分享文章:呆错文章管理系统一键API采集与绑定分类的图文教程-呆错后台管理框架
优采云 发布时间: 2022-12-08 04:52分享文章:呆错文章管理系统一键API采集与绑定分类的图文教程-呆错后台管理框架
采集功能介绍(文章管理系统的核心采集功能包括以下三个模块)
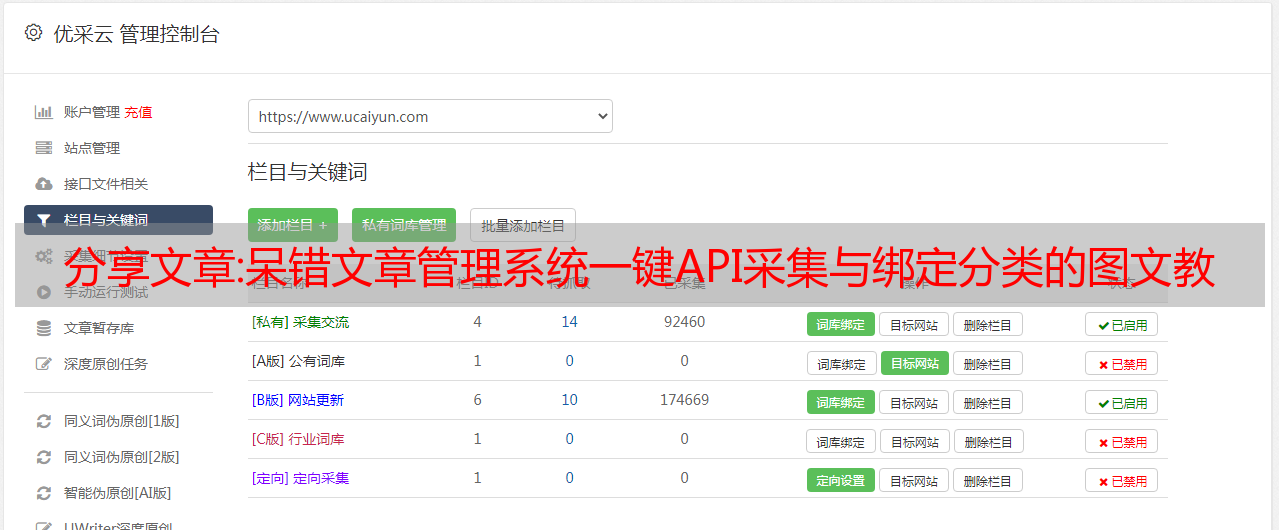
API采集设置
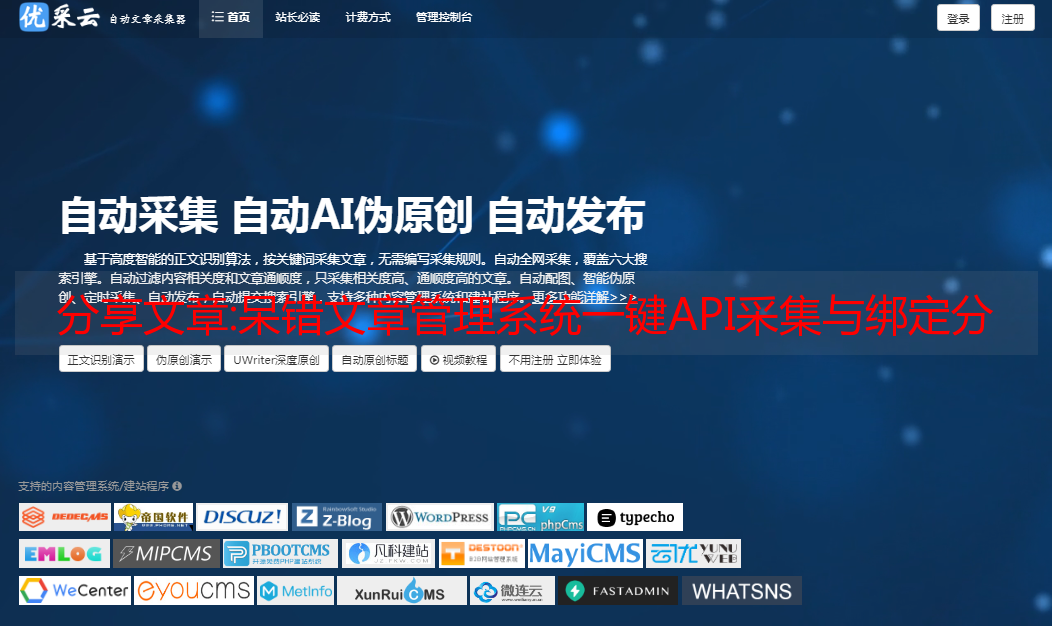
了解文章管理系统的采集功能后,我们使用API客户端连接采集API服务器。我们只需要在后台填写网址和密码即可。点击它(背景 > 文章 > 采集 管理)添加 采集。
API采集转换分类
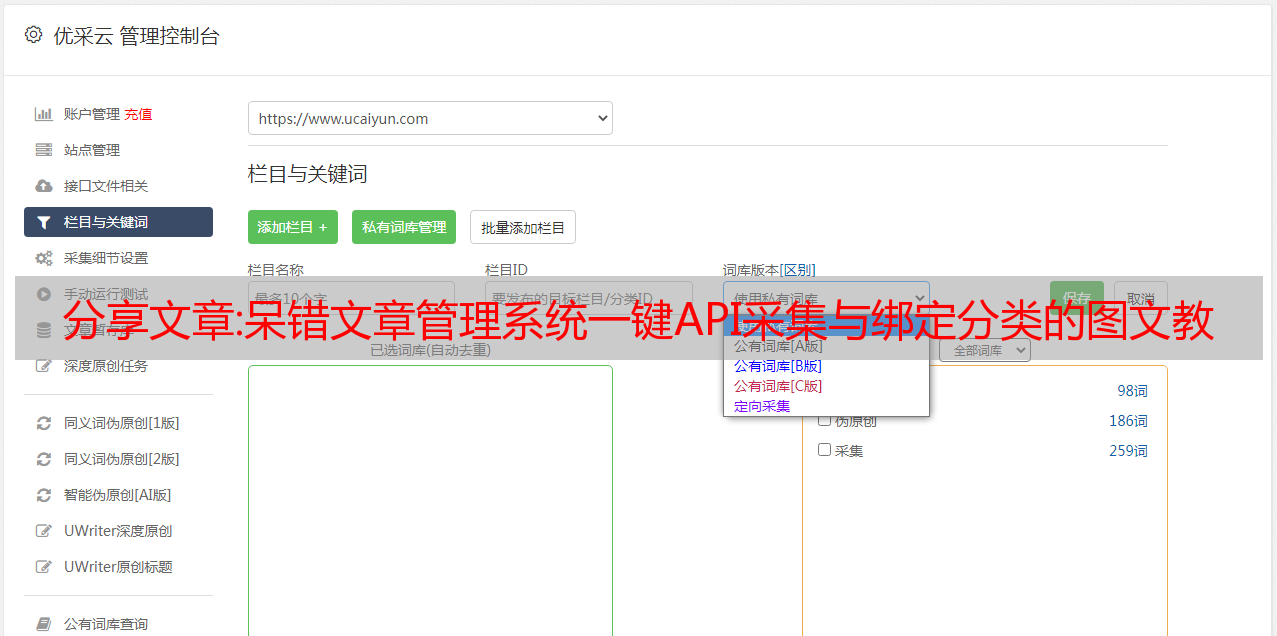
当资源站的分类不是我们想要的分类名称或者分类已经在我们自己的文章系统中构建时,这时候就需要使用“绑定分类”的功能,设置会弹出点击按钮框后up,只需要将需要转换或重命名的列类别一一重命名即可,如下图。
免费云采集 教程:步骤3:修改Xpath
前几天写的关于“大数据”的文章得到了很多朋友的认可。“它从哪里来的?
我们可以简单列举:
1、企业产生的用户数据
比如BAT这样的公司,拥有庞大的用户群,用户的任何行为都会成为他们数据源的一部分
2、数据平台购买数据
比如从全国数据中心数据市场购买等。
3. 政府机构公开数据
比如统计局和银行的公开数据。
4.数据管理公司
比如艾瑞咨询等。
5.爬虫获取网络数据
利用网络爬虫技术爬取网络数据以供使用。
所以其实对于中小企业或者个人来说,想要获取“大数据或者海量数据”,最划算的方法就是利用“网络爬虫技术”来获取有效数据,所以“网络爬虫技术”这几年也很流行!
今天我就来给大家讲解一下“网络爬虫技术的原理与实现”!
1、什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常被称为网络追赶者)是一种按照一定规则自动抓取万维网上信息的程序或脚本。简单地说,它是一个请求网站并提取数据的自动化程序。
最著名的网络爬虫应用程序是谷歌和百度的应用程序。
这两大搜索引擎每天都会从互联网上抓取大量的数据,然后对数据进行分析处理,最后通过搜索展现给我们。可以说网络爬虫是搜索引擎的基础!
2. 网络爬虫的工作流程和原理
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成镜像备份或网络内容。
(1) 网络爬虫的基本结构和工作流程
一般网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一部分精挑细选的*敏*感*词*网址;
2、将这些网址放入待抓取的网址队列中;
3、从待抓网址队列中取出待抓网址,解析DNS,获取主机ip,下载该网址对应的网页,存入下载的网页库中。另外,将这些网址放入已抓取的网址队列中。
4、分析已经抓取的URL队列中的URL,分析其中的其他URL,将URL放入待抓取的URL队列中,进入下一个循环。
(2) 从爬虫的角度划分互联网
相应地,互联网上的所有页面都可以分为五个部分:
1.下载过期的网页
2、下载过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的部分内容发生了变化。这时,这部分抓取的网页已经过期了。
3.待下载网页:待抓取的URL队列中的那些页面
4、可知网页:尚未被抓取的URL,不在待抓取的URL队列中,但可以通过分析已抓取的页面或待抓取的URL对应的页面得到,是被认为是已知网页。
5、还有一些网页是爬虫无法直接爬取下载的。称为不可知页面。
(3) 爬取策略
在爬虫系统中,待爬取的URL队列是一个非常重要的部分。URL队列中待抓取的URL的排列顺序也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。我们以下图为例:
遍历路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入待抓取的URL队列的尾部。也就是说,网络爬虫会先爬取初始网页中链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页中链接的所有网页。还是以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接的数量是指一个网页被其他网页的链接指向的次数。反向链接数表示网页内容被其他人推荐的程度。因此,在很多情况下,搜索引擎的抓取系统会使用这个指标来评估网页的重要性,从而决定抓取不同网页的顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不可能完全等于其他链接的重要性。因此,搜索引擎倾向于考虑一些可靠数量的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要抓取的URL队列中的URL,组成一个网页集合,计算每个页面的PageRank值。计算完成后,将要抓取的URL队列中的URL进行计算,URL按照PageRank值的高低排序,依次抓取页面。
如果每次抓取一个页面都重新计算PageRank值,折衷的做法是:每抓取K页后,重新计算PageRank值。但是这种情况还有一个问题:对于下载页面中分析出来的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:从这个网页的所有传入链接传入的PageRank值会被聚合,从而形成未知页面的PageRank值,从而参与排行。以下示例说明:
5. OPIC战略策略
该算法实际上是页面的重要性分数。在算法开始之前,给所有页面相同的初始*敏*感*词*(cash)。某个页面P被下载后,将P的*敏*感*词*分配给从P分析出来的所有链接,P的*敏*感*词*清空。待抓取的 URL 队列中的所有页面都按照*敏*感*词*数量排序。
6、大站点优先策略
对于所有待抓取的URL队列中的网页,根据它们的网站进行分类。对于网站有大量需要下载的页面,会优先下载。因此该策略也称为大站优先策略。
(4)更新策略
互联网是实时变化的,而且是高度动态的。网页更新策略主要是决定什么时候更新之前下载过的页面。常见的更新策略有以下三种:
1.历史参考策略
顾名思义,就是根据过去页面的历史更新数据,预测未来页面什么时候会发生变化。通常,预测是通过对泊松过程建模来进行的。
2. 用户体验策略 虽然搜索引擎可以针对某个查询条件返回数量庞大的结果,但用户往往只关注结果的前几页。因此,爬虫系统可以优先更新那些出现在查询结果前几页的页面,然后再更新后面的那些页面。此更新策略还需要使用历史信息。用户体验策略保留了网页的多个历史版本,根据过去每次内容变化对搜索质量的影响,得到一个平均值,以此值作为决定何时重新抓取的依据。3.整群抽样策略
上述两种更新策略都有一个前提:都需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页根本没有历史信息,则无法确定更新策略。
该策略认为网页有很多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某类网页的更新频率,只需要对该类网页进行采样,将其更新周期作为整个类的更新周期即可。基本思路如下:
(5) 分布式爬虫系统结构 一般来说,爬虫系统需要面对整个互联网上亿级的网页。单个爬虫无法完成这样的任务。通常需要多个抓取器一起处理。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
底层是分布在不同地理位置的数据中心。每个数据中心都有若干个爬虫服务器,每个爬虫服务器上可能会部署几套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于一个数据中心的不同服务器,有几种协同工作的方式:
1.主从
主从基本结构如图所示:
对于主从模式,有一个专门的Master服务器来维护要抓取的URL队列,负责将每次抓取的URL分发给不同的Slave服务器,Slave服务器负责实际的网页下载工作. Master服务器除了维护要抓取的URL队列和分发URL外,还负责调解各个Slave服务器的负载。为了防止一些Slave服务器太闲或者太累。
在这种模式下,Master容易成为系统的瓶颈。
2.点对点
点对点方程的基本结构如图所示:
在这种模式下,所有的爬虫服务器都没有分工差异。每个爬取服务器可以从需要爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,然后计算H mod m(其中m为服务器数量,上图为例如,m 为 3),计算出的数量就是处理该 URL 的主机的数量。
示例:假设对于URL,计算器哈希值H=8,m=3,则H mod m=2,所以编号为2的服务器爬取该链接。假设此时server 0拿到了url,就会把url传给server 2,由server 2抓取。
这种模型的一个问题是,当一台服务器挂掉或添加一台新服务器时,所有 URL 的哈希余数的结果都会发生变化。也就是说,这种方法的可扩展性不好。针对这种情况,提出了另一种改进方案。这种改进方案是通过一致性哈希来确定服务器分工。
其基本结构如图所示:
Consistent Hashing对URL的主域名进行哈希运算,映射为0-232之间的数字。这个范围平均分配给m台服务器,根据url主域名哈希运算的取值范围来判断爬取哪个服务器。
如果某台服务器出现问题,本该由该服务器负责的网页就会被顺时针顺时针抓取到下一台服务器。这样即使某台服务器出现问题,也不会影响其他工作。
3. 常见网络爬虫的种类
1. 通用网络爬虫
爬取目标资源 在整个互联网中,爬取的目标数据是巨大的。爬取性能要求非常高。应用于大型搜索引擎,具有很高的应用价值。
一般网络爬虫的基本组成:初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等。
一般网络爬虫的爬取策略:主要有深度优先爬取策略和广度优先爬取策略。
2. 专注爬虫
在与主题相关的页面中定位抓取目标
主要用于特定信息的爬取,主要为特定人群提供服务
重点介绍网络爬虫的基本组成:初始URL、URL队列、页面爬取模块、页面分析模块、页面数据库、连接过滤模块、内容评估模块、链接评估模块等。
专注于网络爬虫的爬取策略:
1)基于内容评价的爬虫策略
2)基于链接评价的爬虫策略
3)基于强化学习的爬虫策略
4)基于上下文图的爬虫策略
3.增量网络爬虫
增量更新是指更新时只更新变化的部分,不更新未变化的部分。只抓取内容发生变化的网页或新生成的网页,可以在一定程度上保证抓取到的网页。, 如果可能的话,一个新的页面
4.深网爬虫
Surface网页:无需提交表单,使用静态链接即可到达的静态网页
Deep Web:隐藏在表单后面,无法通过静态链接直接获取。是提交某个关键词后才能获得的网页。
深网爬虫最重要的部分是填表部分
深网爬虫的基本组成:URL列表、LVS列表(LVS是指标签/值集合,即填写表单的数据源)爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析装置等
深网爬虫填表分为两种:
基于领域知识的表单填写(构建一个关键词库来填写表单,需要的时候根据语义分析选择对应的关键词进行填写)
基于网页结构分析的表单填写(一般在字段有限的情况下使用,该方法会根据网页结构进行分析,自动填写表单)
四、教你实现一个简单的网络爬虫
(1)、爬虫流程
在构建程序之前,我们首先需要了解一下爬虫的具体过程。
一个简单的爬虫程序有以下过程:
用文字表达,就是:
1、从任务库(可以是MySQL等关系型数据库)中选择*敏*感*词*URL;
2.在程序中初始化一个URL队列,将*敏*感*词*URL加入到队列中;
3、如果URL队列不为空,则将队列头部的URL出队;如果 URL 队列为空,程序将退出;
4、程序根据出队的URL反映对应的解析类,同时创建一个新的线程开始解析任务;
5、程序会下载该URL指向的网页,判断该页面是详情页还是列表页(如博客中的博客详情、博文列表)。如果是详情页,它会解析出页面内容存入数据库。如果是列表页,则提取页面链接加入URL队列;
6.解析任务完成后,重复步骤3。
(二)程序结构
我们已经知道了爬虫的具体流程,现在我们需要一个合理的程序结构来实现它。
首先介绍一下这个简单的爬虫程序的主要结构组件:
然后,看看程序中的工具类和实体类。
最后,根据类的作用,我们将其放置在上面流程图中的相应位置。具体*敏*感*词*如下:
我们现在已经完成了实际流程到程序逻辑的翻译。接下来,我们将通过源码的介绍,深入到程序的细节。
(3)、任务调度、初始化队列
在简单的爬虫程序中,任务调度和初始化队列都是在SpiderApplication类中完成的。
(4)、插件工厂
在URL循环调度中,有一个语句需要我们注意:
AbstractPlugin plugin = PluginFactory.getInstance().getPlugin(task);
其中,AbstractPlugin是继承自Thread的抽象插件类。
这个语句的意思是插件工厂根据url实例化继承自AbstractPlugin的指定插件。
插件工厂也可以理解为解析类工厂。
在这个程序中,插件工厂的实现主要依赖三个方面:
1.插件
包插件;
导入 java.lang.annotation.*;
/**
* 插件说明
*
* @作者熊猫
* @日期 2017/12/01
*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
公共@interface插件{
String value() 默认"";
}
Plugin其实是一个注解接口,在Plugin的支持下,我们可以通过注解@Plugin让程序识别插件类。这就好比在SpringMVC中,我们通过@[emailprotected]等来标识每一个Bean。
2.Xmu插件
@Plugin(值="")
公共类 XmuPlugin 扩展 AbstractPlugin {
}
XmuPlugin是众多插件(解析类)中的一种,作用由注解@Plugin标注,其具体标识(即对应于哪个url)由注解中的值标注。
3.插件工厂
包装厂;
*敏*感*词*实体。任务;
导入 org.slf4j.Logger;
导入 org.slf4j.LoggerFactory;
导入插件.AbstractPlugin;
导入插件。插件;
导入 util.CommonUtil;
导入java.io.文件;
导入 java.lang.annotation.Annotation;
导入 java.lang.reflect.Constructor;
导入 java.util.ArrayList;
导入 java.util.HashMap;
导入java.util.List;
导入 java.util.Map;
/**
* 插件工厂
*
* @作者熊猫
* @日期 2017/12/01
*/
公共类 PluginFactory {
私有静态最终记录器记录器 = LoggerFactory。getLogger(PluginFactory.class);
private static final PluginFactory factory = new PluginFactory();
私有列表> classList = new ArrayList>();
private Map pluginMapping = new HashMap();
私人插件工厂(){
扫描包(“插件”);
如果 (classList.size() > 0) {
初始化插件映射();
}
}
公共静态 PluginFactory getInstance() {
返厂;
}
/**
* 扫描包、分包
*
* @param 包名
*/
私人无效扫描包(字符串包名){
尝试 {
字符串路径 = getSrcPath() + 文件。分隔符 + changePackageNameToPath(packageName);
文件目录=新文件(路径);
文件 [] 文件 = 目录。列表文件();
如果(文件==空){
logger.warn("包名不存在!");
返回;
}
对于(文件文件:文件){
如果(文件。isDirectory()){
scanPackage(packageName + "."+ file.getName());
} 别的 {
Class clazz = Class.forName(packageName + "."+ file.getName().split("\.")[0]);
classList.add(clazz);
}
}
} 赶上(异常 e){
logger.error("扫描包异常:", e);
}
}
/**
* 获取根路径
*
* @返回
*/
私有字符串 getSrcPath() {
返回系统。getProperty("用户目录") +
文件分隔符+"src"+
文件分隔符+"main"+
文件分隔符 + "java";
}
/**
* 将包名转换为路径格式
*
* @param 包名
* @返回
*/
私有字符串 changePackageNameToPath(String packageName) {
返回 packageName.replaceAll("\.", File.separator);
}
/**
* 初始化插件容器
*/
私有无效 initPluginMapping() {
对于(类克拉兹:类列表){
注释 annotation = clazz. getAnnotation(插件。类);
如果(注释!= null){
pluginMapping.put(((插件)注解).value(), clazz.getName());
}
}
}
/**
* 通过反射实例化插件对象
* @param 任务
* @返回
*/
public AbstractPlugin getPlugin(任务任务){
if (task == null || task.getUrl() == null) {
logger.warn("非法任务!");
返回空值;
}
如果 (pluginMapping.size() == 0) {
logger.warn("当前包中没有插件!");
返回空值;
}
对象对象=空;
字符串插件名称 = CommonUtil。getHost(task.getUrl());
字符串 pluginClass = pluginMapping。得到(插件名称);
如果(pluginClass == null){
logger.warn("没有名为"+ pluginName +"的插件");
返回空值;
}
尝试 {
("找到解析插件:"+ pluginClass);
阶级克拉兹=阶级。名称(插件类);
构造函数构造函数= clazz。getConstructor(任务。类);
对象 = 构造函数。新实例(任务);
} 赶上(异常 e){
logger.error("反射异常:", e);
}
返回(抽象插件)对象;
}
}
PluginFactory 有两个主要功能:
扫描插件包下@Plugin注解的插件类;
根据 url 反射指定插件类。
(5)、分析插件
正如我们上面所说,分析插件其实对应于每一个网站分析类。
在实际的爬虫分析中,总会有很多类似甚至相同的分析任务,比如链接提取。因此,在分析插件中,我们首先要实现一个父接口来提供这些公共方法。
在这个程序中,插件父接口就是上面提到的AbstractPlugin类:
包插件;
*敏*感*词*实体。任务;
*敏*感*词*过滤器。和过滤器;
*敏*感*词*过滤器。文件扩展过滤器;
*敏*感*词*过滤器。链接提取器;
*敏*感*词*过滤器。链接过滤器;
导入 mons.lang3.StringUtils;
导入 org.slf4j.Logger;
导入 org.slf4j.LoggerFactory;
导入服务.DownloadService;
导入 util.CommonUtil;
导入 java.util.ArrayList;
导入java.util.List;
/**
* 插件抽象类
*
* @作者熊猫
* @日期 2017/12/01
*/
公共抽象类 AbstractPlugin 扩展线程 {
私有静态最终记录器记录器 = LoggerFactory。getLogger(AbstractPlugin.class);
受保护的任务任务;
protected DownloadService downloadService = new DownloadService();
私有列表 urlList = new ArrayList();
公共抽象插件(任务任务){
this.task = 任务;
}
@覆盖
公共无效运行(){
("{} 开始运行...", task.getUrl());
字符串主体 = 下载服务。getResponseBody(任务);
如果 (StringUtils.isNotEmpty(body)) {
如果 (isDetailPage(task.getUrl())) {
("开始解析详情页...");
解析内容(正文);
} 别的 {
("开始解析列表页...");
提取页面链接(正文);
}
}
}
public void extractPageLinks(String body) {
LinkFilter hostFilter = new LinkFilter() {
字符串 urlHost = CommonUtil。getUrlPrefix(task.getUrl());
公共布尔接受(字符串链接){
返回链接。收录(urlHost);
}
};
String[] fileExtensions = (".xls,.xml,.txt,.pdf,.jpg,.mp3,.mp4,.doc,.mpg,.mpeg,.jpeg,.gif,.png,.js,.邮编,"+
".rar,.exe,.swf,.rm,.ra,.asf,.css,.bmp,.pdf,.z,.gz,.tar,.cpio,.class").split("," );
LinkFilter fileExtensionFilter = new FileExtensionFilter(fileExtensions);
AndFilter filter = new AndFilter(new LinkFilter[]{hostFilter, fileExtensionFilter});
urlList = 链接提取器。extractLinks(task.getUrl(), body, filter);
}
公共列表 getUrlList() {
返回网址列表;
}
public abstract void parseContent(String body);
public abstract boolean isDetailPage(String url);
}
父接口定义了两条规则:
解析规则,即何时解析文本,何时提取列表链接;
提取链接规则,即过滤掉哪些不需要的链接。
但是我们注意到父接口中用来解析网站 body内容的parseContent(String body)是一个抽象方法。而这正是实际的插件类应该做的。这里,我们以 XmuPlugin 为例:
包插件;
*敏*感*词*实体。任务;
导入 org.jsoup.nodes.Document;
导入 org.jsoup.nodes.Element;
导入 org.jsoup.select.Elements;
导入 org.slf4j.Logger;
导入 org.slf4j.LoggerFactory;
导入 util.CommonUtil;
导入 util.FileUtils;
导入 java.text.SimpleDateFormat;
导入java.util.Date;
/**
* xmu插件
*
* @作者熊猫
* @日期 2017/12/01
*/
@Plugin(值="")
公共类 XmuPlugin 扩展 AbstractPlugin {
私有静态最终记录器记录器 = LoggerFactory。getLogger(XmuPlugin.class);
公共 XmuPlugin(任务任务){
超级(任务);
}
@覆盖
public void parseContent(String body) {
文档 doc = CommonUtil. 获取文档(正文);
尝试 {
String title = doc.select("p.h1").first().text();
String publishTimeStr = doc.select("p.right-content").first().text();
publishTimeStr = CommonUtil.match(publishTimeStr,"(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2} )")[1];
日期发布时间 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(publishTimeStr);
字符串内容=””;
元素元素 = 文档。选择(“p.MsoNormal”);
对于(元素元素:元素){
内容 +="\n"+ 元素。文本();
}
("标题:"+标题);
("发布时间:"+ 发布时间);
(“内容:”+内容);
FileUtils.writeFile(title + ".txt", 内容);
} 赶上(异常 e){
logger.error("解析内容异常:"+ task.getUrl(), e);
}
}
@覆盖
public boolean isDetailPage(String url) {
返回 CommonUtil.isMatch(url,"&a=show&catid=\d+&id=\d+");
}
}
在 XmuPlugin 中,我们做了两件事:
定义详情页的具体规则;
解析出具体的文本内容。
(6)、采集例子
至此,我们就成功完成了Java简单爬虫程序。接下来,让我们看看采集的实际情况。
5.分享几个好用的网络爬虫工具和教程
很多人看了文章,会说写的文章太深奥,需要编程才能实现数据爬取。有什么简单的方法或工具可以实现吗?解决后给大家分享几个好用的网络爬虫工具,使用起来非常简单,也可以达到相应的效果。
1. 优采云云爬虫
官方网站:
简介:优采云Cloud是一个大数据应用开发平台,为开发者提供一整套数据采集、数据分析和机器学习开发工具,为企业提供专业的数据抓取和实时监控。数据监控和数据分析服务。
优势:功能强大,涉及云爬虫、API、机器学习、数据清洗、数据售卖、数据定制和私有化部署等;
纯云端操作,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础用户可直接调用开发的爬虫,开发者基于官方云开发环境开发上传自己的爬虫程序;
领先的防爬技术,如直接获取代理IP、自动识别登录验证码等,全程自动化,无需人工参与;
丰富的发布接口,采集结果以丰富的表格形式展示;
缺点:它的优点在一定程度上也成为了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能。网站看起来很技术很专业,虽然官网也提供了云爬虫市场等现成的爬虫产品,面向广大爬虫开发者开放,丰富爬虫市场的内容,零技术基础的用户不太容易看懂,所以有一定的使用门槛。
是否免费:免费用户没有采集功能和出口限制,不需要积分。
有开发能力的用户可以自行开发爬虫实现免费效果,没有开发能力的用户需要到爬虫市场寻找免费的爬虫。
2. 优采云采集器
官方网站:
简介:优采云采集器是一个可视化的采集器,内置采集模板,支持各种网页数据采集。
优点:支持自定义模式,可视采集操作,简单易用;
支持简单采集模式,提供官方采集模板,支持云端采集操作;
支持代理IP切换、验证码服务等反屏蔽措施;
支持多种数据格式导出。
缺点:功能使用门槛比较高,很*敏*感*词*在本地采集有限制,云端采集收费较高;
采集速度比较慢,很多操作都要卡。云采集说快了10倍但是不明显;
仅支持 Windows 版本,不支持其他操作系统。
是否免费:号称免费,但实际上导出数据需要积分,可以做任务积累积分,但一般情况下基本需要购买积分。
3. 优采云采集器
官方网站:
简介: 优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。
优点:支持智能采集模式,输入URL即可智能识别采集对象,无需配置采集规则,操作非常简单;
支持流程图模式,可视化操作流程,可以通过简单的操作生成各种复杂的采集规则;
支持反屏蔽措施,如代理IP切换等;
支持多种数据格式导出;
支持定时采集和自动发布,丰富的发布接口;
支持 Windows、Mac 和 Linux 版本。
缺点:软件发布时间不长,部分功能还在完善中,暂时不支持云端采集功能
是否免费:完全免费,采集数据和手动导出采集结果没有限制,不需要积分
4.使用“优采云采集器”来爬取数据实例
使用优采云采集瀑布网站图片(百度图片采集
例如)方法。
采集网站:
%E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90
第 1 步:创建一个 采集 任务
1)进入主界面,选择自定义模式
2)将上述网址的网址复制粘贴到网站输入框中,点击“保存网址”
3) 系统自动打开网页。我们发现百度图片网是一个瀑布网页,每次下拉加载都会出现新的数据。当图片足够多的时候,可以加载无数次。所以本网页涉及到AJAX技术,需要设置AJAX超时时间,保证采集时不会遗漏数据。
选择“打开网页”步骤,打开“高级选项”,勾选“页面加载后向下滚动”,设置滚动次数为“5次”(根据自己需要设置),时间为“2秒”,以及“向下滚动一屏”的滚动方法;最后点击“确定”
注:例如网站,没有翻页按钮,滚动次数和滚动方式会影响数据量采集,可根据需要设置
第 2 步:采集 图片网址
1) 选择页面第一张图片,系统会自动识别相似图片。在操作提示框中,选择“全选”
2)选择“采集以下图片地址”
第 3 步:修改 XPath
1) 选择“循环”步骤并打开“高级选项”。可以看到优采云系统自动使用“不固定元素列表”循环,Xpath为: //DIV[@id='imgid']/DIV[1]/UL[1]/LI
2)复制这个Xpath://DIV[@id='imgid']/DIV[1]/UL[1]/LI到火狐浏览器中观察——只能定位到网页中的22张图片
3)我们需要一个能够在网页中定位所有需要的图片的XPath。观察网页源码,修改Xpath为://DIV[@id='imgid']/DIV/UL[1]/LI,网页中所有需要的图片都位于
4)将修改后的Xpath://DIV[@id='imgid']/DIV/UL[1]/LI复制粘贴到优采云中相应位置,完成后点击“确定”
5) 点击“保存”,然后点击“启动采集”,这里选择“启动本地采集”
第 4 步:数据 采集 和导出
1)采集完成后,会弹出提示,选择导出数据
2)选择合适的导出方式导出采集好的数据
第 5 步:将图像 URL 批量转换为图像
经过上面的操作,我们就得到了我们要采集的图片的url。接下来,使用优采云专用图片批量下载工具,将采集图片URL中的图片下载并保存到本地电脑。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式文件)
3)进行相关设置,设置完成后点击确定导入文件
选择EXCEL文件:导入你需要的EXCEL文件下载图片地址
EXCEL表名:对应数据表的名称
文件URL列名:表中URL对应的列名
保存文件夹名称:EXCEL中需要单独一栏列出图片要保存到文件夹的路径,可以设置不同的图片保存在不同的文件夹中
如果要将文件保存到文件夹中,路径需要以“\”结尾,例如:“D:\Sync\”,如果下载后要按照指定的文件名保存文件,则需要收录特定文件名,例如“D :\Sync
.jpg”如果下载的文件路径和文件名完全相同,则删除现有文件

