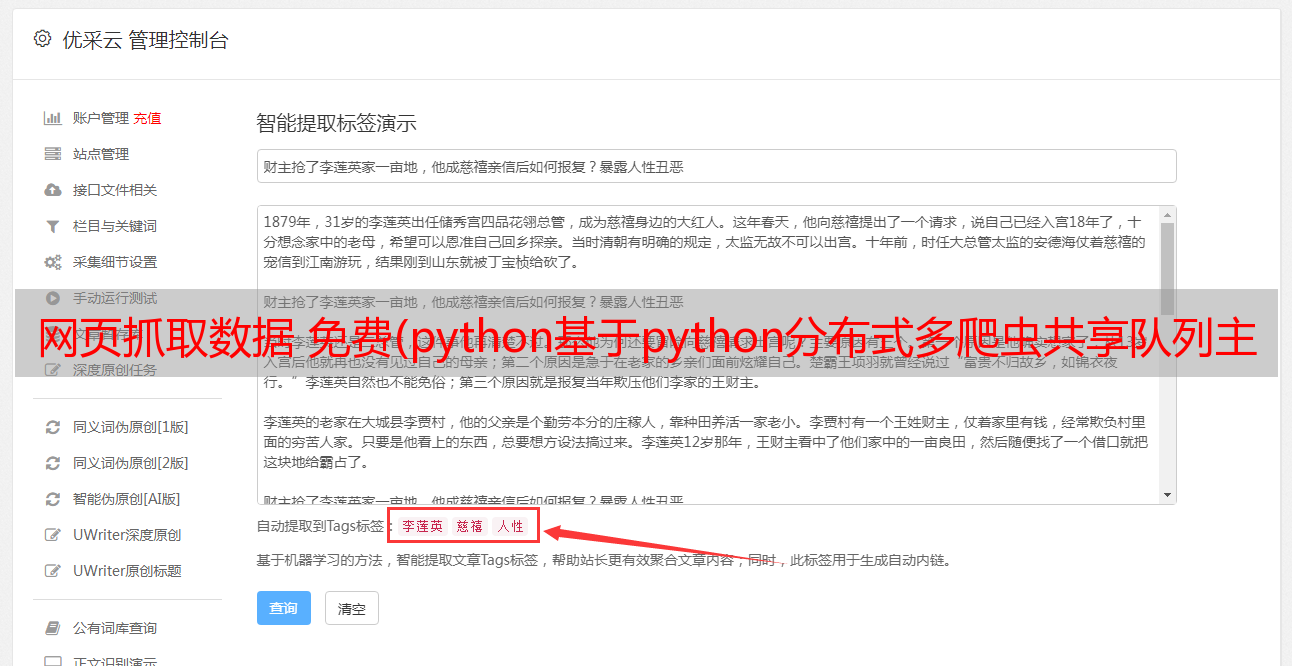
网页抓取数据 免费(python基于python分布式多爬虫共享队列主题爬虫(组图))
优采云 发布时间: 2021-11-06 14:11网页抓取数据 免费(python基于python分布式多爬虫共享队列主题爬虫(组图))
阿里云>云栖社区>主题图>P>Crawler抓取网页指定数据库

推荐活动:
更多优惠>
当前主题:爬虫爬取网页指定数据库添加到采集夹
相关话题:
爬虫爬取网页指定数据库相关的博客。查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有100TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
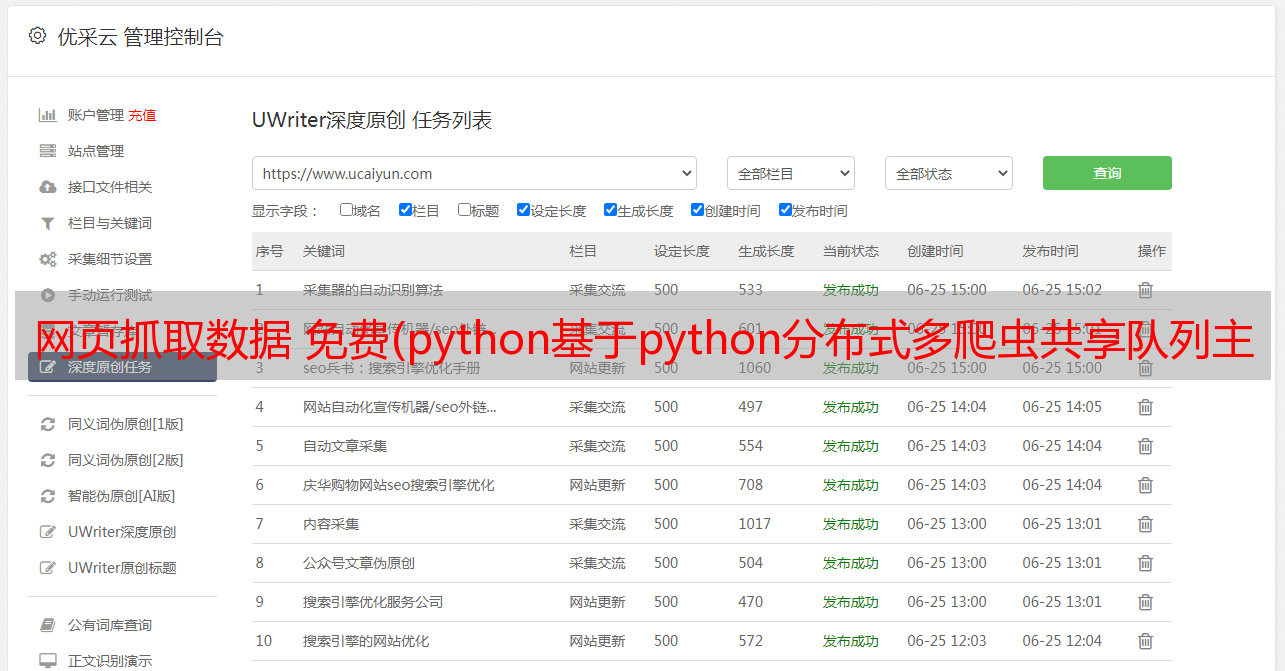
Scrapy分布式、去重增量爬虫的开发设计
作者:技术小能手8758人浏览评论:03年前
基于python的分布式房屋数据采集系统为数据的进一步应用提供数据支持,即房屋推荐系统。本课题致力于解决单进程单机爬虫的瓶颈,打造基于Redis分布式多爬虫共享队列的主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文
使用Python爬虫抓取免费代理IP
作者:小技术专家 2872人浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”之类的网站提示。我们需要等待一段时间或输入验证码才能解锁,但此后仍会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。比如某个ip单位时间请求一个网页的次数过多,服务器就会拒绝服务。在这种情况下,
阅读全文
爬虫和 urllib 库概述(一)
作者:蓝の流星VIP1588人浏览评论:03年前
1 爬虫概述(1)互联网爬虫是一种根据Url抓取网页以获取有用信息的程序(2)抓取网页解析数据的核心任务。难点:爬虫与反的博弈-crawlers(3)爬虫语言PHP多进程多线程支持不好。Java目前对Java爬虫需求旺盛,但代码臃肿,重构成本高。
阅读全文
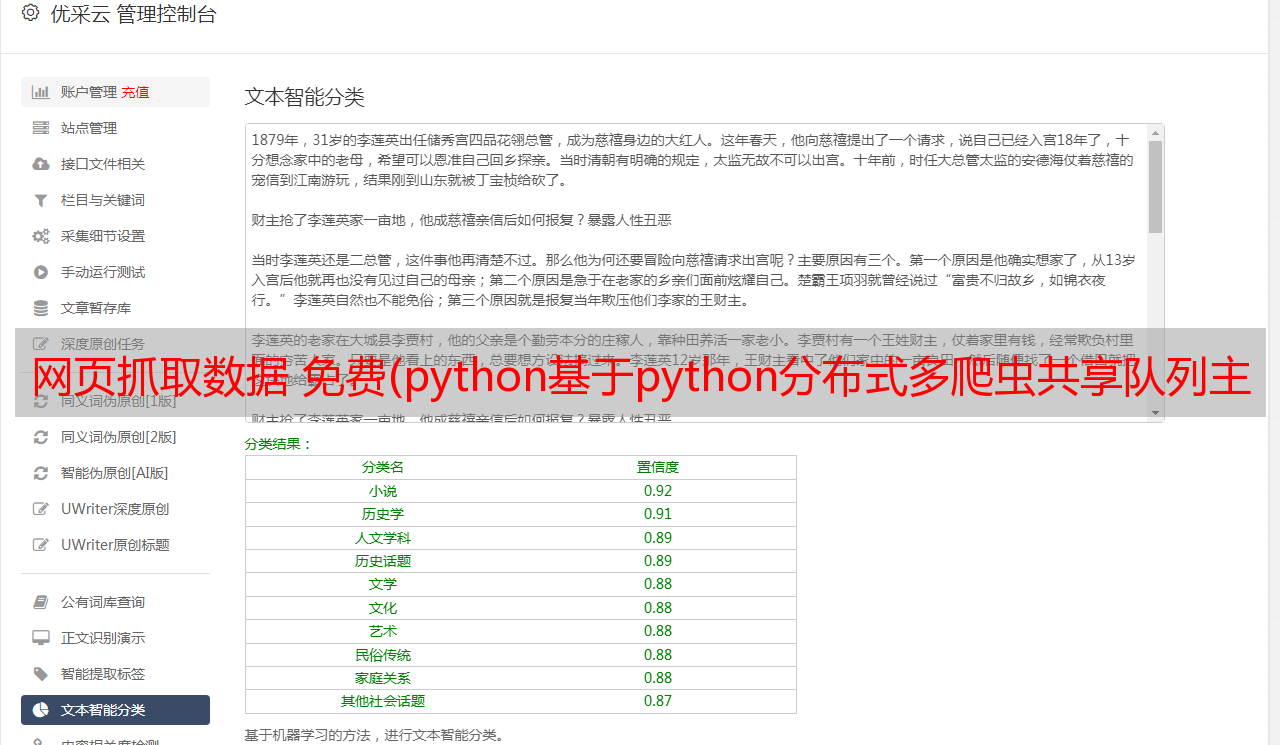
如何使用 Python 抓取数据?(一)网页抓取
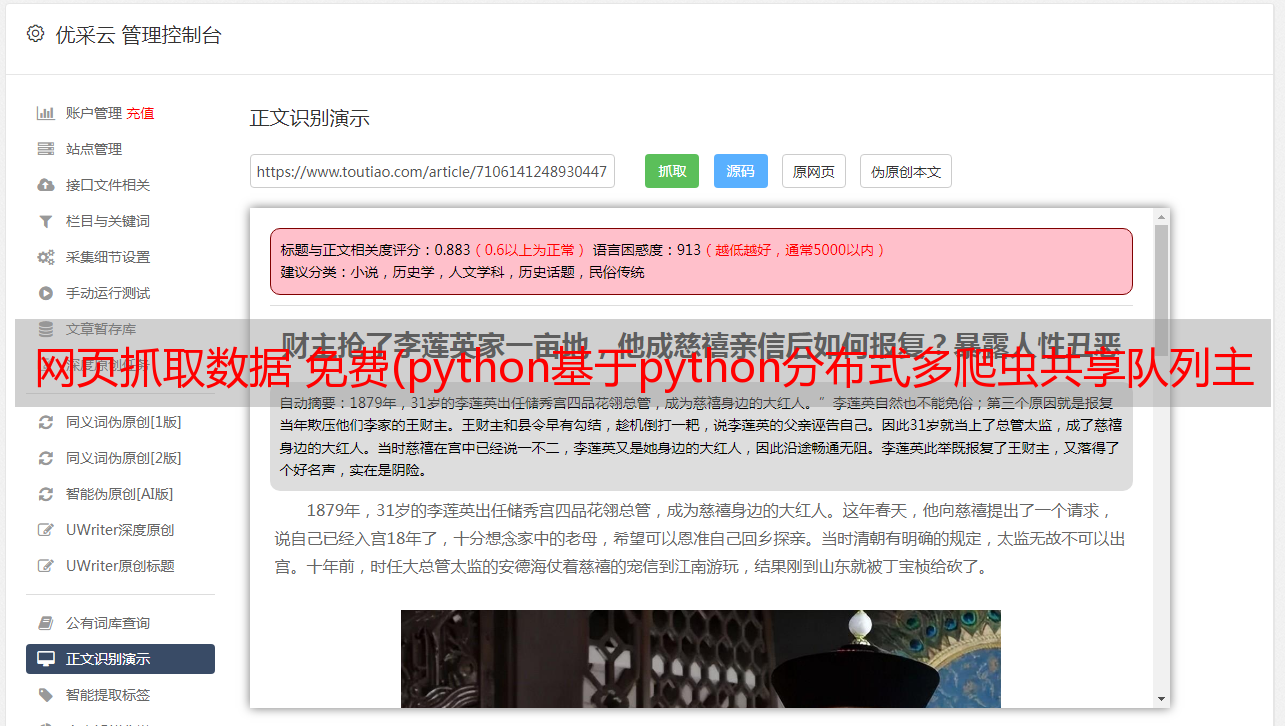
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
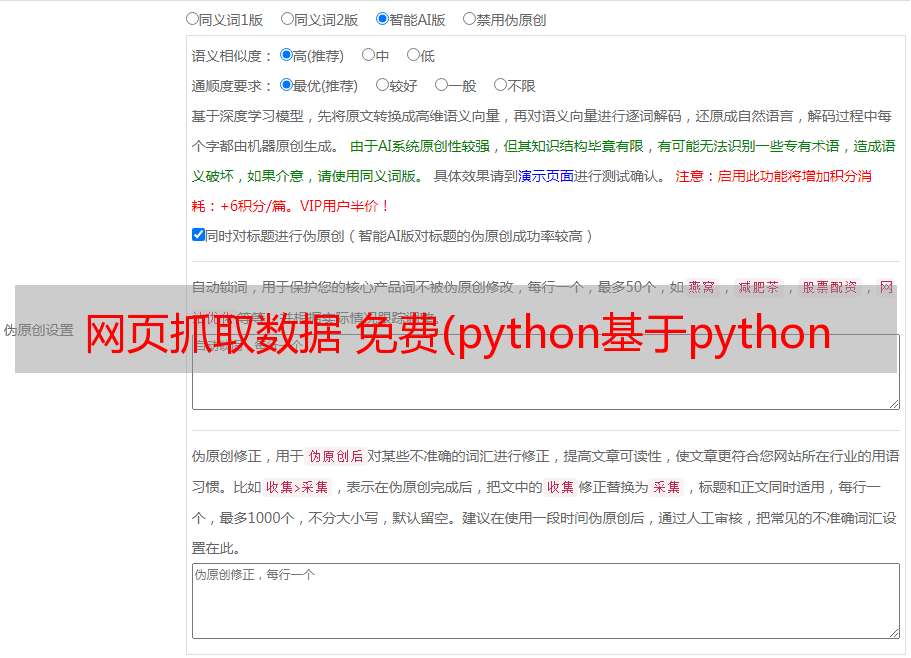
一个小型网络爬虫系统的架构设计
作者:技术组合 902人浏览评论:03年前
一个小型网络爬虫系统的架构设计。网络爬虫服务是互联网上经常使用的服务。在搜索引擎中,蜘蛛(网络爬虫)是必不可少的核心服务。搜索引擎衡量的四个指标“多、快、准、新”中,多、快、新都是对蜘蛛的要求。google、baidu等搜索引擎公司维护
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现成的API来获取数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
爬取网页数据分析
作者:y0umer606 浏览评论人数:010年前
发表于 2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集类别:C#编程自动阅读其他网站网页显示信息类似于a爬虫程序,比如我们有一个系统提取百度网站歌曲搜索排名分析系统
阅读全文
抓取网页数据分析(c#)
作者:wenvi_wu1489 浏览评论人数:012年前
其他网站网页上显示的信息是通过程序自动读取的,类似于爬虫程序。比如我们有一个系统来提取百度网站歌曲搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了完成上述需求,我们需要模拟浏览器浏览网页,并获取页面的数据进行分析。
阅读全文

