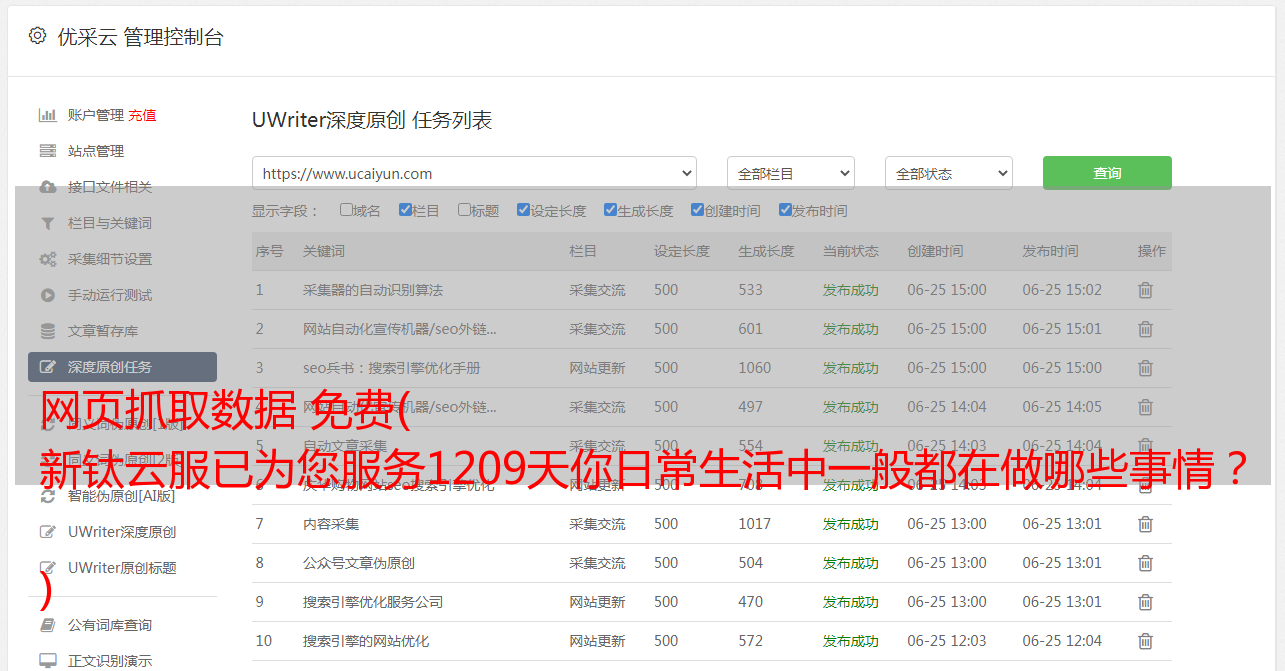
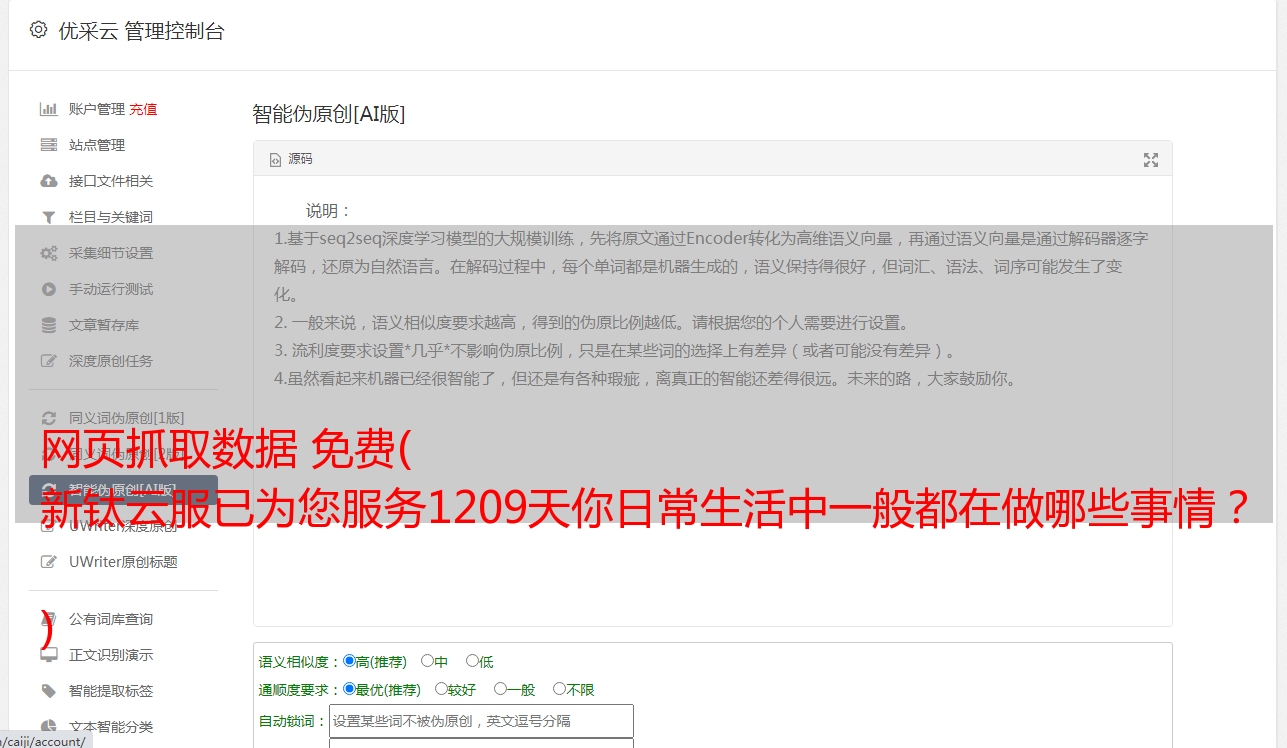
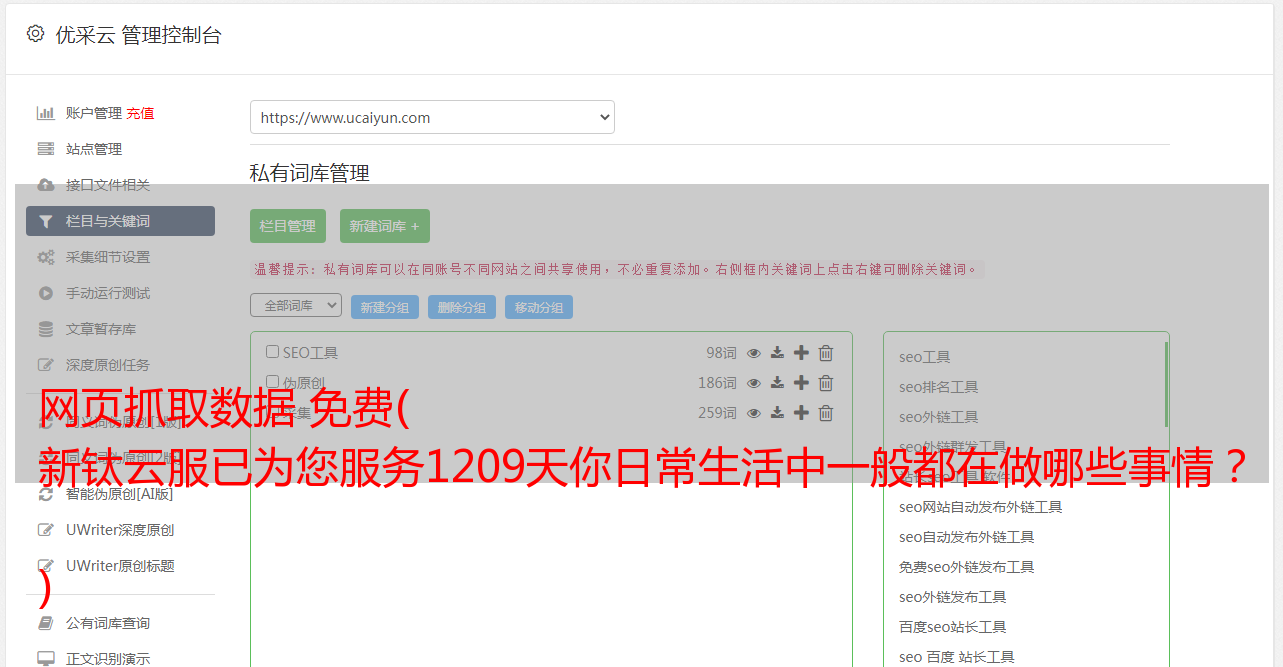
网页抓取数据 免费( 新钛云服已为您服务1209天你日常生活中一般都在做哪些事情? )
优采云 发布时间: 2022-04-19 13:40网页抓取数据 免费(
新钛云服已为您服务1209天你日常生活中一般都在做哪些事情?
)
新钛云服务已为您服务1209天
你在日常生活中通常会做什么?阅读新闻、发送电子邮件、寻找最优惠的价格或在线搜索工作?如您所知,这些任务中的大多数都可以通过网络抓取实现自动化。无需花费数小时浏览 网站,只需几分钟即可使用计算机。
网页抓取是从 网站 中提取数据的过程。学习网页抓取就像学习 Beautiful Soup、Selenium 或 Scrapy 等库如何在 Python 中工作一样简单。但是,如果您不能将所学的所有概念付诸实践,那就是浪费时间。
尝试网络抓取项目不仅可以帮助您学习网络抓取理论,还可以帮助您开发自动执行日常任务的机器人,并让您有动力学习这项新技能。在本文中,我列出了一些自动化大多数人每天遇到的任务的项目。项目按难度排列,所以初学者项目在开头,高级项目在文章的末尾。
一、自动化重复性任务
为了使第一个项目对初学者友好,我们将使用 Beautiful Soup,因为它是用于网络抓取的最简单的 Python 库。
该项目的目标是从任意网站(如新闻文章、帖子等)的一段文章中获取标题和正文段落。在此之后,将所有内容导出到 .txt 文件中,该文件的标题应为 文章。这个项目的演示可以在下面的 gif 中找到。在这种情况下,我没有抓取一条新闻文章,而是抓取了电影泰坦尼克号的文字。第一个项目的代码可以在我的 Github 上找到。
这个初学者项目将帮助我们熟悉 Python 中网页抓取的核心概念,例如如何从 网站 获取 HTML、在 网站 中查找元素以及将数据导出到 .txt 文件。
当然,您可以在不到一分钟的时间内手动复制粘贴数据并创建一个 .txt 文件;但现在想象一下这样做十个或更多文章!手动完成会花费很多时间,但是使用 Python 和 Beautiful Soup,我们可以创建一个脚本来提取数据,然后添加一个 for 循环以在几分钟内抓取多个页面。
下面列出了一些其他可以通过网络抓取自动执行的重复性任务。请记住,您将需要 Selenium 的基本知识来自动化它们(查看本指南以从头开始学习 Selenium)
一种。发送电子邮件
湾。在社交媒体上发布
C。点菜
二、获取足球数据:自动体育分析
如果您喜欢运动,每场比赛后您可以访问 网站,它提供免费的统计数据,例如最终得分和球员表现。在每场新游戏之后获取这些数据不是很酷吗?或者甚至更好地想象能够使用这些数据来创建报告,以找到有关您最喜欢的球队或联赛的有趣见解。
这是第二个项目的目标 - 获取收录您最喜欢的运动统计数据的 网站。大多数情况下,这种类型的数据在表格中,因此请确保以 CSV 格式导出数据,以便您可以使用 Pandas 库读取数据并在以后找到见解。为了更好地理解该项目,请查看下面的 gif。在那个演示中,我提取了过去 3 年中多个足球联赛的比赛得分。

大多数具有运动数据的网站都使用 javascript 来动态更新数据。这意味着我们不能在这个项目中使用 Beautiful Soup 库。相反,我们将使用 Selenium 单击一个按钮,在下拉列表中选择一个元素,然后提取所需的数据。
你可以在我的 Github 上找到这个项目的代码。您可以通过寻找在比赛中得分更多的球队来使这个项目更具挑战性。有了这个,您可以创建一个报告,告诉您具有高得分趋势的比赛。这将帮助您在分析足球比赛时做出更好的决定。在此链接上,您可以找到有关如何完成项目最后部分的指南。
三、Grab Job Portal:自动化求职
通过网络抓取可以降低找工作的难度。如果您手动进行,例如在多个页面中搜索新工作、检查特定工作和工资范围的要求,可能需要大约 20 分钟。幸运的是,所有这些都可以通过几行代码实现自动化。
在这个项目中,您应该创建一个爬取工作门户的机器人,以获取特定工作的要求和提供的薪水。您可以在此项目中使用 Beautiful Soup 或 Selenium,但方法会因您使用的库而异。
如果您使用 Beautiful Soup,请仅关注收录您希望抓取的最终数据的页面。你可以按照这个视频教程来帮助你开始这个项目。
话虽如此,我建议您使用 Selenium,因为您可以自由地在 网站 上做更多事情。最好的是,您可以在每次操作后运行代码,并在浏览器中查看机器人执行的步骤。要使用 Selenium 解决此问题,请考虑从您最喜欢的工作门户获取数据通常要遵循的所有步骤。
例如,访问 网站,写下职位名称,单击搜索按钮,然后浏览每个职位发布以提取任何相关信息。之后,使用 Selenium 库在 Python 中复制这些步骤。
四、抢产品价格:获得最优惠的价格
如果您试图为特定商品找到最优惠的价格,购物可能会变得很耗时。在 网站 上寻找汽车、电视和衣服的最优惠价格可能需要数小时;幸运的是,我们的下一个网络抓取项目将花费您几分钟的时间。
这是本文列出的最高级的项目,分为两部分。首先,访问您最喜欢的在线商店并采集商品名称、价格、折扣和链接等数据,以便您以后找到它们。如果您计划抓取大量页面,我建议您在此项目中使用 Scrapy 库,因为它是 Python 中最快的网络抓取库。您可以按照本教程来帮助您开始这个项目。
对于项目的第二部分,您必须跟踪提款的价格,以便在特定产品的价格大幅下跌时通知您。
请记住,您可以将最终的项目想法应用到您感兴趣的其他领域。举几个例子。
一种。抓住股价
湾。抓住投注赔率
C。获取加密货币价格
例如,我没有抓住产品价格,而是抓住了投注赔率。想法是一样的,在多家*敏*感*词*公司中找到最佳赔率。然后在几率增加时得到通知。
原来的:
了解新的钛云服务
过往技术干货