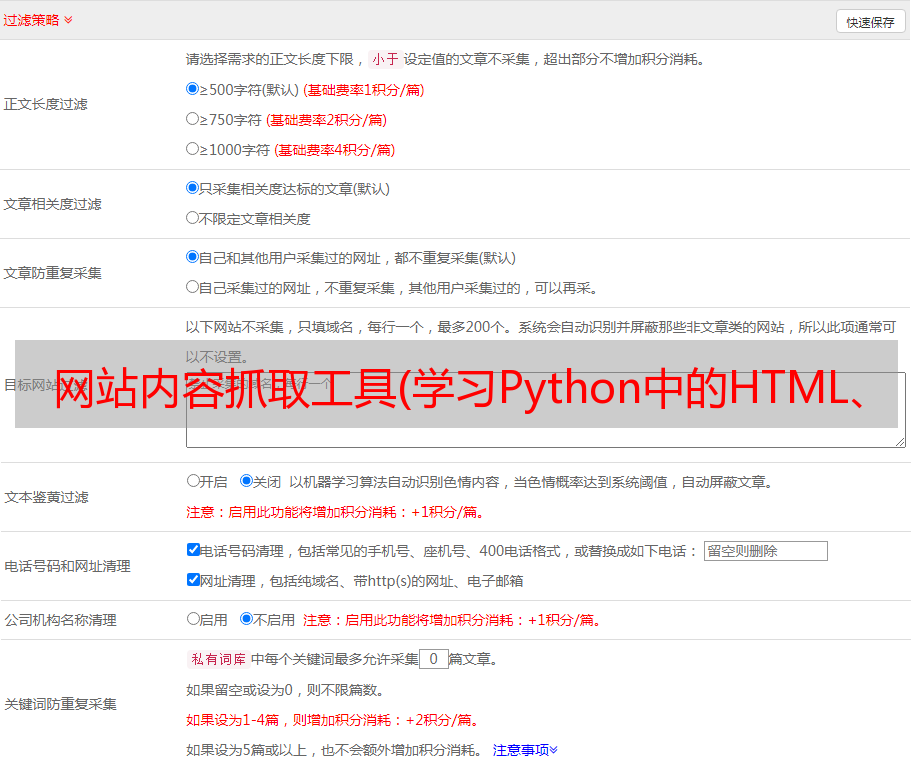
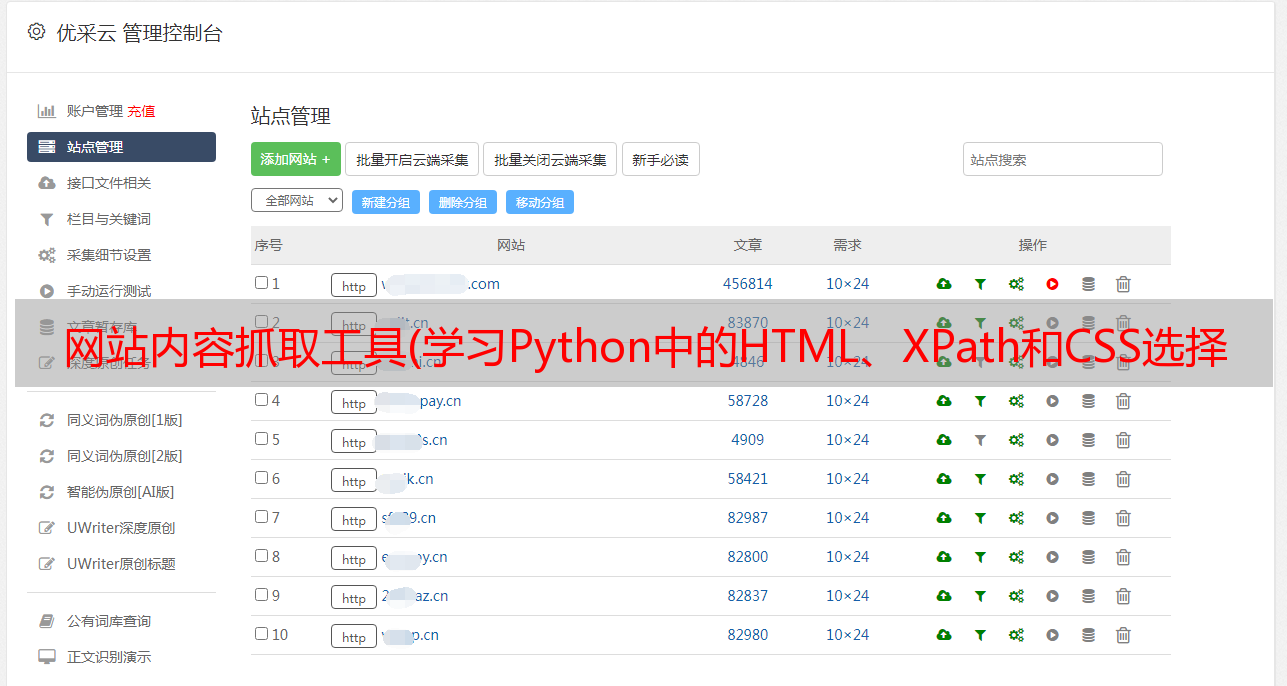
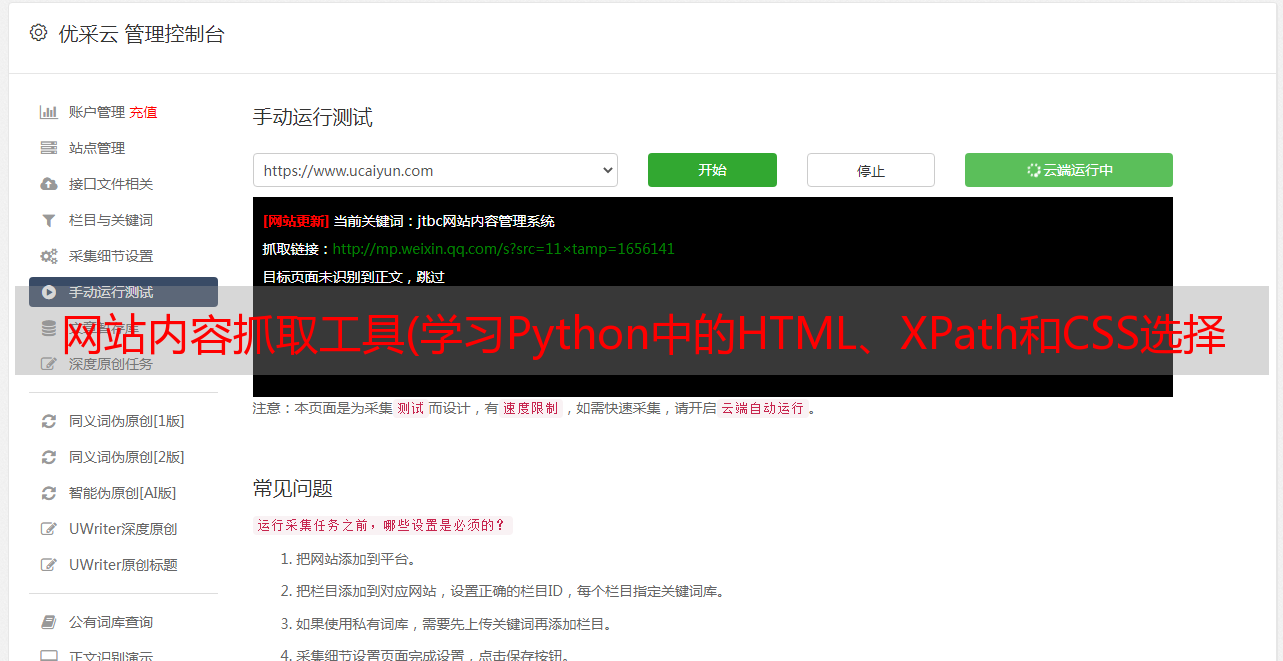
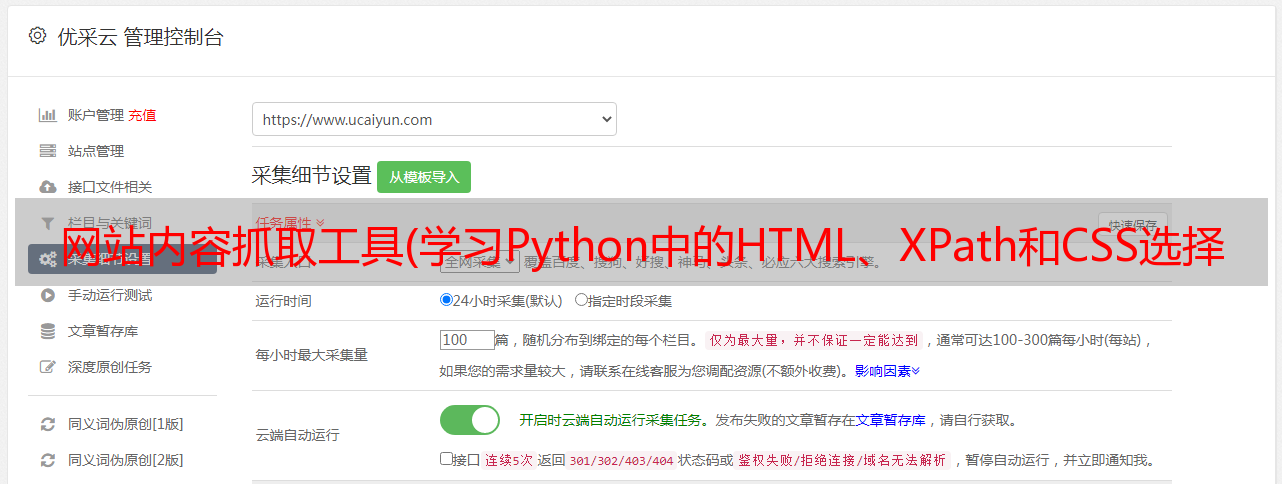
网站内容抓取工具(学习Python中的HTML、XPath和CSS选择器的搜索模式)
优采云 发布时间: 2022-01-12 23:23网站内容抓取工具(学习Python中的HTML、XPath和CSS选择器的搜索模式)
正则表达式
正则表达式(RE 或 Regex)是字符串的搜索模式。您可以使用正则表达式在较大的文本中搜索特定字符或单词,例如,您可以识别网页上的所有电话号码。您还可以轻松地替换字符串,例如在格式不佳的 HTML 中将所有大写标记替换为小写标记。一些输入也可以被验证。
您可能想知道,为什么在进行网络抓取时了解正则表达式很重要?毕竟,有各种 Python 模块用于解析 HTML、XPath 和 CSS 选择器。
在理想的语义世界中,数据很容易被机器读取,信息嵌入在相关的 HTML 元素和有意义的属性中。
但现实世界是混乱的,您经常会在 p 元素中搜索大量文本。当您想在这个巨大的文本块中提取特定数据(如价格、日期或名称)时,您必须使用正则表达式。
注意:本文 文章 仅涵盖了您可以使用正则表达式执行的一小部分内容。您可以使用这个 文章 练习正则表达式,并通过这个很棒的博客了解更多信息。
当您的数据如下所示时,正则表达式就会发挥作用:
<p>Price : 19.99lt;/p>
我们可以使用 XPath 表达式选择此文本节点,然后使用此正则表达式提取价格。请记住,正则表达式模式从左到右应用,并且每个源字符仅使用一次。:
^Price\s:\s(\d+.\d{2})$
要从 HTML 标签中提取文本,使用正则表达式很烦人,但它确实有效:
import re
html_content = '<p>Price : 19.99lt;/p>'
如您所见,通过套接字手动发送 HTTP 请求并使用正则表达式解析响应是可以完成的,但它很复杂。所以有更高级别的 API 可以使这项任务更容易。
urllib3 & LXML
注意:在 Python 中学习 urllib 系列库时,很容易迷失方向。除了作为标准库的一部分的 urlib 和 urlib2 之外,Python 还具有 urlib3。urllib2 在 Python 3 中被拆分为许多模块,但 urllib3 不应该很快成为标准库的一部分。应该有一篇单独的 文章 文章讨论这些令人困惑的细节,在这篇文章中我选择只讨论 urllib 3,因为它在 Python 世界中被广泛使用。
urllib3 是一个高级包,它允许你对 HTTP 请求做任何你想做的事情。我们可以用更少的代码行完成上面的socket操作:
import urllib3
http = urllib3.PoolManager()
r = http.request('GET', 'http://www.google.com')
print(r.data)
比插座版本干净得多,对吧?不仅如此,API 也很简单,您可以轻松地做很多事情,例如添加 HTTP 标头、使用代理、发布表单等等。
例如,如果我们必须设置一些头字段来使用代理,我们会这样做:
import urllib3
user_agent_header = urllib3.make_headers(user_agent="")
pool = urllib3.ProxyManager(f'', headers=user_agent_header)
r = pool.request('GET', 'https://www.google.com/')
你看见了吗?行数完全相同。
但是,有些事情 urllib 3 并不容易处理。如果要添加 cookie,则必须手动创建相应的 header 字段并将其添加到请求中。
此外,urllib 3 可以做一些请求不能做的事情,例如池和代理池的创建和管理,以及重试策略的控制。
简单来说,urllib 3在抽象上是介于requests和sockets之间,虽然它比sockets更接近requests。
为了解析响应,我们将使用 lxml 包和 XPath 表达式。
XPath
XPath 是一种使用路径表达式在 XML 或 HTML 文档中选择节点或节点集的技术。与文档对象模型一样,XPath 自 1999 年以来一直是 W3C 标准。尽管 XPath 本身不是一种编程语言,但它允许您编写可以直接访问特定节点或节点集的表达式,而无需遍历整个 XML 或 HTML 树.
将 XPath 视为特定于 XML 或 HMTL 的正则表达式。
要使用 XPath 从 HTML 文档中提取数据,我们需要做 3 件事:
首先,我们将使用通过 urllib 3 获得的 HTML。我们只想从 Google 主页中提取所有链接,因此我们将使用一个简单的 XPath 表达式 //a 并使用 LXML 来运行它。LXML 是一个快速且易于使用的支持 XPath 的 XML 和 HTML 处理库。
安装 :
pip install lxml
这是上一个片段之后的代码:
from lxml import html
输出如下:
https://books.google.fr/bkshp?hl=fr&tab=wp
https://www.google.fr/shopping?hl=fr&source=og&tab=wf
https://www.blogger.com/?tab=wj
https://photos.google.com/?tab=wq&pageId=none
http://video.google.fr/?hl=fr&tab=wv
https://docs.google.com/document/?usp=docs_alc
...
https://www.google.fr/intl/fr/about/products?tab=wh
请记住,这个示例非常简单,并没有向您展示 XPath 的强大功能。(注意:此 XPath 表达式应更改为 //a/@href 以避免遍历链接以获取其 href)。
如果您想了解有关 XPath 的更多信息,可以阅读这个很棒的介绍性文档。LXML 文档也写得很好,适合基本阅读。.
XPath 表达式与正则表达式一样强大,是从 HTML 中提取信息的最快方法之一。尽管 XPath 和 regexp 一样,很快就会变得杂乱无章,难以阅读和维护。
请求和 BeautifulSoup(库)
Python
Requests 库的下载量超过 11,000,000 次,是 Python 包的领导者,也是 Python 使用最广泛的包。
安装:
pip install requests
使用 Requests 库发送请求非常简单:
import requests
使用 Requests 库可以轻松执行 POST 请求、处理 cookie 和查询参数。
黑客新闻认证
假设我们想要创建一个工具来自动将我们的博客 文章 提交到 Hacker News 或任何其他论坛,如 Buffer。在提交我们的链接之前,我们需要对这些 网站 进行身份验证。这就是我们要用 Requests 和 BeautifulSoup 做的事情!
这是 Hacker News 登录表单和相关的 DOM:
Python
此表单上有三个选项卡。第一个隐藏类型名称是“goto”输入,另外两个是用户名和密码。
如果您在 Chrome 中提交表单,您会发现发生了很多事情:正在设置重定向和 cookie。Chrome 将在每个后续请求中发送此 cookie,以便服务器知道您已通过身份验证。
用 Requests 做这件事会很容易,它会自动为我们处理重定向,而处理 cookie 可以用 _Session_Object 来完成。
接下来我们需要的是 BeautifulSoup,这是一个 Python 库,它将帮助我们解析服务器返回的 HTML 以确定我们是否已登录。
安装:
pip install beautifulsoup4
因此,我们所要做的就是通过 POST 请求将这三个输入与我们的登录凭据一起发送到 /login 终端,并验证一个仅在登录成功时出现的元素。
import requests
from bs4 import BeautifulSoup
BASE_URL = 'https://news.ycombinator.com'
USERNAME = ""
PASSWORD = ""
s = requests.Session()
data = {"gogo": "news", "acct": USERNAME, "pw": PASSWORD}
r = s.post(f'{BASE_URL}/login', data=data)
我们可以尝试提取主页上的每个链接,以了解更多关于 BeautifulSoup 的信息。
顺便说一句,Hacker News 提供了一个强大的 API,所以我们这里只是作为一个例子,你应该直接使用 API,而不是抓取它!_
我们需要做的第一件事是观察和分析 Hacker News 主页,以了解我们必须选择的结构和不同的 CSS 类。
我们可以看到所有的帖子都在那里,所以我们需要做的第一件事就是选择所有这些标签。我们可以使用以下代码行轻松完成:
links = soup.findAll('tr', class_='athing')
然后,对于每个链接,我们将提取其 ID、标题、url 和排名:
import requests
from bs4 import BeautifulSoup
r = requests.get('https://news.ycombinator.com')
soup = BeautifulSoup(r.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
formatted_links = []
for link in links:
data = {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(links[0].td.span.text.replace('.', ''))
}
formatted_links.append(data)
如您所见,Requests 和 BeautifulSoup 是用于提取数据和自动执行各种操作(如填写表单)的出色库。如果你想做一个*敏*感*词*的网络爬虫项目,你仍然可以使用请求,但是你需要自己处理很多事情。
在抓取大量网页时,需要处理很多事情:
幸运的是,我们可以使用工具处理所有这些事情。
刮擦
Python
scrapy 是一个强大的 Python 网页抓取框架。它提供了许多异步下载、处理和保存网页的功能。它处理多线程、抓取(从链接到在 网站 中查找每个 URL 的过程)、站点地图抓取等。
Scrapy 还有一个交互模式叫做 ScrapyShell。您可以使用 ScrapyShell 快速测试 XPath 表达式或 CSS 选择器等代码。
Scrapy 的缺点是陡峭的学习曲线——有很多东西要学。
继续上面的 Hacker News 示例,我们将编写一个 ScrapySpider,它会抓取前 15 页结果并将所有内容保存在 CSV 文件中。
点安装 Scrapy:
pip install Scrapy
然后,您可以使用 scrapycli 为您的项目生成样板代码:
scrapy startproject hacker_news_scraper
在hacker_news_scraper/spider中,我们将使用蜘蛛代码创建一个新的Python文件:
from bs4 import BeautifulSoup
import scrapy
class HnSpider(scrapy.Spider):
name = "hacker-news"
allowed_domains = ["news.ycombinator.com"]
start_urls = [f'https://news.ycombinator.com/news?p={i}' for i in range(1,16)]
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
for link in links:
yield {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(link.td.span.text.replace('.', ''))
}
Scrapy中有很多规定,这里我们定义了一组启动URL。属性名称将用于使用 Scrapy 命令行调用我们的蜘蛛。
为数组中的每个 URL 调用 resolve 方法。
然后,为了让我们的爬虫更好地爬取目标 网站 上的数据,我们需要对 Scrapy 进行微调。
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
AUTOTHROTTLE_ENABLED = True
# The initial download delay
AUTOTHROTTLE_START_DELAY = 5
你应该让这个爬虫一直运行,它会通过分析响应时间和调整并发线程数来确保目标网站不会被爬虫超载。
您可以使用 ScrapyCLI 运行下面的代码并设置不同的输出格式(CSV、JSON、XML 等)。
scrapy crawl hacker-news -o links.json
与此类似,最终的爬取结果会以json格式导出到名为links的json文件中
Selenium & Chrome——无头
Scrapy 非常适合大型网络抓取任务。但是,如果您需要爬取使用 JavaScript 框架编写的单页应用程序,这还不够,因为它无法渲染 JavaScript 代码。
爬取这些 SPA 可能具有挑战性,因为经常涉及许多 Ajax 调用和 WebSocket 连接。如果性能是一个问题,您将不得不一一复制 JavaScript 代码,这意味着使用浏览器检查器手动检查所有网络调用,并复制与您感兴趣的数据相关的 Ajax 调用。
在某些涉及太多异步 HTTP 调用来获取所需数据的情况下,在无头浏览器中呈现页面可能更容易。
另一个很好的用例是截取页面的屏幕截图。这是我们将要做的(再次!)到 Hacker News 主页以 pip 安装 Selenium 包:
pip install selenium
您还需要 Chromedriver:
brew install chromedriver
然后,我们只需从 Selenium 包中导入 Webriver,配置 Chrome 的 Headless=True,并设置一个窗口大小(否则会非常小):
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
然后你应该得到一个漂亮的主页截图。
Python
你可以用 SeleniumAPI 和 Chrome 做更多的事情,比如:
无头模式下的 Selenium 和 Chrome 是抓取您想要的任何数据的完美组合。您可以自动化使用普通 Chrome 浏览器执行的所有操作。
Chrome 最大的缺点是它需要大量的内存/CPU 能力。通过一些微调,您可以将每个 Chrome 实例的内存占用减少到 300-400MB,但每个实例仍需要一个 CPU 内核。
如果您想同时运行多个 Chrome 实例,您将需要一个强大的服务器(其成本迅速上升),并持续监控资源。
总结
我希望这篇概述能帮助你选择你的 Python 爬虫,也希望你从这篇文章中学到了一些东西。
我在这个 文章 中介绍的工具都是我在自己的项目 ScrapingNinja 中使用的,它是一个简单的网络爬虫 API。
对于这个 文章 中提到的每个工具,我将写一篇单独的博客文章来详细介绍。
不要犹豫,在评论中告诉我您还想了解哪些关于爬虫的信息。我将在下一篇文章 文章 中解释分析。
刮痧快乐!

