网页新闻抓取(基于文本及符号密度的网页正文提取方法(图) )
优采云 发布时间: 2021-09-22 08:09网页新闻抓取(基于文本及符号密度的网页正文提取方法(图)
)
项目来源
开发这个项目,我发现了来自自动化算法的纸张,以提取Hownet中的新闻网站文本 - “基于文本密度和符号文本提取方法”)
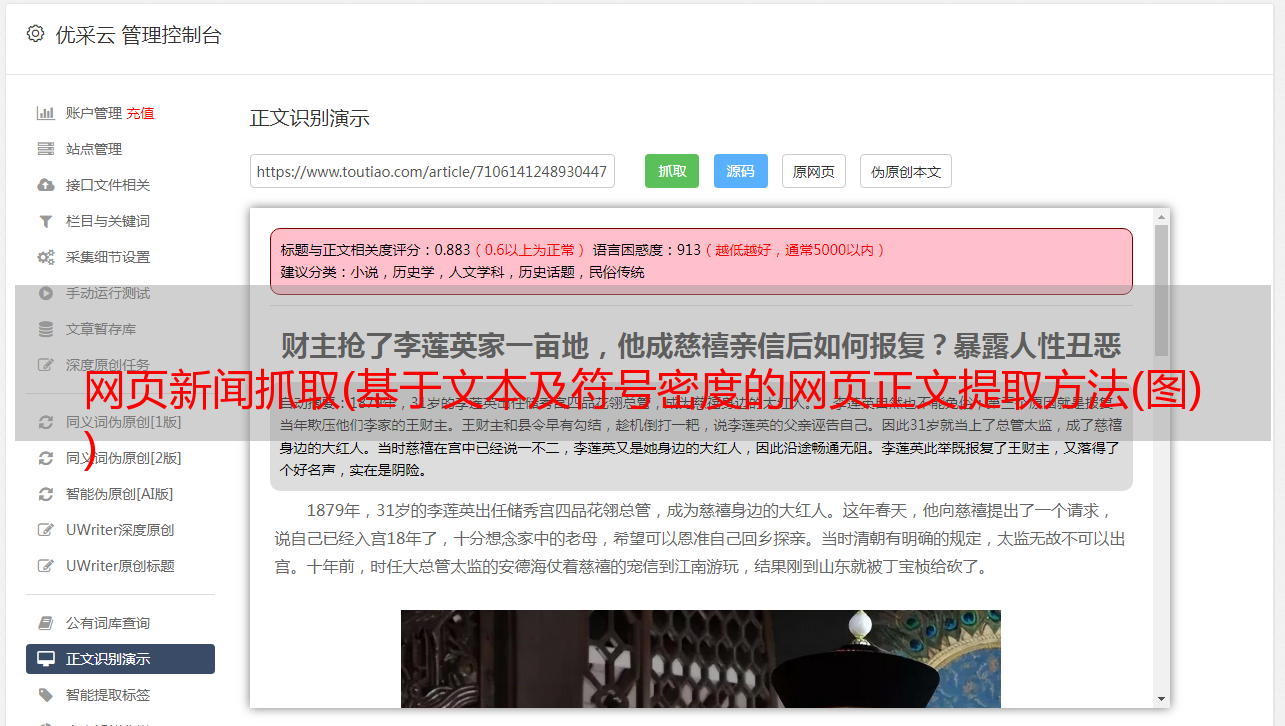
本文描述的算法看起来简单明了,逻辑。但是,由于纸质讨论了算法的原理,没有特定的语言,因此我根据纸张使用提取器的Python实现。并使用今天的头条新闻,网易新闻,无家可归的天空,观察者,凤凰,腾讯新闻,Readhub,新浪新闻做了一个测试,发现提取物非常好,几乎能够实现100%的准确性。
项目状态
本文中描述的文本,基于提取,我添加了标题,文章发布了作者自动检测和功能提取。
目前这个项目是一个非常非常早期的演示,发布它希望尽快让每个人的反馈,以实现更好的目标开发。
命名为提取器,而不是爬行动物,以避免不必要的风险,因此,该项目的输入是HTML,输出为字典。请使用适当的方法获取自己的目标网站 HTML。
项目现在没有,无法在将来提供网站 html函数的主动性。
如何使用在线体验
如果您想体验GNE提取的影响,那么您可以访问。在正常情况下,您只需要将其粘贴到多行文本框的顶部页面中,然后提取按钮。通过更多其他参数,允许更精确地提取。编写特定参数的操作,请参阅
环境
如果要体验GNE功能,请按照以下步骤操作:
安装gne
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade gne
# 使用 pipenv 安装
pipenv install gne
使用gne提取文本
> >来自GNE Import GeneralNewsextractor≫ > > html ='''呈现页面html代码''''> > > Extractor = GeneralNewsextractor()> > >结果= Extractor .Extract(HTML,HOTE_NODE_LIST = ['// div [@ class =“注释列表”list“”)> > >打印(结果){“title”:“xxxx”,“publish_time”:“2019 -09-10 11:12:13”,“作者”:“yyy”,“内容”:“zzzz”,“图像”: [“/xxx.jpg”,“/yyy.png”]}“>
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
有关详细说明,请参阅文档GNE
提取列表页面(beta)
&gt ;; &gt
来自GNE Import ListPapeExtractor> > > html ='''呈现页面html代码''''> > > list_extractor = listpageExtractor()> > >结果= list_extractor .Extract(html,feature ='任何元素xpath的列表“)>>>打印(结果)”
>>> from gne import ListPageExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> list_extractor = ListPageExtractor()
>>> result = list_extractor.extract(html,
feature='列表中任意元素的 XPath")
>>> print(result)
开发环境
如果您需要参加该项目的开发,请按照以下步骤操作。
如果要读取源代码,现在请直接按键盘上的句点键(即,留下问号),您可以获得更好的阅读体验。
本项目使用第三方库的Python Pipenv管理。如果你不知道pipenv是什么,请把我指向跳。
后
已安装pipenv,按以下步骤运行代码:
git clone https://github.com/kingname/GeneralNewsExtractor.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特殊说明
example.py项目代码提供了项目使用的基本示例。
元素选项卡在标签中位于,右侧,选择复制 - 复制offichtml,如图所示
图。
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,上面的措辞将能够解决问题。
但是,将有一些新闻页面评论下面,可能有长啰嗦的评论,它们看起来比真正的新闻更像是文本的正文,所以Extractor.extract()方法有一个默认参数kide_node_list,对于网页提前预处理以查看整个区域被删除。
keate_mode_list值是一个列表,一个列表,其中每个元素是xpath,对应于您提前需要的目标标签删除,可能会导致干扰。
例如,与以*敏*感*词*释XPath对应的查看器Web区域为// div [@ class =“注释列表”。因此,当提取观察者网络时,为了防止干扰评论,可以添加此参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
gne将基于此XPath,自动查找其他数据线内的列表。
运行射击网易新闻
今天的头条新闻
新浪新闻
p> phoenix