多逛逛,看看。我也只能从文档里学到的
优采云 发布时间: 2022-07-20 17:04多逛逛,看看。我也只能从文档里学到的
scrapy分页抓取网页:scrapy1。1。0中文文档网页浏览器分页:scrapy1。1。0中文文档scrapy-python文档|scrapy中文文档scrapy-siteapp文档|scrapy中文文档scrapy-crawler文档|scrapy中文文档scrapy-python中文文档scrapy-startpd爬虫框架中文文档:scrapy-siteapp中文文档scrapy-python中文文档。
scrapy0.3.0中文文档-scrapy中文文档和scrapy0.01版本-scrapy中文文档基于python的web服务器|scrapydocs
项目给出的docid
参考百度镜像站的csdn镜像站的scrapy教程,很全。我也是看别人的博客学到的。
可以直接用scrapy爬虫思想结合爬虫框架构建python爬虫框架scrapy
scrapy有中文文档
目前正在学习中,欢迎大家讨论。
能不能有个人*敏*感*词*教学的,免费的,
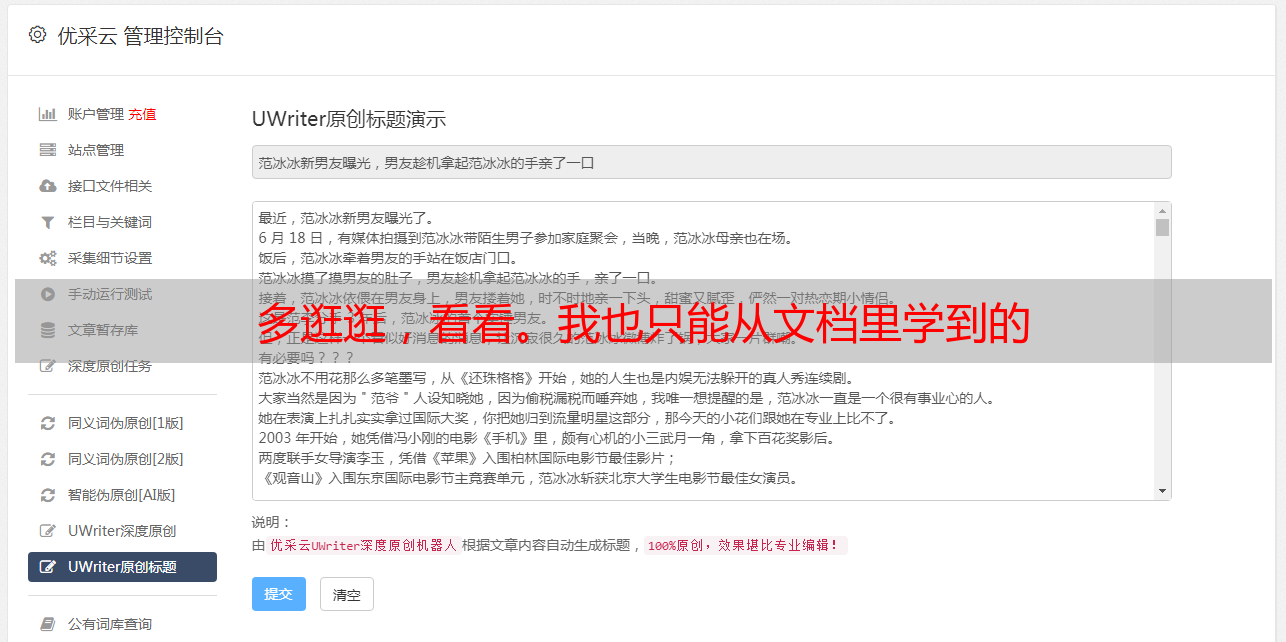
《scrapy中文文档》发布在爬虫资源网上scrapy中文文档:
如果你把http_response想象成scrapy对应文档的html_response的话,这个问题就迎刃而解了。
多逛逛,看看。
我也只能从文档里学到点皮毛。毕竟这本书大半不是我写的。只是入门水平。
让我看一下scrapy的运行过程,再让我看看http的协议有多简单,再让我运行用java写的代码,最后看看scrapy部署。大概需要一个月。

