python抓取网页数据(如何使用Python从头开始进行WEB中Soup进行Web抓取 )
优采云 发布时间: 2021-10-05 10:18python抓取网页数据(如何使用Python从头开始进行WEB中Soup进行Web抓取
)
时间:2020-09-07 点击次数:作者:Sissi
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:
我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:
我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
现在,我们将以 ap 标签的形式将我们的第一个内容添加到页面中。p 标签定义了一个段落,标签内的任何文本都显示为一个单独的段落:
外观如下:
标签的通用名称取决于它们相对于其他标签的位置:
1)child - 孩子是另一个标签中的标签。因此,p 上方的两个标签是 body 标签的子标签。
2)parent——父标签是另一个标签所在的标签。在顶部,html 标签是标签的父主体。
3)sibiling - 同级标签是嵌套在与另一个标签相同的父对象中的标签。例如,head 和 body 是兄弟,因为它们都在内部 html 中。两个 p 标签处于同一级别,因为它们都在内部主体中。
我们还可以向 HTML 标签添加属性来改变它们的行为:
外观如下:
在上面的例子中,我们添加了两个 a 标签。a 标签是一个链接,它告诉浏览器呈现到另一个网页的链接。href 标签的属性决定了链接的位置。
a 和 p 是非常常见的 html 标签。以下是一些其他内容:
1)div — 表示页面的分区或区域。
2)b-将其中的任何文本加粗。
3)i — 里面的任何文字都以斜体显示。
4)table — 创建一个表。
5)form-创建输入表单。
有关完整的标签列表,请参见此处。
在进行实际的网页抓取之前,让我们了解一下 class 和 id 属性。这些特殊属性为 HTML 元素提供名称,并使我们在爬行时更容易与它们交互。一个元素可以有多个类,一个类可以在元素之间共享。每个元素只能有一个ID,一个ID在页面上只能使用一次。Class 和 ID 是可选的,并非所有元素都有它们。
我们可以将类和 ID 添加到示例中:
外观如下:
请求库
我们要抓取网页的第一件事就是下载网页。我们可以使用 Python 来请求库下载页面。请求库将向 GET Web 服务器发送请求,该服务器将为我们下载给定网页的 HTML 内容。我们可以使用多种不同类型的请求,其中只有一种类型的 GET。如果您想了解更多信息,请查看我们的 API 教程。
我们试着下载一个简单的例子网站。我们需要先使用 request.get 方法下载它。
运行请求后,我们得到一个 Response 对象。该对象有一个status_code属性,表示页面是否下载成功:
status_codeof 200 表示页面已成功下载。我们不会在这里全面讨论状态代码,但以“a”开头的状态代码 2 通常表示成功,而以“a” 4 或“a”开头的代码 5 表示错误。
我们可以使用 content 属性来输出页面的 HTML 内容:
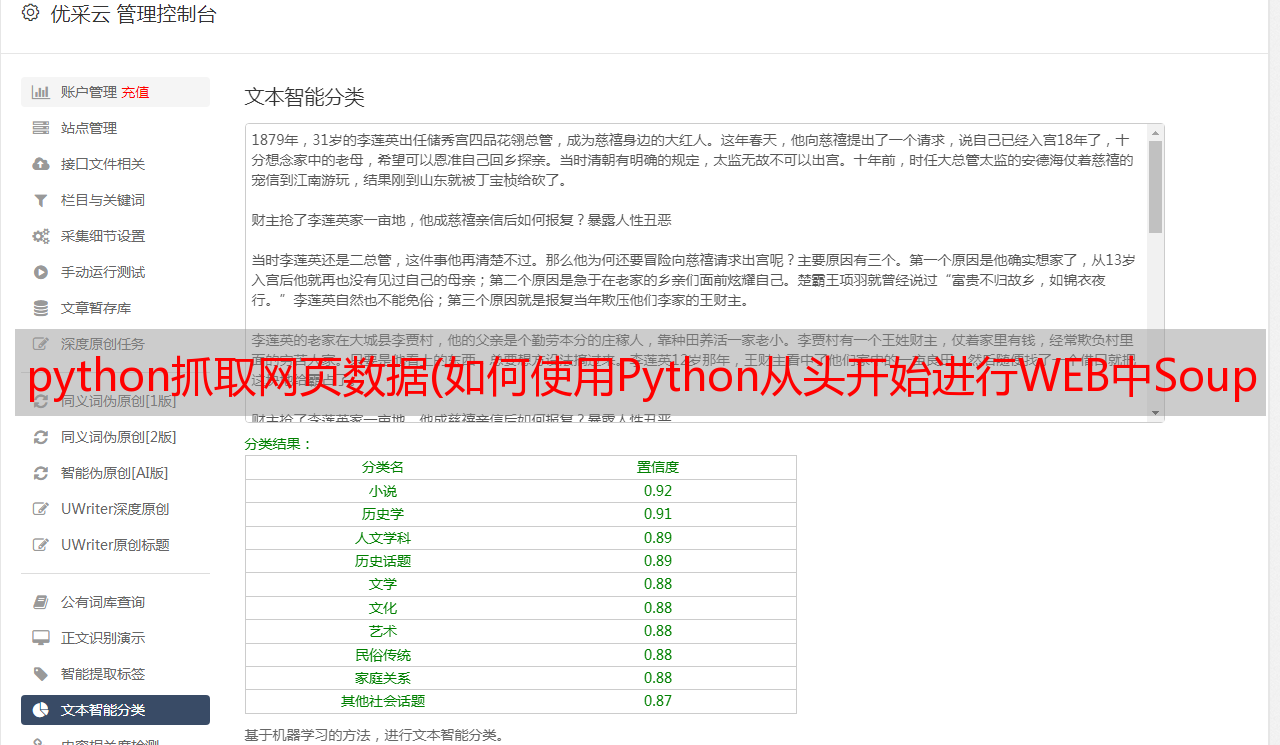
使用 BeautifulSoup 解析页面
正如您在上面看到的,我们现在已经下载了一个 HTML 文档。
我们可以使用 BeautifulSoup 库来解析这个文档并从 p 标签中提取文本。我们必须首先导入库并创建 BeautifulSoup 类的实例来解析我们的文档:
现在,我们可以使用对象 prettify 上的方法在格式良好的页面中打印出 HTML 内容 BeautifulSoup:
由于所有标签都是嵌套的,我们可以一次在整个结构中移动一层。我们可以先使用 children 属性来选择页面顶部的所有汤元素。请注意,它的子节点返回一个列表*敏*感*词*,因此我们需要 list 在其上调用此函数:
上面告诉我们页面顶部有两个标签——初始标签和标签。n 列表中还有一个换行符 ()。让我们看看列表中每个元素的类型是什么:
如您所见,所有项目都是 BeautifulSoup 对象。第一个是 Doctype 对象,它收录有关文档类型的信息。第二个是 NavigableString,它表示在 HTML 文档中找到的文本。最后一项是 Tag 对象,其中收录其他嵌套标签。Object 也是我们最常处理的最重要的对象类型 Tag。
Tag 对象允许我们浏览 HTML 文档并提取其他标签和文本。您可以在此处了解有关各种 BeautifulSoup 对象的更多信息。
现在,我们可以通过选择 html 列表中的第三项来选择标签及其子元素:
children 属性返回的列表中的每一项也是一个 BeautifulSoup 对象,所以我们也可以调用 children 上的 html 方法。
现在,我们可以在 html 标签中找到孩子:
正如你在上面看到的,有两个标签 head 和 body。我们要提取 p 标签内的文本,所以我们将深入研究文本:
现在,我们可以通过查找 body 标签的子标签来获取标签:

