网页新闻抓取(实验内容这里不用管拓展视频是什么,视频涉及的内容很重要 )
优采云 发布时间: 2022-03-16 15:18网页新闻抓取(实验内容这里不用管拓展视频是什么,视频涉及的内容很重要
)
新浪新闻动态网页爬取+热词云分析实验内容
扩展视频在这里无所谓,视频中涉及的内容很简单。
日常生活中,我们经常看到“年度热词”,你会好奇这是怎么获得的?
我们最常见的想法是计算机通过分析大数据来获得它。
下面我用这个例子来展示详细的过程
上面的代码
代码有注释,大家都懂!
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import jieba
from wordcloud import WordCloud
from imageio import imread
import matplotlib.pyplot as plt
def getSinaNews(pages):
# 要爬取的网页
url = 'https://news.sina.com.cn/roll/'
# 获取无界面浏览器
# chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument('--headless')
# browser = webdriver.Chrome(options=chrome_options)
# 有界面模式
browser = webdriver.Chrome()
# 爬
news_list = ''
while pages > 0:
try:
browser.get(url)
news = browser.find_elements_by_xpath('//*[@id="d_list"]/ul/li/span/a')
# 将爬取到的所有新闻标题放到一个String中
for i in news:
news_list = news_list + str(i.text)
except NoSuchElementException:
print('NoSuchElementException')
browser.close()
continue
# 找到下一页按钮,并点击
'''//*[@id="d_list"]/div/span[15]/a'''
browser.find_element_by_xpath('//*[@id="d_list"]/div/span/a').click()
pages = pages - 1
browser.quit()
return news_list
def createWordCloud(news_list):
bg_image = imread("bg.jpg")
stopwords = [line.strip() for line in open('StopWords.txt', encoding='utf-8').readlines()]
mytext = jieba.cut(news_list, cut_all=False)
wt = " /".join(mytext)
# 设置词云相关参数
word_cloud = WordCloud(
# 设置背景颜色
background_color="white",
# 设置最大显示的字数
max_words=200,
# 设置背景图片
mask=bg_image,
# 此处添加停用词库
stopwords=stopwords,
# 设置中文字体,词云默认字体是“DroidSansMono.ttf字体库”,不支持中文
font_path="SimHei.ttf",
# 设置字体最大值
max_font_size=500,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=30,
# 轮廓线宽度
contour_width=3,
# 轮廓线颜色
contour_color='steelblue',
)
mycloud = word_cloud.generate(wt) # 生成词云
# 设置生成图片的标题
plt.title('WordCloudOfSina') # 必须得用英文,否则报错且不显示
plt.imshow(mycloud)
# 设置是否显示 X、Y 轴的下标
plt.axis("off")
plt.show()
if __name__ == '__main__':
page = eval(input('请输入要爬取的页面数量:'))
news_list = getSinaNews(page)
createWordCloud(news_list)
代码中涉及的图片,这个图片是在网上找的,主要是作为词云的背景。
涉及的文件也有好几个,都是我放到百度网盘上的,需要自己捡
关联:
提取码:v3ad
复制完这个内容后,打开百度网盘手机应用,操作起来更方便。
步骤分析首先你要明白,并不是所有的网站都能被你爬上去。网站 的部分源代码只有在您访问时才会为您呈现和生成。因此,万无一失的方法是让计算机模拟人类进行自动访问。这里使用的来自 selenium 库。可以实现自动页面跳转。在查找要抓取的内容时,您可以使用浏览器的检查功能。先用F12打开检查,然后按图中的顺序操作。点击第一步,点击第二步,完成1、2步后,会定位到位置3,在3的基础上点击右键。
这得到下面的评论部分!,通过观察去掉里面的数字部分,就是他的“通项公式”:
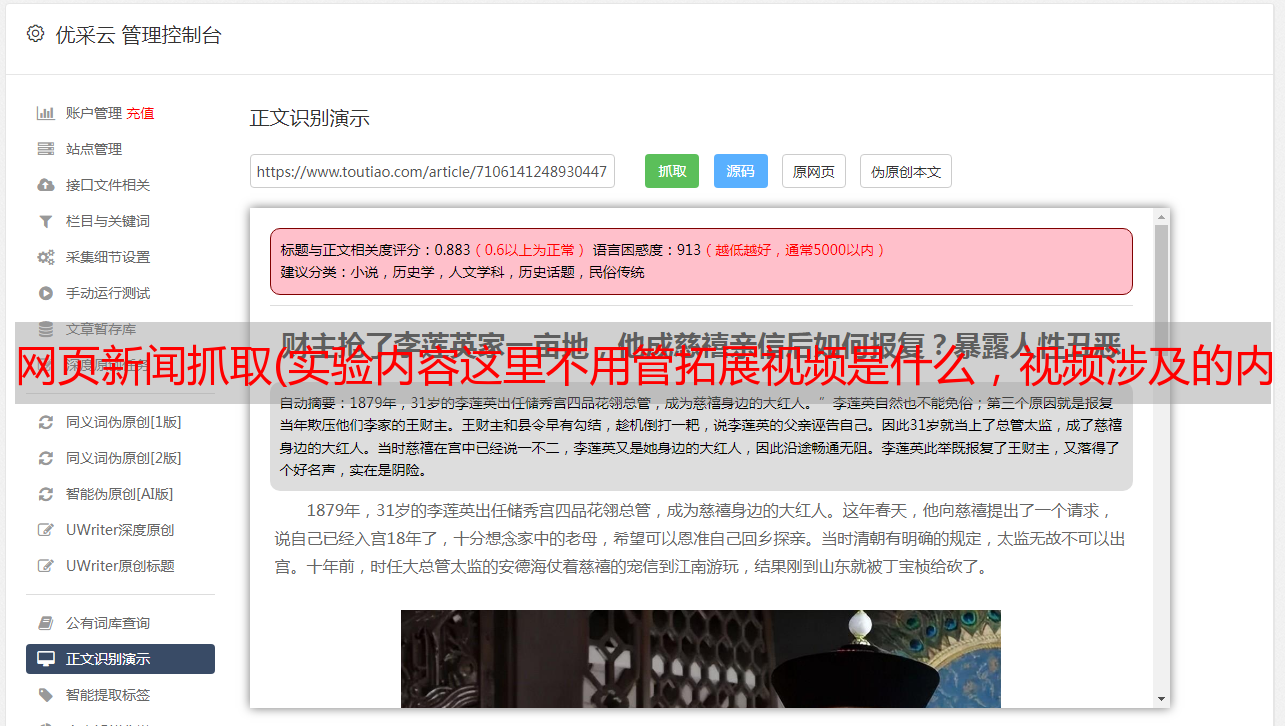
实验结果