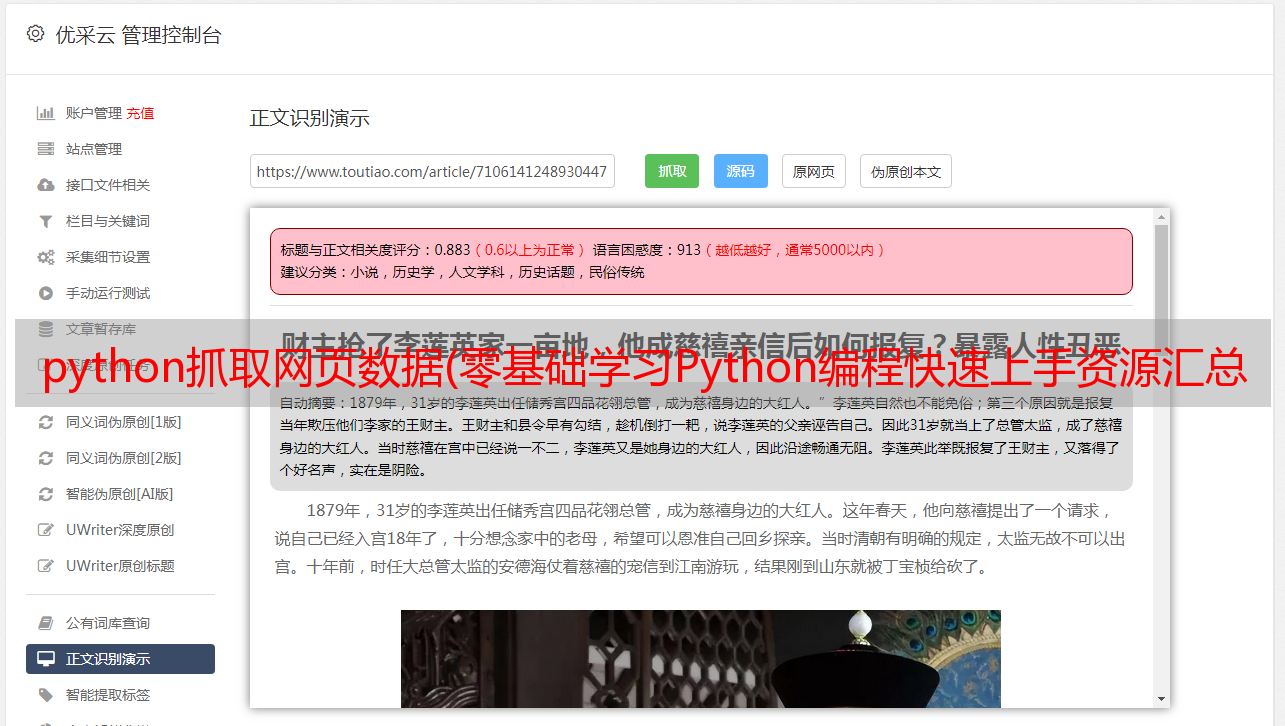
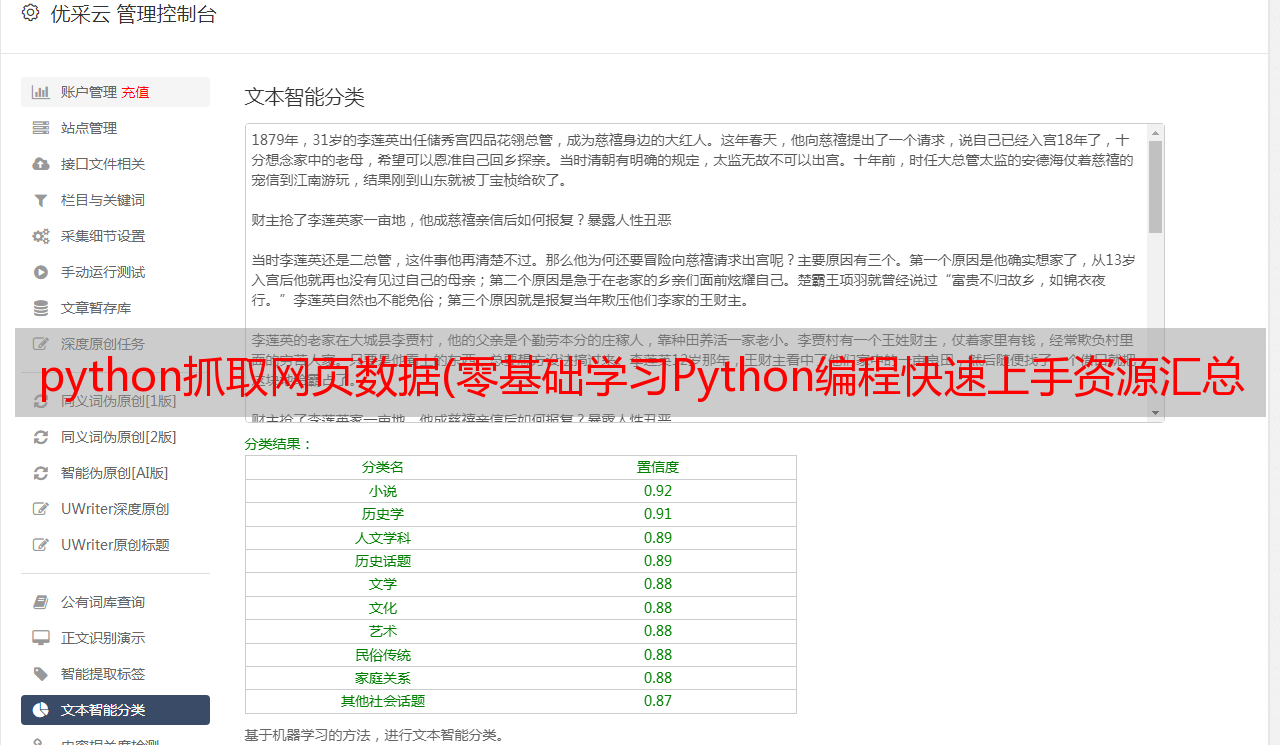
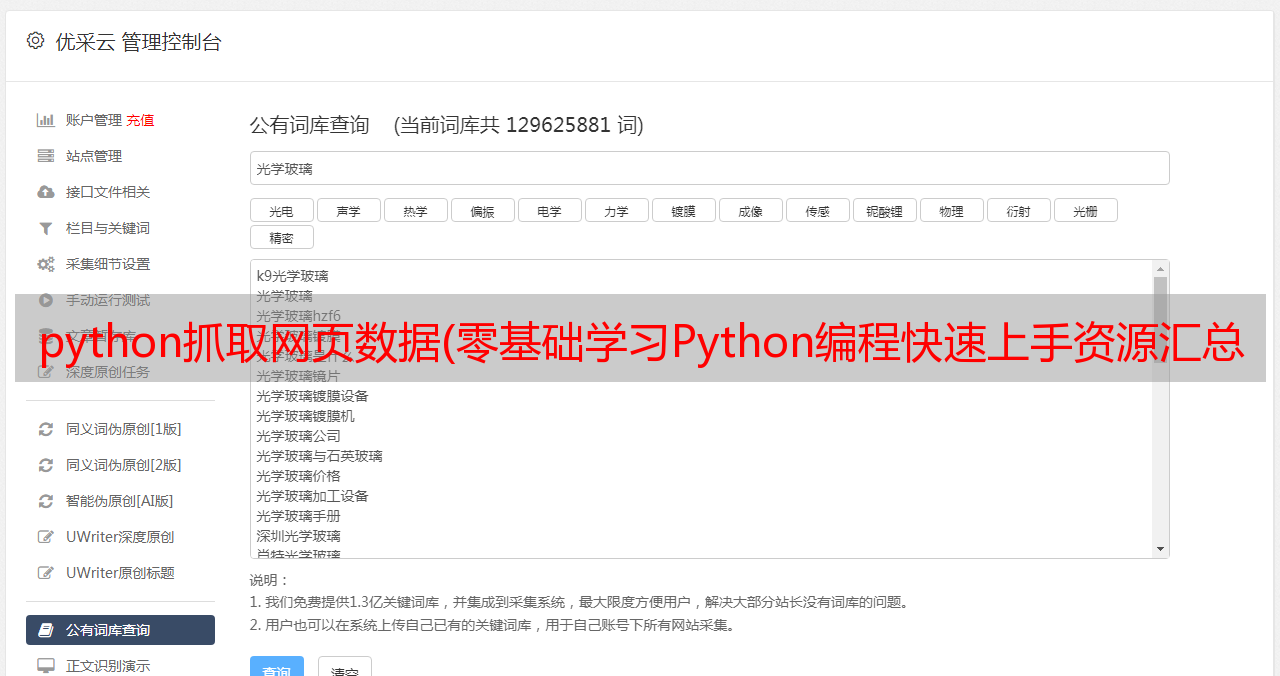
python抓取网页数据(零基础学习Python编程快速上手资源汇总(上))
优采云 发布时间: 2022-01-07 11:13python抓取网页数据(零基础学习Python编程快速上手资源汇总(上))
【我已经打包了下面提到的资源,关注+评论“资源汇总”即可领取】
爬取虽然不是主流技术,但以其快速的爬取速度和优良的数据质量受到越来越多的人的追捧。在互联网时代,爬虫技术的加持对于专业人士来说无疑是锦上添花。
随着爬虫技术的普及,网络上的资源层出不穷,但对于初学者来说,可能就很难选择了。如果选错了,就会在爬虫学习上走一些弯路。
我们专门为零基础的同学整理了python爬虫资源,包括书单、网站博客、框架、工具、项目总结等。至于为什么选择python语言,是因为python对小白来说更容易学习。
-必读清单-
你不需要很多书单和教程。对于python爬虫,只需阅读这8本书。
01 《Python编程:从入门到实践》豆瓣评分:9.1
本书是面向各个层次Python读者的Python入门书籍。
本书分为两部分:第一部分介绍使用Python编程必须了解的基本概念,第二部分将理论付诸实践,讲解如何开发三个项目。
02 《Python编程快速入门》豆瓣评分:9.0
本书是面向实践的 Python 编程的实用指南。不仅介绍了Python语言的基础知识,还通过项目实践教会读者如何应用这些知识和技能。
03《像计算机科学家一样思考Python》豆瓣评分:8.7
本书旨在训练读者像计算机科学家一样理解 Python 编程。这是一本实用的学习指南,适合没有 Python 编程经验的程序员。
04《学习Python的笨方法》豆瓣评分:7.9
本书非常适合想要通过语言核心学习Python编程的初学者。您将通过完成 52 个精心设计的练习来学习 Python。
05 《Python食谱中文版》豆瓣评分:9.2
本书涵盖了 Python 应用程序中的许多常见问题,并提出了通用解决方案。
本书收录大量实用的编程技巧和示例代码,非常适合有一定编程基础的Python程序员阅读。
06《光滑蟒蛇》豆瓣评分:9.4
从语言设计层面分析编程细节,同时考虑 Python 3 和 Python 2。
告诉你Python中非动手实践无法理解的语言陷阱的原因和解决方法,教你写出正宗的Python代码。
07 《简单的学Python》豆瓣评分:8.5
如果你想学习Python编程的基础知识,又不想看一堆枯燥的书籍和教程。那么 Paul Barry 的“Head First Python”就是你最好的选择。
08《Python3网络爬虫开发实战》豆瓣评分:9.0
全面介绍使用Python3开发网络爬虫的知识。
从各类环境配置和爬虫基础知识入手,结合数据爬虫的新鲜案例,教授一些爬虫技巧,是一本很好的实用书。
-网站 博客-
01 awesome-python-login-model
项目采集了一些主要的网站登录方式和一些网站爬虫程序,研究分享主要的网站模拟登录方式和爬虫程序。
网址:awesome-python
02 《Python3 Web爬虫开发实战》作者博客
《python3网络爬虫与开发实战》作者,在本博客分享了自己的一些爬虫案例和经验,内容非常丰富。
网址:
03 Scraping.pro
Scraping.pro是专业的采集软件评测网站,里面有各种国外顶级采集软件评测文章,比如scrapy、octoparse等。
网址:/
04 小甜饼
与scraping.pro相比,Kdnuggets涵盖的范围更广,包括商业分析、大数据、数据挖掘、数据科学等。
网址:/
05章鱼解析
Octoparse 是一款功能强大且免费的 采集 软件。其博客内容丰富,通俗易懂,更适合初级网站采集用户。
网址:
06 大数据新闻
大数据新闻类似于 Kdnuggets。覆盖范围主要在大数据行业。网站采集 是它下面的一个子列。
网址:大数据新闻
07 分析 Vidhya
与大数据新闻类似,Analytics Vidhya是更专业的数据采集网站,涵盖数据科学、机器学习、网站采集等。
网址:analyticsvidhya
-爬虫框架-
01 刮痧
它是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。
网址:
02 蜘蛛侠
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。
后端使用常用的数据库来存储爬取结果,还可以定时设置任务和任务优先级。
网址:pyspider
03 克劳利
Crawley可以高速抓取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
网址:/
04 波西亚
Portia是一款开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!
网址:portia
05 报纸
Newspaper 可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
网址:报纸
06 美汤
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。
它可以实现惯用的文档导航,通过您喜欢的转换器查找和修改文档的方式。
网址:BeautifulSoup/bs4/doc/
07 抢
Grab 是一个用于构建网络爬虫的 Python 框架。
您可以构建各种复杂的网络爬虫工具,从简单的 5 行脚本到处理数百万个网页的复杂异步 网站 爬虫工具。
网址:grab-spider-user-manual
08 可乐
Cola 是一个分布式爬虫框架。对于用户来说,他们只需要写几个具体的函数,而无需关注分布式操作的细节。
项目地址:/chineking/cola
- 工具 -

