爬虫 | 如何构建技术文章聚合平台(一)
优采云 发布时间: 2022-05-08 00:10爬虫 | 如何构建技术文章聚合平台(一)
博客地址:
背景
说到爬虫,大多数程序员想到的是scrapy这样受人欢迎的框架。scrapy的确不错,而且有很强大的生态圈,有gerapy等优秀的可视化界面。但是,它还是有一些不能做到的事情,例如在页面上做翻页点击操作、移动端抓取等等。对于这些新的需求,可以用Selenium、Puppeteer、Appium这些自动化测试框架绕开繁琐的动态内容,直接模拟用户操作进行抓取。可惜的是,这些框架不是专门的爬虫框架,不能对爬虫进行集中管理,因此对于一个多达数十个爬虫的大型项目来说有些棘手。
Crawlab是一个基于Celery的分布式通用爬虫管理平台,擅长将不同编程语言编写的爬虫整合在一处,方便监控和管理。Crawlab有精美的可视化界面,能对多个爬虫进行运行和管理。任务调度引擎是本身支持分布式架构的Celery,因此Crawlab可以天然集成分布式爬虫。有一些朋友认为Crawlab只是一个任务调度引擎,其实这样认为并不完全正确。Crawlab是类似Gerapy这样的专注于爬虫的管理平台。
本文将介绍如何使用Crawlab和Puppeteer抓取主流的技术博客文章,然后用Flask+Vue搭建一个小型的技术文章聚合平台。
Crawlab
在前一篇文章《分布式通用爬虫管理平台Crawlab》已介绍了Crawlab的架构以及安装使用,这里快速介绍一下如何安装、运行、使用Crawlab。(感兴趣的同学可以去作者的掘金主页查看)
安装
到Crawlab的Github Repo用克隆一份到本地。
<p>git clone https://github.com/tikazyq/crawlab
复制代码</p>
安装相应的依赖包和库。
<p>cd crawlab
<br />
# 安装python依赖
pip install -r crawlab/requirements
<br />
# 安装前端依赖
cd frontend
npm install
复制代码</p>
安装mongodb和redis-server。Crawlab将用MongoDB作为结果集以及运行操作的储存方式,Redis作为Celery的任务队列,因此需要安装这两个数据库。
运行
在运行之前需要对Crawlab进行一些配置,配置文件为config.py。
<p># project variables
PROJECT_SOURCE_FILE_FOLDER = '/Users/yeqing/projects/crawlab/spiders' # 爬虫源码根目录
PROJECT_DEPLOY_FILE_FOLDER = '/var/crawlab' # 爬虫部署根目录
PROJECT_LOGS_FOLDER = '/var/logs/crawlab' # 日志目录
PROJECT_TMP_FOLDER = '/tmp' # 临时文件目录
<br />
# celery variables
BROKER_URL = 'redis://192.168.99.100:6379/0' # 中间者URL,连接redis
CELERY_RESULT_BACKEND = 'mongodb://192.168.99.100:27017/' # CELERY后台URL
CELERY_MONGODB_BACKEND_SETTINGS = {
'database': 'crawlab_test',
'taskmeta_collection': 'tasks_celery',
}
CELERY_TIMEZONE = 'Asia/Shanghai'
CELERY_ENABLE_UTC = True
<br />
# flower variables
FLOWER_API_ENDPOINT = 'http://localhost:5555/api' # Flower服务地址
<br />
# database variables
MONGO_HOST = '192.168.99.100'
MONGO_PORT = 27017
MONGO_DB = 'crawlab_test'
<br />
# flask variables
DEBUG = True
FLASK_HOST = '127.0.0.1'
FLASK_PORT = 8000
复制代码</p>
启动后端API,也就是一个Flask App,可以直接启动,或者用gunicorn代替。
<p>cd ../crawlab
python app.py
复制代码</p>
启动Flower服务(抱歉目前集成Flower到App服务中,必须单独启动来获取节点信息,后面的版本不需要这个操作)。
<p>python ./bin/run_flower.py
复制代码</p>
启动本地Worker。在其他节点中如果想只是想执行任务的话,只需要启动这一个服务就可以了。
<p>python ./bin/run_worker.py
复制代码</p>
启动前端服务器。
<p>cd ../frontend
npm run serve
复制代码</p>
使用
首页Home中可以看到总任务数、总爬虫数、在线节点数和总部署数,以及过去30天的任务运行数量。
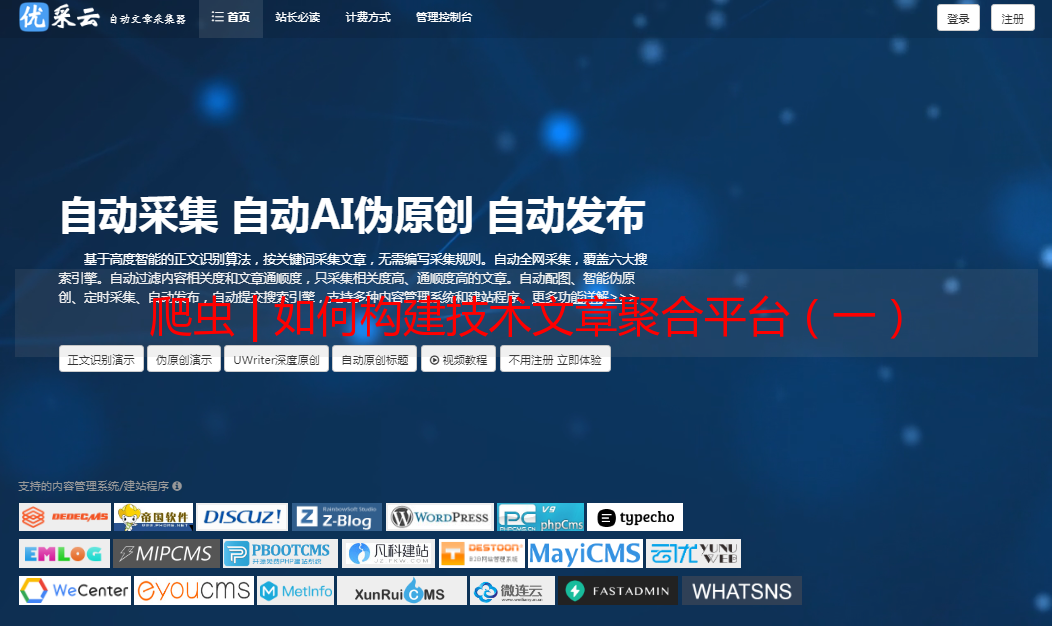
点击侧边栏的Spiders或者上方到Spiders数,可以进入到爬虫列表页。
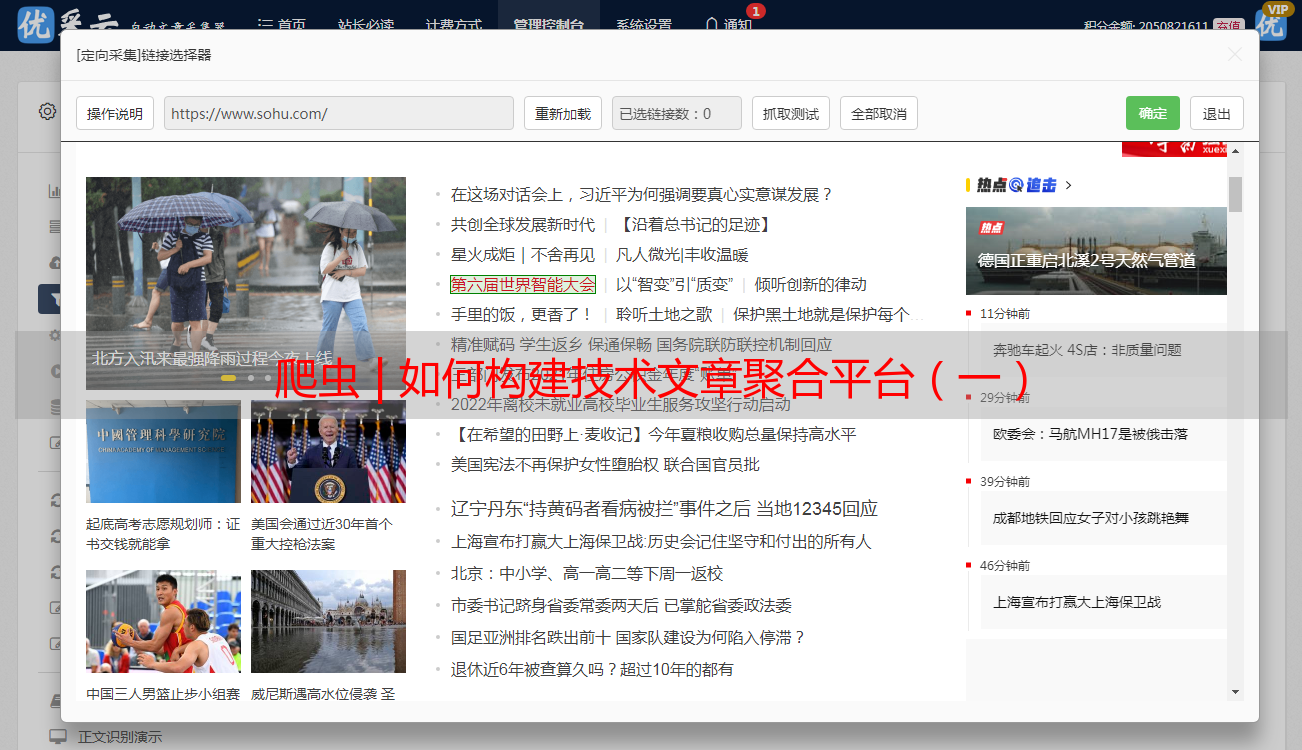
这些是爬虫源码根目录PROJECT_SOURCE_FILE_FOLDER下的爬虫。Crawlab会自动扫描该目录下的子目录,将子目录看作一个爬虫。Action列下有一些操作选项,点击部署Deploy按钮将爬虫部署到所有在线节点中。部署成功后,点击运行Run按钮,触发抓取任务。这时,任务应该已经在执行了。点击侧边栏的Tasks到任务列表,可以看到已经调度过的爬虫任务。
基本使用就是这些,但是Crawlab还能做到更多,大家可以进一步探索,详情请见Github。
Puppeteer
Puppeteer是谷歌开源的基于Chromium和NodeJS的自动化测试工具,可以很方便的让程序模拟用户的操作,对浏览器进行程序化控制。Puppeteer有一些常用操作,例如点击,鼠标移动,滑动,截屏,下载文件等等。另外,Puppeteer很类似Selenium,可以定位浏览器中网页元素,将其数据抓取下来。因此,Puppeteer也成为了新的爬虫利器。
相对于Selenium,Puppeteer是新的开源项目,而且是谷歌开发,可以使用很多新的特性。对于爬虫来说,如果前端知识足够的话,写数据抓取逻辑简直不能再简单。正如其名字一样,我们是在操作木偶人来帮我们抓取数据,是不是很贴切?
掘金上已经有很多关于Puppeteer的教程了(爬虫利器 Puppeteer 实战、Puppeteer 与 Chrome Headless —— 从入门到爬虫),这里只简单介绍一下Puppeteer的安装和使用。
安装
安装很简单,就一行npm install命令,npm会自动下载Chromium并安装,这个时间会比较长。为了让安装好的puppeteer模块能够被所有nodejs爬虫所共享,我们在PROJECT_DEPLOY_FILE_FOLDER目录下安装node的包。
<p># PROJECT_DEPLOY_FILE_FOLDER变量值
cd /var/crawlab
<br />
# 安装puppeteer
npm i puppeteer
<br />
# 安装mongodb
npm i mongodb
复制代码</p>
安装mongodb是为了后续的数据库操作。
使用
以下是Copy/Paste的一段用Puppeteer访问简书然后截屏的代码,非常简洁。
<p>const puppeteer = require('puppeteer');
<br />
(async () => {
const browser = await (puppeteer.launch());
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/40909ea33e50');
await page.screenshot({
path: 'jianshu.png',
type: 'png',
// quality: 100, 只对jpg有效
fullPage: true,
// 指定区域截图,clip和fullPage两者只能设置一个
// clip: {
// x: 0,
// y: 0,
// width: 1000,
// height: 40
// }
});
browser.close();
})();
复制代码</p>
关于Puppeteer的常用操作,请移步《我常用的puppeteer爬虫api》。
编写爬虫
啰嗦了这么久,终于到了万众期待的爬虫时间了。Talk is cheap, show me the code!咦?我们不是已经Show了不少代码了么...
由于我们的目标是建立一个技术文章聚合平台,我们需要去各大技术网站抓取文章。资源当然是越多越好。作为展示用,我们将抓取下面几个具有代表性的网站:
研究发*敏*感*词*为例着重讲解。
掘金
首先是引入Puppeteer和打开网页。
<p>const puppeteer = require('puppeteer');
const MongoClient = require('mongodb').MongoClient;
<br />
(async () => {
// browser
const browser = await (puppeteer.launch({
headless: true
}));
<br />
// define start url
const url = 'https://juejin.im';
<br />
// start a new page
const page = await browser.newPage();
<br />
...
<br />
})();
复制代码</p>
headless设置为true可以让浏览器以headless的方式运行,也就是指浏览器不用在界面中打开,它会在后台运行,用户是看不到浏览器的。browser.newPage()将新生成一个标签页。后面的操作基本就围绕着生成的page来进行。
接下来我们让浏览器导航到start url。
<p> ...
<br />
// navigate to url
try {
await page.goto(url, {waitUntil: 'domcontentloaded'});
await page.waitFor(2000);
} catch (e) {
console.error(e);
<br />
// close browser
browser.close();
<br />
// exit code 1 indicating an error happened
code = 1;
process.emit("exit ");
process.reallyExit(code);
<br />
return
}
<br />
...
复制代码</p>
这里trycatch的操作是为了处理浏览器访问超时的错误。当访问超时时,设置exit code为1表示该任务失败了,这样Crawlab会将该任务状态设置为FAILURE。

