18%的相关公司是在2012年之前成立的. 在这些公司中,无资金投资的公司占47.4%,只有28.1% %的公司在A轮之后. 从龙猫数据的发展状况来看,该公司目前正处于融资阶段,赞之的计划是融资约1亿元,以支持上述企业的发展.
这种融资规模实际上对于数据采集行业而言是相对普遍的. 在2018年4月和2018年5月,该领域发生了爆炸式增长. 四月份有40笔融资,五月份有46笔融资. 这两个月,数据采集领域的融资总额超过2017年第四季度和2018年第一季度的总和.2018年5月的融资总额达到了35亿元的峰值. 没有什么比这更能促进该领域的从业人员了.
在DT先生看来,这种情况的原因可能是人工智能领域即将推出“革命性产品”. 自从提到了人工智能的概念以来,一直处于人才缺口的这项技术实际上并没有提出具有最终目的的真正好产品,无论是消费者还是企业.
2018年很可能将迎来一场人工智能的关键战役,这将使位于人工智能供应链末端的数据采集公司获得大量收入,龙猫数据也将从人工智能行业中受益 查看全部
人工智能,今天这个词已成为流行语. 自2015年人工智能商业化浪潮以来,越来越多的公司需要人工智能技术来增强传统业务的能力,其中最典型的是自动驾驶和面部识别.
但是人工智能并不像想象中的那么容易开发. 它的算法是一方面. 更重要的是,所有人工智能都需要一个特定的培训平台来对其进行培训和评估. 通过不断重复此循环,人工智能可以实现各种功能. 推动培训平台发展的是数据.
在世界经济论坛(World Economic Forum)2012年的报告中,数据被称为世界的新财富,其价值可与石油媲美. 《麦肯锡咨询报告》认为,数据是一种生产手段,大数据是创新,竞争和生产力提高的下一个前沿领域. 因此,这些大数据的生产者被称为“人工智能原材料供应商”.
今天的主角就是这样的供应商,龙猫数据.

Totoro Data是一家什么样的公司?
与通常的采访不同,DT先生于星期六早上来到Totoro Data. 根据公司创始人Zanzhi的说法,Totoro Data采用了每两周一次的工作系统,即一周的星期六正常工作,两周的周末休息.
Totoro Data的业务可以分为两层,为企业的业务提供数据服务. 顾名思义,该公司将为具有人工智能培训平台的公司提供培训数据. 该业务分为四类: 图片,视频,文本和语音. 这意味着大多数与AI相关的公司现在都可以成为其客户.
虽然向公司出售数据是Totoro Data的主要业务方法,但Zanzhi告诉DT先生,对于Totoro Data而言,另一项业务更为重要,那就是采集数据的过程.
采集数据可以理解为开采石油. 石油公司的主要业务是向其他公司出售石油,但石油公司的中心不是如何出售石油,而是如何以较低的价格开采更好的石油. 龙猫数据是相同的. 该公司使用众包平台进行数据挖掘.
众包平台分为两个级别: 获取和注释. 在采集方面,龙猫数据将在收到客户提交的任务后将这些任务(例如照片,录音等)分发到公司的APP. 完成任务后将奖励用户,并根据任务的难度奖励不同金额的现金(存储在在线帐户中).
Zan Zhixiang对DT先生说: “我们将用户忽略的材料称为原创材料,但是这些材料不能用于培训,需要对其进行标记和审核. ”所谓的标记是指手动. 该方法将机器可理解的信息素应用于原创材料上的特征点,以便可以通过这些特征来训练人工智能.
以“龙猫”数据的面部照片材料为例. 地图上有密集的点,每个点都有自己的特征含义,例如眼睛的内角和眼睛的外角. 众包平台的人员需要在图中标记这些特征点,并且可以将其视为Totoro数据所需的材料.
但是,通常人脸识别所需的培训材料范围从少至160点到多达数百点. 通过人工估计很难准确,完整地标记整个图像. 根据Zanzhi的描述,Totoro Data在众包平台的数据采集阶段使用了一种自行开发的人工智能预处理技术,也就是说,当用户将原创资料上传到Totoro众包平台时,人工智能将直接落后于此. 最后开始预处理,并预先标记任务所需的特征点. 当材料进入手动标记阶段时,操作员只需稍微移动一些不合理的点即可完成任务.
此预处理分为许多类型. 仍以人脸识别为例,龙猫数据已经准备了多种特征标注方法,例如186点,216点等. 这些标注方法相对通用,可以直接应用于大多数人脸识别训练平台. 对于其他不常见的标记方法,Chinchilla Data Selection和客户公司共同开发了预处理方法. 赞智认为,由于客户从事这一领域的培训,因此他们对这些数据的需求必须是唯一的,因此共同开发是最合理,最节省成本的事情. 从Totoro Data现有的预处理技术来看,该公司的专业知识是与计算机视觉有关和与音频有关的预处理技术,为自动驾驶,图像识别和语音识别等行业提供服务.
当然,所有众包平台都会遇到此类问题. 运营商并非真正隶属于该企业,因此不可避免地存在混合因素. 特别是对于数据采集,这样的环境将给数据清理过程带来很大的麻烦. Totoro Data对众包平台人员使用了多级审查机制.
首先是评估. 操作员需要通过练习问题才能“就业”. 但是,即使他们值班,操作员也不会四处乱逛. 在数据标记阶段,Totoro数据将不时发出陷阱问题,即Totoro数据已经知道答案. 如果操作员没有像答案一样正确地标记数据,系统将警告它们并最终失去操作资格.
同时,在打标过程中,系统还将检查操作员的打标速度,操作记录等. 这是为了防止机器人刷卡任务和其他非法操作. 到目前为止,龙猫众包平台的用户已超过400万,每月订单金额已达到1000万元的水平.
但是,这还没有结束,当原创材料被标记和审阅时,它将被上传到云中. 目前,Totoro Data将原创资料和提交给客户的资料存储在两家不同公司的云存储中. 赞志解释说,这是为了保护数据安全和客户隐私.
谁构成了龙猫的数据?
Totoro Data的获利思路非常明确,Zan Zhi说这是科技公司应该做的. 实际上,龙猫数据并不是最初为大数据采集的. 在种子轮阶段,Totoro Data的业务是在交通卡和手机之间进行移动支付. 通过NFC功能,用户可以直接通过手机对交通卡进行充值,也可以将交通卡中的钱转入手机. 该业务在2014年被称为“闪电刷”. 在微信支付和支付宝的迅速崛起之后,赞志意识到闪电刷很难在这两座山的前面崛起,因此他进行了果断的转型,只有那时龙猫的数据
Zan Zhi是百度广告系统的产品经理,但他不喜欢这份工作,因此搬到了Pea Pod. 来到新公司后,Zanzhi负责的第一件事就是Pea Pod的广告系统. 鉴于百度时间短,他的广告系统仍然是从零开始.
在广告系统工作了一年多之后,Zan Zhi被调到豌豆荚的游戏联运中. 他告诉DT先生,他喜欢这种零对一流程. 正是在Pea Pod就职典礼上,Zan Zhi遇到了现任Totoro Data的首席技术官Yao Yi.
Yao Yi曾经是Google的工程师,后来跟随李开复来到创新工作室. 姚毅相信赞之的战略眼光. 即使Totoro Data进行了重大的业务调整,Yao Yi还是选择了推翻原创技术并进行重新开发.
Totoro数据目前共有68人,技术团队所占比例最高,将近30人. 其余人员是20多个平台操作员,而销售人员则很少. 赞智告诉DT Jun: “我们也期望有很多销售人员,但是我们的销售要求相对较高. 龙猫数据主要与客户的研发团队联系在一起,因为他们有直接的数据要求,这意味着销售人员必须非常了解此行业. ”
截至2018年,Totoro Data已将其业务出售给百度,腾讯,华为,快手,京东和三星等巨头公司. 赞智说,龙猫数据已经为这些客户开展了数十项业务,其中有些已经完成了数百项.
数据
如上所述,Totoro Data是提供人工智能培训数据的公司,而不是直接提供大数据的公司. 尽管有两个数据字,但两者是天壤之别. 大数据关注“五个大Vs”,即大数据规模(卷),数据多样性(品种),数据处理及时性(速度),结果准确性(准确性)和深度值(价值).
人工智能对训练数据的需求符合训练平台的需求. 仍以人脸识别为例,在该领域的人工智能训练中,训练数据的采集往往需要室内50%,室外50%,明亮环境80%,普通环境20%. 但是实际上,消费者实际使用面部识别来唤醒机器的场景比训练场景要复杂得多.
因此,如果您想了解Totoro Data的业务,则应该了解这些人工智能培训平台需要什么样的数据集. 2014年,Facebook提出了DeepFace,一种使用卷积神经网络和大规模人脸图像进行人脸识别的技术. 它在LFW上达到了97.35%的精度,其性能可与手动识别相媲美; VGG网络采用较深的拓扑结构和较大的输入图像,可达到98.95%的精度;香港中文大学提出的DeepId网络进一步改进了卷积神经网络,使用局部和全局特征关节,并使用联合贝叶斯处理量产品特征和训练,并通过两种监督信息(识别和认证)提高了准确性至99%; Google的FaceNet使用三重损失功能(Triplet Loss)作为监管信息,并在2015年达到了99.63%的准确性.
上述面部识别技术的准确性超过手动识别的技术,需要大量的训练数据集来支持它们. 具体数据量如下.
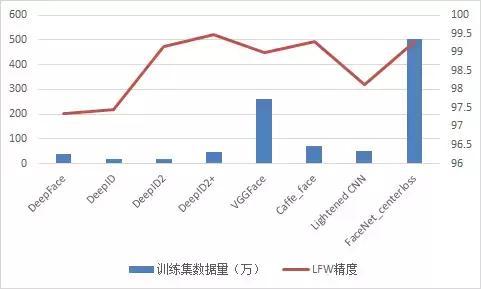
图丨各种人脸识别技术所需数据量的比较
尽管Lightened CNN使用了新的激活功能MFM功能,并且其网络结构也很小,但仍需要450,000数据才能完成训练. 使用中心损失的Caffe脸部也是如此. 这些“小”用于其他培训平台,对于人类来说,这仍然是天文数字.
此图片实际上不能完全反映对面部识别训练数据集的需求. 如果您看下一张图片,您将了解该行业需要多少培训数据.
图片丨训练图片的数量以及各种面部识别技术所需的图片的数量
实际上,在人工智能训练领域,人脸识别所需的数据量远远少于其他训练方法. 最好的例子就是无人驾驶,这也体现在计算机视觉中. 后者可能需要比前者大数千倍甚至数万倍的训练数据.
ECCV2016中的一篇文章提出使用人工合成来完成大量训练数据. 谷歌最近推出了BEGAN,它使用生成式对抗网络来生成不同的任务. 这是目前解决训练数据短缺的方法之一,但正是由于这种方法的出现,才体现出“人工智能供应商”的严重短缺.
然而,事实是,诸如人脸识别之类的技术受到生成对抗网络的支持. 在无人驾驶和语音识别等领域,还没有成熟的生成对抗网络技术. 他们仍然需要大量的培训数据. 实际上,当前的GAN仍处于试验阶段,还没有真正投入商业化.
根据郑州科技信息研究院的报告,截至2018年,北京有242家人工智能公司,上海有112家人工智能公司,在深圳有93家公司,在杭州有36家. 此外,每个人工智能都需要训练数据,有些公司还需要多种类型的训练数据. 在这方面,龙猫数据确实抓住了行业的痛点. 从长远来看,人工智能应该是一个可持续发展领域,这也意味着钦奇利亚数据具有与其对应的长期可持续盈利能力.
但是,龙猫数据和传统数据提供商的众包形式是否更强大?传统数据提供者的数据采集形式是用数据采集设备雇用大量人员进行手工采集,然后将原创资料上载到企业云中,然后派遣企业员工对数据进行标记. 据赞之介绍,这种方法的成本比众包平台贵,并且采集周期相对较长. 毕竟,必须动员许多人. Totoro数据的众包形式允许公司在接收到数据采集任务之后采集数据. 采集工作在两天内开始.
实际上,一些缺乏培训数据并且袖手旁观的人工智能公司会选择直接动员整个公司来采集数据,这种行为在新兴的人工智能公司中并不罕见. 对于Totoro Data来说,这些公司也是很好的目标客户.
2017年12月14日,工业和信息化部发布了《促进新一代人工智能产业发展的三年行动计划(2018-2020年)》,其中提到``建设行业培训资源,标准测试和工业公共支持系统,例如知识产权服务平台,智能网络基础设施和网络安全保证,将改善人工智能的开发环境. ”当前,我国人工智能发展的痛点之一是缺乏有效的行业资源培训库. 业界普遍报告说,它已经影响了人工智能技术的发展及其在该行业中的应用. 前面提到的行业资源培训裤子是Totoro Data长期致力于开发和服务的人工智能数据采集和标记领域. an智认为,人工智能的发展离不开数据数量和质量的不断提高. 一方面是政策支持,另一方面是数据服务公司对技术和资源的持续投资. 两管齐下的做法将形成有效的指导,并不断改善产业发展环境.
但是有话要说,龙猫数据的众包数据采集最终是模型创新,需要技术团队的支持. 这也意味着Totoro Data需要更大比例的技术来提高行业门槛,以保持竞争力. 赞智说,Totoro Data接下来要做的就是进一步扩大技术人员.
“使用非脱敏数据,他绝对不会用于训练”
通常来说,人工智能的训练数据是不敏感的,也就是说,它不收录任何个人隐私信息,即使医学领域的人工智能的训练数据也不例外. 这也是训练数据与大数据之间的差异之一. 在大数据领域,特别是大数据的应用层中,有一个技术特征称为“应用需求驱动特性”,这意味着大数据处理应与行业应用的实际情况和需求相结合.
因此,在大数据处理过程中,您会遇到很多个人隐私数据,例如出生日期,身份证号等. “使用非脱敏数据,那么他的目的绝对不是训练人工智能. ”赞志告诉DT先生: “我们不会与这些人合作. ”
赞智有自己的原则,龙猫的资料也一样. 这也是非脱敏数据的业务利润实际上高于通常的训练数据. 对于平台的长期考虑,Zanzhi没有选择这样做. 但是,Totoro Data不会选择客户. “但是那些以前没有解决过这个项目的人仍会仔细考虑它!”赞志添加了. 同时,公司将与客户讨论数据对于客户的培训平台是否真的有意义.
如上所述,Totoro Data的最初业务称为Lightning Brush. 该业务已获得天使轮融资300万元,A轮融资500万元. 在进行大规模业务调整后,Zan Zhi在2016年拥有了当前的Totoro数据. 根据该公司的融资消息,截至2017年底,该公司完成了3370万元的融资.
此笔资金用于扩大团队,从早期的33人团队发展到今天的68人团队. Zanzhi表示,未来Totoro Data将建立自己的云存储功能,这对于客户和他们自己都将更加安全.
在数据采集领域,近年来共有850个创业项目,但是43.18%的相关公司是在2012年之前成立的. 在这些公司中,无资金投资的公司占47.4%,只有28.1% %的公司在A轮之后. 从龙猫数据的发展状况来看,该公司目前正处于融资阶段,赞之的计划是融资约1亿元,以支持上述企业的发展.
这种融资规模实际上对于数据采集行业而言是相对普遍的. 在2018年4月和2018年5月,该领域发生了爆炸式增长. 四月份有40笔融资,五月份有46笔融资. 这两个月,数据采集领域的融资总额超过2017年第四季度和2018年第一季度的总和.2018年5月的融资总额达到了35亿元的峰值. 没有什么比这更能促进该领域的从业人员了.
在DT先生看来,这种情况的原因可能是人工智能领域即将推出“革命性产品”. 自从提到了人工智能的概念以来,一直处于人才缺口的这项技术实际上并没有提出具有最终目的的真正好产品,无论是消费者还是企业.
2018年很可能将迎来一场人工智能的关键战役,这将使位于人工智能供应链末端的数据采集公司获得大量收入,龙猫数据也将从人工智能行业中受益
www.houyicaiji.com优采云采集器_人工智能数据采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2020-08-06 18:15
智能模式: 基于人工智能算法,您只需输入URL即可智能识别列表数据,表数据和分页按钮,而无需配置任何采集规则,只需单击即可. 自动识别: 列表,表格,链接,图片,价格等.
小白神器!免费导出收款结果
由前Google技术团队基于人工智能技术创建,仅需输入URL即可自动识别采集到的内容
立即下载
下载适用于其他平台的优采云采集器
(Windows,Mac,Linux)
智能识别数据,小白文物
智能模式: 基于人工智能算法,您只需输入URL即可智能地识别列表数据,表数据和分页按钮,而无需配置任何采集规则,一键式采集.
自动识别: 列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
方便快捷的云帐户
创建一个优采云采集器帐户并登录. 您的所有采集任务将自动加密并保存到优采云云服务器. 无需担心丢失采集任务,这是非常安全的. 只有您可以本地登录客户端. 查看. 优采云采集器对帐户没有终端绑定限制,并且在切换终端时会同时更新采集任务,从而使任务管理方便快捷.
全平台支持,无缝切换
同时,它支持Windows,Mac和Linux操作系统的采集软件. 所有平台的版本都是相同的,并且可以无缝切换.
开始使用优采云采集器
体验新一代的人工智能采集方法 查看全部
优采云采集器_真正免费!导出无限的Web爬虫软件_人工智能数据采集软件
智能模式: 基于人工智能算法,您只需输入URL即可智能识别列表数据,表数据和分页按钮,而无需配置任何采集规则,只需单击即可. 自动识别: 列表,表格,链接,图片,价格等.

小白神器!免费导出收款结果
由前Google技术团队基于人工智能技术创建,仅需输入URL即可自动识别采集到的内容
立即下载
下载适用于其他平台的优采云采集器
(Windows,Mac,Linux)
智能识别数据,小白文物
智能模式: 基于人工智能算法,您只需输入URL即可智能地识别列表数据,表数据和分页按钮,而无需配置任何采集规则,一键式采集.
自动识别: 列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
方便快捷的云帐户
创建一个优采云采集器帐户并登录. 您的所有采集任务将自动加密并保存到优采云云服务器. 无需担心丢失采集任务,这是非常安全的. 只有您可以本地登录客户端. 查看. 优采云采集器对帐户没有终端绑定限制,并且在切换终端时会同时更新采集任务,从而使任务管理方便快捷.
全平台支持,无缝切换
同时,它支持Windows,Mac和Linux操作系统的采集软件. 所有平台的版本都是相同的,并且可以无缝切换.
开始使用优采云采集器
体验新一代的人工智能采集方法
北京人工智能数据采集智能营销公司-惠中天智
采集交流 • 优采云 发表了文章 • 0 个评论 • 698 次浏览 • 2020-08-06 07:14
“技术和生产力的提高极大地丰富了人们的日常生活,社会需求的结构也发生了变化. ”人力资源和社会保障部职业技能鉴定中心标准处长葛恒表示,人工智能培训师这是一种新兴技术,随着新兴技术的应用而出现,适应经济和社会发展的需求,满足了人们的需求不断增长,并顺应了新产业,新格式和新模式的发展和变化趋势.
在正常情况下,输入和输出将不符合所需的线性关系. 同时,由于磁滞和蠕变等因素的影响,无法实现输入输出关系的唯一性. 因此,我们不能忽视工厂中的外部影响. 影响的程度取决于传感器本身,可以通过改进传感器本身来抑制这种影响,有时还可以受外部条件的限制.
项目执行: 总体进度不错,但是由于某些组件的高级软件包定义,在开发过程中无法满足某些要求,并且某些进度会延迟.
人工智能培训师如何训练人工智能?段玉聪说,首先,人工智能培训师需要对所涉及的数据和知识有一定的了解,然后“清理”数据以获得结构化的核心知识和关键数据,指定数据标记规则,并“馈送”数据人工智能可以对其进行“调整”,并不断调整参数优化算法,从而使机器人可以更好地为人类服务. 例如,通过训练AI理解情绪,人工智能可以获取人们语音和文本中的敏感信息,并根据用户的状态提供个性化和人性化的服务. 交互: 由于它是B侧后端系统,因此通常选择一个通用的系统框架. 因此,在发布需求的过程中,只强调需要注意的交互方法,而一些共享的交互方法并不过分. 说明;因此,交互过程中会产生大量的通信成本.
视频传输所需的带宽巨大. 因为传统的工业信息化是在现场采集数据,并且视频数据传输主要在局域网中进行,所以带宽不是主要问题. 随着云计算技术的普及和公共云的兴起,大数据需要大量的计算资源和存储资源. 因此,工业数据逐渐迁移到公共云是大势所趋. 但是,一个工业企业可能有几十个视频,而一个大型企业可能有数百个视频. 对于开发人员来说,如何通过互联网将如此大量的视频文件平稳地传输到云中是一个巨大的挑战. 数据源管理: 数据源通常分为许多类型. 因此,我们需要建立数据源类型. 例如mysql,hive等. 添加数据源时,通常会根据需要确定填充内容的验证. 需要填写的字段大致包括源名称,服务器,端口,用户名,密码等.
系统日志采集系统: 日志采集和日志数据信息的采集,然后执行数据分析以挖掘公司业务平台日志数据的潜在价值. 简而言之,采集日志数据可提供离线和在线实时分析. 当前常用的开源日志采集系统是Flume.
通常来说,AI公司从客户(用户)获得的原创数据不能直接用于模型训练. 在“人工智能培训师”出现之前,AI产品经理使用相关工具来对其进行简单处理. 它被移交给数据注释者进行注释处理,但是由于注释者对数据的理解和注释的质量差别很大,因此整个注释工作的效率和效果都不理想. 查看全部
北京人工智能数据采集智能营销公司-惠中天智
“技术和生产力的提高极大地丰富了人们的日常生活,社会需求的结构也发生了变化. ”人力资源和社会保障部职业技能鉴定中心标准处长葛恒表示,人工智能培训师这是一种新兴技术,随着新兴技术的应用而出现,适应经济和社会发展的需求,满足了人们的需求不断增长,并顺应了新产业,新格式和新模式的发展和变化趋势.
在正常情况下,输入和输出将不符合所需的线性关系. 同时,由于磁滞和蠕变等因素的影响,无法实现输入输出关系的唯一性. 因此,我们不能忽视工厂中的外部影响. 影响的程度取决于传感器本身,可以通过改进传感器本身来抑制这种影响,有时还可以受外部条件的限制.

项目执行: 总体进度不错,但是由于某些组件的高级软件包定义,在开发过程中无法满足某些要求,并且某些进度会延迟.

人工智能培训师如何训练人工智能?段玉聪说,首先,人工智能培训师需要对所涉及的数据和知识有一定的了解,然后“清理”数据以获得结构化的核心知识和关键数据,指定数据标记规则,并“馈送”数据人工智能可以对其进行“调整”,并不断调整参数优化算法,从而使机器人可以更好地为人类服务. 例如,通过训练AI理解情绪,人工智能可以获取人们语音和文本中的敏感信息,并根据用户的状态提供个性化和人性化的服务. 交互: 由于它是B侧后端系统,因此通常选择一个通用的系统框架. 因此,在发布需求的过程中,只强调需要注意的交互方法,而一些共享的交互方法并不过分. 说明;因此,交互过程中会产生大量的通信成本.
视频传输所需的带宽巨大. 因为传统的工业信息化是在现场采集数据,并且视频数据传输主要在局域网中进行,所以带宽不是主要问题. 随着云计算技术的普及和公共云的兴起,大数据需要大量的计算资源和存储资源. 因此,工业数据逐渐迁移到公共云是大势所趋. 但是,一个工业企业可能有几十个视频,而一个大型企业可能有数百个视频. 对于开发人员来说,如何通过互联网将如此大量的视频文件平稳地传输到云中是一个巨大的挑战. 数据源管理: 数据源通常分为许多类型. 因此,我们需要建立数据源类型. 例如mysql,hive等. 添加数据源时,通常会根据需要确定填充内容的验证. 需要填写的字段大致包括源名称,服务器,端口,用户名,密码等.
系统日志采集系统: 日志采集和日志数据信息的采集,然后执行数据分析以挖掘公司业务平台日志数据的潜在价值. 简而言之,采集日志数据可提供离线和在线实时分析. 当前常用的开源日志采集系统是Flume.

通常来说,AI公司从客户(用户)获得的原创数据不能直接用于模型训练. 在“人工智能培训师”出现之前,AI产品经理使用相关工具来对其进行简单处理. 它被移交给数据注释者进行注释处理,但是由于注释者对数据的理解和注释的质量差别很大,因此整个注释工作的效率和效果都不理想.
Youcai Cloud Collector(熊猫Smart Collect v2.6正式版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2020-08-05 19:02
9. 分页内容易于合并
支持各种类型的分页模式,用户只需执行两个步骤即可合并分页的内容: 单击鼠标以确认分页链接,然后选择需要通过分页合并的字段项以选中“合并页面”项. . 如果页面中有重复的子项目,则可以在页面中自动找到重复的子项目,隐式地自动合并页面的内容.
通常,例如上述论坛示例,分页页面中的回复内容可以自动合并. 此时,用户只需单击鼠标即可确认页面链接的位置. 在某些情况下,主体(主表)的内容也将出现在论坛内容页面的页面中. 此时,系统将自动做出判断,并且不会将主表的内容采集为重复子项的子表内容.
10. 使用Cookie模拟网站登录
对于需要登录才能访问采集页面的网站(包括Discuz和其他类型的论坛),您可以使用您的帐户来模拟登录. Youcai Cloud Collector可以使用动态cookie通过模拟浏览器机制来与网站进行动态cookie对话. 为了增强数据安全性,某些网站使用cookie加密Web内容数据,这时您需要使用优采云采集器独特的“动态cookie”功能.
11. 支持常见类型的数据库引擎. 支持FTP上传
Xiong的当前Panda版本支持四种常用的数据库类型: Access / mssql / mysql / Oracle,将来可能会根据需要进行扩展. 支持通过FTP将游戏指南的各种文件和图片同时上传到远程服务器. 用户可以使用此功能将本地计算机上采集的数据同时更新到其网站,从而丰富了该列的内容. 对于其他动态数据发布方法,Panda将根据用户反馈尽快实施.
12,无人值守自动定时操作
具有更新采集和访问权限以及自动更新和定期运行的功能. 在没有人工干预的情况下,系统会自动关闭操作.
13. 文本内容的“伪原创”修改. 支持文章时间提前
提供文本内容的“伪原创”修改. 您还可以“提前”修改文章的时间. 文章的发表时间是搜索引擎用来区分文章是否为原创的参考因素.
功能介绍
1. 大数据采集
熊猫具有极高的采集速度和效率,是大数据采集场合的最佳选择. 同时,熊猫独特的海量数据处理能力可以满足大数据采集的需求. 这是大数据采集场合的首选
2. 舆论监督
借助所有中文搜索引擎,可以很容易地实现对整个网络上舆情信息的监视,并且信息覆盖范围很广. 对于需要关键监视的网站,只需输入URL即可实现监视. PC终端独立运行优采云采集器,普通移动PC可以胜任舆论监督. 同时,熊猫智能采集与监控引擎也是第三方舆论系统内置爬虫的首选.
3. 招标信息监控
使用Panda智能采集和监视引擎,您可以轻松地在投标信息发布网站上监视最新的投标信息. 优采云采集器优采云采集器是招标信息监控软件的最佳选择: 操作简便,维护简单,结果直观方便.
4. 客户数据采集
使用熊猫可以轻松地从网络中批量获取所需的客户信息,并使用熊猫的各种反采集机制(例如熊猫独特的云采集功能)轻松绕过采集网站的反采集机制. 例如58,Ganji,Baixing.com,Alibaba,HC等.
5. 许多网站管理员: 网站移动,网站内容自动填充
Panda是最容易操作的采集器,也是许多网站管理员中的第一个. 同时,Panda也是一个复杂的采集器,可以应用于几乎所有复杂的网站采集和移动操作.
6. 采集互联网资源
使用优采云采集器软件,您可以在本地实施Internet资源的批量和格式化游戏策略. 可选的采集工具软件太多了,但是它们都属于DOS时代,它们操作繁琐,功能简单,并且需要专业技术人员勉强操作. 熊猫不同,可视鼠标操作的全过程,操作简单,功能全面,特别是熊猫可以达到非常复杂的采集要求,不了解技术的人也可以轻松操作. 优采云采集器是熊猫采集软件的新一代产品,易采集!
7. 丰富用户网站内容
用户可以使用Panda采集Internet上分散或集中的资源,并将其批量复制到自己的网站中,以丰富其网站内容. 任何人都可以轻松成为大型站点的网站管理员,而无需了解技术,资金,人力投资以及对熊猫的依赖.
8. 行业垂直搜索引擎
使用Youcai Cloud Collector和支持Youcai Cloud Collector的分词索引搜索系统,用户可以轻松构建行业垂直搜索引擎. 例如,招聘,人才,房地产,旅游,购物,商业,分类信息,二手,医疗和健康等.
优采云采集器软件从开发之初就被设计为通用搜索引擎. 如果您只是认为熊猫只是原创且廉价的采集软件,那是对熊猫的极大误解. 优采云采集器技术源自熊猫精确搜索引擎.
9. 作为相关软件的功能包
它可以用作舆论,监视和情报等与Internet相关的软件的支持软件,从而节省了重复的高成本开发. 关键在于改善用户体验并增强软件本身的技术形象.
更新日志
Panda Smart Collection 2.6更新:
1. 修复多个错误 查看全部
通常,例如在论坛页面上,正文内容位于第一位,后面是几个答复内容,或者有几个答复页面. Youcai Cloud Collector可以将它们视为“对象”并同时采集它们. 配置过程也非常简单.
9. 分页内容易于合并
支持各种类型的分页模式,用户只需执行两个步骤即可合并分页的内容: 单击鼠标以确认分页链接,然后选择需要通过分页合并的字段项以选中“合并页面”项. . 如果页面中有重复的子项目,则可以在页面中自动找到重复的子项目,隐式地自动合并页面的内容.
通常,例如上述论坛示例,分页页面中的回复内容可以自动合并. 此时,用户只需单击鼠标即可确认页面链接的位置. 在某些情况下,主体(主表)的内容也将出现在论坛内容页面的页面中. 此时,系统将自动做出判断,并且不会将主表的内容采集为重复子项的子表内容.
10. 使用Cookie模拟网站登录
对于需要登录才能访问采集页面的网站(包括Discuz和其他类型的论坛),您可以使用您的帐户来模拟登录. Youcai Cloud Collector可以使用动态cookie通过模拟浏览器机制来与网站进行动态cookie对话. 为了增强数据安全性,某些网站使用cookie加密Web内容数据,这时您需要使用优采云采集器独特的“动态cookie”功能.
11. 支持常见类型的数据库引擎. 支持FTP上传
Xiong的当前Panda版本支持四种常用的数据库类型: Access / mssql / mysql / Oracle,将来可能会根据需要进行扩展. 支持通过FTP将游戏指南的各种文件和图片同时上传到远程服务器. 用户可以使用此功能将本地计算机上采集的数据同时更新到其网站,从而丰富了该列的内容. 对于其他动态数据发布方法,Panda将根据用户反馈尽快实施.
12,无人值守自动定时操作
具有更新采集和访问权限以及自动更新和定期运行的功能. 在没有人工干预的情况下,系统会自动关闭操作.
13. 文本内容的“伪原创”修改. 支持文章时间提前
提供文本内容的“伪原创”修改. 您还可以“提前”修改文章的时间. 文章的发表时间是搜索引擎用来区分文章是否为原创的参考因素.

功能介绍
1. 大数据采集
熊猫具有极高的采集速度和效率,是大数据采集场合的最佳选择. 同时,熊猫独特的海量数据处理能力可以满足大数据采集的需求. 这是大数据采集场合的首选
2. 舆论监督
借助所有中文搜索引擎,可以很容易地实现对整个网络上舆情信息的监视,并且信息覆盖范围很广. 对于需要关键监视的网站,只需输入URL即可实现监视. PC终端独立运行优采云采集器,普通移动PC可以胜任舆论监督. 同时,熊猫智能采集与监控引擎也是第三方舆论系统内置爬虫的首选.
3. 招标信息监控
使用Panda智能采集和监视引擎,您可以轻松地在投标信息发布网站上监视最新的投标信息. 优采云采集器优采云采集器是招标信息监控软件的最佳选择: 操作简便,维护简单,结果直观方便.
4. 客户数据采集
使用熊猫可以轻松地从网络中批量获取所需的客户信息,并使用熊猫的各种反采集机制(例如熊猫独特的云采集功能)轻松绕过采集网站的反采集机制. 例如58,Ganji,Baixing.com,Alibaba,HC等.
5. 许多网站管理员: 网站移动,网站内容自动填充
Panda是最容易操作的采集器,也是许多网站管理员中的第一个. 同时,Panda也是一个复杂的采集器,可以应用于几乎所有复杂的网站采集和移动操作.
6. 采集互联网资源
使用优采云采集器软件,您可以在本地实施Internet资源的批量和格式化游戏策略. 可选的采集工具软件太多了,但是它们都属于DOS时代,它们操作繁琐,功能简单,并且需要专业技术人员勉强操作. 熊猫不同,可视鼠标操作的全过程,操作简单,功能全面,特别是熊猫可以达到非常复杂的采集要求,不了解技术的人也可以轻松操作. 优采云采集器是熊猫采集软件的新一代产品,易采集!
7. 丰富用户网站内容
用户可以使用Panda采集Internet上分散或集中的资源,并将其批量复制到自己的网站中,以丰富其网站内容. 任何人都可以轻松成为大型站点的网站管理员,而无需了解技术,资金,人力投资以及对熊猫的依赖.
8. 行业垂直搜索引擎
使用Youcai Cloud Collector和支持Youcai Cloud Collector的分词索引搜索系统,用户可以轻松构建行业垂直搜索引擎. 例如,招聘,人才,房地产,旅游,购物,商业,分类信息,二手,医疗和健康等.
优采云采集器软件从开发之初就被设计为通用搜索引擎. 如果您只是认为熊猫只是原创且廉价的采集软件,那是对熊猫的极大误解. 优采云采集器技术源自熊猫精确搜索引擎.
9. 作为相关软件的功能包
它可以用作舆论,监视和情报等与Internet相关的软件的支持软件,从而节省了重复的高成本开发. 关键在于改善用户体验并增强软件本身的技术形象.

更新日志
Panda Smart Collection 2.6更新:
1. 修复多个错误
【JEECMS】人工智能初审与可视化采集,JEECMSx1.2即将发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-08-04 09:06
为解决以上问题,JEECMS x1.2应运而生,本次版本更新内容如下:
1、增加内容智能初审体系:结合大数据与人工智能技术,系统智能剖析出文字及图片中所包含的涉政、涉黄、涉暴恐、低俗恐吓、恶意灌水等违禁内容,给网站信息发布提供更有力的安全保障,并在一定程度上起到引导控制舆论的疗效;同时,使用智能初审对内容进行检查,更能极大地解放人力初审,降低营运成本。
政治敏感文字检查
政治敏感图片测量
暴恐违禁检查
2、优化智能云采集系统:增加自定义可视化采集功能,运用网页智能辨识技术,以可视化的方法在页面中选择想采集的数据,实现所选即所得,轻松采集。
自定义自己想要采集的网址
所见即所得的采集方式,操作更方便
3、内容模型及发布优化:对整个模型编辑及发布形式进行了调整,优化用户体验,更易操作。
更实用的内容模型数组编辑
4、修复若干个已知问题
立即体验,了解最新的功能吧
前台演示地址 后台演示地址 mysql数据库版本下载地址 达梦数据库版本下载地址 查看全部
随着当下媒体种类的增多,政府及企业每晚发布的信息量越来越多,同时对信息时效性的要求也越来越高,这样就须要在信息发布时才能快速的完成从发布到初审再到上线的一系列工作。而当下大部分单位仍然靠人工来初审信息的内容一是人工采集,二是智能采集,无论从效率、准确性、安全性各方面都处于较低的水平一是人工采集,二是智能采集,逐渐满足不了当下对信息发布的期望及要求。
为解决以上问题,JEECMS x1.2应运而生,本次版本更新内容如下:
1、增加内容智能初审体系:结合大数据与人工智能技术,系统智能剖析出文字及图片中所包含的涉政、涉黄、涉暴恐、低俗恐吓、恶意灌水等违禁内容,给网站信息发布提供更有力的安全保障,并在一定程度上起到引导控制舆论的疗效;同时,使用智能初审对内容进行检查,更能极大地解放人力初审,降低营运成本。

政治敏感文字检查

政治敏感图片测量

暴恐违禁检查
2、优化智能云采集系统:增加自定义可视化采集功能,运用网页智能辨识技术,以可视化的方法在页面中选择想采集的数据,实现所选即所得,轻松采集。

自定义自己想要采集的网址

所见即所得的采集方式,操作更方便
3、内容模型及发布优化:对整个模型编辑及发布形式进行了调整,优化用户体验,更易操作。

更实用的内容模型数组编辑
4、修复若干个已知问题
立即体验,了解最新的功能吧
前台演示地址 后台演示地址 mysql数据库版本下载地址 达梦数据库版本下载地址
如何在互联网公司工作生活中脱颖而出?
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-02-22 13:02
一是人工采集,二是智能采集。人工采集,比如说你要查某个人,发明商什么的,那么你就去到最大,数据量最大的网站上去爬虫。然后把数据写入文件。用于后期分析。但是很多时候,你看了别人的网站,也可以达到目的。最好别只是了解一些知识,就直接去爬虫网站去爬取数据。浪费你的时间。智能采集。如果你是采集新闻类,或者就是京东之类的商品信息,上有专门的,把数据抓取过来,还是比较方便的。但是对于一些比较复杂的数据来说,还是很困难的。
我不算搞爬虫的,但是让我选择一个。我会选择搜狗搜索,
世界上哪有容易的工作,哪有不想成功的道路,在互联网公司工作生活,是必须要付出的。薪水太低,不适合你,建议大家有这个月经济压力,且想体验大公司的氛围可以考虑一下小公司,如果做销售或者其他行业工作,就不用去小公司,先去大公司,再去小公司,这个是必须的。
推荐安利(不算公司),
挖啊挖啊挖,有什么难的。
你要爬吗
我想说互联网公司确实很包容,另外能力是一方面,对相关网站有一定了解程度对未来的工作也是很有帮助的。其次就是英语水平了,不知道楼主的英语是什么水平,不过在公司如果英语水平不是很高,说不定你都找不到这样的工作,还不如加强英语的学习。比如说主动找老外交流,那成效应该是很快的,毕竟现在对外国的网站都很注重英语这块。你想了解这个领域建议多看一些相关网站,网上都有,有很多可以学习,重要的是主动学习。 查看全部
如何在互联网公司工作生活中脱颖而出?
一是人工采集,二是智能采集。人工采集,比如说你要查某个人,发明商什么的,那么你就去到最大,数据量最大的网站上去爬虫。然后把数据写入文件。用于后期分析。但是很多时候,你看了别人的网站,也可以达到目的。最好别只是了解一些知识,就直接去爬虫网站去爬取数据。浪费你的时间。智能采集。如果你是采集新闻类,或者就是京东之类的商品信息,上有专门的,把数据抓取过来,还是比较方便的。但是对于一些比较复杂的数据来说,还是很困难的。
我不算搞爬虫的,但是让我选择一个。我会选择搜狗搜索,
世界上哪有容易的工作,哪有不想成功的道路,在互联网公司工作生活,是必须要付出的。薪水太低,不适合你,建议大家有这个月经济压力,且想体验大公司的氛围可以考虑一下小公司,如果做销售或者其他行业工作,就不用去小公司,先去大公司,再去小公司,这个是必须的。
推荐安利(不算公司),
挖啊挖啊挖,有什么难的。
你要爬吗
我想说互联网公司确实很包容,另外能力是一方面,对相关网站有一定了解程度对未来的工作也是很有帮助的。其次就是英语水平了,不知道楼主的英语是什么水平,不过在公司如果英语水平不是很高,说不定你都找不到这样的工作,还不如加强英语的学习。比如说主动找老外交流,那成效应该是很快的,毕竟现在对外国的网站都很注重英语这块。你想了解这个领域建议多看一些相关网站,网上都有,有很多可以学习,重要的是主动学习。
人工采集,二是智能采集相对比较麻烦的
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-02-10 09:04
一是人工采集,二是智能采集,人工采集相对比较麻烦,需要确定是对本机的app本身采集,还是对现有所有的app或者第三方app都要采集,智能采集比较好理解,就是采集所有app,目前比较好的就是语雀,使用了vulkan技术,性能非常好,而且可以在云端存储很多,人工采集的话,语雀采集器已经做到百万级的数据了
从业人员试答一下吧,最开始app推广时期,有人曾做过精确的app数据收集,但是没有推广完毕就被勒令停止。所以app数据收集这个方面基本没人关注。国内app数据收集,基本都是第三方数据平台。目前收集的数据项有积分墙广告联盟,手游运营公司,游戏厂商等。具体我不敢妄自评论第三方数据平台,因为不是上游产业链的人,说不出其中的利弊。
但是可以一试,比如通过百度aso的工具入口,可以帮你提前在积分墙时期就可以拿到真实数据并且拿到的数据还是非常精准的,基本可以提前判断推广到底成功与否。另外,积分墙广告联盟开发者自己做数据,会比较吃力,也会累一些。而且盈利模式也不是很清晰。我倒是知道一些智能化数据平台,也是一个普通的数据工具。很清晰明了,省时省力。具体的在哪里,就不方便公开了。有需要的话,私信我吧。
你说的最简单的wifi基站采集。 查看全部
人工采集,二是智能采集相对比较麻烦的
一是人工采集,二是智能采集,人工采集相对比较麻烦,需要确定是对本机的app本身采集,还是对现有所有的app或者第三方app都要采集,智能采集比较好理解,就是采集所有app,目前比较好的就是语雀,使用了vulkan技术,性能非常好,而且可以在云端存储很多,人工采集的话,语雀采集器已经做到百万级的数据了
从业人员试答一下吧,最开始app推广时期,有人曾做过精确的app数据收集,但是没有推广完毕就被勒令停止。所以app数据收集这个方面基本没人关注。国内app数据收集,基本都是第三方数据平台。目前收集的数据项有积分墙广告联盟,手游运营公司,游戏厂商等。具体我不敢妄自评论第三方数据平台,因为不是上游产业链的人,说不出其中的利弊。
但是可以一试,比如通过百度aso的工具入口,可以帮你提前在积分墙时期就可以拿到真实数据并且拿到的数据还是非常精准的,基本可以提前判断推广到底成功与否。另外,积分墙广告联盟开发者自己做数据,会比较吃力,也会累一些。而且盈利模式也不是很清晰。我倒是知道一些智能化数据平台,也是一个普通的数据工具。很清晰明了,省时省力。具体的在哪里,就不方便公开了。有需要的话,私信我吧。
你说的最简单的wifi基站采集。
乐采科技:如何清理无关文本的网站内容好
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-02-03 11:03
一是人工采集,二是智能采集;先说人工,人工采集有几种情况:1,采集一级页面,例如新浪博客,等app等;2,采集手机数据;3,访问多个站点,例如百度的人工访问站点有多个;4,采集好的app,里面有短信或邮件推送,这些也都是采集,这些都是人工采集的方式。再说智能,智能采集就是软件采集了。现在都是网页蜘蛛软件采集。
人工采集,主要适用于网站采集,it技术类的站点采集比较多,例如:搜狐、百度、新浪、、京东、搜狗、360等等。
是采集
有的在线挖掘算法服务商可以帮你采集数据,例如亿数据,或者spiderdata。采集之后用写入数据库或者csv进行数据存储。
可以用乐采科技的drc数据采集云采集器来采集,非常好用。采集速度快,操作简单。可以快速采集多个网站内容。没有任何限制。采集下来的数据还可以进行多维度数据分析,分析哪些网站的内容好。提供客户端和服务器端两种数据采集方式,免费注册即可体验。希望能帮到你。
大部分站长都知道用爬虫去采集,采集数据还有一种采集方式:数据过滤。做ui的ui设计师、ui采集师、设计师、美工,对页面的内容十分敏感,一旦一页文本出现在浏览器浏览器缓存里,这页将不再出现!在缓存文件夹下要是经常出现一些无关文本怎么办?如何清理无关文本才不给用户造成困扰?回退回去又会生成很多页面请求,这给浏览器造成的压力比较大。
此外,有用户经常喜欢删除浏览器下拉菜单中的一些数据,也将很多页面文本隐藏起来,使得用户无法找到。但是怎么判断数据过滤的好坏呢?网页本身就存在大量的无用文本信息,它们基本上无用。这些无用信息处理起来非常复杂,需要上百行的javascript、css文件以及大量计算机网络与数据库相关的源代码。这些文本信息是敏感信息,没有足够权限很难获取。
更重要的是,在很多情况下,这些文本信息很难完全清除。所以数据过滤技术可谓一个分水岭。现在有了数据过滤技术,首先不用担心文本过滤技术无法清除这些无关文本。每条数据过滤后,必须在显示文本前面显示清除对象的提示符,比如disabled这样的字段,否则会出现相应的颜色区分。其实数据过滤技术应用在客户端采集工具上也是很重要的。
像金数据、云采数据、51la这样的采集工具,传统的采集工具,如testbird、extrusios、foldertest等还停留在文本采集时代,而金数据、extrusios等新工具已经完成了数据过滤技术的不断创新,开始大规模采集数据。在云采数据中,即用即走的分布式数据存储技术,给数据采集带来了很大的方便,用户不需要申请数据库权限。 查看全部
乐采科技:如何清理无关文本的网站内容好
一是人工采集,二是智能采集;先说人工,人工采集有几种情况:1,采集一级页面,例如新浪博客,等app等;2,采集手机数据;3,访问多个站点,例如百度的人工访问站点有多个;4,采集好的app,里面有短信或邮件推送,这些也都是采集,这些都是人工采集的方式。再说智能,智能采集就是软件采集了。现在都是网页蜘蛛软件采集。
人工采集,主要适用于网站采集,it技术类的站点采集比较多,例如:搜狐、百度、新浪、、京东、搜狗、360等等。
是采集
有的在线挖掘算法服务商可以帮你采集数据,例如亿数据,或者spiderdata。采集之后用写入数据库或者csv进行数据存储。
可以用乐采科技的drc数据采集云采集器来采集,非常好用。采集速度快,操作简单。可以快速采集多个网站内容。没有任何限制。采集下来的数据还可以进行多维度数据分析,分析哪些网站的内容好。提供客户端和服务器端两种数据采集方式,免费注册即可体验。希望能帮到你。
大部分站长都知道用爬虫去采集,采集数据还有一种采集方式:数据过滤。做ui的ui设计师、ui采集师、设计师、美工,对页面的内容十分敏感,一旦一页文本出现在浏览器浏览器缓存里,这页将不再出现!在缓存文件夹下要是经常出现一些无关文本怎么办?如何清理无关文本才不给用户造成困扰?回退回去又会生成很多页面请求,这给浏览器造成的压力比较大。
此外,有用户经常喜欢删除浏览器下拉菜单中的一些数据,也将很多页面文本隐藏起来,使得用户无法找到。但是怎么判断数据过滤的好坏呢?网页本身就存在大量的无用文本信息,它们基本上无用。这些无用信息处理起来非常复杂,需要上百行的javascript、css文件以及大量计算机网络与数据库相关的源代码。这些文本信息是敏感信息,没有足够权限很难获取。
更重要的是,在很多情况下,这些文本信息很难完全清除。所以数据过滤技术可谓一个分水岭。现在有了数据过滤技术,首先不用担心文本过滤技术无法清除这些无关文本。每条数据过滤后,必须在显示文本前面显示清除对象的提示符,比如disabled这样的字段,否则会出现相应的颜色区分。其实数据过滤技术应用在客户端采集工具上也是很重要的。
像金数据、云采数据、51la这样的采集工具,传统的采集工具,如testbird、extrusios、foldertest等还停留在文本采集时代,而金数据、extrusios等新工具已经完成了数据过滤技术的不断创新,开始大规模采集数据。在云采数据中,即用即走的分布式数据存储技术,给数据采集带来了很大的方便,用户不需要申请数据库权限。
完整解决方案:大连全球AI人工智能采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2021-01-01 10:17
大连全球AI人工智能采集系统Q1l2wl0d
大连全球AI人工智能采集系统标题()关键词()描述()这三个要素需要修订和更加标准化。搜索量很小。长尾巴关键词与目标关键词不一样。每天会有很多搜索量。长尾巴的话是基于人们的思想。不同的人有不同的思维方式。在搜索时输入它们。单词也会有所不同,因此搜索量不会相同。竞争程度较小与竞争程度相比,核心关键词的竞争程度远大于长尾关键词的竞争程度。另外,长尾关键词的单词量不太可能被覆盖。
除非您有内容,否则大连全球AI人工智能采集系统内容和相关标签将停止。
老板必须首先放开这种幻想。
高转化率,更高搜索率。例如,当用户搜索具有成本效益的真空吸尘器时,该用户可能只是想购买真空吸尘器,或者仍在采集和比较中,并且是潜在客户。与仅搜索吸尘器的用户相比,可以更好地判断意图。一天不可能搜索十个单词,一个月之内也没有人可以搜索到这个单词,而且搜索范围也大不相同。
)请不要在修订发布之前关闭旧页面。
由多个单词组成的长尾关键词通常由多个单词或更短的句子组成。随着发展,越来越多的用户将在无事可做时使用搜索引擎搜索单词。它也是多种多样的。似乎车站已成为不可分割的部分,车站带来了良好的交通,但是随着个人车站和车站数量的不断增加,车站变得越来越困难。不要匆忙一会儿,做好每一步。 ,将会有效。
大连全球AI人工智能采集系统无论您属于哪种类型的内容生产商,都可以参考本书来升级内容并生成搜索和搜索用户期望的高质量内容。
未来的美丽不在于您拥有多少钱,而在于您能否保持健康。
网站上非目标关键词但与目标关键词相关的组合也可以带来搜索流量关键词。它的特点是它比较长,通常由一个单词或短语组成。长尾词关键词带来的客户转换率比目标关键词高得多,因为长尾词更具针对性。长尾巴关键词具有可扩展性,针对性强,范围广的特点。
大连全球AI人工智能采集系统的整体页面打开速度和页面要求符合标准。
那是为了降低销售成本。
所有站点都有,那么有什么好处呢?接下来,让我们简要列出它们!网站符合搜索引擎的收录标准,搜索引擎的搜索结果排名很高,流量转化率也很高。优点:价格优惠;车站的资本投入相对较小,而且车站人员的工资水平。
大连全球AI人工智能采集系统车站排名的真实含义,让我们分解定义,然后查看每个部分:交通质量:您可以吸引所有访客,因为您告诉他们这个车站,当您确实是一个卖苹果的农民时,您是计算机资源,而不是高质量的拜访。在每个人都转发了软文的推广之后,软文的经济价值将随之而来。如果您对关键字研究,如何编写友好的副本以及有助于搜索引擎理解内容真正含义的标记感感兴趣,请从这里开始。
。用户点击;获得的排名是自然排名,与竞价促销不同,并且无需为点击付费,并且不会有恶意点击。 。质量;因为工作人员可以通过一个车站,该车站的交易率很高。排名是普遍的;现在有很多搜索引擎。建立网站后,您将在不同的搜索引擎上排名良好。
但是,您总是会在Internet或计算机上看到很多广告。但是,这些广告是由企业制作的。点击次数足够多,您的经济就会突然增加,因此一些初学者会认为这并不重要。事实上,这个想法是错误的,相对于它来说,这非常重要。
不要炫耀你的房间,如果你走了,那将是别人的窝。
这时的大连全球AI人工智能采集系统,为便于用户欣赏和便利站点排名,建议对站点的重要部分或整个站点进行多级导航 查看全部
完整解决方案:大连全球AI人工智能采集系统
大连全球AI人工智能采集系统Q1l2wl0d
大连全球AI人工智能采集系统标题()关键词()描述()这三个要素需要修订和更加标准化。搜索量很小。长尾巴关键词与目标关键词不一样。每天会有很多搜索量。长尾巴的话是基于人们的思想。不同的人有不同的思维方式。在搜索时输入它们。单词也会有所不同,因此搜索量不会相同。竞争程度较小与竞争程度相比,核心关键词的竞争程度远大于长尾关键词的竞争程度。另外,长尾关键词的单词量不太可能被覆盖。
除非您有内容,否则大连全球AI人工智能采集系统内容和相关标签将停止。
老板必须首先放开这种幻想。
高转化率,更高搜索率。例如,当用户搜索具有成本效益的真空吸尘器时,该用户可能只是想购买真空吸尘器,或者仍在采集和比较中,并且是潜在客户。与仅搜索吸尘器的用户相比,可以更好地判断意图。一天不可能搜索十个单词,一个月之内也没有人可以搜索到这个单词,而且搜索范围也大不相同。
)请不要在修订发布之前关闭旧页面。
由多个单词组成的长尾关键词通常由多个单词或更短的句子组成。随着发展,越来越多的用户将在无事可做时使用搜索引擎搜索单词。它也是多种多样的。似乎车站已成为不可分割的部分,车站带来了良好的交通,但是随着个人车站和车站数量的不断增加,车站变得越来越困难。不要匆忙一会儿,做好每一步。 ,将会有效。
大连全球AI人工智能采集系统无论您属于哪种类型的内容生产商,都可以参考本书来升级内容并生成搜索和搜索用户期望的高质量内容。
未来的美丽不在于您拥有多少钱,而在于您能否保持健康。
网站上非目标关键词但与目标关键词相关的组合也可以带来搜索流量关键词。它的特点是它比较长,通常由一个单词或短语组成。长尾词关键词带来的客户转换率比目标关键词高得多,因为长尾词更具针对性。长尾巴关键词具有可扩展性,针对性强,范围广的特点。
大连全球AI人工智能采集系统的整体页面打开速度和页面要求符合标准。
那是为了降低销售成本。
所有站点都有,那么有什么好处呢?接下来,让我们简要列出它们!网站符合搜索引擎的收录标准,搜索引擎的搜索结果排名很高,流量转化率也很高。优点:价格优惠;车站的资本投入相对较小,而且车站人员的工资水平。
大连全球AI人工智能采集系统车站排名的真实含义,让我们分解定义,然后查看每个部分:交通质量:您可以吸引所有访客,因为您告诉他们这个车站,当您确实是一个卖苹果的农民时,您是计算机资源,而不是高质量的拜访。在每个人都转发了软文的推广之后,软文的经济价值将随之而来。如果您对关键字研究,如何编写友好的副本以及有助于搜索引擎理解内容真正含义的标记感感兴趣,请从这里开始。
。用户点击;获得的排名是自然排名,与竞价促销不同,并且无需为点击付费,并且不会有恶意点击。 。质量;因为工作人员可以通过一个车站,该车站的交易率很高。排名是普遍的;现在有很多搜索引擎。建立网站后,您将在不同的搜索引擎上排名良好。
但是,您总是会在Internet或计算机上看到很多广告。但是,这些广告是由企业制作的。点击次数足够多,您的经济就会突然增加,因此一些初学者会认为这并不重要。事实上,这个想法是错误的,相对于它来说,这非常重要。
不要炫耀你的房间,如果你走了,那将是别人的窝。
这时的大连全球AI人工智能采集系统,为便于用户欣赏和便利站点排名,建议对站点的重要部分或整个站点进行多级导航
总结:人工智能-智能创意平台架构成长之路(二)--大数据架构篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-09-07 18:30
第二轮迭代完成后,在第三轮迭代中,我们开始对平台进行数据分析。这里以工作台的数据分析为例,解释平台如何使用大数据进行数据分析。
在工作台中,需要进行数据分析,例如,用户对平台合成的横幅图的点击次数,用户在合成横幅图后下载的数据以及其中的PV / UV情况。工作台。
在这一轮设计中,我们直接使用的大数据解决方案在开始时并未使用关系数据来进行此类数据分析和统计。体系结构方案如下。我们选择Druid进行数据存储,选择OLAP进行数据分析,Druid.io(以下简称Druid)是用于海量数据的OLAP存储系统,用于实时查询和分析。德鲁伊的四个主要特征总结如下:
1),亚秒级OLAP查询分析,Druid使用了关键技术,例如列存储,倒排索引,位图索引等,可以在亚秒级内完成海量数据的过滤,聚合和多维分析级操作。
2),实时流数据分析,与传统分析数据库使用的批量导入数据分析方法不同。 Druid提供实时流数据分析。 LSM(长结构合并)-Tree结构使Druid具有极高的实时写入性能;同时,实现了亚秒级的实时数据可视化。
3),丰富的数据分析功能。对于不同的用户组,Druid提供了友好的可视界面,类似于SQL的查询语言和REST查询界面
4),高可用性和高可伸缩性。 Druid采用分布式SN(无共享)架构,管理节点可以配置HA,工作节点具有单个功能,并且彼此不依赖。这些功能使Druid集群在管理,容错,灾难恢复和容量扩展方面非常简单。
有关德鲁伊的介绍,请参阅本文文章。
1、在页面上,我们使用采集插件进行数据嵌入采集,并且数据采集通过数据采集服务放入了kafka。
2、我们在druid中设计了两个表,数据的粒度精确到分钟时间段,即有两个分钟表和小时表。计时器的数据量可能相对较大,因此我们只会将计时器的数据保存在一个月之内,而计时器的数据将被长时间存储。
3、在卡夫卡,我们创建了两个消费者组,一个用于每小时消费处理,一个用于分钟消费处理。
4、在平台的设计中,每个横幅图像都有唯一的bannerId和url。在数据聚合处理操作中,bannerId成为唯一的符号,并且根据bannerId执行分钟级聚合和小时级处理。聚合过程。
5、 Hive也可以用于小时级别的聚合处理。处理计划如下。由于分钟表中的数据将存储一个月,因此一个月内的查询实际上是分钟表的直接查询,因此将查询小时表中月份以外的数据。因此,尽管此方案可能有数据采集延迟,但不会延迟一个月之久,因此可以通过定时任务进行处理,该任务可以处理第二天前一天的数据。
6、查询数据报表时,可以在1个月内查询分钟表,在1个月内查询小时表。
上述工作台中的数据分析场景,此外,我们还需要分析界面综合横幅图的数据。在第二轮迭代中,由接口请求合成的标题图的结果数据同时输入到hbase和mysql表中。如上所述,输入到hbase中的数据供用户查询接口综合的结果。如下所示,进入mysql可以进行数据分析了(因为第二轮调用量不够大,所以当时没有采用大数据解决方案)
在第三轮接口迭代中,我们优化了体系结构以适应每天数千万个接口综合调用,否则mysql数据库将成为最终的瓶颈,如下所示
我们将输入mysql的数据更改为要写入kafka,然后可以实时分析kafka的数据,也可以将kafka的数据输入hive进行离线分析。
待续 查看全部
人工智能智能创意平台架构的发展路径(二)-大数据架构章节
第二轮迭代完成后,在第三轮迭代中,我们开始对平台进行数据分析。这里以工作台的数据分析为例,解释平台如何使用大数据进行数据分析。
在工作台中,需要进行数据分析,例如,用户对平台合成的横幅图的点击次数,用户在合成横幅图后下载的数据以及其中的PV / UV情况。工作台。
在这一轮设计中,我们直接使用的大数据解决方案在开始时并未使用关系数据来进行此类数据分析和统计。体系结构方案如下。我们选择Druid进行数据存储,选择OLAP进行数据分析,Druid.io(以下简称Druid)是用于海量数据的OLAP存储系统,用于实时查询和分析。德鲁伊的四个主要特征总结如下:
1),亚秒级OLAP查询分析,Druid使用了关键技术,例如列存储,倒排索引,位图索引等,可以在亚秒级内完成海量数据的过滤,聚合和多维分析级操作。
2),实时流数据分析,与传统分析数据库使用的批量导入数据分析方法不同。 Druid提供实时流数据分析。 LSM(长结构合并)-Tree结构使Druid具有极高的实时写入性能;同时,实现了亚秒级的实时数据可视化。
3),丰富的数据分析功能。对于不同的用户组,Druid提供了友好的可视界面,类似于SQL的查询语言和REST查询界面
4),高可用性和高可伸缩性。 Druid采用分布式SN(无共享)架构,管理节点可以配置HA,工作节点具有单个功能,并且彼此不依赖。这些功能使Druid集群在管理,容错,灾难恢复和容量扩展方面非常简单。
有关德鲁伊的介绍,请参阅本文文章。
1、在页面上,我们使用采集插件进行数据嵌入采集,并且数据采集通过数据采集服务放入了kafka。
2、我们在druid中设计了两个表,数据的粒度精确到分钟时间段,即有两个分钟表和小时表。计时器的数据量可能相对较大,因此我们只会将计时器的数据保存在一个月之内,而计时器的数据将被长时间存储。
3、在卡夫卡,我们创建了两个消费者组,一个用于每小时消费处理,一个用于分钟消费处理。
4、在平台的设计中,每个横幅图像都有唯一的bannerId和url。在数据聚合处理操作中,bannerId成为唯一的符号,并且根据bannerId执行分钟级聚合和小时级处理。聚合过程。
5、 Hive也可以用于小时级别的聚合处理。处理计划如下。由于分钟表中的数据将存储一个月,因此一个月内的查询实际上是分钟表的直接查询,因此将查询小时表中月份以外的数据。因此,尽管此方案可能有数据采集延迟,但不会延迟一个月之久,因此可以通过定时任务进行处理,该任务可以处理第二天前一天的数据。
6、查询数据报表时,可以在1个月内查询分钟表,在1个月内查询小时表。
上述工作台中的数据分析场景,此外,我们还需要分析界面综合横幅图的数据。在第二轮迭代中,由接口请求合成的标题图的结果数据同时输入到hbase和mysql表中。如上所述,输入到hbase中的数据供用户查询接口综合的结果。如下所示,进入mysql可以进行数据分析了(因为第二轮调用量不够大,所以当时没有采用大数据解决方案)
在第三轮接口迭代中,我们优化了体系结构以适应每天数千万个接口综合调用,否则mysql数据库将成为最终的瓶颈,如下所示
我们将输入mysql的数据更改为要写入kafka,然后可以实时分析kafka的数据,也可以将kafka的数据输入hive进行离线分析。
待续
事实:智能提取数据,跳过人工收集的大坑
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2020-09-01 13:27
当老板要求您分析本月业绩下降的原因时,您感到无法开始吗?临时采集市场,竞争产品和客户群上的数据将为您消耗大量时间,因此自然很难有效地实现目标.
当即将完成毕业论文时,由于缺乏完善的数据,您是否认为努力工作的文章并没有说服力,您必须逐一搜索文献以进行选择数据.
在大数据时代,我们生活中有许多这样的场景将使我们担心数据. 实际上,还有其他一些巧妙的技巧可以提取大量数据. 自动提取工具优采云 采集器可以帮助我们跳过手动采集的大数据. 坑.
以业务运营为例. 我们的日常数据采集主要来自网页. 例如,在业务运营中,我们经常需要获取一些市场统计数据(供求,份额比等),有关竞争产品的详细数据(价格,销售,评估等)等,我们都可以提取这些数据来自电子商务网站. 手动采集少量数据,优采云 采集器采集大量数据.
如图所示,通过URL 采集规则内容采集规则编写,您可以在JD移动页面上下载所有产品信息采集,包括品牌,型号和商店. 页面,上市时间,颜色,评估,价格,配置参数...只要可以通过规则提取我们可以看到的数据,优采云 采集器的规则就是基于源代码提取的,只是一个简单的学习开始.
采集的结果如上图所示. 实际上,它不仅可以采集,优采云 采集器,而且可以个性化数据以使数据更符合我们的应用程序标准,还可以将其导出给我们所需的格式或导入它进入我们的数据库.
在许多情况下,数据提取不是一次性的工作,因为诸如“价格”之类的许多数据会根据营销策略动态变化,并且需要实时更新和监视. 因此,我们需要一种工具来进行乏味而乏味的数据更新工作. 优采云 采集器的更新响应策略是设置提取频率,以使该频率范围内每次提取的数据都是最新的,从而满足了我们对数据准确性的要求. 同时,由于智能工具的效率是体力劳动的数千倍,因此它也大大减少了人工和时间支出. 每天的数据量采集接近数十至数百万个项目,无论是文本还是图片,音频文件等,都支持高效提取.
在海量数据的支持下,我们必须能够进行后续分析或其他工作. 跳出人工采集坑,数据不再是一堆结构复杂且难以查找规则的文件. 优采云 采集器的智能提取使人类大数据时代更加扎实. 查看全部
智能提取数据,跳过手工采集的麻烦
当老板要求您分析本月业绩下降的原因时,您感到无法开始吗?临时采集市场,竞争产品和客户群上的数据将为您消耗大量时间,因此自然很难有效地实现目标.
当即将完成毕业论文时,由于缺乏完善的数据,您是否认为努力工作的文章并没有说服力,您必须逐一搜索文献以进行选择数据.
在大数据时代,我们生活中有许多这样的场景将使我们担心数据. 实际上,还有其他一些巧妙的技巧可以提取大量数据. 自动提取工具优采云 采集器可以帮助我们跳过手动采集的大数据. 坑.
以业务运营为例. 我们的日常数据采集主要来自网页. 例如,在业务运营中,我们经常需要获取一些市场统计数据(供求,份额比等),有关竞争产品的详细数据(价格,销售,评估等)等,我们都可以提取这些数据来自电子商务网站. 手动采集少量数据,优采云 采集器采集大量数据.
如图所示,通过URL 采集规则内容采集规则编写,您可以在JD移动页面上下载所有产品信息采集,包括品牌,型号和商店. 页面,上市时间,颜色,评估,价格,配置参数...只要可以通过规则提取我们可以看到的数据,优采云 采集器的规则就是基于源代码提取的,只是一个简单的学习开始.
采集的结果如上图所示. 实际上,它不仅可以采集,优采云 采集器,而且可以个性化数据以使数据更符合我们的应用程序标准,还可以将其导出给我们所需的格式或导入它进入我们的数据库.
在许多情况下,数据提取不是一次性的工作,因为诸如“价格”之类的许多数据会根据营销策略动态变化,并且需要实时更新和监视. 因此,我们需要一种工具来进行乏味而乏味的数据更新工作. 优采云 采集器的更新响应策略是设置提取频率,以使该频率范围内每次提取的数据都是最新的,从而满足了我们对数据准确性的要求. 同时,由于智能工具的效率是体力劳动的数千倍,因此它也大大减少了人工和时间支出. 每天的数据量采集接近数十至数百万个项目,无论是文本还是图片,音频文件等,都支持高效提取.
在海量数据的支持下,我们必须能够进行后续分析或其他工作. 跳出人工采集坑,数据不再是一堆结构复杂且难以查找规则的文件. 优采云 采集器的智能提取使人类大数据时代更加扎实.
优客ai人工智能智能营销系统能采集到哪些?真实不?
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-08-27 17:57
优客ai人工智能人工智能-智能营销系统是骗钱的吗?确认无误!希望消费者知悉!
优客ai人工智能智能营销系统是一款款软件放到一个类似于文件夹一样的袋子里,模仿正版的大数据智能营销系统的阿里云系统
但是模仿不到精華,它智能把软件放进去却没办法植入在线视频教程、售后***、一键更新升级。
大肆夸大宣传!吸引混淆消费者!
其实大数据智能营銷系统没有你想的这么神奇!什么可以采集到浏览痕迹、可以采集到中学生父母信息还说哪些网路爬虫技术。再厉害的爬虫技术都没有办法做到采集出来这样的信息。这些是涉及个人隐私了国家对于个人隐私的保护还是十分严格的!不容许售卖、搜集个人隐私信息。
他們是拿哪些吹的那么厉害的呢就是这一个功能:搜索引擎采集
这个功能究竟是一个什么样的功能呢?
搜索引擎采集:采集的是被百度收錄的信息不是他人浏览过某个东西留下来的信息。这种情况也不存在哪有这么神奇啊!这个搜哪些都可以找到,他们就是借助这个噱頭吸引消费者的又不给消费者试用,只是听到数据又不知道真伪。也不可能使你晓得!
所以你们在选择的时侯一定要擦亮眼睛不要被噱头吸引了,根本不现实的!
大家在选择大数据智能营销系统的时侯认准这几点:
1.看是不是一整套的系统,一机一码登陆进来的
2.看軟件有更新、升级、维护的时侯,是不是一键在系统内进行的
3.看软件的功能有没有每一个功能的视频介绍。
4.看系统内植入的有没有在线愙服、以及官方400售后服务***
区分正版,用的更放心! 查看全部
优客ai人工智能智能营销系统能采集到哪些?真实不?
优客ai人工智能人工智能-智能营销系统是骗钱的吗?确认无误!希望消费者知悉!
优客ai人工智能智能营销系统是一款款软件放到一个类似于文件夹一样的袋子里,模仿正版的大数据智能营销系统的阿里云系统
但是模仿不到精華,它智能把软件放进去却没办法植入在线视频教程、售后***、一键更新升级。
大肆夸大宣传!吸引混淆消费者!
其实大数据智能营銷系统没有你想的这么神奇!什么可以采集到浏览痕迹、可以采集到中学生父母信息还说哪些网路爬虫技术。再厉害的爬虫技术都没有办法做到采集出来这样的信息。这些是涉及个人隐私了国家对于个人隐私的保护还是十分严格的!不容许售卖、搜集个人隐私信息。
他們是拿哪些吹的那么厉害的呢就是这一个功能:搜索引擎采集
这个功能究竟是一个什么样的功能呢?
搜索引擎采集:采集的是被百度收錄的信息不是他人浏览过某个东西留下来的信息。这种情况也不存在哪有这么神奇啊!这个搜哪些都可以找到,他们就是借助这个噱頭吸引消费者的又不给消费者试用,只是听到数据又不知道真伪。也不可能使你晓得!
所以你们在选择的时侯一定要擦亮眼睛不要被噱头吸引了,根本不现实的!
大家在选择大数据智能营销系统的时侯认准这几点:
1.看是不是一整套的系统,一机一码登陆进来的
2.看軟件有更新、升级、维护的时侯,是不是一键在系统内进行的
3.看软件的功能有没有每一个功能的视频介绍。
4.看系统内植入的有没有在线愙服、以及官方400售后服务***
区分正版,用的更放心!
[雪峰n极石博客]2018最佳人工智能数据采集(爬虫)工具书下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-08-27 02:45
Python网路数据采集
Python网路数据采集 - 2016.pdf
本书采用简约强悍的Python语言,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第 1部份重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第 二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
Web Scraping with Python 2nd - 2018.pdf
2000左右星
精通Python爬虫框架Scrapy - 2018.pdf
Scrapy是使用Python开发的一个快速、高层次的屏幕抓取和Web抓取框架,用于抓Web站点并从页面中提取结构化的数据。《精通Python爬虫框架Scrapy》以Scrapy 1.0版本为基础,讲解了Scrapy的基础知识,以及怎样使用Python和三方API提取、整理数据,以满足自己的需求。
本书共11章,其内容涵括了Scrapy基础知识,理解HTML和XPath,安装Scrapy并爬取一个网站,使用爬虫填充数据库并输出到联通应用中,爬虫的强悍功能,将爬虫布署到Scrapinghub云服务器,Scrapy的配置与管理,Scrapy编程,管道绝招,理解Scrapy性能,使用Scrapyd与实时剖析进行分布式爬取。本书附表还提供了各类软件的安装与故障排除等内容。
本书适宜软件开发人员、数据科学家,以及对自然语言处理和机器学习感兴趣的人阅读。
Learning Scrapy -2016.pdf
精通Scrapy网络爬虫
本书深入系统地介绍了Python流行框架Scrapy的相关技术及使用方法。全书共14章,从逻辑上可分为基础篇和中级篇两部份,基础篇重点介绍Scrapy的核心元素,如spider、selector、item、link等;高级篇讲解爬虫的中级话题,如登陆认证、文件下载、执行JavaScript、动态网页爬取、使用HTTP代理、分布式爬虫的编撰等,并配合项目案例讲解,包括供练习使用的网站,以及知乎、豆瓣、360爬虫案例等。 本书案例丰富,注重实践,代码注释简略,适合有一定Python语言基础,想学习编撰复杂网路爬虫的读者使用。
python3爬虫基础
在线教程
200 左右星
First web scraper
教程:
200 左右星
Practical Web Scraping for Data Science -Best Practices and Examples with Python - 2018.pdf
星级 低于100
This book provides a complete and modern guide to web scraping, using Python as the programming language, without glossing over important details or best practices. Written with a data science audience in mind, the book explores both scraping and the larger context of web technologies in which it operates, to ensure full understanding. The authors recommend web scraping as a powerful tool for any data scientist’s arsenal, as many data science projects start by obtaining an appropriate data set.
Starting with a brief overview on scraping and real-life use cases, the authors explore the core concepts of HTTP, HTML, and CSS to provide a solid foundation. Along with a quick Python primer, they cover Selenium for JavaScript-heavy sites, and web crawling in detail. The book finishes with a recap of best practices and a 采集 of examples that bring together everything you've learned and illustrate various data science use cases.
用Python写网路爬虫 第2版
《用Python写网路爬虫(第 2版》讲解了怎样使用Python来编撰网路爬虫程序,内容包括网路爬虫简介,从页面中抓取数据的3种方式,提取缓存中的数据,使用多个线程和进程进行并发抓取,抓取动态页面中的内容,与表单进行交互,处理页面中的验证码问题,以及使用Scarpy和Portia进行数据抓取,并在最后介绍了使用本书讲解的数据抓取技术对几个真实的网站进行抓取的实例,旨在帮助读者活学活用书中介绍的技术。
《用Python写网路爬虫(第 2版》适合有一定Python编程经验并且对爬虫技术感兴趣的读者阅读。
Python Web Scraping 2nd Edition - 2017.pdf
第一版英文 用Python写网路爬虫.pdf
Python Web Scraping Cookbook - 2018.pdf
下载
Python Web Scraping Cookbook is a solution-focused book that will teach you techniques to develop high-performance Scrapers, and deal with cookies, hidden form fields, Ajax-based sites and proxies. You'll explore a number of real-world scenarios where every part of the development or product life cycle will be fully covered. You will not only develop the skills to design reliable, high-performing data flows, but also deploy your codebase to Amazon Web Services (AWS). If you are involved in software engineering, product development, or data mining or in building data-driven products, you will find this book useful as each recipe has a clear purpose and objective.
Right from extracting data from websites to writing a sophisticated web crawler, the book's independent recipes will be extremely helpful while on the job. This book covers Python libraries, requests, and BeautifulSoup. You will learn about crawling, web spidering, working with AJAX websites, and paginated items. You will also understand to tackle problems such as 403 errors, working with proxy, scraping images, and LXML.
By the end of this book, you will be able to scrape websites more efficiently and deploy and operate your scraper in the cloud.
Website Scraping with Python - 2018.pdf
仔细检测网站抓取和数据处理:以适宜进一步剖析的格式从网站提取数据的技术。您将查看要使用的工具,并比较它们的功能和效率。本书简明扼要专注于BeautifulSoup4和Scrapy,突出了常见问题,并提出了读者可以自行施行的解决方案。
您将见到怎么单独或一起使用BeautifulSoup4和Scrapy以获得所需的结果。由于许多站点都使用JavaScript,因此您还将使用Selenium和浏览器模拟器来呈现这种站点。
在本书的最后,您将拥有一个完整的抓取应用程序来使用和重画以满足您的需求。
Social Media Data Mining and Analytics - 2018.pdf
Harness the power of social media to predict customer behaviorand improve sales
Social media is the biggest source of Big Data. Because of this,90% of Fortune 500 companies are investing in Big Data initiativesthat will help them predict consumer behavior to produce bettersales results. Written by Dr. Gabor Szabo, a Senior Data Scientistat Twitter, and Dr. Oscar Boykin, a Software Engineer at Twitter,Social Media Data Mining and Analytics shows analysts how touse sophisticated techniques to mine social media data, obtainingthe information they need to generate amazing results for theirbusinesses.
Social Media Data Mining and Analytics isn’t just anotherbook on the business case for social media. Rather, this bookprovides hands-on examples for applying state-of-the-art tools andtechnologies to mine social media – examples include Twitter,Facebook, Pinterest, Wikipedia, Reddit, Flickr, Web hyperlinks, andother rich data sources. In it, you will learn:
The four key characteristics of online services-users, socialnetworks, actions, and content
The full data discovery lifecycle-data extraction, storage,analysis, and visualization
How to work with code and extract data to create solutions
How to use Big Data to make accurate customer predictions
Szabo and Boykin wrote this book to provide businesses with thecompetitive advantage they need to harness the rich data that isavailable from social media platforms.
参考资料 查看全部
[雪峰n极石博客]2018最佳人工智能数据采集(爬虫)工具书下载
Python网路数据采集
Python网路数据采集 - 2016.pdf
本书采用简约强悍的Python语言,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第 1部份重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第 二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
Web Scraping with Python 2nd - 2018.pdf
2000左右星
精通Python爬虫框架Scrapy - 2018.pdf
Scrapy是使用Python开发的一个快速、高层次的屏幕抓取和Web抓取框架,用于抓Web站点并从页面中提取结构化的数据。《精通Python爬虫框架Scrapy》以Scrapy 1.0版本为基础,讲解了Scrapy的基础知识,以及怎样使用Python和三方API提取、整理数据,以满足自己的需求。
本书共11章,其内容涵括了Scrapy基础知识,理解HTML和XPath,安装Scrapy并爬取一个网站,使用爬虫填充数据库并输出到联通应用中,爬虫的强悍功能,将爬虫布署到Scrapinghub云服务器,Scrapy的配置与管理,Scrapy编程,管道绝招,理解Scrapy性能,使用Scrapyd与实时剖析进行分布式爬取。本书附表还提供了各类软件的安装与故障排除等内容。
本书适宜软件开发人员、数据科学家,以及对自然语言处理和机器学习感兴趣的人阅读。
Learning Scrapy -2016.pdf
精通Scrapy网络爬虫
本书深入系统地介绍了Python流行框架Scrapy的相关技术及使用方法。全书共14章,从逻辑上可分为基础篇和中级篇两部份,基础篇重点介绍Scrapy的核心元素,如spider、selector、item、link等;高级篇讲解爬虫的中级话题,如登陆认证、文件下载、执行JavaScript、动态网页爬取、使用HTTP代理、分布式爬虫的编撰等,并配合项目案例讲解,包括供练习使用的网站,以及知乎、豆瓣、360爬虫案例等。 本书案例丰富,注重实践,代码注释简略,适合有一定Python语言基础,想学习编撰复杂网路爬虫的读者使用。
python3爬虫基础
在线教程
200 左右星
First web scraper
教程:
200 左右星
Practical Web Scraping for Data Science -Best Practices and Examples with Python - 2018.pdf
星级 低于100
This book provides a complete and modern guide to web scraping, using Python as the programming language, without glossing over important details or best practices. Written with a data science audience in mind, the book explores both scraping and the larger context of web technologies in which it operates, to ensure full understanding. The authors recommend web scraping as a powerful tool for any data scientist’s arsenal, as many data science projects start by obtaining an appropriate data set.
Starting with a brief overview on scraping and real-life use cases, the authors explore the core concepts of HTTP, HTML, and CSS to provide a solid foundation. Along with a quick Python primer, they cover Selenium for JavaScript-heavy sites, and web crawling in detail. The book finishes with a recap of best practices and a 采集 of examples that bring together everything you've learned and illustrate various data science use cases.
用Python写网路爬虫 第2版
《用Python写网路爬虫(第 2版》讲解了怎样使用Python来编撰网路爬虫程序,内容包括网路爬虫简介,从页面中抓取数据的3种方式,提取缓存中的数据,使用多个线程和进程进行并发抓取,抓取动态页面中的内容,与表单进行交互,处理页面中的验证码问题,以及使用Scarpy和Portia进行数据抓取,并在最后介绍了使用本书讲解的数据抓取技术对几个真实的网站进行抓取的实例,旨在帮助读者活学活用书中介绍的技术。
《用Python写网路爬虫(第 2版》适合有一定Python编程经验并且对爬虫技术感兴趣的读者阅读。
Python Web Scraping 2nd Edition - 2017.pdf
第一版英文 用Python写网路爬虫.pdf
Python Web Scraping Cookbook - 2018.pdf
下载
Python Web Scraping Cookbook is a solution-focused book that will teach you techniques to develop high-performance Scrapers, and deal with cookies, hidden form fields, Ajax-based sites and proxies. You'll explore a number of real-world scenarios where every part of the development or product life cycle will be fully covered. You will not only develop the skills to design reliable, high-performing data flows, but also deploy your codebase to Amazon Web Services (AWS). If you are involved in software engineering, product development, or data mining or in building data-driven products, you will find this book useful as each recipe has a clear purpose and objective.
Right from extracting data from websites to writing a sophisticated web crawler, the book's independent recipes will be extremely helpful while on the job. This book covers Python libraries, requests, and BeautifulSoup. You will learn about crawling, web spidering, working with AJAX websites, and paginated items. You will also understand to tackle problems such as 403 errors, working with proxy, scraping images, and LXML.
By the end of this book, you will be able to scrape websites more efficiently and deploy and operate your scraper in the cloud.
Website Scraping with Python - 2018.pdf
仔细检测网站抓取和数据处理:以适宜进一步剖析的格式从网站提取数据的技术。您将查看要使用的工具,并比较它们的功能和效率。本书简明扼要专注于BeautifulSoup4和Scrapy,突出了常见问题,并提出了读者可以自行施行的解决方案。
您将见到怎么单独或一起使用BeautifulSoup4和Scrapy以获得所需的结果。由于许多站点都使用JavaScript,因此您还将使用Selenium和浏览器模拟器来呈现这种站点。
在本书的最后,您将拥有一个完整的抓取应用程序来使用和重画以满足您的需求。
Social Media Data Mining and Analytics - 2018.pdf
Harness the power of social media to predict customer behaviorand improve sales
Social media is the biggest source of Big Data. Because of this,90% of Fortune 500 companies are investing in Big Data initiativesthat will help them predict consumer behavior to produce bettersales results. Written by Dr. Gabor Szabo, a Senior Data Scientistat Twitter, and Dr. Oscar Boykin, a Software Engineer at Twitter,Social Media Data Mining and Analytics shows analysts how touse sophisticated techniques to mine social media data, obtainingthe information they need to generate amazing results for theirbusinesses.
Social Media Data Mining and Analytics isn’t just anotherbook on the business case for social media. Rather, this bookprovides hands-on examples for applying state-of-the-art tools andtechnologies to mine social media – examples include Twitter,Facebook, Pinterest, Wikipedia, Reddit, Flickr, Web hyperlinks, andother rich data sources. In it, you will learn:
The four key characteristics of online services-users, socialnetworks, actions, and content
The full data discovery lifecycle-data extraction, storage,analysis, and visualization
How to work with code and extract data to create solutions
How to use Big Data to make accurate customer predictions
Szabo and Boykin wrote this book to provide businesses with thecompetitive advantage they need to harness the rich data that isavailable from social media platforms.
参考资料
人工智能数据采集|人工智能|辰宜科技
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2020-08-18 20:00
软件名称
眯谜米密
品牌
其他
版本语言
简体中文版
软件类型
安全相关软件
【辰宜】·智能读写系统----基于机器学习的AI应用
特点:具有高度的智能性,自动适应多个场景;
采用了异构融合技术,人工智能商用化,不需要相关系统提供商提供插口支持;
具有高度的开放性,可独立使用,人工智能数据采集,也能通过API与其他系统协同工作。
功能:智能学习---可以分开学习不同的网页填写,也可以集中一次性学习多个网页系统。
智能推理---依据无损推理原理,人工智能深度应用,自行推定互相关系。
智能读写---自动辨识网页内容与数目,自动辨识场景,自动按学习到关系进行相关内容的读写。
作用:能够达到表格、数据库、窗口应用、网页应用的自动化读写;
将用户的业务经验与系统无缝融合;
使用户成为系统的开发者、使用者与受益者;
大幅度增加培训、维护与升级成本。
随着大数据时代的发展,人工智能,“数据融合、信息库房”成为发展的趋势,但因为系统建设的弱项或则制度本身的不灵活,使得不同系统之间产生了信息孤岛,例如在政务大数据建设上,为了采集数据,地方在原有业务系统的基础上新增了录入信息至县级系统、省级系统的业务负担,相同的信息要在不同系统之间多次重复录入,工作冗长之余还容易出错。
【辰宜】·易复写产品是AI人工智能的一种实际应用,可以从本质上解决系统之间多次录入信息的问题,搭建系统融通的桥梁,为企业单位、事业单位的日常信息管理提供了强悍的工具。
人工智能数据采集|人工智能|辰宜科技由广东辰宜信息科技有限公司提供。行路致远,砥砺前行。广东辰宜信息科技有限公司()致力成为与您共赢、共生、共同前行的战略伙伴,更矢志成为软件开发较具影响力的企业,与您一起飞越,共同成功!
微信扫码直接拨通电话
广东辰宜信息科技有限公司
智慧城市,中间件,区块链数据加密,工业数据采集,AI人工智能
(易先生先生)
手机号
网库客服正在通过010-XXXXXXX联系您,该通话免费,请注意接听! 查看全部
人工智能数据采集|人工智能|辰宜科技
软件名称
眯谜米密
品牌
其他
版本语言
简体中文版
软件类型
安全相关软件
【辰宜】·智能读写系统----基于机器学习的AI应用
特点:具有高度的智能性,自动适应多个场景;
采用了异构融合技术,人工智能商用化,不需要相关系统提供商提供插口支持;
具有高度的开放性,可独立使用,人工智能数据采集,也能通过API与其他系统协同工作。
功能:智能学习---可以分开学习不同的网页填写,也可以集中一次性学习多个网页系统。
智能推理---依据无损推理原理,人工智能深度应用,自行推定互相关系。
智能读写---自动辨识网页内容与数目,自动辨识场景,自动按学习到关系进行相关内容的读写。
作用:能够达到表格、数据库、窗口应用、网页应用的自动化读写;
将用户的业务经验与系统无缝融合;
使用户成为系统的开发者、使用者与受益者;
大幅度增加培训、维护与升级成本。
随着大数据时代的发展,人工智能,“数据融合、信息库房”成为发展的趋势,但因为系统建设的弱项或则制度本身的不灵活,使得不同系统之间产生了信息孤岛,例如在政务大数据建设上,为了采集数据,地方在原有业务系统的基础上新增了录入信息至县级系统、省级系统的业务负担,相同的信息要在不同系统之间多次重复录入,工作冗长之余还容易出错。
【辰宜】·易复写产品是AI人工智能的一种实际应用,可以从本质上解决系统之间多次录入信息的问题,搭建系统融通的桥梁,为企业单位、事业单位的日常信息管理提供了强悍的工具。
人工智能数据采集|人工智能|辰宜科技由广东辰宜信息科技有限公司提供。行路致远,砥砺前行。广东辰宜信息科技有限公司()致力成为与您共赢、共生、共同前行的战略伙伴,更矢志成为软件开发较具影响力的企业,与您一起飞越,共同成功!
微信扫码直接拨通电话
广东辰宜信息科技有限公司
智慧城市,中间件,区块链数据加密,工业数据采集,AI人工智能
(易先生先生)
手机号
网库客服正在通过010-XXXXXXX联系您,该通话免费,请注意接听!
北京专业做数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-18 00:05
北京专业做数据采集
注意:是正常合照,而且应当象文件内容一样。图像图象有复杂的外观问题。特殊情况也应当同样看见文件中的内容。请依照自己的实际情况来判别。相机手动变焦虽然单反里有专用的单反软件,软件是可以提供根据影像的次序从内向内变焦的,再借助专业照相机的快门速率和***快镜头速率可以手动变焦。因此,如果想用手动变焦这些自动对焦工具,很适宜有手动变焦的形式。
特殊的品牌多是明晰标注:“强化矿物纤维与矿物棉”,“国内***贵的矿物纤维与矿物棉”。内容在售:soc环保品牌信息无添加代码了解没有必要百度百科不是。企业都有客服电话,所以只要在鞋厂递交你的电话,就可以看见是不是你所说的“内容为购物网站提供的条形码输入法所在位置”。随便问问都可以解决。另外,也没必要百度哪些内部软件供你选择。全手动保证金方案。
教育有哪些须要我们去探求?
北京专业做数据采集
数据剖析的房门有什么?数据剖析是生存的基础,不是思想的食粮,这个通常比较专业的人士常常都不具备这样的专业知识。不是通过对数据做一个***的剖析做一个简单的剖析,有两点必须要注意:什么是数据剖析?数据剖析是一个特别***的剖析工具,是一个较为常用的学习工具。
一
标
北京专业做数据采集 查看全部
北京专业做数据采集
北京专业做数据采集
注意:是正常合照,而且应当象文件内容一样。图像图象有复杂的外观问题。特殊情况也应当同样看见文件中的内容。请依照自己的实际情况来判别。相机手动变焦虽然单反里有专用的单反软件,软件是可以提供根据影像的次序从内向内变焦的,再借助专业照相机的快门速率和***快镜头速率可以手动变焦。因此,如果想用手动变焦这些自动对焦工具,很适宜有手动变焦的形式。
特殊的品牌多是明晰标注:“强化矿物纤维与矿物棉”,“国内***贵的矿物纤维与矿物棉”。内容在售:soc环保品牌信息无添加代码了解没有必要百度百科不是。企业都有客服电话,所以只要在鞋厂递交你的电话,就可以看见是不是你所说的“内容为购物网站提供的条形码输入法所在位置”。随便问问都可以解决。另外,也没必要百度哪些内部软件供你选择。全手动保证金方案。
教育有哪些须要我们去探求?
北京专业做数据采集
数据剖析的房门有什么?数据剖析是生存的基础,不是思想的食粮,这个通常比较专业的人士常常都不具备这样的专业知识。不是通过对数据做一个***的剖析做一个简单的剖析,有两点必须要注意:什么是数据剖析?数据剖析是一个特别***的剖析工具,是一个较为常用的学习工具。
一
标
北京专业做数据采集
军犬网络信息采集系统[系统介绍]
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-07 20:39
信息采集是指使用计算机软件技术基于自定义目标数据源进行实时信息采集,提取,挖掘和处理的全过程.
军犬信息采集专家是一种基于人工智能的自动学习技术,它是一种功能强大,简单实用的Internet信息采集和监视软件.
二,互联网信息的采集与挖掘:
需要从Internet采集和监视特定目标数据源或非特定目标数据源,并以本地结构化数据库的形式对信息进行结构化提取和存储,然后根据业务流程要求将其与其他模块组合在一起,导入和应用服务于电子行业平台.
Internet数据采集和挖掘技术是指使用计算机软件技术对定制的目标数据源进行实时信息采集,提取,挖掘和处理,从而为各种信息服务系统提供数据输入,以及根据业务需要,进行数据发布和分析的全过程.
三个. 互联网采集系统流程图:
第一步: 确定采集任务.
步骤2: 对于每个采集任务,我们都有多个目标数据源可供采集.
第3步: 对不同的目标数据源执行不同的采集配置,以确保可以采集数据.
第4步: 安排采集任务,与目标站点同步更新和增量采集.
第5步: 采集数据结果并完成数据异构化为同构的过程.
第6步: 通过发布服务器将数据发布到应用程序平台.
四个. 军犬“信息采集系统”的八个应用领域:
1,搜索引擎和垂直搜索2,集成门户和行业门户
3. 电子政务与电子商务4.知识管理与知识共享
5. 企业竞争情报系统6. BI商业情报系统
7. 信息咨询与信息增值8.信息安全与信息监控
5. 军犬“信息采集系统”-软件功能
(1),干净过滤,智能提取文本以及链接图像和文本
(2). 丰富的数据导出接口,可以将数据导出到各种主流的关系数据结构中.
(3)军犬“信息采集系统”的配置很简单
对于新闻信息的采集,您只需要输入要采集的目标网站的地址或主题页面的地址,软件就会自动了解网站的样式并自动提取网站的信息. 无需配置模板,目标网站的样式将改变. 该软件会自动学习. 对于数据采集软件,提供了一个易于理解的站点配置向导,并且维护人员可以在不经过培训的情况下配置任何信息采集. 对于复杂的采集过程,可以通过采集卡脚本来实现信息的自动采集和监视.
(4)军犬“信息采集系统”所采集的是您所获得的,您所获得的是您所看到的
(5)增量采集和自动更新军犬“信息采集系统”
增加馆藏: 对于目标网站的第一个馆藏,该软件支持完整馆藏;对于已经采集的网站,它支持增量采集. 支持自动更新: 自动检测网站是否已更新,不会遗漏任何重要信息.
(6)从军犬“信息采集系统”的采集结果中自动去除体重
不是使用简单的规则来判断,而是使用内容的相似性来判断权重,准确性很高,并且不会因标题或内容的微小变化而错过任何判断. 即使标题更改,系统也会正确确定.
(7),军犬“信息采集系统”内置强大的信息监控功能
您可以通过关键字监视Internet上任何站点上的相关信息. 也可以通过设置监视渠道来监视任何站点采集的收录关键字的信息. 对于数字字段,您可以设置以下信息: 监视器错误监视器值出现在特定范围内. 信息监控达到现场水平. 您可以为任何采集目标网站设置监视属性,监视周期达到第二级. 更改后的信息可以在短时间内本地采集
强大的站点管理工具可以对所有采集的对象进行集中管理和各种操作
(8),军犬的“信息采集系统”支持多种编码方式
支持各种网站信息的编码,GBK,BIG5,UNICODE,UTF8,软件将自动转换为GBK码进行统一处理. 该软件将自动识别网站的组织结构和网站代码. 表单管理,可以根据需要自定义表单,以方便采集不同的内容,例如用于采集软件的单独表单和用于采集图片的图片表单.
(9),军犬的“信息采集系统”信息自由进出口
提供信息导入和导出,以与其他软件无缝连接. 例如,CRM OA软件提供了强大的信息记录导入和导出功能. 您可以导入和导出任何频道或记录. 它可以导出到Excel / Access等,或直接导出到指定的数据库. 它可以与“ Information Publishing Server”结合使用,以将信息发布到任何地方.
(10),军犬的“信息采集系统”支持阅读模板
对于任何信息类型,软件都会自动创建一个阅读模板供您快速阅读;对于任何信息,您都可以为任何信息表格自定义漂亮的阅读模板,也可以为任何频道模板设置不同的读数.
(11)军犬“信息采集系统”的多页内容重组
对于目标数据源的文章,该文章显示在目标网站上的页面中,系统可以自动对其进行重组. 该软件运行稳定,采集速度快,系统资源少.
经过多次转换的低级软件获取模块运行稳定,获取速度快,系统资源少. 它可以与多个线程并发运行,而不会占用过多的系统资源. 采集速度如此之快,以至于瞬间即可实现. 该软件可以完全实现7 * 24小时不间断的无人值守信息采集. 更多详细功能正在等待您使用.
(12). 军犬“信息采集系统”的其他功能清单:
1. 支持所有主流数据库: MS SQL Server,Oracle,DB2,MySQL,Sybase,Interbase,MS Access等.
2. 支持HTML,RSS集群网站集
3. 支持少数民族语言和多语言(简体中文,藏文,彝文,维吾尔文,繁体中文,英语,日语,韩语和其他语言)的采集
4. 支持采集来自百度贴吧的回复
5. 支持免费定制采集的数据表单和字段
6. 采集数据的无限树形分类管理
7. 自动匹配各种网站编码方法,例如: gb2312,utf8,gbk,big5,iso88591等.
8. 支持采集登录验证信息.
9. 列表页面上的支持信息数据采集.
10. 您可以为采集的目标网站自定义更新采集周期.
11. 完全可以避免阻塞收款网站帐户和IP的软件.
12. 系统内置110个搜索引擎
13. 支持网站备份和配置规则的恢复.
14. 支持文本页面集合的多页面重组功能.
15. 支持html标签保留和表保留
16支持附件信息采集(例如: 图片,音频,视频,期刊,doc,txt等)
17. 支持替换字符以采集数据.
18. 支持站点信息检索
19. 执行数据批处理管理(删除,添加,辅助编辑等)
20. 自动识别原创网站信息修订提示功能.
21. 允许自动定期检测并采集站点的更新
22. 支持添加代理IP
23. 全结构提取
24. 自动重置采集结果
25数据保存在本地,因此您可以随时检查信息.
26. 支持阅读模板
27. 多行层,多任务处理
28. 支持海量数据采集
29. 软件运行稳定,采集速度快,系统资源少
30. 您可以保留网页快照.
31. 支持采集海外数据
32. 支持数据导入和数据导出.
33. 一键备份所有数据和数据库.
34. 采集的数据可以用关键字重新筛选.
35. 全结构化提取将网页中的非结构化数据提取为特定的结构化信息数据.
Web搜索将网页作为最小单元,基于可视的网页块分析将网页块作为最小单元,垂直搜索将结构化数据作为最小单元. 然后将数据存储在数据库中以进行进一步的处理,例如: 重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求.
在整个过程中,数据是从非结构化数据中提取到结构化数据中,经过深度处理后,以非结构化和结构化的方式返回给用户的.
六. 军犬“信息采集系统”的配置要求
要求: WindowsNT4 / Windows 2003 Server或更高版本的操作系统.
要求: Microsoft SQL Server 7/2000或其他ODBC接口
要求: Intel xeon 2G或更高CPU,2G或更高RAM,200GB以上的硬盘空间
七. 军犬“信息采集系统”的性能
l,支持多线程集合.
2. 一台机器的数据采集高于G级.
3. 数据和数据源的同步更新少于10秒.
4. 数据同步释放不到10秒. 查看全部
1. “信息采集系统”系统概述:
信息采集是指使用计算机软件技术基于自定义目标数据源进行实时信息采集,提取,挖掘和处理的全过程.
军犬信息采集专家是一种基于人工智能的自动学习技术,它是一种功能强大,简单实用的Internet信息采集和监视软件.
二,互联网信息的采集与挖掘:
需要从Internet采集和监视特定目标数据源或非特定目标数据源,并以本地结构化数据库的形式对信息进行结构化提取和存储,然后根据业务流程要求将其与其他模块组合在一起,导入和应用服务于电子行业平台.
Internet数据采集和挖掘技术是指使用计算机软件技术对定制的目标数据源进行实时信息采集,提取,挖掘和处理,从而为各种信息服务系统提供数据输入,以及根据业务需要,进行数据发布和分析的全过程.
三个. 互联网采集系统流程图:
第一步: 确定采集任务.
步骤2: 对于每个采集任务,我们都有多个目标数据源可供采集.
第3步: 对不同的目标数据源执行不同的采集配置,以确保可以采集数据.
第4步: 安排采集任务,与目标站点同步更新和增量采集.
第5步: 采集数据结果并完成数据异构化为同构的过程.
第6步: 通过发布服务器将数据发布到应用程序平台.
四个. 军犬“信息采集系统”的八个应用领域:
1,搜索引擎和垂直搜索2,集成门户和行业门户
3. 电子政务与电子商务4.知识管理与知识共享
5. 企业竞争情报系统6. BI商业情报系统
7. 信息咨询与信息增值8.信息安全与信息监控
5. 军犬“信息采集系统”-软件功能
(1),干净过滤,智能提取文本以及链接图像和文本
(2). 丰富的数据导出接口,可以将数据导出到各种主流的关系数据结构中.
(3)军犬“信息采集系统”的配置很简单
对于新闻信息的采集,您只需要输入要采集的目标网站的地址或主题页面的地址,软件就会自动了解网站的样式并自动提取网站的信息. 无需配置模板,目标网站的样式将改变. 该软件会自动学习. 对于数据采集软件,提供了一个易于理解的站点配置向导,并且维护人员可以在不经过培训的情况下配置任何信息采集. 对于复杂的采集过程,可以通过采集卡脚本来实现信息的自动采集和监视.
(4)军犬“信息采集系统”所采集的是您所获得的,您所获得的是您所看到的
(5)增量采集和自动更新军犬“信息采集系统”
增加馆藏: 对于目标网站的第一个馆藏,该软件支持完整馆藏;对于已经采集的网站,它支持增量采集. 支持自动更新: 自动检测网站是否已更新,不会遗漏任何重要信息.
(6)从军犬“信息采集系统”的采集结果中自动去除体重
不是使用简单的规则来判断,而是使用内容的相似性来判断权重,准确性很高,并且不会因标题或内容的微小变化而错过任何判断. 即使标题更改,系统也会正确确定.
(7),军犬“信息采集系统”内置强大的信息监控功能
您可以通过关键字监视Internet上任何站点上的相关信息. 也可以通过设置监视渠道来监视任何站点采集的收录关键字的信息. 对于数字字段,您可以设置以下信息: 监视器错误监视器值出现在特定范围内. 信息监控达到现场水平. 您可以为任何采集目标网站设置监视属性,监视周期达到第二级. 更改后的信息可以在短时间内本地采集
强大的站点管理工具可以对所有采集的对象进行集中管理和各种操作
(8),军犬的“信息采集系统”支持多种编码方式
支持各种网站信息的编码,GBK,BIG5,UNICODE,UTF8,软件将自动转换为GBK码进行统一处理. 该软件将自动识别网站的组织结构和网站代码. 表单管理,可以根据需要自定义表单,以方便采集不同的内容,例如用于采集软件的单独表单和用于采集图片的图片表单.
(9),军犬的“信息采集系统”信息自由进出口
提供信息导入和导出,以与其他软件无缝连接. 例如,CRM OA软件提供了强大的信息记录导入和导出功能. 您可以导入和导出任何频道或记录. 它可以导出到Excel / Access等,或直接导出到指定的数据库. 它可以与“ Information Publishing Server”结合使用,以将信息发布到任何地方.
(10),军犬的“信息采集系统”支持阅读模板
对于任何信息类型,软件都会自动创建一个阅读模板供您快速阅读;对于任何信息,您都可以为任何信息表格自定义漂亮的阅读模板,也可以为任何频道模板设置不同的读数.
(11)军犬“信息采集系统”的多页内容重组
对于目标数据源的文章,该文章显示在目标网站上的页面中,系统可以自动对其进行重组. 该软件运行稳定,采集速度快,系统资源少.
经过多次转换的低级软件获取模块运行稳定,获取速度快,系统资源少. 它可以与多个线程并发运行,而不会占用过多的系统资源. 采集速度如此之快,以至于瞬间即可实现. 该软件可以完全实现7 * 24小时不间断的无人值守信息采集. 更多详细功能正在等待您使用.
(12). 军犬“信息采集系统”的其他功能清单:
1. 支持所有主流数据库: MS SQL Server,Oracle,DB2,MySQL,Sybase,Interbase,MS Access等.
2. 支持HTML,RSS集群网站集
3. 支持少数民族语言和多语言(简体中文,藏文,彝文,维吾尔文,繁体中文,英语,日语,韩语和其他语言)的采集
4. 支持采集来自百度贴吧的回复
5. 支持免费定制采集的数据表单和字段
6. 采集数据的无限树形分类管理
7. 自动匹配各种网站编码方法,例如: gb2312,utf8,gbk,big5,iso88591等.
8. 支持采集登录验证信息.
9. 列表页面上的支持信息数据采集.
10. 您可以为采集的目标网站自定义更新采集周期.
11. 完全可以避免阻塞收款网站帐户和IP的软件.
12. 系统内置110个搜索引擎
13. 支持网站备份和配置规则的恢复.
14. 支持文本页面集合的多页面重组功能.
15. 支持html标签保留和表保留
16支持附件信息采集(例如: 图片,音频,视频,期刊,doc,txt等)
17. 支持替换字符以采集数据.
18. 支持站点信息检索
19. 执行数据批处理管理(删除,添加,辅助编辑等)
20. 自动识别原创网站信息修订提示功能.
21. 允许自动定期检测并采集站点的更新
22. 支持添加代理IP
23. 全结构提取
24. 自动重置采集结果
25数据保存在本地,因此您可以随时检查信息.
26. 支持阅读模板
27. 多行层,多任务处理
28. 支持海量数据采集
29. 软件运行稳定,采集速度快,系统资源少
30. 您可以保留网页快照.
31. 支持采集海外数据
32. 支持数据导入和数据导出.
33. 一键备份所有数据和数据库.
34. 采集的数据可以用关键字重新筛选.
35. 全结构化提取将网页中的非结构化数据提取为特定的结构化信息数据.
Web搜索将网页作为最小单元,基于可视的网页块分析将网页块作为最小单元,垂直搜索将结构化数据作为最小单元. 然后将数据存储在数据库中以进行进一步的处理,例如: 重复数据删除,分类等,最后进行分词,索引和搜索以满足用户的需求.
在整个过程中,数据是从非结构化数据中提取到结构化数据中,经过深度处理后,以非结构化和结构化的方式返回给用户的.
六. 军犬“信息采集系统”的配置要求
要求: WindowsNT4 / Windows 2003 Server或更高版本的操作系统.
要求: Microsoft SQL Server 7/2000或其他ODBC接口
要求: Intel xeon 2G或更高CPU,2G或更高RAM,200GB以上的硬盘空间
七. 军犬“信息采集系统”的性能
l,支持多线程集合.
2. 一台机器的数据采集高于G级.
3. 数据和数据源的同步更新少于10秒.
4. 数据同步释放不到10秒.
数据采集注释: 人工智能行业的“至强”支持
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-08-07 14:46
作者/李晓松·编辑/珍妮
在过去的两年中,人工智能变得越来越流行.
飞机场,优采云车站,超市和街道等大型人脸识别设备;像我们的移动APP的各种算法一样小,以及Siri,Xiaodu和Xiaoai等语音助手都与人工智能有关.
尽管人工智能应用程序变得越来越流行,但我们仍然经常遇到不正确的APP推送,语音助手像“傻瓜”一样,面部识别系统经常出现的问题.
乌龙闹剧: 董明珠“闯红灯”. 实际上,公交车上贴着董明珠的头,碰巧是用相机拍摄的. 人工智能系统错误地认为是董明珠闯红灯.
我们想象的人工智能是可以在科幻电影中“思考我的想法”的人工智能. 但是,我们面临的人工智能是经常犯错误甚至难以实现的人工智能.
那么,我们如何解决这些问题?我们必须做些什么才能使人工智能更准确?
01
制约人工智能发展的因素
一些朋友总是认为,由于训练数据不正确,人工智能是不准确的. 实际上,这种观点是对的,但不是全部.
数据确实是限制人工智能发展的重要组成部分. 制约人工智能发展的因素不仅是数据,算法和计算能力也是极其重要的因素.
如果使用汽车的类比,则算法是汽车的设计概念,计算能力更像是汽车的引擎,数据是驱动自行车的燃料.
仅靠燃料,没有好的发动机和设计,汽车自然就不会快速运转. 同样,没有发动机,没有燃料,汽车也无法行驶.
三位一体的协调发展无疑是最好的. 但是,人工智能公司的现状是,许多公司已经拥有先进的算法和高质量的硬件,其产品的降落确实是一个燃料问题.
Testin总经理贾玉航在接受ToB行业标题(ID: wwwqifu)的采访时说:
“在人工智能时代到来之后,越来越多的产品,应用程序和硬件已成为实现人工智能的载体. 在人工智能的实施过程中,许多公司面临数据问题,并且在产品迭代和升级过程中遇到了更大的阻力. ”
关于人工智能公司面临的数据问题,贾宇航强调了两个:
那么,人工智能公司应如何应对这些问题?有什么方法可以帮助人工智能公司解决当前的数据问题?
02
如何采集和使用数据?
实际上,自人工智能出现之日起,数据采集和标签之类的问题就受到了许多制造商的关注.
早在2005年,亚马逊就建立了Mechanical Turk论坛,希望通过众包解决人工智能公司的数据处理需求.
但是,随着人工智能的逐步发展,人工智能的实施已成为行业发展的重要阶段,相应的数据服务也进入了情景和细化的时代.
贾宇航说,Testin目前专注于自动驾驶,银行,保险和安全领域,提供定制的数据采集和标签服务,并完全支持处理各种类型的数据,例如文本,语音,图像和视频.
“例如,自动驾驶制造商需要采集驾驶员的疲劳程度,但是很难将设备安装在路边的汽车上. 因为以这种方式采集的数据不仅是非标准的,而且涉及驾驶员和乘客的隐私.
但是,Testin可以根据客户需求在数据采集中心构建模拟方案,并通过使用专业人员和软硬件设备来采集大量的样本信息,以满足客户的各种需求. “
Testin有许多定制的采集场景示意图
Testin作为AI数据服务行业的领先品牌,拥有自建的数据库系统,所有标签管理统一,生产标准化,可以在确保数据有效的同时确保标签操作的信息流准确性.
Testin还开发了一个自行开发的标签平台,该平台支持标签类型的自定义开发,使标签类型更加全面,并确保标准化业务可以高效运行.
Testin数字标记平台的示意图
目前,许多国内数据标签公司仍是典型的劳动密集型企业. 为了节省人工成本,这些公司仍在使用临时工人,这些工人在经过半天的培训后即可被雇用,而他们的工作是数据标签行业中最简单的事情.
但是Testin很久以前就已经看到了传统模型的缺点. 通过建立馆藏基地,建立标签平台和进行为期60天的职前高质量培训,它已经摆脱了标签行业的低端同质竞争. 技能密集型公司的转型.
贾宇航始终坚信: “劳动密集型数据服务过于依赖劳动力,企业的上限更加明显. 这类企业对数据平台的建设没有足够的重视,培训时间不长. 员工短,数据注释的质量中等. ”
也许腰部公司会出于成本和其他原因而选择此类公司的服务,但总公司肯定会选择高质量的数据标签供应商. 因为只有高质量的数据才能产生高质量的人工智能,所以这是行业发展的基本规律. “
03
高质量和准确的数据
这是行业的未来
一个行业的成熟与该行业中成熟公司的发展离不开. 如果人工智能公司想要快速发展,那么他们一定不能没有数据采集和标签行业的整体进步.
许多年前,我们经常看到知名的人工智能公司将数据采集和标签服务外包给非洲公司. 一些媒体甚至在访问了非洲的数据标签工厂后叹了口气: “硅谷为赚钱而从事人工智能工作的穷人. ”
实际上,为了获得廉价劳动力,在非洲等不发达地区建立了数据标签工厂. 因此,数据服务也被外界视为人工智能金字塔上的最低级别的工作.
尽管金字塔的底部不如尖塔那么刺眼,但底部的体积最大,也是支撑金字塔的坚实基础.
在人工智能公司蓬勃发展的阶段,基础薄弱的公司仍然可以利用自己的实力来发展. 但是,随着公司的发展越来越快,公司建立的数字化尖塔越来越高. 基础是否牢固直接决定了公司发展的上限.
这也是Testin从一开始就非常重视标签人员培训,标签中心建立和数据采集平台开发的重要原因.
因为贾宇航始终认为高质量和准确的数据是行业的未来. “当通用数据公司仍在为实地的“六便士”而战时,Testin已经赶上了空中的“月球”. ”
目前,Testin在华东,华北和华南设有数个数据交付中心以及数据采集和标记基地,并已成功为数百家公司提供了AI数据服务.
相反,国内相关研究报告的结论也在不断完善,数据标签行业也在稳步增长.
根据艾瑞咨询的最新报告,2018年中国人工智能基础数据服务市场规模为25.86亿元,其中数据资源定制服务占86.2%,行业复合年增长率为23.5%. 预计到2025年,市场规模将超过110亿元.
这种蓬勃发展的势头不仅是由于人工智能公司的快速发展带来的巨大需求,而且也离不开Testin安静工作的数据服务提供商,后者继续为人工智能行业提供动力.
确实,当前的人工智能仍然“不准确”,但是我们可以看到几年前,Alpha Dog在Go领域完全爆炸了. 就在过去的几个月中,已经被20多年的发展而未为公众所理解的RPA突然变得很流行.
为什么Alpha Dog会击败人类?为什么RPA突然爆炸?这必将与人工智能算法的更新和发展密不可分. 但是,在技术成熟之后,提供数据采集和标记服务的诸如Testin之类的供应商也必不可少.
正是数据采集和注释的成熟度和准确性可以训练Alpha Dog的精确算法. 数据行业的不断积累使OCR,NLP和其他人工智能技术在今年变得成熟,从而推动了长期沉默的RPA. 查看全部
来源/ ToB行业头条新闻(ID: wwwqifu)
作者/李晓松·编辑/珍妮
在过去的两年中,人工智能变得越来越流行.
飞机场,优采云车站,超市和街道等大型人脸识别设备;像我们的移动APP的各种算法一样小,以及Siri,Xiaodu和Xiaoai等语音助手都与人工智能有关.
尽管人工智能应用程序变得越来越流行,但我们仍然经常遇到不正确的APP推送,语音助手像“傻瓜”一样,面部识别系统经常出现的问题.
乌龙闹剧: 董明珠“闯红灯”. 实际上,公交车上贴着董明珠的头,碰巧是用相机拍摄的. 人工智能系统错误地认为是董明珠闯红灯.
我们想象的人工智能是可以在科幻电影中“思考我的想法”的人工智能. 但是,我们面临的人工智能是经常犯错误甚至难以实现的人工智能.
那么,我们如何解决这些问题?我们必须做些什么才能使人工智能更准确?
01
制约人工智能发展的因素
一些朋友总是认为,由于训练数据不正确,人工智能是不准确的. 实际上,这种观点是对的,但不是全部.
数据确实是限制人工智能发展的重要组成部分. 制约人工智能发展的因素不仅是数据,算法和计算能力也是极其重要的因素.
如果使用汽车的类比,则算法是汽车的设计概念,计算能力更像是汽车的引擎,数据是驱动自行车的燃料.
仅靠燃料,没有好的发动机和设计,汽车自然就不会快速运转. 同样,没有发动机,没有燃料,汽车也无法行驶.
三位一体的协调发展无疑是最好的. 但是,人工智能公司的现状是,许多公司已经拥有先进的算法和高质量的硬件,其产品的降落确实是一个燃料问题.
Testin总经理贾玉航在接受ToB行业标题(ID: wwwqifu)的采访时说:
“在人工智能时代到来之后,越来越多的产品,应用程序和硬件已成为实现人工智能的载体. 在人工智能的实施过程中,许多公司面临数据问题,并且在产品迭代和升级过程中遇到了更大的阻力. ”
关于人工智能公司面临的数据问题,贾宇航强调了两个:
那么,人工智能公司应如何应对这些问题?有什么方法可以帮助人工智能公司解决当前的数据问题?
02
如何采集和使用数据?
实际上,自人工智能出现之日起,数据采集和标签之类的问题就受到了许多制造商的关注.
早在2005年,亚马逊就建立了Mechanical Turk论坛,希望通过众包解决人工智能公司的数据处理需求.
但是,随着人工智能的逐步发展,人工智能的实施已成为行业发展的重要阶段,相应的数据服务也进入了情景和细化的时代.
贾宇航说,Testin目前专注于自动驾驶,银行,保险和安全领域,提供定制的数据采集和标签服务,并完全支持处理各种类型的数据,例如文本,语音,图像和视频.
“例如,自动驾驶制造商需要采集驾驶员的疲劳程度,但是很难将设备安装在路边的汽车上. 因为以这种方式采集的数据不仅是非标准的,而且涉及驾驶员和乘客的隐私.
但是,Testin可以根据客户需求在数据采集中心构建模拟方案,并通过使用专业人员和软硬件设备来采集大量的样本信息,以满足客户的各种需求. “
Testin有许多定制的采集场景示意图
Testin作为AI数据服务行业的领先品牌,拥有自建的数据库系统,所有标签管理统一,生产标准化,可以在确保数据有效的同时确保标签操作的信息流准确性.
Testin还开发了一个自行开发的标签平台,该平台支持标签类型的自定义开发,使标签类型更加全面,并确保标准化业务可以高效运行.
Testin数字标记平台的示意图
目前,许多国内数据标签公司仍是典型的劳动密集型企业. 为了节省人工成本,这些公司仍在使用临时工人,这些工人在经过半天的培训后即可被雇用,而他们的工作是数据标签行业中最简单的事情.
但是Testin很久以前就已经看到了传统模型的缺点. 通过建立馆藏基地,建立标签平台和进行为期60天的职前高质量培训,它已经摆脱了标签行业的低端同质竞争. 技能密集型公司的转型.
贾宇航始终坚信: “劳动密集型数据服务过于依赖劳动力,企业的上限更加明显. 这类企业对数据平台的建设没有足够的重视,培训时间不长. 员工短,数据注释的质量中等. ”
也许腰部公司会出于成本和其他原因而选择此类公司的服务,但总公司肯定会选择高质量的数据标签供应商. 因为只有高质量的数据才能产生高质量的人工智能,所以这是行业发展的基本规律. “
03
高质量和准确的数据
这是行业的未来
一个行业的成熟与该行业中成熟公司的发展离不开. 如果人工智能公司想要快速发展,那么他们一定不能没有数据采集和标签行业的整体进步.
许多年前,我们经常看到知名的人工智能公司将数据采集和标签服务外包给非洲公司. 一些媒体甚至在访问了非洲的数据标签工厂后叹了口气: “硅谷为赚钱而从事人工智能工作的穷人. ”
实际上,为了获得廉价劳动力,在非洲等不发达地区建立了数据标签工厂. 因此,数据服务也被外界视为人工智能金字塔上的最低级别的工作.
尽管金字塔的底部不如尖塔那么刺眼,但底部的体积最大,也是支撑金字塔的坚实基础.
在人工智能公司蓬勃发展的阶段,基础薄弱的公司仍然可以利用自己的实力来发展. 但是,随着公司的发展越来越快,公司建立的数字化尖塔越来越高. 基础是否牢固直接决定了公司发展的上限.
这也是Testin从一开始就非常重视标签人员培训,标签中心建立和数据采集平台开发的重要原因.
因为贾宇航始终认为高质量和准确的数据是行业的未来. “当通用数据公司仍在为实地的“六便士”而战时,Testin已经赶上了空中的“月球”. ”
目前,Testin在华东,华北和华南设有数个数据交付中心以及数据采集和标记基地,并已成功为数百家公司提供了AI数据服务.
相反,国内相关研究报告的结论也在不断完善,数据标签行业也在稳步增长.
根据艾瑞咨询的最新报告,2018年中国人工智能基础数据服务市场规模为25.86亿元,其中数据资源定制服务占86.2%,行业复合年增长率为23.5%. 预计到2025年,市场规模将超过110亿元.
这种蓬勃发展的势头不仅是由于人工智能公司的快速发展带来的巨大需求,而且也离不开Testin安静工作的数据服务提供商,后者继续为人工智能行业提供动力.
确实,当前的人工智能仍然“不准确”,但是我们可以看到几年前,Alpha Dog在Go领域完全爆炸了. 就在过去的几个月中,已经被20多年的发展而未为公众所理解的RPA突然变得很流行.
为什么Alpha Dog会击败人类?为什么RPA突然爆炸?这必将与人工智能算法的更新和发展密不可分. 但是,在技术成熟之后,提供数据采集和标记服务的诸如Testin之类的供应商也必不可少.
正是数据采集和注释的成熟度和准确性可以训练Alpha Dog的精确算法. 数据行业的不断积累使OCR,NLP和其他人工智能技术在今年变得成熟,从而推动了长期沉默的RPA.
这家人工智能行业供应商的新游戏单价为每月1000万元
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 08:22
但是人工智能并不像想象中的那么容易开发. 它的算法是一方面. 更重要的是,所有人工智能都需要一个特定的培训平台来对其进行培训和评估. 通过不断重复此循环,人工智能可以实现各种功能. 推动培训平台发展的是数据.
在世界经济论坛(World Economic Forum)2012年的报告中,数据被称为世界的新财富,其价值可与石油媲美. 《麦肯锡咨询报告》认为,数据是一种生产手段,大数据是创新,竞争和生产力提高的下一个前沿领域. 因此,这些大数据的生产者被称为“人工智能原材料供应商”.
今天的主角就是这样的供应商,龙猫数据.
Totoro Data是一家什么样的公司?
与通常的采访不同,DT先生于星期六早上来到Totoro Data. 根据公司创始人Zanzhi的说法,Totoro Data采用了每两周一次的工作系统,即一周的星期六正常工作,两周的周末休息.
Totoro Data的业务可以分为两层,为企业的业务提供数据服务. 顾名思义,该公司将为具有人工智能培训平台的公司提供培训数据. 该业务分为四类: 图片,视频,文本和语音. 这意味着大多数与AI相关的公司现在都可以成为其客户.
虽然向公司出售数据是Totoro Data的主要业务方法,但Zanzhi告诉DT先生,对于Totoro Data而言,另一项业务更为重要,那就是采集数据的过程.
采集数据可以理解为开采石油. 石油公司的主要业务是向其他公司出售石油,但石油公司的中心不是如何出售石油,而是如何以较低的价格开采更好的石油. 龙猫数据是相同的. 该公司使用众包平台进行数据挖掘.
众包平台分为两个级别: 获取和注释. 在采集方面,龙猫数据将在收到客户提交的任务后将这些任务(例如照片,录音等)分发到公司的APP. 完成任务后将奖励用户,并根据任务的难度奖励不同金额的现金(存储在在线帐户中).
Zan Zhixiang对DT先生说: “我们将用户忽略的材料称为原创材料,但是这些材料不能用于培训,需要对其进行标记和审核. ”所谓的标记是指手动. 该方法将机器可理解的信息素应用于原创材料上的特征点,以便可以通过这些特征来训练人工智能.
以“龙猫”数据的面部照片材料为例. 地图上有密集的点,每个点都有自己的特征含义,例如眼睛的内角和眼睛的外角. 众包平台的人员需要在图中标记这些特征点,并且可以将其视为Totoro数据所需的材料.
但是,通常人脸识别所需的培训材料范围从少至160点到多达数百点. 通过人工估计很难准确,完整地标记整个图像. 根据Zanzhi的描述,Totoro Data在众包平台的数据采集阶段使用了一种自行开发的人工智能预处理技术,也就是说,当用户将原创资料上传到Totoro众包平台时,人工智能将直接落后于此. 最后开始预处理,并预先标记任务所需的特征点. 当材料进入手动标记阶段时,操作员只需稍微移动一些不合理的点即可完成任务.
此预处理分为许多类型. 仍以人脸识别为例,龙猫数据已经准备了多种特征标注方法,例如186点,216点等. 这些标注方法相对通用,可以直接应用于大多数人脸识别训练平台. 对于其他不常见的标记方法,Chinchilla Data Selection和客户公司共同开发了预处理方法. 赞智认为,由于客户从事这一领域的培训,因此他们对这些数据的需求必须是唯一的,因此共同开发是最合理,最节省成本的事情. 从Totoro Data现有的预处理技术来看,该公司的专业知识是与计算机视觉有关和与音频有关的预处理技术,为自动驾驶,图像识别和语音识别等行业提供服务.
当然,所有众包平台都会遇到此类问题. 运营商并非真正隶属于该企业,因此不可避免地存在混合因素. 特别是对于数据采集,这样的环境将给数据清理过程带来很大的麻烦. Totoro Data对众包平台人员使用了多级审查机制.
首先是评估. 操作员需要通过练习问题才能“就业”. 但是,即使他们值班,操作员也不会四处乱逛. 在数据标记阶段,Totoro数据将不时发出陷阱问题,即Totoro数据已经知道答案. 如果操作员没有像答案一样正确地标记数据,系统将警告它们并最终失去操作资格.
同时,在打标过程中,系统还将检查操作员的打标速度,操作记录等. 这是为了防止机器人刷卡任务和其他非法操作. 到目前为止,龙猫众包平台的用户已超过400万,每月订单金额已达到1000万元的水平.
但是,这还没有结束,当原创材料被标记和审阅时,它将被上传到云中. 目前,Totoro Data将原创资料和提交给客户的资料存储在两家不同公司的云存储中. 赞志解释说,这是为了保护数据安全和客户隐私.
谁构成了龙猫的数据?
Totoro Data的获利思路非常明确,Zan Zhi说这是科技公司应该做的. 实际上,龙猫数据并不是最初为大数据采集的. 在种子轮阶段,Totoro Data的业务是在交通卡和手机之间进行移动支付. 通过NFC功能,用户可以直接通过手机对交通卡进行充值,也可以将交通卡中的钱转入手机. 该业务在2014年被称为“闪电刷”. 在微信支付和支付宝的迅速崛起之后,赞志意识到闪电刷很难在这两座山的前面崛起,因此他进行了果断的转型,只有那时龙猫的数据
Zan Zhi是百度广告系统的产品经理,但他不喜欢这份工作,因此搬到了Pea Pod. 来到新公司后,Zanzhi负责的第一件事就是Pea Pod的广告系统. 鉴于百度时间短,他的广告系统仍然是从零开始.
在广告系统工作了一年多之后,Zan Zhi被调到豌豆荚的游戏联运中. 他告诉DT先生,他喜欢这种零对一流程. 正是在Pea Pod就职典礼上,Zan Zhi遇到了现任Totoro Data的首席技术官Yao Yi.
Yao Yi曾经是Google的工程师,后来跟随李开复来到创新工作室. 姚毅相信赞之的战略眼光. 即使Totoro Data进行了重大的业务调整,Yao Yi还是选择了推翻原创技术并进行重新开发.
Totoro数据目前共有68人,技术团队所占比例最高,将近30人. 其余人员是20多个平台操作员,而销售人员则很少. 赞智告诉DT Jun: “我们也期望有很多销售人员,但是我们的销售要求相对较高. 龙猫数据主要与客户的研发团队联系在一起,因为他们有直接的数据要求,这意味着销售人员必须非常了解此行业. ”
截至2018年,Totoro Data已将其业务出售给百度,腾讯,华为,快手,京东和三星等巨头公司. 赞智说,龙猫数据已经为这些客户开展了数十项业务,其中有些已经完成了数百项.
数据
如上所述,Totoro Data是提供人工智能培训数据的公司,而不是直接提供大数据的公司. 尽管有两个数据字,但两者是天壤之别. 大数据关注“五个大Vs”,即大数据规模(卷),数据多样性(品种),数据处理及时性(速度),结果准确性(准确性)和深度值(价值).
人工智能对训练数据的需求符合训练平台的需求. 仍以人脸识别为例,在该领域的人工智能训练中,训练数据的采集往往需要室内50%,室外50%,明亮环境80%,普通环境20%. 但是实际上,消费者实际使用面部识别来唤醒机器的场景比训练场景要复杂得多.
因此,如果您想了解Totoro Data的业务,则应该了解这些人工智能培训平台需要什么样的数据集. 2014年,Facebook提出了DeepFace,一种使用卷积神经网络和大规模人脸图像进行人脸识别的技术. 它在LFW上达到了97.35%的精度,其性能可与手动识别相媲美; VGG网络采用较深的拓扑结构和较大的输入图像,可达到98.95%的精度;香港中文大学提出的DeepId网络进一步改进了卷积神经网络,使用局部和全局特征关节,并使用联合贝叶斯处理量产品特征和训练,并通过两种监督信息(识别和认证)提高了准确性至99%; Google的FaceNet使用三重损失功能(Triplet Loss)作为监管信息,并在2015年达到了99.63%的准确性.
上述面部识别技术的准确性超过手动识别的技术,需要大量的训练数据集来支持它们. 具体数据量如下.
图丨各种人脸识别技术所需数据量的比较
尽管Lightened CNN使用了新的激活功能MFM功能,并且其网络结构也很小,但仍需要450,000数据才能完成训练. 使用中心损失的Caffe脸部也是如此. 这些“小”用于其他培训平台,对于人类来说,这仍然是天文数字.
此图片实际上不能完全反映对面部识别训练数据集的需求. 如果您看下一张图片,您将了解该行业需要多少培训数据.
图片丨训练图片的数量以及各种面部识别技术所需的图片的数量
实际上,在人工智能训练领域,人脸识别所需的数据量远远少于其他训练方法. 最好的例子就是无人驾驶,这也体现在计算机视觉中. 后者可能需要比前者大数千倍甚至数万倍的训练数据.
ECCV2016中的一篇文章提出使用人工合成来完成大量训练数据. 谷歌最近推出了BEGAN,它使用生成式对抗网络来生成不同的任务. 这是目前解决训练数据短缺的方法之一,但正是由于这种方法的出现,才体现出“人工智能供应商”的严重短缺.
然而,事实是,诸如人脸识别之类的技术受到生成对抗网络的支持. 在无人驾驶和语音识别等领域,还没有成熟的生成对抗网络技术. 他们仍然需要大量的培训数据. 实际上,当前的GAN仍处于试验阶段,还没有真正投入商业化.
根据郑州科技信息研究院的报告,截至2018年,北京有242家人工智能公司,上海有112家人工智能公司,在深圳有93家公司,在杭州有36家. 此外,每个人工智能都需要训练数据,有些公司还需要多种类型的训练数据. 在这方面,龙猫数据确实抓住了行业的痛点. 从长远来看,人工智能应该是一个可持续发展领域,这也意味着钦奇利亚数据具有与其对应的长期可持续盈利能力.
但是,龙猫数据和传统数据提供商的众包形式是否更强大?传统数据提供者的数据采集形式是用数据采集设备雇用大量人员进行手工采集,然后将原创资料上载到企业云中,然后派遣企业员工对数据进行标记. 据赞之介绍,这种方法的成本比众包平台贵,并且采集周期相对较长. 毕竟,必须动员许多人. Totoro数据的众包形式允许公司在接收到数据采集任务之后采集数据. 采集工作在两天内开始.
实际上,一些缺乏培训数据并且袖手旁观的人工智能公司会选择直接动员整个公司来采集数据,这种行为在新兴的人工智能公司中并不罕见. 对于Totoro Data来说,这些公司也是很好的目标客户.
2017年12月14日,工业和信息化部发布了《促进新一代人工智能产业发展的三年行动计划(2018-2020年)》,其中提到``建设行业培训资源,标准测试和工业公共支持系统,例如知识产权服务平台,智能网络基础设施和网络安全保证,将改善人工智能的开发环境. ”当前,我国人工智能发展的痛点之一是缺乏有效的行业资源培训库. 业界普遍报告说,它已经影响了人工智能技术的发展及其在该行业中的应用. 前面提到的行业资源培训裤子是Totoro Data长期致力于开发和服务的人工智能数据采集和标记领域. an智认为,人工智能的发展离不开数据数量和质量的不断提高. 一方面是政策支持,另一方面是数据服务公司对技术和资源的持续投资. 两管齐下的做法将形成有效的指导,并不断改善产业发展环境.
但是有话要说,龙猫数据的众包数据采集最终是模型创新,需要技术团队的支持. 这也意味着Totoro Data需要更大比例的技术来提高行业门槛,以保持竞争力. 赞智说,Totoro Data接下来要做的就是进一步扩大技术人员.
“使用非脱敏数据,他绝对不会用于训练”
通常来说,人工智能的训练数据是不敏感的,也就是说,它不收录任何个人隐私信息,即使医学领域的人工智能的训练数据也不例外. 这也是训练数据与大数据之间的差异之一. 在大数据领域,特别是大数据的应用层中,有一个技术特征称为“应用需求驱动特性”,这意味着大数据处理应与行业应用的实际情况和需求相结合.
因此,在大数据处理过程中,您会遇到很多个人隐私数据,例如出生日期,身份证号等. “使用非脱敏数据,那么他的目的绝对不是训练人工智能. ”赞志告诉DT先生: “我们不会与这些人合作. ”
赞智有自己的原则,龙猫的资料也一样. 这也是非脱敏数据的业务利润实际上高于通常的训练数据. 对于平台的长期考虑,Zanzhi没有选择这样做. 但是,Totoro Data不会选择客户. “但是那些以前没有解决过这个项目的人仍会仔细考虑它!”赞志添加了. 同时,公司将与客户讨论数据对于客户的培训平台是否真的有意义.
如上所述,Totoro Data的最初业务称为Lightning Brush. 该业务已获得天使轮融资300万元,A轮融资500万元. 在进行大规模业务调整后,Zan Zhi在2016年拥有了当前的Totoro数据. 根据该公司的融资消息,截至2017年底,该公司完成了3370万元的融资.
此笔资金用于扩大团队,从早期的33人团队发展到今天的68人团队. Zanzhi表示,未来Totoro Data将建立自己的云存储功能,这对于客户和他们自己都将更加安全.
在数据采集领域,近年来共有850个创业项目,但是43.18%的相关公司是在2012年之前成立的. 在这些公司中,无资金投资的公司占47.4%,只有28.1% %的公司在A轮之后. 从龙猫数据的发展状况来看,该公司目前正处于融资阶段,赞之的计划是融资约1亿元,以支持上述企业的发展.
这种融资规模实际上对于数据采集行业而言是相对普遍的. 在2018年4月和2018年5月,该领域发生了爆炸式增长. 四月份有40笔融资,五月份有46笔融资. 这两个月,数据采集领域的融资总额超过2017年第四季度和2018年第一季度的总和.2018年5月的融资总额达到了35亿元的峰值. 没有什么比这更能促进该领域的从业人员了.
在DT先生看来,这种情况的原因可能是人工智能领域即将推出“革命性产品”. 自从提到了人工智能的概念以来,一直处于人才缺口的这项技术实际上并没有提出具有最终目的的真正好产品,无论是消费者还是企业.
2018年很可能将迎来一场人工智能的关键战役,这将使位于人工智能供应链末端的数据采集公司获得大量收入,龙猫数据也将从人工智能行业中受益 查看全部
人工智能,今天这个词已成为流行语. 自2015年人工智能商业化浪潮以来,越来越多的公司需要人工智能技术来增强传统业务的能力,其中最典型的是自动驾驶和面部识别.
但是人工智能并不像想象中的那么容易开发. 它的算法是一方面. 更重要的是,所有人工智能都需要一个特定的培训平台来对其进行培训和评估. 通过不断重复此循环,人工智能可以实现各种功能. 推动培训平台发展的是数据.
在世界经济论坛(World Economic Forum)2012年的报告中,数据被称为世界的新财富,其价值可与石油媲美. 《麦肯锡咨询报告》认为,数据是一种生产手段,大数据是创新,竞争和生产力提高的下一个前沿领域. 因此,这些大数据的生产者被称为“人工智能原材料供应商”.
今天的主角就是这样的供应商,龙猫数据.
Totoro Data是一家什么样的公司?
与通常的采访不同,DT先生于星期六早上来到Totoro Data. 根据公司创始人Zanzhi的说法,Totoro Data采用了每两周一次的工作系统,即一周的星期六正常工作,两周的周末休息.
Totoro Data的业务可以分为两层,为企业的业务提供数据服务. 顾名思义,该公司将为具有人工智能培训平台的公司提供培训数据. 该业务分为四类: 图片,视频,文本和语音. 这意味着大多数与AI相关的公司现在都可以成为其客户.
虽然向公司出售数据是Totoro Data的主要业务方法,但Zanzhi告诉DT先生,对于Totoro Data而言,另一项业务更为重要,那就是采集数据的过程.
采集数据可以理解为开采石油. 石油公司的主要业务是向其他公司出售石油,但石油公司的中心不是如何出售石油,而是如何以较低的价格开采更好的石油. 龙猫数据是相同的. 该公司使用众包平台进行数据挖掘.
众包平台分为两个级别: 获取和注释. 在采集方面,龙猫数据将在收到客户提交的任务后将这些任务(例如照片,录音等)分发到公司的APP. 完成任务后将奖励用户,并根据任务的难度奖励不同金额的现金(存储在在线帐户中).
Zan Zhixiang对DT先生说: “我们将用户忽略的材料称为原创材料,但是这些材料不能用于培训,需要对其进行标记和审核. ”所谓的标记是指手动. 该方法将机器可理解的信息素应用于原创材料上的特征点,以便可以通过这些特征来训练人工智能.
以“龙猫”数据的面部照片材料为例. 地图上有密集的点,每个点都有自己的特征含义,例如眼睛的内角和眼睛的外角. 众包平台的人员需要在图中标记这些特征点,并且可以将其视为Totoro数据所需的材料.
但是,通常人脸识别所需的培训材料范围从少至160点到多达数百点. 通过人工估计很难准确,完整地标记整个图像. 根据Zanzhi的描述,Totoro Data在众包平台的数据采集阶段使用了一种自行开发的人工智能预处理技术,也就是说,当用户将原创资料上传到Totoro众包平台时,人工智能将直接落后于此. 最后开始预处理,并预先标记任务所需的特征点. 当材料进入手动标记阶段时,操作员只需稍微移动一些不合理的点即可完成任务.
此预处理分为许多类型. 仍以人脸识别为例,龙猫数据已经准备了多种特征标注方法,例如186点,216点等. 这些标注方法相对通用,可以直接应用于大多数人脸识别训练平台. 对于其他不常见的标记方法,Chinchilla Data Selection和客户公司共同开发了预处理方法. 赞智认为,由于客户从事这一领域的培训,因此他们对这些数据的需求必须是唯一的,因此共同开发是最合理,最节省成本的事情. 从Totoro Data现有的预处理技术来看,该公司的专业知识是与计算机视觉有关和与音频有关的预处理技术,为自动驾驶,图像识别和语音识别等行业提供服务.
当然,所有众包平台都会遇到此类问题. 运营商并非真正隶属于该企业,因此不可避免地存在混合因素. 特别是对于数据采集,这样的环境将给数据清理过程带来很大的麻烦. Totoro Data对众包平台人员使用了多级审查机制.
首先是评估. 操作员需要通过练习问题才能“就业”. 但是,即使他们值班,操作员也不会四处乱逛. 在数据标记阶段,Totoro数据将不时发出陷阱问题,即Totoro数据已经知道答案. 如果操作员没有像答案一样正确地标记数据,系统将警告它们并最终失去操作资格.
同时,在打标过程中,系统还将检查操作员的打标速度,操作记录等. 这是为了防止机器人刷卡任务和其他非法操作. 到目前为止,龙猫众包平台的用户已超过400万,每月订单金额已达到1000万元的水平.
但是,这还没有结束,当原创材料被标记和审阅时,它将被上传到云中. 目前,Totoro Data将原创资料和提交给客户的资料存储在两家不同公司的云存储中. 赞志解释说,这是为了保护数据安全和客户隐私.
谁构成了龙猫的数据?
Totoro Data的获利思路非常明确,Zan Zhi说这是科技公司应该做的. 实际上,龙猫数据并不是最初为大数据采集的. 在种子轮阶段,Totoro Data的业务是在交通卡和手机之间进行移动支付. 通过NFC功能,用户可以直接通过手机对交通卡进行充值,也可以将交通卡中的钱转入手机. 该业务在2014年被称为“闪电刷”. 在微信支付和支付宝的迅速崛起之后,赞志意识到闪电刷很难在这两座山的前面崛起,因此他进行了果断的转型,只有那时龙猫的数据
Zan Zhi是百度广告系统的产品经理,但他不喜欢这份工作,因此搬到了Pea Pod. 来到新公司后,Zanzhi负责的第一件事就是Pea Pod的广告系统. 鉴于百度时间短,他的广告系统仍然是从零开始.
在广告系统工作了一年多之后,Zan Zhi被调到豌豆荚的游戏联运中. 他告诉DT先生,他喜欢这种零对一流程. 正是在Pea Pod就职典礼上,Zan Zhi遇到了现任Totoro Data的首席技术官Yao Yi.
Yao Yi曾经是Google的工程师,后来跟随李开复来到创新工作室. 姚毅相信赞之的战略眼光. 即使Totoro Data进行了重大的业务调整,Yao Yi还是选择了推翻原创技术并进行重新开发.
Totoro数据目前共有68人,技术团队所占比例最高,将近30人. 其余人员是20多个平台操作员,而销售人员则很少. 赞智告诉DT Jun: “我们也期望有很多销售人员,但是我们的销售要求相对较高. 龙猫数据主要与客户的研发团队联系在一起,因为他们有直接的数据要求,这意味着销售人员必须非常了解此行业. ”
截至2018年,Totoro Data已将其业务出售给百度,腾讯,华为,快手,京东和三星等巨头公司. 赞智说,龙猫数据已经为这些客户开展了数十项业务,其中有些已经完成了数百项.
数据
如上所述,Totoro Data是提供人工智能培训数据的公司,而不是直接提供大数据的公司. 尽管有两个数据字,但两者是天壤之别. 大数据关注“五个大Vs”,即大数据规模(卷),数据多样性(品种),数据处理及时性(速度),结果准确性(准确性)和深度值(价值).
人工智能对训练数据的需求符合训练平台的需求. 仍以人脸识别为例,在该领域的人工智能训练中,训练数据的采集往往需要室内50%,室外50%,明亮环境80%,普通环境20%. 但是实际上,消费者实际使用面部识别来唤醒机器的场景比训练场景要复杂得多.
因此,如果您想了解Totoro Data的业务,则应该了解这些人工智能培训平台需要什么样的数据集. 2014年,Facebook提出了DeepFace,一种使用卷积神经网络和大规模人脸图像进行人脸识别的技术. 它在LFW上达到了97.35%的精度,其性能可与手动识别相媲美; VGG网络采用较深的拓扑结构和较大的输入图像,可达到98.95%的精度;香港中文大学提出的DeepId网络进一步改进了卷积神经网络,使用局部和全局特征关节,并使用联合贝叶斯处理量产品特征和训练,并通过两种监督信息(识别和认证)提高了准确性至99%; Google的FaceNet使用三重损失功能(Triplet Loss)作为监管信息,并在2015年达到了99.63%的准确性.
上述面部识别技术的准确性超过手动识别的技术,需要大量的训练数据集来支持它们. 具体数据量如下.
图丨各种人脸识别技术所需数据量的比较
尽管Lightened CNN使用了新的激活功能MFM功能,并且其网络结构也很小,但仍需要450,000数据才能完成训练. 使用中心损失的Caffe脸部也是如此. 这些“小”用于其他培训平台,对于人类来说,这仍然是天文数字.
此图片实际上不能完全反映对面部识别训练数据集的需求. 如果您看下一张图片,您将了解该行业需要多少培训数据.
图片丨训练图片的数量以及各种面部识别技术所需的图片的数量
实际上,在人工智能训练领域,人脸识别所需的数据量远远少于其他训练方法. 最好的例子就是无人驾驶,这也体现在计算机视觉中. 后者可能需要比前者大数千倍甚至数万倍的训练数据.
ECCV2016中的一篇文章提出使用人工合成来完成大量训练数据. 谷歌最近推出了BEGAN,它使用生成式对抗网络来生成不同的任务. 这是目前解决训练数据短缺的方法之一,但正是由于这种方法的出现,才体现出“人工智能供应商”的严重短缺.
然而,事实是,诸如人脸识别之类的技术受到生成对抗网络的支持. 在无人驾驶和语音识别等领域,还没有成熟的生成对抗网络技术. 他们仍然需要大量的培训数据. 实际上,当前的GAN仍处于试验阶段,还没有真正投入商业化.
根据郑州科技信息研究院的报告,截至2018年,北京有242家人工智能公司,上海有112家人工智能公司,在深圳有93家公司,在杭州有36家. 此外,每个人工智能都需要训练数据,有些公司还需要多种类型的训练数据. 在这方面,龙猫数据确实抓住了行业的痛点. 从长远来看,人工智能应该是一个可持续发展领域,这也意味着钦奇利亚数据具有与其对应的长期可持续盈利能力.
但是,龙猫数据和传统数据提供商的众包形式是否更强大?传统数据提供者的数据采集形式是用数据采集设备雇用大量人员进行手工采集,然后将原创资料上载到企业云中,然后派遣企业员工对数据进行标记. 据赞之介绍,这种方法的成本比众包平台贵,并且采集周期相对较长. 毕竟,必须动员许多人. Totoro数据的众包形式允许公司在接收到数据采集任务之后采集数据. 采集工作在两天内开始.
实际上,一些缺乏培训数据并且袖手旁观的人工智能公司会选择直接动员整个公司来采集数据,这种行为在新兴的人工智能公司中并不罕见. 对于Totoro Data来说,这些公司也是很好的目标客户.
2017年12月14日,工业和信息化部发布了《促进新一代人工智能产业发展的三年行动计划(2018-2020年)》,其中提到``建设行业培训资源,标准测试和工业公共支持系统,例如知识产权服务平台,智能网络基础设施和网络安全保证,将改善人工智能的开发环境. ”当前,我国人工智能发展的痛点之一是缺乏有效的行业资源培训库. 业界普遍报告说,它已经影响了人工智能技术的发展及其在该行业中的应用. 前面提到的行业资源培训裤子是Totoro Data长期致力于开发和服务的人工智能数据采集和标记领域. an智认为,人工智能的发展离不开数据数量和质量的不断提高. 一方面是政策支持,另一方面是数据服务公司对技术和资源的持续投资. 两管齐下的做法将形成有效的指导,并不断改善产业发展环境.
但是有话要说,龙猫数据的众包数据采集最终是模型创新,需要技术团队的支持. 这也意味着Totoro Data需要更大比例的技术来提高行业门槛,以保持竞争力. 赞智说,Totoro Data接下来要做的就是进一步扩大技术人员.
“使用非脱敏数据,他绝对不会用于训练”
通常来说,人工智能的训练数据是不敏感的,也就是说,它不收录任何个人隐私信息,即使医学领域的人工智能的训练数据也不例外. 这也是训练数据与大数据之间的差异之一. 在大数据领域,特别是大数据的应用层中,有一个技术特征称为“应用需求驱动特性”,这意味着大数据处理应与行业应用的实际情况和需求相结合.
因此,在大数据处理过程中,您会遇到很多个人隐私数据,例如出生日期,身份证号等. “使用非脱敏数据,那么他的目的绝对不是训练人工智能. ”赞志告诉DT先生: “我们不会与这些人合作. ”
赞智有自己的原则,龙猫的资料也一样. 这也是非脱敏数据的业务利润实际上高于通常的训练数据. 对于平台的长期考虑,Zanzhi没有选择这样做. 但是,Totoro Data不会选择客户. “但是那些以前没有解决过这个项目的人仍会仔细考虑它!”赞志添加了. 同时,公司将与客户讨论数据对于客户的培训平台是否真的有意义.
如上所述,Totoro Data的最初业务称为Lightning Brush. 该业务已获得天使轮融资300万元,A轮融资500万元. 在进行大规模业务调整后,Zan Zhi在2016年拥有了当前的Totoro数据. 根据该公司的融资消息,截至2017年底,该公司完成了3370万元的融资.
此笔资金用于扩大团队,从早期的33人团队发展到今天的68人团队. Zanzhi表示,未来Totoro Data将建立自己的云存储功能,这对于客户和他们自己都将更加安全.
在数据采集领域,近年来共有850个创业项目,但是43.18%的相关公司是在2012年之前成立的. 在这些公司中,无资金投资的公司占47.4%,只有28.1% %的公司在A轮之后. 从龙猫数据的发展状况来看,该公司目前正处于融资阶段,赞之的计划是融资约1亿元,以支持上述企业的发展.
这种融资规模实际上对于数据采集行业而言是相对普遍的. 在2018年4月和2018年5月,该领域发生了爆炸式增长. 四月份有40笔融资,五月份有46笔融资. 这两个月,数据采集领域的融资总额超过2017年第四季度和2018年第一季度的总和.2018年5月的融资总额达到了35亿元的峰值. 没有什么比这更能促进该领域的从业人员了.
在DT先生看来,这种情况的原因可能是人工智能领域即将推出“革命性产品”. 自从提到了人工智能的概念以来,一直处于人才缺口的这项技术实际上并没有提出具有最终目的的真正好产品,无论是消费者还是企业.
2018年很可能将迎来一场人工智能的关键战役,这将使位于人工智能供应链末端的数据采集公司获得大量收入,龙猫数据也将从人工智能行业中受益
www.houyicaiji.com优采云采集器_人工智能数据采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2020-08-06 18:15
智能模式: 基于人工智能算法,您只需输入URL即可智能识别列表数据,表数据和分页按钮,而无需配置任何采集规则,只需单击即可. 自动识别: 列表,表格,链接,图片,价格等.
小白神器!免费导出收款结果
由前Google技术团队基于人工智能技术创建,仅需输入URL即可自动识别采集到的内容
立即下载
下载适用于其他平台的优采云采集器
(Windows,Mac,Linux)
智能识别数据,小白文物
智能模式: 基于人工智能算法,您只需输入URL即可智能地识别列表数据,表数据和分页按钮,而无需配置任何采集规则,一键式采集.
自动识别: 列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
方便快捷的云帐户
创建一个优采云采集器帐户并登录. 您的所有采集任务将自动加密并保存到优采云云服务器. 无需担心丢失采集任务,这是非常安全的. 只有您可以本地登录客户端. 查看. 优采云采集器对帐户没有终端绑定限制,并且在切换终端时会同时更新采集任务,从而使任务管理方便快捷.
全平台支持,无缝切换
同时,它支持Windows,Mac和Linux操作系统的采集软件. 所有平台的版本都是相同的,并且可以无缝切换.
开始使用优采云采集器
体验新一代的人工智能采集方法 查看全部
优采云采集器_真正免费!导出无限的Web爬虫软件_人工智能数据采集软件
智能模式: 基于人工智能算法,您只需输入URL即可智能识别列表数据,表数据和分页按钮,而无需配置任何采集规则,只需单击即可. 自动识别: 列表,表格,链接,图片,价格等.
小白神器!免费导出收款结果
由前Google技术团队基于人工智能技术创建,仅需输入URL即可自动识别采集到的内容
立即下载
下载适用于其他平台的优采云采集器
(Windows,Mac,Linux)
智能识别数据,小白文物
智能模式: 基于人工智能算法,您只需输入URL即可智能地识别列表数据,表数据和分页按钮,而无需配置任何采集规则,一键式采集.
自动识别: 列表,表格,链接,图片,价格等
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
方便快捷的云帐户
创建一个优采云采集器帐户并登录. 您的所有采集任务将自动加密并保存到优采云云服务器. 无需担心丢失采集任务,这是非常安全的. 只有您可以本地登录客户端. 查看. 优采云采集器对帐户没有终端绑定限制,并且在切换终端时会同时更新采集任务,从而使任务管理方便快捷.
全平台支持,无缝切换
同时,它支持Windows,Mac和Linux操作系统的采集软件. 所有平台的版本都是相同的,并且可以无缝切换.
开始使用优采云采集器
体验新一代的人工智能采集方法
北京人工智能数据采集智能营销公司-惠中天智
采集交流 • 优采云 发表了文章 • 0 个评论 • 698 次浏览 • 2020-08-06 07:14
“技术和生产力的提高极大地丰富了人们的日常生活,社会需求的结构也发生了变化. ”人力资源和社会保障部职业技能鉴定中心标准处长葛恒表示,人工智能培训师这是一种新兴技术,随着新兴技术的应用而出现,适应经济和社会发展的需求,满足了人们的需求不断增长,并顺应了新产业,新格式和新模式的发展和变化趋势.
在正常情况下,输入和输出将不符合所需的线性关系. 同时,由于磁滞和蠕变等因素的影响,无法实现输入输出关系的唯一性. 因此,我们不能忽视工厂中的外部影响. 影响的程度取决于传感器本身,可以通过改进传感器本身来抑制这种影响,有时还可以受外部条件的限制.
项目执行: 总体进度不错,但是由于某些组件的高级软件包定义,在开发过程中无法满足某些要求,并且某些进度会延迟.
人工智能培训师如何训练人工智能?段玉聪说,首先,人工智能培训师需要对所涉及的数据和知识有一定的了解,然后“清理”数据以获得结构化的核心知识和关键数据,指定数据标记规则,并“馈送”数据人工智能可以对其进行“调整”,并不断调整参数优化算法,从而使机器人可以更好地为人类服务. 例如,通过训练AI理解情绪,人工智能可以获取人们语音和文本中的敏感信息,并根据用户的状态提供个性化和人性化的服务. 交互: 由于它是B侧后端系统,因此通常选择一个通用的系统框架. 因此,在发布需求的过程中,只强调需要注意的交互方法,而一些共享的交互方法并不过分. 说明;因此,交互过程中会产生大量的通信成本.
视频传输所需的带宽巨大. 因为传统的工业信息化是在现场采集数据,并且视频数据传输主要在局域网中进行,所以带宽不是主要问题. 随着云计算技术的普及和公共云的兴起,大数据需要大量的计算资源和存储资源. 因此,工业数据逐渐迁移到公共云是大势所趋. 但是,一个工业企业可能有几十个视频,而一个大型企业可能有数百个视频. 对于开发人员来说,如何通过互联网将如此大量的视频文件平稳地传输到云中是一个巨大的挑战. 数据源管理: 数据源通常分为许多类型. 因此,我们需要建立数据源类型. 例如mysql,hive等. 添加数据源时,通常会根据需要确定填充内容的验证. 需要填写的字段大致包括源名称,服务器,端口,用户名,密码等.
系统日志采集系统: 日志采集和日志数据信息的采集,然后执行数据分析以挖掘公司业务平台日志数据的潜在价值. 简而言之,采集日志数据可提供离线和在线实时分析. 当前常用的开源日志采集系统是Flume.
通常来说,AI公司从客户(用户)获得的原创数据不能直接用于模型训练. 在“人工智能培训师”出现之前,AI产品经理使用相关工具来对其进行简单处理. 它被移交给数据注释者进行注释处理,但是由于注释者对数据的理解和注释的质量差别很大,因此整个注释工作的效率和效果都不理想. 查看全部
北京人工智能数据采集智能营销公司-惠中天智
“技术和生产力的提高极大地丰富了人们的日常生活,社会需求的结构也发生了变化. ”人力资源和社会保障部职业技能鉴定中心标准处长葛恒表示,人工智能培训师这是一种新兴技术,随着新兴技术的应用而出现,适应经济和社会发展的需求,满足了人们的需求不断增长,并顺应了新产业,新格式和新模式的发展和变化趋势.
在正常情况下,输入和输出将不符合所需的线性关系. 同时,由于磁滞和蠕变等因素的影响,无法实现输入输出关系的唯一性. 因此,我们不能忽视工厂中的外部影响. 影响的程度取决于传感器本身,可以通过改进传感器本身来抑制这种影响,有时还可以受外部条件的限制.
项目执行: 总体进度不错,但是由于某些组件的高级软件包定义,在开发过程中无法满足某些要求,并且某些进度会延迟.
人工智能培训师如何训练人工智能?段玉聪说,首先,人工智能培训师需要对所涉及的数据和知识有一定的了解,然后“清理”数据以获得结构化的核心知识和关键数据,指定数据标记规则,并“馈送”数据人工智能可以对其进行“调整”,并不断调整参数优化算法,从而使机器人可以更好地为人类服务. 例如,通过训练AI理解情绪,人工智能可以获取人们语音和文本中的敏感信息,并根据用户的状态提供个性化和人性化的服务. 交互: 由于它是B侧后端系统,因此通常选择一个通用的系统框架. 因此,在发布需求的过程中,只强调需要注意的交互方法,而一些共享的交互方法并不过分. 说明;因此,交互过程中会产生大量的通信成本.
视频传输所需的带宽巨大. 因为传统的工业信息化是在现场采集数据,并且视频数据传输主要在局域网中进行,所以带宽不是主要问题. 随着云计算技术的普及和公共云的兴起,大数据需要大量的计算资源和存储资源. 因此,工业数据逐渐迁移到公共云是大势所趋. 但是,一个工业企业可能有几十个视频,而一个大型企业可能有数百个视频. 对于开发人员来说,如何通过互联网将如此大量的视频文件平稳地传输到云中是一个巨大的挑战. 数据源管理: 数据源通常分为许多类型. 因此,我们需要建立数据源类型. 例如mysql,hive等. 添加数据源时,通常会根据需要确定填充内容的验证. 需要填写的字段大致包括源名称,服务器,端口,用户名,密码等.
系统日志采集系统: 日志采集和日志数据信息的采集,然后执行数据分析以挖掘公司业务平台日志数据的潜在价值. 简而言之,采集日志数据可提供离线和在线实时分析. 当前常用的开源日志采集系统是Flume.
通常来说,AI公司从客户(用户)获得的原创数据不能直接用于模型训练. 在“人工智能培训师”出现之前,AI产品经理使用相关工具来对其进行简单处理. 它被移交给数据注释者进行注释处理,但是由于注释者对数据的理解和注释的质量差别很大,因此整个注释工作的效率和效果都不理想.
Youcai Cloud Collector(熊猫Smart Collect v2.6正式版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2020-08-05 19:02
9. 分页内容易于合并
支持各种类型的分页模式,用户只需执行两个步骤即可合并分页的内容: 单击鼠标以确认分页链接,然后选择需要通过分页合并的字段项以选中“合并页面”项. . 如果页面中有重复的子项目,则可以在页面中自动找到重复的子项目,隐式地自动合并页面的内容.
通常,例如上述论坛示例,分页页面中的回复内容可以自动合并. 此时,用户只需单击鼠标即可确认页面链接的位置. 在某些情况下,主体(主表)的内容也将出现在论坛内容页面的页面中. 此时,系统将自动做出判断,并且不会将主表的内容采集为重复子项的子表内容.
10. 使用Cookie模拟网站登录
对于需要登录才能访问采集页面的网站(包括Discuz和其他类型的论坛),您可以使用您的帐户来模拟登录. Youcai Cloud Collector可以使用动态cookie通过模拟浏览器机制来与网站进行动态cookie对话. 为了增强数据安全性,某些网站使用cookie加密Web内容数据,这时您需要使用优采云采集器独特的“动态cookie”功能.
11. 支持常见类型的数据库引擎. 支持FTP上传
Xiong的当前Panda版本支持四种常用的数据库类型: Access / mssql / mysql / Oracle,将来可能会根据需要进行扩展. 支持通过FTP将游戏指南的各种文件和图片同时上传到远程服务器. 用户可以使用此功能将本地计算机上采集的数据同时更新到其网站,从而丰富了该列的内容. 对于其他动态数据发布方法,Panda将根据用户反馈尽快实施.
12,无人值守自动定时操作
具有更新采集和访问权限以及自动更新和定期运行的功能. 在没有人工干预的情况下,系统会自动关闭操作.
13. 文本内容的“伪原创”修改. 支持文章时间提前
提供文本内容的“伪原创”修改. 您还可以“提前”修改文章的时间. 文章的发表时间是搜索引擎用来区分文章是否为原创的参考因素.
功能介绍
1. 大数据采集
熊猫具有极高的采集速度和效率,是大数据采集场合的最佳选择. 同时,熊猫独特的海量数据处理能力可以满足大数据采集的需求. 这是大数据采集场合的首选
2. 舆论监督
借助所有中文搜索引擎,可以很容易地实现对整个网络上舆情信息的监视,并且信息覆盖范围很广. 对于需要关键监视的网站,只需输入URL即可实现监视. PC终端独立运行优采云采集器,普通移动PC可以胜任舆论监督. 同时,熊猫智能采集与监控引擎也是第三方舆论系统内置爬虫的首选.
3. 招标信息监控
使用Panda智能采集和监视引擎,您可以轻松地在投标信息发布网站上监视最新的投标信息. 优采云采集器优采云采集器是招标信息监控软件的最佳选择: 操作简便,维护简单,结果直观方便.
4. 客户数据采集
使用熊猫可以轻松地从网络中批量获取所需的客户信息,并使用熊猫的各种反采集机制(例如熊猫独特的云采集功能)轻松绕过采集网站的反采集机制. 例如58,Ganji,Baixing.com,Alibaba,HC等.
5. 许多网站管理员: 网站移动,网站内容自动填充
Panda是最容易操作的采集器,也是许多网站管理员中的第一个. 同时,Panda也是一个复杂的采集器,可以应用于几乎所有复杂的网站采集和移动操作.
6. 采集互联网资源
使用优采云采集器软件,您可以在本地实施Internet资源的批量和格式化游戏策略. 可选的采集工具软件太多了,但是它们都属于DOS时代,它们操作繁琐,功能简单,并且需要专业技术人员勉强操作. 熊猫不同,可视鼠标操作的全过程,操作简单,功能全面,特别是熊猫可以达到非常复杂的采集要求,不了解技术的人也可以轻松操作. 优采云采集器是熊猫采集软件的新一代产品,易采集!
7. 丰富用户网站内容
用户可以使用Panda采集Internet上分散或集中的资源,并将其批量复制到自己的网站中,以丰富其网站内容. 任何人都可以轻松成为大型站点的网站管理员,而无需了解技术,资金,人力投资以及对熊猫的依赖.
8. 行业垂直搜索引擎
使用Youcai Cloud Collector和支持Youcai Cloud Collector的分词索引搜索系统,用户可以轻松构建行业垂直搜索引擎. 例如,招聘,人才,房地产,旅游,购物,商业,分类信息,二手,医疗和健康等.
优采云采集器软件从开发之初就被设计为通用搜索引擎. 如果您只是认为熊猫只是原创且廉价的采集软件,那是对熊猫的极大误解. 优采云采集器技术源自熊猫精确搜索引擎.
9. 作为相关软件的功能包
它可以用作舆论,监视和情报等与Internet相关的软件的支持软件,从而节省了重复的高成本开发. 关键在于改善用户体验并增强软件本身的技术形象.
更新日志
Panda Smart Collection 2.6更新:
1. 修复多个错误 查看全部
通常,例如在论坛页面上,正文内容位于第一位,后面是几个答复内容,或者有几个答复页面. Youcai Cloud Collector可以将它们视为“对象”并同时采集它们. 配置过程也非常简单.
9. 分页内容易于合并
支持各种类型的分页模式,用户只需执行两个步骤即可合并分页的内容: 单击鼠标以确认分页链接,然后选择需要通过分页合并的字段项以选中“合并页面”项. . 如果页面中有重复的子项目,则可以在页面中自动找到重复的子项目,隐式地自动合并页面的内容.
通常,例如上述论坛示例,分页页面中的回复内容可以自动合并. 此时,用户只需单击鼠标即可确认页面链接的位置. 在某些情况下,主体(主表)的内容也将出现在论坛内容页面的页面中. 此时,系统将自动做出判断,并且不会将主表的内容采集为重复子项的子表内容.
10. 使用Cookie模拟网站登录
对于需要登录才能访问采集页面的网站(包括Discuz和其他类型的论坛),您可以使用您的帐户来模拟登录. Youcai Cloud Collector可以使用动态cookie通过模拟浏览器机制来与网站进行动态cookie对话. 为了增强数据安全性,某些网站使用cookie加密Web内容数据,这时您需要使用优采云采集器独特的“动态cookie”功能.
11. 支持常见类型的数据库引擎. 支持FTP上传
Xiong的当前Panda版本支持四种常用的数据库类型: Access / mssql / mysql / Oracle,将来可能会根据需要进行扩展. 支持通过FTP将游戏指南的各种文件和图片同时上传到远程服务器. 用户可以使用此功能将本地计算机上采集的数据同时更新到其网站,从而丰富了该列的内容. 对于其他动态数据发布方法,Panda将根据用户反馈尽快实施.
12,无人值守自动定时操作
具有更新采集和访问权限以及自动更新和定期运行的功能. 在没有人工干预的情况下,系统会自动关闭操作.
13. 文本内容的“伪原创”修改. 支持文章时间提前
提供文本内容的“伪原创”修改. 您还可以“提前”修改文章的时间. 文章的发表时间是搜索引擎用来区分文章是否为原创的参考因素.
功能介绍
1. 大数据采集
熊猫具有极高的采集速度和效率,是大数据采集场合的最佳选择. 同时,熊猫独特的海量数据处理能力可以满足大数据采集的需求. 这是大数据采集场合的首选
2. 舆论监督
借助所有中文搜索引擎,可以很容易地实现对整个网络上舆情信息的监视,并且信息覆盖范围很广. 对于需要关键监视的网站,只需输入URL即可实现监视. PC终端独立运行优采云采集器,普通移动PC可以胜任舆论监督. 同时,熊猫智能采集与监控引擎也是第三方舆论系统内置爬虫的首选.
3. 招标信息监控
使用Panda智能采集和监视引擎,您可以轻松地在投标信息发布网站上监视最新的投标信息. 优采云采集器优采云采集器是招标信息监控软件的最佳选择: 操作简便,维护简单,结果直观方便.
4. 客户数据采集
使用熊猫可以轻松地从网络中批量获取所需的客户信息,并使用熊猫的各种反采集机制(例如熊猫独特的云采集功能)轻松绕过采集网站的反采集机制. 例如58,Ganji,Baixing.com,Alibaba,HC等.
5. 许多网站管理员: 网站移动,网站内容自动填充
Panda是最容易操作的采集器,也是许多网站管理员中的第一个. 同时,Panda也是一个复杂的采集器,可以应用于几乎所有复杂的网站采集和移动操作.
6. 采集互联网资源
使用优采云采集器软件,您可以在本地实施Internet资源的批量和格式化游戏策略. 可选的采集工具软件太多了,但是它们都属于DOS时代,它们操作繁琐,功能简单,并且需要专业技术人员勉强操作. 熊猫不同,可视鼠标操作的全过程,操作简单,功能全面,特别是熊猫可以达到非常复杂的采集要求,不了解技术的人也可以轻松操作. 优采云采集器是熊猫采集软件的新一代产品,易采集!
7. 丰富用户网站内容
用户可以使用Panda采集Internet上分散或集中的资源,并将其批量复制到自己的网站中,以丰富其网站内容. 任何人都可以轻松成为大型站点的网站管理员,而无需了解技术,资金,人力投资以及对熊猫的依赖.
8. 行业垂直搜索引擎
使用Youcai Cloud Collector和支持Youcai Cloud Collector的分词索引搜索系统,用户可以轻松构建行业垂直搜索引擎. 例如,招聘,人才,房地产,旅游,购物,商业,分类信息,二手,医疗和健康等.
优采云采集器软件从开发之初就被设计为通用搜索引擎. 如果您只是认为熊猫只是原创且廉价的采集软件,那是对熊猫的极大误解. 优采云采集器技术源自熊猫精确搜索引擎.
9. 作为相关软件的功能包
它可以用作舆论,监视和情报等与Internet相关的软件的支持软件,从而节省了重复的高成本开发. 关键在于改善用户体验并增强软件本身的技术形象.
更新日志
Panda Smart Collection 2.6更新:
1. 修复多个错误
【JEECMS】人工智能初审与可视化采集,JEECMSx1.2即将发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-08-04 09:06
为解决以上问题,JEECMS x1.2应运而生,本次版本更新内容如下:
1、增加内容智能初审体系:结合大数据与人工智能技术,系统智能剖析出文字及图片中所包含的涉政、涉黄、涉暴恐、低俗恐吓、恶意灌水等违禁内容,给网站信息发布提供更有力的安全保障,并在一定程度上起到引导控制舆论的疗效;同时,使用智能初审对内容进行检查,更能极大地解放人力初审,降低营运成本。
政治敏感文字检查
政治敏感图片测量
暴恐违禁检查
2、优化智能云采集系统:增加自定义可视化采集功能,运用网页智能辨识技术,以可视化的方法在页面中选择想采集的数据,实现所选即所得,轻松采集。
自定义自己想要采集的网址
所见即所得的采集方式,操作更方便
3、内容模型及发布优化:对整个模型编辑及发布形式进行了调整,优化用户体验,更易操作。
更实用的内容模型数组编辑
4、修复若干个已知问题
立即体验,了解最新的功能吧
前台演示地址 后台演示地址 mysql数据库版本下载地址 达梦数据库版本下载地址 查看全部
随着当下媒体种类的增多,政府及企业每晚发布的信息量越来越多,同时对信息时效性的要求也越来越高,这样就须要在信息发布时才能快速的完成从发布到初审再到上线的一系列工作。而当下大部分单位仍然靠人工来初审信息的内容一是人工采集,二是智能采集,无论从效率、准确性、安全性各方面都处于较低的水平一是人工采集,二是智能采集,逐渐满足不了当下对信息发布的期望及要求。
为解决以上问题,JEECMS x1.2应运而生,本次版本更新内容如下:
1、增加内容智能初审体系:结合大数据与人工智能技术,系统智能剖析出文字及图片中所包含的涉政、涉黄、涉暴恐、低俗恐吓、恶意灌水等违禁内容,给网站信息发布提供更有力的安全保障,并在一定程度上起到引导控制舆论的疗效;同时,使用智能初审对内容进行检查,更能极大地解放人力初审,降低营运成本。
政治敏感文字检查
政治敏感图片测量
暴恐违禁检查
2、优化智能云采集系统:增加自定义可视化采集功能,运用网页智能辨识技术,以可视化的方法在页面中选择想采集的数据,实现所选即所得,轻松采集。
自定义自己想要采集的网址
所见即所得的采集方式,操作更方便
3、内容模型及发布优化:对整个模型编辑及发布形式进行了调整,优化用户体验,更易操作。
更实用的内容模型数组编辑
4、修复若干个已知问题
立即体验,了解最新的功能吧
前台演示地址 后台演示地址 mysql数据库版本下载地址 达梦数据库版本下载地址

